

使用 PyTorch 构建和训练一个卷积神经网络进行图像分类任务
下面是一个稍微复杂一些的神经网络示例代码。这个例子实现了一个卷积神经网络(CNN),用于处理图像分类任务(例如MNIST手写数字识别)。该网络包含卷积层、池化层、全连接层以及使用了ReLU激活函数和批量归一化层。



import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pyplot as plt # 定义卷积神经网络 class ConvNet(nn.Module): def __init__(self): super(ConvNet, self).__init__() # 第一卷积层:输入通道数为1(灰度图像),输出通道数为32,卷积核大小为3x3,步长为1,填充为1 self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1) # 第一批量归一化层:归一化32个特征图 self.bn1 = nn.BatchNorm2d(32) # 第二卷积层:输入通道数为32,输出通道数为64,卷积核大小为3x3,步长为1,填充为1 self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) # 第二批量归一化层:归一化64个特征图 self.bn2 = nn.BatchNorm2d(64) # 最大池化层:池化窗口大小为2x2,步长为2 self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # 全连接层:输入大小为64*7*7,输出大小为128 self.fc1 = nn.Linear(64 * 7 * 7, 128) # 全连接层:输入大小为128,输出大小为10(对应10个分类) self.fc2 = nn.Linear(128, 10) # Dropout层:在训练过程中随机断开50%的神经元连接,防止过拟合 self.dropout = nn.Dropout(p=0.5) def forward(self, x): # 第一个卷积层,激活函数为ReLU,然后进行最大池化 x = self.pool(F.relu(self.bn1(self.conv1(x)))) # 第二个卷积层,激活函数为ReLU,然后进行最大池化 x = self.pool(F.relu(self.bn2(self.conv2(x)))) # 将特征图展平成一维向量 x = x.view(-1, 64 * 7 * 7) # 第一个全连接层,激活函数为ReLU x = F.relu(self.fc1(x)) # Dropout层 x = self.dropout(x) # 第二个全连接层,输出未经过激活函数 x = self.fc2(x) return x # 数据预处理和加载 # 使用Compose将多个变换组合在一起:ToTensor()将图像转换为张量,Normalize()进行标准化 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) # 下载并加载训练集 train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform) # 下载并加载测试集 test_dataset = datasets.MNIST('./data', train=False, transform=transform) # 使用DataLoader加载数据集 train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False) # 初始化网络、损失函数和优化器 model = ConvNet() criterion = nn.CrossEntropyLoss() # 交叉熵损失函数 optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,学习率为0.001 # 训练网络的函数 def train(model, device, train_loader, optimizer, criterion, epoch): model.train() # 设置模型为训练模式 for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) # 将数据和标签移动到设备上(GPU或CPU) optimizer.zero_grad() # 清空梯度 output = model(data) # 前向传播 loss = criterion(output, target) # 计算损失 loss.backward() # 反向传播 optimizer.step() # 更新参数 if batch_idx % 100 == 0: # 每100个批次打印一次训练信息 print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ' f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}') # 测试网络的函数 def test(model, device, test_loader, criterion): model.eval() # 设置模型为评估模式 test_loss = 0 correct = 0 with torch.no_grad(): # 不计算梯度 for data, target in test_loader: data, target = data.to(device), target.to(device) # 将数据和标签移动到设备上 output = model(data) # 前向传播 test_loss += criterion(output, target).item() # 累加批量损失 pred = output.argmax(dim=1, keepdim=True) # 获取最大概率的索引 correct += pred.eq(target.view_as(pred)).sum().item() # 统计正确预测的数量 test_loss /= len(test_loader.dataset) # 计算平均损失 print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ' f'({100. * correct / len(test_loader.dataset):.0f}%)\n') # 定义一个函数来显示图像及其预测标签和真实标签 def show_images(images, labels, preds): plt.figure(figsize=(10, 5)) for i in range(10): plt.subplot(2, 5, i + 1) plt.imshow(images[i].numpy().squeeze(), cmap='gray') plt.title(f"True: {labels[i].item()}\nPred: {preds[i].item()}") plt.axis('off') plt.show() # 获取一些测试样本并显示 def show_test_samples(model, device, test_loader): model.eval() data, target = next(iter(test_loader)) data, target = data.to(device), target.to(device) output = model(data) preds = output.argmax(dim=1, keepdim=True) # 将图像从GPU移回CPU并转换为numpy格式 images = data.cpu() labels = target.cpu() preds = preds.cpu() # 显示图像及其标签 show_images(images, labels, preds) # 训练和测试循环 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 选择设备 model.to(device) # 将模型移动到设备上 for epoch in range(1, 11): # 进行10个训练周期 train(model, device, train_loader, optimizer, criterion, epoch) # 训练模型 test(model, device, test_loader, criterion) # 测试模型 # 在训练和测试循环后调用这个函数来显示一些测试图像 show_test_samples(model, device, test_loader)
解释
- 卷积神经网络(ConvNet):定义了一个包含两个卷积层、两个批量归一化层、两个池化层、两个全连接层和一个Dropout层的卷积神经网络。
- 数据预处理和加载:使用
transforms对数据进行标准化,并加载 MNIST 数据集。 - 训练和测试函数:定义了训练和测试模型的函数,其中包含前向传播、反向传播和参数更新的过程。
- 训练和测试循环:选择设备(GPU 或 CPU),将模型移动到设备,进行10个训练周期,每个周期结束后进行一次测试。
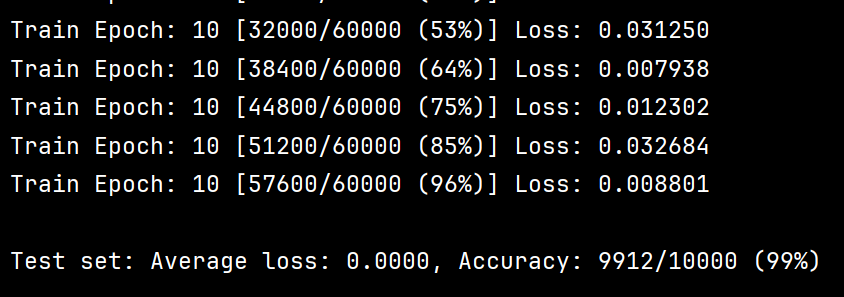
运行结果如下:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理