

pytorch使用交叉熵训练模型学习笔记
python代码:


import torch import torch.nn as nn import torch.optim as optim # 定义一个简单的神经网络模型 class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.fc = nn.Linear(3, 2) # 输入3维,输出2类 def forward(self, x): return self.fc(x) # 创建模型实例 model = SimpleModel() # 创建损失函数 criterion = nn.CrossEntropyLoss() # 创建优化器 optimizer = optim.SGD(model.parameters(), lr=0.01) # 定义固定的训练数据 inputs = torch.tensor([ [0.3, 0.2, 0.1], [0.4, 0.5, 0.6], [9, 8, 7], [10, 11, 102], [3, 2, 1], [4, 5, 6], [9, 8, 7], [1.0, 1.1, 102], [0.3, 0.2, 0.1], [0.4, 0.5, 0.6], ], dtype=torch.float32) # 10个样本,每个样本3维 targets = torch.tensor([0, 1, 0, 1, 0, 1, 0, 1, 0, 1], dtype=torch.long) # 真实标签 # 训练模型1000次 num_epochs = 1000 for epoch in range(num_epochs): # 前向传播 outputs = model(inputs) # 计算损失 loss = criterion(outputs, targets) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() # 打印损失值 if (epoch + 1) % 100 == 0: # 每100次打印一次损失值 print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}') print('Training complete.') # 定义一个待测试的样本 test_sample = torch.tensor([0.5, 5, 500], dtype=torch.float32) # 预测结果 with torch.no_grad(): # 在测试时不需要计算梯度 test_output = model(test_sample) probabilities = torch.softmax(test_output, dim=0) predicted_class = torch.argmax(test_output).item() print(f'Test Sample Prediction: Class {predicted_class}') print(f'Probabilities: {probabilities.tolist()}')
运行结果
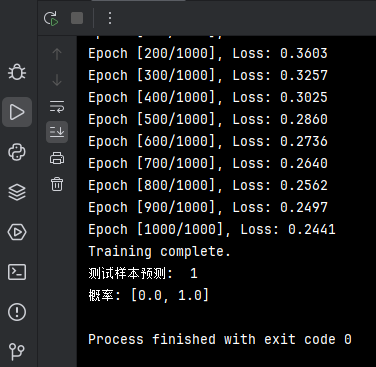
此代码输入10个样本,每个样本3个特征,输出2个类别
下面详细讲解一下 SimpleModel 这个模型的定义和构造
SimpleModel 模型定义
class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.fc = nn.Linear(3, 2) # 输入3维,输出2类 def forward(self, x): return self.fc(x)
1.类定义:
class SimpleModel(nn.Module):
这行代码定义了一个名为 SimpleModel 的类,该类继承自 nn.Module。nn.Module 是 PyTorch 中所有神经网络模块的基类。通过继承 nn.Module,我们可以利用 PyTorch 提供的许多有用的功能,例如参数管理和自动求导。
2.初始化方法:
def __init__(self): super(SimpleModel, self).__init__() self.fc = nn.Linear(3, 2) # 输入3维,输出2类
__init__方法是类的构造函数,当创建SimpleModel类的实例时会被调用。super(SimpleModel, self).__init__()调用父类(即nn.Module)的构造函数,初始化父类中的一些属性self.fc = nn.Linear(3, 2)创建一个全连接层(也叫线性层),输入维度为3,输出维度为2。nn.Linear是 PyTorch 中定义全连接层的类。它接受两个参数:输入特征数和输出特征数。这里输入特征数是3,输出特征数是2。
3.前向传播方法:
def forward(self, x): return self.fc(x)
forward方法定义了模型的前向传播过程,即当输入数据x传递给模型时,数据如何通过各层计算最终输出。self.fc(x)将输入x传递给全连接层self.fc,并返回输出
模型的具体构造
1. 全连接层(Linear Layer):
- 定义:全连接层是指每个输入节点都与输出节点相连,进行线性变换。它的数学表示是:
y = xW^T + b,其中W是权重矩阵,b是偏置向量。 - 输入和输出:在这个模型中,全连接层的输入维度是3,输出维度是2。这意味着输入数据应该有3个特征,输出将是2个类别的分数。
2. 模型的参数:
- 权重矩阵:大小为
[2, 3],表示从3维输入到2维输出的连接权重。 - 偏置向量:大小为
[2],每个输出类别一个偏置。
数据流动
假设输入数据 x 是一个大小为 [batch_size, 3] 的张量,其中 batch_size 是每批数据的样本数量:
- 输入数据
x通过全连接层self.fc。 - 全连接层计算输出
y = xW^T + b,输出是一个大小为[batch_size, 2]的张量,其中每行是一个样本在两个类别上的分数。

