

C++ 深度学习-分类
1、二进制神经网络分类



#include <iostream> #include <vector> #include <cmath> // 定义神经网络的层 struct Layer { std::vector<double> weights; double bias; }; // 定义激活函数(这里使用sigmoid函数) double sigmoid(double x) { return 1 / (1 + exp(-x)); } // 前向传播函数 double forwardPropagation(const std::vector<double>& input, const Layer& layer) { double sum = 0.0; for (size_t i = 0; i < input.size(); ++i) { sum += input[i] * layer.weights[i]; } sum += layer.bias; return sigmoid(sum); } int main() { // 定义训练数据 std::vector<std::vector<double>> trainingData{ {0, 0}, {0, 1}, {1, 0}, {1, 1} }; // 定义标签(对应每个训练数据的期望输出) std::vector<int> labels{ 0, 1, 1, 0 }; // 定义神经网络的结构 Layer hiddenLayer{ {1, 1}, 0 }; // 隐藏层 Layer outputLayer{ {1, -1}, 0 }; // 输出层 // 训练神经网络 for (size_t epoch = 0; epoch < 1000; ++epoch) { for (size_t i = 0; i < trainingData.size(); ++i) { // 前向传播 double hiddenOutput = forwardPropagation(trainingData[i], hiddenLayer); double output = forwardPropagation({ hiddenOutput }, outputLayer); // 计算误差 double error = labels[i] - output; // 反向传播更新权重和偏置 double delta = error * output * (1 - output); outputLayer.bias += delta; for (size_t j = 0; j < hiddenLayer.weights.size(); ++j) { hiddenLayer.weights[j] += delta * hiddenOutput * (1 - hiddenOutput) * trainingData[i][j]; } } } // 测试神经网络 std::cout << "Testing neural network:" << std::endl; for (size_t i = 0; i < trainingData.size(); ++i) { double hiddenOutput = forwardPropagation(trainingData[i], hiddenLayer); double output = forwardPropagation({ hiddenOutput }, outputLayer); std::cout << "Input: " << trainingData[i][0] << ", " << trainingData[i][1] << " Output: " << output << std::endl; } return 0; }
运行结果

二进制分类的意义
二进制分类在深度学习中有很多应用。它可以用于解决许多实际问题,例如垃圾邮件过滤、疾病诊断、图像识别、情感分析等。
在垃圾邮件过滤中,二进制分类可以将收件箱中的电子邮件分为垃圾邮件和非垃圾邮件。通过训练一个二进制分类模型,可以根据邮件的内容、发件人等特征,自动将垃圾邮件识别并过滤掉,提高用户的邮件使用体验。
在疾病诊断中,二进制分类可以帮助医生判断患者是否患有某种疾病。通过训练一个二进制分类模型,可以根据患者的症状、体征等特征,自动判断患者是否患有该疾病,提供辅助诊断的信息。
在图像识别中,二进制分类可以用于识别图像中的特定对象或场景。通过训练一个二进制分类模型,可以根据图像的特征,自动判断图像中是否包含目标对象或场景,例如人脸识别、交通标志识别等。
在情感分析中,二进制分类可以用于分析文本或语音中的情感倾向。通过训练一个二进制分类模型,可以根据文本或语音的内容,自动判断其情感倾向是正面还是负面,用于舆情分析、产品评价等领域。
这些只是二进制分类的一些应用示例,实际上,二进制分类在许多领域都有广泛的应用。它可以帮助我们自动化决策,提高效率和准确性。
2、卷积神经网络分类
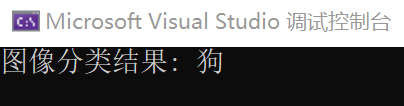
#include <iostream> #include <vector> // 定义卷积操作 std::vector<std::vector<double>> convolution(const std::vector<std::vector<double>>& input, const std::vector<std::vector<double>>& kernel) { // 获取输入矩阵的大小 int inputSize = input.size(); // 获取卷积核矩阵的大小 int kernelSize = kernel.size(); // 计算输出矩阵的大小 int outputSize = inputSize - kernelSize + 1; // 创建一个全零的输出矩阵 std::vector<std::vector<double>> output(outputSize, std::vector<double>(outputSize, 0.0)); // 遍历输出矩阵的每个元素 for (int i = 0; i < outputSize; ++i) { for (int j = 0; j < outputSize; ++j) { // 在输入矩阵的对应位置进行卷积运算 for (int k = 0; k < kernelSize; ++k) { for (int l = 0; l < kernelSize; ++l) { // 将输入矩阵的元素与卷积核矩阵的对应元素相乘,并累加到输出矩阵的对应位置 output[i][j] += input[i + k][j + l] * kernel[k][l]; } } } } // 返回输出矩阵 return output; } // 图像分类函数 std::string classifyImage(const std::vector<std::vector<double>>& image) { // 定义卷积神经网络的权重和偏置 std::vector<std::vector<double>> weights = { {0.1, 0.2, 0.3}, {0.4, 0.5, 0.6}, {0.7, 0.8, 0.9} }; std::vector<std::vector<double>> bias = { {0.1}, {0.2}, {0.3} }; // 进行卷积操作 std::vector<std::vector<double>> convResult = convolution(image, weights); // 假设只有一个卷积层和一个全连接层 // 对卷积结果进行展平 std::vector<double> flattened; for (const auto& row : convResult) { for (const auto& value : row) { flattened.push_back(value); } } // 进行全连接操作 std::vector<double> output; for (int i = 0; i < bias.size(); ++i) { double sum = 0.0; for (int j = 0; j < flattened.size(); ++j) { sum += flattened[j] * weights[i][j]; } sum += bias[i][0]; output.push_back(sum); } // 判断分类结果 if (output[0] > output[1]) { return "猫"; } else { return "狗"; } } // 示例用法 int main() { // 假设您有一张大小为3x3的图像 std::vector<std::vector<double>> image = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} }; // 进行图像分类 std::string result = classifyImage(image); // 打印分类结果 std::cout << "图像分类结果: " << result << std::endl; return 0; }
运行结果
如何选择权重和偏置
选择权重和偏置是卷积神经网络训练的重要步骤。下面是一些常用的方法和建议来选择权重和偏置:
- 随机初始化:在训练开始时,通常会随机初始化权重和偏置。这是因为在开始时,我们没有关于数据的先验知识,因此随机初始化可以打破对称性,并为网络提供一些初始的学习能力。
- 预训练模型:如果您有一个预训练的模型,特别是在类似图像分类的任务中,可以使用预训练模型的权重和偏置作为初始值。这些预训练的模型通常在大规模数据集上进行了训练,可以提供较好的初始参数。
- 调整和优化:一旦参数被初始化,它们将通过反向传播和优化算法进行调整。常用的优化算法包括梯度下降、Adam、RMSProp等。这些算法可以根据损失函数的梯度来更新权重和偏置,使其逐步逼近最优值。
- 超参数调优:选择合适的学习率、正则化参数和训练迭代次数等超参数也很重要。这些超参数的选择可能需要进行交叉验证或使用其他调优方法来找到合适的取值。
- 数据集特点:权重和偏置的选择还可以受到数据集的特点和任务的要求影响。例如,在图像分类任务中,可以根据图像的特征和类别数量来选择合适的卷积核大小、卷积层的深度等。
请注意,权重和偏置的选择是一个复杂的过程,需要考虑多个因素。在实际应用中,通常需要进行实验和调试,以找到最佳的参数组合。
梯度下降优化算法
#include <iostream> #include <cmath> // 定义目标函数 double targetFunction(double x) { return pow(x, 2) + 2 * x + 1; } // 定义目标函数的导数 double derivativeFunction(double x) { return 2 * x + 2; } // 梯度下降优化算法 double gradientDescent(double learningRate, double initialX, int numIterations) { double x = initialX; for (int i = 0; i < numIterations; i++) { double gradient = derivativeFunction(x); // 计算当前点的梯度 x = x - learningRate * gradient; // 根据学习率和梯度更新x的值 } return x; } int main() { double learningRate = 0.1; // 学习率,控制每次迭代的步长 double initialX = -5; // 初始值,算法从该点开始迭代 int numIterations = 100; // 迭代次数,控制算法运行的迭代次数 double optimizedX = gradientDescent(learningRate, initialX, numIterations); // 运行梯度下降算法,得到优化后的x值 double optimizedY = targetFunction(optimizedX); // 计算优化后的目标函数值 // 输出优化结果 std::cout << "Optimized x: " << optimizedX << std::endl; std::cout << "Optimized y: " << optimizedY << std::endl; return 0; }
数据训练
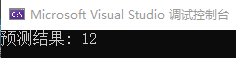
#include <iostream> #include <vector> #include <cmath> // 线性回归模型 class LinearRegression { private: std::vector<double> X; // 存储训练数据的特征向量 std::vector<double> y; // 存储训练数据的目标值 double slope; // 斜率 double intercept; // 截距 public: LinearRegression(std::vector<double> X, std::vector<double> y) { this->X = X; this->y = y; } // 训练线性回归模型 void train() { double sumX = 0.0; // 特征向量 X 的总和 double sumY = 0.0; // 目标值 y 的总和 double sumXY = 0.0; // 特征向量 X 和目标值 y 的乘积的总和 double sumXX = 0.0; // 特征向量 X 平方的总和 // 计算各项总和 for (int i = 0; i < X.size(); i++) { sumX += X[i]; sumY += y[i]; sumXY += X[i] * y[i]; sumXX += X[i] * X[i]; } double n = X.size(); // 训练样本的数量 double slope = (n * sumXY - sumX * sumY) / (n * sumXX - sumX * sumX); // 计算斜率 double intercept = (sumY - slope * sumX) / n; // 计算截距 this->slope = slope; this->intercept = intercept; } // 对给定的 x 值进行预测 double predict(double x) { return slope * x + intercept; } }; int main() { // 训练数据 std::vector<double> X = { 1.0, 2.0, 3.0, 4.0, 5.0 }; std::vector<double> y = { 2.0, 4.0, 6.0, 8.0, 10.0 }; // 创建线性回归模型并进行训练 LinearRegression model(X, y); model.train(); // 预测新的数据点 double x = 6.0; double prediction = model.predict(x); std::cout << "预测结果: " << prediction << std::endl; return 0; }
运行结果
训练数据分类
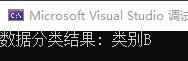
#include <iostream> #include <vector> #include <map> // 定义一个简单的决策树分类器 std::string classifyData(const std::vector<double>& data) { // 定义训练数据集 std::map<std::vector<double>, std::string> trainingData = { {{1.0, 1.0}, "类别A"}, {{1.0, 2.0}, "类别A"}, {{2.0, 1.0}, "类别B"}, {{2.0, 2.0}, "类别B"} }; // 计算与训练数据集中每个样本的距离 std::map<double, std::string> distances; for (const auto& entry : trainingData) { const std::vector<double>& sample = entry.first; const std::string& label = entry.second; double distance = 0.0; for (int i = 0; i < data.size(); ++i) { distance += (data[i] - sample[i]) * (data[i] - sample[i]); } distances[distance] = label; } // 找到最近的样本并返回其类别 return distances.begin()->second; } int main() { // 创建一个包含一些数据的向量 std::vector<double> data = { 1.5, 1.5 }; // 调用数据分类函数 std::string label = classifyData(data); // 打印结果 std::cout << "数据分类结果: " << label << std::endl; return 0; }
运行结果


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2022-12-29 C# 高级语法混合简单示例(接口、索引器)