


dp-runtime去Kafka依赖方案
背景
现有原生kafka connect runtime,在客户环境运行遇到诸多问题,问题列表如下:
- 强依赖Kafka集群做任务分配、connector配置信息、connector状态管理、source进度维护等等
- 当遇到数据量大、并行数多,topic数量较多时,可能引发kakfa集群的不稳定包括(节点宕机,controller切换等)从而引发整个Kafka集群运行状态的不稳定
- Kafka集群同时承担了数据缓存和任务分配协调的工作,他们之间相互干扰,当Kafka集群不稳定影响到kafka connect集群
目标
对kafka集群解藕,去Kafka依赖,为了实现如上目标,需要做如下工作:
- 迁移出kafka集群中connector rebalance管理功能,group coordinate角色迁移(协议、交互、管理)
- 存储功能迁移,从kafka迁移出connector配置信息、connector状态、source进度维护
- 实现raft协议功能,可以自住开发,也可选择第三方集成开发
- 提升系统稳定性,例如可用性从有时宕机到99.95%,jvm不会出现运行时内存溢出情况
原生方案
1.kafka原生rebalance机制
2.Kafka 3.0 for raft优势
3.Connector元数据存储
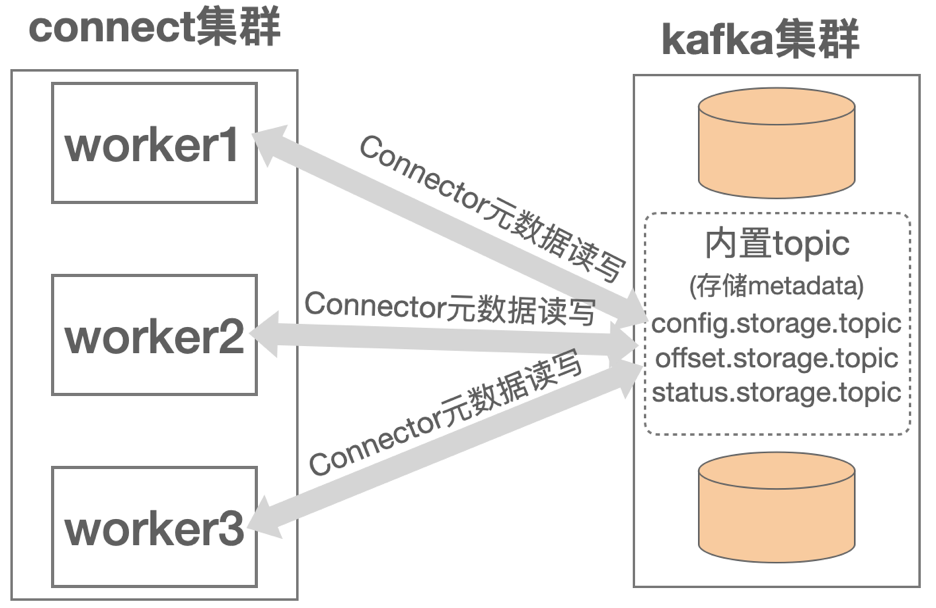
connect把kafka内置topic当作key/value存储
工作量几代码行数统计

新方案
1.rebalance功能迁移
新的rebalance机制如下:
引入raft协议:强一致性: 基于分布式一致性协议保证数据可靠性和一致性
raft leader 负责元数据管理 包括存储本地、存储DB、第三方存储 connector-tasks负载均衡 配置管理等等
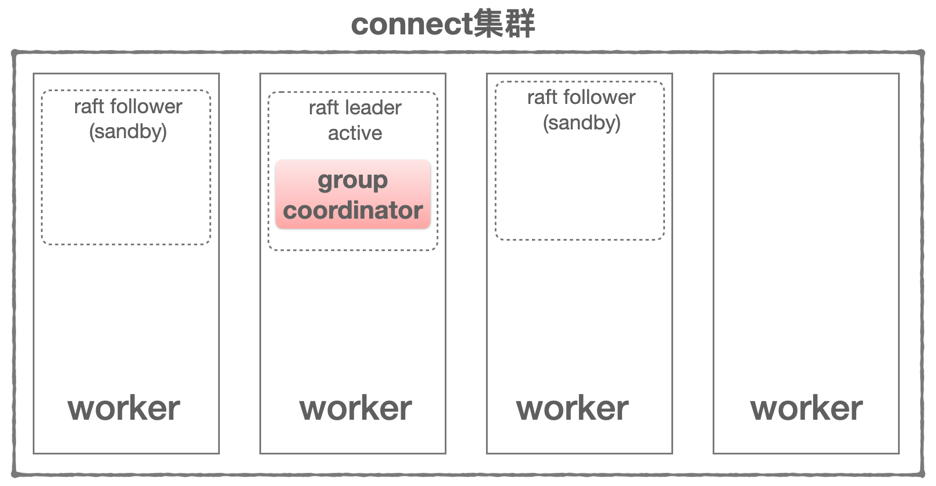
以上connect集群,变化如下:
- worker进程角色变化,当worker启动前,可以配置为单一角色(raft|worker)或组合角色(raft+worker),当配置为raft时,只负责raft leader选择和元数据存储、管理,不执行connetor-tasks任务;当配置组合角色为raft和worker时,同时兼具raft leader选择和元数据存储、管理和执行connetor-tasks任务
- kafka中GroupCoordinate迁移到connect集群中,选择raft leader所在worker节点承担GroupCoordinate工作,且connect集群中运行时只存在唯一且一个GroupCoordinate节点

以上是connect集群,物理部署结构
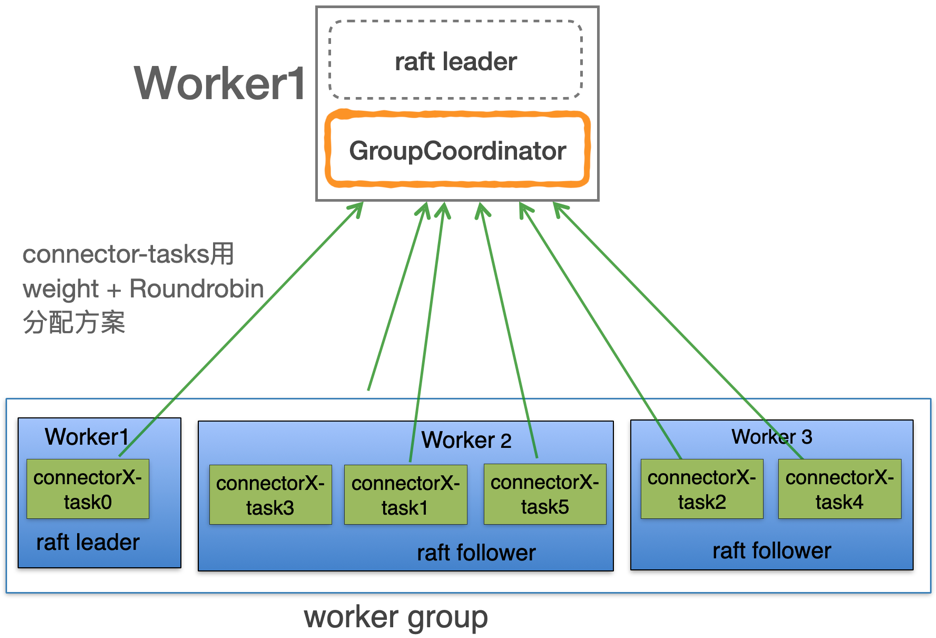
相比原生connect集群用Roundrobin算法对worker节点tasks平均分配,新方案采用weight + Roundrobin算法worker节点tasks平均分配,raft leader所在woker配置低权重少分配task,保证raft leader安全负载和运行稳定性。比如raft leader worker节点tasks分配权重不大于50%
2.元数据存储功能迁移
根据客户场景和业务需要,connector元数据存储需要支持多种方式,并且元数据读写操作需要提供统一编程接口,方便其他存储系统易于接入并做实现,多种元数据存储如下:
- 本地raft leader woker持久化connector元数据
- 支持DB(mysql、oracle、DB2)持久化connector元数据
- 支持第三方存储系统实现编程接口实现持久化connector元数据

下面是持久化connector元数据两种方式对比
- 第一种,worker直接调用存储系统,优点实现容易且简单,不足是在线热切换connector元数据存储系统需要通知所有connect集群所有worker节点变更
- 第二种,worker通过raft leader转发持久化请求,中间代理多了一层集群规模大,不足可能存在性能瓶颈,占用raft leader节点过多;优点是容易在线热切换connector元数据存储系统


3.raft实现选择
3.1 参考Kafka raft实现进行开发
用于集群控制节点leader选举和元数据存储,具体参考:Kafka 3.0 for kraft优势
3.2 选择蚂蚁金服raft框架SOFAJRaft

RheaKV 是一个轻量级的分布式的嵌入式的 KV 存储 lib, rheaKV 包含在 jraft 项目中,是 jraft 的一个子模块。
定位与特性
- 嵌入式: jar 包方式嵌入到应用中
- 强一致性: 基于 multi-raft 分布式一致性协议保证数据可靠性和一致性
- 自驱动 (目前未完全实现): 自诊断, 自优化, 自决策, 自恢复
- 可监控: 基于节点自动上报到PD的元信息和状态信息
- 基本API: get/put/delete 和跨分区 scan/batch put, distributed lock 等等
功能名词
- PD: 全局的中心总控节点,负责整个集群的调度,一个 PD server 可以管理多个集群,集群之间基于 clusterId 隔离;PD server 需要单独部署,当然,很多场景其实并不需要自管理,rheaKV 也支持不启用 PD
- Store: 集群中的一个物理存储节点,一个 store 包含一个或多个 region
- Region: 最小的 KV 数据单元,可理解为一个数据分区或者分片,每个 region 都有一个左闭右开的区间 [startKey, endKey)
- 存储层为可插拔设计, 目前支持 MemoryDB 和 RocksDB 两种实现:
- MemoryDB 基于 ConcurrentSkipListMap 实现,有更好的性能,但是单机存储容量受内存限制
- RocksDB 在存储容量上只受磁盘限制,适合更大数据量的场景
- 数据强一致性, 依靠 jraft 来同步数据到其他副本, 每个数据变更都会落地为一条 raft 日志, 通过 raft 的日志复制功能, 将数据安全可靠地同步到同 group 的全部节点中
3.3. Apache Ratis暂时了解不多
从raft框架活跃度和成熟度考虑、社区支持等等,apache ratis最佳选择。SOFAJRaft是蚂蚁金服一家支持,不过能在金融行业使用,系统稳定性和容灾容错应该是不错且得到验证的。
典型项目:Apache Hadoop Ozone对象存储系统使用了apache ratis框架
博客来自李志涛:https://www.cnblogs.com/lizherui/p/17444150.html

