


Kafka集群升级实施方案
一、背景
我们组内维护的kafka集群承担着公司绝大部分实时数据的收集传输任务。但是,现阶段存在如下问题,已经对集群的稳定性、用户的使用以及管理员的运维造成了很大影响:
- 1. 当前集群版本较低,且触发低版本bug的概率较高,严重影响了集群的稳定性,例如最近violet集群就因为触发bug导致集群不可用;
- 2. 当前多个集群的版本不一致,用户使用时会受到集群版本的制约,另外,由于多版本并存,管理员必须关注各版本间的异同,增加了线上问题排查的耗时和复杂度。
鉴于此,我们决定启动集群升级项目,将当前集群统一升级到较高的release版本 2.2,以提升集群稳定性,提供更优的用户体验,并降低管理员的运维成本。
在参考借鉴 kafka官网、主流企业级服务提供商 (confluent、cloudera)、国内其它公司 (携程)、胡夕文章等的集群升级方案后,结合公司内集群现状,形成了本文的升级方案。
二、目标
根据“对用户影响尽量小,操作尽量高效、安全”的原则,细化为“分批次、分阶段、不停服”的目标:
- 不停服:采取 滚动升级 的方式,避免出现整个集群不可用的情况,尽可能降低用户感知;
- 分批次:将当前所有集群按优先级划分为多个批次,当前批次执行升级且持续运行一周无异常后,再升级下一批次;
- 分阶段:将升级操作流程拆解为多个阶段,每个阶段的checklist确认无误后,再执行下一阶段操作,同时,提前准备好相应的预案 (回滚和线上服务恢复步骤) 以应对异常情况。
三、方案综述
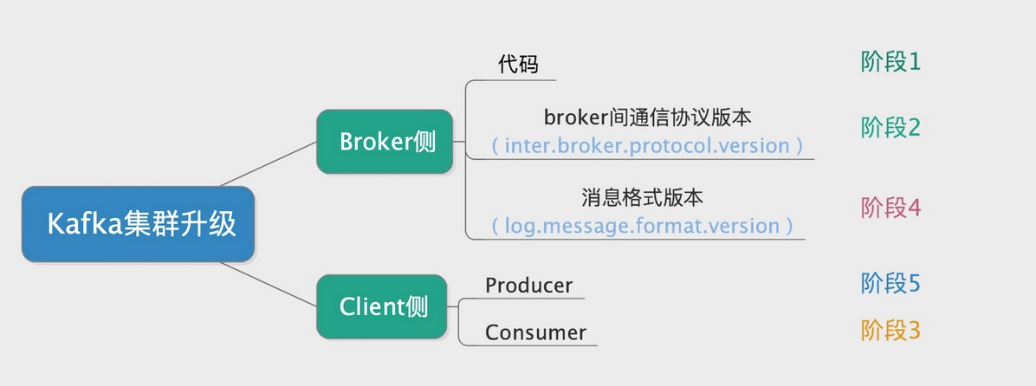
作为C/S架构,Kafka集群的完整升级过程涵盖了broker侧和client侧。
按照执行次序,完整的升级过程可划分为5个阶段,如下:
- [broker侧] 代码升级;
- [broker侧] broker间通信协议版本 (配置项) 升级;
- [client侧] Consumer升级;
- [broker侧] 消息格式版本 (配置项) 升级;
- [client侧] Producer升级。
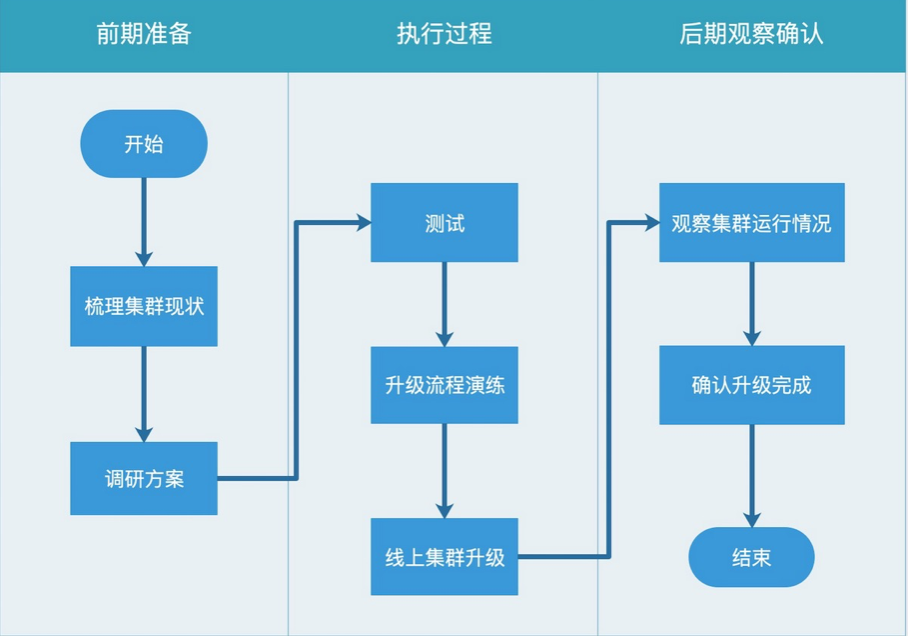
四、执行流程
集群升级的整体执行流程可分为7个环节,如下:
1.组内集群现状
主要关注点:
- 当前版本;
- 部署方式:不同方式部署的集群,升级操作过程可能不同 (取决于测试验证的结果,如果可以通过同一种方案对所有部署方式下的集群执行同等高效安全的操作,最好不过);
- 监控:考虑到后续的监控会全部对接Mon/AXE,借助此次梳理机会,对AXE节点和主机基础监控信息进行规整和完善。
目前,组内运维的Kafka集群共14个,按照部署方式分为两类:
- 通过Cloudera部署的集群 8个:0.8.2版本*4,0.10.2版本*3,0.10.0版本*1
- 手工部署的集群 6个:0.8.2.2版本*2,0.10.2版本*1,1.0.0版本*1,2.1.0版本*1,2.2.1版本*1
各集群详细信息如下:
2.测试
2.1 目标
从可行性、安全性、操作的方便程度 三方面对所有备选方案进行测试验证,选出综合最优者作为最终的执行方案。
2.2 测试方案
手工部署的集群测试方案:
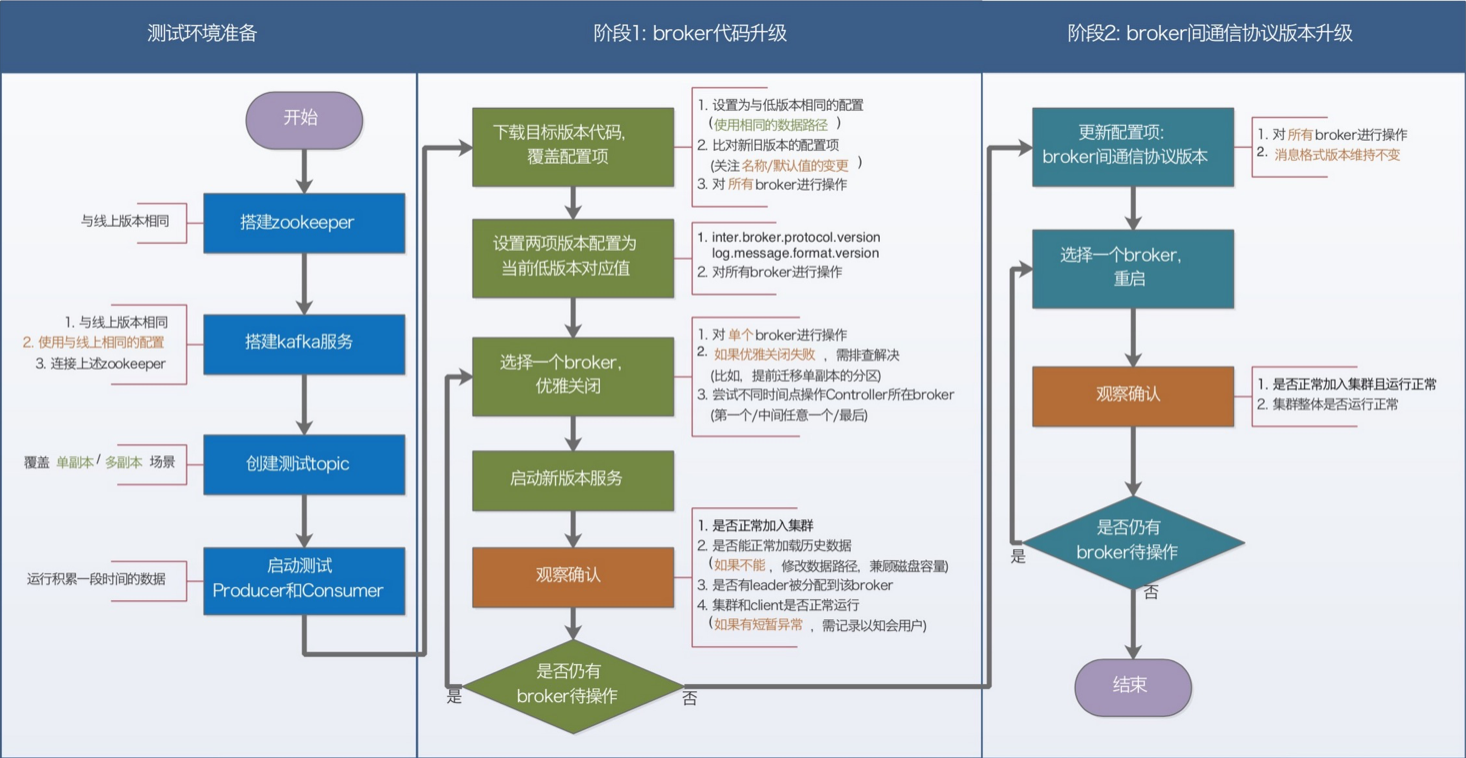
Cloudera部署的集群测试方案,流程与上述方案大体一致,不同点如下:
- 复用当前的Cloudera manager服务进行操作;
- 测试环境zookeeper和kafka的搭建,以及配置项的修改,都是在Cloudera Manager UI上操作完成的;
- 官方推荐采用parcel方式进行升级 (即,新版本代码的下载和部署由Cloudera Manager UI上的parcel操作完成),视该操作的复杂程度决定是否需要进行手工后台操作的尝试。
测试验证选择方案的过程,实际上是不断解决上述方案中的各项“如果”“尝试”的过程。随着这些项的全部解决和确定,最终的执行方案也就确定了。
2.3 测试过程及用例记录
快速搭建测试集群
安装包:由于需要搭建 多个版本 的集群,如果每个版本每次都从官网下载,势必会浪费时间。为此,预先下载好测试需要的所有版本的安装包 (包括kafka、zookeeper、用到的插件以及所依赖的Jar包),并以FTP形式提供,以便测试时随时使用。
安装流程准自动化:手工部署集群的流程相对固定,以自动化形式进行处理,在节省大量时间以更专注于测试任务的同时,也能大幅降低人为误操作的概率。为此,特开发相关脚本。
- __download_scrpits.sh: 下载所有脚本
- download_kafka.sh: 特定版本kafka安装包的下载与前置处理
- download_zookeeper.sh: zookeeper安装包的下载与前置处理
- init_before_download.sh: 安装环境的初始化 (包括服务和数据路径的创建、权限更改等操作,需要在下载安装包之前且以有root权限的账号运行)
测试环境:
- 三台机器分别为:10.103.17.55, 10.103.17.56, 10.103.17.57
- kafka manager上“test-inner”集群
测试验证执行流程 (测试用例)

结论:经测试,方案1即可满足目标,因此将该方案选定为最终的升级方案。
Cloudera部署集群的搭建与测试
以当前生产环境下Cloudera部署集群的最低版本 0.8.2.0 进行测试。
方案的选型与验证策略:优先验证通过手工升级的方式,在升级过程中一并解耦Cloudera环境,是由于Cloudera部署以及日常运维操作中存在如下问题:
• 通过yum部署的方式带来诸多不便,各机器的yum cache的差异会引入各种不确定的问题
• 部署过程中,需要不断在Cloudera manager页面和目标机器之间切换以处理异常
• Cloudera对服务目录和数据目录有特定的权限设置
• 集群日常增减机器的操作也比较繁琐
测试环境:
- 两台机器分别为:10.120.187.33, 10.120.187.34
- kafka manager上“test-inner-cloudera”集群
测试过程:在Cloudera部署的测试集群下验证4.2.3.2节的方案1,执行未发现新问题。
结论:经测试,可以手工通过方案1的方式对Cloudera部署的集群进行升级,升级后,Cloudera manager上的broker将全部被替换。
极端异常场景测试


MirrorMaker相关场景测试
由于线上环境的MirrorMaker只涉及从blue集群(0.8.2)到violet集群(0.8.2)的复制,测试过程也基于该版本的集群进行。
和线上环境保持一致,MirrorMaker部署在源集群上。
名词解释:
- 低版本:本节特指0.8.2版本
- 高版本:本节特指目标版本2.2.1
源集群维持低版本,目的集群升级版本 MirrorMaker工作正常
目的集群为高版本,源集群升级版本,MirrorMaker维持不变 MirrorMaker工作正常
目的集群维持低版本,源集群升级版本,且MirrorMaker升级版本 MirrorMaker工作异常
MirrorMaker的实质是,和其所在broker版本相同的一组Producer & Consumer。出现上述测试结果的原因是,高版本的集群可以兼容低版本客户端,反之则不行。
基于上述测试,升级过程需要注意如下几点:
- 升级blue/violet这两个集群过程中,需要随时关注验证MirrorMaker是否正常工作;
- 本次集群broker侧升级过程,MirrorMaker维持现状 (包括版本和运行路径,由于目前MirrorMaker使用的是Cloudera工作路径和代码,因此,blue集群的Cloudera工作路径和代码需要保留,直至后续MirrorMaker版本升级完成。
其它值得关注的点
1. 新旧版本的元信息记录文件 (如checkpoint) 内容和格式是否有变更?升级前后是否有变化?
0.8版本的元信息记录文件只有 recovery-point-offset-checkpoint 和 replication-offset-checkpoint ;
2.2版本的元信息记录文件在保持上述两个文件且内容格式不变的情况下,新增 meta.properties , log-start-offset-checkpoint 和 cleaner-offset-checkpoint 三个文件。
4.3 线上集群升级
批次划分
可能的影响方
- 外部门用户
- 组内
- CJV数据
- 数据同步
- MirrorMaker
- xxx平台topic监听功能
升级方案
配置项
其一,基本配置项,需要根据实际集群进行修改:
- broker.id:配置文件 server.properties + 数据路径下的 meta.properties 文件 (有些broker的ID有过变更,故需确保该文件中的ID和目标ID一致,或者统一全部删去该文件)
- listeners:对于使用机器名(非IP)进行配置的broker,需要验证机器IP和机器名映射到的IP是否一致,如果不一致,则需要使用IP进行配置。
- 检查上述两种IP是否一致方法:hostname -i VS host $(hostname)
- 校验新增的listeners配置项中使用的机器名是否正确:grep "listeners" server.properties | grep $(hostname)
- log.dirs
- zookeeper.connect
其二,broker配置项中值得关注的变更:


其三,其余配置项,直接追加到新版本配置文件中,并加以注释分割和说明。
手工部署集群升级方案


说明:
- 序号1-8的工作,可以提前操作完成,待正式操作线上前再校验一次;
- 升级broker间通信协议前一定要完全确认集群运行正常!
Cloudera部署集群升级方案
Cloudera部署集群的升级方案,与手工部署集群的升级方案流程大体相同,不同点如下:
- 旧版本服务的启停,是通过Cloudera manager进行操作的;
- 在停止旧版本服务后,必须对数据目录权限进行调整以增加worker账号的读写权限,原因是Cloudera部署的服务是通过kafka账号进行读写的;
- “更新新版本的配置项”步骤中,新增内容“根据brokerId调整预留brokerId范围”,原因是Cloudera自动生成的brokerId是在预留范围以外的



说明:
- 序号1-8的工作,可以提前操作完成,待正式操作线上前再校验一次;
- 升级broker间通信协议前一定要完全确认集群运行正常!
注意事项
- 升级操作应避开集群流量高峰时段;
- 开始操作前,要在用户群里先知会用户预计操作时长和潜在影响;
- 先在线上创建测试topic,并启动Producer和Consumer,用于随时观察集群可用性。
升级方案演练
目标
在测试环境对即将进行升级的集群操作进行全流程演练,主要目的有两点:
- 以文档的形式固化操作步骤 (包括每一步的执行人、执行的具体命令/操作、执行耗时 (作为线上操作预计耗时)、检查点,以及可能的回滚方案),供线上操作使用;
- 演练执行并确认回滚步骤的有效性。
五、其它问题
1.Cloudera manager操作
- Cloudera manager的部署和操作细节,可能需要多请教佳哥和玉才
- 如果在Cloudera manager UI上操作,需要关注每一步操作对应的后台变更 (可以随手记录积累经验)
2.集群与Cloudera环境剥离
在本期升级完成后,对Cloudera环境的依赖将仅剩zookeeper,可考虑在后续进行迁移,以完全脱离Cloudera环境
3.副本数为1 / ISR中只有一个 的topic的处理
这种情况下是否可能有数据丢失,取决于写入的数据是否含key:
- 如果不含key,则某个broker重启过程中,数据会写到其它broker分区中,理论上不会丢失数据;
- 如果含有key,则某些key对应的数据必须写到某个broker,这样,该broker重启过程中,这些数据丢失的可能性就较大,需要提前和用户沟通。
如何判断数据中是否含key呢?使用命令 bin/kafka-run-class.sh kafka.tools.DumpLogSegments -print-data-log -files xxx.log | more 查看落盘的消息格式。
- 具有key的消息内容格式:
offset: 0 position: 0 NoTimestampType: -1 size: 184 magic: 0 compresscodec: NONE crc: 510549616 isvalid: true
| offset: 0 NoTimestampType: -1 keysize: 7 valuesize: 151 crc: 510549616 isvalid: true key: k_abc payload: {"host":{"name":"c-httpserver-te
st-sh-2.ops.prod.bj1"},"env":"prod","source":"/log/httpserver.log","message":"logline - 2","service":"httpserver-test"}
- 没有key的消息内容格式:
offset: 0 position: 0 NoTimestampType: -1 size: 177 magic: 0 compresscodec: NONE crc: 839977979 isvalid: true
| offset: 0 NoTimestampType: -1 keysize: -1 valuesize: 151 crc: 839977979 isvalid: true payload: {"host":{"name":"c-httpserver-test-sh-3.ops.
prod.bj1"},"env":"prod","source":"/log/httpserver.log","message":"logline - 3","service":"httpserver-test"}
4.数据路径下meta.properties文件中brokerId与集群配置文件中不一致
影响:如果上述两种文件中记录的brokerId不一致,服务会启动失败
原因:之前brokerId有变更
解决:启动服务前修改meta.properties文件中的brokerId,以匹配集群配置文件server.properties中的brokerId;或者,全部删除数据路径下的meta.properties文件
5.低版本 (0.8.x) 集群中的topic __consumer_offsets 不健康
影响:集群升级到高版本后,高版本consumer API依然不可用
原因:之前brokerId有变更
解决:最好在升级之前删除该topic (执行相关命令进行删除 + 删除zookeeper元数据 + 删除数据文件),滚动重启集群,然后再进行升级操作
6.机器IP和机器名的双向映射不一致
影响:如果broker配置中绑定机器名,则会导致服务无法启动
原因:机器IP变更
解决:修改broker配置项"listeners",绑定机器IP来替换机器名
7.思考:一个大集群 VS 多个小集群 [TODO]
考虑因素:稳定性 (如,集群之间相互隔离)、运维 (如,便捷程度、重启对客户端的影响) 等
大集群重启broker会慢,在加载数据过程中broker是不可用的。
六、执行计划

七、主要参考
- Kafka官方文档: http://kafka.apache.org/documentation
- Cloudera kafka升级文档: https://docs.confluent.io/current/installation/upgrade.html
- Confluent kafka安装/升级文档: https://www.cloudera.com/documentation/kafka/latest/topics/kafka_installing.html
- Kafka官方文档 - 协议: https://kafka.apache.org/protocol.html
- 携程 Kafka 升级到2.0的实战经验: https://cloud.tencent.com/developer/news/377416
- Kafka版本升级 ( 0.10.0 -> 0.10.2 ): https://www.cnblogs.com/huxi2b/p/6525465.html

