[数据结构]深度优先搜索算法(Depth-First-Search,DFS)
深度优先搜索算法的概念#
与广度优先搜索算法不同,深度优先搜索算法类似与树的先序遍历。这种搜索算法所遵循的搜索策略是尽可能“深”地搜索一个图。它的基本思想如下:首先访问图中某一个起始顶点v,然后由v出发,访问与v相邻且未被访问的任一顶点w1,再访问与w1邻接且未被访问的任一顶点w2,….重复上述过程。当不能再继续向下访问时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续上述搜索过程,直到图中所有顶点均被访问过为止(还是举相同的例子,从你开始遍历你的所有亲戚,例如:先访问你的儿子,再从你的儿子继续访问你的儿子的儿子,直到你的儿子是最后一个顶点,再回退回上一层,访问你儿子的女儿,再访问你儿子的女儿的儿子….依此类推,直到你的所有亲戚都被访问过一次为止,这和广度优先搜索的算法区别还是很大的)。
算法伪代码#
DFS采用的是递归的过程,所以这个过程需要一个递归工作的辅助栈,伪代码如下:
bool visited[MAX_VERTEX_NUM];//访问标记数组
void DFSTraverse(Graph G){
//对图G进行深度优先遍历,访问函数为visit()
for(v=0;v<G.vexnum;++i)
visited[v]=false;//初始化所有顶点的数据,false表示未曾访问过
for(v=0;v<G.vexnum;++v)
if(!visited[v])
DFS(G,v);//这里从0遍历到最后一个顶点是为了防止有极端情况出现:可能存在顶点wi无法从顶点w0遍历到,所以需要对它也调用一次DFS算法
}
void DFS(Graph G,int v){
//从顶点v出发,采用递归的思想,深度优先遍历图G
visit(v);//访问顶点v
visited[v]=true;//设置这个顶点为已经访问过
for(w=FirstNeighbor(G,v);w>=0;w=NextNeighbor(G,v,w))
if(!visited[w])
DFS(G,w);//递归调用查找第一个未被访问的邻接顶点
}实例及分析#
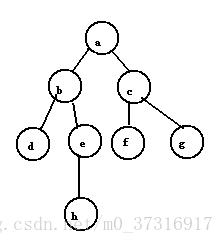
首先访问a,并置a为已经访问;然后访问与a邻接且未被访问的顶点b,置b为已经访问,然后访问与b邻接且未被访问的顶点d,置d为已经访问。此时d已经没有未被访问过的邻接点,这时候返回上一个访问过的顶点b,访问与其邻接且未被访问的顶点e,置e为已经访问……。依此类推,直到途中所有的顶点都被访问一次且仅仅被访问一次,遍历结果为abdehcfg。
DFS算法的性能分析#
DFS算法是一个递归算法,需要借助一个递归工作栈,所以它的空间复杂度是O(|V|)。
遍历图的过程实际上是对每个顶点查找其邻接点的过程,其耗费的时间取决于所采用的存储结构,当以邻接矩阵表示时,查找每个顶点的临界点所需时间为O(|V|),故总的时间复杂度为O(|V|²)。当以邻接表表示时,查找所有顶点的邻接点所需时间为O(|E|),访问顶点所需时间为O(|V|),此时,总的时间复杂度为O(|V|+|E|)。
作者:lizhenghao126
出处:https://www.cnblogs.com/lizhenghao126/p/11053737.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)