

epoll惊群问题详解
引言
惊群问题的存在会使得我们的程序把宝贵的cpu资源花费在无效的上下文切换,用户态与内核态的转换与空转的循环中,这显然对于一个要求高效率的网络程序来说是不可忍受的,而内核在2.6以后已经完全解决了accept的惊群问题,对于epoll的惊群问题却没有完全解决,这个"完全"其实是很耐人寻味的,epoll其实在一定程度上避免了惊群问题,但并没有完全解决,这是为什么呢?

原因就是对于accept来说,内核可以很确定我们是有一个进程希望拿到这个事件,所以可以放心大胆的去完全处理accept的惊群问题,解决的方法就是在监听的fd只在等待队列中唤醒一个进程(线程),这样就可以完美解决了.那epoll呢?显然epoll所处理的事件不仅仅是连接,还有所监听fd的可读可写等事件,这就意味着相比于accept,我们不一定非要使得所有的数据都在同一个进程(线程)处理,可能来了100KB的数据,我们可能希望在A进程处理50KB,在B进程处理50KB,虽然需求及其的奇怪,但是决定权在于用户而不在于操作系统,所以内核并没有完全解决惊群,但是确实在一定程度上解决了惊群,我们先来看一端测试代码:
代码是其他博主的,链接在文末,我觉得很能说明问题,让我写可能也差不多,就直接用啦,侵删
#include<stdio.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<unistd.h>
#include<sys/epoll.h>
#include<netdb.h>
#include<stdlib.h>
#include<fcntl.h>
#include<sys/wait.h>
#include<errno.h>
#define PROCESS_NUM 10
#define MAXEVENTS 64
//socket创建和绑定
int sock_creat_bind(char * port){
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in serveraddr;
serveraddr.sin_family = AF_INET;
serveraddr.sin_port = htons(atoi(port));
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);
bind(sock_fd, (struct sockaddr *)&serveraddr, sizeof(serveraddr));
return sock_fd;
}
//利用fcntl设置文件或者函数调用的状态标志
int make_nonblocking(int fd){
int val = fcntl(fd, F_GETFL);
val |= O_NONBLOCK;
if(fcntl(fd, F_SETFL, val) < 0){
perror("fcntl set");
return -1;
}
return 0;
}
int main(int argc, char *argv[])
{
int sock_fd, epoll_fd;
struct epoll_event event;
struct epoll_event *events;
if(argc < 2){
printf("usage: [port] %s", argv[1]);
exit(1);
}
if((sock_fd = sock_creat_bind(argv[1])) < 0){
perror("socket and bind");
exit(1);
}
if(make_nonblocking(sock_fd) < 0){
perror("make non blocking");
exit(1);
}
if(listen(sock_fd, SOMAXCONN) < 0){
perror("listen");
exit(1);
}
if((epoll_fd = epoll_create(MAXEVENTS))< 0){
perror("epoll_create");
exit(1);
}
event.data.fd = sock_fd;
event.events = EPOLLIN;
if(epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sock_fd, &event) < 0){
perror("epoll_ctl");
exit(1);
}
/*buffer where events are returned*/
events = (epoll_event*)calloc(MAXEVENTS, sizeof(event));
int i;
for(i = 0; i < PROCESS_NUM; ++i){
int pid = fork();
if(pid == 0){
while(1){
int num, j;
num = epoll_wait(epoll_fd, events, MAXEVENTS, -1);
printf("process %d returnt from epoll_wait\n", getpid());
sleep(2);
for(i = 0; i < num; ++i){
if((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) || (!(events[i].events & EPOLLIN))){
fprintf(stderr, "epoll error\n");
close(events[i].data.fd);
continue;
}else if(sock_fd == events[i].data.fd){
//收到关于监听套接字的通知,意味着一盒或者多个传入连接
struct sockaddr in_addr;
socklen_t in_len = sizeof(in_addr);
if(accept(sock_fd, &in_addr, &in_len) < 0){
printf("process %d accept failed!\n", getpid());
}else{
printf("process %d accept successful!\n", getpid());
}
}
}
}
}
}
wait(0);
free(events);
close(sock_fd);
return 0;
}
执行的话我们可以在一个终端中执行程序,一个进程中使用如下命令
telnet 127.0.0.1 端口号
有一点值得一提,我们可以看到在epoll_wait后面我们放了一个sleep,我们后面揭晓它隐藏的背后秘密
我们执行下看看

我们可以显然的看到惊群出现了,内核好像看起来并未为我们做什么事情,十个子进程的epoll_wait都被触发了,然后就是紧接着的十个accept,显然只会有一个成功,剩下都是失败的.我们不如再来看看把epoll_wait后的那个sleep去掉来看看会发生什么,不妨猜猜看,结果一样吗?

我们不妨来看看执行结果,代码注释掉那个sleep即可.
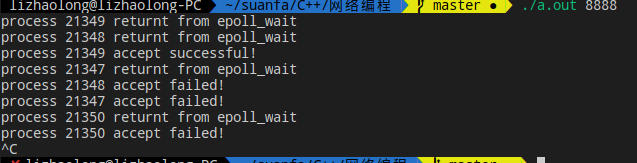
不相信?我们再多看几组

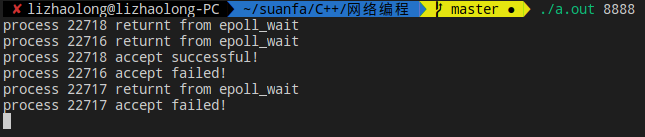

我们可以看到每次的结果都不尽相同,虽然不相同,但是确并没有唤醒全部的进程,也就是说内核不是没有处理epoll的惊群,而是在一定程度上进行了处理,你也许会问,这个程度是什么呢?
答案藏在源码里,我们一起来看看吧,当然这里只是调一点点片段讲解,但基本可以说明白这个问题,有兴趣的朋友可以看一下epoll源码解析系列文章了解epoll的全部秘密,传送门
这是epoll_wait中真正实现功能的函数ep_poll,代码内核版本为2.6.38
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
.........................
retry: //这个标记很重要 下面会说道
write_lock_irqsave(&ep->lock, flags); //自旋锁上锁 一系列宏上面已列出
res = 0;
if (list_empty(&ep->rdllist)) { //如果就绪链表为空的话就进入if 也就是睡眠了,否则的话直接跳出,
//相当于我们如果在epoll_ctl(ADD)后,事件已经发生了后在wait,消耗实际上就只是一个用户态到内核态的转换和拷贝而已,
//不涉及从等待队列中唤醒
/*
* We don't have any available event to return to the caller.
* We need to sleep here, and we will be wake up by
* ep_poll_callback() when events will become available.
*/
init_waitqueue_entry(&wait, current); //用当前进程初始化一个等待队列的entry
add_wait_queue(&ep->wq, &wait);
//把刚刚初始化的这个等待队列节点加到epoll内部的等待队列中去,也就是说在epoll_wait被唤醒时唤醒本进程
for (;;) { //开始睡眠
//我们不希望ep_poll_callback()发送给我们wakeup消息时我们还在沉睡,这就是为什么我们我们要在检查前设置成TASK_INTERRUPTIBLE
set_current_state(TASK_INTERRUPTIBLE);
if (!list_empty(&ep->rdllist) || !jtimeout) //rdllist不为空或者超时
break;
//当阻塞于某个慢系统调用的一个进程捕获某个信号且相应信号处理函数返回时,该系统调用可能返回一个EINTR错误
if (signal_pending(current)) { //收到一个信号的时候也可能被唤醒
res = -EINTR;
break;
}
write_unlock_irqrestore(&ep->lock, flags); //解锁 开始睡眠
jtimeout = schedule_timeout(jtimeout);//schedule_timeout的功能源码中的介绍为 sleep until timeout
write_lock_irqsave(&ep->lock, flags);
}
remove_wait_queue(&ep->wq, &wait); //醒来啦!从等待队列中移除
set_current_state(TASK_RUNNING);
}
/* Is it worth to try to dig for events ? */
/*
* 这里要注意 当rdlist被其他进程访问的时候,ep->ovflist会被设置为NULL,那时rdlist会被txlist替换,
* 因为在遍历rdlist的时候有可能ovlist传入数据,然后写入rdllist,所以rdllist也有可能不为空,
* 但为空且其他进程在访问的时候就会将eavail设置为true,为后面goto到retry再次进行睡眠做准备,
* 这样就避免了用户态的唤醒,从而避免了一定程度上的惊群.
* 至于为什么我们上面的样例代码每次都不一样,我们继续看
*/
eavail = !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
write_unlock_irqrestore(&ep->lock, flags); //解锁
/*
* Try to transfer events to user space. In case we get 0 events and
* there's still timeout left over, we go trying again in search of
* more luck.
*/
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && jtimeout)
//res还得为0 epoll才会继续沉睡,有可能ovflist其中有数据 ,后面赋给了rdllist,这是rdllist有数据,也就是说此时epoll_wait醒来还有数据,所以不必继续沉睡
goto retry;
return res;
}
ep_send_events调用ep_scan_ready_list,
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *, //注意上面调用的回调在这个函数中名为sproc
struct list_head *, void *),
void *priv)
{
int error, pwake = 0;
unsigned long flags;
struct epitem *epi, *nepi;
LIST_HEAD(txlist); //初始化一个链表 作用是把rellist中的数据换出来
/*
* We need to lock this because we could be hit by
* eventpoll_release_file() and epoll_ctl().
*/
mutex_lock(&ep->mtx);//操作时加锁(互斥锁,和ep->lock不是一个东西) 防止ctl中对结构进行修改
/*
* Steal the ready list, and re-init the original one to the
* empty list. Also, set ep->ovflist to NULL so that events
* happening while looping w/out locks, are not lost. We cannot
* have the poll callback to queue directly on ep->rdllist,
* because we want the "sproc" callback to be able to do it
* in a lockless way.
*/
spin_lock_irqsave(&ep->lock, flags); //加锁
list_splice_init(&ep->rdllist, &txlist);
ep->ovflist = NULL; //这里设置为NULL
spin_unlock_irqrestore(&ep->lock, flags);
/*
* Now call the callback function.
*/
//每次结果都不一样的原因在这里 如果我们执行了这里rdllist就为空了,上面的判断就会返回0 从而继续沉睡了,但是各进程每次执行到这里的时机是不确定的 所以会出现每次结果都不同的现象
error = (*sproc)(ep, &txlist, priv);
//对整个txlist执行回调,也就是对rdllist执行回调
//遍历的时候可能所监控的fd也会执行回调,向把fd加入到rellist中,但那个时候可能这里正在遍历,为了不竞争锁,把数据放到ovflist中
spin_lock_irqsave(&ep->lock, flags); //加锁,把其中数据放入rdllist
/*
* During the time we spent inside the "sproc" callback, some
* other events might have been queued by the poll callback.
* We re-insert them inside the main ready-list here.
*/
//上面提到了 当执行sproc回调的时候可能也会有到来的数据,为了避免那时插入rdllist加锁,
//把数据放到ovlist中.在执行完后加入rdllist中
for (nepi = ep->ovflist; (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
/*
* We need to check if the item is already in the list.
* During the "sproc" callback execution time, items are
* queued into ->ovflist but the "txlist" might already
* contain them, and the list_splice() below takes care of them.
*/
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
}
/*
* We need to set back ep->ovflist to EP_UNACTIVE_PTR, so that after
* releasing the lock, events will be queued in the normal way inside
* ep->rdllist.
*/
ep->ovflist = EP_UNACTIVE_PTR; //设置为初始化时的样子
/*
* Quickly re-inject items left on "txlist".
*/
//有可能有未处理完的数据,再插入rdllist中,比如说LT
list_splice(&txlist, &ep->rdllist);
if (!list_empty(&ep->rdllist)) { //rellist不为空的话,进行唤醒
/*
* Wake up (if active) both the eventpoll wait list and
* the ->poll() wait list (delayed after we release the lock).
*/
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
mutex_unlock(&ep->mtx); //我们可以看到在这里的时候两把锁都解开了
...............................................
return error;
}
总结
这样的话我们就搞清楚了epoll对于惊群的态度,即在一定程度上支持,当所监听的fd中还有数据的时候就从epoll_wait中醒来,因为内核不确定用户想如何处理这些数据,所以选择相信用户,这不同于accept,accept内核很确定我们只需要唤醒一个.而epoll不是,但epoll知道到所监听的fd中无数据的时候就不触发epoll_wait,这就在一定程度上避免了惊群,以上是我对这个问题的看法,欢迎大家讨论!
参考
https://www.cnblogs.com/zafu/p/8251849.html
https://blog.csdn.net/russell_tao/article/details/7204260


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!