
MIT 6.824 lab2 PartA
引言
在我学习这一系列课程之前再网上看到了这么一个帖子,说大多数人学6.824都在完成了lab1以后就放弃了。当我完成lec1 lab1的时候嗤之以鼻,MIT的课程难度也不过如此嘛。直到lec2,说实话有点不清楚在讲什么,因为没有课前预习的paper,只是扔了一大段代码,还没有注释,实在是让人有点不知所措,所以只是熟悉了go的RPC的用法和做了一点相关工作后就作罢。到了lec3 lab2,说实话实验难度确实是不小,可以说是骤然提升,这个难度的提升不仅体现在代码量上,更在设计的难度上,而且最让人无语的是直接扔给你一个框架的主体,但是几乎没有一个函数的实现,也就是说几乎是从头实现一个raft,而且代码之间的交互注释也并不详细,只能靠测试代码猜意思,对我这样智商普通的人来说确实是一个不小的挑战,MIT恐怖如斯。。在对比了其他博主的实现后历时两天算是完成了PartA,因为不确定后面的实验是否会修改现在已有的函数,所以计划以实验的步骤分为三篇文章,旨在能够帮到有同样疑问的朋友,不过我貌似违反了Collaboration Policy。。

正文部分
首先在完成这个实验之前一定要详细的读几遍Raft的paper,不然真的是没办法写。而且实验中明确提出 Figure2 是很好的参考材料,不然重头设计一个共识算法,抱歉,溜了溜了。。。
第一部分的任务是实现选举,选举是在长时间接收不到其他节点的信息时开始选举,这句话隐含着我们应该需要一个定时器,而且这里的通信使用RPC,也意味着我们需要自主设计RPC的args和reply。
我要先来看看测试代码,不然会没有一点点实现的头绪:
func TestInitialElection(t *testing.T) { // test of 2A
servers := 3
// 调用Make启动servers个Raft
cfg := make_config(t, servers, false)
defer cfg.cleanup()
fmt.Printf("Test: initial election ...\n")
// is a leader elected?
// 检查是否有leader被选举出来
cfg.checkOneLeader()
// does the leader+term stay the same there is no failure?
//查看当前term
term1 := cfg.checkTerms()
//等待一段时间
time.Sleep(2 * RaftElectionTimeout)
//检查term是否发生改变(用于检测网络正常情况下是否有乱选举的情况)
term2 := cfg.checkTerms()
if term1 != term2 {
fmt.Printf("warning: term changed even though there were no failures")
}
fmt.Printf(" ... Passed\n")
}
最重要的函数就是make_config,它创建N个raft节点的实例,并使他们互相连接。
func make_config(t *testing.T, n int, unreliable bool) *config {
runtime.GOMAXPROCS(4)
cfg := &config{}
cfg.t = t
cfg.net = labrpc.MakeNetwork()
cfg.n = n
cfg.applyErr = make([]string, cfg.n) // 节点的请求的返回信息
cfg.rafts = make([]*Raft, cfg.n) // raft节点数组
cfg.connected = make([]bool, cfg.n) // 是否连接
cfg.saved = make([]*Persister, cfg.n) //
cfg.endnames = make([][]string, cfg.n)// RPC暴露的接口
cfg.logs = make([]map[int]int, cfg.n) // copy of each server's committed entries
cfg.setunreliable(unreliable)
cfg.net.LongDelays(true)
// create a full set of Rafts.
for i := 0; i < cfg.n; i++ {
cfg.logs[i] = map[int]int{}
cfg.start1(i) // make在里面被调用
}
// connect everyone
for i := 0; i < cfg.n; i++ {
cfg.connect(i) //连接剩下的节点
}
return cfg
}
其实还有一个函数非常重要,就是checkOneLeader,这其实是测试代码的正确性检验的函数,也就是判断当前是否只有一个Leader,这里有一个坑点,就是这里的GetState函数是要我们自己去实现的,具体实现取决结构体如何设计。
func (cfg *config) checkOneLeader() int {
for iters := 0; iters < 10; iters++ {
time.Sleep(500 * time.Millisecond)
leaders := make(map[int][]int) // 分别获取每个节点的状态
for i := 0; i < cfg.n; i++ {
if cfg.connected[i] {
if t, leader := cfg.rafts[i].GetState(); leader {
leaders[t] = append(leaders[t], i)
}
}
}
lastTermWithLeader := -1
for t, leaders := range leaders { //如果多于一个leader 直接退出
if len(leaders) > 1 {
cfg.t.Fatalf("term %d has %d (>1) leaders", t, len(leaders))
}
if t > lastTermWithLeader {
lastTermWithLeader = t
}
}
if len(leaders) != 0 {
return leaders[lastTermWithLeader][0]
}
}
cfg.t.Fatalf("expected one leader, got none")
return -1 //没有leader当然也是错的
}
raft节点信息
好了,测试代码看完了,然后我们来实现代码,首先我们需要设计raft的节点信息,这里直接参考论文中的实现,并加一些论文中没有的细节。


(翻译链接我放在了文末 )
type Raft struct {
mu sync.Mutex
peers []*labrpc.ClientEnd
persister *Persister // 目前不知道有什么用
me int // index into peers[]
// Your data here.
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
currentTerm int // 服务器最后一次知道的任期号(初始化为 0,持续递增)
votedFor int // 在当前获得选票的候选人的 Id
logs []LogEntry // 日志条目集;每一个条目包含一个用户状态机执行的指令,和收到时的任期号
// Volatile state on all servers
commitIndex int // 已知的最大的已经被提交的日志条目的索引值
lastApplied int // 最后被应用到状态机的日志条目索引值(初始化为 0,持续递增)
// Volatile state on leaders
nextIndex []int // 对于每一个服务器,需要发送给他的下一个日志条目的索引值
matchIndex []int // 对于每一个服务器,已经复制给他的日志的最高索引值
// 以上成员来源于论文 有一部分目前并没有使用到 但是既然论文写了 就先写上,后面再说
votes_counts int // 记录此次投票中获取的票数 2A
current_state string // 记录当前是三个状态里的哪一个 2A
timer *time.Timer // 对于每一个raft对象都需要一个时钟 在超时是改变状态 进行下一轮的选举 2A
electionTimeout time.Duration // 200-400ms 选举的间隔时间不同 可以有效的防止选举失败 2A
applyCh chan ApplyMsg // 在Part A没用上,但是参数传了,先写上,应该在appendEntry的时候会使用到
}
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft { // 2A
/*
peers参数: 是通往其他Raft端点处于连接状态下的RPC连接
me参数: 是自己在端点数组中的索引
*/
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here.
rf.currentTerm = 0
rf.votedFor = -1
rf.logs = make([]LogEntry, 0)
rf.commitIndex = -1
rf.lastApplied = -1
rf.nextIndex = make([]int, len(peers)) // 记录 ”每一个“ 服务器需要发送的下一个日志索引值
rf.matchIndex = make([]int, len(peers))
rf.current_state = "FOLLOWER" //初始状态为follower
rf.applyCh = applyCh
// 为了降低出现选举失败的概率,选举超时时间随机在[200,400]ms
rf.electionTimeout = time.Millisecond * time.Duration(200+rand.Intn(200))
rf.resetTimer()
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
return rf
}
func (rf *Raft) resetTimer() {
if rf.timer != nil {
rf.timer.Stop() // 在make中我们没有初始化
}
rf.timer = time.AfterFunc(rf.electionTimeout, func() { rf.TimeoutElection() })
}
超时选举
首先说到超时选举我们一定会使用到定时器,这也是Raft结构体中timer的作用。其次既然是选举我们一定需要通信,在本实验中使用RPC通信,所以我们需要设计一个args和reply的结构体用于通信,hint中提醒我们一定要以大写字母开头。这里的结构体设计我们还是参考论文

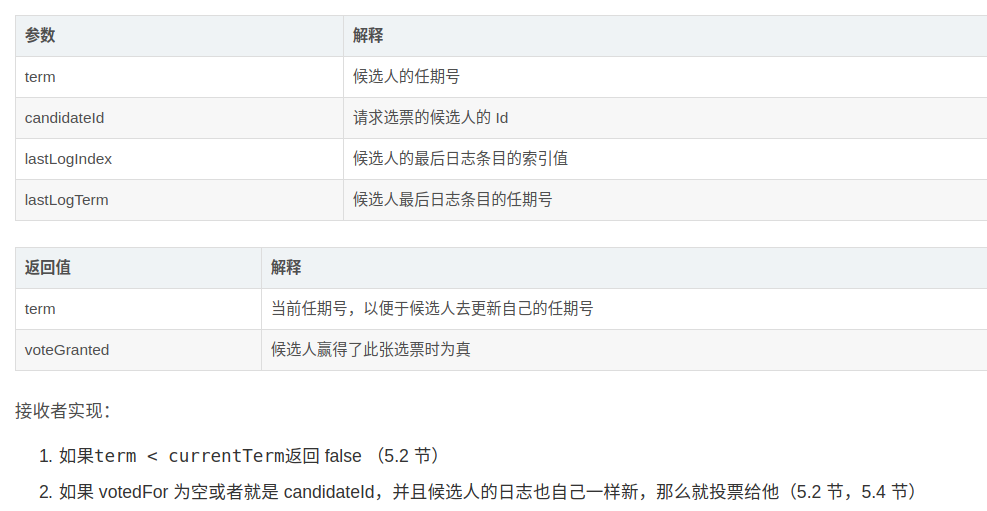
type RequestVoteArgs struct {
// Your data here.
Term int //候选人的任期号 2A
CandidateId int // 请求选票的候选人ID 2A
LastLogIndex int // 候选人的最后日志条目的索引值 2A
LastLogTerm int // 候选人的最后日志条目的任期号 2A
}
//
// example RequestVote RPC reply structure.
//
type RequestVoteReply struct {
// Your data here.
Term int // 当前任期号,便于返回后更新自己的任期号 2A
VoteGranted bool // 候选人赢得了此张选票时为真 2A
}
接下来就有意思啦,就是我们需要去写一个超时时调用的回调函数,也就是放在timer定时器里的那个TimeoutElection,这个函数的作用是在节点超时以后进行选举:
func (rf *Raft) TimeoutElection() { // 超时事件 // 2A
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.current_state != "LEADER" { // 超时时转换成候选者进行选举
rf.current_state = "CANDIDATE" // 改变当前状态为candidate
rf.currentTerm += 1 // Term加1
rf.votedFor = rf.me // 票投给自己handleTimer
rf.votes_counts = 1 // 目前有一票
args := RequestVoteArgs{
Term: rf.currentTerm, // 请求者的纪元
CandidateId: rf.me, // 请求者的ID
LastLogIndex: len(rf.logs) - 1, // 这一项用于在选举中选出最数据最新的节点 论文[5.4.1]
}
if len(rf.logs) > 0 {
args.LastLogTerm = rf.logs[args.LastLogIndex].Term
}
for serverNumber := 0; serverNumber < len(rf.peers); serverNumber++ { // 和其他服务器通信 请求投票给自己
if serverNumber == rf.me { // 当然不需要和自己通信啦
continue
}
go func(server int, args RequestVoteArgs) { // 并行效率更高
var reply RequestVoteReply
ok := rf.sendRequestVote(server, args, &reply) //进行RPC
if ok {
rf.handleVoteResult(reply) //对于获取到的结果进行处理
}
}(serverNumber, args)
}
}
rf.resetTimer() // 重置超时事件
}
这里面sendRequestVote是已经实现好了的,而handleVoteResult则是一个自定义函数,语义就是处理请求投票以后的返回值,这里跑一个goroutine来提升效率。我们来看看实现过程:
/*
* 当投票结果返回的时候执行处理的函数
* 这里可能有三种情况
* 1.返回值Trem小于发送者 -> 无效 抛弃这条信息
* 2.返回值Trem大于发送者 -> 状态转移为follower 并更新纪元
* 3.投票有效
*/
func (rf *Raft) handleVoteResult(reply RequestVoteReply) { // 2A
rf.mu.Lock()
defer rf.mu.Unlock()
// 收到的纪元小于当前纪元
if reply.Term < rf.currentTerm {
return
}
// 收到的纪元大于当前纪元
if reply.Term > rf.currentTerm {
rf.current_state = "FOLLOWER"
rf.currentTerm = reply.Term
rf.votedFor = -1
rf.resetTimer()
return
}
// 条件满足的话此次投票有效 否则的话就不用管了
if rf.current_state == "CANDIDATE" && reply.VoteGranted {
rf.votes_counts += 1 // 投票+1
if rf.votes_counts >= len(rf.peers)/2+1 { //票数超过全部节点的一半
rf.current_state = "LEADER"
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
rf.nextIndex[i] = len(rf.logs)
rf.matchIndex[i] = -1 //这里还不清楚是干什么的
}
rf.resetTimer() // 重置超时事件
}
return
}
}
最后需要实现一个Raft接收到一个节点发送的请求投票以后要做些什么,实现在RequestVote:
//
// example RequestVote RPC handler.
// 也就是收到投票以后干什么
/*
* 我们在这个函数中需要实现将请求者的日志和被请求者的日志作对比
* 1.比较最后一项日志的Term,也就是LastLogTerm,相同的话比较索引,也就是LastLogIndex,如果当前节点较新的话就不会投票
* 2.如果当前节点的Term比候选者节点的Term大,拒绝投票
* 3.如果当前节点的Term比候选者节点的Term小,那么当前节点转换为Follwer状态
* 4.判断是否已经投过票,如果没投票并且能投票(日志更旧),那么就投票给该候选者
*/
func (rf *Raft) RequestVote(args RequestVoteArgs, reply *RequestVoteReply) { // 2A
// Your code here.
rf.mu.Lock()
defer rf.mu.Unlock()
voting := true
// 此节点日志比请求者的日志新
if len(rf.logs) > 0 {
if rf.logs[len(rf.logs)-1].Term > args.LastLogTerm ||
(rf.logs[len(rf.logs)-1].Term == args.LastLogTerm &&
len(rf.logs)-1 > args.LastLogIndex) {
voting = false
}
}
// 此节点Trem大于请求者 忽略请求
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
}
// 此节点Trem小于请求者
if args.Term > rf.currentTerm {
rf.current_state = "FOLLOWER"
rf.currentTerm = args.Term
rf.votedFor = -1
if voting {
rf.votedFor = args.CandidateId
}
rf.resetTimer() //重置超时事件
reply.Term = args.Term
reply.VoteGranted = (rf.votedFor == args.CandidateId)
return
}
// Term相同 判断是否需要投票
if args.Term == rf.currentTerm {
if rf.votedFor == -1 && voting{ // 未投过票且日志没有问题 可以投票
rf.votedFor = args.CandidateId
}
reply.Term = rf.currentTerm
reply.VoteGranted = (rf.votedFor == args.CandidateId)
return
}
}
至此Lab2 PartA就完成了,此时我们已经实现了raft的选举部分,也就是使用Make函数初始化,当初始化的节点超时(各节点不相同)以后触发定时器中的回调TimeoutElection,此时对除了自己以外的节点发送投票请求,其他节点调用RequestVote处理,当纪元有效的时候回复消息,在请求投票方接收到reply以后执行handleVoteResult调整自身状态,并在票数超过一半的时候成为Leader。
按照实验所说,如果我们完成了Part A,执行go test我们可以通过第一,二个测试,如下:
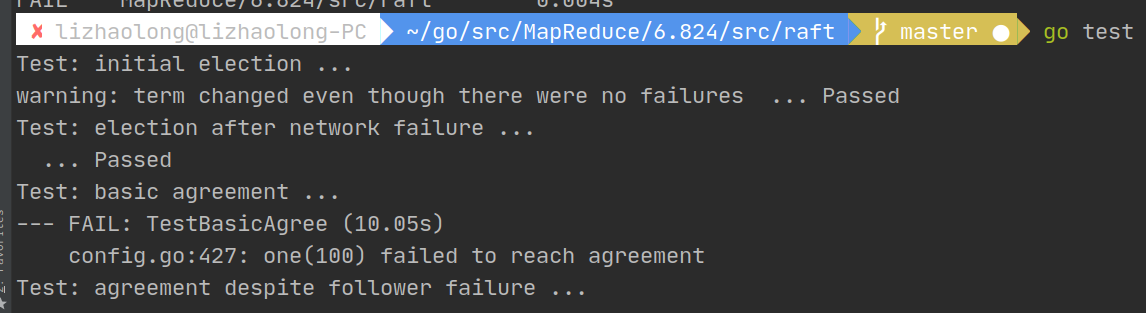
ps:其实还没有完成,因为在选举成功以后没有广播,所以会导致其他的节点再次选举,这可能也是出现了warning的原因,我们的做法应该就是按照论文中的在选举成功发送一个空日志(empty AppendEntries)来表明leader的地位,但是这和Part B有点重复,放在Part B来实现吧。累了,看海贼王去。
总结
实验确实难度越来越大了,希望后面可以坚持下去。
2020.8.1 :
更新了一个6.824每一课后面的问题解答,有很多确实很有意思的问题,有兴趣的朋友可以看看
参考:
- 翻译《Raft》

