
再聊聊Linux IO
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
写这篇文章是因为看到了欢神的一篇博客[1],博客内容固然精彩,但是在我看来宽泛有余,细致不足,欢神这样的人对于这些基础知识自然是炉火纯青的,但是抽出大把的时间去写出来当然就显得成本太高,但是这并不妨碍这篇茶余饭后创作的小几千字的文章仍是让人受益匪浅。在[1]的文末欢神自己也提到了希望这篇文章的读者能够继续往下走一走,所以这篇文章的目的就是更深入的谈谈这个看似简单,但实则让人踩坑无数的问题。当然很多地方理解可能是不全然正确的,遂希望各位抱着批判的态度来看这篇文章。
提出问题
- 在Linux IO中一般来说普通读写需要经过几次数据拷贝?
- 同步IO与异步IO的区别?Linux是否存在异步IO?
- VFS的多级缓冲分别是哪些?
- 电脑突然掉电会丢失数据吗?如果会的话丢失哪些数据?
如果这些全部回答正确且明白其背后的原理的话,那么就没有必要浪费时间再去浏览剩下的内容了。如果有些问题在脑中一瞬间是一片空白的话,那么请耐心的读完剩下的内容,相信一定不会白白浪费你的时间。
块设备与存储介质
系统中能够随机访问固定大小数据片的硬件设备称作块设备,最常见的就是硬盘,也包括软盘驱动器,蓝光光驱,闪存等等,其一般的使用方式是安装文件系统来使用。与之相对应的就是字符设备,字符设备按照字符流的方式被有序访问,最常见的当然就是键盘了,今天不讨论字符设备。
在块设备中最小的可寻址单元是扇区 sector,最小的意思就是块设备无法对比它还小的单位进行寻址和操作,也就是说读1个字节还是更多个字节,如果不大于一个扇区的大小,都在一次磁盘操作中可以完成,最常见的扇区大小就是512字节。
你可以在中断输入如下命令查看某个磁盘相关的数据:
sudo smartctl --all /dev/sda
但是对于文件系统来说最小的单位称为块 block,块是文件系统的一种抽象,我们只能基于块来访问文件系统,当然扇区是物理设备的最小可寻址单元,块当然不能小于扇区,一般是数倍于扇区大小的。
先不讨论其他的块设备,我们来说说磁盘。平时生活中常见的磁盘有5400rpm,7200rpm,10000rpm,15000rpm的规格,第一眼看到这个数据你可能不会有什么感觉,但是我们不妨一起算一个数字,我们以7200rpm举例:
7200rpm = 7200r/min = 120r/s
1000ms / 120 * 2 = 4.17ms
不考虑任何其他算法,每次磁头都旋转半圆,寻道时间为4.17ms,当然不可能每一次都转半圆,而且各种磁盘IO调度算法也不是吃素的,但是我们需要清楚,这种开销是毫秒级别的,这个数字是极其恐怖的,为什么?nginx在我四核七代i5的机器都可以在不跑满CPU负载的情况下轻松得到20000+的RPS,这意味着一个磁盘IO就按一毫秒计算也少处理了200个请求。
为什么要一直聊这些呢?原因是作为一个计算机行业从业者,我想我们应该清楚这种可以称为性能杀手的线程(进程)阻塞何时发生以及为什么发生。
别着急,我们接着往下聊。我们知道用户进程的page cache分为两种,一种称为File-backed Pages,一种称为Anonymous Pages,它们的区别就是前者与文件关联,而后者是与内存无关的匿名内存页,比如为进程分配的进程的堆,栈等,显然可以想象到在大多数情况下Anonymous Pages的数量是要大于File-backed Pages,
我们可以查看/proc/meminfo看看机器的内存消耗分布,这里只是部分的截图,我们可以看到其中Active (anon)和Inactive (anon)的数量是大于Inactive (file)和Active (file)的,Active 链表和Inactive 链表与内存的页面回收算法相关,对此有疑惑可以查阅其他资料。
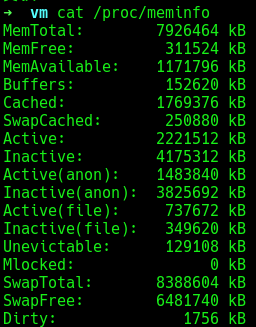
说了这么多,最重要的话就是匿名内存页在内存不足的时候会写入swap分区,而与文件关联的内存页则会回写磁盘,当然这并不是全部的磁盘操作可能的情况,还有一种情况就是脏页的回写,这个由一个内核线程 flusher去做的,这个我们后面再聊。说到内核线程,这里提一个小小的问题,这里说的内核线程和一般使用pthread_create创建的线程有什么区别?(或者这里的内核线程和OS教材上的内核线程是一个玩意儿吗?)
既然已经说了这么多磁盘,雨露均沾,我们就再来说说内存吧,一般而言我们的内存使用的是DRAM,DRAM由许多重复的“单元”——cell组成,每一个cell由一个电容和一个晶体管构成,电容可储存1bit数据量,充放电后电荷的多少(电势高低)分别对应二进制数据0和1。由于电容会有漏电现象,因此过一段时间之后电荷会丢失,导致电势不足而丢失数据,因此必须经常进行充电保持电势,这个充电的动作叫做刷新(self-refresh),这个刷新的操作一直要持续到数据改变或者断电。因此,DRAM具有掉电易失性。
与DRAM相比,SRAM使用晶体管代替电容来存储信息,其相比于DRAM不需要定期刷新,更复杂,更大,更昂贵,所以适合于快速内存,一般CPU高阶缓存时候SRAM,其虽然快,但是也具有掉电易失性。
这里我们在心里有这样一个概念,即DRAM和SRAM都是掉电易失的,至于数据如何我们后面再说。
当然虽然我们现在是基于这样易失性的介质讨论,但是世界总归是要进步的,Intel的持久化内存傲腾(Optane)已经如火如荼的流行起来,前一阵的阿里云的天池挑战赛的赛题就是基于持久化内存去设计一个解决单机kv的热点问题,显然我当时和狗勋的理解出现了偏差,把重心放在了高效的防止热点,而忽略了这种特殊的介质。从这个事情至少我们可以看到国内的领头羊们一定已经开始去尝试这种新兴事物了。
当然不敢大言不惭,但是我还是想斗胆做出本文的第一个预测,那就是这种可持久化内存(Persistent Memory)一定会在一定程度上影响未来的编程模型,很多大型软件的优化行为甚至架构都会有很大的不同。
单机应用比如数据库,像这种数据先写内存,然后在一次性刷到磁盘的优化就毫无意义了,可能以后的优化方向会趋向于高效的用户态的buffer,以减少系统调用。
分布式应用最经典的就是像Redis这样需要持久化的分布式缓存框架,那么显然也有很多机会获得更好的性能优化;再比如Spark RDD这种in memory分布式计算框架最初就是为了避免Map/Reduce的中间计算数据直接进入存放到可靠稳定的环境中,比如分布式文件系统。显然可持久化内存使得这种情况下拥有巨大的优化潜力,当然这一定会涉及到一些数据结构的修改,使其更适合访问可持久话内存的内存特性。
Linux存储栈图
我们先来看看Linux存储栈的结构,以此引出更深层次的讨论:
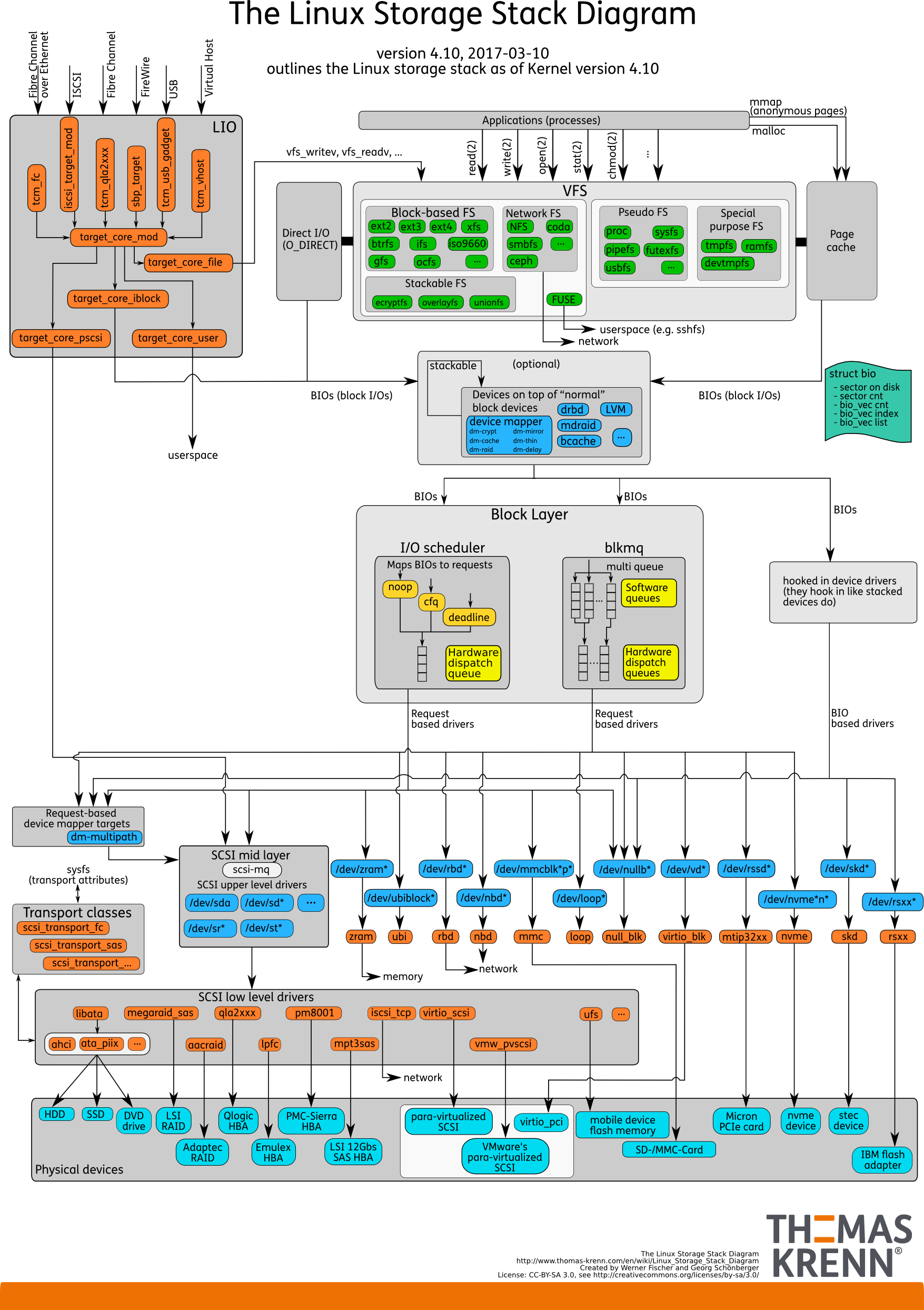
首先我们可以从这幅图中看出整个Linux的IO协议栈可以大致分成三层:
- 文件系统层:可以在图中看到我们针对于文件的系统调用都首先经过
VFS,然后要么通过Direct I/O到下一层,要么通过Page Cache到下一层,当然所有的IO请求都被组织为BIO,BIO对应的结构体是struct bio,该结构体代表以片段(segment)链表形式组织的块I/O操作。 - 块层:管理块设备的IO队列,其实就是去应用
I/O调度程序,将这个bio或合并到已存在的request中,或创建一个新的request,并将这个新创建的request插入到设备的请求队列中去,以减少磁盘中磁头的转动时间,增加I/O请求的效率。 - 设备层:通过DMA与内存直接交互,完成数据和具体设备之间的交互。其驱动程序也会处理请求队列中的请求,直到这个队列为空为止。
上图简化一点其实就是这样:
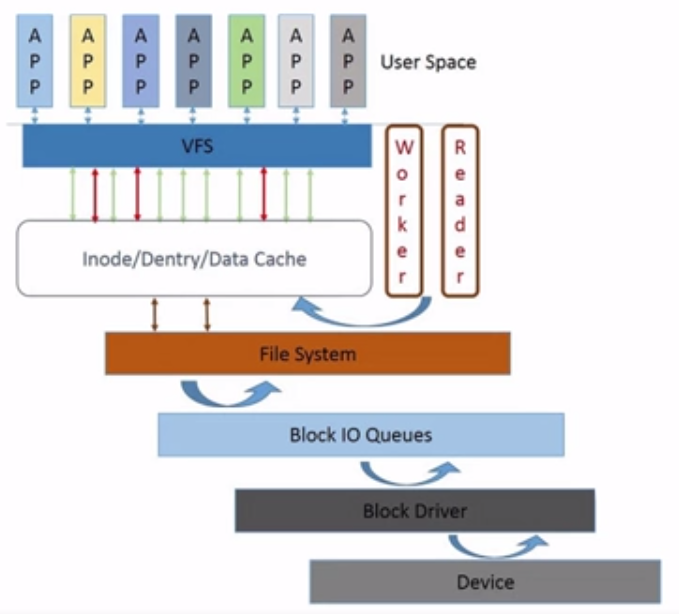
我们来简略的看看一次文件的写入过程会经过哪些过程,其中代码基于内核2.6.38.
- 首先在
task_struct中找到files_struct。 - 在
files_struct中找到file字段,这是一个数组,存放这fd和file的映射,当然文件对象本身并没有磁盘中的数据。 file结构体中存在address_space对象,这个结构其实就是page_cache的实体,其中的的page_tree字段是一颗包含此文件目前所有缓冲页面的radix树,如果在page_tree中找到了内容,显然就没必要再通过磁盘去读取文件中内容了,因为已经被缓存在page_cache中了。- 如果在page_cache中没有发现数据的话,此时就会启动一个I/O请求,在磁盘内读取数据,结构体为
bio,需要注意的是bio中只有一个起始扇区的地址,却有一条链的请求,每一个请求项为bio_vec,其中存储着这个缓冲区驻留的物理页和偏移量与长度,很难想象如何组织这一条链的请求,答案就是一个BIO所请求的数据在存储设备中是连续的。 - 然后把请求到的数据放入到
page_tree字段中。这里要提一下,因为address_space属于inode结构体,所以实际多个file如果打开的是同一个文件,那么它们的page_cache其实是一样的。
在上面的描述中我们可以看出在一次的文件读取过程中page_cache处于一个很重要的位置,因为如果其中存储着所属文件的缓存的话就可以不需要从磁盘中请求数据了,这可以剩下大量的时间,因为一次请求磁盘的过程是毫秒级别的。
我们接下来会详细聊聊page_cache这个东西,当然虽然这个东西很牛B,但是它其实也就是对文件内容的缓存,不过是VFSN级缓存中的其中一级,也就会这讨论page_cache之前我们必须心里清楚其实VFS中也是拥有多级缓存的。
Linux使用了四种和文件系统相关的传统抽象概念,也就是:
- 文件
- 目录项
- 索引结点
- 挂载点(mount point)
其实缓冲区本质来说就是内存空间的一部分,也就是在内存空间中预留了一定的存储空间,用这些存储空间来缓冲输入或者输出的数据。
VFS缓存
缓存这个概念实在是太大了,所以我们今天只讨论VFS层的缓存,再深的东西我也不敢多言了。
首先我们来看看VFS层缓存的示意图。
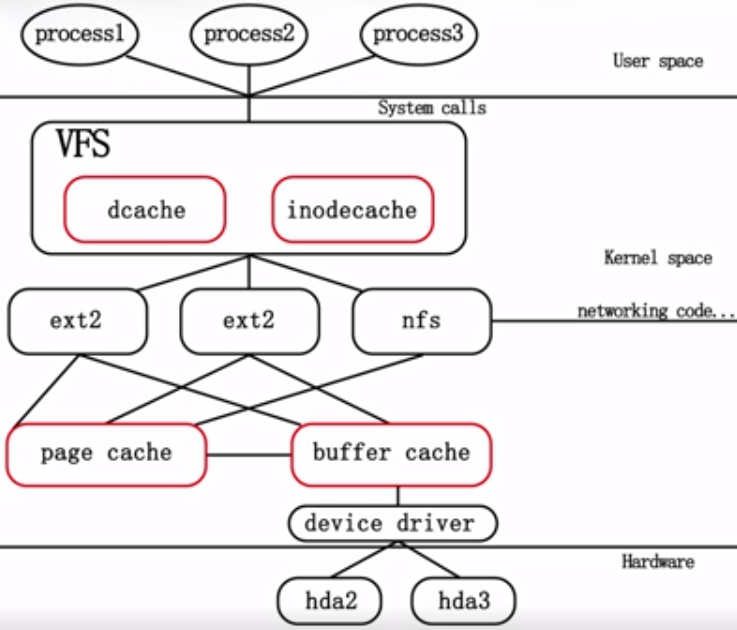
其中标记红色框的其实都是缓存,意义分别如下:
- dcache:对于
dentry对象的缓存,用于方便查找操作。 - inodecache:索引结点对象,即
inode对象包含了内核在操作文件或者目录时所需要的全部信息,一个dentry对象对应着一个inode对象。 - page cache:对于文件内容的缓存。
- buffer cache:也叫块缓冲,是对物理磁盘上的一个磁盘块进行的缓冲,其大小为通常为1k,磁盘块也是磁盘的组织单位。设立buffer cache的目的是为在程序多次访问同一磁盘块时,减少访问时间。其具体的结构就是
buffer_head,这个数据结构把内存中的页与磁盘中的块关联起来了。
我们来看看打开一个文件到底做了哪些事情,通常把查找的过程分为两部分,第一个部分是查找根目录的信息,第二个部分是循环查找路径名后续分量。
查找的主要过程是do_lookup,其查找dentry和inode,do_lookup会先查找dcache,如果不存在的话就会调用文件系统的钩子函数inode.lookup查找对应的inode和dentry,在查找时首先在inodecache中查找是否存在inode,如果不存在的话只能去更底层的磁盘去查找对应的inode信息。
去磁盘查找inode信息时,首先去buffer cache中查找相应的块,如果有相应的块存在,则从相应的buffer cache中提取inode的信息,并将其转换为对应的文件系统的inode结构。
其次在说说dcache,其组织结构其实就是哈希表(还有LRU链表),其包含了所有活动对象的dentry对象,对象名为dentry_hashtable,位于fs/dcache.c中,dentry通过其d_hash字段链入哈希表,那么如何查找在dcache中进行查找呢?答案藏在__d_lookup_rcu函数中,简单的逻辑如下:
// 第二个参数为当前目录项的信息,包含字符串和哈希值
struct dentry *__d_lookup_rcu(struct dentry *parent, struct qstr *name,
unsigned *seq, struct inode **inode)
{
unsigned int len = name->len;
unsigned int hash = name->hash;
const unsigned char *str = name->name;
struct hlist_bl_head *b = d_hash(parent, hash); // 内核哈希表采用链地址法,得到对应链表
struct hlist_bl_node *node;
struct dentry *dentry;
// 查找,未找到则返回null
hlist_bl_for_each_entry_rcu(dentry, node, b, d_hash) {
...
return dentry;
}
return NULL;
其实参数中参数中的name在link_path_walk函数中被创建,其中存储着当前搜索路径的路径名指针,字符串长度和哈希值。
总而言之,VFS的各级缓存有以下作用:
dcache可以加速文件路径名的解析。inode cache可以加速文件元数据的查找。page cache可以加速数据的查找。Buffer cache合并多个访问同一磁盘块的请求,减少磁盘的访问时间。
Page cache
我们在前面的文字中知道了page cache其实就是文件系统的一层缓冲,其负责缓存文件的内容。它对于整个IO系统至关重要,因为不仅是读取的时候我们可以从其中读取,使得不需要经过磁盘;在写入的时候也可以先写入Page cache,称为脏页,而不直接写入磁盘,以增加效率,因为可以把多次的写入合并成一次落盘,这极大的提升了性能。
脏页的回写有两种方法,一种是靠内核线程flusher;一种是看用户的意愿,即fsync/fdatasync系统调用;
很多nosql都支持持久化,比如redis,其中持久化可以支持多种等级,例如always/everysec/no,其中的评判标准就是多少间隔跑一次fsync。
至于flusher,与其相关的配置在/proc/sys/vm中,具体的配置信息可参考[8],当然中文文档参考[9]。
Page Cache的基本维护算法是基于“时间局部性”(Temporal Locality)的。wiki对其的解释如下:
Temporal locality: If at one point a particular memory location is referenced, then it is likely that the same location will be referenced again in the near future. There is temporal proximity between adjacent references to the same memory location. In this case it is common to make efforts to store a copy of the referenced data in faster memory storage, to reduce the latency of subsequent references. Temporal locality is a special case of spatial locality (see below), namely when the prospective location is identical to the present location.
经过了前面大段的描述,我想你应该已经很清楚磁盘操作是一个相当昂贵的操作,内存操作相比之下就要快的多了,几乎是两到三个数量级,学过微机原理的话就应该知道CPU和存储器都属于主机设备,通过数据总线相连,一个总线周期最小只有四个时钟周期,相比与现在机器的GHZ单位就显得太微不足道了。
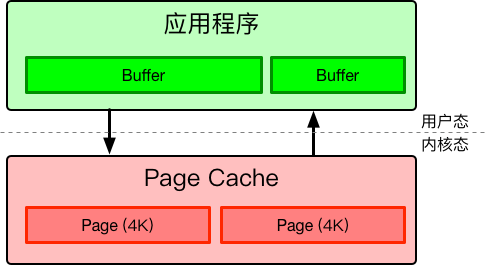
既然Page cache是缓存,那么显然我们需要把数据拷贝到内存中的缓存中,而且诸如write/read/send/recv这样的系统调用从应用程序到Page Cache也会拷贝数据,也就是我们常说的内核态到用户态的拷贝。
这就有了两次数据拷贝,而且都是CPU copy,也就是这些拷贝都是CPU来做的,消耗CPU时间,影响服务器正常的逻辑执行。
我们有几个办法可以绕开这两次拷贝。你也许想问,绕过用户态到内核态的拷贝也就算了,为了要绕过Page Cache呢,因为它在满足时间局部性的时候很高效啊。答案就是因为它只在满足时间局部性的时候很高效,但是如果我们预先知道接下来的访问不会遵循时间局部性,那么到Page cache的拷贝就是低效的了。对Page cache做假设最经典的也就是fadvise系统调用了。
Direct IO
故名思意,其实就是“直接”的IO,这里的直接指的是跳过Page cache的IO,这样当然会使得操作低效,但是有些特殊的场景就需要直接写入,比如数据库中的预写日志就必须直接写入磁盘,不能够放入缓存中。
当然写入的时候要注意一点,就是如果Direct IO如果要把数据写入磁盘的话必须程序员必须自行保证块对齐,即write时给的buffer的offset和size要刚好与VFS中的“块”对应,不然就会得到EINVAL错误。如果使用Page cache的话j内核就会帮助我们自动解决这个问题了,但是如果选择绕过的话我们只能自己做这件事情了,对应的posix_memalign可以分配块对齐的内存地址。
我们写一个简单的程序看看Direct IO的简单过程:
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> // posix_memalign
int main(){
char *buf;
size_t buf_size = 1024;
off_t offset = 4096;
posix_memalign((void **)&buf, getpagesize(), buf_size);
printf("%d\n", getpagesize());
//buf = (char*)malloc(buf_size);
scanf("%s", buf);
int writefd =open("test.txt",O_RDWR|O_DIRECT);
if(writefd<0){
printf("can't open the file!\n");
exit(1);
}
if(lseek(writefd,offset,SEEK_SET)<0){
printf("lseekthe disk is error!\n");
exit(1);
}
printf("%d %d\n", buf_size, write(writefd,buf,buf_size));
perror("");
if(buf_size != read(writefd,buf,buf_size)){
perror("readdata from the disk is error!");
printf("the tem_size is %d\n",buf_size);
exit(1);
}
}
输出为:
4096
45
1024 1024
Success
readdata from the disk is error!: Success
the tem_size is 1024
如果把posix_memalign注释掉,把malloc取消注释,就会出现下面的结果:
4096
12
1024 -1
Invalid argument
readdata from the disk is error!: Invalid argument
the tem_size is 1024
mmap
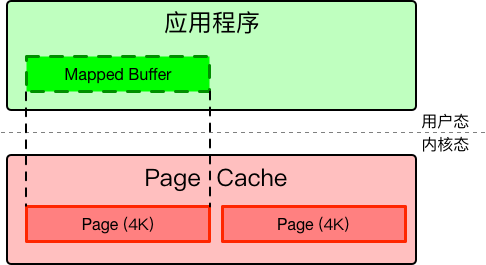
mmap可以把page cache的直接映射到用户空间中,这样我们就省掉了从用户态到内核态的拷贝,我们可以像访问一个字符串一样去随机访问内核空间,而不需要每次都使用lseek这样的函数去频繁定位文件的位置,这可以减少很多次系统调用的开销。
你可能对这样的功能感到十分的疑惑,如何才能做到这样呢,其实内核的做法相当简单。我们这就来说道说道mmap的本质:就是task_struct结构体中的mm_struct中的mmap成员与mm_rb成员的每一项,即vm_area_struct结构体,其就是虚拟内存的实际表示形式,具体点其实就是一个虚拟地址区间,而mmap的过程其实就是创建这么一个结构。值得一提的是malloc在分配大块内存的时候也用到了这个操作。
当然mmap的映射建立好以后并不是已经万事大吉了,原因是我们只是创建了虚拟内存,更细致点其实就是用户态到内核态虚拟地址空间映射,还没有完成虚拟地址空间到物理空间的映射,这一般是通过缺页中断来完成的,内核会根据缺页的VMA属性来选择相对应的操作。假如缺页的VMA属于匿名映射,则调用do_anonymous_page来处理,否则调用do_fault来处理,这里面更细致的部分可以参考[11][12],
这里关于mmap有两点还想说说,就是mmap的一个小优化,即madvise,一般情况下我们会发现对某块内存进行了mmap映射以后,在一段时间处理的时延会很高,究其原因就是我们只是分配了虚拟地址,却尚未分配物理地址,这就意味着刚刚映射完以后一段时间内会触发多次缺页中断,因为映射的页除了匿名页还有对于文件的映射。前者只需要分配一个物理页,并修改页表项和MMU,后者则需要磁盘操作,后者的开销只能用恐怖来形容。
此时有一个办法就是madvise,这个函数会传入一个地址指针,已经是一个区间长度,madvise会向内核提供一个针对于于地址区间的I/O的建议,内核可能会采纳这个建议,会做一些预读的操作,具体内容可查看[13]。
还有一点就是在内存统计的时候,也就是/proc/meminfo中的数据。其实与文件关联的页面也可能被计算到匿名页中,比如MAP_PRIVATE映射的页面被修改时会产生一个匿名页拷贝,被计算到AnonPages中。其实mmap所映射的页有四种类型,即私有映射与共享映射,以及后备文件与匿名隐射,两两组合,共四种情况,各有各的作用:
后备文件的共享映射:用作内存映射IO来对大文件进行操作,比一般的IO少一次CPU拷贝,但是内存映射IO涉及到内核的很多操作,比如vm_area_struct的创建,页表的修改等等,比普通IO的操作更复杂。小文件的读写使用普通IO更合适。后备文件的私有映射:用作共享库二进制文件代码段,数据段的加载匿名文件的共享映射:用作fork时让父子进程共享匿名映射分配的内存,即进程间通信的共享内存。匿名文件的私有映射:用作进程的私有内存分配,比如堆,栈,数据段等等。
sendfile
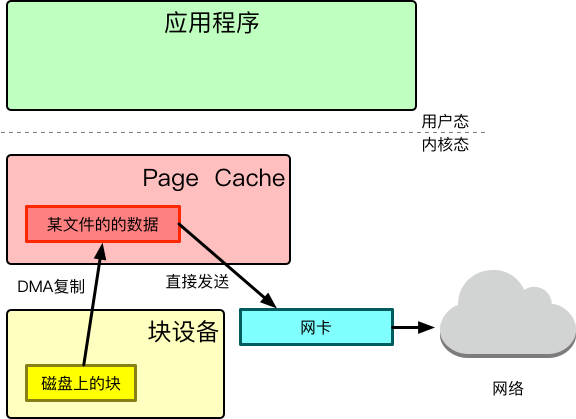
显然这在网络编程中是一个必不可少的“性能利器”,其可以在转发文件的时候直接从块设备进入到Page Cache,这是通过dma来做的,然后让网卡直接从Page Cache中获取数据发送给网络,如果Page Cache中存在数据的话,可以跳过第一步DMA拷贝,整个过程不消耗CPU时间。所以这个过程也被称为零拷贝,虽然是零拷贝,但是其实其时间消耗也是有的,在自己实现的Web服务器RabbitServer的性能测试中,sendfile的消耗赫然位居第三位:
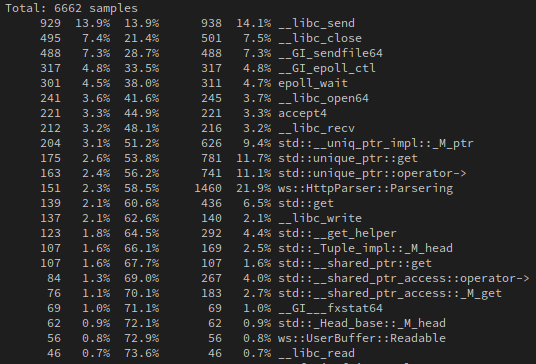
sendfile也是有缺点的,就是无法对数据进行任何的加工,因为数据根本没经过CPU,所有向对数据进行一点点的修改也必须老老实实的读到用户态来,当然可以用mmap+madvise这样的操作减少一次拷贝并提升性能。
对于sendfile印象最深的当属编写WebServer时outputbuffer的考虑,因为一般情况下我对buffer的理解就是一个操作字符串的特殊集合,但是想在outputbuffer中使用sendfile就意味着不能这样写,因为一个http响应报文的文件内容处于响应报文中间,后面还有一个\r\n字符串,如果硬写判断逻辑话会导致代码非常的臃肿丑陋,而且容易出错。最终选择的方法是一个双端队列,其中存储的对象为function,优雅的解决了这个问题。
同步IO与异步IO
我觉得这个概念百分之九十九的Linux/C程序员都听过,但其中至少一半都没有真正的搞清楚这个概念,我们参考POSIX.1对同步IO和异步IO的定义:即:
同步IO操作导致发出请求的进程被阻塞直到IO操作完成
异步IO操作在IO操作期间不导致发出请求的进程被阻塞
或者wiki[15]中对这个问题的解释:
In fact, they are completely different things: nonblocking-I/O is completely synchronous: data is only being transferred to the application doing the I/O during the I/O call, while with asynchronous I/O, the data is actually transferred while the application does other things.
说简单一点其实就是IO操作分为两个步骤:发起IO请求和实际的IO操作,同步IO和异步IO的区别就在于第二个步骤是否阻塞。
根据以上定义我们可以看出在Linux中,阻塞,非阻塞,IO多路复用,信号驱动都属于同步IO,因为这些系统调用只是告诉用户态事件已经就绪,仍旧需要用户态去内核中把数据读出来,此时显然对于用户态来说是阻塞的,因为此时执行权交给了内核。
而异步IO是内核通知我们的时候,数据已经帮我们放在一个用户态可以直接拿的缓冲区中了,此时就不存在阻塞,直接取就好。在Linux下很多人把同步非阻塞模型错认为异步模型,这其实是很多新手的一个误区。
既然我们上面说了那些常见的IO模型都属于同步IO,那么Linux到底存在异步IO吗?答案是肯定的。
| 阻塞 | 非阻塞 | |
|---|---|---|
| 同步 | write, read | read/write + poll / select/epoll |
| 异步 | — | aio, io_uring |
其中aio局限很大,估计是个搞数据库的大哥提交的,因为只能用于Direct IO。。
而io_uring是一个很新的特性,在内核5.1版本以后才能使用,但是它可以说是一个面向未来的尝试,因为它可以直接用于网络套接字,我想没有一个学过网络编程的人看到这句话不热血沸腾!io_uring的出现意味着什么?我再次大胆的做出本文第二个预测:io_uring将会在未来大幅度影响高性能网络框架的设计!
这其实很好想象,因为使用io_uring至少可以减少一次系统调用,而且是每一次请求的每一次IO中。从这里我们也可以看出io_uring的出现将会使Proactor模型在未来大放异彩!
我有私下问过就职于字节跳动内核组的新酱,了解到其实现在在他们那边基本已经淘汰了AIO,转而拥抱io_uring了。
虽然已经被AIO已经被淘汰,但是我想为了知识体系的连贯性,我们还是有必要去了解下AIO的。
最后再说说io_uring,这个东西现在给我的感觉就是不成熟,io_uring的原生接口,也就是系统调用的使用极其复杂,所以为了简单的使用,作者封装了一个liburing[16]来让用户更为方便的使用这个特性,但是这个牛B的东西到目前为止竟然只有不到600个star。
再说说这个库的使用,因为在编写RabbitServer的时候发现read,send,recv花费了大量的CPU时间,如果能够引入io_uring,整个服务器性能将会有质的提升,但是这个库用起来很有问题,因为我希望用epoll去监听ring_fd,在IO完成以后通知用户,但是有一个问题,就是必须把很多事件放到一个io_ring中,但是我们又必须监听io_uring中的ring_fd,这就使得使用epoll毫无意义了;而且使用ring_fd我们只能判断一次来了几个事件,问题是没办法判断事件的类型,这意味着没办法判断套接字何时关闭。我在RabbitServer中对io_uring封装了一个简单的使用类,代码在/src/net/中,感兴趣的朋友可以看一看。
基于以上的经历,这个玩意给我的感觉就是在未来可能会发展为一个特殊的IO多路复用,也许类似于异步的epoll。
当然也可能是我的用法有问题,但是现在的问题就是这东西基本没啥资料,唯一的官方样例就是[16]中examples目录中的例子,但是其中也没有针对于网络套接字的例子。
关于AIO与io_uring我并不想在这篇文章多言,因为我自己用到它们的地方也很少,只是知道其基本的实现原理,理解还尚浅,不敢信口开河,等后面有机会深入的了解此方面的知识点以后再回来补充。
总结
经历了三天时间,在不知不觉间完成了这篇文章,不禁让人感叹,学生时代真是奢侈,可以心无旁骛,无所顾忌的花费这么长时间去做这样一件事情,希望以后还能够不忘我写博客的初衷,继续坚持下去。
又仔细梳理了一遍文章的结构,基本上也算是有头有尾,对于文章开头提出的问题也基本上都做了解答。
这篇文章基本上把我对于Linux I/O的理解简单的阐述了一遍,但是春招和期末都像闪着森寒幽光的刀,已经架在了脖颈上,实在是没办法再去抽出精力润色润色这篇文章。细想写下这篇文章最初的原因,其实就是想把欢神《聊聊 Linux IO》这一篇文章再更加细致的描述一下,现在看起来倒是写成了一篇入门文章了,虽然偏离了本来的想法,但是结局也不差。
最后还是想告诉每一个看到这篇文章的朋友和小组后辈的同学,对Linux系统编程的学习不可停留在只会用的层面,多去了解其原理,从原理出发思考用法;不可浮躁,急于求成,抛弃了那些真正对你有用的东西;
博观而约取,厚积而薄发,如是而已。
参考:
- 《聊聊 Linux IO》
- 《DRAM基本知识及操作系统内存管理策略》
- 《聊聊BIO,NIO和AIO (2)磁盘IO磁盘IO的优化AIO反思AIO》
- 《HDD/SSD基础知识及工作原理》
- 《持久化内存编程及其思考》
- 《linux 同步IO: sync、fsync与fdatasync》
- Linux Storage Stack Diagram 图片引自维基
- https://en.wikipedia.org/wiki/Locality_of_reference
- https://www.kernel.org/doc/Documentation/sysctl/vm.txt
- 《/proc/sys/vm虚拟内存参数》
- 《匿名映射/线性映射的VMA分配和对应的缺页处理》
- 《分析匿名页(anonymous_page)映射》
- https://www.man7.org/linux/man-pages/man2/madvise.2.html
- 《深入理解内存映射mmap》
- https://en.wikipedia.org/wiki/Talk%3AAsynchronous_I/O
- https://github.com/axboe/liburing

