
从false sharing到缓存一致性,这其实与我们息息相关
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
缓存对于我们广大程序员来说显然是一个极度重要的东西,但是很多人其实在大多数时候忽视了它的存在,这实在是一个非常遗憾的事情,我们今天不谈类似于Redis,memcache,Tair这样的分布式缓存,也不谈操作系统中逻辑上的缓存,比如说VFS中的四级缓存[1]。我们只是谈谈CPU中的高速缓存中的两个问题,即缓存一致性和false sharing问题。
这两个问题我想大多数情况下大家根本不会去花太多的心思去注意它们,因为如此底层的东西与我们的编程能有多大关系呢?答案是息息相关,它们可能在不经意间影响着我们代码的运行效率,但是我们却不得而知,如此看来,学习它们就很有必要了。不过也不必担心,辅以代码展示,这个问题很容易被避免。
false sharing
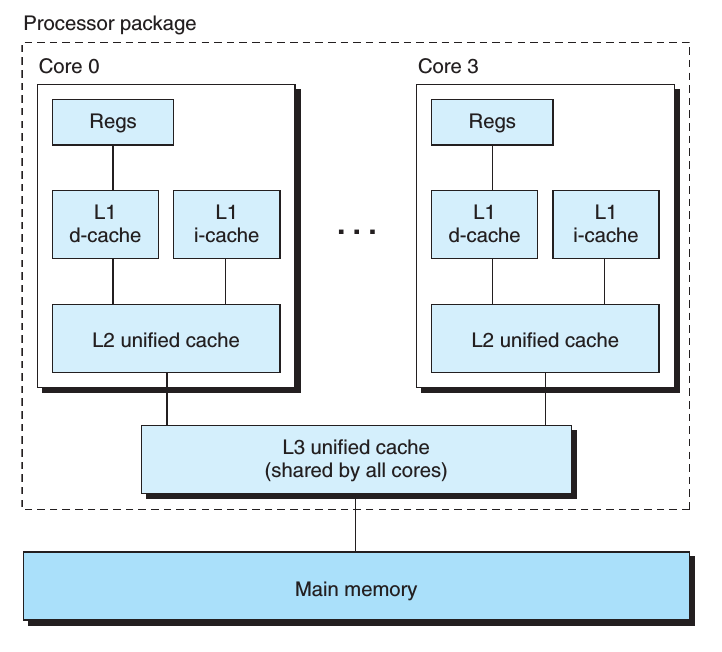
这是一个CPU内多个核心上的高速缓存分布,我们可以看到虽然它们在同一个CPU中,但是仍然有自己私有的高速缓冲,在图中的体现就是L1和L2级别的cache。这样看起来其实没什么问题,因为缓存越多,正常情况下命中率(时间局部性与空间局部性)就会越高,当然这是正常情况下,假如我们引入了多线程呢,我们都知道一个进程内的所有线程共享多级页表和mm_struct, 也就是它们可以共享几乎所有数据,但是线程同时也是调度的单位,意味着它们可以运行在不同的core[2]或者不同的CPU上,那么修改自然而然的写入不同的高速缓存。
如果此时刚刚写入cache line,其他core上的修改就进行了[2],此时就引出了缓存一致性,当然现在还没聊,我们暂且知道它的作用是保证对某一个地址的读操作返回的值一定是那个地址的最新值,这意味这多个不同core的缓存行要同步数据,这显然是一个不小的开销。
此时假设一种情况,就是两个线程不停的在修改同处于一个缓存行上的变量(当然包括同一个),那么会发生什么?就是两个缓存行会不停的失效,重新加载。
我们来看看wiki对false sharing的定义:
In computer science, false sharing is a performance-degrading usage pattern that can arise in systems with distributed, coherent caches at the size of the smallest resource block managed by the caching mechanism. When a system participant attempts to periodically access data that will never be altered by another party, but those data share a cache block with data that are altered, the caching protocol may force the first participant to reload the whole unit despite a lack of logical necessity. The caching system is unaware of activity within this block and forces the first participant to bear the caching system overhead required by true shared access of a resource.
其实也就是上面我们描述的意思。
我们来写一段代码验证一下,我的机器配置如下4 x Intel® Core i5-7200U CPU @ 2.50GHz。代码其实思路很简单,就是申请两个全局变量,让他们紧密排布,能够处于同一个缓存行内,然后两个线程分别修改10亿次,看一看时间的消耗就可以了,为了确保两个线程不跑在同一个核上,我们可以设置一下CPU的亲和性,具体的代码如下:
bool SetCPUaffinity(int param){
cpu_set_t mask; // CPU核的集合
CPU_ZERO(&mask); // 置空
CPU_SET(param,&mask); // 设置亲和力值,把cpu加到集合中 https://man7.org/linux/man-pages/man3/CPU_SET.3.html
// 第一个参数为零的时候默认为调用线程
if (sched_setaffinity(0, sizeof(mask), &mask) == -1){ // 设置线程CPU亲和力
return false;
// 看起来五种errno没有必要处理;
} else {
return true;
}
}
int num0;
int num1;
void thread0(int index){
SetCPUaffinity(index);
int count = 100000000; // 1亿
while(count--){
num0++;
}
return;
}
void thread1(int index){
SetCPUaffinity(index);
int count = 100000000;
while(count--){
num1++;
}
return;
}
int main(){
vector<std::thread> pools;
pools.push_back(thread(thread0, 0));
pools.push_back(thread(thread1, 1));
for_each(pools.begin(), pools.end(), std::mem_fn(&std::thread::join));
return 0;
}
执行结果如下:

我们在对代码做一点修改,就是让两个线程串行,只需要修改main函数部分即可,代码如下:
int main(){
vector<std::thread> pools;
pools.emplace_back(thread(thread0, 0));
pools[0].join();
pools.emplace_back(thread(thread1, 1));
pools[1].join();
return 0;
}

震惊吧,几乎四倍的差异。
显然只要我们使得那两个变量不处于一个缓存行的话,就不会出现这样的问题,我们可以做出一下修改,让两个线程修改的变量64位对齐,当然这里的64并不固定,需要根据自己的机器配置来修改,可以执行cat /proc/cpuinfo查看其中的cache_alignment,也可以直接执行cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size来查看[4]:
int num0 __attribute__ ((aligned(64)));
int num1 __attribute__ ((aligned(64)));
当然写成这样也可:
int num0;
char arr[60]; // 可设置一些标记位
int num1;
我们可以看到消耗再次降下来了。


那么我们可以尝试把两个线程分配到同一个CPU上看下效果,在设置CPU亲和性的时候把参数设置一样就可以了,main大概如下:
int num0;
int num1;
int main(){
vector<std::thread> pools;
pools.emplace_back(thread(thread0, 1));
pools.emplace_back(thread(thread1, 1));
for_each(pools.begin(), pools.end(), std::mem_fn(&std::thread::join));
return 0;
}

可以看到结果是符合预期的。
缓存一致性
false sharing问题出现的原因就是因为需要缓存一致性去同步缓存间的一致性,保证每个CPU能够读到最新的值。第一次对这个问题感兴趣是在思考原子操作如何实现时,当时知道了一般CAS操作还是要基于CMPXCHG(Intel x86)指令来做,再往下就是总线锁和缓存一致性了,前者就是在系统总线中发出一个#lock信号,此时其他CPU就没办法去使用系统总线,以排它的方式保证这个操作是原子的。当然我们也可以看出这种锁定粒度太大了,因为使用LOCK#是把CPU和内存之间的通信锁住了,这使得锁定时期间,其它处理器不能操作其内存地址的数据,当然不一定原子操作一定使用#LOCK信号,即;
Beginning with the P6 family processors, when the LOCK prefix is prefixed to an instruction and the memory area being accessed is cached internally in the processor, the LOCK# signal is generally not asserted. Instead, only the processor’s cache is locked. Here, the processor’s cache coherency mechanism ensures that the operation is carried out atomically with regards to memory. See “Effects of a Locked Operation on Internal Processor Caches” in Chapter 8 of Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A, the for more information on locking of caches.
对于Intel486和Pentium处理器,即使正在锁定的内存区域被缓存在处理器中,也始终在LOCK操作期间在总线上声明LOCK#信号。
对于P6和更新的处理器系列,如果在执行LOCK操作的处理器中缓存了在LOCK操作期间锁定的内存区域作为回写内存,并且完全包含在缓存行中,则处理器可能不会声明 总线上的LOCK#信号。 相反,它将在内部修改内存位置,并允许其缓存一致性机制来确保该操作是原子执行的。 该操作称为“缓存锁定”。 缓存一致性机制会自动阻止已缓存同一内存区域的两个或更多处理器同时修改该区域中的数据。
具体可参考[6],[7]。
我们继续,修改内存以后可能有一些缓存中存在这个修改的数据,为了每次读取仍能读到最新的数据,我们就需要缓存一致性来做这件事情了。这里比较经典的当属MESI[8]协议。Intel的处理器使用从MESI中演化出的MESIF[10]协议,而AMD使用MOESI[9]协议,基本都参考MESI用一个状态机去解决问题。
我不想去聊其中某个协议的具体实施方案,因为已经有了很多文章陈述这些,我想聊的是基于对这几个协议的简单学习[10][11][12]得到的一点启发,即在一个分布式系统中如何保持缓存一致性。
其实这个问题刚提出来脑子里就冒出了这几个场景:
- Chubby的客户端缓存一致性
- Chubby的keeplive机制
- GFS中客户端chunk信息的缓存一致性
- GFS中master和chunk的租约机制
- 缓存数据库与数据库的一致性
其实上面五个场景中1,3,5不必说一定是我们理解中的缓存一致性,那么为什么我又把2,4放进去了呢?
我们首先来看看维基[13]对于缓存一致性的定义:
In computer architecture, cache coherence is the uniformity of shared resource data that ends up stored in multiple local caches. When clients in a system maintain caches of a common memory resource, problems may arise with incoherent data, which is particularly the case with CPUs in a multiprocessing system.
在计算机体系结构中,缓存一致性是最终存储在多个本地缓存中的共享资源数据的一致性。 当系统中的客户端维护通用内存资源的缓存时,数据不一致可能会出现问题,在多处理系统中的CPU尤其如此。
显然我们可以看到缓存的定义被称为shared resource data,也就意味着范围非常广,那么我们是否可以把两端之间维护的lease看做缓存呢?再说的细致一点,比如分布式锁,我们是否可以把双方维护的锁的信息当做缓存呢?在《ChubbyGo的安全性论证与展望》中我分析过分布式锁为了避免死锁引入超时机制最大的问题,此时看来其实分布式锁最大的问题就是使得lock server(锁服务器)和client(持锁者)的视图一致,其实看起来本质就是缓存一致性,甚至于我认为我们在分布式中讨论的一致性不就是特殊的缓存一致性吗?当然是我个人想法,如有错误还请海涵。
经过以上思考,我把2,4放了进去。前者是Chubby对于分布式锁对于超时机制的解决思路,后者是GFS中master对于chunk服务器维护的租约。
第五个场景解法可以参考[14][18],虽然我认为这是分布式事务(强一致性)的问题。
一,三就是最直观的数据一致性,在[16]2.7中描述了一场景,解决思路非常的简单,直接阻塞写请求,向所有有此修改数据缓存的客户端发送缓存失效信息,收到所有的回复以后结束写操作,此时显然满足缓存一致性,但是显然写效率也很低下。至于三,在[15]3.2的第二段有描述,虽然非常的简洁,但也透漏了非常重要的一点,就是chunk在失效以后可以回复已经不持有租约,这其实可以大量减少写操作的开销。以上两点分别在两个阶段解决了这个问题。
至于二,四,则是两个系统对于双方维护lease的一个解决方法,虽然[15]中没有详细描述,但[16]2.8对于keepalive机制描述的很清楚,本质就是维护超时时间,在客户端超时以后认为资源(缓存)失效,在租约重新维护时有效;且因为双方时间差异的关系和通信的不确定性,客户端会有一个宽限期,具体可以了解[16]。在 ChubbyGo 中我采用了fence的方法避免这个问题。
显然我们可以发现一个很有意思的地方,分布式系统中没有任何一种方案采用了像操作系统高速缓存中那样的缓存一致性策略,即类似于MESI基于消息传递的状态机转换。
为什么?我认为原因就是网络通信不同于系统总线,前者的时延是没有上确界的(比如说唯一路由的某个路由器损坏),而总线的通信基本上我们认为其是可靠的。也就是说在总线中这样基于消息通信的方式确实是很高效的,因为基本上没有任何浪费的时间(二,四中维护超时时间;分布式事务的多轮消息通信2PC,3PC),每一步都是必需的。如果分布式系统中这样做,就会有操作长时间阻塞的可能性,因为某个请求可能会延迟很长时间(一个没到,剩下都成功,使得系统的容错性很差)。
总结
从这里也可以看出来,同一个问题在不同的约束下就会有不同的解决方案,尤其是在分布式系统下因为通信的延迟不可靠使得很多问题变得困难了许多。
虽然我才二十岁,但是真切希望在我有生之年可以看到现代通信技术真的能到保证数据在一定时延(较短)内确定交付的一天。
参考:
- 《再聊聊Linux IO》
- 《(概念)多个CPU和多核CPU以及超线程(Hyper-Threading)》
- https://en.wikipedia.org/wiki/False_sharing
- 《CPU Cache对性能的影响》
- https://www.kernel.org/doc/Documentation/ABI/testing/sysfs-devices-system-cpu
- 《聊聊CPU的LOCK指令》
- 《Intel LOCK前缀指令》
- https://en.wikipedia.org/wiki/MESI_protocol
- https://en.wikipedia.org/wiki/MOESI_protocol
- https://www.realworldtech.com/common-system-interface/5/
- 《《大话处理器》Cache一致性协议之MESI》
- 《聊聊缓存一致性协议》
- Cache coherence wiki
- 《分布式缓存(一致性)》
- 论文《The Google File System》
- 论文《The Chubby lock service for loosely-coupled distributed systems》
- 论文《Leases: an efficient fault-tolerant mechanism for distributed file cache consistency 》
- 《分布式之数据库和缓存双写一致性方案解析》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号