
从X86架构中cahe的组织结构引发的各种思考
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
有写这篇文章的冲动并不是因为想聊聊X86架构中cahe的组织结构,而是为了聊一聊这个问题《Why is transposing a matrix of 512x512 much slower than transposing a matrix of 513x513?》。这个问题想要真正了解必须明白cache line的组织方式与命中方式。在明白以后又联想到了一些其他的东西,当然这也是这个题目的由来。
对于cache这个概念第一次了解是在大一学习[7]6.4的时候,当时因为整个计算机体系的学习还是不够深入,所以导致其实看完以后只是有一个印象,对于如何把这个知识点融合到我们的代码中一概是不了解不知道,恰逢看到了在前面提到的问题,在明白以后顿觉打通了以前糊涂的地方。废话少说,我们开始吧!
cache的组织形式
首先我们要清楚的是对于地址到cache映射并不唯一,基于从地址映射到缓存方法的不同,共有三种方案:
- 直接映射高速缓存
- 组相连高速缓存
- 全相连高速缓存
这里不想谈论1和3,因为现在我们的机器基本都使用的是组相连高速缓存,所以为了文章简洁,我们只谈论2。
我们先来看看组相连高速缓存的组织方式:
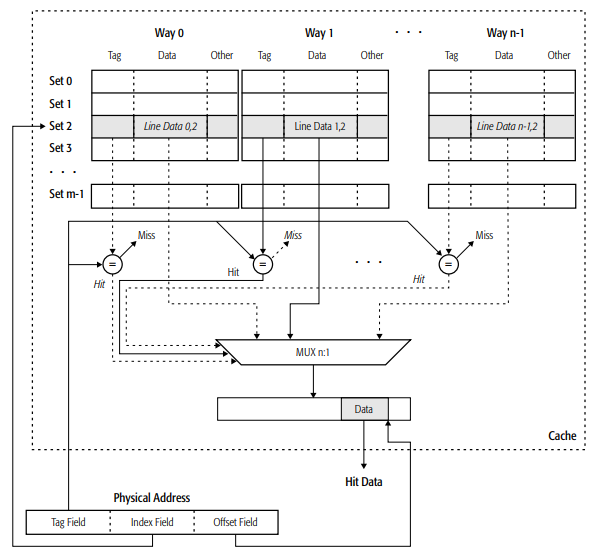
基本上把一个高速缓存可以划分为3个评判标准,即几点可以决定一个高速缓存的大小,显然在图中我们可以看到有三点直接决定了缓存的大小:
- 组数m
- 每一组的缓存块数量,又被称为
路(ways) - 缓存块大小(data)
我们可以使用lscpu命令查看CPU信息:
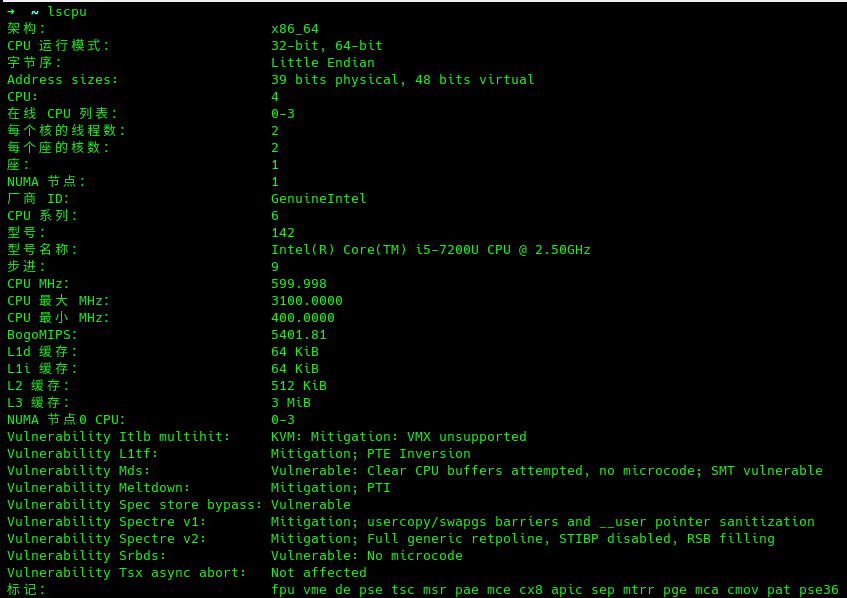
但是我们可以看到其中的信息并不细致,对于各级高速缓存的细致信息一个也没有,所以对信息精细程度要求比较高的话可以使用如下命令cat /proc/cpuinfo,每一项具体含义可参考[9]:
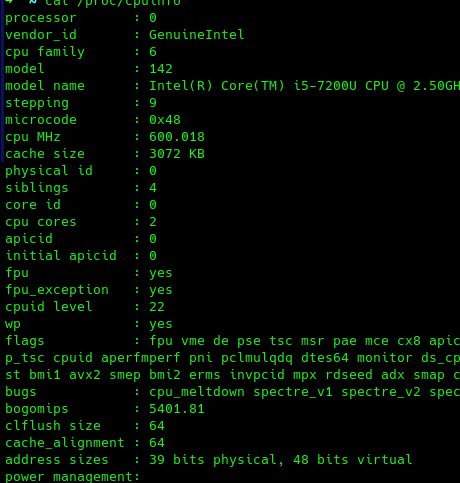
我们可以看到cache_alignment这一项,其实也就是cache line的大小,这个信息还是不够精细,我们需要的是每一个高速缓存的所有信息!祭出最后的办法,那就是/sys/devices/system/cpu/
这个目录信息非常的丰富,我们进入cpu0/cache看一看,其他的几个也都是大同小异,此目录中index0为L1数据缓存,index1为L1指令缓存,index2为L2缓存,index3为L3缓存。
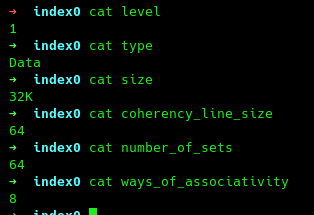
从以上信息我们可以知道这是一个L1高速数据缓存,大小为32K,分为64个set,每个set中有8个组(ways),e每个数据块占64字节。
好了,现在我们已经基本了解了缓存的组织形式了,那么当我们拥有一块内存数据的时候怎么把它映射到缓存行上呢?
在[7]中描述的非常清楚,基本的映射方式就是下图:
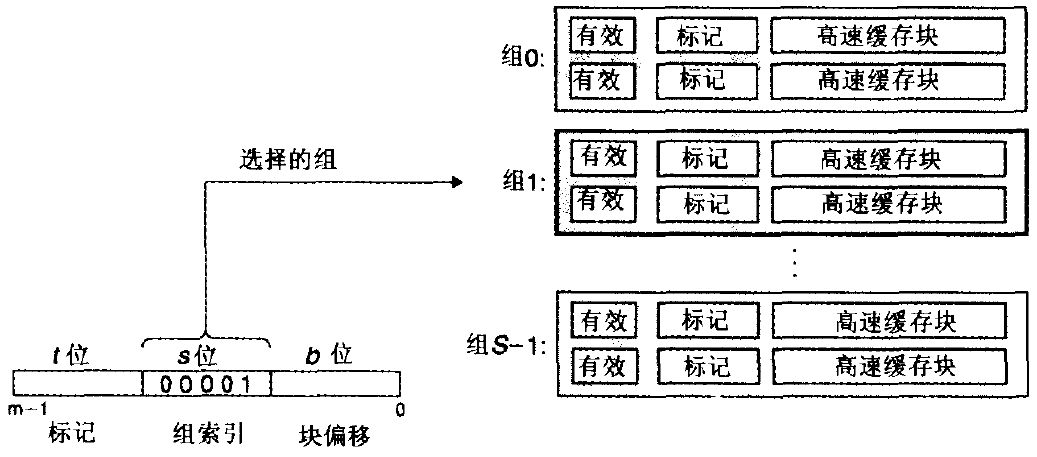
即把一个虚拟地址分为三个部分,利用中间的组索引去匹配缓存的set,后面b位为块偏移,剩下的位数作为标记,用来判断同一set的多路缓存中某个特定的cache line到底在哪里。
有一个问题很有意思,为什么会使用中间的地址位作为组索引呢?[7]6.4.2
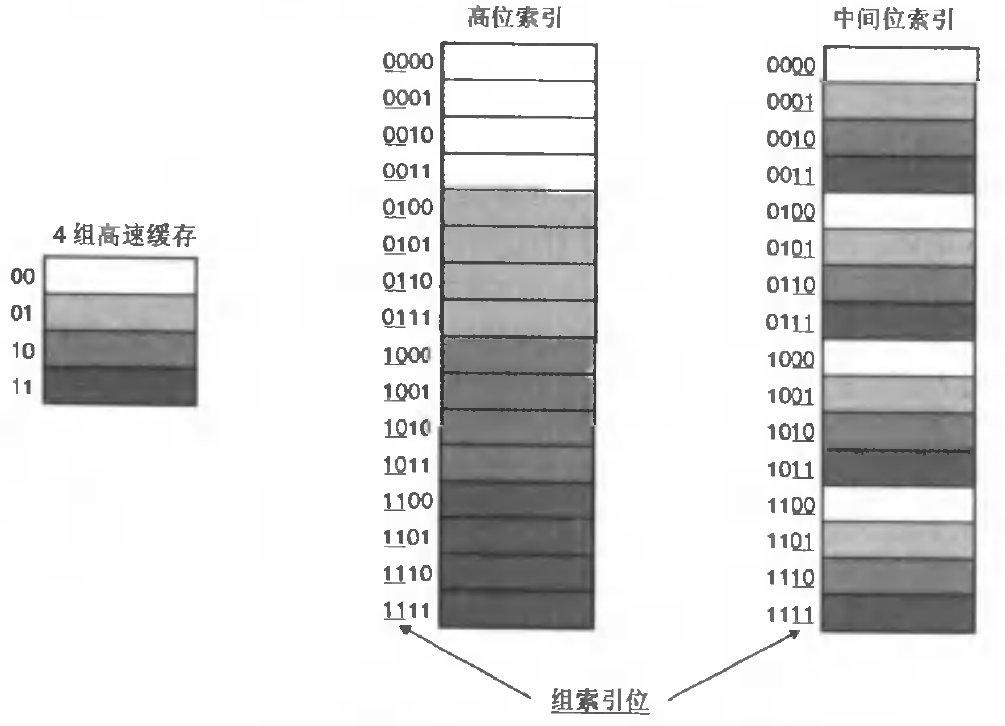
原因就是想让相邻的地址块处于不同的缓存行,当然至少现在看起来我认为前者没有什么不行的,因为无论是前者还是后者在一个空间局部性良好的程序中缓存行失效的次数是差不多的,拿上图举例就都是四次(当然失效的时间不一样),所以我个人认为就是基于大量数据权衡之下的结果。为什么提这个,因为其实从这里我们可以看到slab缓存着色的原理(当然也可以一定程度解释为什么选择后者),不急,我们后面再说。
特殊的矩阵转置
好了,回到一切的起点,做了这么多铺垫,终于可以开始这个问题了,没看问题的朋友可以回到文首看一看stackoverflow上那个老大哥的疑惑是什么,我们把他的代码直接拿过来用,如下:
#define SAMPLES 100
#define MATSIZE 512
int mat[MATSIZE][MATSIZE];
void transpose()
{
int i, j, aux;
for (i = 0; i < MATSIZE; i++) {
for (j = 0; j < MATSIZE; j++) {
aux = mat[i][j];
mat[i][j] = mat[j][i];
mat[j][i] = aux;
}
}
}
int main(void)
{
int i, j;
for (i = 0; i < MATSIZE; i++) {
for (j = 0; j < MATSIZE; j++) {
mat[i][j] = i + j;
}
}
for (i = 0; i < SAMPLES; i++) {
transpose();
}
return 0;
}
我们分别看看长宽均为512和513的矩阵转置到底消耗有多大差距:
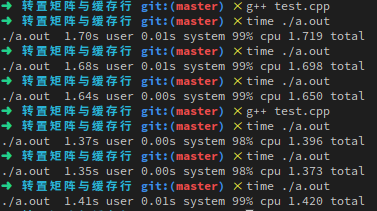
奇怪,数据测试结果与网上不一致啊,那个国外老大哥基本是3倍到4倍的差别,欢神则是四倍左右,到了我这虽然有差别,但是比想象的差很多。或者说,在我的机器上那个数字才能产生数倍的效果呢?显然写一个程序暴力跑一跑就知道了,但是太不优雅。
既然我们在第一节已经知道了CPU的各种信息,我们就来算一算这个数字吧!
首先我们知道一个缓存块是64,即2的六次方。
其次一个32KB的L1 cache拥有64个set,即2的六次方。
也就是虚拟地址在映射缓存的时候采用后12位。
矩阵转置的公式其实就是循环中swap(arr[i][j], arr[j][i])。
所有那两个项可以映射到同一个cache line呢?我们首先可以列出下式:
i*(一行的数据总量) + j*4 == j*(一行的数据总量) + i*4
当后12位的循环跑完以后会出现i和j每次都隐射到同一个cache set中,这也是出现速度断崖式下降的原因,因为set只有8路,满了以后就会被逐出。
也就是当一行的数据总量等于2的12次方时这个问题最严重,因为是int数组,所以这个数字是1024,我们来测试 一下1024和1025的区别:
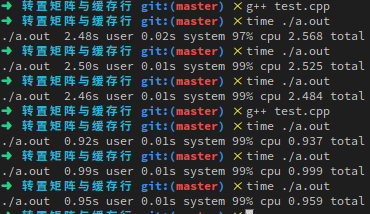
完美符合预期。
memory type
我们先提出一个问题:存储系统中的每个数据都可以被Cache缓存吗?
我们来看看intel开发者手册对这个问题的描述[5]:
The processor allows any area of system memory to be cached in the L1, L2, and L3 caches. In individual pages or
regions of system memory, it allows the type of caching (also called memory type) to be specified (see Section
11.5). Memory types currently defined for the Intel 64 and IA-32 architectures are (see Table 11-2):
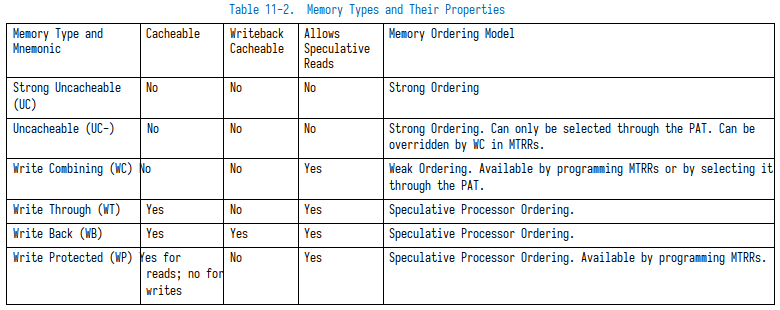
在这里我们可以看到intel定义了六种write type,分别代表了六种caching与ordering的行为,其中前者指定了数据的缓存行为,而后者指定了memory order。缓存的行为其实就是我们前面提出问题的解答,而memory order则是一个很大的问题,我想单独用一篇文章去描述,这篇文章暂且不谈。
当然在这张表中我们可以看到其实还指定了回写的策略,其实也就是WT和WB,说巧不巧,维基中也有对此问题的描述:
When a system writes data to cache, it must at some point write that data to the backing store as well. The timing of this write is controlled by what is known as the write policy. There are two basic writing approaches:[3]
- Write-through: write is done synchronously both to the cache and to the backing store.
- Write-back (also called write-behind): initially, writing is done only to the cache. The write to the backing store is postponed until the modified content is about to be replaced by another cache block.
其实我们可以看到就是WT和WB这两种write type。
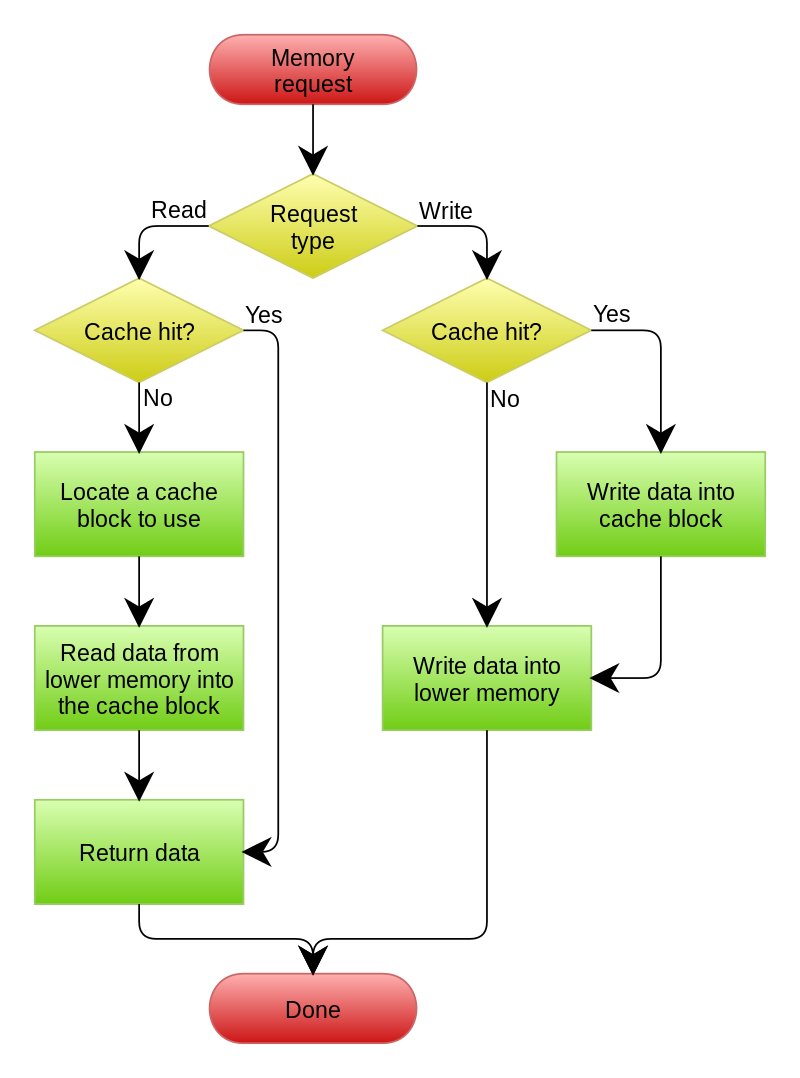
我们看看WT和WB的流程[6]:
WT流程:
WB流程:
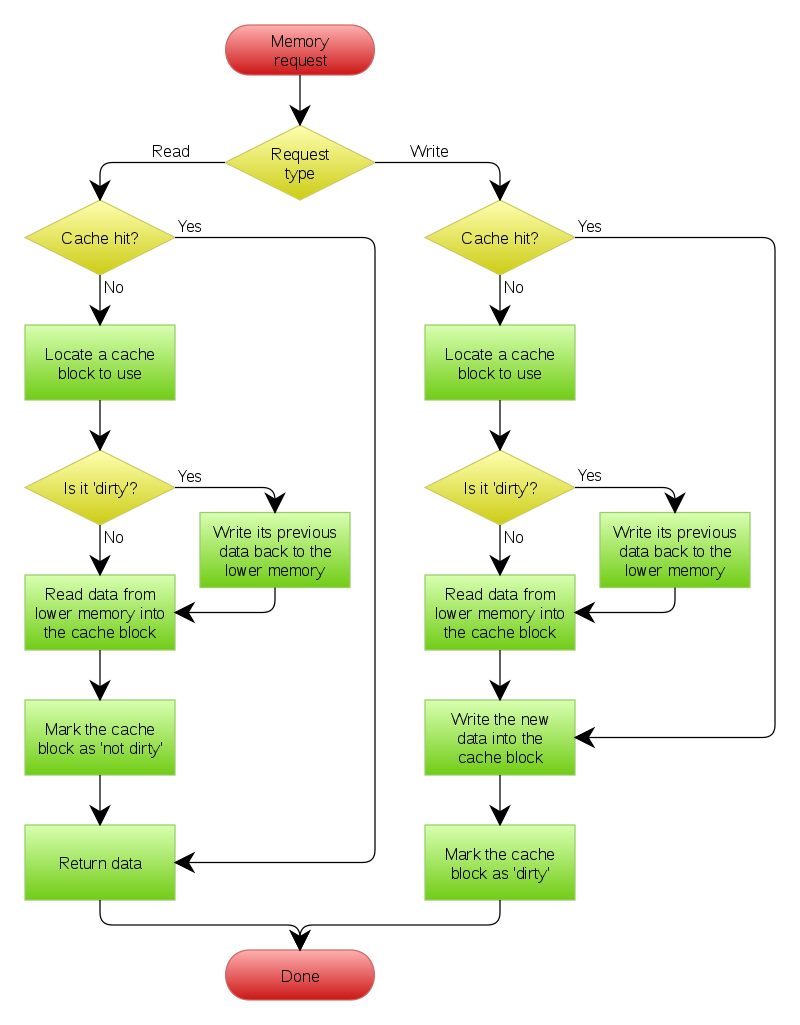
我们可以看到正如维基所言,WB的流程确实是要复杂一点:
A write-back cache is more complex to implement, since it needs to track which of its locations have been written over, and mark them as dirty for later writing to the backing store. The data in these locations are written back to the backing store only when they are evicted from the cache, an effect referred to as a lazy write. For this reason, a read miss in a write-back cache (which requires a block to be replaced by another) will often require two memory accesses to service: one to write the replaced data from the cache back to the store, and then one to retrieve the needed data.
Other policies may also trigger data write-back. The client may make many changes to data in the cache, and then explicitly notify the cache to write back the data.
在[5]中我们可以看到允许caching的策略除了WB和WT以外还有WP,后者就类似一个“绕过”缓存,写WP类型memory不会更新cache,而是直接更新main memory。发生cache hit的写操作并不会更新cache,却会让该行cache line 失效。[11]对此问题有一定描述。
经过一段时间的查资料,发现基本对于缓存类型的描述就是WB和WT,对其他几种基本鲜有人提起,可能是当前工业界用的少吧。而且x86居然没在表格里,搞得人挺无奈的[5]:
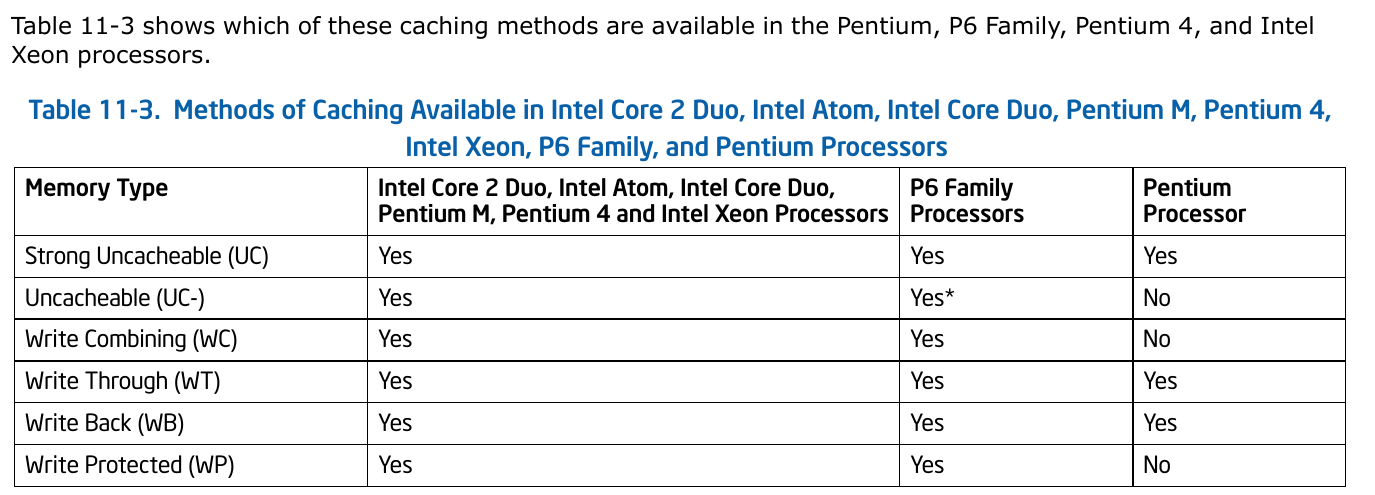
不了解,不提这个问题了,后续有了新发现再说吧。
缓存着色问题
我们都知道slab内存分配器除了减少内存分配的消耗以外最大的特点就是缓存着色。缓存着色是什么呢?我们来看看维基的解释[12]:
In computer science, cache coloring (also known as page coloring) is the process of attempting to allocate free pages that are contiguous from the CPU cache’s point of view, in order to maximize the total number of pages cached by the processor. Cache coloring is typically employed by low-level dynamic memory allocation code in the operating system, when mapping virtual memory to physical memory. A virtual memory subsystem that lacks cache coloring is less deterministic with regards to cache performance, as differences in page allocation from one program run to the next can lead to large differences in program performance.
其中最重要的一句就是缓存着色是尝试分配从CPU缓存的角度看连续的空闲页面的过程,以使处理器缓存的页面总数最大化。如何,是不是和上面我们聊的CPU高速缓存的命中过程联系起来了。

我们都知道目前Linux系统上页面大小默认为4k,我们可以使用getconf PAGE_SIZE查看系统默认的大小:

我们来汇总下我的机器目前的部分配置,L1 cahce 32KB,64 set,8 way,数据块64byte;page size 4KB。
也就是一个页面可以填满8个set,但是我们前面提到了一个东西,就是虚拟地址映射cache line的过程,只有地址的后12位会进行匹配。前六位代表set的选择,后六位代表数据块的偏移。有意思,因为我们可以发现一个4KB的页面恰好可以保证把L1 cache的每一个set都填充一个,这下你应该知道slab为什么效率这么高了吧,因为同一个页面内的对象一定不会在一个set内出现竞争,当然限定在这个特定的配置下。
好了,我的脑海中又冒出两个有趣的问题:
- slab的页面内对象组织形式
- huge page对缓存着色的影响
slab页面内对象组织形式
我们首先看第一个问题。
slab是如何组织page内对象的呢?我们以linux-4.15.0-rc3版本代码做一个简单的分析(分析slub),首先来看看slub的结构体:
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
slab_flags_t flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
int inuse; /* Offset to metadata */
int align; /* Alignment */
int reserved; /* Reserved bytes at the end of slabs */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
struct kmem_cache_node *node[MAX_NUMNODES];
};
其中与页面内对象划分相关的有以下几项;
flags:object分配掩码,例如SLAB_HWCACHE_ALIGN标志位,代表创建的kmem_cache管理的object按照硬件cache对齐。想想我们上面的分析size:实际每个对象分配的object sizeobject_size:实际的object size,即创建kmem_cache时候传的参数。size是各种地址对齐之后的大小,所以size要大于等于object_size。offset:很巧妙的一个设计,在很多地方都有用到,比如std::alloctor。其实就是利用没有使用的内存,在其上设置一个指针,指向下一个空闲的内存块,把所有空闲地址连成一个单链表。offset就是存储下个object地址数据(指针)相对于这个object首地址的偏移。oo:低16位代表一个slab中所有object的数量(oo & ((1 << 16) - 1)),高16位代表一个slab管理的page数量((2^(oo 16)) pages)。align:字节对齐大小。
其实本来向把slub的部分简单源码分析一下,但是很遗憾,在最关键的地方竟然找不到函数定义了,因为想看看在一个页面内slub是如何组织对象的排布的,所以需要去查看kmem_cache_alloc部分的源码,因为分配对象必然要经过这里,但是这里的代码实在是过于复杂,看了半天也没找到对象排布的代码,遂放上一个对象插入和移出freelist的部分:
static inline void set_freepointer(struct kmem_cache *s, void *object, void *fp)
{
unsigned long freeptr_addr = (unsigned long)object + s->offset;
#ifdef CONFIG_SLAB_FREELIST_HARDENED
BUG_ON(object == fp); /* naive detection of double free or corruption */
#endif
*(void **)freeptr_addr = freelist_ptr(s, fp, freeptr_addr);
}
```cpp
static inline void *freelist_ptr(const struct kmem_cache *s, void *ptr,
unsigned long ptr_addr)
{
#ifdef CONFIG_SLAB_FREELIST_HARDENED
return (void *)((unsigned long)ptr ^ s->random ^ ptr_addr); // 不知道为啥要这样
#else
return ptr;
#endif
}
我们可以看到freeptr_addr其实就是指向下一个对象的指针,然后fp一般是freelist或者slab partial,其实就是把这个对象再放回链表。
再看看从链表中分配的时候是如何做的,不过因为这里代码实在太多,我们假设已经从freelist中找到了一个对象,要把freelist的链表头修改掉,此时调用c->freelist = get_freepointer(s, freelist);,get_freepointer的定义如下:
/* Returns the freelist pointer recorded at location ptr_addr. */
static inline void *freelist_dereference(const struct kmem_cache *s,
void *ptr_addr)
{
return freelist_ptr(s, (void *)*(unsigned long *)(ptr_addr),
(unsigned long)ptr_addr);
}
static inline void *get_freepointer(struct kmem_cache *s, void *object)
{
return freelist_dereference(s, object + s->offset);
}

虽然没有找到源码,但是通过各种博客也了解了object在页面内的对象排布情况,即通过在空闲内存块指针内置的方法把所有的object连接成一个单链表,然后其中每一个对象要求至少8个字节,然后要遵循字长和创建slub对象时传入的align对齐,最后一定会剩下一点点不需要的地方,也就是图中的unused。
huge page
第二个问题,huge page对系统到底有什么影响呢?
首先聊聊怎么查看当前系统对于huge page的使用情况,当然查看page大小就可以,但是有些方法可以得到更精细的信息,即cat /proc/meminfo | grep HugePages字段可参考[14]:
使用sudo sysctl -a | grep -I huge也可以得到部分信息。
其实具体的可以参考[15][18],作为没玩过这东西的人,只能从理论分析分析了。
首先TLB的压力减轻是必然的(TLB真的会造成性能的下降,见[4]的第四页),因为同样的项数可以包含更多的内存,缺页的几率就减小了不少;然后就是huge page必然导致部分的内部内存碎片,这也很难避免。
但是从本篇文章主要描述的内容的角度看,huge page会导致slab同一个页面内的object出现冲突,如果恰好那几个冲突的object在slab的单链表中相邻(分配以后释放),然后被不停的分配释放,就会造成cache line的大量失效,不过这种情况太极端了。
对了,huge page还有一个很有意思的特性,[17]中这样描述:
Pages that are used as huge pages are reserved inside the kernel and cannot be used for other purposes. Huge pages cannot be swapped out under memory pressure.
即huge page是不支持swap out的,这可以使因为swap而降低系统性能的程序不再担心这件事情。
有兴趣的朋友可以看看[4],是一篇很良心的翻译,基于其中第四页的讨论,我想提一个问题,就是如何写一个程序知道自己的TLB项数呢?
先写下答案,免得自己忘了,其实也就是基于[4]第四页的讨论,我们可以使用posix_memalign分配1到N个偏移量为一个page size大小的数据,然后不停的进行访问,看在什么时候时间消耗陡然上升,基本就可以判断出来了。太懒了,等有时间写个代码验证下。
至于命令查看的话可以参考[16]。lshw在我机器没有显示TLB的信息。
2022.1.17:偶然在《Transparent Huge Pages: Why We Disable It for Databases》这篇文章中提到Huge Page对于连续访问的场景更为有利,因为稀疏的访问会导致大量的Huge Page被分配,进而导致内存资源的迅速下降,而直接内存回收和内存压缩会导致性能波动。
总结
这篇文章写了很多东西了,就到这吧。
参考:
- 《Gallery of Processor Cache Effects》
- 《7个示例科普CPU CACHE》
- 《给老婆普及计算机知识》
- 《每个程序员都应该了解的 CPU 高速缓存》
- 64-ia-32-architectures-software-developer-vol-3a-part-1-manual 11.3
- https://en.wikipedia.org/wiki/Cache_(computing)
- 书籍《CSAPP》
- 《浅析 x86 架构中 cache 的组织结构》
- 《/proc/cpuinfo 文件分析(查看CPU信息)》
- 《4路组相连cache设计_CPU TechTalk:Cache与存储一致性协议(中)》
- 《WC vs WB memory? Other types of memory on x86_64?》
- https://en.wikipedia.org/wiki/Cache_coloring
- 《Linux 系统如何进行大页面配置》
- https://man7.org/linux/man-pages/man5/procfs.5.html
- 《HugePage优点缺点大盘点》
- 《Linux - cpuid 命令查看 TLB 信息》
- https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt
- 《Linux传统Huge Pages与Transparent Huge Pages再次学习总结》

