
浅谈内存屏障,C++内存序与内存模型
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
这个问题在我的计划中至少已经搁置十个月了,中间有多次下定决心想写一篇文章仔细的梳理一下其中的知识点,但是总是没有勇气动笔,究其原因就是因为对于这里的知识掌还是握度不够,怕写出来的东西成了流水账,贻笑大方。
这段时间又仔细的重新思考了这个问题,终于是可以鼓起勇气简单的聊一聊这个问题了。
首先参考欢神的理解,其实内存屏障很类似于CPU给用户提供的接口,因为其作用就是在保证缓存一致性效率的同时防止store buffer和Invaildate queue异步执行带来的一致性问题,这个问题在用户的角度来说通常被描述成不可见性。既然是接口,那显然是人家厂商定义的,也就是说不同的CPU架构中,此类操作的功能也是不一样的,这是因为内存一致性模型的定义是不一样的,所以本篇文章中所有的讨论都基于Intel® 64 and IA-32架构。
一个有意思的问题
问题的原描述为[1]。具体的问题就是:
多个线程可以读一个变量,只有一个线程可以对这个变量进行写,到底要不要加锁?
这个问题远比看上去的有意思的多,我们该如何对这个变量下一个定义?变量不同操作还是相同的吗?首先我们先定义原子操作,资料来源于《Intel® 64 and IA-32 Architectures Software Developer’s Manual 3a 8.1.1》:

图中的为intel保证的原子操作,当然这里的原子操作表示的是basic memory operations,也就是说表示这种内存访问操作是原子的,不可分割的,而不是说我们应用层对一个假如64位对齐的变量操作是原子的。从上图我们可以看出很多时候其实单指令并不是一个不可分割的操作,比如mov,只有其操作数满足某些条件的时候才是原子的。那么为什么呢?图中蓝色部分说明了部分原因,翻译如下:
Intel Core 2 Duo,Intel®AtomTM,Intel Core Duo,Pentium M,Pentium 4,Intel Xeon,P6系列,Pentium和Intel486不保证对跨缓存行和页面边界划分的可缓存内存的访问是原子的。Intel Core 2 Duo,Intel Atom,Intel Core Duo,Pentium M,Pentium 4,Intel Xeon和P6家族处理器提供总线控制信号,这些信号允许外部内存子系统以原子方式进行拆分访问。 但是,未对齐的数据访问将严重影响处理器的性能,应避免使用。
其次现代CPU基本上都支持流水线(pipeline)上的指令重排,且编译器也会把一些代码在编译期重排,已减少对内存的访问和一些无效的计算,这就意味着我们的代码在真正的载入内存和执行的时候可能和我们写下它的时候长的不太一样。而且除去上面两点,在多线程访问同一个变量的时候还有一种匪夷所思的情况,我们先来看一段代码,同样是手册中的一个例子:

确实指令重排可能造成这种情况,但是在X86下不允许写写重排(一定程度)的[3]:
那么为什么会出现 r2 = 0 且 r4 = 0 这种奇怪的事情出现呢?
答案在于缓存一致性的操作,以intel的MESI协议为例,假设在cache line中状态为share,在某个核更新数据时候会向总线发送Invalidate消息以获取数据的所有权,其他消息得到此消息后更新相应cache line状态为I,并回复Invalidate Acknowledge消息。显然我们可以看到这个过程非常的繁琐,如果每个操作生效前都需要这么多操作那也太低效了,所以引入了Invaildate queue和Store Buffer,为的就是异步执行指令,提高以上过程的效率。
那么这样会带来怎样的问题呢?答案是脏读,因为写入到Invaildate queue和Store Buffer的数据并不会被立即执行。在执行写操作的核会把数据写入store buffer,后面异步的刷新到cache line,当然也会广播失效消息。而当另一个执行读操作的核收到这个失效消息时,会把消息写入自身的Invalidate Queue中,随后异步将cache line设为Invalid状态。写操作的核在读取的时候会扫描store buffer,而这个执行读操作的核在读取数据的时候并不会扫描Invaildate queue,这意味着读操作可能会在一段时间内读到老旧数据。
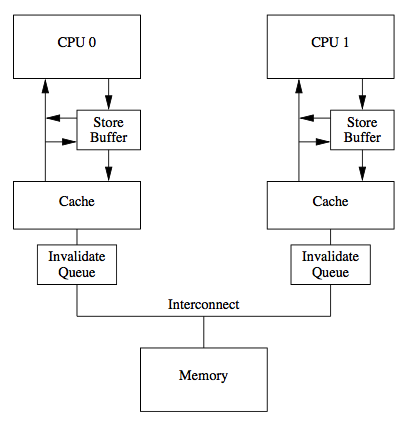
我们回到刚刚那个代码,来回想一下为什么会造成这种情况,首先process 0和process 1把1放入到地址_x和_y的内存上,但是此时可能这些数据还存在store buffer中,也就是对方都还没意识到数据已经发生修改,然后执行操作r2和r4的操作,此时就发生脏读,导致 r2 = 0 且 r4 = 0这种奇怪的事情发生。我们在手册中也可以看到如下文字:
- The memory-ordering model imposes no constraints on the order in which the two stores appear to execute by the two processors. This fact allows processor 0 to see its store before seeing processor 1’s, while processor 1 sees its store before seeing processor 0’s. (Each processor is self consistent.) This allows r2 = 0 and r4 = 0.
- In practice, the reordering in this example can arise as a result of store-buffer forwarding. While a store is temporarily held in a processor’s store buffer, it can satisfy the processor’s own loads but is not visible to (and cannot satisfy) loads by other processors.
- 内存排序模型对两个处理器执行两个存储的顺序没有任何限制。 这一事实允许处理器0在看到处理器1之前先看到其存储,而处理器1在看到处理器0之前先看到其存储。 (每个处理器都是自一致的)这允许r2 = 0和r4 = 0。
- 实际上,此示例中的重新排序可能是存储缓冲区转发的结果。 当存储暂时保存在处理器的存储缓冲区中时,它可以满足处理器自身的负载,但其他处理器看不到(也不能满足)负载。
我们跑一个小小的demo看一看[4]:
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <pthread.h>
#include <semaphore.h>
#include <atomic>
sem_t beginSema1;
sem_t beginSema2;
sem_t endSema;
int X,Y;
int r1,r2;
void* thread1Func(void* param) {
while (1) {
sem_wait(&beginSema1);
while ( (rand() / (double)RAND_MAX) > 0.2 ) ;
X=1;
__asm__ __volatile__("":::"memory");
r1 = Y;
sem_post(&endSema);
}
return NULL;
}
void* thread2Func(void* param) {
while (1) {
sem_wait(&beginSema2);
while ( (rand() / (double)RAND_MAX) > 0.2 ) ;
Y=1;
__asm__ __volatile__("":::"memory");
r2 = X;
sem_post(&endSema);
}
return NULL;
}
int main() {
sem_init(&beginSema1,0,0);
sem_init(&beginSema2,0,0);
sem_init(&endSema,0,0);
pthread_t thread1,thread2;
pthread_create(&thread1,NULL,thread1Func,NULL);
pthread_create(&thread2,NULL,thread2Func,NULL);
int detected = 0;
int iterations = 0;
for (iterations=1;;iterations++) {
X=0;
Y=0;
sem_post(&beginSema1);
sem_post(&beginSema2);
sem_wait(&endSema);
sem_wait(&endSema);
if (r1 == 0 && r2 == 0) {
detected++;
printf("%d reorders detected after %d iterations\n", detected, iterations);
}
}
return 0;
}
代码很容易,语义和最上面的样例差不多,就是都设置为0,然后赋值以后分别获取对方更新过的值。我们可以从结果中看出会出现答案均为零的情况。
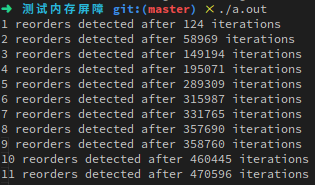
我们可以避免这种情况吗?当然,内存屏障一定程度上就是来做这件事情的,对其作用我们先不详细解释,先加入代码看看结果,其实就是加一句话,类似这样:
void* thread1Func(void* param) {
while (1) {
sem_wait(&beginSema1);
while ( (rand() / (double)RAND_MAX) > 0.2 ) ;
X=1;
__asm__ __volatile__("":::"memory");
// __asm__ volatile("mfence":::"memory"); 这个也可以
std::atomic_thread_fence(std::memory_order_seq_cst);
r1 = Y;
sem_post(&endSema);
}
return NULL;
}
我们再编译执行就不会出现前面的情况了。
前置知识提完了,我们回到问题本身,多个线程可以读一个变量,只有一个线程可以对这个变量进行写,到底要不要加锁?,其实[1]中很多大神都对这个问题做出了解答,虽然说法不尽相同,但是意思也都近似,其中我认为刘然的回答最为全面,他把这个问题分为四种情况:
- 可以把多核看做一个分布式系统,其中绝对时间并没有意义,重要的是因果关系,换句话说,如果写操作A后的所有操作不依赖于一个操作B,这个操作B依赖于写操作A,那么就可以支持多变量读,单变量写。(变量操作必须是原子操作,参见文首,不然会出现数据不完整)。
- 逻辑上允许读线程读到旧数据(这个缓存最终一致性的时间不会很长)。(其实没有因果关系的话并没有什么影响,直接看做为通信的时延就可以)
- 写线程写的数据处于同一条cache line内部,且可以原子的一条指令写完,此时不需要加锁,需要在读写两侧加上合适的Memory Barrier,在x86上是lock前缀指令和fence指令等。这里的限制条件其实很严格,两个条件分别限定了变量大小和操作类型,甚至于对齐要求。但是在加上内存屏障以后确实可以实现强一致性(会刷新
Invaildate queue和Store Buffer,而且显然应该是读写都加屏障而不是某一侧加,只是写端加可能出现一定的延迟,只是读端则可能数据还没到Invaildate queue中)。 - 加读写锁,相比于所有线程直接加互斥锁效率要高,前提是多读的情况下。对于读写锁中写锁的饥饿问题可以参考[6]。
内存屏障
上面我提到内存屏障在一定程度上就是避免缓存一致性所带来的问题的,但是它还有别的功能,即防止CPU流水线乱序执行,Intel定义了三种内存屏障:

SFENCE,LFENCE和MFENCE指令提供了一种性能高效的方式,可确保在产生弱排序结果的例程和使用该数据的例程之间load和store内存排序。 这些指令的功能如下:
- SFENCE:序列化程序指令流中在SFENCE指令之前发生的所有 store(写)操作,但不影响 load(读)操作。
- LFENCE:序列化程序指令流中在LFENCE指令之前发生的所有 load(读)操作,但不影响 store(写)操作。
- MFENCE:序列化程序指令流中在MFENCE指令之前发生的所有 store 和 load 操作。
请注意,与CPUID指令相比,SFENCE,LFENCE和MFENCE指令提供了一种更有效的控制内存顺序的方法。
这里我们可以看到这些内存屏障禁止了指令的排序。我们再来看看还有哪些操作也可以起到与内存屏障一样的作用。


总线上的内存映射设备和其他I / O设备通常对其I / O缓冲区的写入顺序敏感。可以使用I / O指令(IN和OUT指令)对此类访问施加强的写入顺序,如下所示。在执行I / O指令之前,处理器将等待程序中所有先前的指令完成,并等待所有缓冲的写入操作耗尽到内存。只有指令提取和页表遍历可以传递I / O指令。直到处理器确定I / O指令已完成,后续指令的执行才开始。
多处理器系统中的同步机制可能取决于强大的内存排序模型。在这里,程序可以使用诸如XCHG指令或LOCK前缀之类的锁定指令,以确保原子地执行对存储器的读-修改-写操作。锁定操作通常类似于I / O操作,因为它们等待所有先前的指令完成并且等待所有缓冲的写操作排入内存。
程序同步也可以通过序列化指令执行(请参见第8.3节)。这些指令通常用于关键过程或任务边界,以在跳到新的代码段或上下文切换之前强制完成所有先前的指令。像I / O和锁定指令一样,处理器在执行序列化指令之前要等到所有先前的指令都已完成并且所有缓冲的写操作都已排入内存为止。
手册写的很清楚,内存屏障,带#Lock前缀的指令,I/O操作都会把数据载入内存,自然就不存在前面我们提到的脏读问题了。
当然除了运行时指令排序以外还有编译器导致的指令排序。前者已经讨论过了,后者会在两个语句没有显式因果关系时重排指令,这个我们可以使用优化屏障 Optimization Barrier 来避免。
其实也就是__asm__ __volatile__ ("" ::: "memory");这个操作。参考[10],这个语句的解释如下:
- __asm__用于指示编译器在此插入汇编语句。
- __volatile__用于告诉编译器,严禁将此处的汇编语句与其它的语句重组合优化。即:原原本本按原来的样子处理这这里的汇编。
- memory 强制 gcc 编译器假设 RAM 所有内存单元均被汇编指令修改,这样 cpu 中的 registers 和 cache 中已缓存的内存单元中的数据将作废。cpu 将不得不在需要的时候重新读取内存中的数据。这就阻止了 cpu 又将 registers, cache 中的数据用于去优化指令,而避免去访问内存。
- “”::: 表示这是个空指令。barrier() 不用在此插入一条串行化汇编指令。
- __asm __,__volatile __, memory 在前面已经解释。
我们可以看出优化屏障的作用主要有两个,即:
- 屏障后面的操作会从内存中重新取值
- 编译器优化代码时不得使优化越过屏障。
在[9]中可以看到也可以用__sync_synchronize()来代替,一般看别人代码这么用,虽然我觉得这样用有点不妥:
#if __GNUC__ < 4
static inline void barrier(void) {__asm__ volatile("":::"memory");}
#else
static inline void barrier(void) {__sync_synchronize();}
#endif
GCC 4以后的版本也提供了Built-in的屏障函数__sync_synchronize(),这个屏障函数既是编译屏障又是内存屏障,代码插入这个函数的地方会被安插一条mfence指令。[11]中有如下描述:
__sync_synchronize (…)
This builtin issues a full memory barrier.
我们跑一个简单的代码,gcc 版本 10.2.0 (GCC) 4 x Intel® Core i5-7200U CPU @ 2.50GHz X86_64:
int main(){
int a = 10;
__sync_synchronize();
int b = a;
return 0;
}
我们可以看到汇编中加入了一个屏障:
subq $16, %rsp
movl $10, -8(%rbp)
call _ZL7barrierv
movl -8(%rbp), %eax
movl %eax, -4(%rbp)
movl $0, %eax
如果使用__asm__ volatile("":::"memory");的话:
int main(){
int a = 10;
__asm__ volatile("":::"memory");
int b = a;
return 0;
}
汇编中没有内存屏障了。
movl $10, -8(%rbp)
movl -8(%rbp), %eax
movl %eax, -4(%rbp)
movl $0, %eax
popq %rbp
倘若我们使用我们以为会生成内存屏障的代码,比如:
std::atomic_thread_fence(std::memory_order_acq_rel);
我们会发现汇编中还是没有屏障出现:
movl -12(%rbp), %eax
movl %eax, -8(%rbp)
movl $0, %eax
popq %rbp
以上问题的原因我们会在后面聊到内存模型的时候讨论。
内存模型
首先内存模型到底描述的是一个怎样的问题,对此问题网上可谓是群魔乱舞,说什么的都有,我们来看看维基百科对此问题的定义[16]:
内存一致性模型描述的是程序在执行过程中内存操作正确性的问题。内存操作包括读操作和写操作,每一操作又可以用两个时间点界定:发出(Invoke)和响应(Response)。在假定没有流水线的情况下(即单个处理器内指令的执行是按顺序执行的),设系统内共有N个处理器,每个处理器可发出 s n ( 0 < n ≤ N ) {\displaystyle s_{n}(0<n\leq N)} sn(0<n≤N)个内存操作(读或写),那么总共有: ( ∑ n = 1 n = N s n ) ! ∏ n = 1 n = N s n ! {\displaystyle {\frac {(\sum _{n=1}^{n=N}s_{n})!}{\prod _{n=1}^{n=N}s_{n}!}}} ∏n=1n=Nsn!(∑n=1n=Nsn)!种可能的执行顺序。内存一致性模型描述的就是这些操作可能的执行顺序中哪些是正确的。
描述的非常清楚。我们前面提到了程序运行时的指令重排,内存模型其实规定的就是这些指令的重排哪些排列顺序是正确的,也就是哪些是可能出现的,哪些是绝对不可能出现的。
事实上对于内存模型的描述我们可以从两个方面来看,一个是硬件角度的内存模型,也就是厂商给我们提供了怎样的一种一致性保证;还有一种是软件级别的内存模型,其实说直白一点就是一些高级语言给程序员提供的一致性保证,显然此时我们可以不必费尽心机去考虑代码如何适配不同的机器。
比如X86的强模型和ARM的弱模型,如果仅仅依靠硬件提供的内存屏障这个代码将非常难写, 因为不同硬件本身的提供的内存模型是不一样的,甚至有时操作也不相同。但是如果基于软件级别的内存模型,比如使用C++的内存模型(手段为内存序),那么编译器就会帮我们自动去适配不同的机器,因为这是语言保证的。
cppreference.com memory order一节中有如下描述[17]:
std::memory_order specifies how memory accesses, including regular, non-atomic memory accesses, are to be ordered around an atomic operation. Absent any constraints on a multi-core system, when multiple threads simultaneously read and write to several variables, one thread can observe the values change in an order different from the order another thread wrote them. Indeed, the apparent order of changes can even differ among multiple reader threads. Some similar effects can occur even on uniprocessor systems due to compiler transformations allowed by the memory model.
显然站在语言级别的内存来说,其不对硬件内存模型做任何假设,从上文的黑体字就可以看出来。
上面提到了强模型与弱模型,基本上目前主流的CPU与其映射如下所示[15]:

- x86_64和Sparc是强顺序模型(Total Store Order),这是一种接近程序顺序的顺序模型。所谓Total,就是说,内存(在写操作上)是有一个全局的顺序的(所有人看到的一样的顺序), 就好像在内存上的每个Store动作必须有一个排队,一个弄完才轮到另一个,这个顺序和你的程序顺序直接相关。所有的行为组合只会是所有CPU内存程序顺序的交织,不会发生和程序顺序不一致的地方[4]。TSO模型有利于多线程程序的编写,对程序员更加友好,但对芯片实现者不友好。CPU为了TSO的承诺,会牺牲一些并发上的执行效率。
- 弱内存模型(简称WMO,Weak Memory Ordering),是把是否要求强制顺序这个要求直接交给程序员的方法。换句话说,CPU不去保证这个顺序模型(除非他们在一个CPU上就有依赖), 程序员要主动插入内存屏障指令来强化这个“可见性”[4]。ARMv8,PowerPC和MIPS等体系结构都是弱内存模型。每种弱内存模型的体系架构都有自己的内存屏障指令,语义也不完全相同。弱内存模型下,硬件实现起来相对简单,处理器执行的效率也高, 只要没有遇到显式的屏障指令,CPU可以对局部指令进行reorder以提高执行效率。
显然强弱模型描述的就是在特定架构上哪些指令是合法的,哪些是非法的。很好理解强模型限制了程序的优化执行,因为在很多情况下分支预测和指令的并行执行因为内存模型的限制都没办法很好的工作,相反弱模型则可以很好的发挥硬件的潜力,但是对于程序员的要求则高了不少。
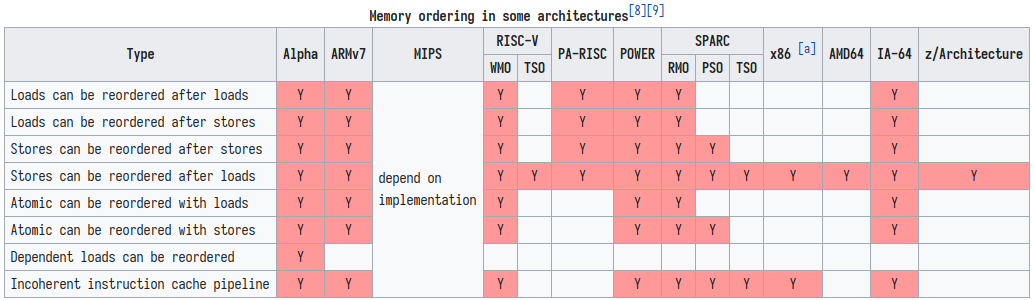
那么各家厂商对于指令重排的限制是怎样的呢?我们来看一张上面已经出现过的图[3]:
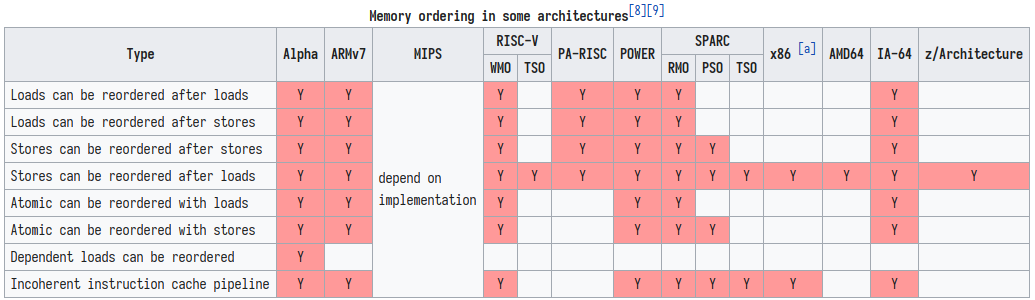
可以看出X86和SPARC的TSO模型下都只支持store load的重排,而ARM则是所有的排序都可能出现。
当然在intel手册中可以看到其实X86是支持写写重排的,不过条件比较苛刻:

英特尔酷睿2双核,英特尔凌动,英特尔酷睿双核,奔腾4和P6家族处理器还使用处理器排序的内存排序模型,该模型可以进一步定义为“使用存储缓冲区转发进行写入排序”。 该模型的特征如下。
在用于定义为WB的内存区域的单处理器系统中,内存排序模型遵循以下原则(请注意,单处理器和多处理器系统的内存排序原则是从在以下环境中执行软件的角度编写的。其中术语“处理器”是指逻辑处理器。例如,支持多核和/或Intel超线程技术的物理处理器被视为多处理器系统。)
- 读操作之间无法排序
- 写操作不能和旧的读操作之间排序
- 写操作与写操作之间除了以下情况以外不能重新排序:
- 带有non-temporal move指令的流存储(写入)(MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, 和 MOVNTPD)
- 串操作- 执行CLFLUSH指令不能重新排序对存储器的写操作。 可以通过执行CLFLUSHOPT指令的执行来重新排序写操作,该指令将刷新除正在写入的高速缓存行以外的其他高速缓存行。 CLFLUSH指令的执行不会相互重新排序。 访问不同缓存行的CLFLUSHOPT的执行可能会相互重新排序。 CLFLUSHOPT的执行可以与访问不同缓存行的CLFLUSH的执行重新排序。
- 读取可能会与不同地址的较旧写入重新排序,但对不同地址的较旧写入则不会重新排序。(store load重排)
- 读写操作不能与IO操作,带LOCK的指令,序列化指令重排序。(上面曾提到过这个问题)
- 读操作不能越过前面的LFENCE和MFENCE操作
- 写操作和CLFLUSH和CLFLUSHOPT的执行不能越过前面的LFENCE,SFENCE和MFENCE指令。
- LFENCE不能越过前面的读操作
- SFENCE不能越过前面的写操作
- MFENCE不能越过前面的读写操作以及CLFLUSH和CLFLUSHOPT的执行。
显然我们可以看到在两种特殊情况下允许写写重排,这是一个串操作的例子:

显然此时可能出现写写重排,我们知道有一些memcpy的实现中可能会使用串操作指令,这也是kfifo中put/get操作更新索引前加屏障的原因之一[18]。
回到我们前面提出的一个问题,那就是为什么在我这个X86的机器上加入memory_order_acq_rel的汇编中都没有产生屏障呢?原因就是X86本身就是强模型,acquire-release模型中所避免情况X86中本身就不存在,所以根本没有必要加入一条屏障。
从[17]中我们知道acquir语义是load之后的读写操作无法被重排到load之前,即load-load,load-store无法重排;而release语义是store之前的读写操作无法被重排到store之后,即load-store和store-store不能重排。X86本身只支持store-load的重排,所以可以说X86天然就是满足acquire-release模型的,所以相关的代码在X86不会有任何的操作。
相近的,因为mfence不允许读写操作越过屏障;memory_order_seq_cst的一致性语义(顺序一致性)强于X86,所以这两个操作在X86的机器上是可以看到屏障的,顺序一致性语义如下[19]:
- the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor were to appear in this sequence in the order specified by its program.
我们写个小demo看一看:
#include <atomic>
std::atomic<int> count;
int flag = 0;
void test_w_1(){
flag = 1;
count.store(10, std::memory_order_seq_cst);
}
int test_r_1(){
count.load(std::memory_order_seq_cst);
return flag;
}
void test_w_2(){
flag = 1;
count.store(10, std::memory_order_release);
}
int test_r_2(){
count.load(std::memory_order_acquire);
return flag + 1;
}
int test_mfence(){
int a = 5;
__asm__ volatile("mfence":::"memory");
return a;
}
int main(){
return 0;
}
我们分别生成X86和ARM的汇编,编译器为X86 gcc 8.2和ARM gcc 9.2.1,编译选项加入-std=c++11 -O2,结果如下:
首先是X86的:
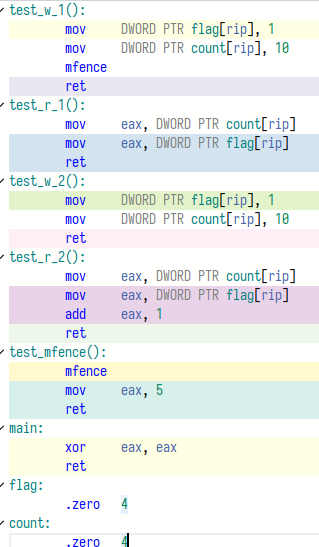
下面是ARM的,我们前面说过__sync_synchronize会插入一个full memory barrier,其实也就是mfence:


C++内存序
我们上面基本上已经把这个问题描述了一遍了,不过都是东扯一句西扯一句,没有章法,现在我们集中精力,会一会这个磨人的小妖精。
第一次了解到这个东西是大概去年这个时间点,在《C++并发编程实战》这本书中学习到的,当时没有其他的前缀知识,自己硬学实在是事倍功半,只能看一些博客文档去学习。现在看来网上描述这个问题的博客百分之七十以上都是一知半解的人写的,越看让人越糊涂,其中甚至很多概念都是错的。罢了罢了。
首先我们前面提到了内存模型可以分为两个角度,一个是硬件角度,一个是软件角度(语言实现的);显然不同的硬件架构之间内存模型可能并不相同,此时语言相关的一致性模型则可以帮我们抹平差异,会基于不同的硬件生成不同的代码来满足语言提供的一致性。
以C++内存序为例,六种内存序其实就指定了四种一致性模型,即:
- sequentially-consistent模型
- acquire-release模型
- consume-release模型
- relaxed模型
分别通过施加不同的内存序来实现不同的一致性模型,且最弱的一致性模型为硬件提供的模型,即使用的一致性模型 = min(内存序指定,硬件指定)。举个例子X86本身就是acquire-release模型,再怎么写其都不可能出现relaxed的语义。
[13]中描述了在不同架构中C++内存序所映射的指令,我们可以看到在X86中除了memory_order_seq_cst以外其他的操作都没有加屏障,现在这个问题也很好理解了。
不过值得一提的是,其中的consume-release模型目前官方并不建议使用,[17]中有如下描述:
- Note that currently (2/2015) no known production compilers track dependency chains: consume operations are lifted to acquire operations.
- The specification of release-consume ordering is being revised, and the use of memory_order_consume is temporarily discouraged.
- 注意到 2015 年 2 月为止没有产品编译器跟踪依赖链:均将consume操作提升为acquire操作。
- release-consume顺序的规范正在修订中,而且暂时不鼓励使用 memory_order_consume 。(C++17 起)
目前所有的consume操作都会被提升为acquire操作。
至于每个操作都是干什么的我实在是不想再白费口舌描述一遍了,[17]中的描述非常详细,直接参考即可。
那么内存序到底做了什么事情呢?其实它就是规定了在一个线程中指令排序中所有可能性中哪些是正确的,虽然指令重排以后在本线程内不会影响结果,但是在其他线程眼中执行的顺序和逻辑可能是不一样的,这在有时可能会造成问题,内存序就是防止这件事情的(store buffer[22]或者乱序执行引起,虽然结果差不多),说简单点就是描述通过限制一个线程的指令执行顺序从而影响其他线程读取相关变量的可见性。
[23]中的观点也很有意思,值得一读。
总结
感觉通过一段时间的学习自己可以给自己讲清楚了,所有的逻辑可以形成一个闭环,实验内容也都符合预期,观点也基本与文档相符,算是初步的理解了这个问题,知道了在什么情况下该怎么写代码了,但是你说我闲的没事会去写lock-free的代码吗?那绝对不可能。一个无锁代码要证明正确性是很难的,当前业界用的比较多的也是已经经过论文证明和工业验证的无锁队列,无锁B树,无锁跳表(golang的sync.map也是无锁的),自己想用无锁的数据结构还是直接用库吧,不要脑子一热自己实现一个,百分之九十九点九九是错的。
基本上mutex,Condition variable,semaphore已经可以满足绝大多数需求了;而一些特殊的地方可以使用原子操作优化,比如计数器这样的场景;而future/promise,future/packaged_task等操作有时也可以替换前面的操作满足我们的同步需求;至于shared_timed_mutex(C++14),shared_mutex(C++17),recursive_mutex(C++11)以及利用原子操作实现的自旋锁则是看特定场景的需要。
基本上如果架构没有太大问题,整个系统的瓶颈不会出现在某个锁上,换句话说,出现因为锁的性能瓶颈时大都是因为架构的问题,很多时候根本没必要上lock-free,一般的同步手段完全可以满足我们的需求。但是因为这样我们就可以不了解这个问题吗?我想作为一个IT行业未来的从业者不应该这样想,我们应该很清楚我们的代码经过了哪些变化,指令重排有时会对代码造成影响(RabbitServer就遇到了一种情况),就算在X86上没踩坑,ARM就可能让你的代码瞬间GG。
当然知道某些数据结构有lock-free的开源实现直接拿来用也是极好的,因为一般来说相比于有锁的代码性能确实会提升不少[21],RabbitServer就使用了无锁队列做一个全局的负载均衡。
这个问题水太深,以上只是我的个人观点,错误之处还请指出。
参考:
- https://www.zhihu.com/question/31325454
- 《聊聊原子变量、锁、内存屏障那点事》
- https://en.wikipedia.org/wiki/Memory_ordering
- 《一个关于Memory Reordering的实验》
- 《事件,时间与偏序关系》
- 《读写锁中写锁的饥饿问题》
- 64-ia-32-architectures-software-developer-vol-3a-part-1-manual
- 《difference in mfence and asm volatile (“” : : : “memory”)》
- https://zh.wikipedia.org/wiki/%E5%86%85%E5%AD%98%E5%B1%8F%E9%9A%9C
- 《内存屏障— asm volatile("" ::: “memory”)》
- https://gcc.gnu.org/onlinedocs/gcc-4.1.1/gcc/Atomic-Builtins.html
- 《volatile与内存屏障总结》
- 《C/C++11 mappings to processors》
- 《Memory Model 一堆资料》
- 《深入理解C11/C++11内存模型》
- https://zh.wikipedia.org/wiki/%E5%86%85%E5%AD%98%E4%B8%80%E8%87%B4%E6%80%A7%E6%A8%A1%E5%9E%8B
- https://en.cppreference.com/w/cpp/atomic/memory_order
- 《linux内核之无锁缓冲队列kfifo原理(结合项目实践)》
- https://en.wikipedia.org/wiki/Sequential_consistency
- https://www.zhihu.com/question/23572082
- 《C++ 的无锁数据结构在工业界有真正的应用吗?》
- 《内存一致性模型笔记 (Memory Consistency Model)》
- 《Weak vs. Strong Memory Models》

