
Userspace RCU的使用与原理
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
所讨论的内核版本为2.6.26。
引言
我们先来看看维基对于RCU的描述:
- In computer science, read-copy-update (RCU) is a synchronization mechanism that avoids the use of lock primitives while multiple threads concurrently read and update elements that are linked through pointers and that belong to shared data structures (e.g., linked lists, trees, hash tables).[1]
- Whenever a thread is inserting or deleting elements of data structures in shared memory, all readers are guaranteed to see and traverse either the older or the new structure, therefore avoiding inconsistencies (e.g., dereferencing null pointers).[1]
- It is used when performance of reads is crucial and is an example of space–time tradeoff, enabling fast operations at the cost of more space. This makes all readers proceed as if there were no synchronization involved, hence they will be fast, but also making updates more difficult.
- 在计算机科学中,read-copy-update是一种同步机制,多个线程同时读取和更新通过指针链接并属于共享数据结构的元素(例如,链表,树 ,哈希表)可避免使用锁原语。
- 每当线程在共享内存中插入或删除数据结构的元素时,都保证所有读取都可以查看和遍历旧结构或新结构,因此避免了不一致(例如,取消引用空指针)。
- 当读取的性能至关重要时,可以使用它,它是时空权衡的一个示例,可以以更多空间为代价实现快速操作。 这使所有读者都像没有同步一样继续进行,因此它们将很快,但也会使更新更加麻烦。
RCU锁无疑是提升小数据块多读操作效率极高的一种方案,因为可以做到任何数据读操作完全无锁(这难道不值得欢呼吗!),当然写操作在绝大多数情况下都需要上一把自旋锁以保护多个写操作之间的临界区[1]。
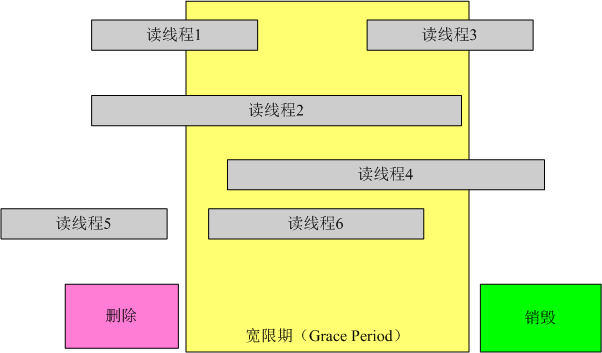
读写操作之间的联系是一件不太好做的事情,原因其实就是Grace period(宽限期),内核中的做法[1]非常优雅,不但简单,直观,而且对用户代码的侵入性也很低,其在rcu_read_lock和rcu_read_unlock接口中分别关开中断,这样使得读操作临界区中不发生上下文切换,这样对于写操作来说,只要每个核都经历过一次上下文切换就可以退出宽限期了。
但是用户态就想要无入侵代码的做到这件事情就比较麻烦了,这里比较知名的用户态RCU库就是[5](当然这会也就400不到的star), 这里读操作首先要加入全局链表,并设置为上线状态(入侵较大),这样在写操作等待宽限期的时候就可以自旋知道是否可以退出宽限期,退出条件为所有的上线的读线程数据为最新,在读操作调用rcu_quiescent_state接口即可更新当前的最新数据版本,一般读操作结束以后使用。
学习这个玩意的目的主要是为了完善我撸的那个HotRing库[7],明眼人都能看出来其中最复杂的部分就是无锁并发操作,这方面需要花点功夫,所以在干活之前养精蓄锐一下,我想这还是很有必要的。
这篇文章主要是对liburcu中的test_urcu_qsbr.c测试文件做一个简单的源码分析,以此了解这个库的基本用法与原理。
正文
首先这个测试的参数需要我们自己去配置,懒得看源码的同学可以使用这个命令来跑测试./test_urcu_qsbr 5 5 5 -v -c 1000000 -e 100000,其中各个参数的意义如下:
- 前三个参数,读线程数,写线程数,测试运行时长
- -v 显示调试信息
- -c 每一个读操作的间隔时长,用于测试宽限期
- -e 每一个写操作的间隔时长
- 间隔时长单位为时钟周期,其调用所传参数次
__asm__ __volatile__ ("rep; nop" : : : "memory")指令[8]
前面的代码没有看的必要,其实下面的代码也比较简单,放在这里主要是为了看看我们拥有哪些线程。
// 前两个单位为pthread_t,后两个单位为unsigned long long,当然都是指针
tid_reader = calloc(nr_readers, sizeof(*tid_reader)); // 存储所有读线程的tid
tid_writer = calloc(nr_writers, sizeof(*tid_writer)); // 存储所有写线程的tid
count_reader = calloc(nr_readers, sizeof(*count_reader)); // 存储运行线程函数的参数,传入一个指针,所以是同步修改的
count_writer = calloc(nr_writers, sizeof(*count_writer));
next_aff = 0;
for (i_thr = 0; i_thr < nr_readers; i_thr++) {
err = pthread_create(&tid_reader[i_thr], NULL, thr_reader,
&count_reader[i_thr]);
if (err != 0)
exit(1);
}
for (i_thr = 0; i_thr < nr_writers; i_thr++) {
err = pthread_create(&tid_writer[i_thr], NULL, thr_writer,
&count_writer[i_thr]);
if (err != 0)
exit(1);
}
cmm_smp_mb(); // mfence,全屏障。序列化程序指令流中在MFENCE指令之前发生的所有 store 和 load 操作
test_go = 1;
sleep(duration); // 测试线程跑duration秒
test_stop = 1; // 测试线程循环结束
for (i_thr = 0; i_thr < nr_readers; i_thr++) {
err = pthread_join(tid_reader[i_thr], &tret);
if (err != 0)
exit(1);
tot_reads += count_reader[i_thr]; // 总读操作数
}
for (i_thr = 0; i_thr < nr_writers; i_thr++) {
err = pthread_join(tid_writer[i_thr], &tret);
if (err != 0)
exit(1);
tot_writes += count_writer[i_thr]; // 总写操作数
}
我们来看看读线程做的事情,这里就逐渐有意思起来了:
void *thr_reader(void *_count)
{
unsigned long long *count = _count;
int *local_ptr;
printf_verbose("thread_begin %s, tid %lu\n",
"reader", urcu_get_thread_id()); // 执行时加上-v 就可以显示出来,看做printf就可以
set_affinity(); // 修改CPU亲和性,默认关闭,使用use_affinity控制
rcu_register_thread(); // 将自己挂接在全局链表registry上,执行读操作必须调用这个
assert(rcu_read_ongoing());
rcu_thread_offline();
assert(!rcu_read_ongoing());
rcu_thread_online(); // 设置为上线状态,即把每线程私有的urcu_qsbr_reader的ctr更新至与全局相同
/* // rcu_thread_online最后调用如下代码
static inline void _urcu_qsbr_thread_online(void){
urcu_assert(URCU_TLS(urcu_qsbr_reader).registered);
cmm_barrier(); // 优化屏障,禁止编译期重排
_CMM_STORE_SHARED(URCU_TLS(urcu_qsbr_reader).ctr, CMM_LOAD_SHARED(urcu_qsbr_gp.ctr));
cmm_smp_mb(); // mfence
}
*/
while (!test_go) // 看不出来有什么用处
{
}
cmm_smp_mb(); // mfence
for (;;) {
rcu_read_lock(); // 空操作,加了个寂寞,其实个人认为这里是为了以后做准备,内核这里的操作是有意义的
assert(rcu_read_ongoing());
local_ptr = rcu_dereference(test_rcu_pointer); // 下面重点聊
rcu_debug_yield_read(); // debug操作
if (local_ptr)
assert(*local_ptr == 8);
if (caa_unlikely(rduration))// caa_unlikely与分支预测有关,其实就是rduration有效的话睡眠,可以给-c加两个零试试
loop_sleep(rduration);
rcu_read_unlock(); // 空操作
URCU_TLS(nr_reads)++; // 读操作次数加1
/* QS each 1024 reads */ // 每1024次才调用同步,意味着如果rduration时间较长,写操作会一直被阻塞
if (caa_unlikely((URCU_TLS(nr_reads) & ((1 << 10) - 1)) == 0))
rcu_quiescent_state(); // 每1024次调用rcu_quiescent_state,进入静默期,更新自己的c_str,让写操作可以退出宽限期
if (caa_unlikely(!test_duration_read())) // 与test_stop有关,睡眠duration秒后在主线程中修改
break;
}
rcu_unregister_thread(); // 从全局链表中去掉
/* test extra thread registration */
rcu_register_thread();
rcu_unregister_thread();
*count = URCU_TLS(nr_reads);
printf_verbose("thread_end %s, tid %lu\n",
"reader", urcu_get_thread_id());
return ((void*)1);
}
rcu_dereference调用过程如下:
#define _rcu_dereference(p) \
__extension__ \
({ \
__typeof__(p) _________p1 = CMM_LOAD_SHARED(p); \
cmm_smp_read_barrier_depends(); \ // 在我的机器是个空操作,因为我的机器X86,弱模型,要是arm就该生成代码了
(_________p1); \ //
})
#define CMM_LOAD_SHARED(p) \
__extension__ \
({ \
cmm_smp_rmc(); \ // 在我的机器是优化屏障。arm的话就该是LFENCE了。
_CMM_LOAD_SHARED(p); \
})
#define _CMM_LOAD_SHARED(p) CMM_ACCESS_ONCE(p)
#define CMM_ACCESS_ONCE(x) (*(__volatile__ __typeof__(x) *)&(x))
因为指针赋值(八字节)本身是原子操作,所以指令级别操作是原子的[9]。为了cache一致性,插上了内存屏障。可以让其它的读者/写者可以看到保护指针的最新值。
我们再来看看写线程的操作:
void *thr_writer(void *_count)
{
unsigned long long *count = _count;
int *new, *old;
printf_verbose("thread_begin %s, tid %lu\n",
"writer", urcu_get_thread_id());
set_affinity();
while (!test_go)
{
}
cmm_smp_mb();
// 和上面如出一辙
for (;;) {
new = malloc(sizeof(int));
assert(new);
*new = 8;
old = rcu_xchg_pointer(&test_rcu_pointer, new); // 一会我们细看,其实就是一个原子交换并返回旧值
if (caa_unlikely(wduration))
loop_sleep(wduration);
printf("before\n");
synchronize_rcu(); // 等待宽限期
printf("after\n");
if (old)
*old = 0;
free(old);
URCU_TLS(nr_writes)++;
if (caa_unlikely(!test_duration_write()))
break;
if (caa_unlikely(wdelay))
loop_sleep(wdelay);
}
printf_verbose("thread_end %s, tid %lu\n",
"writer", urcu_get_thread_id());
*count = URCU_TLS(nr_writes);
return ((void*)2);
}
我们先来看看synchronize_rcu的简化代码,只看简化的原因是原代码太复杂了,不想看了。
void synchronize_rcu(void)
{
CDS_LIST_HEAD(qsreaders);
DEFINE_URCU_WAIT_NODE(wait, URCU_WAIT_WAITING);
......
urcu_wait_add(&gp_waiters, &wait) /* 将writer自身置于wait状态 */
......
wait_for_readers(®istry, &cur_snap_readers, &qsreaders); /* writer阻塞在这里 */
cmm_barrier();
.....
}
// 这其实就是一个自旋等待的一个过程
static void wait_for_readers(struct cds_list_head *input_readers,
struct cds_list_head *cur_snap_readers,
struct cds_list_head *qsreaders)
{
unsigned int wait_loops = 0;
struct rcu_reader *index, *tmp;
/*
* Wait for each thread URCU_TLS(rcu_reader).ctr to either
* indicate quiescence (offline), or for them to observe the
* current rcu_gp.ctr value.
*/
for (;;) { /* 直到所有reader.ctr已经到最新才跳出循环 */
uatomic_set(&rcu_gp.futex, -1);
cds_list_for_each_entry(index, input_readers, node) {
_CMM_STORE_SHARED(index->waiting, 1);
/* 遍历所有输入的reader */
cds_list_for_each_entry_safe(index, tmp, input_readers, node) {
switch (rcu_reader_state(&index->ctr)) {
case RCU_READER_ACTIVE_CURRENT: /* reader.ctr已经最新 */
case RCU_READER_INACTIVE: /* reader处于offline状态 */
cds_list_move(&index->node, qsreaders); /* 从遍历列表中移除 */
break;
case RCU_READER_ACTIVE_OLD: /* reader.ctr不是最新 */
break;
}
}
if (cds_list_empty(input_readers)) {
uatomic_set(&rcu_gp.futex, 0); /* 列表空了,表示所有reader已更新 跳出循环 */
break;
}
}
}
我们再来看看rcu_xchg_pointer,其设计调用如下代码:
#define _rcu_xchg_pointer(p, v) \
__extension__ \
({ \
__typeof__(*p) _________pv = (v); \
uatomic_xchg(p, _________pv); \
})
#define uatomic_xchg(addr, v) \
UATOMIC_COMPAT(xchg(addr, v))
#define UATOMIC_COMPAT(insn) (_uatomic_##insn)
// uatomic_xchg实际调用_uatomic_xchg
#define _uatomic_xchg(addr, v) \
((__typeof__(*(addr))) __uatomic_exchange((addr), \
caa_cast_long_keep_sign(v), \
sizeof(*(addr))))
static inline __attribute__((always_inline))
unsigned long __uatomic_exchange(void *addr, unsigned long val, int len)
{
/* Note: the "xchg" instruction does not need a "lock" prefix. */
switch (len) {
case 1:
{ // CMPXCHG
unsigned char result;
__asm__ __volatile__(
"xchgb %0, %1"
: "=q"(result), "+m"(*__hp(addr))
: "0" ((unsigned char)val)
: "memory");
return result;
}
case 2:
{
unsigned short result;
__asm__ __volatile__(
"xchgw %0, %1"
: "=r"(result), "+m"(*__hp(addr))
: "0" ((unsigned short)val)
: "memory");
return result;
}
case 4:
{
unsigned int result;
__asm__ __volatile__(
"xchgl %0, %1"
: "=r"(result), "+m"(*__hp(addr))
: "0" ((unsigned int)val)
: "memory");
return result;
}
#if (CAA_BITS_PER_LONG == 64)
case 8: // 将第二个参数x放入寄存器中与第一个指针参数所指的内容交换,返回所指内容原先的值。
{
unsigned long result;
__asm__ __volatile__( // 交换指令
"xchgq %0, %1"
: "=r"(result), "+m"(*__hp(addr))
: "0" ((unsigned long)val)
: "memory");
return result;
}
#endif
}
/*
* generate an illegal instruction. Cannot catch this with
* linker tricks when optimizations are disabled.
*/
__asm__ __volatile__("ud2");
return 0;
}
这里其实理论来讲应该还要有一个内存屏障的,为了避免写操作未完成时这个原子交换就已经执行,我认为这样的原因可以在intel手册中的一些文字解释,就是内存屏障,带#Lock前缀的指令,I/O操作都会把数据载入内存,也就是刷新Invaildate queue中的数据,而交换类指令本身假设一定带#Lock指令:

而且锁定指令保证原子是不收内存边界是否对齐的影响的(在weakly ordered memory 的机器上可能出现例外,arm就是弱模型):

总结
好了这个简单的样例到这就结束了,liburcu中有五种类型的RCU锁,这里只是分析了一下qsbr的使用和大概实现方式,前面也提到学习这个东西其实是为了我那个HotRing的轮子,与我而言暂时来说已经够了,更多的探索大家有兴趣可以自己玩玩,有关其使用就放到下一篇博客再讨论了。
参考:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话