
一个魔数引发的学习
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
在看Redis的代码的时候偶然间发现了一个魔数(叫魔数也不完全对,因为是一个规范的排列),就是下面这个东西:
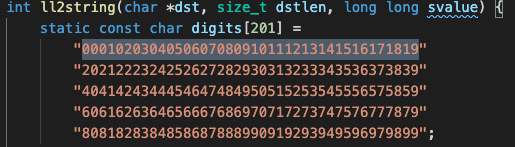
antirez大哥在注释中留下的一个链接很有意思,于是就抱着学习的态度周末浏览下这篇文章,顺便记录下学到的东西,这是这篇文章的由来。这应该是facebook的某个大牛工程师技术分享的主题,原文中留下了分享的视频和PPT,不过视频链接貌似进不去。
这里还有一个小彩蛋就是当时学习文章之前想看看网上有没有关于这篇文章的中文资料,搜索过程中发现了一个宝藏博主[付哲],曾在谷歌,阿里云工作,而且这个老哥所在的部门Tablestore貌似就在我们这层楼上,也是巧了,现在他就职于PingCap。我已经把他的链接放到我的博客导航中了,有兴趣的朋友可以看一看,文章都非常有学习价值。
这篇文章其实基本上把PPT上有的东西都加上了,但是内容上来讲有意思的地方一笔带过,例子举的也比较极端,所以从技术文章的角度来讲这篇文章没啥稀奇的,但是我想作为一个技术Talk,配合着一个技术大牛的讲解这一定非常的有意思。
内容
一个忠告,我想每个喜欢钻牛角尖的人都应该仔细思考下。
But no worries. All we need to remember is that intuition is an ineffective approach to writing efficient code. Everything should be validated by measurements; at the very best, intuition is a good guide in deciding approaches to try when optimizing something (and therefore pruning the search space). And the best intution to be ever had is "I should measure this." As Walter Bright once said, measuring gives you a leg up on experts who are too good to measure.
测试时要注意的地方,一些常见的“陷阱”。
- Measuring the speed of debug builds. We’ve all done that, and people showing puzzling results may have done that too, so keep it in mind whenever looking at numbers.
- Setting up the stage such that the baseline and the benchmarked code work under different conditions. (Stereotypical example: the baseline runs first and changes the memory allocator state for the benchmarked code.)
- Including ancillary work in measurement. Typical noise is added by ancillary calls to the likes of malloc and printf, or dealing with clock primitives and performance counters. Try to eliminate such noise from measurements, or make sure it’s present in equal amounts in the baseline code and the benchmarked code.
- Optimizing code for statistically rare cases. Making sort work faster for sorted arrays to the detriment of all other arrays is a bad idea (http://stackoverflow.com/questions/6567326/does-stdsort-check-if-a-vector-is-already-sorted).>
写代码时需要注意的地方
- Prefer static linking and position-dependent code (as opposed to PIC, position-independent code).
- Prefer 64-bit code and 32-bit data.
- Prefer array indexing to pointers (this one seems to reverse every ten years).
- Prefer regular memory access patterns.
- Minimize control flow.
- Avoid data dependencies.
操作花费的时间对比,这些地方可能可以做性能的优化
- comparisons
- (u)int add, subtract, bitops, shift
- floating point add, sub (separate unit!)
- indexed array access (caveat: cache effects)
- (u)int32 mul
- FP mul
- FP division, remainder
- (u)int division, remainder
举的例子:
- 一个digits10的例子,就是求一个数字十进制有几位。
- integer to string优化1.0
- integer to string优化2.0
基本上优化在于把较慢的操作转化为更快的操作。
这里我想提下为什么优化2.0比优化1.0快了近两倍,我的想法是这样的。
优化2.0其实就是引入了一个静态局部数组去做索引,我们发现用到这个digits的地方其实就是求出索引以后得到这个两位数的两个数字,其实也就是把每次都需要的取余操作和除法优化成了两个数字只需要一个取余,一个乘法,两次内存访问以及一个加法,而取余和除法是很慢的,这就是优化的地方。
Redis中就使用上面的1,3作为相关函数的实现。
总结
例子比较极端,但是带给我们的启发就是当一个调用的热点路径存在大量的运算操作时,花一点时间做这种小Trick也许是很有意义的一件事情,但是最好不要一直做这样的事情,这毕竟只是锦上添花。
参考:

