
LevelDB中的Compaction流程
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
LSM树(Log Structed Merge)因为其高性能的写入已经成为了当今存储领域最为流行的引擎数据结构之一,已被广泛应用于各大NoSQL,NewSQL系统中,并且现在仍旧是一个蓬勃发展的数据结构,每年关于LSM树的论文也是层出不穷,这篇文章的目的是基于LevelDB的代码阐述清楚LSM树中的 compaction 的过程。
这篇文章的目的有两个,即帮你搞清楚:
- 何时触发Compaction
- merge的过程到底是怎么做的
Compaction
compaction分为两个步骤,一个是 minor compaction,另一种是 major compaction,前者将一个memtable(immutable)持久化为一个SSTable,后者执行多个SSTable的合并。
minor compaction
这里相对来说比较简单,调用CompactMemTable即可。本质就是把imm_写入到磁盘上,然后更新一个版本(日志)。
void DBImpl::CompactMemTable() {
mutex_.AssertHeld();
assert(imm_ != nullptr);
// Save the contents of the memtable as a new Table
VersionEdit edit;
Version* base = versions_->current();
base->Ref();
// 最重要的一步
Status s = WriteLevel0Table(imm_, &edit, base);
base->Unref();
if (s.ok() && shutting_down_.load(std::memory_order_acquire)) {
s = Status::IOError("Deleting DB during memtable compaction");
}
// Replace immutable memtable with the generated Table
if (s.ok()) {
edit.SetPrevLogNumber(0);
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
s = versions_->LogAndApply(&edit, &mutex_);
}
if (s.ok()) {
// Commit to the new state
imm_->Unref();
imm_ = nullptr;
has_imm_.store(false, std::memory_order_release);
RemoveObsoleteFiles();
} else {
RecordBackgroundError(s);
}
}
major compaction
基本的一次压缩的调用链如下:
- MaybeScheduleCompaction
- BackgroundCompaction
- {PickCompaction | DoCompactionWork}
- MakeInputIterator
- {FinishCompactionOutputFile | InstallCompactionResults}
我们一个一个看。
MaybeScheduleCompaction
这里其实阐述了何时发起Compaction的时机:
Minor Compaction:imm_ != NULL 表示需要将Memtable dump成SSTableManual Compaction:manual_compaction_ != NULL 表示手动发起CompactionMajor Compaction:versions_->NeedsCompaction函数返回True
void DBImpl::MaybeScheduleCompaction() {
mutex_.AssertHeld();
if (background_compaction_scheduled_) {
// Already scheduled
} else if (shutting_down_.load(std::memory_order_acquire)) {
// DB is being deleted; no more background compactions
} else if (!bg_error_.ok()) {
// Already got an error; no more changes
} else if (imm_ == nullptr && manual_compaction_ == nullptr &&
!versions_->NeedsCompaction()) {
// No work to be done
} else {
background_compaction_scheduled_ = true;
env_->Schedule(&DBImpl::BGWork, this);
}
}
// 非常简单的一个函数,里面的两个参数在PickCompaction中解释
bool NeedsCompaction() const {
Version* v = current_;
return (v->compaction_score_ >= 1) || (v->file_to_compact_ != nullptr);
}
BackgroundCompaction
这个函数由后台线程执行,所以不会阻碍主线程,但是合并的过程本身是非常消耗资源(磁盘带宽,CPU)的。
void DBImpl::BackgroundCompaction() {
mutex_.AssertHeld();
if (imm_ != nullptr) {
// 把immutable table 写到磁盘,versionset调用LogAndApply,应用此次修改,伴随着老旧文件的删除
CompactMemTable();
return;
}
Compaction* c;
bool is_manual = (manual_compaction_ != nullptr);
InternalKey manual_end;
// 是否是手动执行compaction
if (is_manual) {
ManualCompaction* m = manual_compaction_;
// 找到level层中与[begin,end]重合的所有file,并放入c中
c = versions_->CompactRange(m->level, m->begin, m->end);
m->done = (c == nullptr);
if (c != nullptr) {
manual_end = c->input(0, c->num_input_files(0) - 1)->largest;
}
Log(options_.info_log,
"Manual compaction at level-%d from %s .. %s; will stop at %s\n",
m->level, (m->begin ? m->begin->DebugString().c_str() : "(begin)"),
(m->end ? m->end->DebugString().c_str() : "(end)"),
(m->done ? "(end)" : manual_end.DebugString().c_str()));
} else {
// 重点函数,找到目标level与level+1中需要合并的所有文件,一会看
c = versions_->PickCompaction();
}
Status status;
// 没有需要压缩的文件,当然不需要压缩啦
if (c == nullptr) {
// 一个优化,如果存在大量重叠的grandparent数据,请避免移动。否则,移动可能会创建一个父文件,以后需要进行非常昂贵的合并。
} else if (!is_manual && c->IsTrivialMove()) {
// Move file to next level
assert(c->num_input_files(0) == 1);
FileMetaData* f = c->input(0, 0);
// level层删除一个文件,level+1层创建一个文件,然后应用这次修改
c->edit()->RemoveFile(c->level(), f->number);
c->edit()->AddFile(c->level() + 1, f->number, f->file_size, f->smallest,
f->largest);
// LogAndApply是VersionSet中非常重要的一个函数,其应用edit的修改,并生成一个新的version,然后记录到MANIFEST中
status = versions_->LogAndApply(c->edit(), &mutex_);
if (!status.ok()) {
RecordBackgroundError(status);
}
VersionSet::LevelSummaryStorage tmp;
Log(options_.info_log, "Moved #%lld to level-%d %lld bytes %s: %s\n",
static_cast<unsigned long long>(f->number), c->level() + 1,
static_cast<unsigned long long>(f->file_size),
status.ToString().c_str(), versions_->LevelSummary(&tmp));
} else {
CompactionState* compact = new CompactionState(c);
// 执行压缩的过程,后面解释
status = DoCompactionWork(compact);
if (!status.ok()) {
RecordBackgroundError(status);
}
// 释放compact中的申请的一些资源
CleanupCompaction(compact);
// 对inputversion做unref处理
c->ReleaseInputs();
// 删除所有不需要的文件和过时的内存条目,还是基于log文件的number来判断的
RemoveObsoleteFiles();
}
delete c;
......
}
PickCompaction
这里要提一下的是PickCompaction的有效性基于current_->compaction_score_,后者在Finalize被调用,Finalize其实就是去更具level的层数的不同去计算最适合进行compaction的level。
调用的地方比较多,但是总而言之一下几个点会触发major compaction:
- 当执行
get操作的时候会记录下其中遍历的第一个file,因为此文件在读的过程中没有提供答案但是却被seek了,此时allowed_seeks减1,当file的allowed_seeks超过阈值的时候就会触发compaction。 - level 0 层:sstable 文件个数超过指定个数。因为 level0 是从 Immutable 直接转储而来,所以用个数限制而不是文件大小。
- level i 层:第 i 层的 sstable size 总大小超过(10^i) MB。level 越大,说明数据越冷,读取的几率越小,因此对于 level 更大的层,给定的 size 阈值更大,从而减少 comaction 次数。
Compaction* VersionSet::PickCompaction() {
Compaction* c;
int level;
// 我们倾向于执行由于过多数据触发的压缩,而不是由seek触发的压缩。
const bool size_compaction = (current_->compaction_score_ >= 1); // 又过多数据触发
const bool seek_compaction = (current_->file_to_compact_ != nullptr); // 搜索触发
if (size_compaction) {
// 由Finalize算出最适合压缩的level
level = current_->compaction_level_;
assert(level >= 0);
assert(level + 1 < config::kNumLevels);
c = new Compaction(options_, level);
// Pick the first file that comes after compact_pointer_[level]
// 选择紧跟在 compact_pointer_[level] 之后的第一个文件
for (size_t i = 0; i < current_->files_[level].size(); i++) {
FileMetaData* f = current_->files_[level][i];
if (compact_pointer_[level].empty() ||
icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) {
c->inputs_[0].push_back(f);
break;
}
}
// 不存在的话就把第一项插进去
if (c->inputs_[0].empty()) {
// Wrap-around to the beginning of the key space
c->inputs_[0].push_back(current_->files_[level][0]);
}
} else if (seek_compaction) {
// 在UpdateStats中可以看到这部分的逻辑
level = current_->file_to_compact_level_;
c = new Compaction(options_, level);
c->inputs_[0].push_back(current_->file_to_compact_);
} else {
return nullptr;
}
c->input_version_ = current_;
c->input_version_->Ref();
// level0比较特殊,因为多个SSTable之间允许重叠,所以这一步是找出所有重叠的SSTable,并扩展smallest和largest
if (level == 0) {
InternalKey smallest, largest;
// 其实就是一个赋值操作,因为这里inputs_[0].size 肯定是1
GetRange(c->inputs_[0], &smallest, &largest);
// 这里可以拿到level0中所有相交的SSTable,还会扩展smallest和largest
current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]);
assert(!c->inputs_[0].empty());
}
// 以上只拿到了一层需要合并的的SSTable,获取level+1中重叠的level,挺复杂的一个函数
SetupOtherInputs(c);
return c;
}
其实那里的SetupOtherInputs类似于这样(图来自[1]):
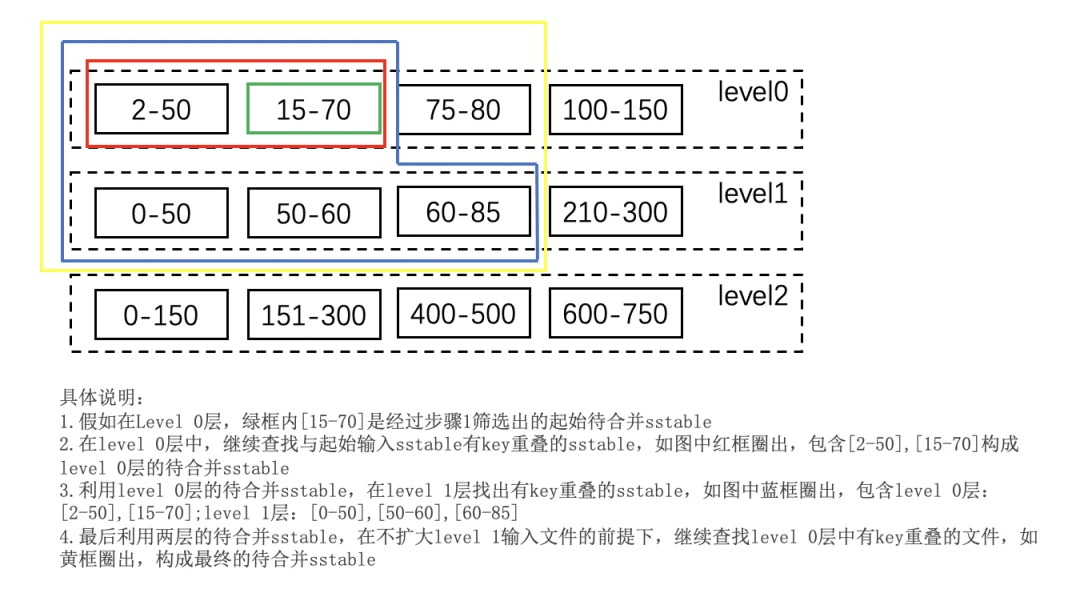
SetupOtherInputs
这部分在[2]中描述的比较清楚。
void VersionSet::SetupOtherInputs(Compaction* c) {
const int level = c->level();
InternalKey smallest, largest;
// 这个操作的含义貌似是用compaction_files中最大的文件去level_files中寻找smallest.user_key相同的一项,然后加到compaction_files
AddBoundaryInputs(icmp_, current_->files_[level], &c->inputs_[0]);
// 用新区间更新smallest和largest
GetRange(c->inputs_[0], &smallest, &largest);
// 获取更高一层重合的所有SSTable
current_->GetOverlappingInputs(level + 1, &smallest, &largest,
&c->inputs_[1]);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &c->inputs_[1]);
// 重新计算start和limit
InternalKey all_start, all_limit;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
// See if we can grow the number of inputs in "level" without
// changing the number of "level+1" files we pick up.
if (!c->inputs_[1].empty()) {
std::vector<FileMetaData*> expanded0;
// 再返回到第一层的过程查找重叠的过程
current_->GetOverlappingInputs(level, &all_start, &all_limit, &expanded0);
AddBoundaryInputs(icmp_, current_->files_[level], &expanded0);
const int64_t inputs0_size = TotalFileSize(c->inputs_[0]);
const int64_t inputs1_size = TotalFileSize(c->inputs_[1]);
/
const int64_t expanded0_size = TotalFileSize(expanded0);
// 至少要在生成level+1以后和level有重叠且加起来小于阈值才执行
if (expanded0.size() > c->inputs_[0].size() &&
inputs1_size + expanded0_size <
ExpandedCompactionByteSizeLimit(options_)) { // 不希望一次compaction的大小太大
InternalKey new_start, new_limit;
GetRange(expanded0, &new_start, &new_limit);
std::vector<FileMetaData*> expanded1;
current_->GetOverlappingInputs(level + 1, &new_start, &new_limit,
&expanded1);
AddBoundaryInputs(icmp_, current_->files_[level + 1], &expanded1);
// 加入这个SSTable没有和Level+1的某一项有重叠,有重叠就不再无限套娃了
if (expanded1.size() == c->inputs_[1].size()) {
Log(options_->info_log,
"Expanding@%d %d+%d (%ld+%ld bytes) to %d+%d (%ld+%ld bytes)\n",
level, int(c->inputs_[0].size()), int(c->inputs_[1].size()),
long(inputs0_size), long(inputs1_size), int(expanded0.size()),
int(expanded1.size()), long(expanded0_size), long(inputs1_size));
smallest = new_start;
largest = new_limit;
c->inputs_[0] = expanded0;
c->inputs_[1] = expanded1;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
}
}
}
// 计算和grandparent重叠的文件
if (level + 2 < config::kNumLevels) {
current_->GetOverlappingInputs(level + 2, &all_start, &all_limit,
&c->grandparents_);
}
// Update the place where we will do the next compaction for this level.
// We update this immediately instead of waiting for the VersionEdit
// to be applied so that if the compaction fails, we will try a different
// key range next time.
compact_pointer_[level] = largest.Encode().ToString();
c->edit_.SetCompactPointer(level, largest);
}
MakeInputIterator
我们在经过了PickCompaction以后有了一个compaction结构,基于此结构我们可以调用MakeInputIterator,其返回一个可以N个SSTable中提取出来不重复key的迭代器。
Iterator* VersionSet::MakeInputIterator(Compaction* c) {
ReadOptions options;
options.verify_checksums = options_->paranoid_checks;
options.fill_cache = false;
// Level-0 files have to be merged together. For other levels,
// we will make a concatenating iterator per level.
// TODO(opt): use concatenating iterator for level-0 if there is no overlap
const int space = (c->level() == 0 ? c->inputs_[0].size() + 1 : 2);
Iterator** list = new Iterator*[space];
int num = 0;
for (int which = 0; which < 2; which++) {
if (!c->inputs_[which].empty()) {
if (c->level() + which == 0) {
// 在level0的话我们需要创建多个迭代器
const std::vector<FileMetaData*>& files = c->inputs_[which];
for (size_t i = 0; i < files.size(); i++) {
list[num++] = table_cache_->NewIterator(options, files[i]->number,
files[i]->file_size);
}
} else {
// 其他的话创建一个LevelFileNumIterator
list[num++] = NewTwoLevelIterator(
new Version::LevelFileNumIterator(icmp_, &c->inputs_[which]),
&GetFileIterator, table_cache_, options);
}
}
}
assert(num <= space);
// MergingIterator,一个归并的过程,迭代器返回这些SSTable和memtable合并后的不重复的value
Iterator* result = NewMergingIterator(&icmp_, list, num);
delete[] list;
return result;
}
MergingIterator其实也很有意思,本质上是一个归并的过程,其实问题就是在多个存在重复的有序数组中取到不重复的key。可以参考[3]
DoCompactionWork
Status DBImpl::DoCompactionWork(CompactionState* compact) {
const uint64_t start_micros = env_->NowMicros();
int64_t imm_micros = 0; // Micros spent doing imm_ compactions
Log(options_.info_log, "Compacting %d@%d + %d@%d files",
compact->compaction->num_input_files(0), compact->compaction->level(),
compact->compaction->num_input_files(1),
compact->compaction->level() + 1);
assert(versions_->NumLevelFiles(compact->compaction->level()) > 0);
assert(compact->builder == nullptr);
assert(compact->outfile == nullptr);
// 如果没有快照,则重复的旧k/v数据都可以删掉
if (snapshots_.empty()) {
compact->smallest_snapshot = versions_->LastSequence();
} else {
// 如果有快照,则只有sequenceNumber小于最老的快照的sequenceNumber的旧k/v数据才可以删掉
compact->smallest_snapshot = snapshots_.oldest()->sequence_number();
}
// 获取一个MergingIterator,其可以按照大小顺序遍历所有compact中包含的SStable,Memtable
Iterator* input = versions_->MakeInputIterator(compact->compaction);
// Release mutex while we're actually doing the compaction work
mutex_.Unlock();
// 迭代器使用前需要seek下
input->SeekToFirst();
Status status;
ParsedInternalKey ikey;
std::string current_user_key;
bool has_current_user_key = false;
SequenceNumber last_sequence_for_key = kMaxSequenceNumber;
while (input->Valid() && !shutting_down_.load(std::memory_order_acquire)) {
// Prioritize immutable compaction work
if (has_imm_.load(std::memory_order_relaxed)) {
const uint64_t imm_start = env_->NowMicros();
mutex_.Lock();
if (imm_ != nullptr) {
// 如果存在imm就暂停compaction的过程去把imm刷到磁盘,
CompactMemTable();
// Wake up MakeRoomForWrite() if necessary.
background_work_finished_signal_.SignalAll();
}
mutex_.Unlock();
imm_micros += (env_->NowMicros() - imm_start);
}
Slice key = input->key();
if (compact->compaction->ShouldStopBefore(key) &&
compact->builder != nullptr) {
// 检查当前输出文件是否与level+2层文件有过多冲突,如果是就要完成当前输出文件并产生新的输出文件
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
// 是否可以丢掉当前kv对,默认是否
bool drop = false;
// 把一个internaalkey解析到ikey中
if (!ParseInternalKey(key, &ikey)) {
// Do not hide error keys
current_user_key.clear();
has_current_user_key = false;
last_sequence_for_key = kMaxSequenceNumber;
} else {
if (!has_current_user_key || // 两个key相等到话显然不会进入这个循环
user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) !=
0) {
// 该user_key是第一次出现
current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());
has_current_user_key = true;
//因为第一次出现的user_key不允许删除,所有将last_sequence_for_key设为最大值
last_sequence_for_key = kMaxSequenceNumber;
}
if (last_sequence_for_key <= compact->smallest_snapshot) {
// 已经有相同user_key出现了,并且上一个user_key的sequenceNumber还小于等于
// compact->smallest_snapshot,注意直到遇到第二个user_key的sequenceNumber
// 小于等于smallest_snapshot才能丢弃
drop = true; // (A)
} else if (ikey.type == kTypeDeletion &&
ikey.sequence <= compact->smallest_snapshot &&
compact->compaction->IsBaseLevelForKey(ikey.user_key)) {
//当前kv是距离最小版本smallest_snapshot最近的user_key,但因为它是条删除操作,并且
//没有已经比它还老的user_key了。所有可以丢弃掉。
drop = true;
}
last_sequence_for_key = ikey.sequence;
}
#if 0
Log(options_.info_log,
" Compact: %s, seq %d, type: %d %d, drop: %d, is_base: %d, "
"%d smallest_snapshot: %d",
ikey.user_key.ToString().c_str(),
(int)ikey.sequence, ikey.type, kTypeValue, drop,
compact->compaction->IsBaseLevelForKey(ikey.user_key),
(int)last_sequence_for_key, (int)compact->smallest_snapshot);
#endif
// 如果某个key我们没有drop的话就用build建立一个新的SSTable,然后把这个kv插进去
if (!drop) {
// Open output file if necessary
if (compact->builder == nullptr) {
// 蕴含着向compact.outputs写数据的操作
status = OpenCompactionOutputFile(compact);
if (!status.ok()) {
break;
}
}
if (compact->builder->NumEntries() == 0) {
compact->current_output()->smallest.DecodeFrom(key);
}
compact->current_output()->largest.DecodeFrom(key);
compact->builder->Add(key, input->value());
// Close output file if it is big enough
if (compact->builder->FileSize() >=
compact->compaction->MaxOutputFileSize()) {
// 生的新文件size过大,完成新文件的写,下次将产生一个更新的文件作为输出文件
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
}
input->Next();
}
if (status.ok() && shutting_down_.load(std::memory_order_acquire)) {
//在合并过程中遇到数据库关机,这个时候退出合并,这次合并将无效
status = Status::IOError("Deleting DB during compaction");
}
if (status.ok() && compact->builder != nullptr) {
status = FinishCompactionOutputFile(compact, input);
}
if (status.ok()) {
status = input->status();
}
delete input;
input = nullptr;
// 统计数据相关
CompactionStats stats;
stats.micros = env_->NowMicros() - start_micros - imm_micros;
for (int which = 0; which < 2; which++) {
for (int i = 0; i < compact->compaction->num_input_files(which); i++) {
stats.bytes_read += compact->compaction->input(which, i)->file_size;
}
}
for (size_t i = 0; i < compact->outputs.size(); i++) {
stats.bytes_written += compact->outputs[i].file_size;
}
mutex_.Lock();
stats_[compact->compaction->level() + 1].Add(stats);
// 将合并产生的新文件应用到新版本中,并删除掉旧文件,最后用新版本替换旧版本
if (status.ok()) {
status = InstallCompactionResults(compact);
}
if (!status.ok()) {
RecordBackgroundError(status);
}
VersionSet::LevelSummaryStorage tmp;
Log(options_.info_log, "compacted to: %s", versions_->LevelSummary(&tmp));
return status;
}
InstallCompactionResults
这个函数把此次compaction涉及到的文件修改记录到versionEdit,然后对versionSet应用这个versionEdit
Status DBImpl::InstallCompactionResults(CompactionState* compact) {
mutex_.AssertHeld();
Log(options_.info_log, "Compacted %d@%d + %d@%d files => %lld bytes",
compact->compaction->num_input_files(0), compact->compaction->level(),
compact->compaction->num_input_files(1), compact->compaction->level() + 1,
static_cast<long long>(compact->total_bytes));
// compact.input中的两行数据都需要删掉
compact->compaction->AddInputDeletions(compact->compaction->edit());
const int level = compact->compaction->level();
// 新创建的SSTable的信息
for (size_t i = 0; i < compact->outputs.size(); i++) {
const CompactionState::Output& out = compact->outputs[i];
compact->compaction->edit()->AddFile(level + 1, out.number, out.file_size,
out.smallest, out.largest);
}
// 应用此次edit并更新版本
return versions_->LogAndApply(compact->compaction->edit(), &mutex_);
}
参考:

