
从LevelDB SnapShot到内存快照的思考
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
SnapShot技术在数据库领域的重要性不言而喻,这种记录整个数据库某一时间点全部视图并快速恢复的能力非常重要,这相当于是一颗后悔药。存储网络行业协会SNIA(StorageNetworking Industry Association)对于Snapshot的定义是:
A point in time copy of a defined collection of data.
而维基对SnapShot的定义是:
a snapshot is the state of a system at a particular point in time.
我们可以看出Snapshot本身是什么并不重要,可以是其所表示的数据的一个副本,也可以是数据的一个复制品,重要的是其记录了系统某一个时间点的状态,这其实类似与Git,LevelDB中的Version以及容器分层的概念,其实就是一个版本控制而已。但是上面术语中定义的SnapShot本身的粒度可能与Git更为类似,因为这两者的版本概念更为具体,这里的版本是我们可以直接恢复到的某一个手动执行SnapShot的时间点。
而LevelDB中Version的概念是去标识SSTable结构的变动,信息存储在 MANIFEST 文件中,这里的粒度就更细了,当然粒度更细的就是所谓的PITR(Point-in-time recovery)了,可以恢复至任意时间点的数据库状态。
扯了一大堆,其实我真正想谈的其实是SnapShot本身的开销问题,不管是Raft算法的SnapShot也好,还是Redis的RDB也罢,本身的开销其实是不小的,尤其是Redis的RDB,会直接Fork当前主进程,然后会序列化当前的内存状态,当内存数据多了以后这显然是一个既消耗CPU又消耗磁盘带宽的行为,虽然有ROW。经典的Fork分为两步,Fork时资源复制时复制页表项并且将其都设置为只读,缺页异常中识别COW引发的错误并实际分配资源实现地址空间隔离。父进程内存占用过大的时候开始页表项和vma内容虽然共享,但是本身对象的复制开销也非常大[10](好文),其他私有数据也需要拷贝,后面缺页时还是需要拷贝[8][9].
Raft的Snapshot就不提了,虽然TiKV对Snapshot做了特殊的处理,但是这个处理其实只是在收发的时候引入SnapChunk,利用了gRPC的Stream发送来防止把SnapShot一次载入内存的情况,其实在进行SnapShot的时候还是比较慢,毕竟需要把日志数据存入磁盘,序列化本身的的CPU消耗以及磁盘IO都是需要考虑的。
本质上的问题来源于大量的磁盘IO以及对于CPU资源的消耗,这些都可能会影响到工作线程从而使得服务时延出现毛刺,你可能会说都已经使用了SnapShot了,这种开销显然无法避免啊,其实是可以的。首先简单思考,需要dump到磁盘的原因是因为我们磁盘上没有存储已有数据,假如已经有的话我们是否可以利用呢?
显然在现代数据库数据库中MVCC和LSM Tree的出现频率已经非常高了,我们能否基于这两个机制的冗余数据做到零开销的内存快照呢?其实LevelDB中的SnapShot我个人认为实现的非常优秀,其可以几乎零开销的生成一个SnapShot(分配一个SSequenceNumber而已),虽然这个快照是只读的。
LevelDB SnapShot
我们来看一看LevelDB的SnapShot是如何实现的,首先前置知识是SSTable中Block的数据被组织为这样:
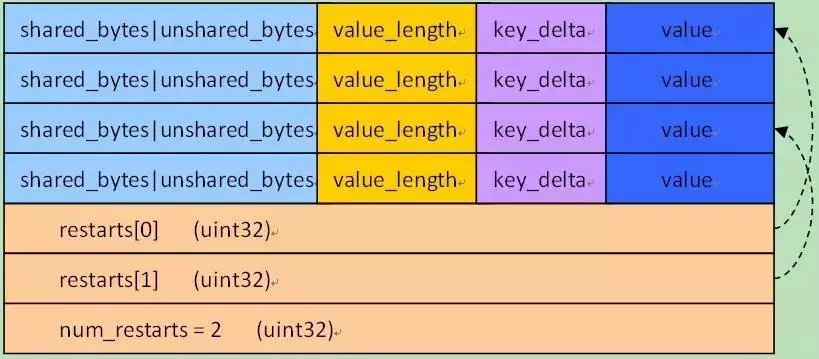
其中的key会被压缩,但是每分隔16个就会全量存储,后面restarts记录的是这些全量存储的offset。
其中key的数据被组织为这样:
// klength varint32
// userkey char[klength]
// tag (sequence + type) uint64
也就是所有的key其实都带着一个sequence。
然后我们再来看看InternalKeyComparator::Compare:
int InternalKeyComparator::Compare(const Slice& akey, const Slice& bkey) const {
// 首先根据user key按升序排列
// 然后根据sequence number按降序排列
// 最后根据value type按降序排列
int r = user_comparator_->Compare(ExtractUserKey(akey), ExtractUserKey(bkey));
if (r == 0) {
const uint64_t anum = DecodeFixed64(akey.data() + akey.size() - 8);
const uint64_t bnum = DecodeFixed64(bkey.data() + bkey.size() - 8);
if (anum > bnum) {
r = -1;
} else if (anum < bnum) {
r = +1;
}
}
return r;
}
LevelDB获取SnapShot的接口为Snapshot* GetSnapshot(),我们来看看其实现:
typedef uint64_t SequenceNumber;
class SnapshotImpl : public Snapshot {
public:
SnapshotImpl(SequenceNumber sequence_number)
: sequence_number_(sequence_number) {}
SequenceNumber sequence_number() const { return sequence_number_; }
private:
friend class SnapshotList;
// SnapshotImpl is kept in a doubly-linked circular list. The SnapshotList
// implementation operates on the next/previous fields direcly.
SnapshotImpl* prev_;
SnapshotImpl* next_;
const SequenceNumber sequence_number_;
#if !defined(NDEBUG)
SnapshotList* list_ = nullptr;
#endif // !defined(NDEBUG)
};
可以看到其实只有1个uin64_t类型的成员,根据这个SequenceNumber和上面的比较运算符,我们就可以在Get的时候拼接出一个带着某个SnapShot的SequenceNumber的key,然后去取数据了,这部分代码我们在DBImpl::Get也可以找到:
SequenceNumber snapshot;
if (options.snapshot != nullptr) {
snapshot =
static_cast<const SnapshotImpl*>(options.snapshot)->sequence_number();
} else {
snapshot = versions_->LastSequence();
}
当然最大的问题在于Compaction的时候可能会把某些老旧的key删除掉,这个问题很好解决,代码在DoCompactionWork中,也就是在compaction中判断哪些key需要丢弃的时候引入对于snapshot的判断:
// 是否可以丢掉当前kv对,默认是否
bool drop = false;
if (!ParseInternalKey(key, &ikey)) {
// Do not hide error keys
current_user_key.clear();
has_current_user_key = false;
last_sequence_for_key = kMaxSequenceNumber;
} else {
if (!has_current_user_key ||
user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) !=
0) {
// 该user_key是第一次出现
current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());
has_current_user_key = true;
//因为第一次出现的user_key不允许删除,所有将last_sequence_for_key设为最大值
last_sequence_for_key = kMaxSequenceNumber;
}
if (last_sequence_for_key <= compact->smallest_snapshot) {
// 已经有相同user_key出现了,并且上一个user_key的sequenceNumber还小于等于
// compact->smallest_snapshot,注意直到遇到第二个user_key的sequenceNumber
// 小于等于smallest_snapshot才能丢弃
drop = true; // (A)
} else if (ikey.type == kTypeDeletion &&
ikey.sequence <= compact->smallest_snapshot &&
// 在下面的层级中这个key不存在了
compact->compaction->IsBaseLevelForKey(ikey.user_key)) {
//当前kv是距离最小版本smallest_snapshot最近的user_key,但因为它是条删除操作,并且
//没有已经比它还老的user_key了。所有可以丢弃掉。
//对于已经存在的key在第一个条件中已经被删除了
// For this user key:
// (1) there is no data in higher levels
// (2) data in lower levels will have larger sequence numbers
// (3) data in layers that are being compacted here and have
// smaller sequence numbers will be dropped in the next
// few iterations of this loop (by rule (A) above).
// Therefore this deletion marker is obsolete and can be dropped.
drop = true;
}
last_sequence_for_key = ikey.sequence;
}
这样即可保证Snapshot存在时比其SequenceNumber小的数据中最新的那一个不会被删,从而保证SnapShot可以读到最新的数据。
MVCC的启发
这里其实给了我新的想法,这种方法能否利用在MVCC中呢,因为MVCC中也有冗余数据,我们完全可以基于时间来做SnapShot,不过这要求MVCC的垃圾回收需要重新设计,因为其需要考虑到已有的Snapshot,如果做的好,这项工作可以使得基于MVCC的数据库都可以立马拥有完美的零开销的内存快照功能。
这其实很好理解,因为处于RR隔离级别来看,事务眼中确实就是一个不可变的视图,为什么我们不能把这看作一个SnapShot呢。
我认为这是一个很有价值的思考,我想后续可以找机会调研下这项工作。
可回滚数据结构
第一次学习到这个概念实在学习HAMT(Hash Array Mapped Trie)时了解到的[4],具体可以参考[5]进行学习,这其实也是一种forkless的思路。
COW与ROW
COW(Copy-On-Write)与ROW(Redirect-on-write)是经典的SnapShot的实现方案,感觉上就是以Page为单位去做SnapShot了,这其实数据抽象(也就是如何用到我们的代码中)也需要一些时间,但是确实是很有用的,因为把一次很大的资源消耗均摊到多次操作中了,基本上就是一种惰性的思路,具体可以参考[2][6]。
在[6]的评论区提到NetApp有一种很优秀的SnapShot的实现方案,但是看了[7]以后,觉得原理类似与ROW类似。
当然Redis的RDB本质上就是一种COW的实现,在Fork以后直接在子进程执行数据的RDB操作,代码在rdb.c中可以看到。
Cgroup
前面提到Fork的方案会带来一些问题,如果我们已有的代码无法支持我们像是LevelDB一样做这种轻量级的快照,我们怎么才能保证快照的过程不影响工作线程呢,显然资源隔离的方案是一个看起来不错的实现,我们可以起一个进程,对其隔离资源,然后通过工作线程的LOG去做SnapShot,显然这也是一种可行的做法。
总结
从SnapShot到PITR,这种企业级的能力值得我们花时间去思考,如何更快速,更不影响工作线程,还不大幅增加系统的写放大的实现SnapShot是一个很有价值的问题。
参考:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律