
eBPF: 深入探究 Map 类型
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
内核版本为5.4.119
文章目录
- 引言
- Map Cmd
- Map Type
- Generic maps
- BPF_MAP_TYPE_HASH
- BPF_MAP_TYPE_ARRAY
- BPF_MAP_TYPE_PERCPU_HASH / BPF_MAP_TYPE_PERCPU_ARRAY
- BPF_MAP_TYPE_LRU_HASH / BPF_MAP_TYPE_LRU_PERCPU_HASH
- BPF_MAP_TYPE_HASH_OF_MAPS / BPF_MAP_TYPE_ARRAY_OF_MAPS
- BPF_MAP_TYPE_PERF_EVENT_ARRAY
- BPF_MAP_TYPE_RINGBUF
- BPF_MAP_TYPE_LPM_TRIE
- BPF_MAP_TYPE_QUEUE / BPF_MAP_TYPE_STACK
- BPF_MAP_TYPE_BLOOM_FILTER
- Non-generic maps
- BPF_MAP_TYPE_PROG_ARRAY
- BPF_MAP_TYPE_STACK_TRACE
- BPF_MAP_TYPE_SOCKMAP / BPF_MAP_TYPE_SOCKHASH
- BPF_MAP_TYPE_DEVMAP / BPF_MAP_TYPE_DEVMAP_HASH
- BPF_MAP_TYPE_CPUMAP
- BPF_MAP_TYPE_XSKMAP
- BPF_MAP_TYPE_REUSEPORT_SOCKARRAY
- BPF_MAP_TYPE_CGROUP_STORAGE
- BPF_MAP_TYPE_CGROUP_ARRAY
- BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE
- BPF_MAP_TYPE_SK_STORAGE
- BPF_MAP_TYPE_STRUCT_OPS
- BPF_MAP_TYPE_INODE_STORAGE
- BPF_MAP_TYPE_TASK_STORAGE
- 性能
- 总结
引言
前面几篇文章提到为了加速内存数据库,我需要在内核里面放置一块缓存,原理其实和DB前面放置一个cache,CPU cache大同小异,我有很多文章已经描述过这个问题了[5][4][6][7],无非前者为了跳过协议栈,后者为了跳过DB和访存操作,也就是说功能上三者应该是差不多的,当然需要解决的问题也是差不多的,基本重难点就是一致性和缓存策略上。
缓存的写入方案在[7]中也写的很清楚,基本就是WT,WB此类;遇到的问题中[6]基本是过时设置(stale sets)和惊群(thundering herds)诸如此类,不过facebook已经使用lease机制解决这些问题[9],至于缓存策略,则是一个难点,在暨[4]中描述了cache的缺陷又在[5]中打自己的脸以后,对这个问题我实在是避之不及,但是没办法,现在又要面对这个玩意了。
这次项目中的缓存淘汰基本上策略应该是不变的,但是需要考虑的东西更多,内存碎片,是否扩容,key/value大小限制,实现复杂性等等,所以这篇文章分析现有的map类型,看看是否满足需求,以及不满足需求时的解决方案。
这里map类型的资料其实我在linux的各种文档上都没有找到详细的描述([1],Cilium和其他内核的documentation),[8]中的第三章节是相对来说比较全面的一个描述,bcc的docs[11]中也比较全面,所以本篇文章参考以上资料,辅以自己的一些理解。
Map Cmd
在[12]中把map类型分为Generic maps和Non-generic maps,这样的分法确实也比较清晰,前者是一个适普的数据结构,后者是一个特定问题的解决方案:
Generic maps: They all use the same common set of BPF helper functions in order to perform lookup, update or delete operations while implementing a different backend with differing semantics and performance characteristics.
Non-generic maps: These types of maps tackle a specific issue which was unsuitable to be implemented solely through a BPF helper function since additional (non-data) state is required to be held across BPF program invocations.
上面提到Generic maps使用相同的BPF操作集合,这里的操作我个人认为可以分为用户态中和内核态中两种,参考[15]中的例子,对比 sockex1_user.c 和 sockex1_kern.c的使用格式:
// 用户态
int bpf_map_lookup_elem(int fd, const void *key, void *value)
// 内核态
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)
根据这个对比我提出三个希望解决的问题:
- fd 和 bpf_map 类型如何对应
- 用户态可用的辅助函数
- 内核态可用的辅助函数
再加上这篇文章本来的目的:
- 对比已有的map类型,并做出选型
解决这四个问题就是本篇文章的目的了。
fd 和 bpf_map 类型如何对应
着其实是一个我一直接比较疑惑的问题,eBPF程序里面的 maps 是如何和用户态中创建的fd对应的呢?
可以看看bpf.o文件的反汇编部分中 map_lookup_elem 函数调用涉及的指令,根据调用规则,r1寄存器是第一个参数,可以看到my_map此时还是零。
$ clang -O2 -target bpf -c sockex1_kern.c -o sockex1_kern.o
$ llvm-objdump -S sockex1_kern.o
0000000000000000 <bpf_prog1>:
// ...
; value = bpf_map_lookup_elem(&my_map, &index); # 备注:编译的机器启用了 BTF
7: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
9: 85 00 00 00 01 00 00 00 call 1
// ...
所以最重要的其实是两步动作:
- 用户态的fd如何传输到内核态的fd
- 内核态中如何获取对应的
struct bpf_map,以此替换这个零。
[14][21]中已经分析了这个问题,说实话真没想到 verifier 将 loader 注入到指令中的 map fd 替换成 bpf_map 指针。
内核态可用的辅助函数
这里比较细的文档在[16],目前可以找到如下函数,相对来说API还是比较简单的:
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)在map中通过key获取value,返回值强转下就可以。long bpf_map_update_elem(struct bpf_map *map, const void *key, const void *value, u64 flags)把map中的key更新成value。long bpf_map_delete_elem(struct bpf_map *map, const void *key)遍历maps。
剩下的辅助函数实在是太多了,每个类型都可能有自己特有的,具体可以参考[16]。
执行bpftool feature probe也可以查看每种类型的辅助函数。
有关的例子可以参考[18]。
用户态可用的辅助函数
所谓用户态使用的辅助函数其实是bpf系统调用(int bpf(int cmd, union bpf_attr *attr, unsigned int size))的 cmd 参数支持的类型,目前我机器上支持与map有关的操作如下:
enum bpf_cmd {
// 基础增删改查
BPF_MAP_CREATE = 0,
BPF_MAP_LOOKUP_ELEM = 1,
BPF_MAP_UPDATE_ELEM = 2,
BPF_MAP_DELETE_ELEM = 3,
// 在指定的map中通过key查找元素,并返回下一个元素的key,用于遍历相关
BPF_MAP_GET_NEXT_KEY = 4,
// 查找id大于start_id的eBPF map,并在成功时更新next_id,获取当前加载到内核中的下一个eBPF程序
BPF_MAP_GET_NEXT_ID = 12,
// 打开与 map_id 对应的 eBPF 映射的 文件描述符。
BPF_MAP_GET_FD_BY_ID = 14,
// 找到并删除
BPF_MAP_LOOKUP_AND_DELETE_ELEM = 21,
// [20]中是这个patch的信息,没看懂为什么要引入。
// 但是功能就是可以通过传递零标志freeze指定的map。
// 成功后,未来的系统调用调用不会改变map_fd的映射状态,来自eBPF程序的写操作仍然可以用于这个被freeze的map。
BPF_MAP_FREEZE = 22,
// batch系列的操作
BPF_MAP_LOOKUP_BATCH = 24,
BPF_MAP_LOOKUP_AND_DELETE_BATCH = 25,
BPF_MAP_UPDATE_BATCH = 26,
BPF_MAP_DELETE_BATCH = 27,
// 很有意思的特性,将map绑定到eBPF程序的生命周期,把map_fd标识的映射绑定到 prog_fd 标识的程序,只有在prog_fd释放时才释放
BPF_PROG_BIND_MAP = 35,
};
这部分比较详细的文档在[17],具体使用的例子可以参考/tools/testing/selftests/bpf/map_tests/,其他地方是真的没找到资料。
Map Type
从内核 5.2 开始,只要开启了 CONFIG_DEBUG_INFO_BTF(grep CONFIG_DEBUG_INFO_BTF /boot/config-5.4.119-19-0009),在编译内核时,内核数据结构的定义就会自动内嵌在内核二进制文件 vmlinux.h 中[3],还可以调用bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h 导出BTF格式的内核数据结构定义,在 vmlinux.h 中可以看到目前内核(5.4.119)中支持的map类型。还可以从[10]中看到每种类型是哪个内核版本引入的。
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC = 0,
BPF_MAP_TYPE_HASH = 1,
BPF_MAP_TYPE_ARRAY = 2,
BPF_MAP_TYPE_PROG_ARRAY = 3,
BPF_MAP_TYPE_PERF_EVENT_ARRAY = 4,
BPF_MAP_TYPE_PERCPU_HASH = 5,
BPF_MAP_TYPE_PERCPU_ARRAY = 6,
BPF_MAP_TYPE_STACK_TRACE = 7,
BPF_MAP_TYPE_CGROUP_ARRAY = 8,
BPF_MAP_TYPE_LRU_HASH = 9,
BPF_MAP_TYPE_LRU_PERCPU_HASH = 10,
BPF_MAP_TYPE_LPM_TRIE = 11,
BPF_MAP_TYPE_ARRAY_OF_MAPS = 12,
BPF_MAP_TYPE_HASH_OF_MAPS = 13,
BPF_MAP_TYPE_DEVMAP = 14,
BPF_MAP_TYPE_SOCKMAP = 15,
BPF_MAP_TYPE_CPUMAP = 16,
BPF_MAP_TYPE_XSKMAP = 17,
BPF_MAP_TYPE_SOCKHASH = 18,
BPF_MAP_TYPE_CGROUP_STORAGE = 19,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY = 20,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE = 21,
BPF_MAP_TYPE_QUEUE = 22,
BPF_MAP_TYPE_STACK = 23,
BPF_MAP_TYPE_SK_STORAGE = 24,
BPF_MAP_TYPE_DEVMAP_HASH = 25,
BPF_MAP_TYPE_STRUCT_OPS = 26,
BPF_MAP_TYPE_RINGBUF = 27,
BPF_MAP_TYPE_INODE_STORAGE = 28,
BPF_MAP_TYPE_TASK_STORAGE = 29,
BPF_MAP_TYPE_BLOOM_FILTER = 30,
};
当然也可以执行bpftool feature probe | grep map_type。
Generic maps
BPF_MAP_TYPE_HASH
基础的哈希表类型,申请时类型如下:
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, type1); // key的类型
__type(value, type2); // value类型
__uint(max_entries, 1024); // 最大 entry 数量
} hash_map SEC(".maps");
[1]中提到map_update_elem可以以原子方式替换现有元素。
BPF_MAP_TYPE_ARRAY
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, u32);
__type(value, type1);
__uint(max_entries, 256);
} my_map SEC(".maps");
可以发现和hash的声明没啥区别,但是在操作的时候key的语义是index。
BPF_MAP_TYPE_PERCPU_HASH / BPF_MAP_TYPE_PERCPU_ARRAY
[10]中提到此类型会在每一个CPU上创建一个哈希map或者array map,每个 CPU 将拥有该Map的单独副本,副本不会以任何方式保持同步。
基本使用方法还是一样的。
BPF_MAP_TYPE_LRU_HASH / BPF_MAP_TYPE_LRU_PERCPU_HASH
普通 hash map 的问题是有大小限制,超过最大数量后无法再插入了。LRU map 可以避 免这个问题,如果 map 满了,再插入时它会自动将最久未被使用(least recently used)的 entry 从 map 中移除。
[22]中对BPF_MAP_TYPE_LRU_PERCPU_HASH的描述非常简单: a per-CPU hash table that only retains the most recently used items.
BPF_MAP_TYPE_HASH_OF_MAPS / BPF_MAP_TYPE_ARRAY_OF_MAPS
map结构中的结构是一个map,现在支持的外层结构array和map,基本逻辑可以参考下图:
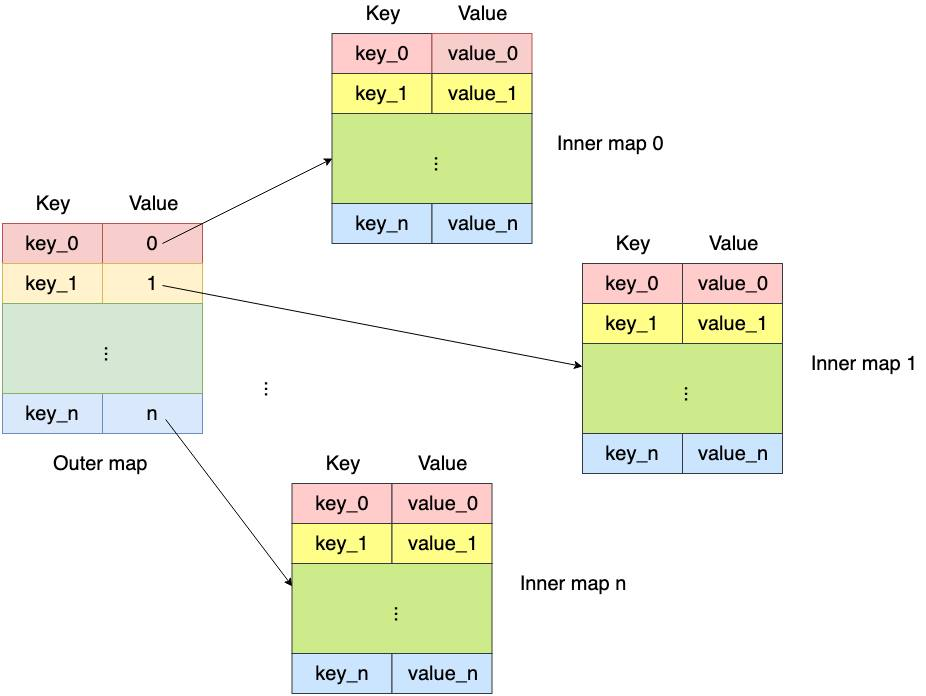
使用方法可以查看[23]。
BPF_MAP_TYPE_PERF_EVENT_ARRAY
用户态程序使用 bpf(BPF_MAP_UPDATE_ELEM) 将由 sys_perf_event_open() 取得的文件描述符传递给 eBPF 程序,ebpf程序可以调用bpf_perf_event_output从内核向用户态程序传递数据,用户态可以调用perf_buffer__new,perf_buffer__poll()监听,这里可以参考[25]。
当然ebpf程序中还可以调用bpf_perf_event_read(man文档不建议使用),bpf_perf_event_read_value,分别用户读取对应CPU上的count计数器和struct bpf_perf_event_value[16],这里的例子可以参考bpf/tracex6_kern.c。
BPF_MAP_TYPE_RINGBUF
BPF_MAP_TYPE_PERF_EVENT_ARRAY的升级版,是一个多生产者、单消费者 (MPSC) 队列,API与BPF_MAP_TYPE_PERF_EVENT_ARRAY大体相同,但是写入被划分为三个API,bpf_ringbuf_reserve()/bpf_ringbuf_commit()/bpf_ringbuf_discard() ,同时允许用户态监听。ring_buffer为了解决perf event的这两个问题而被创建:
- more efficient memory utilization by sharing ring buffer across CPUs;
- preserving ordering of events that happen sequentially in time, even across multiple CPUs (e.g., fork/exec/exit events for a task).
bpf perf event 最大的问题是每一个CPU上都有单独的缓冲区,上面两个问题都是此架构导致的。
详细的文章在[27][28]。
BPF_MAP_TYPE_LPM_TRIE
LPM(Longest prefix match)的语义就是最长的前缀匹配,[8]中提到key的限制是八的倍数,范围为[8,2048],可以使用bpf_lpm_tire_key来作为key,value随意。
能找到例子就是bpf/map_perf_test_kern.c和[8]中经典的路由转发了。
BPF_MAP_TYPE_QUEUE / BPF_MAP_TYPE_STACK
队列结构和栈,bpf_map_update_elem是push,bpf_map_lookup_elem是begin,bpf_map_lookup_and_delete是pop,这里查看[8]。
BPF_MAP_TYPE_BLOOM_FILTER
正常的布隆过滤器实现,相关patch查看[29]。
Non-generic maps
BPF_MAP_TYPE_PROG_ARRAY
用于尾调用,细节可以参考[24]。
BPF_MAP_TYPE_STACK_TRACE
储存栈帧信息,核心函数是bpf_get_stackid,一般需要辅助另外一个map,把bpf_get_stackid返回的ID存进去,这样就可以在用户态打印栈帧了,但是貌似是符号,可以参考bpf/offwaketime_kern.c。
BPF_MAP_TYPE_SOCKMAP / BPF_MAP_TYPE_SOCKHASH
用于套接字的转发,value为bpf_sock_ops结构,在hash中key需要自己指定,调 long bpf_sock_map_update(struct bpf_sock_ops *skops, struct bpf_map *map, void *key, u64 flags)更新map。
调用如下函数可以实现转发:
long bpf_msg_redirect_hash(struct sk_msg_buff *msg, struct bpf_map *map, void *key, u64 flags)long bpf_sk_redirect_hash(struct sk_buff *skb, struct bpf_map*map, void *key, u64 flags)long bpf_msg_redirect_map(struct sk_msg_buff *msg, struct bpf_map*map, u32 key, u64 flags)long bpf_sk_redirect_map(struct sk_buff *skb, struct bpf_map *map, u32 key, u64 flags)
分别用于BPF_PROG_TYPE_SOCK_OPS和BPF_PROG_TYPE_SK_SKB。
参数大同小异:
5. struct bpf_sock_op / sk_buff:用户可访问的待发送数据的元信息(metadata)
6. struct bpf_map:这个 BPF 程序 attach 到的 sockhash map
7. key:在 map 中索引用的 key
8. flags BPF_F_INGRESS:放到 RX 还是 TX
BPF_MAP_TYPE_DEVMAP / BPF_MAP_TYPE_DEVMAP_HASH
内存储的是网络设备号ifindex,XDP程序可以将包直接转发到存储在这里的设备中,提升包转发性能。类比上面的sock。
BPF_MAP_TYPE_CPUMAP
用于在XDP中数据转发到其他CPU中,我们知道XDP中的三种模式分别工作在网卡,驱动和netif_receive_skb中,而硬中断和软中断的处理是在一个CPU中,虽然不知道是怎么做的,但是感觉可能是和GRO差不多。
BPF_MAP_TYPE_XSKMAP
用于AF_XDP,这东西我确实在学习XDP转发的时候钻研过一下午,提供了零拷贝( zero-copy)的前提下将包从网卡驱动送到用户空间,用户空间用一个套接字接收消息就可以了,其两组ring_buf的设计还是比较秀的,但是操作起来属实麻烦。
我怎么怎么感觉这有点革了DPDK的命了。
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY
关于reuseport,这就不得不提dog250大师,我毫不吝啬对这位大师的赞美,称其为艺术家也不过分。
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY 被用于SO_REUSEPORT参数的负载均衡,内核中的函数就是reuseport_select_sock,这是一个经过一系列演进的功能,
为了致敬dog250大神来看看5.4.119是怎么做的:
struct sock *reuseport_select_sock(struct sock *sk,
u32 hash,
struct sk_buff *skb,
int hdr_len)
{
struct sock_reuseport *reuse;
struct bpf_prog *prog;
struct sock *sk2 = NULL;
u16 socks;
rcu_read_lock();
reuse = rcu_dereference(sk->sk_reuseport_cb);
// 如果内存分配失败或添加reuseport没添加
if (!reuse)
goto out;
prog = rcu_dereference(reuse->prog);
socks = READ_ONCE(reuse->num_socks);
if (likely(socks)) {
/* paired with smp_wmb() in reuseport_add_sock() */
smp_rmb();
// 执行bpf的逻辑
if (!prog || !skb)
goto select_by_hash;
if (prog->type == BPF_PROG_TYPE_SK_REUSEPORT)
sk2 = bpf_run_sk_reuseport(reuse, sk, prog, skb, hash);
else
sk2 = run_bpf_filter(reuse, socks, prog, skb, hdr_len);
// 朴素的选择算法
select_by_hash:
/* no bpf or invalid bpf result: fall back to hash usage */
if (!sk2) {
int i, j;
/*
static inline u32 reciprocal_scale(u32 val, u32 ep_ro)
{
return (u32)(((u64) val * ep_ro) >> 32);
}
*/
i = j = reciprocal_scale(hash, socks);
// 对于TCP来说只有出于
while (reuse->socks[i]->sk_state == TCP_ESTABLISHED) {
i++;
if (i >= socks)
i = 0;
if (i == j)
goto out;
}
sk2 = reuse->socks[i];
}
}
out:
rcu_read_unlock();
return sk2;
}
// net/ipv4/udp.c
/*
static u32 udp_ehashfn(const struct net *net, const __be32 laddr,
const __u16 lport, const __be32 faddr,
const __be16 fport)
{
static u32 udp_ehash_secret __read_mostly;
// 随机字符串,最终调用get_random_bytes
net_get_random_once(&udp_ehash_secret, sizeof(udp_ehash_secret));
return __inet_ehashfn(laddr, lport, faddr, fport,
udp_ehash_secret + net_hash_mix(net));
}
*/
hash = udp_ehashfn(net, daddr, hnum,
saddr, sport);
reuseport_result = reuseport_select_sock(sk, hash, skb,
sizeof(struct udphdr));
----
// jhash_3words
return __inet_ehashfn(laddr, lport, faddr, fport,
udp_ehash_secret + net_hash_mix(net));
---
static inline u32 net_hash_mix(const struct net *net)
{
return net->hash_mix;
}
基本可以看到是使用双方addr和端口以及net->hash_mix做一个jhash_3words算法。
我十分赞同dog250大师对于UDP/TCP使用reuseport的看法。TCP连接建立以后五元组就固定了,只有在Listen的时候需要reuseport,而UDP则是时刻都需要reuseport,只要两个socket都reuseport同一个port,就可能出现socket1处理了一部分以后剩下的数据被发送到socket2(因为哈希算法中是带一个随机值的,这意味着监听同一个端口的两个套接字对于五元组完全相同的包也可能先发到socket1再发到socket2),这就可能出现应用数据的传输出现中断,好在我们已经拥有了bpf。
TCP的每一条连接均可以由完全的五元组信息自行维护一个唯一的标识,只需要按照唯一的五元组信息就可以找出一个TCP连接,但是对于Listen状态的TCP套接字就不同了,一个来自客户端的SYN到达时,五元组信息尚未确立,此时正是需要找出是reuseport套接字组中到底哪个套接字来处理这个SYN的时候。待这个套接字确定以后,就可以和发送SYN的客户端建立唯一的五元组标识了,因此对于TCP而言,只有Listen状态的套接字需要reuseport机制的支持。对于UDP而言,则所有的套接字均需要reuseport机制的支持,因为UDP不会维护任何连接信息,也就是说,协议栈不会记录哪个客户端曾经来过或者正在与之通信,没有这些信息,因此对于每一个数据包,均需要reuseport的查找逻辑来为其对应一个处理它的套接字。
对于UDP协议而言,我们不希望由于客户端切换了一个IP地址而导致整个应用层数据传输的中断,毕竟UDP仅仅只是起到运输的作用,它不像TCP那样和应用进程是强关联的。这种切换IP和端口的场景在移动设备上特别常见,就我个人而言,当我发现Wifi信号差的时候,就会直接禁掉Wifi,如此这般频繁切换,这个时候如果后台有数据正在传输,我当然不希望它由于我的这次切换而中断。那显然不能再用IP和Port来做hash计算源了。
具体的信息可以参考[31][32][33]。
浙江温州皮鞋湿,下雨进水不会胖。
下面这些结构大概扫了下和我本次的需求没啥关系,留置以后有缘再来。小组有同学做拥塞相关,BPF_MAP_TYPE_STRUCT_OPS可能是比较早补充的,优先级 Cgroup 可能再次一级,最后才是 STORAGE 族的了,想象是美好的,当然可能我也不会再碰这篇文章了。
BPF_MAP_TYPE_CGROUP_STORAGE
BPF_MAP_TYPE_CGROUP_ARRAY
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE
BPF_MAP_TYPE_SK_STORAGE
BPF_MAP_TYPE_STRUCT_OPS
BPF_MAP_TYPE_INODE_STORAGE
BPF_MAP_TYPE_TASK_STORAGE
性能
性能这个问题是我比较关心的,目前可以找到的资料就是[21]中公布出来的大概数据:
- 一般来说 eBPF 程序作为数据面更多是查询,常用的 map 的查询性能:array > percpu array > hash > percpu hash > lru hash > lpm。map 查询对 eBPF 性能有不少的影响,比如:lpm 类型 map 的查询在我们测试发现最大影响 20% 整体性能、lru hash 类型 map 查询影响 10%。
- 特别注意,array 的查询性能比 percpu array 更好,hash 的查询性能也比 percpu hash 更好,这是由于 array 和 hash 的 lookup helper 层面在内核有更多的优化。对于数据面读多写少情况下,使用 array 比 percpu array 更优(hash、percpu hash 同理),而对于需要数据面写数据的情况使用 percpu 更优,比如统计计数。
- 尽可能在一个 map 中查询到更多的数据,减少 map 查询次数。
- 尽可能使用 array map,在控制面实现更复杂的逻辑,如分配一个 index,将一些 hash map 查询转换为 array map 查询。
- eBPF map 也可以指定 numa 创建,另外不同类型的 map 也会有一些额外的 flags 可以用来调整特性,比如:lru hash map 有 no_common_lru 选项来优化写入性能。( Schematic example of how BPF_F_NO_COMMON_LRU works could be seen on Picture 4 Each CPU updates (write) only dedicated area (color coded) but can do lookup (read) across whole map.)
总结
其他问题都已经解决了,回到最初也是最关键的问题,选型。
本来看起来对于缓存来说语义最符合的是BPF_MAP_TYPE_LRU_PERCPU_HASH,但是巨量引擎的测试结果显示这样是效率最低的,不过好在这几个Generic maps接口使用起来差不多,再加上第四点的忠告,可以先用BPF_MAP_TYPE_PERCPU_ARRAY加自己实现hash函数跑起来,后面再逐步替换,检查性能。
key/value限制目前好像没什么好办法,只能先pass到用户态处理了。
碎片目前已有的类型不能拿来即用,也许可以爱array上做一层封装,先不管这个,跑起来再说。
扩容的话也没啥好办法,不过已经到链路层设cache了,扩容真的还重要吗。
从学习一个技术的角度来看这篇文章还差Map原理的分析以及Object Pinning这个重要的子功能,但是我的的确确是累了(我使用了形容词,这代表我的的确确的这样觉得),留给读者自己探索罢。
正在啃晚饭的第二个苹果,就开始想明天到底要干什么,这篇文章的坑还没填完,却又想着代码的事情,好不让人怅然若失而又焦头烂额。就这样过去三年,而后看来期间一些所谓大事都只在一念之间促成,说很难却又简单,说很有趣却很无聊,我性格最大的缺点和优点大抵如此了。
参考:
- man bpf
- eBPF, part 2: Syscall and Map Types
- What is vmlinux.h?
- Don‘t Put a Cache in Front of Database
- 微软技术探究之FASTER
- facebook技术探究之基于memcache的扩展
- 从X86架构中cahe的组织结构引发的各种思考
- 《Linux内核观测技术BPF》
- Scaling Memcache at Facebook
- bcc docs
- bcc bpf-table
- cilium docs
- BPF-HELPERS man
- 揭秘 BPF map 前生今世
- samples/bpf/sockex1_user.c
- man bpf-helper
- ebpf syscall.html
- BPF数据传递的桥梁——BPF MAP(一)
- lore.kernel.org/bpf/20190829064511
- bpf: add syscall side map freeze support
- 边缘网络 eBPF 超能力:eBPF map 原理与性能解析
- A thorough introduction to eBPF
- Use Map-in-Map in BPF programs via Libbpf
- eBPF: 从 BPF to BPF Calls 到 Tail Calls
- eBPF 系列三:eBPF map
- [bpf-next,3/3] bpf: add sample for BPF_MAP_TYPE_QUEUE
- ring_buf
- Andrii Nakryiko’s Blog BPF ring buffer
- lore.kernel.org/bpf/20210921210225
- 利用 ebpf sockmap/redirection 提升 socket 性能(2020)
- Linux 4.6内核对TCP REUSEPORT的优化
- Introduce BPF_MAP_TYPE_REUSEPORT_SOCKARRAY and BPF_PROG_TYPE_SK_REUSEPORT
- 关于Linux UDP/TCP reuseport 二三事

 浙公网安备 33010602011771号
浙公网安备 33010602011771号