

把Qos扯到排队论上去
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
悔恨呐,我说过很多次大学期间最遗憾的事情就是没好好学数学,以至于现在提到概率论,统筹学脑子里一片空白,就连算是好好刷过题的离散也基本不剩什么了。
Qos Vulnerabilities
事实上我们总会对客户做出Qos的保证,但是Kernel如此复杂,牵一发而动全身,可怜的Qos受到了除了用户态的一些限制以外的威胁。memcache是一个极为成熟的KV存储系统,其大多数的CPU时间花费在内核中,这也使得其成为一个很好的分析对象。
经过[2]的分析,Queuing delay 是影响Qos的主要原因之一,发生在大量请求快速或者同时到达时,而且即使进程在单独的CPU内核上运行,共享系统的共用,比如缓存、内存通道和 I/ O 通道也会降低 latency-critical workload 的服务速率。
在分析问题之前,我们总要建立一个模型,我们假设系统的排队模型为经典 M/M/N 模型,单位时间顾客到达数遵循泊松分布,单位时间能被服务完成的顾客数服从负指数分布。
假设服务方数量为1,即 λ λ λ 为单位时间平均到达的请求数, µ µ µ 为单位时间可以系统服务的请求数:
基于此假设,我们可以推导出如下结论[3]:
- 稳态情况下任意时刻t,系统队列中有N个元素的概率为 P n = ( 1 − λ µ ) ( λ µ n ) P_n=(1-\frac{λ}{µ})(\frac{λ}{µ}^n) Pn=(1−µλ)(µλn)
- 系统空闲时间,队列长度为特定数字时的概率都可以基于 P n Pn Pn去做计算
- 系统队列中无元素的概率为 1 − λ µ 1-\frac{λ}{µ} 1−µλ
- 任意用户请求的处理时间+等待时间为 1 µ − λ \frac{1}{µ-λ} µ−λ1
- 任意用户请求的等待时间为 1 µ − λ − 1 µ \frac{1}{µ-λ}-\frac{1}{µ} µ−λ1−µ1
- 第95个百分位延迟大约为 ln 100 100 − 95 µ − λ \frac{\ln\frac{100}{100-95}}{µ-λ} µ−λln100−95100,是一般延迟的三倍
- 系统平均队伍长度 1 − λ µ 1 − ( 1 − λ µ ) \frac{1-\frac{λ}{µ}}{1-(1-\frac{λ}{µ})} 1−(1−µλ)1−µλ
基于6结论,我们可以发现在标准模型下百分之九十五的延迟时间为平均处理时间的三倍,所以在排队论的角度来看,系统中的排队延迟就是无法避免的。
在上文描述的标准模型中,我们可以看到实际上 µ µ µ代表着系统实际的处理能力,而影响 µ µ µ的因素有非常多,共享系统的共用,比如缓存、内存通道和 I/ O 通道都会造成影响,不过从论文中的描述来看L3缓存的争用是高负载时延迟递增的主要因素。
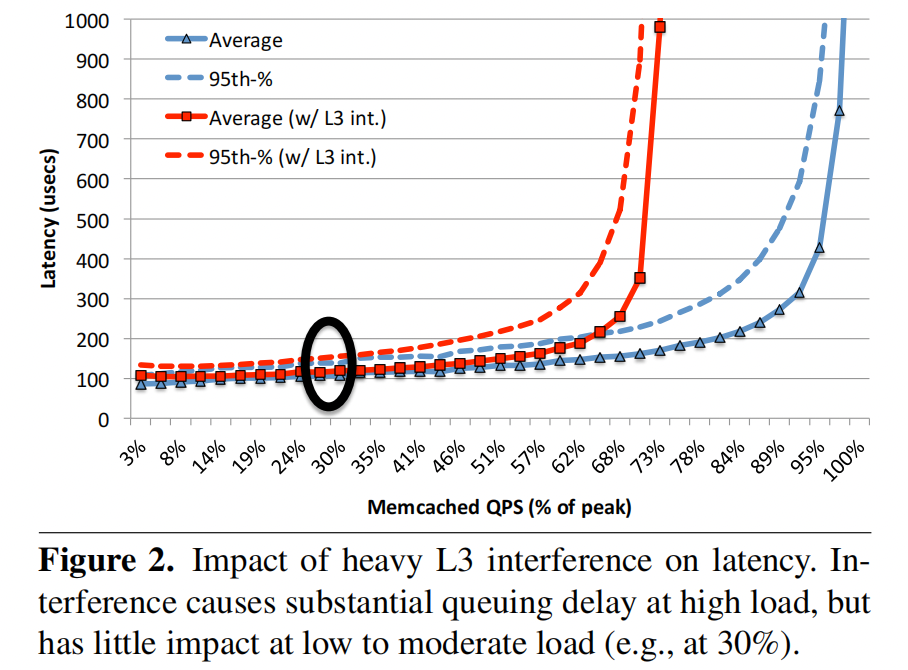
且排队延迟的主要时间其实花费在epoll中,在负载较高的时候,epoll_wait会一次返回大量的就绪事件,处理这些事件需要时间,意味着下一次epoll_wait的调用需要处理完上次的事件,哪怕中间来了数据也需要等待。
用户态未被处理时接收端的内核数据包排队,发送端的内核数据包排队,软中断未处理时NAPI机制造成的排队,中间服务器和网络交换机中的多层队列都会造成排队延迟,
其次系统负载上升时,带来的直观感受就是 µ µ µ 降低且 λ λ λ升高,造成每一个请求的平均等待时间大幅度增加。
总结
只要跳不出排队论,这种延迟就看似是无解的,在[2]中也提到:
- Since queuing delay is a function both of throughput (service rate) and load, we can tolerate a reduction in throughput (due to interference) if we also reduce the load on the service for any given server.
- Additional servers can be added to pick up the slack for the lowlatency service. Thus, we propose that load be provisioned to services in an interference-aware manner, that takes into account the reduction in throughput that a service might experience when deployed on servers with co-located workloads.
参考:
- 延时敏感服务QoS根因分析
- Network Stack Specialization for Performance
- 运筹学-32-排队论-单服务台排队系统-(详细推导版)标准M/M/1模型例题
- The Tail at Scale
- Heracles: Improving Resource Efficiency at Scale
- Google: Taming The Long Latency Tail - When More Machines Equals Worse Results
- Managing Tail Latency in Datacenter-Scale File Systems Under Production Constraints
- RobinHood: Tail Latency Aware Caching – Dynamic Reallocation from Cache-Rich to Cache-Poor
- Preventing Long Tail Latency(译)
- Long-tail traffic


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具