
关于IO故障注入的系列Trick
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
我不是人肉朴素贝叶斯工具人。
故障注入的方法论我认为就是在调用路径上寻找可行的侵入点,但是如何确定调用路径呢?就以我们要谈的IO注入来看,大体可以把执行流划分为内核态和用户态(不考虑网络文件系统)。
用户态的的逻辑其实很好搞清楚,判断下是否使用-static强制静态链接,是否使用-z,now提前载入所有的动态链接,使得GOT表不可写,以防止程序被篡改,除去这两点顾虑,基本GDB就可以把一直到systemcall的步骤看清楚了。
内核IO栈
到了内核态,问题的重点就成了Linux IO栈[3]:
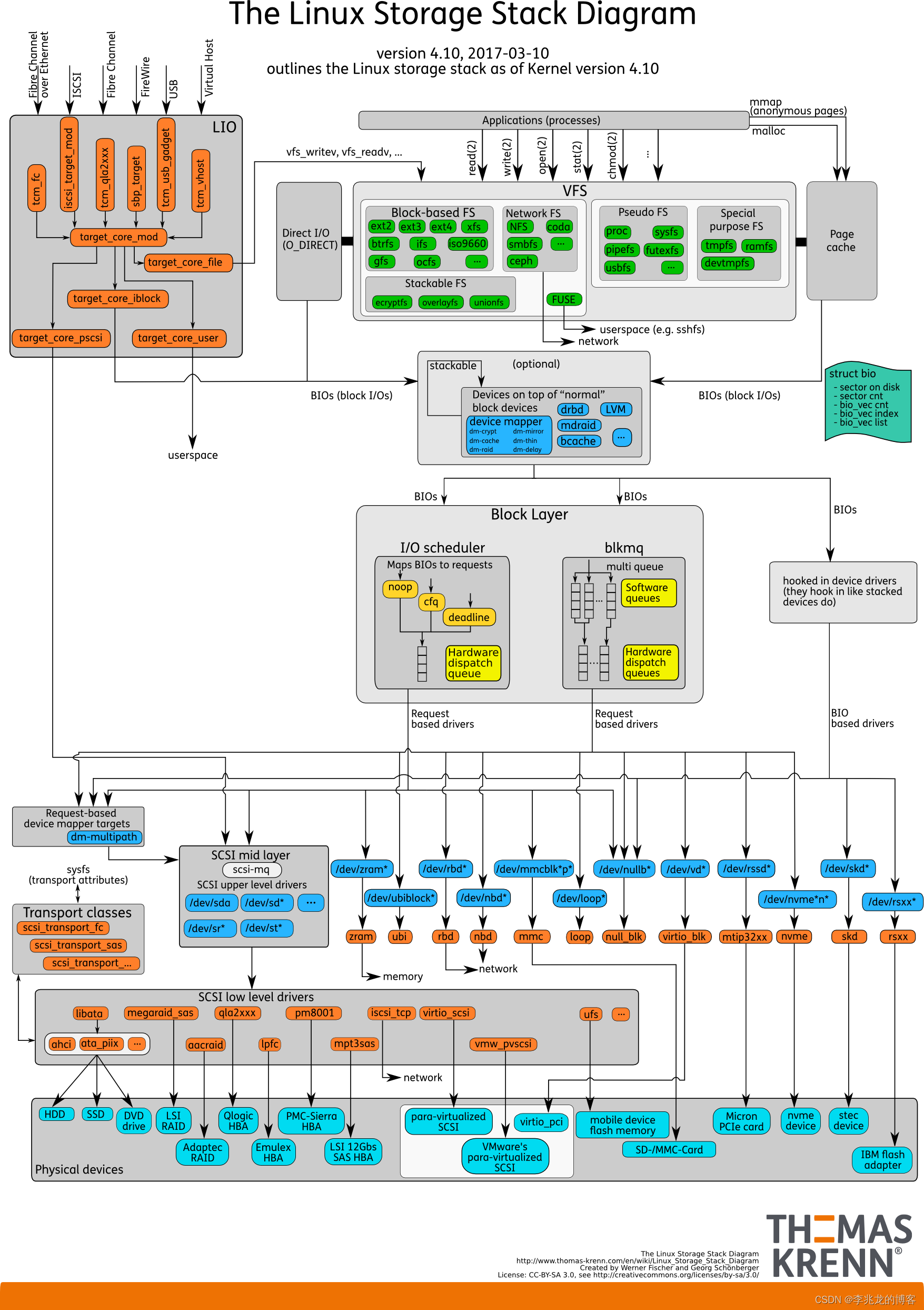
以前在[4]这篇文章中简单的分析过VFS,Page Cache,这其实也是平时工作学习中与我们关系最紧密的一层,
再向下一点就是挂载到VFS中的各种文件系统,显然要开始处理文件,用户需要在存储设备 之上构建文件系统布局,然后将新创建的文件系统挂载到根文件系统层次结构中的某个位置 (mount),后来在这个文件树分支上的文件操作就会调用对应的特化接口执行相关逻辑。
最终文件IO还是会被发送向存储设备,请求的调度(noop、cfq、deadline),合并,排序,统计等是Block Layer的职责,BIO的特殊结构封装了一组IO请求,这些请求指向块设备需要读取/写入的各个内存页面,上层通过BIO来统一描述发往块设备的IO请求。
这幅图是4.10的IO栈,但实际在5.0中因为其本身具有局限性,blk-sq(包括基于blk-sq的IO调度器,如cfq、noop)代码已经被移除了。
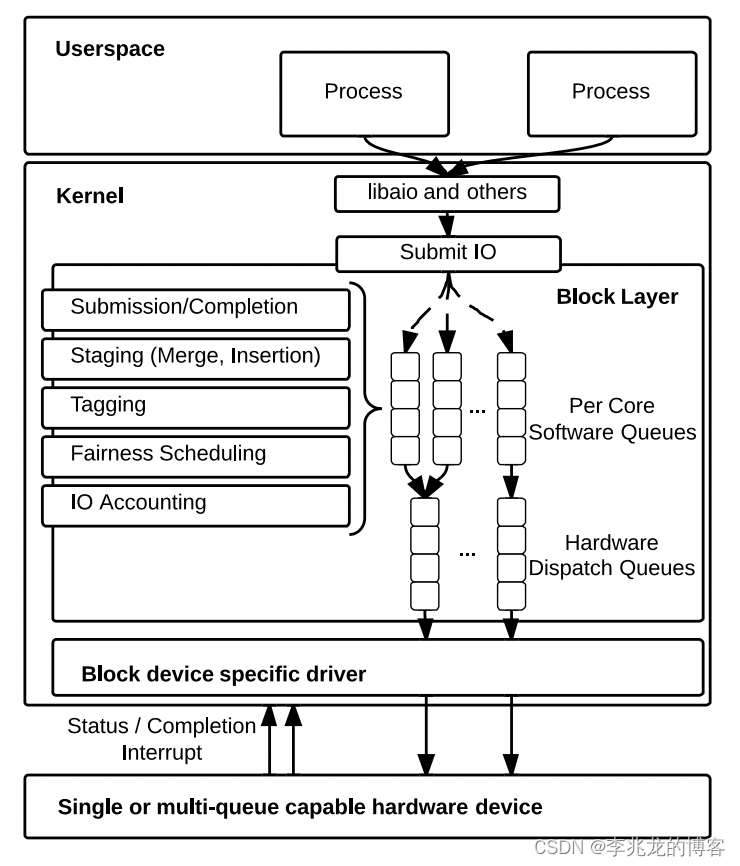
由于采用每个块设备1个请求队列的设计,传统的Block Layer对多核体系scalability不佳。当系统配备现代高速存储器件时,单队列引入的软件开销变得突出(在多socket体系中尤为严重),在2010年是一个CPU可以达到80万的IOPS,但是就算磁盘本身性能足够,多个CPU也只能到达100万左右的IOPS,这使得Block Layer成为IO性能的瓶颈,主要瓶颈如下:
- 请求队列锁竞争,出队,入队,batch,重排,调度都需要获取锁。
- 硬件中断,一个CPU负责处理所有的硬件中断,并将他们作为软中断发送给其他核。
- 远端内存访问:如果提交IO请求的cpu不是接收硬件中断的cpu,就会出现锁所在缓存行的共享,从而触发
false sharing[10]
而blk-mq(Block multi-queue)则是为了适配现代存设备(高速SSD等)高IOPS、低延迟的特征而被创造的块设备层框架,基本架构如下[8]:
越过Block Layer,就到了块设备和 SCSI 层,SCSI曾负责与使用 SCSI 协议的存储设备(几乎意味着所有的存储设备)进行通信,这一层和我目前从事的工作脱离较远,遂没有花时间学习,更多可参考[7][11]
OK,以上思考大概理清楚以后我们其实就可以开始正事,也就是如何注入IO故障了。
IO故障注入
我们称XX级别注入为以XX粒度做注入,比如pid级别就是指定pid的故障注入。
现有的技术方案其实有两个,一个是基于systemTap的忙等注入(可以是pid,设备,文件系统级别注入),一个是Pingcap基于fuse的文件系统级别注入[1],这两种业界已有的实现分别有自己的弊端。
基于systemTap虽然可支持的注入粒度多,且简单易实现,但是目前了解到的资料来看使用systemTap这种基于内核模块注入延迟故障的方案是不安全的,因为udelay/mdelay可能会在在一些kprobe/tracepoint中阻塞整个系统,因为这本质上是在禁用中断的情况下执行忙等,我正在尝试复现,除此之外还会引入debuginfo这个沉重的依赖。
Chaos-mesh基本原理在整个IO栈上嵌入一层fuse文件系统,大致细节是将容器的挂载点mount-move,然后基于ftrace替换容器中已存在的fd,这种方法的实验范围为一个容器(文件系统),粒度较大。
以上两种方案的注入其实都是在VFS级别的,不过一种是嵌入可编程的逻辑(eBPF现有限制使得我们无法执行任意延迟),一种是嵌入一个中间层罢了,打开思路,显然我们还可以向下或者向上,要么走到Block Layer,要么走到用户态。
其实我认为把Block Layer的blk-mq看作网络栈中的TC没什么不妥,一个是块设备的BIO请求调度,一个是网络数据包的调度。现在已经知道的是IO Schedulers是运行时可插入的[5],那我们是否可以实现一个内核模块,然后动态替换IO调度策略,已实现类似于TC的延迟功能呢?
可以从/sys/block/DEVName/queue/scheduler中看到目前的IO调度策略,当前选择的调度程序在括号中,可以在/sys/block/nbd0/queue/iosched看到IO调度队列的可调参数[13]。偶然间看到了mq-deadline有两个可调参数read_expire/write_expire,其解释如下[14]:
read_expire: This tunable allows you to set the number of milliseconds in which a read request should be serviced. By default, this is set to 500 ms (half a second).
write_expire: This tunable allows you to set the number of milliseconds in which a write request should be serviced. By default, this is set to 5000 ms (five seconds).
说实话很疑惑,which a read request should be serviced?这个请求被服务的时间默认是500ms?最后在SUSE的文档找到了容易理解的解释[15]:
read_expire: Sets the deadline (current time plus the read_expire value) for read operations in milliseconds. Default is 500.
write_expire: Sets the deadline (current time plus the write_expire value) for write operations in milliseconds. Default is 5000.
虽然弄清楚了参数的含义,但是问题还是没有被解决。
偶然间看到了Kyber这个IO调度器,其可调参数看起来可以满足我们的需求,但是实际测试以后和预期不符合,也许需要看看源码解答疑惑:
read_lat_nsec: Sets the target latency for read operations in nanoseconds. Default is 2000000.
write_lat_nsec: Sets the target latency for write operations in nanoseconds. Default is 10000000.
但就算在IO调度器我们可以做手脚也不精准,因为块设备IO没到IO调度程序时已经返回了(Page Cache),这意味着用户看来并不是所有的写操作都能被注入。
题外话,不同的IO调度器适应与不同的负载,可以参考redhat的配置文档[16]:
| 场景 | 应用 |
|---|---|
| Traditional HDD with a SCSI interface | Use mq-deadline or bfq. |
| High-performance SSD or a CPU-bound system with fast storage | Use none, especially when running enterprise applications. Alternatively, use kyber. |
| Desktop or interactive tasks | Use bfq. |
| Virtual guest | Use mq-deadline. With a multi-queue host bus adapter (HBA), use none. |
最终我和y7n05h在讨论了一段时间时间以后给出了一种在以上两个方法中折衷的一个做法.
这样的实现可以做到pid级别的任意延迟注入,但是现在累了,具体实现和优缺点暂时不说了。
总结
结果本身有意义,但是过程也是足够有趣的。
参考:
- How to Simulate I/O Faults at Runtime
- libco源码解析(8) hook机制探究
- Linux Storage Stack Diagram
- 再聊聊Linux IO
- docs kernel blk-mq
- [转载] Multi-queue 架构分析
- Storage Stack
- Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems
- High Performance Storage with blk-mq and scsi-mq
- 从false sharing到缓存一致性,这其实与我们息息相关
- SCSI wiki
- 浅谈动态追踪:从SystemTap到bpfTrace
- Linux kernel Block Layer docs
- Deadline I/O Scheduler
- Tuning I/O Performance
- redhat Configuration Tools
