

Morsel-Driven Parallelism: 一种NUMA感知的并行Query Execution框架
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
一段时间前看到OSAPP中polarDB社区中有一个核心数据结构支持 NUMA Aware 的题目,虽然我已经报了ChaosBlade社区做OS级别的故障注入的项目,但是对于前者的实现我也是有很大兴趣的,不出意外的话我会一直关注polarDB这个PR的实现过程。
前几天和琪宝去了一趟重庆,近一周之内没有出行计划,又逢毕设答辩延迟了几天,遂难得的有了几天空闲时间钻研下自己感兴趣的知识,便想到那个 NUMA Aware 的题目。大概花了一天时间温故了一下NUMA相关的问题,包括几篇NUMA导致毛刺的排查过程,NUMA API的使用(包括migrate_pages和mbind这两个系统调用,和numactl,numademo,numastat这几个终端工具),几种memory policy的实际意义以及可能与NUMA相关的PMU获取方式。
其实按照预定计划来说,在大学的最后一个月里,我本是不再去再做技术的钻研,而是应该安心当一只懒狗的,尤其是今天还是端午,自我放弃式的接收奶头乐本是一件板上钉钉的事。但是。突然看到timeline中有一篇与NUMA相关的论文未读,既然学了,就学全套吧,这是这篇文章的由来。
Morsel-Driven Parallelism
Morsel-Driven Parallelism 最大的贡献是创造了一个全新细粒度的并行Query Execution框架和将NUMA思想应用至数据库设计中。
依我拙见,随着新硬件的不断增强,现代NUMA系统跨node访问的成本其实是越来越低的[4][5],而且只有在高阶cache未命中时才会可能对内存执行远程访问,这也意味着除非false shareding[3]出现,否则NUMA远程访问导致瓶颈的情况很难出现,所以这篇文章的核心其实是提出了一个更加细粒度的Query Execution框架,为了适配框架也对重要的 relational operators 设计了一套并行算法。
文章开头就提到并行Query Execution有两个问题与计算机体系的发展(计算机速度提升逐渐体现在多核而不是单核速度)有冲突:
- 为了利用多核,所有查询工作必须在数百个线程之间均匀分布。
- 现代内核的复杂性,导致即使具有准确的数据统计也很难均匀分配查询。
以上问题导致了多核间负载不平衡和上下文切换瓶颈,因此不再可扩展,所以这篇文章实际是解决上述问题的,但是解决的过程可以很轻松的做到NUMA友好,以此解决算子内并行的不平衡。
从执行粒度的角度来看Morsel-Driven Parallelism 与传统的 Volcano 模型没有什么不同,对于 plan-driven 来说优化器在查询编译时静态确定应该运行多少线程,为每个线程实例化一个查询运算符计划,并将这些与交换运算符连接起来。以我稚嫩的数据库经验来看Volcano实际上是以算子为最小执行单位的(当然算子内也可并行,假设数据分布在不同节点,这就是一个典型的算子内并行,当然这是站在计算节点来看的),这也意味着在一个Query Plan中只有在EXCHANGE operator算子时[1][6]才可以算子间并行。
实际上在单个算子执行时也是可以并行的,不过这里没有办法做到多核间均匀分布,Morsel-Driven Parallelism使用工作窃取在线程之间动态分配工作(想到了以前的线程池实现), 这可以防止由于负载不平衡而导致未使用的 CPU 资源,并可以允许弹性,即可以随时在不同查询之间重新分配 CPU 资源。
但是从流水线执行的角度来看Morsel-Driven Parallelism 与传统的 Volcano 模型有本质上的不同,即push和pull之间的差别,基本区别见下图[13]:
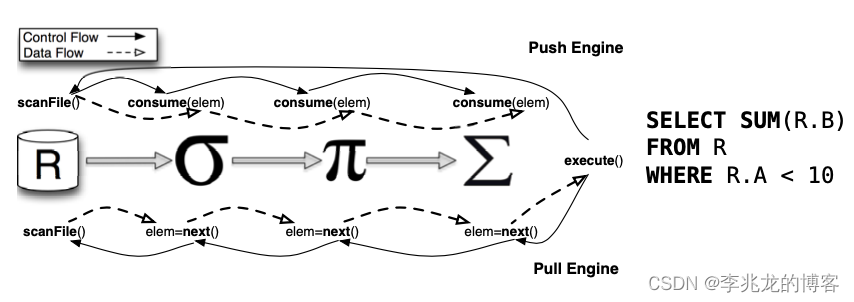
两者最大的差别我认为是传统以 Volcano 模型为代表的push是以Operator为中心的,而Morsel-Driven Parallelism这样的模型是以数据为中心的,后者更加容易实现并行友好,因为执行的线程其实是绑定核心的,并且数据的来源是工作线程自行获取的,这样就是并行友好的,这其实就是一个简洁高效的调度器。
以ClickHouse为例,在通过AST生成Query Plan后,经过一些RBO优化,将QueryPlan按照后序遍历的方式将其转化为Pipeline,这种方式生成的Pipeline,其实和push是一样的,接下来Pipeline如何执行则是并行友好的关键,这本质上需要一个设计优良的调度器,Morsel-Driven Parallelism的实现就很优秀。
基本的执行流程如下:一个Query Execution会生成一个QEPobject,管理所有pipeline-job之间的依赖关系,这类似于Volcano中的query plan,在一个pipeline job执行完成时,会触发QEPobject的被动状态机,选择下一个可以执行的pipeline job,传递给dispatcher,每一个worker都会绑定一个CPU核,并主动从dispatcher中拉取morsel,这里可以做到NUMA亲和,并可以加入优先级调度,输出的结果物化在NUMA本地的存储area中,后续pipeline可以基于此做处理。
可以看到Morsel-Driven Parallelism其实是把算子的实现变的标准化,即所有算子都用细粒度的单元(morsel)来衡量,并把算子内的并行集成到Query Execution来,这样做不仅可以做到多核间负载均匀,还可以做到NUMA感知,甚至做到优先级调度。
Cool!
站在更高角度来看,Morsel能否把思路扩展至更大的领域而不是仅仅是内存数据库呢?因为我们要引入IO,所以执行流需要用coroutinue来表示,但是coroutinue所属线程还是绑核的,每个核跑n个coroutine,channel通知另外一个pipeline,这种架构看起来也是很棒的(matrixone目前就是这样玩的)。换种思路,在论文中看整体架构像是一个三级控制,worker一级,dispatcher一级,QEPobject一级,逐级push,迁移出核心思想看起来只需要修改底层worker那一层,其他两层都是可以复用的,这样看起来也不错,不过需要pipeline的细化拆分,实现相对复杂一些。
当然以上讨论其实是在讨论调度器的实现,如何基于Query Execution细粒度拆分pepeline也是一个需要考虑的问题,毕竟并行的基础来源于pipeline的组合(后序遍历?),但是我是一个计算引擎的小白,这个讨论就此打住吧。
具体的如何解决可以去看论文[1][2],这里不提了。
总结
数据库博大精深,事务,Query Execution,两点想搞清楚就至少得以年记,更不必说一致性,多副本/多活,存储引擎,索引,性能调优,bug排查,慢慢走吧,一个板块搞清楚于我而言已经很满足了。
这篇文章并不代表我学习的大方向,只是茶余饭后的消遣罢了。现阶段最重要的事情还是实践与使用工具,无论是可预见的具体工作需求也好,还是预期引入工作的创新想法与混沌工程的理解,都是那两点的具现化。
对了英语也很重要,指不定过两年润出去2333
参考:
- Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age 论文解读
- Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age
- 从false sharing到缓存一致性,这其实与我们息息相关
- Corey: an operating system for many cores.
- Everything you always wanted to know about synchronization but were afraid to ask.
- EXCHANGE operator
- OLAP 任务的并发执行与调度
- PolarDB-X 面向 HTAP 的混合执行器
- JOIN与子查询的优化和执行
- 并行查询(Parallel Query)
- PolarDB 并行查询的前世今生
- 深度解析PolarDB数据库并行查询技术
- Push versus pull-based loop fusion in query engines
- Push还是Pull,这是个问题么?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界