

scrapy简单教程以及实战
1.scrapy基础
首先看看本学习视频的学习大纲

1.1 简介
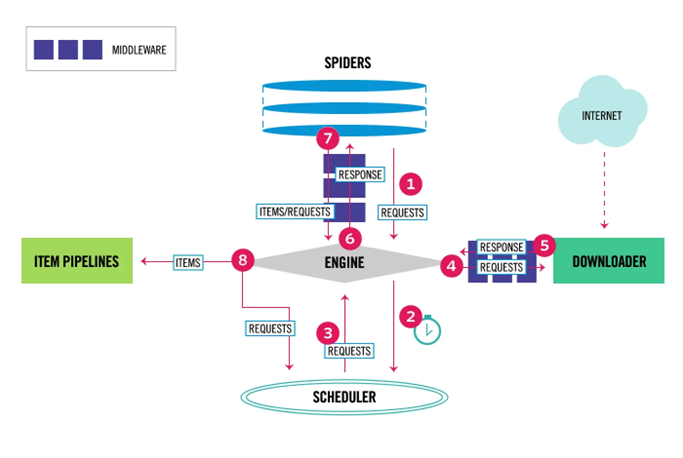
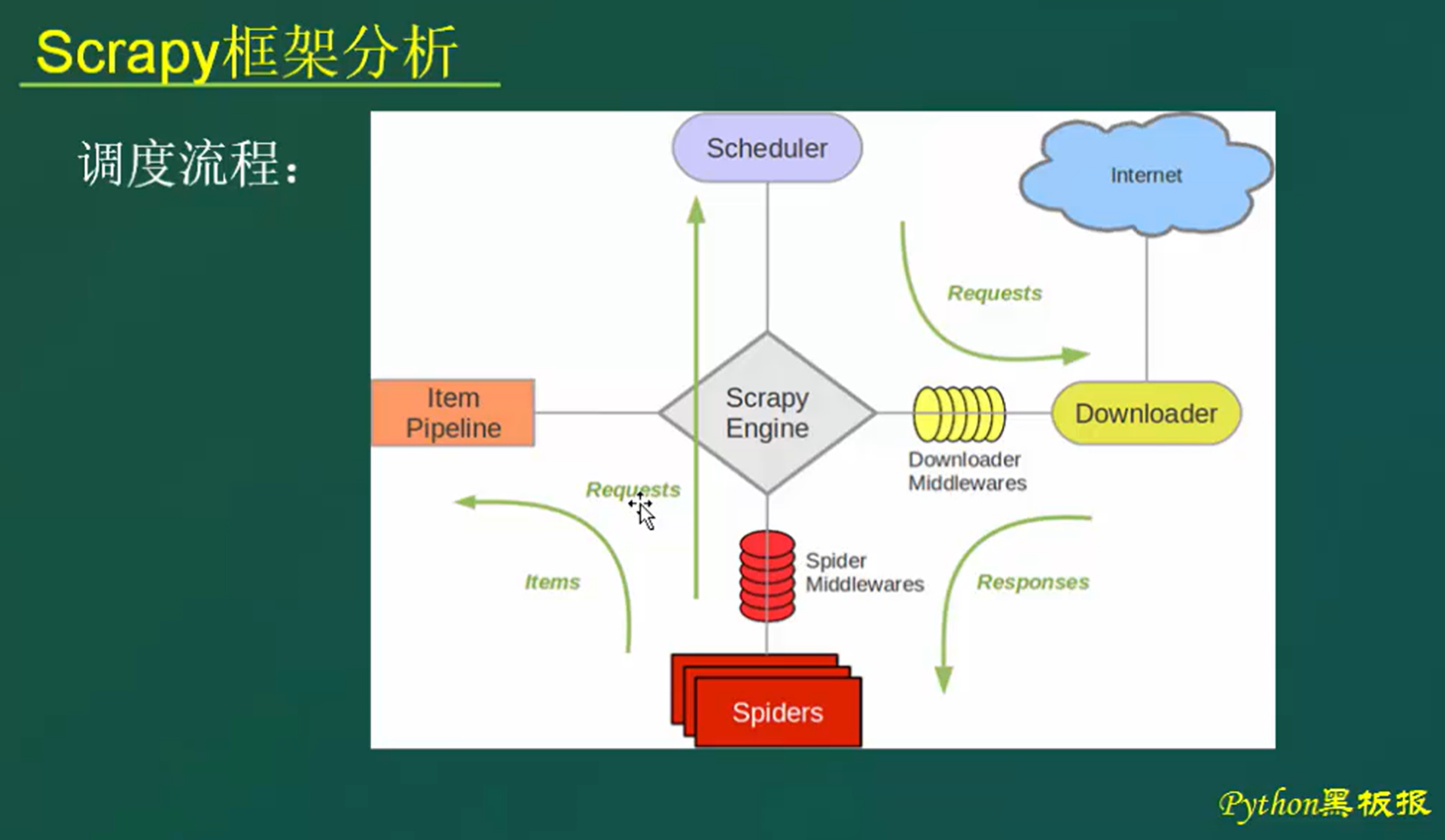
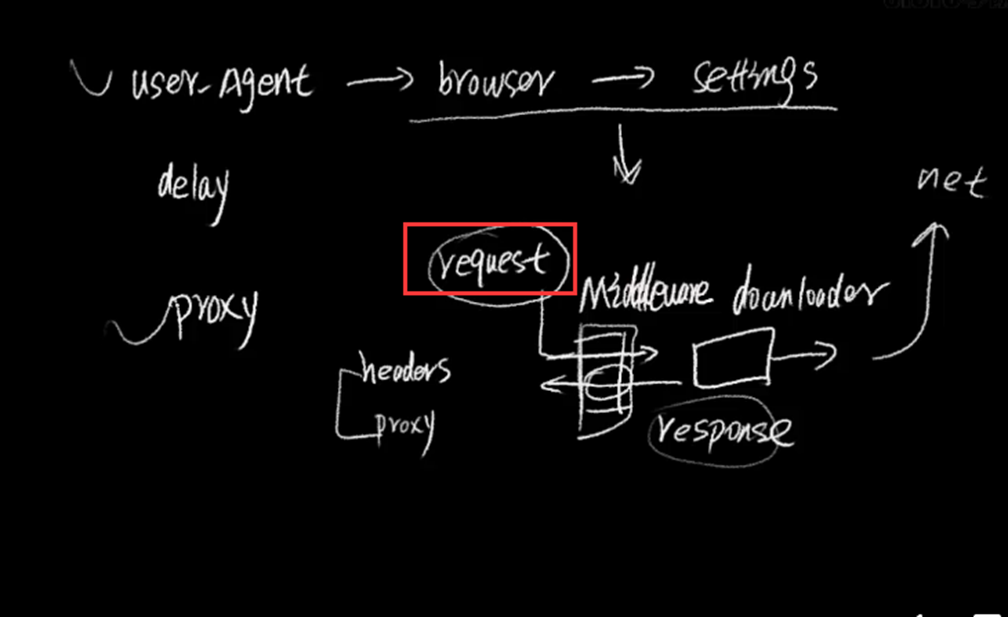
Scrapy是用python实现的一个为了爬取网站数据,提取结构性数据而编写的应用框架。使用Twisted高效异步网络框架来处理网络通信。Scrapy架构:
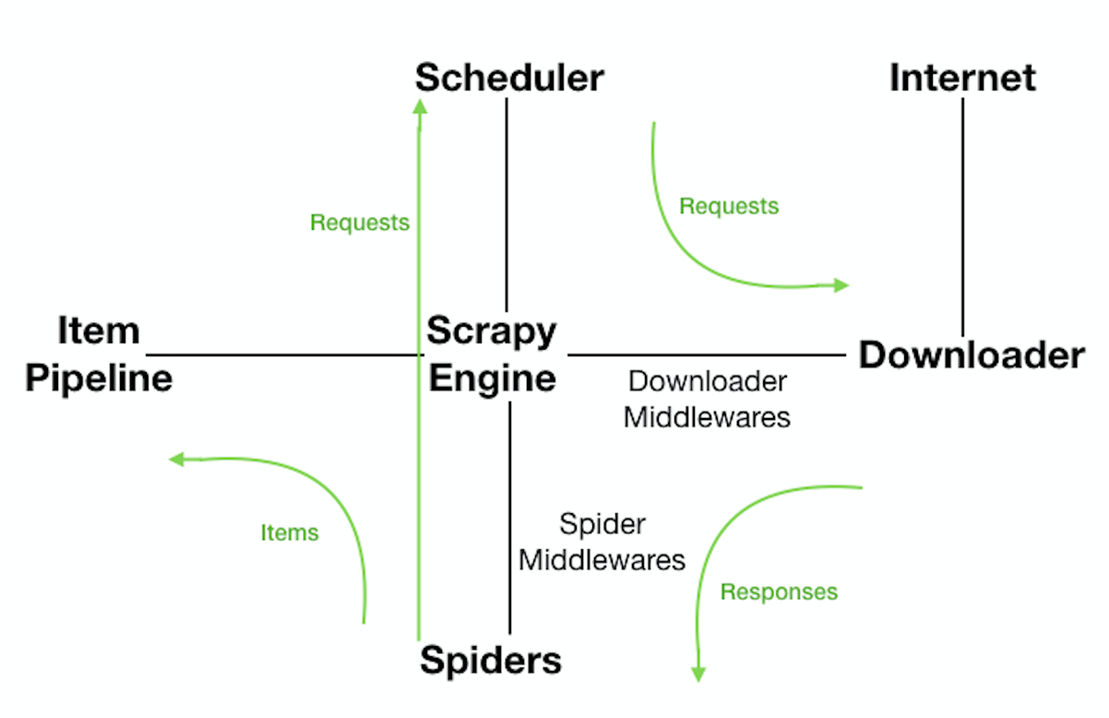
关于Scrapy架构各项说明,如下所示:
- ScrapyEngine:引擎。负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 此组件相当于爬虫的“大脑”,是 整个爬虫的调度中心。
- Schedule:调度器。接收从引擎发过来的requests,并将他们入队。初始爬取url和后续在页面里爬到的待爬取url放入调度器中,等待被爬取。调度器会自动去掉重复的url。
- Downloader:下载器。负责获取页面数据,并提供给引擎,而后提供给spider。
- Spider:爬虫。用户编些用于分析response并提取item和额外跟进的url。将额外跟进的url提交给ScrapyEngine,加入到Schedule中。将每个spider负责处理一个特定(或 一些)网站。
- ItemPipeline:负责处理被spider提取出来的item。当页面被爬虫解析所需的数据存入Item后,将被发送到Pipeline,并经过设置好次序
- DownloaderMiddlewares:下载中间件。是在引擎和下载器之间的特定钩子(specific hook),处理它们之间的请求(request)和响应(response)。提供了一个简单的机制,通过插入自定义代码来扩展Scrapy功能。通过设置DownloaderMiddlewares来实现爬虫自动更换user-agent,IP等。
- SpiderMiddlewares:Spider中间件。是在引擎和Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items或requests)。提供了同样简单机制,通过插入自定义代码来扩展Scrapy功能。
Scrapy数据流:
- ScrapyEngine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个(批)要爬取的url(s);
- ScrapyEngine向调度器请求第一个要爬取的url,并加入到Schedule作为请求以备调度;
- ScrapyEngine向调度器请求下一个要爬取的url;
- Schedule返回下一个要爬取的url给ScrapyEngine,ScrapyEngine通过DownloaderMiddlewares将url转发给Downloader;
- 页面下载完毕,Downloader生成一个页面的Response,通过DownloaderMiddlewares发送给ScrapyEngine;
- ScrapyEngine从Downloader中接收到Response,通过SpiderMiddlewares发送给Spider处理;
- Spider处理Response并返回提取到的Item以及新的Request给ScrapyEngine;
- ScrapyEngine将Spider返回的Item交给ItemPipeline,将Spider返回的Request交给Schedule进行从第二步开始的重复操作,直到调度器中没有待处理的Request,ScrapyEngine关闭。
1.2 运行环境
由于本笔记记录的时间间隔有6,7年,所以在第二次复习的时候,w10,w11都出来了,所以这里记录两种安装环境。
1.2.1 Window7
环境windows7 + python3.6 + scrapy1.40
scarpy在windows7环境下安装需要安装以下组件,否则报错。

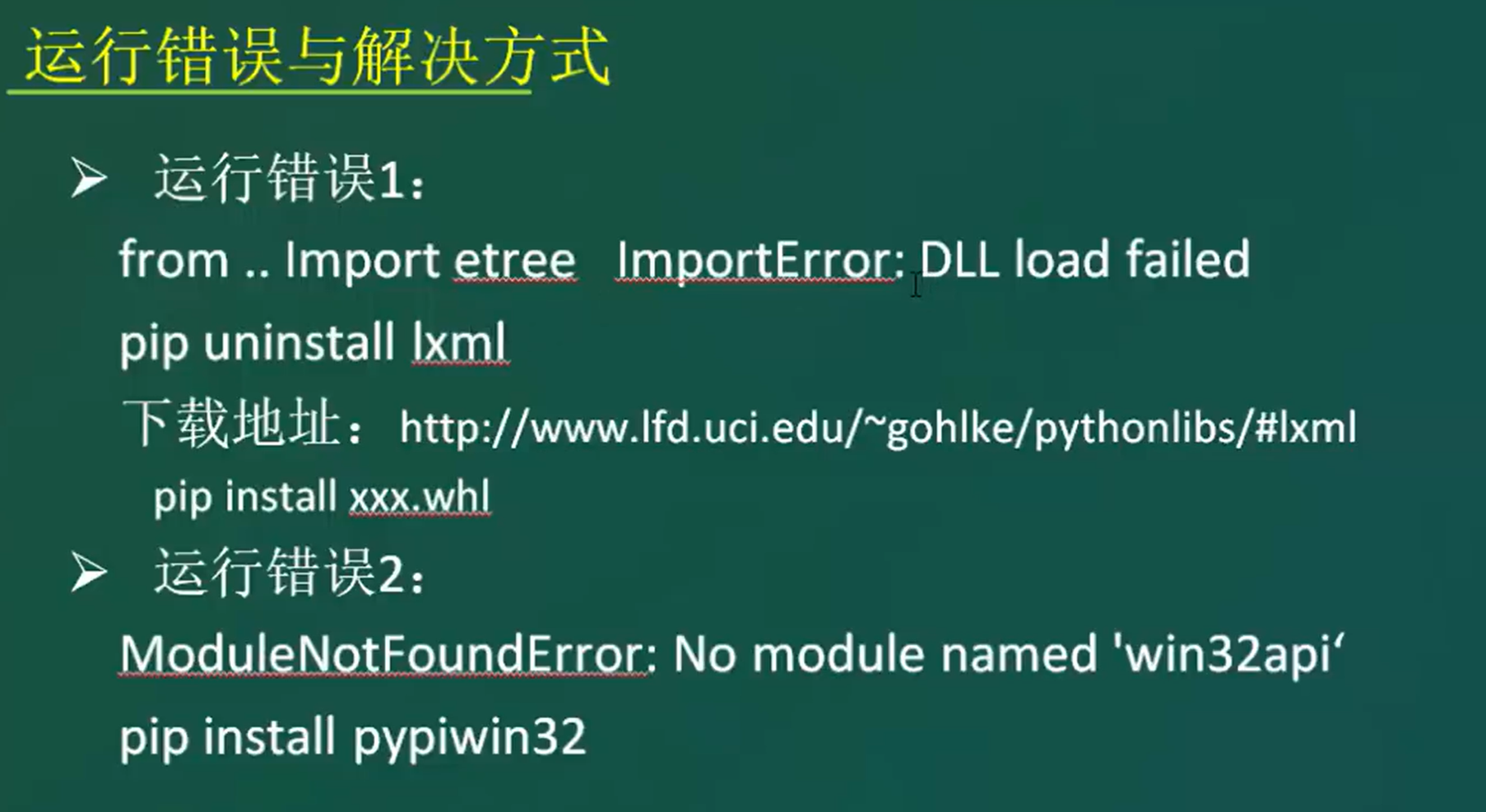
以下有两种处理方式,这里选择第一种。
第一种:通过wheel来安装lxml.whl、twisted.whl
第二种:安装vs2015,并勾选各种支持python的选项
1)在这个网址 http://www.lfd.uci.edu/~gohlke/pythonlibs/下载lxml.whl和twisted.whl对应windows版本和python版本的文件(如图所示):
这里windows 7 64位系统不知道为什么要下载win32的版本
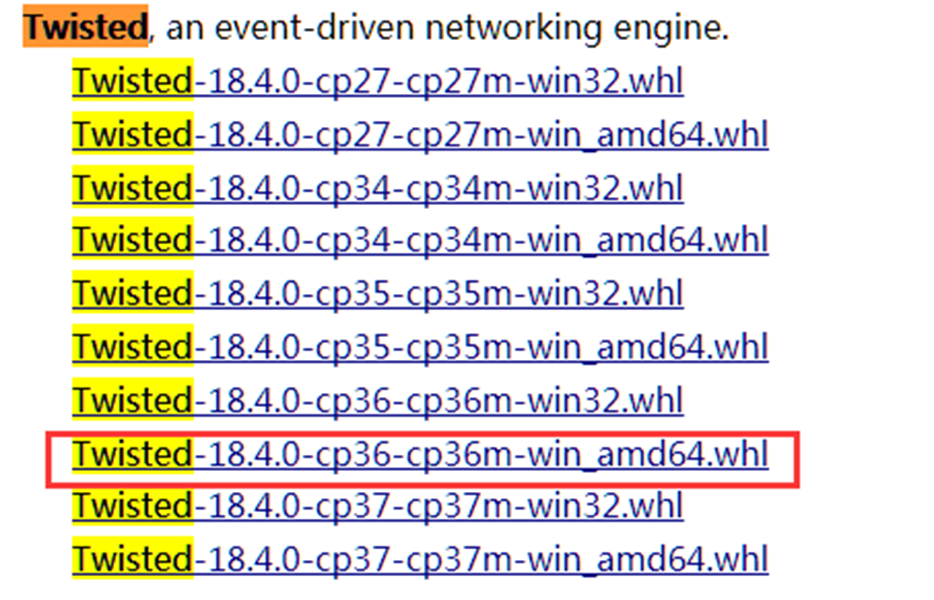
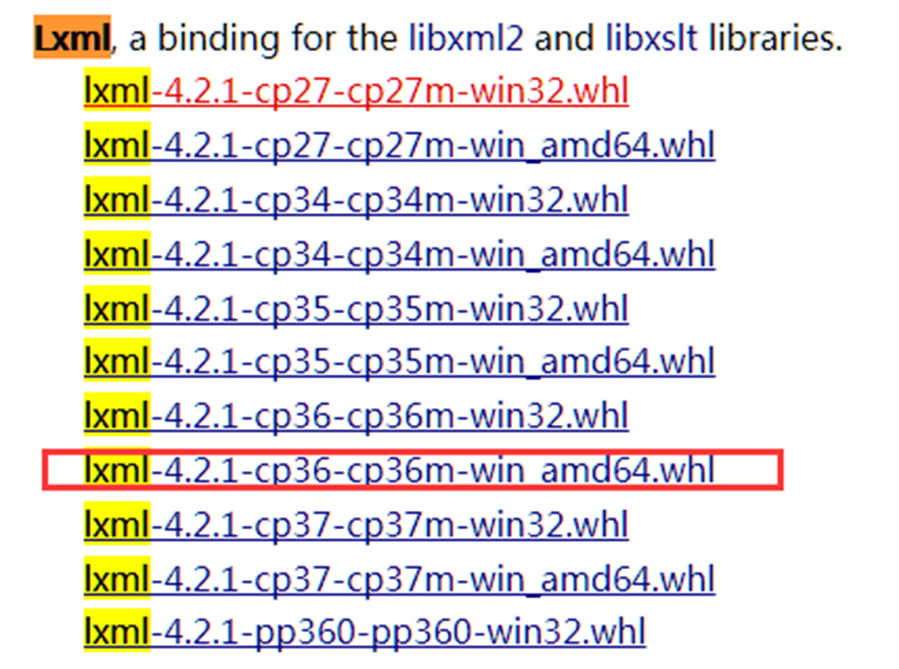
2)安装wheel模块:python3 –m pip install wheel
3)安装lxml,twisted.
把下载的包放置在python3.6的download(没有自己创建)下,然后进入该目录。
![]()
![]()
4)安装Scrapy即可:python3 –m install Scrapy
1.1.2 Windows10
至于windows10 + python3.10 + scrapy2.9.0可能出现以上报错,按照w7方式修复即可,但是我这边目前直接使用pip install scrapy安装即可,没有报错。
1.3 创建第一个scrapy项目
本章目的:


1)创建一个spider
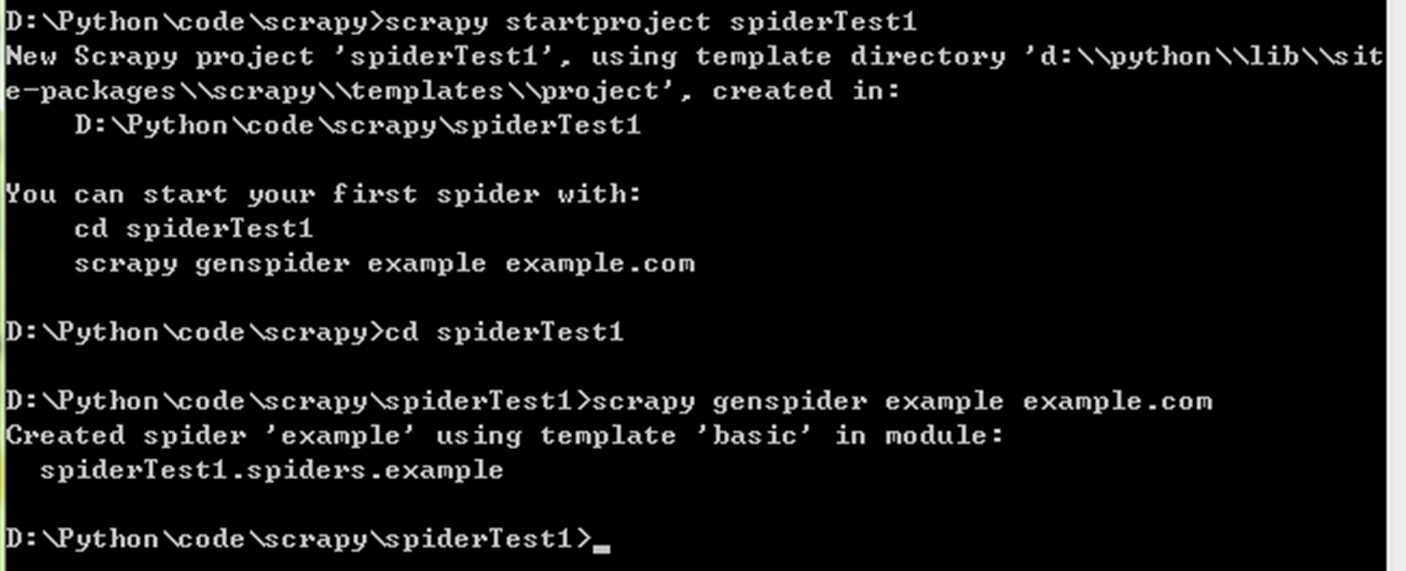
2)获取httpbin.org/get的信息
代码:
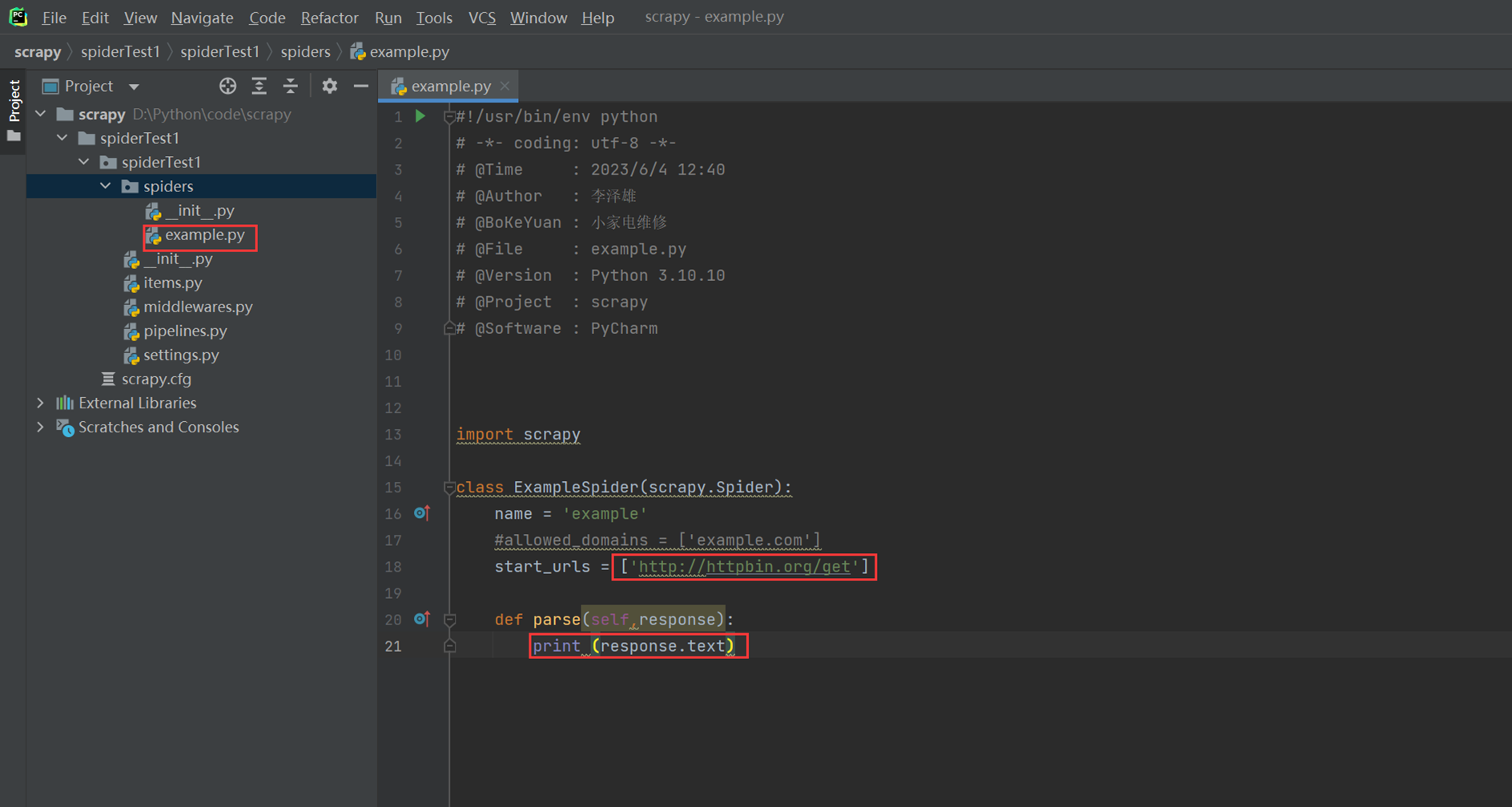
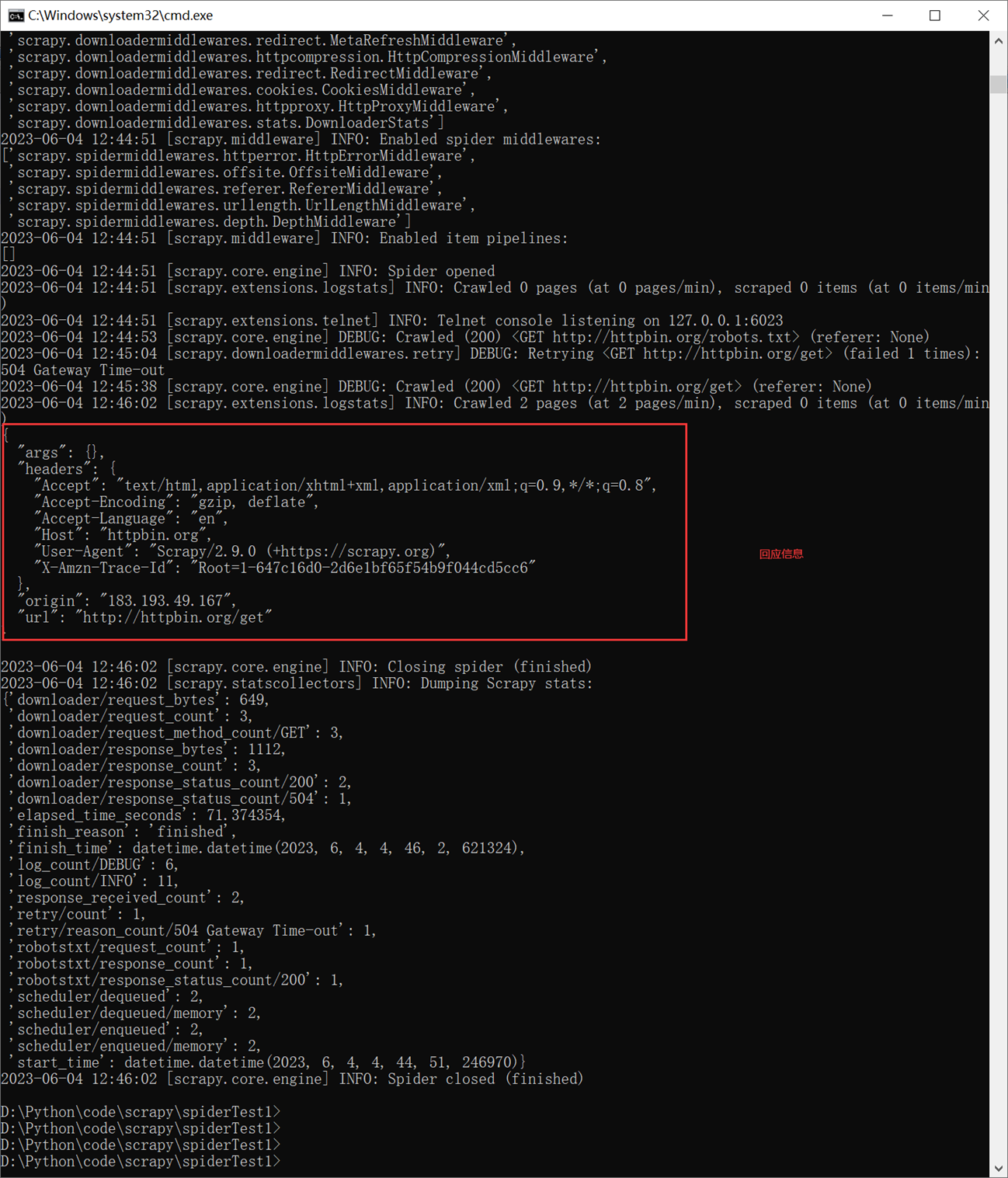
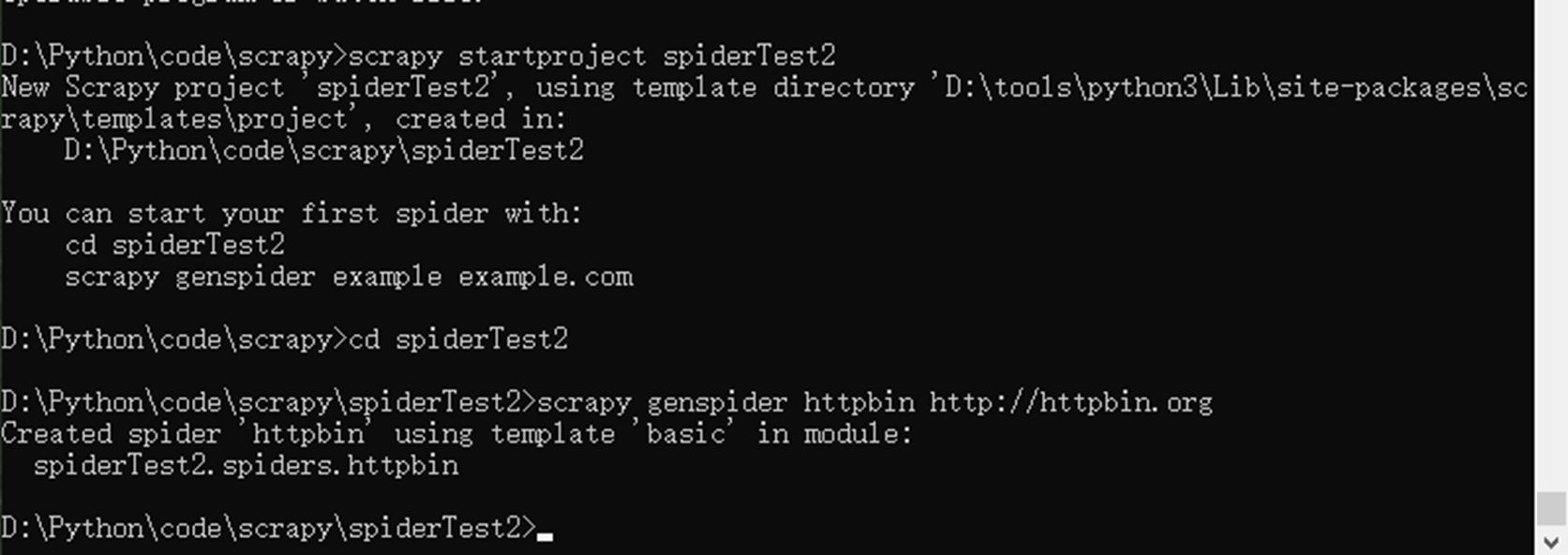
现在使用cmd来执行scrapy
![]()
3)上一步,已经获取到httpbin.org的信息,但是执行在cmd,现在使用直接在pycharm里面直接执行。
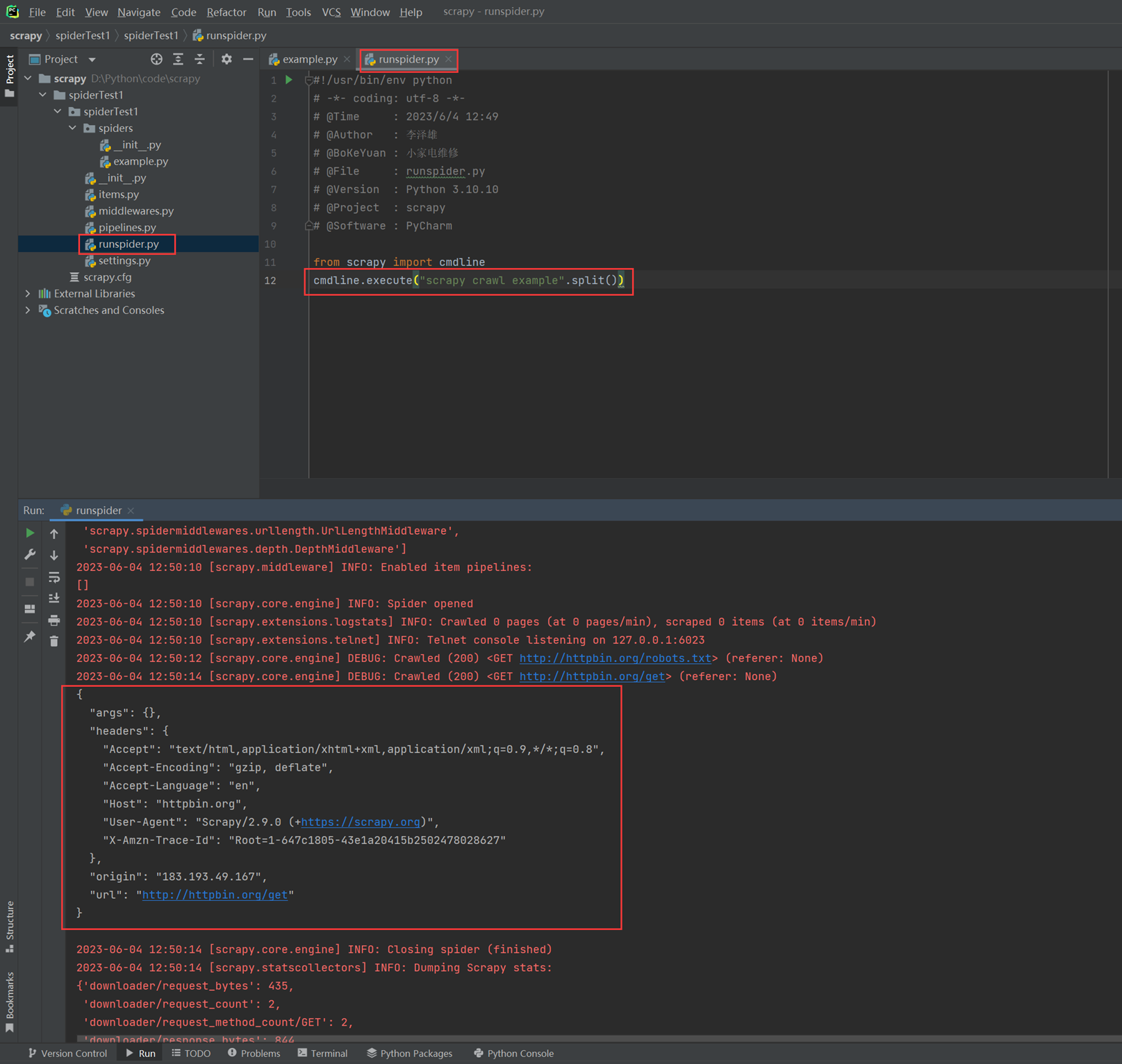
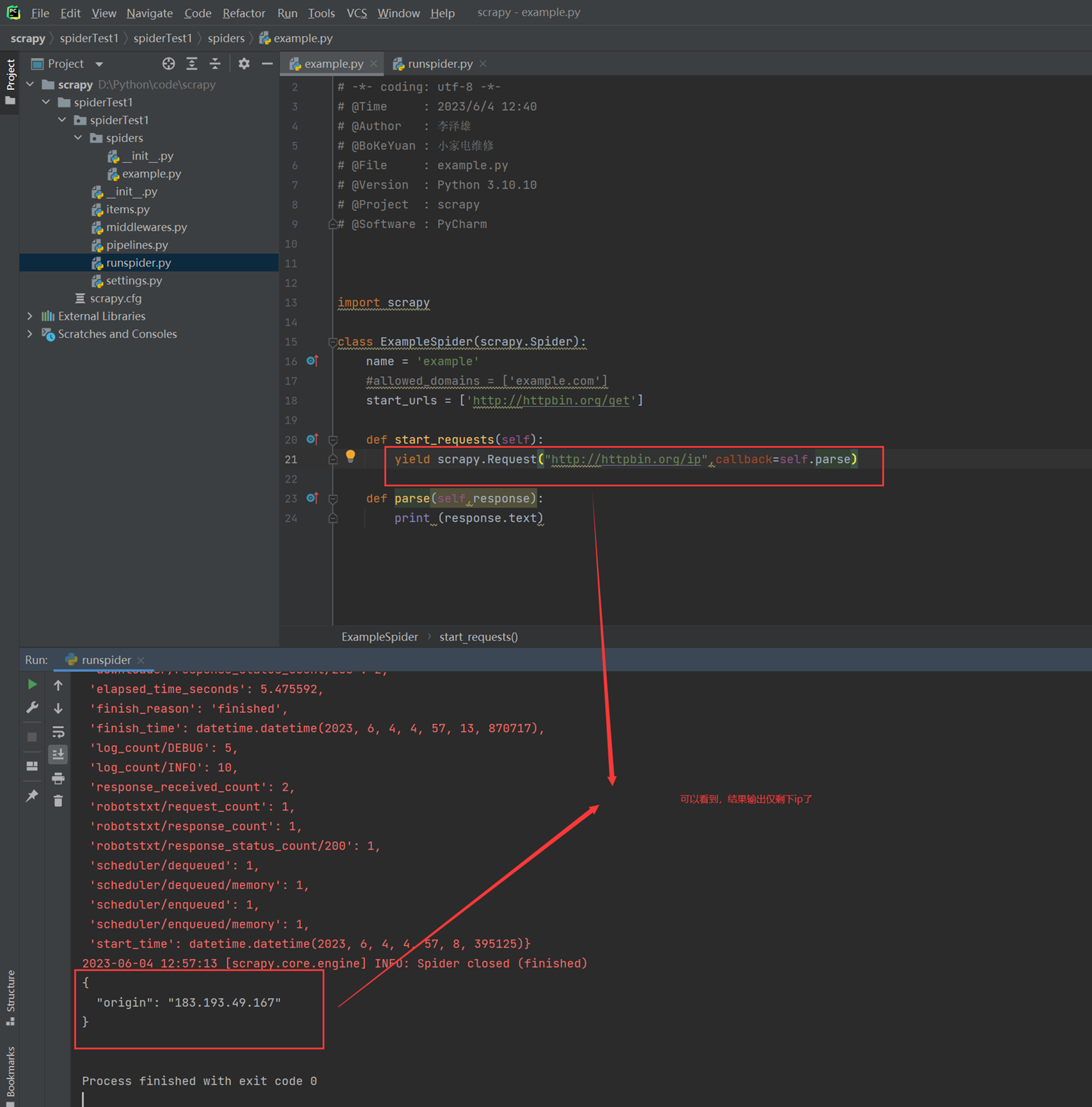
4)start_urls 和 start_request并存的优先级。
通过实验可以看出结果,如果两者并存,start_urls就不生效了
本章总结:
Spider作用
Resuest(发起请求)
Spider:
Response(信息的请求) → 信息的提取
再次发起请求
1.4 User-Agent设置与scrapy Shell使用

在一些网站中使用scrapy 爬取数据的时候会出现403错误,这里可以使用禁用robots协议和伪造浏览器User-Agent来实现。
现在首先测试爬取豆瓣网的T250的电影,然后查看请求头部。
1)首先创建一个豆瓣的spider.
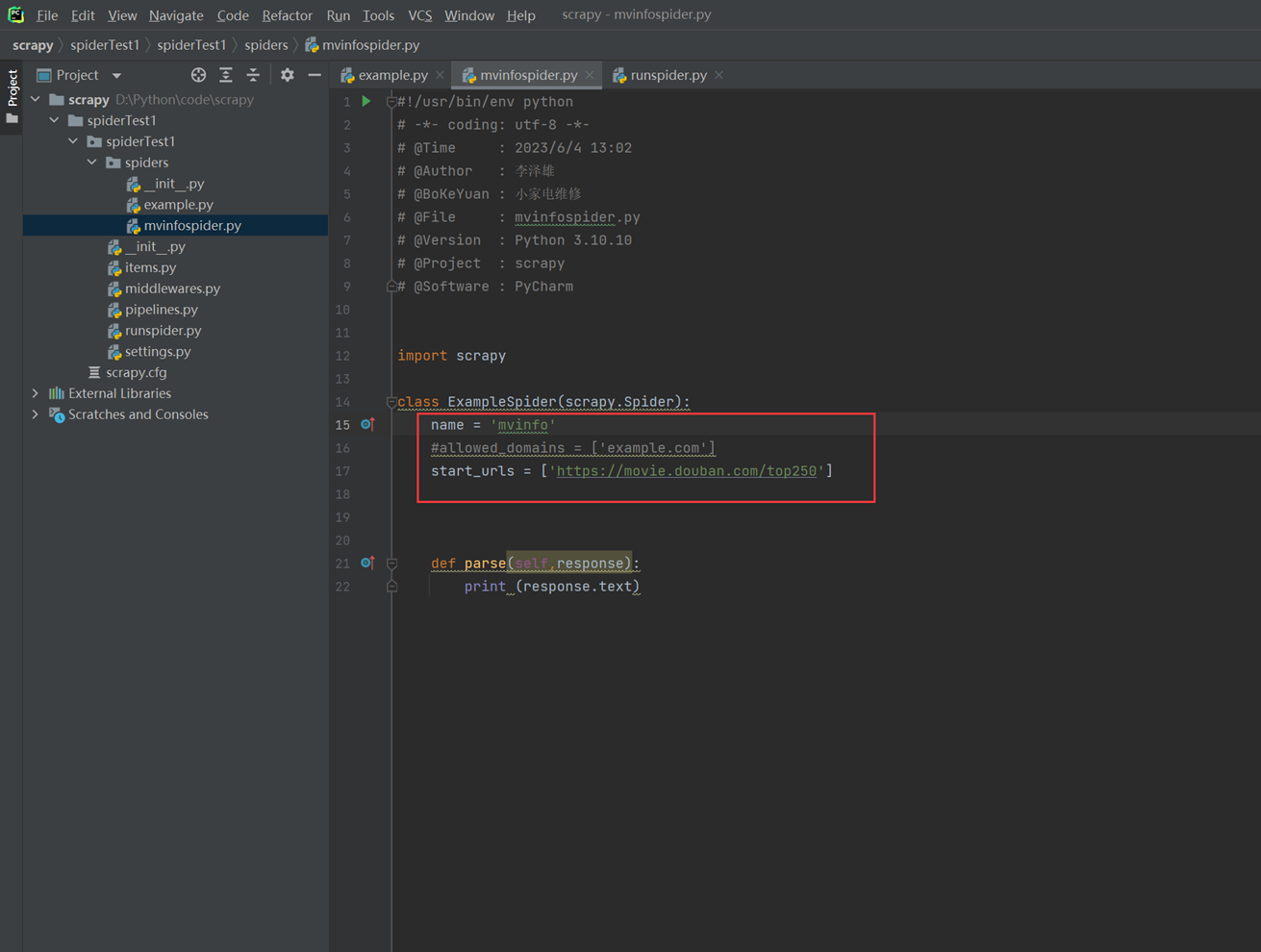
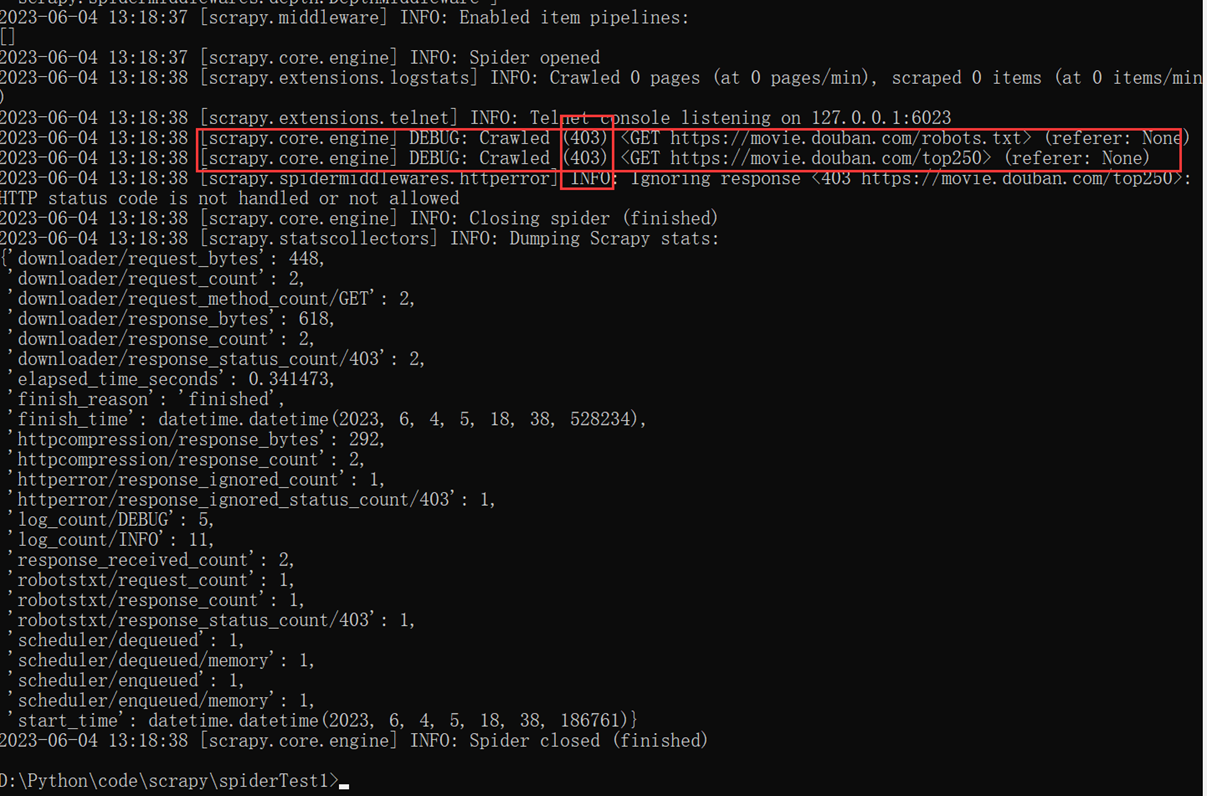
然后去爬取豆瓣,发现403错误。
![]()
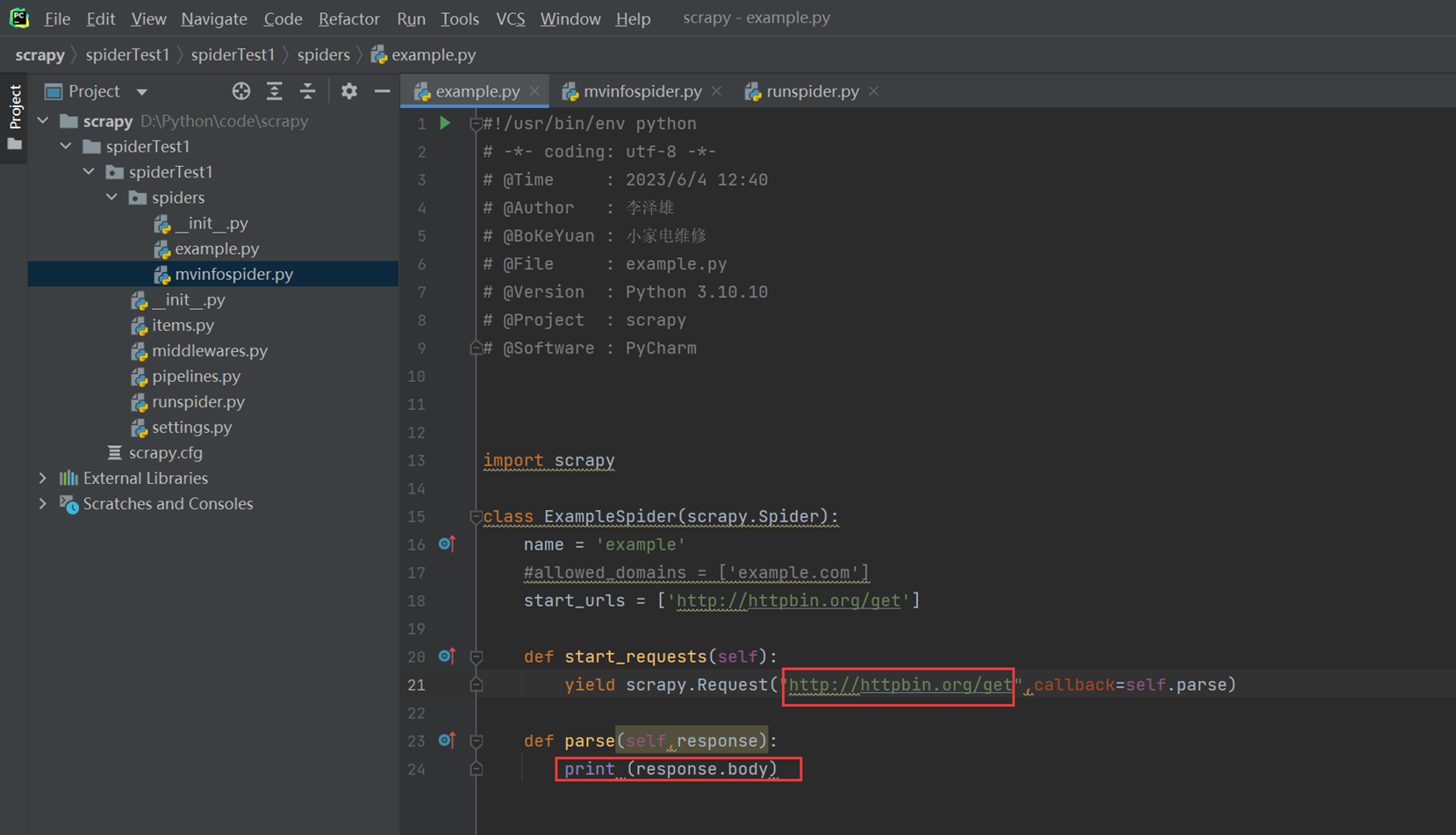
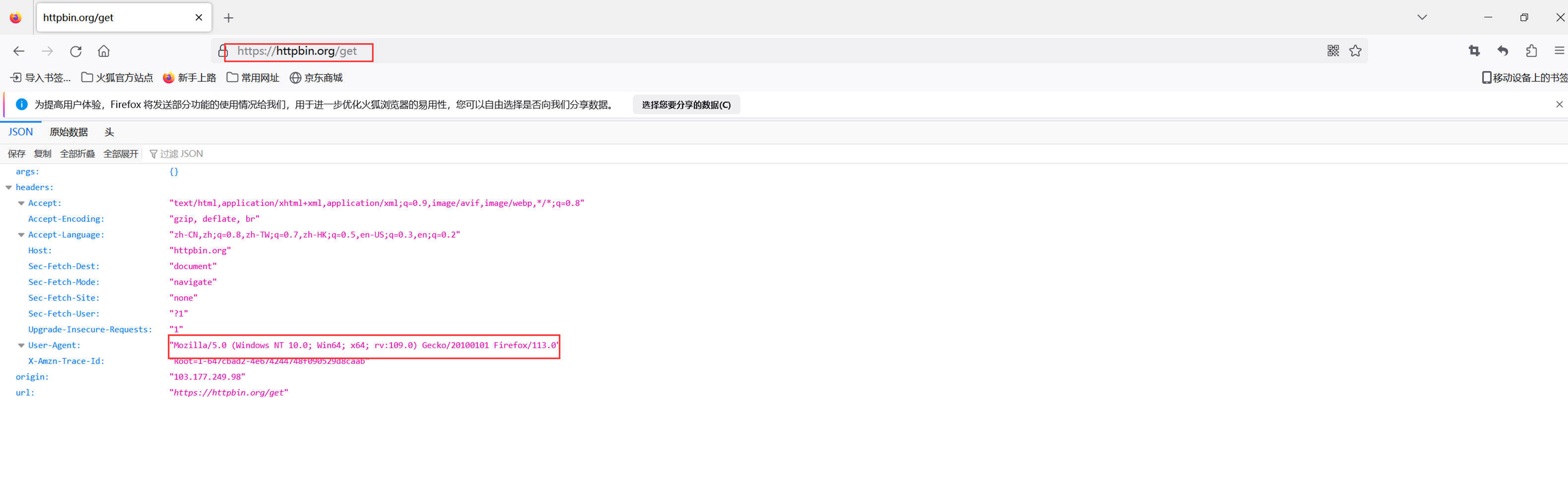
2)现在查看访问 example的请求头部
Httpbin是一个测试网站,这里spider需要小做更改。打印出回应的body信息,这个body里面包含了很多我们想要的信息,比如请求头等等。
![]()
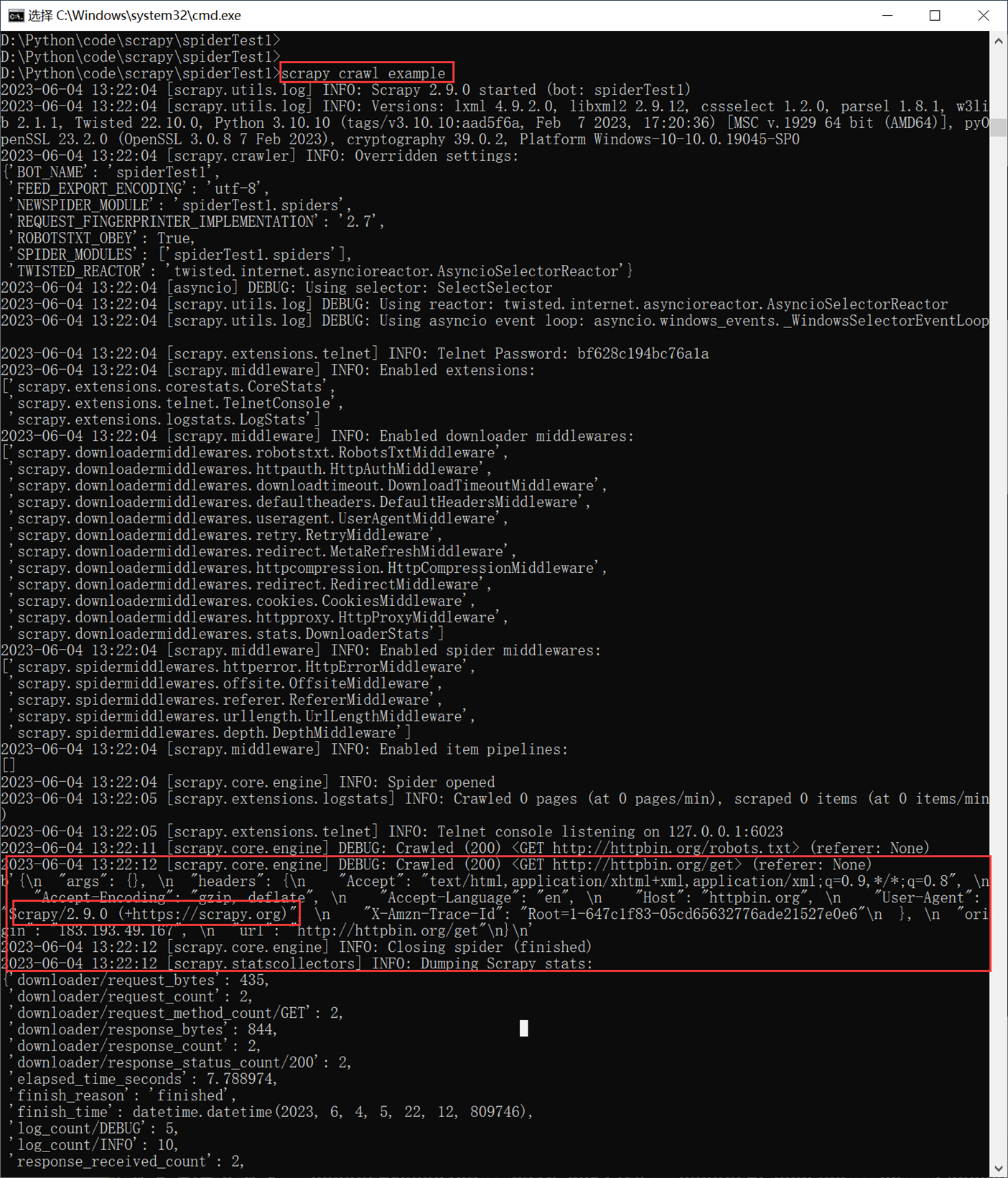
可以看到,我们的User-agent是scrapy的,所以被阻止掉了。
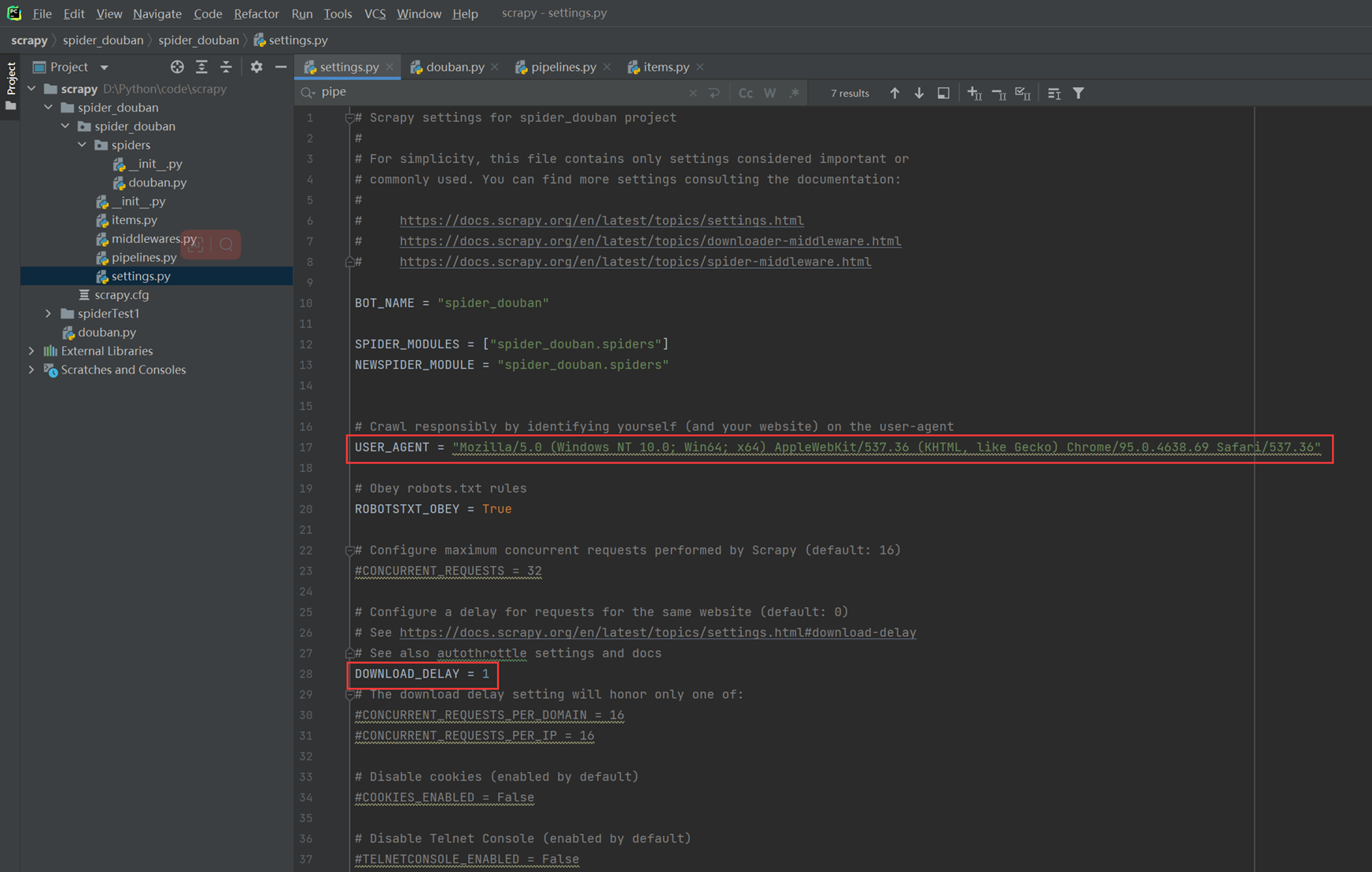
3)接下来,更改配置文件,使用火狐浏览器的User-Agent.
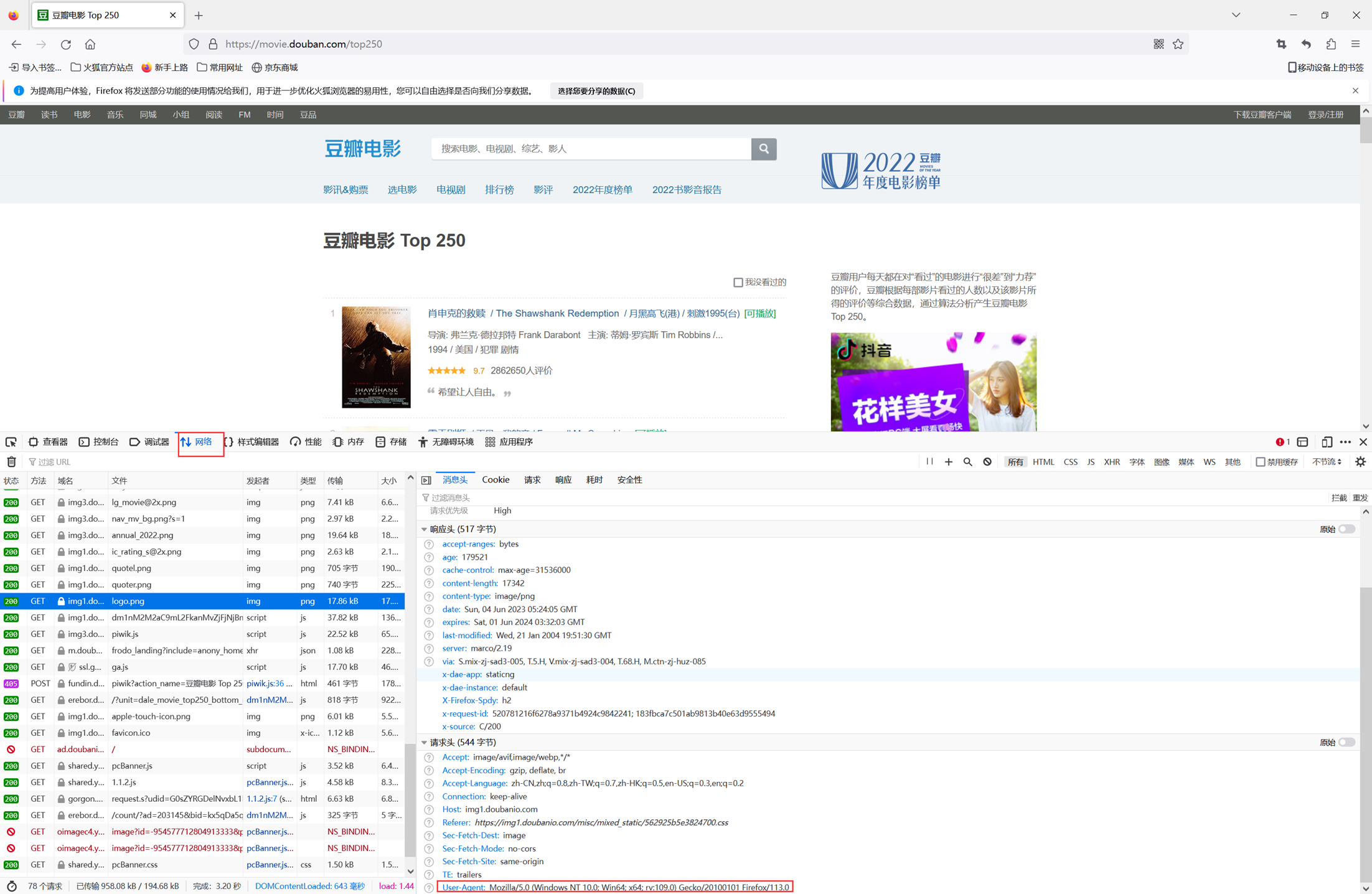
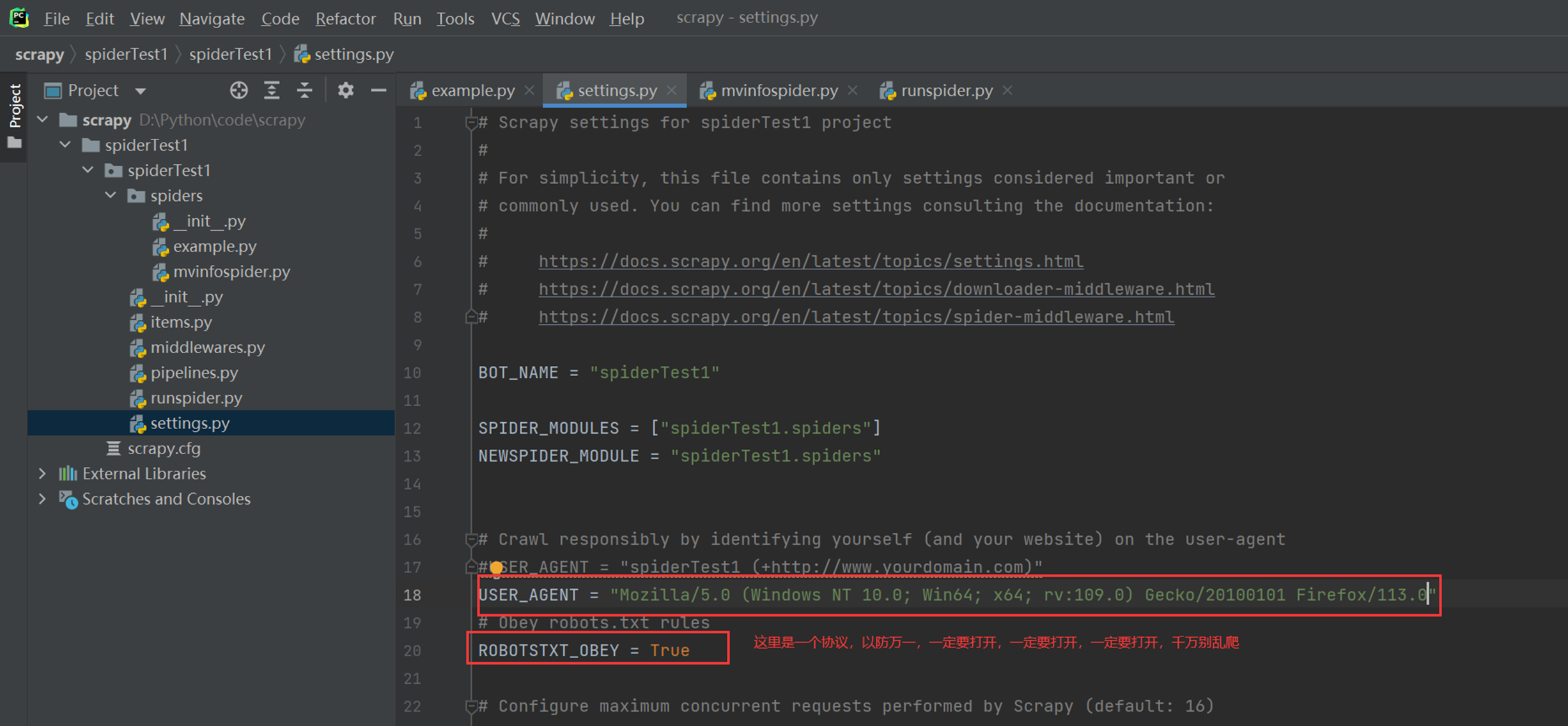
更改配置文件,模拟成为火狐浏览器访问。
再次爬取example,查看User-Agent.
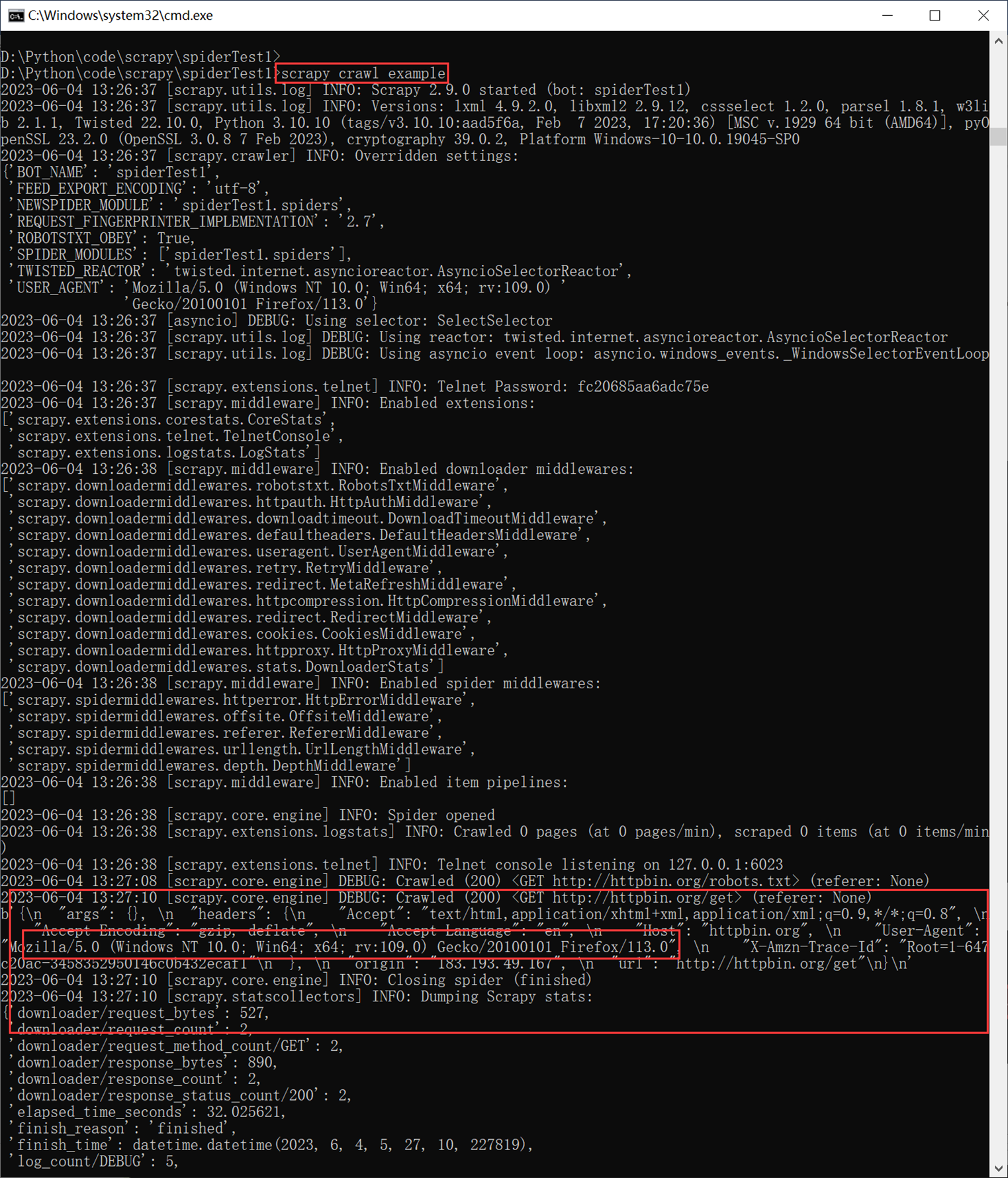
4)现在爬取豆瓣
返回值为200了,代表正常访问
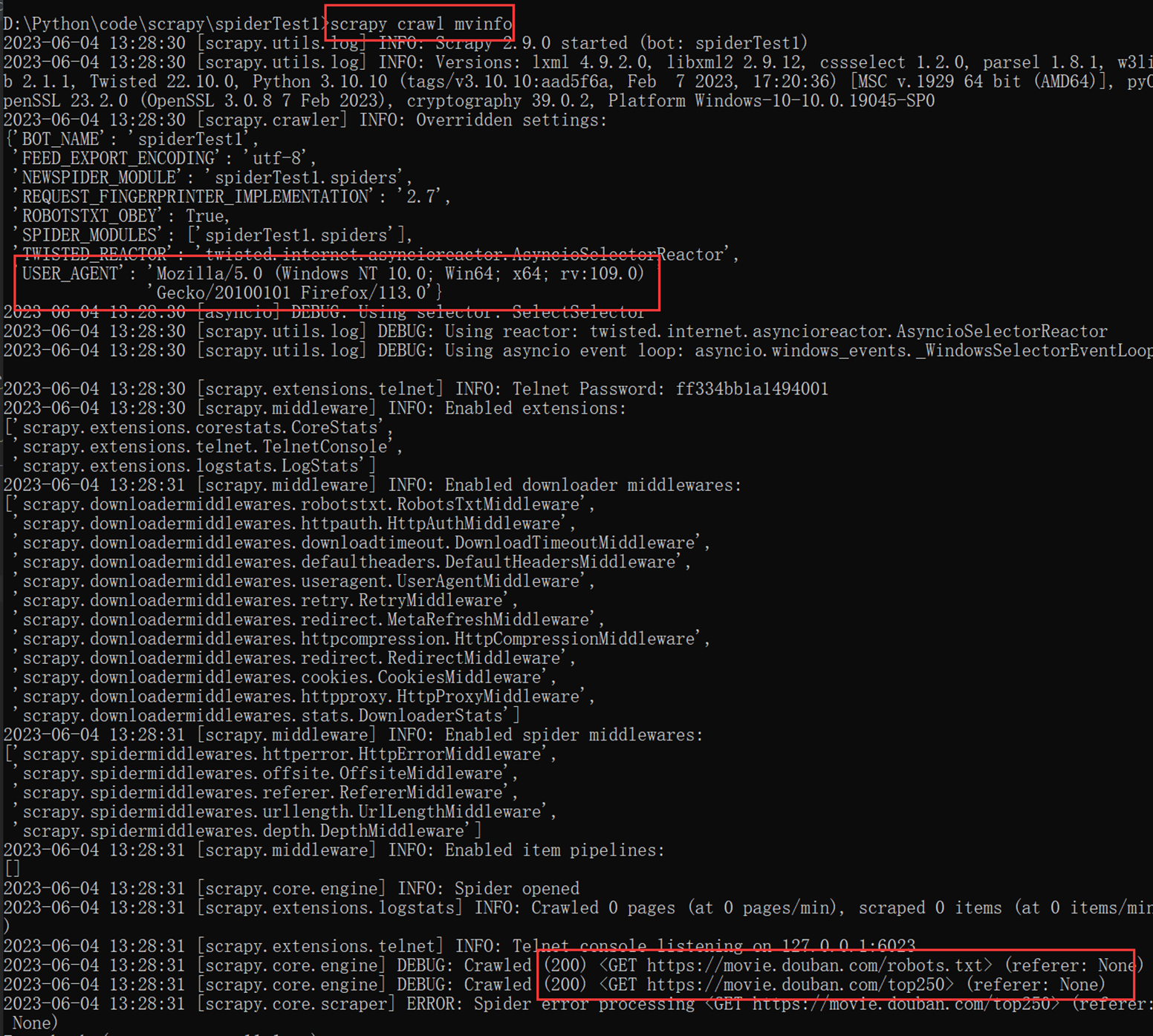
总结和技巧

我们访问网址的时候,一共有三种方式。
1.直接请求URL,在seeting配置文件里面直接设置User-Agent即可。设置之后,不管是shell还是用户终端,都可以直接进行访问,上面已经演示过了。
2.shell访问,在shell访问的时候直接指定用户user-agent,如:
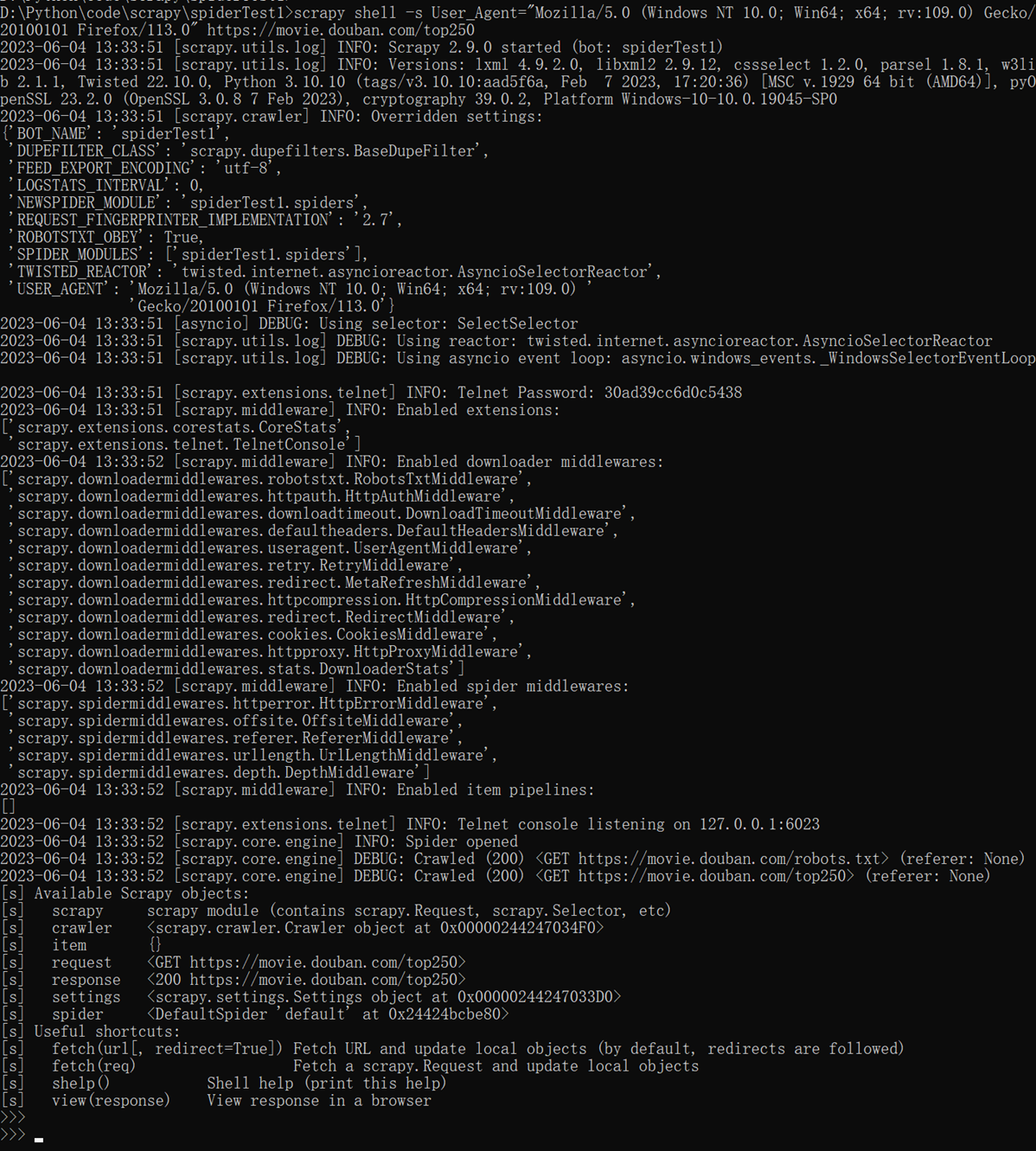
先进入shell,以上是加了网址的,可以直接进行对这个网址的访问
3.不指定网址,直接进入shell,然后自己自定义网址操作。
这个和第二种方式区别不大,只是一个在进入shell之前的时候指定网址,一个在进入shell之后指定网址。
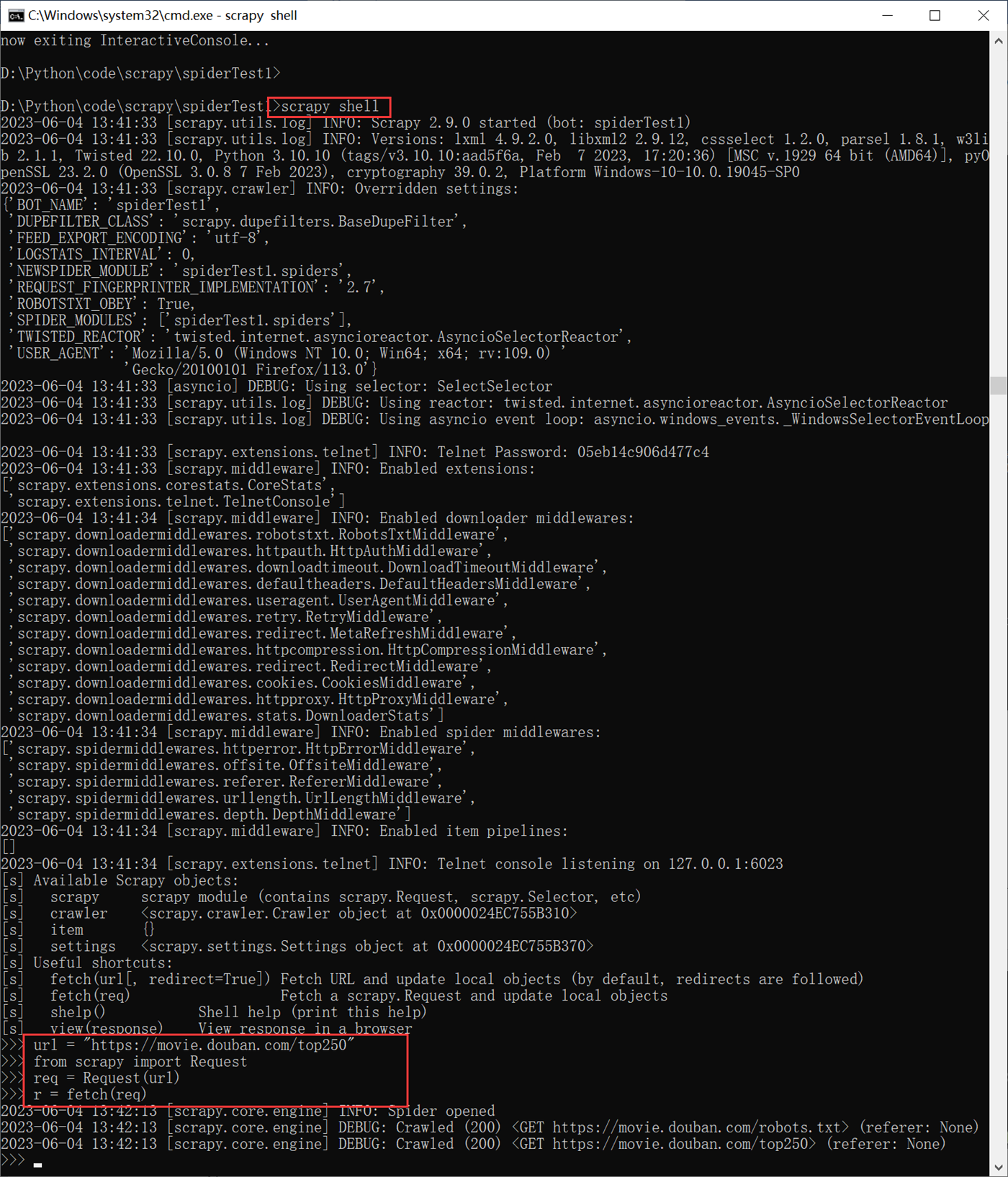
然后可以通response来获取网页的信息,有了这些信息,我们就可以根据标签去爬数据了。

1.5 Xpath与CSS选择器
上面章节中已经可以通过response来获取整个网页想要的信息,接下来,我们就要提取这些我们需要的信息。
1.5.1 Xpath
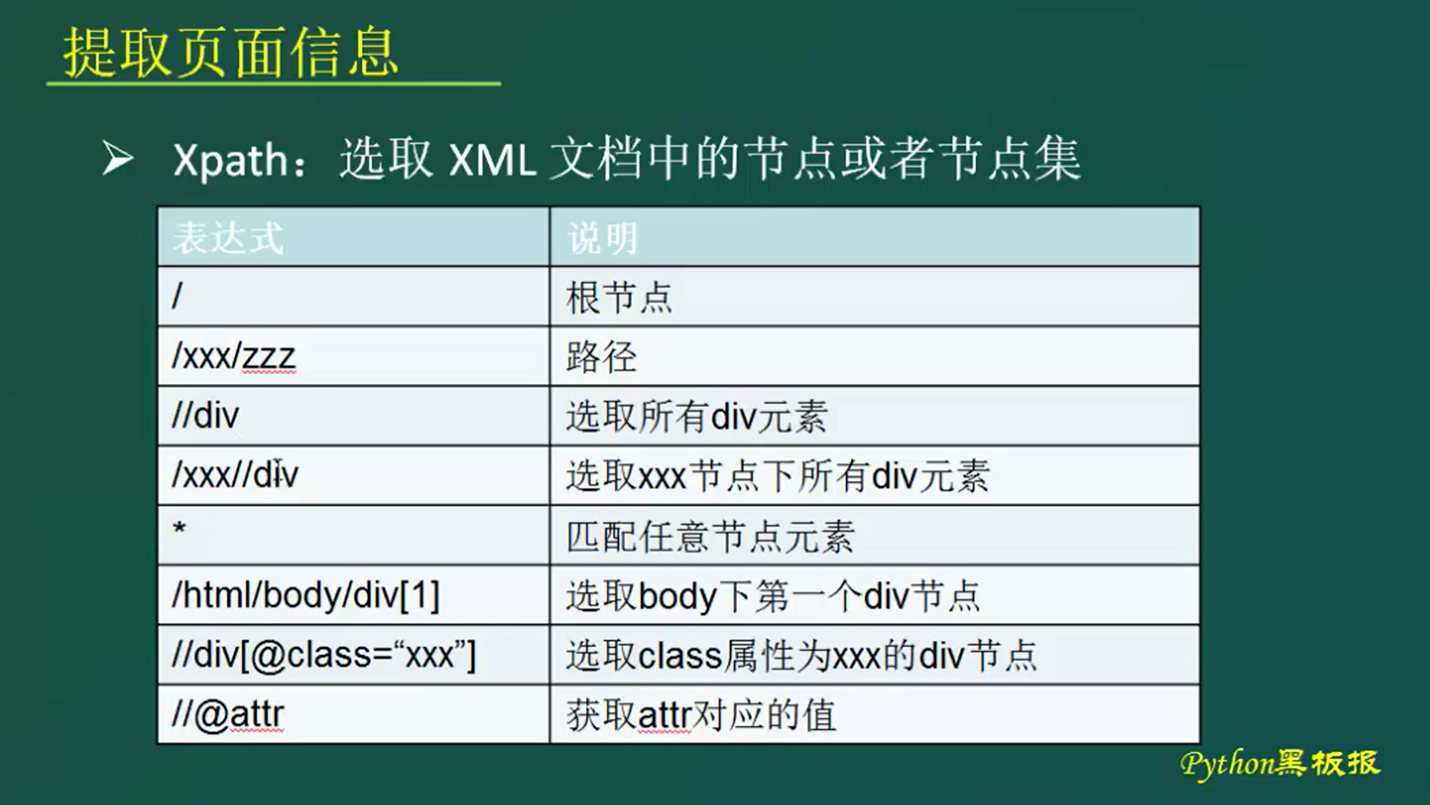
- / 根节点 /xxx/zzz
根据html的区块来找到对应的标签,关系为层级父子关系

比如 /html 里面又包含 head 和 body ,head里面还包含 title
- 匹配任意节点元素
匹配根下面的所有元素
跟下面就一个html的最大元素

然后匹配html下的所有元素,html下有head和body2大元素

如果直接匹配*,那么也是有head和body2大元素

匹配body下的所有元素
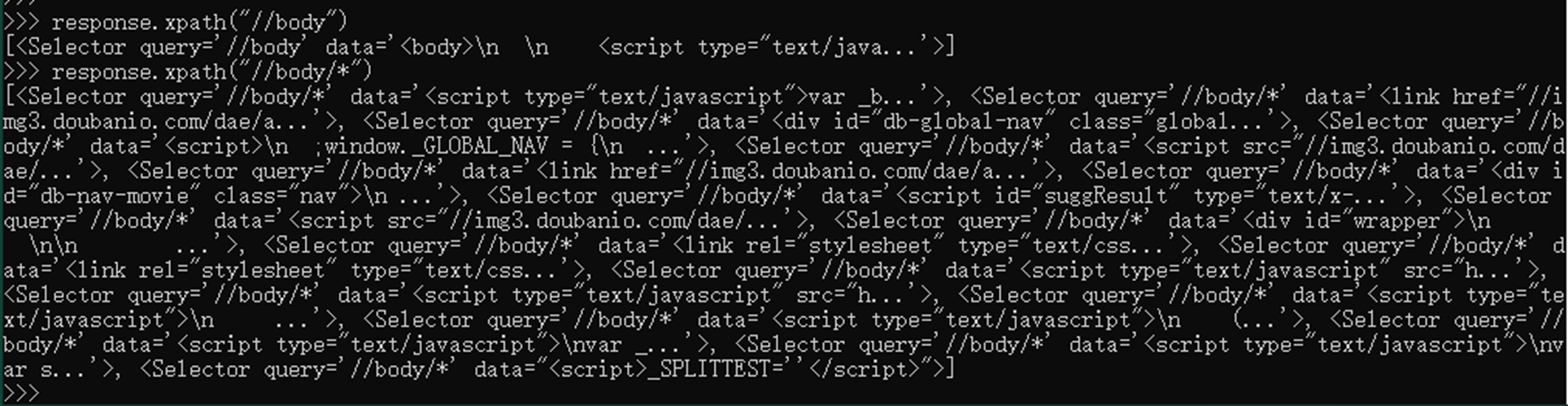
- //div 选择一个网页选择器的所有元素
如选择这个网页所有标签为title的元素

匹配head下的meta元素

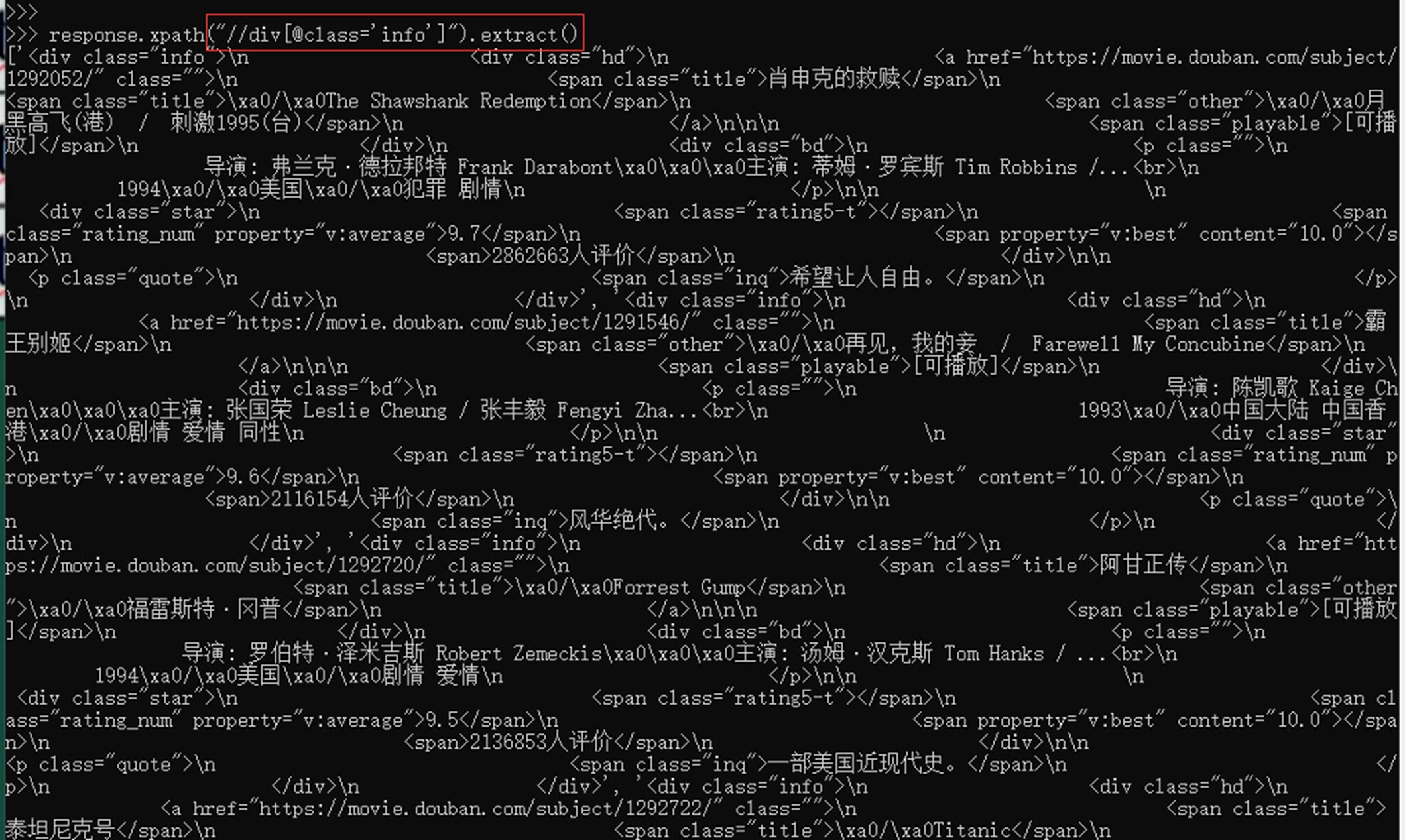
- //div[@class=”xxx”]
例如,选取class属性为info 的div节点
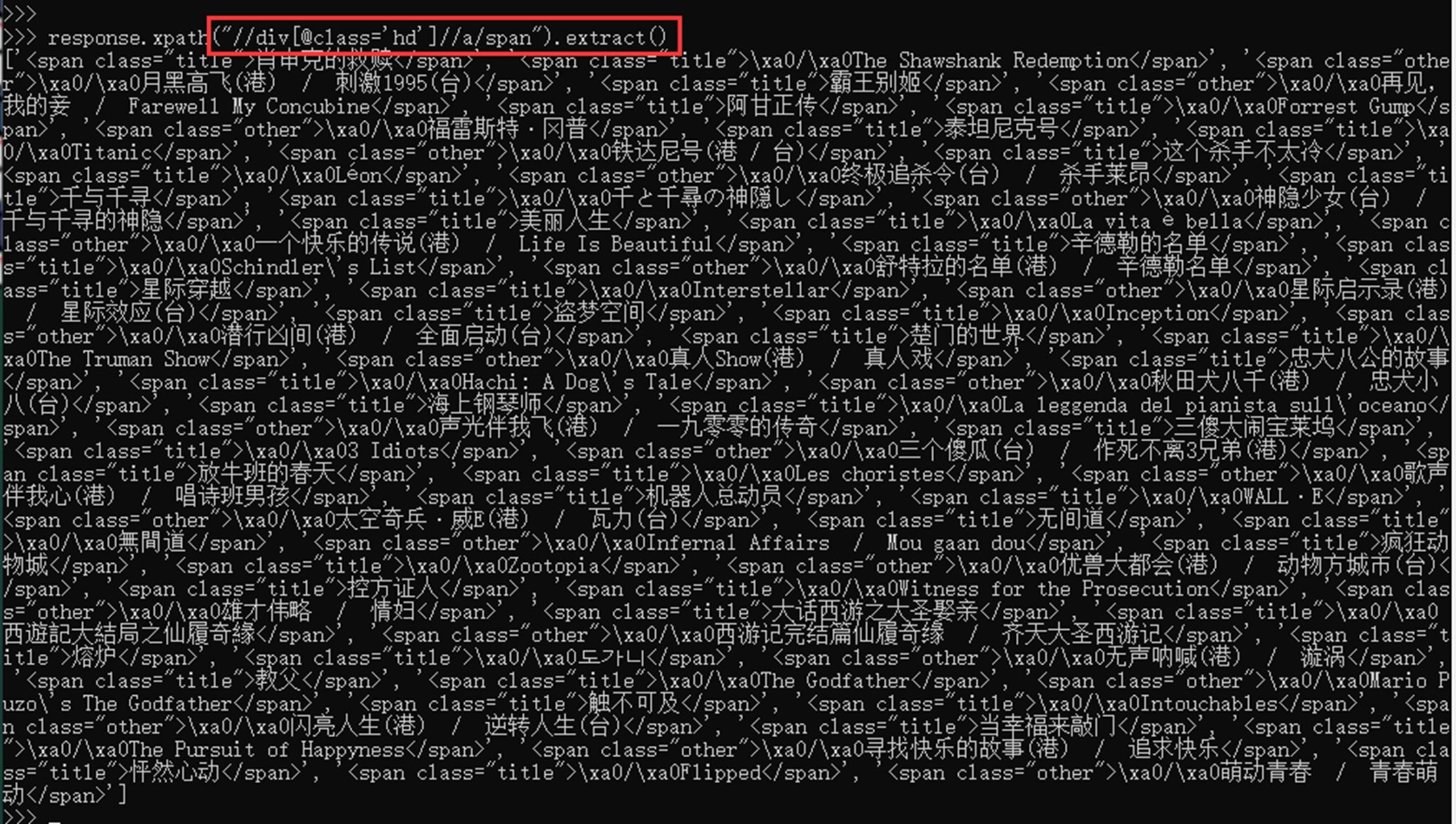
或者选取class属性为hd的div节点下所有a标签下的span
或者选取class属性为hd的div节点下所有a标签下href属性的值

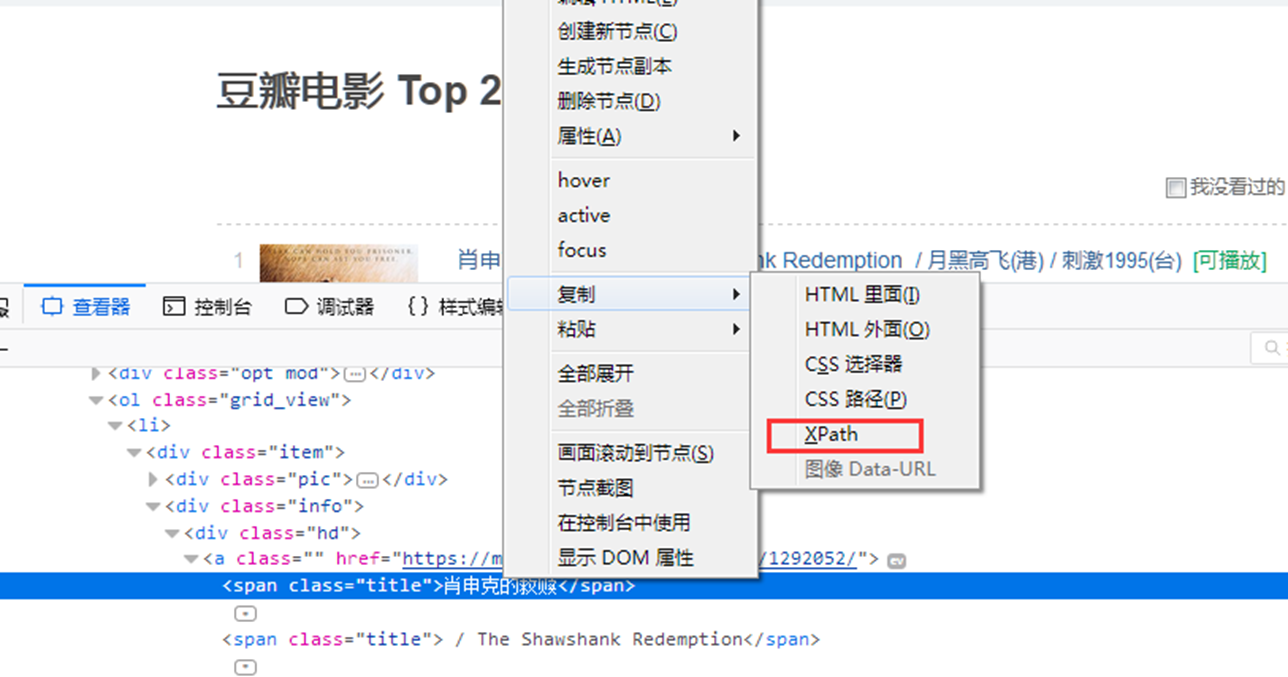
- 使用浏览器的xpath直接定位
如,直接定位到一个电影的名称,使用浏览器的xpath功能

更高级的用法,使用函数
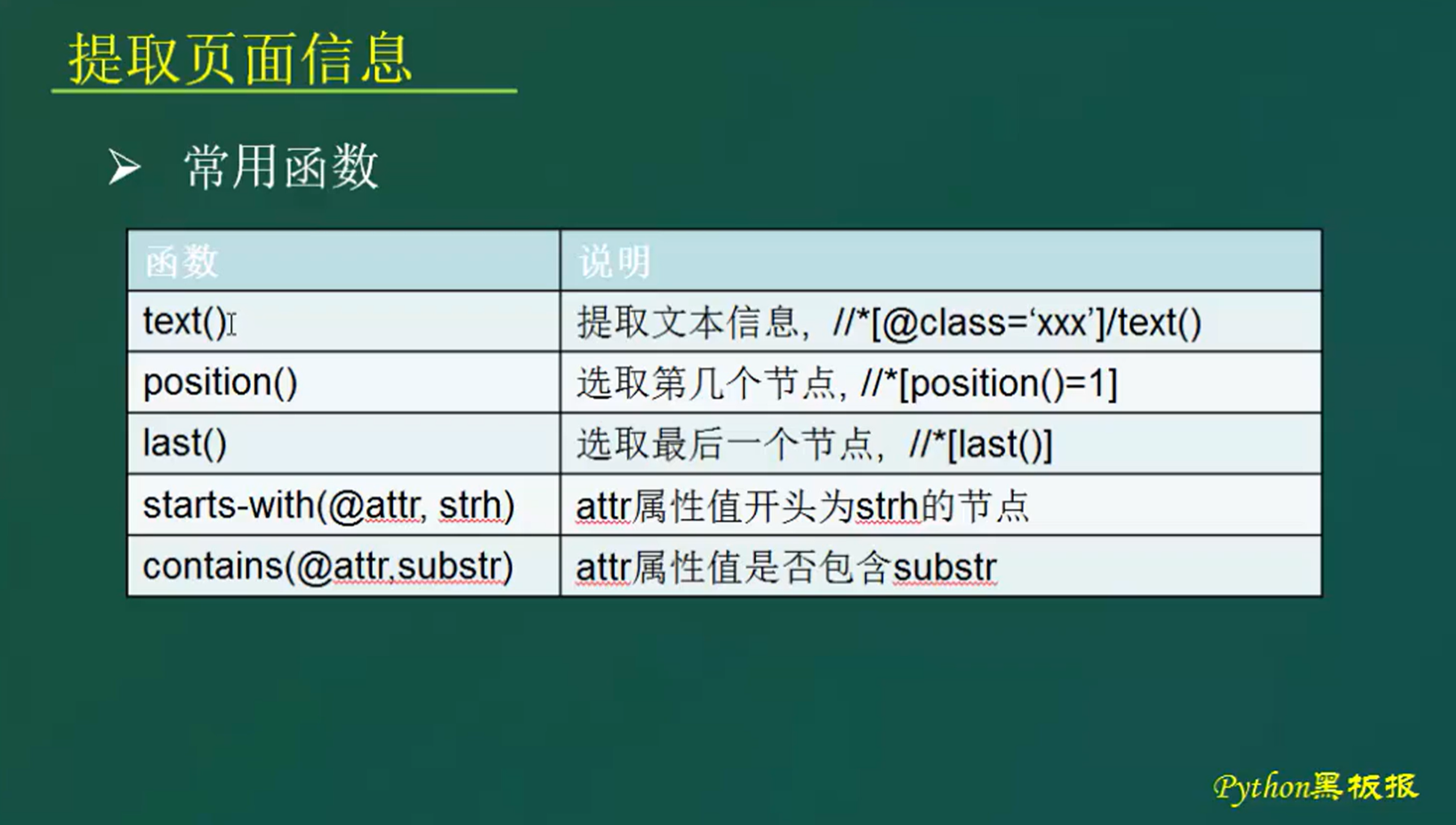
- text提取文本信息
- position() 选取第几个节点,类似于数组的下标

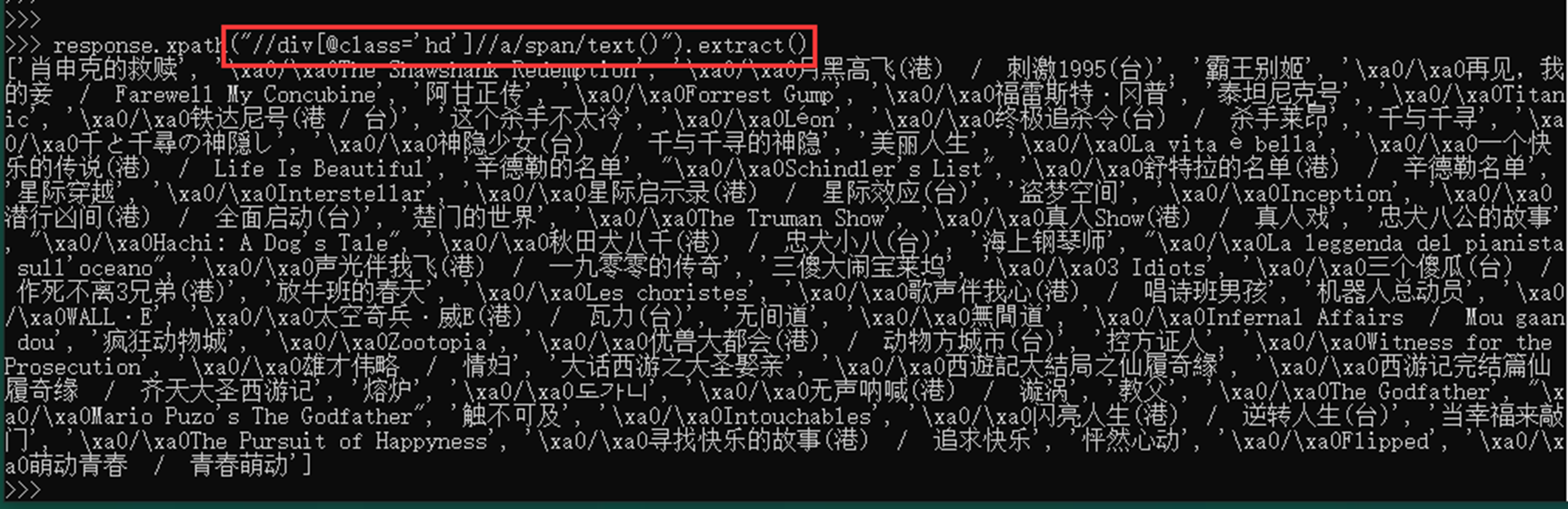
- last或者直接选取最后一个节点
由于有时候不知道该节点有多长,所以可以直接使用last选择最后一个节点
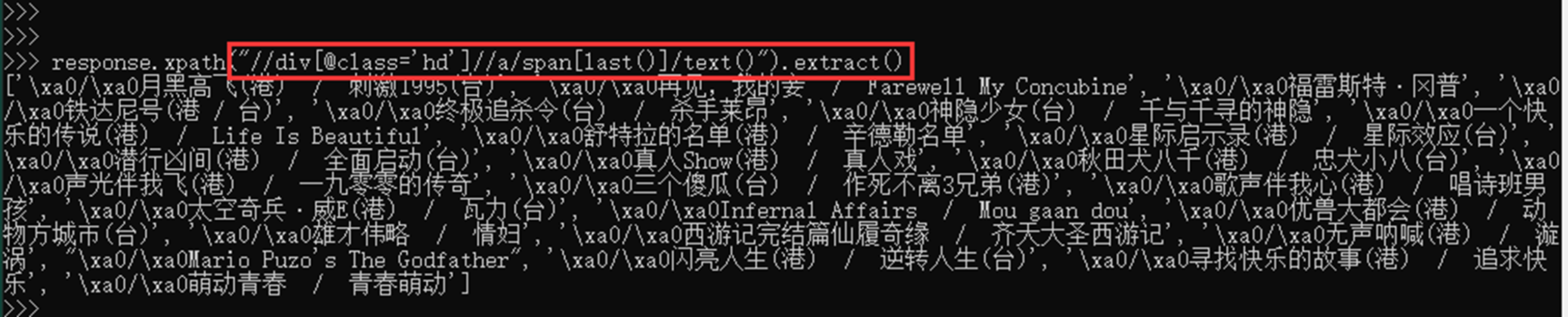
- starts-with 匹配属性开头为xx的节点
如匹配 所有div下a标签下的span,class属性为title开头的节点,并且取出最后一个节点的值,注意,这里外层使用单引号

- | 或
取出如果所有div或者li标签

- 比较运算符 + 逻辑运算符 + 算数运算符
把大于9.4评分的电影全部找出来,至于为什么要使用and,占时还不清楚

或者把找到的结果+0.1然后还大于9.4找出来。

- 提取页面的下一页标签

1.5.2 CSS
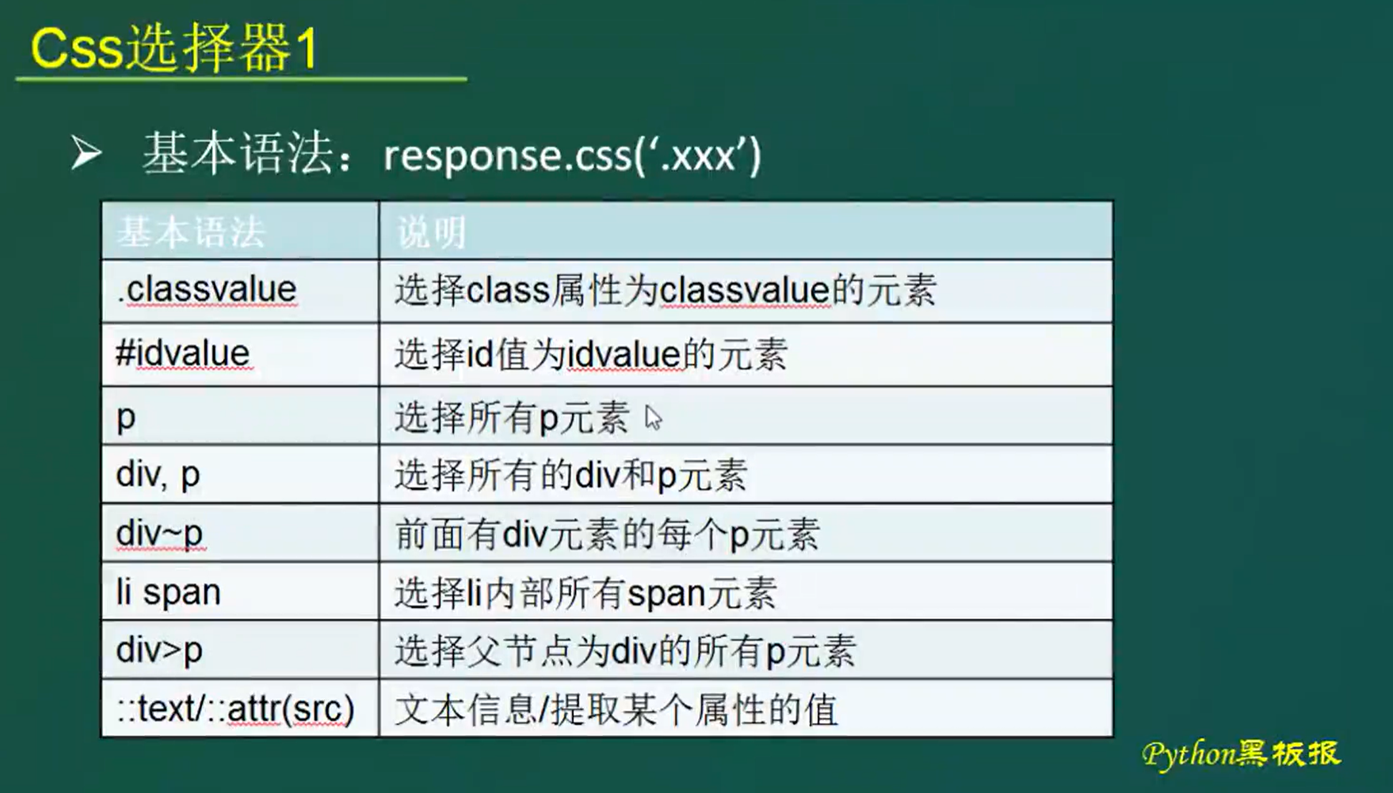
- .classvalue
选取类属性为title的元素
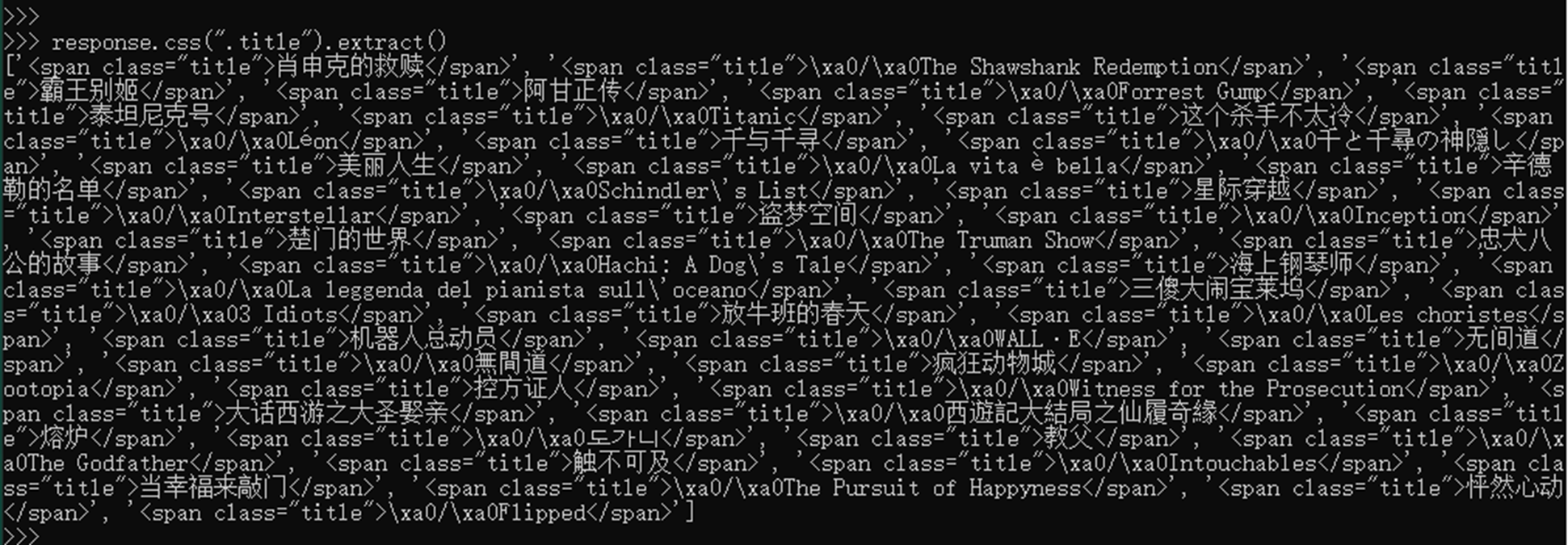
- div~p 选取前面有div元素的每个p元素
例如:选取 前面有a元素的每个span元素
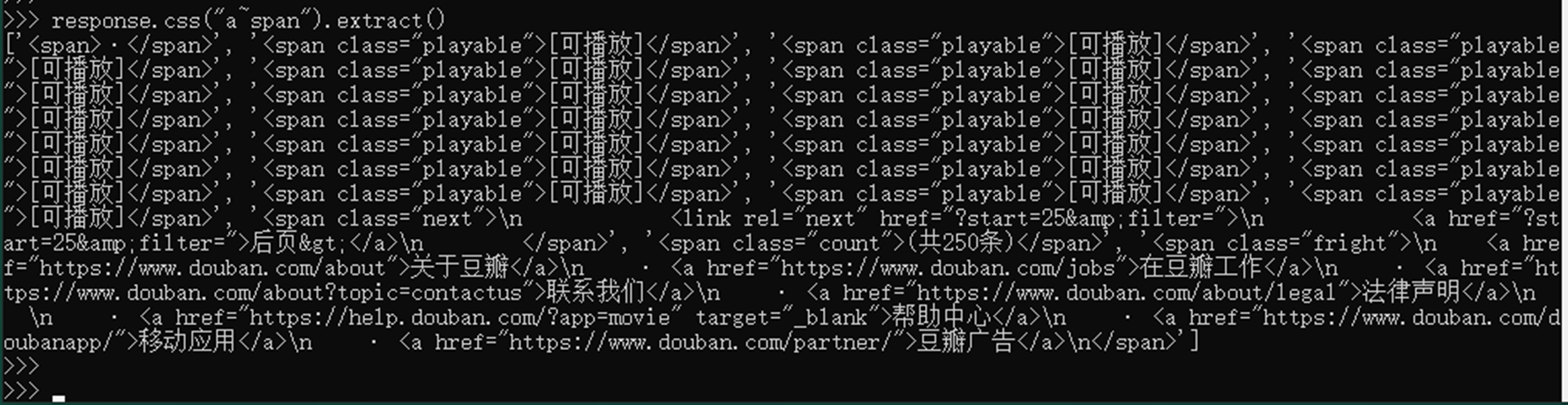
- li span选取li内部所有span元素(不管子节点还是孙节点)
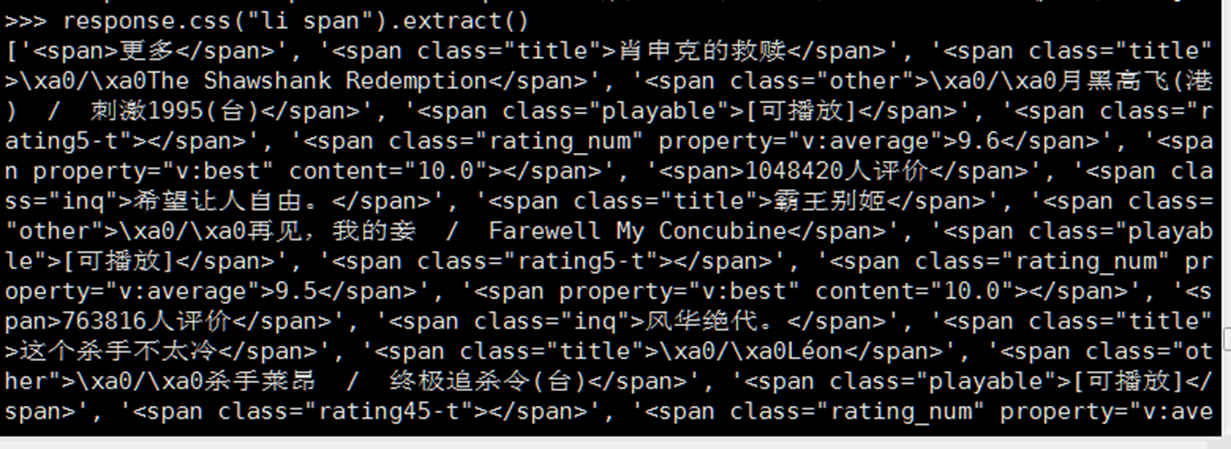
- div>p 选择父节点为div的所有p元素 以及提取值
例如:找出a标签下所有span并且取出值
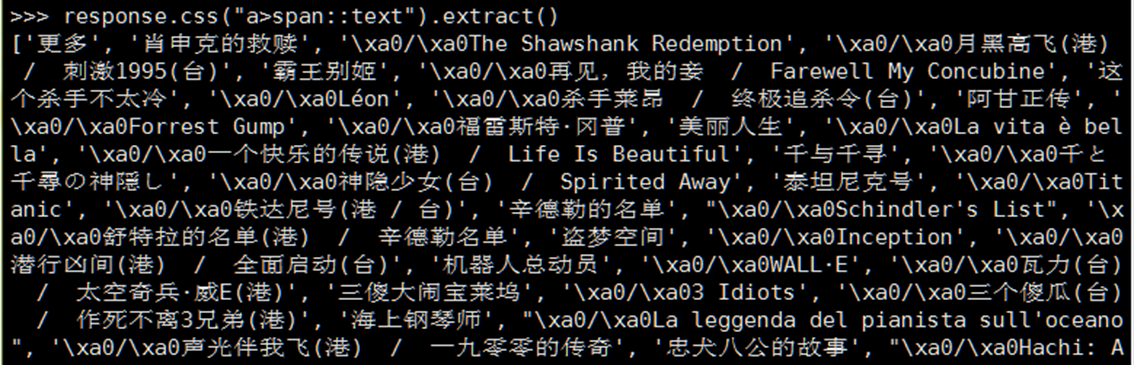
在或者找到li 标签下的a标签并且提取href的值
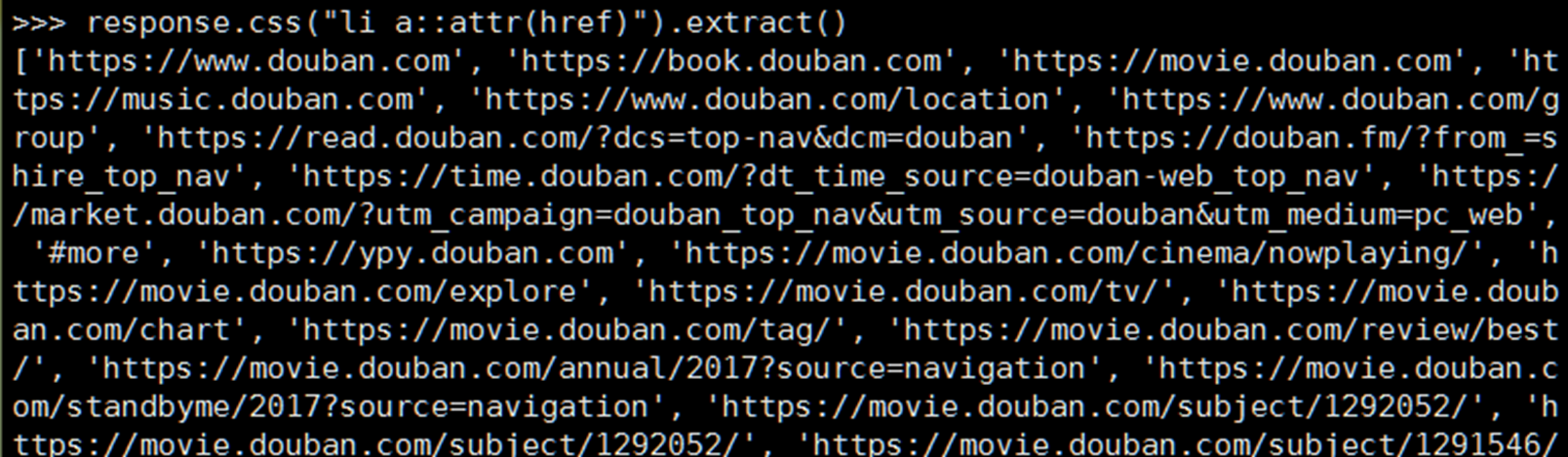

- [attr=val] 选取attr为val的所有元素
例如选取class为rating_num的元素

- [attr^=val] 属性值以xx开头的的元素 [attr$=val]属性以xx结尾的元素
例如找到src属性结尾为jpg的速度,并且提取出来src的值
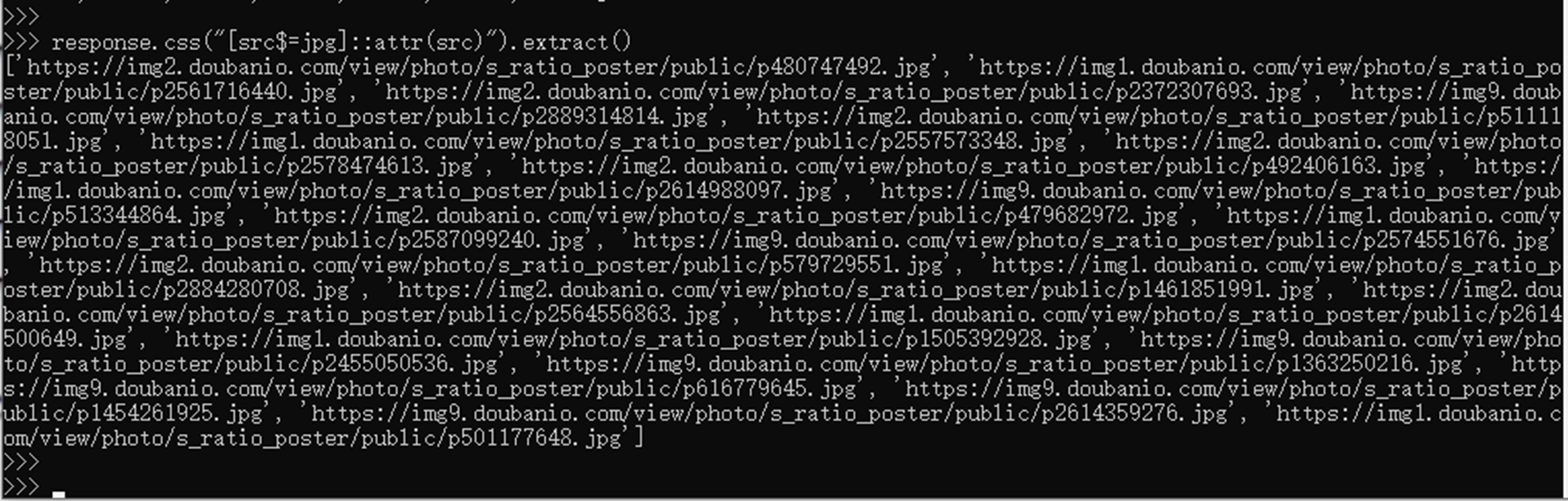
- [attr*=val] 属性包含xx的元素
例如提取src属性包含doubanio的元素并提取值


- first-of-type 选取子元素为xx的第一个元素
例如找到class=hd 下的为a的元素 a为子节点,其实在前面章节 > 已经做到了

First-child 第一个元素为xx的元素,因为要求hd下面第一个为span的,所以没有找到

1.6 提取页面信息

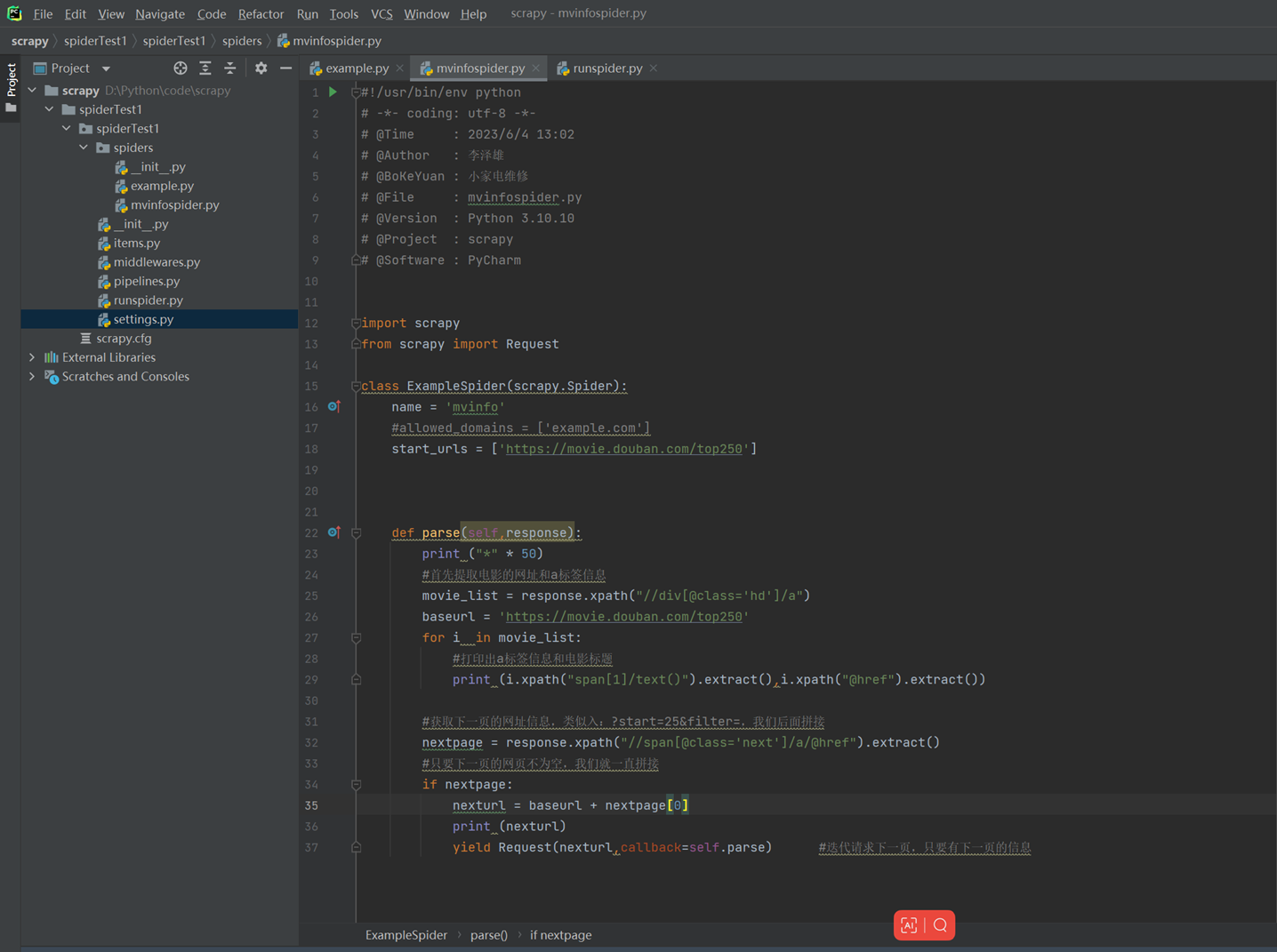
查看获取下一页电影信息的结果
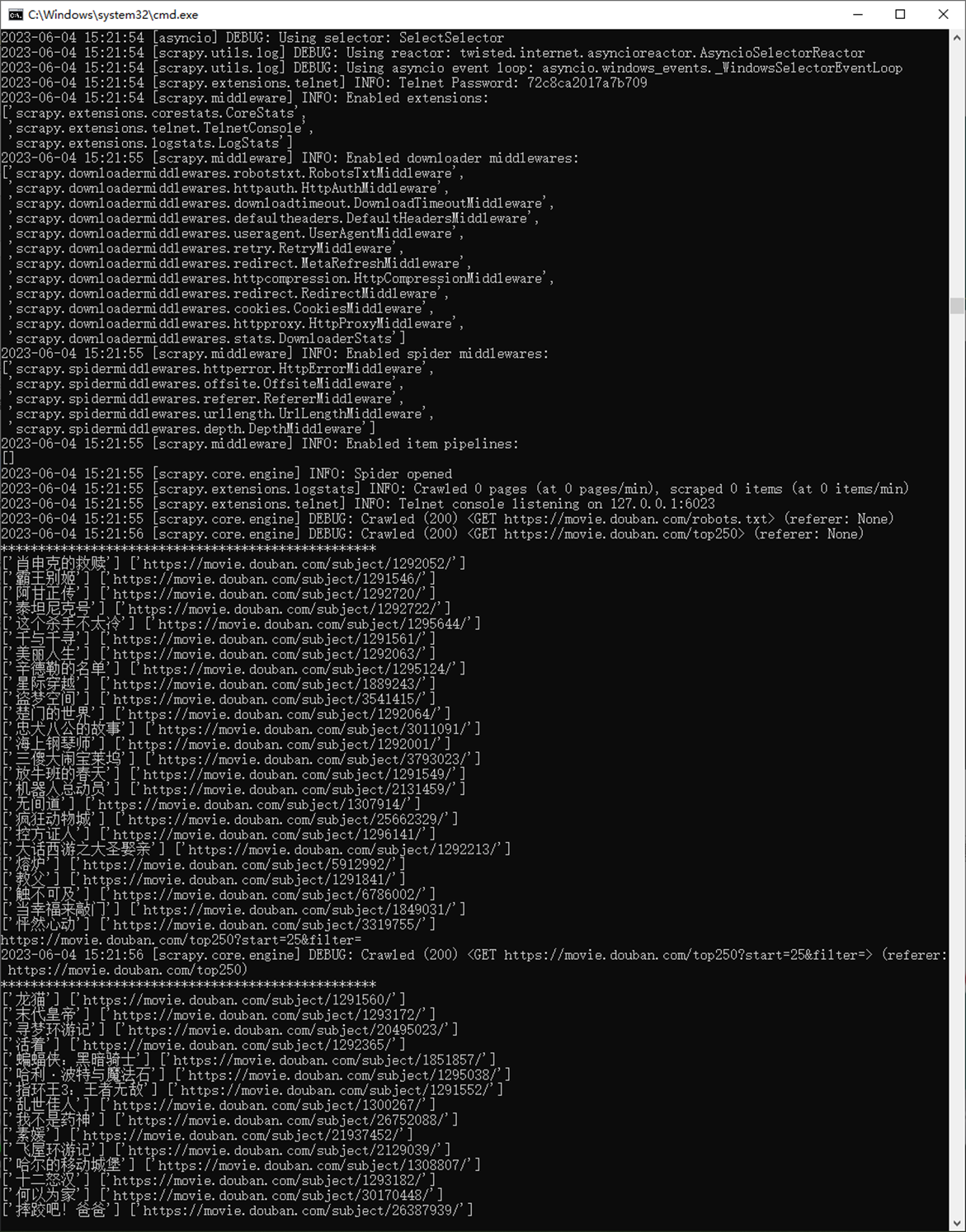
1.7 Scrapy运行及分析
文章开头其实解释过,但是这里还是用另一篇博客的方式讲解一下。
何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总共有四大部分,请求、响应、解析、存储,scrapy框架都已经搭建好了。scrapy是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架,scrapy使用了一种非阻塞(又名异步)的代码实现并发的,Scrapy之所以能实现异步,得益于twisted框架。twisted有事件队列,哪一个事件有活动,就会执行!Scrapy它集成高性能异步下载,队列,分布式,解析,持久化等。
1.五大核心组件
引擎(Scrapy)
框架核心,用来处理整个系统的数据流的流动, 触发事务(判断是何种数据流,然后再调用相应的方法)。也就是负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等,所以被称为框架的核心。
调度器(Scheduler)
用来接受引擎发过来的请求,并按照一定的方式进行整理排列,放到队列中,当引擎需要时,交还给引擎。可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
下载器(Downloader)
负责下载引擎发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。Scrapy下载器是建立在twisted这个高效的异步模型上的。
爬虫(Spiders)
用户根据自己的需求,编写程序,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。跟进的URL提交给引擎,再次进入Scheduler(调度器)。
项目管道(Pipeline)
负责处理爬虫提取出来的item,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
2.工作流程
Scrapy中的数据流由引擎控制,其过程如下:
(1)用户编写爬虫主程序将需要下载的页面请求requests递交给引擎,引擎将请求转发给调度器;
(2)调度实现了优先级、去重等策略,调度从队列中取出一个请求,交给引擎转发给下载器(引擎和下载器中间有中间件,作用是对请求加工如:对requests添加代理、ua、cookie,response进行过滤等);
(3)下载器下载页面,将生成的响应通过下载器中间件发送到引擎;
(4) 爬虫主程序进行解析,这个时候解析函数将产生两类数据,一种是items、一种是链接(URL),其中requests按上面步骤交给调度器;items交给数据管道(数据管道实现数据的最终处理);
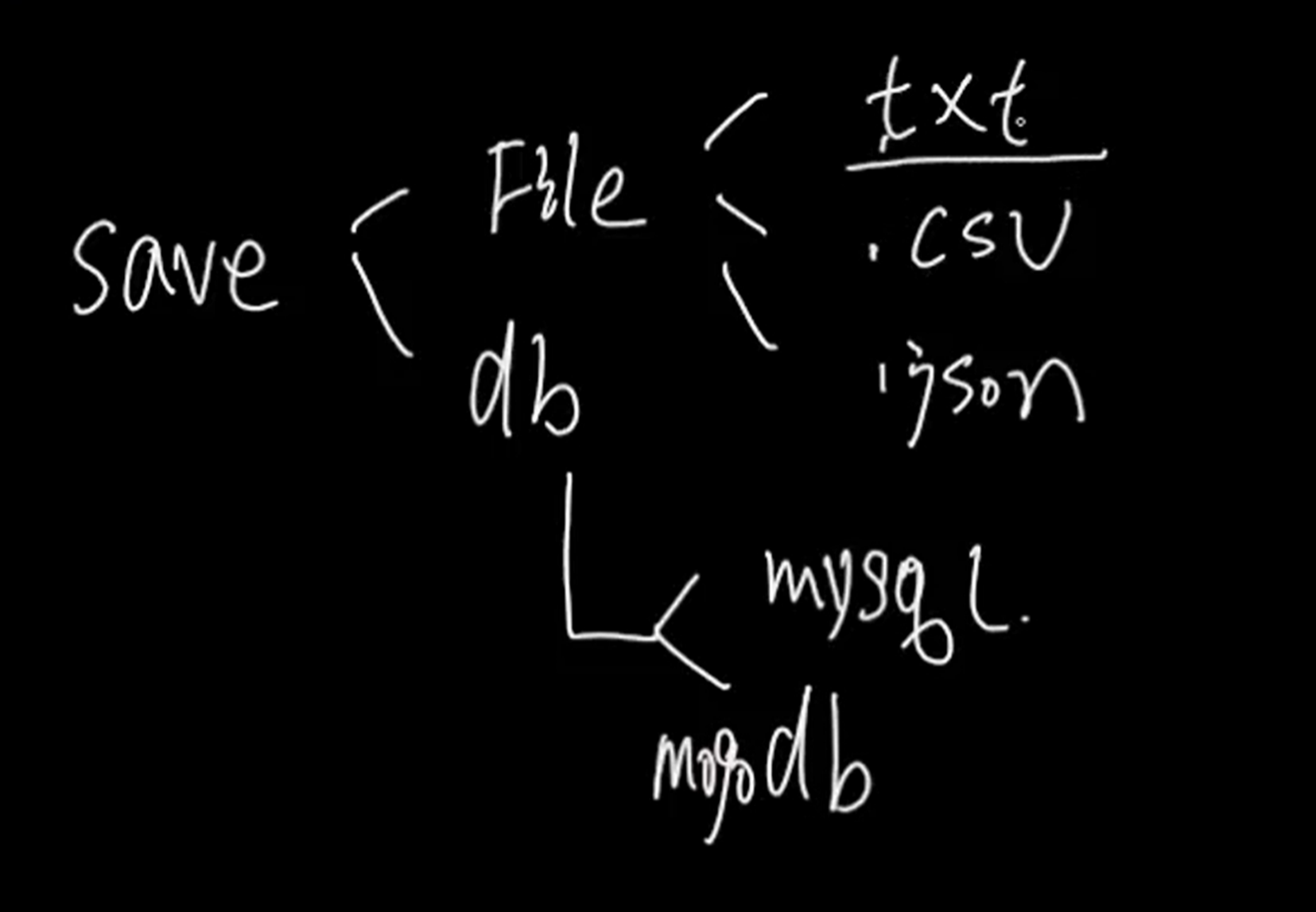
1.8 scrapy 提取信息存储方式及问题分析

保存信息方式可以保存到文件中,也可以保存到数据库中
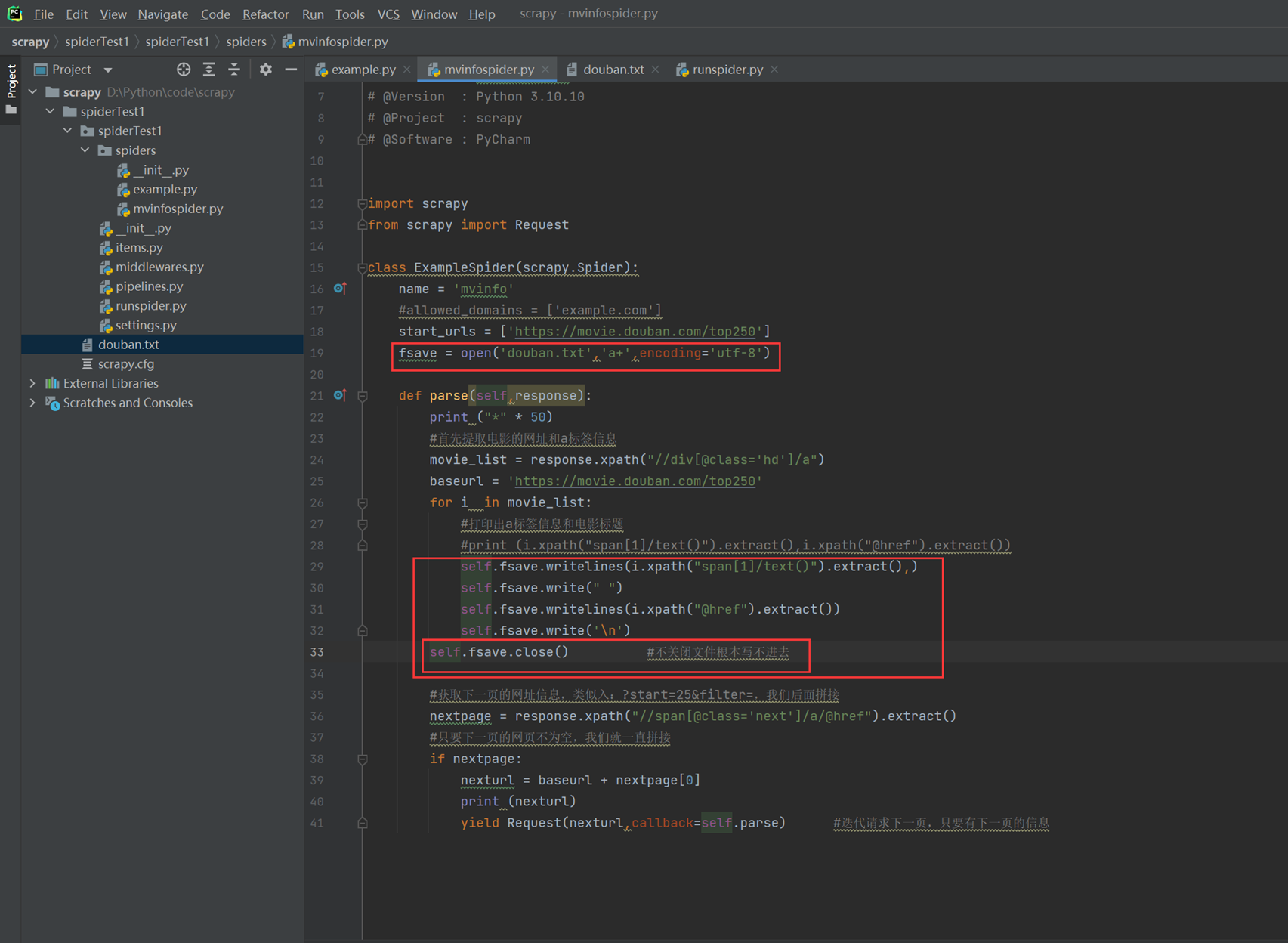
(上面的代码,文件处理是做做个简单的样子,逻辑并不严谨,比如只能保存一次循环的数据,由于是演示不合理的代码,这里就这么保持吧。)
查看结果
上面的方式采用了文件存储,那么spider模块也掺合了存储的事情,那么程序设计以及维护就不太合理和方便了,因为你spider专心做好你爬数据的事情,存储应该交给其他人做才好,不然,每次修改存储,可能会到到spider的代码,这样,代码的耦合性就太重了。
1.9 scrapy item 使用与提取信息保存




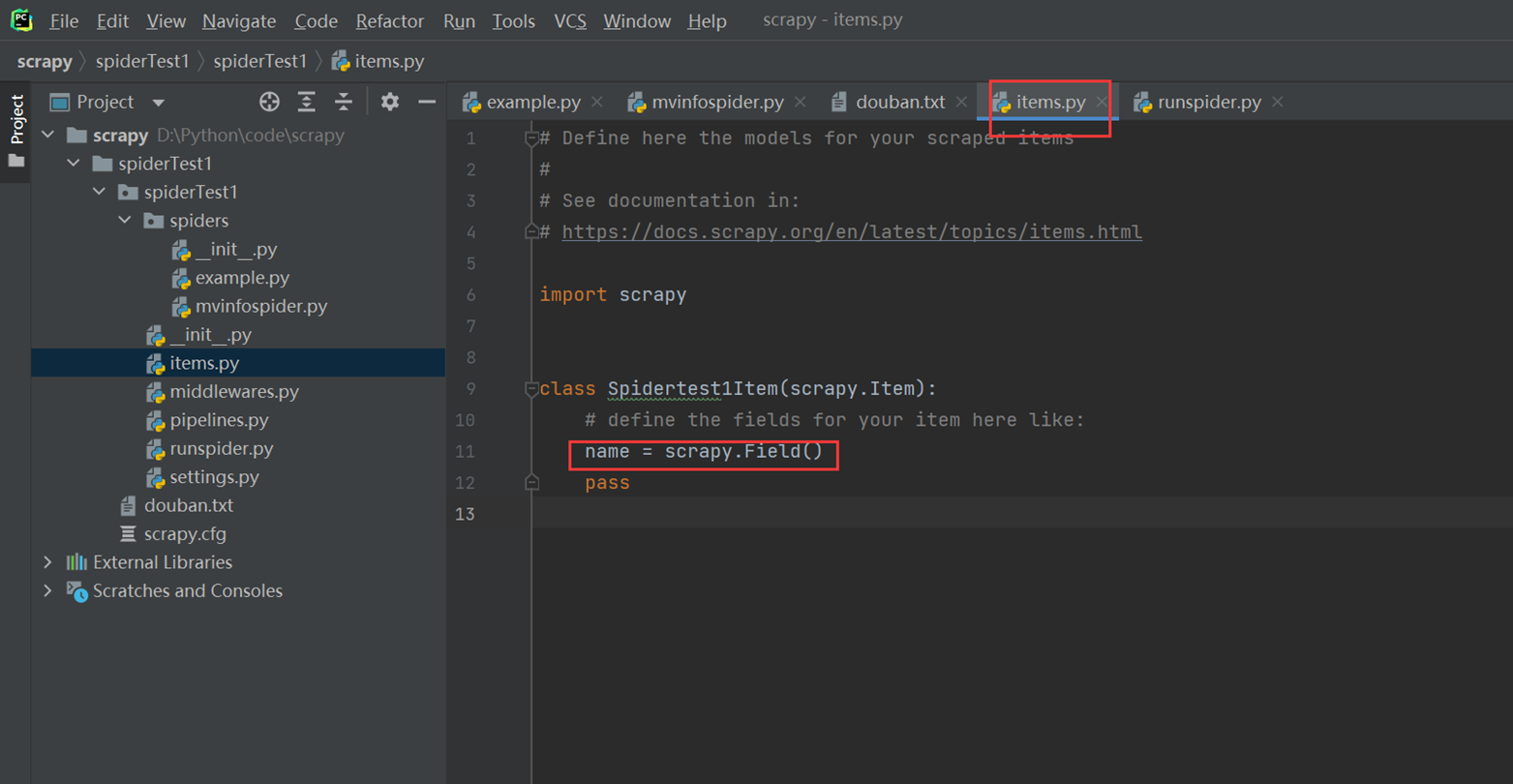
简单的使用item来定义提取的信息,这里简单演示仅使用一个name
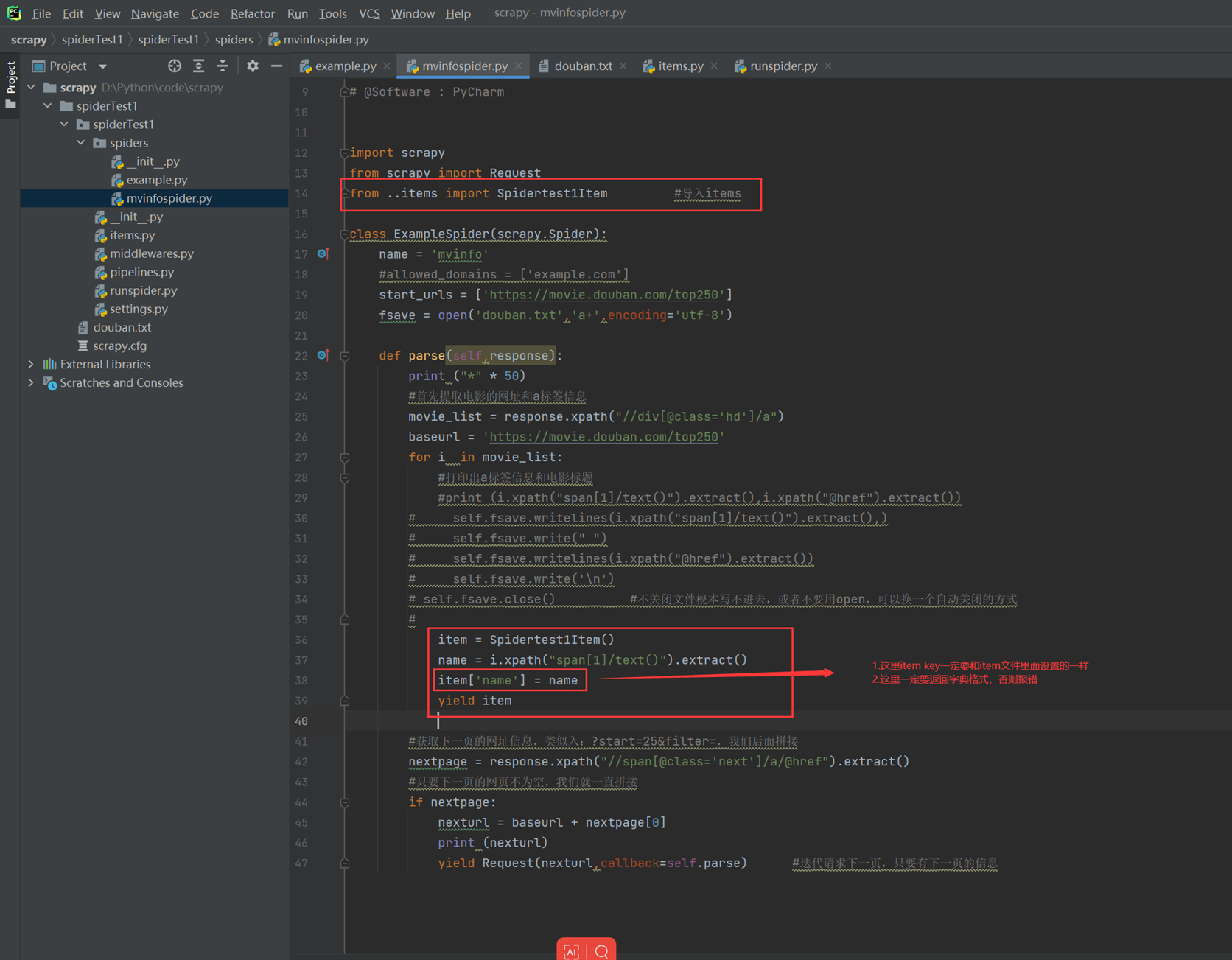
接下来可以将值保存成不同的存储类型。
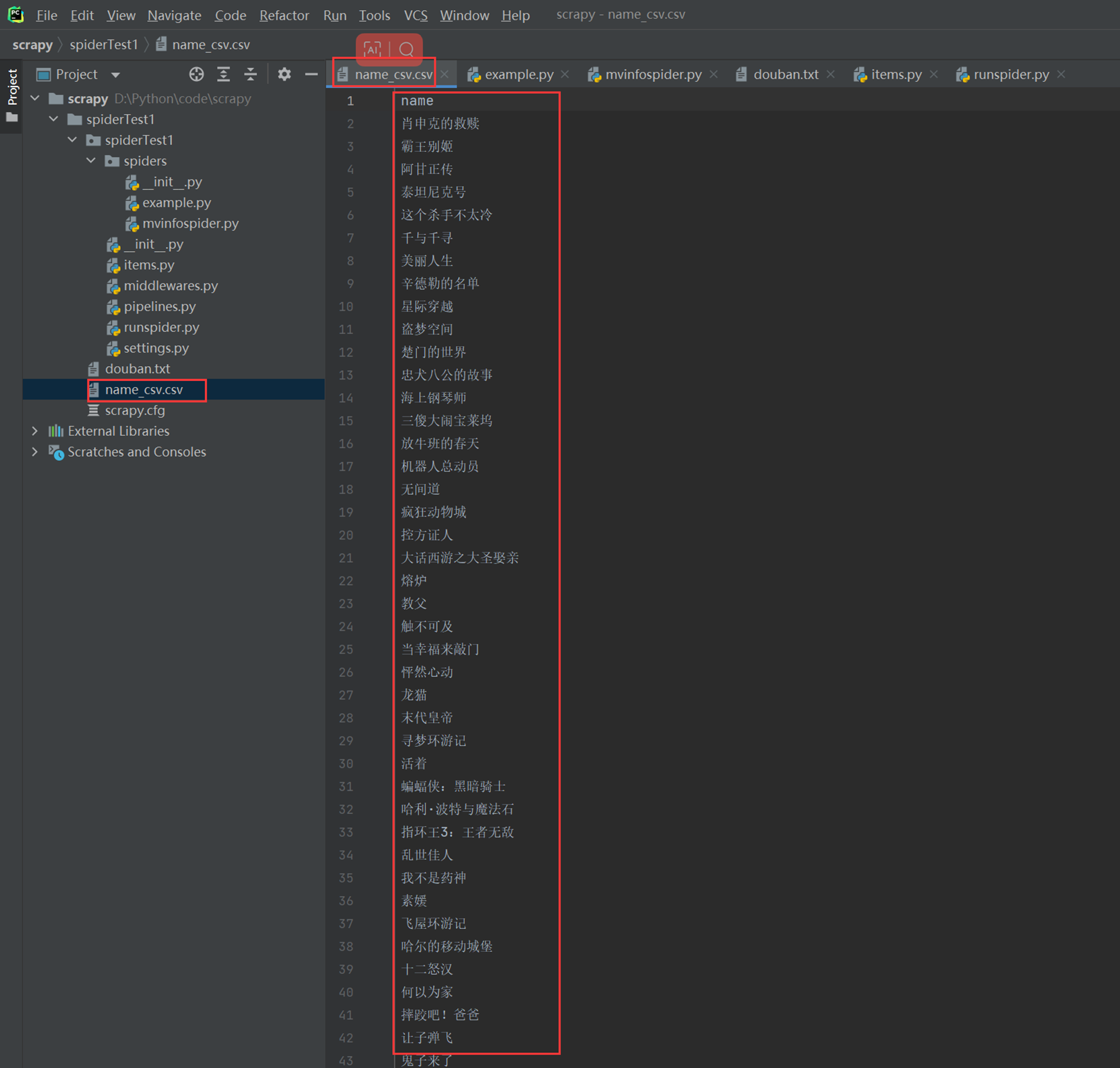
如:
csv
![]()
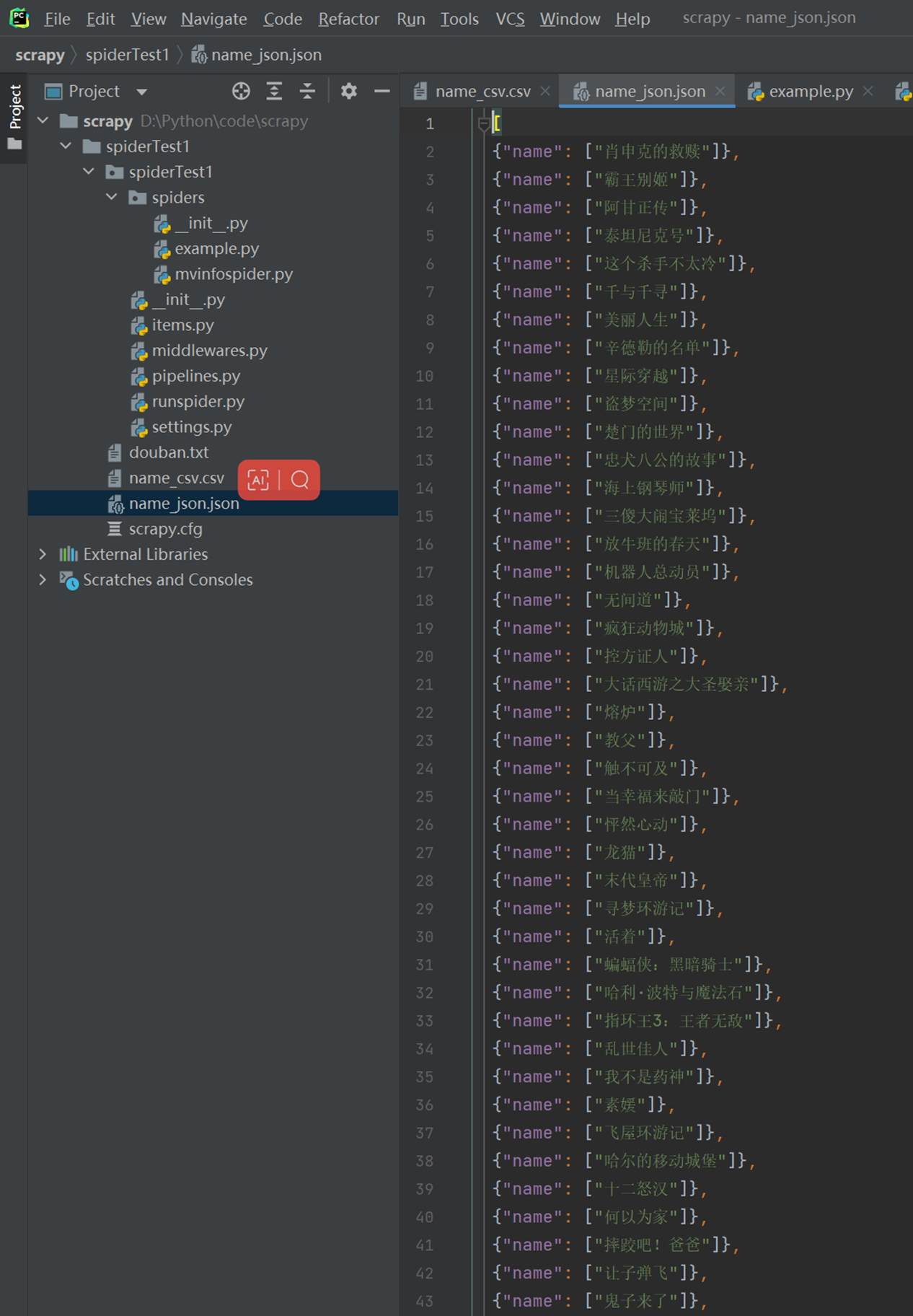
Json
![]()
在特殊场景下,json默认使用的是unicode编码,所以这里要指定格式
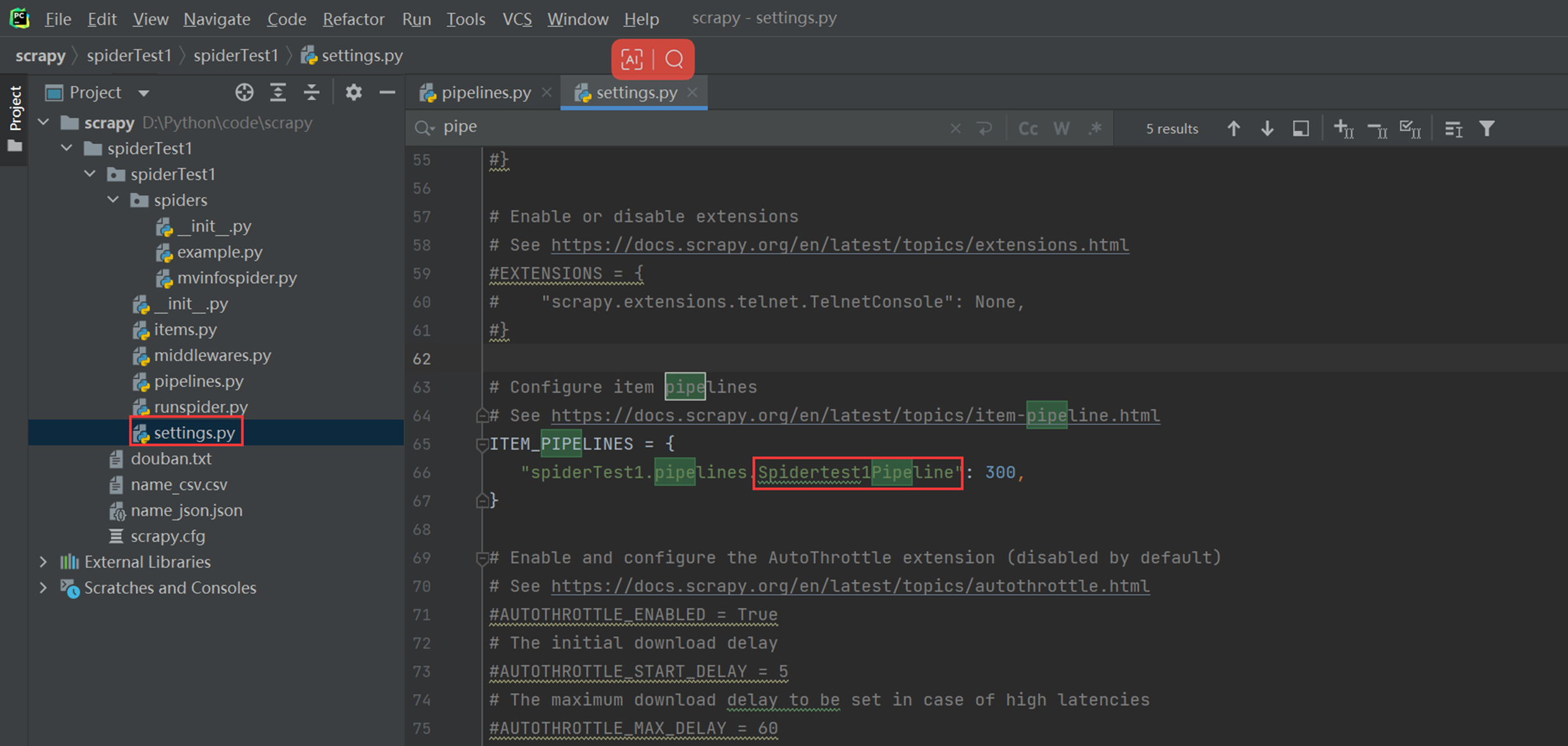
1.10 ItemPipeline详解



首先完成一个需求,如果想保存文件的时候想过滤,比如删除一些字段,那么怎么解决,这里有一个内置的方法。
首先启动ItemPipeline插件
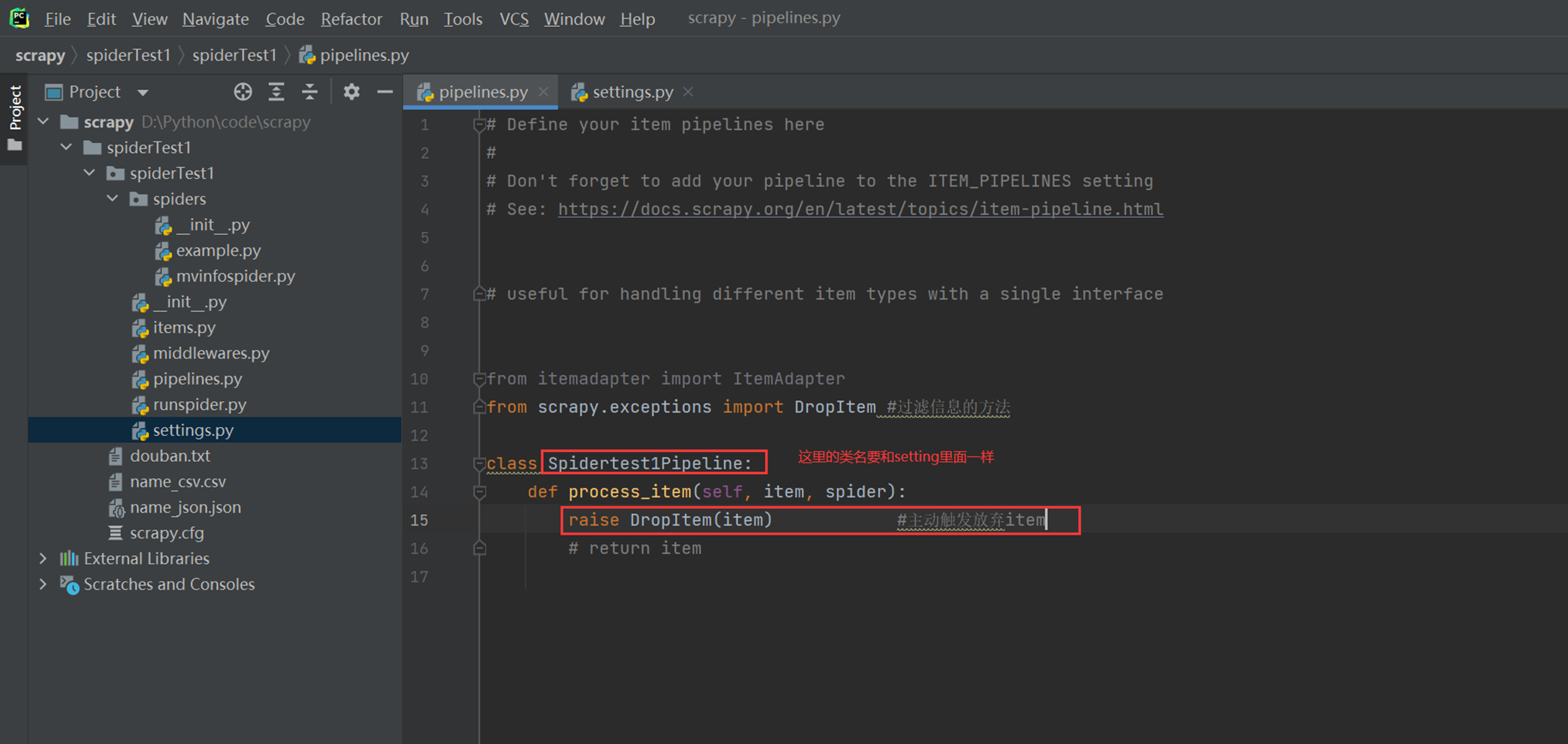
保存为csv测试
![]()
查看执行过程,已经过滤掉了
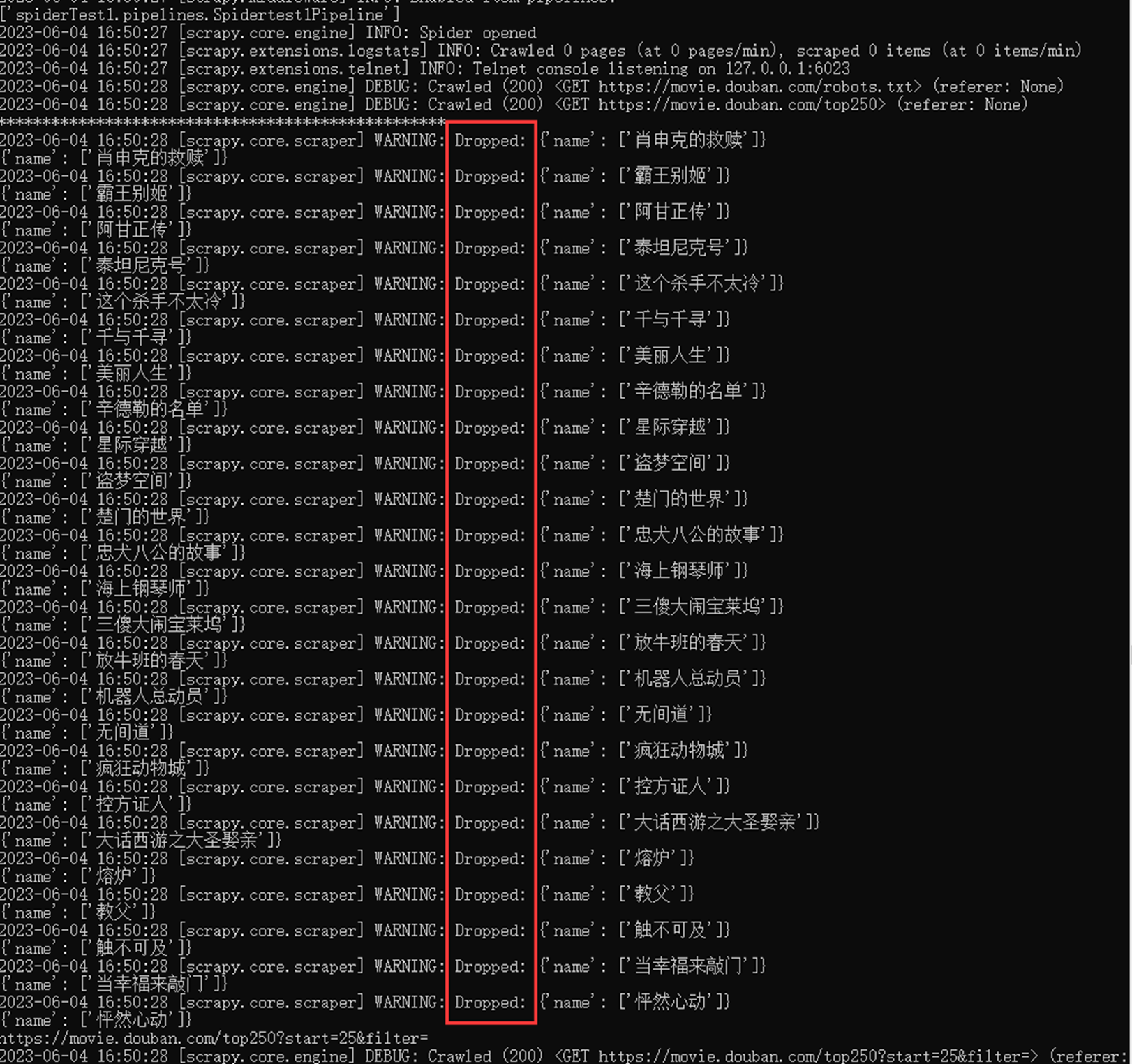
文件里面肯定也是空的
现在使用Pipeline类的方式来保存信息,如保存成为txt的方式。
Open_spider:打开文件
Close_spider:关闭文件
Process_item:中间的逻辑处理
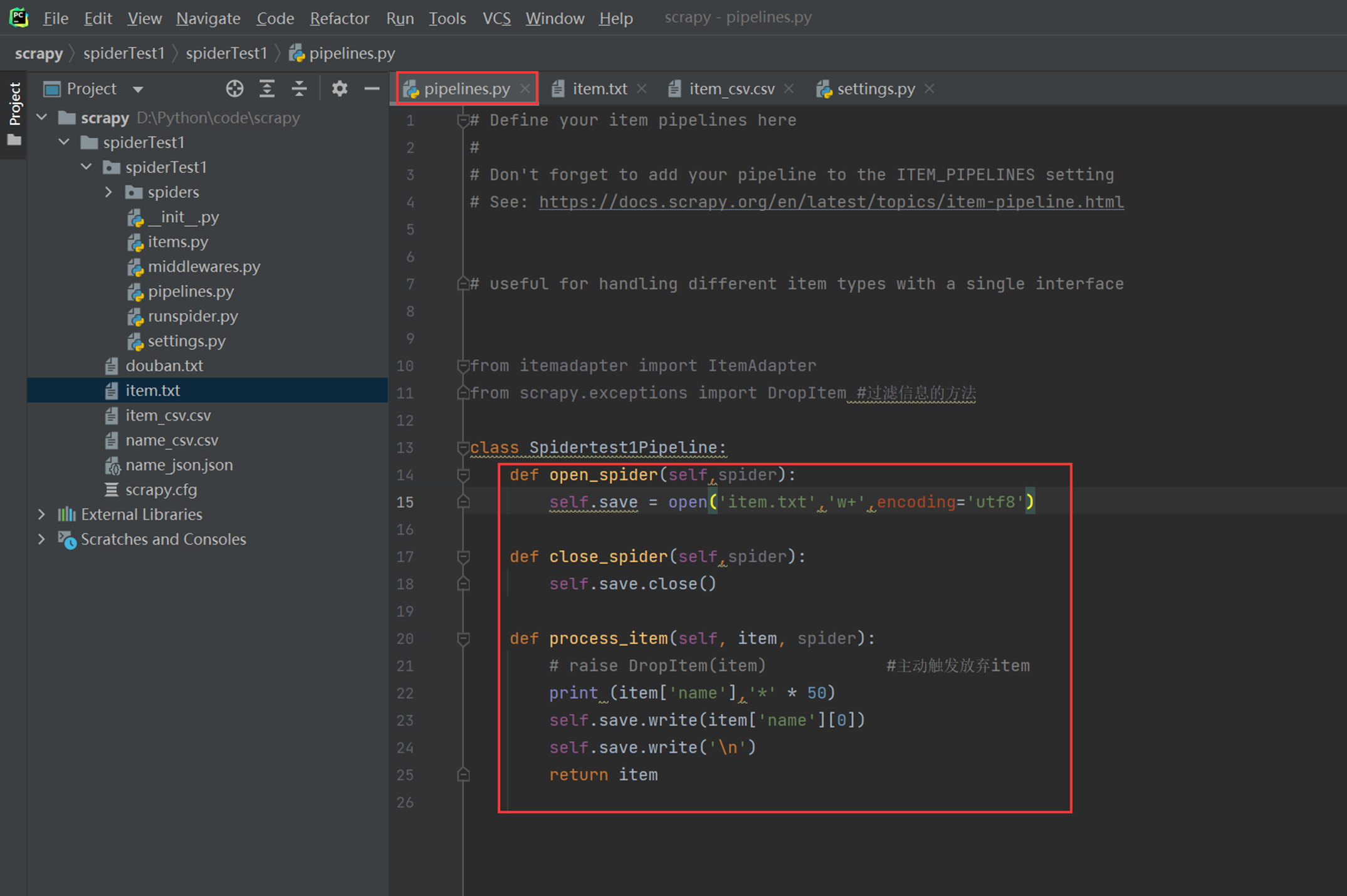
执行后查看item.txt
![]()
如果现在需要保存2个存储方式,一个csv,一个json,那么我们这里有一种办法,就是开启两个Item_pipelines项。
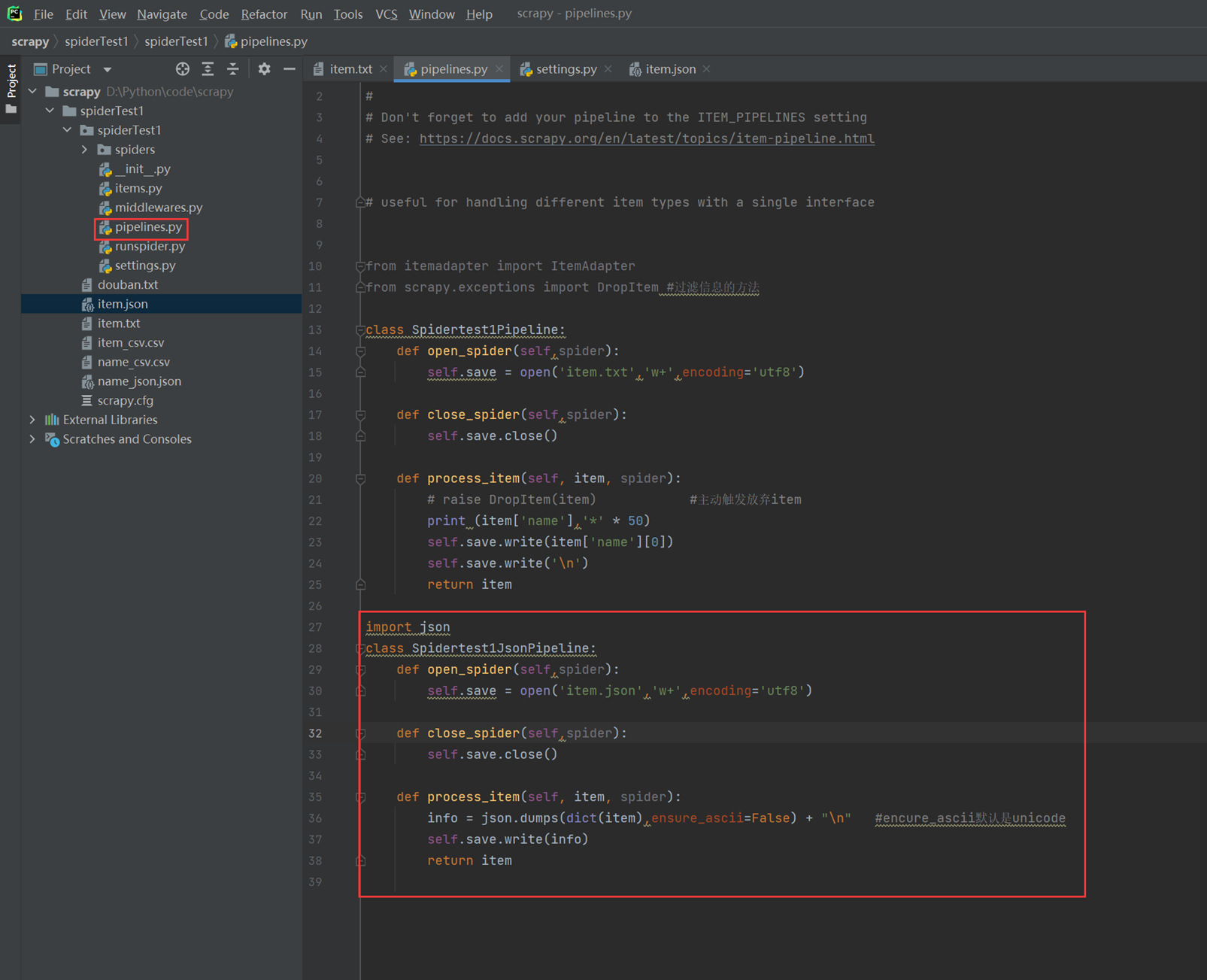
现在再将Item_pipelinse设置管道打开。
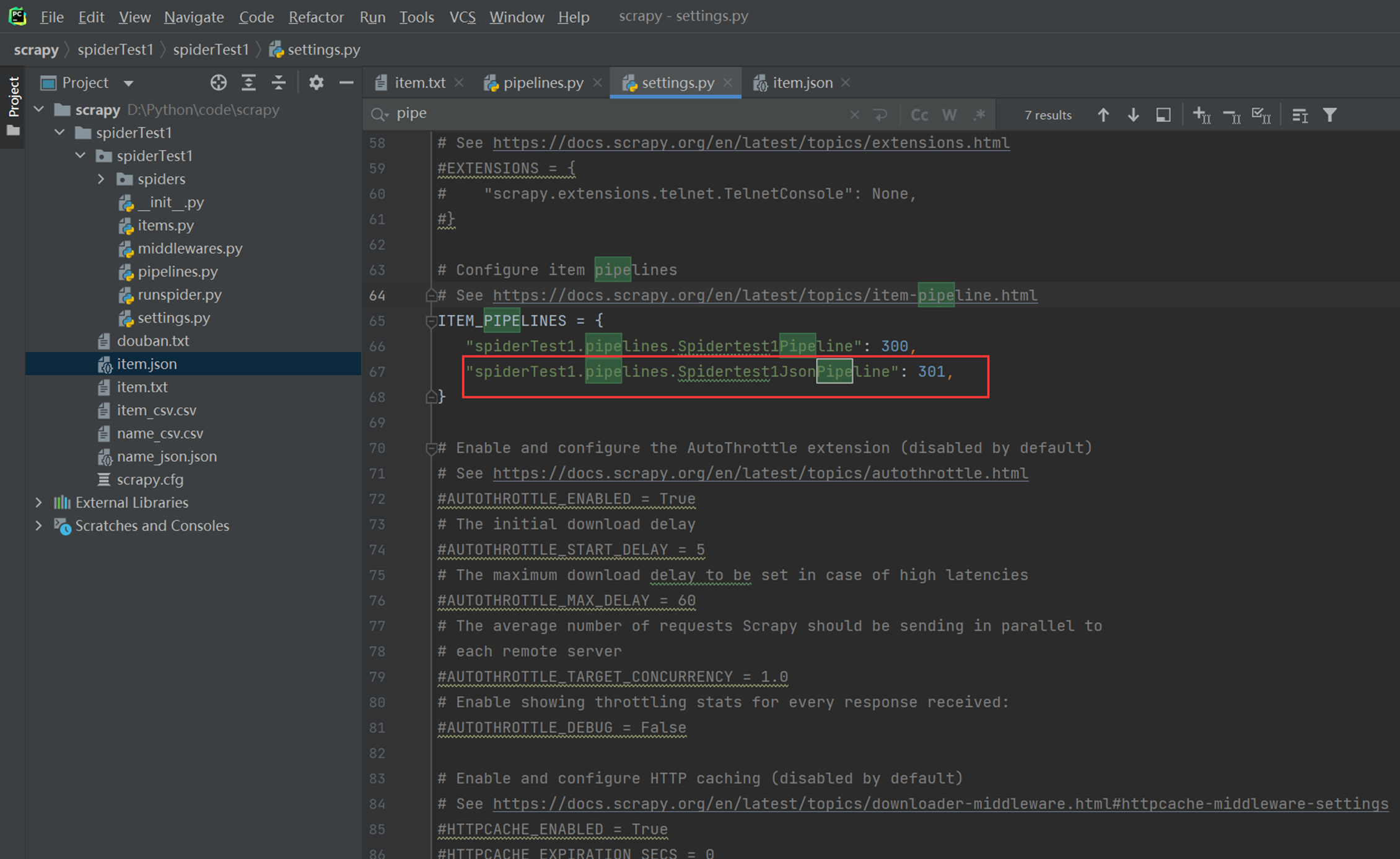
再次执行
![]()
1.11 ItemPipeline获取settings设置信息
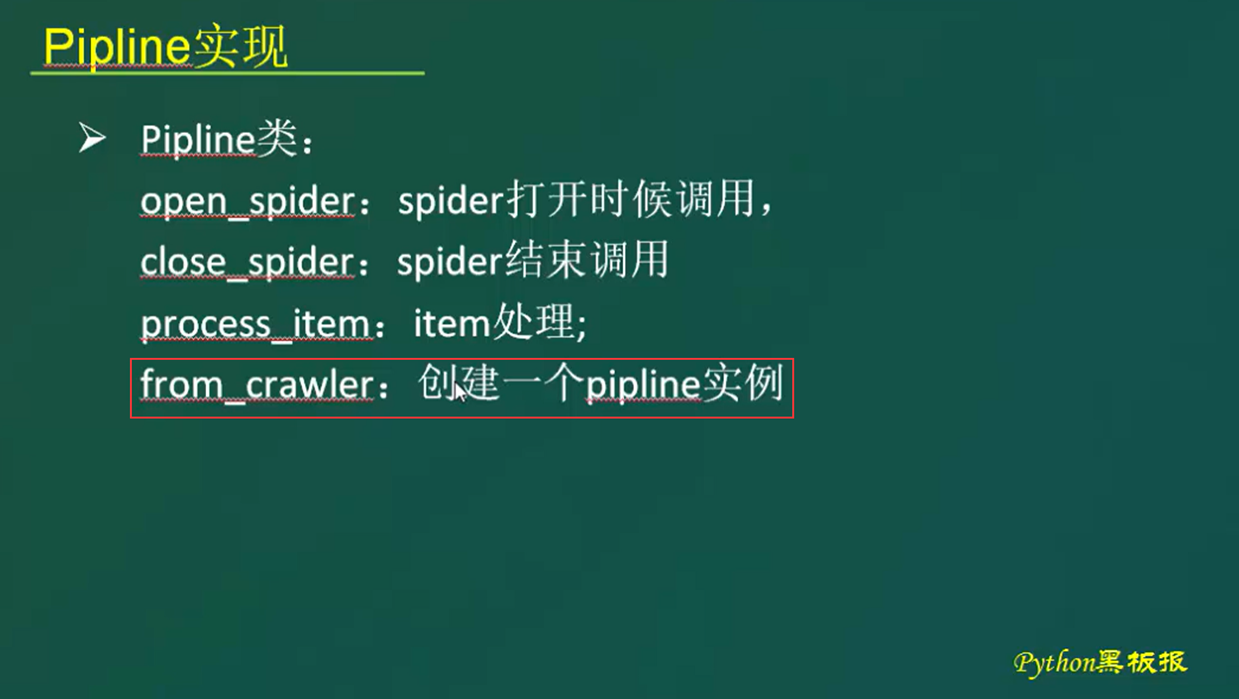
本节课主要目的就是用类方法来获取settings里面的配置信息,比如,这里的json要存储,存储在那个路径,文件名是什么,我们想放入到settings里面,而不是写在代码里面。
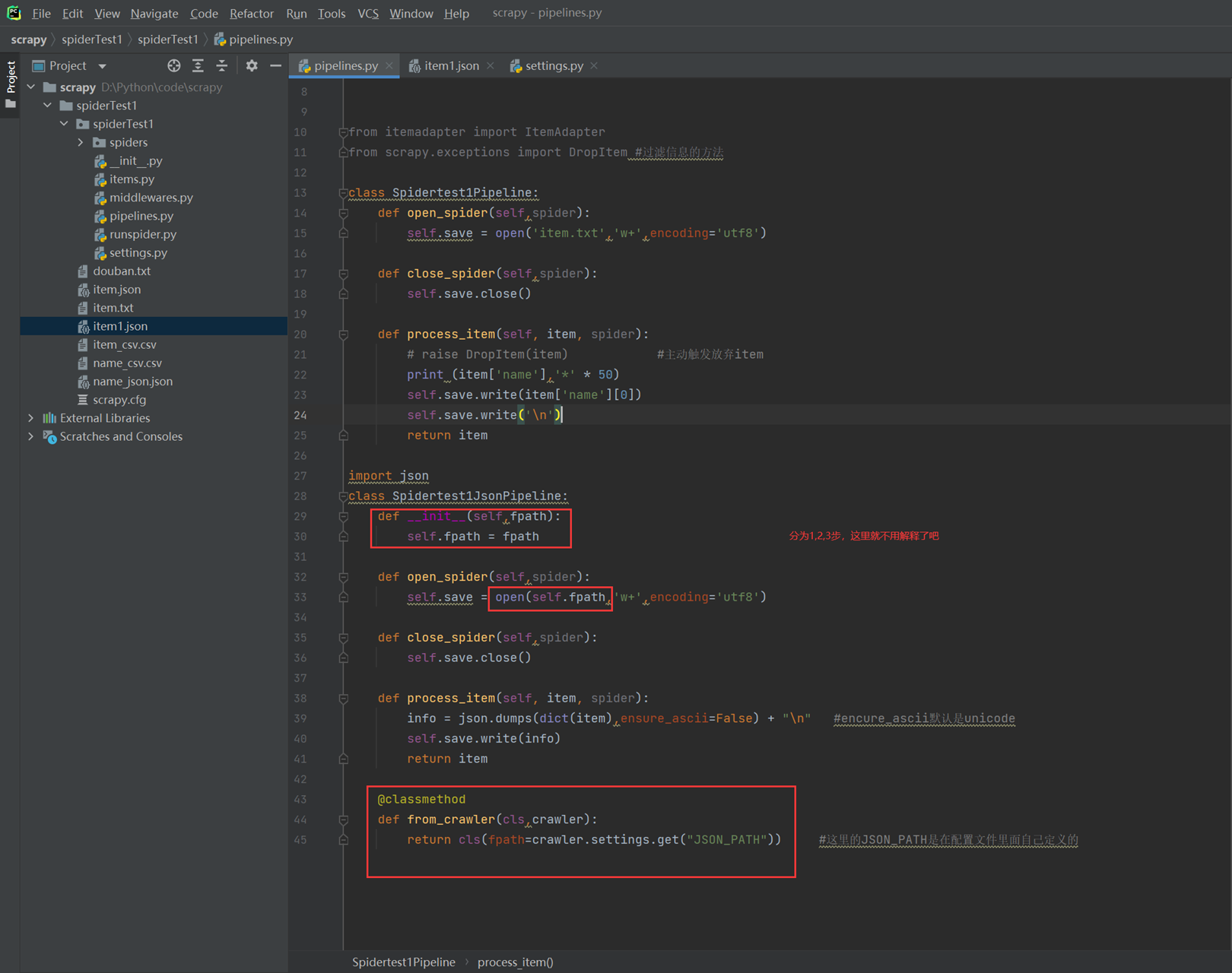
配置文件信息
至于结果就不演示了
1.12 使用pipe实现mysql存储
本章需求,把数据存储到mysql。当然需要两个前提条件。
1.会使用pymysql模块
2.数据库库以及表准备好
代码见以下:
pipelinese
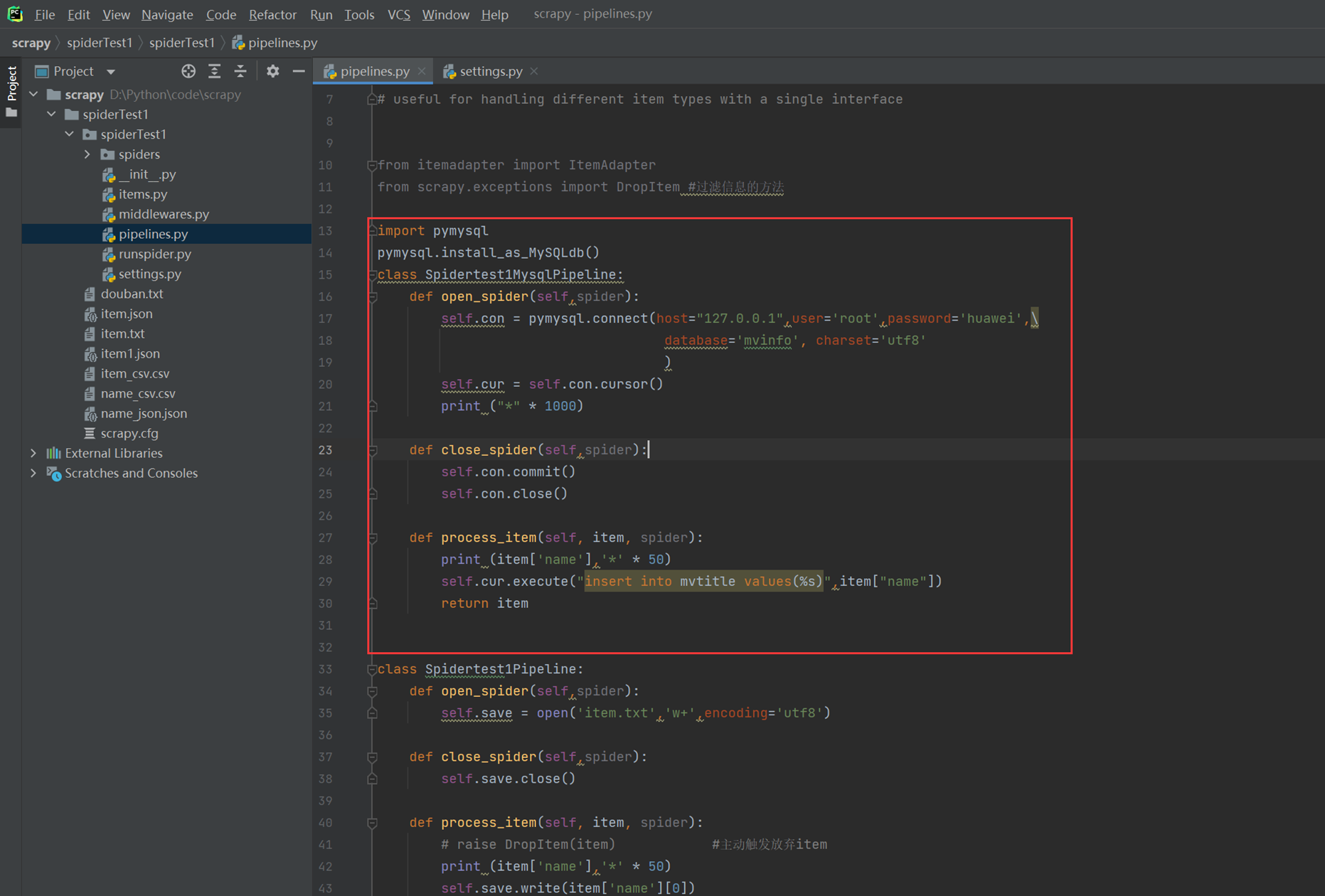
最后别忘了pipe里面设置存储方式
查看mysql的结果
2.scrapy 项目实战
2.1 scrapy项目需求分析与实现思路详解

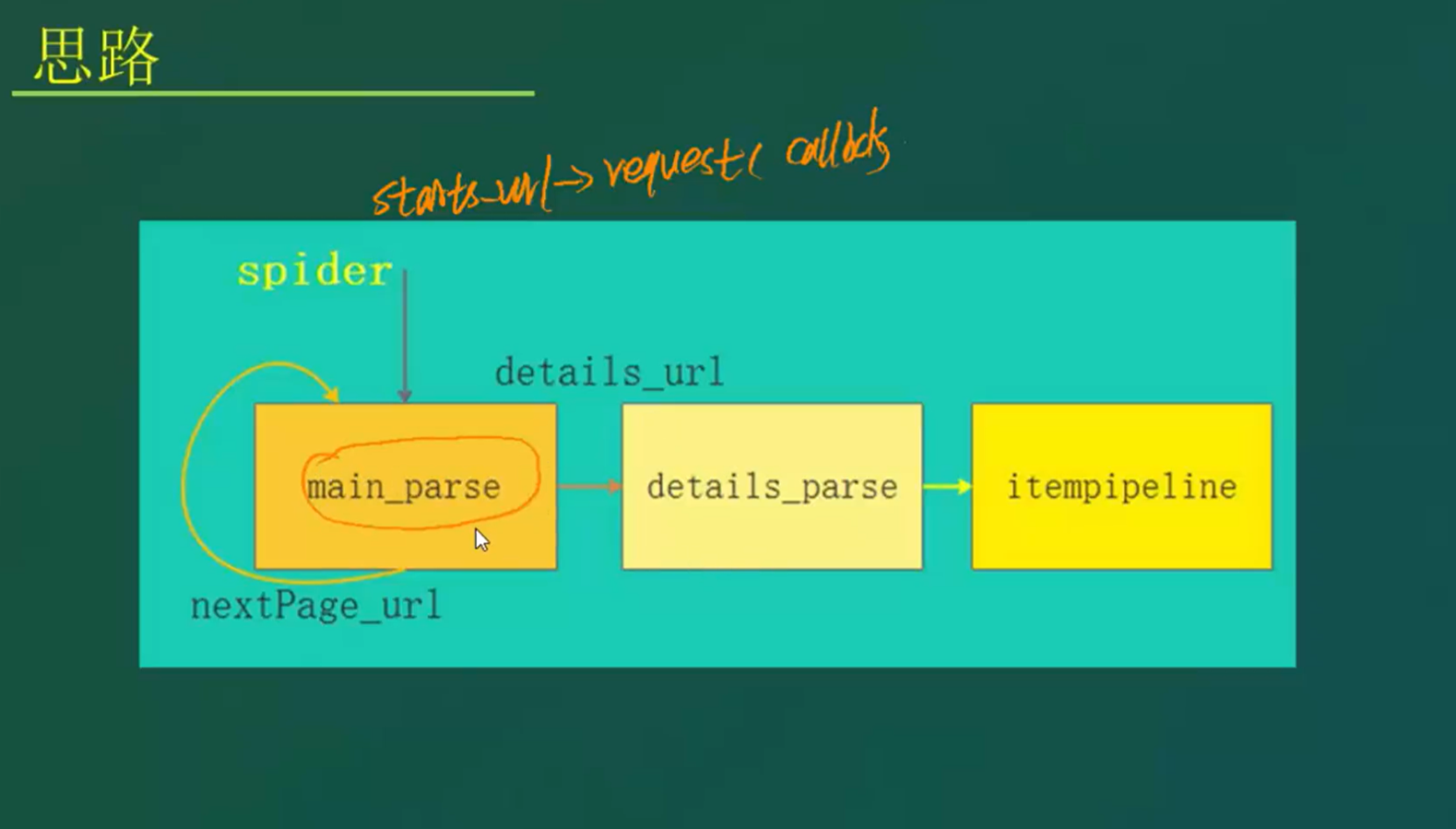
2.2 scrapy 实战一

本章目的:
1.创建scrapy 项目。
2.对setting进行设置,比如User-Agent
3.简单的编写,对详情页进行解析
创建项目
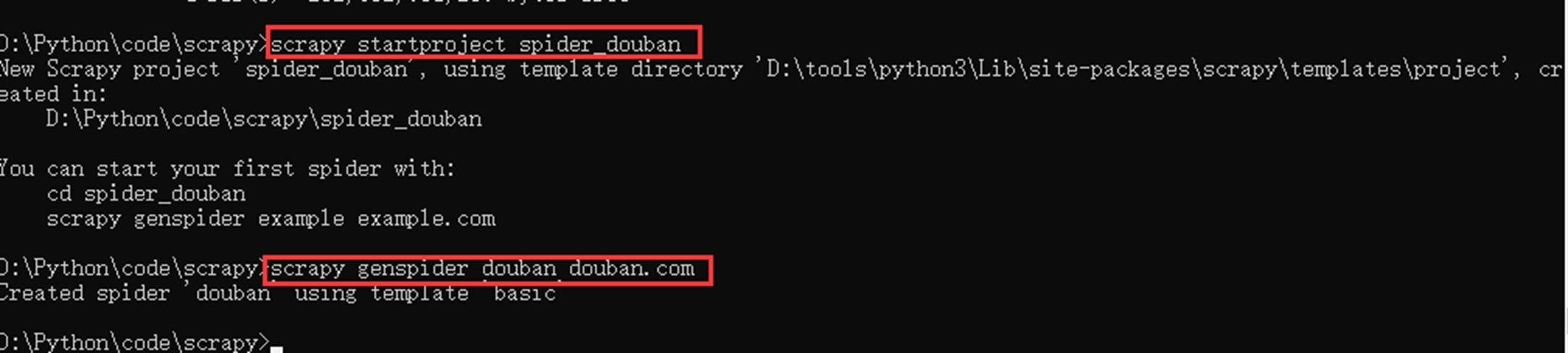
(这里有一步错误,这里就不更正了,执行第二条语句,一定要切换到项目里面)
设置Uset-Agent
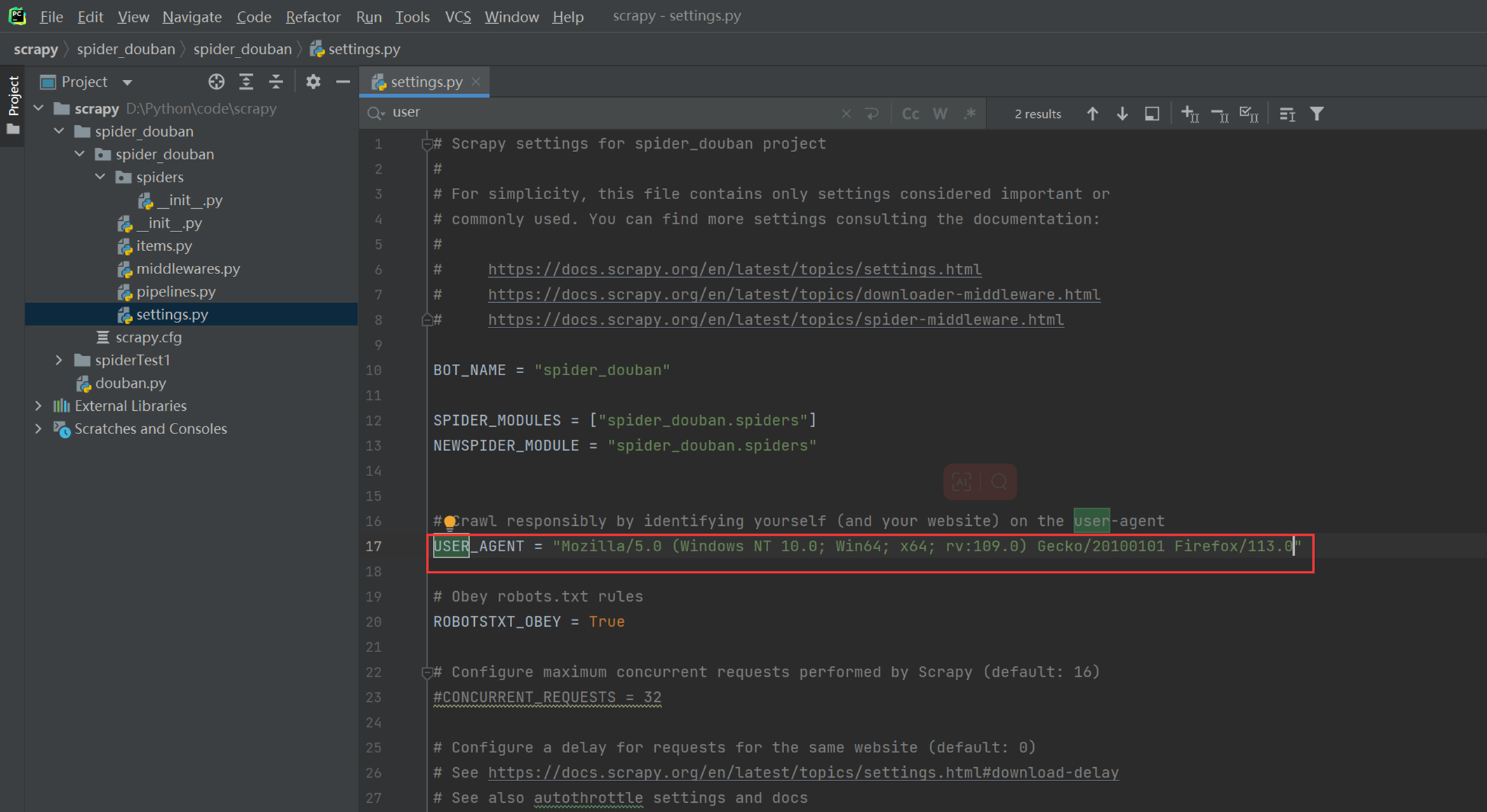
简单编写,提取详细页信息
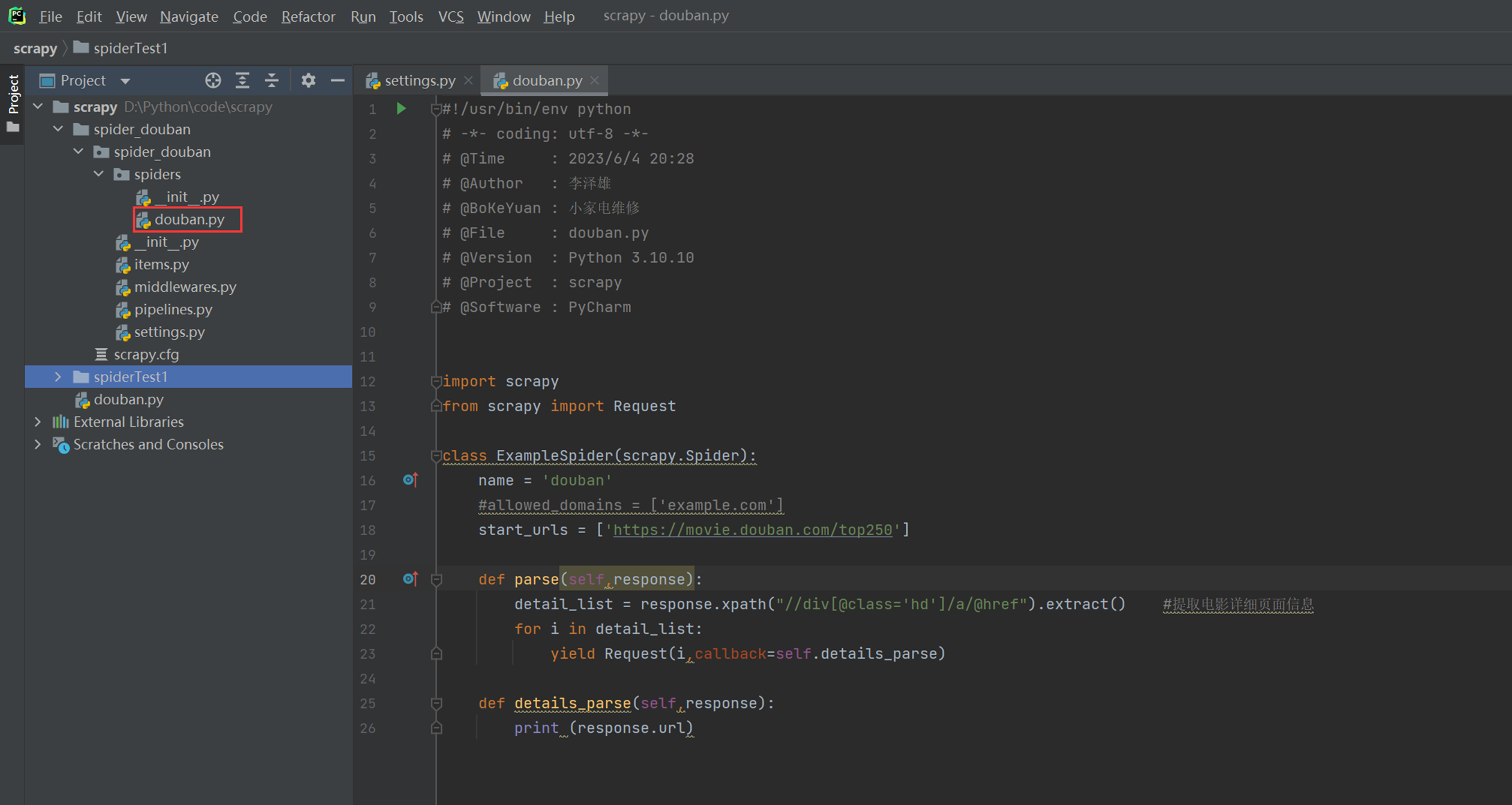
运行测试
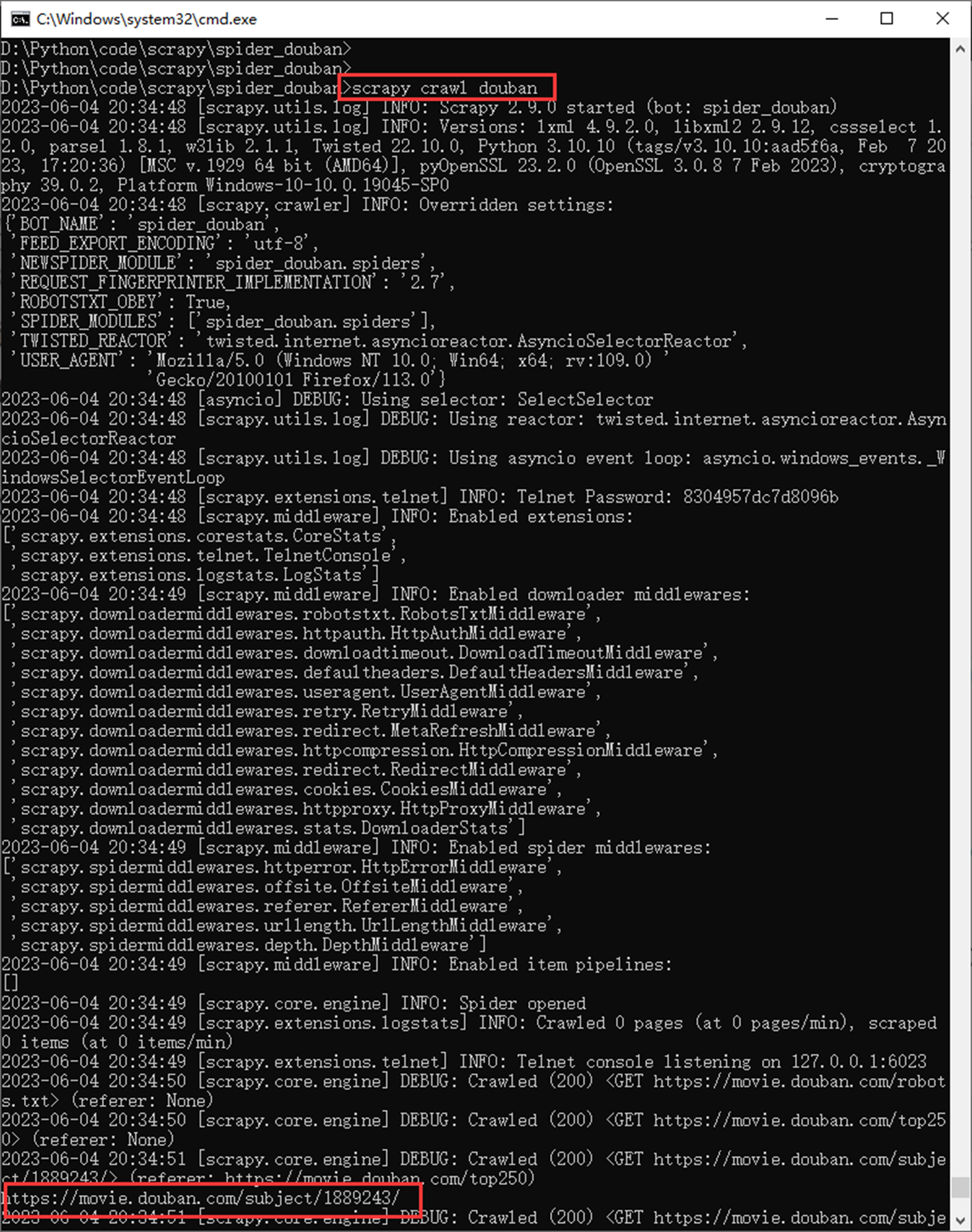
2.3 scrapy 实战二
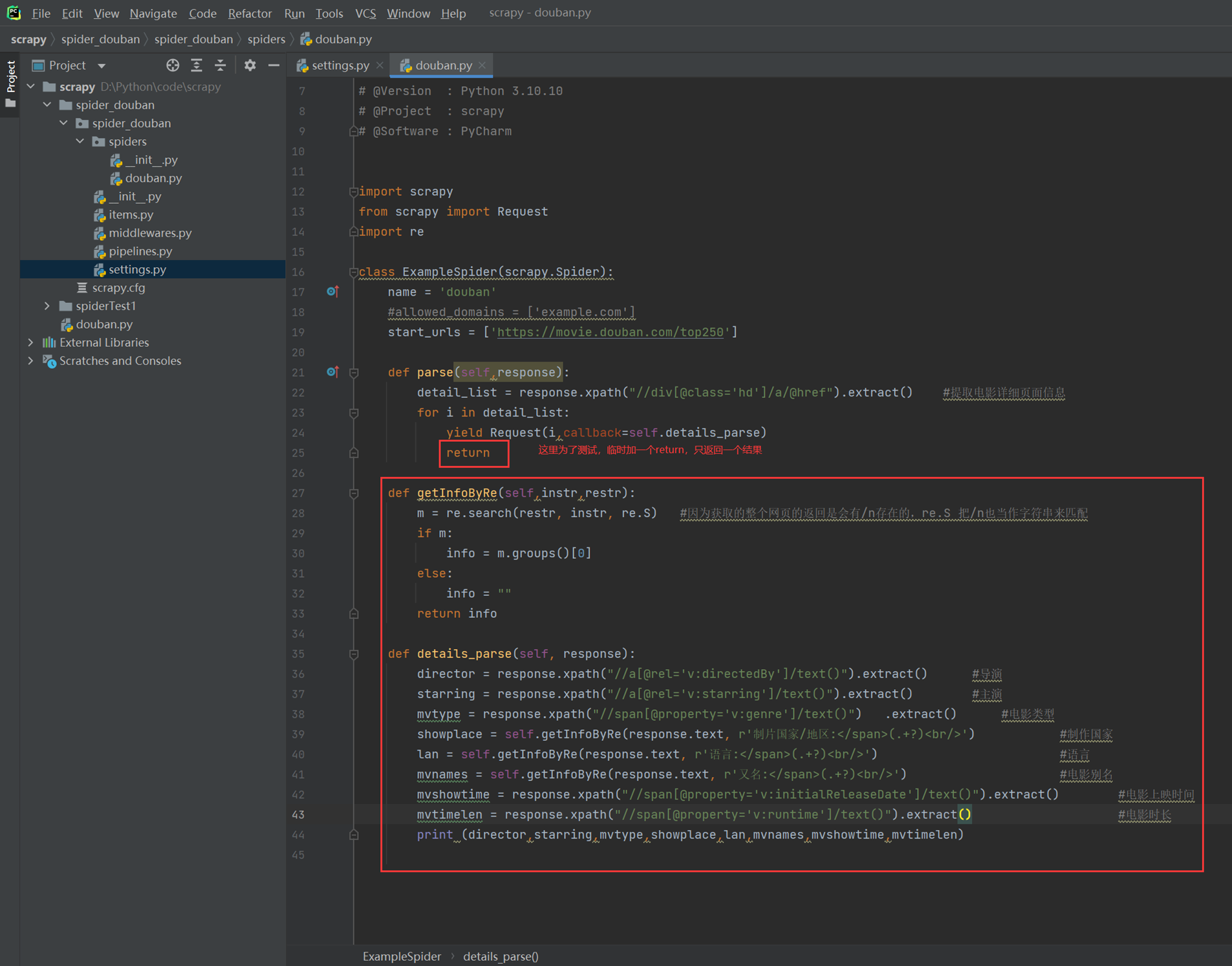
本章目的。
提取详细页的导演名称,主演,电影别名,电影类型,国家等,由于有些标签没有固定属性,这里使用xpath+re来操作。
访问测试
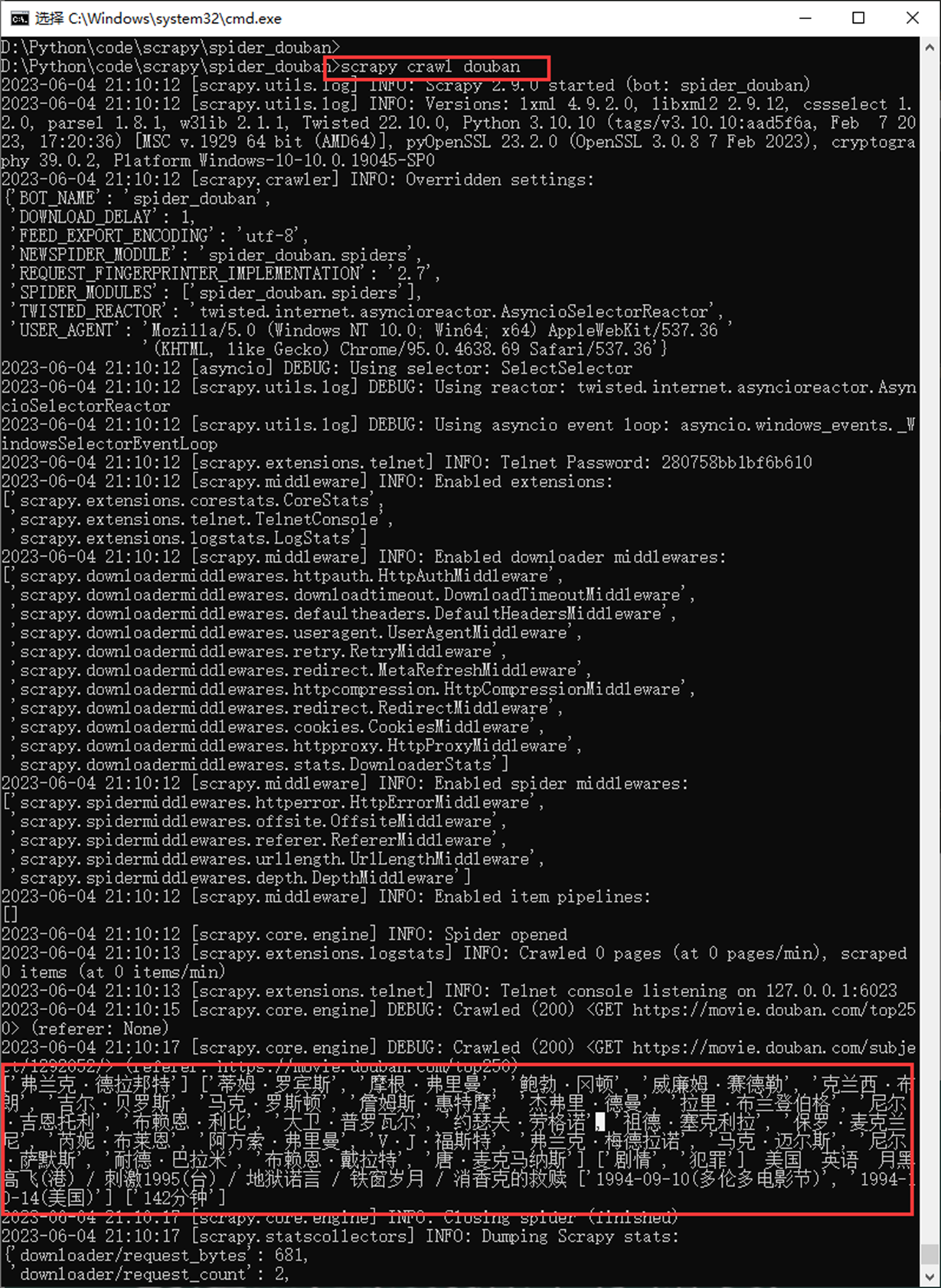
2.4 scrapy 实战三

本章主要使用代码优化,引入itemloader方法的使用,优化内容的提取。
编写items
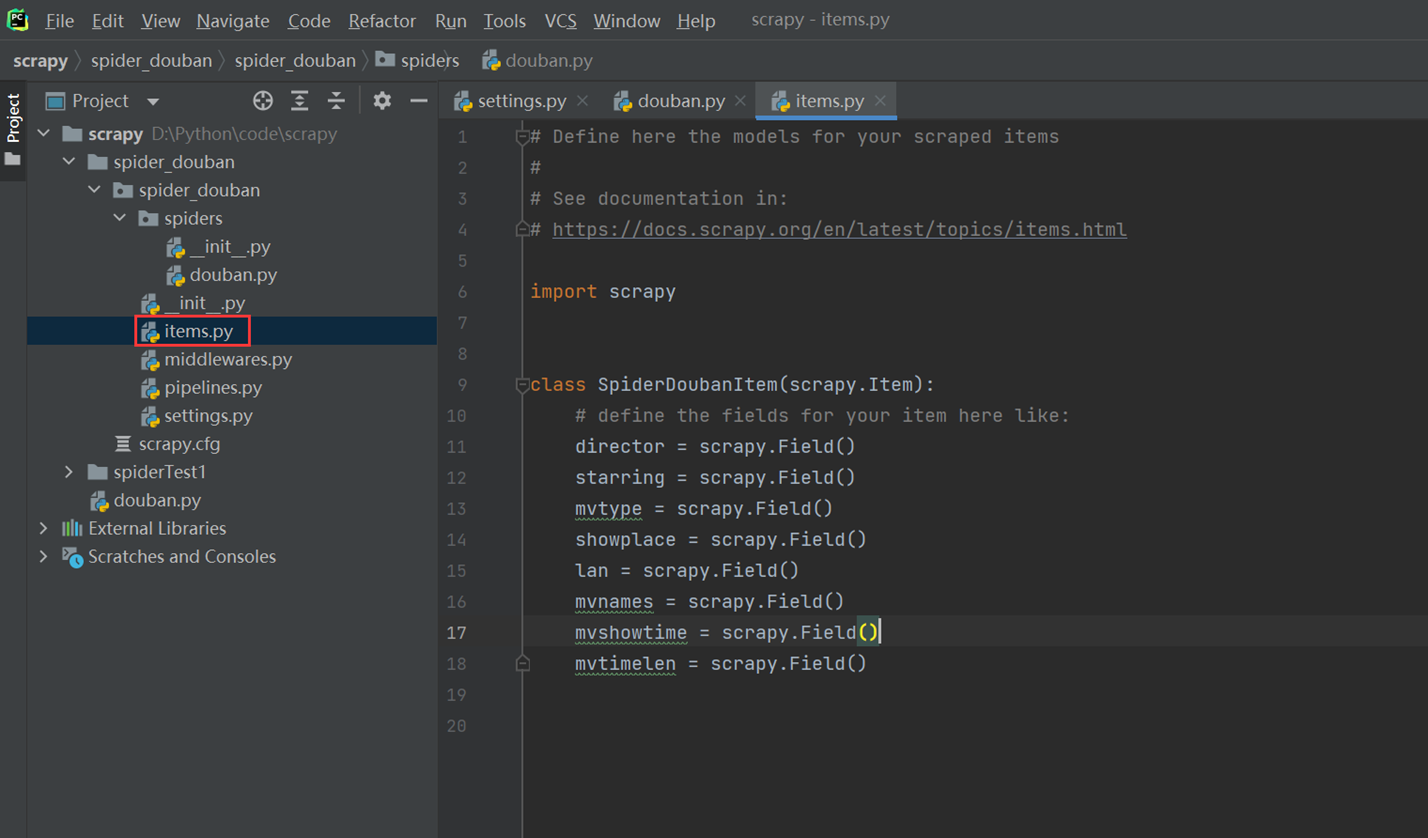
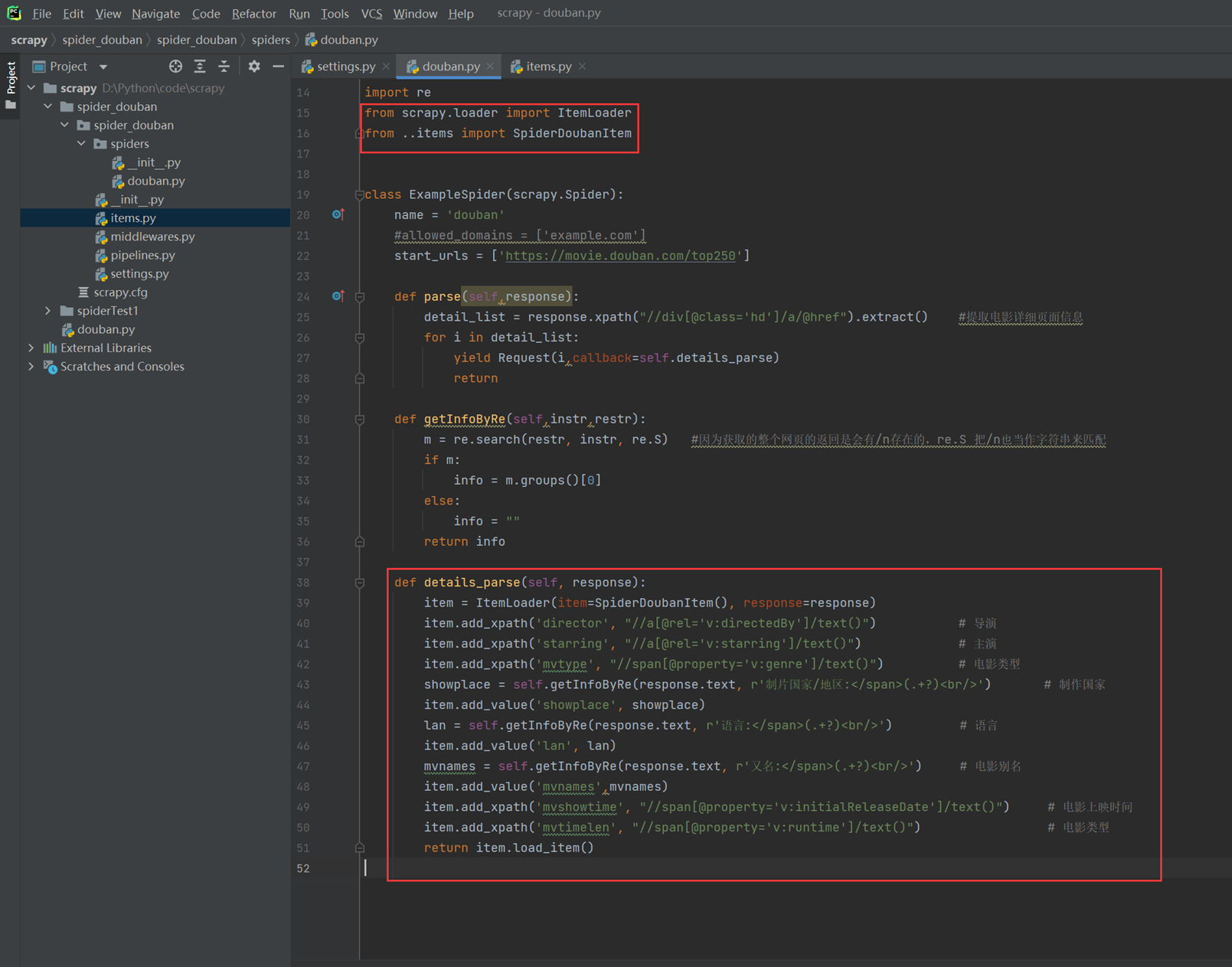
现在执行爬虫,会发现每个item的值都是列表形式的
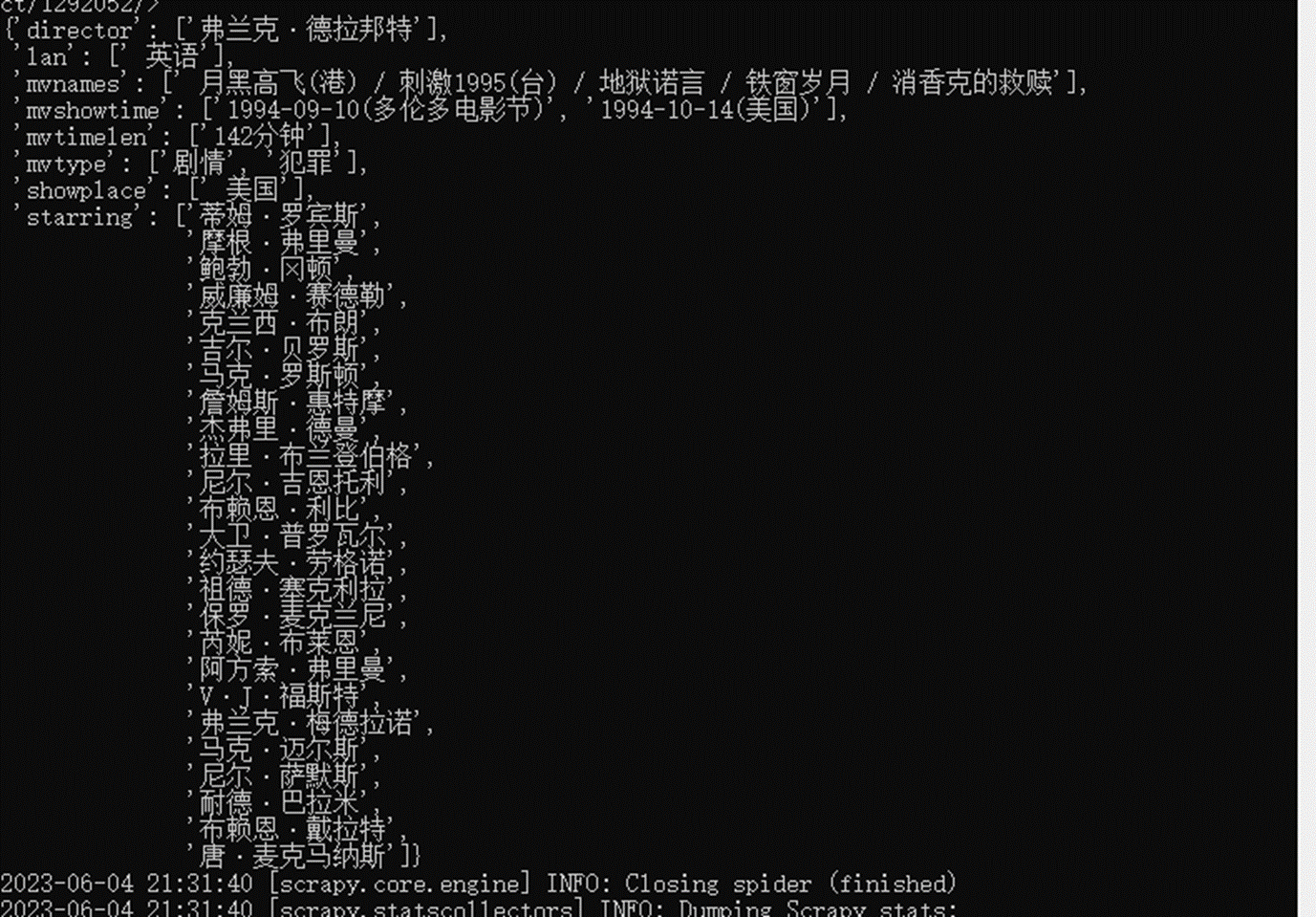
下节课就是将列表给取消。
2.5 scrapy 实战四
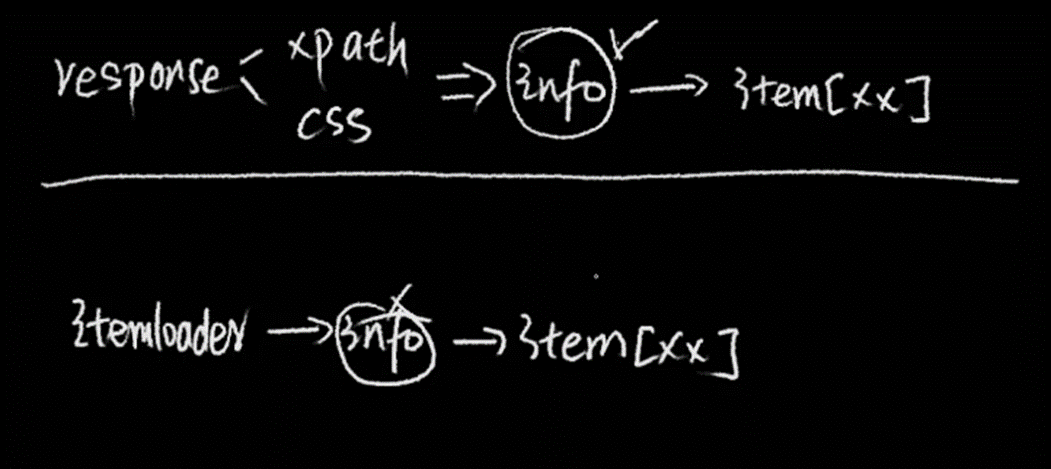
上图中是两种对我们已经获取到的数据处理的方式。
第一种是通过xpath或者css得到的结果,我们进行自己的逻辑处理之后,在传给item,这种比较繁琐,等于自己写大量代码,不推荐。
第二种,如果直接使用itemloader,那么我们就没有办法对数据去进行处理,因为直接将值传给itemloader了,我们没有办法得到直接的数据,这个怎么办?这个当然有办法,就是item自己有的办法,本章就是讲解这个。
就是下图中的input_processor和output_processor,等于item早就准备好了方法,数据进来的时候有处理方式,数据出去的时候还可以再处理一遍。



数据进来的时候,使用mapCompose,这个函数,这个函数和python的map函数使用方式一样。假设 map传入了三个函数f1,f2,f3,这三个函数分别作用是split,join,等,那么就会把使用了map后,f1处理完了之后,会把值传给f2,然后再传给f3.
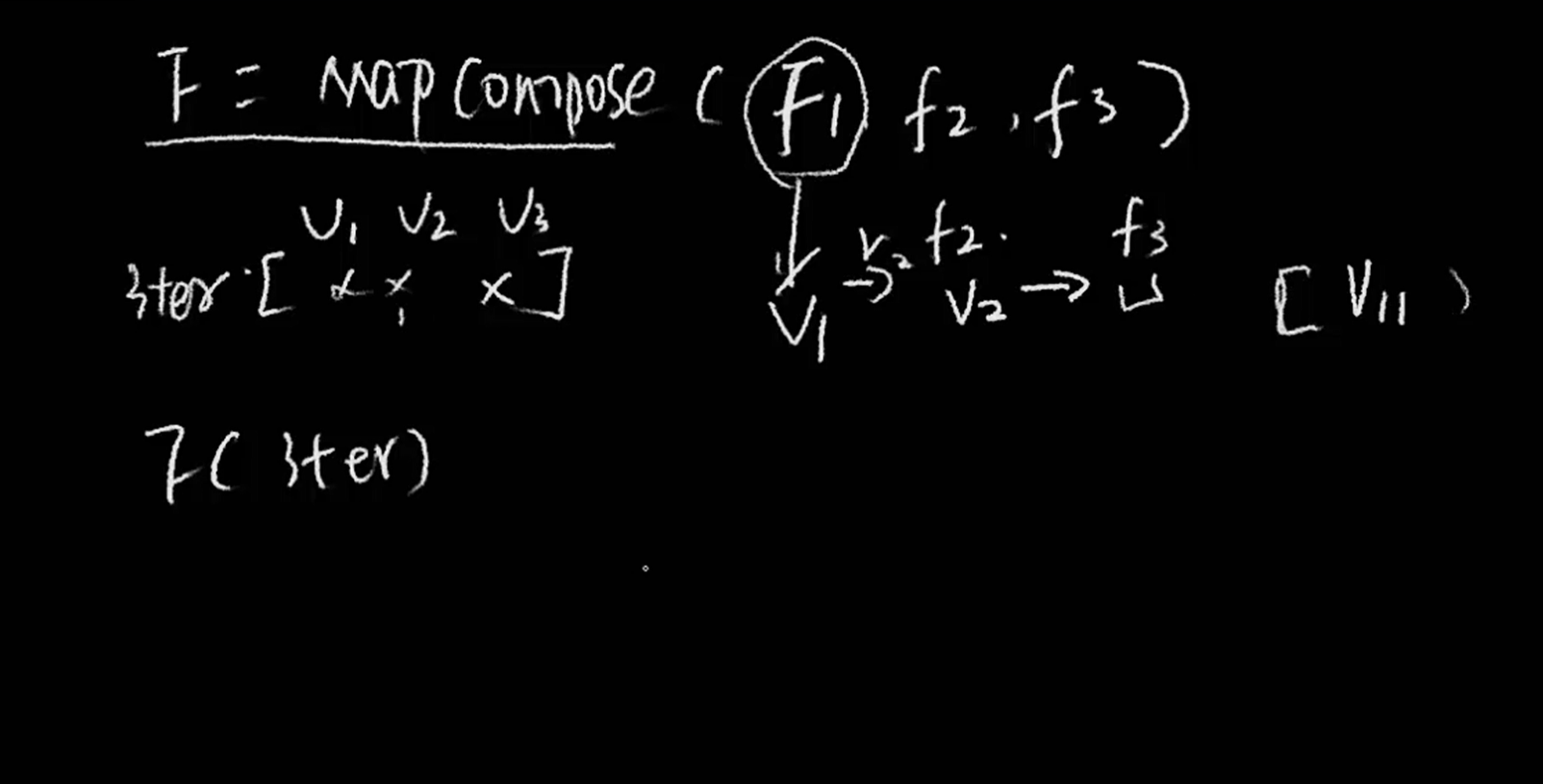
下图就是MapCompose的具体使用方式
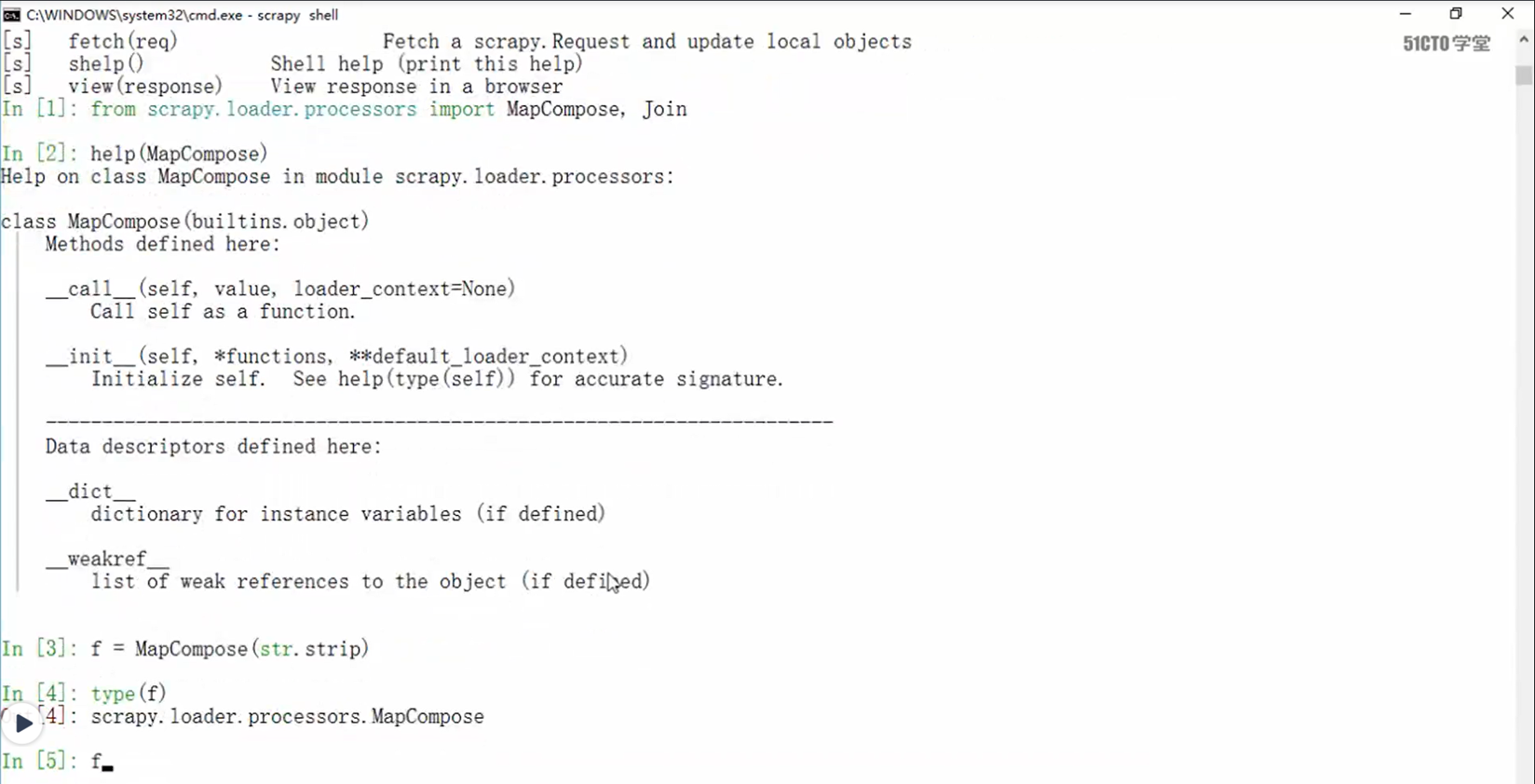
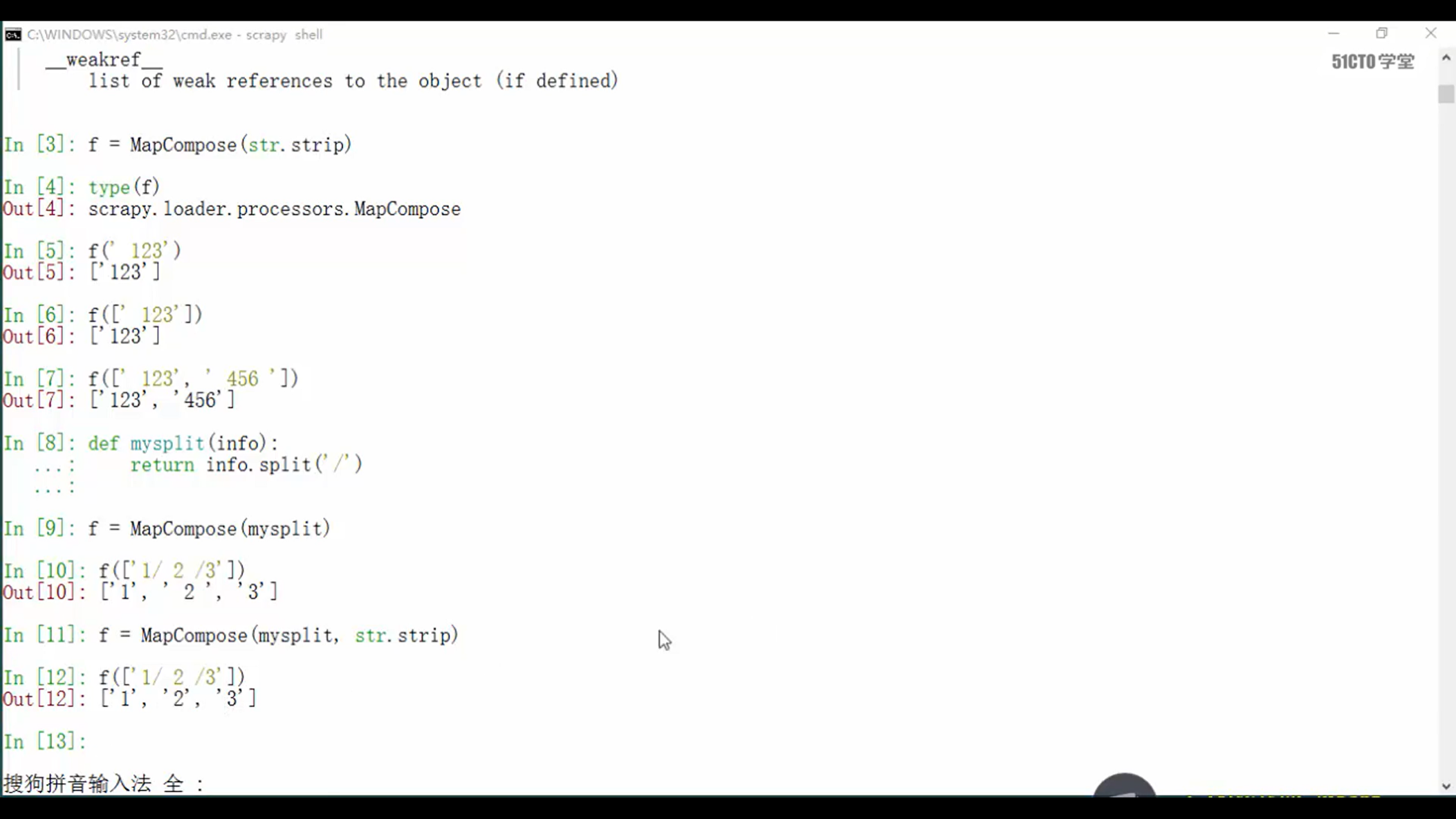
接下来在items中演示MapCompose的使用,使数据在pipeline的之前进行处理。
如果输入到items的数据是字符串类型,那么其实可以省略这些步骤
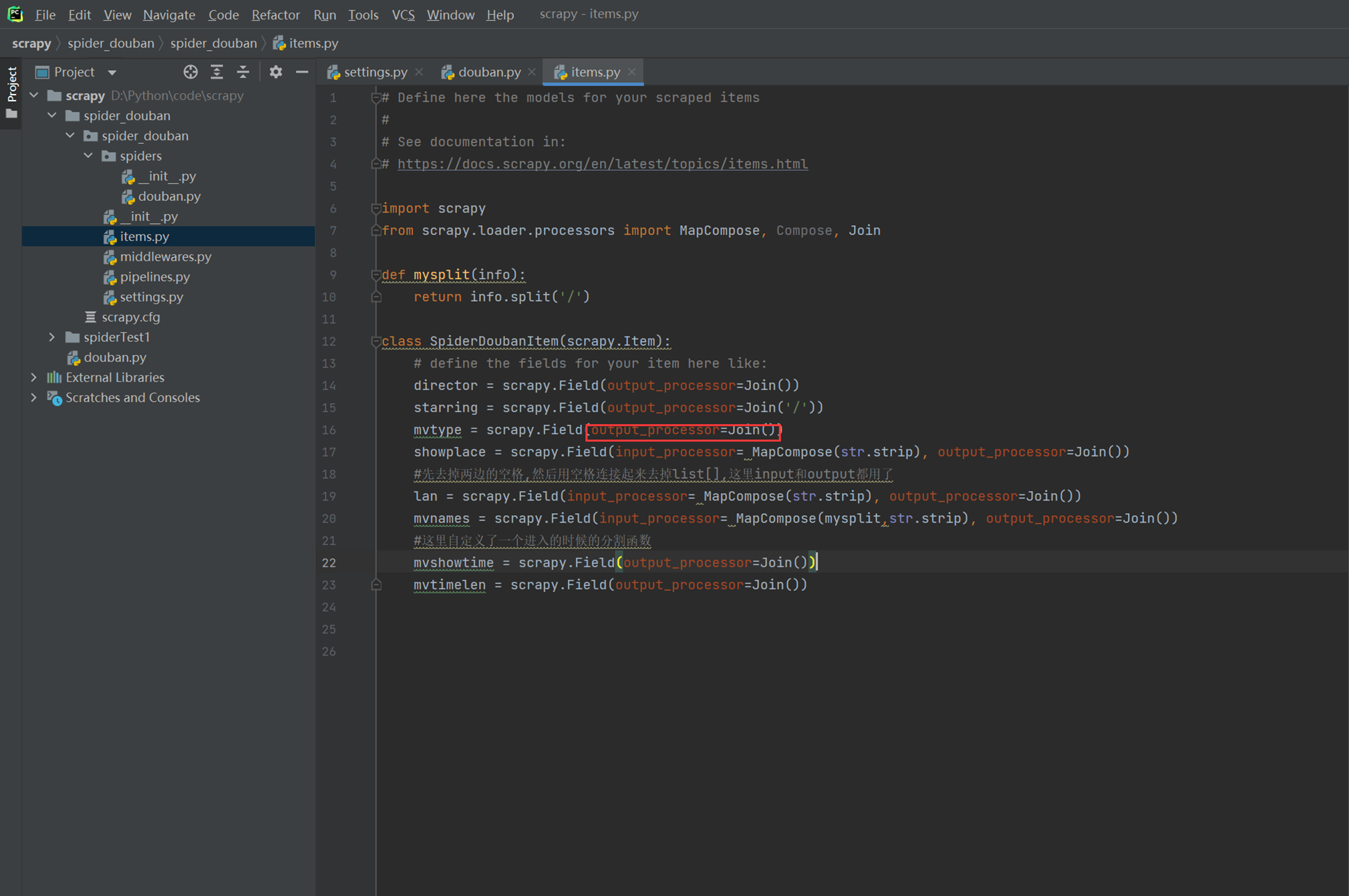
现在查看一下执行结果,都依照进出的规则去将字符串处理了

2.6 scrapy 实战五
本章主要补全一些要获取的信息,如电影评分等信息,以及请求下一页的信息完善。
首先在items里面增加需要抓取的字段。
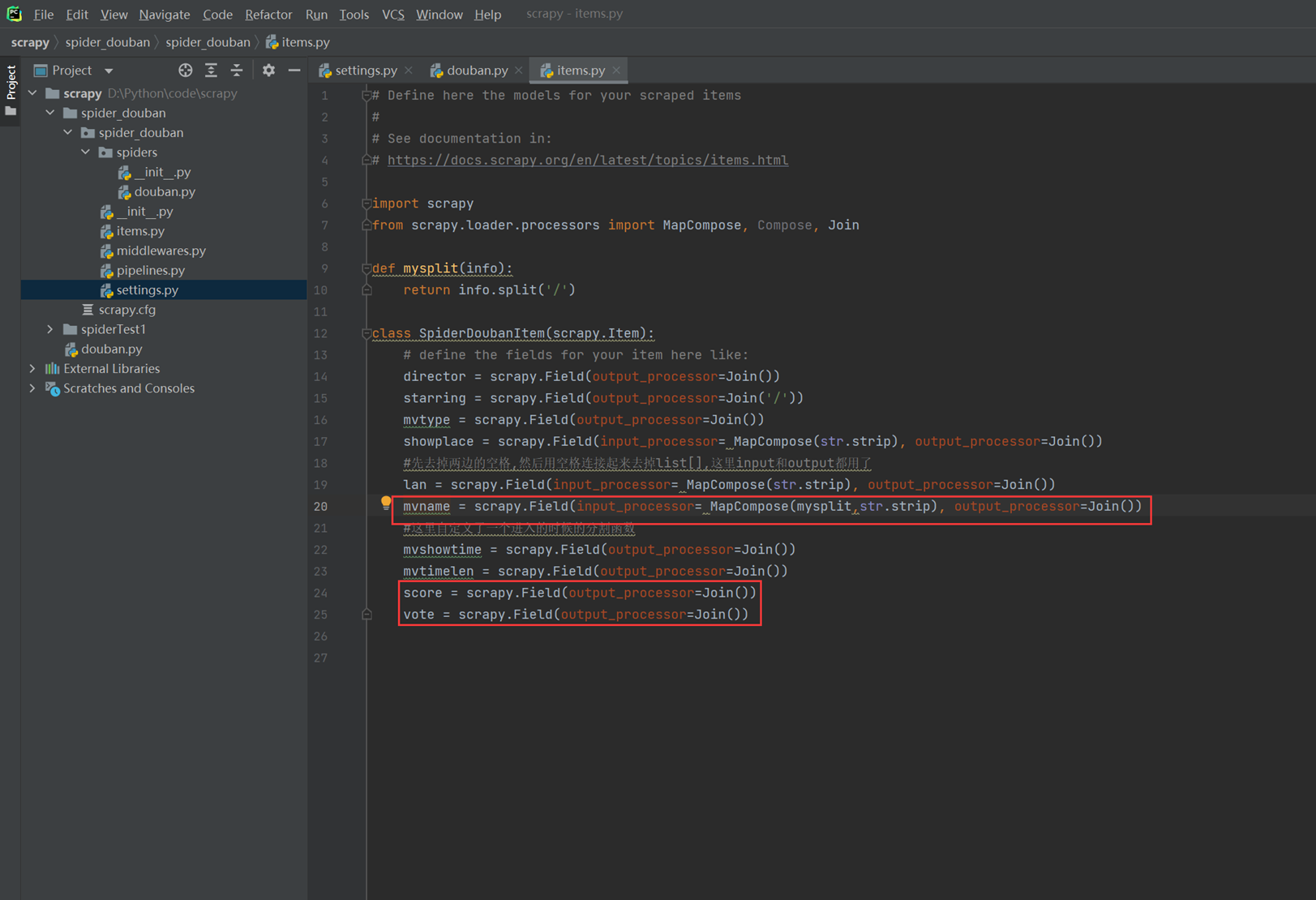
接下来抓取新增的信息
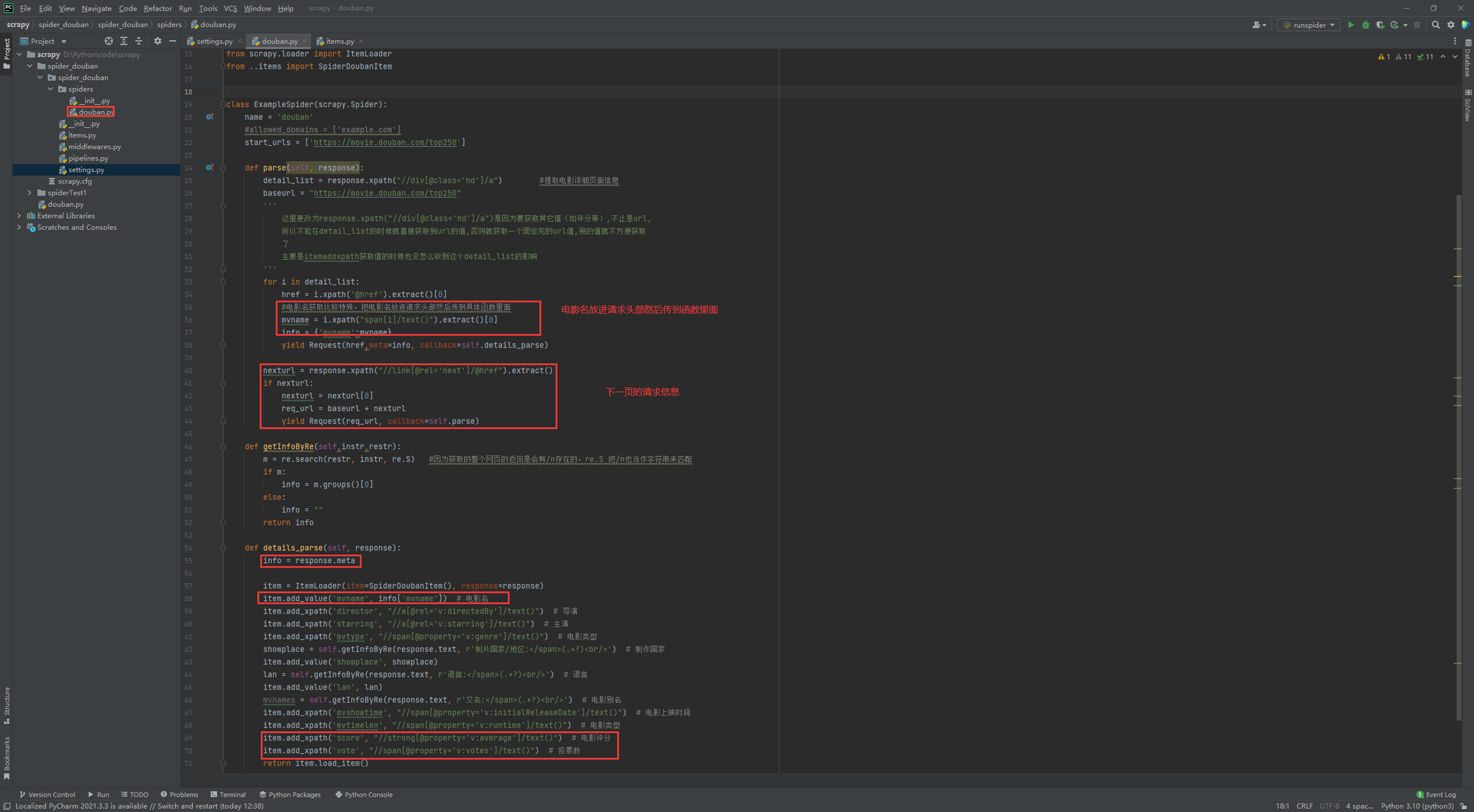
测试结果
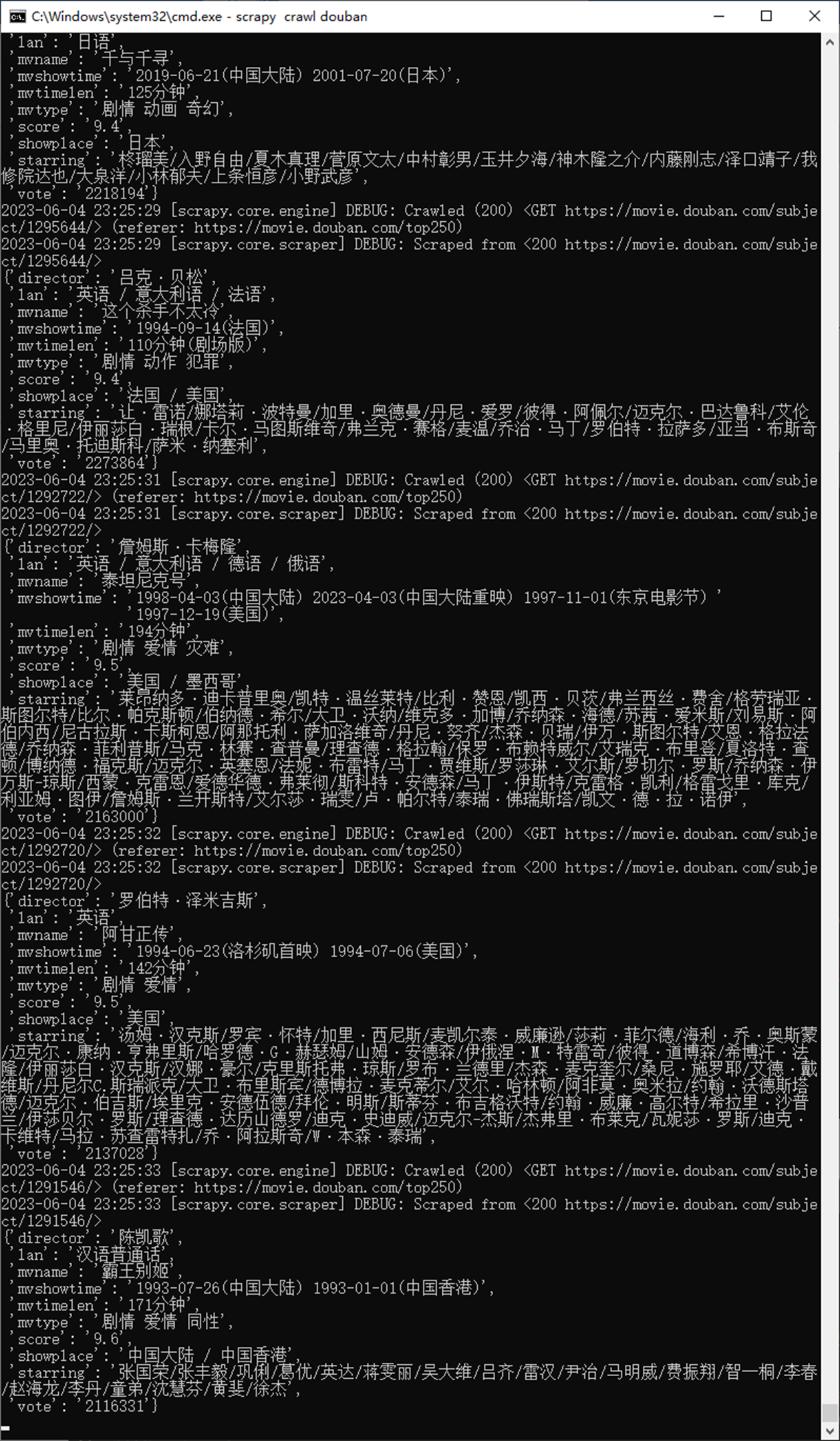
本章结果已经完成了信息的补充,下一页的抓取,最后一节讲解怎么解决存储到数据库。
2.7 scrapy 实战六
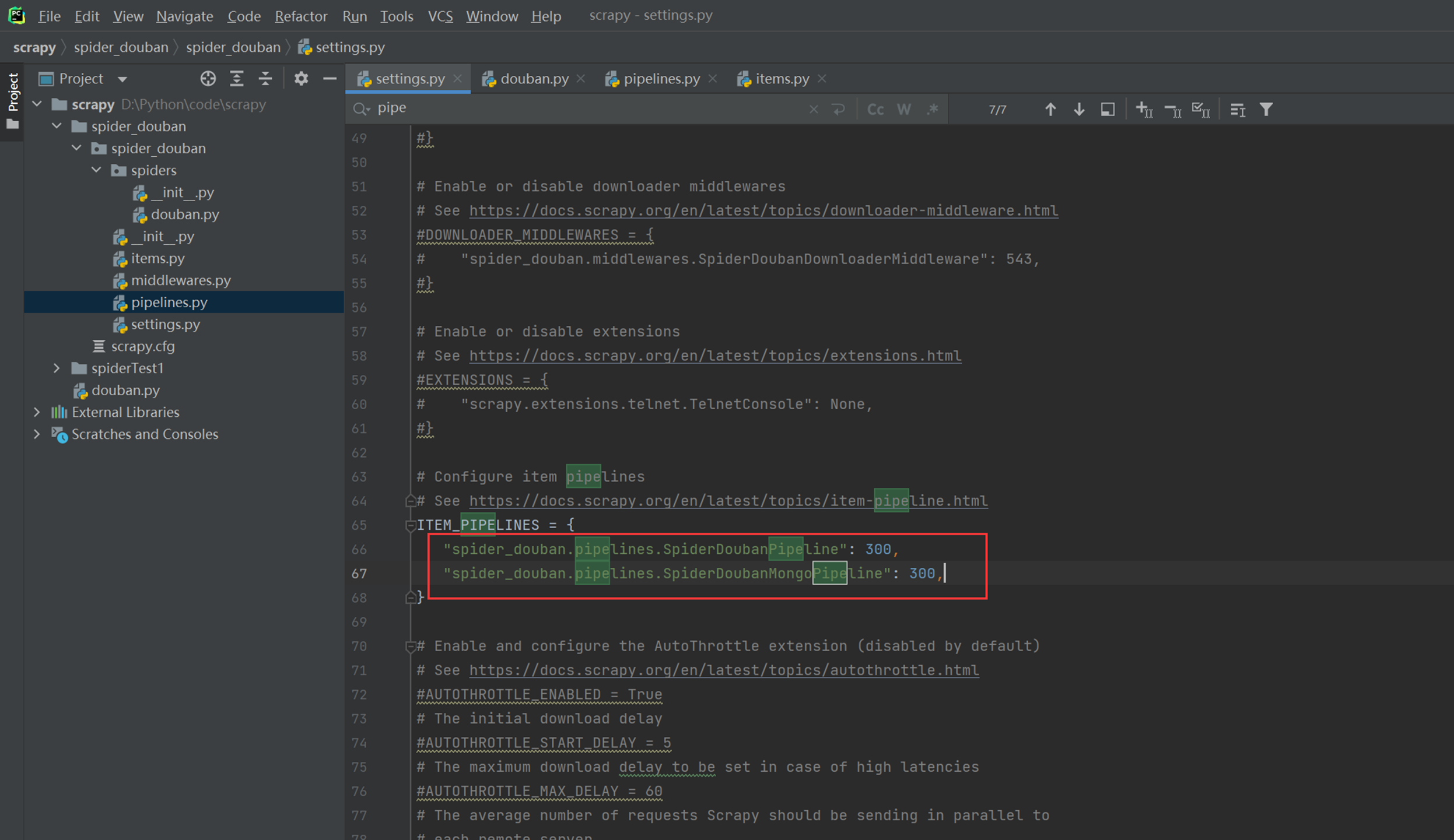
本章主要是实现痛过pipelines将数据存储到mongo中。
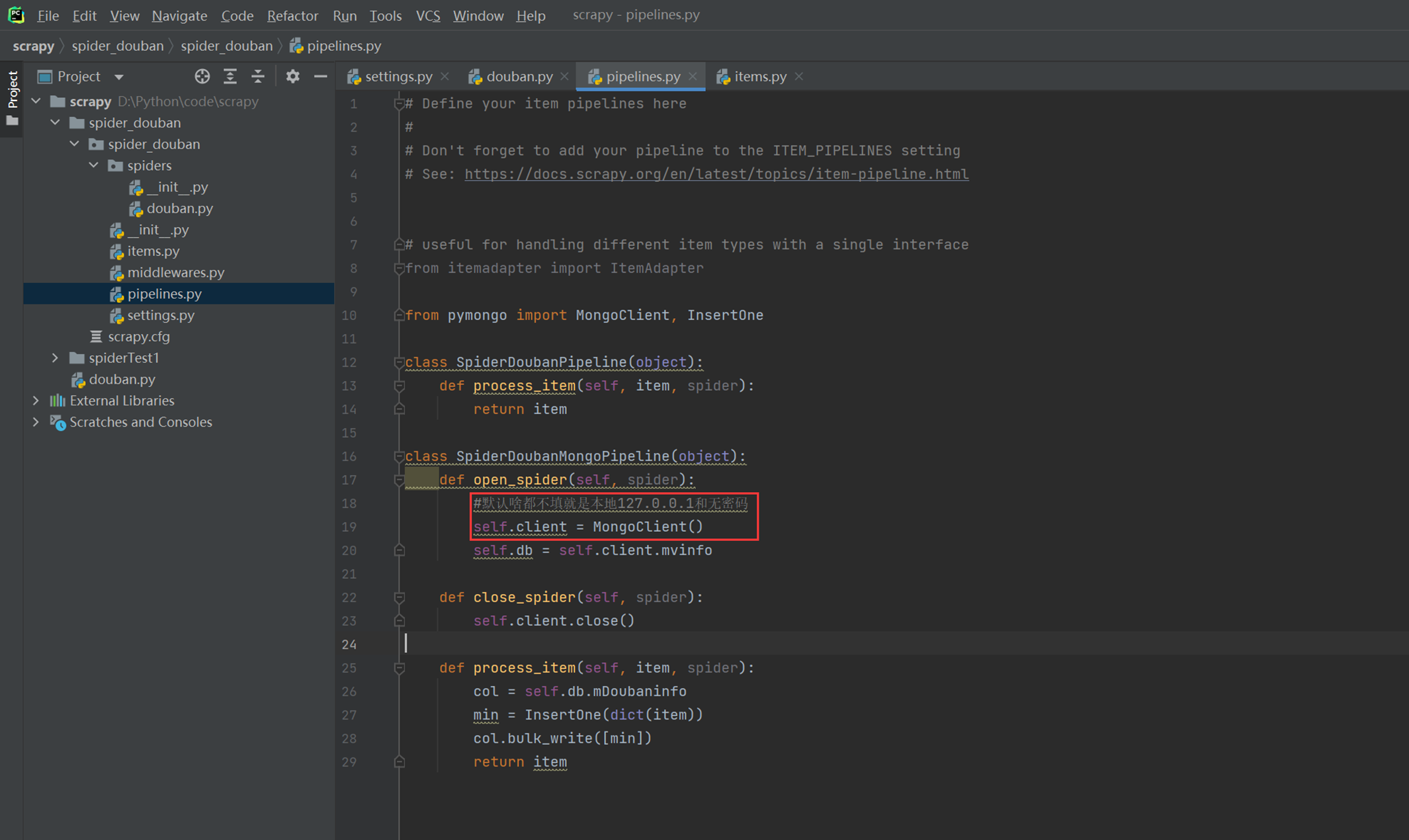
记得在settings里面开启
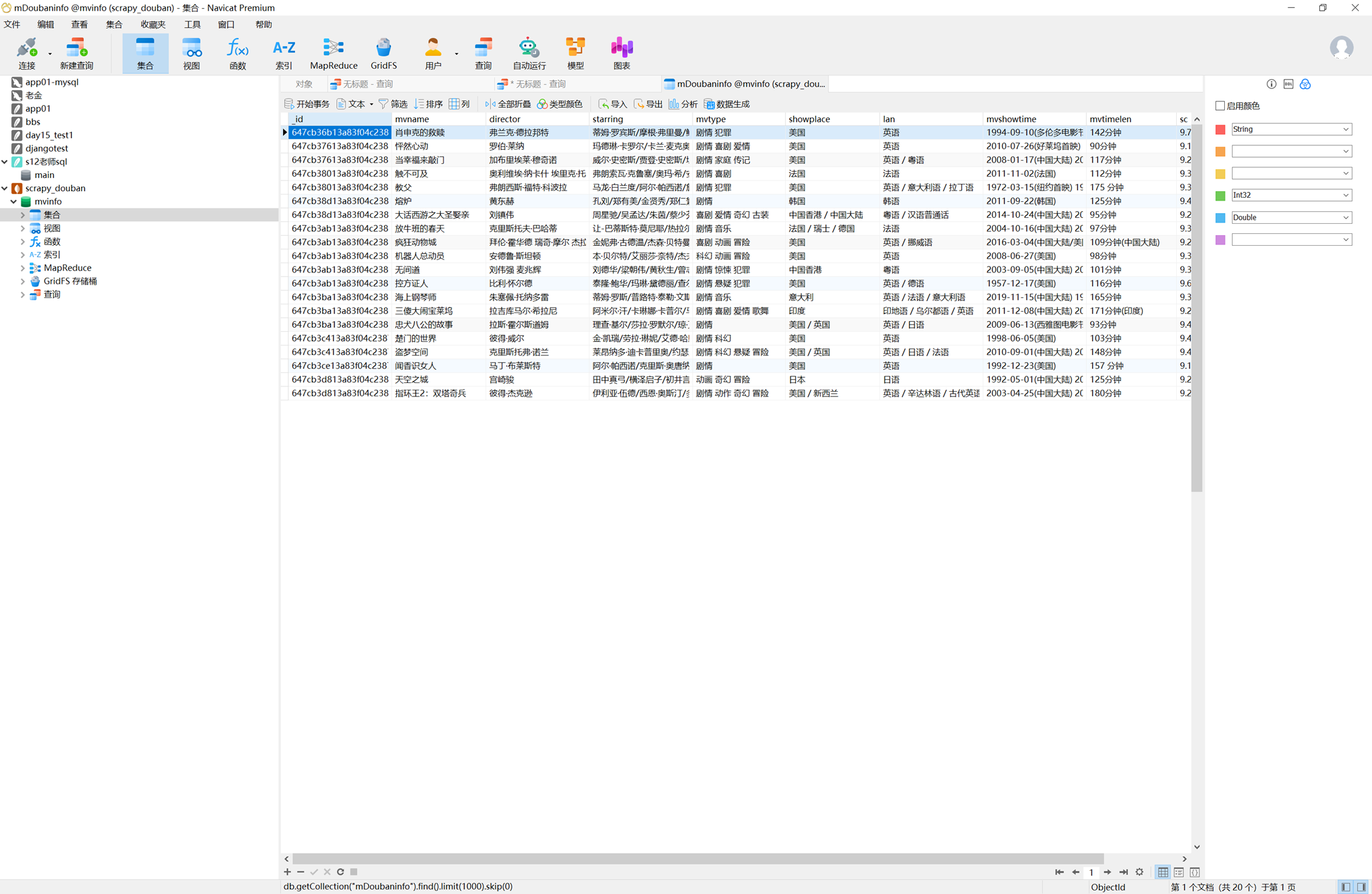
在mongo里面验证结果
总结

3.Scrapy 反爬机制
3.1 常见反爬机制与应对方式

User-agent看看是不是浏览器
Cookie登录来限制访问和ip访问次数来限制访问

User-agent伪装以及请求延时设置
接下来的方式下一章讲解
3.2 反爬机制应对处理

User-Agent动态更新
在scrapy的流程中,给到download之前,我可以使用中间件对request做操作


本章重新创建一个项目来实现,主要使用DOWNLOADER插件的方法,然后查看User—Agent有没有更新。
安装fake_useragent模块

创建测试项目
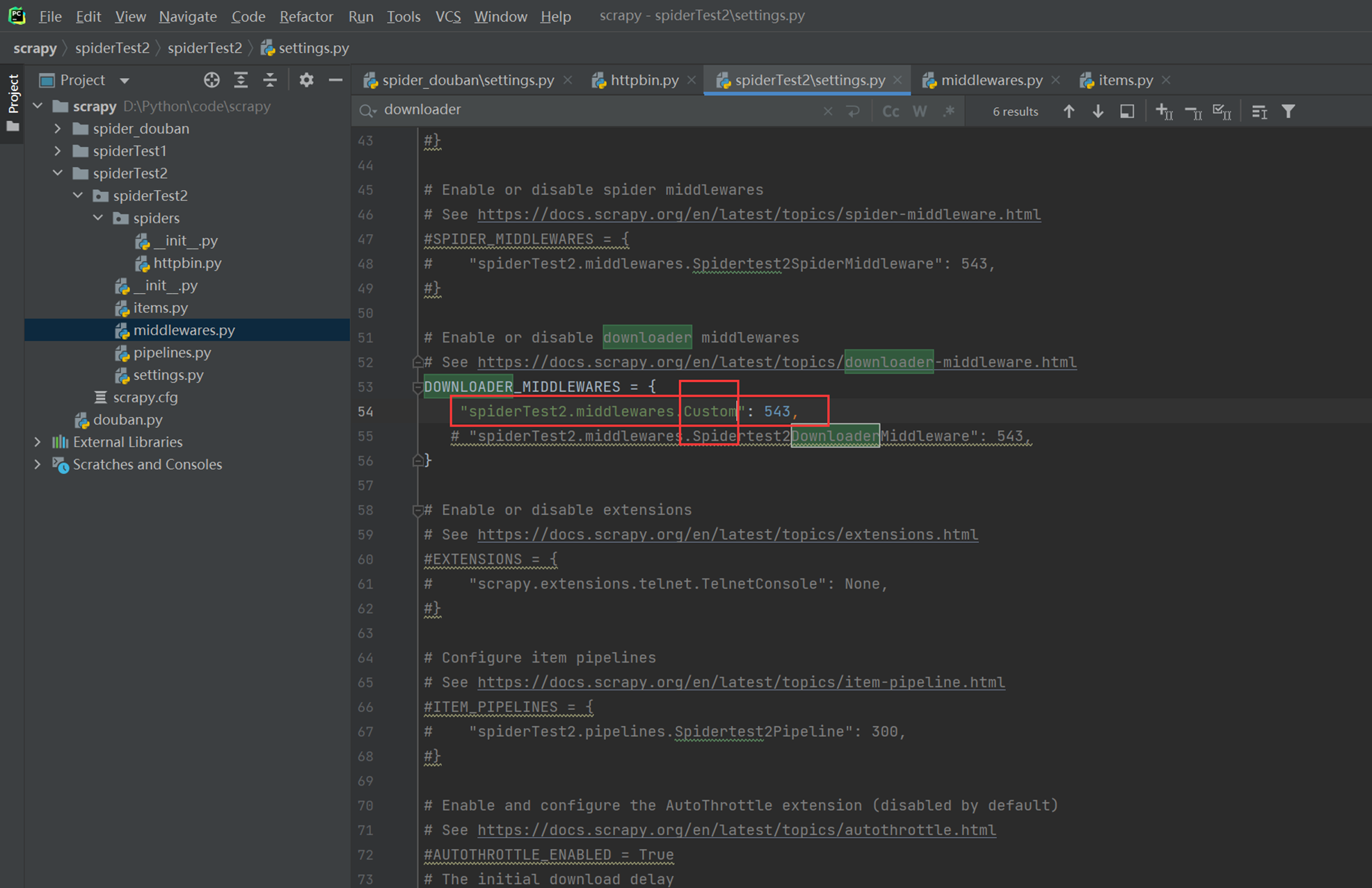
老规矩还是把settings配置文件配置,只不过这里配置的是中间件。
现在编写middleware插件
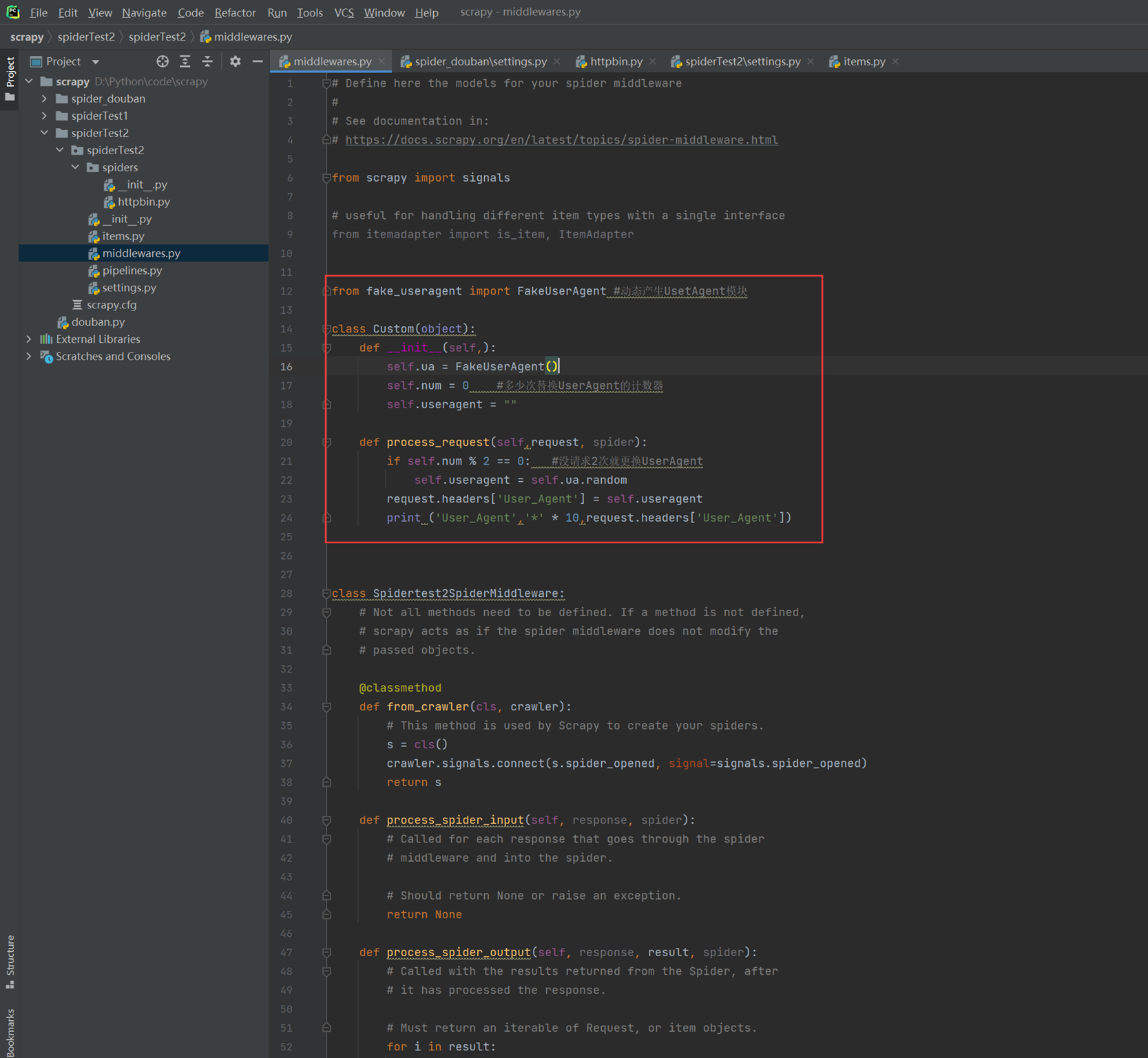
现在访问查看UserAgent是否发生改变。
![]()
第一次访问

第二次访问

本节课简单讲了换ip代理,但是没有细讲,这里留一个记录吧,后面如果有机会再补充。
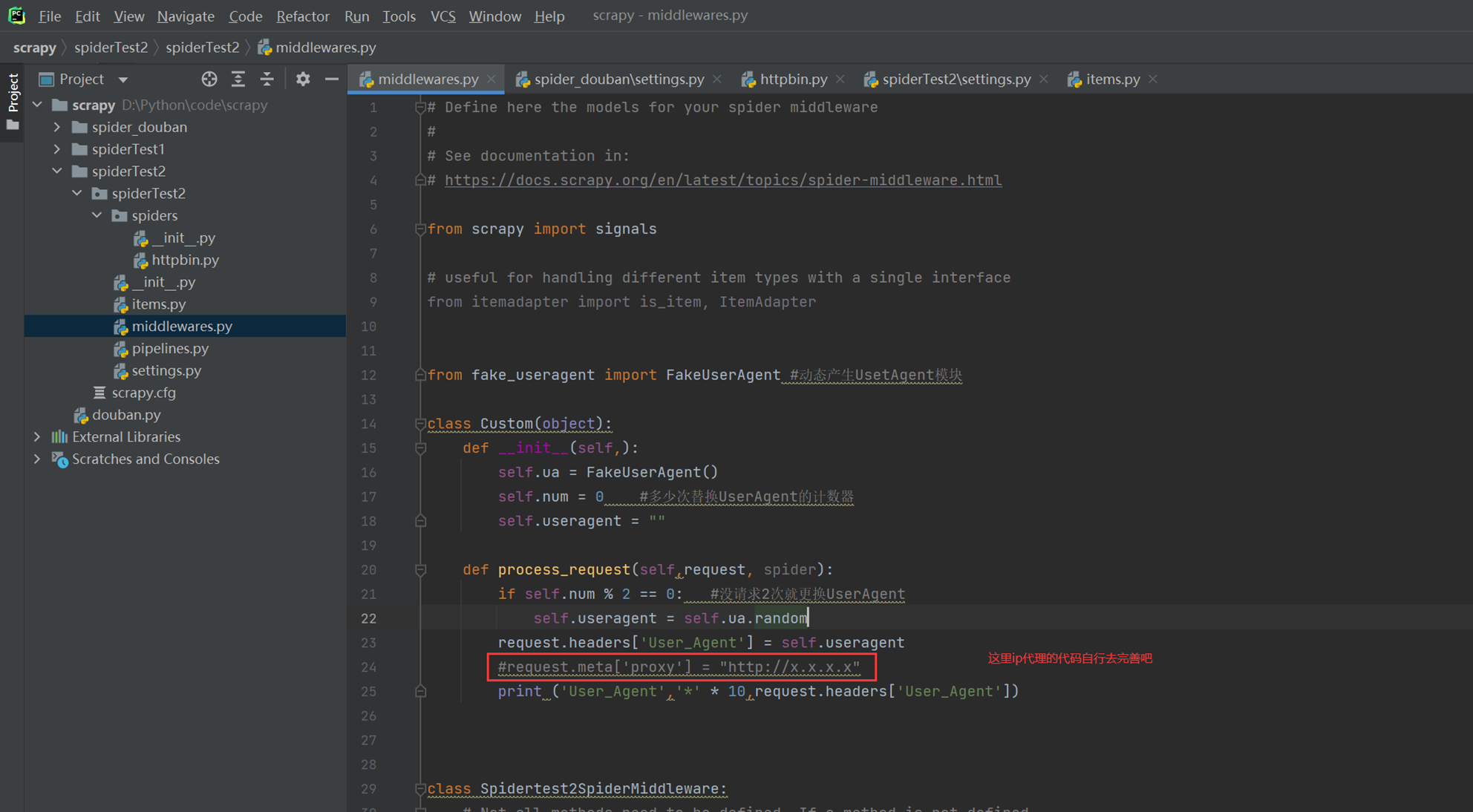
动态获取ip代理,老师源码里面也有,可以自己研究。
4.scrapy登录实战
4.1 scrapy Post请求详解
创建一个scrapy_post的post测试请求项目,由于浏览器默认只能发送get请求,现在来看看scrapy怎么发送post请求
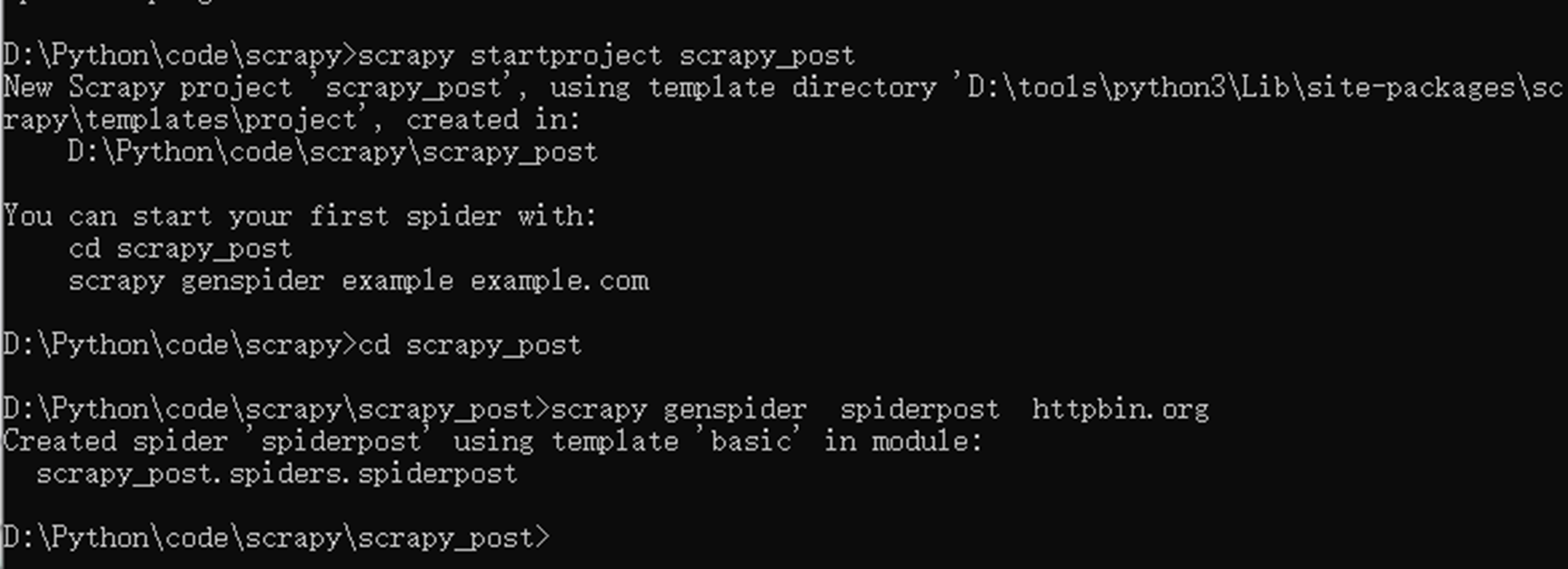
以下代码模拟怎么发送一个post请求到httpbin.org
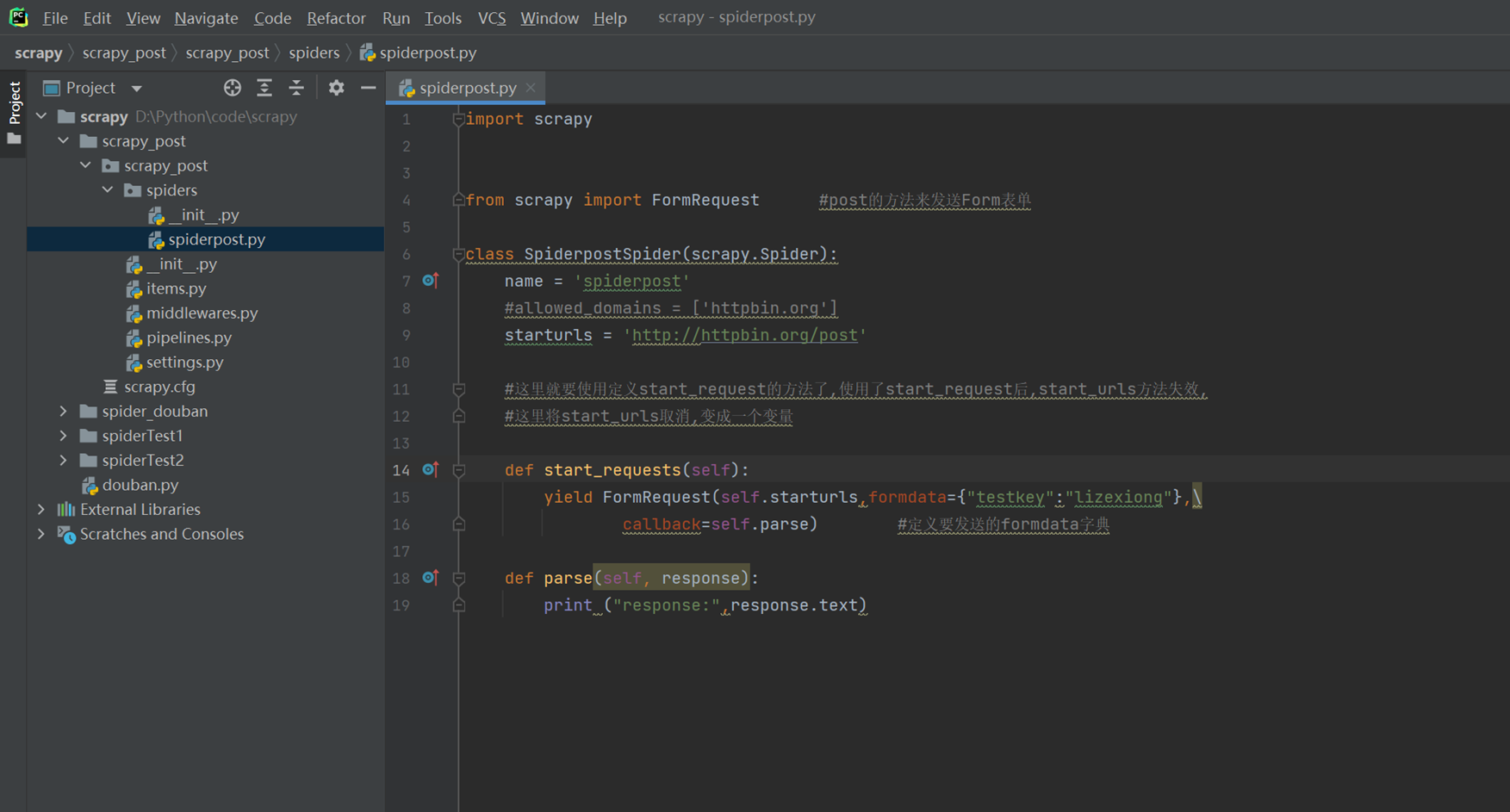
主要注意,starturls是一个变量,不再是start_urls了,然后FormRequest来发送post表单的请求。
查看执行结果
![]()
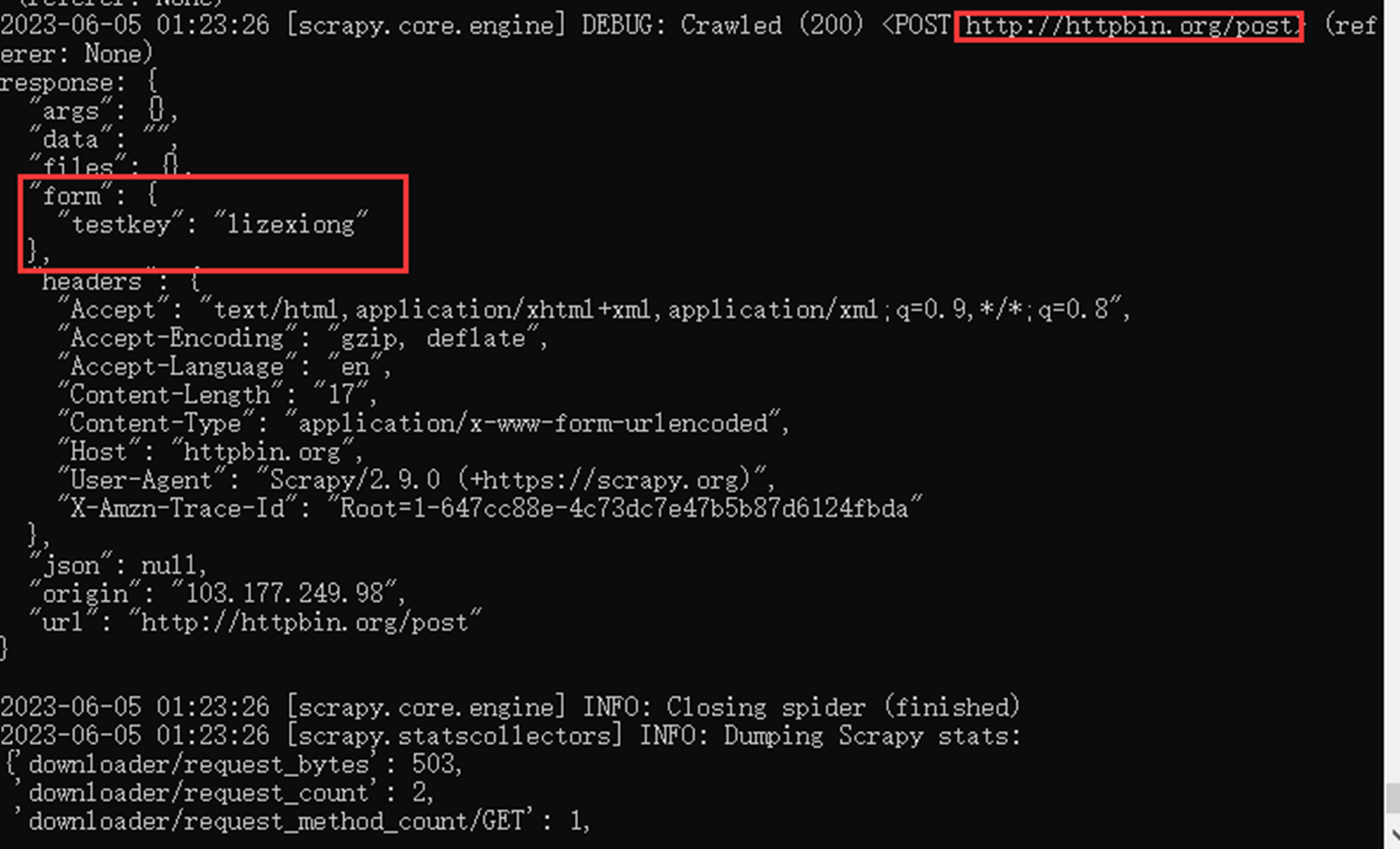
以上是测试的form表单post的数据。
4.2 scrapy 模拟登陆github
首先要解析login
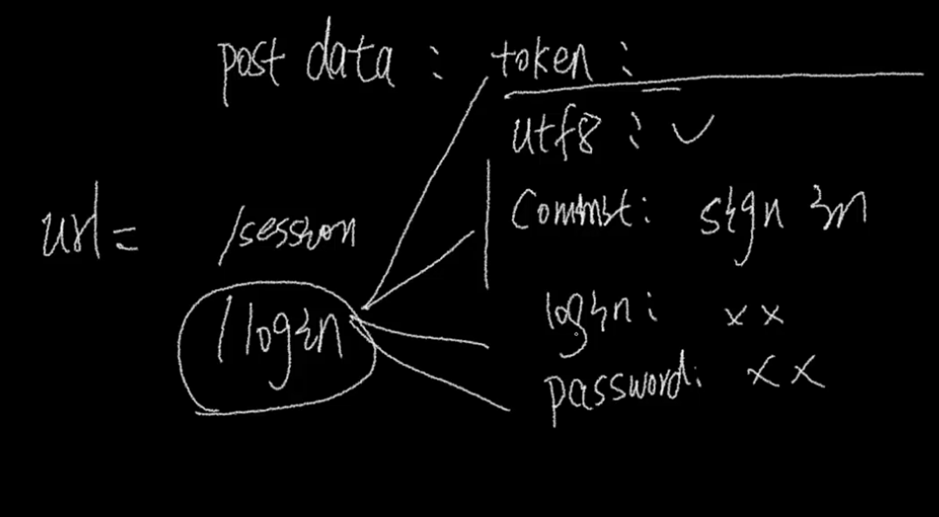
这个玩意的原理就是首先登陆github的地址是一个https://github.com/login,这个界面首先需要get请求,然后提交用户名密码以及token和github所需要的信息是一个post请求,所以这里肯定会有2步操作,一个get获取登录界面,一个post像服务器发送用户名密码。
所以我们需要分析页面,需要提交的时候我们需要哪些数据才能符合提交要求。
就是这一步疑惑好久,视频第二遍都没看出这个老师说的原理,终于在网上看到一篇文章,搞清楚了自动登录的过程,视频中老师常说提交post的需要什么utf8,commit字段,我一直郁闷,我怎么知道提交的时候需要这些字段。原来,这个东西是需要踩点的。
比如,我们登录网页的时候,会有post,我们完全可以在浏览器的调试界面知道这个form需要post哪些数据,我们去模拟出来即可。
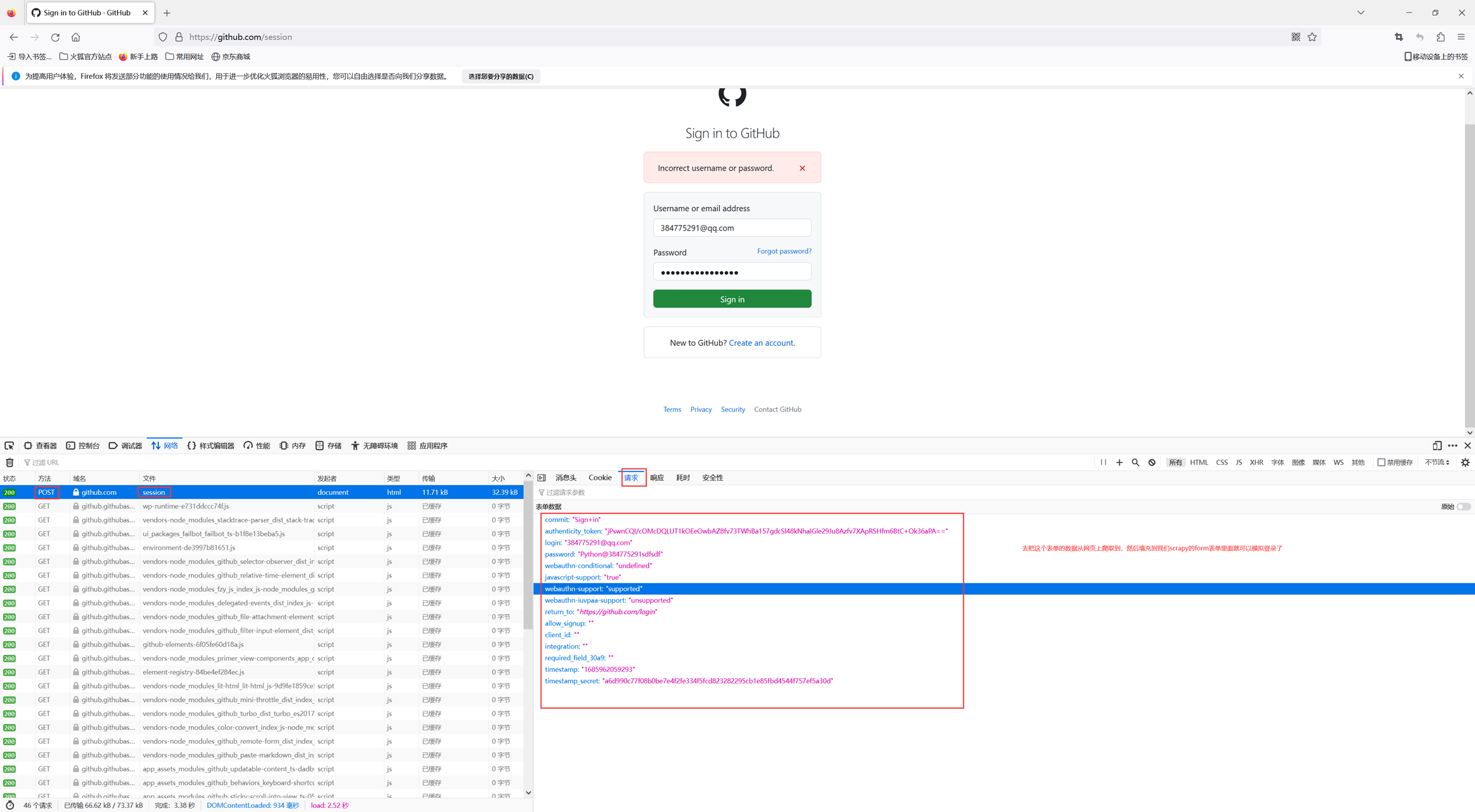
这里可以看到表单需要的数据在登录界面的源代码中,使用input隐藏标签将表单数据隐藏,我们都可以通过xpath或者css获取。
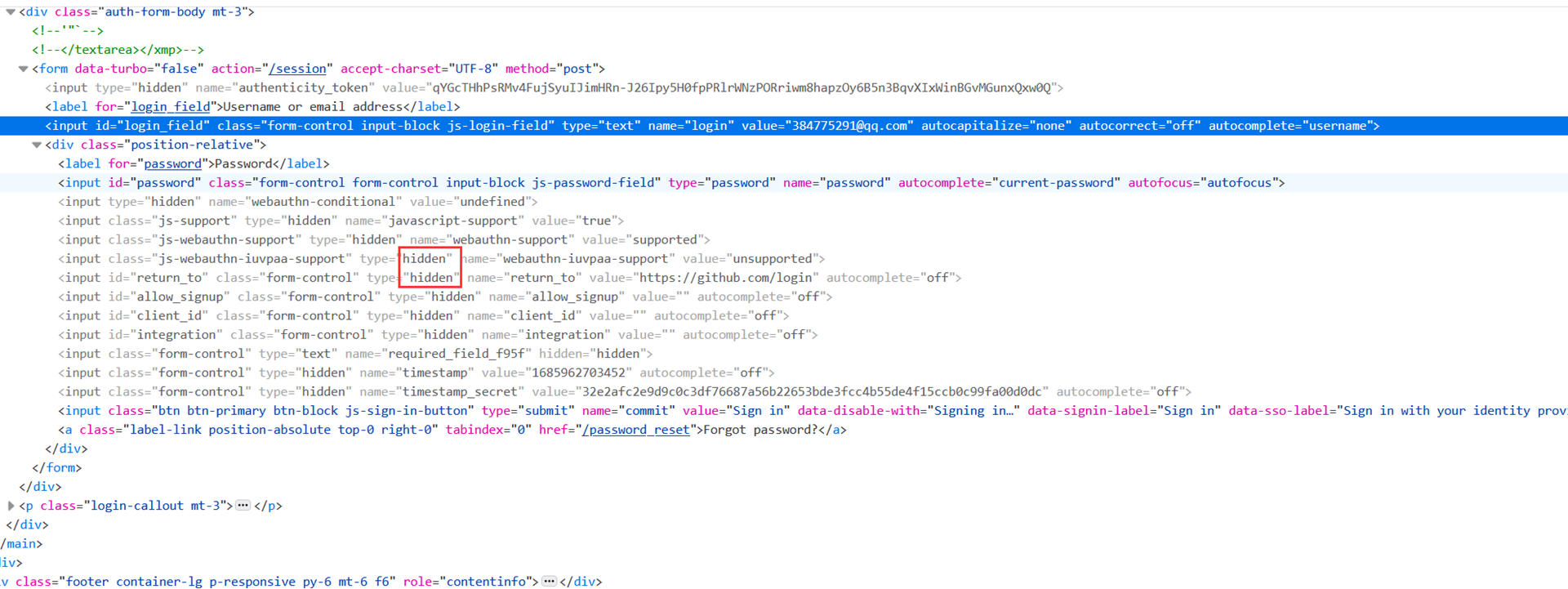
现在这里新建一个项目,开始github自动登录的过程
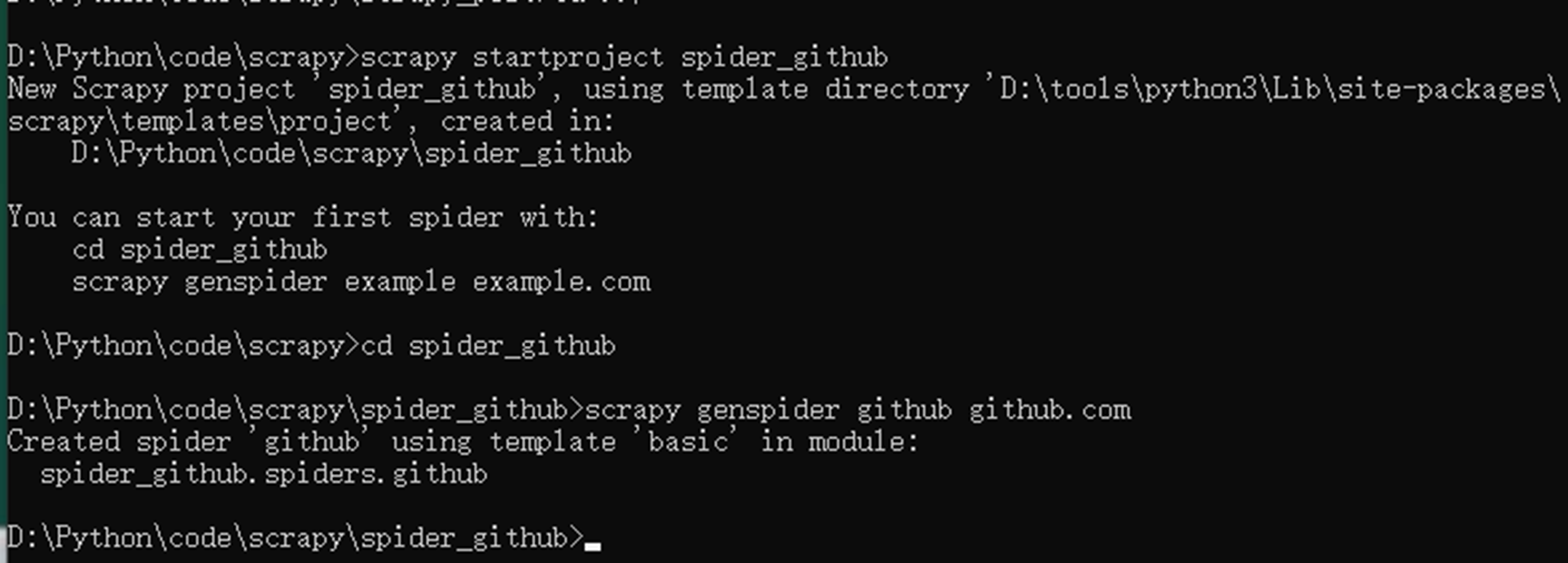
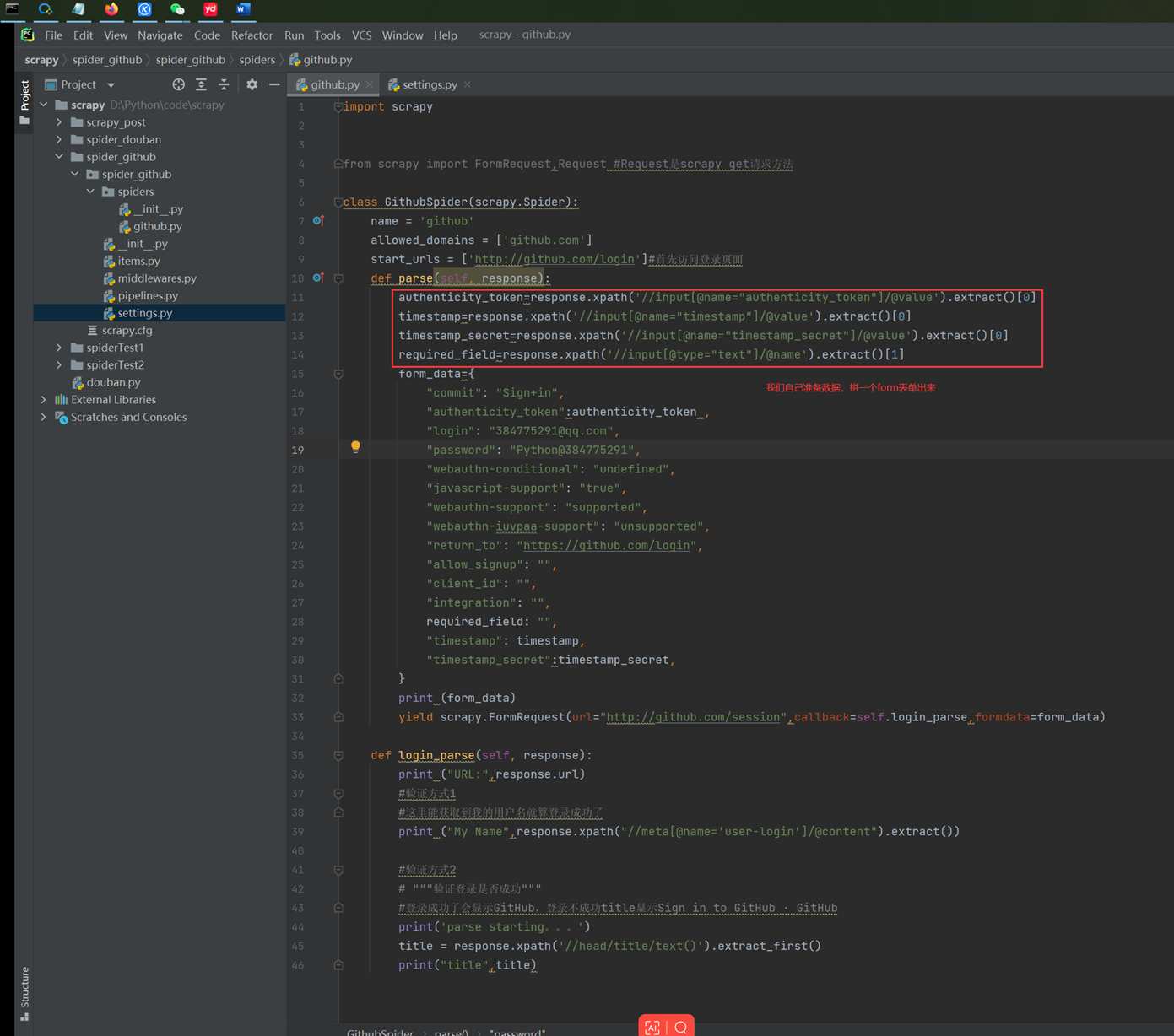
登录访问测试-不成功的结果

登录访问测试-成功的结果

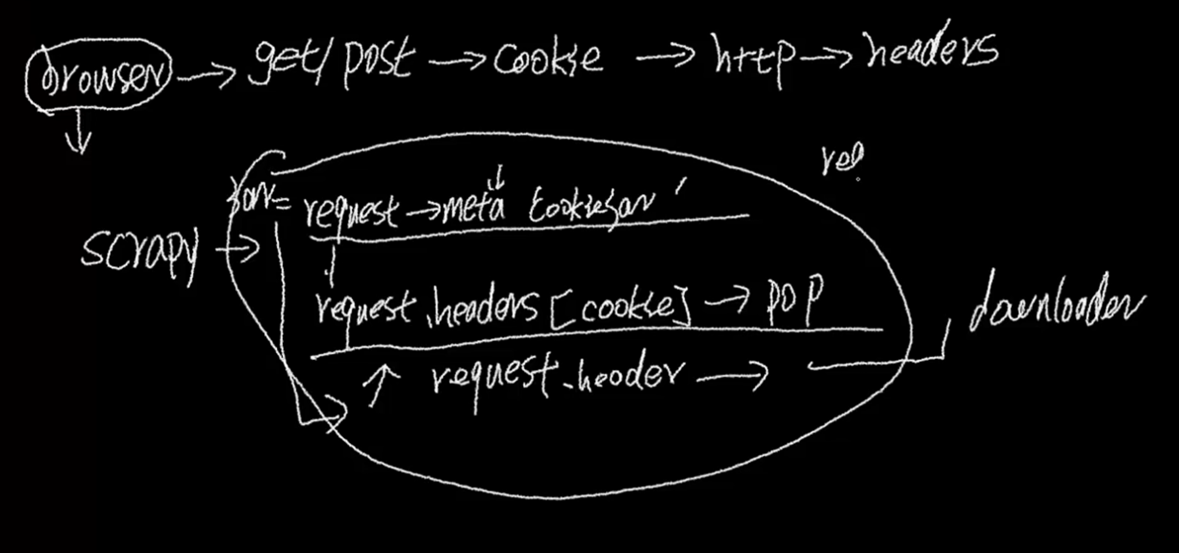
4.3 scrapy cookie处理详解
接下来,这里仅解释cookie的一些简单事例,暂无实战课程,老师直接讲源码。
登陆完成了,服务器怎么知道我一直是一个登陆的状态,现在就需要cookie
5.Scrapy爬取图片实战
本章项目难点过高,如有需要,需要回来温习视频,现阶段不做记录
5.1 项目需求分析

由于年代太久远,360升级了反爬方式,根据xpath定位根本就找不到标签,源码里面啥都没有,就比如视频开头的li标签。整个源代码里面哪里有?
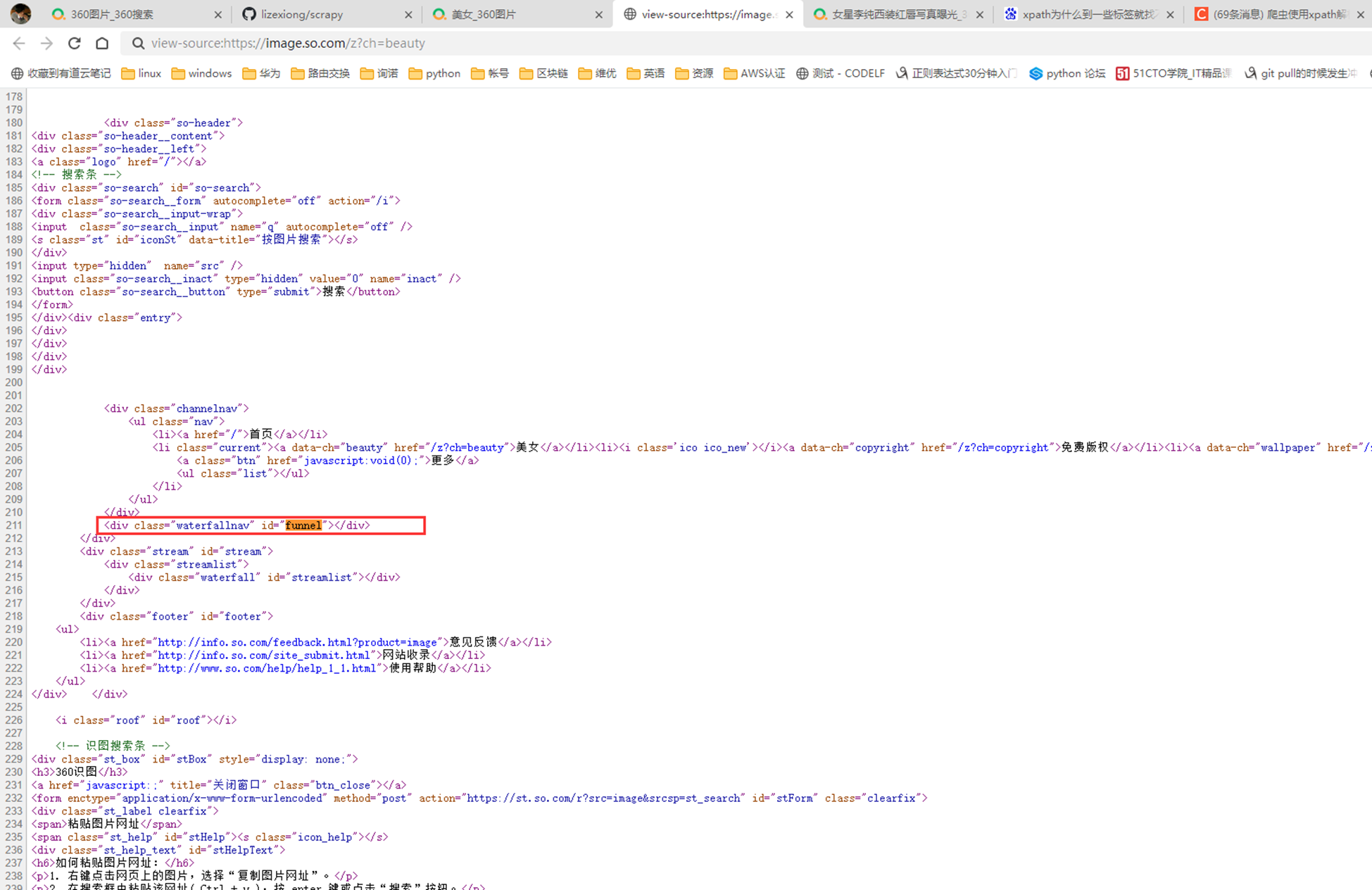
整个网页都没有li标签。虽然这个实验坐不了,但是老师的源码思路还是保留一份。
这里也记录一下为什么xpath定位不到的原因。
在写爬虫的时候解析网页,使用最多的解析方式就是xpath解析,但是在使用在使用xpath解析的时候,明明自己写的xpath语句正确,但是返回值还是为空
原因通常是前端做的一些反爬措施,在编写网页的时候通常省略一层标签,但是被省略的标签浏览器会自动补充,修改成正确的结构。。
我们通过浏览器进行检查的时候,看到的代码结构是已经被浏览器修改后的,而爬虫获取到的是源代码
所以根据修改后的xpath解析源代码会找不到相应的元素,返回值自然为空
举例
浏览器修改后的代码
xpath语句'/html/body/div[5]/div[3]/div[2]/table/tbody/tr[1]/td[2]/a/@href'
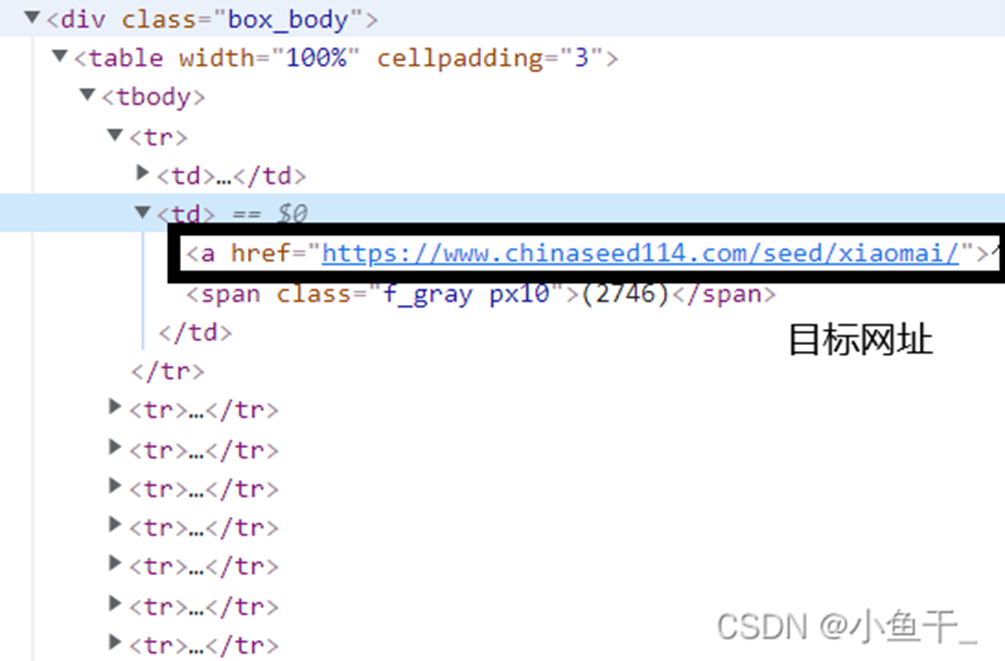
源码
缺少一个tbody标签,
xpath/html/body/div[5]/div[3]/div[2]/table/tr[1]/td[2]/a/@href 将tbody删除

总结 当使用xpath获取不到向相应的元素的时候,观察一下源码结构,根据源码进行解析。
而我们的环境更苛刻,整个网页都是动态生成的,根本爬不了。
Giithub自动登录参考: https://blog.csdn.net/qq_63713328/article/details/127779889
Xpath定位不到的原因参考:https://blog.csdn.net/qq_52007481/article/details/124353861

