Python3之sqlalchemy
1.SQLAlchemy介绍
SQLAlchemy是Python中一款非常优秀的ORM框架,它可以与任意的第三方web框架相结合,如flask、tornado、django、fastapi等。
SQLALchemy相较于Django ORM来说更贴近原生的SQL语句,因此学习难度较低。
ORM 全称 Object Relational Mapping, 翻译过来叫对象关系映射。简单的说,ORM 将数据库中的表与面向对象语言中的类建立了一种对应关系。这样,我们要操作数据库,数据库中的表或者表中的一条记录就可以直接通过操作类或者类实例来完成。SQLAlchemy 是Python 社区最知名的 ORM 工具之一,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。
ORM对主流的数据库普遍支持:MySQL,Oracle,SqlServer,PostgreSQL,SQLite3。
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
说明:
SQLAchemy 本身无法操作数据库,其本质上是依赖pymysql.MySQLdb,mssql等第三方插件。
Dialect用于和数据库API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作。
SQLALchemy由以下5个部分组成:
- Engine:框架引擎
- Connection Pooling:数据库链接池
- Dialect:数据库DB API种类
- Schema/Types:数据库架构类型
- SQL Exprression Language:SQL表达式语言
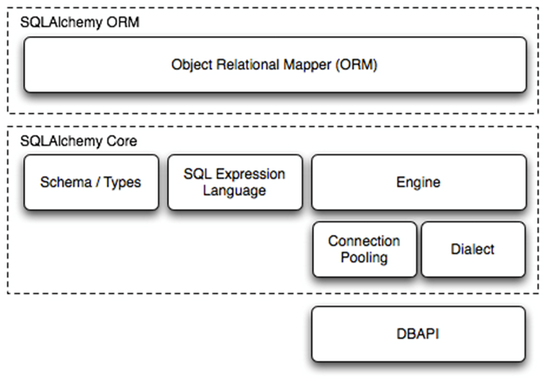
运行流程:
- 首先用户输入的操作会交由ORM对象
- 接下来ORM对象会将用户操作提交给SQLALchemy Core
- 其次该操作会由Schema/Types以及SQL Expression Language转换为SQL语句
- 然后Egine会匹配用户已经配置好的egine,并从链接池中去取出一个链接
- 最终该链接会通过Dialect调用DBAPI,将SQL语句转交给DBAPI去执行
下载SQLALchemy:
pip3 install sqlalchemy
值得注意的是,SQLAlchemy必须依赖其他操纵数据库的模块才能进行使用,也就是上面提到的DBAPI。
SQLAlchemy配合DBAPI使用时,链接字符串也有所不同,如下所示:
MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
2.Sqlalchemy基础操作
2.1 连接引擎
任何SQLAlchemy应用程序的开始都是一个Engine对象,此对象充当连接到特定数据库的中心源,提供被称为connection pool的对于这些数据库连接。
Engine对象通常是一个只为特定数据库服务器创建一次的全局对象,并使用一个URL字符串进行配置,该字符串将描述如何连接到数据库主机或后端。
from sqlalchemy import create_engine engine = create_engine( "mysql+pymysql://root:huawei@127.0.0.1:3306/lizexiong?charset=utf8mb4", )
create_engine的参数有很多,我列一些比较常用的:
- echo=False -- 如果为真,引擎将记录所有语句以及 repr() 其参数列表的默认日志处理程序。
- enable_from_linting -- 默认为True。如果发现给定的SELECT语句与将导致笛卡尔积的元素取消链接,则将发出警告。
- encoding -- 默认为 utf-8
- future -- 使用2.0样式
- hide_parameters -- 布尔值,当设置为True时,SQL语句参数将不会显示在信息日志中,也不会格式化为 StatementError 对象。
- listeners -- 一个或多个列表 PoolListener 将接收连接池事件的对象。
- logging_name -- 字符串标识符,默认为对象id的十六进制字符串。
- max_identifier_length -- 整数;重写方言确定的最大标识符长度。
- max_overflow=10 -- 允许在连接池中“溢出”的连接数,即可以在池大小设置(默认为5)之上或之外打开的连接数。
- pool_size=5 -- 在连接池中保持打开的连接数
- plugins -- 要加载的插件名称的字符串列表。
2.2 连接会话
创建了数据库连接引擎对象之后,我们需要获取和指定数据库之间的连接,通过连接进行数据库中数据的增删改查操作,和数据库的连接我们称之为和指定数据库之间的会话,通过指定的一个模块
sqlalchemy.sessionmaker进行创建 # 引入创建session连接会话需要的处理模块 from sqlalchemy.orm import sessionmaker # 创建一个连接会话对象;需要指定是和那个数据库引擎之间的会话 Session = sessionmaker(bind=engine) session = Session() # 接下来~就可以用过session会话进行数据库的数据操作了。
2.3 ORM之Object操作
我们的程序中的对象要使用sqlalchemy的管理,实现对象的orm操作,就需要按照框架指定的方式进行类型的创建操作,sqlalchemy封装了基础类的声明操作和字段属性的定义限制方式,开发人员要做的事情就是引入需要的模块并在创建对象的时候使用它们即可
基础类封装在sqlalchemy.ext.declarative.declarative_base模块中
字段属性的定义封装在sqlalchemy模块中,通过sqlalchemy.Column定义属性,通过封装的Integer、String、Float等定义属性的限制
2.3.1 基础类
创建基础类的方式如下:
# 引入需要的模块 from sqlalchemy.ext.declarative import declarative_base # 创建基础类 BaseModel = declarative_base()
2.3.2 数据类型创建
创建数据模型的操作
# 引入需要的模块 from sqlalchemy import Column, String, Integer # 创建用户类型 class User(BaseModel): # 定义和指定数据库表之间的关联 __tabelname__ = “user” # 创建字段类型 id = Column(Integer, primary_key=True) name = Column(String(50)) age = Column(Integer)
PS:定义的数据类型必须继承自之前创建的BaseModel,同时通过指定tablename确定和数据库中某个数据表之间的关联关系,指定某列类型为primary_key设定的主键,其他就是通过Column指定的自定义属性了。
sqlalchemy会根据指定的tablename和对应的Column列字段构建自己的accessors访问器对象,这个过程可以成为instrumentation,经过instrumentation映射的类型既可以进行数据库中数据的操作了。
2.3.3 数据类型映射操作
完成了类的声明定义之后,Declarative会通过python的metaclass对当前类型进行操作,根据定义的数据类型创建table对象,构建程序中类型和数据库table对象之间的映射mapping关系
通过类型对象的metadata可以实现和数据库之间的交互,有需要时可以通过metadata发起create table操作,通过Base.metadata.create_all()进行操作,该操作会检查目标数据库中是否有需要创建的表,不存在的情况下创建对应的表
if __name__ == “__main__”: Base.metadata.create_all()
2.4 增加和更新
下面就是核心的数据对象的处理了,在程序代码中根据定义的数据类型创建对象的方式比较简单,执行如下的操作创建一个对象:
$ user = User(name=”lizexiong”, age=18) $ print(user.name) lizexiong $ print(user.id) None
通过会话对象将对象数据持久化到数据库的操作
$ session.add(user) $ print(user.id) None $ session.commit() $ print(user.id) 1
2.5 查询对象Query
Session是sqlalchemy和数据库交互的桥梁,Session提供了一个Query对象实现数据库中数据的查询操作
2.5.1 常规查询query
直接指定类型进行查询
user_list = session.query(User) for user in user_list: print(user.name)
2.5.2 指定排序查询
通过类型的属性指定排序方式
user_list = session.query(User).order_by(User.id) # 默认顺序 user_list = session.query(User).order_by(-User.id) # 指定倒序 user_list = session.query(User).order_by(-User.id, User.name) # 多个字段
2.5.3 指定列查询
指定查询数据对象的属性,查询目标数据
user_list = session.query(User, User.name).all() for u in user_list: print(u.User, u.name)
2.5.4 指定列属性别名
对于名称较长的字段属性,可以指定名称在使用时简化操作
user_list = session.query(Usre.name.label(‘n’)).all() for user in user_list: print(user.n)
2.5.5 指定类型别名
对于类型名称较长的情况,同样可以指定别名进行处理
from sqlalchemy.orm import aliased user_alias = aliased(User, name=’u_alias’) user_list = session.query(u_alias, u_alias.name).all() for u in user_list: print(u.u_alias, u.name)
2.5.6 切片查询
对于经常用于分页操作的切片查询,在使用过程中直接使用python内置的切片即可
user_list = session.query(User).all()[1:3]
2.6 条件筛选filter
前一节中主要是对于数据查询对象query有一个比较直观的感受和操作,在实际使用过程中经常用到条件查询,主要通过filter和filter_by进行操作,重点讲解使用最为频繁的filter条件筛选函数
2.6.1 等值条件——equals / not equals
# equals session.query(User).filter(User.id == 1) # 相等判断 # not equals session.query(User).filter(User.name != ‘tom’)# 不等判断
2.6.2 模糊条件——like
session.query(User).filter(User.name.like(‘%tom%’))
2.6.3 范围条件——in / not in
# IN session.query(User).filter(User.id.in_([1,2,3,4])) session.query(User).filter(User.name.in_([ session.query(User.name).filter(User.id.in_[1,2,3,4]) ])) # NOT IN session.query(User).filter(~User.id.in_([1,2,3]))
2.6.4 空值条件——is null / is not null
# IS NULL session.query(User).filter(User.name == None) session.query(User).filter(User.name.is_(None)) # pep8 # IS NOT NULL session.query(User).filter(User.name != None) session.query(User).filter(User.name.isnot(None)) # pep8
2.6.5 并且条件——AND
from sqlalchemy import and_ session.query(User).filter(User.name=’tom’).filter(User.age=12) session.query(User).filter(User.name=’tom’, User.age=12) session.query(User).filter(and_(User.name=’tom’, User.age=12))
2.6.6 或者条件——OR
from sqlalchemy import or_ session.query(User).filter(or_(User.name=’tom’, User.name=’jerry’))
2.6.7 SQL语句查询
某些特殊情况下,我们也可能在自己的程序中直接使用sql语句进行操作
from sqlalchemy import text session.query(User).from_statement( text(‘select * from users where name=:name and age=:age’)) .params(name=’tom’, age=12).all()
2.7 查询结果
2.7.1 all()函数返回查询列表
session.query(User).all()
[..]
2.7.2 filter()函数返回单项数据的列表生成器
session.query(User).filter(..)
<..>
2.7.3 one()/one_or_none()/scalar()返回单独的一个数据对象
session.query(User).filter(..).one()/one_or_none()/scalar()
3.实例操作
第二章讲解了许多理论,这里用一些真实案例来加深一下印象
3.1 创建和修改
3.1.1 创建单表
SQLAlchemy不允许修改表结构,如果需要修改表结构则必须删除旧表,再创建新表,或者执行原生的SQL语句ALERT TABLE进行修改。
这意味着在使用非原生SQL语句修改表结构时,表中已有的所有记录将会丢失,所以我们最好一次性的设计好整个表结构避免后期修改:
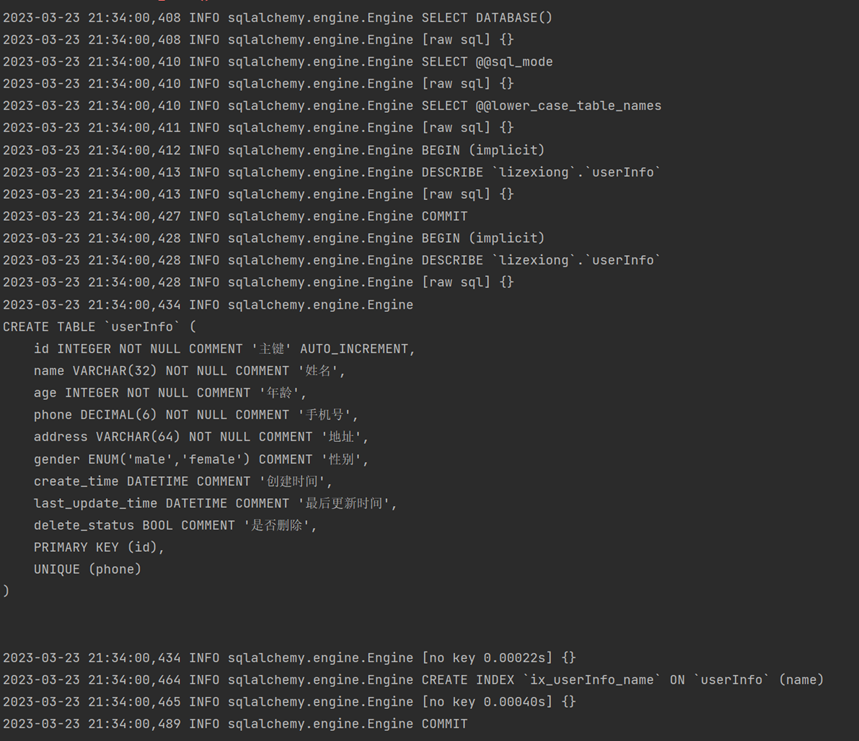
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/23 21:10 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : models.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm import datetime from sqlalchemy.orm import sessionmaker from sqlalchemy.orm import scoped_session from sqlalchemy import ( create_engine, Column, Integer, String, Enum, DECIMAL, DateTime, Boolean, UniqueConstraint, Index ) from sqlalchemy.ext.declarative import declarative_base # 基础类 Base = declarative_base() ''' echo=False -- 如果为真,引擎将记录所有语句以及 repr() 其参数列表的默认日志处理程序。 enable_from_linting -- 默认为True。如果发现给定的SELECT语句与将导致笛卡尔积的元素取消链接,则将发出警告。 encoding -- 默认为 utf-8 future -- 使用2.0样式 hide_parameters -- 布尔值,当设置为True时,SQL语句参数将不会显示在信息日志中,也不会格式化为 StatementError 对象。 listeners -- 一个或多个列表 PoolListener 将接收连接池事件的对象。 logging_name -- 字符串标识符,默认为对象id的十六进制字符串。 max_identifier_length -- 整数;重写方言确定的最大标识符长度。 max_overflow=10 -- 允许在连接池中“溢出”的连接数,即可以在池大小设置(默认为5)之上或之外打开的连接数。 pool_size=5 -- 在连接池中保持打开的连接数 plugins -- 要加载的插件名称的字符串列表。 ''' # 创建引擎 engine = create_engine( "mysql+pymysql://root:huawei@127.0.0.1:3306/lizexiong?charset=utf8mb4", # "mysql+pymysql://root@127.0.0.1:3306/lizexiong?charset=utf8mb4", # 无密码时 # 超过链接池大小外最多创建的链接 max_overflow=0, # 链接池大小 pool_size=5, # 链接池中没有可用链接则最多等待的秒数,超过该秒数后报错 pool_timeout=10, # 多久之后对链接池中的链接进行一次回收 pool_recycle=1, # 查看原生语句(未格式化),如果为真,引擎将记录所有语句以及 repr() 其参数列表的默认日志处理程序。 echo=True ) # 绑定引擎 Session = sessionmaker(bind=engine) # 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象conn # 内部会采用threading.local进行隔离 session = scoped_session(Session) class UserInfo(Base): """ 必须继承Base """ # 数据库中存储的表名 __tablename__ = "userInfo" # 对于必须插入的字段,采用nullable=False进行约束,它相当于NOT NULL id = Column(Integer, primary_key=True, autoincrement=True, comment="主键") name = Column(String(32), index=True, nullable=False, comment="姓名") age = Column(Integer, nullable=False, comment="年龄") phone = Column(DECIMAL(6), nullable=False, unique=True, comment="手机号") address = Column(String(64), nullable=False, comment="地址") # 对于非必须插入的字段,不用采取nullable=False进行约束 gender = Column(Enum("male", "female"), default="male", comment="性别") create_time = Column( DateTime, default=datetime.datetime.now, comment="创建时间") last_update_time = Column( DateTime, onupdate=datetime.datetime.now, comment="最后更新时间") delete_status = Column(Boolean(), default=False, comment="是否删除") __table__args__ = ( UniqueConstraint("name", "age", "phone"), # 联合唯一约束 Index("name", "addr", unique=True), # 联合唯一索引 ) #这个地方的使用查看原生sql章节 def __str__(self): return f"object : <id:{self.id} name:{self.name}>" #执行的时候可以在终端看到返回的字段变量 def __repr__(self): #return "执行的时候返回自定义字段测试" return f"object : <id:{self.id} name:{self.name}>" if __name__ == "__main__": # 删除表 Base.metadata.drop_all(engine) # 创建表 Base.metadata.create_all(engine)
查看执行后输出
3.1.2 新增记录
新增单条记录:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 11:48 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : NewRecord.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models user_instance = models.UserInfo( name="Jack", age=18, phone=330621, address="Beijing", gender="male" ) models.session.add(user_instance) # 提交 models.session.commit() # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.1.3 批量新增
批量新增能减少TCP链接次数,提升插入性能:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 12:20 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : BatchAddition.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models user_instance1 = models.UserInfo( name="Tom", age=19, phone=330624, address="Shanghai", gender="male" ) user_instance2 = models.UserInfo( name="Mary", age=20, phone=330623, address="Chongqing", gender="female" ) models.session.add_all( ( user_instance1, user_instance2 ) ) # 提交 models.session.commit() # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.1.4 修改记录
修改某些记录:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 12:25 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : ModificationRecord.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models # 修改的信息: # - Jack -> Jack + son # 在SQLAlchemy中,四则运算符号只能用于数值类型 # 如果是字符串类型需要在原本的基础值上做改变,必须设置 # - age -> age + 1 # synchronize_session=False models.session.query(models.UserInfo)\ .filter_by(name="Jack")\ .update( { "name": models.UserInfo.name + "son", "age": models.UserInfo.age + 1 }, synchronize_session=False ) # 本次修改具有字符串字段在原值基础上做更改的操作,所以必须添加 # synchronize_session=False # 如果只修改年龄,则不用添加 # 提交 models.session.commit() # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.1.5 删除记录
删除记录用的比较少,了解即可,一般都是像上面那样增加一个delete_status的字段,如果为1则代表删除:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 12:28 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : DeleteRecord.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models models.session.query(models.UserInfo).filter_by(name="Mary").delete() # 提交 models.session.commit() # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2 单表查询
3.2.1 单表查询
基本查询
查所有记录、所有字段,all()方法将返回一个列表,内部包裹着每一行的记录对象:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 12:42 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : SingleTableQuery.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query(models.UserInfo).all() print(result) # [<models.UserInfo object at 0x7f4d3d606fd0>, <models.UserInfo object at 0x7f4d3d606f70>] for row in result: print(row) # object : <id:1 name:Jackson> # object : <id:2 name:Tom> # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
查所有记录、某些字段(注意,下面返回的元组实际上是一个命名元组,可以直接通过.操作符进行操作):
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 12:45 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : SingleTableQuery2.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo.id, models.UserInfo.name, models.UserInfo.age ).all() print(result) # [(1, 'Jackson', 19), (2, 'Tom', 19)] for row in result: print(row) # (1, 'Jackson', 19) # (2, 'Tom', 19) # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
只拿第一条记录,first()方法将返回单条记录对象(注意,下面返回的元组实际上是一个命名元组,可以直接通过.操作符进行操作):
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 12:46 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : SingleTableQuery3.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo.id, models.UserInfo.name, models.UserInfo.age ).first() print(result) # (1, 'Jackson', 19) # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2.2 AS别名——label
通过字段的label()方法,我们可以为它取一个别名:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 12:51 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : Alias.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo.name.label("s_name"), models.UserInfo.age.label("s_age") ).all() for row in result: print(row.s_name) print(row.s_age) # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2.3 条件查询——AND-OR
一个条件的过滤:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 13:58 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : ConditionQuery.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo, ).filter( models.UserInfo.name == "Jackson" ).all() # 上面是Python语句形式的过滤条件,由filter方法调用 # 亦可以使用ORM的形式进行过滤,通过filter_by方法调用 # 如下所示 # .filter_by(name="Jackson").all() # 个人更推荐使用filter过滤,它看起来更直观,更简单,可以支持 == != > < >= <=等常见符号 # 过滤成功的结果数量 print(len(result)) # 1 # 过滤成功的结果 print(result) # [<models.UserInfo object at 0x7f11391ea2b0>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
AND查询:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:00 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : ConditionQueryAnd.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models # 导入AND from sqlalchemy import and_ result = models.session.query( models.UserInfo, ).filter( and_( models.UserInfo.name == "Jackson", models.UserInfo.gender == "male" ) ).all() # 过滤成功的结果数量 print(len(result)) # 1W # 过滤成功的结果Q print(result) # [<models.UserInfo object at 0x7f11391ea2b0>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
OR查询:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:02 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : ConditionQueryOr.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models # 导入OR from sqlalchemy import or_ result = models.session.query( models.UserInfo, ).filter( or_( models.UserInfo.name == "Jackson", models.UserInfo.gender == "male" ) ).all() # 过滤成功的结果数量 print(len(result)) # 1 # 过滤成功的结果 print(result) # [<models.UserInfo object at 0x7f11391ea2b0>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
NOT查询:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:03 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : ConditionQueryNot.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models # 导入NOT from sqlalchemy import not_ result = models.session.query( models.UserInfo, ).filter( not_( models.UserInfo.name == "Jackson", ) ).all() # 过滤成功的结果数量 print(len(result)) # 1 # 过滤成功的结果 print(result) # [<models.UserInfo object at 0x7f11391ea2b0>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2.4 范围查询——BETWEEN
BETWEEN查询:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:05 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : RangeQueryBetween.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo, ).filter( models.UserInfo.age.between(15, 21) ).all() # 过滤成功的结果数量 print(len(result)) # 1 # 过滤成功的结果 print(result) # [<models.UserInfo object at 0x7f11391ea2b0>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2.5 包含查询——In-NotIn
IN查询:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:06 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : InclusionQueryIn.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo, ).filter( models.UserInfo.age.in_((18, 19, 20)) ).all() # 过滤成功的结果数量 print(len(result)) # 2 # 过滤成功的结果 print(result) # [<models.UserInfo object at 0x7fdeeaa774f0>, <models.UserInfo object at 0x7fdeeaa77490>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
NOT IN,只需要加上~即可:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:08 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : InclusionQueryNotIn.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo, ).filter( ~models.UserInfo.age.in_((18, 19, 20)) ).all() # 过滤成功的结果数量 print(len(result)) # 0 # 过滤成功的结果 print(result) # [] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2.6 模糊匹配——like
LIKE查询:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:10 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : FuzzyQueryLike.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo, ).filter( models.UserInfo.name.like("Jack%") ).all() # 过滤成功的结果数量 print(len(result)) # 1 # 过滤成功的结果 print(result) # [<models.UserInfo object at 0x7fee1614f4f0>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2.7 分页查询
对结果all()返回的列表进行一次切片即可:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:12 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : PagingQuery.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo, ).all()[0:1] # 过滤成功的结果数量 print(len(result)) # 1 # 过滤成功的结果 print(result) # [<models.UserInfo object at 0x7fee1614f4f0>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2.8 排序查询——sort
ASC升序、DESC降序,需要指定排序规则:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:14 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : SortQuery.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.UserInfo, ).filter( models.UserInfo.age > 12 ).order_by( models.UserInfo.age.desc() ).all() # 过滤成功的结果数量 print(len(result)) # 2 # 过滤成功的结果 print(result) # [<models.UserInfo object at 0x7f90eccd26d0>, <models.UserInfo object at 0x7f90eccd2670>] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.2.9 聚合分组
聚合分组与having过滤:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:15 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : AggregateQuery.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models # 导入聚合函数 from sqlalchemy import func result = models.session.query( func.sum(models.UserInfo.age) ).group_by( models.UserInfo.gender ).having( func.sum(models.UserInfo.id > 1) ).all() # 过滤成功的结果数量 print(len(result)) # 1 # 过滤成功的结果 print(result) # [(Decimal('38'),)] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.3 多表操作
3.3.1 多表创建
五表关系:
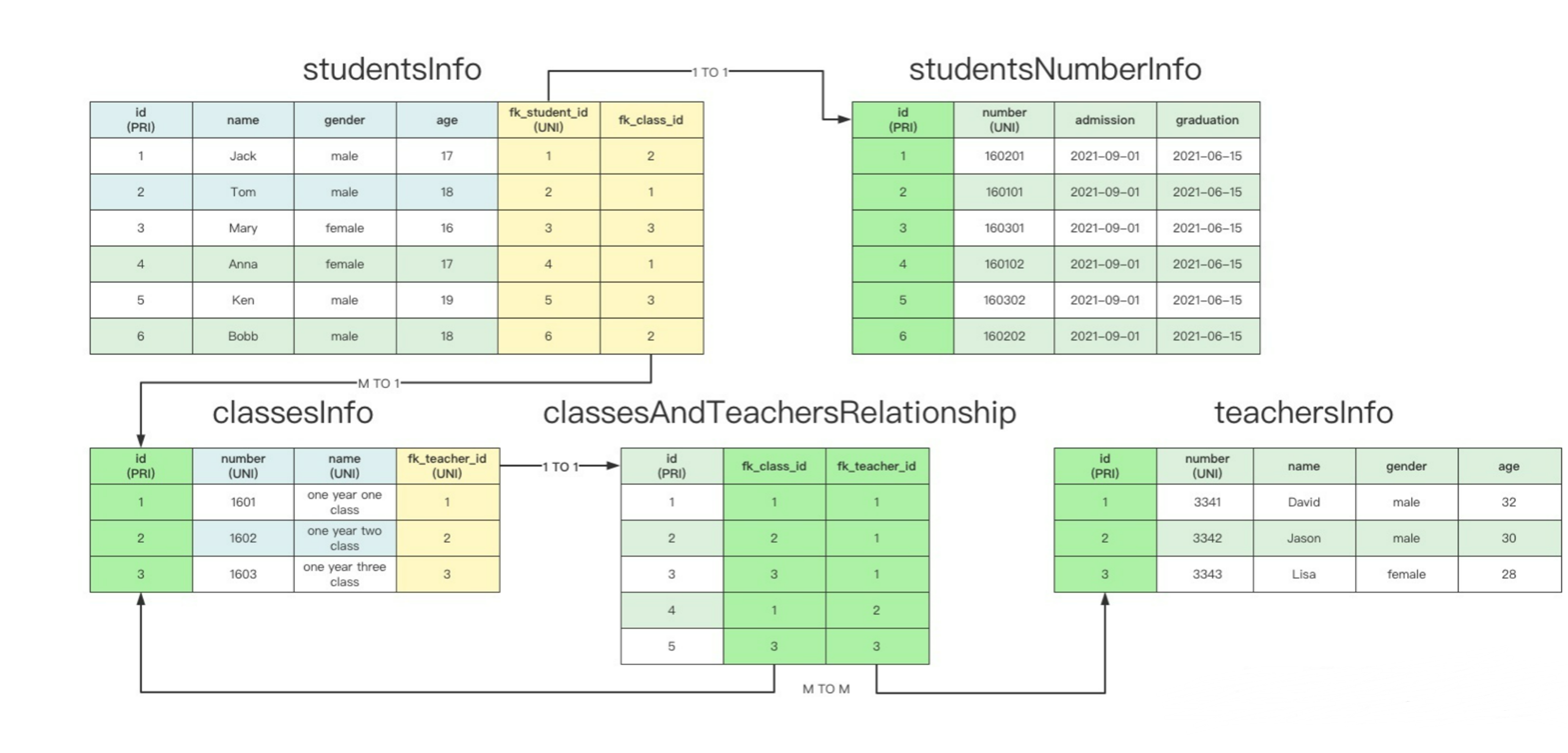
建表语句:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 14:34 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : models.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm from sqlalchemy.orm import sessionmaker from sqlalchemy.orm import scoped_session from sqlalchemy.orm import relationship from sqlalchemy import ( create_engine, Column, Integer, Date, String, Enum, ForeignKey, UniqueConstraint, ) from sqlalchemy.ext.declarative import declarative_base # 基础类 Base = declarative_base() # 创建引擎 engine = create_engine( "mysql+pymysql://root:huawei@127.0.0.1:3306/lizexiong?charset=utf8mb4", # "mysql+pymysql://tom@127.0.0.1:3306/db1?charset=utf8mb4", # 无密码时 # 超过链接池大小外最多创建的链接 max_overflow=0, # 链接池大小 pool_size=5, # 链接池中没有可用链接则最多等待的秒数,超过该秒数后报错 pool_timeout=10, # 多久之后对链接池中的链接进行一次回收 pool_recycle=1, # 查看原生语句 # echo=True ) # 绑定引擎 Session = sessionmaker(bind=engine) # 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象 # 内部会采用threading.local进行隔离 session = scoped_session(Session) class StudentsNumberInfo(Base): """学号表""" __tablename__ = "studentsNumberInfo" id = Column(Integer, primary_key=True, autoincrement=True, comment="主键") number = Column(Integer, nullable=False, unique=True, comment="学生编号") admission = Column(Date, nullable=False, comment="入学时间") graduation = Column(Date, nullable=False, comment="毕业时间") class TeachersInfo(Base): """教师表""" __tablename__ = "teachersInfo" id = Column(Integer, primary_key=True, autoincrement=True, comment="主键") number = Column(Integer, nullable=False, unique=True, comment="教师编号") name = Column(String(64), nullable=False, comment="教师姓名") gender = Column(Enum("male", "female"), nullable=False, comment="教师性别") age = Column(Integer, nullable=False, comment="教师年龄") class ClassesInfo(Base): """班级表""" __tablename__ = "classesInfo" id = Column(Integer, primary_key=True, autoincrement=True, comment="主键") number = Column(Integer, nullable=False, unique=True, comment="班级编号") name = Column(String(64), nullable=False, unique=True, comment="班级名称") # 一对一关系必须为连接表的连接字段创建UNIQUE的约束,这样才能是一对一,否则是一对多 fk_teacher_id = Column( Integer, ForeignKey( "teachersInfo.id", ondelete="CASCADE", onupdate="CASCADE", ), nullable=False, unique=True, comment="班级负责人" ) # 下面这2个均属于逻辑字段,适用于正反向查询。在使用ORM的时候,我们不必每次都进行JOIN查询,而恰好正反向的查询使用频率会更高 # 这种逻辑字段不会在物理层面上创建,它只适用于查询,本身不占据任何数据库的空间 # sqlalchemy的正反向概念与Django有所不同,Django是外键字段在那边,那边就作为正 # 而sqlalchemy是relationship字段在那边,那边就作为正 # 比如班级表拥有 relationship 字段,而老师表不曾拥有 # 那么用班级表的这个relationship字段查老师时,就称为正向查询 # 反之,如果用老师来查班级,就称为反向查询 # 另外对于这个逻辑字段而言,根据不同的表关系,创建的位置也不一样: # - 1 TO 1:建立在任意一方均可,查询频率高的一方最好 # - 1 TO M:建立在M的一方 # - M TO M:中间表中建立2个逻辑字段,这样任意一方都可以先反向,再正向拿到另一方 # - 遵循一个原则,ForeignKey建立在那个表上,那个表上就建立relationship # - 有几个ForeignKey,就建立几个relationship # 总而言之,使用ORM与原生SQL最直观的区别就是正反向查询能带来更高的代码编写效率,也更加简单 # 甚至我们可以不用外键约束,只创建这种逻辑字段,让表与表之间的耦合度更低,但是这样要避免脏数据的产生 # 班级负责人,这里是一对一关系,一个班级只有一个负责人 leader_teacher = relationship( # 正向查询时所链接的表,当使用 classesInfo.leader_teacher 时,它将自动指向fk的那一条记录 "TeachersInfo", # 反向查询时所链接的表,当使用 teachersInfo.leader_class 时,它将自动指向该老师所管理的班级 backref="leader_class", ) class ClassesAndTeachersRelationship(Base): """任教老师与班级的关系表""" __tablename__ = "classesAndTeachersRelationship" id = Column(Integer, primary_key=True, autoincrement=True, comment="主键") # 中间表中注意不要设置单列的UNIQUE约束,否则就会变为一对一 fk_teacher_id = Column( Integer, ForeignKey( "teachersInfo.id", ondelete="CASCADE", onupdate="CASCADE", ), nullable=False, comment="教师记录" ) fk_class_id = Column( Integer, ForeignKey( "classesInfo.id", ondelete="CASCADE", onupdate="CASCADE", ), nullable=False, comment="班级记录" ) # 多对多关系的中间表必须使用联合唯一约束,防止出现重复数据 __table_args__ = ( UniqueConstraint("fk_teacher_id", "fk_class_id"), ) # 逻辑字段 # 给班级用的,查看所有任教老师 mid_to_teacher = relationship( "TeachersInfo", backref="mid", ) # 给老师用的,查看所有任教班级 mid_to_class = relationship( "ClassesInfo", backref="mid" ) class StudentsInfo(Base): """学生信息表""" __tablename__ = "studentsInfo" id = Column(Integer, primary_key=True, autoincrement=True, comment="主键") name = Column(String(64), nullable=False, comment="学生姓名") gender = Column(Enum("male", "female"), nullable=False, comment="学生性别") age = Column(Integer, nullable=False, comment="学生年龄") # 外键约束 # 一对一关系必须为连接表的连接字段创建UNIQUE的约束,这样才能是一对一,否则是一对多 fk_student_id = Column( Integer, ForeignKey( "studentsNumberInfo.id", ondelete="CASCADE", onupdate="CASCADE" ), nullable=False, comment="学生编号" ) # 相比于一对一,连接表的连接字段不用UNIQUE约束即为多对一关系 fk_class_id = Column( Integer, ForeignKey( "classesInfo.id", ondelete="CASCADE", onupdate="CASCADE" ), comment="班级编号" ) # 逻辑字段 # 所在班级, 这里是一对多关系,一个班级中可以有多名学生 from_class = relationship( "ClassesInfo", backref="have_student", ) # 学生学号,这里是一对一关系,一个学生只能拥有一个学号 number_info = relationship( "StudentsNumberInfo", backref="student_info", ) if __name__ == "__main__": # 删除表 Base.metadata.drop_all(engine) # 创建表 Base.metadata.create_all(engine)
3.3.2 插入数据
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 15:06 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : InsertData.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models import datetime models.session.add_all( ( # 插入学号表数据 models.StudentsNumberInfo( number=160201, admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)), graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15)) ), models.StudentsNumberInfo( number=160101, admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)), graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15)) ), models.StudentsNumberInfo( number=160301, admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)), graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15)) ), models.StudentsNumberInfo( number=160102, admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)), graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15)) ), models.StudentsNumberInfo( number=160302, admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)), graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15)) ), models.StudentsNumberInfo( number=160202, admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)), graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15)) ), # 插入教师表数据 models.TeachersInfo( number=3341, name="David", gender="male", age=32, ), models.TeachersInfo( number=3342, name="Jason", gender="male", age=30, ), models.TeachersInfo( number=3343, name="Lisa", gender="female", age=28, ), # 插入班级表数据 models.ClassesInfo( number=1601, name="one year one class", fk_teacher_id=1 ), models.ClassesInfo( number=1602, name="one year two class", fk_teacher_id=2 ), models.ClassesInfo( number=1603, name="one year three class", fk_teacher_id=3 ), # 插入中间表数据 models.ClassesAndTeachersRelationship( fk_class_id=1, fk_teacher_id=1 ), models.ClassesAndTeachersRelationship( fk_class_id=2, fk_teacher_id=1 ), models.ClassesAndTeachersRelationship( fk_class_id=3, fk_teacher_id=1 ), models.ClassesAndTeachersRelationship( fk_class_id=1, fk_teacher_id=2 ), models.ClassesAndTeachersRelationship( fk_class_id=3, fk_teacher_id=3 ), # 插入学生表数据 models.StudentsInfo( name="Jack", gender="male", age=17, fk_student_id=1, fk_class_id=2 ), models.StudentsInfo( name="Tom", gender="male", age=18, fk_student_id=2, fk_class_id=1 ), models.StudentsInfo( name="Mary", gender="female", age=16, fk_student_id=3, fk_class_id=3 ), models.StudentsInfo( name="Anna", gender="female", age=17, fk_student_id=4, fk_class_id=1 ), models.StudentsInfo( name="Bobby", gender="male", age=18, fk_student_id=6, fk_class_id=2 ), ) ) models.session.commit() # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.3.3 JOIN查询
INNER JOIN:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 15:09 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : INNERJOIN.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models result = models.session.query( models.StudentsInfo.name, models.StudentsNumberInfo.number, models.ClassesInfo.number ).join( models.StudentsNumberInfo, models.StudentsInfo.fk_student_id == models.StudentsNumberInfo.id ).join( models.ClassesInfo, models.StudentsInfo.fk_class_id == models.ClassesInfo.id ).all() print(result) # [('Jack', 160201, 1602), ('Tom', 160101, 1601), ('Mary', 160301, 1603), ('Anna', 160102, 1601), ('Bobby', 160202, 1602)] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
LEFT JOIN只需要在每个JOIN中指定isouter关键字参数为True即可:
session.query( 左表.字段, 右表.字段 ) .join( 右表, 链接条件, isouter=True ).all()
RIGHT JOIN需要换表的位置,SQLALchemy本身并未提供RIGHT JOIN,所以使用时一定要注意驱动顺序,小表驱动大表(如果不注意顺序,MySQL优化器内部也会优化):
session.query( 左表.字段, 右表.字段 ) .join( 左表, 链接条件, isouter=True ).all()
3.3.4 UNION&UNION ALL
将多个查询结果联合起来,必须使用filter(),后面不加all()方法。
因为all()会返回一个列表,而filter()返回的是一个<class 'sqlalchemy.orm.query.Query'>查询对象,此外,必须单拿某一个字段,不能不指定字段直接query():
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 15:13 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : union.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models students_name = models.session.query(models.StudentsInfo.name).filter() students_number = models.session.query(models.StudentsNumberInfo.number)\ .filter() class_name = models.session.query(models.ClassesInfo.name).filter() result = students_name.union_all(students_number).union_all(class_name) print(result.all()) # [ # ('Jack',), ('Tom',), ('Mary',), ('Anna',), ('Bobby',), # ('160101',), ('160102',), ('160201',), ('160202',), ('160301',), ('160302',), # ('one year one class',), ('one year three class',), ('one year two class',) # ] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.3.5 子查询
子查询使用subquery()实现,如下所示,查询每个班级中年龄最小的人:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 15:14 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : SubQuery.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 获取链接池、ORM表对象 import models from sqlalchemy import func # 子查询中所有字段的访问都需要加上c的前缀 # 如 sub_query.c.id、 sub_query.c.name等 sub_query = models.session.query( # 使用label()来为字段AS一个别名 # 后续访问需要通过sub_query.c.alias进行访问 func.min(models.StudentsInfo.age).label("min_age"), models.ClassesInfo.id, models.ClassesInfo.name ).join( models.ClassesInfo, models.StudentsInfo.fk_class_id == models.ClassesInfo.id ).group_by( models.ClassesInfo.id ).subquery() result = models.session.query( models.StudentsInfo.name, sub_query.c.min_age, sub_query.c.name ).join( sub_query, sub_query.c.id == models.StudentsInfo.fk_class_id ).filter( sub_query.c.min_age == models.StudentsInfo.age ) print(result.all()) # [('Jack', 17, 'one year two class'), ('Mary', 16, 'one year three class'), ('Anna', 17, 'one year one class')] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3.3.6 正反查询
上面我们都是通过JOIN进行查询的,实际上我们也可以通过逻辑字段relationship进行查询。
下面是正向查询的示例,正向查询是指从有relationship逻辑字段的表开始查询:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 15:16 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : ProsAndConsQuery.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 查询所有学生的所在班级,我们可以通过学生的from_class字段拿到其所在班级 # 另外,对于学生来说,班级只能有一个,所以have_student应当是一个对象 # 获取链接池、ORM表对象 import models students_lst = models.session.query( models.StudentsInfo ).all() for row in students_lst: print(f""" student name : {row.name} from : {row.from_class.name} """) # student name : Mary # from : one year three class # student name : Anna # from : one year one class # student name : Bobby # from : one year two class # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
下面是反向查询的示例,反向查询是指从没有relationship逻辑字段的表开始查询:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/3/24 15:19 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : ProsAndConsQuery2.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm # 查询所有班级中的所有学生,学生表中有relationship,并且它的backref为have_student,所以我们可以通过班级.have_student来获取所有学生记录 # 另外,对于班级来说,学生可以有多个,所以have_student应当是一个序列 # 获取链接池、ORM表对象 import models classes_lst = models.session.query( models.ClassesInfo ).all() for row in classes_lst: print("class name :", row.name) for student in row.have_student: print("student name :", student.name) # class name : one year one class # student name : Jack # student name : Anna # class name : one year two class # student name : Tom # class name : one year three class # student name : Mary # student name : Bobby # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
总结,正向查询的逻辑字段总是得到一个对象,反向查询的逻辑字段总是得到一个列表。
3.3.7 反向方法
使用逻辑字段relationship可以直接对一些跨表记录进行增删改查。
由于逻辑字段是一个类似于列表的存在(仅限于反向查询,正向查询总是得到一个对象),所以列表的绝大多数方法都能用。
<class 'sqlalchemy.orm.collections.InstrumentedList'> - append() - clear() - copy() - count() - extend() - index() - insert() - pop() - remove() - reverse() - sort()
下面不再进行实机演示,因为我们上面的几张表中做了很多约束。
# 比如 # 给老师增加班级 result = session.query(Teachers).first() # extend方法: result.re_class.extend([ Classes(name="三年级一班",), Classes(name="三年级二班",), ]) # 比如 # 减少老师所在的班级 result = session.query(Teachers).first() # 待删除的班级对象,集合查找比较快 delete_class_set = { session.query(Classes).filter_by(id=7).first(), session.query(Classes).filter_by(id=8).first(), } # 循换老师所在的班级 # remove方法: for class_obj in result.re_class: if class_obj in delete_class_set: result.re_class.remove(class_obj) # 比如 # 清空老师所任教的所有班级 # 拿出一个老师 result = session.query(Teachers).first() result.re_class.clear()
3.4 查询案例
1)查看每个班级共有多少学生:
JOIN查询:
# 获取链接池、ORM表对象 import models from sqlalchemy import func result = models.session.query( models.ClassesInfo.name, func.count(models.StudentsInfo.id) ).join( models.StudentsInfo, models.ClassesInfo.id == models.StudentsInfo.fk_class_id ).group_by( models.ClassesInfo.id ).all() print(result) # [('one year one class', 2), ('one year two class', 2), ('one year three class', 1)] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
正反查询:
# 获取链接池、ORM表对象 import models result = {} class_lst = models.session.query( models.ClassesInfo ).all() for row in class_lst: for student in row.have_student: count = result.setdefault(row.name, 0) result[row.name] = count + 1 print(result.items()) # dict_items([('one year one class', 2), ('one year two class', 2), ('one year three class', 1)]) # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
2)查看每个学生的入学、毕业年份以及所在的班级名称:
JOIN查询:
# 获取链接池、ORM表对象 import models result = models.session.query( models.StudentsNumberInfo.number, models.StudentsInfo.name, models.ClassesInfo.name, models.StudentsNumberInfo.admission, models.StudentsNumberInfo.graduation ).join( models.StudentsInfo, models.StudentsInfo.fk_class_id == models.ClassesInfo.id ).join( models.StudentsNumberInfo, models.StudentsNumberInfo.id == models.StudentsInfo.fk_student_id ).order_by( models.StudentsNumberInfo.number.asc() ).all() print(result) # [ # (160101, 'Tom', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)), # (160102, 'Anna', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)), # (160201, 'Jack', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)), # (160202, 'Bobby', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)), # (160301, 'Mary', 'one year three class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)) # ] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
正反查询:
# 获取链接池、ORM表对象 import models result = [] student_lst = models.session.query( models.StudentsInfo ).all() for row in student_lst: result.append(( row.number_info.number, row.name, row.from_class.name, row.number_info.admission, row.number_info.graduation )) print(result) # [ # (160101, 'Tom', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)), # (160102, 'Anna', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)), # (160201, 'Jack', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)), # (160202, 'Bobby', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)), # (160301, 'Mary', 'one year three class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)) # ] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
3)查看David所教授的学生中年龄最小的学生:
JOIN查询:
# 获取链接池、ORM表对象 import models result = models.session.query( models.TeachersInfo.name, models.StudentsInfo.name, models.StudentsInfo.age, models.ClassesInfo.name ).join( models.ClassesAndTeachersRelationship, models.ClassesAndTeachersRelationship.fk_class_id == models.ClassesInfo.id ).join( models.TeachersInfo, models.ClassesAndTeachersRelationship.fk_teacher_id == models.TeachersInfo.id ).join( models.StudentsInfo, models.StudentsInfo.fk_class_id == models.ClassesInfo.id ).filter( models.TeachersInfo.name == "David" ).order_by( models.StudentsInfo.age.asc(), models.StudentsInfo.id.asc() ).limit(1).all() print(result) # [('David', 'Mary', 16, 'one year three class')] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
正反查询:
# 获取链接池、ORM表对象 import models david = models.session.query( models.TeachersInfo ).filter( models.TeachersInfo.name == "David" ).first() student_lst = [] # 反向查询拿到任教班级,反向是一个列表,所以直接for for row in david.mid: cls = row.mid_to_class # 通过任教班级,反向拿到其下的所有学生 cls_students = cls.have_student # 遍历学生 for student in cls_students: student_lst.append( ( david.name, student.name, student.age, cls.name ) ) # 筛选出年龄最小的 min_age_student_lst = sorted( student_lst, key=lambda tpl: tpl[2])[0] print(min_age_student_lst) # ('David', 'Mary', 16, 'one year three class') # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
4)查看每个班级的负责人是谁,以及任课老师都有谁:
JOIN查询:
# 获取链接池、ORM表对象 import models from sqlalchemy import func # 先查任课老师 sub_query = models.session.query( models.ClassesAndTeachersRelationship.fk_class_id.label("class_id"), func.group_concat(models.TeachersInfo.name).label("have_teachers") ).join( models.ClassesInfo, models.ClassesAndTeachersRelationship.fk_class_id == models.ClassesInfo.id ).join( models.TeachersInfo, models.ClassesAndTeachersRelationship.fk_teacher_id == models.TeachersInfo.id ).group_by( models.ClassesAndTeachersRelationship.fk_class_id ).subquery() result = models.session.query( models.ClassesInfo.name.label("class_name"), models.TeachersInfo.name.label("leader_teacher"), sub_query.c.have_teachers.label("have_teachers") ).join( models.TeachersInfo, models.ClassesInfo.fk_teacher_id == models.TeachersInfo.id ).join( sub_query, sub_query.c.class_id == models.ClassesInfo.id ).all() print(result) # [('one year one class', 'David', 'Jason,David'), ('one year two class', 'Jason', 'David'), ('one year three class', 'Lisa', 'David,Lisa')] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
正反查询:
# 获取链接池、ORM表对象 import models result = [] # 获取所有班级 classes_lst = models.session.query( models.ClassesInfo ).all() for cls in classes_lst: cls_message = [ cls.name, cls.leader_teacher.name, [], ] for row in cls.mid: cls_message[-1].append(row.mid_to_teacher.name) result.append(cls_message) print(result) # [['one year one class', 'David', ['David', 'Jason']], ['one year two class', 'Jason', ['David']], ['one year three class', 'Lisa', ['David', 'Lisa']]] # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close()
4.原生SQL
查看执行命令
如果一条查询语句是filter()结尾,则该对象的__str__方法会返回格式化后的查询语句:
print( models.session.query(models.StudentsInfo).filter() ) SELECT `studentsInfo`.id AS `studentsInfo_id`, `studentsInfo`.name AS `studentsInfo_name`, `studentsInfo`.gender AS `studentsInfo_gender`, `studentsInfo`.age AS `studentsInfo_age`, `studentsInfo`.fk_student_id AS `studentsInfo_fk_student_id`, `studentsInfo`.fk_class_id AS `studentsInfo_fk_class_id` FROM `studentsInfo`
执行原生命令
执行原生命令可使用session.execute()方法执行,它将返回一个cursor游标对象,如下所示:
# 获取链接池、ORM表对象 import models cursor = models.session.execute( "SELECT * FROM studentsInfo WHERE id = (:uid)", params={'uid': 1}) print(cursor.fetchall()) # 关闭链接,亦可使用session.remove(),它将回收该链接 models.session.close() # 获取链接池、ORM表对象
5.另一种创建表的方式
在对表对象进行创建的时候,一般有两种方式能够完成,如下是两种方式的创建过程对比
首先导入须要的模块,获取一个声明层
from sqlalchemy.sql.schema import Table, Column from sqlalchemy.sql.sqltypes import Integer from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
两种方法,
- 第一种首先对__tablename__进行赋值,肯定表名,随后创建列实例,赋值给同名的类属性;
- 第二种方法是直接利用Table()类对__table__进行赋值,经过Table类创建起表的各项属性信息。
Note: 此处两种方法都使用声明层做为基类,第一种方法未传入metadata,会自动使用Base.metadata,第二种方法则直接进行了传入。
# Method one: class table_one(Base): __tablename__ = 'table_one' id = Column(Integer, primary_key=True) # Method two: class table_two(Base): __table__ = Table('table_two', Base.metadata, Column('id', Integer, primary_key=True))
最后运行显示
print(type(table_one), type(table_one.id), table_one.id, sep='\n') print(type(table_two), type(table_two.id), table_two.id, sep='\n')
输出结果
<class 'sqlalchemy.ext.declarative.api.DeclarativeMeta'> <class 'sqlalchemy.orm.attributes.InstrumentedAttribute'> table_one.id <class 'sqlalchemy.ext.declarative.api.DeclarativeMeta'> <class 'sqlalchemy.orm.attributes.InstrumentedAttribute'> table_two.id
从输出的结果中能够看出,两种方式创建的表是相同类型的。
