

python模块-XML模块
XML即可扩展标记语言,XML是互联网数据传输的重要工具,它可以跨越互联网任何的平台,不受编程语言和操作系统的限制,可以说它是一个拥有互联网最高级别通行证的数据携带者。
1.XML语法

<?xml version="1.0" encoding="utf-8" ?> <root xmlns='http:autosar.org/schema/r4.0'> <part id="01" name="选项一"> <name>我是李泽雄</name> <age>今年29岁</age> <sex>男</sex> </part> <part id="02" name="选项二"> <name>我是吴鑫哲</name> <age>今年39岁</age> <sex>男</sex> </part> </root>
1.1 文档申明
<?xml version="1.0" encoding="utf-8" ?>
version –文档符合XML1.0规范,我们学习1.0
encoding –文档字符编码,比如”gb2312”或者”utf-8”
standalone –文档定义是否独立使用。standalone=”no”为默认值。yes代表是独立使用,而no代表不是独立使用
1.2 元素和节点 element
<part id="01" name="选项一"> <name>我是李泽雄</name> <age>今年29岁</age> <sex>男</sex> </part>
1.元素包含标签tag,属性attrib(非必须)和文本text(最内侧元素才有)三要素
2.元素可以嵌套元素,每个XML文档必须有且只有一个根元素
3.标签分为开始标签和结束标签,标签必须遵守以下规范
区分大小写,
不能以数字或下划线”_”开头
不能包含空格,不能包含冒号
4.一个元素可以有多个属性,它的基本格式为:
<标签 属性名1="属性值1" 属性名2="属性值2">
属性值用双引号""或单引号''分隔
等号两边不能有空格
属性值不能包括<,>,&,如果一定要包含,也要使用实体字符
5.文本中出现的所有空格和换行,XML解析程序都会当做文本内容进行处理
6.具体的元素称为节点,元素是节点的类,节点是元素的实例。同一元素的节点具有相同的标签
1.3 命名空间
在 XML 中,当两个不同的文档使用相同的元素名时,就会发生命名冲突,而XML 命名空间提供避免元素命名冲突的方法。XML命名空间被放置于元素的root标签之中,并有两种命名方式:
1.默认的命名空间
<root xmlns="namespaceURI"> <part> </part>
其中,root是根节点,xmlns是固定术语(xml name space),"http:autosar.org/schema/r4.0"是唯一的namespaceURI
定义了默认的命名空间后,xml所有节点标签的全民都要加上前缀,比如part节点实际节点名称为:{http:autosar.org/schema/r4.0}part,为了书写方便,通常在python中这样定义:
xmlns = "{http:autosar.org/schema/r4.0}" node = xmlns+"part"
2.显式的命名空间
<?xml version='1.0' encoding='UTF-8'?> <nvd xmlns:vuln="http://bulabula" xmlns:cvss="http://abulaabula" xmlns="http://alulalula"> <entry id="CVE-2011-0001"> <vuln:cvss> <cvss:base_metrics> <cvss:score>5.0</cvss:score> </cvss:base_metrics> </vuln:cvss> </entry> <nvd>
其中默认的命名空间为xmls,另外声明了两个命名空间xmlns:vuln和xmlns:cvss。
cvss:score节点被显式声明为cvss命名空间,需要这样访问:
cvss = “{http://abulabula}”
node.find(cvss + 'score')
1.4 实体字符
XML有5个预定义的实体字符,用于文本非格式语句
| 实体字符 | 说明 |
| < | < |
| > | > |
| & | & |
| ' | ’ |
| " | " |
1.5 CDATA节
如果要传递的内容包含大量的<,>,&或者“等一些特殊的不合法的字符,就要用到CDATA节,于把整段文本解释为纯字符数据而不是标记。CDATA节中可以输入任意字符(除]]>外),但是不能嵌套
<![CDATA[文本]]>
1.6 注释
<!--这是一个注释-->
1.7 处理指令
我们也可以使用css样式表来修饰XML文件
2.XML模块(内置库)
本文主要学习的 xml.etree.ElementTree 是python的XML处理模块,它提供了一个轻量级的对象模型。在使用 ET 模块时,需要import xml.etree.ElementTree的操作。ElementTree表示整个XML元素层级,而Element表示元素层级中的一个元素或者一个节点。
import xml.etree.ElementTree as ET
2.1 方法列表
| ET模块 | 说明 |
| ET.ElementTree(root) -> ElementTree | 指定根节点,创建层级关系,返回ElementTree类 root->Element类 |
| ET.parse(file) -> ElementTree | 读取XML文件的层级关系,返回ElementTree类 file->字符串 |
| ET.Element(tag) -> Element | 创建根节点,返回Element类 tag->字符串 |
| ET.SubElement(elem, tag) -> Element | 创建子节点,返回Element类 elem->现有节点Element类 tag->新节点的标签 |
| ET.tostring(elem) -> str | 将节点转为文本,返回字符串 elem->Element类 |
| self=ElementTree类 | 说明 |
| self.write(file) | 写入XML文件 file->字符串 |
| self.getroot() -> Element | 得到根节点,返回Element类 |
| Element类 | 说明 |
| self.set(key, value) | 添加、修改节点属性 key, value->字符串 |
| self.find(path) -> Element | 通过层级路径查找子节点,只返回第一个,返回Element类 path->输入字符串 |
| self.findall(path) -> list of Element | 通过层级路径查找子节点,用列表返回所有符合条件节点 path->输入字符串 |
| self.iter(elem) -> Iter of Element | 查找所有符合条件子节点,返回迭代器 elem->Element类 |
| self.clear() | 删除节点 |
| self.text -> str self.text = str |
读写节点文本,字符串类型 |
| self.tag -> str self.tag = str |
读写节点标签,字符串类型 |
| self.attrib -> str self.attrib = str |
读写节点属性,字典类型 |
2.2 新建XML文件
import xml.etree.ElementTree as ET root = ET.Element('root') # 创建根节点 class1 = ET.SubElement(root, 'class') # root节点下创建clss元素的class1节点 student1 = ET.SubElement(class1, 'student') student1.set('id', '101') student1.set('name', '李泽雄') # set方法在原有属性后加上新属性,或者修改同名属性 age1 = ET.SubElement(student1, 'age') age1.text = '29岁' sex1 = ET.SubElement(student1, 'sex') sex1.text = '男' student2 = ET.SubElement(class1, 'student') student2.attrib = {'id': '102', 'name': '吴鑫哲'} # attrib会完全替换原有属性 age2 = ET.SubElement(student2, 'age') age2.text = '39岁' sex2 = ET.SubElement(student2, 'sex') sex2.text = '男' class2 = ET.SubElement(root, 'class') student3 = ET.SubElement(class2, 'student') student3.attrib = {'id': '202', 'name': '刘稳'} age3 = ET.SubElement(student3, 'age') age3.text = '32岁' sex3 = ET.SubElement(student3, 'sex') sex3.text = '男' tree = ET.ElementTree(root) # 以root为根节点创建层级关系 tree.write('simple.xml', encoding="utf-8", xml_declaration=True) # 写入文件声明
用浏览器打开simple.xml文件
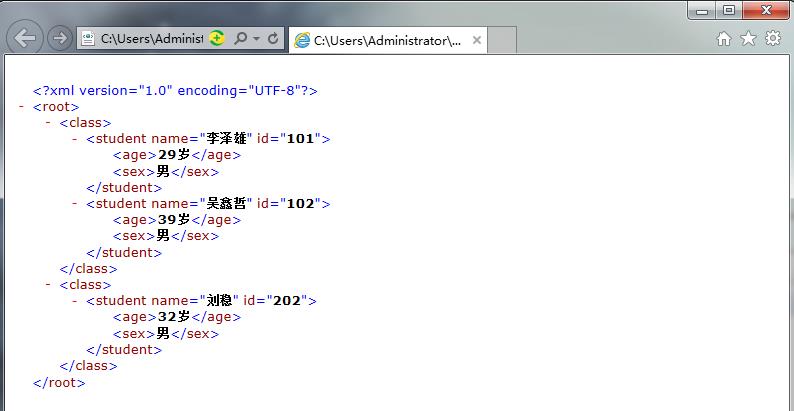
2.3 查找XML文件
2.3.1 按路径定位一个节点 getroot find
getroot()返回根节点
find()根据一个当前节点和层级路径,往下寻找指定元素的第一个节点
import xml.etree.ElementTree as ET tree = ET.parse('simple.xml') root = tree.getroot() # 查找根节点 print(root.tag) # 结果:root elem1 = root.find('class') # 绝对路径不包括root,只能搜索到第一个符合条件的节点 print(elem1.tag) # 结果:class print(elem1.attrib) # 结果:{} print(elem1.text) # 结果: None elem2 = root.find('class/student') # 绝对路径用/分割,只能搜索到第一个符合条件的节点 print(elem2.tag) # 结果:student print(elem2.attrib) # 结果:{'id': '101', 'name': '李泽雄'} print(elem2.text) # 结果:None elem3 = elem1.find('student/age') # 绝对路径不包括elem1,只能搜索到第一个符合条件的节点 print(elem3.tag) # 结果:age print(elem3.attrib) # 结果:{} print(elem3.text) # 结果:29岁
2.3.2 按路径遍历节点 findall
findall()根据一个当前节点和层级路径,往下寻找指定元素的所有节点,返回列表
import xml.etree.ElementTree as ET tree = ET.parse('simple.xml') root = tree.getroot() elem1 = root.findall('class') # 返回2个class节点的列表 elem2 = elem1[0].findall('student') # 列表可以切片 for e in elem2: # 列表可以遍历 print(e.attrib) #结果输出: {'id': '101', 'name': '李泽雄'} {'id': '102', 'name': '吴鑫哲'}
2.3.3 按范围遍历节点 iter
iter()在当前节点下搜索指定元素的所有节点,无需层级路径,返回一个迭代器
import xml.etree.ElementTree as ET tree = ET.parse('simple.xml') root = tree.getroot() elem1 = root.iter('age') for e in elem1: print(e.text) #结果输出: 29岁 39岁 32岁
2.3.4 打印节点 tostring
tostring()将节点转化成字符串格式输出
import xml.etree.ElementTree as ET tree = ET.parse('simple.xml') root = tree.getroot() elem1 = root.findall('class/student') for e in elem1: print(ET.tostring(e, encoding="unicode")) #结果输出: <student id="101" name="李泽雄"><age>29岁</age><sex>男</sex></student> <student id="102" name="吴鑫哲"><age>39岁</age><sex>男</sex></student> <student id="202" name="刘稳"><age>32岁</age><sex>男</sex></student>
2.4 修改和删除XML数据
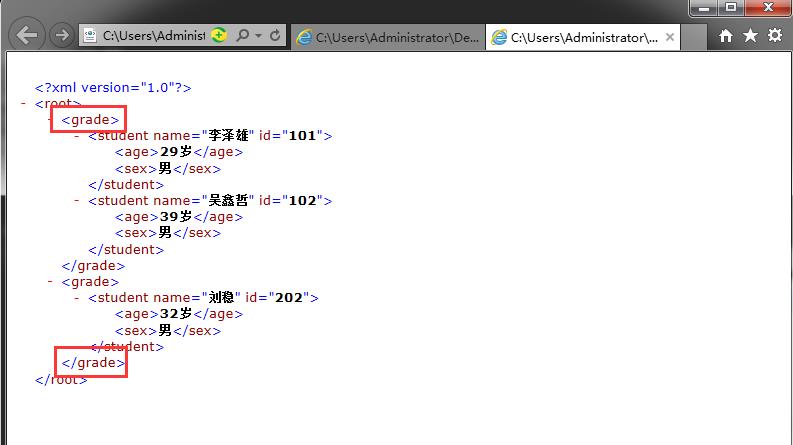
1.修改节点标签、属性和文本可直接用节点的tag,attrib,text属性,添加节点的属性用set()2.删除节点用clear()
3.配合遍历可批量修改
import xml.etree.ElementTree as ET tree = ET.parse('simple.xml') root = tree.getroot() elem1 = root.findall('class') for e in elem1: e.tag = 'grade' # 将class元素改名为grade元素 tree.write('simple.xml')
3.findall()方法对XPath的支持
xml.etree.ElementTree中的findall()方法支持部分XPath语法
3.1 创建相对xpath
1.支持.作为当前节点tag,/作为下一级子节点tag分隔符。
root.findall("./country/neighbor")
2.所有实际tag,如果有定义namespace,都必须带有对应的namespace,不可省略
root.findall("./{namespace}country/{namespace}cneighbor")
3.支持*表示任意节点tag,进行模糊匹配
root.findall("./*/neighbor")
4.支持//表示任意间隔级子节点分隔符
root.findall(".//neighbor")
5.支持..表示父节点(官方文档说支持,实测不支持,存疑)
root.findall("../country")
3.2 xpath的附加条件
1.支持[@attrib]表示筛选带有特定属性的节点,[@attrib!='value']表示筛选属性为特定值的节点,[@attrib!='value']表示筛选属性不为特定值的节点
root.findall(".//year[@name='Singapore']") root.findall("./*[@name='Singapore']/year")
2.支持[.='text']表示筛选具有对应text内容的节点
[.!='text']表示筛选不具有对应text内容的节点
root.findall(".//year[.='2011']") root.findall("./*[.='2011']/year")
3.支持[tag]表示筛选具有对应tag子节点(必须是紧挨着下一级)的节点
[tag='text']表示筛选具有对应tag和text内容子节点(必须是紧挨着下一级)的节点
[tag!='text']表示筛选具有对应tag,但是不具有对应text内容子节点(必须是紧挨着下一级)的节点
root.findall("./country[year='2011']")
3.3 按list定位子节点
XPath支持将节点视为自身所有子节点的list,可以直接使用下标返回对应的子节点
node = root[0][1]
学习转载于: https://blog.csdn.net/u011079613/article/details/108202248



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY