pyhton模块-shelve
1.shelve简介
shelve是Python当中数据储存的方案,类似key-value数据库,便于保存Python对象,shelve只有一个open()函数,用来打开指定的文件(字典),会返回一个对象shelf,shelf也是类似字典的对象。
简单来说shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式,可以说是一个pickle的一个封装加强版。后面也会对比shelve和pickle的一个很主要的区别。
2.open()函数
open()函数的格式:shelve.open(file_name, flag='', writeback=True\False)
file_name:文件名
flag:打开数据存储文件的格式:
(1)、flag='r' 只读模式打开存在数据的文件
(2)、flag='w'读写模式打开存在数据的文件
(3)、flag='c'读写模式打开存在数据的文件,如果不存在则创建
(4)、flag='n'总是创建一个新的、空数据的文件
writeback:一般情况下,我们通过shelve.open()一个对象后,只能进行一次赋值,但是可以通过设定writeback:True来实现,这里writeback的默认值为False。
3.演示
序列化对象代码
import shelve d = shelve.open('shelve_test') #打开一个文件 class Test(object): def __init__(self,n): self.n = n t1 = Test(123) t2 = Test(456) name = ["lizexiong","rain","test"] d["test"] = name #持久化列表 d["t1"] = t1 #持久化类 d["t2"] = t2 d.close()
执行一下,多出了三个文件
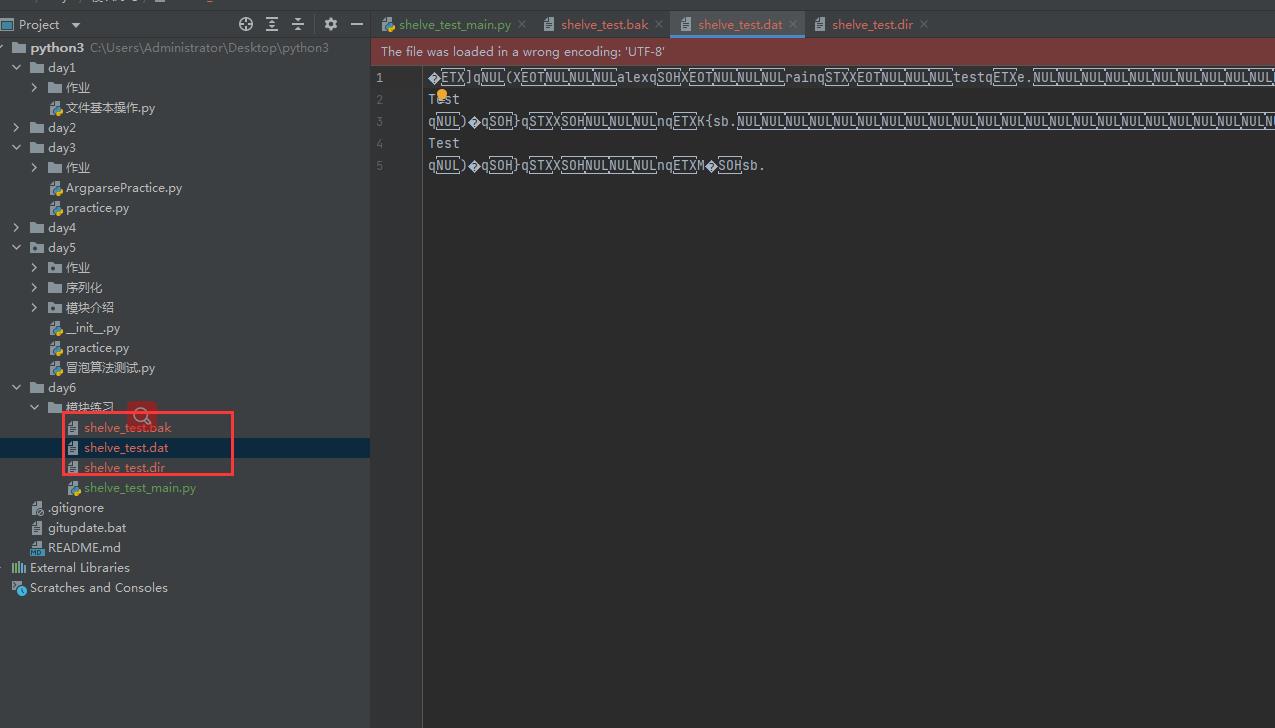
现在演示,在命令行获取。
(3.7.5后貌似不能持久化类了,所以这里没有演示,具体细节麻烦大佬们自己翻看官网吧)
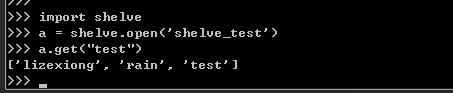
差不多就是这个样子,和pickle功能差不多,持久化了一个列表
为什么感觉没啥大用?平时我们使用pickle的dump和load的时候,是不是dump一次,在load一次?如果要dump两次呢?前一次dump的数据被覆盖了?其实并没有,这里用2个文件演示一下。
先dump3次,是否前面两次会被最后一次的dump覆盖呢?
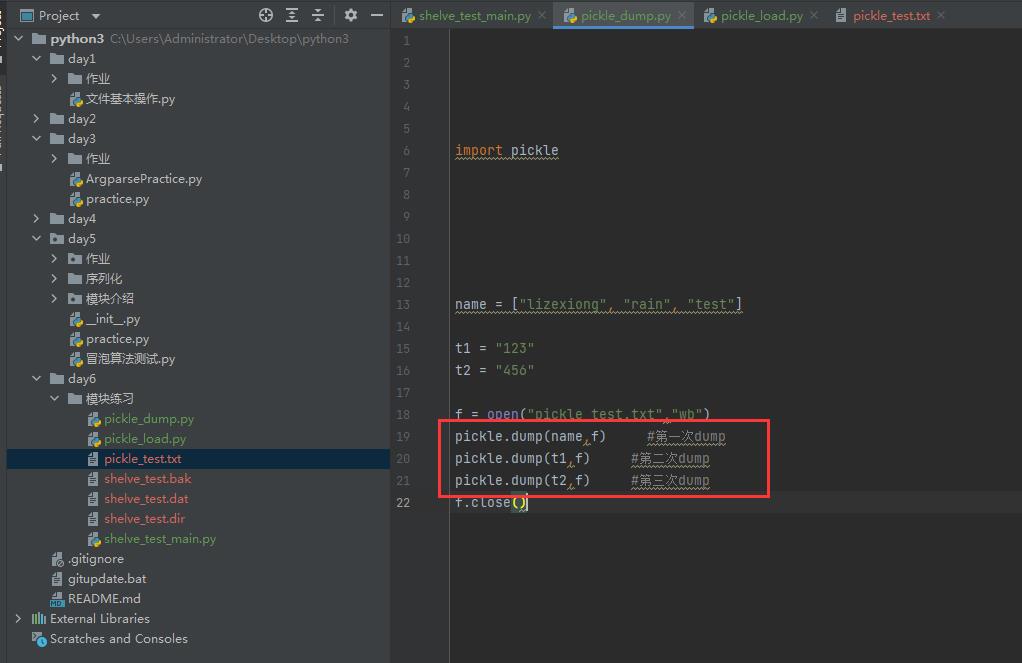
现在load看看
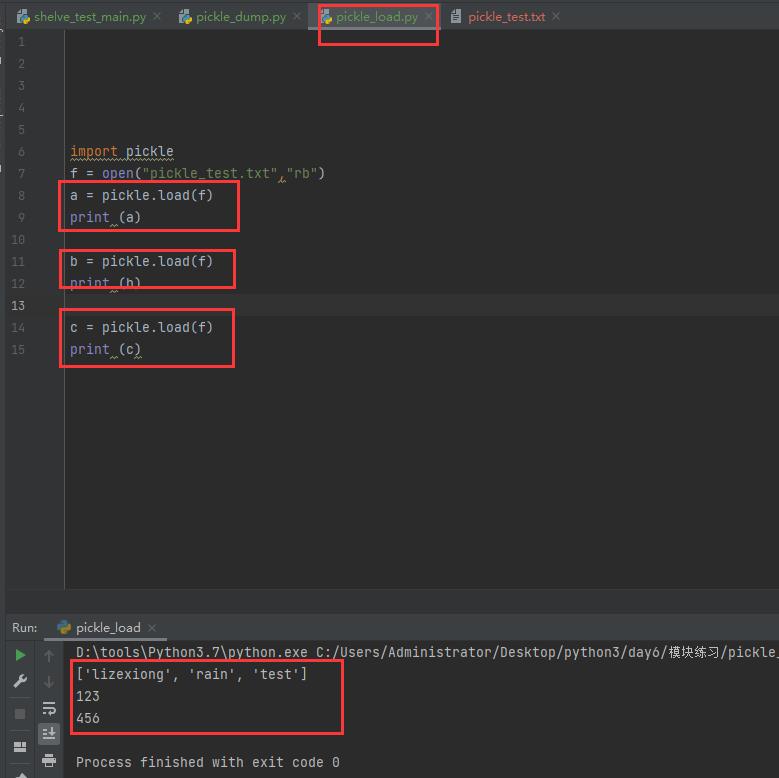
看到了哈,pickle虽然不说覆盖,但是按照dump的顺序load的,可以看出差别了吧,shelve可以指定key来读取,而不是按照顺序,好处就在这里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号