
Python学习之路-Python3-35天学习笔记
1.L01
第一天课程比较简单,本人在2.7版本学习笔记也有记录,所以第一章记录的会比较粗略。
1.1 开课介绍
今天主要介绍人员老师,以及后续课程流程。

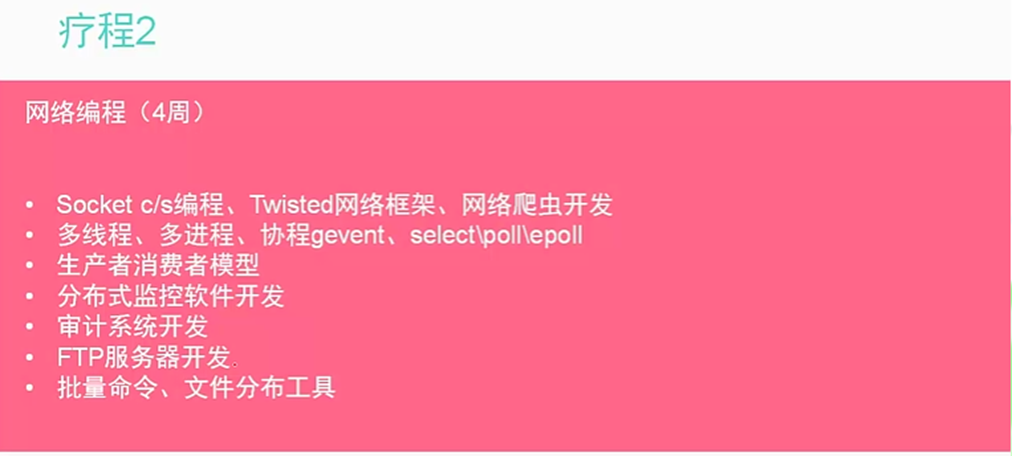




1.2 Python简史介绍


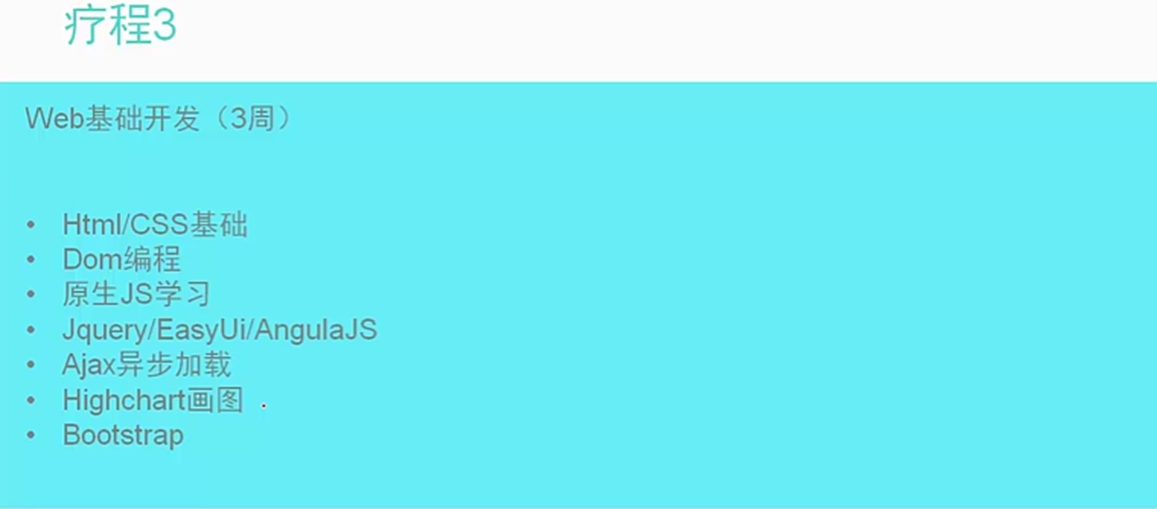
1.3 Python3的新特性
1.4 开发工具IDE介绍
1.5 HelloWorld程序
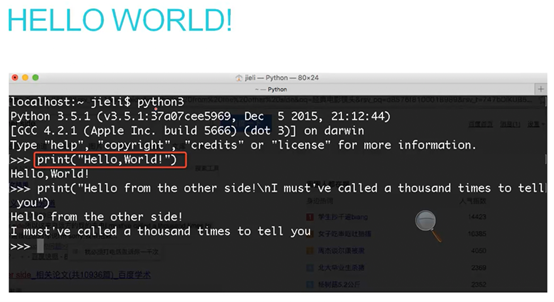
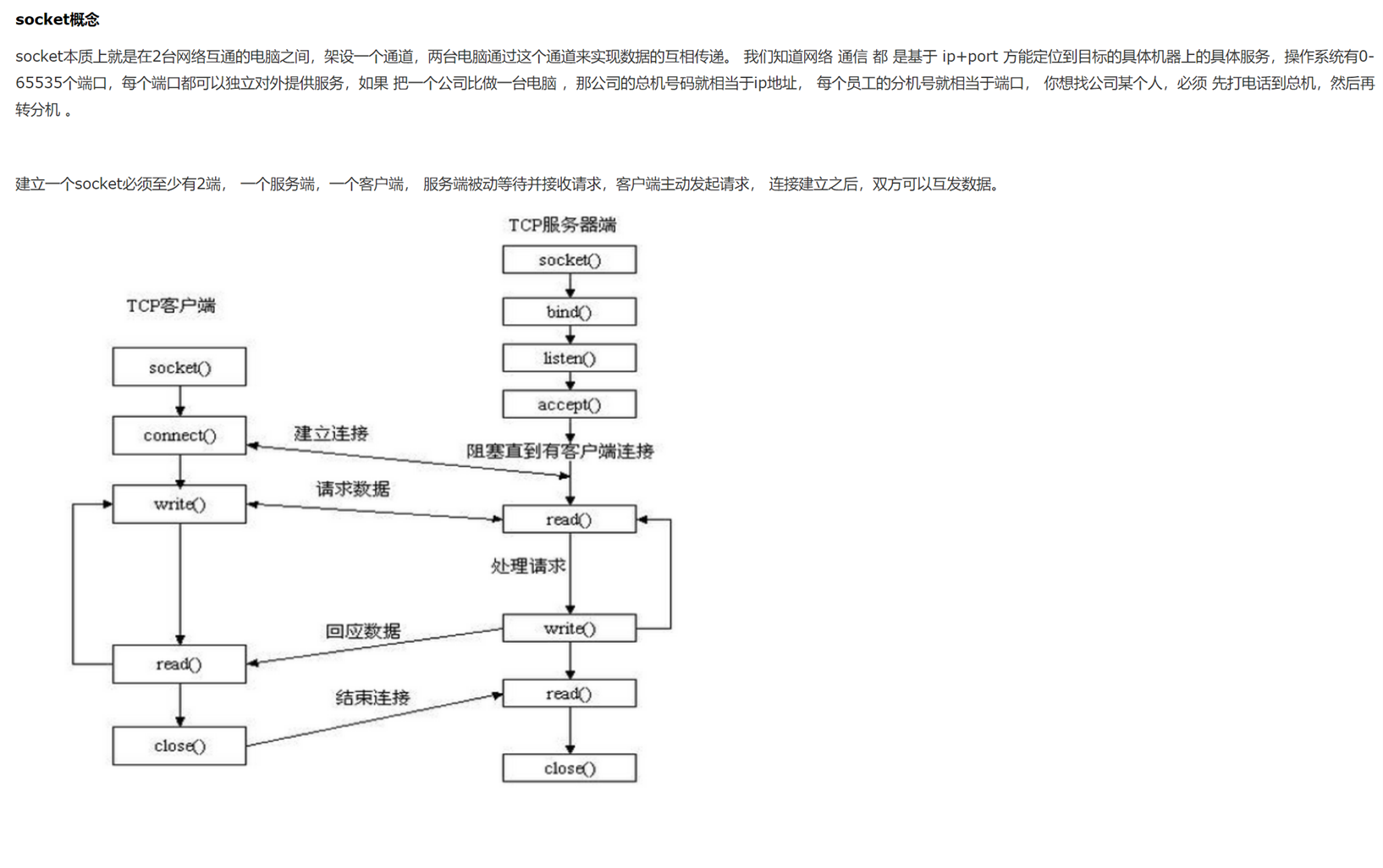
使用.执行脚本,告诉运行环境用什么执行。Python也是可以使用.来执行的,就是因为在脚本开头声明使用什么解释器环境来执行脚本。
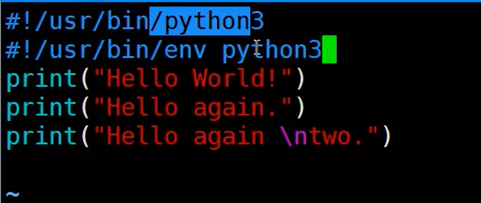
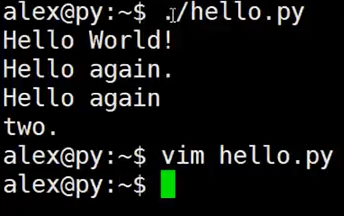
1.6 变量与赋值
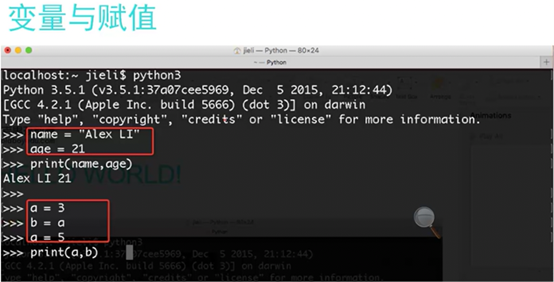
查看内存地址
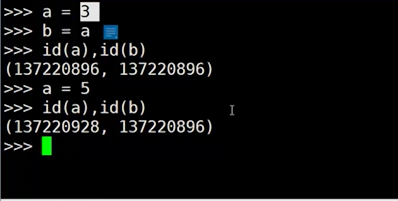
这里a=3,b=a,a=5讲解了内存地址的调用,参考专门讲解这一张的博客,由于这是第一章基础,所以这里不会做详细介绍。
具体的可以参考博客: Python学习之路-初识Python-第一篇
1.7 用户交互
1.8 条件判断与缩进

1.9 循环控制
就是简单的判断猜对了就跳出循环的操作,本章作业搞懂就行,这里不用过于纠结。
1.10 循环次数限制
这里的需求就是限制循环的次数,没什么好演示。
1.11 常用数据类型
参考Python学习之路-基础数据类型-第二篇,详细的课参考本人博客
1.12 字符串格式化
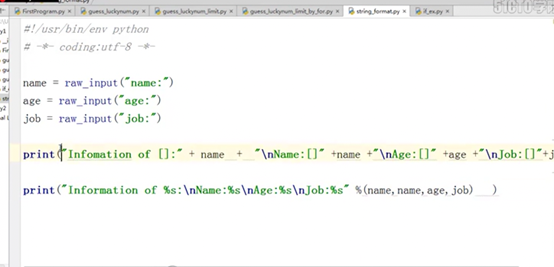
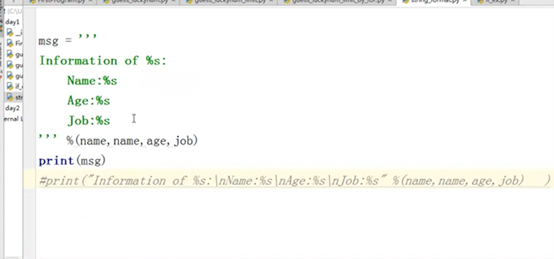
字符串格式化的方式有几种,这里列出了两种。这里用第二种,因为第一种叫万恶的加号,加号每一个变量都会去内存开辟一块空间
还有一种方式,使用’’’’’’,这样空格和换行都可以保留。
1.13 列表常用操作
基础方法,查看博客Python学习之路-基础数据类型-第二篇
1.14 列表的后续操作
基础方法,查看博客Python学习之路-基础数据类型-第二篇
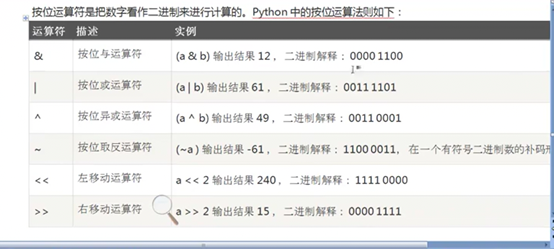
1.15 二进制位运算
位运算,需要详细了解可以直接翻看视频。

1.16 简单的嵌套循环

1.17 文件基本操作及作业

老师讲的有些粗糙,看下面本人写的博客:Python3文件操作
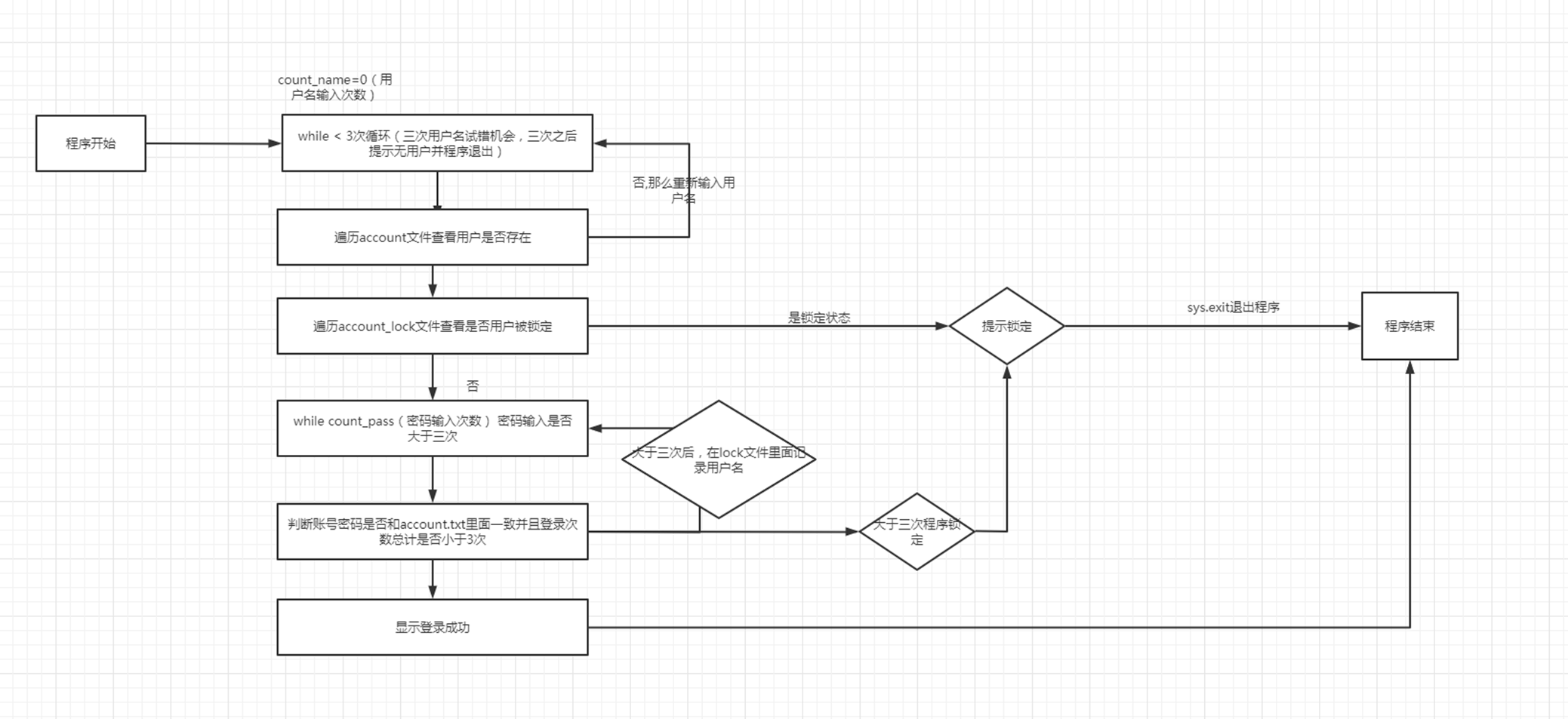
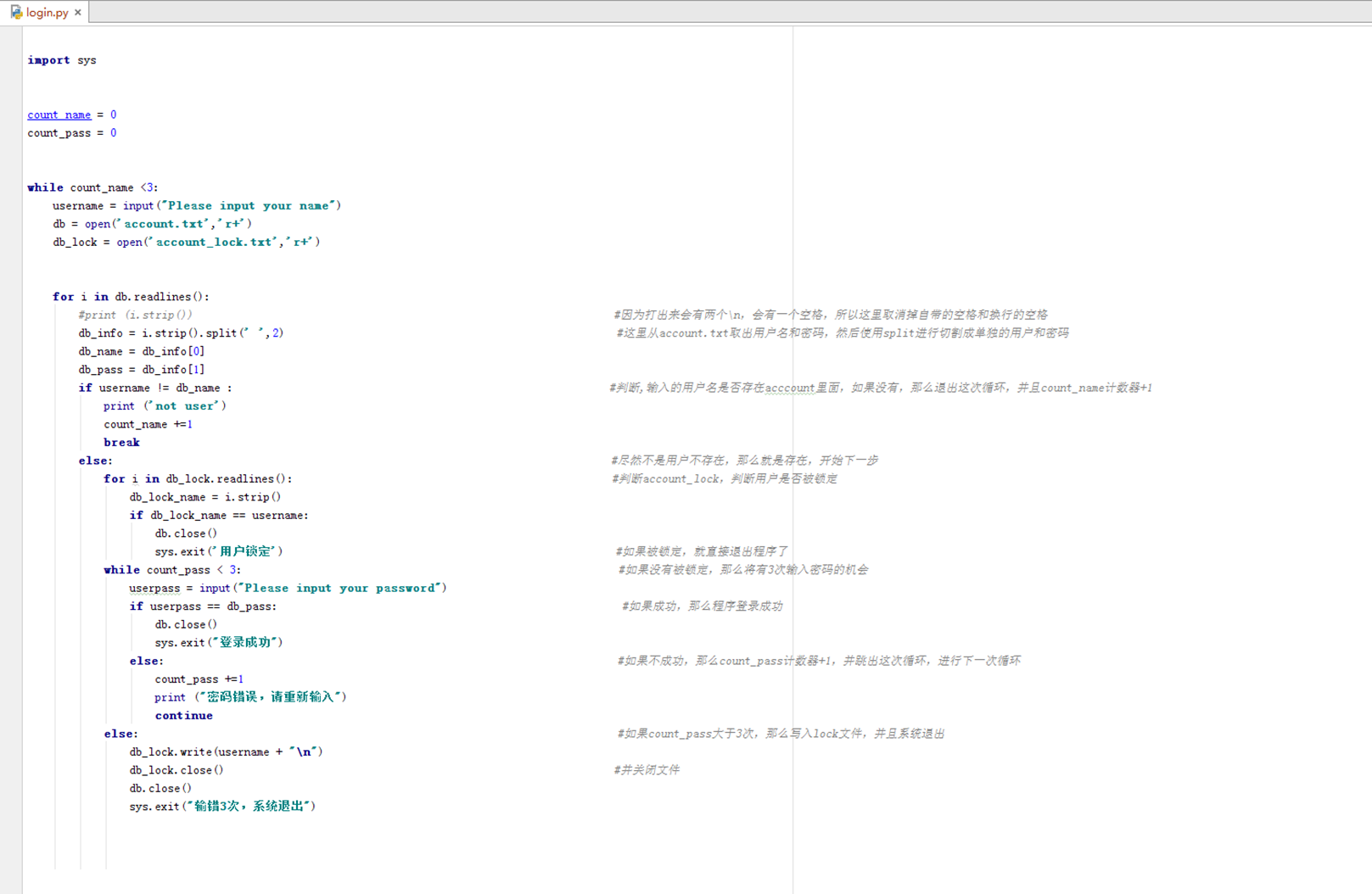
1.18 作业
这里还是把作业分开来作为一章比较直观。
Login
这里就不贴出git地址,以免后期地址变更,所有的作业都在git地址里面可以看到
2.L02
第二天课程和第一天课程内容重复,这里不做记录,作业在git上
3.L03
3.1 本节内容概要
看今天课表即可。
3.2 上节内容回顾与SET
看基础课表,也可以略过。如果想快速回顾,而不想重新学习,可以看上节课内容回顾,这个方式能够快速回顾一些基础知识和上一节课知识。
本视频有2小结,后面讲解的是set。由于第一节讲解的都是set的基础用法,在本人博客有详细记录,这里只做一下本小节的课堂实验即可。
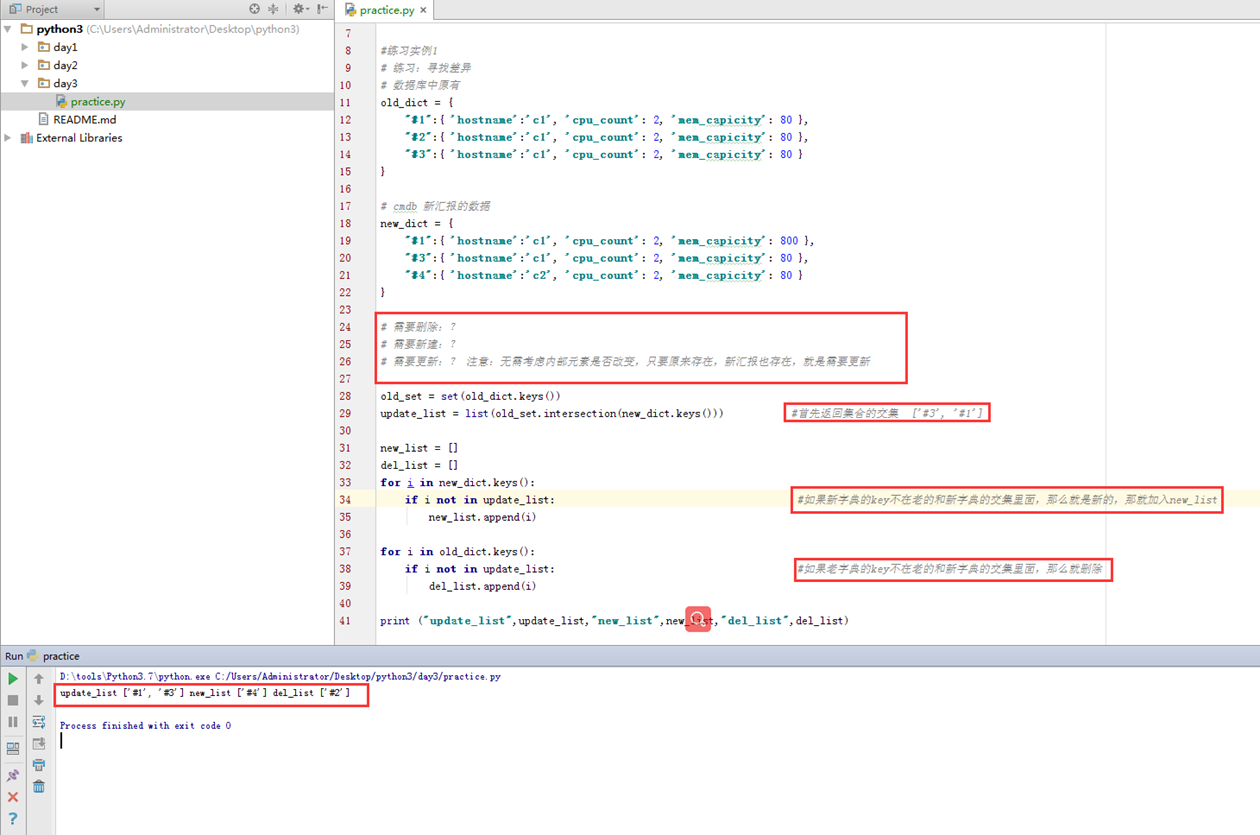
具体作业代码在day3 practice [#练习实例1]中。
3.3 计数器counter
关于collctions的所有章节参考博客。这里不做详细介绍:
3.3-3.8章节,参考本人博客
https://www.cnblogs.com/lizexiong/p/16230189.html

3.4 有序字典ordereddict
关于collctions的所有章节参考博客。这里不做详细介绍:
3.3-3.8章节,参考本人博客
https://www.cnblogs.com/lizexiong/p/16230189.html
3.5 默认字典defaultdict
关于collctions的所有章节参考博客。这里不做详细介绍:
3.3-3.8章节,参考本人博客
https://www.cnblogs.com/lizexiong/p/16230189.html
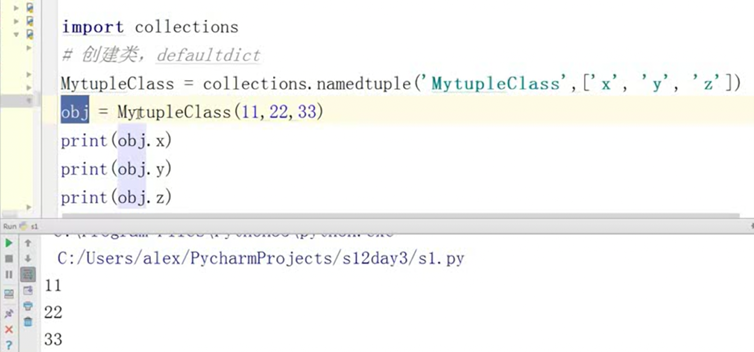
3.6 可命名元祖namedtuple
关于collctions的所有章节参考博客。这里不做详细介绍:
3.3-3.8章节,参考本人博客
https://www.cnblogs.com/lizexiong/p/16230189.html
简单来说就是给元祖的下标起个名字
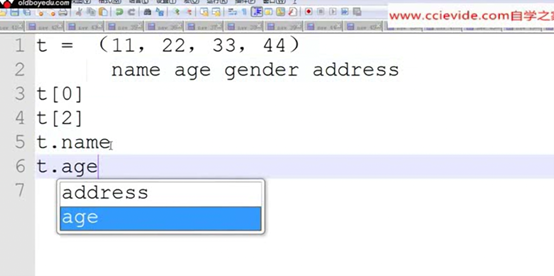
可命名元祖没有提供类,所以要先提前创建一个类
可以使用help(MytupleClass)来查看有哪些方法
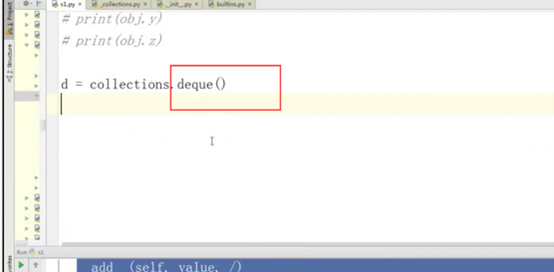
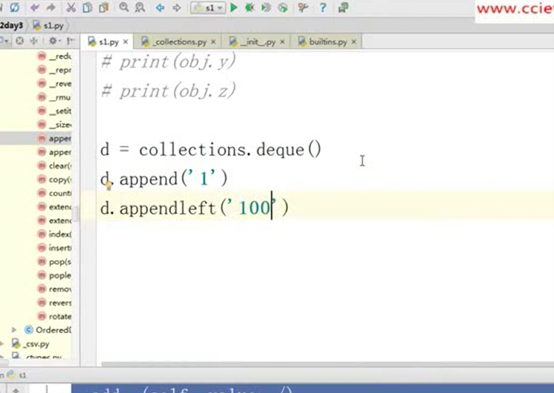
3.7 双向队列deque
关于collctions的所有章节参考博客。这里不做详细介绍:
3.3-3.8章节,参考本人博客
https://www.cnblogs.com/lizexiong/p/16230189.html
单向队列和多向队列的区别

点击这个对应做联系,看看提供了哪些方法
3.8 单项队列queue
Queue模块,并没有怎么讲解
3.9 深浅拷贝原理
深浅拷贝区别
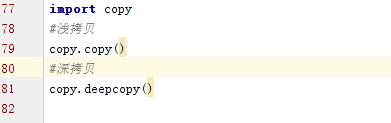
浅拷贝不拷贝更深的内容,比如字典key下更深层次的值,但是深拷贝多少层的什么都会去拷贝。
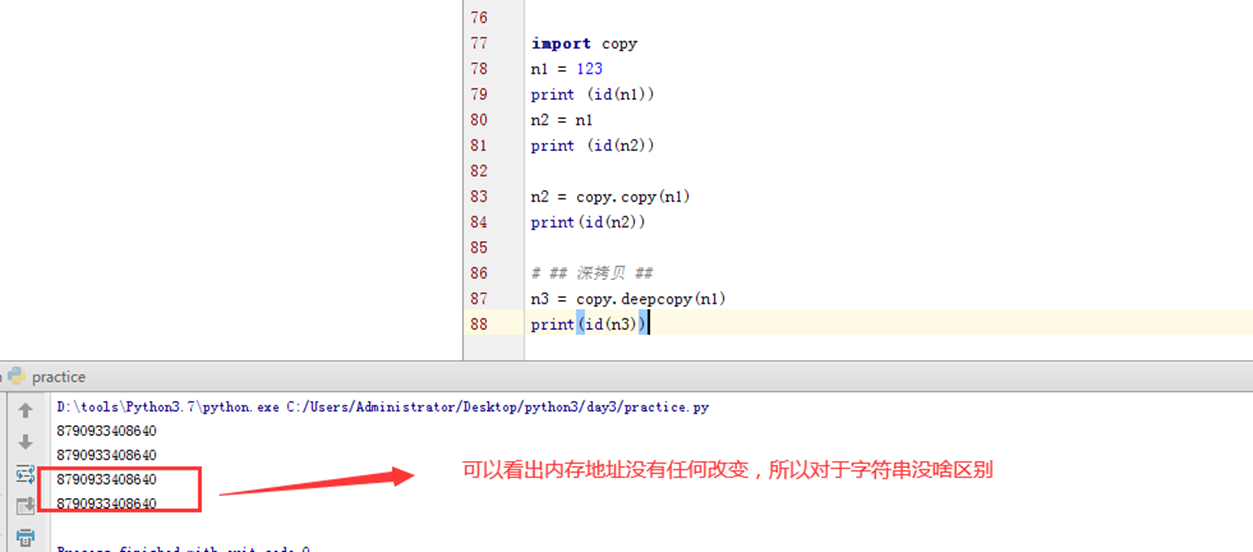
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
那么对于其他类型,比如字典的浅拷贝,可以看到,内存地址发生了变化。
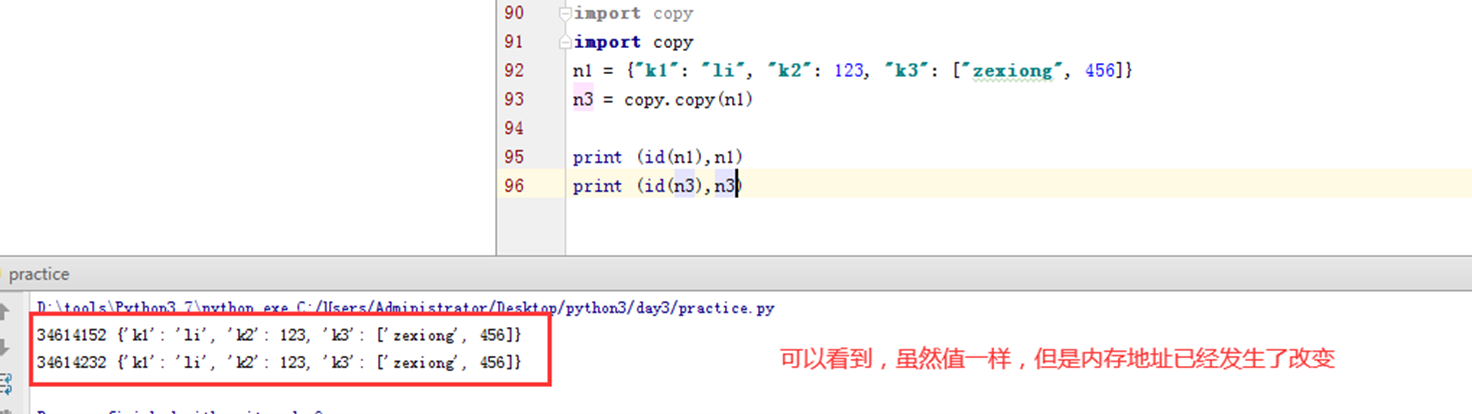
那么这不是发现改变了吗?
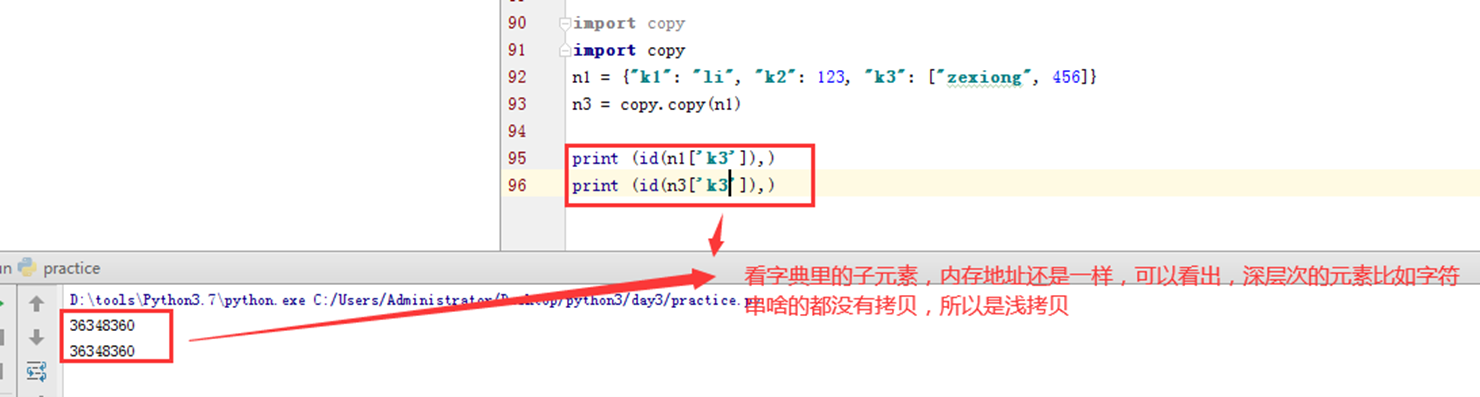
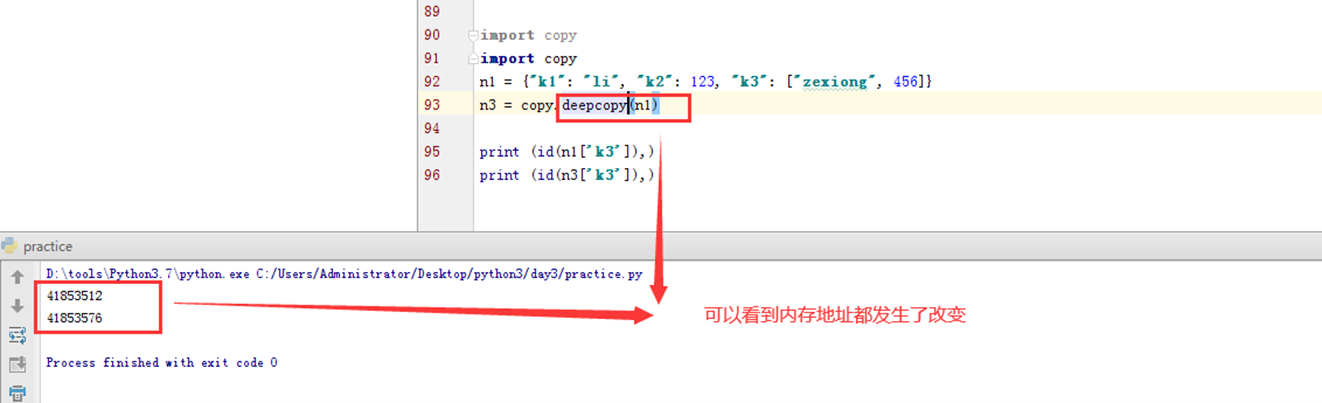
那如果换成深拷贝呢
3.10 深浅拷贝应用
假设有个主机的监控模版

突然监控指标变了,需要一个CPU50就告警的,可以看出,浅拷贝会影响原始的字典。
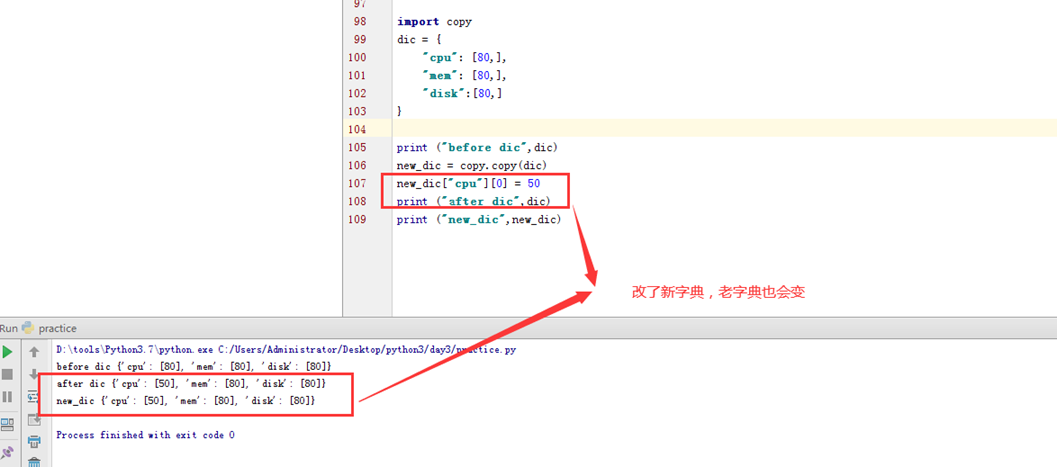
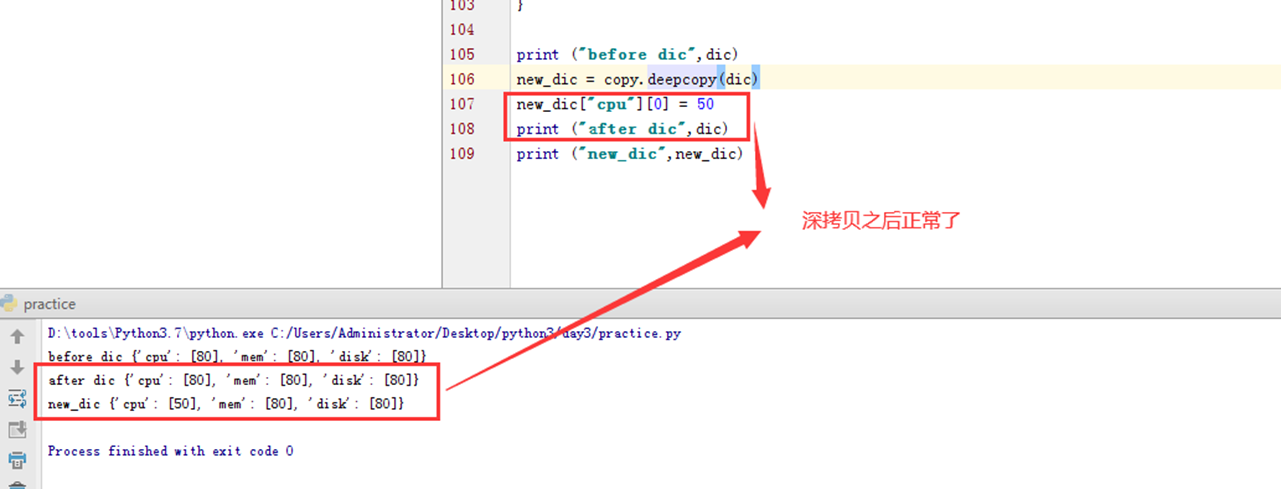
那么使用深拷贝看看
3.11 函数的基本定义
为什么要用函数?
代码重用性和可读性
函数基础写法

3.12 函数的返回值(一)

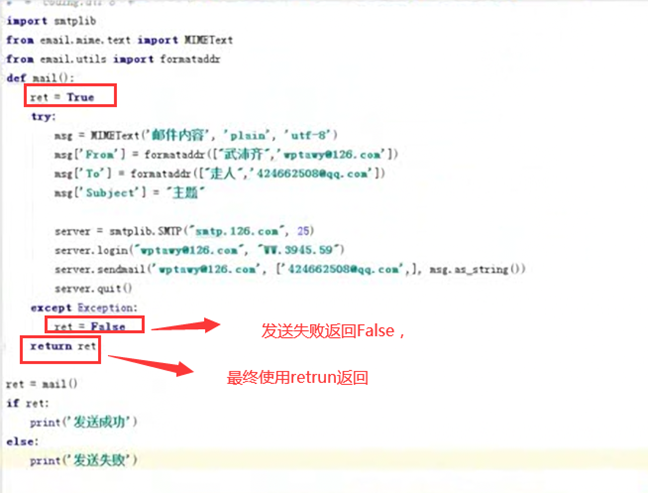
3.13 python函数的返回值(二)
如果一个函数没有出现return,那么函数返回的就是None。
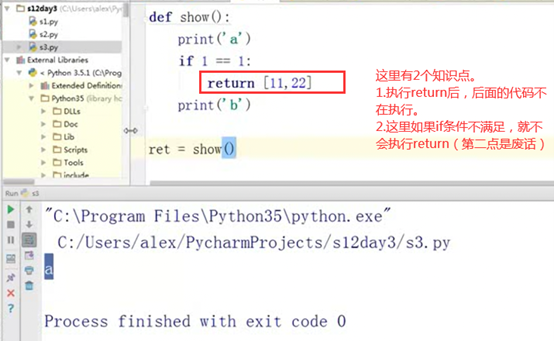
3.14 函数的普通参数
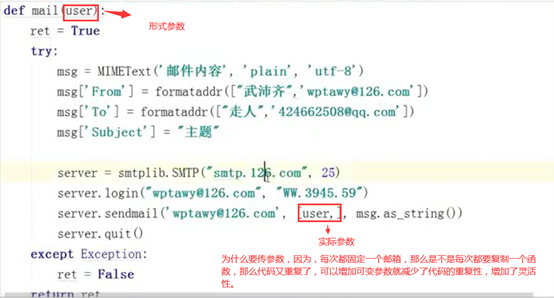
3.15 函数的默认参数
因为上述例子就只是传了一个参数。如果有多个参数可以传多个参数呢,这个不做演示。但是,有时候如果有的参数有时候不用赋值呢?所以默认参数就来了,但是也有以下几点注意。
- 默认参数要放在函数()的后面,按照顺序赋值,或者指定变量名赋值,不然报错。
- 如果没有默认参数,调用函数的时候参数不复制,代码可是会报错的
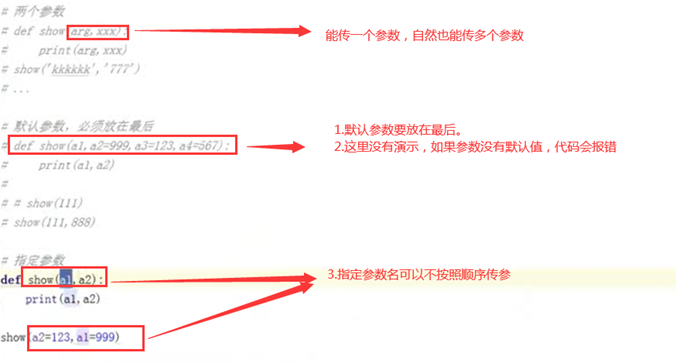
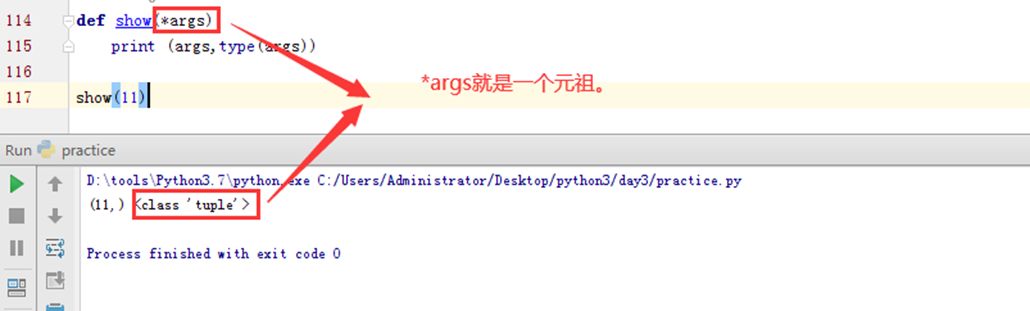
3.16 函数的动态参数(一)
如果要传入列表元祖怎么办?那么使用单“*”。那么根据约定,传入的就是元祖
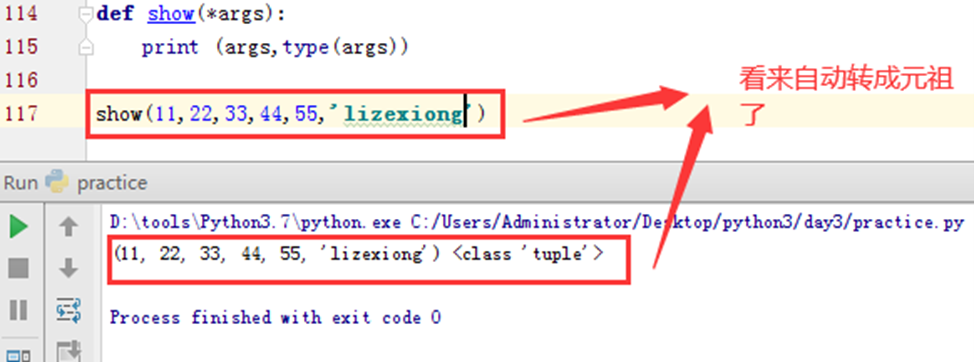
如果传入多个字符串,可以接收吗?试试
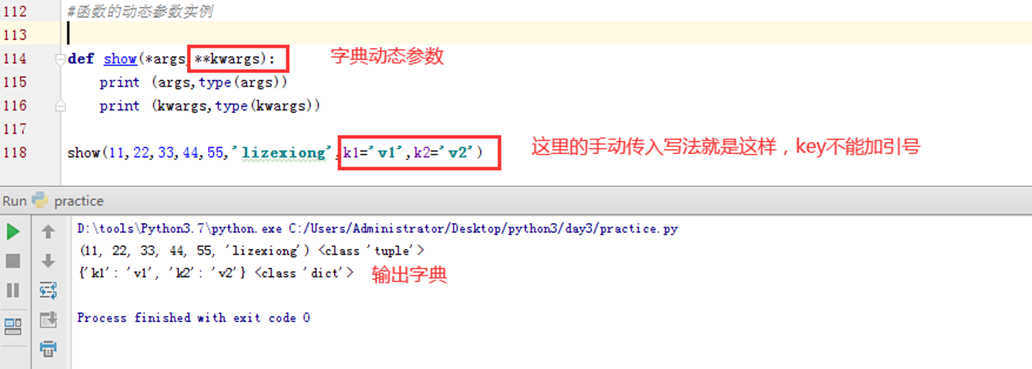
那么如果有字典怎么办?有元祖传入,自然也有字典传入。那么就用两个**,约定的写法就是**kwargs
3.17 函数的动态参数
如果有一个列表和字典想直接传入进去改怎么办?直接函数传参可不可以?那么见以下示例。
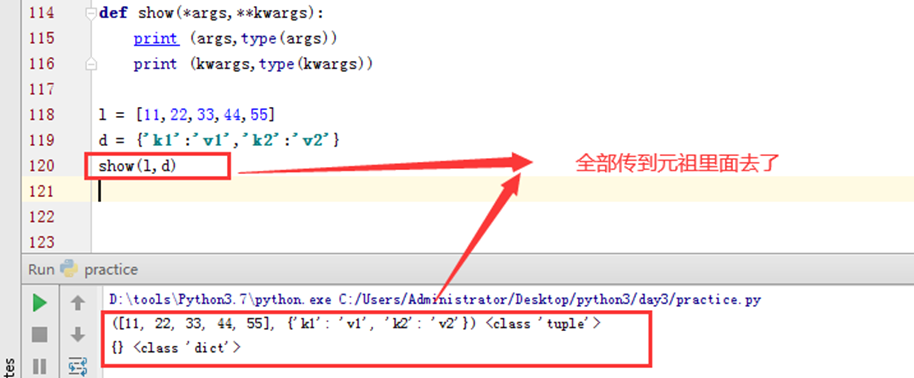
所以用一下方式才是正确的,这样函数才知道你传入的是列表还是字典。
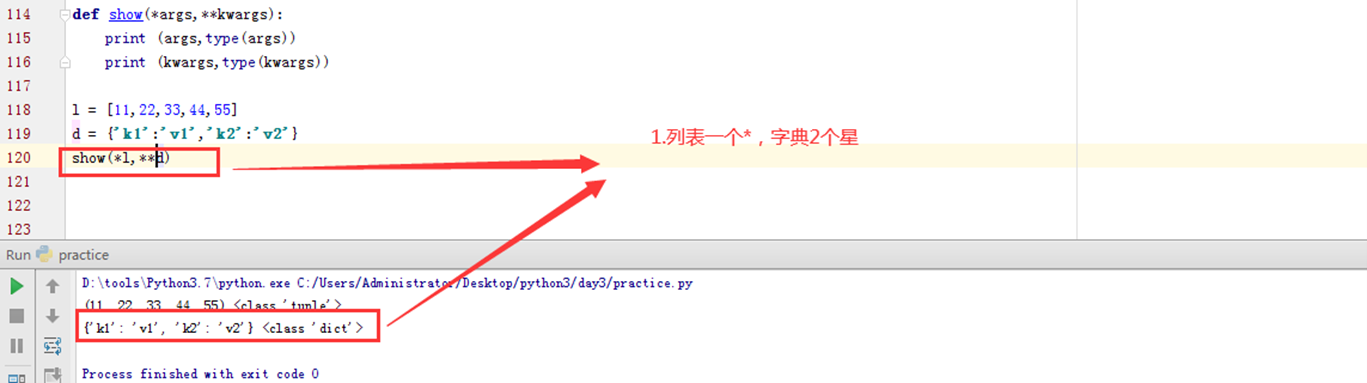
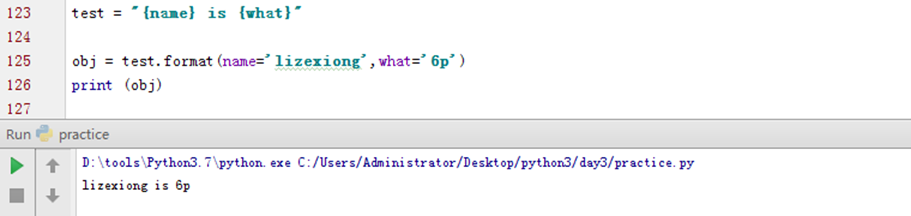
3.18 使用动态参数实现字符串格式化
看看format,之前学习使用的%一个一个传参,现在看看format源码,看看有没有其他方式?

format看来也是可以传元祖和列表,看以下实验。
这种方式平平无奇。
如果我这里有一个字典,那么是否能够传入?是否能够更加方便?
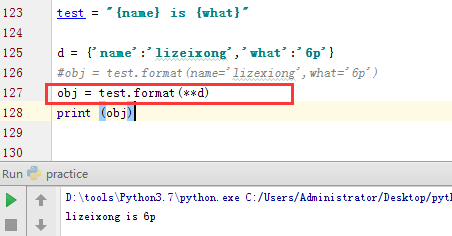
可以看出,使用**更加方便。
3.19 lambda表达式
简单来说就是简化一些少量代码的书写方式。可以实现简单函数一行搞定。
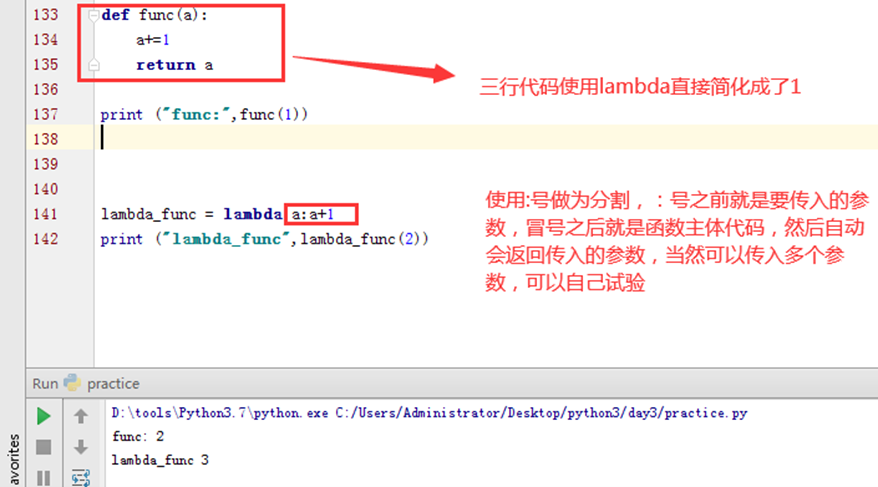
3.20 内置函数
内置函数合并为一章。
3.21 文件操作
略过
3.22 作业
修改hxproxy配置,该作业在git代码day3下。
4.L04
上节课回顾这里就不做回顾,自己查看上节内容。
4.1 迭代器原理及使用
今日内容

迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件
特点:
- 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容
- 不能随机访问集合中的某个值 ,只能从头到尾依次访问
- 访问到一半时不能往回退
- 便于循环比较大的数据集合,节省内存
生成一个迭代器:
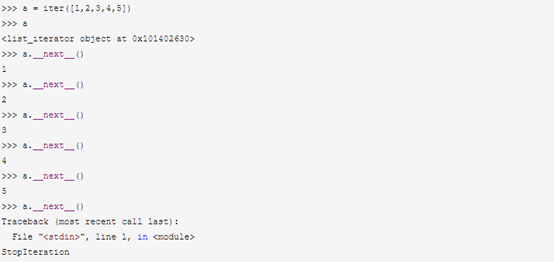
4.2 生成器的使用
生成器generator
定义:一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator),如果函数中包含yield语法,那这个函数就会变成生成器
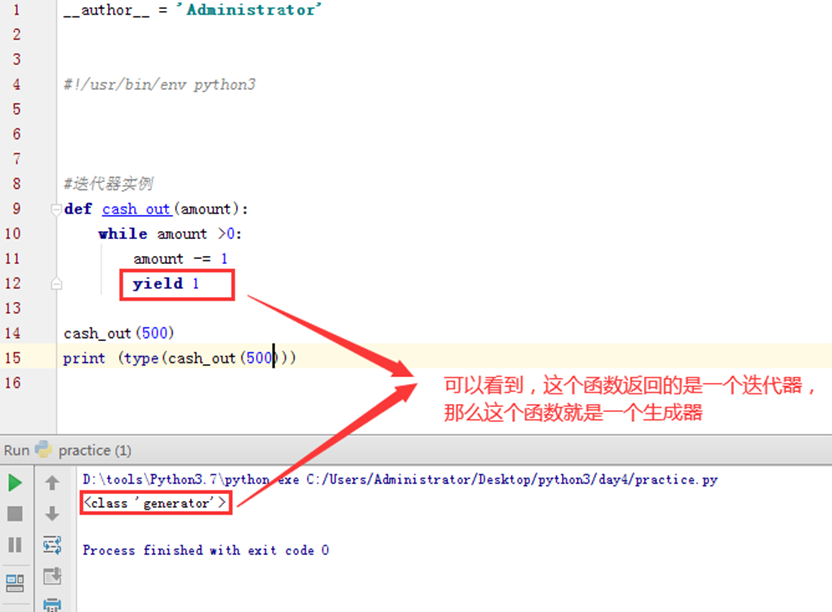
那么怎么使用这个生成器?因为里面是yield,那么就用next方法。
作用:
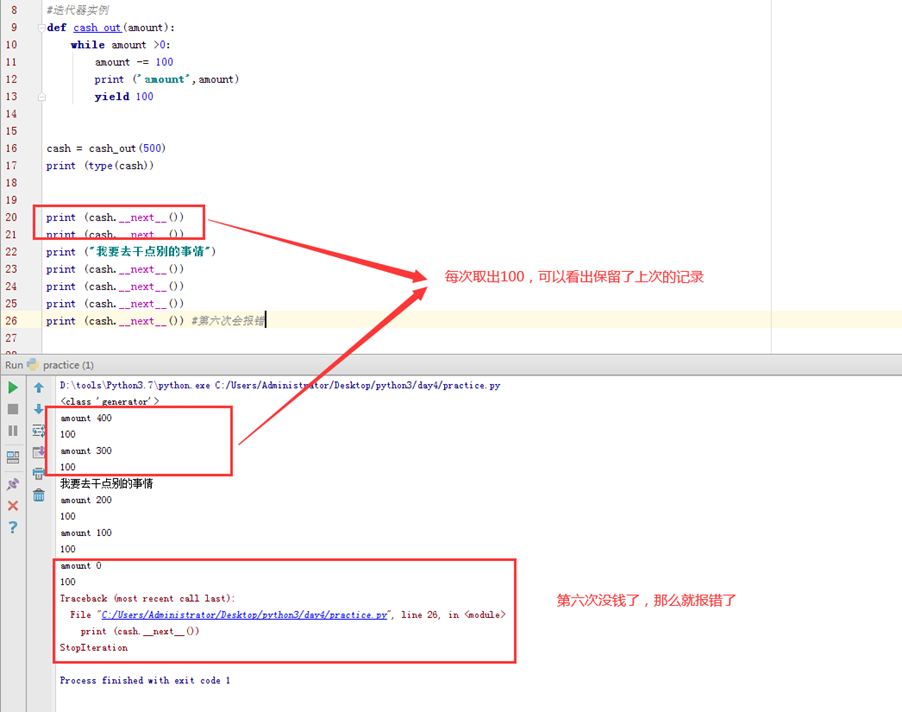
这个yield的主要效果呢,就是可以使函数中断,并保存中断状态,中断后,代码可以继续往下执行,过一段时间还可以再重新调用这个函数,从上次yield的下一句开始执行。
另外,还可通过yield实现在单线程的情况下实现并发运算的效果
4.3 使用yield实现单线程中的异步并发效果
这里使用生产者和消费者模型的方式来讲解。以一个包子的例子。
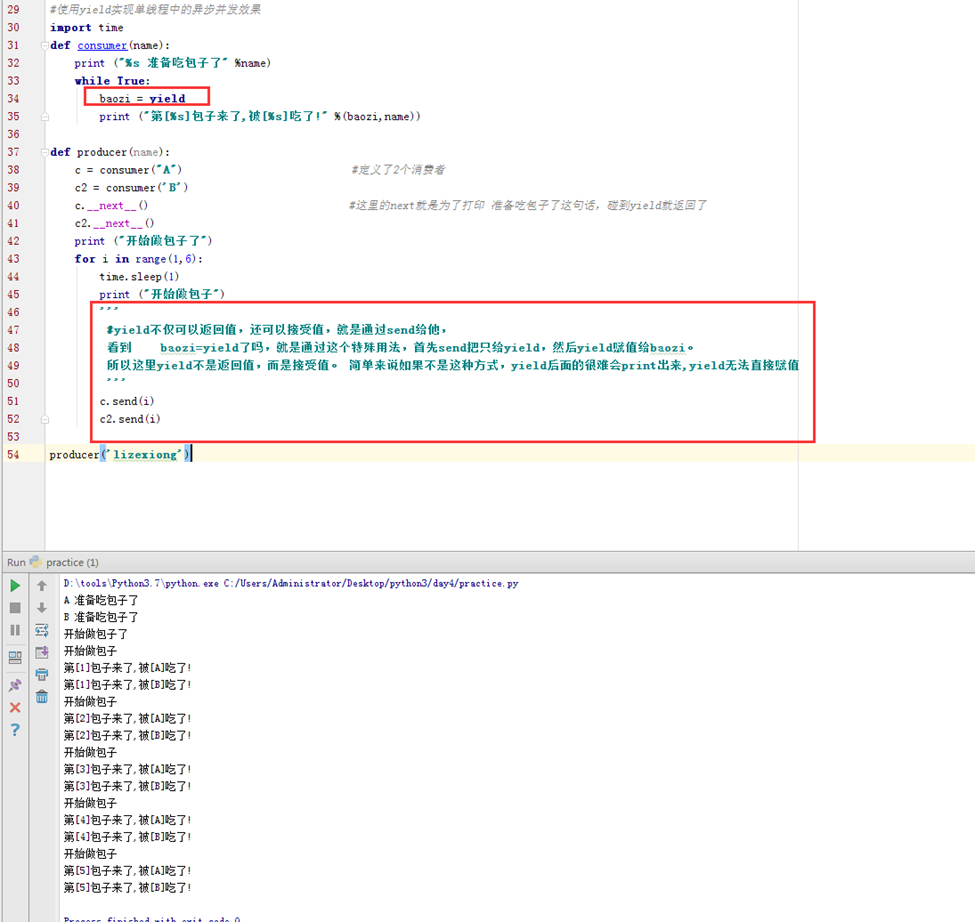
以上就是异步的一个简单demo,其实也是串行执行的,实现了可以同时做其它事情的效果。
4.4 装饰器原理介绍和基本实现
现在有个需求,就是比如电影网站,有主页,有TV界面,有image界面。但是突然发现,登录任何界面都没有认证,那么怎么办?
改变代码逻辑?那么秉着遵循开发封闭原则,直接更改实现好的功能的代码显然不太合适。所以这里就有了装饰器。
接下来,一步一步的看看装饰器怎么实现。那么我们看看不输入传参的简单装饰器实现思路。
第一版:
Login函数作为验证使用
那么具体看以下图示
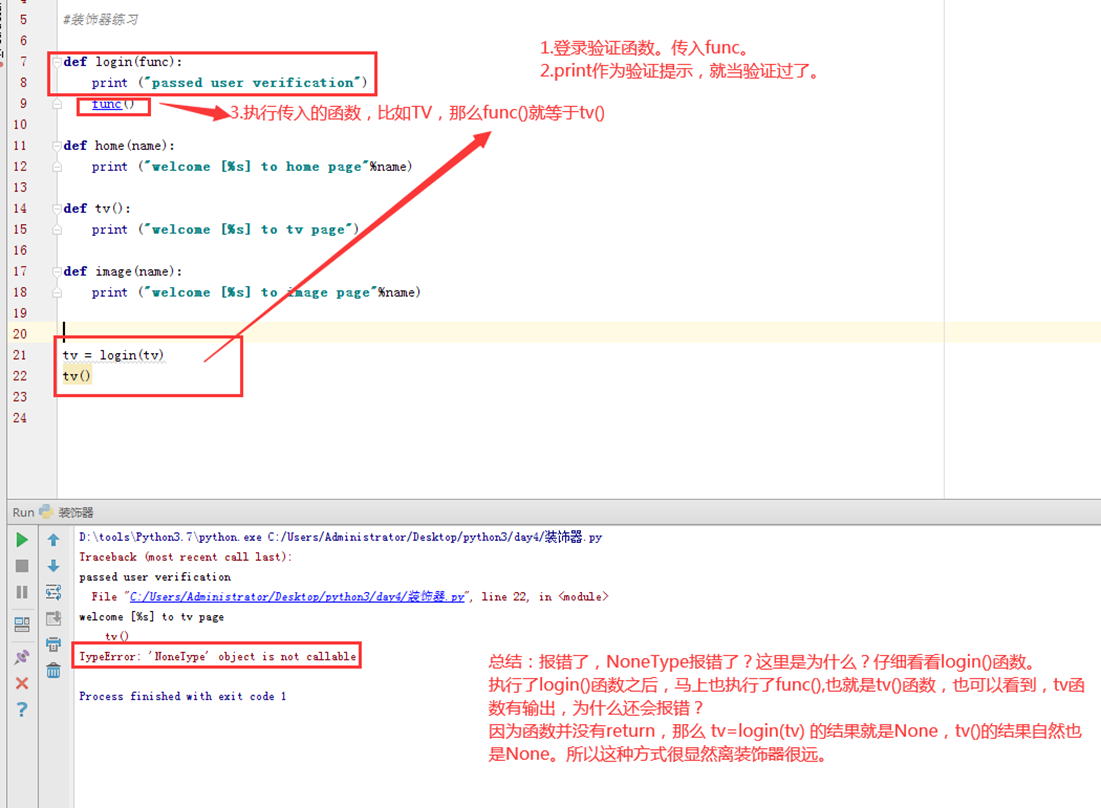
最后报错,TypeError,是因为虽然login验证函数和tv函数都执行了,但是login函数是没有返回值的,在执行tv(),那么就是执行None(),当然会报错。
第二版:
Return func的内存地址,然后手动调用执行。
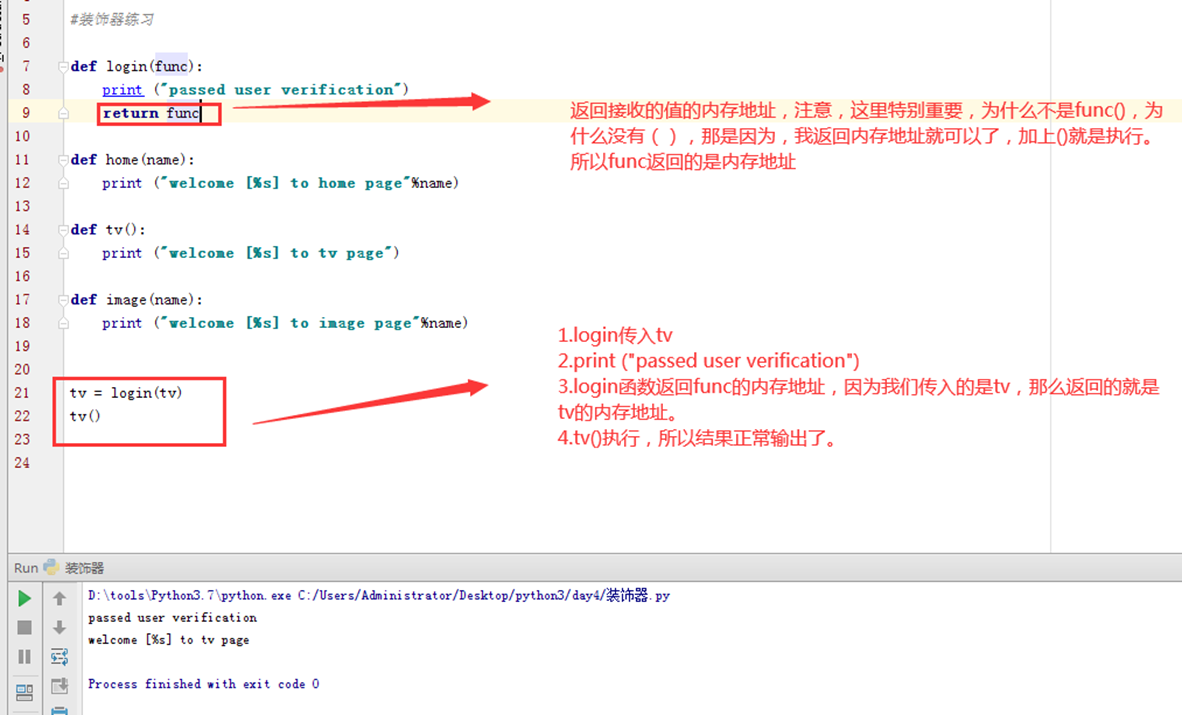
4.5 装饰器实现
接上面的课程讲解,可以看到,不带参数,已经实现了简单的装饰器功能,可以验证了,现在我们来看看带带参数可以吗?
第三版:在tv函数也需要传入参数。
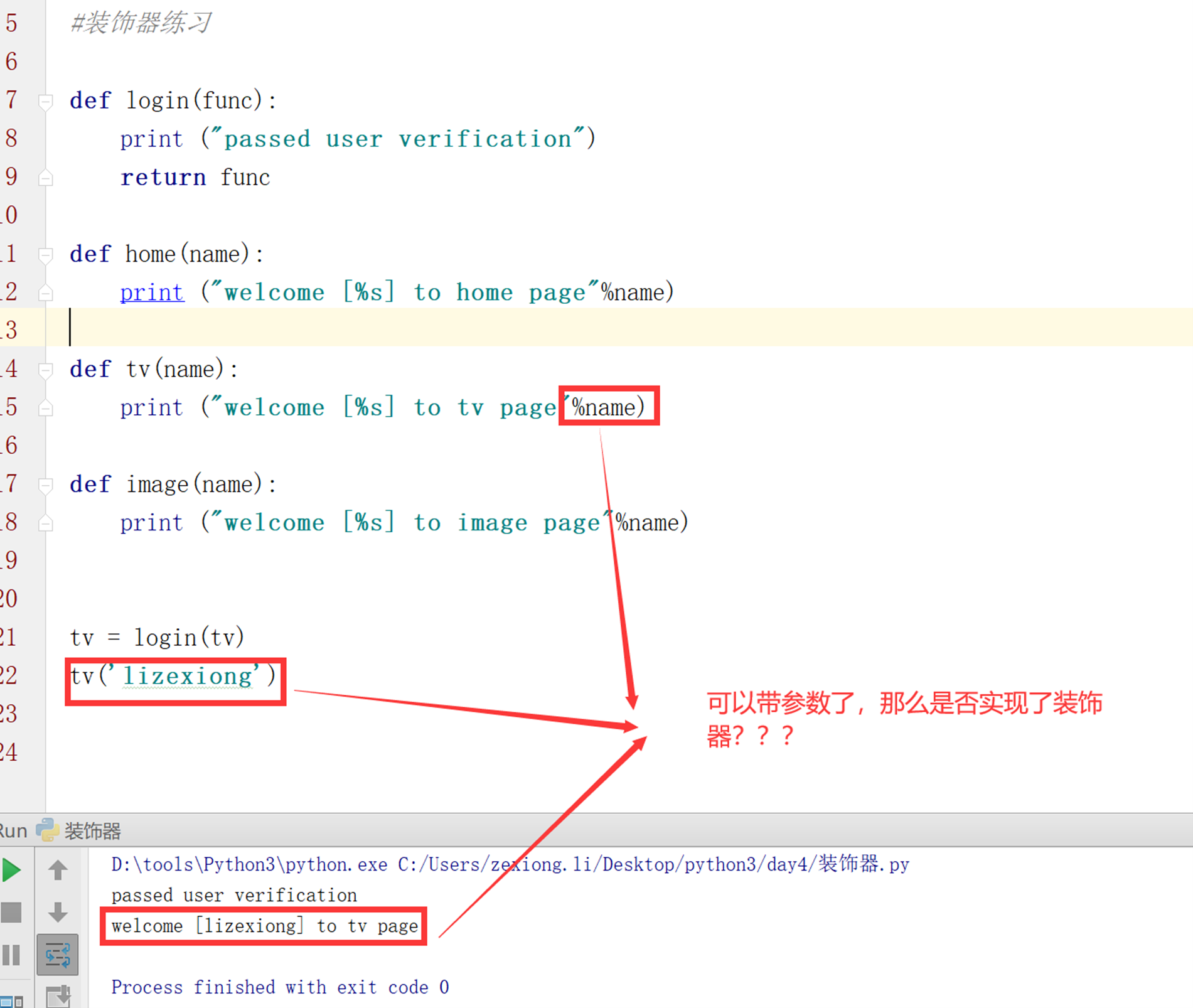
看到以上,可以看到已经可以带了参数?那么是否实现了装饰器呢?但是装饰器有专门的语法堂,不用每次专门tv=login(tv)一下调用。所以,接下来第4版,看看装饰器语法堂使用。
第四版:装饰器语法糖使用。
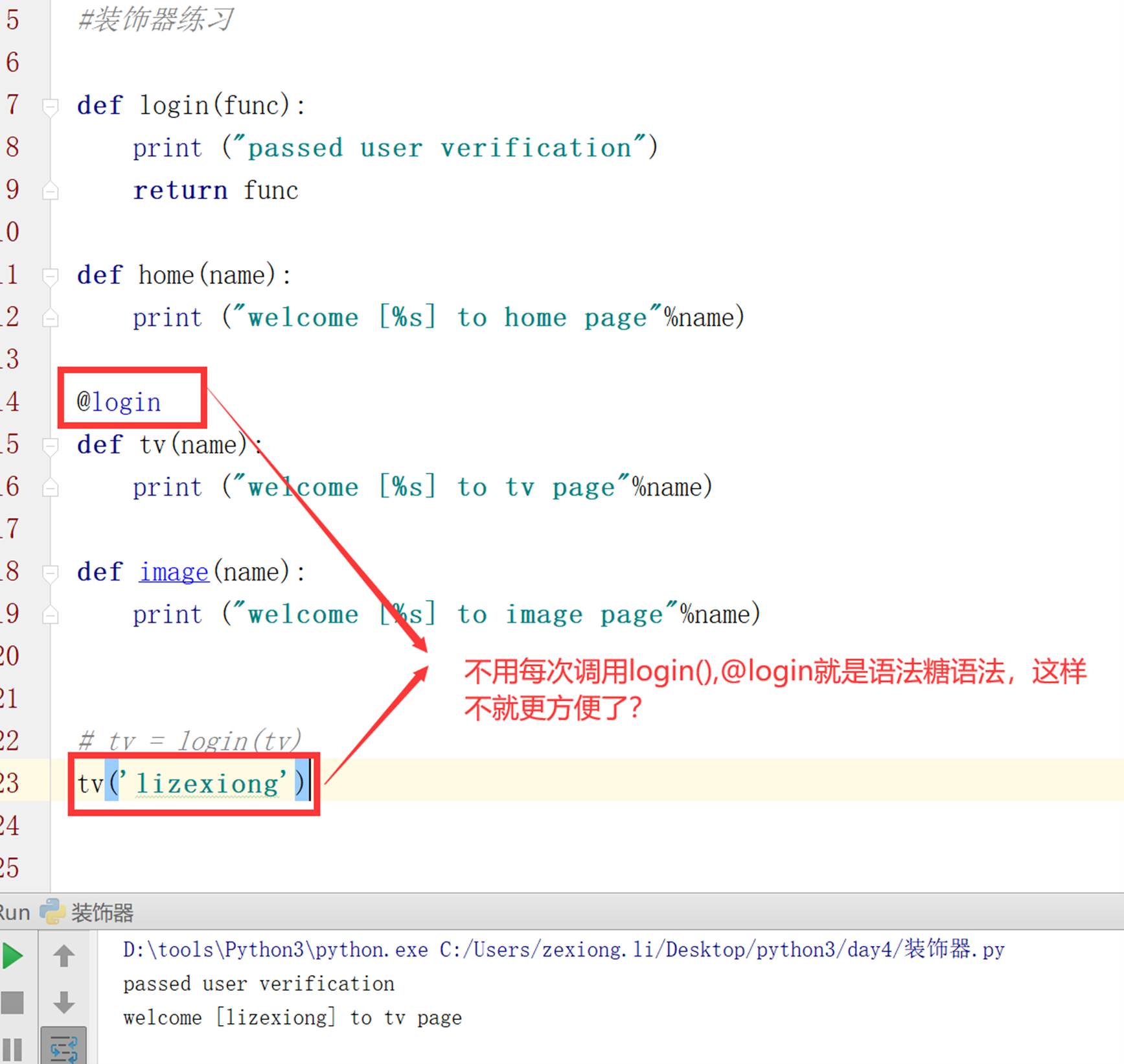
以上,已经实现了装饰器的使用?
不对,貌似看没问题,我们这里把tv()执行函数取消看看结果?
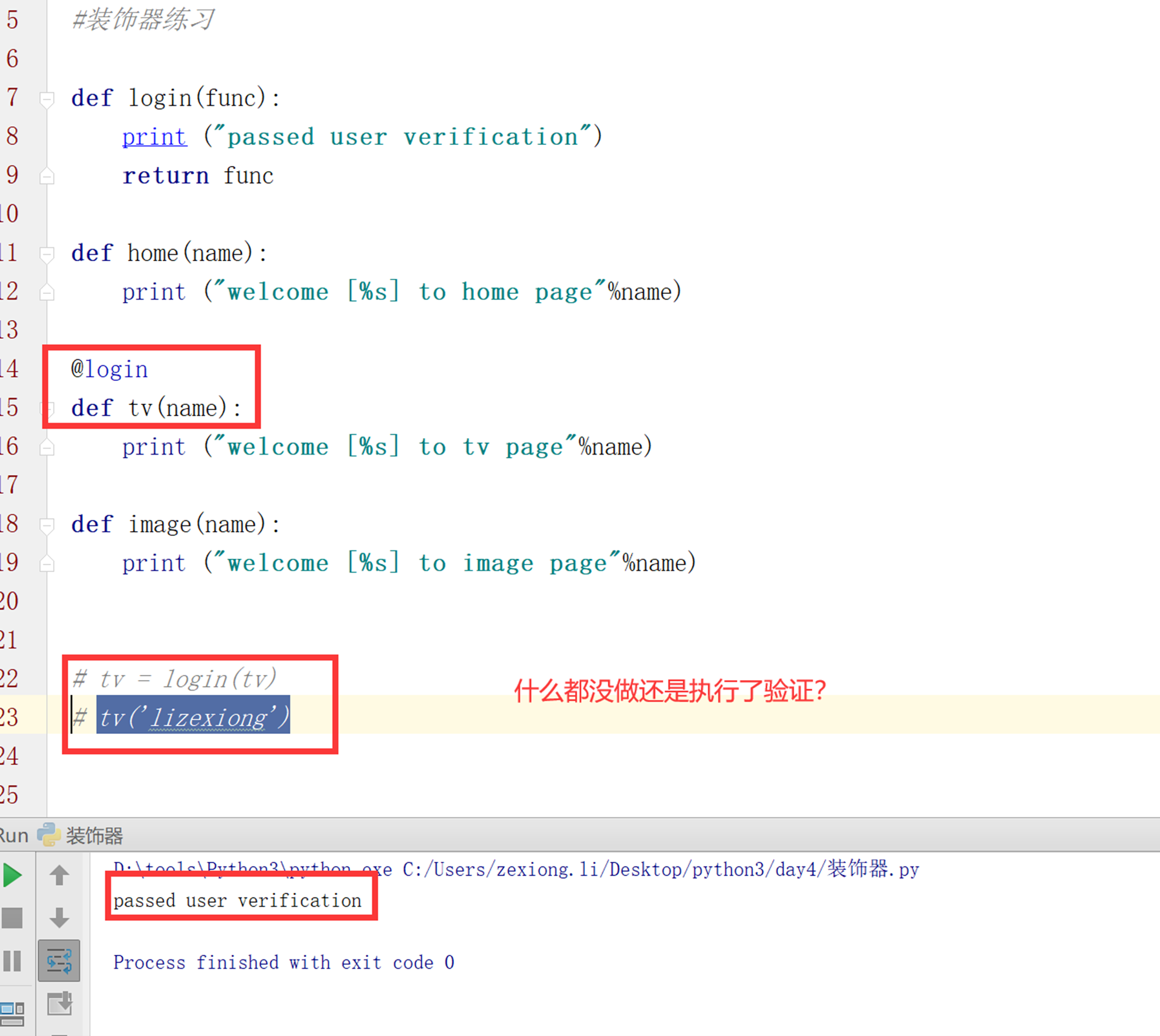
可以看到,以上什么都没做,还是执行了验证?因为python把代码加载到内存的时候,就执行了login()的函数了,这不是我们想要的效果。所以,装饰器还没完成。
第五版:装饰器初版。
实现带了简单参数,并且,只有执行tv函数的时候才会执行验证。
看一下例子,简单来说,就是包2层,执行第二层函数的时候才会做验证以及执行主体函数。第二层函数包含了验证、以及主体函数,但是并不执行,只有调用的时候执行这个第二层函数,第二层函数因为包含了验证和主体函数,所以就一并执行了。
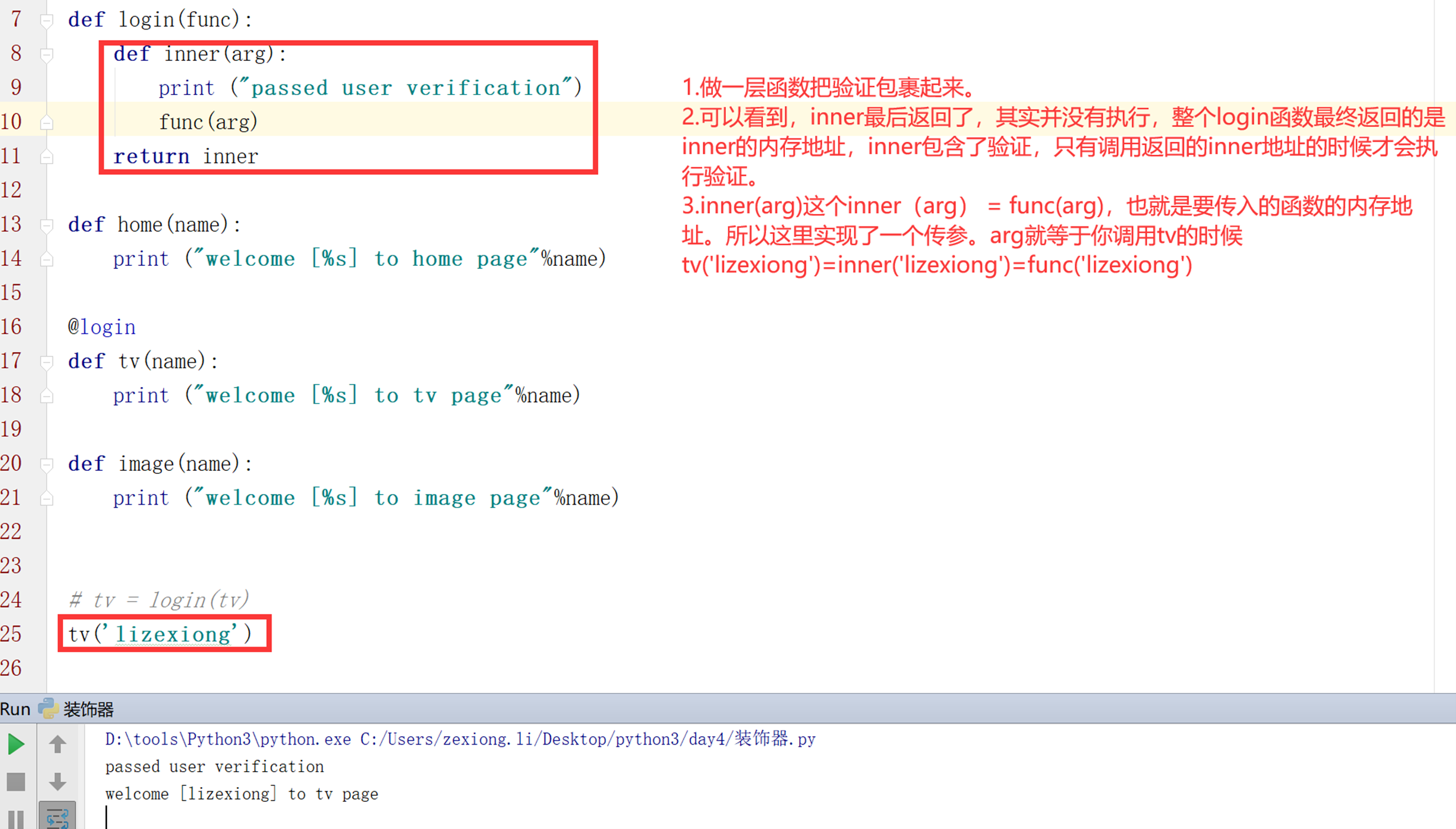
看图片里面的注释,是否已经实现了简单的装饰器功能?不调用就不执行验证,并且还可以传参数。
4.6 实现带参数的复杂装饰器
那么,以上实现了简单装饰器,也实现了传一个参数,但是你会不会有其它需求,复杂一点的?比如,传2个参数?或者多个参数?或者说带返回值的函数?
第六版:多参数装饰器
比如可以传入*args和**kwargs。
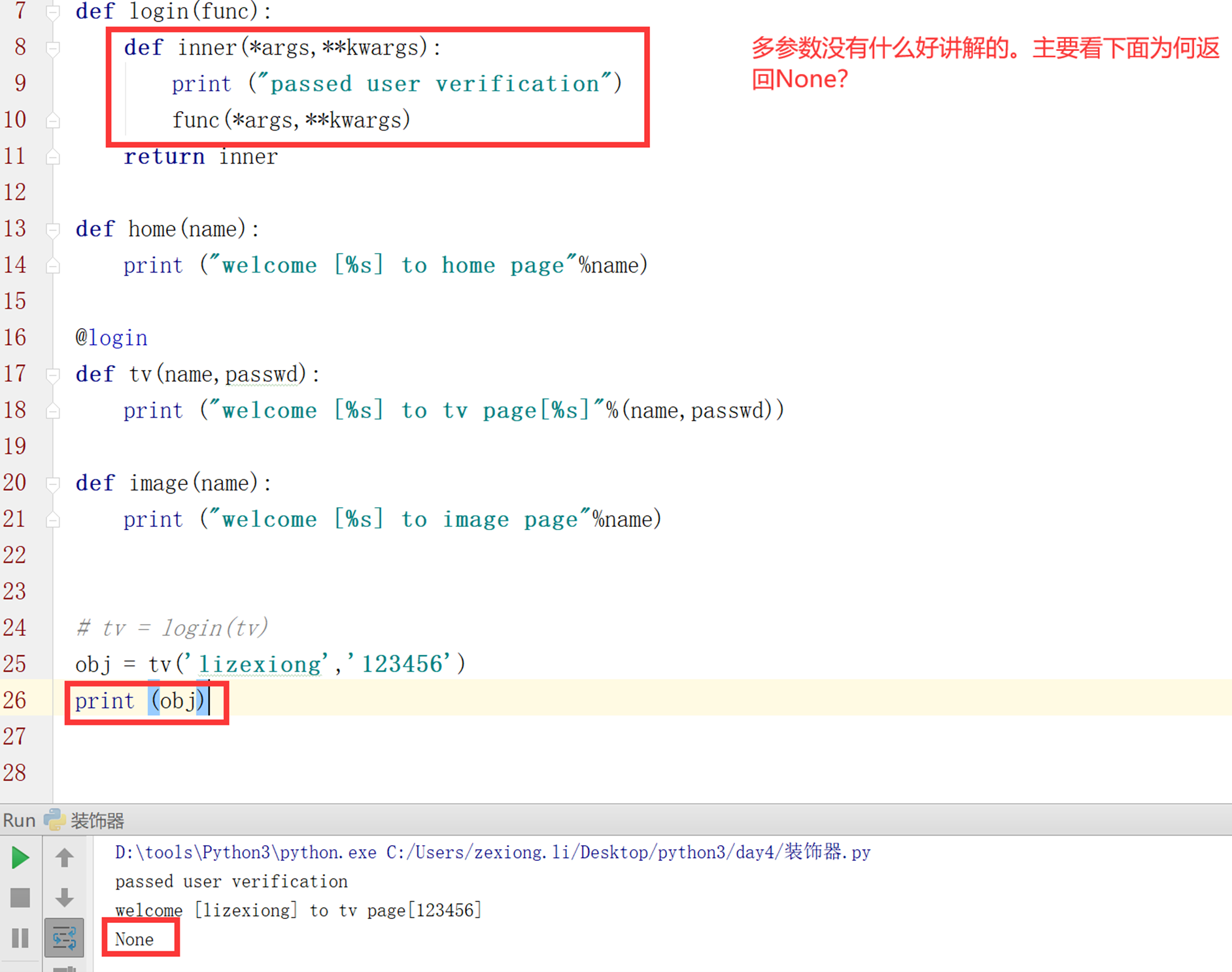
第七版:多参数装饰器带返回值版
上面的例子可以看到,虽然可以传入多个参数,但是返回确实None?
其实这个也非常好解决。
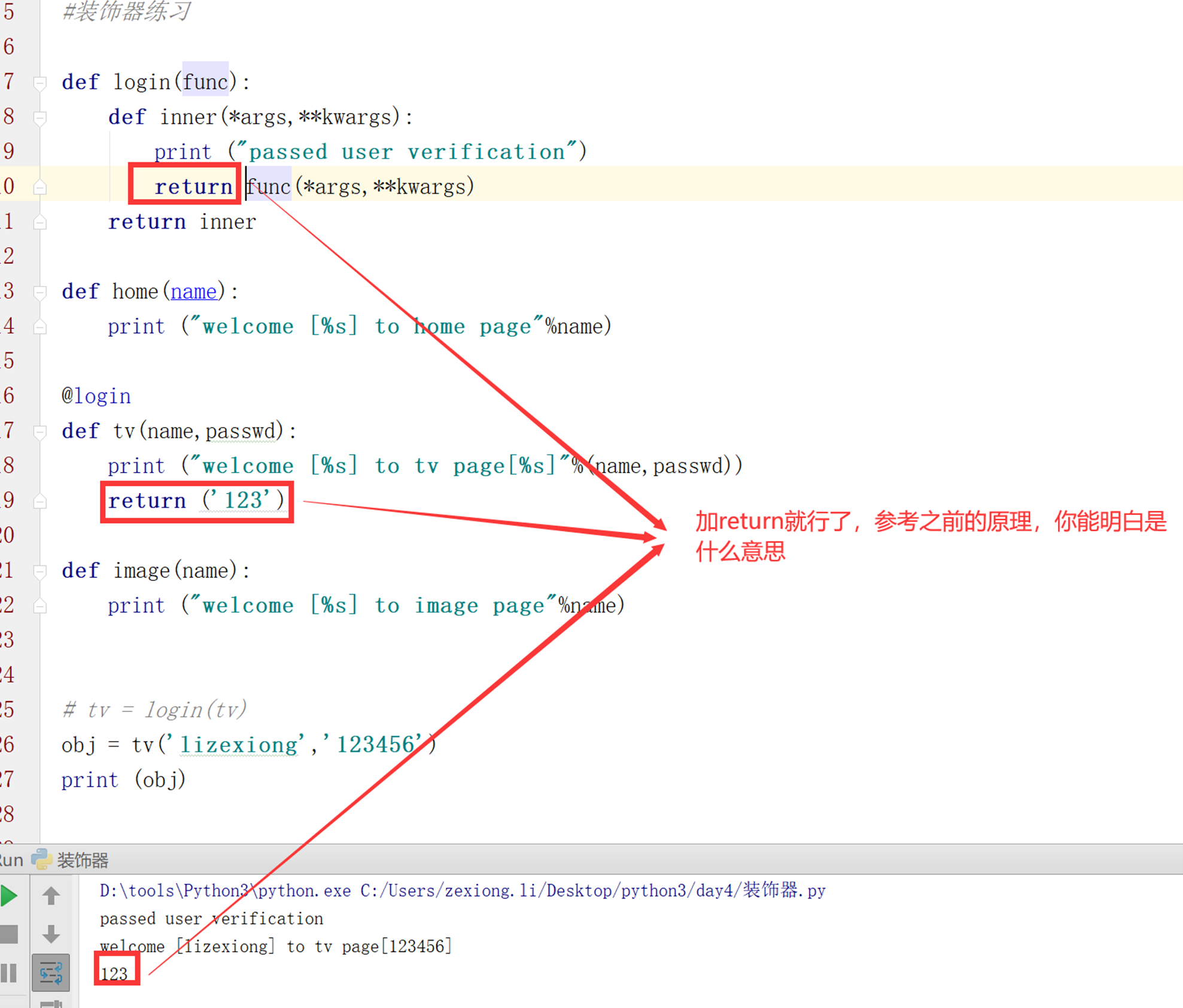
第八版:带参数的3层装饰器,终极版
其实这种3重函数的装饰器在实际中很少碰到,但是也有可能碰到这种场景,所以还是需要学习。
比如,要在装饰器传入参数判断,比如有个场景,这里要先登录验证,登录验证的时候要传入参数,然后在执行主函数,得到主函数的返回值什么的之后,在判断是否输入一些内容。总结简单来说,就是装饰器带参数的联系。
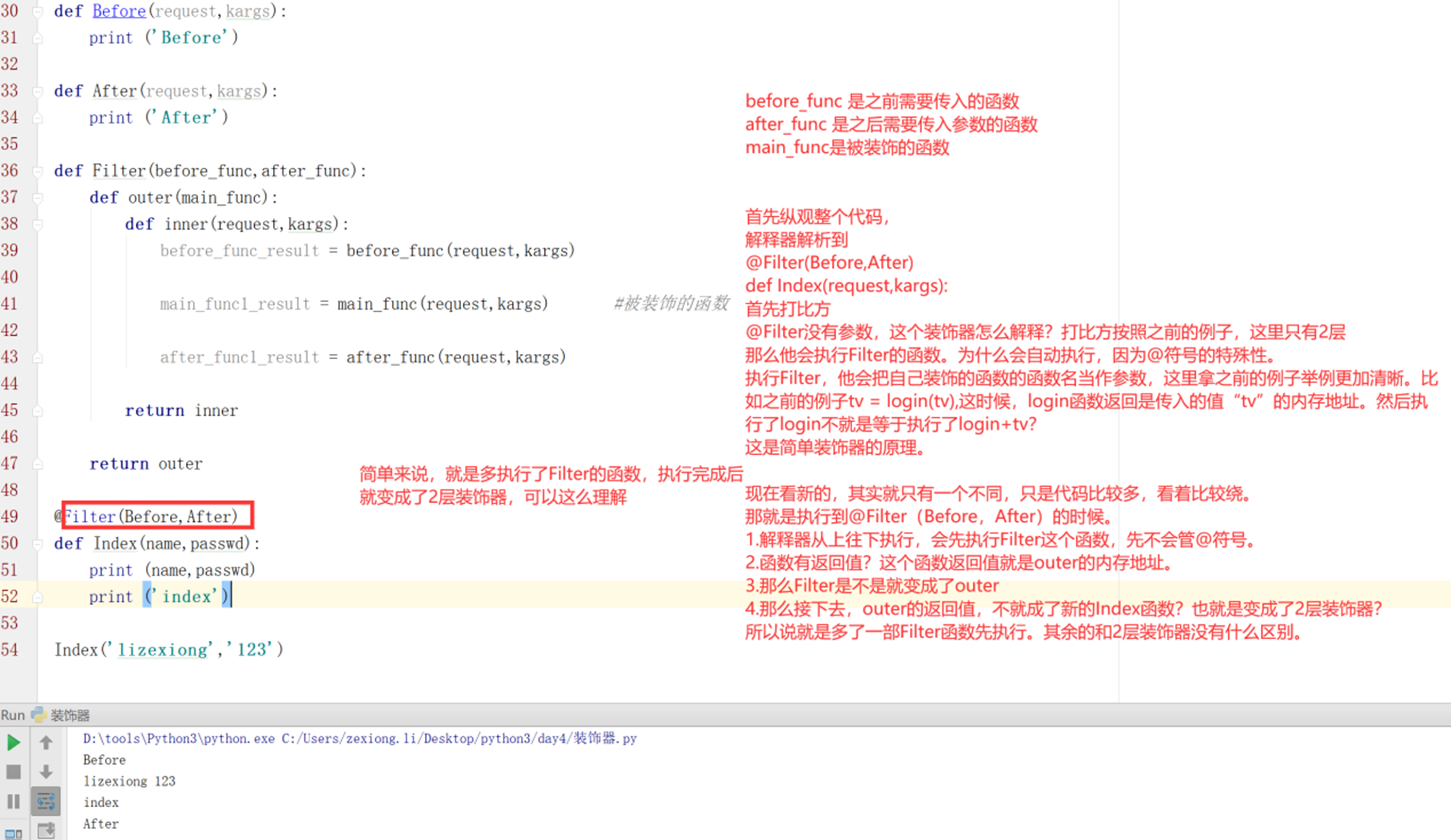
before_func 是之前需要传入的函数
after_func 是之后需要传入参数的函数
main_func是被装饰的函数
首先纵观整个代码,
解释器解析到
@Filter(Before,After)
def Index(request,kargs):
首先打比方
@Filter没有参数,这个装饰器怎么解释?打比方按照之前的例子,这里只有2层
那么他会执行Filter的函数。为什么会自动执行,因为@符号的特殊性。
执行Filter,他会把自己装饰的函数的函数名当作参数,这里拿之前的例子举例更加清晰。比如之前的例子tv = login(tv),这时候,login函数返回是传入的值“tv”的内存地址。然后执行了login不就是等于执行了login+tv?
这是简单装饰器的原理。
现在看新的,其实就只有一个不同,只是代码比较多,看着比较绕。
那就是执行到@Filter(Before,After)的时候。
- 解释器从上往下执行,会先执行Filter这个函数,先不会管@符号。
执行这个函数是不是就返回了outer。
2.函数有返回值?这个函数返回值就是outer的内存地址。
3.那么Filter执行完成之后是不是就变成了outer,这时候outer加上@符号就是@outer。
4.那么接下去,@outer也就是变成了2层装饰器?接下来2层装饰器可可以理解了吧。
所以说就是多了一部Filter函数先执行。其余的和2层装饰器没有什么区别。
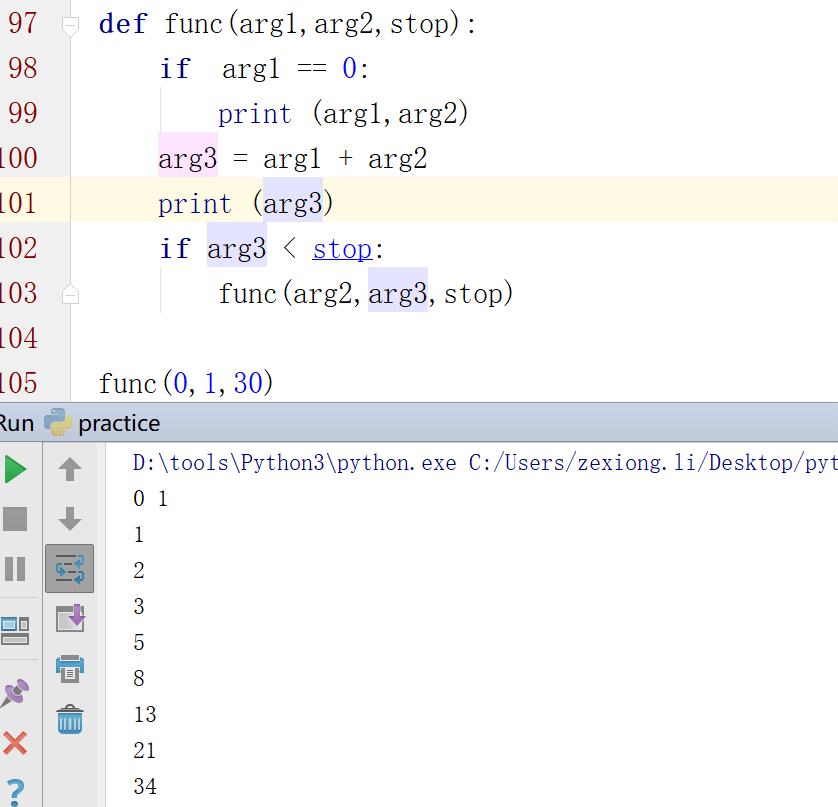
4.7 递归原理及实现
特点
递归算法是一种直接或者间接地调用自身算法的过程。在计算机编写程序中,递归算法对解决一大类问题是十分有效的,它往往使算法的描述简洁而且易于理解。
递归算法解决问题的特点:
(1) 递归就是在过程或函数里调用自身。
(2) 在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。
(3) 递归算法解题通常显得很简洁,但递归算法解题的运行效率较低。所以一般不提倡用递归算法设计程序。
(4) 在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储。递归次数过多容易造成栈溢出等。所以一般不提倡用递归算法设计程序。
要求
递归算法所体现的“重复”一般有三个要求:
一是每次调用在规模上都有所缩小(通常是减半);
二是相邻两次重复之间有紧密的联系,前一次要为后一次做准备(通常前一次的输出就作为后一次的输入);
三是在问题的规模极小时必须用直接给出解答而不再进行递归调用,因而每次递归调用都是有条件的(以规模未达到直接解答的大小为条件),无条件递归调用将会成为死循环而不能正常结束。
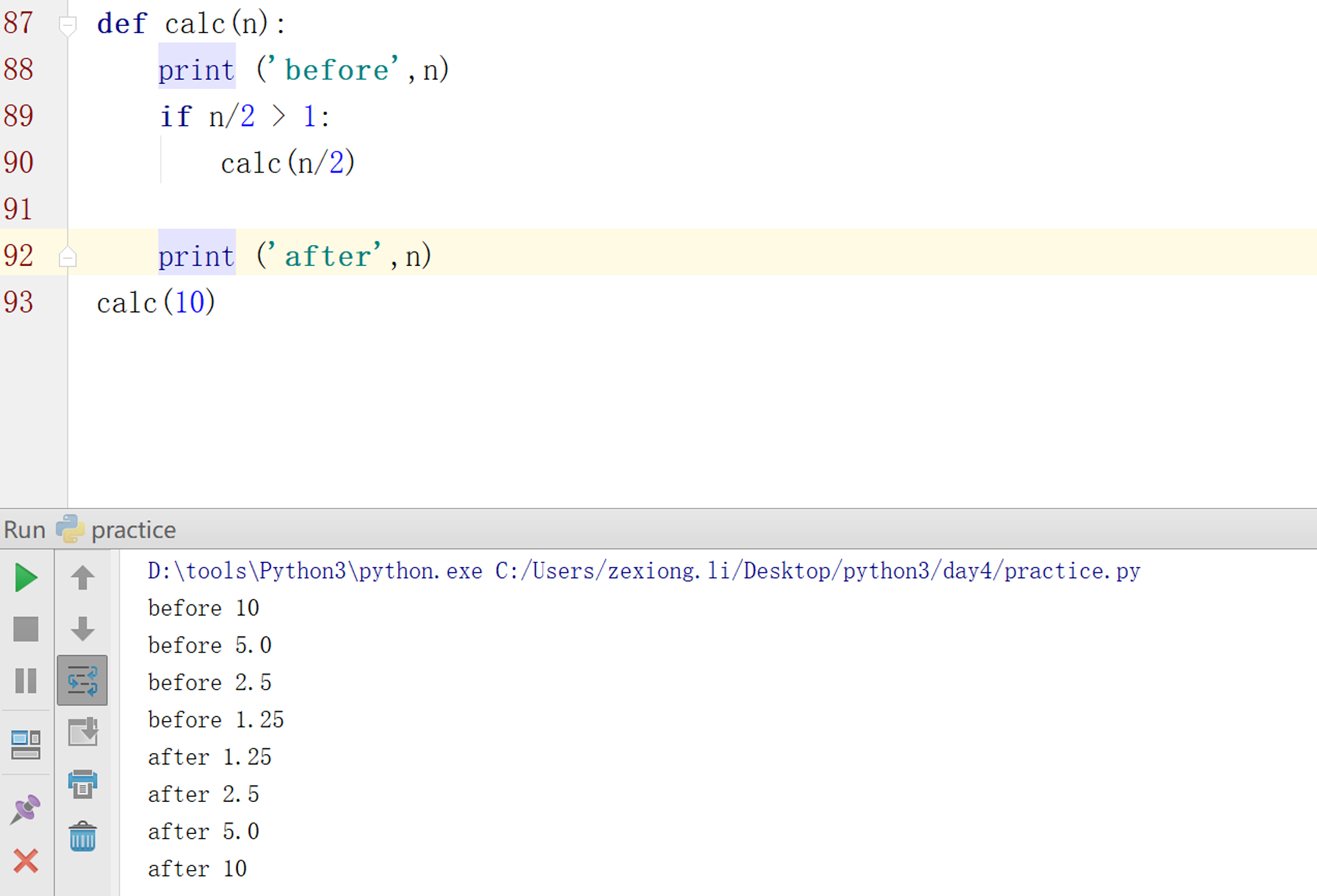
这里跟老师讲解的不一样,这里首先没加return,为什么后续的打出了1.25,2.5之后的数字,本人也迷糊了小半小时。
因为误区在于,我认为,只要>1,那么就调用函数,小于1,就打印出来,并且退出函数,其实并不是。
这可能就是老师说的还有一个退出的效果。
仔细看看,你把他当作一个函数执行即可。>1的时候再次调用自己。这个没问题,也就是误区所在。仔细看看,内部调用的calc执行完成之后,我这里是个if,我不在调用内部的clac之后是不是还是回到了最初始的函数,所以,显示出了一个打印出增长的效果。
简单来说,这个 print (‘after’,n)每次返回的,并不是外层的calc(n)这个函数打印的,只是代码只有这么一句,断点根本看不出来。
所以,这一点比较绕。但是应用不多,因为学习过程都加了一个return。
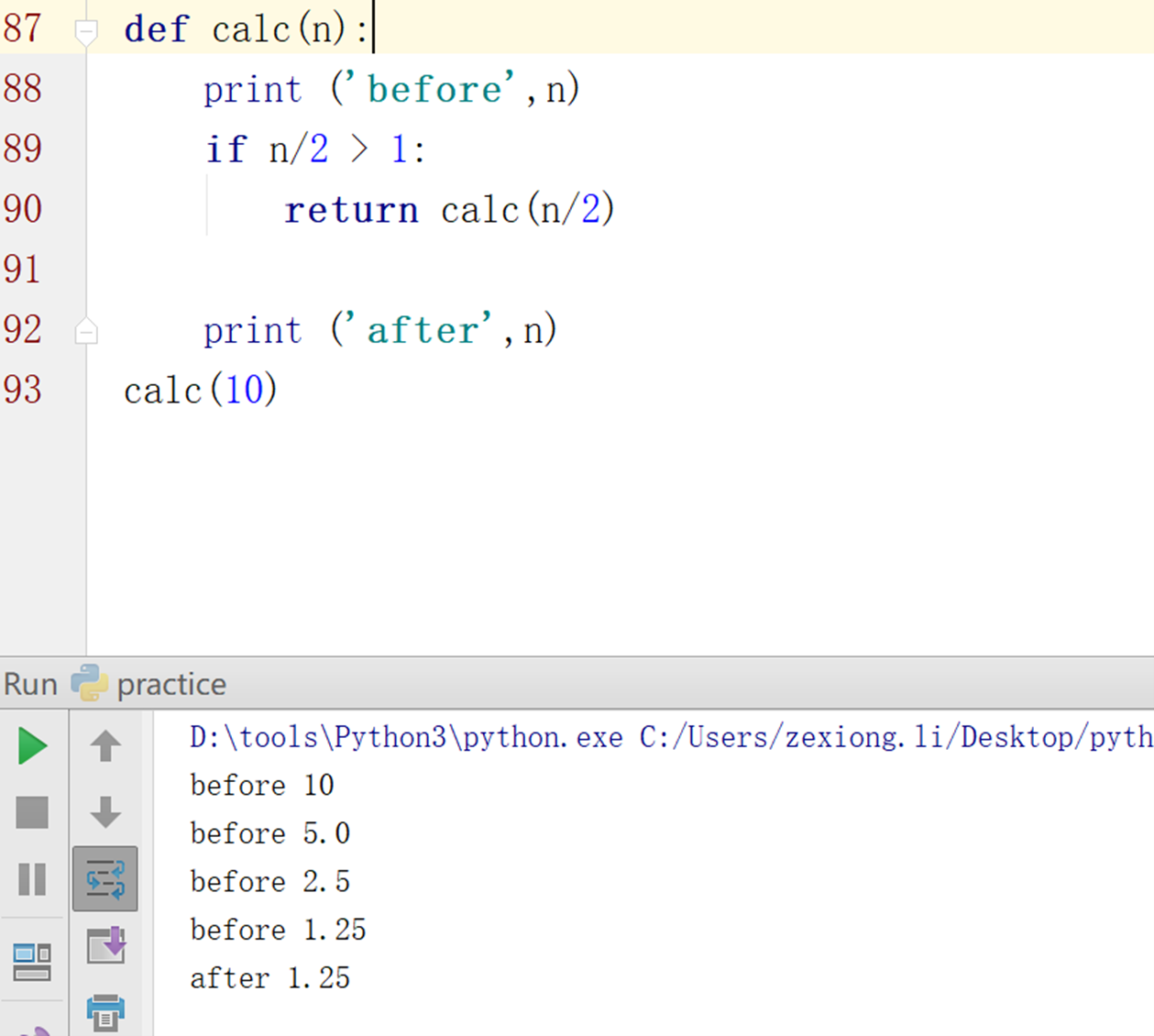
加了return就不会输出了,因为加了return之后,那个函数就结束了。所以只有不满足if条件的时候输出了一个。
这大概就是老师想讲解的往外退的效果。
诉我直言,这个老师根本没搞清楚。
或者如课堂上的代码,return放在最后
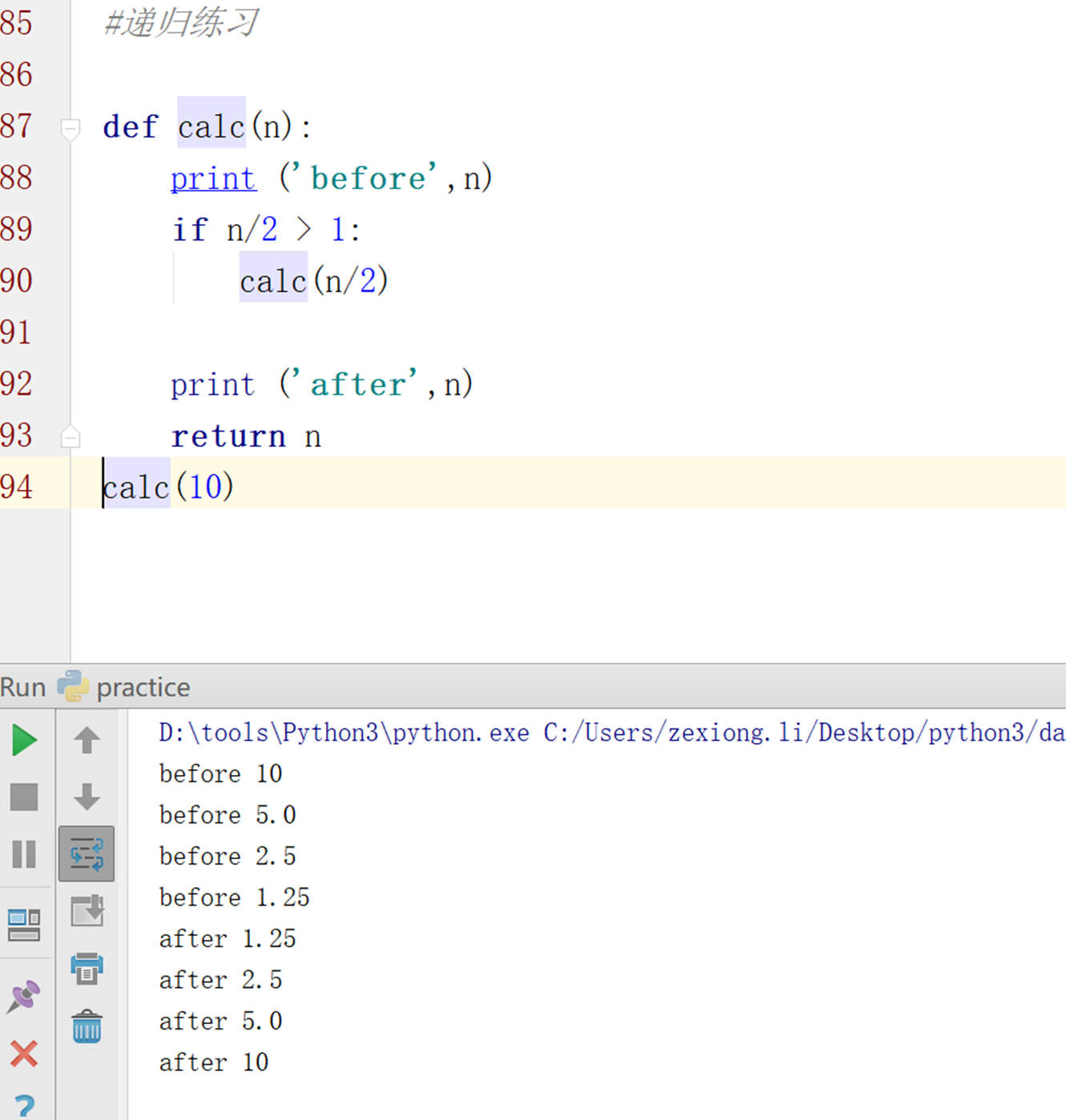
他所讲的return根本就没关系,return放在这里根本就是错误的。没什么用,最多最终返回一个结果。
4.8 通过递归实现斐波那契数列
虽然老师讲的差,实例还是要做的。
斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368,每一个值等于前2个数相加。
武老师博客里面的例子有点小问题,没有停止。所以这里优化一下代码。
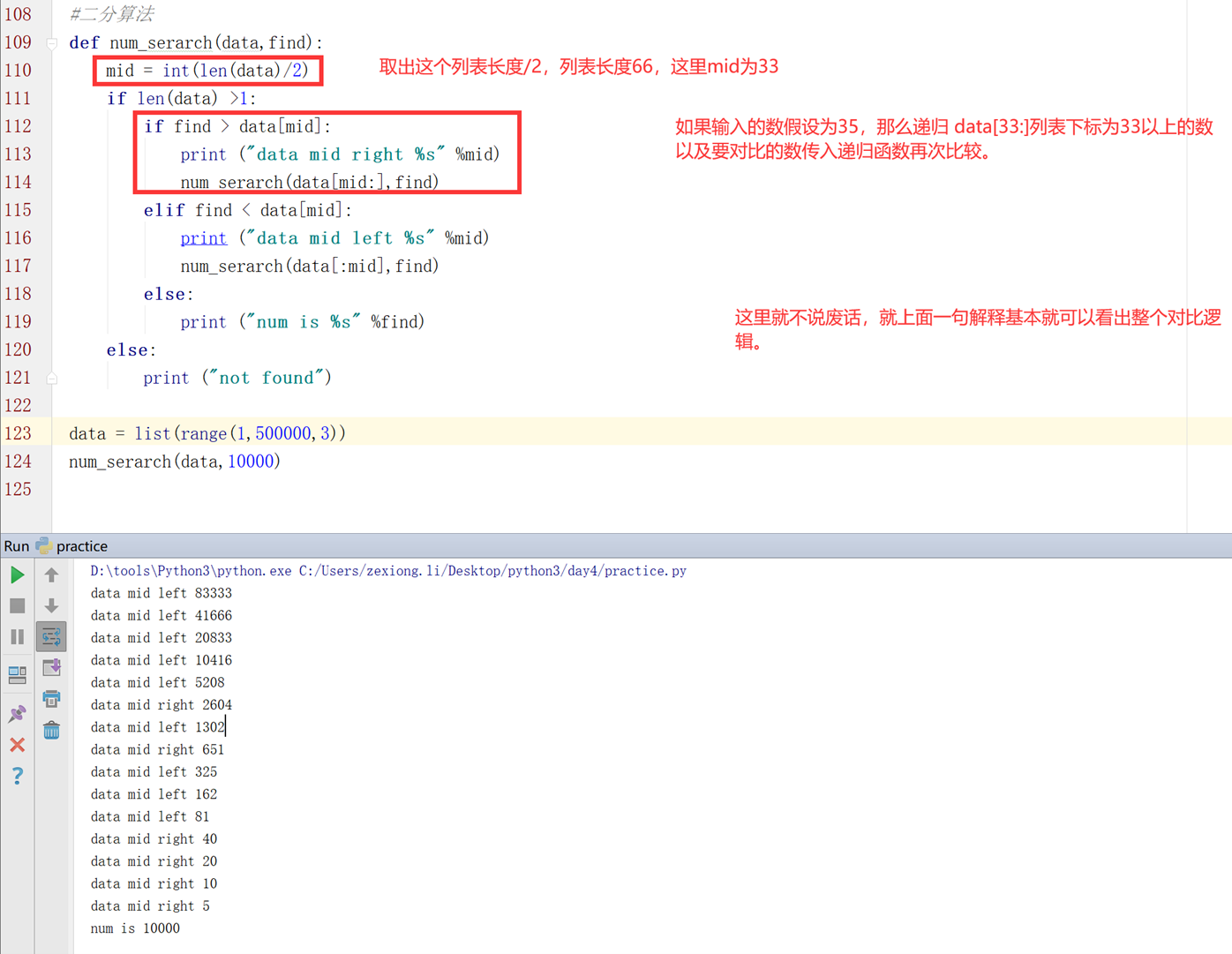
4.9 算法基础之二分查找
二分原理就不多做介绍,后面会有详细的博客解释。
看看上述,2分算法的基本原理?比如,现在有100个数,我需要查找数字15,那么怎么办?
使用if 一直判断循环?那么就得对比100次。效率以及性能实在太慢。
所以这种方式使用二分算法,什么是二分算法?
比如,假设我现在需要找数据15,得知整个要查找的长度是100个数,并且大小都是递增的,那么我可以先将100个数分成2份,使用列表的长度取出中间值,如果这个数大于这个中间值,那么[mid:],再次把这个数与大于这个数列表比较,如果小于,则[:mid],把这个数与小于这个数的列表比较。然后依次递归。这样是不是就不用有100个数就对比100次了?这就是算法。
4.10 算法基础之2维数组90度旋转
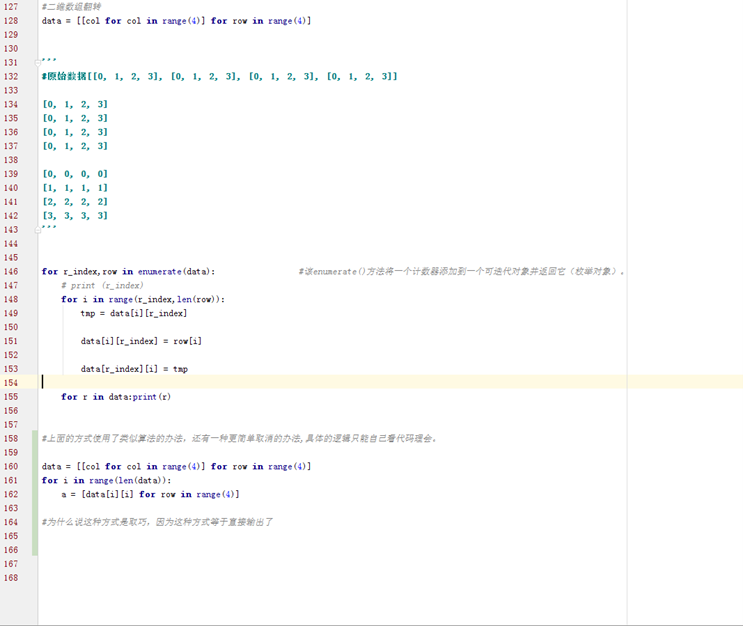
代码在day4-practice.py 二维数组翻转下
5.L05
前面的5小节不做过多讲解,但是讲解上节作业计算器的时候,确实老师的思路和我差不多,但是老师实现的功能不够全面,可能会有一些小bug,但是老师讲解的代码够简洁。比如如下:匹配到第一个小括号,我用了很长的正则,老师只用了如下图片中的一小行。
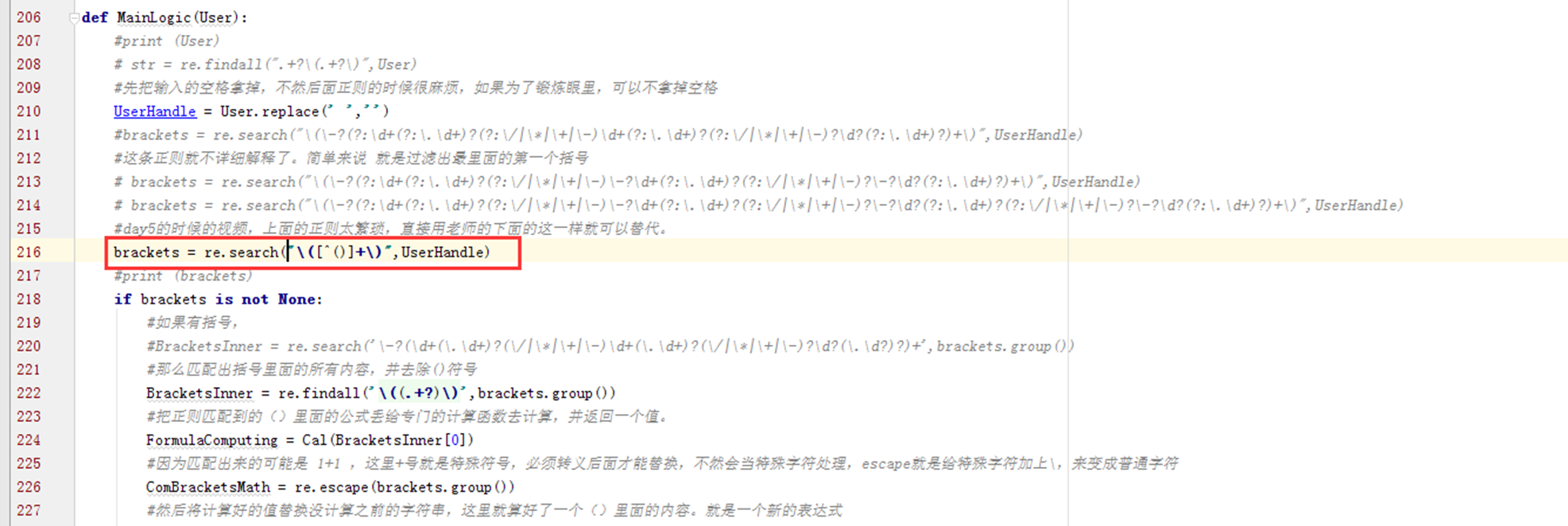
Day4的作业修改已上传至github
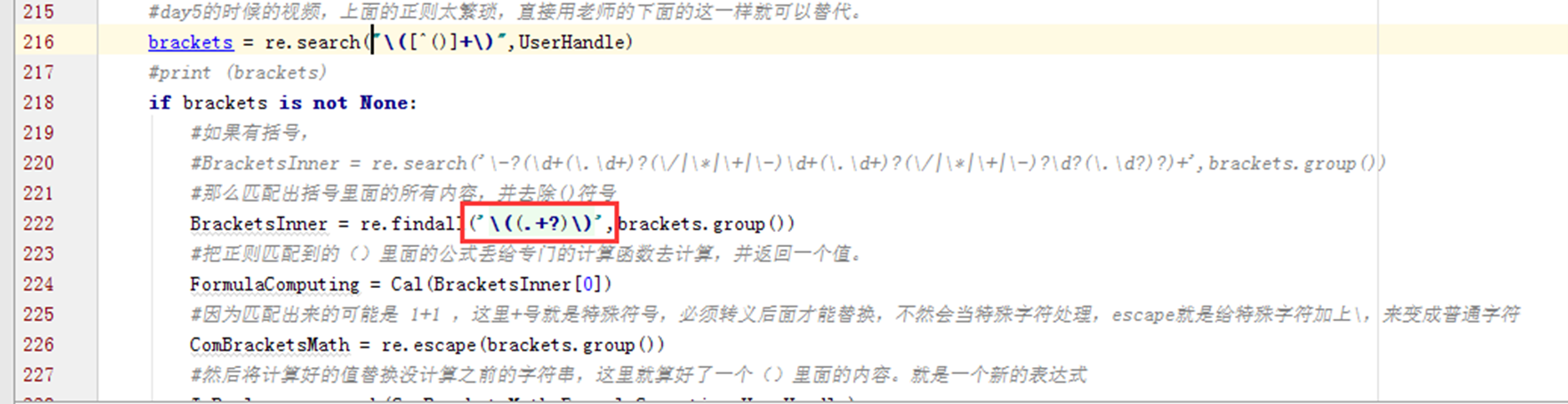
在比如我过滤出()里面的公式,使用的是正则
而老师使用strip(“()”)去掉()就行。
很多优秀的简洁的方式可以借鉴,但是前面找到()里面的内容整体思路是一样的。
计算的思路,老师讲解的比较繁琐,有兴趣的在可以回去看视频,但是没有必要。
5.1 正则表达式深入
本章详细的讲解,本人博客已经单独记录详细的使用方式。当然不包括正则语法的使用方式,正则语法使用方式整个互联网到处都是,本人博客不做记录,只做Python re模块的使用方法。
当然,本章也就听听看,将的也是比较浅的,但是还是做一个简单的记录。
课件博客地址: https://www.cnblogs.com/alex3714/articles/5143440.html


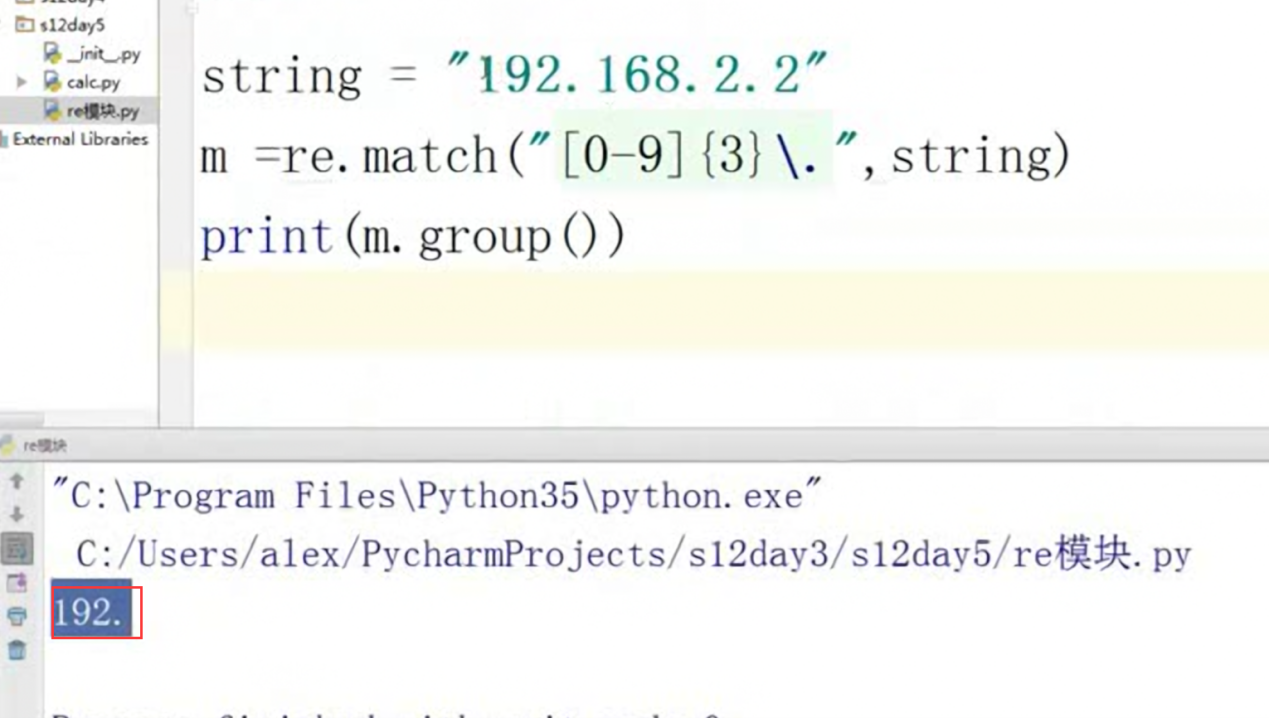
匹配IP实验:
第一步,过滤出IP的第一个段。
IP有2个段,怎么才能不重复的匹配出来剩下的iP呢?那么就用正则语法的分组+重复,把这个![]() 给重复就好了。
给重复就好了。
重复2次,匹配2个段

重复3次匹配3个段。这里还有一点,就是下图红框的1,3因为有的IP不一定是三个数字。所以是1,3.
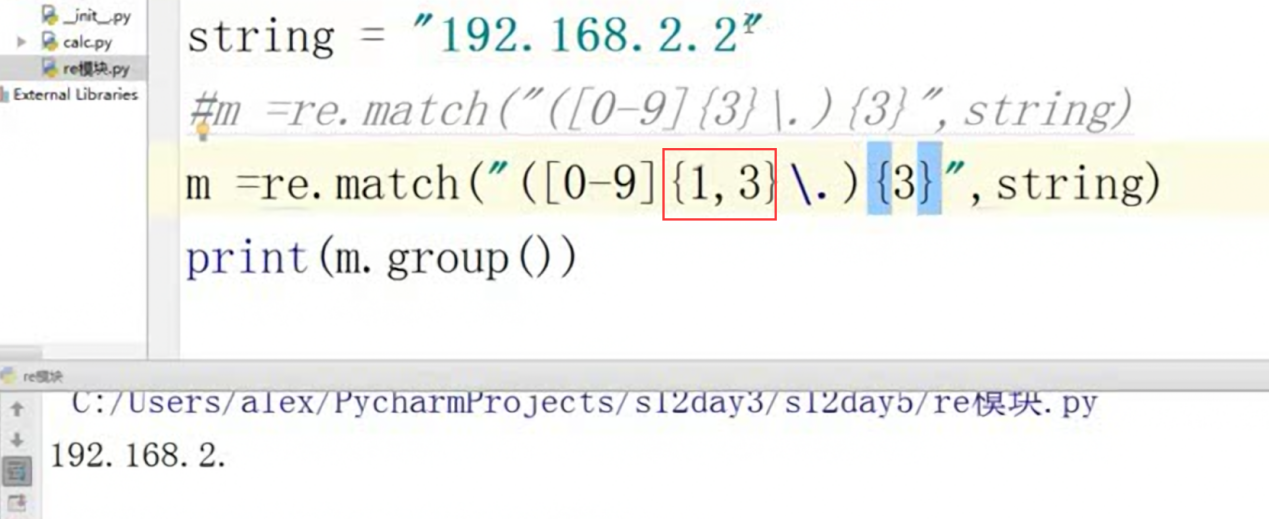
最后结尾,IP地址没有点,直接在匹配一个[0-9]{1,3}即可。
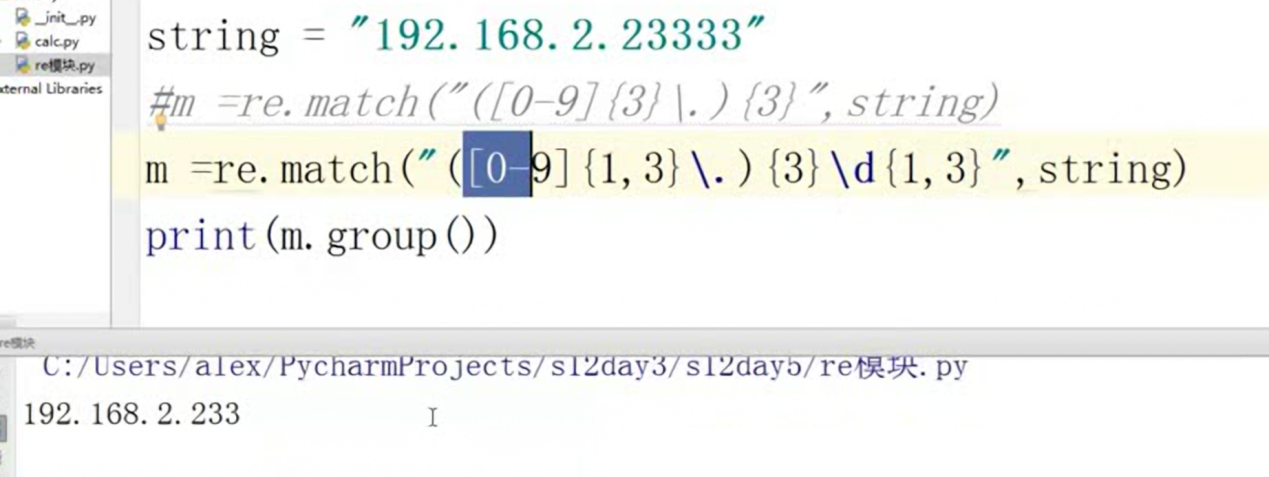
接下来讲解的内容都是及其简单,比如老师原文博客:https://www.cnblogs.com/alex3714/articles/5143440.html
当然也可以参考本人博客的内容学习python re模块的使用: https://www.cnblogs.com/lizexiong/p/16286399.html
5.2 算法基础之冒泡排序
5.3 时间复杂度介绍
这张这老师讲的,还是建议自己找其他视频或者书籍学习。
时间复杂度
(1)时间频度 一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(2)时间复杂度 在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
指数时间
指的是一个问题求解所需要的计算时间m(n),依输入数据的大小n而呈指数成长(即输入数据的数量依线性成长,所花的时间将会以指数成长)
for (i=1; i<=n; i++)
x++;
for (i=1; i<=n; i++)
for (j=1; j<=n; j++)
x++;
第一个for循环的时间复杂度为Ο(n),第二个for循环的时间复杂度为Ο(n2),则整个算法的时间复杂度为Ο(n+n2)=Ο(n2)。
常数时间
若对于一个算法,T(n)的上界与输入大小无关,则称其具有常数时间,记作O(1)时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称O(n)时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
对数时间
若算法的T(n) = O(log n),则称其具有对数时间
对数时间的算法是非常有效的,因为每增加一个输入,其所需要的额外计算时间会变小。
递归地将字符串砍半并且输出是这个类别函数的一个简单例子。它需要O(log n)的时间因为每次输出之前我们都将字符串砍半。 这意味着,如果我们想增加输出的次数,我们需要将字符串长度加倍。
线性时间
如果一个算法的时间复杂度为O(n),则称这个算法具有线性时间,或O(n)时间。非正式地说,这意味着对于足够大的输入,运行时间增加的大小与输入成线性关系。例如,一个计算列表所有元素的和的程序,需要的时间与列表的长度成正比。
5.4 模块介绍
本节大纲:
- 模块介绍
- time &datetime模块
- random
- os
- sys
- shutil
- json & picle
- shelve
- xml处理
- yaml处理
- configparser
- hashlib
- subprocess
- logging模块
- re正则表达式
模块,用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
模块分为三种:
自定义模块
内置标准模块(又称标准库)
开源模块
自定义模块 和开源模块的使用参考 http://www.cnblogs.com/wupeiqi/articles/4963027.html
就是简单讲解了模块的下载和安装方式,可以不用记录。
具体的会在课件模块博客中更新。
当然,本章还有一个小实验,虽然比较繁琐,条理不清楚,但是可以很好的学习模块的调用。
首先场景是一个模拟一个网站的前端后端调用数据库。可能前端要调用后端,后端调用数据库这样一个模块调用的实验案例。
比如有frontend,backend。这个实验前端没有用到,比如后端里面有db模块,logic处理模块。接下来就用创建这些东西来演示。
注意:一定是要选择python package,至于原因,本章后面会解释。
接下来创建的目录就如下。
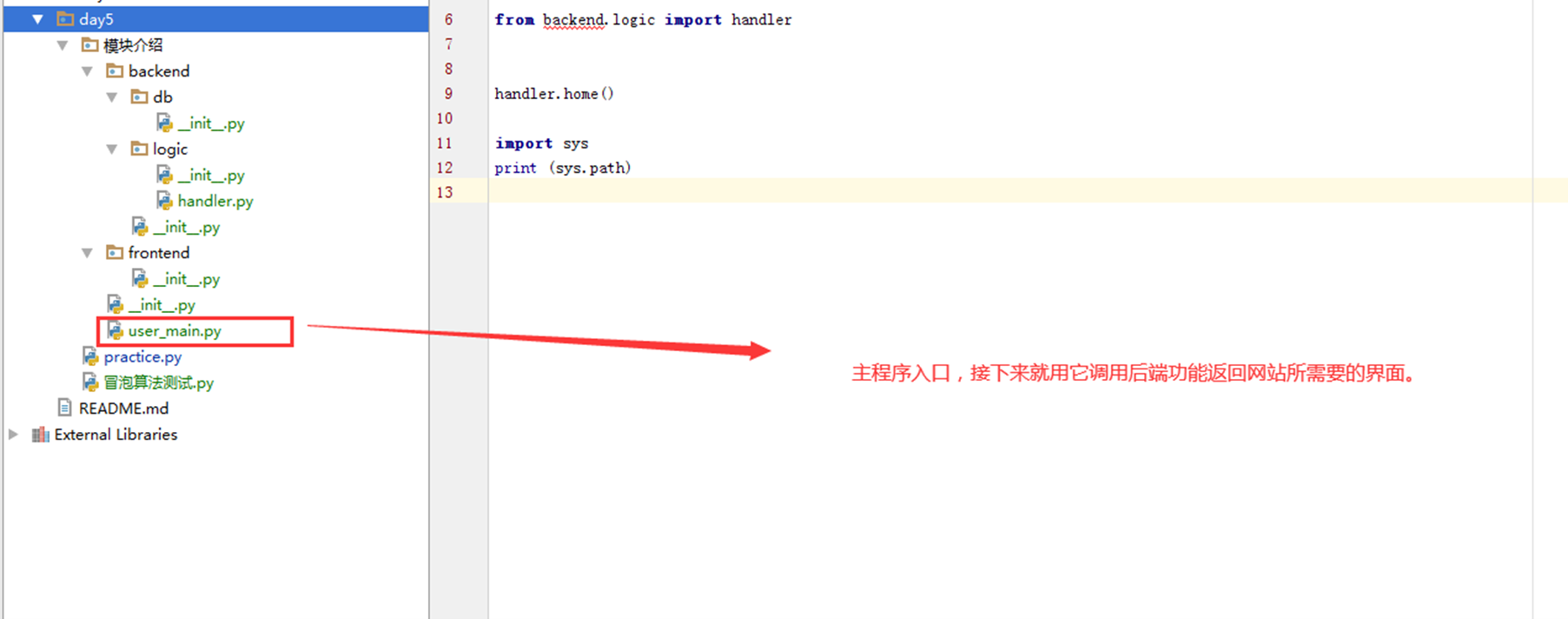
调用逻辑顺序就是,user_main主函数调用backend.logic下面的handler里面的一个方法。
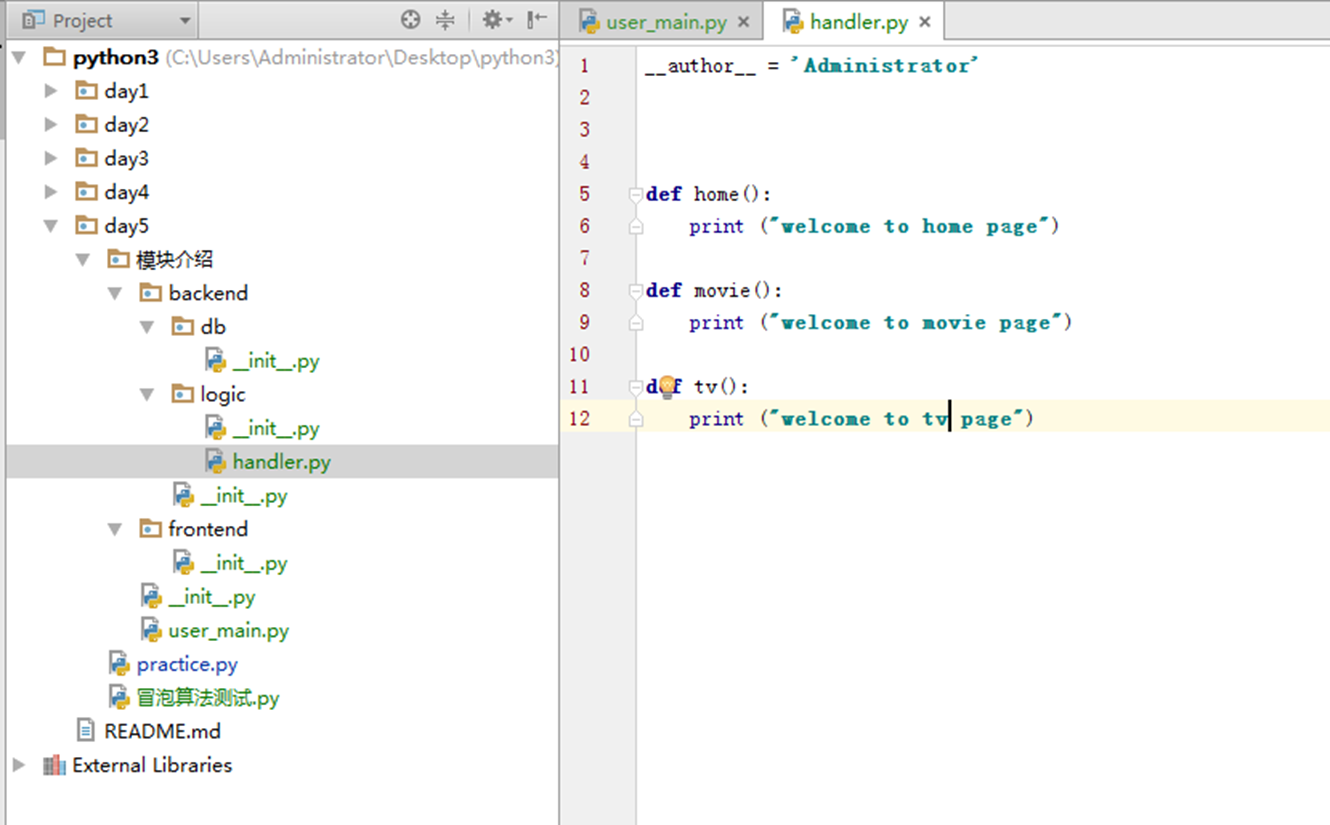
接下来看主函数调用backend.logic下面的handler下面的方法。
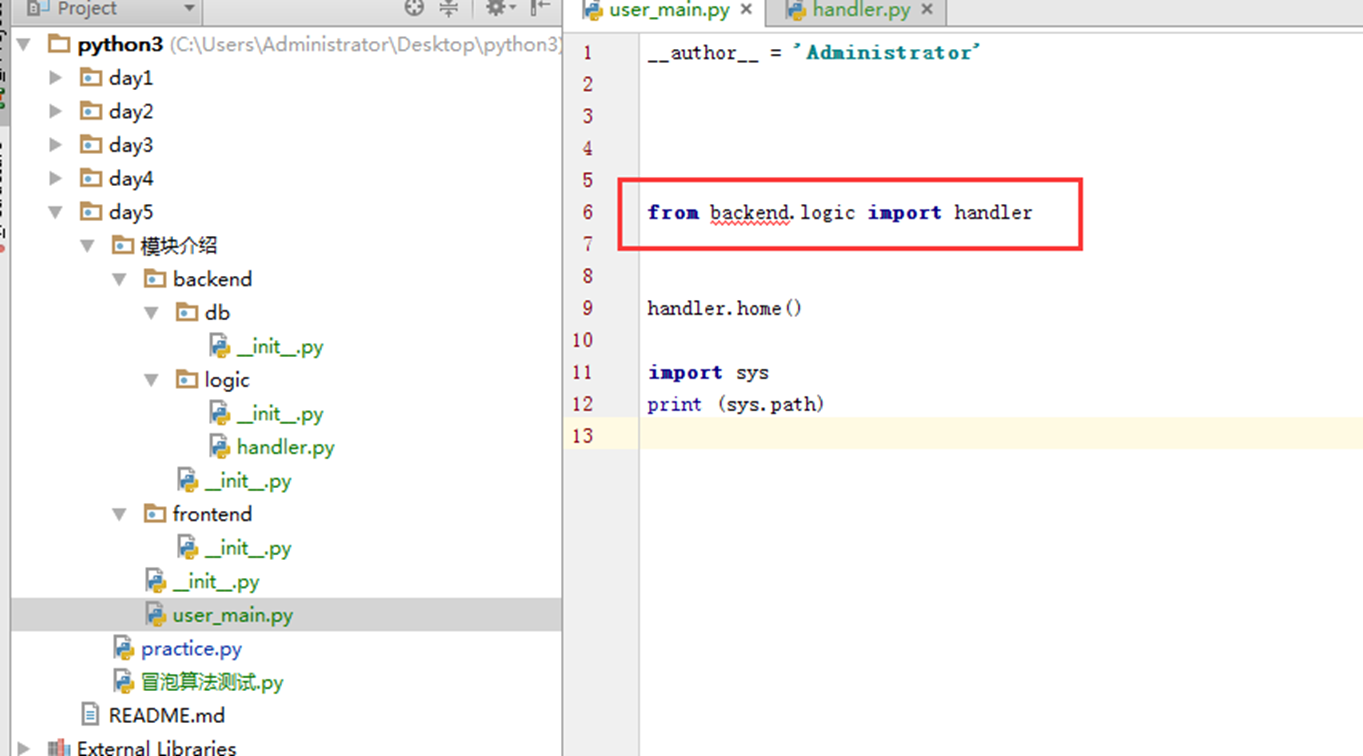
执行先查看结果。
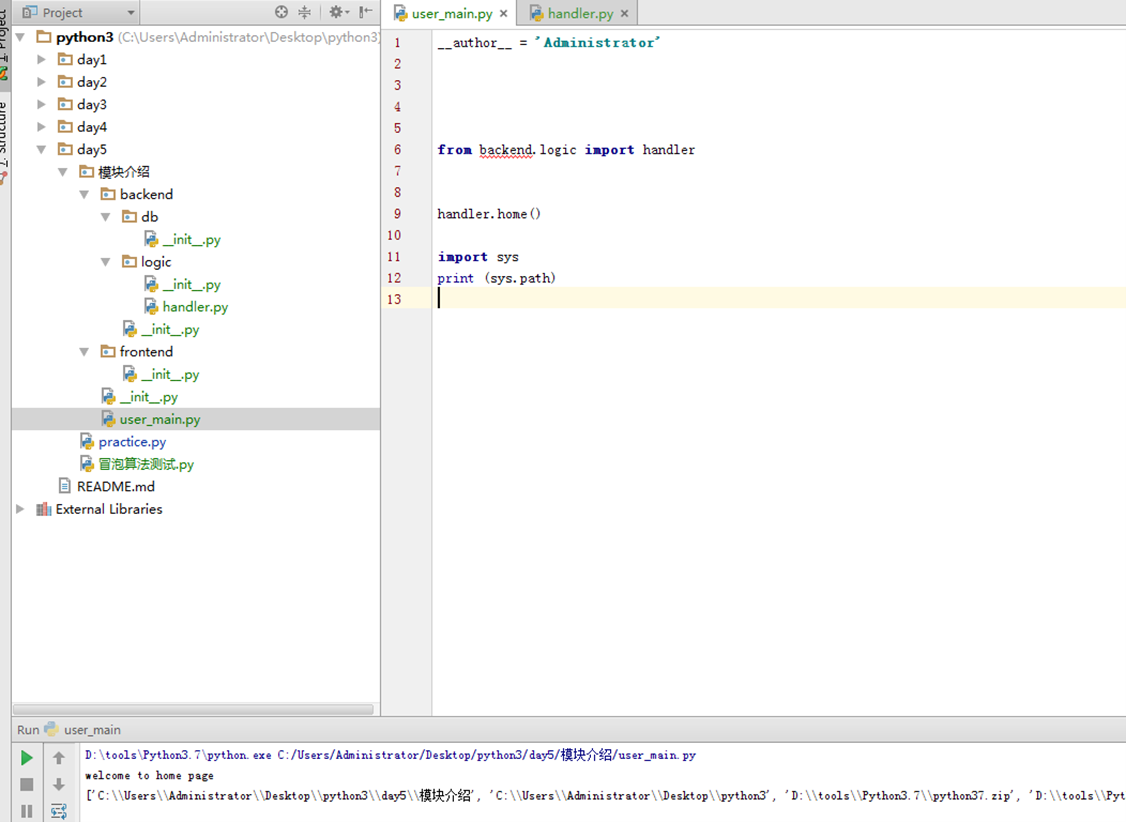
访问正常。实验结束,但是引申出2个问题。
1.from backend.logic import handler凭什么能找到,或者说handler.home()凭什么能找到。
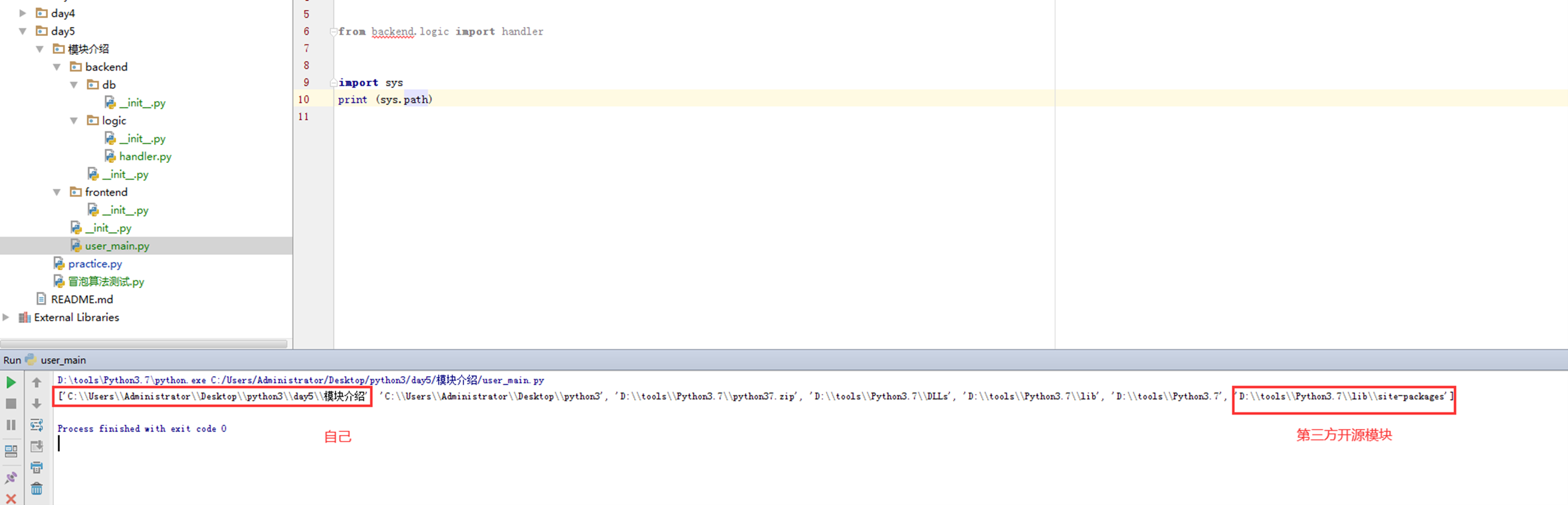
通过sys.path可以看出自己的路径在第一行。user_main和backend在同一级,当然可以直接找到。
2.为什么在本章开头说要创建python package包,_init_的作用是干什么的?
因为只有_init_在才认为是一个python package,也就是一个模块,可以调用,这也是python package和普通文件夹的区别。如果这里删除__init__那么调用肯定报错。当然,这是在python3.2之前,3.2之后就没有这个问题了,有没有都无所谓,但是为了整洁,还是建议加上。
5.5 如何自定义模块
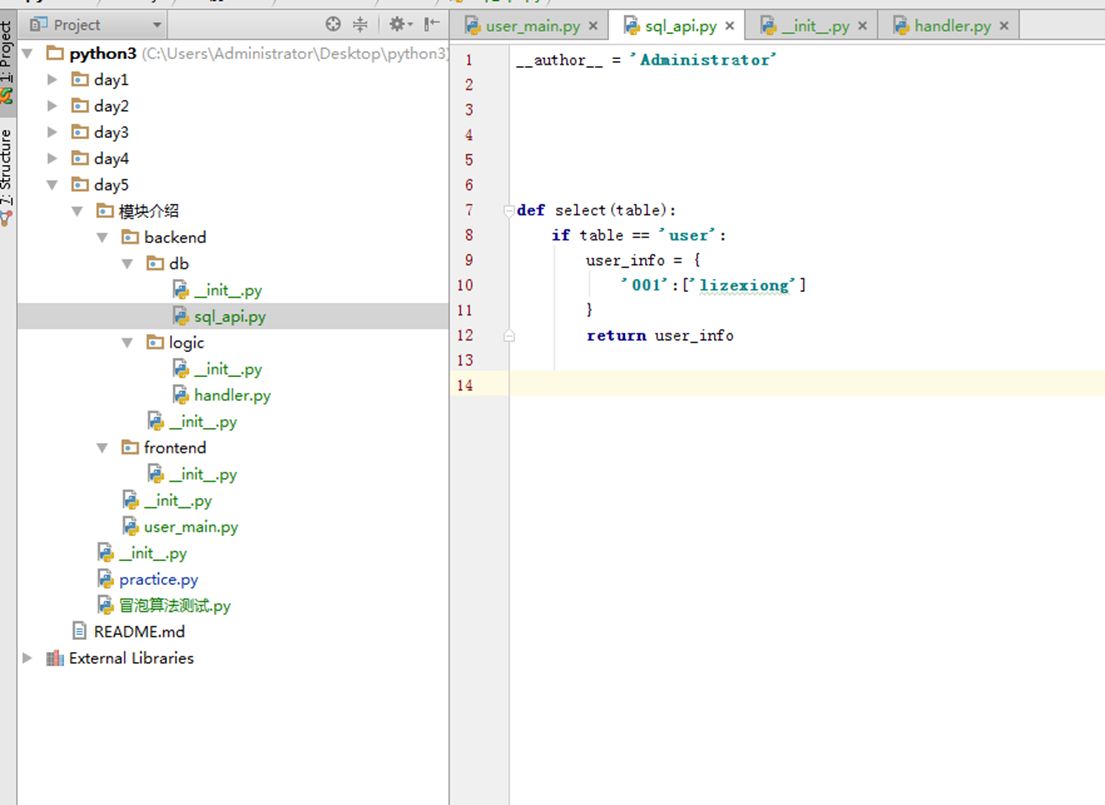
本节是延续上一节的环境来演示。主要实现。
1.调用home的时候,home去新函数sql_api申请一些用户数据库。
如下
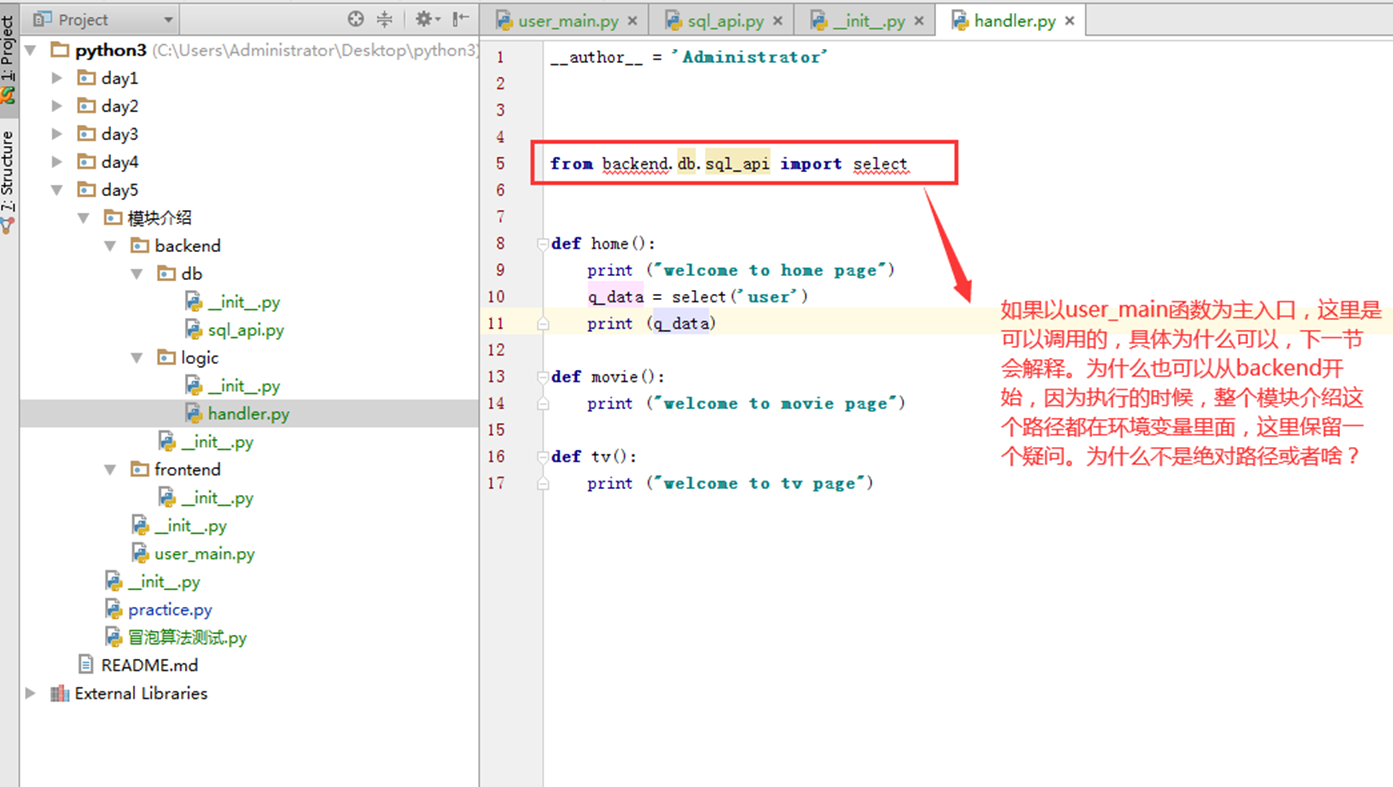
2.模拟正常网站访问,在调用数据的时候,应该是有一个认证的。那咱们在做一做。这里单独出来一个模块,类django一样,模拟一个settings的文件。
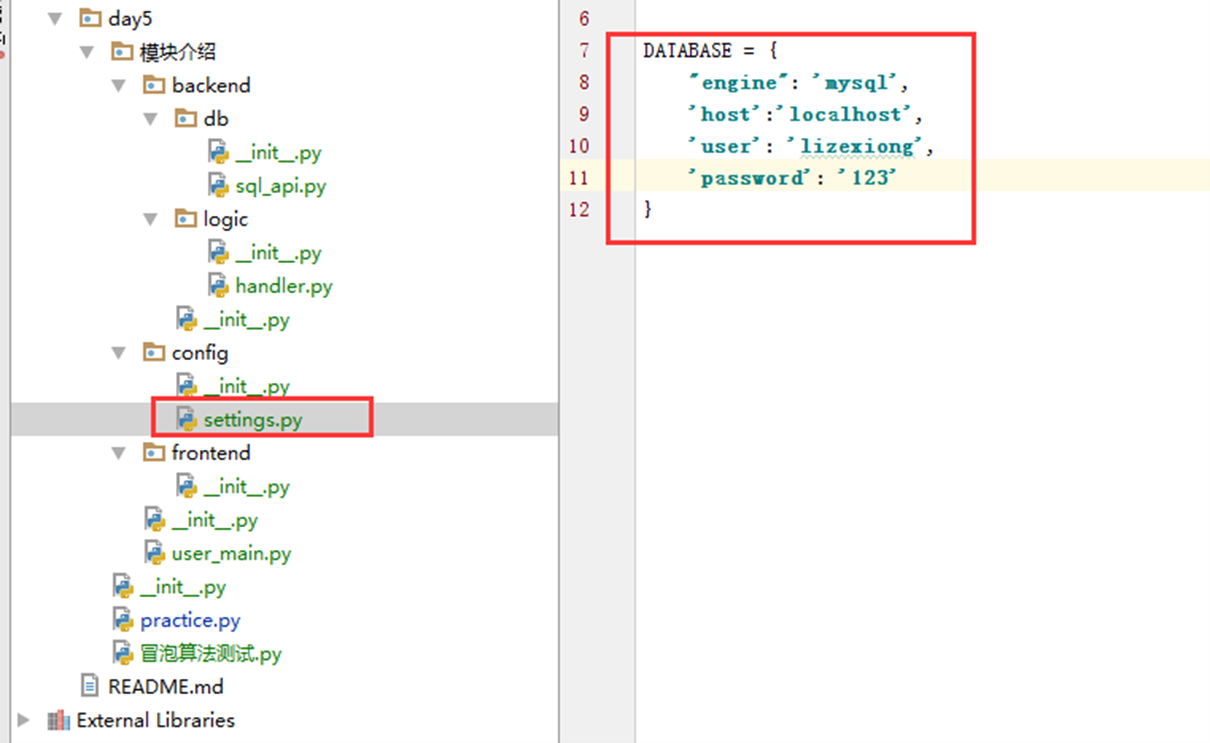
尽然是要验证,那么就要调用db,也就是sql_api,这个验证函数应该写到其它地方,这里为了方便。就和sql_api写在一起了。
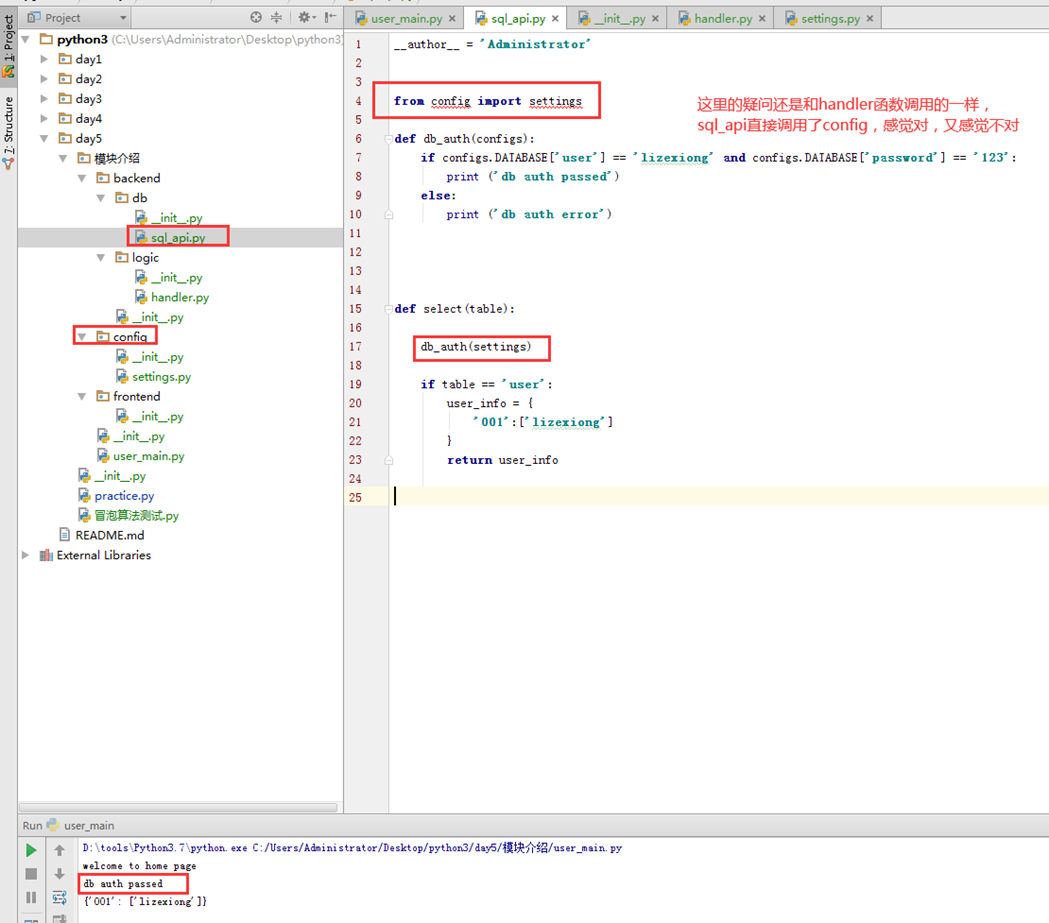
以上实验就完成了,本小节留一个问题,就是sql_api为什么能直接from config,按
照原理,因为整个模块介绍文件夹都在环境变量里,对,但是又感觉不对,这个问题,下小结解释。
这里对本小节的调用顺序做一个小小的总结。
5.6 不同目录之前的模块调用
上一章节说过
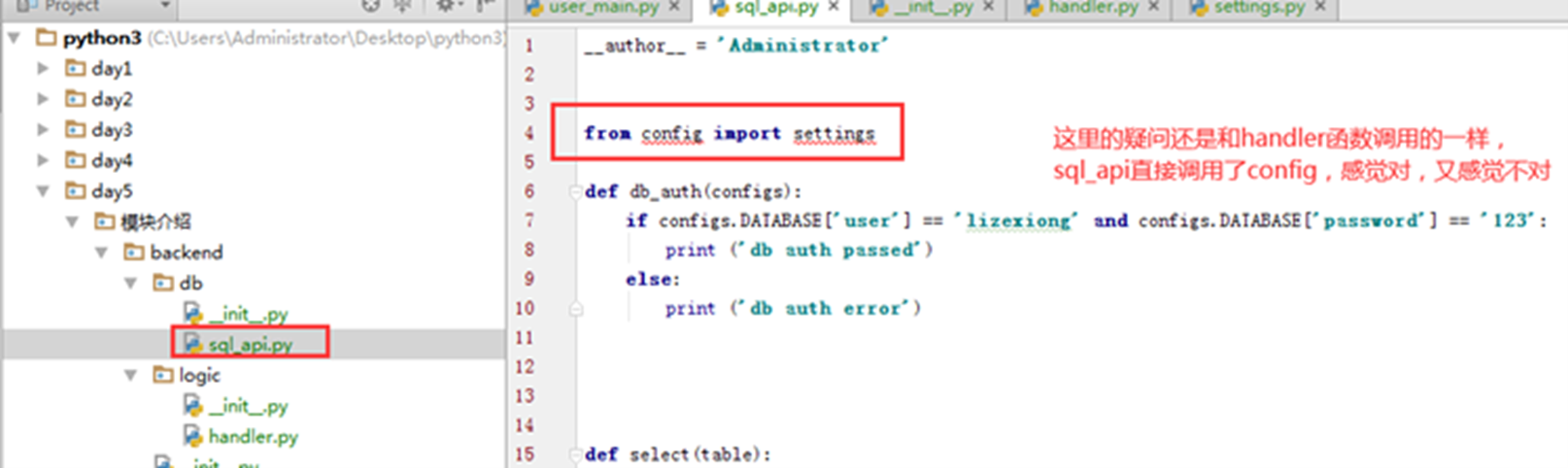
sql_api直接调用,感觉对,又感觉那里不对。
现在来说哪里不对。直接使用user_main来执行正常,但是直接执行sql_api就报错了
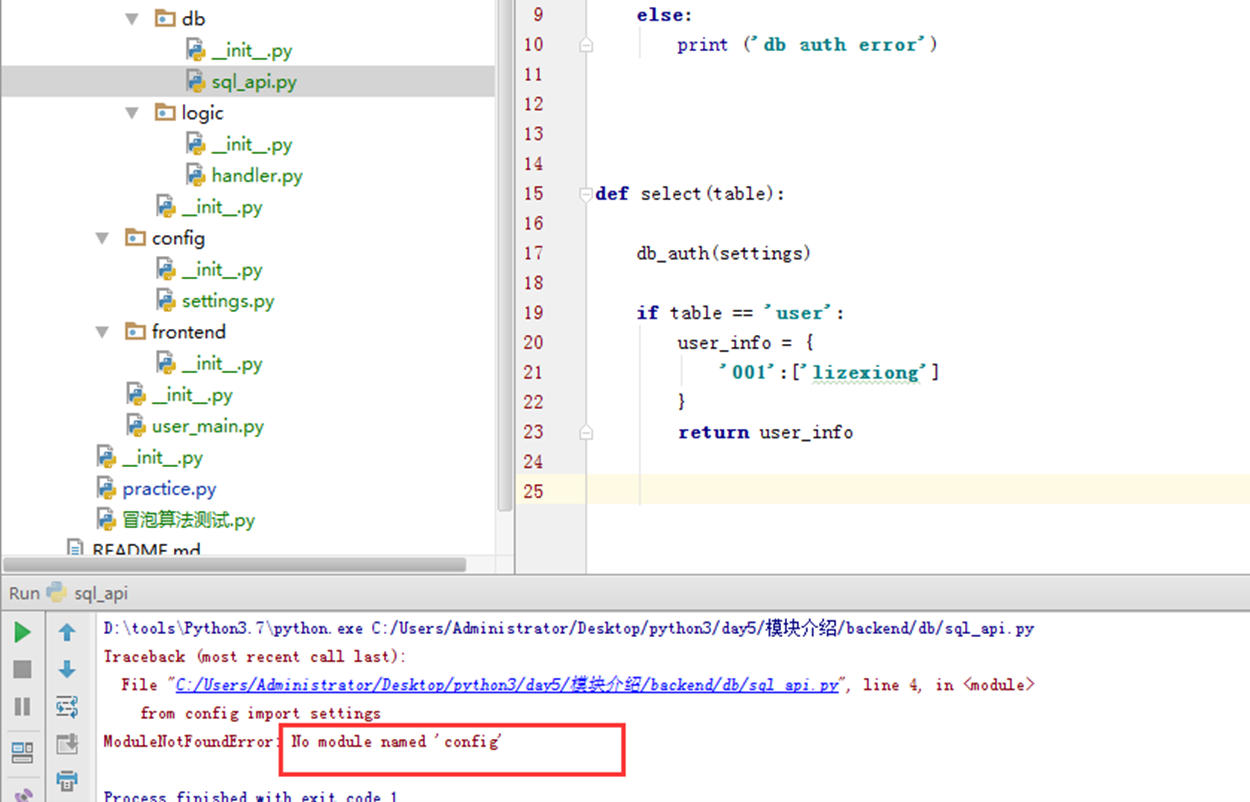
因为执行sql_api的时候是在当前目录下找config这个模块,但是config模块不在这个目录下。我们打开sys.path调试一下,看看就知道了。
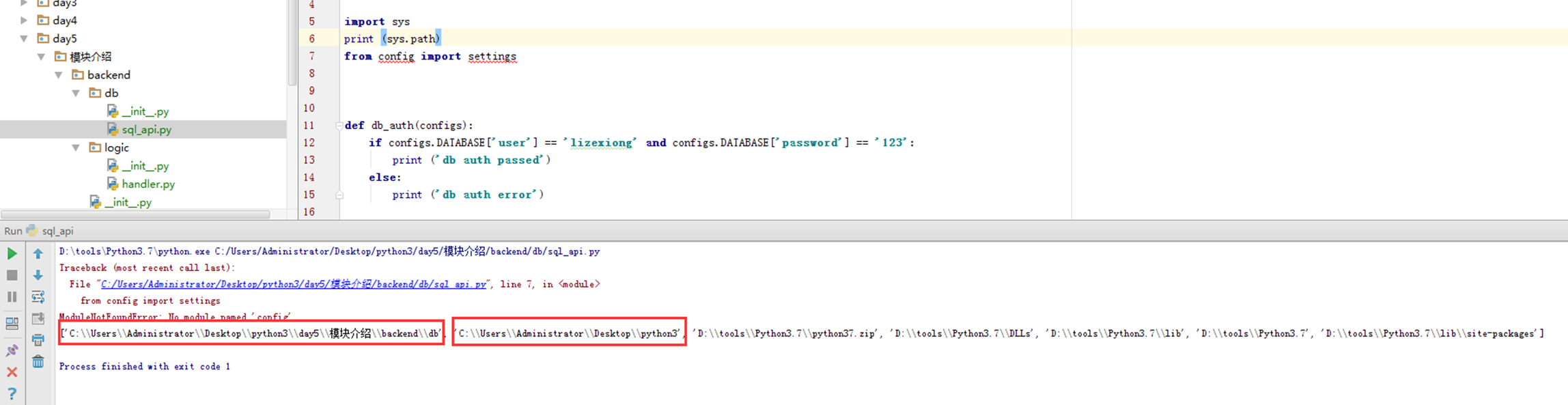
可以看到上面,打印了db的绝对路径以及python3学习主目录的绝对路径,就是没有config的。模块介绍这个目录不在环境变量里面。所以找不到config,就报错了。
为什么user_main执行就没问题?
因为user_main作为程序入口的时候,当前目录就是模块介绍这个目录,是user_main来调用的config,下面有config,那个时候可以导入config,所以user_main不会报错,而sql_api没有些个准确的变量。
有没有办法让sql_api不报错?
导入模块的绝对路径?当然不可以,程序移到其它机器就执行不了。
所以现在介绍一个默认方法,__file__.
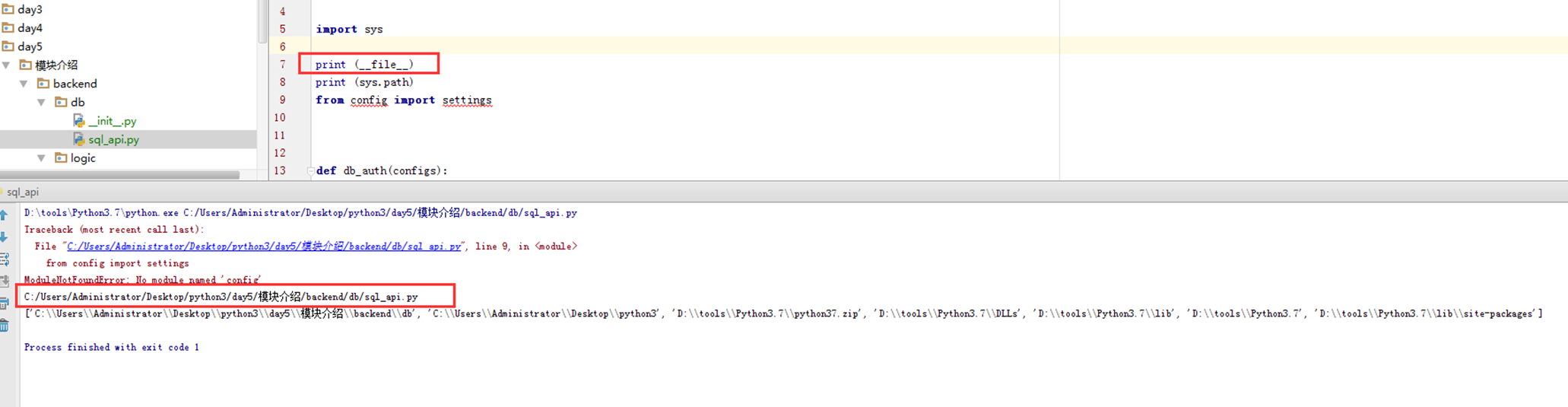
该方法在pycharm中显示的绝对路径,然后并不是它的本意,是因为pycharm强制识别了路径,在命令行中看看__file__的效果就知道了。

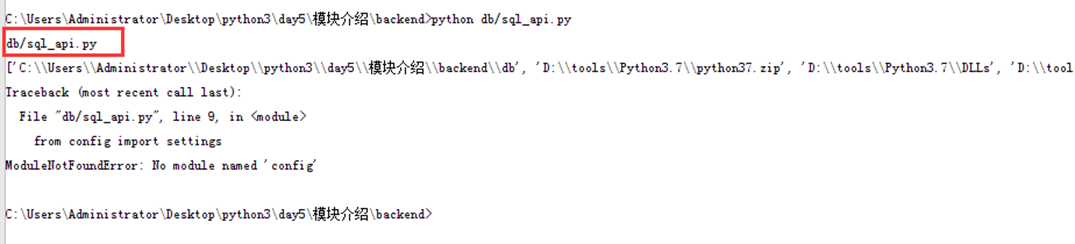
可以看到,在哪个目录执行,就打印出在哪个路径。所以接下来,又有一个方法获取动态获取绝对路径。
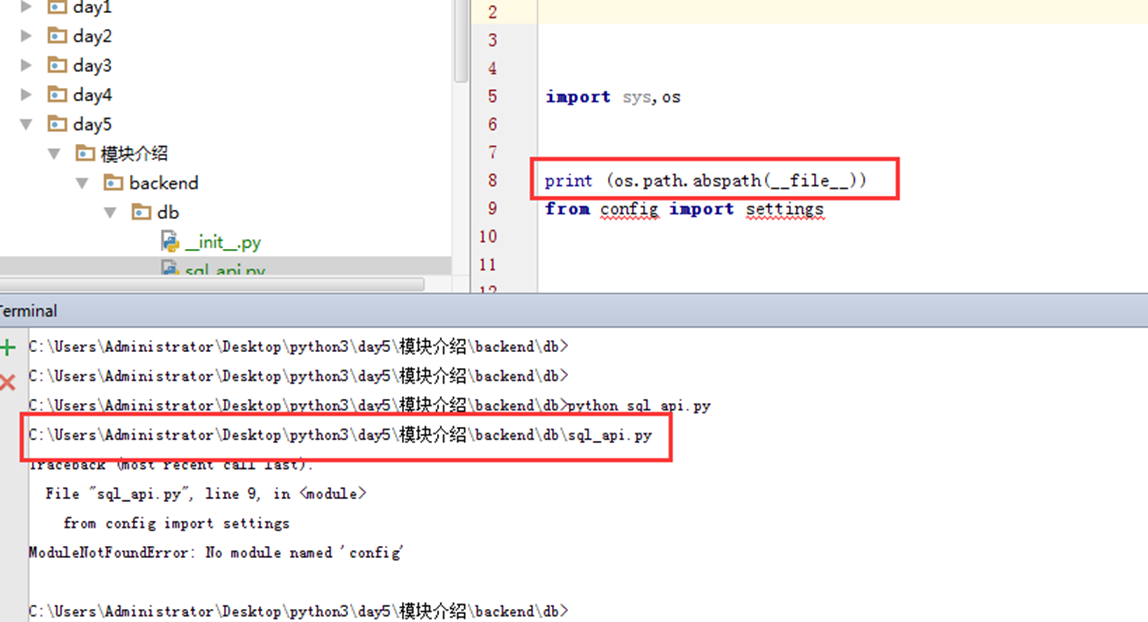
上面就已经获取到绝对路径了。接下来找到config,也就是sql_api的父级的父级。用什么办法呢?使用os的dirname方法。他会把目录的最后一层去掉,那么有几层不就去几层?那样就可以找到config的具体路径了。
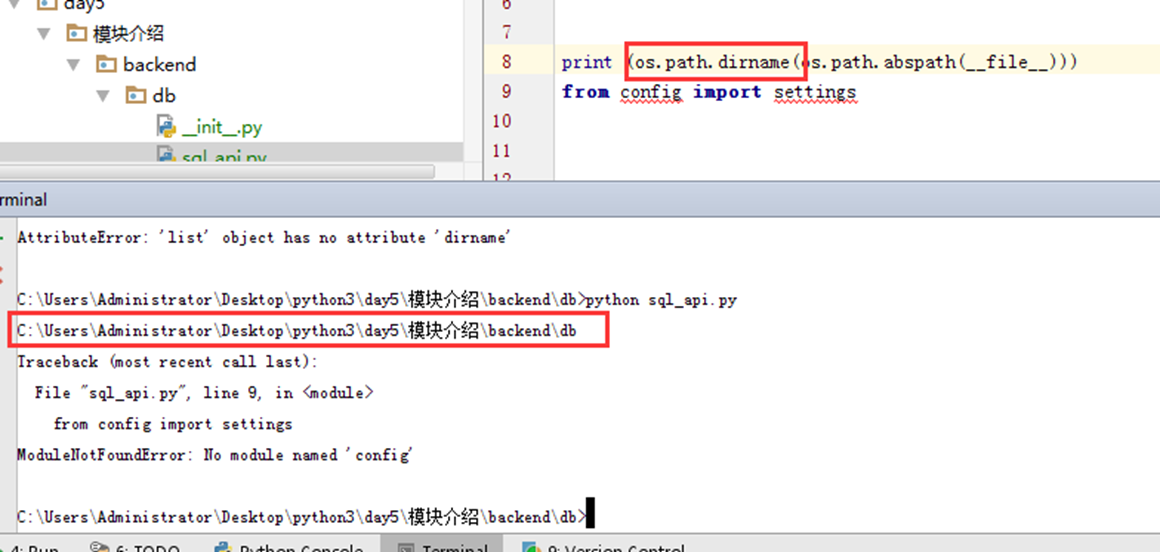
上面只只用了一次os.path.dirname,在使用两次就可以找到模块介绍这个目录了。
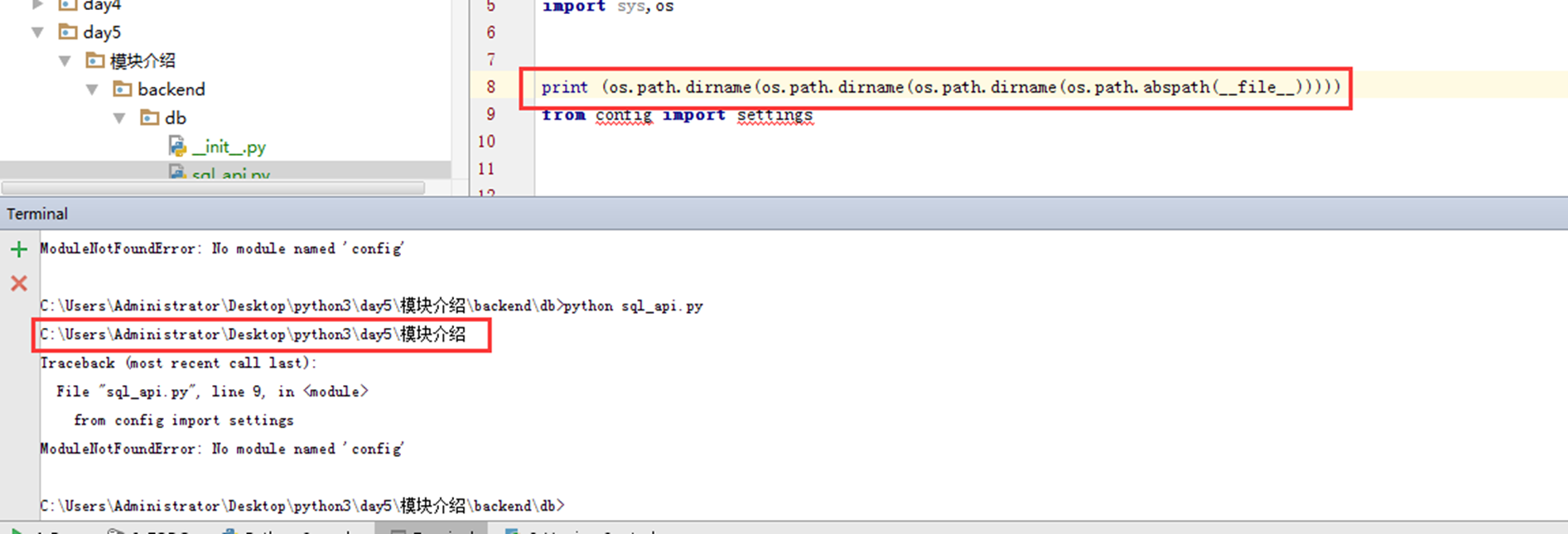
最后,把这个路径加入系统环境变量里面,那么就不会报错了。
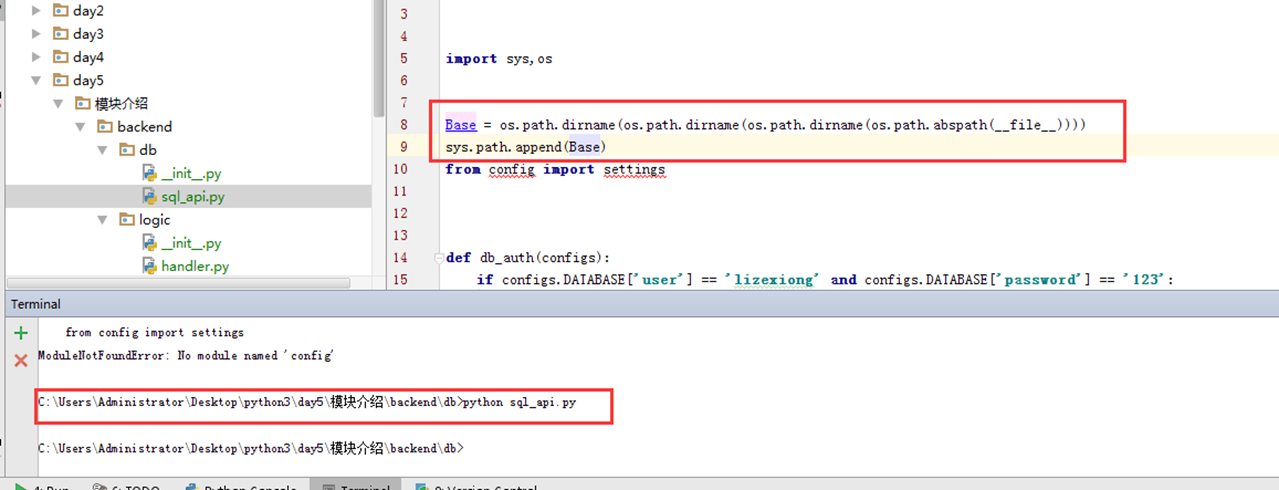
5.7 序列化
本章内容和家庭作业在一起,但是笔记记录还是分开来的好。
json 和 pickle
用于序列化的两个模块
-
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
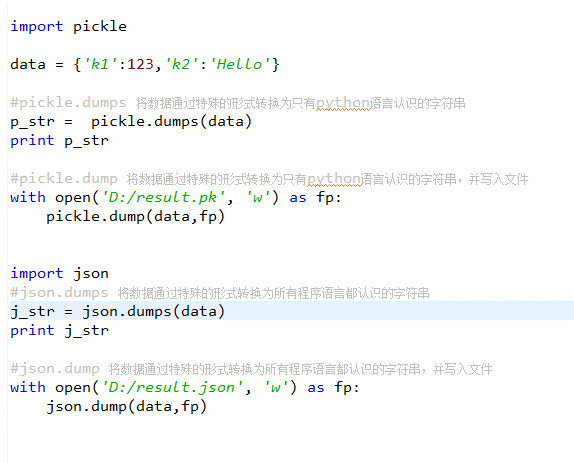
具体的这里将用一个例子来演示。
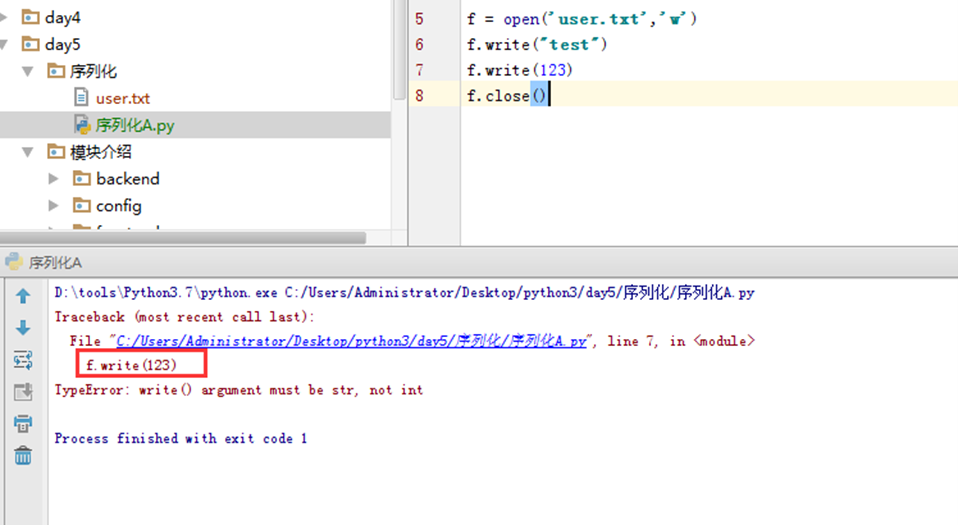
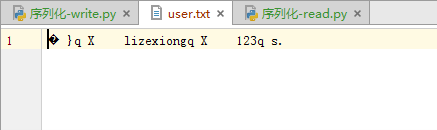
首先简单来看一看文件写入,如下所示,报错了,因为python的文件写入只能写入字符串类型的,123是数字,所以报错了
那么现在有一个需求,假设有一个写的程序,向文件写入一个字典格式(注意是格式,不是类型)本质上还是字符串的内容写进文件,那么在一个专门读取的程序,想以字典的格式读取出来,这个怎么办?接下来看看简单案例模版。
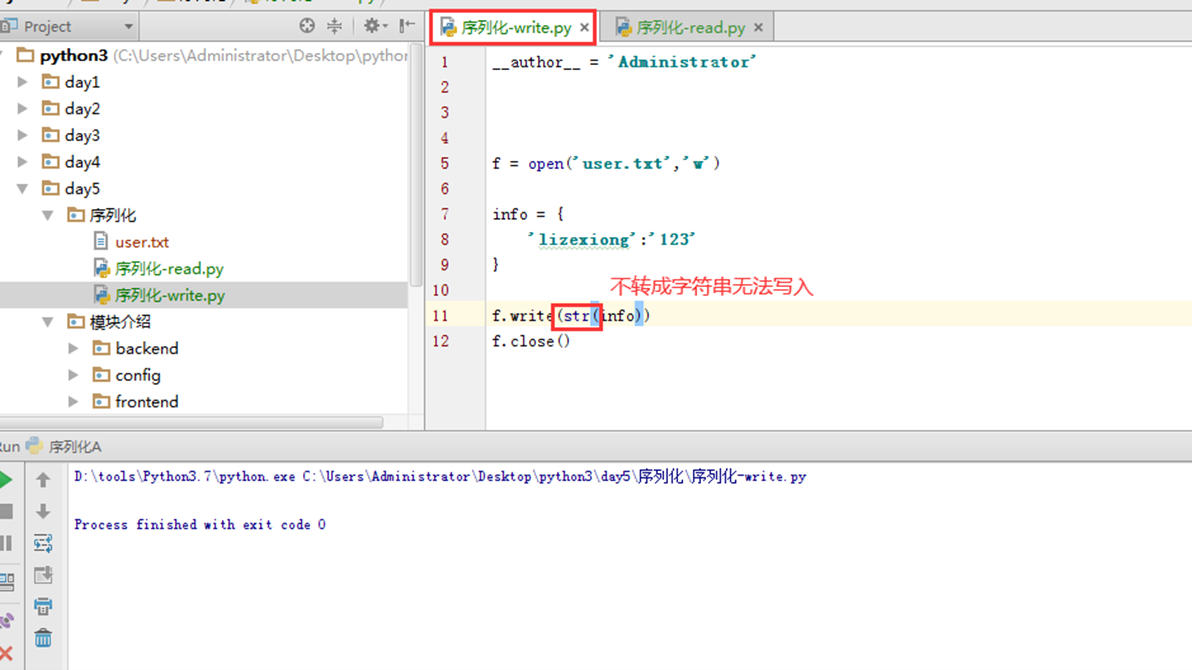
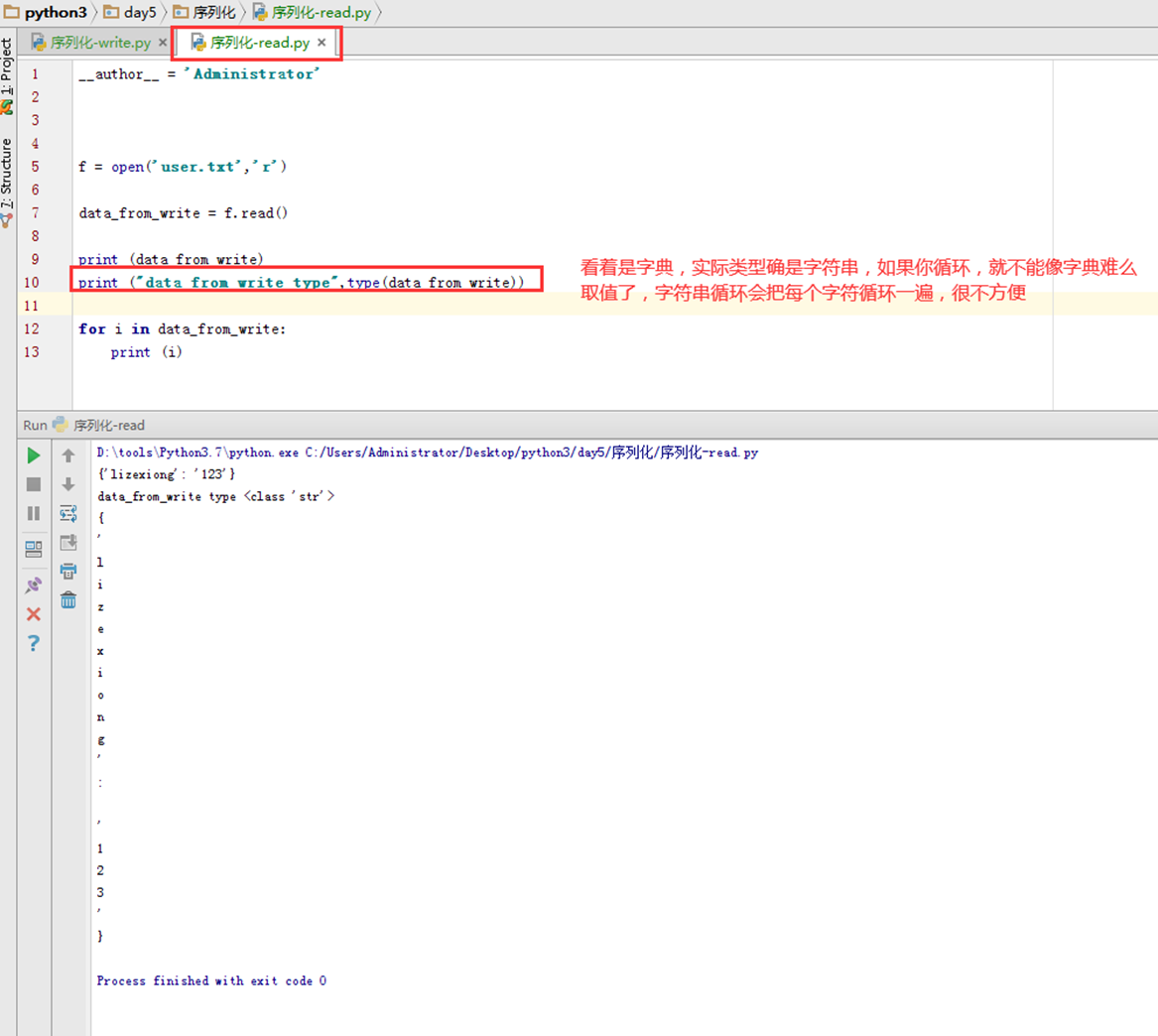
那么需求来,就是要以字典的方式写入或者读取出来,怎么办?
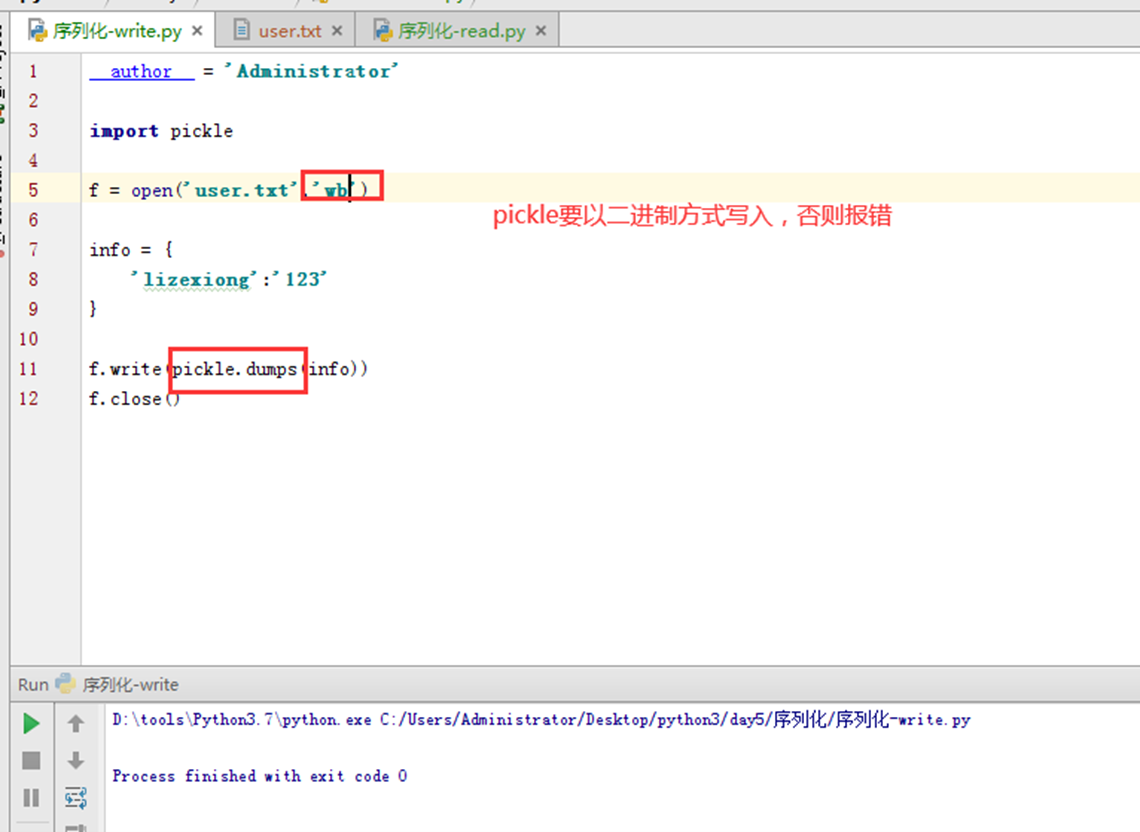
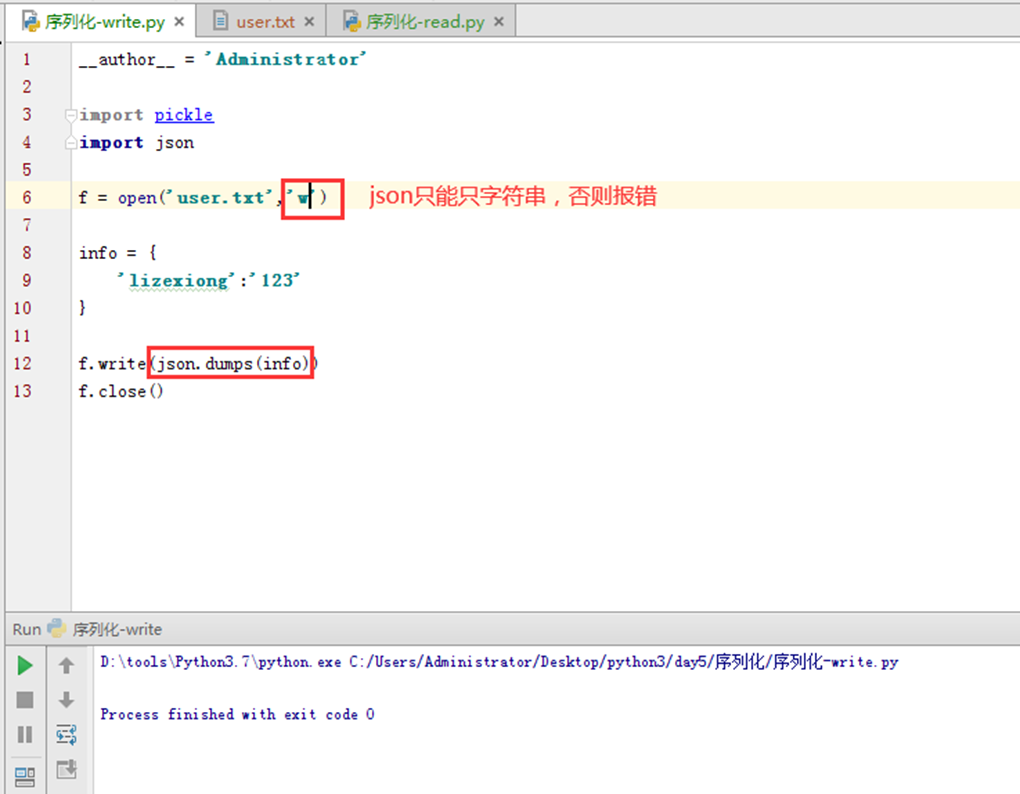
那么使用json 与 pickle
这里先演示pickle,pickle使用方式和json有点不同,那就是要以二进制的方式写进去和读出来,否则会报错。并且pickle写入显式是乱码的。
写入之后查看是乱码
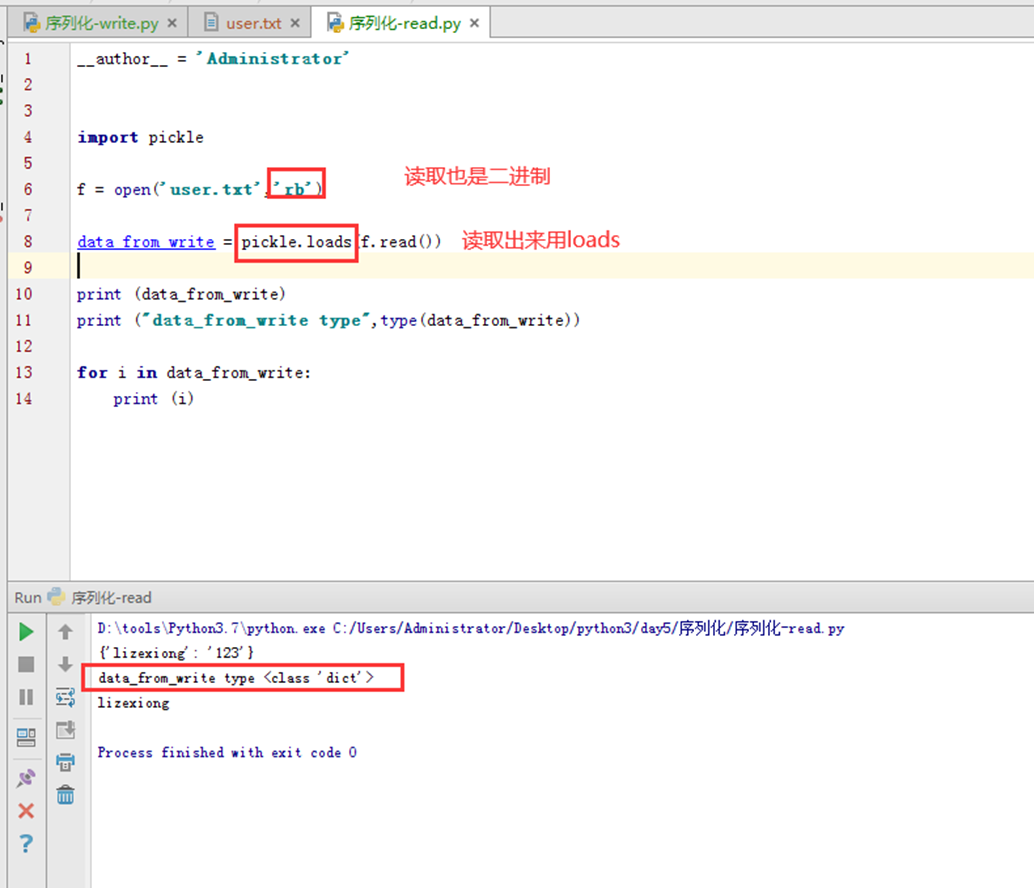
那么现在读取也要以二进制读取。
现在把pickle转成为json看看,前面也提到过,json转换不能是二进制,只能是字符串,否则报错。
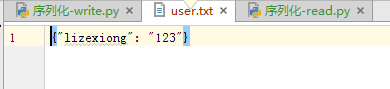
查看json写入的内容,没有乱码了
现在读取测试
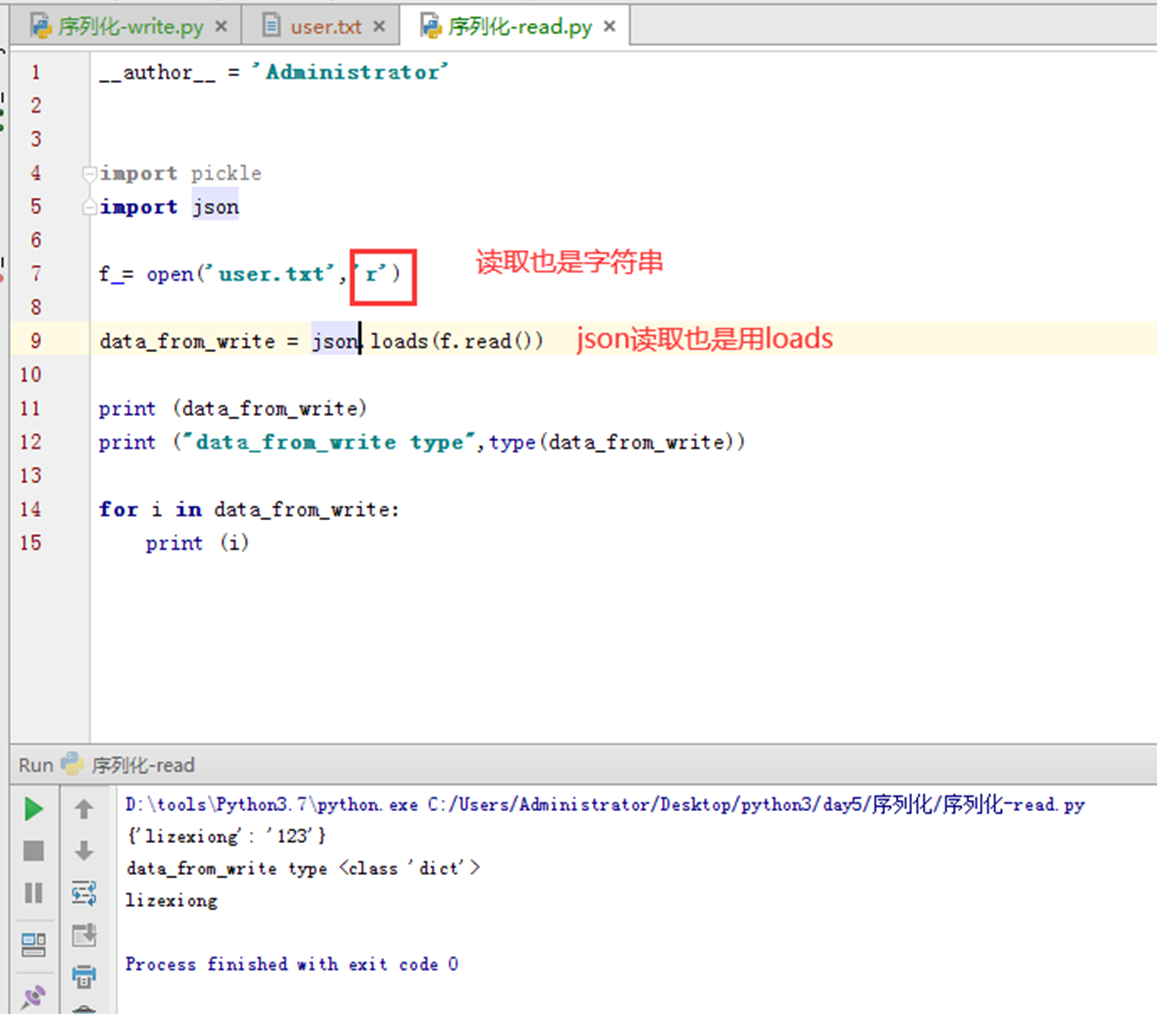
现在看来,好像两者区别不大,甚至感觉json不用转二进制,更方便一点。
所以这里我们先说说二者的区别。
-
- json 序列化之后得到的是字符串,仅支持字典和字符串,应用范围极广,各种编程语言几乎都能支持 json
- pickle 序列化之后得到的是字节,支持 Python 中大部分对象,仅被 Python 支持
- pickle 序列化不会改变字典键的数据类型;json 序列化,如果键是数字,会转为字符串
- pickle对python的什么类型都可以进行序列化,包括函数,对象等类型。几乎python所有的类型都支持。Json只有字符串和字典。
所以接下来演示一下pickle的强大之处。序列化一个函数来试试。先看看json报不报错。
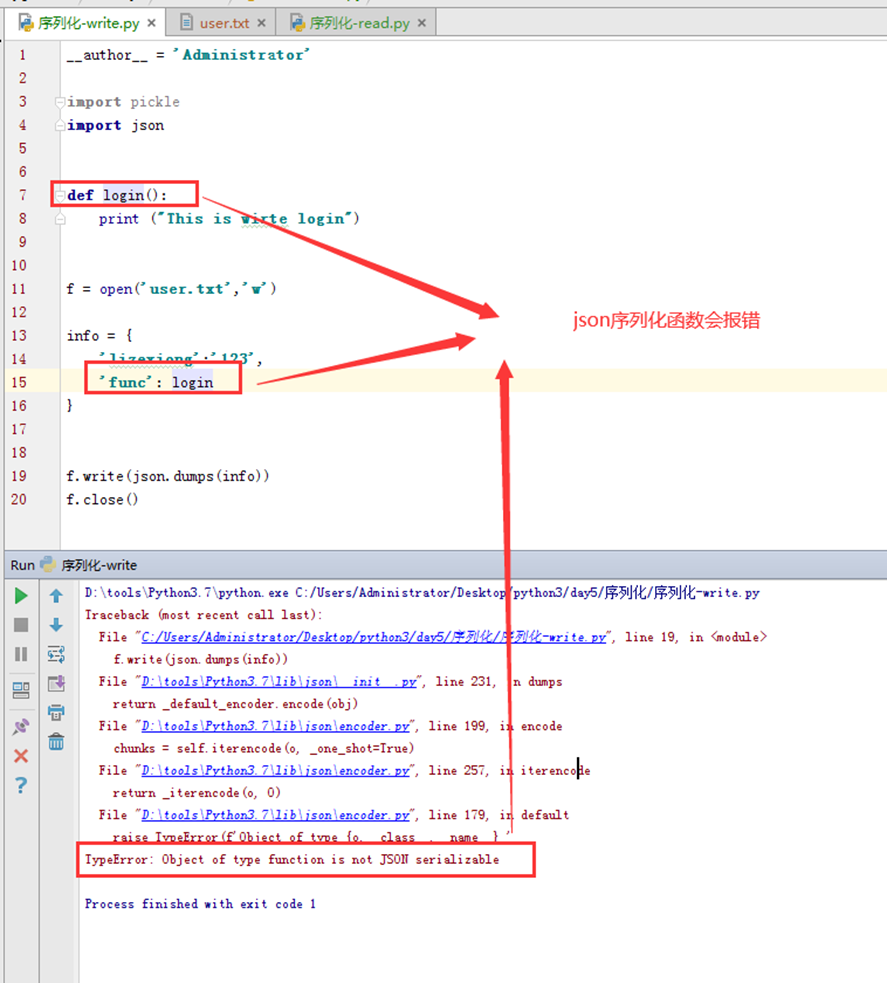
现在使用pickle测试。
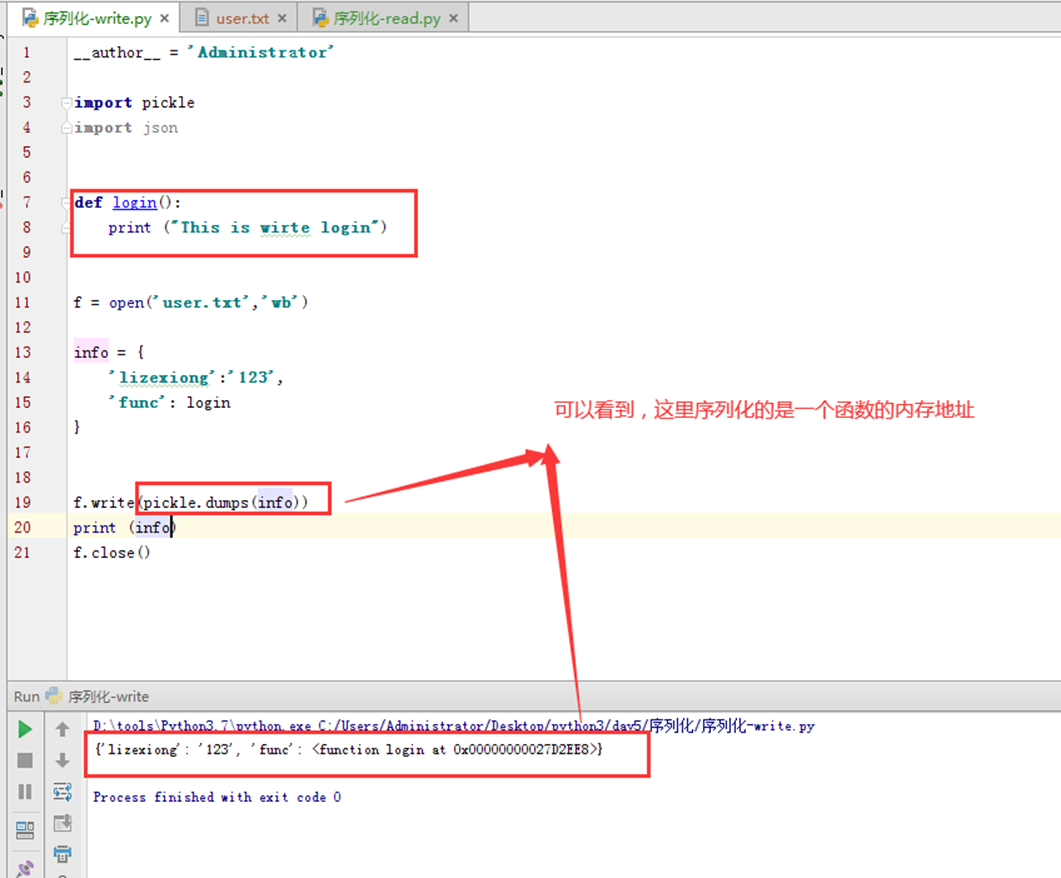
文件里也可以看到
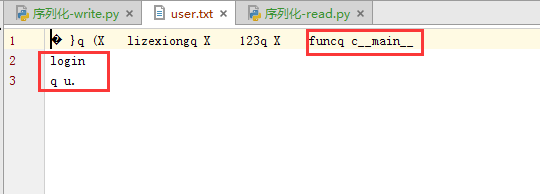
当然在接收方肯定也是需要有一个相同的函数来接受,虽然会执行接收方的函数,那是因为会调用执行的时候会覆盖本身的内存地址,所以有2点。
- 接收方必须有一个相同的函数存在,否则报错
- 即使不报错,执行的肯定是接收方的函数。
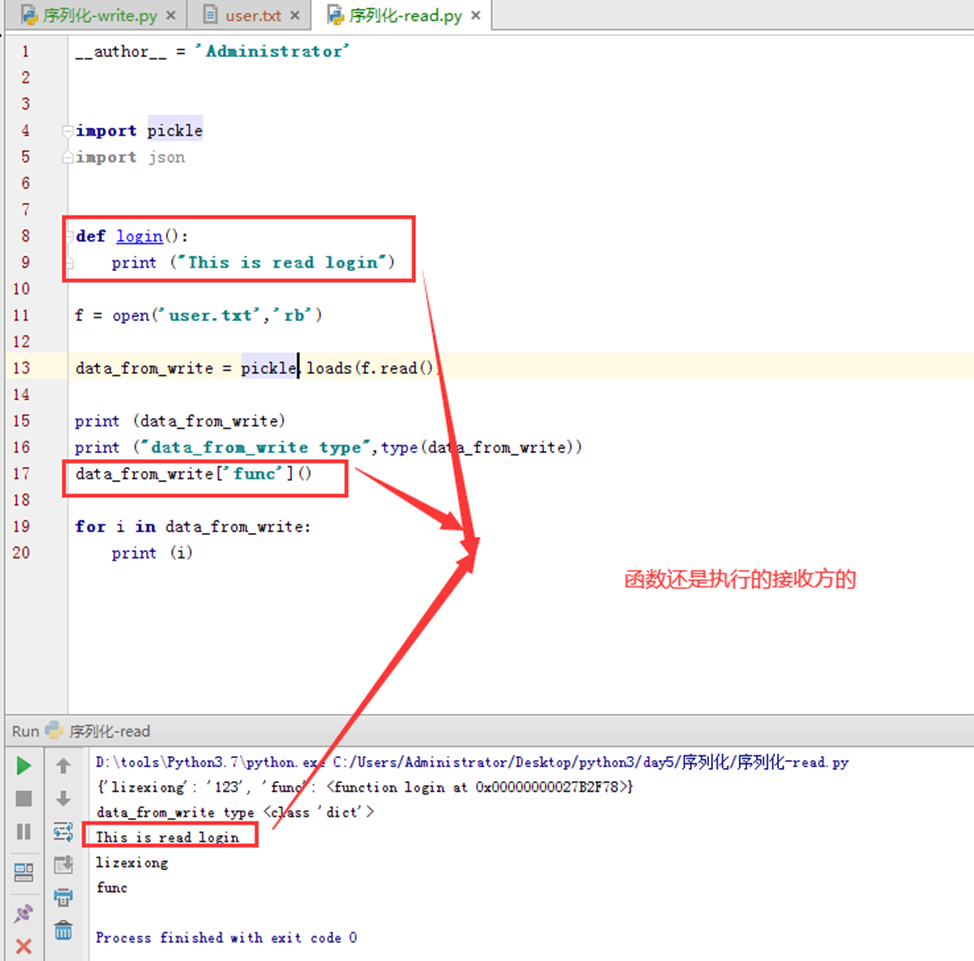
接下来还有dump和load没有讲解?这个用法很少,所以这里就简单演示一下吧,
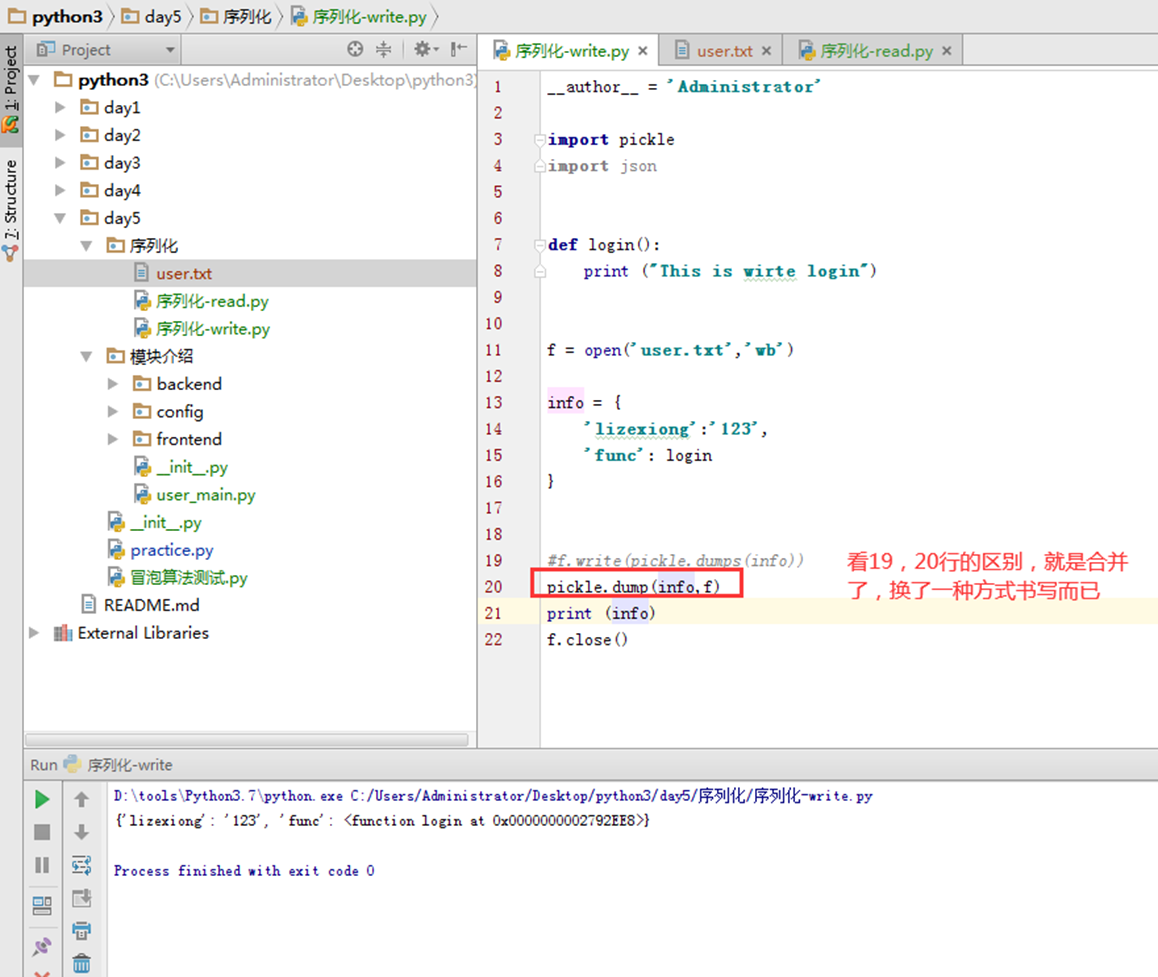
Load也是一样
5.8 作业
作业需求:
模拟实现一个ATM+购物商城程序
- 额度15000或者自定义
- 实现购物商城,买东西加入购物车,调用信用卡接口结账
- 可以提现,手续费5%。
- 每月22号出账单,每月10号为还款日,过期未还,按欠款总额万分之5每日计息
- 支持多用户登录。
- 支持账户间转账
- 记录每月日常消费流水
- 提供还款接口
- ATM记录操作日志
- 提供管理接口,包括添加账户、用户额度、冻结账户等
6.L06
6.1 鸡汤
2节课鸡汤直接跳过.
6.2 atm示例代码展示
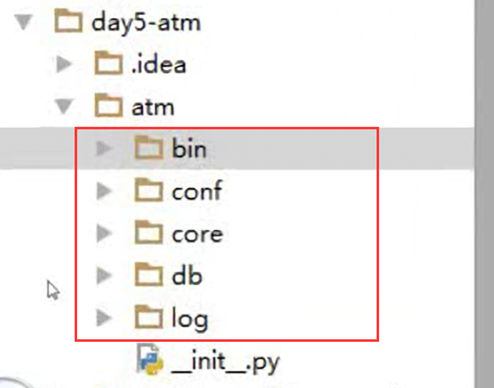
老师讲解的简单作业demo,由于老师也未完全完成,也没有源码,可以后期回来复习视频,该视频中有3点值得学习的。
1.项目架构
对应的模块放到对应的文件夹下,本人该次作业会错了意,写成了2个系统,但是不要紧。
2.配置文件
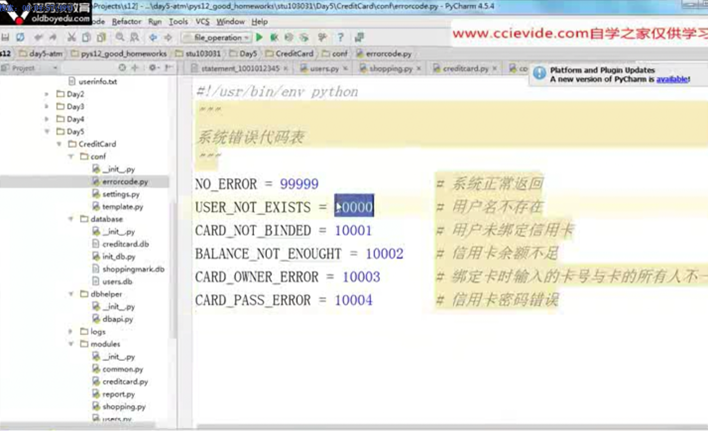
比如错误码什么的使用配置文件,我这里当时没有想到这一步。
这张图片是在0095鸡汤里面的视频,这里整合到这一节里面,复习的时候要注意。
3.if不要那么low
比如10个选项,就写了10个if,下面有非常好的解决方法。
6.3 常用模块之shutil
视频前面一半都是讲解os模块和sys模块
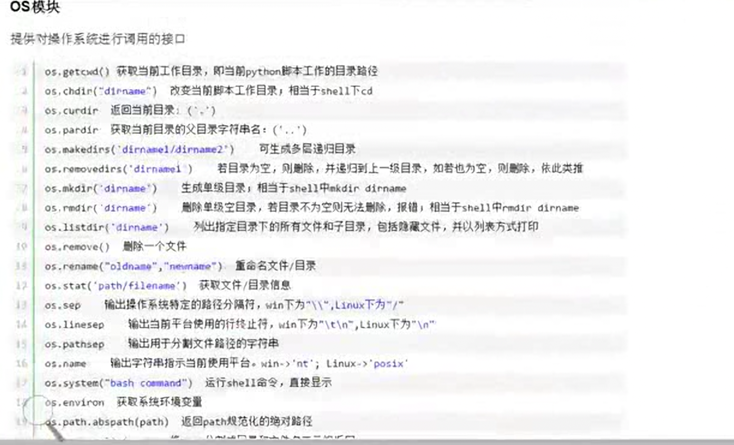
其余的都是讲解shutil模块,该视频没怎么讲解,就是带着同学文档过了一遍,这老师是真有点…
具体使用方式参考本人博客: https://www.cnblogs.com/lizexiong/p/16678352.html
6.4 常用模块之shelve
https://www.cnblogs.com/lizexiong/p/16683165.html
6.5 常用模块之xml处理
https://www.cnblogs.com/lizexiong/p/16686203.html
6.6 常用模块之configparser
https://www.cnblogs.com/lizexiong/p/16688796.html
6.7 常用模块之hashlib
https://www.cnblogs.com/lizexiong/p/16694257.html
6.8 常用模块之subprocess
https://www.cnblogs.com/lizexiong/p/16695079.html
6.9 常用模块之logging
https://www.cnblogs.com/lizexiong/p/16696509.html
6.10 面向对象介绍
本节主要讲解了
1.面向过程和面向对象区别对比
2.面向对象是什么
编程范式
编程是 程序 员 用特定的语法+数据结构+算法组成的代码来告诉计算机如何执行任务的过程 , 一个程序是程序员为了得到一个任务结果而编写的一组指令的集合,正所谓条条大路通罗马,实现一个任务的方式有很多种不同的方式, 对这些不同的编程方式的特点进行归纳总结得出来的编程方式类别,即为编程范式。 不同的编程范式本质上代表对各种类型的任务采取的不同的解决问题的思路, 大多数语言只支持一种编程范式,当然也有些语言可以同时支持多种编程范式。 两种最重要的编程范式分别是面向过程编程和面向对象编程。
面向过程编程(Procedural Programming)
Procedural programming uses a list of instructions to tell the computer what to do step-by-step.
面向过程编程依赖 - 你猜到了- procedures,一个procedure包含一组要被进行计算的步骤, 面向过程又被称为top-down languages, 就是程序从上到下一步步执行,一步步从上到下,从头到尾的解决问题 。基本设计思路就是程序一开始是要着手解决一个大的问题,然后把一个大问题分解成很多个小问题或子过程,这些子过程再执行的过程再继续分解直到小问题足够简单到可以在一个小步骤范围内解决。
举个典型的面向过程的例子, 数据库备份, 分三步,连接数据库,备份数据库,测试备份文件可用性。
代码如下
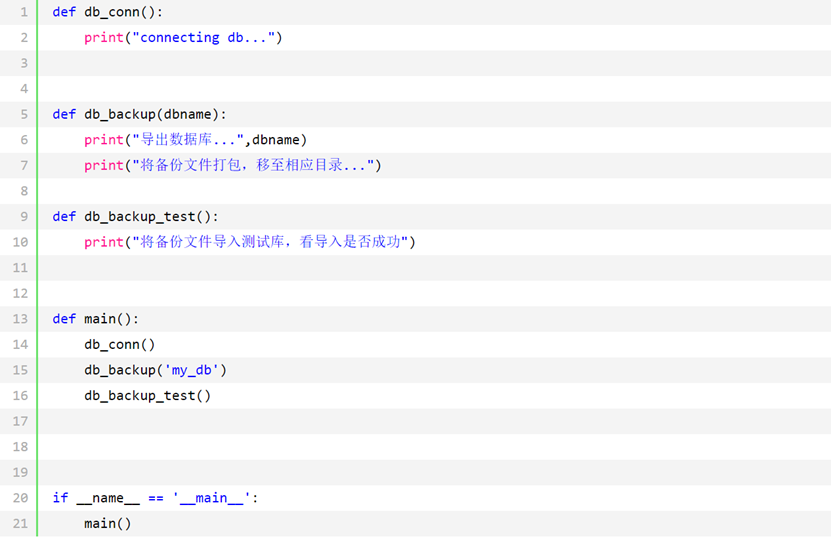
这样做的问题也是显而易见的,就是如果你要对程序进行修改,对你修改的那部分有依赖的各个部分你都也要跟着修改, 举个例子,如果程序开头你设置了一个变量值 为1 , 但如果其它子过程依赖这个值 为1的变量才能正常运行,那如果你改了这个变量,那这个子过程你也要修改,假如又有一个其它子程序依赖这个子过程 , 那就会发生一连串的影响,随着程序越来越大, 这种编程方式的维护难度会越来越高。
所以我们一般认为, 如果你只是写一些简单的脚本,去做一些一次性任务,用面向过程的方式是极好的,但如果你要处理的任务是复杂的,且需要不断迭代和维护 的, 那还是用面向对象最方便了。
面向对象编程
OOP编程是利用“类”和“对象”来创建各种模型来实现对真实世界的描述,使用面向对象编程的原因一方面是因为它可以使程序的维护和扩展变得更简单,并且可以大大提高程序开发效率 ,另外,基于面向对象的程序可以使它人更加容易理解你的代码逻辑,从而使团队开发变得更从容。
面向对象的几个核心特性如下
Class 类
一个类即是对一类拥有相同属性的对象的抽象、蓝图、原型。在类中定义了这些对象的都具备的属性(variables(data))、共同的方法
Object 对象
一个对象即是一个类的实例化后实例,一个类必须经过实例化后方可在程序中调用,一个类可以实例化多个对象,每个对象亦可以有不同的属性,就像人类是指所有人,每个人是指具体的对象,人与人之前有共性,亦有不同
Encapsulation 封装
在类中对数据的赋值、内部调用对外部用户是透明的,这使类变成了一个胶囊或容器,里面包含着类的数据和方法
Inheritance 继承
一个类可以派生出子类,在这个父类里定义的属性、方法自动被子类继承
Polymorphism 多态
多态是面向对象的重要特性,简单点说:“一个接口,多种实现”,指一个基类中派生出了不同的子类,且每个子类在继承了同样的方法名的同时又对父类的方法做了不同的实现,这就是同一种事物表现出的多种形态。
编程其实就是一个将具体世界进行抽象化的过程,多态就是抽象化的一种体现,把一系列具体事物的共同点抽象出来, 再通过这个抽象的事物, 与不同的具体事物进行对话。
对不同类的对象发出相同的消息将会有不同的行为。比如,你的老板让所有员工在九点钟开始工作, 他只要在九点钟的时候说:“开始工作”即可,而不需要对销售人员说:“开始销售工作”,对技术人员说:“开始技术工作”, 因为“员工”是一个抽象的事物, 只要是员工就可以开始工作,他知道这一点就行了。至于每个员工,当然会各司其职,做各自的工 作。
多态允许将子类的对象当作父类的对象使用,某父类型的引用指向其子类型的对象,调用的方法是该子类型的方法。这里引用和调用方法的代码编译前就已经决定了,而引用所指向的对象可以在运行期间动态绑定
面向对象编程(Object-Oriented Programming )介绍
对于编程语言的初学者来讲,OOP不是一个很容易理解的编程方式,大家虽然都按老师讲的都知道OOP的三大特性是继承、封装、多态,并且大家也都知道了如何定义类、方法等面向对象的常用语法,但是一到真正写程序的时候,还是很多人喜欢用函数式编程来写代码,特别是初学者,很容易陷入一个窘境就是“我知道面向对象,我也会写类,但我依然没发现在使用了面向对象后,对我们的程序开发效率或其它方面带来什么好处,因为我使用函数编程就可以减少重复代码并做到程序可扩展了,为啥子还用面向对象?”。 对于此,我个人觉得原因应该还是因为你没有充分了解到面向对象能带来的好处,今天我就写一篇关于面向对象的入门文章,希望能帮大家更好的理解和使用面向对象编程。
无论用什么形式来编程,我们都要明确记住以下原则:
1.写重复代码是非常不好的低级行为
2.你写的代码需要经常变更
开发正规的程序跟那种写个运行一次就扔了的小脚本一个很大不同就是,你的代码总是需要不断的更改,不是修改bug就是添加新功能等,所以为了日后方便程序的修改及扩展,你写的代码一定要遵循易读、易改的原则(专业数据叫可读性好、易扩展)。
如果你把一段同样的代码复制、粘贴到了程序的多个地方以实现在程序的各个地方调用 这个功能,那日后你再对这个功能进行修改时,就需要把程序里多个地方都改一遍,这种写程序的方式是有问题的,因为如果你不小心漏掉了一个地方没改,那可能会导致整个程序的运行都 出问题。 因此我们知道 在开发中一定要努力避免写重复的代码,否则就相当于给自己再挖坑。
还好,函数的出现就能帮我们轻松的解决重复代码的问题,对于需要重复调用的功能,只需要把它写成一个函数,然后在程序的各个地方直接调用这个函数名就好了,并且当需要修改这个功能时,只需改函数代码,然后整个程序就都更新了。
其实OOP编程的主要作用也是使你的代码修改和扩展变的更容易,那么小白要问了,既然函数都能实现这个需求了,还要OOP干毛线用呢? 呵呵,说这话就像,古时候,人们打仗杀人都用刀,后来出来了枪,它的主要功能跟刀一样,也是杀人,然后小白就问,既然刀能杀人了,那还要枪干毛线,哈哈,显而易见,因为枪能更好更快更容易的杀人。函数编程与OOP的主要区别就是OOP可以使程序更加容易扩展和易更改。
小白说,我读书少,你别骗我,口说无凭,证明一下,好吧,那我们就下面的例子证明给小白看。
相信大家都打过CS游戏吧,我们就自己开发一个简单版的CS来玩一玩。
暂不考虑开发场地等复杂的东西,我们先从人物角色下手, 角色很简单,就俩个,恐怖份子、警察,他们除了角色不同,其它基本都 一样,每个人都有生命值、武器等。 咱们先用非OOP的方式写出游戏的基本角色
暂不考虑开发场地等复杂的东西,我们先从人物角色下手, 角色很简单,就俩个,恐怖份子、警察,他们除了角色不同,其它基本都 一样,每个人都有生命值、武器等。 咱们先用非OOP的方式写出游戏的基本角色

上面定义了一个恐怖份子Alex和一个警察Jack,但只2个人不好玩呀,一干就死了,没意思,那我们再分别一个恐怖分子和警察吧,
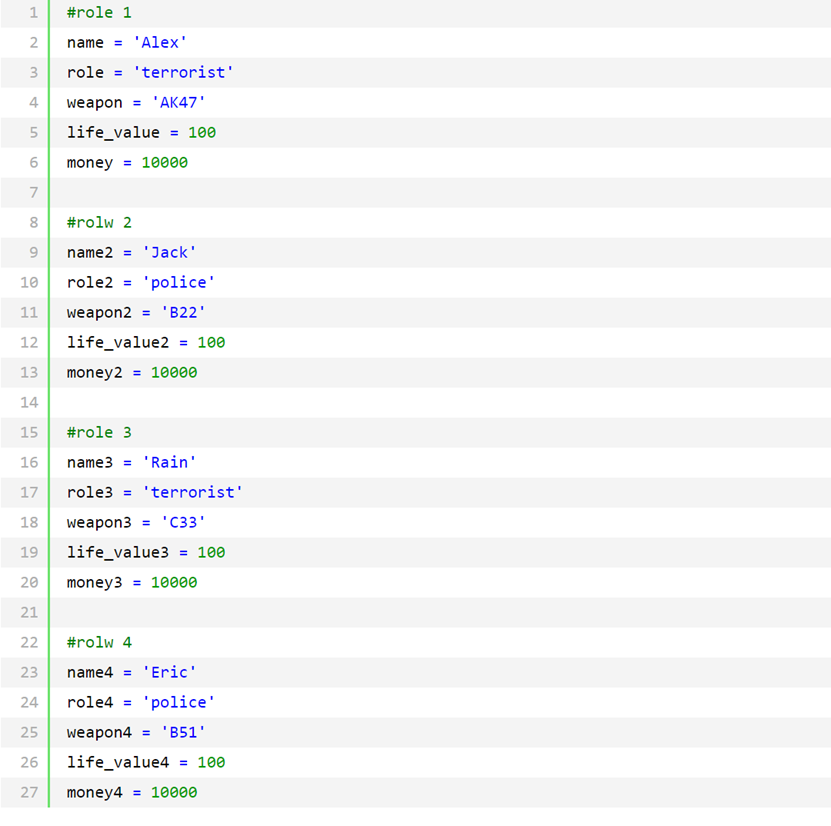
4个角色虽然创建好了,但是有个问题就是,每创建一个角色,我都要单独命名,name1,name2,name3,name4…,后面的调用的时候这个变量名你还都得记着,要是再让多加几个角色,估计调用时就很容易弄混啦,所以我们想一想,能否所有的角色的变量名都是一样的,但调用的时候又能区分开分别是谁?
当然可以,我们只需要把上面的变量改成字典的格式就可以啦。
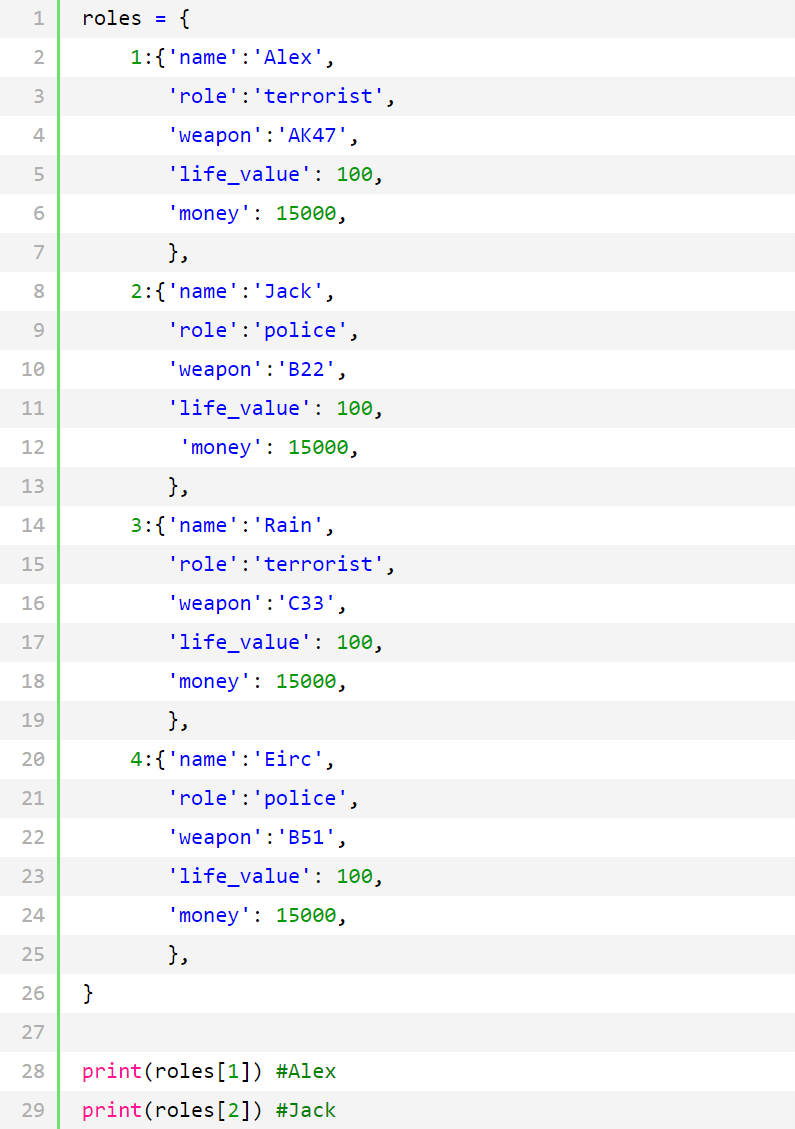
很好,这个以后调用这些角色时只需要roles[1],roles[2]就可以啦,角色的基本属性设计完了后,我们接下来为每个角色开发以下几个功能
- 被打中后就会掉血的功能
- 开枪功能
- 换子弹
- 买枪
- 跑、走、跳、下蹲等动作
- 保护人质(仅适用于警察)
- 不能杀同伴
- 。。。
我们可以把每个功能写成一个函数,类似如下:
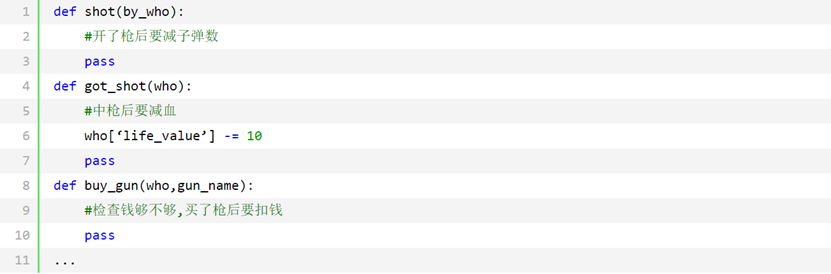
so far so good, 继续按照这个思路设计,再完善一下代码,游戏的简单版就出来了,但是在往下走之前,我们来看看上面的这种代码写法有没有问题,至少从上面的代码设计中,我看到以下几点缺陷:
- 每个角色定义的属性名称是一样的,但这种命名规则是我们自己约定的,从程序上来讲,并没有进行属性合法性检测,也就是说role 1定义的代表武器的属性是weapon, role 2 ,3,4也是一样的,不过如果我在新增一个角色时不小心把weapon 写成了wepon , 这个程序本身是检测 不到的
- terrorist 和police这2个角色有些功能是不同的,比如police是不能杀人质的,但是terrorist可能,随着这个游戏开发的更复杂,我们会发现这2个角色后续有更多的不同之处, 但现在的这种写法,我们是没办法 把这2个角色适用的功能区分开来的,也就是说,每个角色都可以直接调用任意功能,没有任何限制。
- 我们在上面定义了got_shot()后要减血,也就是说减血这个动作是应该通过被击中这个事件来引起的,我们调用get_shot(),got_shot()这个函数再调用每个角色里的life_value变量来减血。 但其实我不通过got_shot(),直接调用角色roles[role_id][‘life_value’] 减血也可以呀,但是如果这样调用的话,那可以就是简单粗暴啦,因为减血之前其它还应该判断此角色是否穿了防弹衣等,如果穿了的话,伤害值肯定要减少,got_shot()函数里就做了这样的检测,你这里直接绕过的话,程序就乱了。 因此这里应该设计 成除了通过got_shot(),其它的方式是没有办法给角色减血的,不过在上面的程序设计里,是没有办法实现的。
- 现在需要给所有角色添加一个可以穿防弹衣的功能,那很显然你得在每个角色里放一个属性来存储此角色是否穿 了防弹衣,那就要更改每个角色的代码,给添加一个新属性,这样太low了,不符合代码可复用的原则
上面这4点问题如果不解决,以后肯定会引出更大的坑,有同学说了,解决也不复杂呀,直接在每个功能调用时做一下角色判断啥就好了,没错,你要非得这么霸王硬上弓的搞也肯定是可以实现的,那你自己就开发相应的代码来对上面提到的问题进行处理好啦。 但这些问题其实能过OOP就可以很简单的解决。
之前的代码改成用OOP中的“类”来实现的话如下:
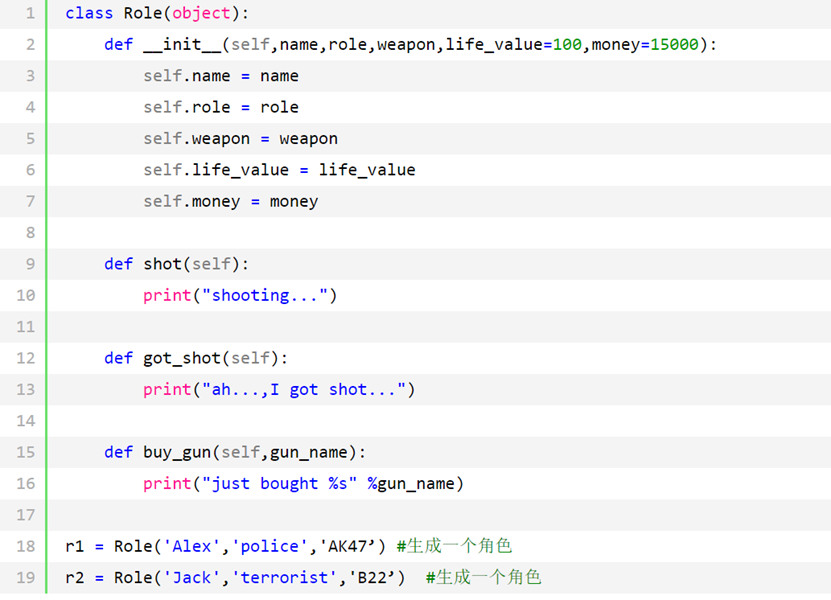
先不考虑语法细节,相比靠函数拼凑出来的写法,上面用面向对象中的类来写最直接的改进有以下2点:
- 代码量少了近一半
- 角色和它所具有的功能可以一目了然看出来
在真正开始分解上面代码含义之之前,我们现来了解一些类的基本定义
类的语法

上面的代码其实有问题,想给狗起名字传不进去。
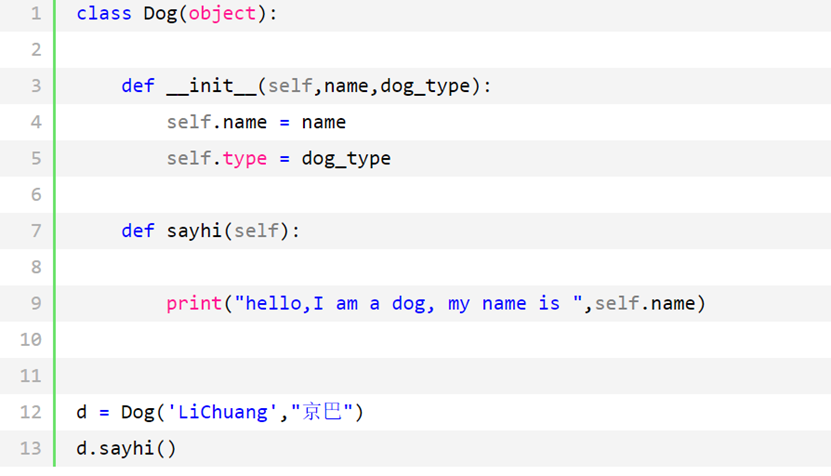
为什么有__init__? 为什么有self? 此时的你一脸蒙逼,相信不画个图,你的智商是理解不了的!
画图之前, 你先注释掉这两句
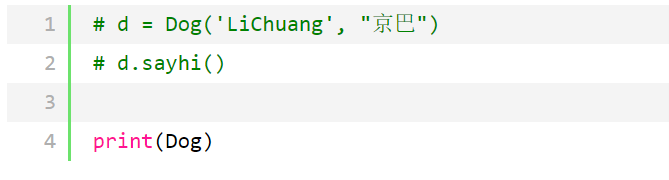
没实例直接打印Dog输出如下

这代表什么?代表 即使不实例化,这个Dog类本身也是已经存在内存里的对不对, yes, cool,那实例化时,会产生什么化学反应呢?
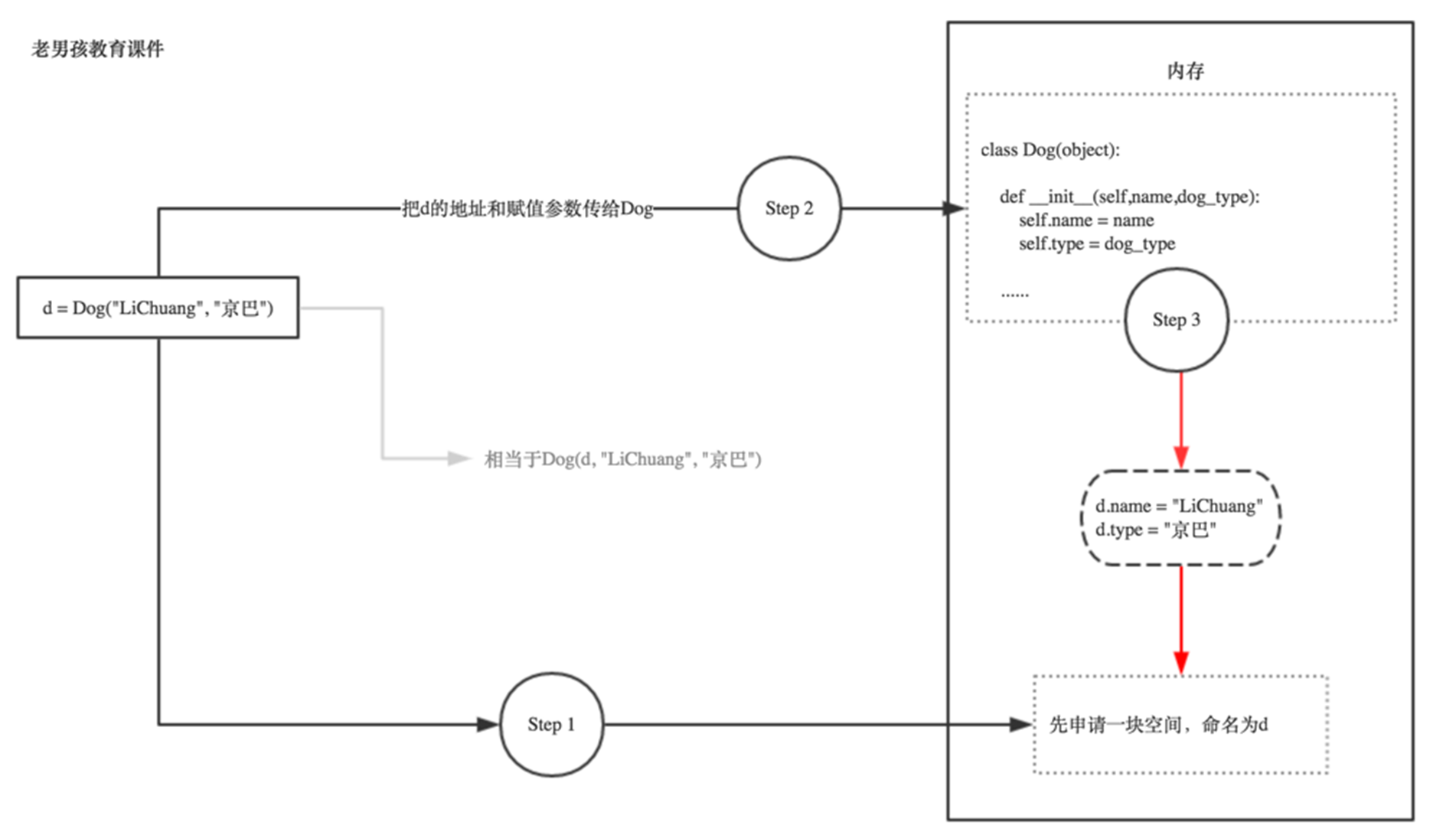
根据上图我们得知,其实self,就是实例本身!你实例化时python会自动把这个实例本身通过self参数传进去。
你说好吧,假装懂了, 但下面这段代码你又不明白了, 为何sayhi(self),要写个self呢?

这个问题在下个小结课程讲解
好了,明白 了类的基本定义,接下来我们一起分解一下上面的代码分别 是什么意思

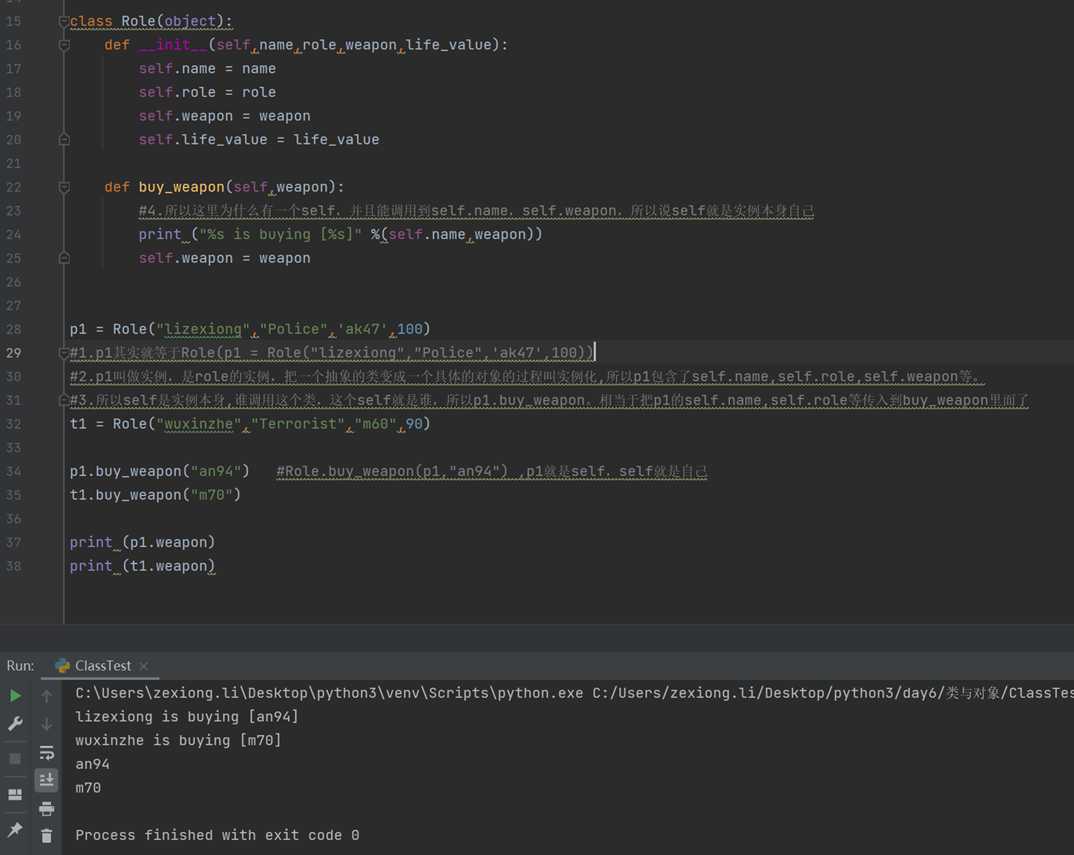
上面的这个__init__()叫做初始化方法(或构造方法), 在类被调用时,这个方法(虽然它是函数形式,但在类中就不叫函数了,叫方法)会自动执行,进行一些初始化的动作,所以我们这里写的__init__(self,name,role,weapon,life_value=100,money=15000)就是要在创建一个角色时给它设置这些属性,那么这第一个参数self是干毛用的呢?
初始化一个角色,就需要调用这个类一次:

我们看到,上面的创建角色时,我们并没有给__init__传值,程序也没未报错,是因为,类在调用它自己的__init__(…)时自己帮你给self参数赋值了,

为什么这样子?你拉着我说你有些犹豫,怎么会这样子?
你执行r1 = Role('Alex','police','AK47’)时,python的解释器其实干了两件事:
- 在内存中开辟一块空间指向r1这个变量名
- 调用Role这个类并执行其中的__init__(…)方法,相当于Role.__init__(r1,'Alex','police',’AK47’),这么做是为什么呢? 是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,重要的事情说3次, 因为关联起来后,你就可以直接r1.name, r1.weapon 这样来调用啦。所以,为实现这种关联,在调用__init__方法时,就必须把r1这个变量也传进去,否则__init__不知道要把那3个参数跟谁关联呀。
- 明白了么哥?所以这个__init__(…)方法里的,self.name = name , self.role = role 等等的意思就是要把这几个值 存到r1的内存空间里。
如果还不明白的话,哥,去测试一下智商吧, 应该不会超过70,哈哈。
为了暴露自己的智商,此时你假装懂了,但又问, __init__(…)我懂了,但后面的那几个函数,噢 不对,后面那几个方法 为什么也还需要self参数么? 不是在初始化角色的时候 ,就已经把角色的属性跟r1绑定好了么?
good question, 先来看一下上面类中的一个buy_gun的方法:

上面这个方法通过类调用的话要写成如下:

执行结果
#Alex has just bought B21
依然没给self传值 ,但Python还是会自动的帮你把r1 赋值给self这个参数, 为什么呢? 因为,你在buy_gun(..)方法中可能要访问r1的一些其它属性呀, 比如这里就访问 了r1的名字,怎么访问呢?你得告诉这个方法呀,于是就把r1传给了这个self参数,然后在buy_gun里调用 self.name 就相当于调用r1.name 啦,如果还想知道r1的生命值 有多少,直接写成self.life_value就可以了。 说白了就是在调用类中的一个方法时,你得告诉人家你是谁。
好啦, 总结一下2点:
- 上面的这个r1 = Role('Alex','police','AK47’)动作,叫做类的“实例化”, 就是把一个虚拟的抽象的类,通过这个动作,变成了一个具体的对象了, 这个对象就叫做实例
- 刚才定义的这个类体现了面向对象的第一个基本特性,封装,其实就是使用构造方法将内容封装到某个具体对象中,然后通过对象直接或者self间接获取被封装的内容
6.11 面向对象之类和构造方法
本章主要用案例讲解:
1.self主要是干嘛
2.加self和不加self有什么不同,出现什么样的执行结果
相关的笔记其实已经在上一小节全部复制下来了,但是这里还是根据课堂的视频来做一份笔记。
6.12 面向对象之类变量与实例变量
本章主要讲解
1.类变量与实例变量区别
2.类变量哪种场景可以使用
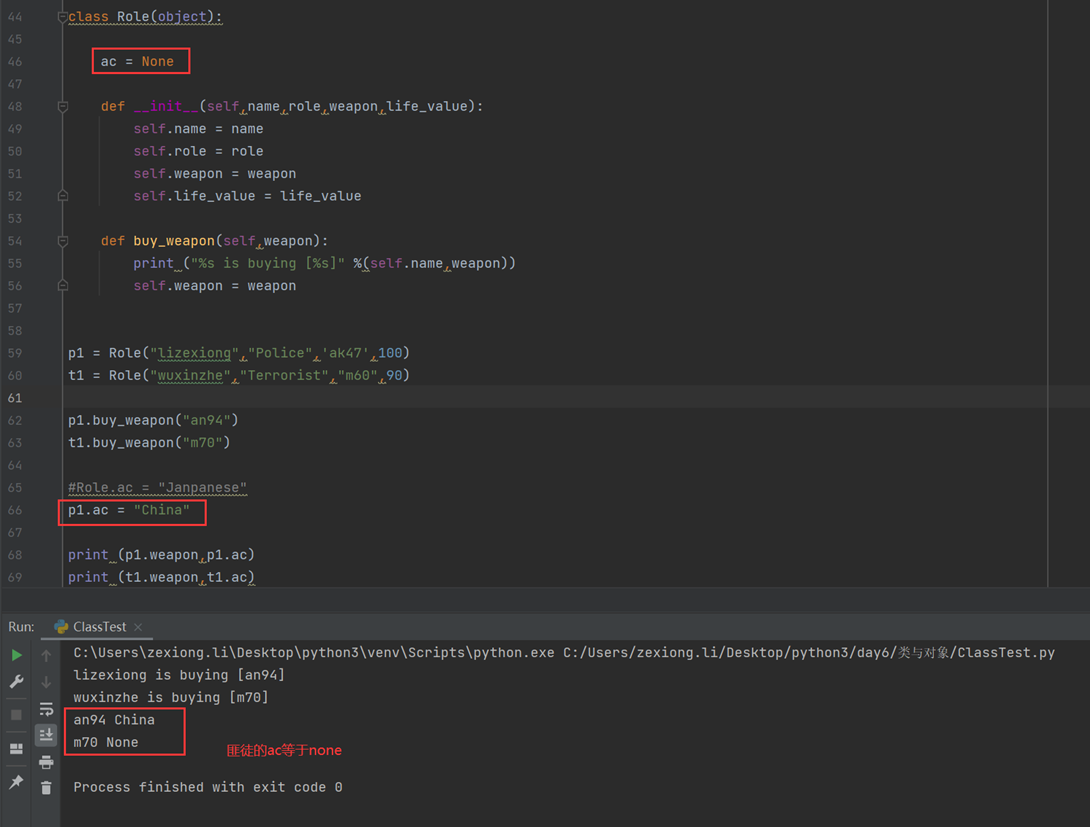
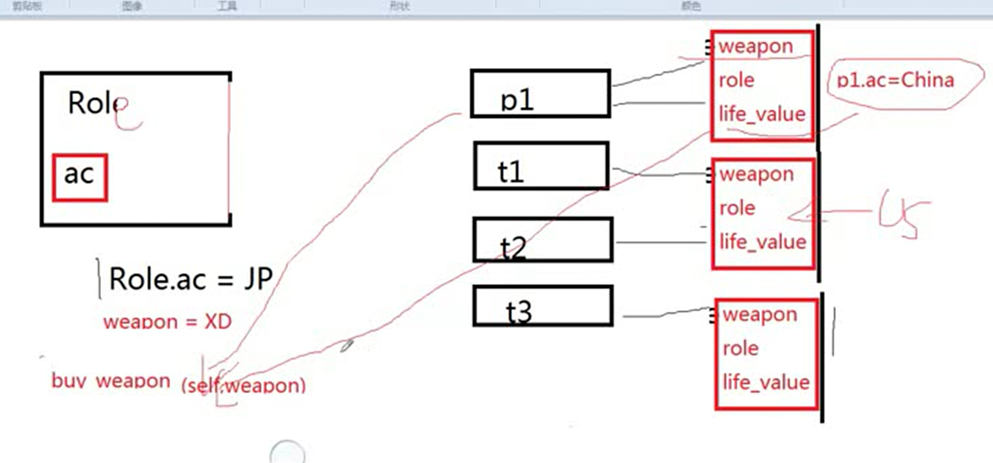
现在直接改变一下类的ac值,在看看对于没有设置t1ac的值有什么结果现象。
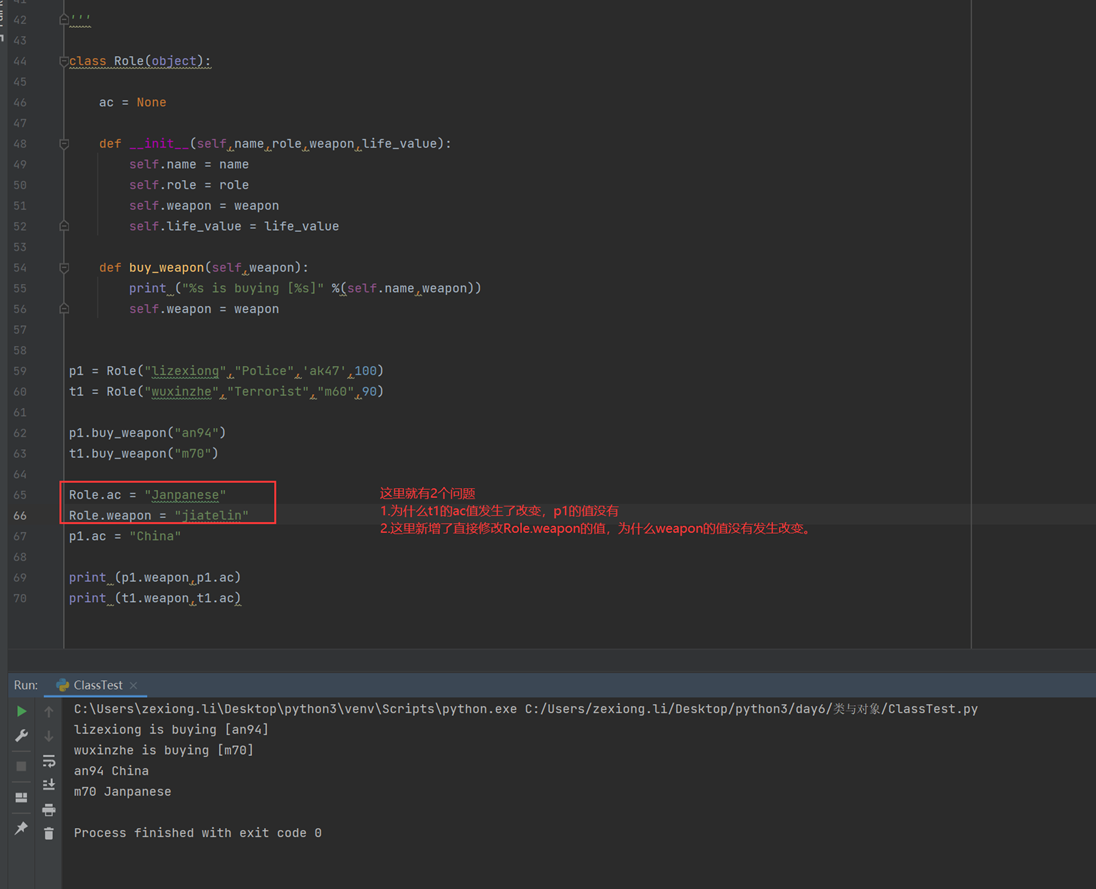
根据上图所示,设置了
1.Role.ac
2.Role.weapon
3.init下面的name,role,weapon
Role.ac只存在类里面,直接调用不会出错。
name,role,weapon是实例化对象之后才有的,如果name,role,weapon没有实例化,调用肯定是报错的,因为他们都还不存在。
Role.weapon也不会报错,为什么?而且self里面有一个weapon,这里Role.weapon算怎么回事?如果代码写成Role.weapon,那么肯定是报错的,因为类里面没有这个属性,
调用肯定报错,如果代码写成Role.weapon=’jiatelin’,那么就不会报错,因为这是赋值。
上述代码中,同时给Role.ac和Role.weapon赋值,结果输出p1的ac的值还是我单独设置的China,因为这里是我没有去访问类的ac值,只是我创建了一个ac的变量,存储在p1自己的内存里面了。但是t1却变成了Role.ac设置的Janpanese,是因为我没有创建ac的变量,所以我直接调用了类的值。所以t1.ac最后等于Janpanese
小总结:类变量是属于类的,可以直接调用,而实例变量是单独存储在实例里面的,只有实例化之后才能使用,没有实例化之前都是不存在的
接下来,类变量应用场景?
这里还是用游戏来说,如果我想知道一共注册了多少人,那么我可以定义一个变量,每注册一个人,我类变量就+1,最后不就统计有多少人了?一般都用在一些公共的场景。
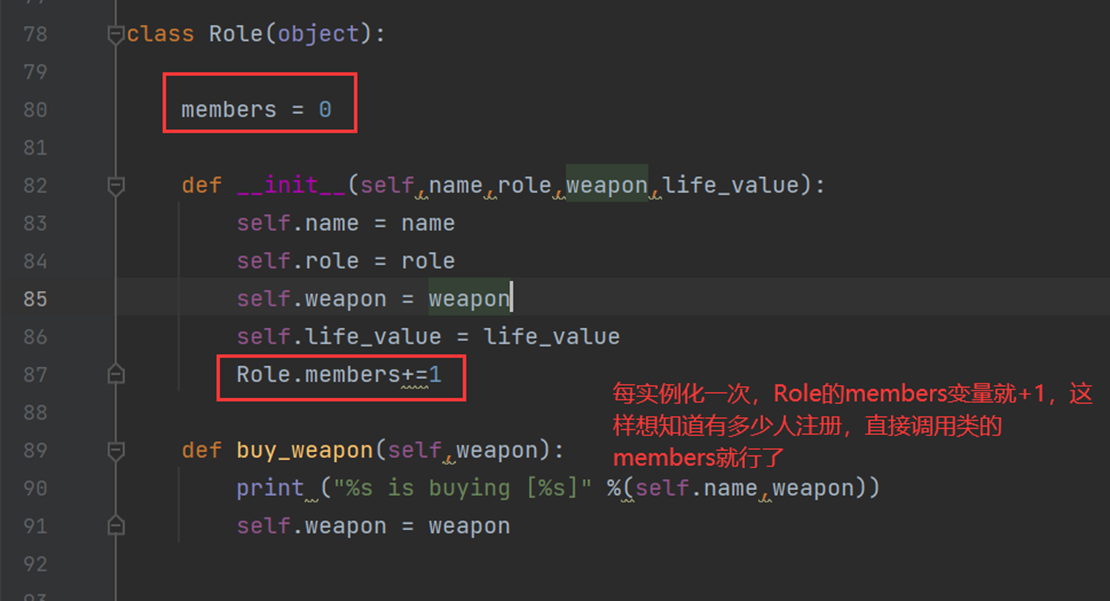
小总结:实例化对象后,除了init的内容被实例化,方法是不会被实例化的,因为没有必要,不然占用太多没必要资源,而且,即使被实例化了,还是要通过self告诉函数,是谁来调用我,所以说函数没有必要实例化,肯定还要回去调用类的方法,方法公共一份就行。且在类里面,函数不叫函数,叫类的方法,为什么不叫实例的方法,因为方法属于类,不属于实例。
6.13 面向对象之类的继承
本章用学校成员的案例来讲解了继承方式的使用。主要实现了
1.怎么使用继承
2.继承的好处,比如权限隔离
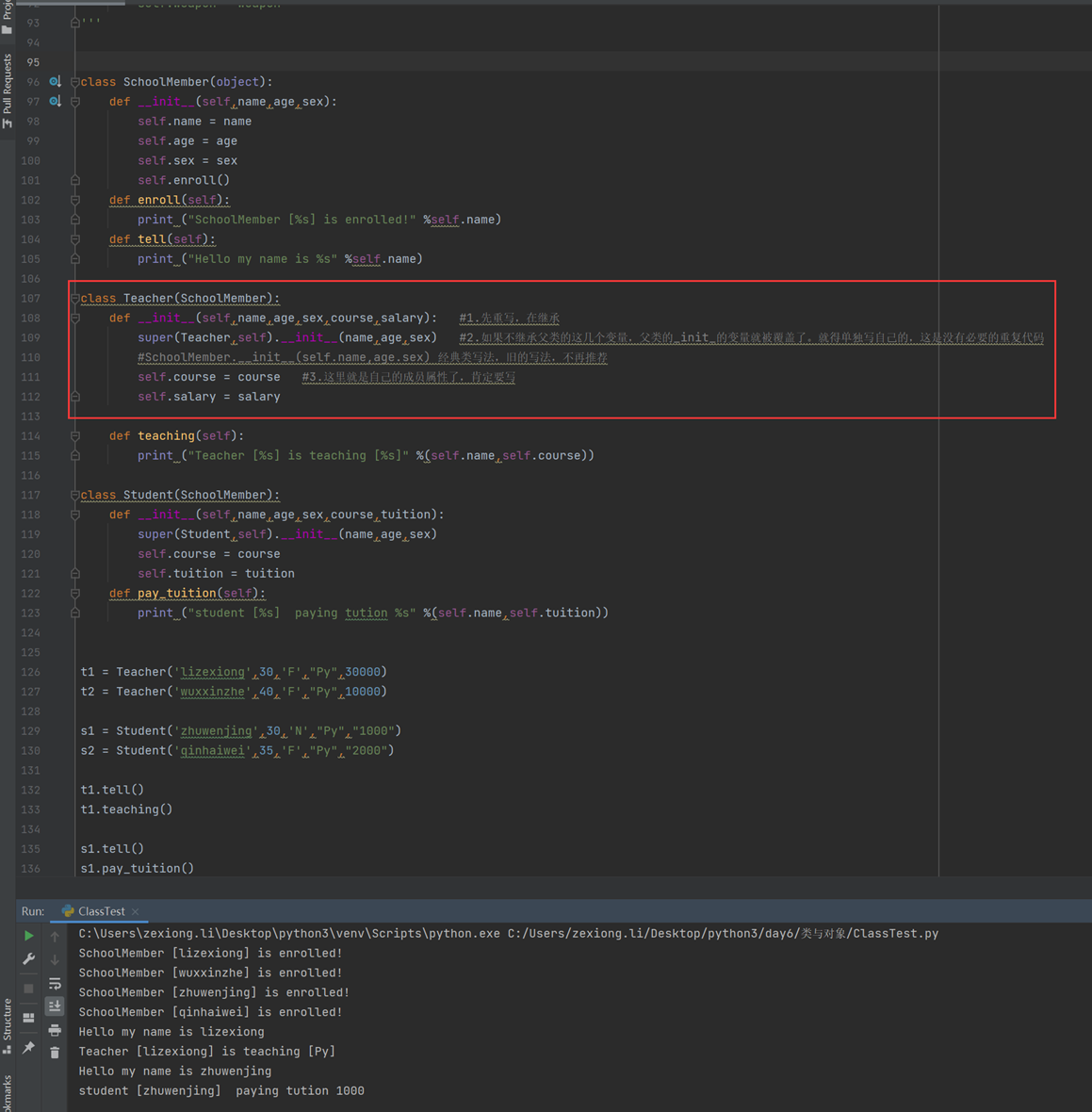
以下其实是L07的课程,但是个人觉得放在L06里面更好
6.14 面向对象之回顾
就是上一章的回顾,可以不用记录
6.15 面向对象之类的静态方法类方法及属性
本章主要讲解(代码ClassTest2)
1.python没有多态,但是通过其他方式可以实现一个多态。
2.类变量(静态字段)和实例变量(普通字段),上节已经讲解过
3.类方法,普通方法、静态方法
4.属性
1.关于多态
这个没什么好解释的,不同的对象调用同一个接口,表现出不同的状态,称为多态。但是这里老师解释成,父类调用子类方法就是多台,且,并且python没有多态,要自己想办法实现,于是询问了java的朋友,朋友回复子类那么多方法?父类调用哪个?
其实怎么说呢?就是一个接口,多种形态的表现就是多态,就比如如下代码。通过func的自定义函数封装,可以调用不同的子类的方法,也就是实现了不同的形态和功能。
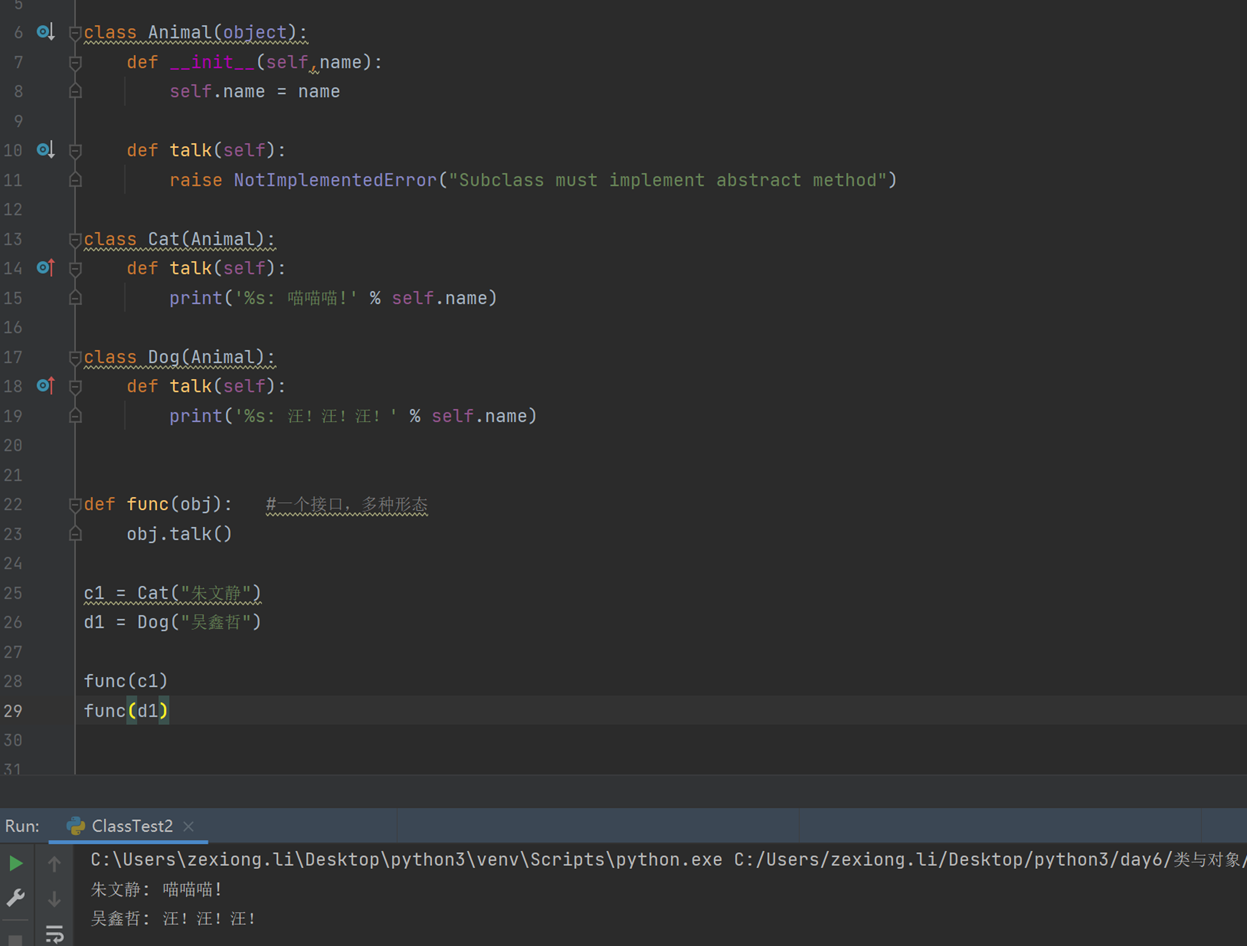
2.类变量(静态字段)和实例变量(普通字段)的调用方式啥的,上节讲解过,这里就放一张图片
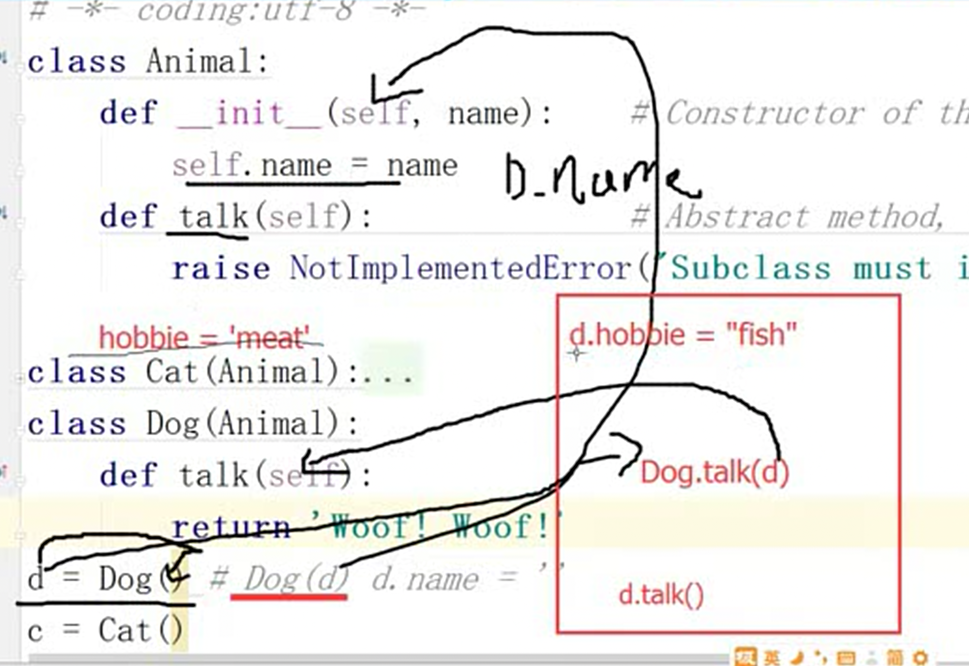
3.类方法,普通方法、静态方法
普通方法就不做过多解释
这里看看类方法
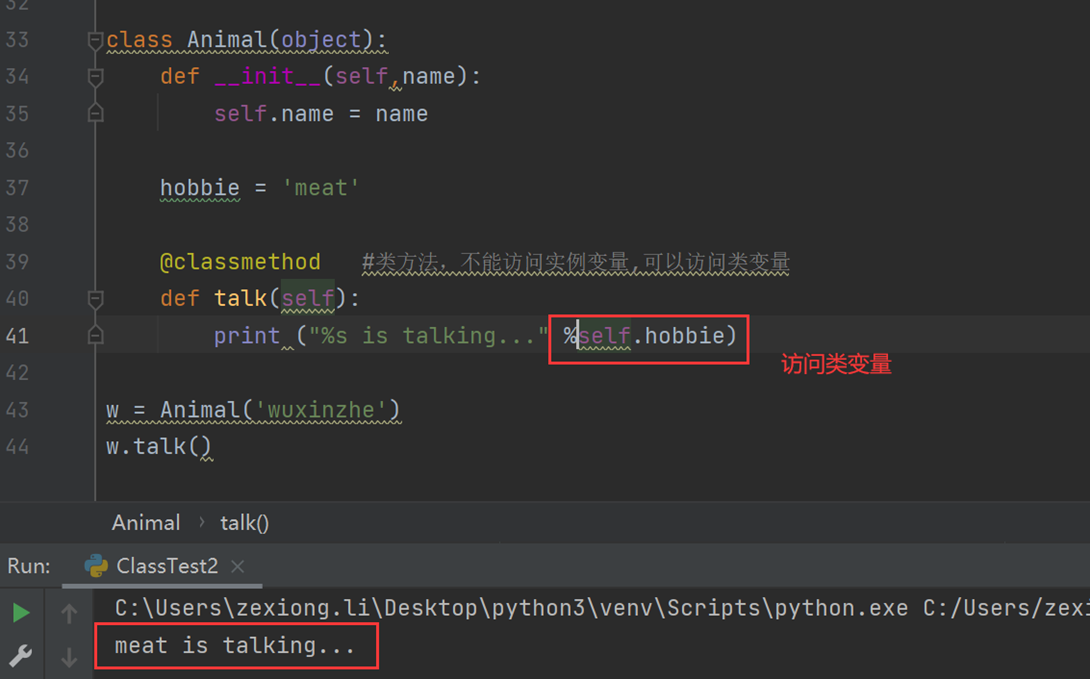
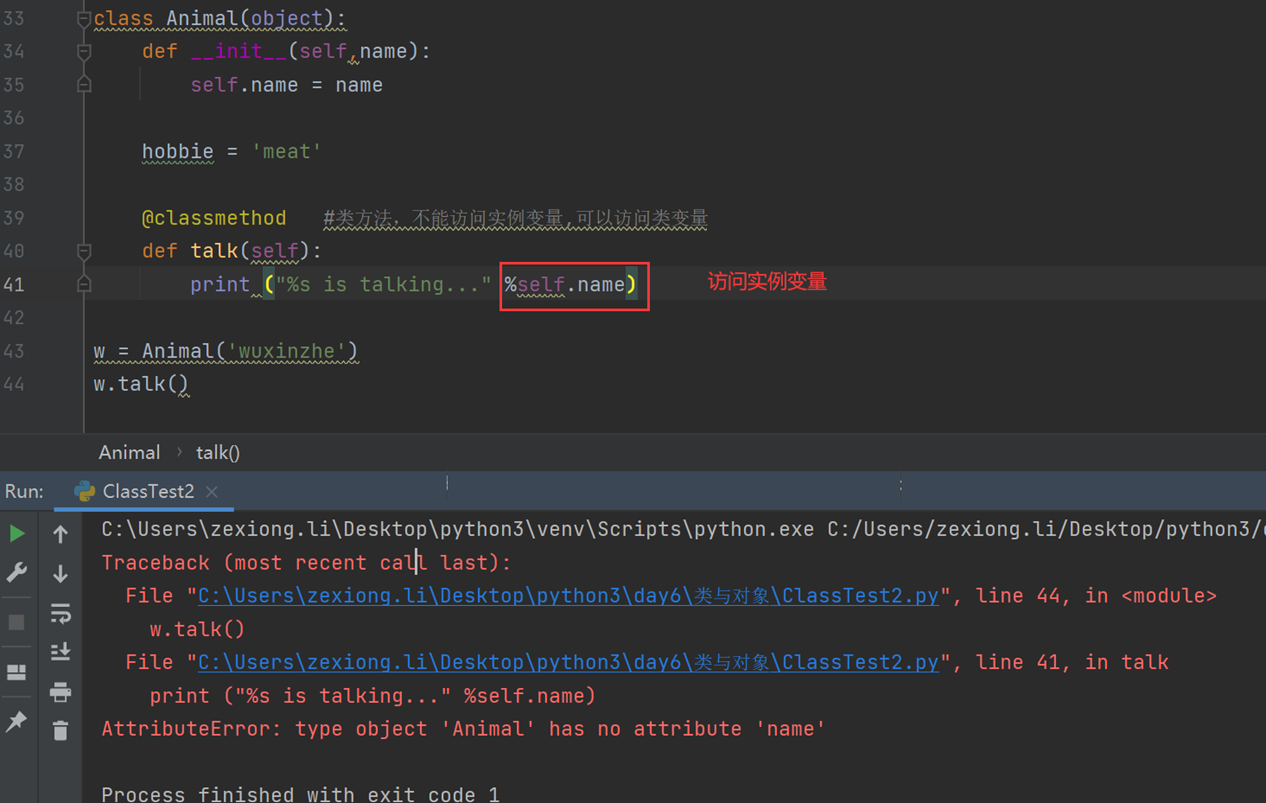
静态方法
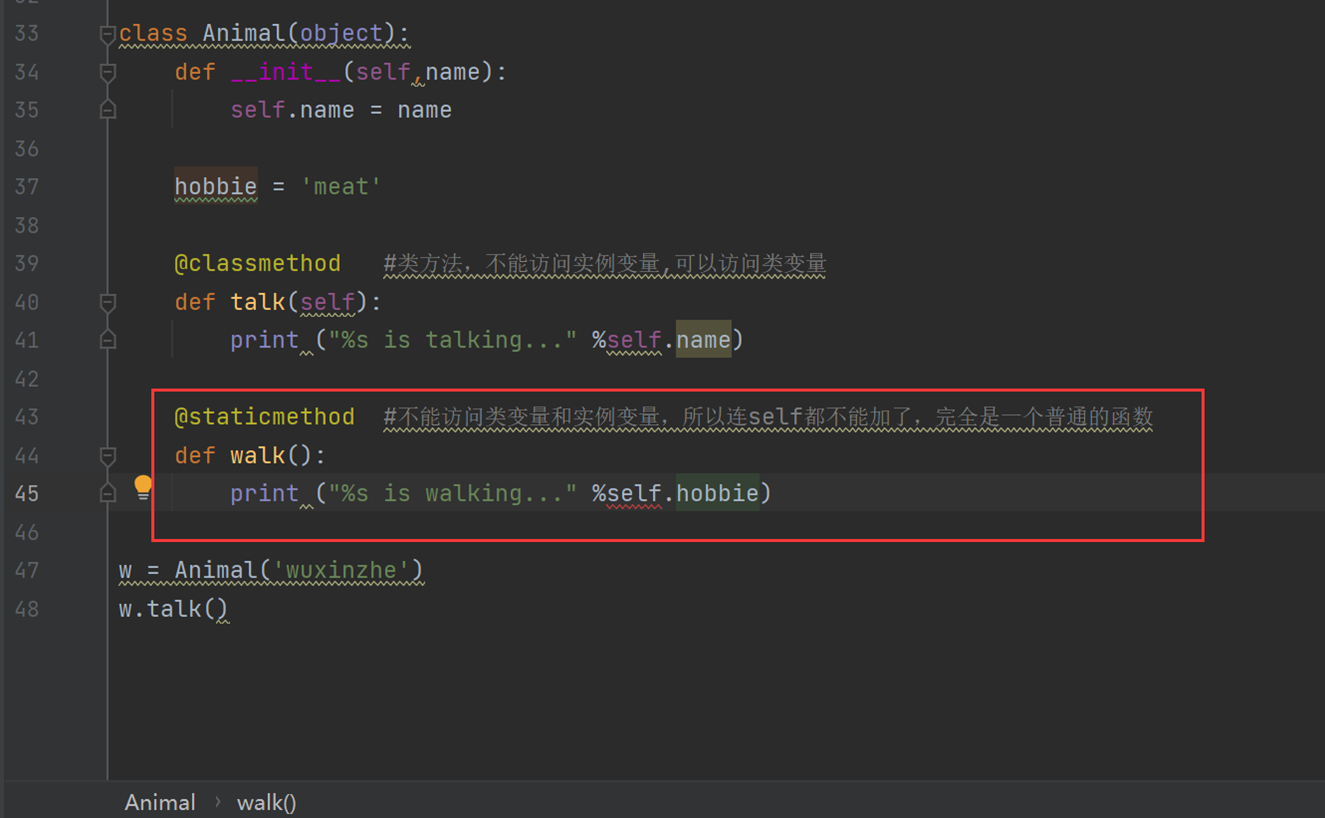
4.属性
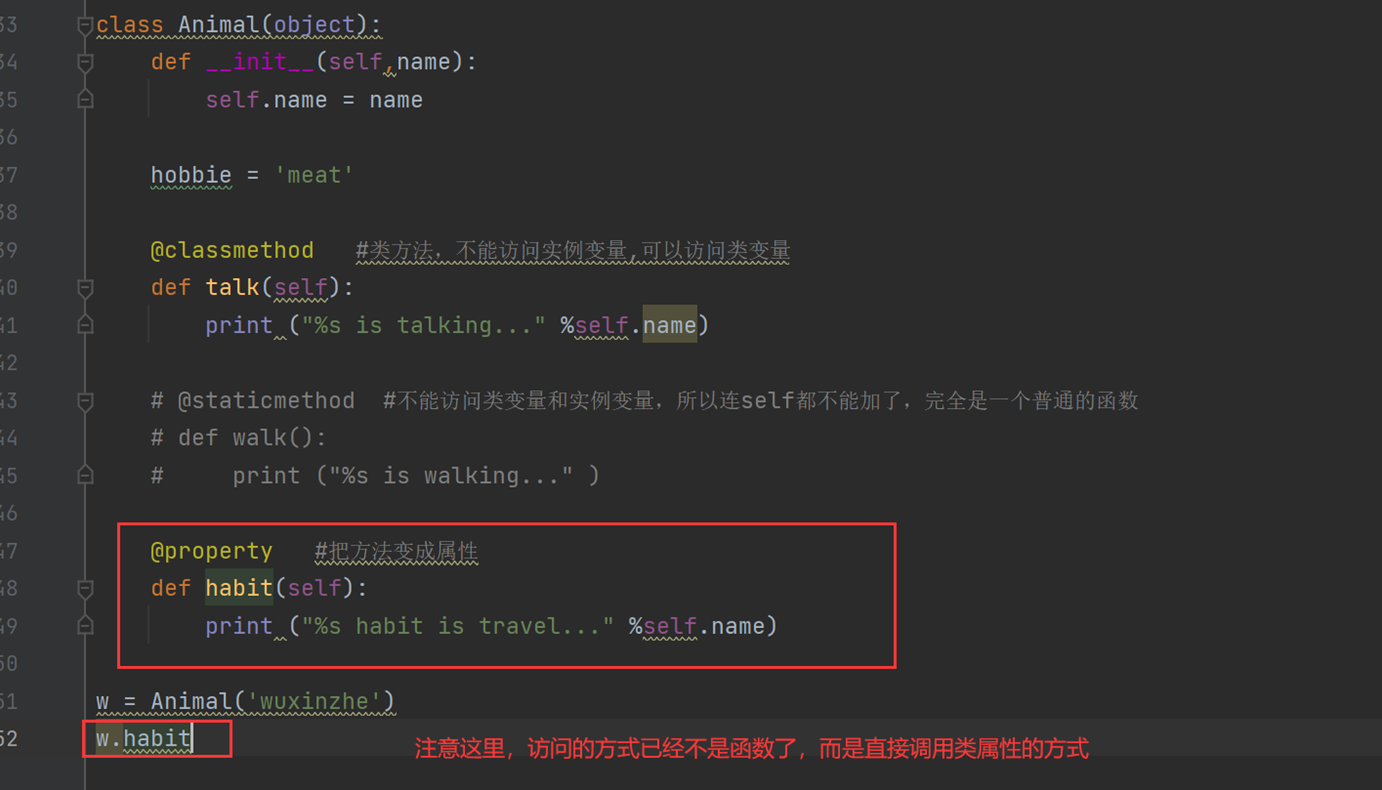
具体的使用方式可以参考学习教材
6.16 面向对象新式类与经典类
本章主要讲解
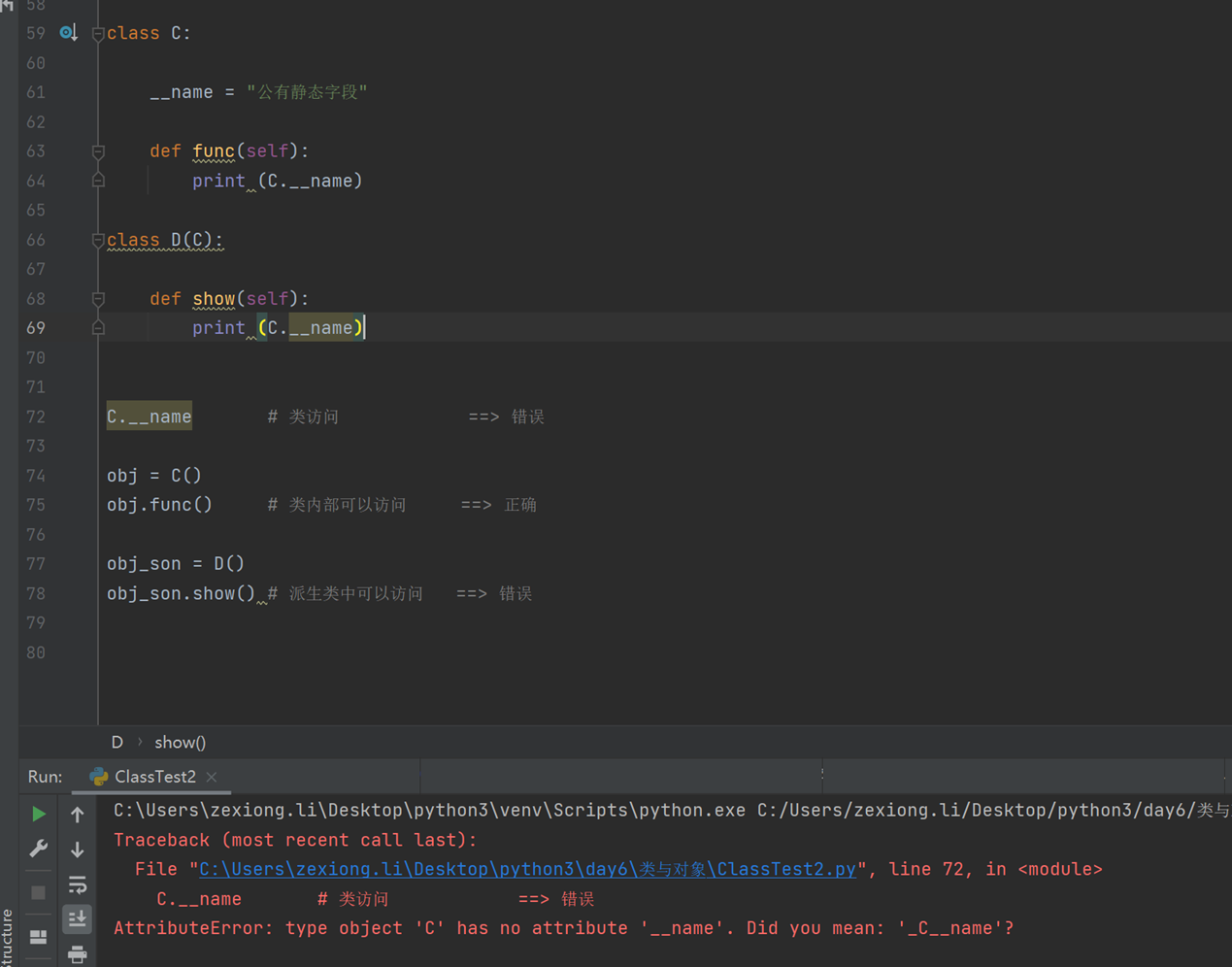
1.私有字段
2.新式类和经典类的深度优先和广度优先
1.私有字段(这老师用的例子太乱,这里换一个例子讲解)
2.新式类和经典类的深度优先和广度优先
这个老师讲解新式类和经典类的区别就是深度优先和广度优先,如果需要更详细的区别,可以参考本人博客的面向对象篇。
-
- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了跟多的功能,也是之后推荐的写法,从写法上区分的话,如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类。
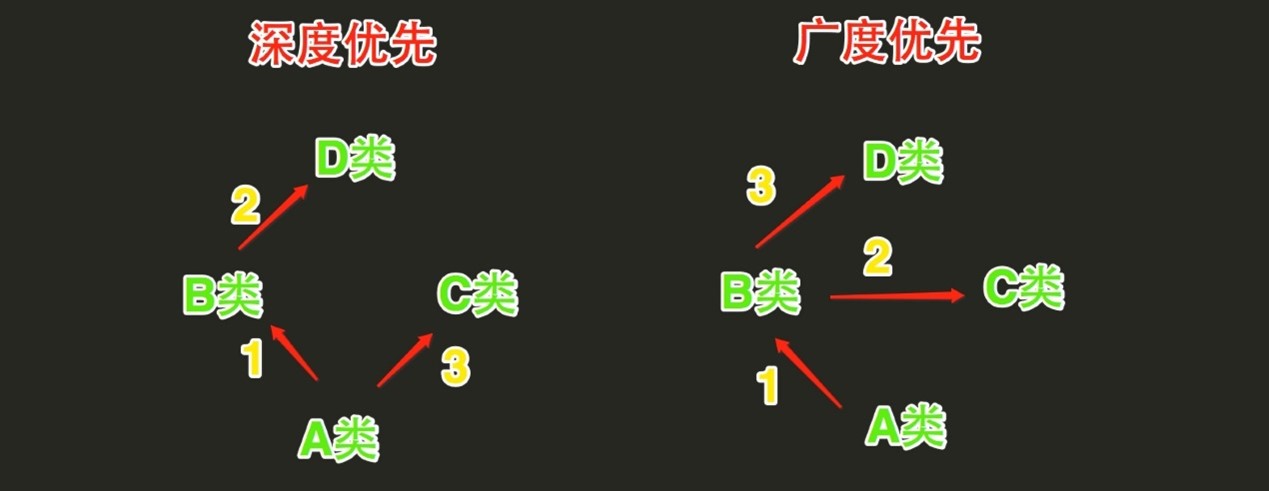
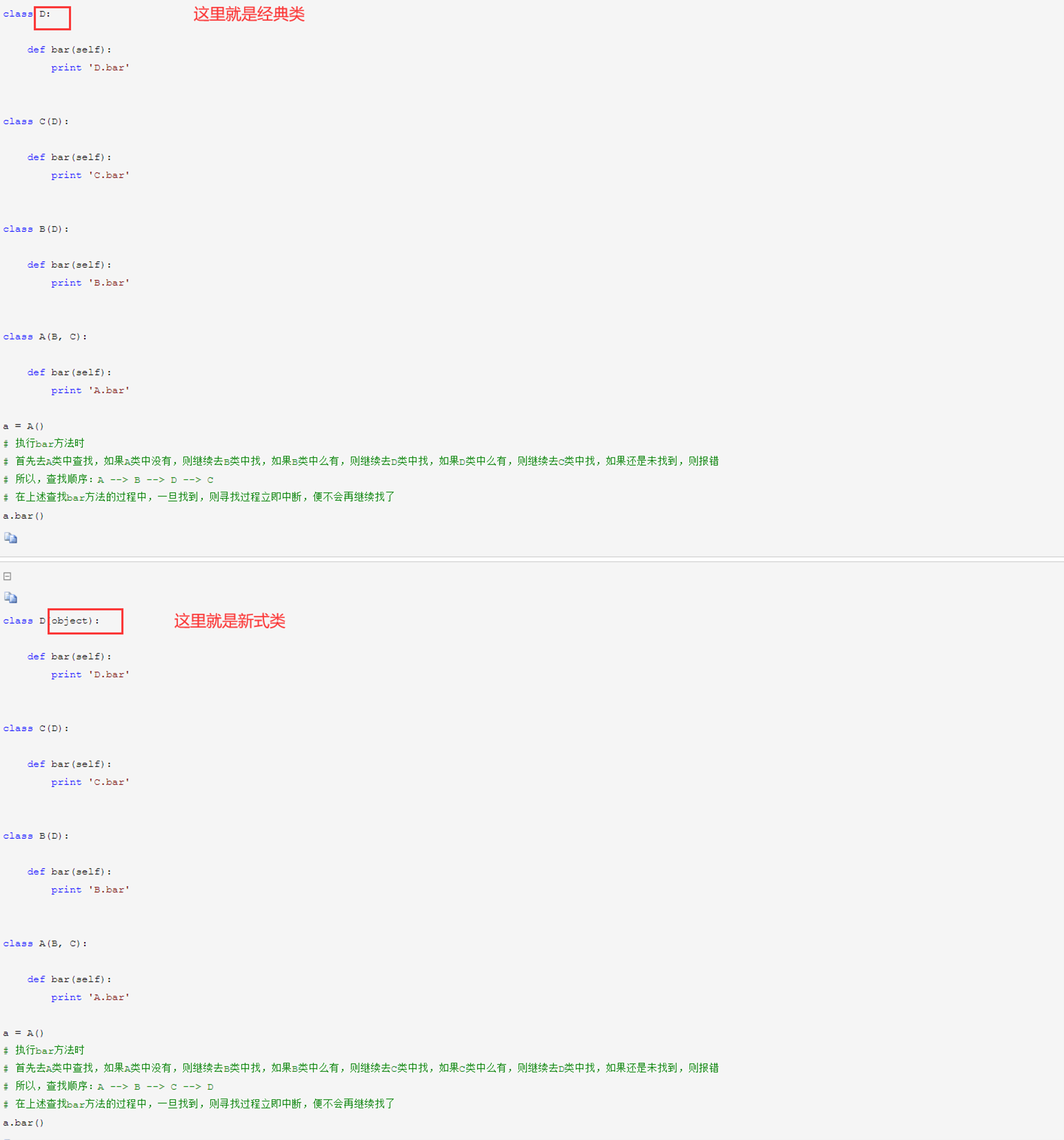
经典类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
新式类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
注意:在上述查找过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
但是要注意一个非常重要的问题,测试中发现,不管是经典类还是新式类,都使用了广式查找,即使是经典类也一样,这是为什么?因为在python3.0之后的版本,不管是新式类还是经典类都是广式查找,因为这种方法比深度查找好处多太多了。
6.17 面向对象特性之多态(类的特殊成员)
这篇文章的视频文件名错了,应该是类的特殊成员,这里为了更好查找,所以这里标题就不做修改。这里备注一下是类的特殊成员就行。
类的特殊成员这里也不做详细讲解,这里参考本人博客。
6.18 面向对象反射的妙用
python中的反射功能是由以下四个内置函数提供:hasattr、getattr、setattr、delattr,改四个函数分别用于对对象内部执行:检查是否含有某成员、获取成员、设置成员、删除成员。
这里以一个服务器启动,停止,的案例来看
首先是一个需求,服务器启动和停止,用了以下方法,先生成字典,然后通过判断字典里面有没有这个key,这个方法是不是很好?
但是cmd_dic的代码是重复的,有重复的代码就不是最好的方法
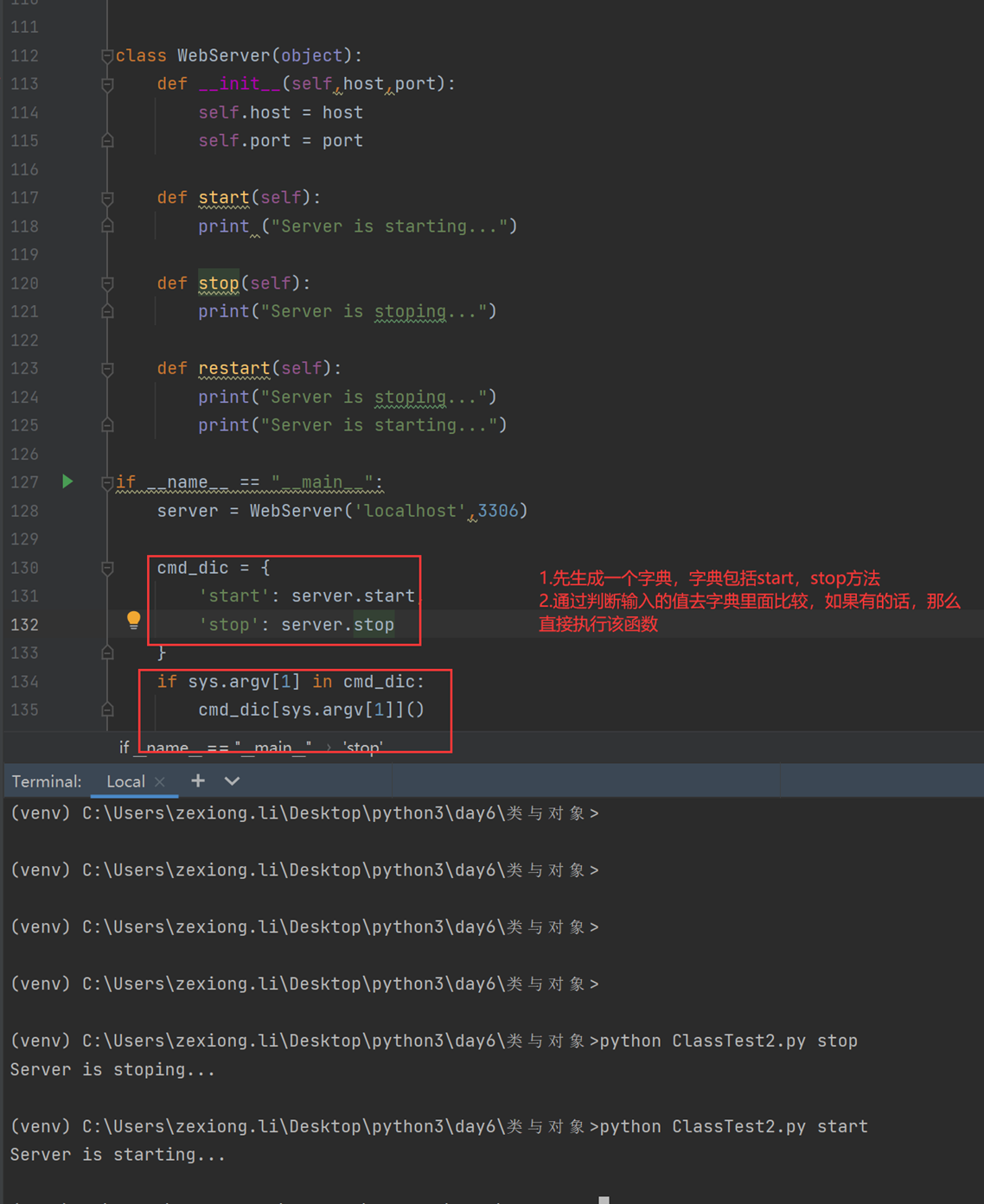
所以我们使用了反射
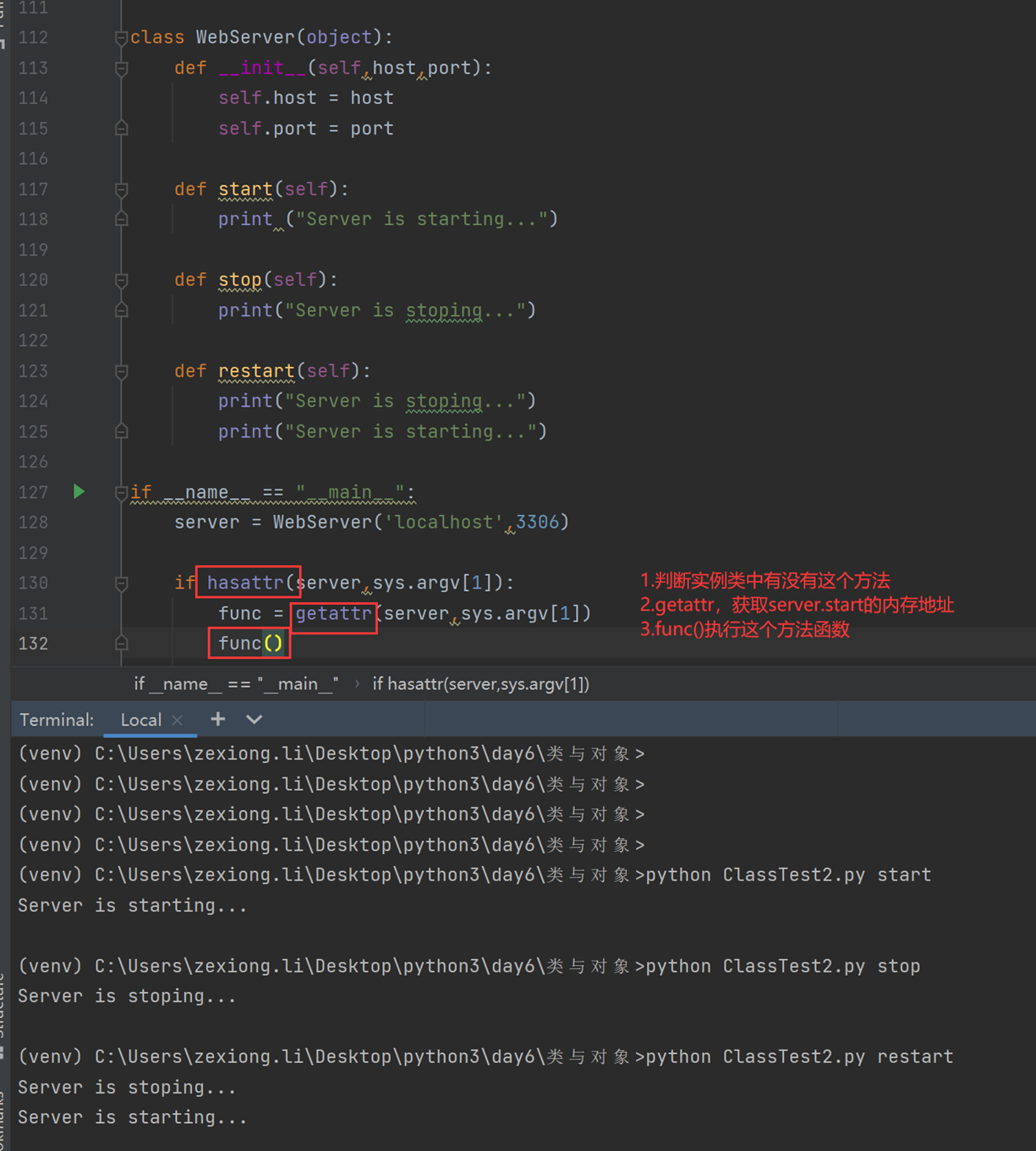
上面讲解了hasattr和getattr,现在讲解set的作用,是将一个外部函数绑定到这个实例化对象中,而不是类中。其它实例化对象不可调用这个绑定的函数。
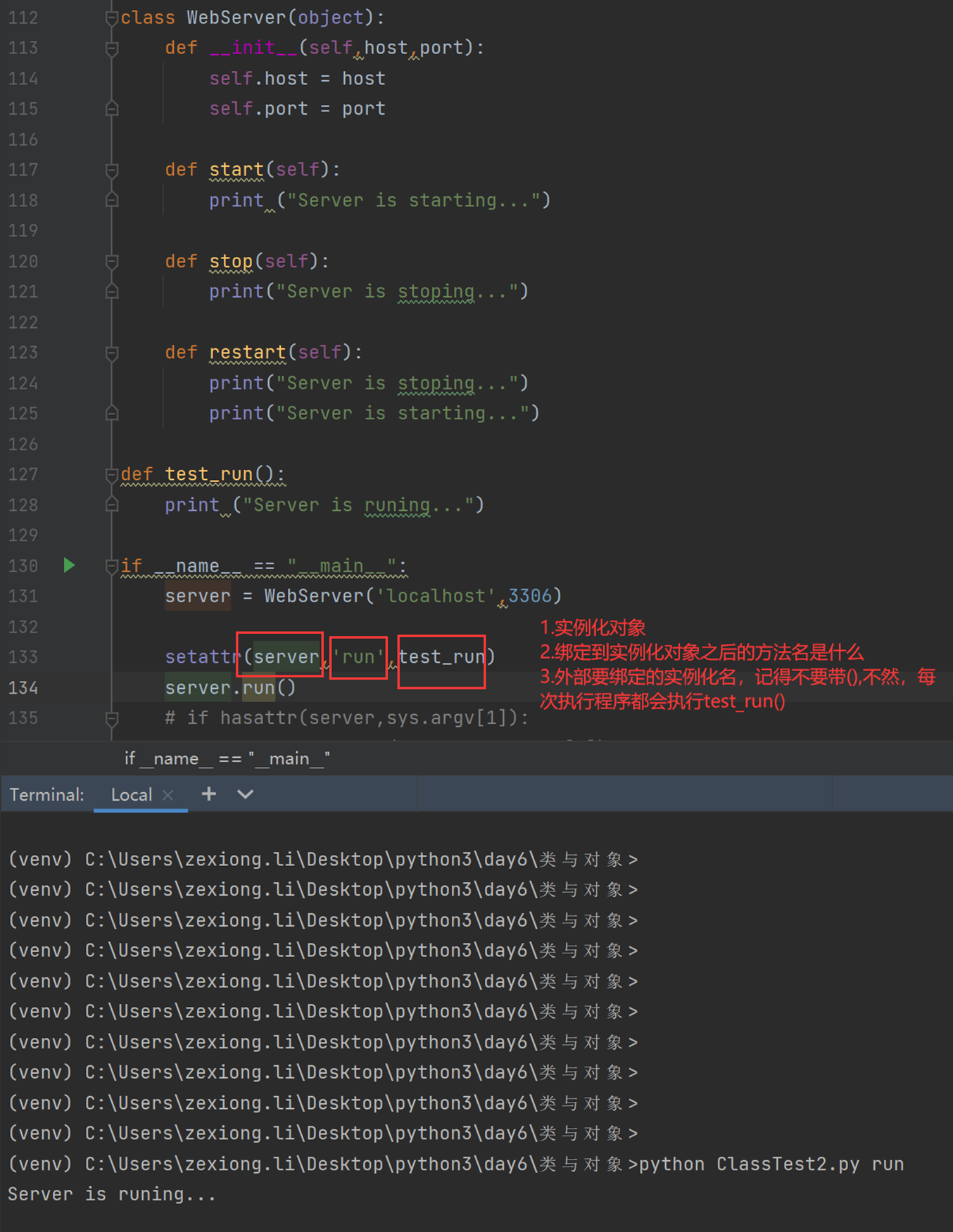
接下来如果是外部的,可以给test_run加参数吗?当然,普通的参数肯定没问题,我说的是怎么调用实例化内部的参数?
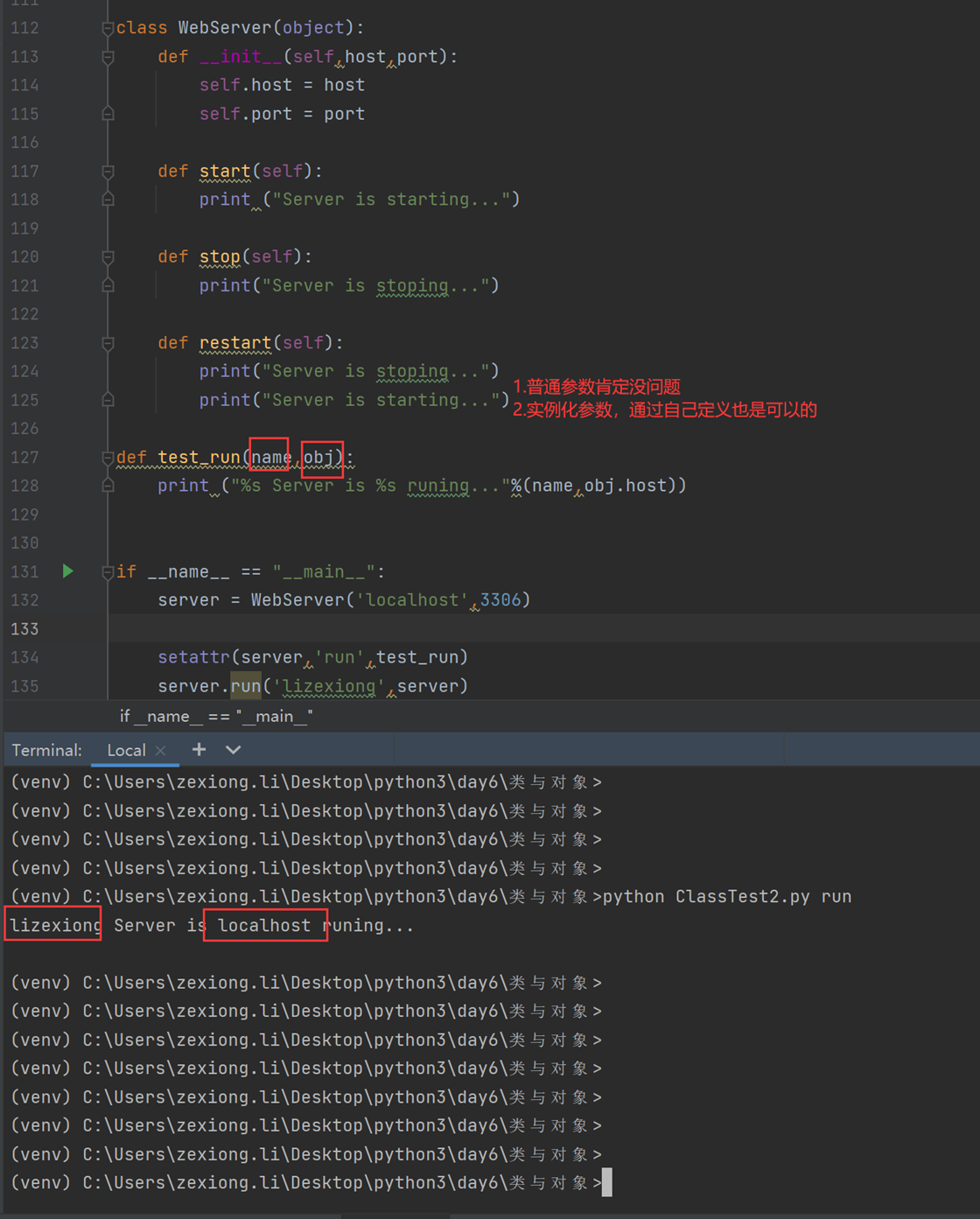
这是时候验证一下test_run()能让server2来访问吗?
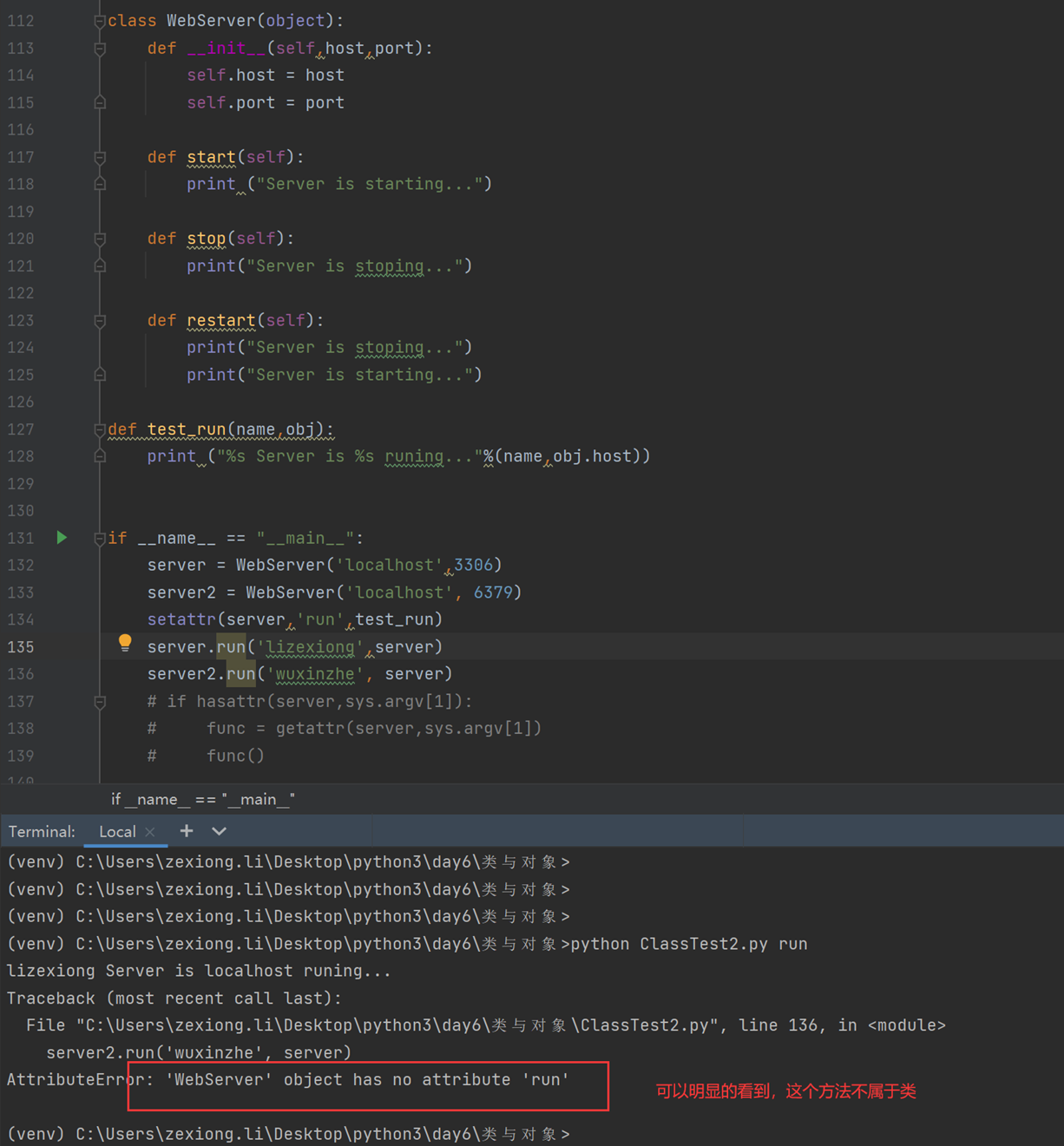
当然这里记一下,没办法将方法绑定到类,会报错,本人已经测试过了
现在讲解delattr,但是记住,删除的时候,不要删类里面的东西。类里面的东西跟你无关,你只能删除实例化里面的东西,比如slef.host等
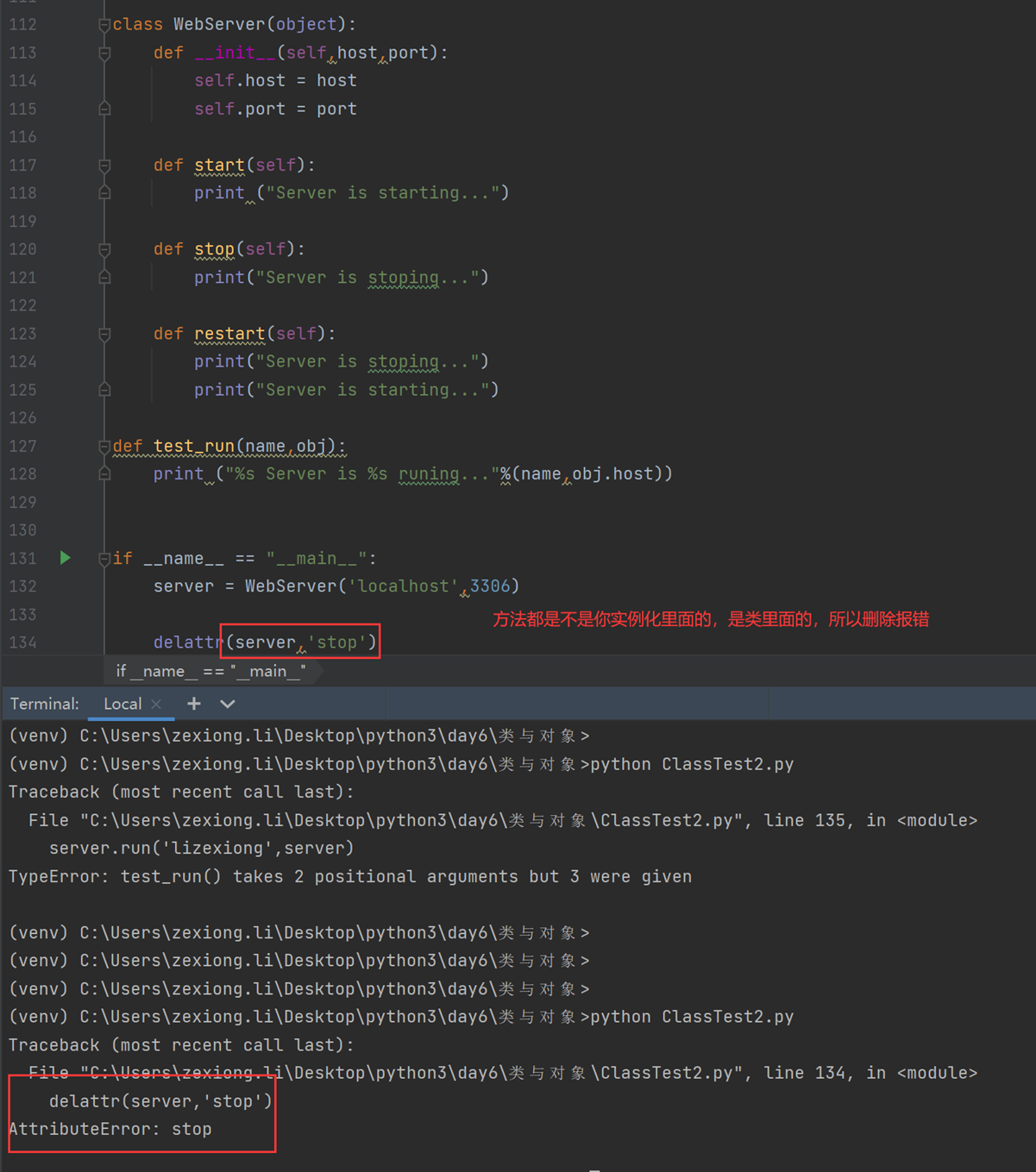
所以我们现在删除类里面的stop看看
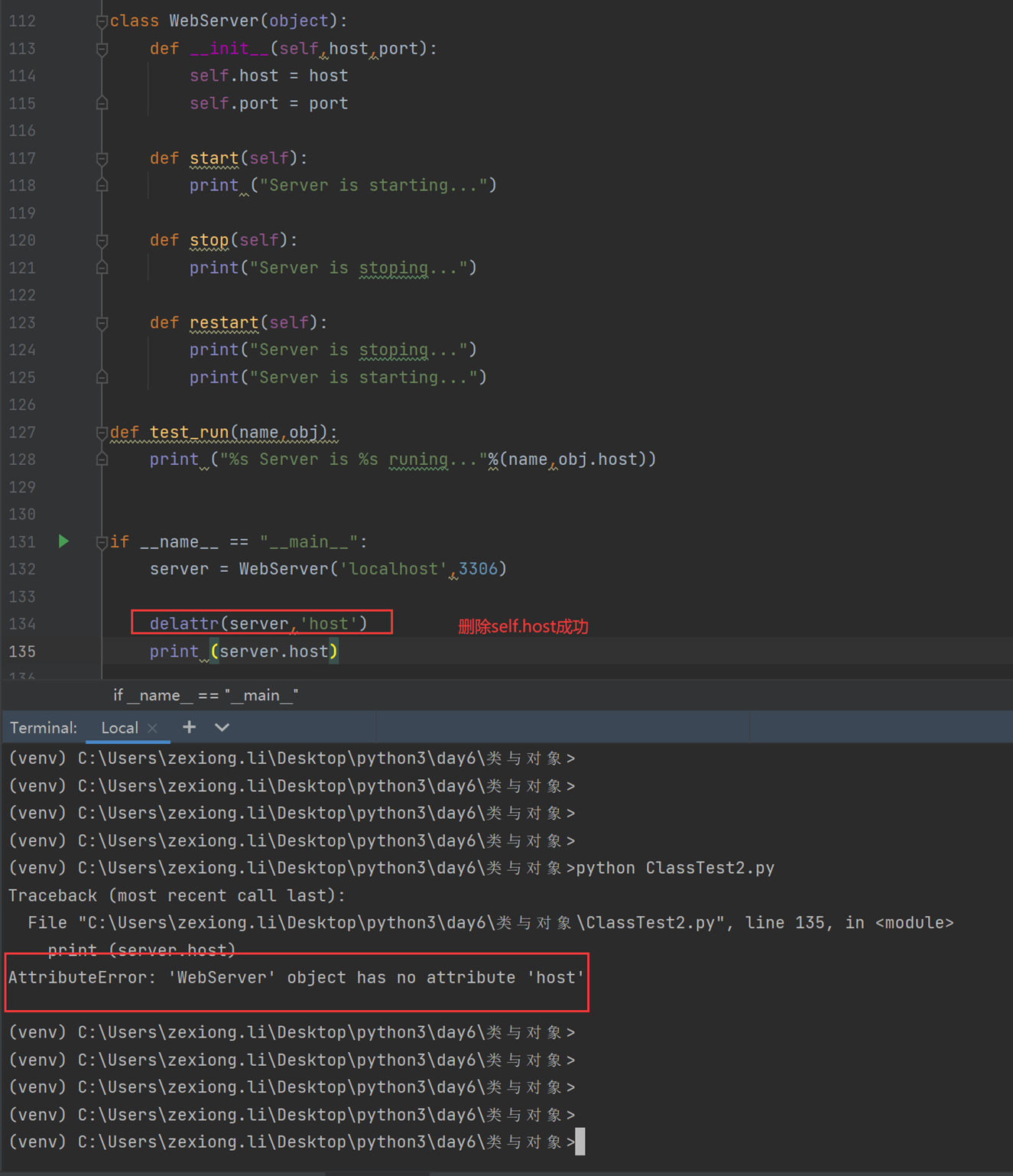
当然del和set不同的是,del可以删除类的方法,比如直接删除start,执行restart方法,那么执行stop是成功的,删除的start是失败报错的
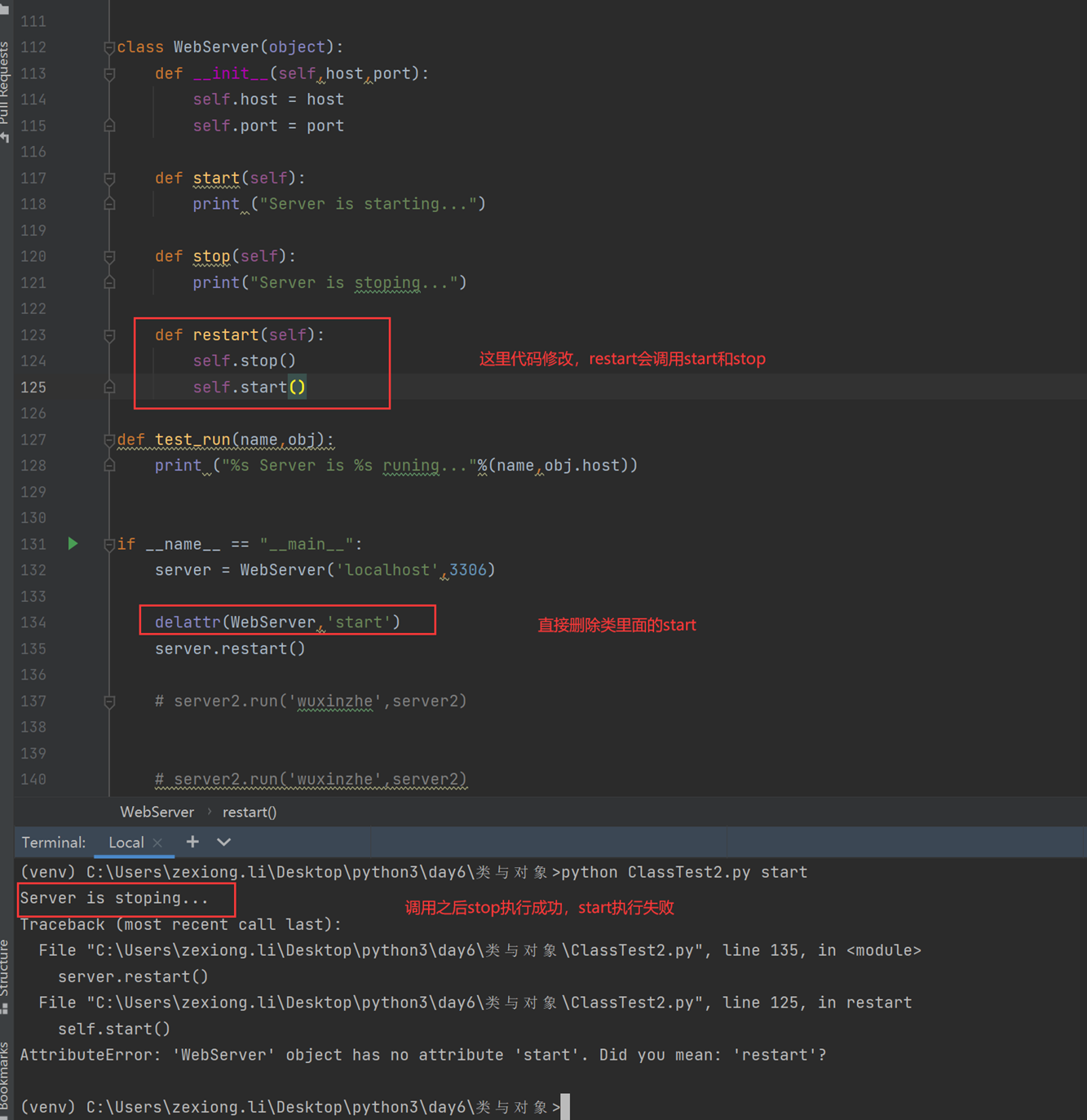
这和set的一点小区别,set不能绑定函数方法到类,但是del可以删除类的方法
7.L07
7.1 socket基础
本章内容:
1.主要讲解tcp原理,本人不需要
2.讲解了socket的原理
3.简单演示一个socket的服务器和客户端通信的代码实例
socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求。
socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,对于文件用【打开】【读写】【关闭】模式来操作。socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭)
socket和file的区别:
file模块是针对某个指定文件进行【打开】【读写】【关闭】
socket模块是针对 服务器端 和 客户端Socket 进行【打开】【读写】【关闭】
这里设想一下,我们平常的http请求,有多个用户来请求,这时,一个用户请求数据,服务器返回数据,然后断开,这个就叫做短链接。有http,当然还有tcp,http基于tcp创建的,这个过程就是首先创建一个tcp连接。怎么创建一个tcp连接呢?在这里叫做socket。
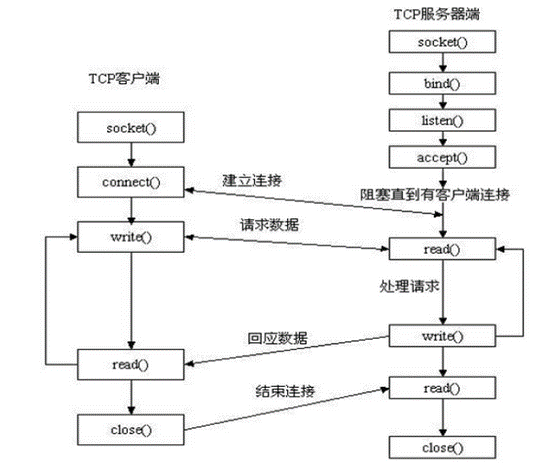
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM,0)
参数一:地址簇
socket.AF_INET IPv4(默认)
socket.AF_INET6 IPv6
socket.AF_UNIX 只能够用于单一的Unix系统进程间通信
参数二:类型
socket.SOCK_STREAM 流式socket , for TCP (默认)
socket.SOCK_DGRAM 数据报式socket , for UDP
socket.SOCK_RAW 原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以;其次,SOCK_RAW也可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头。
socket.SOCK_RDM
是一种可靠的UDP形式,即保证交付数据报但不保证顺序。SOCK_RAM用来提供对原始协议的低级访问,在需要执行某些特殊操作时使用,如发送ICMP报文。SOCK_RAM通常仅限于高级用户或管理员运行的程序使用。
socket.SOCK_SEQPACKET
可靠的连续数据包服务
参数三:协议
0 (默认)与特定的地址家族相关的协议,如果是 0 ,则系统就会根据地址格式和套接类别,自动选择一个合适的协议
sk.bind(address)
s.bind(address) 将套接字绑定到地址。address地址的格式取决于地址族。在AF_INET下,以元组(host,port)的形式表示地址。
sk.listen(backlog)
开始监听传入连接。backlog指定在拒绝连接之前,可以挂起的最大连接数量。
backlog等于5,表示内核已经接到了连接请求,但服务器还没有调用accept进行处理的连接个数最大为5
这个值不能无限大,因为要在内核中维护连接队列
sk.setblocking(bool)
是否阻塞(默认True),如果设置False,那么accept和recv时一旦无数据,则报错。
sk.accept()
接受连接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址。
接收TCP 客户的连接(阻塞式)等待连接的到来
sk.connect(address)
连接到address处的套接字。一般,address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
sk.connect_ex(address)
同上,只不过会有返回值,连接成功时返回 0 ,连接失败时候返回编码,例如:10061
sk.close()
关闭套接字
sk.recv(bufsize[,flag])
接受套接字的数据。数据以字符串形式返回,bufsize指定最多可以接收的数量。flag提供有关消息的其他信息,通常可以忽略。
sk.recvfrom(bufsize[.flag])
与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。
sk.send(string[,flag])
将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。即:可能未将指定内容全部发送。
sk.sendall(string[,flag])
将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。
内部通过递归调用send,将所有内容发送出去。
sk.sendto(string[,flag],address)
将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。该函数主要用于UDP协议。
sk.settimeout(timeout)
设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如 client 连接最多等待5s )
sk.getpeername()
返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。
sk.getsockname()
返回套接字自己的地址。通常是一个元组(ipaddr,port)
sk.fileno()
套接字的文件描述符
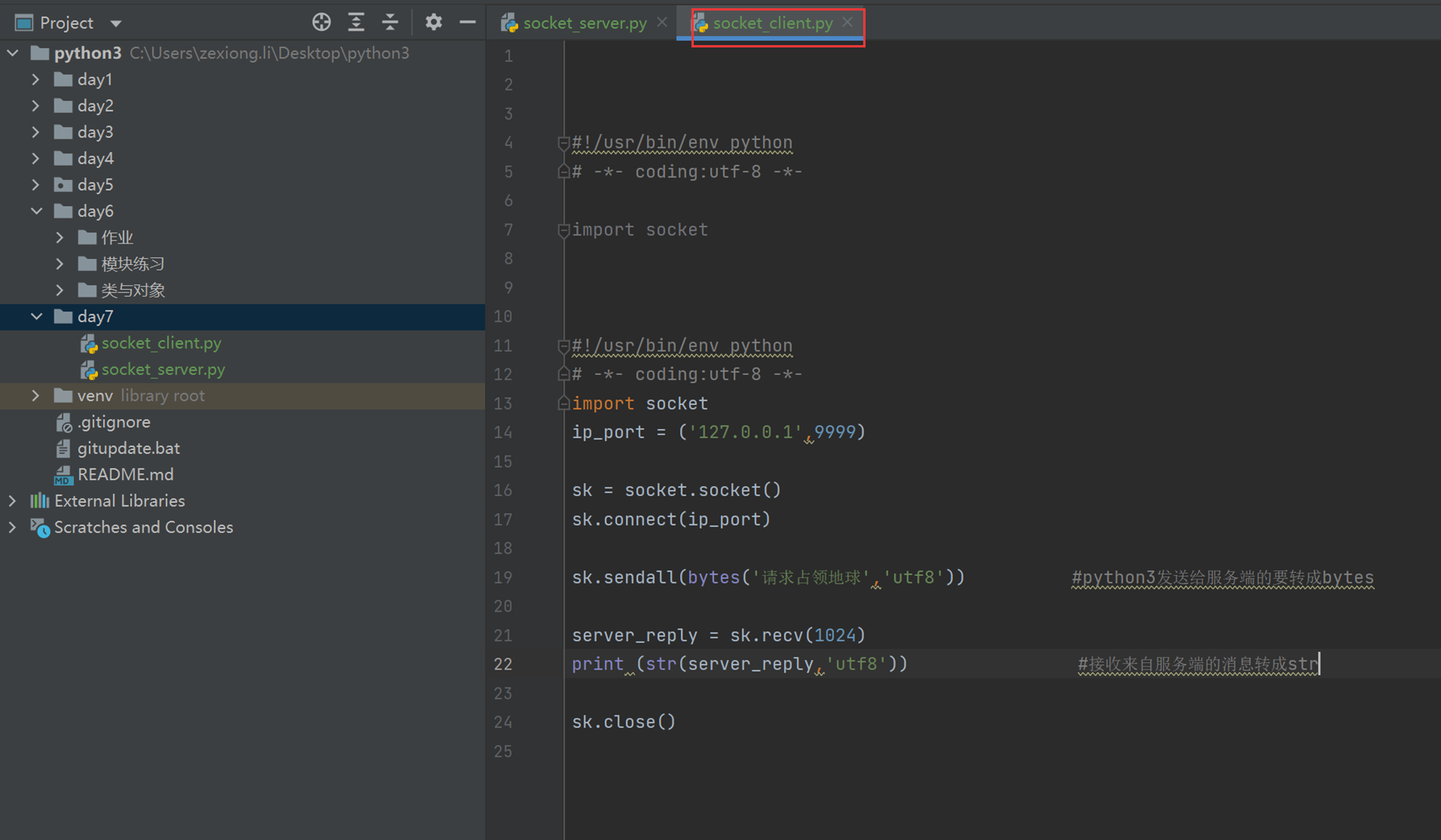
查看客户端执行脚本(服务端没必要看)

7.2 socket连续交互通信
本章讲解内容
1.实现客户端发送一条,服务端返回一条交互
2.第一个客户端断掉,第二个客户端正常连上去,注意,是正常连接上去,如果两个同时连接,第二个连接的会hold住
本章与下一章节联合讲解。
因为这个课程老师讲的有问题,所以才延伸出下一章(python3 socket的坑)
老师说的坑为:
第一版代码,如果客户端突然断掉,那么服务端会进入死循环,在window正常,在linux就循环,可能年代比较久远,目前2022年,win也会进入死循环。
(这2章有点绕,如果不记得上面的意思,只能从新翻看视频了)
第一版代码:
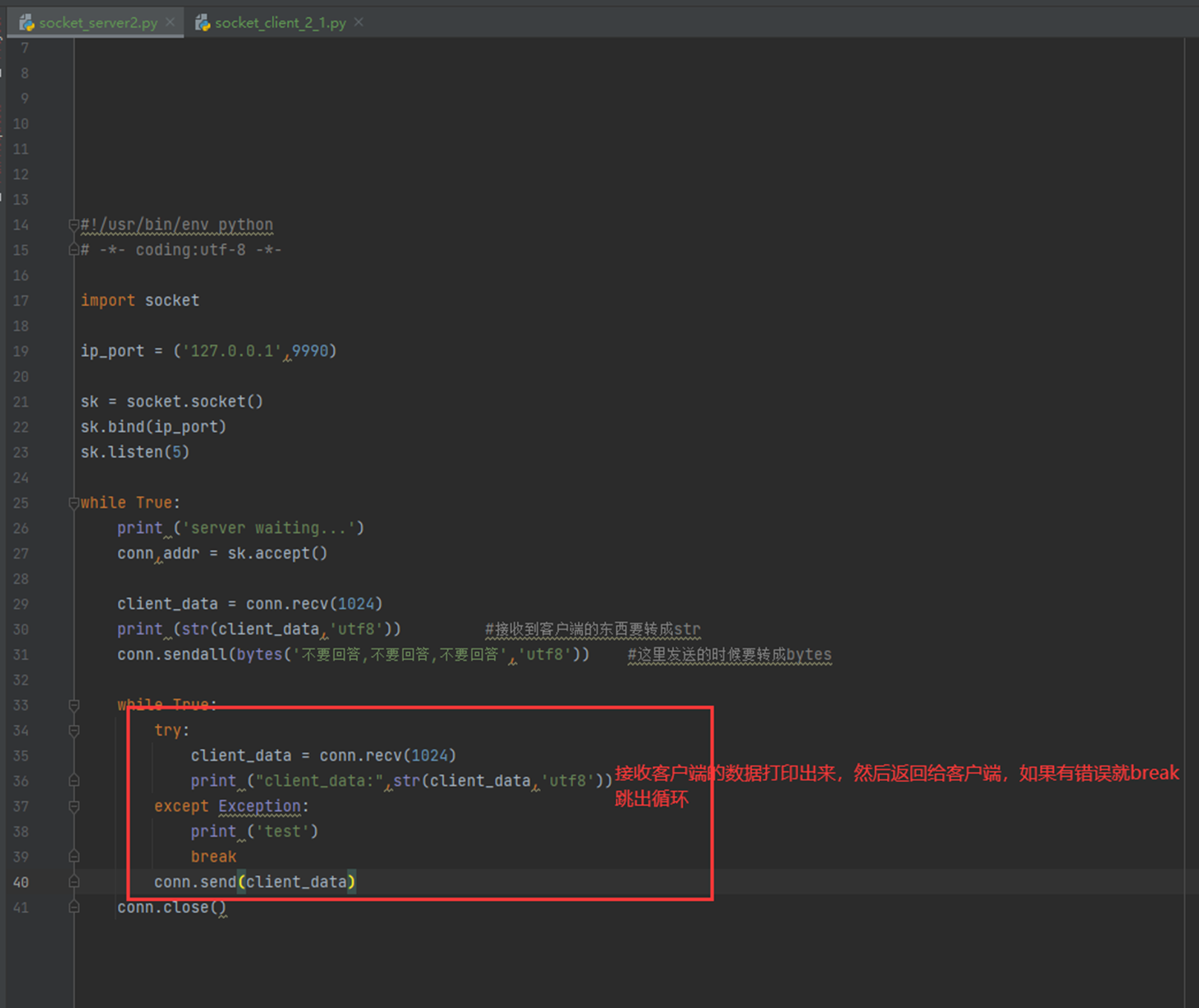
结果
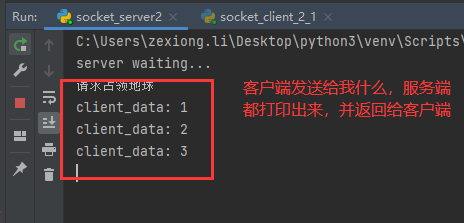
以上一切都没有毛病,但是这里多了一遍,老师演示的视频中,客户端断掉,服务端正常等待下一个连接,window就是正常等待,linux服务端直接进入死循环,但是这里,本人的window也直接进入死循环。
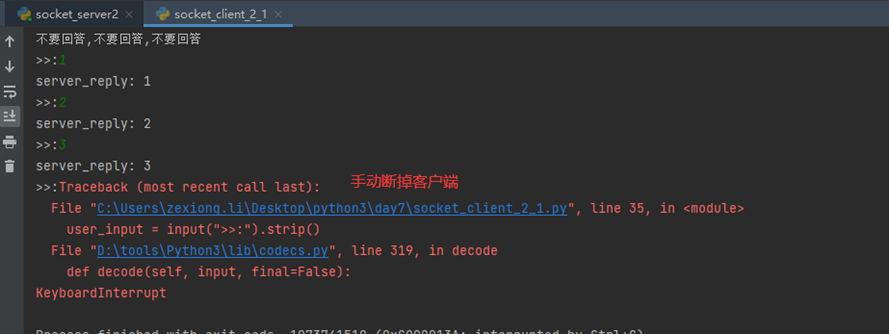
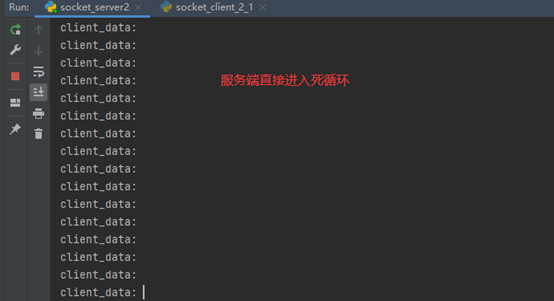
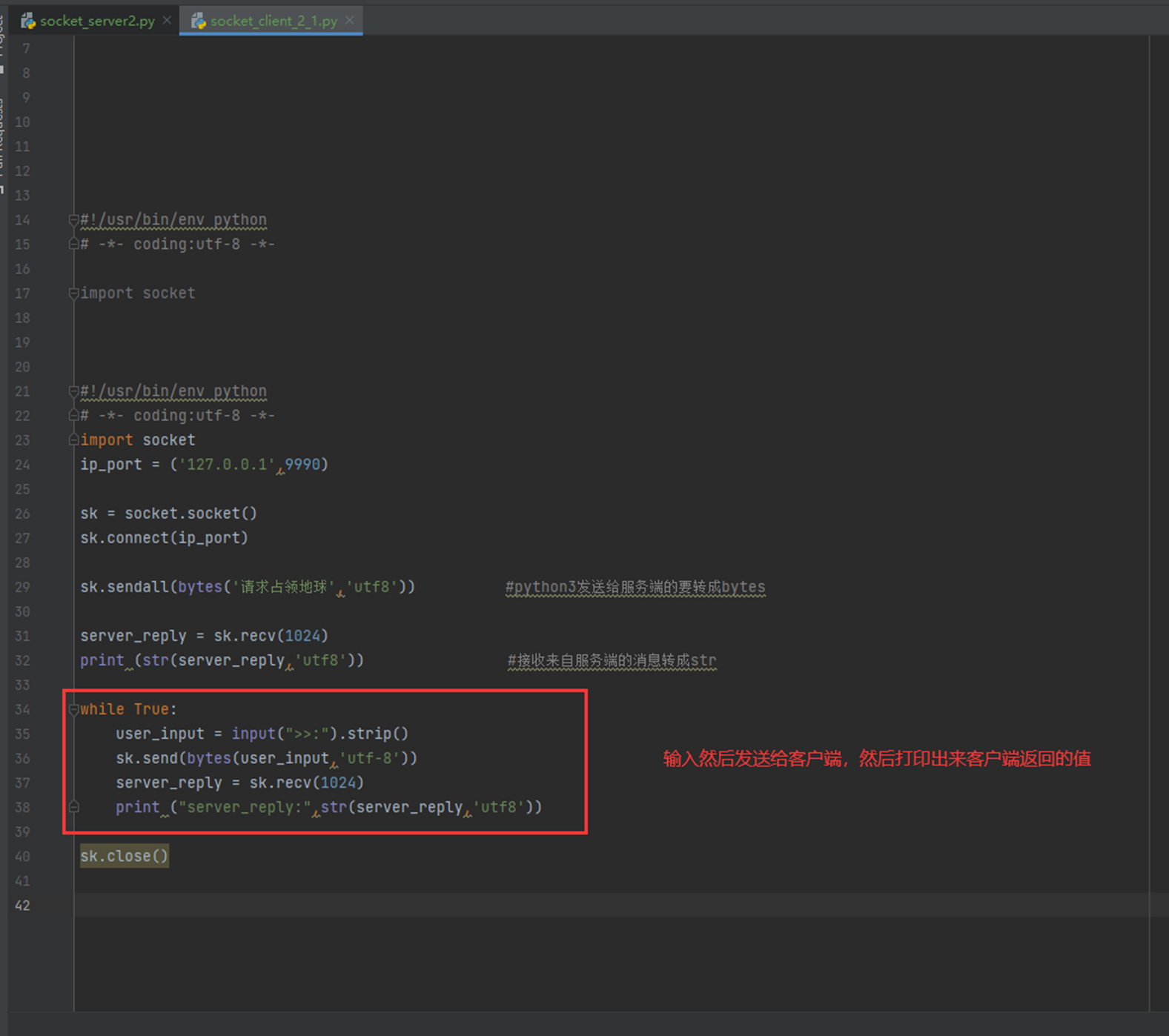
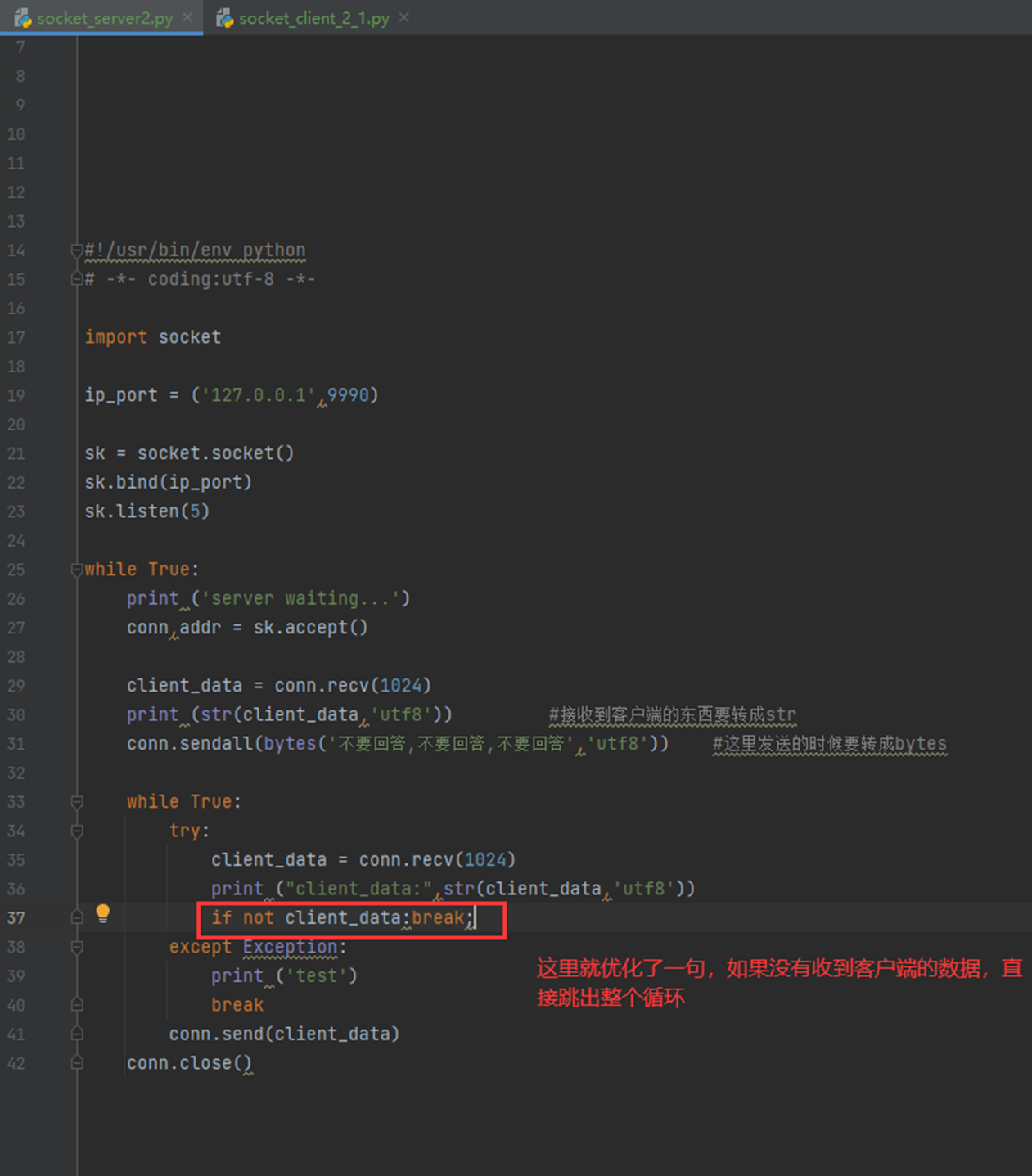
所以这里就是所谓的坑,本人没有遇到,window和linux效果相同,不过为了避免让服务端进入死循环,这里要知道服务端进入死循环的原理,是因为,客户端断掉之后,不会再有人给服务端发送数据了,而服务端一直接不到数据,就进入死循环了,所以,代码优化一下:
现在查看一下结果
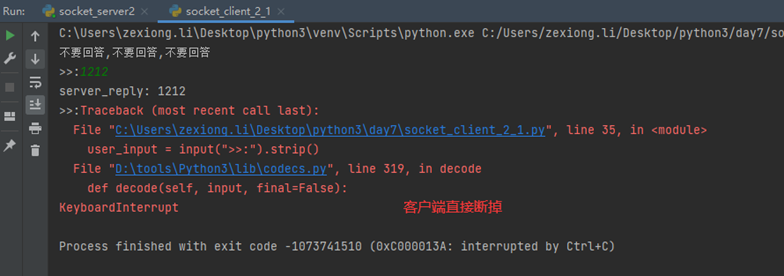
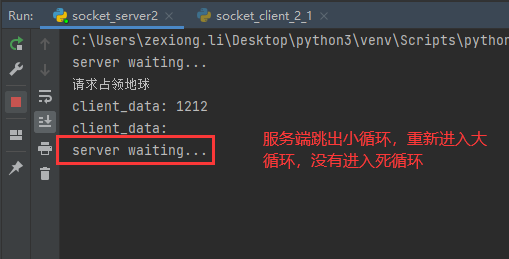
现在演示一下,第一个客户端连接中,第二个客户端连接会有什么结果
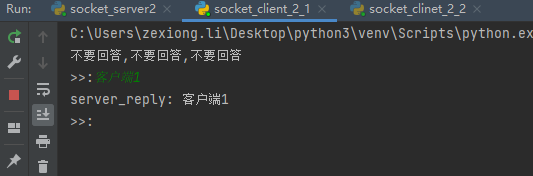
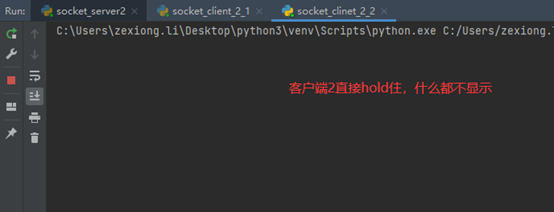
现在断掉客户端1,然后在看看客户端2
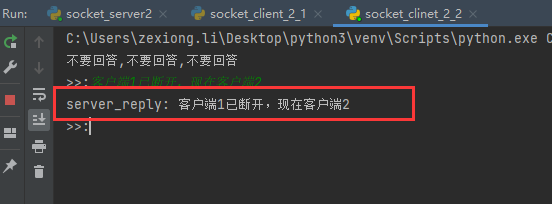
在看看服务端表现
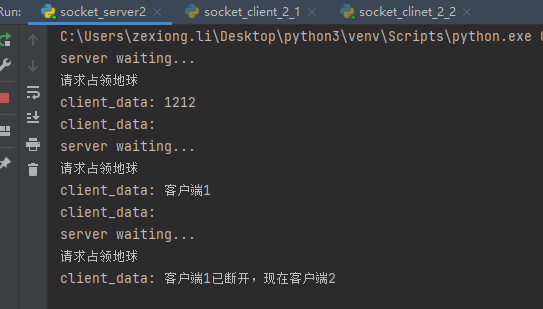
可以看到,同时只能有一个socket保持连接,想要第二个连接,必须断掉第一个。
小总结:
视频中win代码没有bug,放在linux上却有了,本人这里并没有出现,可能是5年前的教程视频,那时候存在bug,现在修复了吧
7.3 python3的socket坑
上一章和这一张合并了
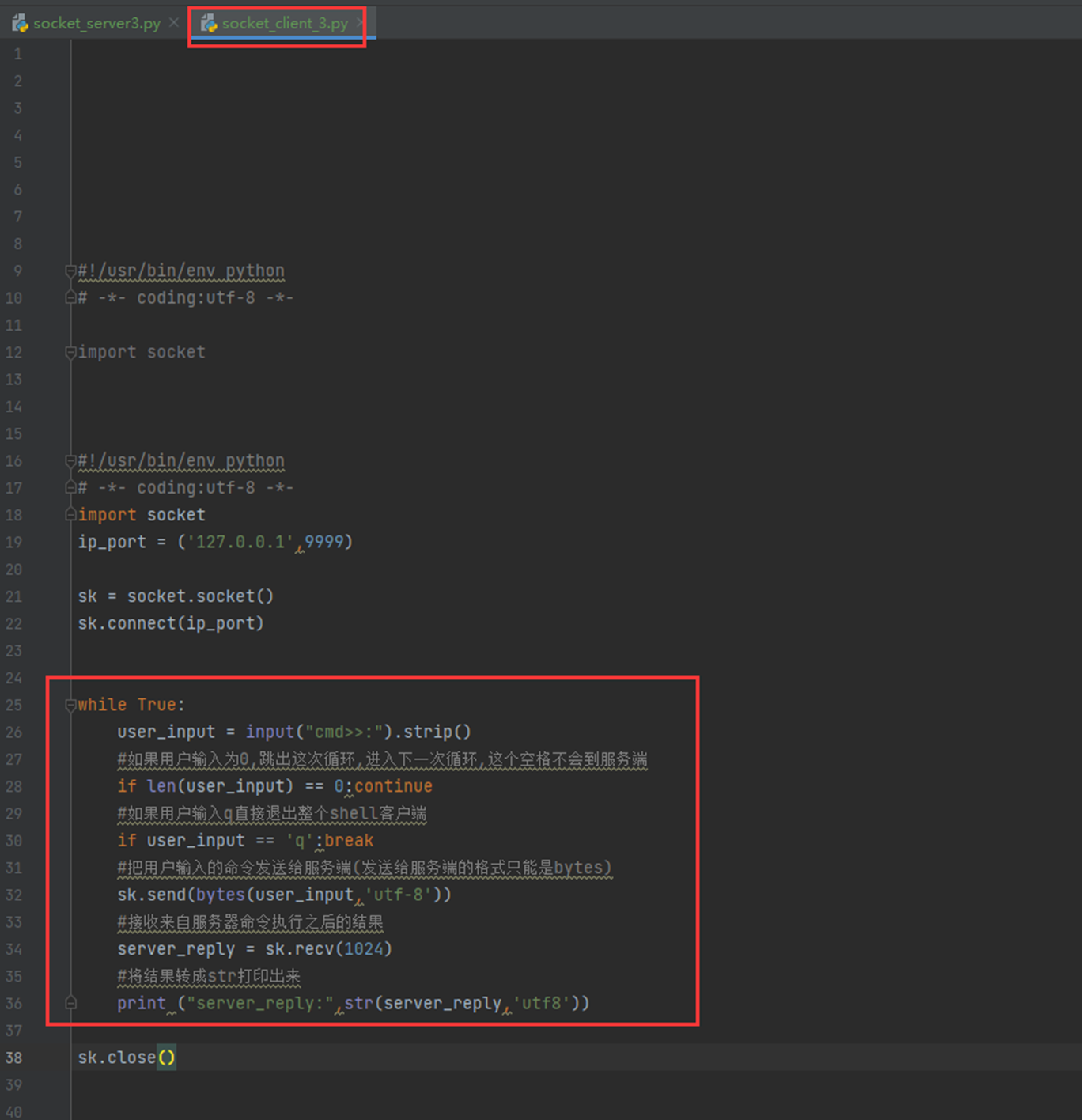
7.4 通过socket模拟实现简单的ssh功能
本章内容:
1.简单执行可以执行linux系统命令
2.用户执行回车问题怎么修复
3.用户执行命令返回错误怎么修复
服务端
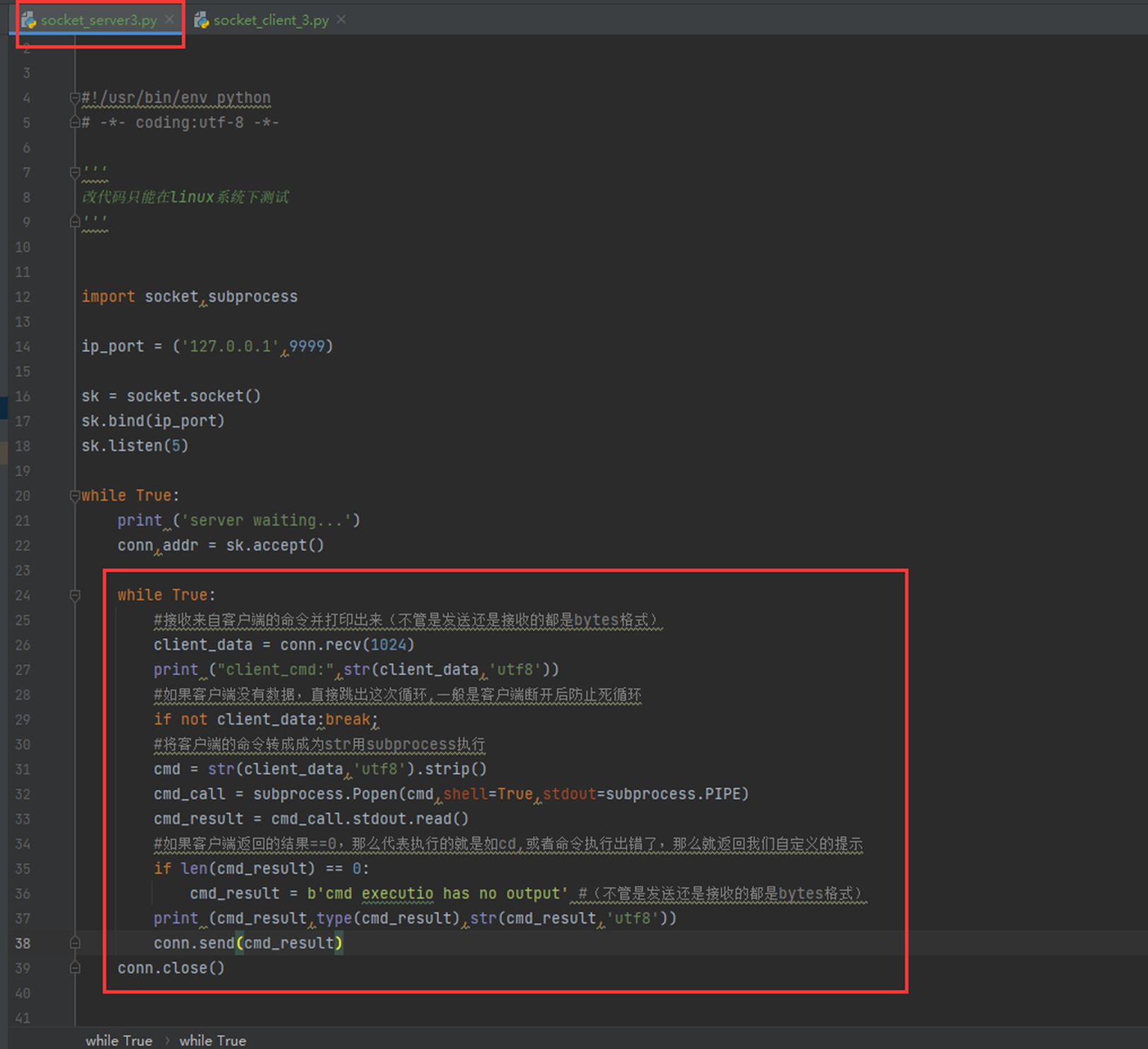
客户端
在linux下测试
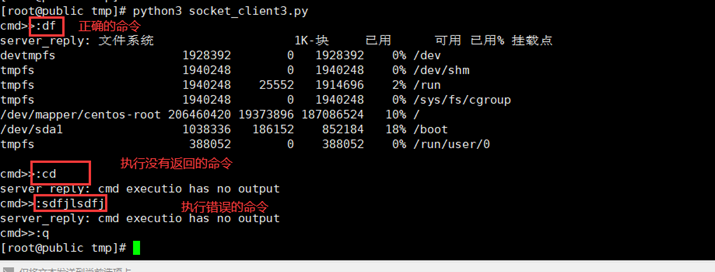
7.5 通过socket实现大数据的传输(3章合1)
其实接下来三章可以合并在一起,因为那个老师老是演示出现问题,所以作业这里全部整合在一起。
上面章节遗漏问题,上章节没有图片演示,因为本人执行的命令比较小,所以这里就文字描述一下,比如我客户端的接收是1024,但是服务端返回的字符大于1024,那么服务端没有传输完成,在输入正确命令的时候,返回的可能就不是正确命令,而是上一次命令没有传输完成的结果,这个就叫做粘包。
本章内容
1.处理粘包的问题
客户端处理代码

服务端处理代码

结果

7.6 本章作业

8.L08
8.1 上节作业
过
8.2 鸡汤与电影
过
8.3 上节内容回顾
1.回顾类与对象
2.socket基本用法
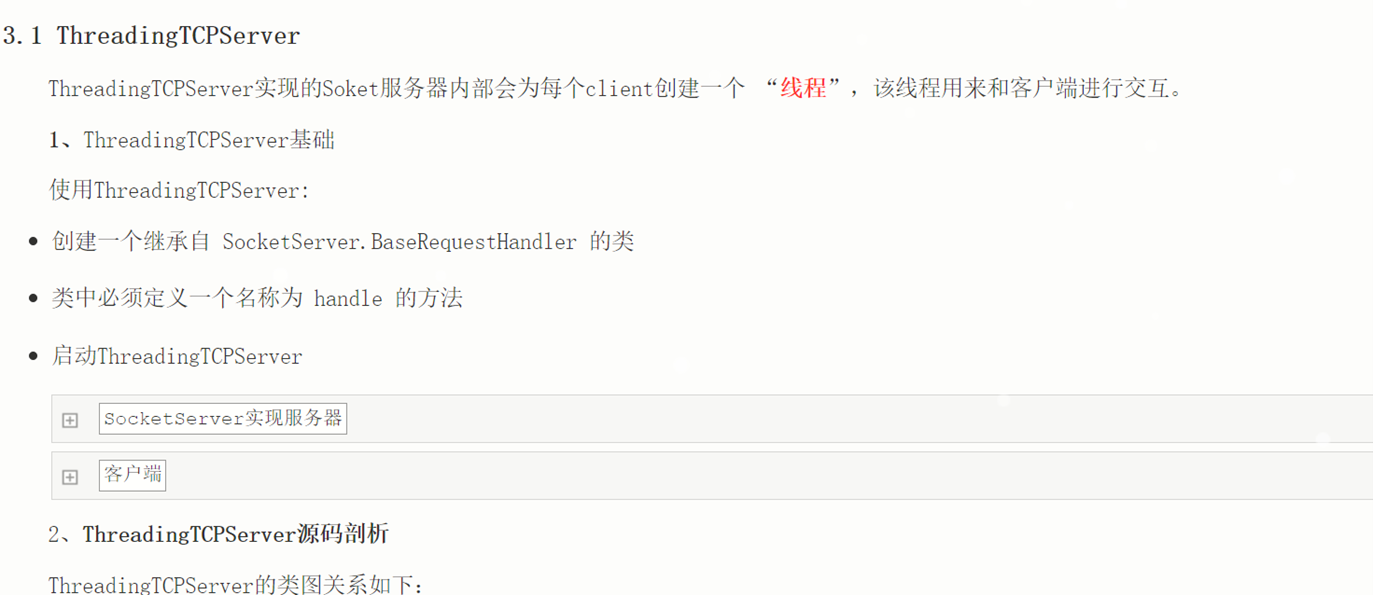
8.4 socket常用语法
基本就是讲解socket的一些方法,如下图



原文链接: https://www.cnblogs.com/alex3714/articles/5227251.html
本人博客园: https://www.cnblogs.com/lizexiong/articles/17018500.html
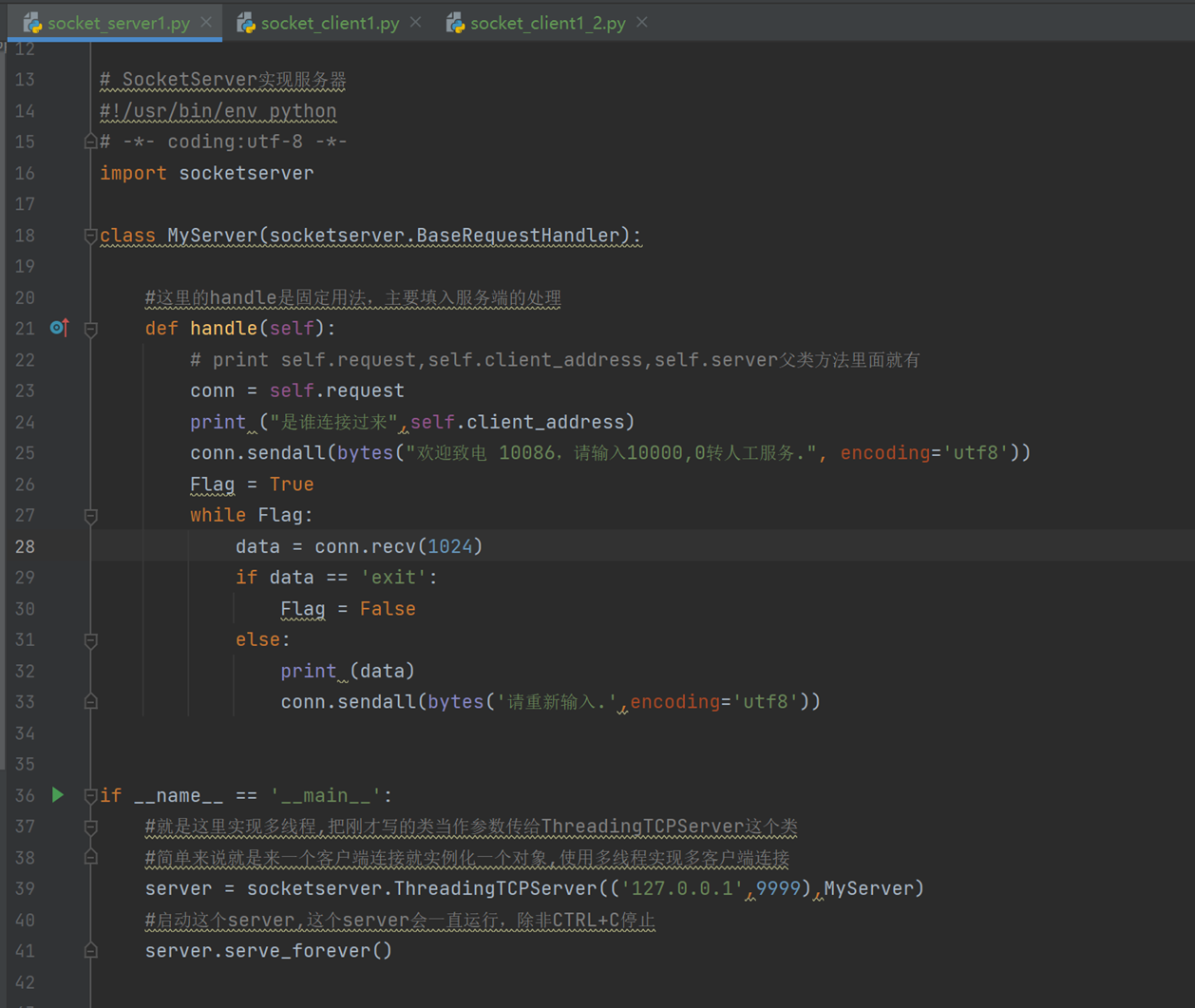
8.5 socketserver实例
本章就是讲解怎么多线程或者多进程运行,可以让socketserver不止连接一个客户端请求,在上节作业的时候其实已经完成了,这里还是单独讲解一下
这里就不贴图了,还是参考连接里面的SocketServer章节
原文链接: https://www.cnblogs.com/alex3714/articles/5227251.html
本人博客园: https://www.cnblogs.com/lizexiong/articles/17018500.html
Server
Client
现在测试一下多线程(客户端的所有代码完全一样,不知道是版本变更原因,现在的pycharm无法同时点击一个py文件运行,只能复制出多个客户端)
现在解释一下服务端代码:(以下是python2课程的笔记,只不过SocketServer变成socketserverr了,源码变动还是比较小的)
首先不说父类
1.就class MyServer(SocketServer.BaseRequestHandler),一定要自定义一个类,并且继承以下类。
2. 类中必须定义一个名称为 handle 的方法,注意,这里是必须.
3.启动ThreadingTCPServer,这里才是实现真正的多线程。
这里描述一下执行步骤:
1.启动服务端程序,每一个客户但进程过来的时候,SocketServer.ThreadingTCPServer就回把MyServer实例化,但是MyServer实例化没有__init__参数,那么就会去父类里面找
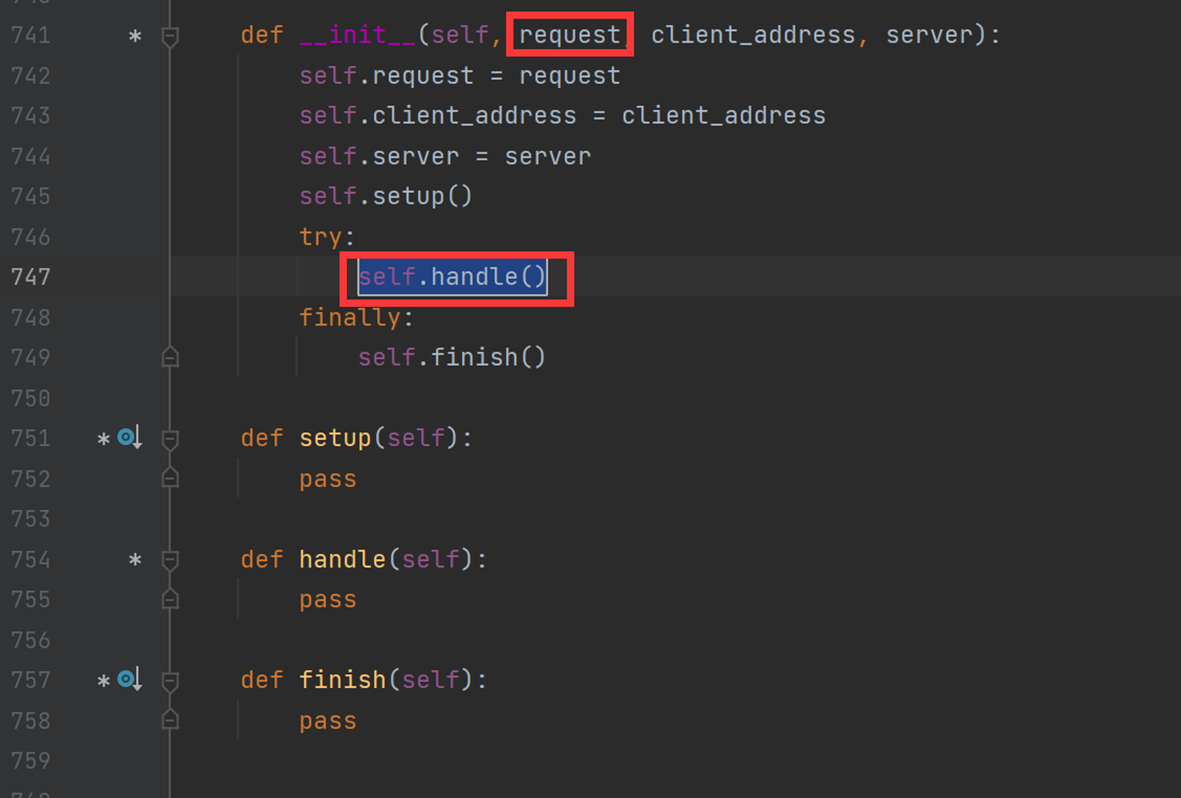
看到这,大概就知道为什么函数名称为什么要为handle了,因为在实例化的时候,执行的就是handle名的函数,实例化过后就会拿着这个实例化的线程去和客户端交互。Server_foreve()相当于一个死循环,接收到一个来自客户端的请求时,就会实例化MyServer这个类,没一个请求来了,就创建一个Myserver的对象,就这么实现了多线程。
如果想要更官方的说法,这里可以去参考源码
内部调用流程为:
-
- 启动服务端程序
- 执行 TCPServer.__init__ 方法,创建服务端Socket对象并绑定 IP 和 端口
- 执行 BaseServer.__init__ 方法,将自定义的继承自SocketServer.BaseRequestHandler 的类 MyRequestHandle赋值给self.RequestHandlerClass
- 执行 BaseServer.server_forever 方法,While 循环一直监听是否有客户端请求到达 ...
- 当客户端连接到达服务器
- 执行 ThreadingMixIn.process_request 方法,创建一个 “线程” 用来处理请求
- 执行 ThreadingMixIn.process_request_thread 方法
- 执行 BaseServer.finish_request 方法,执行 self.RequestHandlerClass() 即:执行 自定义 MyRequestHandler 的构造方法(自动调用基类BaseRequestHandler的构造方法,在该构造方法中又会调用 MyRequestHandler的handle方法)
Socket只会干两个事情,一个是收,一个是发。他是网络协议的基础。
当然,这里只能收发,在handle函数里面干什么随我们的意,这里,实现执行远程命令,并且返回。
接下来的例子,就是python2的课程了,这里觉得有必要可以补充温习一下,就是复制python2的笔记,本人很多博客也写了以下的例子,都可以参考
也可以参考博客https://www.cnblogs.com/lizexiong/p/17015965.html,这里有更加详细的解释
Server
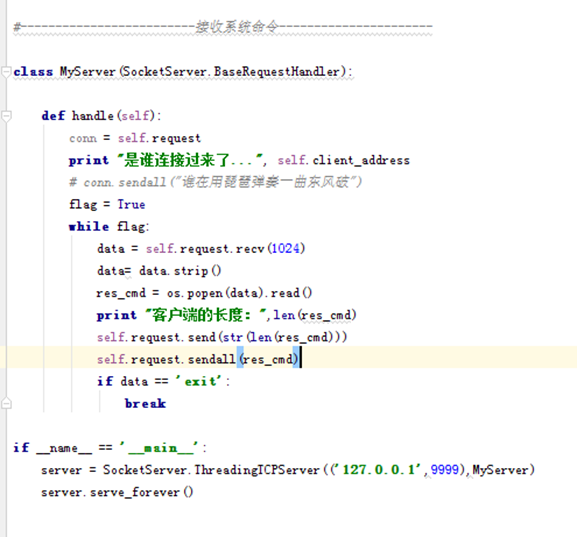
这里先讲解服务端代码
这里没有sk.accept来接收用户请求,而是self.request来接收用户请求。
还有执行系统命令使用os模块的popen方法,可以返回系统命令,这里Self.request.send(str(len(res_cmd)))将客户端的长度先发送给客户端,这里等会在客户有判定。然后在把数据全部发送给客户端。
这里为什么要现将发送的长度发送给客户端?
因为一次接收1024个包,但是这时如果来了2000个包,sendall会将所有数据放入缓冲区,客户端第一次循环会接收1024个包,剩下的900多个会在第二次不管输入什么首先返回给客户端,所以这里就出现了问题,但是我服务器的包都发送完毕了,我服务端就没什么关系了,剩下的到客户端来处理。
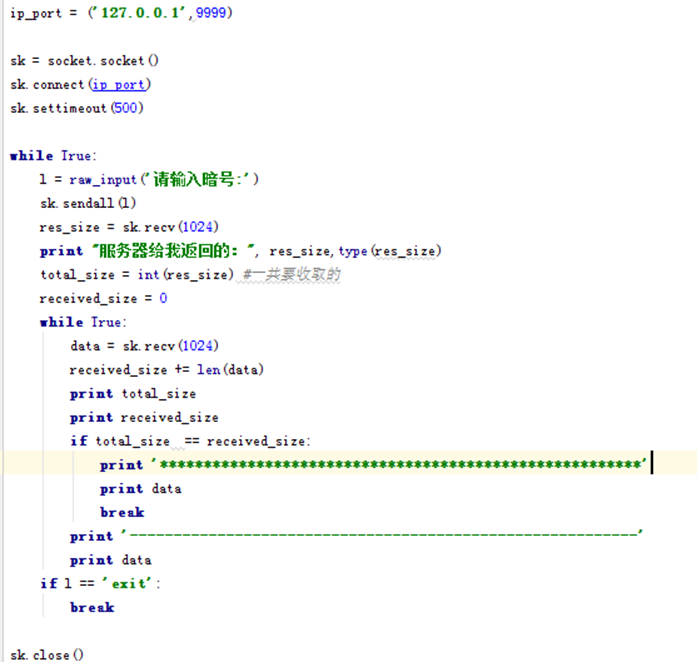
首先定义一个变量,用来接收服务器返回给我的长度res_size,长度类型为字符串。
然后在将这个值设置为总长度total_size,然后在设置一个已经接收到的长度received_size=0,然后while正式开始接收数据,没接收一次数据长度,就将已经接收的长度变化。if 已接收的长度 == 总长度的时候,那么就是最后一次接收了,那么就回将缓存区里面的数据最后一次打印出来并退出。这样就实现一次将数据接收完成。
现在输出结果查看
中间部分省略
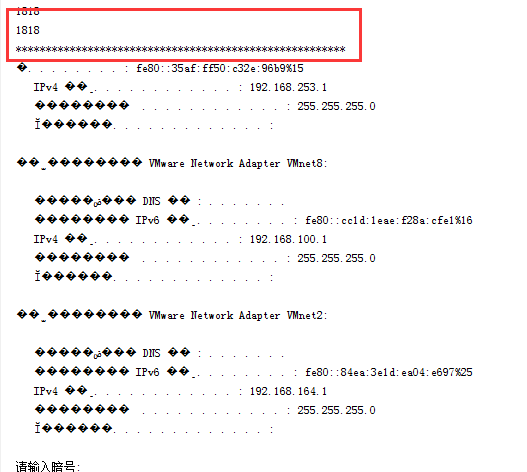
这里完成了,但是还有一个问题,在这里多输入几次ipconfig,会概率出现以下情况。

这种情况叫做socket的粘包,为什么会出现粘包?
上面说我int了一个不合法的数据。但是我int了ipconfig的结果,那当然报错了。
这是因为服务端发送数据过来的时候,发过来了长度和结果,但是别误会,并不是发送过了2次,而是当缓冲区满了之后才回发送
发送端和接收端都有缓存区,2端都是等都满了才会发出去,缓冲区还有超时时间,时间到了即使没有满,也发出去,但是时间在1秒之下。如果没有这种情况,首先长度到了缓冲区,长度没有发送出去,结果又来到了缓冲区,这种情况,长度和结果一起发给了客户端,就出现了粘包。
解决这种办法的方式就是在服务器发送长度后是单独的,也就是说想办法将发送长度和法从返回结果隔开就可以了。
在服务端将长度发送给客户端后,客户端发送一个我要开始接收了,然后客户端在开始接收数据。
完整代码
Server
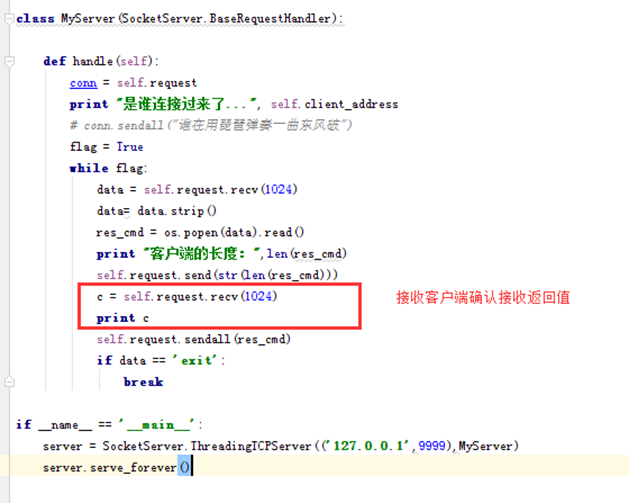
Client
执行结果
8.6 多并发ftpserver代码示例讲解
简单来说基本就是按照day7的逻辑讲解的,但是day7的作业比这个老师逻辑更加严谨,代码更加优美,功能更加完善,所以这个视频就是讲解day7的逻辑。
另外,本节视频值得注意的就是下面的图片
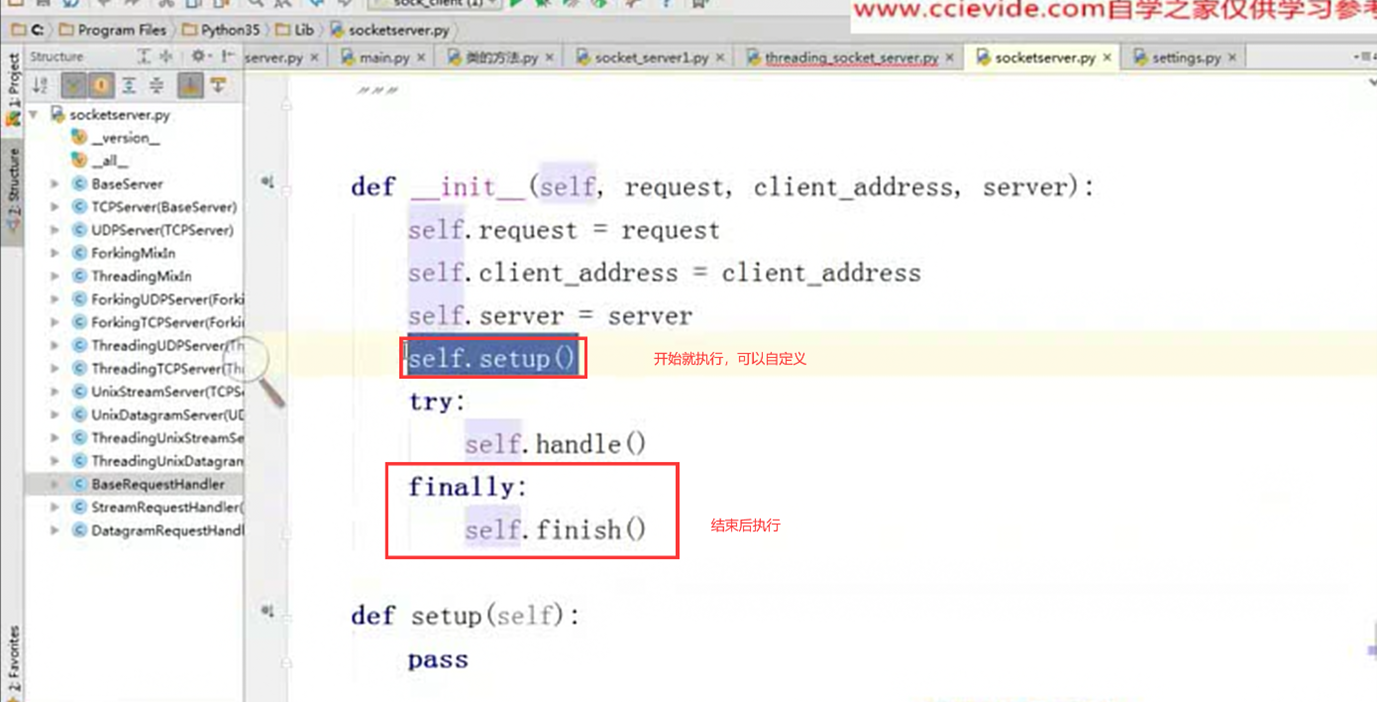
setup():在执行handle之前自动执行
finish():在执行handle之后自动执行
大家可以在这2个函数里面自定义
8.7 午后鸡汤
过
8.8 异常处理
老师就是照着博客:Python之路【第五篇】:面向对象及相关 里面的2.3章节讲解了一下,本人还有更完善的博客https://www.cnblogs.com/lizexiong/p/16213827.html,或者也可以参考python11期的课堂笔记,都比这里详细
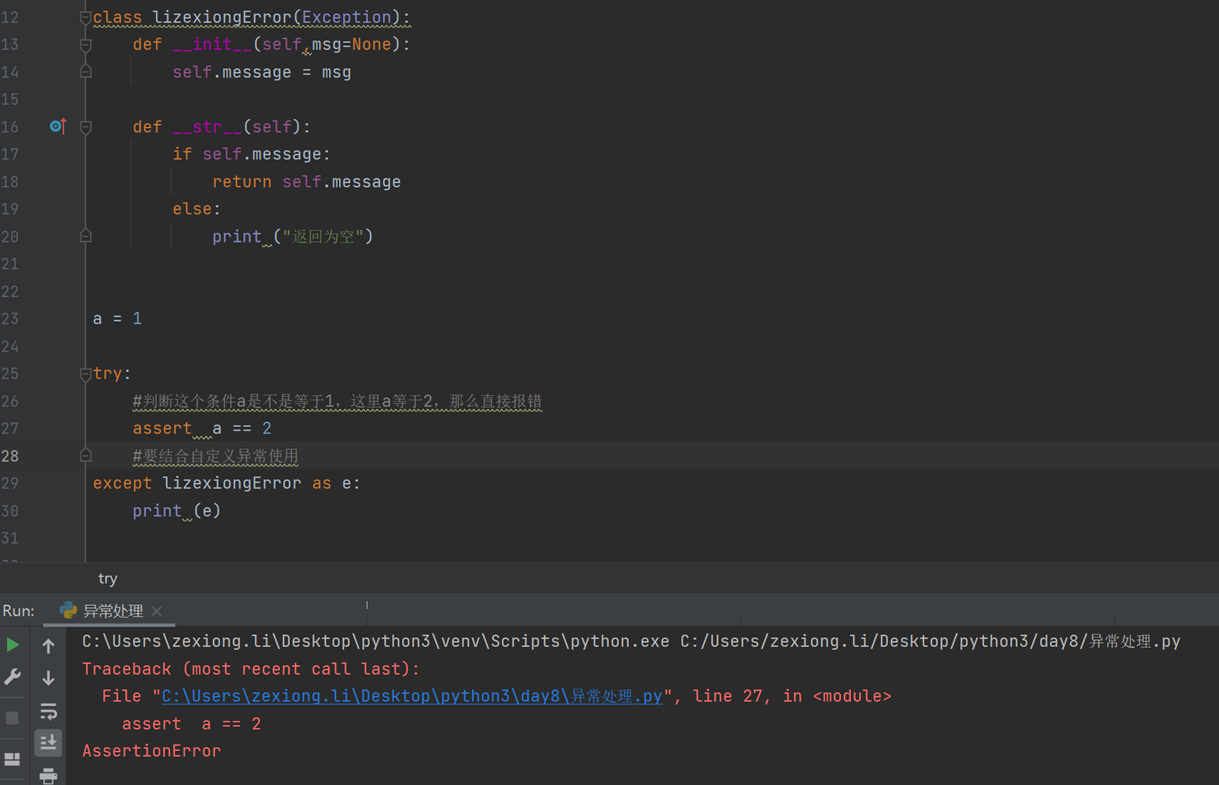
8.9 自定义异常与断言
本章主要讲解:
1.自定义异常
2.断言
3.finally和else(笔记里面为了方便,自定义异常讲解完成后就讲解这个)
自定义异常
这里的自定义异常讲解的非常不清不楚,这里还是拿python2课程的例子来讲解。
Tips:自定义异常用在哪里?主要是明确告诉其他写代码的人,这里是个异常,这个作用
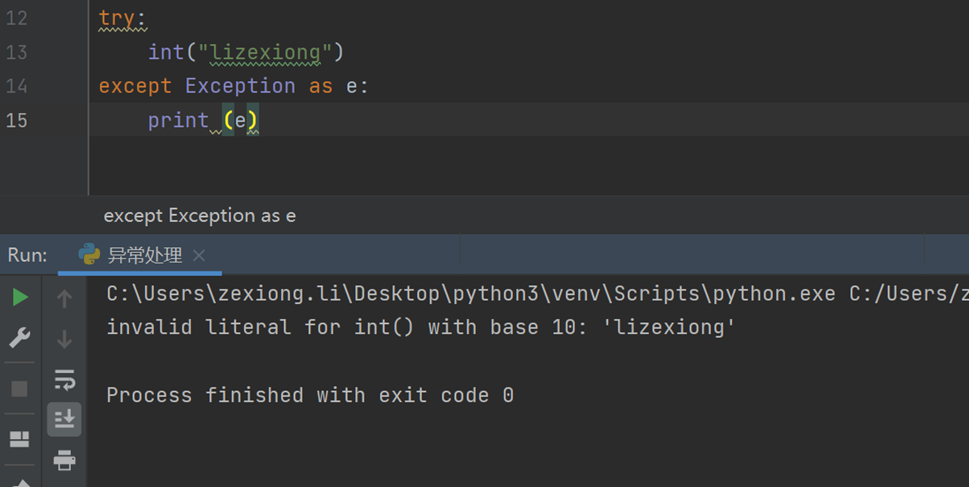
可以看到Exception已捕获到异常而且传给i了。
那么i是怎么拿到异常的呢?
这里i是对象,i是怎么来的?是Exception类创建的,那么print的是一个对象。
假设这里有一个对象
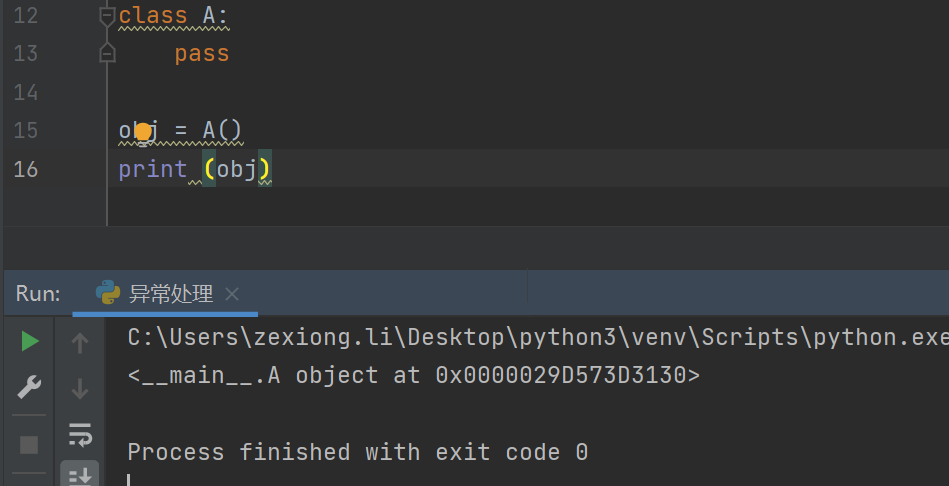
这里得到一个内存地址,为什么前面print i可以拿到异常呢?因为__str__方法
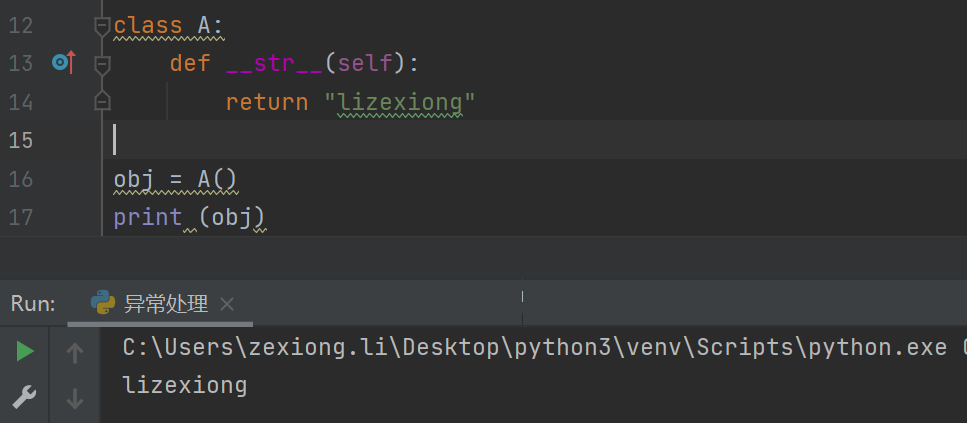
所以现在自定义一个异常,继承Exception类
那么我现在定一个异常,并且主动触发一个异常。
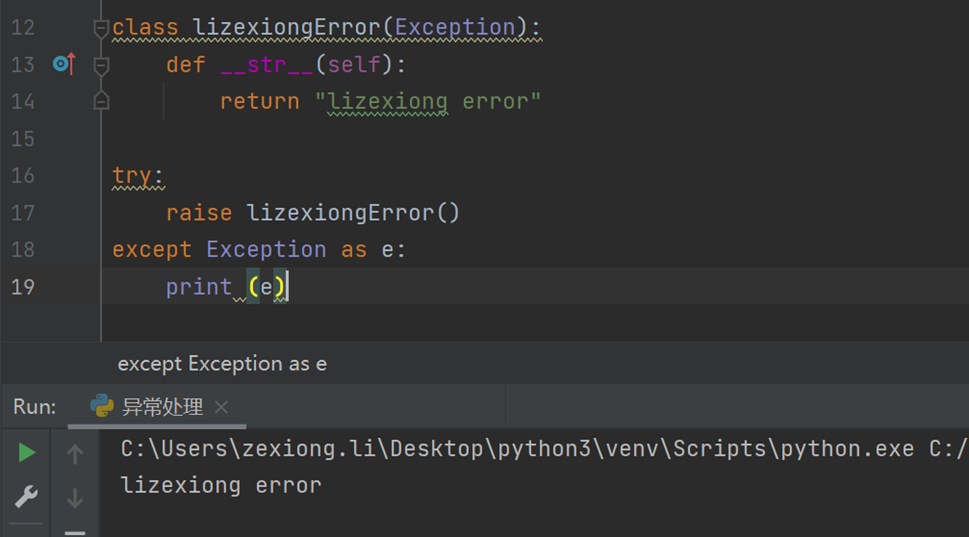
但是这里的异常就写死了,现在让异常动态起来。
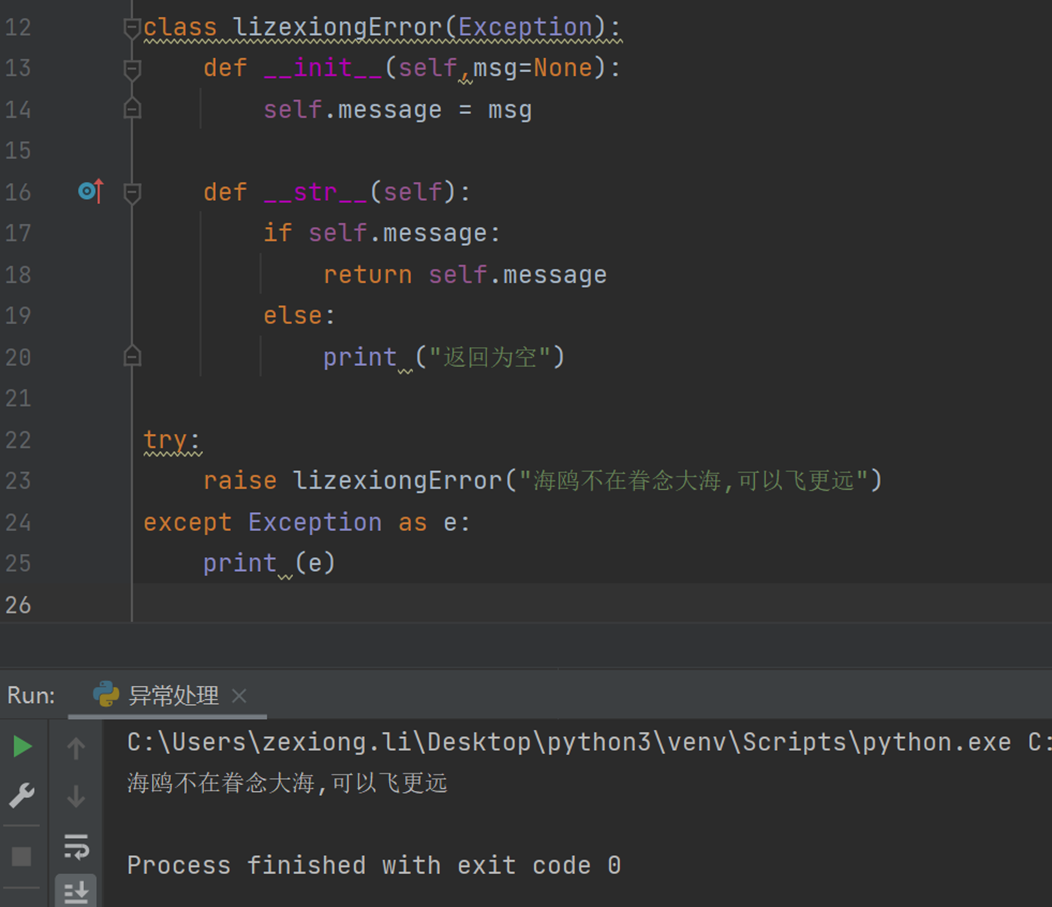
分析自定义异常代码,应用场景,自定义返回某些特定字符串以及网页。
如果执行lizexiongError()这个类,会返回__str__里面的字符串,所以,这里我直接给LizexiongError里面创建初始方法,然后传送参数。在使用__str__判断返回什么,由于
LizexiongError继承Exception类,所以,将值复制给i,并打印出来。
(所以说回刚才的,这里其实就是主动告诉其他写代码的哥们,这里有个异常)
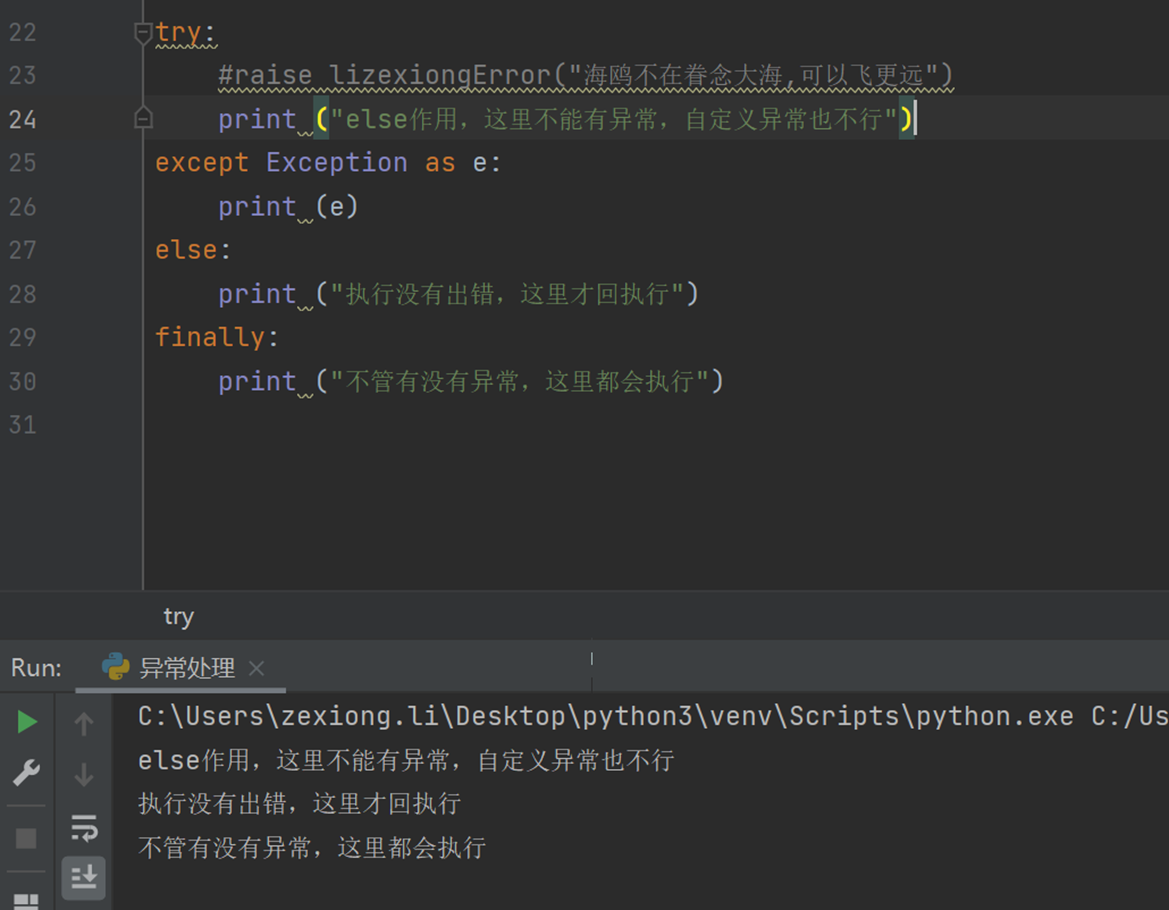
finally和else
finally不管是否有异常,都会执行这里的代码
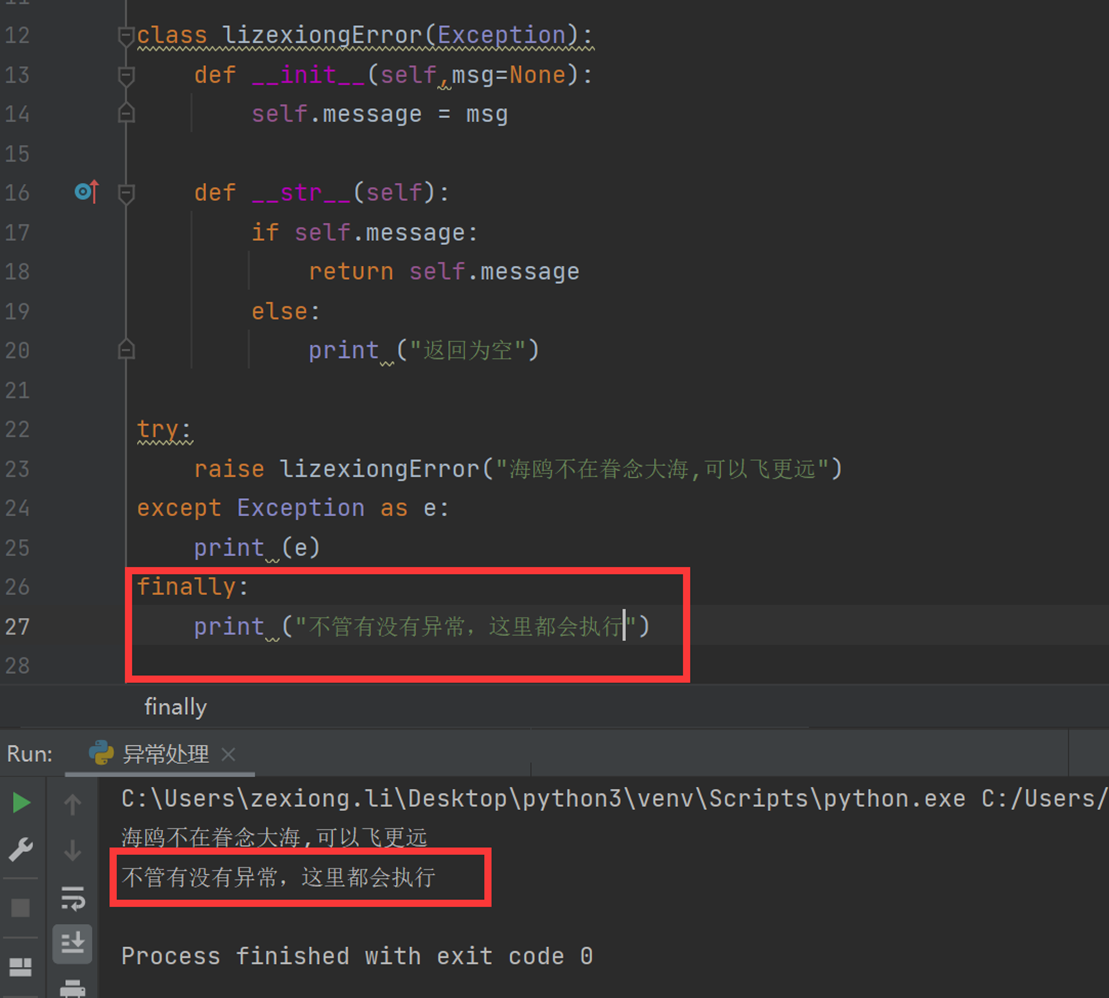
else:如果没有执行出错,就会执行else的语句
断言
1.一般在调试的时候使用
2.明确的告诉别人,这个条件是至关重要的,如果条件不满足,程序走不下去
8.10 cpu运行原理与多线程
本章主要讲解了(纯理论)
1.CPU的原理。
2.进程线程的原理与区别
根据博客https://www.cnblogs.com/lizexiong/articles/17018552.html#blogTitle6讲解
8.11 pythongil介绍与影响
根据博客https://www.cnblogs.com/lizexiong/articles/17018552.html#blogTitle6讲解
也可以参考本人比较详细的博客: https://www.cnblogs.com/lizexiong/p/17141988.html
8.12 多线程实例
多线程的实现有2种方式,两种的的结果都是一样的,只是看可能偏向哪一种
第一种:
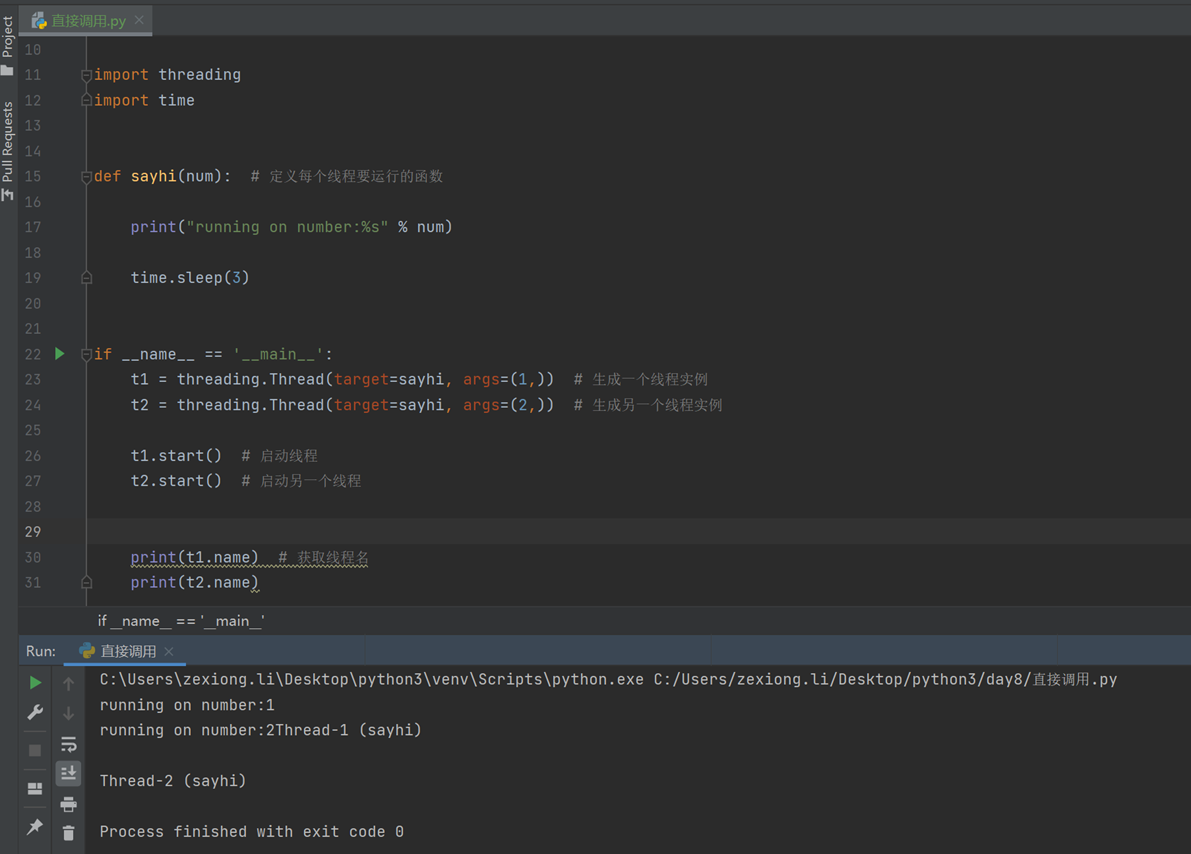
第二种:
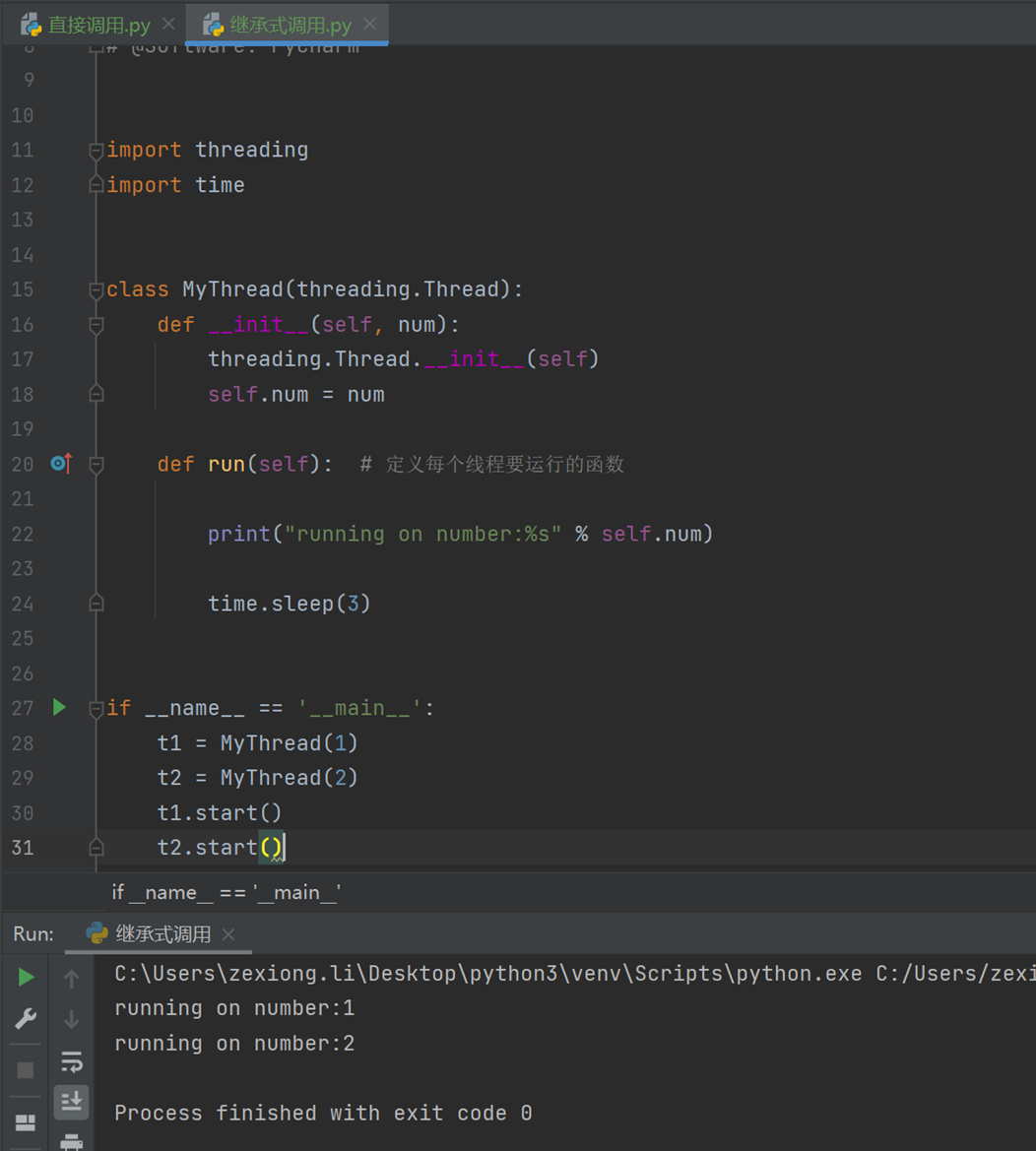
以上两种方式都可以,但是很显然,第一种方式更加简单
以下根据第一种方式延伸讲解一下join的用法。
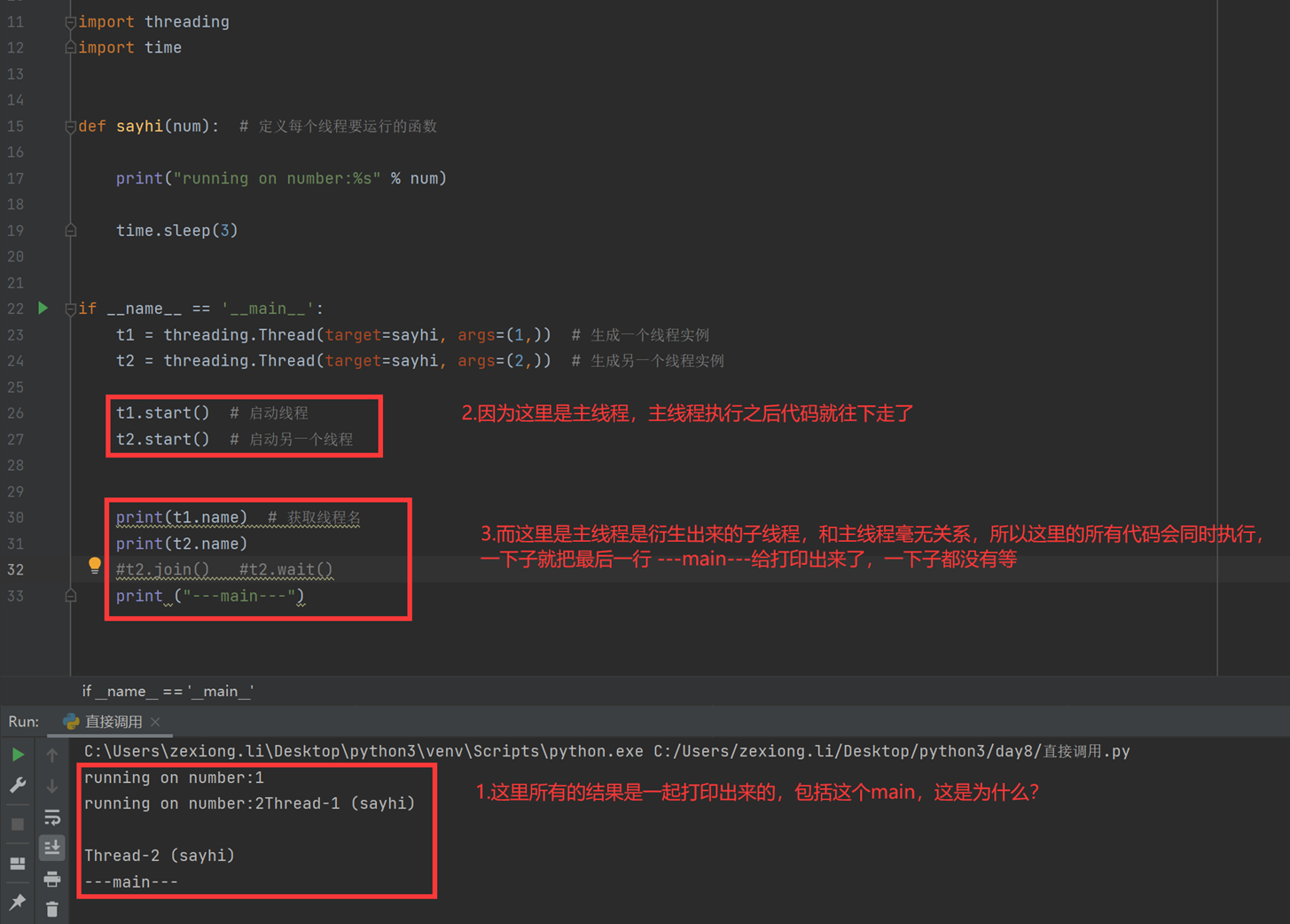
如果想要等一下怎么办?那么使用join
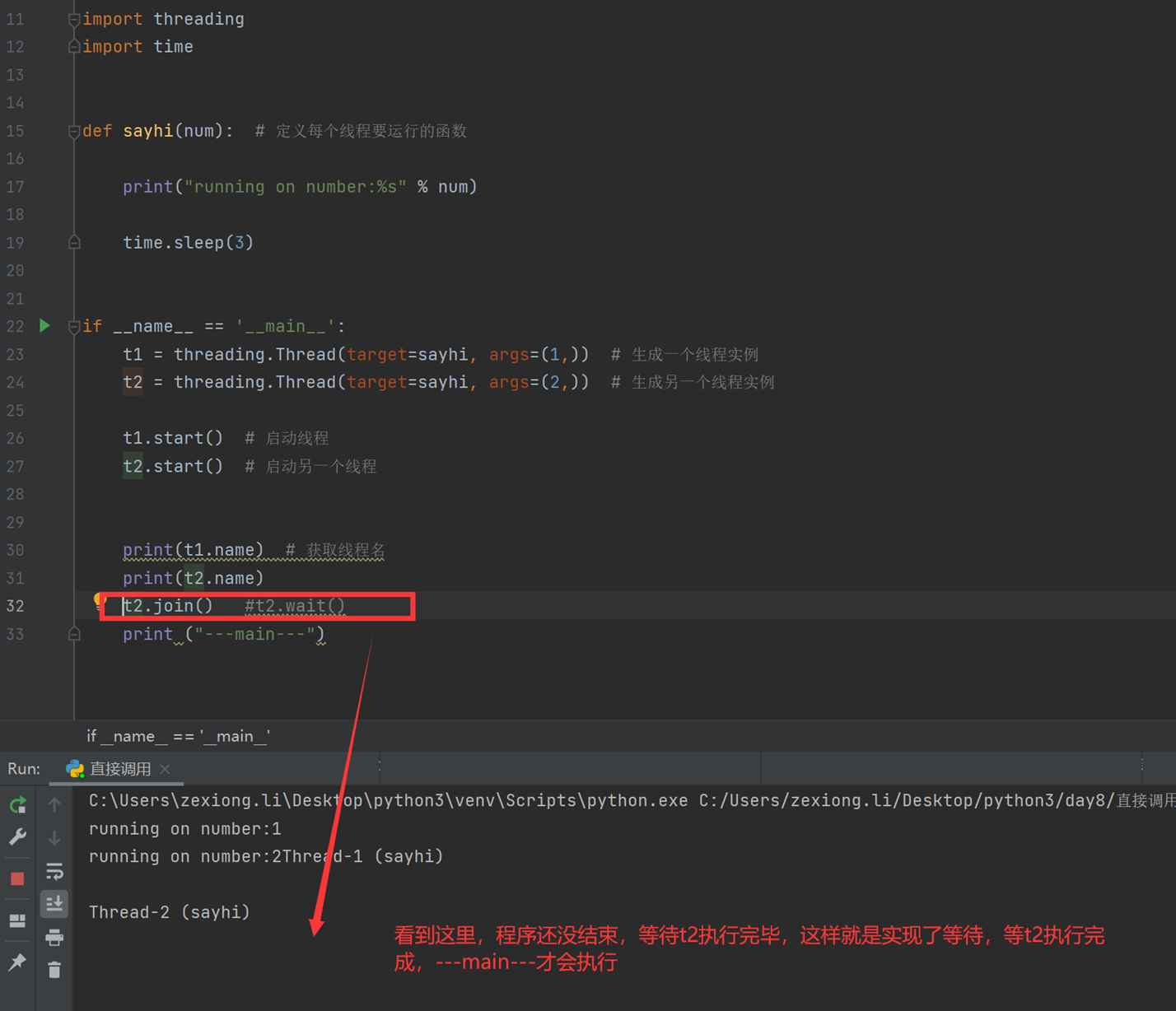
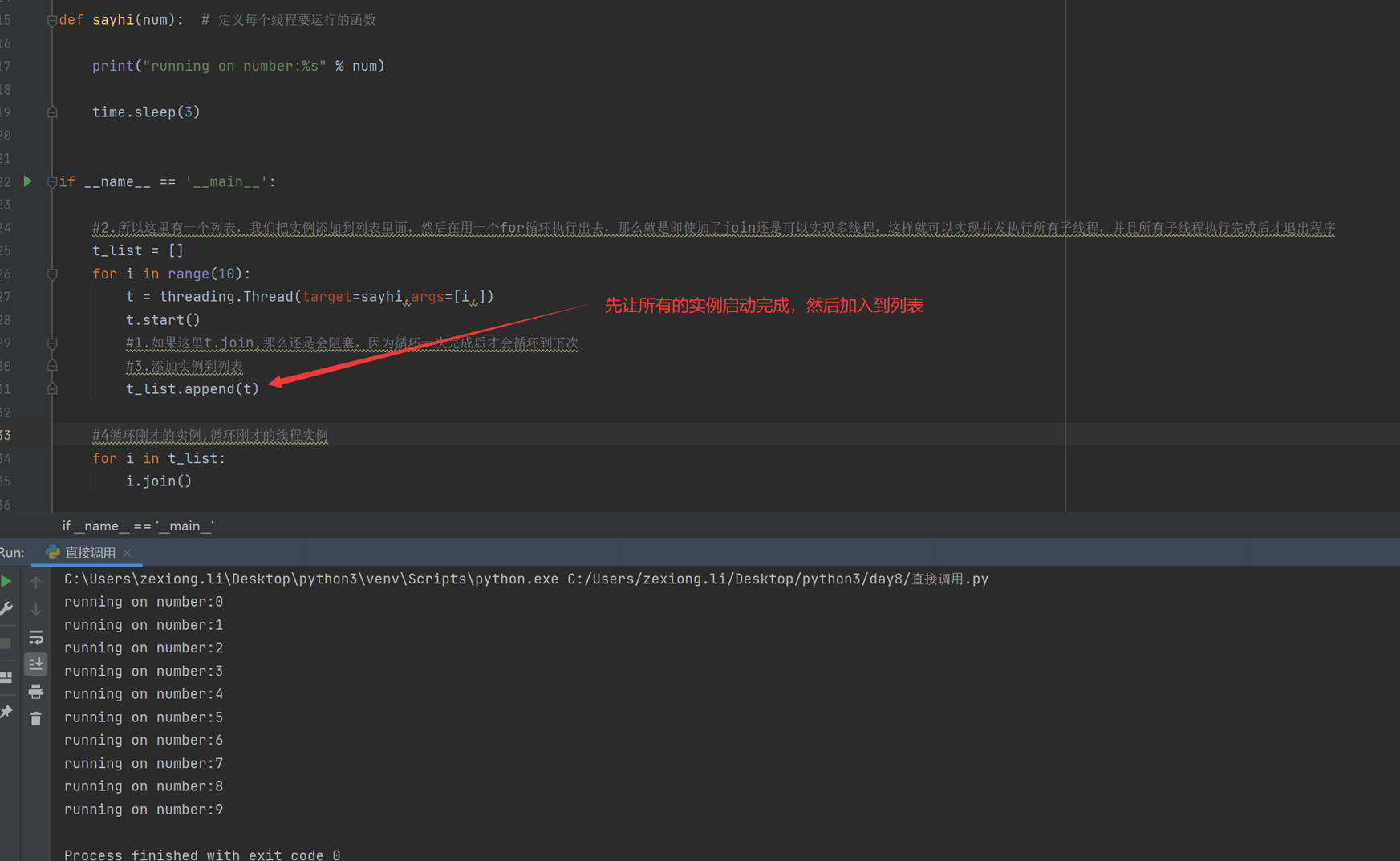
如果上图那个,t2.join没有执行完那么就会阻塞,那如果要执行10个线程,不是要等上一个join执行完成才会执行下一个join吗?这样就不是多线程了?那么怎么办?见如下代码:
8.13 守护线程与join
本章,这个老师又又又的演示失败,无话可说。主要是讲解setDaemon和join的使用,但是演示失败了,这里还是贴出参数的使用方式,后面还是参考本人博客。(太简单,没有写单独的博客)
- start线程准备就绪,等待CPU调度
- setName为线程设置名称
- getName获取线程名称
- setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
- join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run 线程被cpu调度后自动执行线程对象的run方法
8.14 gil与多线程锁的关系
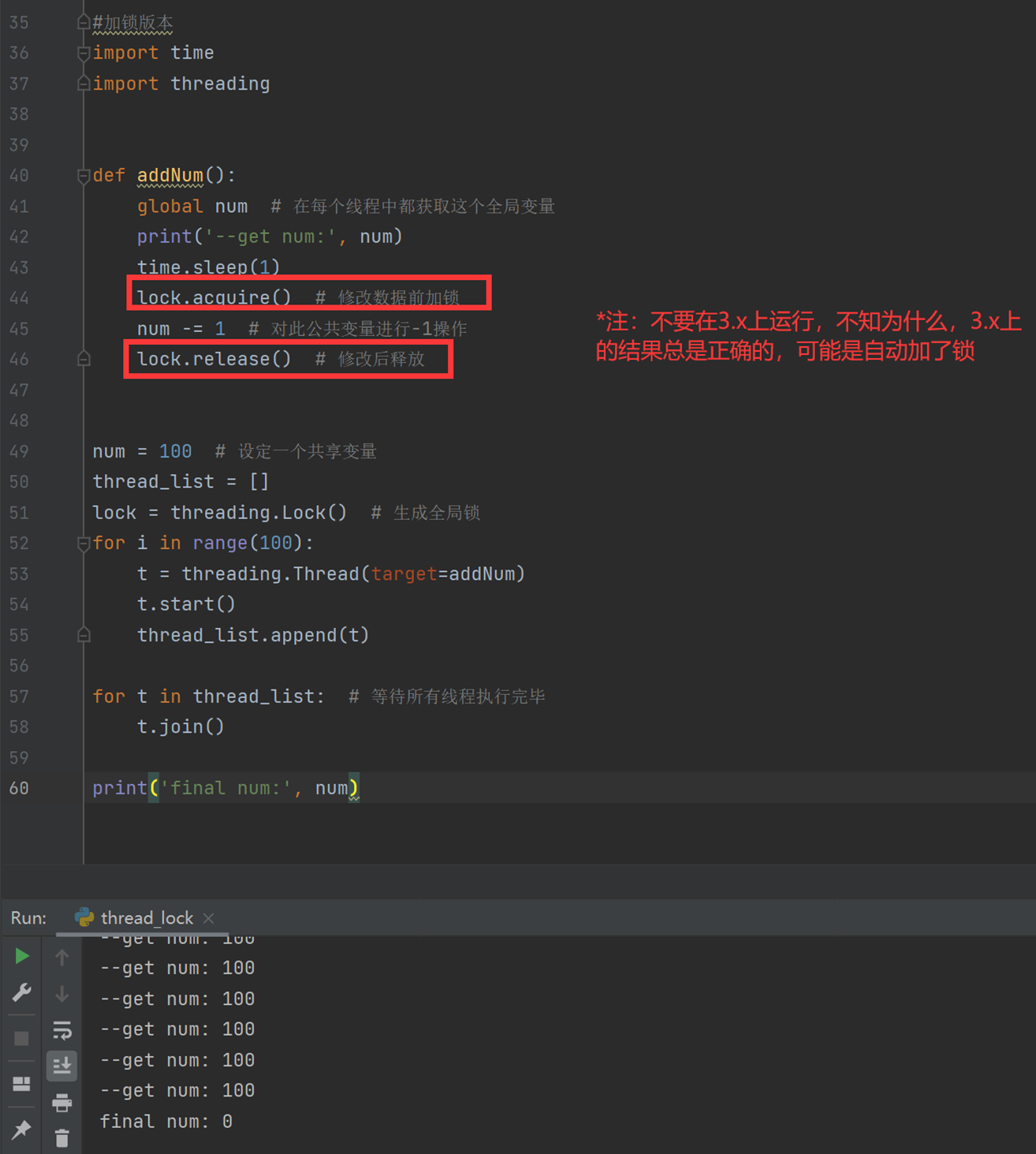
这篇老师讲的还是不错,有必要可以重新回去看视频,这篇慢慢道来。先看代码和执行结果。
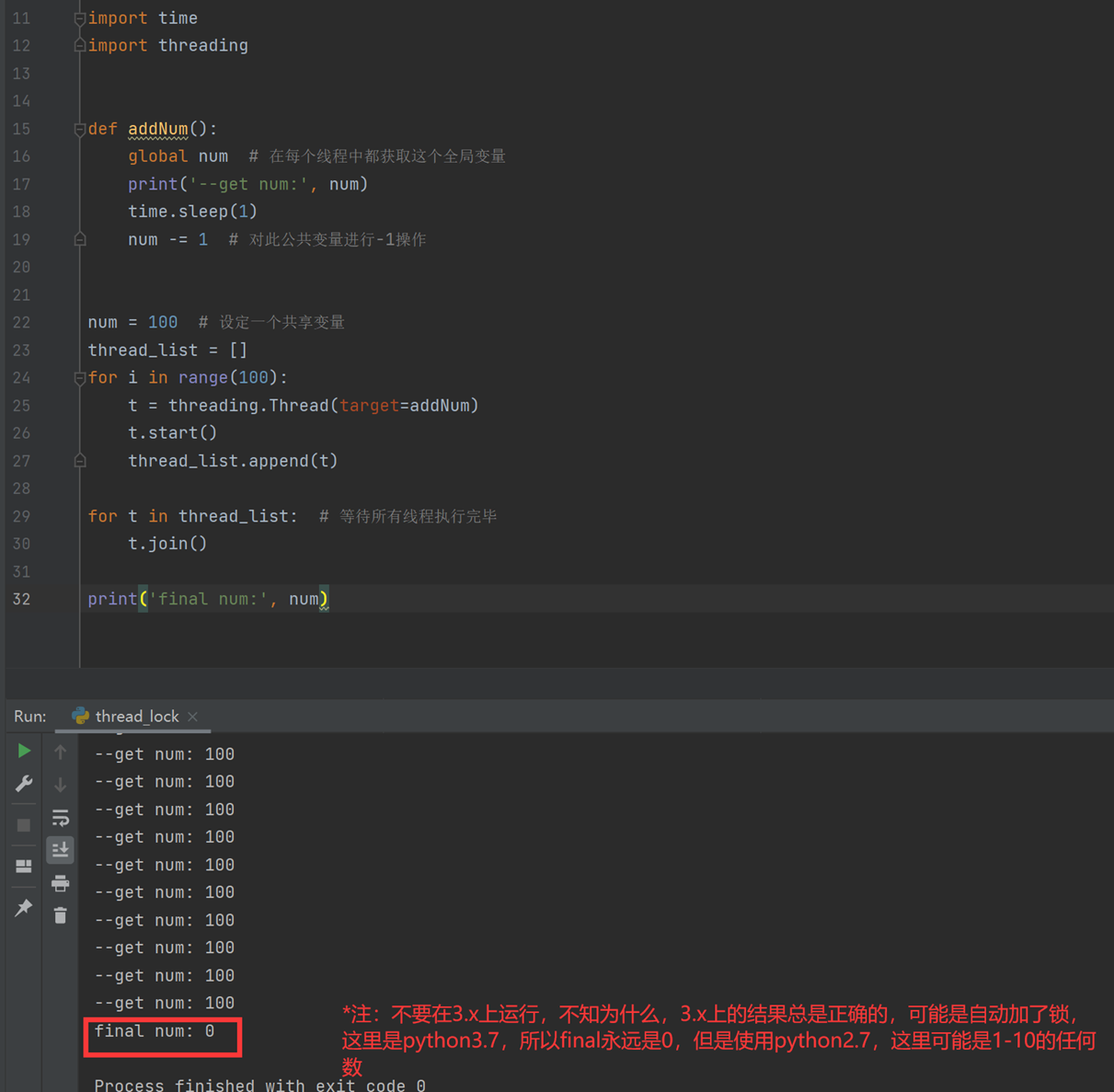
这里用老师课上的一张图来讲解一下。
1.为什么每次final num :0的值都不是一样的?
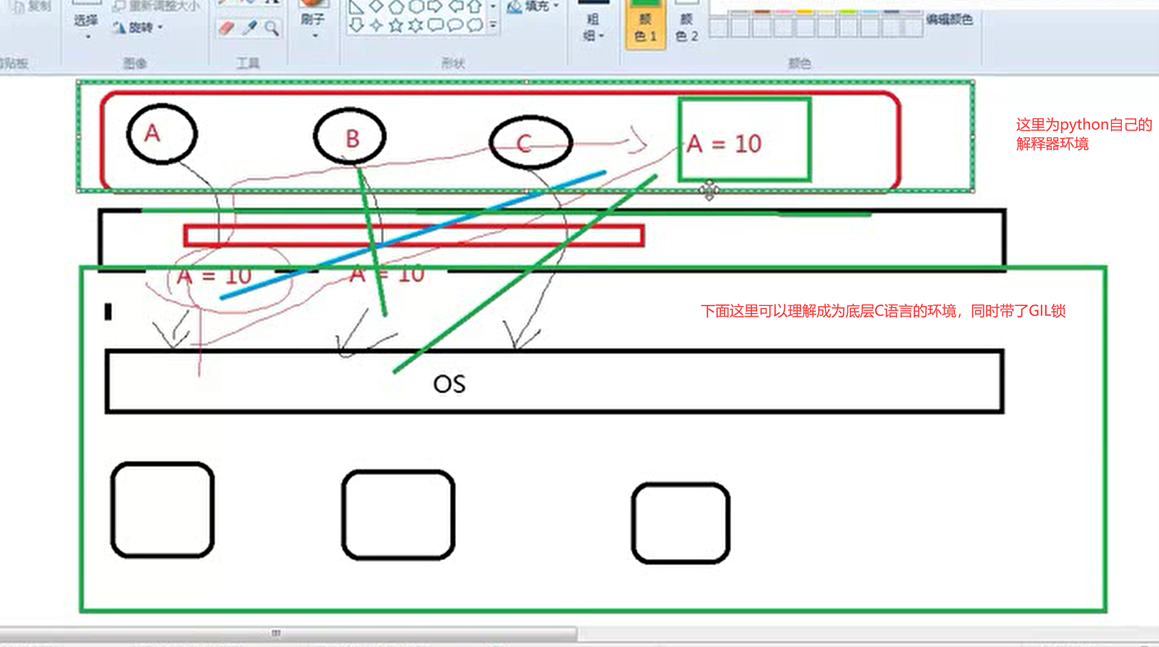
这里首先讲解一下python自己的解释器环境。
比如 num(图片上为A,老师标错了)=10。
假设有这种奇葩的情况
这里A函数调用num-1,那么等于9,这时候还没把结果9返回给全局变量num。然后有个切换时间,这时候轮到B函数调用num-1,那么等于9,那么b返回全局变量num,那么num这时候等于9,然后这时候A函数同时也返回全局变量num等于9,这时候,就把B函数返回的结果给冲掉了。如果c这时候调用num-1,返回,那么等于8.
所以说为什么很奇葩,这是一个概率问题,如果运气好,全部调用就返回,按照顺序快速执行,那么结果肯定正确。但是肯定不能保证都是上一个函数执行好并返回数据,下一个接着执行。更多的还是如同上面讲解的情况,很多次函数的值被覆盖,所以就出现了num的值不正常的
2.不是说python受GIL锁的印象,不会出现这种非线程安全的问题吗?
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual
C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL。
简单来说,python调用c的原生线程去执行,那么是c的特性上了锁,python完全不依赖,只是默认我们用的都是cpython,所以受了c的锁的影响.既然有锁,为什么num的结果不同。
这里请出上面的图。
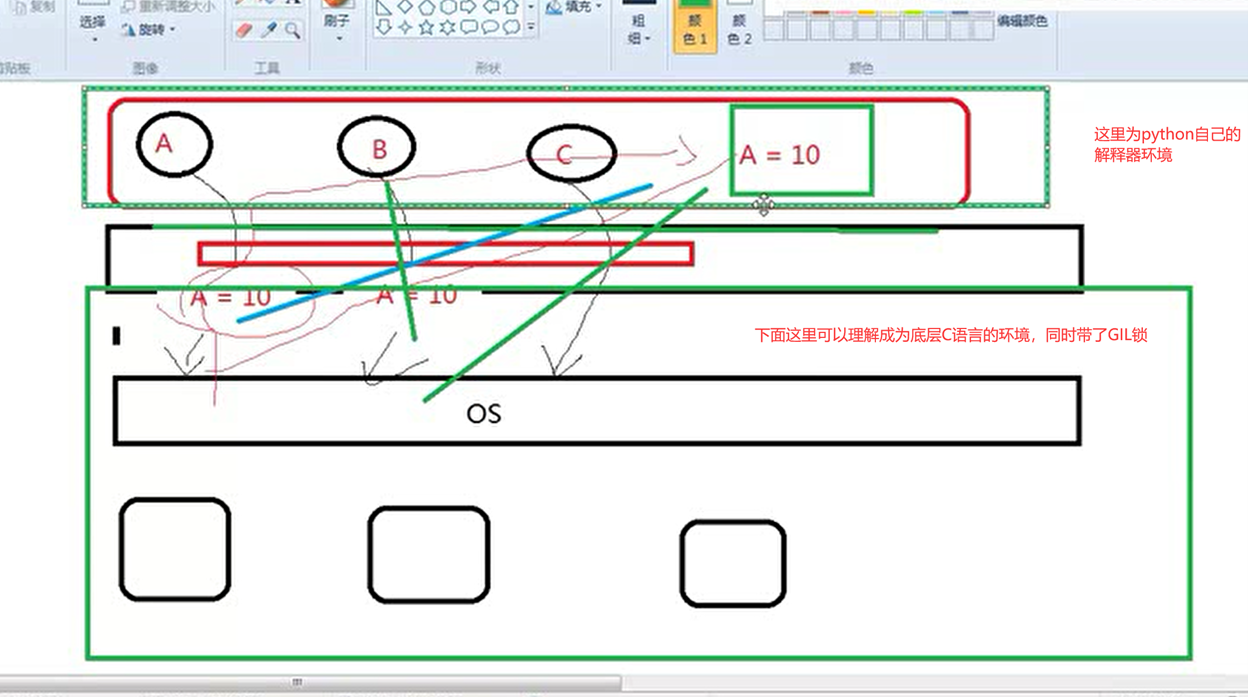
下面的大绿框里面,就是c语言环境,都是有一把锁的,为什么把上图分为2部分,因为C语言的特性给原生线程上了锁,(简单来说,就是只予许同一时间,只有一个线程在操作这个全局变量。)虽然同一时间只有一个线程在运行,但是,python A线程返回的结果是9,B线程返回的结果也是9,(因为python的线程是并发执行的,大家同时获取的num都是10,串行等待执行的时候,大家要执行的结果都是10-1这个概念)这样还是冲掉了,因为python上面的线程是直接丢出去并行执行的,python内存的数据是没有保护的,所以,这里还差一把锁,锁住的就是上面框(python那边线程)的数据不被线程胡乱的修改。
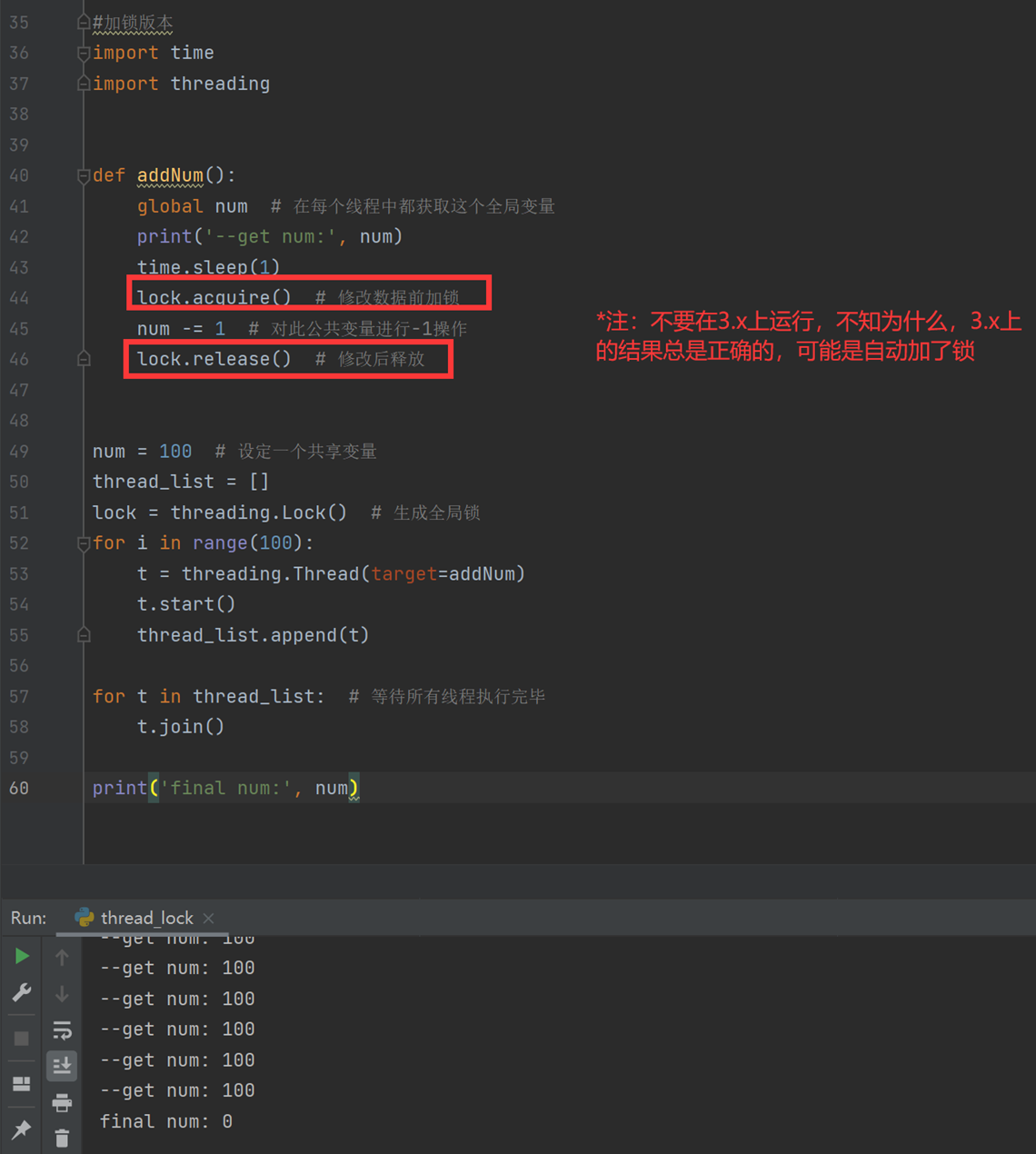
当然,这样加了锁,串行就变成并行了,就没有多线程了,如果要执行任务,不需要确定结果,就可以使用多线程不加锁。如果要计算结果,大家还是慎重
本章第一次觉得老师讲解的不错,时间久了有遗忘,建议返回来在看视频
补充:以下是老师博客的补充,但是本人觉得,视频已经讲解的很清楚了,这里还是贴出来一下。
机智的同学可能会问到这个问题,就是既然你之前说过了,Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock? 注意啦,这里的lock是用户级的lock,跟那个GIL没关系 ,具体我们通过下图来看一下+配合我现场讲给大家,就明白了。
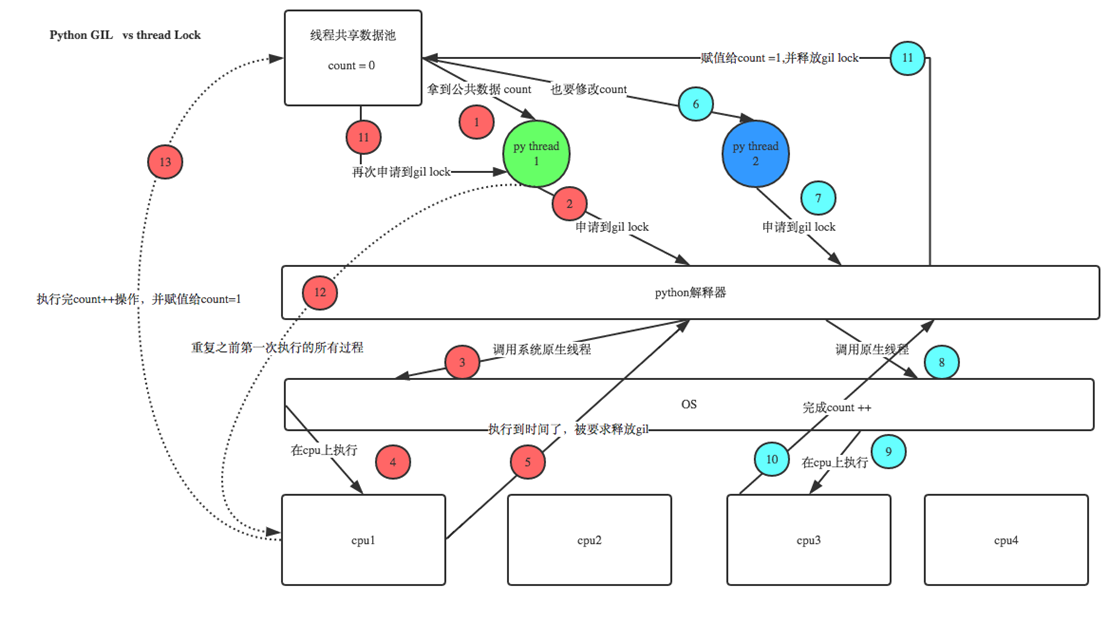
那你又问了, 既然用户程序已经自己有锁了,那为什么C python还需要GIL呢?加入GIL主要的原因是为了降低程序的开发的复杂度,比如现在的你写python不需要关心内存回收的问题,因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
当然,这样加了锁,串行就变成并行了,就没有多线程了,如果要执行任务,不需要确定结果,就可以使用多线程不加锁。如果要计算结果,大家还是慎重
本章第一次觉得老师讲解的不错,时间久了有遗忘,建议返回来在看视频
8.15 递归锁与信号量
本章讲解2个简单的概念,可以一笔带过:
1.递归锁
2.信号量
递归锁
说白了就是在一个大锁中还要再包含子锁
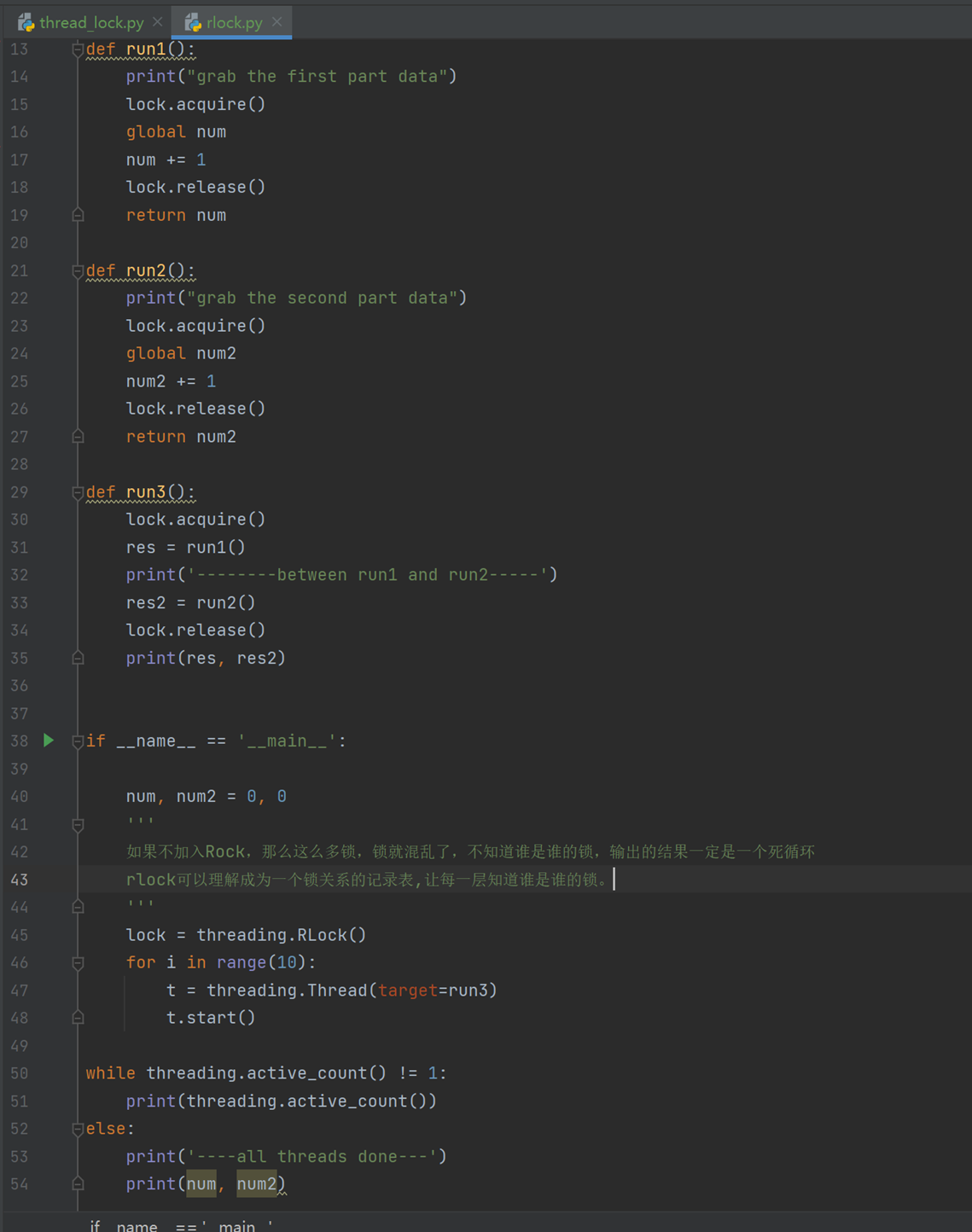
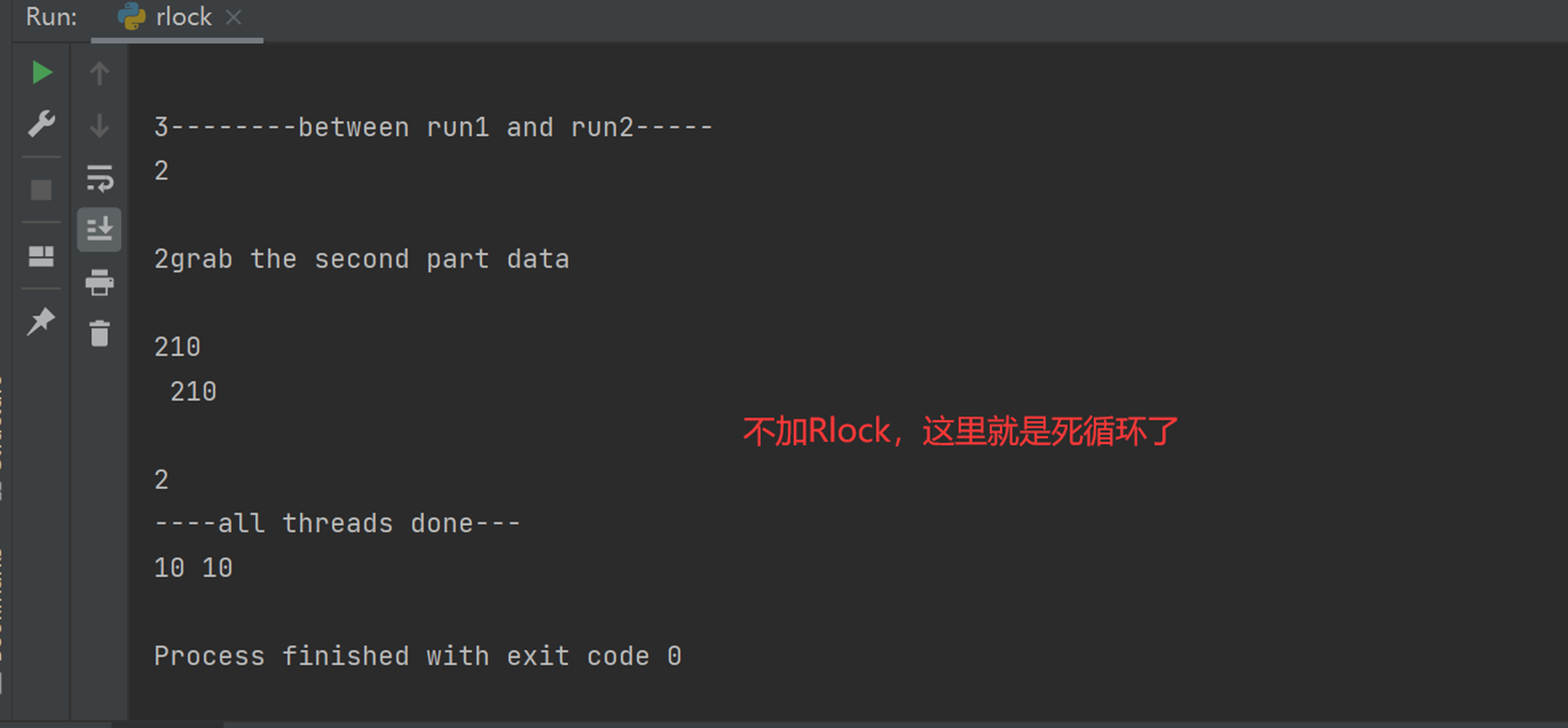
查看加入了Rlock的输出
Semaphore(信号量)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
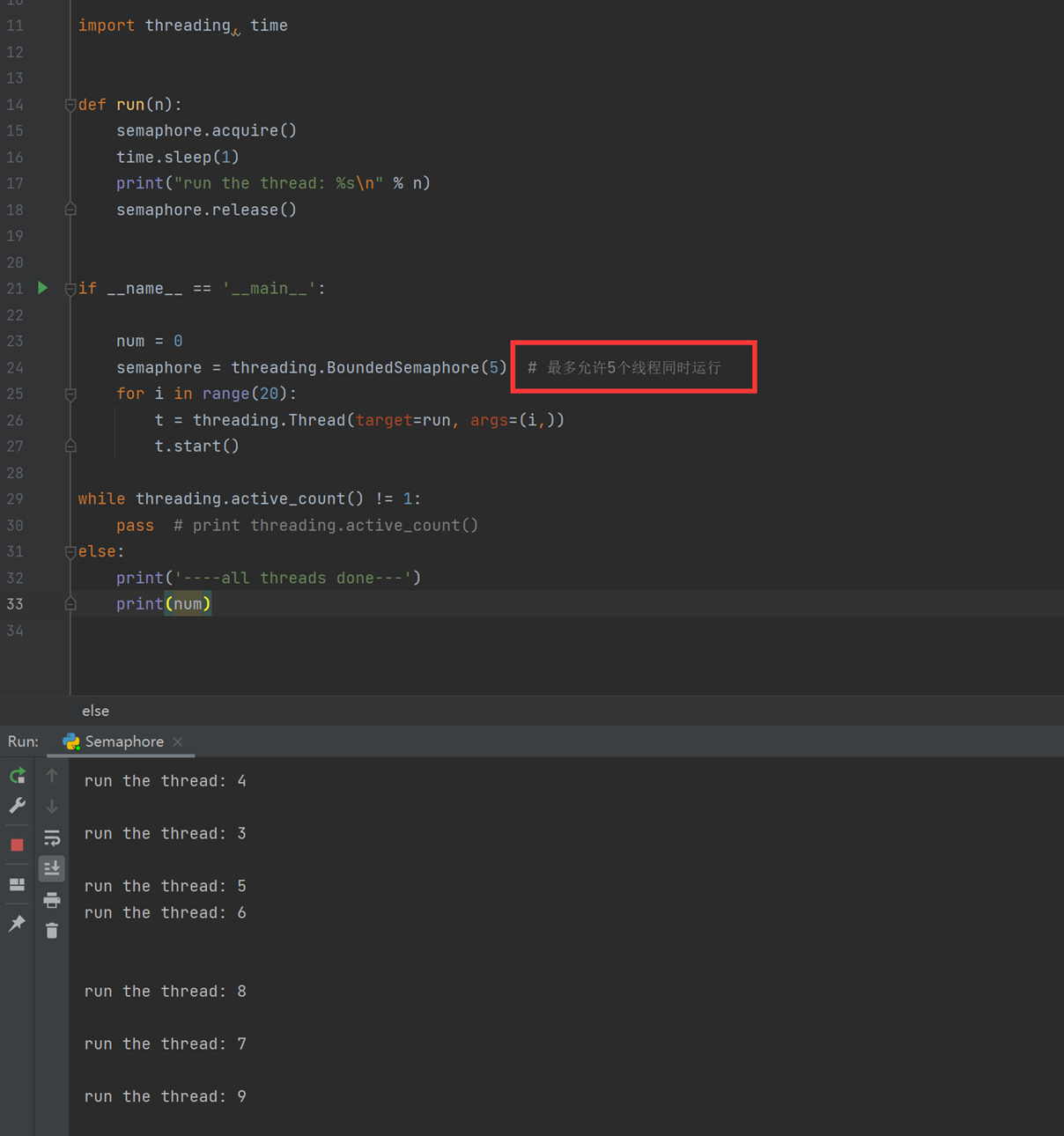
8.16 线程间同步和交互
本章主要内容是让线程产生因果关系,比如车因为红绿灯而走或者停,怎么实现呢?
通过Event来实现两个或多个线程间的交互,下面是一个红绿灯的例子,即起动一个线程做交通指挥灯,生成几个线程做车辆,车辆行驶按红灯停,绿灯行的规则。
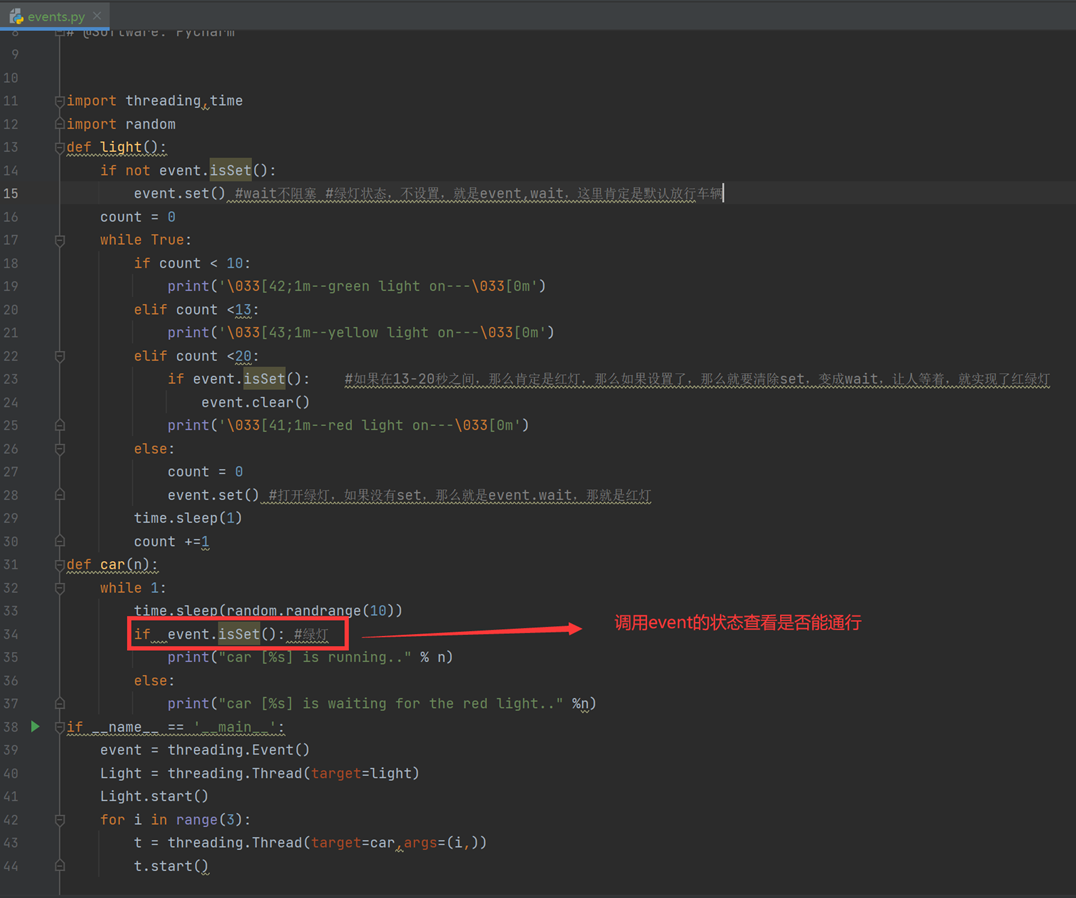
上面的内容很简单,比较绕的地方在于:event.set()和event.wait,这里要反着想,event.set()有了这个,就是指示可以通行,意思如果没有设置event.set(),那么就是默认event.wait(),所有车都得等着,记住这一条在去看代码,就会清晰很多。
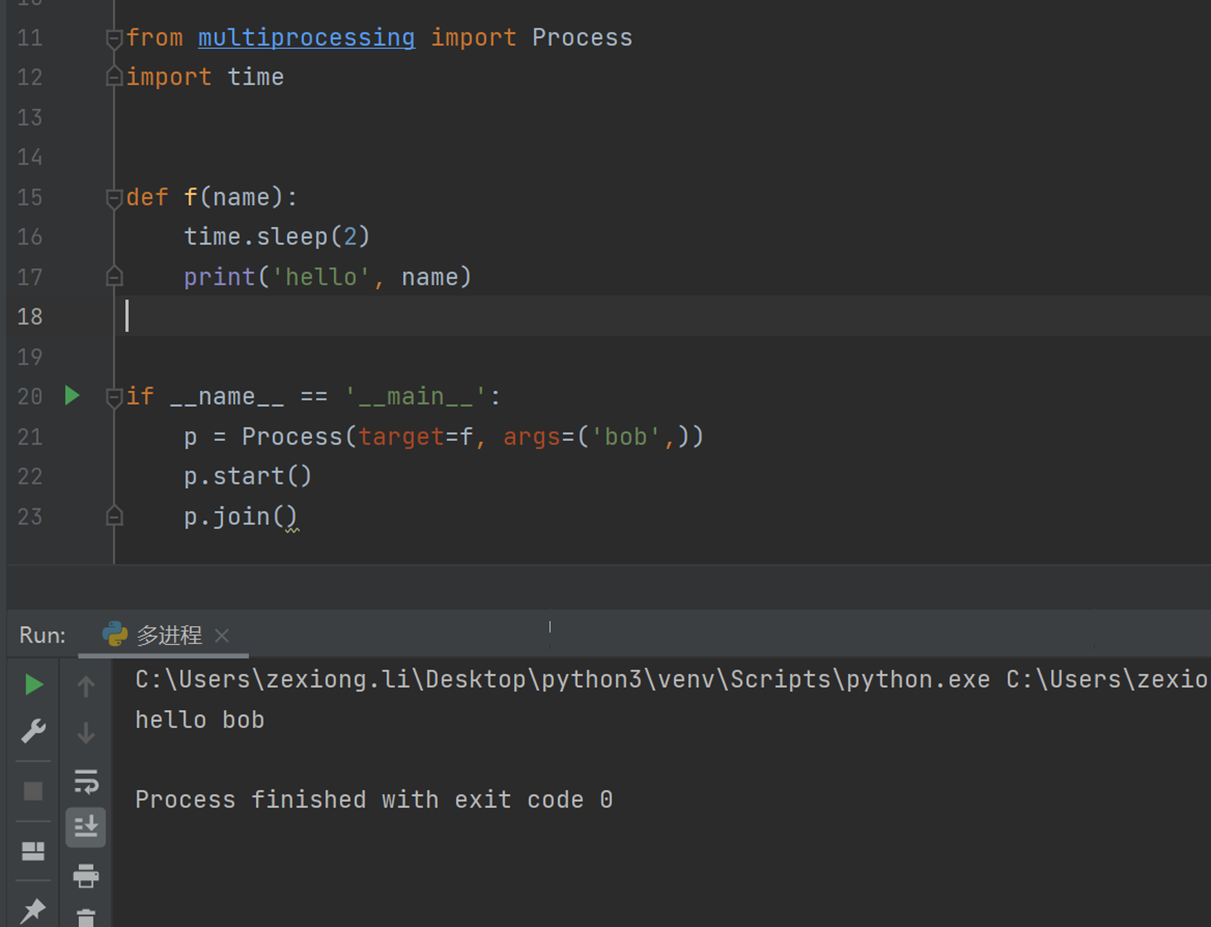
8.17 多进程实例
这里老师讲了一个问题,虽然说多线程实际是还是单线程运行,为什么多线程还是比单线程快,因为根据《8.14》章讲解,只是在在C语言的GIL那里慢,其它的时候比如io切换,上下文切换等一些时候还是快的,因为python和C的CIL锁是2个维度
这里首先简单演示一下多进程代码,具体的多进程原理可以参考本人对应的博客。
这一篇比较简单,和多线程没有太过区别,主要就是原理方面和多线程不一样需要深究。
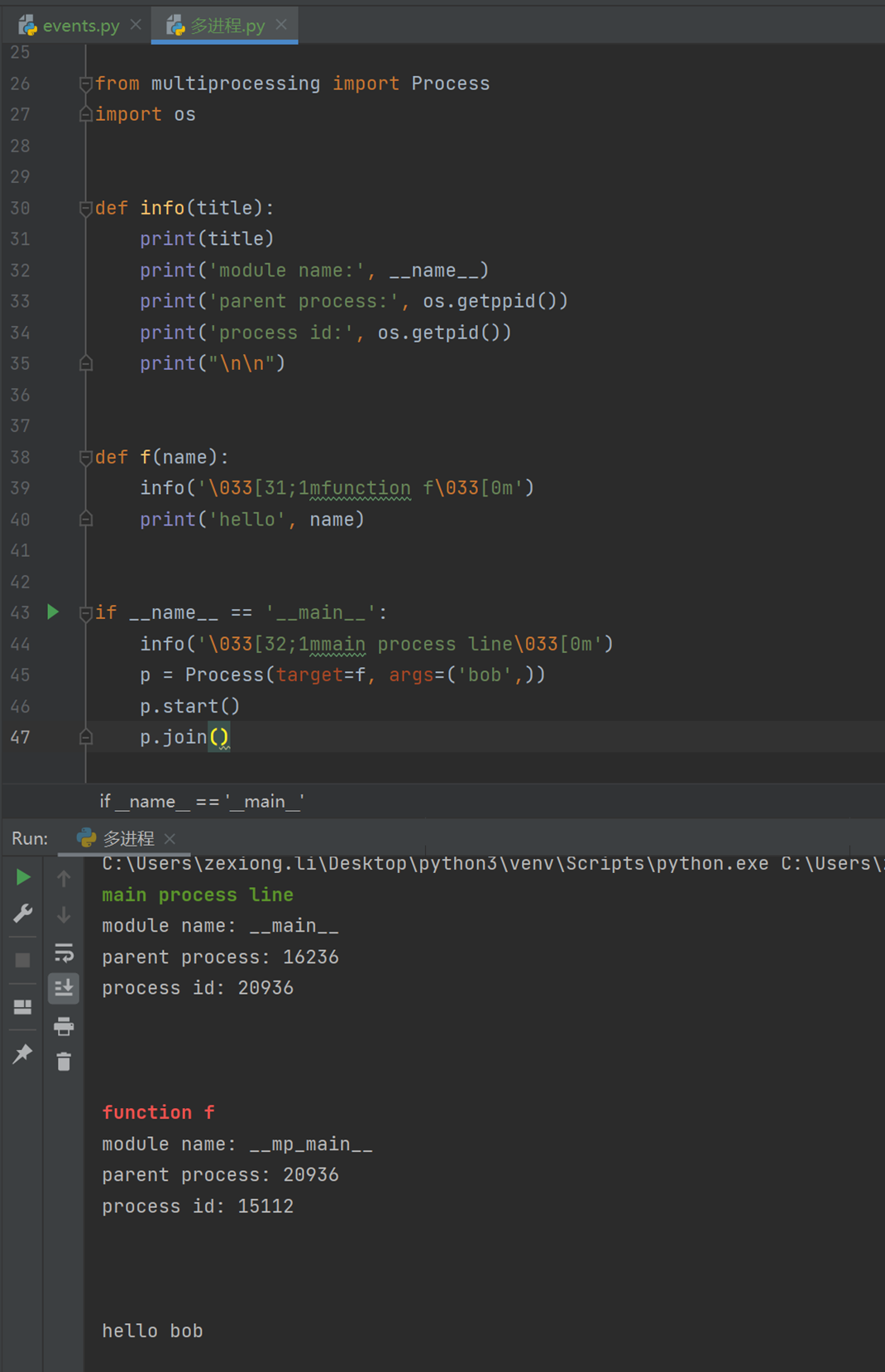
然后在看一下主进程和子进程ID,他们的ID肯定是不同的,学过linux的都知道这个原理
接下来,本章稍微讲解了一下进程间的通讯,不同进程间内存是不共享的,要想实现两个进程间的数据交换,可以用以下方法:
这里是其中一种方式Queues
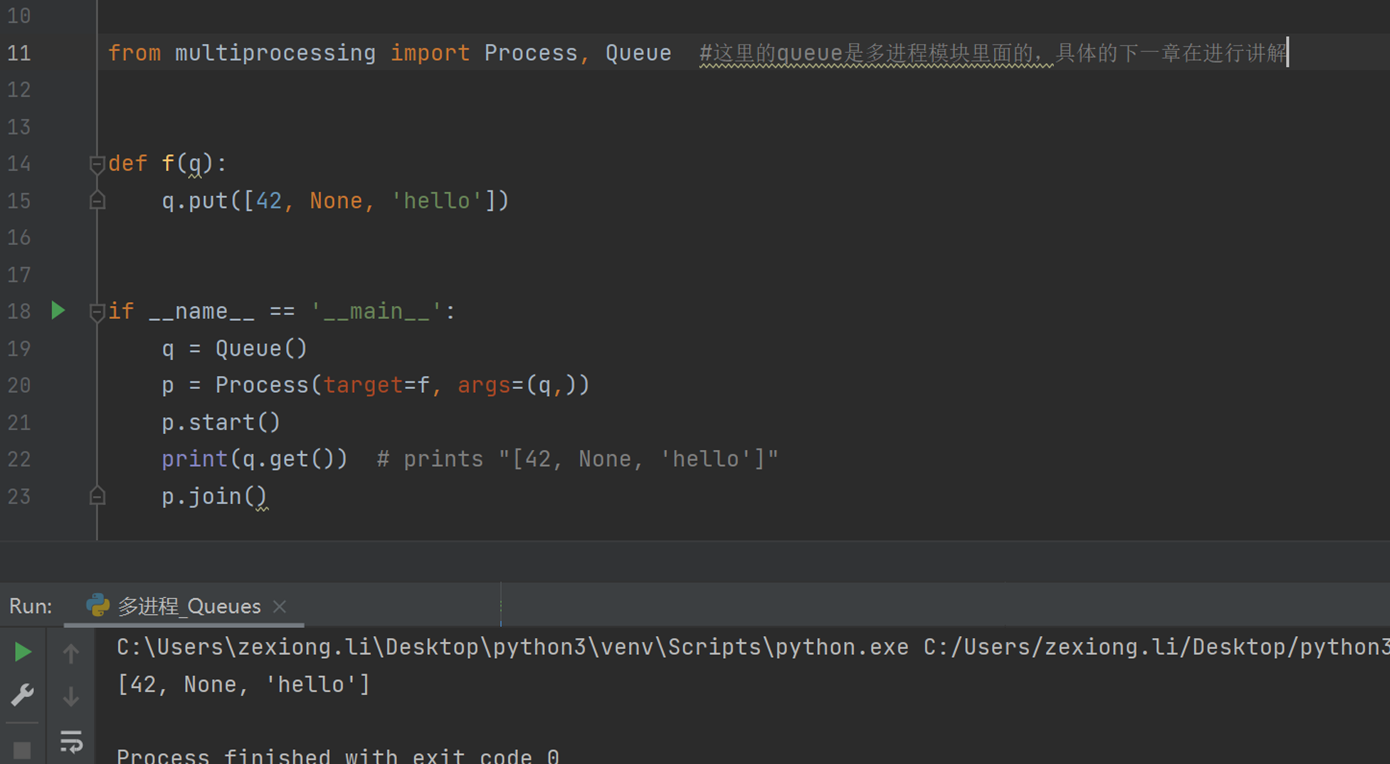
这里的Queue(还是多进程模块里面的Queue)本章只是稍微讲解了一下,具体的pipes进程间通讯和数据共享等下一章里面讲解。
8.18 进程间通讯和数据共享
简单来说,不管是queues还是pipes都只是进程间的传递,这里还有一种进程间传递数据的办法,就是pipes。
pipes

上面也说了,这里更适合叫做进程间的数据传递,但是也有可以类似进程间数据共享的方式,那什么叫做进程间数据共享?那么就是说2个进程都可以修改这个数据,比如一个字典,2个进程都可以同时往里面放数据,见以下代码。
通过manages实现
manager()返回的管理器对象控制一个服务器进程,该进程持有Python对象,并允许其他进程使用代理操作它们。
由manager()返回的管理器将支持列表、字典、命名空间、锁、RLock、信号量、BoundedSemaphore、条件、事件、Barrier、队列、值和数组类型。例如,
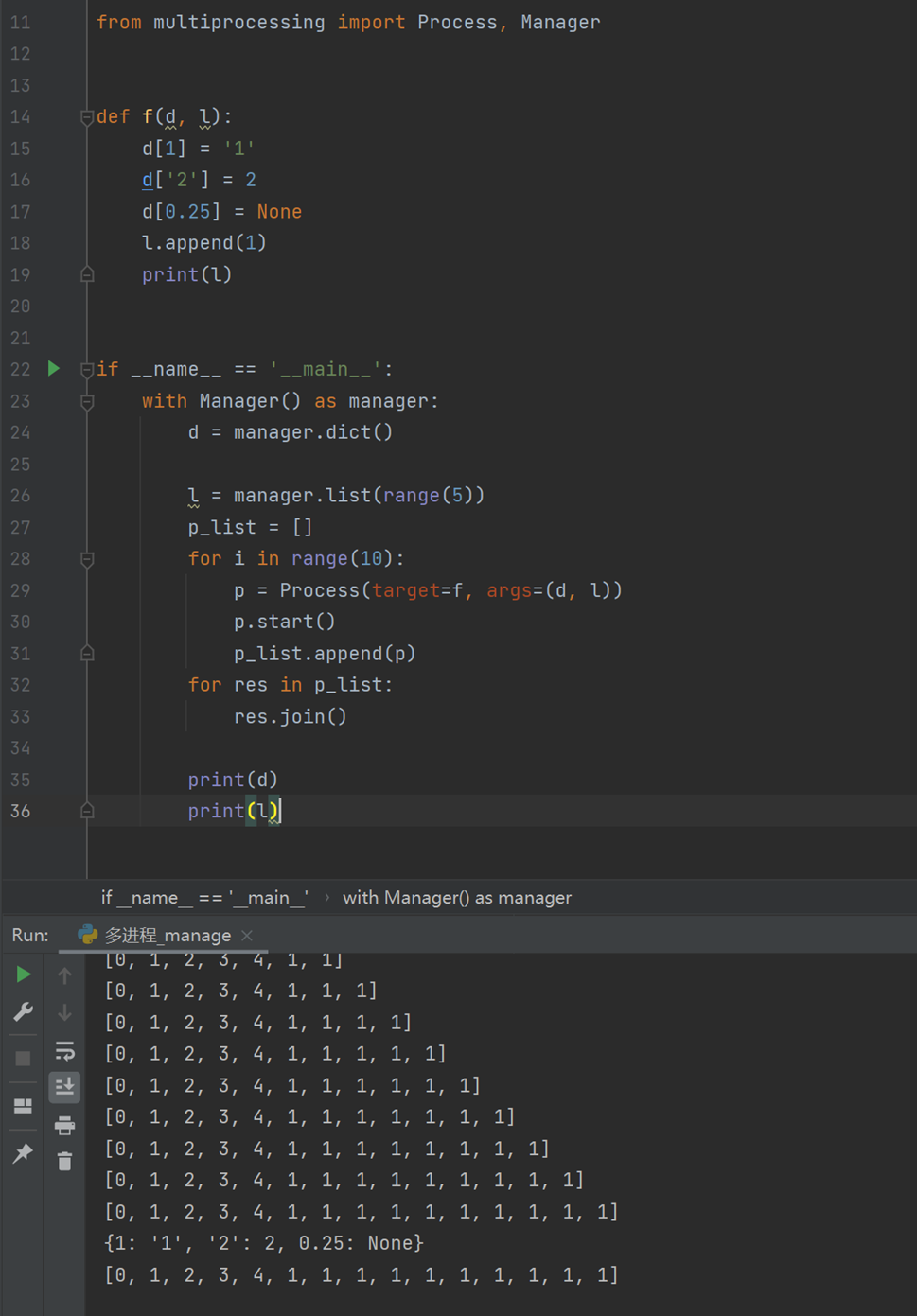
(这章还是有点晦涩难懂,还是需要多看)
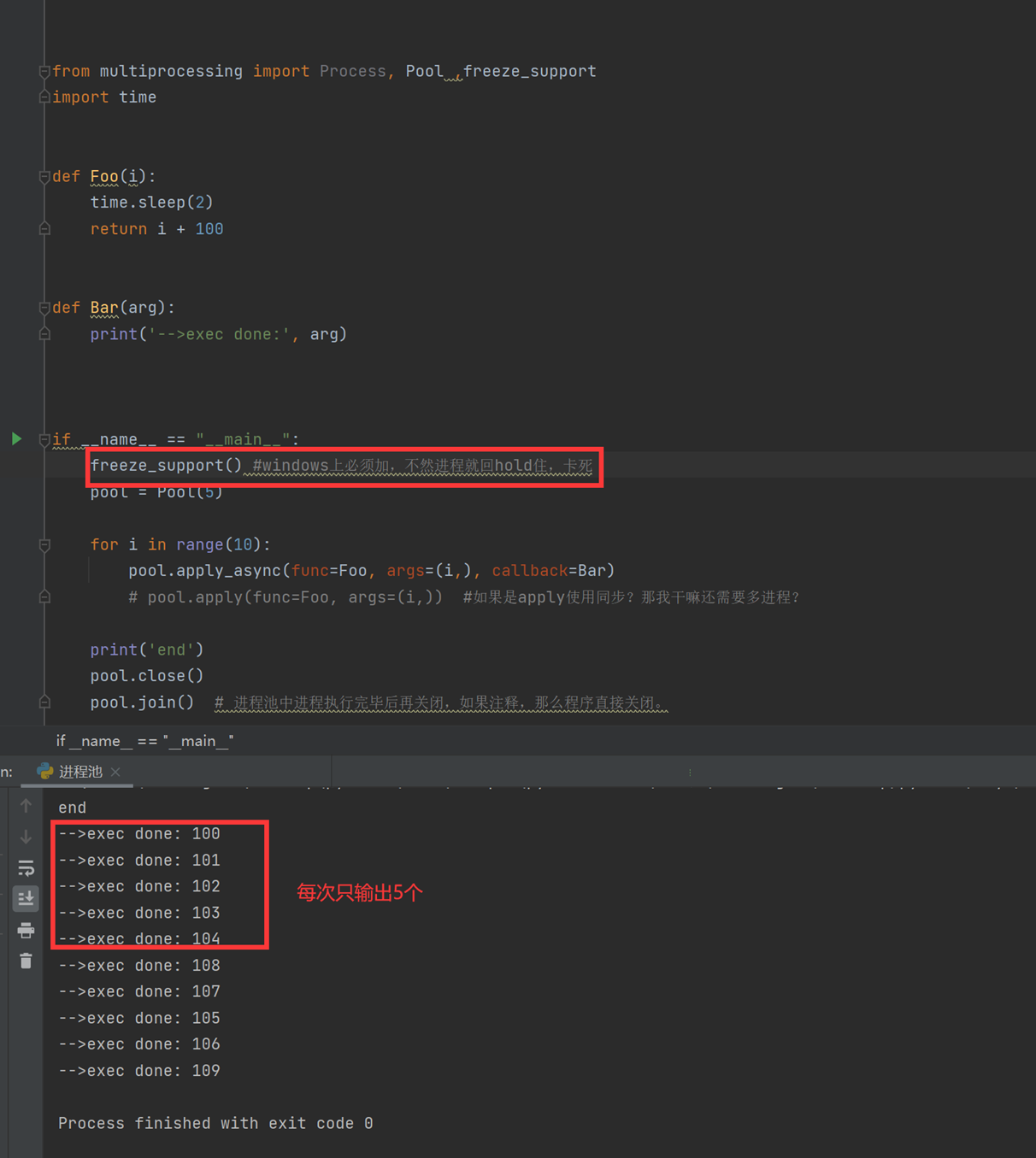
8.19 进程池代码

进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
- apply
- apply_async
(本章这个老师讲解进程池的作用不太全面,还是需要参考其他博客文章)
8.20 paramiko简单讲解及作业需求

9.L09
9.1 鸡汤之只能当配角的人生是悲惨的
9.2 上节内容回顾

9.3 队列queue
本章就是讲解了老师博客一些简单的queue的用法,见下图.
具体的可以见本人博客。
现在看一下课程里面的简单演示
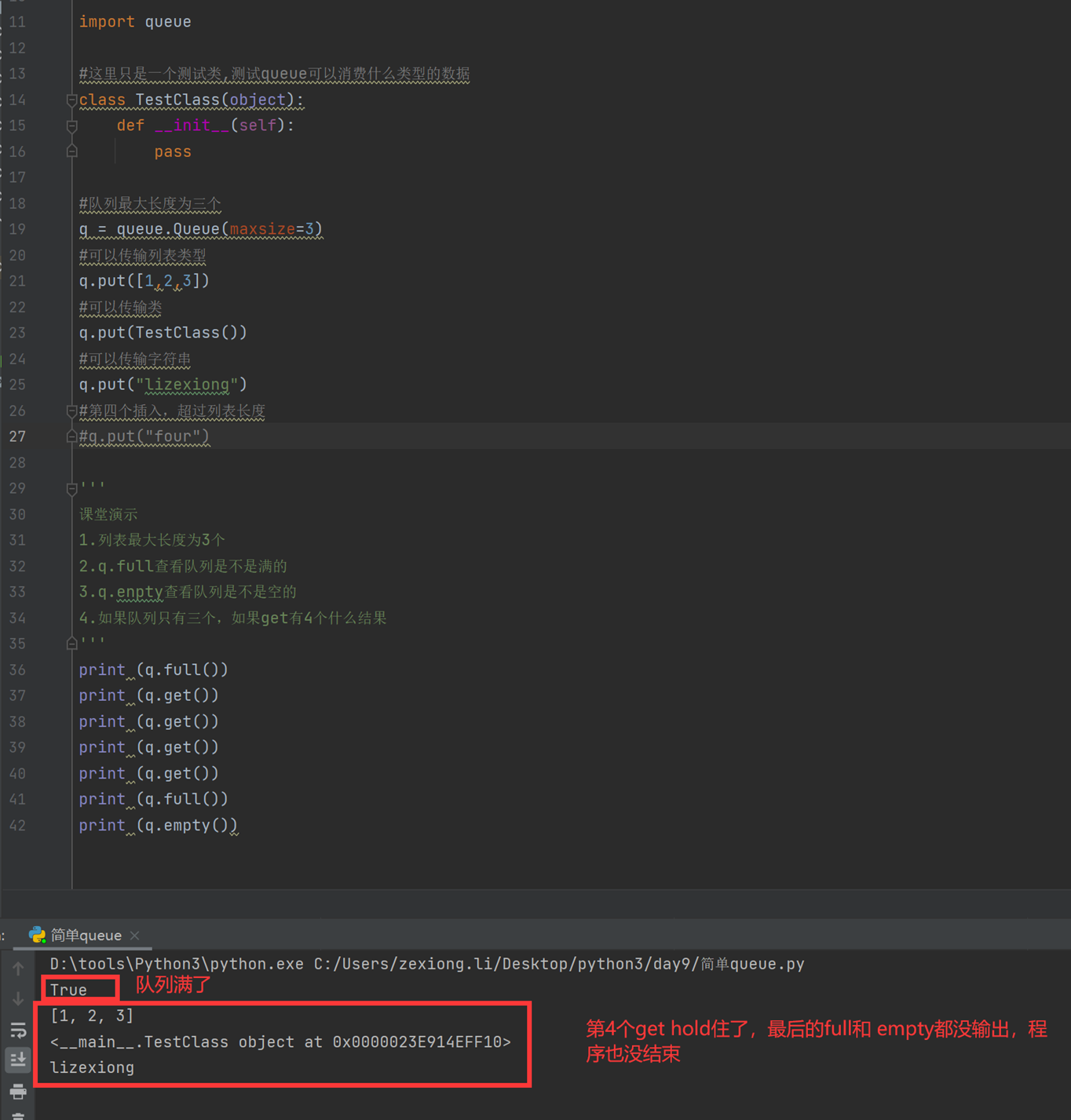
具体可以参考博客: https://www.cnblogs.com/lizexiong/p/17181469.html
9.4 生产者消费者模型
9.4和9.5两章合并讲解,因为9.5只是一个补充,没怎么演示
本章中,老师使用了以下
q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号
q.join() 实际上意味着等到队列为空,再执行别的操作
并且最后一个功能没有做完,就是如果有1000个厨师,那么只有一个顾客,那么1000个厨师都会同时生产1个包子,那么就会浪费,这个章节老师讲的又绕又长,并且上面两个函数的用法还讲解错了。这里还是根据理解,自己记录一下博客的,有兴趣的在去翻视频吧。(不建议翻视频了,都没讲清楚,最后还讲出错了)
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
按照课上的例子讲解
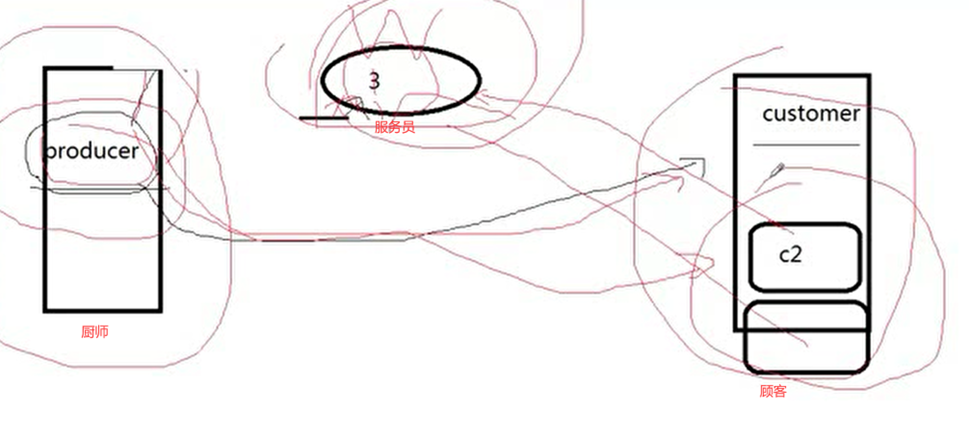
课上的例子是一个厨师和顾客还有服务员之间的例子。
如果现在有顾客想要来买包子吃,假设现在还没有服务员,那么可以直接告诉厨师,我需要一个包子,那么厨师就做一个包子给顾客,这么看来毫无问题,那么这里就延伸出来几个问题。
1.如果有几个顾客都需要包子,那厨师忙不过来怎么办?厨师可能只能服务一个顾客。
2.如果同样的顾客想吃第二个包子,那怎么办?如果多个顾客都想要第二个包子怎么办?
3.比如只有一个厨师,只能招待一个顾客,其余的顾客可能觉得等的时间长了,先去干其他事情了,那么厨师不能把一个包子卖给这个去干其他事情的顾客,又卖给刚来的顾客,一个包子不能买给多个顾客。最好是先到先得。
那么有个想法看看能不能解决以上3个问题?厨师能否先做好100个包子?然后等客户来了给客户?那是当然可以,但是有2点,你不知道有多少客户,少了不够用,多了就浪费了,就阻塞了。
那么最好的解决方案就是招一个服务员,消费者去找服务员,服务员担任顾客之间的桥梁,厨师只生产包子,顾客只吃包子,至于传递要多少包子,交给服务员。那么我顾客多,我就可以多几个厨师,有了服务员记录菜单,厨师也不会把包子做多,那么效率就高起来了。
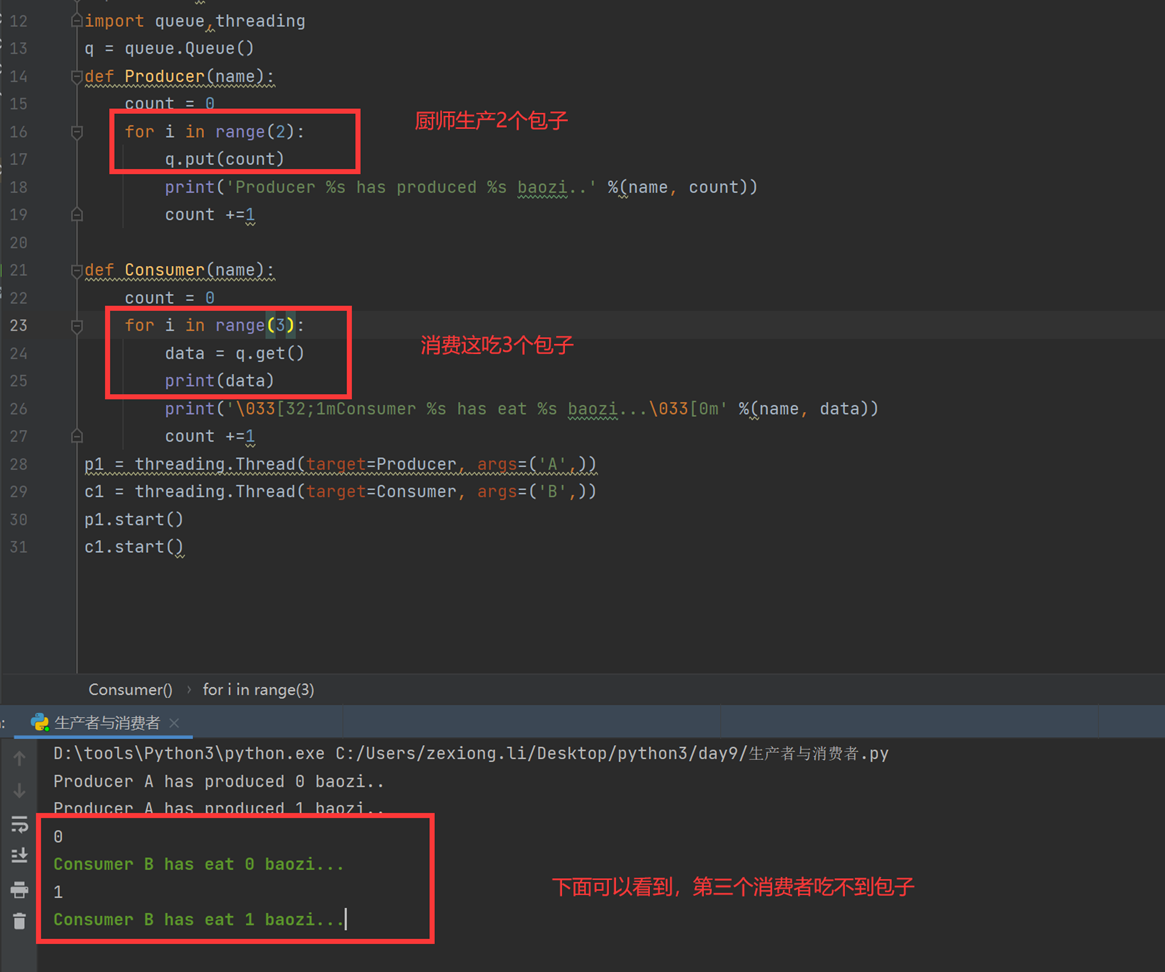
至于老师讲的join和task_done,不是那么用的,所以不要乱听视频,那么场景直接升级一下,直接调到老师课堂上没有解决的问题,就是假设1个人什么时候会去要包子吃?厨师怎么知道?就比如,有100个厨师,会不会一个人要包子,结果就是100个厨师做了1个包子?如果不断的起生产者的线程,那么就会1个顾客要吃包子,那么100个厨师都要做一个,其实这是个悖论,这老师课上没有解决,因为没有说,消费者要去吃包子,厨师才去做,而是厨师做好了,你消费者才有的吃,问题不应该是怎么解决一个人要吃包子,有100个厨师,只让一个厨师做,问题应该是,消费者怎么知道没有包子了,如果没有包子了,那么就不需要等待了。所以见如下终极代码。
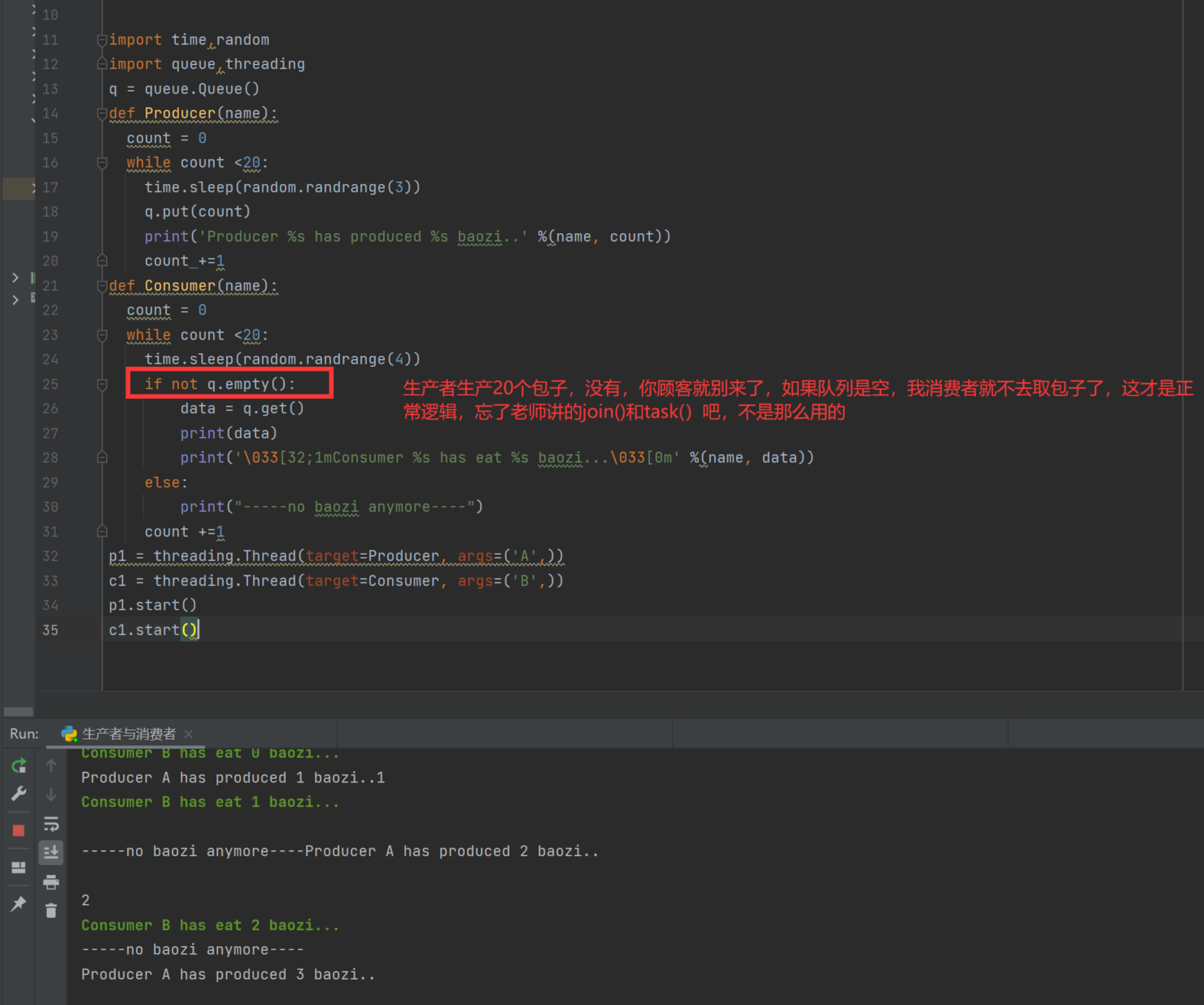
上述代码限制了生产者生产的数量,但是一般程序是不会这么限制的,这里只是测试,所以无所谓,上面的代码已经是基本接近优化的了。
当然我们现在回来讨论一下老师课堂上讲解的问题,就是以下2个用法
Queue.task_done():表示前面的排队任务已经完成,被队列的消费者线程使用。每个get()被用于获取一个任务,后续调用task_done()告诉队列,该任务的处理已经完成。如果join()当前正在阻塞,在所有条目都被处理后,将解除阻塞(意味着每个put()进队列的条目task_done()都被收到)。
Queue.join():阻塞至对列的所有数据都被接收和处理完毕。当数据被添加到队列时,未完成的任务的计数就会增加。每当消费者线程调用task_done()表示这个条目已经被收回,未完成的计数就会减少,当完成计数降到0的时候,阻塞就会解除。

可以看到这2个基本上是组合使用的。可以实现,如果没有包子了,顾客会通知厨师开始做包子,但是这样感觉会阻塞队列。见如下代码:
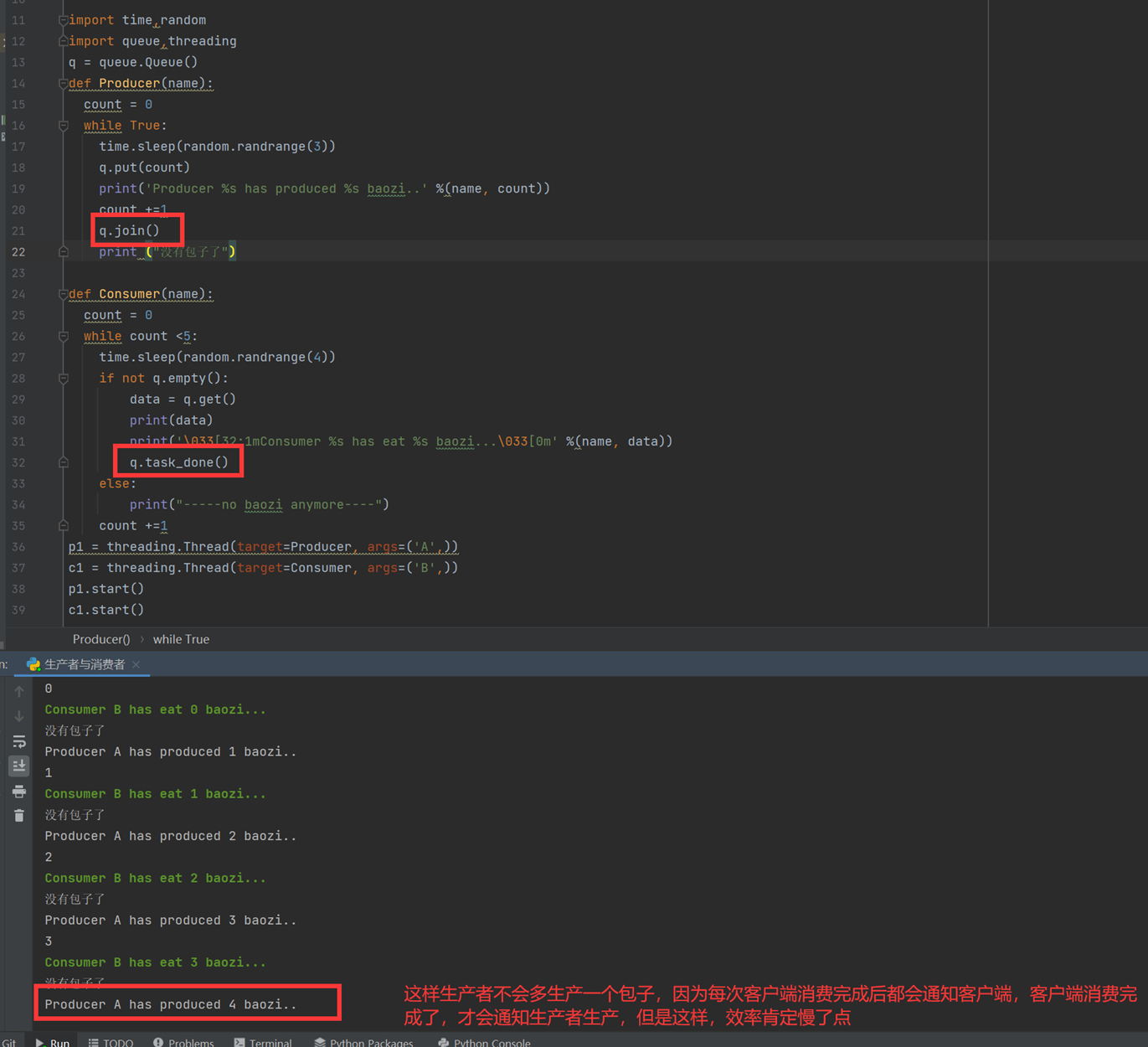
以上的基本也完成了需求,课堂上的遗留问题就是,如果有多个厨师,一个顾客,怎么只让一个厨师做一个包子?这个问题目前没解决,还是一个顾客只要一个包子,结果2个厨师都做了?这个问题在后面的课程中老师解释,没有这样的场景,如果厨师多了,那么设计就是有问题的,只有一个顾客,却有100个厨师,本身这个问题就有问题,所以这个问题不用纠结 了,所以见以下针对这个问题的代码:
9.5 生产者消费者模型再捋一捋
本章合并到上一章,本节也就是解决如果有100个厨师,顾客只要一个包子,怎么不让100个厨师同时生产的,这节课也没有解决,他说没有这种场景,这种场景不合理,这老师真nb。
9.6 协程初探
这几张讲的不怎么深,也不怎么对,还是自己查询资料吧,这里就是做个参考吧,真想复习还是得看视频。
协程,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程。(不是操作系统的行为,是用户做的,操作系统不知道)
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
协程的好处:
- 无需线程上下文切换的开销(因为是在一个线程里)
- 无需原子操作锁定及同步的开销
- "原子操作(atomic operation)是不需要synchronized",所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序是不可以被打乱,或者切割掉只执行部分。视作整体是原子性的核心。
- 方便切换控制流,简化编程模型
- 高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序(因为是串行的),这个问题可以解决,见下面的讲解案例,解决大概思路,遇到阻塞就切换协程
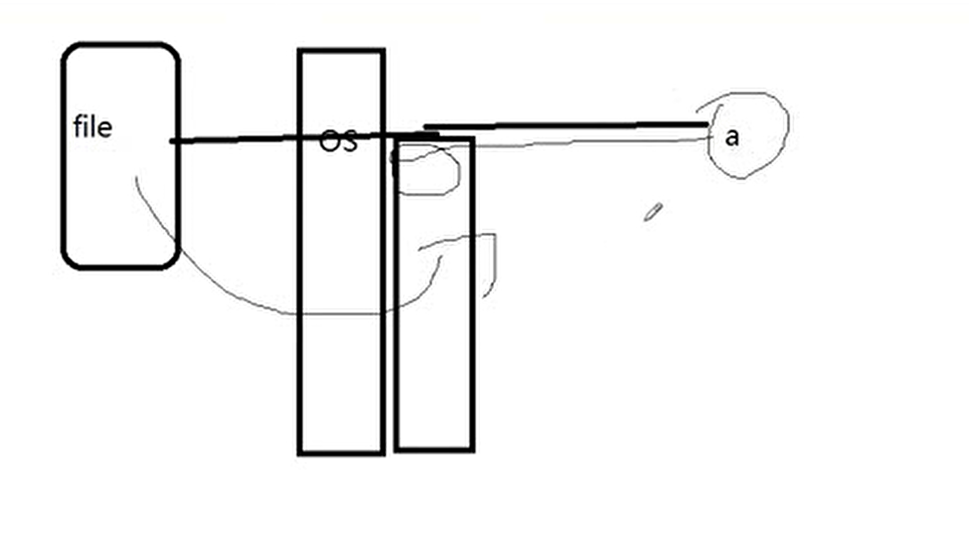
刚才的缺点有一个是“进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序(因为是串行的)”,这个问题可以解决,见上图的讲解案例,解决大概思路,遇到阻塞就切换协程,这里也是课堂上简约的一个解决方案。
假设协程a调用os的接口,然后把硬盘上的file读取,这个过程是阻塞的,因为是串行的,怎么才能不阻塞?
那么如果我文件开始读取的时候,我把这个任务丢到操作系统的队列里面,然后我就去干其他事情,等会协程在切换回来,这时候可能file就读取到了。如果没读取完后,那么在放到队列里面,等会在切换回来看看读取完成,这样是否就可以不阻塞了。
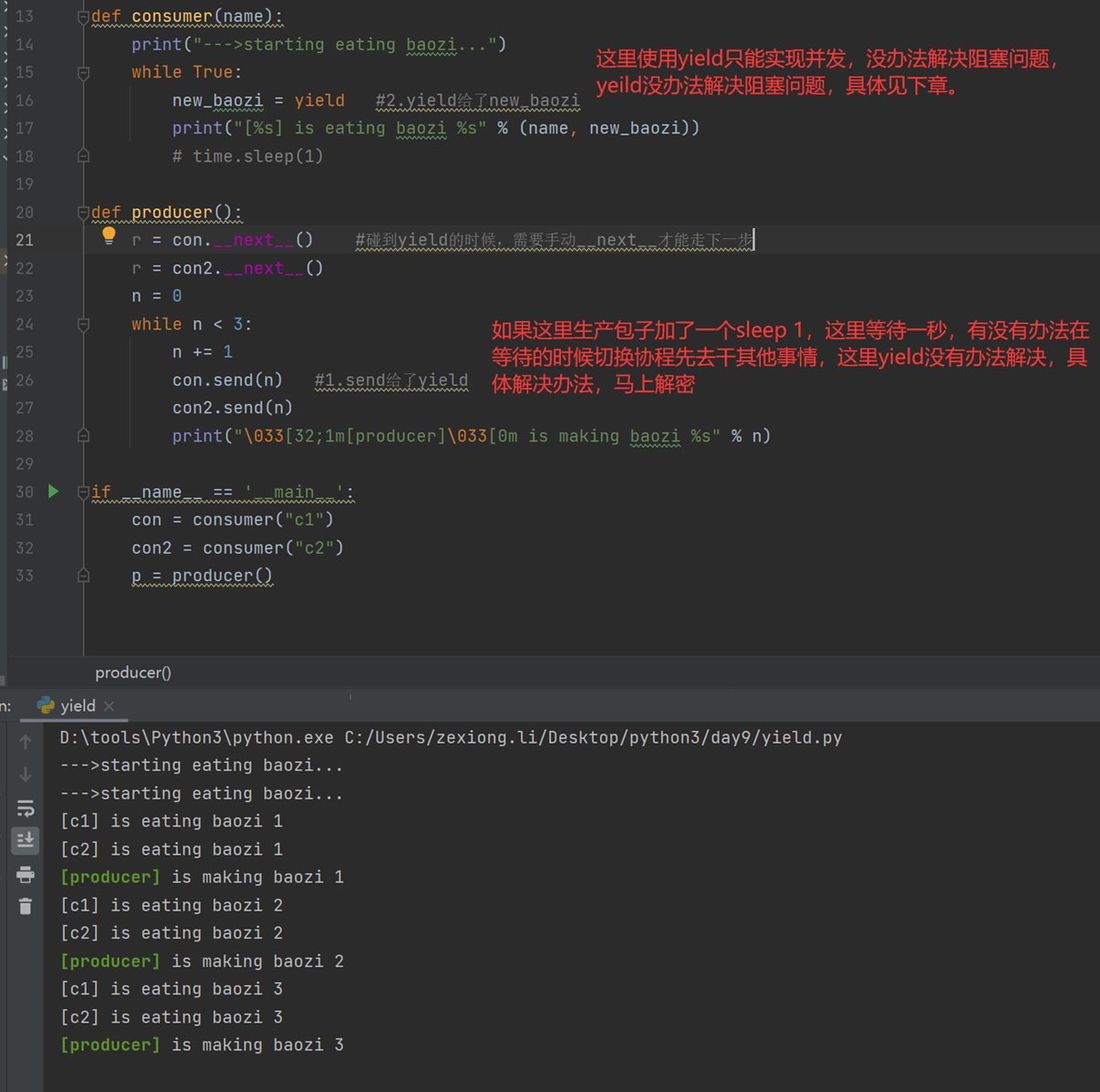
现在用一个案例来演示。
使用yield实现协程操作例子
看楼上的例子,我问你这算不算做是协程呢?你说,我他妈哪知道呀,你前面说了一堆废话,但是并没告诉我协程的标准形态呀,我腚眼一想,觉得你说也对,那好,我们先给协程一个标准定义,即符合什么条件就能称之为协程:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 一个协程遇到IO操作自动切换到其它协程
基于上面这4点定义,我们刚才用yield实现的程并不能算是合格的线程,因为它有一点功能没实现,哪一点呢?那就是阻塞切换。
下面先来一个过渡产品:Greenlet
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
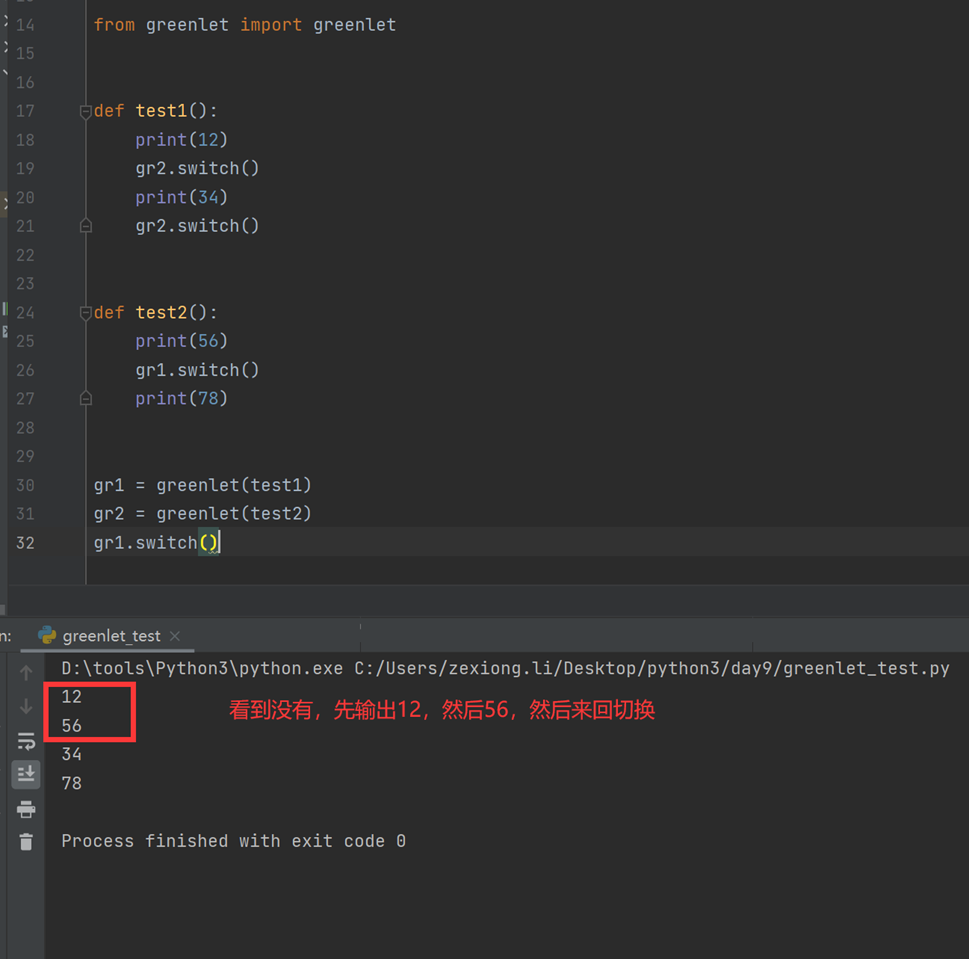
这里来个更高级的,其实也是对Greenlet的封装,叫做Gevent。
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
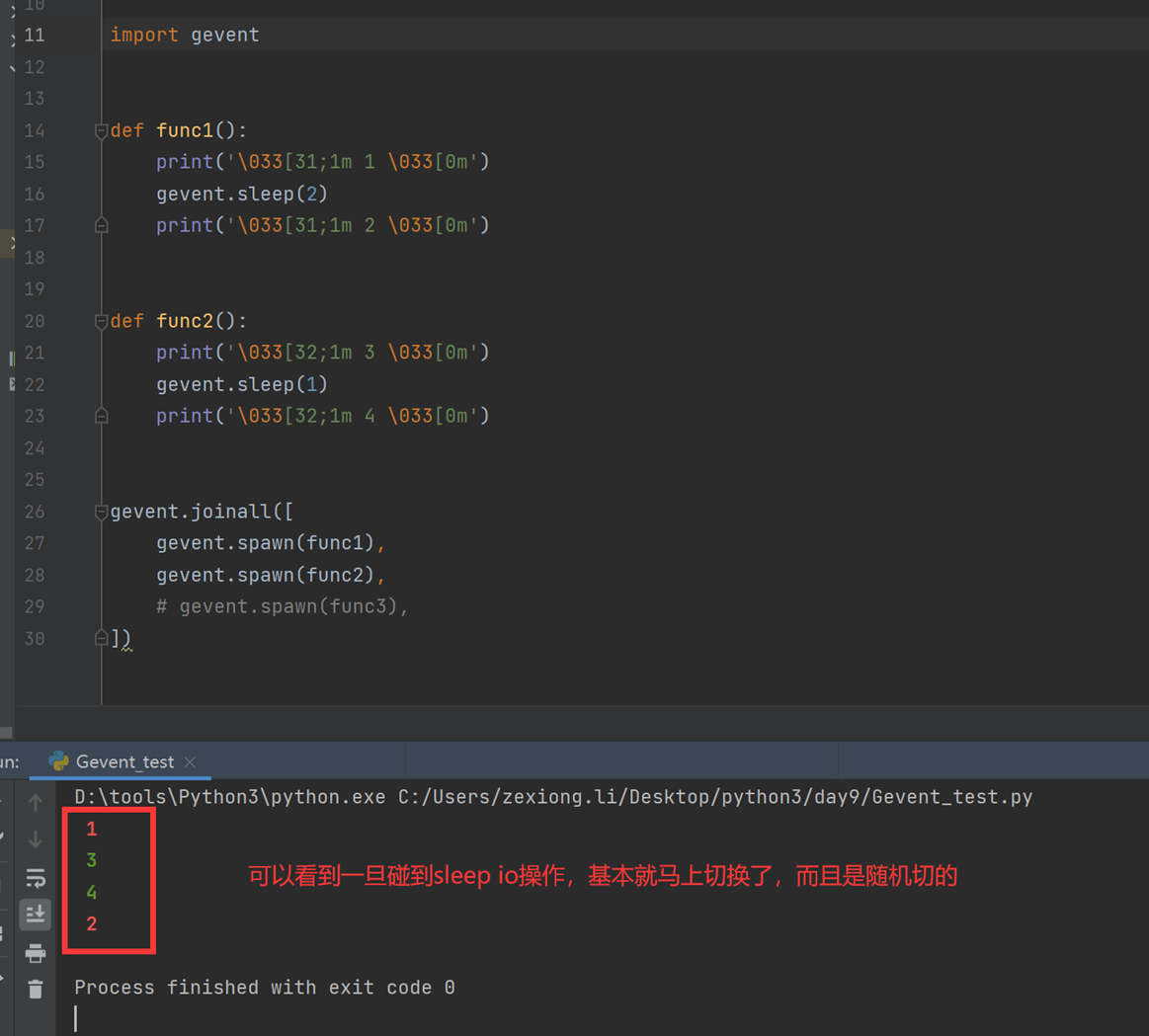
9.7 协程异步非阻塞
上节课直接在sleep查看切换的效果,这里在单线程并发的下载多个页面看看效果。就是gevent的spawn用法。
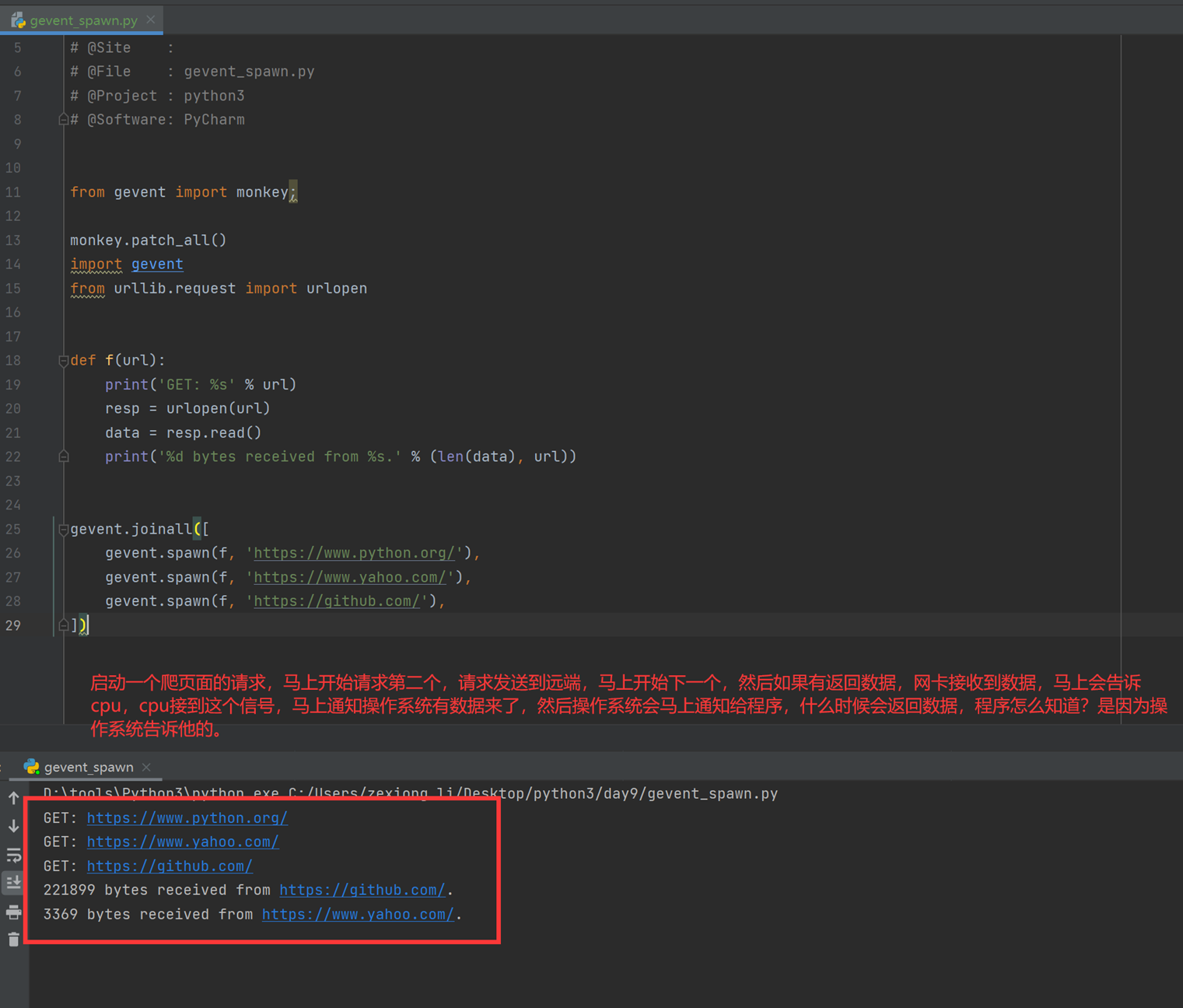
现在再看一个更牛逼的例子,就是通过gevent实现单线程下的多socket并发
通常socket是一对一的,一个socket只能跟一个socket客户端,后面就把单个socket改成了多线程的socket,每一个客户端连接过来,都会给客户端分配一个新的线程给客户端连接。一个线程给一个客户端服务。那么这是低效的。
比如客户端跟socket连接上了,但是不跟socket server传输数据,socket server又不好主动断掉,会话只能保持着,还得没事检查一下这个连接是不是活跃的,大部分都是空跑,所以开销很大,效率很低。
怎么实现单线程下实现多socket并发,只维护一个线程,过来一个连接创建一个实例,只有活跃的连接才会通信,不活跃的就切换走,但是这样有个问题,如果一个socket客户端连接一直在传输,是活跃的,那么其它的就阻塞了,这个还是有阻塞,这个怎么办。
这个可以让socket server和client不直接通信,就比如client的消息放到一个小盒子里,server去轮询,看看有谁在跟我说话,然后我在快速的去回复。这样就解决了这个阻塞的问题,怎么实现的呢?见如下代码:(这个代码最好不好在windows下测试,各种麻烦报错)
Server
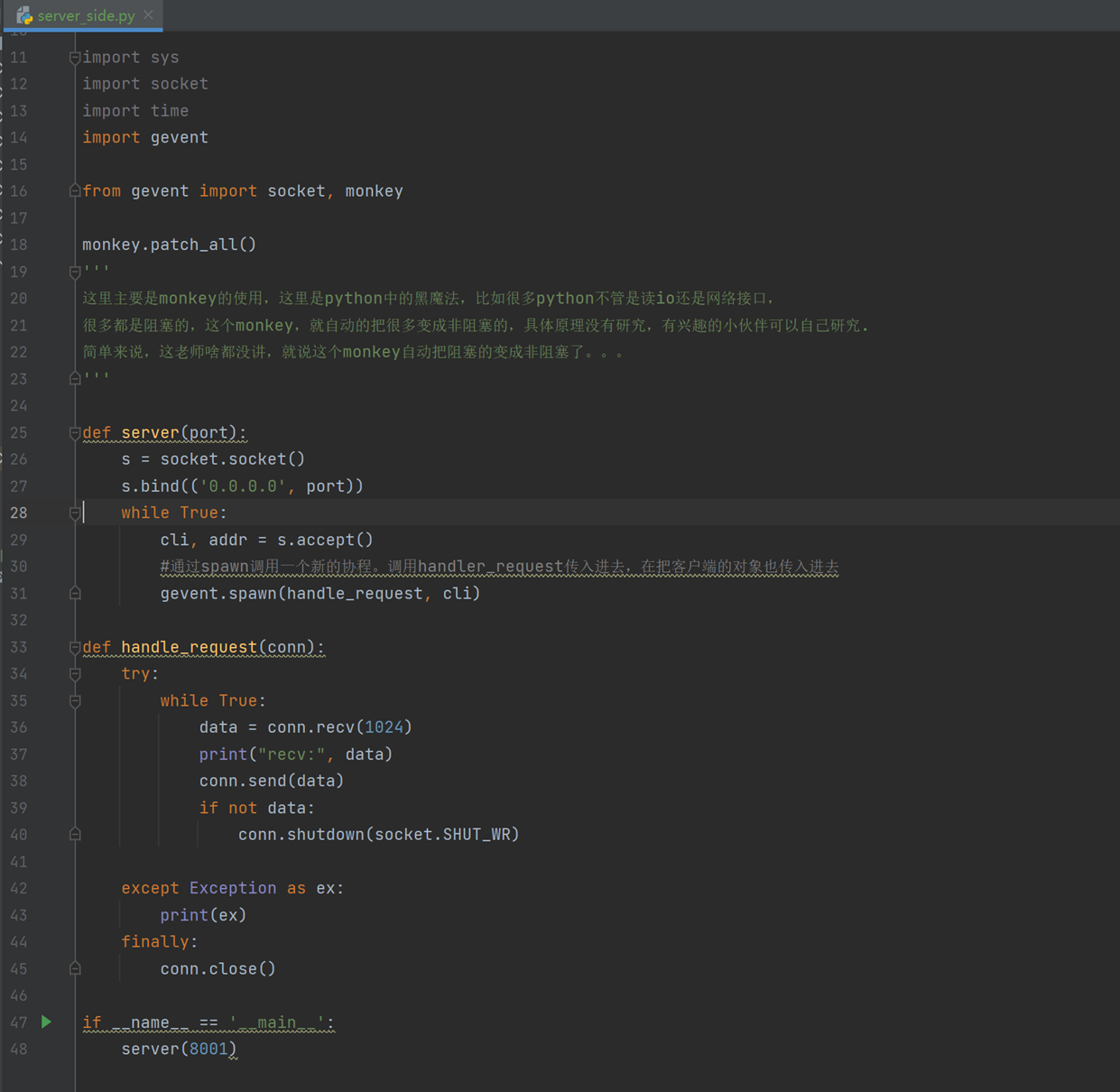
Client
因为是手动输入,看不出啥并发的效果,手的速度太慢了,有兴趣的同学可以把客户端写成一个死循环,然后多开几个客户端测试。这里还是贴一下代码,因为下一课的开头他也演示了,这里演示一下吧。
以下是并发100的请求代码

9.8 论事件驱动与异步io模型
这节课他讲的也不清楚,还是看教程吧。什么叫事件?鼠标点击一下就是一个事件,带着这个理论下面的教程可能会清晰一点。
通常,我们写服务器处理模型的程序时,有以下几种模型:
(1)每收到一个请求,创建一个新的进程,来处理该请求;
(2)每收到一个请求,创建一个新的线程,来处理该请求;
(3)每收到一个请求,放入一个事件列表,让主进程通过非阻塞I/O方式来处理请求
上面的几种方式,各有千秋,
第(1)中方法,由于创建新的进程的开销比较大,所以,会导致服务器性能比较差,但实现比较简单。
第(2)种方式,由于要涉及到线程的同步,有可能会面临死锁等问题。
第(3)种方式,在写应用程序代码时,逻辑比前面两种都复杂。
综合考虑各方面因素,一般普遍认为第(3)种方式是大多数网络服务器采用的方式
看图说话讲事件驱动模型
在UI编程中,常常要对鼠标点击进行相应,首先如何获得鼠标点击呢?
方式一:创建一个线程,该线程一直循环检测是否有鼠标点击,那么这个方式有以下几个缺点:
1. CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
2. 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
3. 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
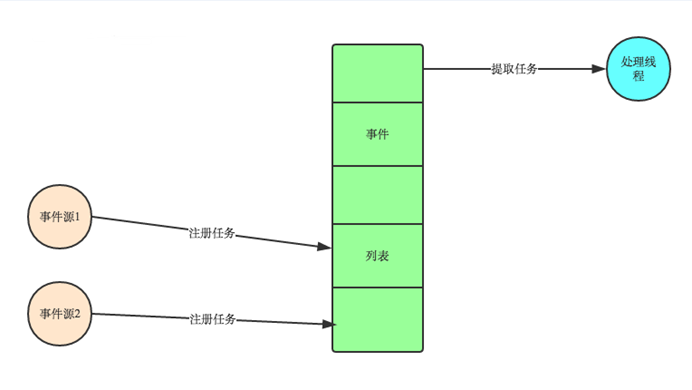
方式二:就是事件驱动模型
目前大部分的UI编程都是事件驱动模型,如很多UI平台都会提供onClick()事件
这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外两种常见的编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。
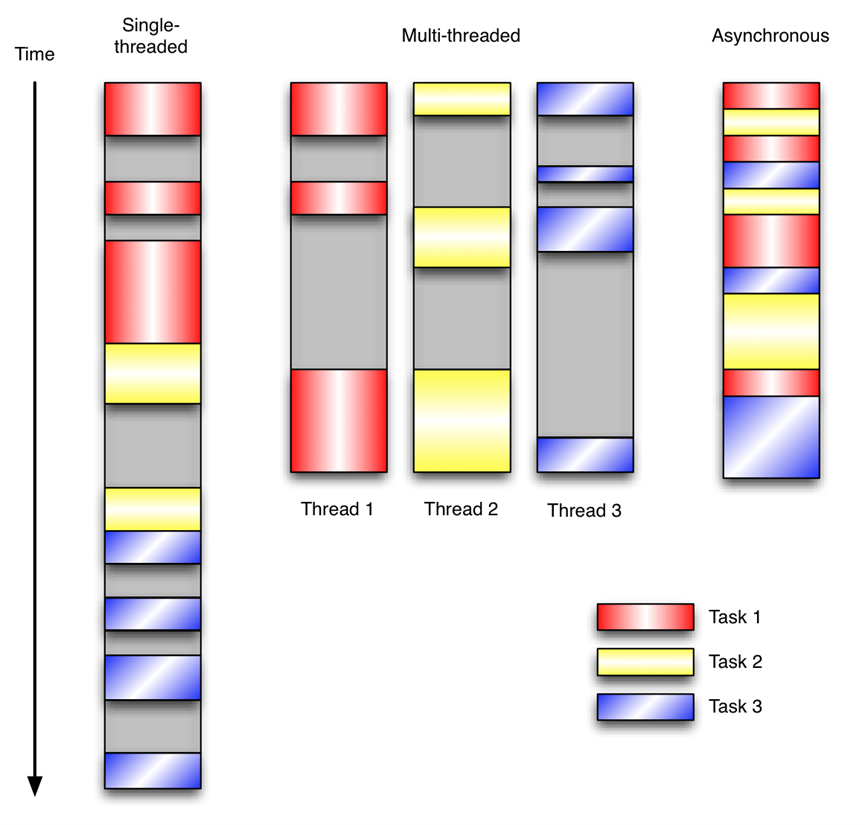
以上的图片就是总结一句话,异步io的效率是最高的,但是有个缺点,就是只能在单线程里面实现多任务的异步。
详细的理论见以下:
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务,而且…
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)而且…
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
Nginx就是一个典型的采用异步的模型。(epoll),并且nginx多进程单线程
此处要提出一个问题,就是,上面的事件驱动模型中,只要一遇到IO就注册一个事件,然后主程序就可以继续干其它的事情了,只到io处理完毕后,继续恢复之前中断的任务,这本质上是怎么实现的呢?哈哈,下面我们就来一起揭开这神秘的面纱。。。。
9.9 selectpollepoll异步io模型剖析
就是把下面的博客念了一遍,那老师自己都不知道自己的念什么: https://www.cnblogs.com/lizexiong/articles/17019084.html
9.10 select异步io模型剖析代码实例
本章也是按照博客把该代码讲解了一遍: https://www.cnblogs.com/lizexiong/articles/17019084.html,需要的时候还是重新温习视频吧
9.11 paramiko讲解
视频不用看了,直接参考本人博客: https://www.cnblogs.com/lizexiong/p/17142524.html
9.12 mysql常用操作
本章讲解的是mysql的基本使用,作为运维,该章不需要记录
9.13 pythonmysqlapi常用调用及回滚和事务操作
python3不支持这个模块
简单就是掩饰了博客的东西,自己整理一篇博客出来,并且找出一个python的操作mysql的模块
9.14 本周作业

10.L10
10.1 上节作业回顾
复习了一下队列,协程,最后将select没有讲清楚,下章准备重新讲解select。
10.2 再回顾select
10.2和10.3合并讲解。
还是使用上节课的例子回顾了一下select的讲解,以下笔记在select案例的每一行代码上都做了解释。如果时间长远忘记了概念,还是可以回去看看视频的。
也可以参考以下博客:
1.哪5种IO模型?什么是selectpollepoll?同步异步阻塞非阻塞有啥区别?
2. socket阻塞与非阻塞,同步与异步,IO模型,select与poll和epoll总结
10.3 再回顾select2
10.4 事件驱动
提示:如果要回顾视频,直接从第8分钟开始看
事件驱动可以说是一个概念,还是用一个官方的语言来讲解一下吧
事件驱动专业的解释是指在持续事务管理中,进行决策的一种策略,当事件被触发时计算机调动可用资源,执行相关任务,这样使得不断出现任务得以执行,防止实务的堆积。这种策略相比起非事件驱动的程序来说,让计算机 CPU 资源更优的利用起来,通过对事务的有效管理让计算机得到最好的性能。
现在的编程基本都是基于事件驱动的,例如服务器端的 IO 处理、网络请求;特别是在 UI 的编程中,鼠标的点击事件、屏幕的触摸事件、键盘的事件等等。
因为是一个概念,本人能力道不清,说不明。所以用以下几种方式来解释一下什么是事件驱动,看的多了,就可以意会了。
例子1:
以下笔记中:Day9 - 异步IO数据库队列缓存 2.3章节
例子2:
在回到课堂上看看老师的另一种方式的讲解。(感觉有点跑题,不知道是不是自己理解不透的问题)
首先python跟其他语言相比,没有事件和委托,python是没有的。在其他语言中,这两者是什么呢?简单来说就是函数列表或者类的列表
Python里面没有事件?那事件能不能自己创造呢?
其他语言事件是怎么做的?比如C++语言的。是怎么驱动的?
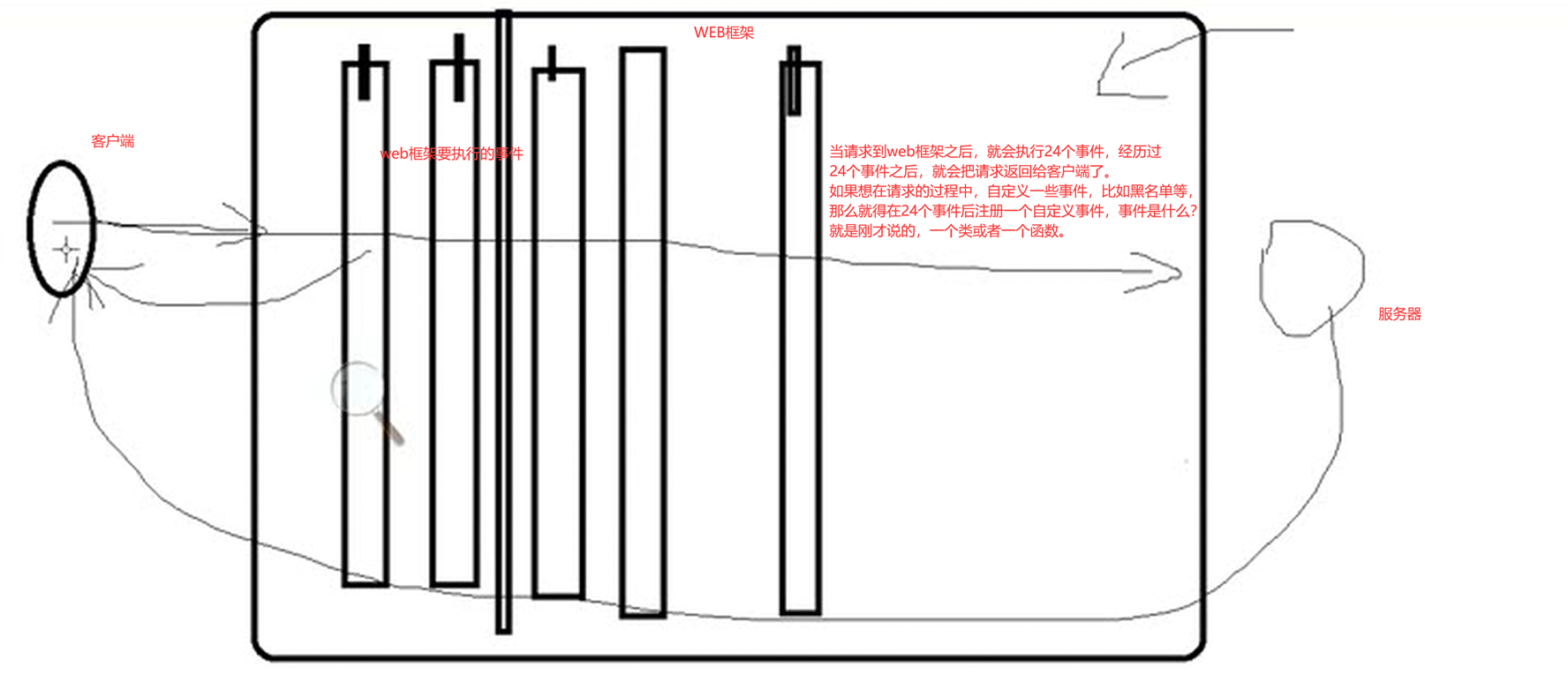
当请求到web框架之后,就会执行24个事件,经历过24个事件之后,就会把请求返回给客户端了。
如果想在请求的过程中,自定义一些事件,比如黑名单等,那么就得在24个事件后注册一个自定义事件,事件是什么?就是刚才说的,一个类或者一个函数。
这里举一个例子
假设下面这个框架有10万行代码,使用pip安装的,不知道里面是什么东西。
如果想使用这个框架,就需要按照框架开发者的约定,做以下几个事情。
- 自己写个类,集成Baseler
- 必须在类里面写execute方法
- 把类注册到event_list.
- Run方法
简单来说假设自己下载了一个web框架,自己要做的,就是把自己想要执行的函数按照框架约定放进去,那么就可以使用web框架了。
这里的例子就用课堂一个代码演示一下。
见以下链接中的4.1章节,就是一个使用框架,然后我们自己自定义事件的例子。
10.5 twisted构架介绍
twisted两章讲解的稀烂,跟s一样,自己都不知道自己讲解的什么,反正作业代码就在这个里面。可以复习视频,也可以看以下等会展露的博客连接来搞懂这个框架,目前没必要花大时间在这个上面。
并且,视频学习的时候twisted由2.7移植只3.X上面的工作还没完成,只能在2.7上面测试
博客连接:
1. Day9 - 异步IO数据库队列缓存 8.5章节
10.6 twisted简单文件异步传输
10.5和10.6的章节 概要基本一样。
10.7 午后鸡汤
10.8 redis介绍及常用操作
课程内容比较简单,就是照着博客敲了一遍,可以参考课堂博客,也可以参考以下博客学习:python redis使用介绍
10.9 redis发布与订阅
同上
10.10 rabbitmq介绍与使用
以下三章的内容整合到下面的博客中了: Python3 RabbitMQ
10.11 rabbitmq常用使用场景
10.12 rabbitmq实现rpccall及作业需求
11.L11
11.1 上节内容回顾
可无视
11.2 sqlalchemyorm介绍与使用
关于sqlalchemyorm的课表就不写那么多了,讲的简直无话可说,需要学习sqlalchemyorm的参考本人博客: Python3之sqlalchemy
这里还是提一嘴,视频sqlalchemy关联join查询开头讲解了relationship,backref,back_populates.(前10分钟)
11.3 堡垒机的开发需求介绍
堡垒机需求就是把这篇文章念了一遍,浪费了40分钟: https://www.cnblogs.com/lizexiong/articles/17255730.html
11.4 通过paramiko纪录用户操作日志
这篇视频是个音频,没有录像,好像是讲解一个单独的功能,不影响讲解,可以无视
11.5 设计堡垒机表结构且进行项目实例展示.
本章只是讲了数据表结构,然后老师拿自己之前写好的随便演示了一下怎么创建表,需要的去看本章作业源码吧,但是这个老师讲的很烂,源码仅仅只能作为参考。
当天总结:其实当天的课程不管是堡垒机还是sqlalchemyorm章节,其实都是讲解的sqlalchemyorm,堡垒机里面啥都没讲,就是讲该有几个表,哪些表有关联,堡垒机功能没讲,并且,sqlalchemyorm讲的很烂,常常讲错,并且不知道自己讲什么的,所以,这天的内容,参考本人的博客就行了
12.L12
12.1 上节回顾
回顾了一下sqlalchemyorm。包括relationship,backref,back_populates.等。
12.2 鸡汤
过
12.3 python
讲解为什么需要写前端
12.4 前端内容前瞻
讲解前端需要学习那些东西。
比如HTML,CSS,JS等,并介绍这三者的作用
12.5 本节可见介绍
就是讲解你不能用其它网上的模版写作业,前期全部靠手写。不能使用别人的代码。
12.6 http请求中如何是用html
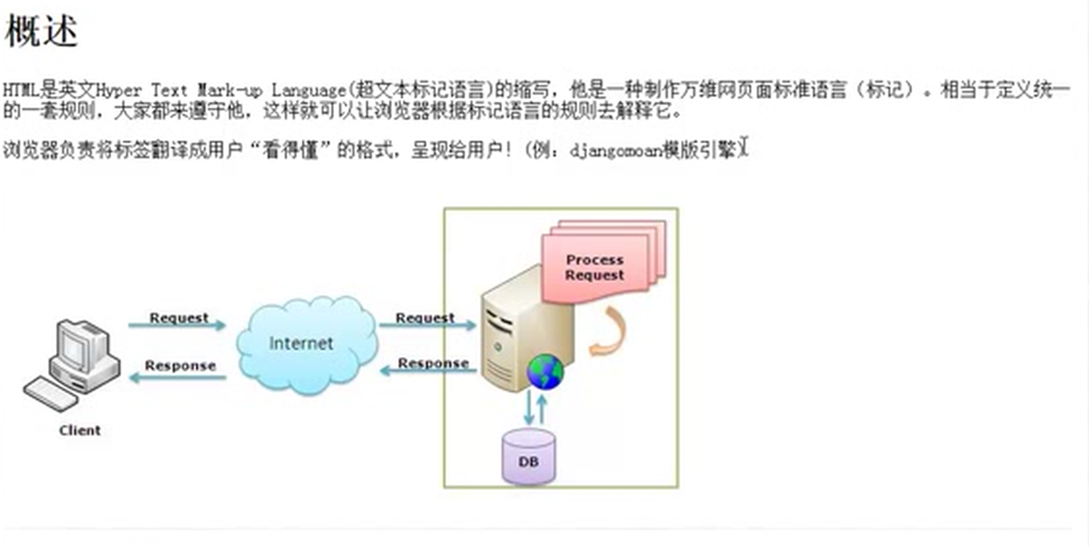
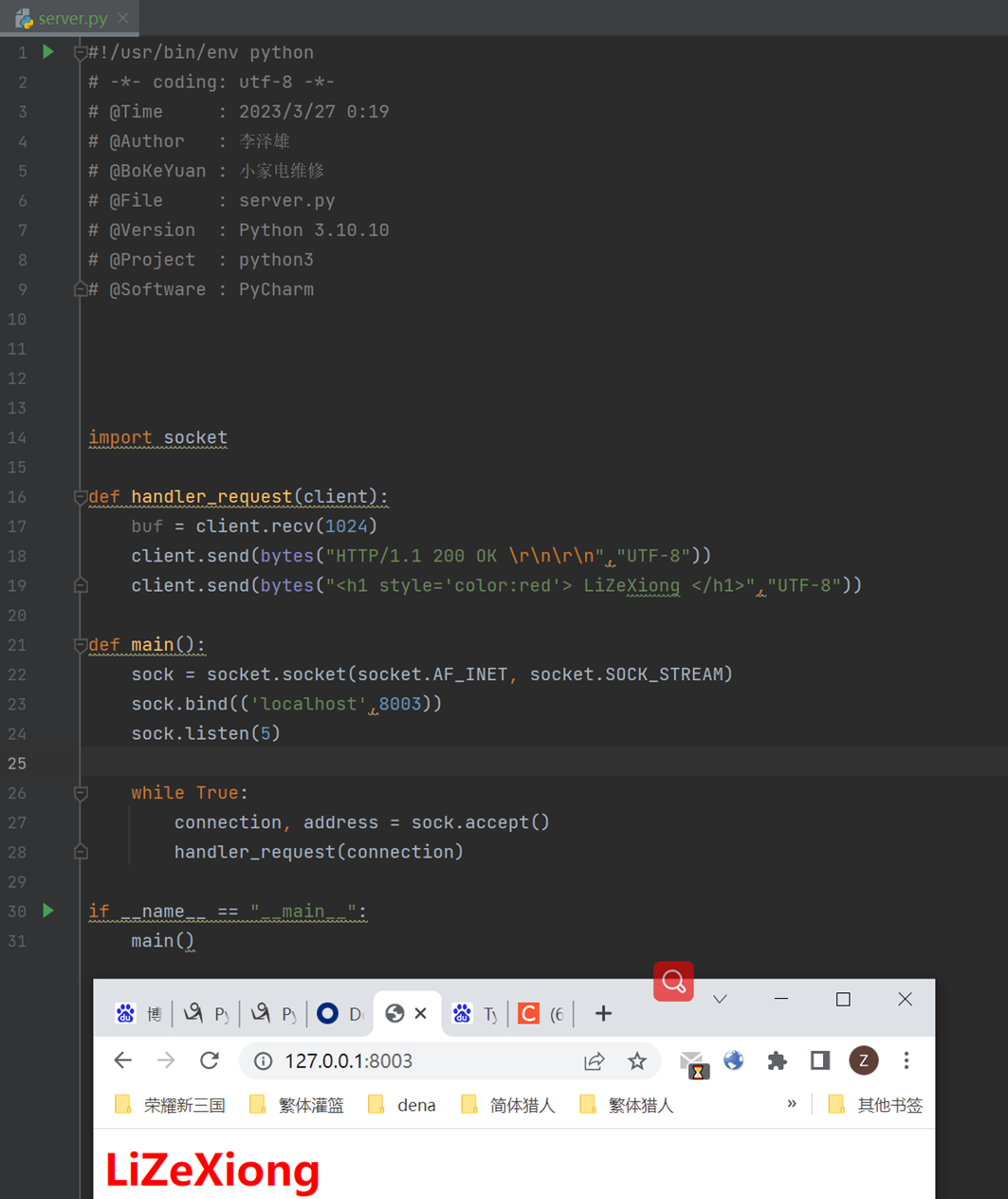
简单来说就是服务器返回的其实是字符串给浏览器,浏览器根据预定的规则给你显示成用户看的很爽的界面。
看以下用Socket模拟的返回演示。
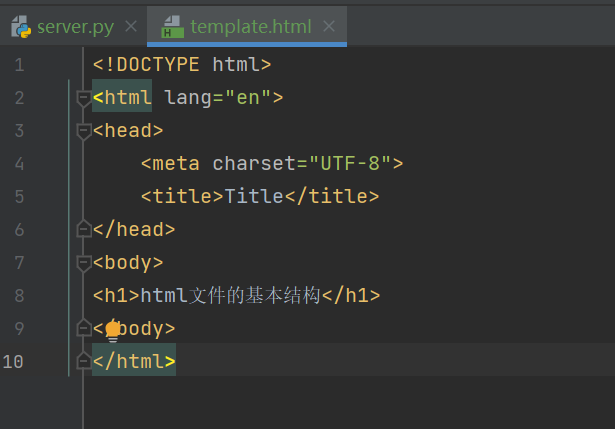
12.7 html文件的基本结构
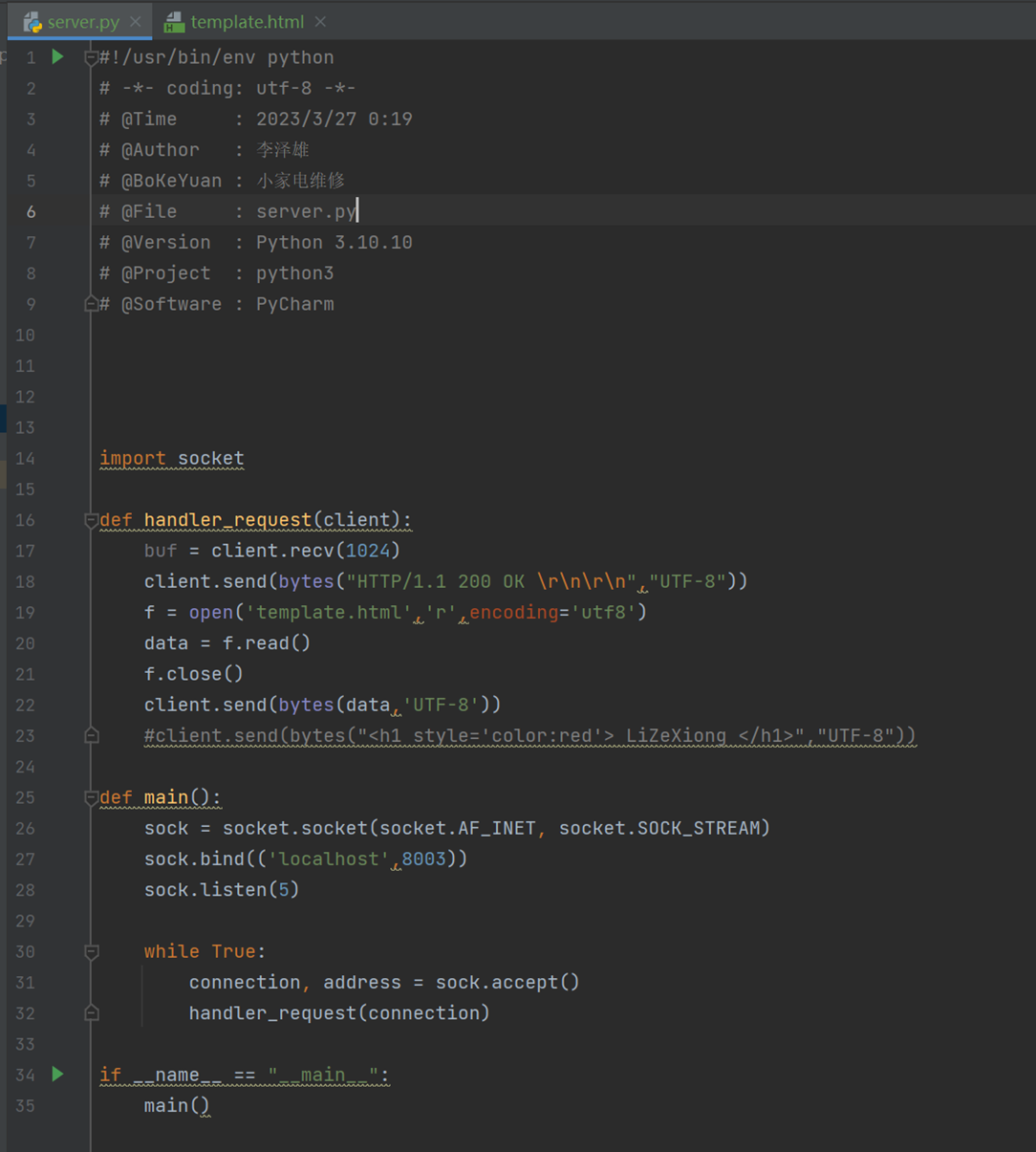
简单来说,最简单的就下面就是基础的html框架。
然后基本上所有语言的web框架都是通过读取这样的文件然后把字符串返回给客户端
12.8 html结构之head

第五点就是为了兼容ie6为生的

12.9 html结构之head2
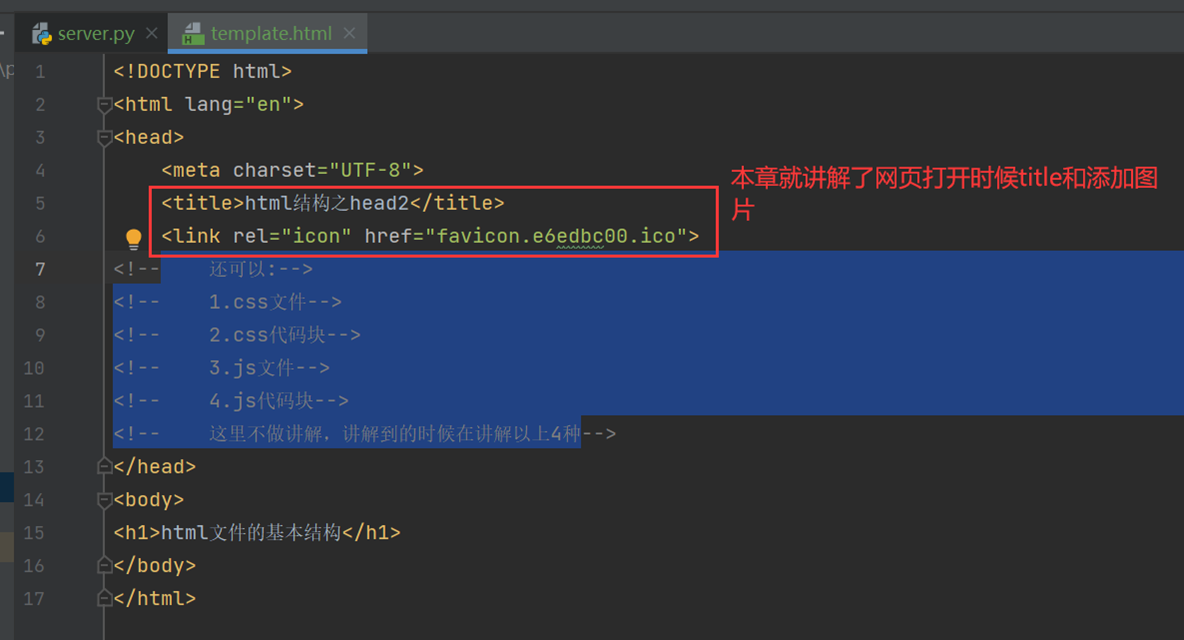
注意,打开这个html的时候,这里就不要用socket去打开了,如果使用socket打开,需要调整socket代码,这里目前不必深究,这里直接双击html即可。
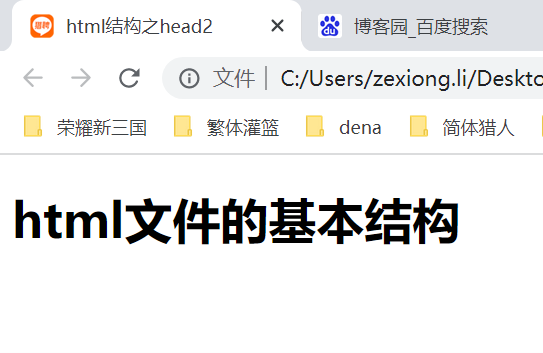
12.10 html标签之标签分类、符号、p已经br标签
块级标签和内联标签,但是没有绝对的,可以通过css更改它原本的属性。
教学笔记里面就是


12.11 html标签之a标签

代码实例:

12.12 html标签之select标签
以下总结一些东西,id,style所有的标签都可以定义属性,而targer和href属性是a标签独有的,img又独有title和src。

还有一个select


带上值

12.13 html标签之input系列和form标签


提交form的信息
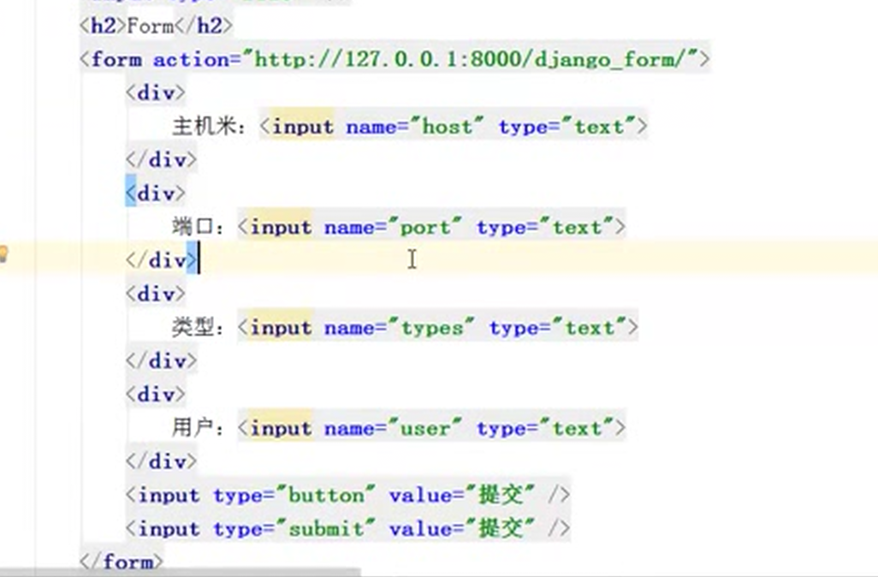
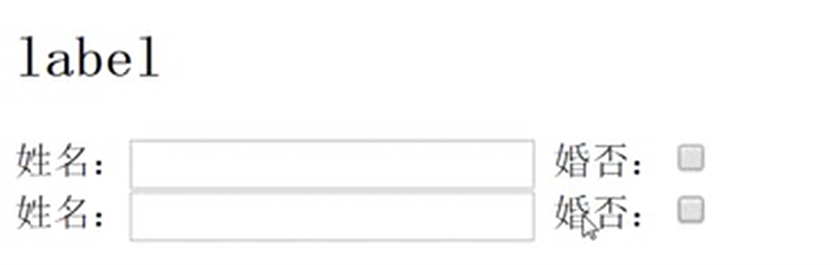
12.14 html标签之label和列表标签
点姓名或者婚否就可以直接到输入框里或者选中。

列表
12.15 html标签之tabel标签

水平合并单元格

垂直合并单元格
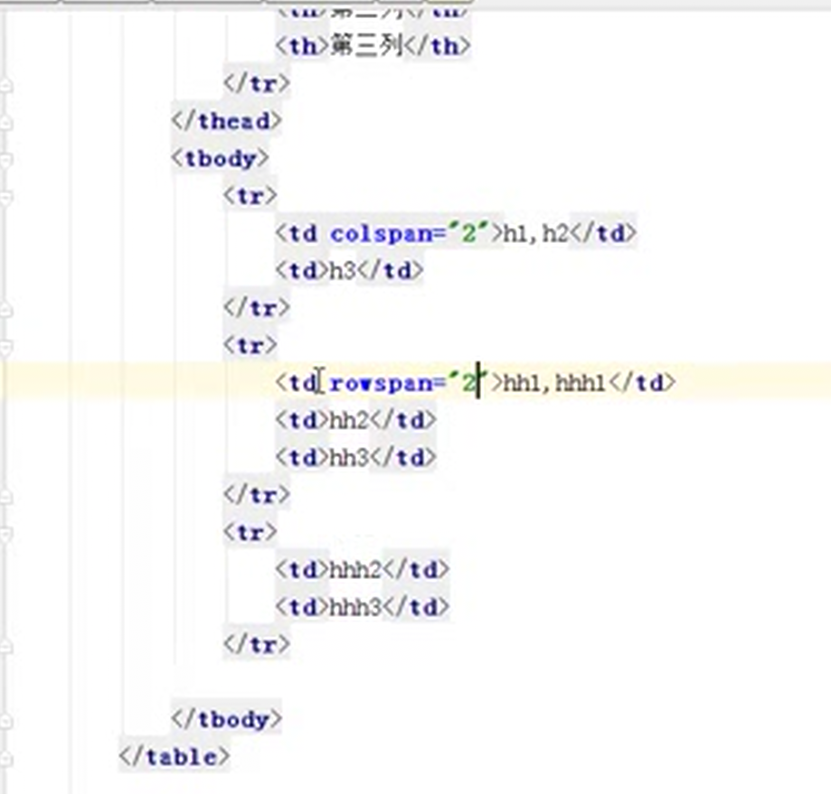
也可以不要thead和tbody,但是不太标准,建议还是加上
12.16 html标签梳理和实例
本章复习了视频上半天的所有html标签,并且按照以上标签写了一个实例,实例代码在本章笔记最下面
在框上写文字。

总结:







以上是对html的总结,下面是对于总结的演示代码
12.17 作业一

12.18 css样式存在位置
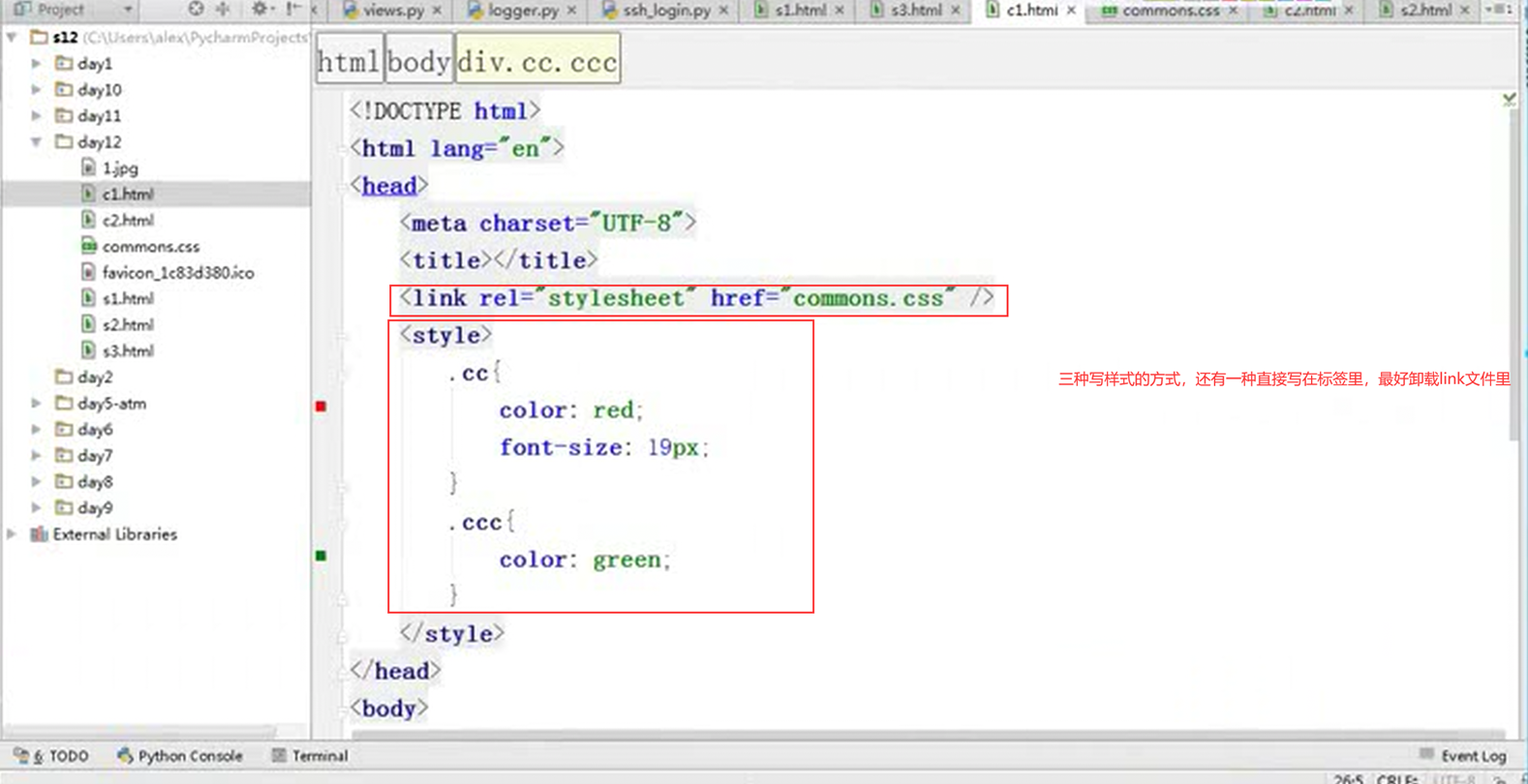
12.19 css之基本选择器
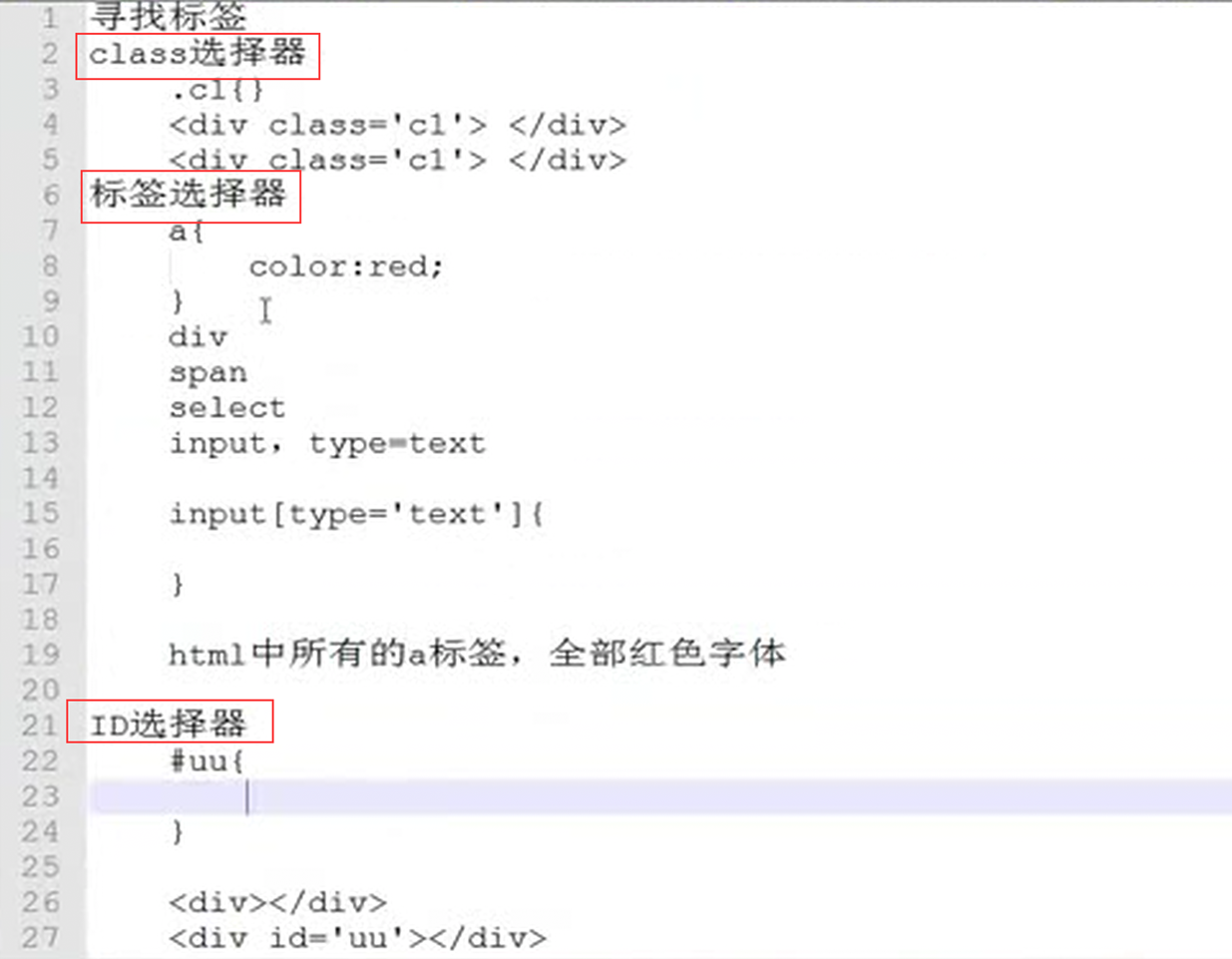
12.20 css之其他选择器

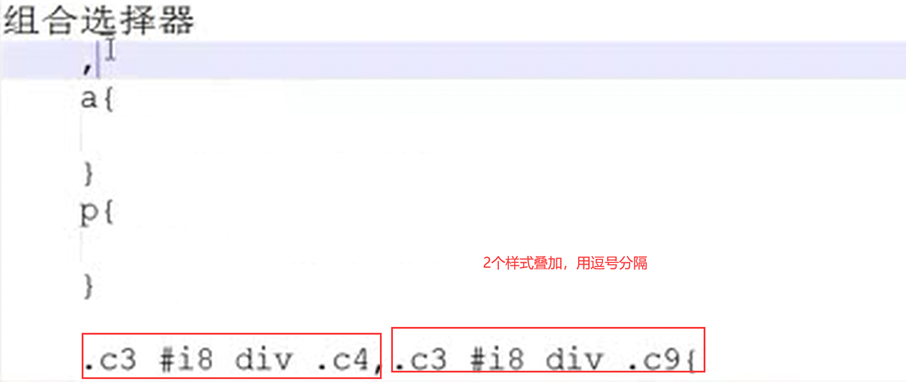
12.21 css之backgroud属性

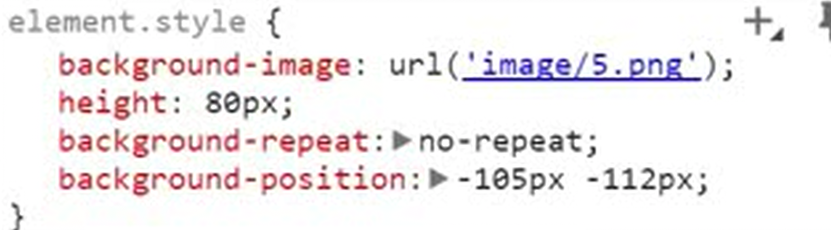
都是组合用法,比如想用position,需要先设置高度啥的,抠个洞才能设置位置,以上几个用法要自己测试。
有必要的话还是回来翻视频吧。
12.22 css之border属性
边框

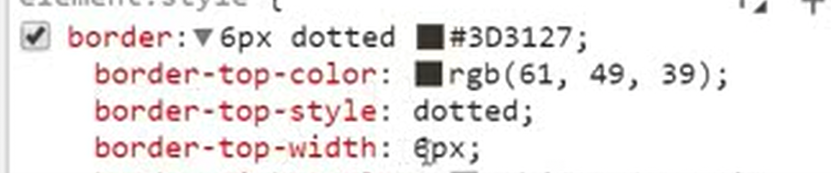
12.23 css之display属性

None是隐藏.
Block是把块级标签变成内联标签
inline是把内联变成块级标签
12.24 css之cursor属性
改变鼠标放置上去的样式。

还有一个自定义,比如鼠标放上去显示一张图片或者你自定义的东西

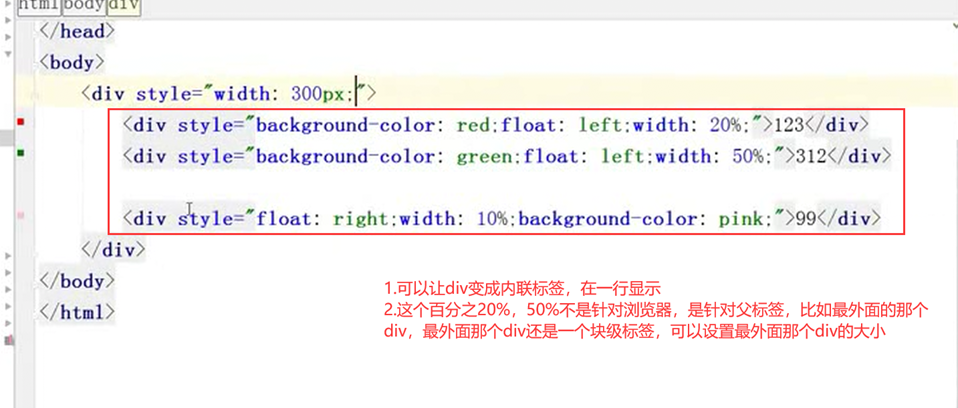
12.25 css之float属性
可以让块级标签,比如div可以一行显示,浮动起来。
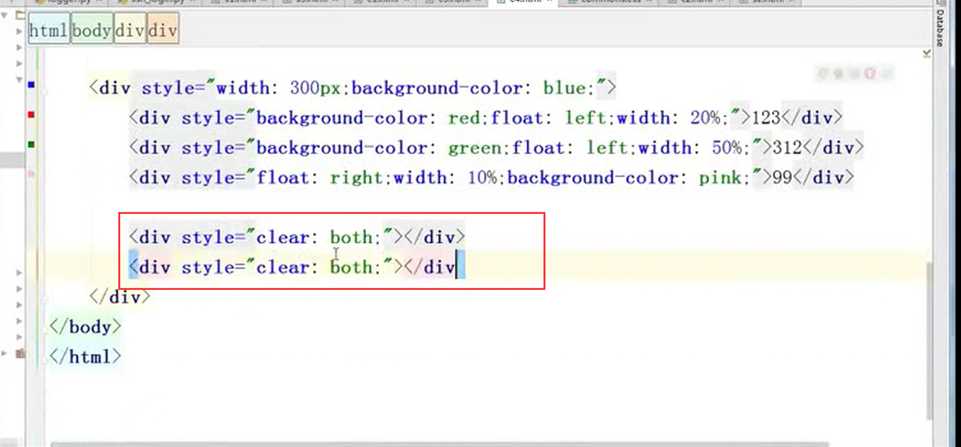
12.26 css之float属性2
如果一个div里面定义了float,那么父标签就消失了。
比如一个div里面有10个<p>,那么div会根据这10个<p>标签变大,如果用了float,那么就不会变大了。因为父标签大小消失了。
用了float怎么才能让父标签回来,就下图这个参数即可
本章比较饶,需要多做实验或者复习视频。
12.27 css之position属性


12.28 css之透明度和层级
每个层级不一定谁会在谁上面,但是可以使用z-index控制谁在最上面,数字越大,越在最上面。
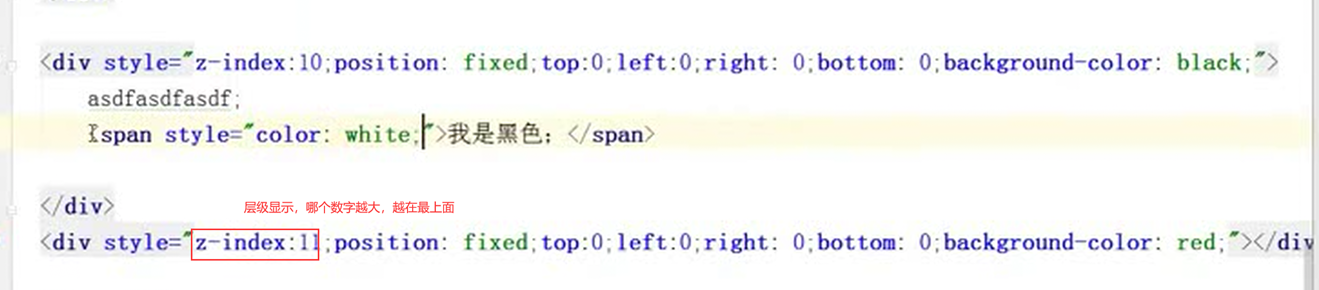
12.29 css之padding和margin属性
不管是内边距还是外边距,都需要增加一个边框或者有一个固定高度的东西才能实现。

12.30 作业二
13.L13
13.1 前端内容概要

13.2 今日内容介绍

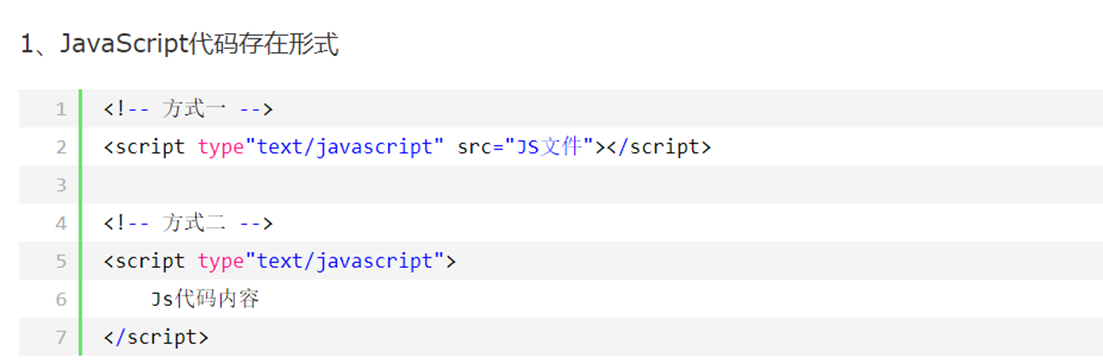
13.3 javascript代码存在形式以及存放位置
2种方式
比如写一个alert出一个ft然后弹出f2弹窗的效果,可以这么写。
(f2函数在comons.js里面,这里就不截图了)

13.4 javascript声明变量

13.5 javascript数据类型之数字
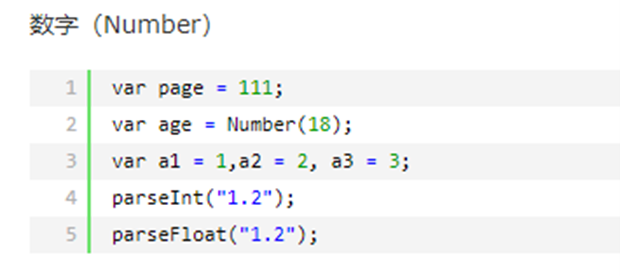
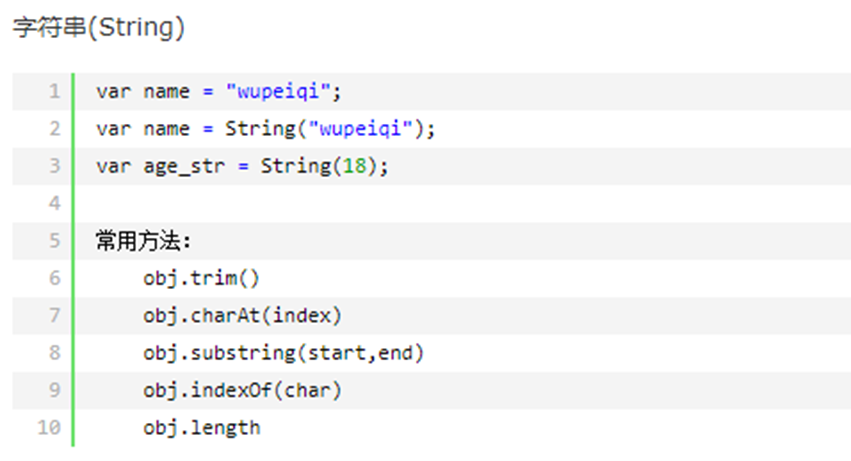
13.6 javascript数据类型之字符串
13.7 javascript数据类型之数组和字典

13.8 javascript序列化和反序列化

13.9 javascript两种for循环
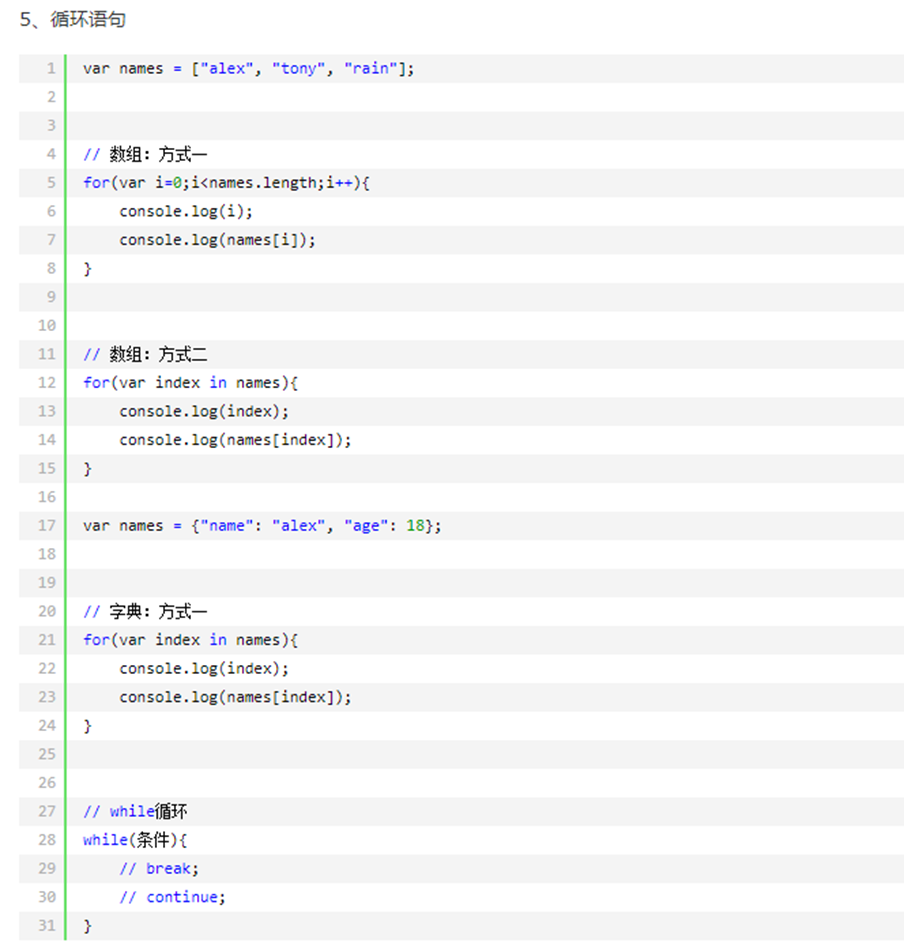
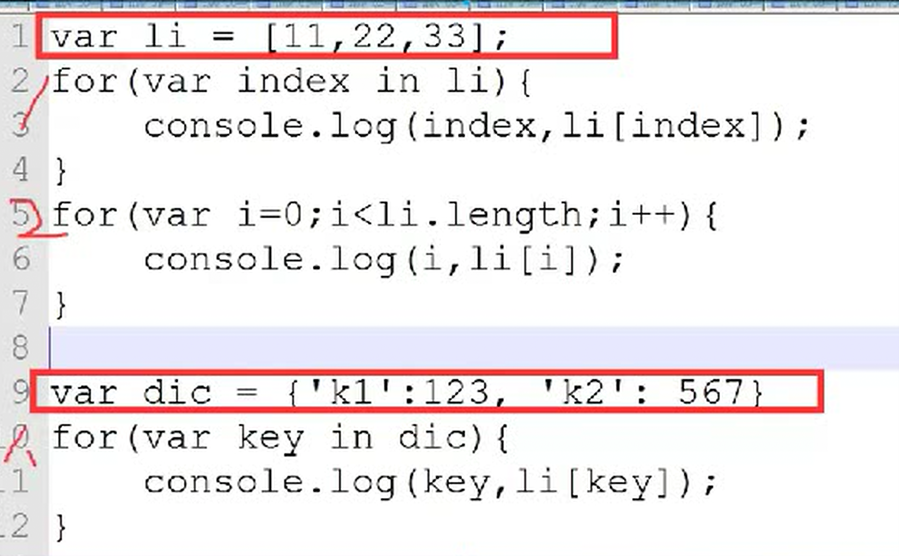
课堂实例:数组有2种循环,字典默认只有一种
13.10 javascript条件语句和异常处理
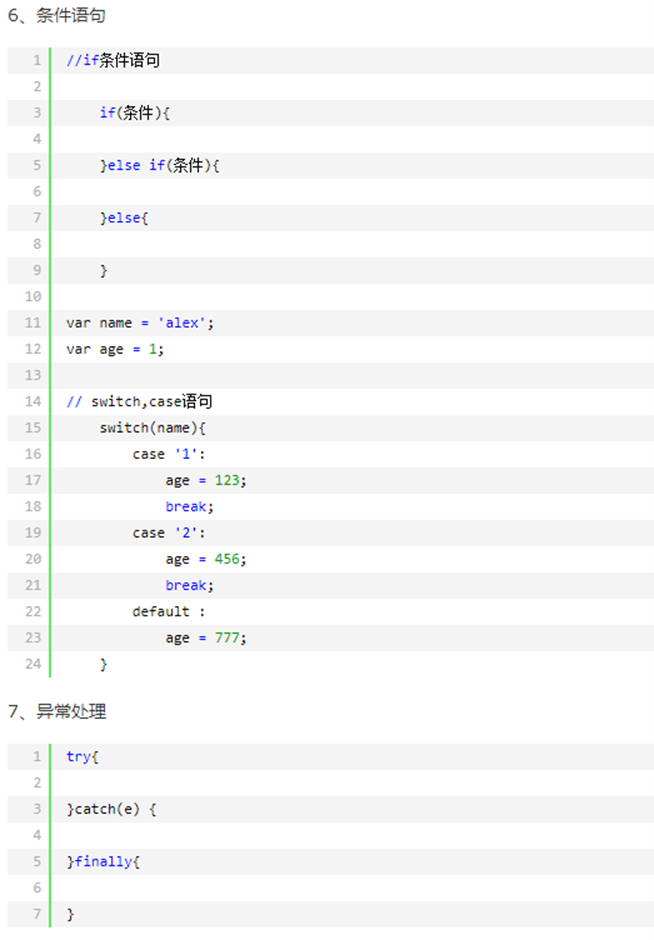
13.11 javascript函数

13.12 javascript面向对象
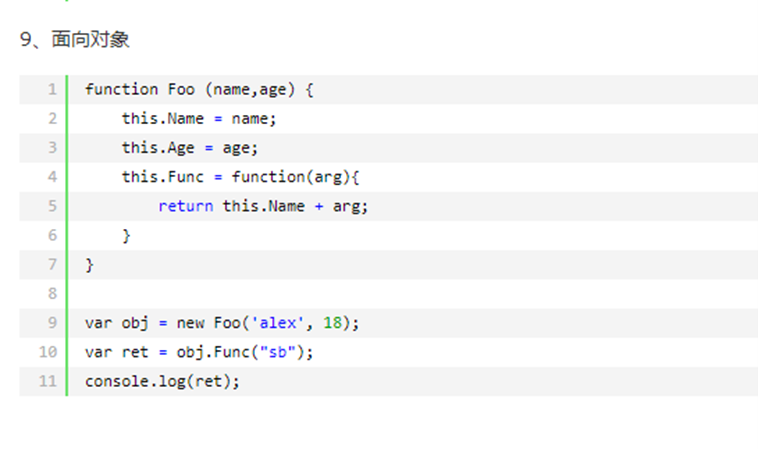
13.13 今日作业(其实是昨日作业)
就是讲解了一下昨天的作业
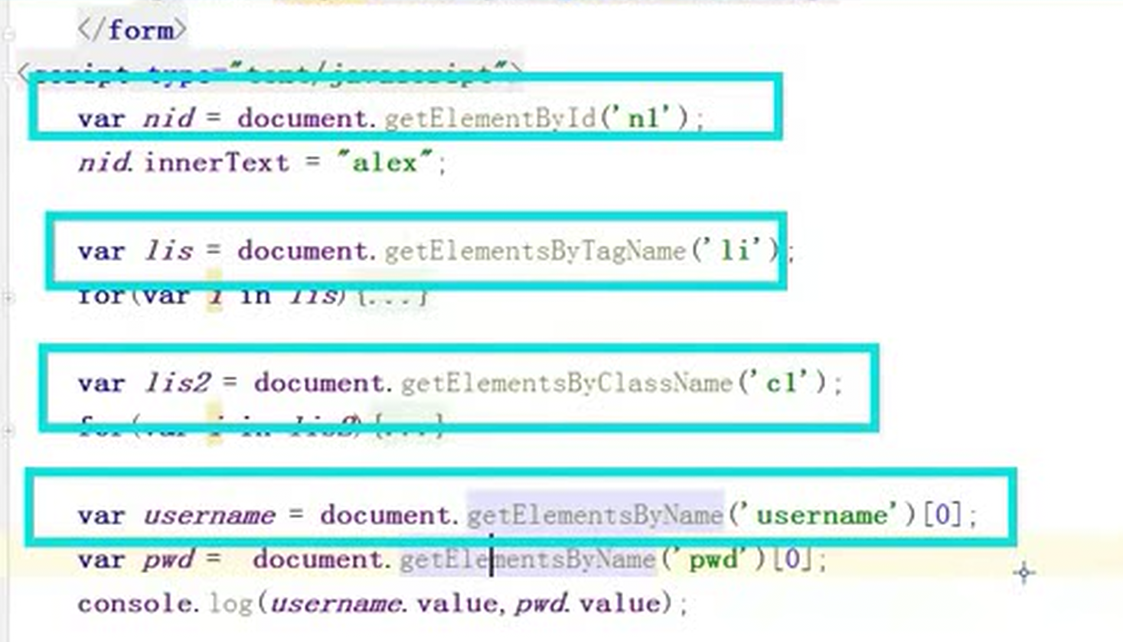
13.14 dom编程之选择器
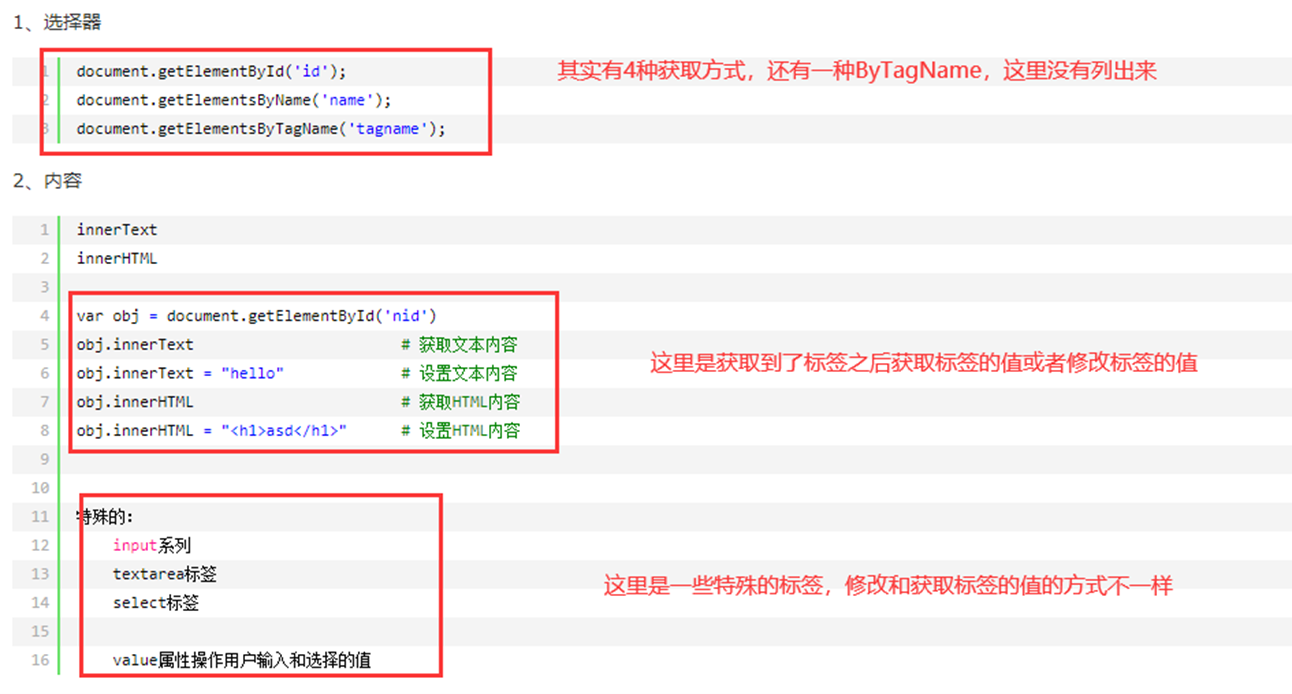
课堂实例,这里获取标签的方式有4中,在上图中已有补充,这里贴出来只是做个简单的记录。
具体的使用方式见以下博客:
13.15 dom编程之自增数字实例
这里是一个网页有个h1标签。值为1的比钱,点击一下增加,这个数字就会自增的案例。
查看源码
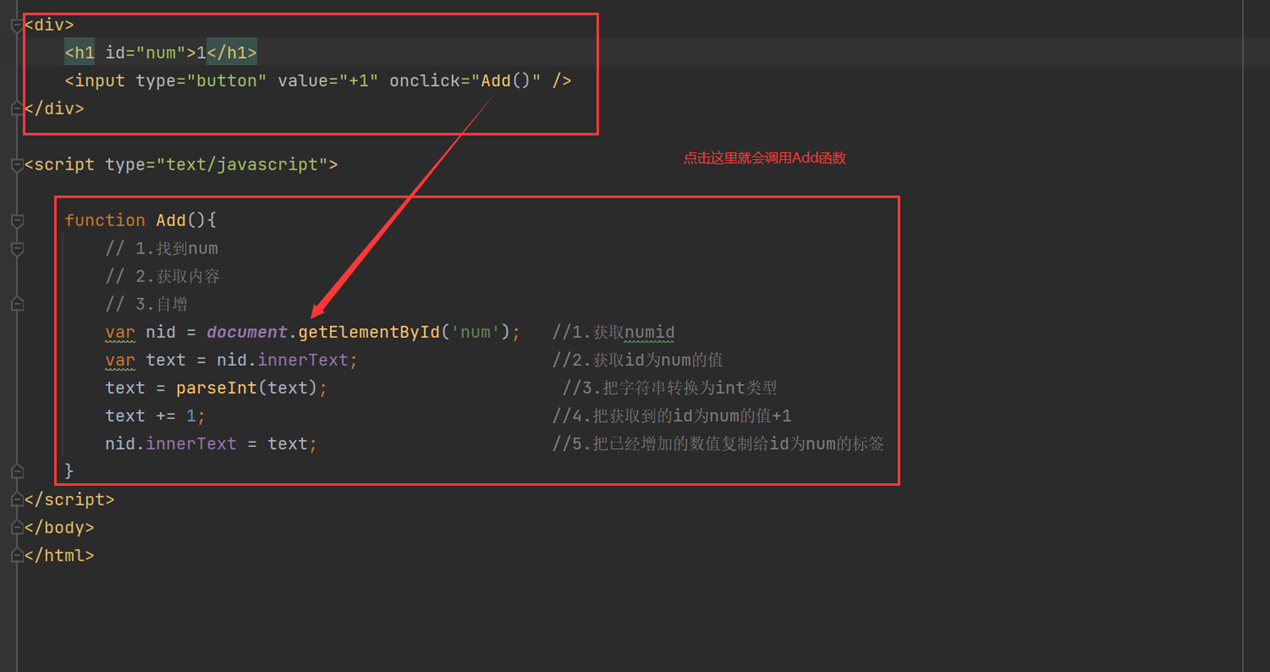
查看网页结果

13.16 dom编程之操作文本内容

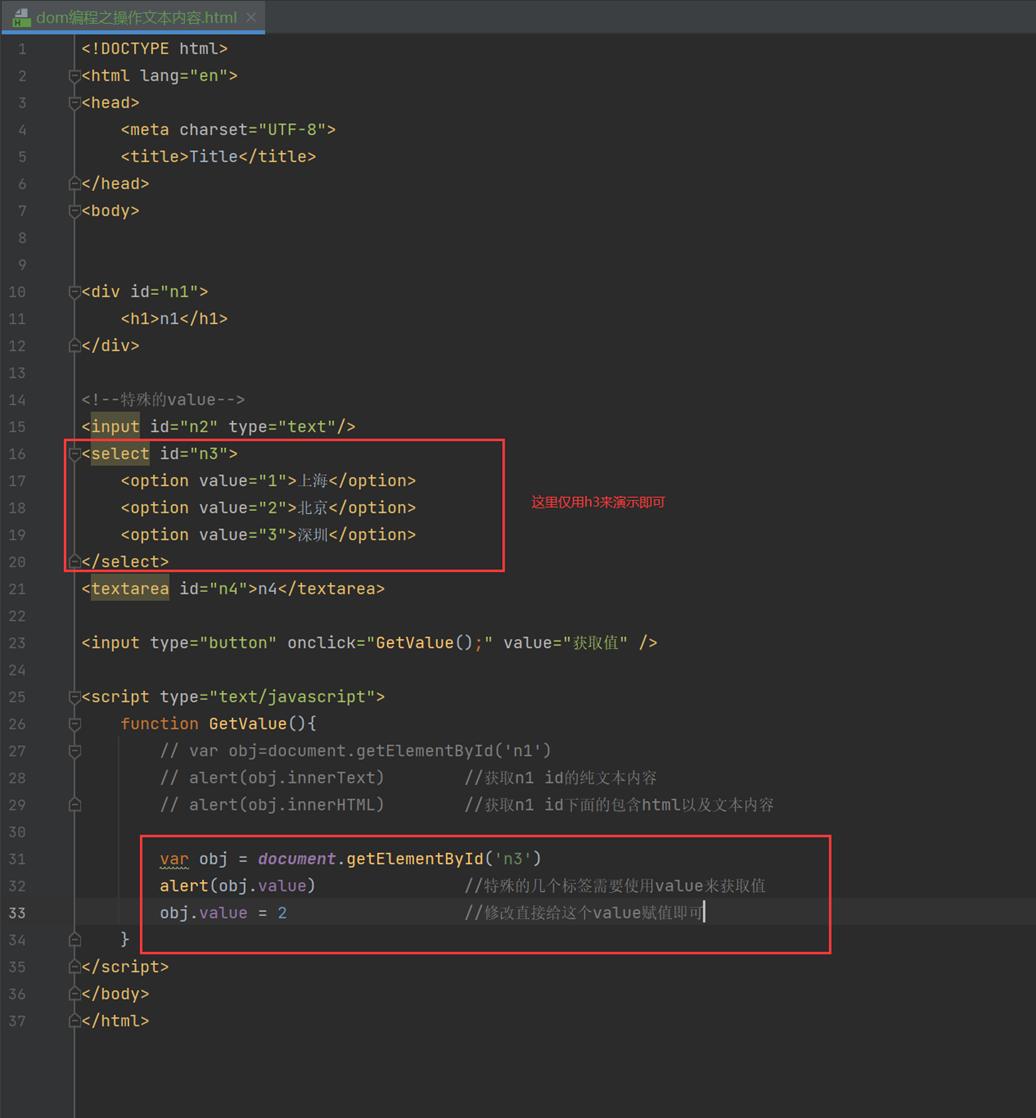
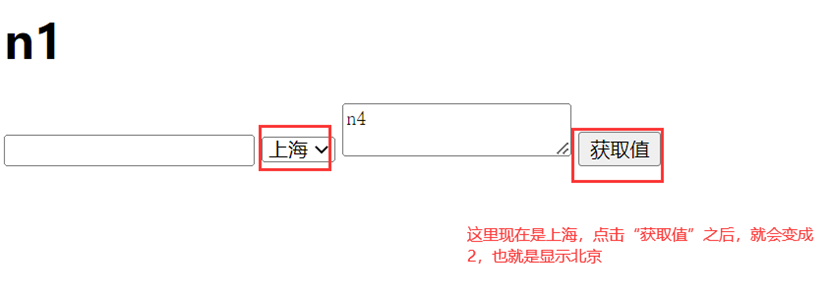
课堂使用4个实例的标签来演示怎么获取值以及修改值。
如以下的n1,一个普通标签,使用innerText就可以修改和获取
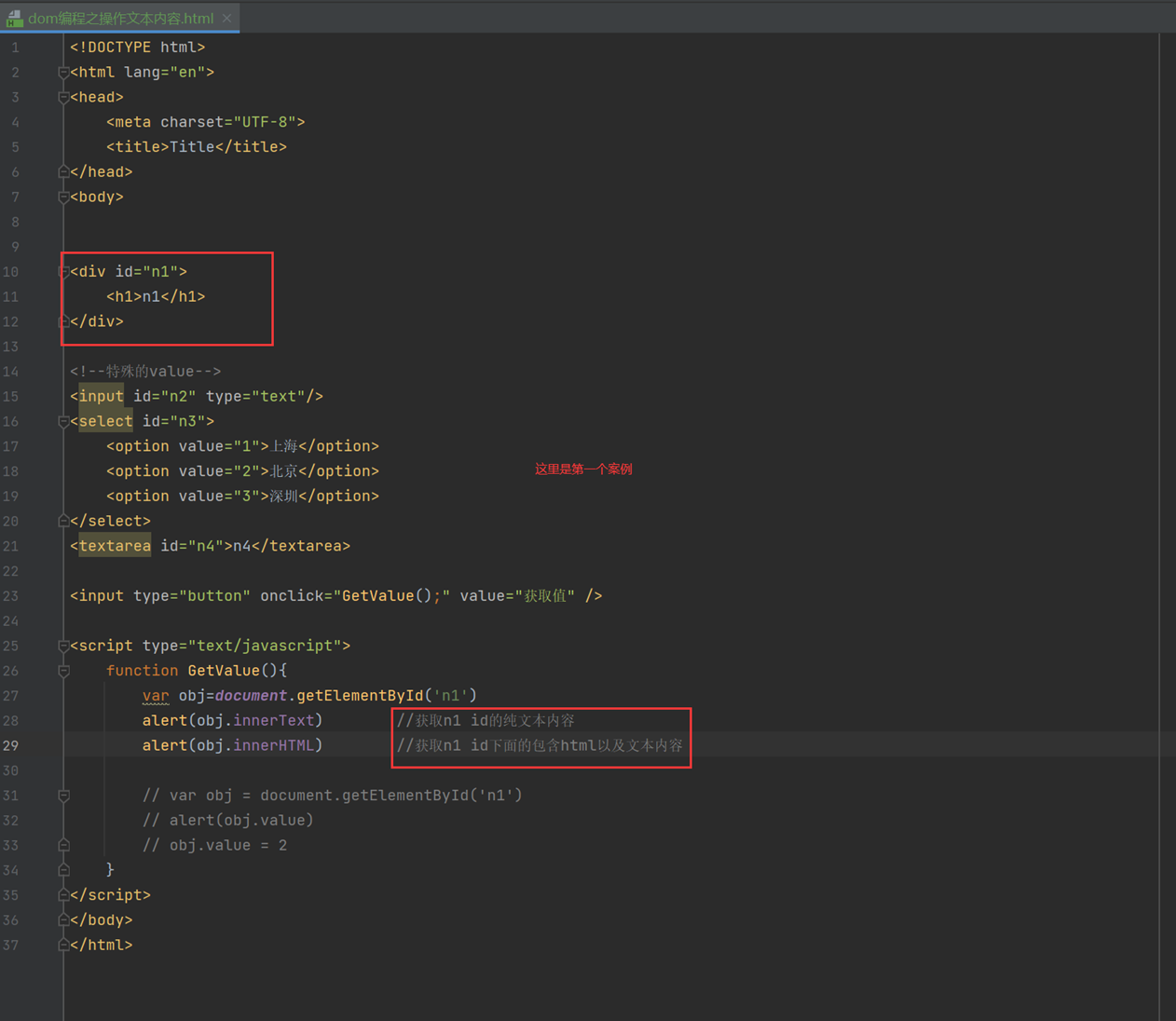
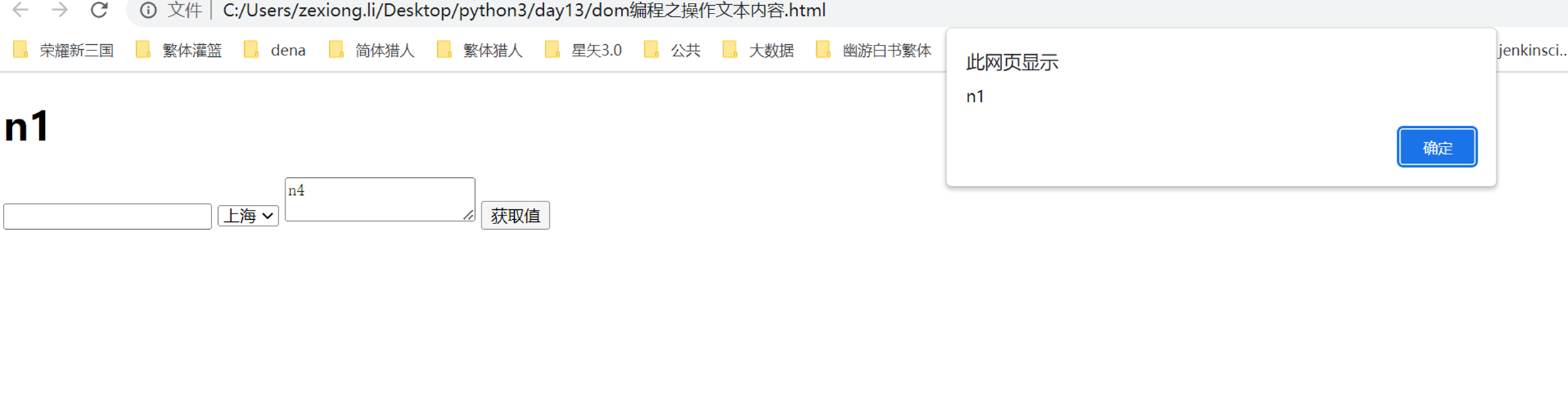
结果
会有有个弹出对话框
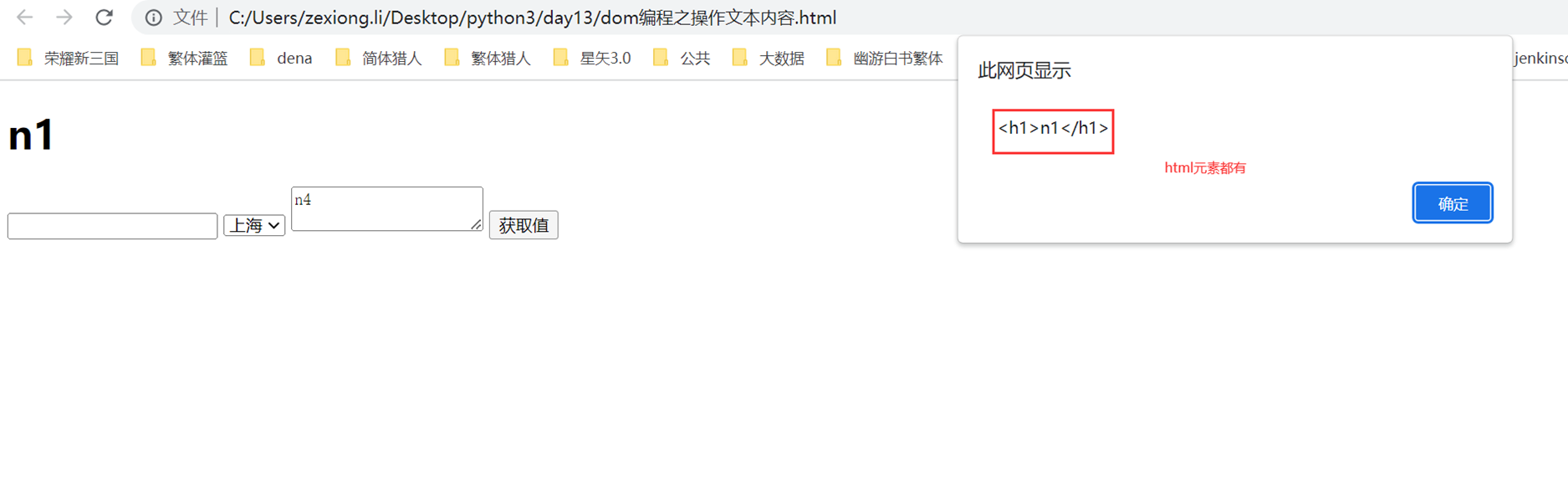
接下来就是比较特殊的元素标签,需要使用value来获取值以及修改值。
n2,n3,n4都是特殊的需要使用value来获取值以及修改值,所以这里只用n3来演示即可。
查看网页
点击前
点击后
13.17 dom编程之事件和搜索框实例
dom还有很多事件,这里的搜索框实例,需要使用以下2种事件。
这里就是案例代码
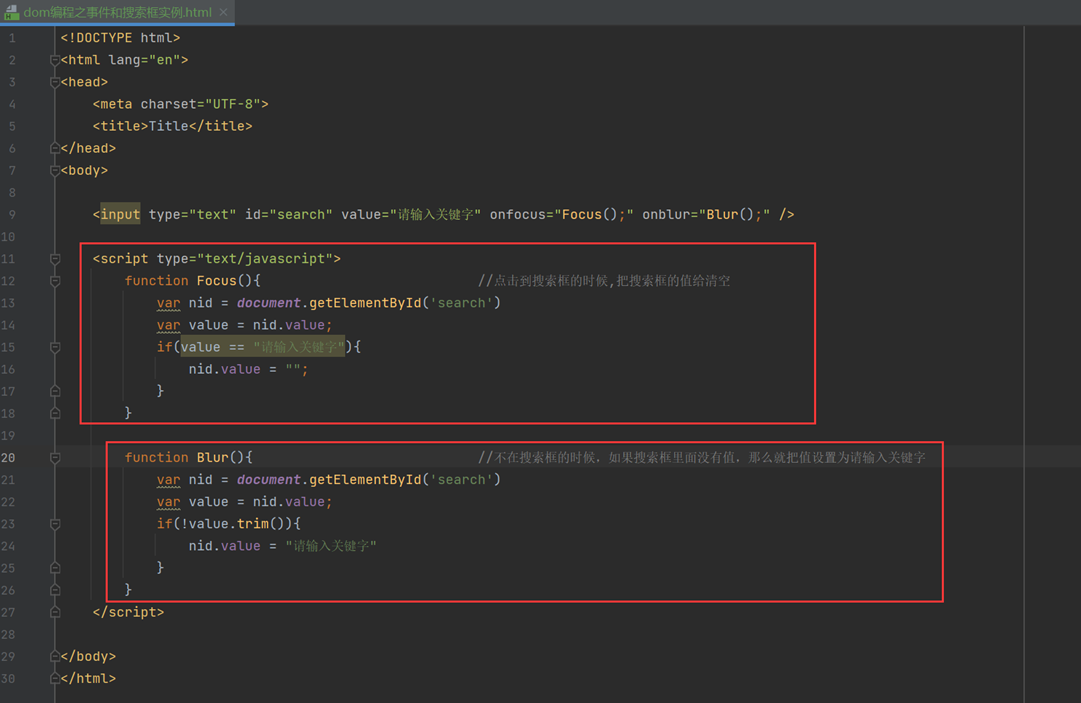
由于结果是个动图,就不贴出浏览器显示效果了
13.18 dom编程之创建标签
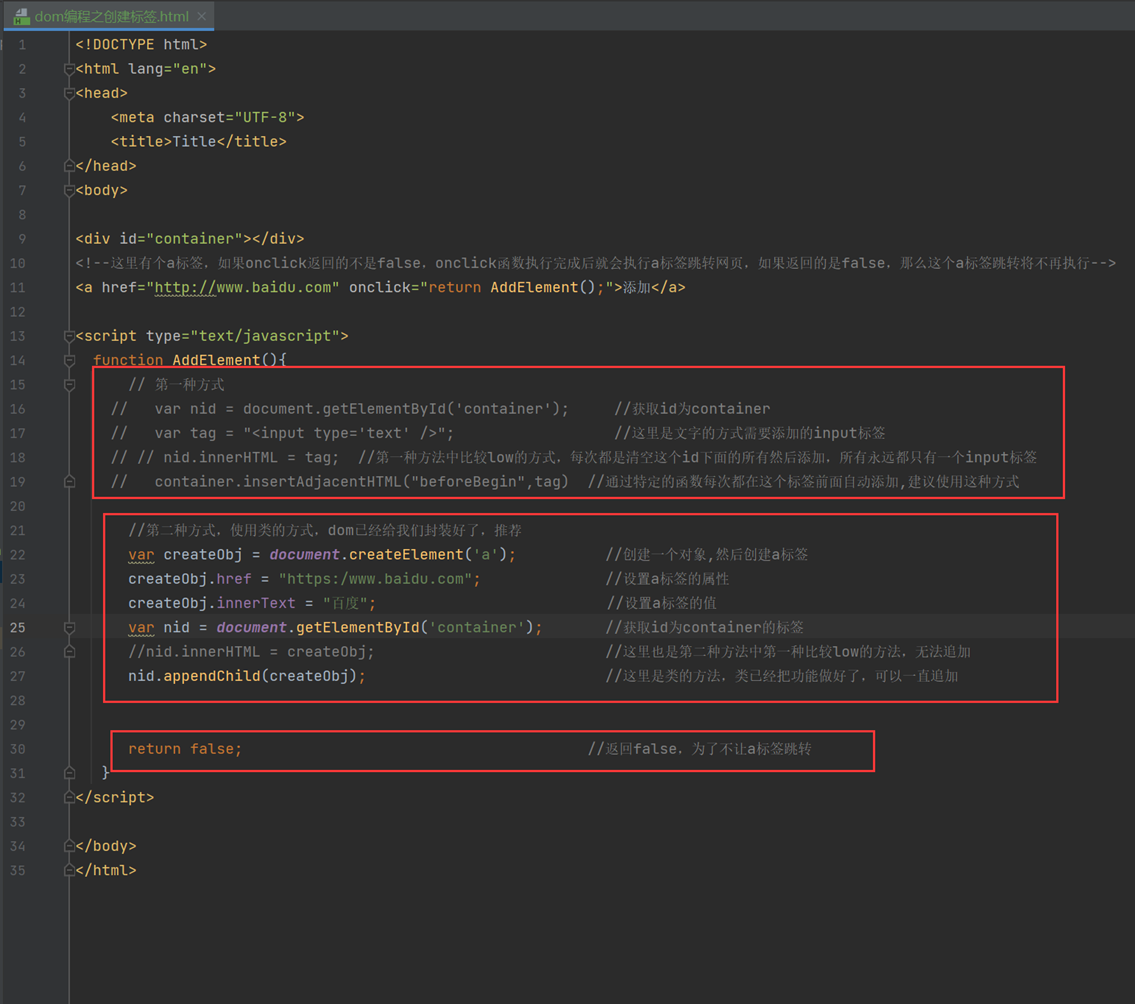
创建标签的用途就是比如点击一个按钮自动创建一个input输入框,或者一个a链接,当然创建方式有2种,一种是直接字符串的方式,另一种是直接使用dom的类功能添加(推荐)。
第一种方式,直接添加字符串的方式。第二种直接对象的方式创建一个标签,然后在设置属性,都在下图代码中有实例。
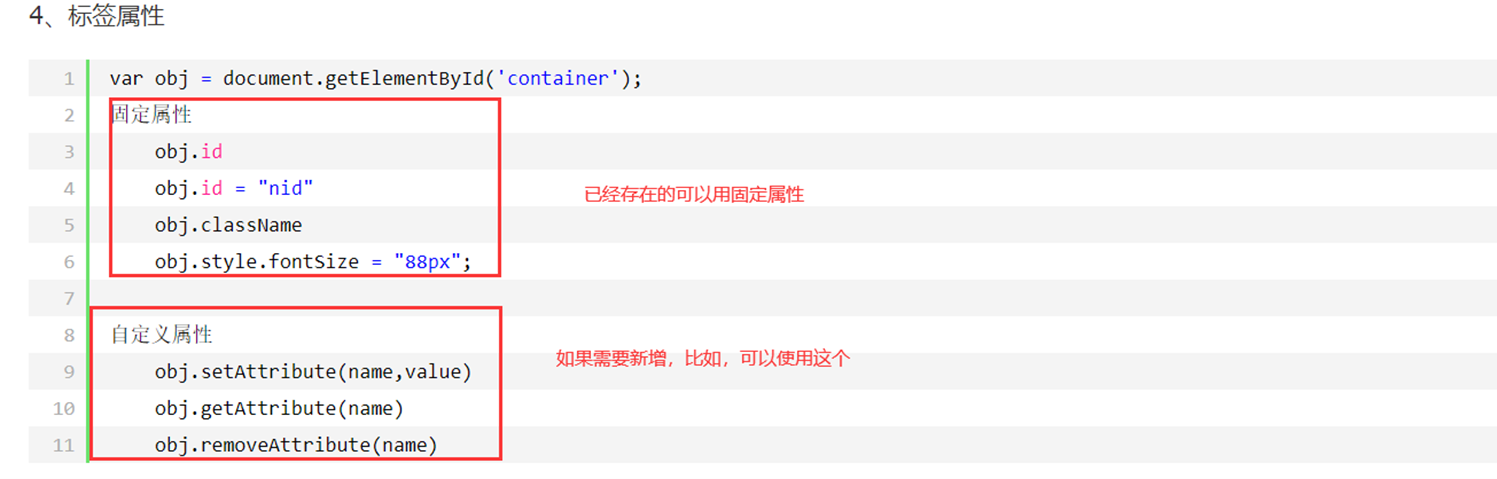
13.19 dom编程之操作标签属性
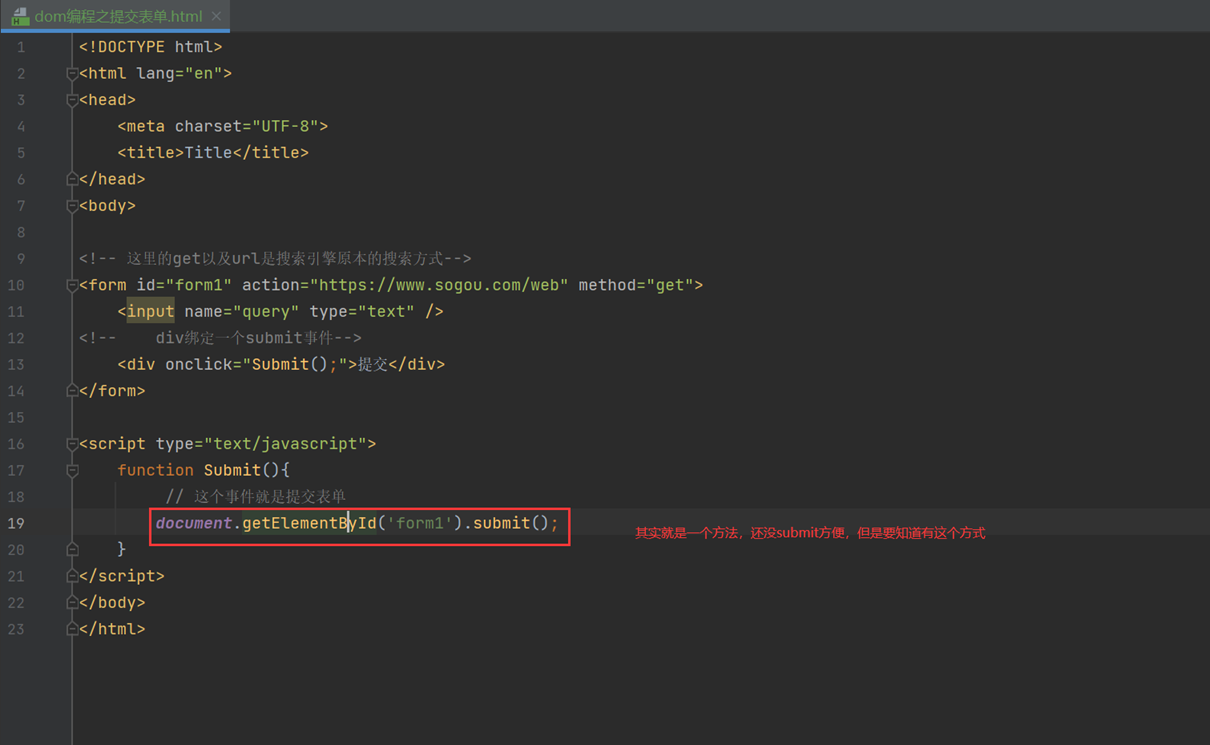
13.20 dom编程之提交表单
提交from表单一般都是使用input的type为submit提交,这里js也是有个submit方法来提交的。
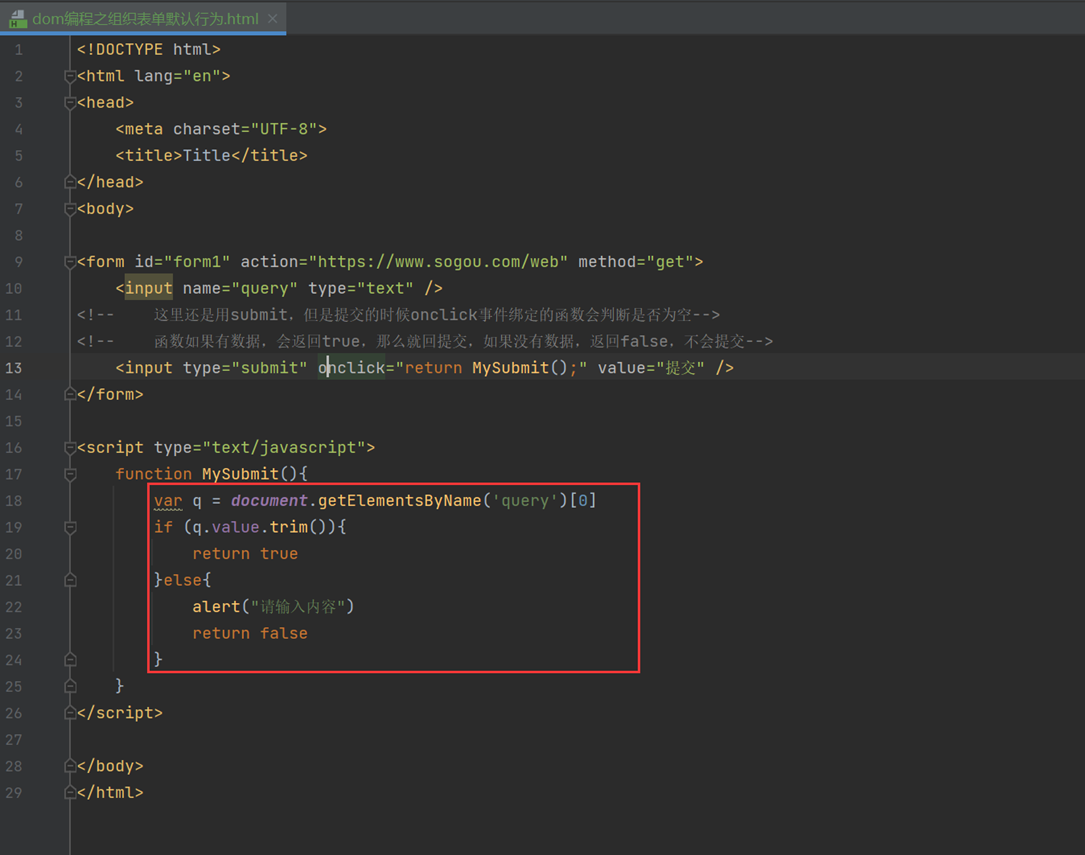
13.21 dom编程之组织表单默认行为
跟着上面的例子,我们说第一种方式input的type=submit,如果要提交一个form表单,是不是form表单里面有数据时才提交,没有数据时不提交?
根据之前学习的原理,函数返回是false不提交,是true才执行submit或者a跳转的操作,那么这个问题就很简单了。创建一个点击事件,判断input里面是否有值,有值返回true,没有值返回false就可以解决。
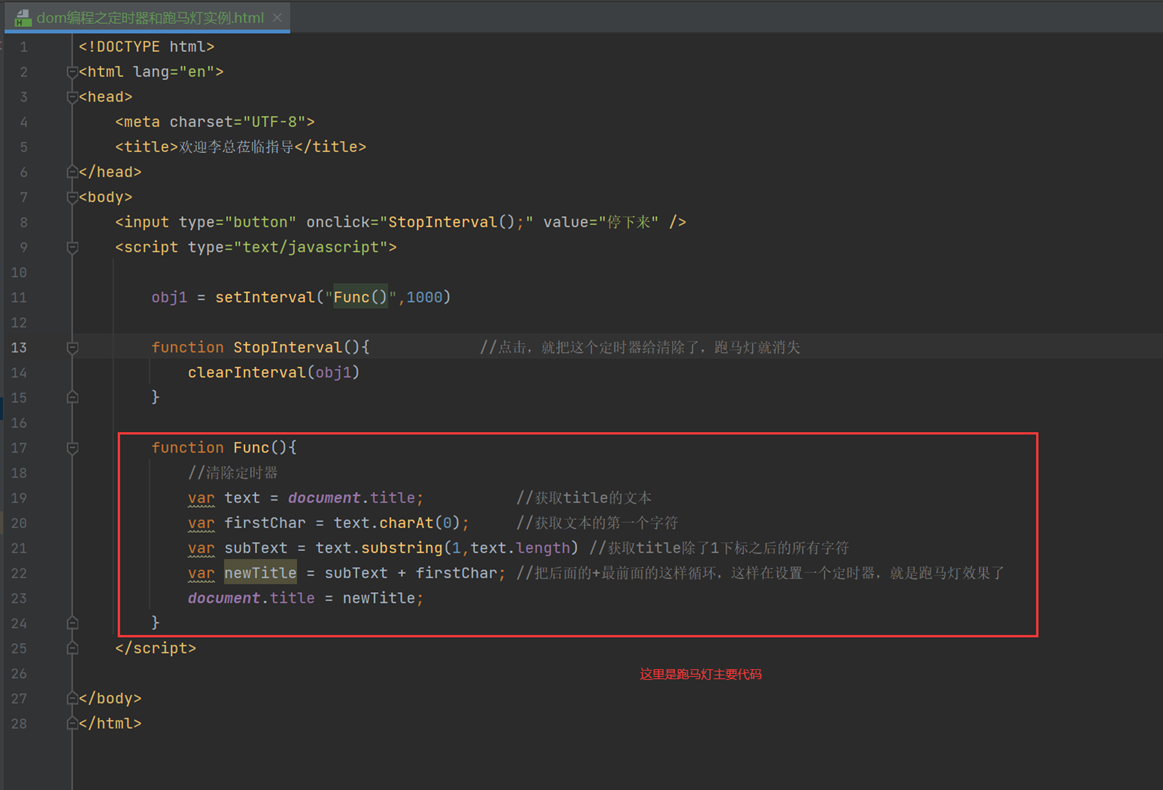
13.22 dom编程之定时器和跑马灯实例
现在进入跑马灯学习
13.23 jquery简介
jQuery是一个兼容多浏览器的javascript库,核心理念是write less,do more(写得更少,做得更多),对javascript进行了封装,是的更加便捷的开发,并且在兼容性方面十分优秀。
http://www.php100.com/manual/jquery/
本章就是讲解了怎么下载jquery以及引用jquery。
13.24 jquery之基本选择器
id选择器
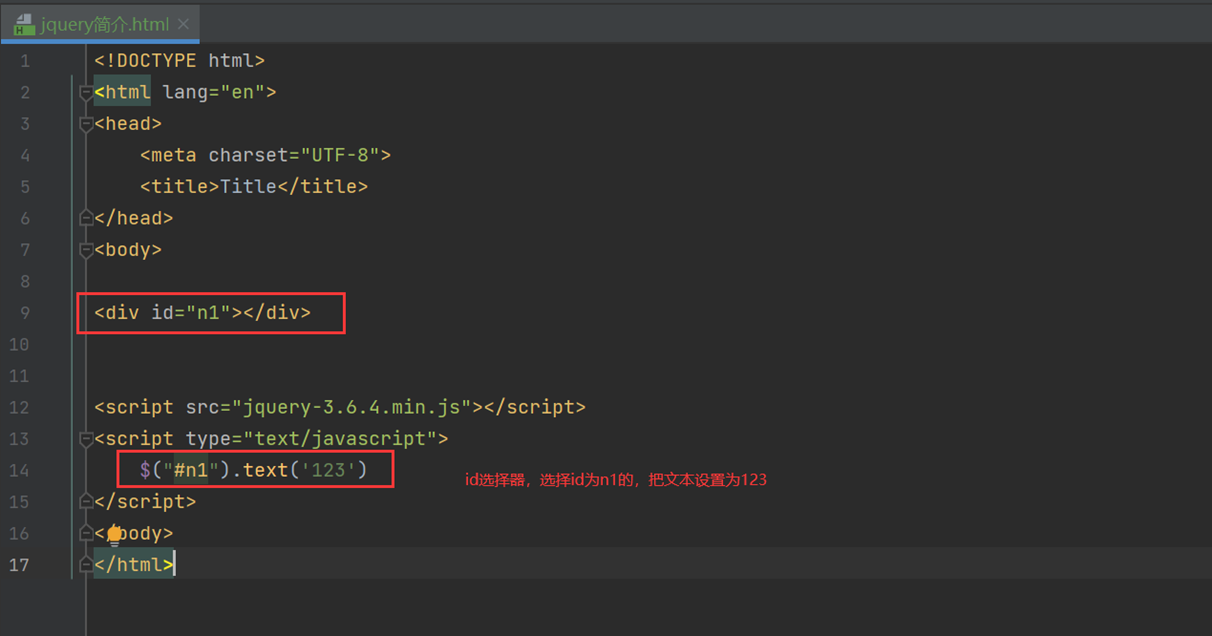
找到所有的div
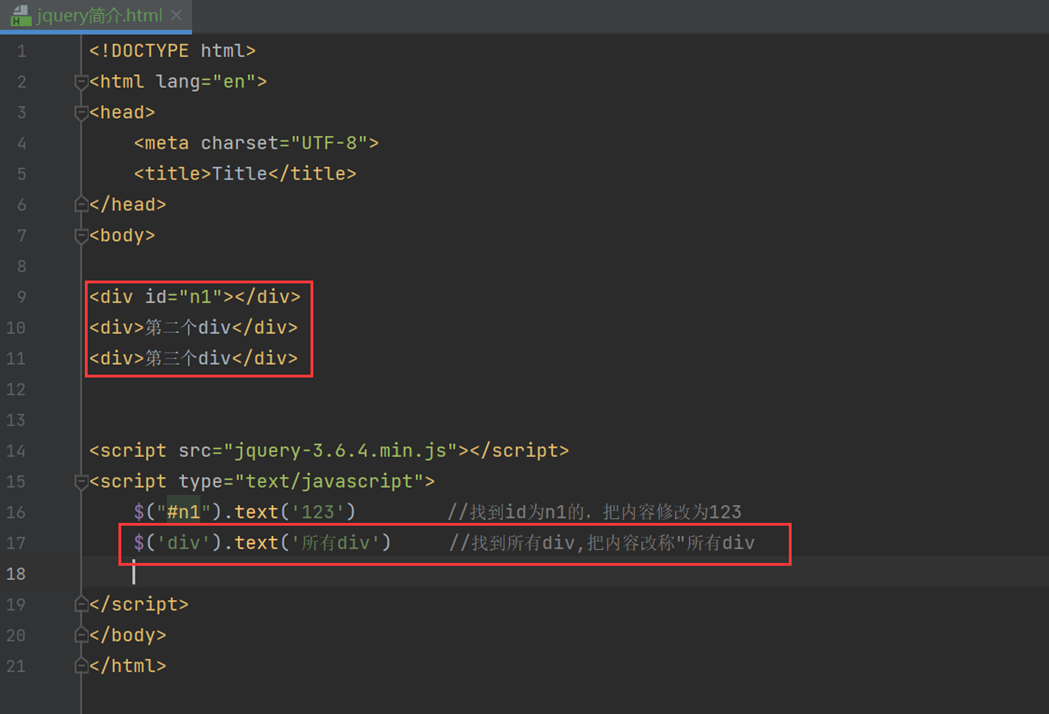
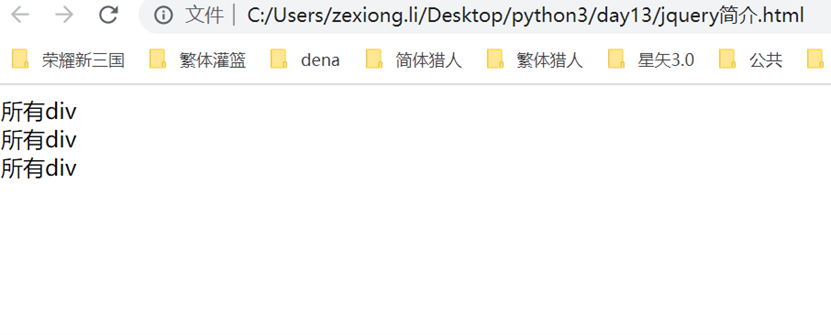
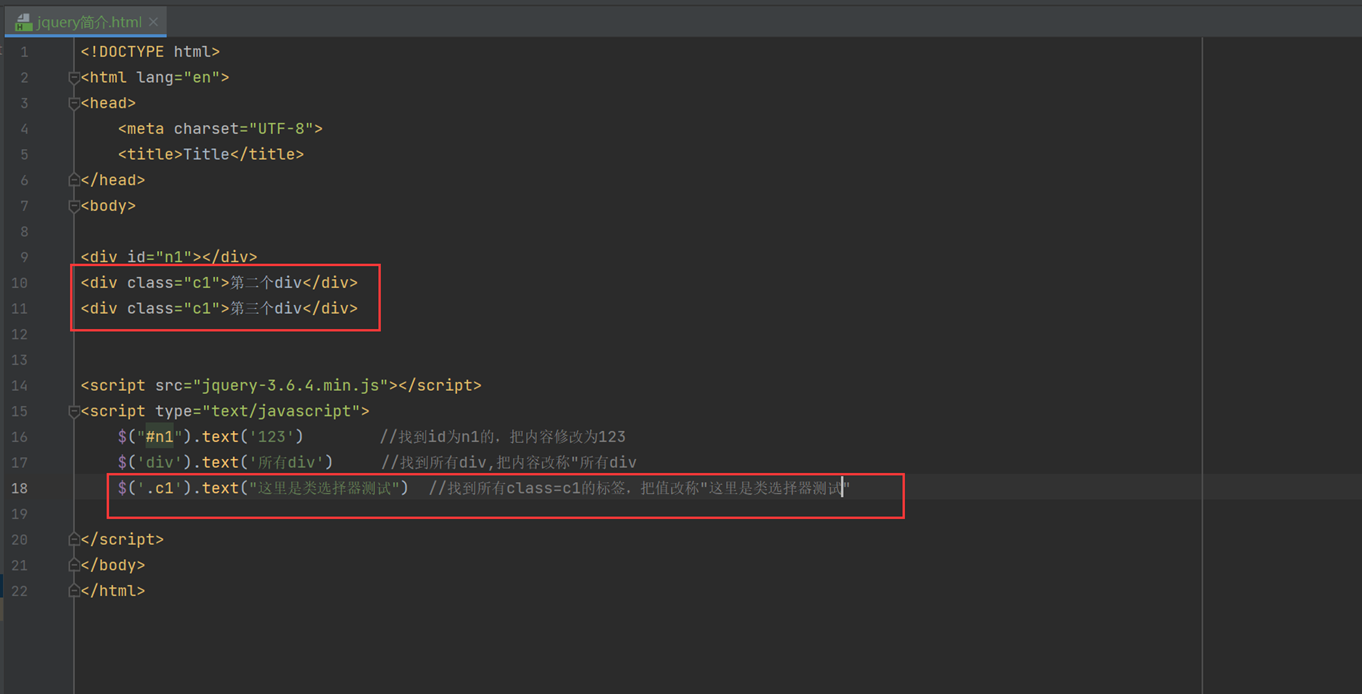
结果
类选择器
结果
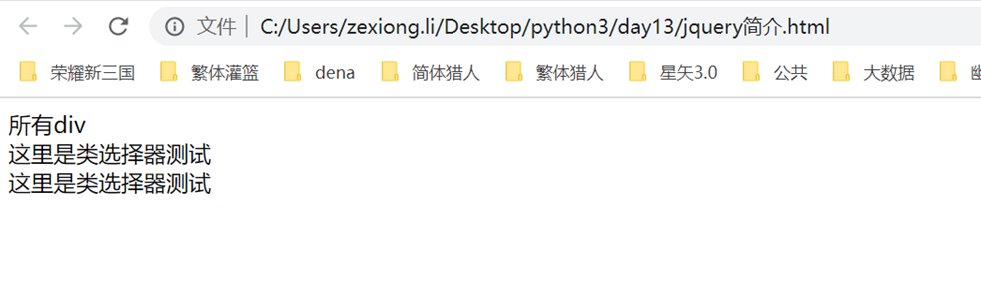
匹配多个标签
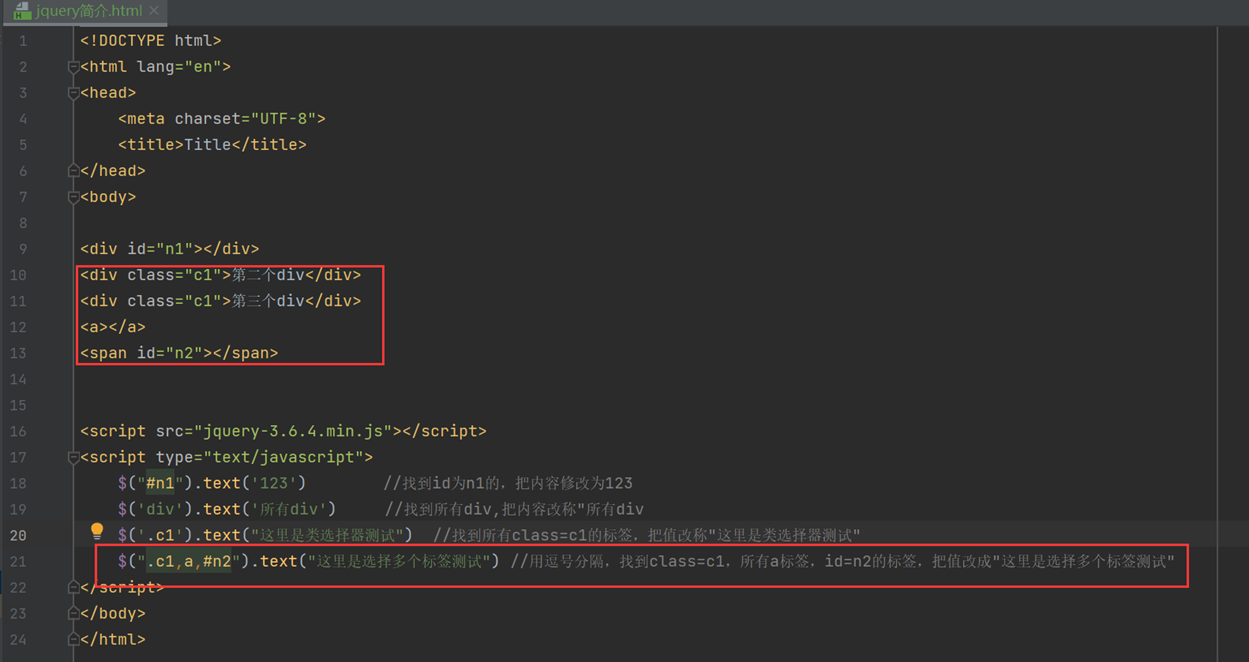
结果
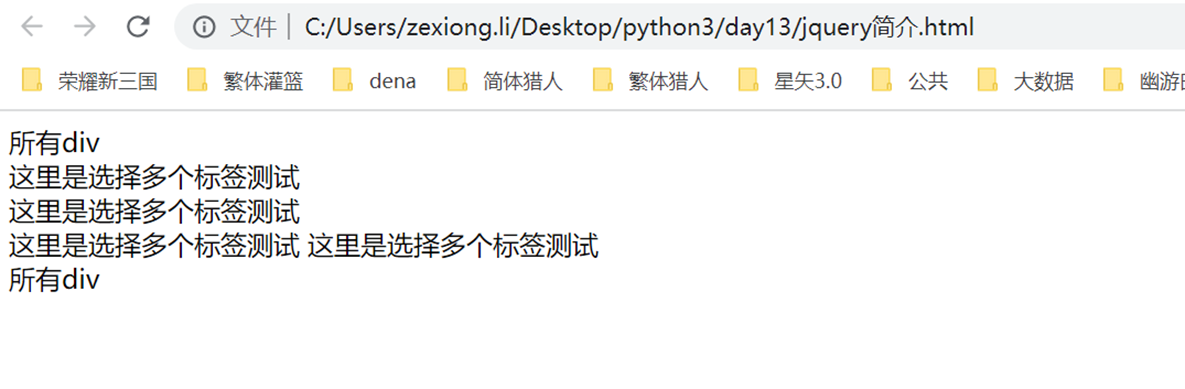
组合选择器,一层一层往下面找
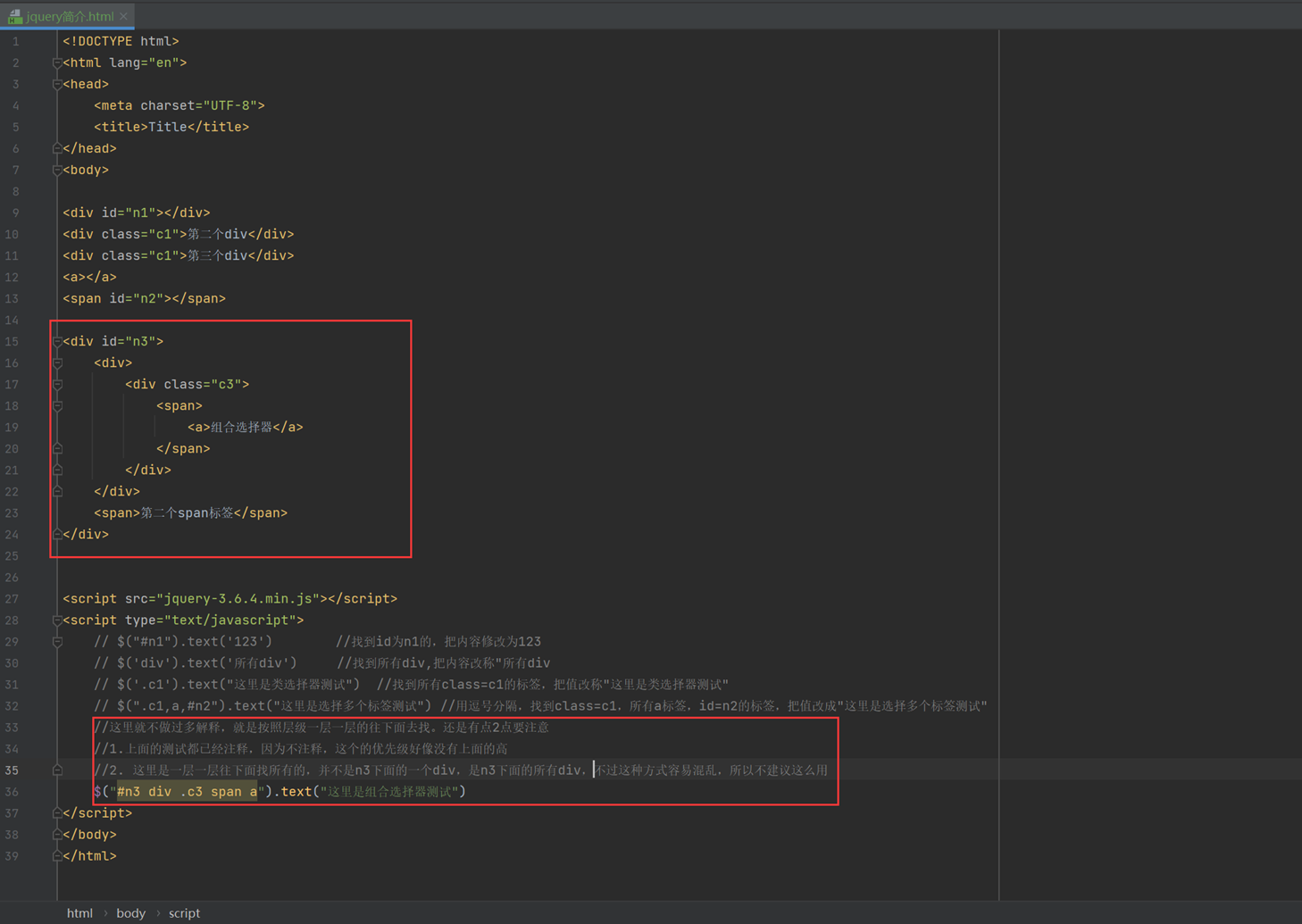
结果
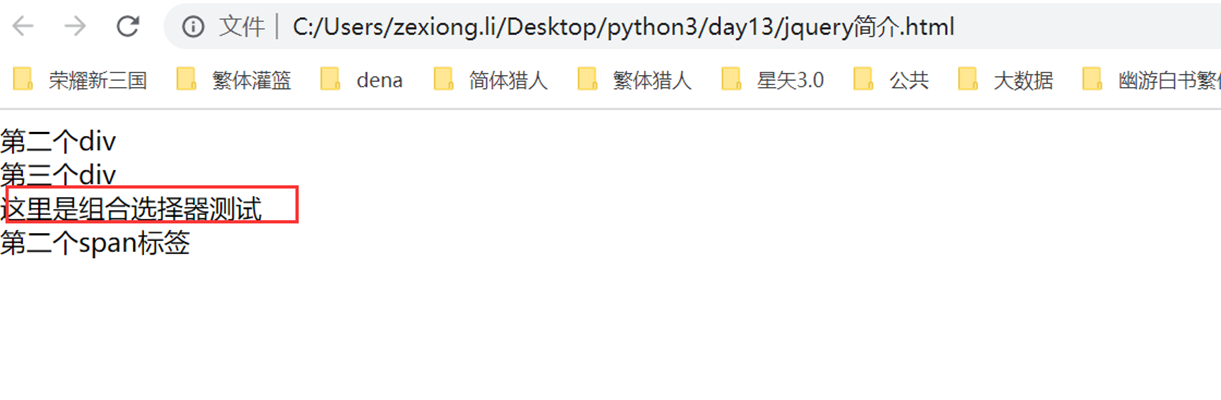
13.25 jquery之选择器和筛选器
直接博客讲解吧,这里就不多说了,参考本人博客: jquery教程练习
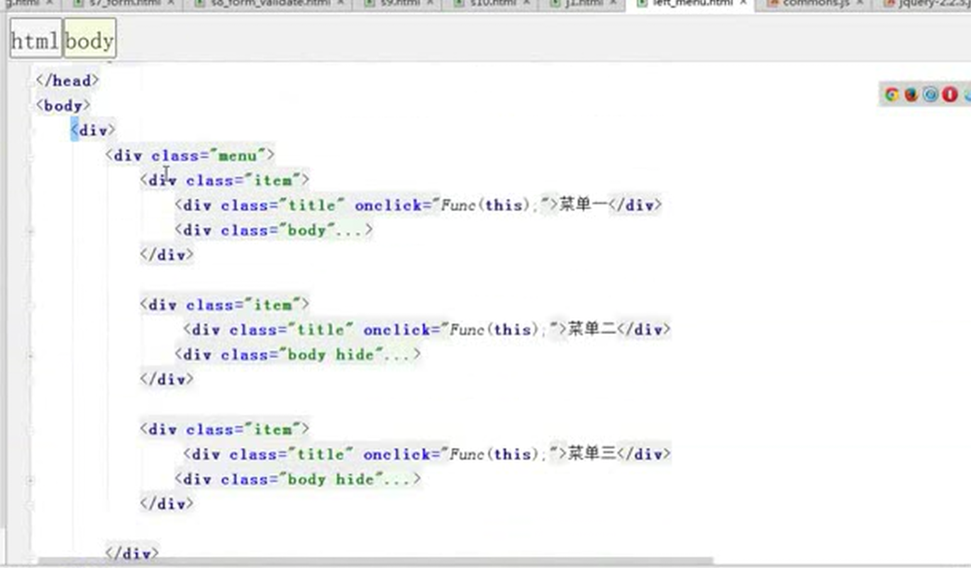
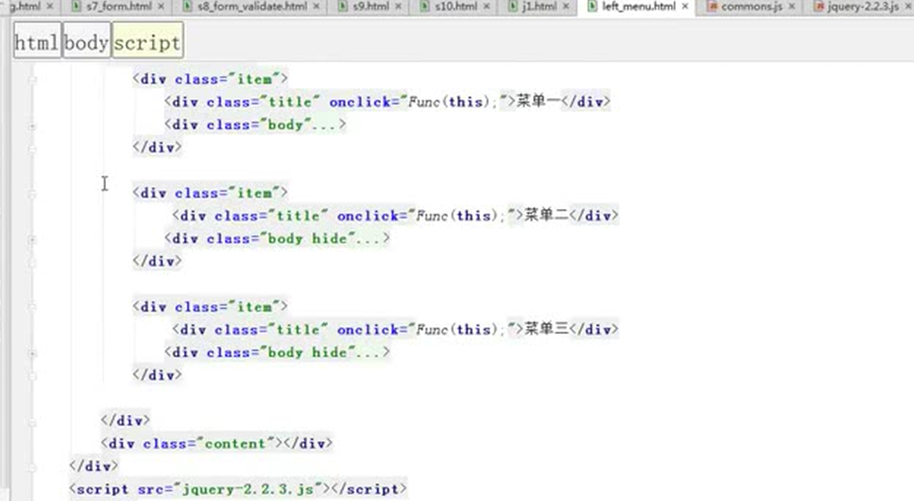
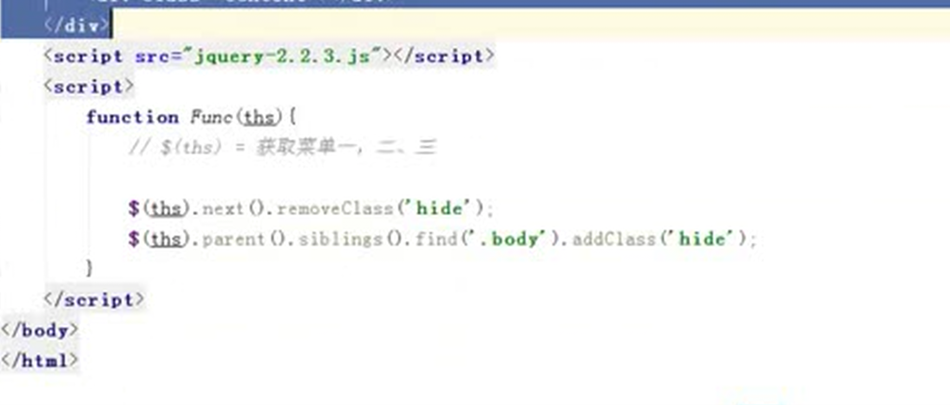
13.26 jquery之左侧菜单实例

13.27 今日作业
全选反选
14.L14
本节课视频声音画面都有点延迟,不过勉强可以看,建议直接看11期笔记。
及其必要情况下才建议复习该节课视频,不然这个视频会很浪费时间。
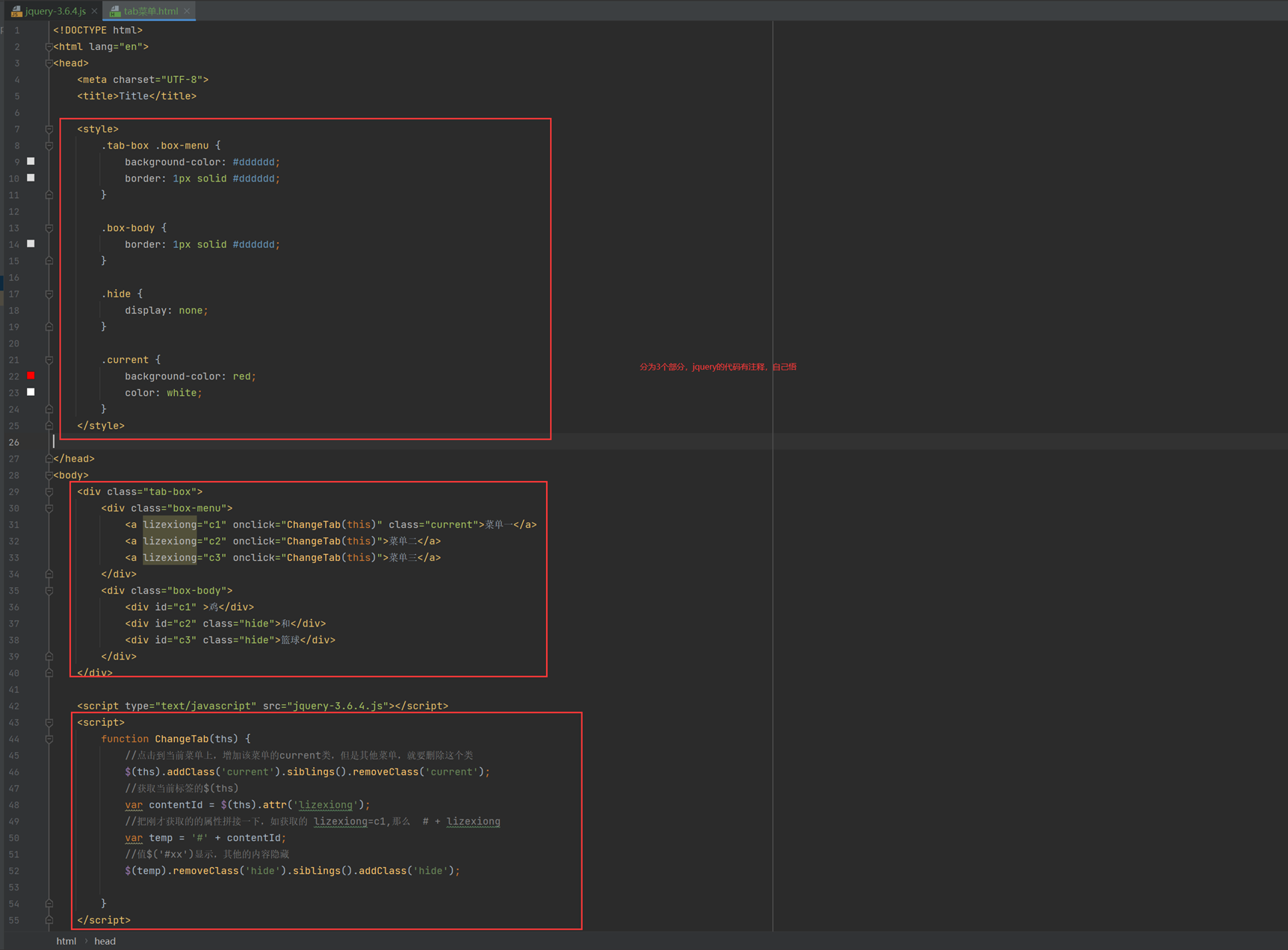
14.1 课前小实例:tab菜单
前10分钟课程讲解今天的内容是什么,基本上都是jquery的内容。
以下是tab菜单的课堂实例代码,里面有注释
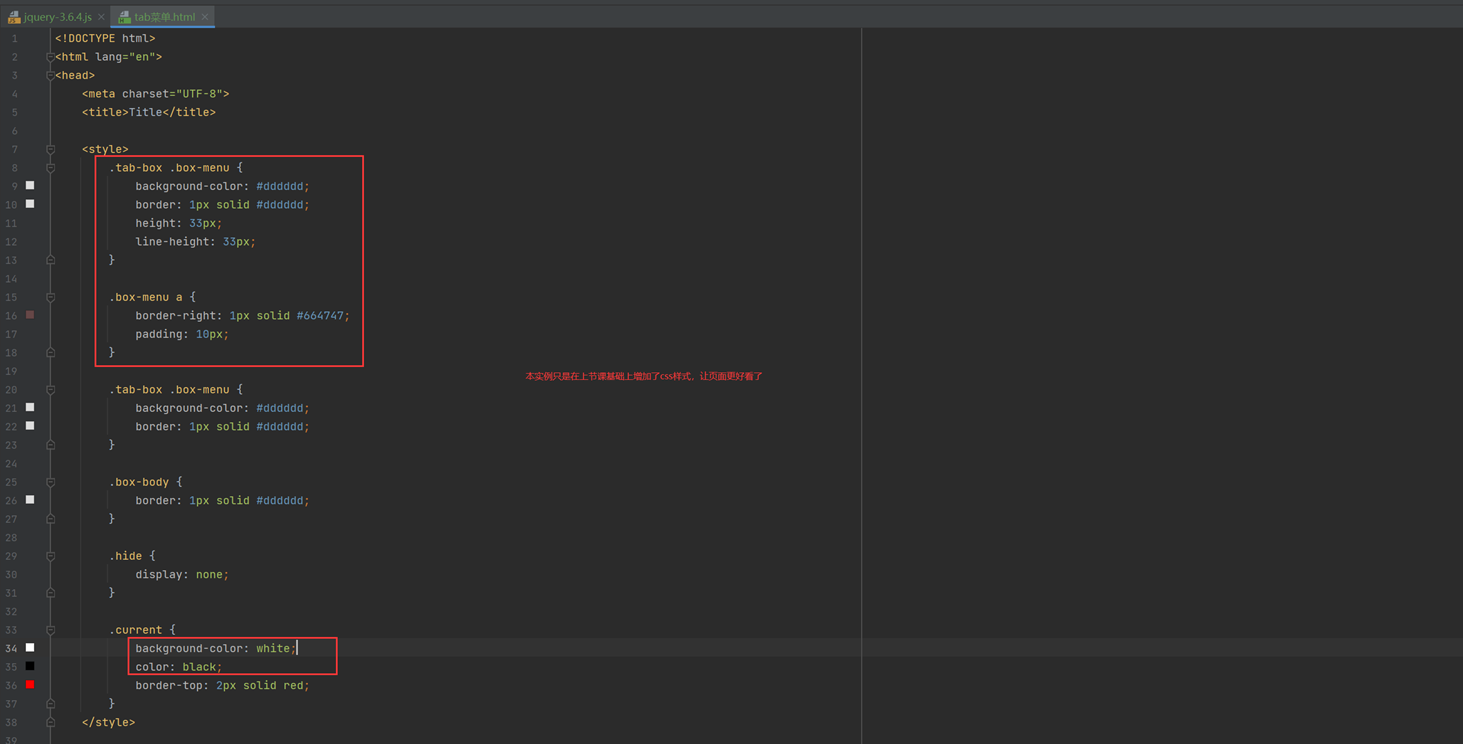
14.2 课前小实例:tab菜单2
本节讲解的就是调整这个菜单的css样式,因为tab菜单一课里面的样式都是默认的,太丑了,当然本节课实验老师演砸了,只演示成功了一大部分,剩下的如果碰到了在补充。
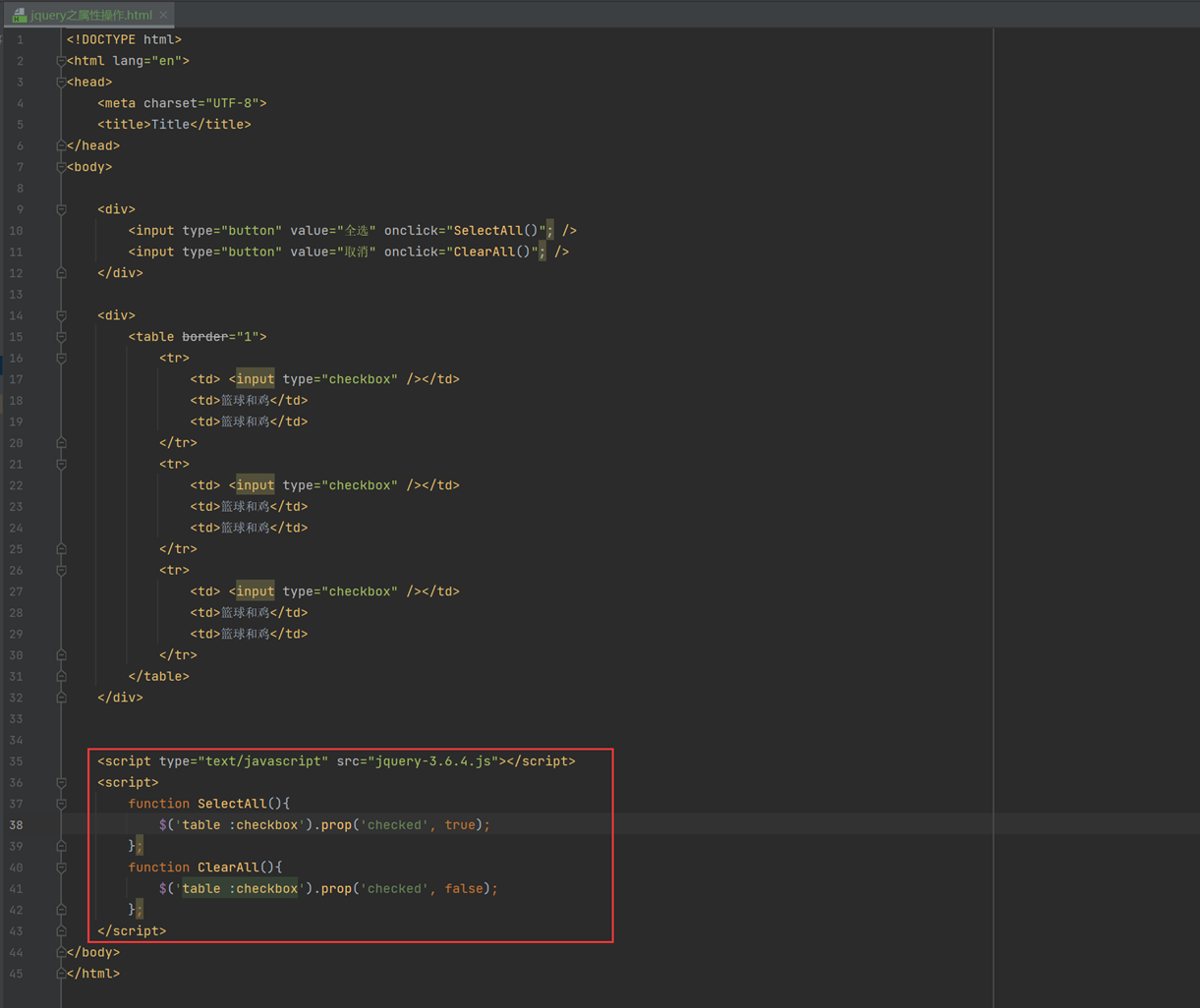
14.3 jquery之属性操作

接下来一个操作checkbox标签的示例。
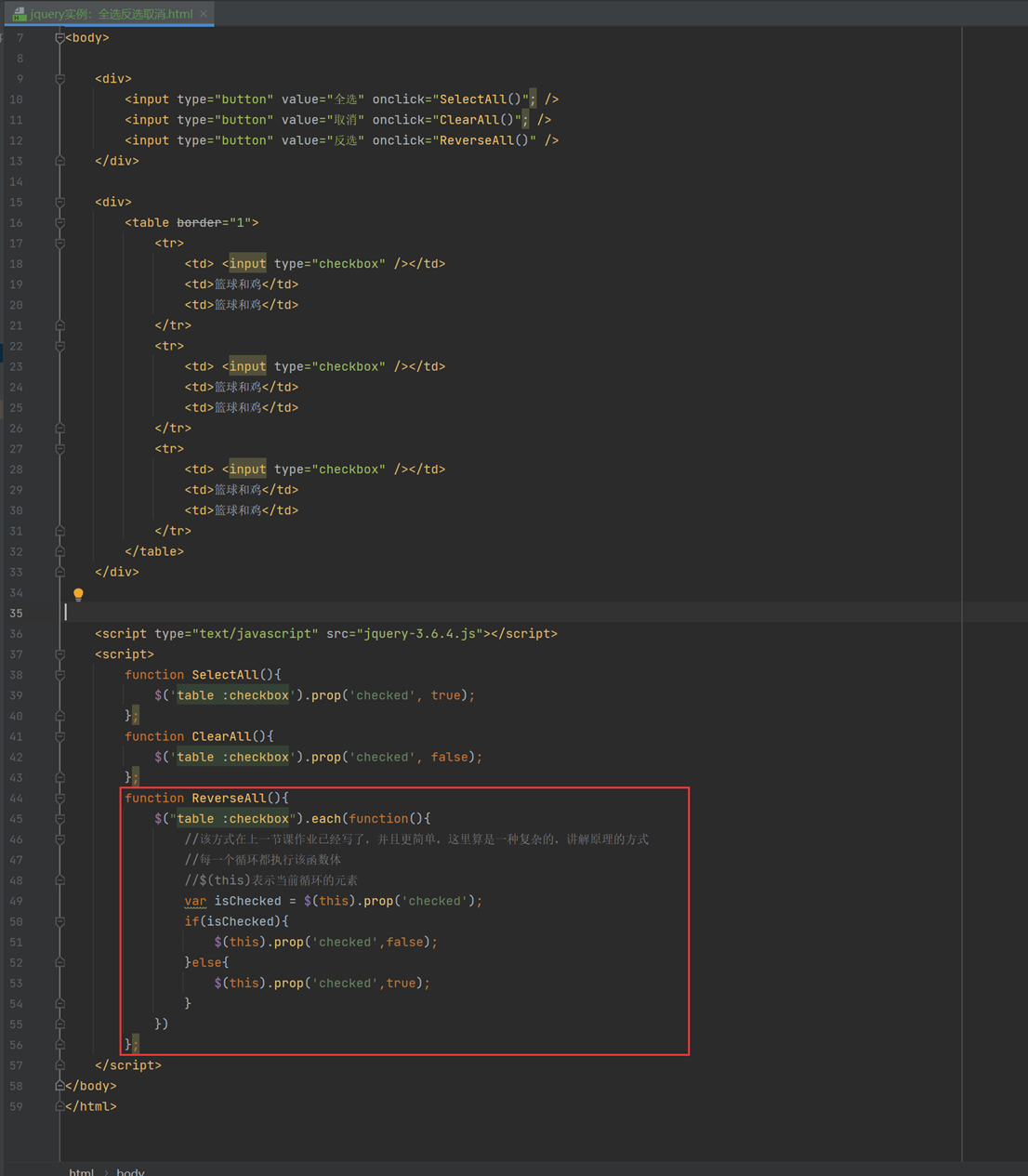
14.4 jquery实例:全选反选取消
该实例是在上一节的基础上加强的,多出了反选功能,当然,上节课作业的反选比这个更简洁,本节课实例虽然实现了循环,但是有点复杂,更偏向讲解原理。
14.5 jquery之for循环
jquery两种for循环的方式就是用上一章的环境来演示。
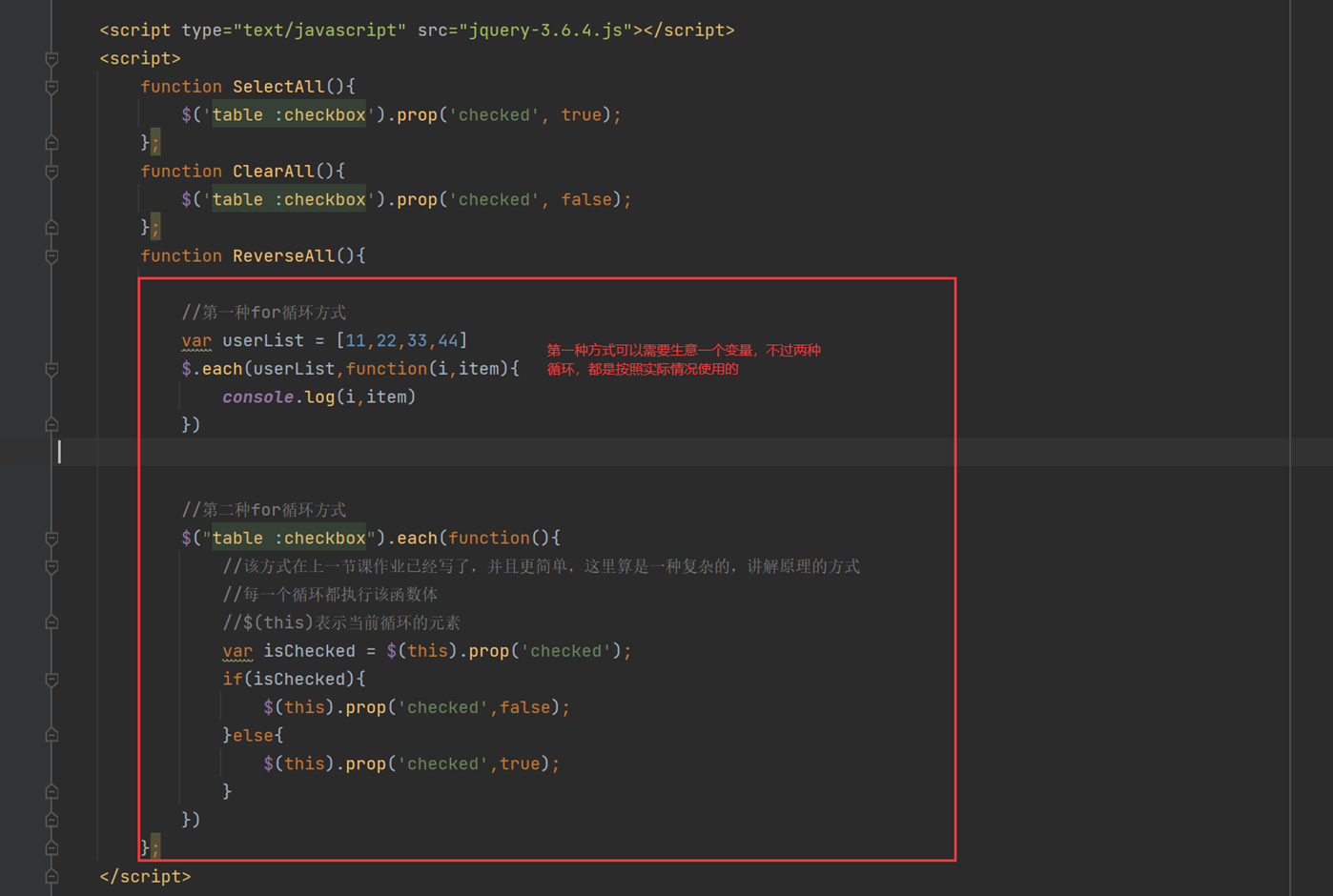
14.6 jquery之内容操作
就讲解了以下三个的作用

14.7 jquery实例:返回顶部
本章和下一章一起讲解,下一章的内容就是实现滚动条没有到设置的地方一个地方,不显示返回顶部。
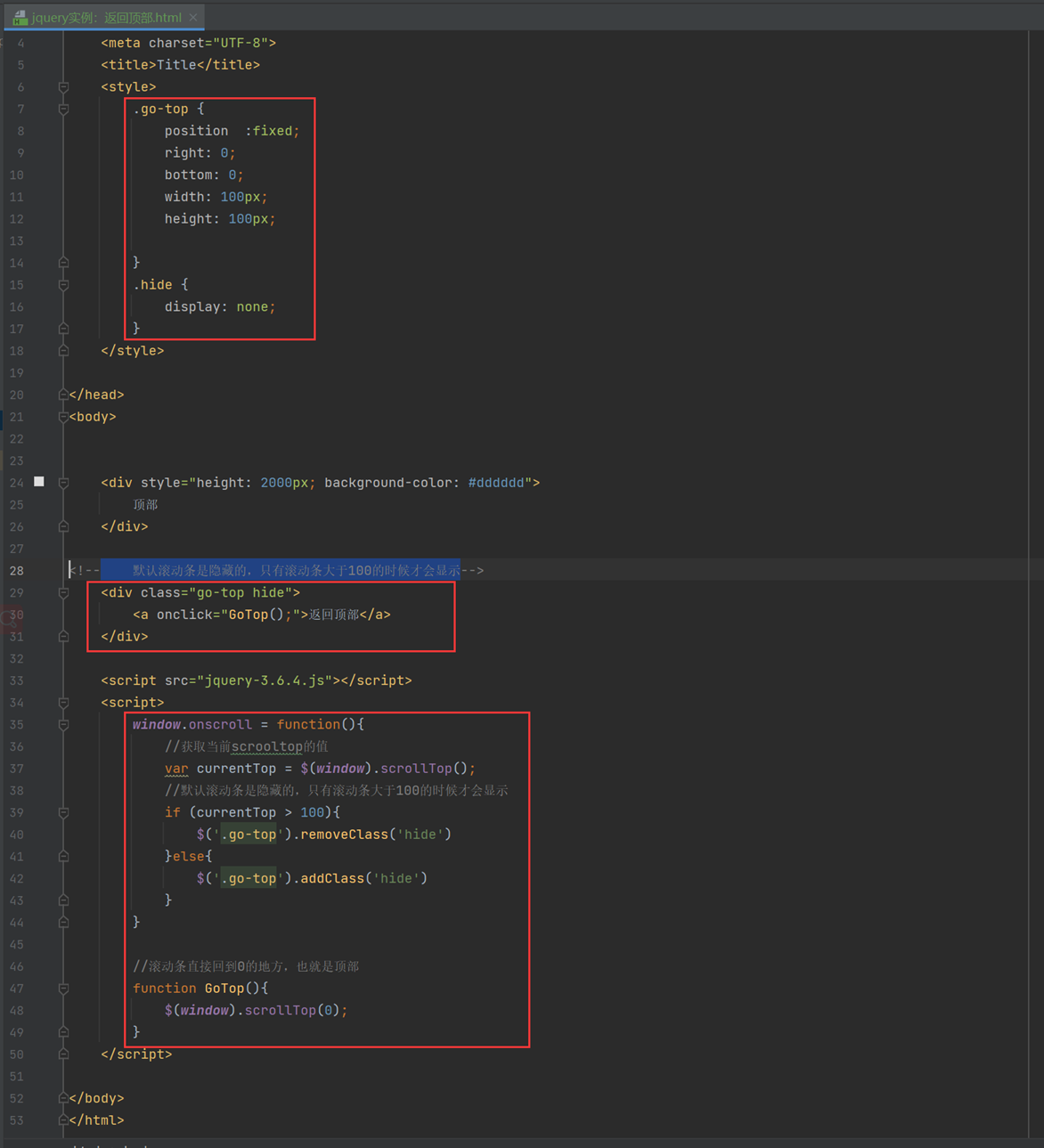
14.8 jquery实例:返回顶部2
和上一章一起讲解了。
14.9 jquery之位置操作和滚动菜单实例
offset和position的区别在下面截图中,很重要。

本章有点绕并且视频有点语音延迟,视频直接作废了,所以这里只能借用11期的代码了。
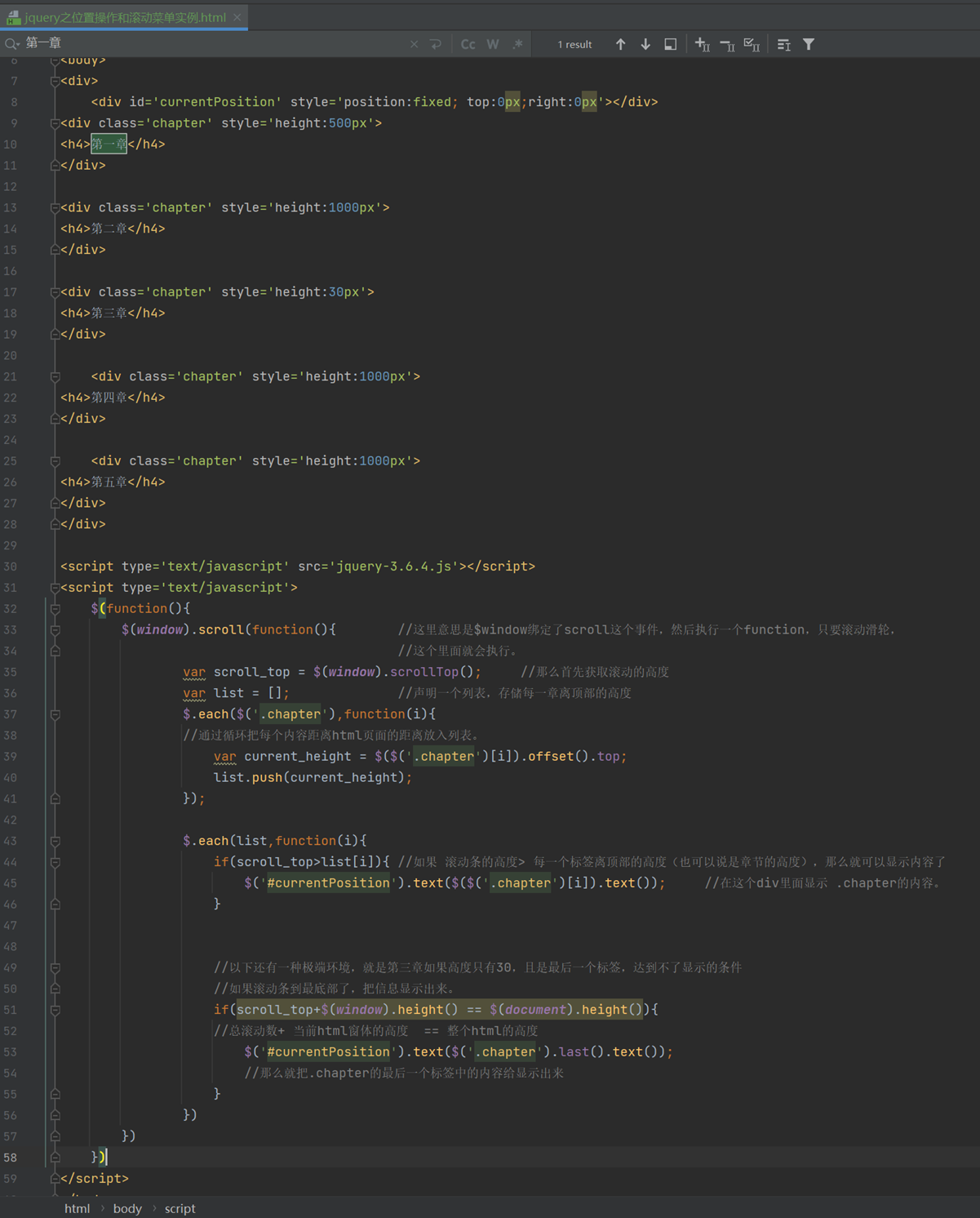
14.10 jquery实例:滚动菜单
这里和上一章是同一个内容,就是上章节有个功能没有实现,如第三章高度只有30,且是最后一个标签,达到不了显示的条件,改怎么处理,由于14.9视频混乱,所以这2节课直接跳过,把11期的作业复制过来了。
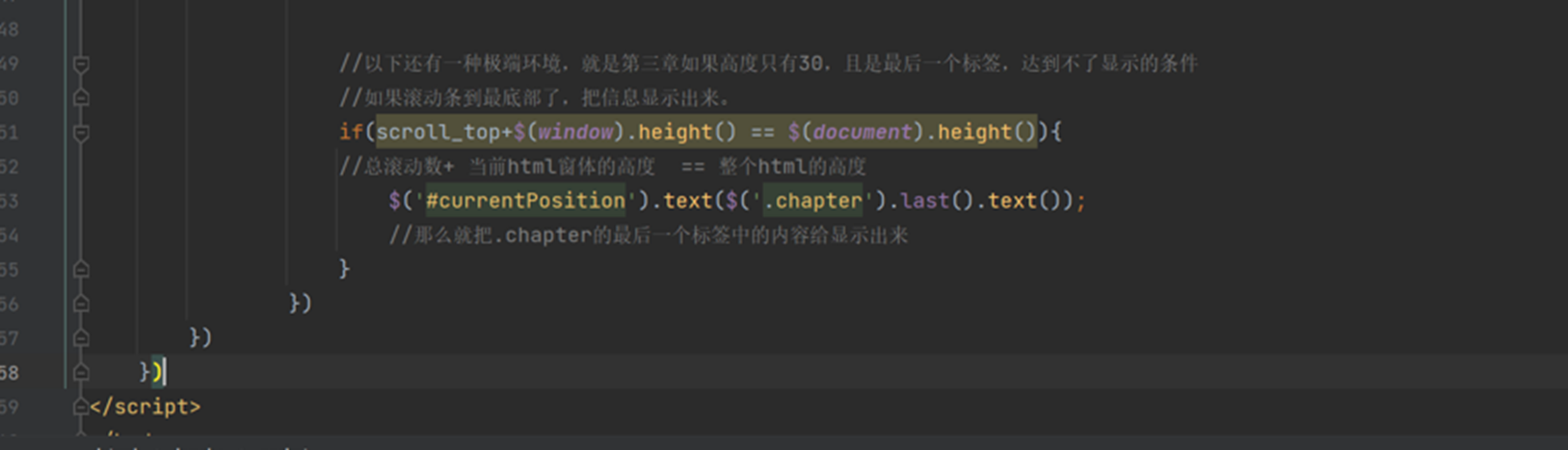
14.11 jquery之文本操作
本章就是讲解了一些改变文本的方法。具体的没有细讲,需要自己去尝试。

14.12 jquery之事件
本节主要讲解一些时间的使用方式,一共三种方式。
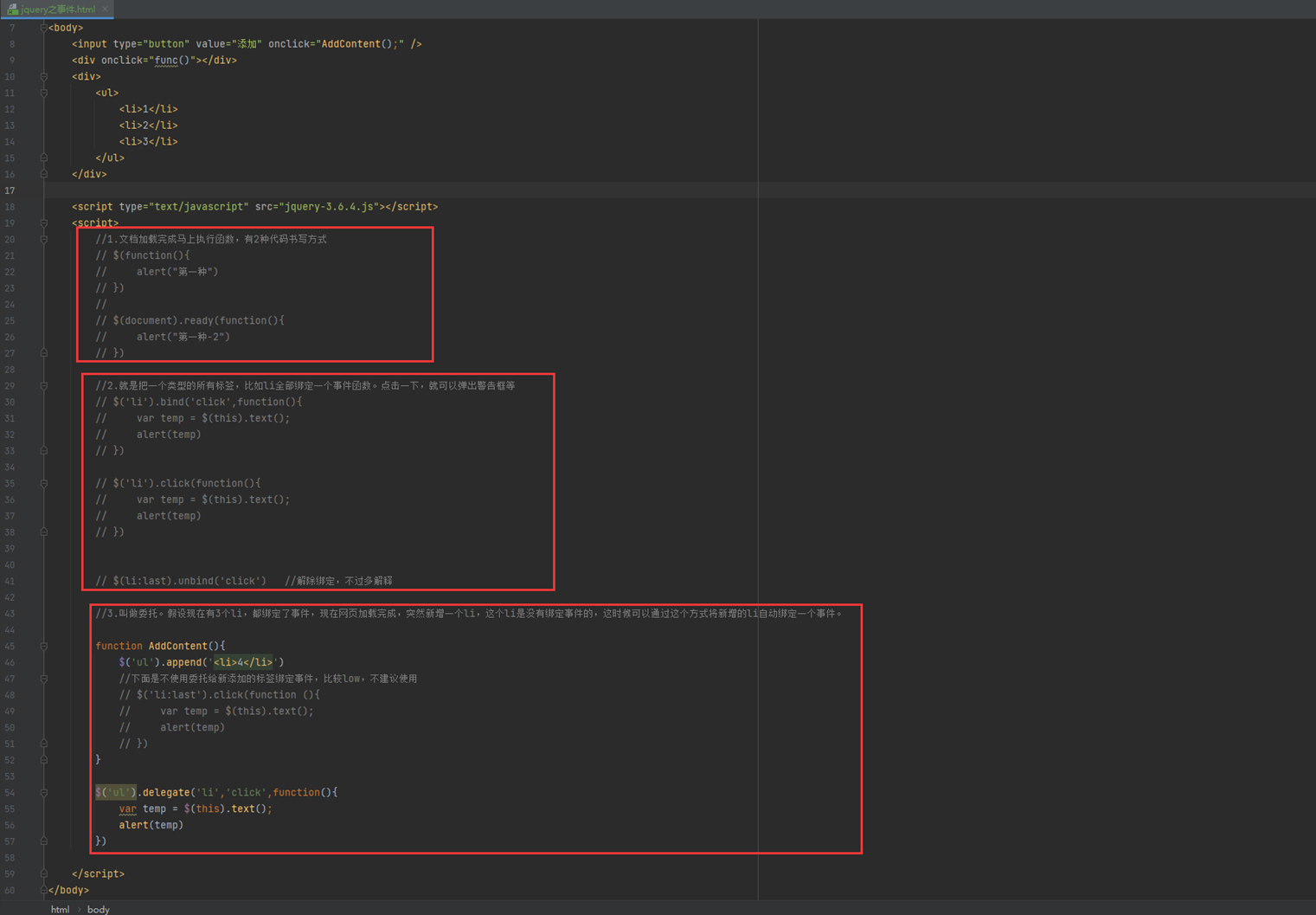
1.文档加载完成马上执行函数,有2种代码书写方式
2.就是把一个类型的所有标签,比如li全部绑定一个事件函数。点击一下,就可以弹出警告框等,也是两种方式
3.这个更牛逼了,叫做委托。假设现在有3个li,都绑定了事件,现在网页加载完成,突然新增一个li,这个li是没有绑定事件的,这时候可以通过这个方式将新增的li自动绑定一个事件。

代码实例
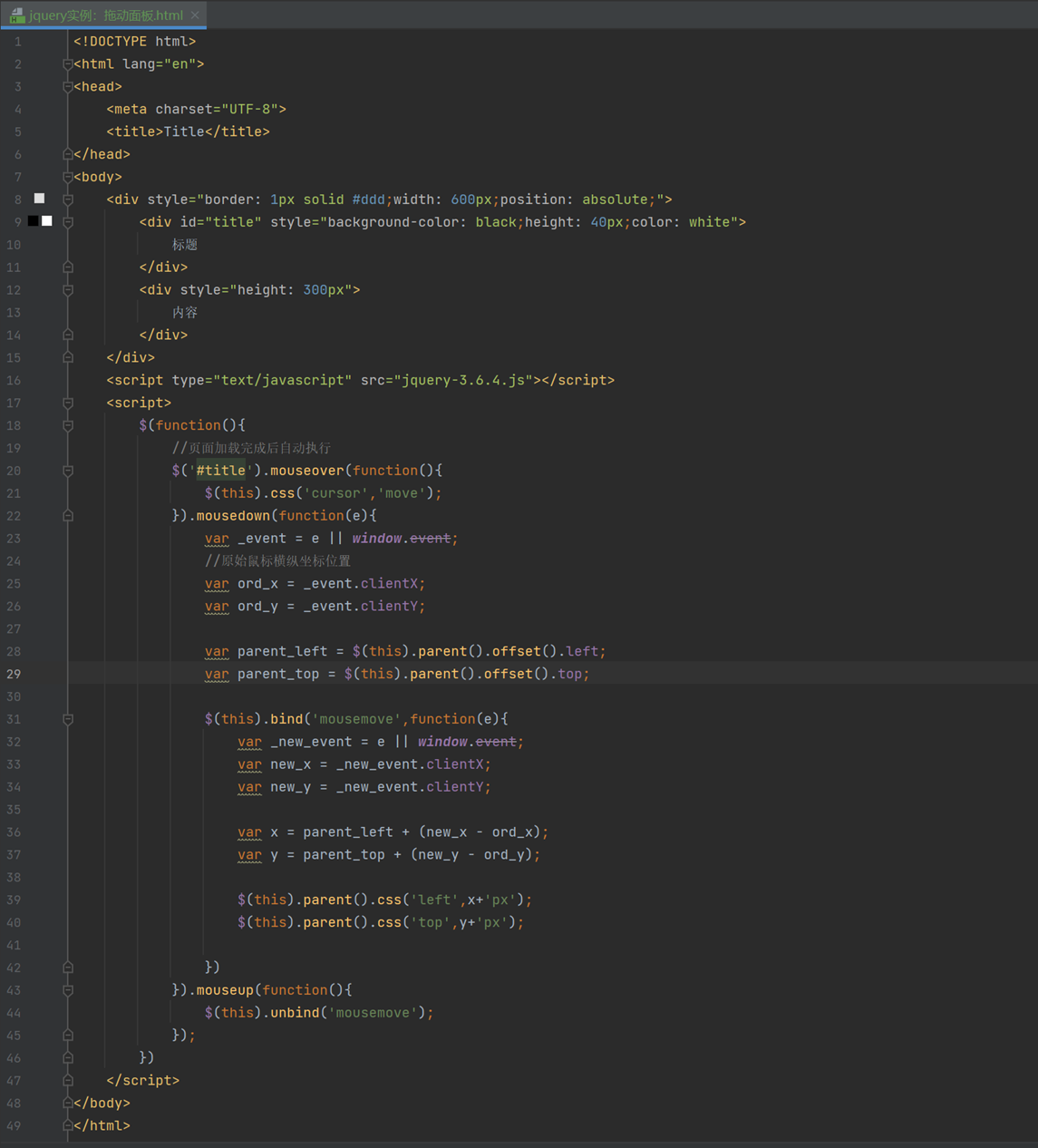
14.13 jquery实例:拖动面板
本节视频有问题,部分中间视频没有声音,这里保留代码,自行学习。
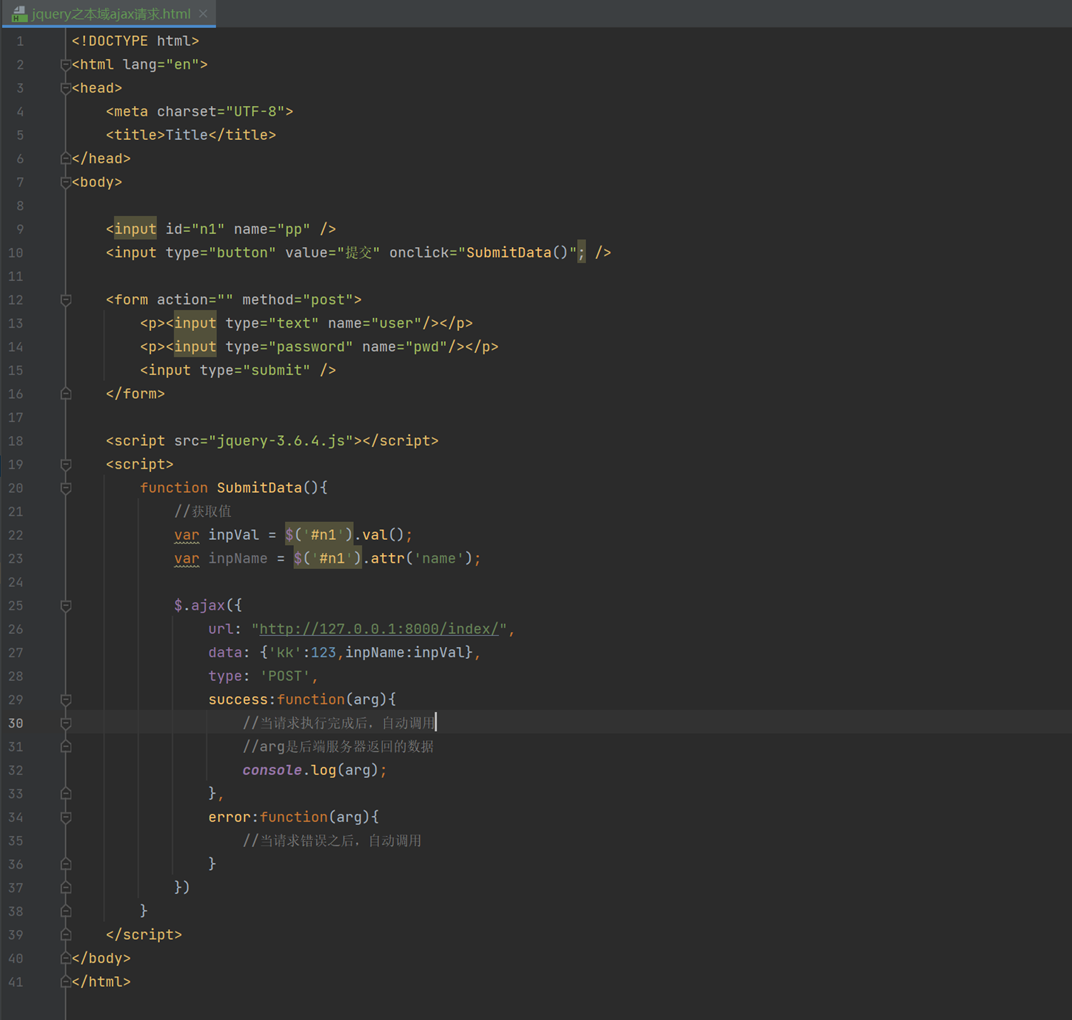
14.14 jquery之本域ajax请求
这个ajax只是演示怎么往后台发送数据,目前是最简单的demo,所以这里没有django后台,只是这里简单列出一下代码,这是ajax的雏形,目前只能在本域内测试。(什么是本域和跨域,后面会讲解)
14.15 jquery之跨域ajax请求和电视节目实例
这里视频还是有点卡顿,还是使用11期的笔记吧,基本上一模一样。
Ajax请求简单来说就是页面不刷新就可以提交请求。
Ajax分为本地和跨域请求。
-
- 本地:本地起一个程序,发送请求然后在返回数据。
- 跨域:访问和别人协商好的网站,发送请求,拿回数据。
本地的需要写一个d程序,这里还没学习,所以直接演示跨域。
本地和跨域还是有区别的。
在跨域请求中有三个字段。
dataType:’jsonp’
jsonp:’callback’
jsonpCallback:’list’ //需要注意的就是这里
上面的list是和其它平台已协商好的,通过list()把内容给封装进去。
跨域请求
查看平台返回的数据类型。
这里,开始一步一步完善在网页上要展示的内容
1.首先,只是获取数据,在console输出
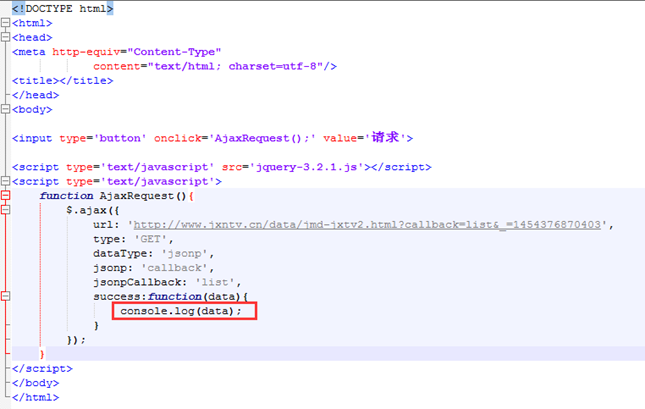
这里的数据首先是对象Object{data:array[7]}.
那么要取出数据就是data.data

2.数据格式详解
首先弄清楚数据格式。
上述获取到的类型注意是个对象data,然后data里面放了数据。
Console.log(data.data) 的数据格式如下,里面有一个数组。
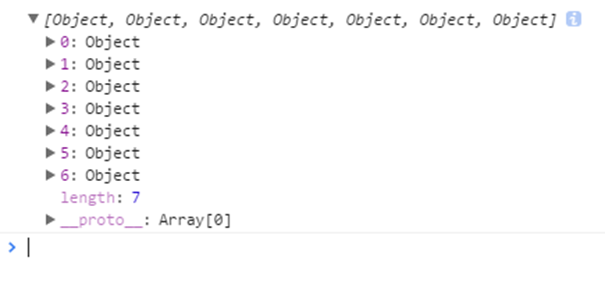
既然是数组,那么就需要循环了。
接下来,for循环data.data[i]

又得到一个对象。
那么在取值就是data.data.[i].week
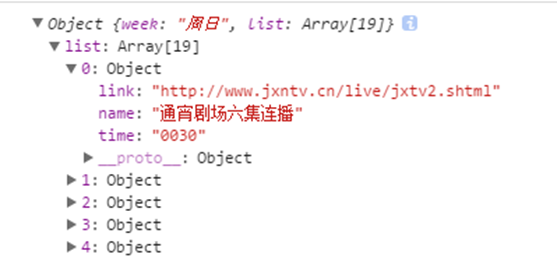
这里注意,每次取出的都是一个object,data.data是由一个对象取出的,data.data[i]的值还是一个对象。
本章小规律,出现了object和数据,如果数据取值,那么就是循环,如果object取值,那么就是.
3.以下,首先实现简单的,将获取到日期显示到网页上。
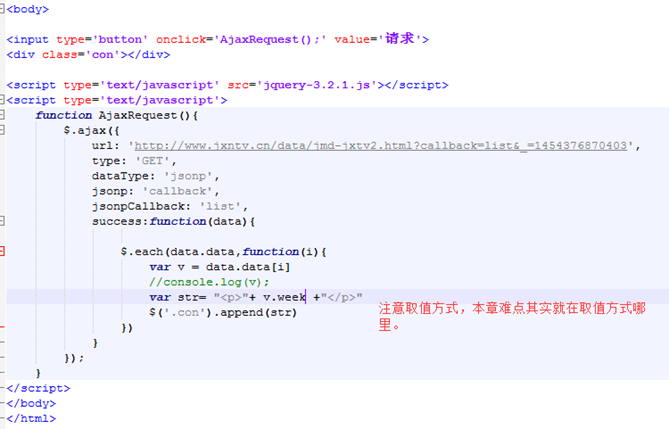

接下来把节目给列出来。
首先查看v.list又是一个数组,那么就要用到for循环
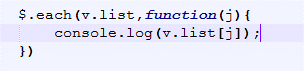
查看每个数组下标内的数据。

那么可以看到有time,name,link等字段。
那么就可以继续把这些信息像网页上显示。
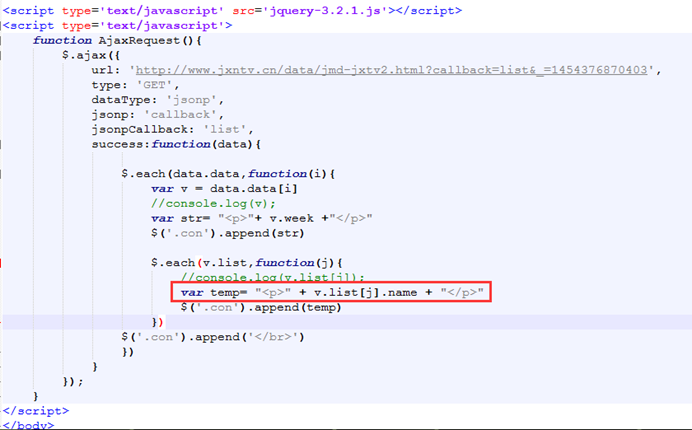

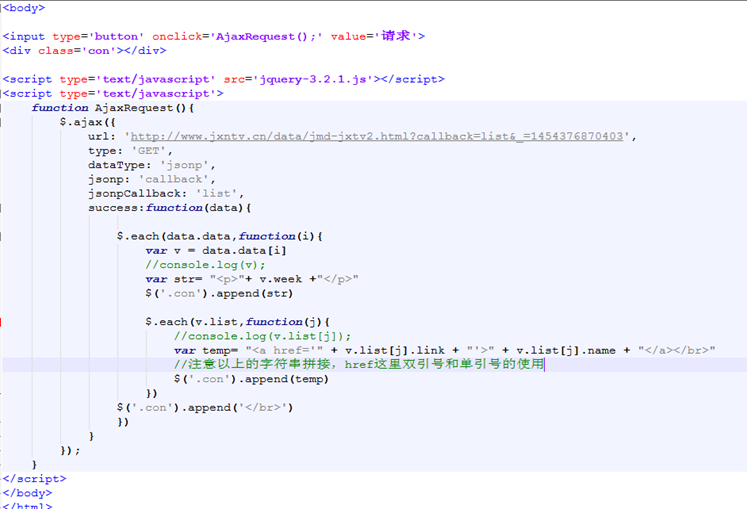
上述中link字段我们也获取到了,所以,这里也可以直接设置为链接的形式。
也是优化本章的最后一部。
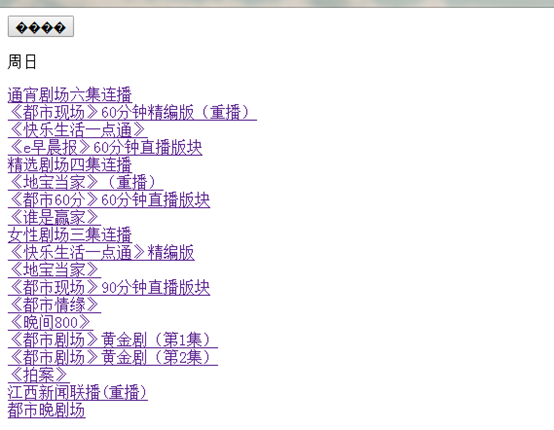
14.16 jquery之ajax请求总结

14.17 jquery之扩展方法
本章主要就是讲解这2个的区别和用法。

比如,两种方式都可以扩展一些函数调用,但是调用方式不一样,但是结果基本都是一样的
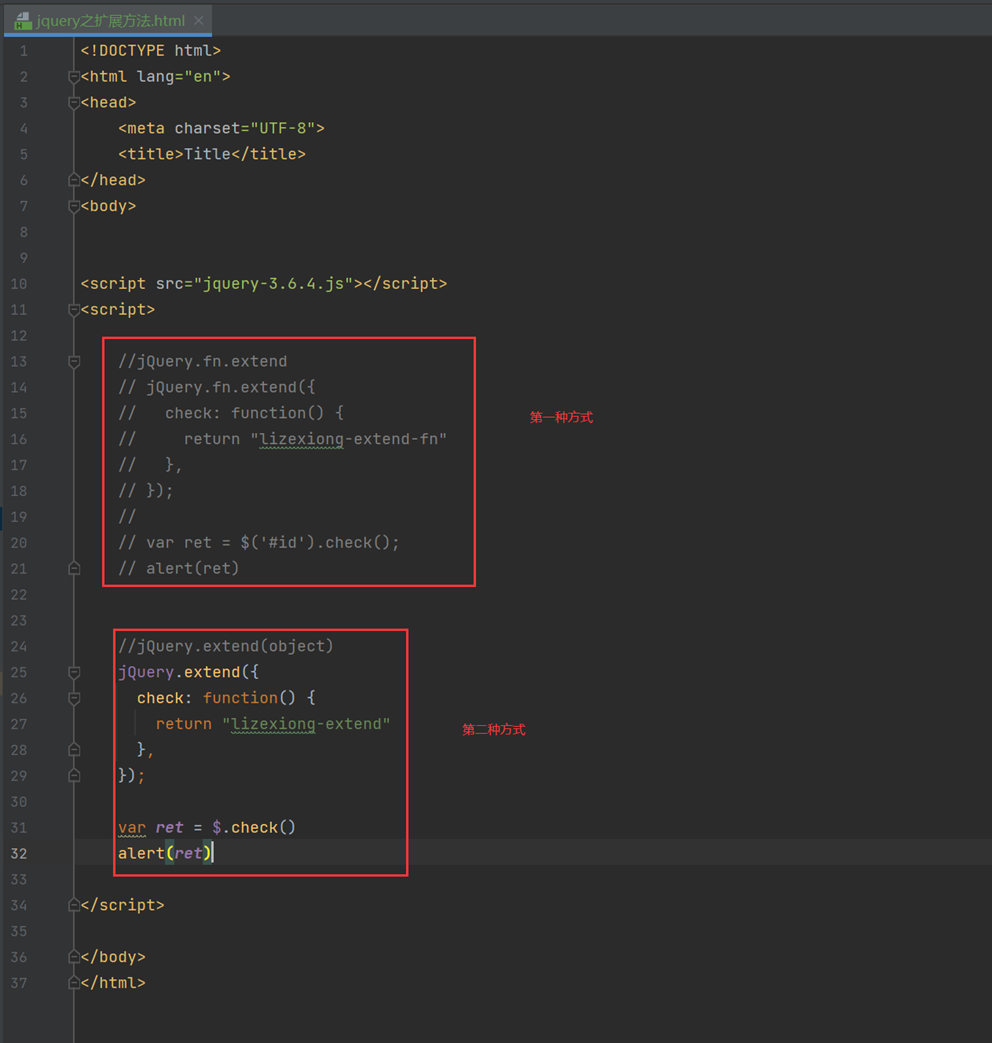
但是,如果这样,有什么用呢?
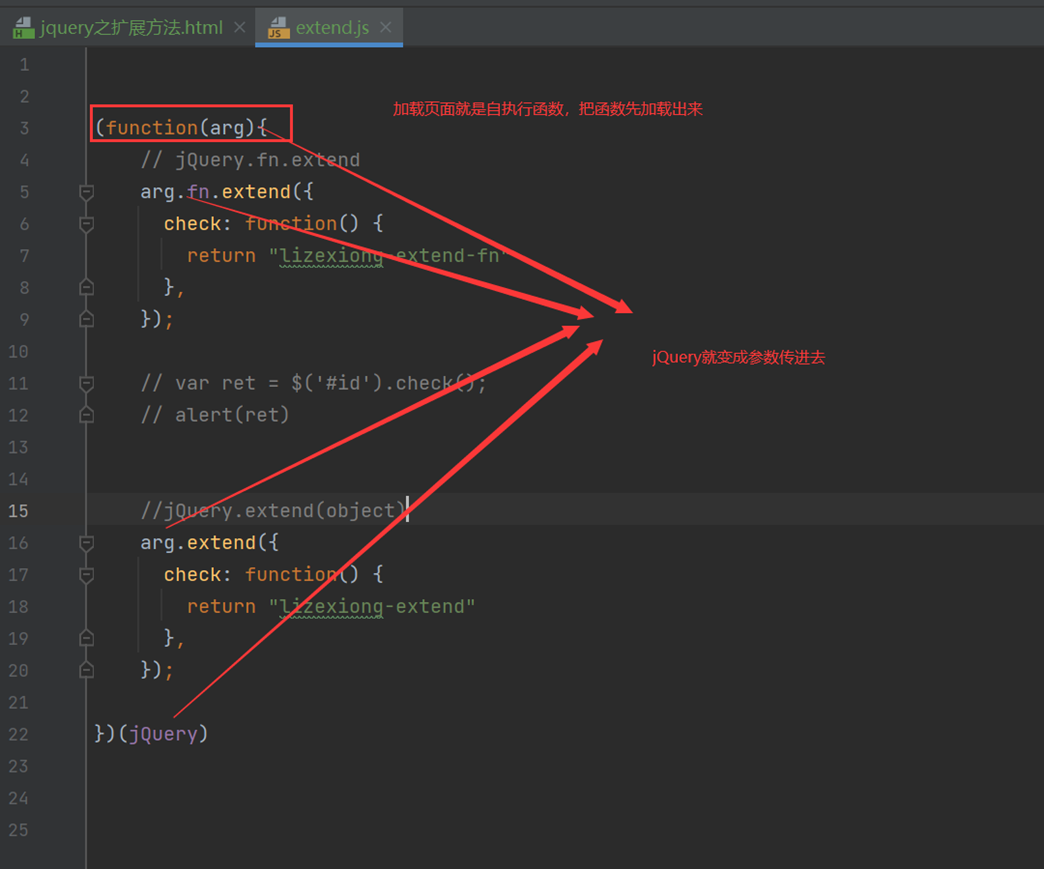
作用在于,可以把部分扩展的函数放到另一个文件里面,我们需要使用的时候可以直接调用,比如放到extend.js里面,这个extend.js里面可以放一些登录验证等函数。可以方便以及美观代码。
扩展文件
网页文件
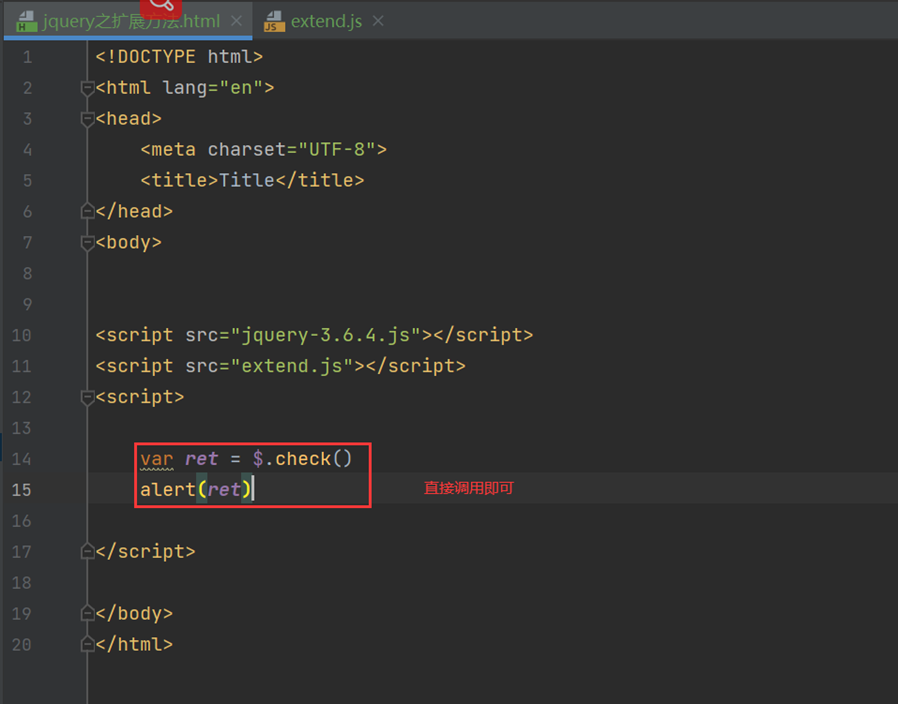
在说回刚才的话题,这个有什么用?比如,可以在extend.js里面放一些功能函数,比如登录是否合法,输入是否合法等问题,本节视频后面有演示,这里就不做截图了。
14.18 本节作业

15.L15
15.1 今日内容介绍
本天主要课程讲解:
1.jquery的其它框架
2.web框架介绍
3.django的简单使用


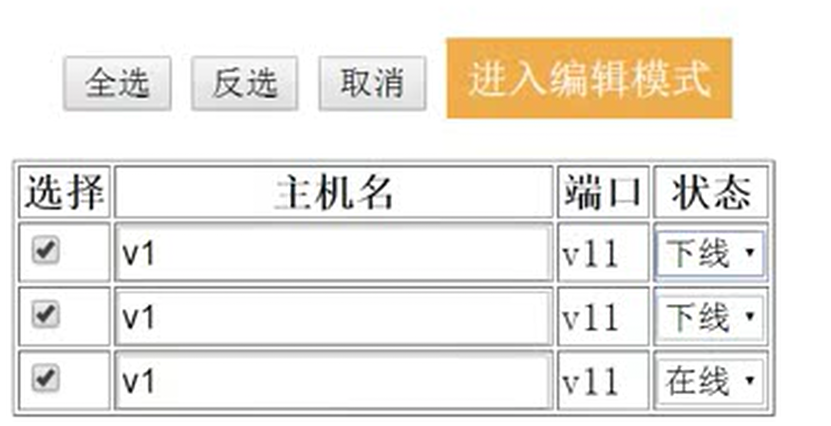
15.2 编辑行实例之功能分析
接下来的几篇,都是讲解以下实现的功能。
这里几个篇章直接跳过,因为这里在11期笔记做的非常详细。由于时间关系,这里不足深究,直接搬来11期的代码,如果有需求,可以慢慢的看12期视频复习,这里本人跳过。
以下是11期的笔记
15.2.1 上周作业剖析(一)
本章实现。
首先,如果用户进入编辑模式,那么怎么判断字段是否可以编辑?怎么知道用户是否进入编辑模式?
1. 规范了文件分类,将js放在一个单独的文件夹下。
2. 实现点击进入编辑模式,然后选择全选,可以进入编辑模式。
3. 通过editing字段判断是否进入编辑模式。
4. 通过edit=True判断td标签是否可编辑。
5. 通过children()来得到每个tr,每个td的内容。
本章主要是实现CheckAll以及EditMode的部分小功能。
本章代码 index_1.html edit_row_1.html
15.2.2 上周作业剖析(二)
本章主要讲解取消功能以及反选功能。
首先讲解取消功能思路。
CheckCancel
1.取消选中的checkbox,如果已经进入编辑模式,让选中行退出编辑状态。
如果是选中状态,取消选中。
如果是编辑状态,退出编辑状态,并把<input>内的值设置为文本框固定的值。
CheckReverse
1.是否进入编辑模式
遍历所有tr,找到checkbox标签。
如果是选中状态,变为不选中。
找到td标签,查看是否可编辑字段,将input值变为固定值。
如果不是选中状态,变为选中状态。
找到td标签,查看是否可编辑字段。
如果td标签现在是input标签,那么将input变为固定字段
否则将固定变为input字段。
如果不是编辑模式
只需要将选中的状态改变即可。
本章内容较饶,但是知识点就讲解了取消和反选。
本章代码index_2.html edit_row_2.html
15.2.3 上周作业剖析(三)
本章主要讲解 EditMode函数,实现首先选择之后在进入编辑模式和退出编辑模式。
本章思路。
1.判断是否进入编辑模式。
如果已经进入编辑模式。
那么删除编辑模式样式,这里可以说退出编辑模式。
如果判断checked是选中状态,那么将input标签转为固定字段。
否则没有选中
那么判断没有选择的标签是否为input。
如果为input标签那么就将input内容转换为固定字段。
否则什么都不做。
如果没有进入编辑模式
那么进入编辑模式。
判断checked是否选中,如果选择,将固定字段转为input标签。
本章代码 edit_row_3.js
15.2.4 上周作业剖析(四)
本章节主讲两个内容。
首先讲解优化代码。
优化代码章节很简单,就是将相同的代码写成函数,然后在调用的时候直接调用,省去了代码书写以及修改的便捷。
这里由于和视频讲解的代码不完全相同(已经做了优化),所以会复杂一点,这里还是简写为2个函数,但是RowIntoEditMode本人做了优化,所以为RowIntoEditModeEx版本。
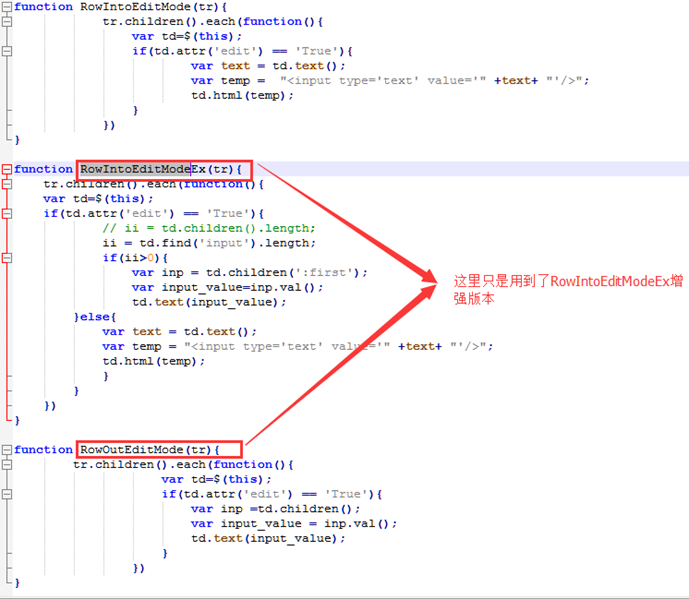
本小节代码
edit_row_4_1.js
本章重点讲解,如果在判断的时候出现select标签,那么怎么编辑select的内容
首先,可以声明一个字典来存储值。(注意这里的单引号和双引号)以及字典名称的关键字。

本章要讲解思路。
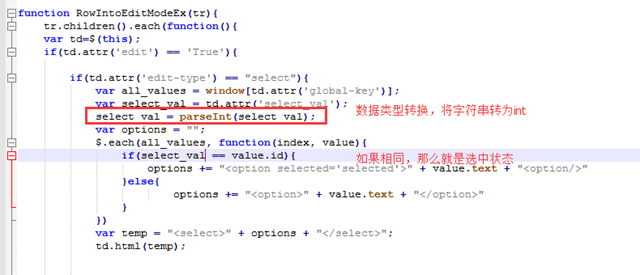
首先td.attr判断该标签是否可编辑之后然后在判断是否为select标签,如果是select标签,那么就开始做select的处理,否则,做input等的处理。
首先以下是简单的判断为select后把td改成select标签,但是改标签内容是死的。
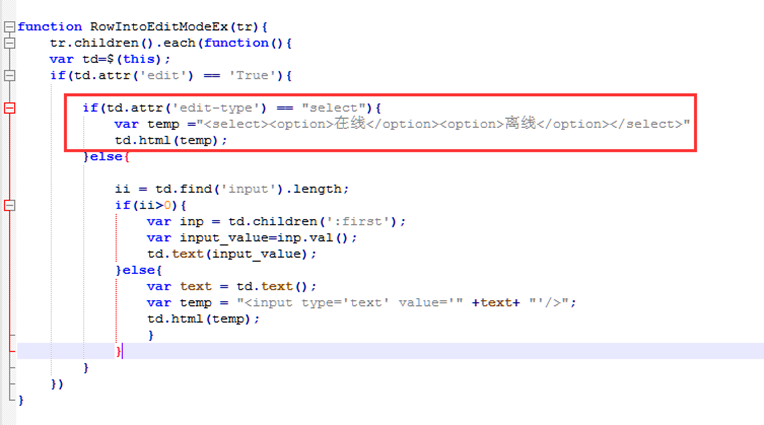
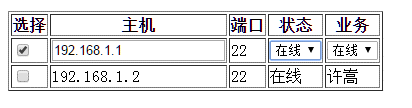
上图可见,直接套了判断是否为select类型,是的话转换为select类型,但是这种格式固定死了,怎么办呢?
那么首先搞两个全局变量,前文已经提到过全局变量,相当于存储值。
那么怎么使用?看alert的实例。
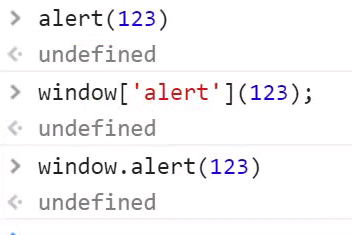
这是alert的三种方式,主要注意下面2个。
那么我全局变量的值是否可以这样取出来。

那么我就可以在html标签里面再次定义一个值。
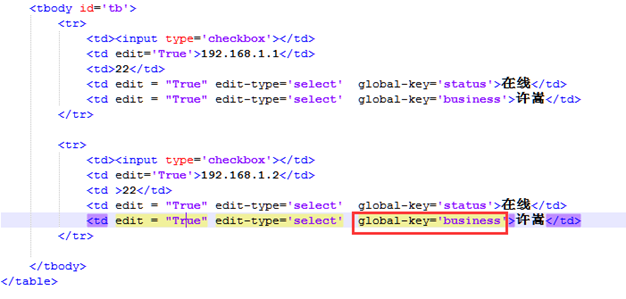
那么就可以通过for方法获取全局key。
JS for循环里面,第一个都是索引,第二个就是value。
现在可以获取全局变量value的值,那么现在动态构造select的值。
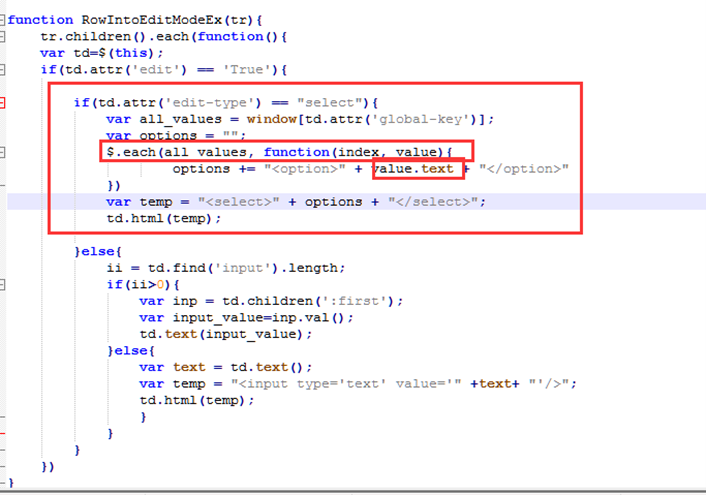
可以看到如果循环 index代表字典的键,value代表字典的值。
以下为实现效果。
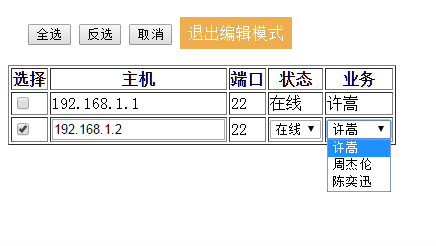
本章实现思路。
1. 判断是否为edit可以编辑字段。
判断类型是否为select。
通过window获取字典的值,然后开始循环,然后字符串拼接。
如果不是进入else处理,一般为input等标签
本章的代码更新不多,只更新了RowIntoEditModeEx函数。但是index和js都需要更新。
edit_row_4_2.js index_4_2.html
15.2.5 上周作业剖析(五)
在上一章,实现了下拉框的遍历显示,但是还有一个问题,我的下拉框本来是有默认值的,但是在可编辑状态,变成了第一个值,怎么使选中的默认值保持不变呢?
本章思路。
只需要在遍历字典的时候与html标签页的默认值做对比,如果字典取出来的id等于html的值,那么就加上selected默认选中类型就可以了。
Index主页文件也需要更改。
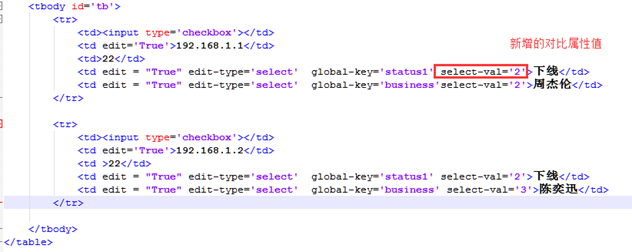

本章也比较简单,只是简单的几行代码。
本章代码:
edit_row_5.js index_5.html
15.3 编辑行实例之数据行进入编辑模式代码剖析
同上章
15.4 编辑行实例之数据行退出编辑模式
同上章
15.5 编辑行实例之单行事件绑定
同上章
15.6 编辑行实例之批量修改内容
同上章
15.7 jquery插件之验证、图片轮播和图标
本节讲解了一些插件的网站,包括字体,图标,图片轮播的特效等等,由于是复习,这里就没必要记录这些插件怎么使用了。不过这里列出一下给到的网址,可以供大家参考。

15.8 jquery插件之jqueryui和easyui
还是讲解第三方牛逼的插件。有哪些功能什么的,讲的不深,需要自己研究。

15.9 bootstrap介绍
首先讲解了bootstrap的结构。
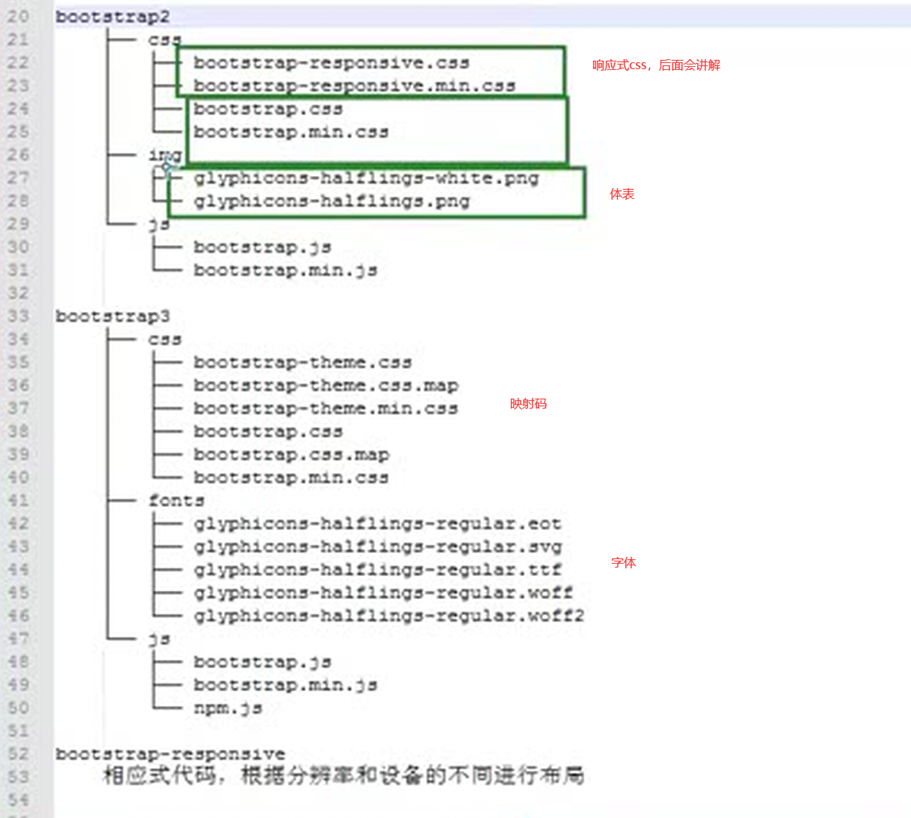
上面图中有bootstrap2和3(当然,在复习本视频的时候,已经出到5了),就是一些文件差异,基本可以混合使用。不用强制用哪个版本,不过用最新的最好。
上图中说了响应式代码,什么叫响应式代码?
就是上图说的,简单理解,比如,根据网页的大小显示某种样式,比如,网页宽度低于700,那么就不显示背景颜色,大于700才显示,这就是响应式。
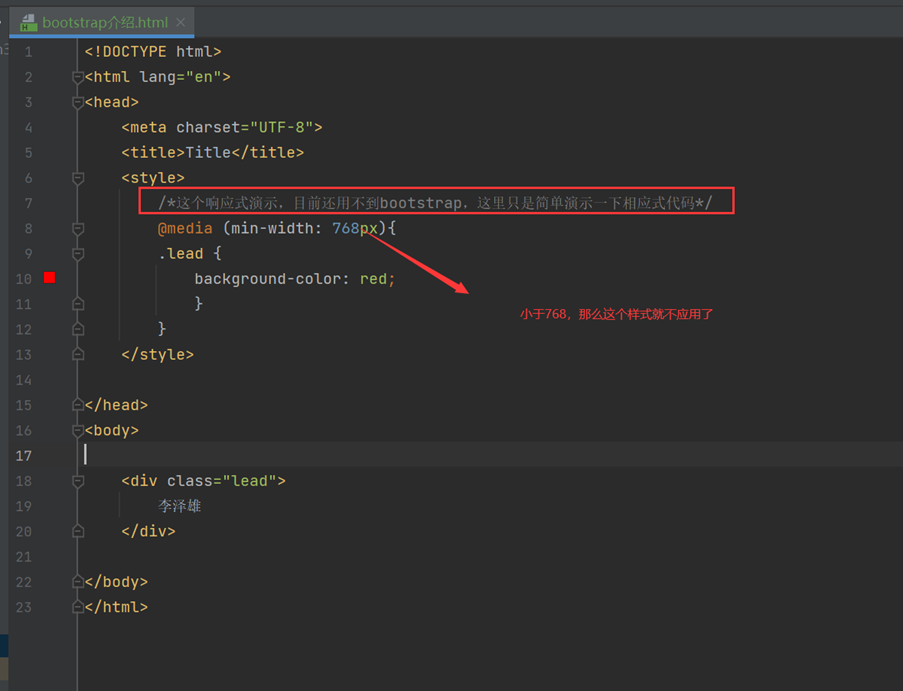
当然不止网页宽度大小这样可以调节,很多事件下都可以调节,见如下图片。

15.10 css内容补充之伪类
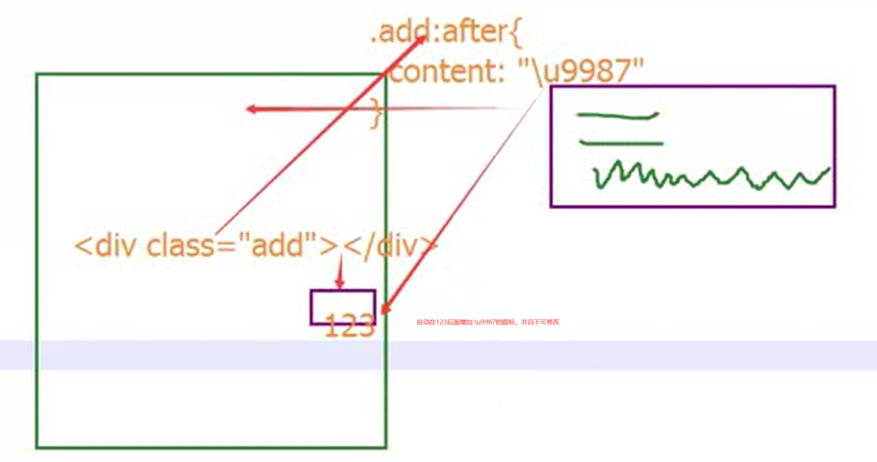
比如如下例子,如果float之后,div就无法应用颜色了。要怎么样才能保证有颜色,又要float,那么就是在div加上clear:both,但是这样需要每次指定,怎么让他自动指定?那么就使用了伪类:after,在这个样式之后自动添加对应样式。
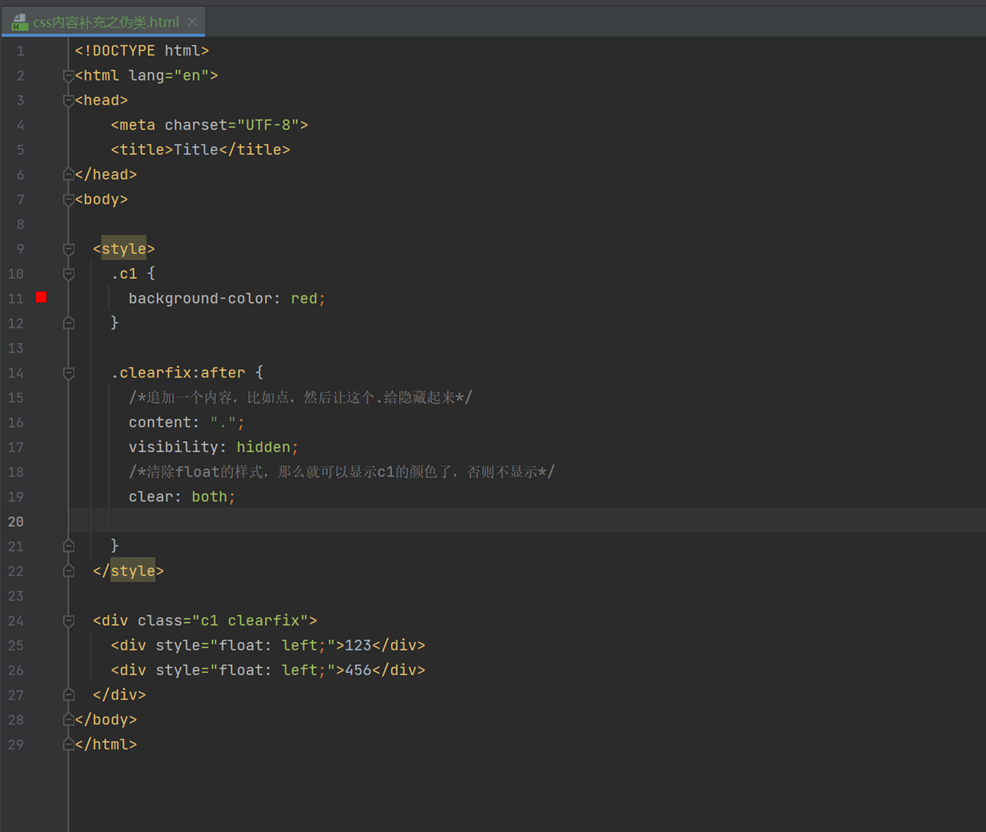
以上是课堂上的演示伪类的案例。根据w3cschool,官方的解释可以看出:

也可以根据博客学习: CSS教程练习
15.11 伪类实例:返回顶部终极版
根据伪类来完成返回顶部终极版。本章老师没有过多讲解,需要代码的直接去git查看。

15.12 bootstrap介绍2
本章非常粗略的介绍了bootstrap怎么使用,没必要做笔记。
具体的可以参考bootstrap官网或者参考11期视频里面的16.14章节: Python学习之路-30天笔记

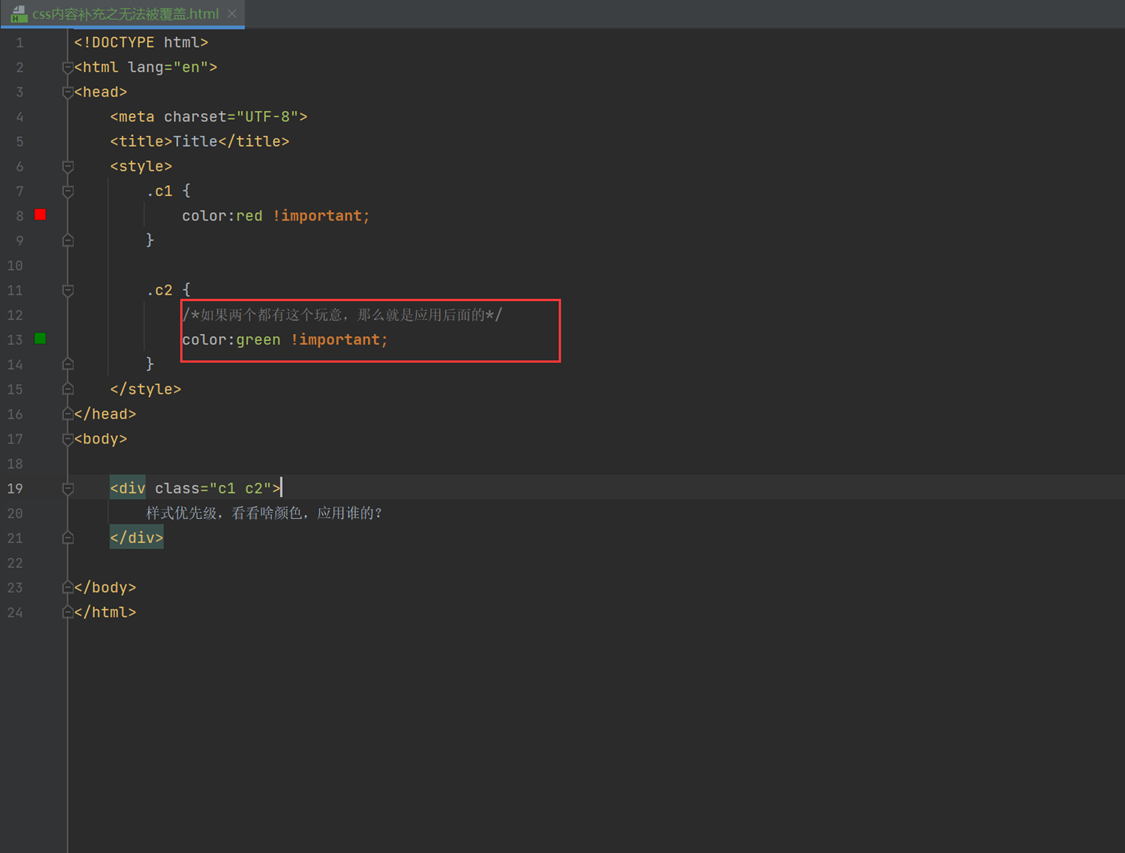
15.13 css内容补充之无法被覆盖
比如一个div里面的内容需要显示颜色,一个c1样式是红色,c2样式是绿色,一般情况下,同时应用了c1和c2,那么c2在后面,根据代码的执行顺序肯定是c2生效,有什么办法让指定的生效?那么加个关键词就行。
15.14 前端内容总结和安排
啥也没说
15.15 自定义web框架(web框架原理,重要)
a)tornado为什么只有他才有异步?其它没有
b)为什么torando没有wsgi
c)Wsgi是什么
d)各大框架区别
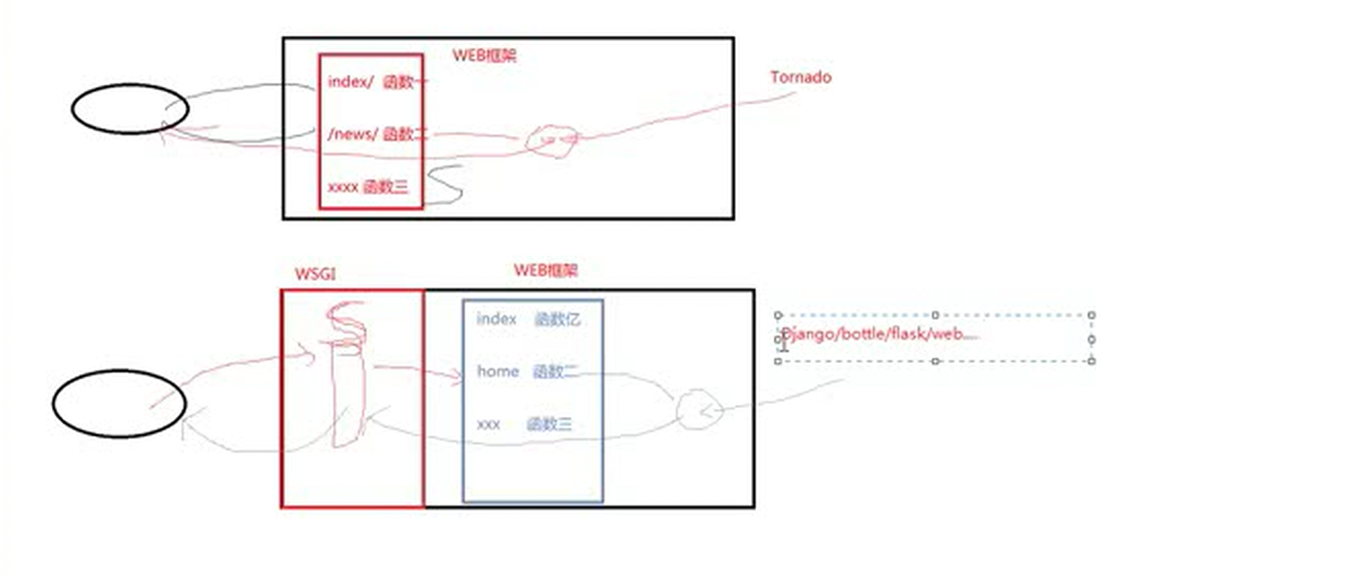
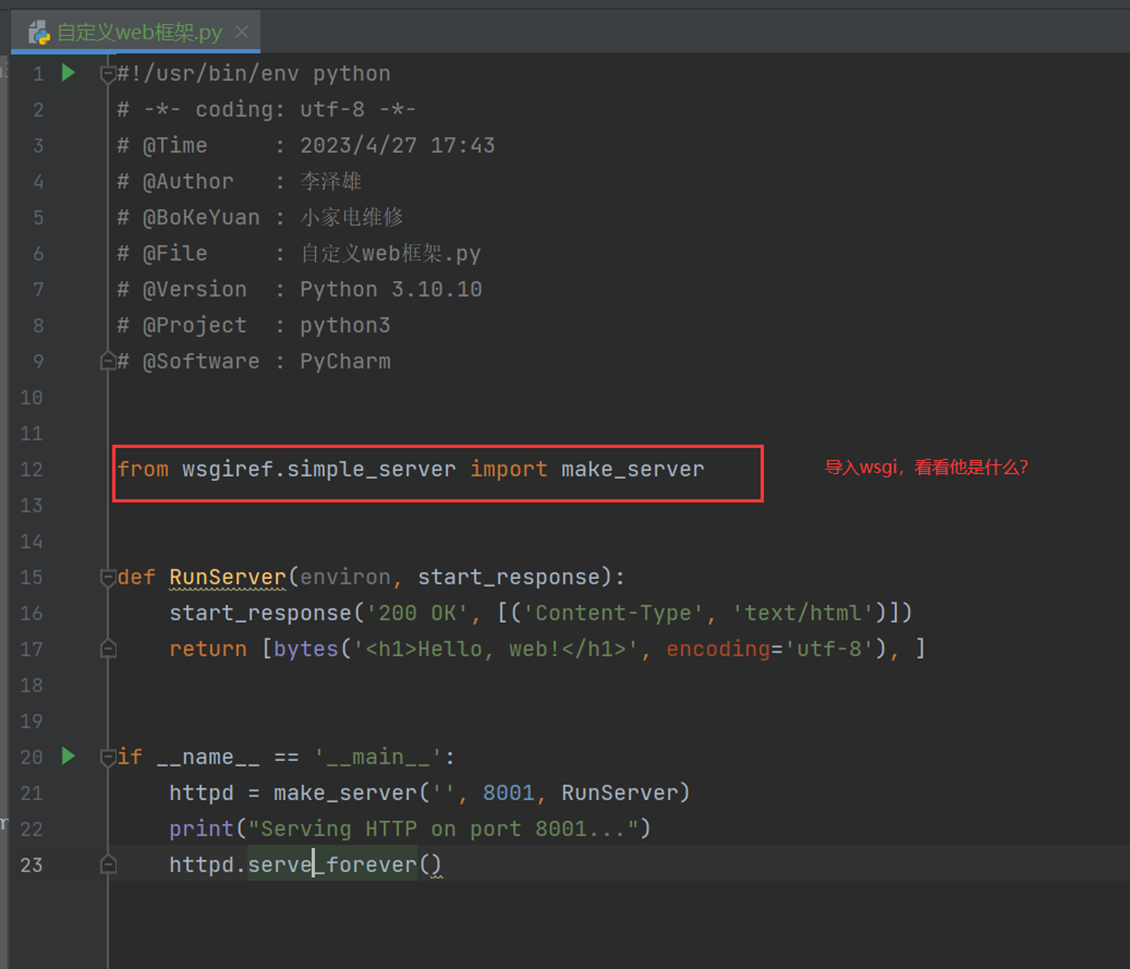
根据上图中,老师说wsgi的原理本质上就是socket,wsgi帮我们做了很多事情,比如一些数据处理等,然后在把数据交给web框架,而只有tornado没有wsgi,其余的框架基本都有,但是只有tornado有异步处理。
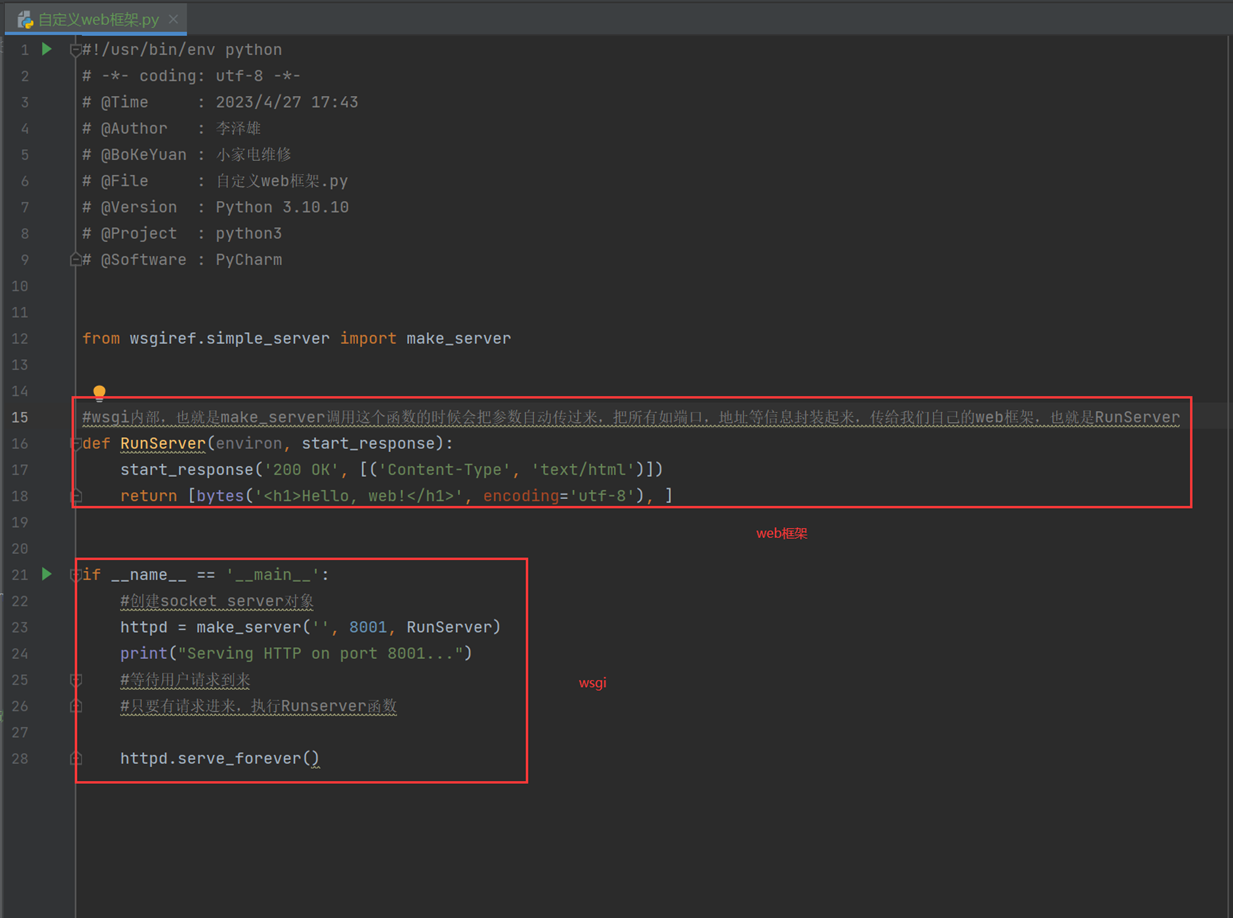
接下来,用一个简单的代码一步一步来剖析一下这个web框架的底层原理。
首先下面的代码,就是利用wsgi来写一个web框架。
接下来
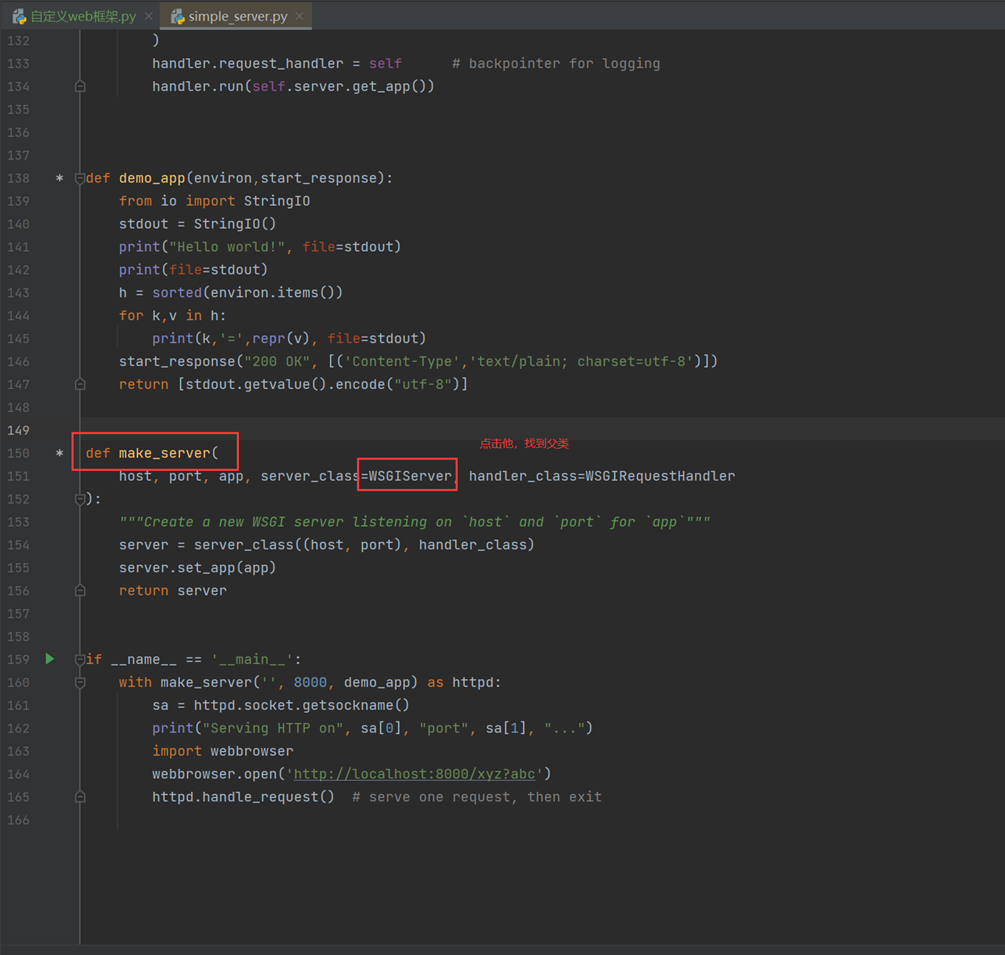
继续
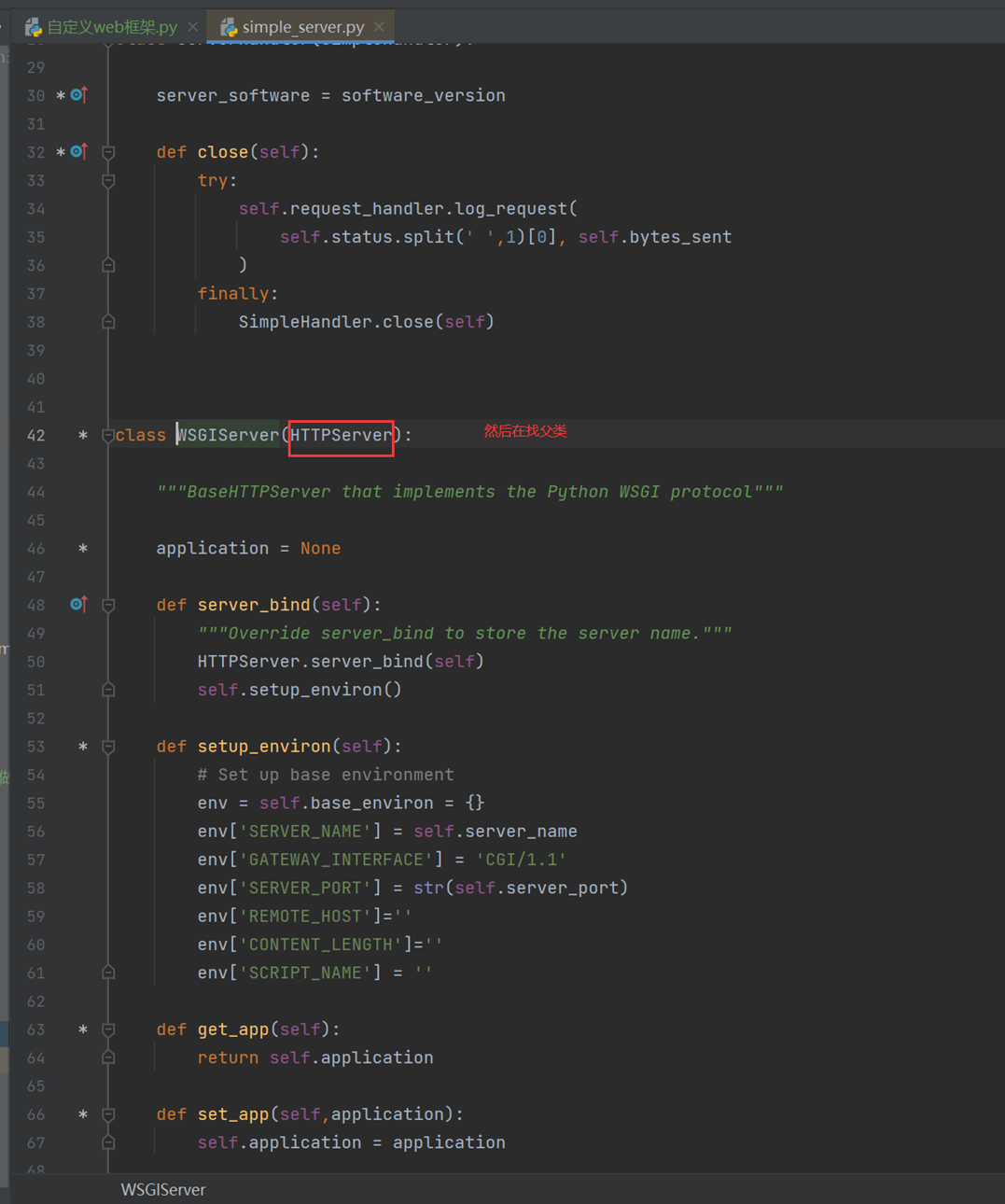
结果,本质上就是socket
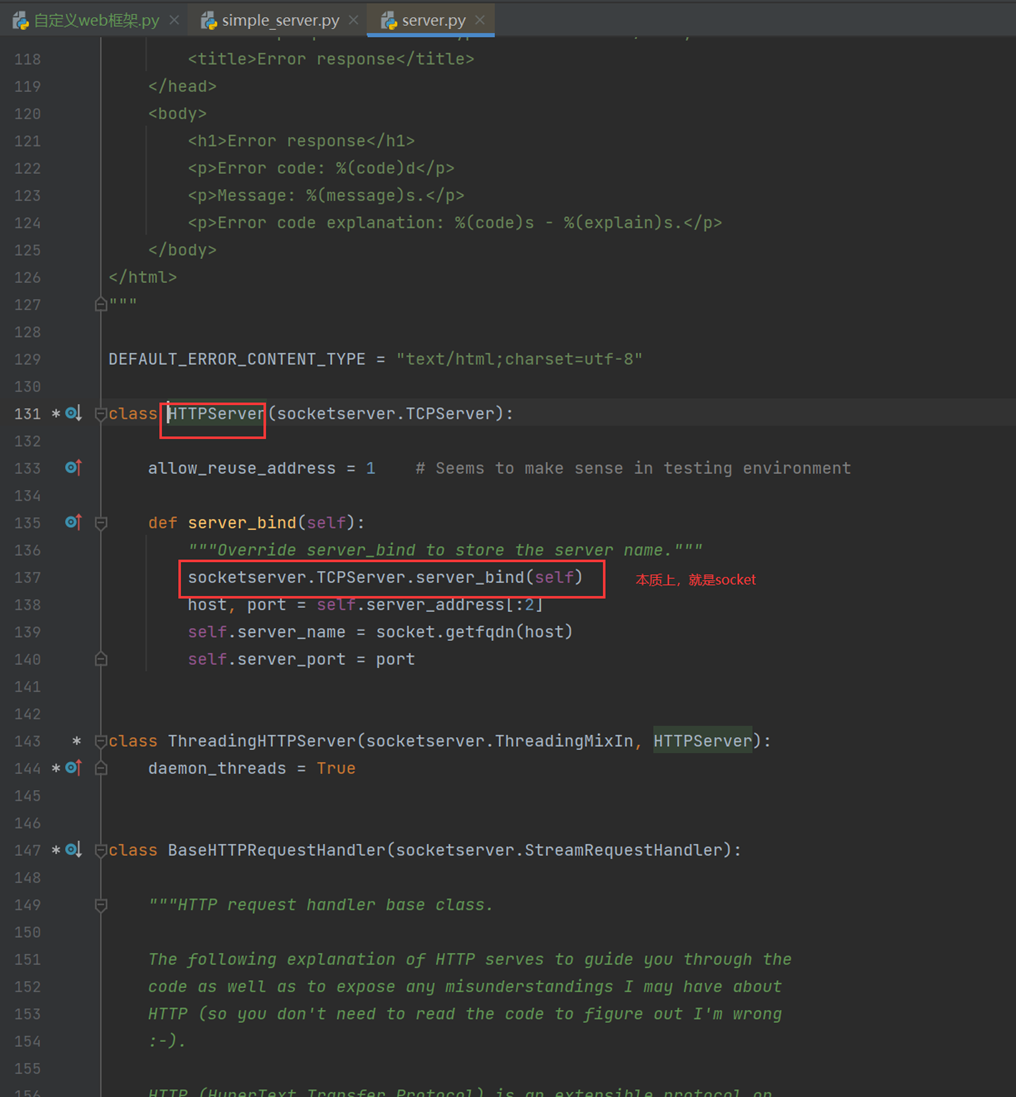
搞清楚wsgi后,看看所有的代码的作用
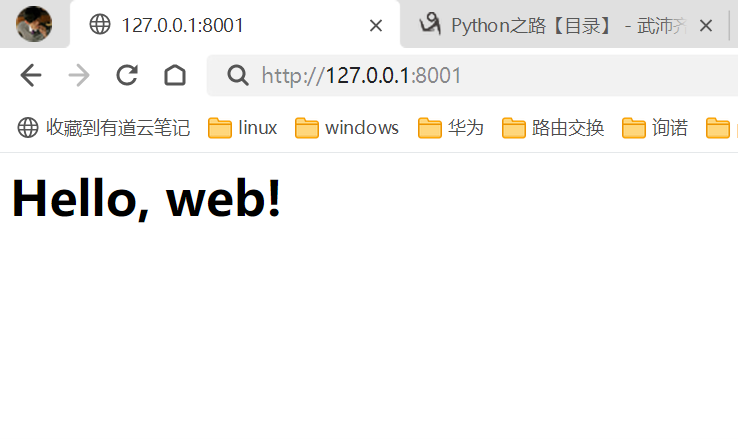
使用web界面访问,就会返回以下
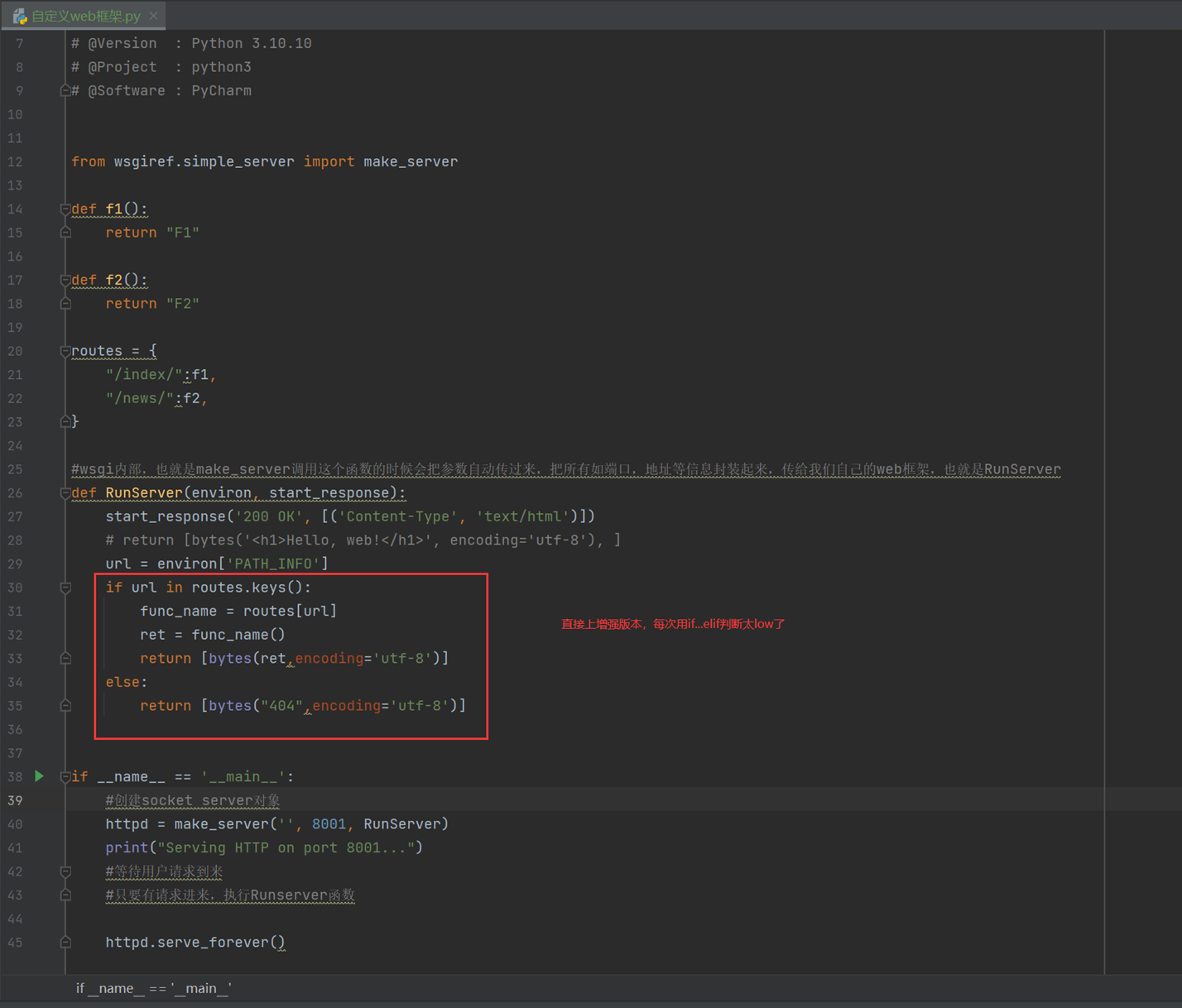
但是这样只是固定的永远返回的相同的字符,这样肯定不行,所以,需要根据用户输入的url来判断,然后进行返回不一样的内容。
15.16 自定义web框架2
可以看出来,可以直接返回一个函数结果,那么如果我有很多字符要返回,可以写在函数里面吗?当然可以,只是整个代码变的特别乱。
所以,比如,返回一个html的文件,我完全可以直接读取,html文件放在另一个文件里面,这样不就解决了吗?
首先看看html
在看看web框架
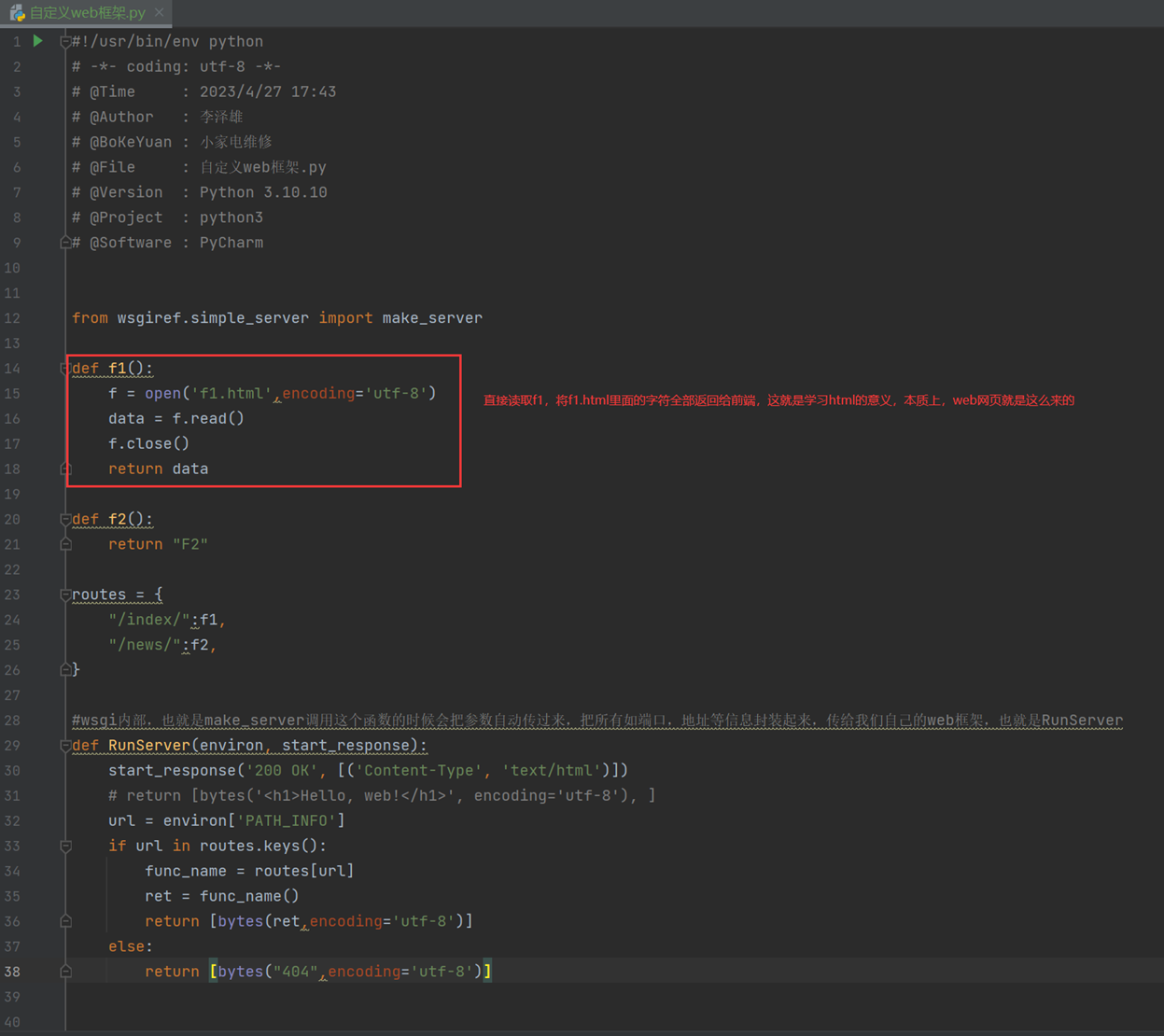
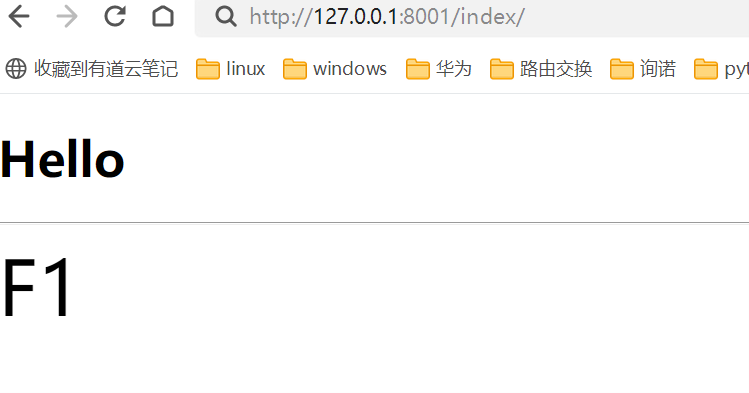
看看结果
这样的就是web框架和网页的原理,当然f1是个固定的值,能否把他改为动态的东西?比如时间?那么这就是模版的雏形,我将f1替换成可以变动的时间。
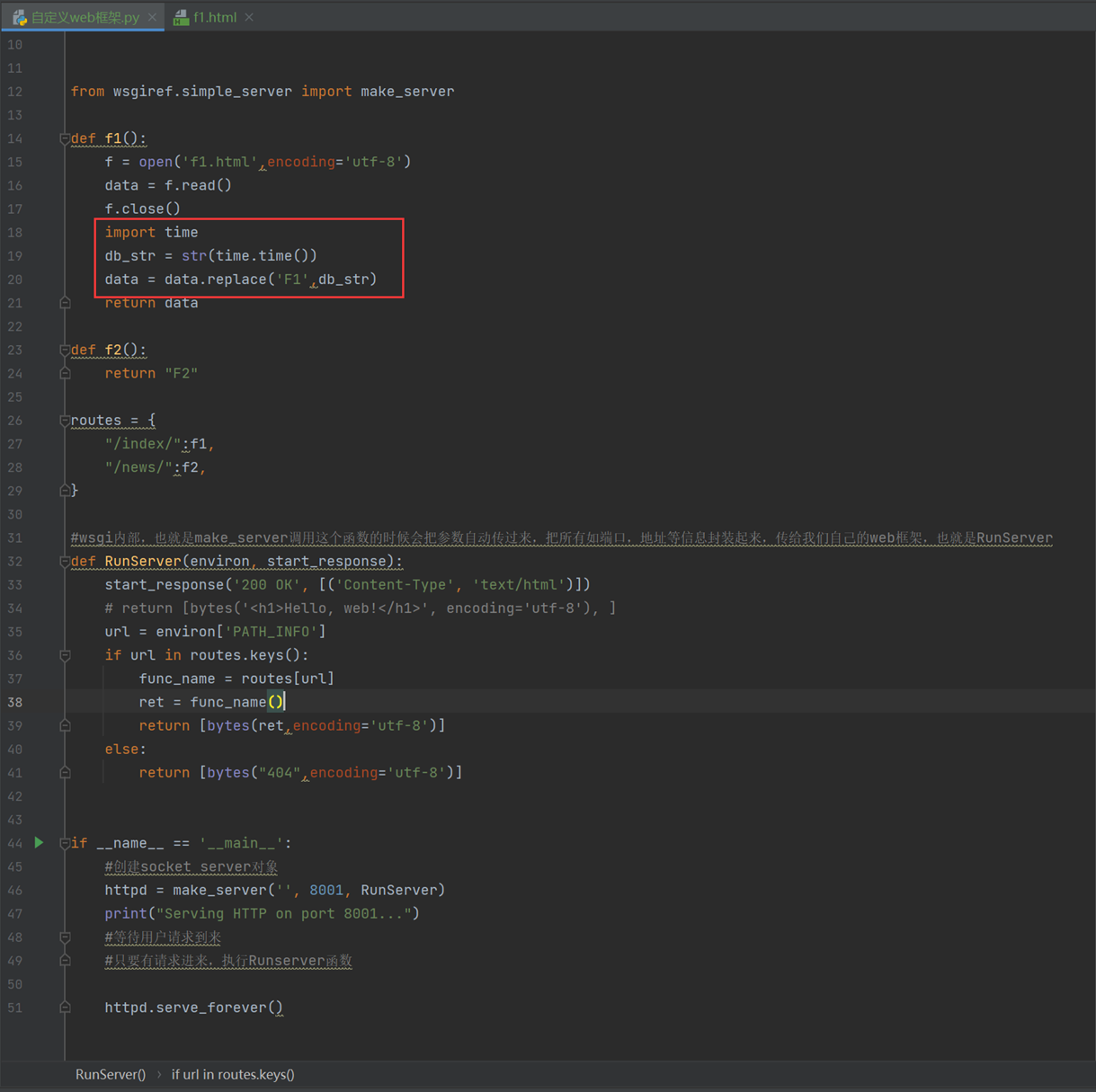
这样好吗?好,但是还不够好,所以出来一个模版系统,叫做jinja2,django底层用的也是他,他有固定的语法和方便的书写方式,根据他的规则,可以简化很多模版方便的问题。
这里使用F2函数来演示。
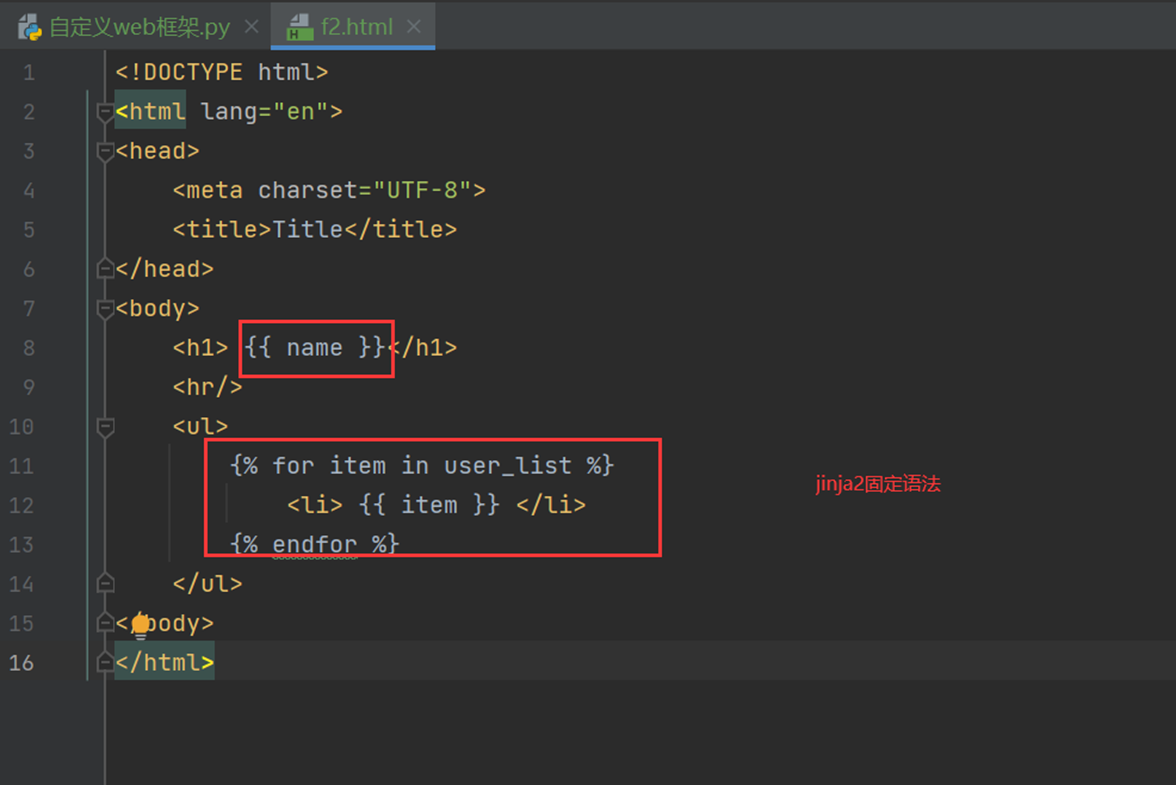
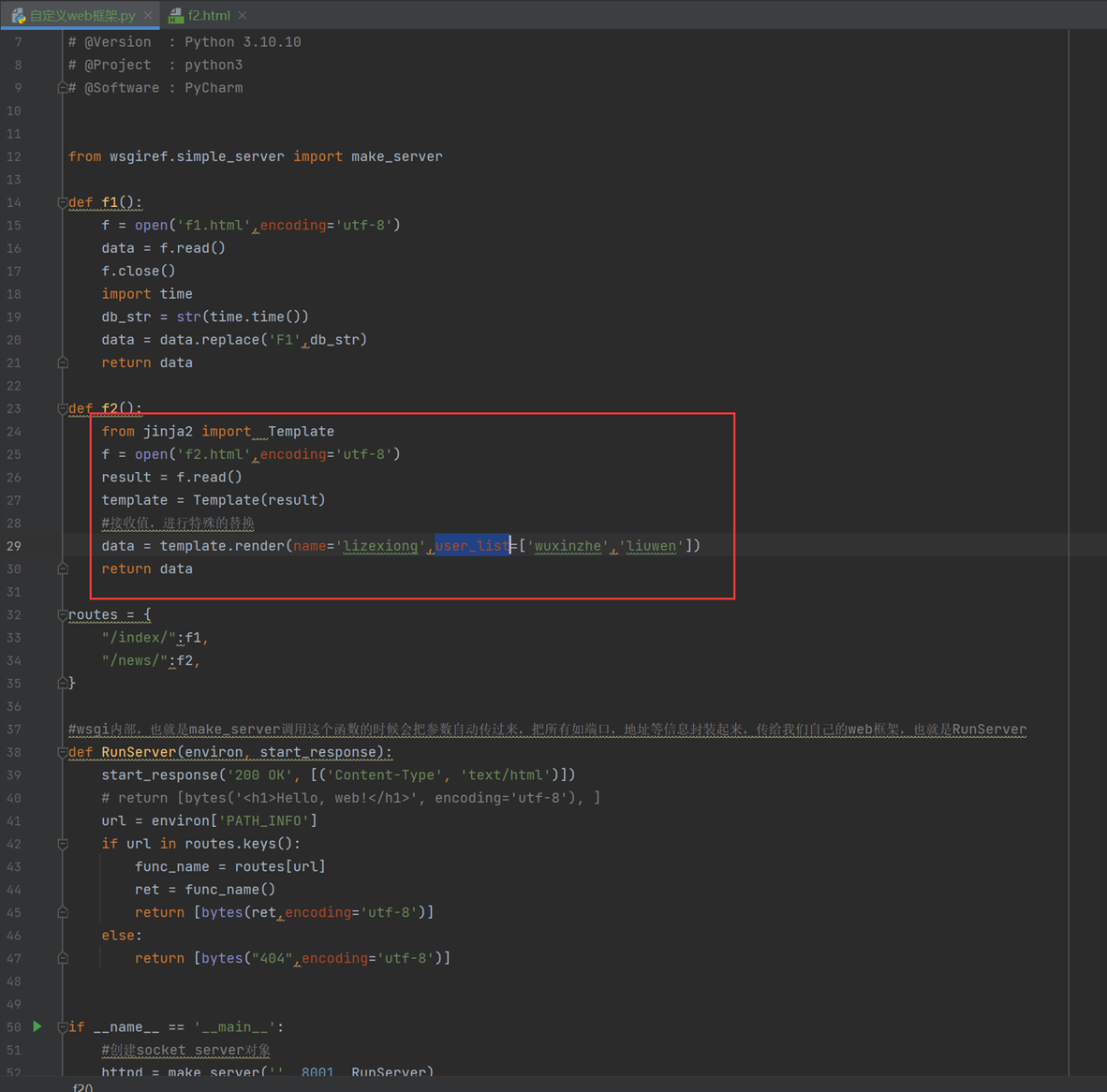
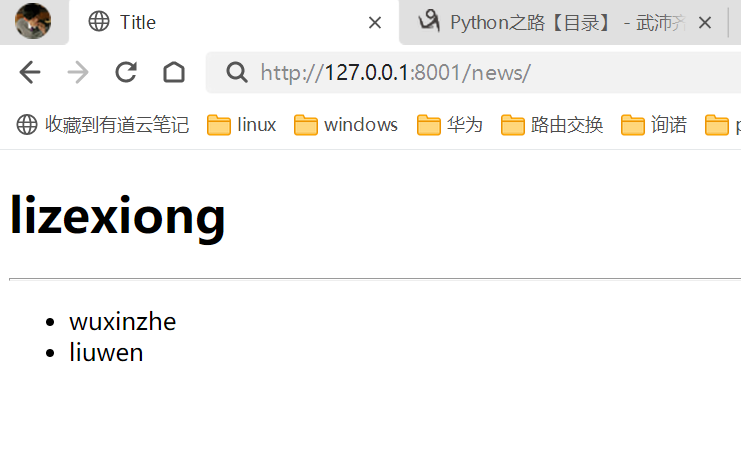
查看网页返回
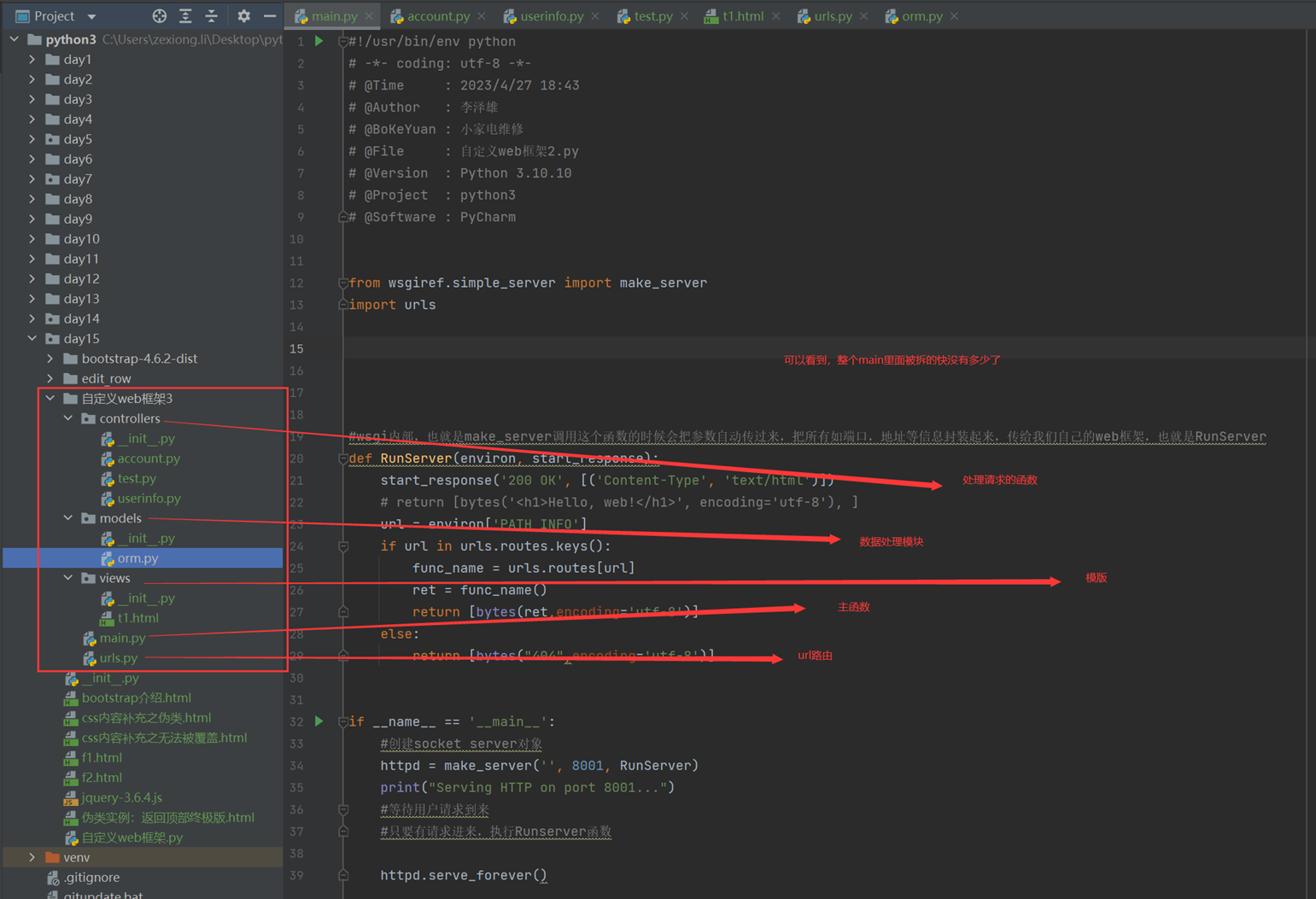
15.17 自定义web框架3
本章其实就是讲解了mvc框架和mtv框架是什么样子的,简单来说,就是把之前main函数里面的东西全部进行拆分,什么功能放到什么文件夹下面,如下图:
简单总结mvc和mtv
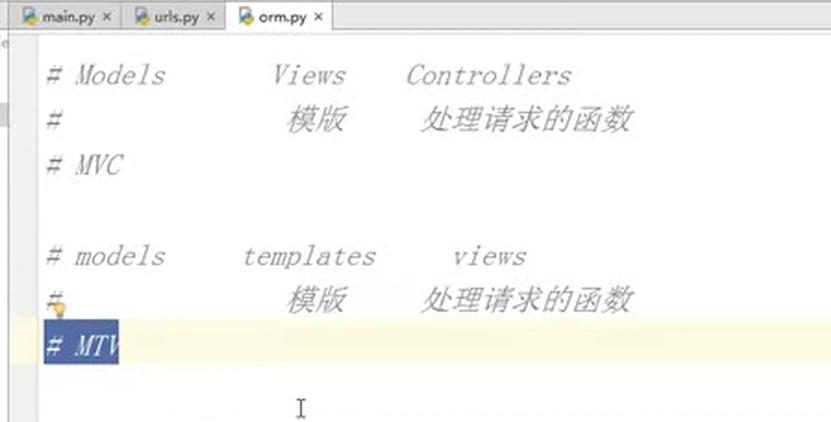
15.18 自定义web框架4

15.19 django基础之创建程序


首先要安装django

创建django程序
终端命令:django-admin startproject sitename
IDE创建Django程序时,本质上都是自动执行上述命令
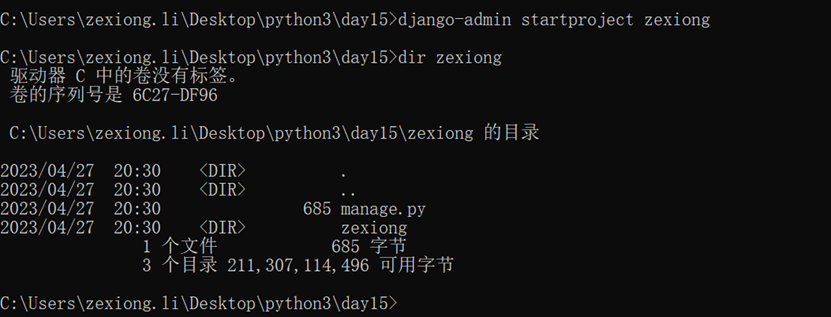
其他常用命令:
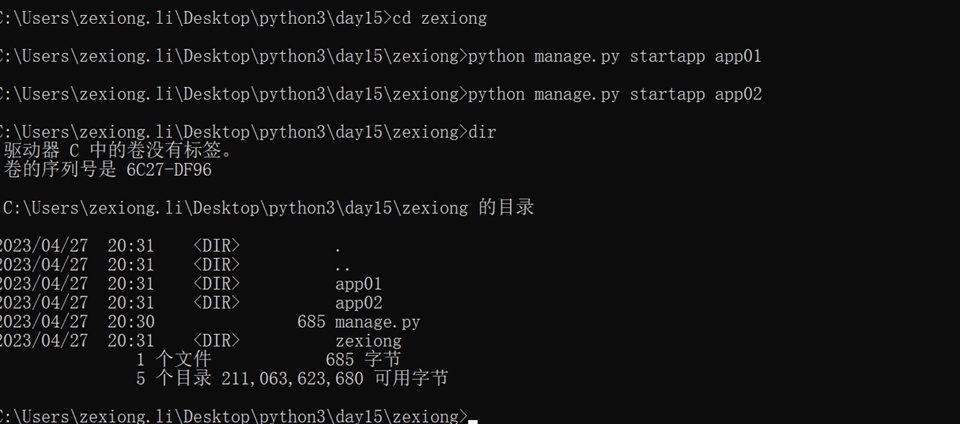
python manage.py runserver 0.0.0.0
python manage.py startapp appname
python manage.py syncdb
python manage.py makemigrations
python manage.py migrate
python manage.py createsuperuser
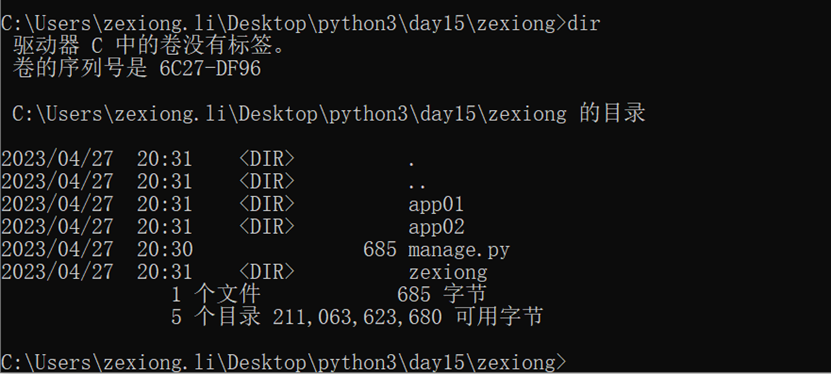
这样与我创建的zexiong全部在同级目录下。
查看一下目录结构
15.20 django基础之基本请求流程
本节就是写了一个基本的url和函数,然后请求访问有回应,没有讲其它的。
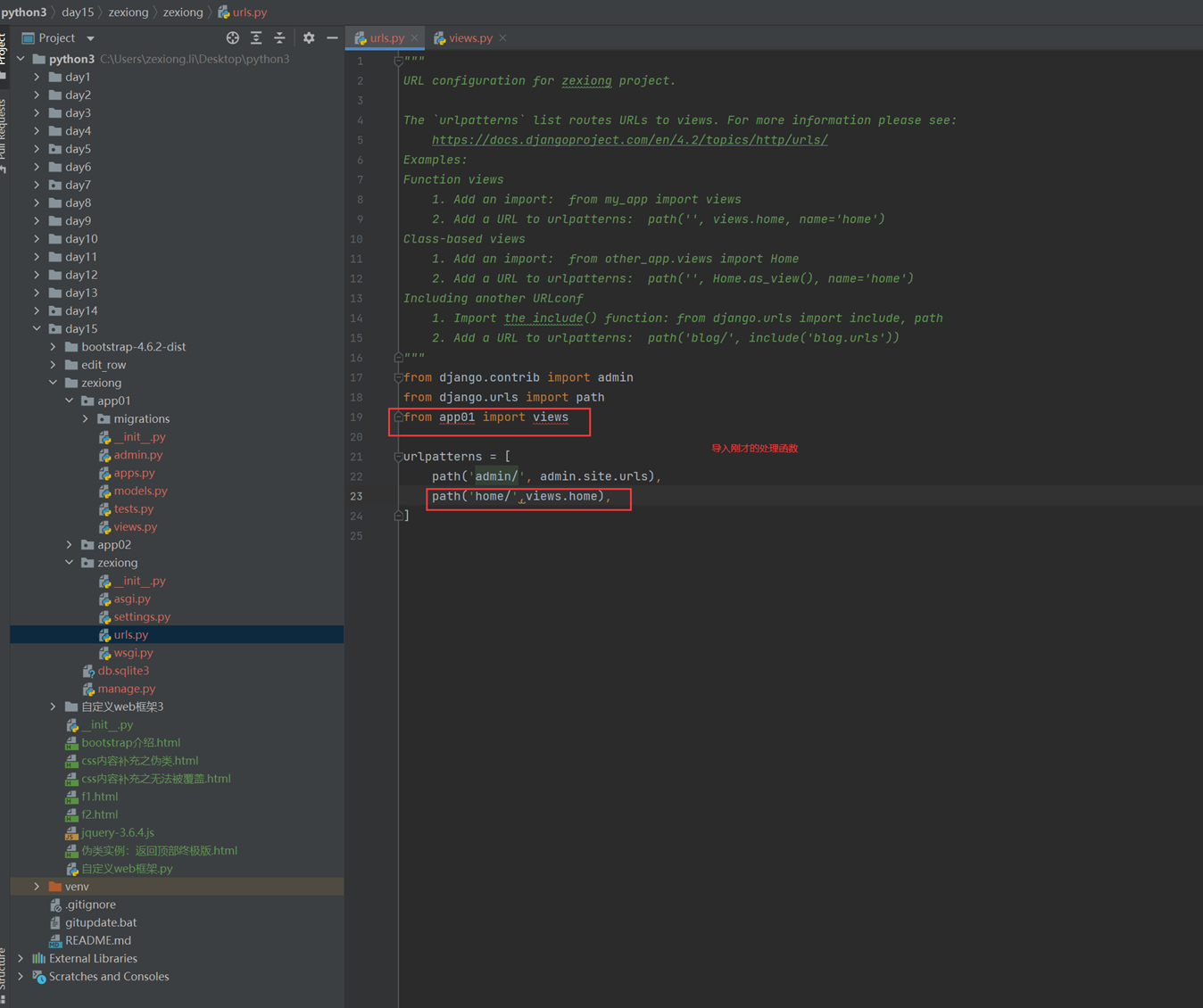
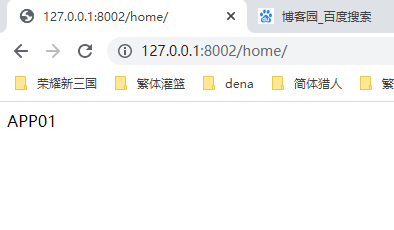
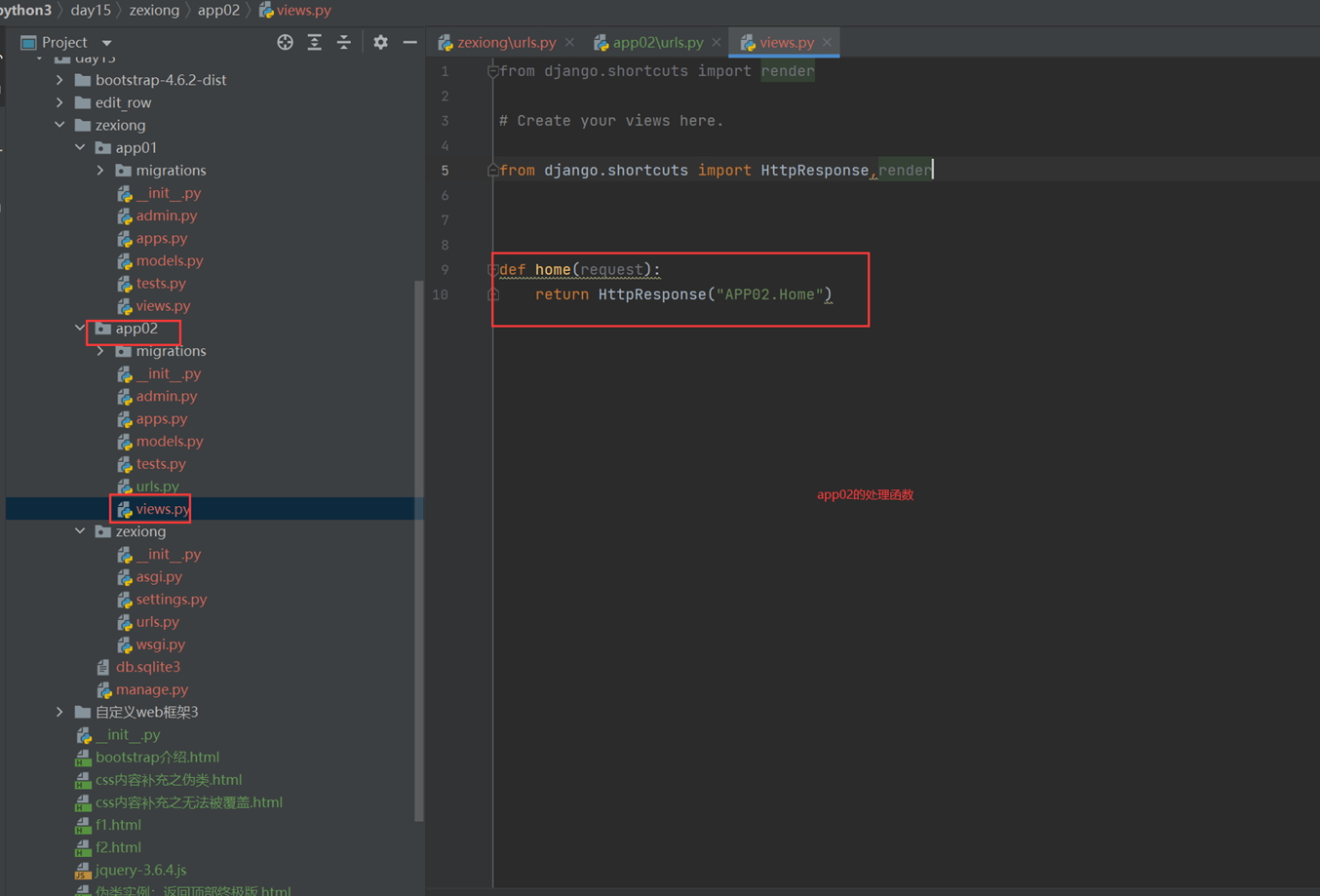
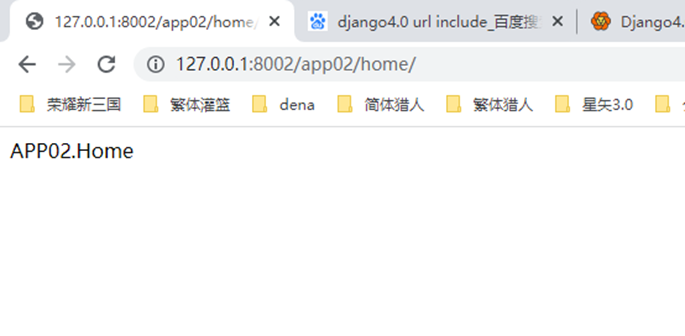
1.app01的返回函数
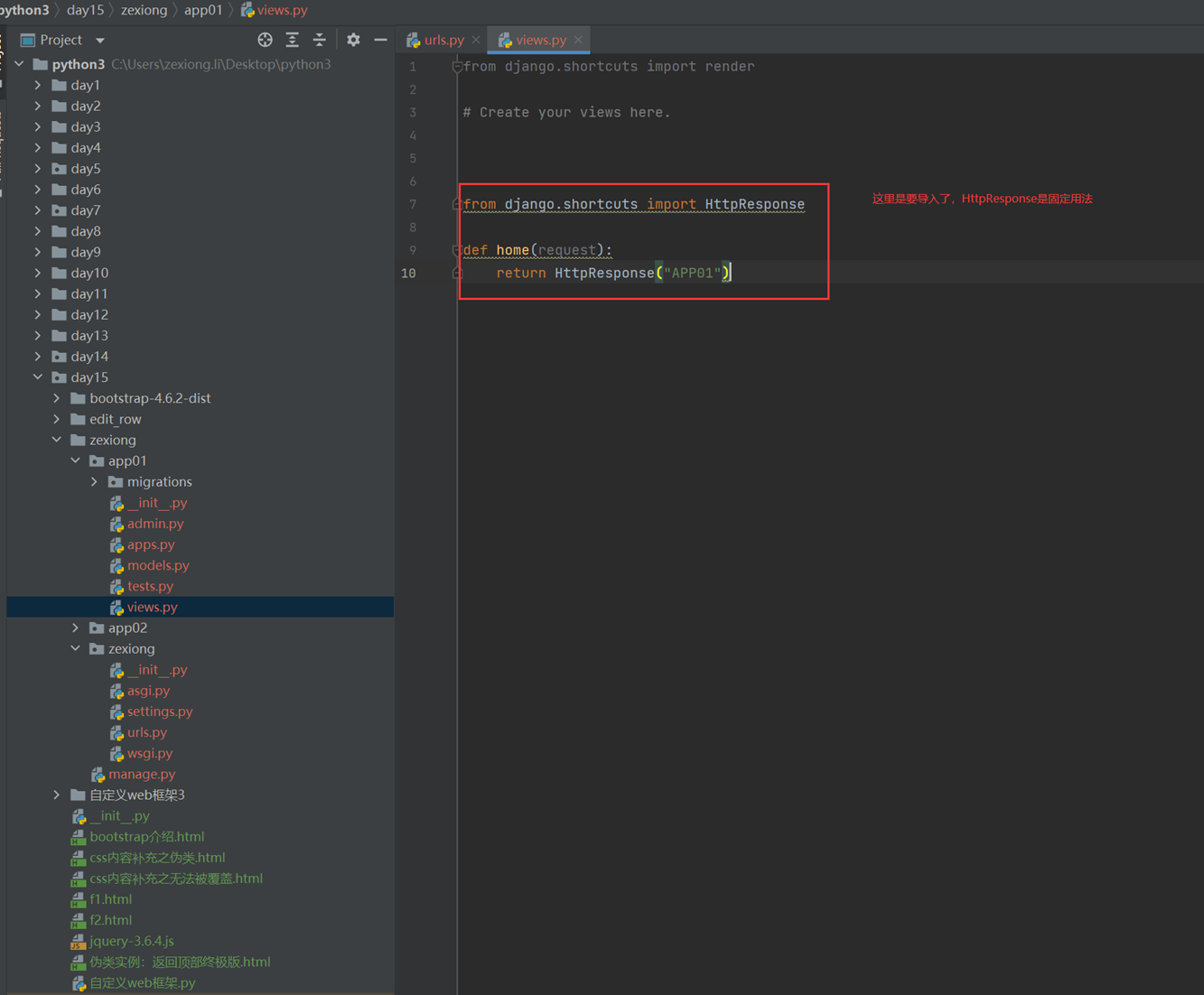
2.url路由系统
3.启动django
4.访问查看
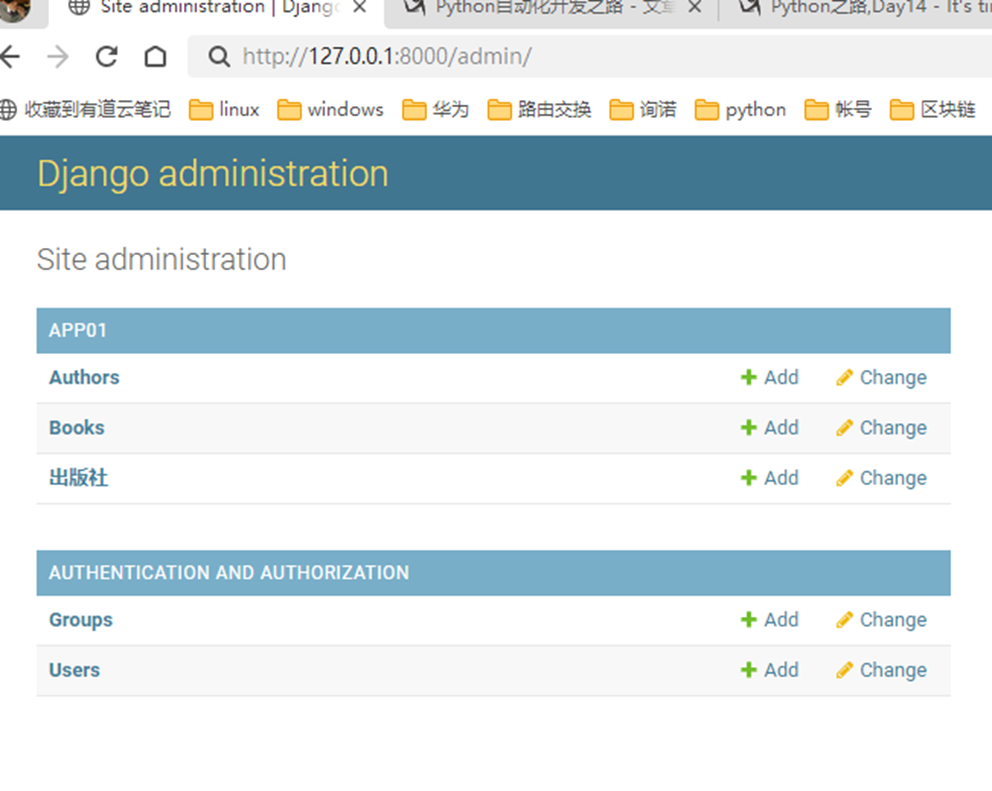
15.21 django基础之admin功能前瞻
本章就是演示了一下怎么创建django默认的admin后台用户,很简单的几个步骤。
在这之前,如果需要用户,那么就需要有个数据库存储用户的帐号信息,这个存储在哪里?
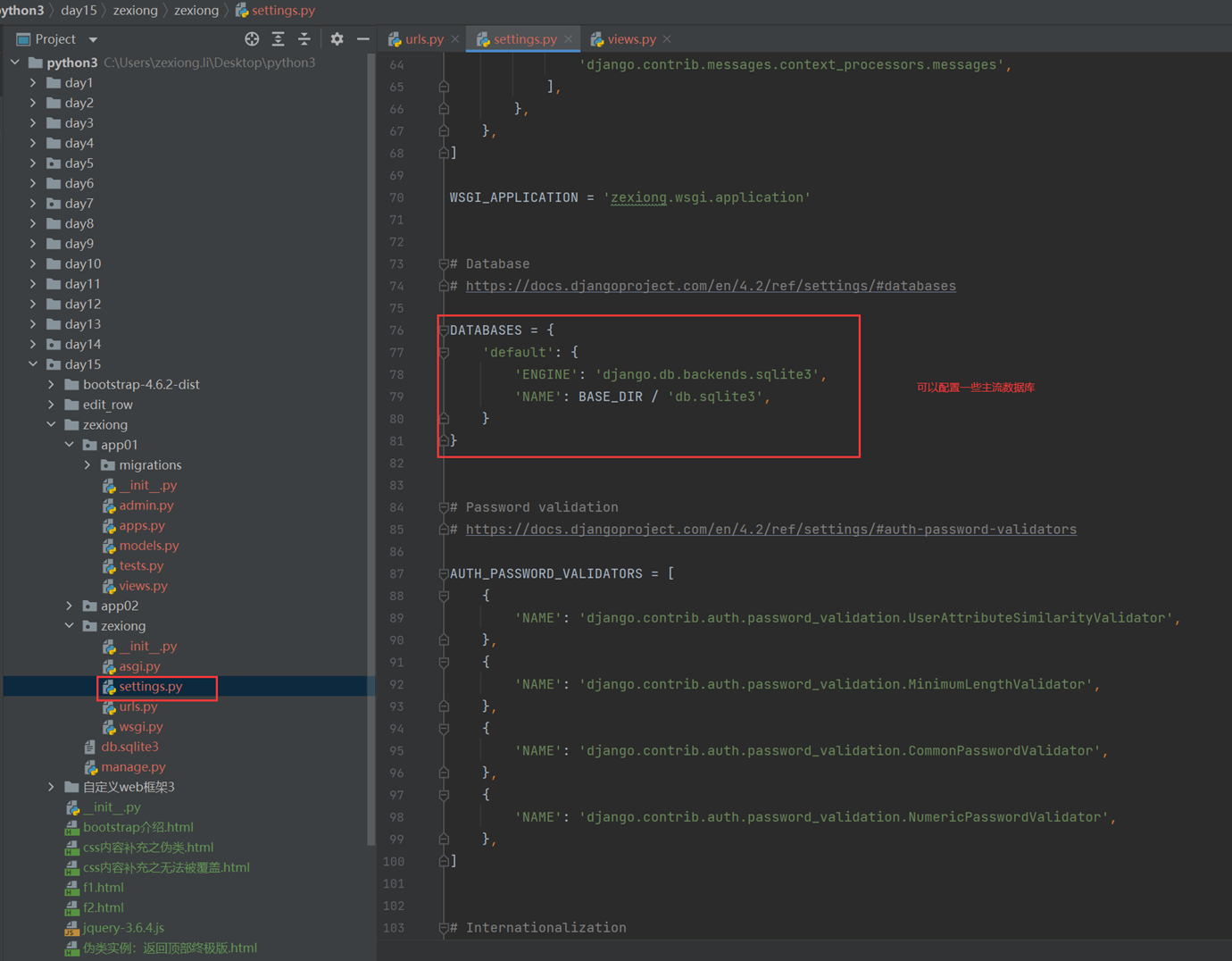
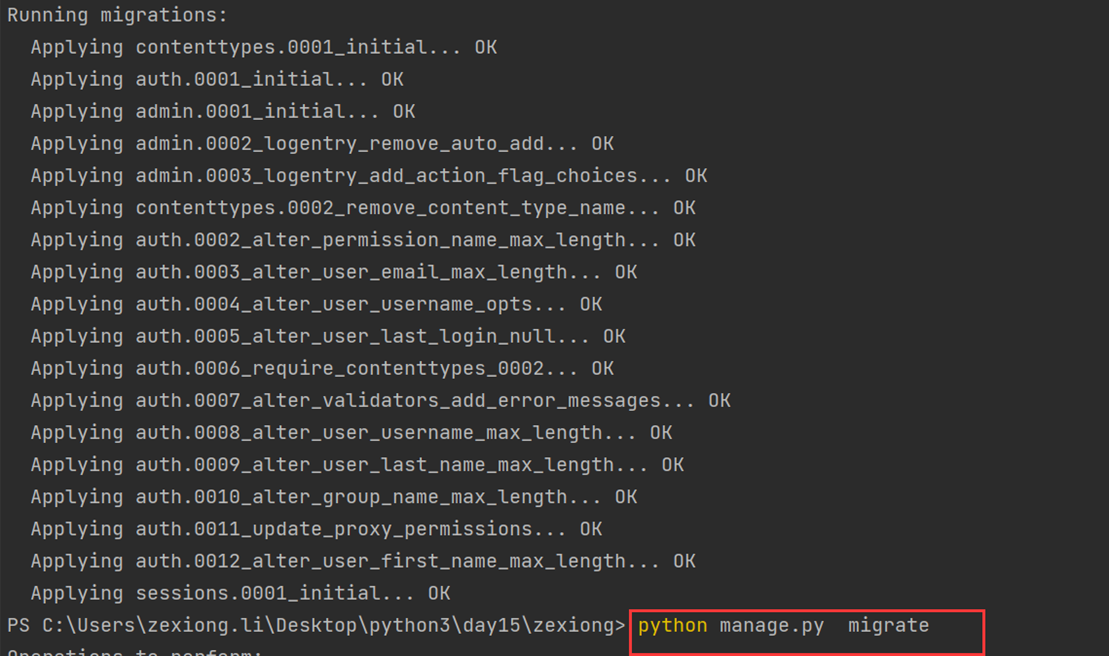
1.生成配置文件以及根据配置文件创建数据库相关

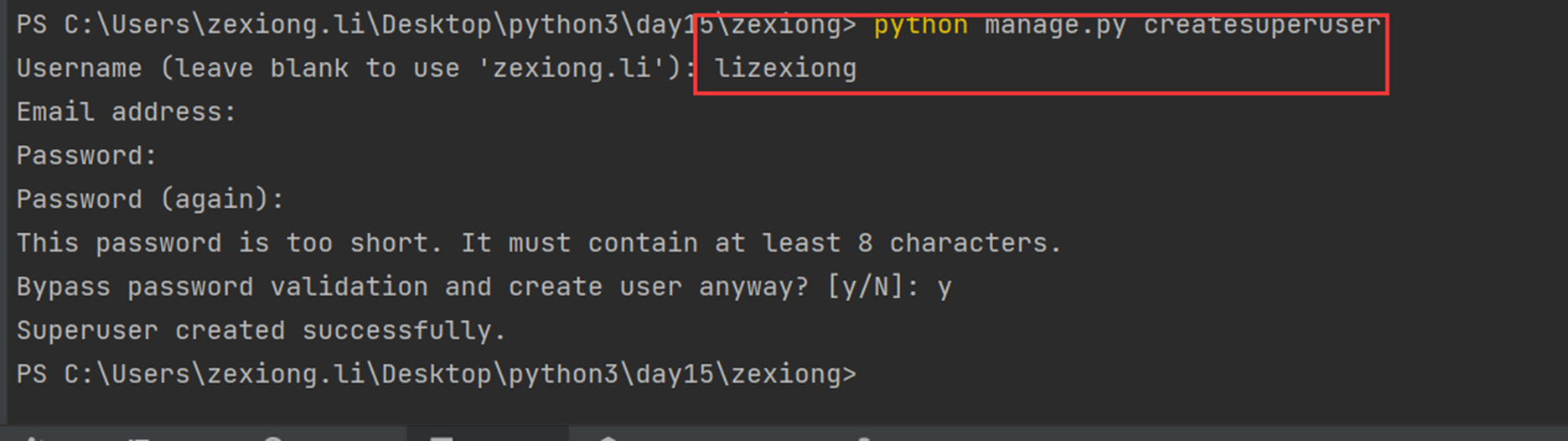
2.创建超级用户
3.启动django,登录127.0.0.1:8002/admin/验证
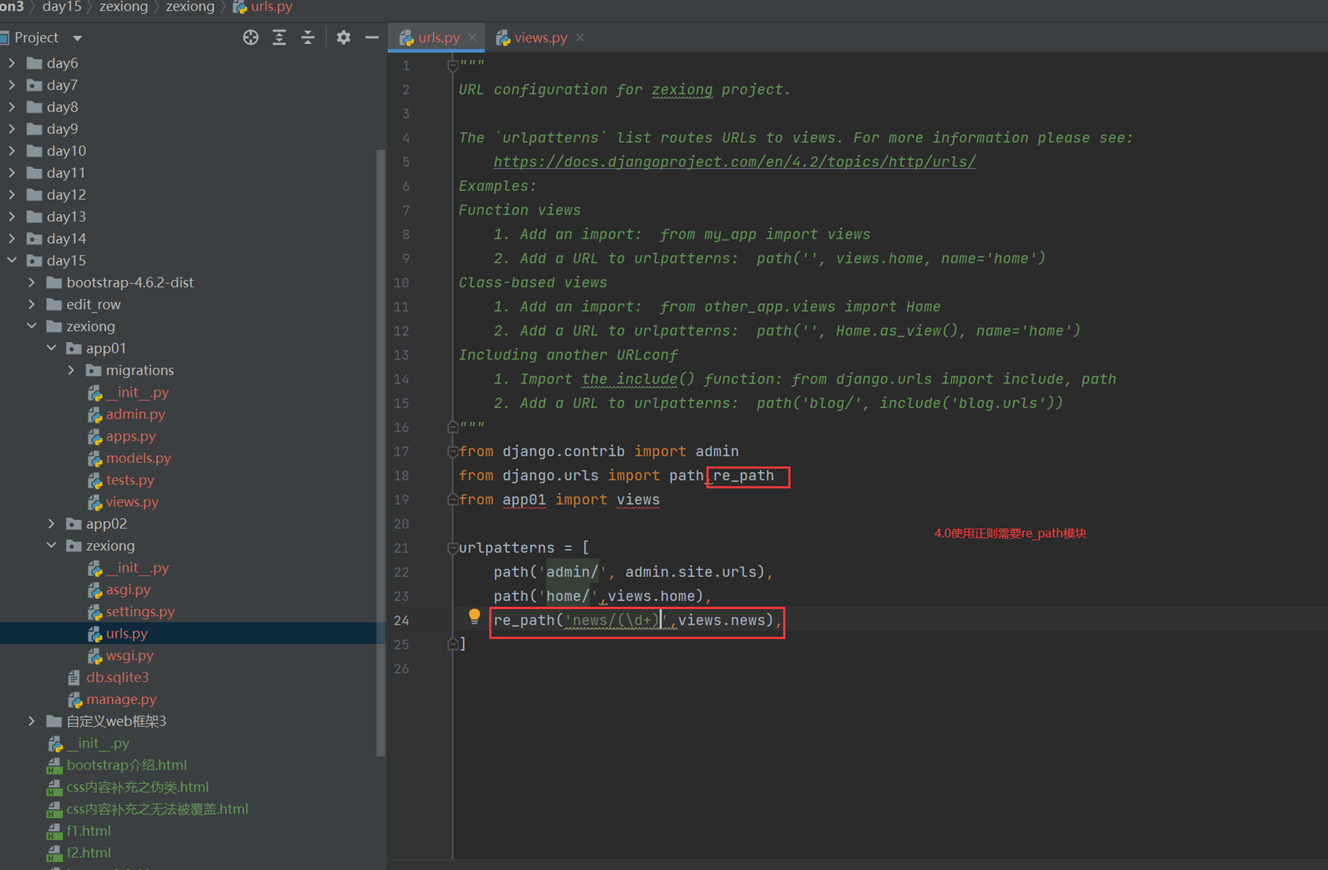
15.22 django基础之路由系统

本章讲解了几个案例。
1.静态路由,通过固定的url,匹配到url结果后执行对应的函数。
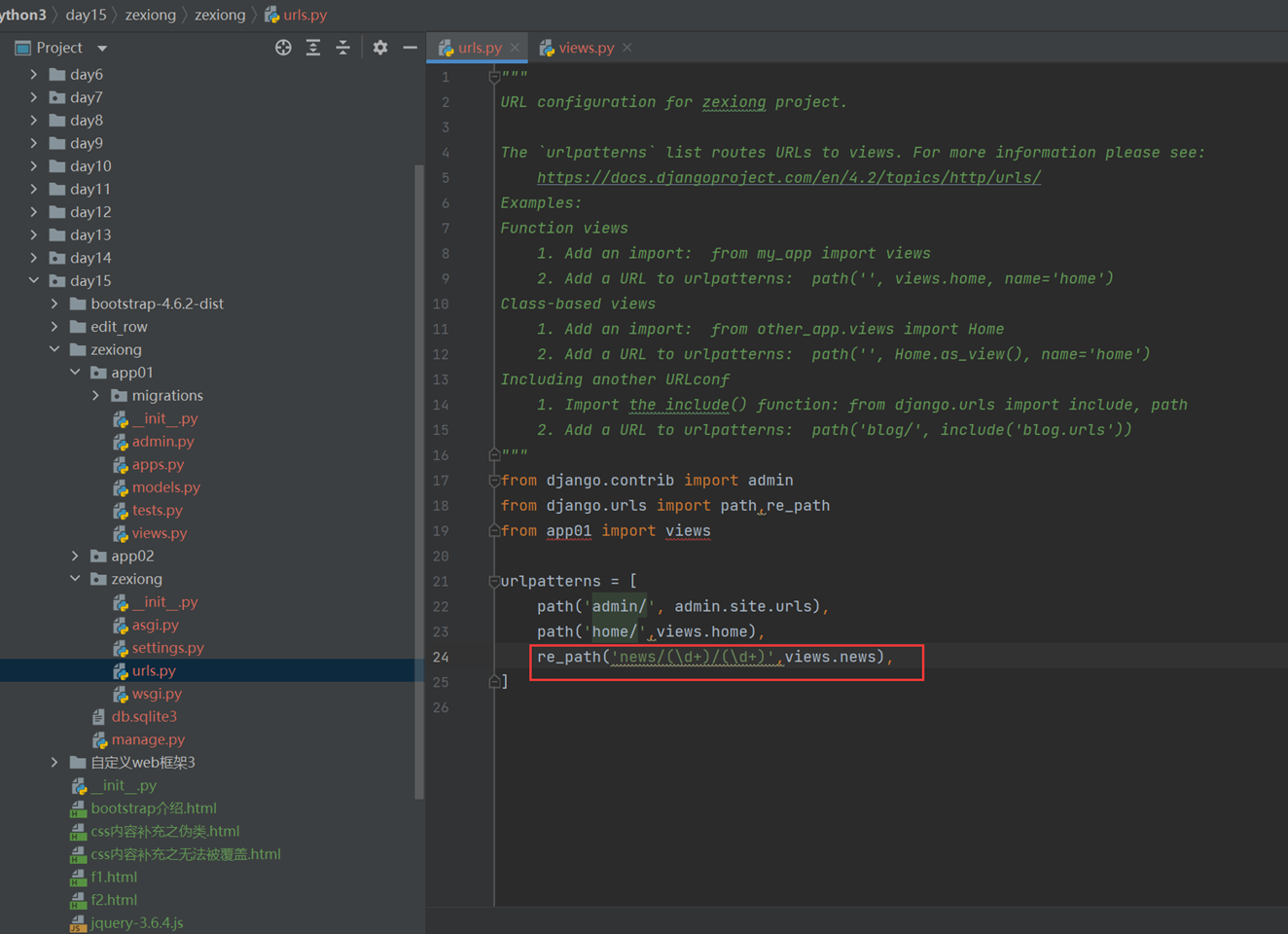
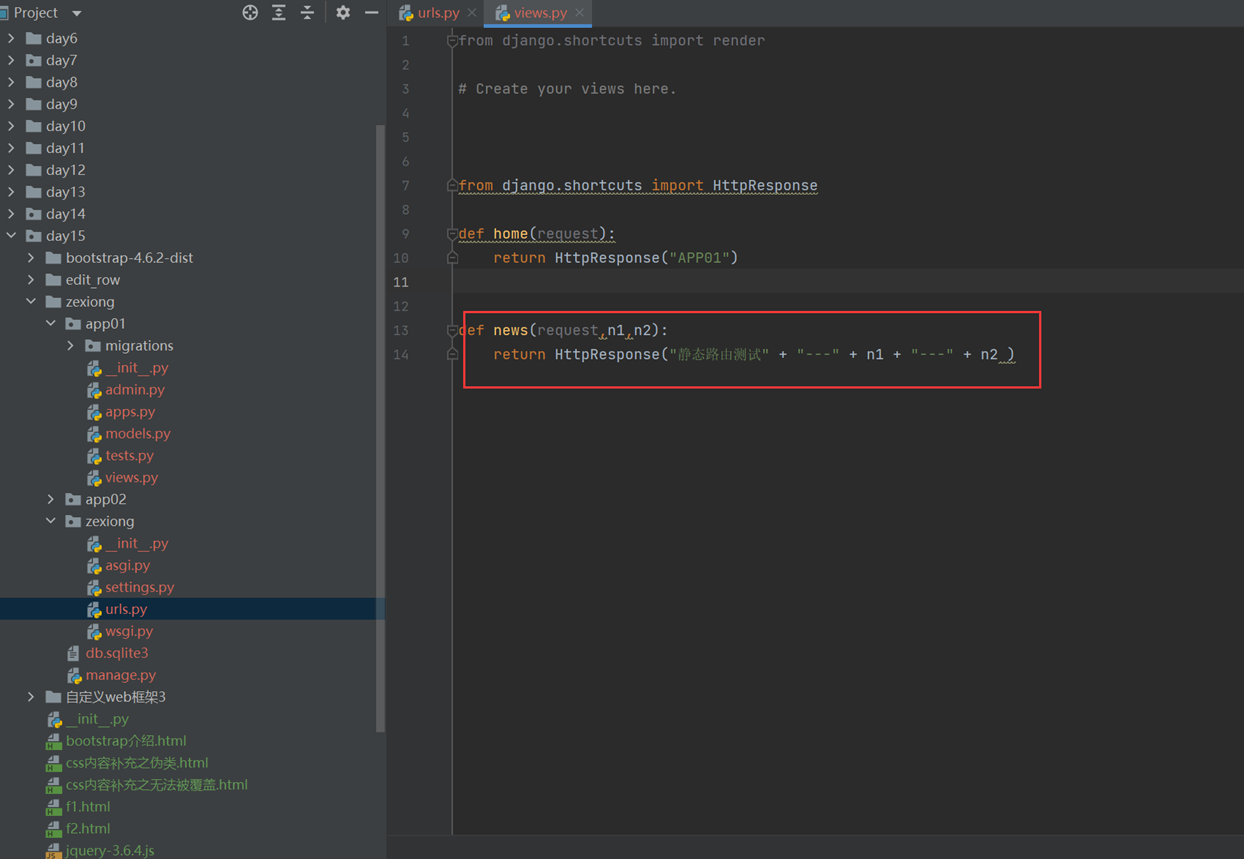
2.动态路由,在静态路由上稍微升级一点点,根据第n个匹配的采纳数,交给函数的第n个参数,严格按照顺序执行
第二个小案例就是模版的方法,按照匹配的参数,传给指定的形式参数
3.就是二级路由,比如,把一个项目的url全部放到那个项目下面,方便管理和调用
1.静态路由
稍微使用点小正则,其实本次测试算不上静态路由了,都有正则了
(本次测试使用django4.X版本,所以语法和视频稍微有点不同)
访问结果
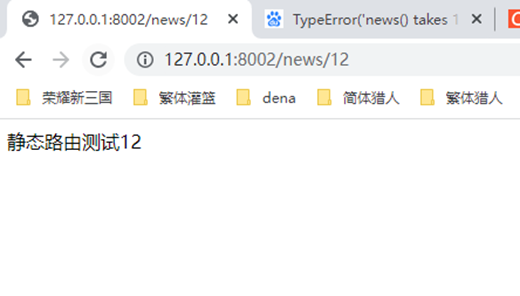
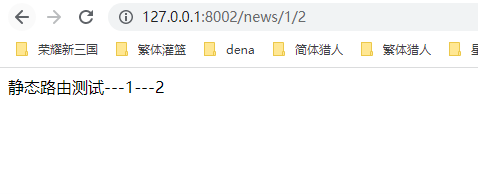
2.动态路由,在静态路由上稍微升级一点点,根据第n个匹配的采纳数,交给函数的第n个参数,严格按照顺序执行
访问结果
第二个小案例就是模版的方法,按照匹配的参数,传给指定的形式参数
这个views里面的函数的参数顺序不管怎么调换都没用,因为已经指定传给谁了
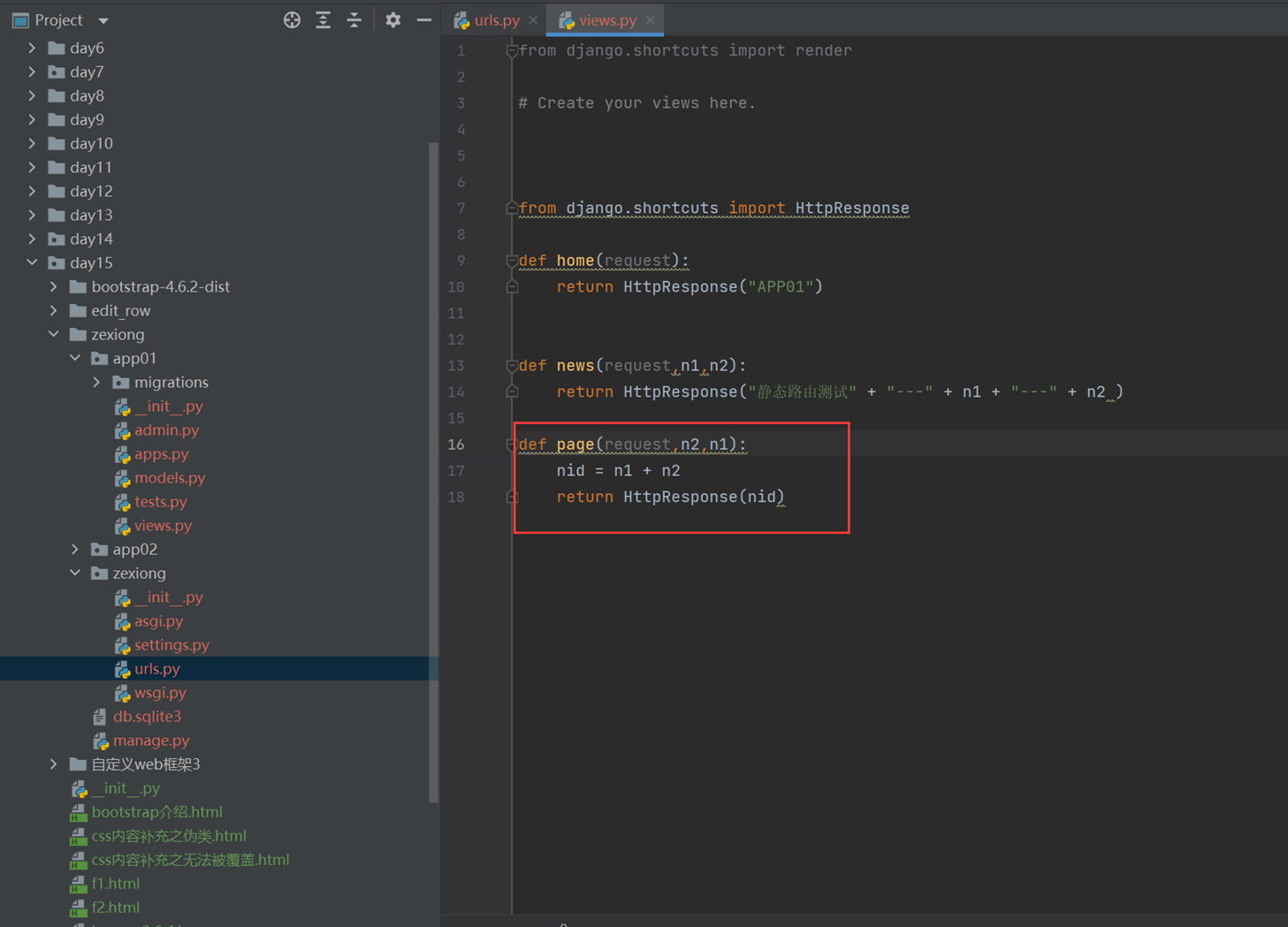
结果
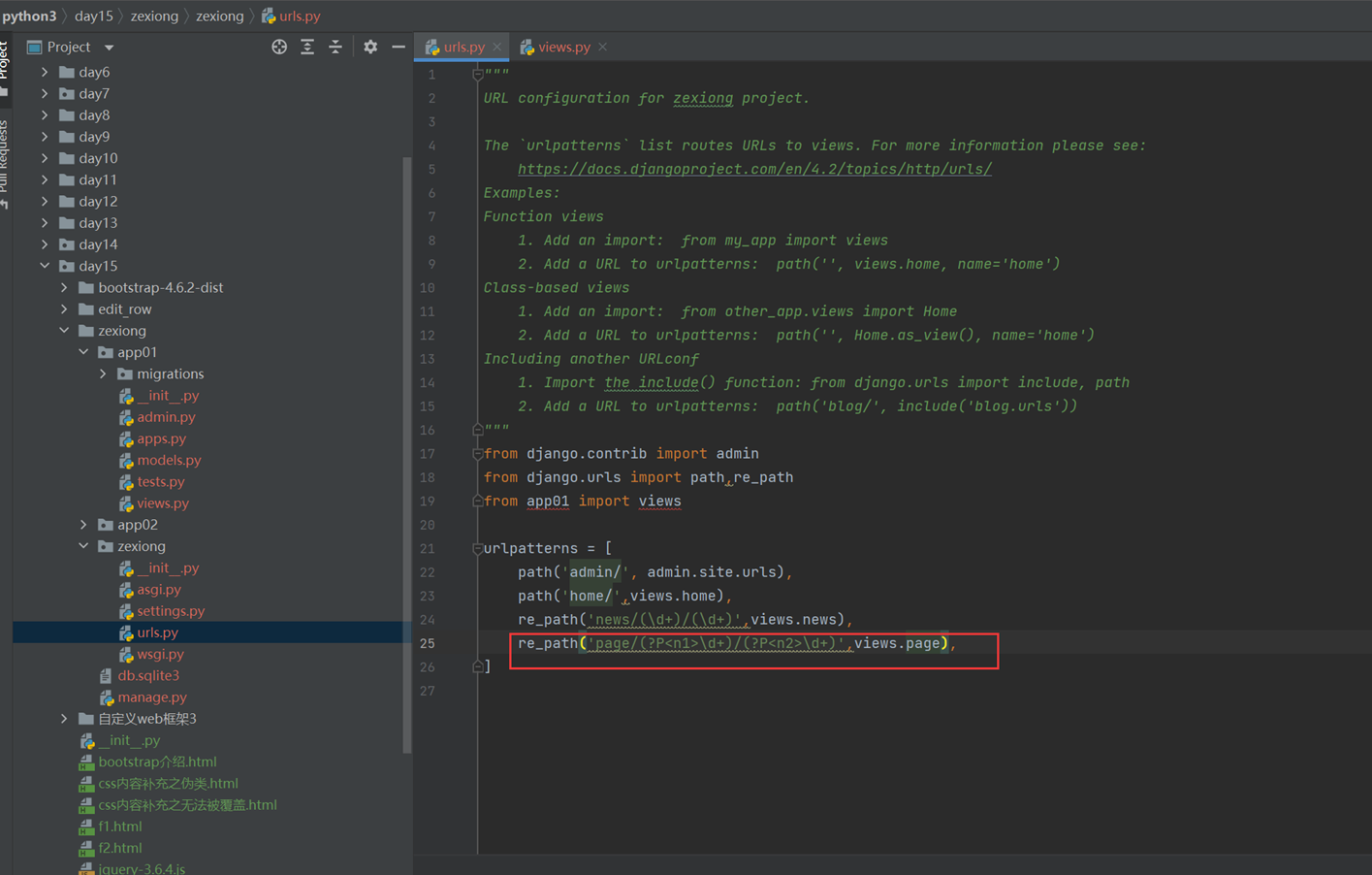
3.二级路由,比如,把一个项目的url全部放到那个项目下面,方便管理和调用
比如,app02的路由文件全部放在app02项目的url下面。
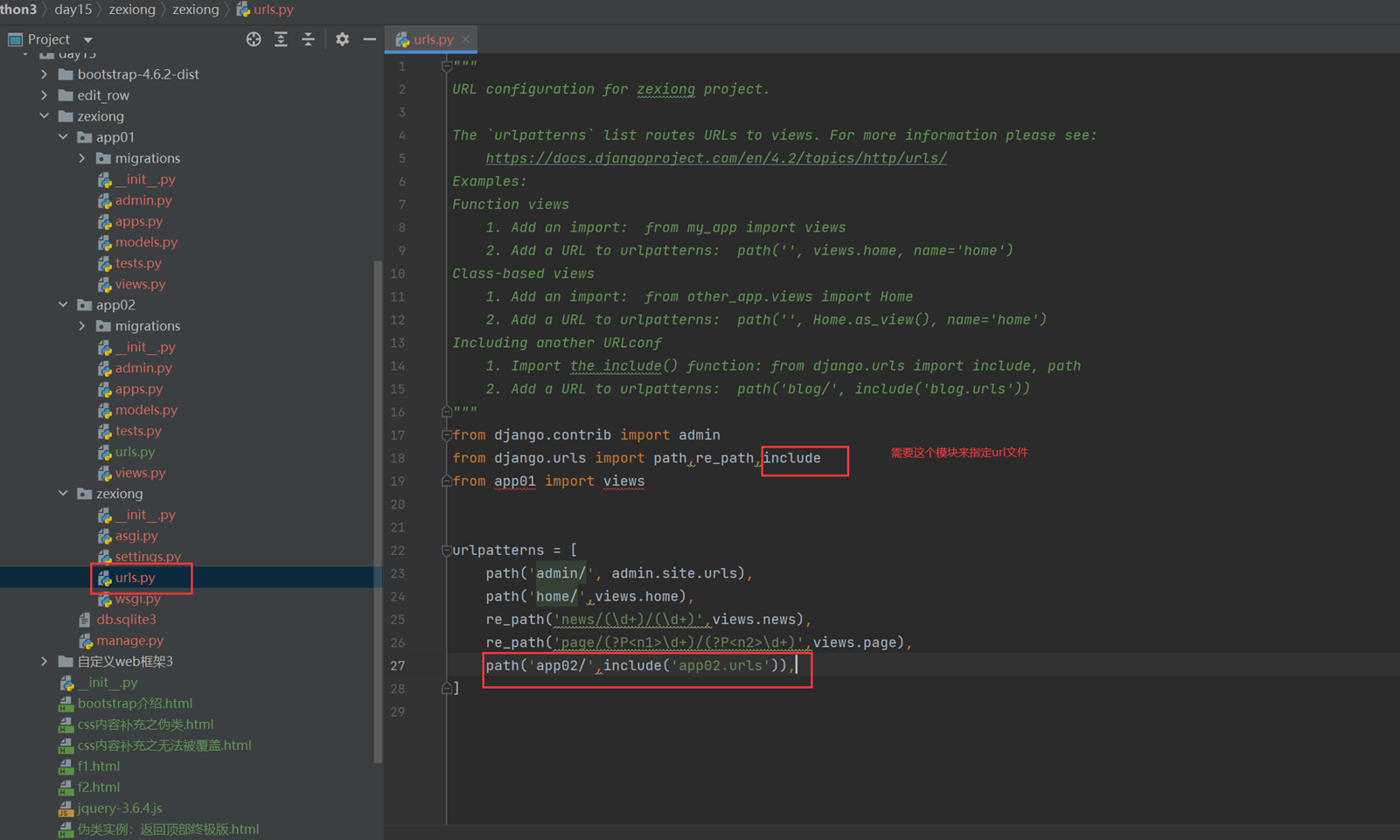
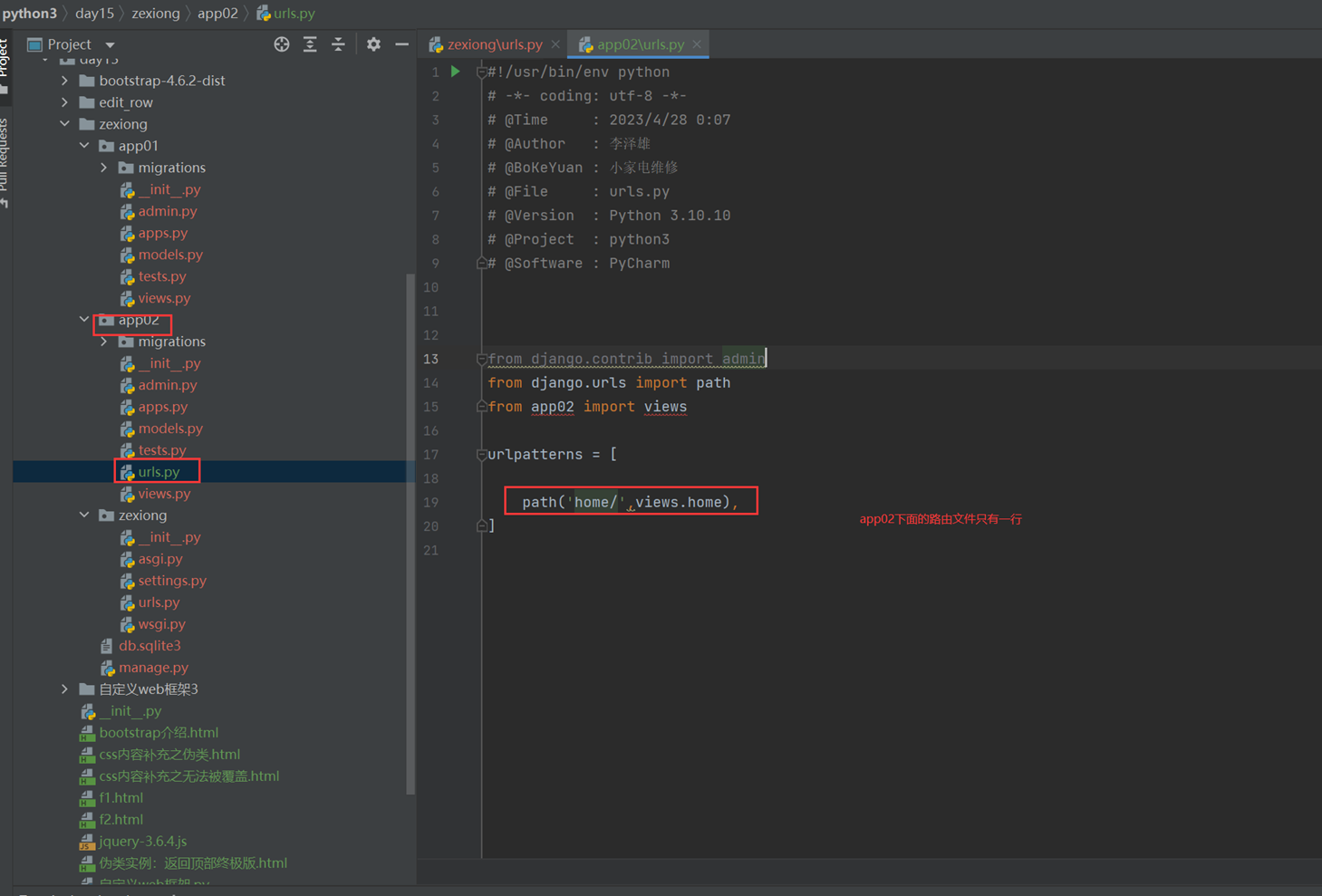
结果
15.23 django基础之数据库增删改查
Django有自己的orm,而且,上述也说过。
1.可以通过自己写类,全部通过类控制。
2.自己创建表,通过类来操作表
这里我们使用第一种方式,这样方便些
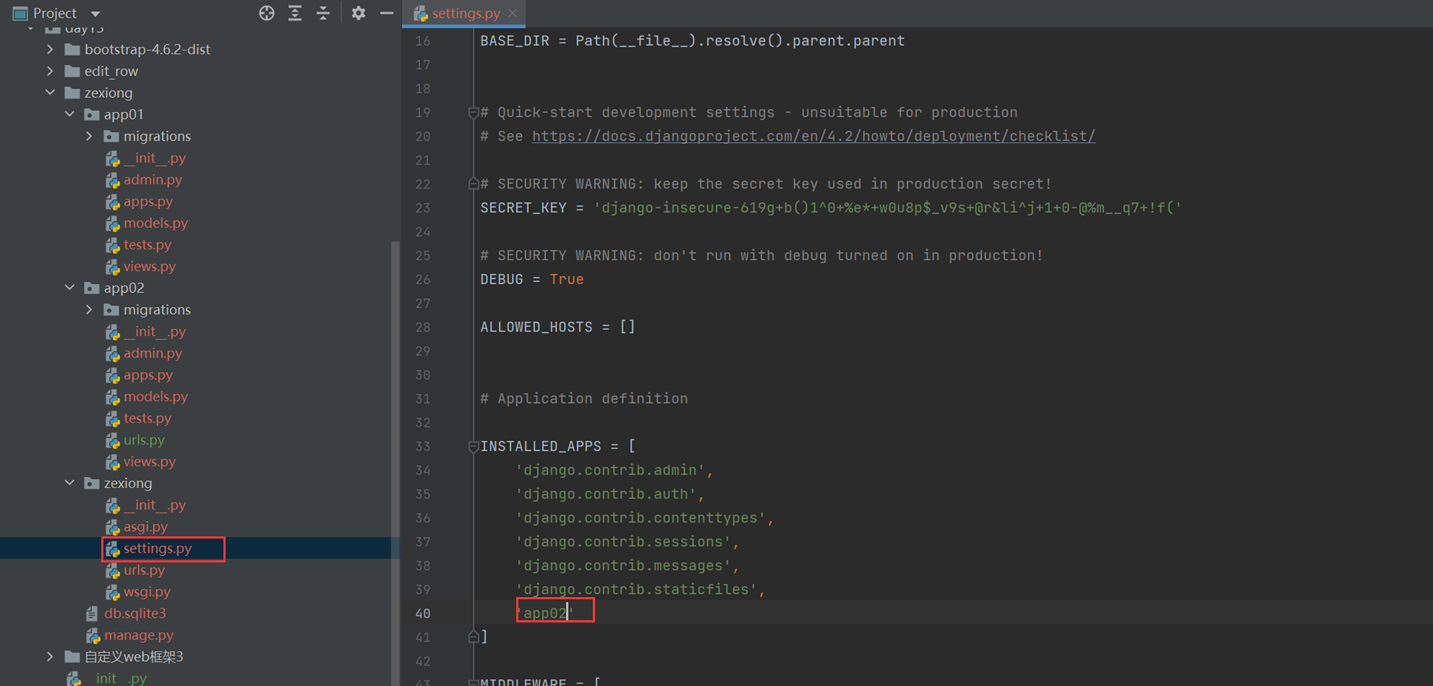
1.配置settings.py
配置数据库需要在settings.py里面添加项目
2.创建类
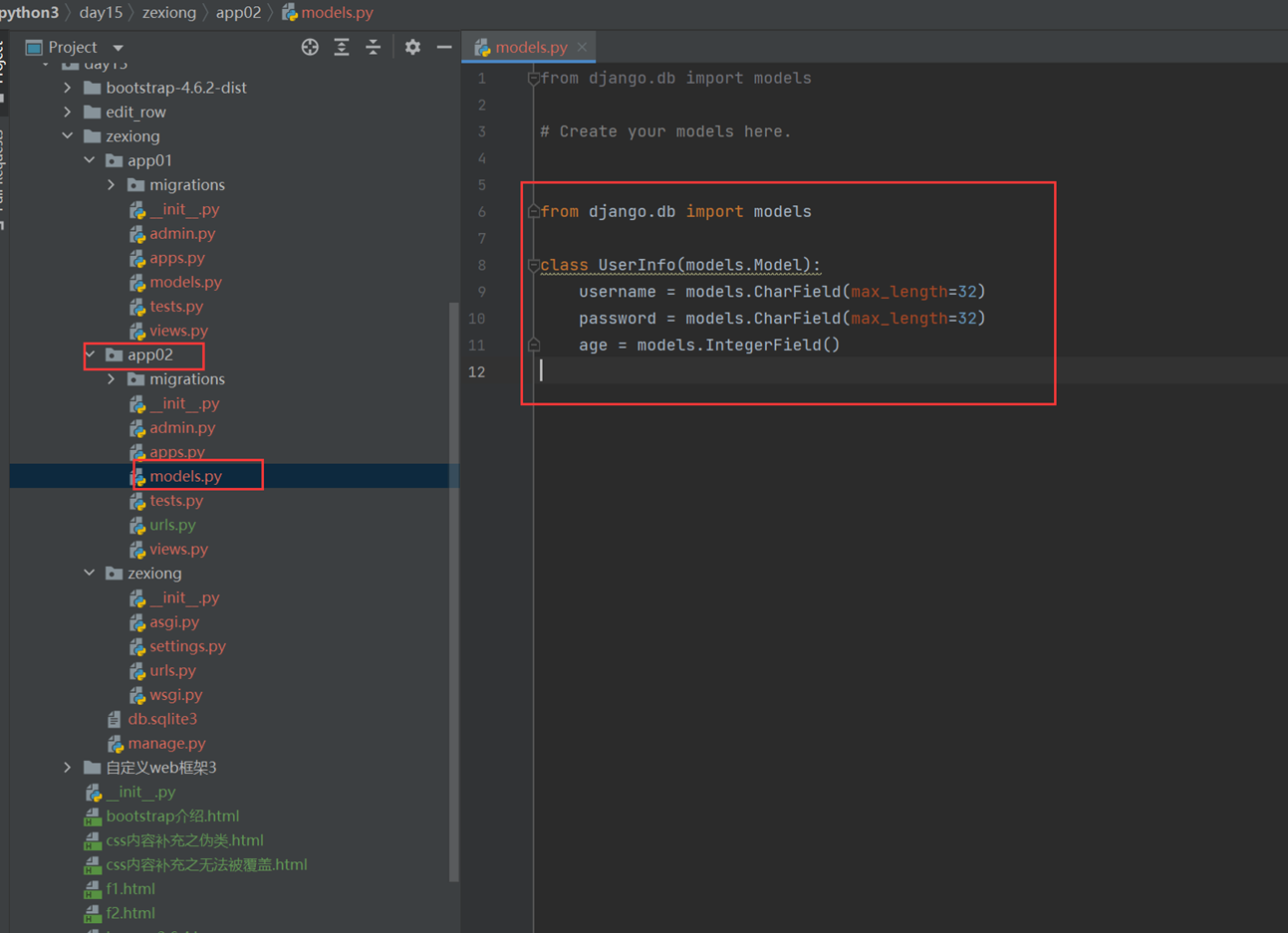
3.使用命令根据类创建表
首先生成配置文件

查看一下配置文件
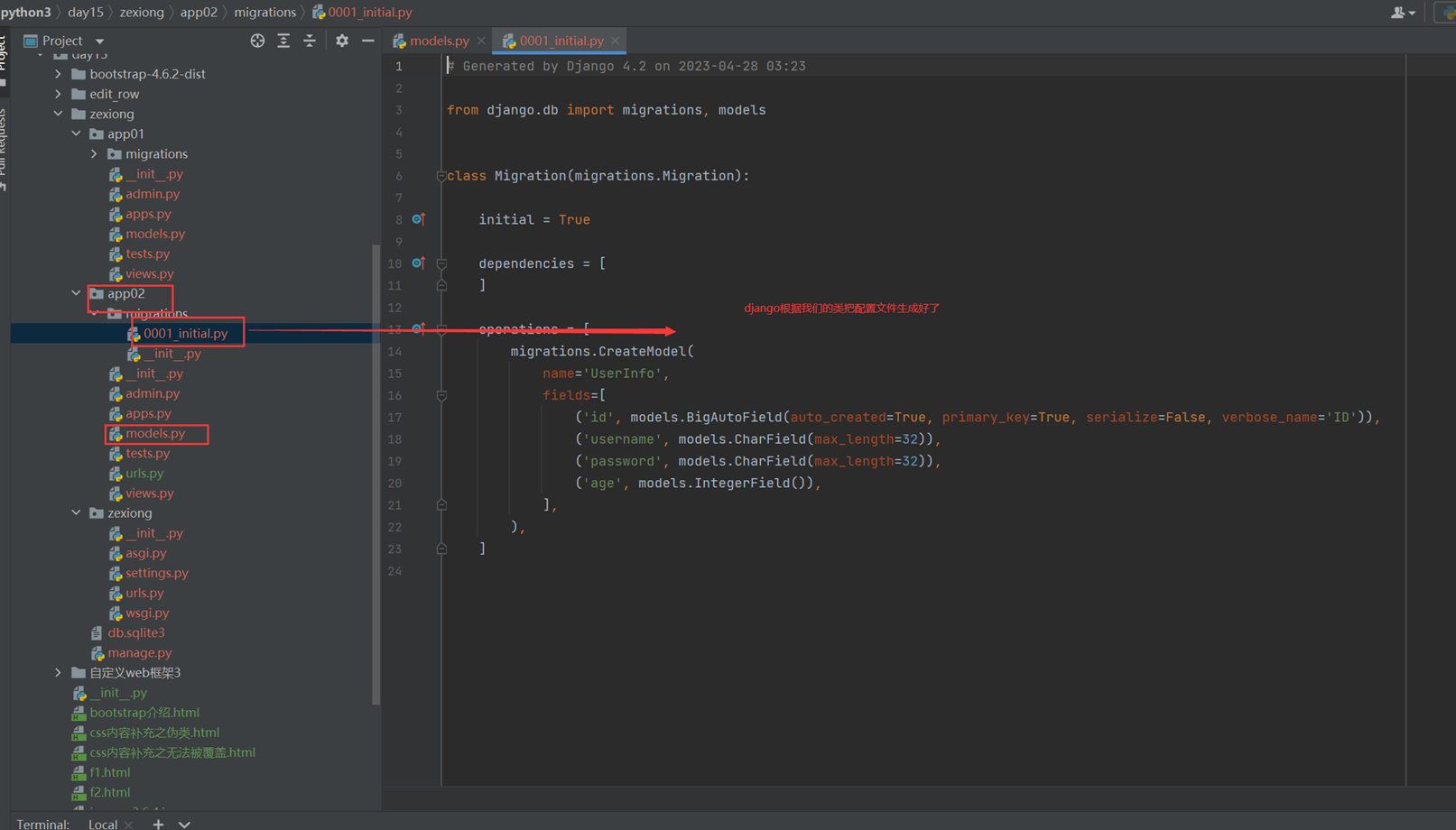
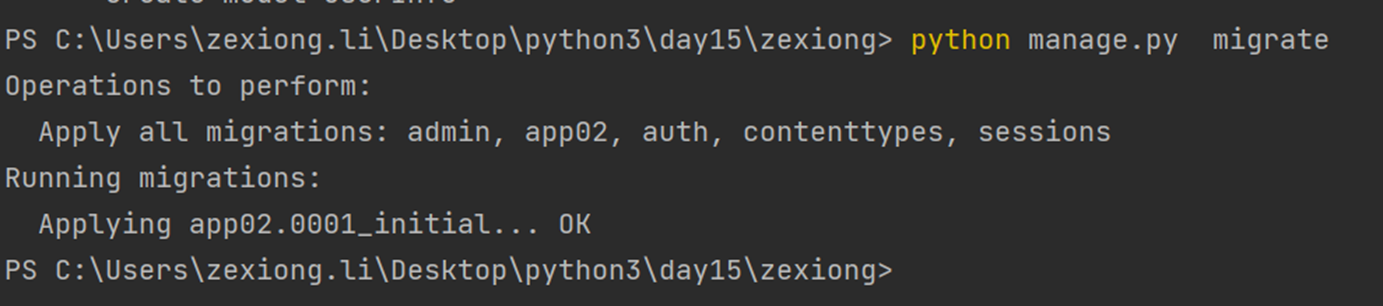
根据配置文件创建数据库相关
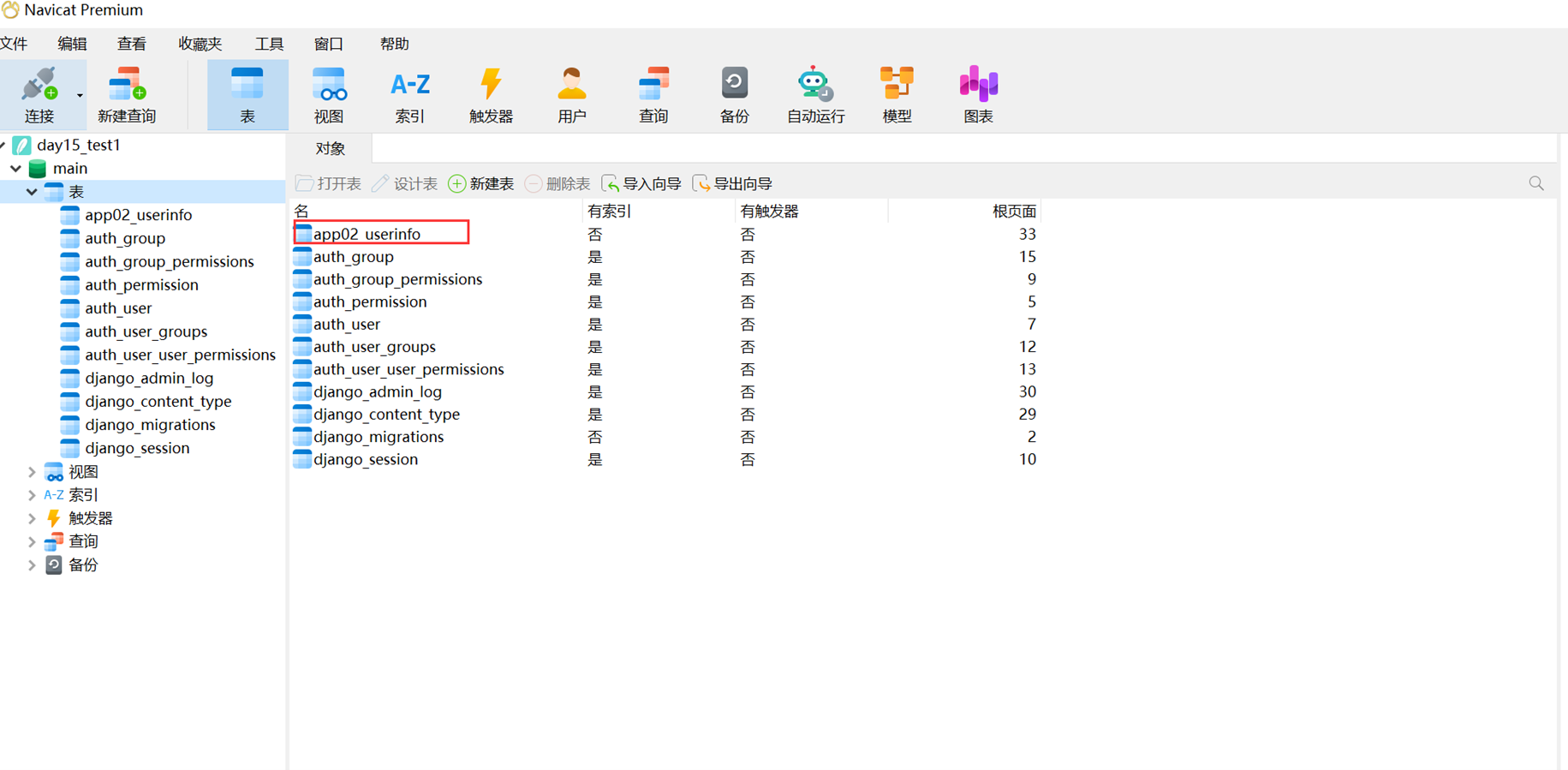
现在查看一下数据库
现在来操作数据库的增删改查
1.首先增加一个测试函数,就是db_handler(URL就不演示了)
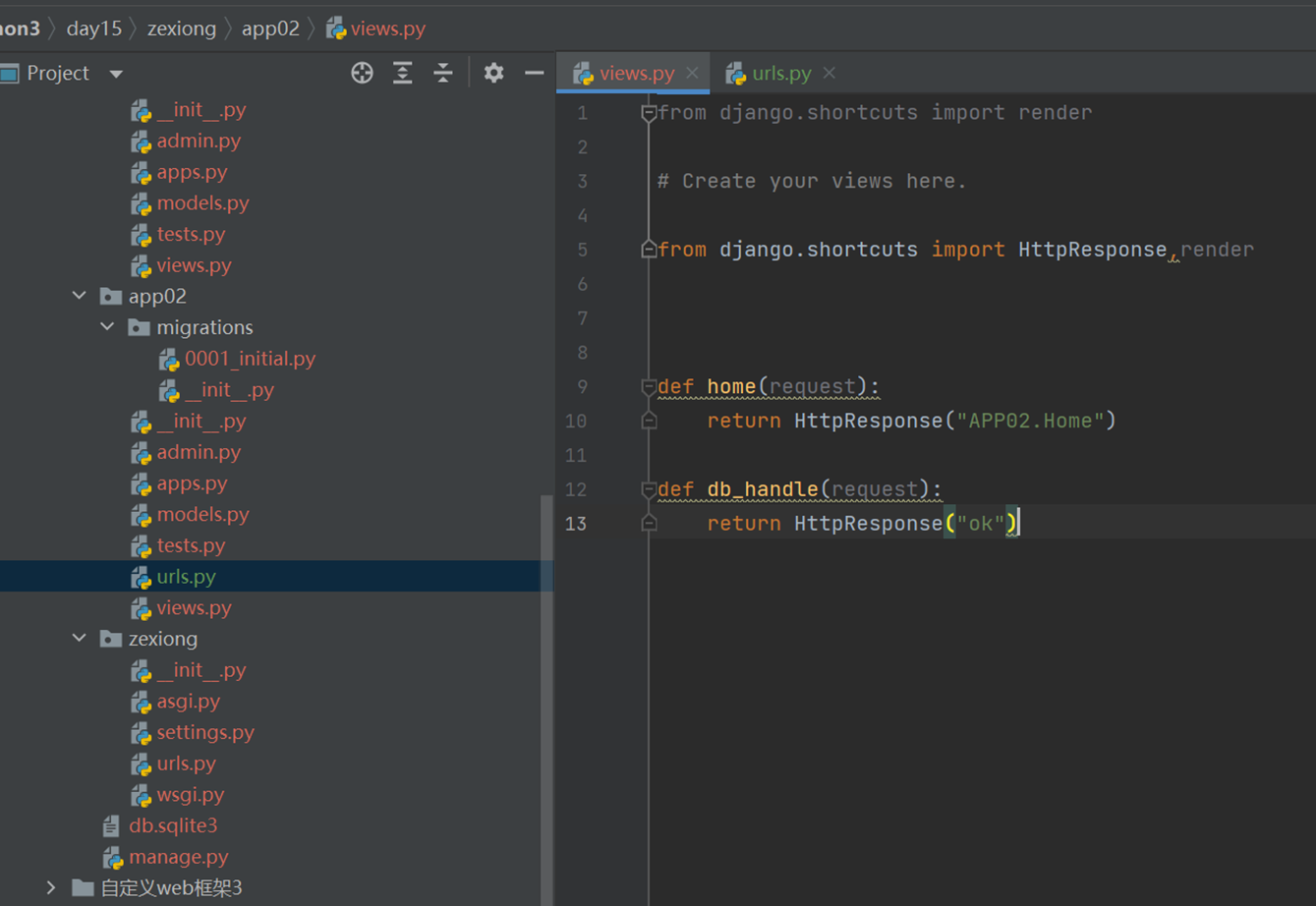
2.增加
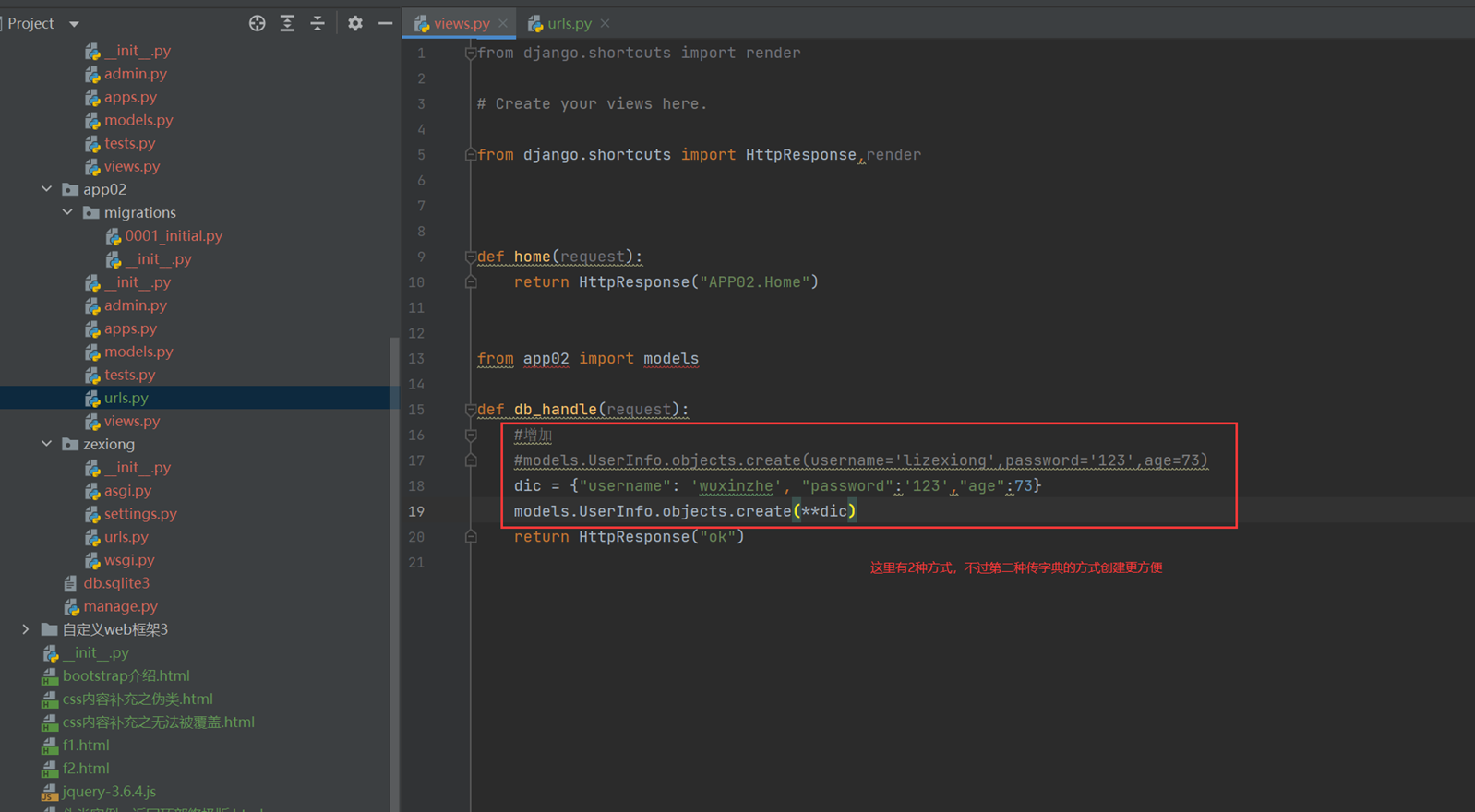
查看结果
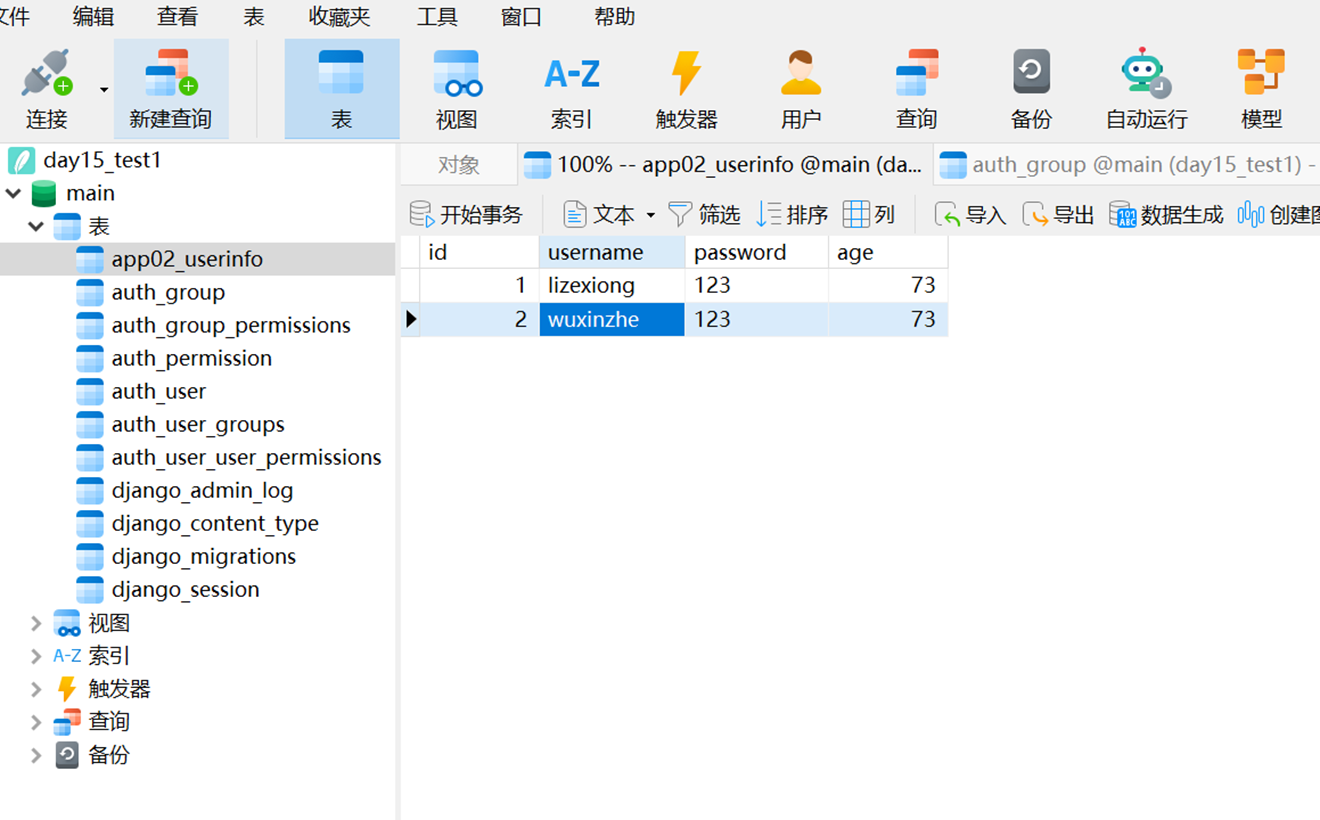
3.删除
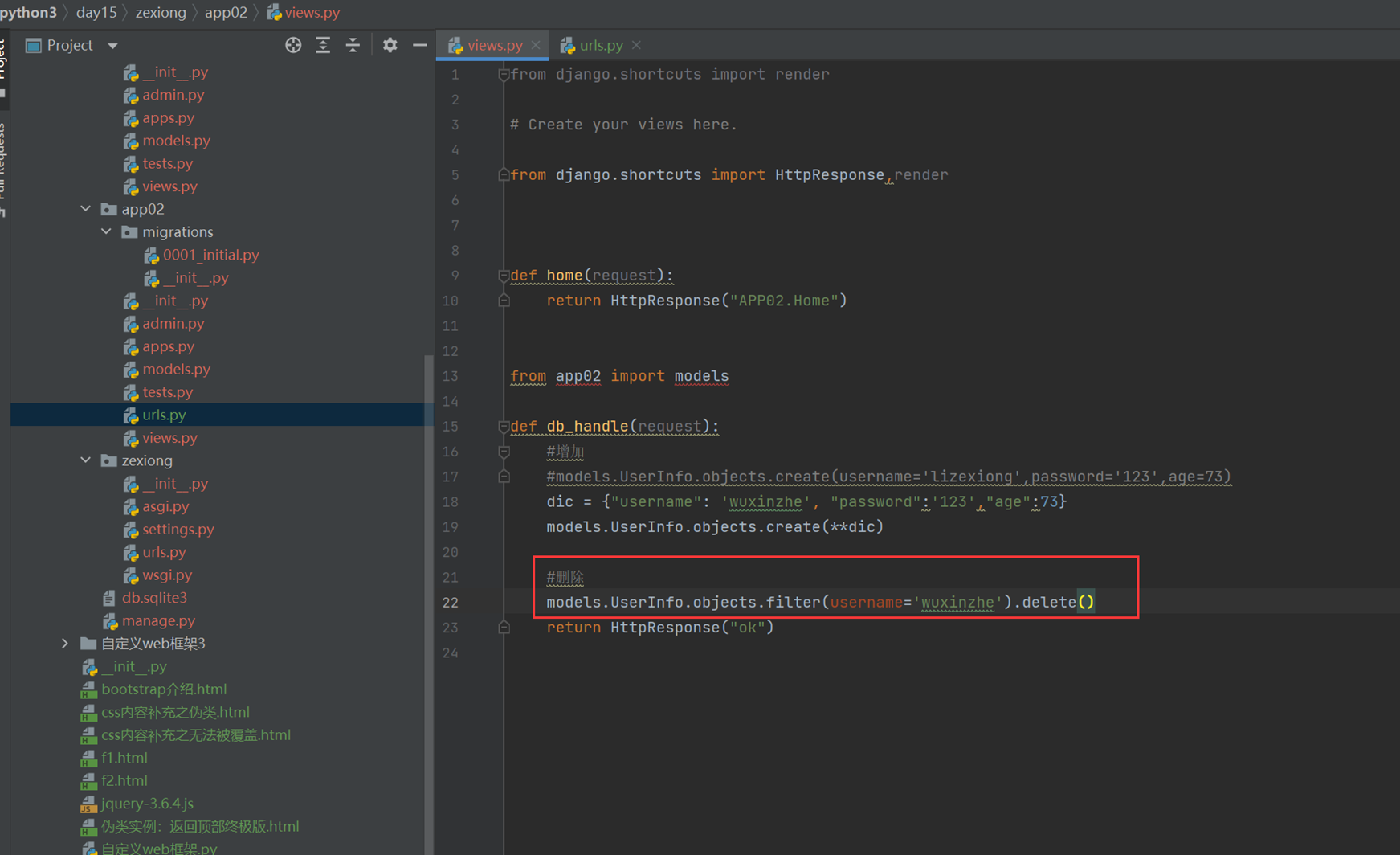
查看结果
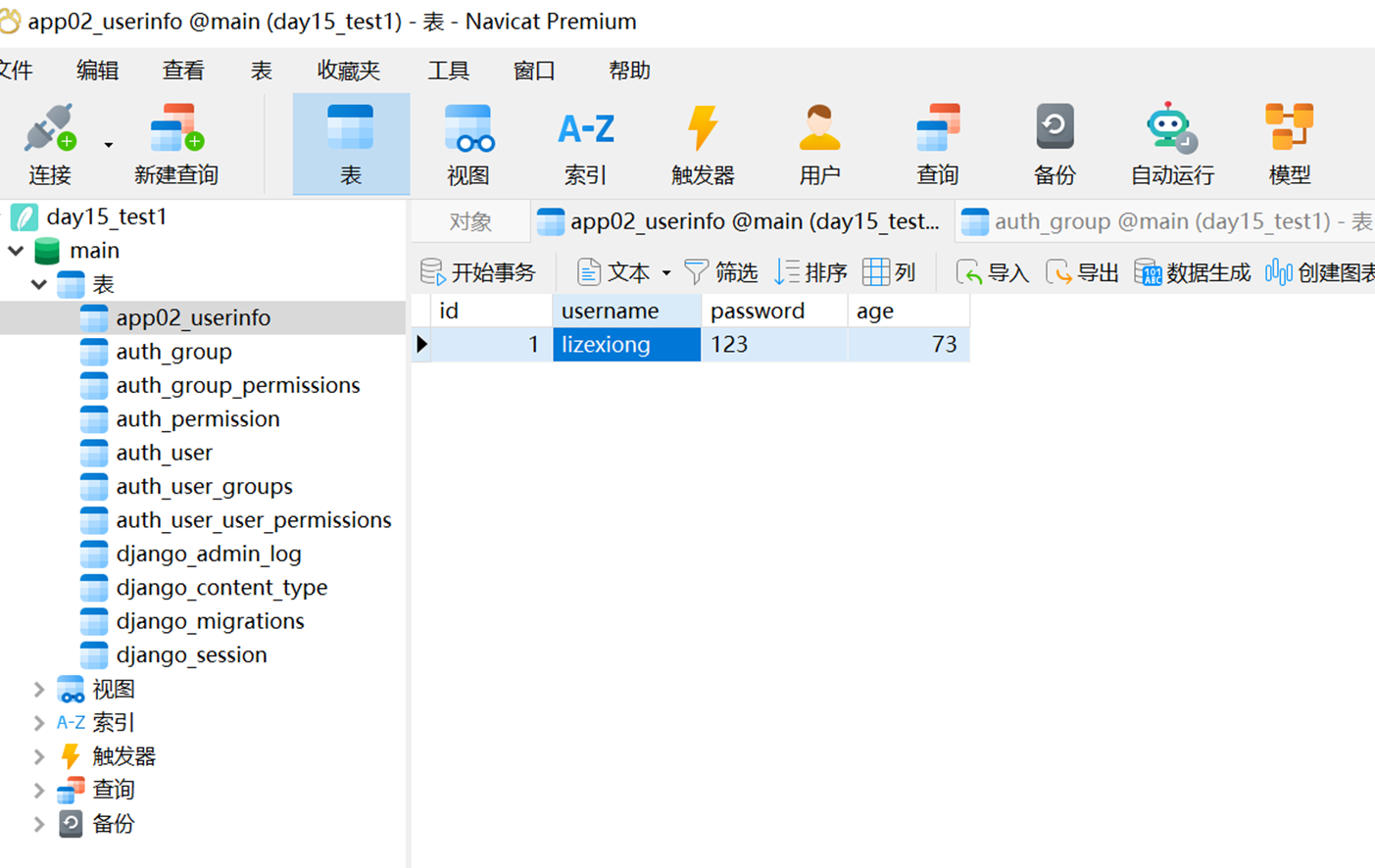
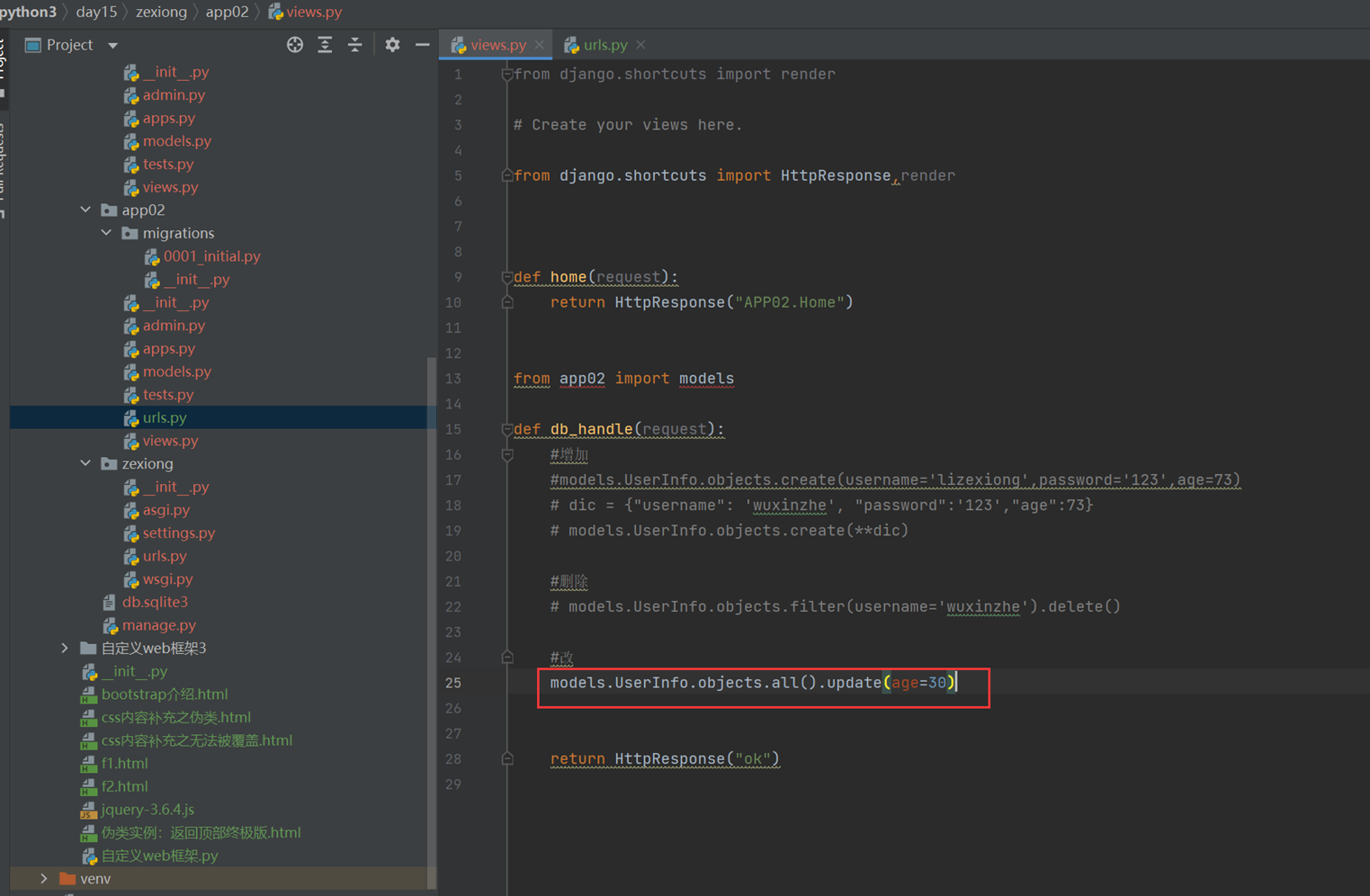
4.改
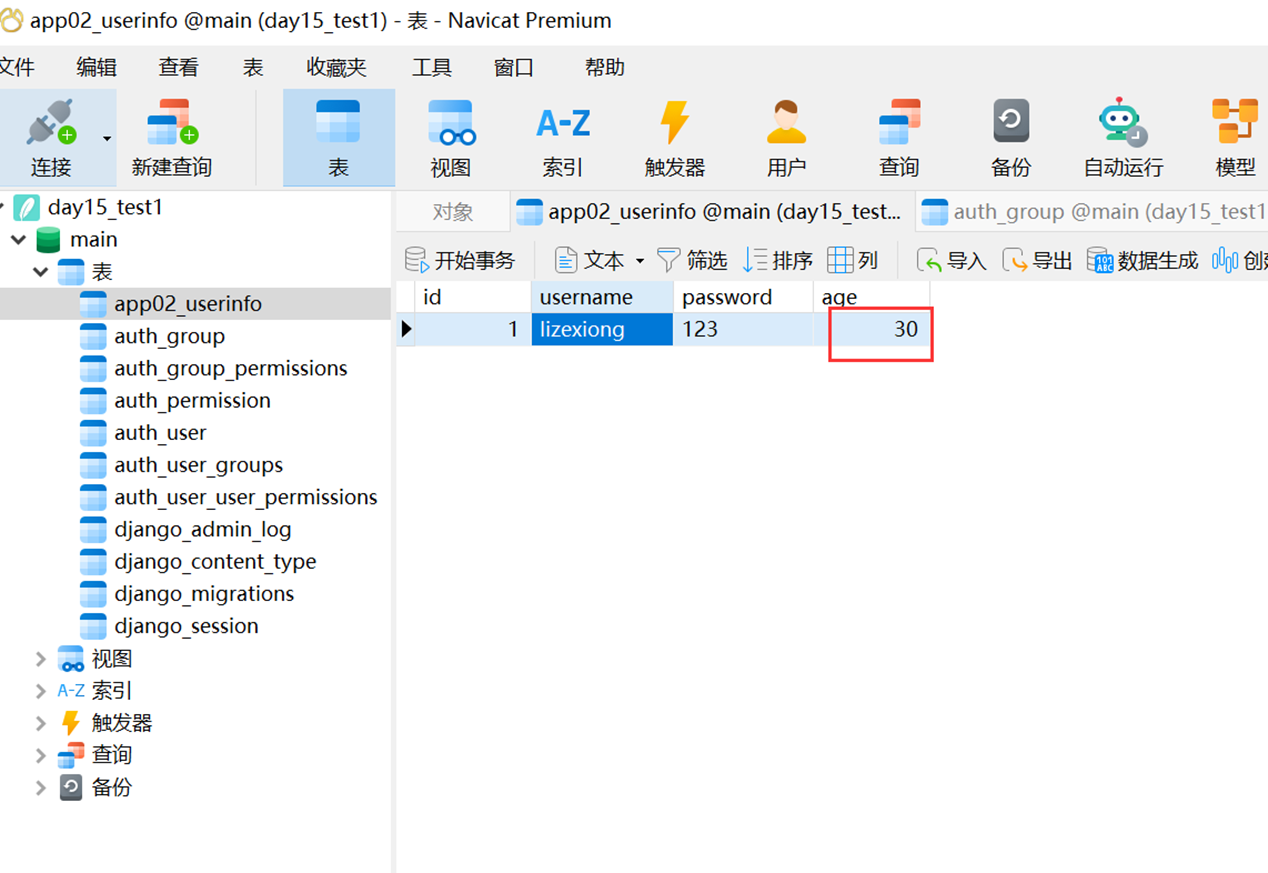
结果
5.查
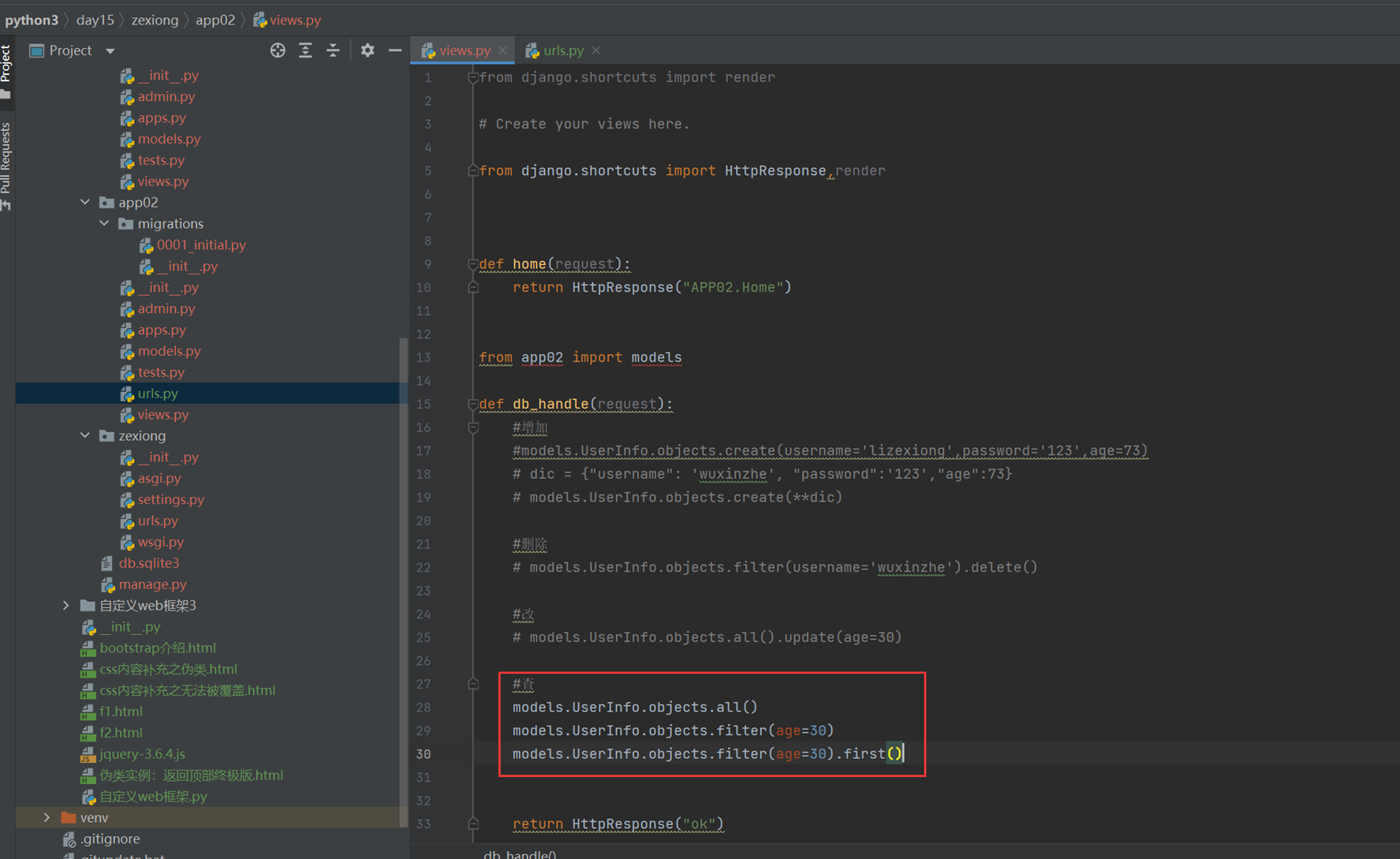
15.24 django基础之展示后台数据
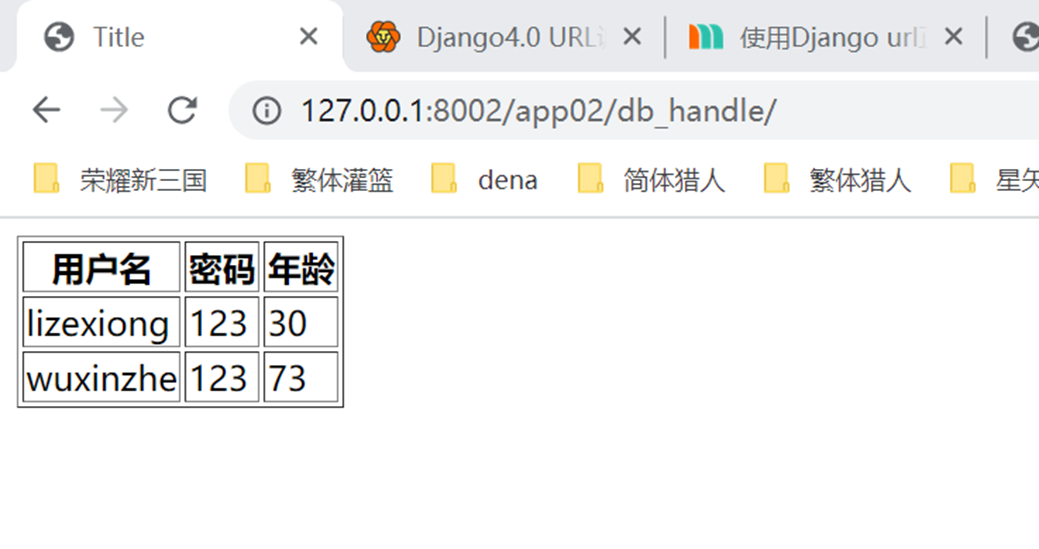
假设现在有个需求,需要把上节课查到的用户信息返回给前端用户,怎么做?很简单
1.使用render方法,返回一个网页,并将查询到的数据一并返回给前端渲染。
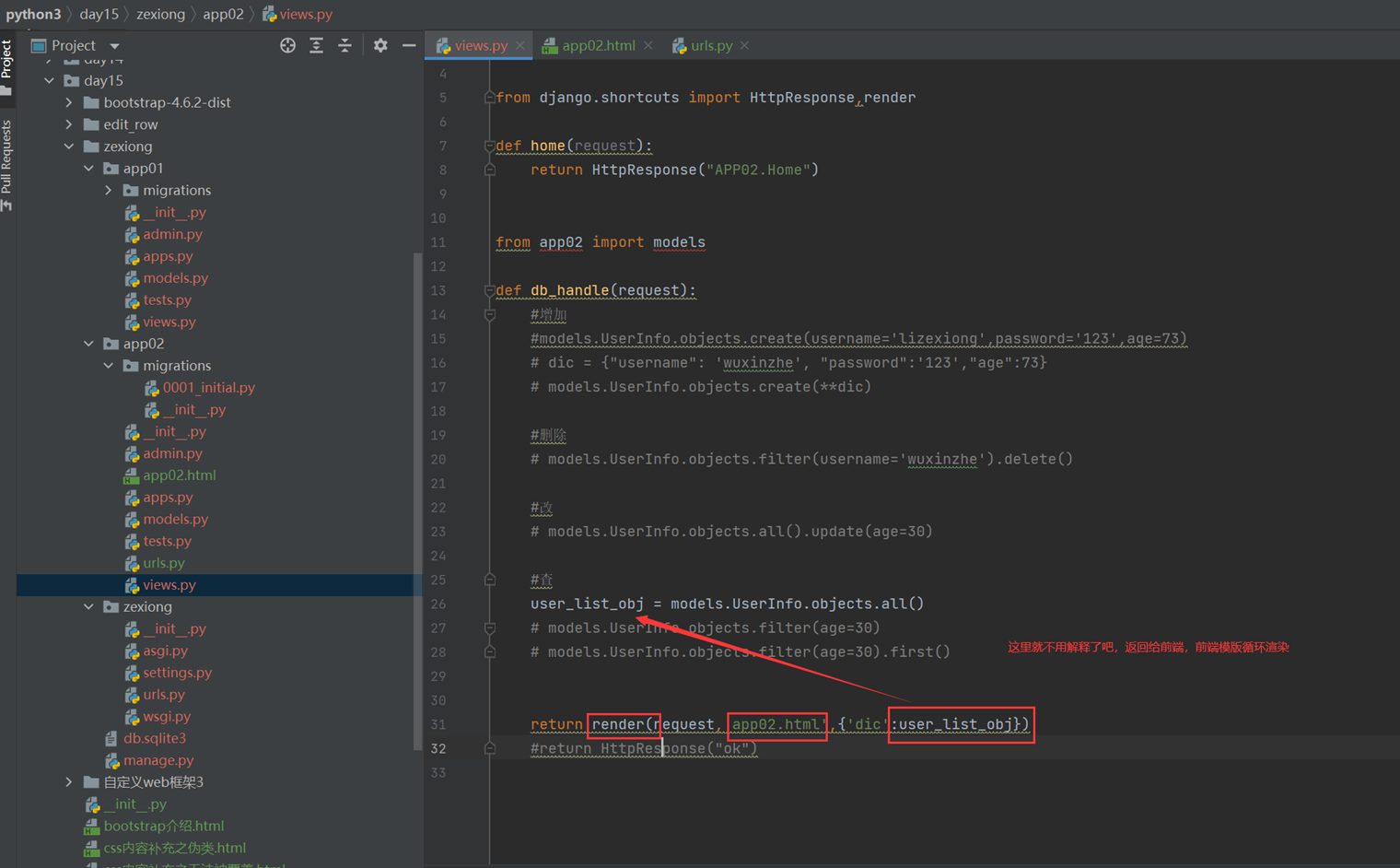
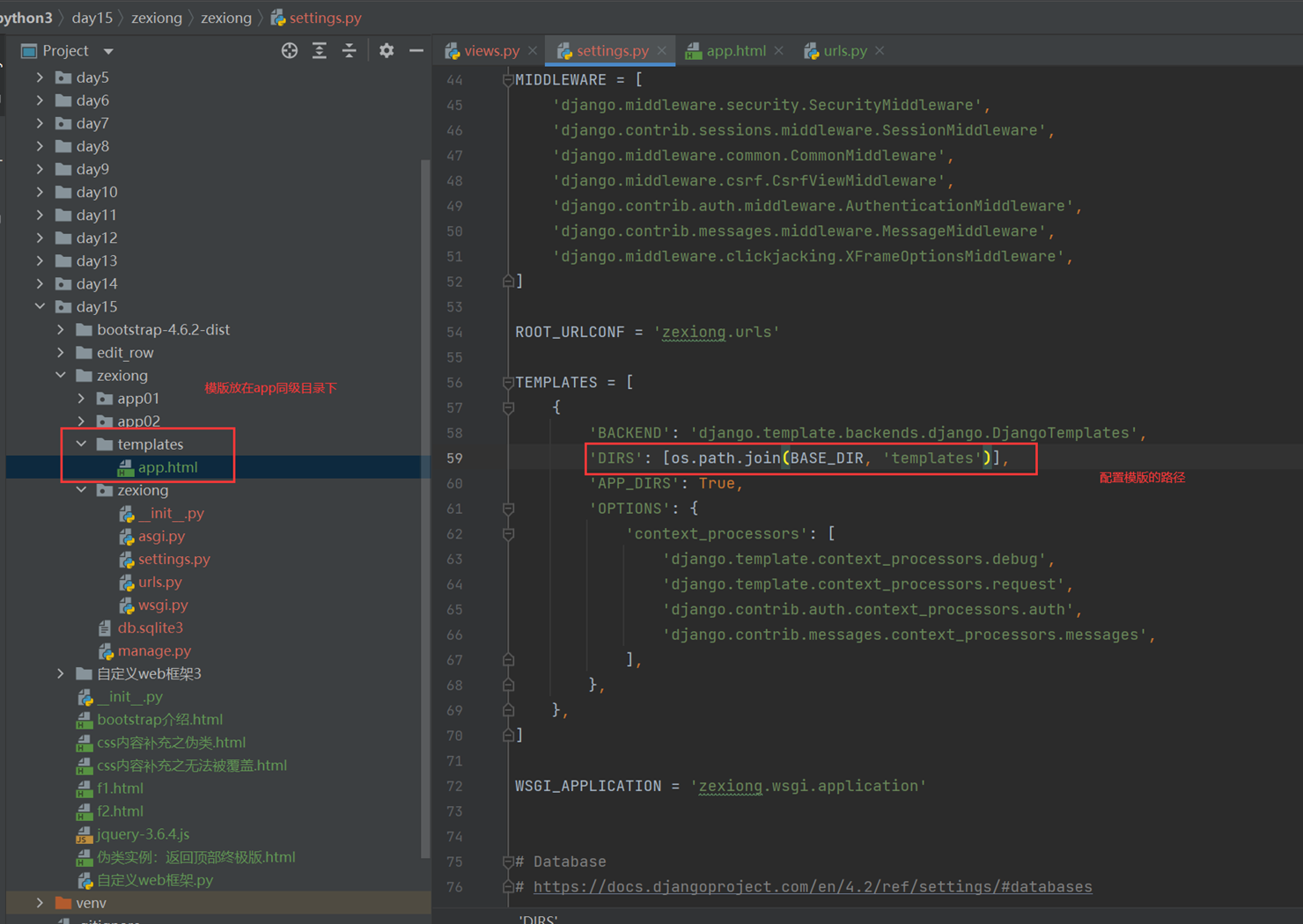
2.前端渲染
首先,django4.X需要在settings里面配置templages的路径,否则报错
查看前端网页
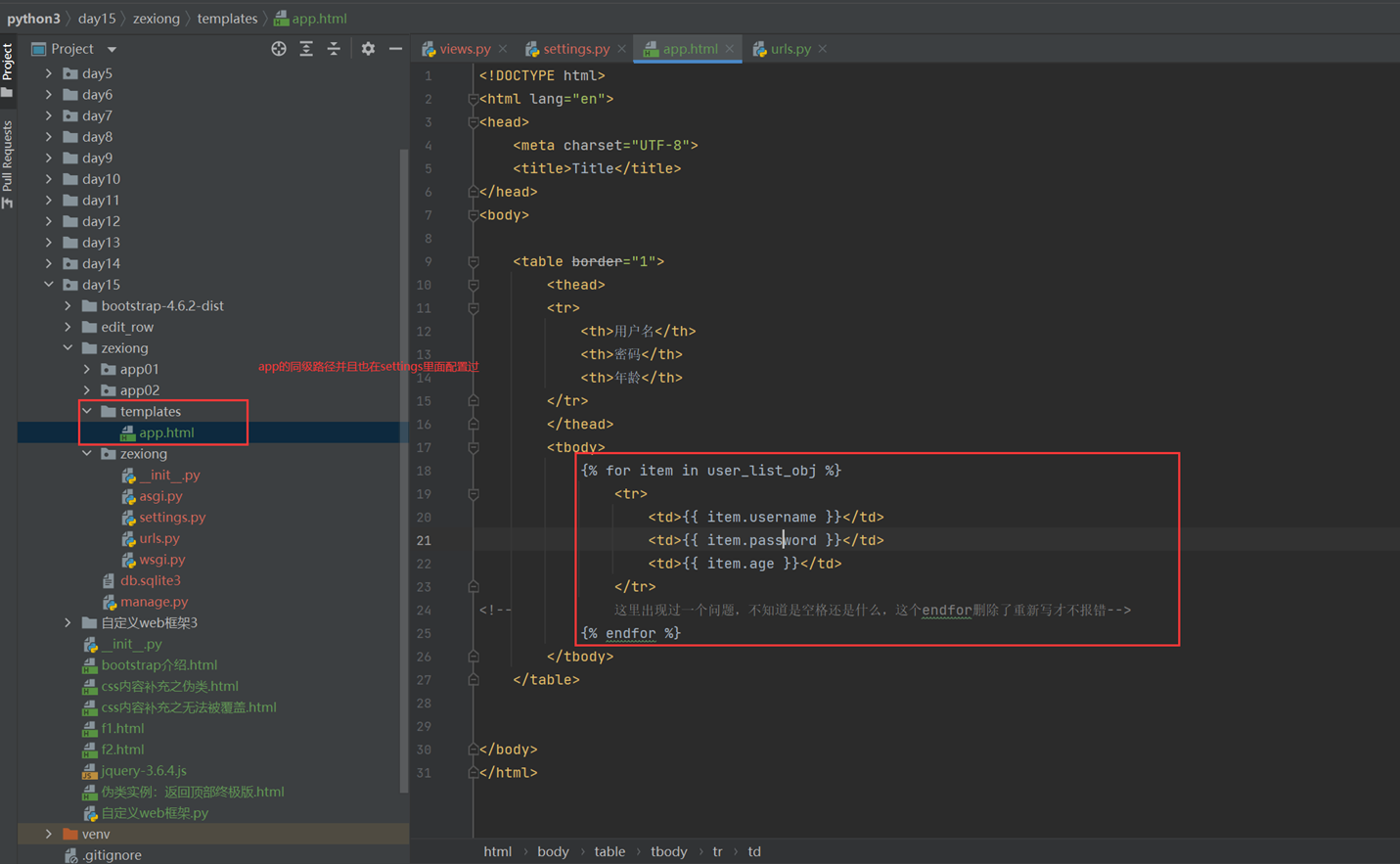
查看结果
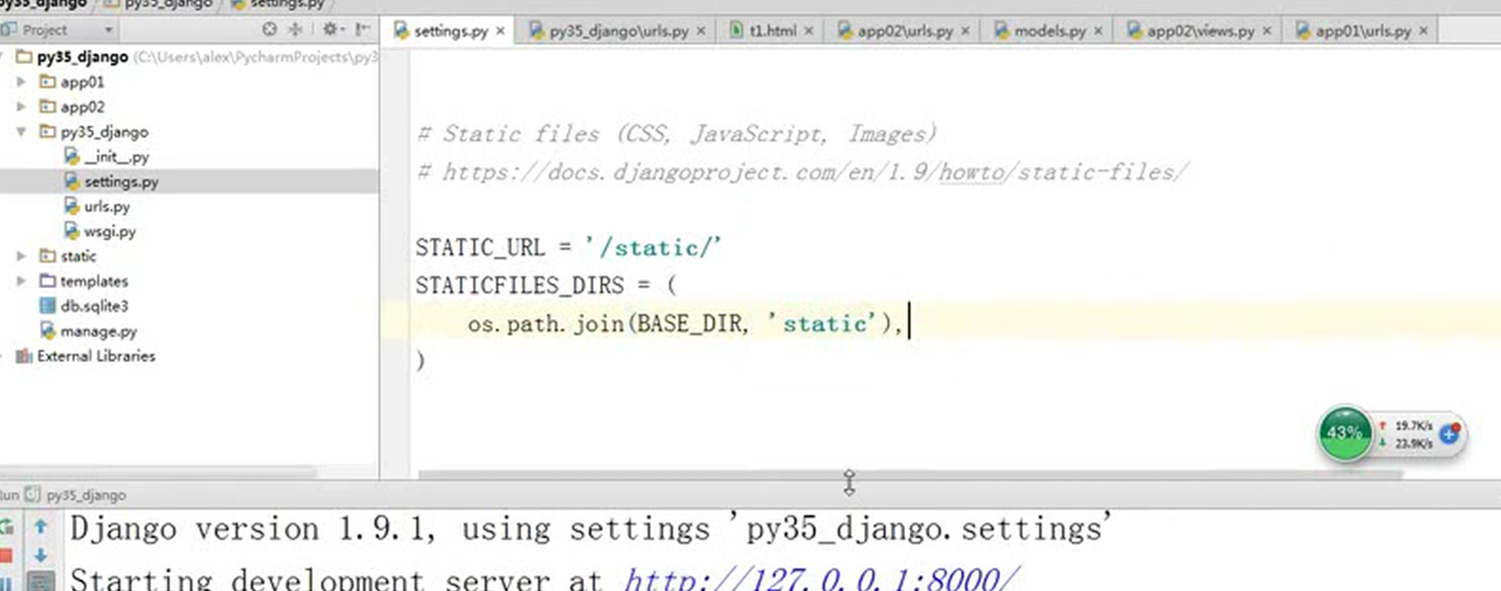
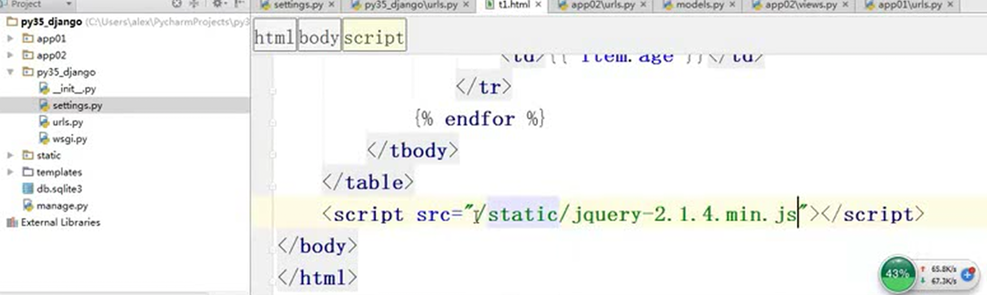
15.25 django基础之静态文件的配置
就是刚才讲解的配置templates的位置和本章新增的js文件的配置,这里没什么好多讲解的。就不做案例了,直接看视频截图。
Html配置
15.26 django基础之创建数据
还是用上节课的代码来接下来的演示,本节课需求简单就是前端一个网页,输入用户名密码提交,然后后端存储到数据库里面
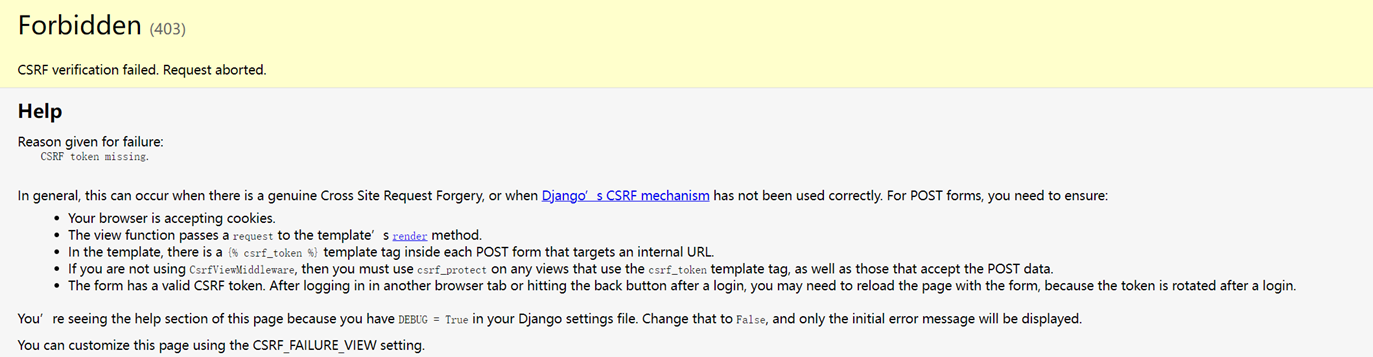
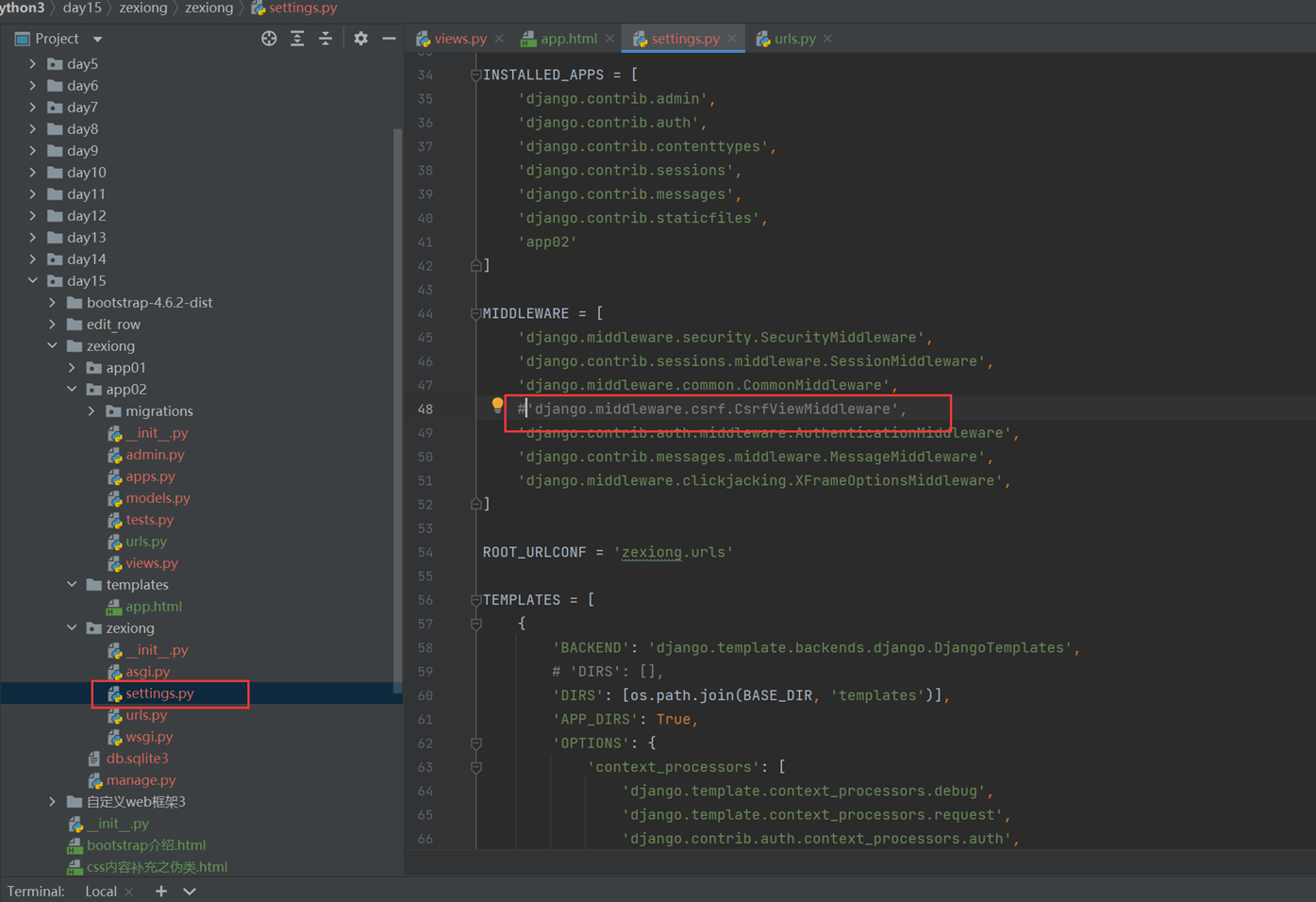
1.关闭csrf跨站请求伪造
不关闭的处理方式后续课程在讲解
修改settings的以下配置
2.前端网页
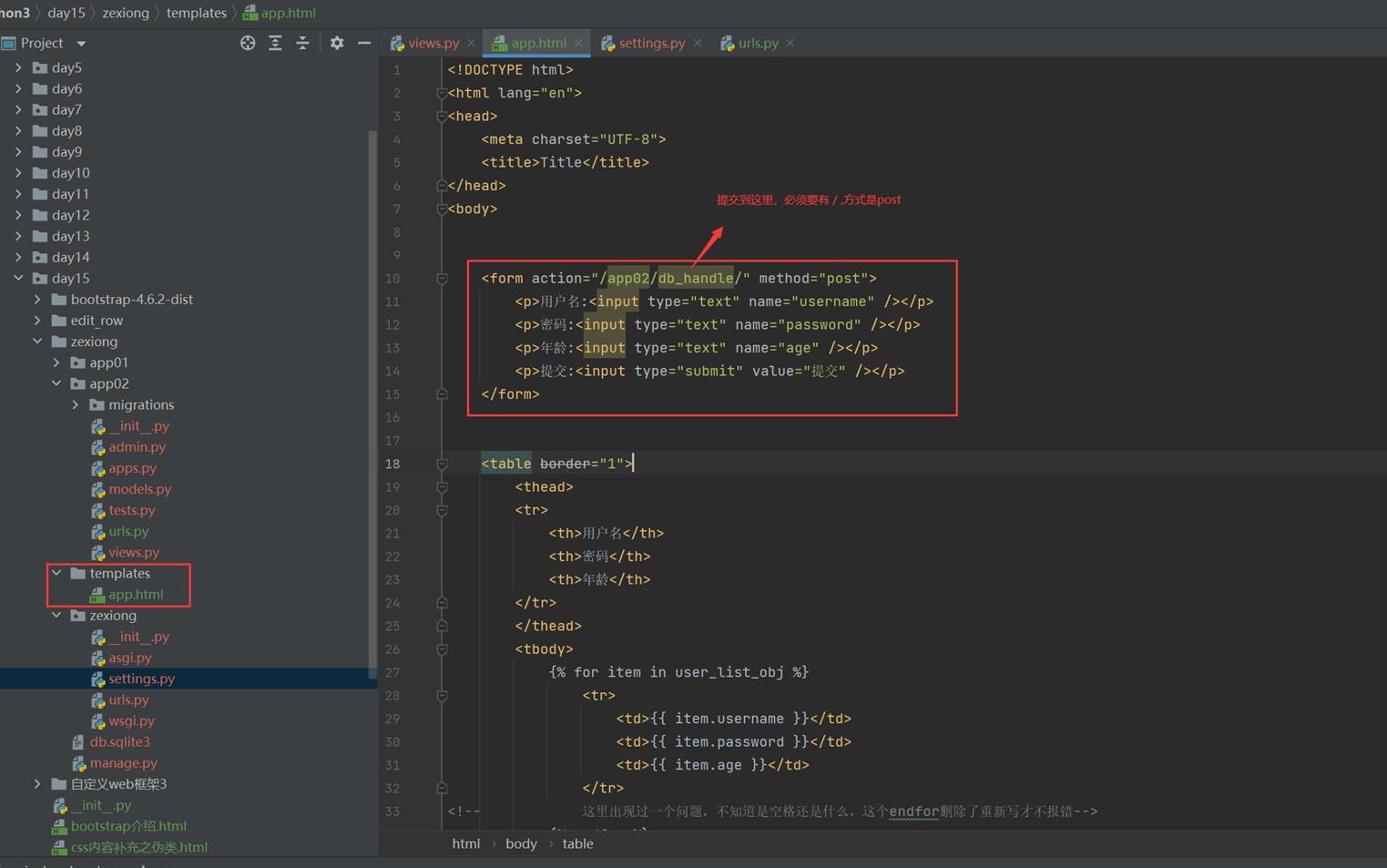
3.后台处理函数
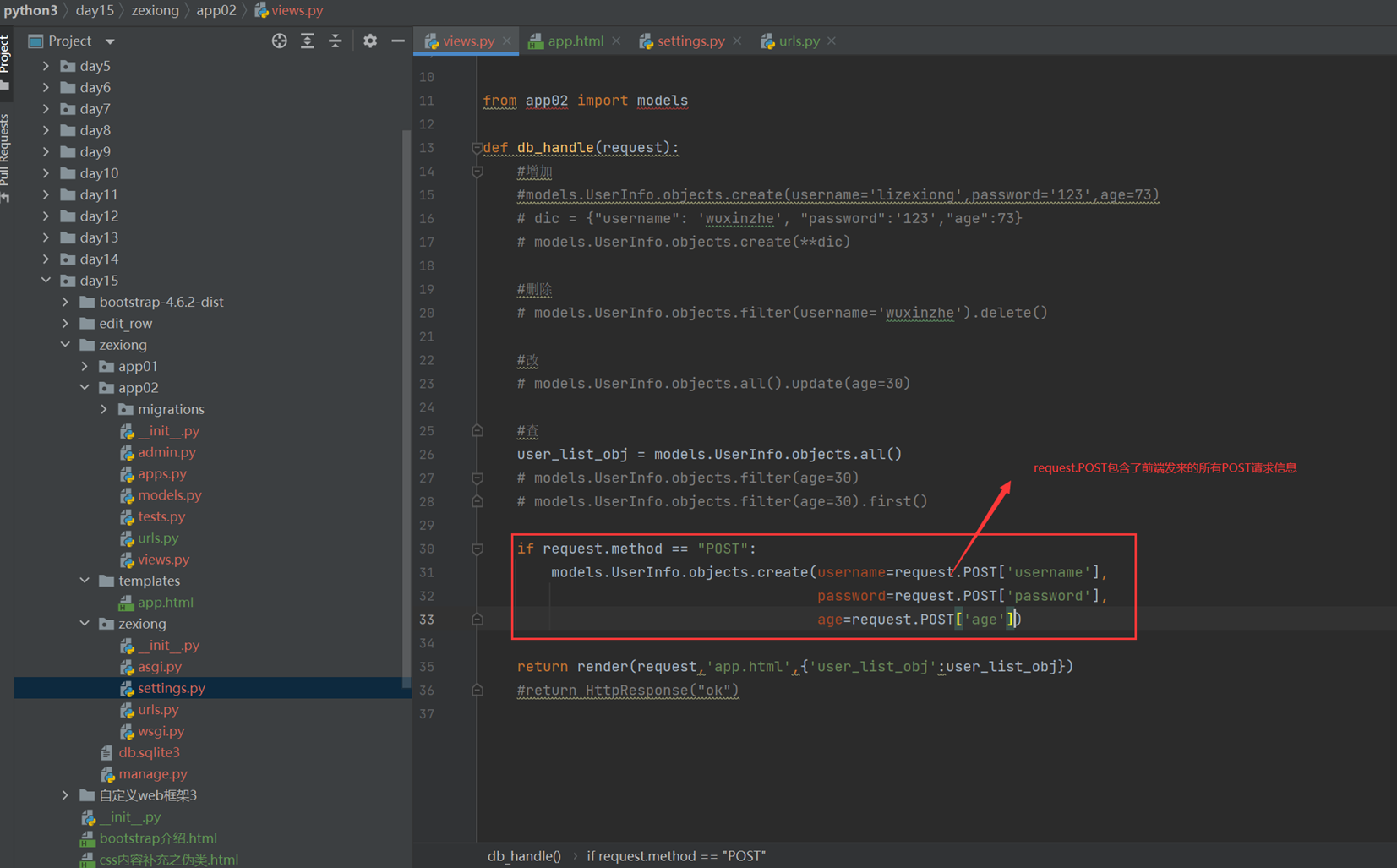
4.网页提交查看结果
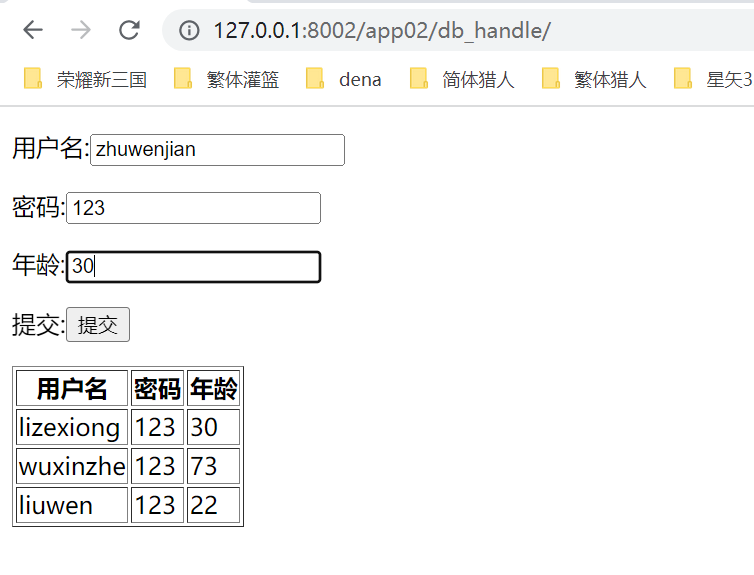
提交查看
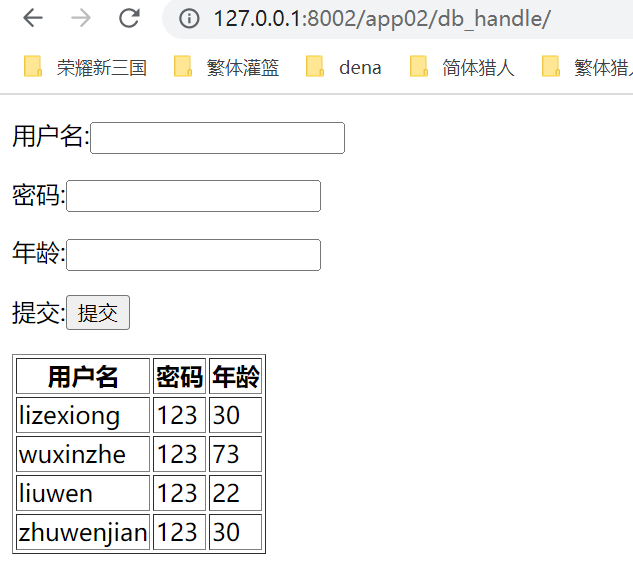
15.27 今日作业以及知识分析
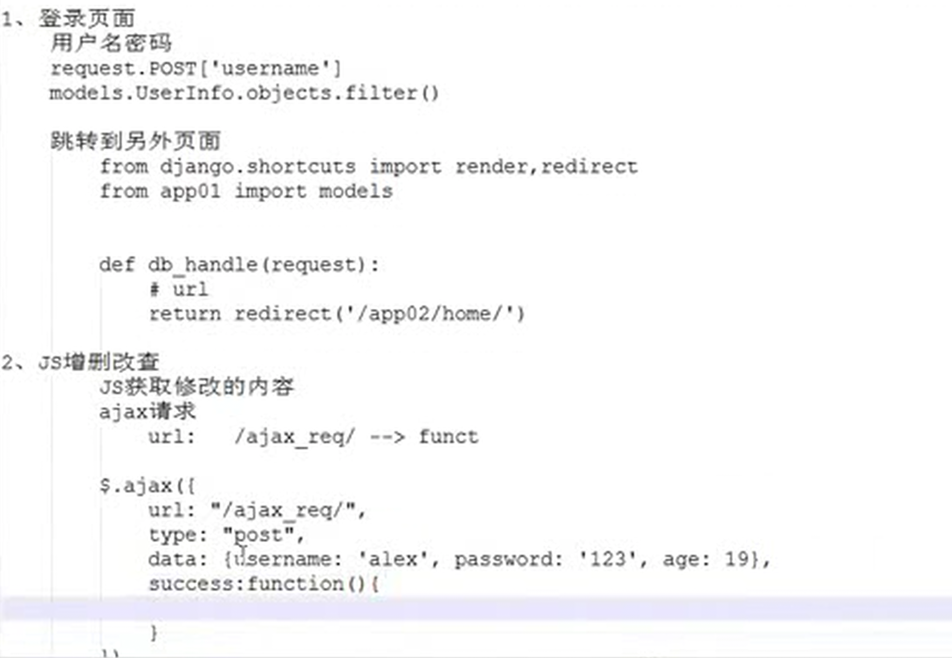
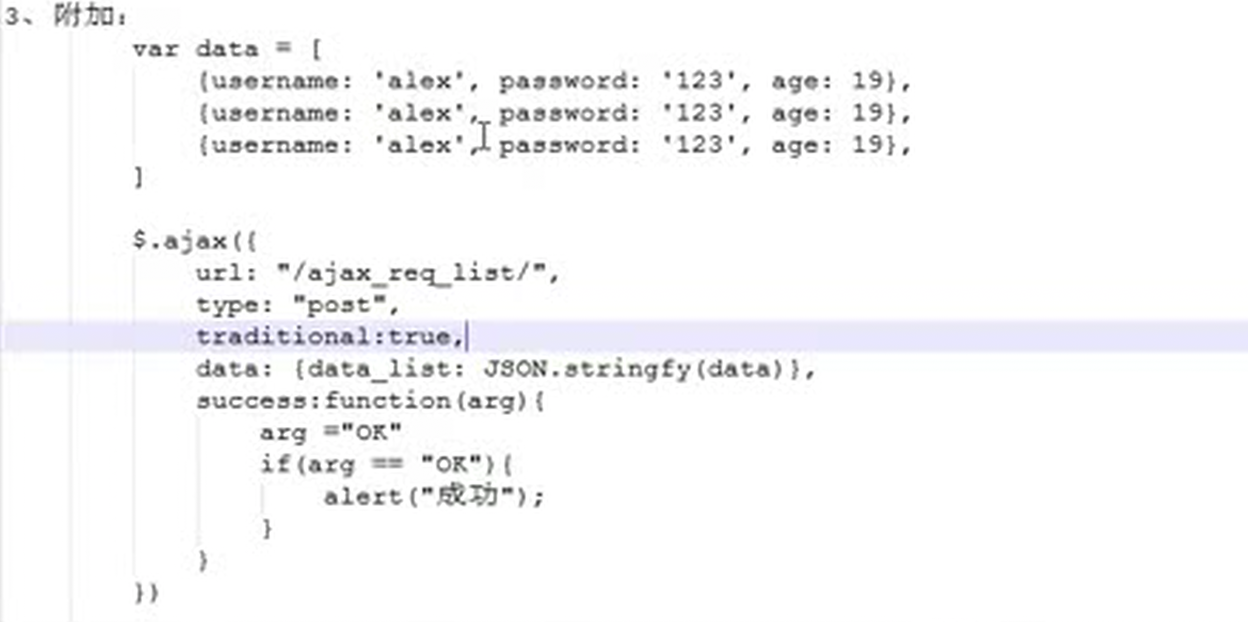
16.L16
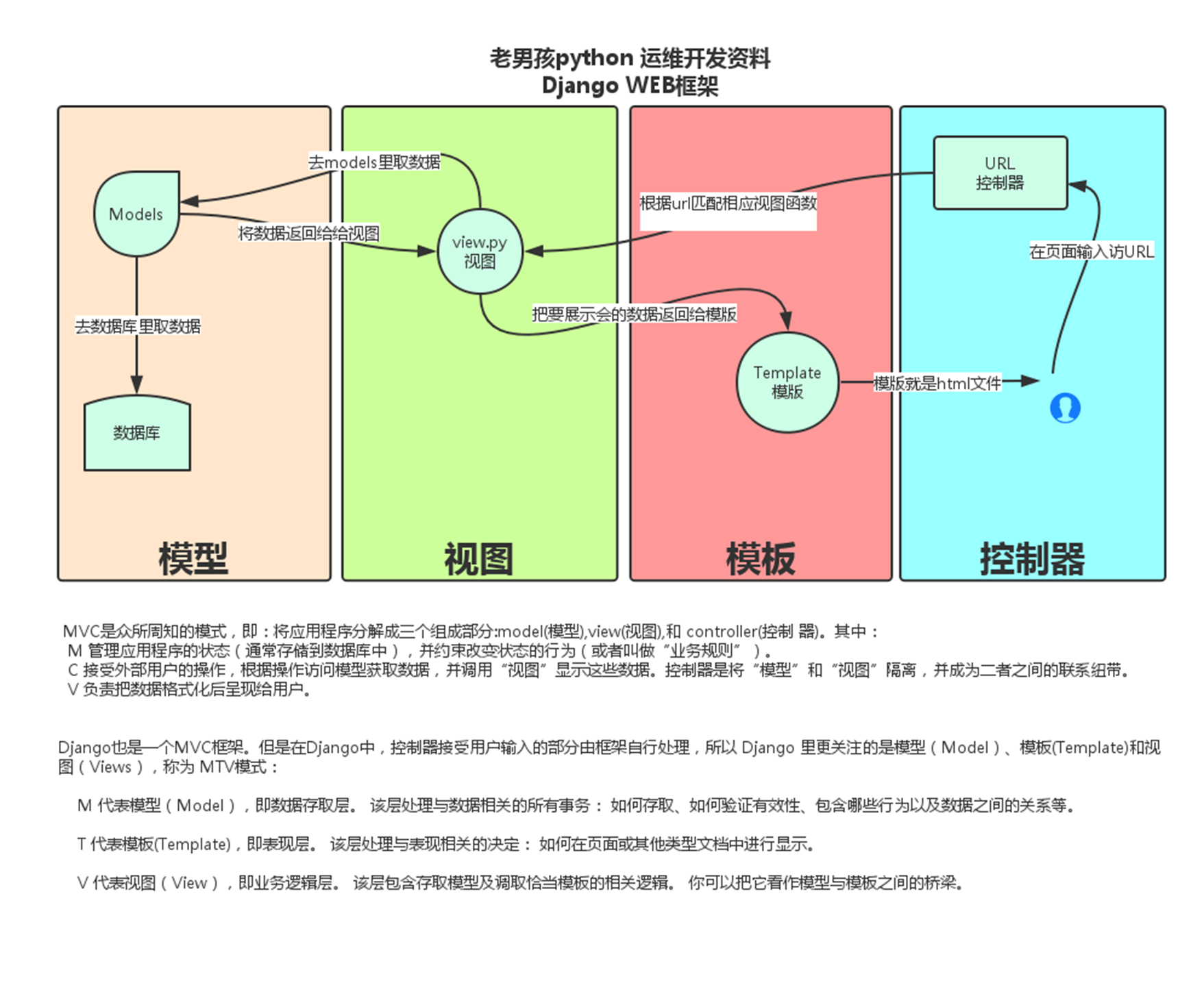
16.1 Djangomtv架构讲解
今日内容
16.2 djangourl常用匹配语法
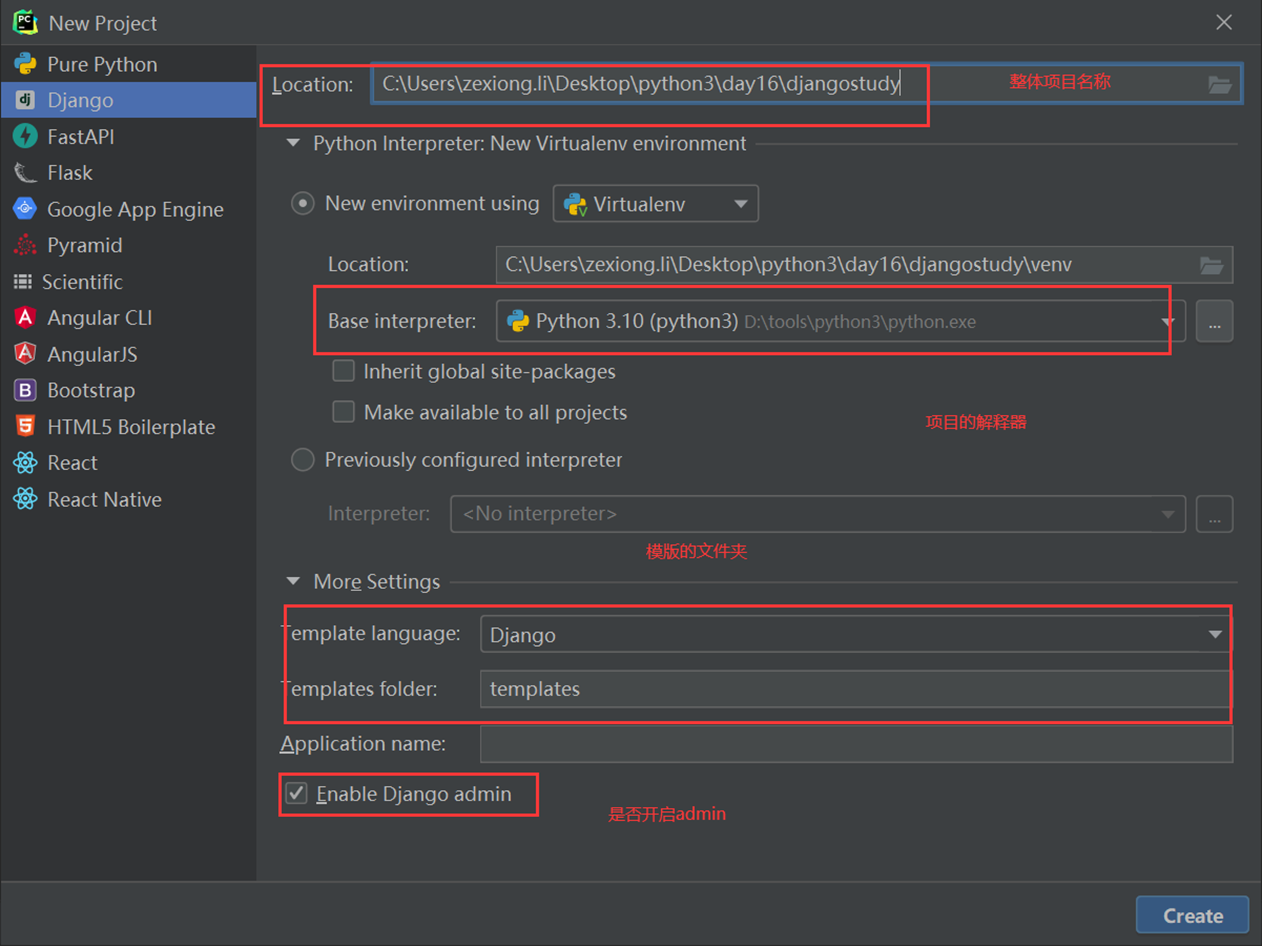
前半部分介绍怎么用pycharm创建django项目,以及django的目录结构等,基本都是废话,可以略过。
创建项目
完成以下图片中的案例
1.普通正规匹配
url
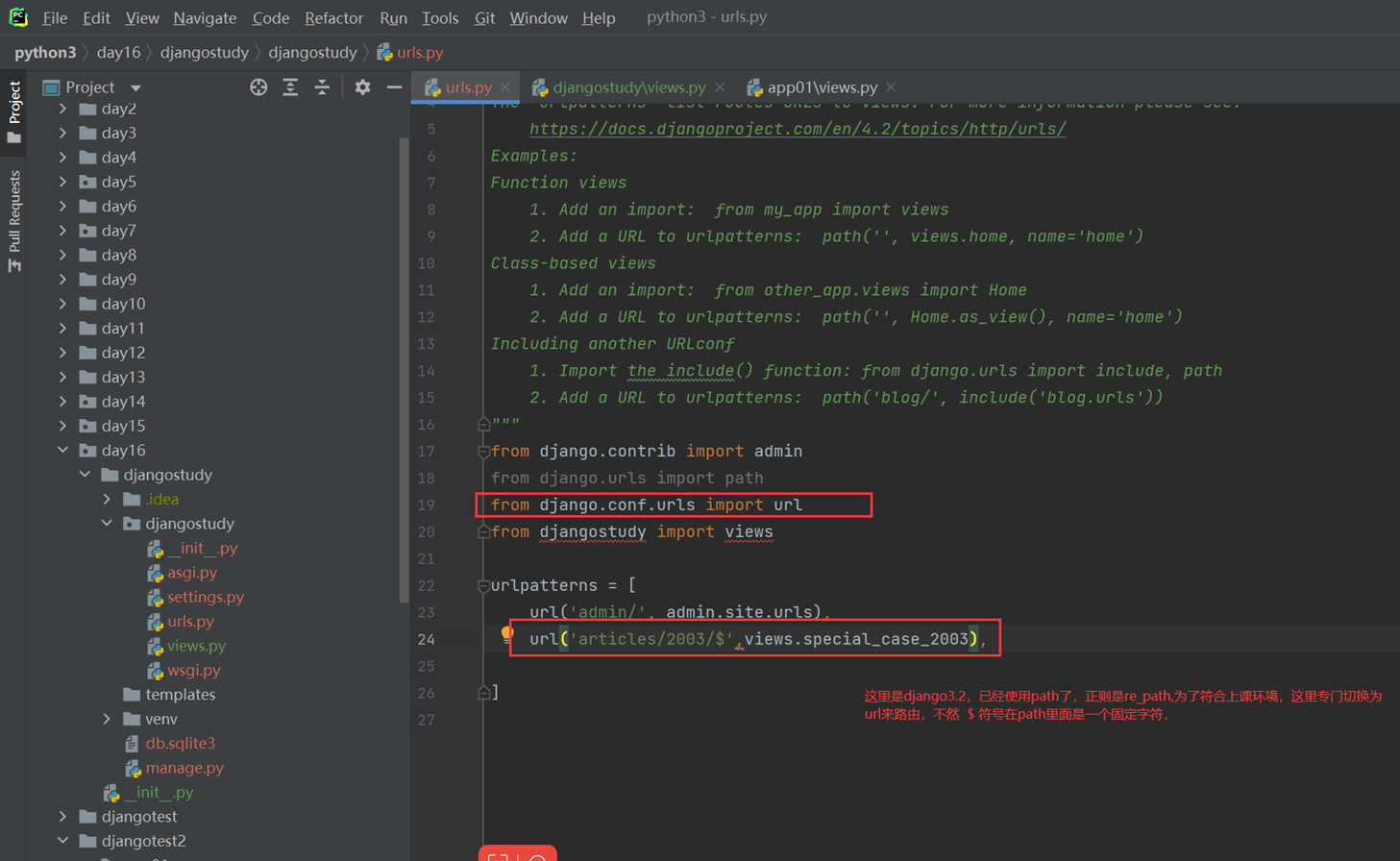
View要自己创建文件
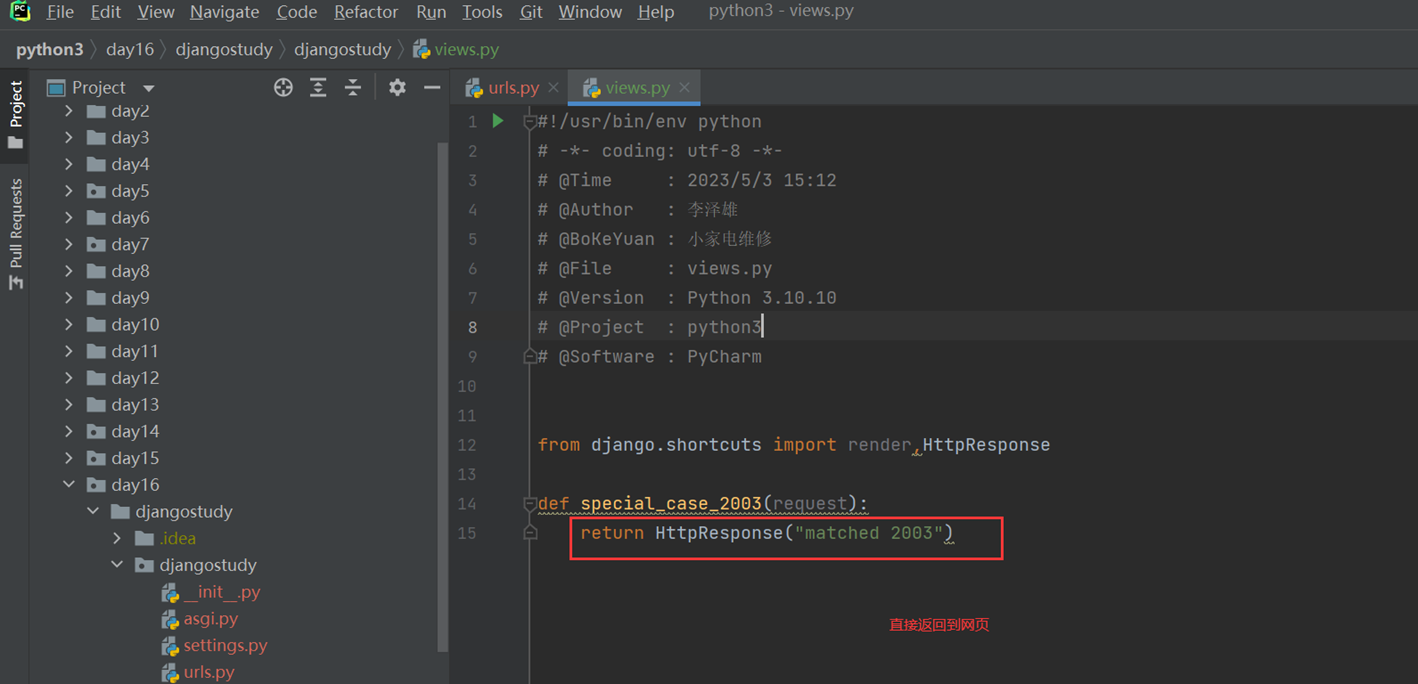
结果
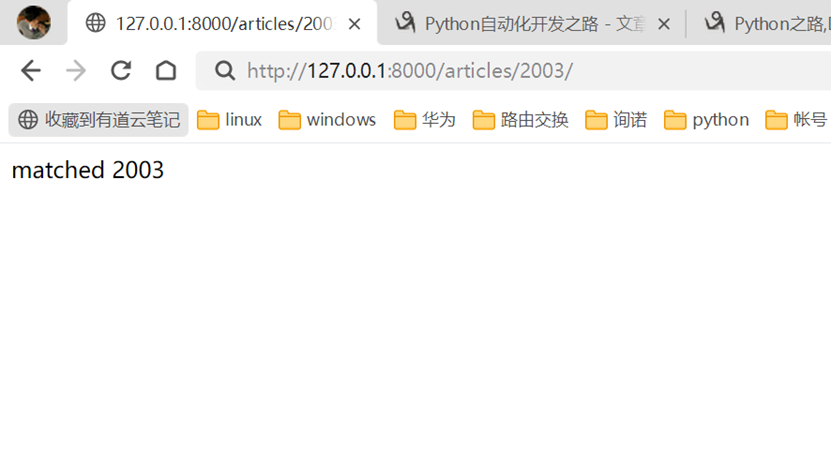
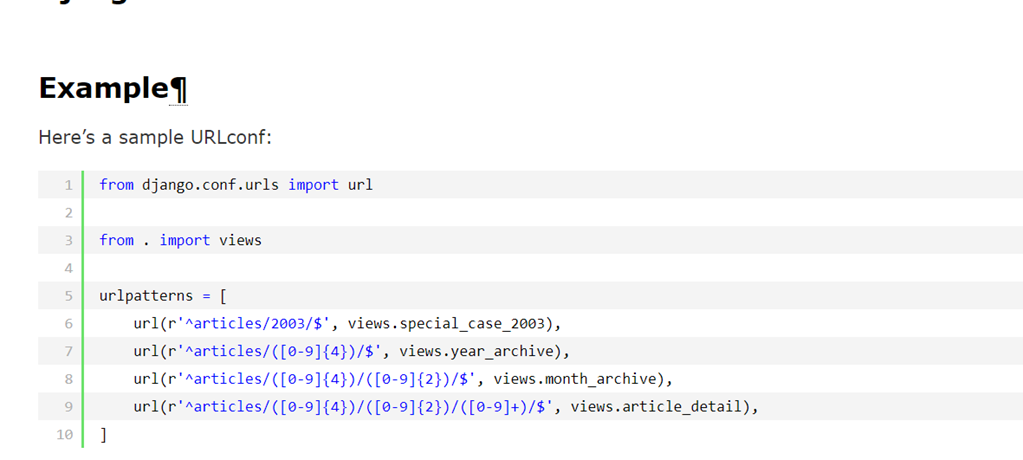
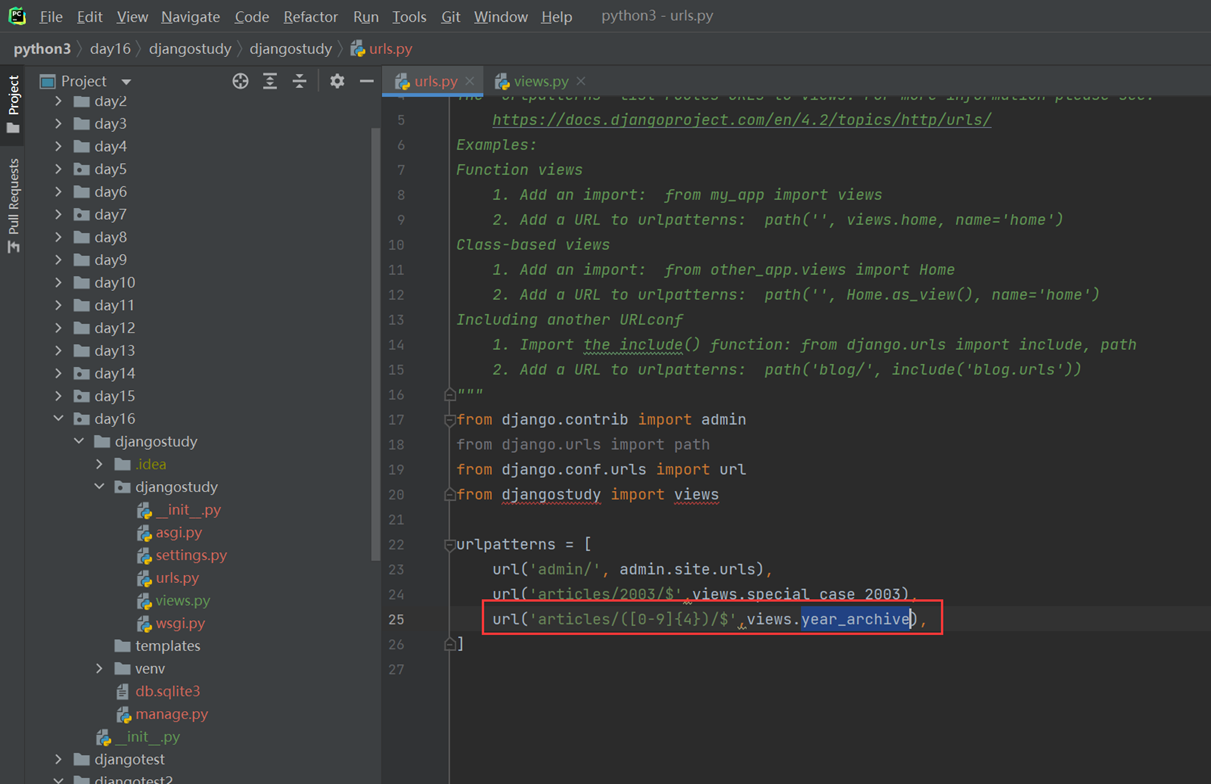
2.正则匹配年份,根据输出的年份返回到网页。
url
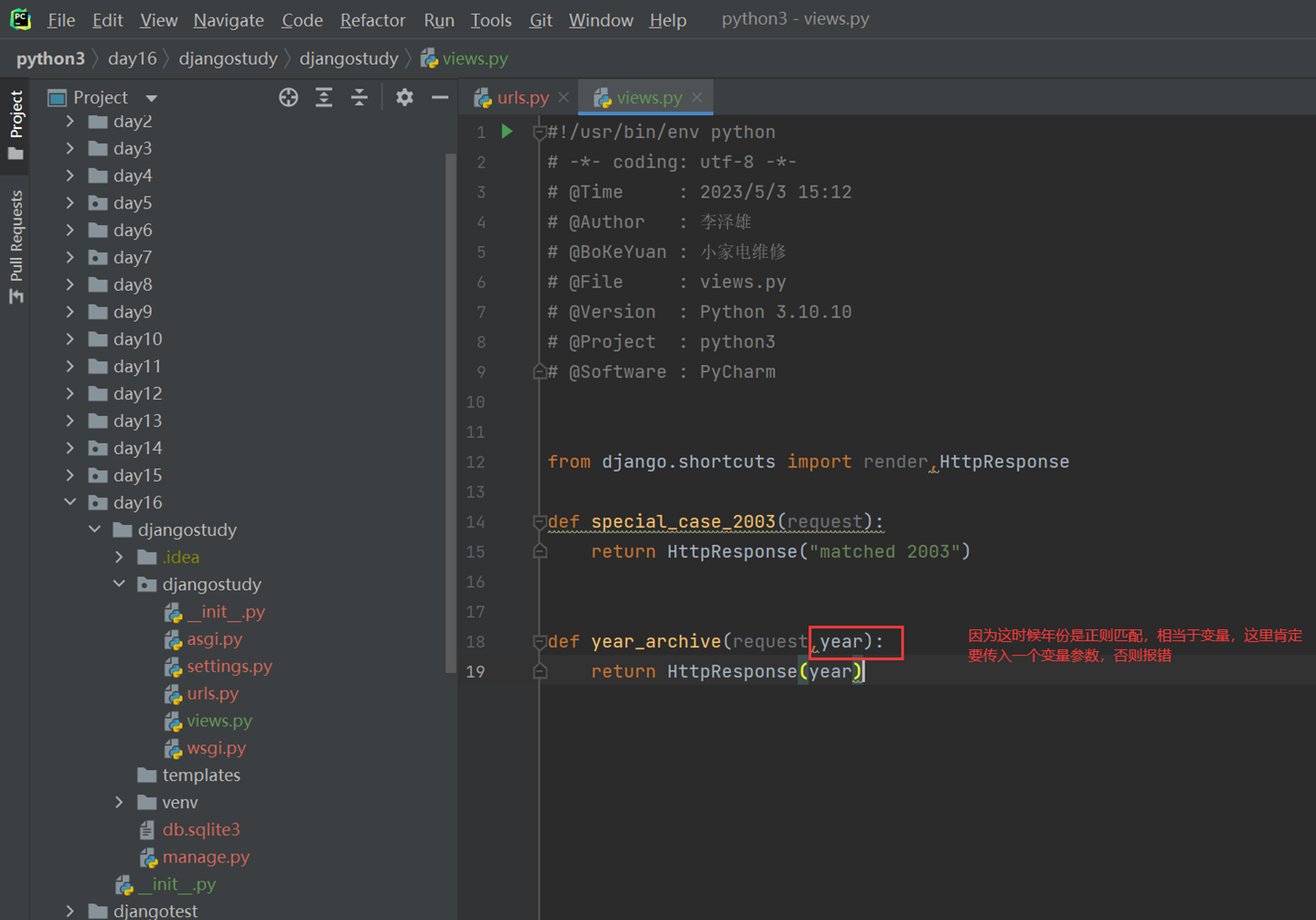
views
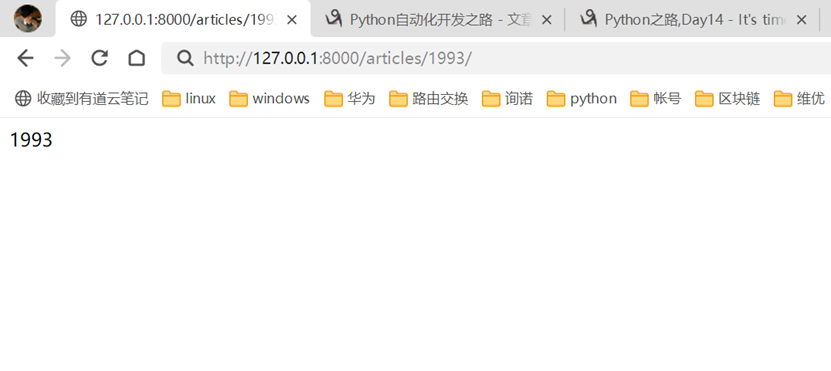
结果
3.传入年份和月份和
url
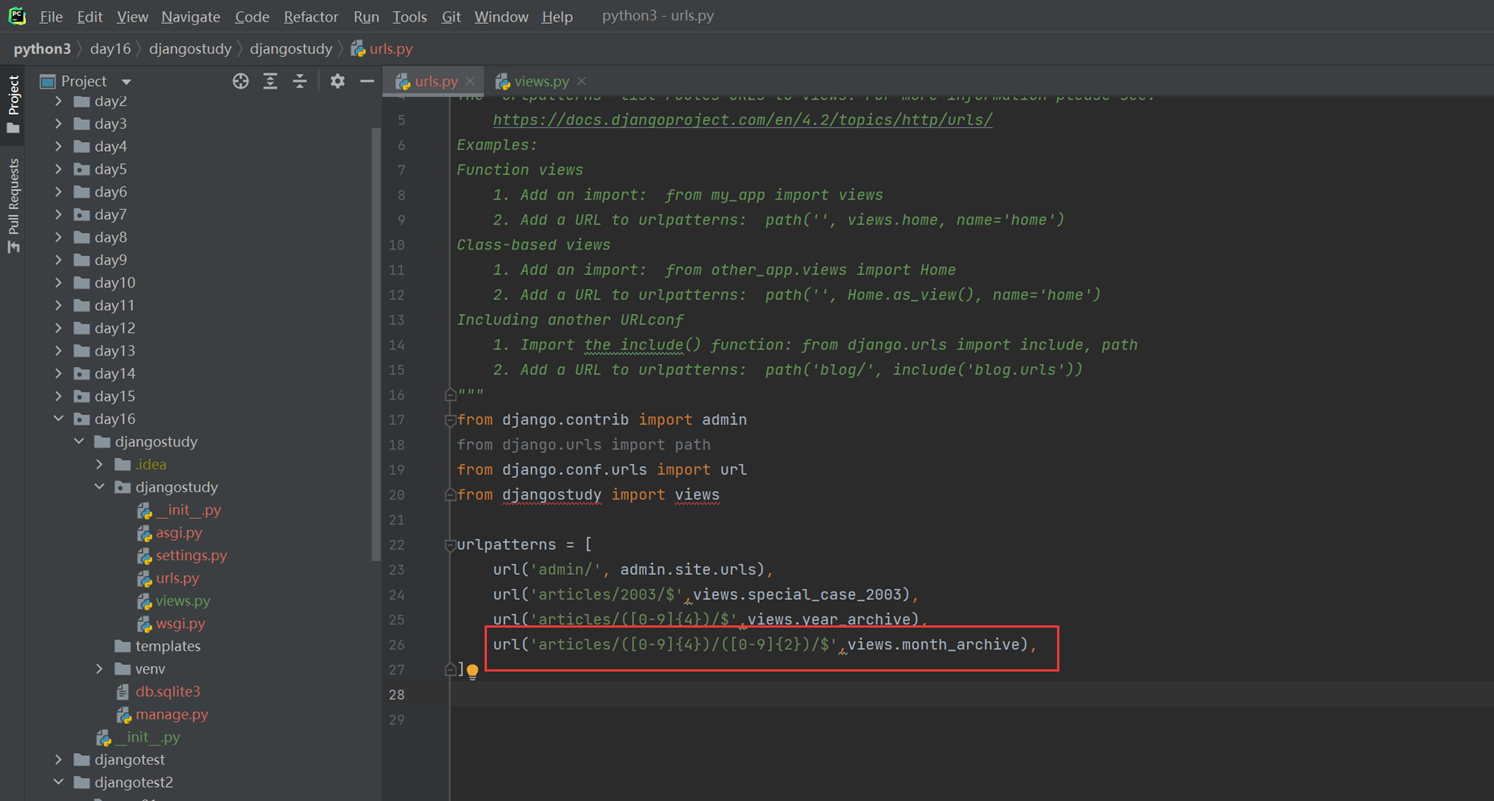
views
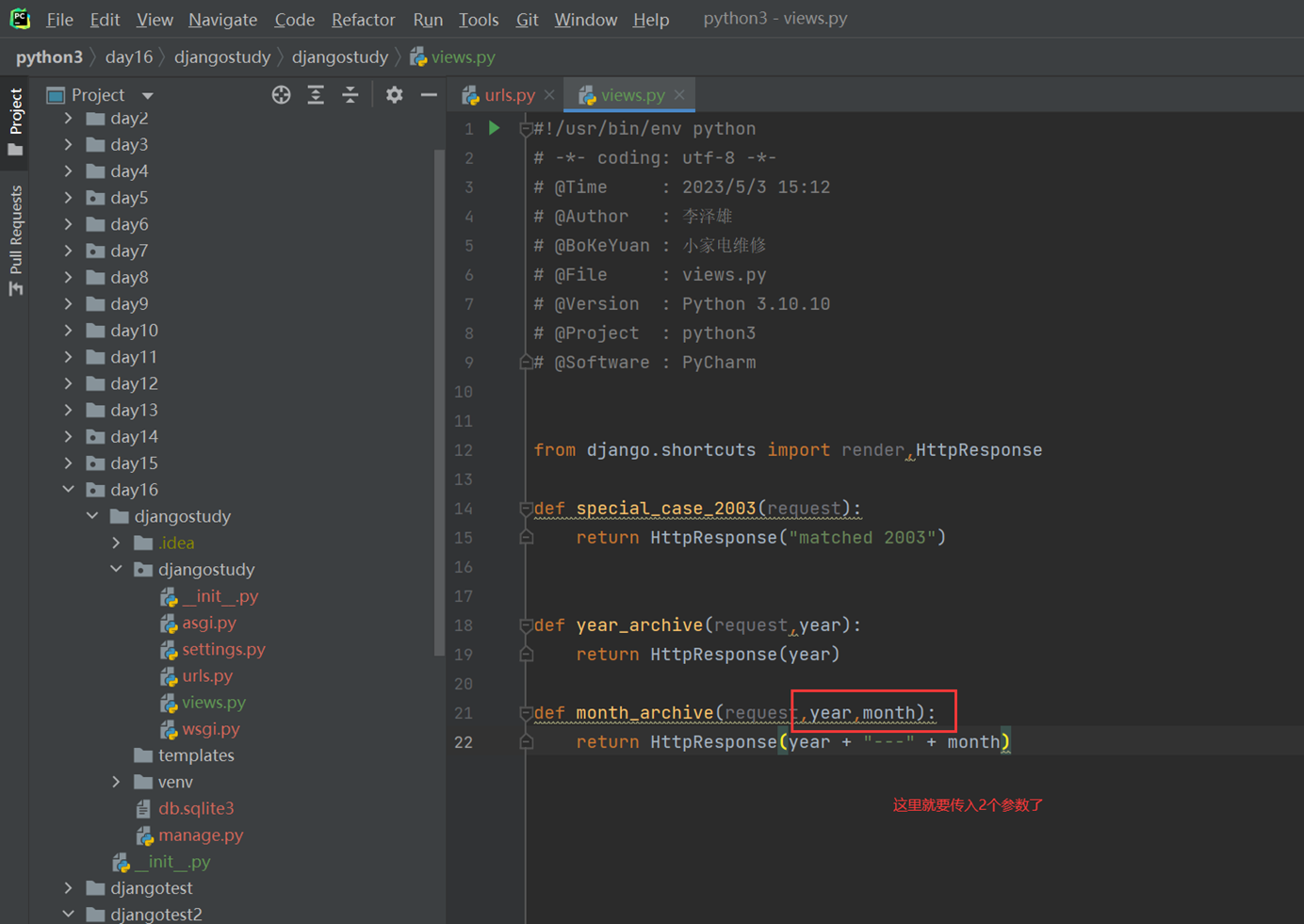
4.传入年份和月份和文章id
url
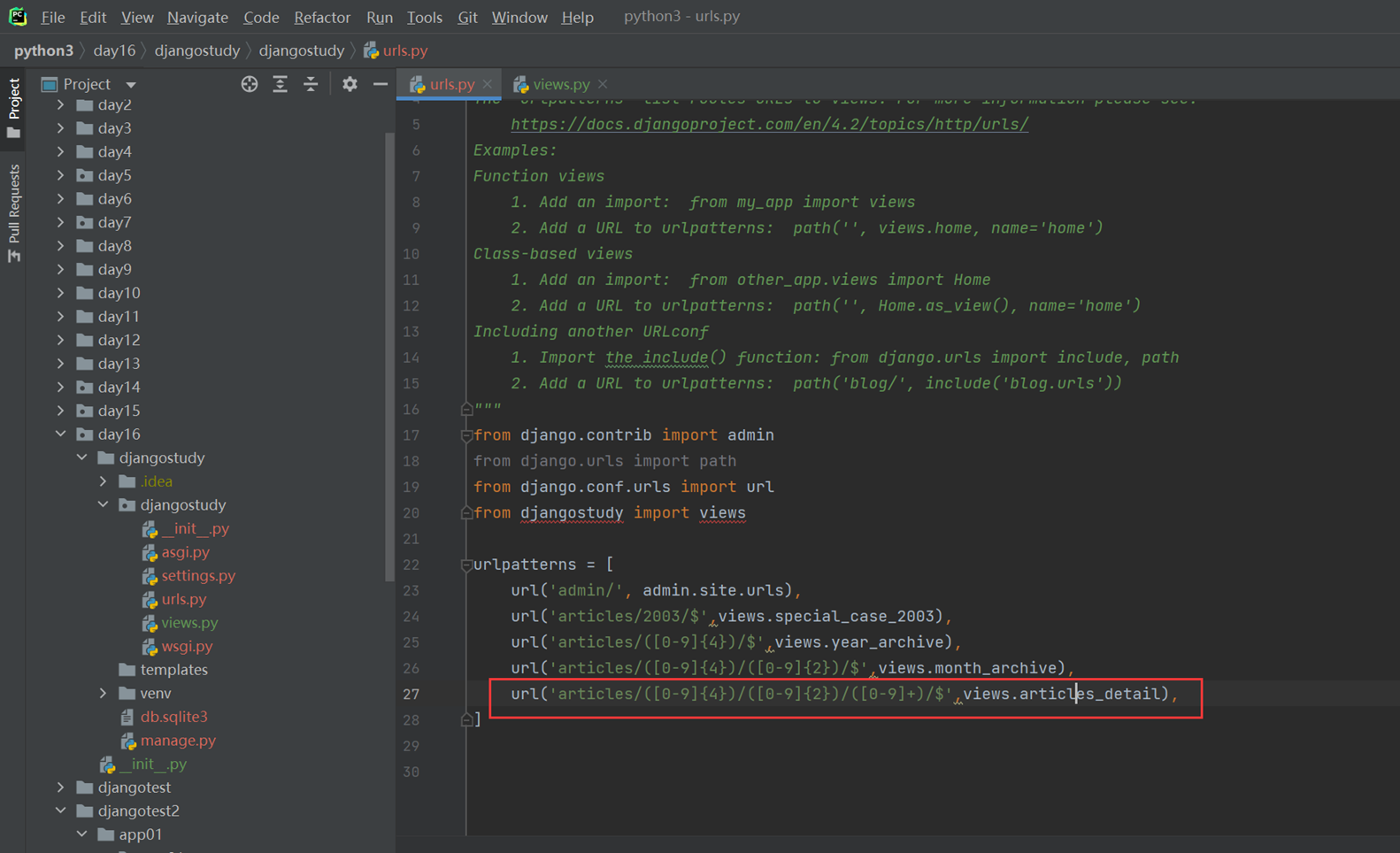
views
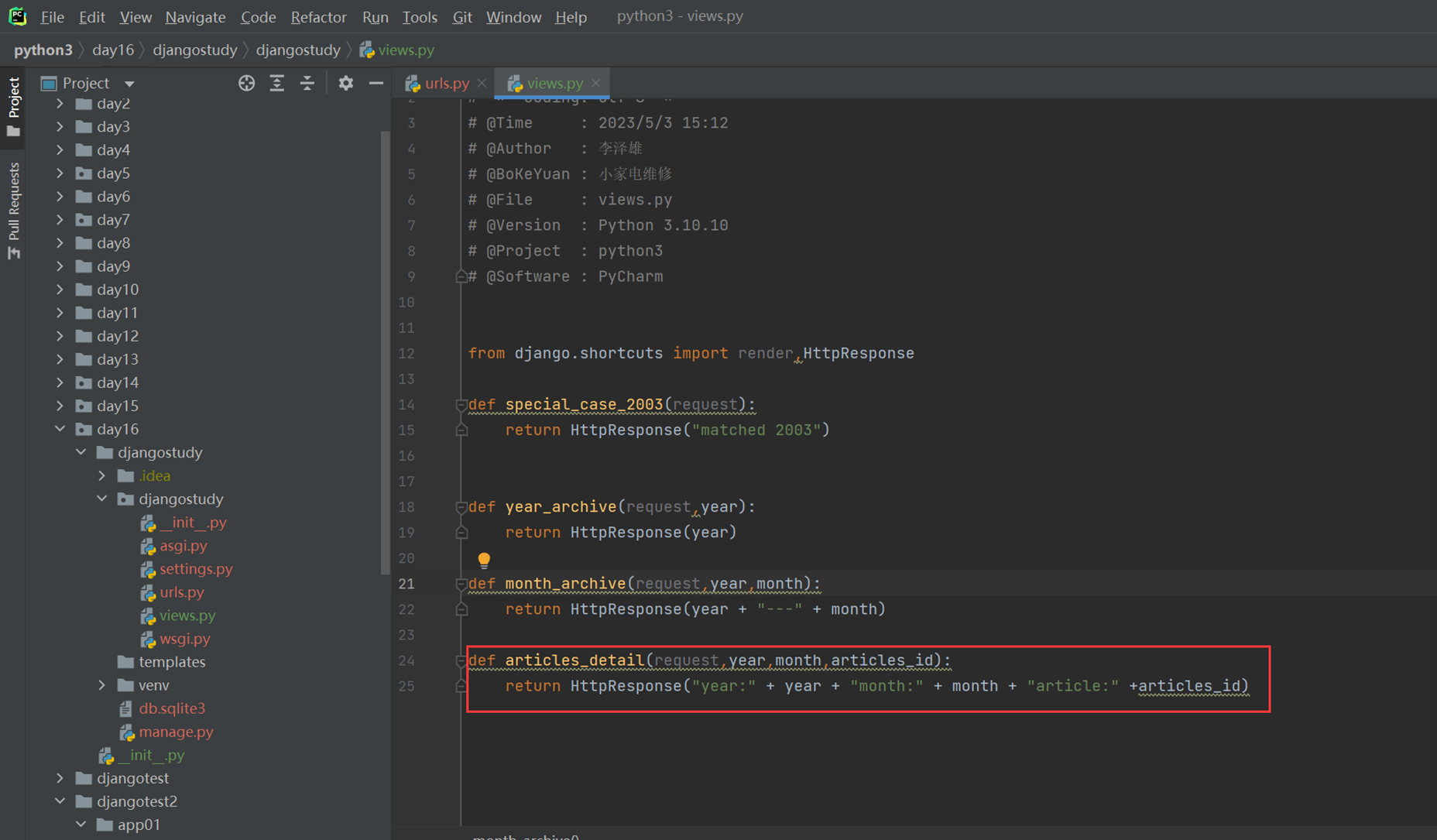
结果
本节课把上面4个ulr实验做完就行,剩下的不知道那老师在做什么sb实验,讲的真垃圾。
16.3 djangourl常用匹配语法2
开篇讲正则,也是废话,直接跳过到include,就是路由分发
url尽量写名词,不要写动词
1.先创建一个模块app01

这个app01的模块的所有url全部有他自己管理。那么就需要接下来,将路由分发到app01的url下面去。
2.主项目的url配置文件
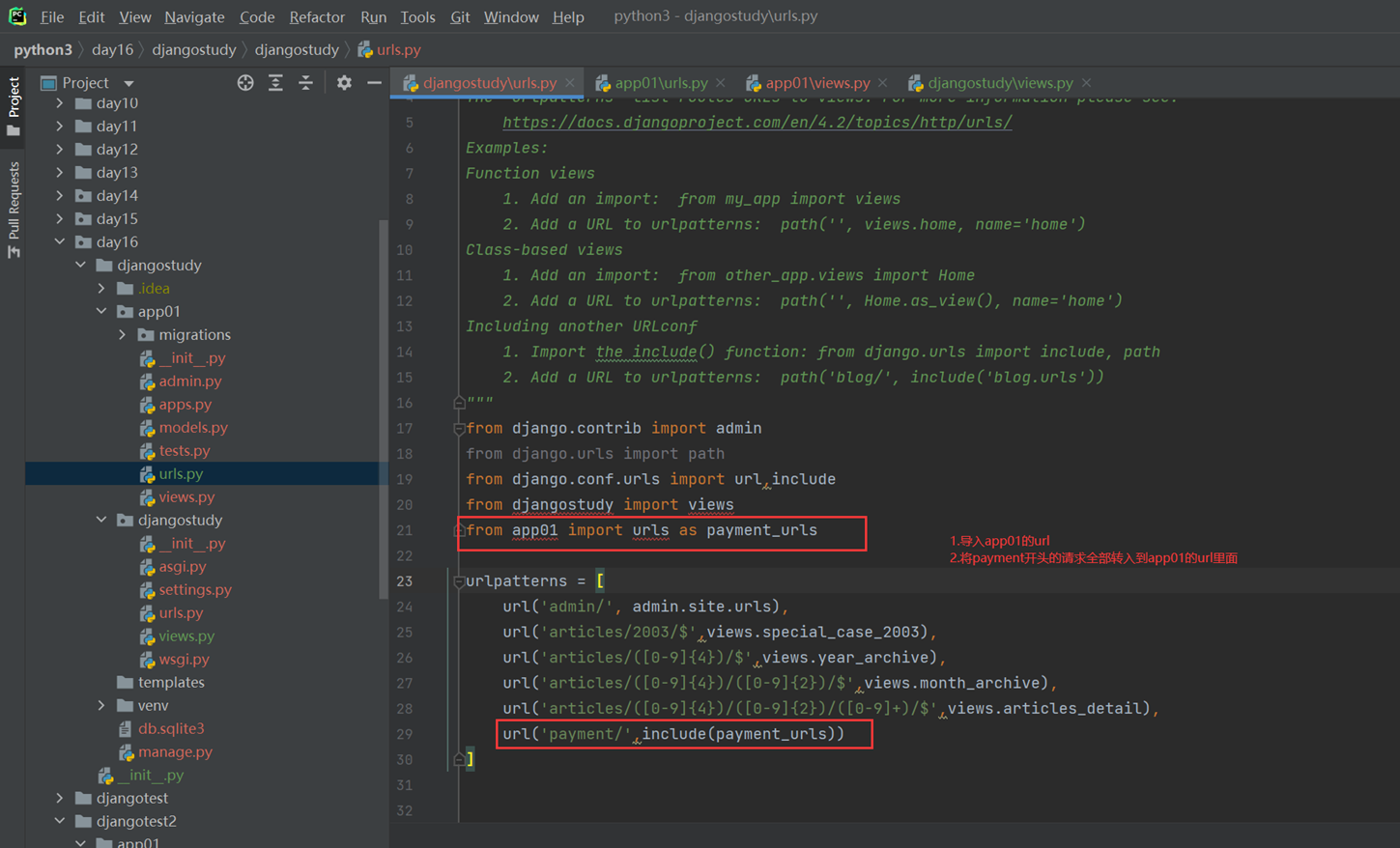
3.app01的url
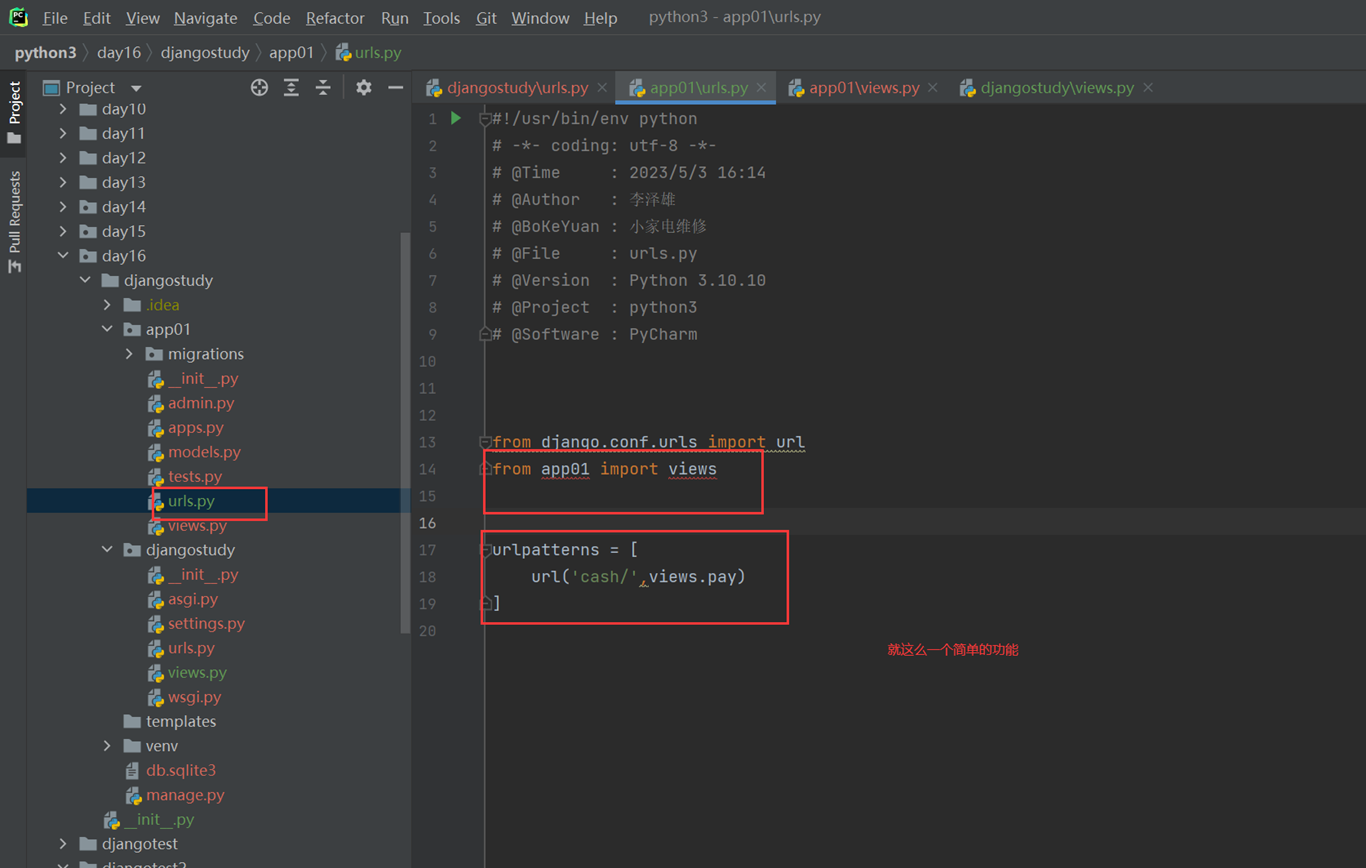
4.app01的views
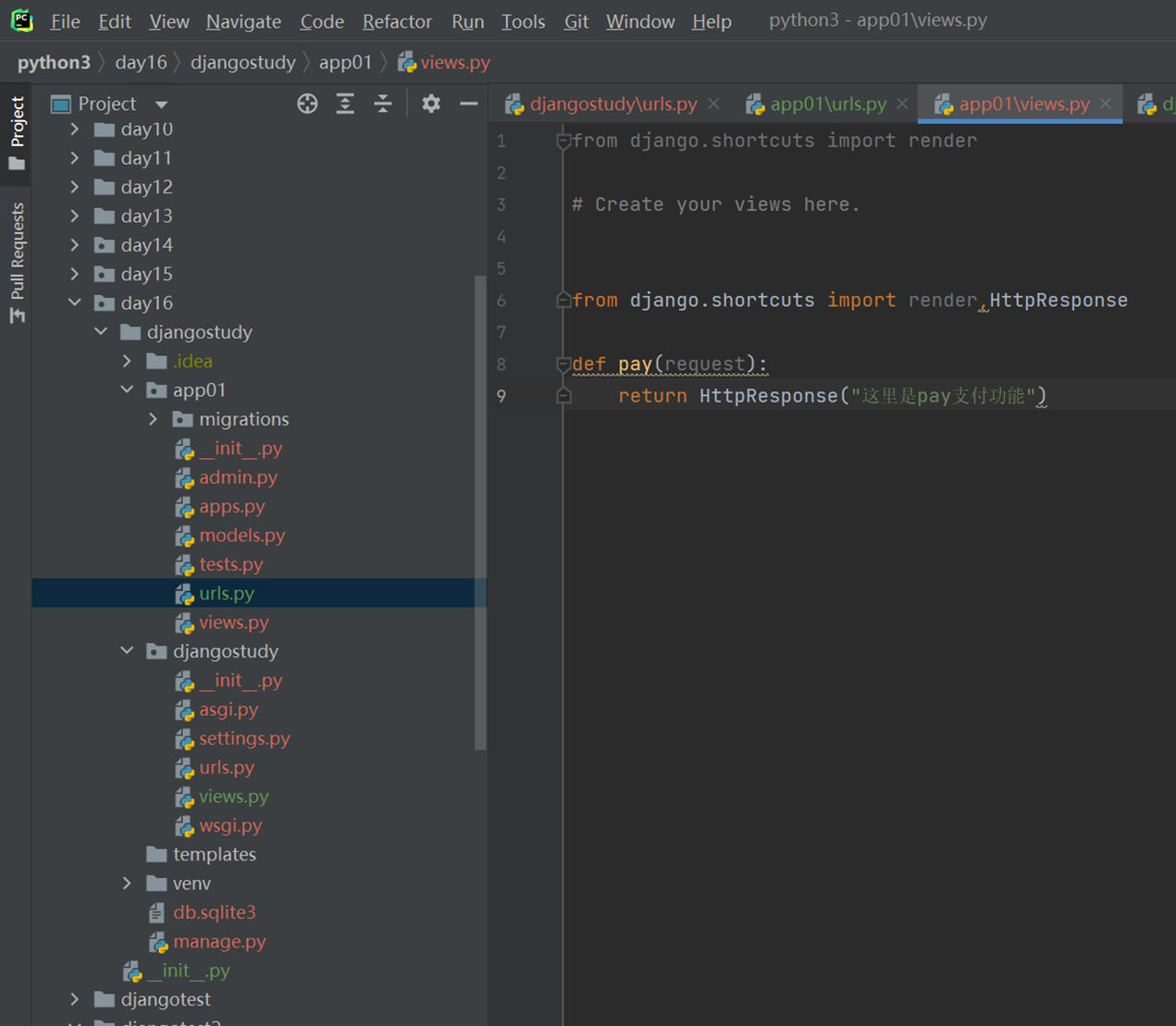
5.访问查看
16.4 djangourl常用匹配语法3
开篇就讲解了一个小知识点,就是上章节讲解的,如果有多个前缀相同的url,也可以使用include,见以下:
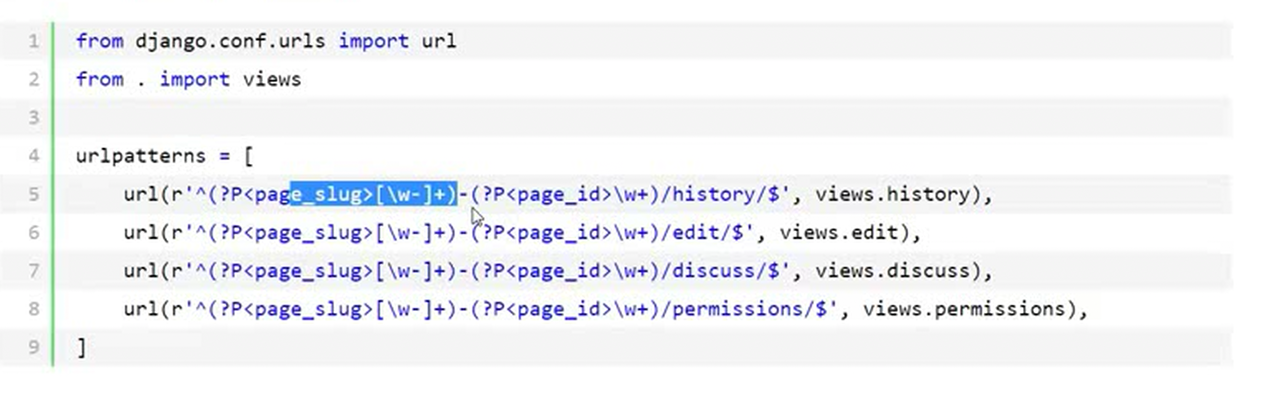
使用include后
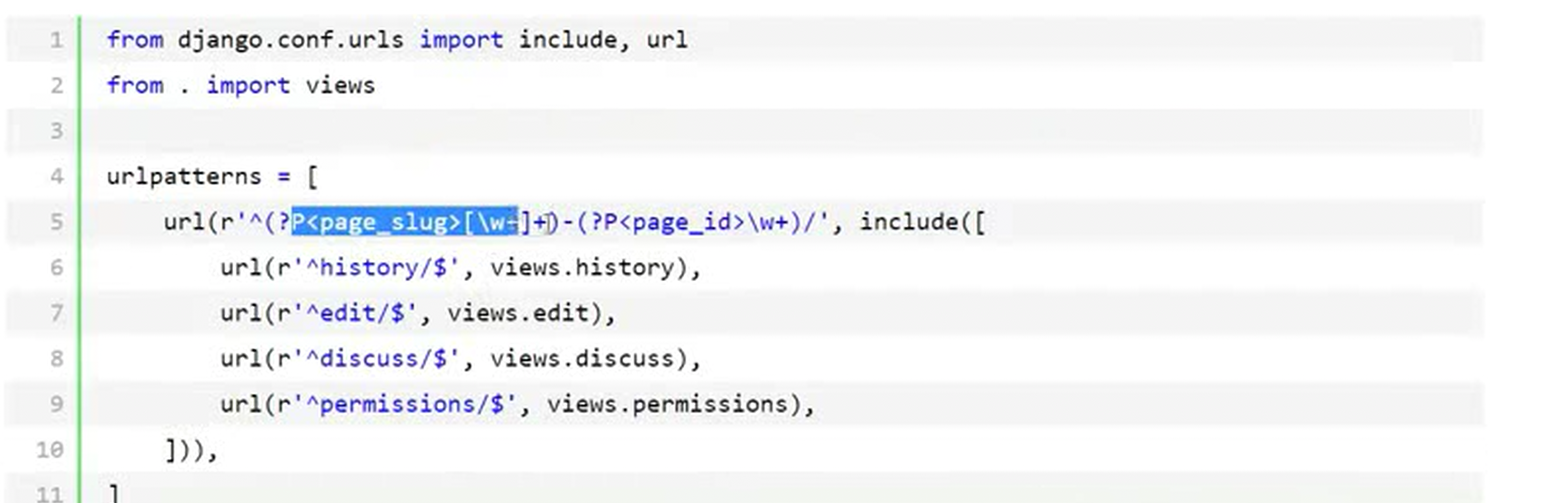
接下来一个重要的知识点,就是往视图里面传额外的参数,什么叫额外的参数?
比如,用户一旦在主界面登录成功,就可以在payment下面的所有功能都不需要去进行验证,那么就需要在主界面把用户认证后的对象,比如,名称,密码,session,过期时间等等一系列参数传过去,不需要payment单独验证。那么就需要这个传额外的参数。
主程序urls,payment的url不需要在传了
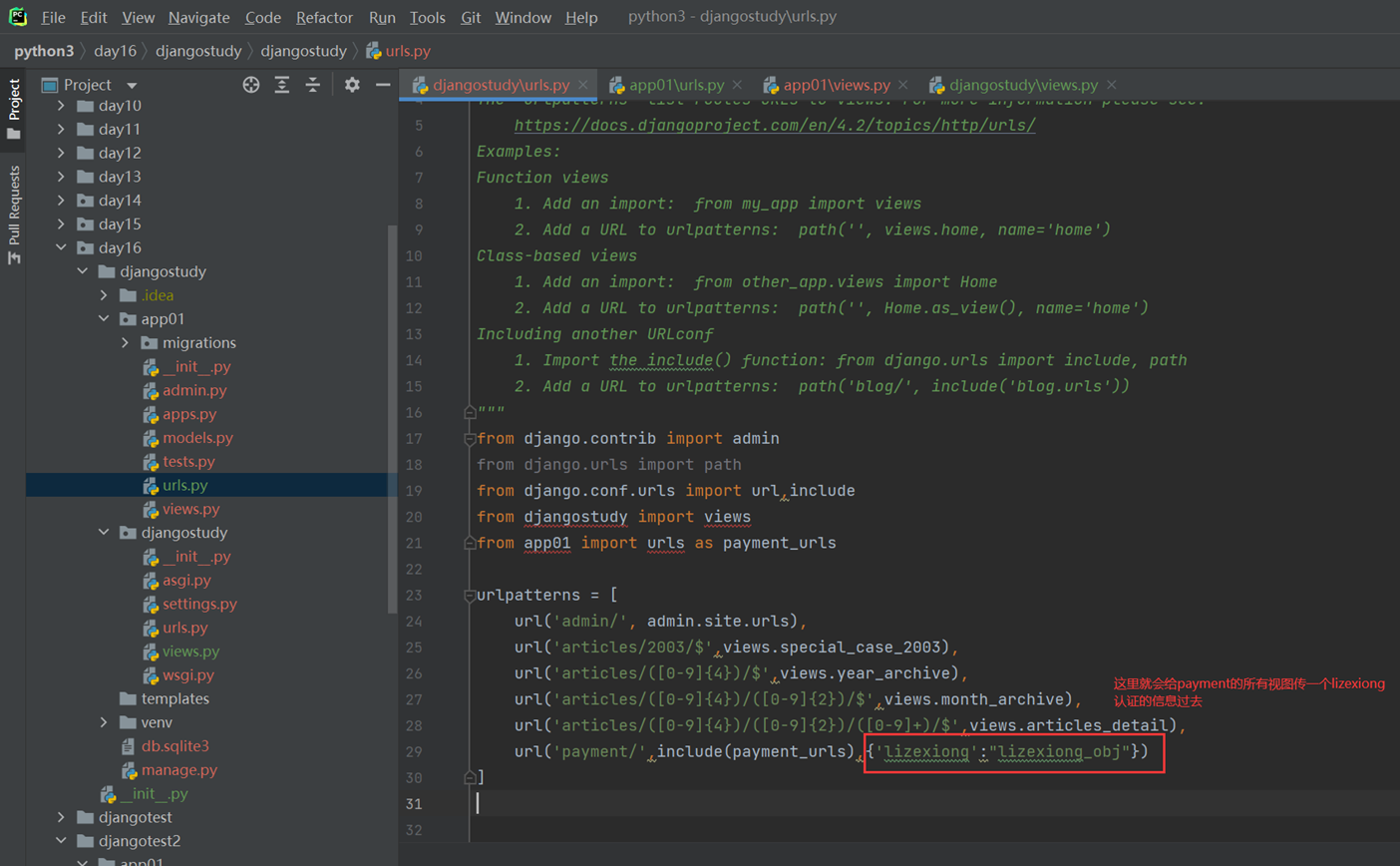
App01的views
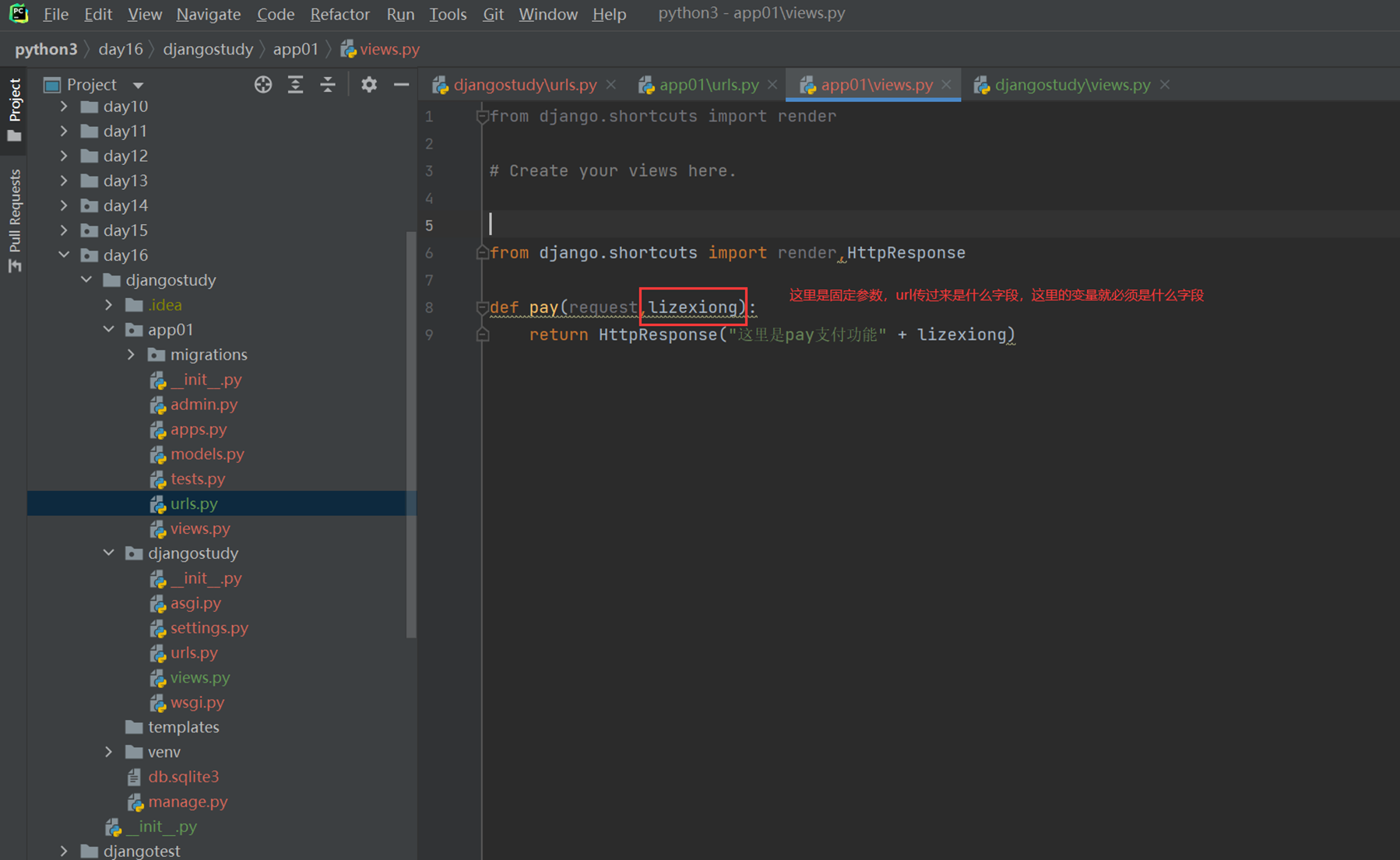
访问查看
16.5 djangoget和post请求方法
该篇视频不清晰,就是简单讲解了一下get和post的区别,get和post的作用,对复习的我来说这个篇章无所谓
16.6 djangotemplate渲染
本章节,使用循序渐进的方式来讲解为什么要使用模版,比如直接把html写在代码里面的坏处。

然而本章节也只是按照他的博客讲解了,怎么使用模版,还没联合前端代码一起讲解。

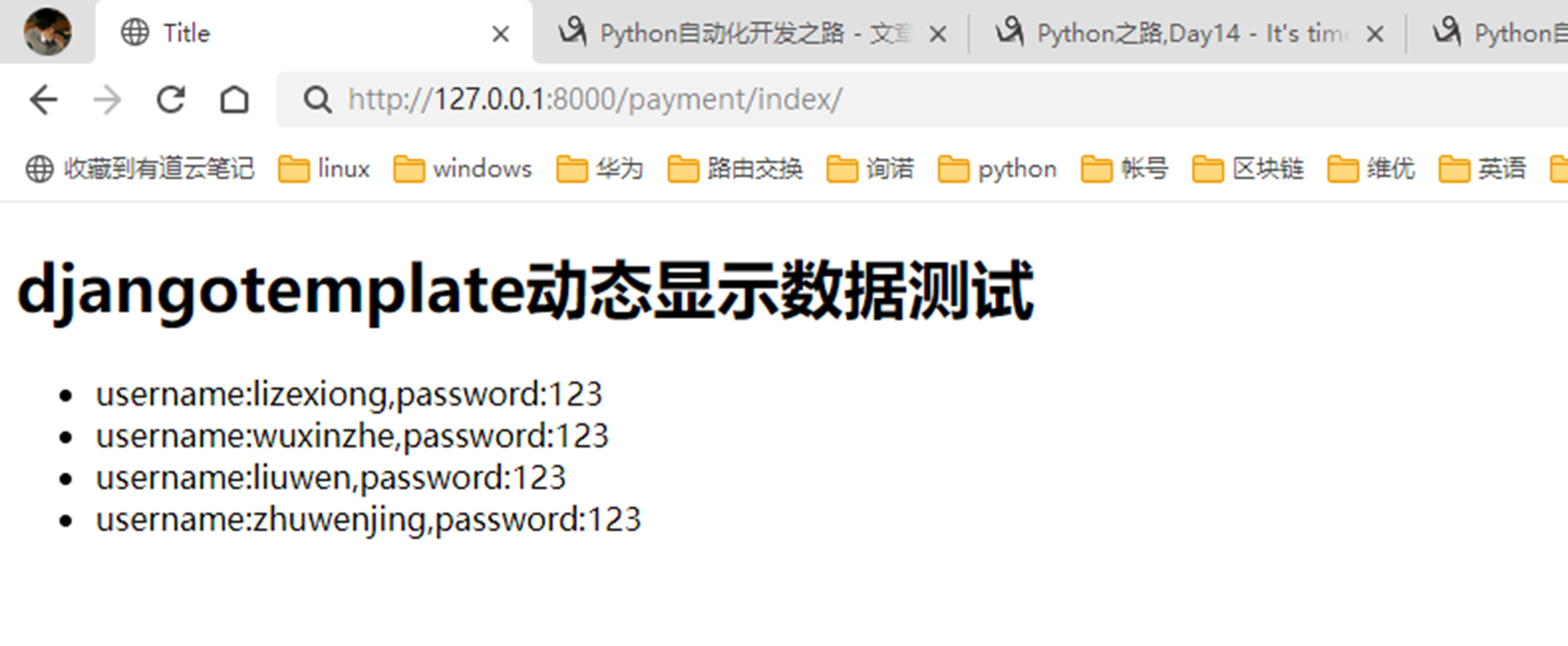
16.7 djangotemplate动态显示数据
本章就是演示怎么把后端python的数据通过模版渲染到前端html,有几个小实验,接下来看代码。
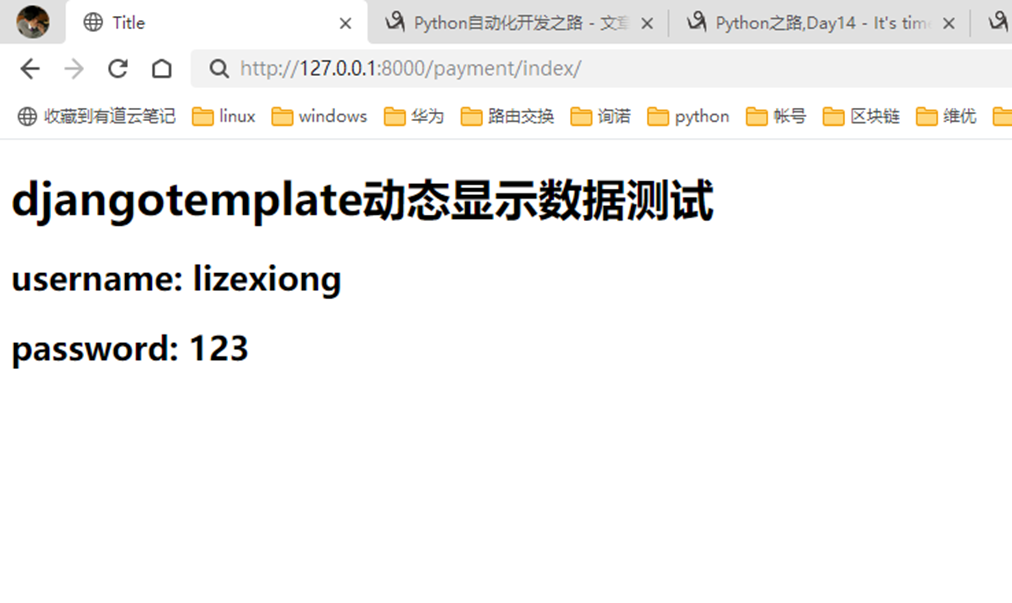
1.返回用户名和密码。
views
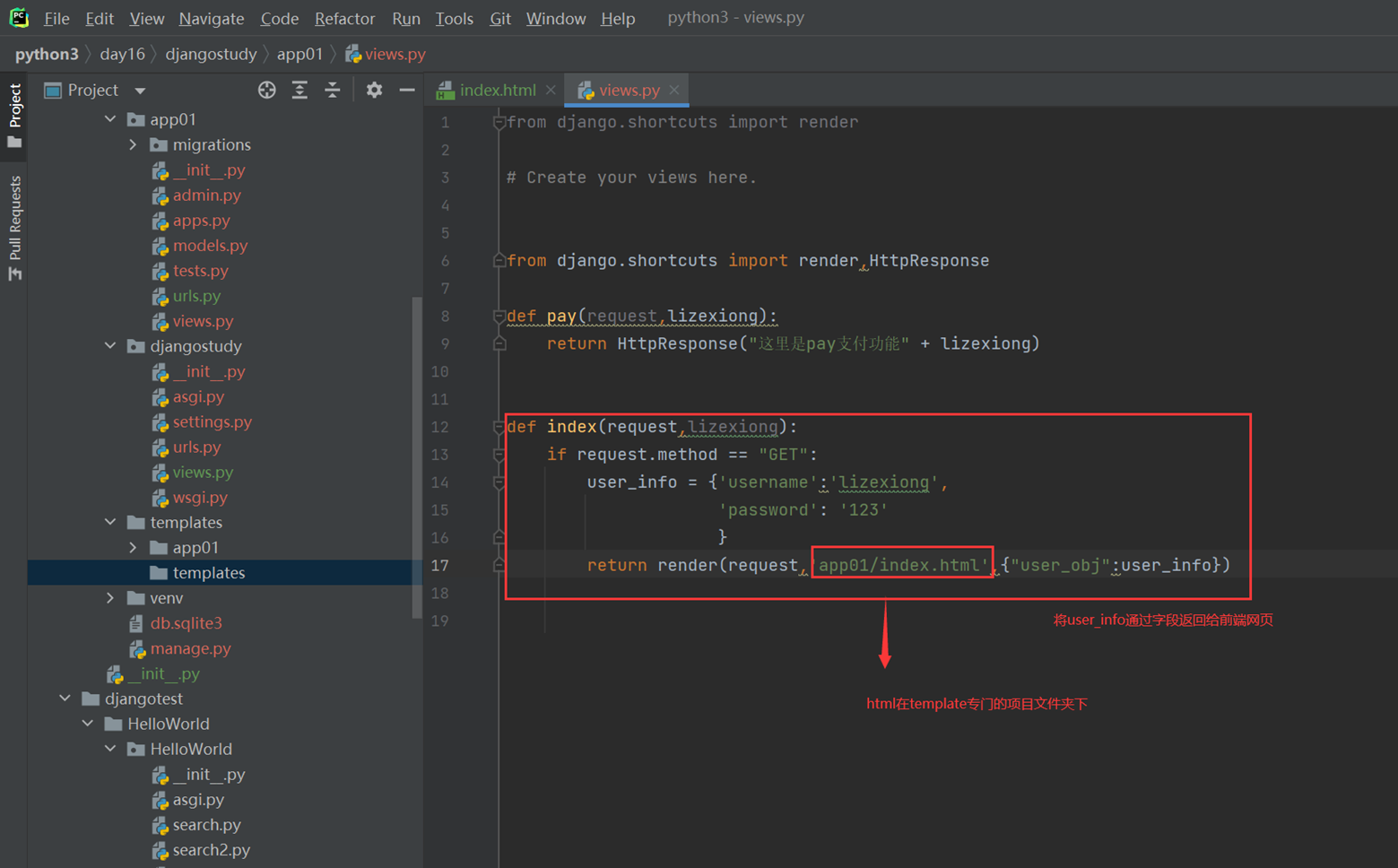
html
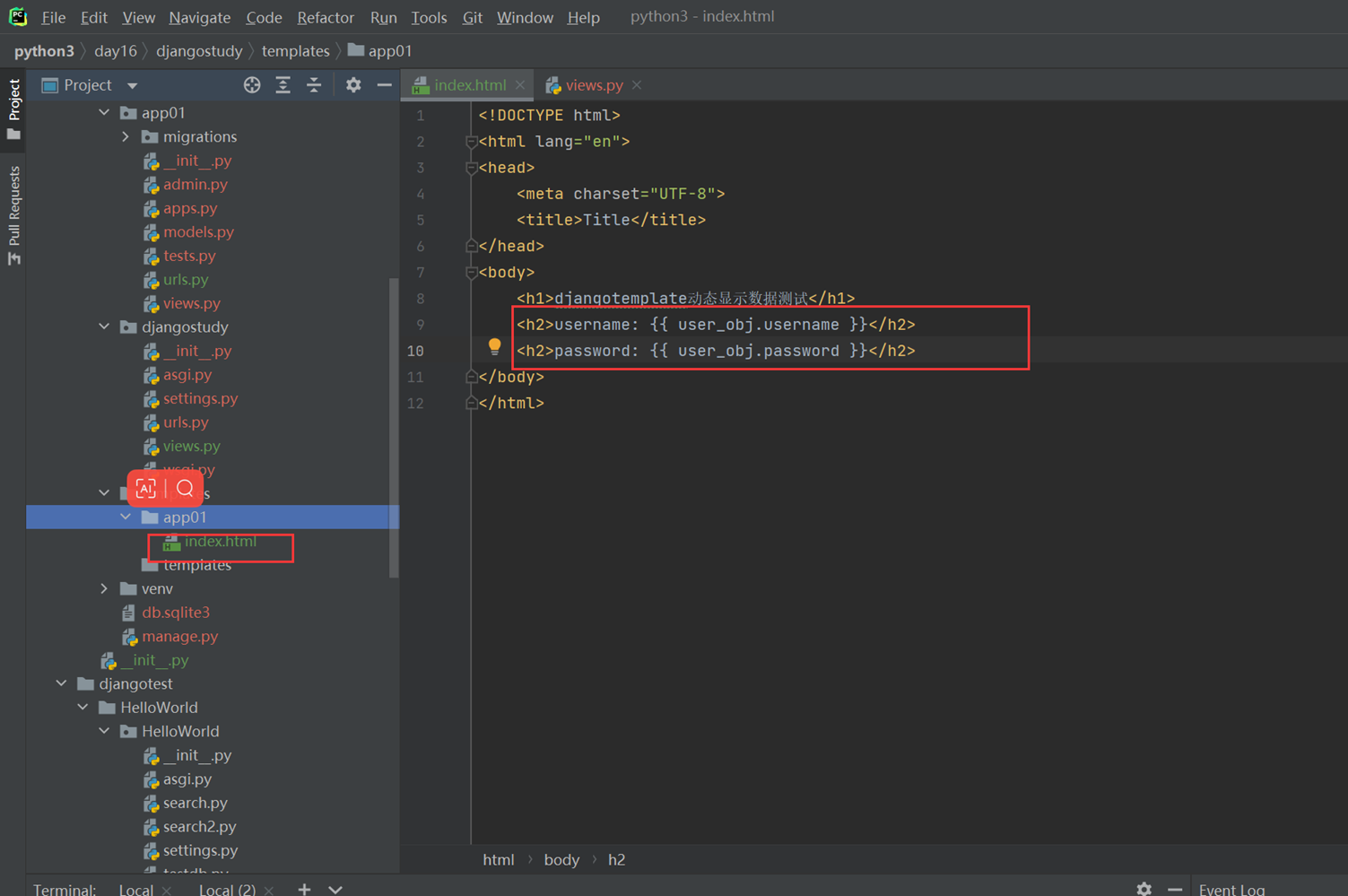
结果
2.来了一个需求,如果有多条用户信息,这个怎么展示?
前端模版渲染使用for循环。
views
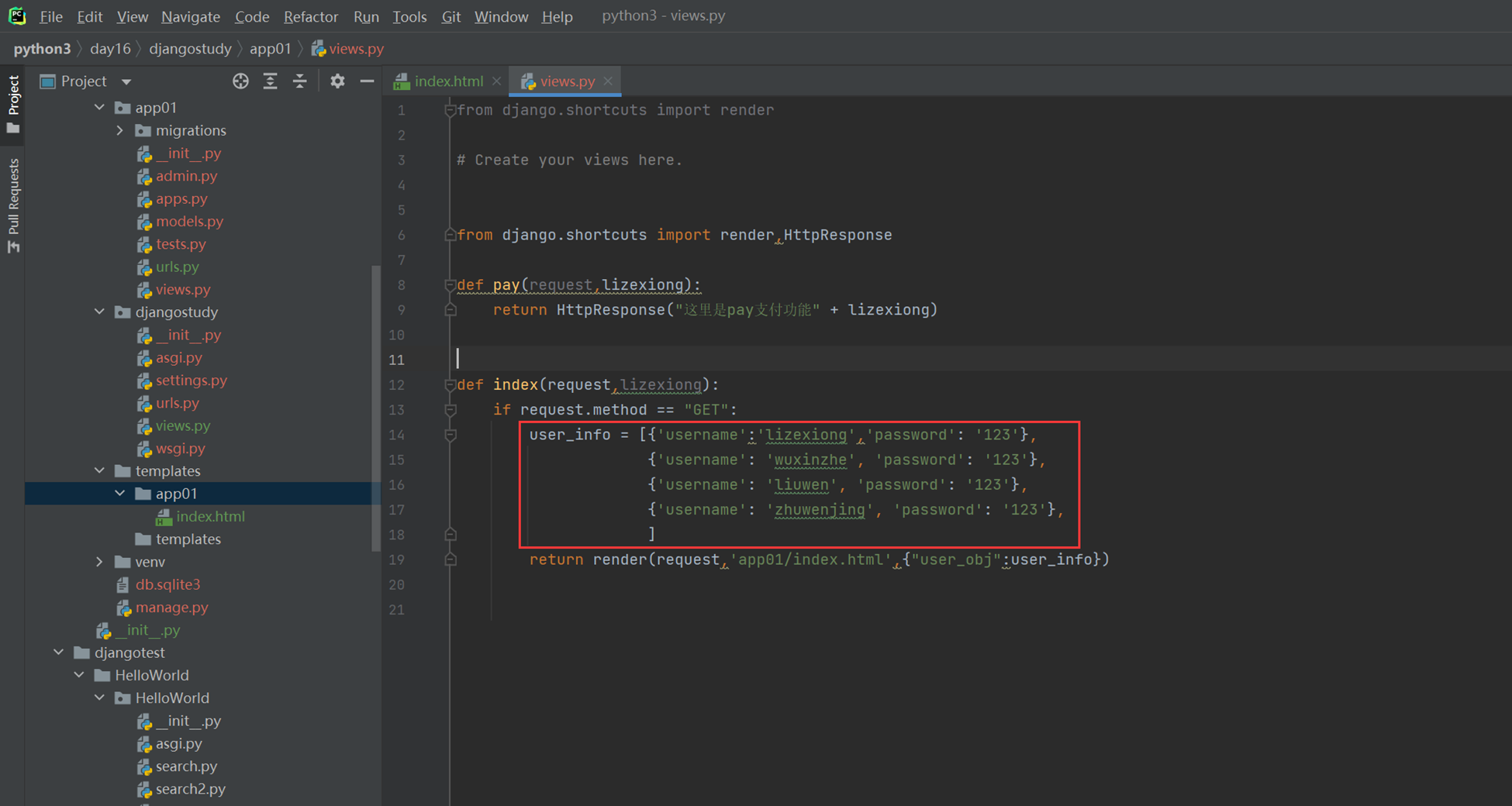
html
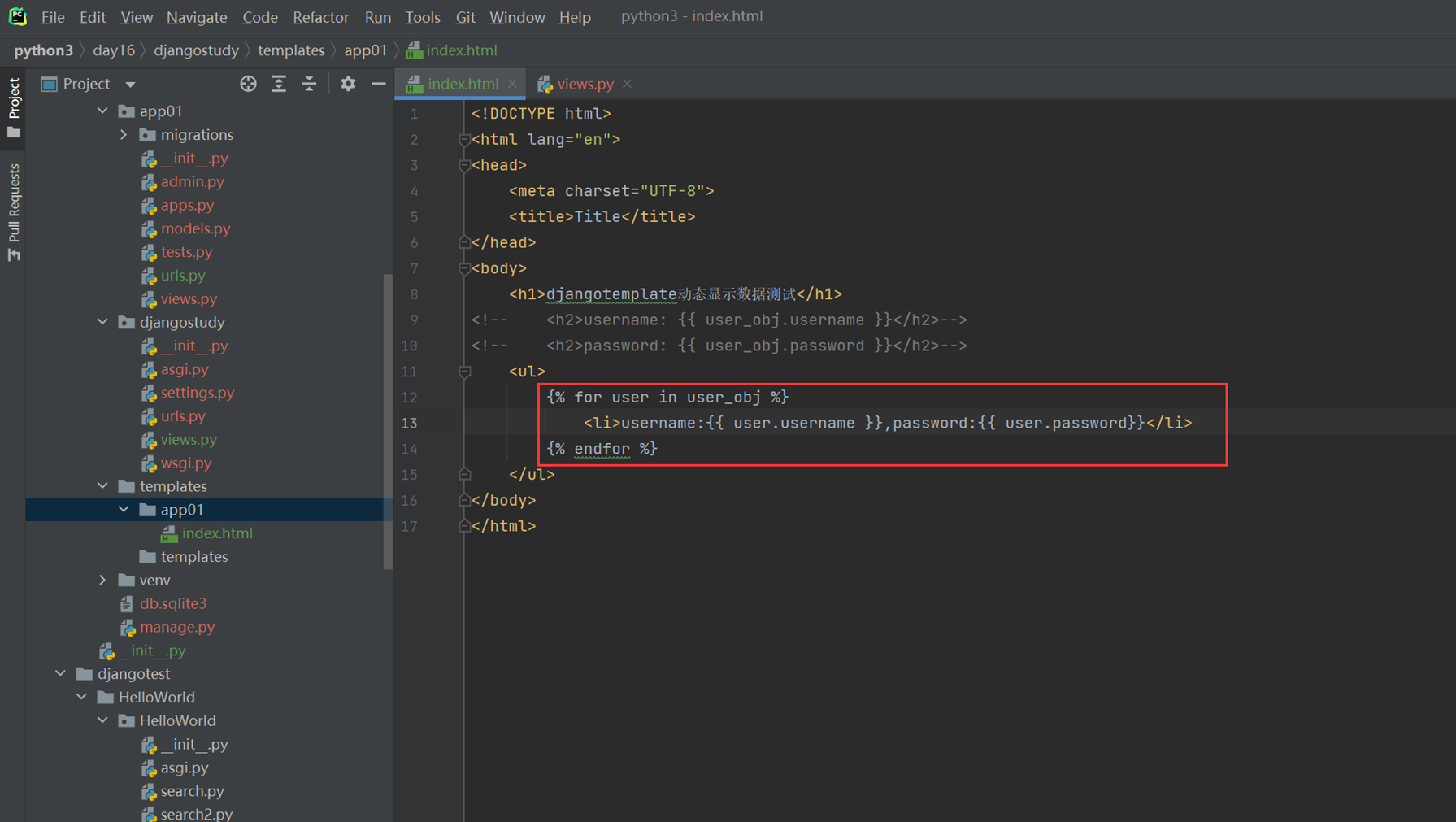
结果
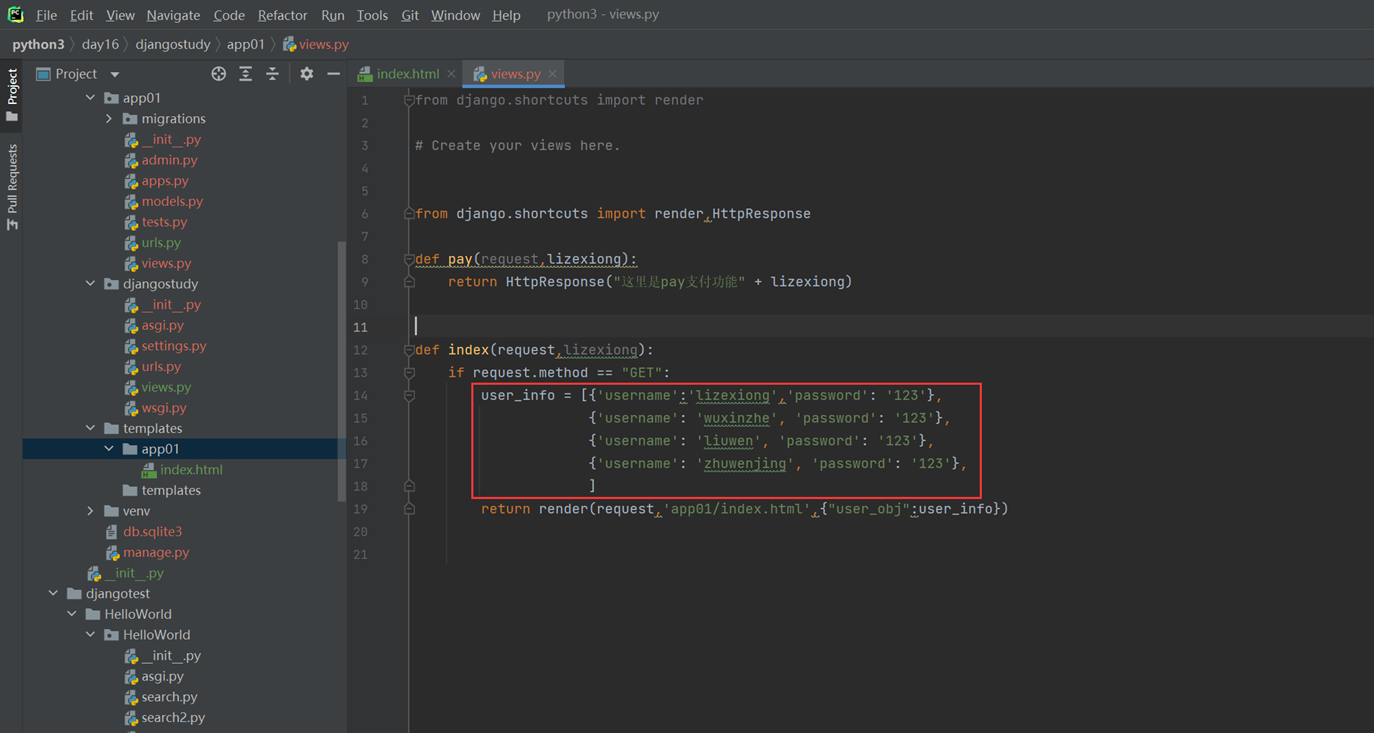
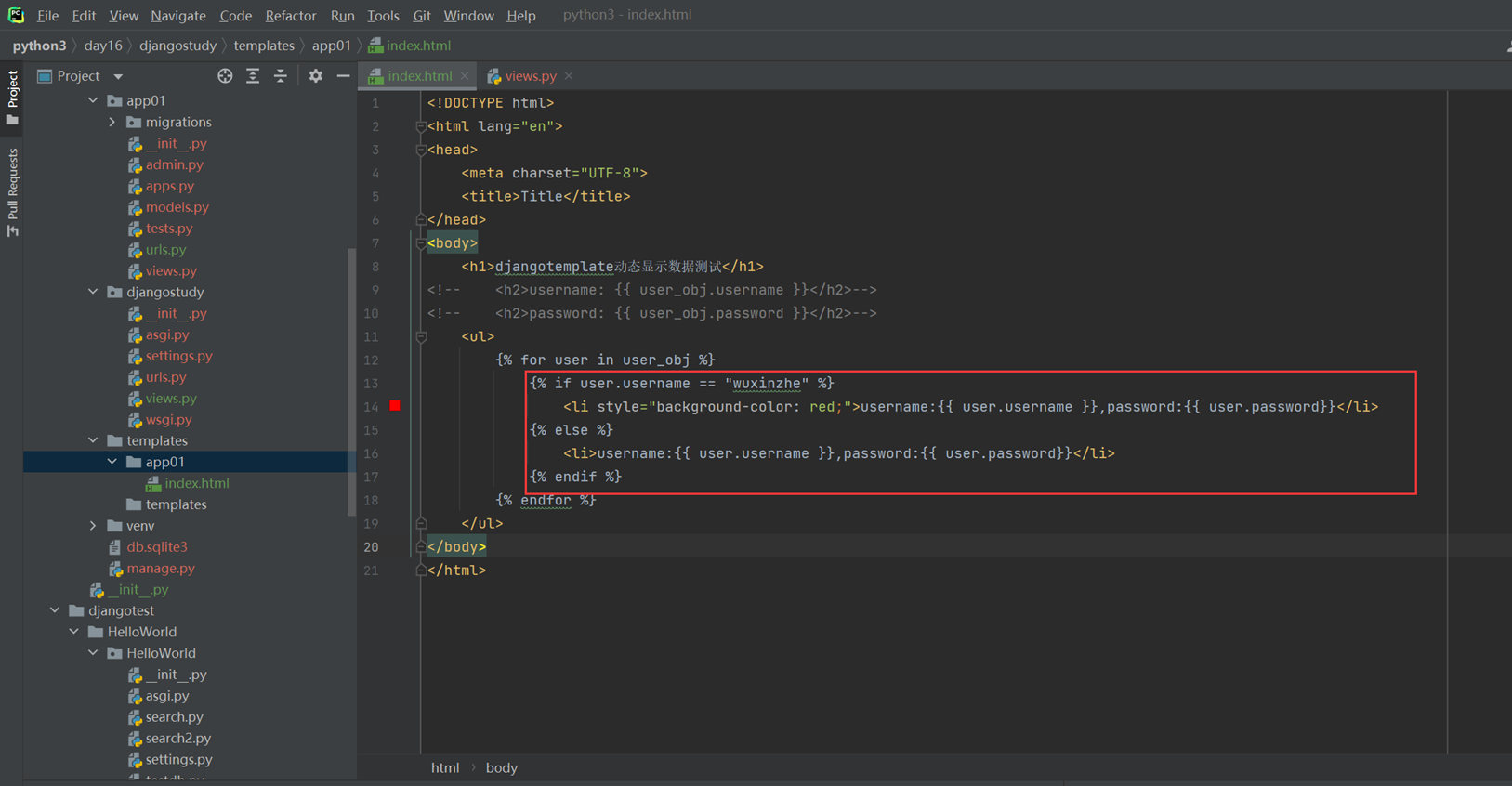
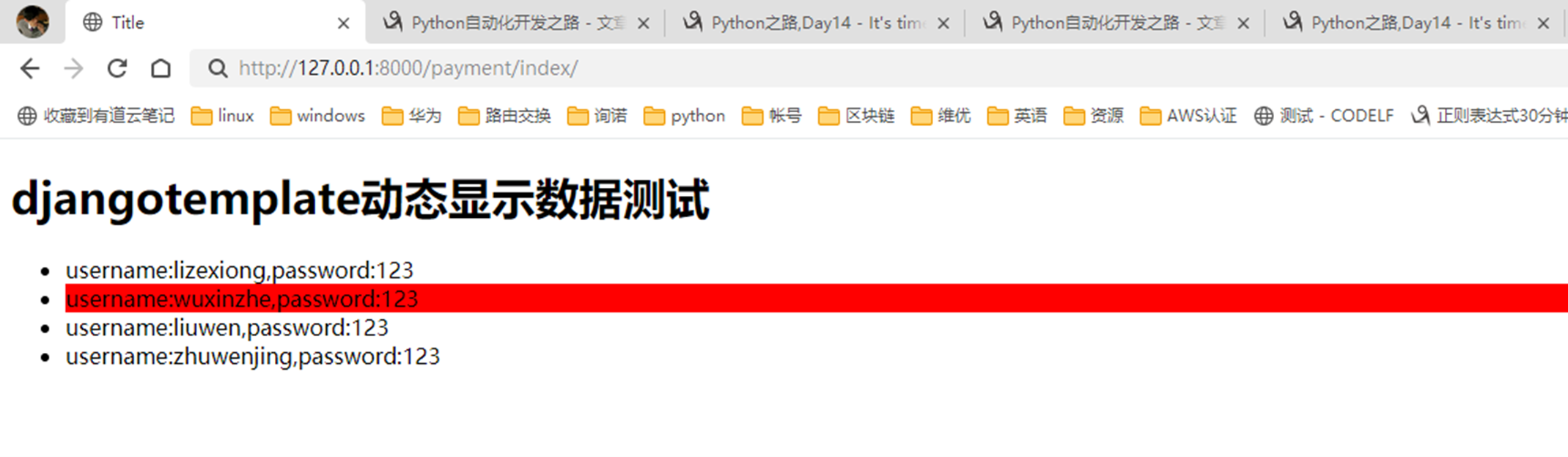
3.如果需要名字是wuxinzhe的,前端背景显示红色。那么就需要if
views
html
结果
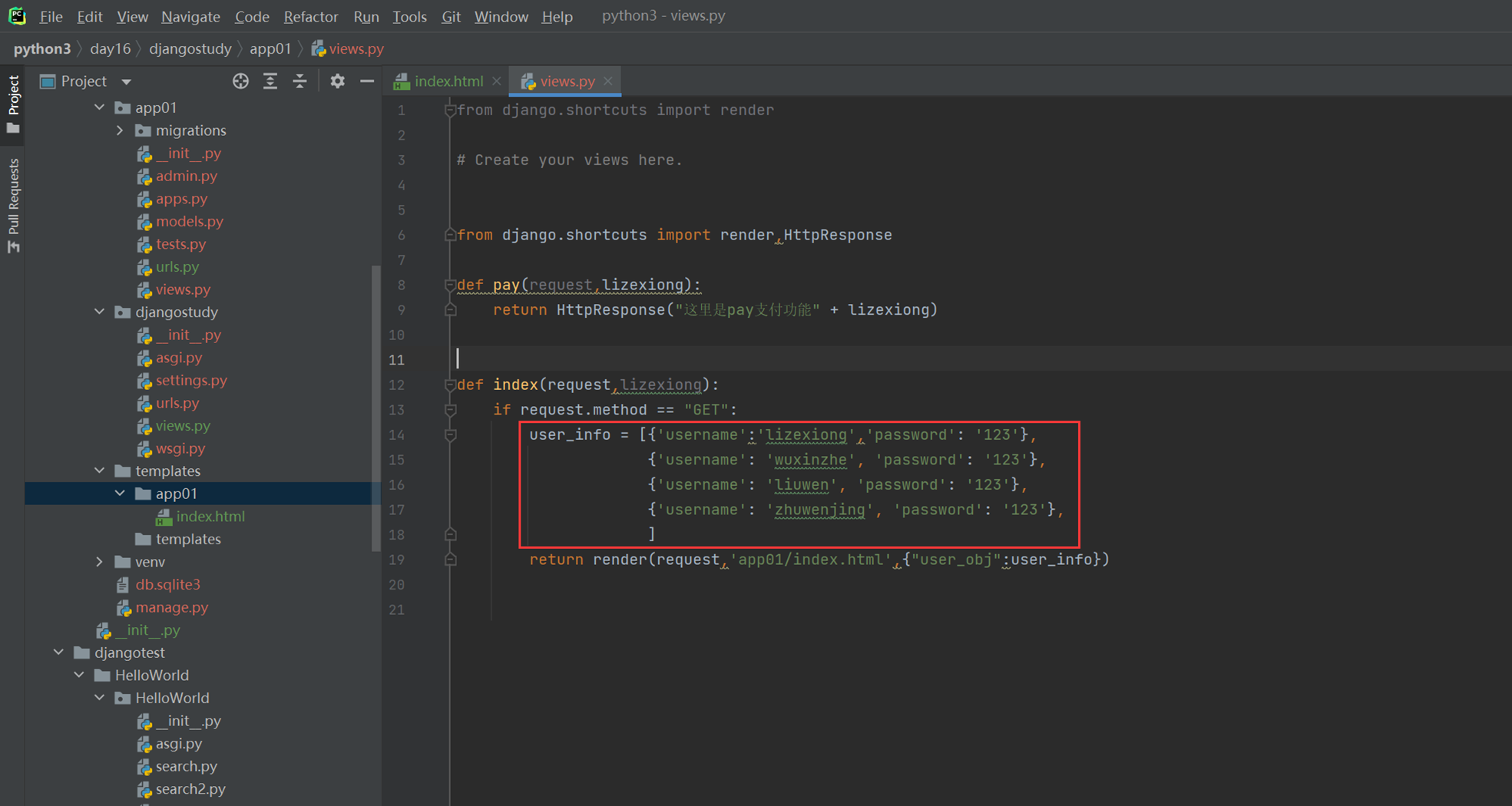
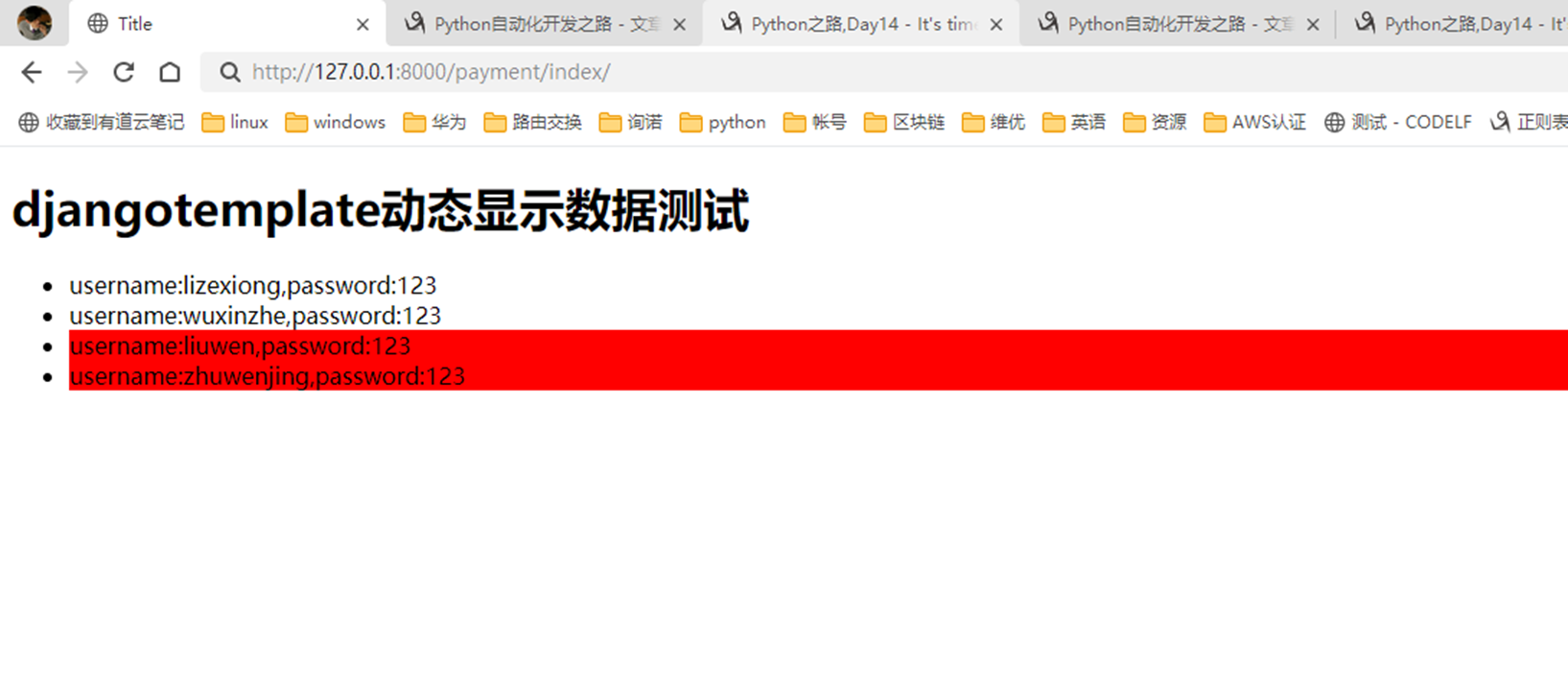
4.如果输出2条以上的数据,全部背景都是红色,这个怎么做?
views
html

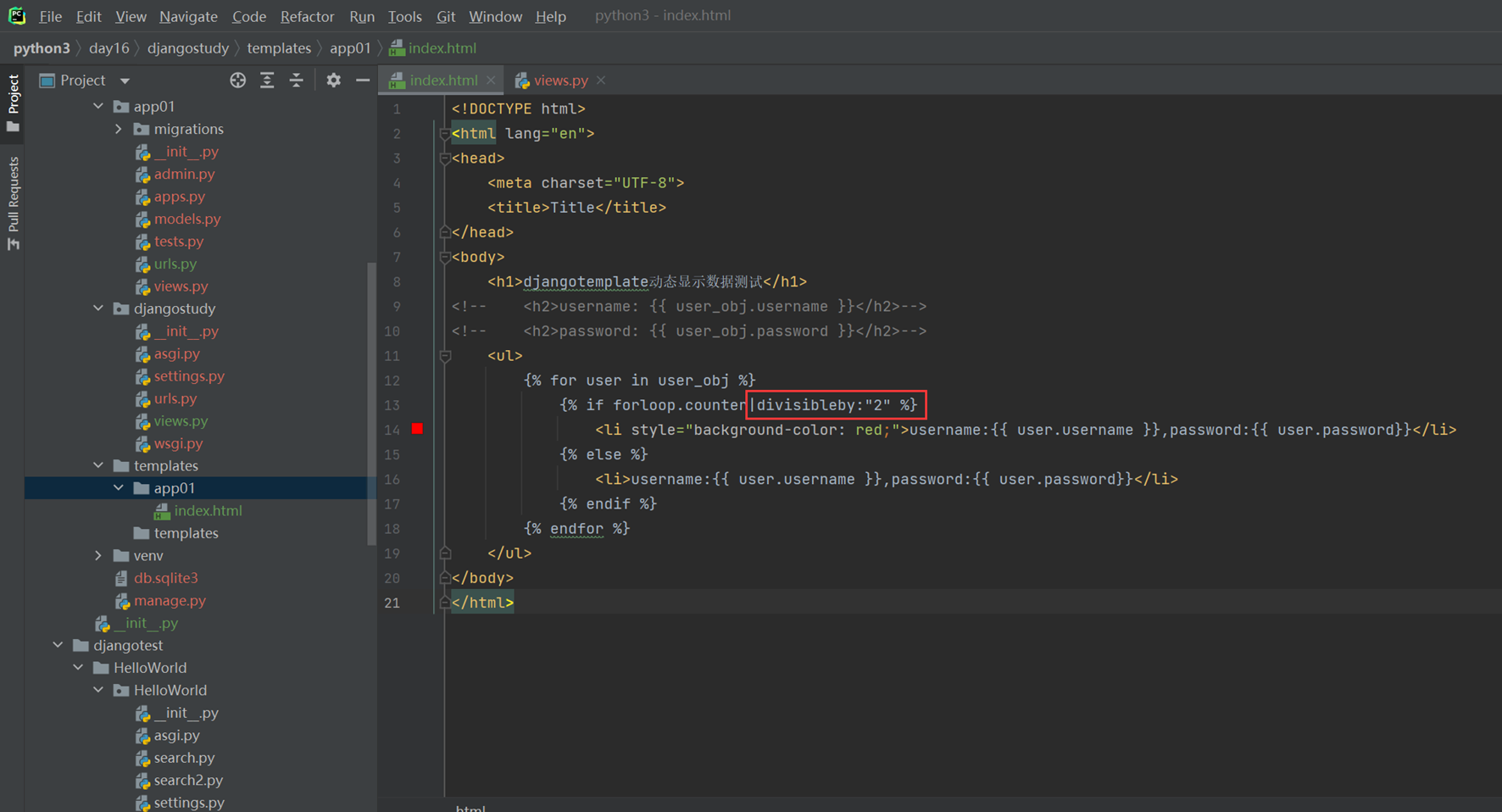
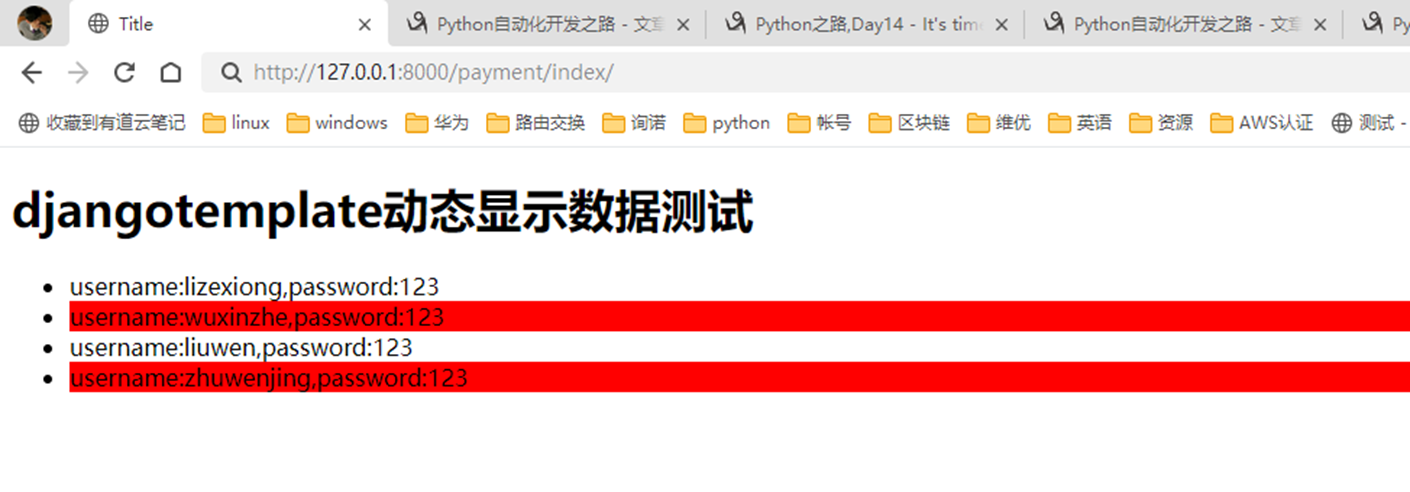
结果
5.最后一个需求,如果需要基础行显示红色,这个怎么做。
View代码都是一样的,这里只贴出html代码
结果
16.8 djangotemplate常用语法学习-这篇内容其实是模版继承
本章主要目的就是让page1.html来继承index.html,来看看继承效果
1.创建url。
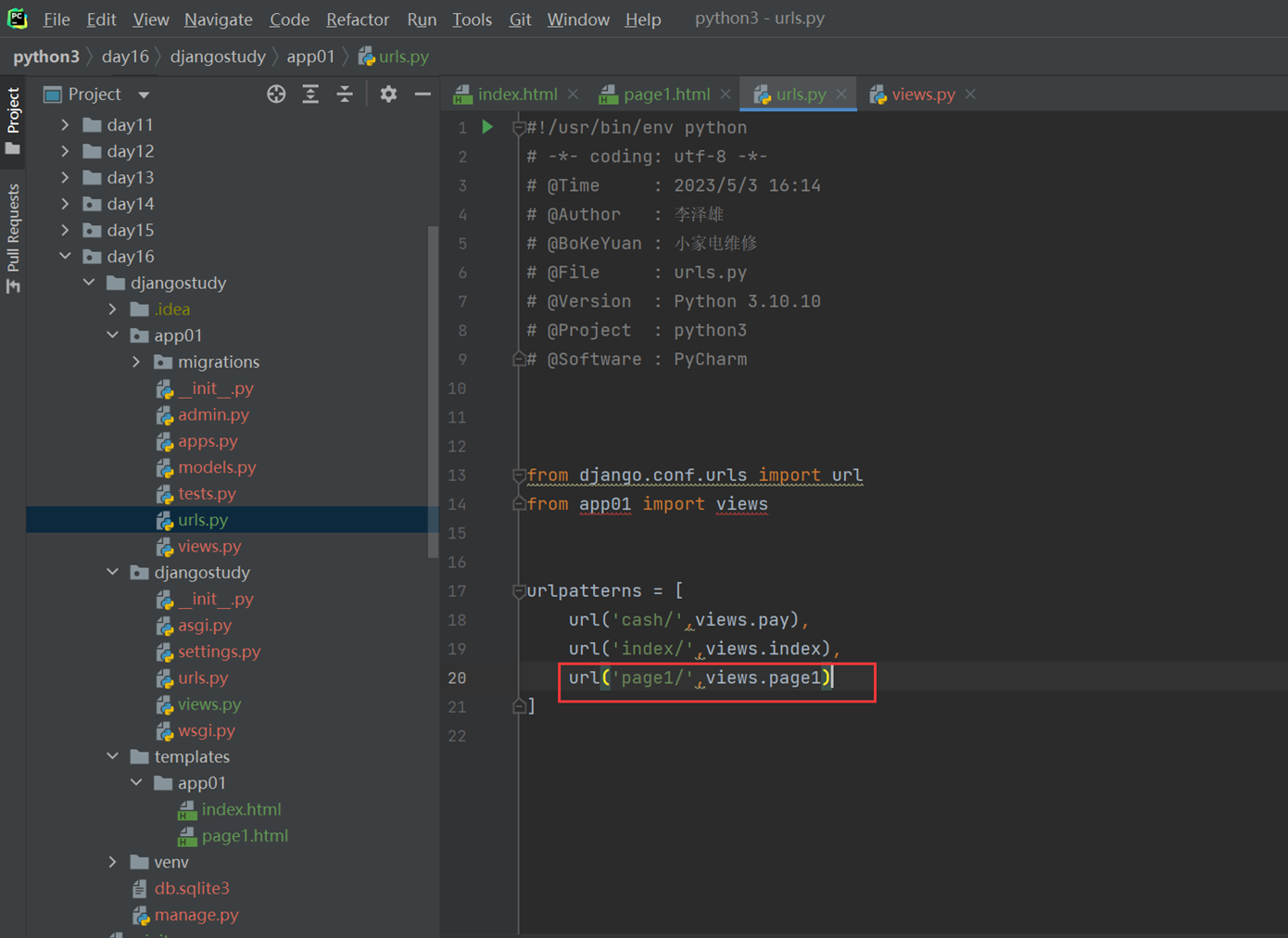
2.创建views处理函数。
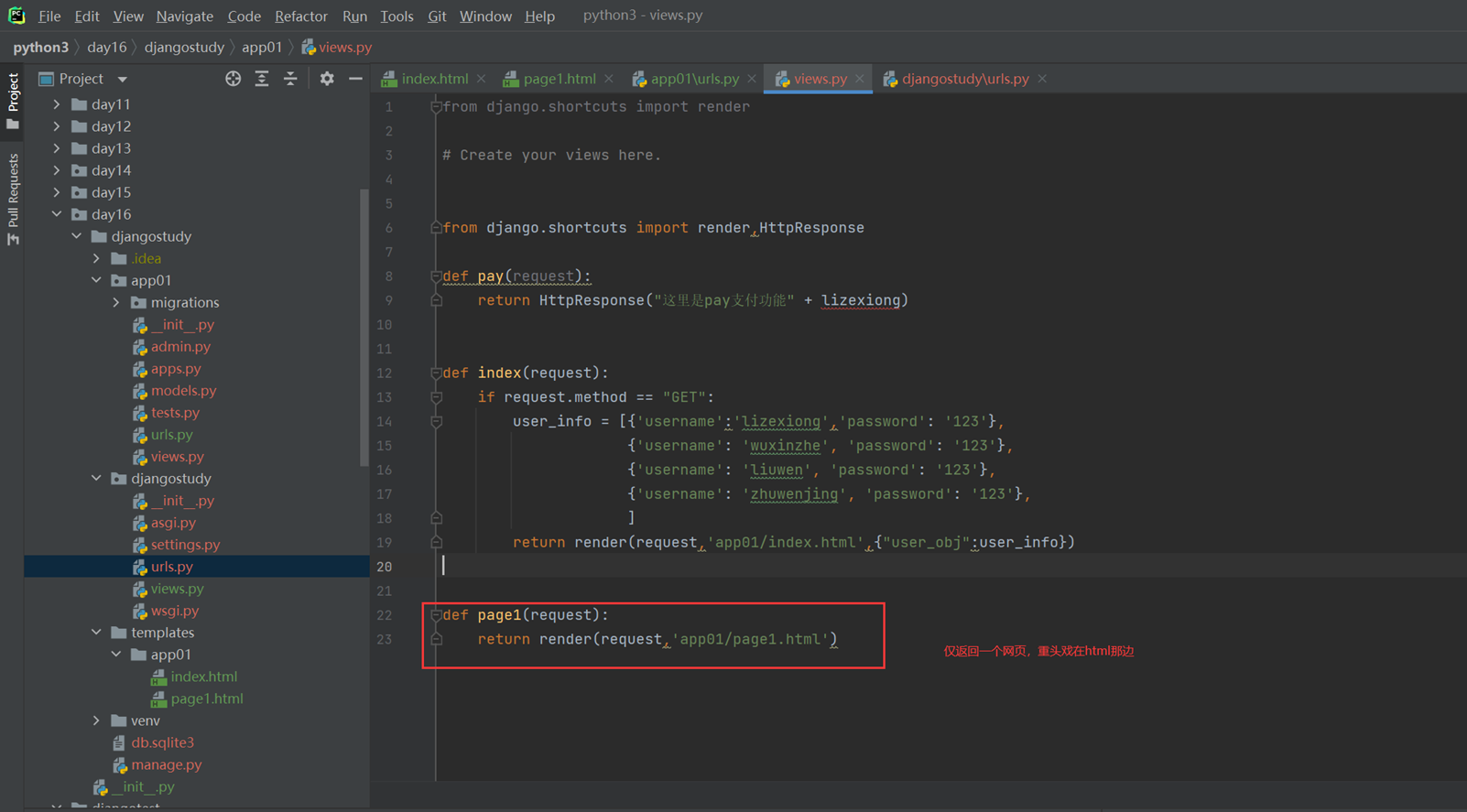
3.html继承
首先查看父页面,也就是index的内容。
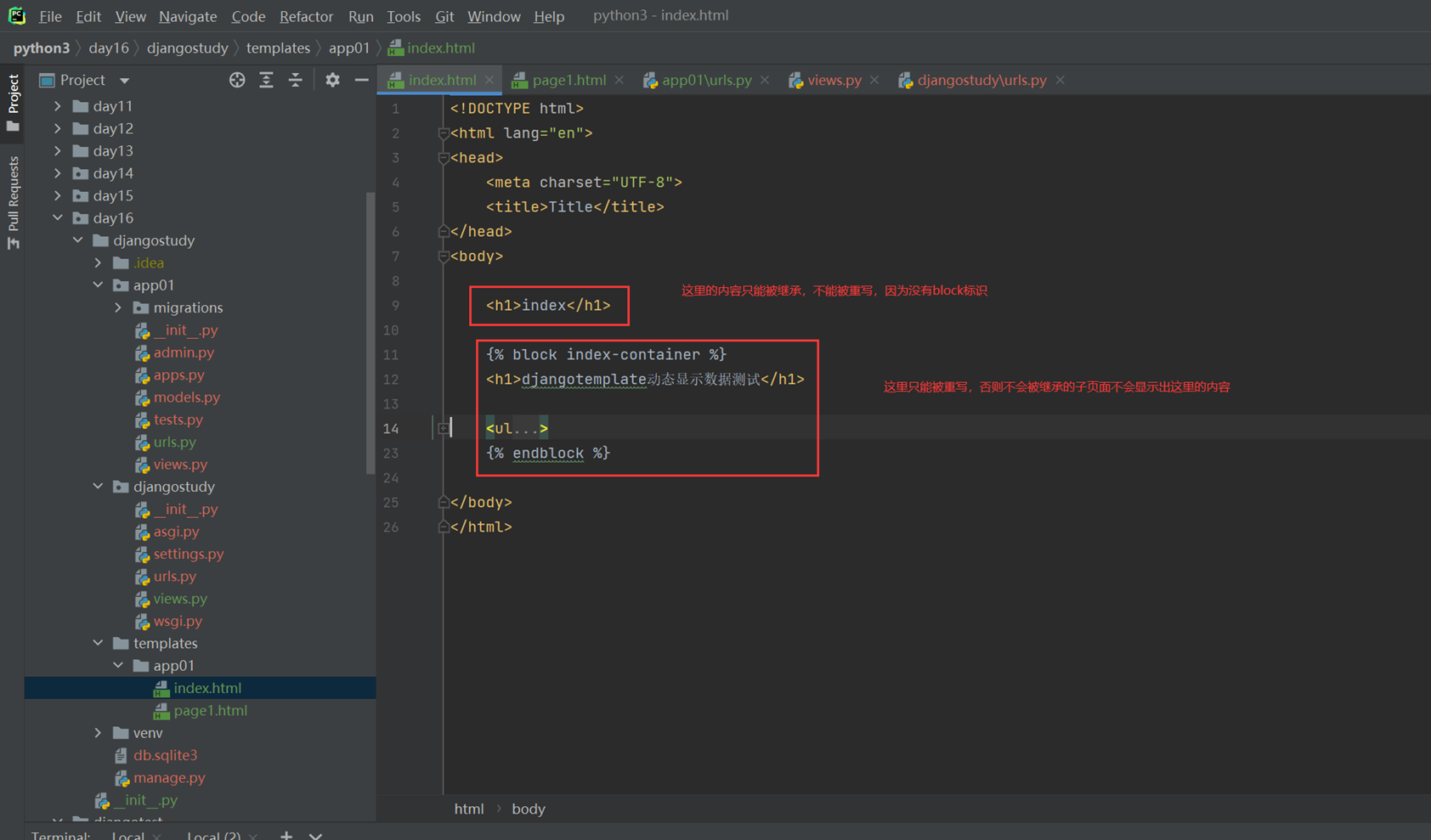
看看page的内容
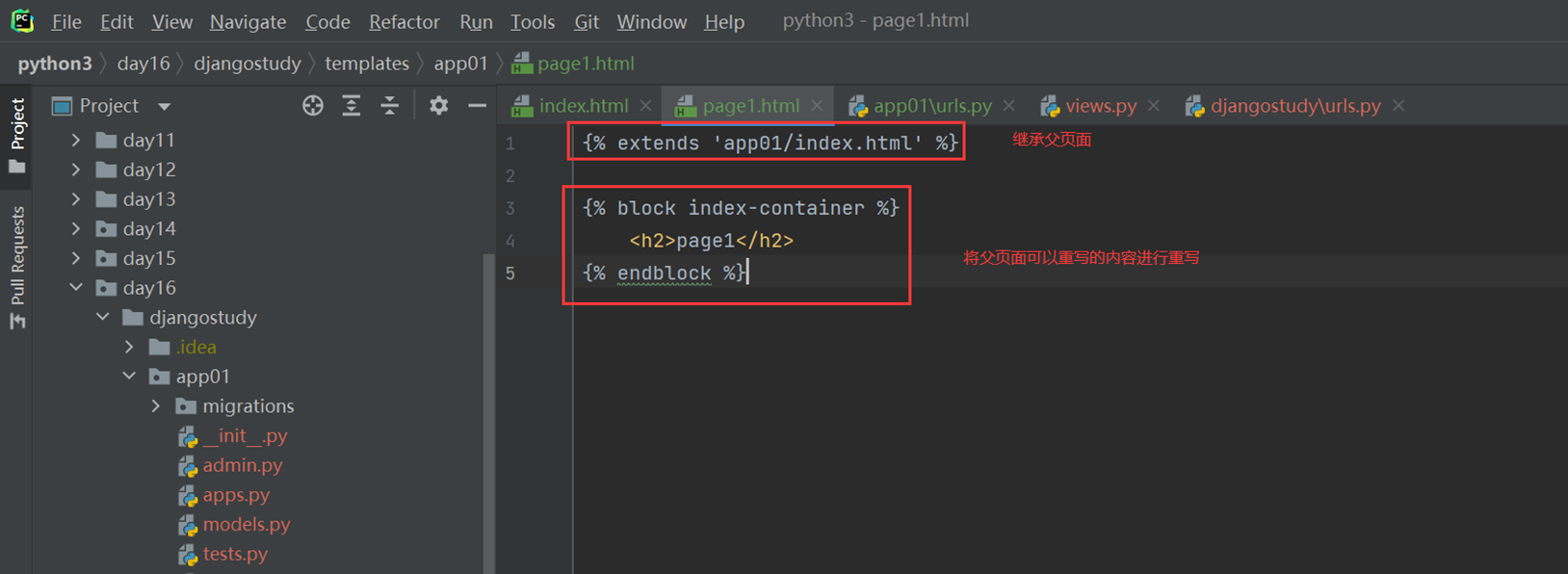
4.查看结果
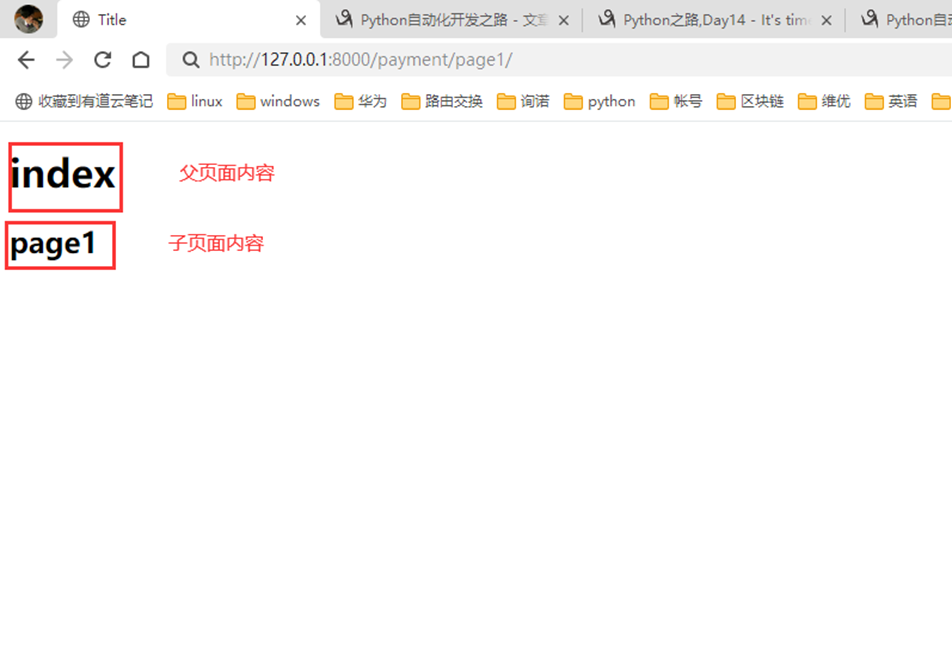
16.9 djangotemplate模版继承和复用
现在在上一节的基础上加强需求和练习。
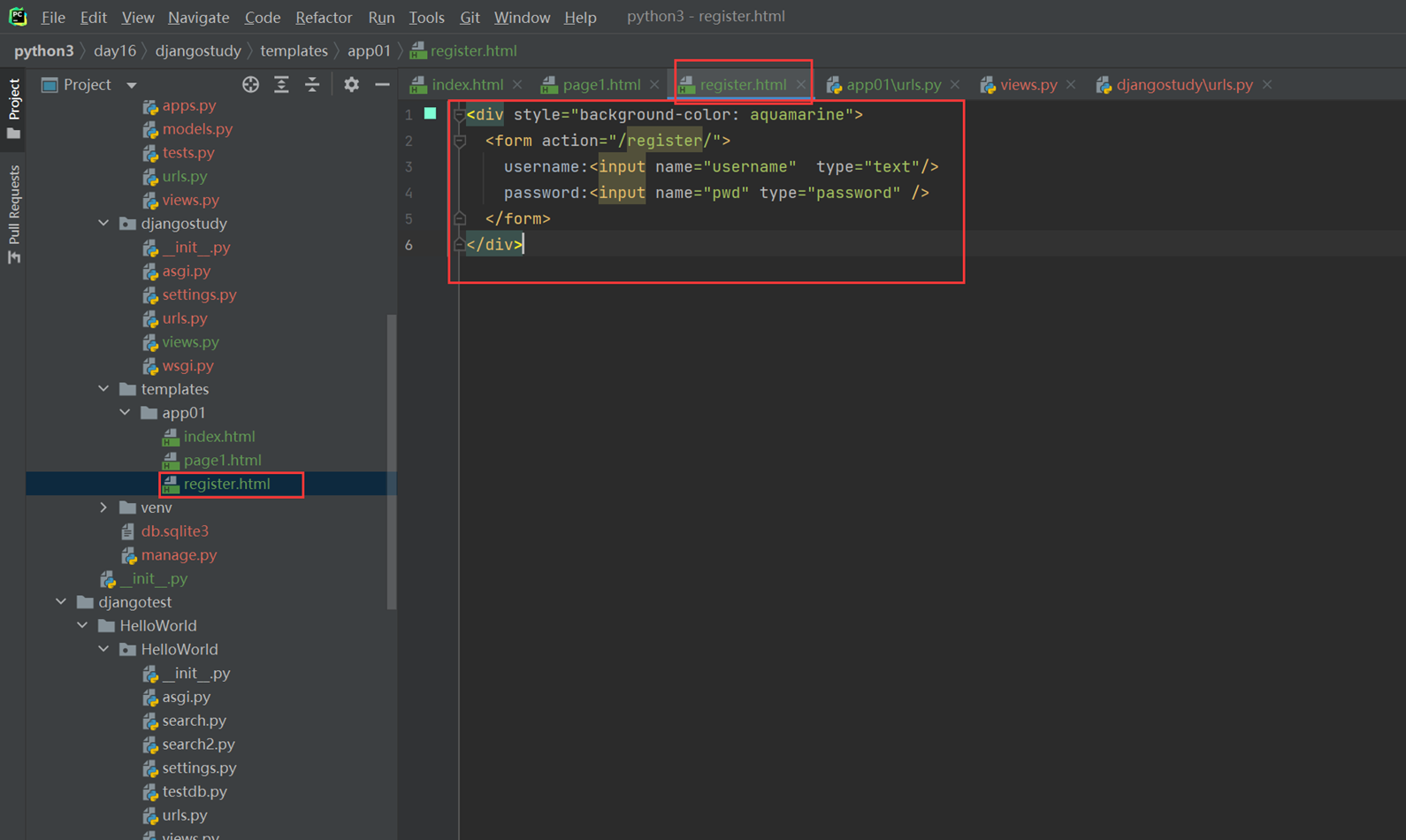
1.如果,现在有一个register的form表单的单独的功能网页,怎么导入进来
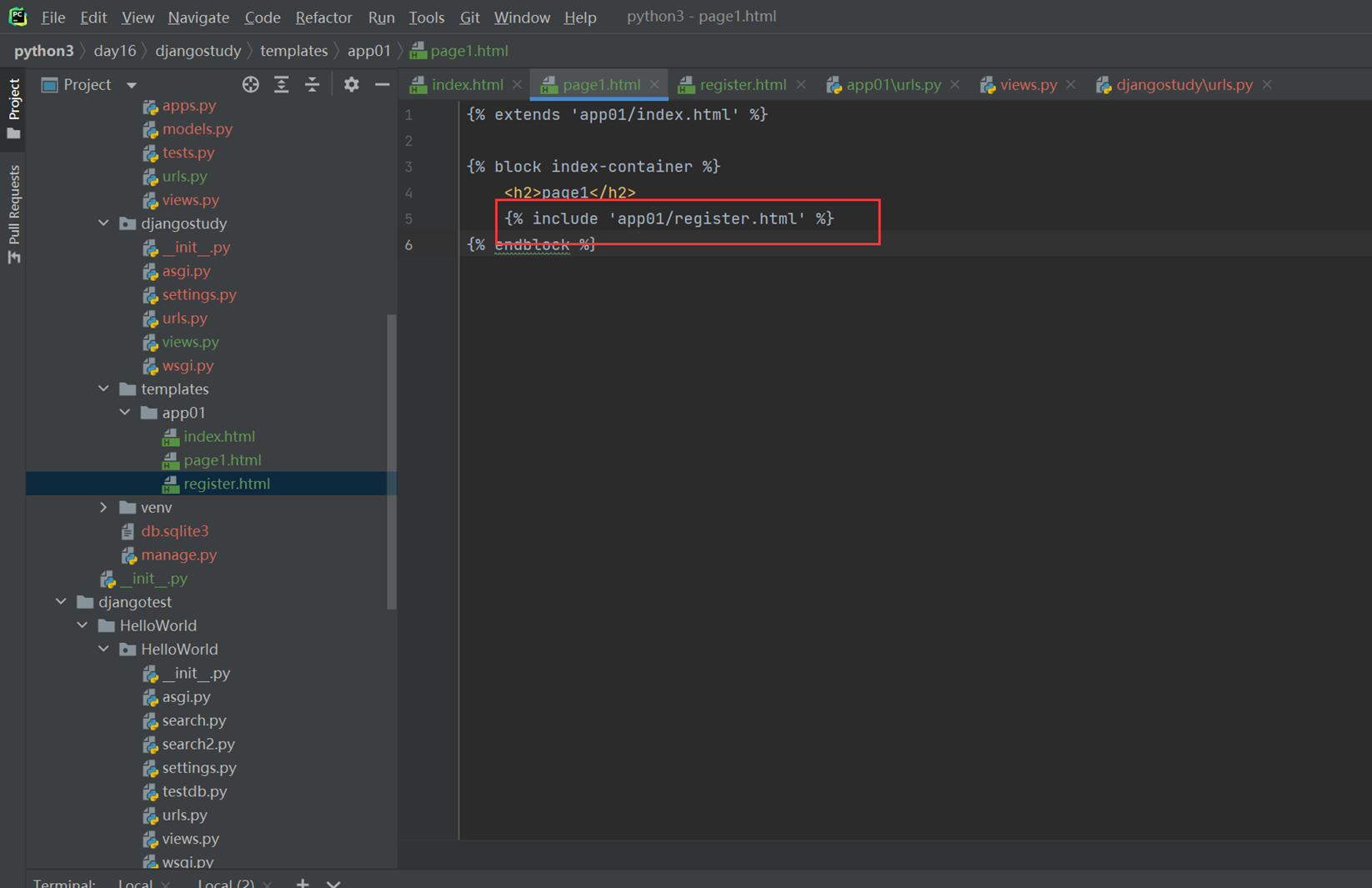
register网页
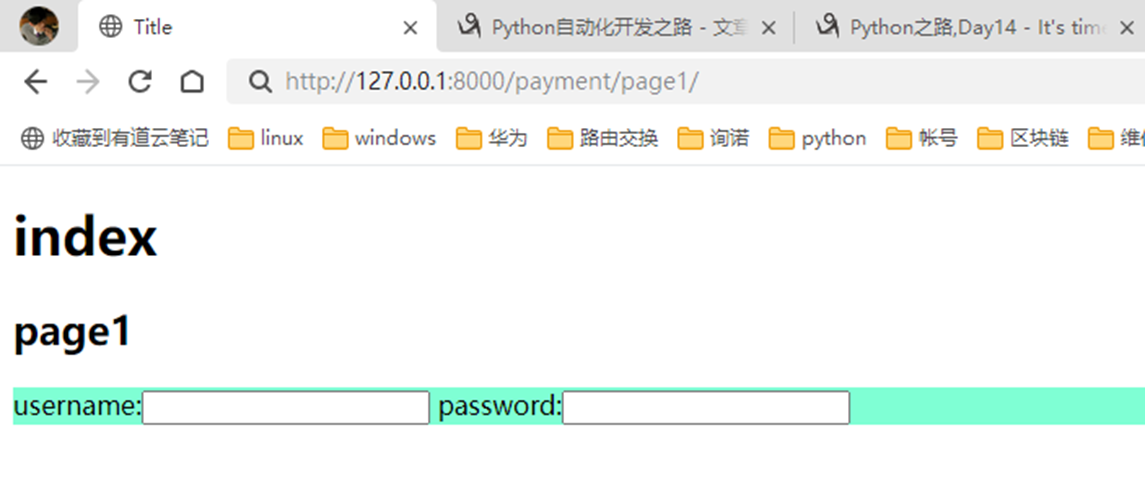
Page界面导入
访问查看
那么index父页面能不能导入呢?
可以看到,父页面不管是block里面的还是外面的,也可以继承,这里还是用page的方式访问的,使用urlindex访问结果也差不多
2.现在又来了一个新需求,再来个孙子界面,能继承page1和index的内容吗?
首先在创建个第三级的url。
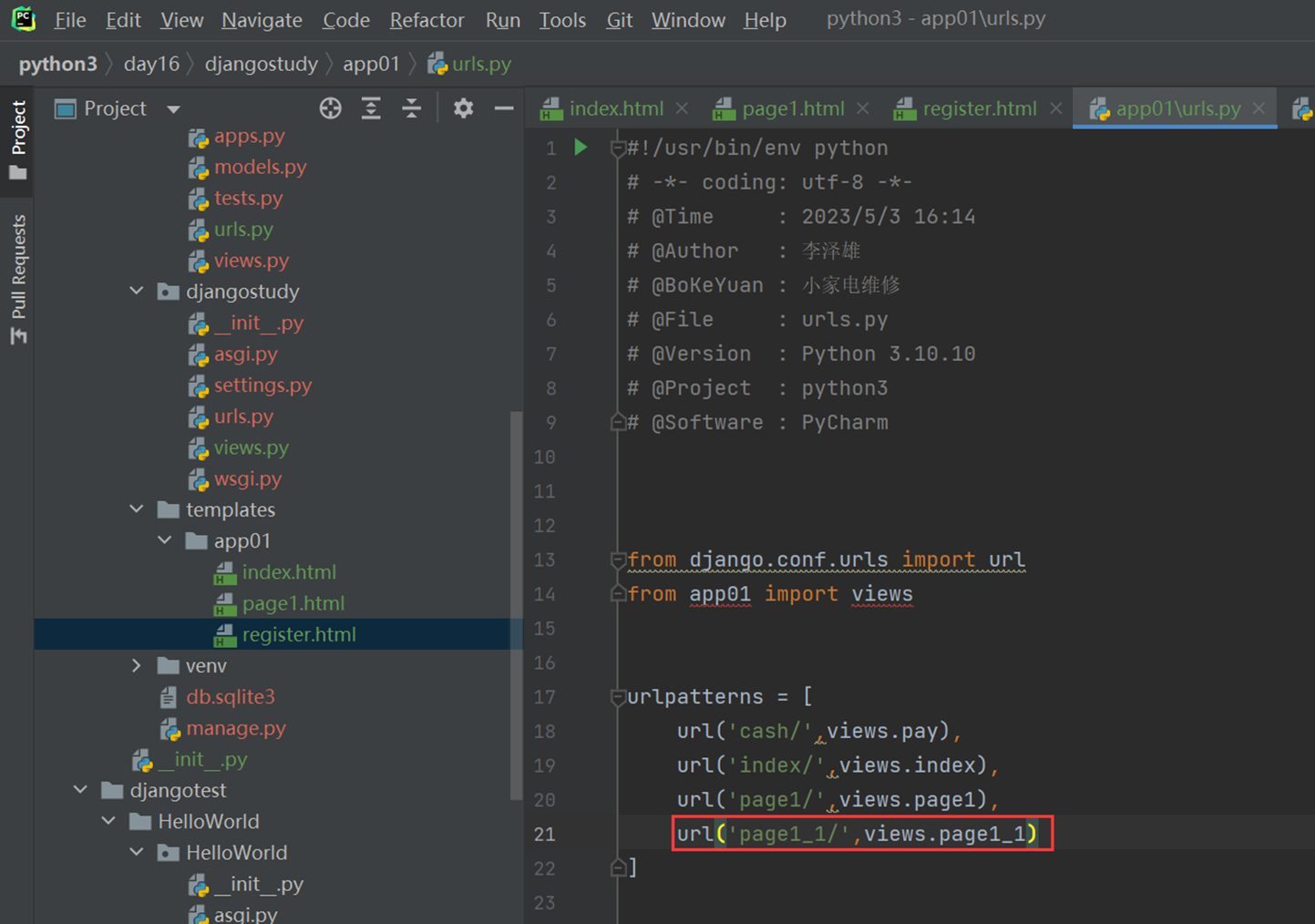
views
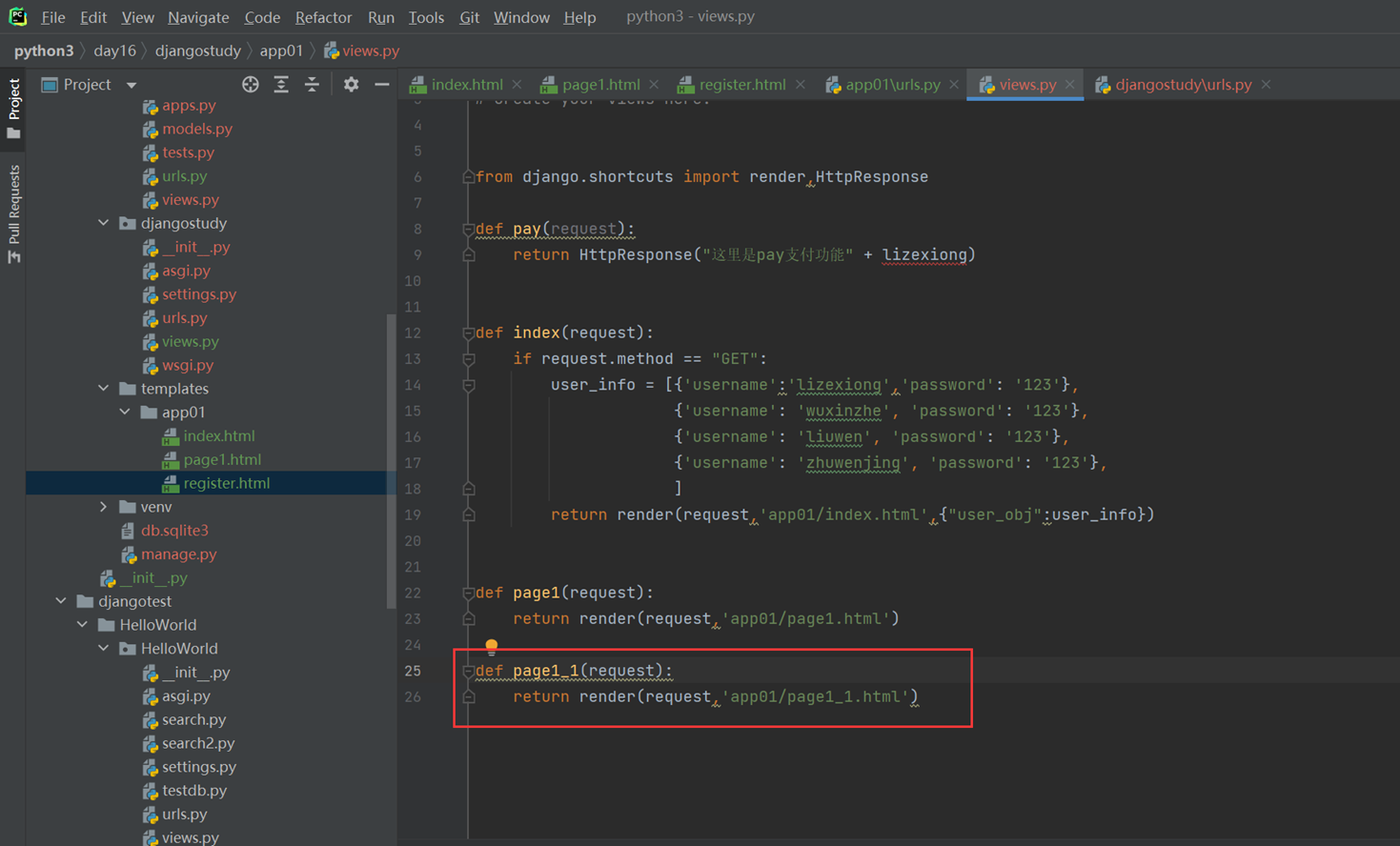
测试一下page1_1继承page1的内容
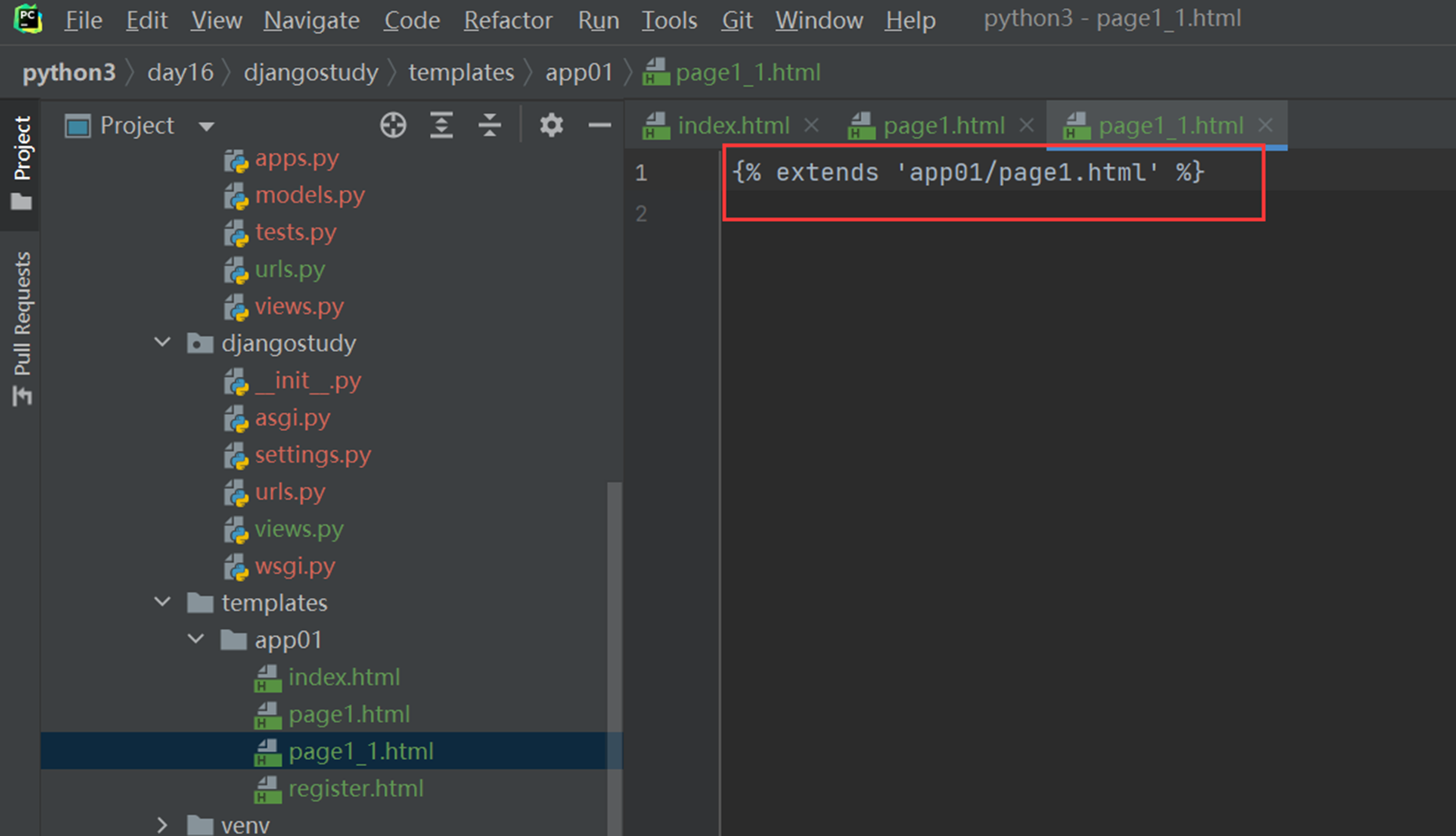
现在测试一下,page1_1单独继承他爷爷的内容可否
现在测试一下单独继承他父亲的,首先,父亲里面得有一个block。
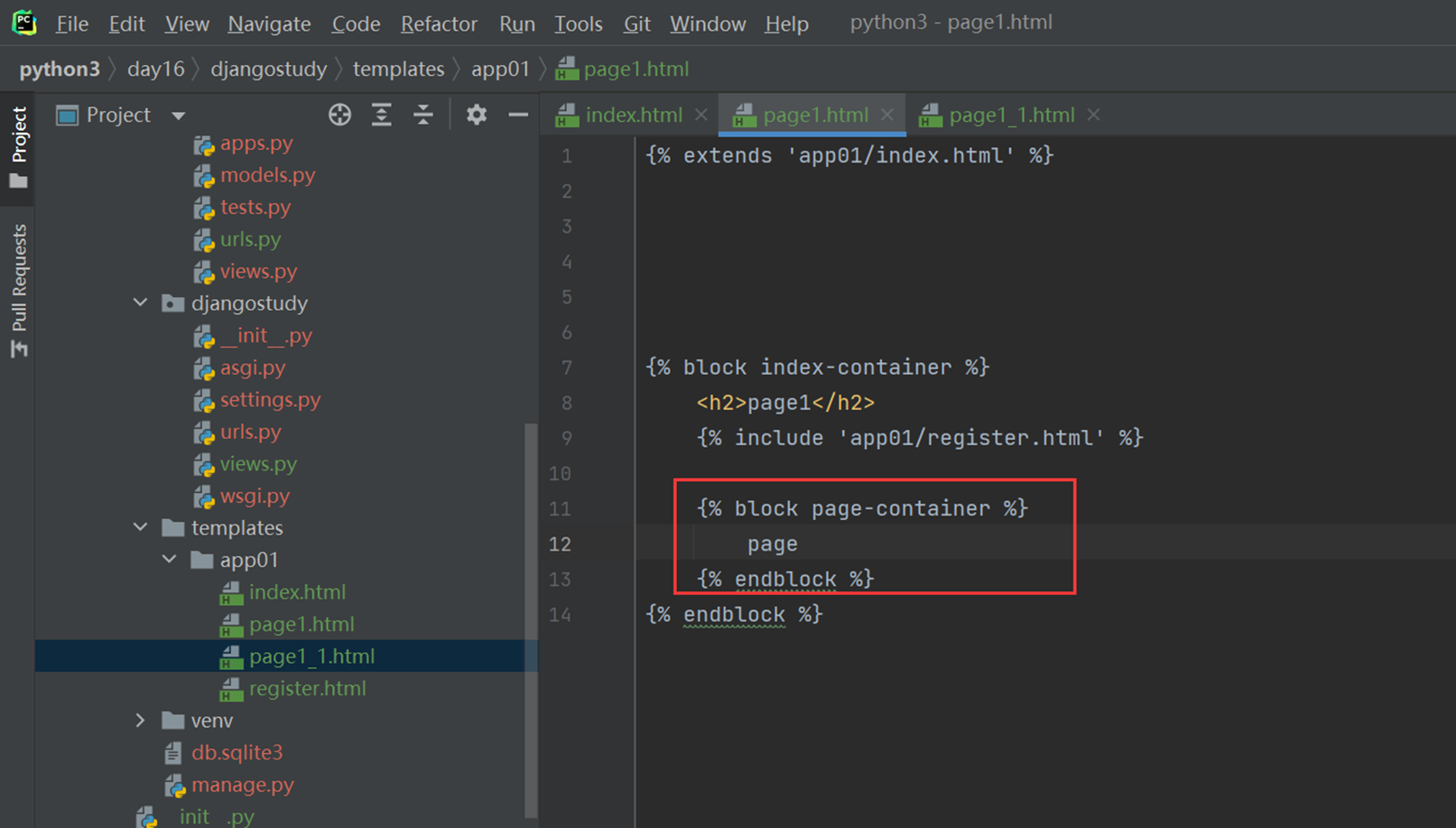
现在page1_1继承
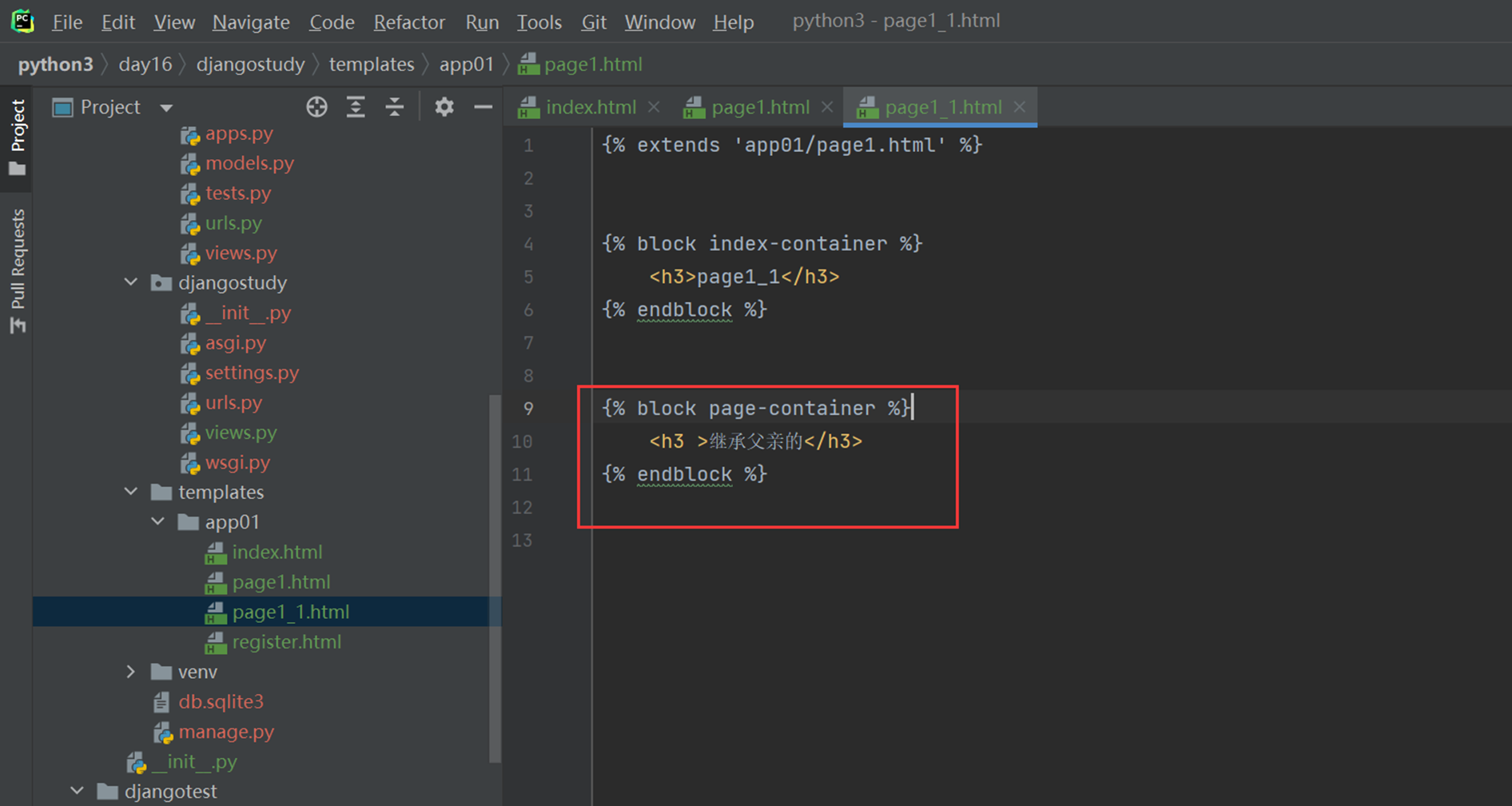
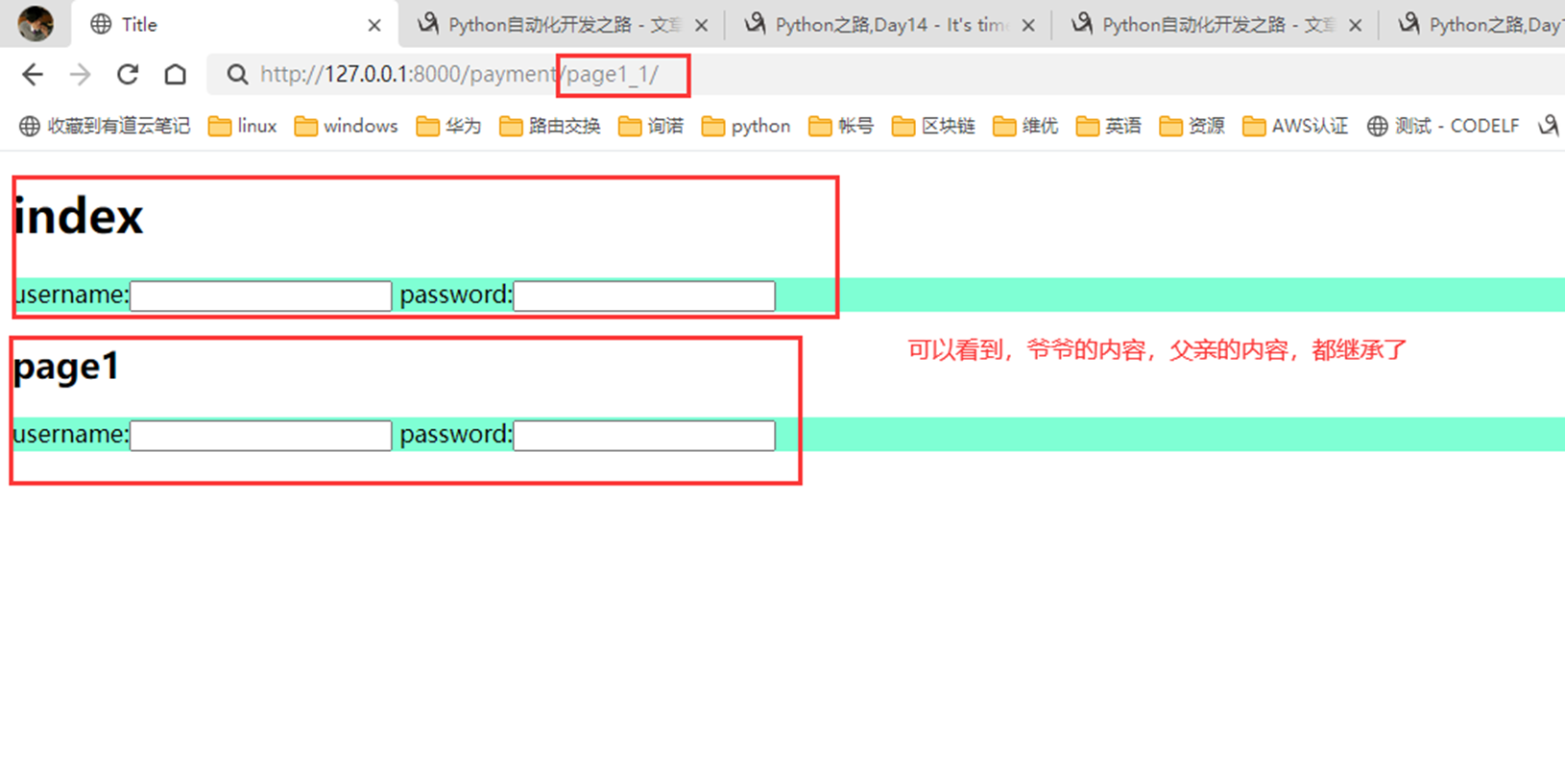
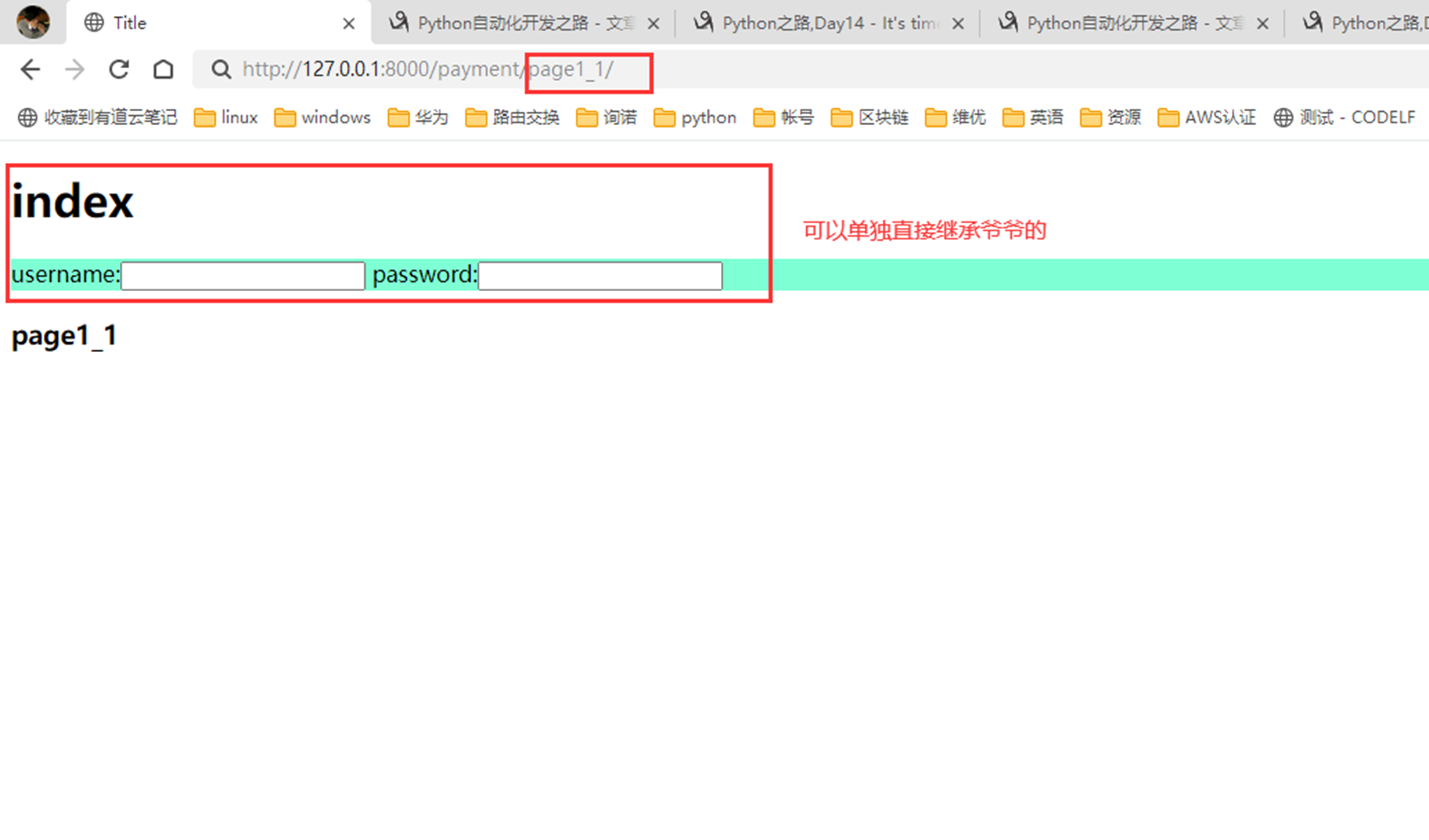
访问
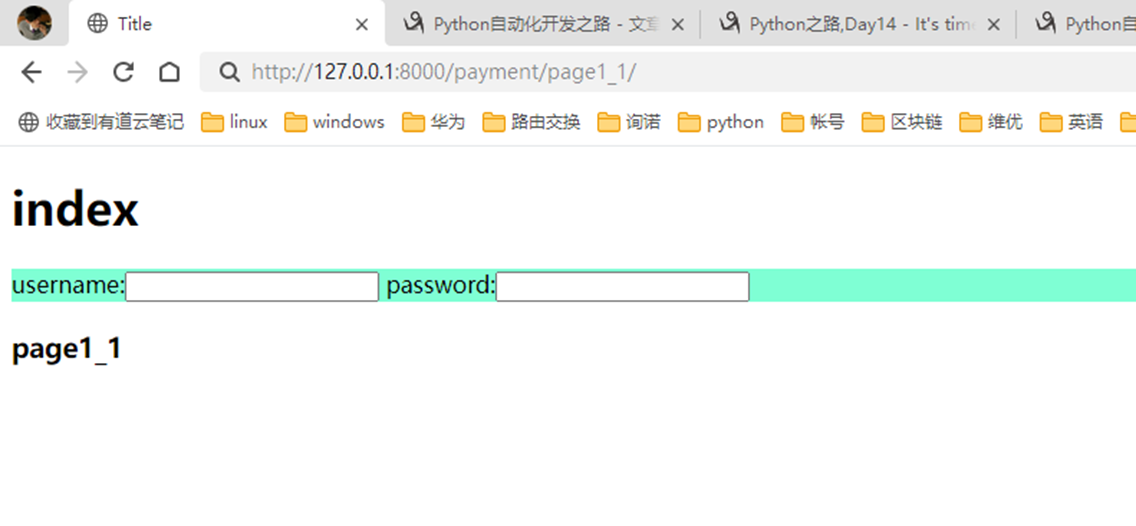
没有继承,因为已经继承了父亲的,父亲的已经改写了,所以没有成功。除非直接集成爷爷的。嵌套集成,只能继承自己最近的一级的,也就是page1.html爸爸的。
本节课最后一个实验不用做,后面我自己理了一下,这sb老师把自己绕晕了,这需求基本就是跟前面做的是相同的,就是嵌套了一下讲解,不用管。
注意:同时继承2个模版,会报错,只能继承一个。
16.10 django配置使用数据库
本章节就是简单讲解了settings的每一行配置的含义和配置连接mysql的方式。这里仅列出连接mysql的方式。

16.11 djangoorm常用语法
本章就是一个目的,按照步骤给演示一步一步创建数据库,并且可以在django的admin后台就行管理。下面一步一步按照步骤来演示。
1.在settings里面配置项目信息,不然后面数据库创建好了之后无法找到关联,会报错。

2.配置django连接mysql数据库
首先需要在mysql里面手动创建要连接的数据库。
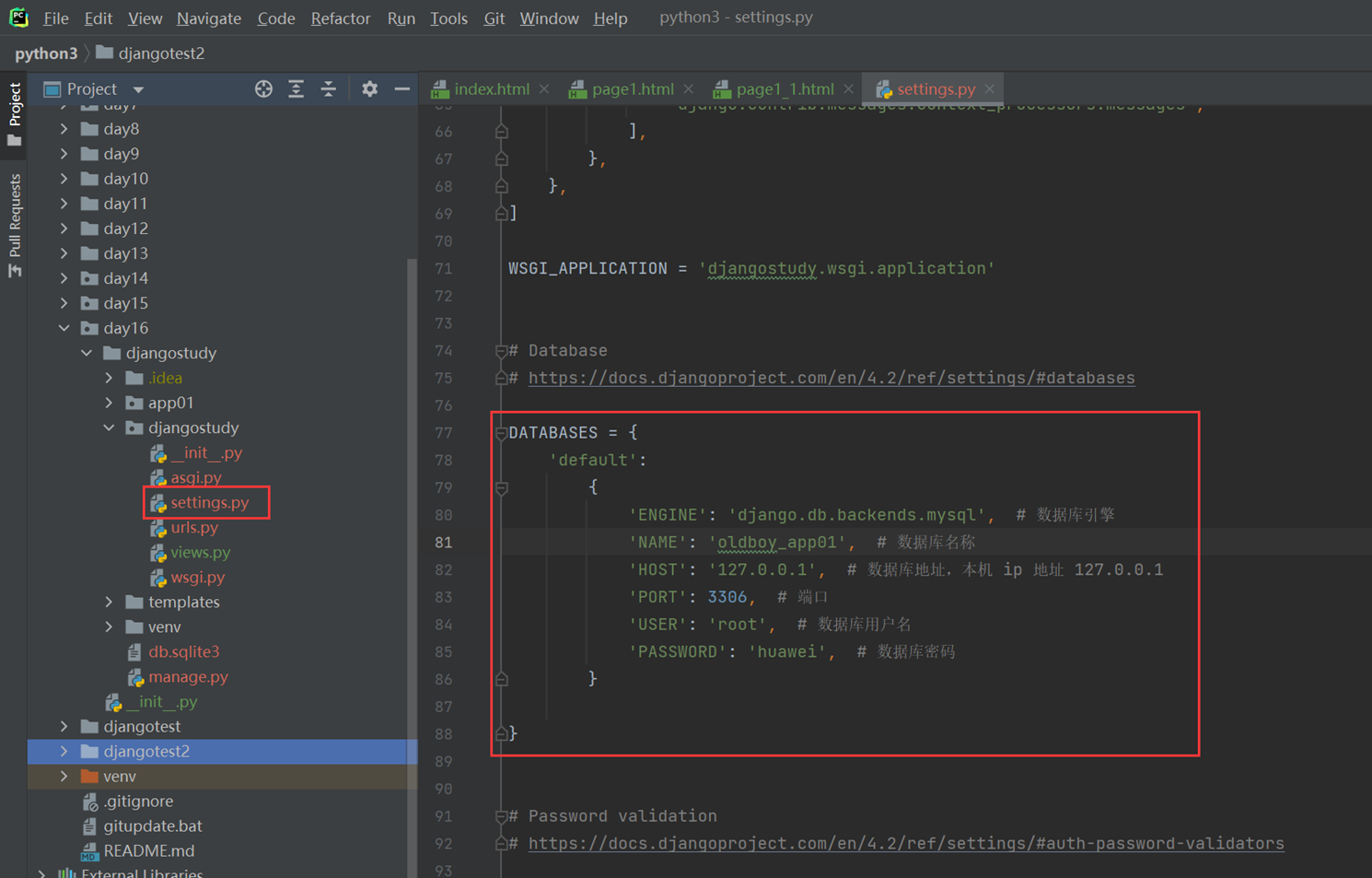
3.写数据库表结构
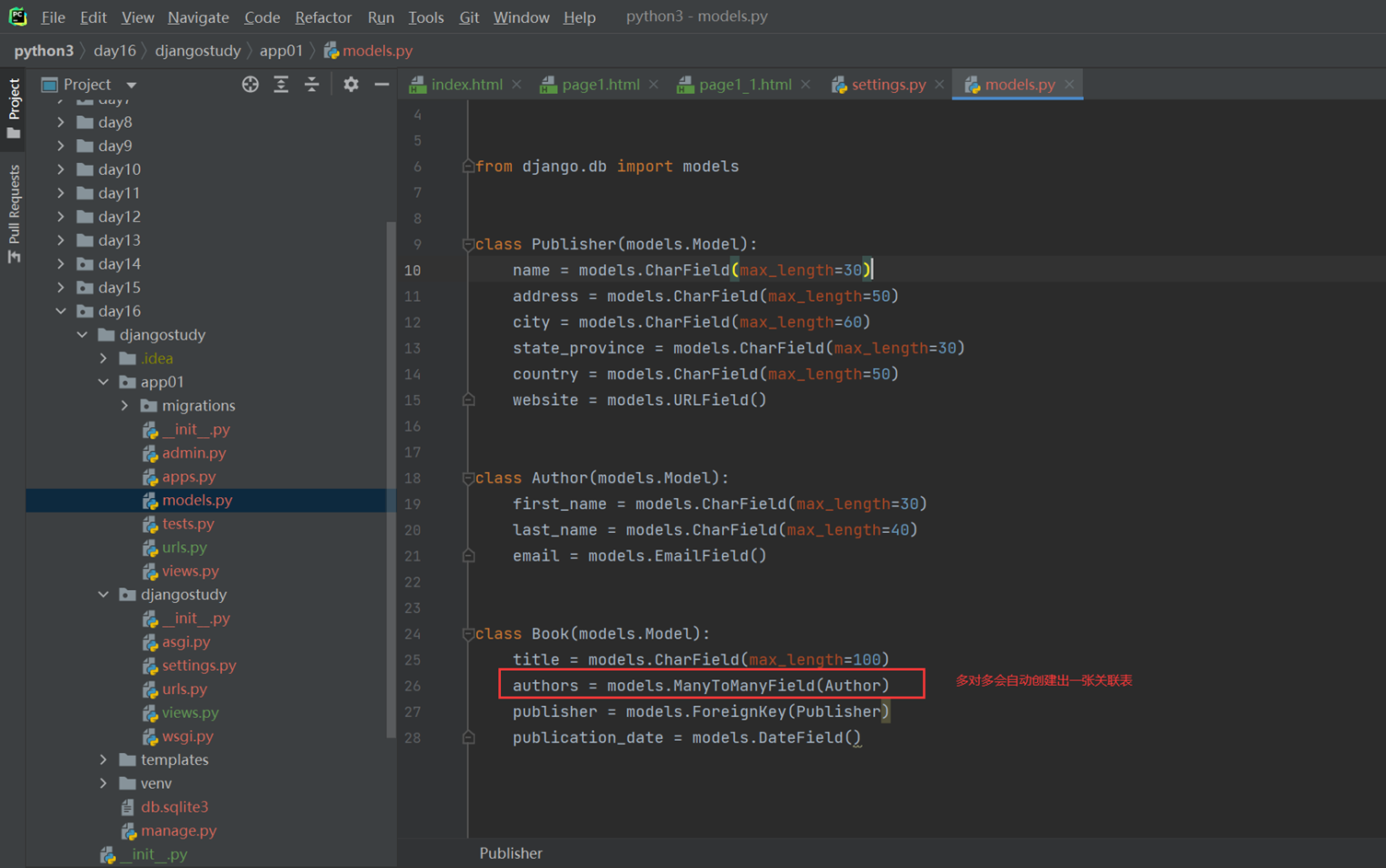
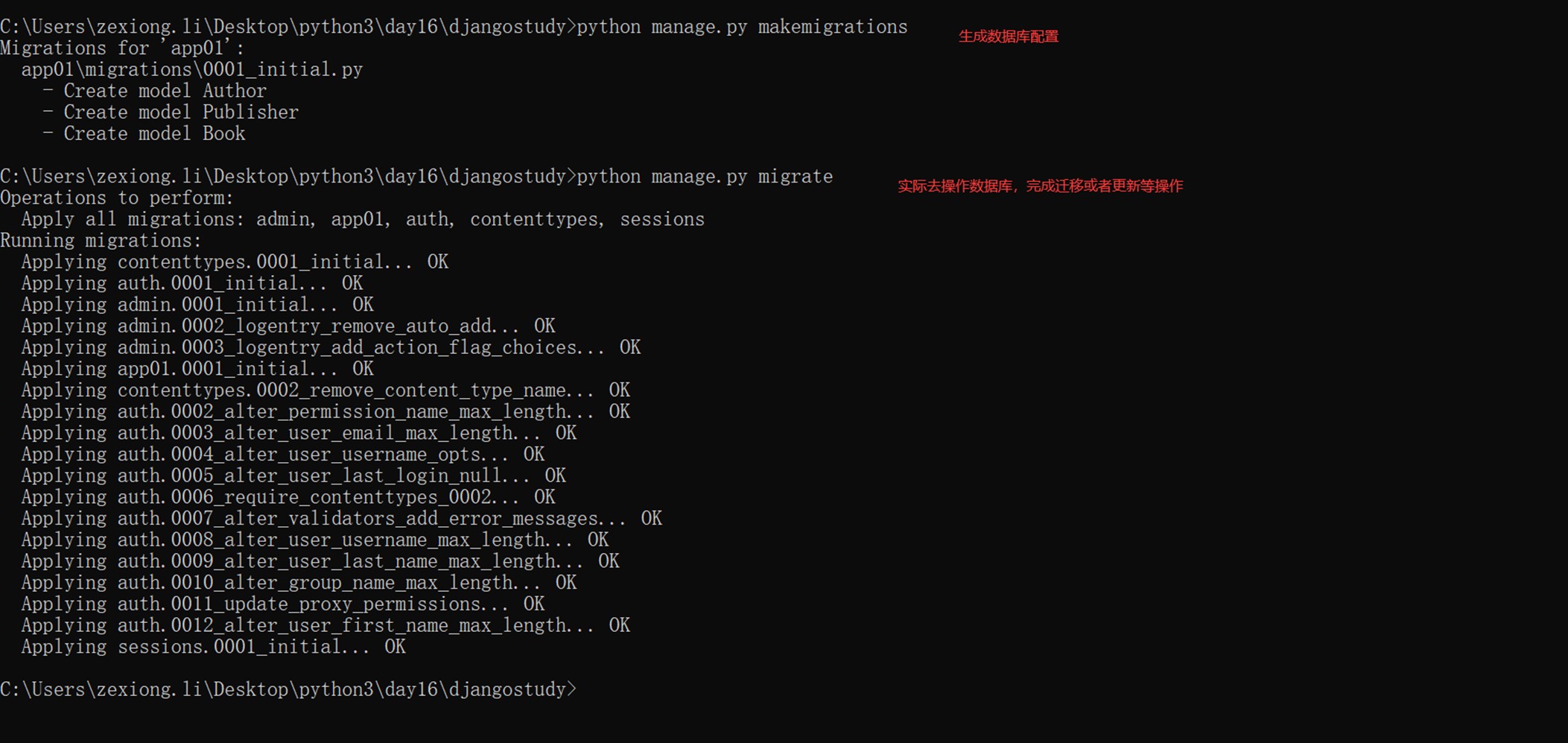
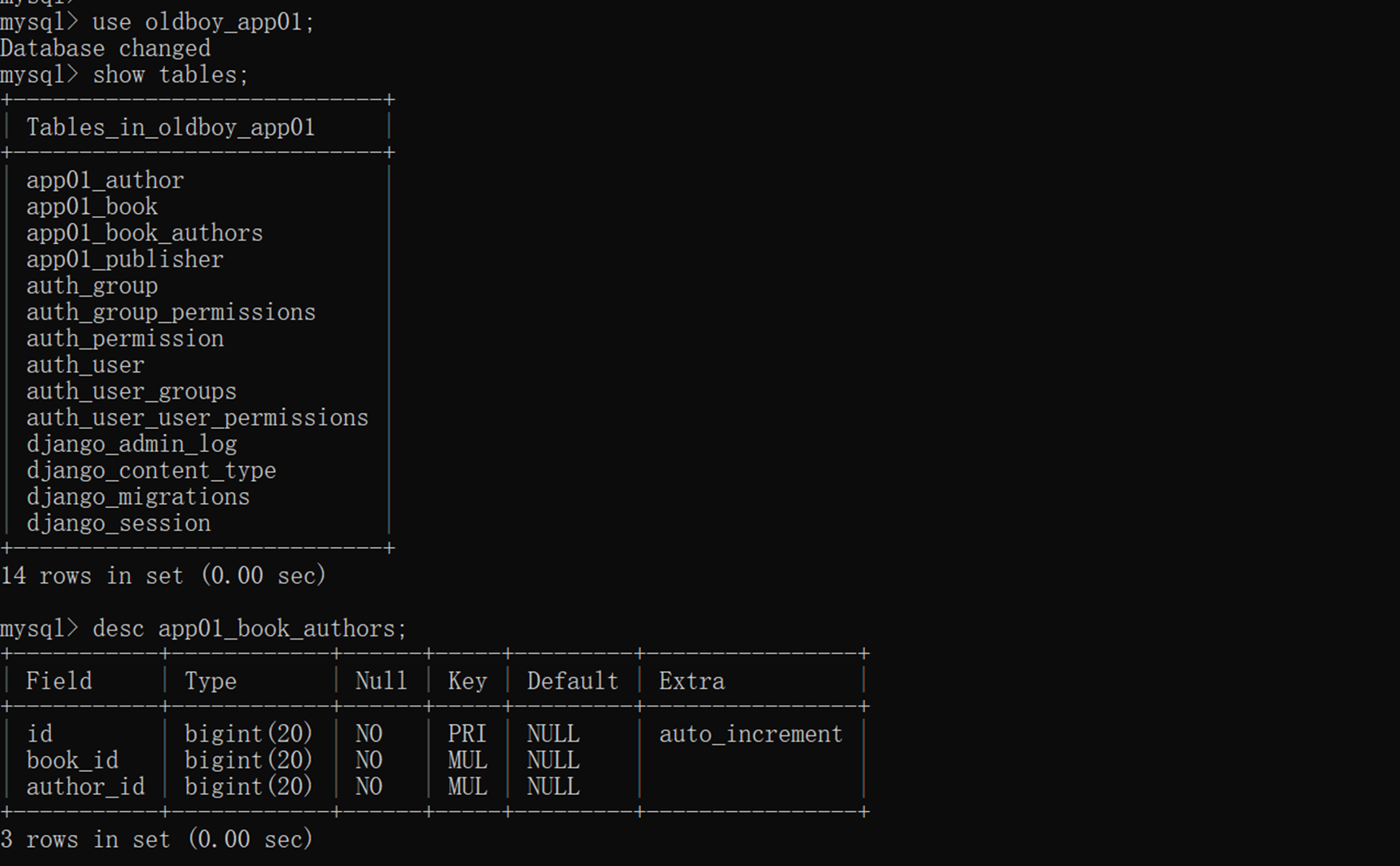
4.生成数据库配置然后生成数据库表结构
查看一下数据库,是不是创建了4张表?因为有一张多对多的关联表会自动创建。
5.django后台管理表前置操作。
6.创建django超级用户。

7.启动django服务器,访问django管理后台查看
启动
访问
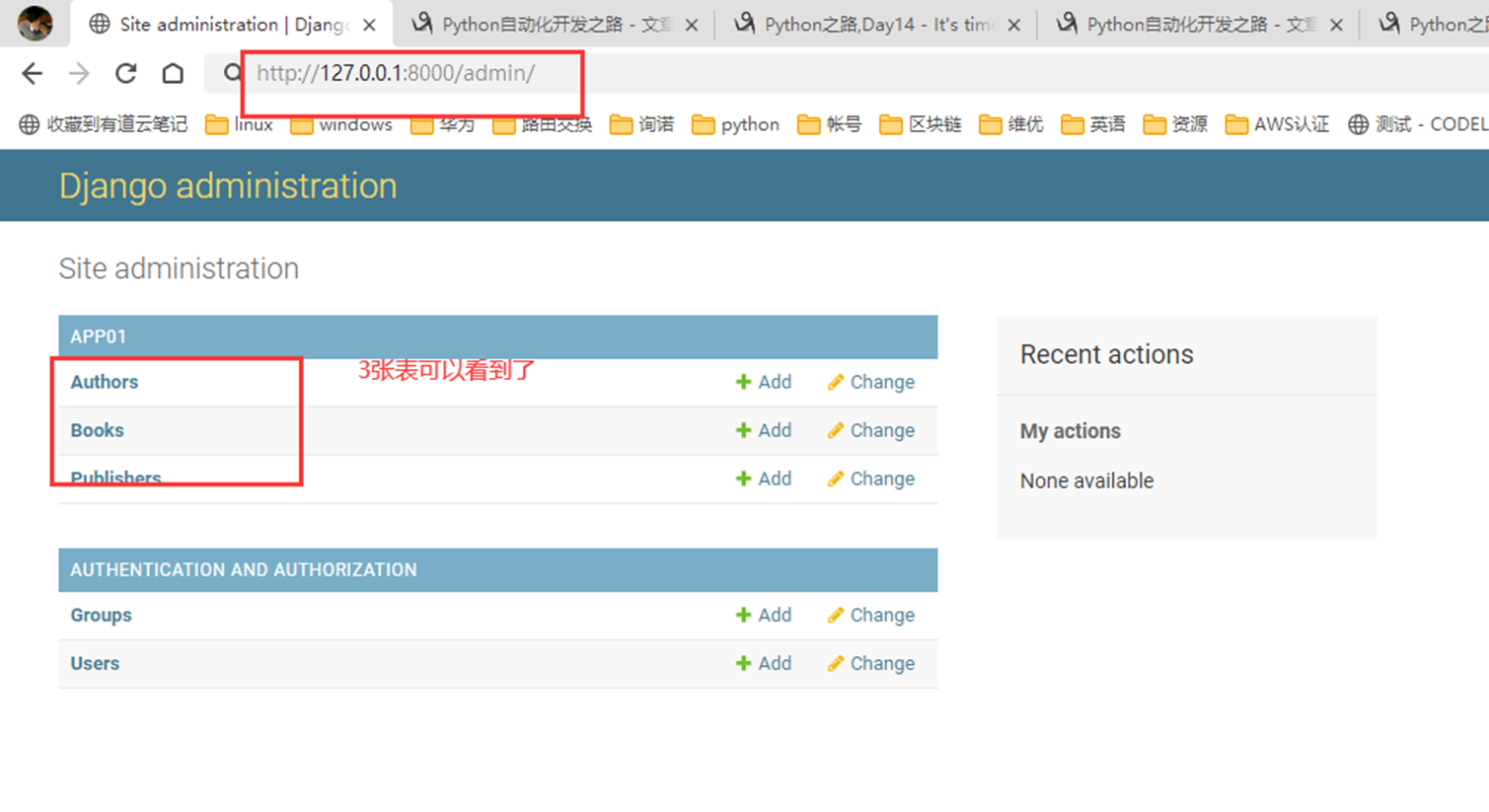
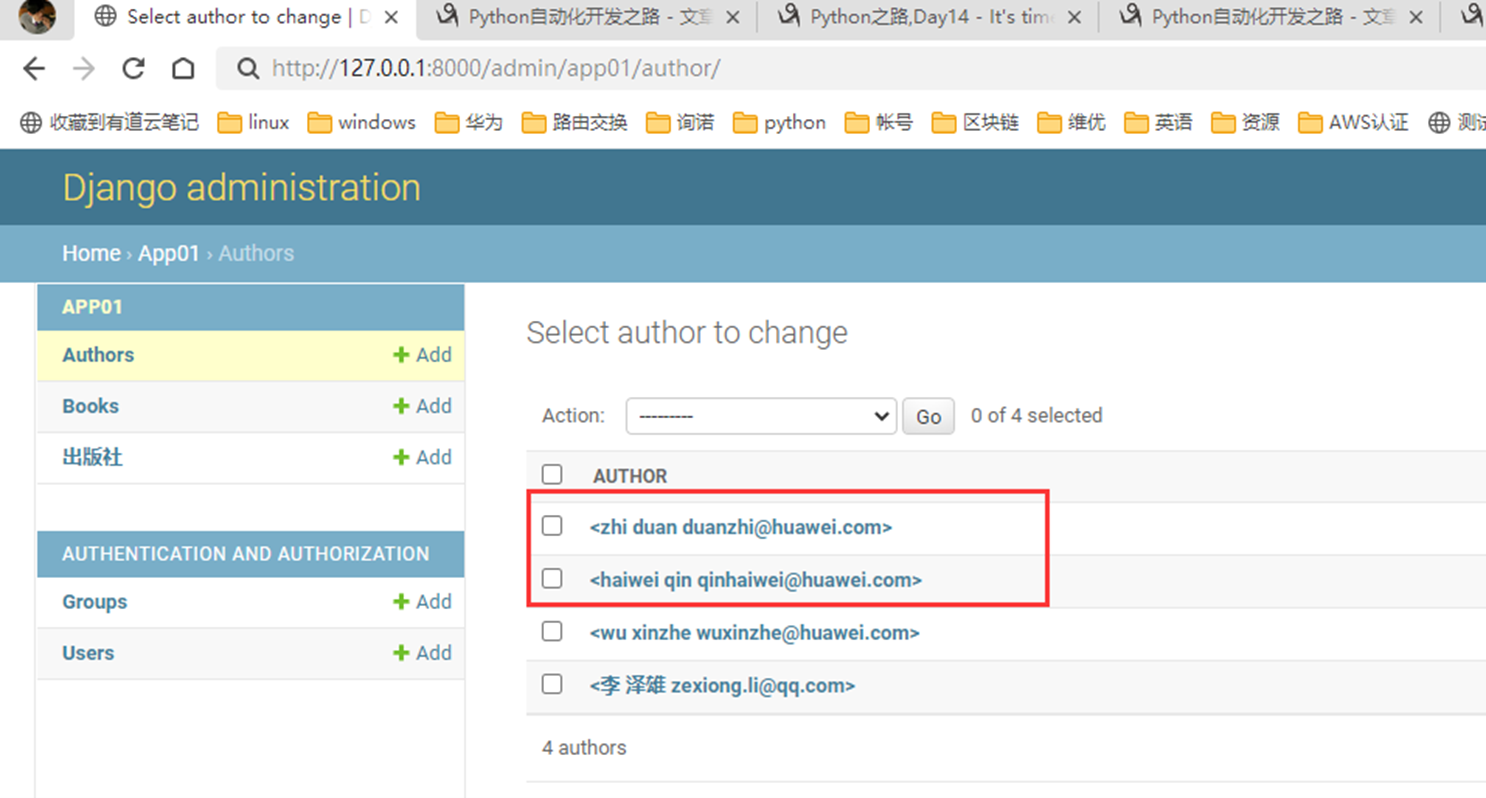
8.尝试添加“作者”记录试试看。
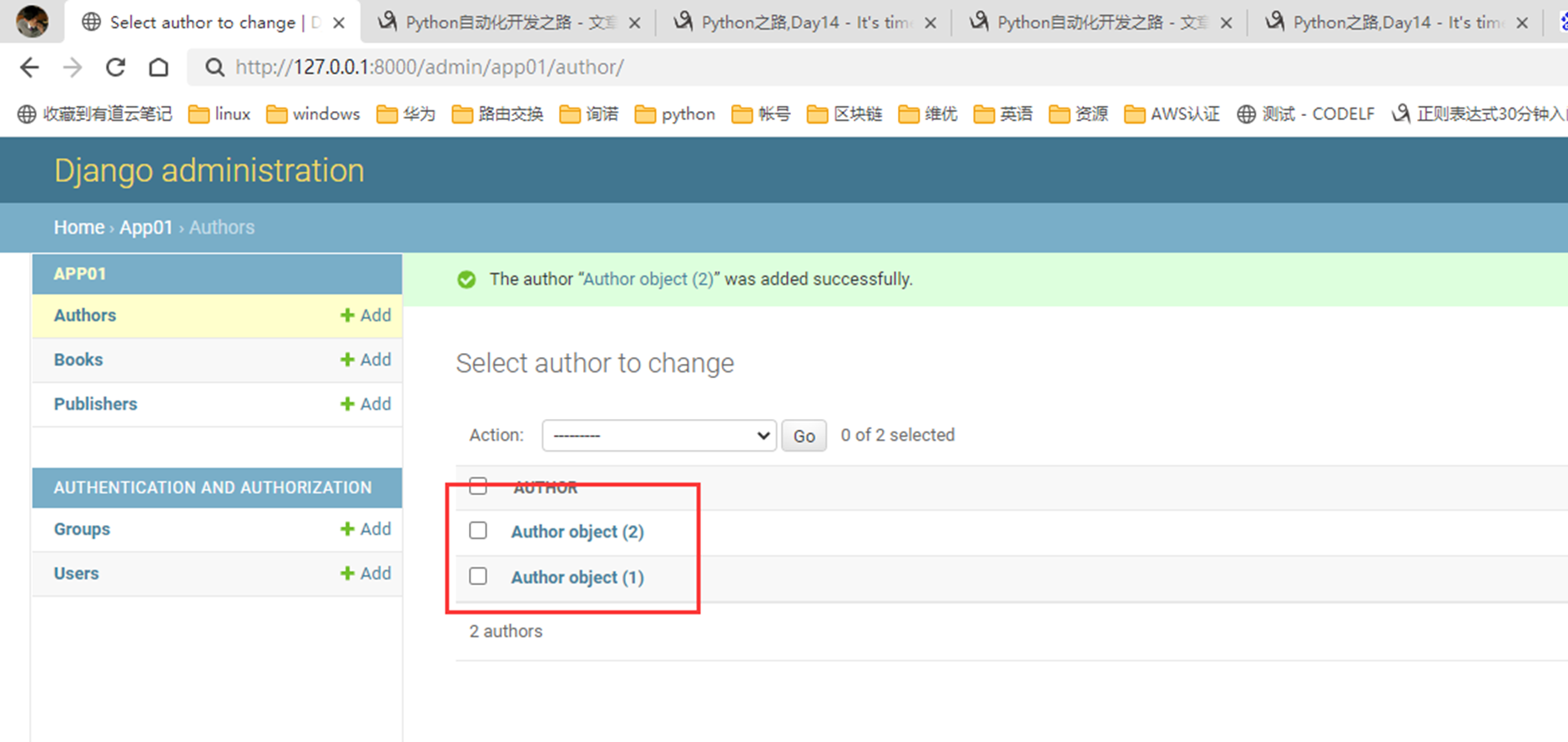
添加了2条记录,但是可以看到,显示并不友好,所以这里,我们来优化一下。
课堂使用的是django1.7版本,可以这么添加,但是现在是3.2版本,需要另一种方式
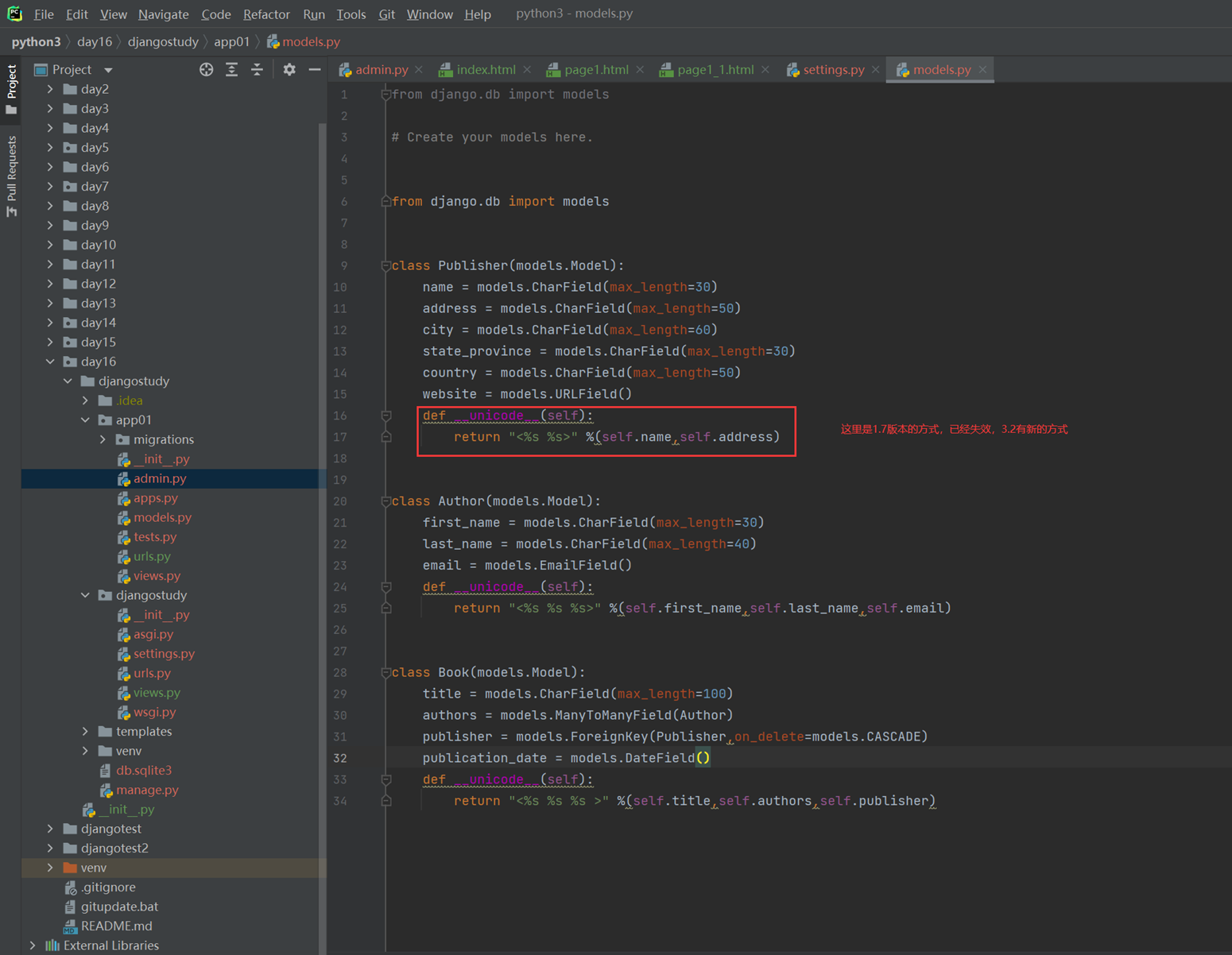
接下来看看python3.2的方式
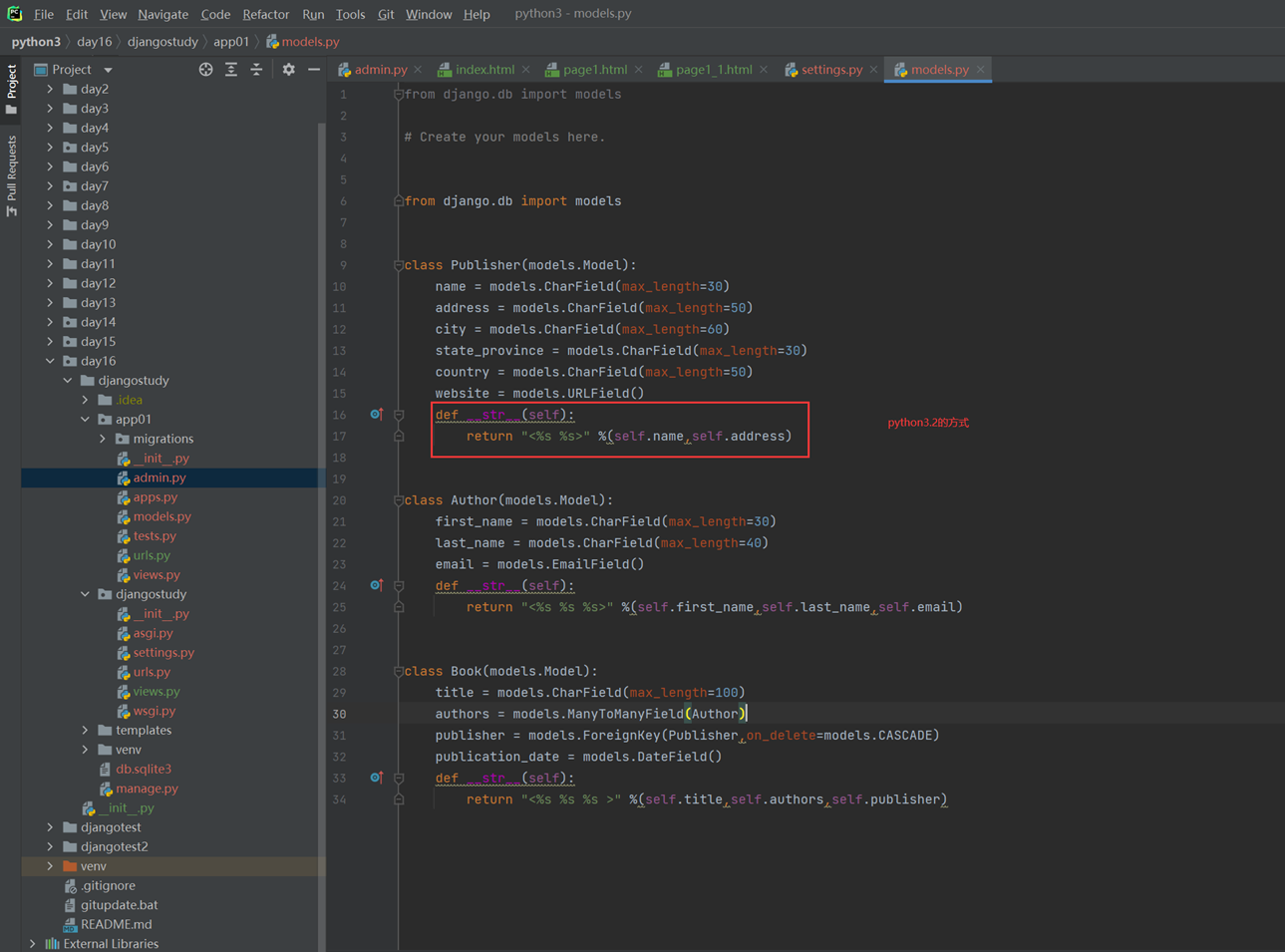
查看结果
这里还有另一种方式:参考博客Django教程的10.6章节。
9.自行添加一些记录
然后在查看一下多对多表是否有数据产生
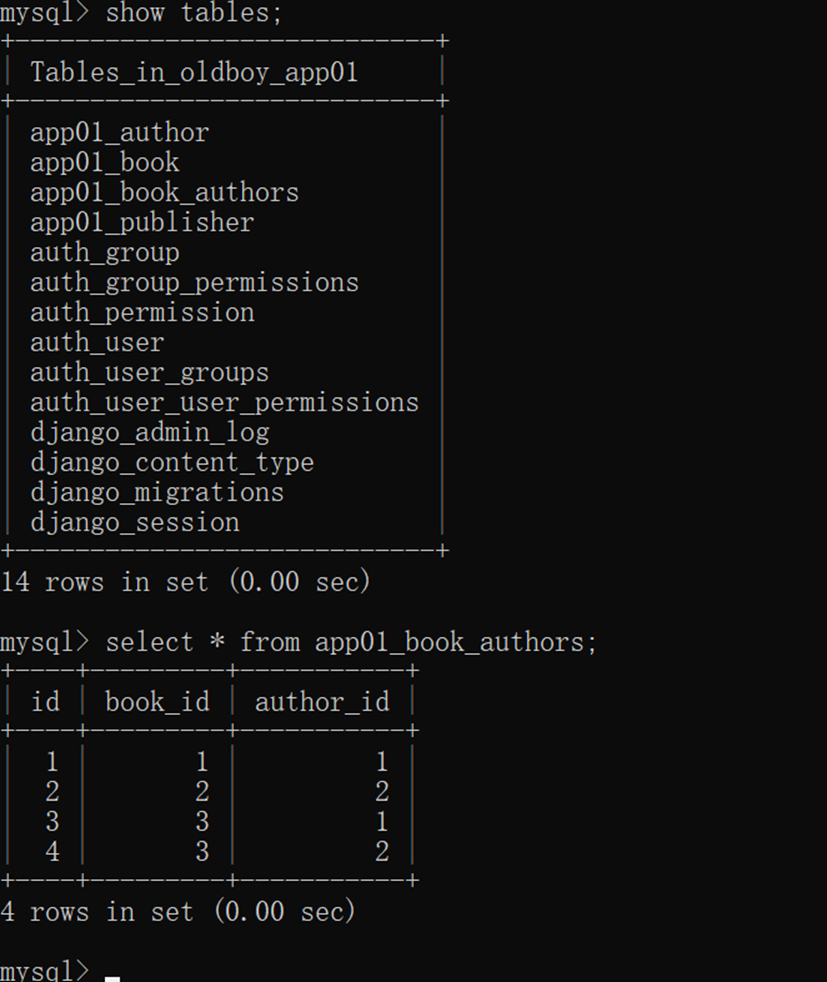
16.12 djangoorm常用字段
本节就是讲解了常用字段,可以参考网址https://docs.djangoproject.com/en/3.2/ref/models/fields/去学习(可能因为版本变动导致网页失效,重新输入版本号就可以显示)
这里还是演示几个常用的玩意。
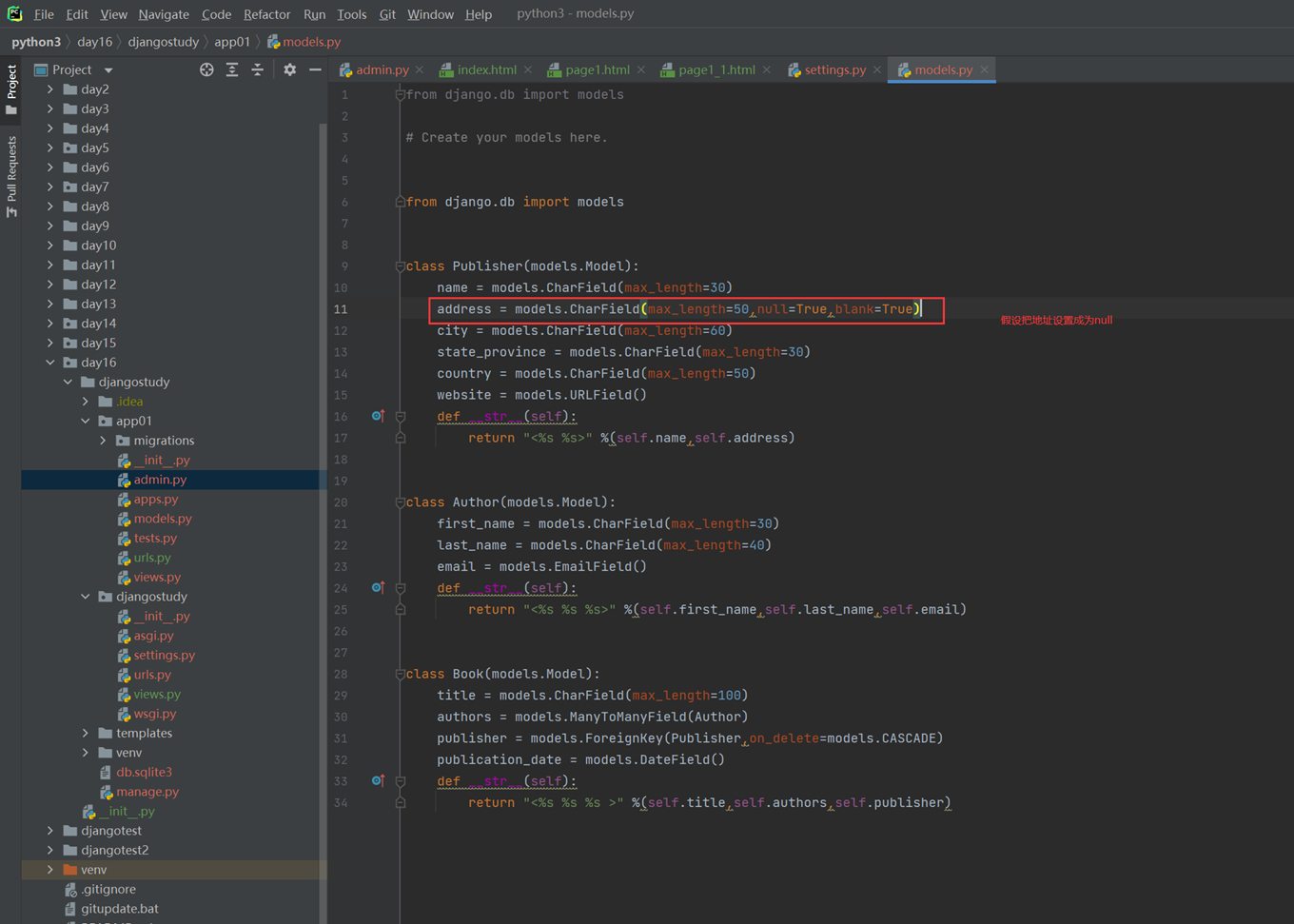
null和blank
为什么这2个参数要一起演示?那是因为
Null是针对数据库字段可以设置null,但是blank是针对django的admin后台来设置的,所以如果在django后台操作数据库并设置成为null,那么需要2个参数都进行设置,如果不使用django,设置null即可(null因为操作数据库,所以需要重新生成表结构。)

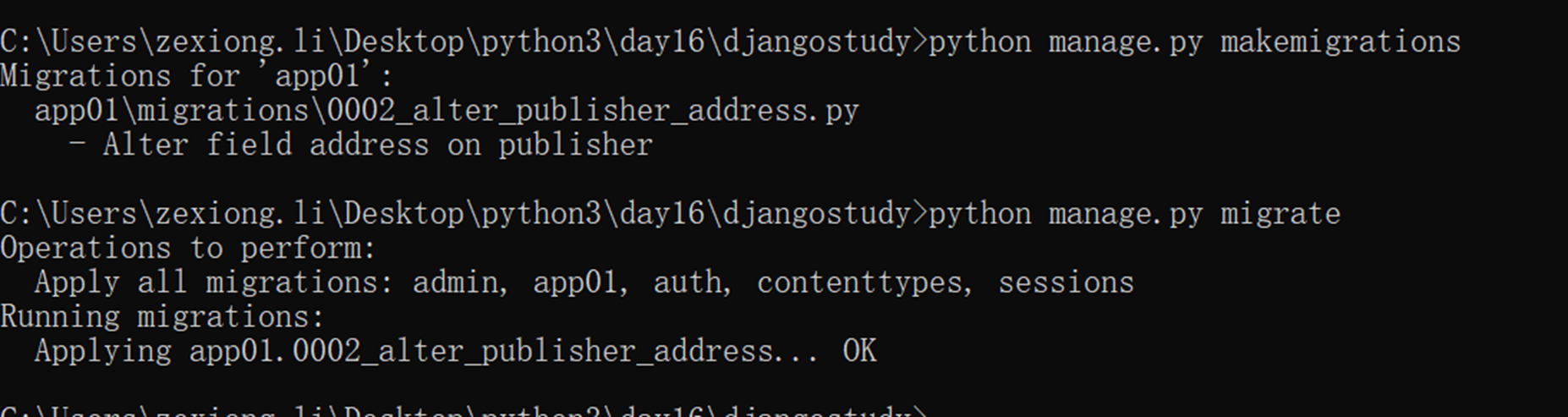
接下来进行测试
重新同步表结构
使用django-admin更改测试
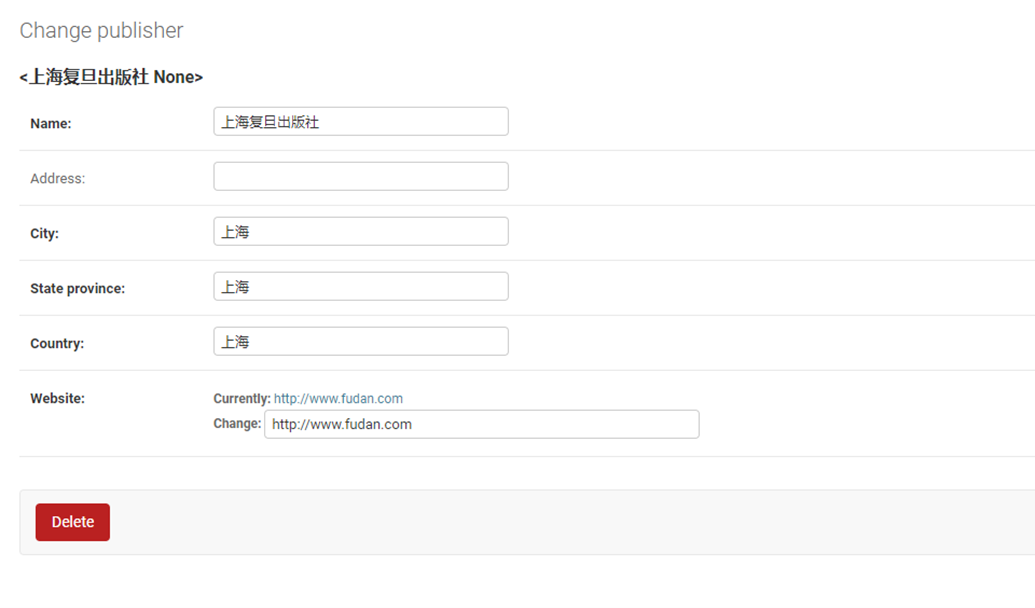
help_text
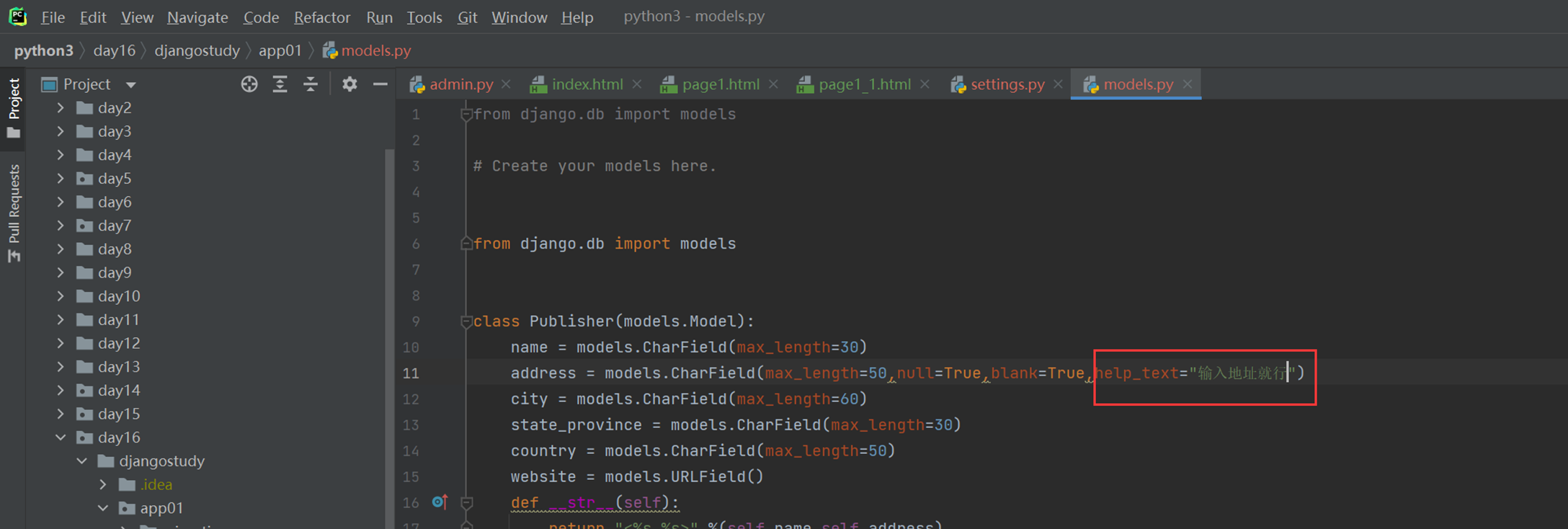
刷新网页看看
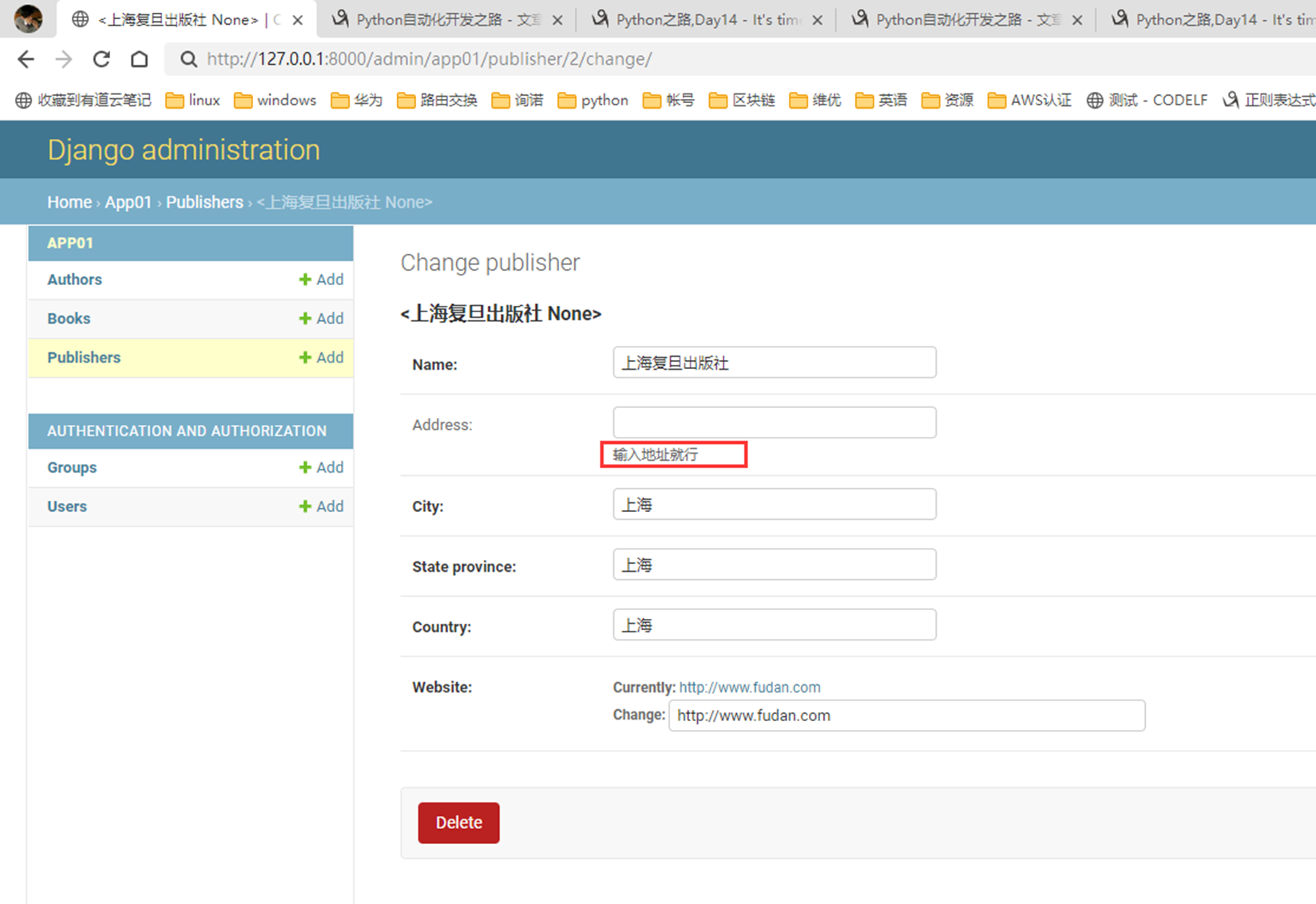
再来一个扩展,就是网页怎么让数据表显示为中文?其实也很简单
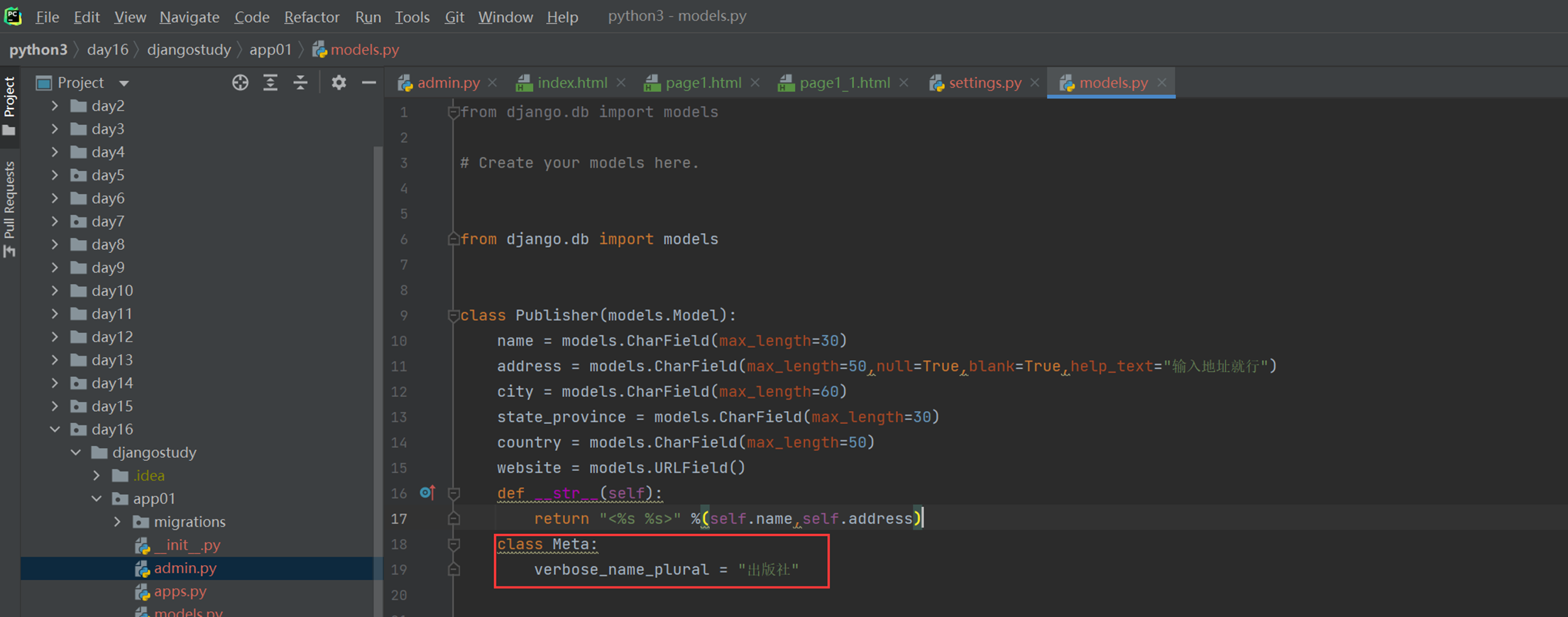
查看显示
本篇章有个小问题,就是有的修改需要执行修改数据库命令,有些不需要,目前就一个null需要执行python manage.py migrate?这是为什么?
因为除了null,其余的都是对django的显示进行修改,null是针对数据库表结构进行修改,所以需要改动数据库结构的等一些操作都需要执行python manage.py migrate。还是要根据实际情况看来看。
16.13 djangoadmin创建数据库数据
简单来说就是使用django-admin的shell,使用命令行而不是代码来操作数据库。
来看看下面的简单演示

现在使用shell来操作一下数据库,比如新增记录

现在查看一下是否新增了
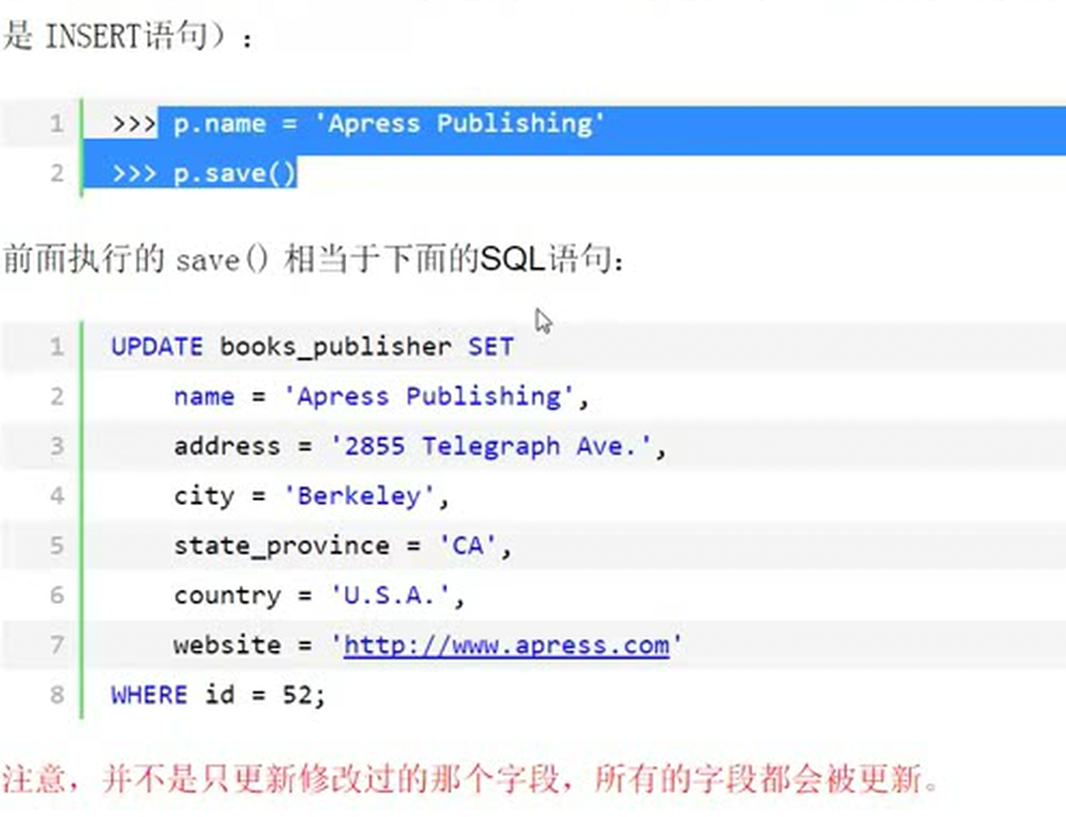
而且尽量不用用save(),因为save没还执行的时候,你修改了字段,即使修改一个字段,在使用save()的时候,等于所有的字段全部会被更新。
现在演示一下查询,例如,查询一下,lastname有没有qin的。

16.14 django增册改查命令
接着上一节课,再来点查询的案例。
查询一下第一个和到第三个用户有哪些。

再来一个,根据一本书名,关联查询有多少个作者

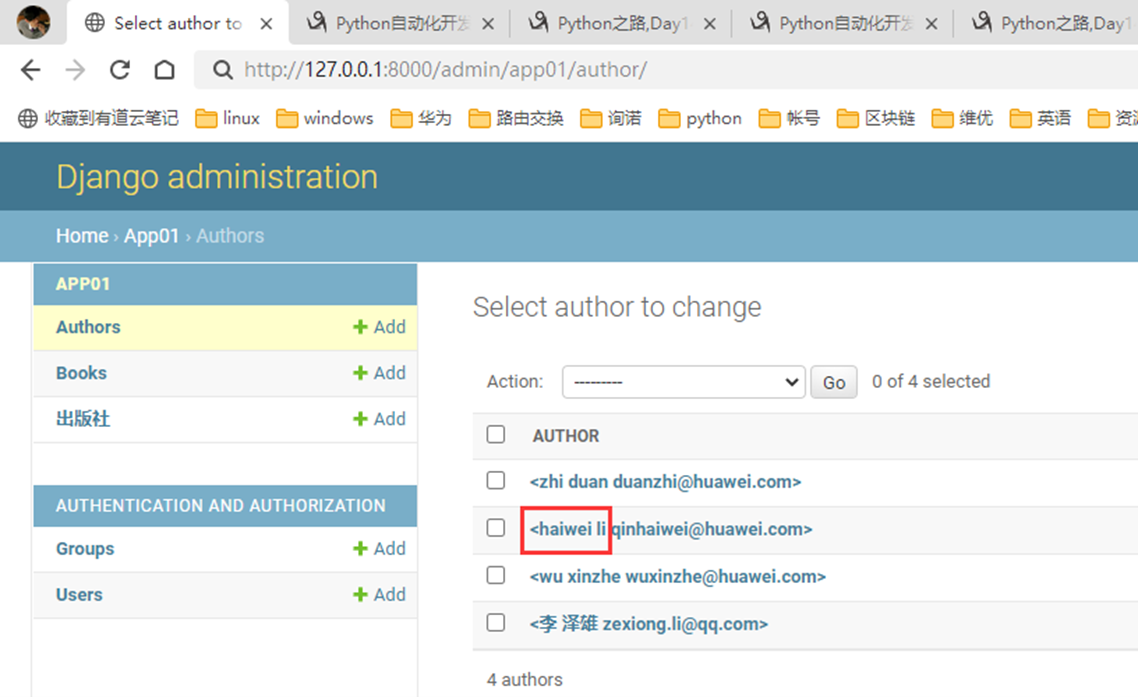
这里在补充一个修改案例
将所有last name=qin的全部改成li

查看结果
删除就不进行演示了,老师说自己去测试
另外,该天没有作业。因为视频没有并且和昨天的课程内容差不多。
17.L17
算法章节,如果不是特别熟练,只学习一遍,基本很快就会忘记,算法,需要的时候回来找资料或者复习视频吧。。。该篇就记录的潦草一点。。
另外,该篇作业代码都是使用11期的代码,这里并没有怎么复习,这个老师讲的是真他吗的混乱。需要复习的时候要有耐心,下点功夫。
17.1 51CTO学院-算法概要
就是讲解为什么需要算法,其余的没多说,可以略过。
17.2 时间复杂度
那老师估计自己都没讲清楚,还是参考博客来看吧。
https://www.cnblogs.com/lizexiong/articles/17370007.html

17.3 冒泡排序
冒泡排序原理就是2个相邻的值一直比较,每一个大循环结束,就可以选出最大的或者最小的,然后依次类推,有多少个数就循环多少个大循环。
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
data_set = [ 9,1,22,31,45,3,6,2,11 ] loop_count = 0 for j in range(len(data_set)): for i in range(len(data_set) - j- 1): # -1 是因为每次比对的都 是i 与i +1,不减1的话,最后一次对比会超出list 获取范围,-j是因为,每一次大loop就代表排序好了一个最大值,放在了列表最后面,下次loop就不用再运算已经排序好了的值 了 if data_set[i] > data_set[i+1]: #switch tmp = data_set[i] data_set[i] = data_set[i+1] data_set[i+1] = tmp loop_count +=1 print(data_set) print(data_set) print("loop times", loop_count)
17.4 选择排序
选择排序的原理就是大循环拿一个数来和后面所有的数比较,如果大或者小就更换,第一个大循环完成之后就不在比较它,从下一个数再次开始比较。
17.5 选择排序优化版
选择排序优化版,记住最大或者最小值的下标,但是值只在外层循环结束后更改
17.6 插入排序
本章很饶,但是代码在里面全部都有注释。
17.7 快速排序
快速排序非常的绕,后期时间长在回来查看,需要配合视频以及这里的笔记才能回忆,在代码里只有简单的注释,这里会有详细的排序过程。
例如这里有一个数组。
array = [86, 29, 86, 47, 96, 75, 3, 21, 16, 58]
我们从下标0 开始比较,生成一个变量 k= array[start]我们要跟这个数开始比较, 那么下标i=0,j=9,从右边开始比较,那么
[58, 29, 86, 47, 96, 75, 3, 21, 16, 86] i=0,j=9, 9<0,那么调换位置
J比较过一次了,那么就要从i开始比较,i的下标从1 到3都没有大于86的,到i=4,那么
结果就是
[58, 29, 86, 47, 86, 75, 3, 21, 16, 96] i=4,j=9 然后在从 j开始比较,就这样当i=j的时候就不在比较了,那么也列表肯定也是左边的逗比 86小,右边都比86大,然后在从中间开始分开,然后再次循环上述动作,直到比较完成为止。
本章长时间不看肯定会忘掉,视频在快速排序30分钟左右开始讲解。
本章排序要注意。
1.不管是从i 移动比较还是从 j 移动比较,都是与 k=86比较,不管86换到哪个地方,这一轮比较里面都是和它比较并调换位置。
2.从j开始比较,如果比k小的调换位置之后然后在从i开始比较,如果j没有找到比k小的,那么一直自身-1 找下去,直到满足条件或者跳出循环。
3.第一轮比较完成,我们要递归循环分成2组一直循环,就比如代码里面的
quick_sort(array,start,left_flag-1)
quick_sort(array,left_flag+1,end)
这里分组再次递归,并不是所有的时候是将这个列表等分,所以传入函数的值为left_flag -1 或者left_flag+1,因为有时候left_flag第一次替换的时候就满足i=j这个条件了,那时候left的下标肯定是最大的,因为数组越界问题,所以要减一或者加一,也可以理解,在n次递归的时候,最后一个值已经确定大小了,自己已经排序完毕,不需要在排序了。
下面是视频比较的笔记,这里就不删除了。

设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。值得注意的是,快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动
注:在待排序的文件中,若存在多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,该排序方法是稳定的;若具有相同关键字的记录之间的相对次序发生改变,则称这种排序方法是不稳定的。
要注意的是,排序算法的稳定性是针对所有输入实例而言的。即在所有可能的输入实例中,只要有一个实例使得算法不满足稳定性要求,则该排序算法就是不稳定的。
排序演示
示例
假设用户输入了如下数组:
|
下标 |
0 |
1 |
2 |
3 |
4 |
5 |
|
数据 |
6 |
2 |
7 |
3 |
8 |
9 |
创建变量i=0(指向第一个数据), j=5(指向最后一个数据), k=6(赋值为第一个数据的值)。
我们要把所有比k小的数移动到k的左面,所以我们可以开始寻找比6小的数,从j开始,从右往左找,不断递减变量j的值,我们找到第一个下标3的数据比6小,于是把数据3移到下标0的位置,把下标0的数据6移到下标3,完成第一次比较:
|
下标 |
0 |
1 |
2 |
3 |
4 |
5 |
|
数据 |
3 |
2 |
7 |
6 |
8 |
9 |
i=0 j=3 k=6
接着,开始第二次比较,这次要变成找比k大的了,而且要从前往后找了。递加变量i,发现下标2的数据是第一个比k大的,于是用下标2的数据7和j指向的下标3的数据的6做交换,数据状态变成下表:
|
下标 |
0 |
1 |
2 |
3 |
4 |
5 |
|
数据 |
3 |
2 |
6 |
7 |
8 |
9 |
i=2 j=3 k=6
称上面两次比较为一个循环。
接着,再递减变量j,不断重复进行上面的循环比较。
在本例中,我们进行一次循环,就发现i和j“碰头”了:他们都指向了下标2。于是,第一遍比较结束。得到结果如下,凡是k(=6)左边的数都比它小,凡是k右边的数都比它大:
|
下标 |
0 |
1 |
2 |
3 |
4 |
5 |
|
数据 |
3 |
2 |
6 |
7 |
8 |
9 |
如果i和j没有碰头的话,就递加i找大的,还没有,就再递减j找小的,如此反复,不断循环。注意判断和寻找是同时进行的。
然后,对k两边的数据,再分组分别进行上述的过程,直到不能再分组为止。
注意:第一遍快速排序不会直接得到最终结果,只会把比k大和比k小的数分到k的两边。为了得到最后结果,需要再次对下标2两边的数组分别执行此步骤,然后再分解数组,直到数组不能再分解为止(只有一个数据),才能得到正确结果。
#_*_coding:utf-8_*_ __author__ = 'Alex Li' def quick_sort(array,left,right): ''' :param array: :param left: 列表的第一个索引 :param right: 列表最后一个元素的索引 :return: ''' if left >=right: return low = left high = right key = array[low] #第一个值 while low < high:#只要左右未遇见 while low < high and array[high] > key: #找到列表右边比key大的值 为止 high -= 1 #此时直接 把key(array[low]) 跟 比它大的array[high]进行交换 array[low] = array[high] array[high] = key while low < high and array[low] <= key : #找到key左边比key大的值,这里为何是<=而不是<呢?你要思考。。。 low += 1 #array[low] = #找到了左边比k大的值 ,把array[high](此时应该刚存成了key) 跟这个比key大的array[low]进行调换 array[high] = array[low] array[low] = key quick_sort(array,left,low-1) #最后用同样的方式对分出来的左边的小组进行同上的做法 quick_sort(array,low+1, right)#用同样的方式对分出来的右边的小组进行同上的做法 if __name__ == '__main__': array = [96,14,10,9,6,99,16,5,1,3,2,4,1,13,26,18,2,45,34,23,1,7,3,22,19,2] #array = [8,4,1, 14, 6, 2, 3, 9,5, 13, 7,1, 8,10, 12] print("before sort:", array) quick_sort(array,0,len(array)-1) print("-------final -------") print(array)
17.8 二叉树
17.8.1 树的特征和定义
树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构,很象自然界中的树那样。树结构在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构都可用树形象表示。树在计算机领域中也得到广泛应用,如在编译源程序时,可用树表示源程序的语法结构。又如在数据库系统中,树型结构也是信息的重要组织形式之一。一切具有层次关系的问题都可用树来描述。
树(Tree)是元素的集合。我们先以比较直观的方式介绍树。下面的数据结构是一个树:
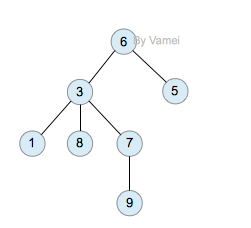
树有多个节点(node),用以储存元素。某些节点之间存在一定的关系,用连线表示,连线称为边(edge)。边的上端节点称为父节点,下端称为子节点。树像是一个不断分叉的树根。
每个节点可以有多个子节点(children),而该节点是相应子节点的父节点(parent)。比如说,3,5是6的子节点,6是3,5的父节点;1,8,7是3的子节点, 3是1,8,7的父节点。树有一个没有父节点的节点,称为根节点(root),如图中的6。没有子节点的节点称为叶节点(leaf),比如图中的1,8,9,5节点。从图中还可以看到,上面的树总共有4个层次,6位于第一层,9位于第四层。树中节点的最大层次被称为深度。也就是说,该树的深度(depth)为4。
如果我们从节点3开始向下看,而忽略其它部分。那么我们看到的是一个以节点3为根节点的树:
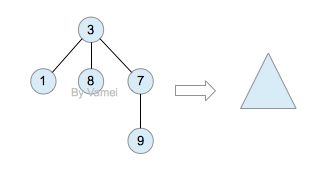
三角形代表一棵树
再进一步,如果我们定义孤立的一个节点也是一棵树的话,原来的树就可以表示为根节点和子树(subtree)的关系:

上述观察实际上给了我们一种严格的定义树的方法:
1.树是元素的集合。
2.该集合可以为空。这时树中没有元素,我们称树为空树 (empty tree)。
3.如果该集合不为空,那么该集合有一个根节点,以及0个或者多个子树。根节点与它的子树的根节点用一个边(edge)相连。
上面的第三点是以递归的方式来定义树,也就是在定义树的过程中使用了树自身(子树)。由于树的递归特征,许多树相关的操作也可以方便的使用递归实现。我们将在后面看到。
17.8.2 树的实现
树的示意图已经给出了树的一种内存实现方式: 每个节点储存元素和多个指向子节点的指针。然而,子节点数目是不确定的。一个父节点可能有大量的子节点,而另一个父节点可能只有一个子节点,而树的增删节点操作会让子节点的数目发生进一步的变化。这种不确定性就可能带来大量的内存相关操作,并且容易造成内存的浪费。
一种经典的实现方式如下:
17.8.3 树的内存实现
拥有同一父节点的两个节点互为兄弟节点(sibling)。上图的实现方式中,每个节点包含有一个指针指向第一个子节点,并有另一个指针指向它的下一个兄弟节点。这样,我们就可以用统一的、确定的结构来表示每个节点。
计算机的文件系统是树的结构,比如Linux文件管理背景知识中所介绍的。在UNIX的文件系统中,每个文件(文件夹同样是一种文件),都可以看做是一个节点。非文件夹的文件被储存在叶节点。文件夹中有指向父节点和子节点的指针(在UNIX中,文件夹还包含一个指向自身的指针,这与我们上面见到的树有所区别)。在git中,也有类似的树状结构,用以表达整个文件系统的版本变化 (参考版本管理三国志)。
17.8.4 二叉树:
二叉树是由n(n≥0)个结点组成的有限集合、每个结点最多有两个子树的有序树。它或者是空集,或者是由一个根和称为左、右子树的两个不相交的二叉树组成。
特点:
(1)二叉树是有序树,即使只有一个子树,也必须区分左、右子树;
(2)二叉树的每个结点的度不能大于2,只能取0、1、2三者之一;
(3)二叉树中所有结点的形态有5种:空结点、无左右子树的结点、只有左子树的结点、只有右子树的结点和具有左右子树的结点。
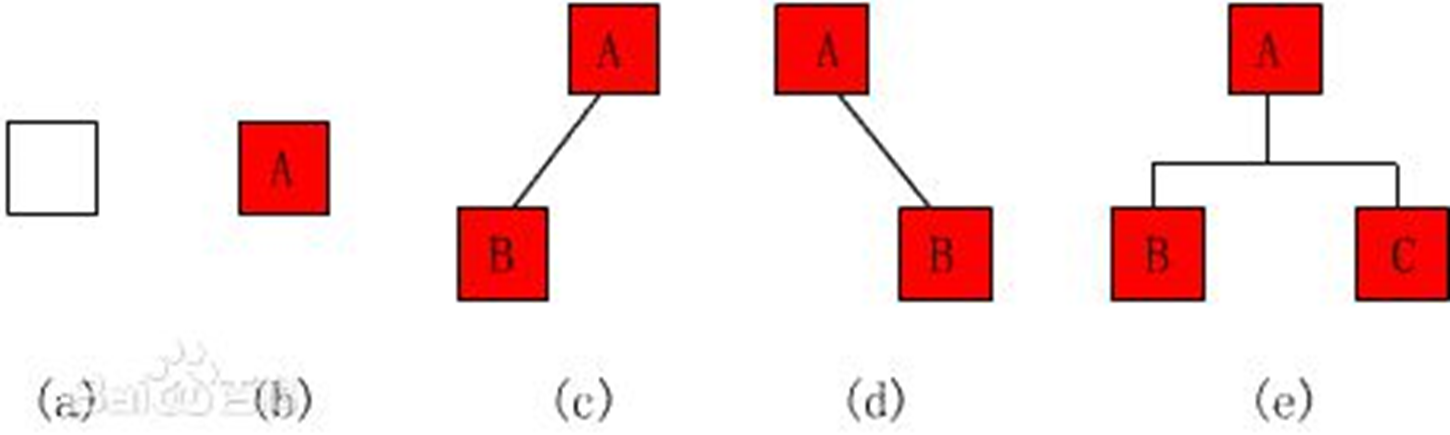

二叉树(binary)是一种特殊的树。二叉树的每个节点最多只能有2个子节点:
二叉树
由于二叉树的子节点数目确定,所以可以直接采用上图方式在内存中实现。每个节点有一个左子节点(left children)和右子节点(right children)。左子节点是左子树的根节点,右子节点是右子树的根节点。
如果我们给二叉树加一个额外的条件,就可以得到一种被称作二叉搜索树(binary search tree)的特殊二叉树。二叉搜索树要求:每个节点都不比它左子树的任意元素小,而且不比它的右子树的任意元素大。
(如果我们假设树中没有重复的元素,那么上述要求可以写成:每个节点比它左子树的任意节点大,而且比它右子树的任意节点小)
二叉搜索树,注意树中元素的大小
二叉搜索树可以方便的实现搜索算法。在搜索元素x的时候,我们可以将x和根节点比较:
1.如果x等于根节点,那么找到x,停止搜索 (终止条件)
2.如果x小于根节点,那么搜索左子树
3.如果x大于根节点,那么搜索右子树
二叉搜索树所需要进行的操作次数最多与树的深度相等。n个节点的二叉搜索树的深度最多为n,最少为log(n)。
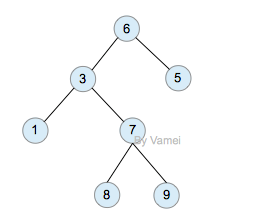
17.8.5 二叉树的遍历
遍历即将树的所有结点访问且仅访问一次。按照根节点位置的不同分为前序遍历,中序遍历,后序遍历。
前序遍历:根节点->左子树->右子树
中序遍历:左子树->根节点->右子树
后序遍历:左子树->右子树->根节点
例如:求下面树的三种遍历
前序遍历:abdefgc
中序遍历:debgfac
后序遍历:edgfbca
17.8.6 二叉树的类型
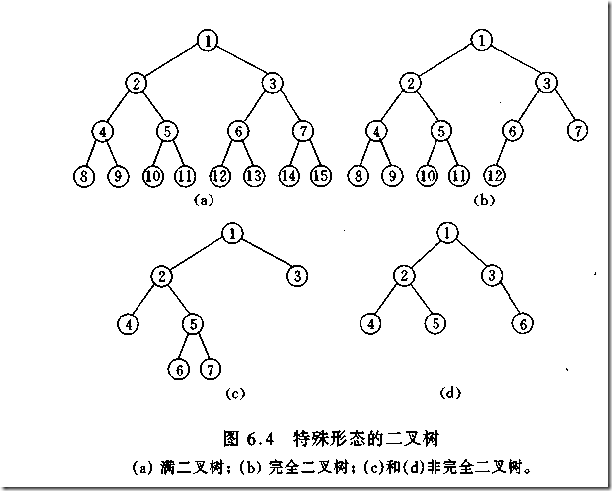
(1)完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)平衡二叉树——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
如何判断一棵树是完全二叉树?按照定义,
教材上的说法:一个深度为k,节点个数为 2^k - 1 的二叉树为满二叉树。这个概念很好理解,
就是一棵树,深度为k,并且没有空位。
首先对满二叉树按照广度优先遍历(从左到右)的顺序进行编号。
一颗深度为k二叉树,有n个节点,然后,也对这棵树进行编号,如果所有的编号都和满二叉树对应,那么这棵树是完全二叉树。
- 如何判断平衡二叉树?
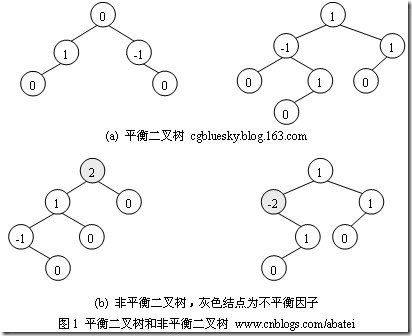
(b)左边的图 左子数的高度为3,右子树的高度为1,相差超过1
(b)右边的图 -2的左子树高度为0 右子树的高度为2,相差超过1
17.8.7 二叉树遍历实现
class TreeNode(object): def __init__(self,data=0,left=0,right=0): self.data = data self.left = left self.right = right class BTree(object): def __init__(self,root=0): self.root = root def preOrder(self,treenode): if treenode is 0: return print(treenode.data) self.preOrder(treenode.left) self.preOrder(treenode.right) def inOrder(self,treenode): if treenode is 0: return self.inOrder(treenode.left) print(treenode.data) self.inOrder(treenode.right) def postOrder(self,treenode): if treenode is 0: return self.postOrder(treenode.left) self.postOrder(treenode.right) print(treenode.data) if __name__ == '__main__': n1 = TreeNode(data=1) n2 = TreeNode(2,n1,0) n3 = TreeNode(3) n4 = TreeNode(4) n5 = TreeNode(5,n3,n4) n6 = TreeNode(6,n2,n5) n7 = TreeNode(7,n6,0) n8 = TreeNode(8) root = TreeNode('root',n7,n8) bt = BTree(root) print("preOrder".center(50,'-')) print(bt.preOrder(bt.root)) print("inOrder".center(50,'-')) print (bt.inOrder(bt.root)) print("postOrder".center(50,'-')) print (bt.postOrder(bt.root))
17.9 堆排序介绍
参考git代码和博客https://www.cnblogs.com/lizexiong/articles/17370007.html的最后一章
18.L18
18.1 上节回顾
上节课就是回顾了一下16天的内容(因为17天讲的是单独的算法,没有衔接性),什么url,template,这些就不多说了。
因为目前看来16课是少一个视频的,今天复习的时候,大概能猜到就是讲了一下使用post和get来操作一下数据库。
当然也不能说是缺失了视频,这个部分,后续视频里面也会讲解。
18.2 form表单
该篇视频1个小时,因为这个老师讲课老是这样,自己讲不清楚,导致课程时间搞到了1个小时。本章讲解的就是django自带的from表单验证。就3个功能,还有一个不知道怎么写。无话可说。接下来看本人根据课堂优化过的代码。
该篇还是沿用day16的代码,直接copy过来了
为什么需要前后端都需要验证?
因为前端防的是普通用户的非法插入,但是牛逼一点的,不使用前端,直接通过python的各种库,直接发送post请求,那么就直接绕过了前端,所以需要后端也要验证。前端有验证也可以减轻对后端频繁请求的压力。因为可以挡住很多没有通过的非法验证。
1.url
2.创建一个专门的django forms的文件
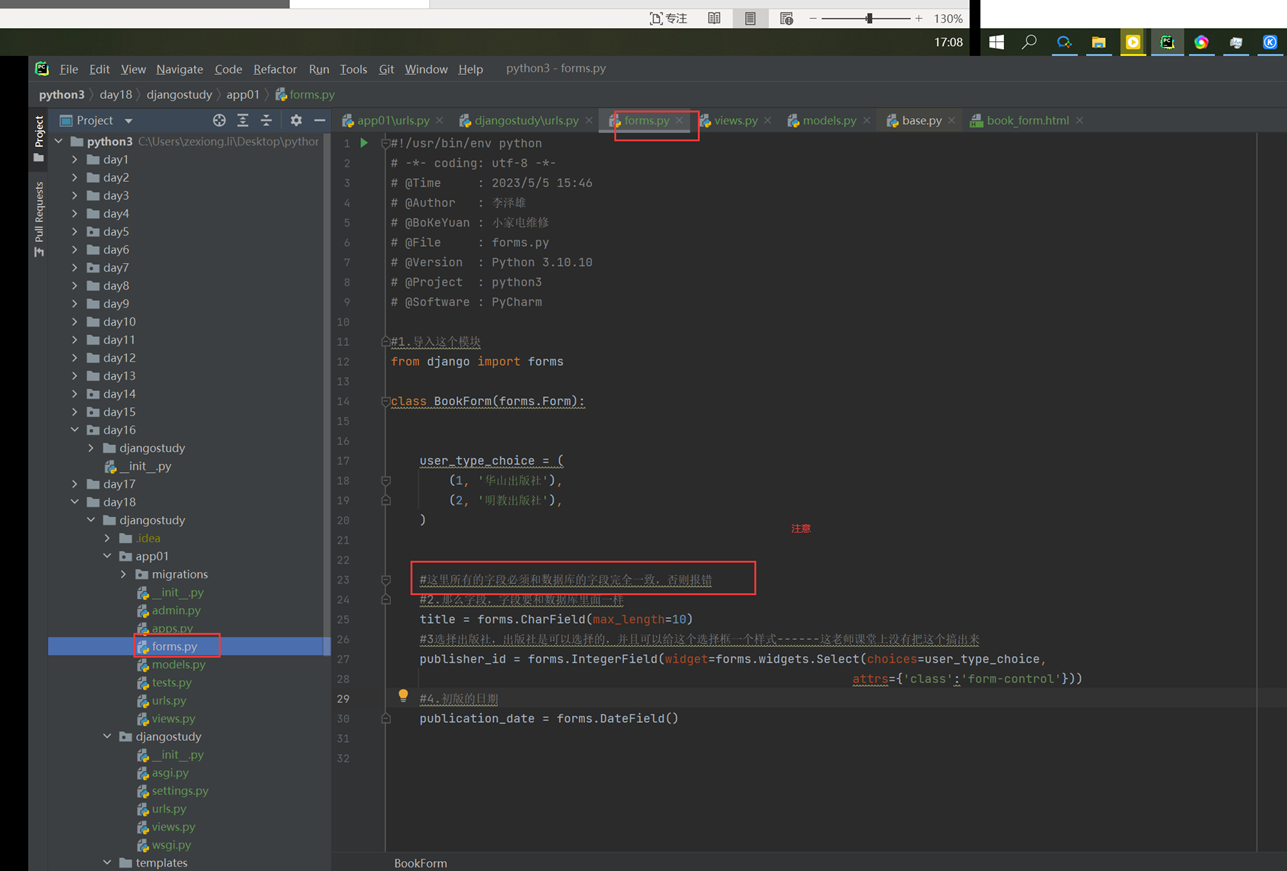
3.html界面
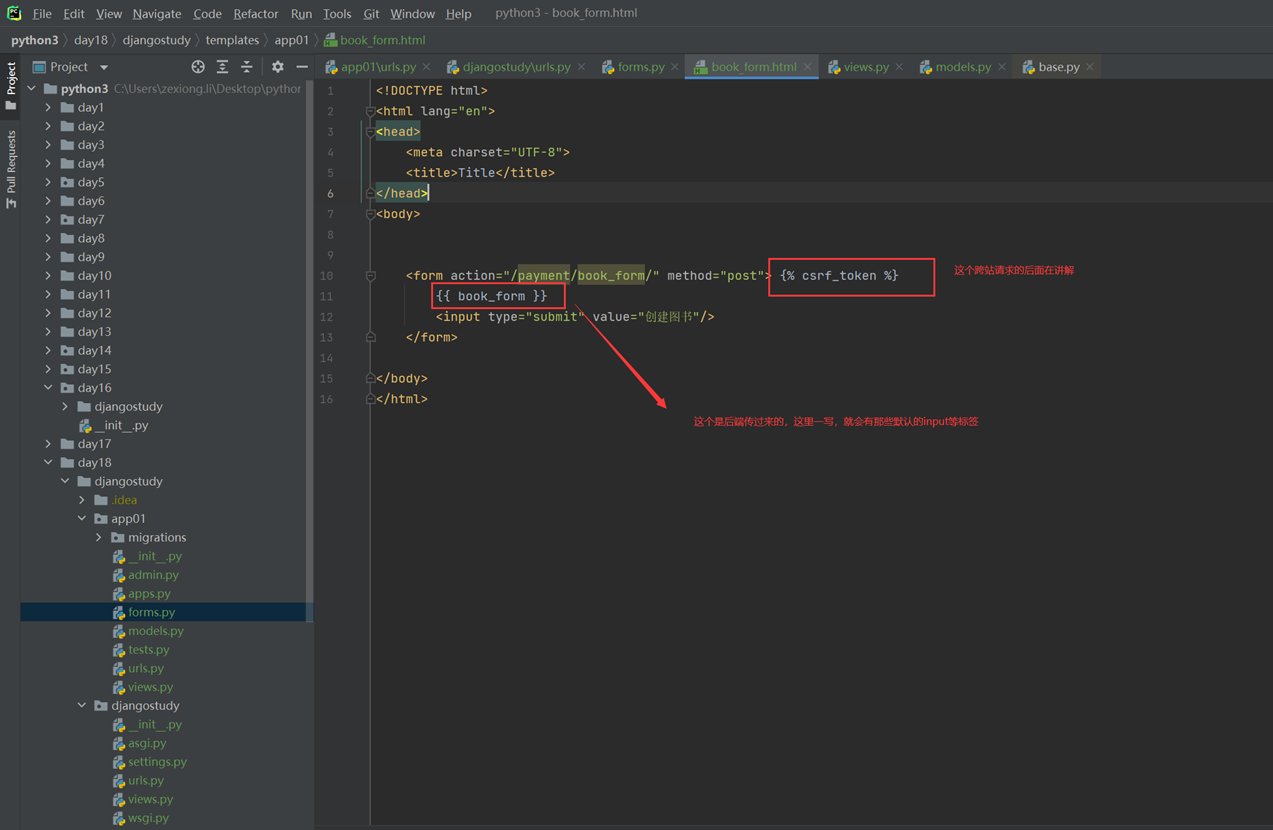
4.views
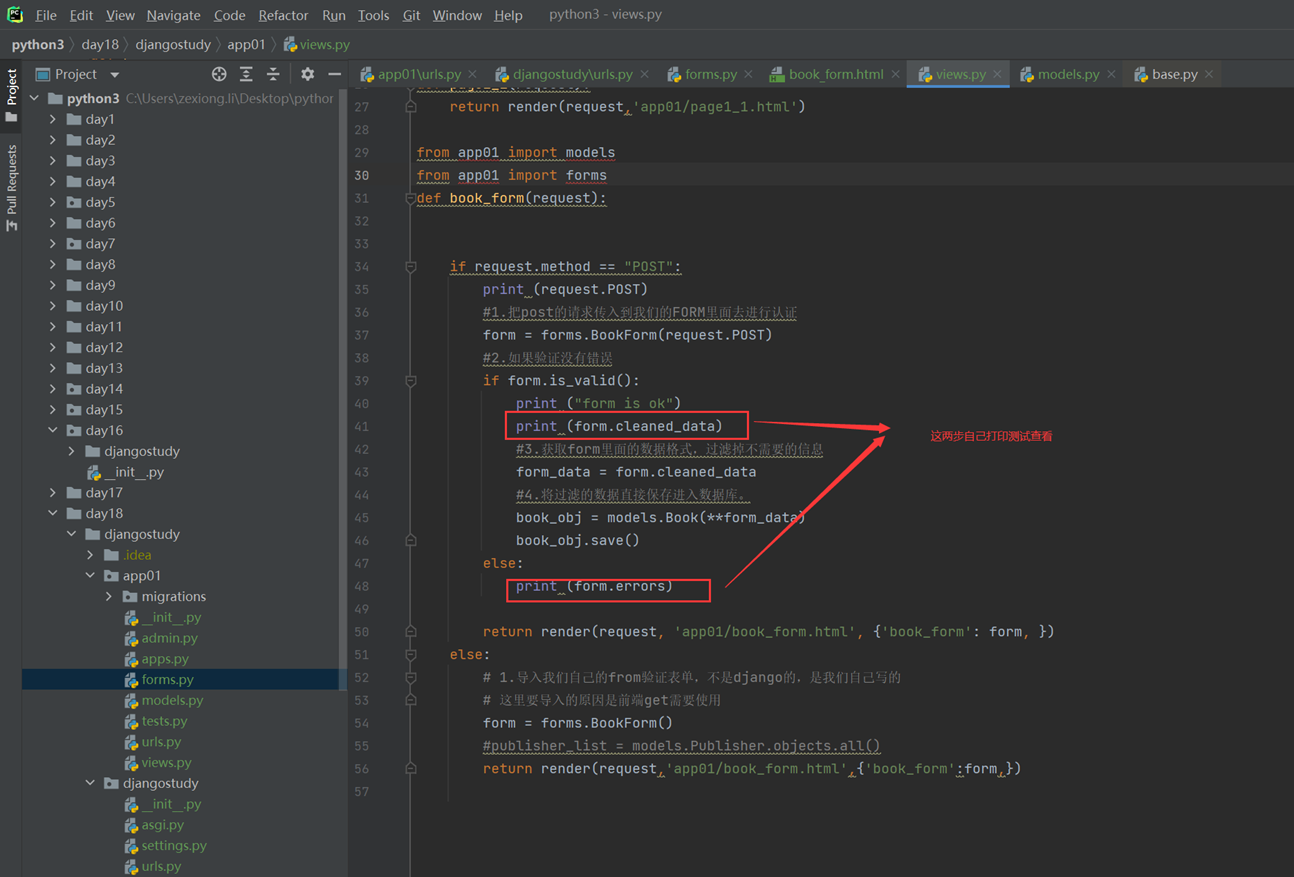
访问界面查看
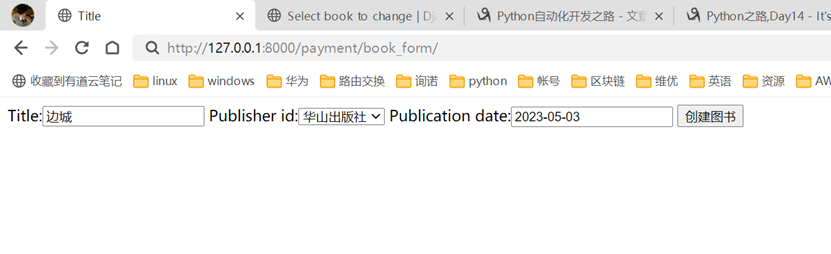
现在查看一下终端的打印

看一下数据库有没有存储
18.3 form表单定制
啥也没说,就是把下面这个代码讲解了一遍,课件博客里面也有
#!/usr/bin/env python # -*- coding:utf-8 -*- import re from django import forms from django.core.exceptions import ValidationError def mobile_validate(value): mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}$') if not mobile_re.match(value): raise ValidationError('手机号码格式错误') class PublishForm(forms.Form): user_type_choice = ( (0, u'普通用户'), (1, u'高级用户'), ) user_type = forms.IntegerField(widget=forms.widgets.Select(choices=user_type_choice, attrs={'class': "form-control"})) title = forms.CharField(max_length=20, min_length=5, error_messages={'required': u'标题不能为空', 'min_length': u'标题最少为5个字符', 'max_length': u'标题最多为20个字符'}, widget=forms.TextInput(attrs={'class': "form-control", 'placeholder': u'标题5-20个字符'})) memo = forms.CharField(required=False, max_length=256, widget=forms.widgets.Textarea(attrs={'class': "form-control no-radius", 'placeholder': u'详细描述', 'rows': 3})) phone = forms.CharField(validators=[mobile_validate, ], error_messages={'required': u'手机不能为空'}, widget=forms.TextInput(attrs={'class': "form-control", 'placeholder': u'手机号码'})) email = forms.EmailField(required=False, error_messages={'required': u'邮箱不能为空','invalid': u'邮箱格式错误'}, widget=forms.TextInput(attrs={'class': "form-control", 'placeholder': u'邮箱'})) ''' def __init__(self, *args, **kwargs): super(SampleImportForm, self).__init__(*args, **kwargs) self.fields['idc'].widget.choices = models.IDC.objects.all().order_by('id').values_list('id','display') self.fields['business_unit'].widget.choices = models.BusinessUnit.objects.all().order_by('id').values_list('id','name') Forms '''
18.4 modelform
又出现一个问题,上面的那个form没办法显示数据库里面的数据,自己使用上面那个form也能实现,但是太繁琐,怎么样才能直接显示数据库里面的数据,所以这里就有一个modelform。
1.url
2.forms
3.html
4.views
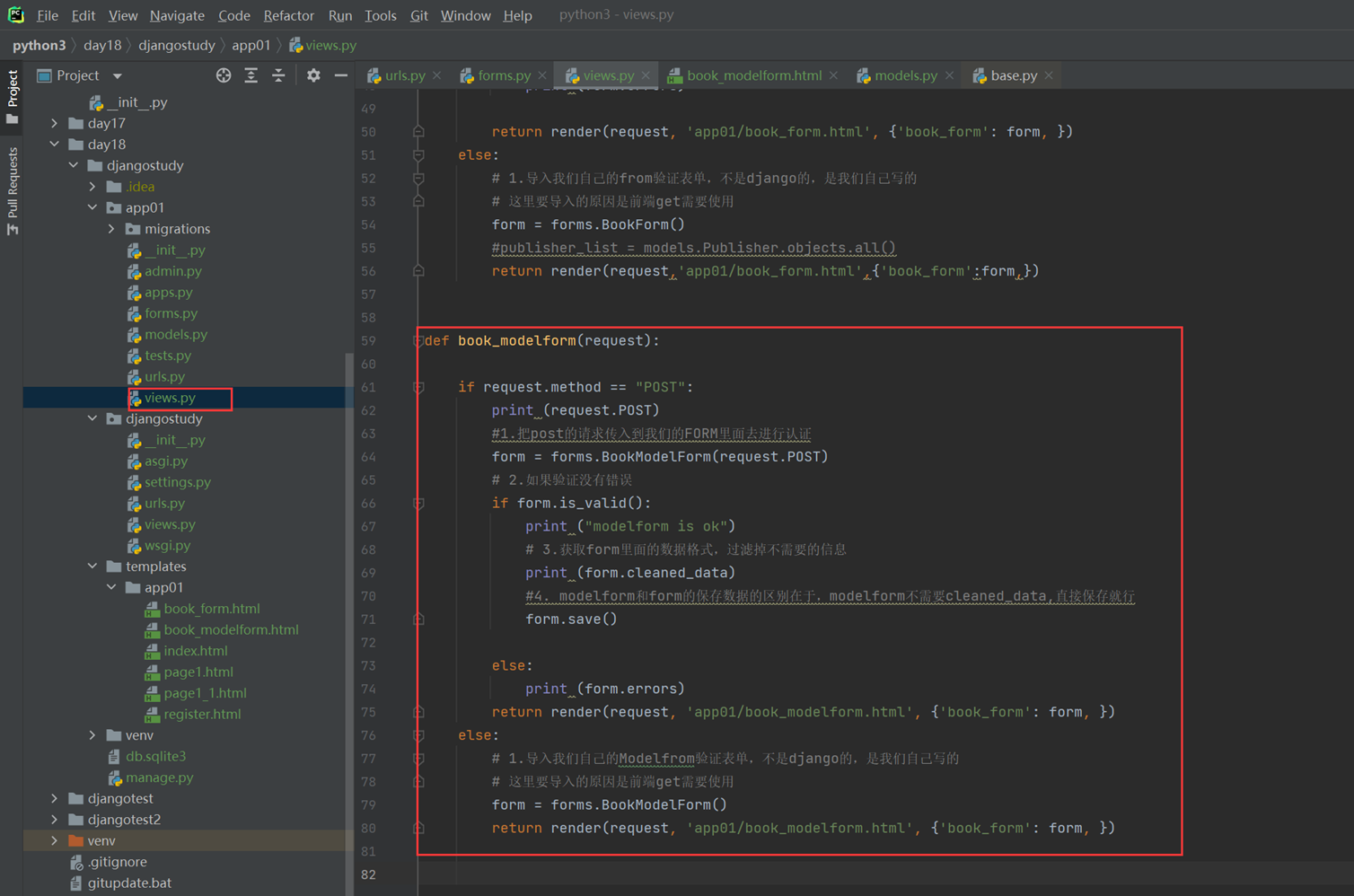
访问界面查看
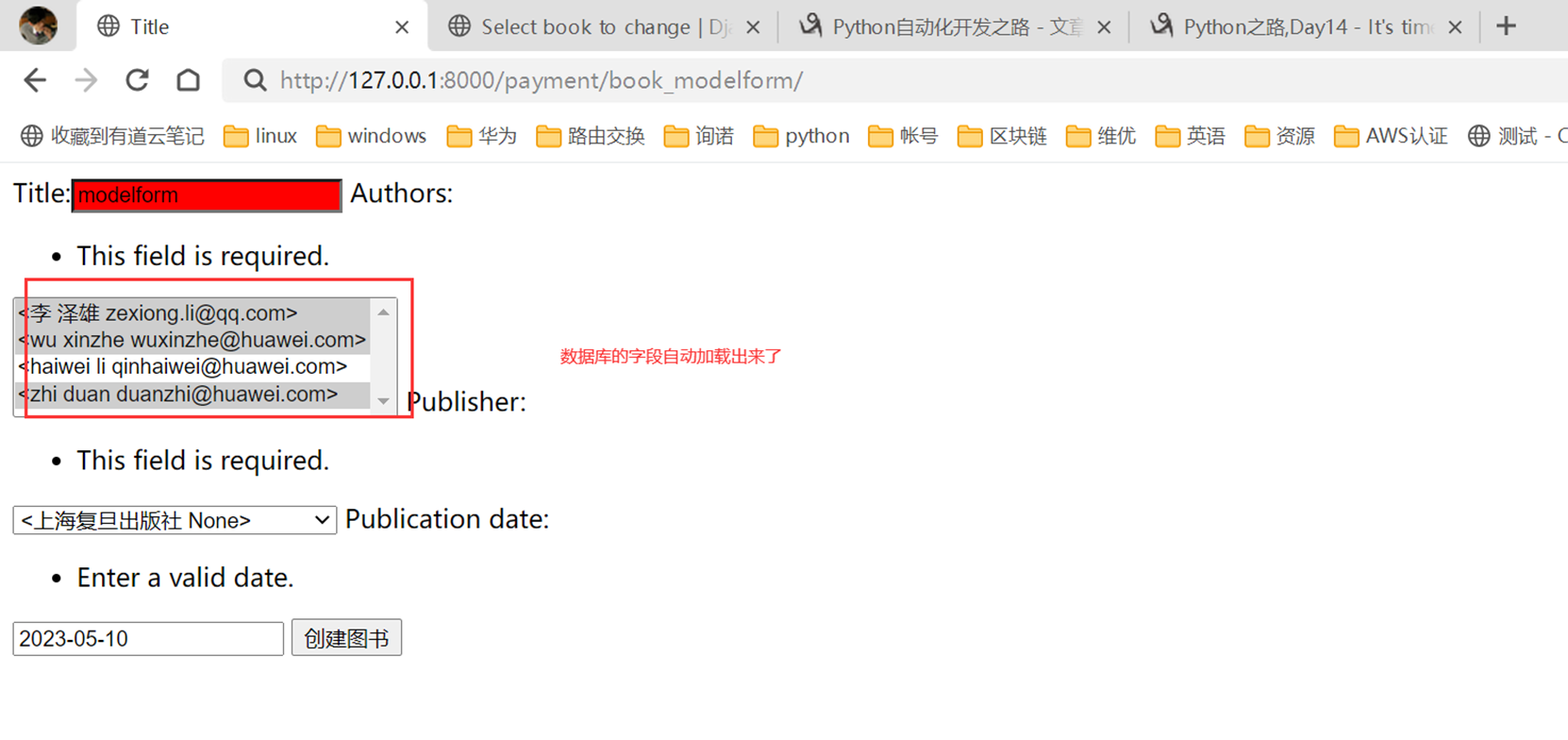
现在查看一下终端的打印

看一下数据库有没有存储
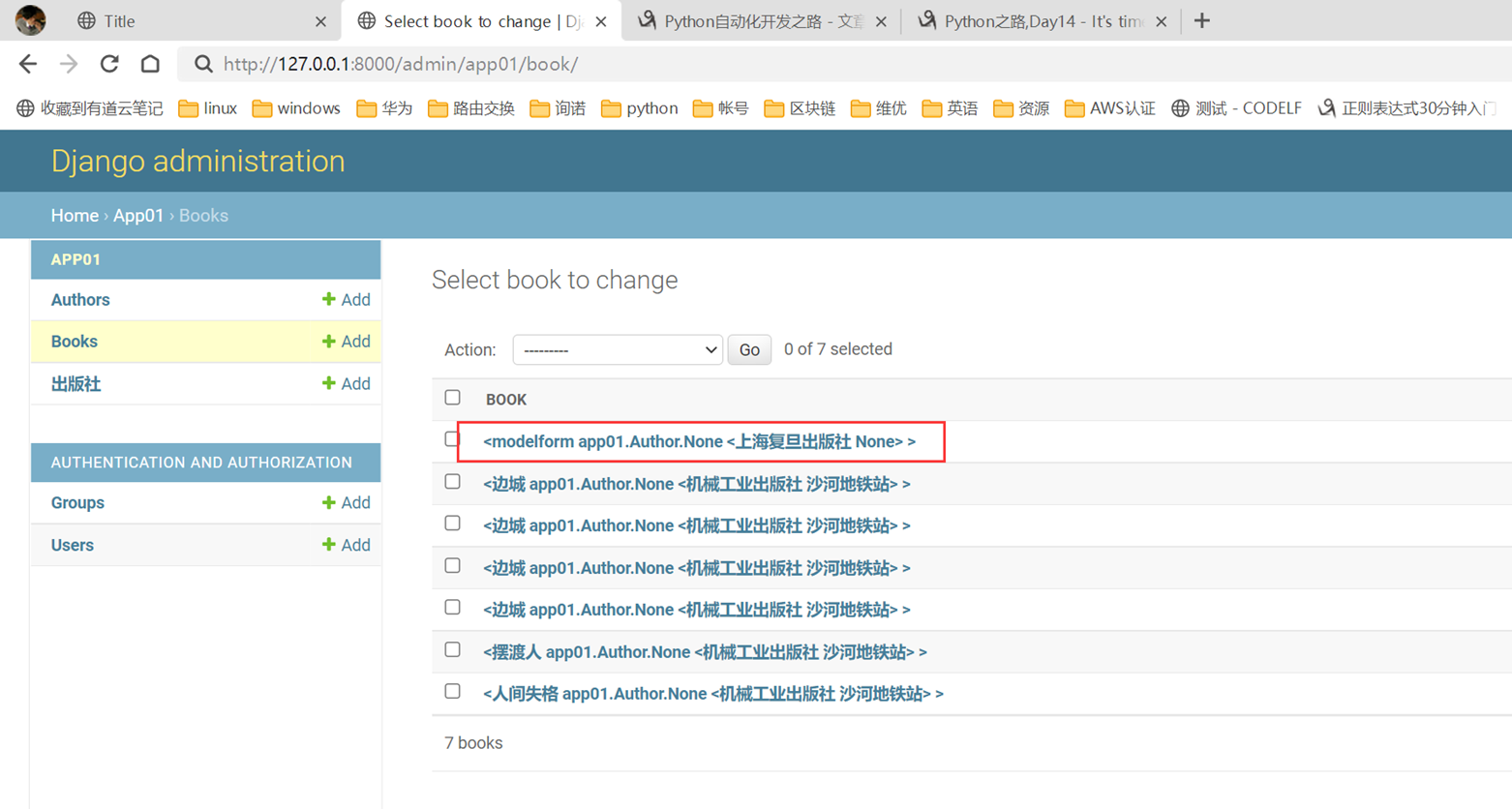
18.5 admin定制
首先讲解了一下怎么使用django admin,由于前面讲过,这里贴一下记录,跳过了
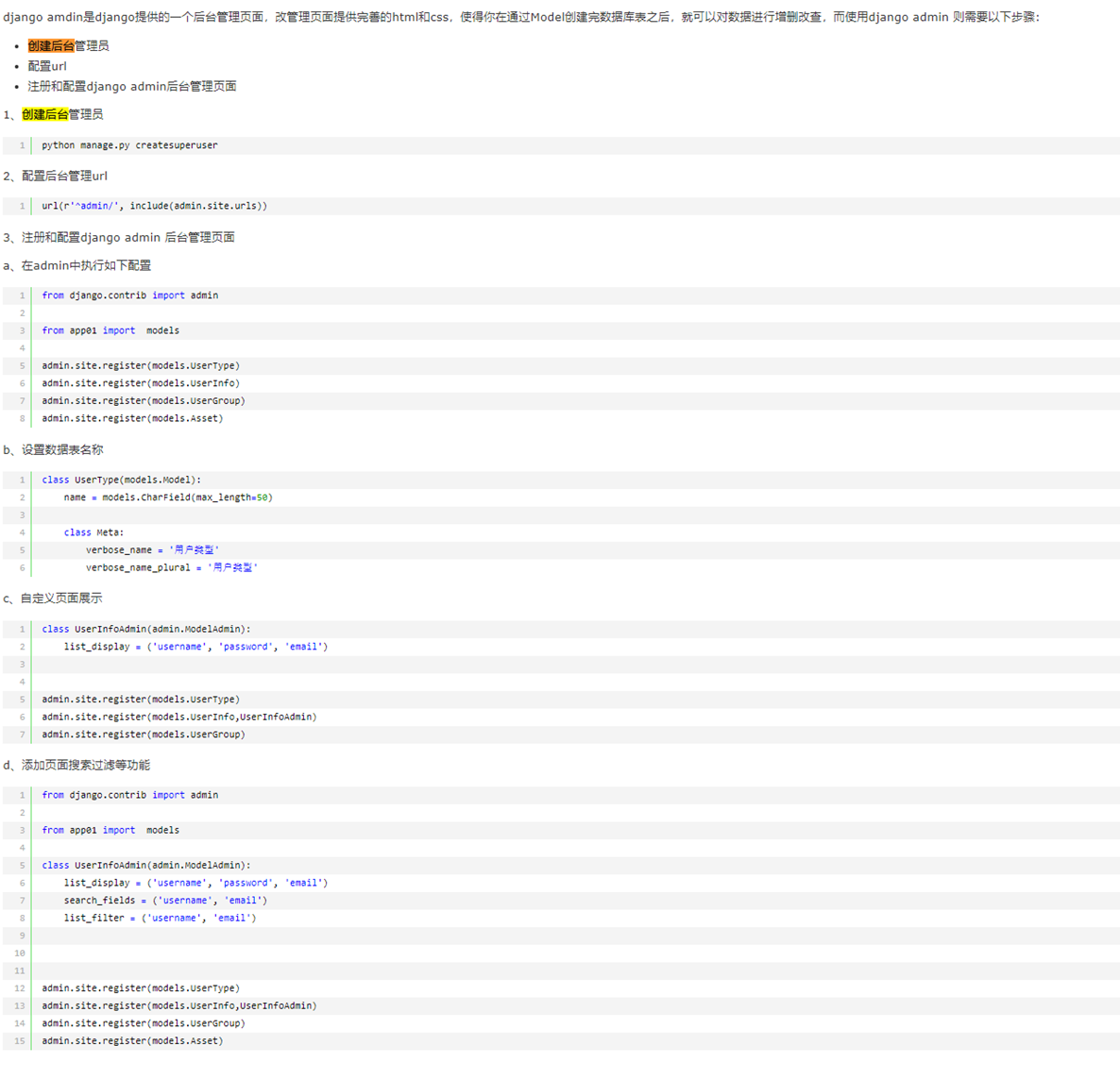
现在演示一下django admin后台可以自定义的一些功能,有哪些好处
展示多个字段
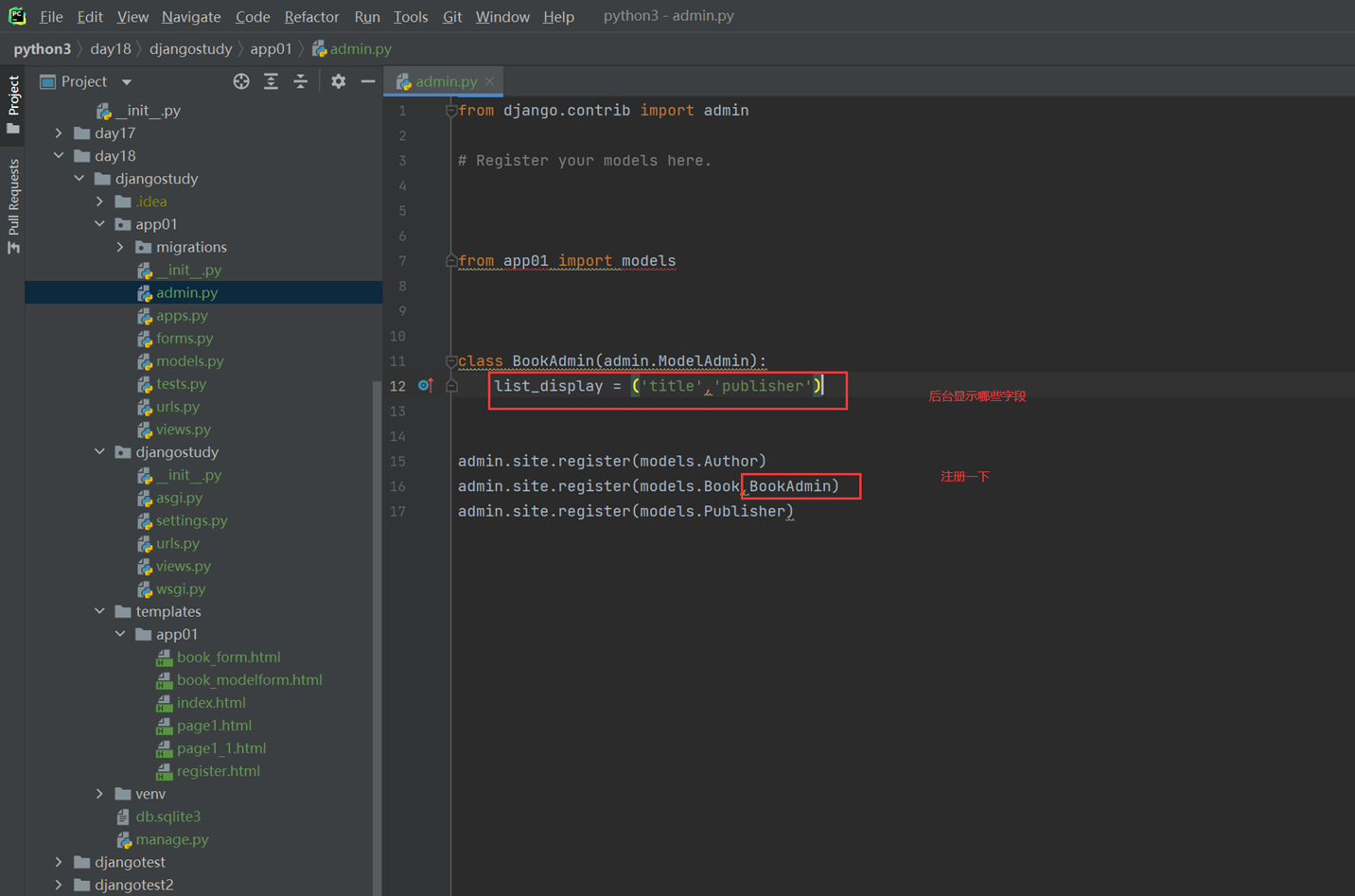
后台结果
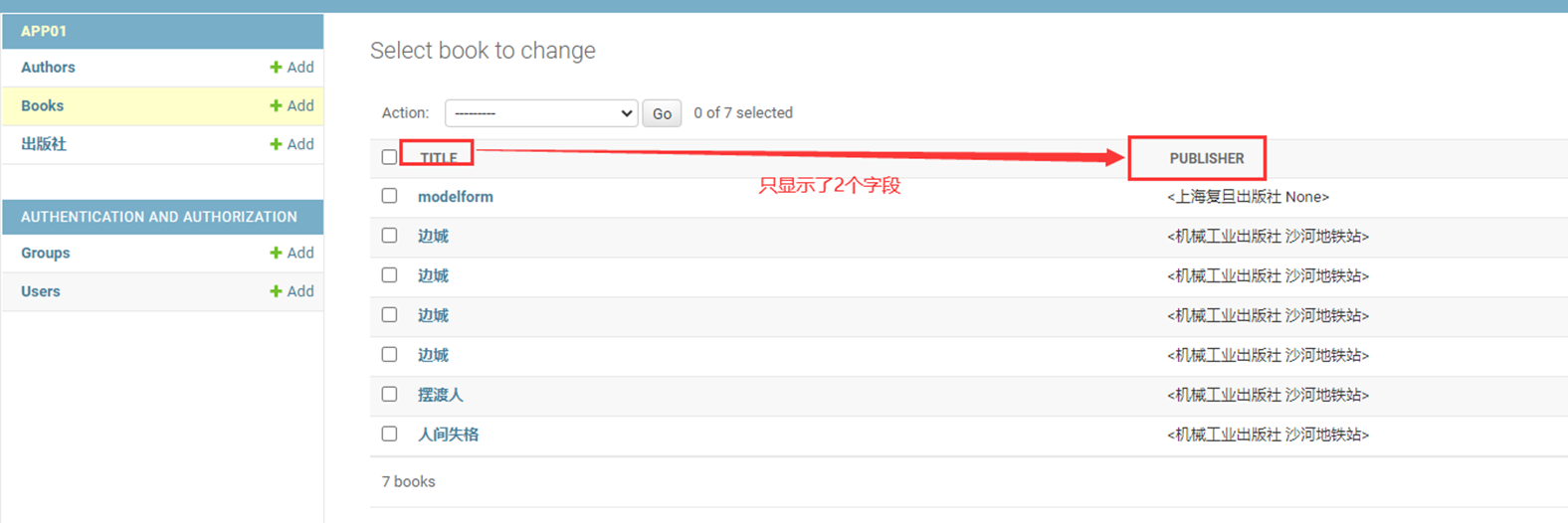
不能显示多对多,
1,因为多对多可能有很多条记录,一个网页无法显示
2,如果多对多,不知道关联了多少表,查询效率慢
加搜索框
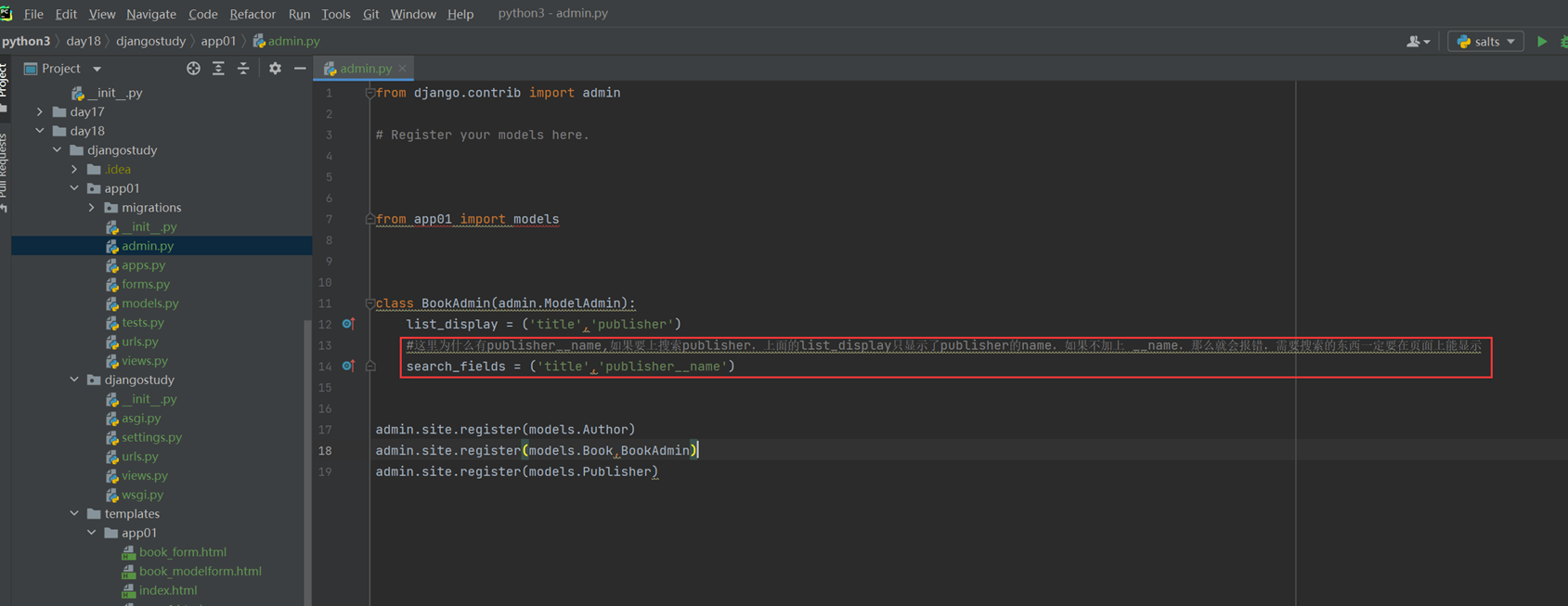
结果
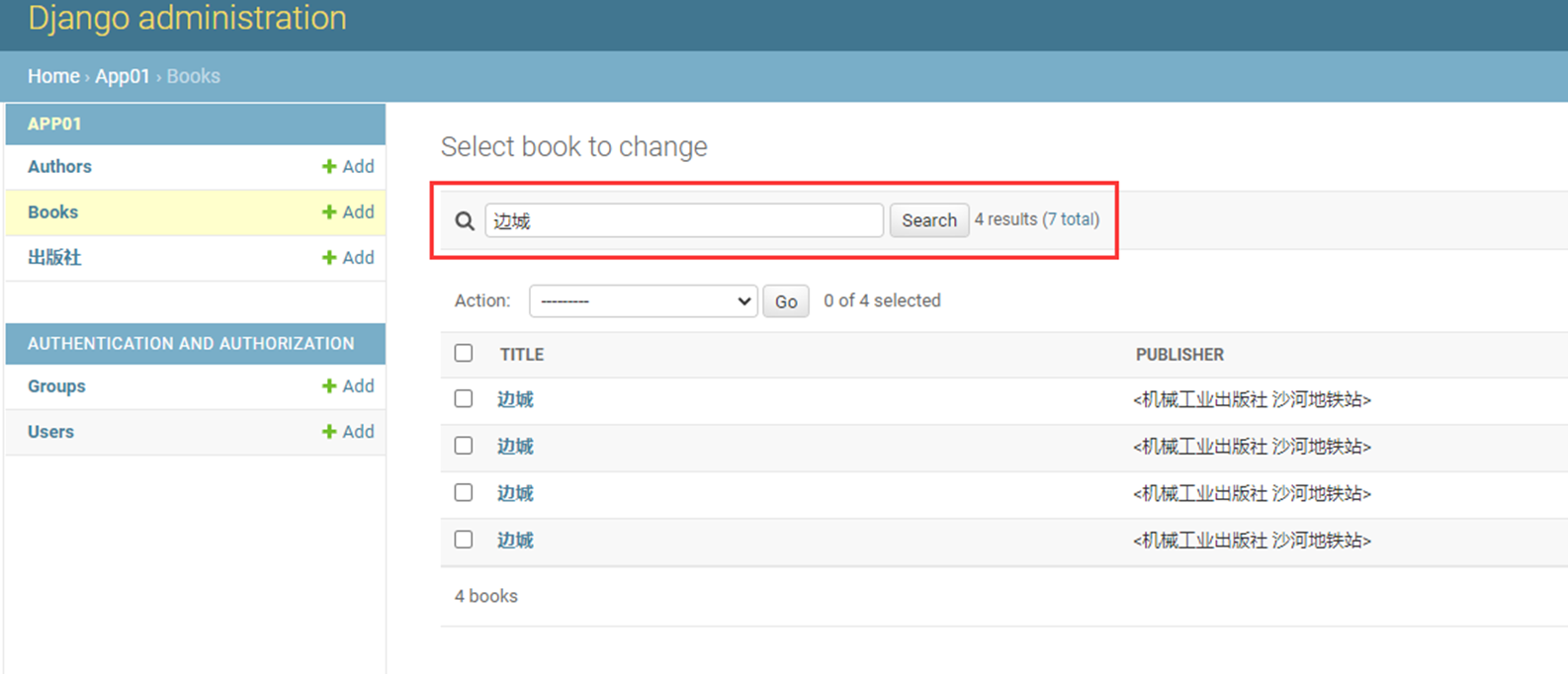
过滤器条件
在边上的过滤查看列表里面可以通过什么过滤
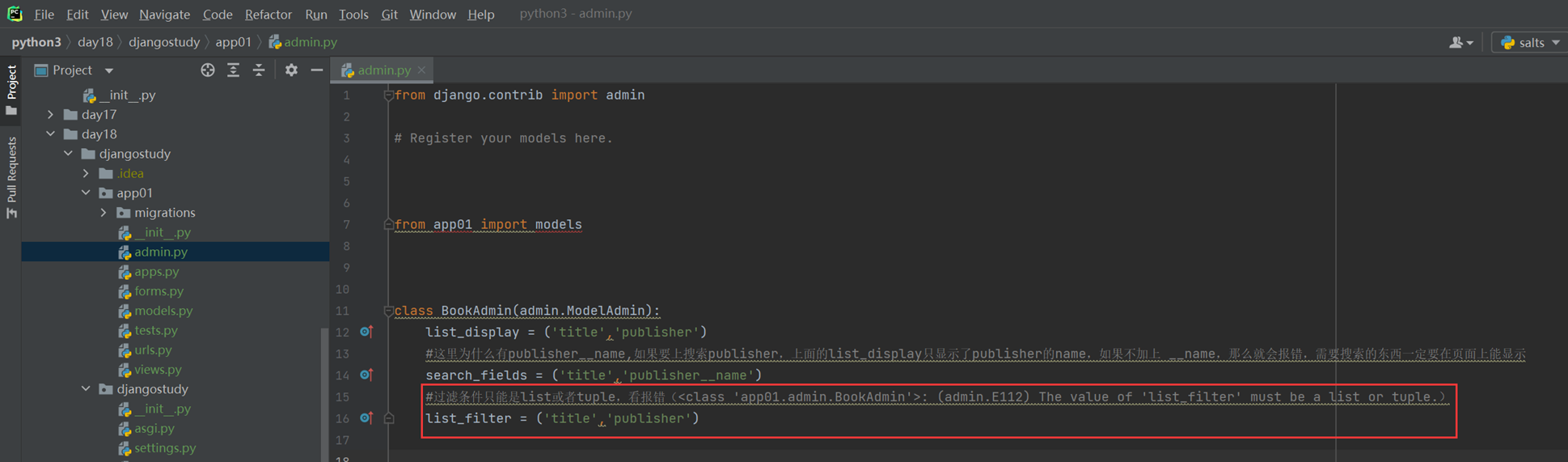
看结果
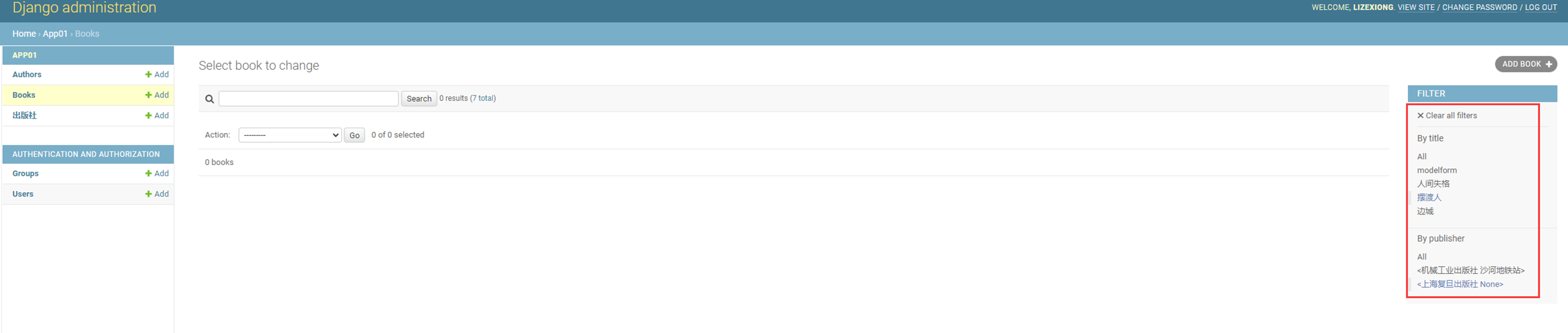
每页显示多少内容
这里改成2个
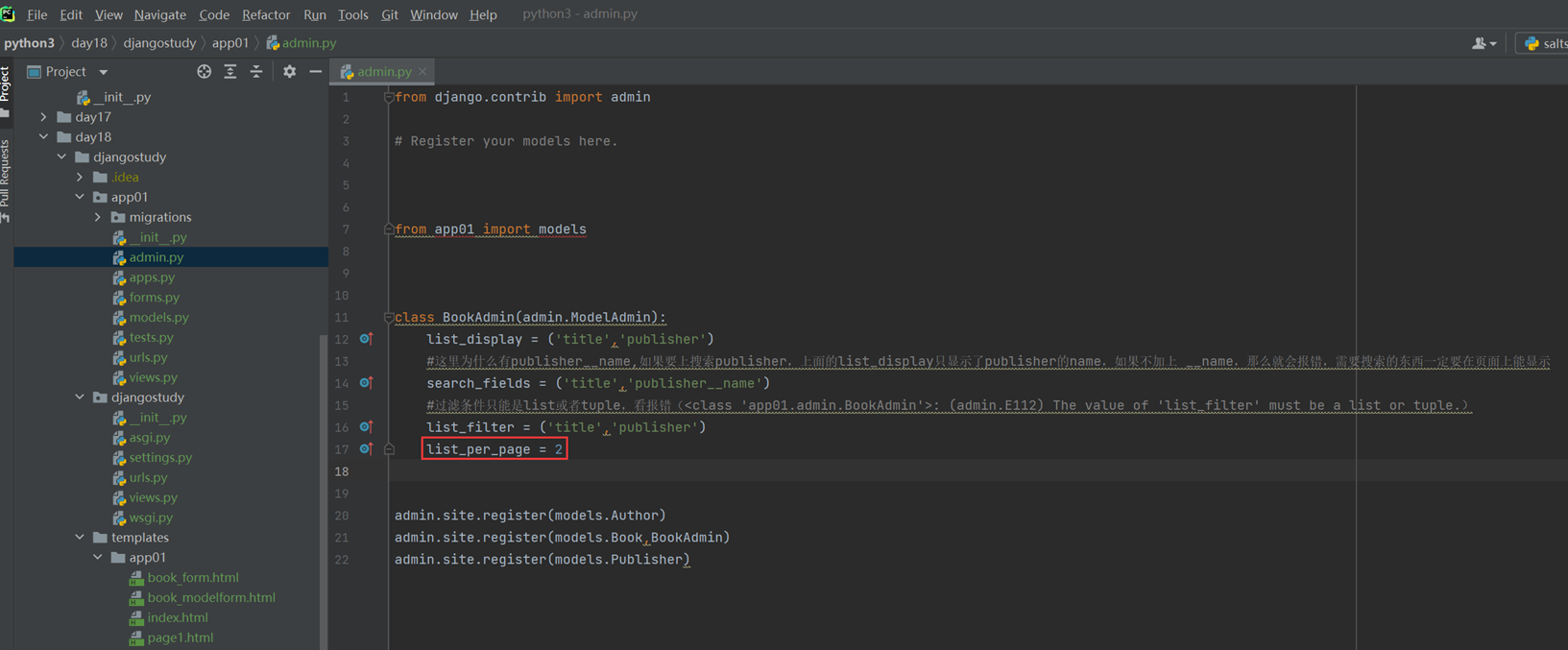
结果
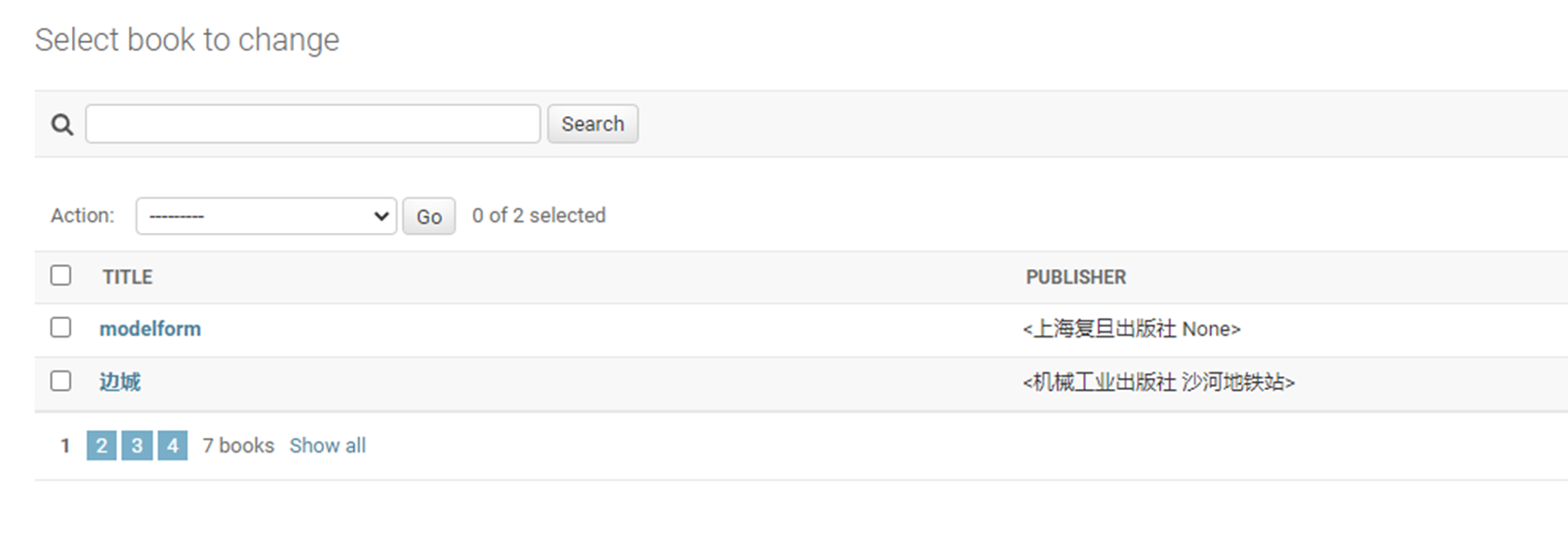
美化编辑框,可以多选,反选等操作
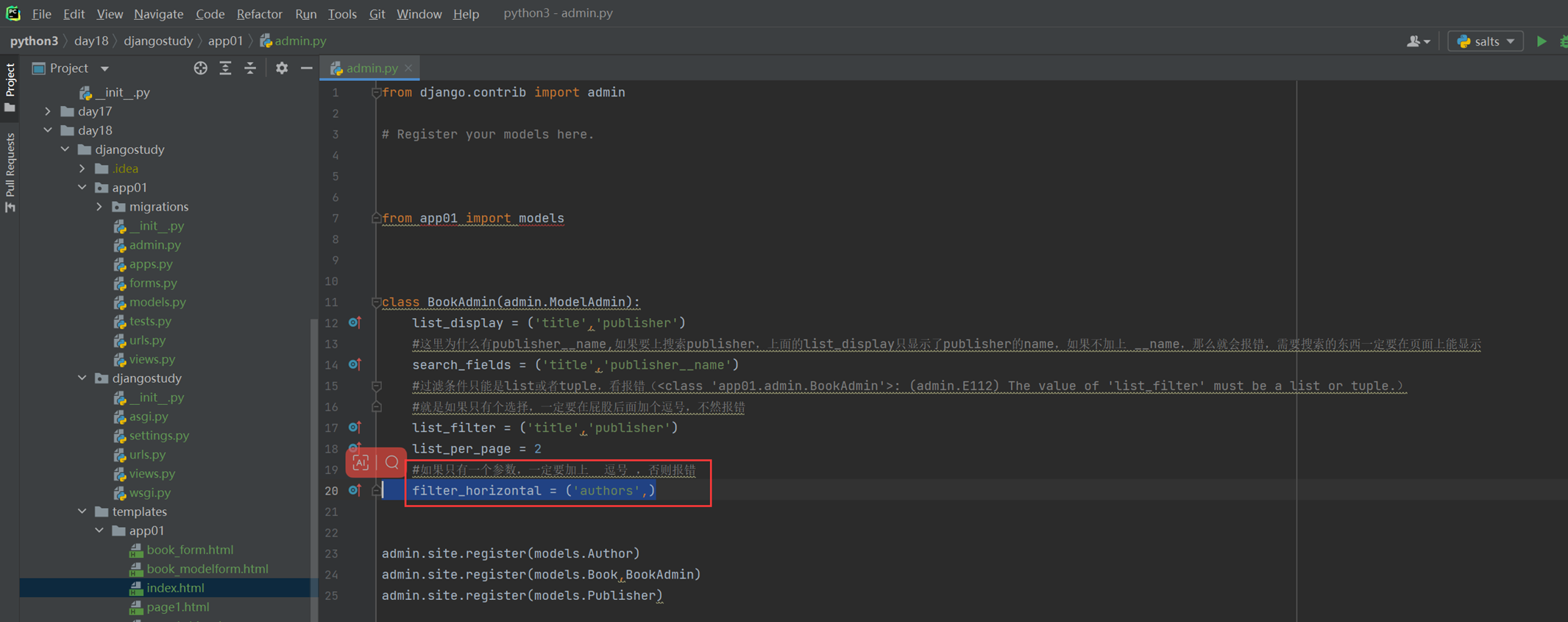
美化前
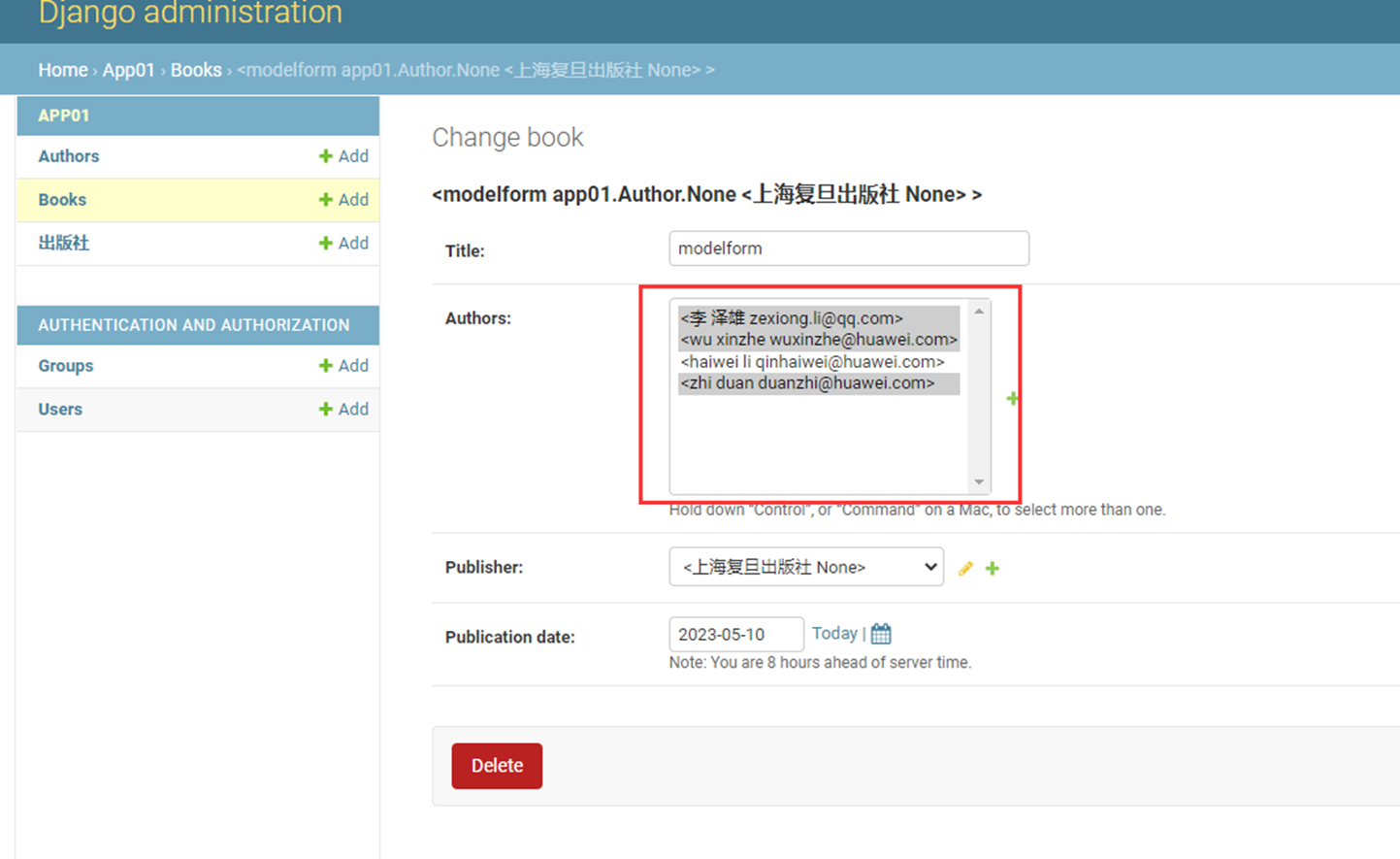
美化后
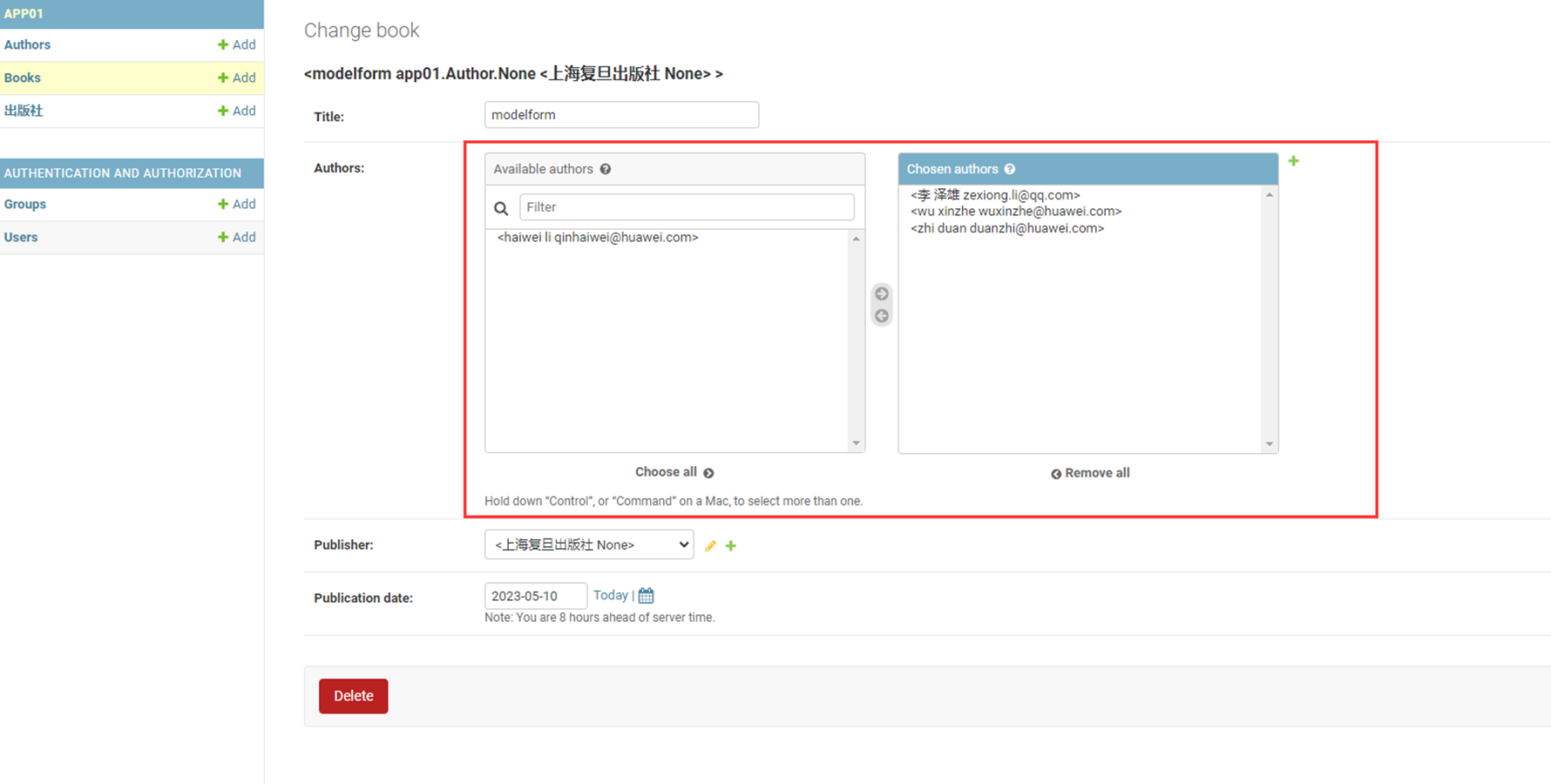
还有一个多编辑补充,可以看到,非常凶悍
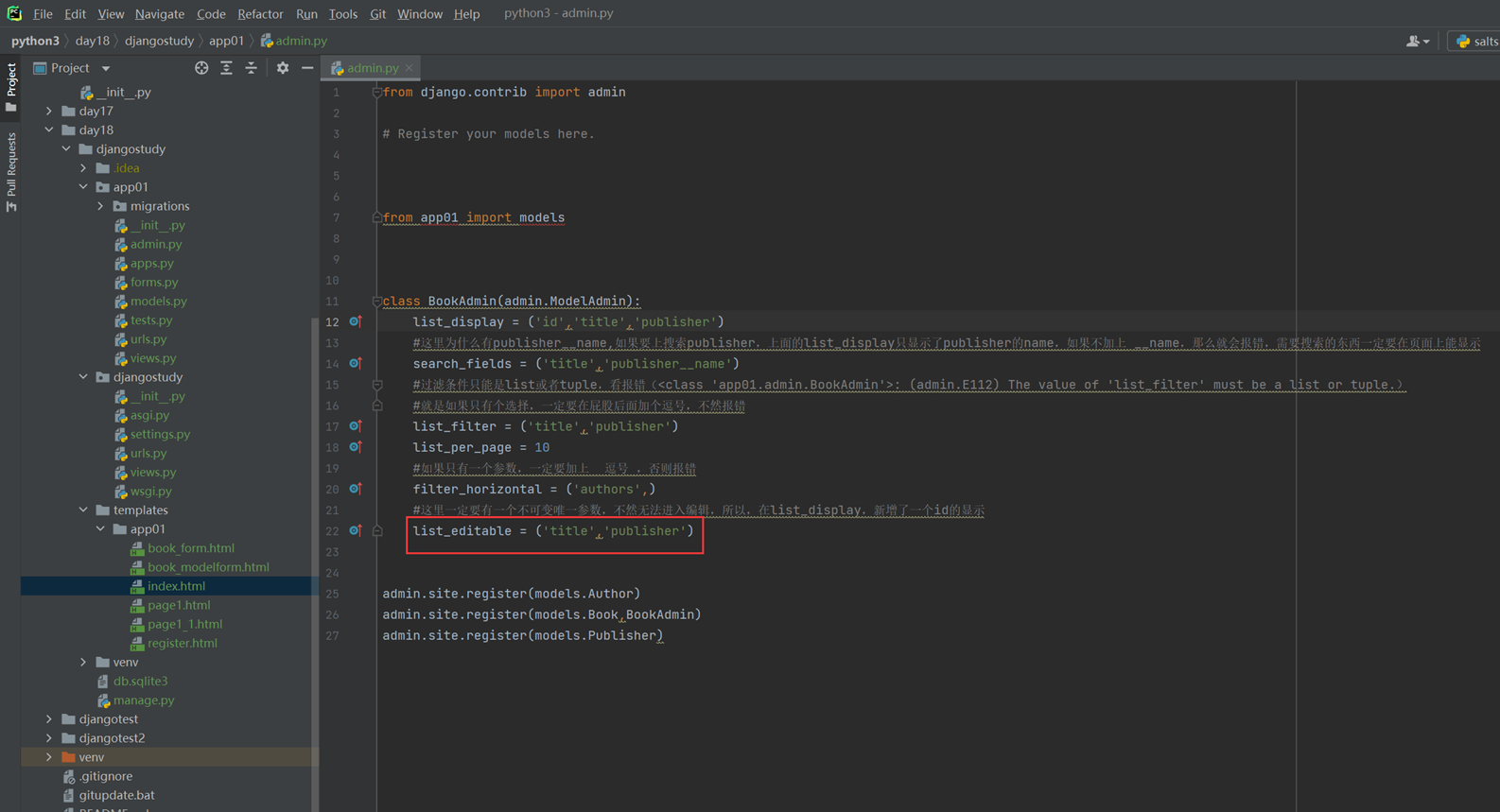
结果
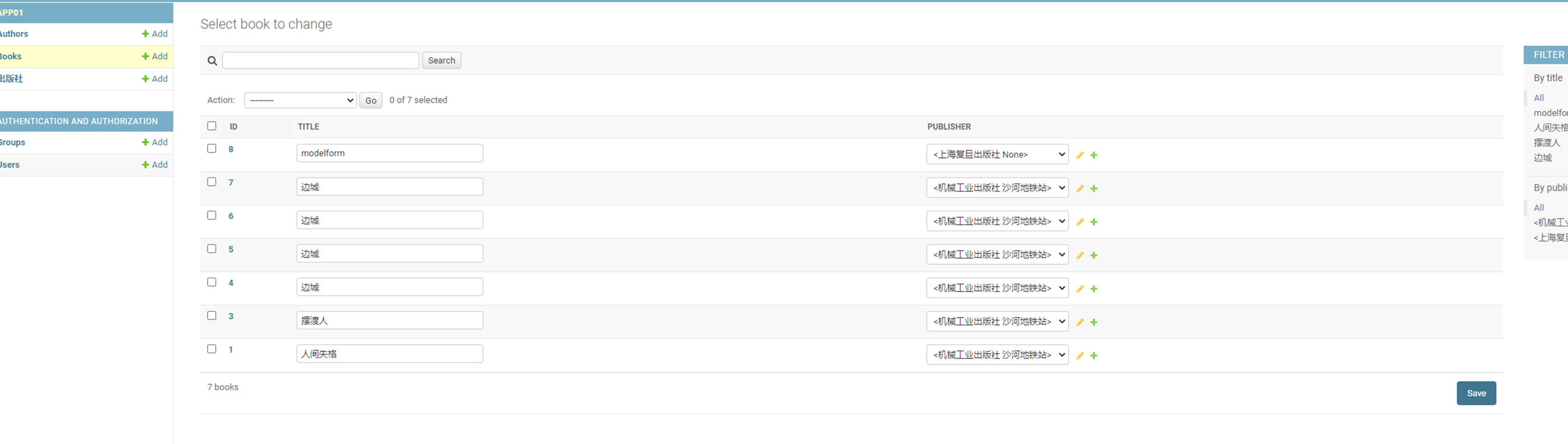
18.6 adminactions
这里有个需求,假设我有5本书,有一个状态就是“出版”、“待出版中”两个状态,我需要选择其中3本书,把他改称出版中,怎么操作?这就可以用到actions,其实默认也有一个功能存在,那就是删除。选择多一些条件,然后统一删除,这里我们自定义一下出版这个功能。
1.首先,我们要给book表加上这个字段。
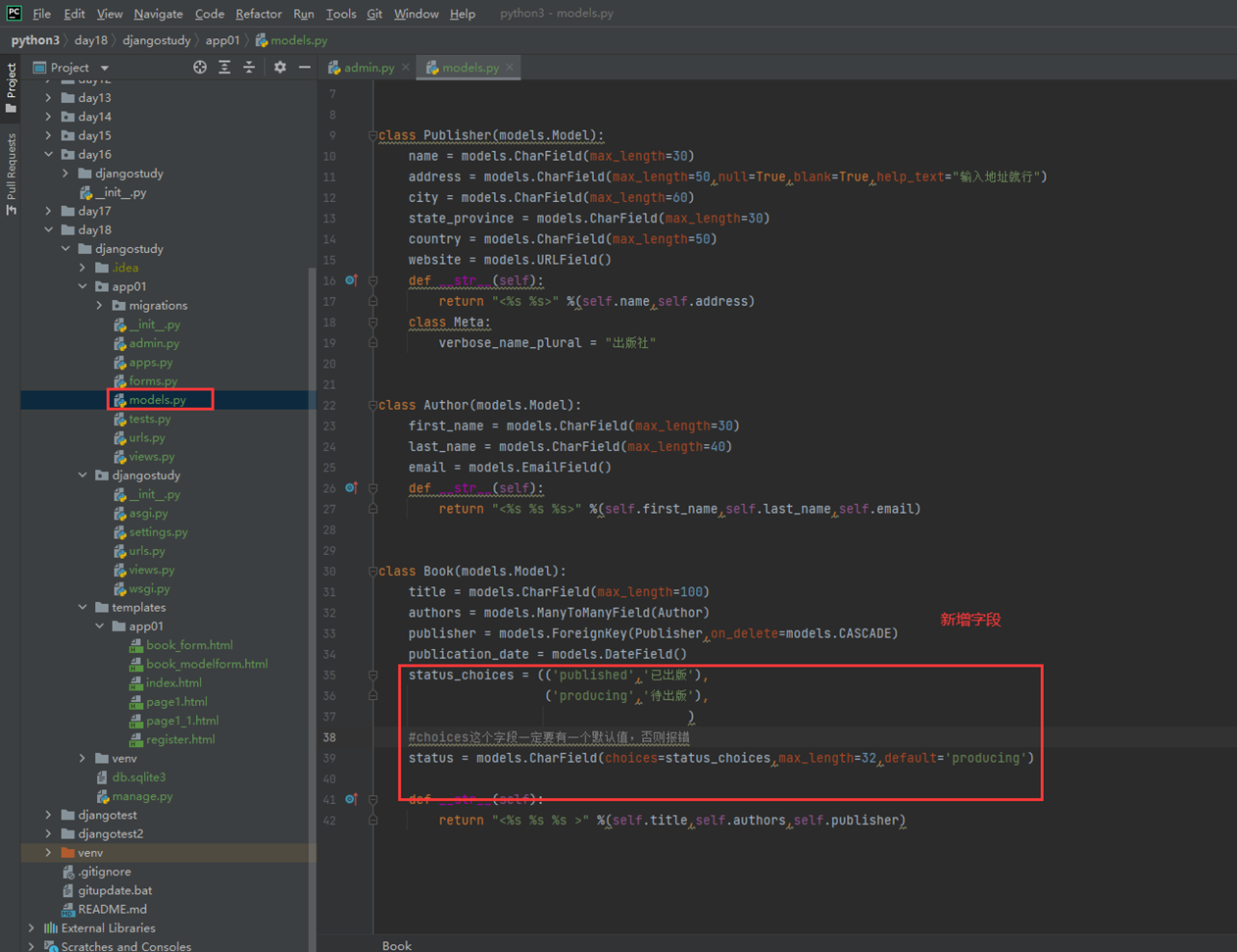
2.生成数据库配置以及数据库表
3.配置actions
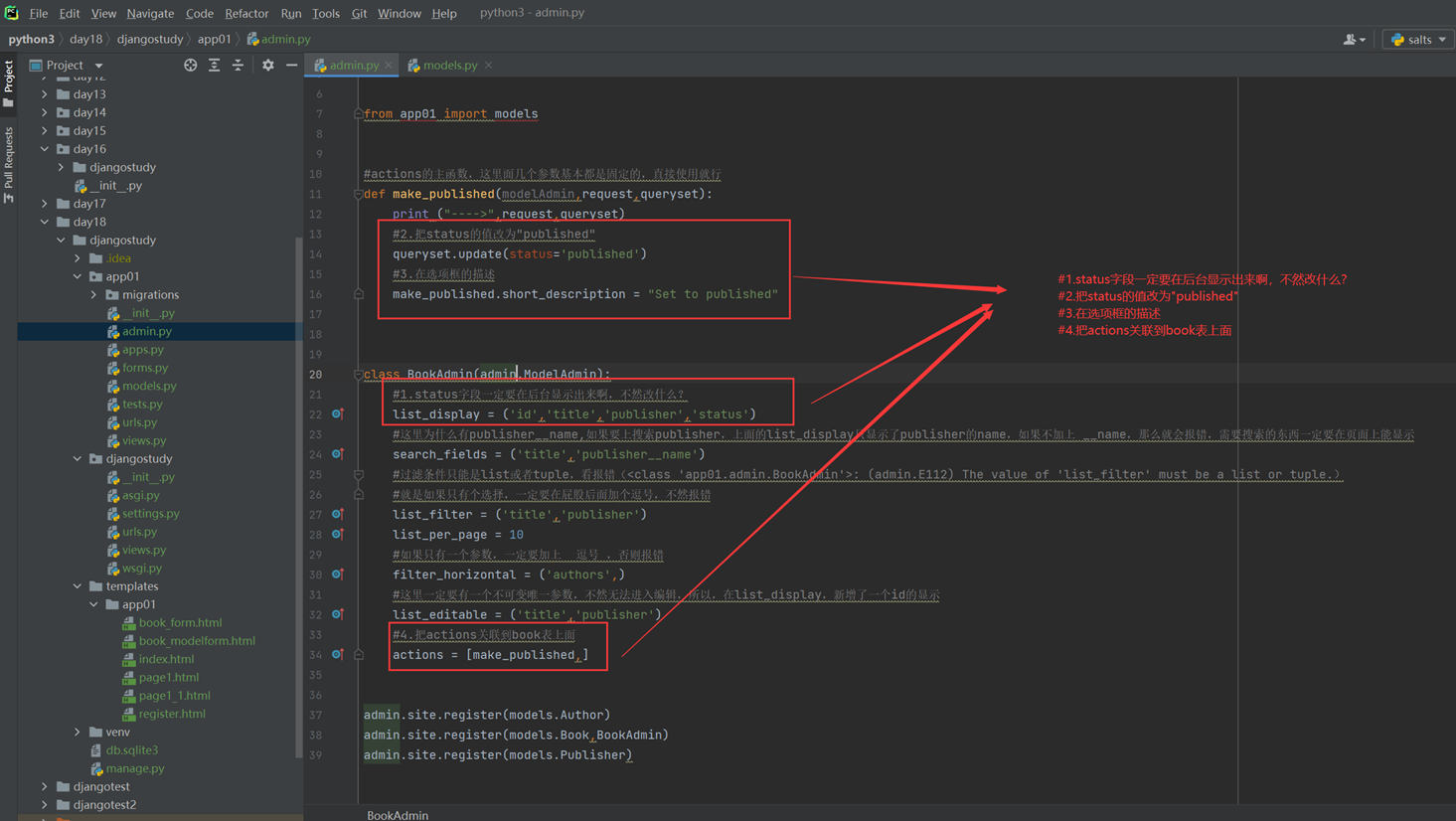
4.点开book表,查看能否批量修改
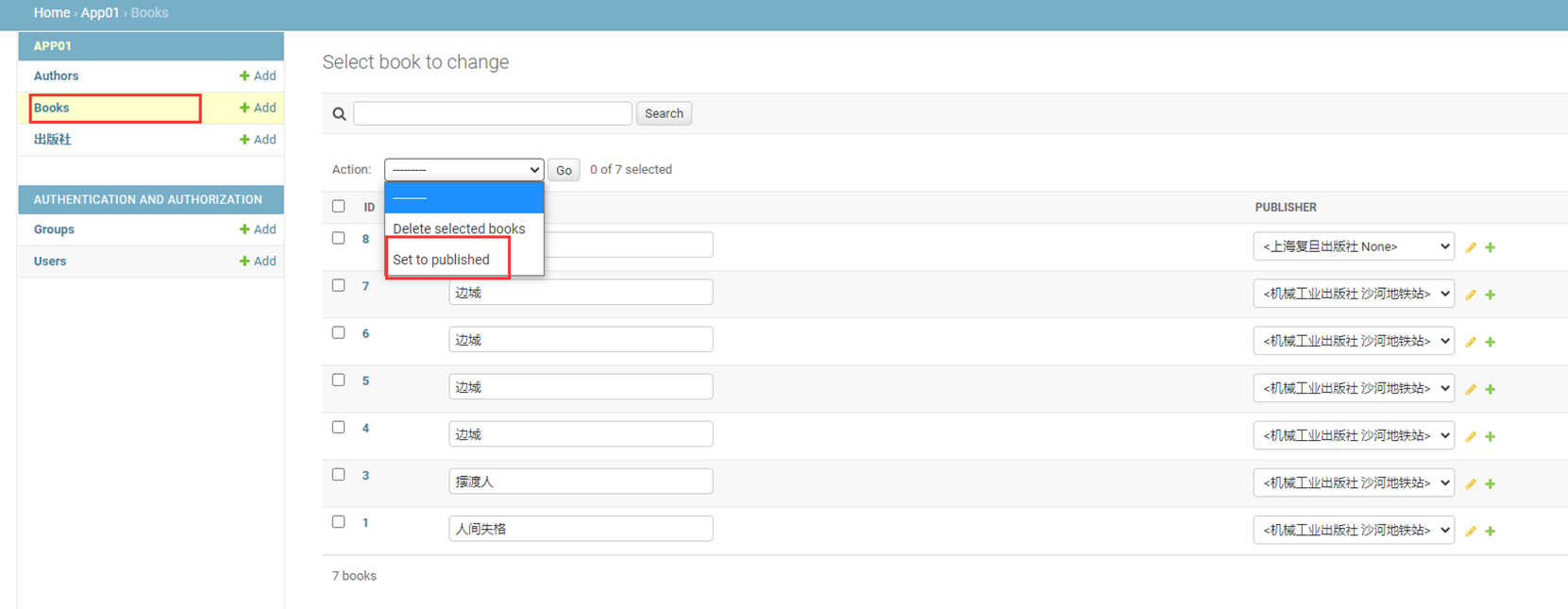
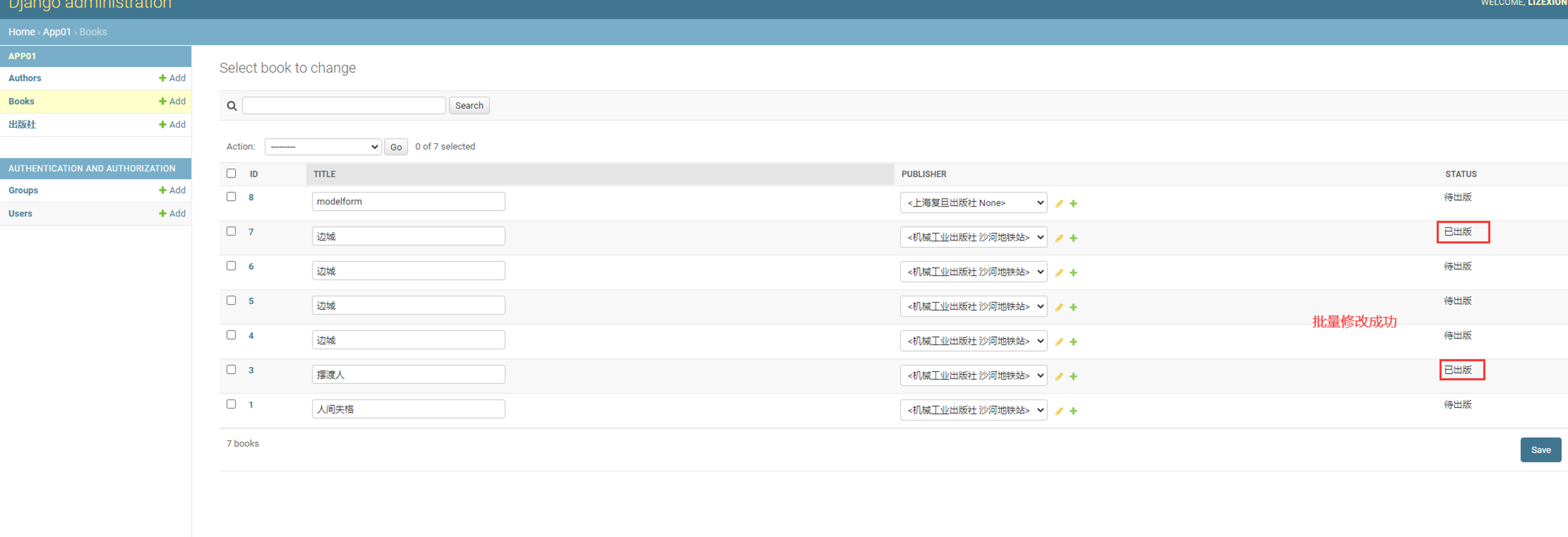
18.7 admin定制2
本章其实是接着上一章的,就是给status加个颜色。
1.直接上代码
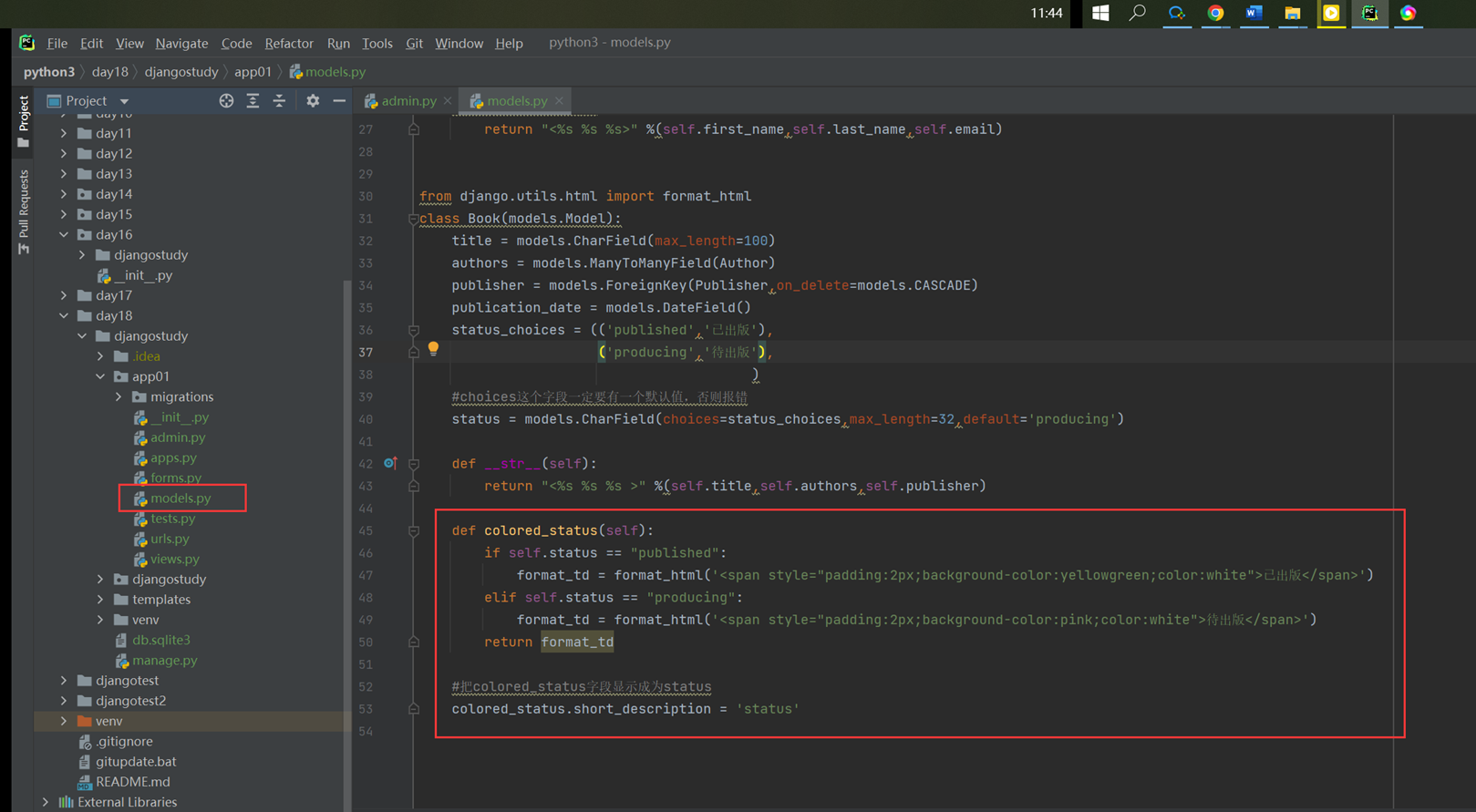
2.有了这个字段,要在django后台显示出来
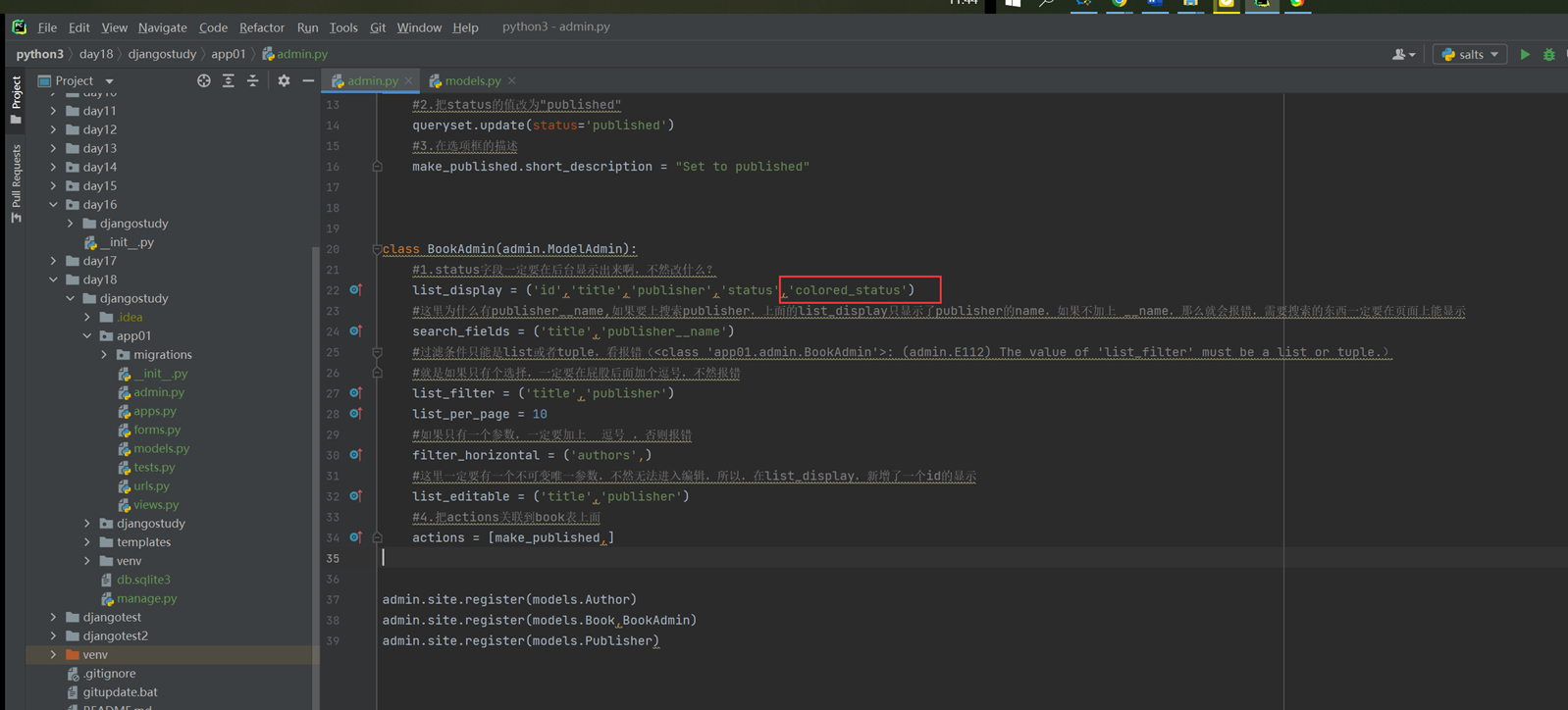
查看后台效果
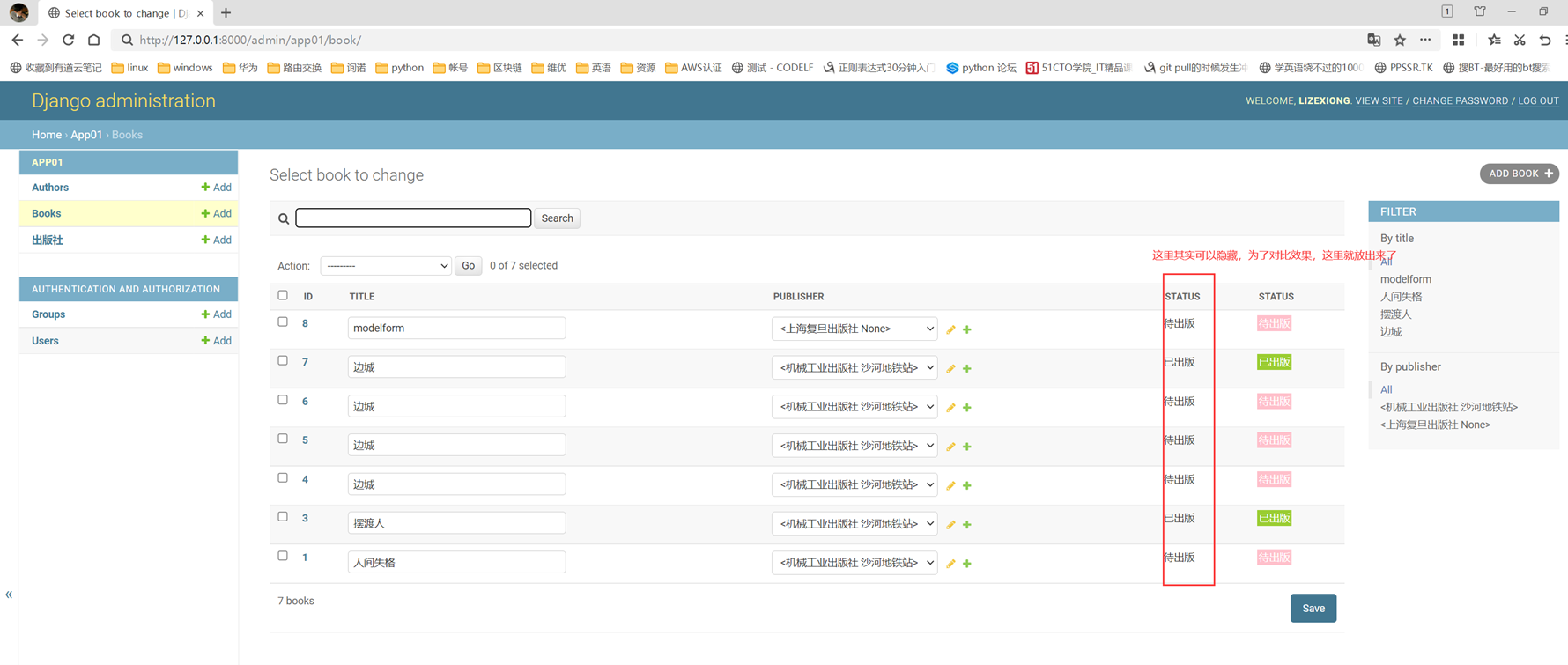
18.8 orm操作进阶(视频文件3分钟后损坏)
虽然视频后面是坏的,但是大概用的这里的代码。阶操作将的就是数据库更加细化的操作,比如什么更高难度的查询等等,没什么好说的。
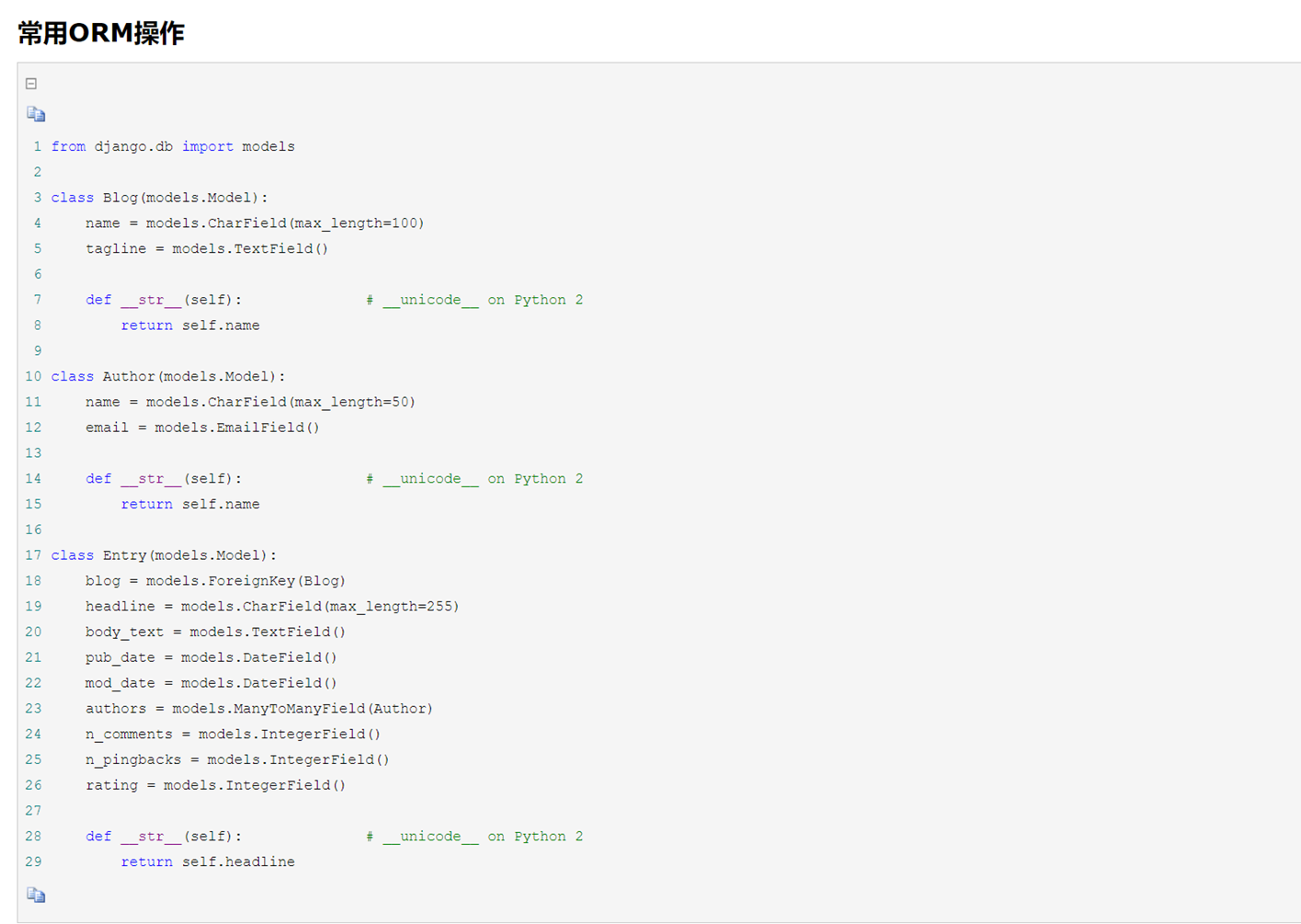
但是根据后面的章节,大概可以判断剩下的8分钟讲解的什么,讲了一下表结构,顺便创建了几张表,大概就是这个内容。
首先是Blog表
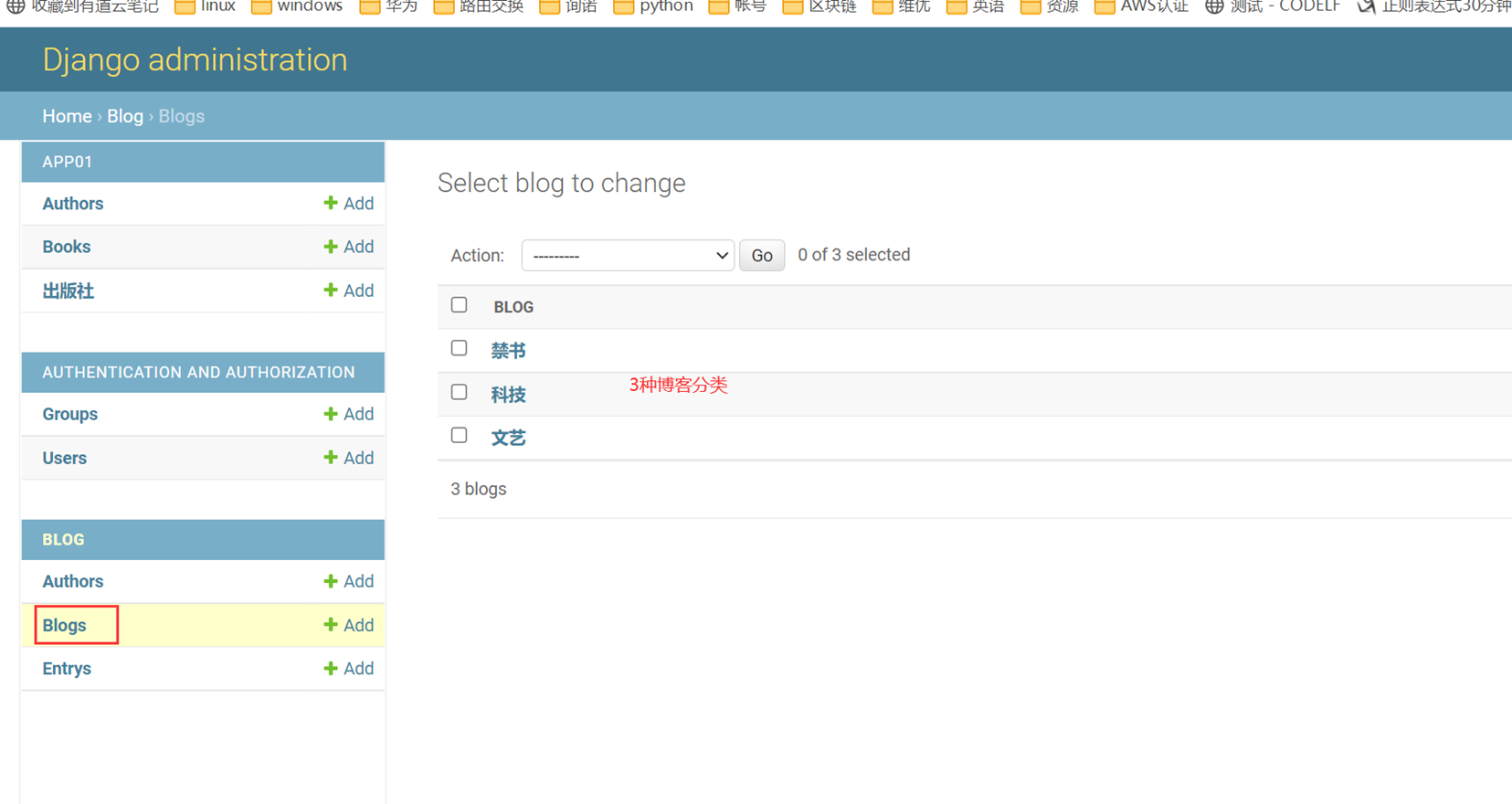
然后是作者表
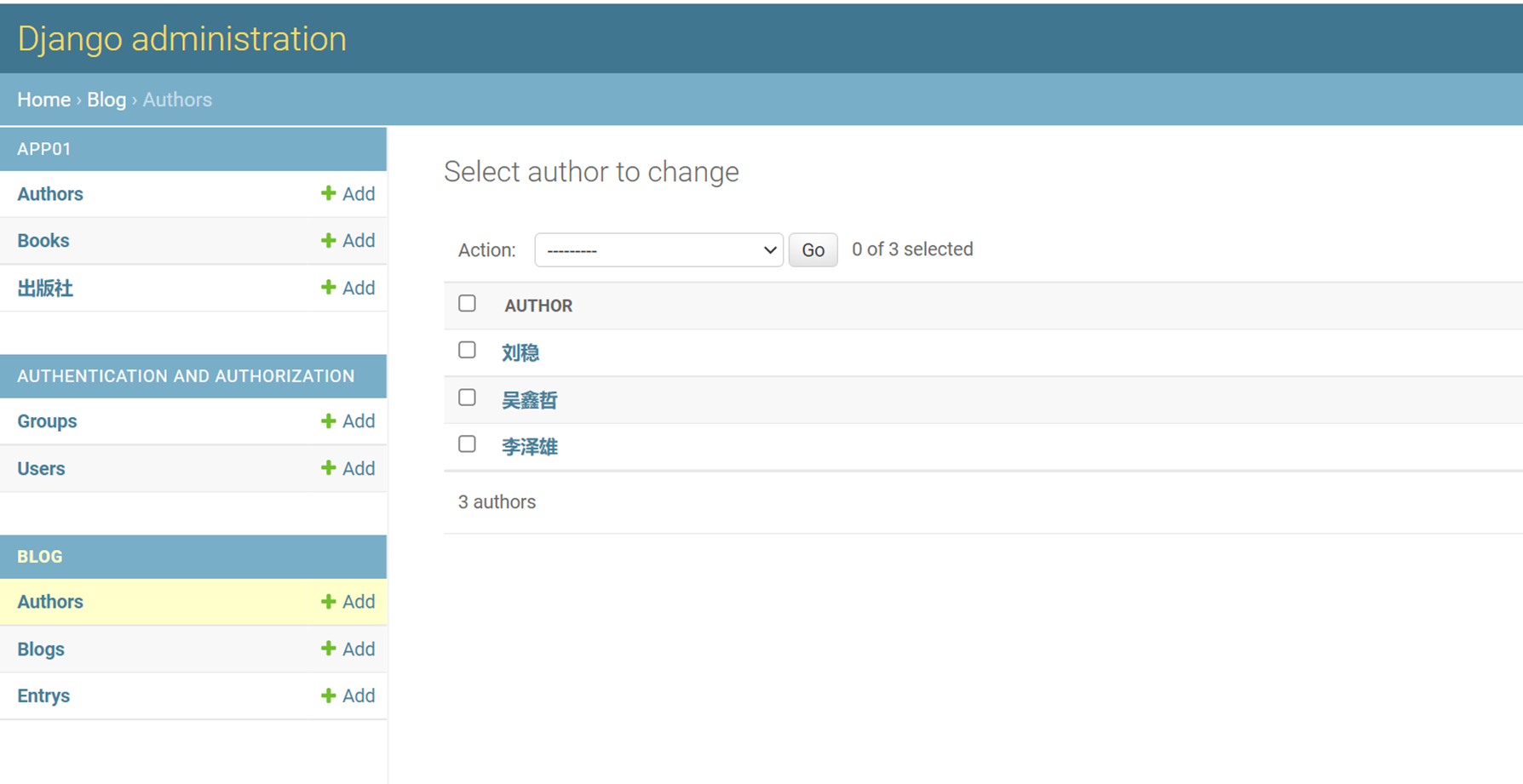
最后是文章表
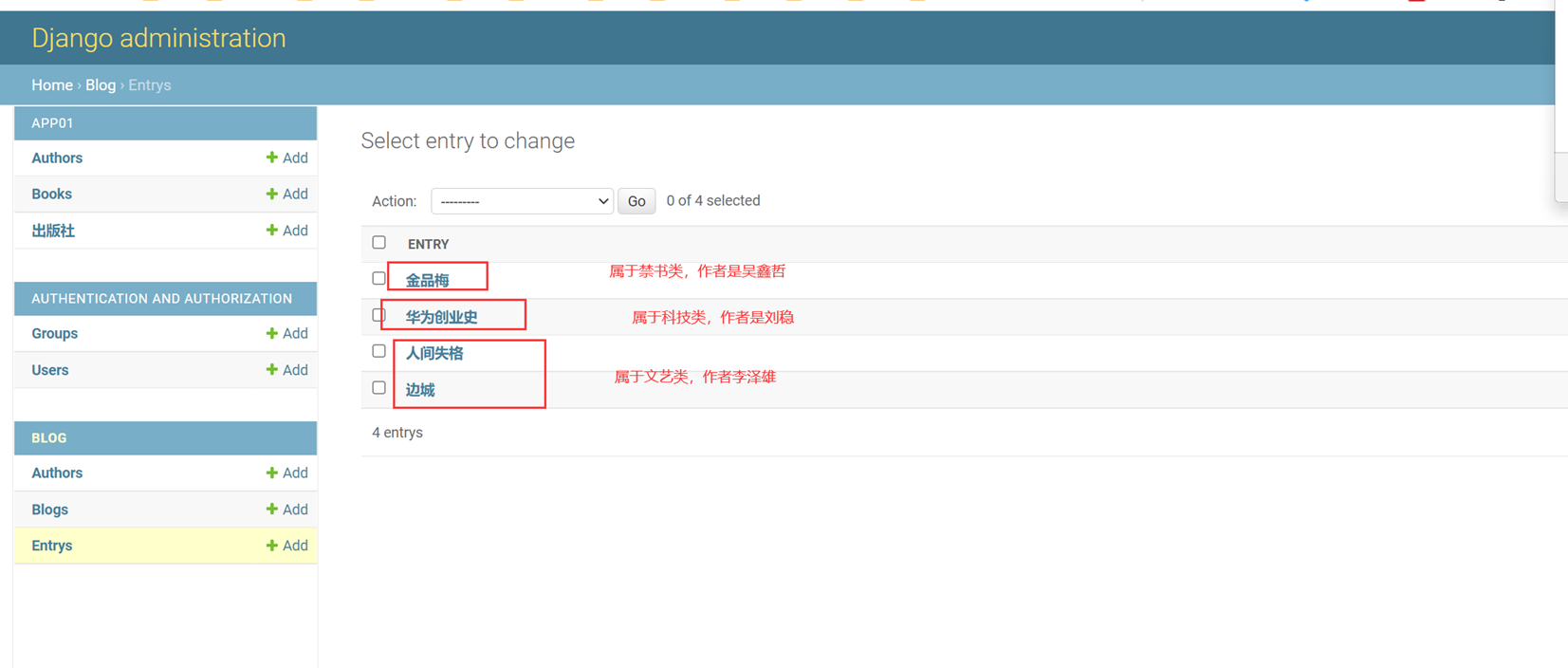
最后还会在数据库自动创建一张多对多的关联表
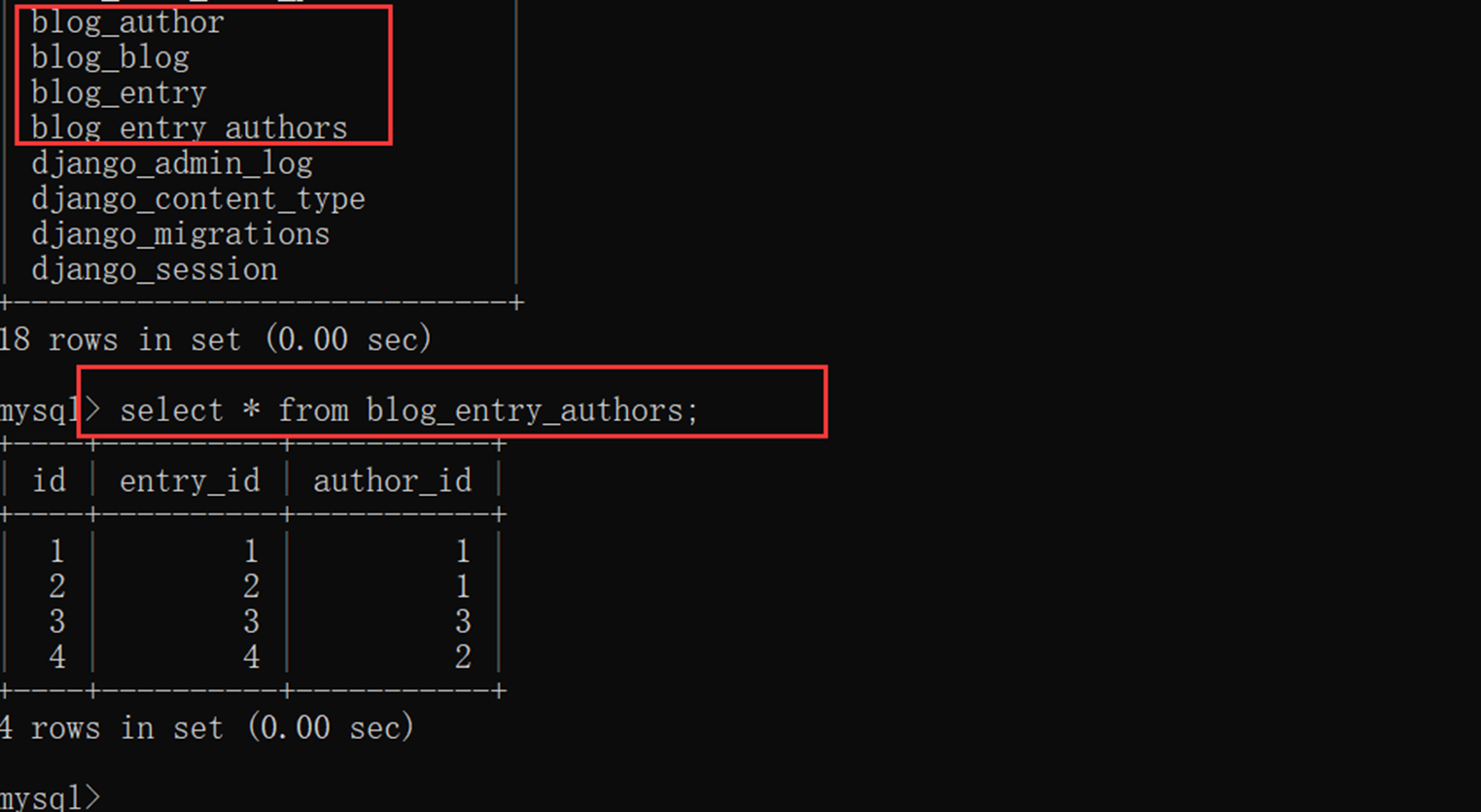
18.9 在自己写的脚本里调用djangomodels
django.setup() 初始化一个django环境,便于orm操作练习
原始的是在控制台中console中输入python manage.py shell ,然后再执行orm操作
首先,我们使用shell来操作一下
这样操作没有问题,我们怎么在python的脚本里面直接这么使用呢?那么就要使用django.setup()了。
这篇老师演砸了,视频后面没有,还是我网上自己搜索的。干!!!
18.10 orm增删改查
就是简单的操作一个查询以及修改,目的就是把属于禁书类的“金品梅”分类改为“科技”。
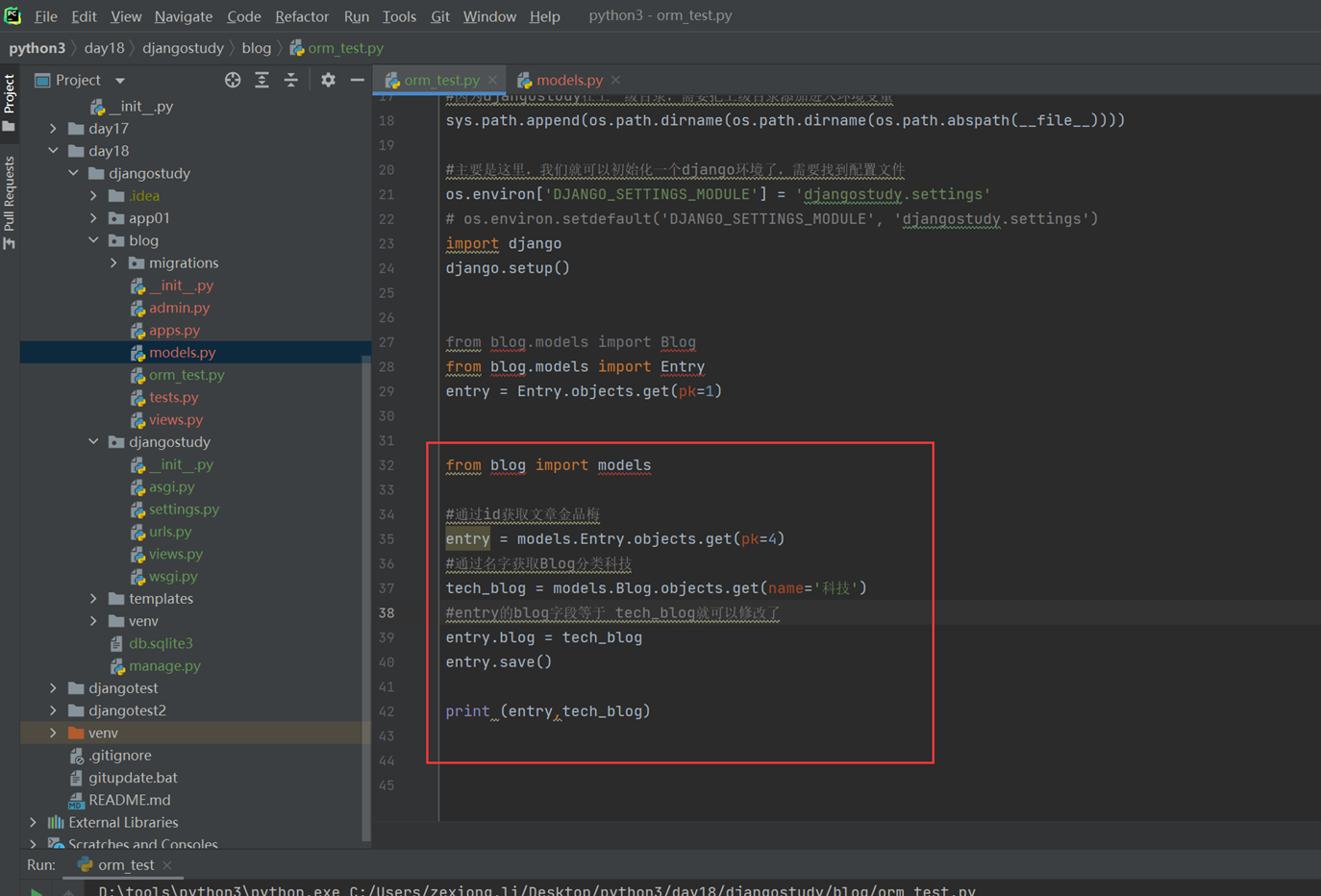
网页查看更改没有
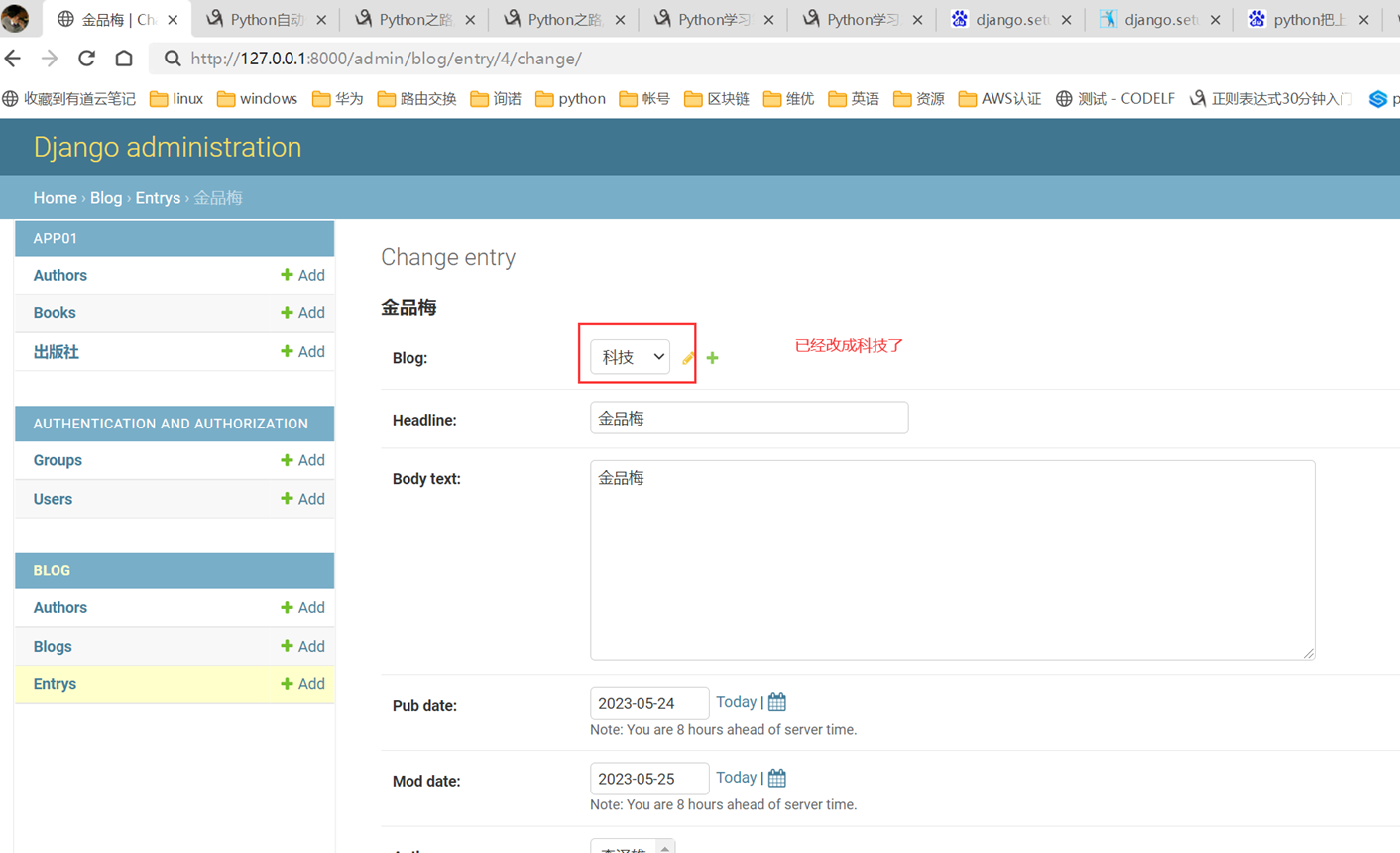
18.11 orm增删改查2
课程前9分钟讲解了一些查询的方式,没有演示,有需要的自己去做测试,讲的是博客的这里的案例
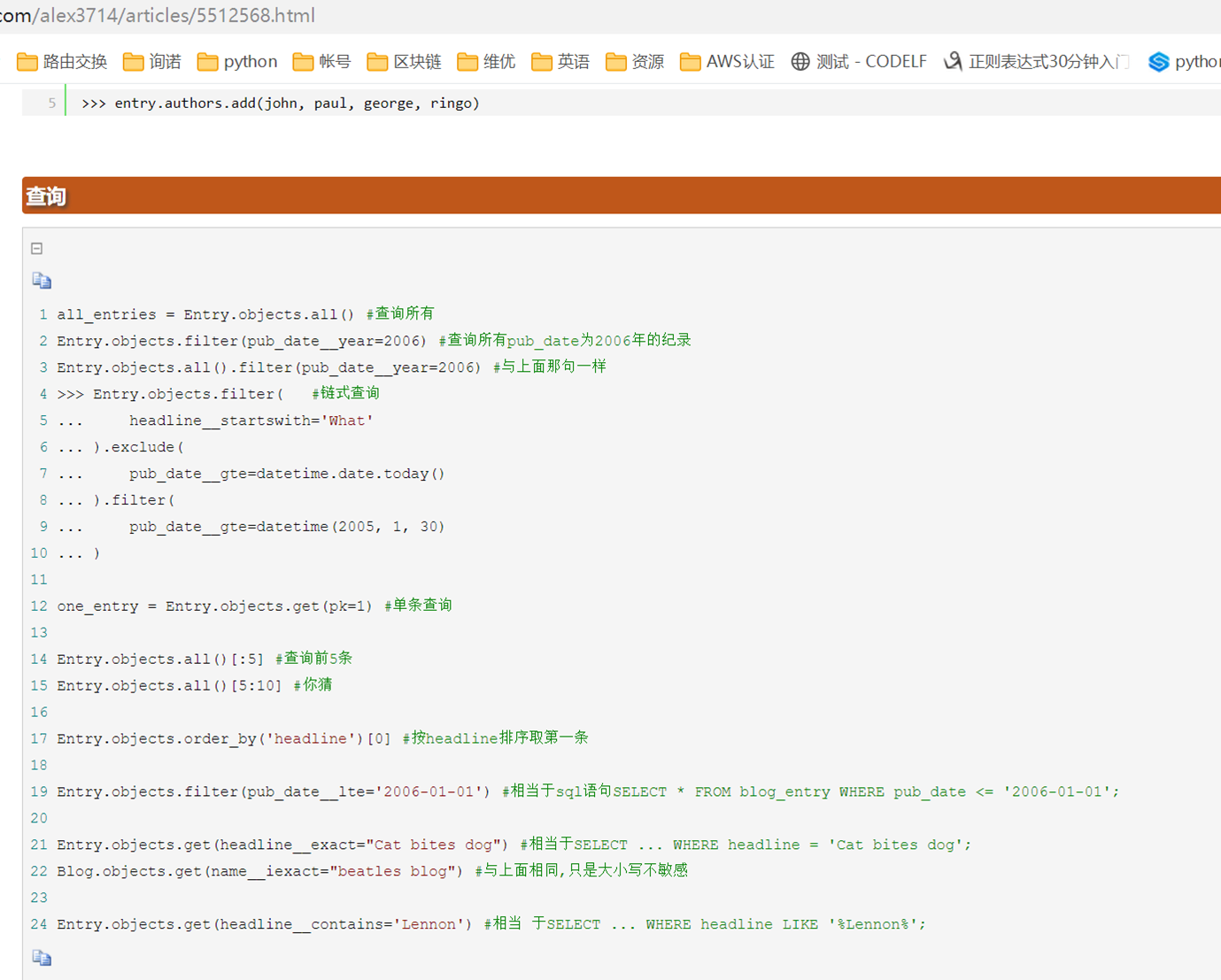
只演示了下面这个关联查询

这里还是演示一下关联查询
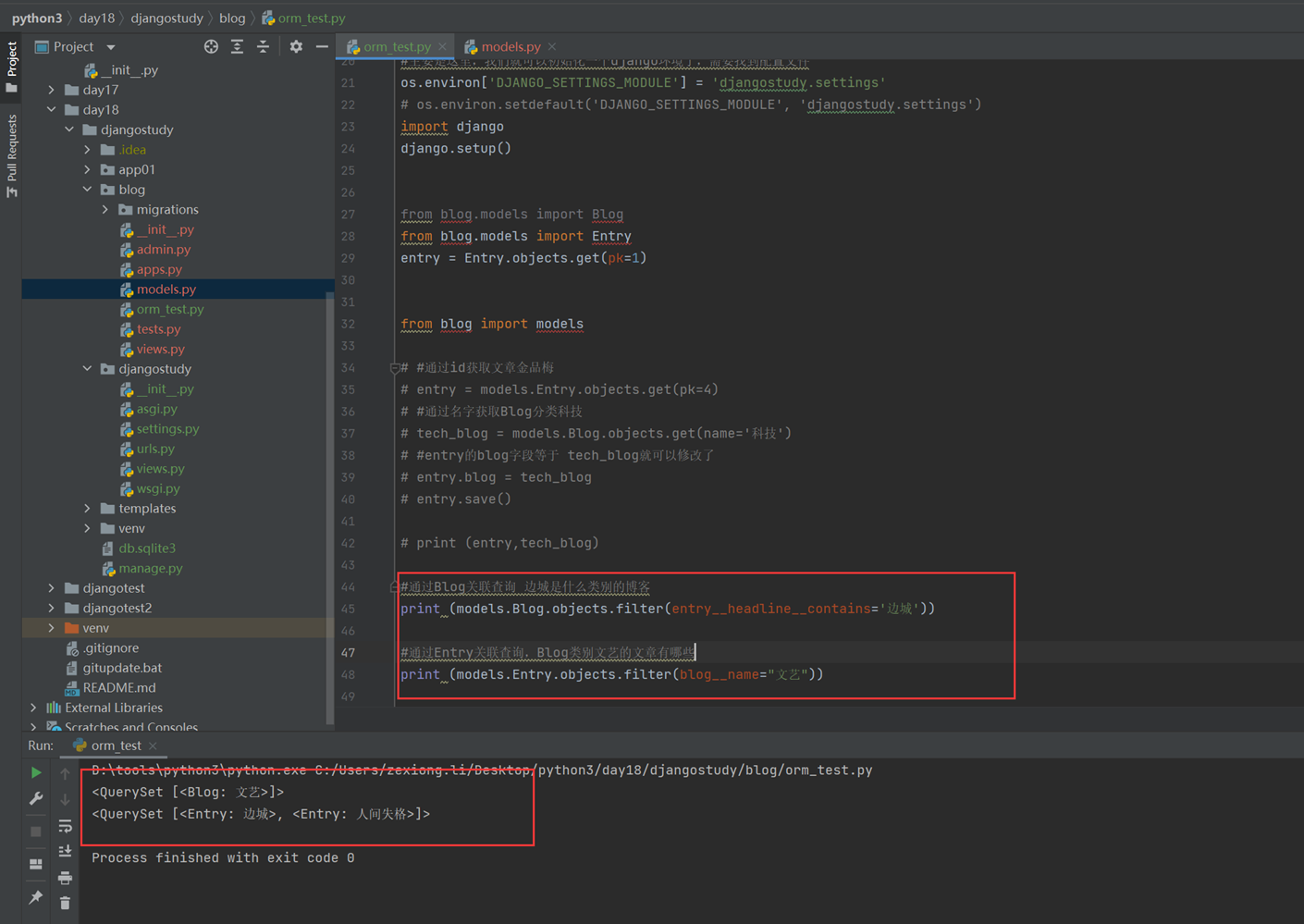
接下来就是讲解django 的F查询。
F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
之前构造的过滤器都只是将字段值与某个常量做比较,如果想要对两个字段的值做比较,就需要用到 F()。
使用前要先从 django.db.models 引入 F:
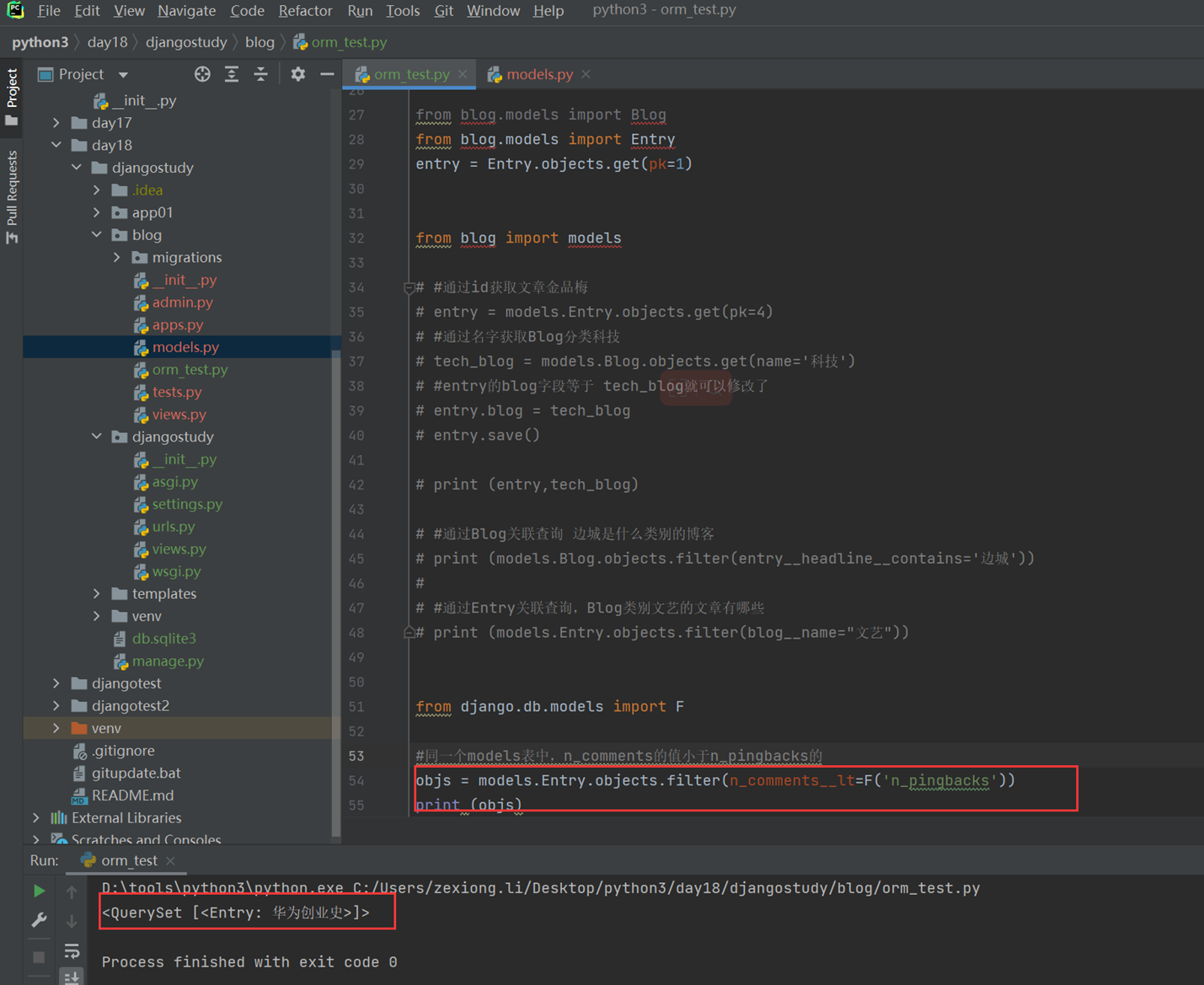
看看结果是不是你想要的
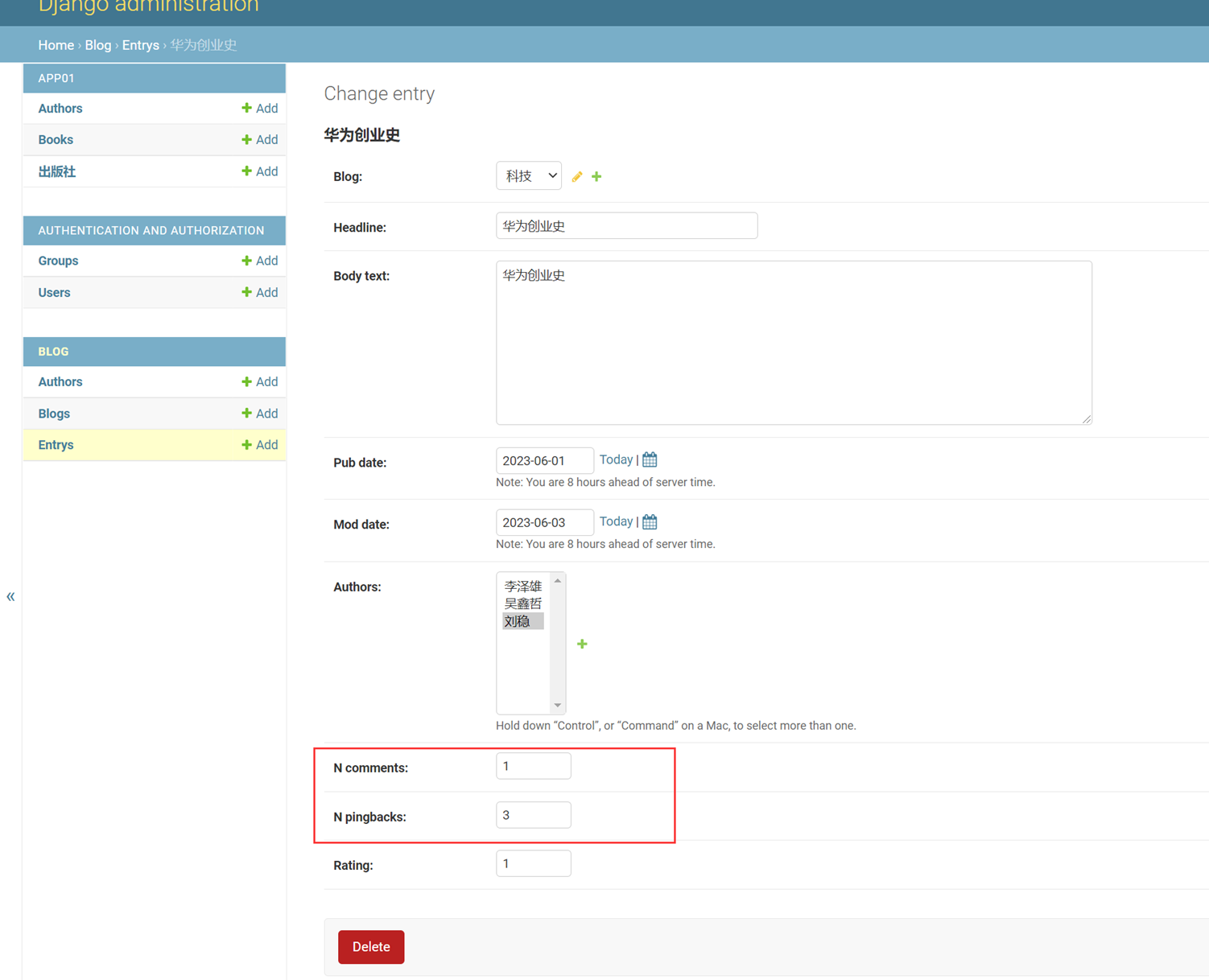
18.12 orm增删改查缓存
前面4分钟部分还是直接用嘴讲F的作用,没有演示,有兴趣的可以自己测试

后面讲解缓存也全部是理论,这里还是梳理一下
18.13 ormq语句
简单来说就是复杂查询,可以使用and和or这样一些复杂的条件,也可以和F以及普通语句配合查询。
以下就是课件
这里还是演示两个吧,这样看笔记的时候会轻松点。
1.查询 n_comments大于n_pingbacks的,并且,初版日期大于0519的看看有几个
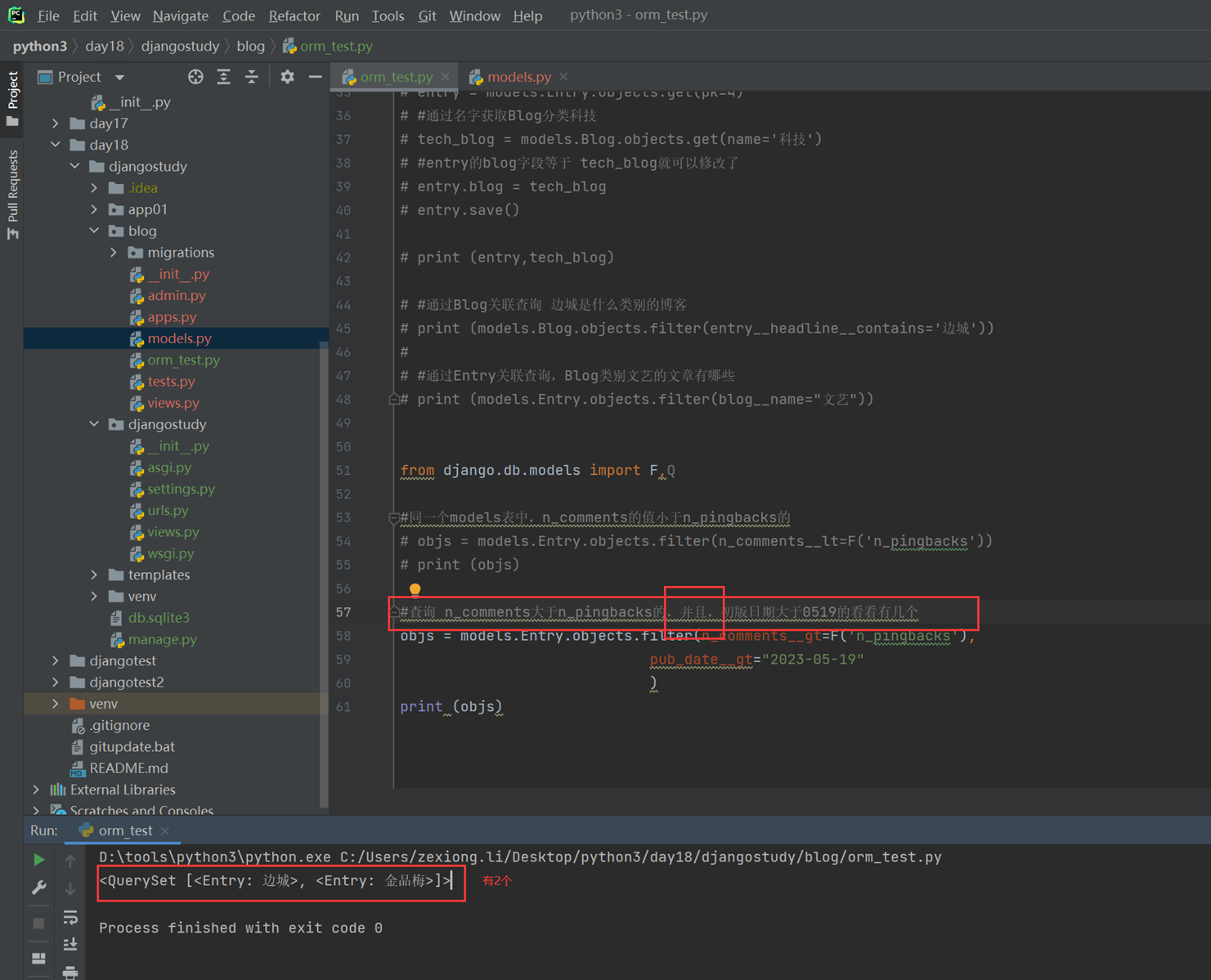
2.查询 n_comments小于n_pingbacks的,活着,初版日期大于0519的看看有几个
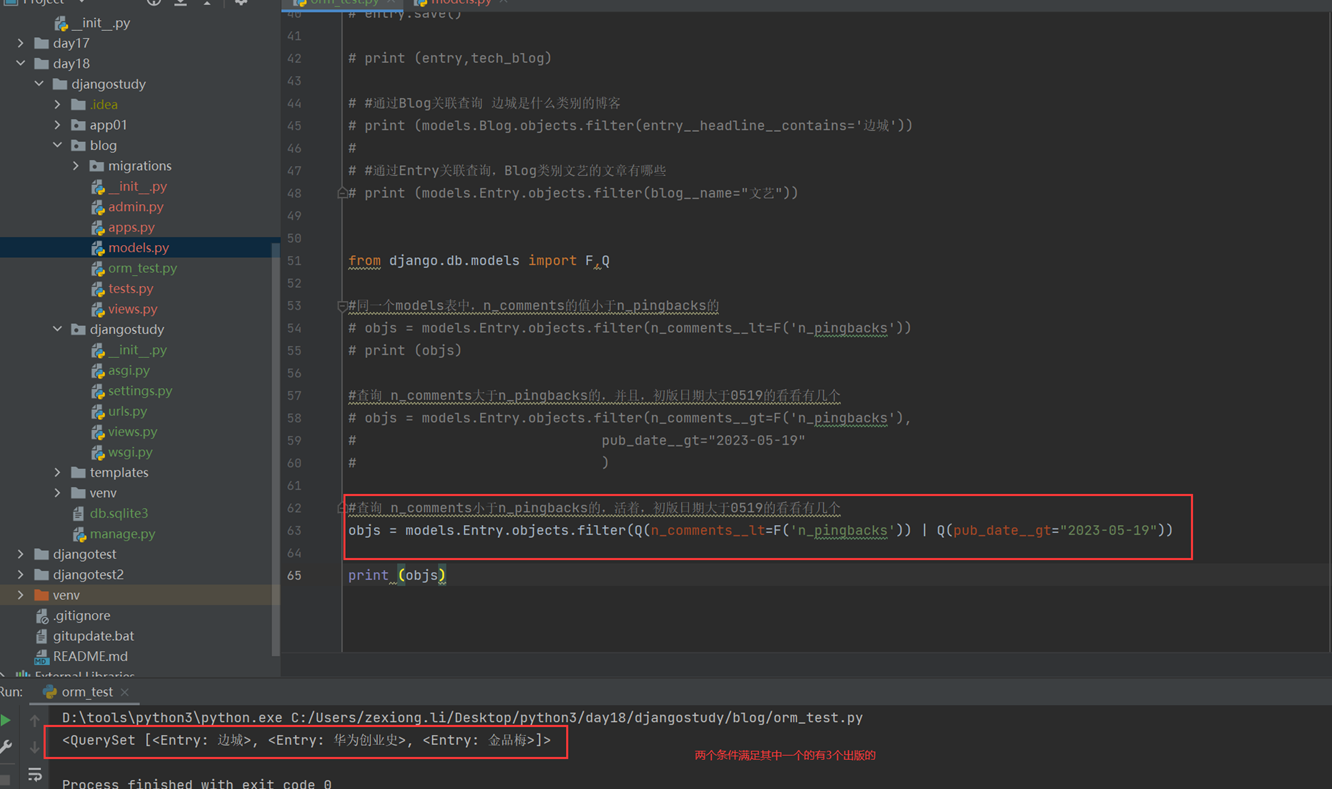
18.14 orm聚合查询
简单来说就是求一些平均值,最大值,最小值,总和的这样的一些值,这里我们演示一下。
由于演示过于简单,前面2个例子不用课件博客中的数据表,继续沿用老的数据库表结构。
1.求pingbacks的平均值,最大值,最小值
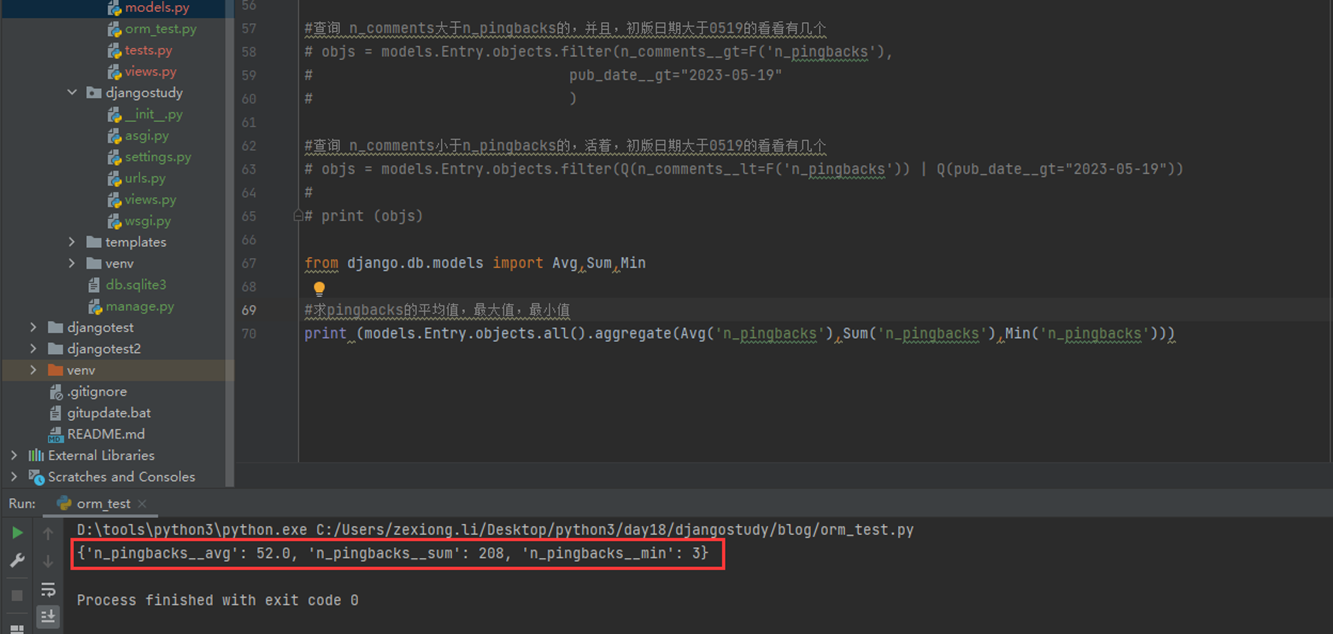
现在演示需要点条件,博客这个数据结构不足以支撑我们做测试,所以用回app01的数据库表结构。
1.反向关联查出“机械工业出版社”出版的所有书籍(这个是补充讲解,跟聚合没有关系)
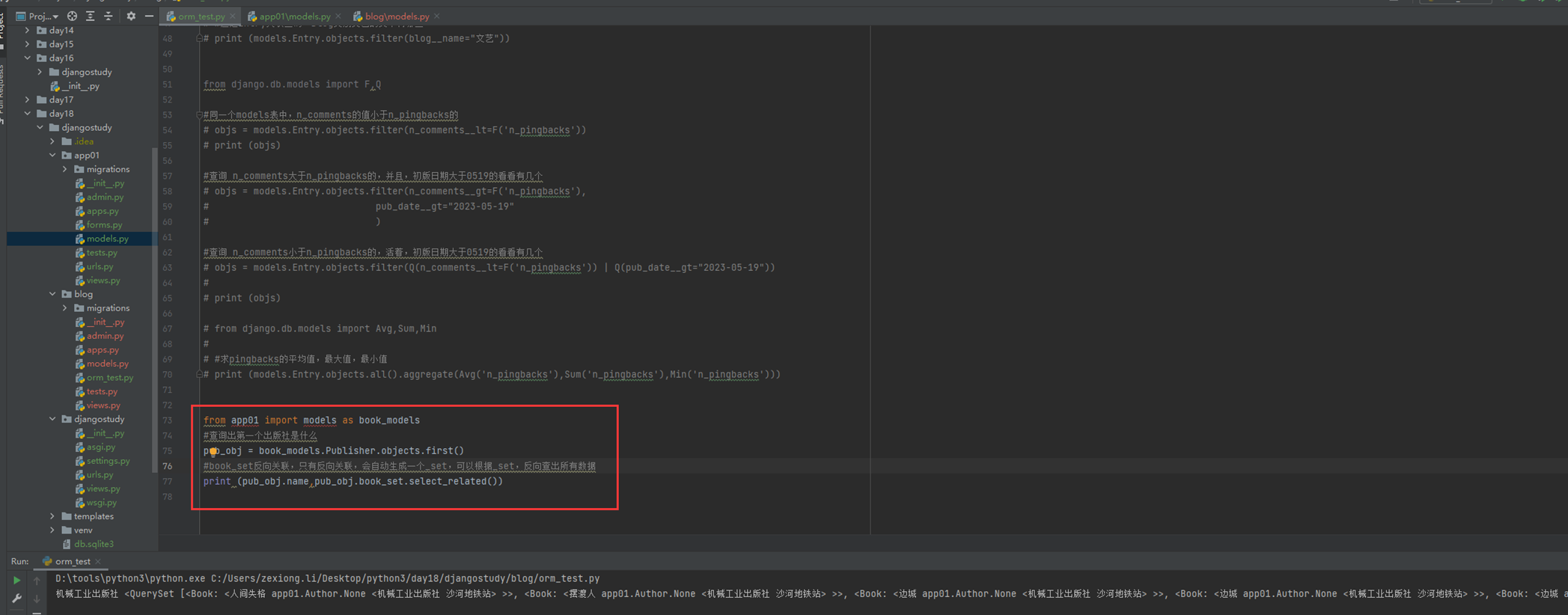
2.分类聚合,查出所有出版社各出版了多少书籍总数
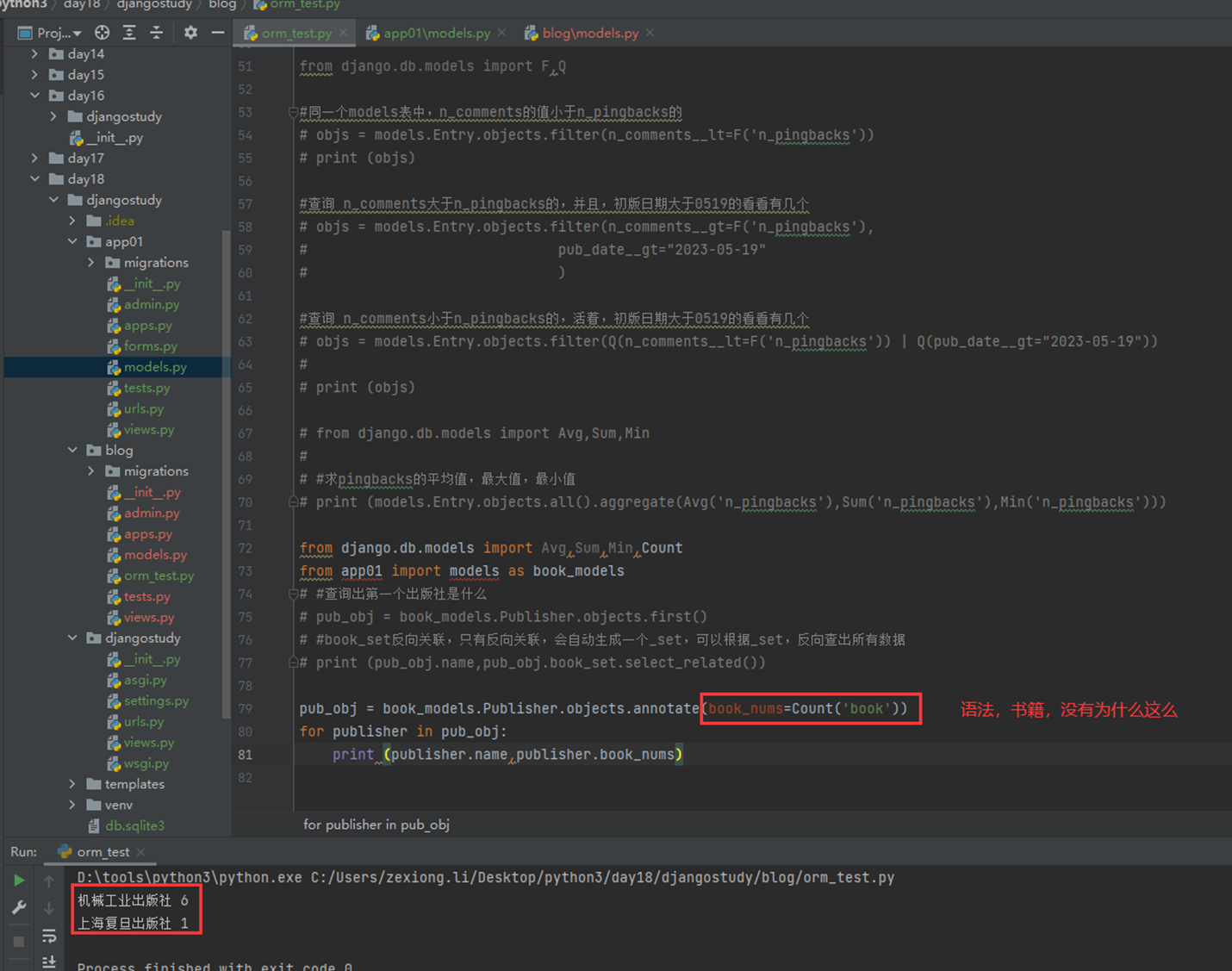
18.15 orm聚合查询2
再来一个需求,根据日期统计,该日期当天出版了多少本书。
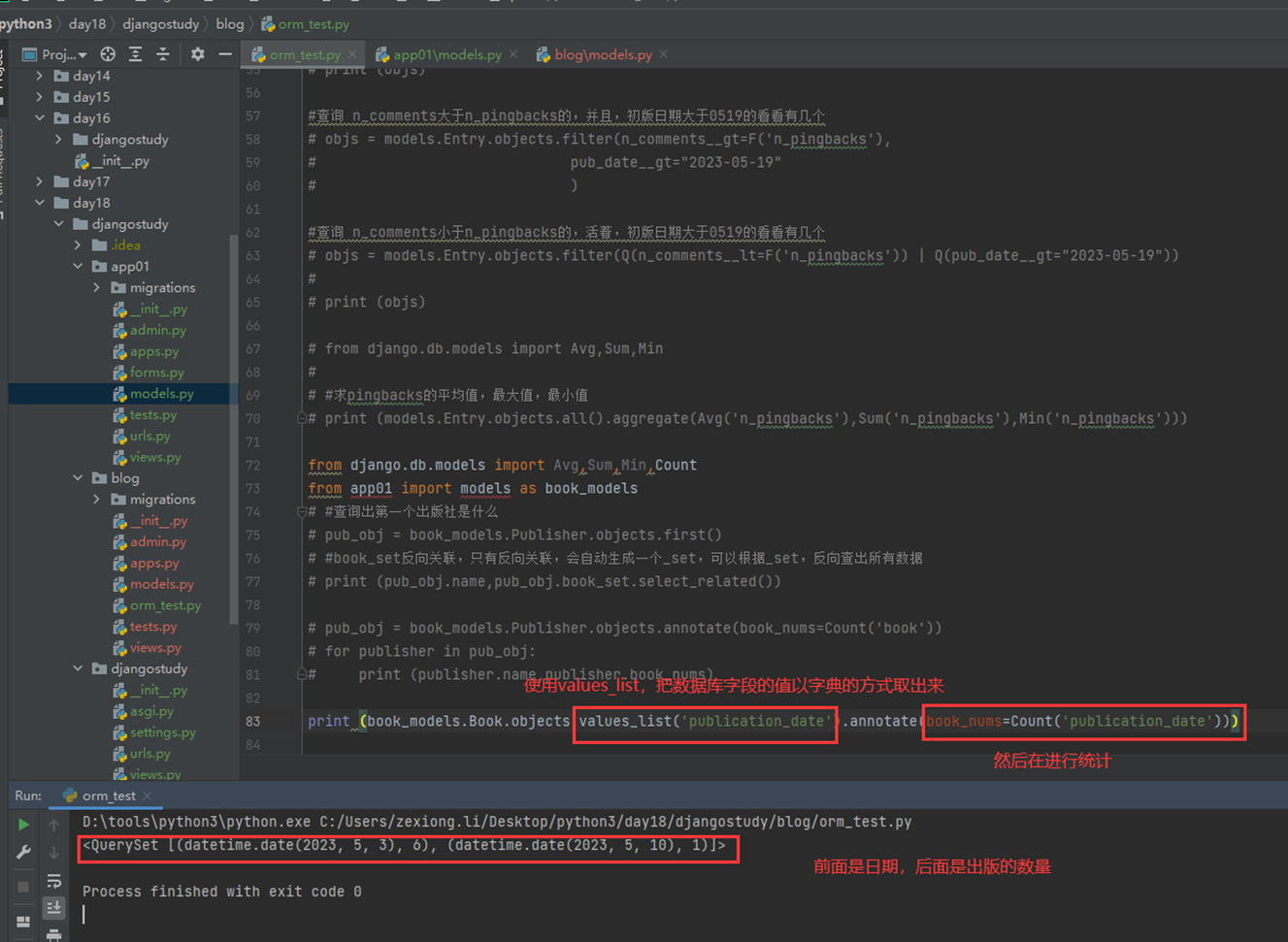
18.16 练习项目之学员管理系统开发
简单讲了一下这个小项目的需求,顺便讲了一下session原理,没有讲cookie,还讲了一下用户登录密码加严的原理,这个加严还不知道讲的是不是对的,听起来很乱。

18.17 用户认证及onetoonefield
就讲了以下理论
18.18 创建及设计学员系统表结构
本节课就讲解了数据表结构,顺便创建了数据表数据。后续会把数据表结构放置上git。


#学员管理系统表结构 #_*_coding:utf-8_*_ from django.db import models # Create your models here. from django.core.exceptions import ValidationError from django.db import models from django.contrib.auth.models import User class_type_choices= (('online',u'网络班'), ('offline_weekend',u'面授班(周末)',), ('offline_fulltime',u'面授班(脱产)',), ) class UserProfile(models.Model): user = models.OneToOneField(User) name = models.CharField(u"姓名",max_length=32) def __unicode__(self): return self.name class School(models.Model): name = models.CharField(u"校区名称",max_length=64,unique=True) addr = models.CharField(u"地址",max_length=128) staffs = models.ManyToManyField('UserProfile',blank=True) def __unicode__(self): return self.name class Course(models.Model): name = models.CharField(u"课程名称",max_length=128,unique=True) price = models.IntegerField(u"面授价格") online_price = models.IntegerField(u"网络班价格") brief = models.TextField(u"课程简介") def __unicode__(self): return self.name class ClassList(models.Model): course = models.ForeignKey('Course') course_type = models.CharField(u"课程类型",choices=class_type_choices,max_length=32) semester = models.IntegerField(u"学期") start_date = models.DateField(u"开班日期") graduate_date = models.DateField(u"结业日期",blank=True,null=True) teachers = models.ManyToManyField(UserProfile,verbose_name=u"讲师") #def __unicode__(self): # return "%s(%s)" %(self.course.name,self.course_type) class Meta: verbose_name = u'班级列表' verbose_name_plural = u"班级列表" unique_together = ("course","course_type","semester") class Customer(models.Model): qq = models.CharField(u"QQ号",max_length=64,unique=True) name = models.CharField(u"姓名",max_length=32,blank=True,null=True) phone = models.BigIntegerField(u'手机号',blank=True,null=True) stu_id = models.CharField(u"学号",blank=True,null=True,max_length=64) #id = models.CharField(u"身份证号",blank=True,null=True,max_length=128) source_type = (('qq',u"qq群"), ('referral',u"内部转介绍"), ('51cto',u"51cto"), ('agent',u"招生代理"), ('others',u"其它"), ) source = models.CharField(u'客户来源',max_length=64, choices=source_type,default='qq') referral_from = models.ForeignKey('self',verbose_name=u"转介绍自学员",help_text=u"若此客户是转介绍自内部学员,请在此处选择内部学员姓名",blank=True,null=True,related_name="internal_referral") course = models.ForeignKey(Course,verbose_name=u"咨询课程") class_type = models.CharField(u"班级类型",max_length=64,choices=class_type_choices) customer_note = models.TextField(u"客户咨询内容详情",help_text=u"客户咨询的大概情况,客户个人信息备注等...") status_choices = (('signed',u"已报名"), ('unregistered',u"未报名"), ('graduated',u"已毕业"), ) status = models.CharField(u"状态",choices=status_choices,max_length=64,default=u"unregistered",help_text=u"选择客户此时的状态") consultant = models.ForeignKey(UserProfile,verbose_name=u"课程顾问") date = models.DateField(u"咨询日期",auto_now_add=True) class_list = models.ManyToManyField('ClassList',verbose_name=u"已报班级",blank=True) def __unicode__(self): return "%s,%s" %(self.qq,self.name ) class ConsultRecord(models.Model): customer = models.ForeignKey(Customer,verbose_name=u"所咨询客户") note = models.TextField(u"跟进内容...") status_choices = ((1,u"近期无报名计划"), (2,u"2个月内报名"), (3,u"1个月内报名"), (4,u"2周内报名"), (5,u"1周内报名"), (6,u"2天内报名"), (7,u"已报名"), ) status = models.IntegerField(u"状态",choices=status_choices,help_text=u"选择客户此时的状态") consultant = models.ForeignKey(UserProfile,verbose_name=u"跟踪人") date = models.DateField(u"跟进日期",auto_now_add=True) def __unicode__(self): return u"%s, %s" %(self.customer,self.status) class Meta: verbose_name = u'客户咨询跟进记录' verbose_name_plural = u"客户咨询跟进记录" class CourseRecord(models.Model): course = models.ForeignKey(ClassList,verbose_name=u"班级(课程)") day_num = models.IntegerField(u"节次",help_text=u"此处填写第几节课或第几天课程...,必须为数字") date = models.DateField(auto_now_add=True,verbose_name=u"上课日期") teacher = models.ForeignKey(UserProfile,verbose_name=u"讲师") def __unicode__(self): return u"%s 第%s天" %(self.course,self.day_num) class Meta: verbose_name = u'上课纪录' verbose_name_plural = u"上课纪录" unique_together = ('course','day_num') class StudyRecord(models.Model): course_record = models.ForeignKey(CourseRecord, verbose_name=u"第几天课程") student = models.ForeignKey(Customer,verbose_name=u"学员") record_choices = (('checked', u"已签到"), ('late',u"迟到"), ('noshow',u"缺勤"), ('leave_early',u"早退"), ) record = models.CharField(u"上课纪录",choices=record_choices,default="checked",max_length=64) score_choices = ((100, 'A+'), (90,'A'), (85,'B+'), (80,'B'), (70,'B-'), (60,'C+'), (50,'C'), (40,'C-'), (0,'D'), (-1,'N/A'), (-100,'COPY'), (-1000,'FAIL'), ) score = models.IntegerField(u"本节成绩",choices=score_choices,default=-1) date = models.DateTimeField(auto_now_add=True) note = models.CharField(u"备注",max_length=255,blank=True,null=True) def __unicode__(self): return u"%s,学员:%s,纪录:%s, 成绩:%s" %(self.course_record,self.student.name,self.record,self.get_score_display()) class Meta: verbose_name = u'学员学习纪录' verbose_name_plural = u"学员学习纪录" unique_together = ('course_record','student')
现在我们重新启动一个新项目

settings添加项目
创建数据库表(其实不需要指定app01,因为django自带的还没创建,如果是第一次不需要指定项目)
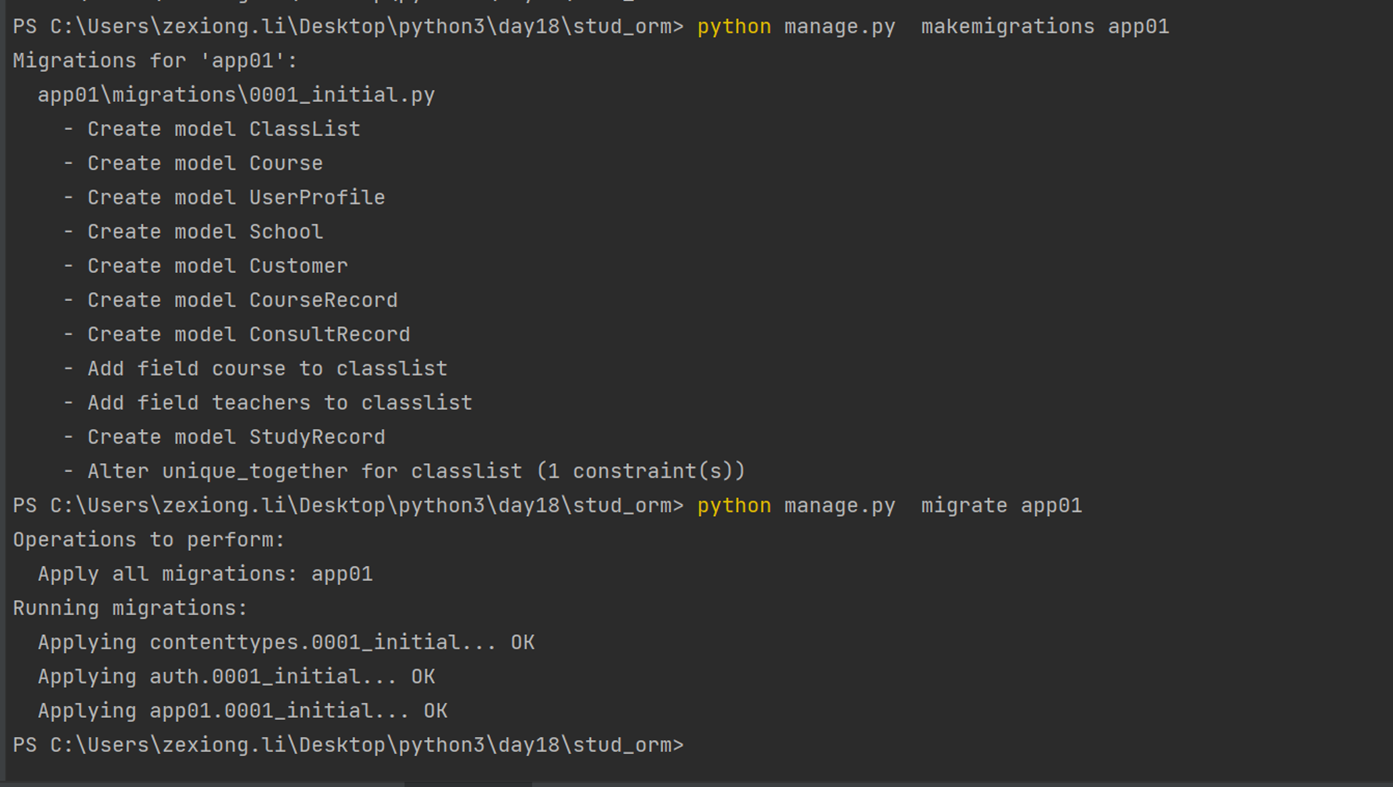
在django-admin后台可以看到数据表,方便管理。
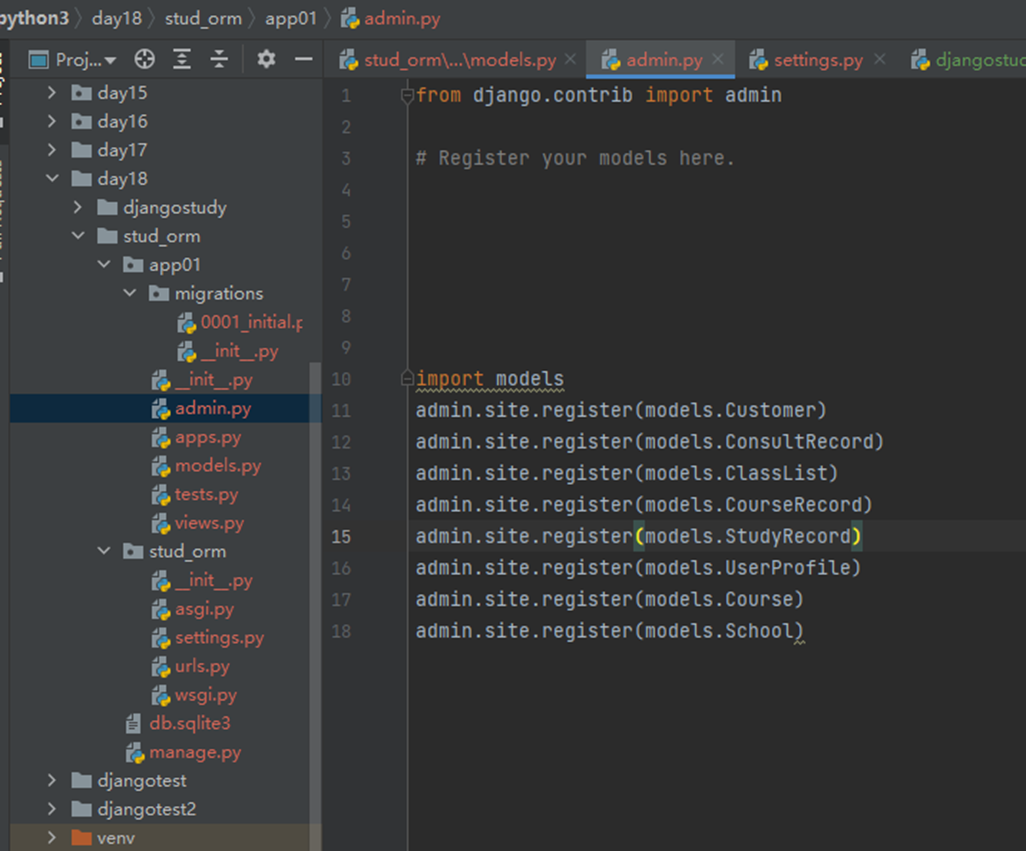
顺便自己创建管理员账户,这里就不演示了

创建数据表数据
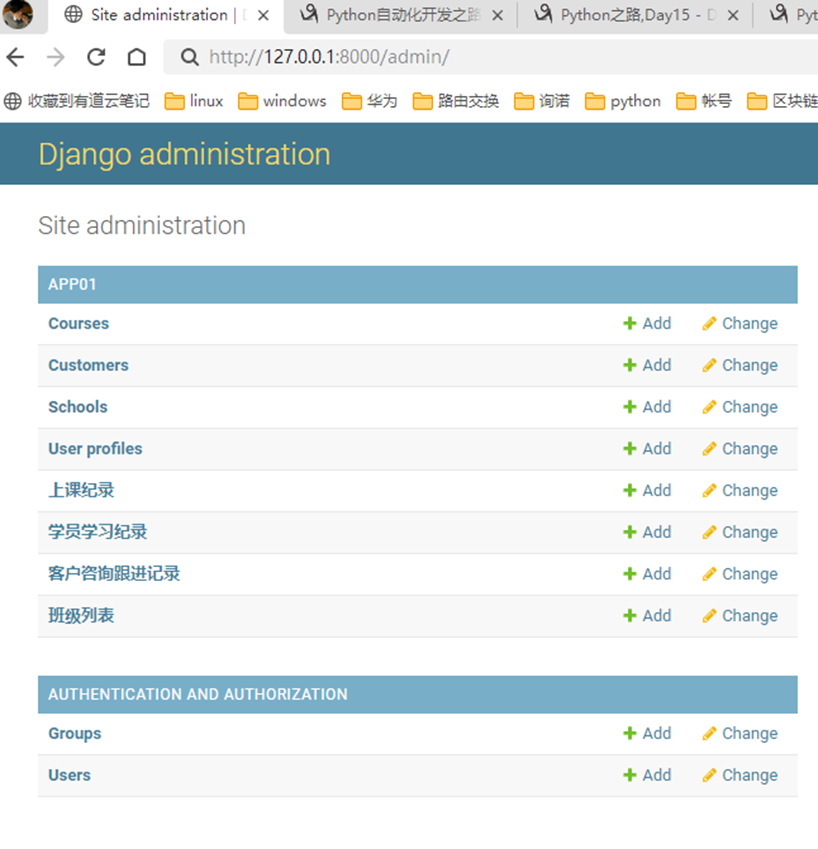
创建课程
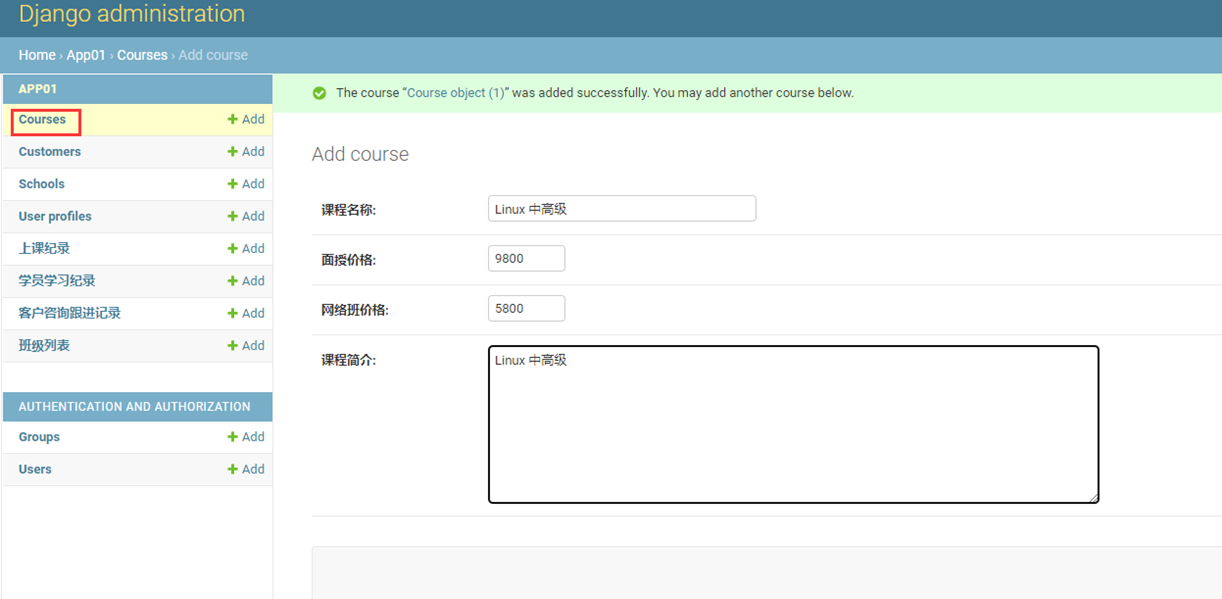
创建班级

在多创建一个讲师
创建学员
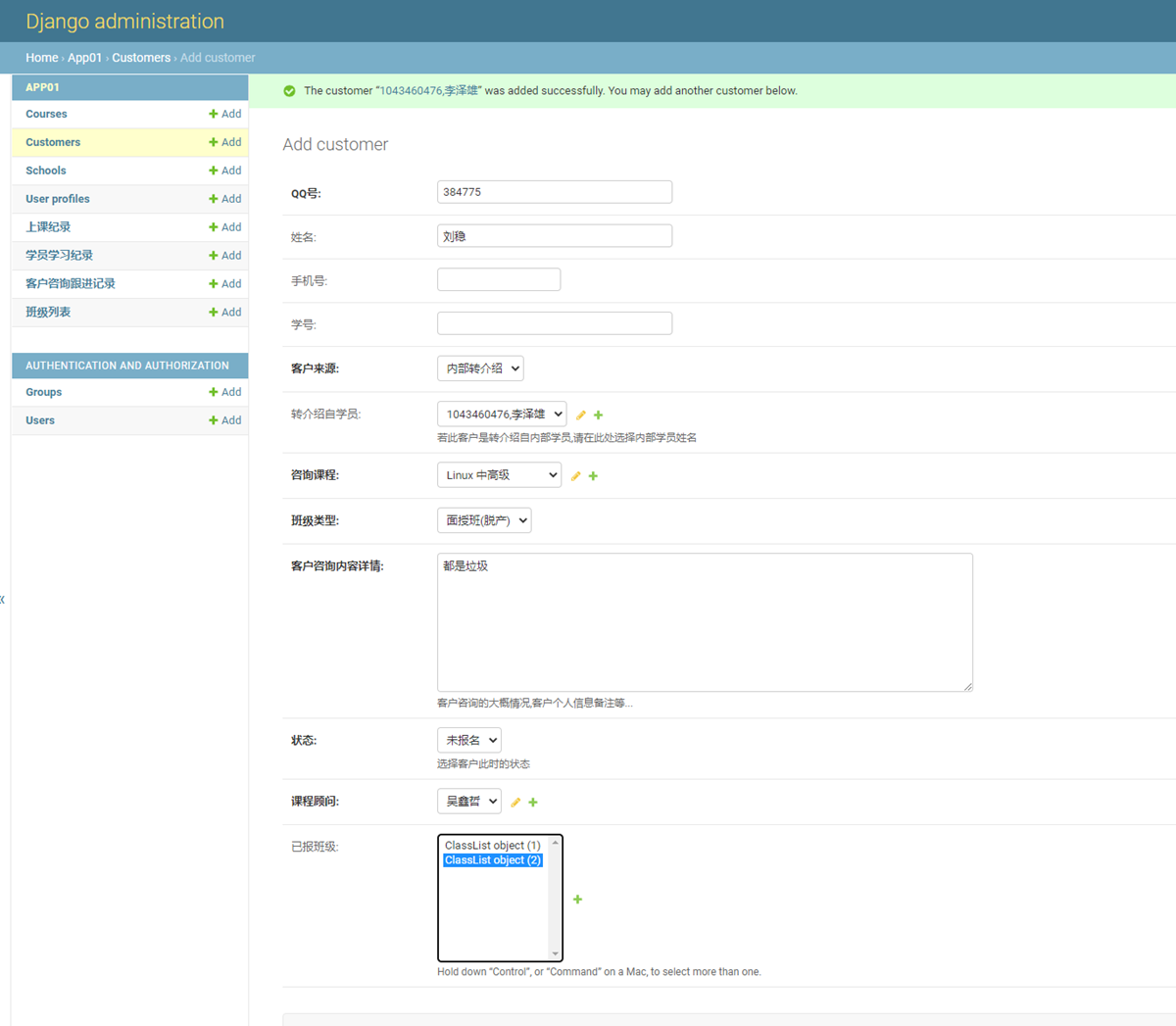
上课记录
小插曲:这里因为看不到班级,改一下班级的models显示
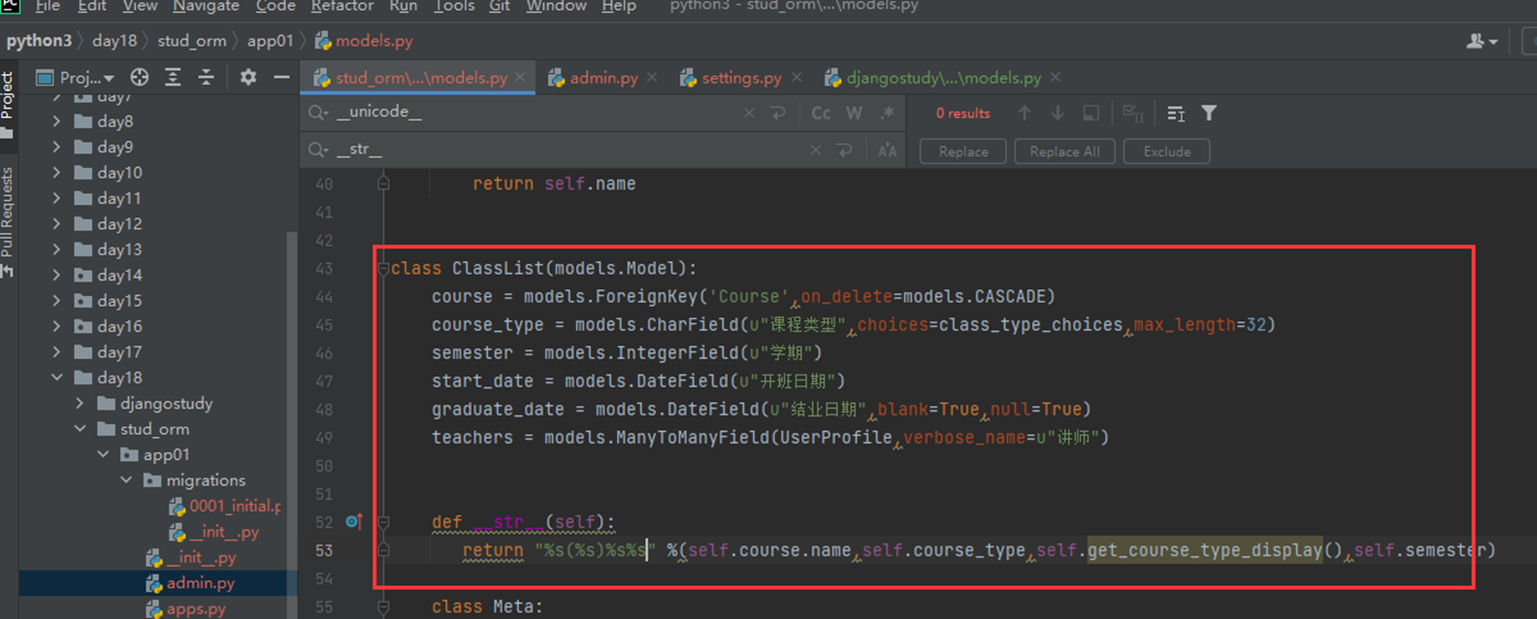
客户咨询记录
创建校区
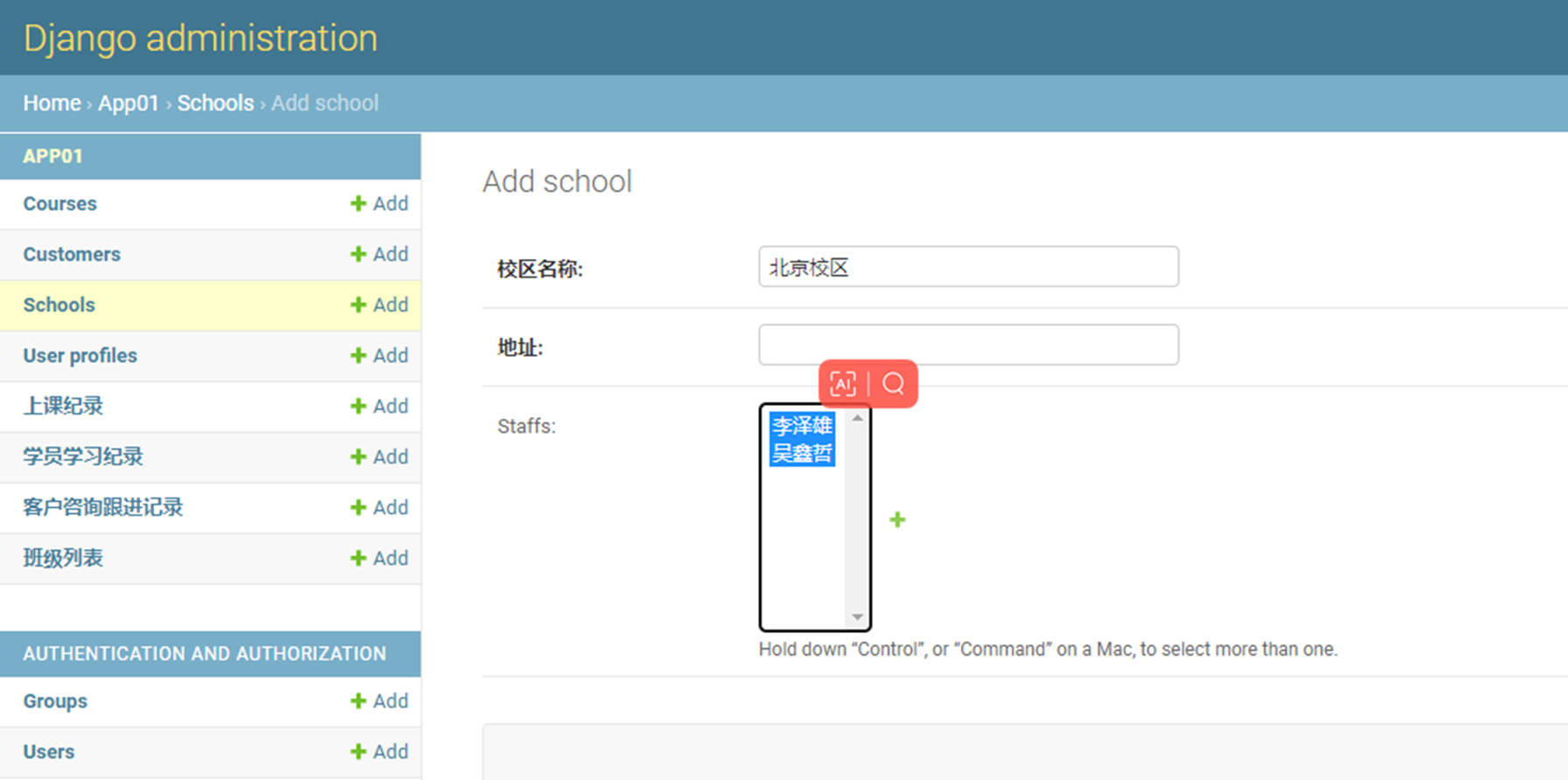
18.19 用户认证的实现
简单的就是自己写一个用户登录的认证,由于某些网页没有登录是无法进行查看的,只有登录了才能查看,满足这个需求。
1.创建一个主页出来,这个主页只有登录后才能看到,先写URL
2.views
3.html(别忘了在settings里面配置模版路径,这里就省略了)
4.加上验证,看看能不能访问主页
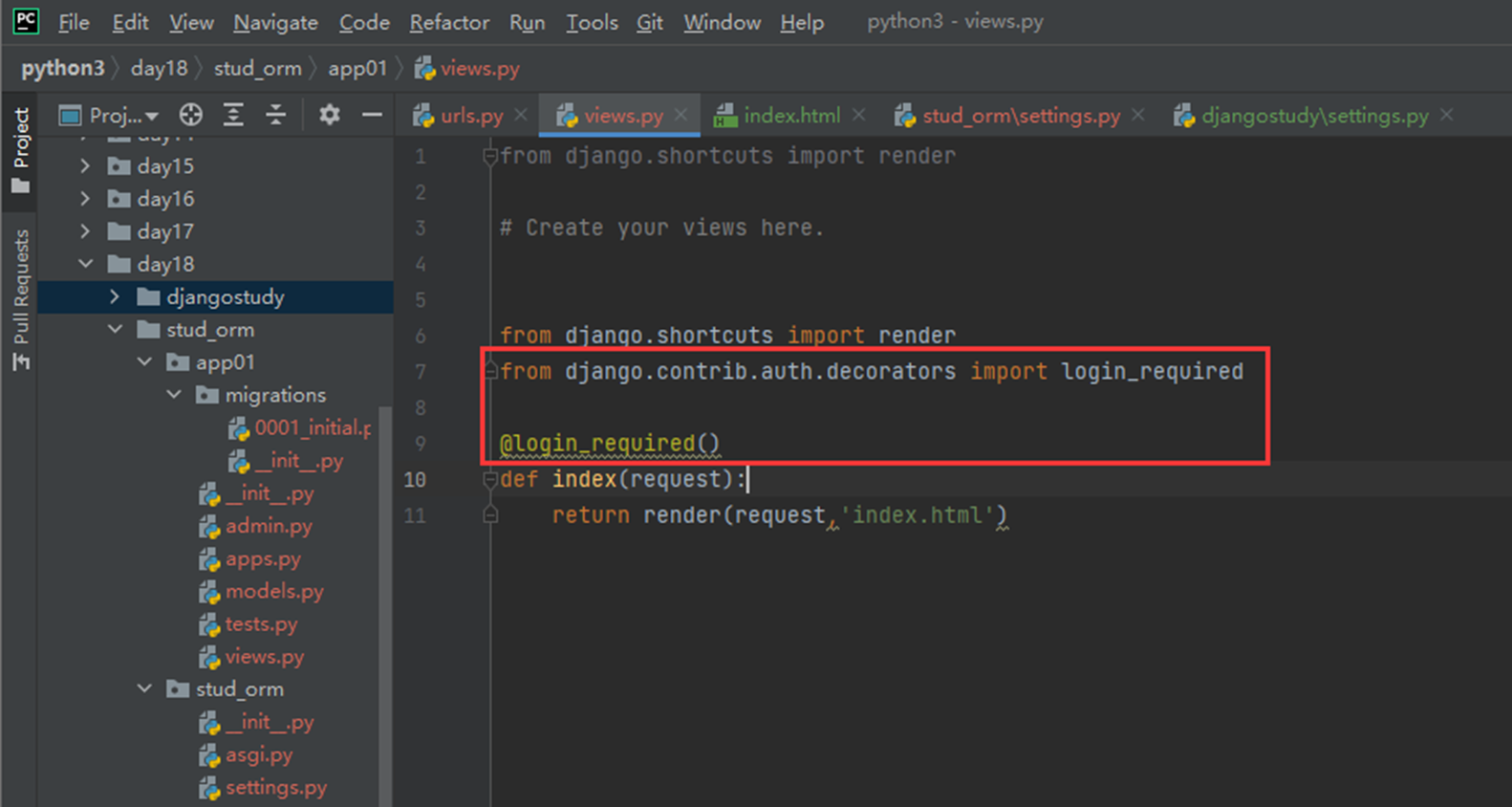
刷新页面还是可以访问。
那是因为我们用的django的验证系统,django admin刚才登录了,现在退出django,看看会出现什么
在访问
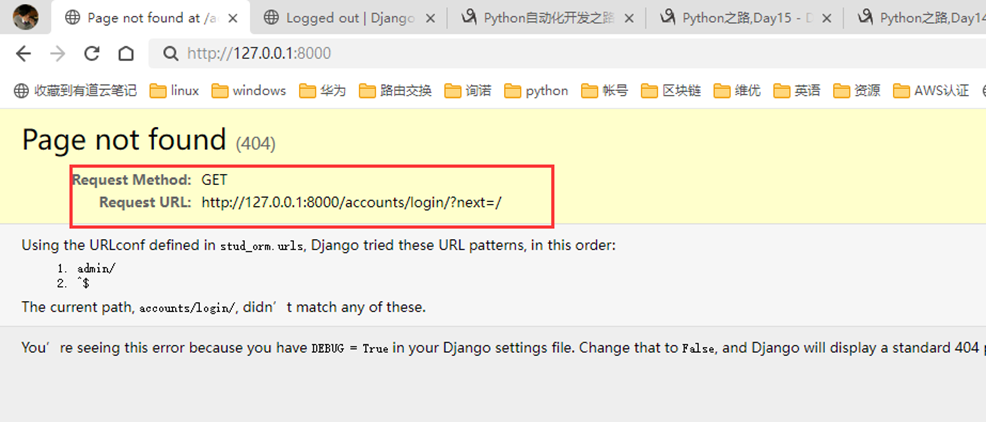
出现一个很不友好的报错界面,那么我们完善一下,如果发现没有登录,那么就跳转到登录界面。
5.写一个登录界面
url
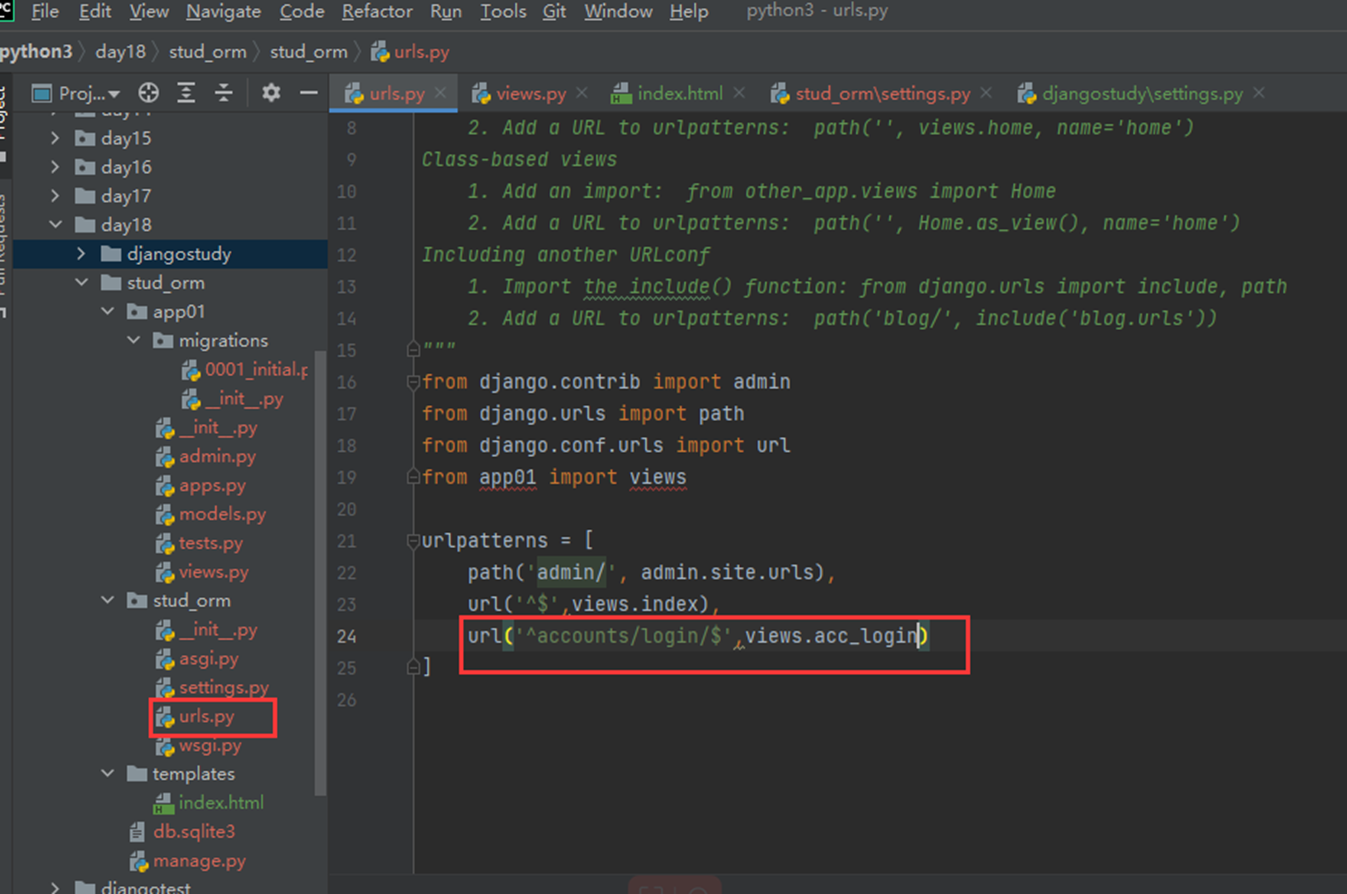
views
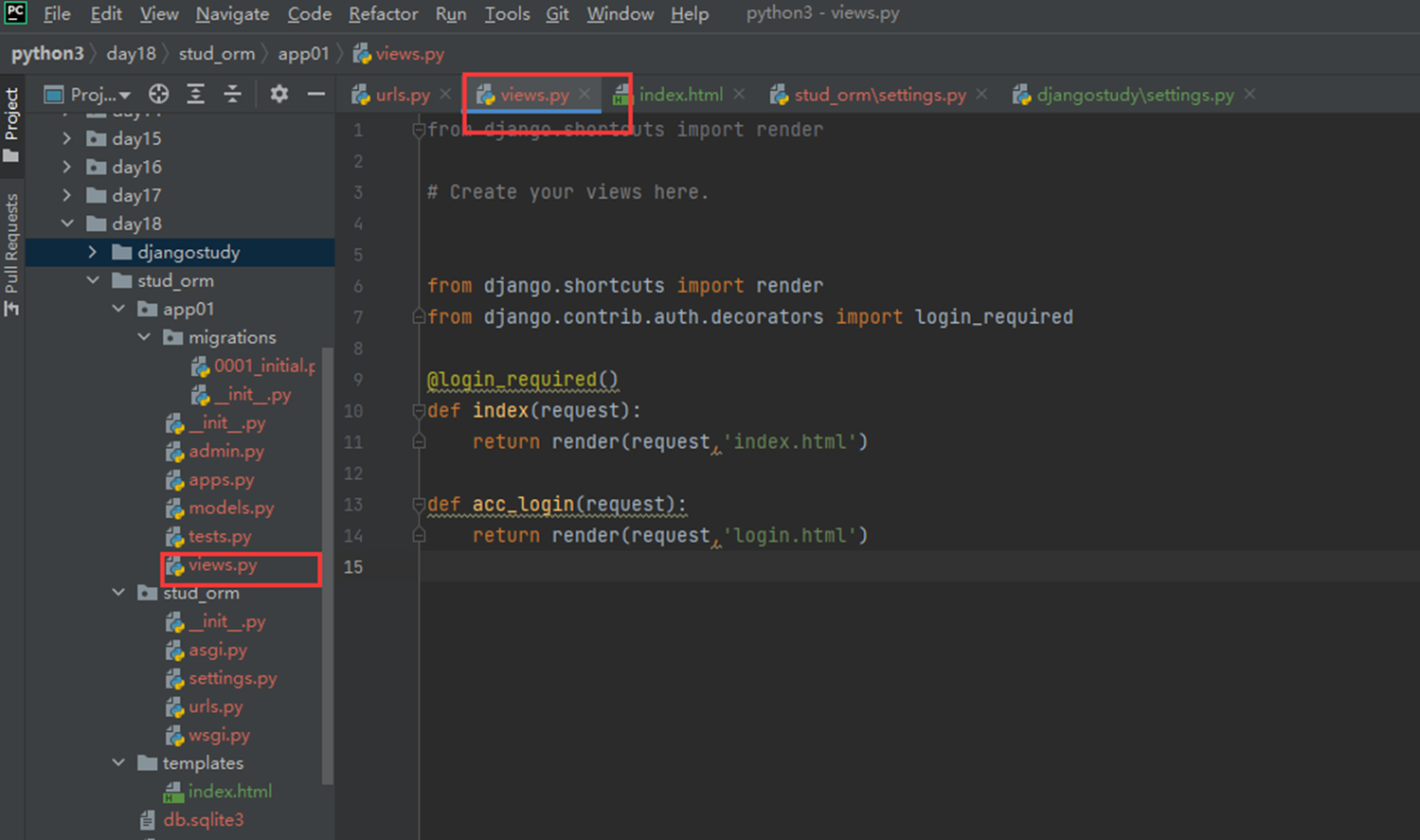
html
那么直接继承index
login.html
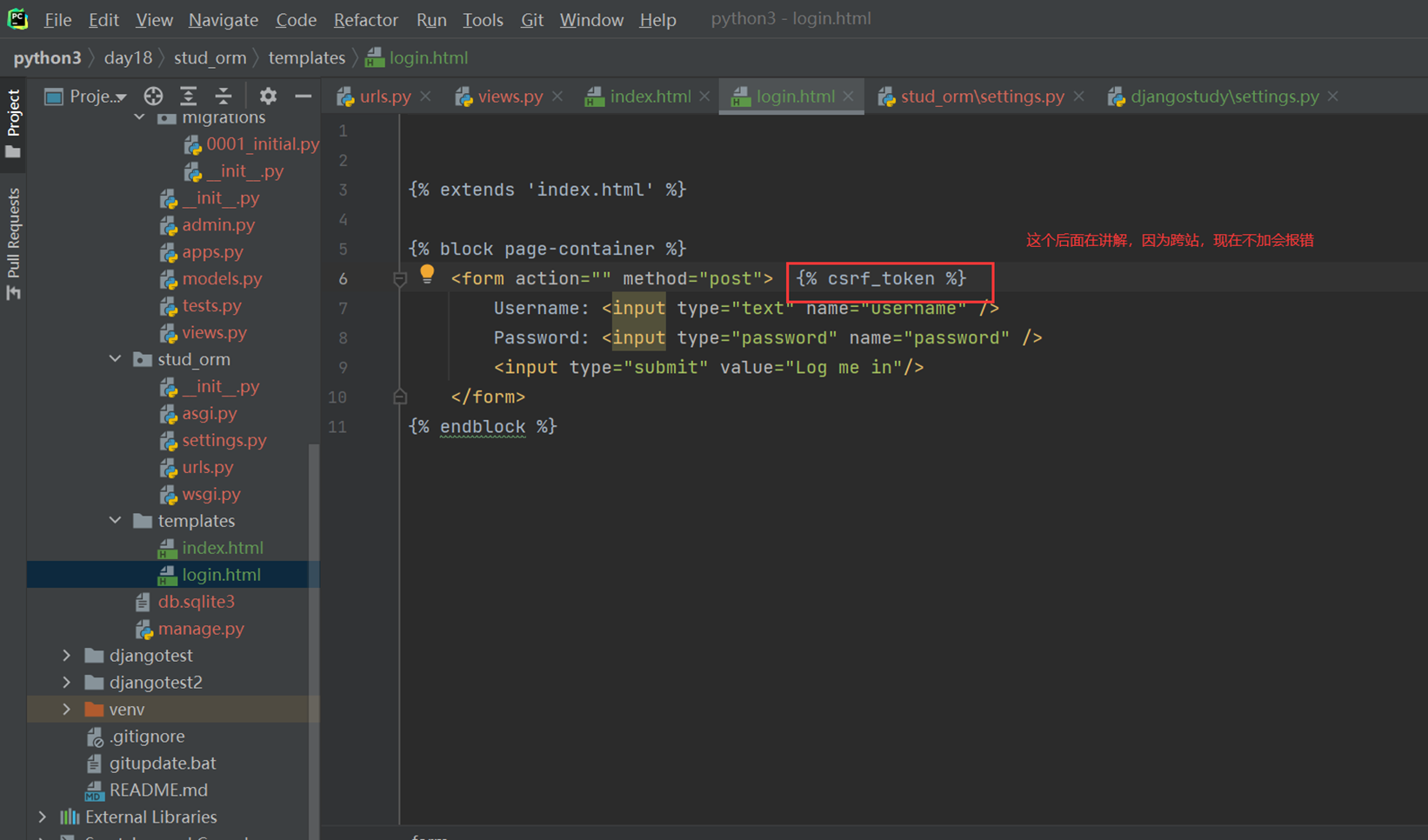
访问查看,发现登录成功后还是这个界面,没有任何变化
那是因为只是把发送成功的请求发送过去,验证成功了,没有保存session,函数里面还没有处理用户去认证以及返回对应的界面。
6.用户验证函数处理
因为这里的用户权限全是django自己的,所以我们这里直接调用django自己的就行
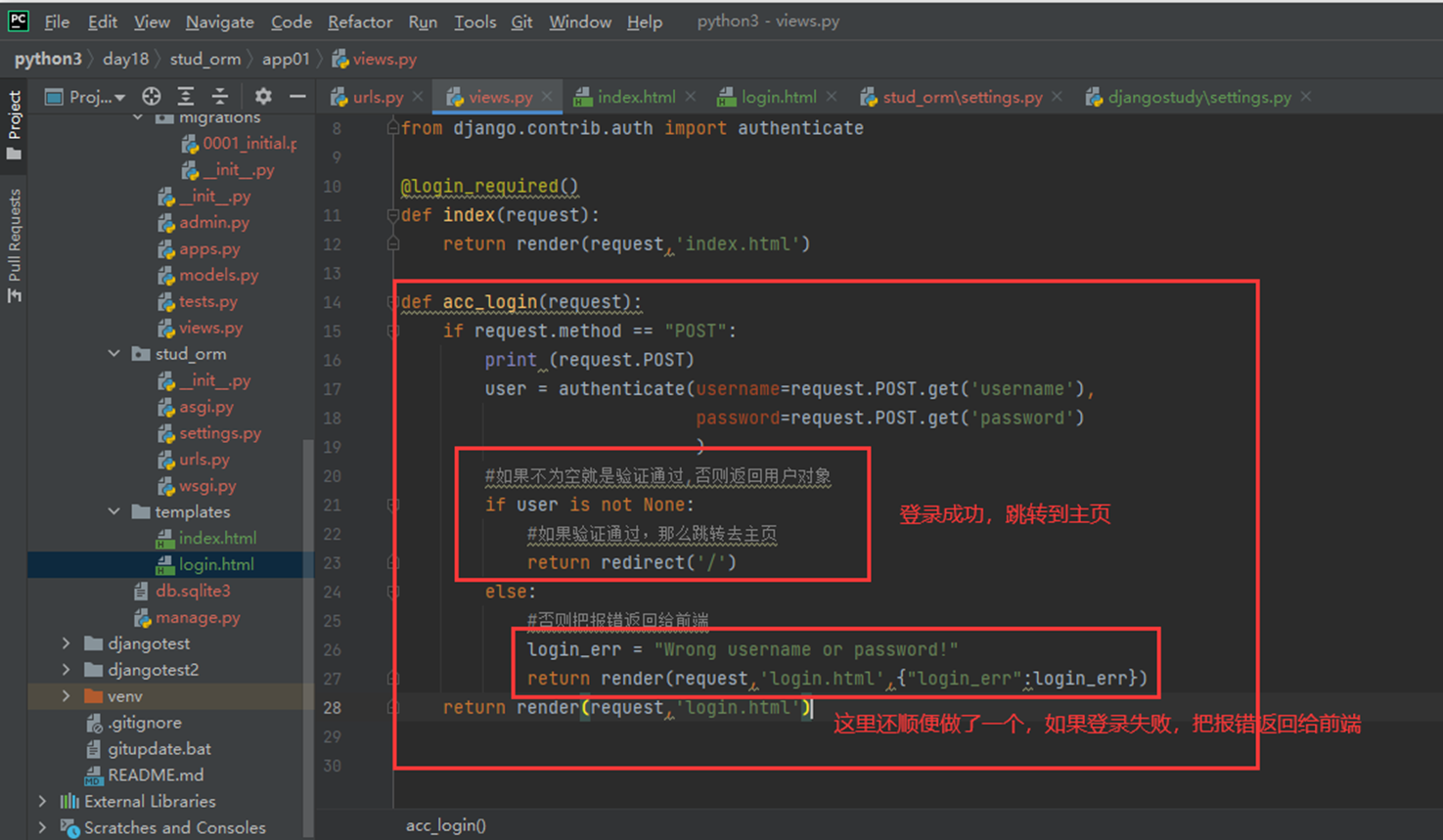
由于要把登录错误的信息返回给前端,前端也需要更改
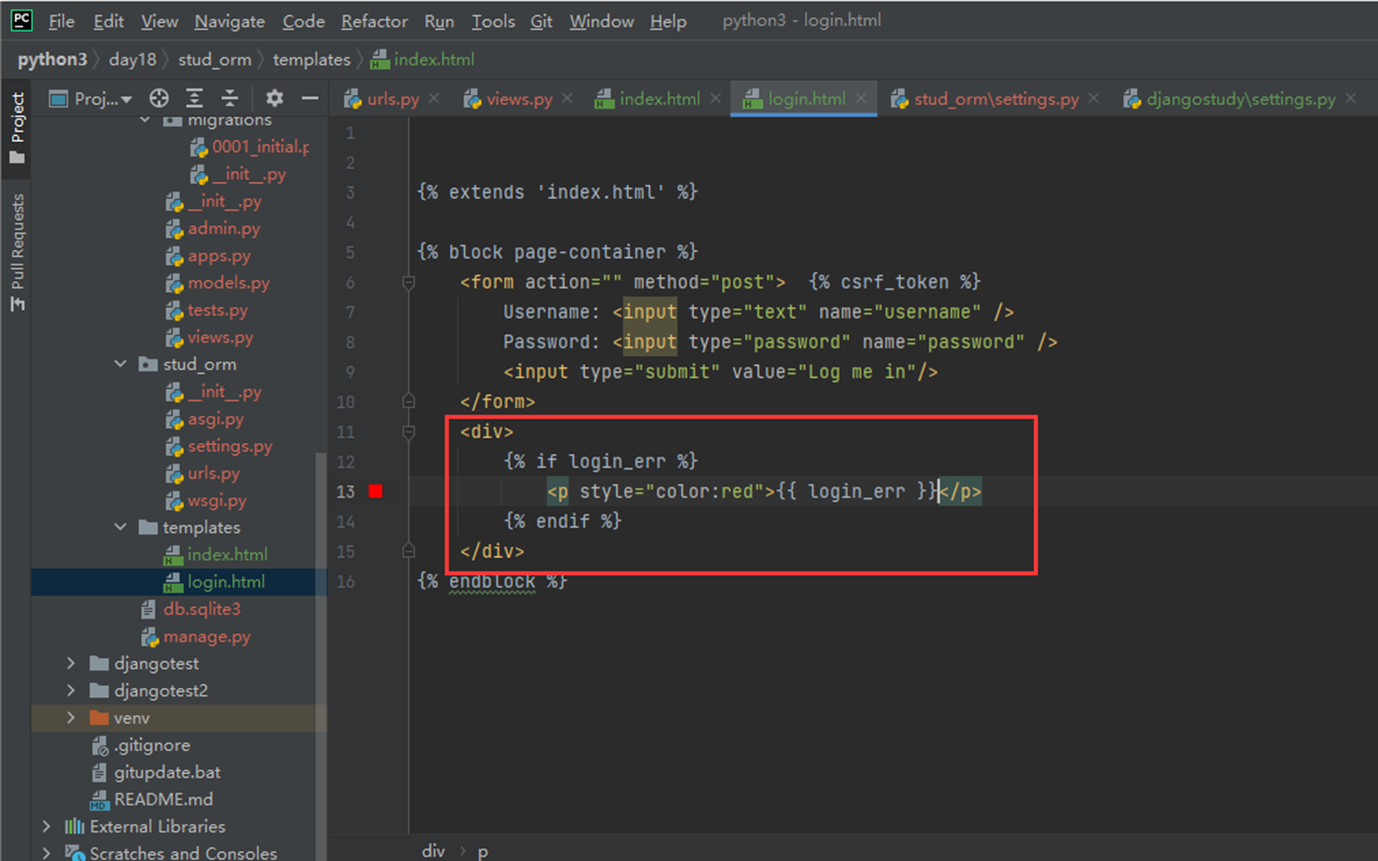
这里故意登录错误看看
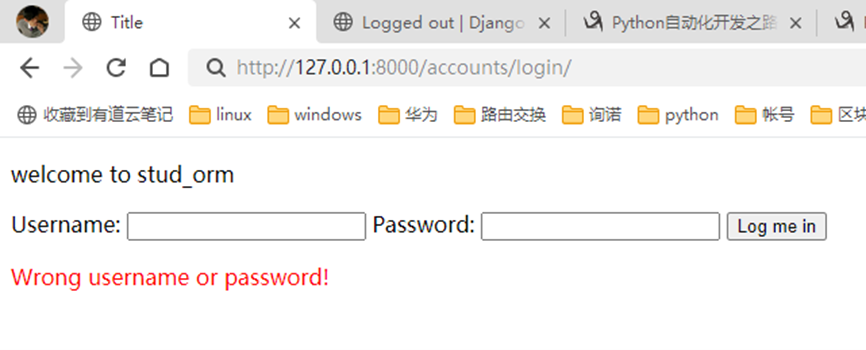
在演示一下登录成功
还是登录不了,那是因为还有一个知识点,就是session,我们登录成功没有保持session,所以即使登录成功,下一次http短连接请求还是会当作是新用户,所以要加个session保持用户状态。

在次登录,跳转主页成功
7.额外拓展需求,比如,在很多登录界面,都会显示登录名,这个怎么做?
这里我们就写在主页index里
访问查看
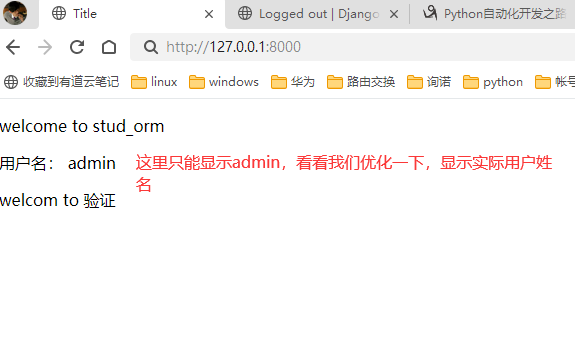
上面只显示了admin,我们优化一下显示实际姓名
在看看
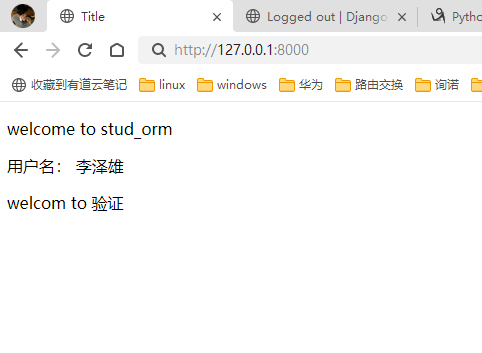
8.有了登录,自然有退出logout,这里本来是最后一节视频的,这里直接演示
首先index简单做一个logout按钮。

url
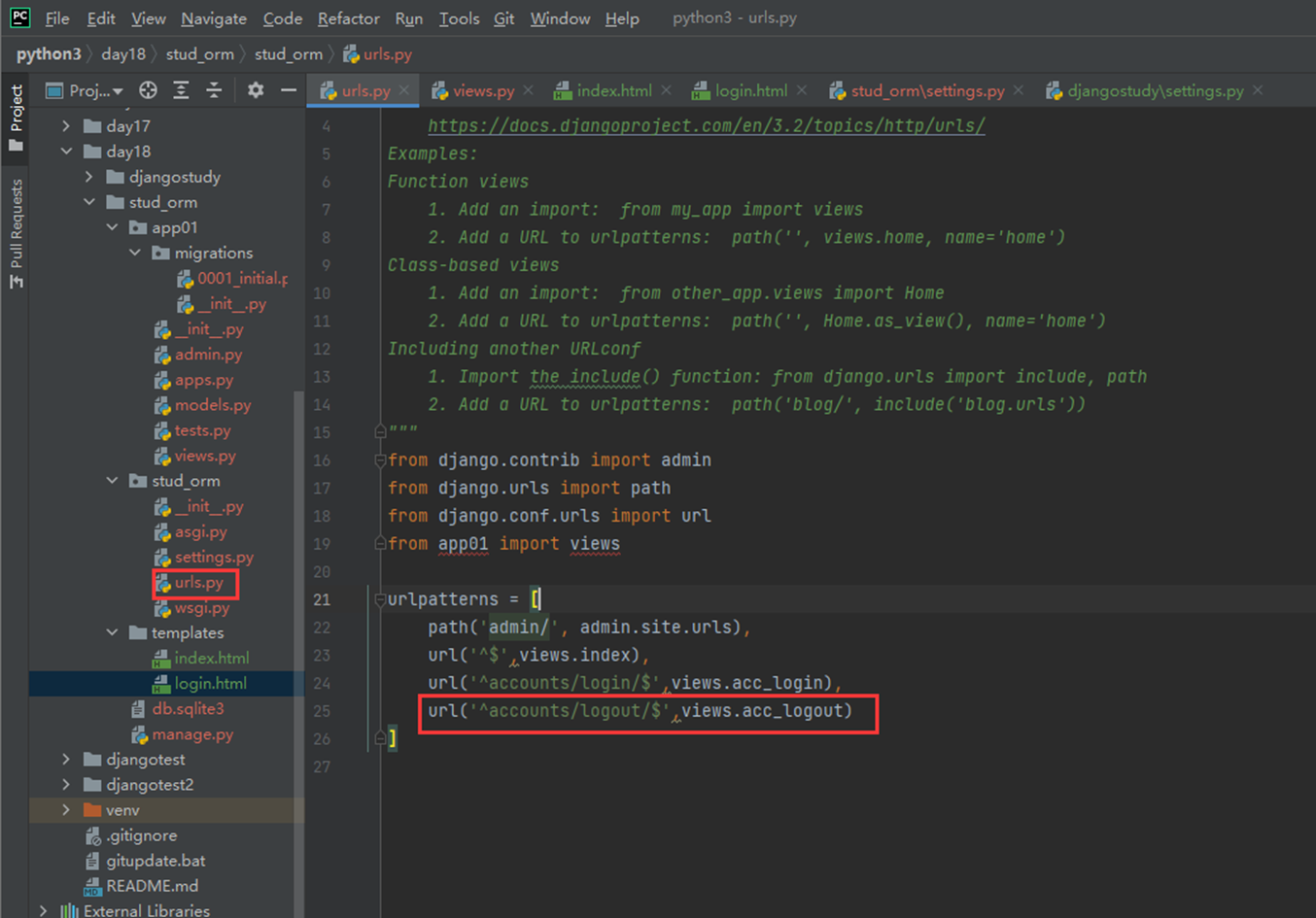
views
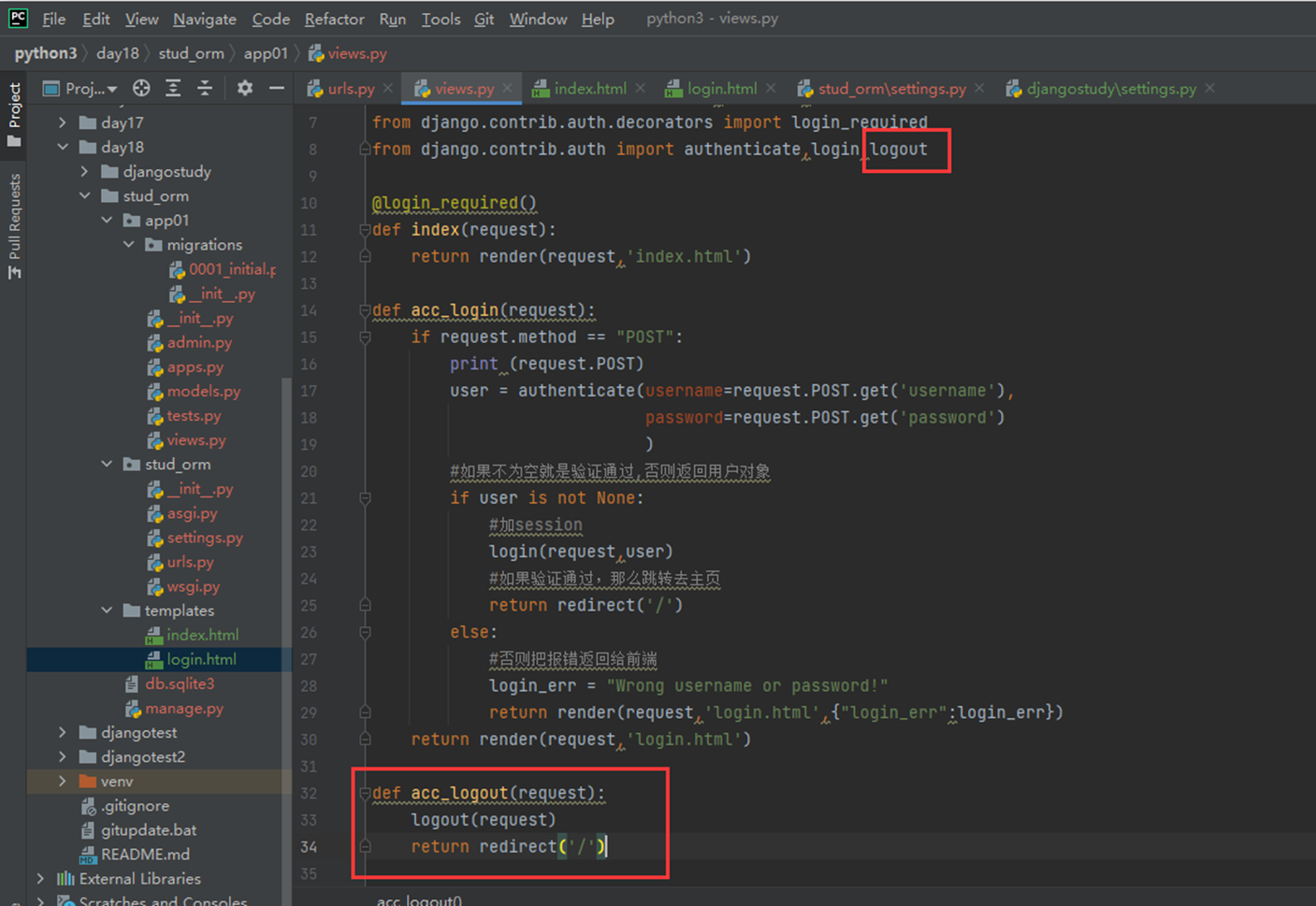
访问主页查看
点击就跳转到主页了

18.20 退出用户及作业需求
退出用户在上小节最后一个部分讲解过了,这里就不演示了

19.L19
19.1 学员管理系统表结构设计
又把表结构讲了一遍,但是是今天自己写了一遍,3节课专门写表结构。
这里就不解说了,如果需要复习肯定是看视频。
这里贴出数据库表结构。
from django.db import models # Create your models here. from django.db import models from django.contrib.auth.models import User course_type_choices = (('online', u'网络班'), ('offline_weekend', u'面授班(周末)',), ('offline_fulltime', u'面授班(脱产)',), ) class School(models.Model): name = models.CharField(max_length=128,unique=True) city = models.CharField(max_length=64) addr = models.CharField(max_length=128) def __str__(self): return self.name class UserProfile(models.Model): #关联django的user表,使用django的用户权限等功能, #最好使用onetoone,因为我自己关联django的表,我自己可以设置很多相同用户的名称,那么就乱了,所以这里我自己对django的user表也有限制,说一对一就是一对一 user = models.OneToOneField(User,on_delete=models.CASCADE) name = models.CharField(max_length=64) school = models.ForeignKey('School',on_delete=models.CASCADE) def __str__(self): return self.name class Customer(models.Model): qq = models.CharField(max_length=64,unique=True) name = models.CharField(max_length=32,blank=True,null=True) phone = models.BigIntegerField(blank=True,null=True) course = models.ForeignKey('Course',on_delete=models.CASCADE) course_type = models.CharField(max_length=64,choices=course_type_choices,default="offline_weekend") consult_memo = models.TextField() source_type_choices = (('qq',u"qq群"), ('referral',u"内部转介绍"), ('51cto',u"51cto"), ('agent',u"招生代理"), ('others',u"其它"), ) source_type = models.CharField(max_length=64,choices=source_type_choices) #自己关联自己,因为介绍人可能是内部人员,所以这里要自己关联自己 referral_from = models.ForeignKey('self',blank=True,null=True,related_name="referraled_who",on_delete=models.CASCADE) status_choices = (('signed',u"已报名"), ('unregistered',u"未报名"), ('graduated',u"已毕业"), ('drop-off','已退学') ) status = models.CharField(choices=status_choices,max_length=64) consultant = models.ForeignKey("UserProfile",on_delete=models.CASCADE,verbose_name='课程顾问') class_list = models.ManyToManyField("ClassList",blank=True,null=True) date = models.DateField(auto_now_add=True,verbose_name="咨询日期") def __str__(self): return "%s(%s)" %(self.qq,self.name) class CustomerTrackRecord(models.Model): customer = models.ForeignKey(Customer,on_delete=models.CASCADE) track_record = models.TextField(verbose_name="跟踪记录") track_date = models.DateField(auto_now_add=True) follower = models.ForeignKey(UserProfile,on_delete=models.CASCADE) status_choices = ((1,u"近期无报名计划"), (2,u"2个月内报名"), (3,u"1个月内报名"), (4,u"2周内报名"), (5,u"1周内报名"), (6,u"2天内报名"), (7,u"已报名"), ) status = models.IntegerField(choices=status_choices, verbose_name="状态",help_text=u"选择客户此时的状态") def __str__(self): return self.customer class Course(models.Model): name = models.CharField(max_length=64,unique=True) online_price = models.IntegerField() offine_price = models.IntegerField() introduction = models.TextField() def __str__(self): return self.name class ClassList(models.Model): course = models.ForeignKey(Course,verbose_name="课程",on_delete=models.CASCADE) semester = models.IntegerField(verbose_name="学期") course_type = models.CharField(max_length=64,choices=course_type_choices,default="offline_weekend") teachers = models.ManyToManyField(UserProfile) start_date = models.DateField() graduate_date = models.DateField() def __str__(self): return "%s(%s)(%s)" %(self.course.name,self.course_type,self.semester) class Meta: #网络班,面授班,课程三个字段唯一,因为课程里面一个成员可能存在网络和面授班同时存在,所以不能2个字段唯一 unique_together = ('course','semester','course_type') class CourseRecord(models.Model): class_obj = models.ForeignKey(ClassList,on_delete=models.CASCADE) day_num = models.IntegerField(verbose_name="第几节课") course_date = models.DateField(auto_now_add=True,verbose_name="上课时间") teacher = models.ForeignKey(UserProfile,on_delete=models.CASCADE) def __str__(self): return "%s,%s" %(self.class_obj,self.day_num) class Meta: unique_together = ('class_obj','day_num') class StudyRecord(models.Model): course_record = models.ForeignKey(CourseRecord,on_delete=models.CASCADE) student = models.ForeignKey(Customer,on_delete=models.CASCADE) record_choices = (('checked', u"已签到"), ('late',u"迟到"), ('noshow',u"缺勤"), ('leave_early',u"早退"), ) record = models.CharField(choices=record_choices,default="checked",max_length=64,verbose_name="上课记录") score_choices = ((100, 'A+'), (90,'A'), (85,'B+'), (80,'B'), (70,'B-'), (60,'C+'), (50,'C'), (40,'C-'), (0,'D'), (-1,'N/A'), (-100,'COPY'), (-1000,'FAIL'), ) score = models.IntegerField(choices=score_choices,default=-1,verbose_name="本节成绩") date = models.DateTimeField(auto_now_add=True) note = models.CharField(max_length=255,blank=True,null=True,verbose_name="备注") def __str__(self): return "%s,%s,%s" %(self.course_record,self.student,self.record)
创建数据库表以及超级用户
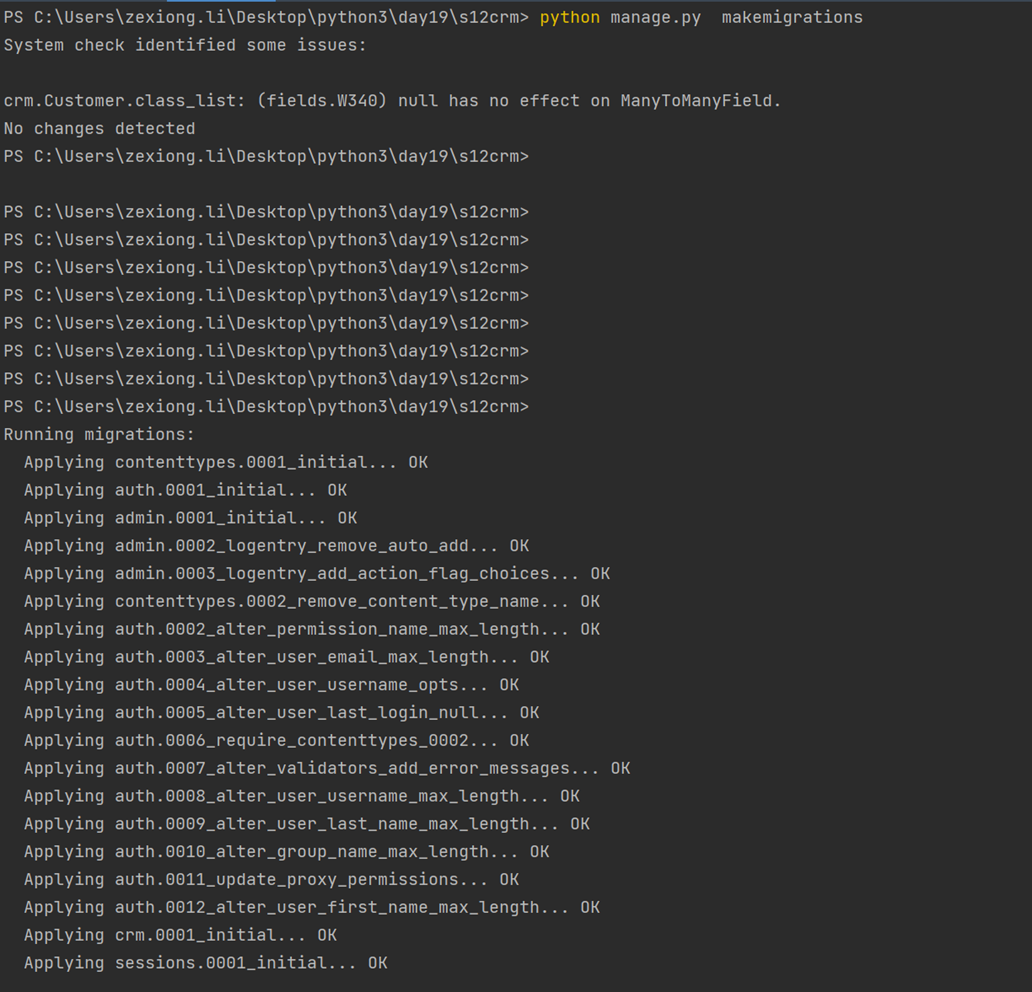
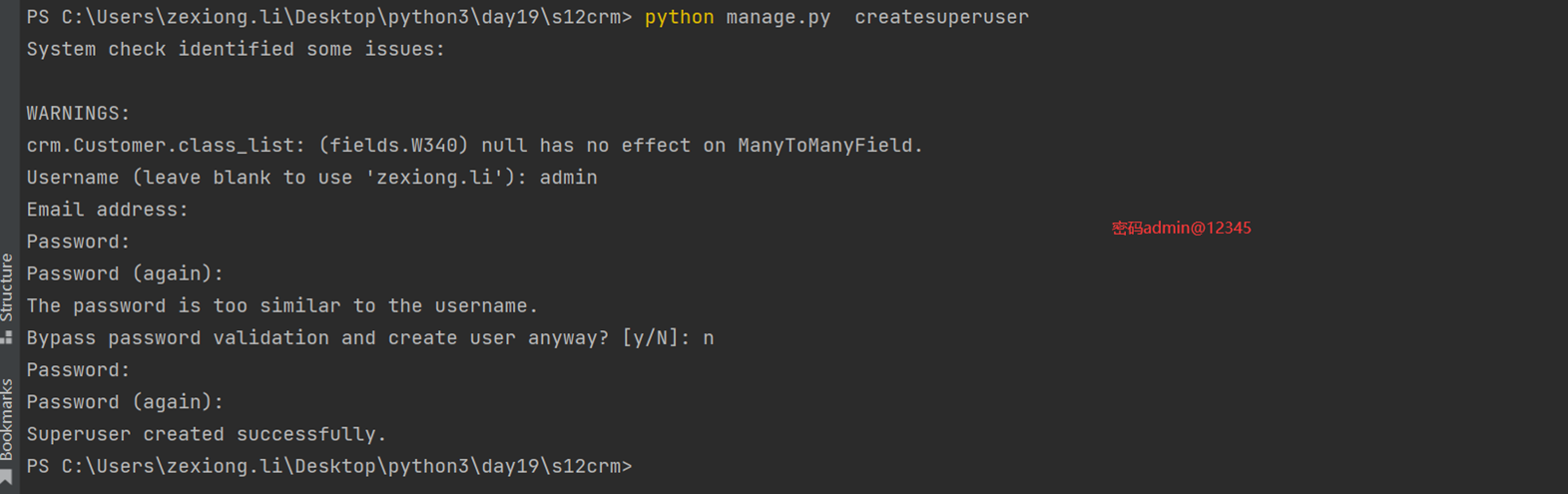
19.2 学员管理系统表结构设计2
19.3 学员管理系统表结构设计3
三节课都是讲解这个数据库表结构,合并到第一节课里面了
19.4 django中引用bootstrap
需求

访问bootstrap,下载一个网页,自己改
怎么改,我们等会再说,我们先把项目前置环境准备好。
1.URL
所有crm的请求转到crm的urls里面去
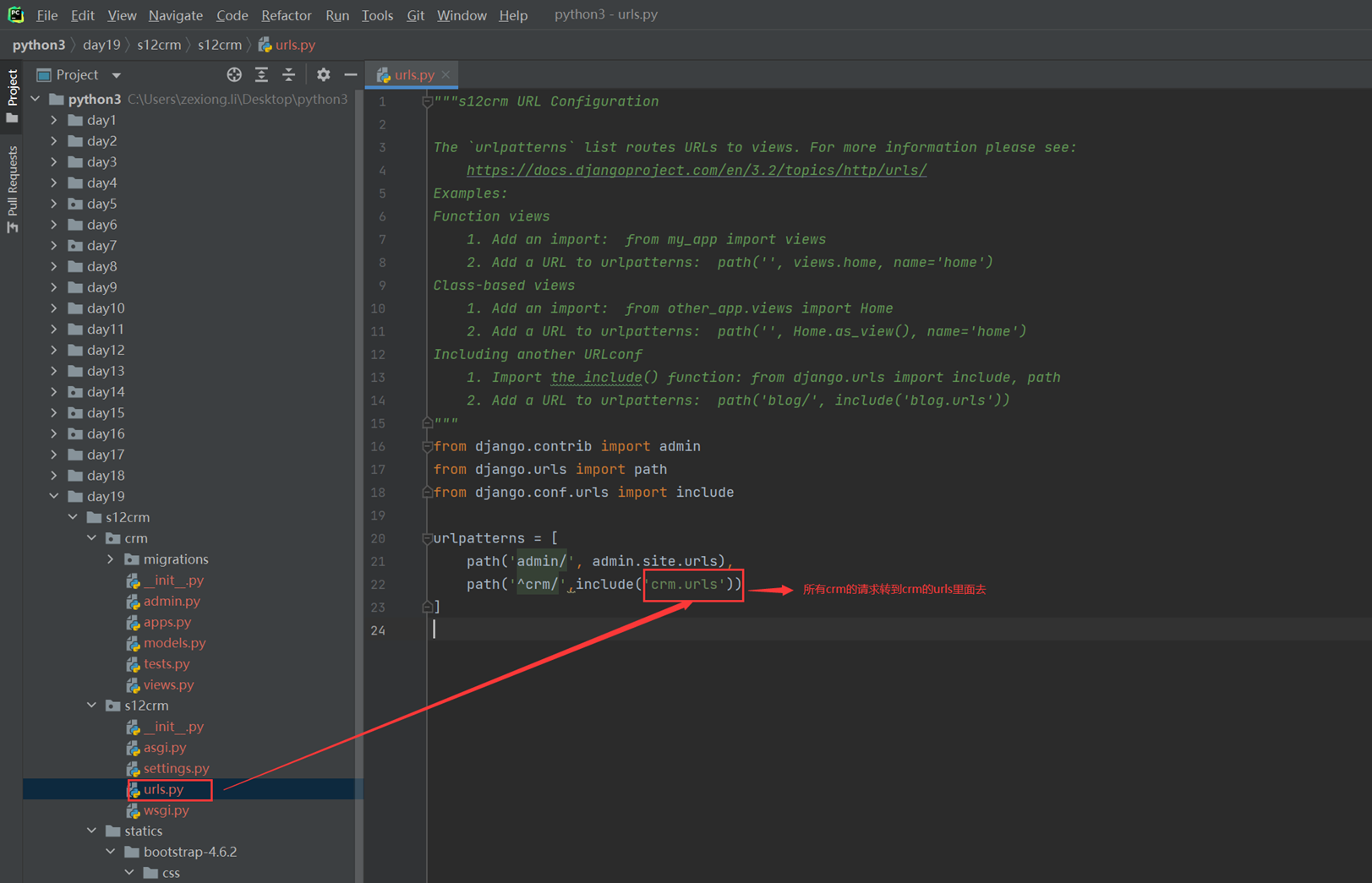
crm的urls
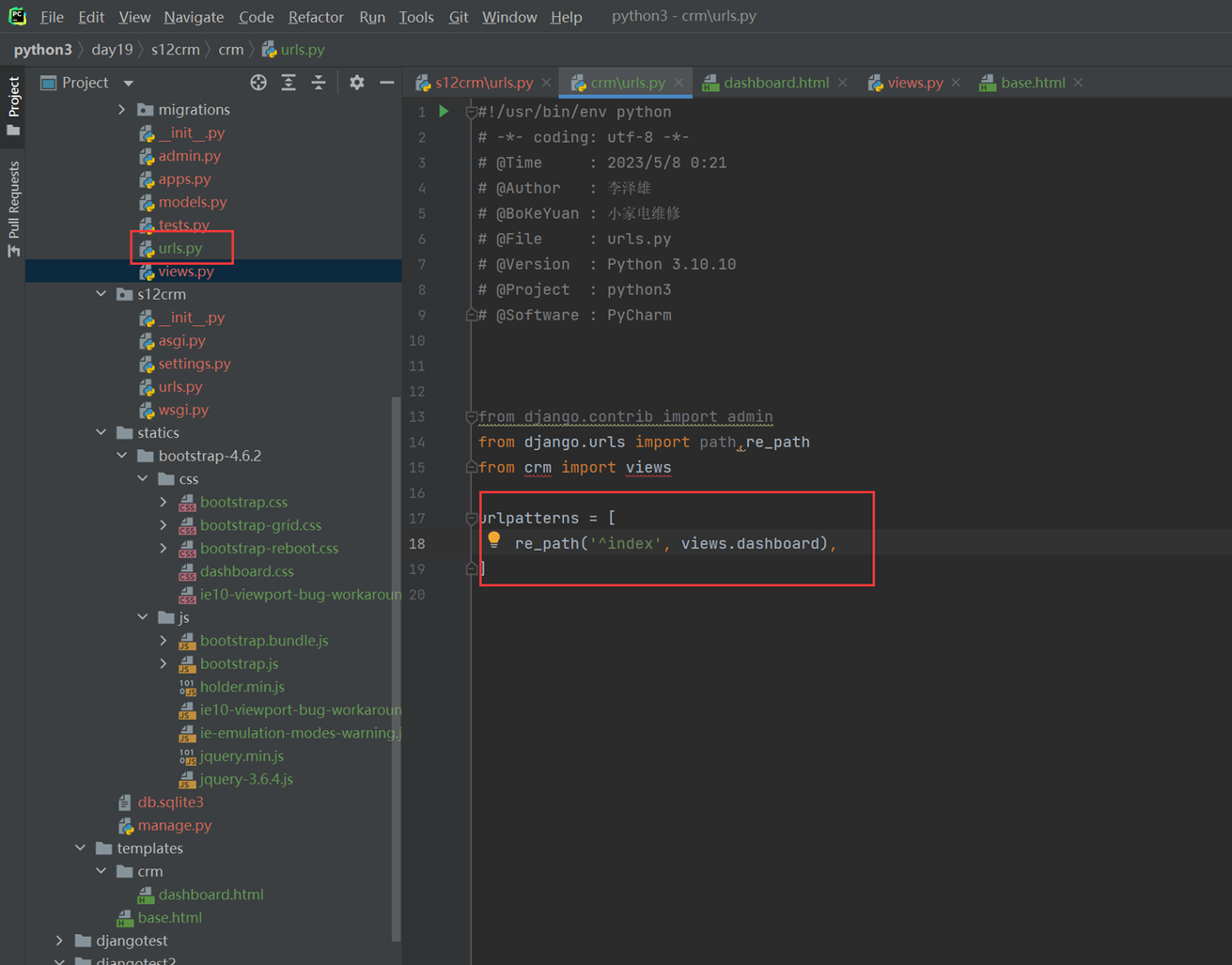
views
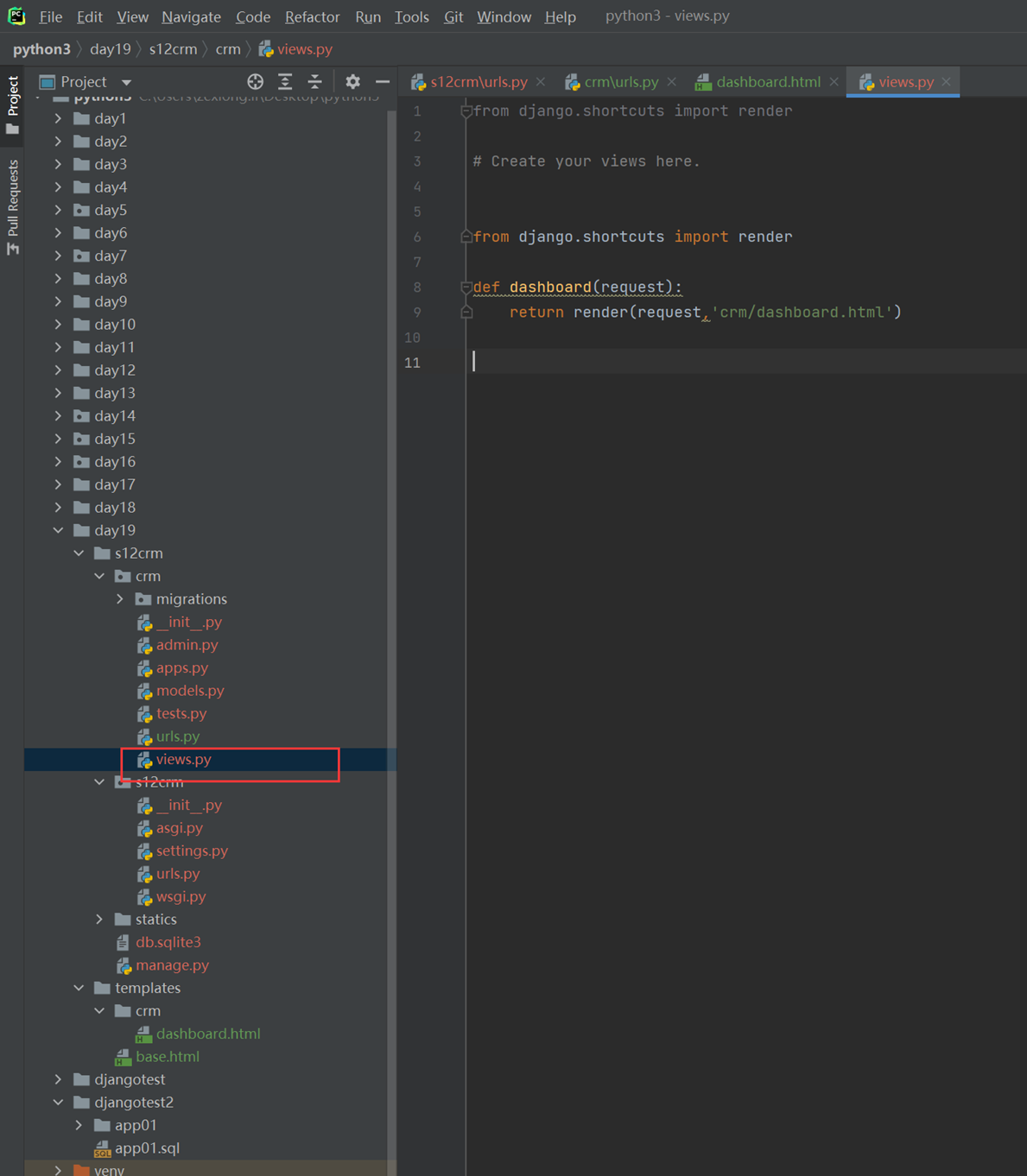
接下来才是重头戏,刚才我们下载了bootstrap的样式,我们怎么自己使用?
首先,我们要解决css和js的存放问题
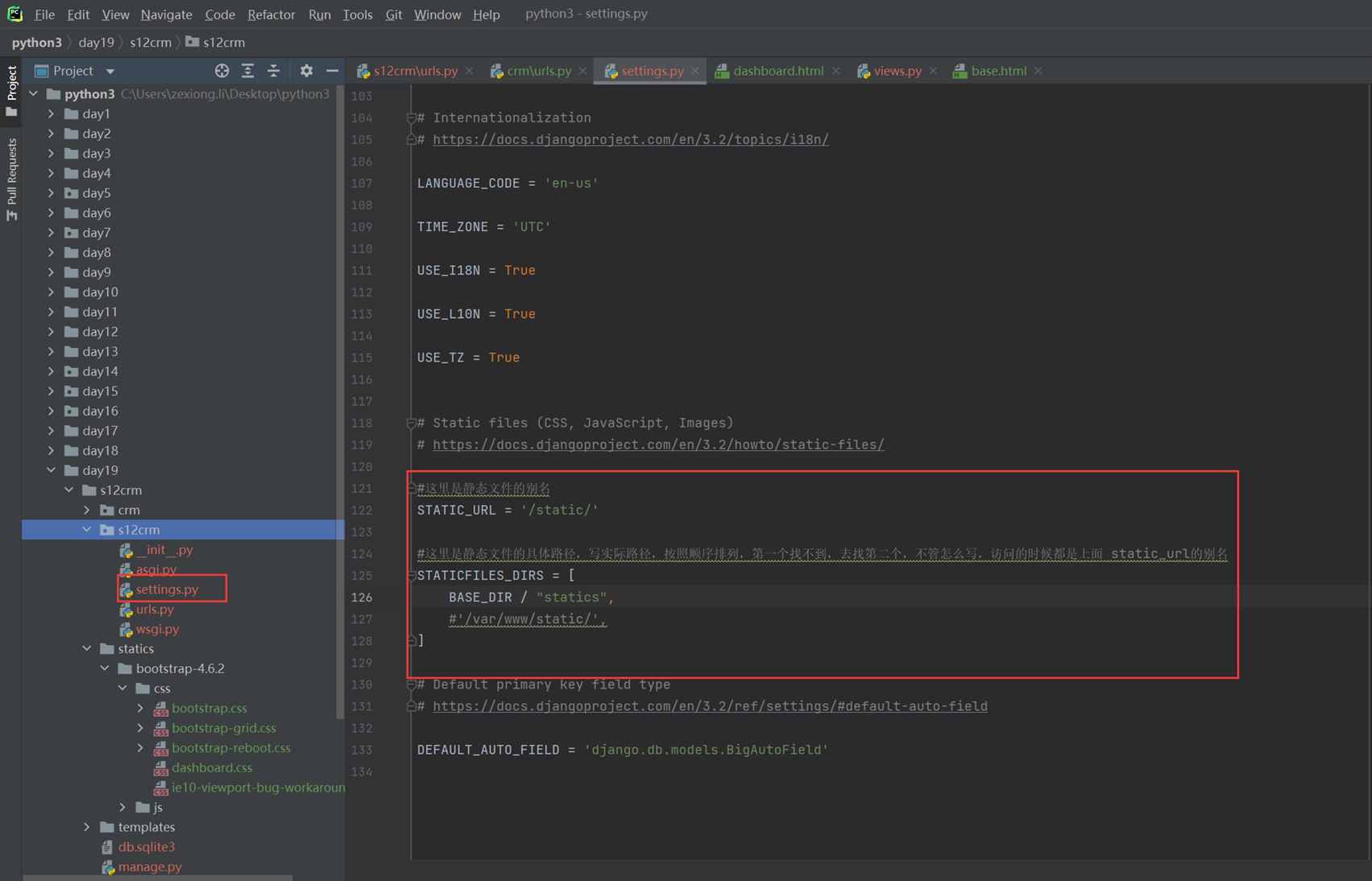
那么css和js以及jquery都得在这个目录下面了
现在修改bootstrap下载下来的内容,把相关的连接指向这个目录
Dashboard.html继承base.html
访问查看
19.5 前端展示用户列表
本章需求就是从数据库取出数据展示在前端,所以该篇有个前置条件,就是数据库里面得有数据啊。
所以前置条件就是创建数据。
先配置admin后台,直接在后台管理界面创建数据。
课程
用户
创建的时候顺便创建学校
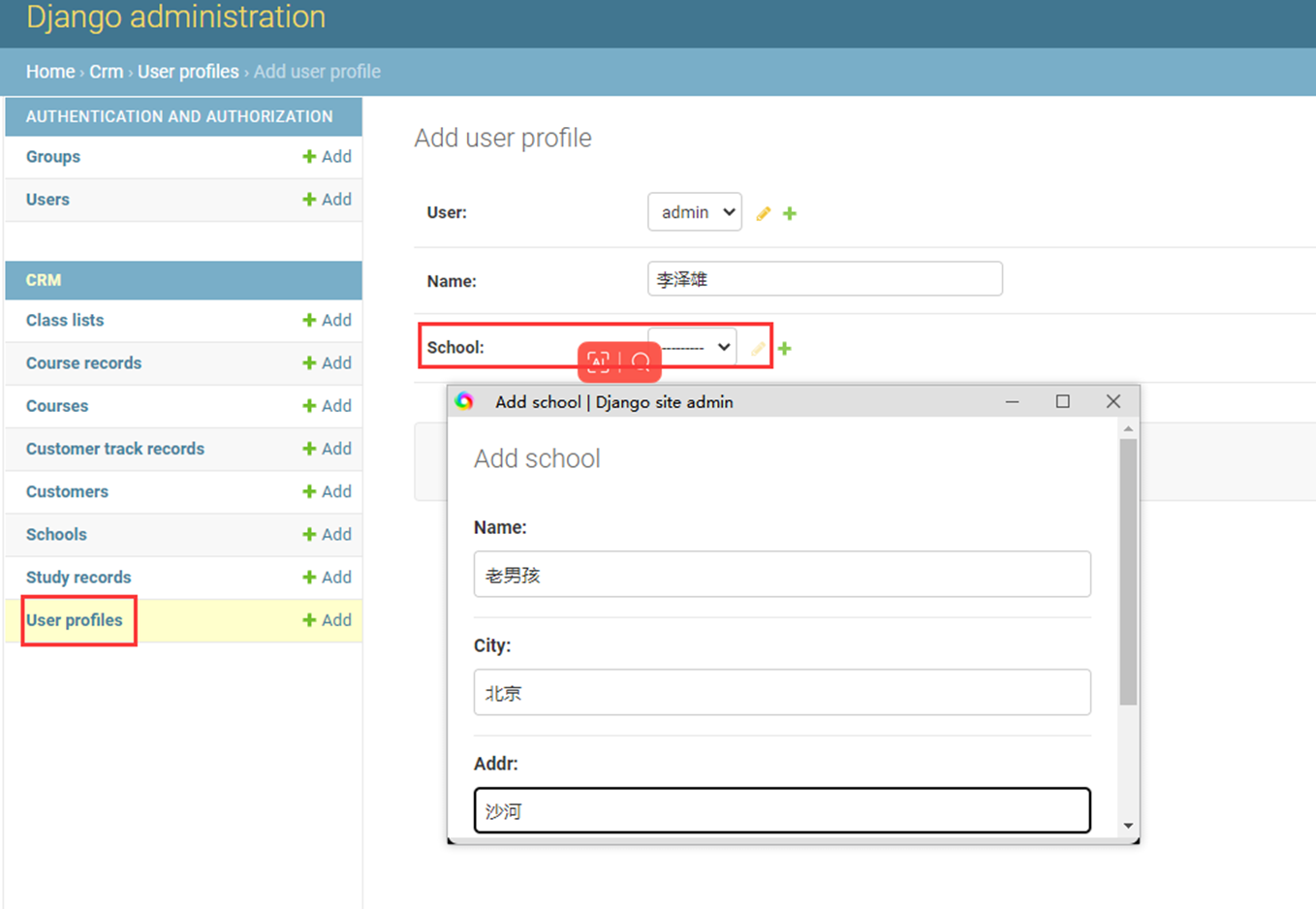
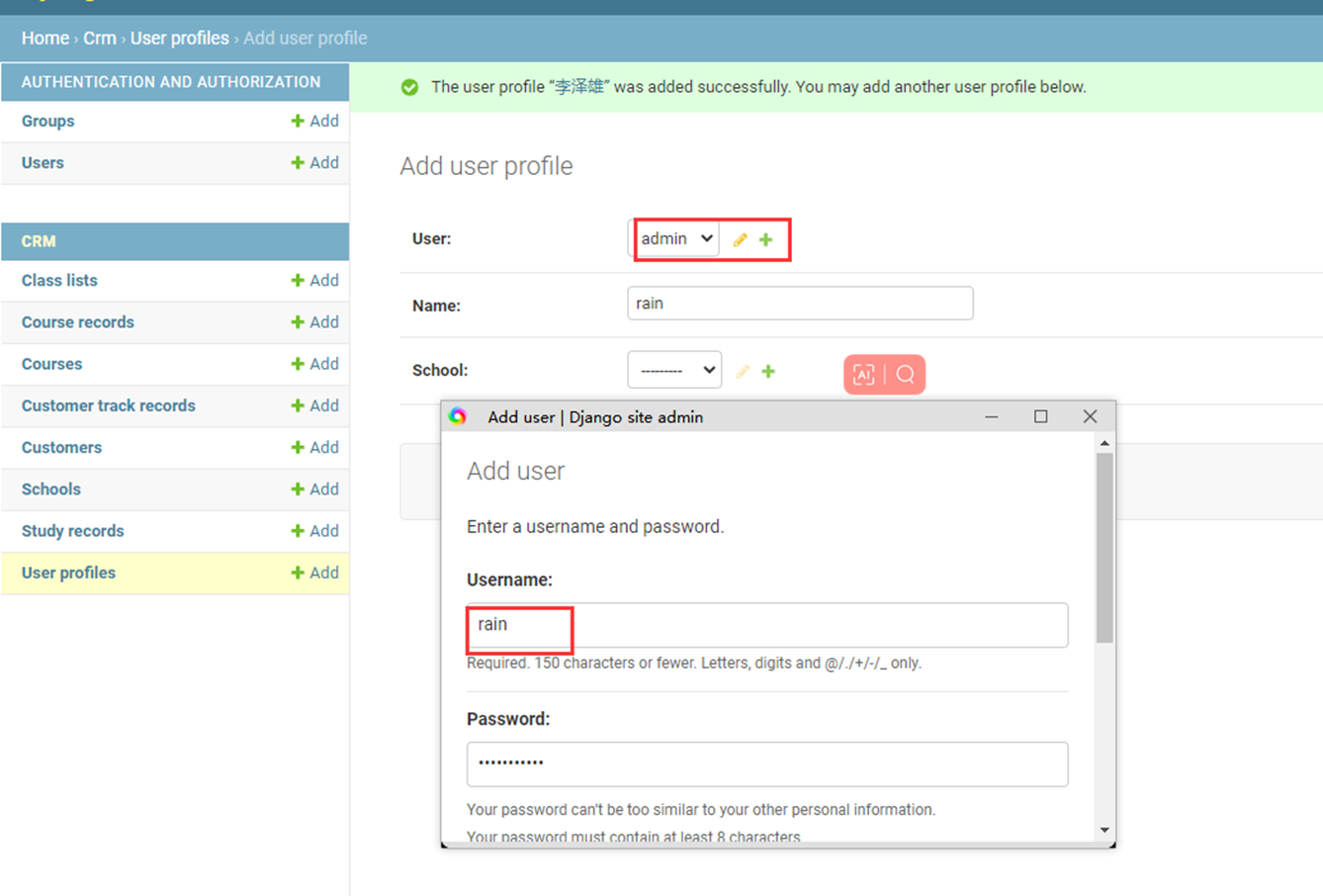
客户
为了演示效果,可以多创建几个
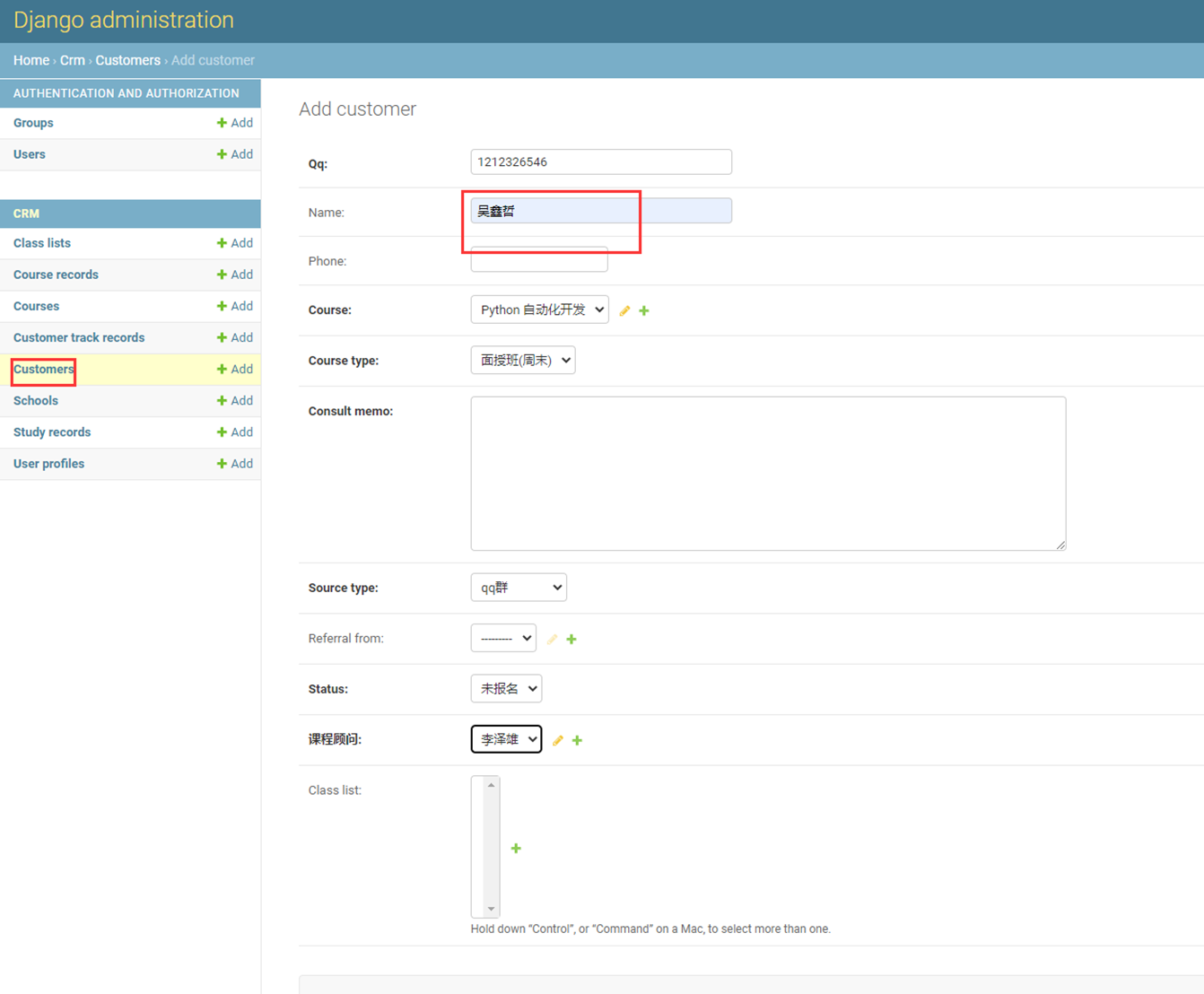
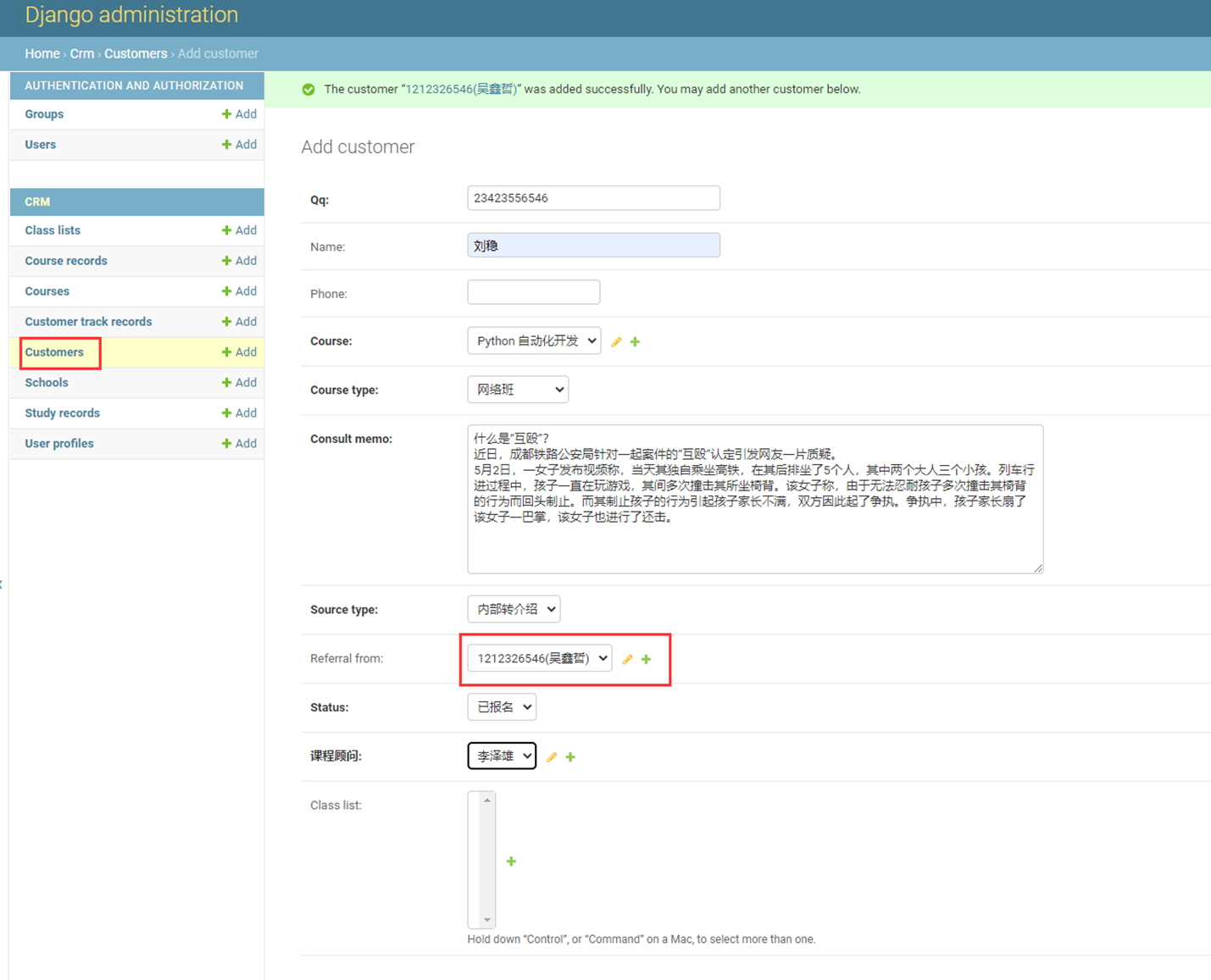
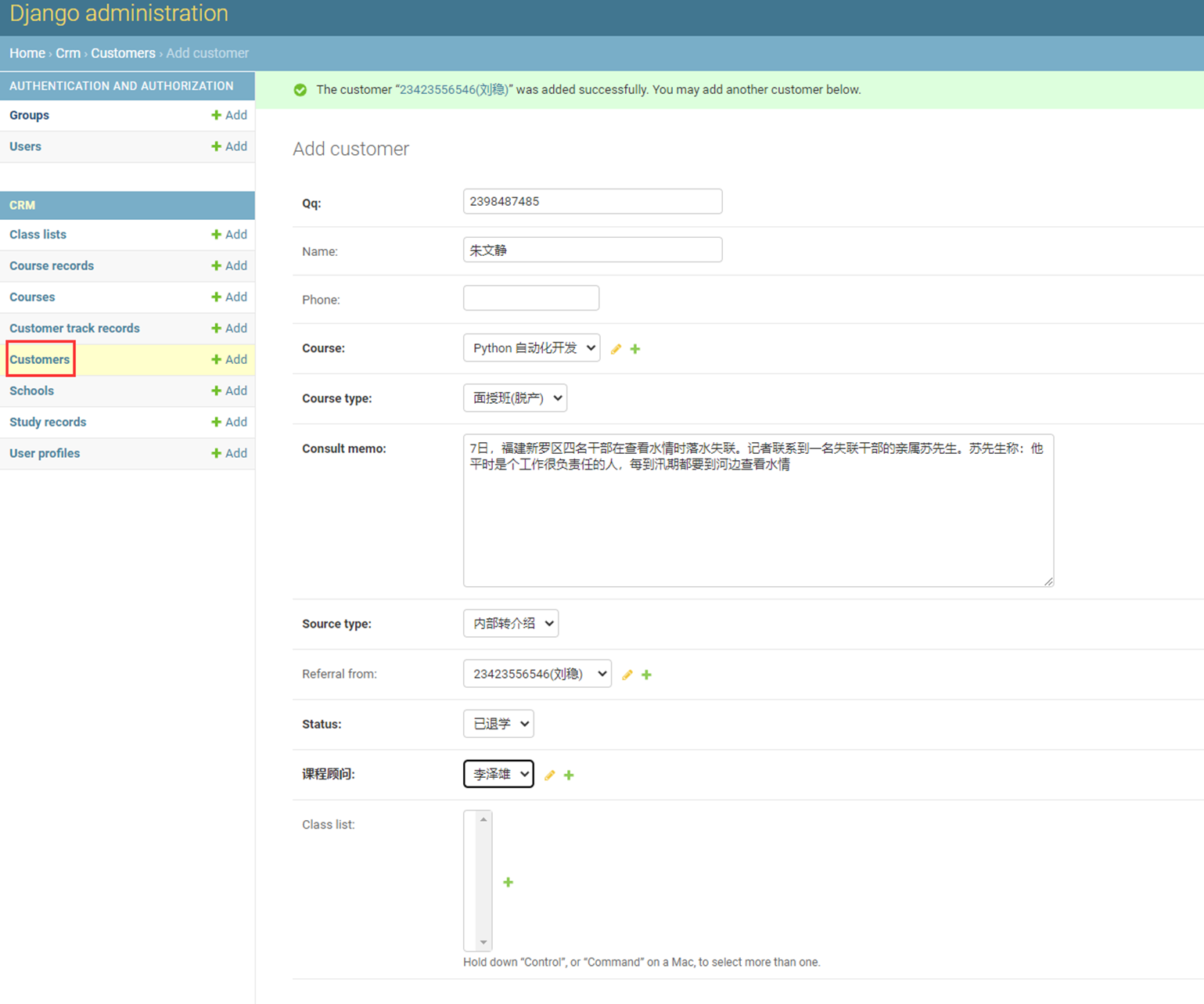
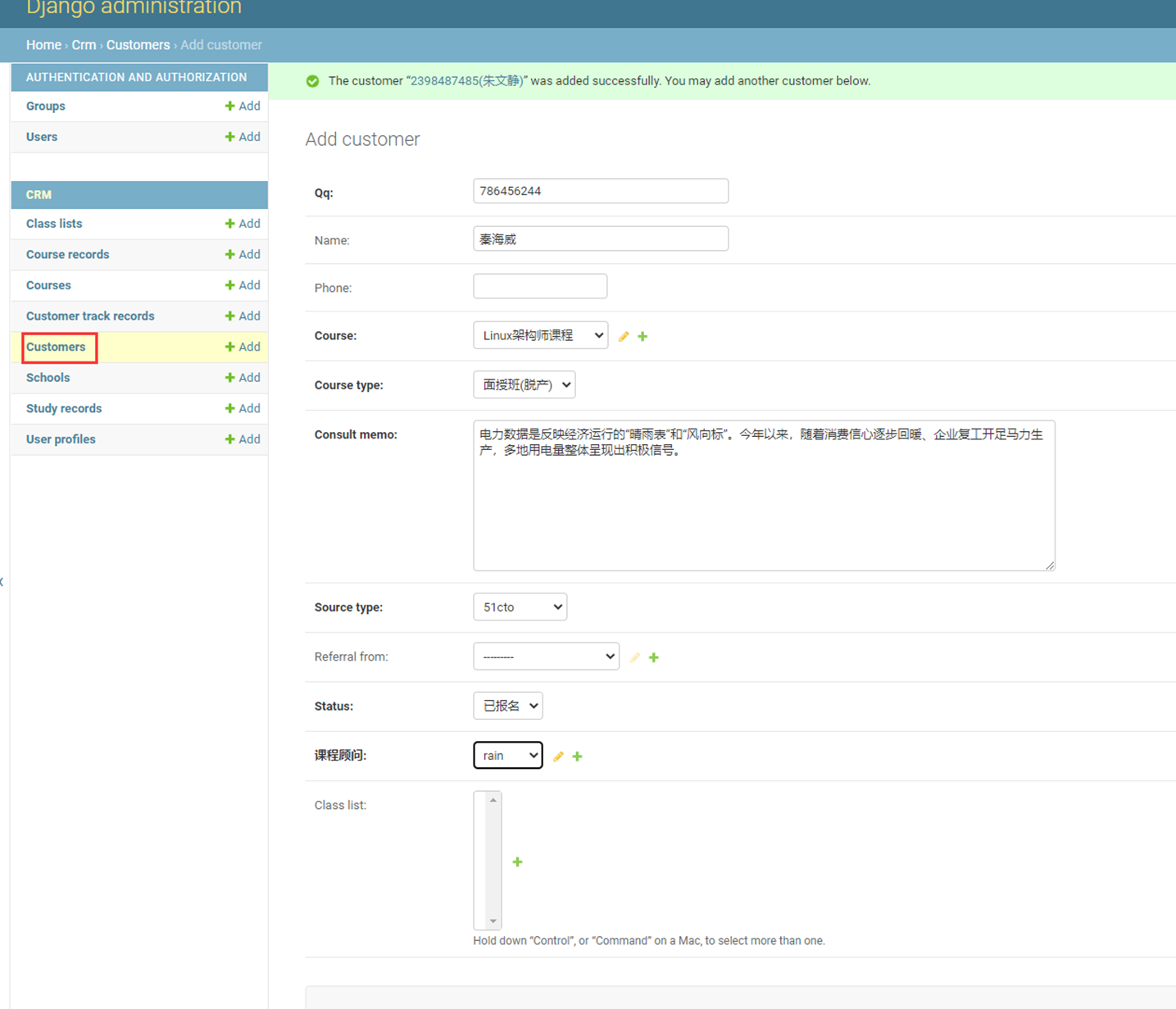
1.URL,一个客户信息的url
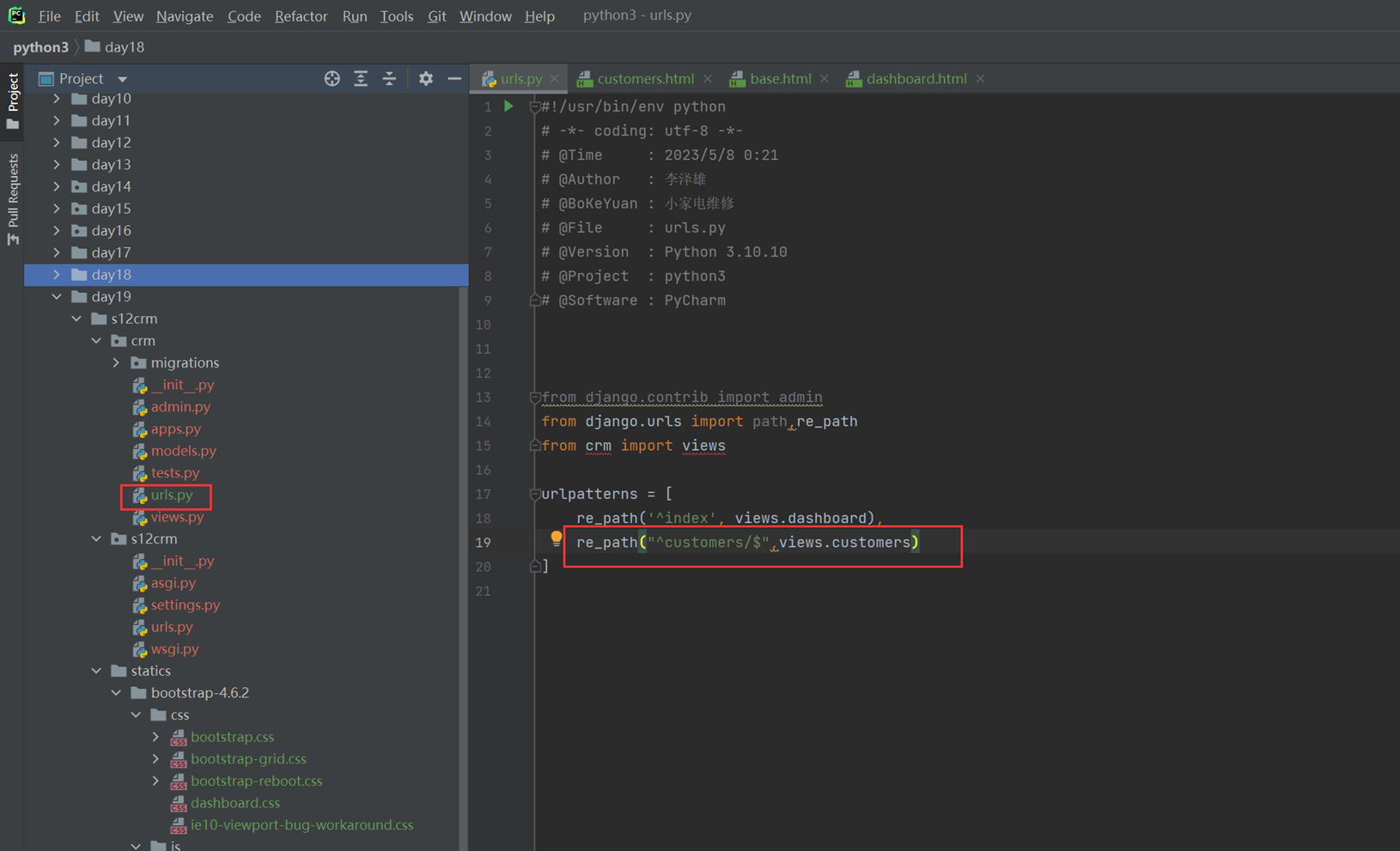
views
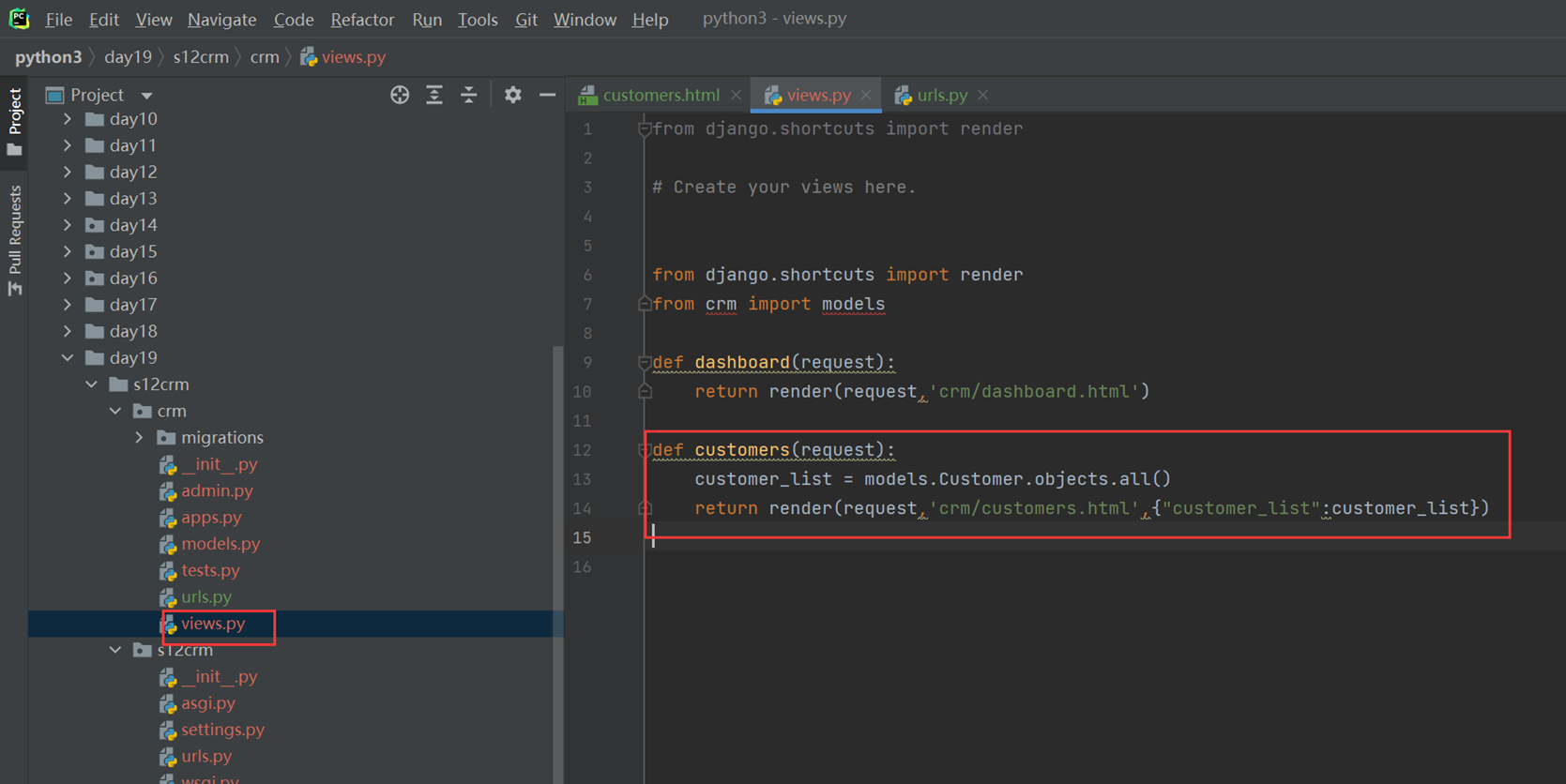
html
重头戏和工作量都在这里
首先base.html要清理掉没有用的内容,然后预留模版空间。
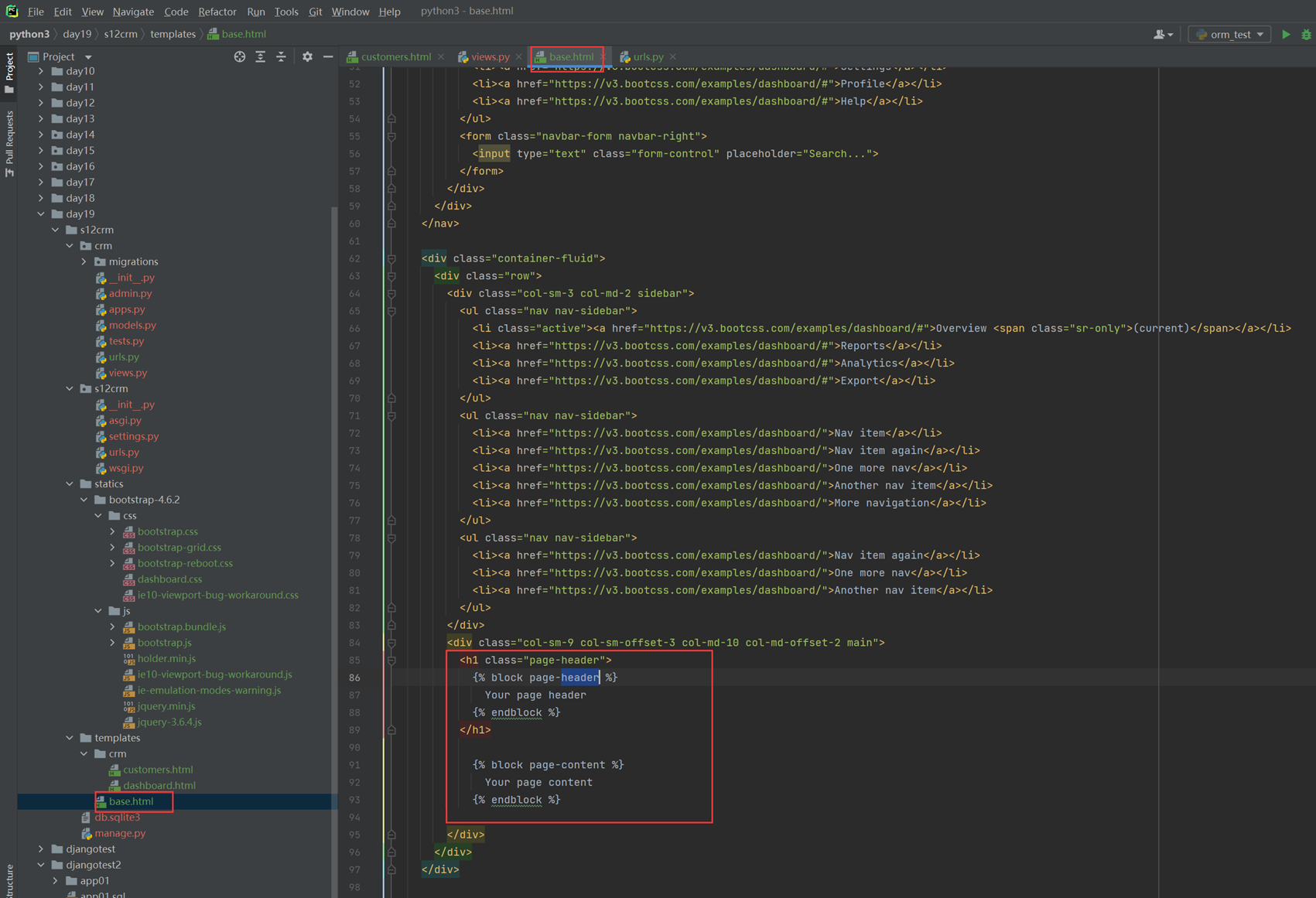
然后customers.html来继承base.html
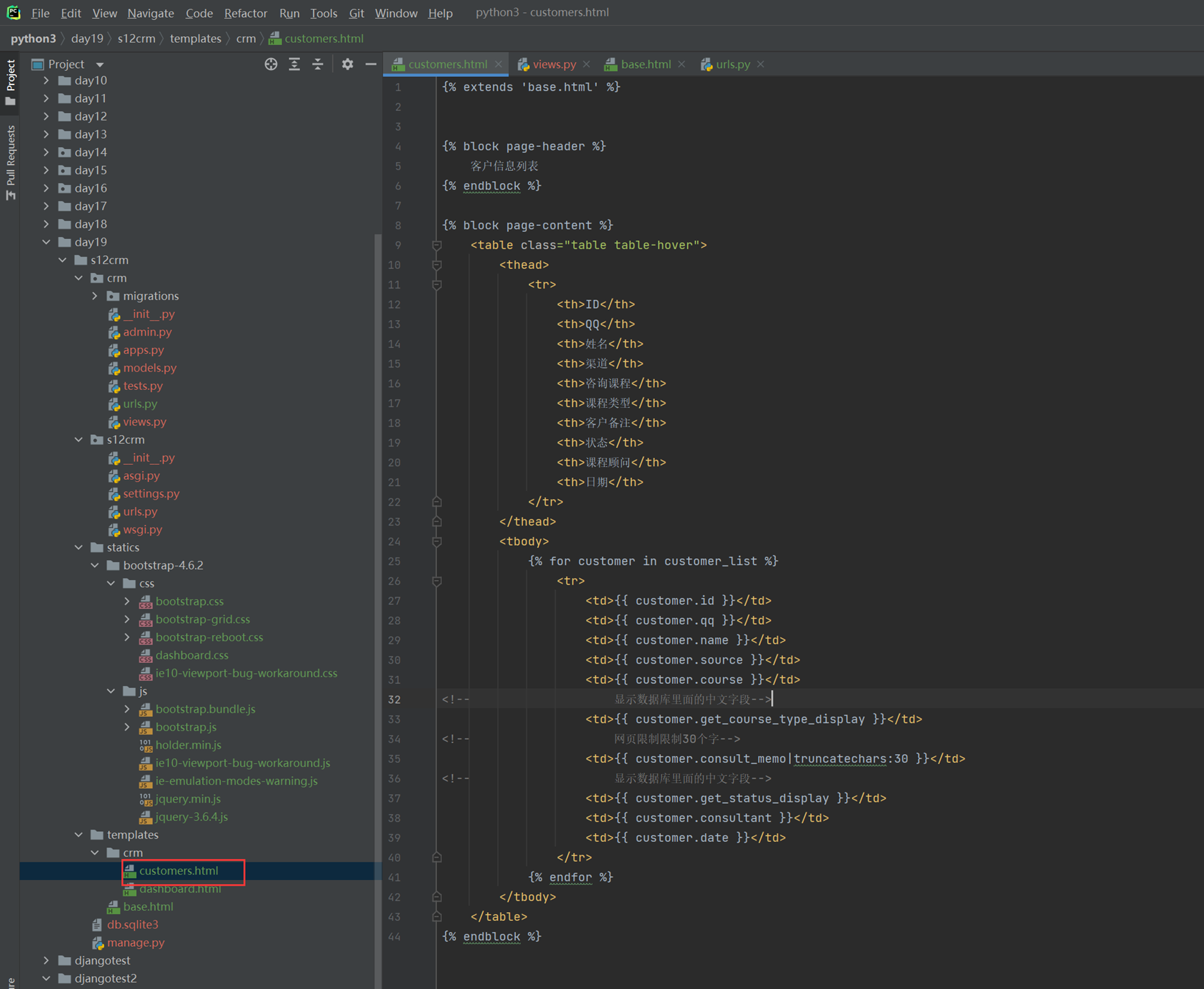
访问查看
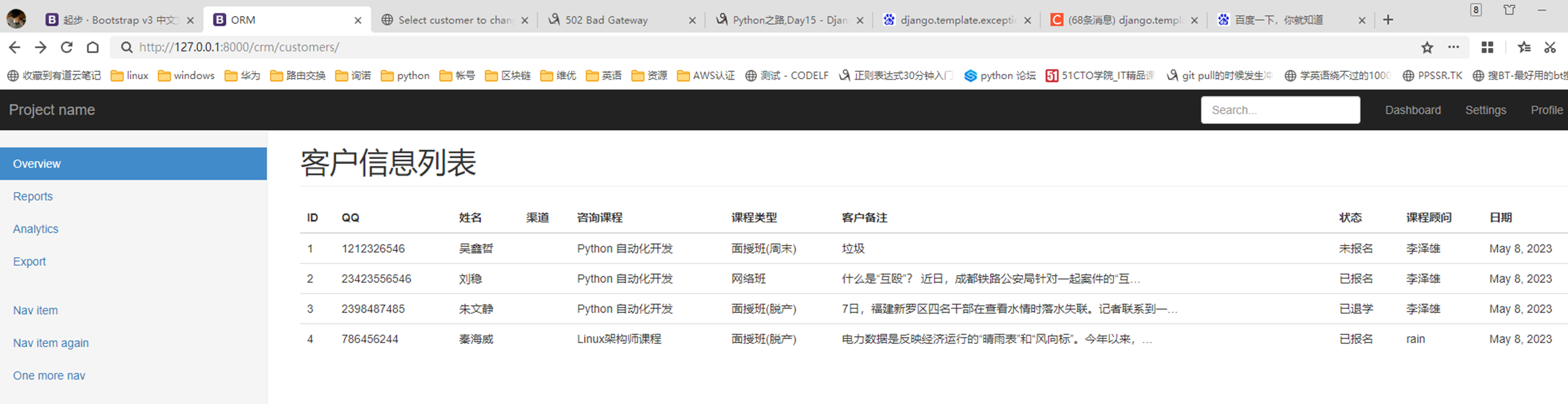
完成了,但是这里在多一个新的需求出来,要在状态那边显示不同颜色,这里有个小技巧。
不需要用if判断,直接使用提前准备css的方式。
首先创建一个自定义css,然后引用。
引用
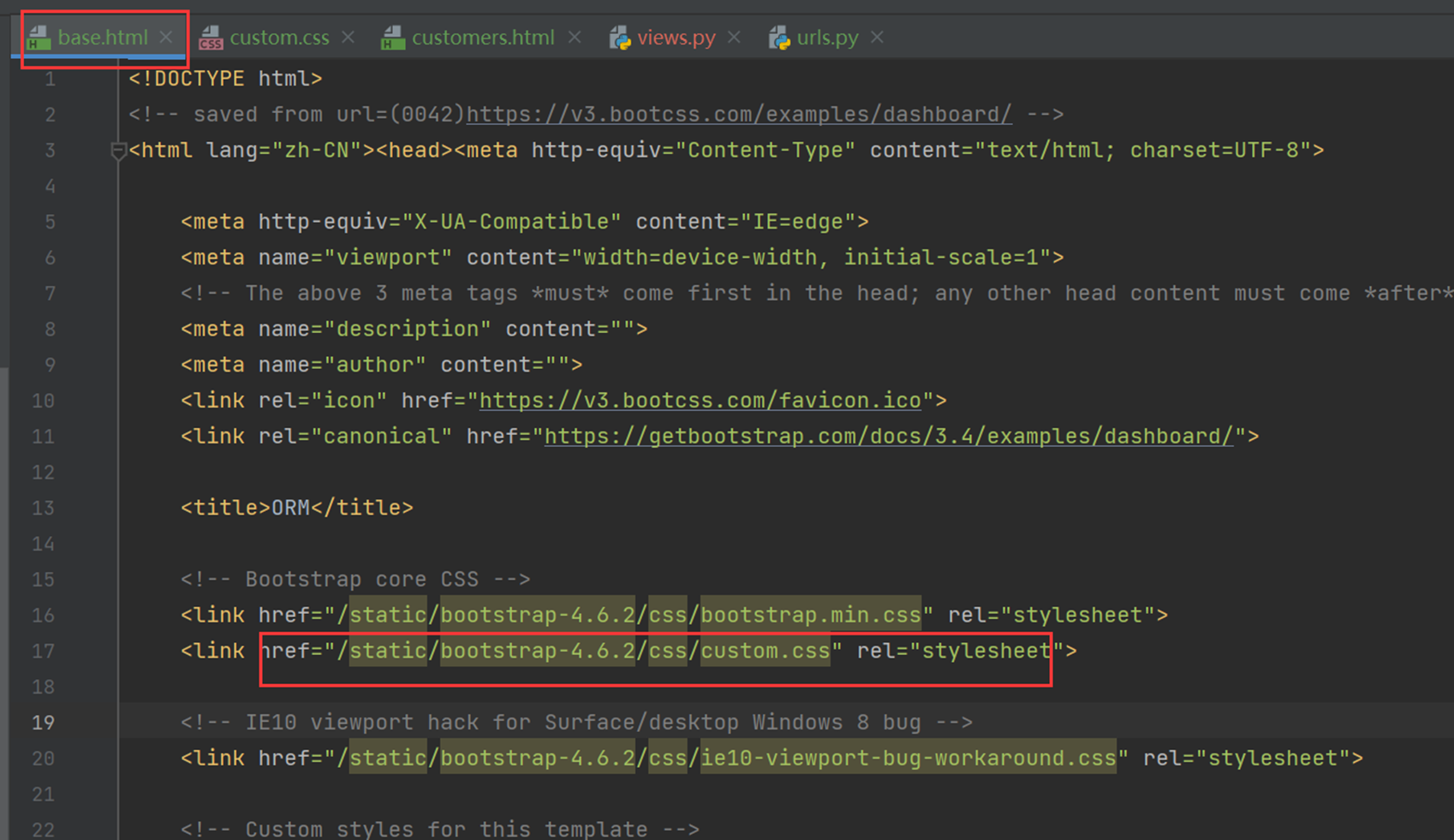
最后大招看
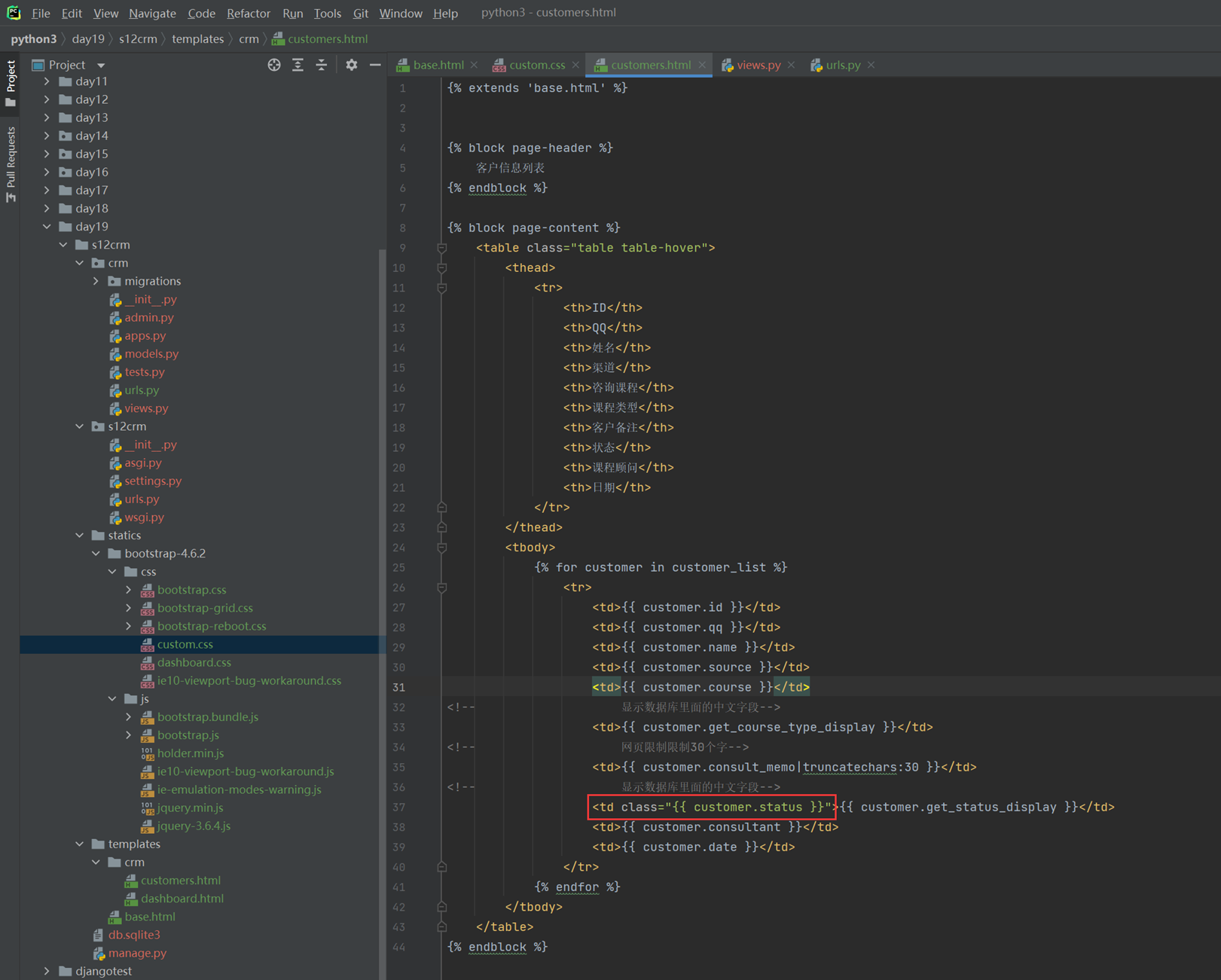
访问查看
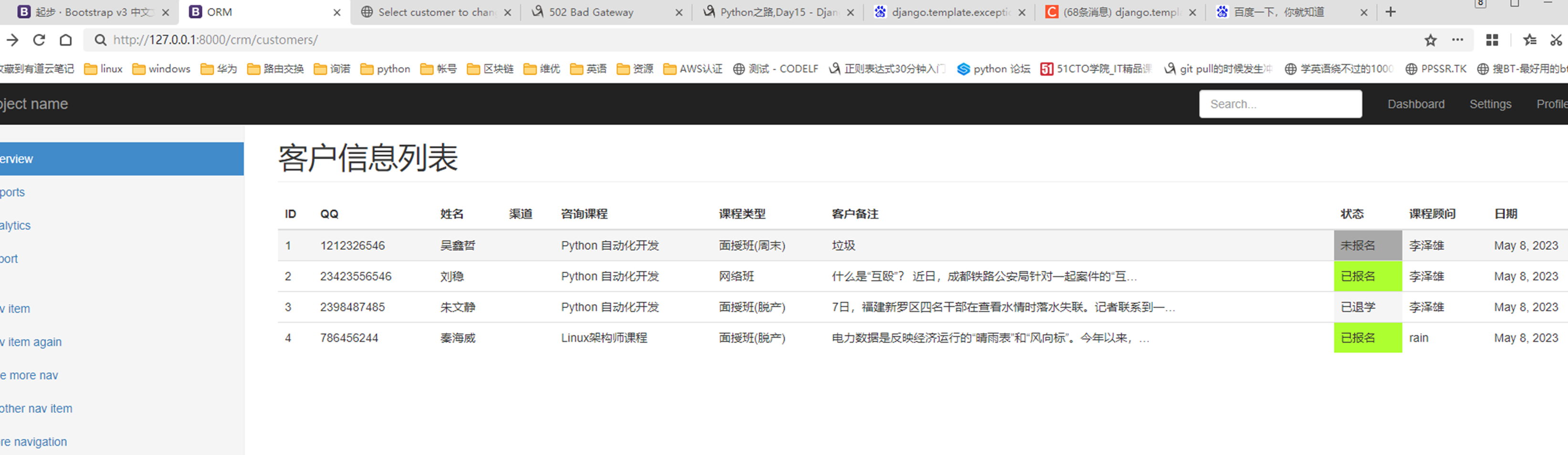
19.6 分页功能
Django自带分页,且分页功能及其简单。看官网链接。
https://docs.djangoproject.com/en/3.2/topics/pagination/
就是一个自带的模块
前端后端案例都有

我们这里还是自己演示一下。也是比较简单
1.views
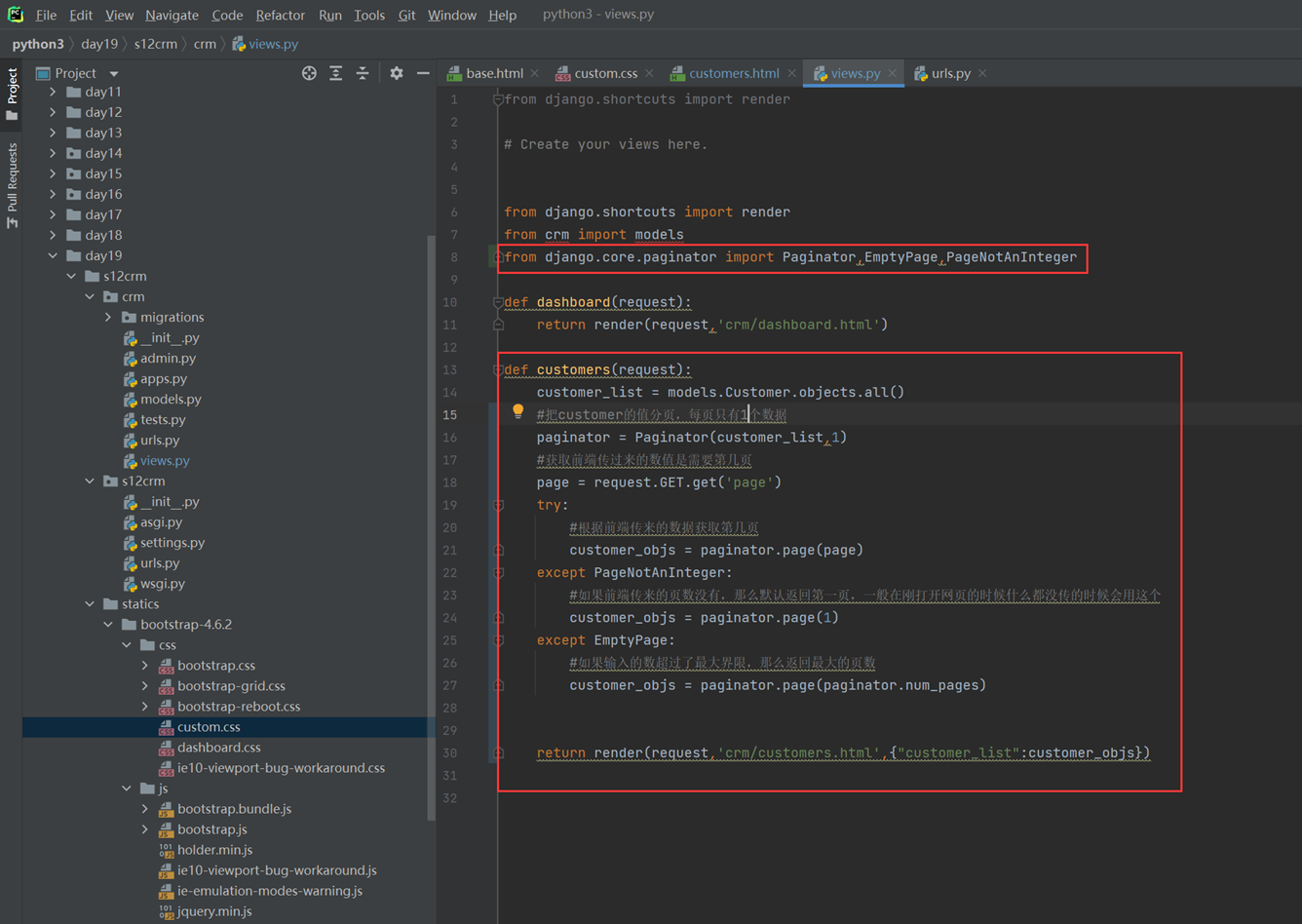
2.html

查看结果
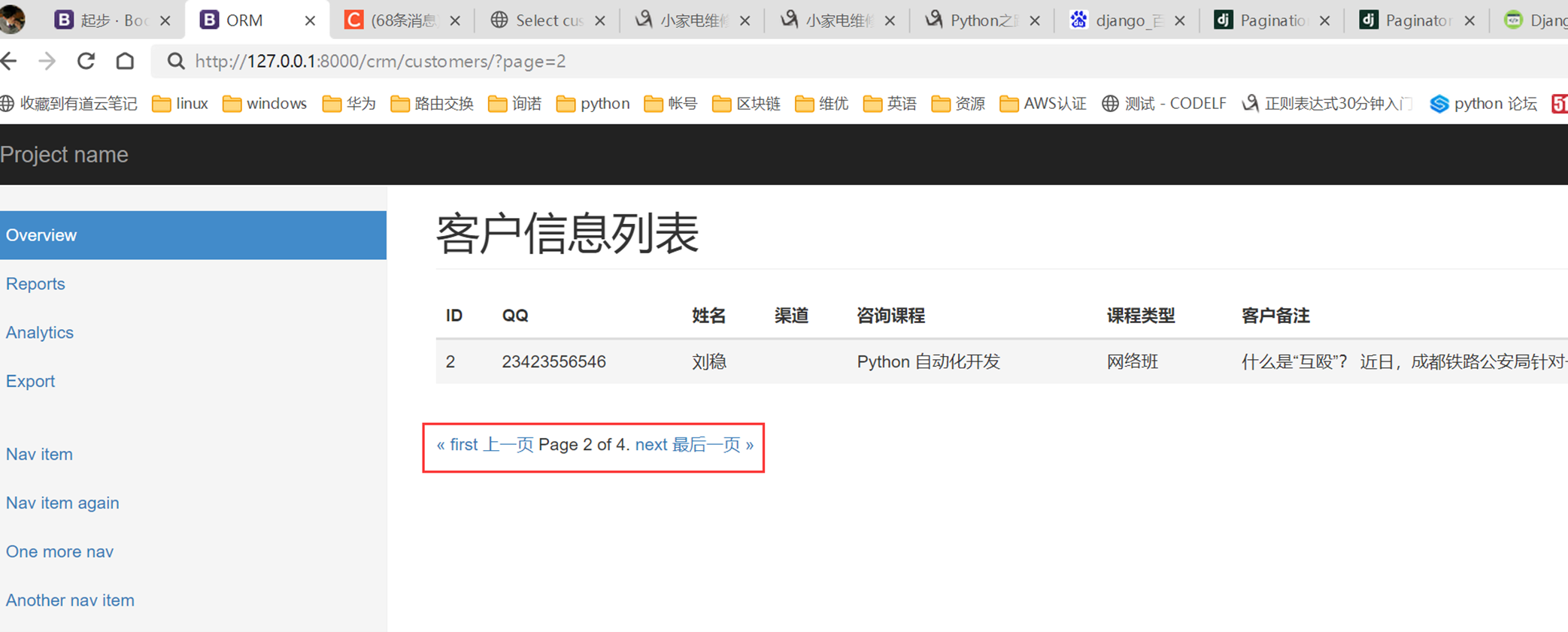
19.7 分页功能2
增强一下分页的功能,我们这里还是用bootstrap。
该操作只用操作前端,不需要在后端做更改。见以下代码。
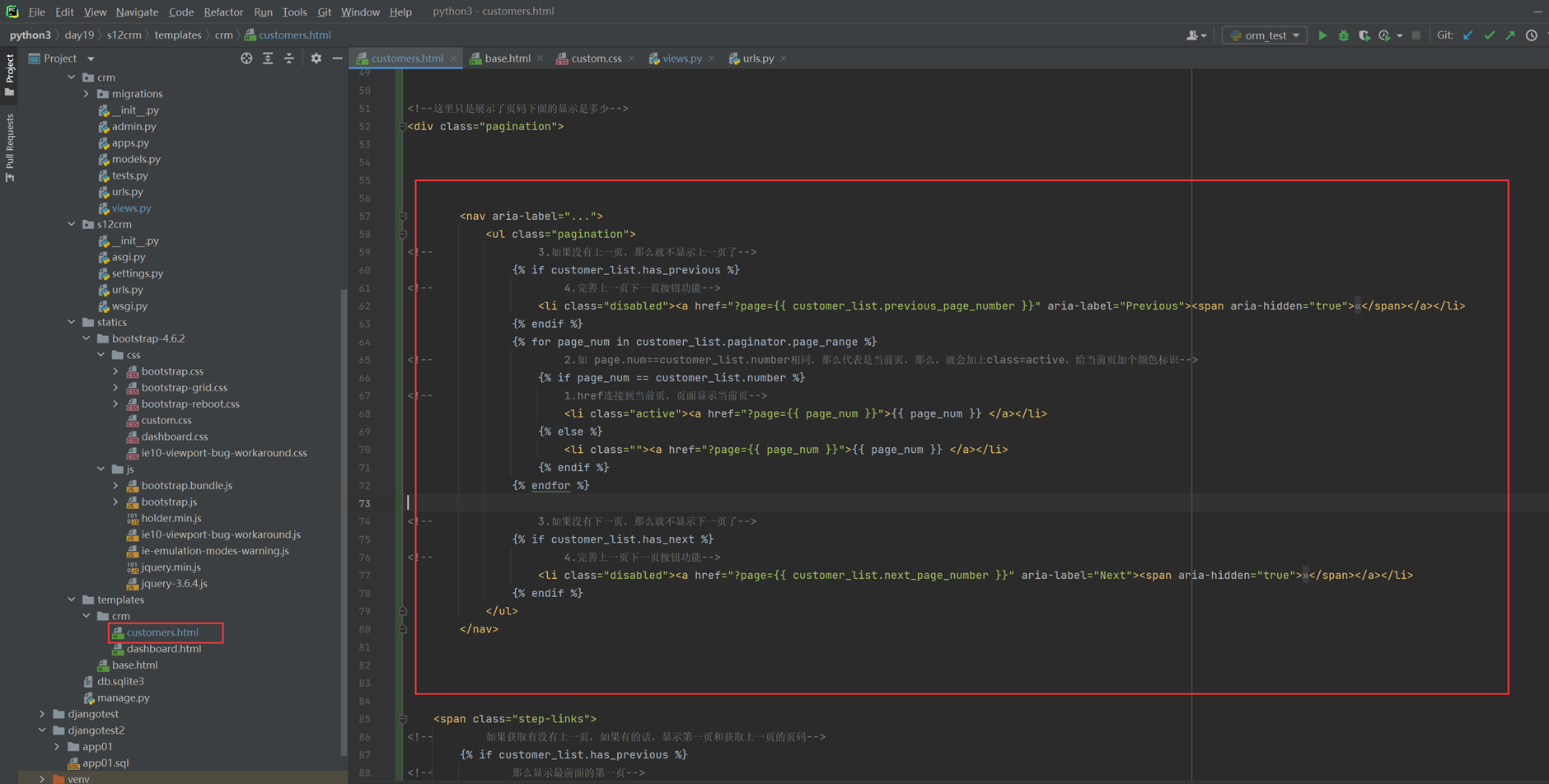
访问查看
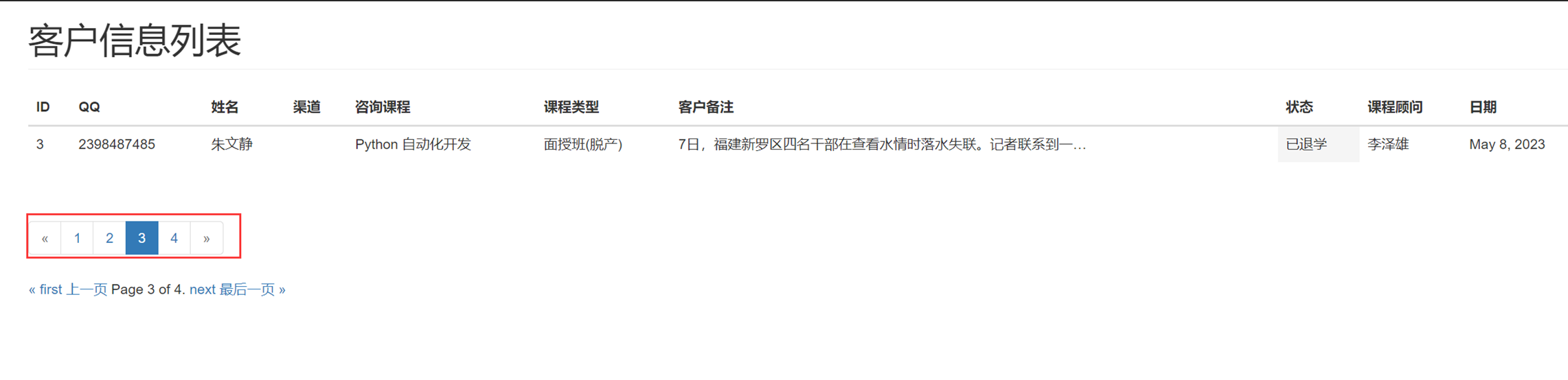
视频一共18分钟,视频到了13分钟左右还有一个需求,就是像百度一样,假设有100页,我在50页,那么我这里只显示我前后5页的页码。演示失败,见下个视频。

19.8 分页功能优化
上节课的实现思路就是使用绝对值,但是前端没有绝对值函数,所以我们要前端自定义标签。
自定义标签,django官网也有介绍。
https://docs.djangoproject.com/en/3.2/howto/custom-template-tags/
这里先演示一个简单的功能,让我们知道自定义标签怎么使用。
1.创建templatetags目录和自己的自定义标签文件,这里的文件夹一定是指定路径,否则不生效。
2.自定义标签
这里自定义一个可以把小写转为大写的函数。
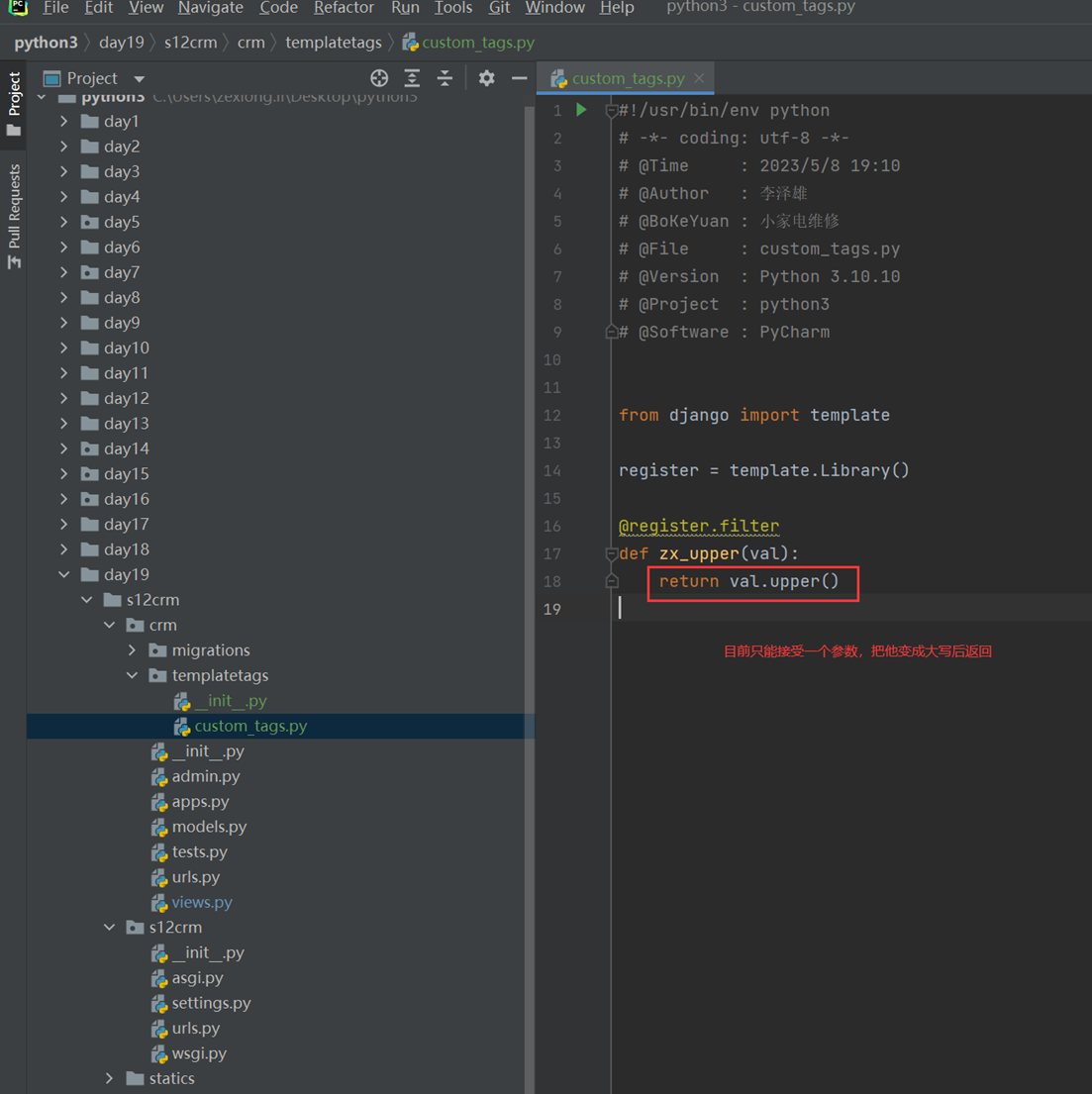
3.前端调用
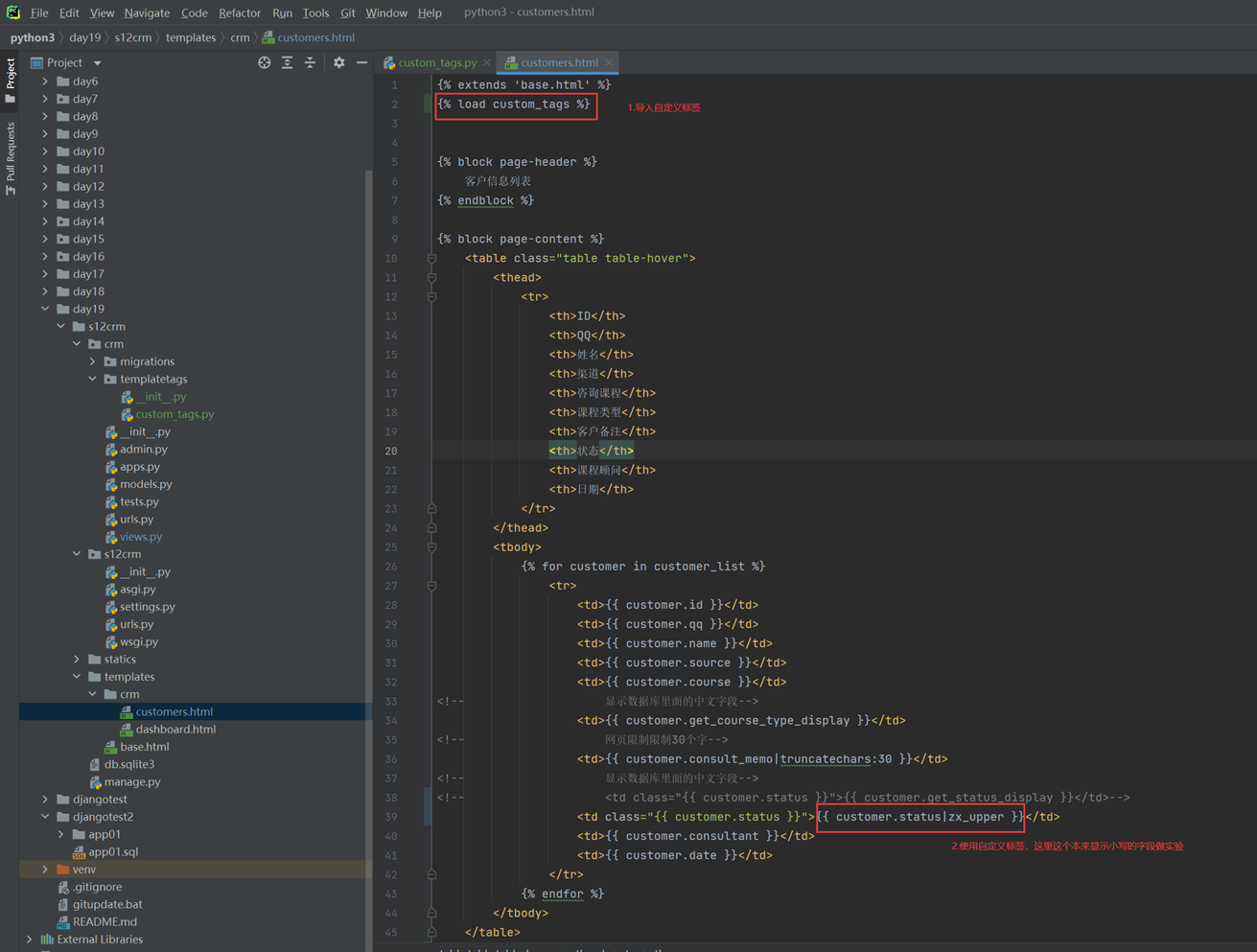
4.查看结果

上面是传入一个参数,然后转变一个大小写,是一个简单的需求,如果有一个非常复杂的需求,比如我们的分页,传入2个参数,那怎么办?
html
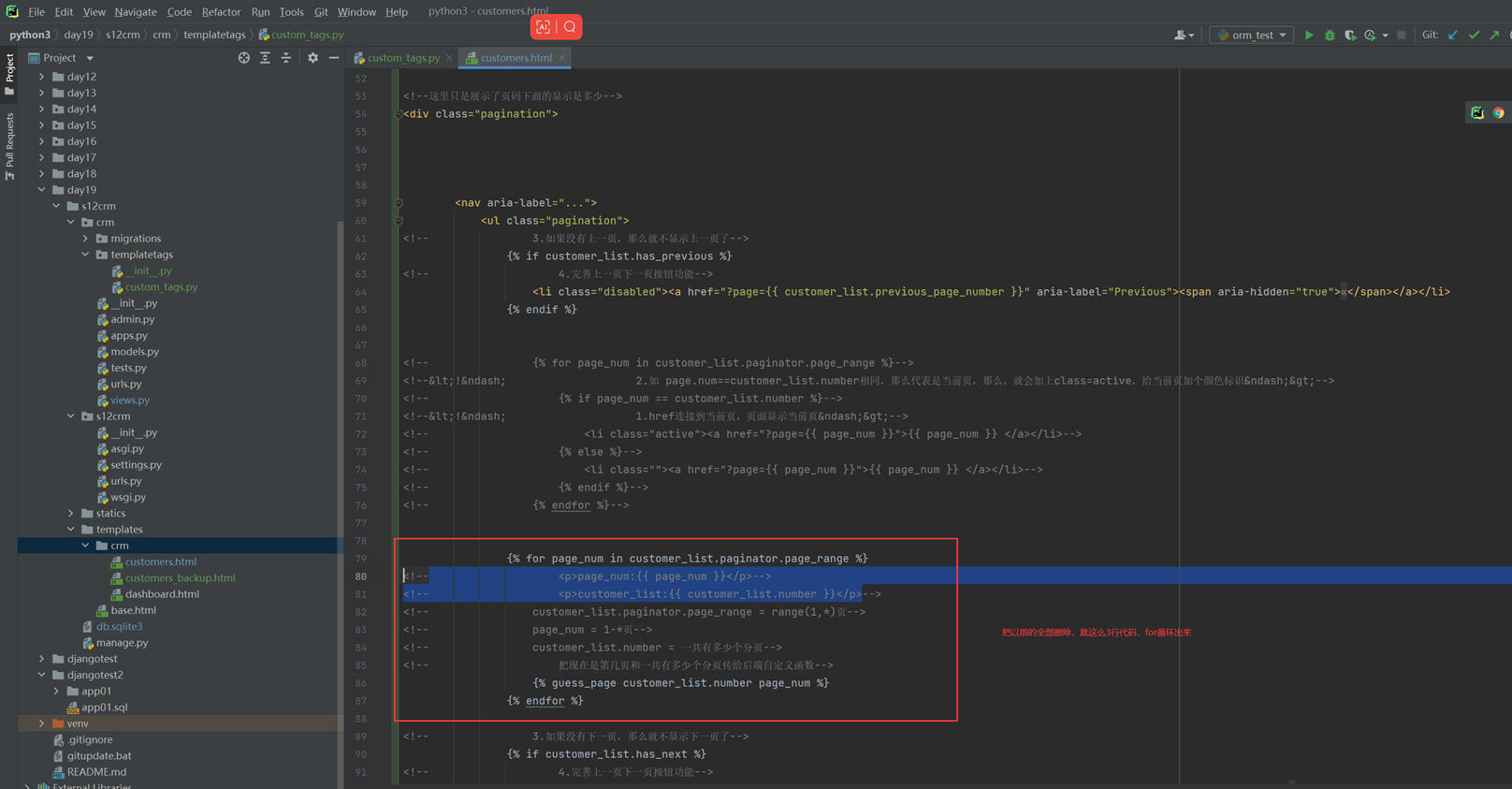
自定义标签
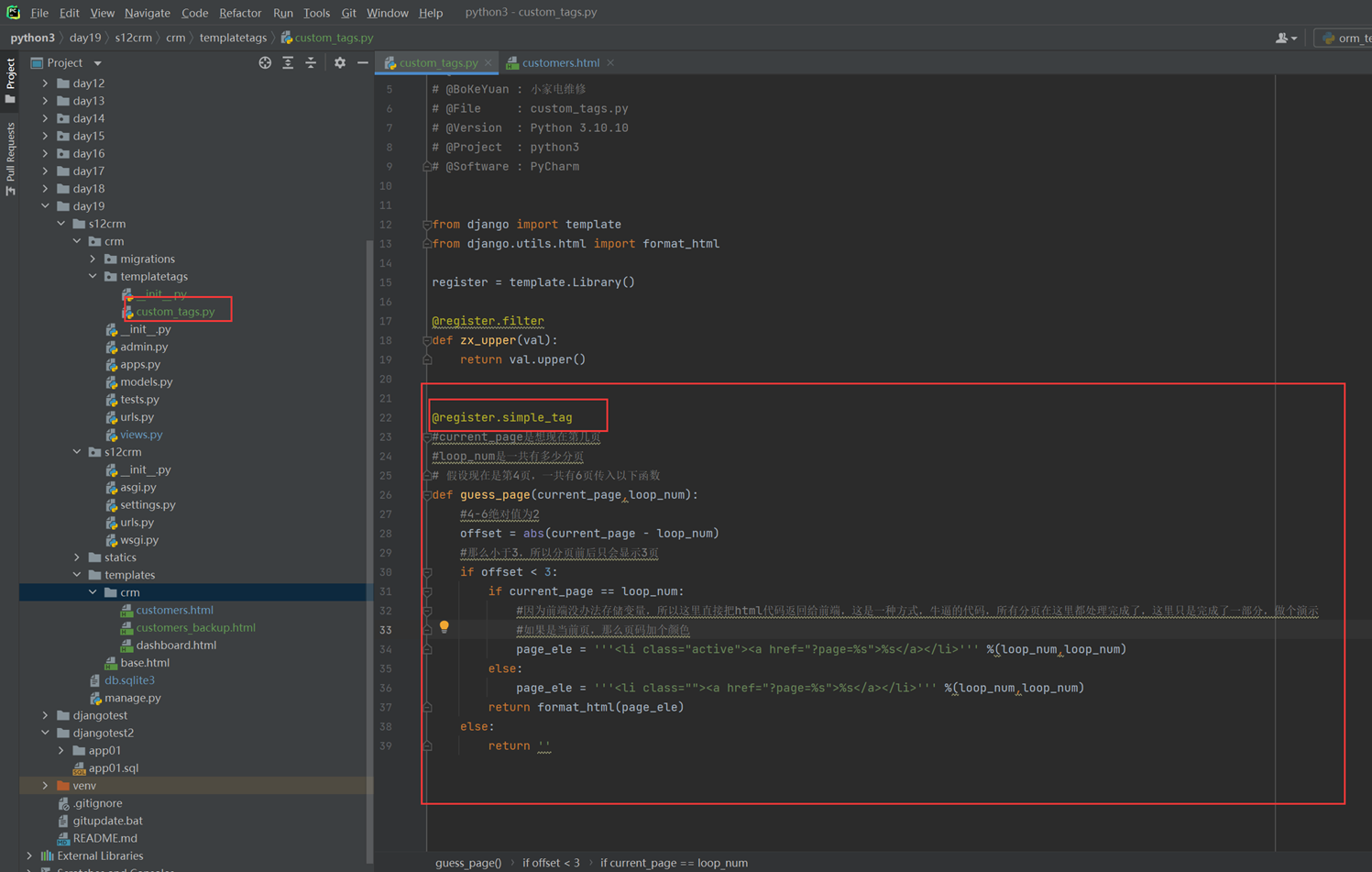
结果
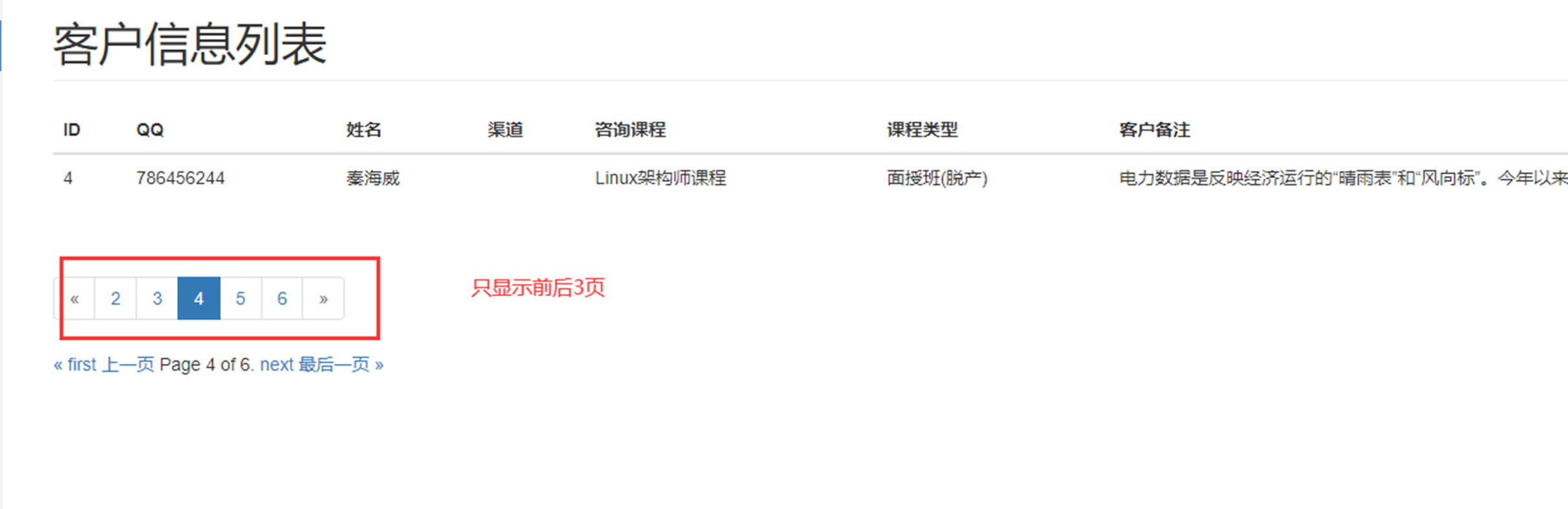
19.9 充分使用modelform
这节课的需求简单来说就是通过form和modelform来把数据库的数据自动展示在前端或者可以通过前端自动保存到后端。很简单的需求。
1.首先我们就不直接访问了url来跳转这个界面,直接在当前界面加一个a标签跳转。
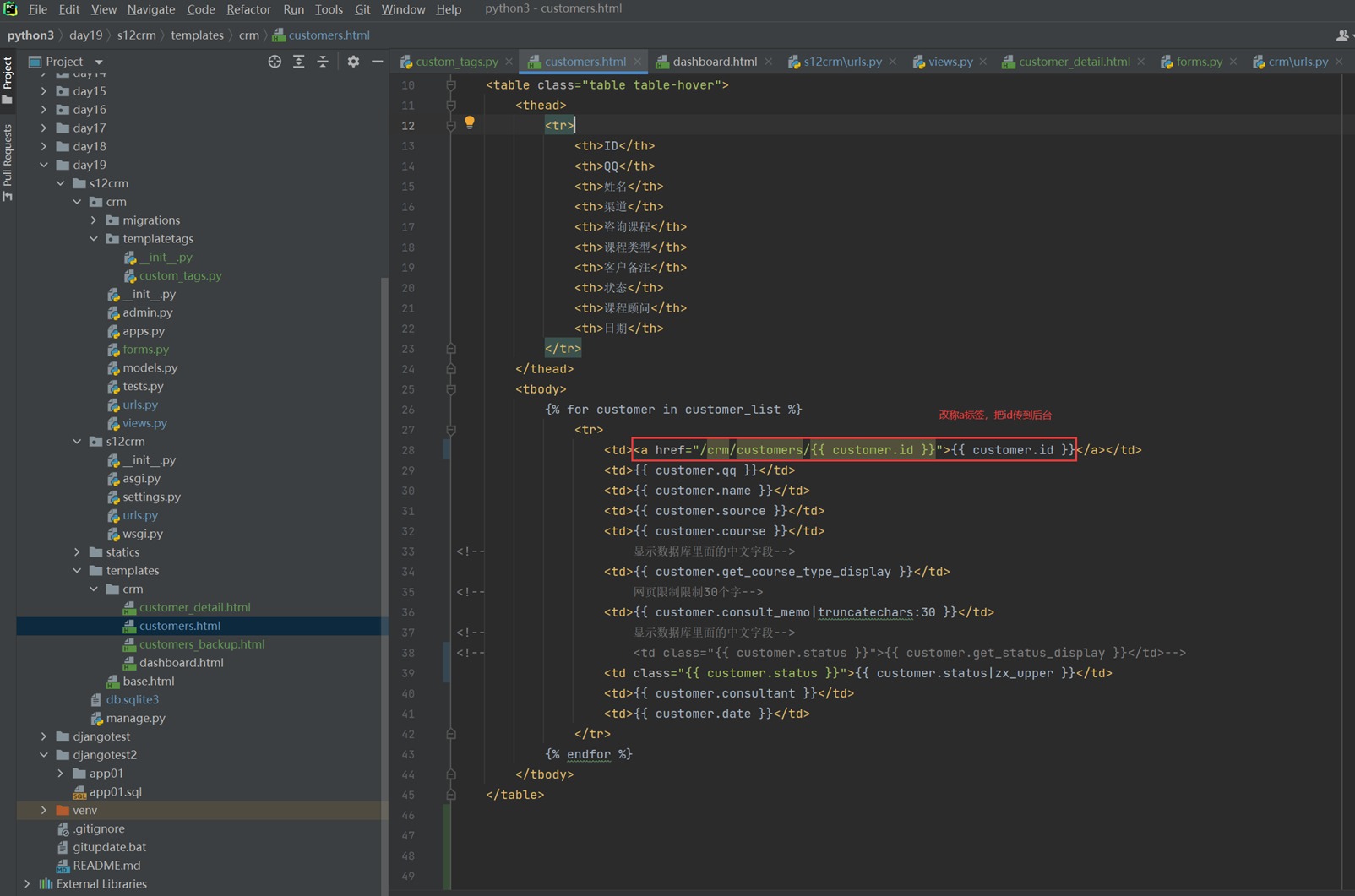
2.url
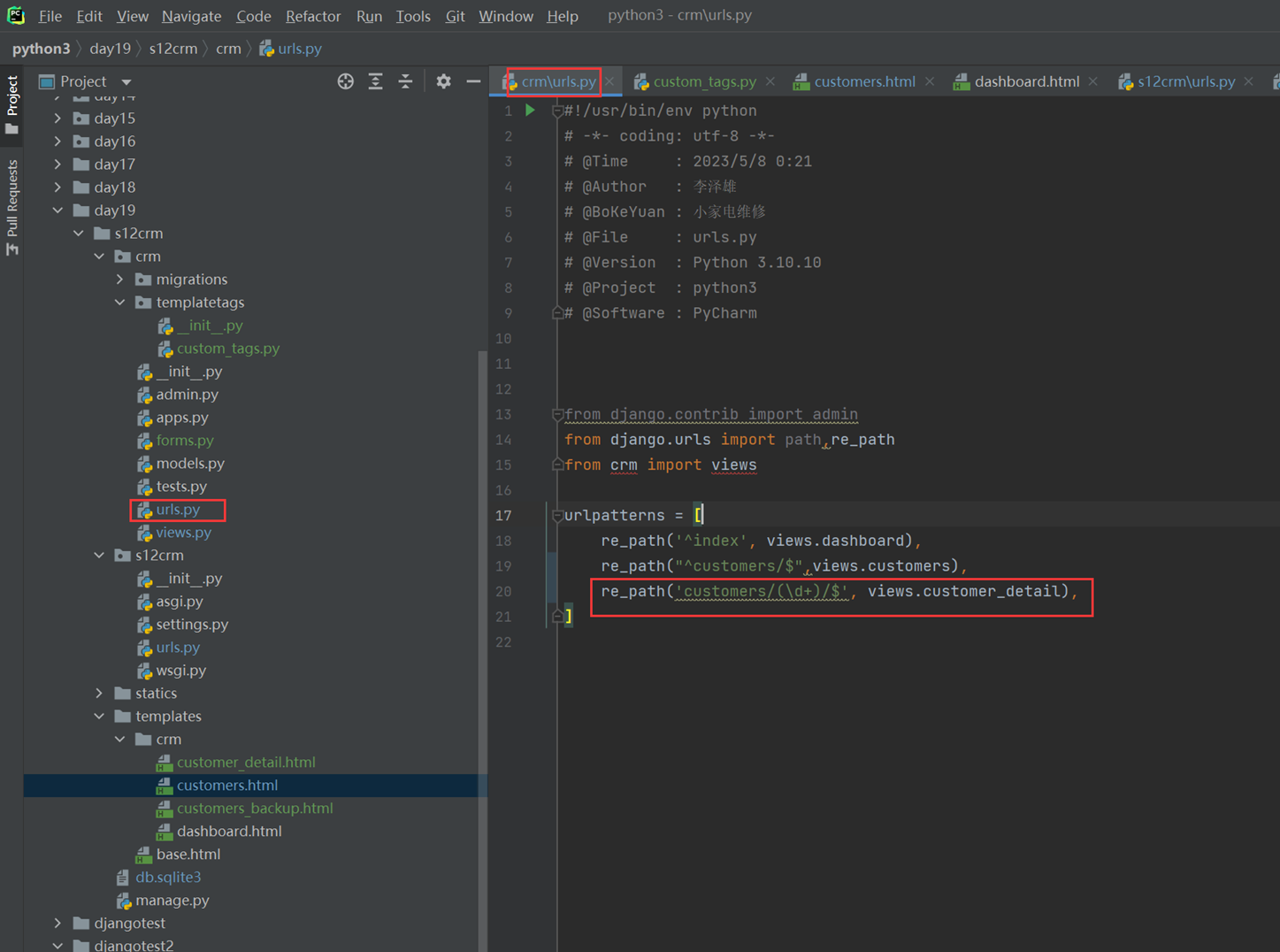
3.views
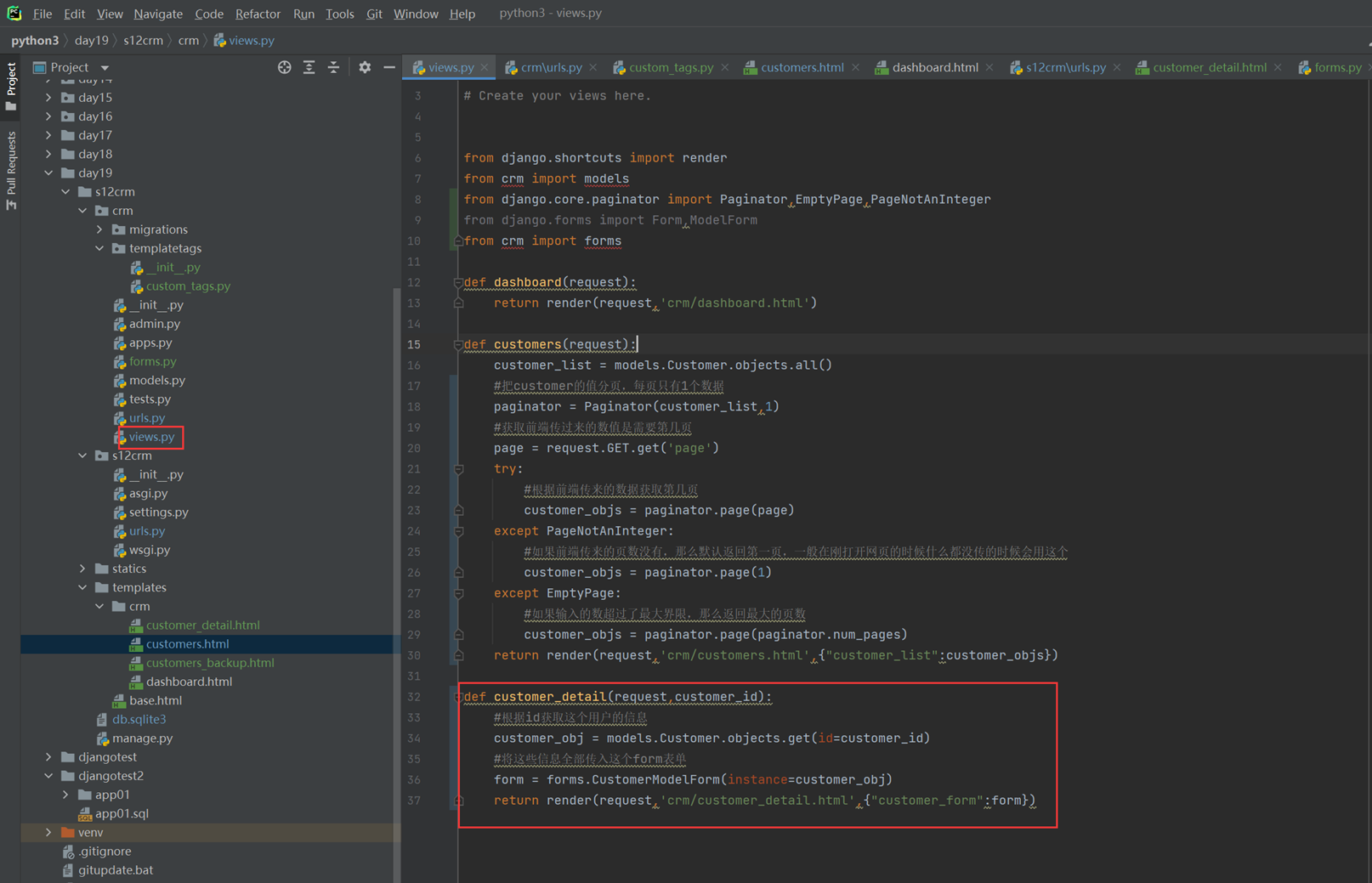
4.forms
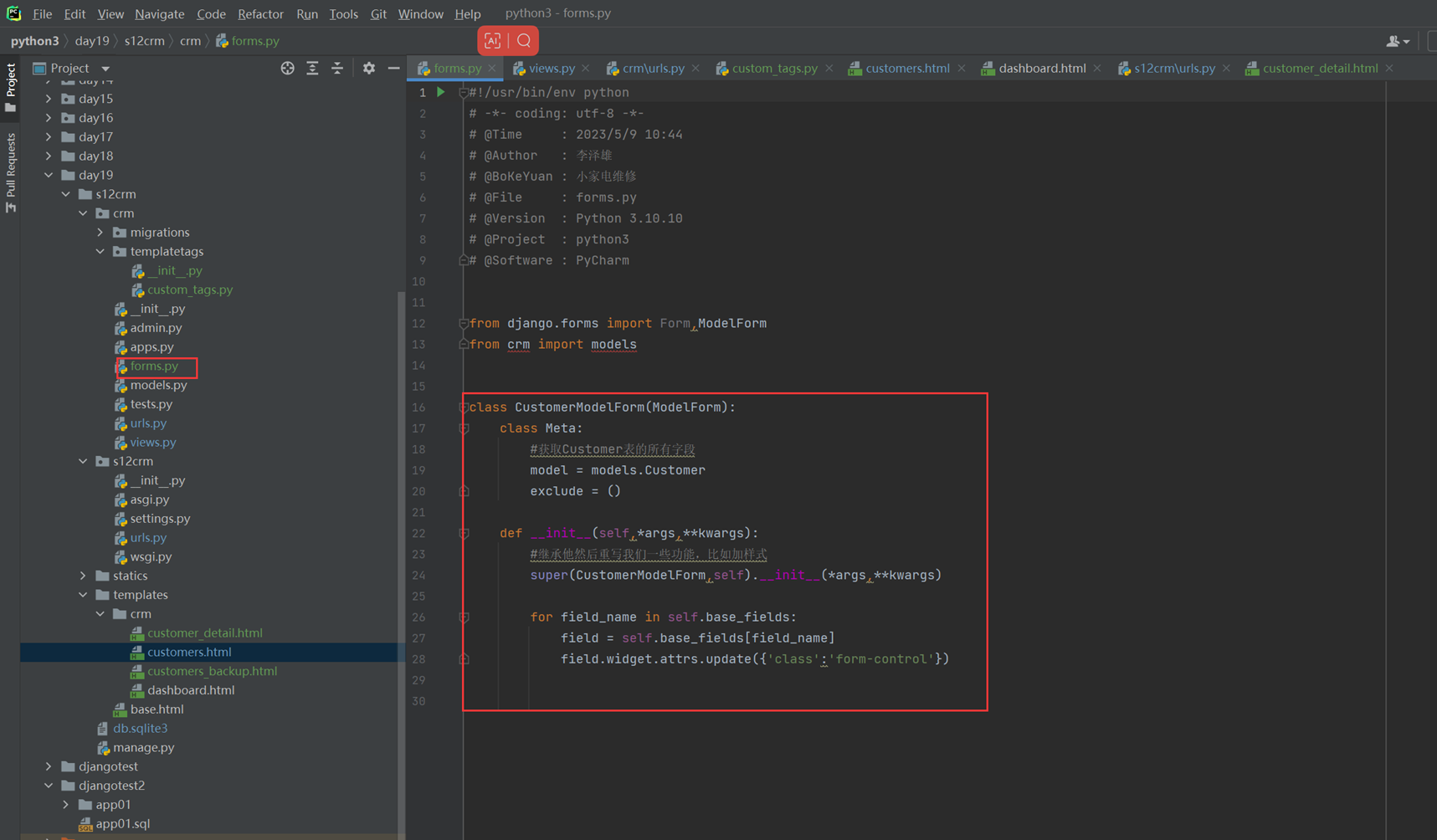
5.html
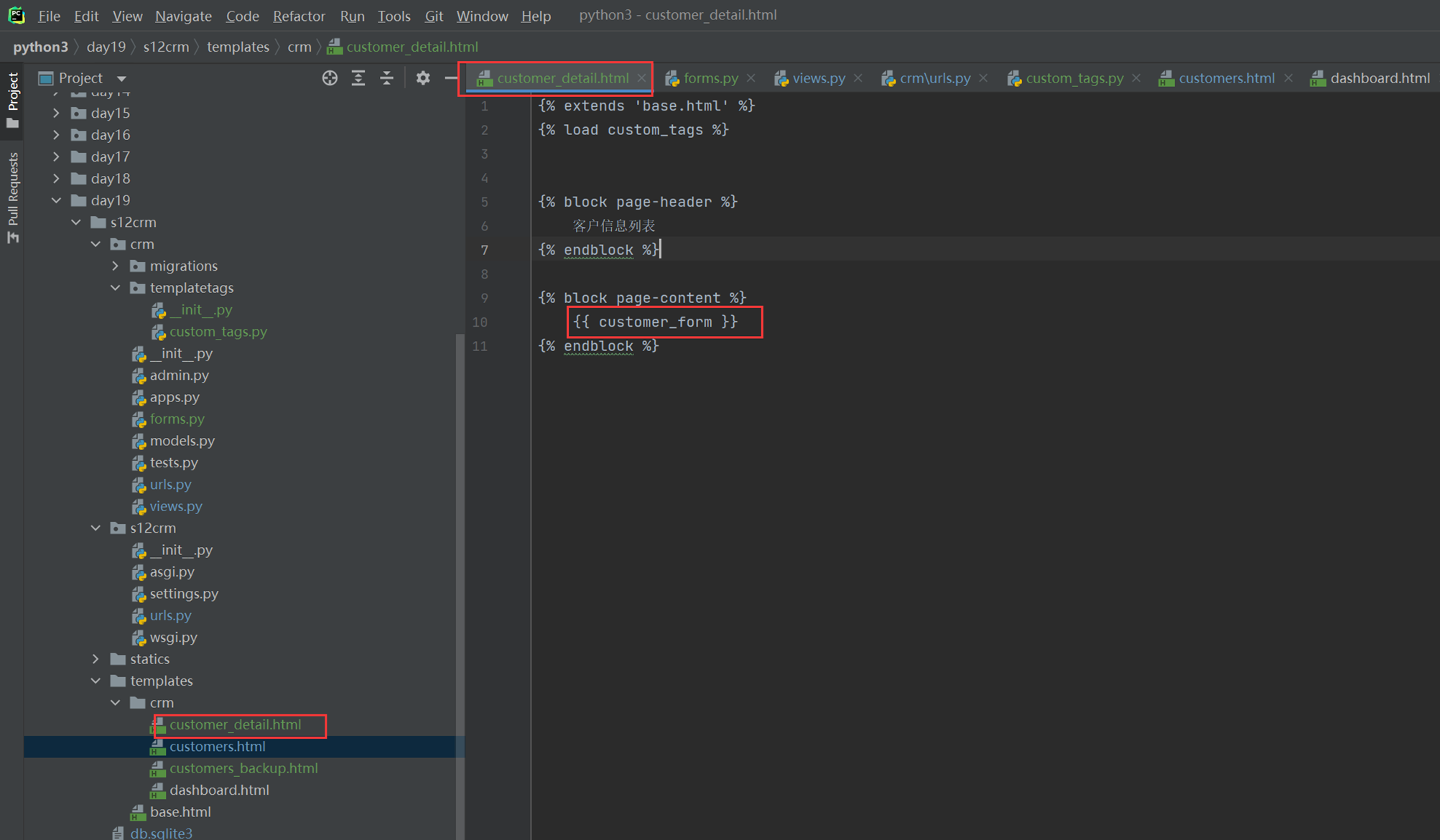
访问结果查看
已经可以获取后台数据自动填充了。
19.10 使用modelform修改数据库数据
接着上面的课程讲解,他还不是一个表单,现在变成一个表单,变得更加好看一下,完善一下和django后台差不多的样式,可以修改并提交
这里还是使用bootstrap的样式。
https://v3.bootcss.com/css/#forms
本章是一共完成了几个需求
1.前端input美化,前端美化
2.可以提交修改数据到数据库
3.前端美化错误消息
4.前端必填字段和非必填字段样式区分。
5.后端提交完成后返回主页,必须是动态参数
本章就是在上一章基础上优化的,所以,只有2个代码文件有了修改
html
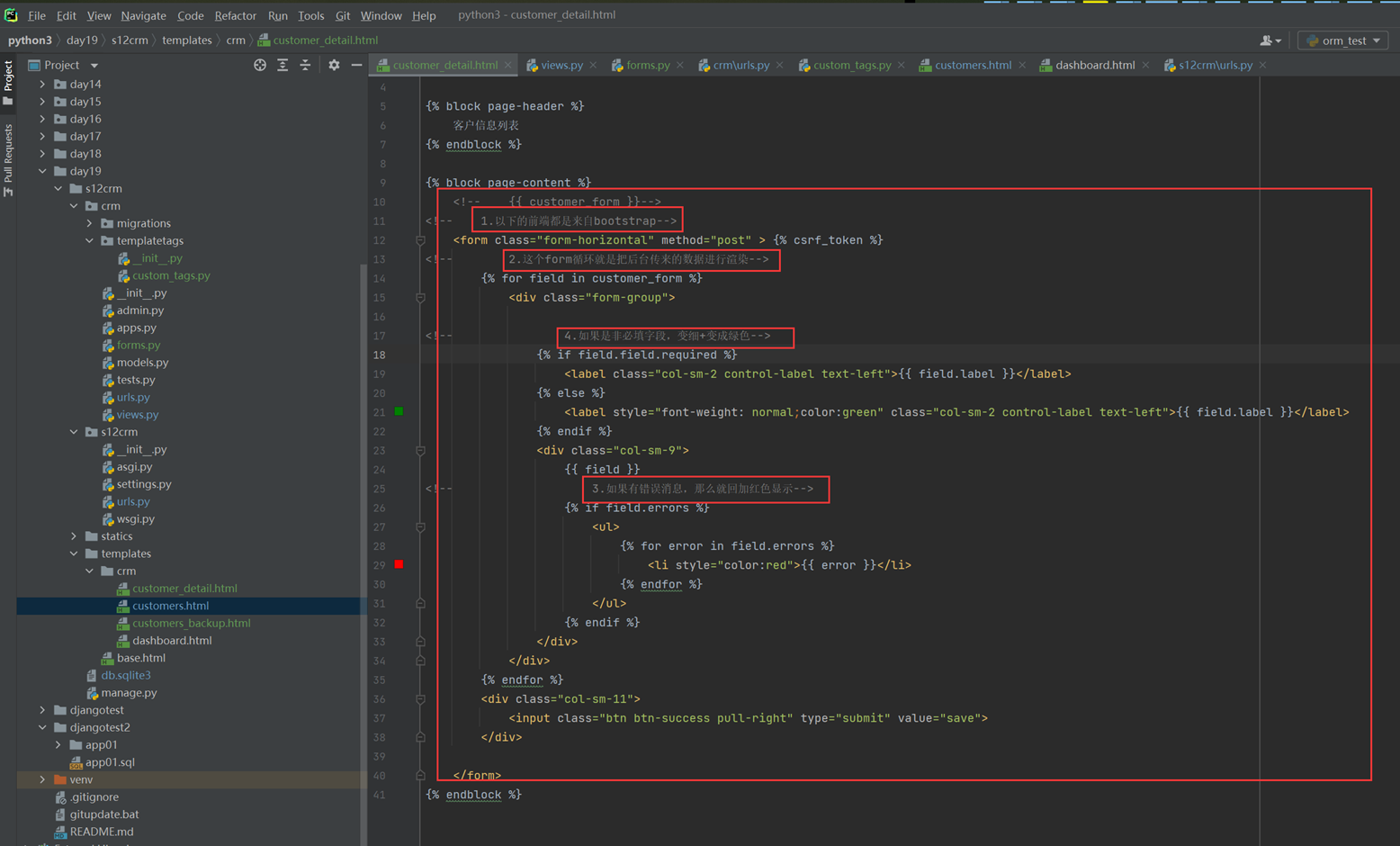
views
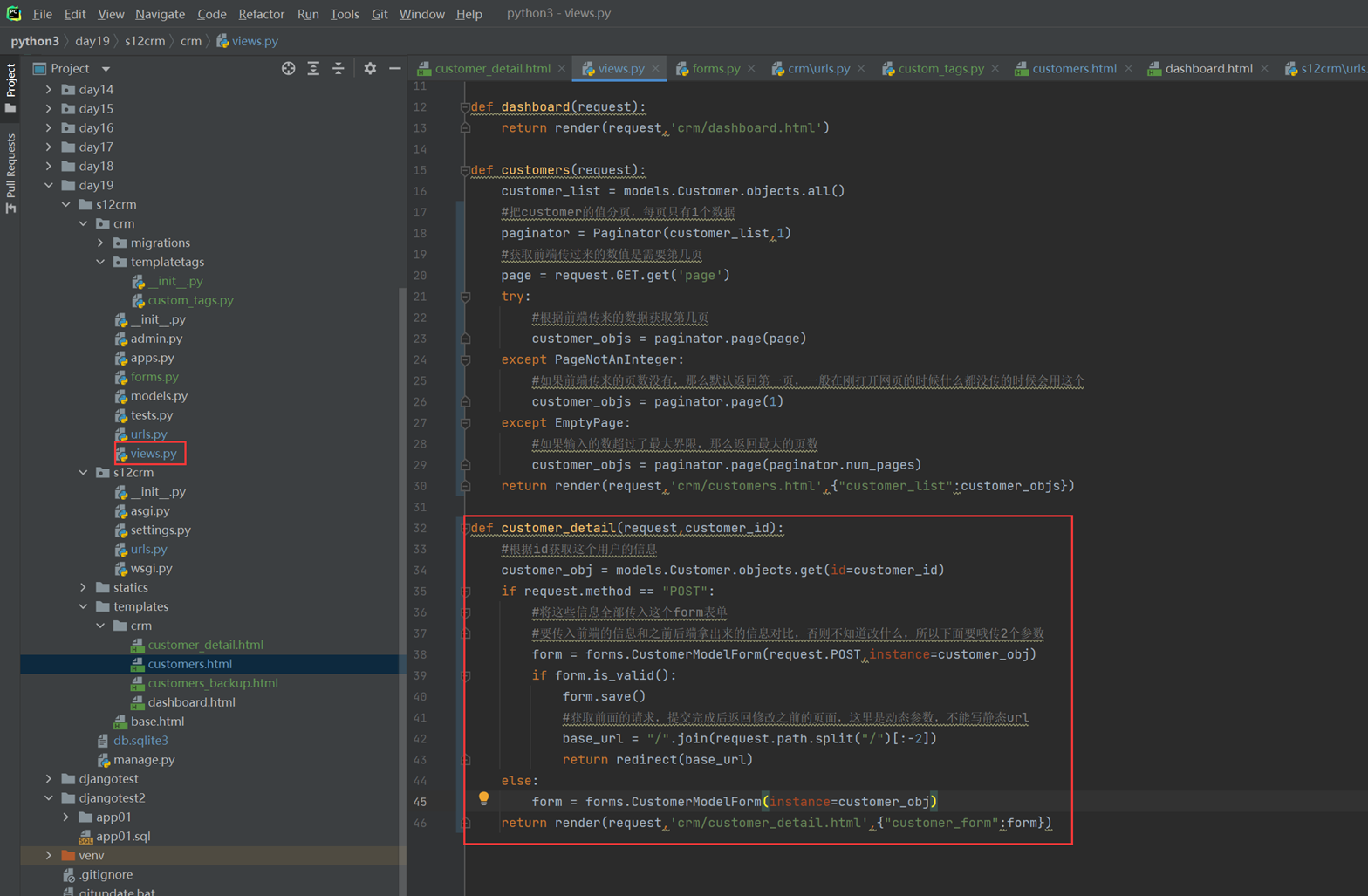
简单查看一下结果,具体结果只有运行代码
19.11 通用权限系统的设计思路
第一章就是讲理论,还没深入讲,说django的权限不够细。这个没办法做笔记,只能看视频。
怎么说呢,看完了剩下3章,合并在一起吧。
也没有自己设计权限系统,就是讲解django权限系统是什么样子实现的,以及怎么扩展自定义增加django的权限。
Django的权限是什么样子呢?建议还是复习视频,这里尽量用文字描述清楚点。
每个权限在数据库就是一个字段

比如view_customer_list,可以在数据库里面是一个字段或者是一个字典,一般都是数据库里面存储字段。这个view_customer_list就是一个权限,那么就靠这个怎么实现权限?

匹配到这个字段后,后面肯定还有东西,那么就是三个参数 第一个是url,第二个是请求方式,第三个是参数,会有一个函数检测这三个参数是否存在,是否满足,如果3个全部满足,那么代表就有权限,如果没有,那么就是没有权限,没有权限可以自定义操作,比如跳转至没有权限的网页。
简单总结来说,django的权限就是一个字段,这个字段对应三个参数,这3个参数的本质就是对于一个url能不能进行操作请求,比如post,比如get。如果检查能够请求这个url,那么就有权限。
那么还是演示一下吧。
1.首先要创建这个数据库权限字段,在任何一个model里面都可以,django都能识别到。但是最好自己分类,比如就在我们的userprofile里面创建。
因为修改了数据库,所以需要重新生成数据库配置。
2.自定义权限文件
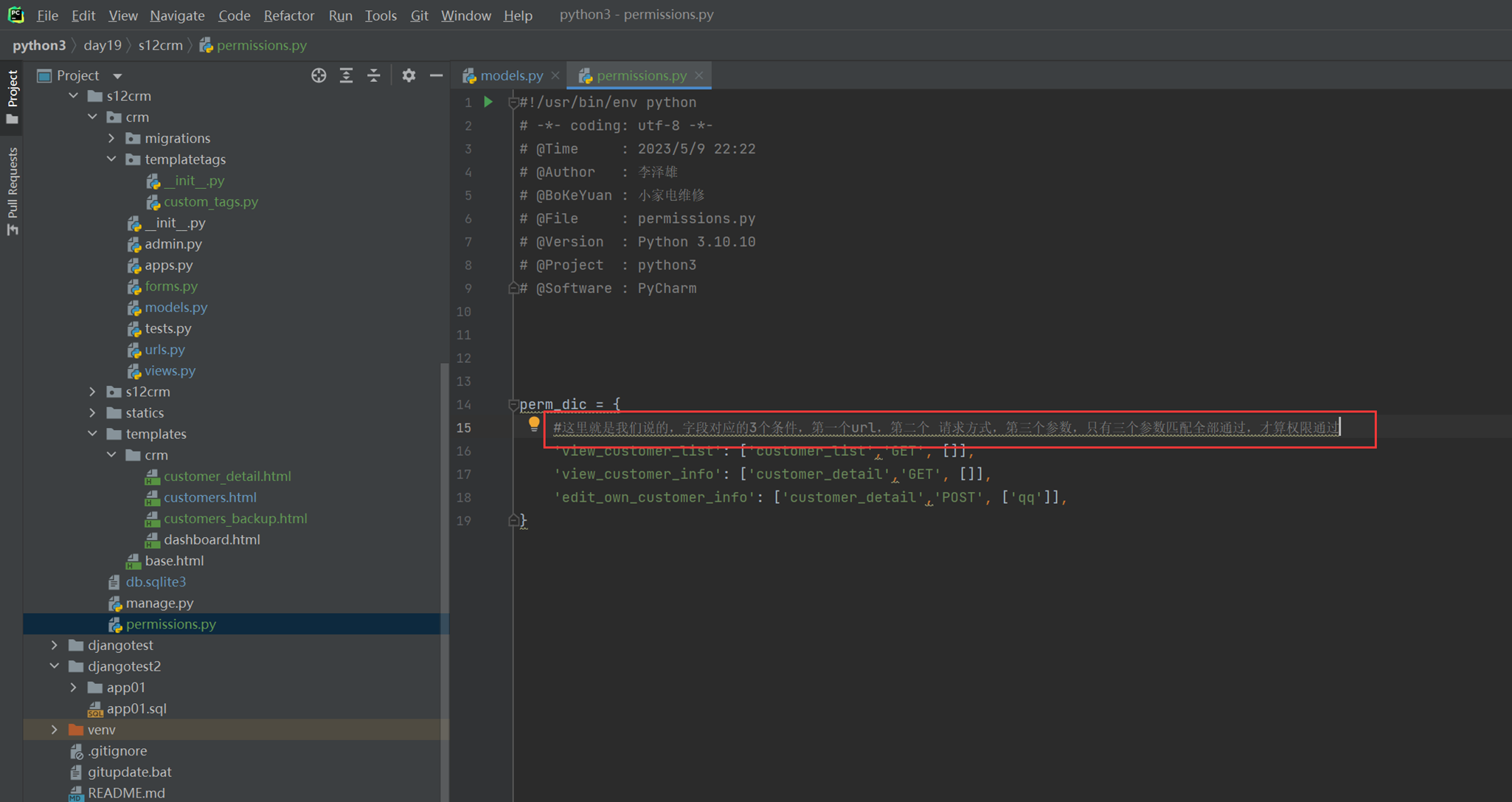
3.URl别名(必须)
上面说过,权限第一个参数就是url,如果url有了更改怎么办?这里有url别名,只要指定url别名,url怎么变,url别名都不会变。
这里还有一个小技巧,与本篇章无关,就是前端模版也可以引用别名
比如
4.自定义权限文件
url可变问题解决了,现在还是回到自定义权限文件上面。基本所有的操作验证,都是在这个文件里面,然后做成一个装饰器,其它函数引用他就是。
这里就贴出代码吧。
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/5/9 22:22 # @Author : 李泽雄 # @BoKeYuan : 小家电维修 # @File : permissions.py # @Version : Python 3.10.10 # @Project : python3 # @Software : PyCharm #from django.core.urlresolvers import resolve #老写法 from django.urls import reverse,resolve from django.shortcuts import render,redirect perm_dic = { #这里就是我们说的,字段对应的3个条件,第一个url,第二个 请求方式,第三个参数,只有三个参数匹配全部通过,才算权限通过 'view_customer_list': ['customer_list','GET', []], 'view_customer_info': ['customer_detail','GET', []], 'edit_own_customer_info': ['customer_detail','POST', ['qq']], } def perm_check(*args,**kwargs): request = args[0] #这个模块可以根据路径得到url的别名 url_resovle_obj = resolve(request.path_info) current_url_namespace = url_resovle_obj.url_name #app_name = url_resovle_obj.app_name #use this name later print("url namespace:",current_url_namespace) matched_flag = False # find matched perm item matched_perm_key = None #剩下的就是检查3个参数,只有三个参数检查通过,才会返回True,否则False if current_url_namespace is not None:#if didn't set the url namespace, permission doesn't work print("find perm...") for perm_key in perm_dic: perm_val = perm_dic[perm_key] if len(perm_val) == 3:#otherwise invalid perm data format url_namespace,request_method,request_args = perm_val print(url_namespace,current_url_namespace) if url_namespace == current_url_namespace: #matched the url if request.method == request_method:#matched request method if not request_args:#if empty , pass matched_flag = True matched_perm_key = perm_key print('mtched...') break #no need looking for other perms else: for request_arg in request_args: #might has many args request_method_func = getattr(request,request_method) #get or post mostly #print("----->>>",request_method_func.get(request_arg)) if request_method_func.get(request_arg) is not None: matched_flag = True # the arg in set in perm item must be provided in request data else: matched_flag = False print("request arg [%s] not matched" % request_arg) break #no need go further if matched_flag == True: # means passed permission check ,no need check others print("--passed permission check--") matched_perm_key = perm_key break else:#permission doesn't work return True if matched_flag == True: #pass permission check perm_str = "crm.%s" %(matched_perm_key) if request.user.has_perm(perm_str): print("\033[42;1m--------passed permission check----\033[0m") return True else: print("\033[41;1m ----- no permission ----\033[0m") print(request.user,perm_str) return False else: print("\033[41;1m ----- no matched permission ----\033[0m") #需要验证的views加上这个装饰器 def check_permission(func): def wrapper(*args,**kwargs): if perm_check(*args,**kwargs) is not True: return render(args[0],'crm/403.html') return func(*args,**kwargs) return wrapper
整个脚本里面有2个函数,第二个是装饰器,第一个就是验证函数,函数的主体内容就是我们说的,字段对应的3个条件,第一个url,第二个 请求方式,第三个参数,只有三个参数匹配全部通过,才算权限通过
5.view引用装饰器
6.权限拒绝页面
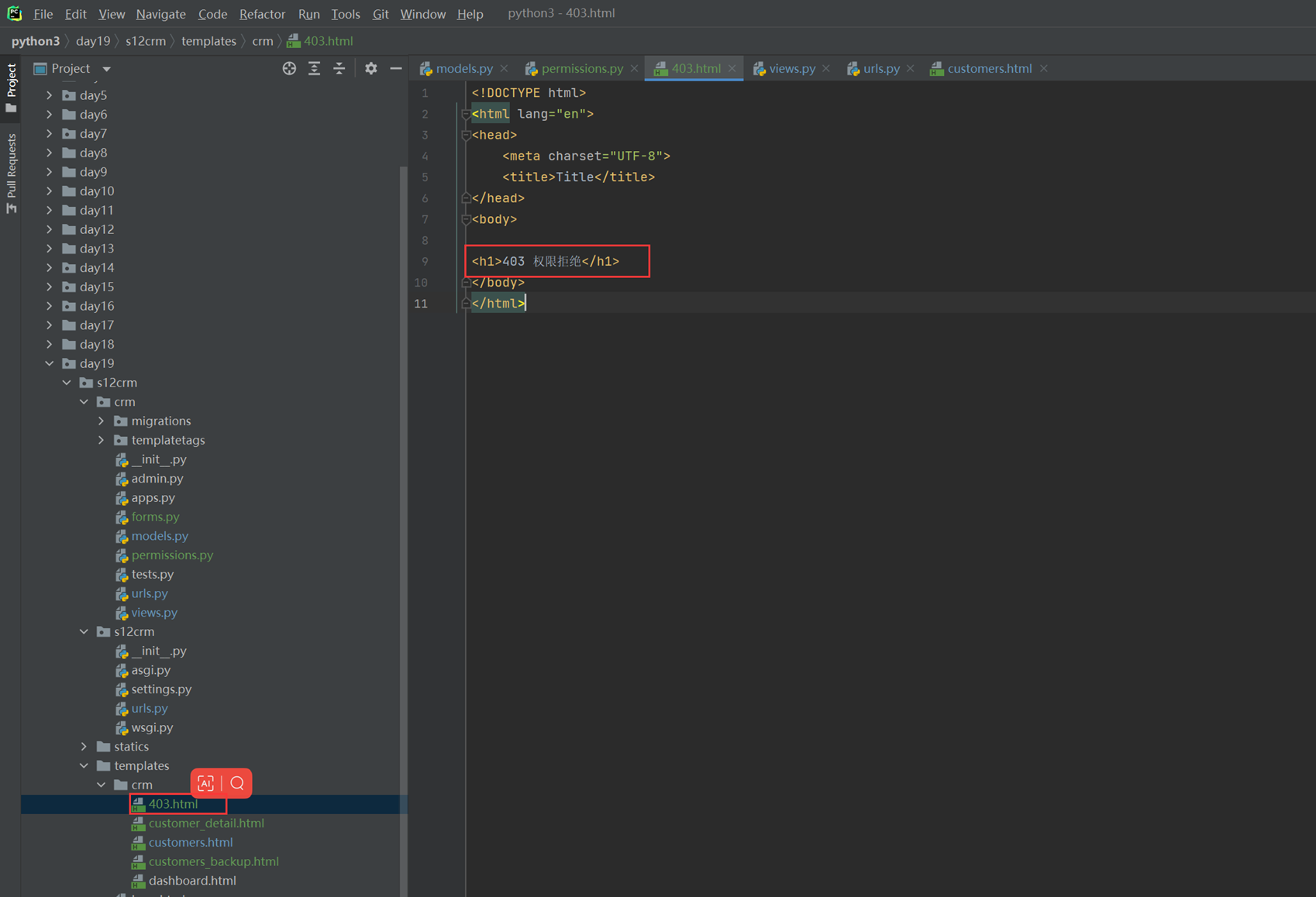
7.测试
创建一个test01用户,只给查看权限
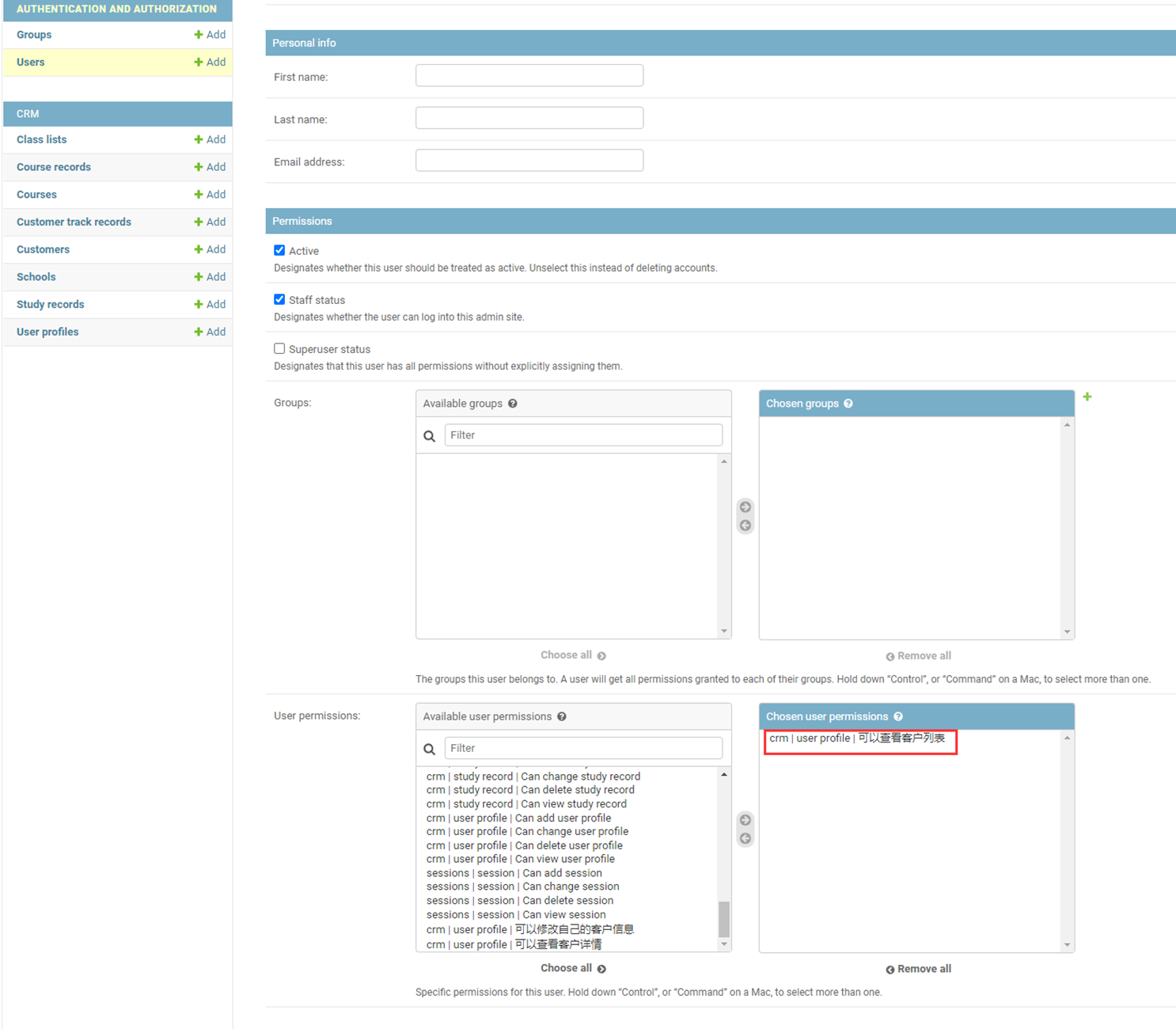
然后使用test01登录django,因为我们的系统使用的django的权限系统
点击用户详细信息会被拒绝
如果有参数,参数里面的值必须完全匹配上,这里演示的是没有参数的
另外,后面的3个视频内容全部已经在这个里面了
19.12 通用权限系统的设计思路2
19.13 通用权限系统的设计思路及实现
19.14 通用权限系统的代码实现及作业需求
20.L20
20.1 项目实战之BBS开发介绍
就是讲开发需求,开发一个和虎嗅网还有抽屉网的博客系统和论坛系统。
20.2 项目实战之BBS设计表结构
咱们还是循序渐进的来。
1.首先要先创建项目

2.写表结构,刚开始也是想记录最原始的,一步一步优化models的,结果在下一节视频中,添加后台数据的时候各种报错,没办法,只能把已经完善好了的models贴在这里。
from django.db import models # Create your models here. from django.db import models from django.contrib.auth.models import User from django.core.exceptions import ValidationError import datetime # Create your models here. class Article(models.Model): title = models.CharField(max_length=255) #描述,简介 brief = models.CharField(null=True,blank=True,max_length=255) #外键的这个表用引号的原因是程序从上往下走的,这时候没有这个表,为了不报错,所以用引号 category = models.ForeignKey("Category",on_delete=models.CASCADE) content = models.TextField(u"文章内容") author = models.ForeignKey("UserProfile",on_delete=models.CASCADE) pub_date = models.DateTimeField(blank=True,null=True) last_modify = models.DateTimeField(auto_now=True) #帖子置顶,给个优先级就行 priority = models.IntegerField(u"优先级",default=1000) head_img = models.ImageField(u"文章标题图片",upload_to="uploads",blank=True,null=True) status_choices = (('draft',u"草稿"), ('published',u"已发布"), ('hidden',u"隐藏"), ) status = models.CharField(choices=status_choices,default='published',max_length=32) def __str__(self): return self.title #官网地址复制过来的:https://docs.djangoproject.com/en/3.2/ref/models/instances/#django.db.models.Model.clean def clean(self): # Don't allow draft entries to have a pub_date. if self.status == 'draft' and self.pub_date is not None: raise ValidationError(('Draft entries may not have a publication date.')) # Set the pub_date for published items if it hasn't been set already. if self.status == 'published' and self.pub_date is None: self.pub_date = datetime.date.today() class Comment(models.Model): article = models.ForeignKey(Article,verbose_name=u"所属文章",on_delete=models.CASCADE) #评论的层级关系字段 parent_comment = models.ForeignKey('self',related_name='my_children',blank=True,null=True,on_delete=models.CASCADE) comment_choices = ((1,u'评论'), (2,u"点赞")) comment_type = models.IntegerField(choices=comment_choices,default=1) user = models.ForeignKey("UserProfile",on_delete=models.CASCADE) comment = models.TextField(blank=True,null=True) date = models.DateTimeField(auto_now_add=True) def clean(self): if self.comment_type == 1 and len(self.comment) ==0: raise ValidationError(u'评论内容不能为空,sb') def __str__(self): return "C:%s" %(self.comment) class Category(models.Model): name = models.CharField(max_length=64,unique=True) #板块描述,简介 brief = models.CharField(null=True,blank=True,max_length=255) #动态展示板块 set_as_top_menu = models.BooleanField(default=False) #板块展示的顺序 position_index = models.SmallIntegerField() #版主 admins = models.ManyToManyField("UserProfile",blank=True) def __str__(self): return self.name class UserProfile(models.Model): user = models.OneToOneField(User,on_delete=models.CASCADE) name =models.CharField(max_length=32) signature= models.CharField(max_length=255,blank=True,null=True) head_img = models.ImageField(height_field=150,width_field=150,blank=True,null=True) #for web qq friends = models.ManyToManyField('self',related_name="my_friends",blank=True) def __str__(self): return self.name
3.表结构写好之后,其实在创建表结构之前有2个事要提前准备一下
1.注册app,这个不过多解释。
2.因为有图片字段,需要安装额外的模块

3.生成表配置以及表结构
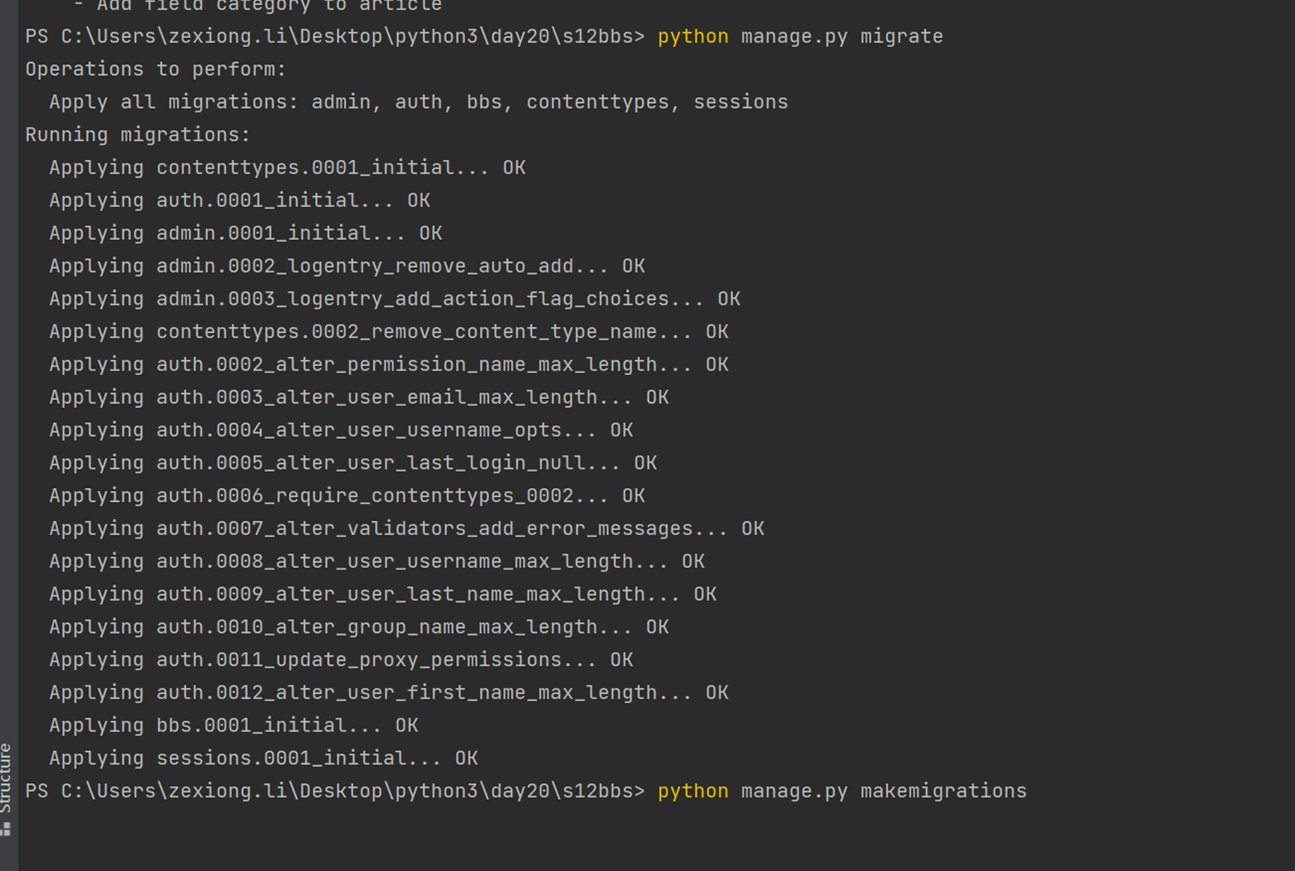
4.还顺便讲解了评论层级的关系

20.3 项目实战之BBS配置admin
本章就是在后台显示一些字段
然后再创建一个超级用户,密码还是admin@123

由于我们写的是论坛系统,这里在django后台随便创建一些网页数据就可以了,自己随便写一点。
20.4 BBS选择合适的前端模版
使用的bootstrap的这个模版: https://v3.bootcss.com/examples/navbar-fixed-top/
把上面的玩意保存下来,然后按照19.4的步骤把网页给改成可以访问即可。
1.URL
所有bbs的请求转到bbs的urls里面去,因为后面还会有聊天室的功能
bbs的urls
views
接下来才是重头戏,刚才我们下载了bootstrap的样式,我们怎么自己使用?
首先,我们要解决css和js的存放问题
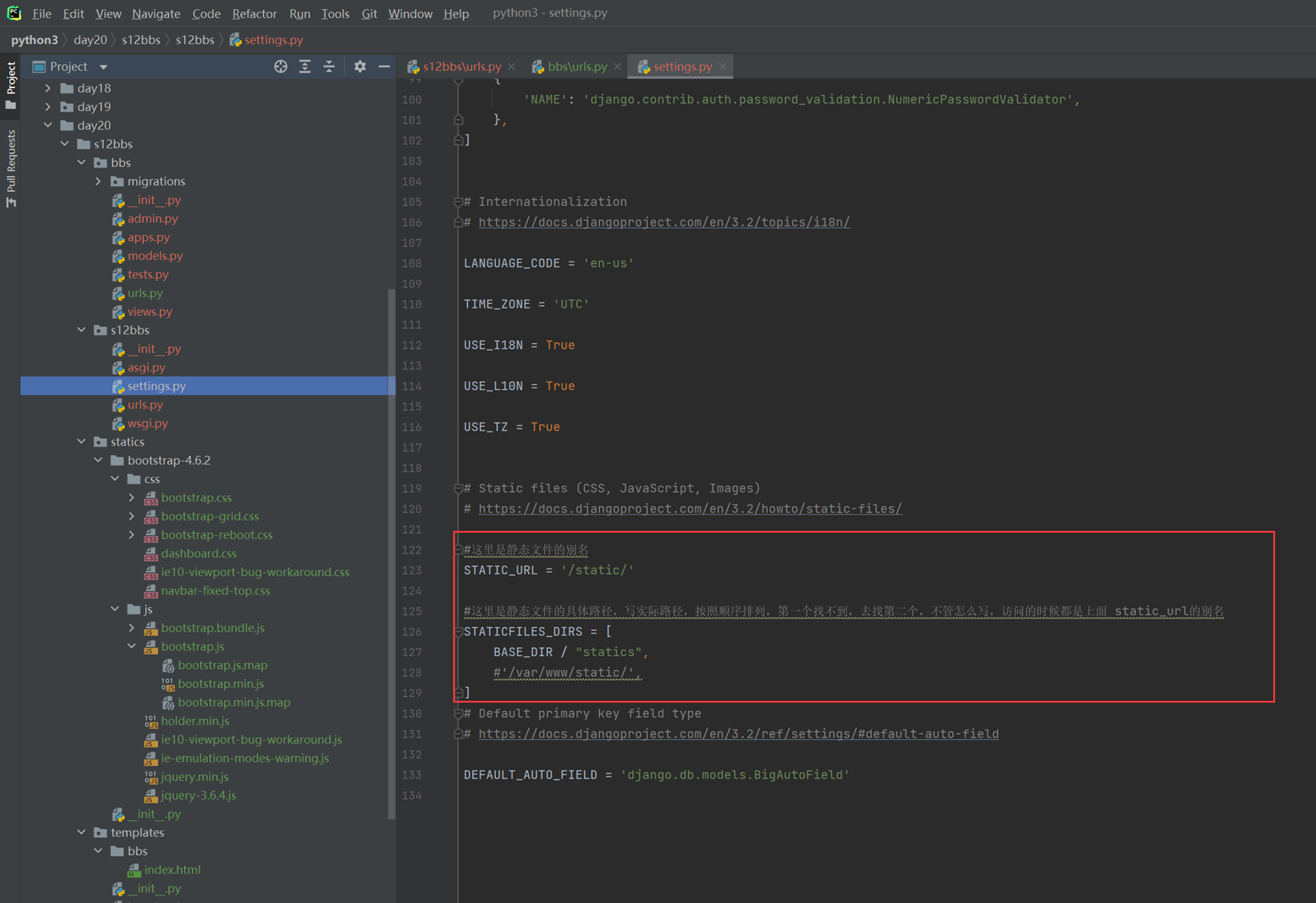
现在修改bootstrap下载下来的内容,把相关的连接指向这个目录
现在修改bootstrap下载下来的内容,把相关的连接指向这个目录
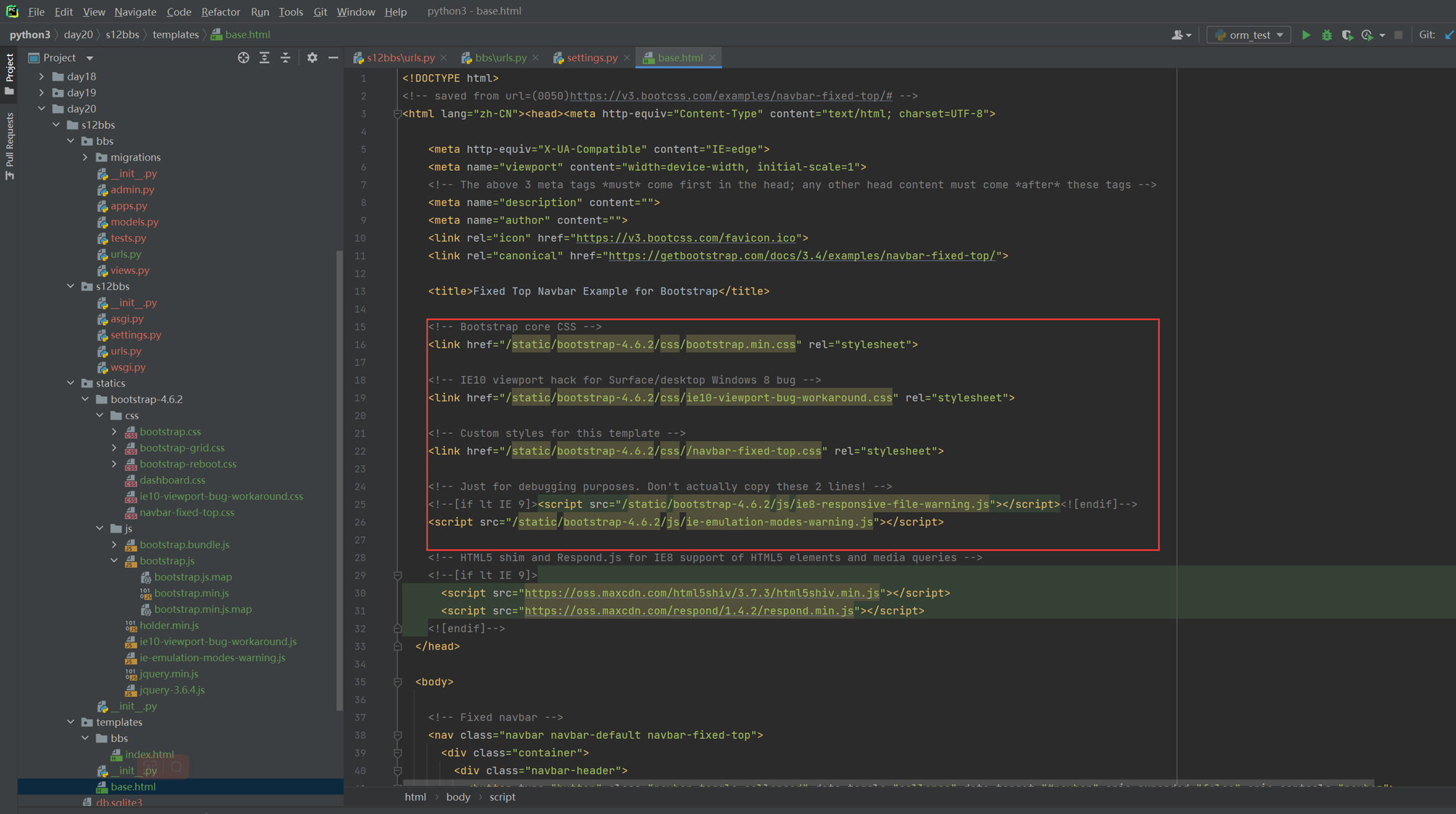
bbs/index.html继承base.html

访问查看
20.5 前端实现动态菜单
本章讲解的很简单,就是把上面的导航栏给变了,啥也没做。
本章准备工作就是做多创建一些测试板块
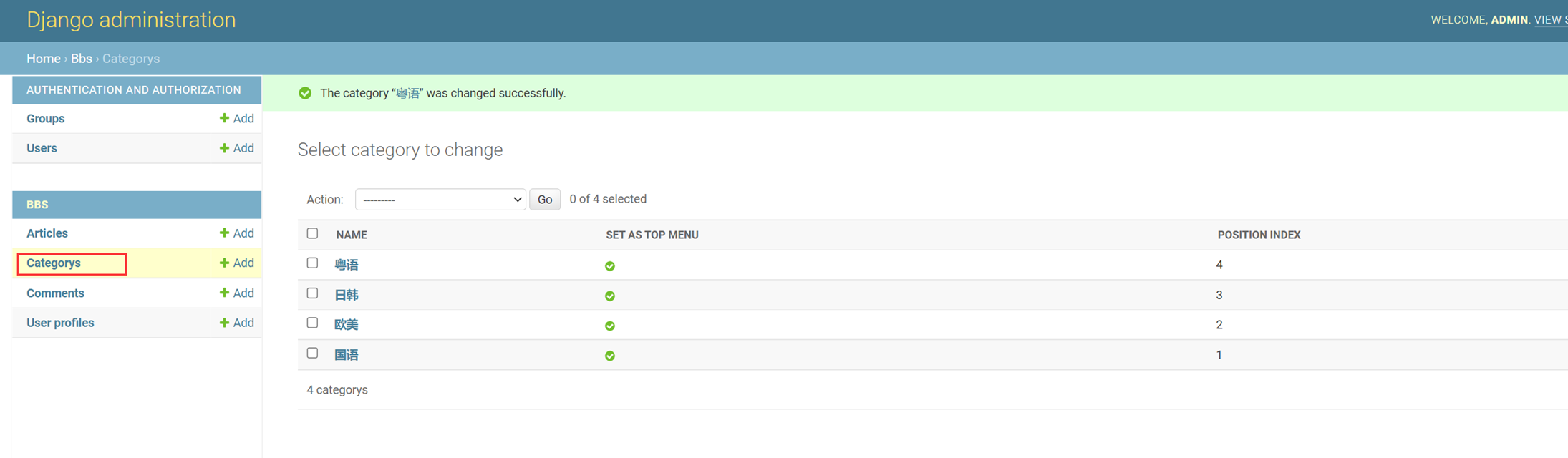
现在进入正题
1.views
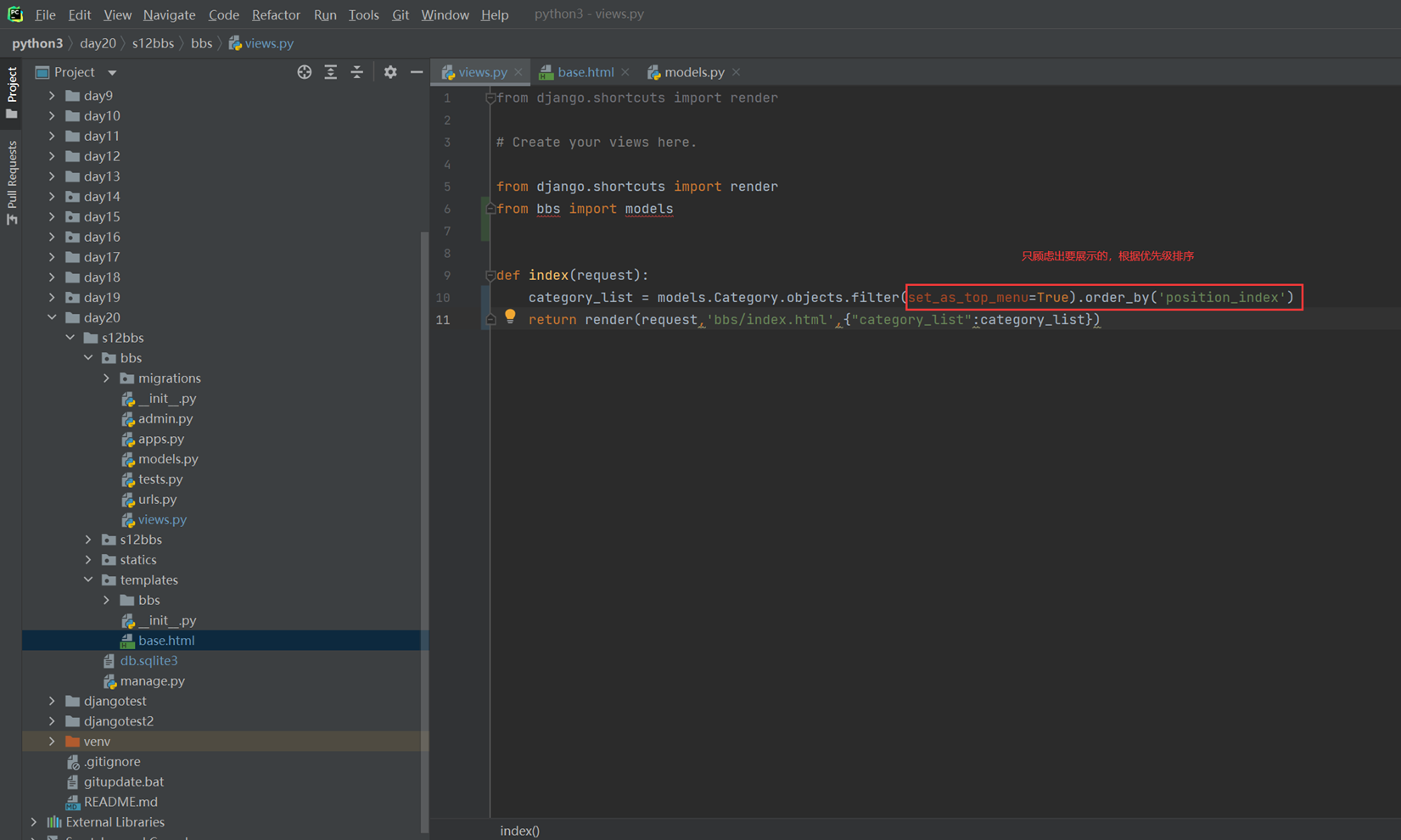
2.base.html
因为是导航栏,我们直接在base里面修改
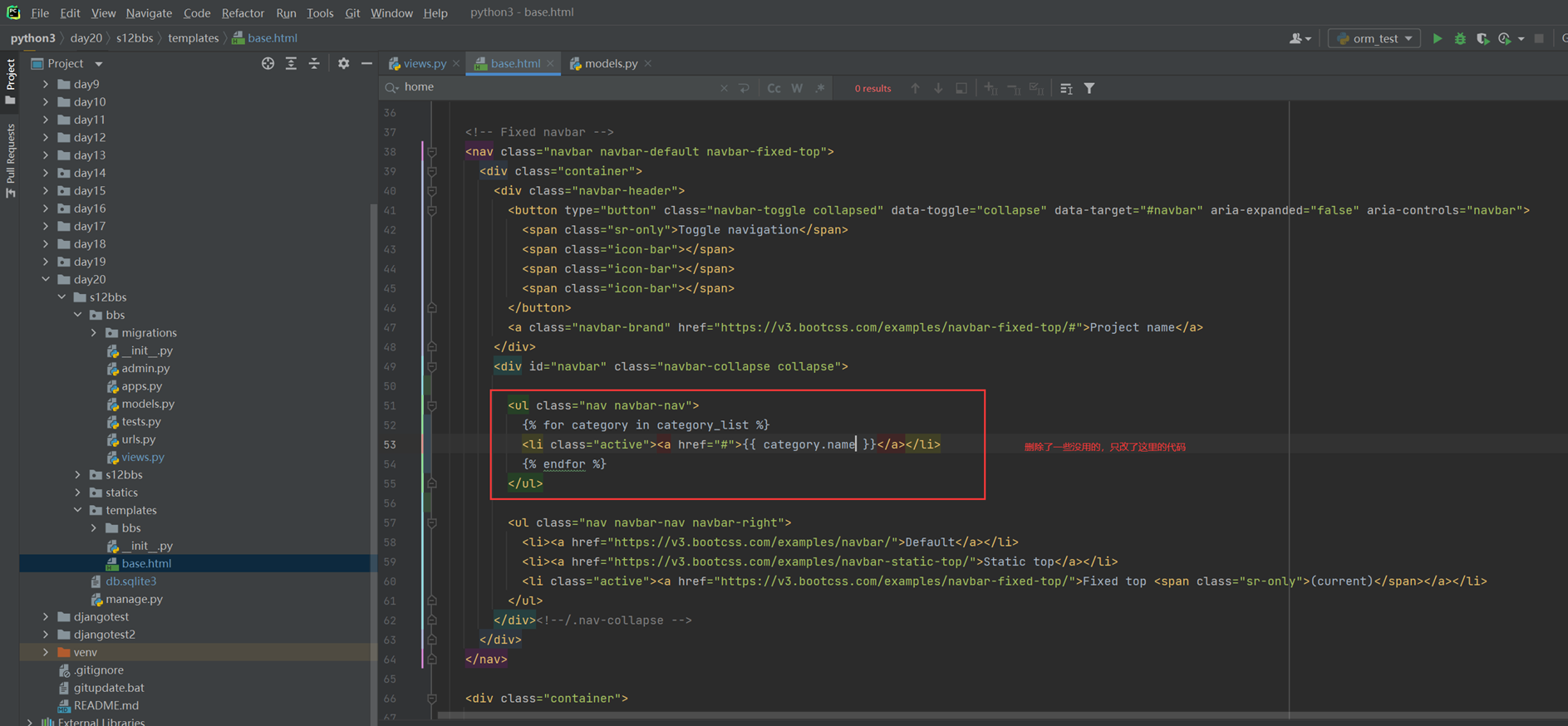
查看结果

20.6 编写通用版块展示模板
本章实现了2个功能。
1.点击板块可以实现板块跳转,给当前板块加active样式。
2.实现登录注销页面
1.点击板块可以实现板块跳转,给当前板块加active样式。
1.我们这里先看前端,因为这样好解释一点。
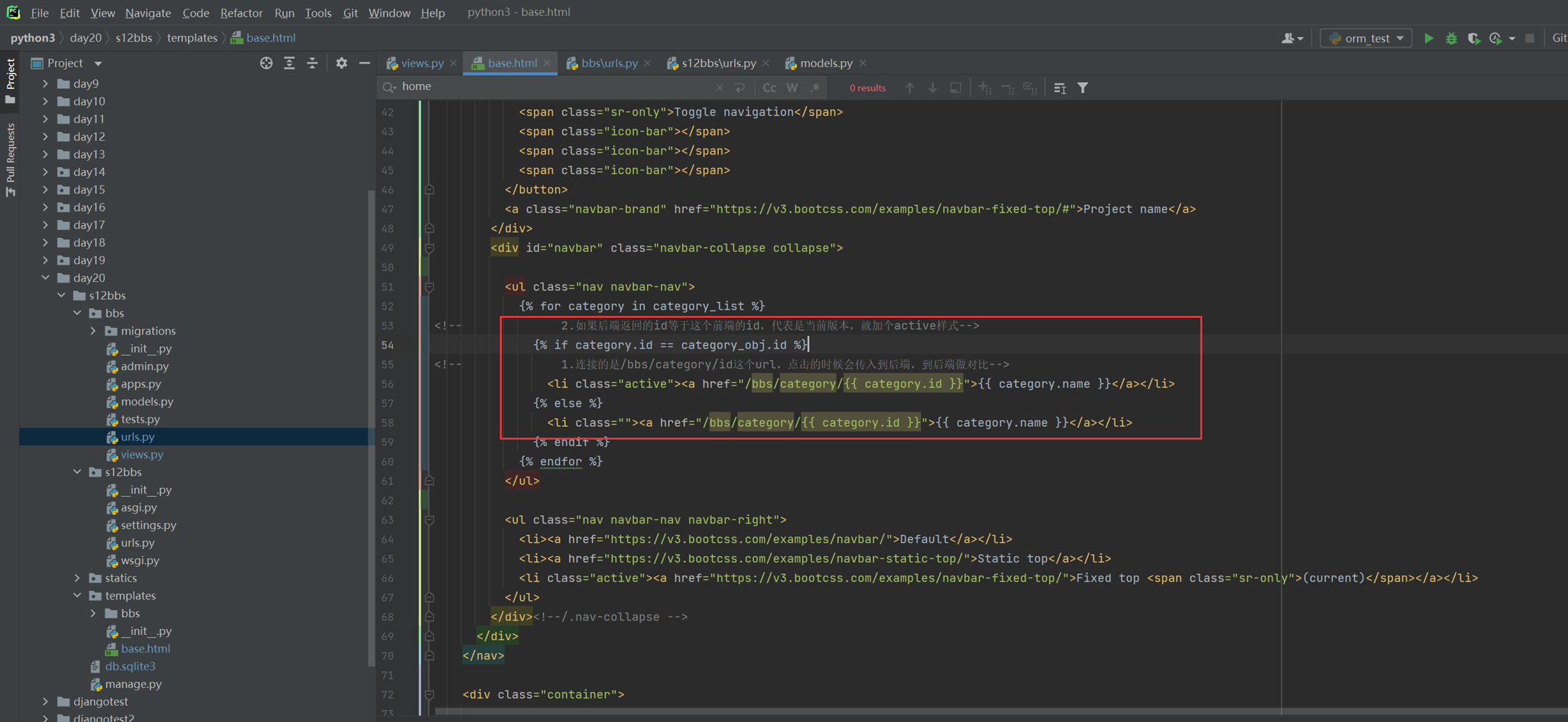
2.url很简单,就一个正则匹配的url到后端函数
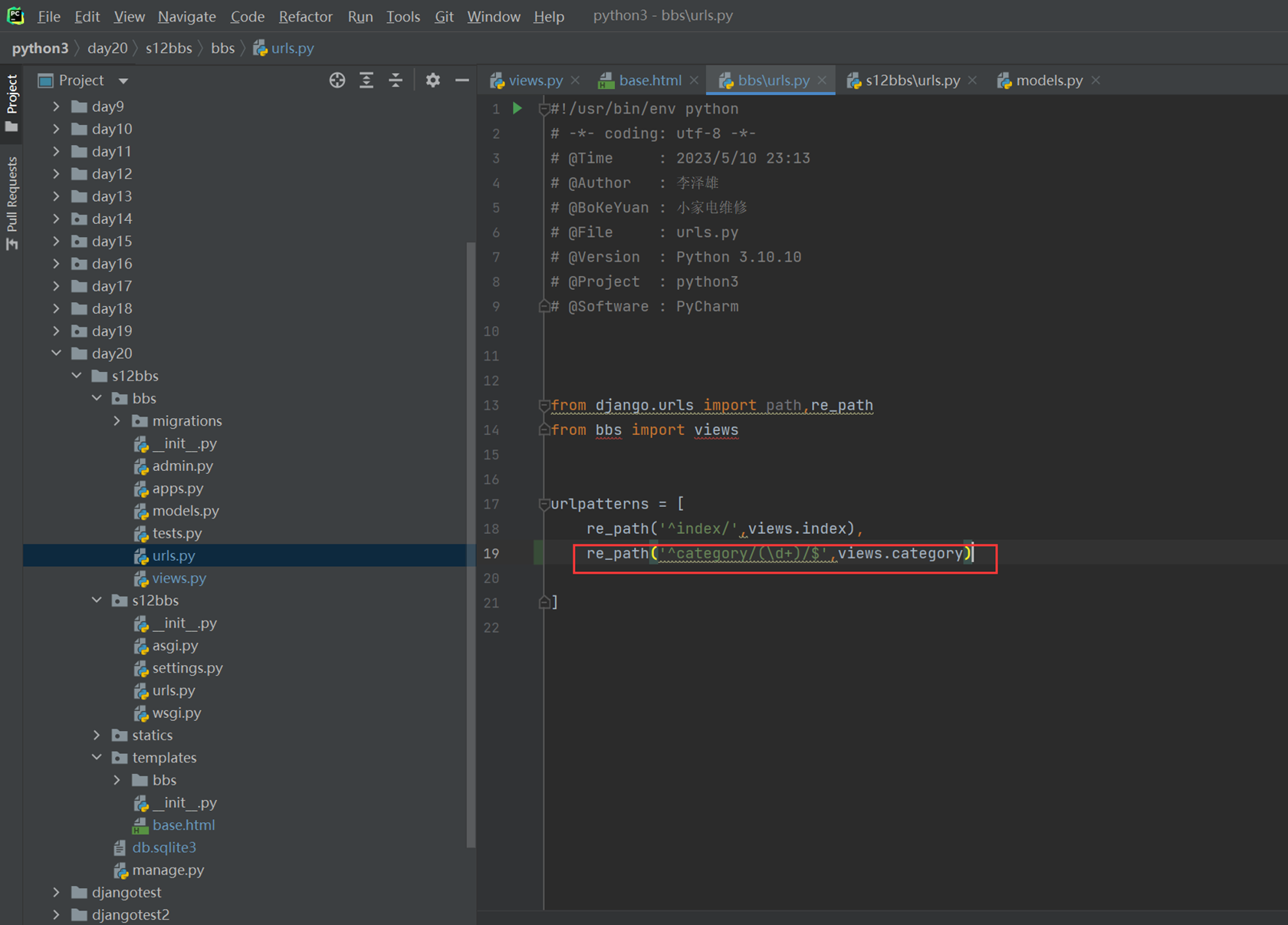
3.views
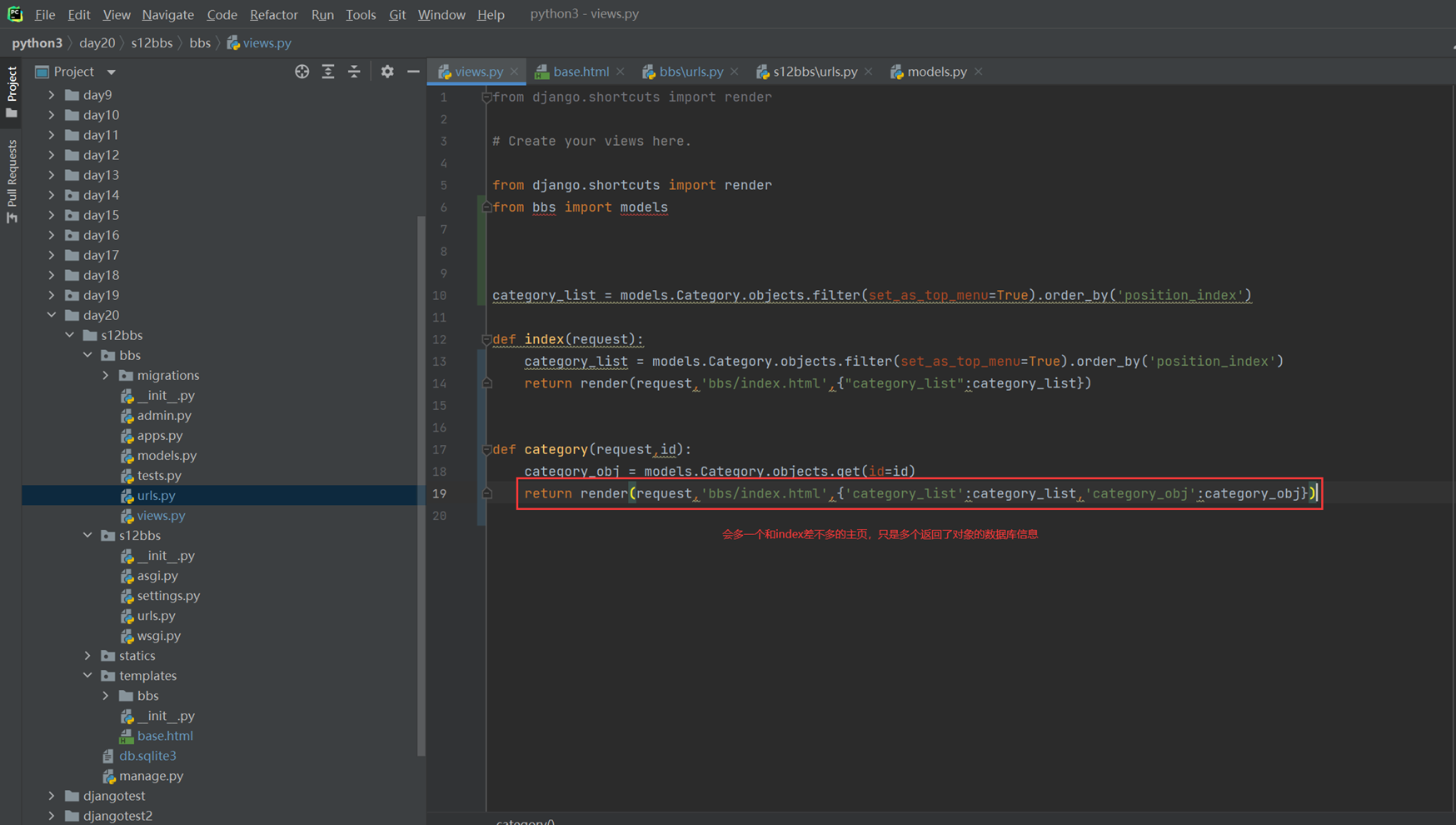
实现登录注销页面
这里会使用base.html和login.html页面
1.前端页面-base.html
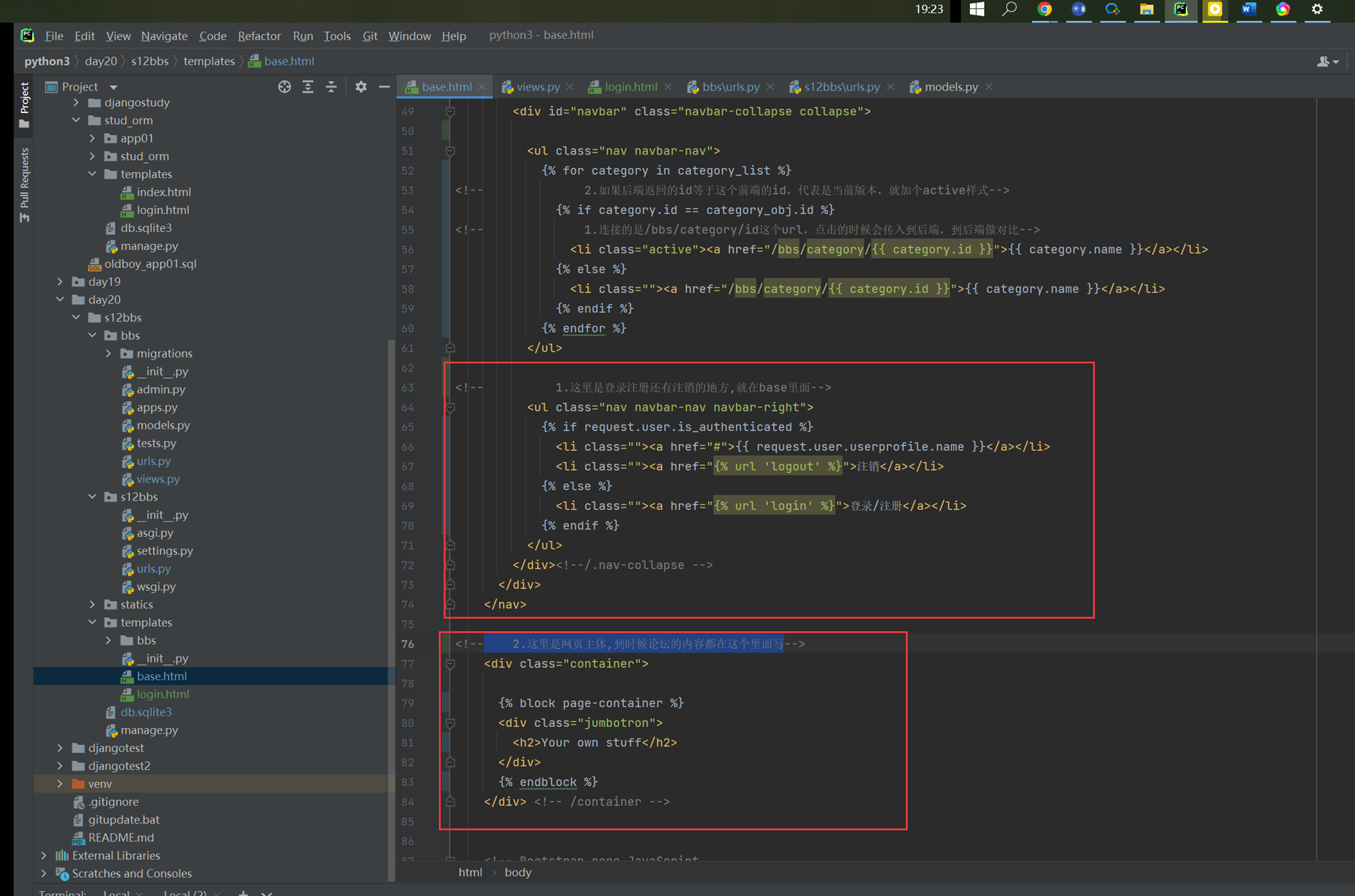
2.URL
由于是公共功能,直接写在主项目下
由于前端使用了别名,URL也需要使用别名
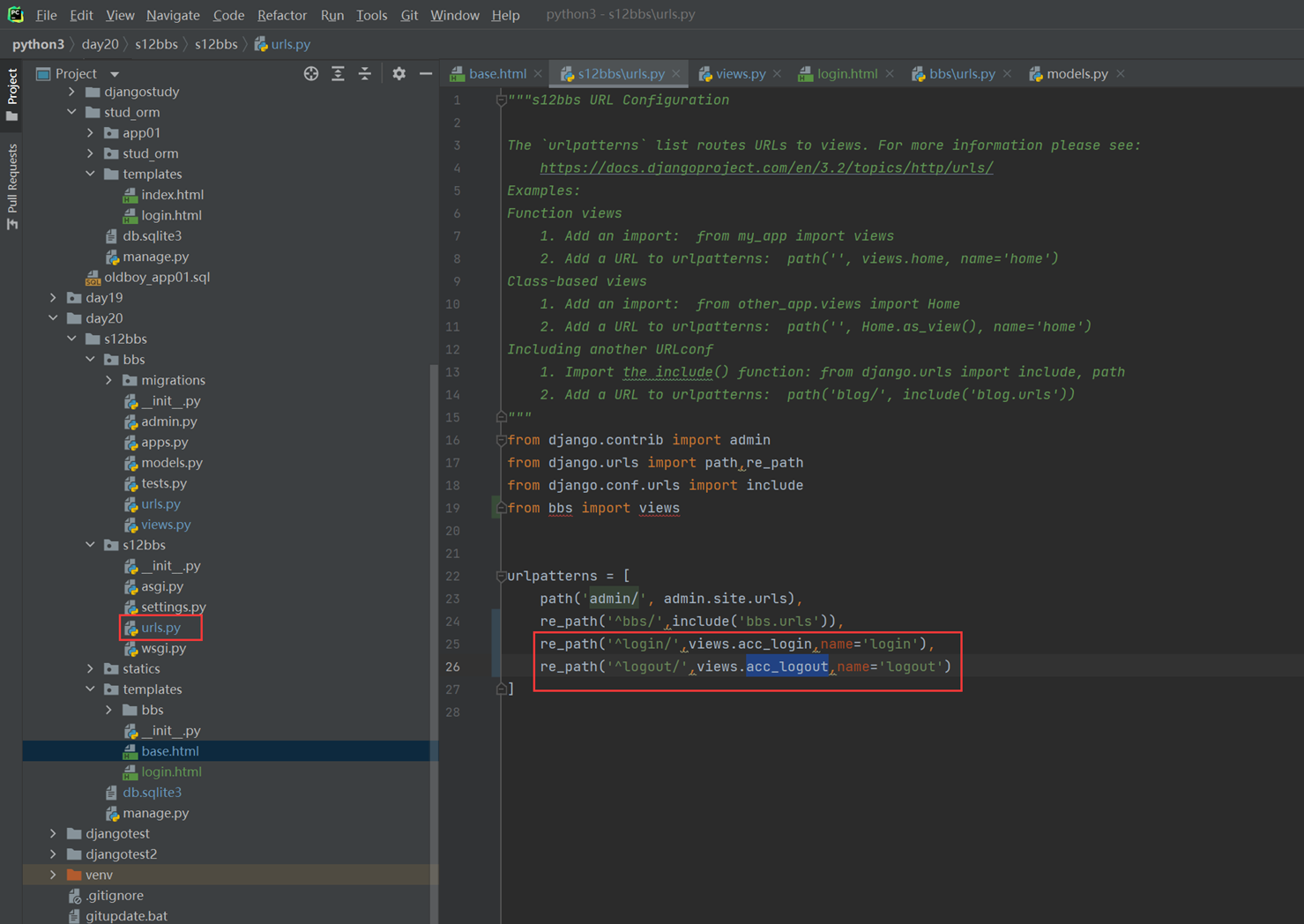
3.views
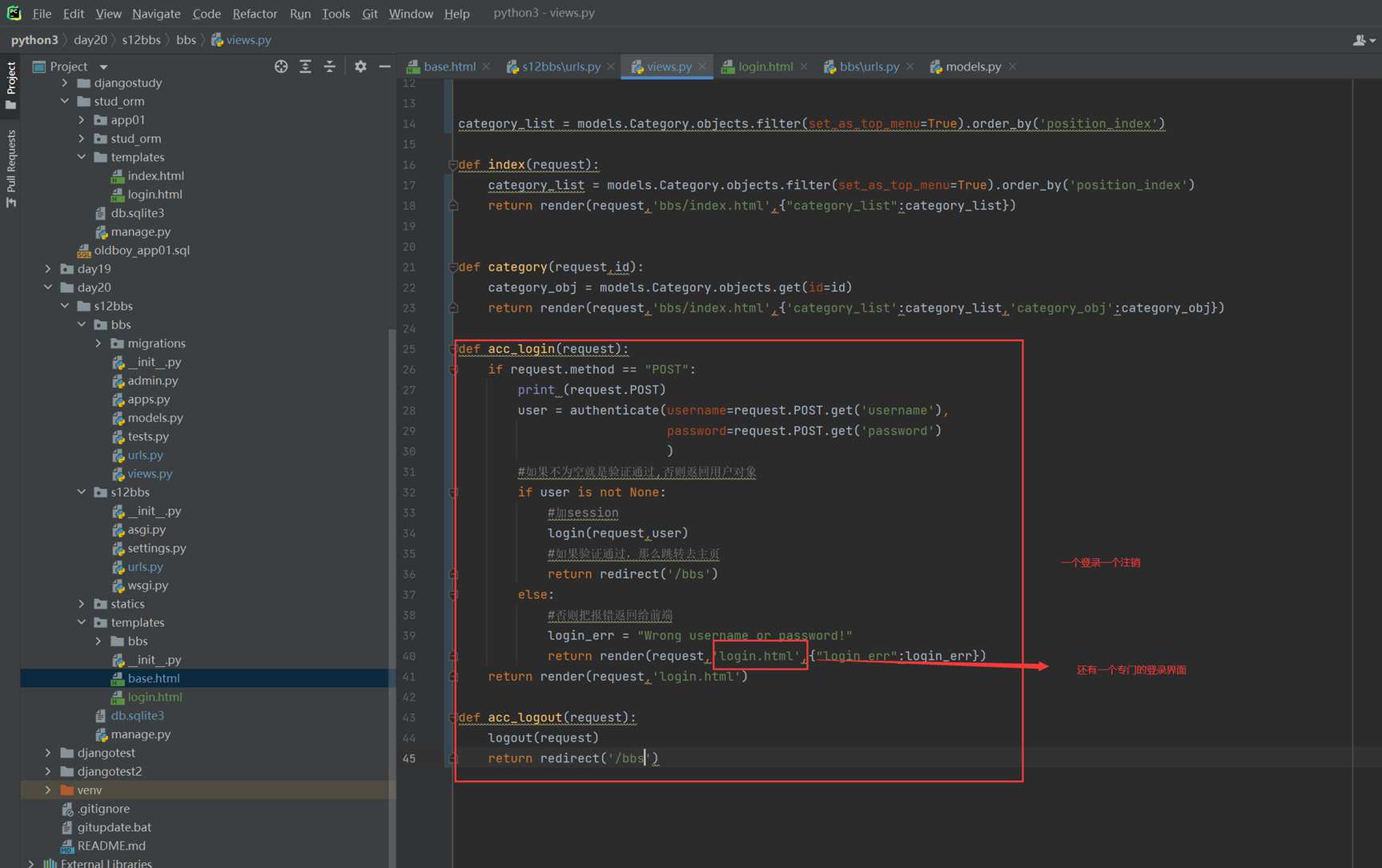
4.html-login.html
这里主要是登录界面
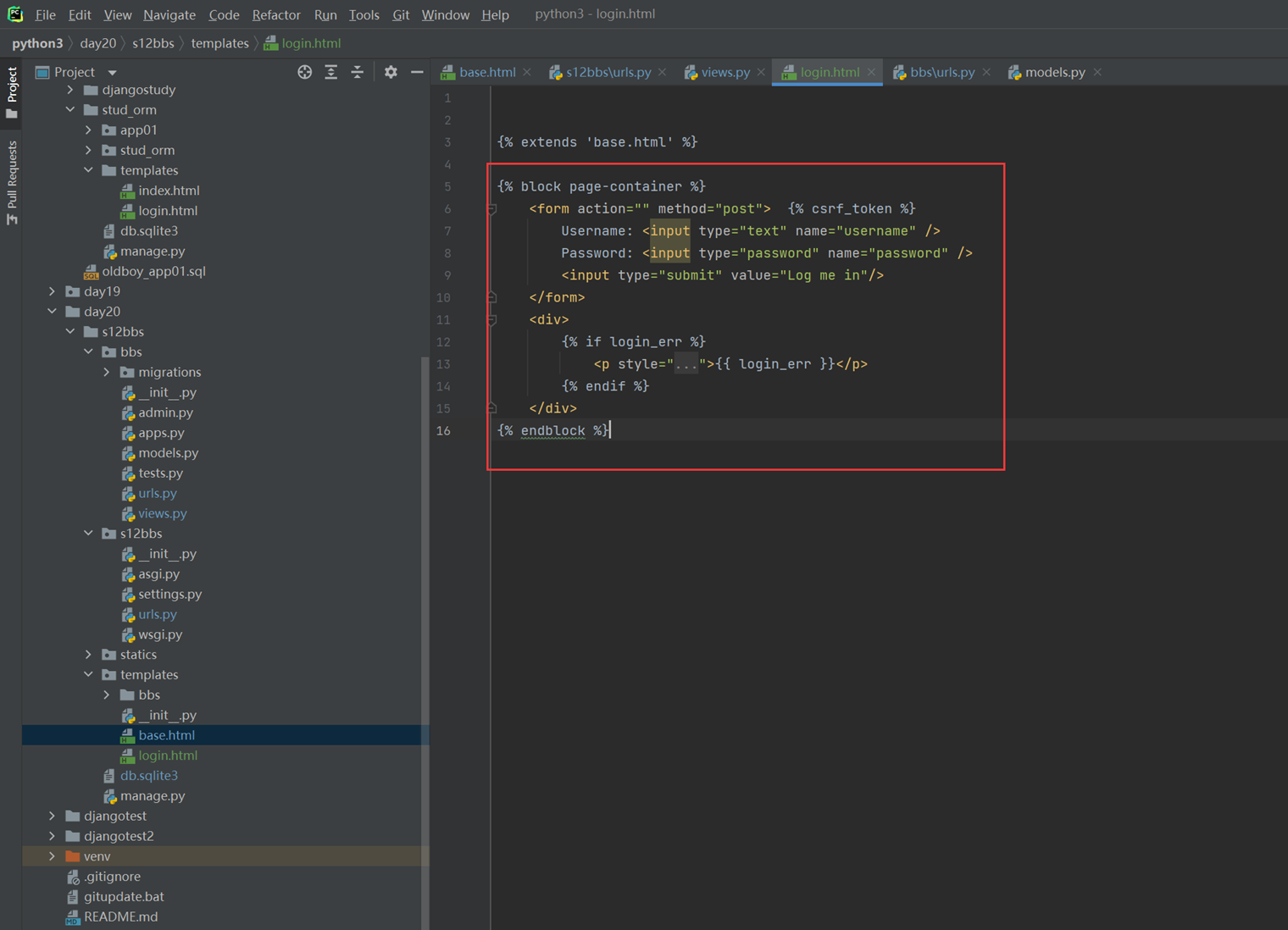
5.查看结果
登录进去看看
20.7 编写通用版块展示模板2
本章讲解的功能很简单,就一个。
1.把文章展示在前端,并且全部里面也有内容
2.默认输入/bbs的主页url的时候,会默认进入全部,并且全部是高亮显示
PS:本节课1,2小点,老师实现的方式都非常low,将就着用吧
首先准备测试数据,每个板块有点文章。
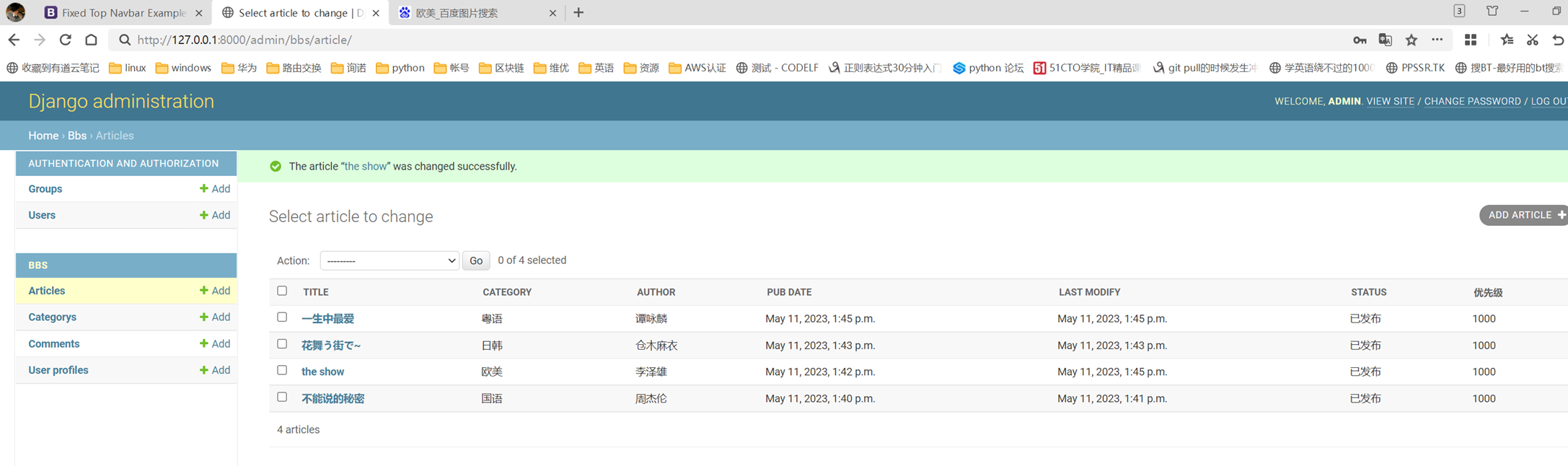
然后设置配置views
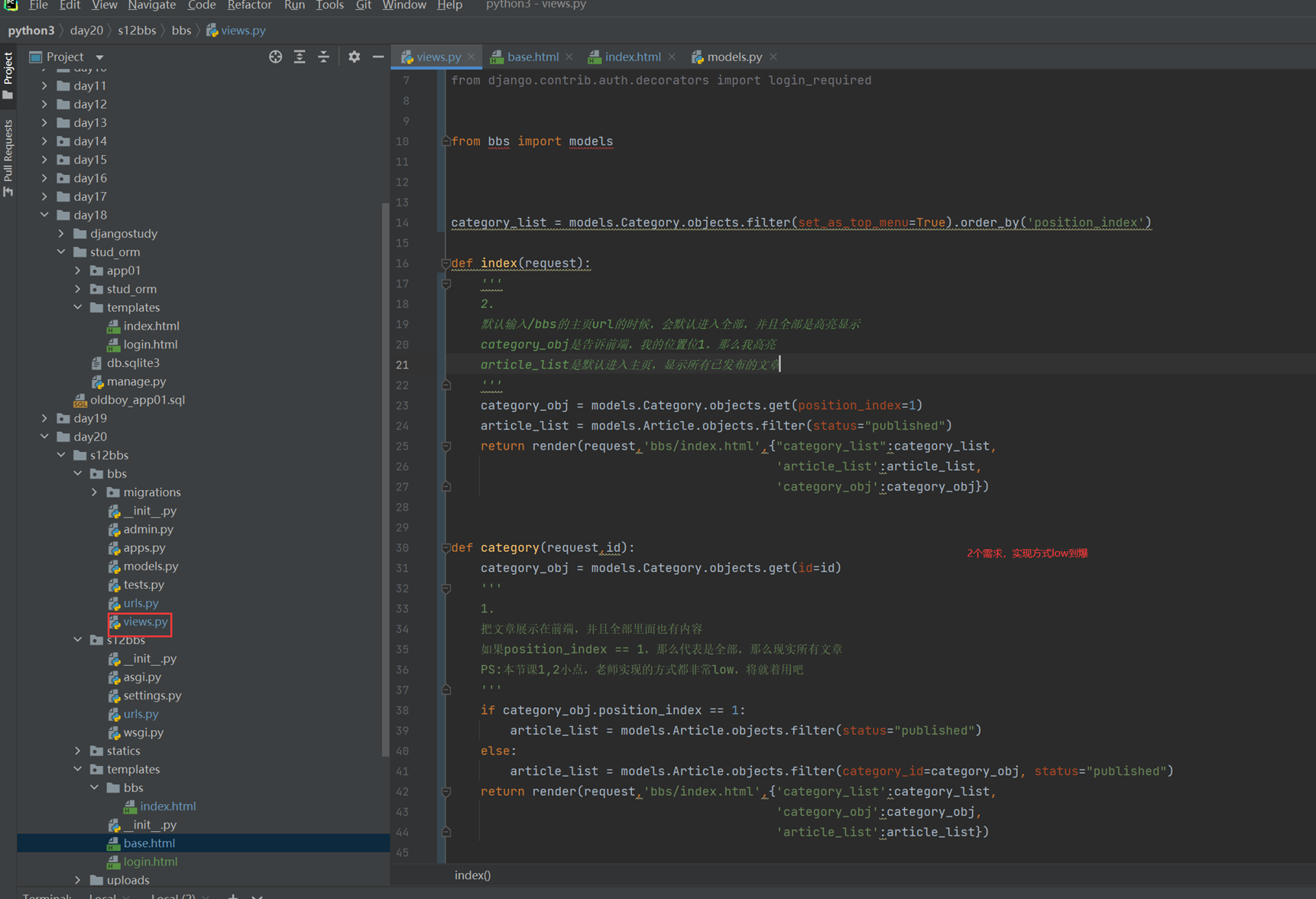
在看看前端
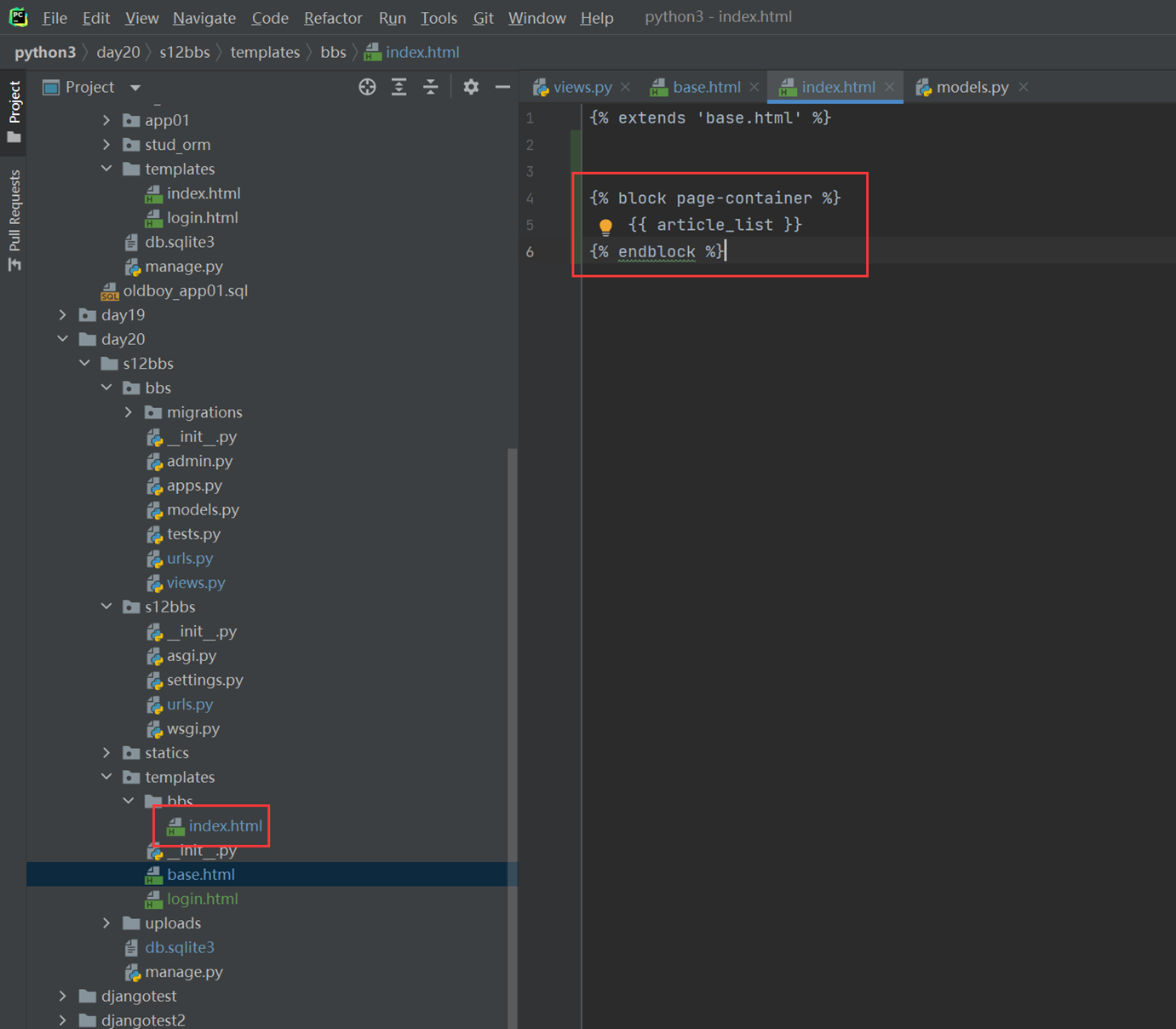
看看结果
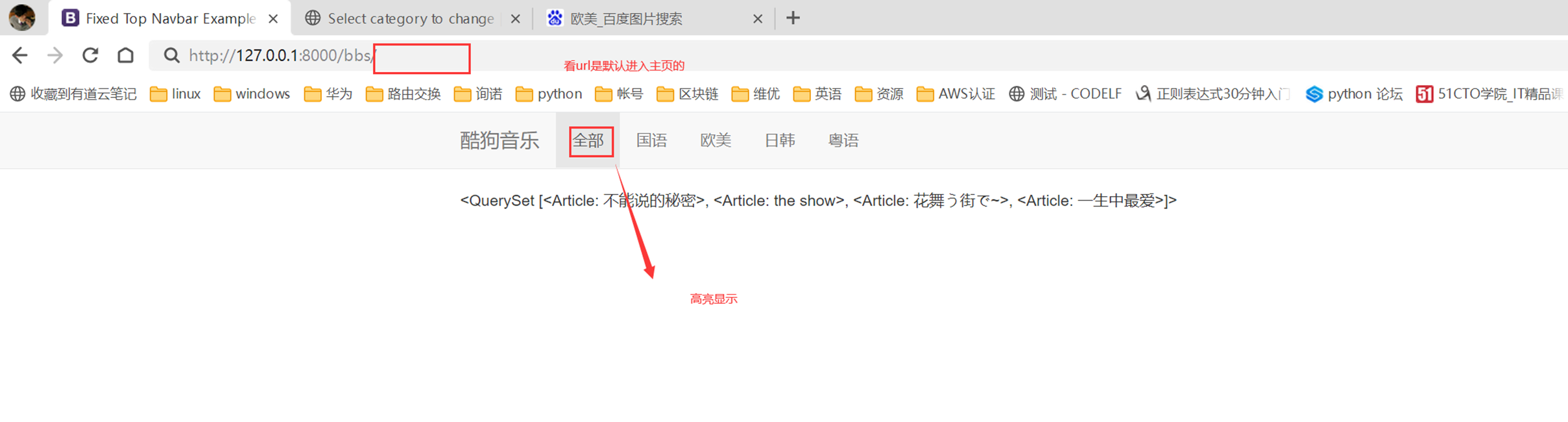
20.8 前端页面布局配置
还是一句话,这老师讲的是真j-b烂,一个前端,调成gs。真的是lj,1小时的课程,55分钟在拍错。wr。
这里两章合并,因为都是讲解前端怎么布局。这两章主要实现的是
1.前端的模块调整的好看(时间都尼玛浪费在这个上面了,讲的是真jb烂),显示文章,显示文章图片。就这个需求。
首先,我们要处理图片的显示问题,这是一个遗留问题,前面几章的时候,忘记写了,就是图片默认上传会在项目跟下面的uploads目录,因为我们提前做了设置,为什么要提这个,是因为我们后面用的到
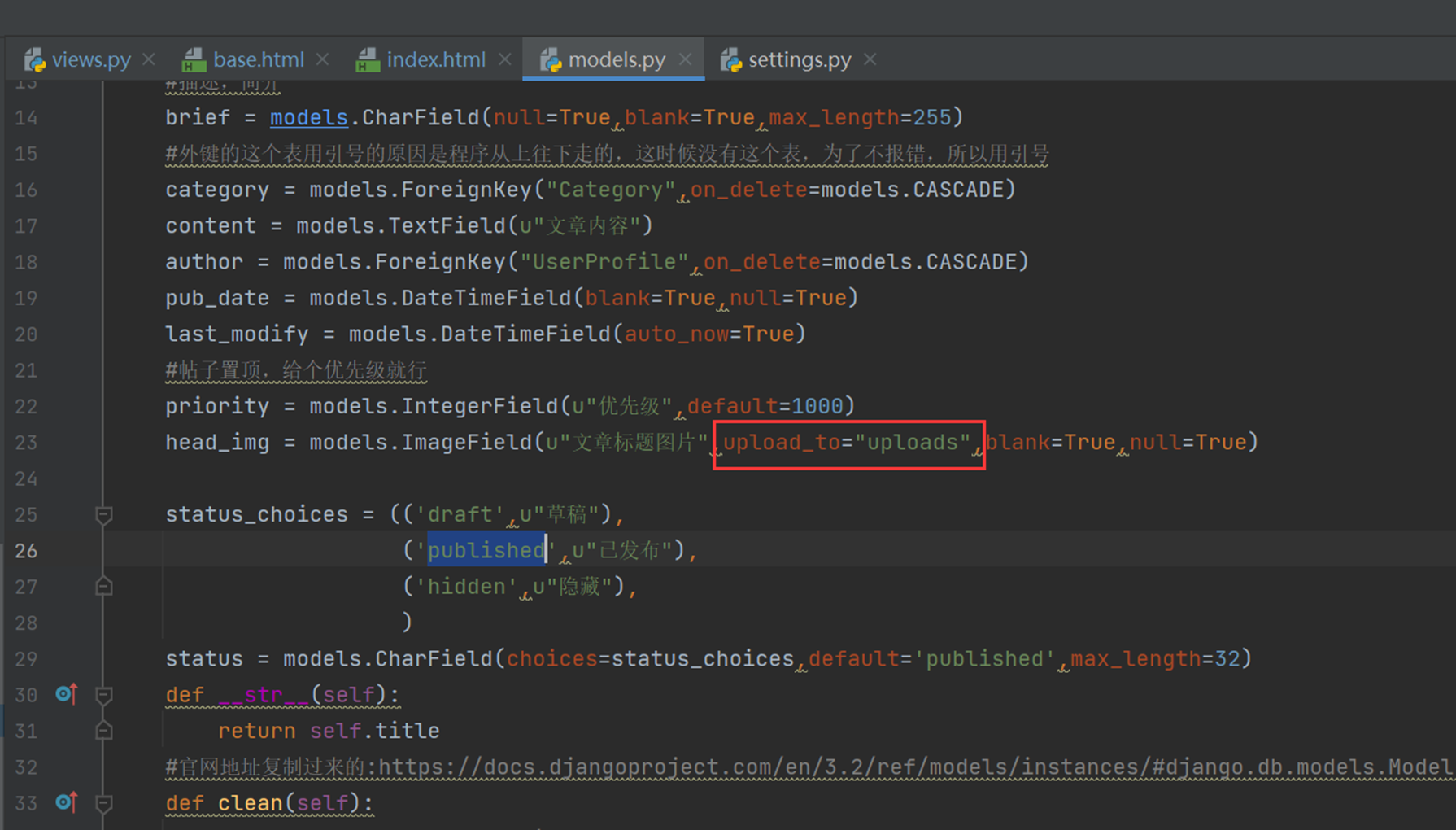
讲的太乱了,我们还是一步一步来把,然后再做个总结,讲的什么jb玩意。
首先是index.html
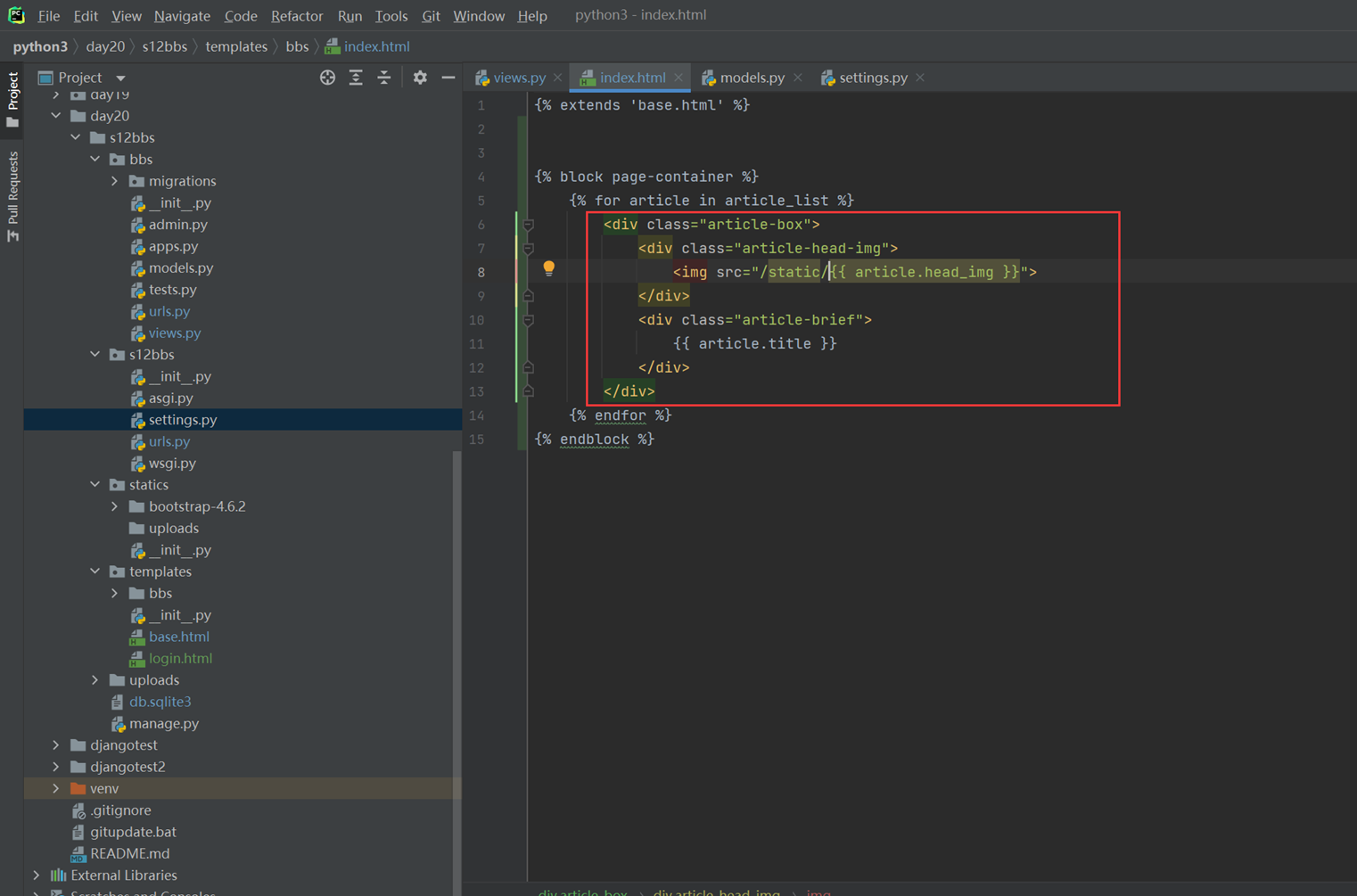
显示图片和文章的简介。
但是这里会报错
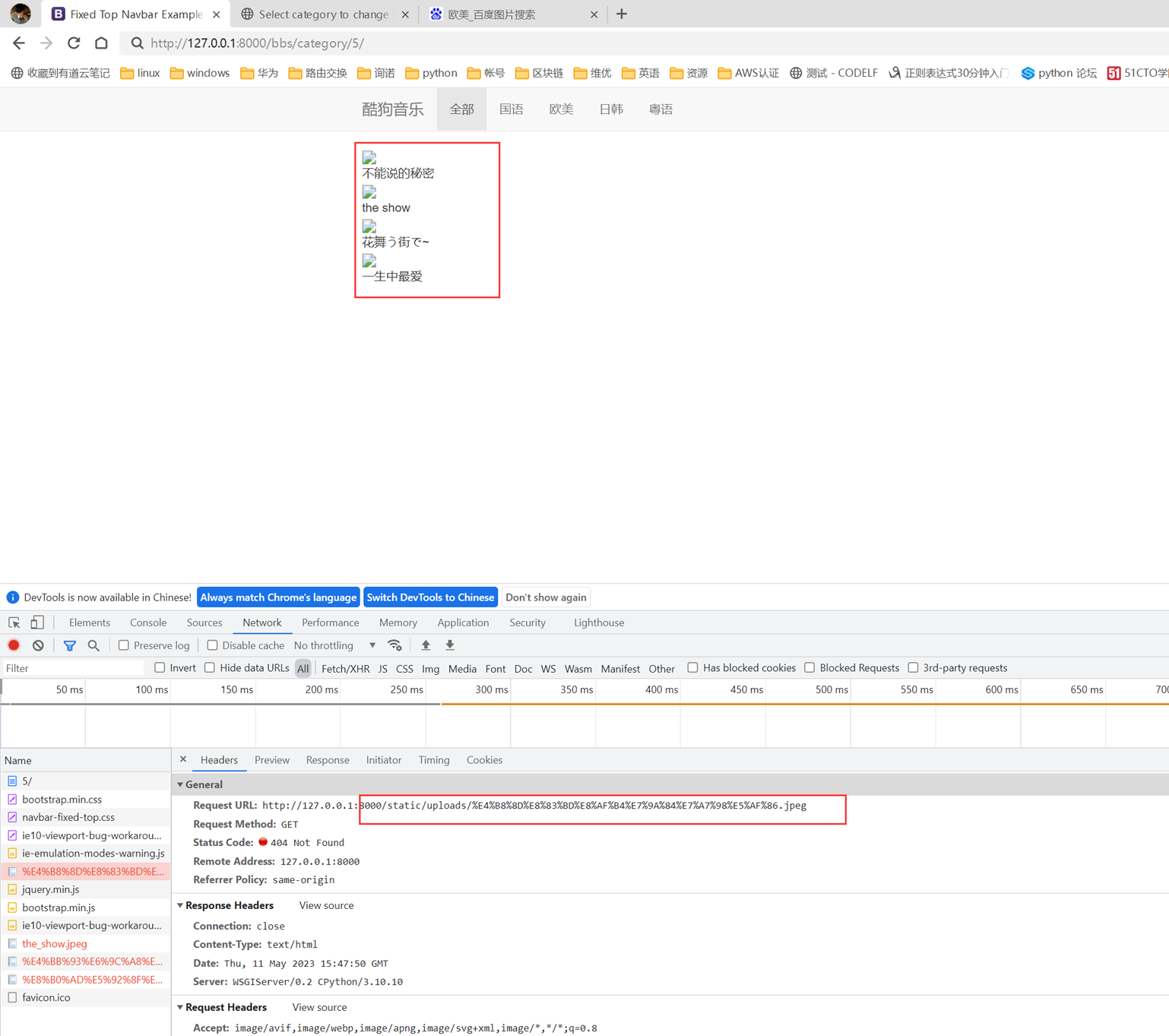
图片显示不了,所以这里我们要使用中间件把多余的uploads字符给过滤掉。
中间件之前讲过,这里就不详细说明了,就截个图意思一下就行。
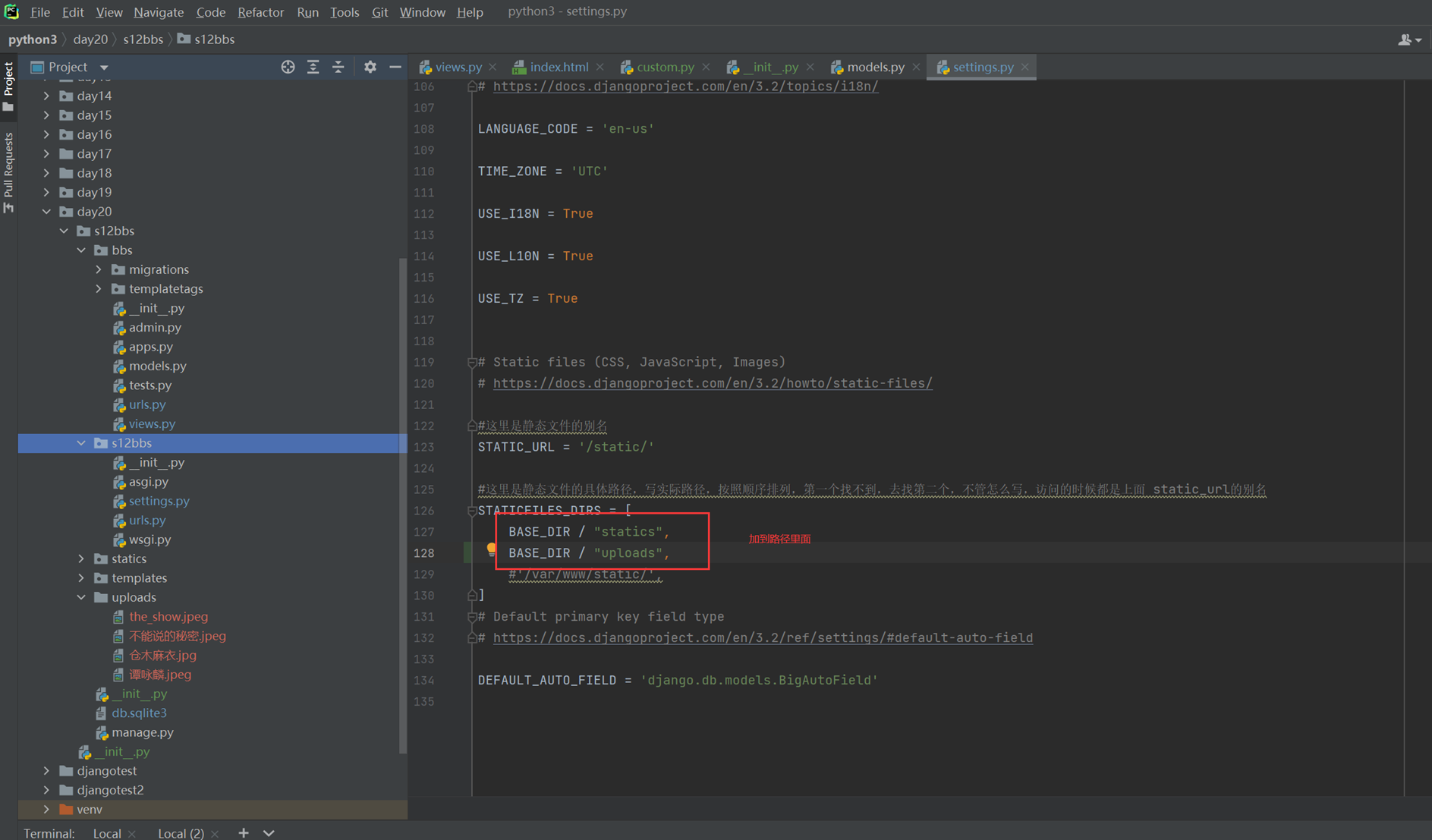
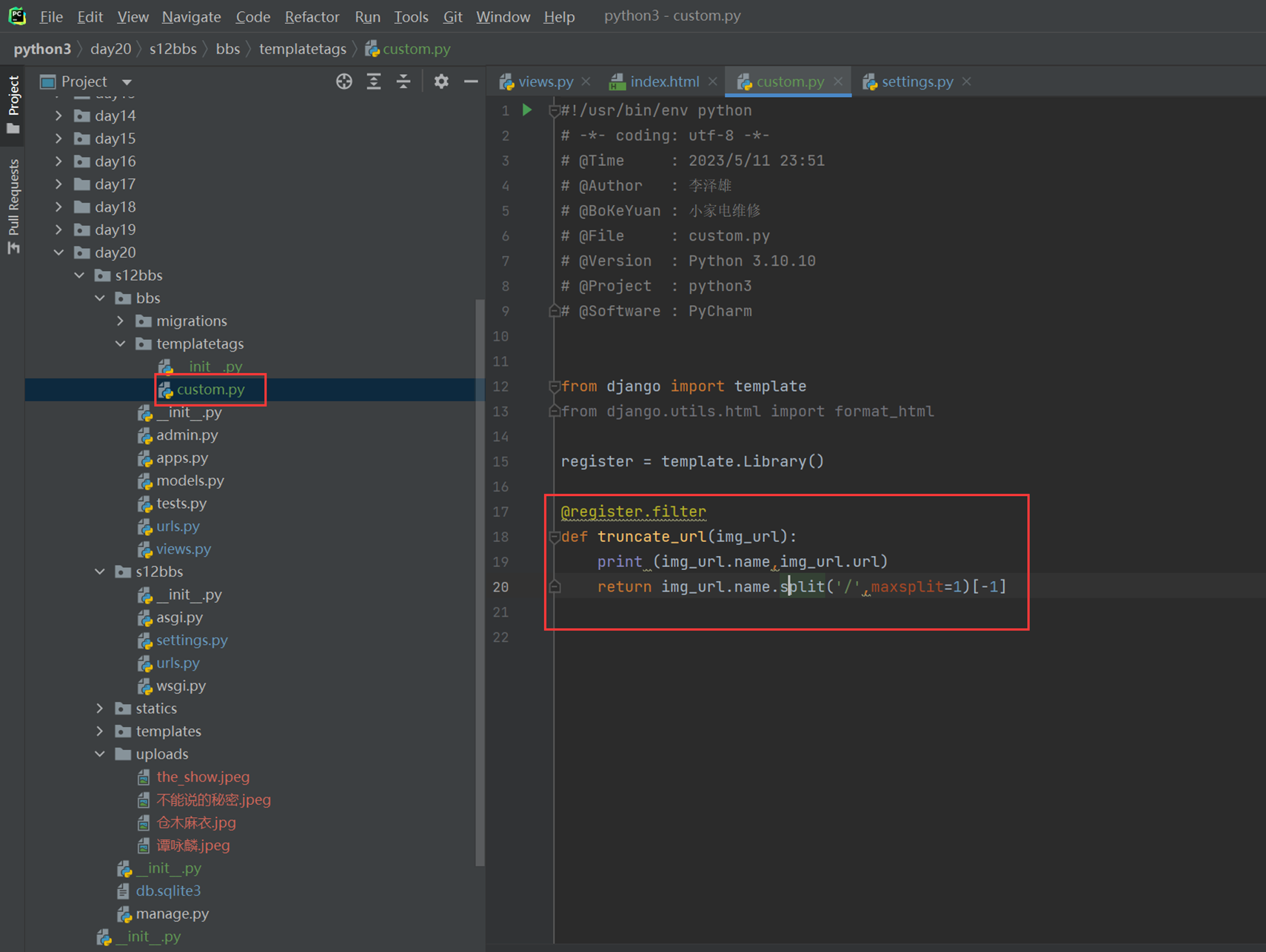
前端
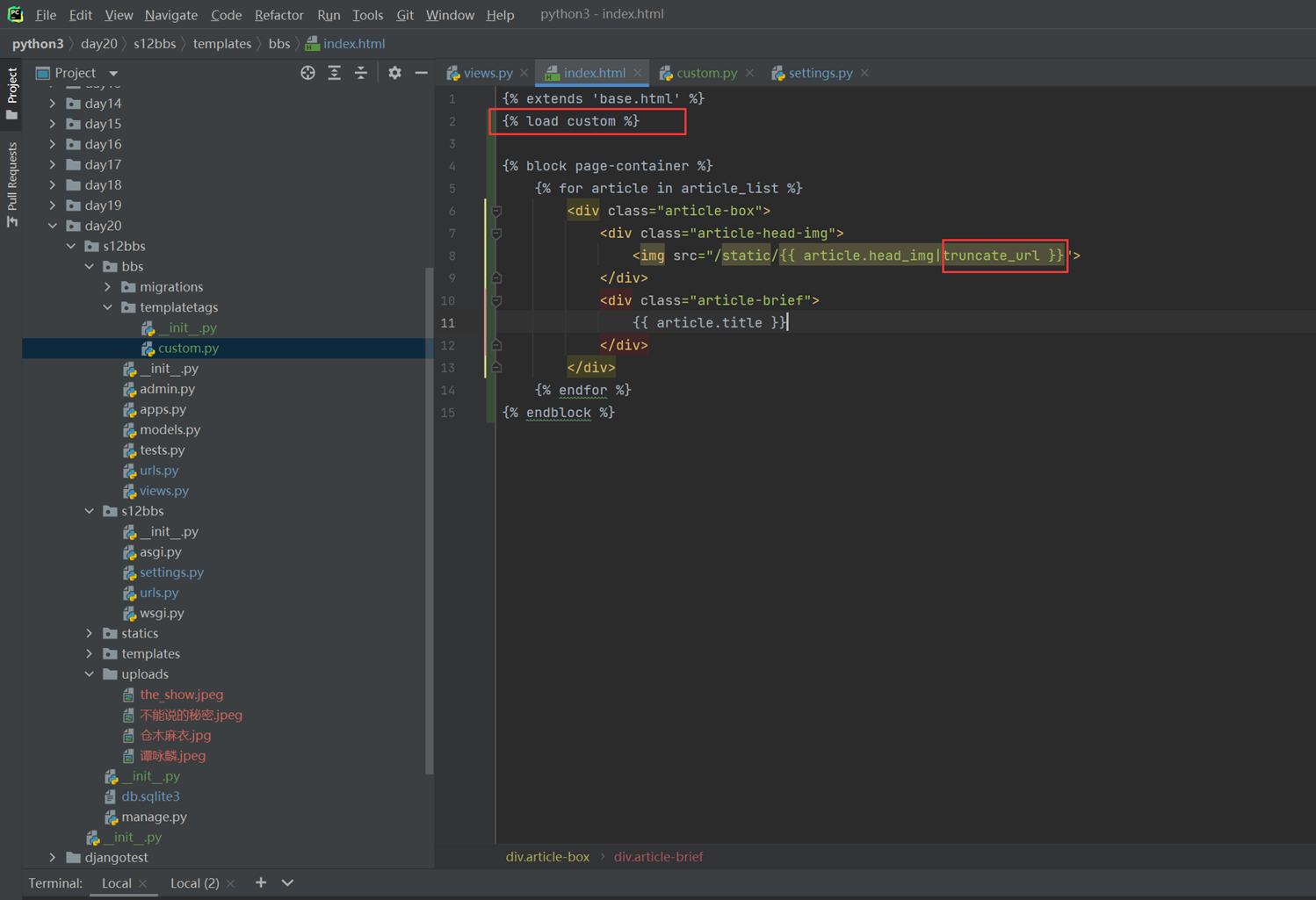
刷新前端看看效果
前端很乱,我们继续优化
我们自定义样式,首先导入自己的样式
然后看看本章修改过的html代码和css样式
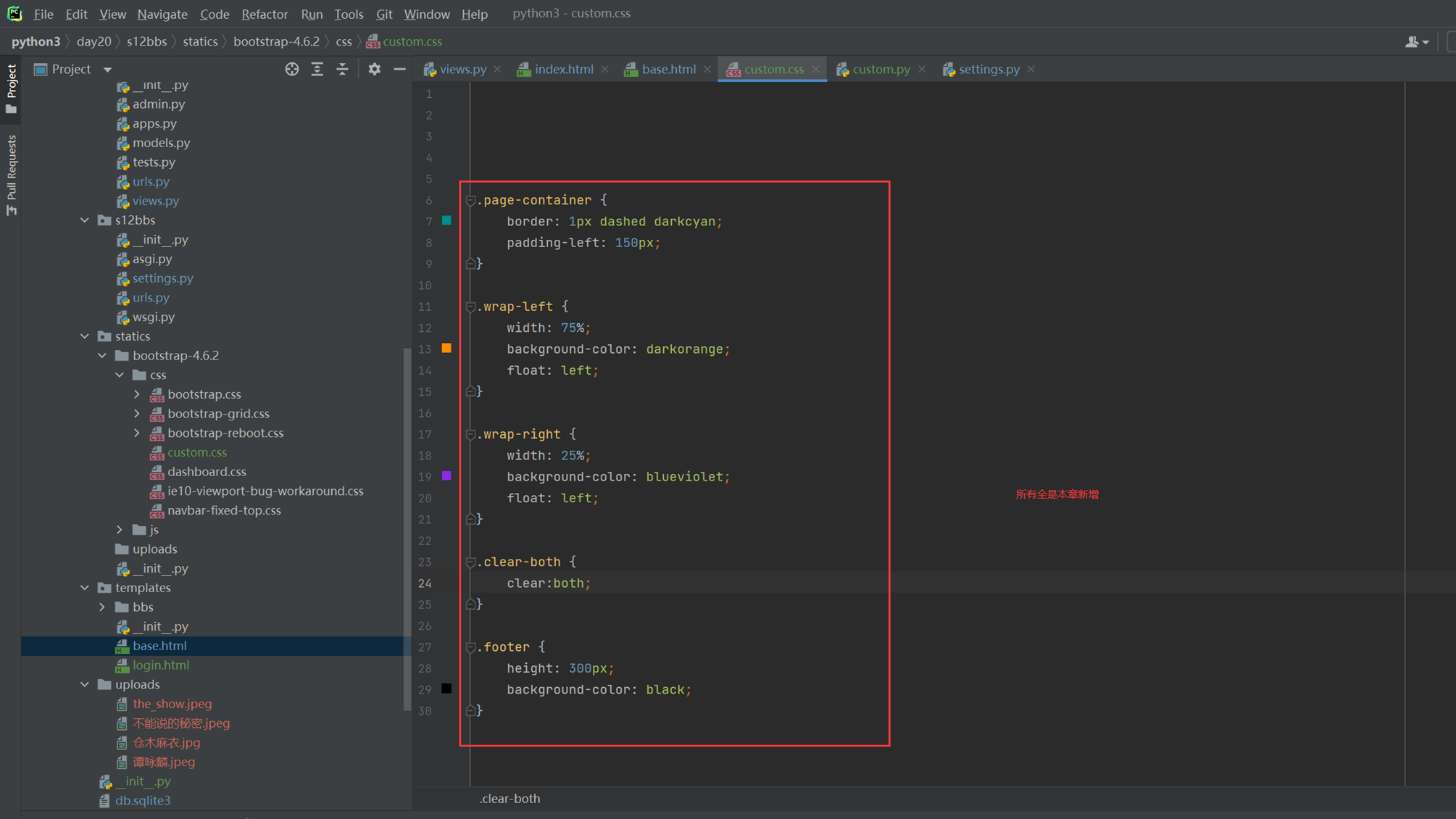
看看index.html,就增加了3个div
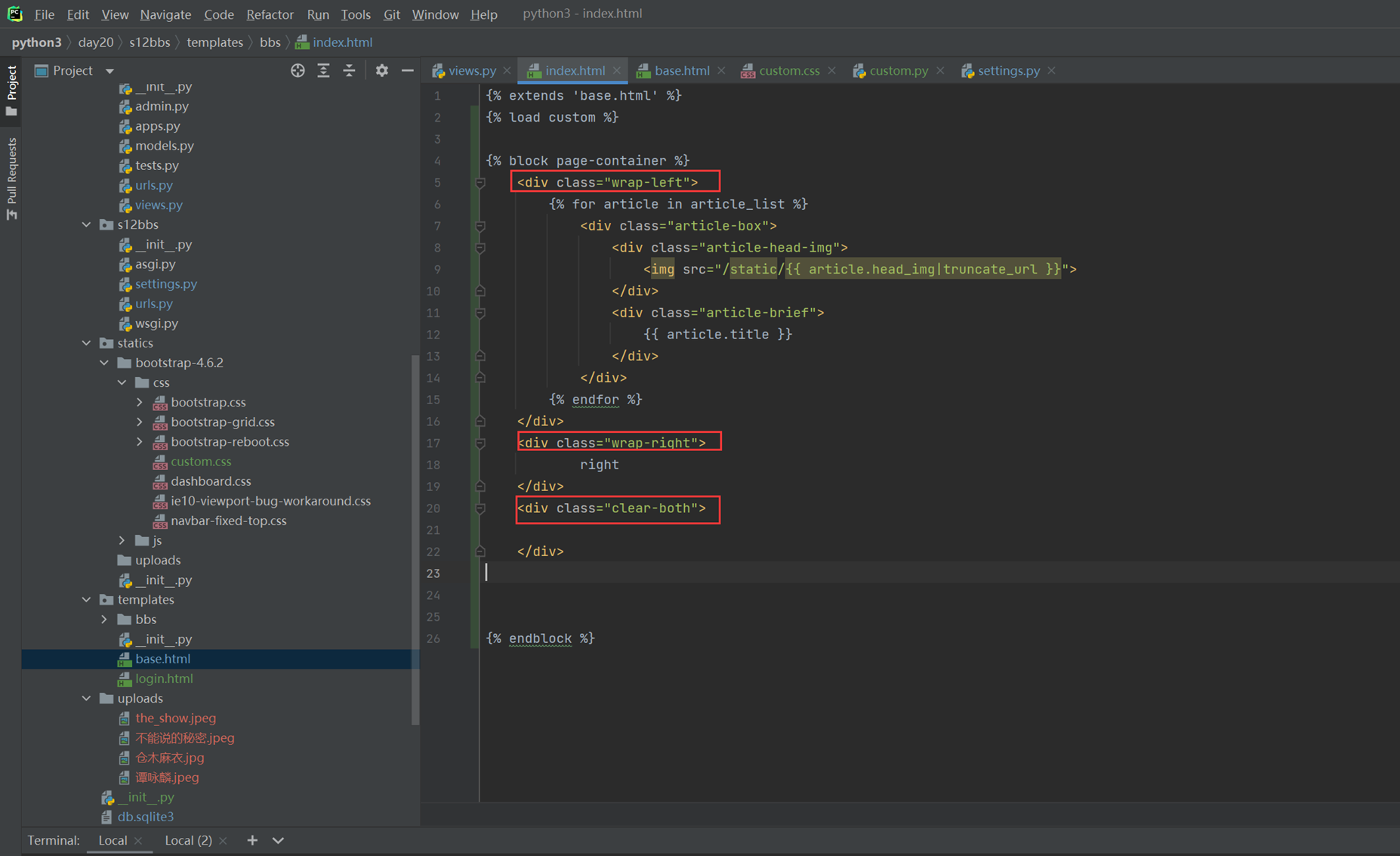
看看base.html
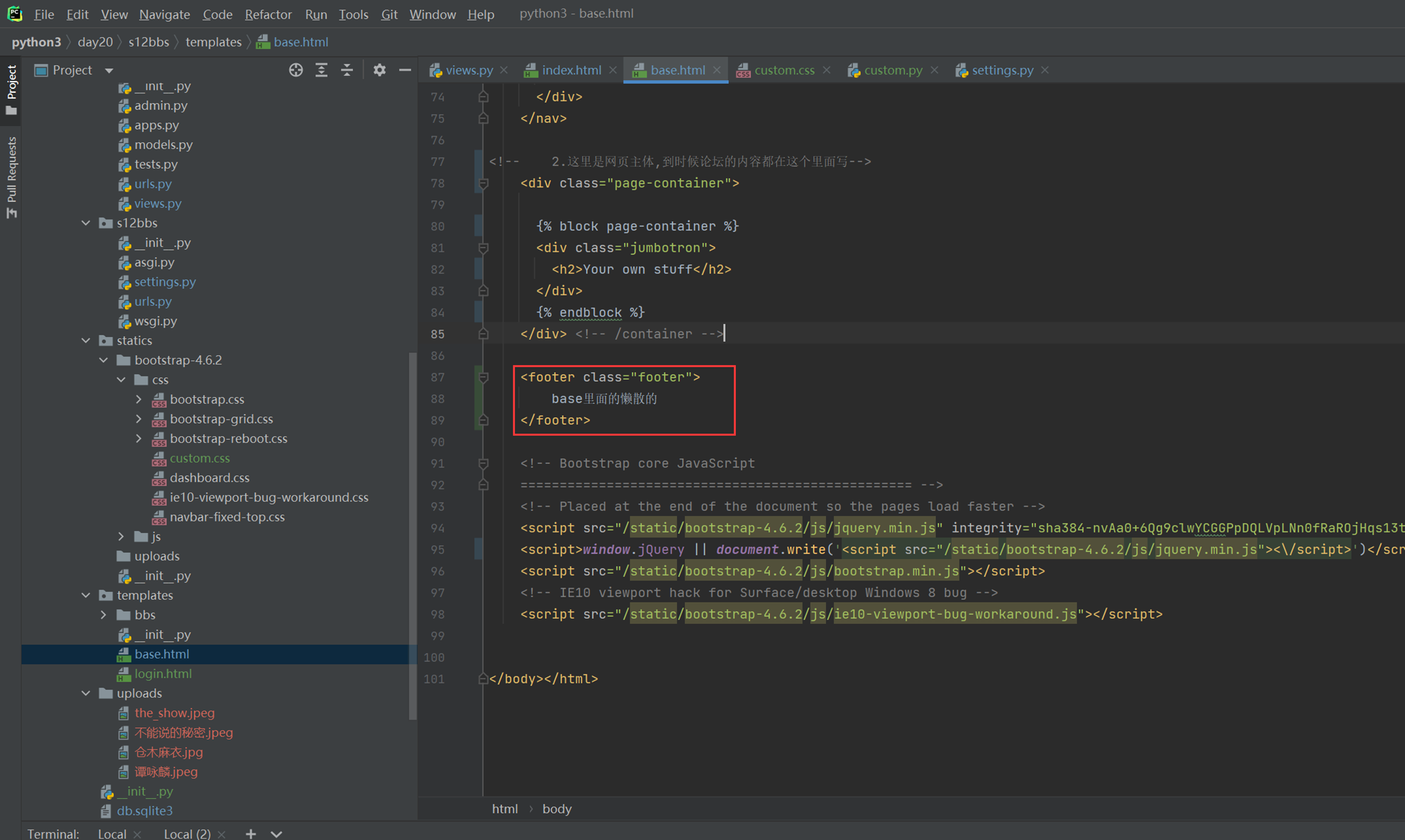
就增加了一个footer标签
看看结果
本章结束
20.9 前端页面布局配置2
完全接上面一章,没有中断过
本节课2个内容
1.优化了上一节课的样式,让前端更加好看一点了
2.展示出了文章作业,发布时间,评论数等数据(这个很简单,就写了一个div,然后后端数据传到前端就行了)
html
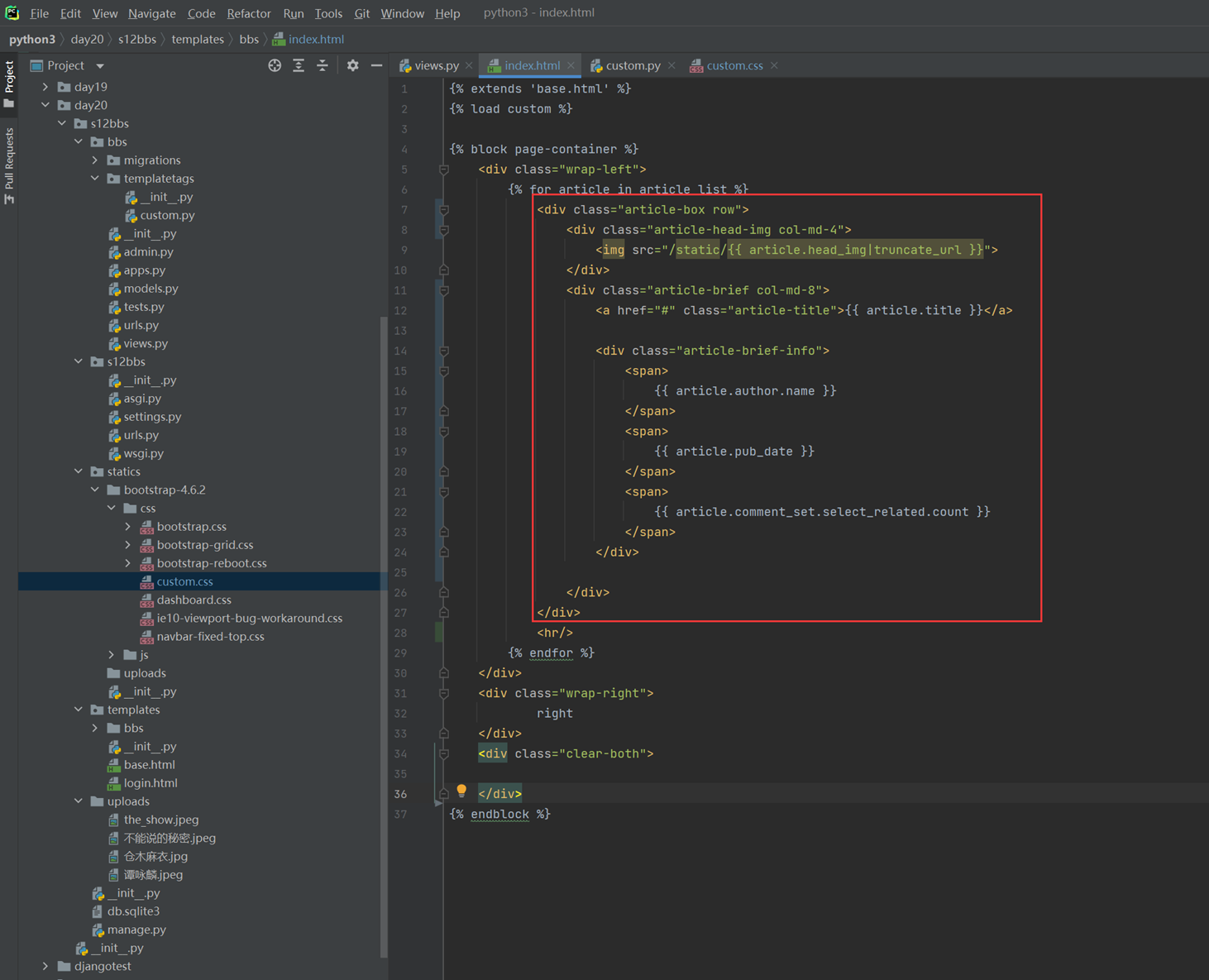
custom.css
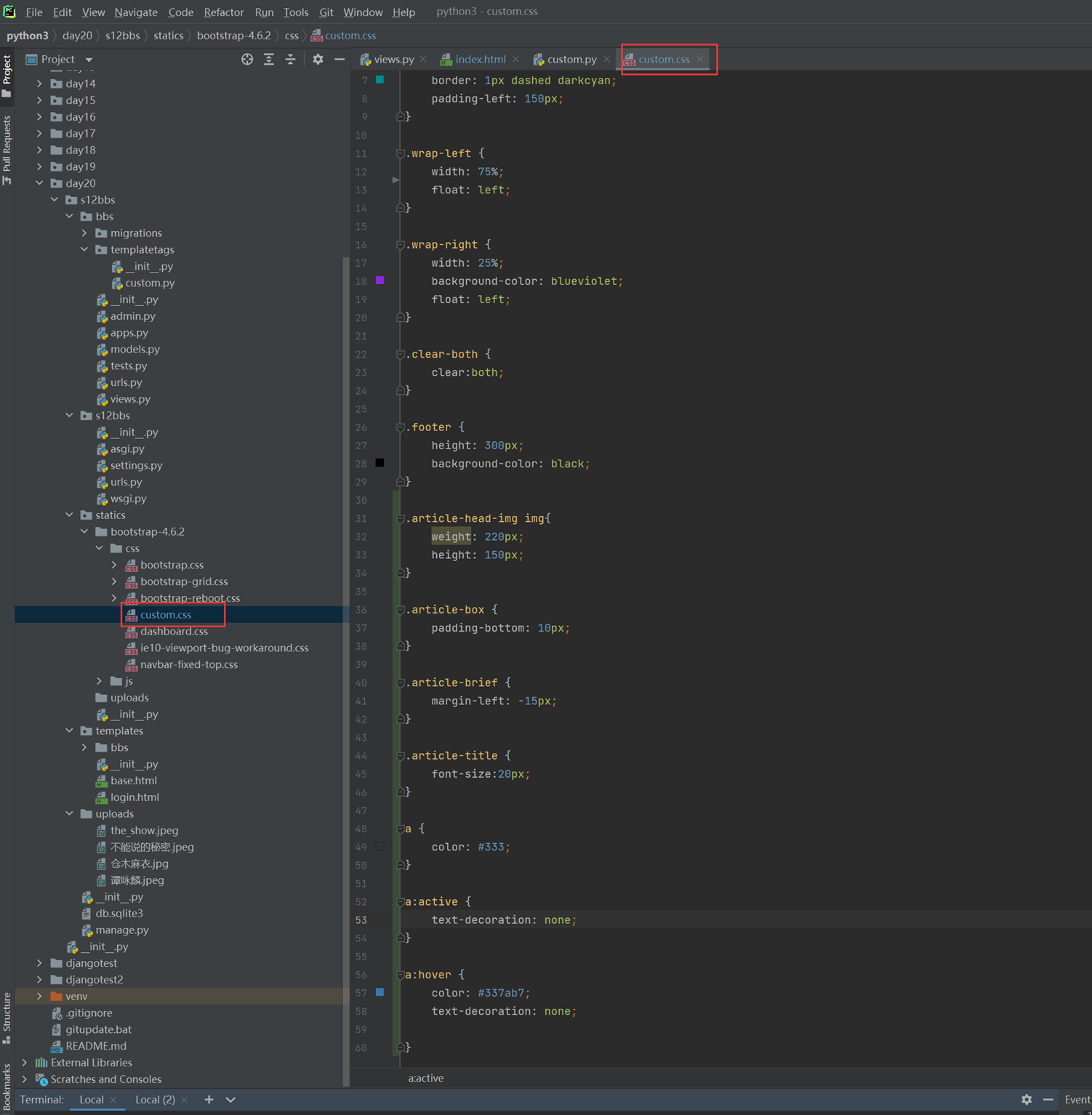
看一下显示
20.10 前端展示评论和点赞数
展示评论和点赞,包括给评论和点赞加图标,也是很简单的需求,只是评论和点赞前端不能直接显示,需要使用中间件。
index
custom.css
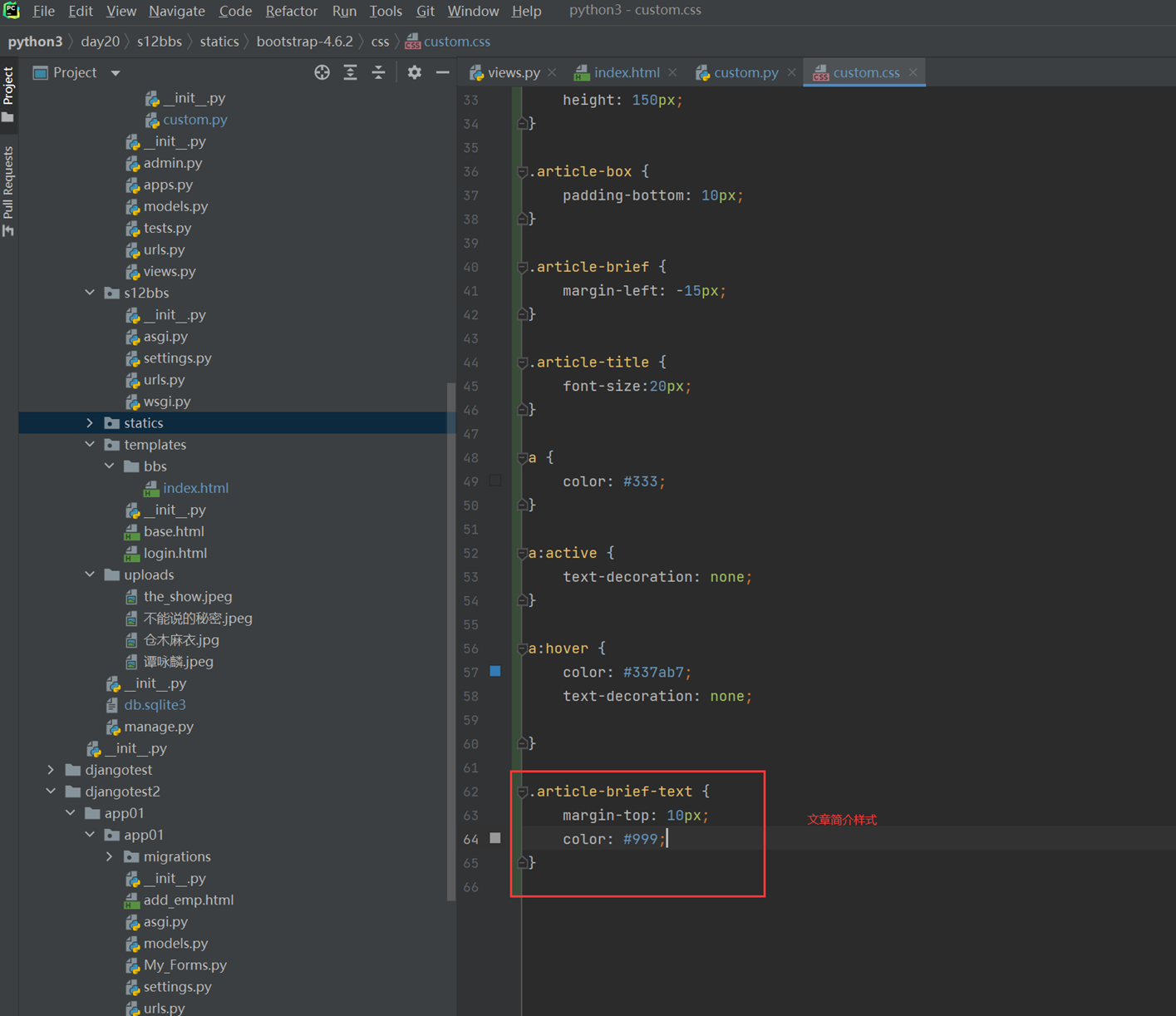
中间件custom.py
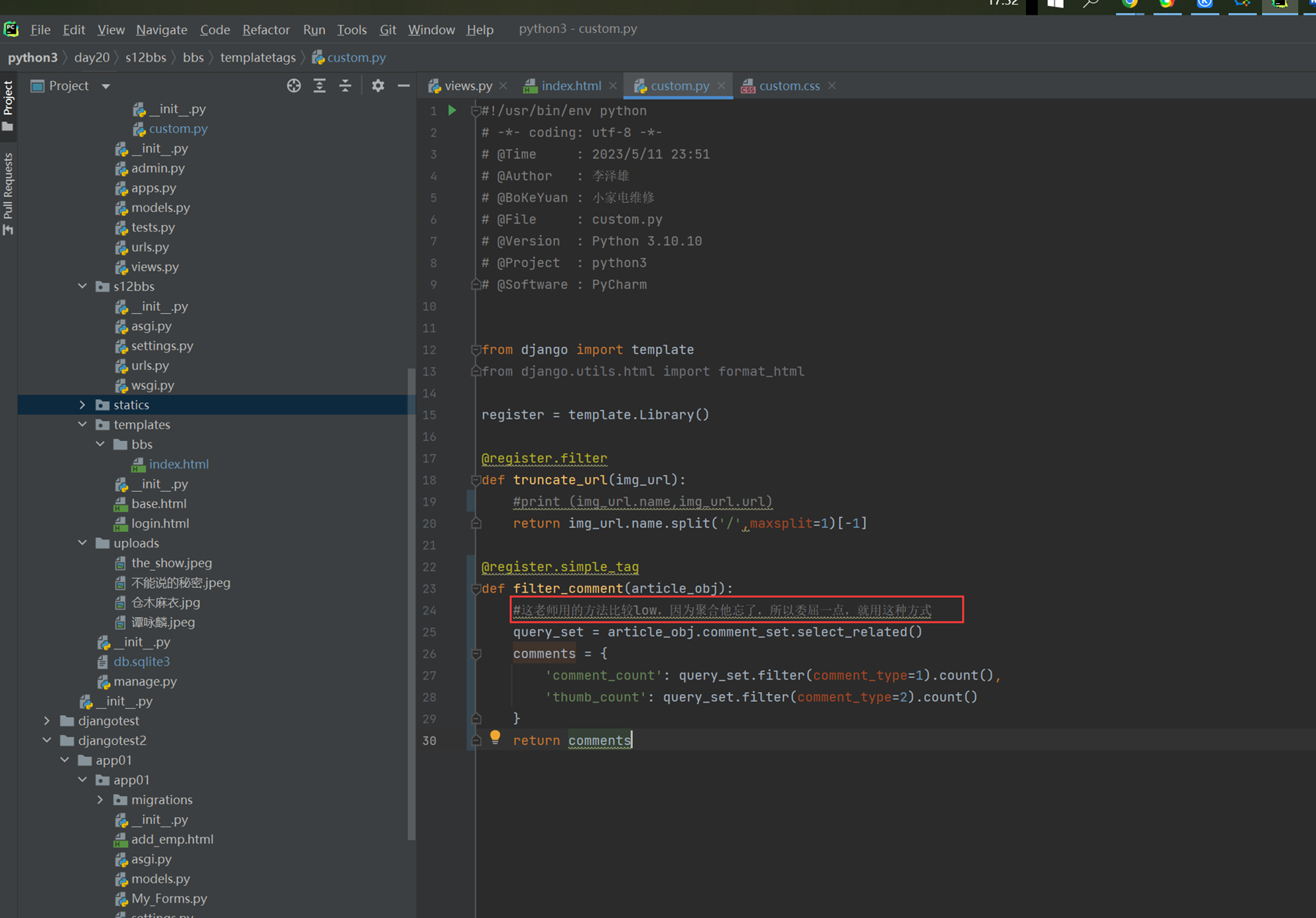
看看结果
20.11 用户登录
本章不是用户登录,主要是论坛详情页。
可以点击超链接跳转到轮胎博客的详情页。
只需要如下顺序即可。
1.url
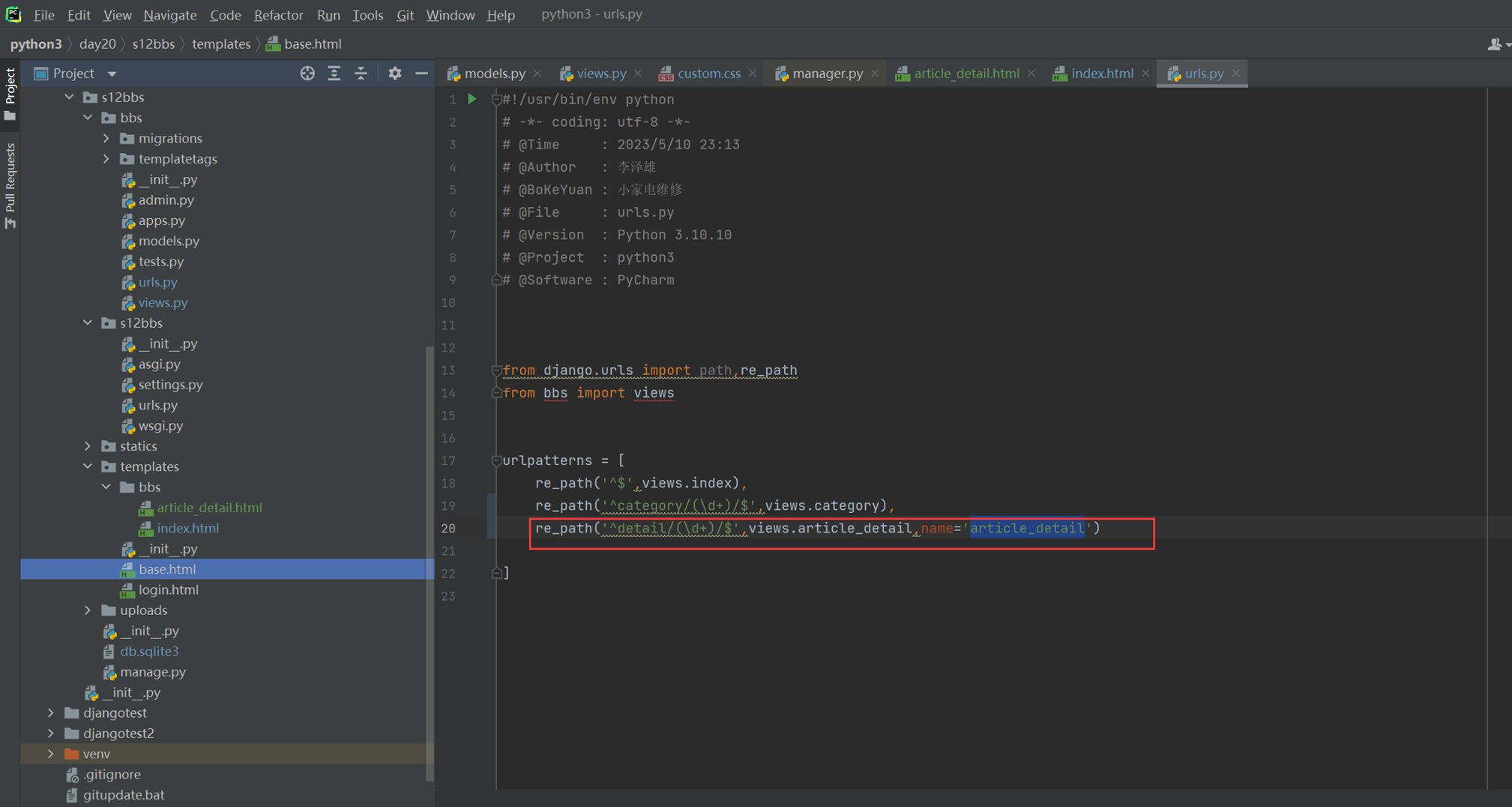
2.views
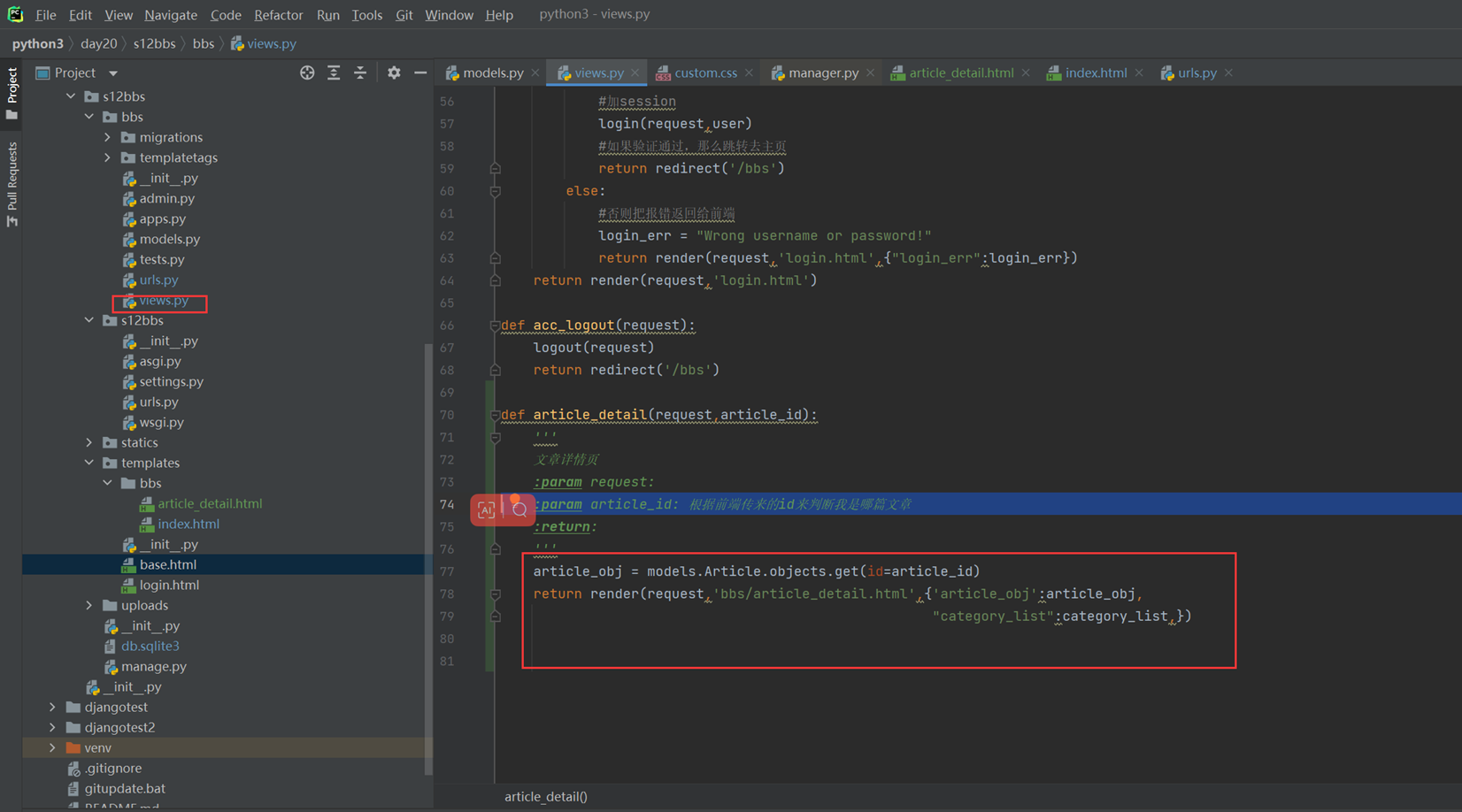
3.index.html
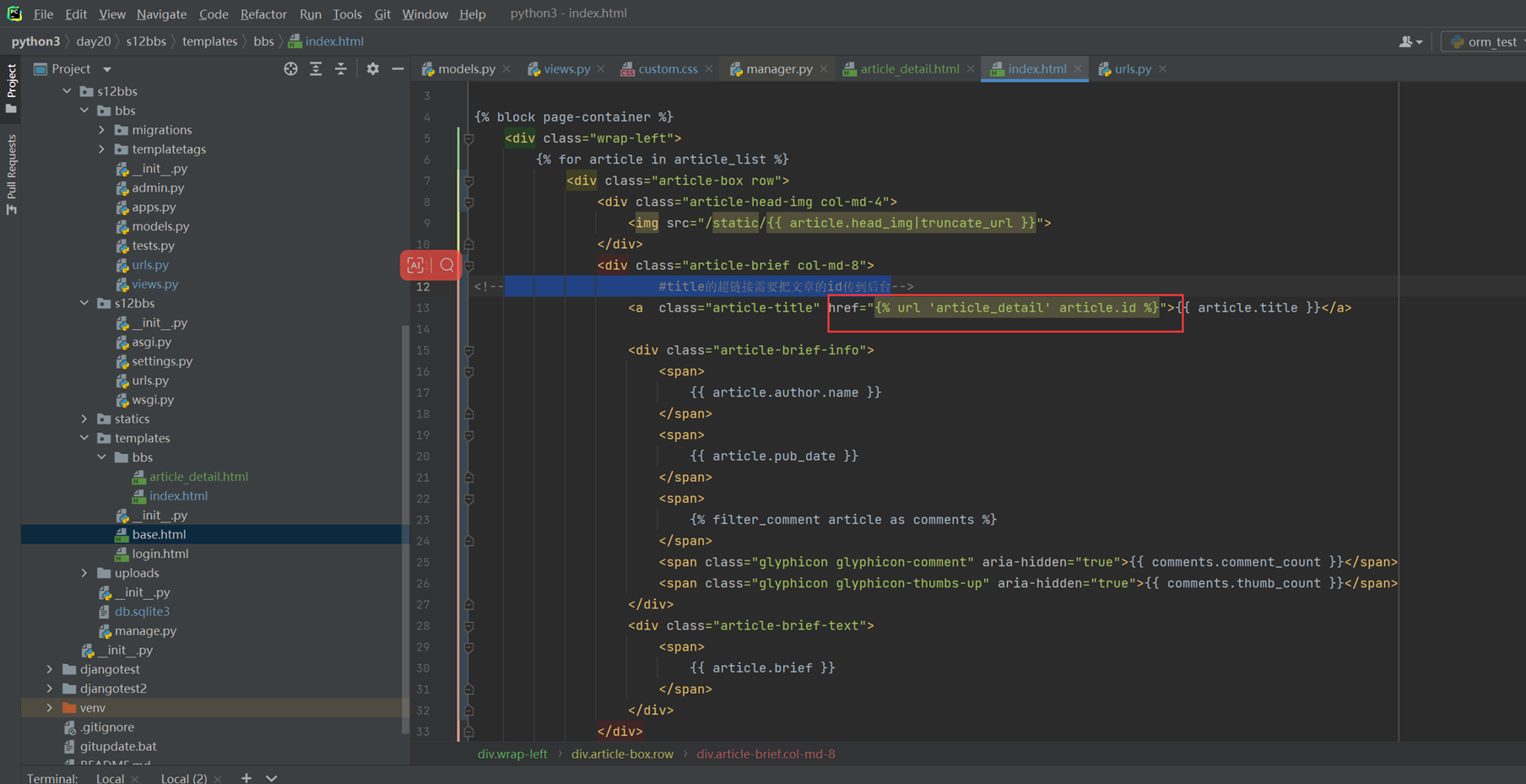
4.article_detail.html
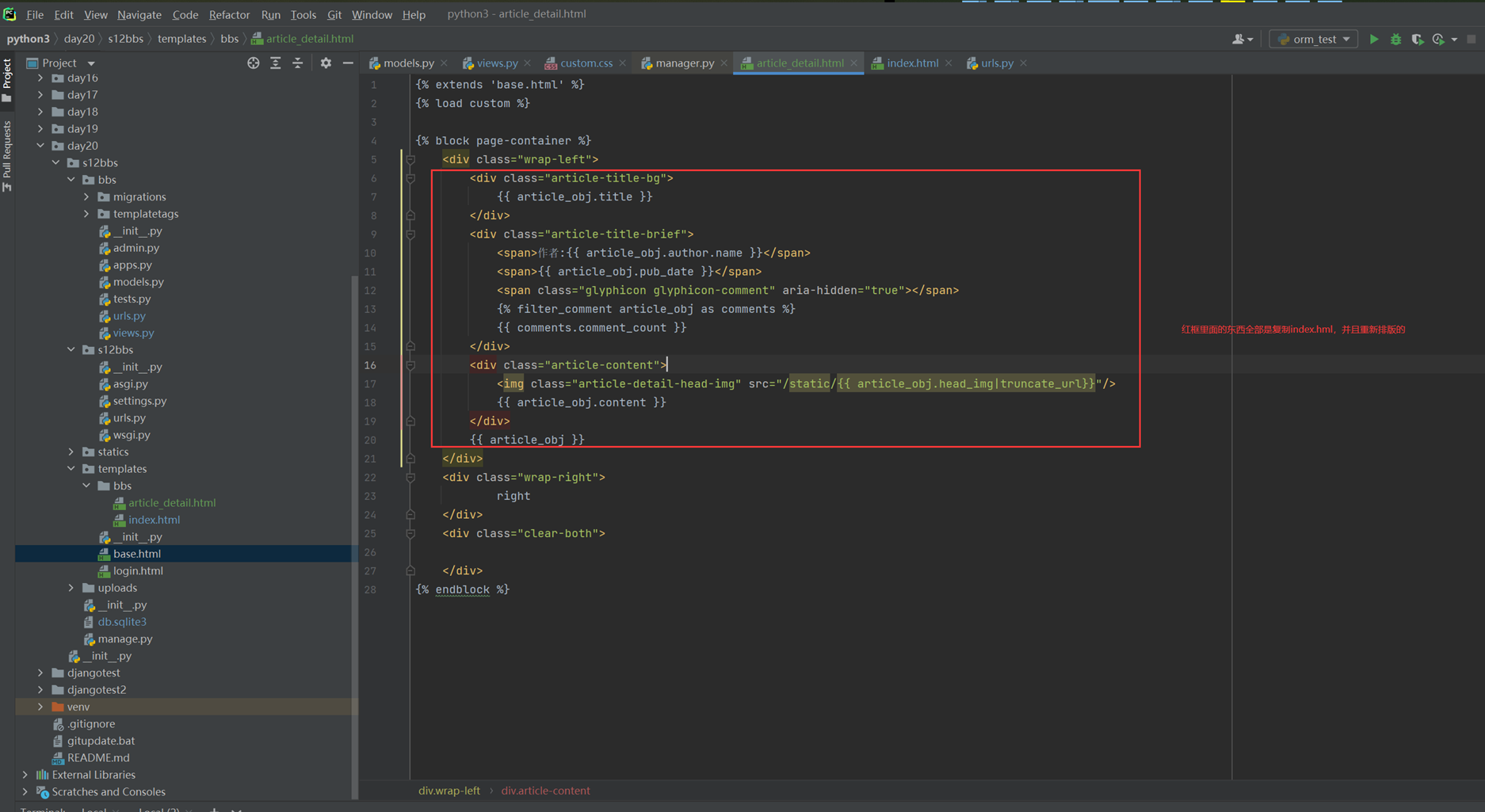
5.custom.css
Css就不做解释了,这玩意解释不清
6.访问查看
20.12 创建文章评论
本章内容
1.用户评论前要保证先登录
2.提交用户的评论到后台(功能没完成,没办法保存到数据库,先用ajax把前端功能完成)
本章实验在提交post请求到后端的时候,因为csrf原因结束了,所以提交到后端报错,本章就结束了。
本章代码。
url
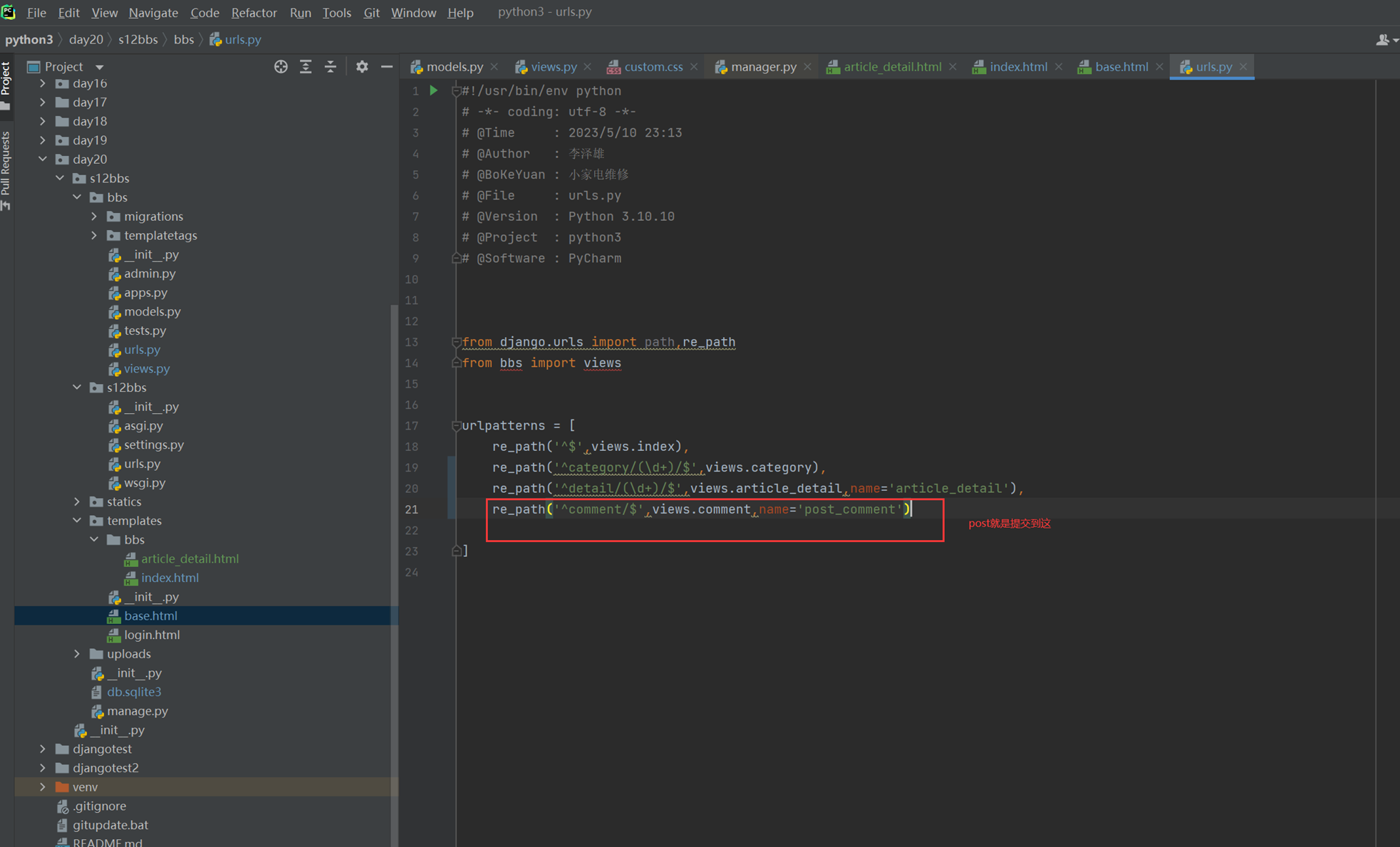
views
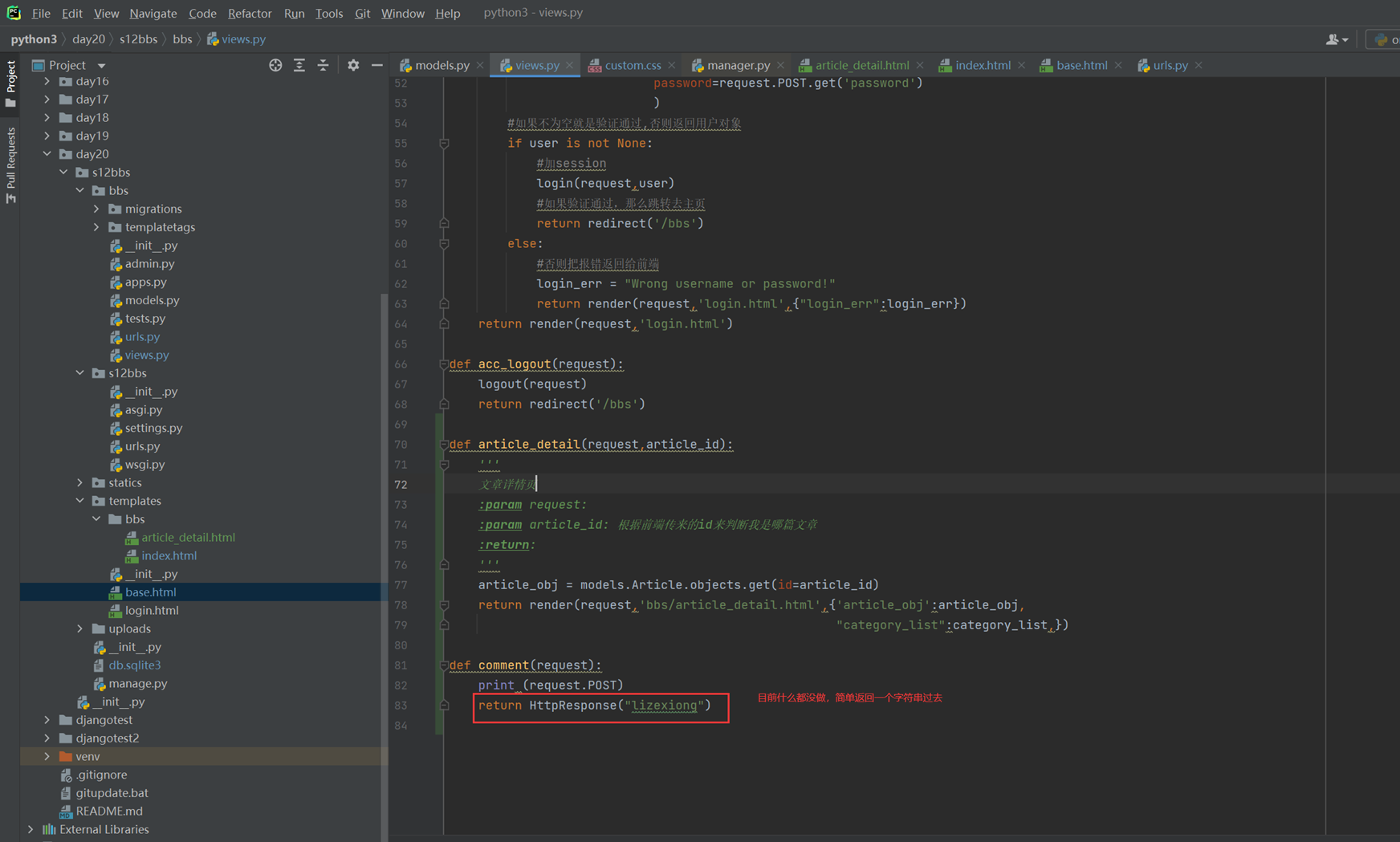
html-base.html
因为index来继承,这样代码不会乱,所以base.html里面有block
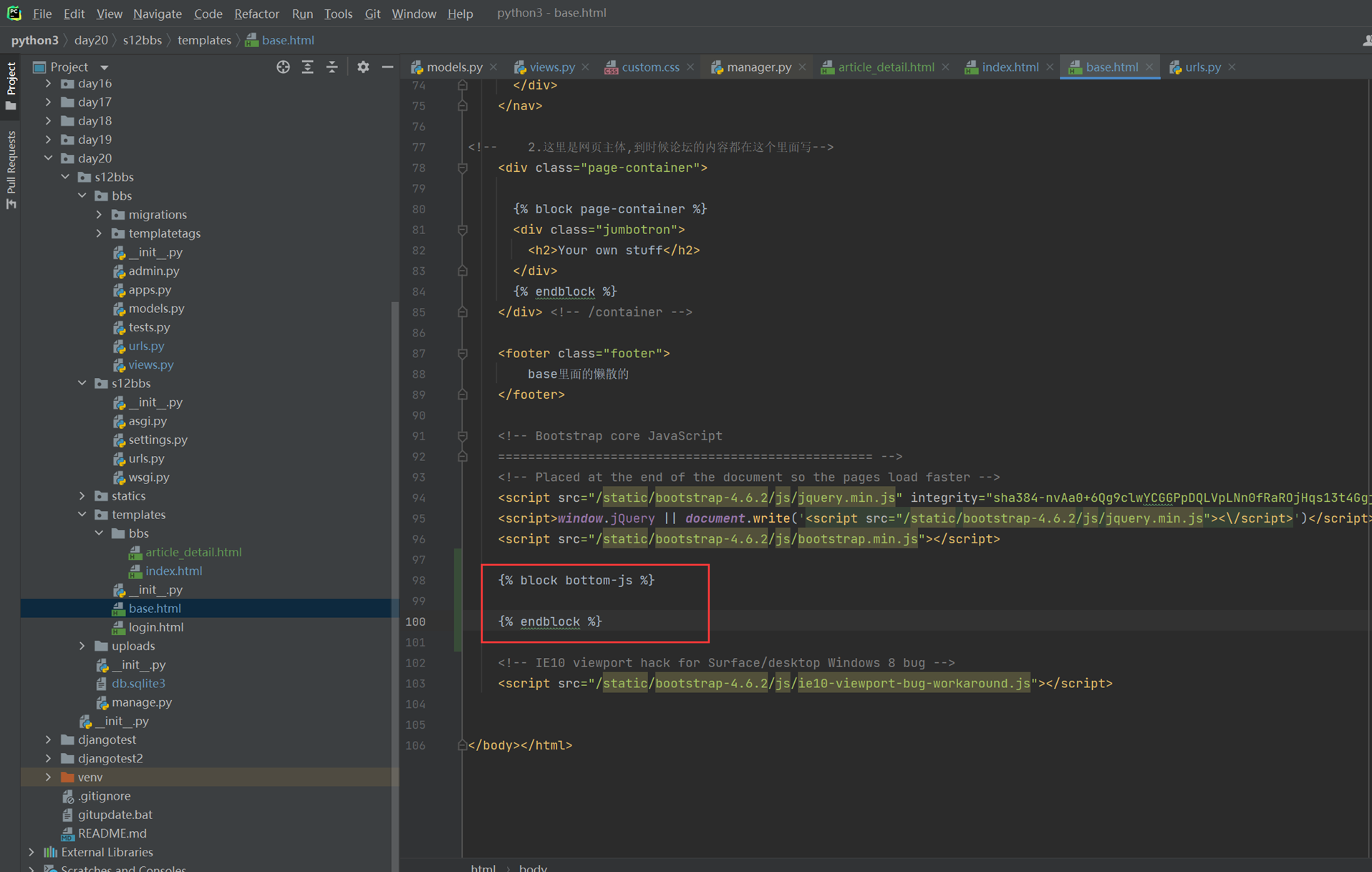
article_detail.html
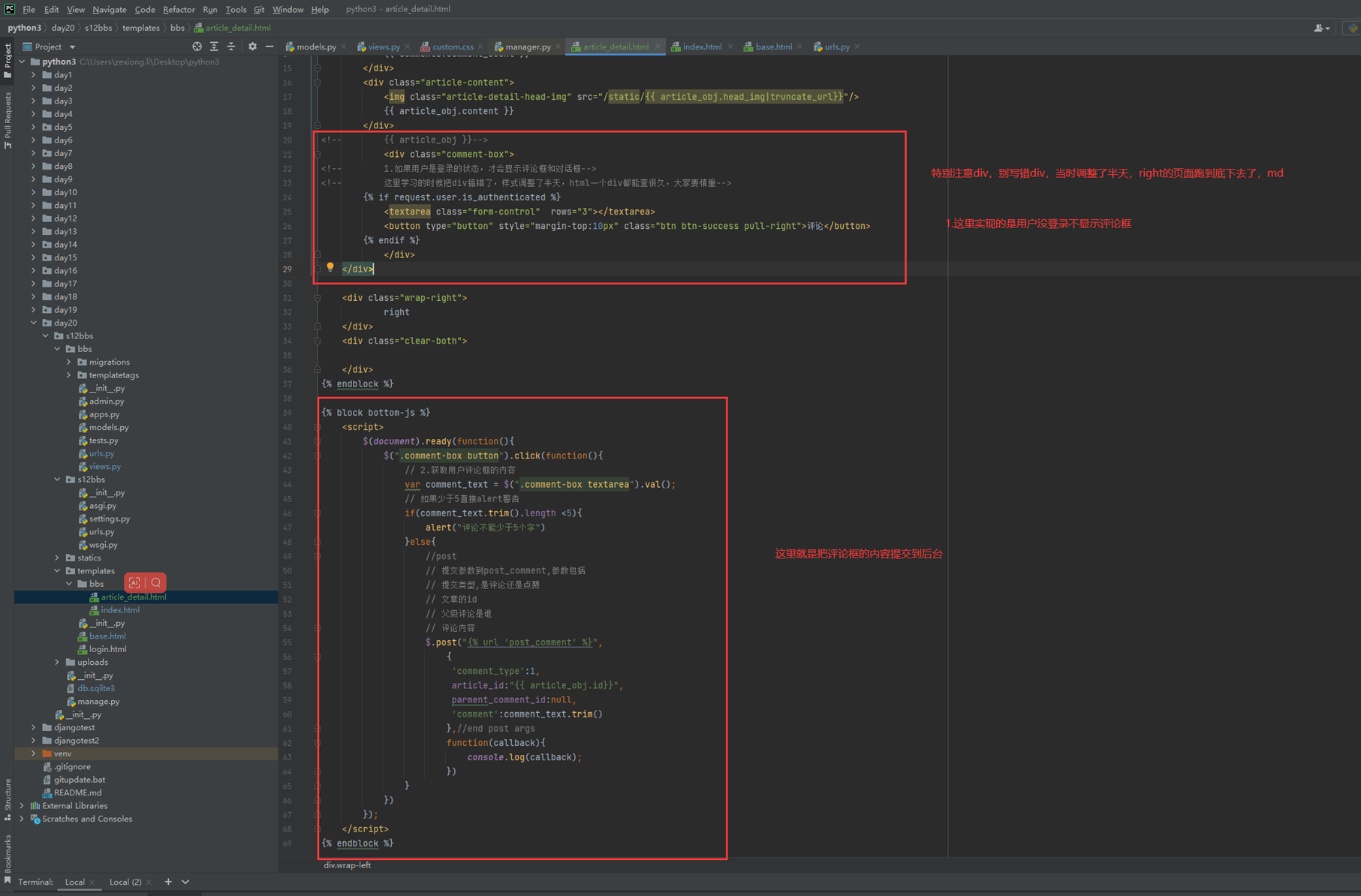
结果
前端提交报错
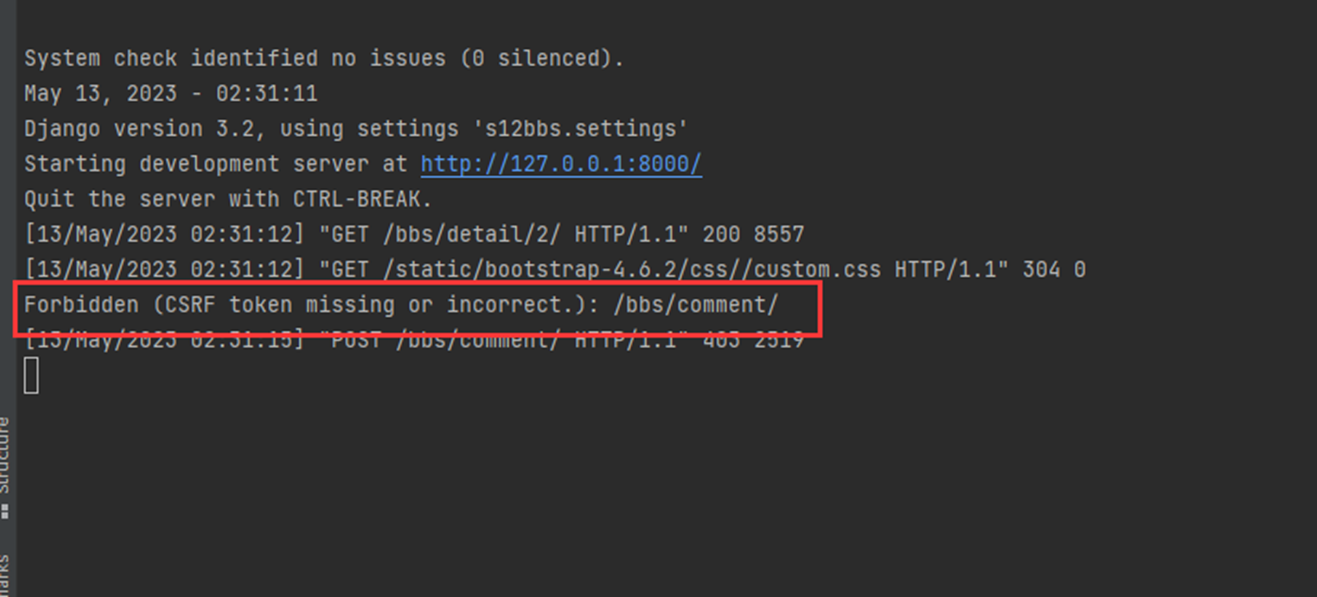
csrf报错,下一章继续讲解。
20.13 CSRF攻击原理及防护
本章就是解释为什么需要csrf

简单来说,就是你正常要访问的网站会再你的网站里面埋一个字段,你请求你需要访问的网站的时候会带上这个字段,正常网段的服务端拿到这个字段去解密对比,而钓鱼网站是获取不到这个埋的字段的。
现在演示一下,因为我所有的页面的form表单都需要,所以这里就放在base.html下面了
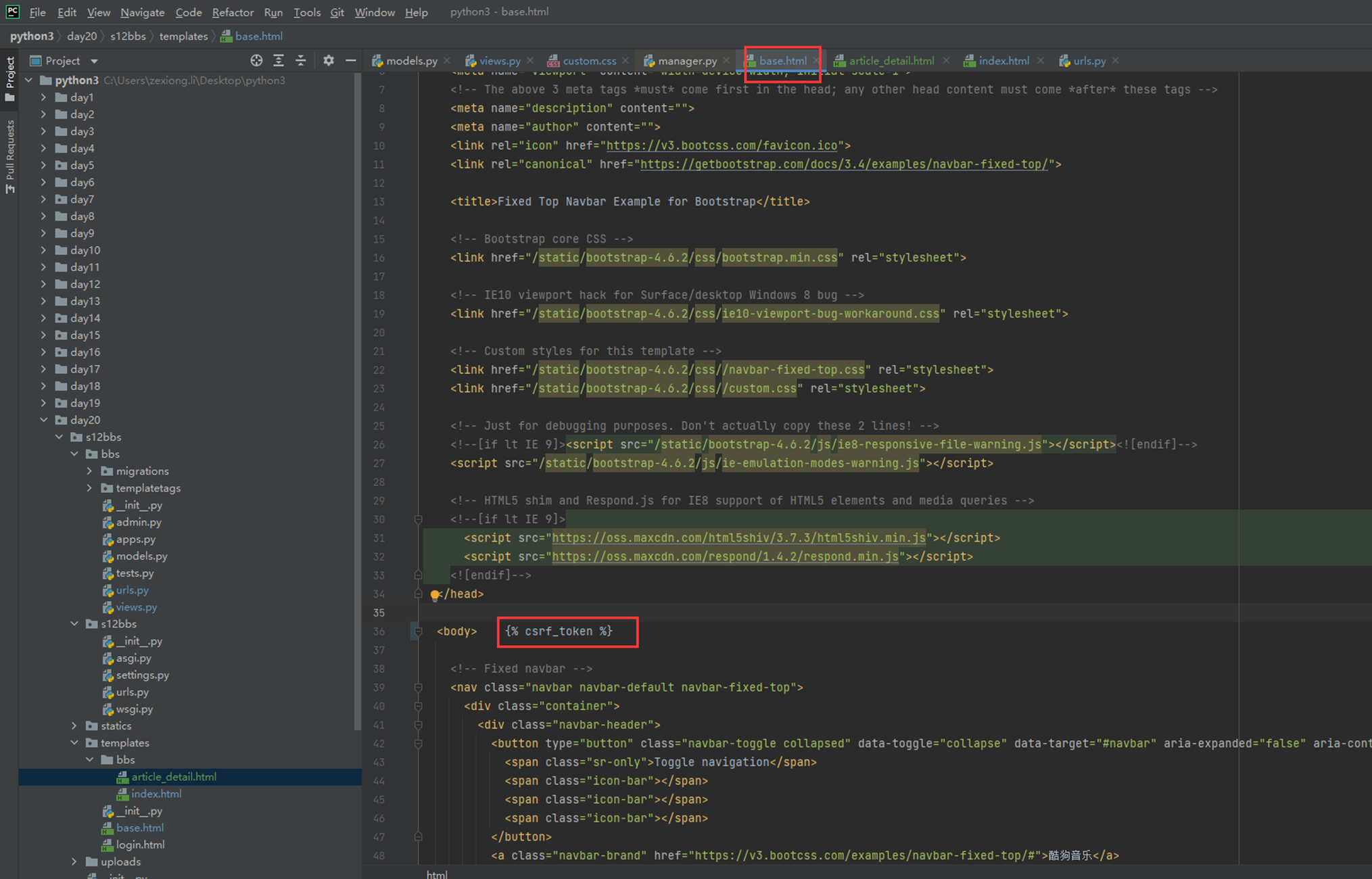
可以在前端网页看到
现在需要再ajax的时候带上我们的csrf
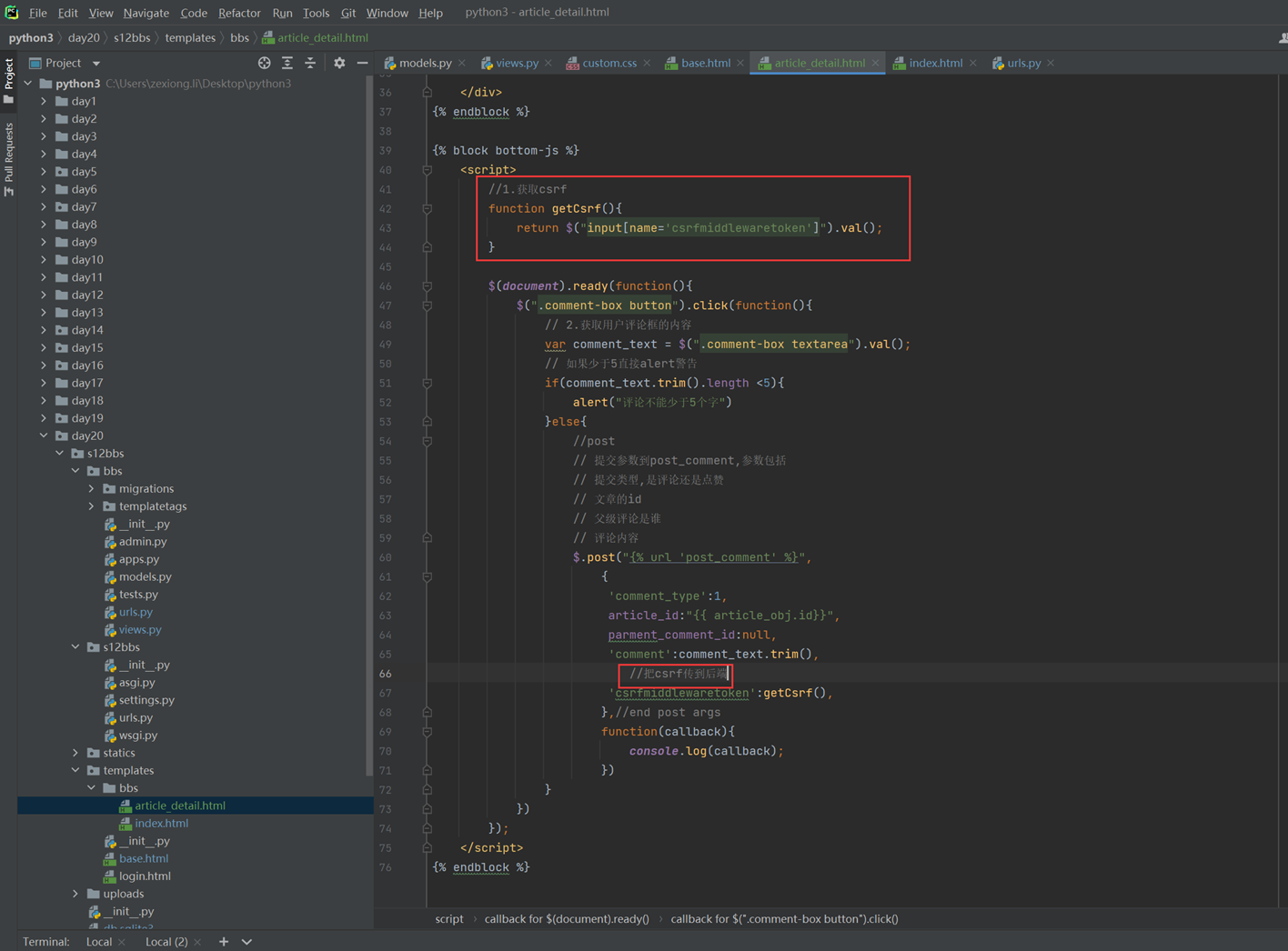
可以看到可以正常返回字符串了
额外知识点:当然,每次这样去带个字段也麻烦,官方也给了写全局的方式,这里就不演示了。
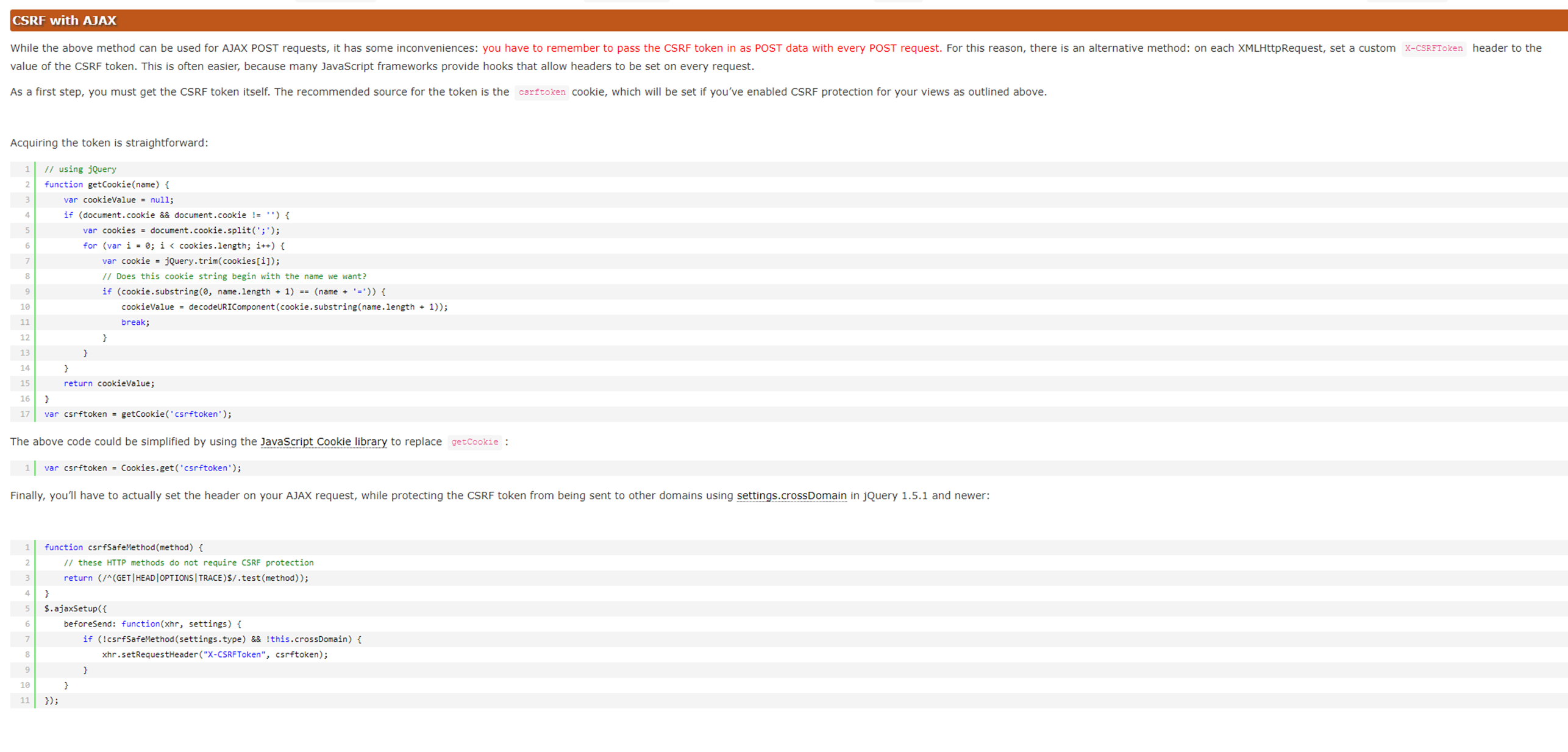
20.14 提交评论到后台
本章完成以下需求。
1.没有登录显示必须登录后才能评论,并且给出登录提示。
2.登录后还能跳转到当前文章
登录界面还是bootstrap,这里只是做个记录,让人知道在哪里找bootstrap这个样式
atticle_detail.html
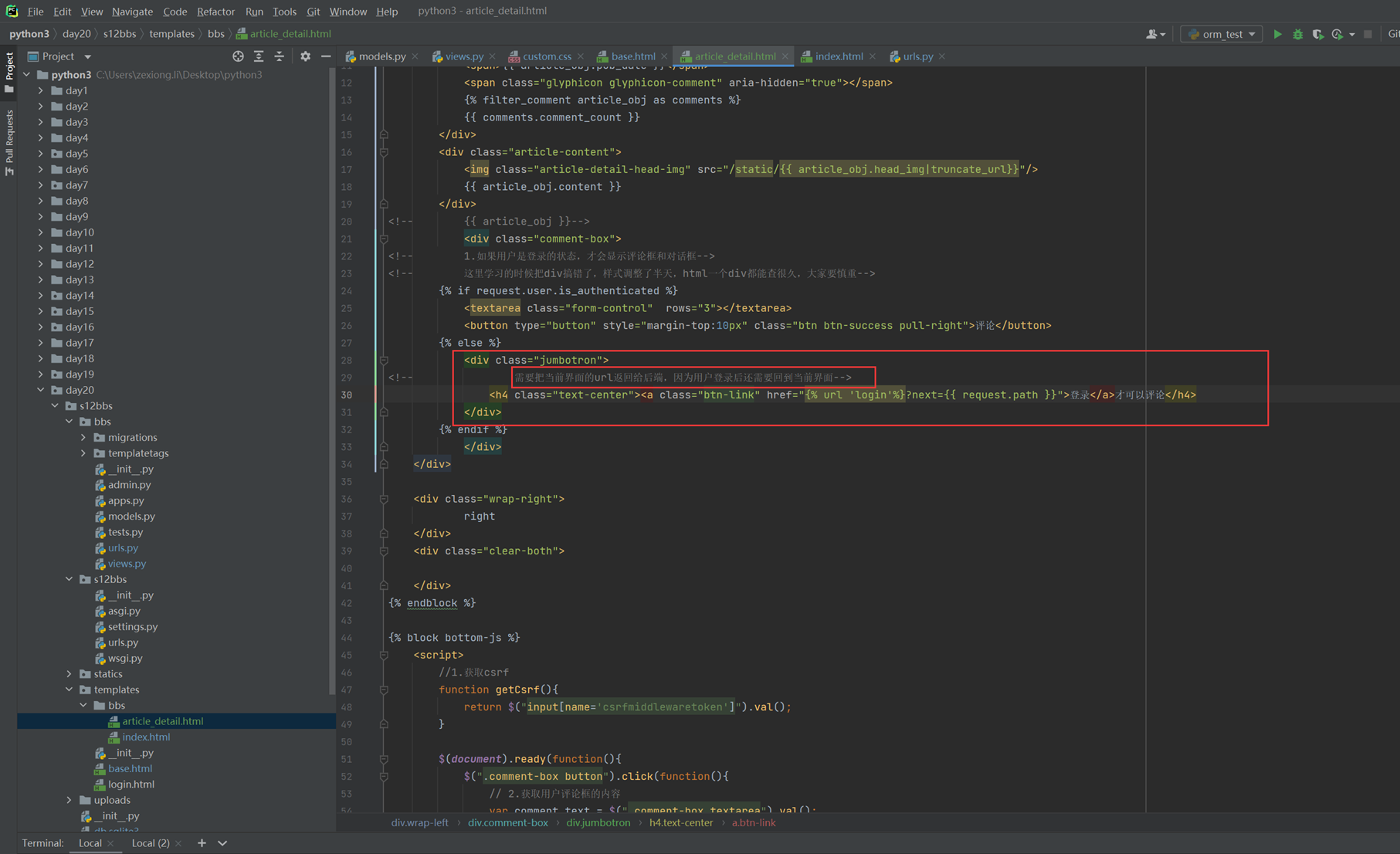
views
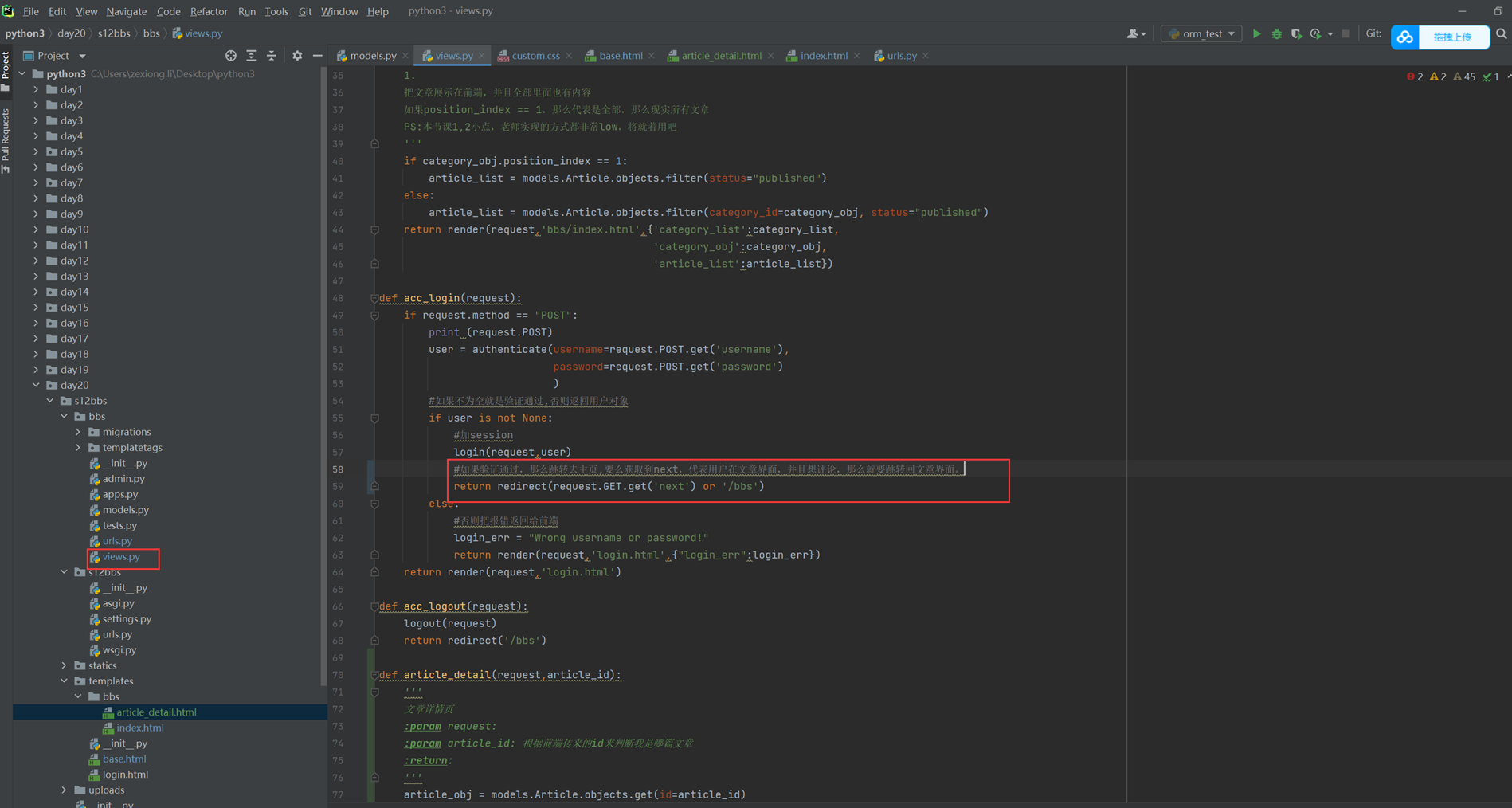
查看结果

本章内容比较简单,没什么多讲的。
20.15 提交评论到后台2
因为后面要讲解比较麻烦的评论展示,所以本章就是简单的把评论存储到数据库,并且给前端返回一个简单的alert就没了。
views
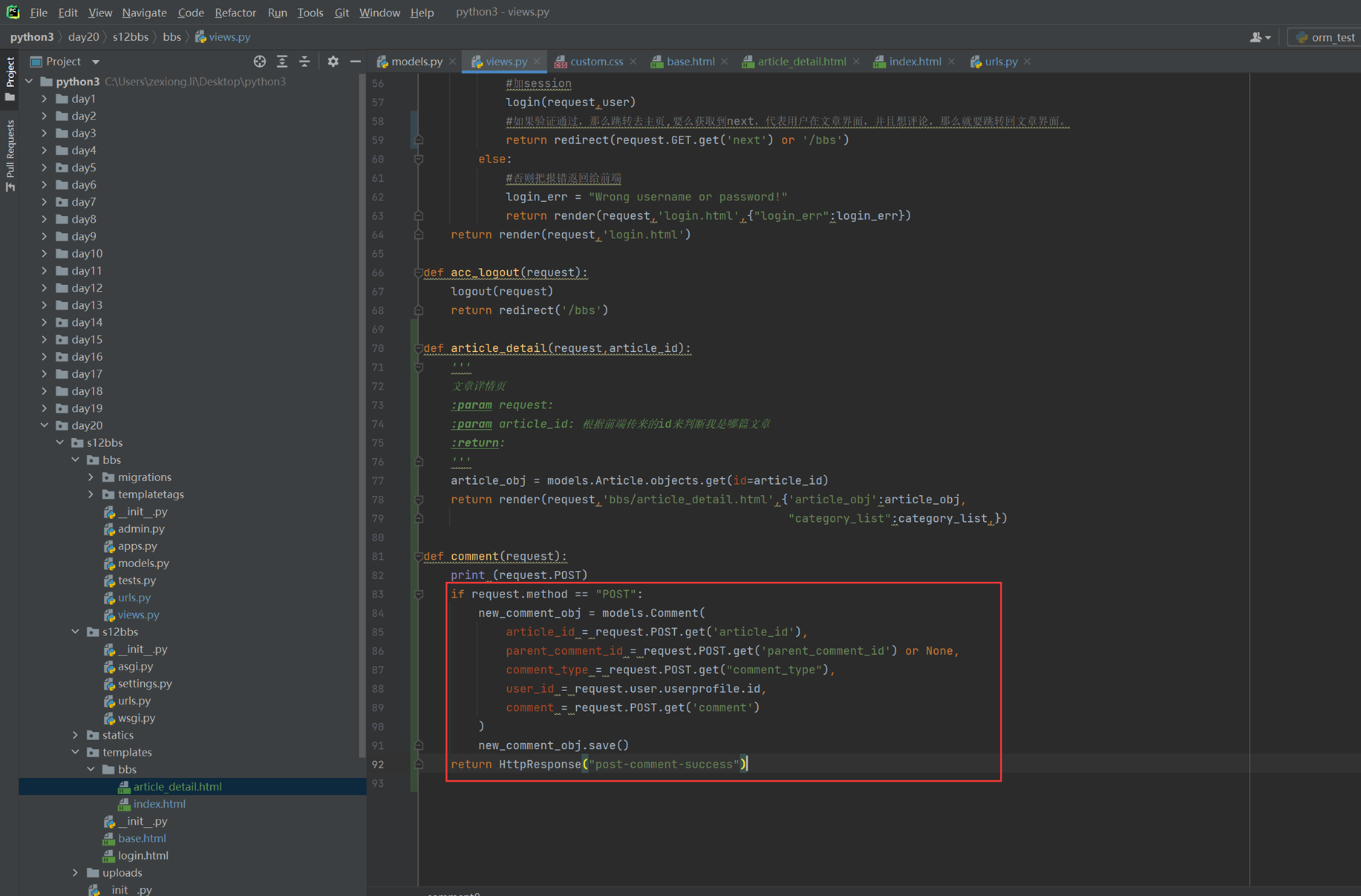
article_detail
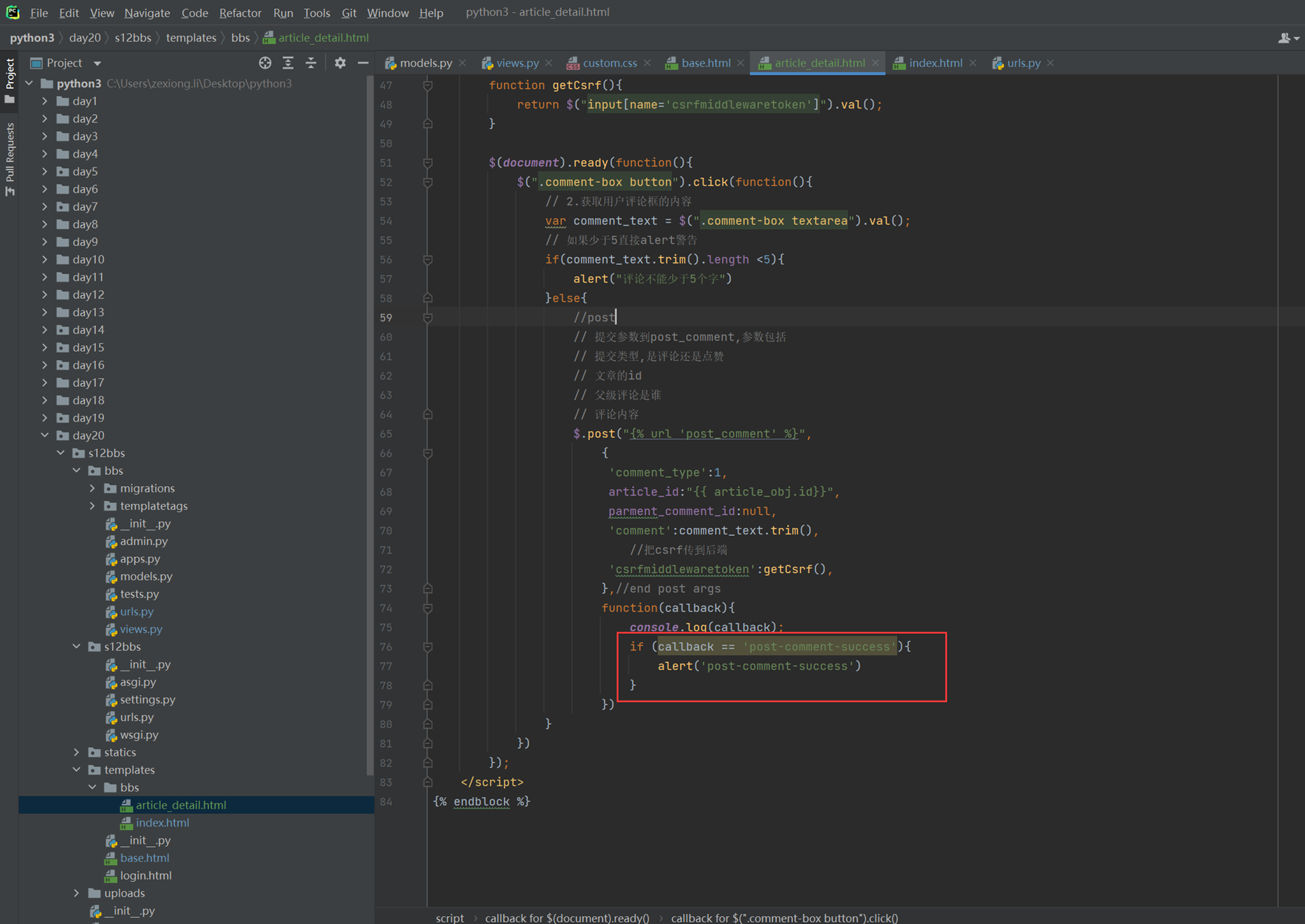
提交评论

查看后台是否有评论
20.16 如何实现多级评论
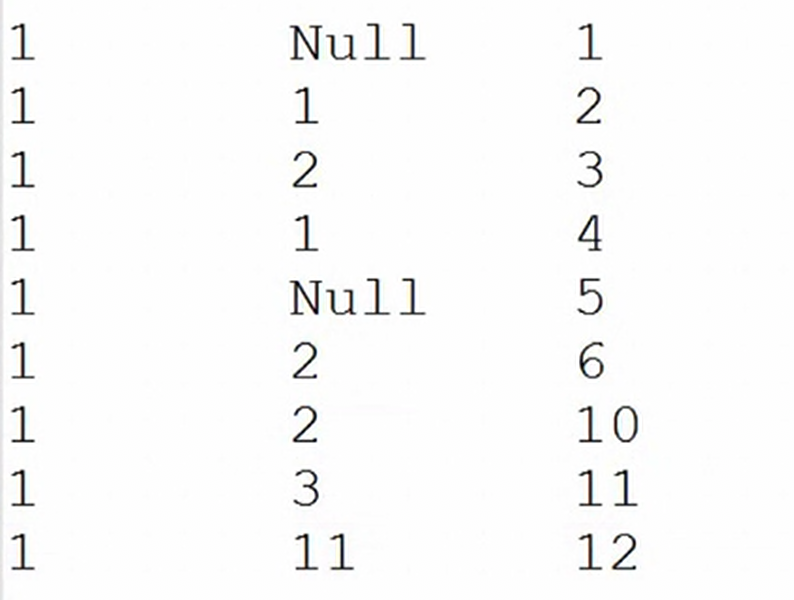
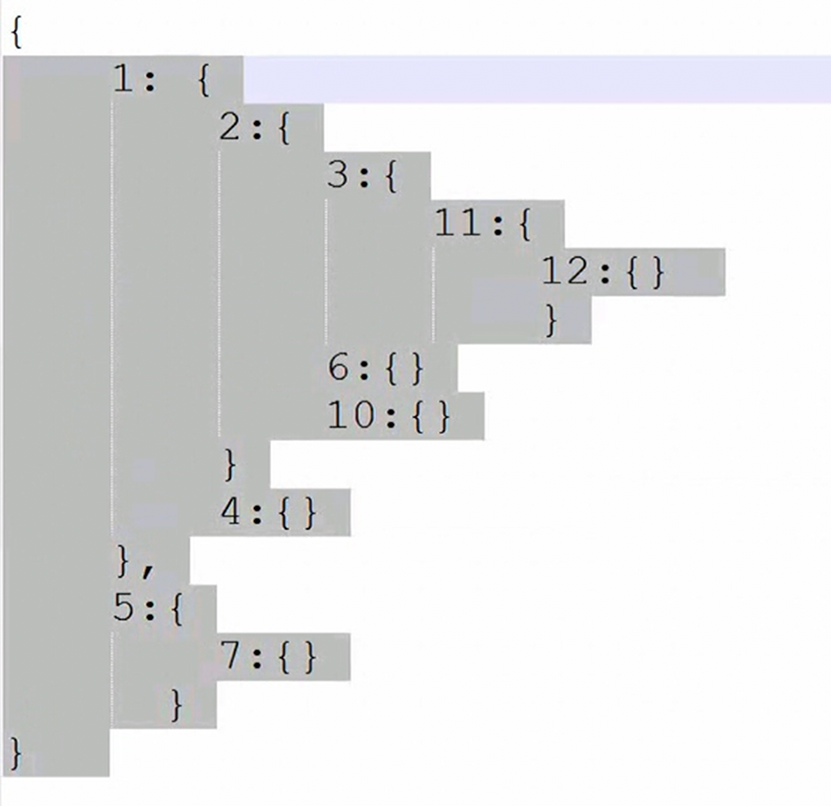
27分钟之前全部讲猜想和理论。以上是可能出现的数据情况。
本章开始前,按照以下数据格式来创建评论。

接下来我们来写一下代码
首先要创建一个专门处理这个评论父子关系的函数comment_handler.build_tree。
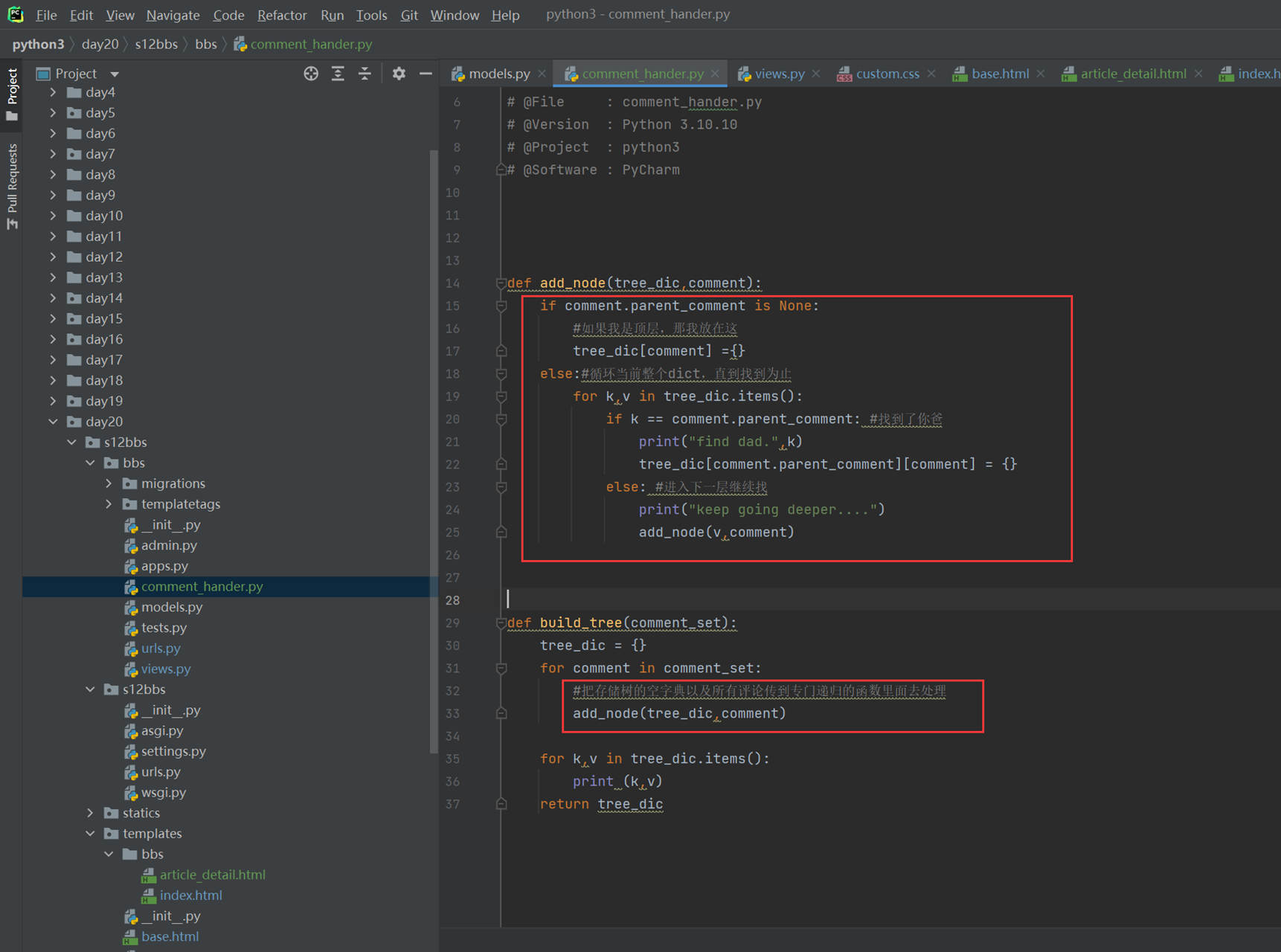
查看一下后端调试界面打印出来的结果
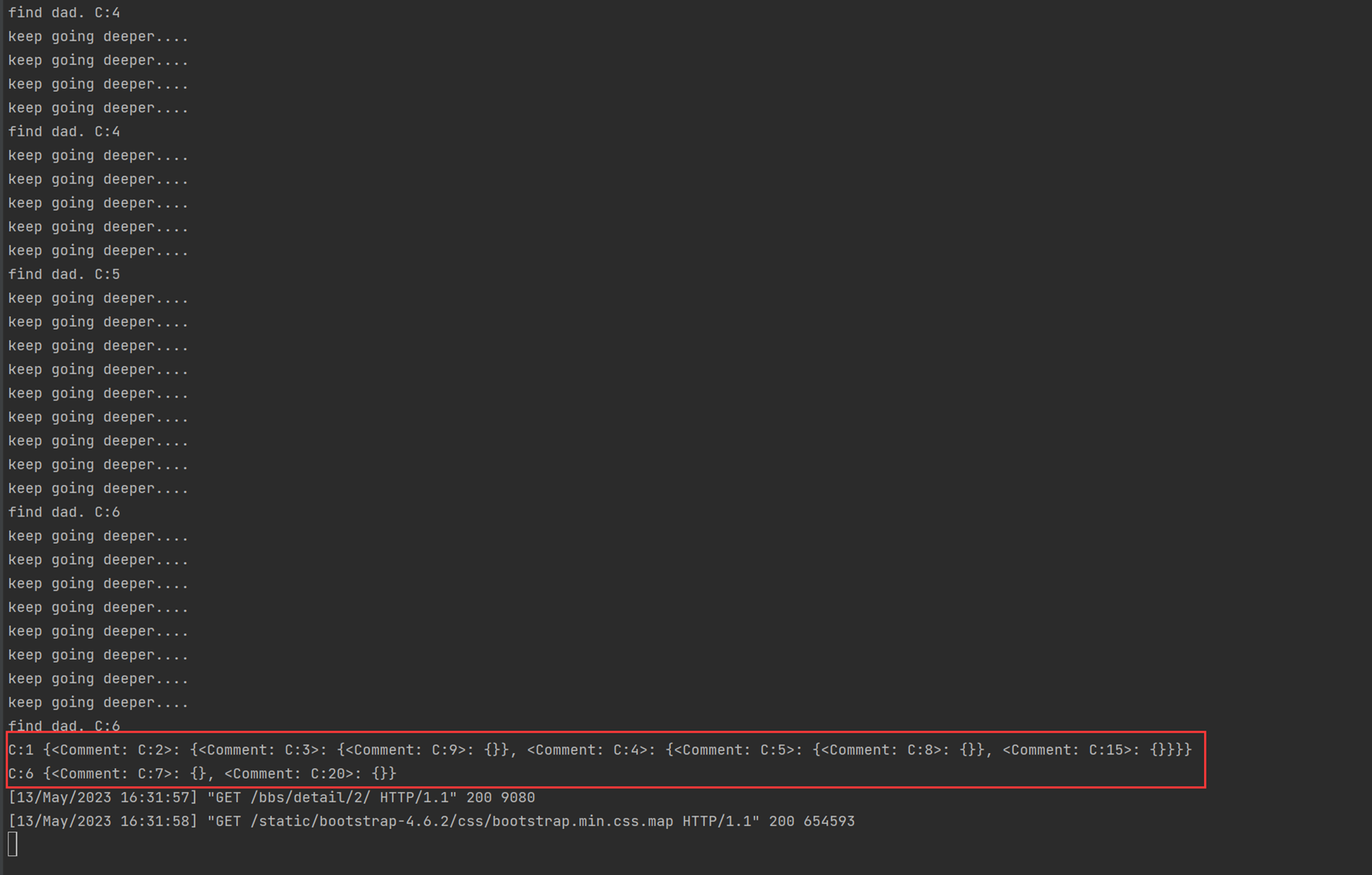
本章讲解了1个小时,结果就这么点代码结束,在11期的时候做了详细笔记,结果复习的时候啥都忘了,根本看不懂文字描述,所以说,如果需要复习,最好的方式看视频吧,相信看视频的时间绝对比看文档的时间短。
但是这个评论数还是可以总结成一句话,如果没有父亲,那么它就是顶级,否则,遍历每一层字典去找,直到找到为止。
20.17 多级评论展示到前台页面
前端没有递归方法,所以只能在后端把评论等一些东西拼好了通过后端返回,但是本节视频不讲,本章就是讲解前置条件。
本章就是把多级评论展示在前端的前置条件,比如url,函数等写好。
url
views
article_detail
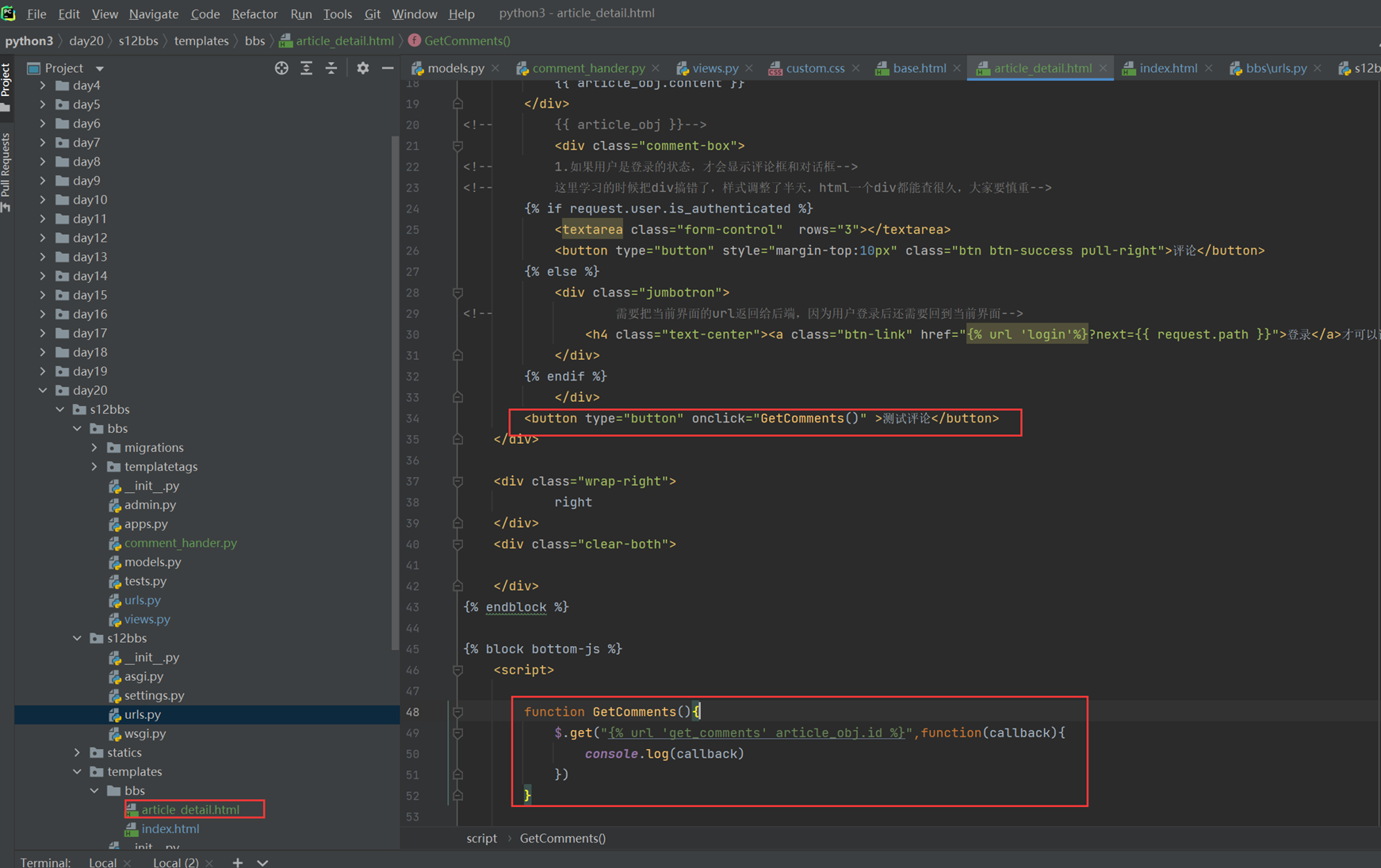
结果
返回的不是字符串,是一个对象,报错,本章结束,下一章无缝衔接。
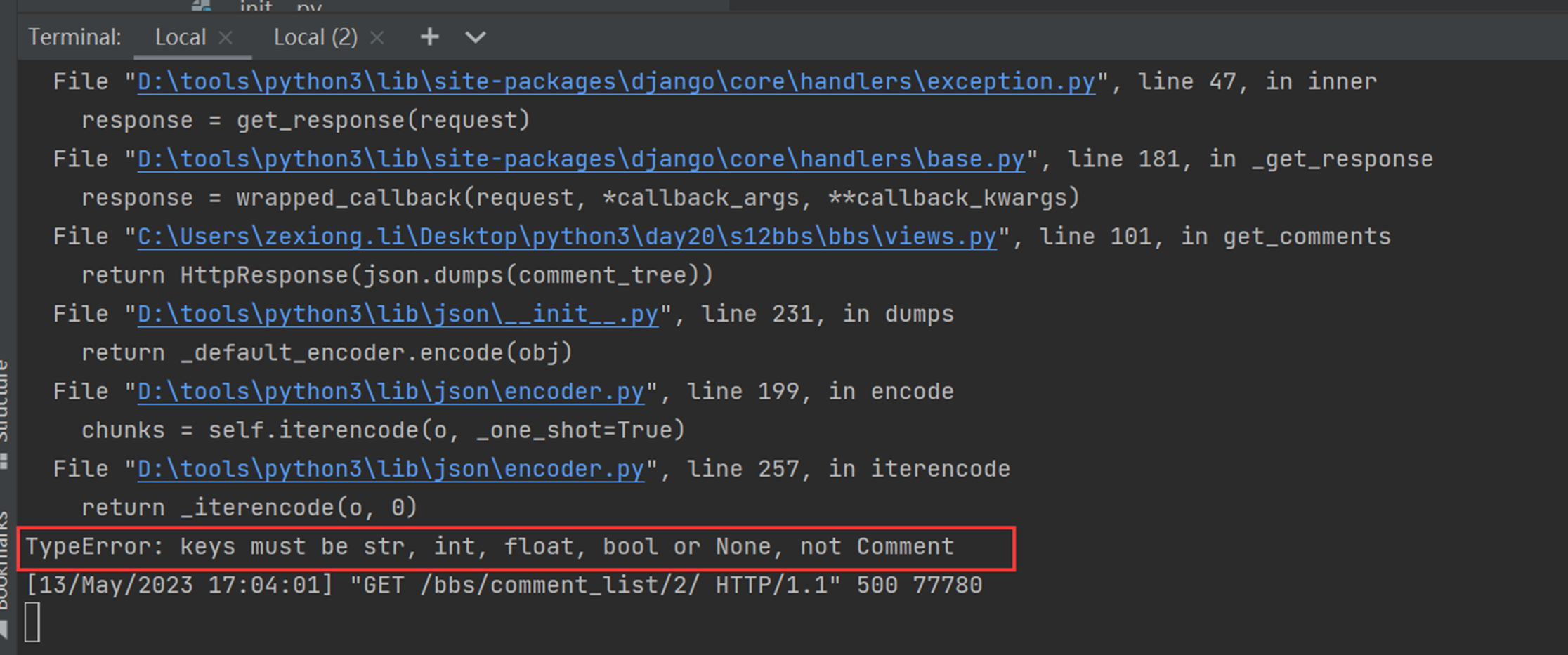
20.18 多级评论展示到前台页面2及作业要求
接下来就是后台拼接html,然后返回给前端,使用了2个函数,一个拼接父评论,然后递归拼接子评论
views
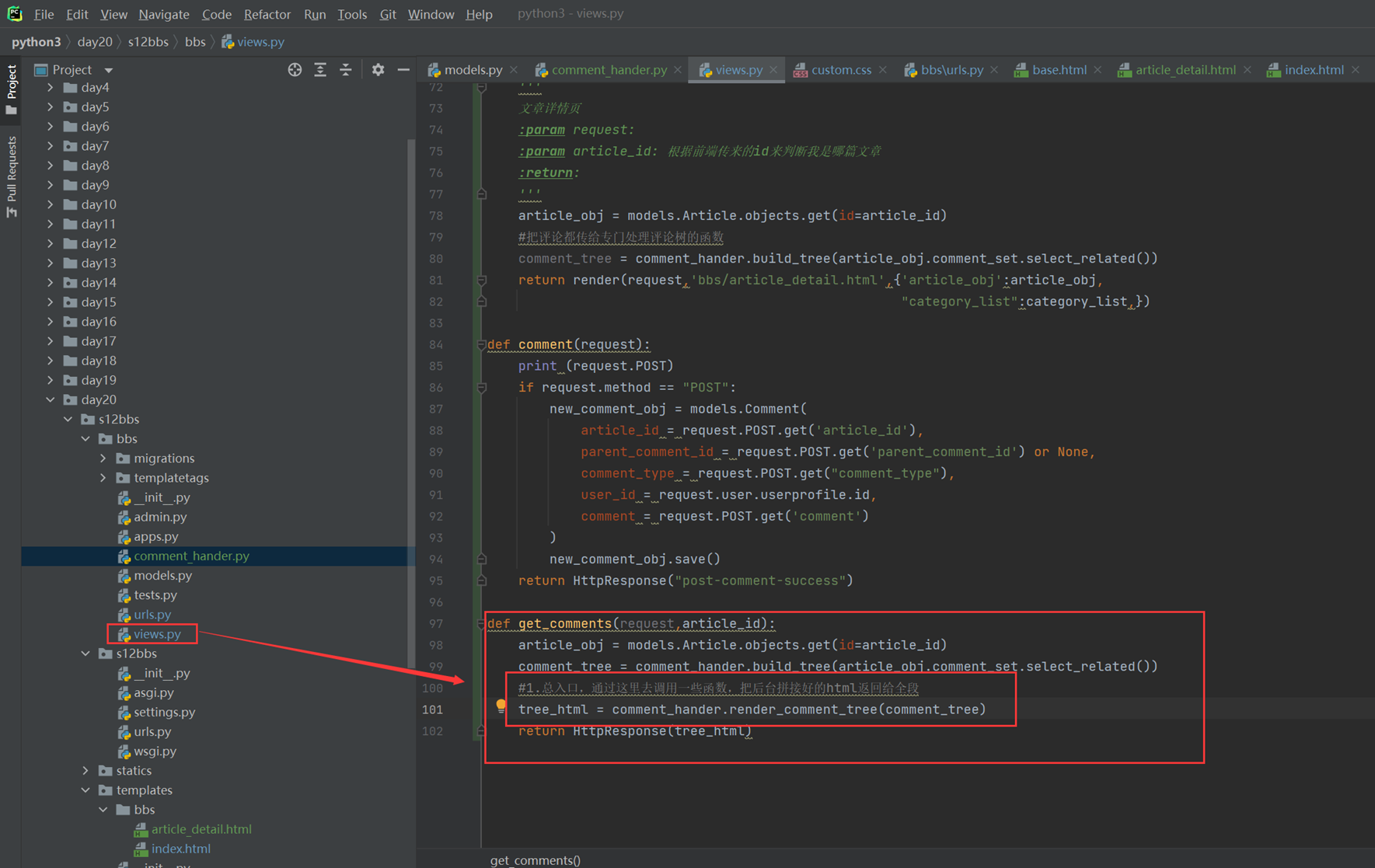
comment_hander
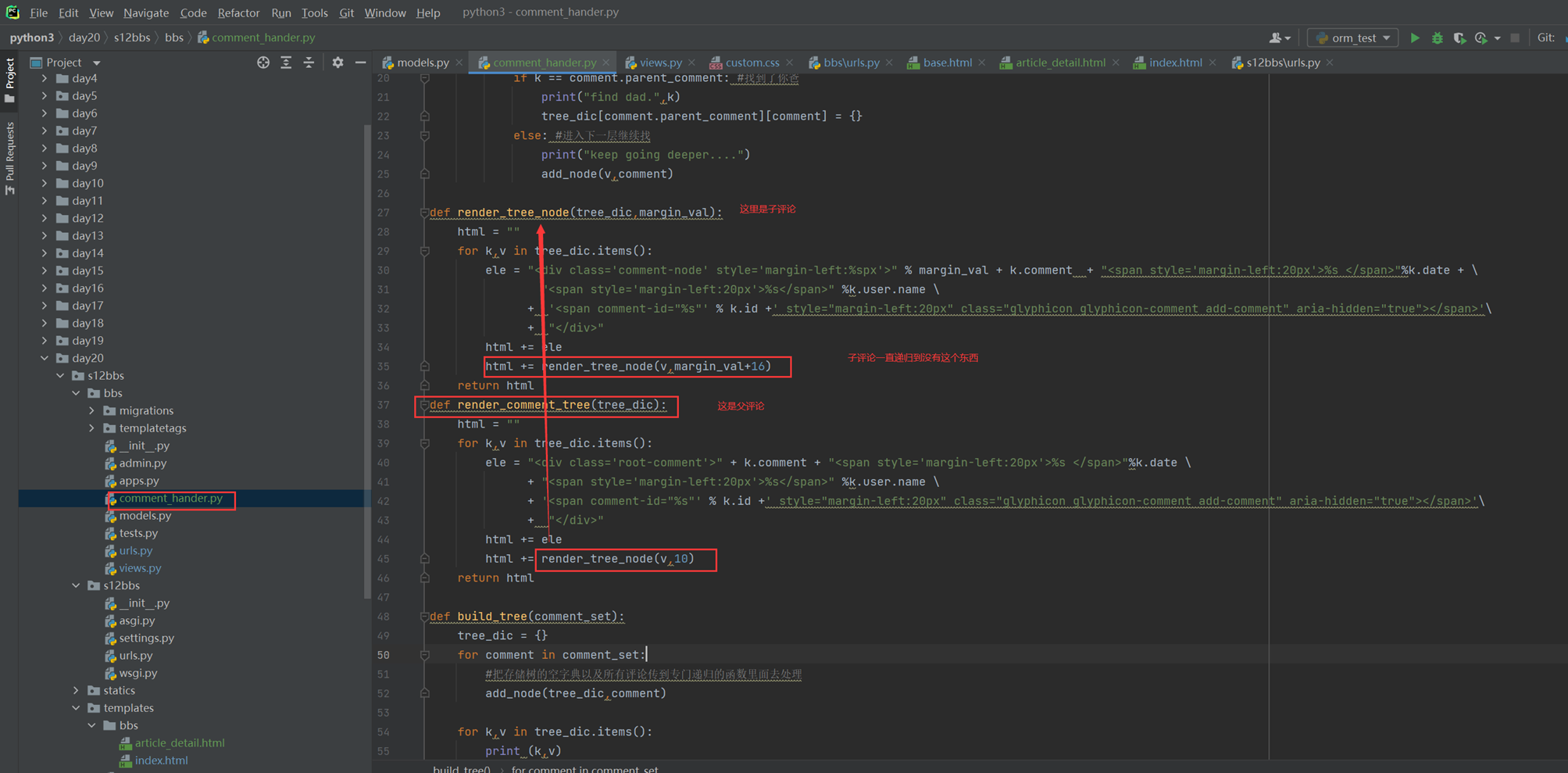
article_detail
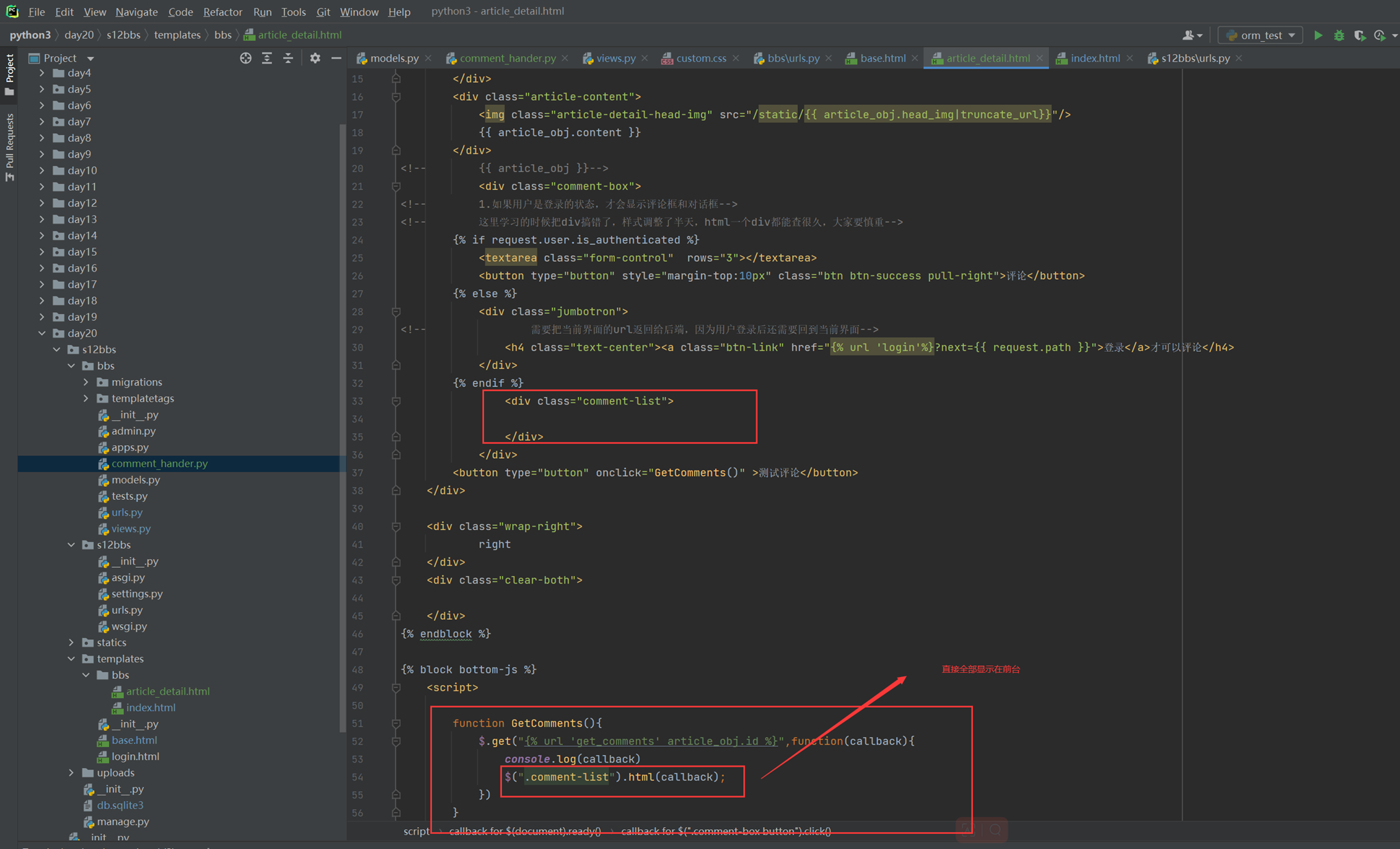
custome.css
查看网页结果

当天课程完成,最后几章课程怎么说呢?只能说个大概思路,像11期写的那么详细的解释,时间久了,还是看不懂,所以12期的项目都是标注重点,每节课展示每节课的代码,做了详细拆分。至于代码的详细解释,只能自己一步一步的运行再去看。
21.L21
21.1 BBS自动加载评论
本章就是演示一下2个内容,还有一个没讲完成。
1.登录用户自动加载bbs评论。
2.点击评论,可以直接在当前网页进行评论。(未完成,下一节完善)
自动加载评论,没什么好说的,在页面加载完成后直接调用加载评论的函数就行。
主要是第二个,点击当前任意子评论或者父评论,可以直接在当前页面评论。
这个就还是得用后端先把模版写好,传到前端。
comment_hander.py
先看看前端样式(ps,昨天课程复制代码的时候其实这部分已经搞过来了,这里还是象征性展示一下)

article_detail.html
这个前端就是简单的看看能不能获取评论的id。
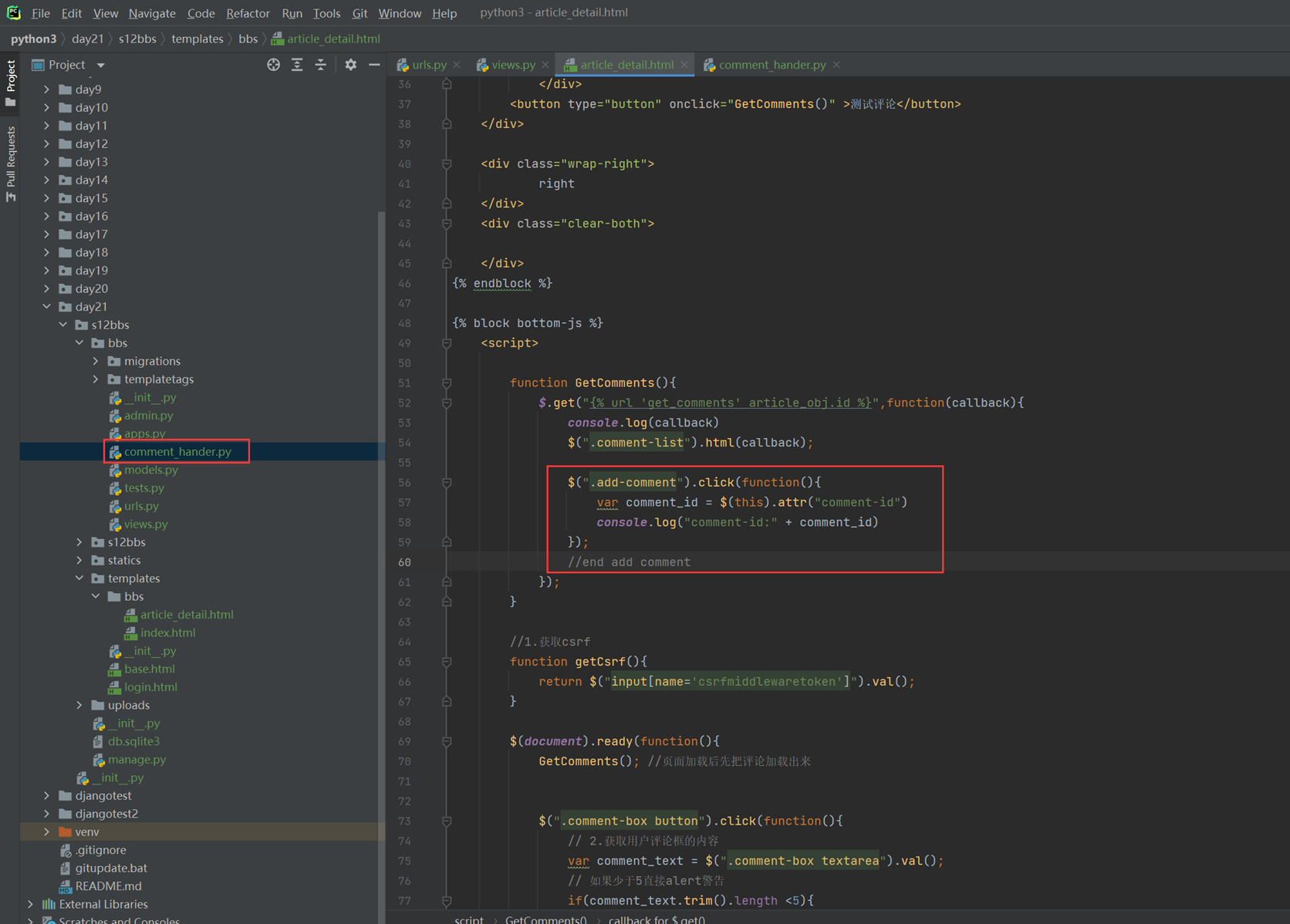
就点击评论图标获取一个评论ID,本章就没了。
21.2 BBS动态添加评论
本章实现的就是评论之后,评论框重新出现在最上面。
1.如果用户是登录的状态,才会显示评论框和对话框

2.克隆这个评论框,并且删除老的评论框,然后把这个clone的评论框加到点击评论的地方
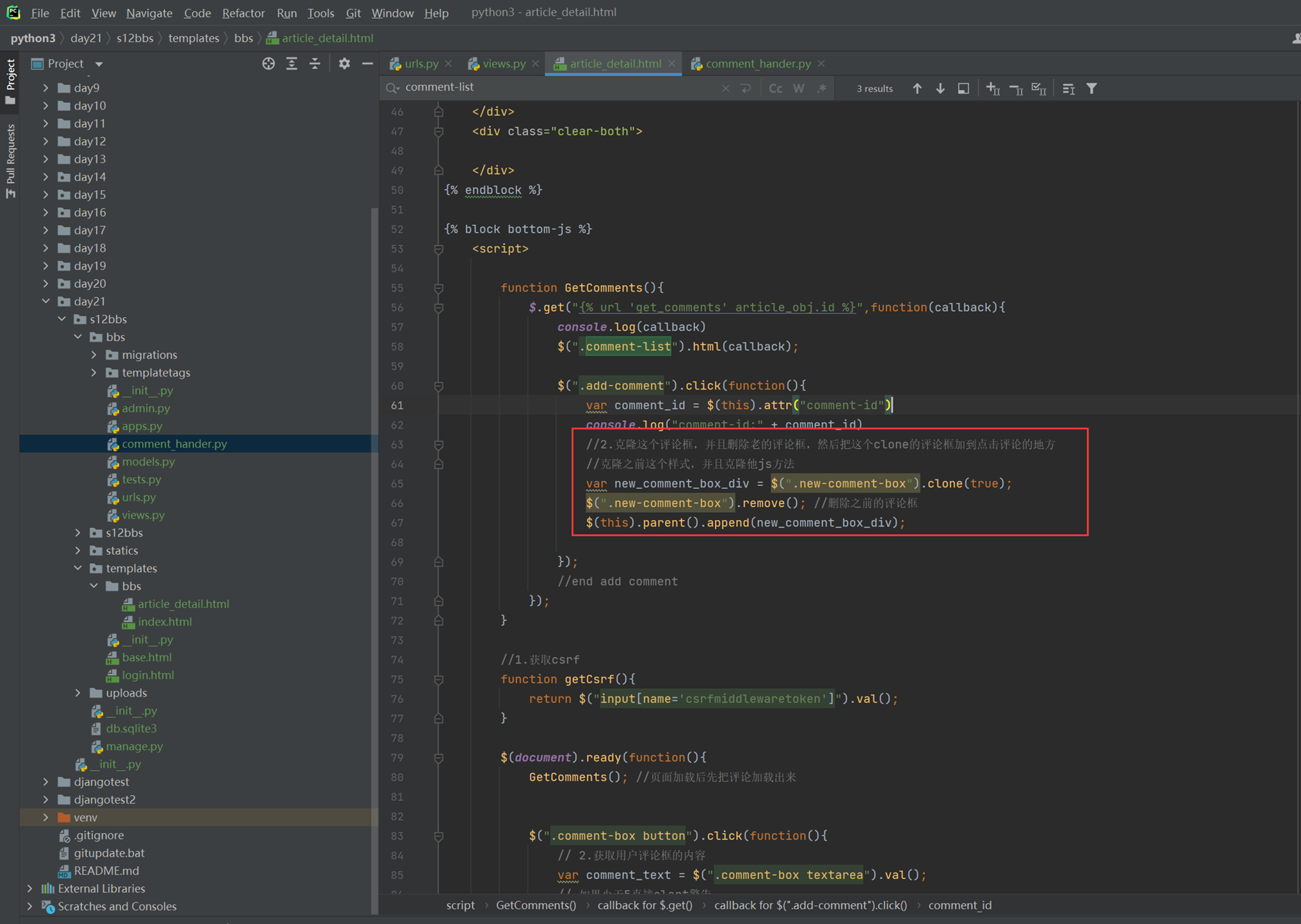
3.现在可以加父id了
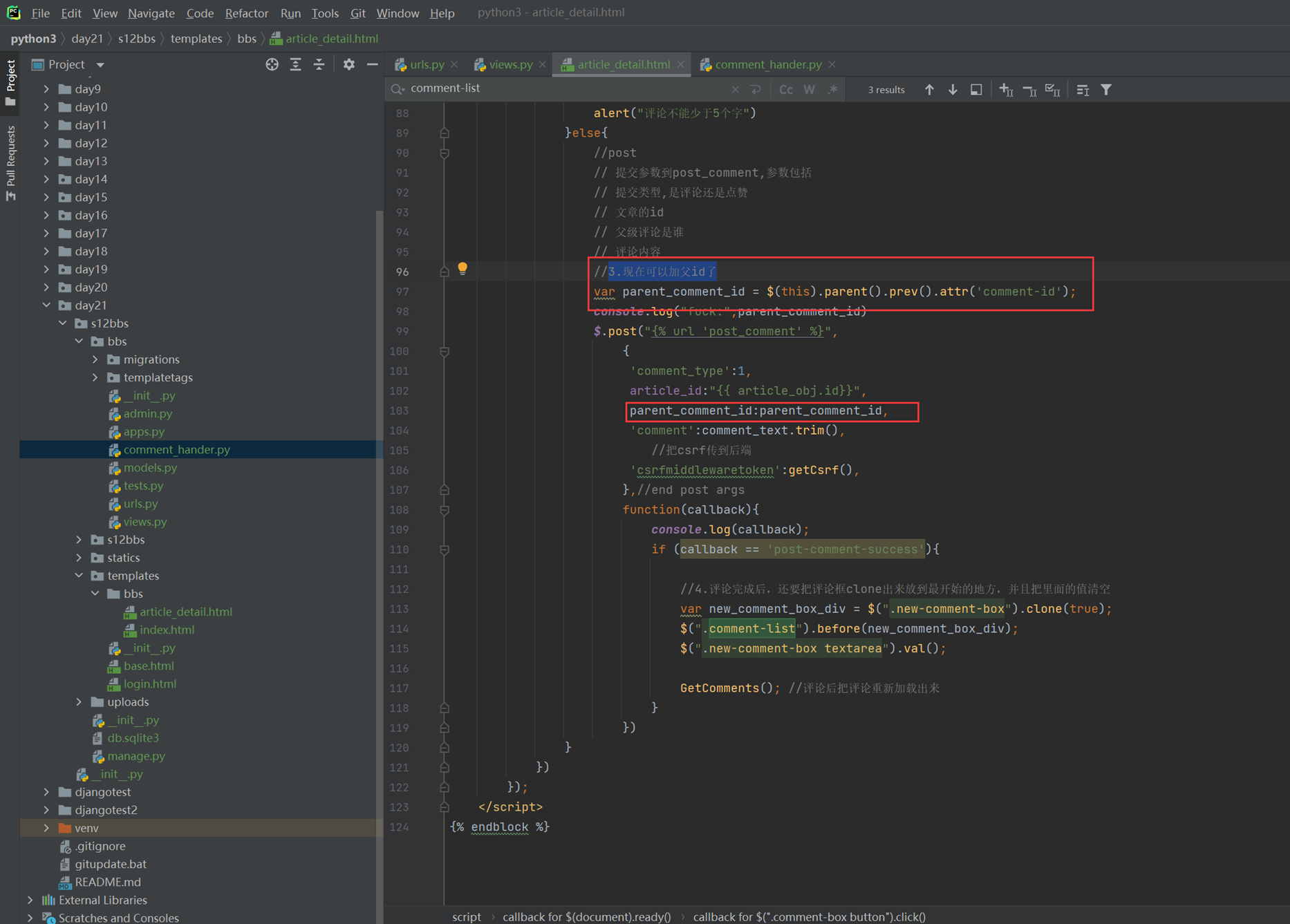
4.评论完成后,还要把评论框clone出来放到最开始的地方,并且把里面的值清空
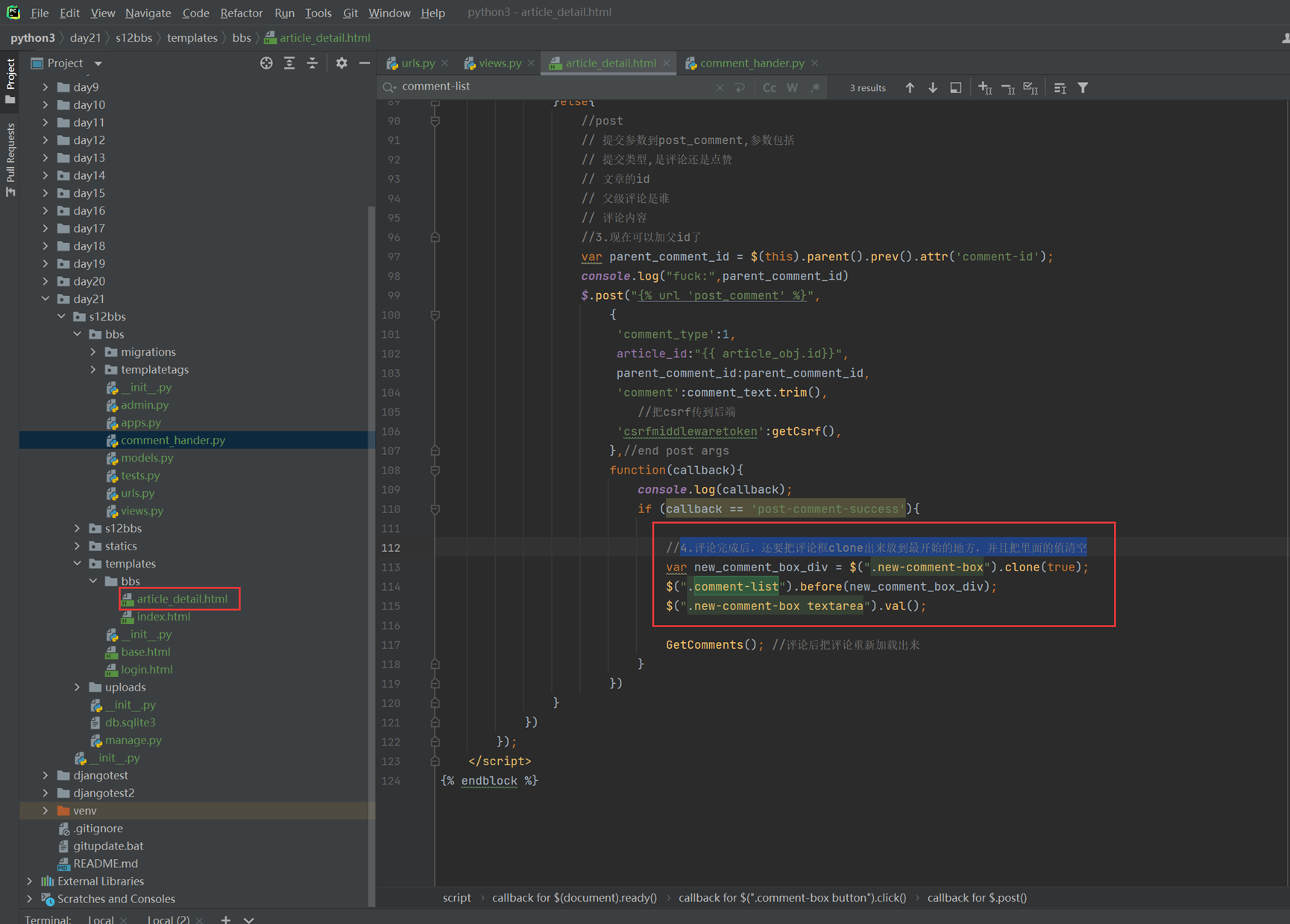
21.3 BBS创建新贴页面开发
本章就是一个新的发帖功能的需求,按照顺序看代码就行。
1.发帖
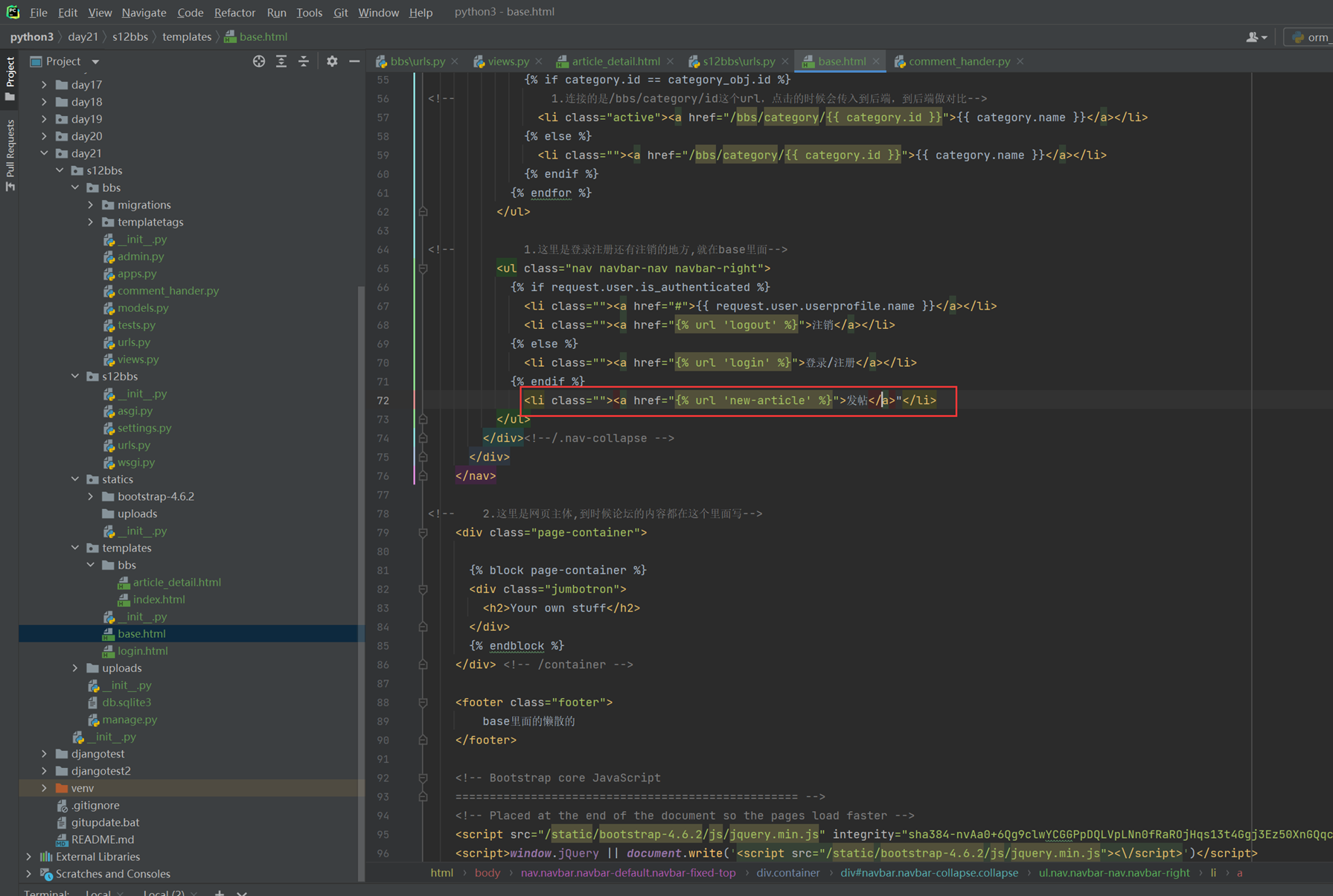
2.url
3.new_article.html
这里富文本编辑器,还是用视频里面的,用4的版本,当然有兴趣的去看看最新的官网
https://ckeditor.com/docs/ckeditor5/latest/index.html
这里还是用4
4.from表单
5.views
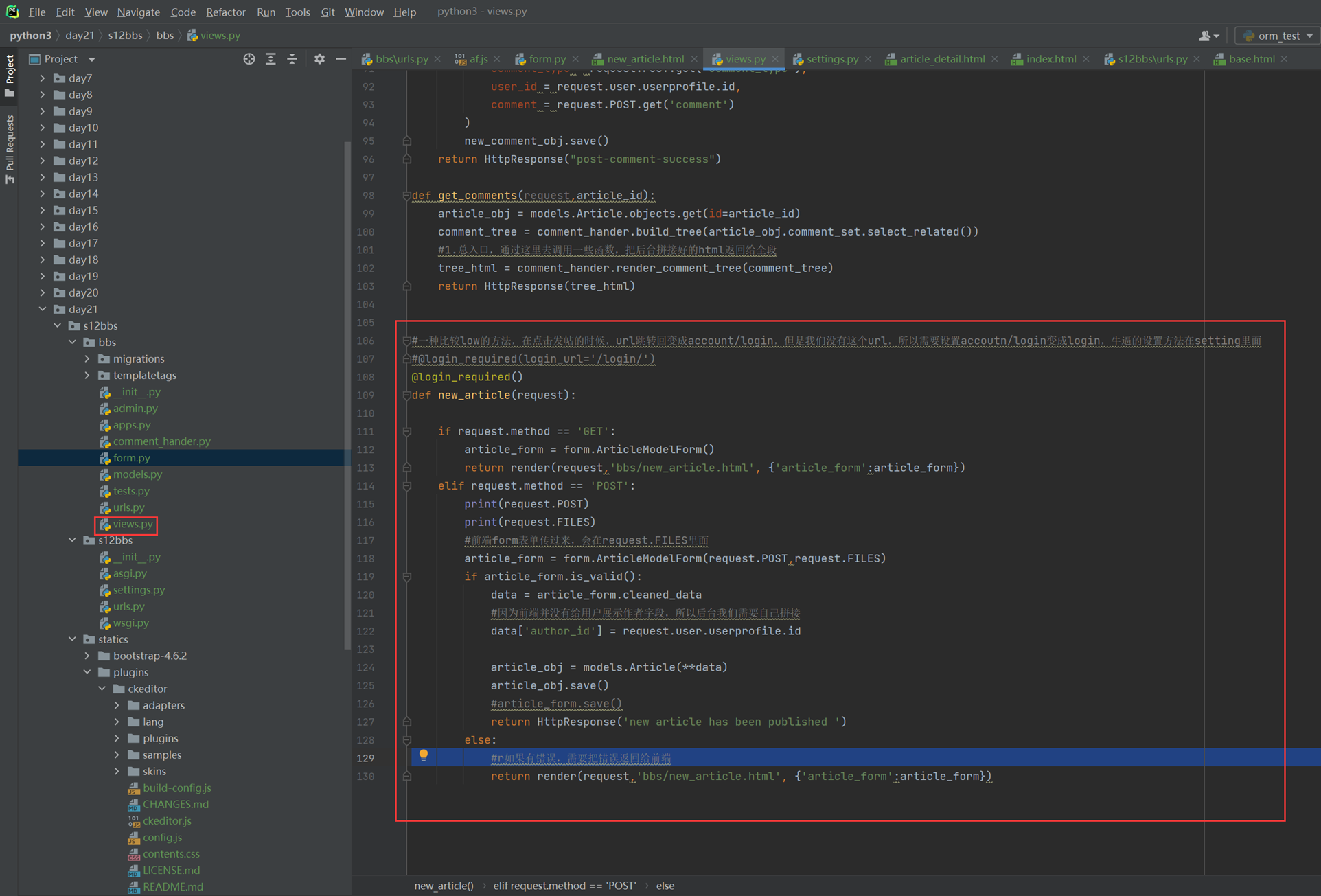
关于上面的@login_required还是解释一下。
点击发帖的时候会莫名其妙出现一个accounts的url,有两种设置方式,
第一种
![]()
第二种(推荐,全局)
不过,新版本的django没有碰到这个问题,课堂老师也没有解释原因。
这里还是要做个记录
本节到这里就可以正常发发贴了,发帖就不演示了
但是还是补充2个小技巧
第一个,safe,如果发帖前端是html或者python这样的代码,为了以文字显示,需要加上这个玩意
第二个,博客列表最新的在最上面,reserver反转功能
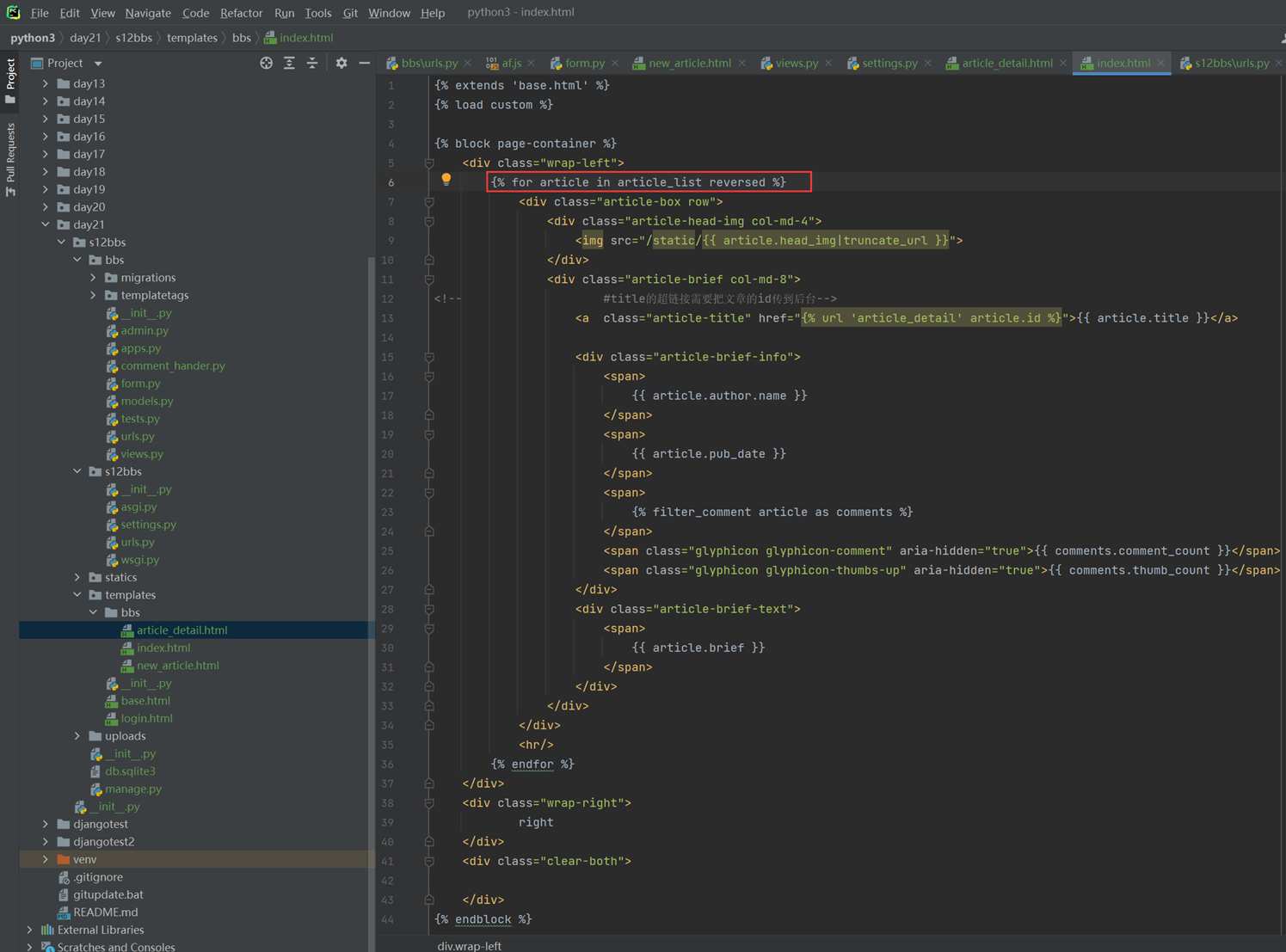
21.4 BBS实现文件上传
就是传文件,不解释了。非常垃圾的,进度条啥都没有
1.url
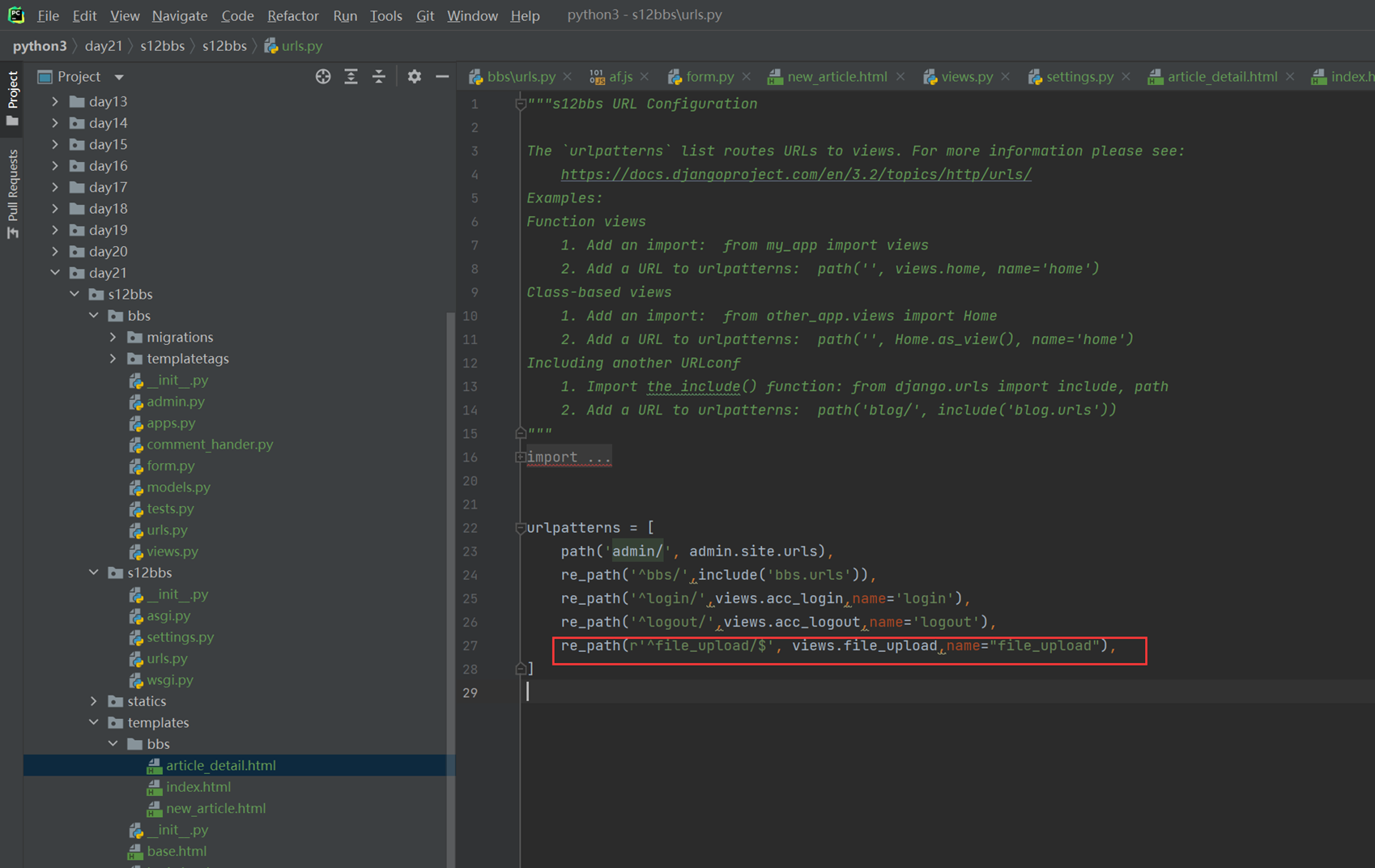
2.views
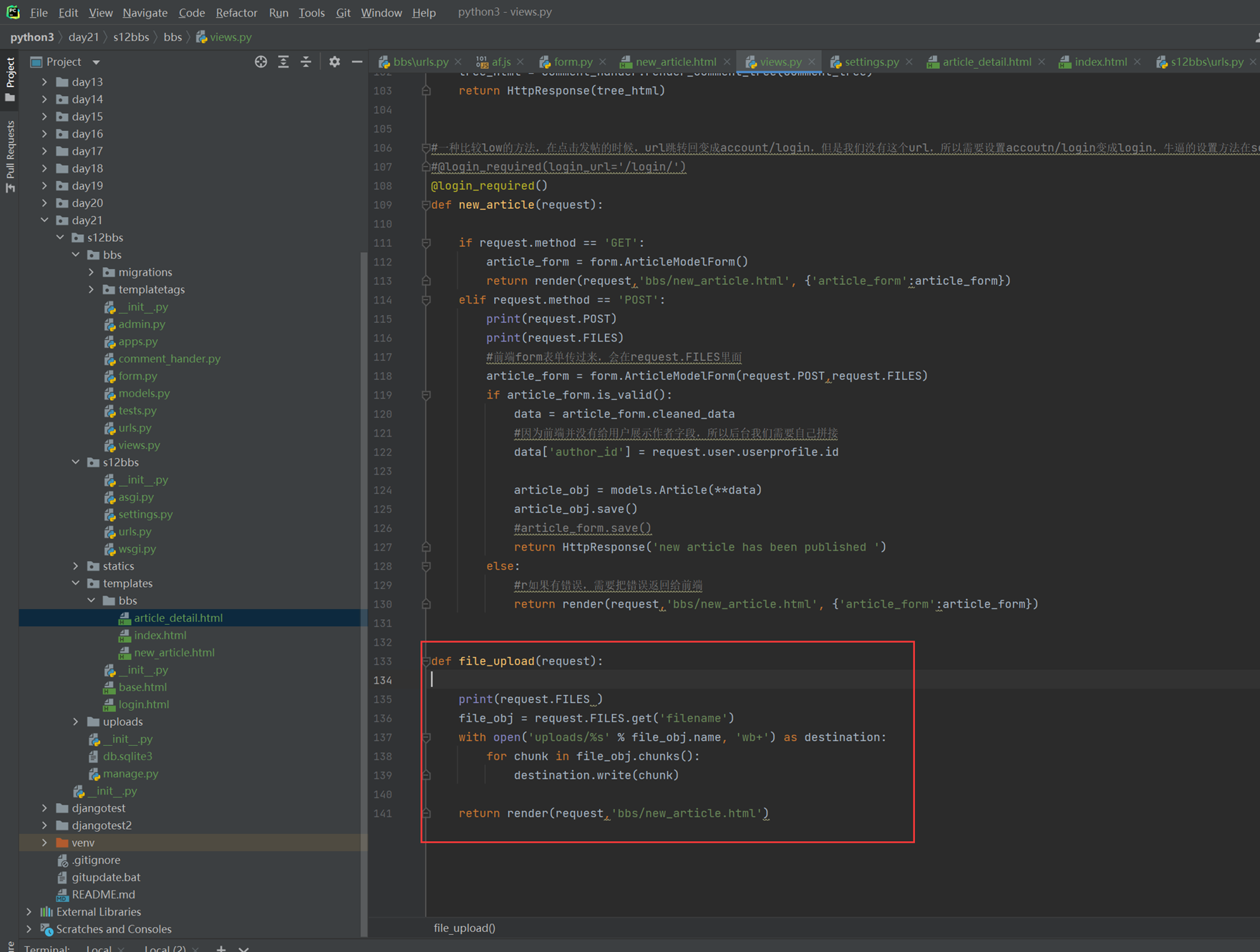
3.new_article.html
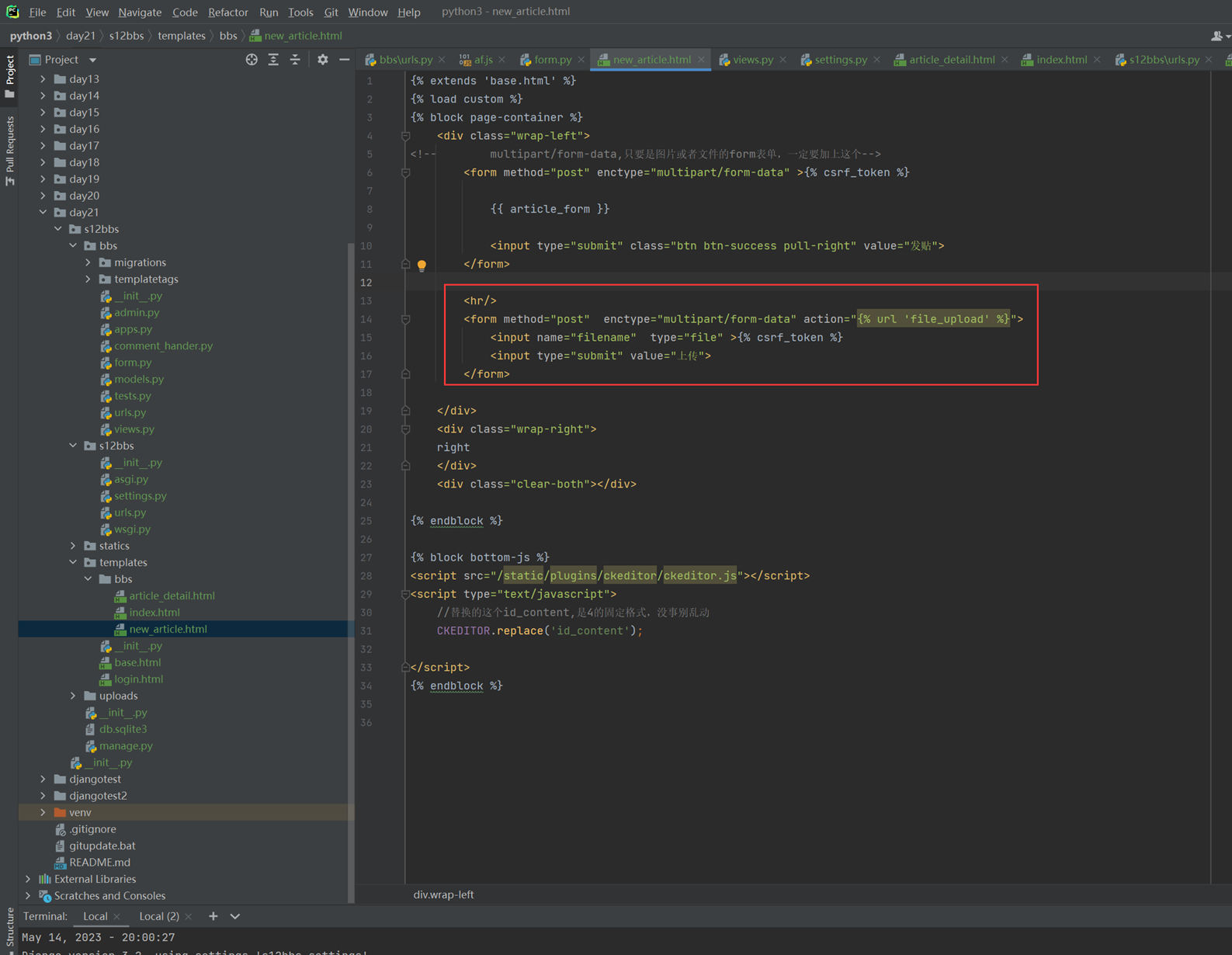
就这么几行代码,就不演示了
21.5 BBS实现页面新消息自动提醒
如果有新文章,那么在主页提示,并且点击这个提示可以显示出新文章,就这个需求,直接上代码。
1.url
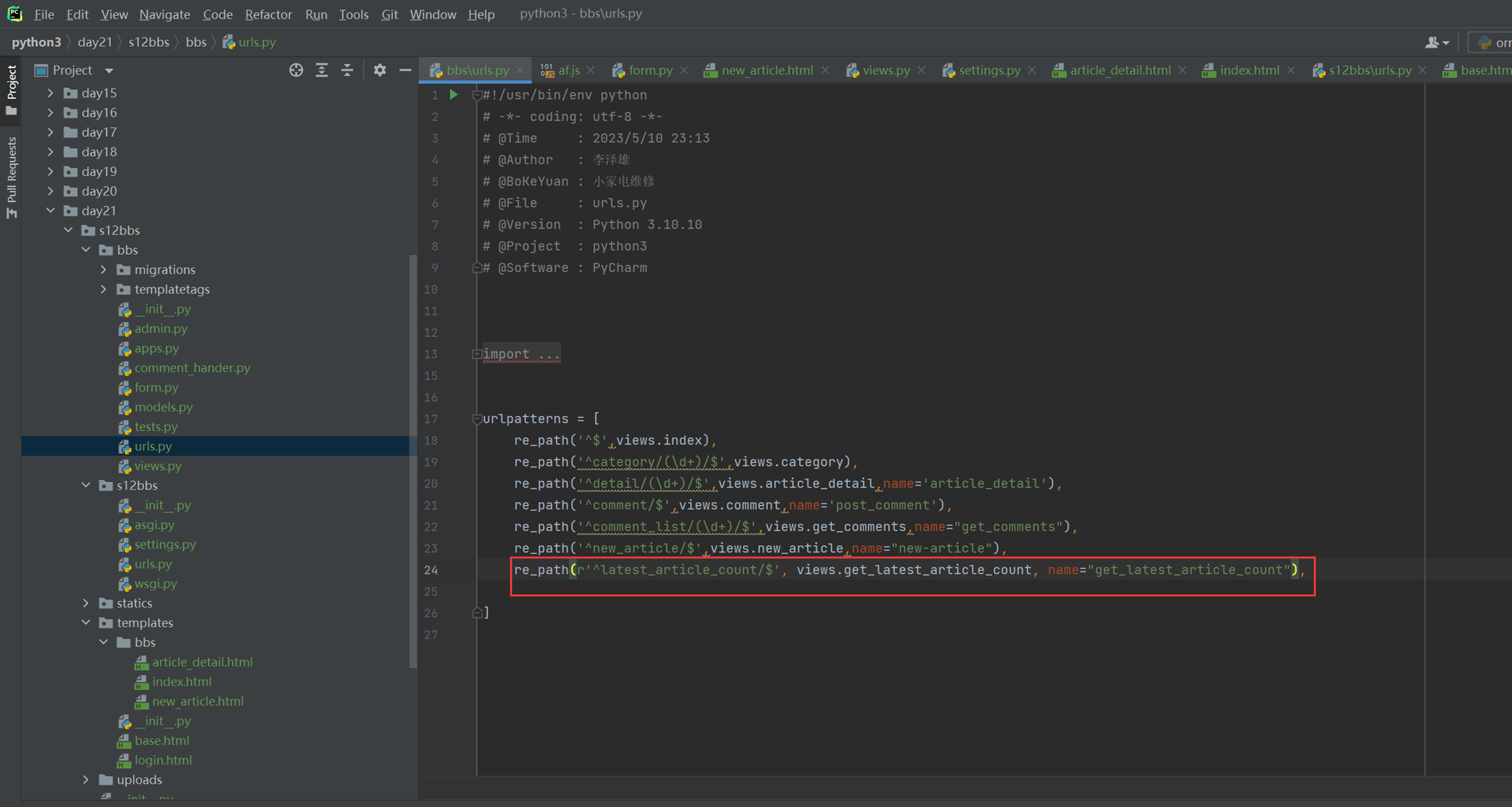
2.views
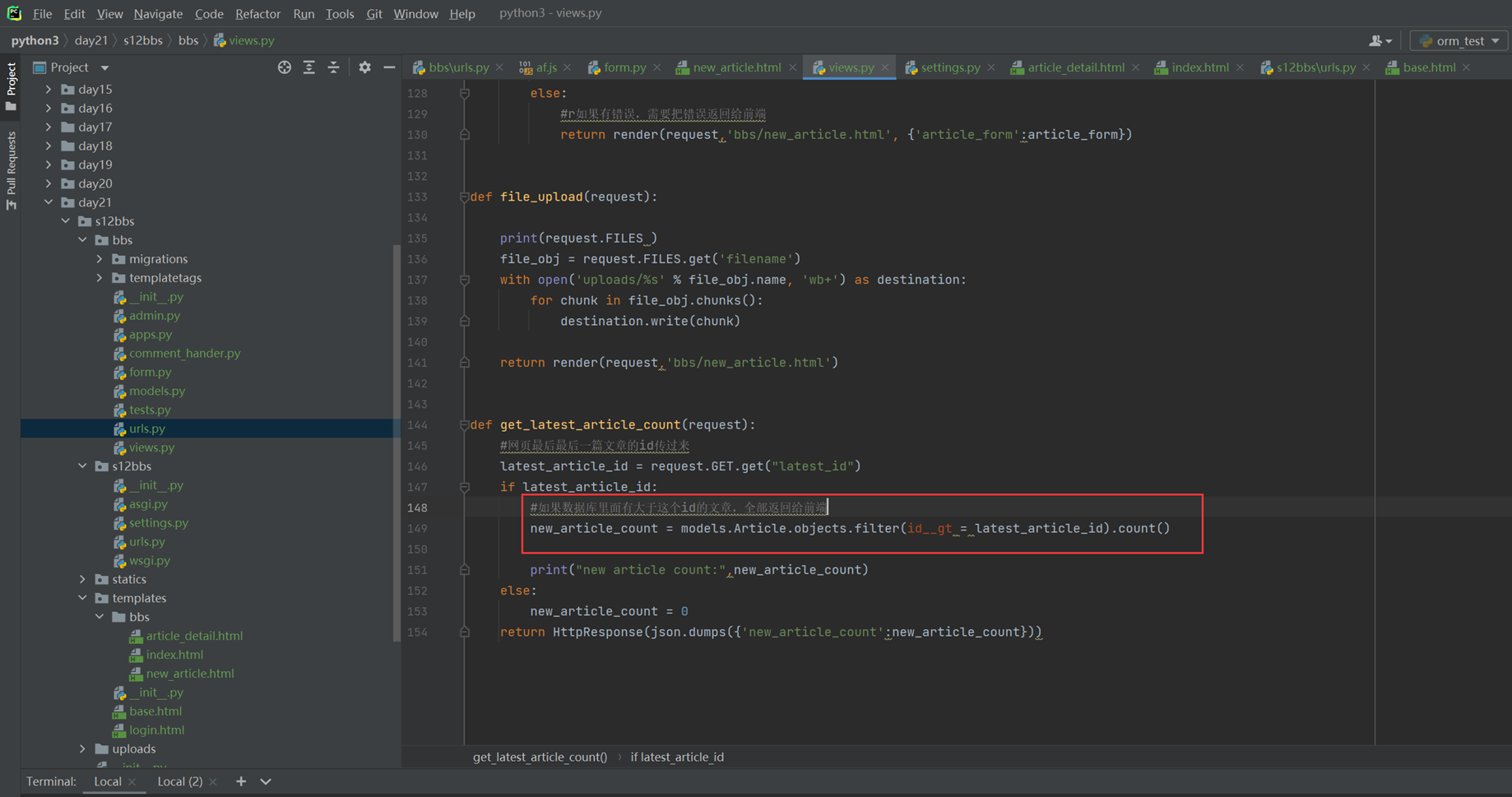
3.index.html
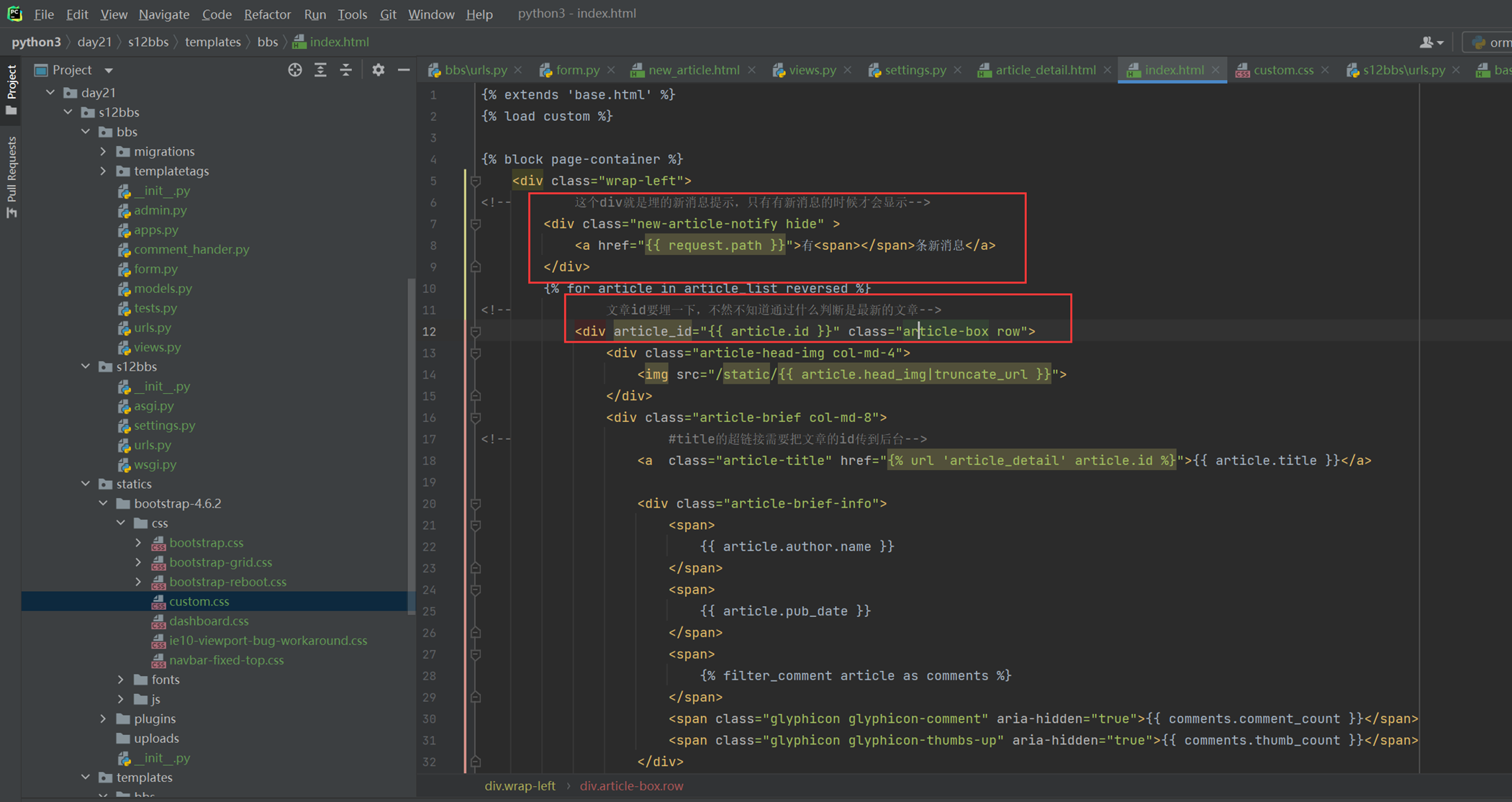
Index.html。还没完,接下来才是主旋律
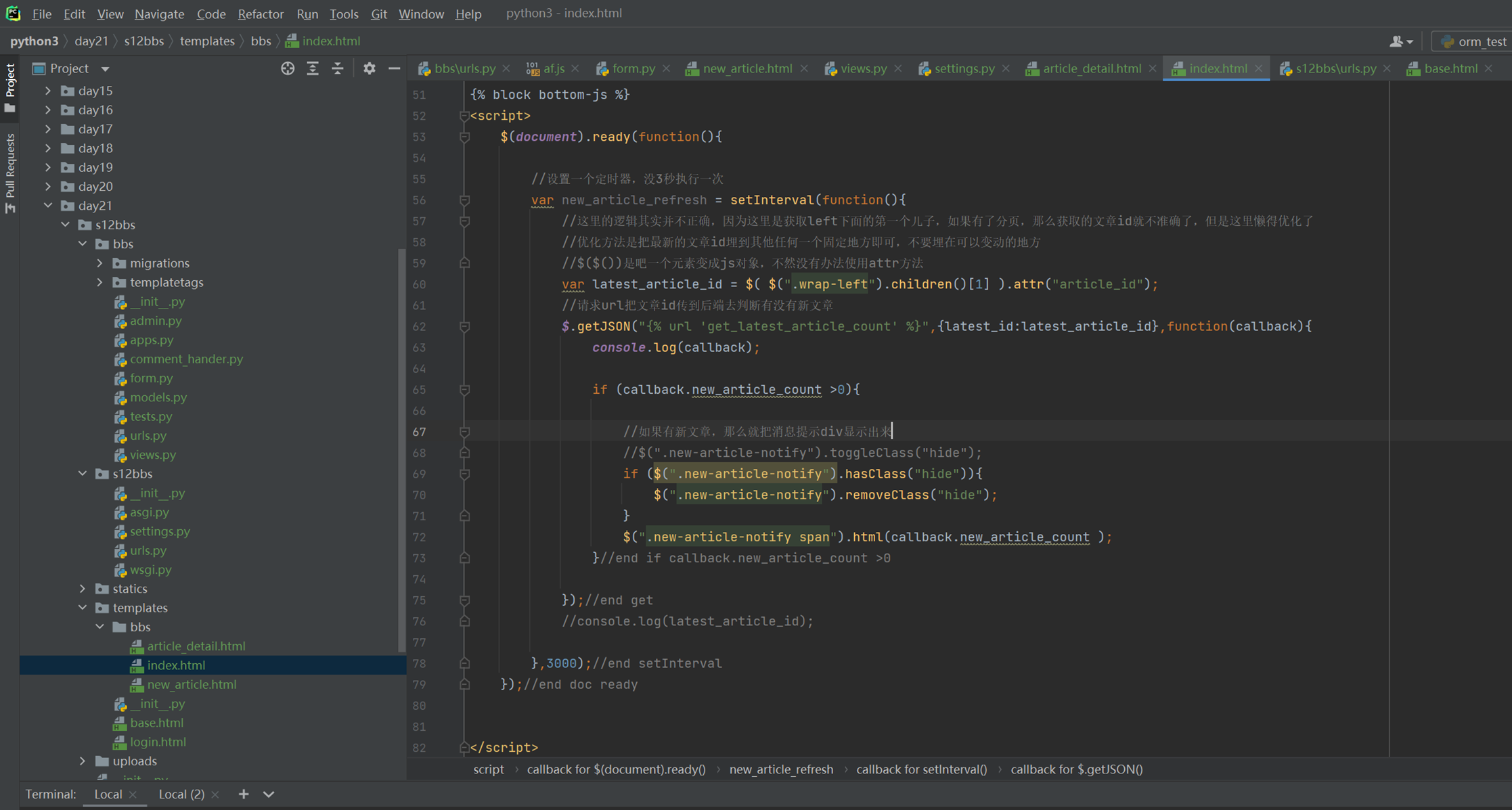
custom.css优化一下新消息提示的div,
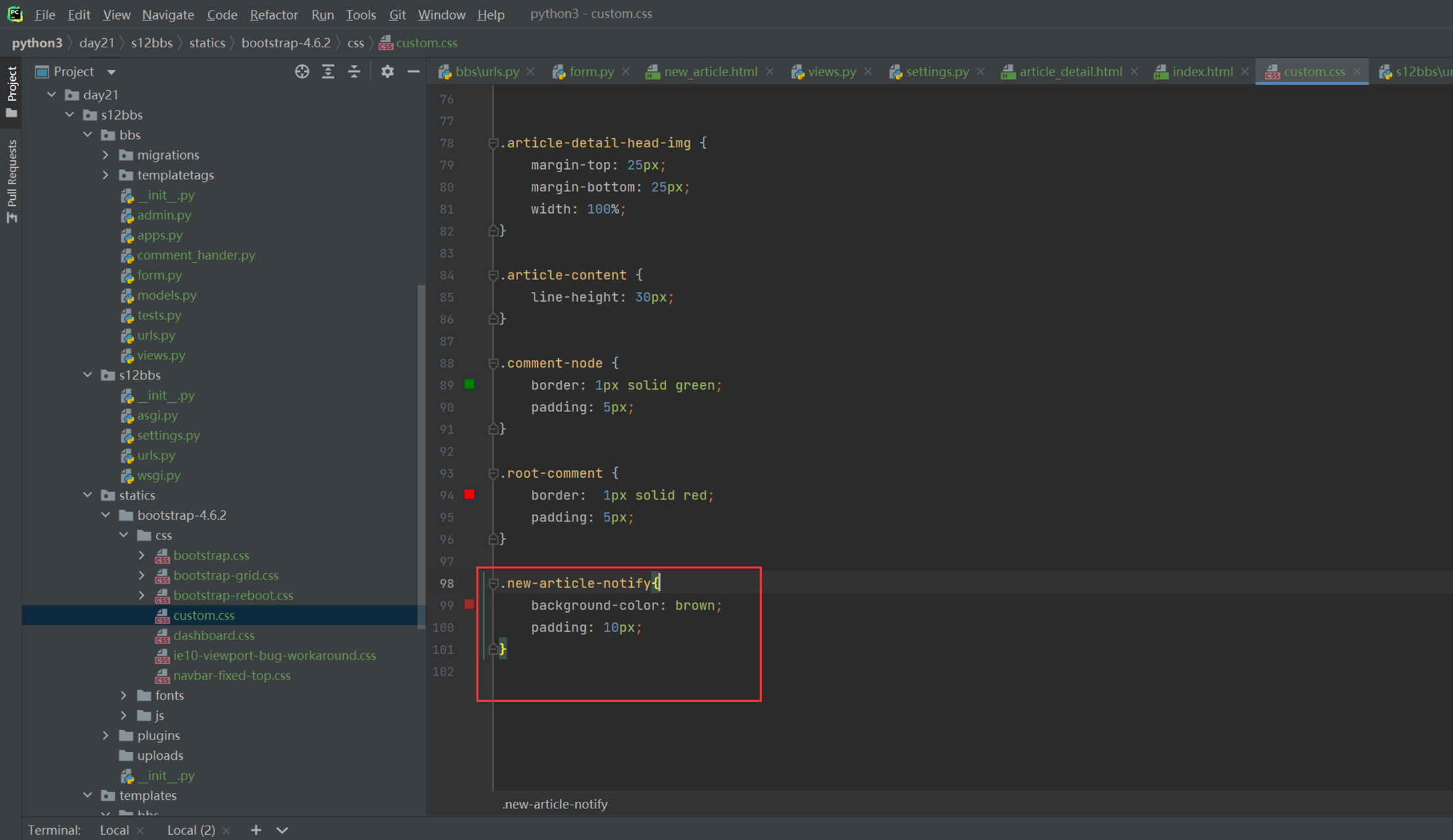
查看网页结果
21.6 WEB聊天室几种实现方式介绍

就是讲什么实现这个聊天,哪种方式比较好。具体见博客: Python之路,Day18 - 开发一个WEB聊天来撩妹吧
21.7 WEB聊天室表结构设计
首先单独创建一个项目webchat

然后注册app
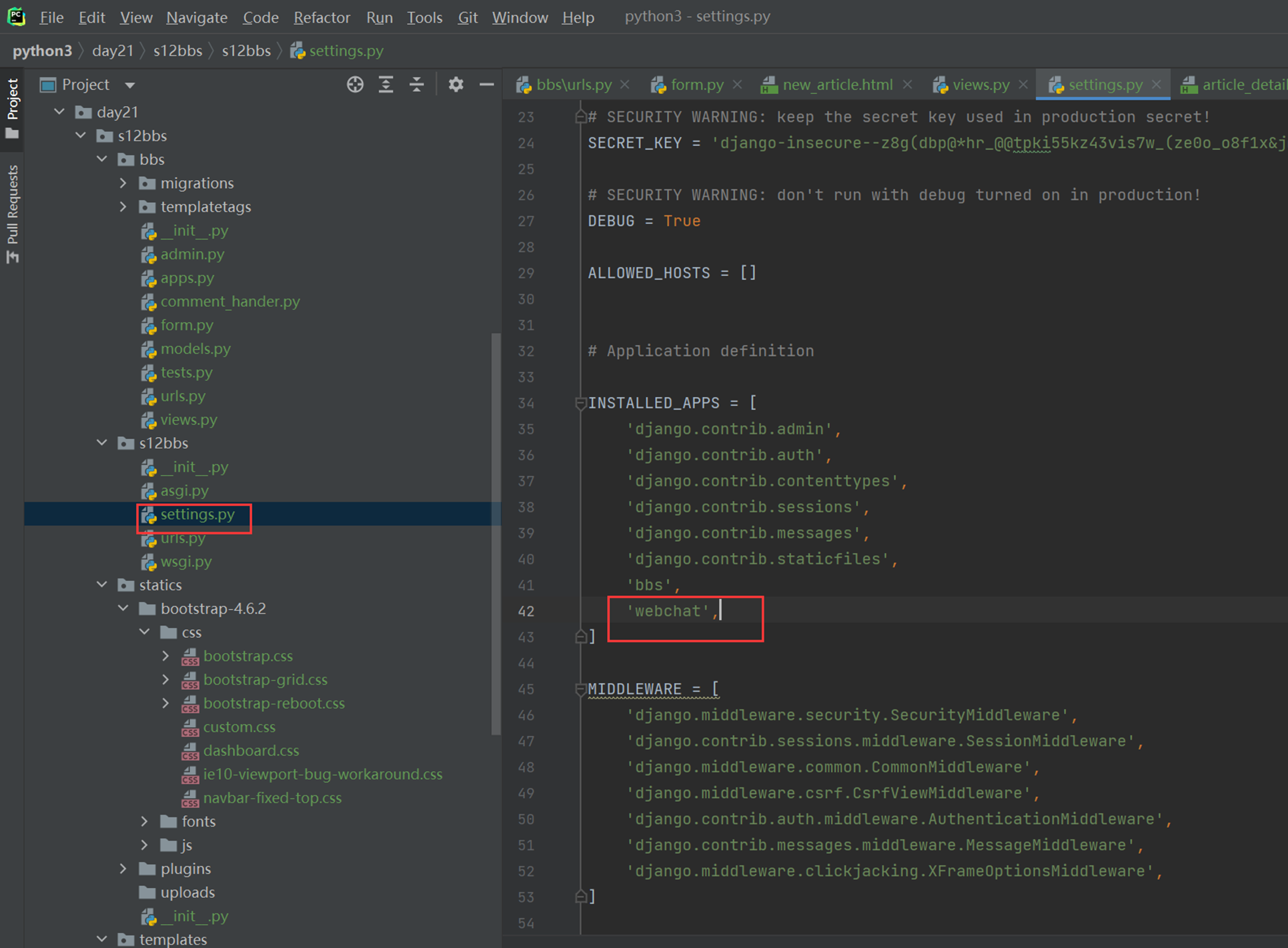
表这里由于还是使用django的,所以在bbs的userprofile加个字段就行
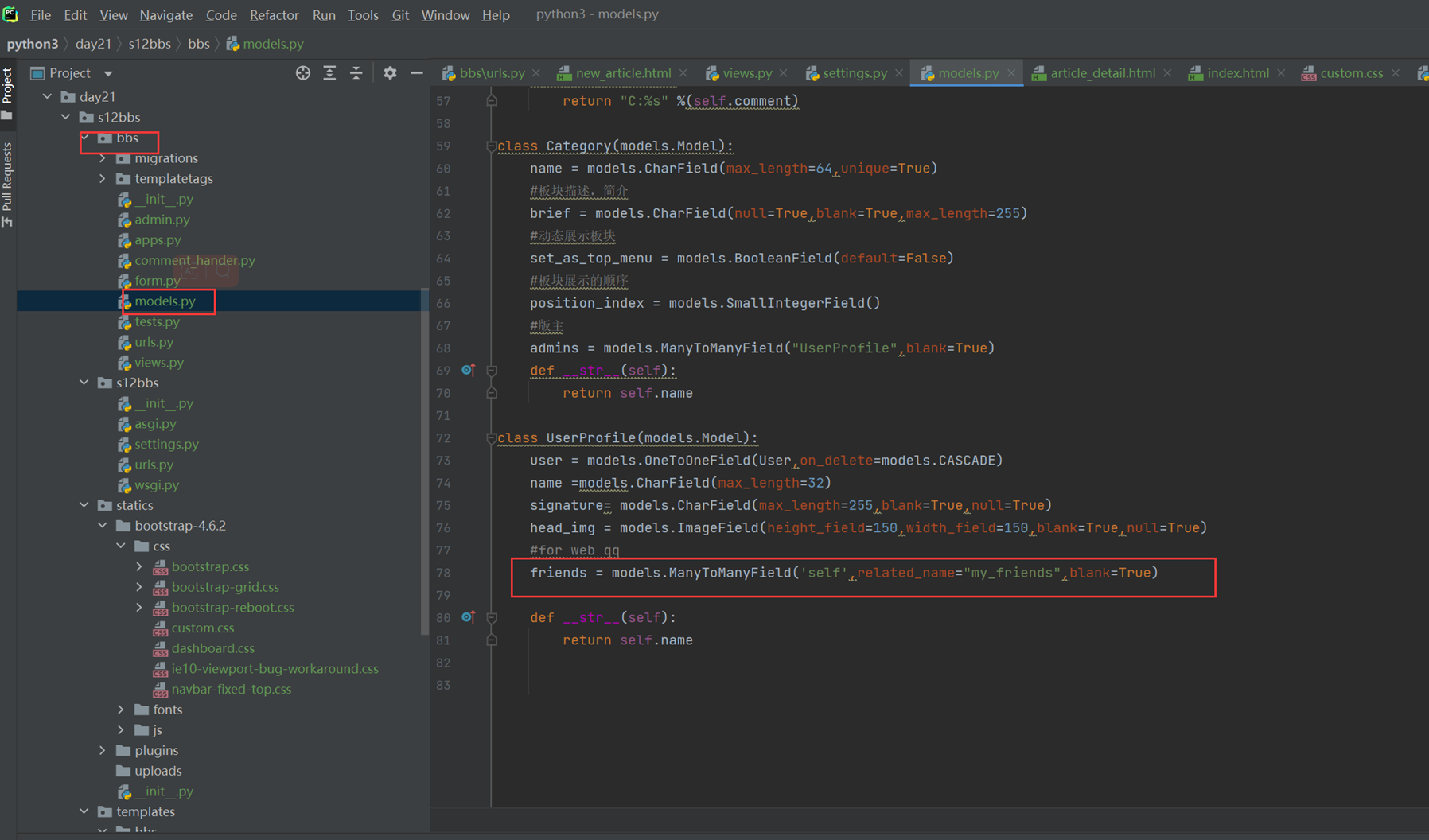
然后自己的model里面需要有一个自己的表
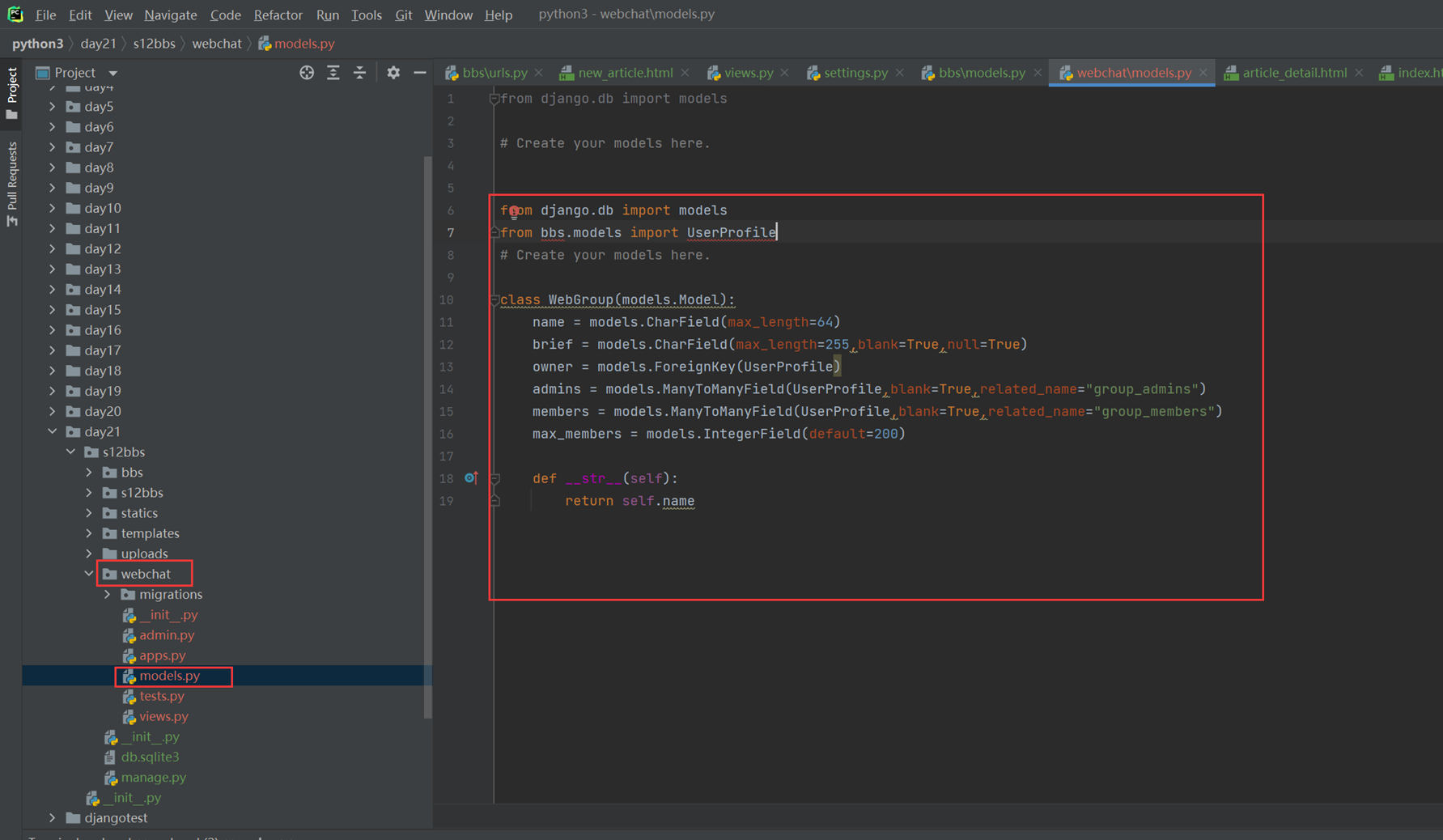
然后生成数据表结构
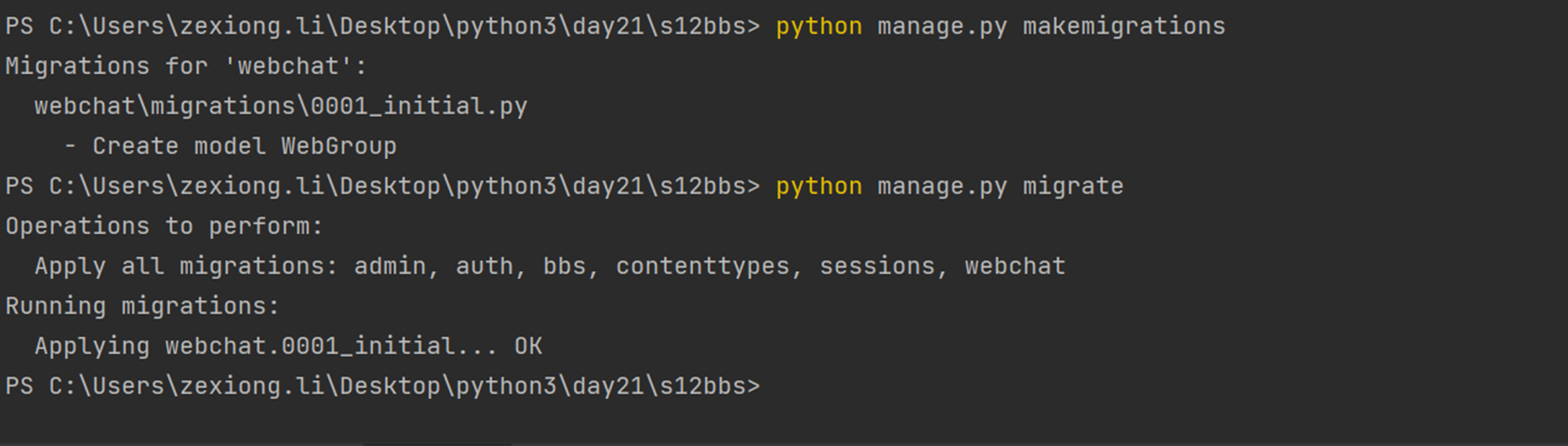
然后再admin可以管理
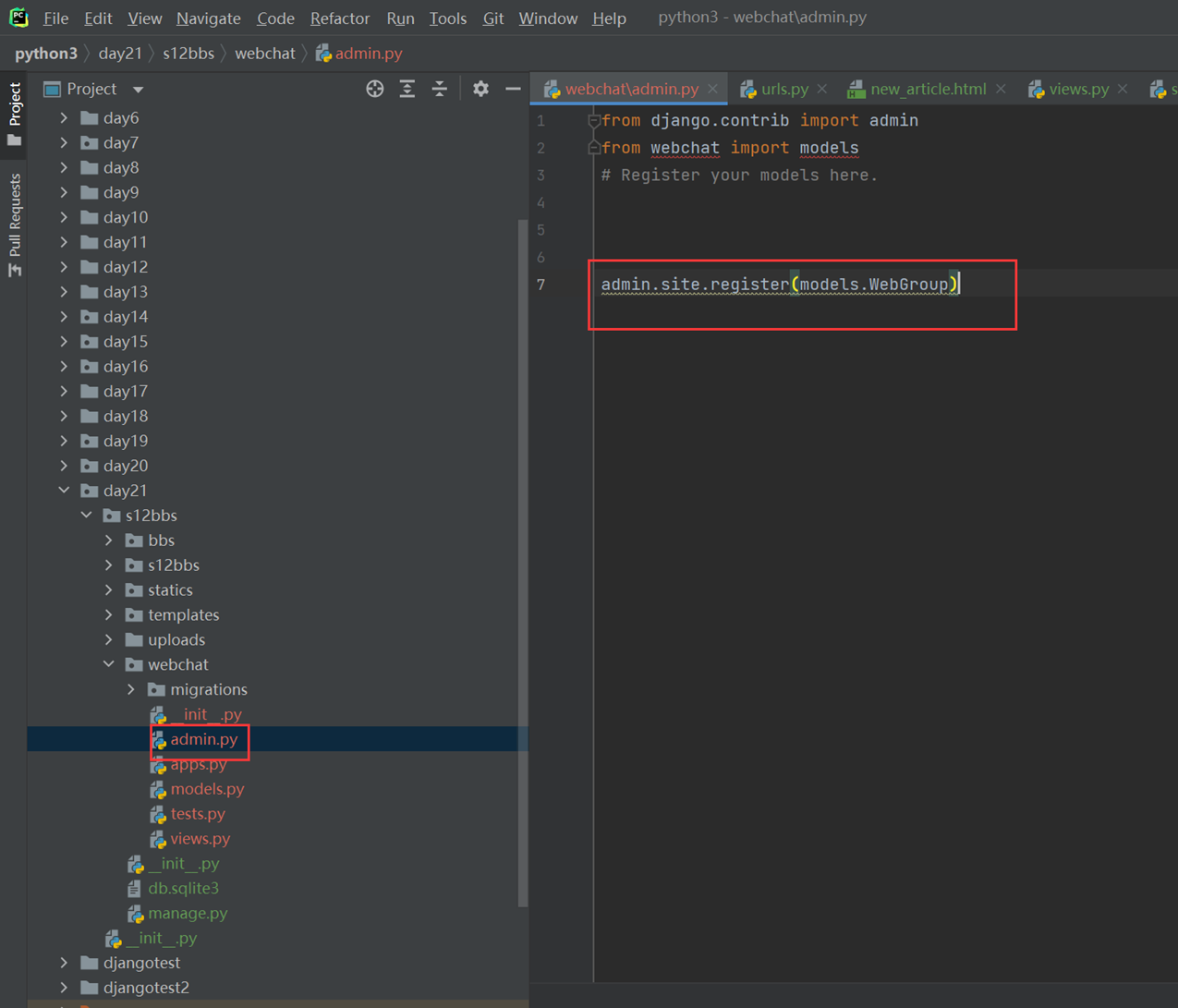
21.8 WEB聊天室聊天面板设计
本节课就是把面板的框架给搞出来,加一些简单的样式。
按照这个框架给整出来。

1.url
url
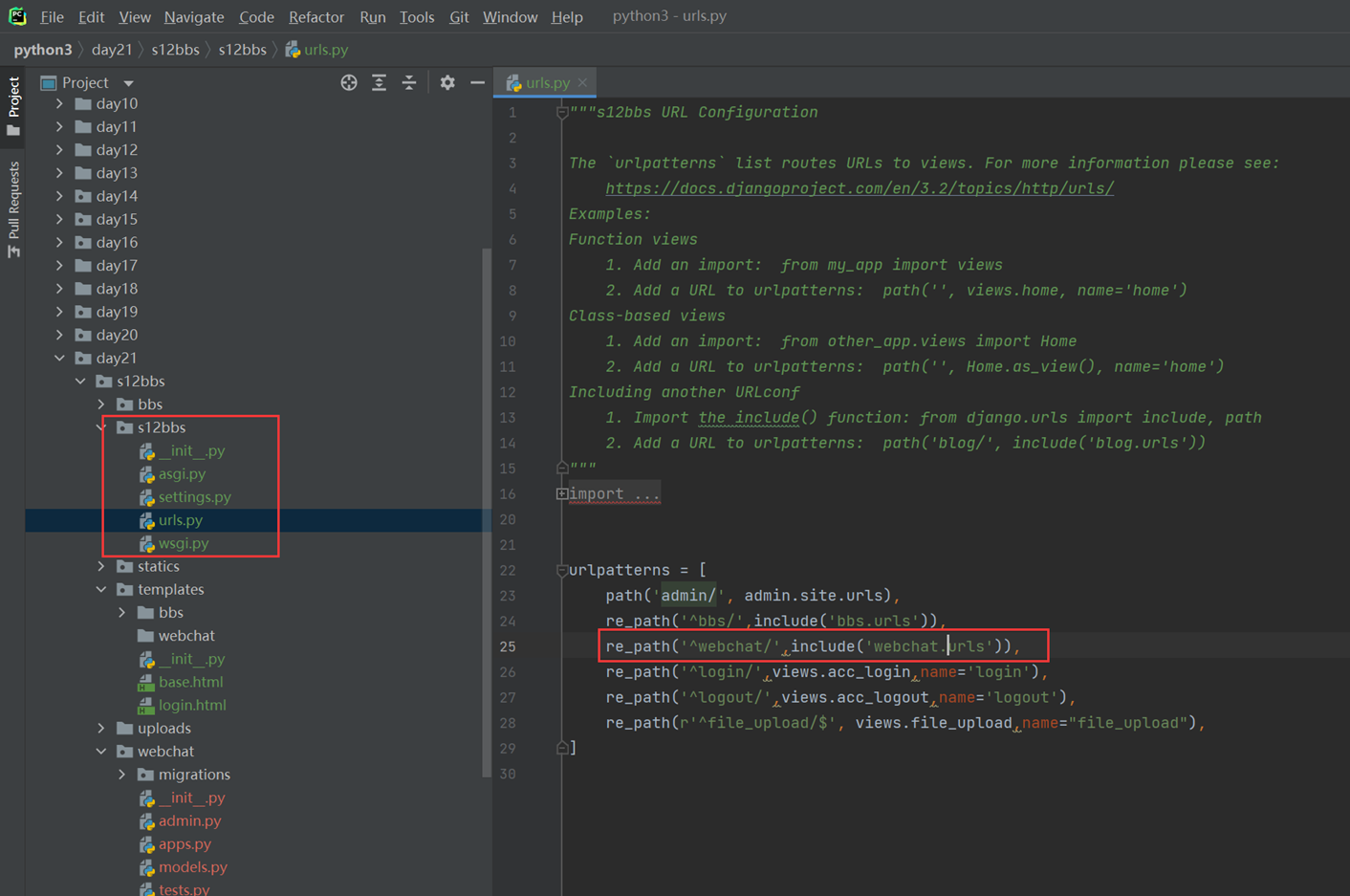
webchat.url

2.views
3.html
base.html
Dashboard.html
首先,我们要实现,点击聊天专区跳转到这个界面,并且选择框active样式
加个js就行了
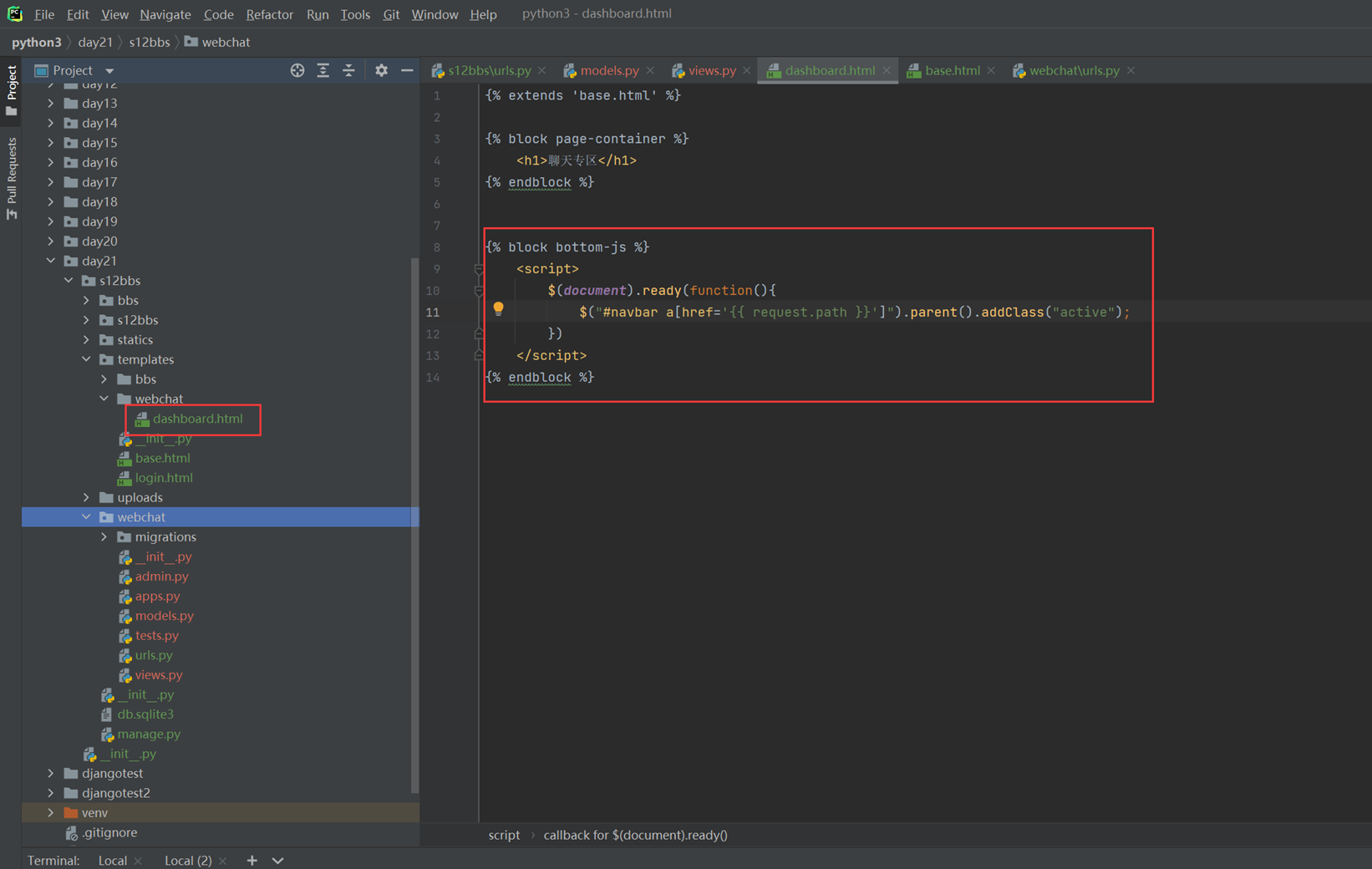
现在完成网页框架
Dashboard.html
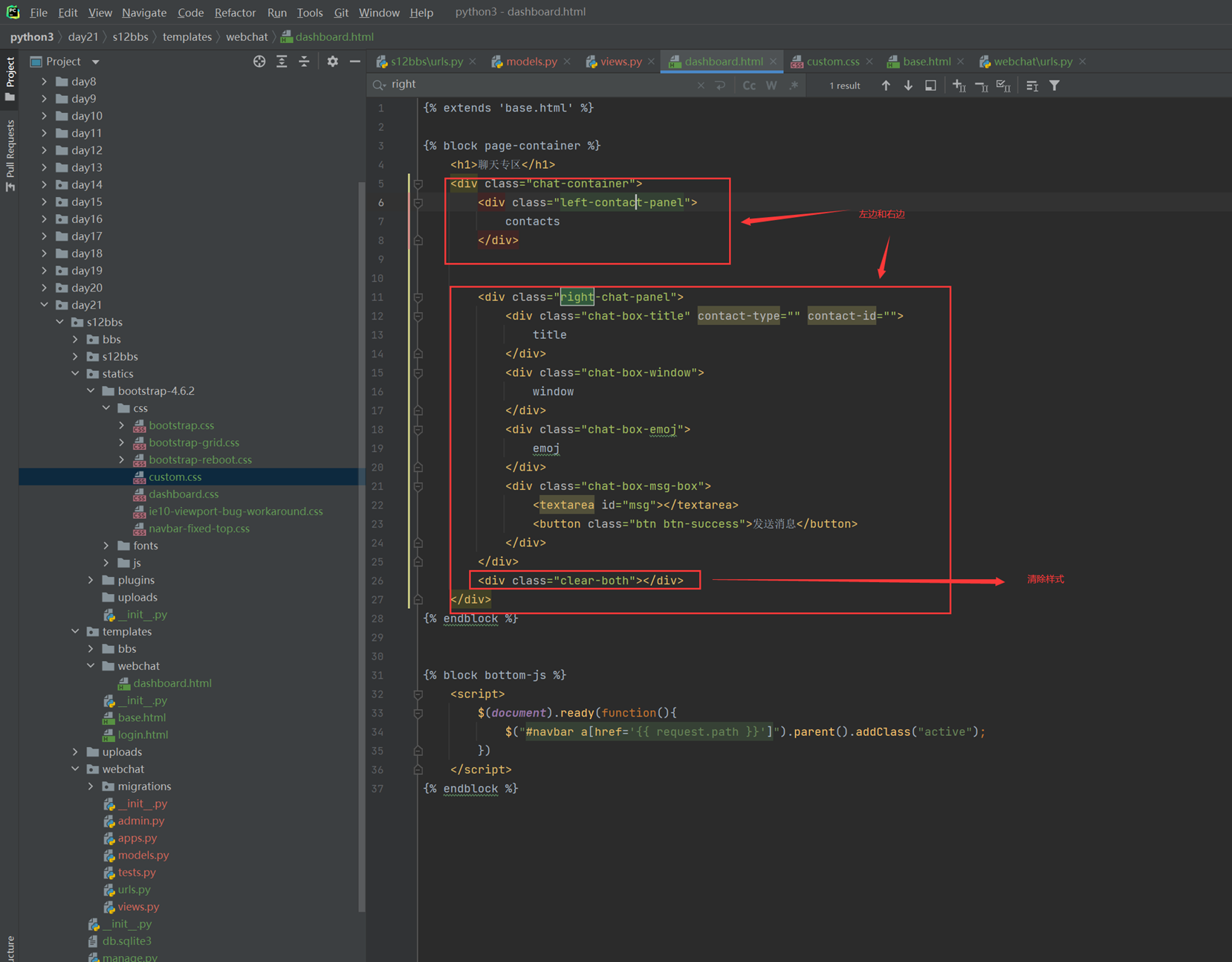
custom.css
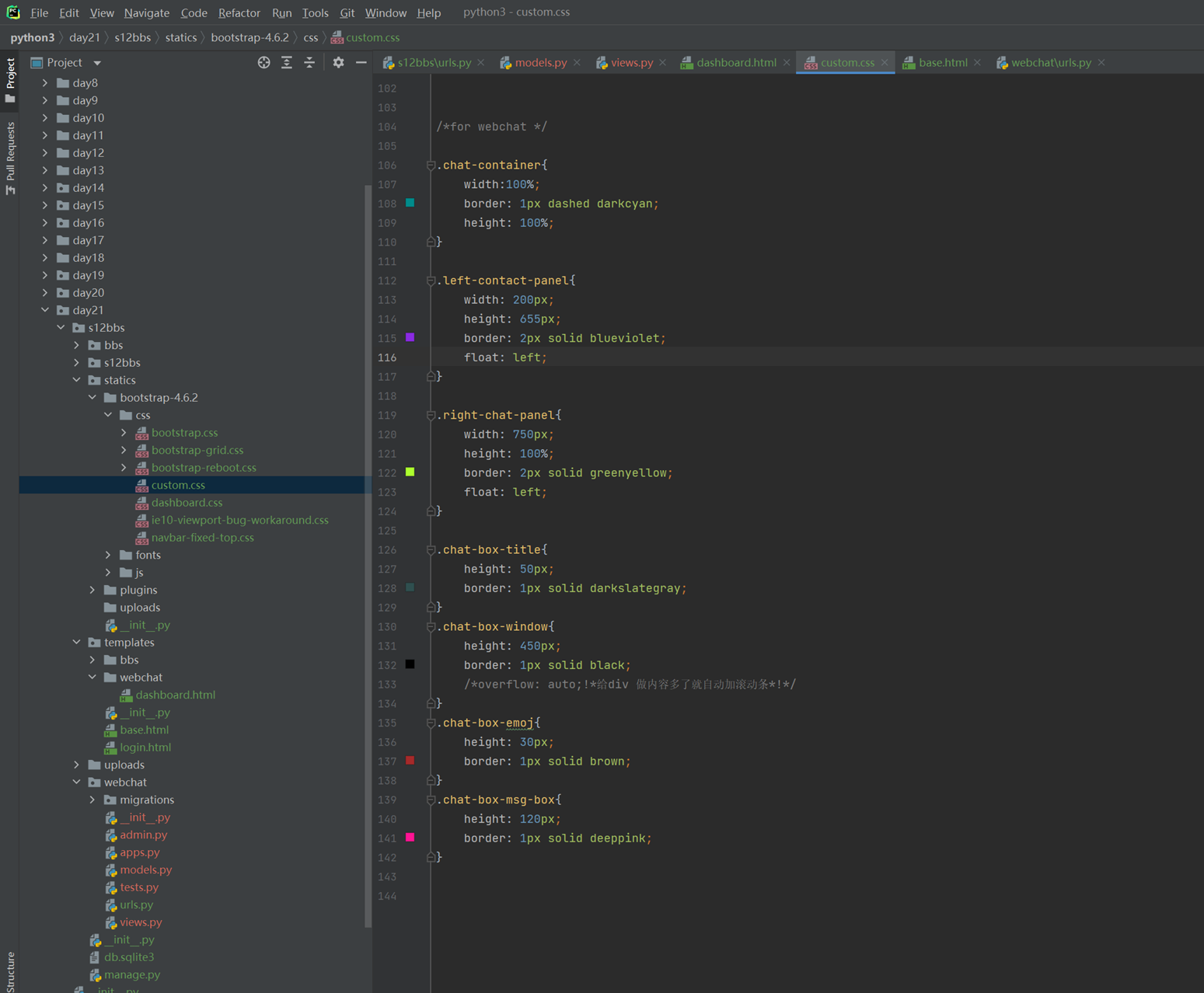
查看访问效果
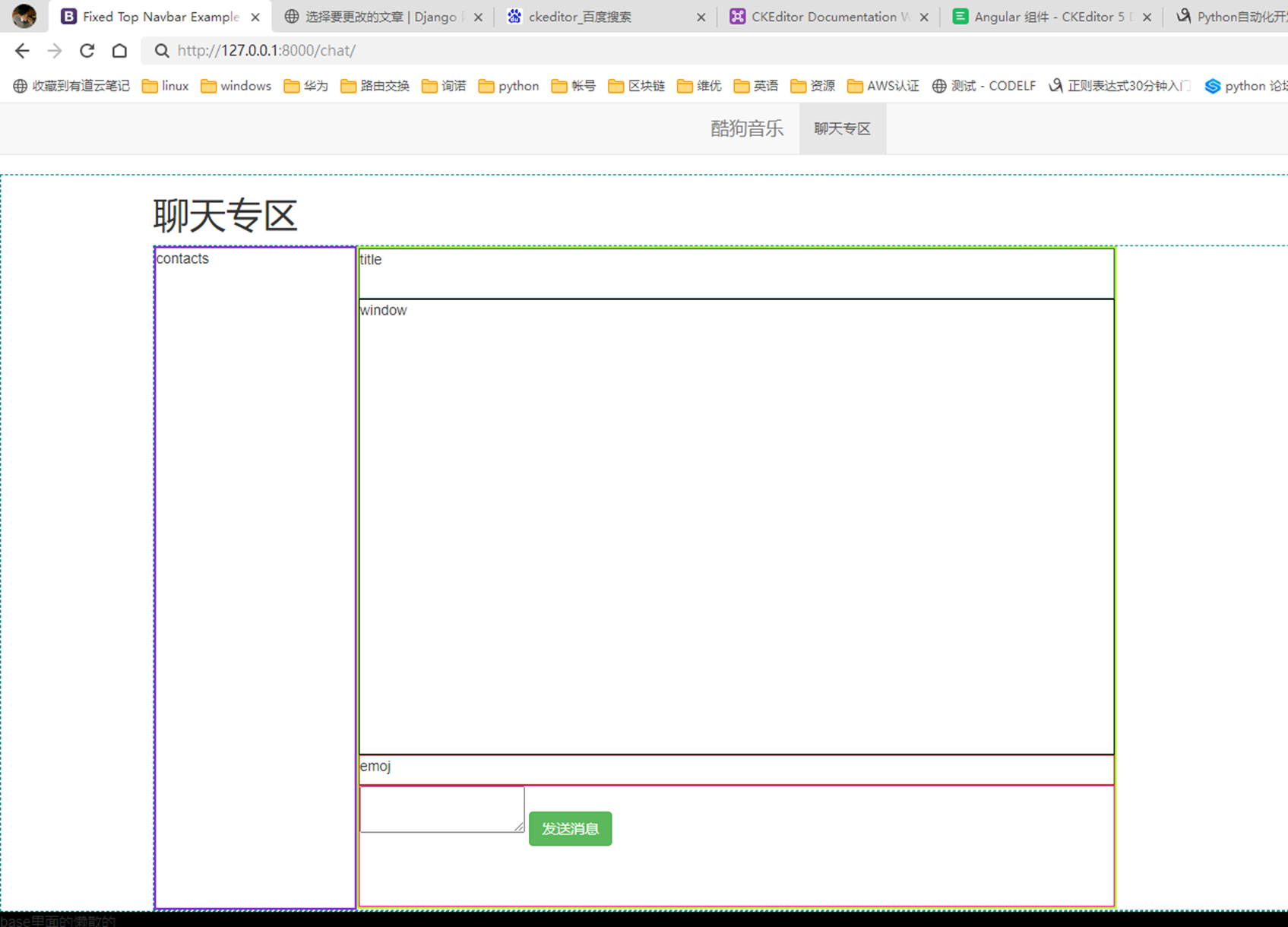
21.9 WEB聊天室后台如何处理消息讨论
本章就是把左边联系人好友群组给展示出来了。
顺便讨论了一下,如果要聊天,消息需要哪些信息。如下:

首先还是前端把好友和群组展示出来吧。
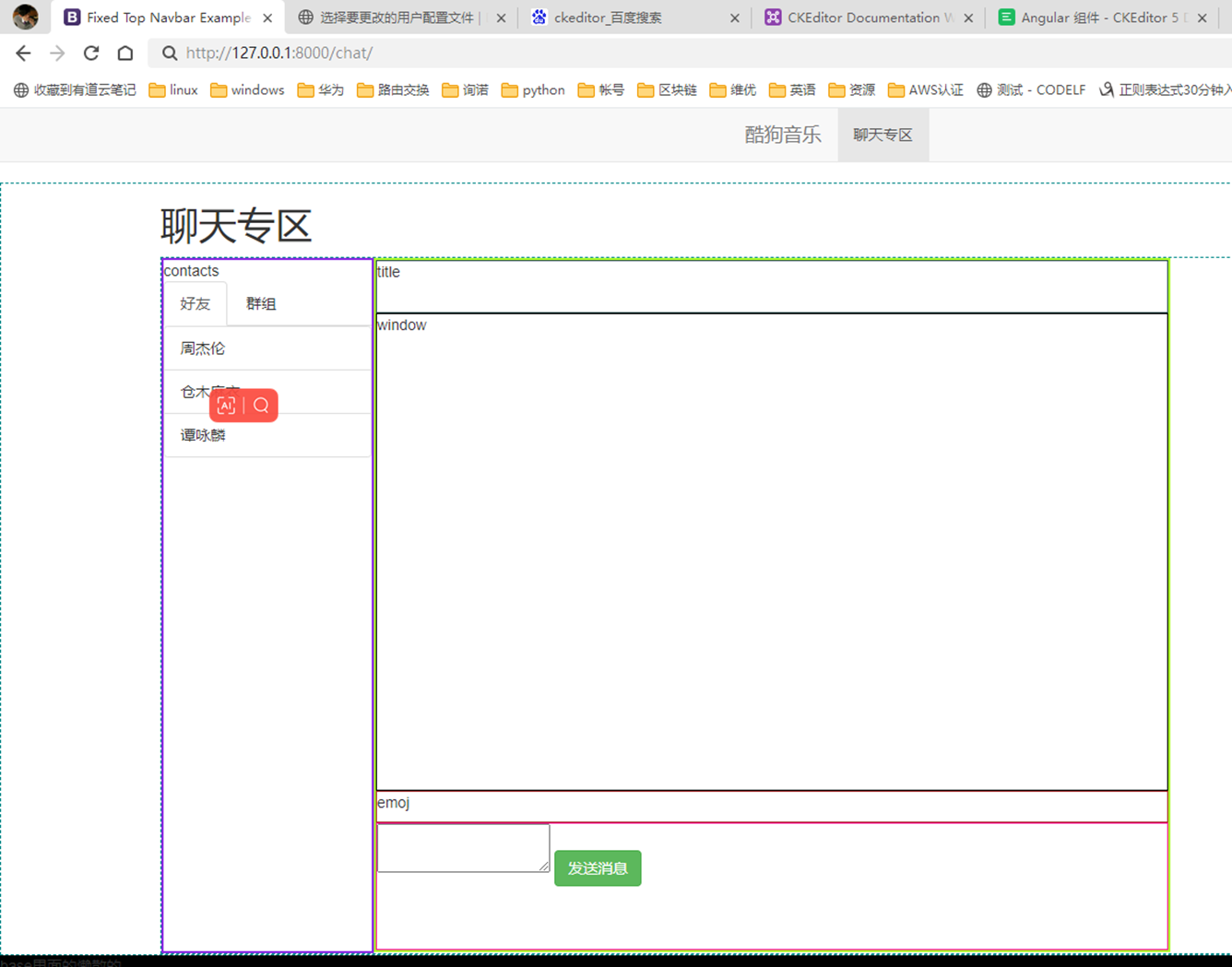
21.10 WEB聊天室聊天页面开发(本节课视频损坏)
虽然视频文件损坏,但是根据后面的课程,大概能猜出来本章讲解了什么。
1.完成之间的切换,完成聊天窗口,正在跟谁聊天功能
2.按下回车可以发送消息,并实现滚动条。(但是未完成可以和别人发送消息)
完成之间的切换,完成聊天窗口,正在跟谁聊天功能
可以看一下状态
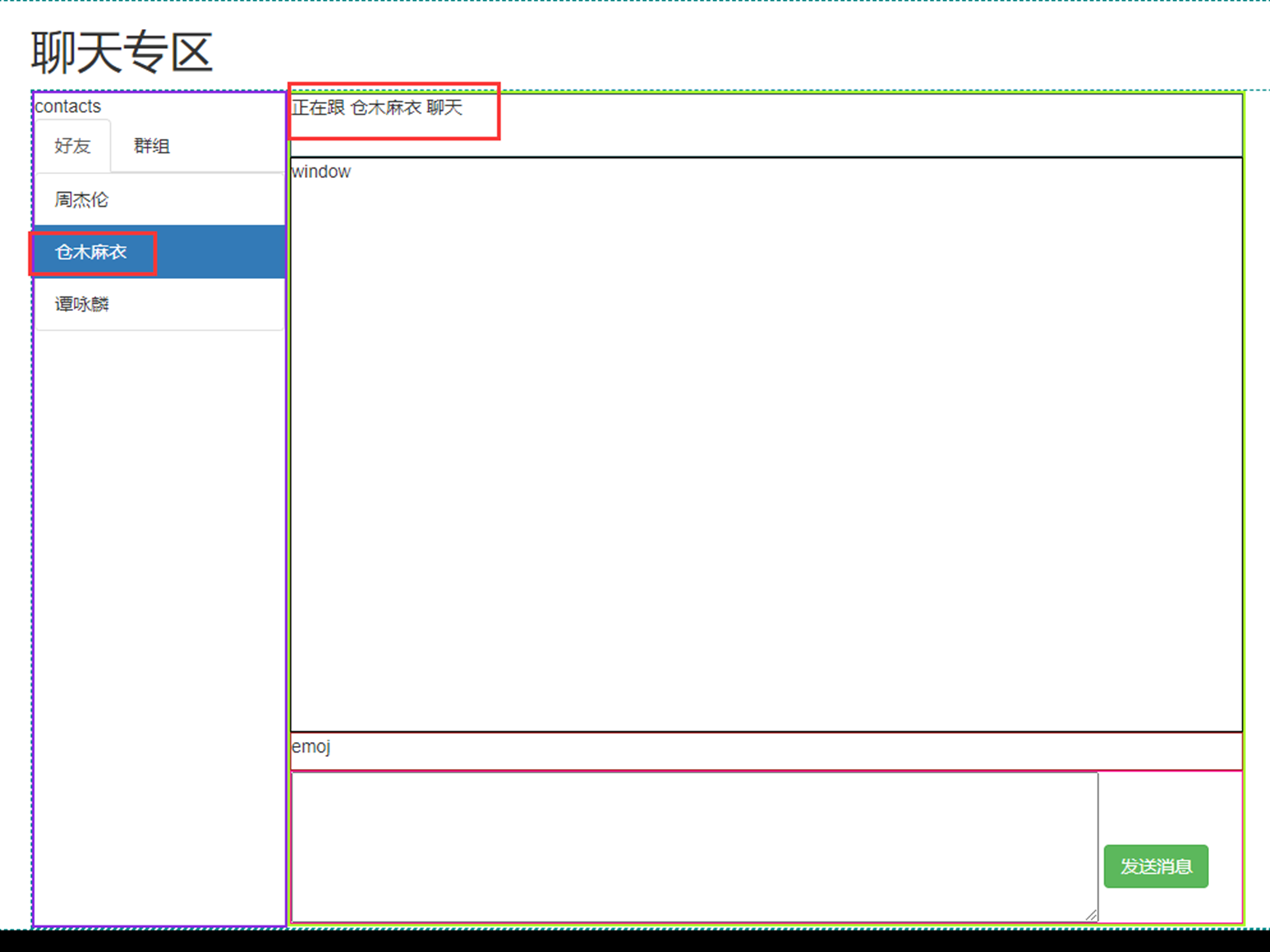
接下来就是麻烦一点的,发送消息到网页(用户点对点聊天这节课没实现)
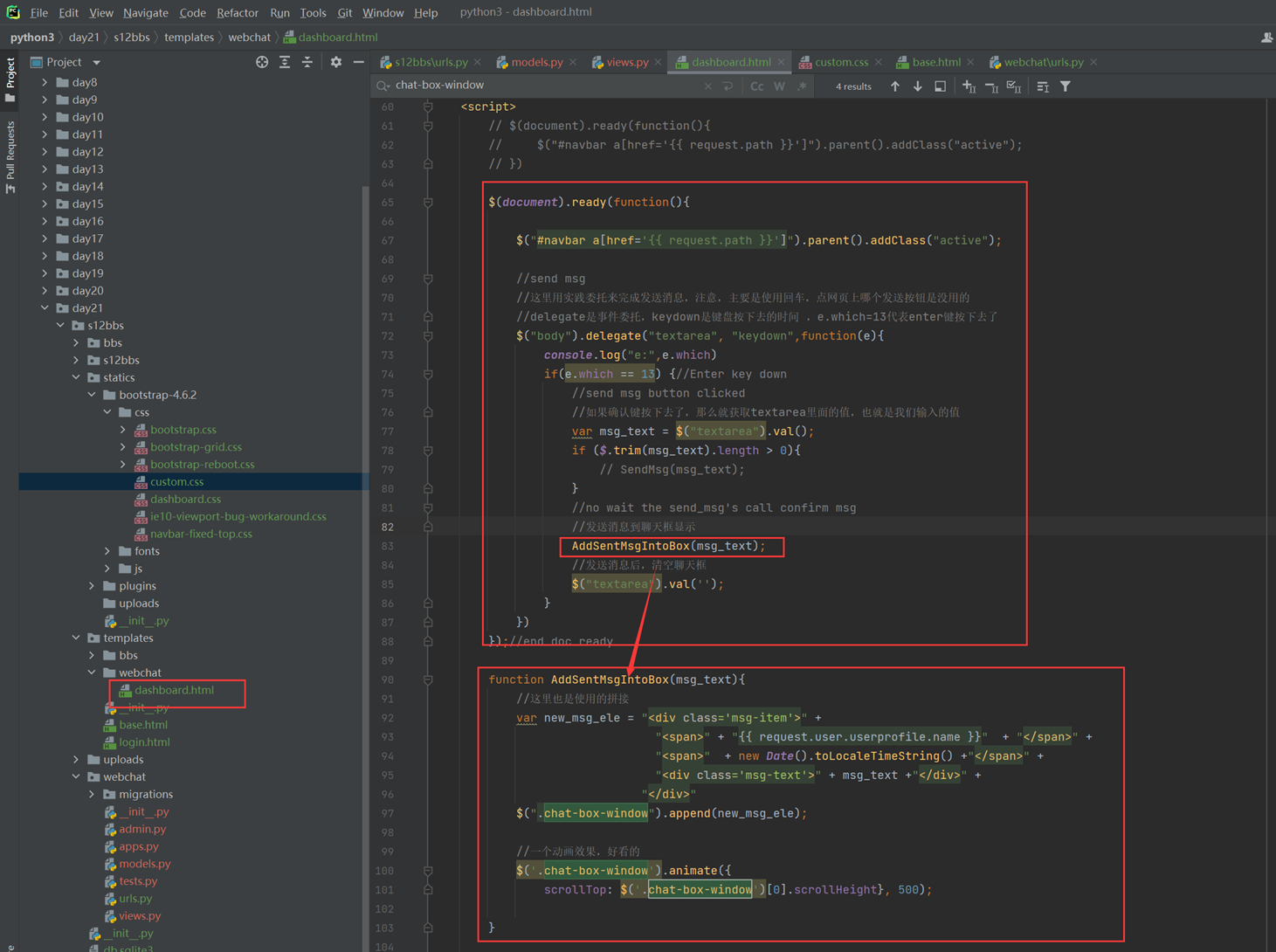
custome.css加个样式
就是聊天框消息如果多了,加个滚动条。
还有就是聊天框搞的好看一点(这个之前就加过好像)
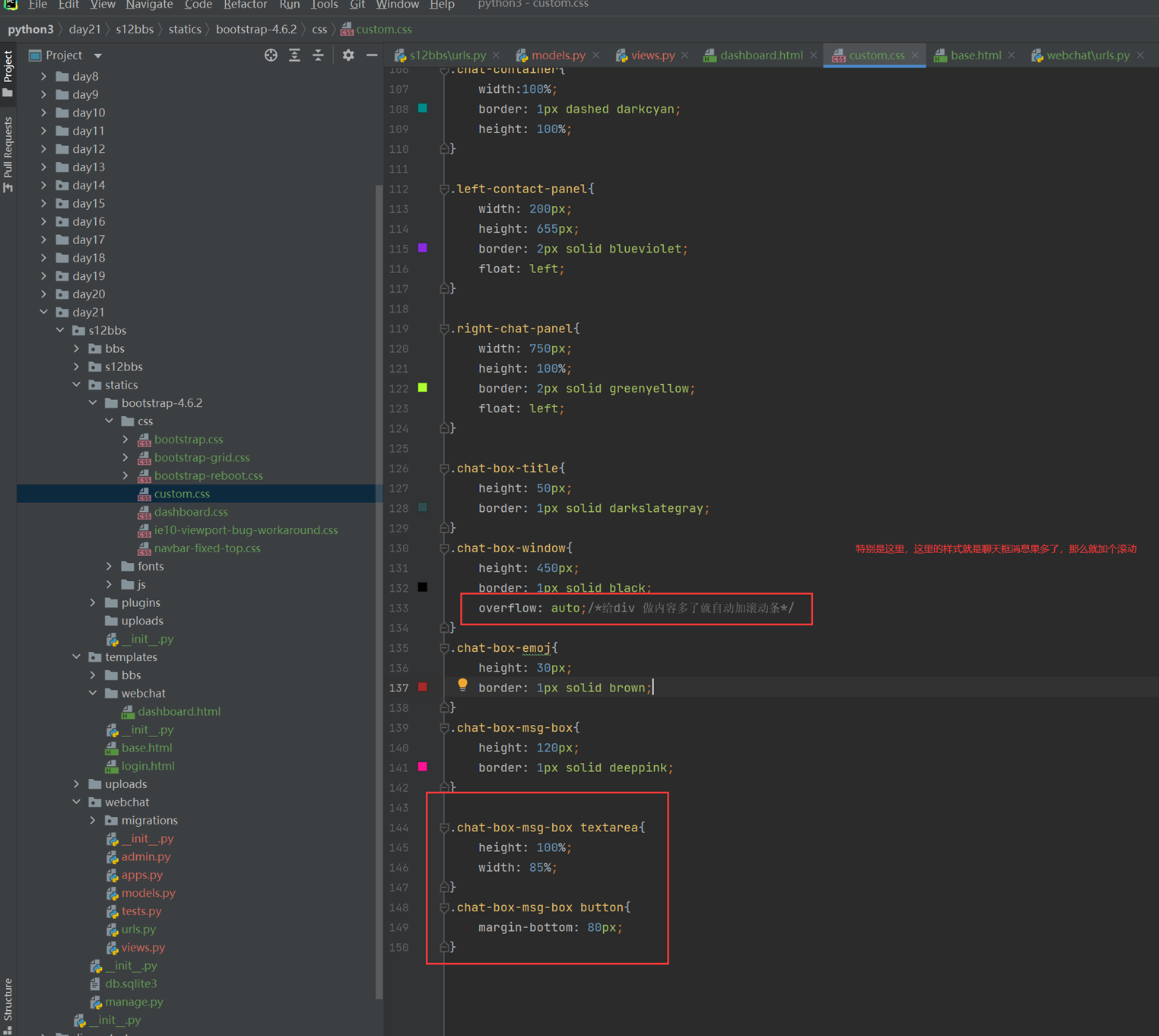
查看网页效果
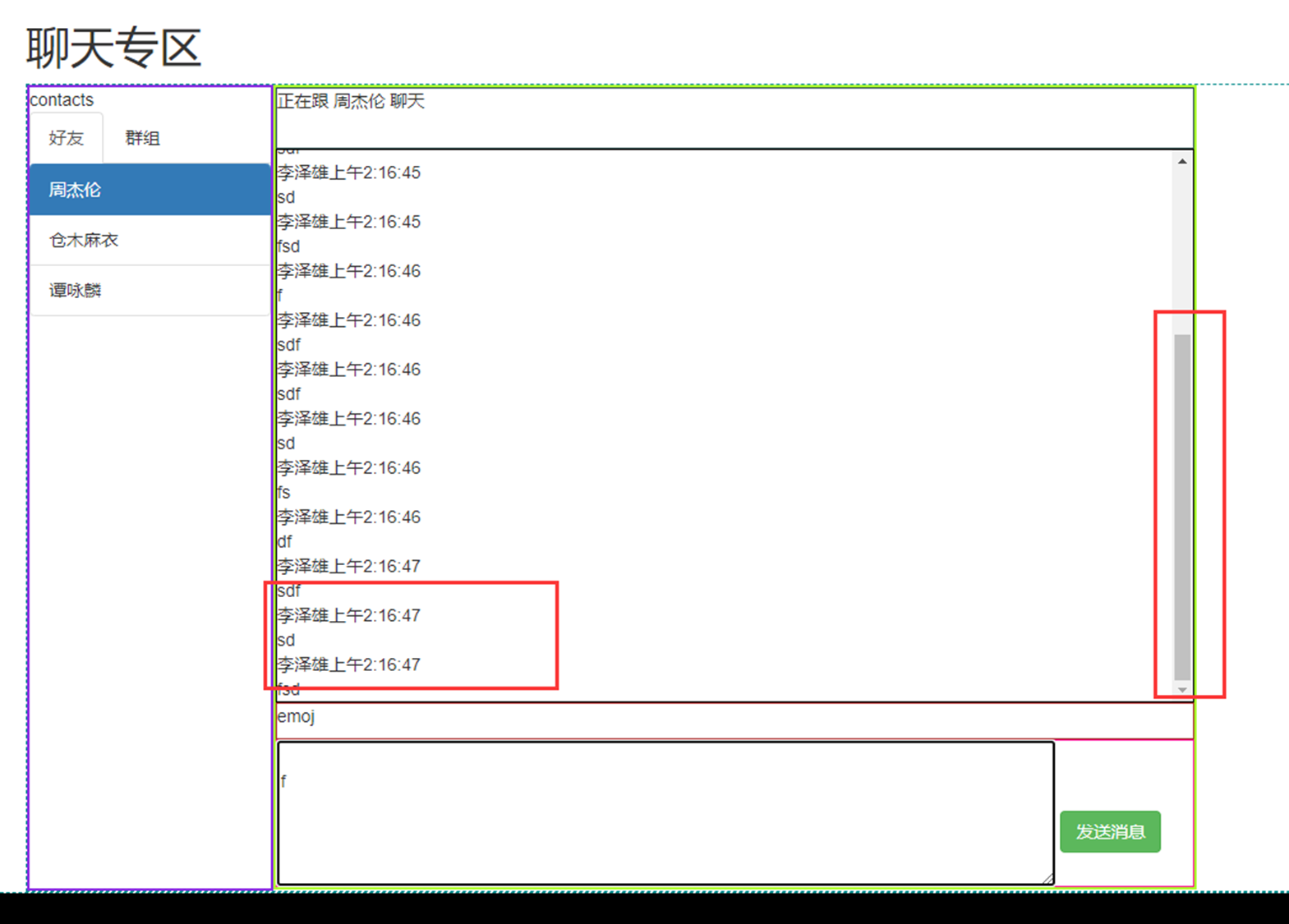
21.11 WEB聊天室发送消息到后台
为什么要发送到后台?因为用户不可能实时在线,需要发送到后台的queue里面存着。用户上线了自己去队列里面取。
1.url
2.views
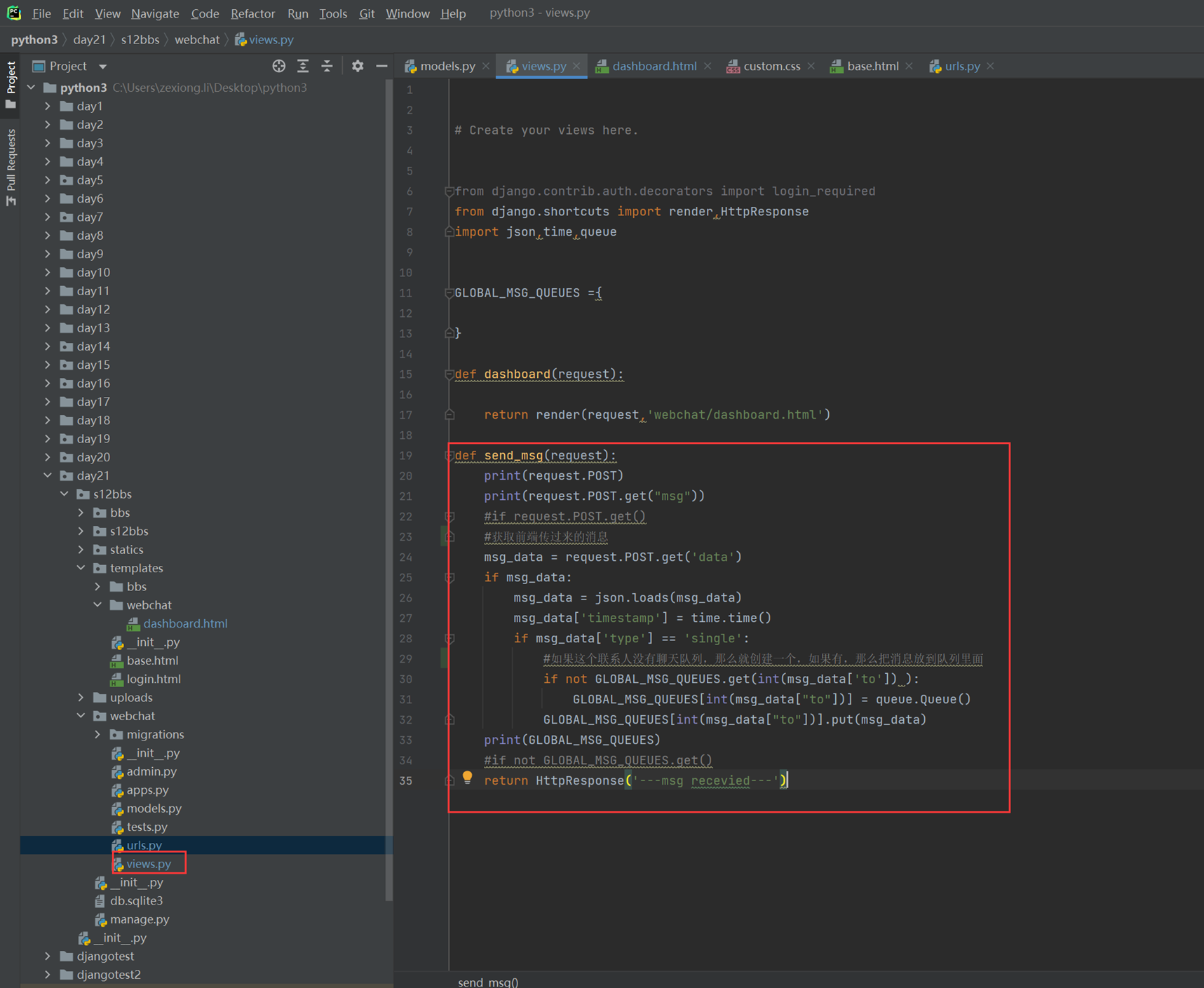
3.dashboard.html
首先还是先看看最重要的发送消息的逻辑
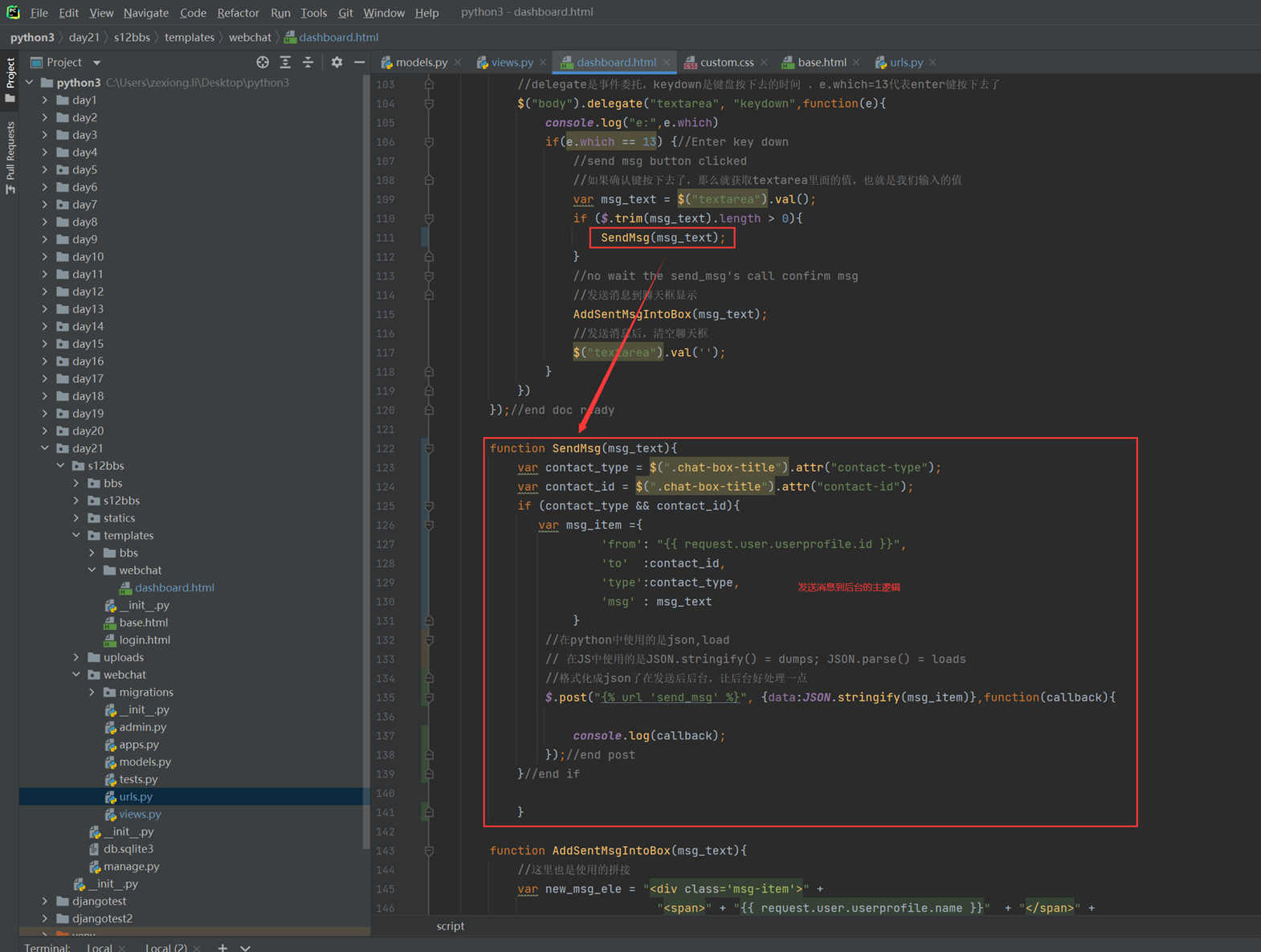
但是在此之前其实还有2个准备工作要做
1、 怎么知道当前聊天框是和哪个联系人发消息
这个就需要在聊天界面把id和联系人信息提前埋进去
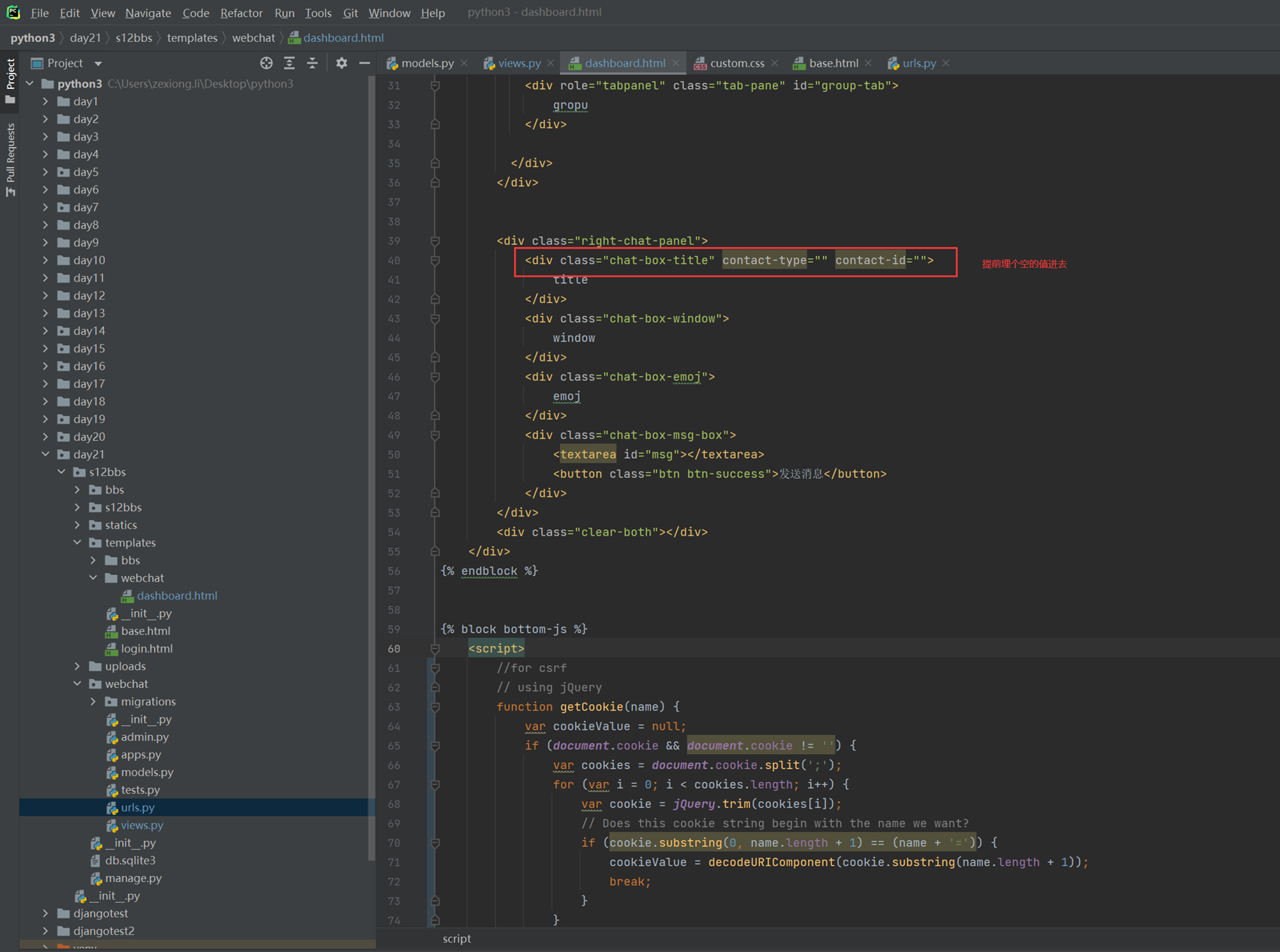
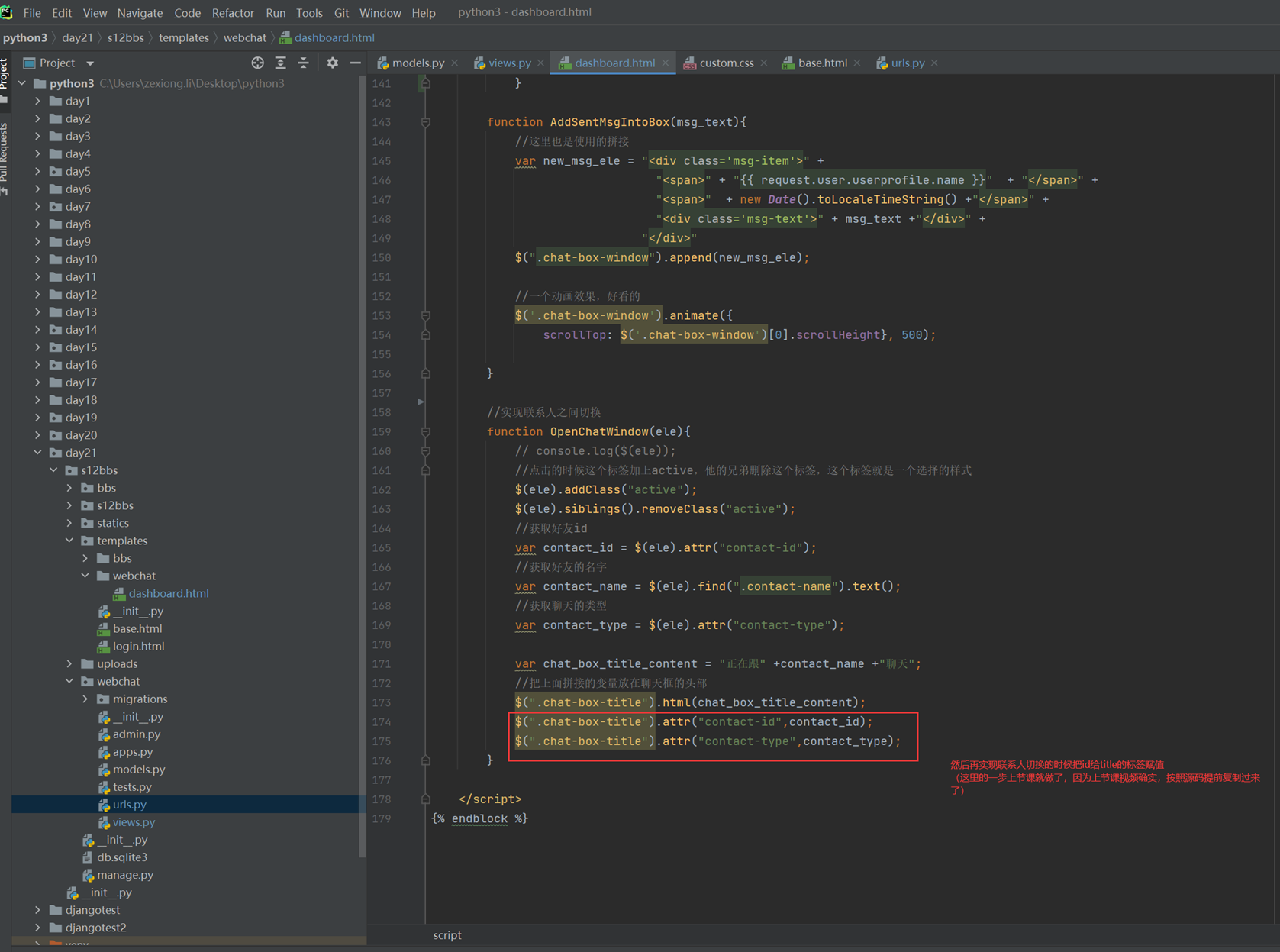
2、post请求需要csrf
之前每次都是获取一次,太麻烦了,这次我们直接全局获取,就不需要每个post单独获取csrf了
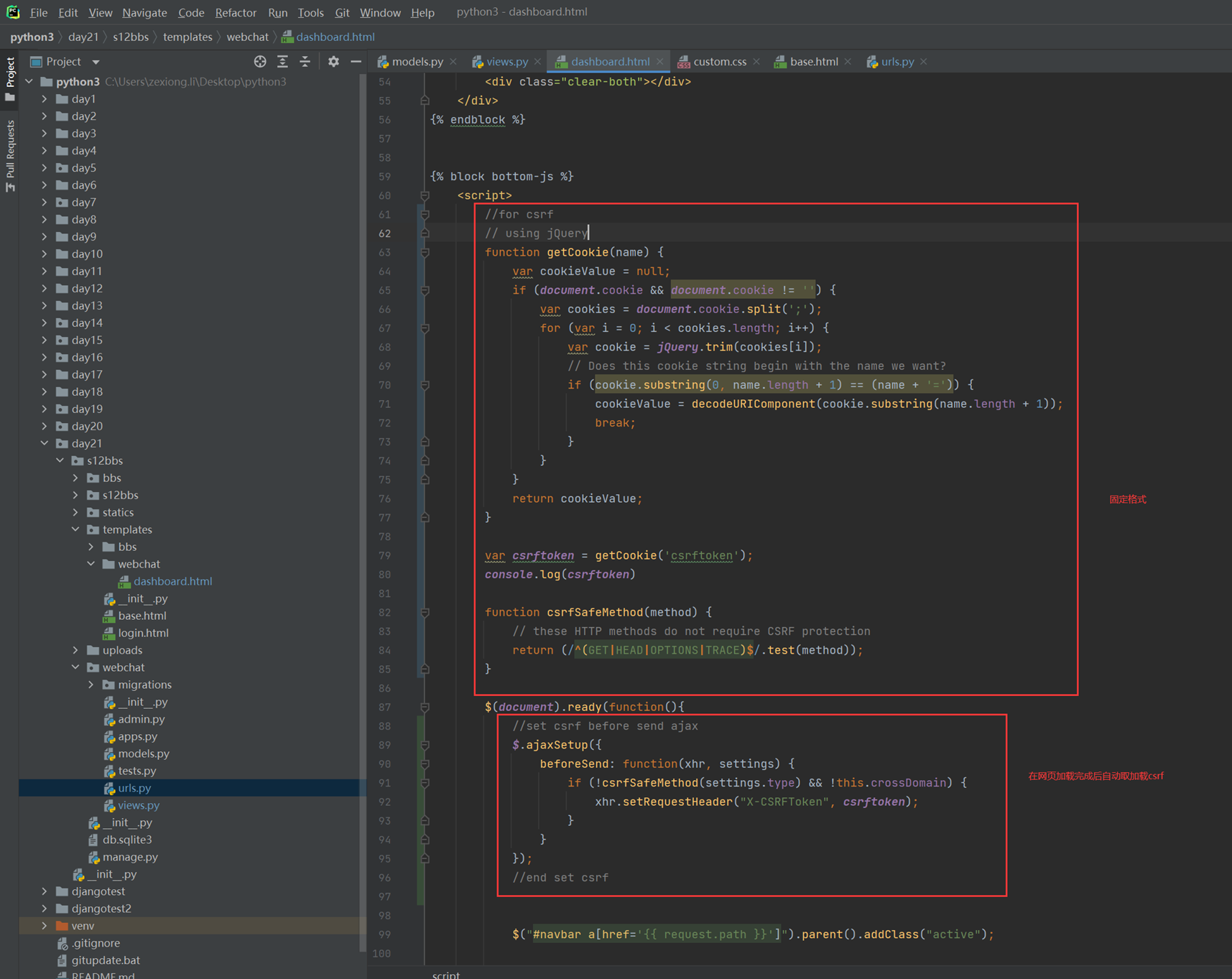
测试,在网页发消息,后端是否能收到
21.12 WEB聊天室用户到后台取消息
两课合并,简单来说就是可以实现取消息,两个用户实时发送消息,但是没有实现在前端界面展示,只是后端可以看到实时发接收消息了。
1.url
2.views
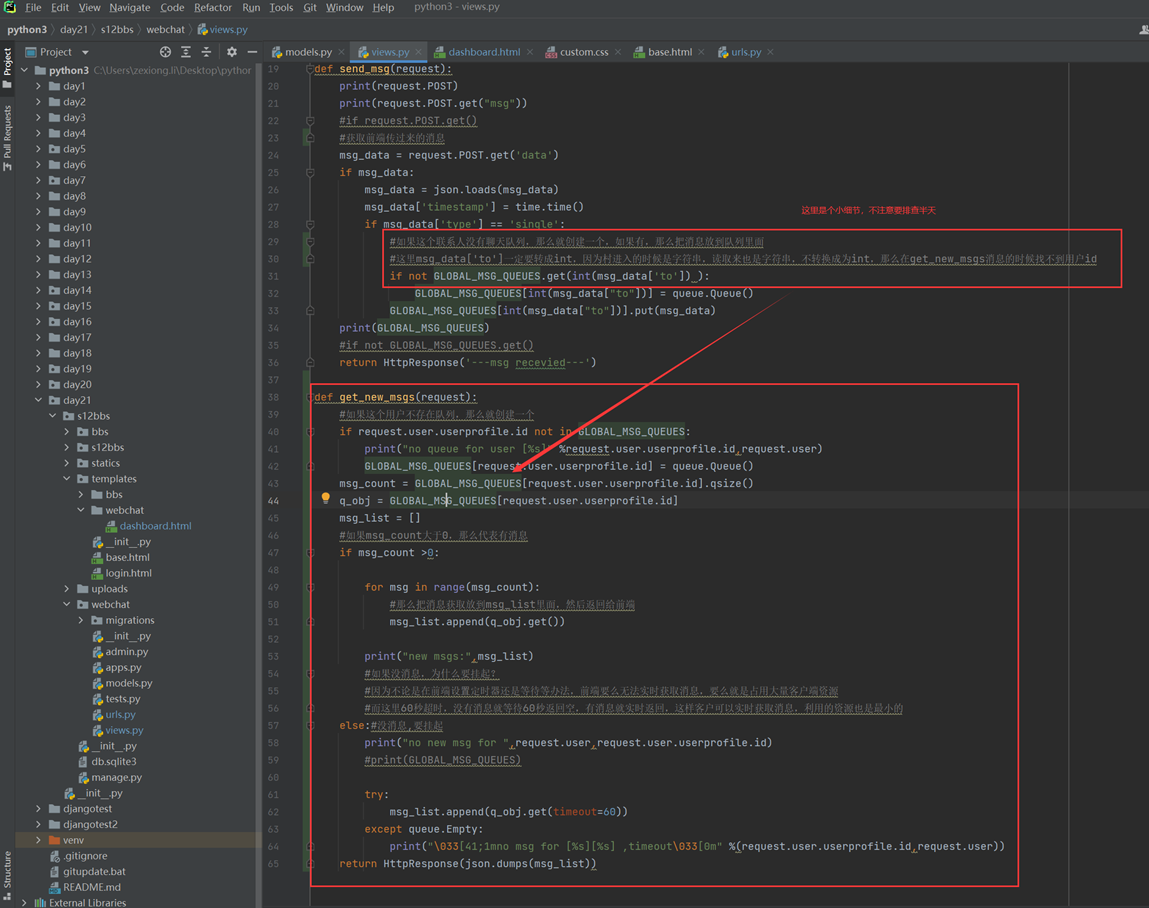
3.dashboard.html
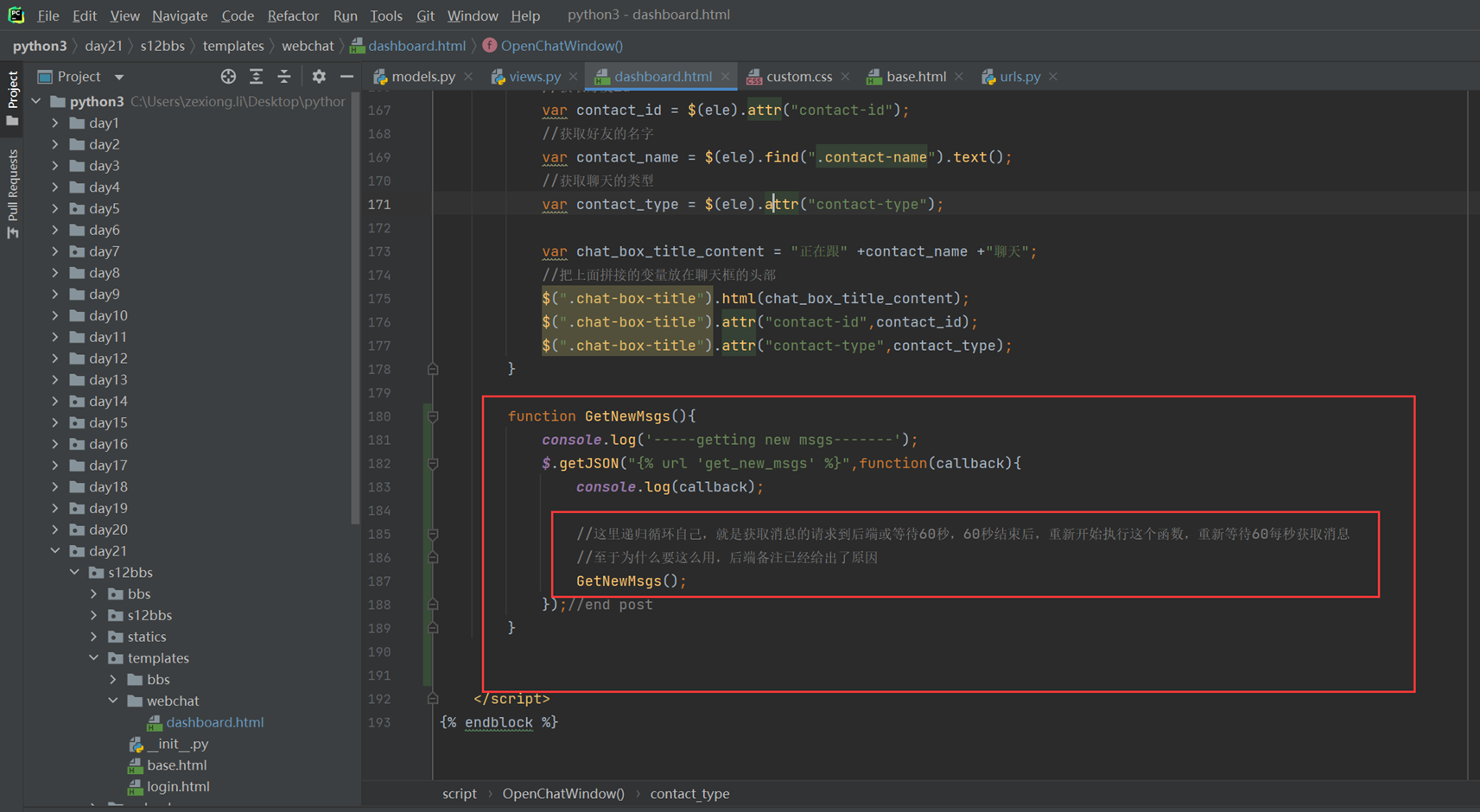
网页测试查看console
周杰伦给李泽雄发送消息,李泽雄可以实时收到
今天课程还没将聊天记录展示在web端就结束了。Day22会讲,但是视频损坏
21.13 WEB聊天室实时聊天效果实现
合并到上一章了
22.L22
22.1 不同聊天窗口间的切换(视频损坏)
即使没有视频,鄙人也能根据下一章的视频把这章的内容给猜出来。
这是在22.2视频里面的截图,这里做个留档。
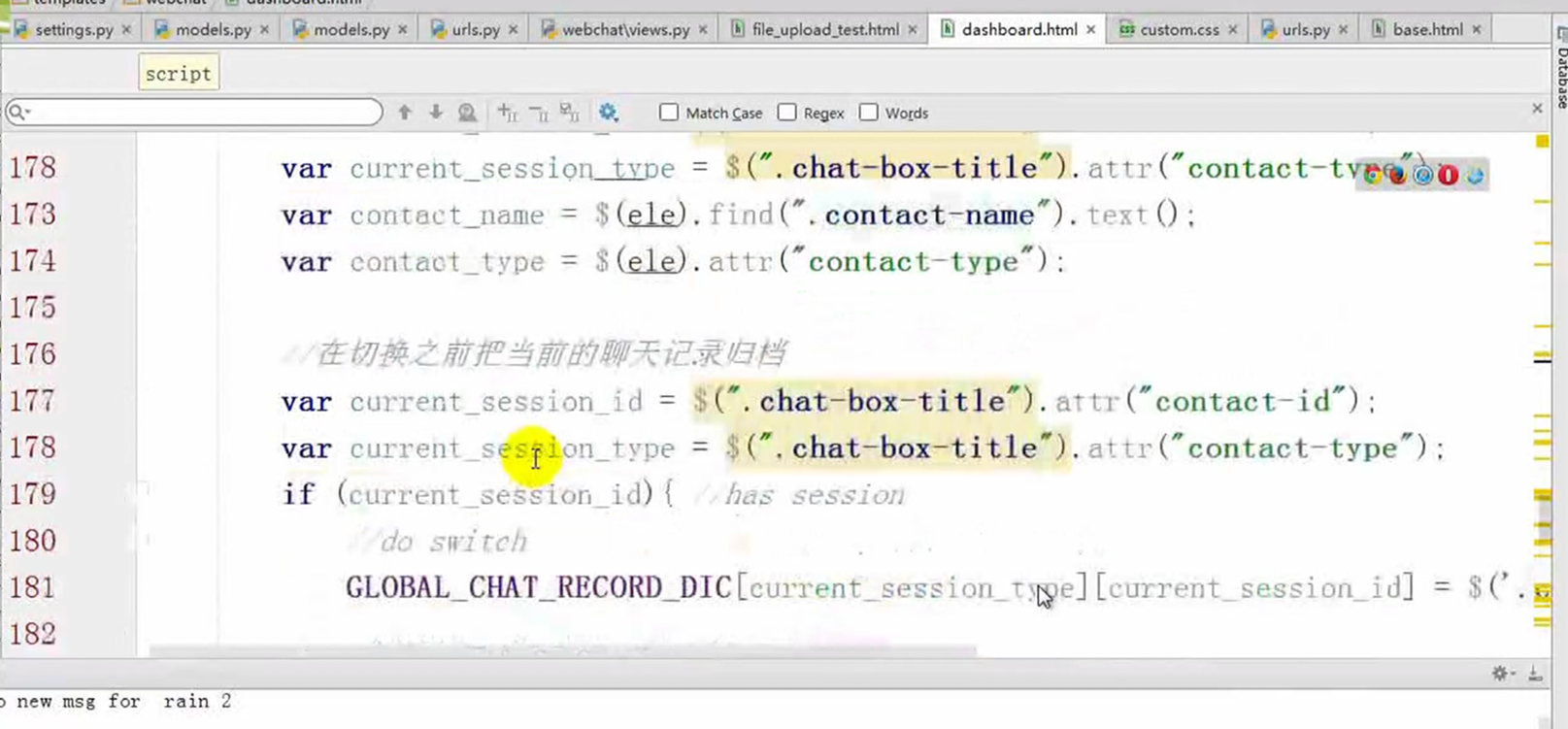
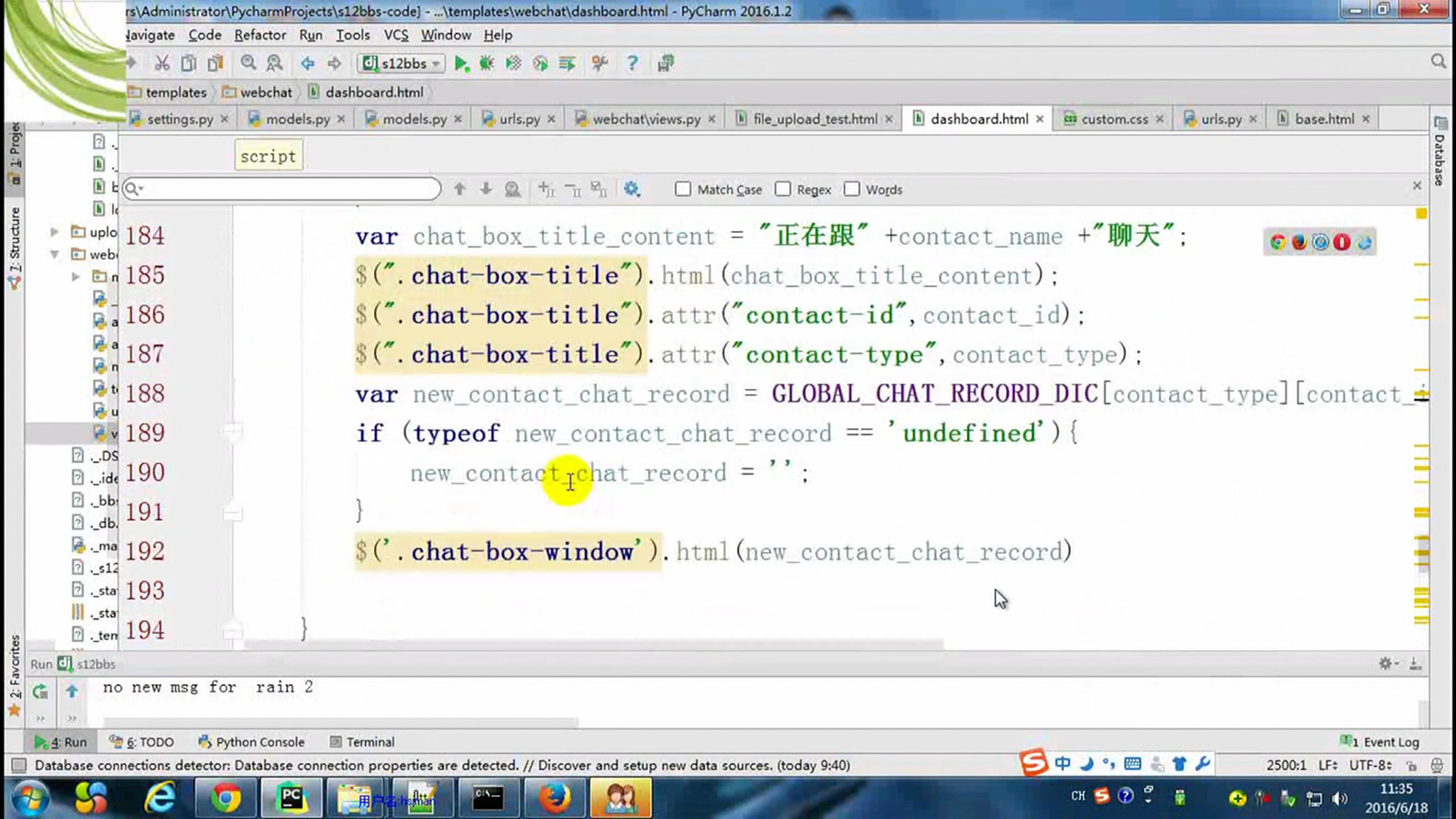
本章做的操作就是,切换聊天窗口,可以只显示该好友的聊天记录。
大概的代码就这么2处就可以实现功能。
1.增加一个字典存储好友的聊天界面
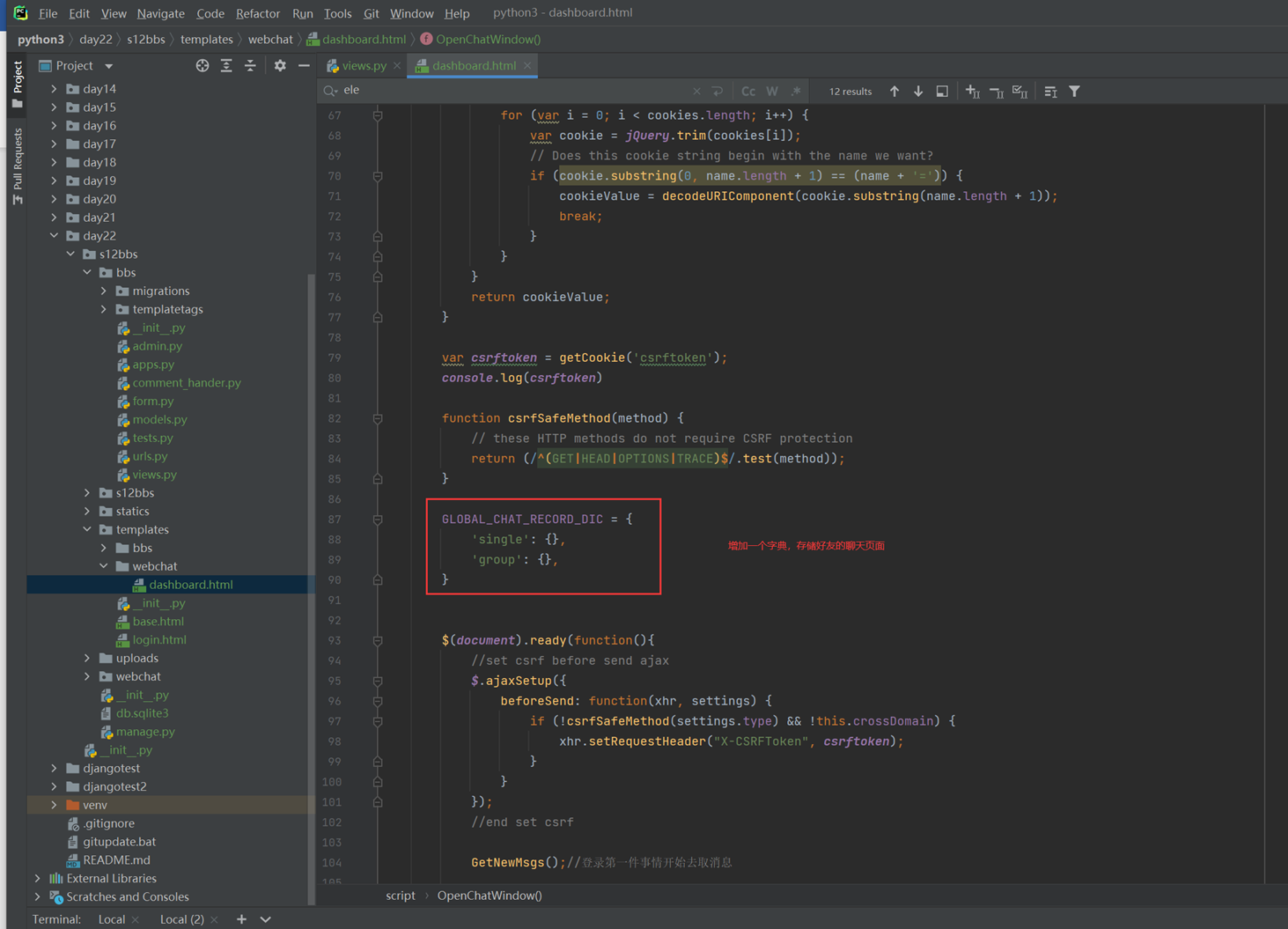
2.具体的js逻辑
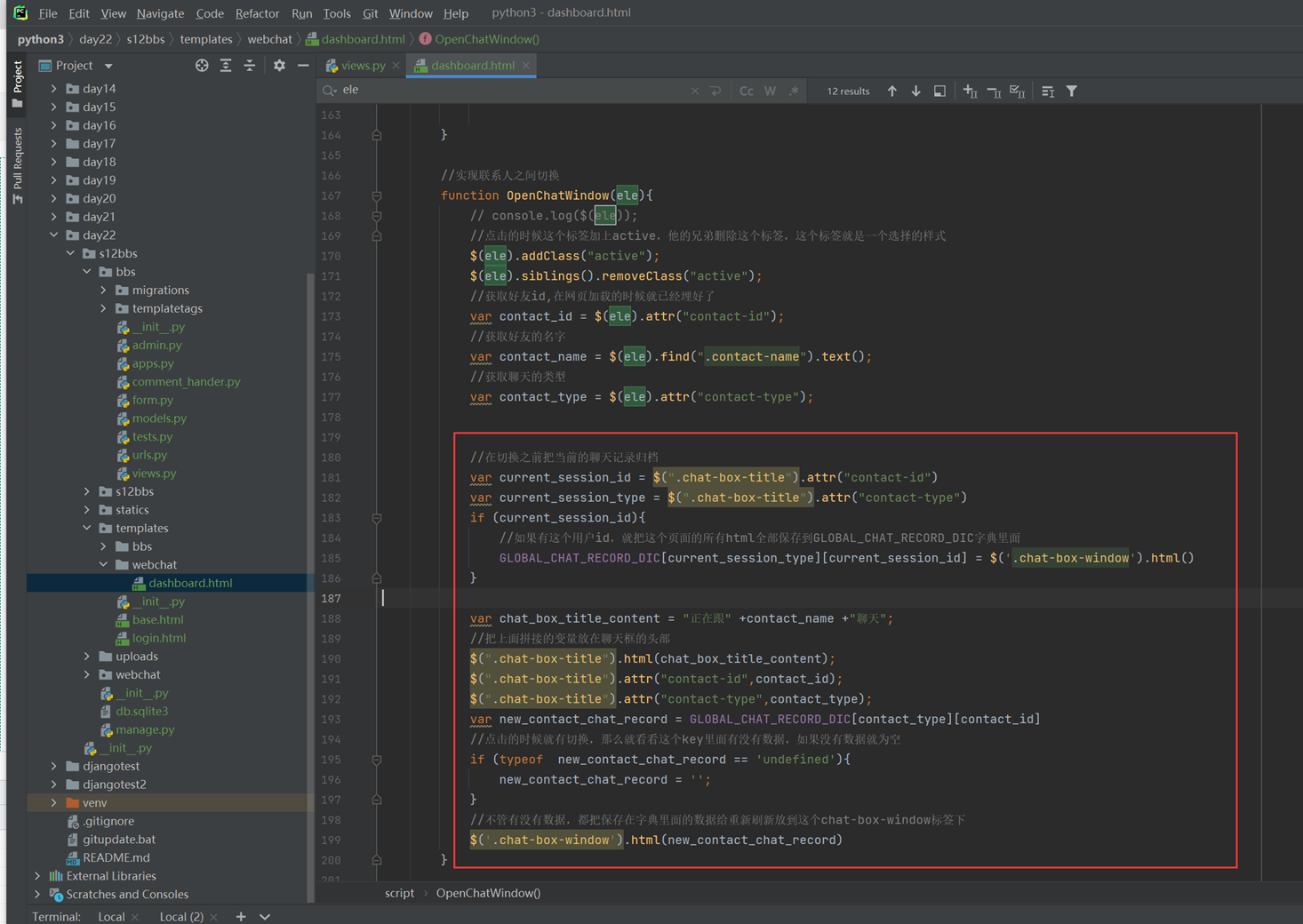
就这么简单的两步,就不演示结果了。
22.2 把后端消息进行解析并在前端展示
简单来说,就是后端接受到了消息,要在前端的聊天框里面显示。并且判断是跟哪个用户在聊天,如果不是当前聊天的好友,那么消息就先不接收,切换过去的时候在接收。
就这么多,当然,这个目标本章实现的有点小bug,但是,大题上没啥大问题。
1.接收人回复消息的时候,聊天框显示的是接收人的id,而不是姓名
2.windows上有时候实时接收,不太稳定,有时候接收有延迟,甚至断开
以上几个问题,都是小问题,问题不大,后期有机会再修复。
本章代码也比较简单。见以下:
本节也是两课合并。
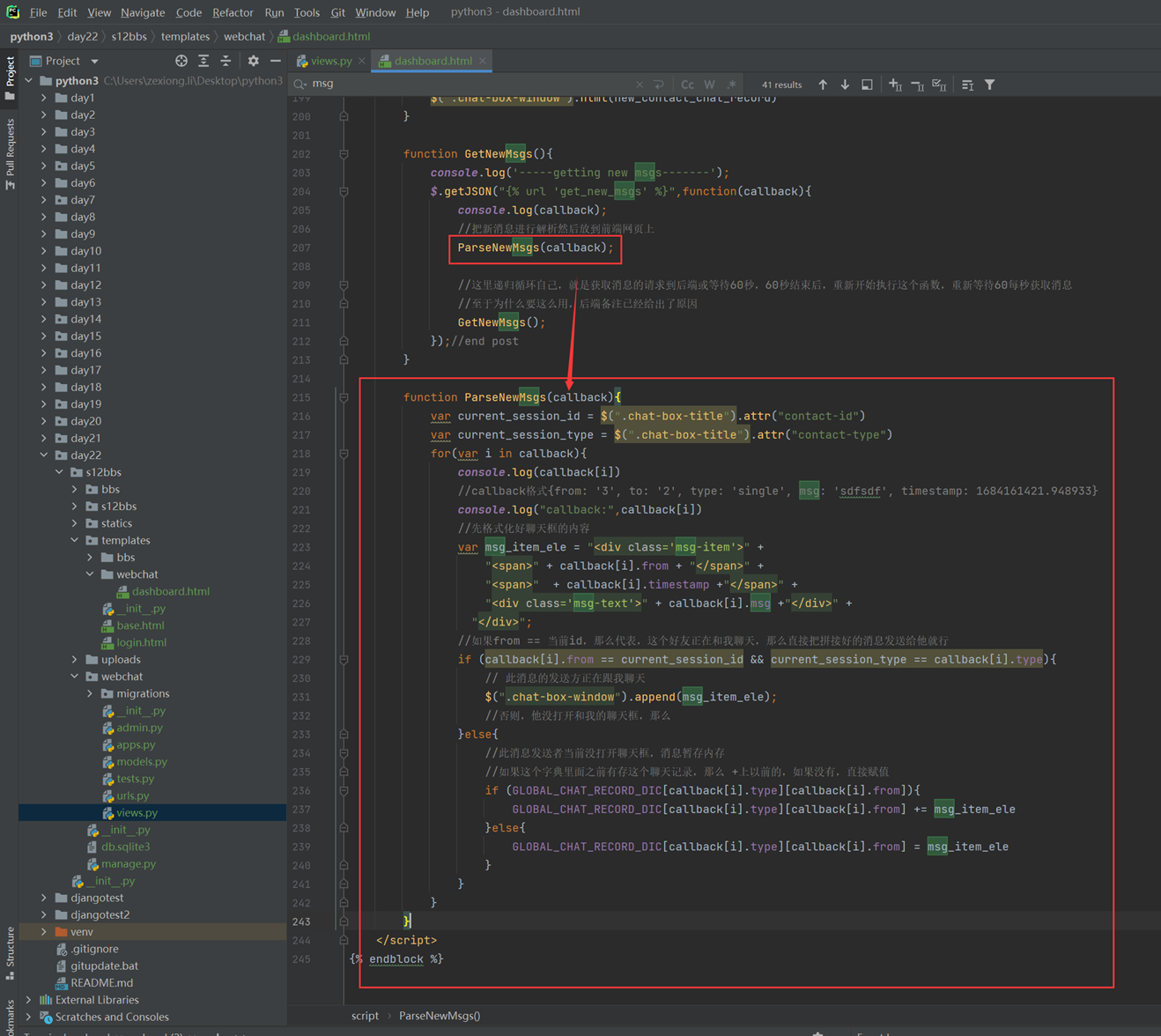
22.3 把后端消息进行解析并在前端展示2
合并到上一节课了。
22.4 新消息提醒
简单来说就是如果不在当前聊天窗口,给一个未读消息提示。一旦点击到当前窗口了,提示就没了,很简单,就是找到标签,隐藏和+未读消息数就行,这章就不多做解释。
首先,最重要的一点,很小的问题,但是排查了半天,就是要给操作的标签设置一个初始值,比如0,不然字符串和数字相加,会出现“NaN”的莫名其妙的东西。一定要注意。
不在聊天窗口,消息来了,出现消息提示
点击聊天窗口,消息提示清空
本章也没啥好演示的,这个代码,结果是成功的就行。
22.5 实现群组聊天
简单来说,就是实现群组里面可以发消息。
原理就是,在群里发送一条消息,会往群组里面的所有人的id queue里面存一条数据。
接下来,要修改的有这么几个地方。
首先,展示群组
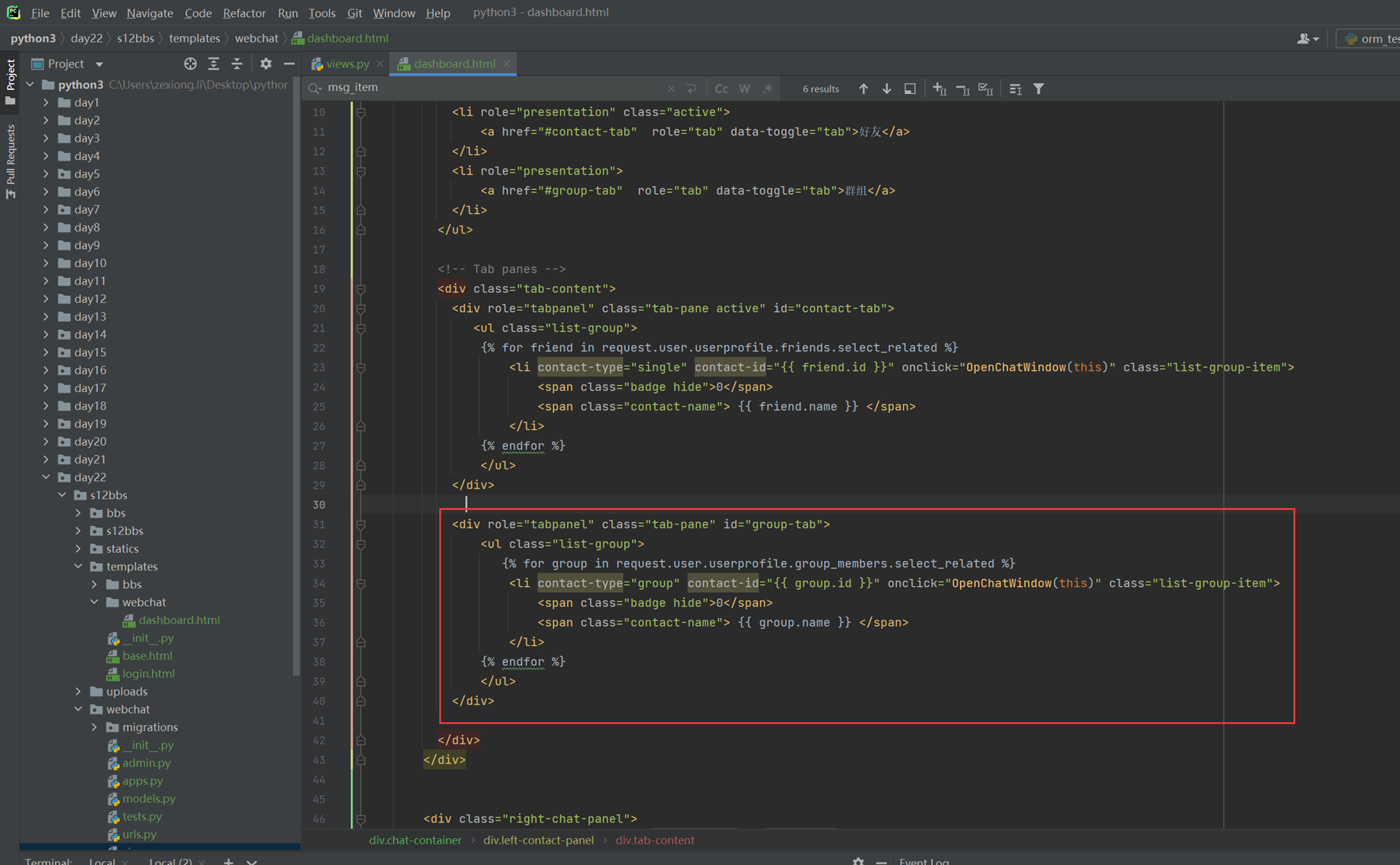
然后后端处理消息的存储和返回前端。
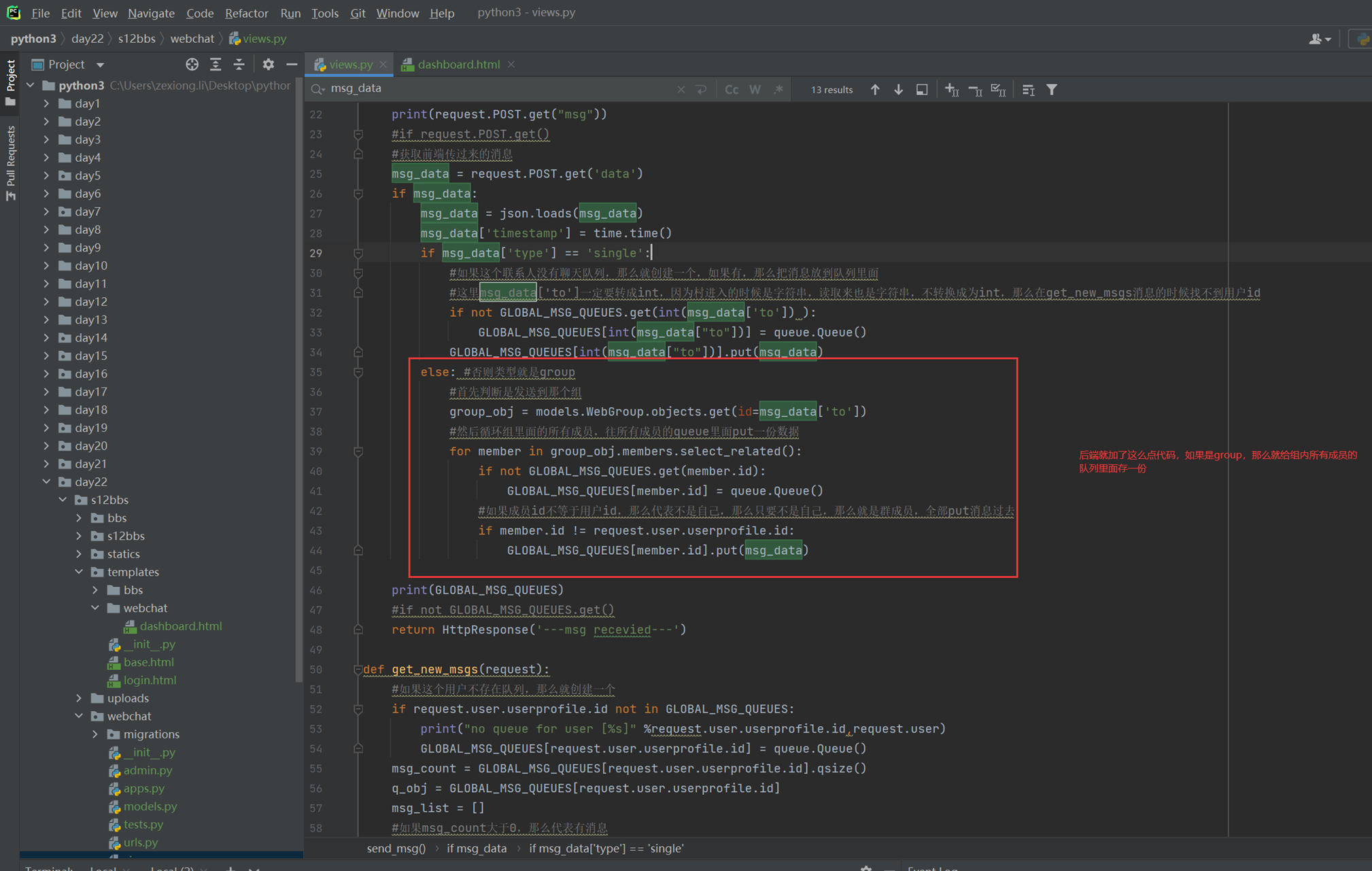
接下来全是前端的活了
前端需要加个判断,以前单对单的时候,是可以依据来自哪个用户id来判断,这里因为加了一个群,所以需要通过去哪里来判断是否是当前窗口以及一系列情况。
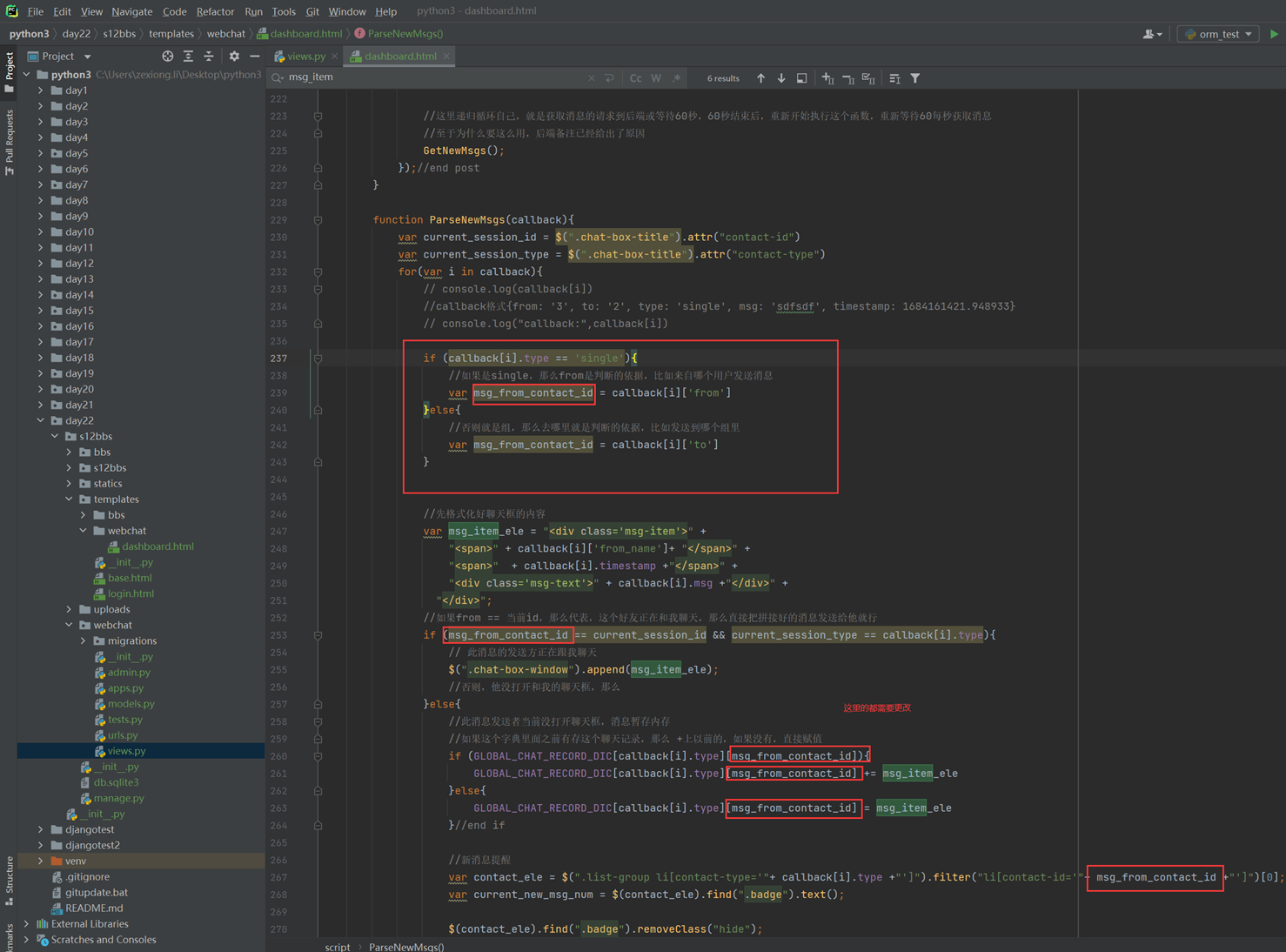
现在其实就已经结束了,可以在群里发送接收消息了,但是在上一课的时候有个遗漏问题,那就是回复的人是id而不是用户名,这里我们优化一下。
原理就是在发送消息的时候传的时候多传一个用户名即可。
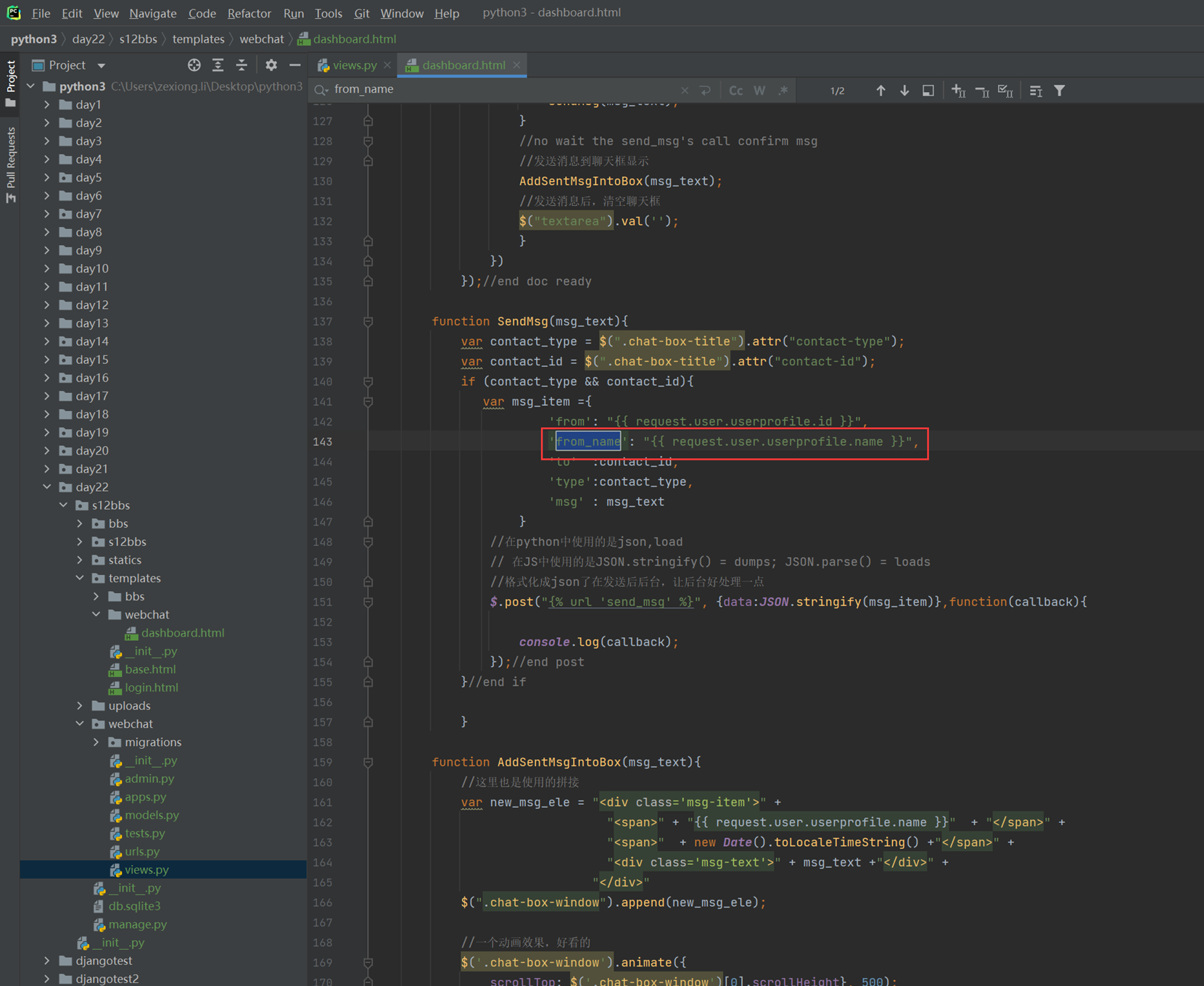
引用
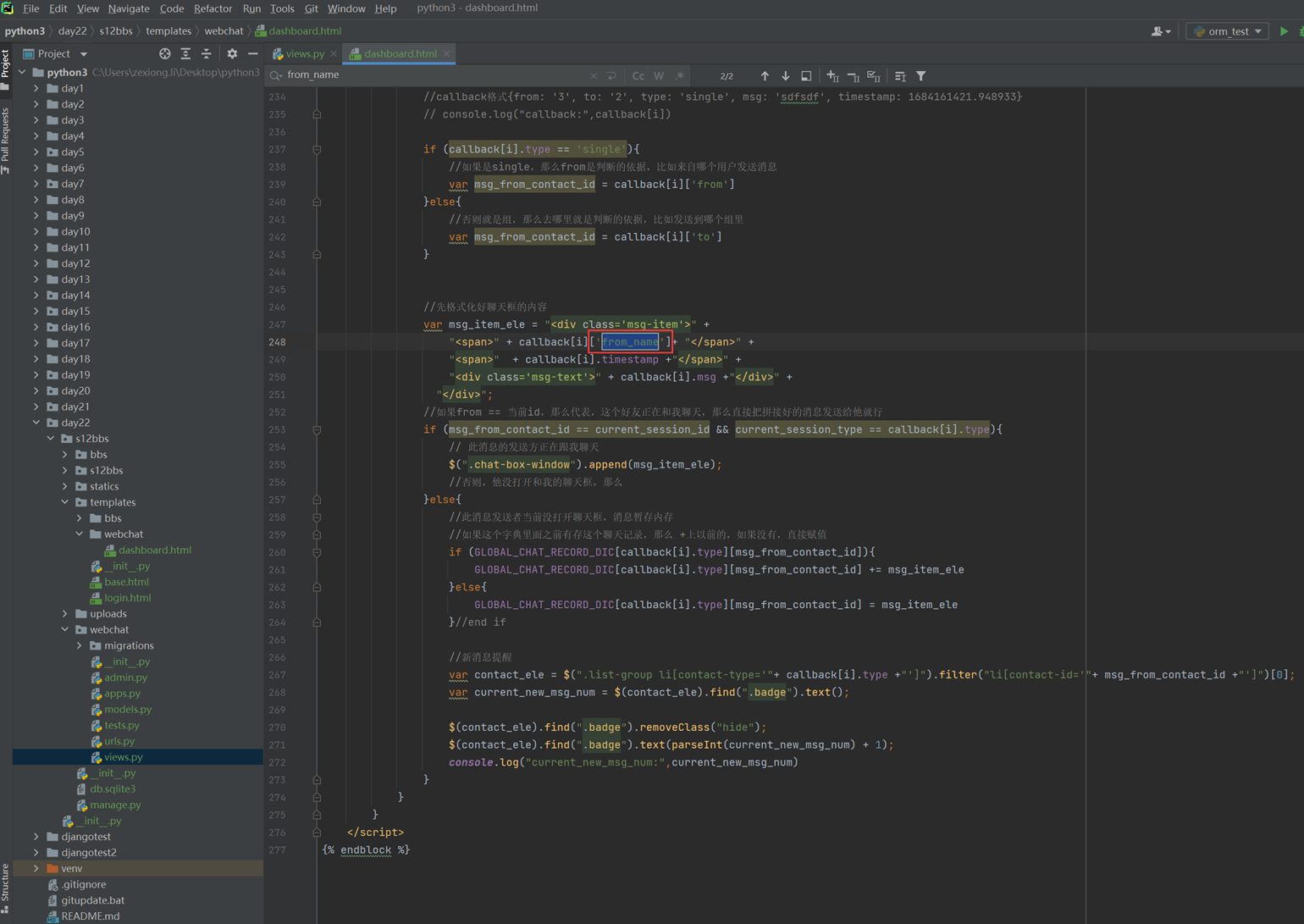
基本的功能都完成了,本章我还是做个测试结果出来,毕竟做了这么久了。

22.6 实现异步文件上传
因为开篇全是废话,25分钟视频,前面自己不知道怎么写,后面把以前的代码复制出来讲解,还讲的结结巴巴。所以两课合并。
本节课只做课堂简单记录,简单来说,啥都没演示成功,就是做了一个上传文件的按钮,然后上传文件成功了,结果最重要的一课,2小时的视频损坏,但是这2个功能不重要,可以无视,或者后面自己网上去搜索。
1.url
2.views
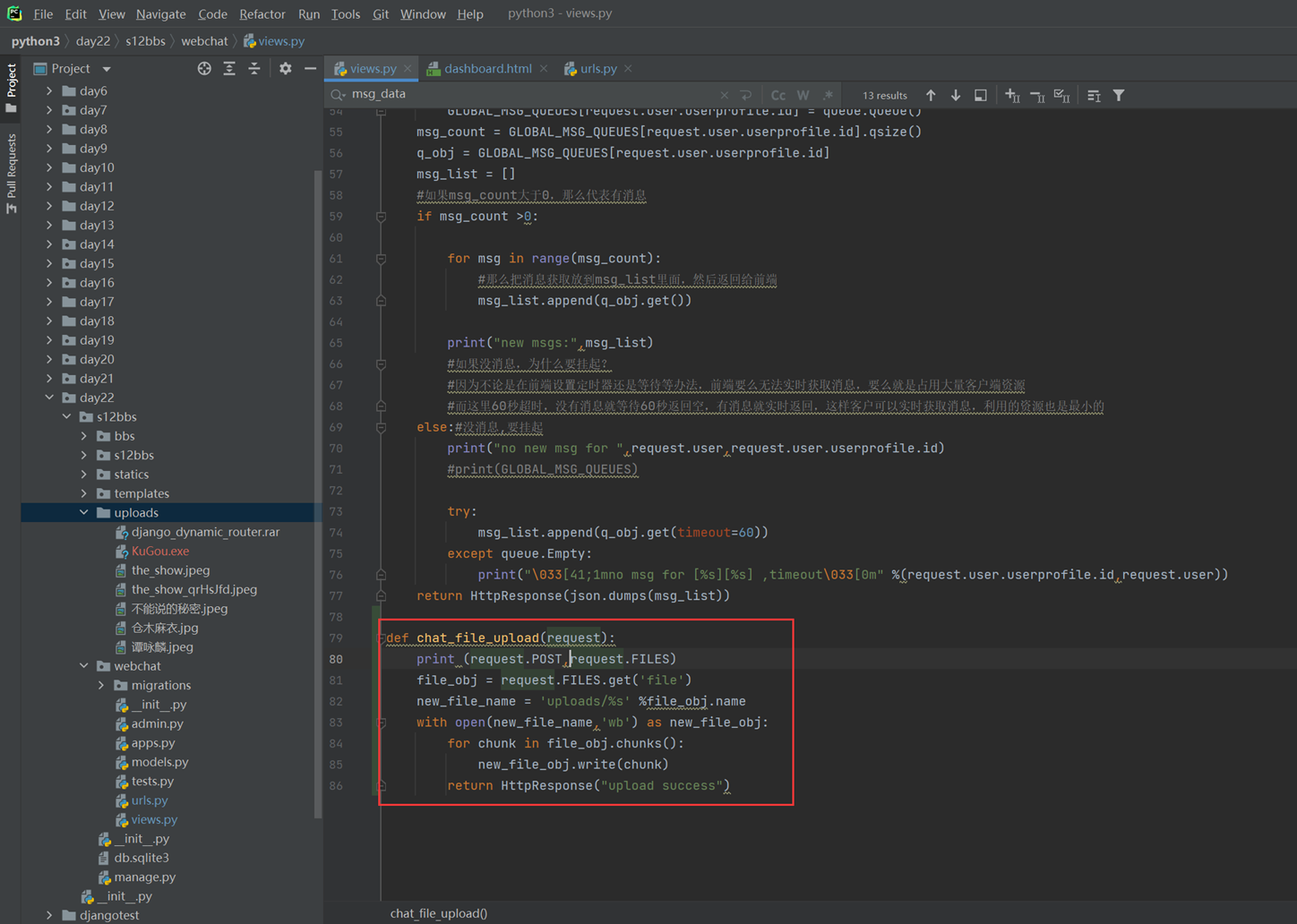
3.html
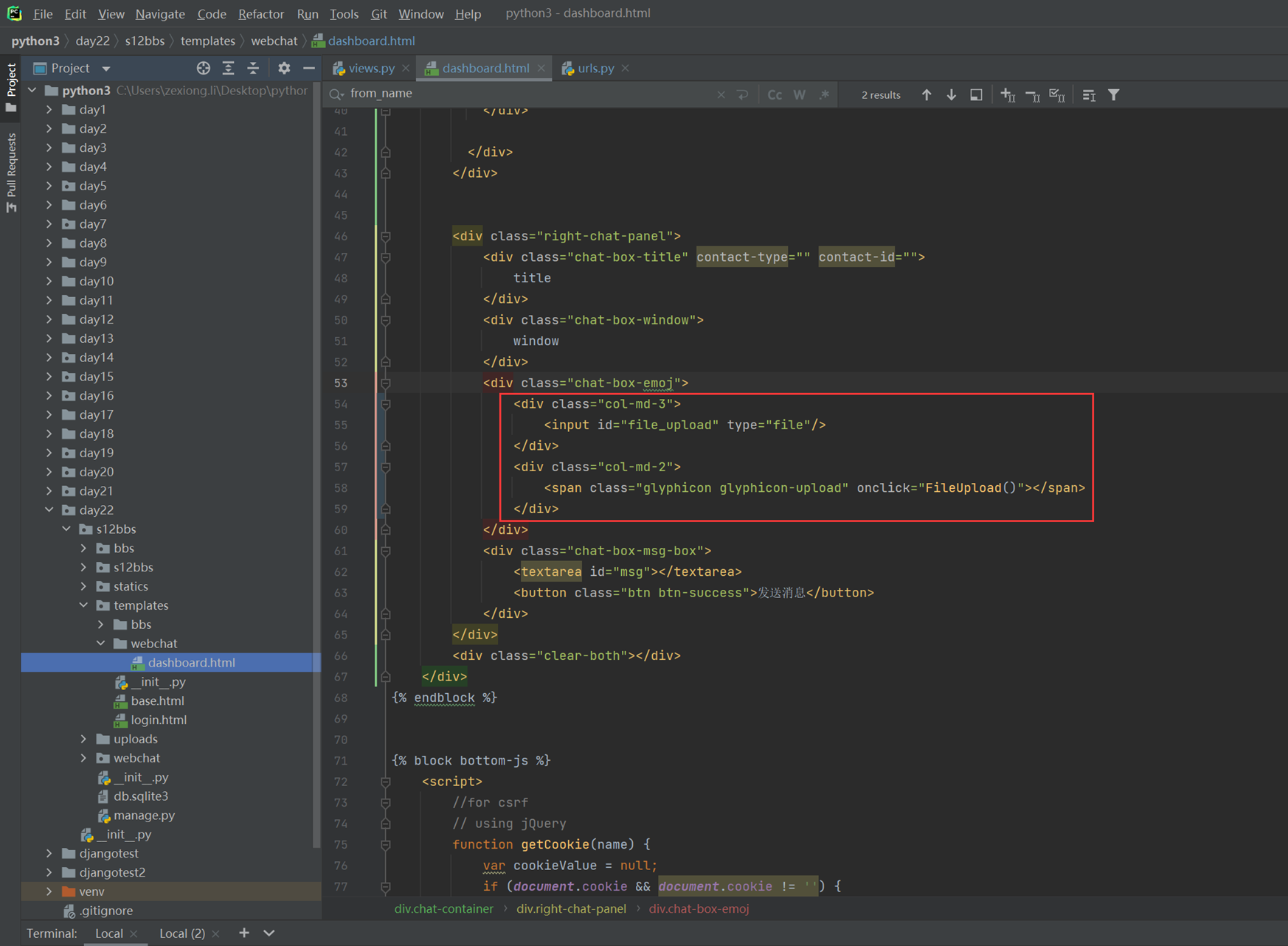
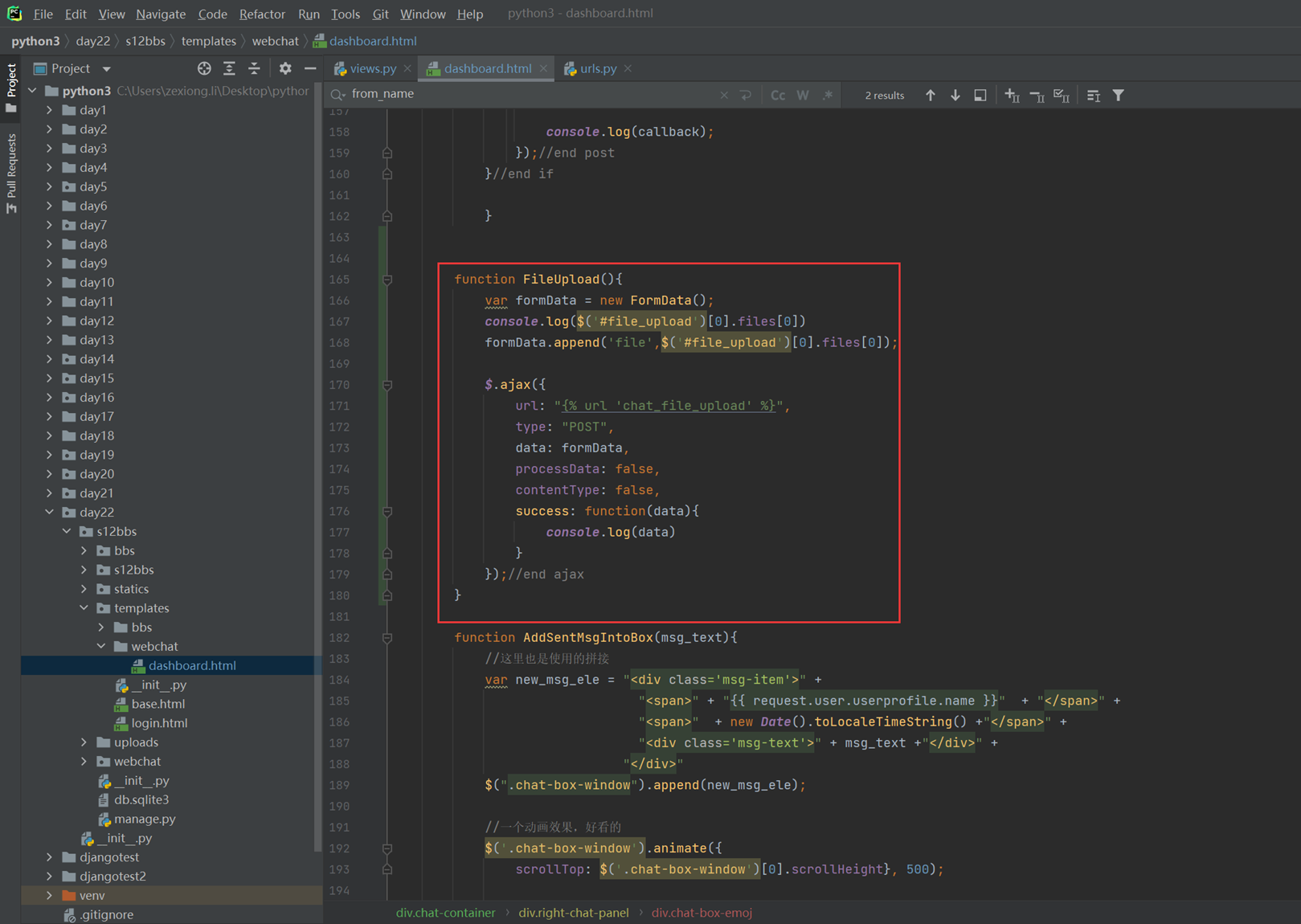
就一个上传成功,就不演示了。
22.7 实现异步文件上传2
两章合并
22.8 实现文件上传的进度条展示(视频损坏)
两个小时视频损坏,这里就不猜了,很难猜出来。
22.9 实现图片发送及在聊天框中展示
与上节课衔接性太重,没办法学习这一课,需要用到上一节课的代码,但是就这么一个功能了,可以跳过。
22.10 本节作业需求
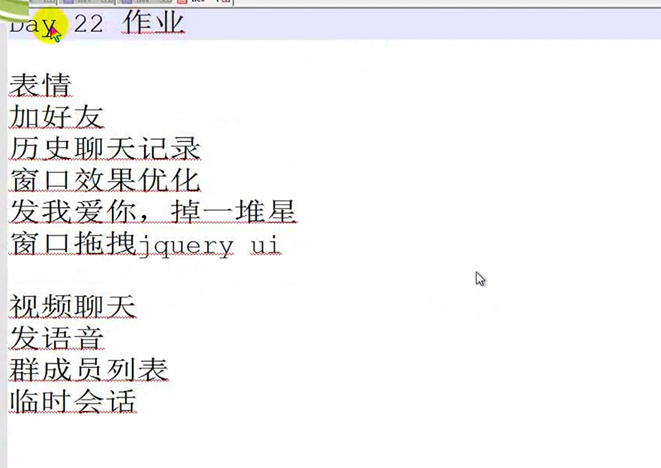
22.11 中间件介绍及使用
前15分钟在讲理论,讲的啥玩意,基本都是在秀自己的英文,原理讲的真垃圾。
讲真是垃圾,所以直接过吧。可以参考博客:https://www.cnblogs.com/lizexiong/p/17367090.html 比这个详细的多。
23.L23
23.1 主机管理项目需求分析
本节课就是简单聊一下需求,还有一些存在的问题怎么处理


后面又跳到saltstack的官网里面去讲解salt的原理,自己都不清楚,出现什么讲什么,讲的混乱不堪,垃圾。
最后用自己的一张图来解释后面我们的项目怎么写。
简单来说,就是发送任务→任务解析→任务放入队列→执行任务→然后把结果返回给队列→最后队列里面信息返回给Master
23.2 主机管理项目架构设计
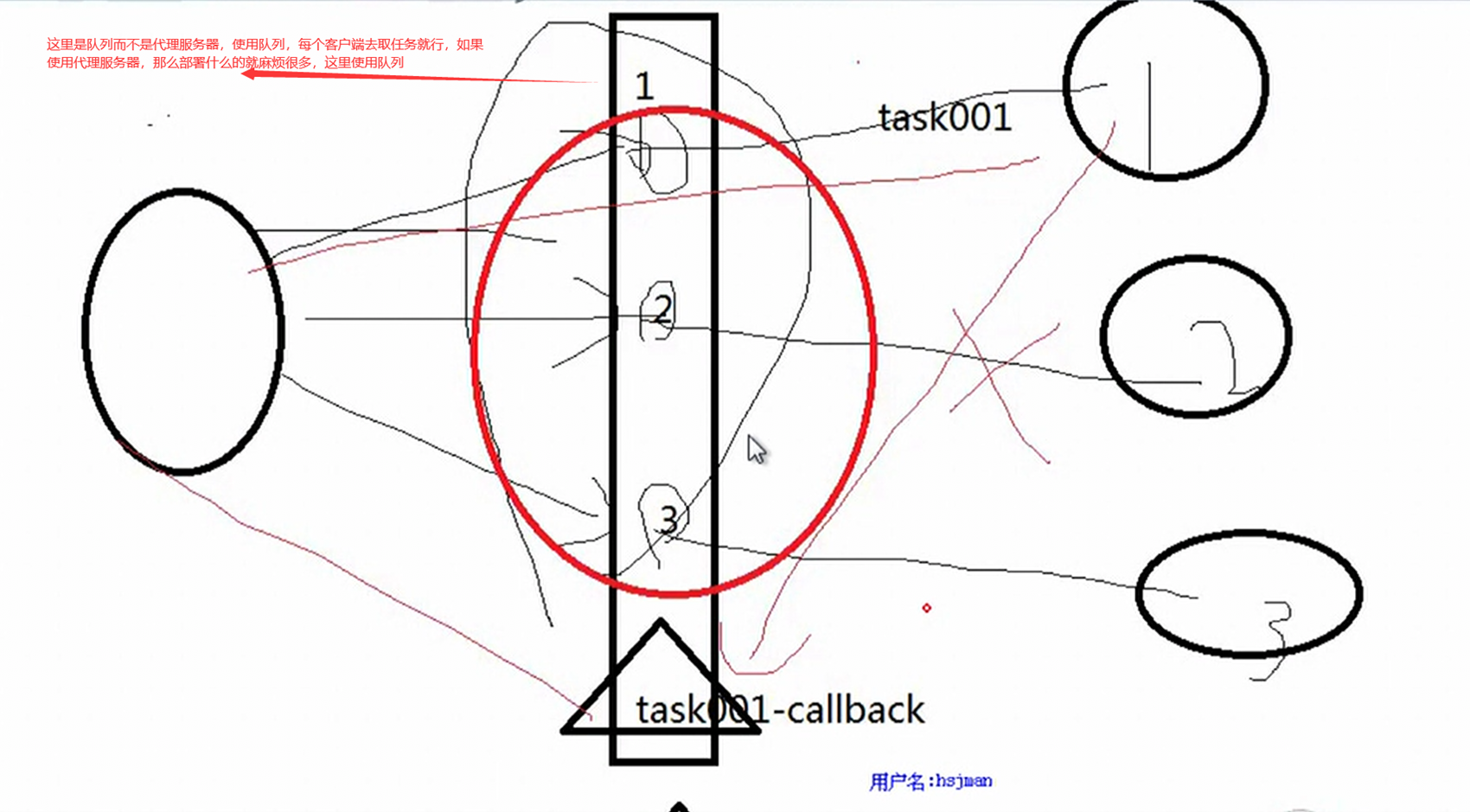
23.3 主机管理项目架构设计2
就是讲解salt的配置文件。
23.4 主机管理项目初始构建
本章就是创建项目,创建app,然后创建数据结构,就没了。
创建数据库表
剩下的settings里面添加app,生成数据表配置,表结构,这个就自行处理吧,不做全部的步骤演示了。
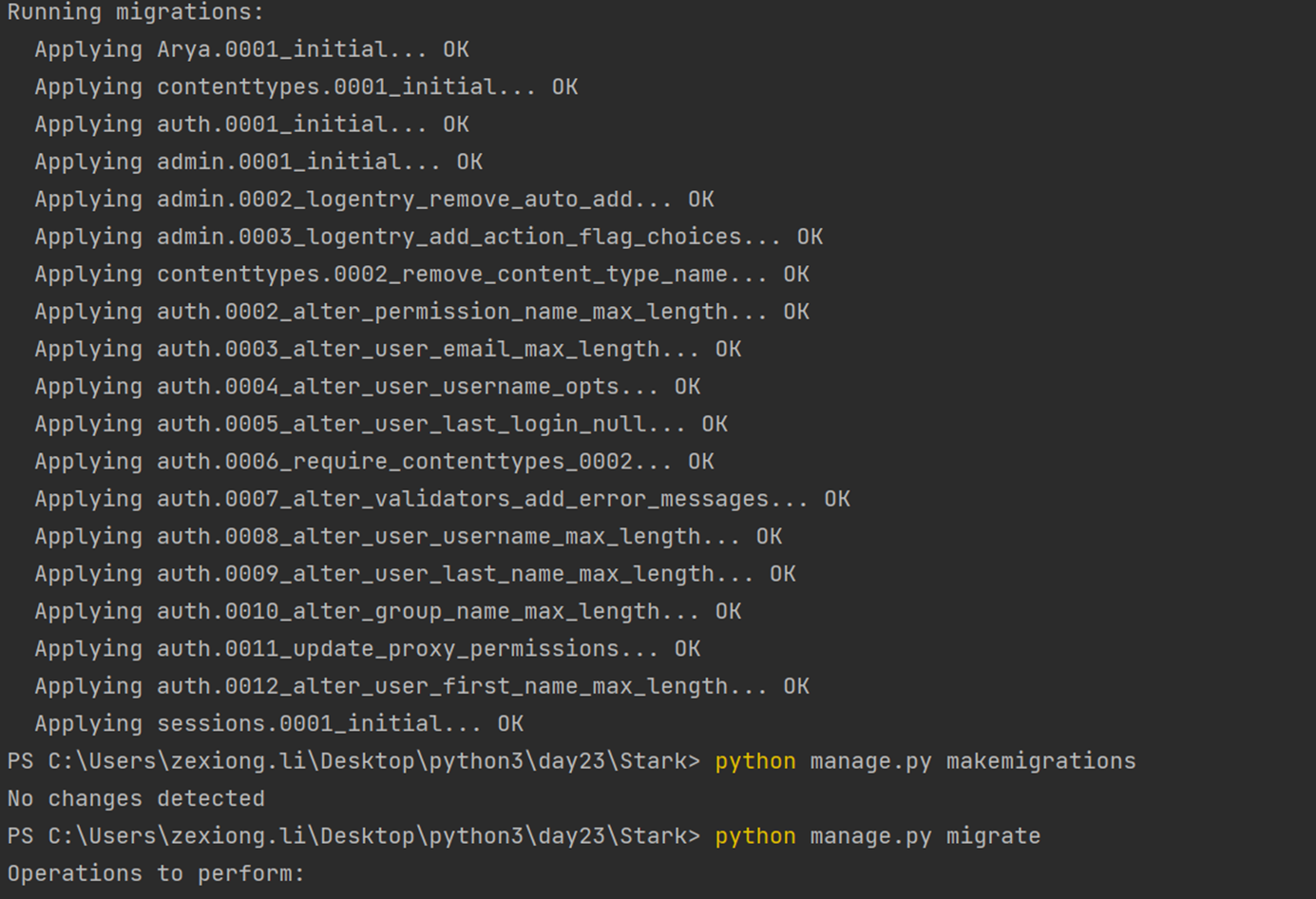
23.5 主机管理项目命令分发器
两章合并,不然笔记做起来不方便
专门的模块处理专门的事情,所以叫做分发器
我们一步一步的截图,看清楚作用以及调用规则。
本章就是把基础框架文件给搞出来
首先是入口文件salt.py,我们写了之后根据它一步一步调用看看结构
然后就是action_list文件,看看有哪些动作
然后就是插件,actions_list需要去调用具体的模块
最后就是用户输入的参数解析功能,比如,用户总不能随便输入吧,输入的一定是有规律的,把用户输入的命令判断是否合法。
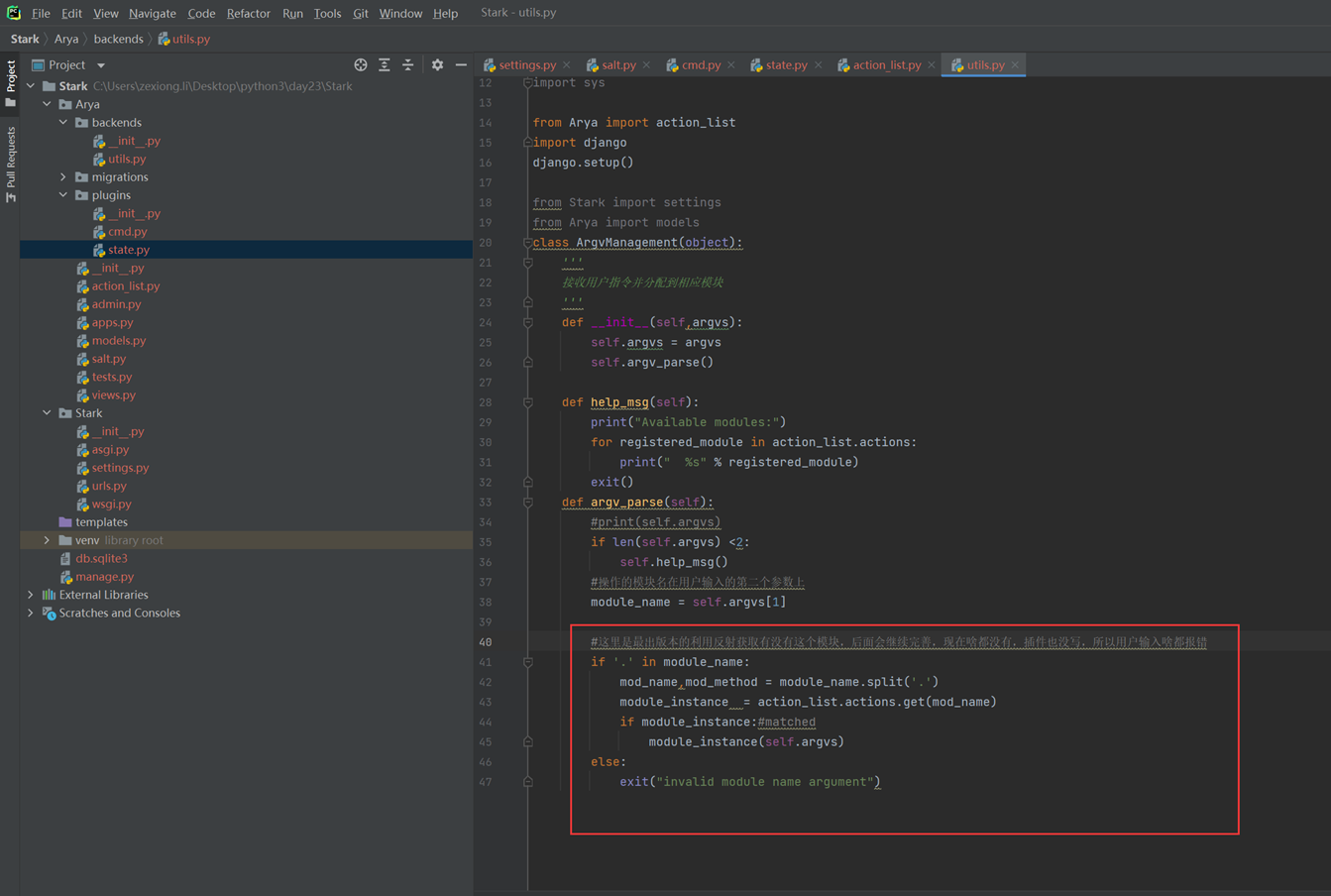
然后我们输入命令测试一下,看看是否可以正常跑
帮助文档啥都有了。
23.6 主机管理项目命令分发器2
和上一章合并了
23.7 主机管理项目编写插件基类
编写cmd插件的基类。
为什么要写这个基类?
为了能够提取主机,比如,每次发送命令的时候,我怎么知道我是什么系统的主机,我的ip是什么?所以这里要单独写一个类,用来从数据库里面提取主机信息,每次调用模块之前,会从数据库里面获取主机ip,主机的系统类型等。
刚开始,我以为是怎么判断,原来主机信息是存在数据库里面,直接通过这个类把主机信息从数据库里面提取出来。无法理解这个老师的思路,设计出这样的系统,用的麻烦,但是这里主要是学习开发思想,就不要计较了。
这里只是写一个简单的demo
然后只要我的cmd或者继承以及使用这个类的插件,都会自动提取主机。
23.8 主机管理项目提取主机列表
本章目的就是为了把主机信息从数据库里面提取出来(简直就是脱裤子放屁,这个系统设计)。
我们现在数据库里面没有主机,首先需要创建一些数据库数据,并且,数据库之前没有系统类型,我们这里也需要先添加上去。
首先更新数据库表结构。
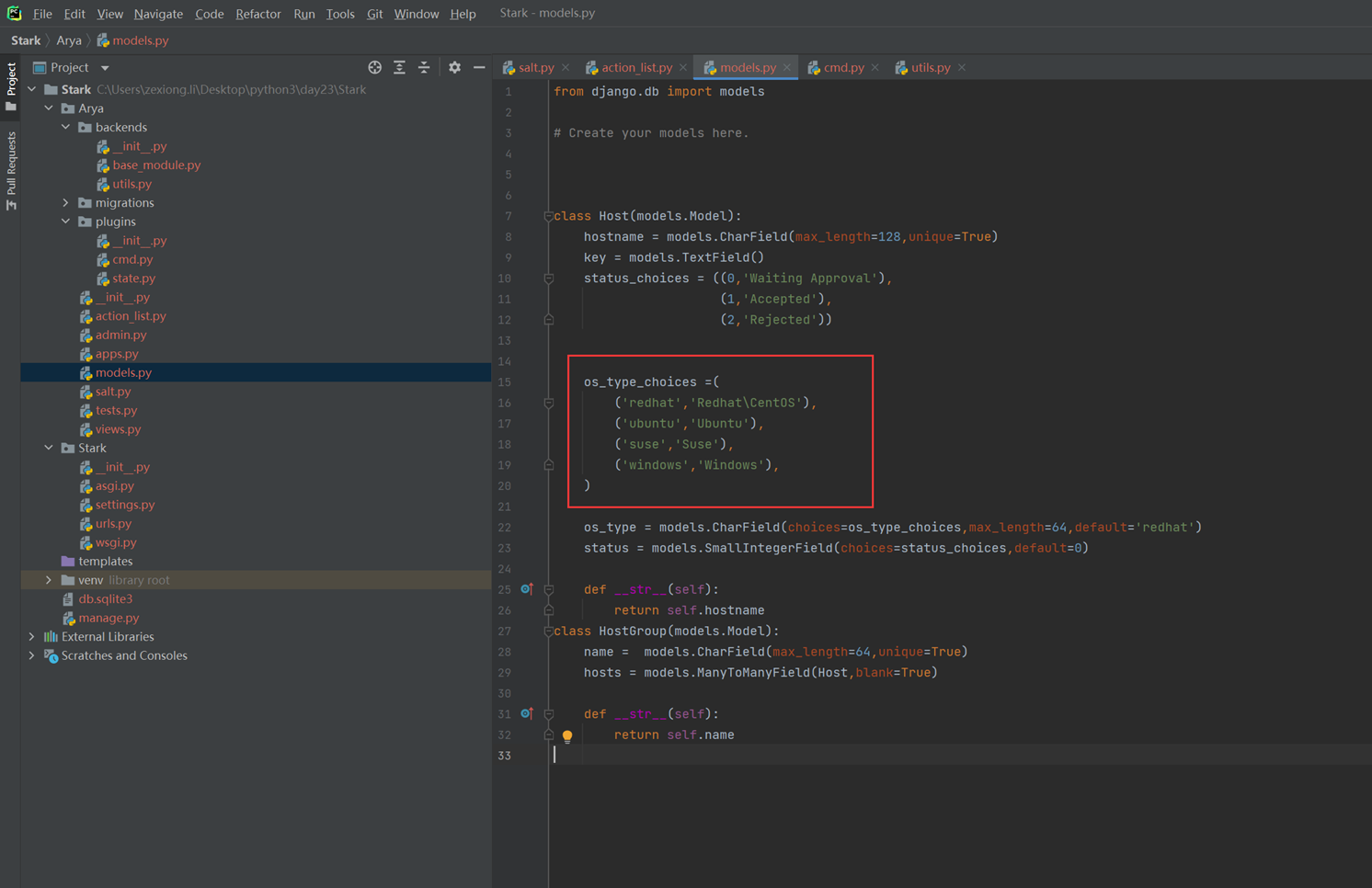
然后更新表结构等等
现在需要再数据库里面添加一些主机数据。
注册一下admin,用django后台管理
然后开始搞提取主机列表的程序
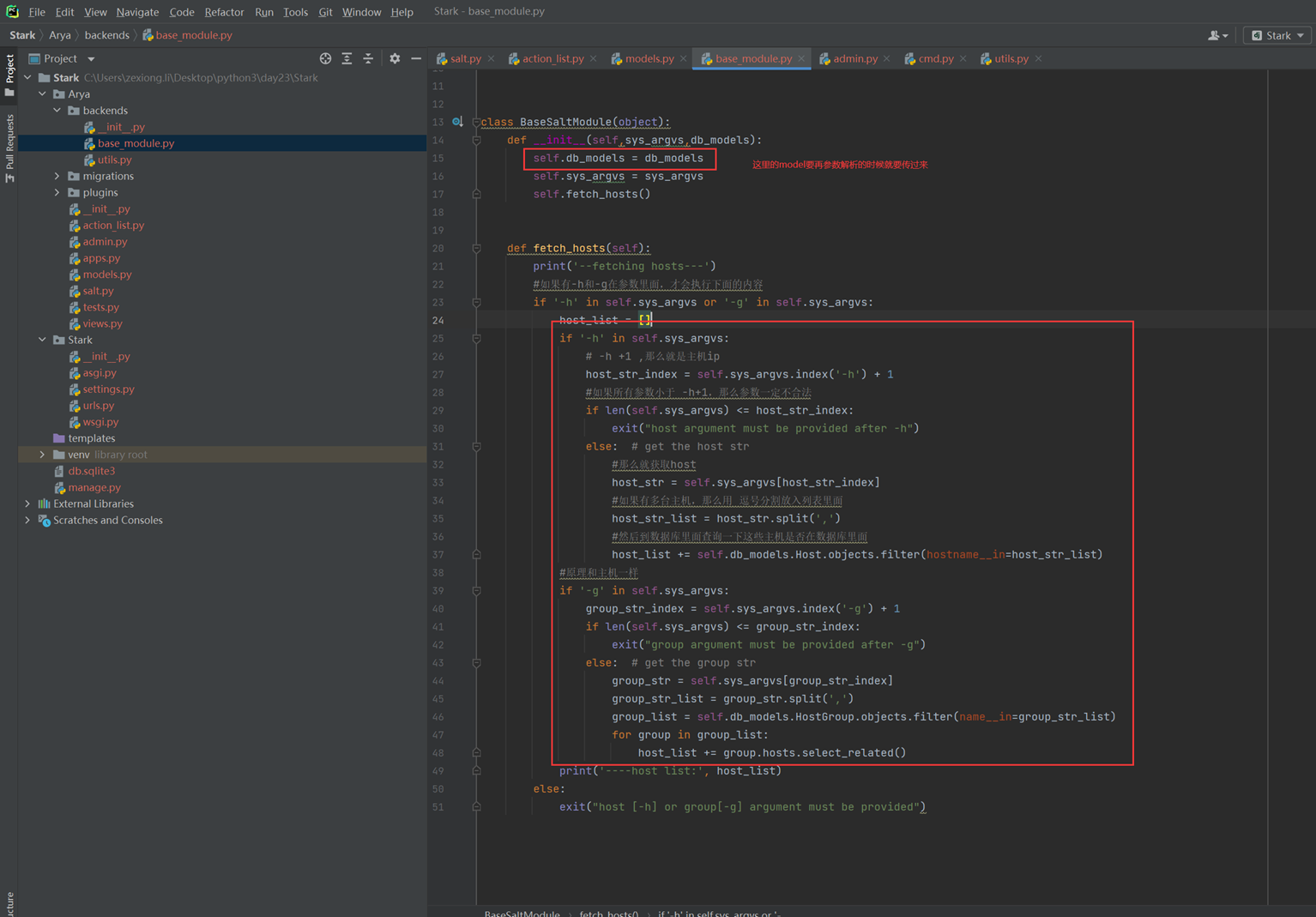
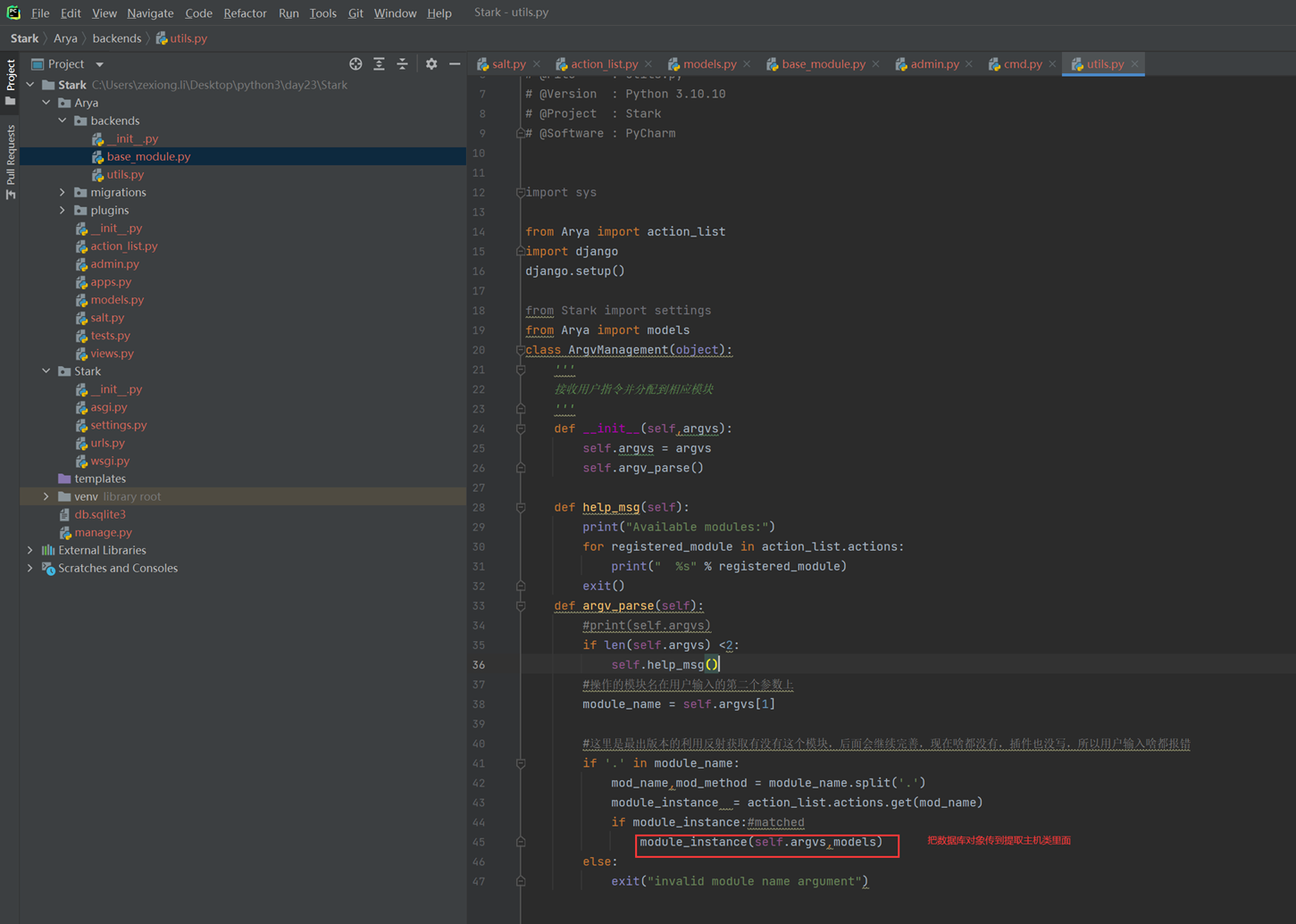
测试一下

23.9 主机管理项目提取yaml配置文件
后面章节的讲解我们都已state.apply解析应用一个配置为主,本章主要实现,通过命令 python saly.py state.apply -h 主机 -f 配置文件,来把配置文件读取出来。目前只做读取,复杂的功能下一章讲解。
本章内容根据源码复刻的,所以对比视频中有点细小的差别,但是问题不大。最后的课堂上的代码也会变成源码一样的。
1.首先需要获取主机类型
因为后面要针对不同类型执行一些细小的不同的操作,这个操作对本章学习的内容没有用。
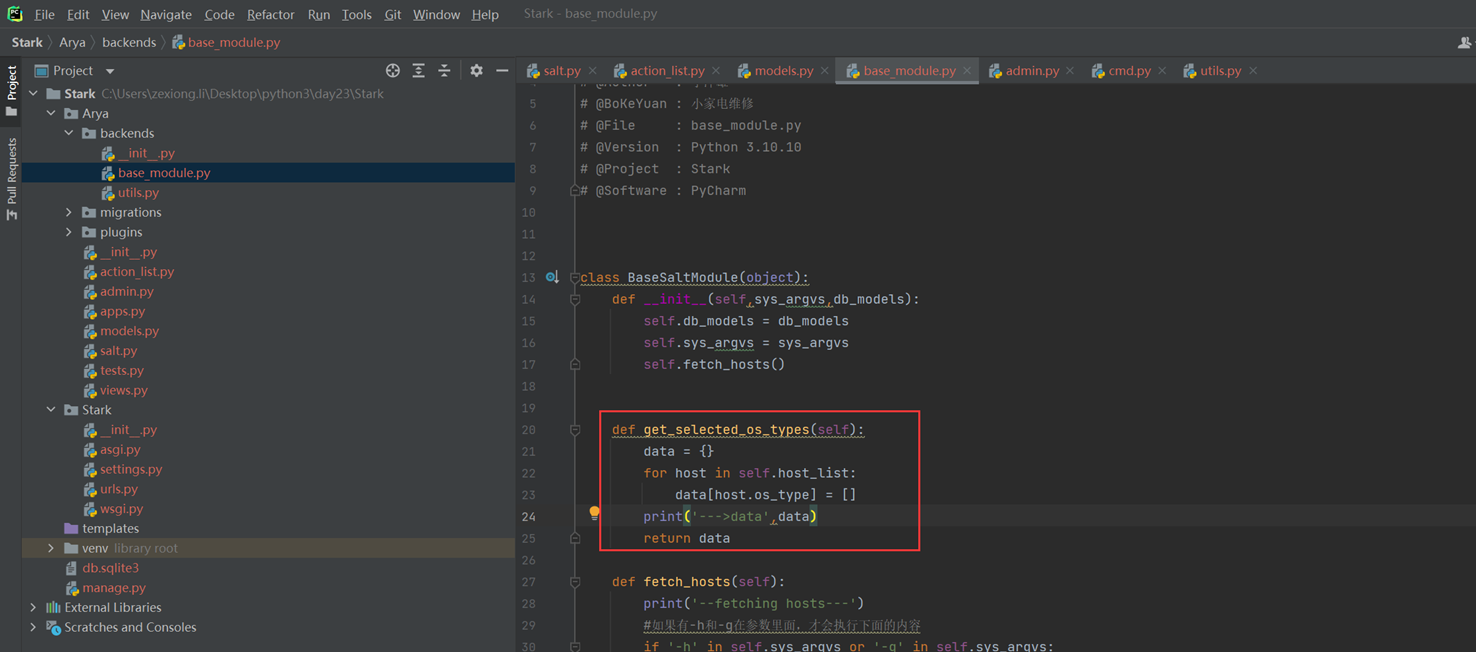
2.其实这里才是第一步,那就是需要解析配置。
其实本章绕来绕去,核心的其实就三步
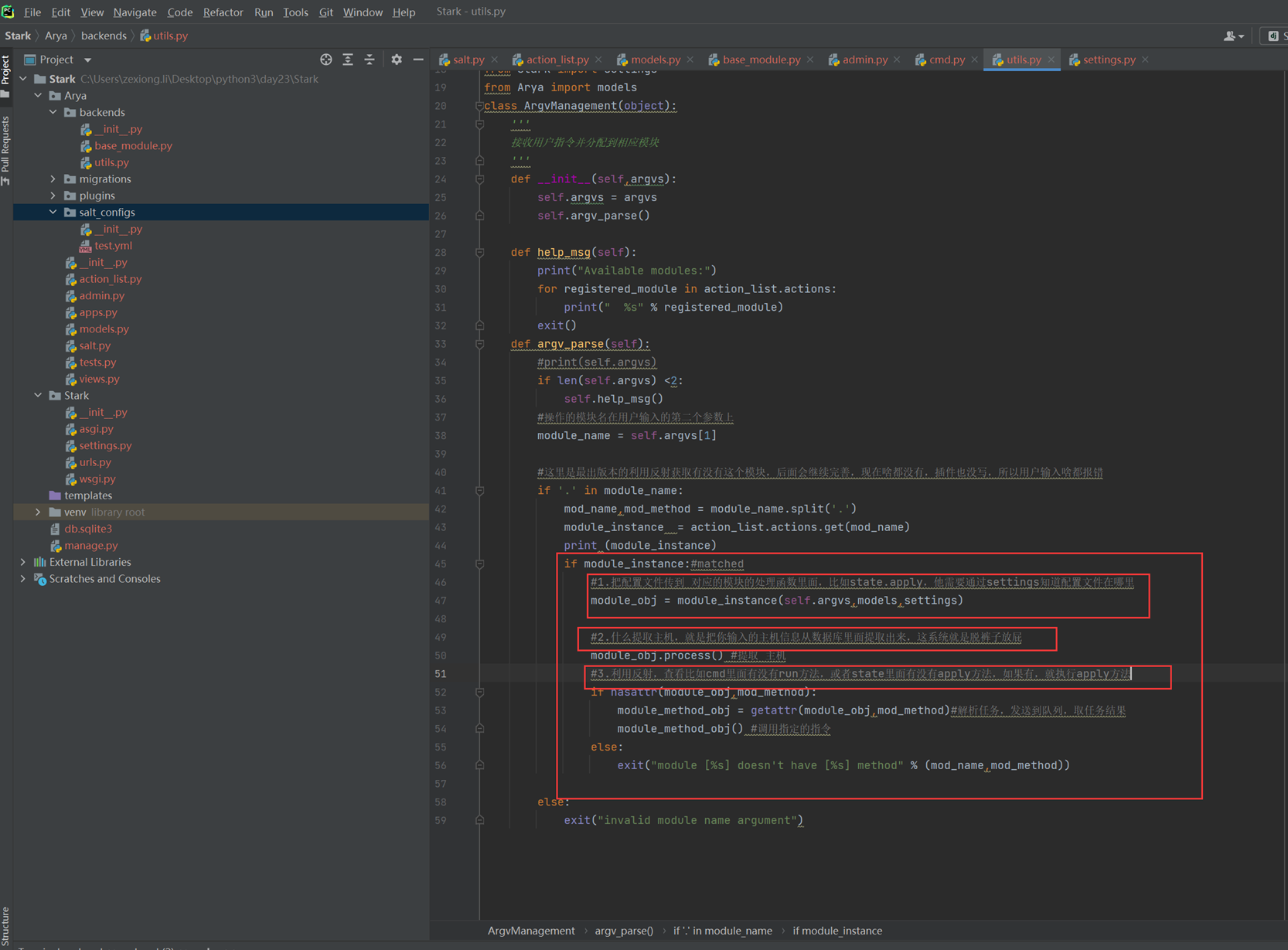
Yaml配置需要先写好
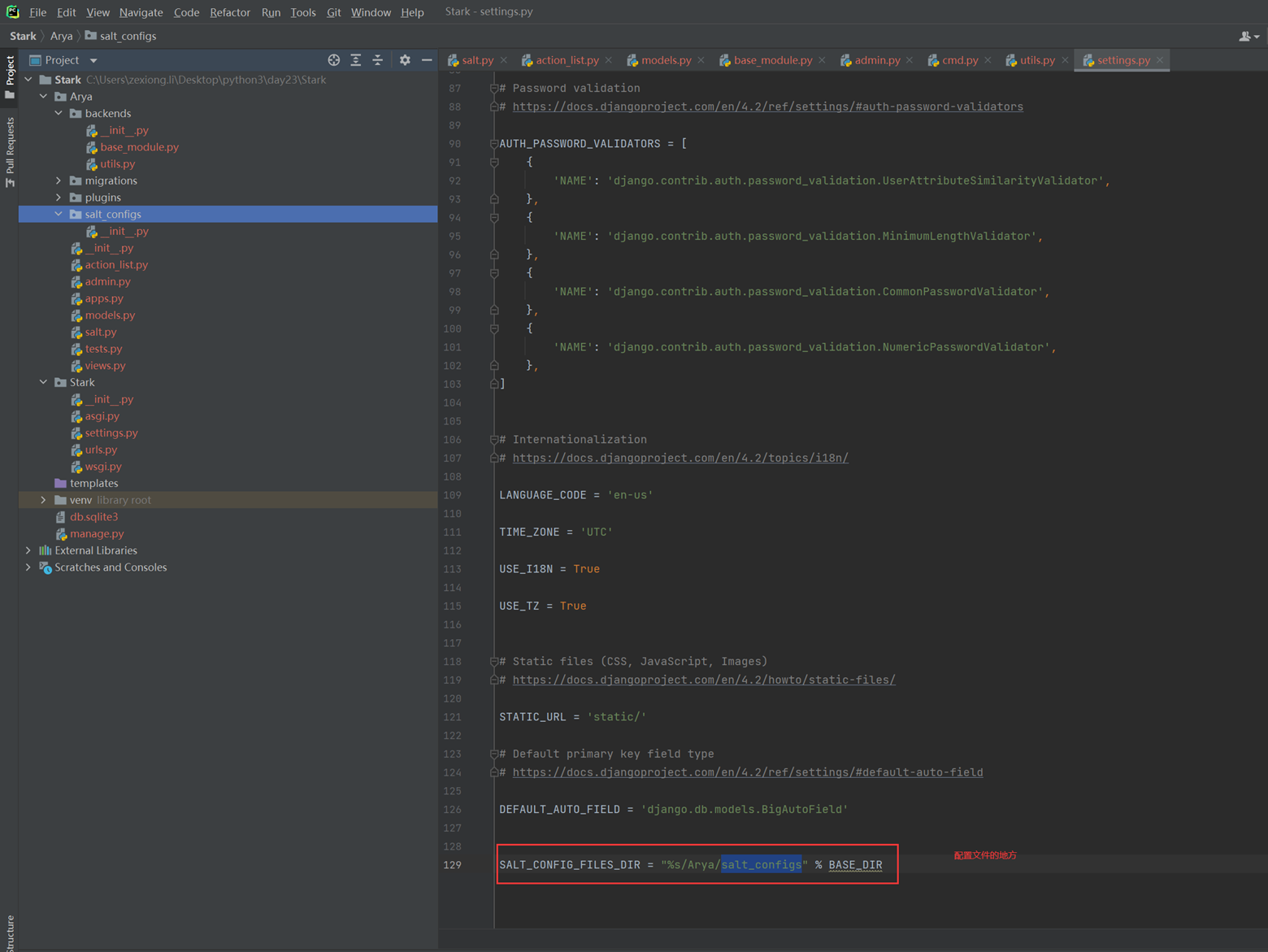
2.1 这一步没什么大的作用,就是根据用户输入的命令判断模块对象,比如cmd,state等,上面的图片中已经标出来了。
2.2 提取主机信息,就是从数据库里面把主机的ip,系统类型提出出来。在解析配置文件的时候通过self来调用这个变量在判断是什么系统。
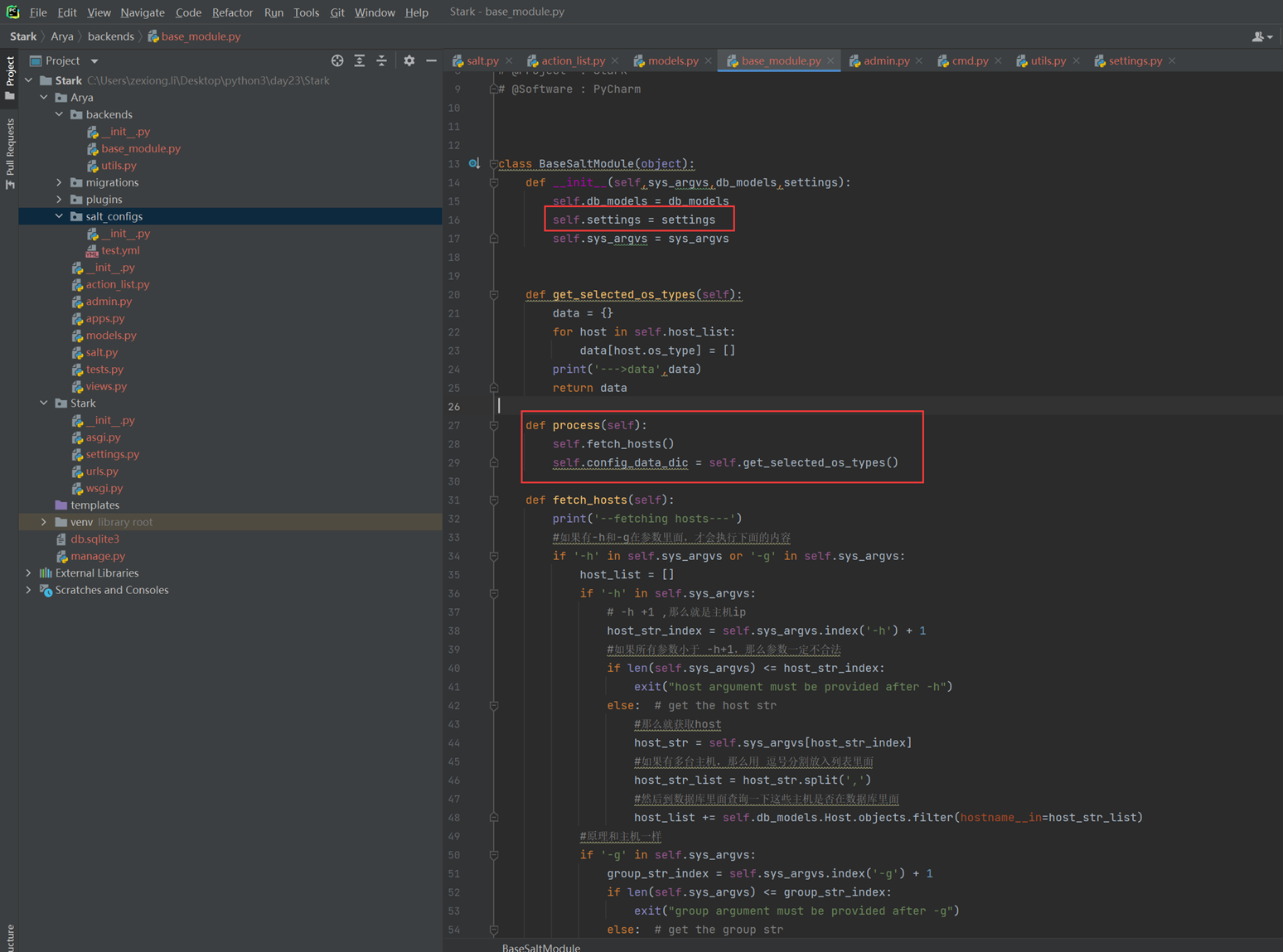
2.3 本章的主题就是假设用户输入state.apply,那么我就需要判断是否有apply这个功能,这个功能能否解析出完整的yaml文件。本章实现的就没那么高端,仅仅能在yaml解析打印出来就结束了
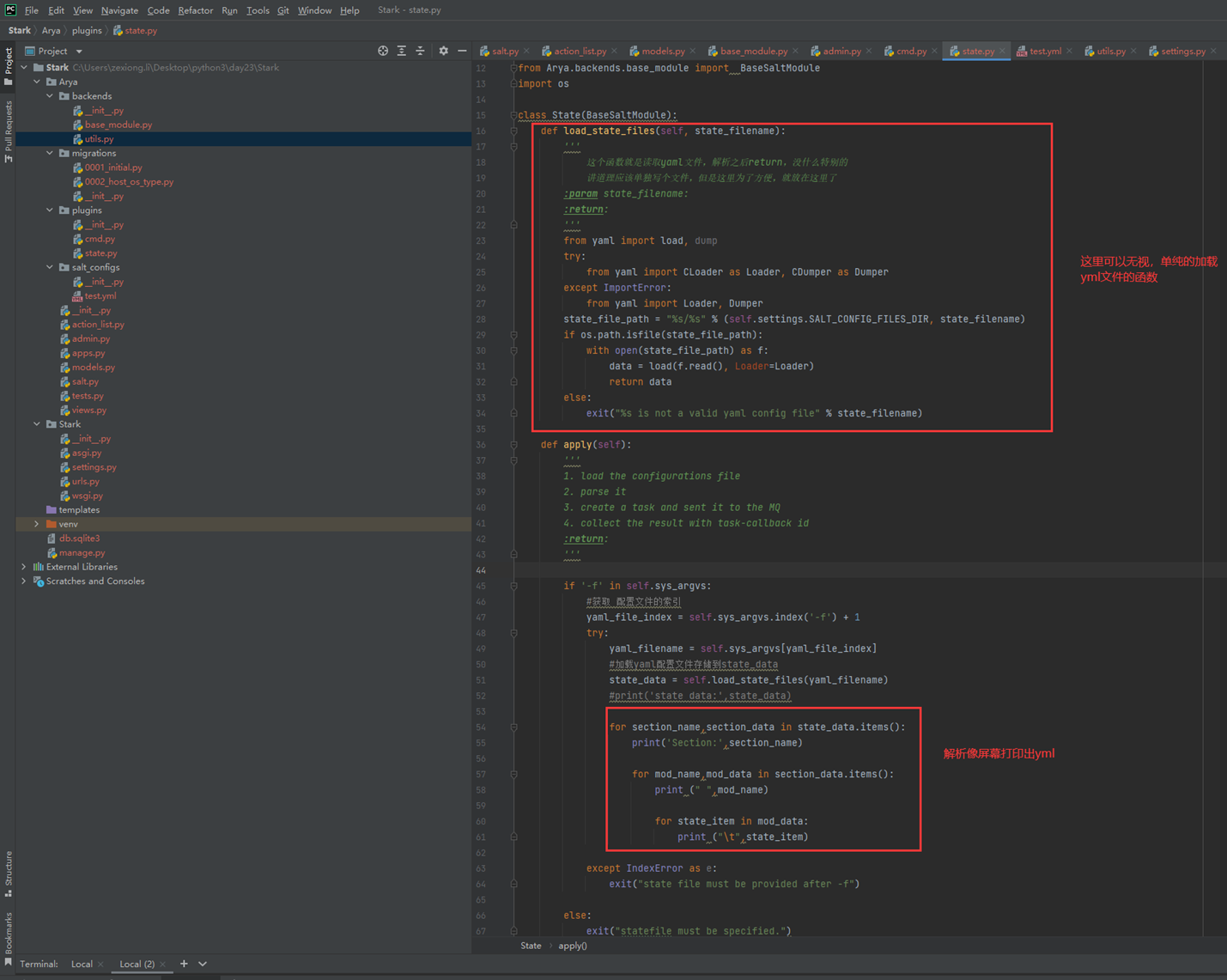
执行命令查看结果

23.10 主机管理项目动态调用插件进行数据解析
简单来说,就是具体解析yml文件的每一个区域,每一个模块,每个模块的方式交给每个方法去处理,比如user,group,pkg,file全部拆分交给每个模块自己去解析,本节课代码虽然少,但是讲解了一个多小时,一直报错,牛逼的老师大概20分钟就能讲完。
本节就是做了简单的解析,能通过yml文件解析到具体的比如pkg.install,user,present,1小时做的仅限能找到plugIns下面的模块。什么都没做,什么都没做
首先,还是在state下面完善apply方法
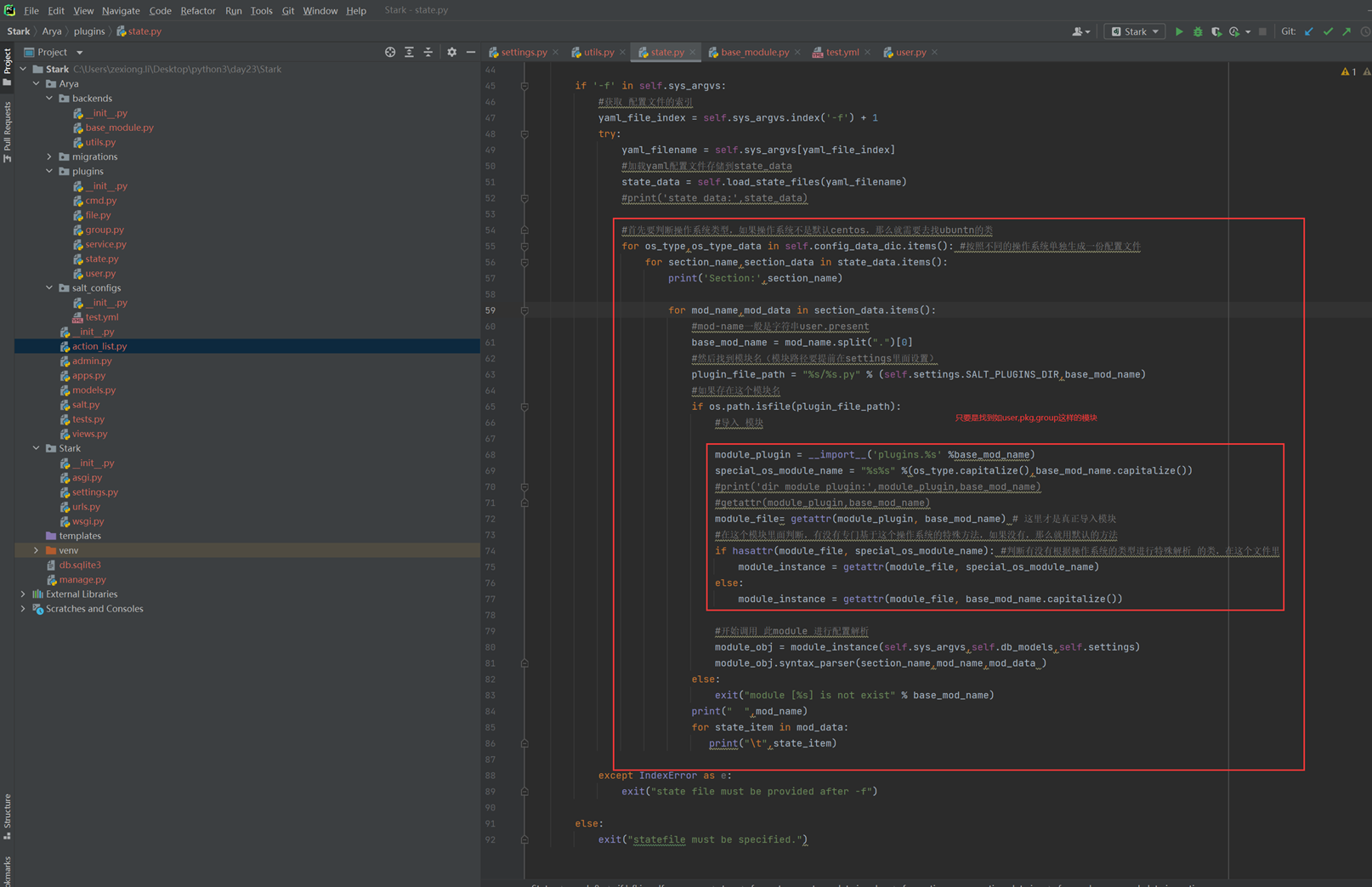
下面看看plugins里面的模块怎么搞的,就拿一个user举例子
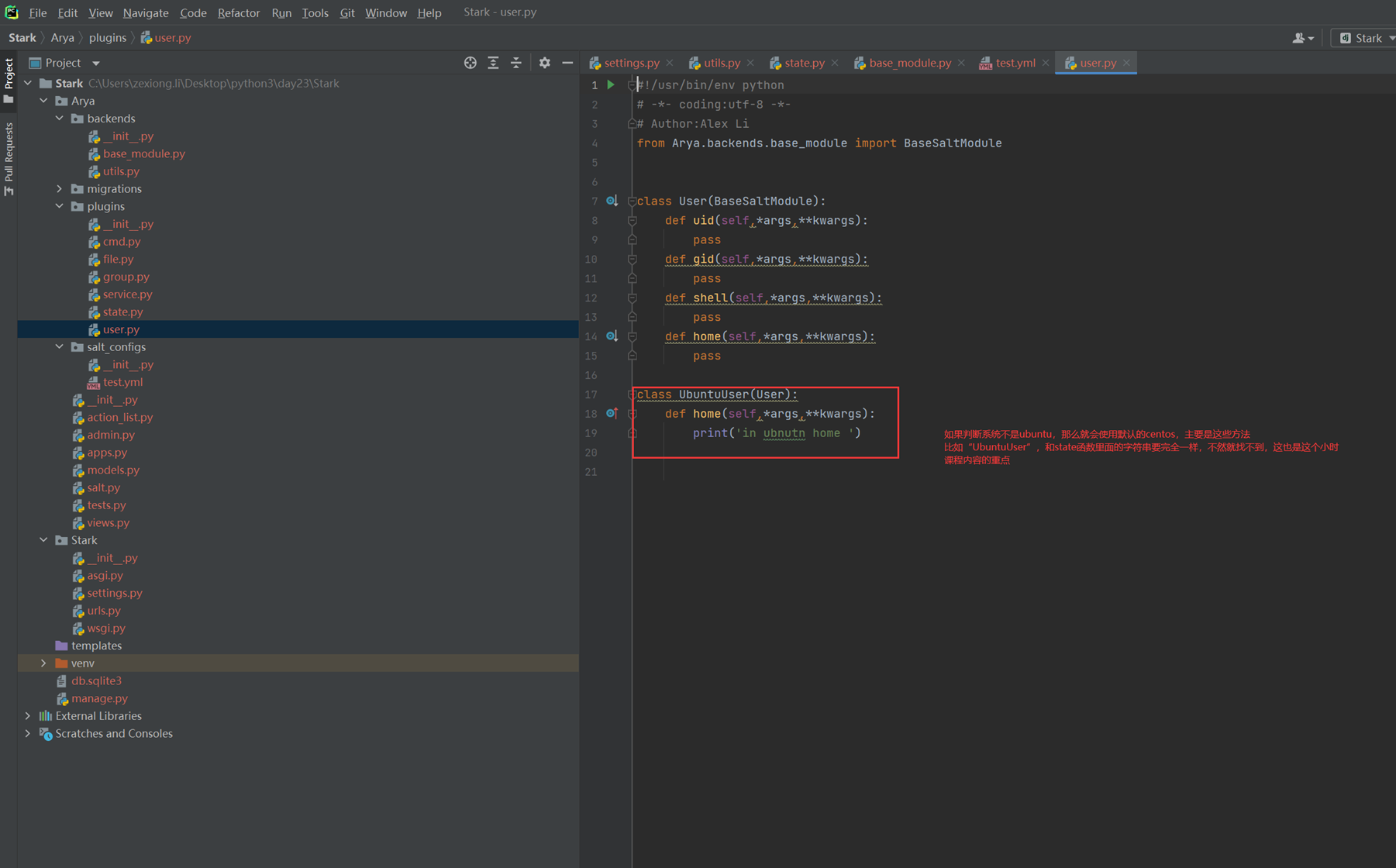
还在base_module里面写了一个解析模块,但是是空的,什么都没有,估计是下节课或者明天讲解。
执行看看结果
23.11 主机管理项目动态调用插件进行数据解析2
合并到了上一课
23.12 主机管理项目对模块中的参数进行解析
本节基本啥也没讲,就多了一个优化参数解析的功能,刚到具体参数的地方,课程就结束了。
由于能力有限,哪个老师注释了yml一部分配置,说是为了先解决简单的,注释后的yml如下:
然后基类里面优化了一点解析的功能,但是没完成。
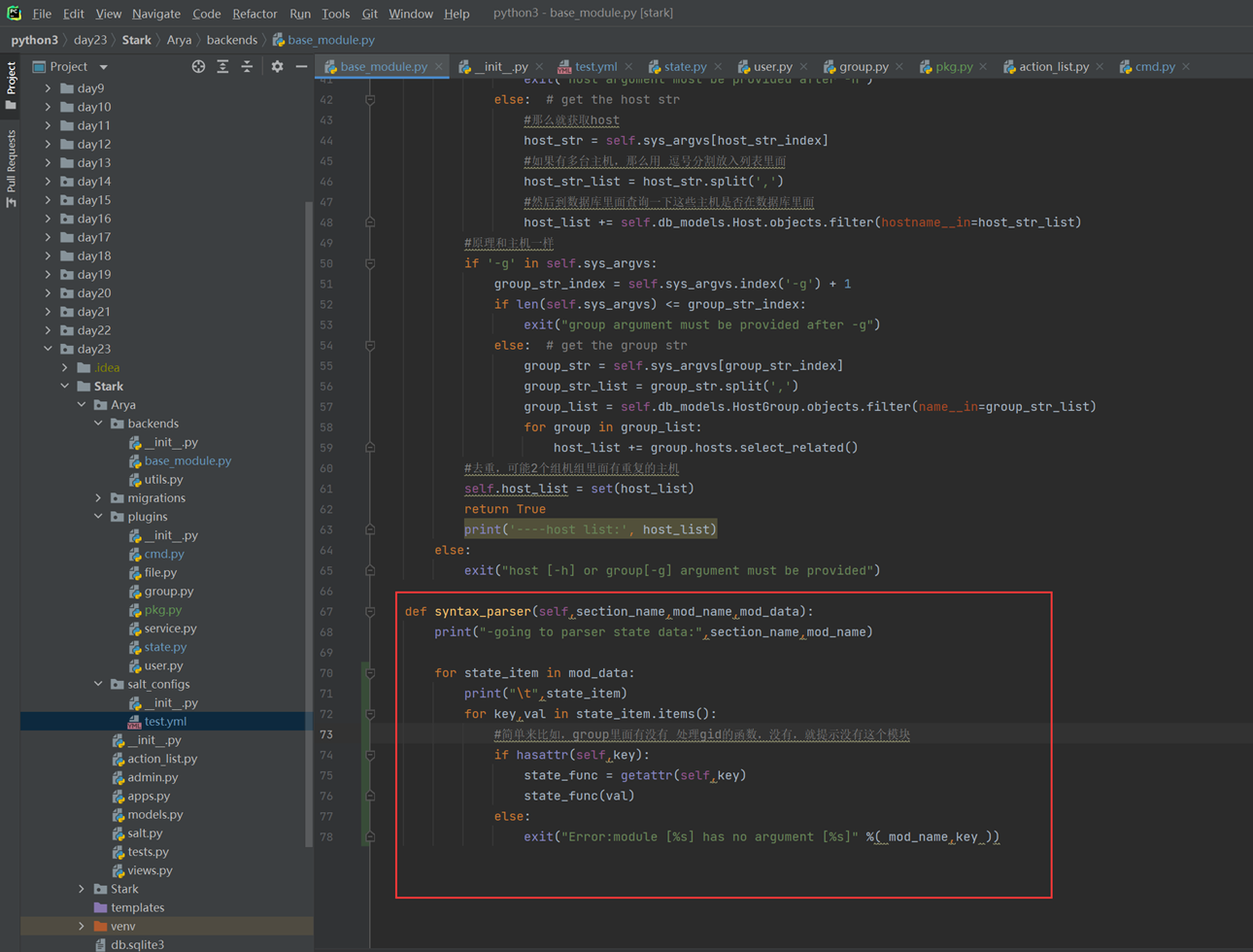
查看结果,这里会有一个小报错,还有一个小小小的知识点。
关于require这个字段,很多都必须要有这个,所以这个可以加到公共的base_module里面,所有模块都可以调用。

再次执行看看有没有报错
本天课程结束。
24.L24
24.1 上节鸡汤之上半年的变化
跳过
24.2 捋一捋上节内容
本章就是复习上节课的,如果熟悉,不需要看笔记,如果时间久了,忘记了,看这里做的笔记也没用,所以本节课不做记录
24.3 生成解析数据
生成解析数据的目的就是为了把命令拼接成为字符串命令。
本节课40多分钟,其实啥都没讲,真的啥都没怎么讲,就是做了一下简单的检查的参数是否正确,然后做了一个及其及其简单的拼接。
包括做了一个比如配置文件 user.present: present这个动作的简单解析(甚至都没开始写,这节课就结束了)
首先,判断参数是否是正确的类型,是一个公共参数,很多方法都需要使用,所以写到公共里面。
然后具体的插件方法里面去判断,比如user的方法里面去判断。
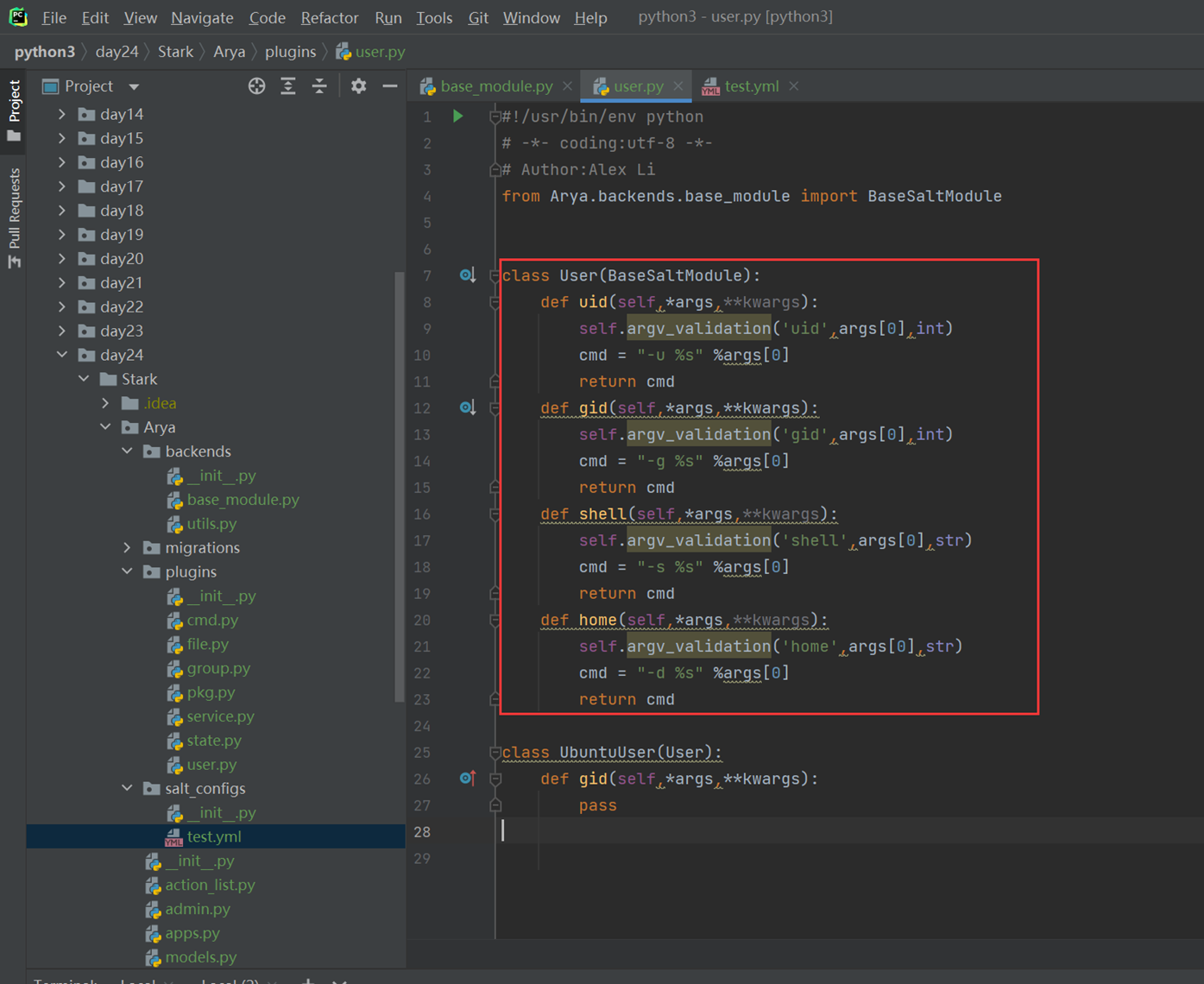
简单执行命令测试,肯定没有报错,因为配置文件都是正确的。
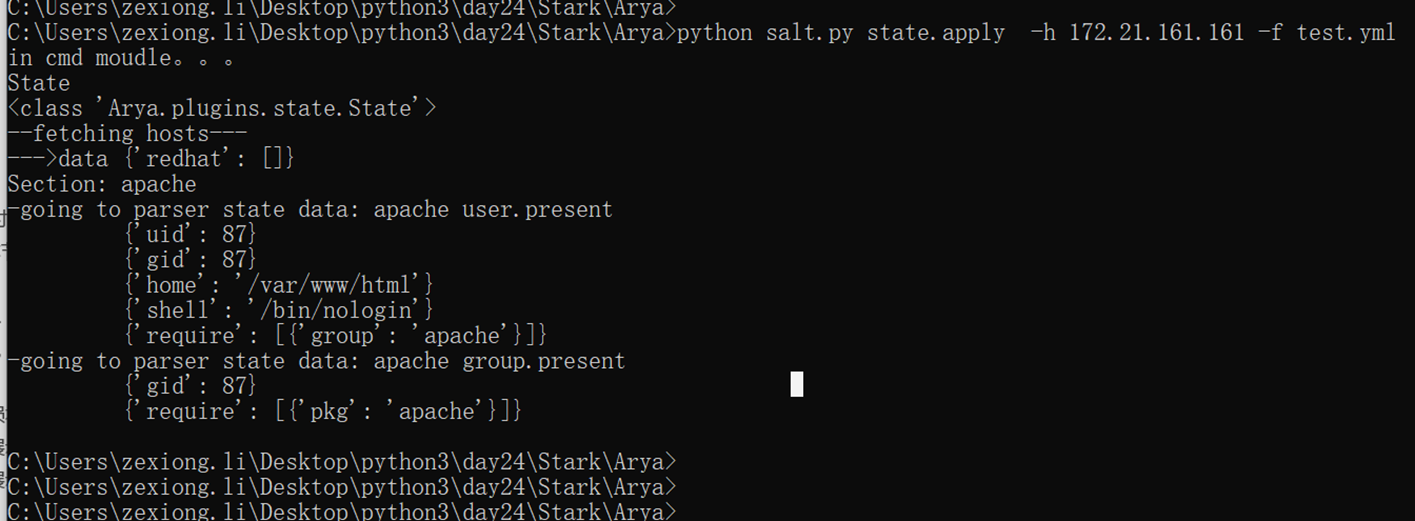
这时候,突然有一个事情,解析完这些uid,gid都是用来干什么?
这里就会有一个参数
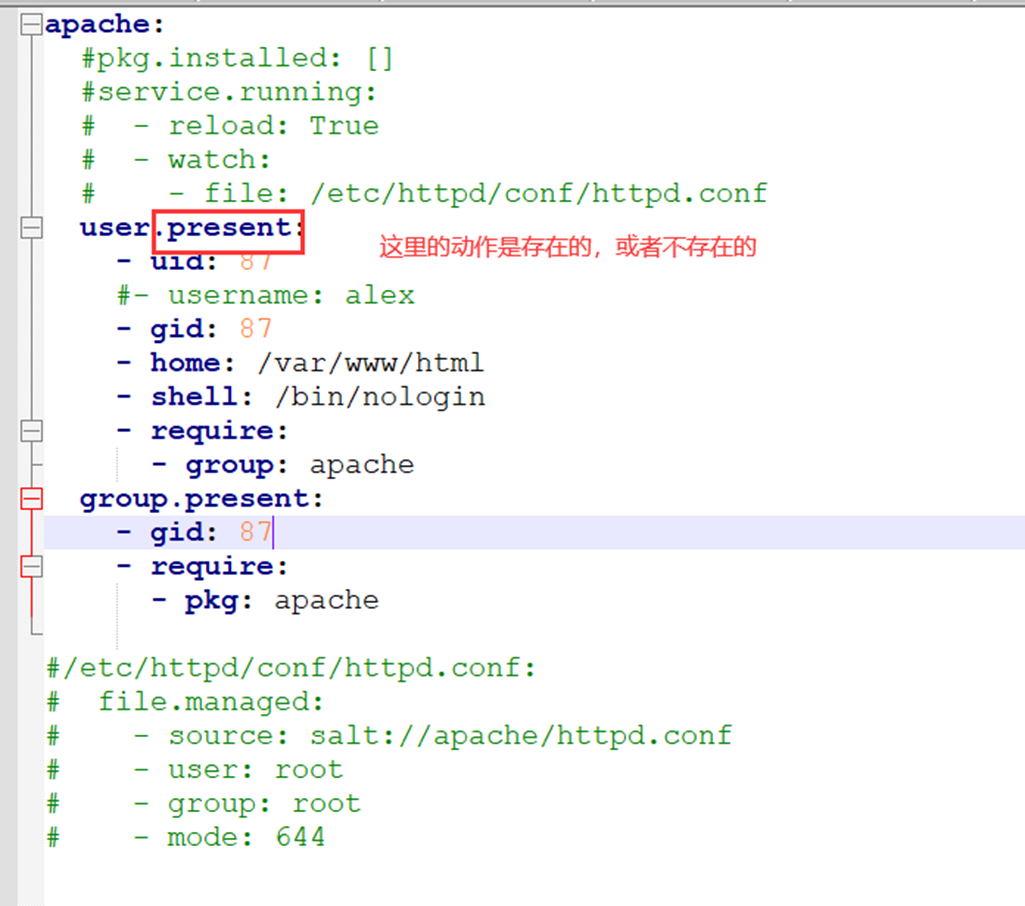
比如user下面的uid,gid等等解析完成之后,都是一个个单独的参数命令,我们怎么把他汇聚起来呢?
那么在解析完成后通过一个动作或者参数,也就是present来判断,在这个方法里面具体处理。
(present在salt里面代表的意思是参数要存在,还有一个是unpresent,是不存在的)
所以User的插件里面加一个present方法
然后,我们看看判断动作的函数
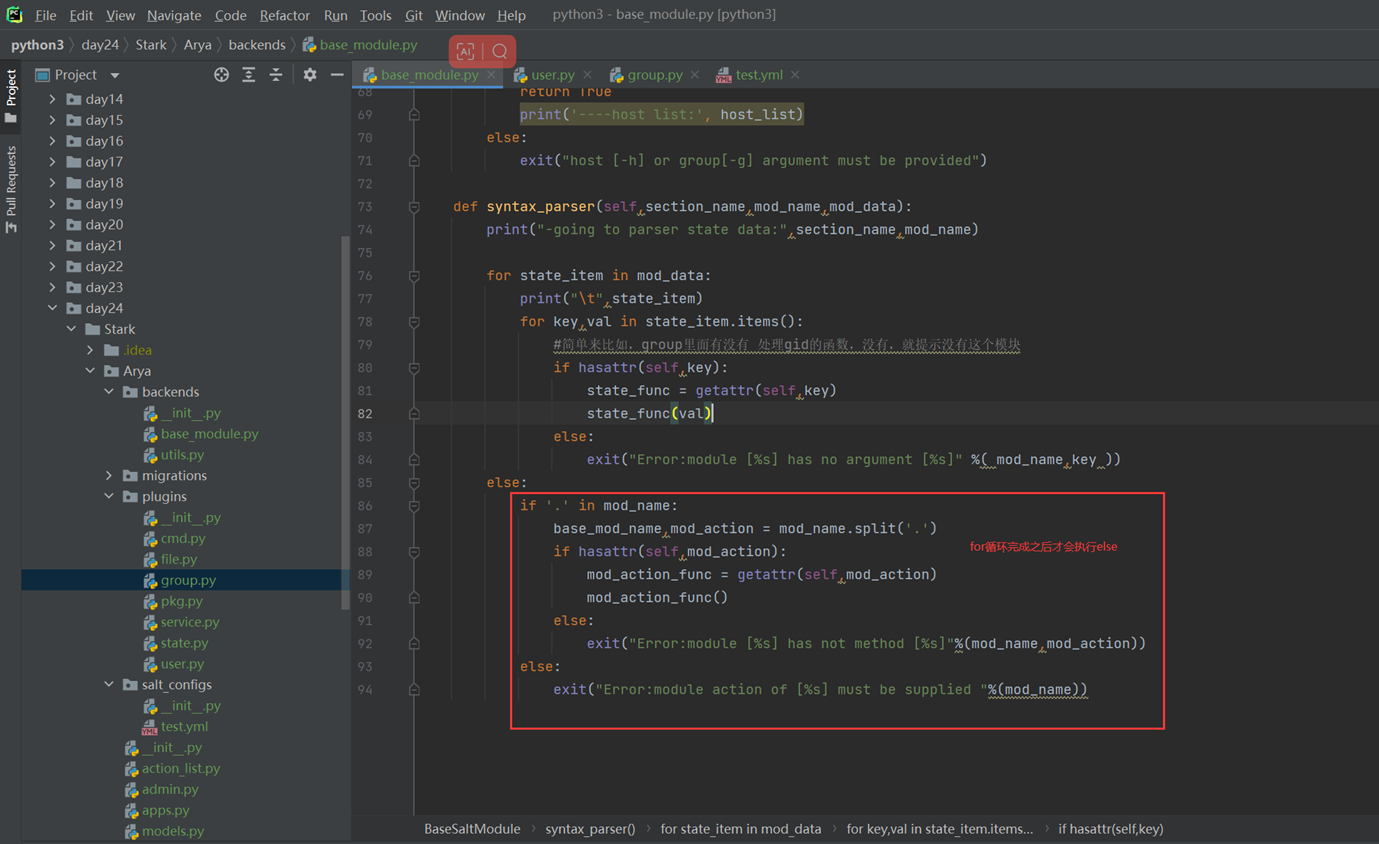
再次执行
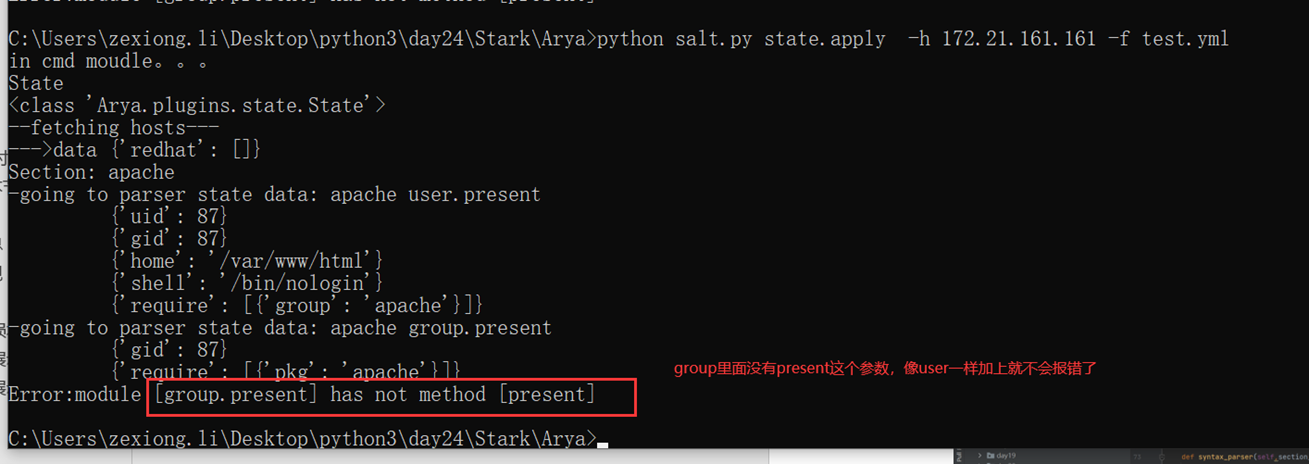
结束了,接下一节课
24.4 生成解析数据2
本章的目的就是把创建用户以及修改密码的配置拼接成2条命令。
首先要创建2个列表保存2种类型的拼接命令。
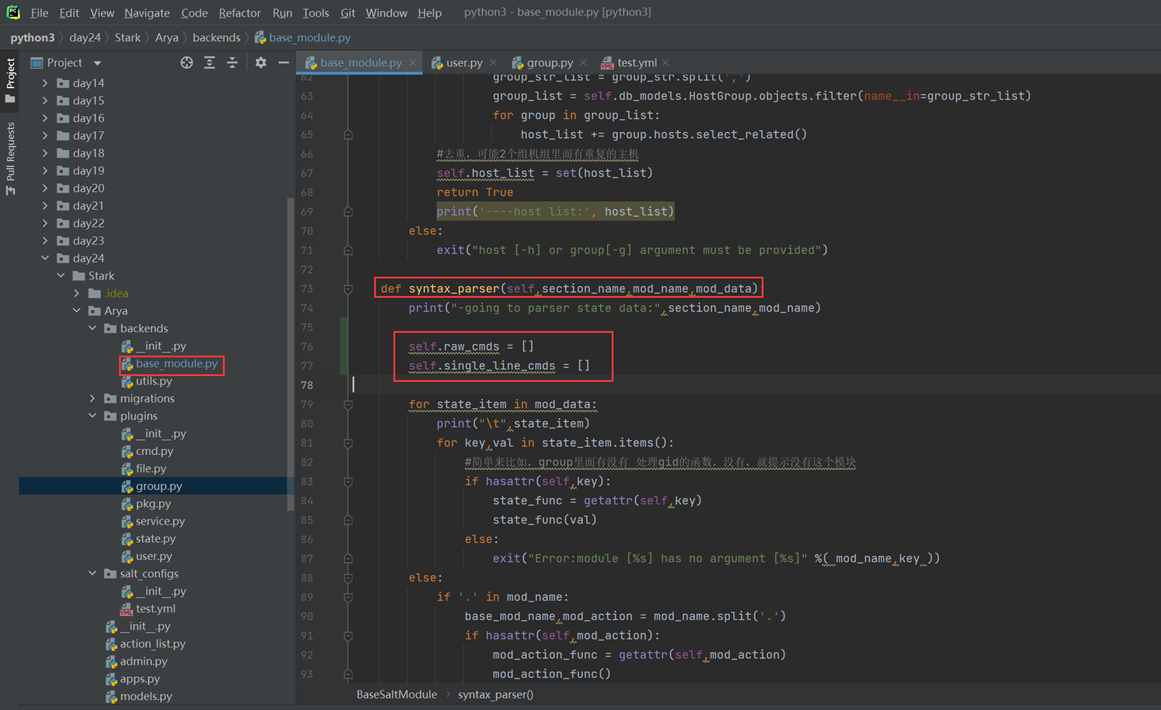
把需要拼接的命令放入到raw_cmds列表里面。
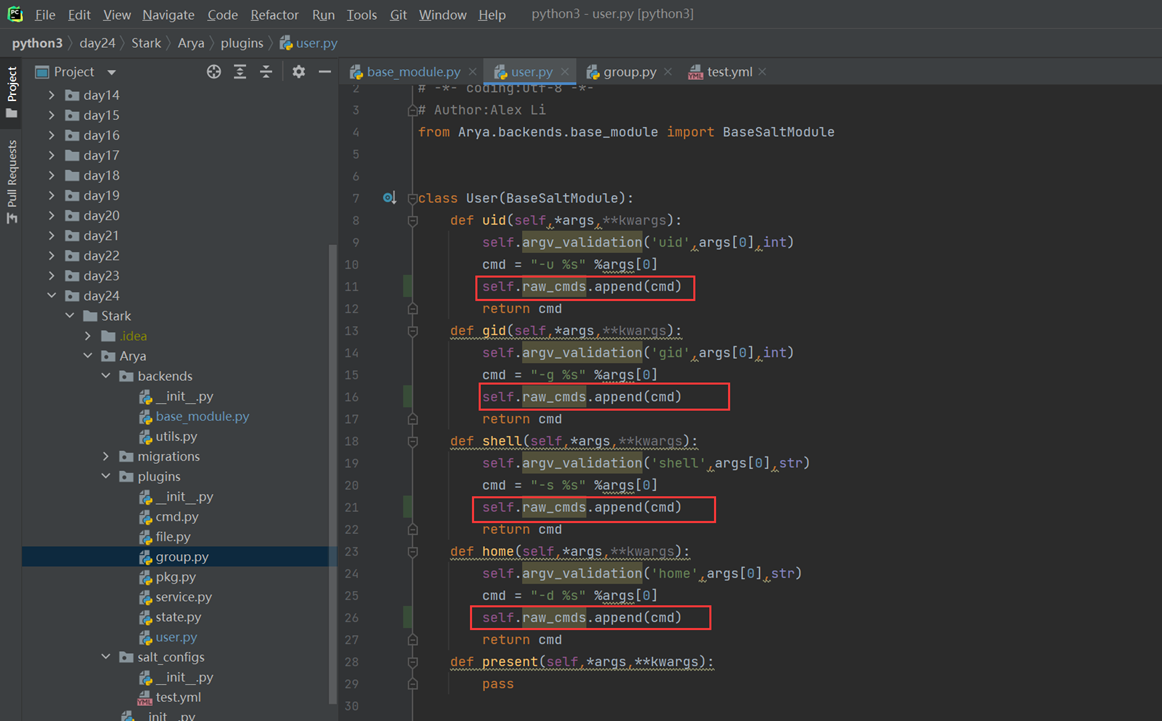
还有一个创建/修改密码的单独命令。
我们这里用ubuntu来举例子
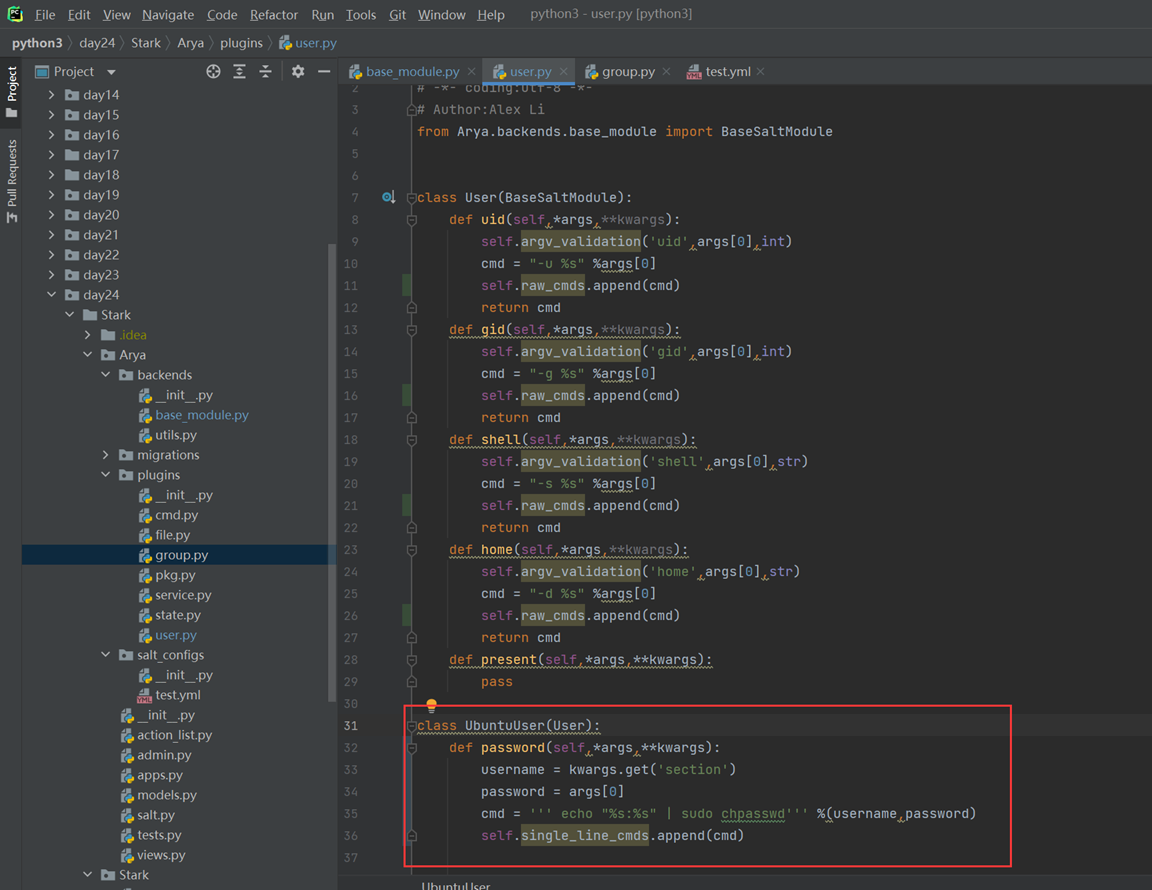
还需要把用户名和密码传给这个password方法
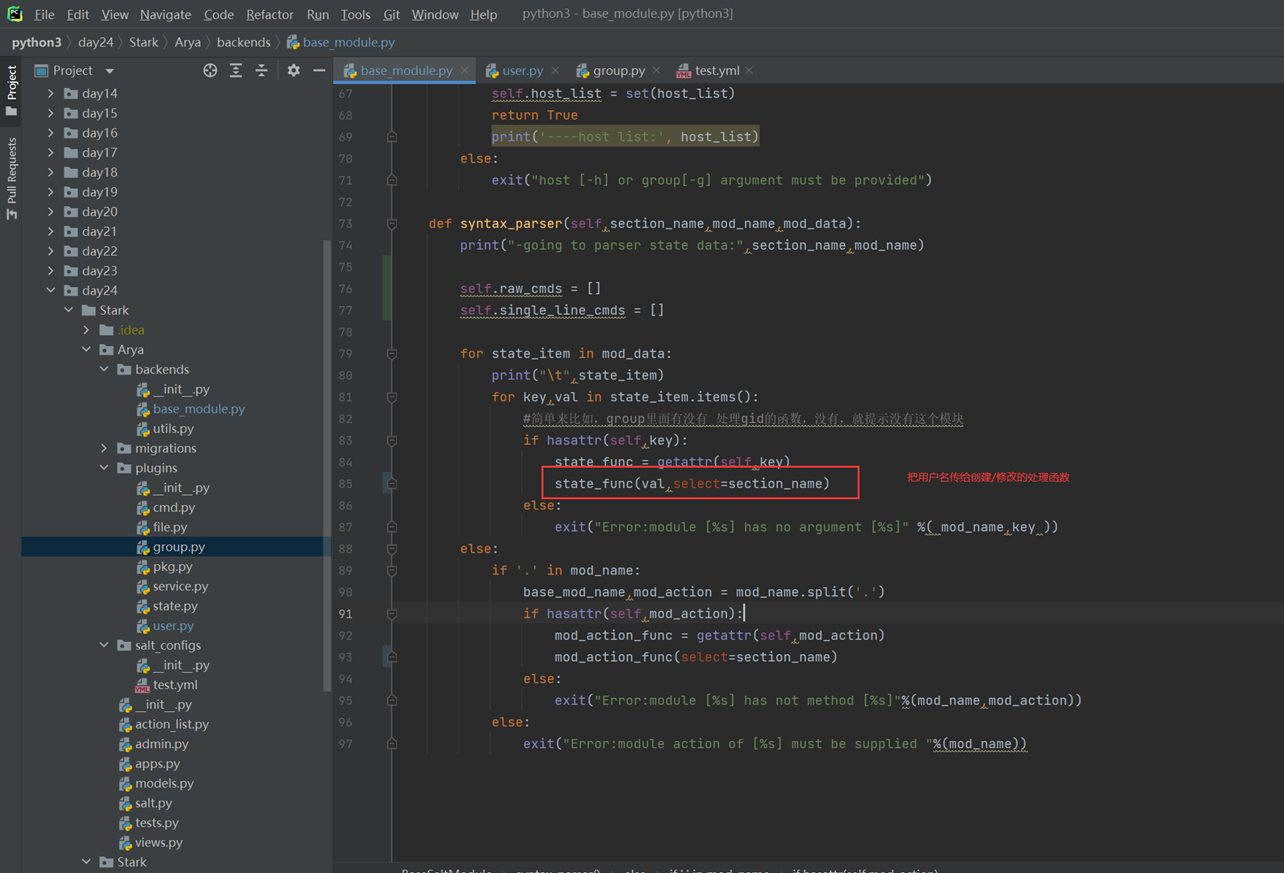
现在可以拿到最初的那2个列表raw_list和single_list拼接命令了
先来个前提条件
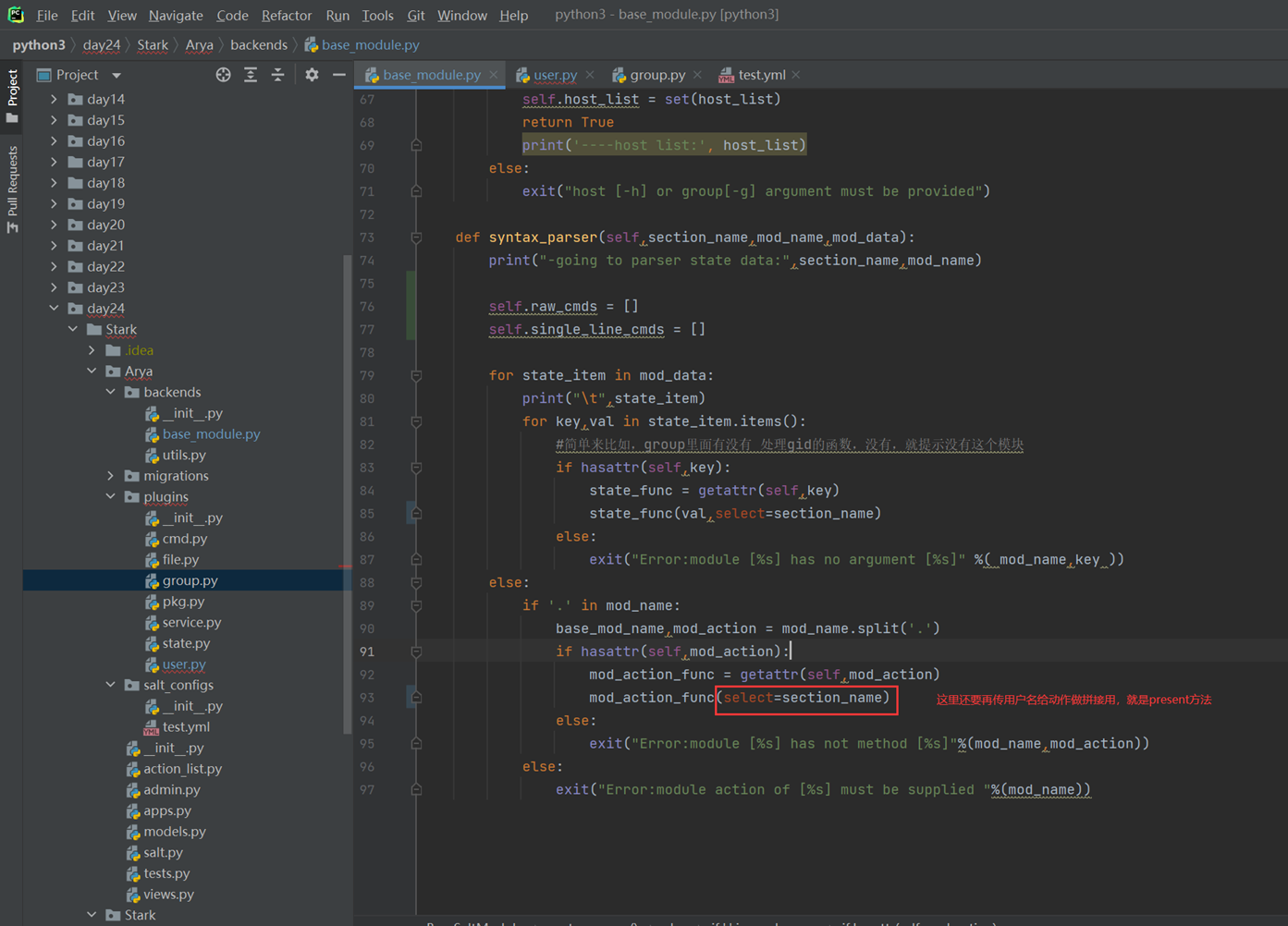
因为命令会解析group的参数,所以group的参数里面present也写一份处理的,否则报错。
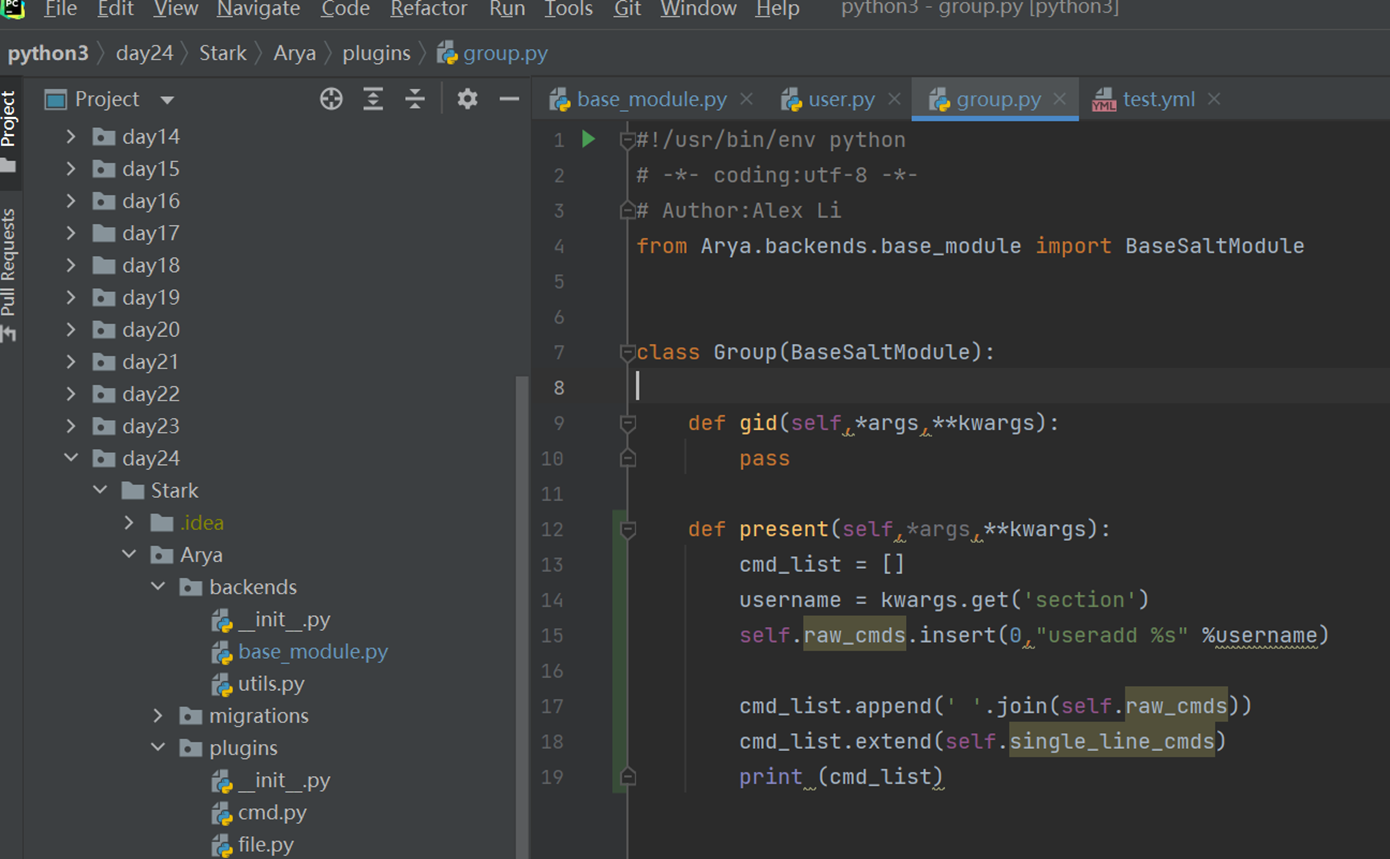
执行看看结果,user的命令是否拼接成功
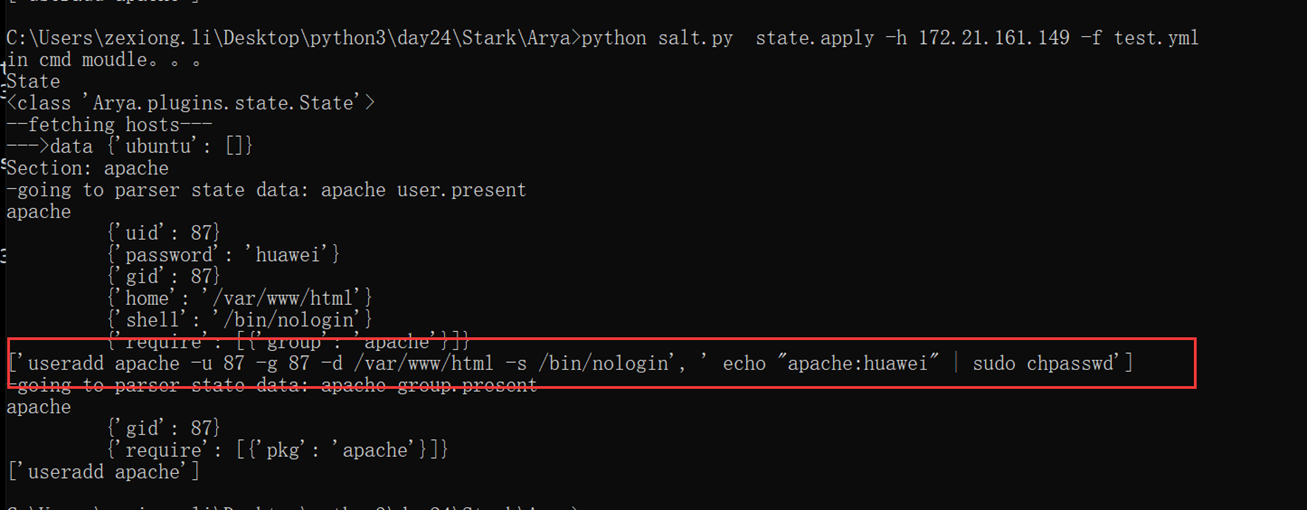
24.5 生成解析数据3
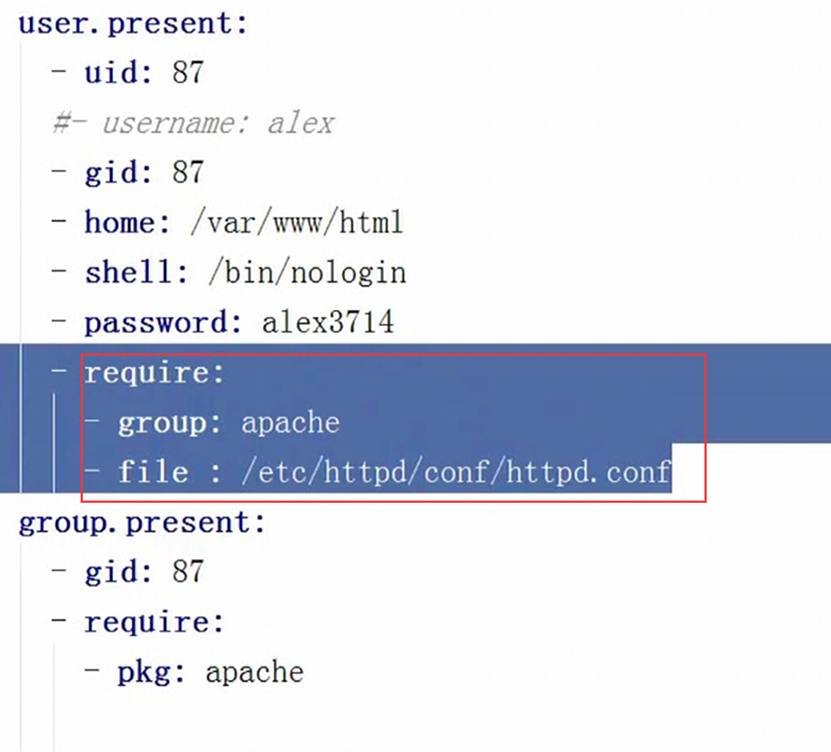
本节课处理require,require是必要前置依赖条件,简单来说,就是把require里面的条件拼成命令在返回,不是require返回,require和要执行的命令一起返回。
重要的事情说三遍!!!
本章没有详细注释!
本章没有详细注释!
本章没有详细注释!
不得不说,这个老师真的是lj啊,写的自己都看不懂把?就会吹牛比。
本章照着视频把代码跑通了,本章没有备注,只有代码截图,将就着看吧。只能说代码是没问题的,后面有机会在学第二遍的时候有了代码方便一点,但是估计不会有人去模仿这么lj的代码了。
优化成2行了
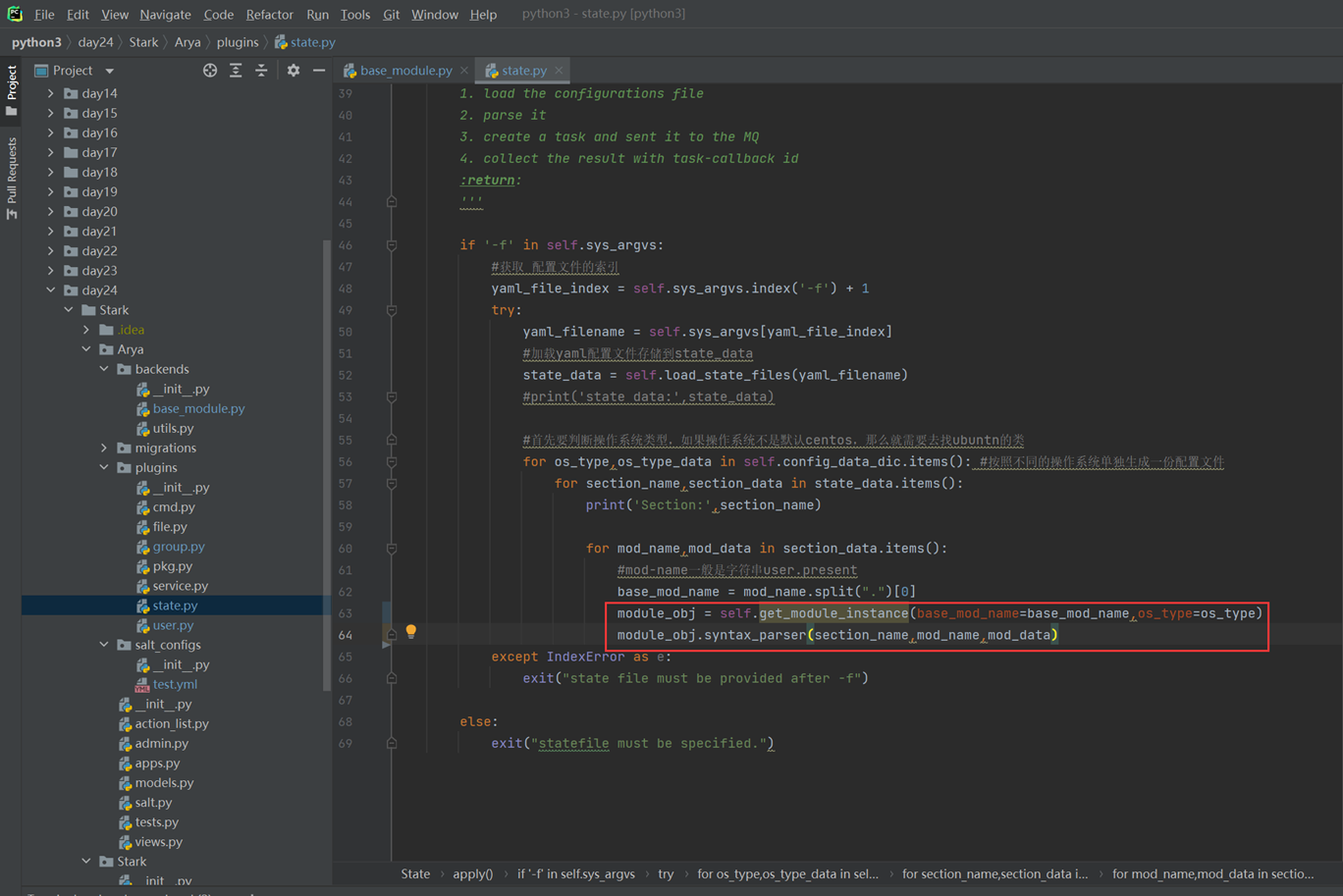
上面的做了那么多,就做了一件事,知道有哪些require,
然后下面就是把require交给每个具体的模块去处理。
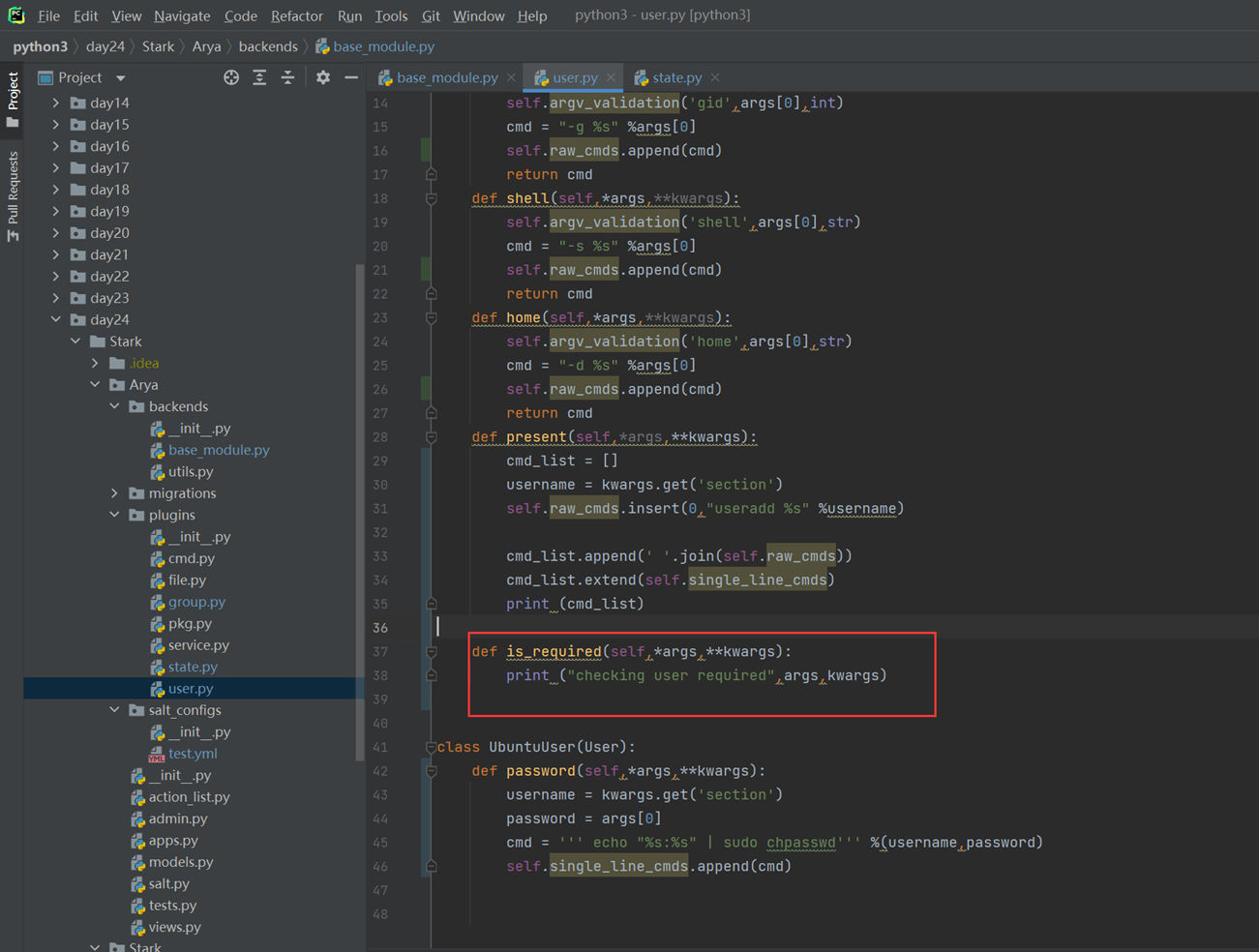
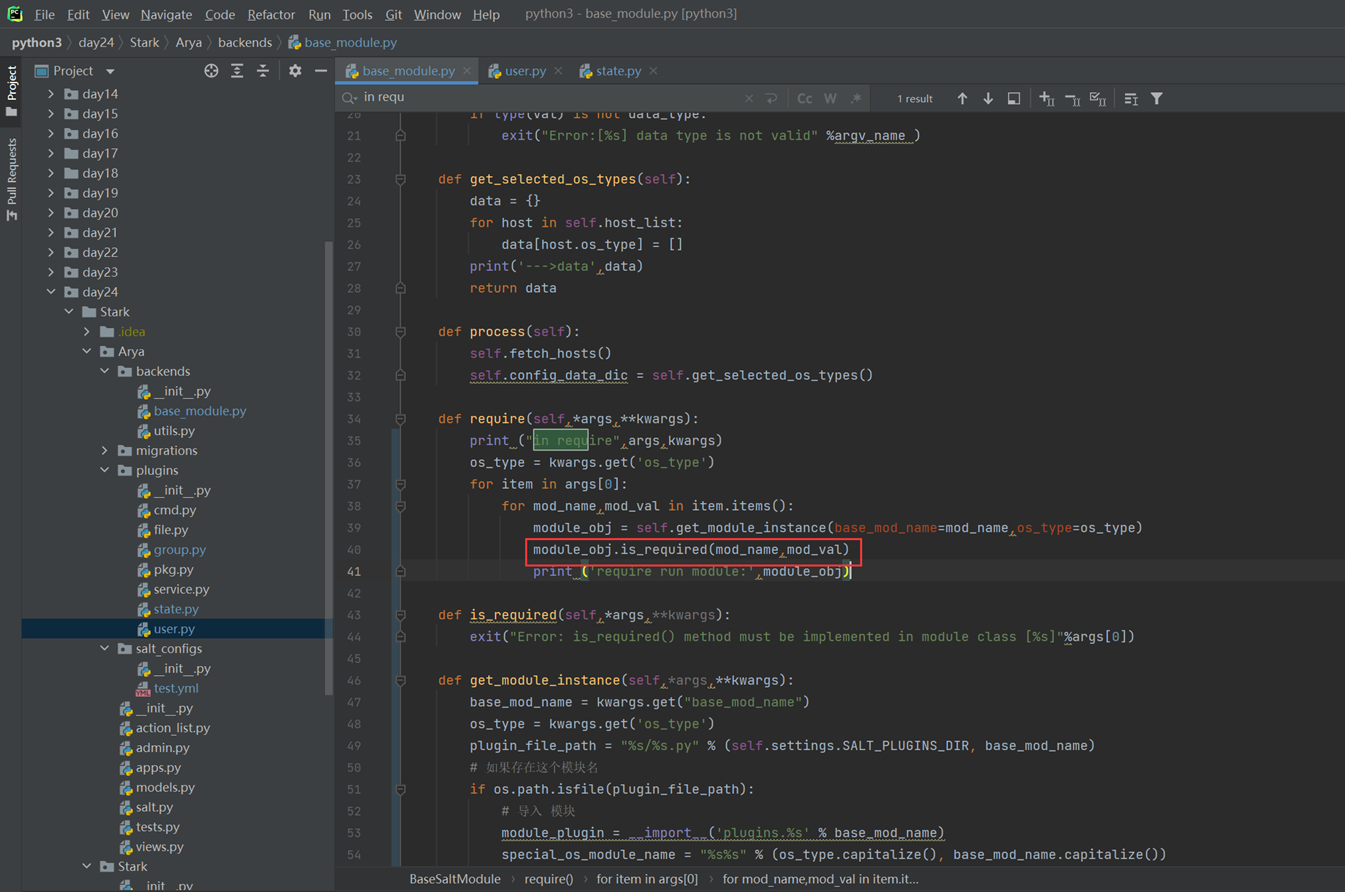
每个模块默认有个require方法,如果没有required,全局应该有个检测,因为不是所有人都有require,如果他没有required这个方法,那么就会调用父类的require,而父类的require就是个报错,告诉你没有这个方法,要自己去写
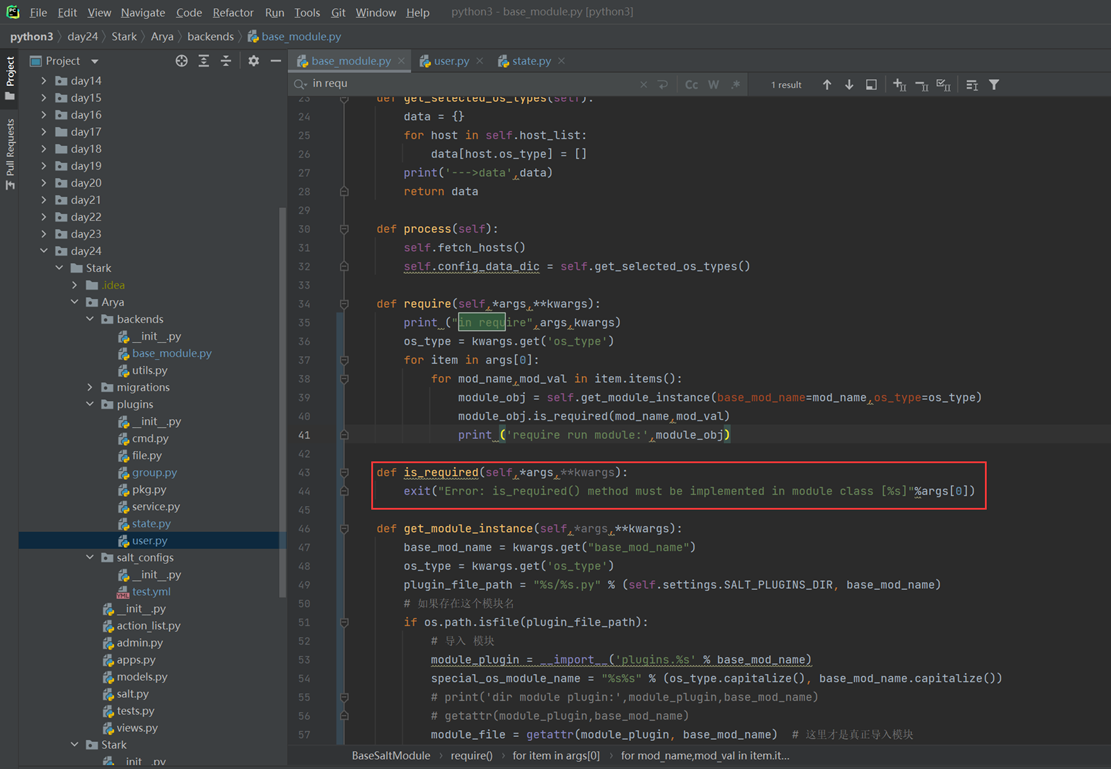
所有模块都要写这个required这个方法,不然会调用父类的is_required,会导致报错。
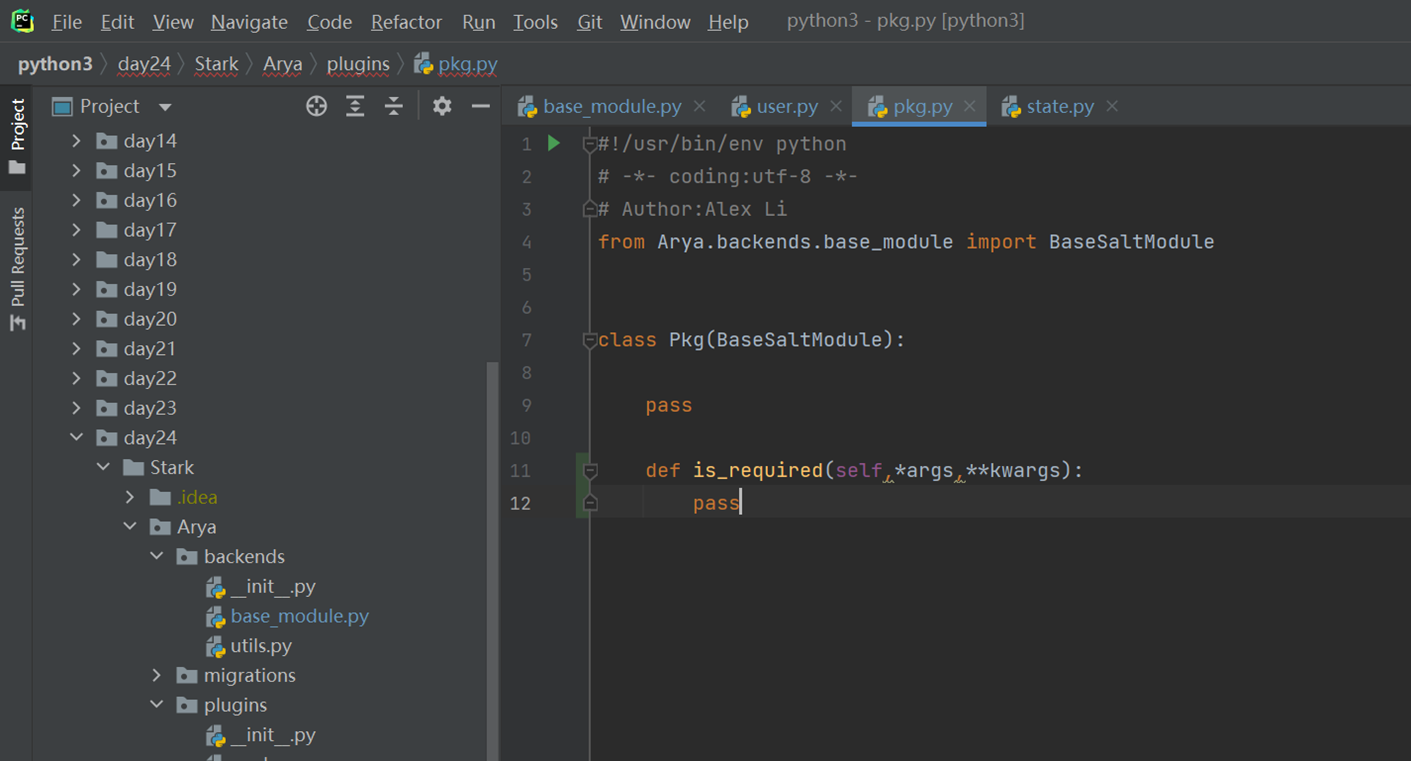
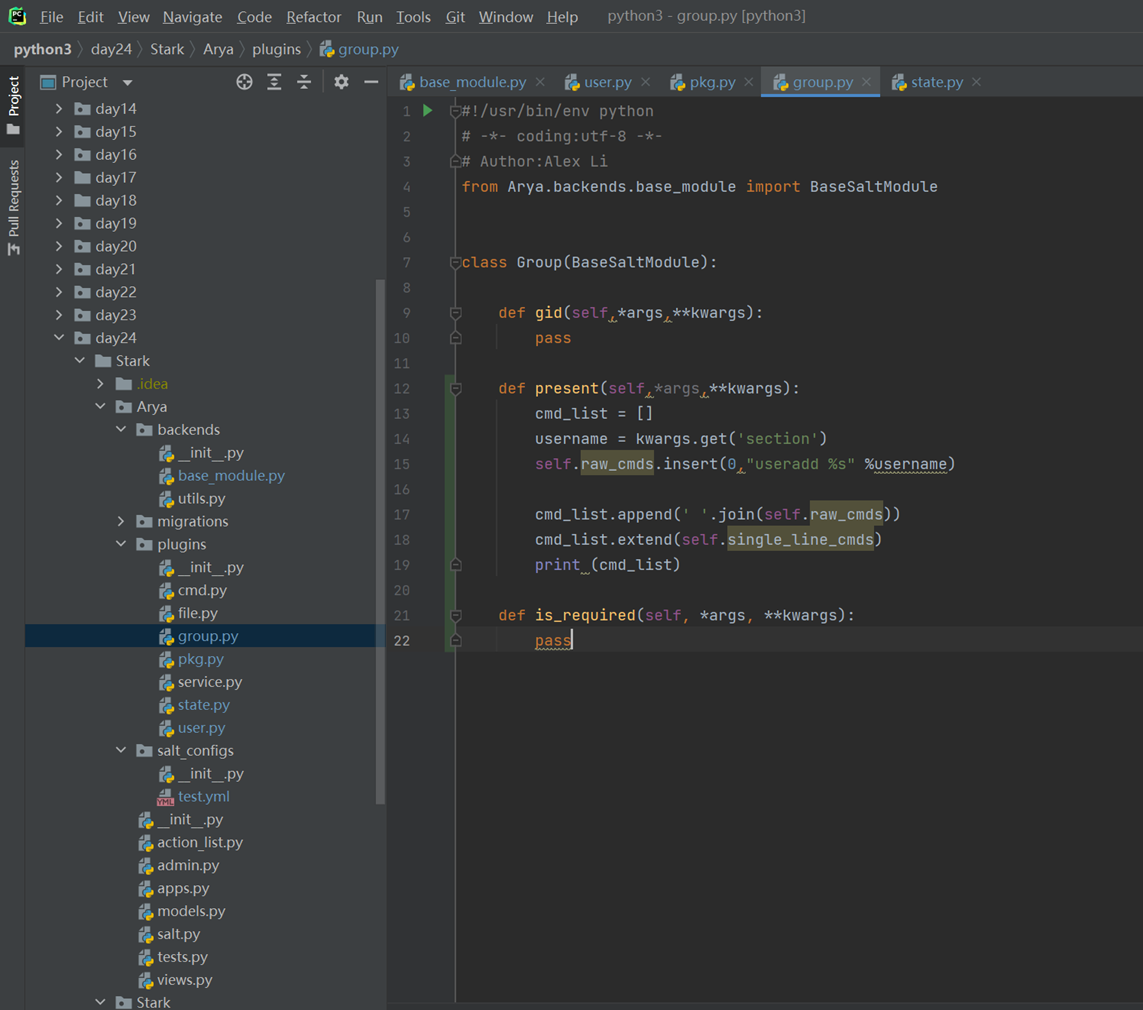
最后全部返回结果,把命令或者依赖的命令给返回。
最后state打印返回的所有拼接命令。
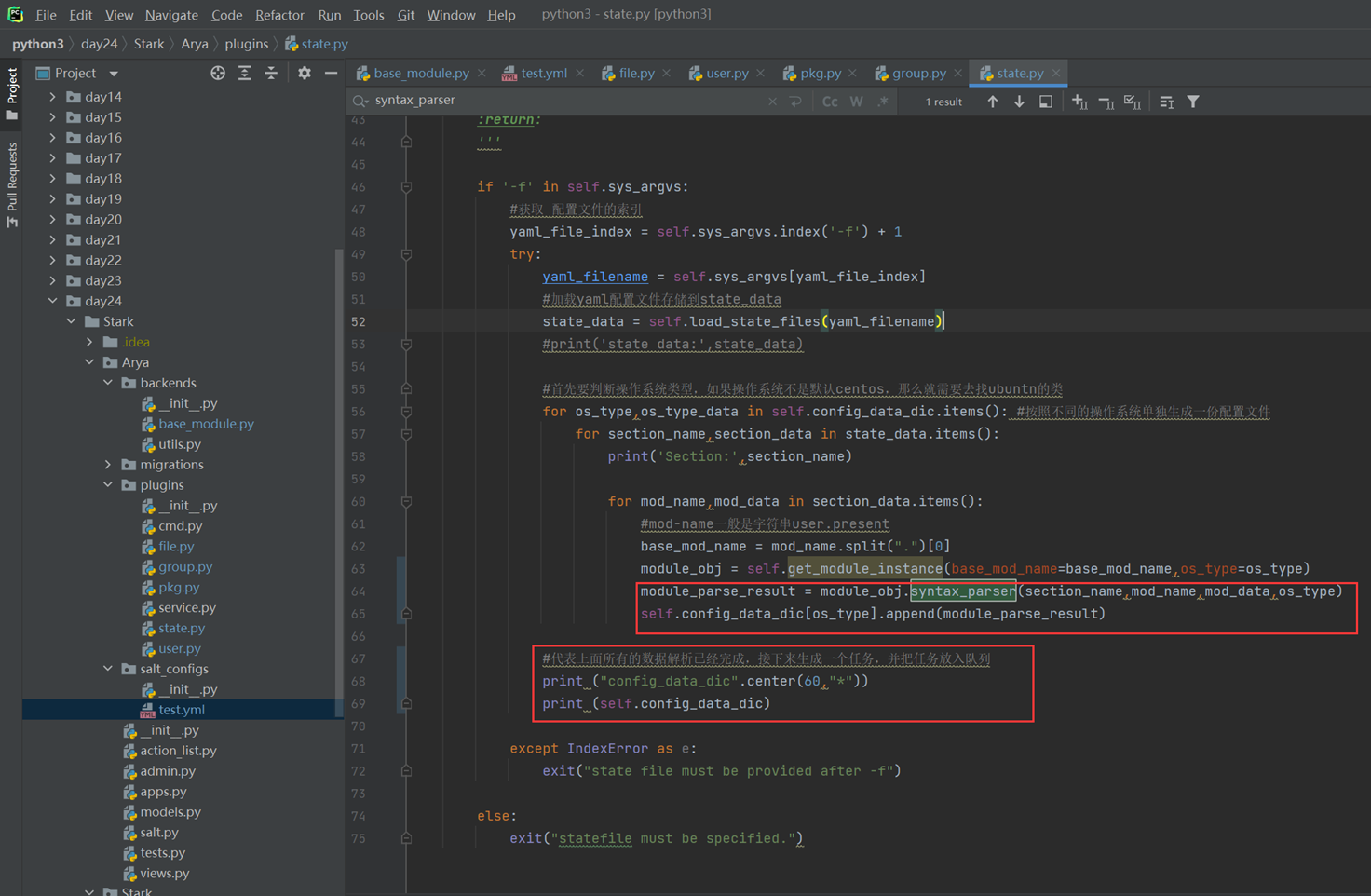
执行,不管是命令还是依赖的命令,都直接返回了
24.6 生成解析数据4
接下来把配置文件的section部分给解析了
视频35分钟,他想了15分钟,而且以一种及其low的方式实现。
然后base_module里面把mod_data,也就是所有找到数据,现在格式是一个字典直接传进去,然后判断cmd_list是个字典,那么字典模块就设置为True?简单来说,啥都没做,这都不叫bug了,这叫啥都不会写。
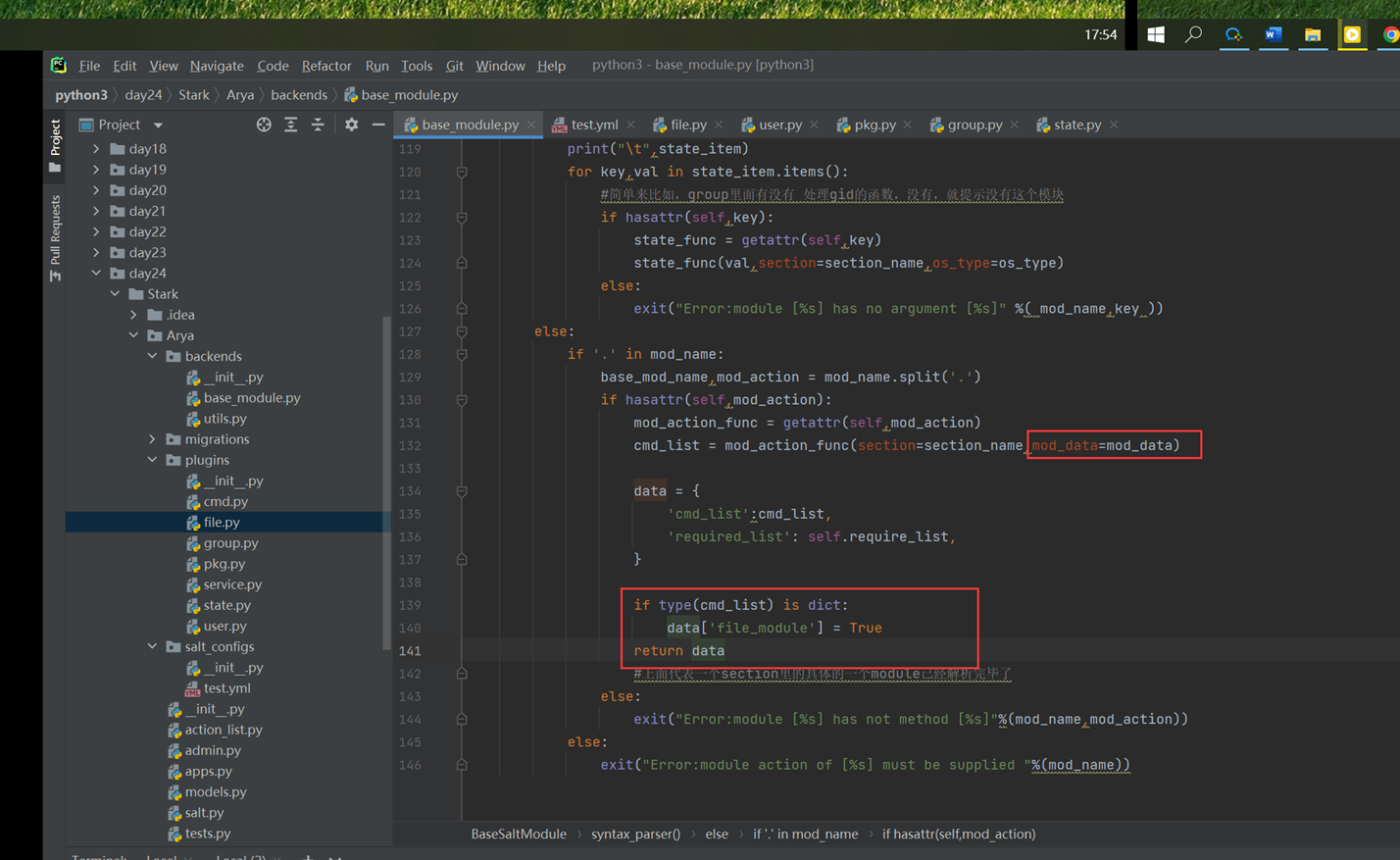
执行看看结果。就是直接把这个section下的所有东西放在一个字典里返回了。
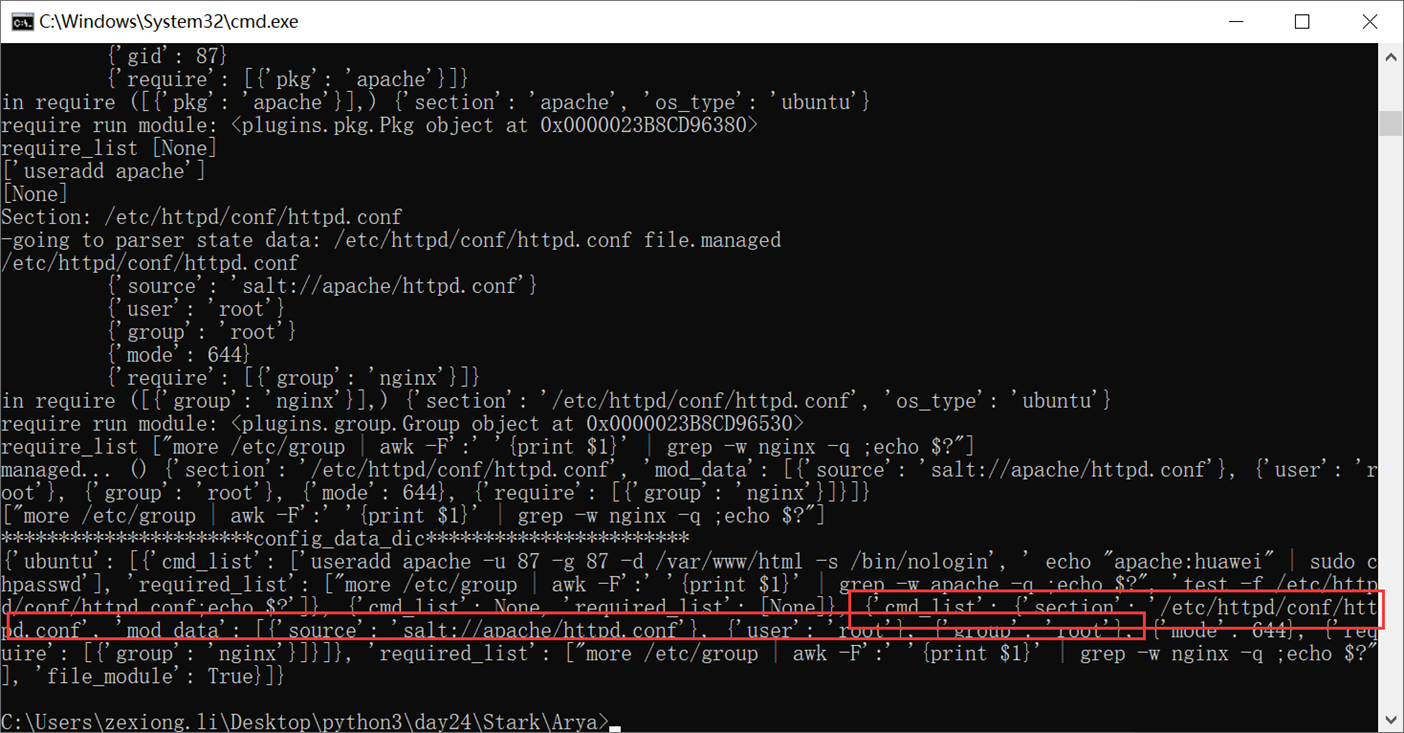
24.7 将新任务放到队列
本章那老师写不动了,直接复制过来的代码,本人翻着视频手打了一份代码出来。视频在以下时候会翻一遍代码。本章就是讲解代码,根本没自己写,视频后半部分在装rabbit,装了半个视频,服了。
本章根据标题一样,把任务放到队列。所以基本就是创建rabbit相关的功能。
首先
要修改models,加一个表
然后tasks.py专门的队列功能函数
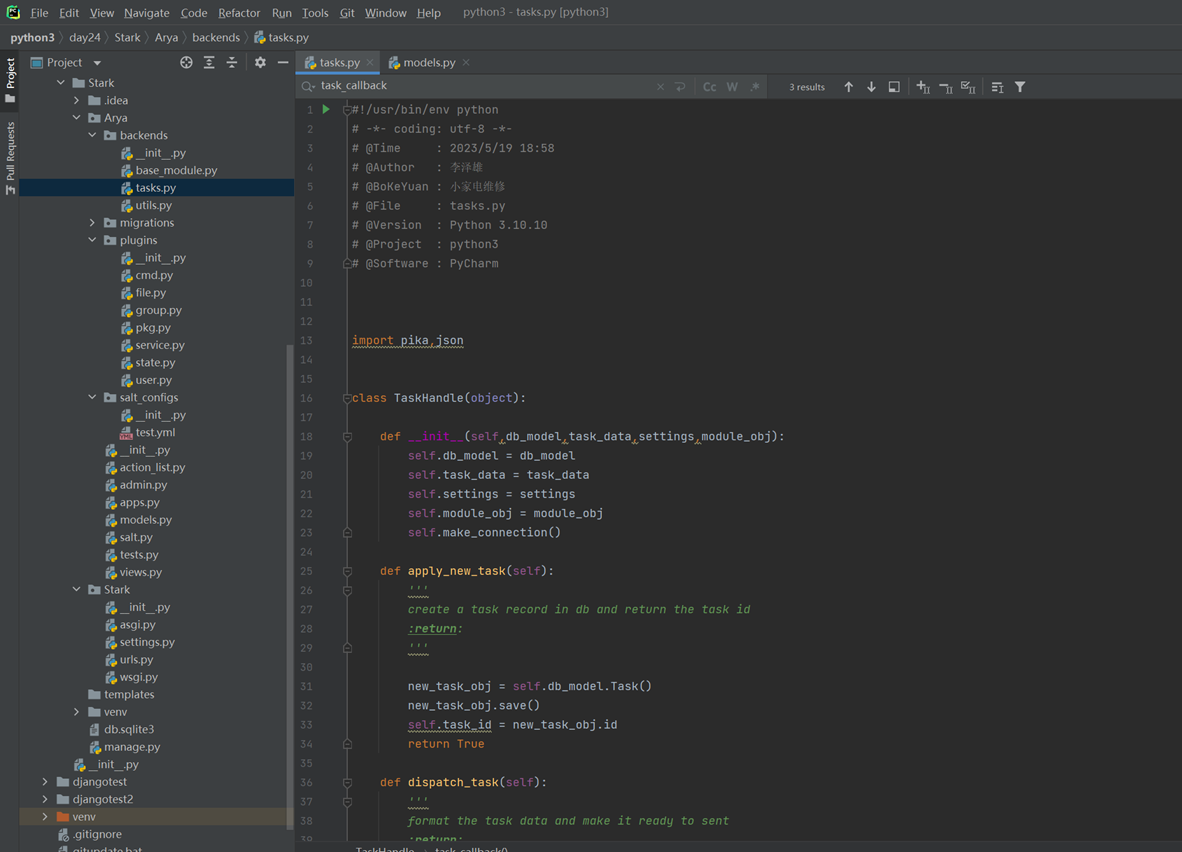
最后调用队列功能
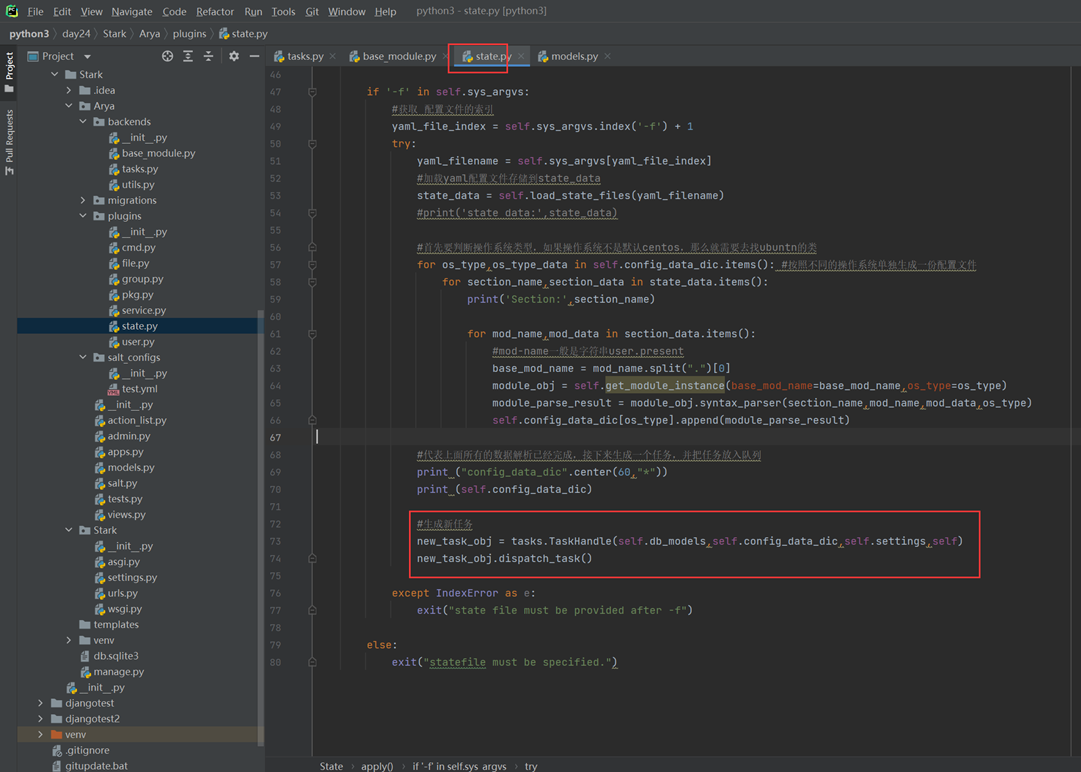
执行查看一下结果
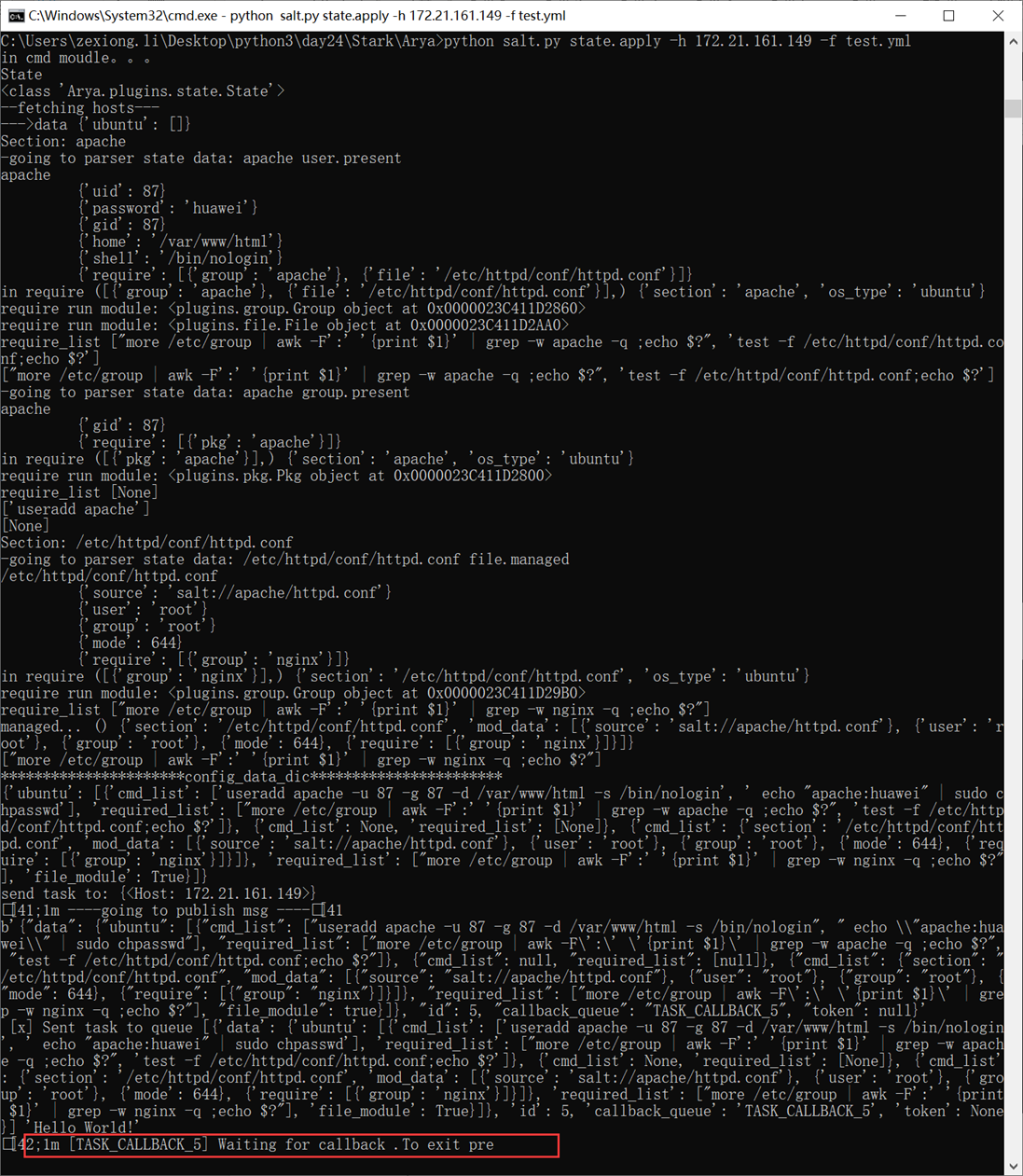
24.8 客户端开发流程及任务解析方式介绍
后面三章全部是讲解客户端安装的,就是照着自己写的讲,这里没有源码,如果想考靠视频拼出来客户端源码,起码需要3天以上时间,这个垃圾系统没有必要,学习思路就行了,如果有必要,可以花时间回来学习视频,但是目前看来,基本不可能有这个必要。
24.9 客户端解析任务并执行
24.10 客户端通过http自动下载文件
25.L25
25.1 CMDB开发之ITIL介绍
理论介绍,什么是ITIL。

25.2 CMDB开发之ITIL的实施目标
和上一章一样,理论。
25.3 CMDB开发之CMDB功能讨论

25.4 CMDB开发之CMDB架构设计及表结构设计
本章就讲解了一下在Stark下面创建了一个Sansa项目。一个子项目。CDMB所有代码都是直接复制过来讲解,好在在博客上找到了源码。

本章就讲解了一个资产表。
25.5 CMDB开发之CMDB表结构设计2
全篇都是复制过来讲解,这里就没必要截图了,表结构文件在git上。
25.6 CMDB开发之CMDB自定义用户认证系统
之前的项目中我们使用django的认证系统,这里的自定义,简单来说没看起来那么牛逼,就是把django的认证系统稍微可以自己定制一些,根本不叫自定义,应该叫自定制系统,因为还是依赖django。比如,我的必填登录字段,可以改成邮箱的方式。就这些。
Django官网也告诉了我们方式,直接复制过来,稍微改改就能用。这里给出官网连接。
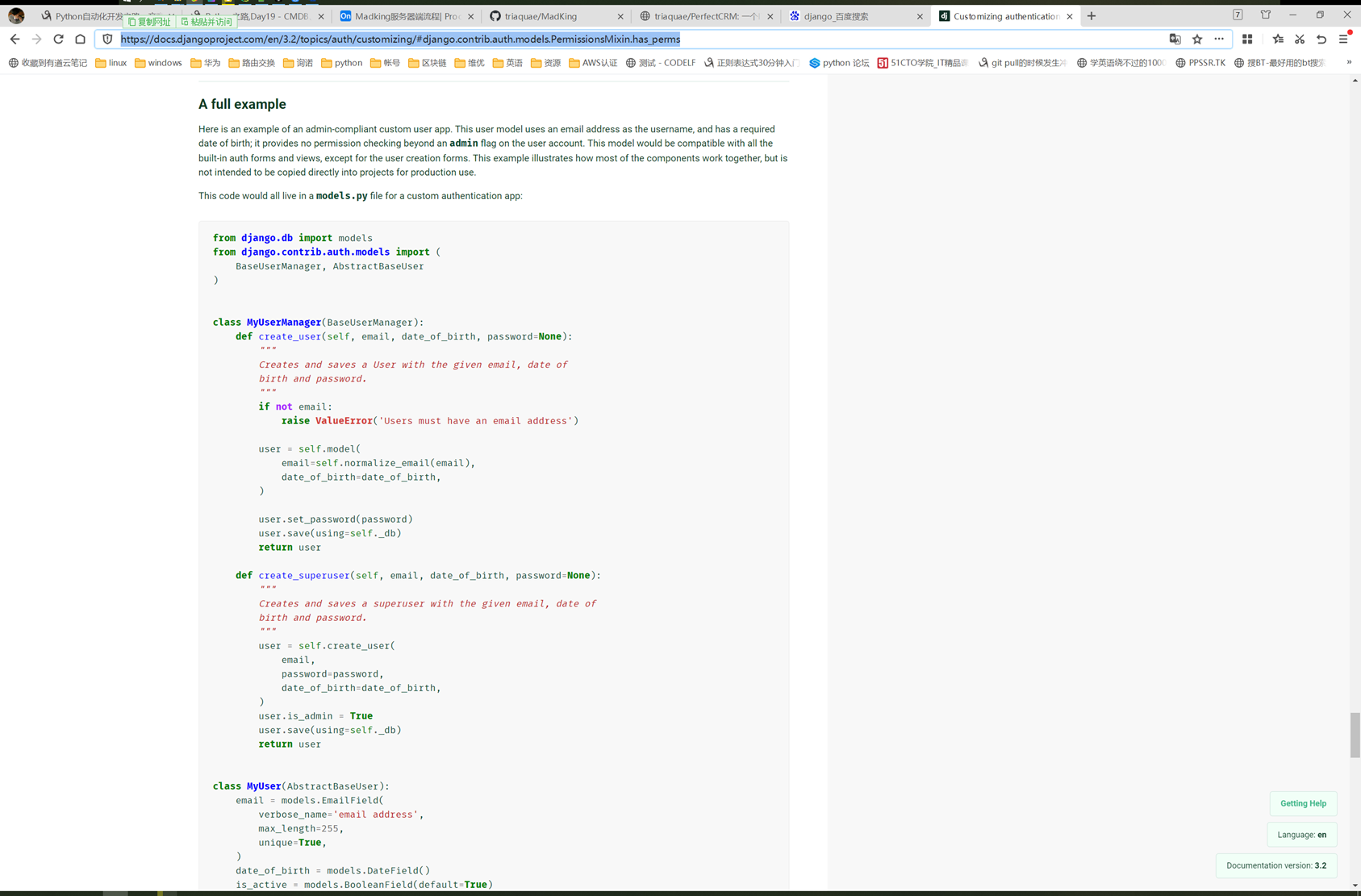
这里我们直接拿过来使用就行。
因为我们这里是要使用自己的用户认证系统,所以,我们要先把用户认证系统创建好了才能创建我们自己项目的表结构。
因为这个认证系统django设计的人觉得她是一个app,所以我们也创建一个app,不然后面不好引用。(当然,不用创建app项目的方式好像也可以,这里就不做测试了)
首先创建一个认证系统app。

然后复制认证文件到这个项目的models下。
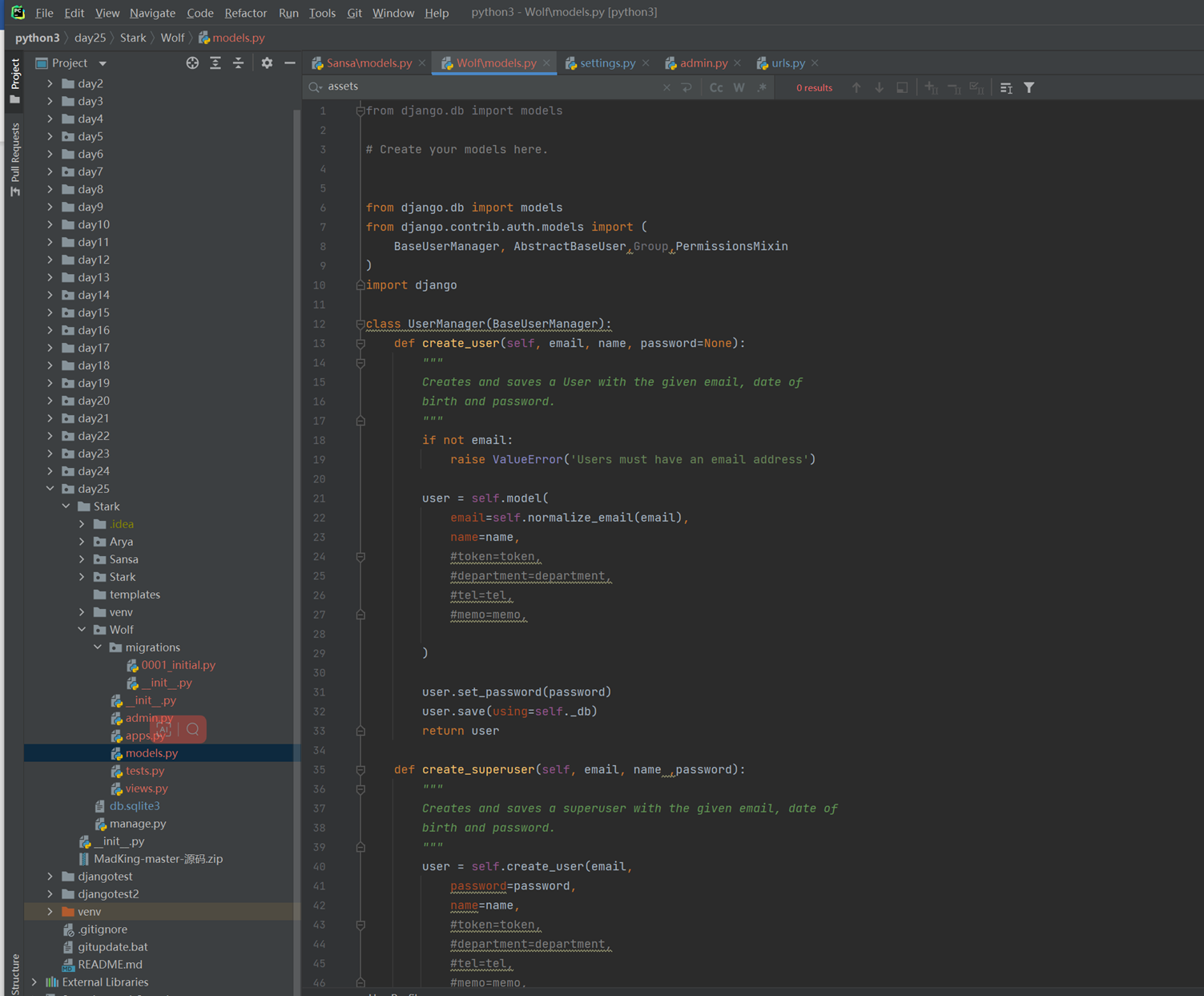
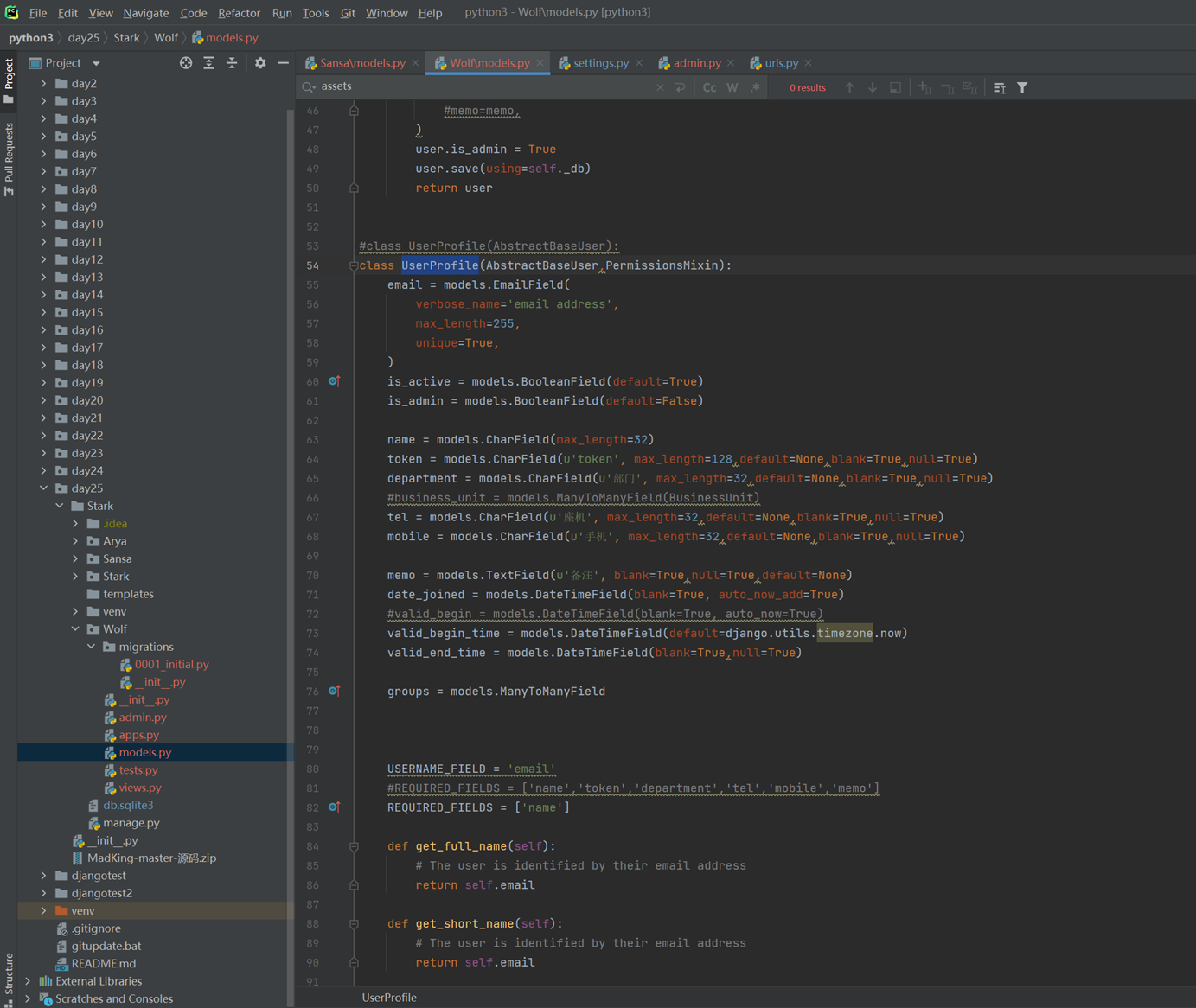
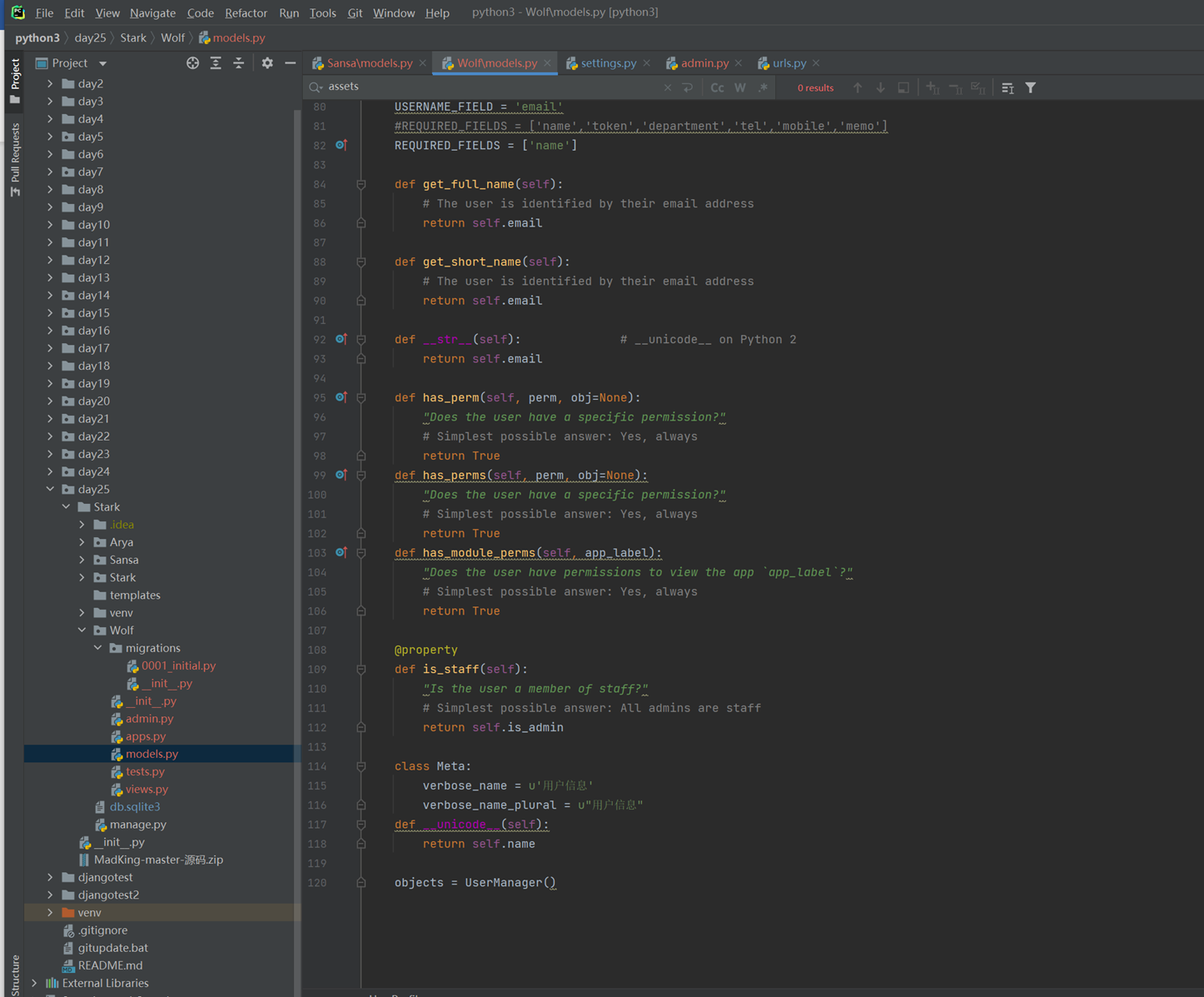
然后Stark的settings里面注册app
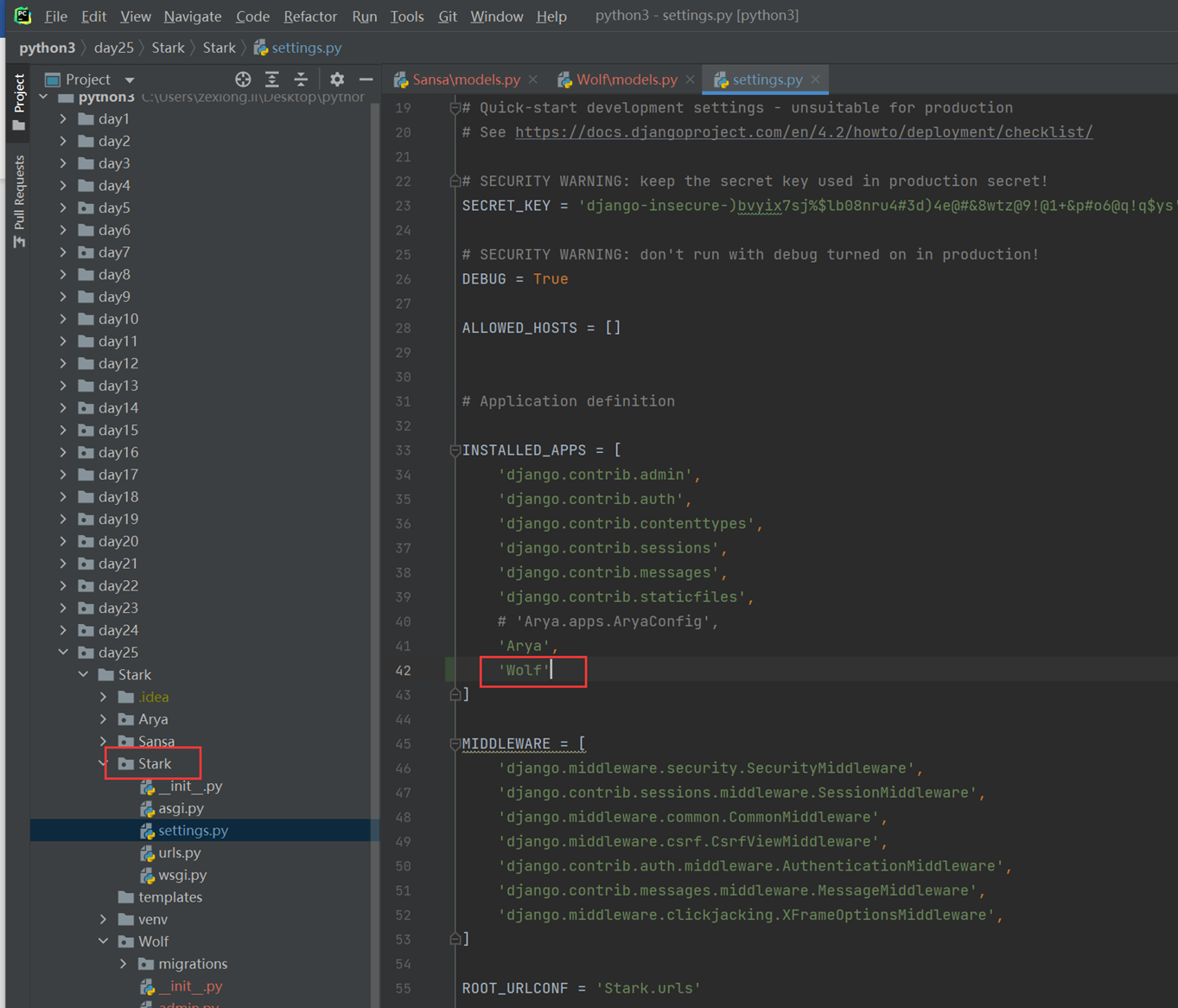
然后覆盖原始的django的认证系统以及数据库表结构。我们这里和课堂不一样,如果我们直接执行以下命令
python manage.py makemigrations
python manage.py migrate
那么就会有以下报错,课堂上没有,因为我们之前学习salt的时候有admin数据了。课堂上执行的时候没有历史数据,可以选择直接覆盖初始数据,所以没有报错。
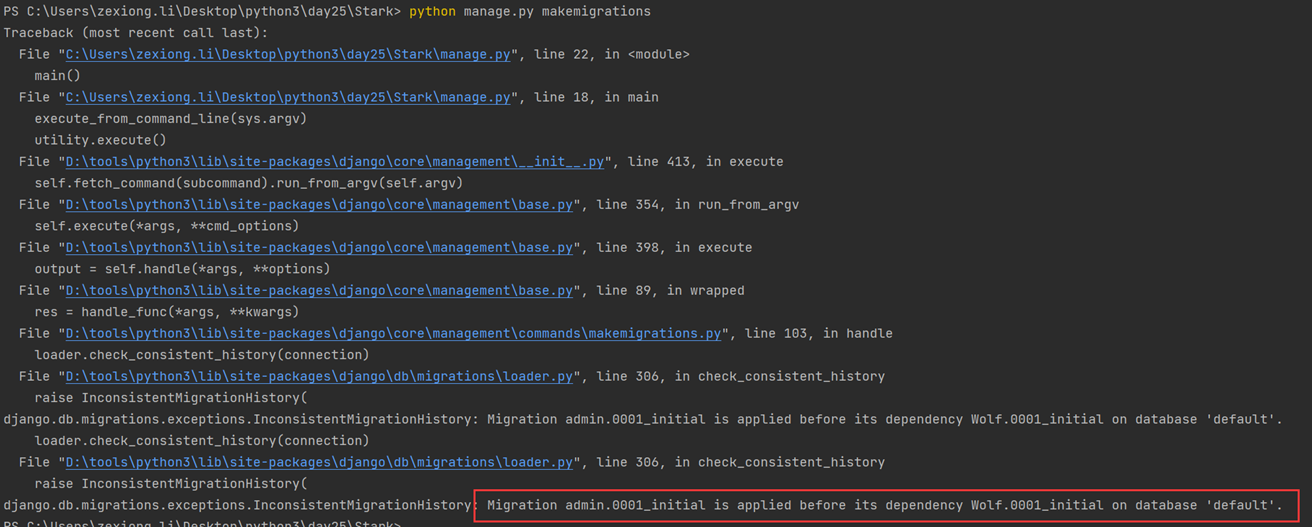
那么解决方案就是。
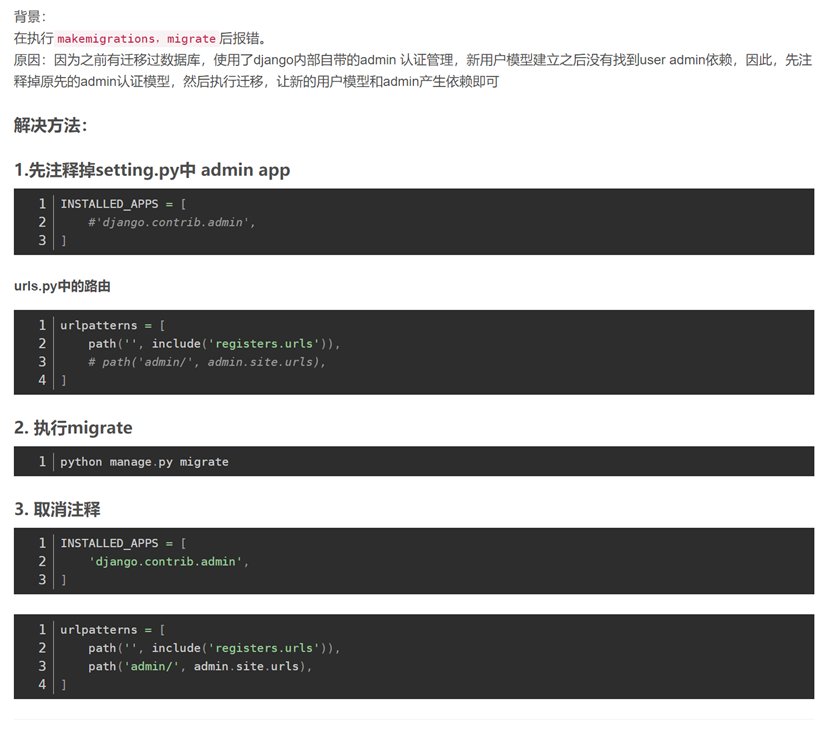
然后我们就成功了。
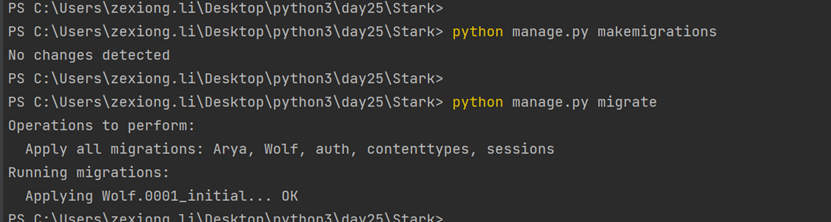
现在创建一个超级用户,我们看看后台变成什么样了。
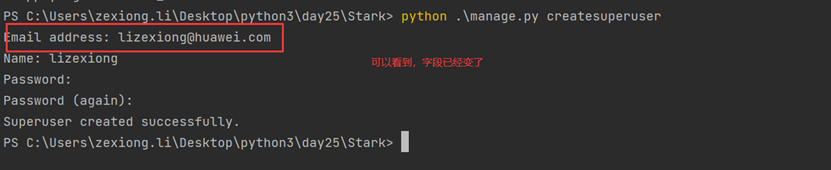
登录后台,发现后台什么都没有。那么我们在amdin把userprofile展示一下
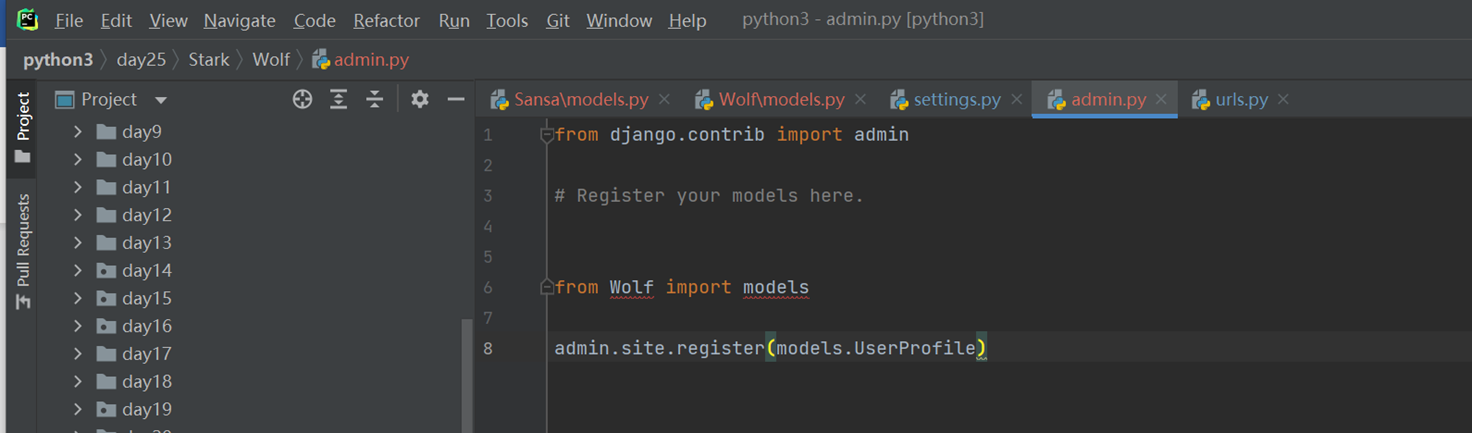
然后登录admin后台,看看创建用户等功能。连密码是密文的功能都没了。
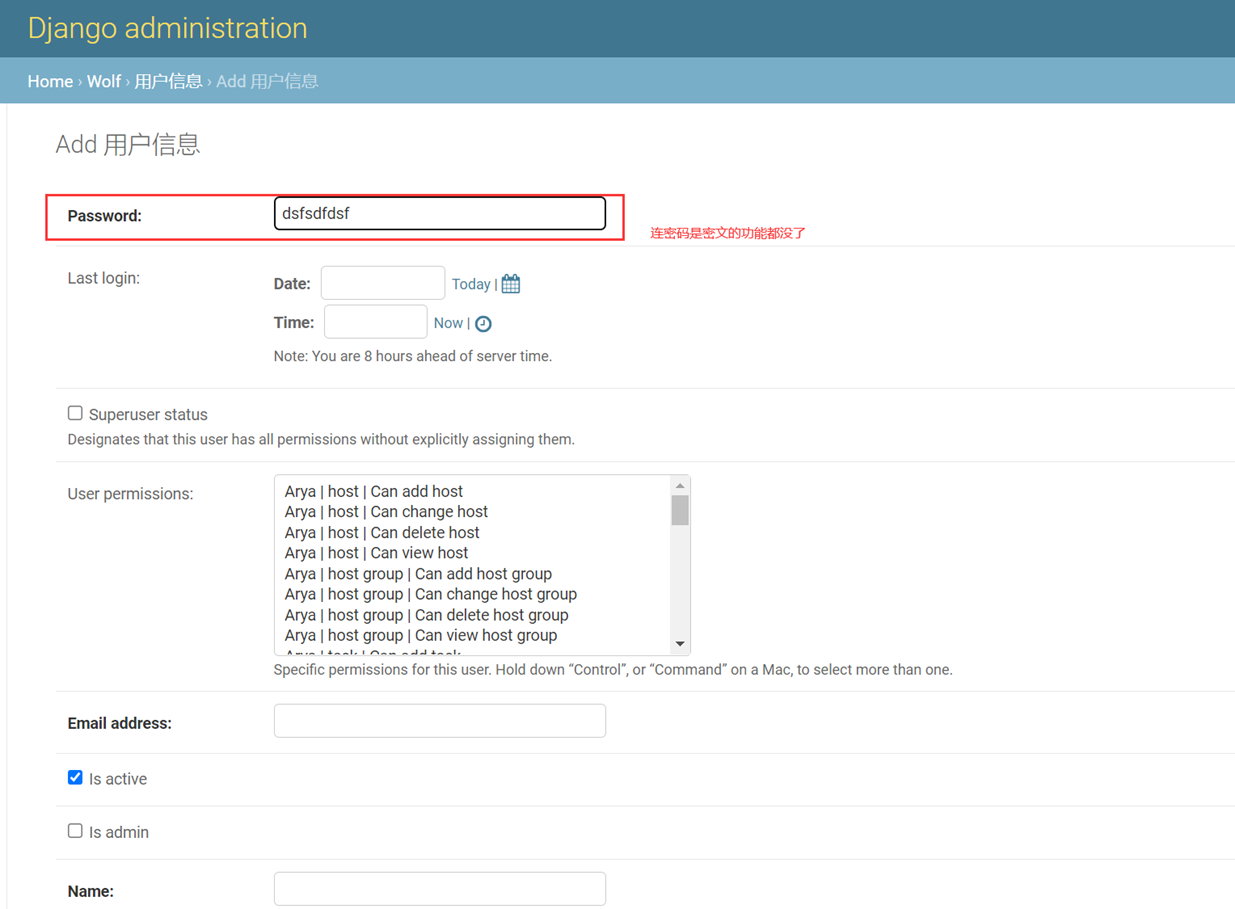
所以我们还需要升级。还是直接复制过来,下面的代码就是增强功能,定义字段和界面的。
然后访问django后台创建一个用户看看结果,就变的很强大了。
25.7 CMDB开发之CMDB自定义用户认证系统2
和上面一章合并了,就是讲解Wolf.admin.py的代码,给admin的后台添加一些自定义的展示和密码密文等美化功能。
25.8 CMDB开发之CMDB客户端设计
在admin里面在添加点东西,那老师也没讲明白,反正就是admin里面的,大家用就行了。
因为这老师非要装逼,自己绕来绕去,所以本章也很绕
首先,admin添加点东西,注意图片的红字
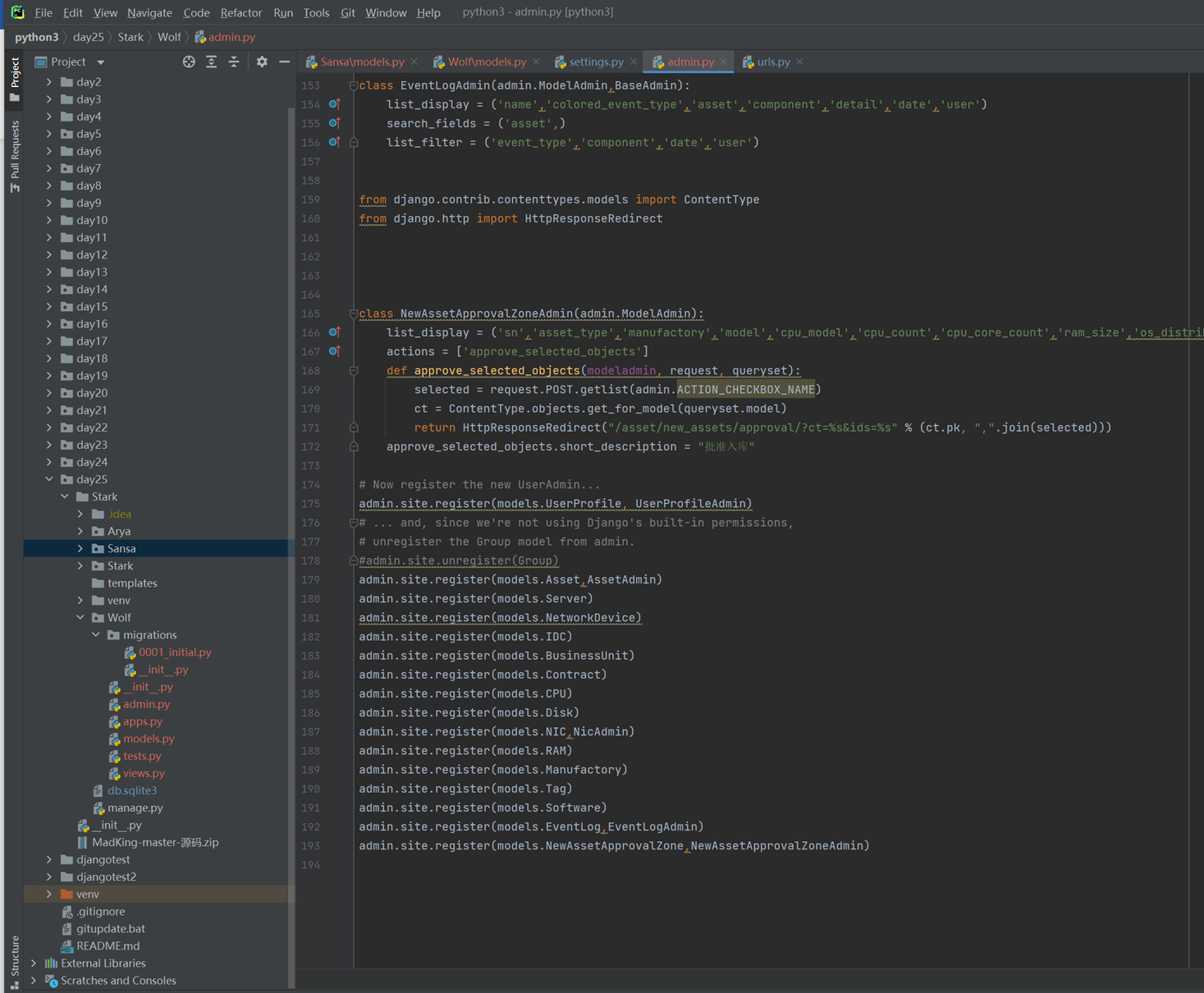
在Sansa下面因为python版本的原因,还有两处修改
生成表结构
后面的视频声音问题,这里直接拷贝过来,脚本不报错就好。
客户端是pyton2的,现在已经停止维护了,所以把客户端很多代码改成了python3,至于改了那里,这里就不记录了,改了2小时,已经忘记改了哪里了,这里能做实验就行。后面有兴趣可以完善这个系统,现在没有必要。
执行收集客户端数据是这个样子的。
汇报的接口也通了
25.9 CMDB开发之CMDB服务器端处理客户端汇报的数据
本章和下一章合并,就是把客户端发送过来的数据存入数据库。
本章基本都是讲代码,下一章稍微有点动作,没什么意思。
主要就是core代码,基本就是这个,其他的没怎么动。
URL
Views
接下来,就是最主要的core文件。这里就不截图全了,太多了,整个文件直接复制过来的
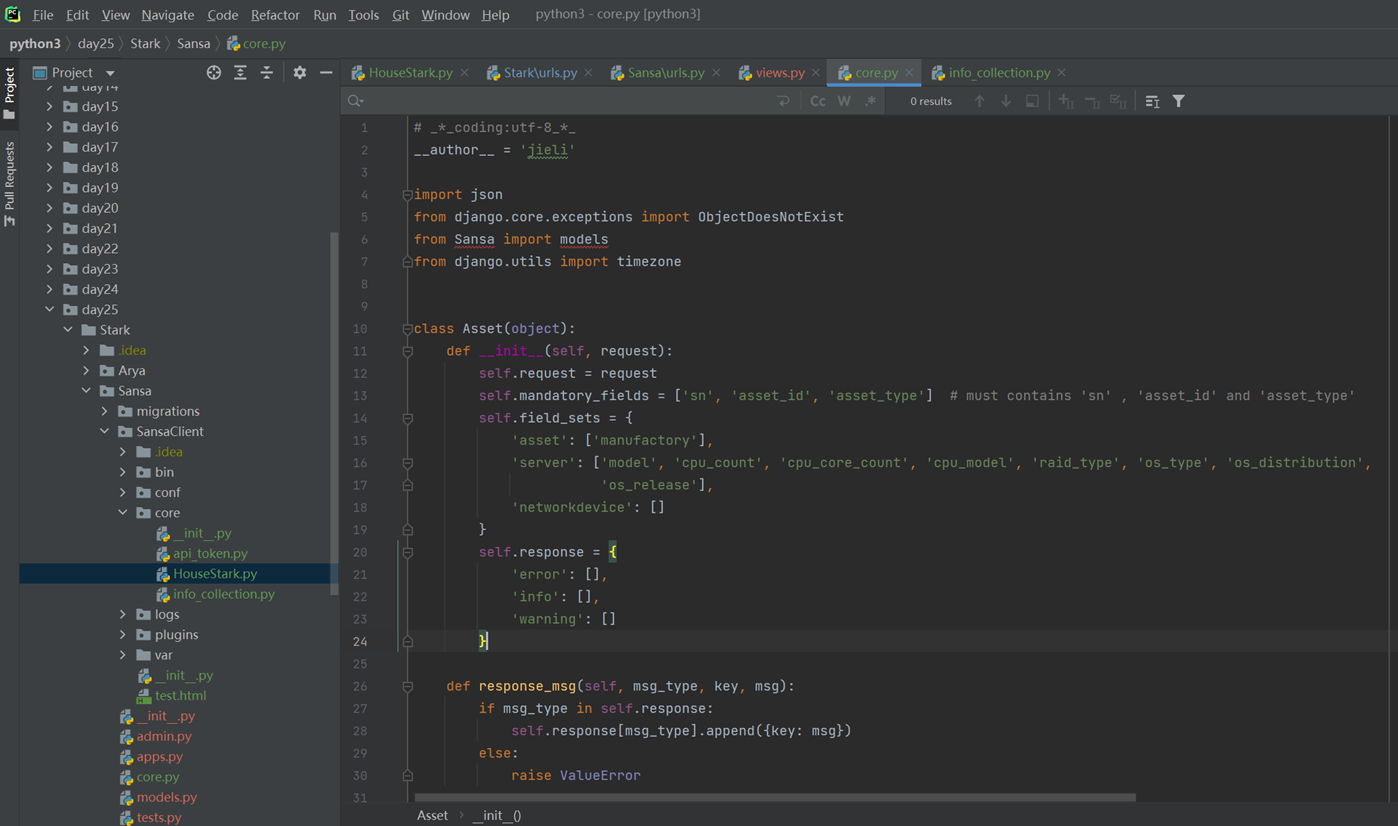
然后客户端上报,会有错误,因为这里只是一部分代码功能,现在SN和资产id必须要在服务器数据库里面有记录,才能记录到服务器里面去。
现在我们手动创建一个资产id为1的记录
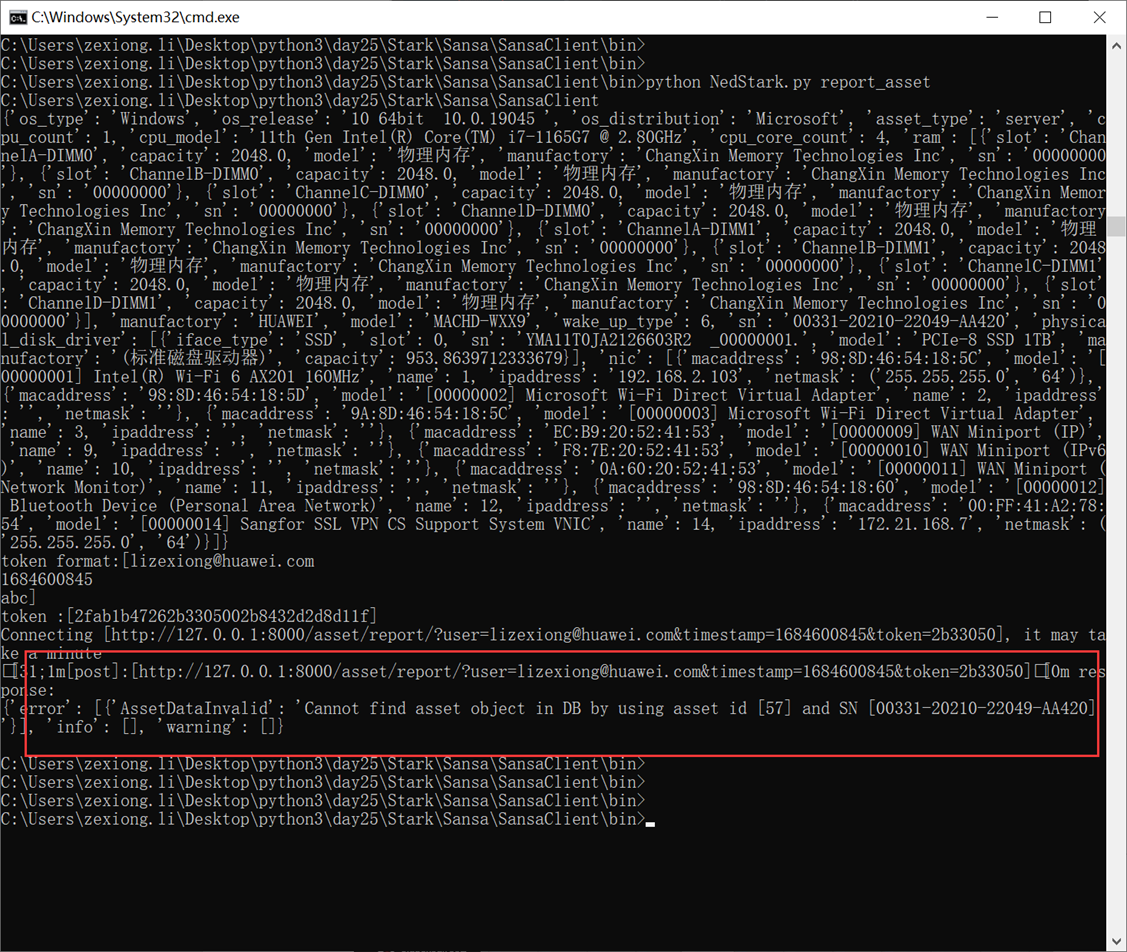
现在去服务端后台添加一下资产记录。
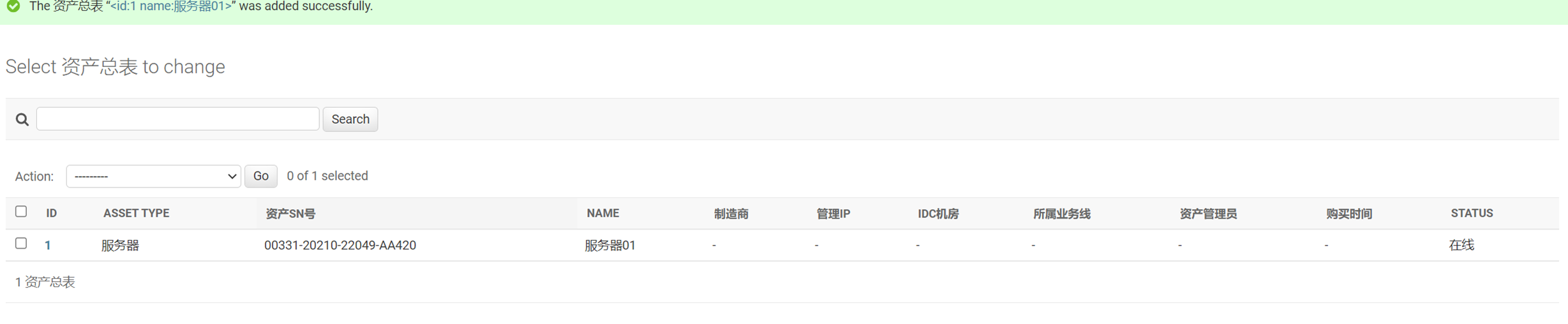
里面什么信息都没有,再次上报。虽然服务端会出现一点错误,但是现在也没有能力处理了
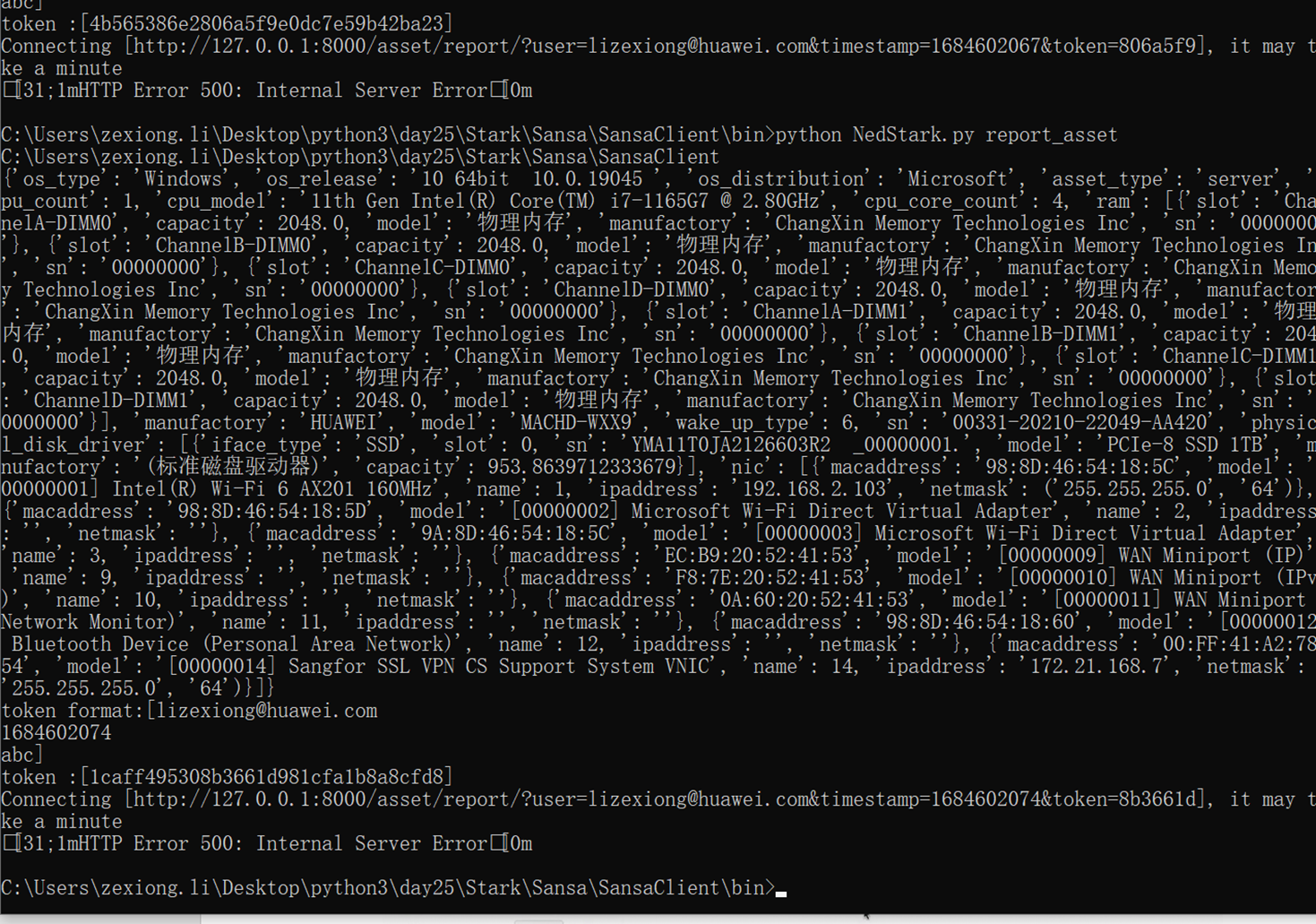
服务端错误
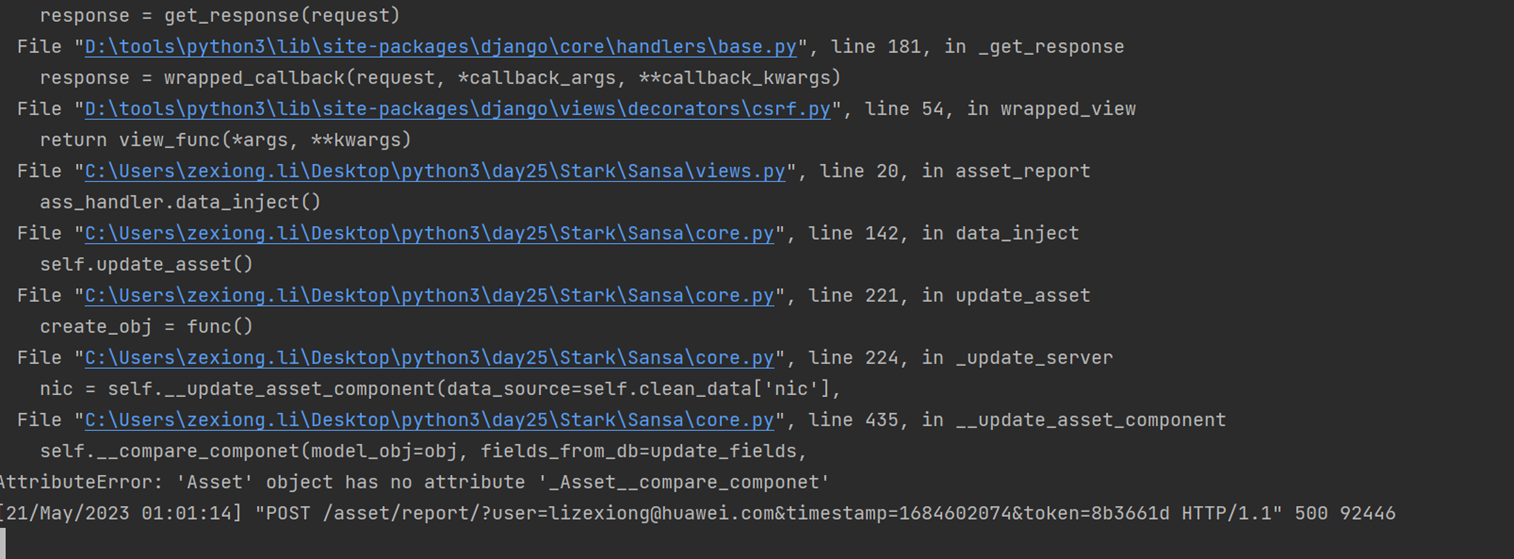
但是数据已经存进去了
25.10 CMDB开发之CMDB将客户端自动纪录硬件变更信息
简单来说就是把服务的资产我们自己改掉,然后让客户端重新上报,客户端会上报成最新的,也就是正确的。整片口述core文件,但是由于上节课的报错,我们这里没有演示成功。
26.L26
所有CDMB章节跳过,包括最安全的身份认证也不做记录,讲的都可能是个错的。我真的是。太垃圾了。
讲api的时候也不知道讲的什么,自己做博客记录把。
26.1 分布式监控项目需求讨论

26.2 分布式监控项目架构介绍
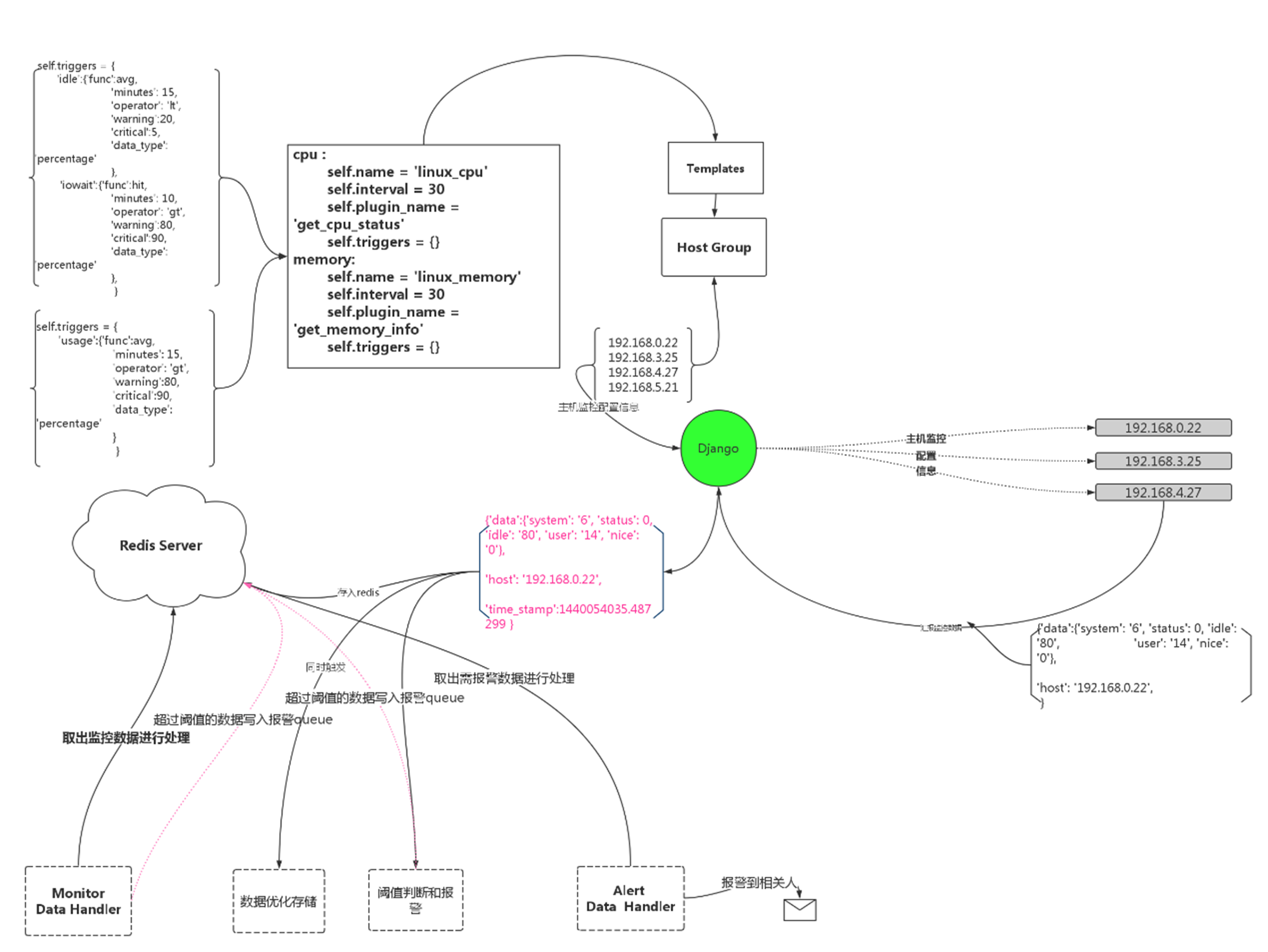
26.3 分布式监控项目表结构设计
首先创建app

然后就是基础表结构,感觉今天肯定是没讲完了,这里讲多少贴出来多少把。
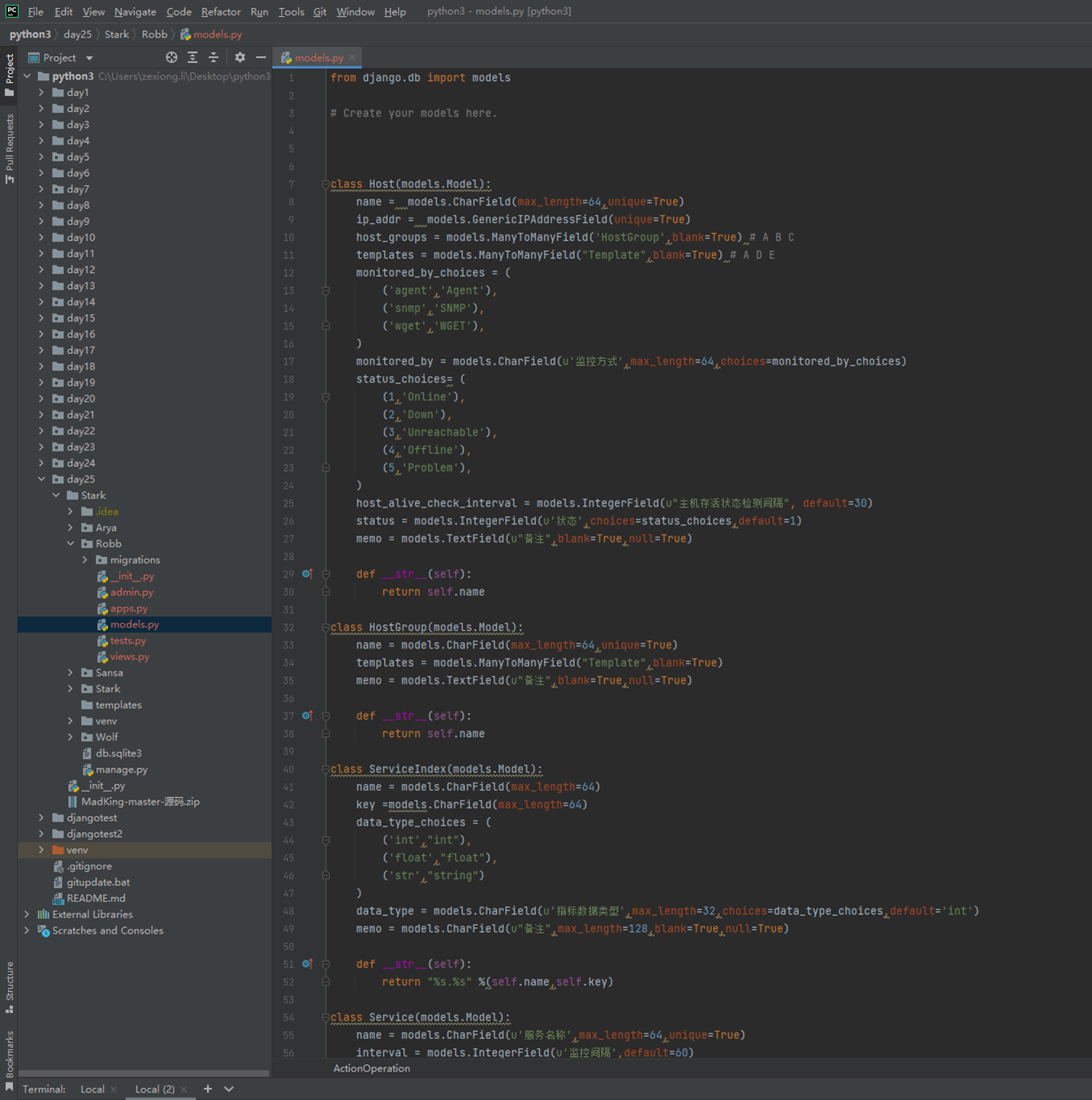
27.L27
27.1 分布式监控表结构回顾
回顾昨天的数据库表结构,不用记录笔记。
27.2 分布式监控创建监控模板相关
首先,得把数据库表结构给创建了。由于使用的自定义的userprofile,所以这里还要关联一下Wolf的认证相关。
关联Userprofile的地方在python3中不能使用引号。
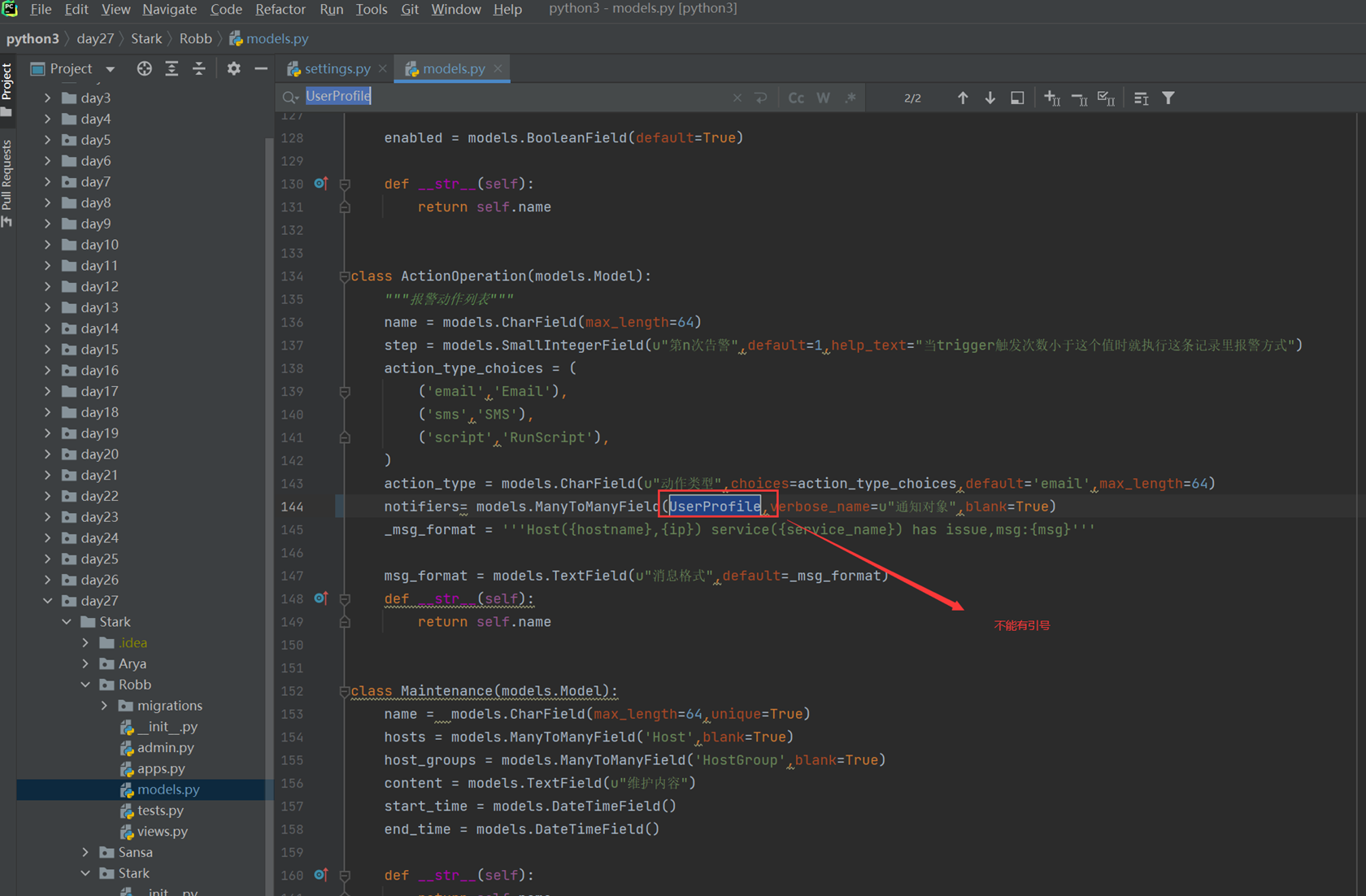
首先生成数据库表结构。
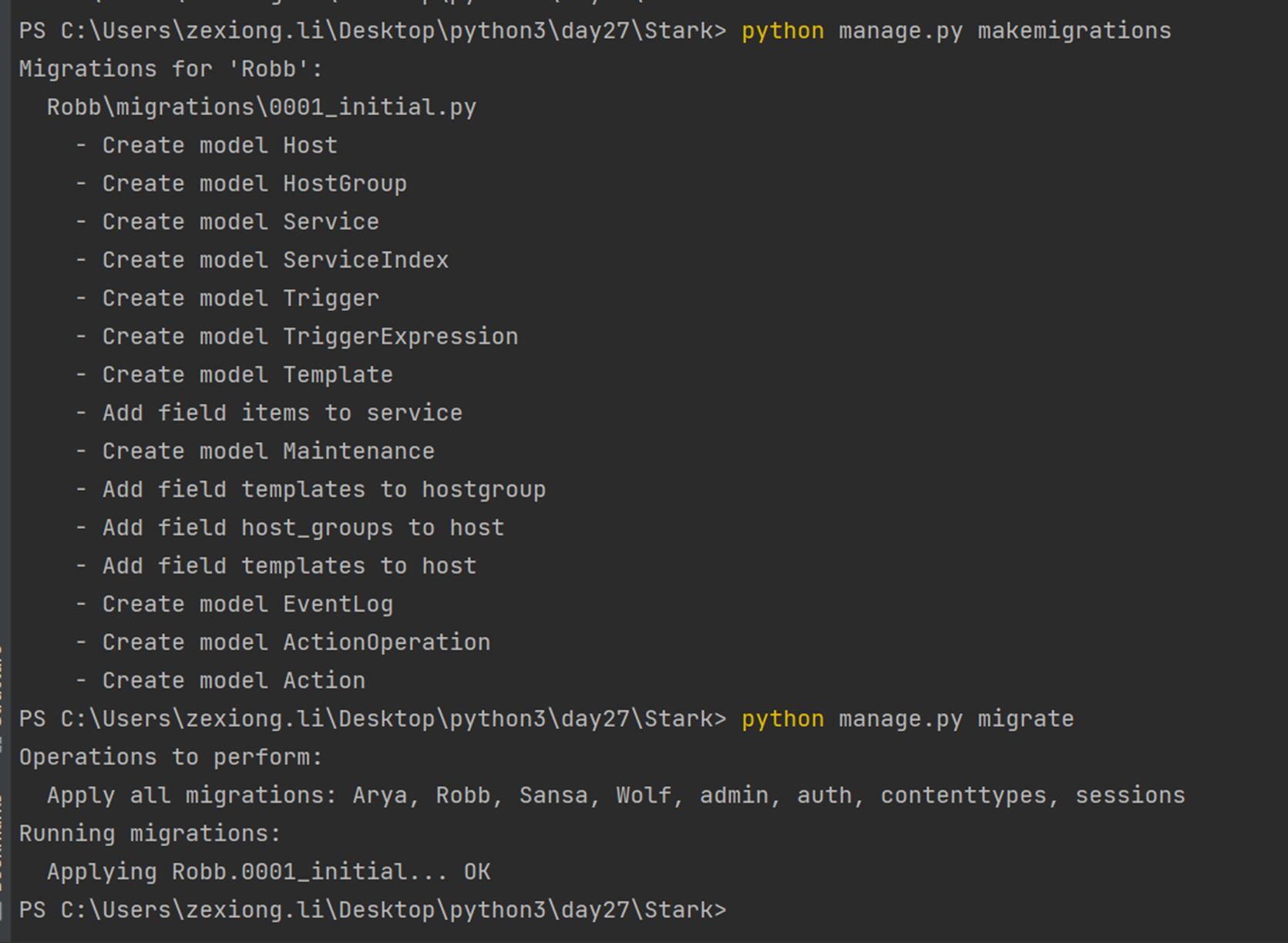
然后配置表在django admin后台展示。
启动服务器访问django后台。
现在准备一些测试数据。
创建3台主机。

在创建一个主机组

创建一些服务和监控指标
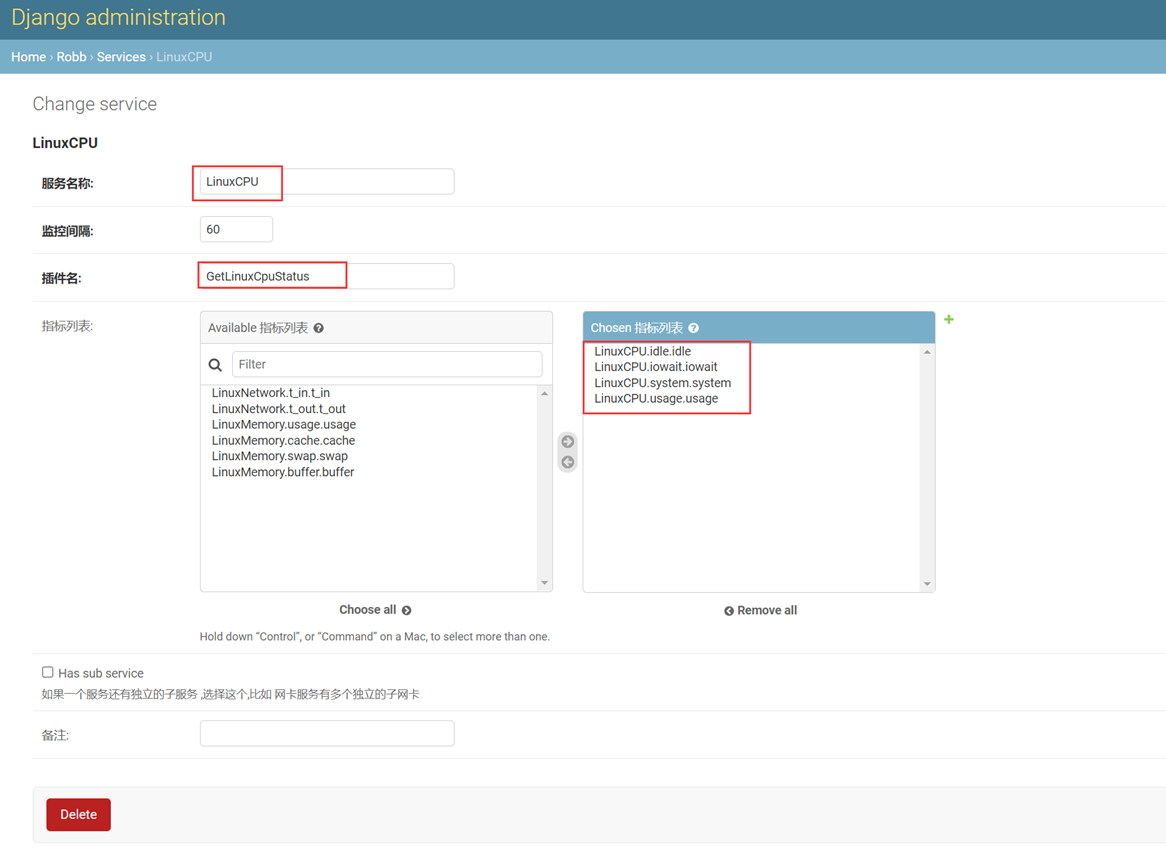
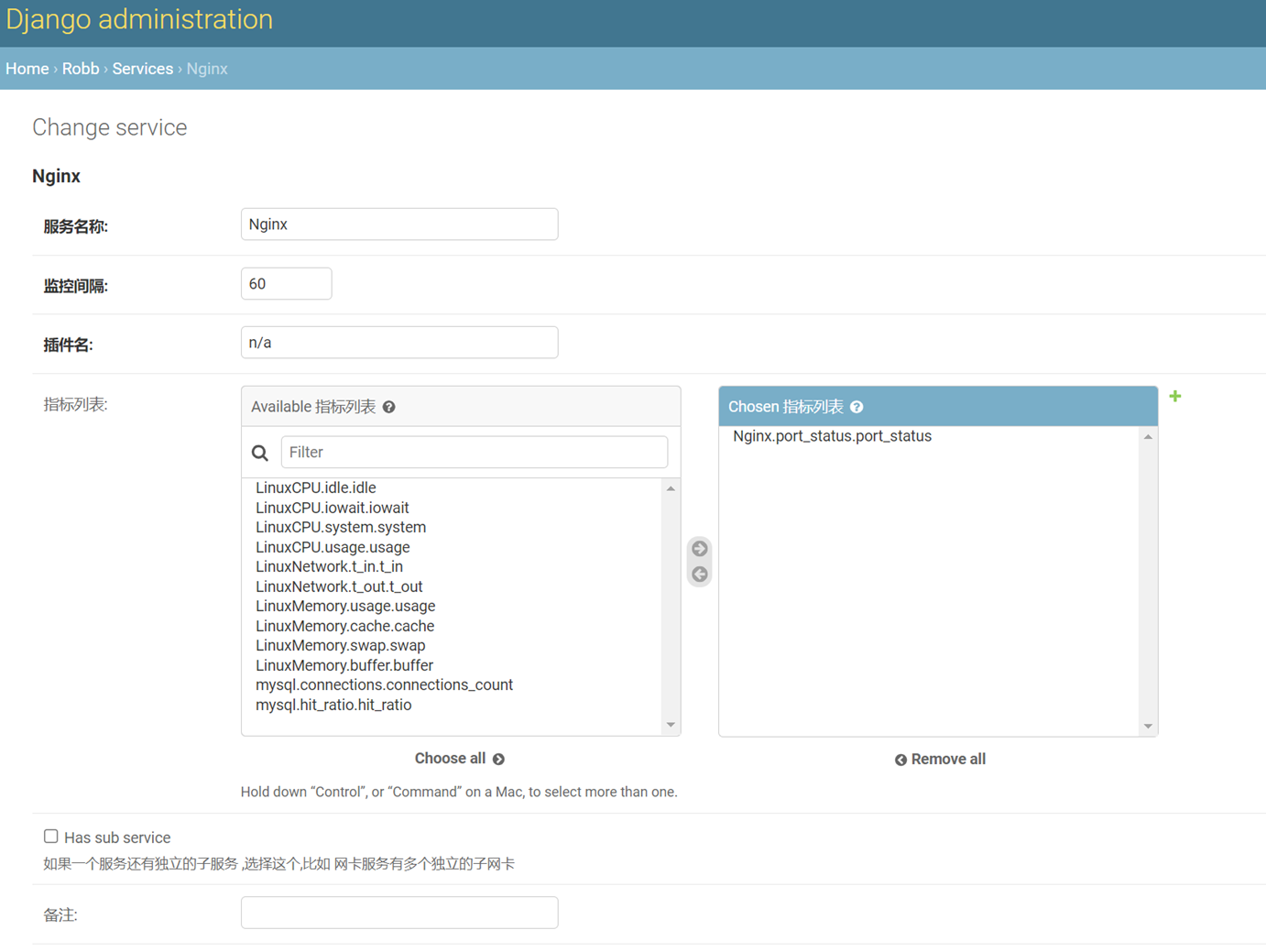
创建模版
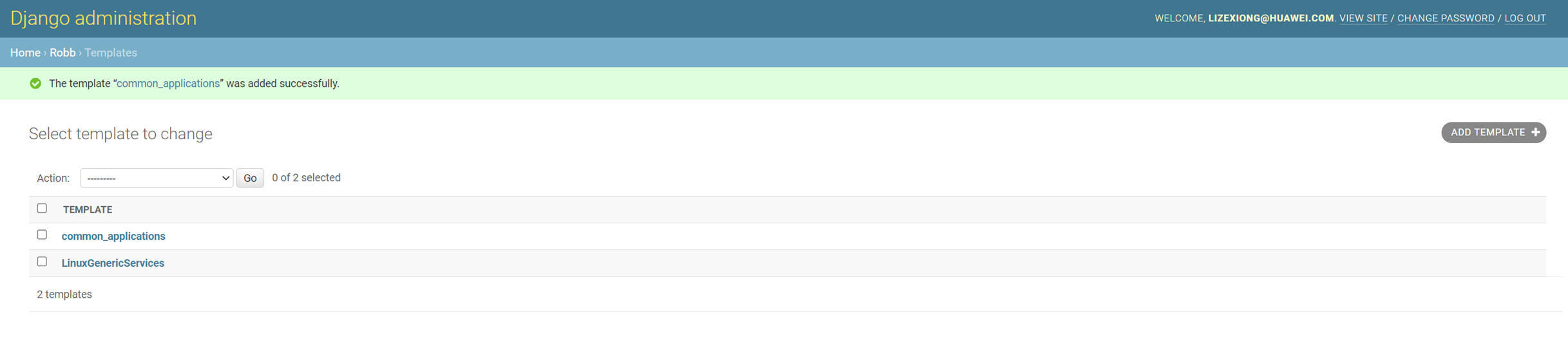
现在主机应用组和一个模版。
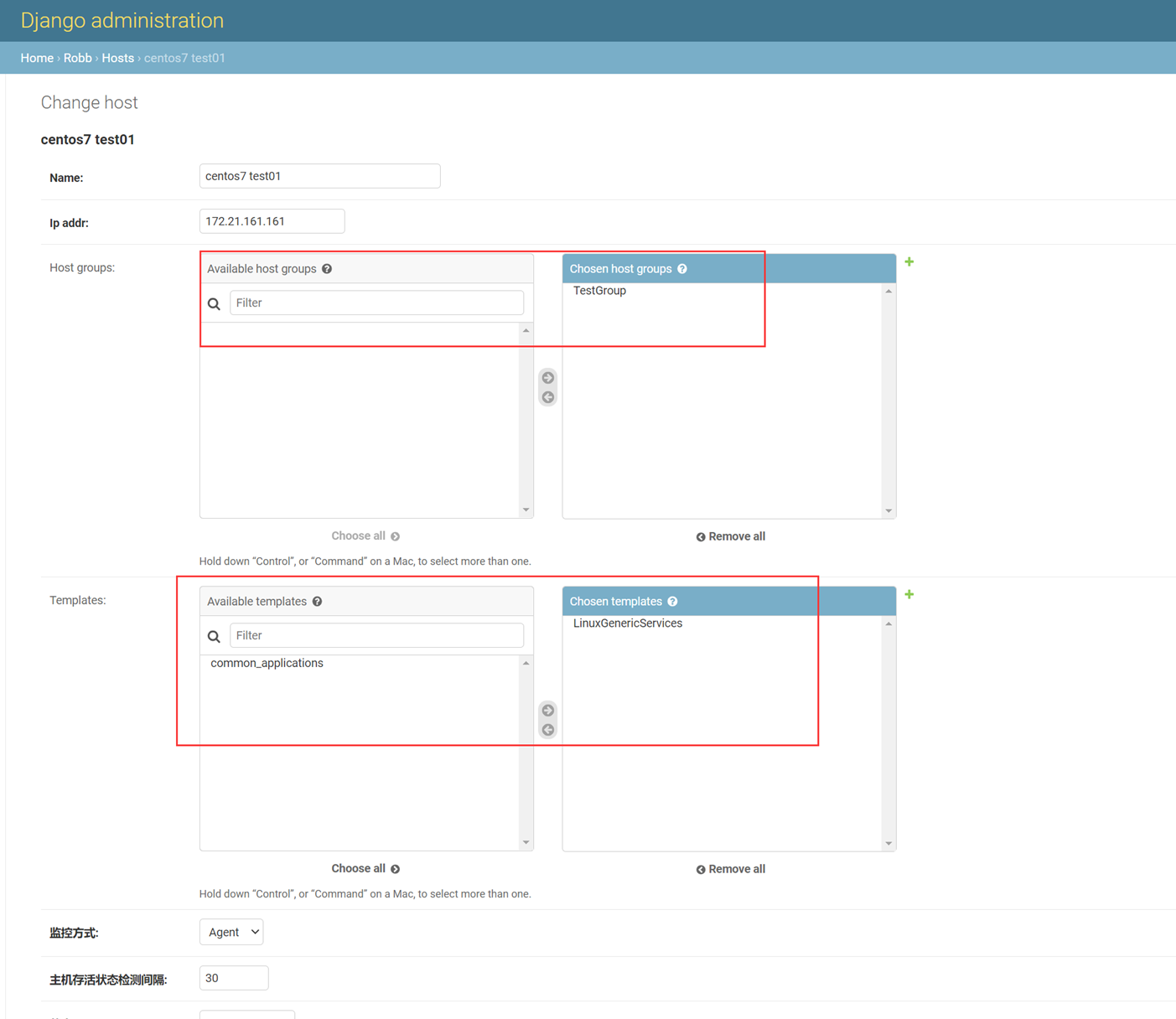
然后组应用2个模版
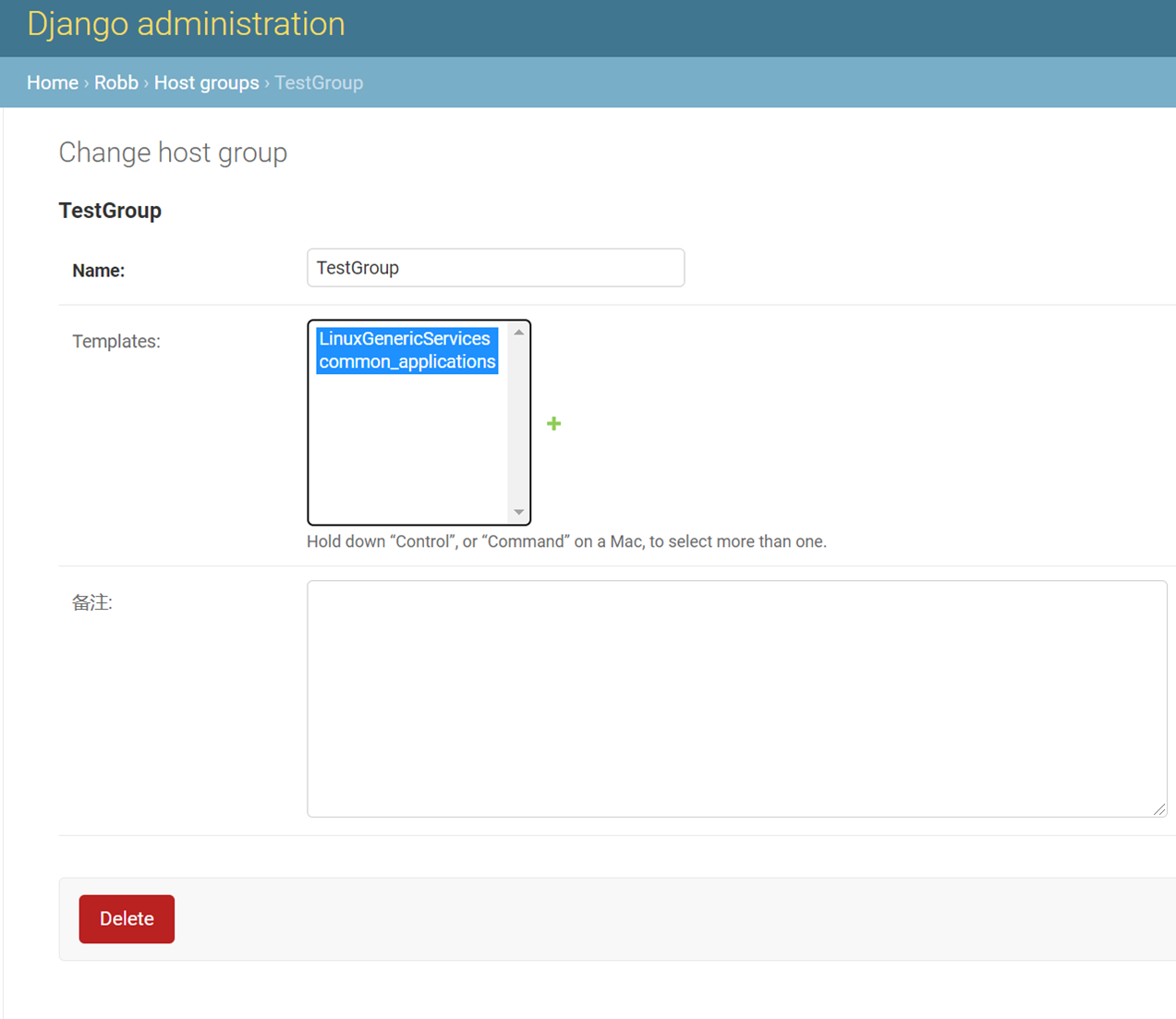
那么主机2,肯定应用了2个模版,因为他在TestGroup组里面,但是在主机那里,却不会显示应用了2个模版,因为是TestGroup关联的,显示问题。
27.3 分布式监控-客户端开发并获取监控配置
卧槽,讲的什么lj。客户端复制过来,还非要改成一个特殊的名字,啥几把也没讲好,全是调整自己乱来搞的错误。Sb。
首先把客户端代码复制过来,然后客户端命名Theon
然后服务端更加一点url,因为客户端配置文件上报是以下url
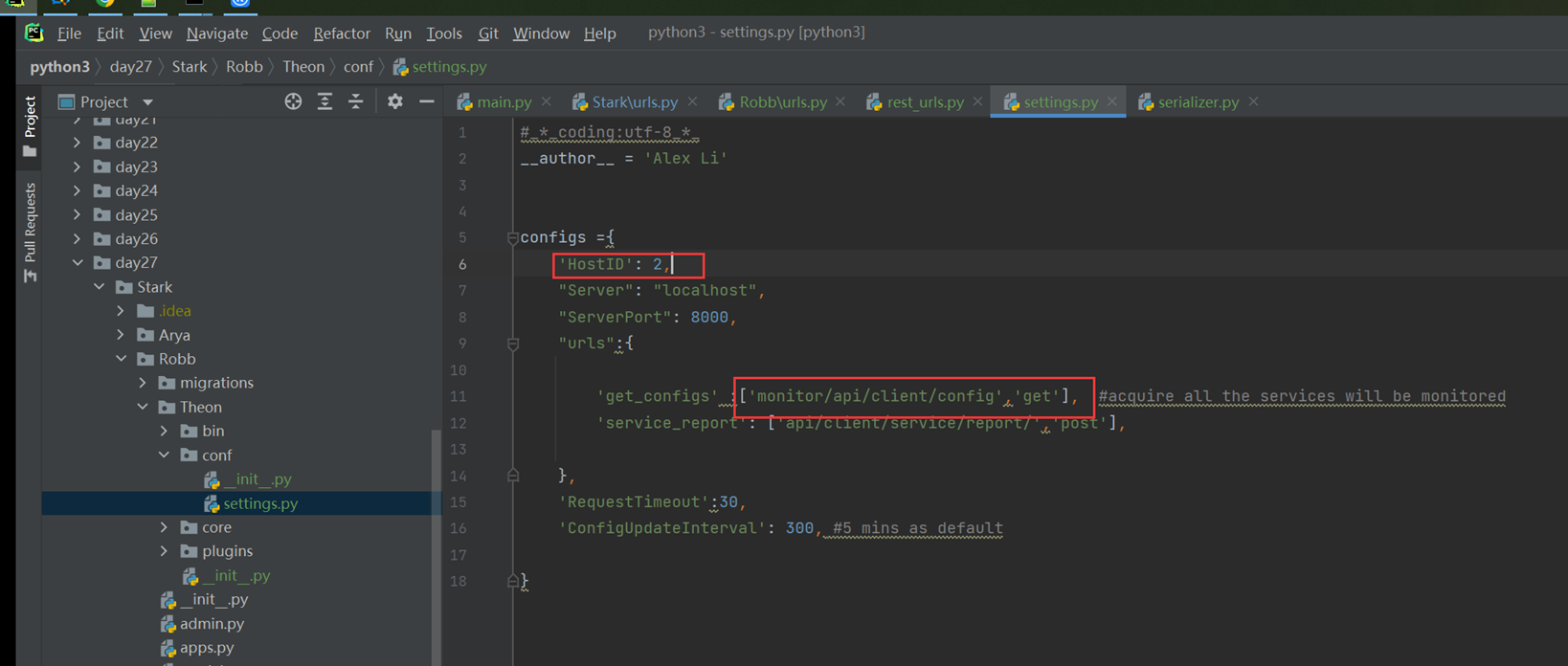
服务端url
Stark.url
Robb.url
rest_urls.py
现在执行客户端,可以看到这个机器绑定的监控模版
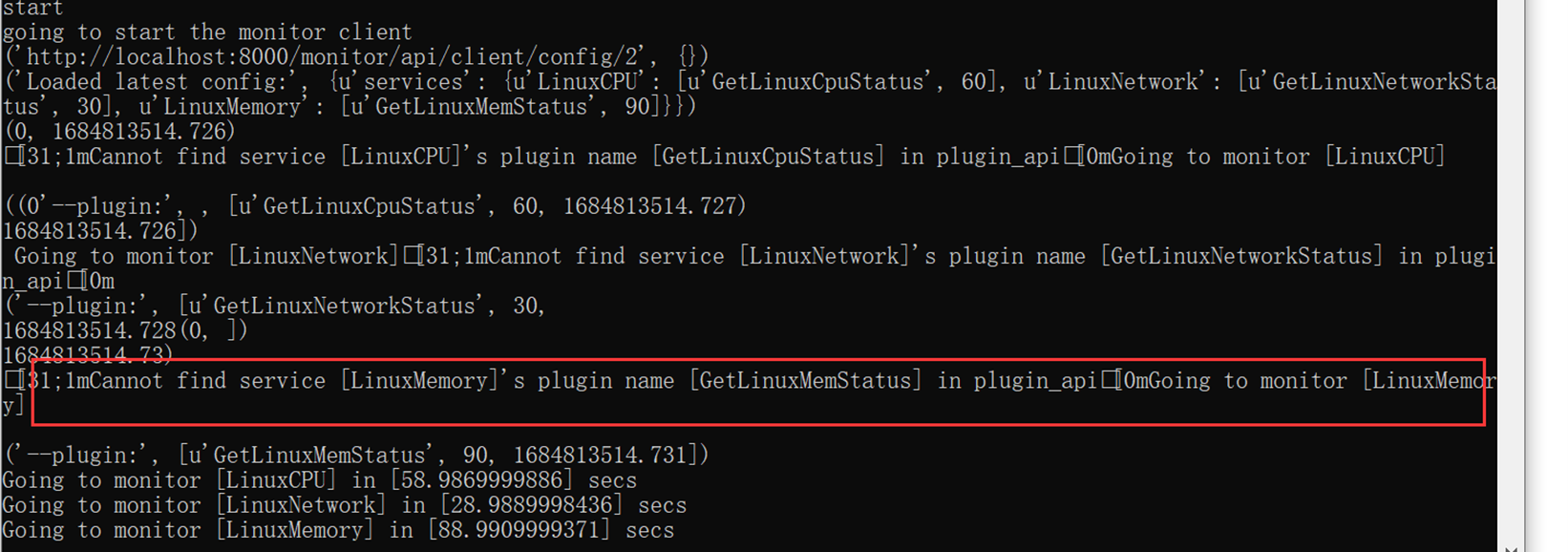
27.4 分布式监控-客户端将监控数据汇报到服务器端
就是讲解core下面的client代码,这没办法记录。就是客户端可以收集内存和网络数据发送给服务端(只做了这2个收集插件),服务端也收到了,这里就全部在linux上演示。因为公司网络原因,服务端和客户端没办法访问。
27.5 分布式监控-监控数据存储与优化
本章讲解的是10分钟的数据怎么存储,一周的数据怎么存储,1小时的数据怎么存储,3小时的数据怎么存储,1天的数据怎么存储,1个月的数据怎么存储,1年的数据怎么存储。
本章基本等于讲解的理论,还把需要拷贝的代码拷贝过去了。
现在把数据优化的代码拷贝过去。
27.6 分布式监控-监控数据存储与优化代码分析
本章完全就是解析代码,就是解析,数据存储以及优化的方式,就一个函数代码,但是函数代码调用了本章里面的其他函数,所以讲解的时间长了点,没有办法写笔记,只能看视频复习。自求多福。
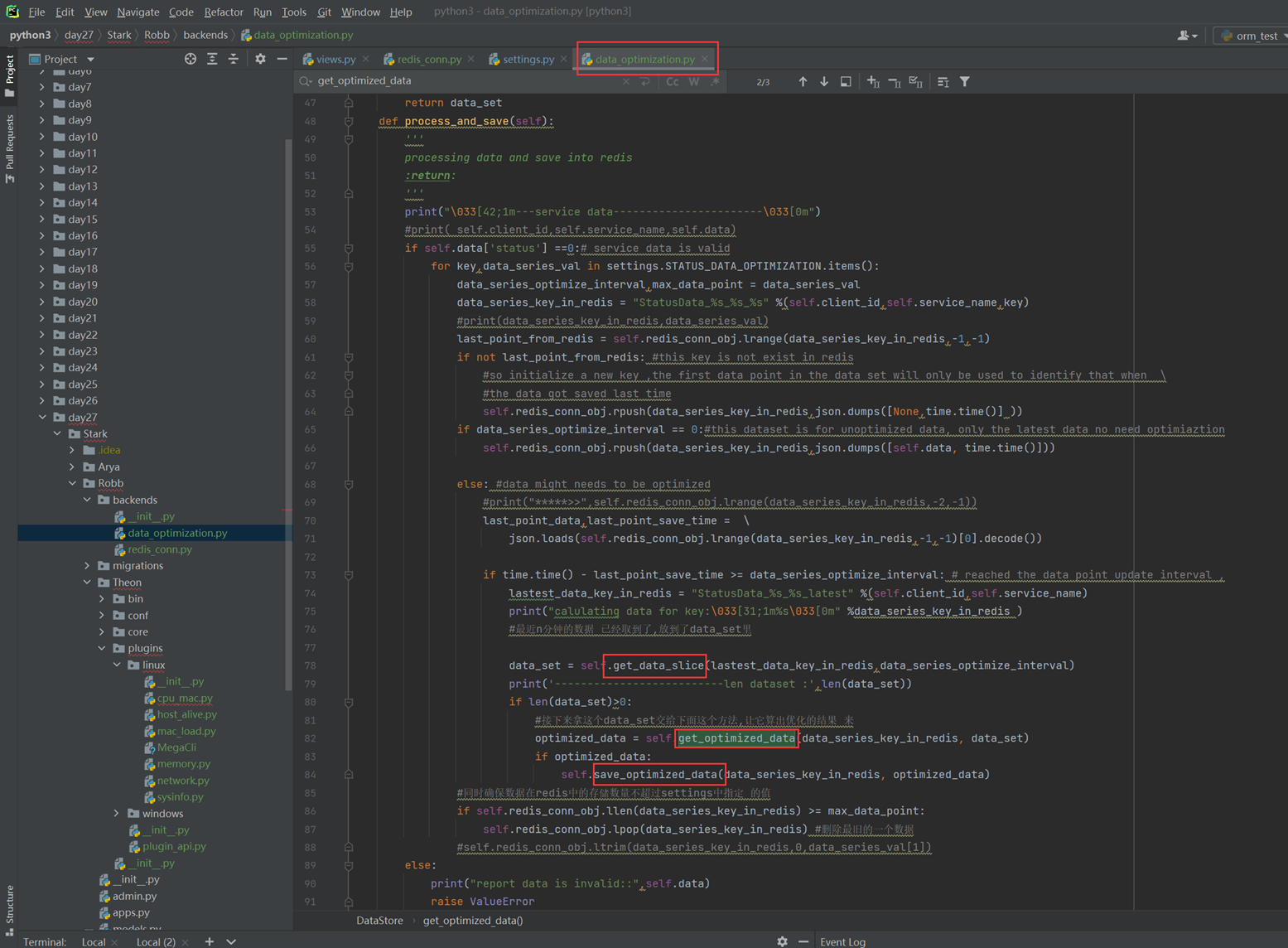
27.7 分布式监控-监控数据triggers处理
把上节课的数据存储演示了一下。能跑起来,redis里面有数据就算成功,这里就不演示了。
这节课视频讲的就是如果redis有值,怎么判断告警的条件,有那么多告警条件,告警的条件是什么?怎么去判断的。
本节主要也是围绕以下的代码去拓展的。
具体的引用代码里面就不演示了,没有意义。
另外,本节课结束前创建了几个trigger,由于本人测试环境如果使用课堂上的方式,告警就很那触发,这里,本人就创建一个简单点的,和课堂就不保持一致了。
27.8 分布式监控-判断多条件trigger并触发报警
讲解data_processing里面说明怎么处理trigger的逻辑。到触发告警部分,讲解结束。
27.9 分布式监控-trigger触发报警
整节课基本上都在排错,由于我们的代码是从git上直接拷贝的,所以没有这些错误。就最后2分钟把告警策略和key改了一下,触发了一条告警,什么原因都没讲,课程就结束了。
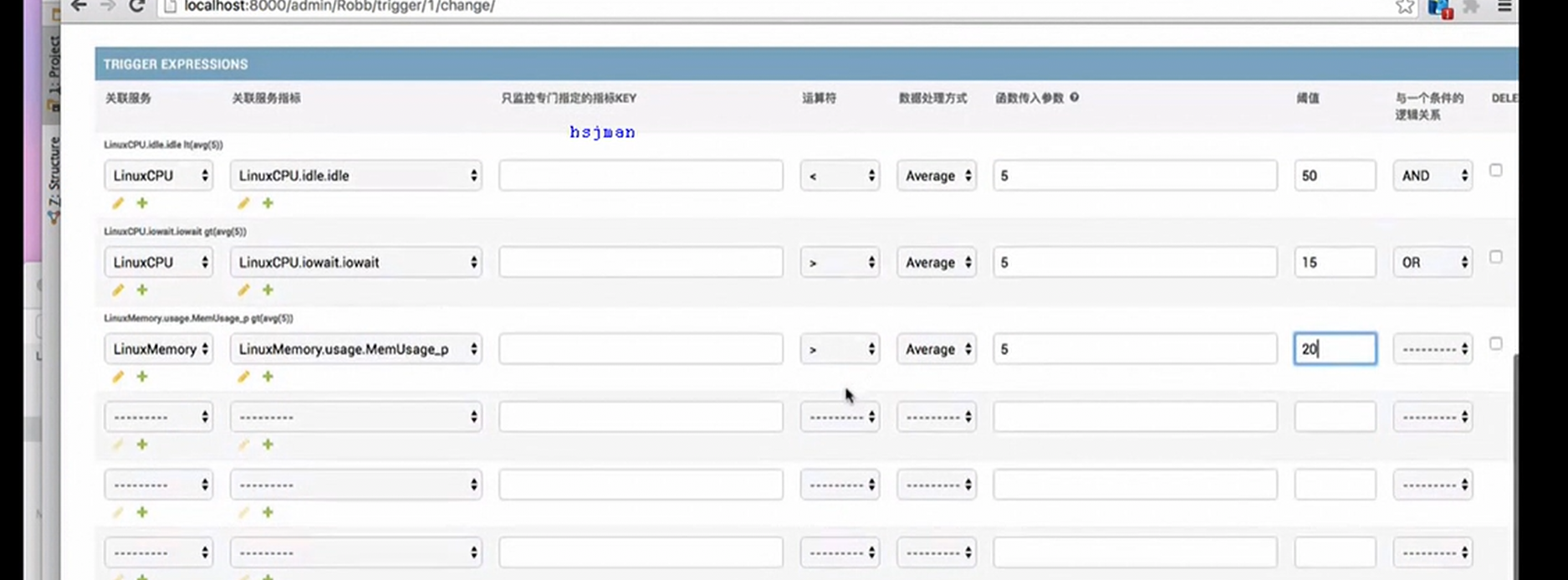
这里不一定非要改,他要改,我们不一定需要。
然后查看有告警出现了。
当然,这里django后台要绑定告警,很小的问题,查了半天。原来是没关联告警。
触发告警的代码是从下面的地方开始的。
27.10 分布式监控-trigger触发及前端基本页面展示
前提条件:因为告警使用的rabbitmq的发布订阅,需要安装rabbitmq。
告警服务是一个单独的服务。主要是这么几个文件。
本节课,这老师直接说忘了什么意思,所以代码没怎么讲解,反正就是拷贝了3个文件,后台添加了一个告警动作,就是接收告警了。至于详细的代码,有时间自己去研究吧。
第一个主入口文件:RobbServer.py
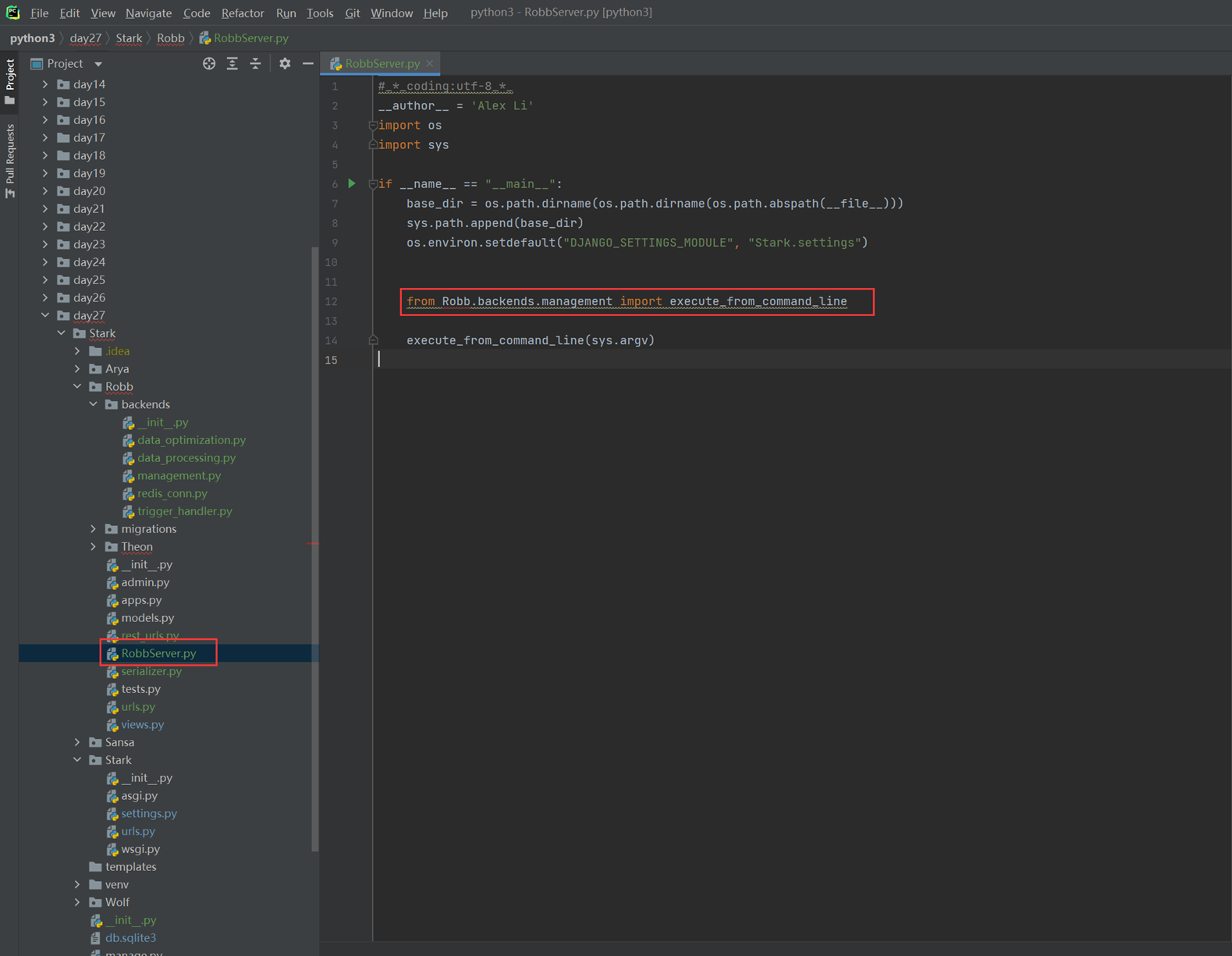
第二个: management.py
第三个: trigger_handler.py
最后后台添加一个告警动作。
最后启动这个告警发送的单独服务。
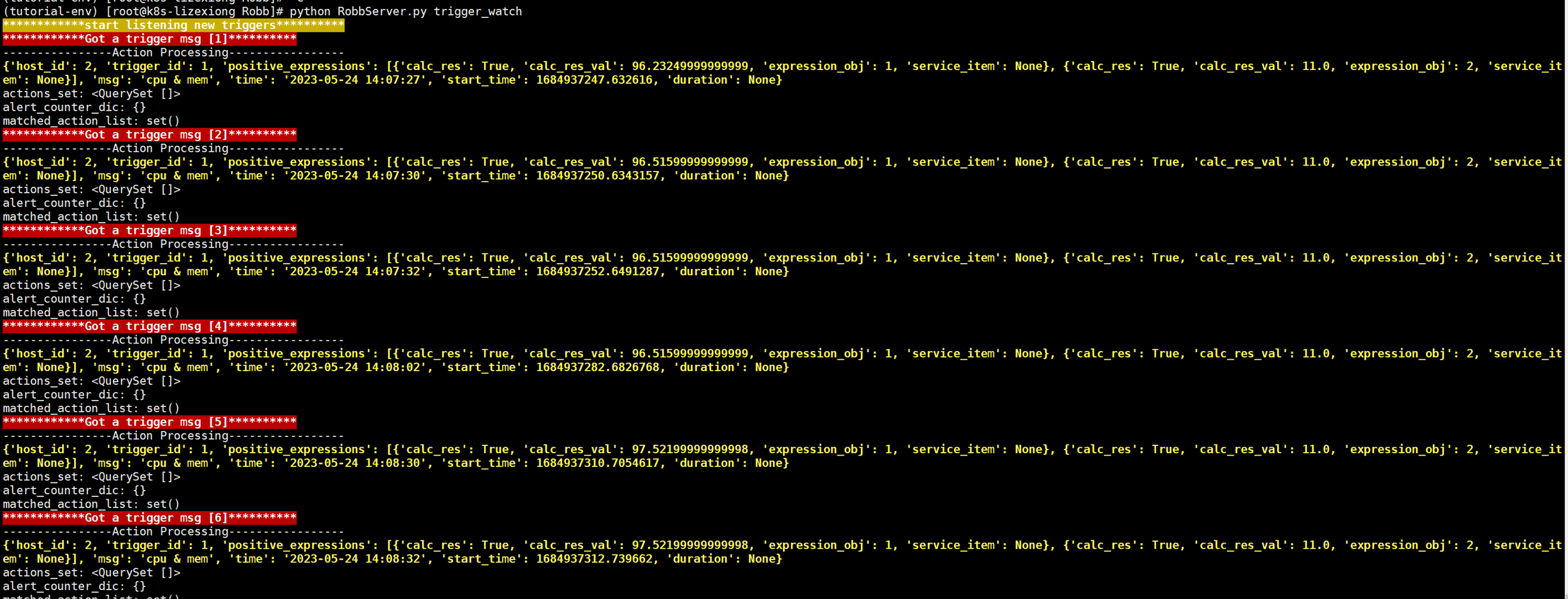
28.L28
28.1 分布式监控上节内容回顾
这个就不必说了,因为他们是一个星期就上一天课,必须有个回顾,我们自己看视频,一天有时候就看两节课。所以没有必要。
28.2 实现监控画图
前15分钟在装环境,本节课其实只有30分钟,整节课都在拷贝,复制,排错,最后网站跑起来才算结束。
本章的目的就是以下,能在网页弹出报警。
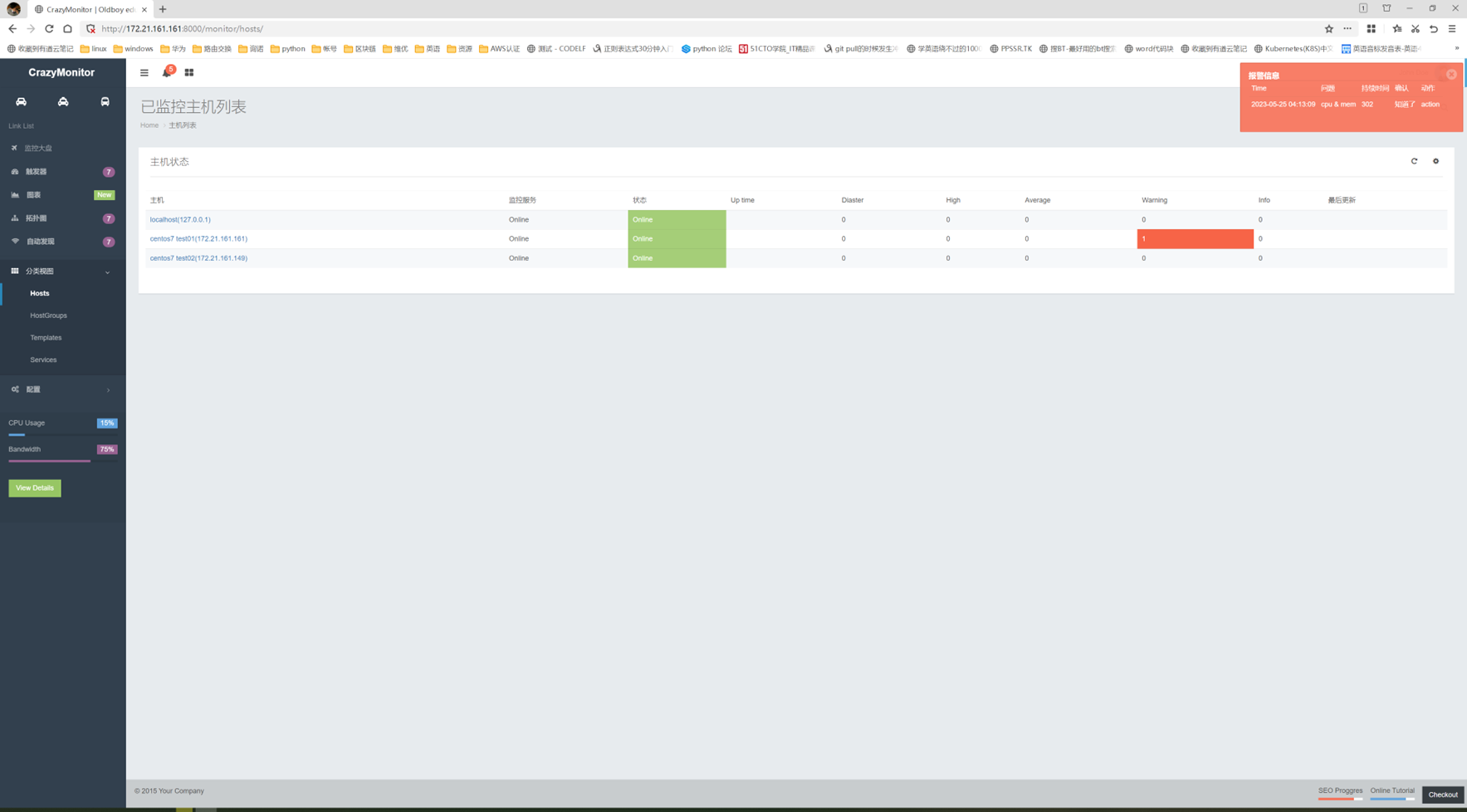
整篇视频都在复制和排错,其实最后很简单。就是复制html文件,views文件,url文件,没了,理清楚了就很简单。
url
rest_urls.py
views
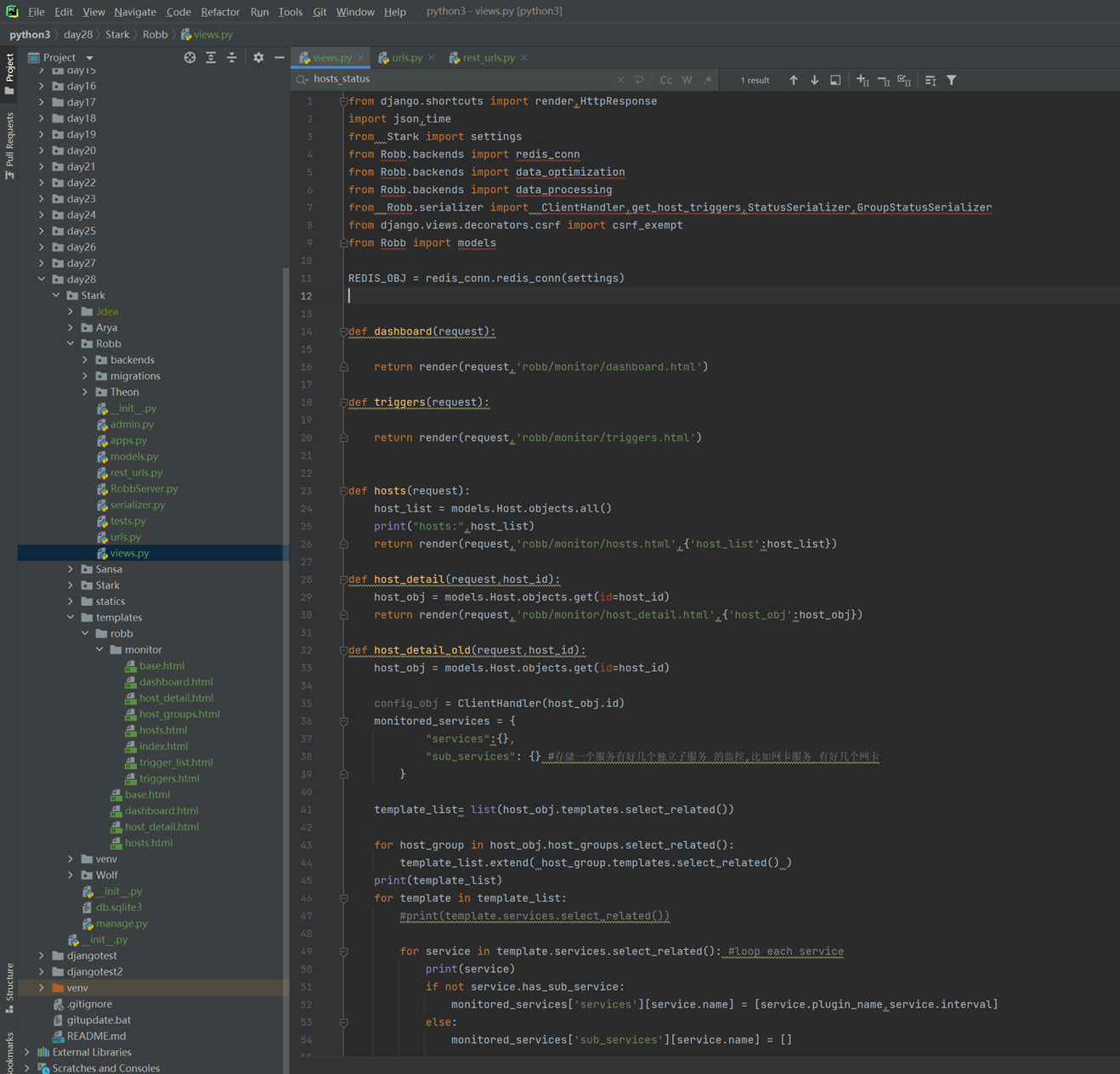
html
由于文件比较多,内容就不展示了
基本完成这些就可以访问测试了,目前只是完成了告警展示,什么主机详情还没做,点击会报错。
28.3 画图软件介绍
本节完成了上节课主机详情点击报错的优化。
主要是有一些网页需要自定义标签,之前我们没有导入。
然后就是如果要设置自定义标签。Setting的templates一定要设置,否则找不到报错,本人就是在这里耽误了半天。
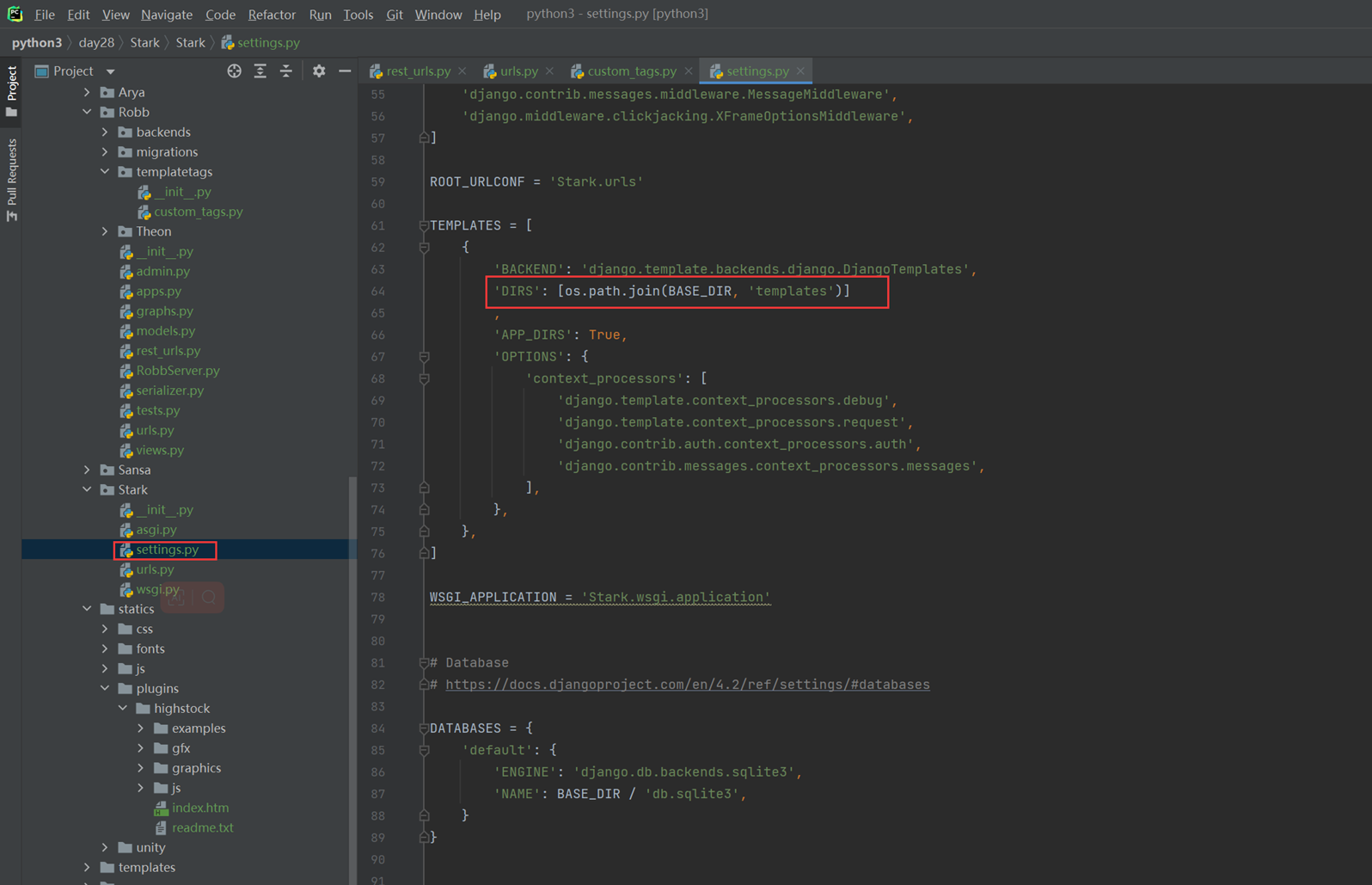
然后本章就是讲解Highcharts,就是按照代码讲解了一些,没怎么细讲,和bootstrap一样,这里就不做过多记录了。
这里还是演示一下监控画图的效果,虽然没有zabbix哪些比较好,但是起码功能实现了。
url
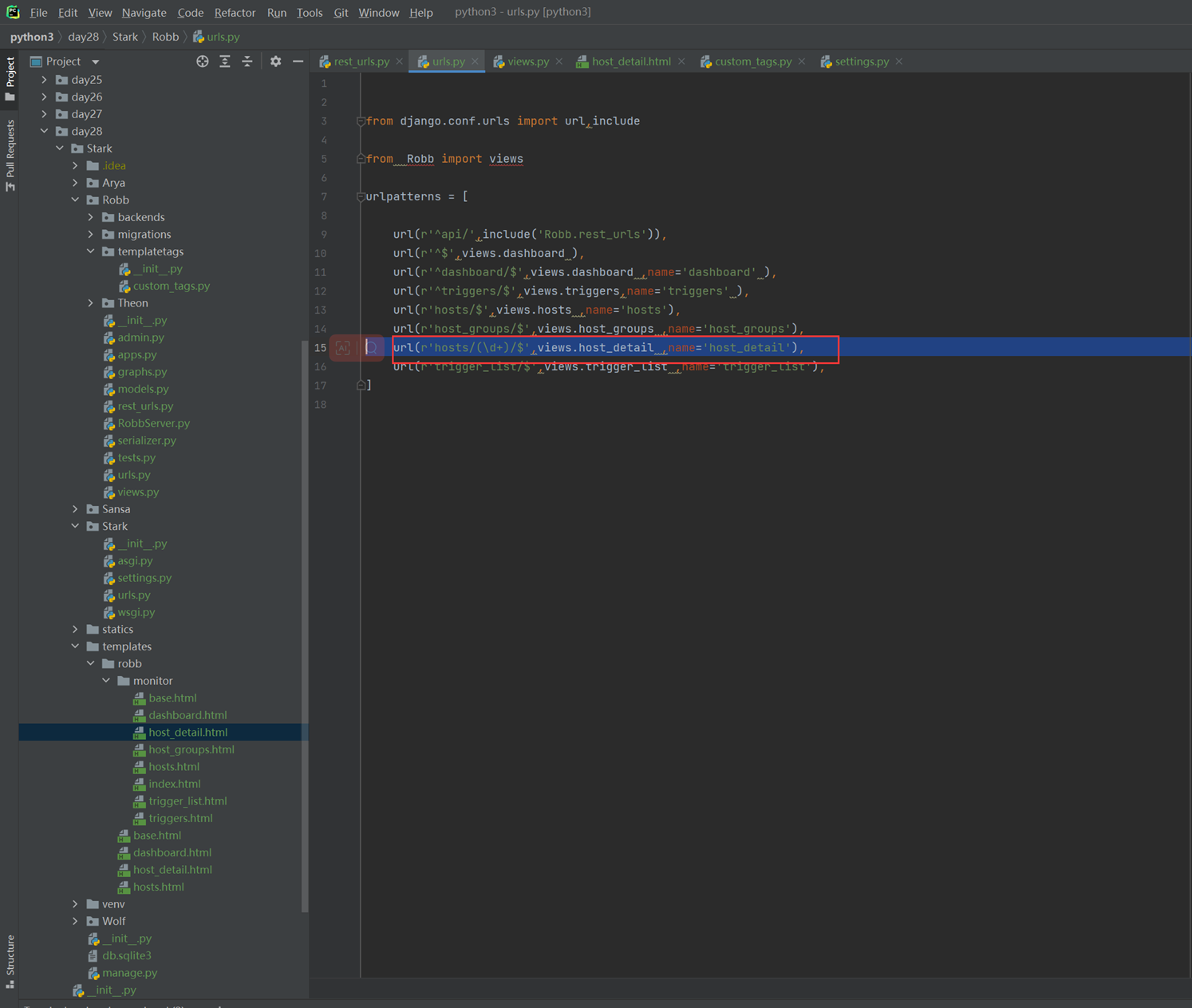
views
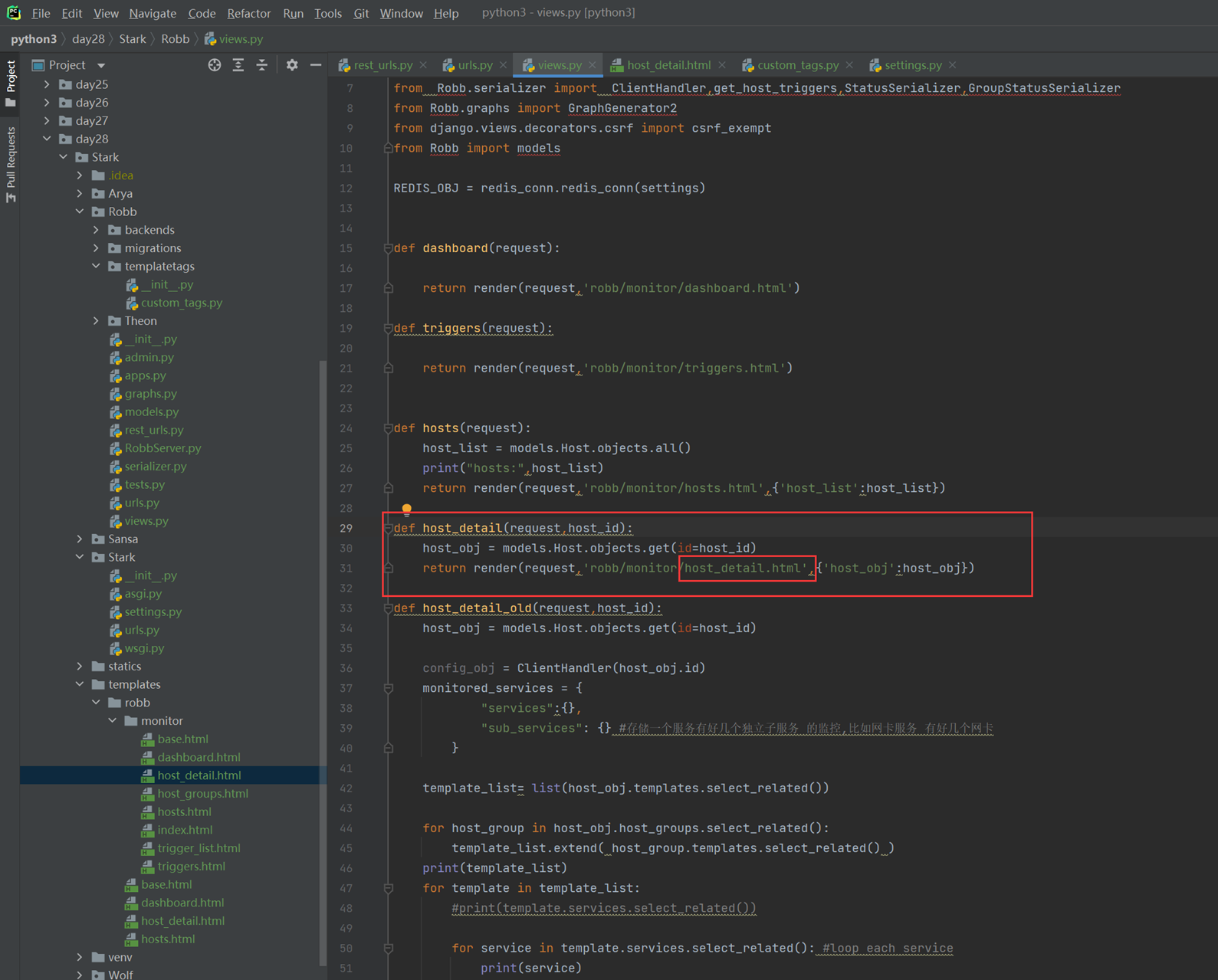
html
主要是html,里面使用了higtcharts
最后看看效果
监控项目结束。
28.4 网站用户质量分析监测项目介绍
简单来说就是实现一个类似与腾讯云测,监控宝的玩意。
28.5 浏览器各项加载数据接口介绍
简单来说就是把用户当个肉鸡,访问我们网站的时候返回一些我们需要的数据。本章基本都是在讲解理论。需要哪些数据见以下:

怎么获取这些数据?现在很多浏览器都支持。
28.6 用户数据汇报到前端
从这里开始,就是开始实战了,这里独立与Stark项目,老师的项目名师peiqi,app是app01,我们这里规范一点。项目名MonitorTreasure,app名app01。


首先生成数据库数据。
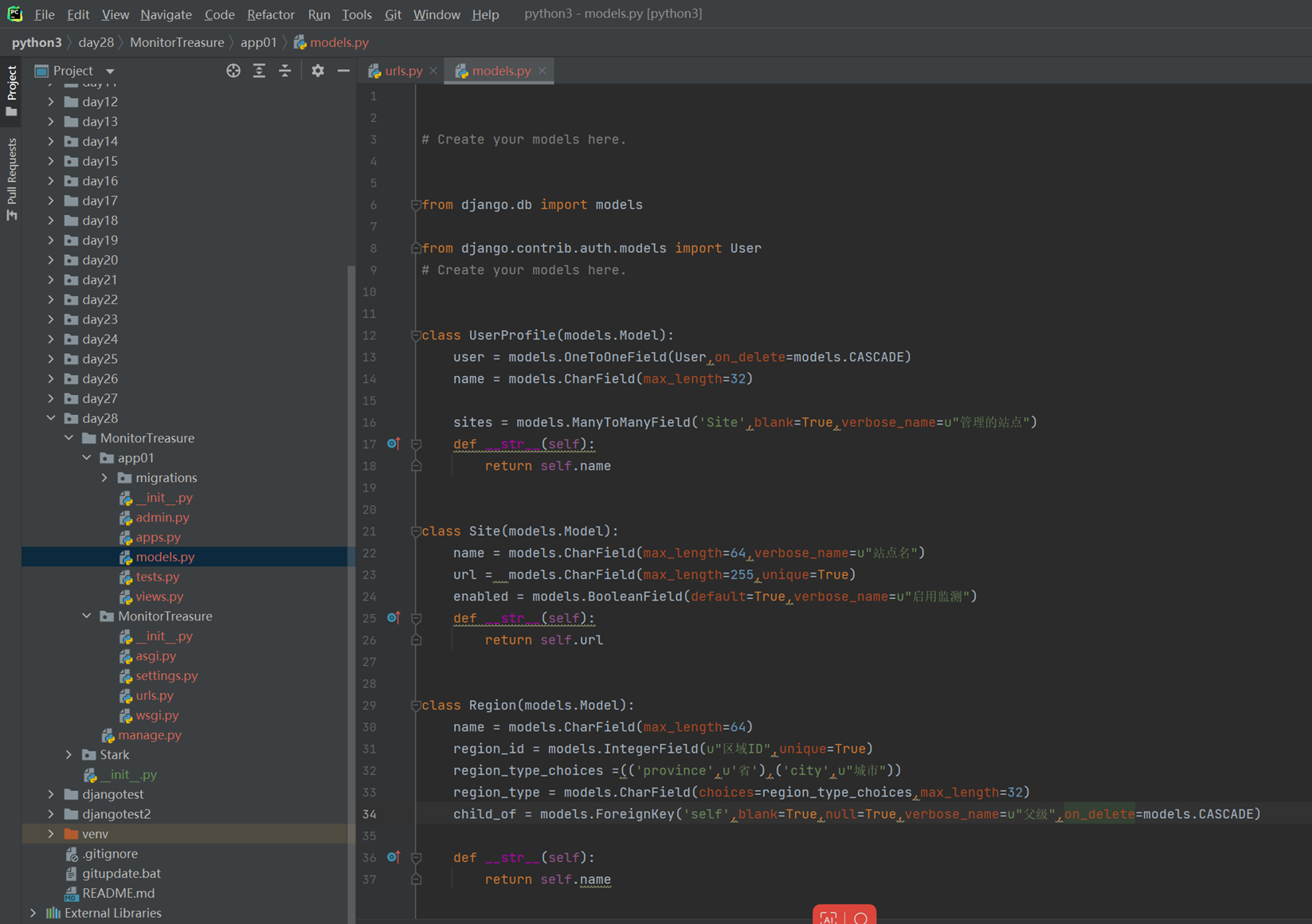
别忘了settings里面注册。
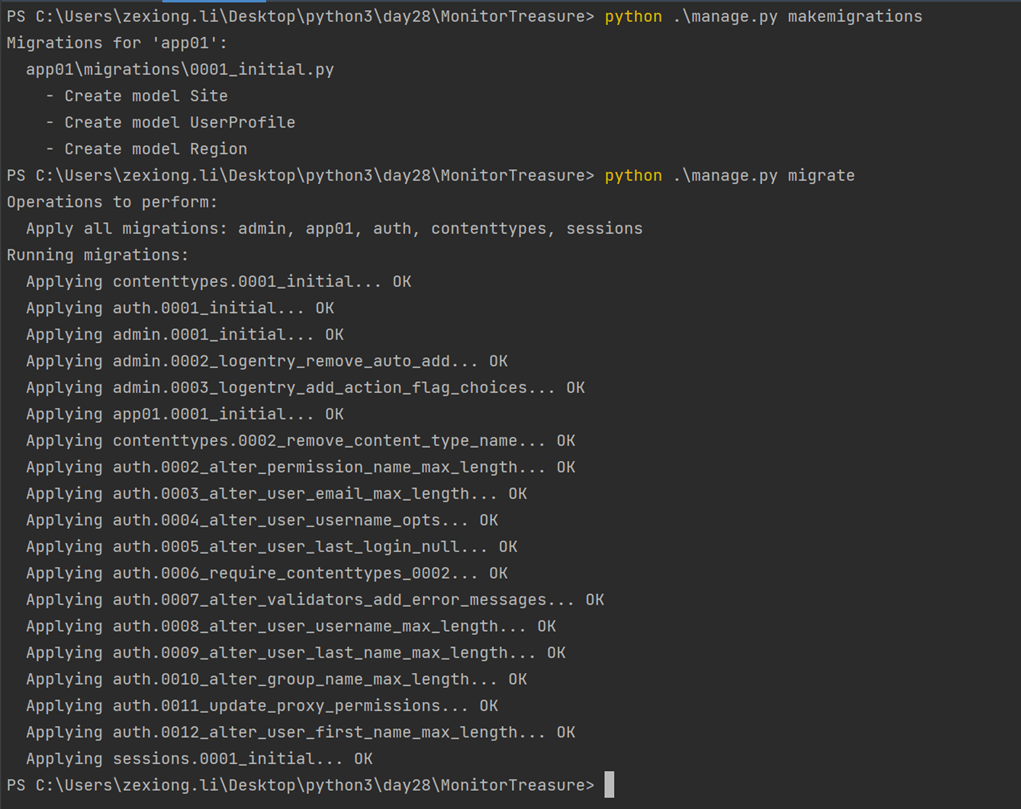
admin后台也需要注册
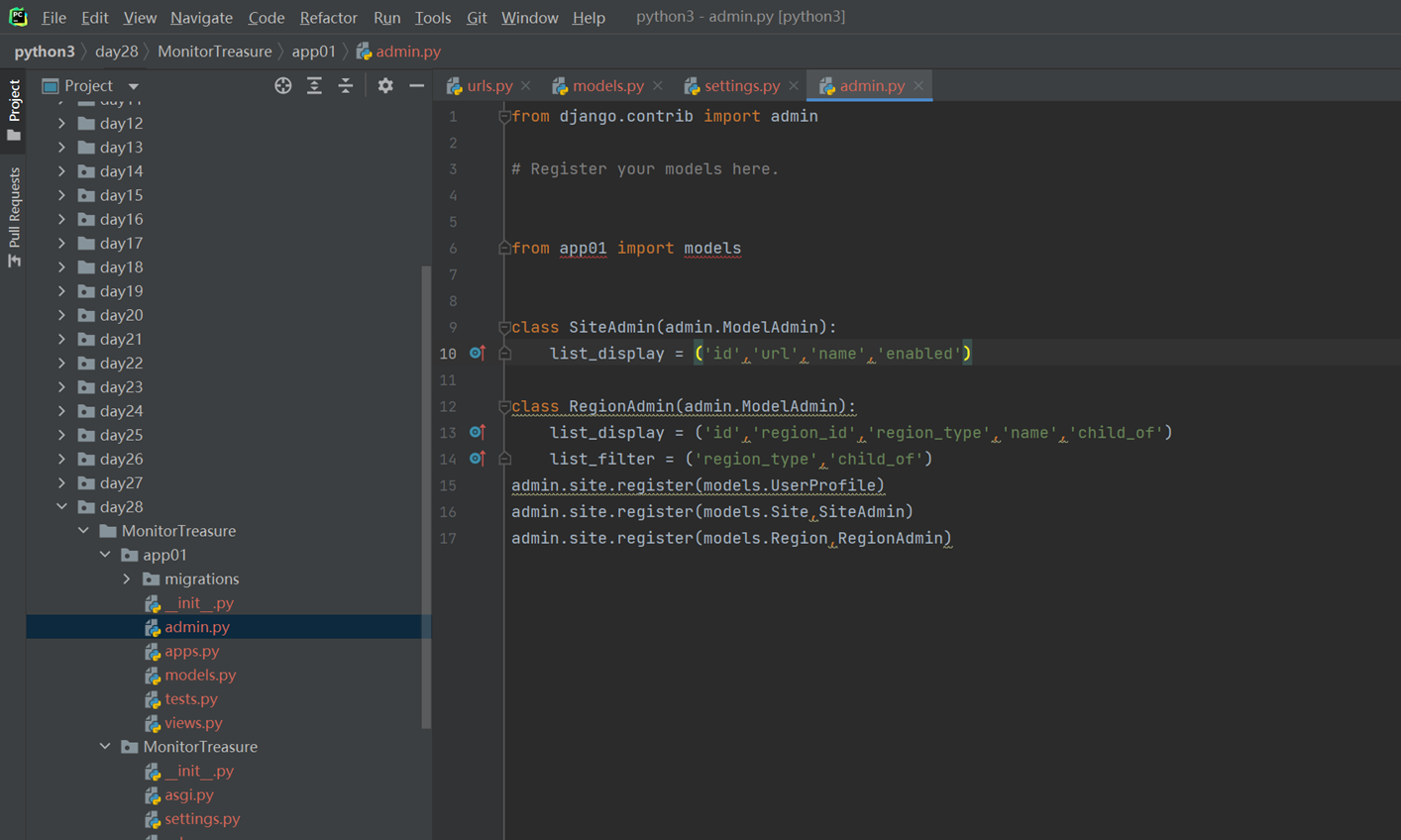
MonitorTreasure.url
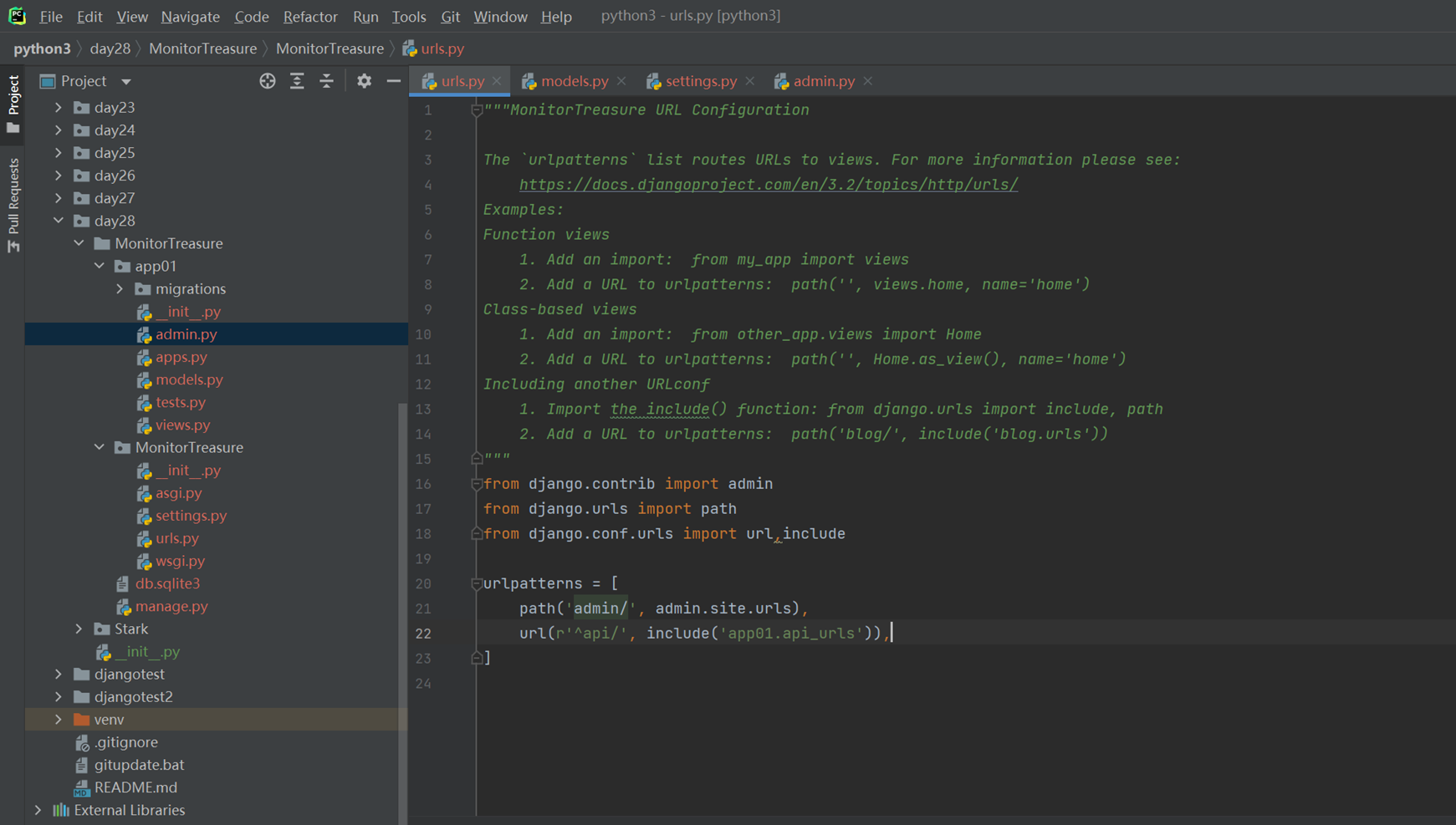
app01.api_urls
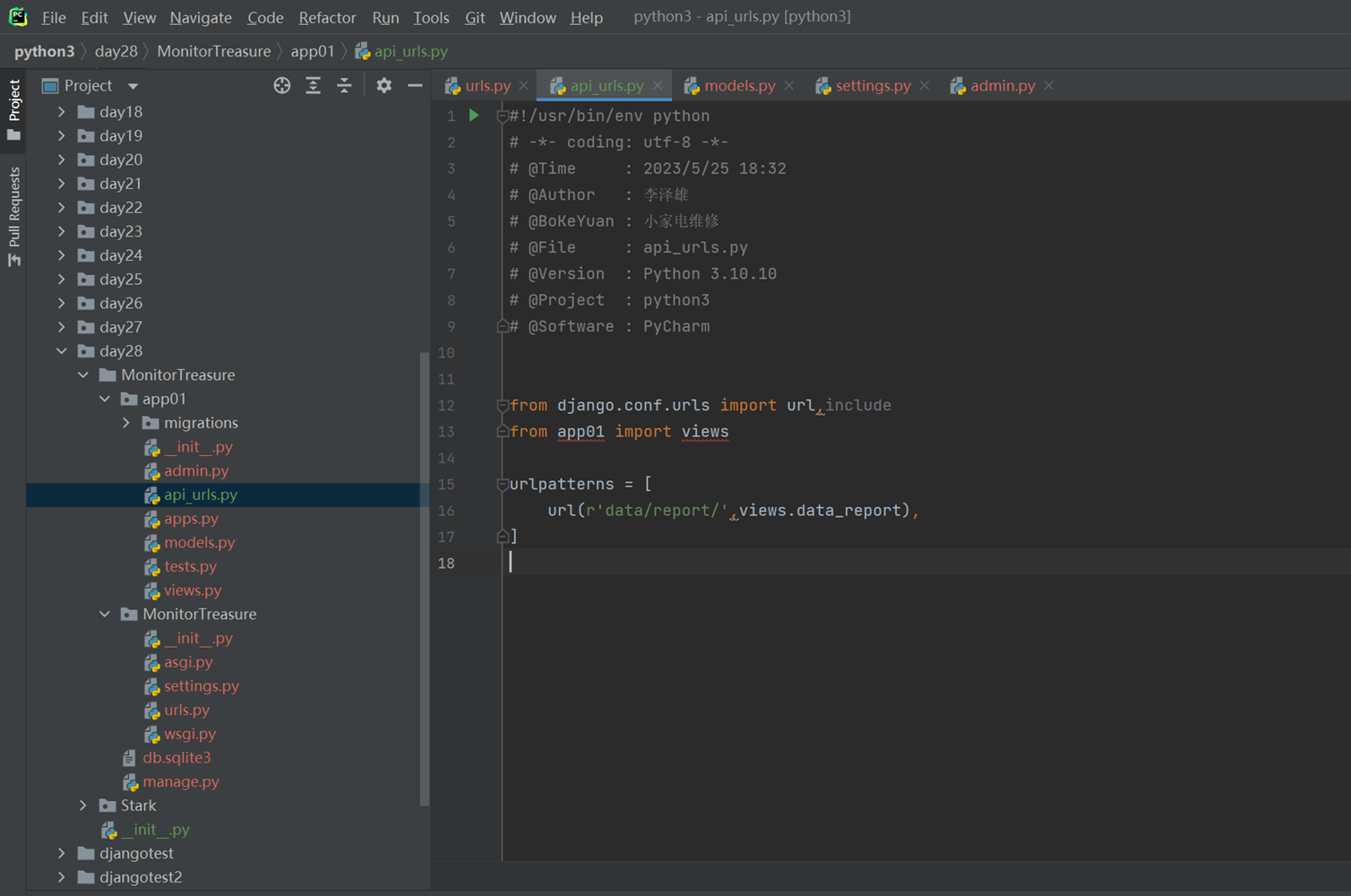
views
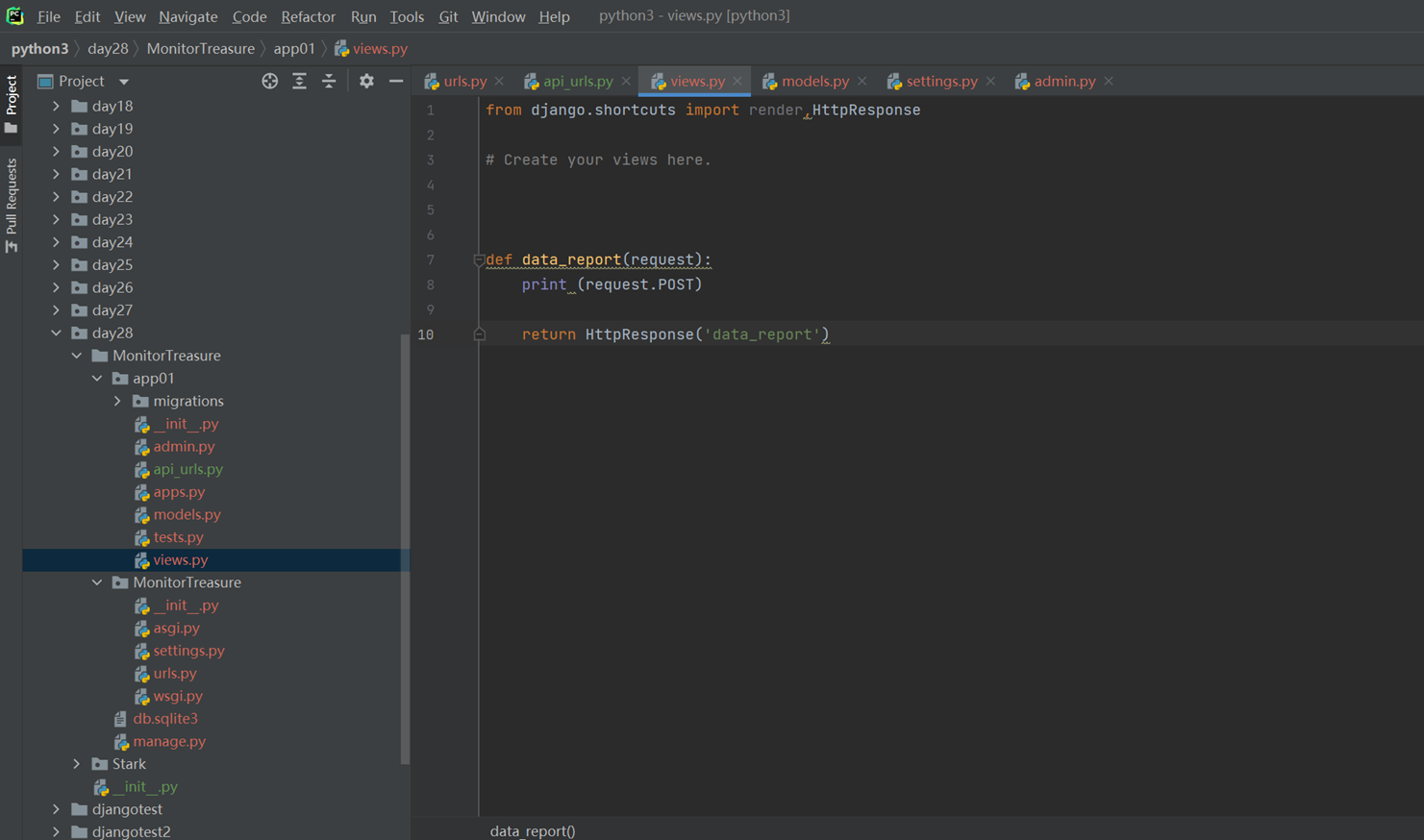
启动没有报错,本章结束。
28.7 用户信息收集脚本代码介绍
以上就是埋在网页主页的代码,通过这个来发送数据给后端分析服务器。
本节课基本都是理论,主要是下面这个js的代码,所有的收集逻辑都在这个里面。(这个js不是放在我这个监控宝项目下,是放在要被监控的网站目录下)
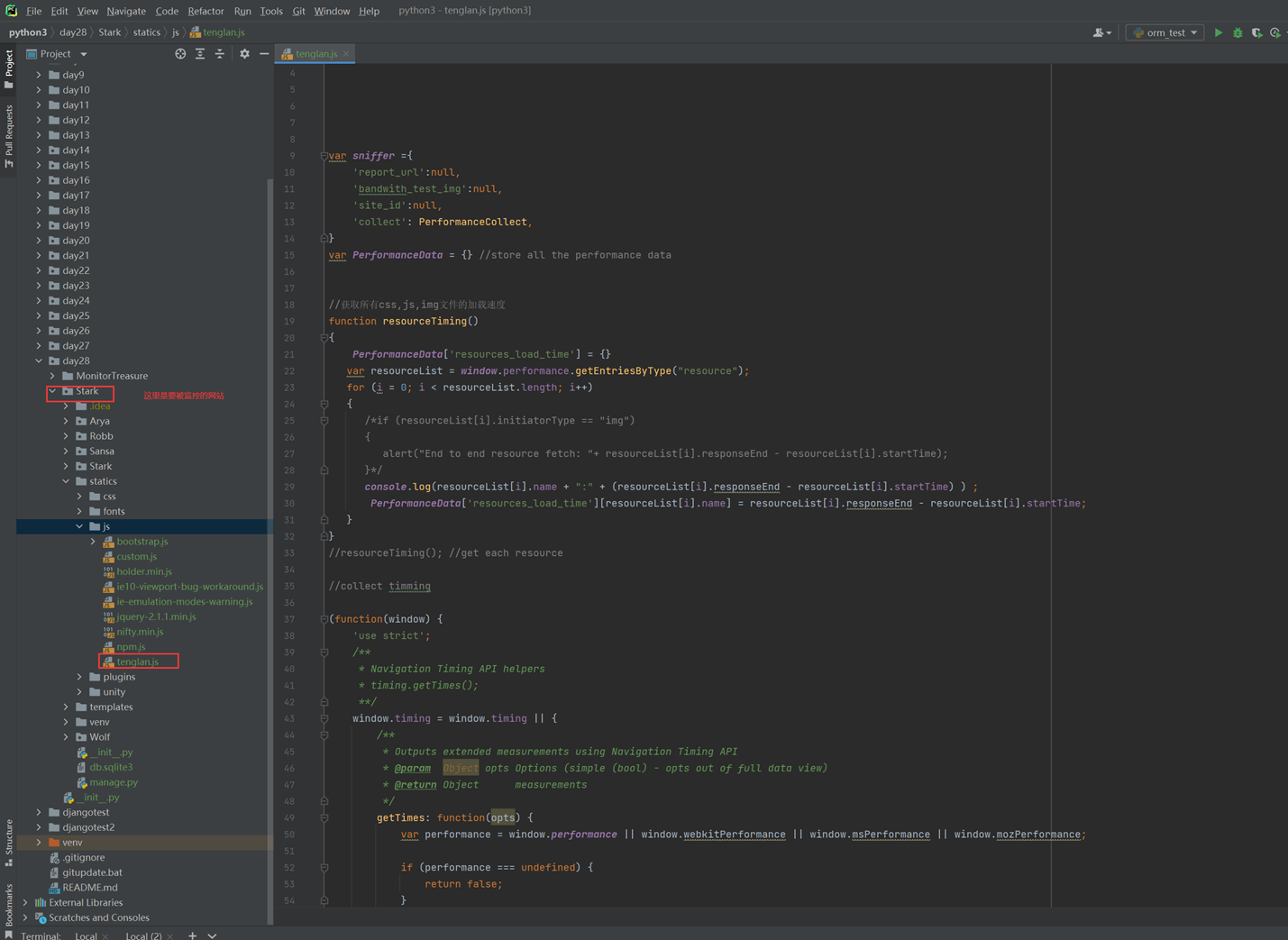
28.8 用户信息收集脚本代码介绍2
本章就是演示怎么把tenglan.js埋在要被监控的网站里面。就导入就行,非常简单。
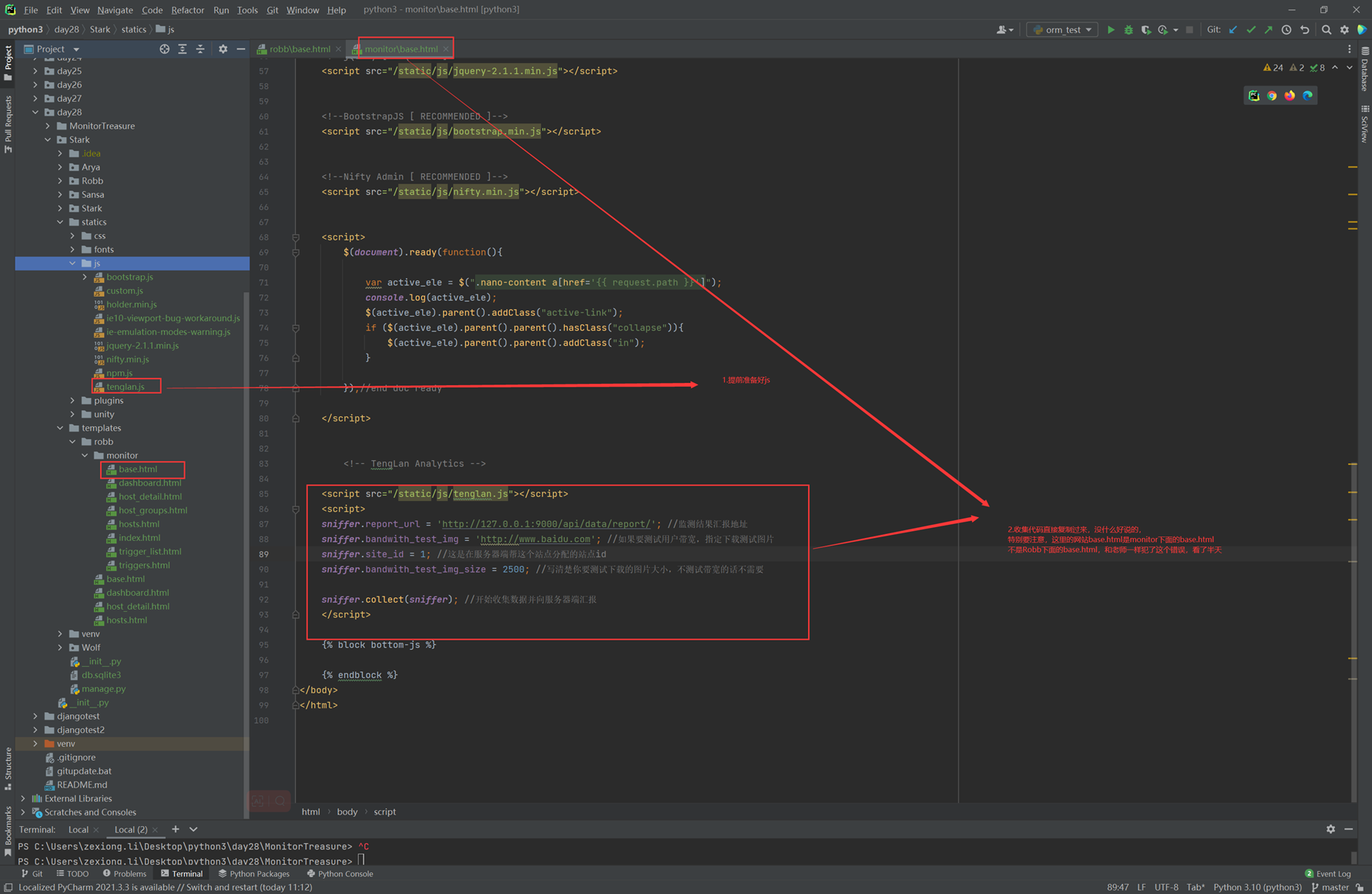
然后访问我们被监控网站看看有没有获取到需要监测的数据。
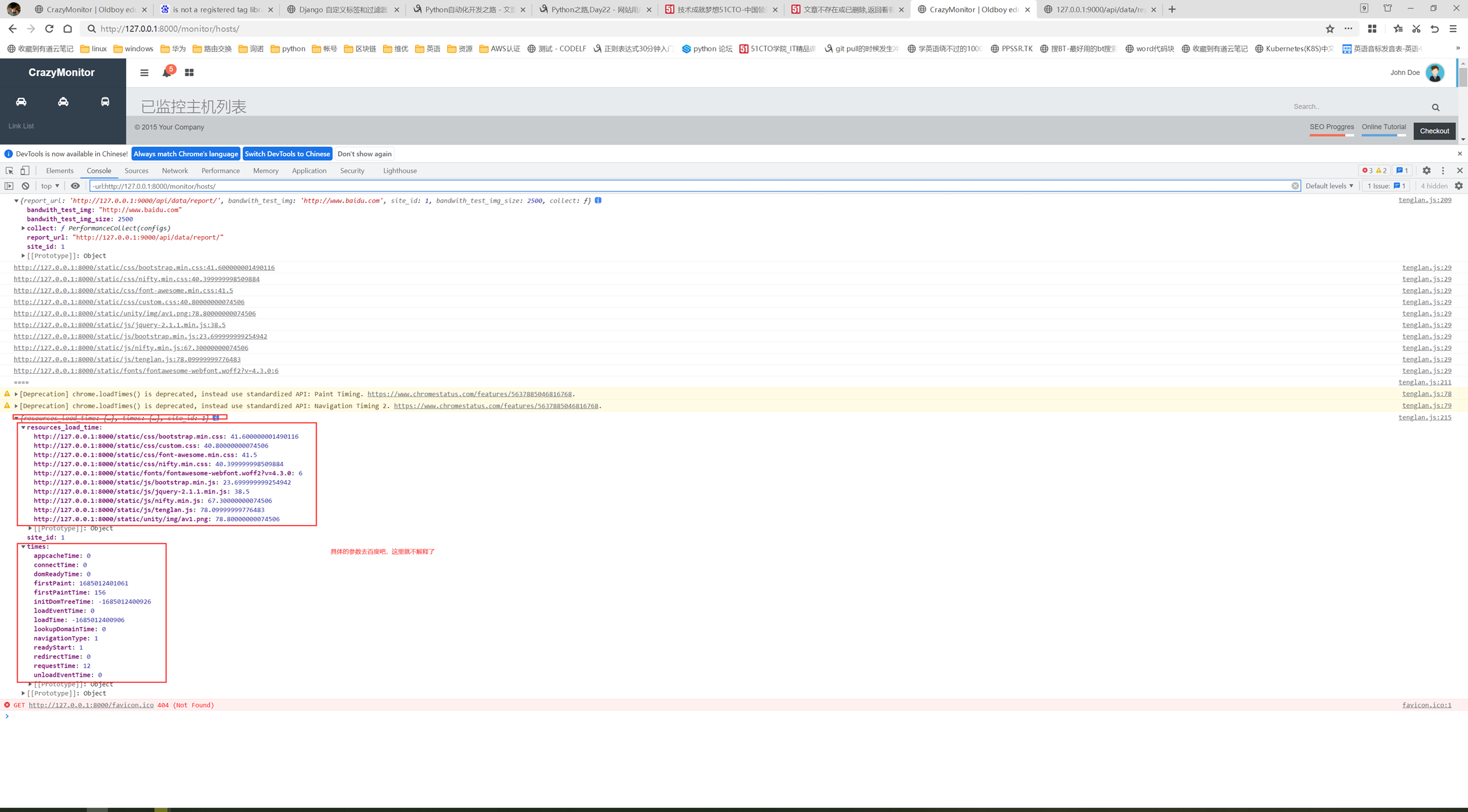
28.9 使用JSONP实现跨域请求访问
比如我们现在使用一个网站给另一个网站发送数据请求,会有如下报错。
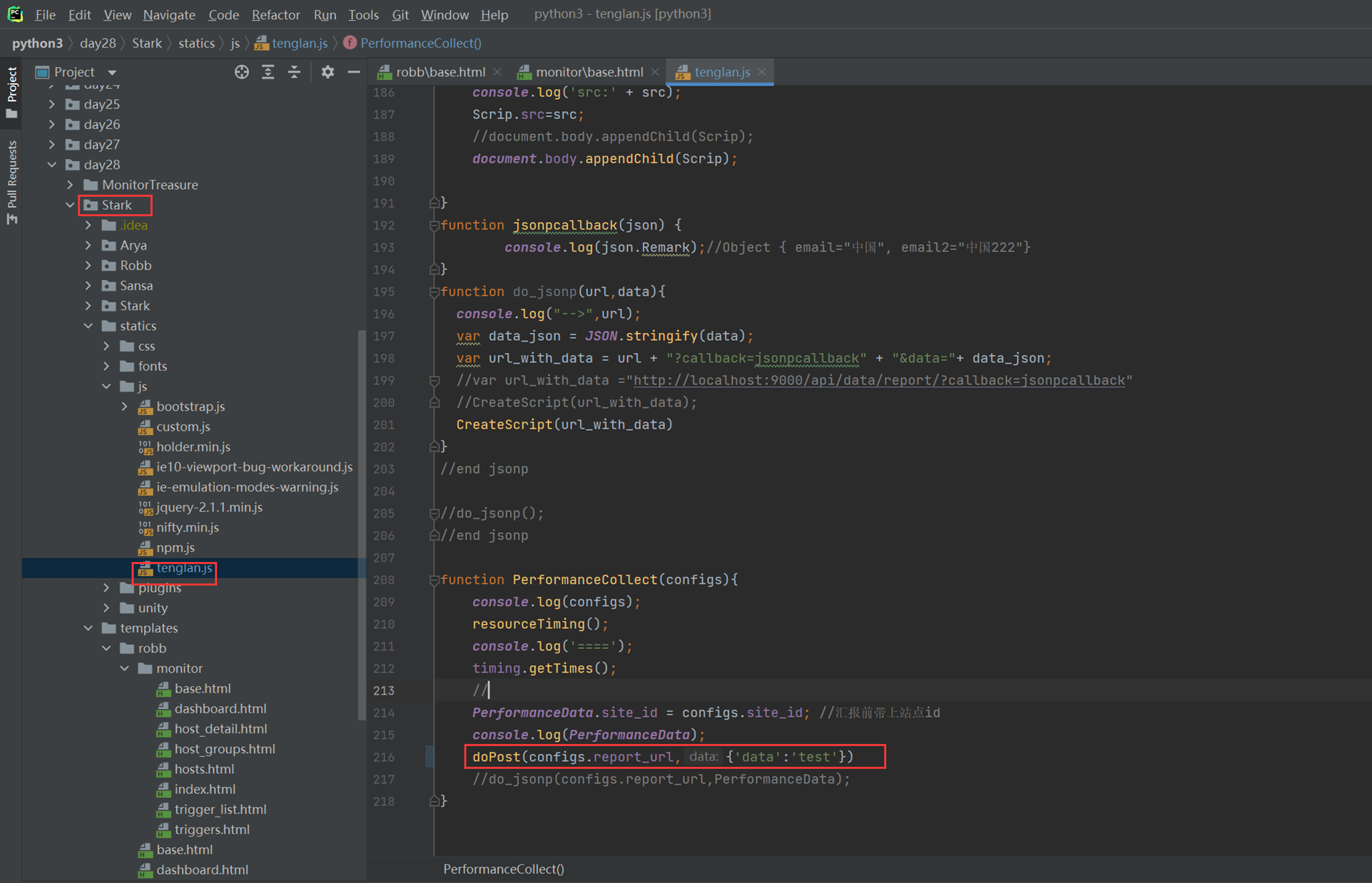
以上是发送请求的代码打开,下面是访问情况。
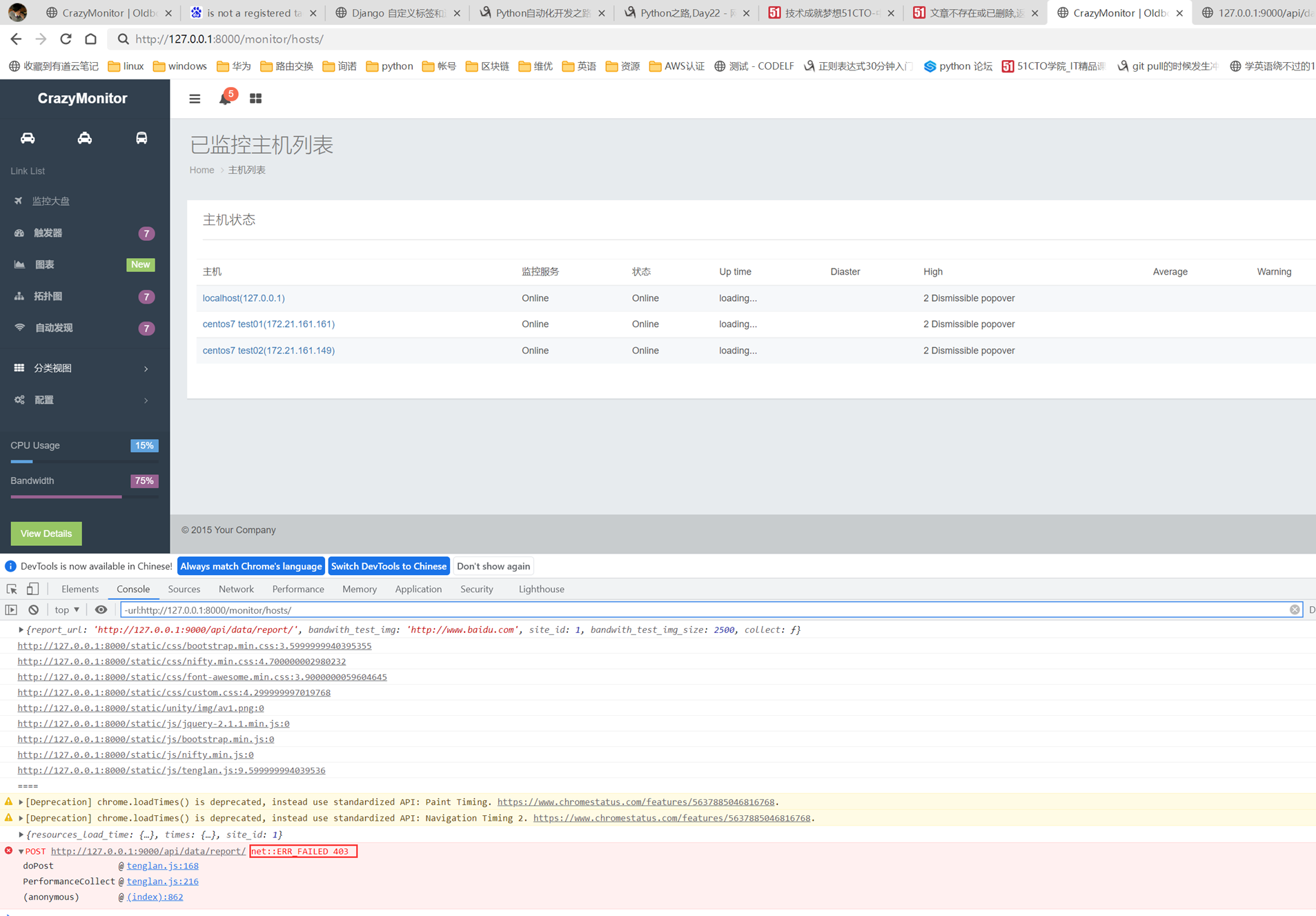
以上原因是因为我们跨站了,直接发送数据到另一个站点去了,这是不被允许的,所以诞生了jsonp。
关于jsonp是什么的原因参考博客: https://www.cnblogs.com/lizexiong/p/17419590.html
Jsonp的具体解决方案其实就是下图中的一句话。可以使用src等方式把数据包裹着传输,跟卧底一样。

这里具体的过程我们就不一步一步掩饰了,我们还是一步一步演示一下:
1、我们知道,哪怕跨域js文件中的代码(当然指符合web脚本安全策略的),web页面也是可以无条件执行的。
远程服务器remoteserver.com根目录下有个remote.js文件代码如下:
服务端代码:
客户端代码:
查看访问结果
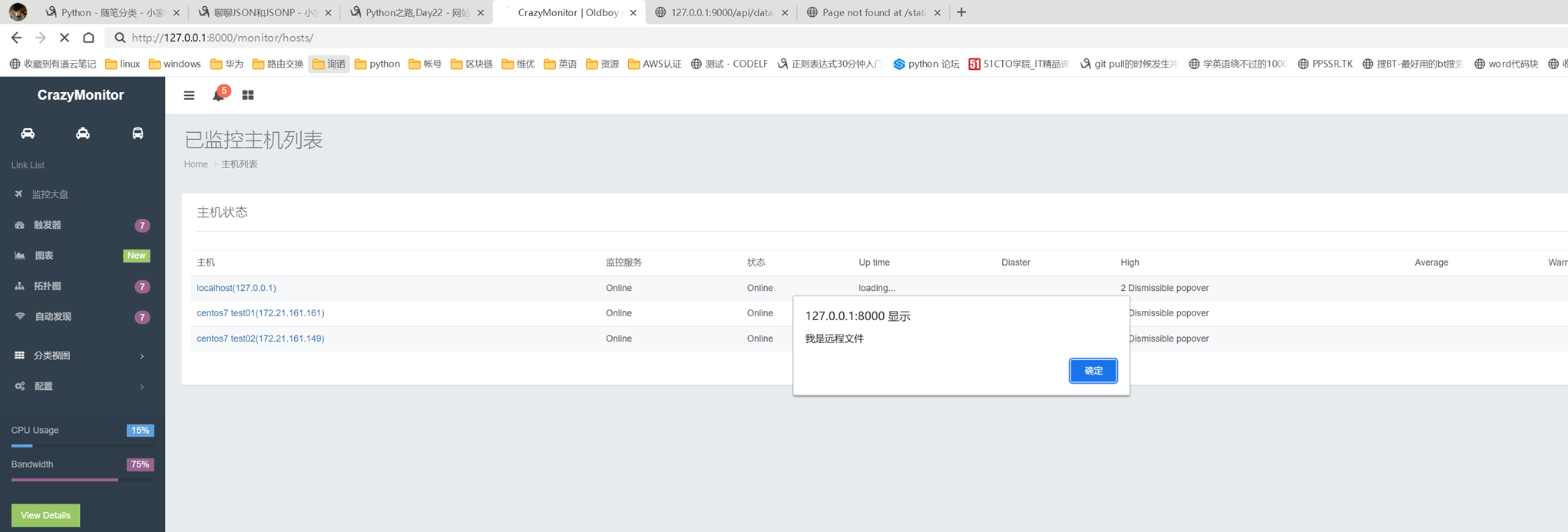
毫无疑问,页面将会弹出一个提示窗体,显示跨域调用成功。
2、现在我们在jsonp.html页面定义一个函数,然后在远程remote.js中传入数据进行调用。
jsonp.html页面代码如下:
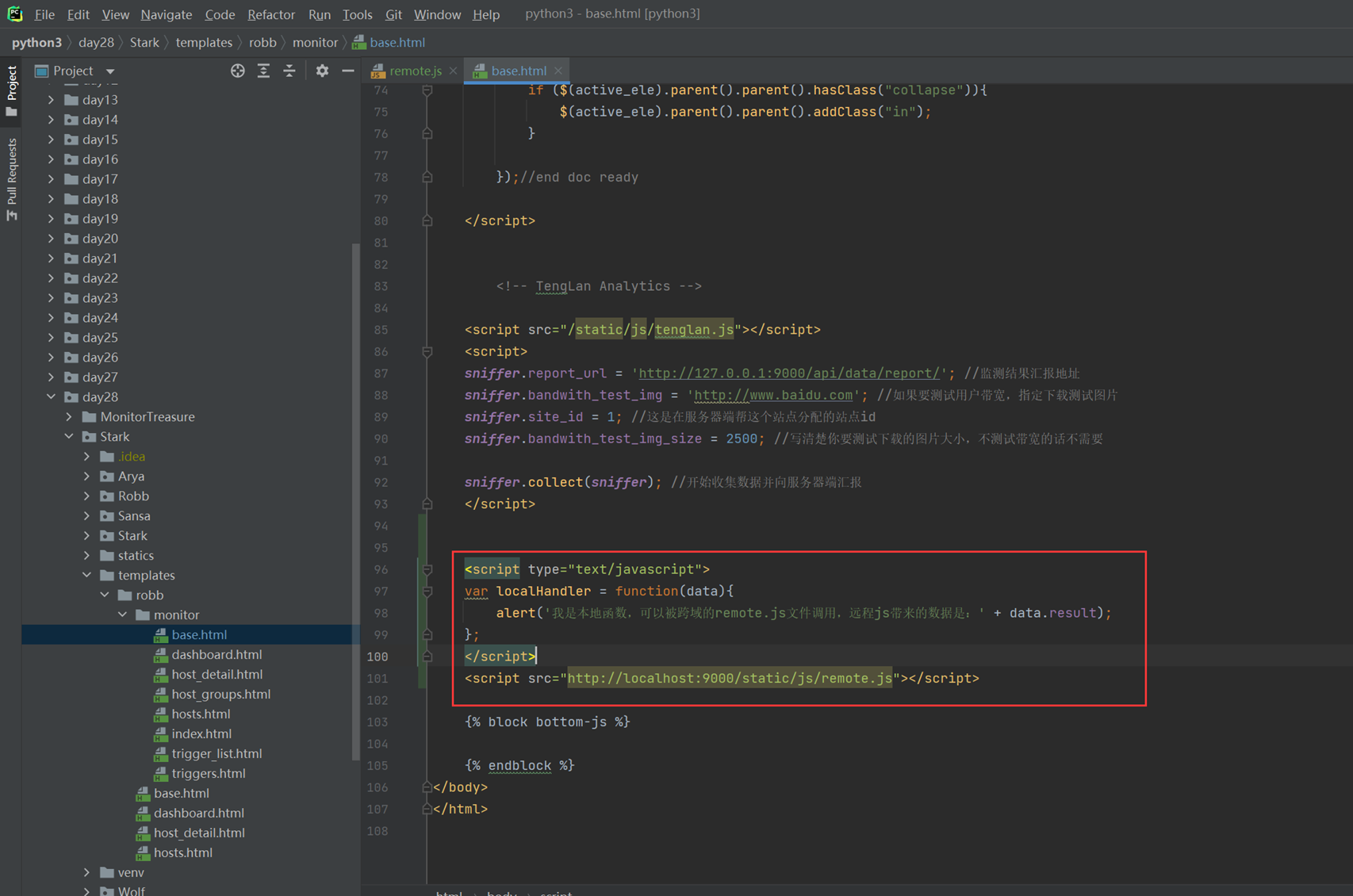
remote.js文件代码如下:
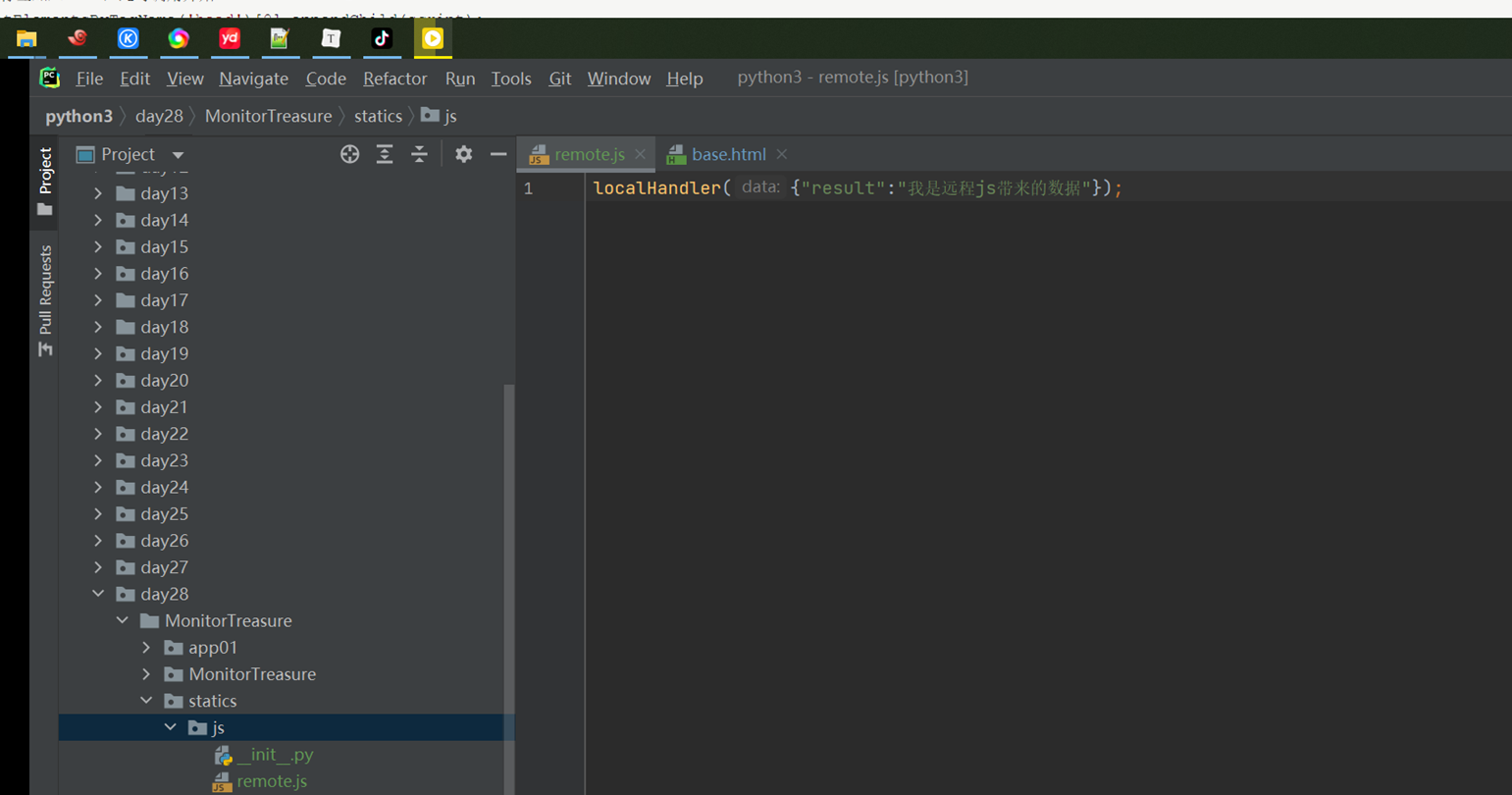
访问结果
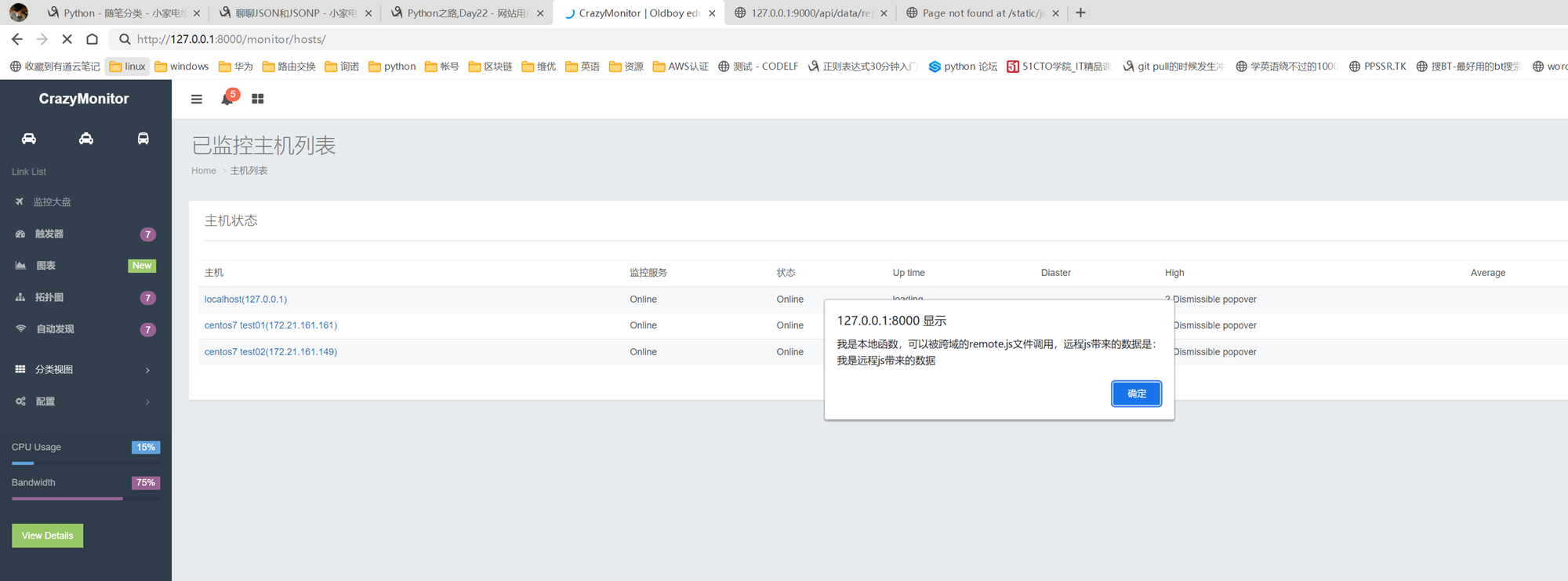
运行之后查看结果,页面成功弹出提示窗口,显示本地函数被跨域的远程js调用成功,并且还接收到了远程js带来的数据。很欣喜,跨域远程获取数据的目的基本实现了,但是又一个问题出现了,我怎么让远程js知道它应该调用的本地函数叫什么名字呢?毕竟是jsonp的服务者都要面对很多服务对象,而这些服务对象各自的本地函数都不相同啊?我们接着往下看。
3、聪明的开发者很容易想到,只要服务端提供的js脚本是动态生成的就行了呗,这样调用者可以传一个参数过去告诉服务端“我想要一段调用XXX函数的js代码,请你返回给我”,于是服务器就可以按照客户端的需求来生成js脚本并响应了。
看jsonp.html页面的代码:
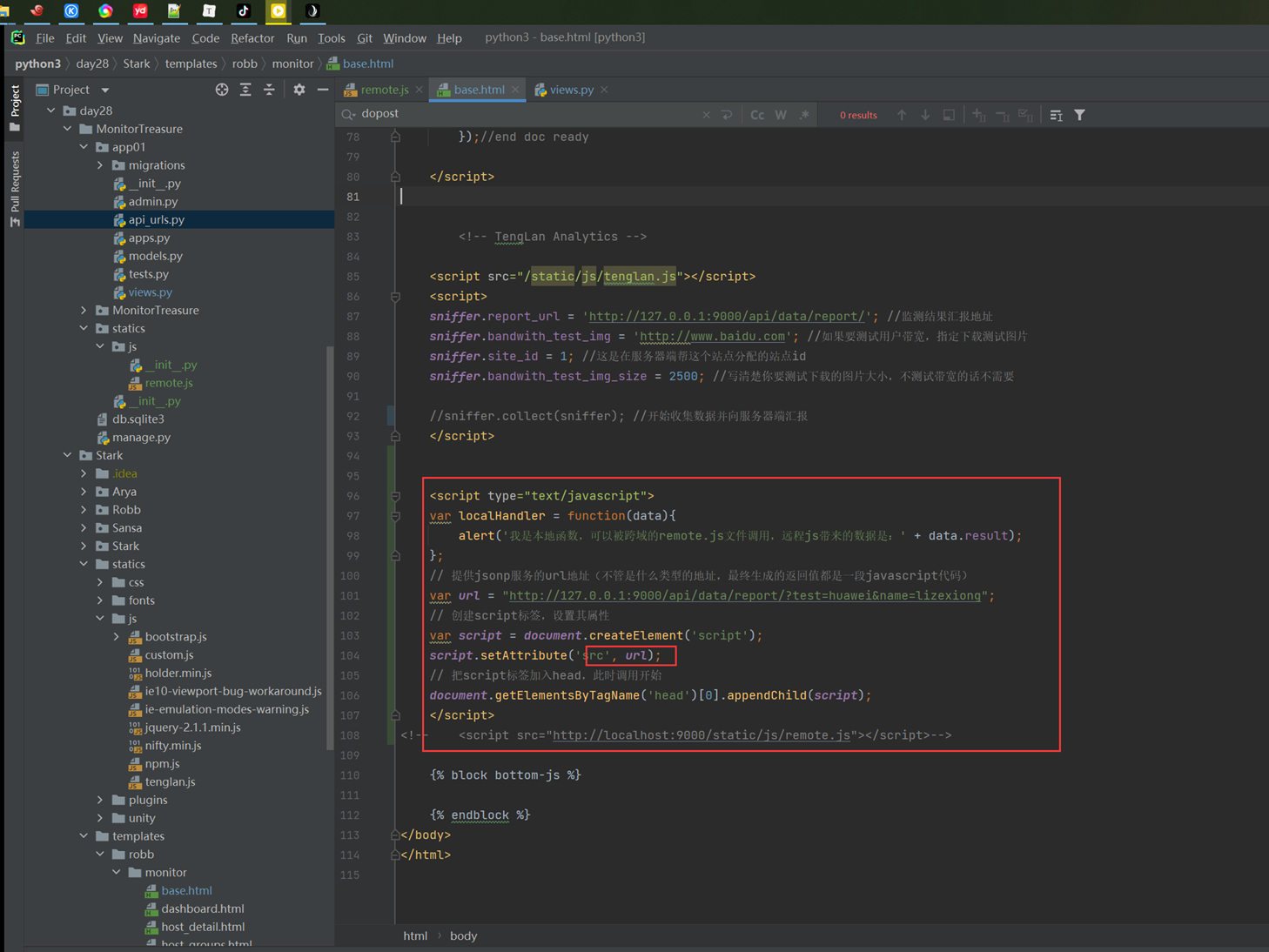
因为浏览器的安全防护,这个方式到这里就演示失败了,因为增加给src的属性,不能是一个链接,2023年这种方式不在适用。会报错CORB的错误。具体的报错参考浏览器给的链接。
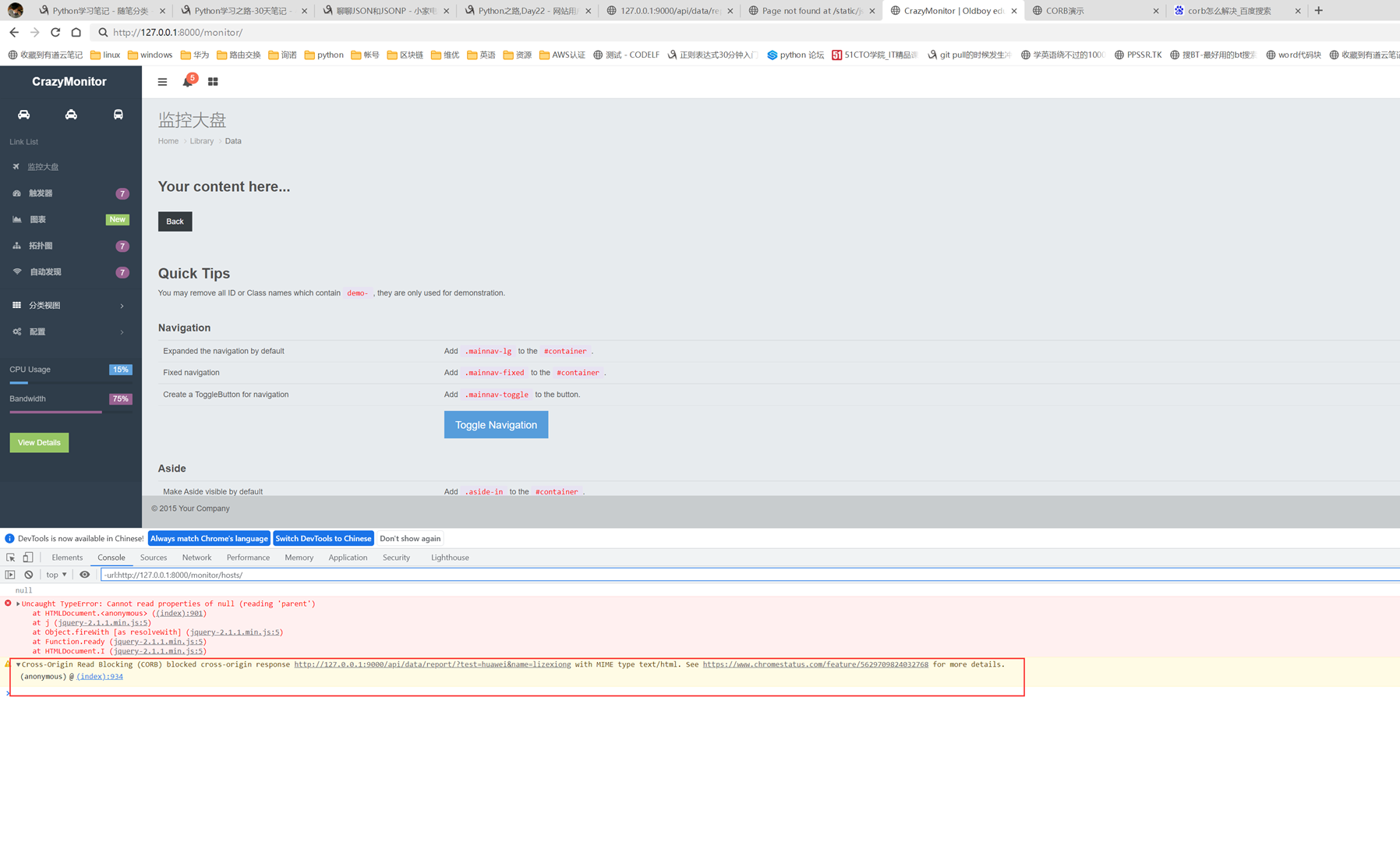
28.10 后端接收用户数据并保存
本节课并没有演示结果,就是专门讲解代码,本来这节课都已经不准备记录了,但是想着,课程只有3天了,还是简单记录一下算了。
数据的存储主要是围绕以下的代码进行的。
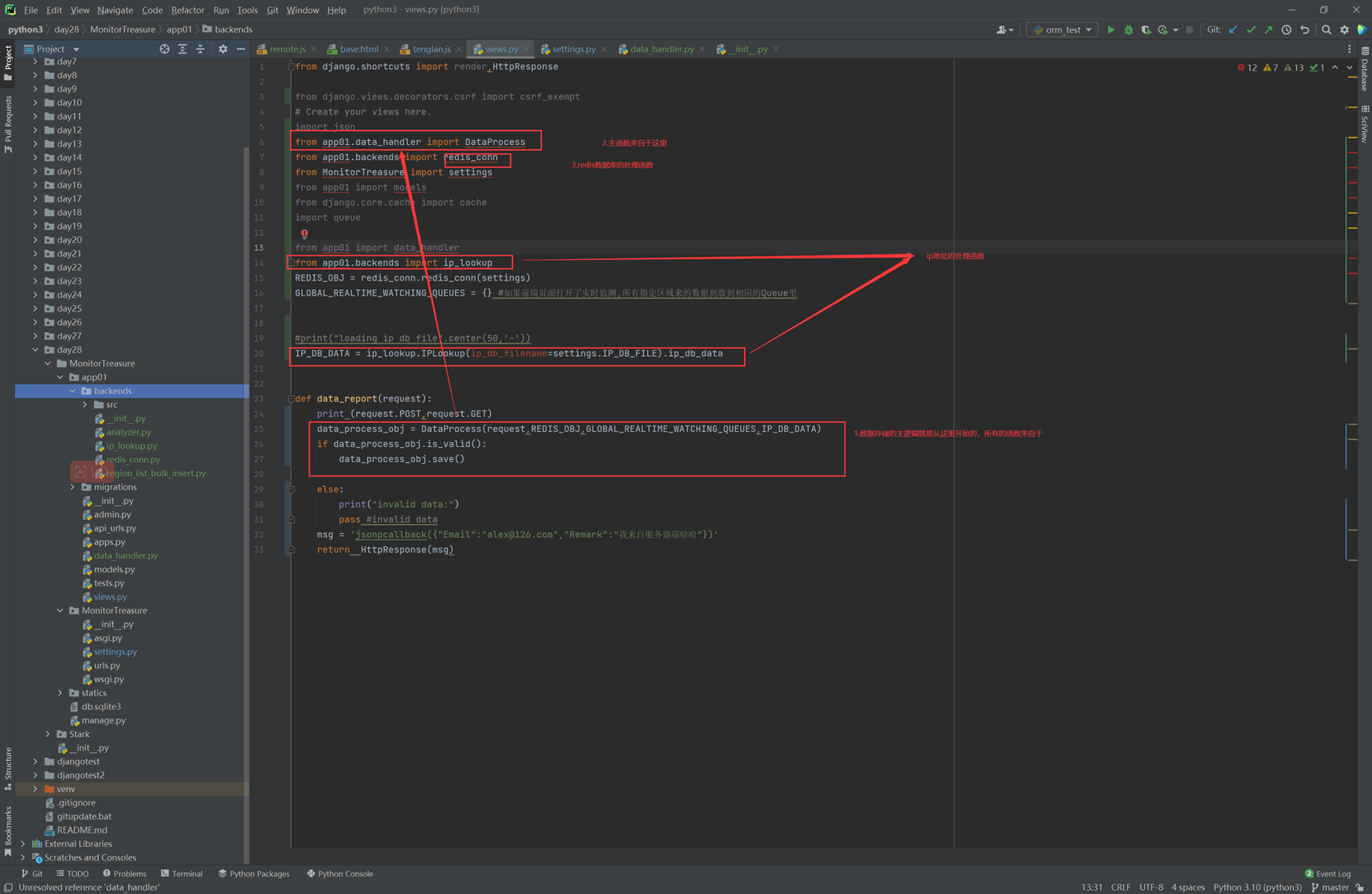
具体的代码截图这里就不展示了,没有意义,直接去git上看源码即可。
这个项目基本都是他在口述讲解,没什么好说的,并且最后一节课视频损坏,所以基本学习一下这个项目思路就行了。
另外,老师讲解的源码也会放在day28的git下面。
28.11 前端画图、IP地址解析等介绍
视频损坏
29.L29
29.1 设计模式介绍
老师就是照着念,这里直接贴博客的内容吧。

29.2 设计模式6大原则
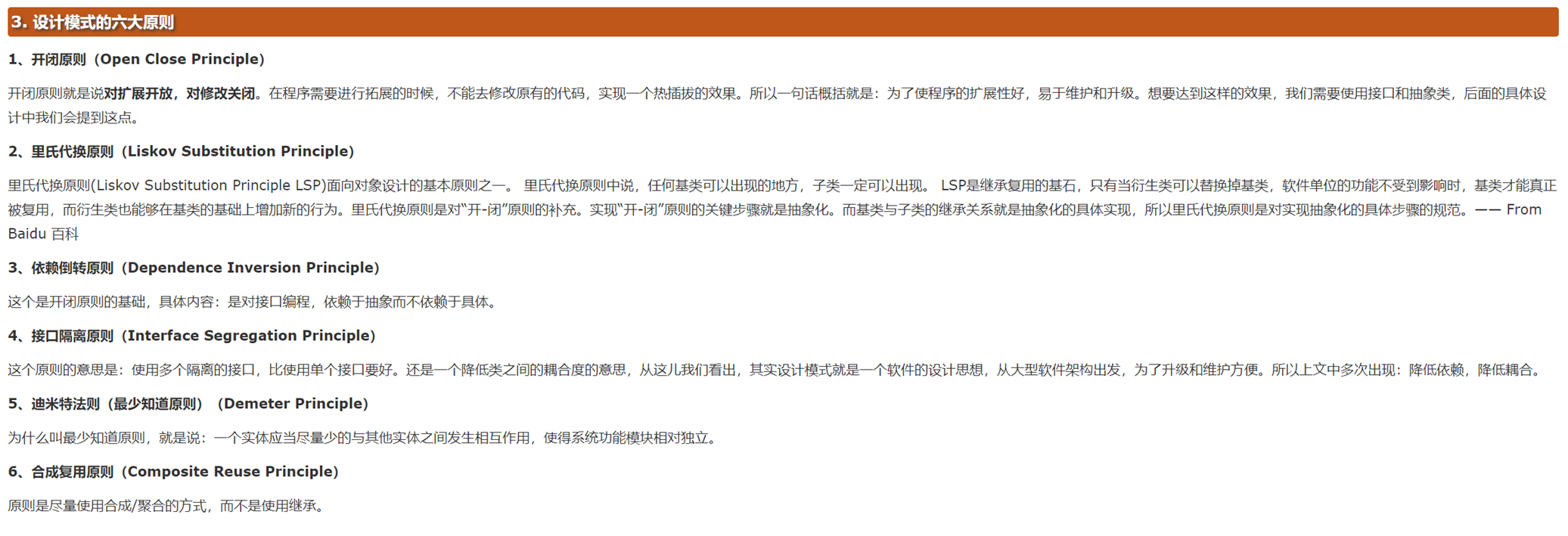
本天视频内所有的模式都是简单演示,简单告诉你是干什么的,并没有深入解释,所以,这里直接参考git上day29天的代码即可。
30.L30
30.1 Tornado实例简介

本章其实就讲解了2个东西的最基本的使用,一个是tornado,一个是docker,至于docker就没必要做了,tornado参考以下博客:Tornado简单教程
30.2 Docker简介
31.L31
31.1 Tornado回顾
开篇2章的回顾就没必要了
31.2 Docker回顾
31.3 用户登录实现
这里有些前置操作:
1.把day30天的数据库表结构创建。

2.创建一个默认管理用户,密码要使用md5加密后的

以下是登录逻辑,由于没有老师的文档,这里就做一个简单的截图吧。

以下登录设计到的代码有以下:
url
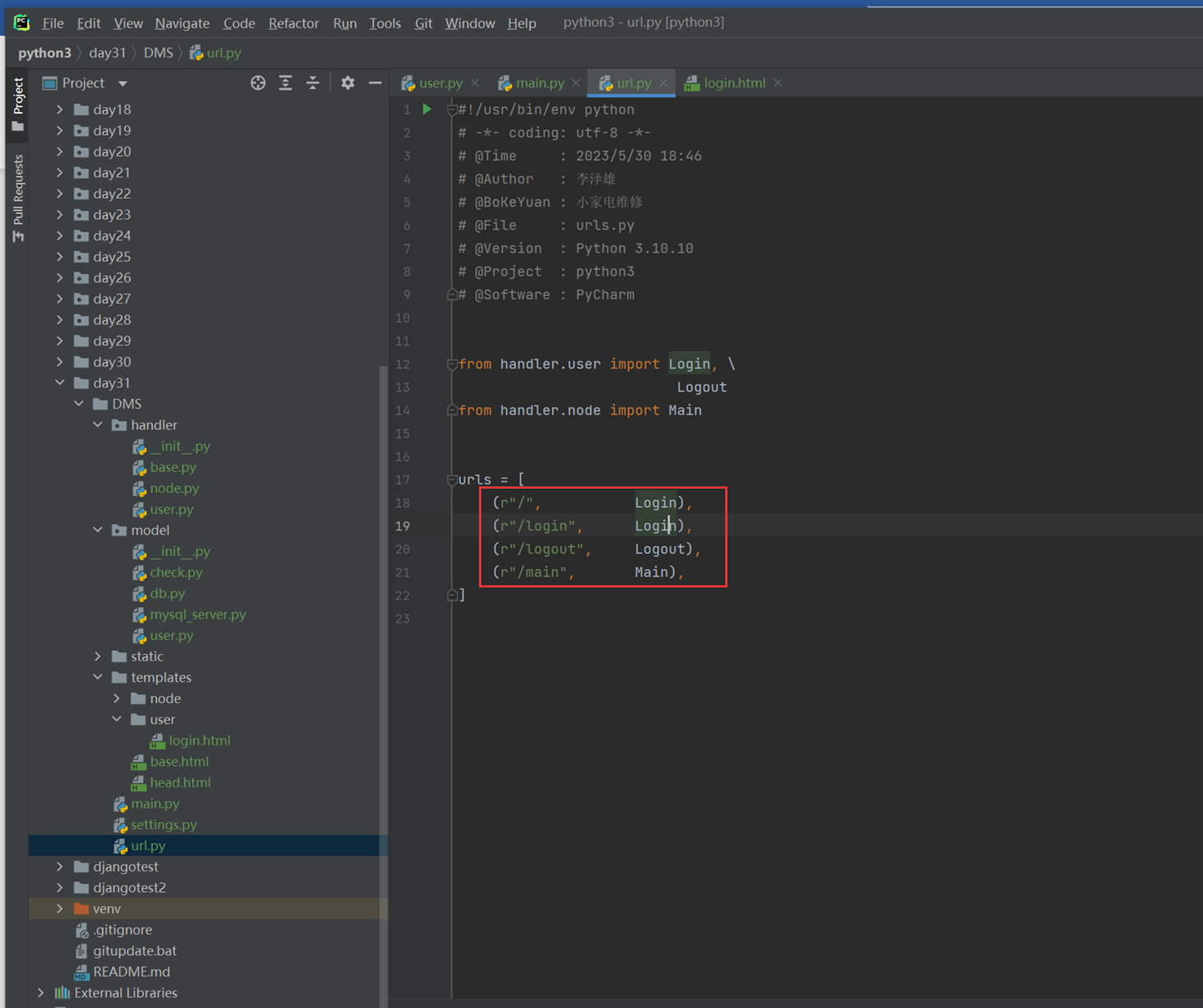
views
这里会去调用验证函数
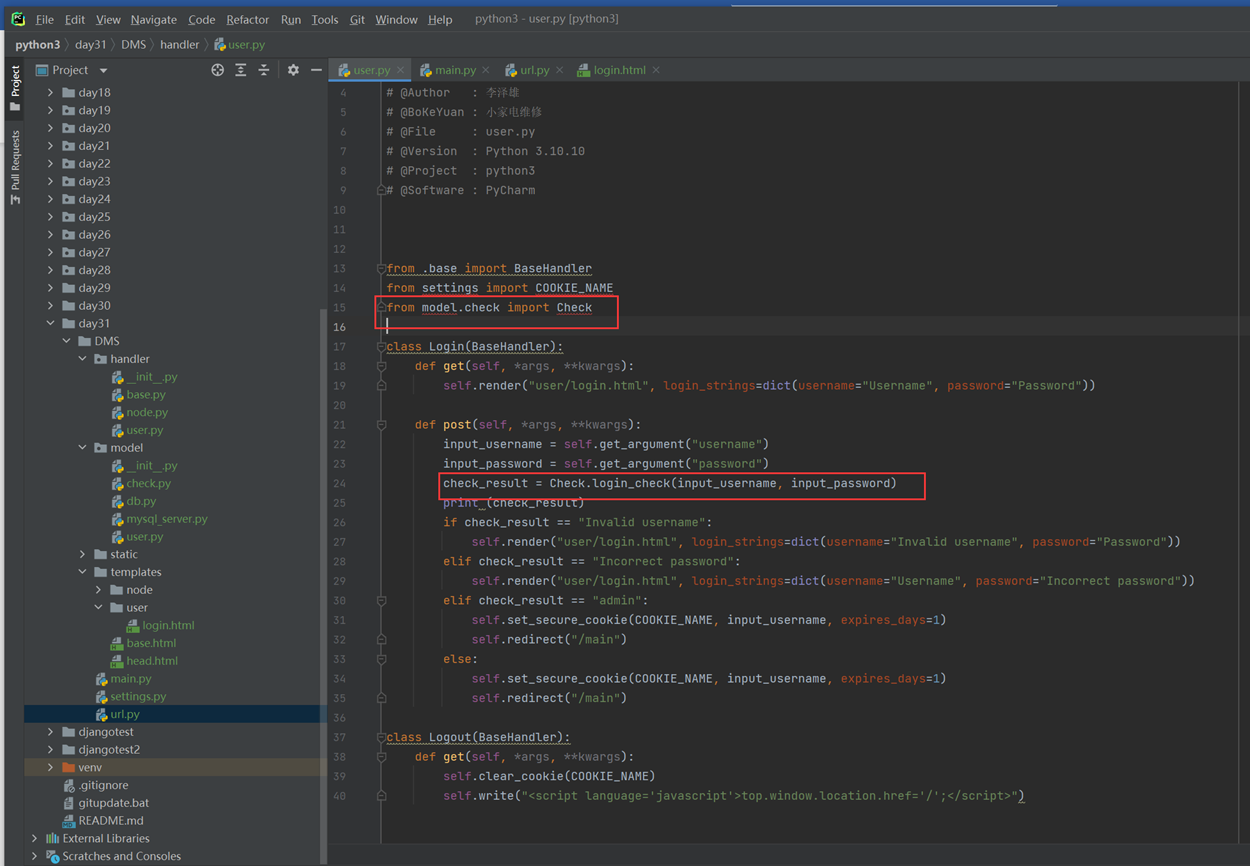
Check验证密码函数
一个用户密码验证调用了三个函数
主函数main
html这里只列出名字
测试登录
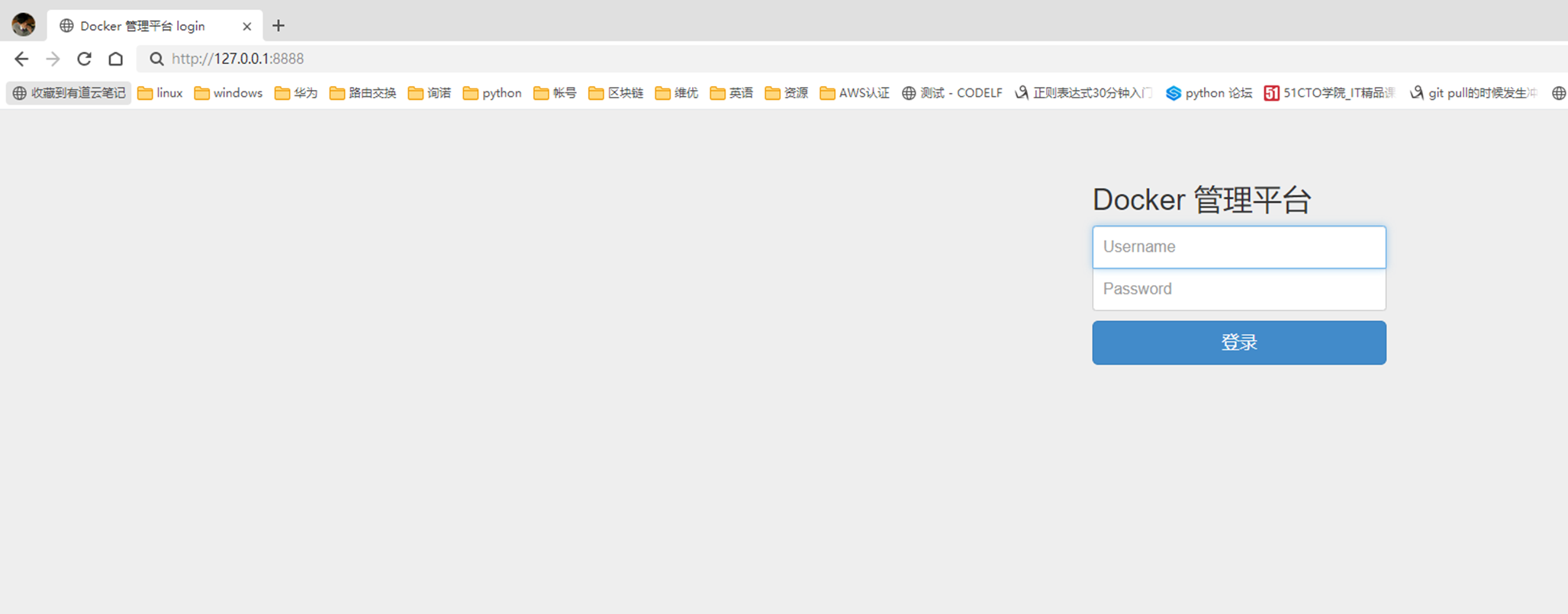
登录进入
进入主界面
31.4 节点管理实现
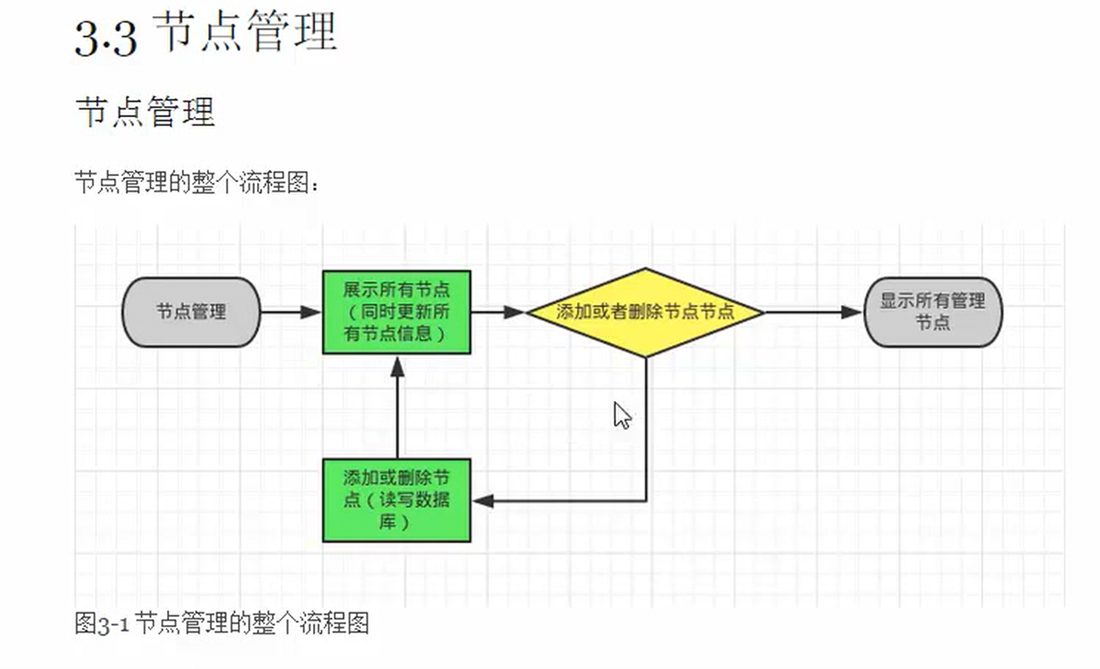
上节课可以登录成功,进入节点管理的界面,但是一片404,本节课就是为了处理那么多404。本节课和下节课合并
在这两节课直接,有个前置条件,就是创建2条node记录,等会测试用

url
views
简单看看引用的这三个函数的代码(只简单展示没具体查看源码)
models.node
model.data_manage
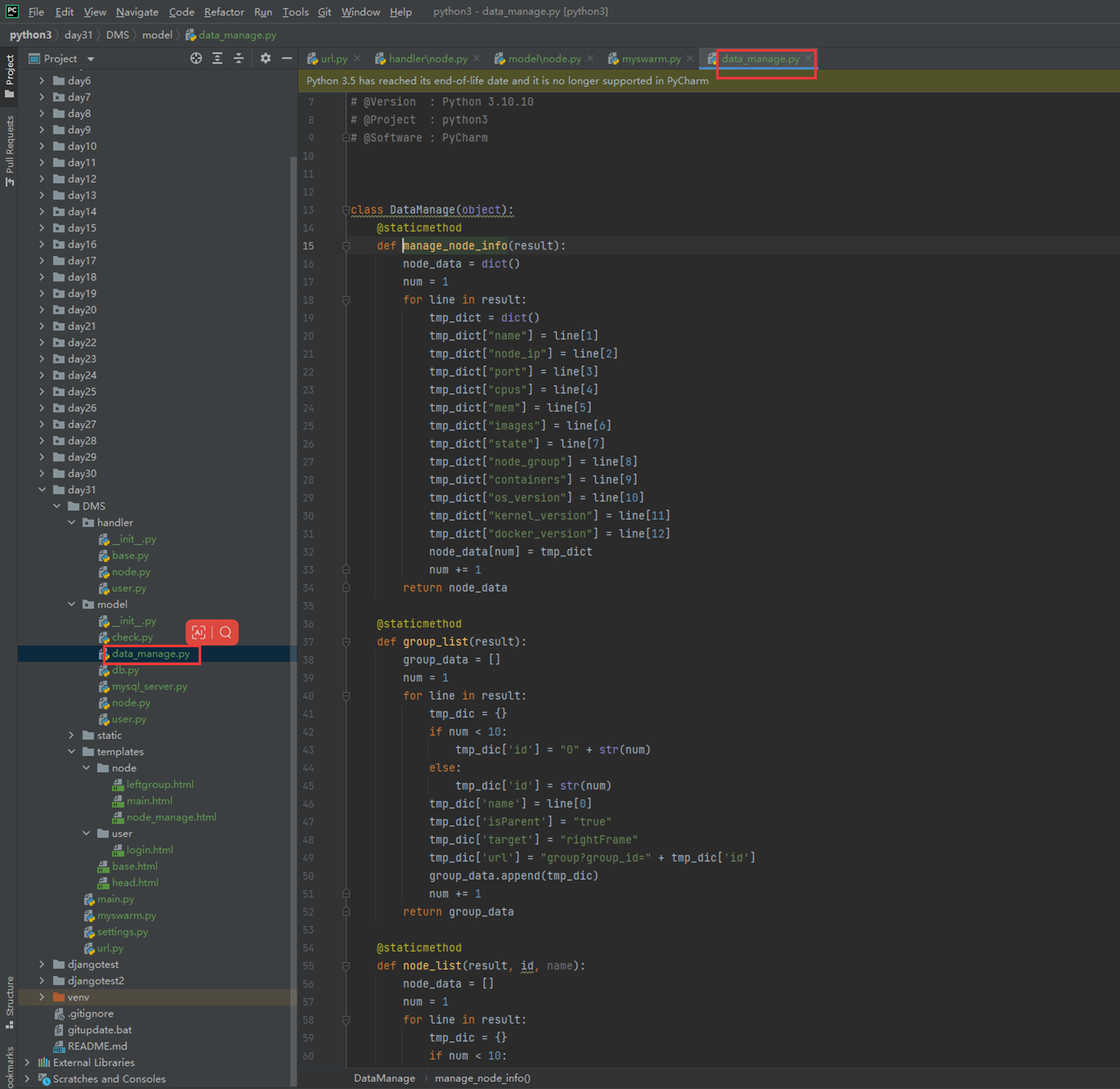
myswarm
html这里只列出名字
测试登录
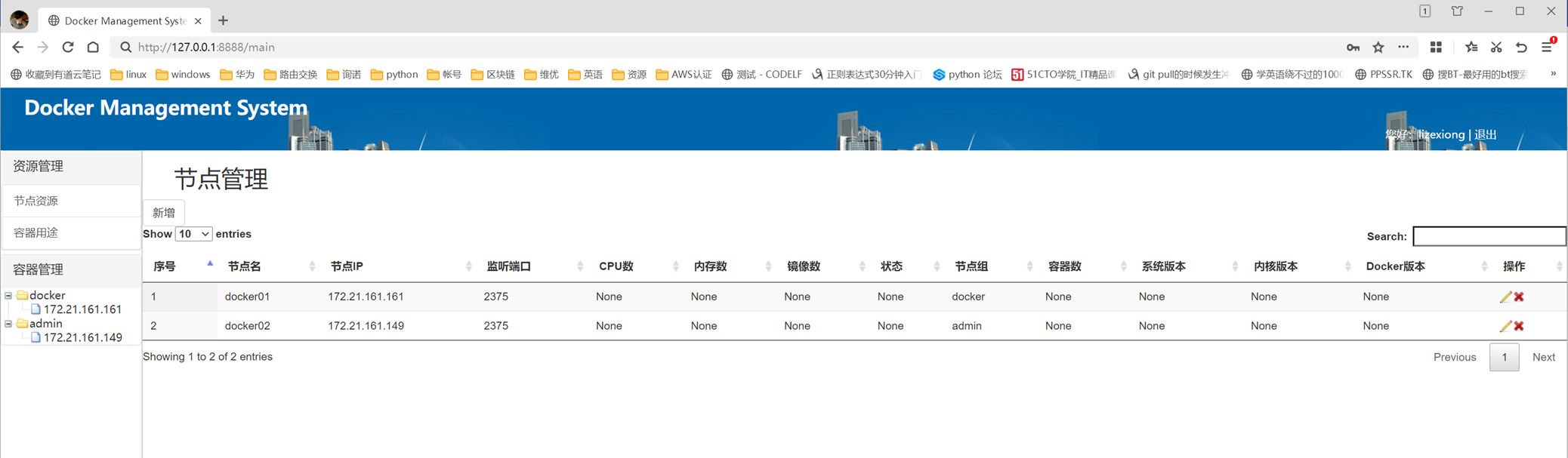
各个默认登录进去的界面都展示了,但是功能什么的都还没有,点击详情什么就会报错。
31.5 系统框架实现
和上一章合并讲解。
31.6 容器管理实现
简单来说,就是展示出每个节点的具体容器,这里不做过多解释,就是完成上一章没有完成的。
url
views
这里还是引用了myswarm模块和node模块,当然,代码在之前的章节我就拷贝过去准备好了。
model.node
myswarm
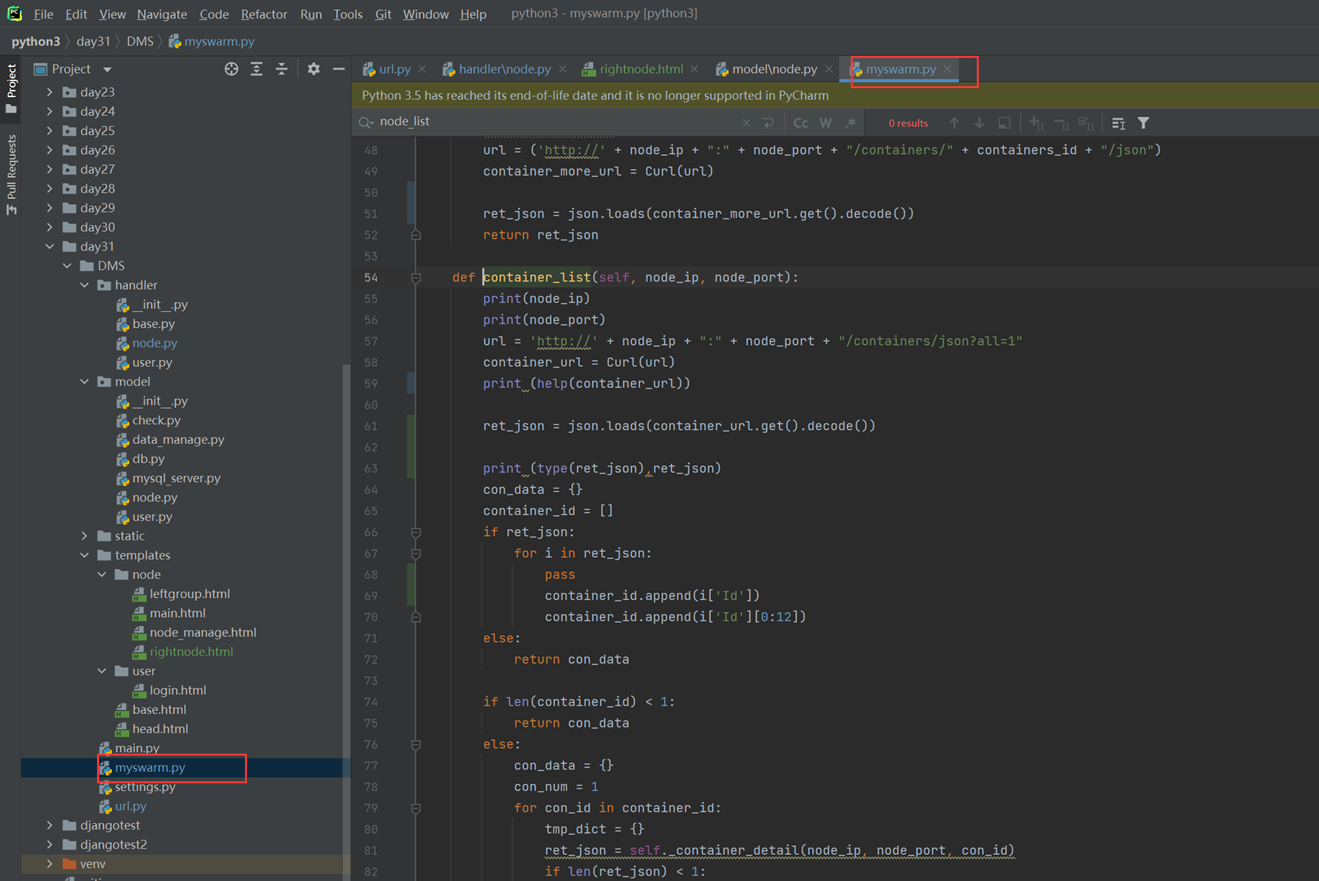
html
查看结果
31.7 容器生命周期管理
简单来说,完成本项目的最后部分,操作容器的创建,启动,停止,销毁,重启,修改等等。一样的套路就不多做解释了,只能多看看代码。
由于代码接口经过了7年变更,部分代码已经不在使用,比如创建,无法调用docker的老的创建api,所以失败了,这里也就不再修复了,这里学习的是代码思路,这个小问题如果真的需要,在来修改吧。(创建功能未完成)。
url
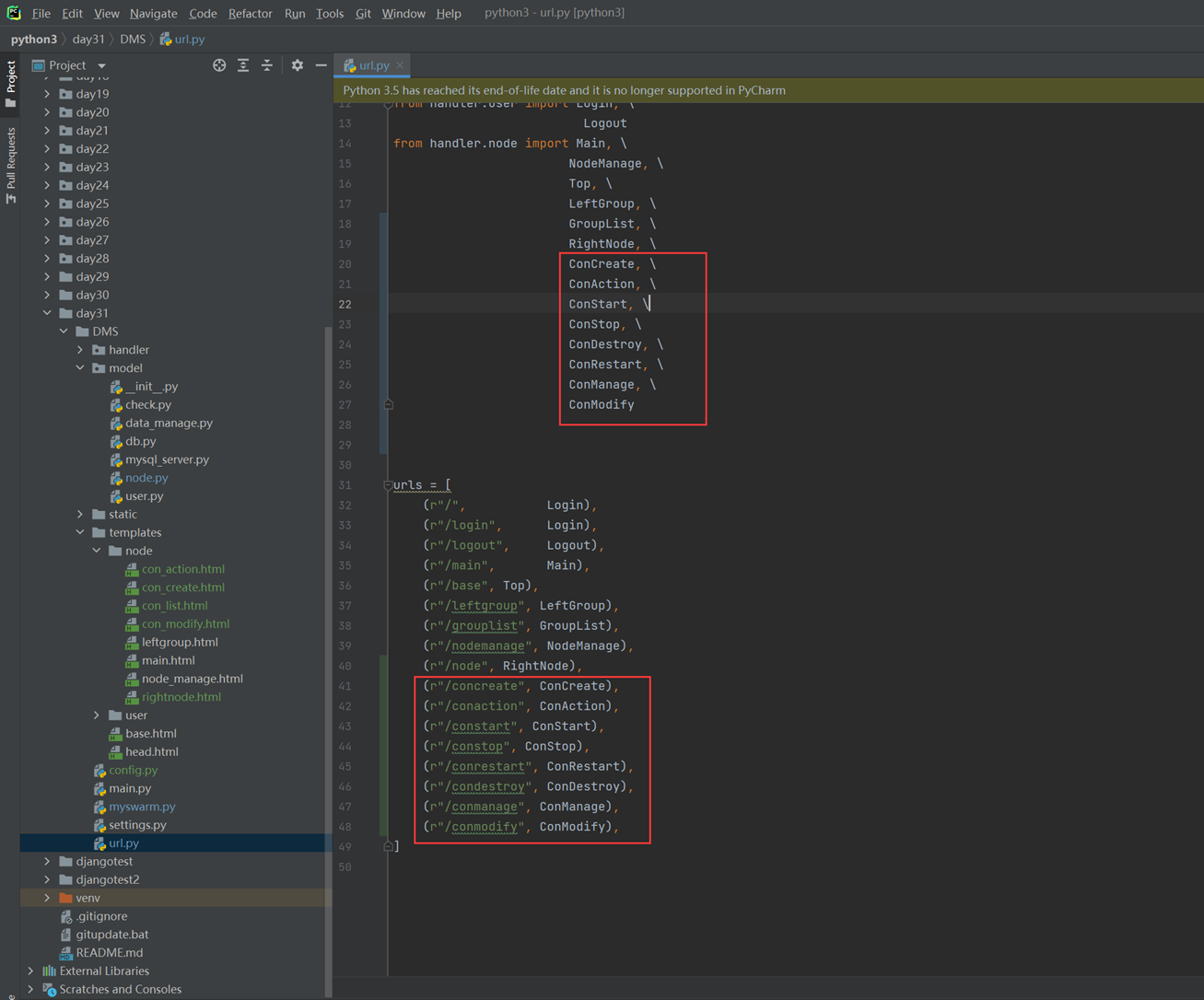
views
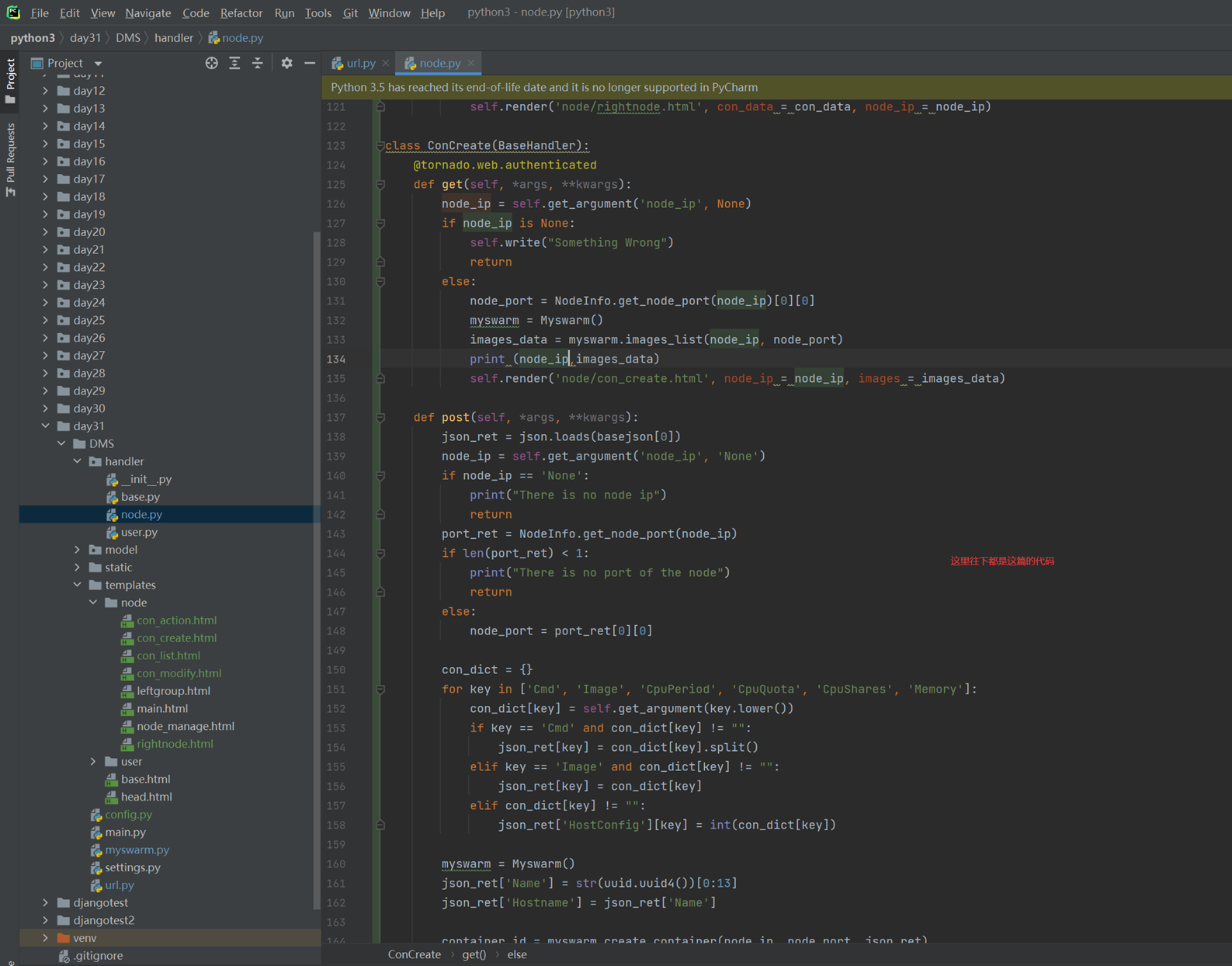
html
结果
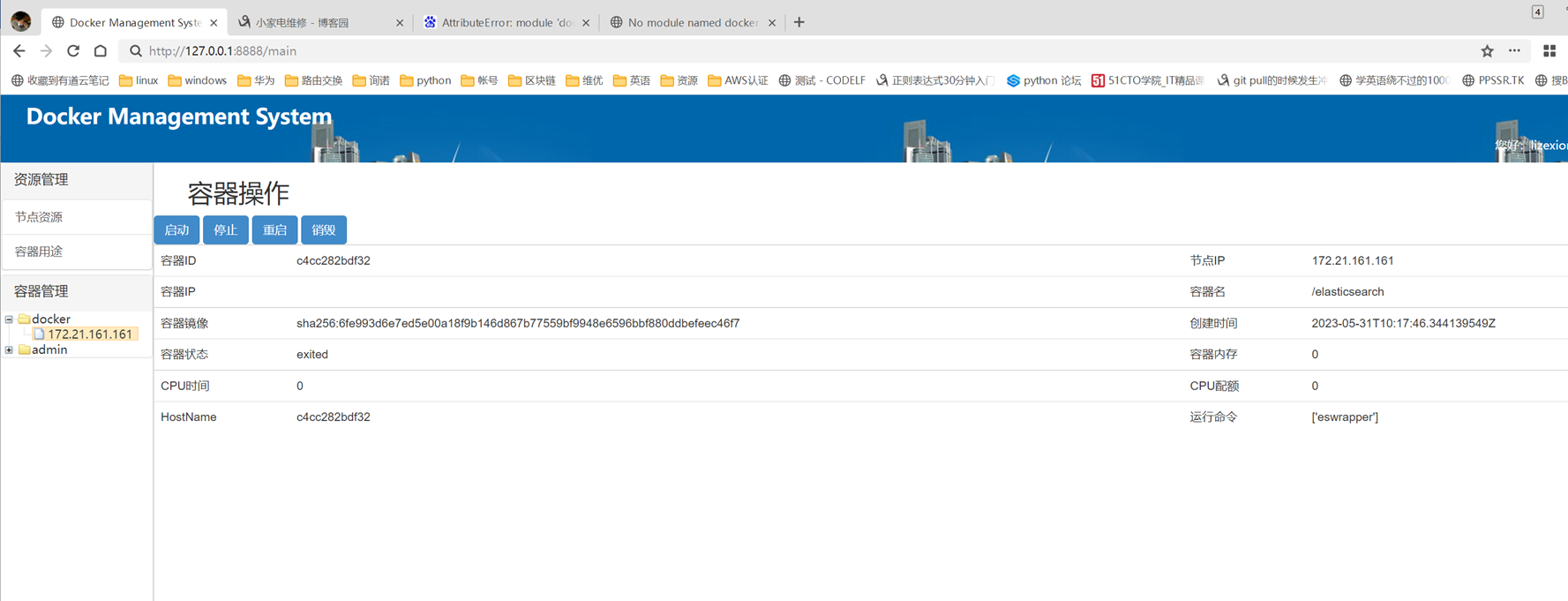
以上功能都完成了,除了容器创建,可能由于版本兼容问题,createapi报错,这里就不深究了。

