

Python学习之路-基础数据类型-第二篇
1.运算符
1.1 算数运算
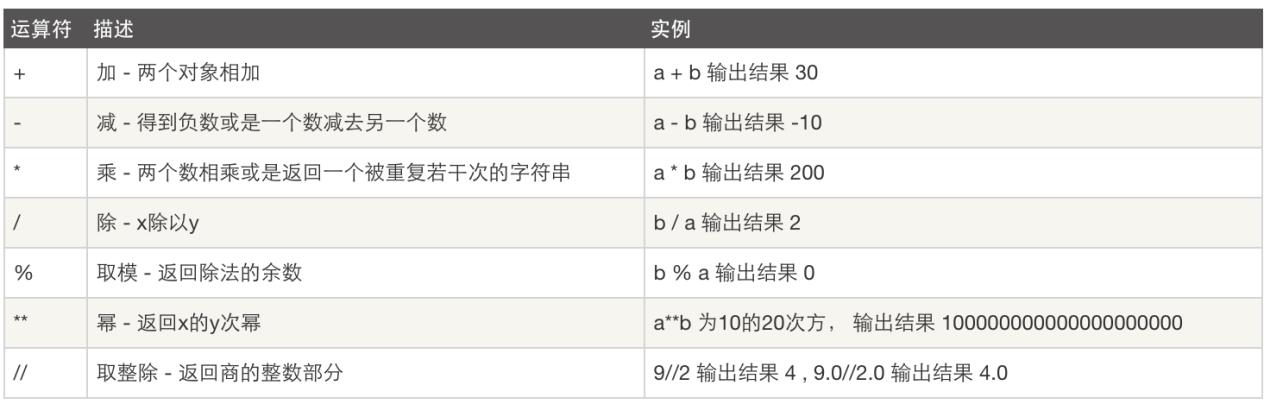
1.2 比较运算

1.3 赋值运算
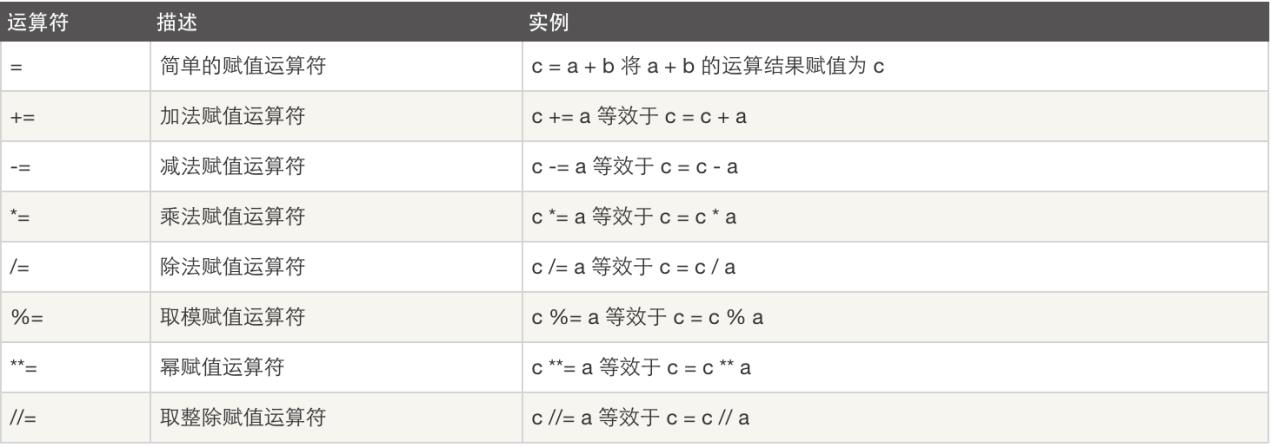
1.4 逻辑运算

1.5 成员运算

2.基础数据类型
2.1 数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807


class int(object): """ int(x=0) -> int or long int(x, base=10) -> int or long Convert a number or string to an integer, or return 0 if no arguments are given. If x is floating point, the conversion truncates towards zero. If x is outside the integer range, the function returns a long instead. If x is not a number or if base is given, then x must be a string or Unicode object representing an integer literal in the given base. The literal can be preceded by '+' or '-' and be surrounded by whitespace. The base defaults to 10. Valid bases are 0 and 2-36. Base 0 means to interpret the base from the string as an integer literal. >>> int('0b100', base=0) 4 """ def bit_length(self): """ 返回表示该数字的时占用的最少位数 """ """ int.bit_length() -> int Number of bits necessary to represent self in binary. >>> bin(37) '0b100101' >>> (37).bit_length() 6 """ return 0 def conjugate(self, *args, **kwargs): # real signature unknown """ 返回该复数的共轭复数 """ """ Returns self, the complex conjugate of any int. """ pass def __abs__(self): """ 返回绝对值 """ """ x.__abs__() <==> abs(x) """ pass def __add__(self, y): """ x.__add__(y) <==> x+y """ pass def __and__(self, y): """ x.__and__(y) <==> x&y """ pass def __cmp__(self, y): """ 比较两个数大小 """ """ x.__cmp__(y) <==> cmp(x,y) """ pass def __coerce__(self, y): """ 强制生成一个元组 """ """ x.__coerce__(y) <==> coerce(x, y) """ pass def __divmod__(self, y): """ 相除,得到商和余数组成的元组 """ """ x.__divmod__(y) <==> divmod(x, y) """ pass def __div__(self, y): """ x.__div__(y) <==> x/y """ pass def __float__(self): """ 转换为浮点类型 """ """ x.__float__() <==> float(x) """ pass def __floordiv__(self, y): """ x.__floordiv__(y) <==> x//y """ pass def __format__(self, *args, **kwargs): # real signature unknown pass def __getattribute__(self, name): """ x.__getattribute__('name') <==> x.name """ pass def __getnewargs__(self, *args, **kwargs): # real signature unknown """ 内部调用 __new__方法或创建对象时传入参数使用 """ pass def __hash__(self): """如果对象object为哈希表类型,返回对象object的哈希值。哈希值为整数。在字典查找中,哈希值用于快速比较字典的键。两个数值如果相等,则哈希值也相等。""" """ x.__hash__() <==> hash(x) """ pass def __hex__(self): """ 返回当前数的 十六进制 表示 """ """ x.__hex__() <==> hex(x) """ pass def __index__(self): """ 用于切片,数字无意义 """ """ x[y:z] <==> x[y.__index__():z.__index__()] """ pass def __init__(self, x, base=10): # known special case of int.__init__ """ 构造方法,执行 x = 123 或 x = int(10) 时,自动调用,暂时忽略 """ """ int(x=0) -> int or long int(x, base=10) -> int or long Convert a number or string to an integer, or return 0 if no arguments are given. If x is floating point, the conversion truncates towards zero. If x is outside the integer range, the function returns a long instead. If x is not a number or if base is given, then x must be a string or Unicode object representing an integer literal in the given base. The literal can be preceded by '+' or '-' and be surrounded by whitespace. The base defaults to 10. Valid bases are 0 and 2-36. Base 0 means to interpret the base from the string as an integer literal. >>> int('0b100', base=0) 4 # (copied from class doc) """ pass def __int__(self): """ 转换为整数 """ """ x.__int__() <==> int(x) """ pass def __invert__(self): """ x.__invert__() <==> ~x """ pass def __long__(self): """ 转换为长整数 """ """ x.__long__() <==> long(x) """ pass def __lshift__(self, y): """ x.__lshift__(y) <==> x<<y """ pass def __mod__(self, y): """ x.__mod__(y) <==> x%y """ pass def __mul__(self, y): """ x.__mul__(y) <==> x*y """ pass def __neg__(self): """ x.__neg__() <==> -x """ pass @staticmethod # known case of __new__ def __new__(S, *more): """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __nonzero__(self): """ x.__nonzero__() <==> x != 0 """ pass def __oct__(self): """ 返回改值的 八进制 表示 """ """ x.__oct__() <==> oct(x) """ pass def __or__(self, y): """ x.__or__(y) <==> x|y """ pass def __pos__(self): """ x.__pos__() <==> +x """ pass def __pow__(self, y, z=None): """ 幂,次方 """ """ x.__pow__(y[, z]) <==> pow(x, y[, z]) """ pass def __radd__(self, y): """ x.__radd__(y) <==> y+x """ pass def __rand__(self, y): """ x.__rand__(y) <==> y&x """ pass def __rdivmod__(self, y): """ x.__rdivmod__(y) <==> divmod(y, x) """ pass def __rdiv__(self, y): """ x.__rdiv__(y) <==> y/x """ pass def __repr__(self): """转化为解释器可读取的形式 """ """ x.__repr__() <==> repr(x) """ pass def __str__(self): """转换为人阅读的形式,如果没有适于人阅读的解释形式的话,则返回解释器课阅读的形式""" """ x.__str__() <==> str(x) """ pass def __rfloordiv__(self, y): """ x.__rfloordiv__(y) <==> y//x """ pass def __rlshift__(self, y): """ x.__rlshift__(y) <==> y<<x """ pass def __rmod__(self, y): """ x.__rmod__(y) <==> y%x """ pass def __rmul__(self, y): """ x.__rmul__(y) <==> y*x """ pass def __ror__(self, y): """ x.__ror__(y) <==> y|x """ pass def __rpow__(self, x, z=None): """ y.__rpow__(x[, z]) <==> pow(x, y[, z]) """ pass def __rrshift__(self, y): """ x.__rrshift__(y) <==> y>>x """ pass def __rshift__(self, y): """ x.__rshift__(y) <==> x>>y """ pass def __rsub__(self, y): """ x.__rsub__(y) <==> y-x """ pass def __rtruediv__(self, y): """ x.__rtruediv__(y) <==> y/x """ pass def __rxor__(self, y): """ x.__rxor__(y) <==> y^x """ pass def __sub__(self, y): """ x.__sub__(y) <==> x-y """ pass def __truediv__(self, y): """ x.__truediv__(y) <==> x/y """ pass def __trunc__(self, *args, **kwargs): """ 返回数值被截取为整形的值,在整形中无意义 """ pass def __xor__(self, y): """ x.__xor__(y) <==> x^y """ pass denominator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """ 分母 = 1 """ """the denominator of a rational number in lowest terms""" imag = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """ 虚数,无意义 """ """the imaginary part of a complex number""" numerator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """ 分子 = 数字大小 """ """the numerator of a rational number in lowest terms""" real = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """ 实属,无意义 """ """the real part of a complex number""" int
2.2 布尔值
真或假
1 或 0
2.3 字符串
"hello world"
字符串常用功能:
- 移除空白
- 分割
- 长度
- 索引
- 切片
class str(basestring): """ str(object='') -> string Return a nice string representation of the object. If the argument is a string, the return value is the same object. """ def capitalize(self): """ 首字母变大写 """ """ S.capitalize() -> string Return a copy of the string S with only its first character capitalized. """ return "" def center(self, width, fillchar=None): """ 内容居中,width:总长度;fillchar:空白处填充内容,默认无 """ """ S.center(width[, fillchar]) -> string Return S centered in a string of length width. Padding is done using the specified fill character (default is a space) """ return "" def count(self, sub, start=None, end=None): """ 子序列个数 """ """ S.count(sub[, start[, end]]) -> int Return the number of non-overlapping occurrences of substring sub in string S[start:end]. Optional arguments start and end are interpreted as in slice notation. """ return 0 def decode(self, encoding=None, errors=None): """ 解码 """ """ S.decode([encoding[,errors]]) -> object Decodes S using the codec registered for encoding. encoding defaults to the default encoding. errors may be given to set a different error handling scheme. Default is 'strict' meaning that encoding errors raise a UnicodeDecodeError. Other possible values are 'ignore' and 'replace' as well as any other name registered with codecs.register_error that is able to handle UnicodeDecodeErrors. """ return object() def encode(self, encoding=None, errors=None): """ 编码,针对unicode """ """ S.encode([encoding[,errors]]) -> object Encodes S using the codec registered for encoding. encoding defaults to the default encoding. errors may be given to set a different error handling scheme. Default is 'strict' meaning that encoding errors raise a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and 'xmlcharrefreplace' as well as any other name registered with codecs.register_error that is able to handle UnicodeEncodeErrors. """ return object() def endswith(self, suffix, start=None, end=None): """ 是否以 xxx 结束 """ """ S.endswith(suffix[, start[, end]]) -> bool Return True if S ends with the specified suffix, False otherwise. With optional start, test S beginning at that position. With optional end, stop comparing S at that position. suffix can also be a tuple of strings to try. """ return False def expandtabs(self, tabsize=None): """ 将tab转换成空格,默认一个tab转换成8个空格 """ """ S.expandtabs([tabsize]) -> string Return a copy of S where all tab characters are expanded using spaces. If tabsize is not given, a tab size of 8 characters is assumed. """ return "" def find(self, sub, start=None, end=None): """ 寻找子序列位置,如果没找到,返回 -1 """ """ S.find(sub [,start [,end]]) -> int Return the lowest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0 def format(*args, **kwargs): # known special case of str.format """ 字符串格式化,动态参数,将函数式编程时细说 """ """ S.format(*args, **kwargs) -> string Return a formatted version of S, using substitutions from args and kwargs. The substitutions are identified by braces ('{' and '}'). """ pass def index(self, sub, start=None, end=None): """ 子序列位置,如果没找到,报错 """ S.index(sub [,start [,end]]) -> int Like S.find() but raise ValueError when the substring is not found. """ return 0 def isalnum(self): """ 是否是字母和数字 """ """ S.isalnum() -> bool Return True if all characters in S are alphanumeric and there is at least one character in S, False otherwise. """ return False def isalpha(self): """ 是否是字母 """ """ S.isalpha() -> bool Return True if all characters in S are alphabetic and there is at least one character in S, False otherwise. """ return False def isdigit(self): """ 是否是数字 """ """ S.isdigit() -> bool Return True if all characters in S are digits and there is at least one character in S, False otherwise. """ return False def islower(self): """ 是否小写 """ """ S.islower() -> bool Return True if all cased characters in S are lowercase and there is at least one cased character in S, False otherwise. """ return False def isspace(self): """ S.isspace() -> bool Return True if all characters in S are whitespace and there is at least one character in S, False otherwise. """ return False def istitle(self): """ S.istitle() -> bool Return True if S is a titlecased string and there is at least one character in S, i.e. uppercase characters may only follow uncased characters and lowercase characters only cased ones. Return False otherwise. """ return False def isupper(self): """ S.isupper() -> bool Return True if all cased characters in S are uppercase and there is at least one cased character in S, False otherwise. """ return False def join(self, iterable): """ 连接 """ """ S.join(iterable) -> string Return a string which is the concatenation of the strings in the iterable. The separator between elements is S. """ return "" def ljust(self, width, fillchar=None): """ 内容左对齐,右侧填充 """ """ S.ljust(width[, fillchar]) -> string Return S left-justified in a string of length width. Padding is done using the specified fill character (default is a space). """ return "" def lower(self): """ 变小写 """ """ S.lower() -> string Return a copy of the string S converted to lowercase. """ return "" def lstrip(self, chars=None): """ 移除左侧空白 """ """ S.lstrip([chars]) -> string or unicode Return a copy of the string S with leading whitespace removed. If chars is given and not None, remove characters in chars instead. If chars is unicode, S will be converted to unicode before stripping """ return "" def partition(self, sep): """ 分割,前,中,后三部分 """ """ S.partition(sep) -> (head, sep, tail) Search for the separator sep in S, and return the part before it, the separator itself, and the part after it. If the separator is not found, return S and two empty strings. """ pass def replace(self, old, new, count=None): """ 替换 """ """ S.replace(old, new[, count]) -> string Return a copy of string S with all occurrences of substring old replaced by new. If the optional argument count is given, only the first count occurrences are replaced. """ return "" def rfind(self, sub, start=None, end=None): """ S.rfind(sub [,start [,end]]) -> int Return the highest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0 def rindex(self, sub, start=None, end=None): """ S.rindex(sub [,start [,end]]) -> int Like S.rfind() but raise ValueError when the substring is not found. """ return 0 def rjust(self, width, fillchar=None): """ S.rjust(width[, fillchar]) -> string Return S right-justified in a string of length width. Padding is done using the specified fill character (default is a space) """ return "" def rpartition(self, sep): """ S.rpartition(sep) -> (head, sep, tail) Search for the separator sep in S, starting at the end of S, and return the part before it, the separator itself, and the part after it. If the separator is not found, return two empty strings and S. """ pass def rsplit(self, sep=None, maxsplit=None): """ S.rsplit([sep [,maxsplit]]) -> list of strings Return a list of the words in the string S, using sep as the delimiter string, starting at the end of the string and working to the front. If maxsplit is given, at most maxsplit splits are done. If sep is not specified or is None, any whitespace string is a separator. """ return [] def rstrip(self, chars=None): """ S.rstrip([chars]) -> string or unicode Return a copy of the string S with trailing whitespace removed. If chars is given and not None, remove characters in chars instead. If chars is unicode, S will be converted to unicode before stripping """ return "" def split(self, sep=None, maxsplit=None): """ 分割, maxsplit最多分割几次 """ """ S.split([sep [,maxsplit]]) -> list of strings Return a list of the words in the string S, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done. If sep is not specified or is None, any whitespace string is a separator and empty strings are removed from the result. """ return [] def splitlines(self, keepends=False): """ 根据换行分割 """ """ S.splitlines(keepends=False) -> list of strings Return a list of the lines in S, breaking at line boundaries. Line breaks are not included in the resulting list unless keepends is given and true. """ return [] def startswith(self, prefix, start=None, end=None): """ 是否起始 """ """ S.startswith(prefix[, start[, end]]) -> bool Return True if S starts with the specified prefix, False otherwise. With optional start, test S beginning at that position. With optional end, stop comparing S at that position. prefix can also be a tuple of strings to try. """ return False def strip(self, chars=None): """ 移除两段空白 """ """ S.strip([chars]) -> string or unicode Return a copy of the string S with leading and trailing whitespace removed. If chars is given and not None, remove characters in chars instead. If chars is unicode, S will be converted to unicode before stripping """ return "" def swapcase(self): """ 大写变小写,小写变大写 """ """ S.swapcase() -> string Return a copy of the string S with uppercase characters converted to lowercase and vice versa. """ return "" def title(self): """ S.title() -> string Return a titlecased version of S, i.e. words start with uppercase characters, all remaining cased characters have lowercase. """ return "" def translate(self, table, deletechars=None): """ 转换,需要先做一个对应表,最后一个表示删除字符集合 intab = "aeiou" outtab = "12345" trantab = maketrans(intab, outtab) str = "this is string example....wow!!!" print str.translate(trantab, 'xm') """ """ S.translate(table [,deletechars]) -> string Return a copy of the string S, where all characters occurring in the optional argument deletechars are removed, and the remaining characters have been mapped through the given translation table, which must be a string of length 256 or None. If the table argument is None, no translation is applied and the operation simply removes the characters in deletechars. """ return "" def upper(self): """ S.upper() -> string Return a copy of the string S converted to uppercase. """ return "" def zfill(self, width): """方法返回指定长度的字符串,原字符串右对齐,前面填充0。""" """ S.zfill(width) -> string Pad a numeric string S with zeros on the left, to fill a field of the specified width. The string S is never truncated. """ return "" def _formatter_field_name_split(self, *args, **kwargs): # real signature unknown pass def _formatter_parser(self, *args, **kwargs): # real signature unknown pass def __add__(self, y): """ x.__add__(y) <==> x+y """ pass def __contains__(self, y): """ x.__contains__(y) <==> y in x """ pass def __eq__(self, y): """ x.__eq__(y) <==> x==y """ pass def __format__(self, format_spec): """ S.__format__(format_spec) -> string Return a formatted version of S as described by format_spec. """ return "" def __getattribute__(self, name): """ x.__getattribute__('name') <==> x.name """ pass def __getitem__(self, y): """ x.__getitem__(y) <==> x[y] """ pass def __getnewargs__(self, *args, **kwargs): # real signature unknown pass def __getslice__(self, i, j): """ x.__getslice__(i, j) <==> x[i:j] Use of negative indices is not supported. """ pass def __ge__(self, y): """ x.__ge__(y) <==> x>=y """ pass def __gt__(self, y): """ x.__gt__(y) <==> x>y """ pass def __hash__(self): """ x.__hash__() <==> hash(x) """ pass def __init__(self, string=''): # known special case of str.__init__ """ str(object='') -> string Return a nice string representation of the object. If the argument is a string, the return value is the same object. # (copied from class doc) """ pass def __len__(self): """ x.__len__() <==> len(x) """ pass def __le__(self, y): """ x.__le__(y) <==> x<=y """ pass def __lt__(self, y): """ x.__lt__(y) <==> x<y """ pass def __mod__(self, y): """ x.__mod__(y) <==> x%y """ pass def __mul__(self, n): """ x.__mul__(n) <==> x*n """ pass @staticmethod # known case of __new__ def __new__(S, *more): """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __ne__(self, y): """ x.__ne__(y) <==> x!=y """ pass def __repr__(self): """ x.__repr__() <==> repr(x) """ pass def __rmod__(self, y): """ x.__rmod__(y) <==> y%x """ pass def __rmul__(self, n): """ x.__rmul__(n) <==> n*x """ pass def __sizeof__(self): """ S.__sizeof__() -> size of S in memory, in bytes """ pass def __str__(self): """ x.__str__() <==> str(x) """ pass
2.4 列表
创建列表:
name_list = ['lizexiong', 'seven', 'eric'] 或 name_list = list(['lizexiong', 'seven', 'eric'])
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
class list(object): """ list() -> new empty list list(iterable) -> new list initialized from iterable's items """ def append(self, p_object): # real signature unknown; restored from __doc__ """ L.append(object) -- append object to end """ pass def count(self, value): # real signature unknown; restored from __doc__ """ L.count(value) -> integer -- return number of occurrences of value """ return 0 def extend(self, iterable): # real signature unknown; restored from __doc__ """ L.extend(iterable) -- extend list by appending elements from the iterable """ pass def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ """ L.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present. """ return 0 def insert(self, index, p_object): # real signature unknown; restored from __doc__ """ L.insert(index, object) -- insert object before index """ pass def pop(self, index=None): # real signature unknown; restored from __doc__ """ L.pop([index]) -> item -- remove and return item at index (default last). Raises IndexError if list is empty or index is out of range. """ pass def remove(self, value): # real signature unknown; restored from __doc__ """ L.remove(value) -- remove first occurrence of value. Raises ValueError if the value is not present. """ pass def reverse(self): # real signature unknown; restored from __doc__ """ L.reverse() -- reverse *IN PLACE* """ pass def sort(self, cmp=None, key=None, reverse=False): # real signature unknown; restored from __doc__ """ L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*; cmp(x, y) -> -1, 0, 1 """ pass def __add__(self, y): # real signature unknown; restored from __doc__ """ x.__add__(y) <==> x+y """ pass def __contains__(self, y): # real signature unknown; restored from __doc__ """ x.__contains__(y) <==> y in x """ pass def __delitem__(self, y): # real signature unknown; restored from __doc__ """ x.__delitem__(y) <==> del x[y] """ pass def __delslice__(self, i, j): # real signature unknown; restored from __doc__ """ x.__delslice__(i, j) <==> del x[i:j] Use of negative indices is not supported. """ pass def __eq__(self, y): # real signature unknown; restored from __doc__ """ x.__eq__(y) <==> x==y """ pass def __getattribute__(self, name): # real signature unknown; restored from __doc__ """ x.__getattribute__('name') <==> x.name """ pass def __getitem__(self, y): # real signature unknown; restored from __doc__ """ x.__getitem__(y) <==> x[y] """ pass def __getslice__(self, i, j): # real signature unknown; restored from __doc__ """ x.__getslice__(i, j) <==> x[i:j] Use of negative indices is not supported. """ pass def __ge__(self, y): # real signature unknown; restored from __doc__ """ x.__ge__(y) <==> x>=y """ pass def __gt__(self, y): # real signature unknown; restored from __doc__ """ x.__gt__(y) <==> x>y """ pass def __iadd__(self, y): # real signature unknown; restored from __doc__ """ x.__iadd__(y) <==> x+=y """ pass def __imul__(self, y): # real signature unknown; restored from __doc__ """ x.__imul__(y) <==> x*=y """ pass def __init__(self, seq=()): # known special case of list.__init__ """ list() -> new empty list list(iterable) -> new list initialized from iterable's items # (copied from class doc) """ pass def __iter__(self): # real signature unknown; restored from __doc__ """ x.__iter__() <==> iter(x) """ pass def __len__(self): # real signature unknown; restored from __doc__ """ x.__len__() <==> len(x) """ pass def __le__(self, y): # real signature unknown; restored from __doc__ """ x.__le__(y) <==> x<=y """ pass def __lt__(self, y): # real signature unknown; restored from __doc__ """ x.__lt__(y) <==> x<y """ pass def __mul__(self, n): # real signature unknown; restored from __doc__ """ x.__mul__(n) <==> x*n """ pass @staticmethod # known case of __new__ def __new__(S, *more): # real signature unknown; restored from __doc__ """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __ne__(self, y): # real signature unknown; restored from __doc__ """ x.__ne__(y) <==> x!=y """ pass def __repr__(self): # real signature unknown; restored from __doc__ """ x.__repr__() <==> repr(x) """ pass def __reversed__(self): # real signature unknown; restored from __doc__ """ L.__reversed__() -- return a reverse iterator over the list """ pass def __rmul__(self, n): # real signature unknown; restored from __doc__ """ x.__rmul__(n) <==> n*x """ pass def __setitem__(self, i, y): # real signature unknown; restored from __doc__ """ x.__setitem__(i, y) <==> x[i]=y """ pass def __setslice__(self, i, j, y): # real signature unknown; restored from __doc__ """ x.__setslice__(i, j, y) <==> x[i:j]=y Use of negative indices is not supported. """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ L.__sizeof__() -- size of L in memory, in bytes """ pass __hash__ = None
2.5 元祖
创建元祖:
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
元祖顺序不可变
基本操作:
- 索引
- 切片
- 循环
- 长度
- 包含
lass tuple(object): """ tuple() -> empty tuple tuple(iterable) -> tuple initialized from iterable's items If the argument is a tuple, the return value is the same object. """ def count(self, value): # real signature unknown; restored from __doc__ """ T.count(value) -> integer -- return number of occurrences of value """ return 0 def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ """ T.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present. """ return 0 def __add__(self, y): # real signature unknown; restored from __doc__ """ x.__add__(y) <==> x+y """ pass def __contains__(self, y): # real signature unknown; restored from __doc__ """ x.__contains__(y) <==> y in x """ pass def __eq__(self, y): # real signature unknown; restored from __doc__ """ x.__eq__(y) <==> x==y """ pass def __getattribute__(self, name): # real signature unknown; restored from __doc__ """ x.__getattribute__('name') <==> x.name """ pass def __getitem__(self, y): # real signature unknown; restored from __doc__ """ x.__getitem__(y) <==> x[y] """ pass def __getnewargs__(self, *args, **kwargs): # real signature unknown pass def __getslice__(self, i, j): # real signature unknown; restored from __doc__ """ x.__getslice__(i, j) <==> x[i:j] Use of negative indices is not supported. """ pass def __ge__(self, y): # real signature unknown; restored from __doc__ """ x.__ge__(y) <==> x>=y """ pass def __gt__(self, y): # real signature unknown; restored from __doc__ """ x.__gt__(y) <==> x>y """ pass def __hash__(self): # real signature unknown; restored from __doc__ """ x.__hash__() <==> hash(x) """ pass def __init__(self, seq=()): # known special case of tuple.__init__ """ tuple() -> empty tuple tuple(iterable) -> tuple initialized from iterable's items If the argument is a tuple, the return value is the same object. # (copied from class doc) """ pass def __iter__(self): # real signature unknown; restored from __doc__ """ x.__iter__() <==> iter(x) """ pass def __len__(self): # real signature unknown; restored from __doc__ """ x.__len__() <==> len(x) """ pass def __le__(self, y): # real signature unknown; restored from __doc__ """ x.__le__(y) <==> x<=y """ pass def __lt__(self, y): # real signature unknown; restored from __doc__ """ x.__lt__(y) <==> x<y """ pass def __mul__(self, n): # real signature unknown; restored from __doc__ """ x.__mul__(n) <==> x*n """ pass @staticmethod # known case of __new__ def __new__(S, *more): # real signature unknown; restored from __doc__ """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __ne__(self, y): # real signature unknown; restored from __doc__ """ x.__ne__(y) <==> x!=y """ pass def __repr__(self): # real signature unknown; restored from __doc__ """ x.__repr__() <==> repr(x) """ pass def __rmul__(self, n): # real signature unknown; restored from __doc__ """ x.__rmul__(n) <==> n*x """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ T.__sizeof__() -- size of T in memory, in bytes """ pass
2.6字典(无序)
创建字典:
person = {"name": "mr.li", 'age': 18}
或
person = dict({"name": "mr.li", 'age': 18})
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
class dict(object): """ dict() -> new empty dictionary dict(mapping) -> new dictionary initialized from a mapping object's (key, value) pairs dict(iterable) -> new dictionary initialized as if via: d = {} for k, v in iterable: d[k] = v dict(**kwargs) -> new dictionary initialized with the name=value pairs in the keyword argument list. For example: dict(one=1, two=2) """ def clear(self): # real signature unknown; restored from __doc__ """ 清除内容 """ """ D.clear() -> None. Remove all items from D. """ pass def copy(self): # real signature unknown; restored from __doc__ """ 浅拷贝 """ """ D.copy() -> a shallow copy of D """ pass @staticmethod # known case def fromkeys(S, v=None): # real signature unknown; restored from __doc__ """ dict.fromkeys(S[,v]) -> New dict with keys from S and values equal to v. v defaults to None. """ pass def get(self, k, d=None): # real signature unknown; restored from __doc__ """ 根据key获取值,d是默认值 """ """ D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None. """ pass def has_key(self, k): # real signature unknown; restored from __doc__ """ 是否有key """ """ D.has_key(k) -> True if D has a key k, else False """ return False def items(self): # real signature unknown; restored from __doc__ """ 所有项的列表形式 """ """ D.items() -> list of D's (key, value) pairs, as 2-tuples """ return [] def iteritems(self): # real signature unknown; restored from __doc__ """ 项可迭代 """ """ D.iteritems() -> an iterator over the (key, value) items of D """ pass def iterkeys(self): # real signature unknown; restored from __doc__ """ key可迭代 """ """ D.iterkeys() -> an iterator over the keys of D """ pass def itervalues(self): # real signature unknown; restored from __doc__ """ value可迭代 """ """ D.itervalues() -> an iterator over the values of D """ pass def keys(self): # real signature unknown; restored from __doc__ """ 所有的key列表 """ """ D.keys() -> list of D's keys """ return [] def pop(self, k, d=None): # real signature unknown; restored from __doc__ """ 获取并在字典中移除 """ """ D.pop(k[,d]) -> v, remove specified key and return the corresponding value. If key is not found, d is returned if given, otherwise KeyError is raised """ pass def popitem(self): # real signature unknown; restored from __doc__ """ 获取并在字典中移除 """ """ D.popitem() -> (k, v), remove and return some (key, value) pair as a 2-tuple; but raise KeyError if D is empty. """ pass def setdefault(self, k, d=None): # real signature unknown; restored from __doc__ """ 如果key不存在,则创建,如果存在,则返回已存在的值且不修改 """ """ D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D """ pass def update(self, E=None, **F): # known special case of dict.update """ 更新 {'name':'alex', 'age': 18000} [('name','sbsbsb'),] """ """ D.update([E, ]**F) -> None. Update D from dict/iterable E and F. If E present and has a .keys() method, does: for k in E: D[k] = E[k] If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v In either case, this is followed by: for k in F: D[k] = F[k] """ pass def values(self): # real signature unknown; restored from __doc__ """ 所有的值 """ """ D.values() -> list of D's values """ return [] def viewitems(self): # real signature unknown; restored from __doc__ """ 所有项,只是将内容保存至view对象中 """ """ D.viewitems() -> a set-like object providing a view on D's items """ pass def viewkeys(self): # real signature unknown; restored from __doc__ """ D.viewkeys() -> a set-like object providing a view on D's keys """ pass def viewvalues(self): # real signature unknown; restored from __doc__ """ D.viewvalues() -> an object providing a view on D's values """ pass def __cmp__(self, y): # real signature unknown; restored from __doc__ """ x.__cmp__(y) <==> cmp(x,y) """ pass def __contains__(self, k): # real signature unknown; restored from __doc__ """ D.__contains__(k) -> True if D has a key k, else False """ return False def __delitem__(self, y): # real signature unknown; restored from __doc__ """ x.__delitem__(y) <==> del x[y] """ pass def __eq__(self, y): # real signature unknown; restored from __doc__ """ x.__eq__(y) <==> x==y """ pass def __getattribute__(self, name): # real signature unknown; restored from __doc__ """ x.__getattribute__('name') <==> x.name """ pass def __getitem__(self, y): # real signature unknown; restored from __doc__ """ x.__getitem__(y) <==> x[y] """ pass def __ge__(self, y): # real signature unknown; restored from __doc__ """ x.__ge__(y) <==> x>=y """ pass def __gt__(self, y): # real signature unknown; restored from __doc__ """ x.__gt__(y) <==> x>y """ pass def __init__(self, seq=None, **kwargs): # known special case of dict.__init__ """ dict() -> new empty dictionary dict(mapping) -> new dictionary initialized from a mapping object's (key, value) pairs dict(iterable) -> new dictionary initialized as if via: d = {} for k, v in iterable: d[k] = v dict(**kwargs) -> new dictionary initialized with the name=value pairs in the keyword argument list. For example: dict(one=1, two=2) # (copied from class doc) """ pass def __iter__(self): # real signature unknown; restored from __doc__ """ x.__iter__() <==> iter(x) """ pass def __len__(self): # real signature unknown; restored from __doc__ """ x.__len__() <==> len(x) """ pass def __le__(self, y): # real signature unknown; restored from __doc__ """ x.__le__(y) <==> x<=y """ pass def __lt__(self, y): # real signature unknown; restored from __doc__ """ x.__lt__(y) <==> x<y """ pass @staticmethod # known case of __new__ def __new__(S, *more): # real signature unknown; restored from __doc__ """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __ne__(self, y): # real signature unknown; restored from __doc__ """ x.__ne__(y) <==> x!=y """ pass def __repr__(self): # real signature unknown; restored from __doc__ """ x.__repr__() <==> repr(x) """ pass def __setitem__(self, i, y): # real signature unknown; restored from __doc__ """ x.__setitem__(i, y) <==> x[i]=y """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ D.__sizeof__() -> size of D in memory, in bytes """ pass __hash__ = None
3.三元运算
三元运算(三目运算),是对简单的条件语句的缩写。
# 书写格式 result = 值1 if 条件 else 值2 # 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2”赋值给result变量
4.基本数据类型补充
4.1 set
set集合,是一个无序且不重复的元素集合
class set(object): """ set() -> new empty set object set(iterable) -> new set object Build an unordered collection of unique elements. """ def add(self, *args, **kwargs): # real signature unknown """ Add an element to a set,添加元素 This has no effect if the element is already present. """ pass def clear(self, *args, **kwargs): # real signature unknown """ Remove all elements from this set. 清除内容""" pass def copy(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of a set. 浅拷贝 """ pass def difference(self, *args, **kwargs): # real signature unknown """ Return the difference of two or more sets as a new set. A中存在,B中不存在 (i.e. all elements that are in this set but not the others.) """ pass def difference_update(self, *args, **kwargs): # real signature unknown """ Remove all elements of another set from this set. 从当前集合中删除和B中相同的元素""" pass def discard(self, *args, **kwargs): # real signature unknown """ Remove an element from a set if it is a member. If the element is not a member, do nothing. 移除指定元素,不存在不保错 """ pass def intersection(self, *args, **kwargs): # real signature unknown """ Return the intersection of two sets as a new set. 交集 (i.e. all elements that are in both sets.) """ pass def intersection_update(self, *args, **kwargs): # real signature unknown """ Update a set with the intersection of itself and another. 取交集并更更新到A中 """ pass def isdisjoint(self, *args, **kwargs): # real signature unknown """ Return True if two sets have a null intersection. 如果没有交集,返回True,否则返回False""" pass def issubset(self, *args, **kwargs): # real signature unknown """ Report whether another set contains this set. 是否是子序列""" pass def issuperset(self, *args, **kwargs): # real signature unknown """ Report whether this set contains another set. 是否是父序列""" pass def pop(self, *args, **kwargs): # real signature unknown """ Remove and return an arbitrary set element. Raises KeyError if the set is empty. 移除元素 """ pass def remove(self, *args, **kwargs): # real signature unknown """ Remove an element from a set; it must be a member. If the element is not a member, raise a KeyError. 移除指定元素,不存在保错 """ pass def symmetric_difference(self, *args, **kwargs): # real signature unknown """ Return the symmetric difference of two sets as a new set. 对称差集 (i.e. all elements that are in exactly one of the sets.) """ pass def symmetric_difference_update(self, *args, **kwargs): # real signature unknown """ Update a set with the symmetric difference of itself and another. 对称差集,并更新到a中 """ pass def union(self, *args, **kwargs): # real signature unknown """ Return the union of sets as a new set. 并集 (i.e. all elements that are in either set.) """ pass def update(self, *args, **kwargs): # real signature unknown """ Update a set with the union of itself and others. 更新 """ pass
5.深浅拷贝
5.1 数字和字符串
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
import copy # ######### 数字、字符串 ######### n1 = 123 # n1 = "i am lizexiong age 10" print(id(n1)) # ## 赋值 ## n2 = n1 print(id(n2)) # ## 浅拷贝 ## n2 = copy.copy(n1) print(id(n2)) # ## 深拷贝 ## n3 = copy.deepcopy(n1) print(id(n3))
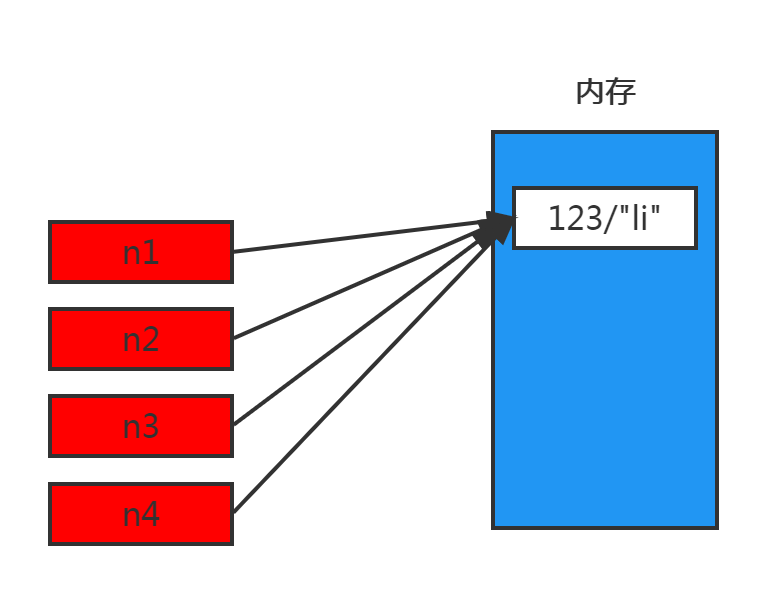
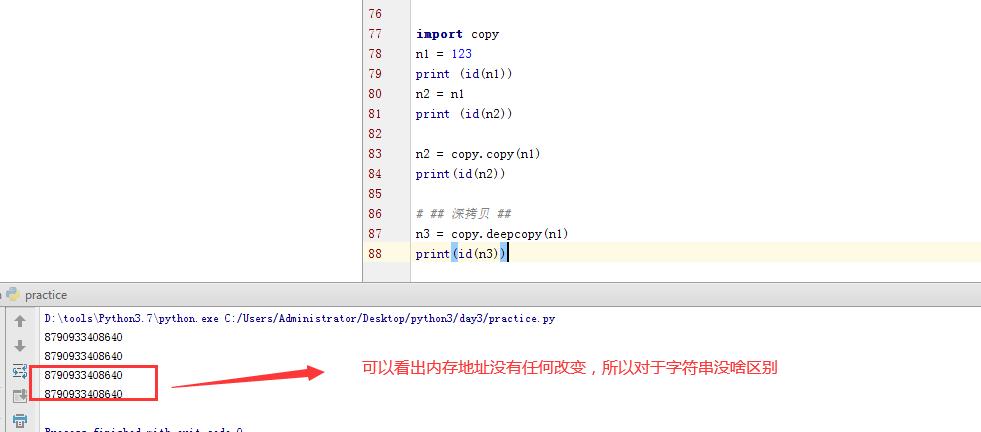
5.2 其他基本数据类型
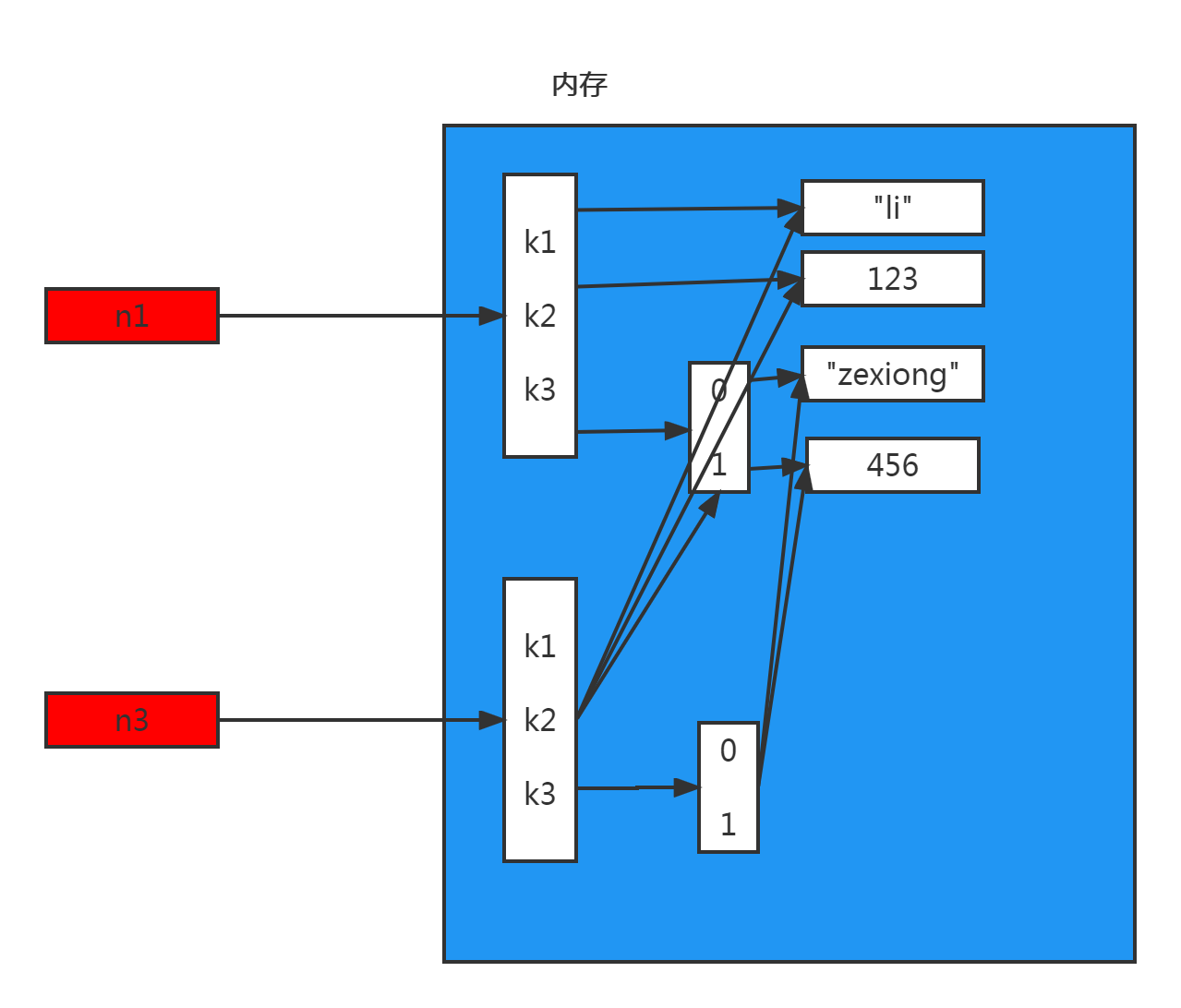
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
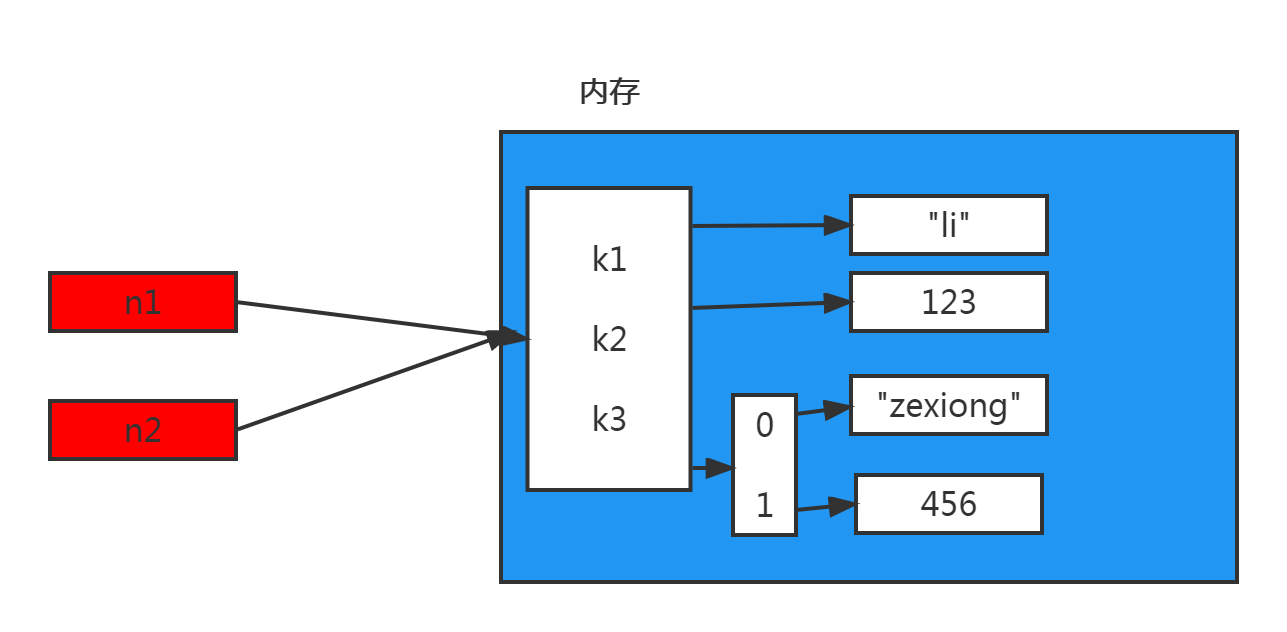
1.赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
n1 = {"k1": "li", "k2": 123, "k3": ["zexiong", 456]}
n2 = n1
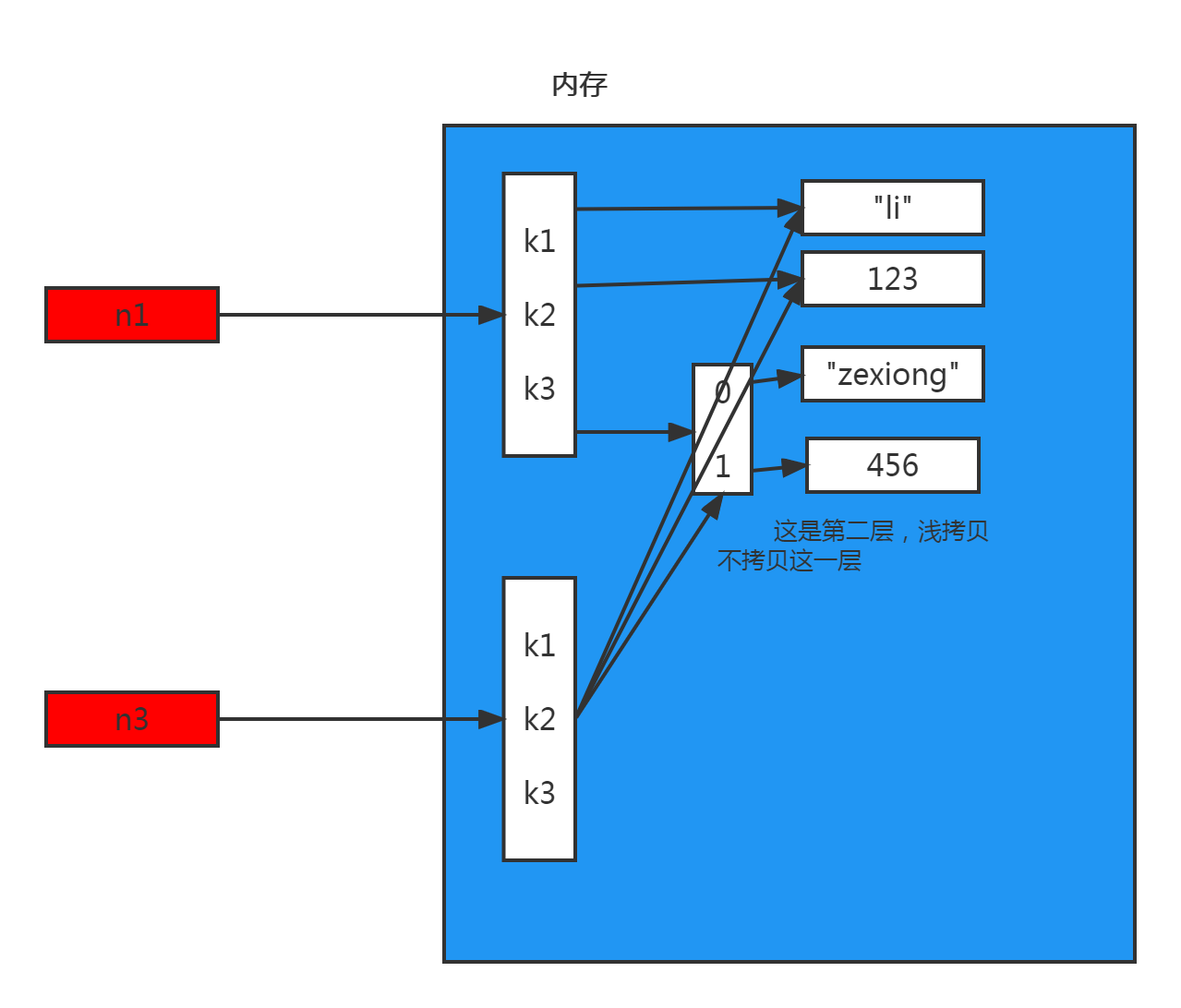
2.浅拷贝
浅拷贝,在内存中只额外创建第一层数据
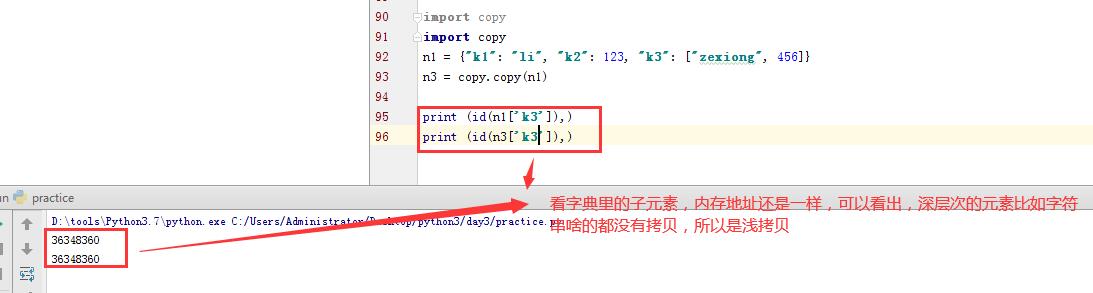
import copy n1 = {"k1": "li", "k2": 123, "k3": ["zexiong", 456]} n3 = copy.copy(n1)
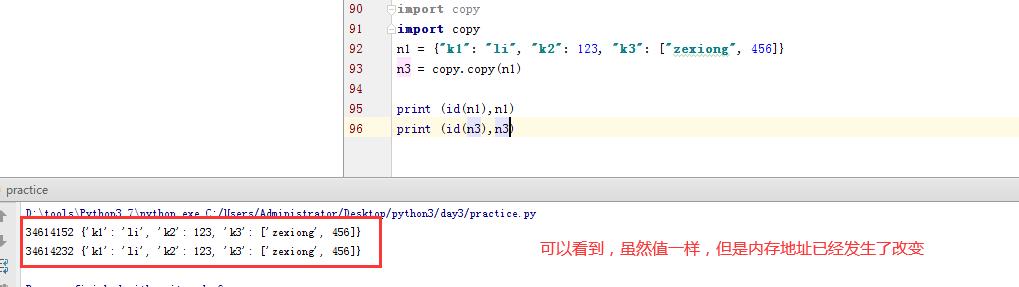
那么这不是发生改变了吗?接下来看
3.深拷贝
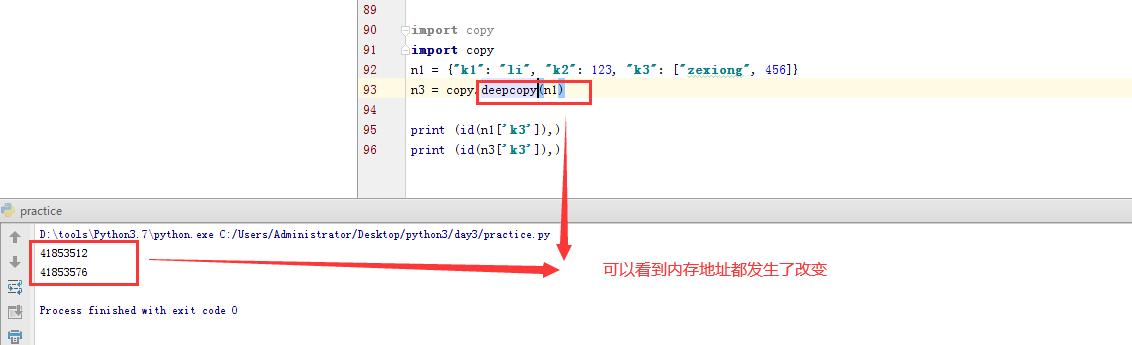
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
import copy n1 = {"k1": "li", "k2": 123, "k3": ["zexiong", 456]} n4 = copy.deepcopy(n1)
6.数据类型扩展篇-collections
6.1 计数器(counter)
Counter是对字典类型的补充,用于追踪值的出现次数。
ps:具备字典的所有功能 + 自己的功能
c = Counter('abcdeabcdabcaba') print c 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
######################################################################## ### Counter ######################################################################## class Counter(dict): '''Dict subclass for counting hashable items. Sometimes called a bag or multiset. Elements are stored as dictionary keys and their counts are stored as dictionary values. >>> c = Counter('abcdeabcdabcaba') # count elements from a string >>> c.most_common(3) # three most common elements [('a', 5), ('b', 4), ('c', 3)] >>> sorted(c) # list all unique elements ['a', 'b', 'c', 'd', 'e'] >>> ''.join(sorted(c.elements())) # list elements with repetitions 'aaaaabbbbcccdde' >>> sum(c.values()) # total of all counts >>> c['a'] # count of letter 'a' >>> for elem in 'shazam': # update counts from an iterable ... c[elem] += 1 # by adding 1 to each element's count >>> c['a'] # now there are seven 'a' >>> del c['b'] # remove all 'b' >>> c['b'] # now there are zero 'b' >>> d = Counter('simsalabim') # make another counter >>> c.update(d) # add in the second counter >>> c['a'] # now there are nine 'a' >>> c.clear() # empty the counter >>> c Counter() Note: If a count is set to zero or reduced to zero, it will remain in the counter until the entry is deleted or the counter is cleared: >>> c = Counter('aaabbc') >>> c['b'] -= 2 # reduce the count of 'b' by two >>> c.most_common() # 'b' is still in, but its count is zero [('a', 3), ('c', 1), ('b', 0)] ''' # References: # http://en.wikipedia.org/wiki/Multiset # http://www.gnu.org/software/smalltalk/manual-base/html_node/Bag.html # http://www.demo2s.com/Tutorial/Cpp/0380__set-multiset/Catalog0380__set-multiset.htm # http://code.activestate.com/recipes/259174/ # Knuth, TAOCP Vol. II section 4.6.3 def __init__(self, iterable=None, **kwds): '''Create a new, empty Counter object. And if given, count elements from an input iterable. Or, initialize the count from another mapping of elements to their counts. >>> c = Counter() # a new, empty counter >>> c = Counter('gallahad') # a new counter from an iterable >>> c = Counter({'a': 4, 'b': 2}) # a new counter from a mapping >>> c = Counter(a=4, b=2) # a new counter from keyword args ''' super(Counter, self).__init__() self.update(iterable, **kwds) def __missing__(self, key): """ 对于不存在的元素,返回计数器为0 """ 'The count of elements not in the Counter is zero.' # Needed so that self[missing_item] does not raise KeyError return 0 def most_common(self, n=None): """ 数量从大到写排列,获取前N个元素 """ '''List the n most common elements and their counts from the most common to the least. If n is None, then list all element counts. >>> Counter('abcdeabcdabcaba').most_common(3) [('a', 5), ('b', 4), ('c', 3)] ''' # Emulate Bag.sortedByCount from Smalltalk if n is None: return sorted(self.iteritems(), key=_itemgetter(1), reverse=True) return _heapq.nlargest(n, self.iteritems(), key=_itemgetter(1)) def elements(self): """ 计数器中的所有元素,注:此处非所有元素集合,而是包含所有元素集合的迭代器 """ '''Iterator over elements repeating each as many times as its count. >>> c = Counter('ABCABC') >>> sorted(c.elements()) ['A', 'A', 'B', 'B', 'C', 'C'] # Knuth's example for prime factors of 1836: 2**2 * 3**3 * 17**1 >>> prime_factors = Counter({2: 2, 3: 3, 17: 1}) >>> product = 1 >>> for factor in prime_factors.elements(): # loop over factors ... product *= factor # and multiply them >>> product Note, if an element's count has been set to zero or is a negative number, elements() will ignore it. ''' # Emulate Bag.do from Smalltalk and Multiset.begin from C++. return _chain.from_iterable(_starmap(_repeat, self.iteritems())) # Override dict methods where necessary @classmethod def fromkeys(cls, iterable, v=None): # There is no equivalent method for counters because setting v=1 # means that no element can have a count greater than one. raise NotImplementedError( 'Counter.fromkeys() is undefined. Use Counter(iterable) instead.') def update(self, iterable=None, **kwds): """ 更新计数器,其实就是增加;如果原来没有,则新建,如果有则加一 """ '''Like dict.update() but add counts instead of replacing them. Source can be an iterable, a dictionary, or another Counter instance. >>> c = Counter('which') >>> c.update('witch') # add elements from another iterable >>> d = Counter('watch') >>> c.update(d) # add elements from another counter >>> c['h'] # four 'h' in which, witch, and watch ''' # The regular dict.update() operation makes no sense here because the # replace behavior results in the some of original untouched counts # being mixed-in with all of the other counts for a mismash that # doesn't have a straight-forward interpretation in most counting # contexts. Instead, we implement straight-addition. Both the inputs # and outputs are allowed to contain zero and negative counts. if iterable is not None: if isinstance(iterable, Mapping): if self: self_get = self.get for elem, count in iterable.iteritems(): self[elem] = self_get(elem, 0) + count else: super(Counter, self).update(iterable) # fast path when counter is empty else: self_get = self.get for elem in iterable: self[elem] = self_get(elem, 0) + 1 if kwds: self.update(kwds) def subtract(self, iterable=None, **kwds): """ 相减,原来的计数器中的每一个元素的数量减去后添加的元素的数量 """ '''Like dict.update() but subtracts counts instead of replacing them. Counts can be reduced below zero. Both the inputs and outputs are allowed to contain zero and negative counts. Source can be an iterable, a dictionary, or another Counter instance. >>> c = Counter('which') >>> c.subtract('witch') # subtract elements from another iterable >>> c.subtract(Counter('watch')) # subtract elements from another counter >>> c['h'] # 2 in which, minus 1 in witch, minus 1 in watch >>> c['w'] # 1 in which, minus 1 in witch, minus 1 in watch -1 ''' if iterable is not None: self_get = self.get if isinstance(iterable, Mapping): for elem, count in iterable.items(): self[elem] = self_get(elem, 0) - count else: for elem in iterable: self[elem] = self_get(elem, 0) - 1 if kwds: self.subtract(kwds) def copy(self): """ 拷贝 """ 'Return a shallow copy.' return self.__class__(self) def __reduce__(self): """ 返回一个元组(类型,元组) """ return self.__class__, (dict(self),) def __delitem__(self, elem): """ 删除元素 """ 'Like dict.__delitem__() but does not raise KeyError for missing values.' if elem in self: super(Counter, self).__delitem__(elem) def __repr__(self): if not self: return '%s()' % self.__class__.__name__ items = ', '.join(map('%r: %r'.__mod__, self.most_common())) return '%s({%s})' % (self.__class__.__name__, items) # Multiset-style mathematical operations discussed in: # Knuth TAOCP Volume II section 4.6.3 exercise 19 # and at http://en.wikipedia.org/wiki/Multiset # # Outputs guaranteed to only include positive counts. # # To strip negative and zero counts, add-in an empty counter: # c += Counter() def __add__(self, other): '''Add counts from two counters. >>> Counter('abbb') + Counter('bcc') Counter({'b': 4, 'c': 2, 'a': 1}) ''' if not isinstance(other, Counter): return NotImplemented result = Counter() for elem, count in self.items(): newcount = count + other[elem] if newcount > 0: result[elem] = newcount for elem, count in other.items(): if elem not in self and count > 0: result[elem] = count return result def __sub__(self, other): ''' Subtract count, but keep only results with positive counts. >>> Counter('abbbc') - Counter('bccd') Counter({'b': 2, 'a': 1}) ''' if not isinstance(other, Counter): return NotImplemented result = Counter() for elem, count in self.items(): newcount = count - other[elem] if newcount > 0: result[elem] = newcount for elem, count in other.items(): if elem not in self and count < 0: result[elem] = 0 - count return result def __or__(self, other): '''Union is the maximum of value in either of the input counters. >>> Counter('abbb') | Counter('bcc') Counter({'b': 3, 'c': 2, 'a': 1}) ''' if not isinstance(other, Counter): return NotImplemented result = Counter() for elem, count in self.items(): other_count = other[elem] newcount = other_count if count < other_count else count if newcount > 0: result[elem] = newcount for elem, count in other.items(): if elem not in self and count > 0: result[elem] = count return result def __and__(self, other): ''' Intersection is the minimum of corresponding counts. >>> Counter('abbb') & Counter('bcc') Counter({'b': 1}) ''' if not isinstance(other, Counter): return NotImplemented result = Counter() for elem, count in self.items(): other_count = other[elem] newcount = count if count < other_count else other_count if newcount > 0: result[elem] = newcount return result Counter
6.2 有序字典(orderedDict )
orderdDict是对字典类型的补充,他记住了字典元素添加的顺序,python3已经自动在字典添加了这个功能。
class OrderedDict(dict): 'Dictionary that remembers insertion order' # An inherited dict maps keys to values. # The inherited dict provides __getitem__, __len__, __contains__, and get. # The remaining methods are order-aware. # Big-O running times for all methods are the same as regular dictionaries. # The internal self.__map dict maps keys to links in a doubly linked list. # The circular doubly linked list starts and ends with a sentinel element. # The sentinel element never gets deleted (this simplifies the algorithm). # Each link is stored as a list of length three: [PREV, NEXT, KEY]. def __init__(self, *args, **kwds): '''Initialize an ordered dictionary. The signature is the same as regular dictionaries, but keyword arguments are not recommended because their insertion order is arbitrary. ''' if len(args) > 1: raise TypeError('expected at most 1 arguments, got %d' % len(args)) try: self.__root except AttributeError: self.__root = root = [] # sentinel node root[:] = [root, root, None] self.__map = {} self.__update(*args, **kwds) def __setitem__(self, key, value, dict_setitem=dict.__setitem__): 'od.__setitem__(i, y) <==> od[i]=y' # Setting a new item creates a new link at the end of the linked list, # and the inherited dictionary is updated with the new key/value pair. if key not in self: root = self.__root last = root[0] last[1] = root[0] = self.__map[key] = [last, root, key] return dict_setitem(self, key, value) def __delitem__(self, key, dict_delitem=dict.__delitem__): 'od.__delitem__(y) <==> del od[y]' # Deleting an existing item uses self.__map to find the link which gets # removed by updating the links in the predecessor and successor nodes. dict_delitem(self, key) link_prev, link_next, _ = self.__map.pop(key) link_prev[1] = link_next # update link_prev[NEXT] link_next[0] = link_prev # update link_next[PREV] def __iter__(self): 'od.__iter__() <==> iter(od)' # Traverse the linked list in order. root = self.__root curr = root[1] # start at the first node while curr is not root: yield curr[2] # yield the curr[KEY] curr = curr[1] # move to next node def __reversed__(self): 'od.__reversed__() <==> reversed(od)' # Traverse the linked list in reverse order. root = self.__root curr = root[0] # start at the last node while curr is not root: yield curr[2] # yield the curr[KEY] curr = curr[0] # move to previous node def clear(self): 'od.clear() -> None. Remove all items from od.' root = self.__root root[:] = [root, root, None] self.__map.clear() dict.clear(self) # -- the following methods do not depend on the internal structure -- def keys(self): 'od.keys() -> list of keys in od' return list(self) def values(self): 'od.values() -> list of values in od' return [self[key] for key in self] def items(self): 'od.items() -> list of (key, value) pairs in od' return [(key, self[key]) for key in self] def iterkeys(self): 'od.iterkeys() -> an iterator over the keys in od' return iter(self) def itervalues(self): 'od.itervalues -> an iterator over the values in od' for k in self: yield self[k] def iteritems(self): 'od.iteritems -> an iterator over the (key, value) pairs in od' for k in self: yield (k, self[k]) update = MutableMapping.update __update = update # let subclasses override update without breaking __init__ __marker = object() def pop(self, key, default=__marker): '''od.pop(k[,d]) -> v, remove specified key and return the corresponding value. If key is not found, d is returned if given, otherwise KeyError is raised. ''' if key in self: result = self[key] del self[key] return result if default is self.__marker: raise KeyError(key) return default def setdefault(self, key, default=None): 'od.setdefault(k[,d]) -> od.get(k,d), also set od[k]=d if k not in od' if key in self: return self[key] self[key] = default return default def popitem(self, last=True): '''od.popitem() -> (k, v), return and remove a (key, value) pair. Pairs are returned in LIFO order if last is true or FIFO order if false. ''' if not self: raise KeyError('dictionary is empty') key = next(reversed(self) if last else iter(self)) value = self.pop(key) return key, value def __repr__(self, _repr_running={}): 'od.__repr__() <==> repr(od)' call_key = id(self), _get_ident() if call_key in _repr_running: return '...' _repr_running[call_key] = 1 try: if not self: return '%s()' % (self.__class__.__name__,) return '%s(%r)' % (self.__class__.__name__, self.items()) finally: del _repr_running[call_key] def __reduce__(self): 'Return state information for pickling' items = [[k, self[k]] for k in self] inst_dict = vars(self).copy() for k in vars(OrderedDict()): inst_dict.pop(k, None) if inst_dict: return (self.__class__, (items,), inst_dict) return self.__class__, (items,) def copy(self): 'od.copy() -> a shallow copy of od' return self.__class__(self) @classmethod def fromkeys(cls, iterable, value=None): '''OD.fromkeys(S[, v]) -> New ordered dictionary with keys from S. If not specified, the value defaults to None. ''' self = cls() for key in iterable: self[key] = value return self def __eq__(self, other): '''od.__eq__(y) <==> od==y. Comparison to another OD is order-sensitive while comparison to a regular mapping is order-insensitive. ''' if isinstance(other, OrderedDict): return dict.__eq__(self, other) and all(_imap(_eq, self, other)) return dict.__eq__(self, other) def __ne__(self, other): 'od.__ne__(y) <==> od!=y' return not self == other # -- the following methods support python 3.x style dictionary views -- def viewkeys(self): "od.viewkeys() -> a set-like object providing a view on od's keys" return KeysView(self) def viewvalues(self): "od.viewvalues() -> an object providing a view on od's values" return ValuesView(self) def viewitems(self): "od.viewitems() -> a set-like object providing a view on od's items" return ItemsView(self) OrderedDict
6.3 默认字典(defaultdict)
学前需求:
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
#原生字典解决办法 values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = {} for value in values: if value>66: if my_dict.has_key('k1'): my_dict['k1'].append(value) else: my_dict['k1'] = [value] else: if my_dict.has_key('k2'): my_dict['k2'].append(value) else: my_dict['k2'] = [value]
#默认字典解决办法 from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in values: if value>66: my_dict['k1'].append(value) else: my_dict['k2'].append(value)
defaultdict是对字典的类型的补充,他默认给字典的值设置了一个类型。
6.4 可命名元组(namedtuple)
根据nametuple可以创建一个包含tuple所有功能以及其他功能的类型。
import collections Mytuple = collections.namedtuple('Mytuple',['x', 'y', 'z']) obj = Mytuple(11,22,33) print (obj.x)
class Mytuple(__builtin__.tuple) | Mytuple(x, y) | | Method resolution order: | Mytuple | __builtin__.tuple | __builtin__.object | | Methods defined here: | | __getnewargs__(self) | Return self as a plain tuple. Used by copy and pickle. | | __getstate__(self) | Exclude the OrderedDict from pickling | | __repr__(self) | Return a nicely formatted representation string | | _asdict(self) | Return a new OrderedDict which maps field names to their values | | _replace(_self, **kwds) | Return a new Mytuple object replacing specified fields with new values | | ---------------------------------------------------------------------- | Class methods defined here: | | _make(cls, iterable, new=<built-in method __new__ of type object>, len=<built-in function len>) from __builtin__.type | Make a new Mytuple object from a sequence or iterable | | ---------------------------------------------------------------------- | Static methods defined here: | | __new__(_cls, x, y) | Create new instance of Mytuple(x, y) | | ---------------------------------------------------------------------- | Data descriptors defined here: | | __dict__ | Return a new OrderedDict which maps field names to their values | | x | Alias for field number 0 | | y | Alias for field number 1 | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | _fields = ('x', 'y') | | ---------------------------------------------------------------------- | Methods inherited from __builtin__.tuple: | | __add__(...) | x.__add__(y) <==> x+y | | __contains__(...) | x.__contains__(y) <==> y in x | | __eq__(...) | x.__eq__(y) <==> x==y | | __ge__(...) | x.__ge__(y) <==> x>=y | | __getattribute__(...) | x.__getattribute__('name') <==> x.name | | __getitem__(...) | x.__getitem__(y) <==> x[y] | | __getslice__(...) | x.__getslice__(i, j) <==> x[i:j] | | Use of negative indices is not supported. | | __gt__(...) | x.__gt__(y) <==> x>y | | __hash__(...) | x.__hash__() <==> hash(x) | | __iter__(...) | x.__iter__() <==> iter(x) | | __le__(...) | x.__le__(y) <==> x<=y | | __len__(...) | x.__len__() <==> len(x) | | __lt__(...) | x.__lt__(y) <==> x<y | | __mul__(...) | x.__mul__(n) <==> x*n | | __ne__(...) | x.__ne__(y) <==> x!=y | | __rmul__(...) | x.__rmul__(n) <==> n*x | | __sizeof__(...) | T.__sizeof__() -- size of T in memory, in bytes | | count(...) | T.count(value) -> integer -- return number of occurrences of value | | index(...) | T.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present.
6.5 双向队列(deque)
一个线程安全的双向队列
from collections import deque
注:既然有双向队列,也有单项队列(先进先出 FIFO )
import queue q = queue.Queue()
