
Prometheus实战之联邦+高可用+持久
|
导航:这里主要是列出一个prometheus一些系统的学习过程,最后按照章节顺序查看,由于写作该文档经历了不同时期,所以在文中有时出现 的云环境不统一,但是学习具体使用方法即可,在最后的篇章,有一个完整的腾讯云的实战案例。 8.kube-state-metrics 和 metrics-server 13.Grafana简单用法 参考: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config https://www.bookstack.cn/read/prometheus_practice/introduction-README.md |
有了上述几章的学习之后,这里将总结一下之前所有内容;正好,在我司架构中正好是多数据中心,多项目,且k8s环境,宿主机环境共存,这里正好将学习的知识用在实战中.
以下可能不会贴出所有配置,但是会将重要的展示出来.
基础概念:
高可用: 2台汇总所有数据的prometheus 做负载均衡,这样即使有一台down机也不会影响任务,这2台机器汇总所有联邦prometheus的数据.
持久:2台汇总所有数据的prometheus 数据保存在本地这样不利于迁移和更长之间的持久,所以2台prometheus的数据保存至远端数据库.
联邦:简单来说就是zabbix-proxy的概念,这些prometheus不需要去持久化数据,只要能采集数据,主prometheus需要数据时能采集到即可.
这样,多数据中心,多集群,多环境就可以使用这种架构解决.
1.环境信息
| 角色 | 部署方式 | 信息 | 云环境 | 作用 |
| Prometheus 主(总)/alertmanager01 | 宿主 | 10.1.1.10 | 腾讯云 | 汇总prometheus |
| Prometheus 备(总)/alertmanager02 | 宿主 | 10.1.1.5 | 腾讯云 | 汇总prometheus |
| 联邦 Prometheus | K8s | K8s | 阿里云 | Lcm k8s环境 |
| 联邦 Prometheus | 宿主 | 阿里云内网 | 阿里云 | 罪恶王冠游戏 |
| 软件对应版本 | |
| 软件名称 | 软件版本 |
| 主prometheus | 2.13.1 |
| 联邦子prometheus | 2.13.1 |
| Node-exporter | 0.18.1 |
| blackbox_exporter | 0.16.0 |
| Consul | 1.6.1 |
| Metrics-server | 0.3.5 |
| Kube-state-metrics | 1.8.0 |
这里我们由小变大来配置这个项目.
本章不讲解任何prometsql和alert告警规则的方法,只讲解集群的配置方式。
2.子联邦配置
2.1 K8s集群联邦点
因为子联邦节点是监控k8s集群的,为了方便,肯定是部署在prometheus里,下面看看deploy的配置文件。
这里不讲解获取数据来源工具组件等一些授权以及安装,默认当作已安装完成的情况,需要的去查看kube-state-metrics和metrics-server章节。
apiVersion: v1 kind: "Service" metadata: name: prometheus namespace: monitoring labels: name: prometheus spec: ports: - name: prometheus protocol: TCP port: 9090 targetPort: 9090 nodePort: 30946 selector: app: prometheus type: NodePort --- apiVersion: apps/v1 kind: Deployment metadata: labels: name: prometheus name: prometheus namespace: monitoring spec: replicas: 1 selector: matchLabels: app: prometheus template: metadata: labels: app: prometheus spec: serviceAccountName: prometheus containers: - name: prometheus image: prom/prometheus:v2.3.0 env: - name: ver value: "15" command: - "/bin/prometheus" args: - "--config.file=/etc/prometheus/prometheus.yml" - "--log.level=debug" ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: "/etc/prometheus" name: prometheus-config volumes: - name: prometheus-config configMap: name: prometheus-config
当然也不能少了RBAC的授权。
apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: prometheus rules: - apiGroups: [""] resources: - nodes #node发现模式的授权资源,不然通过kubelet自带的发现模式不授权这个资源,会在prometheus爆出403错误 - nodes/metrics - nodes/proxy - services - endpoints - pods - namespaces verbs: ["get", "list", "watch"] - apiGroups: - extensions resources: - ingresses verbs: ["get", "list", "watch"] - nonResourceURLs: ["/metrics","/api/*"] verbs: ["get"] --- apiVersion: v1 kind: ServiceAccount metadata: name: prometheus namespace: monitoring --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: monitoring
上面的deploy挂载了一个卷,就是配置文件,如下的配置文件,没有告警条目,没有持久化存储,因为他们不需要,只要总prometheus来向它收集数据就可以了.它也是一个prometheus,只是做的工作比较少罢了.
这个prometheus包含了以下采集任务:
- kubernetes-kubelet
- kubernetes-cadvisor
- kubernetes-pods
- kubernetes-apiservers
- kubernetes-services
- kubernetes-ingresses
- kubernetes-service-endpoints
基本涵盖了k8s 的大部分的key,所以k8s内联邦prometheus角色需要注意这么几点就可以.
下面的配置文件如下,可能(cn-lcm-prod)项目标识不太一样,这里可以忽略,改成自己对应的项目即可


apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: monitoring data: prometheus.yml: | global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'cn-lcm-prod-kubernetes-kubelet' scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics - job_name: 'cn-web-prod-kubernetes-cadvisor' scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: node relabel_configs: - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'cn-lcm-prod-kubernetes-pods' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'cn-lcm-prod-kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - target_label: __address__ replacement: kubernetes.default.svc:443 - job_name: 'cn-lcm-prod-kubernetes-services' metrics_path: /probe params: module: [http_2xx] kubernetes_sd_configs: - role: service relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe] action: keep regex: true - source_labels: [__address__] target_label: __param_target - target_label: __address__ replacement: blackbox-exporter.monitoring.svc.cluster.local:9115 - source_labels: [__param_target] target_label: instance - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] target_label: kubernetes_name - job_name: 'cn-lcm-prod-kubernetes-ingresses' metrics_path: /probe params: module: [http_2xx] kubernetes_sd_configs: - role: ingress relabel_configs: - source_labels: [__meta_kubernetes_ingress_annotation_prometheus_io_probe] action: keep regex: true - source_labels: [__meta_kubernetes_ingress_scheme,__address__,__meta_kubernetes_ingress_path] regex: (.+);(.+);(.+) replacement: ${1}://${2}${3} target_label: __param_target - target_label: __address__ replacement: blackbox-exporter.monitoring.svc.cluster.local:9115 - source_labels: [__param_target] target_label: instance - action: labelmap regex: __meta_kubernetes_ingress_label_(.+) - source_labels: [__meta_kubernetes_namespace] target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_ingress_name] target_label: kubernetes_name - job_name: 'cn-lcm-prod-kubernetes-service-endpoints' scrape_interval: 10s scrape_timeout: 10s #这个job配置不太一样,采集时间是10秒,因为使用全局配置的15秒,会出现拉取数据闪断的情况,所以,这里单独配置成10秒 kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name
2.2 宿主机联邦及consul自动发现
其实在,主prometheus端, 联邦角色在 k8s集群内还是集群外,主prometheus并不关注,但是运维人员需要关注,因为在k8s集群内和宿主机采集方式和自动发现方式都不一样.
下面的宿主机联邦节点也配置监控进程以及端口的方式,具体的配置解释,翻阅前面相关章节的文档
Consul的使用这里不再做介绍.这里仅贴出配置。
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. scrape_configs: - job_name: 'cn-gc-consul-node' consul_sd_configs: - server: '127.0.0.1:8500' #手动填写的方式 #services: ['cn-gc-game02'] relabel_configs: - source_labels: [__meta_consul_tags] regex: .*cn-gc.* action: keep - source_labels: [__meta_consul_service_id] target_label: "hostname" - job_name: 'cn-gc-consul-process' consul_sd_configs: - server: '127.0.0.1:8500' relabel_configs: - source_labels: [__meta_consul_tags] regex: .*cn-gc.* action: keep - source_labels: [__meta_consul_service_id] target_label: "hostname" - source_labels: [__address__] regex: ((?:(?:\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.){3}(?:\d|[1-9]\d|2[0-4]\d|25[0-5])):(\d{1,4}) target_label: __address__ replacement: ${1}:9256 - job_name: 'cn-gc-nginx01' metrics_path: /probe params: module: [http_2xx] static_configs: - targets: ['10.10.3.4:80/admin#/login'] #consul_sd_configs: #- server: '127.0.0.1:8500' #services: [] relabel_configs: #- source_labels: [__meta_consul_tags] #regex: .*cn-gc-port.* #action: keep - source_labels: [__address__] target_label: __param_target - target_label: __address__ replacement: 10.10.3.4:9115 - job_name: 'cn-gc-nginx02' metrics_path: /probe params: module: [http_2xx] static_configs: - targets: ['10.10.3.10:80/admin#/login'] relabel_configs: - source_labels: [__address__] target_label: __param_target - target_label: __address__ replacement: 10.10.3.10:9115 - job_name: 'port' metrics_path: /probe params: module: [tcp_connect] #static_configs: #- targets: ['10.1.1.9:12020',] consul_sd_configs: - server: '127.0.0.1:8500' services: [] relabel_configs: - source_labels: [__meta_consul_tags] regex: .*cn-gc.* action: keep - source_labels: [__meta_consul_service_id] target_label: "hostname" #- source_labels: [__address__] #target_label: __param_target - source_labels: [__address__] #regex: ((?:(?:\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.){3}(?:\d|[1-9]\d|2[0-4]\d|25[0-5])):(\d{1,5}) target_label: __param_target replacement: 127.0.0.1:11000 - source_labels: [__address__] regex: ((?:(?:\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.){3}(?:\d|[1-9]\d|2[0-4]\d|25[0-5])):(\d{1,5}) target_label: __address__ replacement: ${1}:9115
3.主联邦高可用
分布在各环境、各数据中心的prometheus已经正常运行,并且能够采集到数据,现在需要把这些散落在各数据中心的数据汇总并展示出来.
这里汇总数据,规则计算,告警,全部由主prometheus来完成.
3.1 主prometheus联邦k8s集群配置
- job_name: "cn-lcm-prod" scrape_interval: 30s scrape_timeout: 30s honor_labels: true #horbor_labels配置true可以确保当采集到的监控指标冲突时,能够自动忽略冲突的监控数据。如果为false时,prometheus会自动将冲突的标签替换为”exported_“的形式。 #只是联邦prometheus采集的默认接口 metrics_path: '/federate' params: 'match[]': #这一行也默认配置,经过测试,建议保留(没有得出实际作用是什么,但是建议还是不要取消,不会影响采集) #job和name都支持正则,目前没有对比出2个用户的区别,官网没有对于__name__的解释,但是用以下办法可以采集数据监控即可 - '{job="prometheus"}' #这里相当于其实已经匹配除了所有的job任务,这里是一种采集方式,根据语法可以看到,匹配所有job;使用更下面的job标签指定任务,是会让自己的采集更加清晰一点 ,以便更好的根据标签分类 - '{__name__=~"job:.*"}' #子联邦prometheus 上有哪些 target项,在这里写出来,这里写指定的job,是为了让我们的监控更加清晰一点,以便更好的标签分类,在job=prometheus的注释里面提到过(可以支持正则,但是正则比较麻烦,所以放弃) - '{job="cn-lcm-prod-kubernetes-kubelet"}' - '{job="cn-lcm-prod-kubernetes-cadvisor"}' - '{job="cn-lcm-prod-kubernetes-pods"}' - '{job="cn-lcm-prod-kubernetes-apiservers"}' - '{job="cn-lcm-prod-kubernetes-services"}' - '{job="cn-lcm-prod-kubernetes-service-endpoints"}' static_configs: - targets: #要采集的子prometheus的地址 - 'x.x.x.x:9090' #给prometheus加上一个标签,可以通过这个标签过滤项目 labels: project: cn-lcm-prod
3.2 主联邦宿主机配置
- job_name: "cn-gc" scrape_interval: 2s scrape_timeout: 2s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' - '{job="cn-gc-consul"}' static_configs: - targets: - 'x.x.x.x:9090' labels: project: cn-gc
可以看出,在主prometheus上配置基本差不多,因为主prometheus去找联邦子prometheus固定的接口去采集数据就行了.
4.持久
持久化配置更简洁,新版直接支持http的访问方式;这里选择的是influxdb,当然还可以选择其它存储,但是需要注意,有些存储不支持远端同时读写.
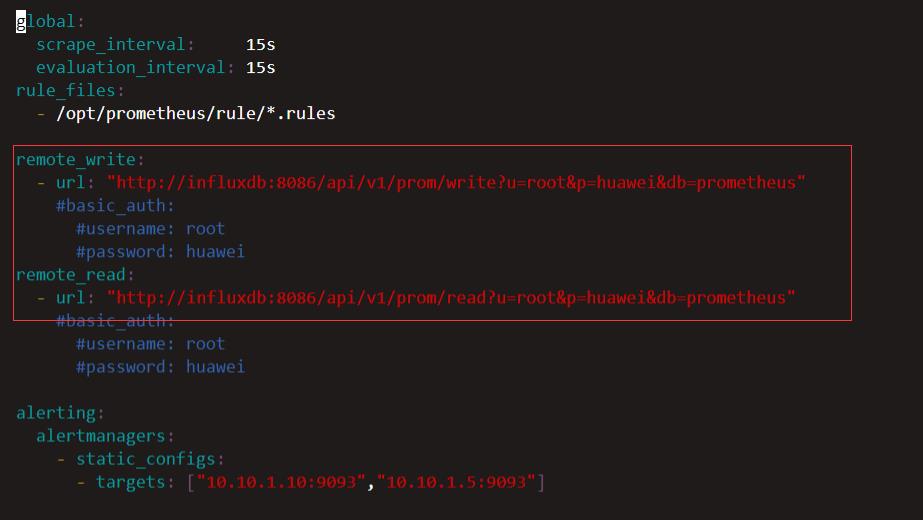
更多存储信息可参考官方文档链接:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
5.告警规则
首先要明确一点,发送告警是alertmanager的工作,但是计算告警规则,是否需要告警,由prometheus来处理,Prometheus 将要告警的内容发送给alertmanager,再由alertmanager把告警内容发送给“告警介质”.
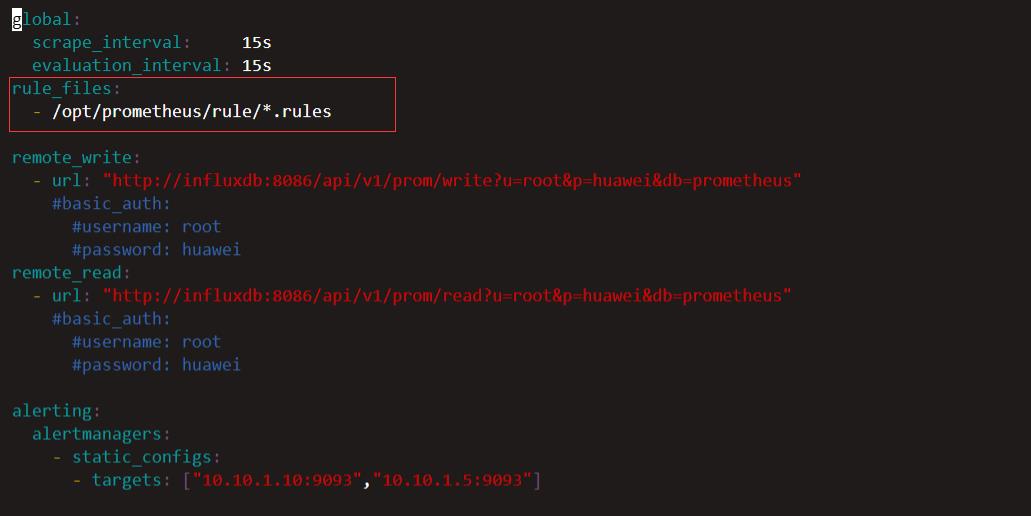
将告警规则定义在以下路径的文件夹,现在我这里是一个项目一个规则文件,这里就用k8s的规则来做简单讲解.


6.Alertmanager
在本项目环境中,由于采用了邮件,钉钉,webchat的告警方式,所以直接整篇配置直接讲解.
以下讲解一下各告警方式的区别.
企业微信:可以单独给不同联系发送告警,但是需要信息多,配置麻烦
钉钉:使用扩展webhook的方式,使用默认转发器发送的格式为默认格式,不直观;要么使用自定义的消息转发器,使用python的flask开发.
邮件:可以自定义模版,但是建议使用默认模版
怎么申请企业微信,申请钉钉机器人这里不做详细讲解.但是会讲解自定义钉钉机器人怎么使用.
这里还是将配置拆分,后面会专门将配置汇总展示
6.1 邮件告警以及基础配置
[root@prometheus01 rule]# cat /opt/alertmanager/alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'smtp.qiye.163.com:465' smtp_from: 'monitor@em.denachina.com' smtp_auth_username: 'monitor@em.denachina.com' smtp_auth_password: '3tkvGD8G4giGmAu' smtp_require_tls: false templates: - "/opt/alertmanager/templates/*.tmpl" route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1m receiver: 'cn-web-prod' receivers: - name: 'cn-web-prod' email_configs: - to: '{{ template "lizexiongmail" }}' send_resolved: true #html: '{{ template "email.html" .}}' headers: { Subject: "{{ .CommonAnnotations.summary }}" }
邮件告警没什么好说的,见以下结果
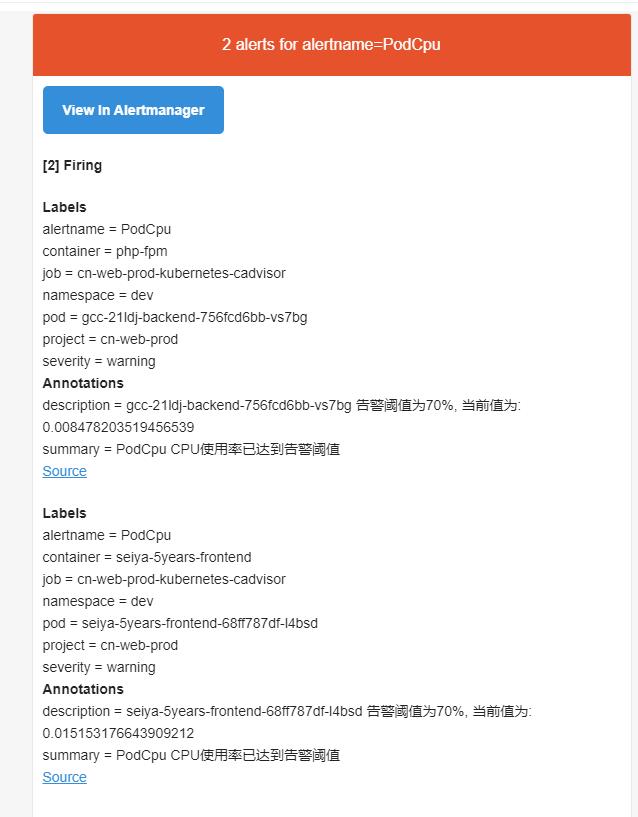
6.2 钉钉告警
这里用的自定义的,前面章节也讲解过,这里不做过多解释。
以下两种方式都可以,不强求:
webhook_configs: - url: "http://10.10.1.16:8060/dingtalk/ops_dingding/send" send_resolved: true #自定义python脚本 webhook_configs: - url: "http://10.10.1.16:5000" send_resolved: true
6.3 微信告警
实战案例中没有使用企业微信,但是前面的alertmanager章节也有讲解
6.4 自定义邮件模版
在之前单独讲解alertmanager的章节已经讲解过了模版,但是可能有人不太理解,这里重新做一个简单的演示,这里的模版简单来说就是自己定义变量或者引用已有的默认变量,在alertmanager中引用即可。根据自己实际情况使用。
首先编写模版规则
[root@prometheus01 templates]# vim email.tmpl [root@prometheus01 templates]# pwd /opt/alertmanager/templates [root@prometheus01 templates]# cat email.tmpl {{ define "lizexiongmail" }} zexiong.li@dena.com {{ end }} {{ define "email.html" }} <table border="5"> <tr><td>报警项</td> <td>磁盘</td> <td>报警阀值</td> <td>开始时间</td> </tr> {{ range $i, $alert := .Alerts }} <tr><td>{{ index $alert.Labels "alertname" }}</td> <td>{{ index $alert.Labels "instance" }}</td> <td>{{ index $alert.Labels "value" }}</td> <td>{{ $alert.StartsAt }}</td> </tr> {{ end }} </table> {{ end }}
上面定义了lizexiongmail这个模版变量还有一个email.html模版变量,可以看到email.html模版变量是一个邮件发送的模版,这里支持html和text格式,这里为了显示好看,采用html格式简单显示信息。
演示时会用到模版变量,真是环境会取消模版变量这2个配置,因为本人还是比较喜欢默认的告警模版。
简单看看alertmanager使用模版的配置文件
[root@prometheus01 rule]# cat /opt/alertmanager/alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'smtp.qiye.163.com:465' smtp_from: 'monitor@em.denachina.com' smtp_auth_username: 'monitor@em.denachina.com' smtp_auth_password: '3tkvGD8G4giGmAu' smtp_require_tls: false templates: - "/opt/alertmanager/templates/*.tmpl" route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1m receiver: 'cn-web-prod' receivers: - name: 'cn-web-prod' email_configs: - to: '{{ template "lizexiongmail" }}' send_resolved: true html: '{{ template "email.html" .}}' headers: { Subject: "{{ .CommonAnnotations.summary }}" }
可以看到收件人邮箱使用了模版变量,告警邮件模版使用了模版变量。
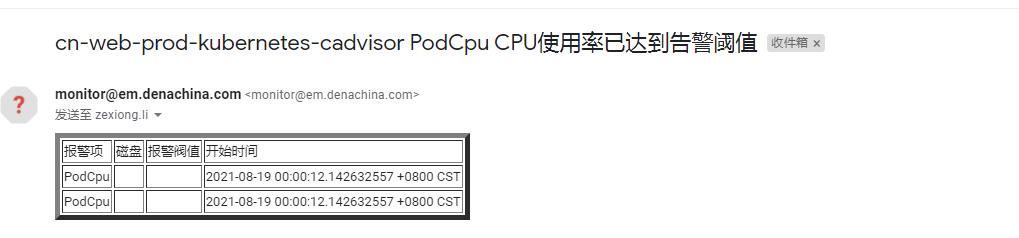
由于模版变量的值没有定义好,所以有些数据是空白,如果有兴趣,可以自己定义比默认模版更强大更丰富的告警信息,但是这里本人需求足够还是喜欢用默认模版。
当然模版也有官方给的一些定义好的,可以参考官方git链接:https://github.com/prometheus/alertmanager/blob/master/template/default.tmpl
7 程序管理
因为在联邦总prometheus的服务器,不管是alertmanager,proemethues,dingding转换器,都是负载均衡模式的,所以这里使用supervisord管理。当然,配置就alertmanager集群配置不太一样。
7.1 主prometheus supervisorod配置
[root@prometheus01 infra]# cat /etc/supervisord.d/prometheus.ini [program:prometheus] command=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data/ --storage.tsdb.retention.time=30d --query.max-samples=5000000 --query.max-concurrency=10 --web.enable-lifecycle autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true eillasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/prometheus.log [program:alertmanager] command=/opt/alertmanager/alertmanager --web.listen-address="10.10.1.10:9093" --cluster.listen-address="10.10.1.10:8001" --config.file=/opt/alertmanager/alertmanager.yml --web.external-url='http://alertmanager.mobage.cn:9093/' --log.level=debug autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/alertmanager.log [program:node_exporter] command= /opt/node_exporter/node_exporter autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/node-exporter.log [program:dingtalk] command= python3 /opt/dingding.py autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/dingtalk.log
7.2 备prometheus supervisorod配置
[root@prometheus02 infra]# cat /etc/supervisord.d/prometheus.ini [program:prometheus] command=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data/ --storage.tsdb.retention.time=30d --query.max-samples=5000000 --query.max-concurrency=10 --web.enable-lifecycle autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/prometheus.log [program:alertmanager] command=/opt/alertmanager/alertmanager --web.listen-address="10.10.1.5:9093" --cluster.listen-address="10.10.1.5:8001" --cluster.peer="10.10.1.10:8001" --config.file=/opt/alertmanager/alertmanager.yml --web.external-url='http://alertmanager.mobage.cn:9093/' autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/alertmanager.log [program:node_exporter] command= /opt/node_exporter/node_exporter autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/node-exporter.log [program:dingtalk] command= python3 /opt/dingding.py autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/dingtalk.log
7.3 宿主机联邦子prometheus supervisord配置
[root@cn-gc-monitoring-proxy ~]# cat /etc/supervisord.d/* [program:consul] #在一个datacenter中期望提供的server节点数目,当该值提供的时候,consul一直等到达到指定sever数目的时候才会引导整个集群,该标记不能和bootstrap公用(推荐使用的方式) command=consul agent -server -ui -bootstrap-expect 1 -data-dir=/opt/consul/data/ -config-dir=/opt/consul/config/ autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/consul.log [program:prometheus] command=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data/ --web.enable-lifecycle autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/prometheus.log [program:blackbox_exporter] command=/opt/blackbox_exporter/blackbox_exporter --config.file=/opt/blackbox_exporter/blackbox.yml autostart=true autorestart=true startsecs=5 priority=1 stopasgroup=true killasgroup=true redirect_stderr = true stdout_logfile_maxbytes = 50MB stdout_logfile=/var/log/supervisor/blackbox_exporter.log

