
kube-state-metrics 和 metrics-server
|
导航:这里主要是列出一个prometheus一些系统的学习过程,最后按照章节顺序查看,由于写作该文档经历了不同时期,所以在文中有时出现 的云环境不统一,但是学习具体使用方法即可,在最后的篇章,有一个完整的腾讯云的实战案例。 8.kube-state-metrics 和 metrics-server 13.Grafana简单用法 参考: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config https://www.bookstack.cn/read/prometheus_practice/introduction-README.md |
安装了这些东西,才能获取k8s的部分监控key.
| 服务 | 版本 |
| Metrics-server | 0.3.5 |
| Kube-state-metrics | 1.8.0 |
1.简介
对于Kubernetes的集群监控一般我们需要考虑一下几方面
- Kubernetes节点的监控;比如节点的cpu、load、fdisk、memory等指标
- 内部系统组件的状态;比如kube-scheduler、kube-controller-manager、kubedns/coredns等组件的运行状态
- 编排级的metrics;比如Deployment的状态、资源请求、调度和API延迟等数据指标
2.监控方案
Kubernetes集群的监控方案主要有以下几种方案
- Heapster:Herapster是一个集群范围的监控和数据聚合工具,以Pod的形式运行在集群中。1.8+被遗弃

Kubelet/cAdvisor之外,我们还可以向Heapster添加其他指标源数据,比如kube-state-metrics
Heapster已经被废弃,使用metrics-server代替
- cAvisor:cAdvisor是Google开源的容器资源监控和性能分析工具,它是专门为容器而生,本身也支持Docker容器,Kubernetes中,我们不需要单独去安装,cAdvisor作为kubelet内置的一部分程序可以直接使用
- Kube-state-metrics:通过监听API Server生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储
- metrics-server:metrics-server也是一个集群范围内的资源数据局和工具,是Heapster的代替品,同样的,metrics-server也只是显示数据,并不提供数据存储服务。他当前的核心作用是:为HPA等组件提供决策指标支持。也可以将接收到的数据存储到influxdb进行存储,简单来说,如果想基础监控,那么就要安装这个组件
不过kube-state-metrics和metrics-server之前还有很大不同的,二者主要区别如下
1.kube-state-metrics主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等
2.metrics-service主要关注的是资源度量API的实现,比如CPU、文件描述符、内存、请求延时等指标
3.metrics-server
3.1 介绍
从 Kubernetes 1.8 开始,资源使用指标(如容器 CPU 和内存使用率)通过 Metrics API 在 Kubernetes 中获取, metrics-server 替代了heapster。Metrics Server 实现了Resource Metrics API,Metrics Server 是集群范围资源使用数据的聚合器。
Metrics Server 从每个节点上的 Kubelet 公开的 Summary API 中采集指标信息。
项目地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server
配置文件有两种获取方式:
1.https://github.com/kubernetes-incubator/metrics-server/tree/master/deploy/1.8%2B
2.https://github.com/kubernetes/kubernetes/tree/release-1.14/cluster/addons/metrics-server(推荐使用此方式)
这里安装分为 1.7和1.8+的版本,一般选择1.8+的版本安装

简单来说,如果不安装执行不了kubectl top node这样的命令,并且hpa的获取判断是否扩缩容的时候依赖它的数据。如果不安装,hpa获取的阈值那一栏一直都是未知
3.2 安装
3.2.1 EKS
1.安装文件以及目录

2.配置
这里有1点需要修改。如果不修改,日志和查询会有以下的报错

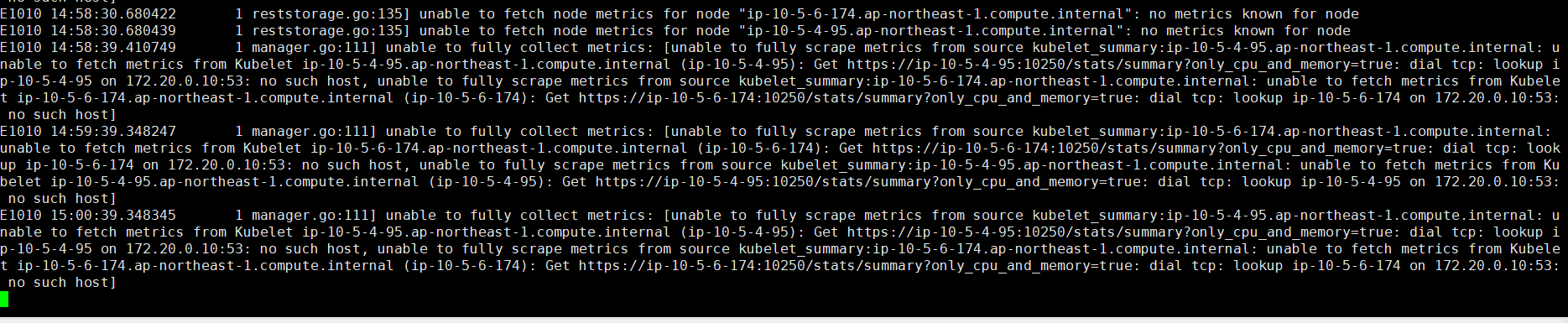
metrics-server-deployment.yaml
新增以下4行

通过以上的command可以增加很多自定义的参数,这些参数可以参考git的文档,并且在该版本里面,经过实验,自建k8s,eks没有这三行参数,那么metrics-server是采集不到数据的,kubect top node会报错
注意:可能出现的问题
## 在新的版本中,授权文内没有 node/stats 的权限,需要手动去添加 [root@k8s-master01 metrics]# vim resource-reader.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: system:metrics-server rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats ## 添加此参数 - namespaces
3.验证
新增之后,如果查看metrics-server的服务还是会报错,但是等待1分钟左右就可以正常查询了

3.2.2 二进制
该服务在不同平台的部署方式不同,因为在不同平台,安装的组件不一样,比如阿里云,一切额外操作都准备好了.
自建的集群安装metrics-server需要满足以下条件;
1.metrics-server-deployment.yaml增加3行参数(参考eks安装)
2.master01上安装flanneld和kube-proxy,,因为api访问metrics-server是通过10.0.0.0段的集群ip去访问的,如果不安装flanneld和kube-prxoy,metrics-server和kube-apiserver是无法连通的.
3.自建集群的api-server需要添加额外参数开启聚合层
- 安装flanneld和kube-proxy
这里安装不做演示,如果不安装,将会有以下报错;
二进制部署,所以刚开始并没有在master节点部署kubelet、kube-proxy组件,所以导致一直安装失败:
执行命令kubectl get apiservices v1beta1.metrics.k8s.io -o yaml 看到报错信息:"metrics-server error "Client.Timeout exceeded while awaiting headers"",这是因为mertics无法与 apiserver服务通信导致,因此需要在master节点安装部署kubelet、kube-proxy组件(可以选择给master节点打污点,来决定是否让master参与pod调度上来)

- 开启聚合层
如果不开启聚合层,这里不会有什么影响,但是在使用prometheus opterator的时候,会有类似以下的报错;(网上文档说,二进制可能只要不metrics-server就会有以下报错,所以建议不管有么有prometheus opterator,都建议开启聚合层)

并且prometheus opterator的一个镜像会直接报错

- metrics-server-deployment.yaml
新增以下4行
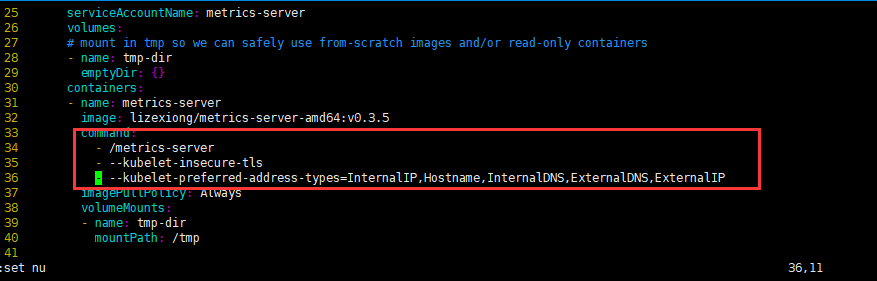
通过以上的command可以增加很多自定义的参数,这些参数可以参考git的文档,并且在该版本里面,经过实验,自建k8s,eks没有这三行参数,那么metrics-server是采集不到数据的,kubect top node会报错
注意:可能出现的问题
## 在新的版本中,授权文内没有 node/stats 的权限,需要手动去添加 [root@k8s-master01 metrics]# vim resource-reader.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: system:metrics-server rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats ## 添加此参数 - namespaces
1.Kube-apiserver配置文件修改
注意:这是二进制1.12版本,当时没有增加参数以及复用证书,是为metrics重新生成证书。
编辑kube-apiserver.conf 添加如下红色参数,从下面参数中可以看出,需要生产新的证书,因此我们还需要为metrics生产证书
KUBE_APISERVER_OPTS="--logtostderr=true \ --v=4 \ --etcd-servers=https://172.21.161.157:2379,https://172.21.161.158:2379,https://172.21.161.159:2379 \ --bind-address=172.21.161.145 \ --secure-port=6443 \ --advertise-address=172.21.161.145 \ --allow-privileged=true \ --service-cluster-ip-range=10.0.0.0/24 \ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \ --authorization-mode=RBAC,Node \ --kubelet-https=true \ --enable-bootstrap-token-auth \ --token-auth-file=/opt/kubernetes/cfg/token.csv \ --service-node-port-range=30000-50000 \ --tls-cert-file=/opt/kubernetes/ssl/server.pem \ --tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \ --client-ca-file=/opt/kubernetes/ssl/ca.pem \ --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \ --etcd-cafile=/opt/etcd/ssl/ca.pem \ --etcd-certfile=/opt/etcd/ssl/server.pem \ --etcd-keyfile=/opt/etcd/ssl/server-key.pem \ --requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \ --requestheader-allowed-names="" \ --requestheader-extra-headers-prefix=X-Remote-Extra- \ --requestheader-group-headers=X-Remote-Group \ --requestheader-username-headers=X-Remote-User \ --proxy-client-cert-file=/opt/kubernetes/ssl/metrics-proxy.pem \ --proxy-client-key-file=/opt/kubernetes/ssl/metrics-proxy-key.pem" #这7行配置一定要配置在最后
参数说明:
- --requestheader-XXX、--proxy-client-XXX 是 kube-apiserver 的 aggregator layer 相关的配置参数,metrics-server & HPA 需要使用;
- --requestheader-client-ca-file:用于签名 --proxy-client-cert-file 和 --proxy-client-key-file 指定的证书(ca证书),在启用了 metric aggregator 时使用;
注:如果 --requestheader-allowed-names 不为空,则--proxy-client-cert-file 证书的 CN 必须位于 allowed-names 中,默认为 aggregator;
如果 kube-apiserver 机器没有运行 kube-proxy,则还需要添加 --enable-aggregator-routing=true 参数
在1.20版本中,复用了master的证书,不需要重新生成,并且,在安装部署k8s集群的时候,就已经增加了该参数了
KUBE_APISERVER_OPTS="--logtostderr=false \ --v=2 \ --log-dir=/opt/kubernetes/logs \ --etcd-servers=https://172.21.161.112:2379,https://172.21.161.113:2379,https://172.21.161.114:2379 \ --bind-address=172.21.161.110 \ --secure-port=6443 \ --advertise-address=172.21.161.110 \ --allow-privileged=true \ --service-cluster-ip-range=10.0.0.0/24 \ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \ --authorization-mode=RBAC,Node \ --enable-bootstrap-token-auth=true \ --token-auth-file=/opt/kubernetes/cfg/token.csv \ --service-node-port-range=30000-32767 \ --kubelet-client-certificate=/opt/kubernetes/ssl/server.pem \ --kubelet-client-key=/opt/kubernetes/ssl/server-key.pem \ --tls-cert-file=/opt/kubernetes/ssl/server.pem \ --tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \ --client-ca-file=/opt/kubernetes/ssl/ca.pem \ --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \ --service-account-issuer=api \ --service-account-signing-key-file=/opt/kubernetes/ssl/server-key.pem \ --etcd-cafile=/opt/etcd/ssl/ca.pem \ --etcd-certfile=/opt/etcd/ssl/server.pem \ --etcd-keyfile=/opt/etcd/ssl/server-key.pem \ --requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \ --proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \ --proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \ --requestheader-allowed-names=kubernetes \ --requestheader-extra-headers-prefix=X-Remote-Extra- \ --requestheader-group-headers=X-Remote-Group \ --requestheader-username-headers=X-Remote-User \ --enable-aggregator-routing=true \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/opt/kubernetes/logs/k8s-audit.log"
2.为metrics server生成证书
上面可以看到,kube-apiserver开启聚合层,也需要使用证书,为了便于区分,我们这里为mertics 单独生产证书
关于证书的创建也可参考之前部署其它组件时创建证书时候的步骤
## 创建kube-proxy证书请求
[root@k8s-master01 ~]# vim /opt/k8s/certs/metrics-proxy-csr.json { "CN": "metrics-proxy", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "ShangHai", "L": "ShangHai", "O": "metrics-proxy", "OU": "System" } ] }
## 生成kube-proxy证书与私钥
[root@k8s-master01 ~]# cd /opt/k8s-certs/ [root@k8s-master01 certs]# cfssl gencert -ca=/opt/kubernetes/ssl/ca.pem \ -ca-key=/opt/kubernetes/ssl/ca-key.pem \ -config=/opt/k8s-certs/ca-config.json \ -profile=kubernetes metrics-proxy-csr.json | cfssljson -bare metrics-proxy ## 证书分发
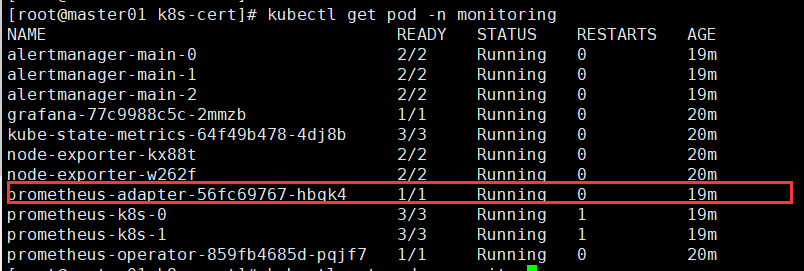
然后重启kube-apiserver就可以了,使用如下命令可以简单验证

如果有安装prometheus operator,看以下pod的状态是否正常
4.kube-state-metrics
4.1 介绍
已经有了cadvisor、heapster、metric-server,几乎容器运行的所有指标都能拿到,但是下面这种情况却无能为力:
- 我调度了多少个replicas?现在可用的有几个?
- 多少个Pod是running/stopped/terminated状态?
- Pod重启了多少次?
- 我有多少job在运行中
而这些则是kube-state-metrics提供的内容,它基于client-go开发,轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics。
kube-state-metrics是一个简单的服务,它监听Kubernetes API服务器并生成相关指标数据,它不单关注单个Kubernetes组件的运行情况,而是关注内部各种对象的运行状况
在K8s集群上Pod、DaemonSet、Deployment、Job、CronJob等各种资源对象的状态也需要监控,这些指标主要来自于apiserver和kubelet中集成的cAvisor,但是并没有具体的各种资源对象的状态指标。对于Prometheus来说,当然是需要引入新的exporter来暴露这些指标,Kubernetes提供了一个kube-state-metrics
kube-state-metrics已经给出了在Kubernetes部署的文件,我们直接将代码Clone到集群中执行yaml文件即可
将kube-state-metrics部署在kubernetes上之后,会发现kubernetes集群中的prometheus会在kube-state-metrics这个job下自动发现kube-state-metrics,并开始拉去metrics,这是因为部署kube-state-metrics的manifest定义文件kube-state-metrics-server.yaml对Service的定义包含prometheus.io/scrape: 'true'这样的一个annotation。因此kube-state-metrics的endpoint可以被Prometheus自动发现
关于kube-state-metrics暴露所有监控指标可以参考kube-state-metrics的文档kube-state-metrics Documentation:https://github.com/kubernetes/kube-state-metrics/tree/master/docs
简单来说可以在prometheus里面使用endpoint的方式获取监控key
Git地址: https://github.com/kubernetes/kube-state-metrics
监控项地址: https://github.com/kubernetes/kube-state-metrics/tree/master/docs
下面是版本对比
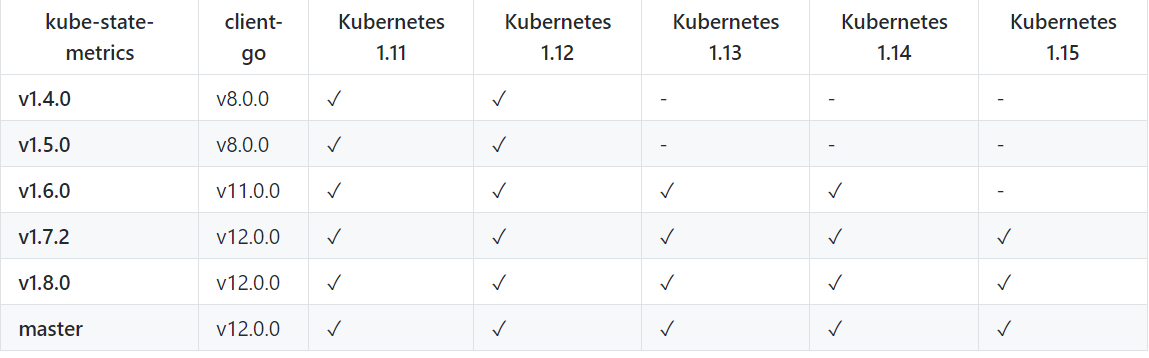
安装介绍都在git文档里面,只是有一些在prometheus获取key需要在prometheus里面配置。
4.2 安装
1.安装文件以及目录
在1.8的版本里面,只剩下5个文件,归纳为 权限文件和部署文件

2.配置
这里有2点需要修改。
1).deployment
在默认的文件里面,配置了node亲和性,导致没有标签的node无法调度

2).service.yaml
因为prometheus从kube-state-metrics获取信息,就要prometeus能够获取到它的api,所以需要增加以下:(kube-state-metrics的service文件就要加,因为prometehus通过这个配置自动发现kube-state-metrics,然后获取监控数据,如果不加上,即使安装成功kube-state-metrics,很多key也是没有数据的)

3.prometheus收集
在配置里面 kube-state-metrics的service开启了annotations,Prometheus就是通过这个来过滤出这个service的。
Prometheus的具体配置在文章 <监控pormetheus集群的方式>→ Kubernetes监控配置 →集群内监控配置
4.使用endpoinits监控service(番外)

以上可以看出prometheus已经寻找到了,接下来,在prometheus就可以看到监控指标了
4.3 遗留问题
4.3.1 限制值
本案例在这里没有限制
(该文章摘自git)
集群状态指标的资源使用量随集群的Kubernetes对象(Pods / Nodes / Deployments / Secrets等)的大小而变化。在某种程度上,集群中的Kubernetes对象与集群的节点数成正比
作为一般规则,您应该分配
- 200MiB内存
- 0.1核心
对于超过100个节点的集群,至少分配
- 每个节点2 MiB内存
- 每个节点0.001个核心
这些数字基于每个节点30个Pod的可伸缩性测试。
请注意,如果将CPU限制设置得太低,则将无法足够快地处理kube-state-metrics的内部队列,从而导致随着队列长度的增加而增加的内存消耗。如果遇到内存分配过多导致的问题,请尝试增加CPU限制。
4.3.2 优化点和问题
kube-state-metrics在之前的版本中暴露出两个问题:
1./metrics接口响应慢(10-20s)
2.内存消耗太大,导致超出limit被杀掉
问题一的方案就是基于client-go的cache tool实现本地缓存,具体结构为:
var cache = map[uuid][]byte{}
问题二的的方案是:对于时间序列的字符串,是存在很多重复字符的(如namespace等前缀筛选),可以用指针或者结构化这些重复字符。
4.4 指标
具体指标可以参考本文介绍的git地址








 浙公网安备 33010602011771号
浙公网安备 33010602011771号