
Mongo服务器管理之部署MongoDB讨论
虽然现在是云时代,很少会接触服务器底层硬件,但是本章将会就部署生产服务器给出相关建议。也可以更好的了解底层。具体来讲,包括以下几方面:
-
- 选购硬件、挑选设置方法;
- 使用虚拟化环境;
- 重要的内核与磁盘10设定;
- 网络设置:哪些组件之间需要建立连接。
1.设计系统结构
通常,我们会希望对系统进行优化,以保证数据安全和存取速度。本节将探讨在选 择磁盘、RAID (磁盘阵列)配置、CPU等硬件以及基本软件组件的过程中,达成以上目标的最佳方法。
1.1 选择存储介质
如果只考虑性能,可按照以下顺序选择介质,从而进行数据存取:
-
- 内存;
- 固态磁盘;
- 机械磁盘。
可惜,大多情况下,由于预算有限或数据过多,无法将所有数据存入内存,而固态磁盘又过于昂贵。因此,标准的部署方案是使用较少的内存空间(具体大小取决干总数据大小)和较大的机械磁盘空间。这种情况下需注意,工作集大小应小于内存容量,同时应做好在工作集增长时进行设备扩展的准备。
如果没有经费限制,那就去购买更多的内存或固态磁盘。
从内存中读取数据需几纳秒的时间(比如100纳秒)。相反地,从磁盘中读取数据需几毫秒的时间(比如10毫秒)。单看这两个数字很难想像出二者间的差距,但如果 我们将它们按比例放大就会明白:如果访问内存耗时1秒钟,则访问磁盘需耗时超 过1天的时间!
100 纳秒 X 10 000 000 = 1 秒
10 毫秒 x 10 000 000 = 1.16 天
这些只是近似的计算(磁盘可能略快或内存略慢),但差距的大小不会有太大差别。 所以我们会想要尽量少地访问磁盘。
即使是更快的机械磁盘,也不会使磁盘读取时间缩短太多,所以没有必要花太多钱在这种磁盘上。更多的内存或固态磁盘效果会更好。
一个示例
图23-1至图23-6展示了固态磁盘的优势。这些图片中显示的,是一个在8月8日中午上线的新分片的情况。开始时仅在机械磁盘上部署了一个分片,随后又在固态 磁盘上部署了一个新的分片,接下来两个分片同时运行。
如图23-1所示,机械磁盘的性能峰值可接近每秒5000次査询,但一般情况下只能做到每秒几百次查询。

作为对照,图23-2中的图表显示了在固态磁盘上进行查询的状况。固态磁盘的性能可保持每秒处理5000次请求,峰值则可达到每秒30000次!这一新的分片完全可以独立承担整个集群的工作。

有关机械磁盘和固态磁盘的对比中,另一点值得注意的是频繁的磁盘访问对系统的压力大小。在使用机械磁盘的服务器上,我们可从其硬件监控信息(图23-3)中看到,磁盘工作十分繁忙。图中位于上部的曲线表示IO延迟,即CPU等待磁盘IO的时间所占总时间的百分比。可以看到该百分比至少为10%,高峰时常达到50%以上。这意味着磁盘成为了限制性能的短板(所以此人新添了固态磁盘)。

作为对比,图23-4显示了使用固态磁盘的机器上CPU的使用情况。图中甚至已经看不出IO延迟的痕迹,上下两条明显的曲线分别表示系统时间(system time)和用户时间(user time)。因此,限制这一机器性能的短板就是CPU的运行速度。图中曲线超过了 100%,这也说明系统利用了多个处理器核心。将其与图23-3进行对比可发现,之前的机器由于磁盘IO速度过慢,导致得到充分利用的处理器核心甚至还不足一个。

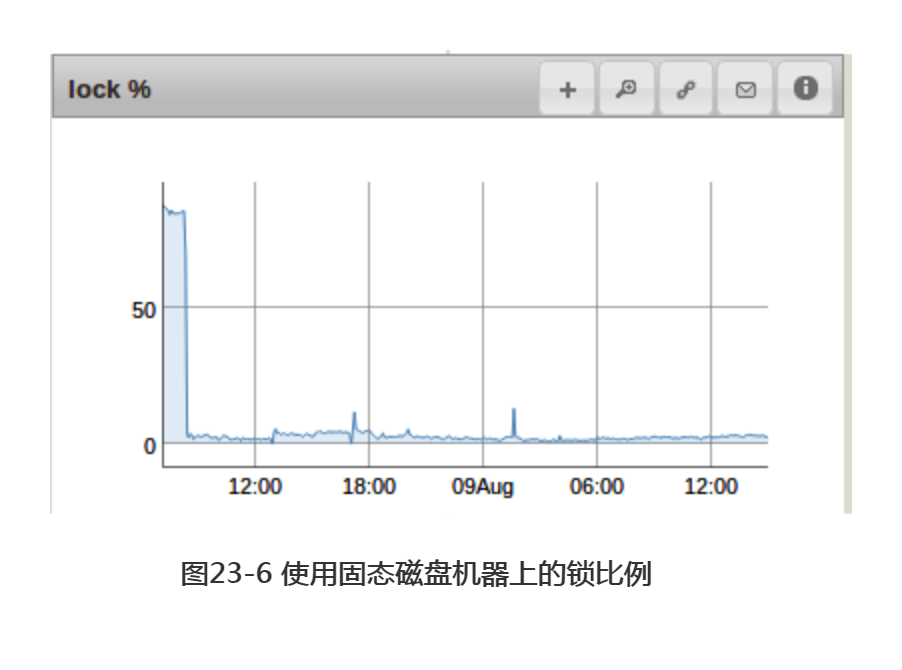
最后,在有关锁时间的图23-5中可以看到其对MongoDB的影响。在机械磁盘上,数据库10%到25%的时间处在锁状态,有时峰值甚至会达到100%。

与图23-6中使用固态磁盘机器上的锁比例进行比较。MongoDB基本上一直保持非锁定状态。(曲线开始部分的凸起是在加上固态磁盘之前的数据读取操作造成的。)
可以看到,固态磁盘可以承担比机械磁盘多得多的工作,但不幸的是,它们无法被大量部署。如果能够使用它们,那就用吧。就算不可能在整个集群中使用固态磁盘,也应考虑尽量多得部署,然后使用之前提到的强制热点数据模型进行优化。
注意:通常我们不能向已有的副本集中添加固态磁盘(如副本集中存在机械磁盘的话)。如果使用固态磁盘的机器成为主成员(primary member),并接管处理它所能处理的一切工作,则其他成员受速度所限,无法及时复制数据,从而被落在后面。因此,如果要引入固态磁盘的话,向集群中增加一个新的分片不失为一种更好的方法。
注意:固态磁盘对干处理普通数据而言表现优异,但实际上机械磁盘完全可以用于记录日志(journal)。用机械磁盘来记录日志,而用固态磁盘记录数据,这样既能节省固态磁盘的空间,也不会影响性能。
1.2 推荐的RAID配置
RAID (Redundant Array of Independent Disk,独立磁盘冗余阵列,旧称 Redundant Array of Inexpensive Disk,廉价磁盘冗余阵列)是一种可以让我们把多块磁盘当作单独一块磁盘来使用的技术。可使用它来提高磁盘的可靠性或性能,或二者兼有。一组使用RAID技术的磁盘被称作RAID磁盘阵列。
RAID根据性能的不同,存在着多种配置方式,通常兼顾了速度与容错性。下列是几种最常见的配置方式。
- RAID0
使用磁盘分割技术(disk striping)将多个磁盘并列起来以提升性能。每块磁盘保存一部分数据,与MongoDB中的分片类似。由于存在多个底层磁盘,因此大量数据可在同一时间写人磁盘内。这一方式可提高写入效率。然而,如果其中一块磁盘发生故障导致数据丢失,则这些数据不会存在备份。这也会导致读取速度变慢(尤其是在Amazon的Elastic Block Store服务上),因为一些数据卷可能比另一些要慢。
- RAID1
使用镜像来提高可靠性。同样的数据副本会被写入到阵列的每一个成员当中。这一方法的性能要比RAID0低,因为阵列中一个速度慢的成员会拖慢整个阵列的写入速度。然而,如果其中一块磁盘发生故障,还可以在阵列中的其他成员上找到数据副本。
- RAID5
在使用磁盘分割技术的基础上,额外存储数据的校验信息,以防服务器故障导致数据丢失。一般情况下,在一块磁盘发生故障时RAID5可以自动处理它,用户并不会感觉到故障的发生。然而,这也使得RAID5成为这些RAID配置方案中最慢的一种,因为它需要在写入数据时计算校验信息。而MongoDB所进行的恰恰是典型的多次少量的数据写入工作,因此使用RAID5所带来的代价尤为可观。
- RAID 10
RAID10是一种RAID0和RAID1的组合:数据被分割以提升速度,又被复制镜像以提高可靠性。
推荐使用RAID10,它比RAID0更安全,也能解决RAID1的性能问题。有人觉得在副本集的基础上再使用RAID1有些浪费,从而选择RAID0。这是个人喜好问题:你原意为了性能承担多大的风险呢?
不要使用RAID5,它非常非常慢。
1.3 CPU
MongoDB对于CPU的负载很轻(注意在图23-3和图23-4中:两个CPU的处理能力即可满足每秒10 000次査询)。如需在内存和CPU间选择一个进行硬件投资,一定要选择内存。理论上来讲,在进行读取或在内存中进行排序时,会耗尽多核的运算资源,但在实践中这种情况很少发生。在建立索引和进行MapReduce ( —个用于大规模数据集并行运算的软件架构)运算时,对CPU的负载很大,但直到本书写作之时,增加处理器核数仍无法对这两种操作起到优化作用。
如需在速度和核数间做出选择,应选择前者。相比更多的并行运算,MongoDB能更好地利用单处理器上的更多周期进行运算。
1.4 选择操作系统
64位Linux操作系统是运行MongoDB的最好选择。可能的话应选择它作为内核系统。CentOS和RedHat企业版可能是最普遍的选择,其他的发行版也应能够运行MongoDB (Ubuntu和Amazon Linux也很常用)。应使用最新发布的稳定版本,因为老旧的、存在缺陷的软件包或内核有时会产生问题。
64位Windows系统也能很好地运行MongoDB。
MongoDB对于其他版本Unix系统的支持并没有那么好:如果使用Solaris或者基于BSD的系统,那么应该小心,因为这些系统发布的MongoDB,都存在(至少曾经存在)很多问题。
关于跨平台兼容,有一点需特别注意:MongoDB在所有系统中使用同样的线路协议(wire protocol),对于数据文件中的内容也使用同样的格式进行存储,所以我们可以基于不同系统的组合来部署MongoDB。例如,可在Windows系统上运行mongos进程,而在Linux上运行mongods来作为其分片。也可在Windows和Linux间复制数据文件,而不必考虑跨平台兼容的问题。
如服务器需处理大量数据,则不要使用32位系统,因为这会限制我们最多只能处理2 GB的数据(这是由于MongoDB使用内存映射的文件)。副本集的仲裁器和mongos进程可以运行在32位机器上。不要在32位机器上运行其他类型的MongoDB 服务。
MongoDB只支持小端(little-endian,即存储二进制内容时,数字的低位组置于最前面)系统结构。大部分驱动都支持小端和大端(big-endian)两种系统结构,因此客户端在两种系统中均可运行。然而,服务器只能运行在小端结构的机器上。
1.5 交换空间
应分配一小块交换空间,以防系统内存使用过多,从而导致内核终止MongoDB的运行。然而,MongoDB通常并不会使用任何交换空间。
MongoDB所使用的大部分内存都是“不稳定的”:只要系统因某些原因而请求内存空间,这部分内存中的内容就会被刷新到磁盘中,然后原内存则被替换成其他内容。因此,数据库数据绝不应该被写入交换空间,因为它首先会被刷新回磁盘。
然而,MongoDB在需要对数据进行排序,即建立索引或进行排序操作时,会使用交换空间。在进行此类操作时,MongoDB会尽量不去使用过多内存,但如果同时进行很多这种操作,最终就会使用到交换空间。
如果应用程序在服务器上用到了交换空间,则应想办法重新设计应用程序,或者减少那台服务器上的负载。
1.6 文件系统
在Linux系统上,推荐使用ext4或XFS文件系统作为数据卷。具有一个能够在备份时进行文件系统快照(filesystem snapshot)的文件系统是不错的,但是会影响到性能。
不推荐使用ext3文件系统,因为它在对数据文件进行预分配时耗时过长。MongoDB会定期分配2 GB大小的数据文件并将其内容填充为0。在ext3文件系统上,这一操作会造成几分钟的卡顿。如果一定要使用ext3文件系统,有几个相关的优化措施可供选择。不过如果可以的话,还是应尽量使用其他文件系统。
在Windows系统上,使用NTFS和FAT文件系统都是可以的。
提示:不要直接使用被挂载的NFS文件系统作为MongoDB的存储区域。有些版本的客户端会隐瞒数据刷新的真实情况,随机重新挂载和刷新页面缓存(page cache),且不支持排他文件锁定(exclusive file lock)。使用NFS文件系统会造成日志(journar)内容损坏,因此应尽量避免使用。
2.虚拟化
运用虚拟化(virtualization)技术可方便地使用廉价的硬件来部署系统,并且能够迅速做出扩展。然而,虚拟化也存在缺点,尤其是无法预知的网络和磁盘IO状况。本节将探讨有关虚拟化的具体问题。
2.1 禁止内存过度分配
内存过度分配(memory overcommitting)的设置值决定了当进程向操作系统请求过多内存时应采取的策略。基于这一设置,内核可能会为进程分配内存,哪怕那些内存当前是不可用的(期望的结果是,当进程用到这段内存时它已变为可用的)。这种内核向进程许诺不存在的内存的行为,就叫做内存过度分配。这一特性使得MongoDB无法很好地运作。
vm.overcommit_memeory的值可能为0 (让内核来猜测过度分配的大小),可能为1(满足所有内存分配请求),也可能为2 (分配的虚拟地址空间最多不超过交换空间与一小部分过度分配的和)。将此值设为2所代表的意义最为复杂,同时也是最佳选择。运行以下命令将此值设为2:
$ echo 2 > /proc/sys/vm/overcommit_memory
更改这一设置后无需重启MongoDB。
2.2 神秘的内存
有时虚拟层无法正确地配备内存。因此,一台虚拟机号称拥有100 GB可用内存,但可能只能使用其中的60GB。相反,我们曾经发现应该只能使用20GB内存的用户,却可以将100 GB的数据集全部存入内存!
没这么幸运也无所谓。如果预读大小设置合理,而虚拟机就是无法使用全部内存,这时切换虚拟机即可。
2.3 处理网络磁盘的IO问题
磁盘速度的越发缓慢是使用虚拟化技术的最大问题之一。我们通常要和其他使用者共享磁盘,由于每个人都在争夺磁盘io,因此这加剧了磁盘的性能负担。也正因为此,虚拟磁盘的性能无法预知:当其他使用者并不频繁使用磁盘时,磁盘可以工作地很好,而一旦其他人开始压榨磁盘时,其性能就会迅速下降。
另一个问题是,存储设备时与MongoDB运行的机器间常常并不存在物理上的连接,所以即使磁盘仅供自己使用,依然会比本地磁盘速度慢。这也可能(虽然可能性不大)导致MongoDB服务器与数据间失去了网络连接。
Amazon拥有可能是最常用的网格存储服务,称为EBS (Elastic Block Store,弹性块存储)。EBS中的卷可连接到EC2 (Elastic Compute Cloud,弹性云计算)实例,并立即为机器提供近乎任意数量的磁盘空间。从积极的一面来看,这使得备份变得非常简单(在备份节点上制作快照,挂载EBS驱动到另一个实例上,启动mongod)。但另一方面,性能的起伏会非常明显。
如希望提高性能的可预测性,有以下几个选项。要保证系统性能和期望中的一样,最直接的做法是不要将MongoDB托管在云端。将其托管在自己的服务器上可以保证性能不会被其他使用者拖慢。不过,许多人不会选择这种做法。于是,仅次于前一种选项的就是选择能够保证一定数量IOPS (IO Operations Per Second,每秒IO操作)的实例。可访问http://docs.mongodb.org,査看最新的推荐托管服务。
如果这些选项都无法实现,而一个高负载的EBS卷所提供的磁盘IO又无法满足需求,那么可以使些手段。
基本上,我们能做的就是监视MongoDB所使用的卷。一旦某个卷的速度变慢,立即终止这一实例的运行,接着启动一个使用另一数据卷的新实例。
可对以下数据进行监视。
-
- IO利用率的峰值(MMS中的“IO延迟”),原因显而易见。
- 页缺失(page faults)发生频率的峰值。注意,应用程序本身的行为变化也会造成工作集的变化:在部署新版本的应用程序前,应先禁用这一不断结束并切换实例的脚本。
- TCP丢包数的增长情况(在Amazon的服务上这一点尤其严重:当性能开始下降时,会频繁发生TCP丢包的情况)。
- MongoDB读写队列的峰值(该数据可在MMS或mongo stat的qr/qw列中找到)。
如果负载发生周期性变化,应确保脚本考虑了计划任务的情况,以免其在工作格外繁忙的星期一早上,由于执行计划任务造成的影响而终止所有实例的运行。
在使用这些手段之前,应保证对数据留有备份,或存在可与其进行同步的数据集。如果让每个实例都保存上TB的数据,我们可能会希望寻找替代方法。另外,该方法不一定有效,如果新分卷上的负荷也很大,则会和原来一样慢。
2.4 使用非网络磁盘
本节中使用了一些Amazon服务中特有的词汇。然而,它也可能适用于其他提供商。
临时驱动器(ephemeral drive)是真正和虚拟机(VM)所在的机器间存在物理连接的磁盘,所以并不存在很多网络存储中出现的问题。本地磁盘依然可能由于同一个盒子(box)中其他用户的使用而超过负载,但通过使用更大的盒子可基本确保不会与特别多的用户共享磁盘。即使是一个稍小的实例,只要其他使用者没有造成大量的IOPS,临时驱动器就能经常提供比网络驱动器更好的性能。
它的缺点从名字上就可以看出来:这些磁盘是临时的。如果EC2实例停止运行,则无法保证重新启动实例后还能在同一个盒子里,数据也随之不见了。
因此,应小心使用临时驱动器。应确保不要将任何重要的,或者没有备份的数据存放到这些磁盘里。尤其不要把日记信息存放在这些临时磁盘里,或是网络另一端的数据库里。通常来讲,应将临时驱动器当作一个速度稍慢的缓存来使用,而非一块速度快的磁盘。
3.系统配置
以下几个系统设置可使MongoDB的运行更加稳定,且主要与磁盘和内存的访问有关。本节将具体学习这些选项及其调整方法。
3.1 禁用 NUMA
当机器中只有一个CPU时,所有内存的存取时间(access time)基本相同。当机器中开始有更多的处理器时,工程师们发现,与其将所有内存与CPU的距离保持相同(如图23-7所示),不如为毎个CPU都设置一些距其更近、访问速度更快的内存,这样做的效率会更高。

这种每个CPU都具有自己“本地”内存的结构,叫做NUMA (Non-uniform Memory Architecture,非一致内存结构),如图23-8所示。

对于很多应用程序,NUMA都能够很好地运作:不同的处理器运行不同的程序,因此通常需要不同的数据。然而,这一结构面对数据库,尤其是MongoDB时,则表现非常糟糕,这是因为数据库访问内存的模式与其他应用程序不同。MongoDB需要使用大量内存,同时需要CPU能够访问其他CPU的“本地内存”。然而,很多系统上默认的NUMA设定很难满足这一需求。
CPU倾向于优先使用自身的“本地内存”,而进程则倾向于优先使用同一CPU。这意味着内存通常不会被平均地占用,结果就是一个处理器使用了其100%的“本地内存”,而其他处理器只使用了其一小部分内存,如图23-9所示。
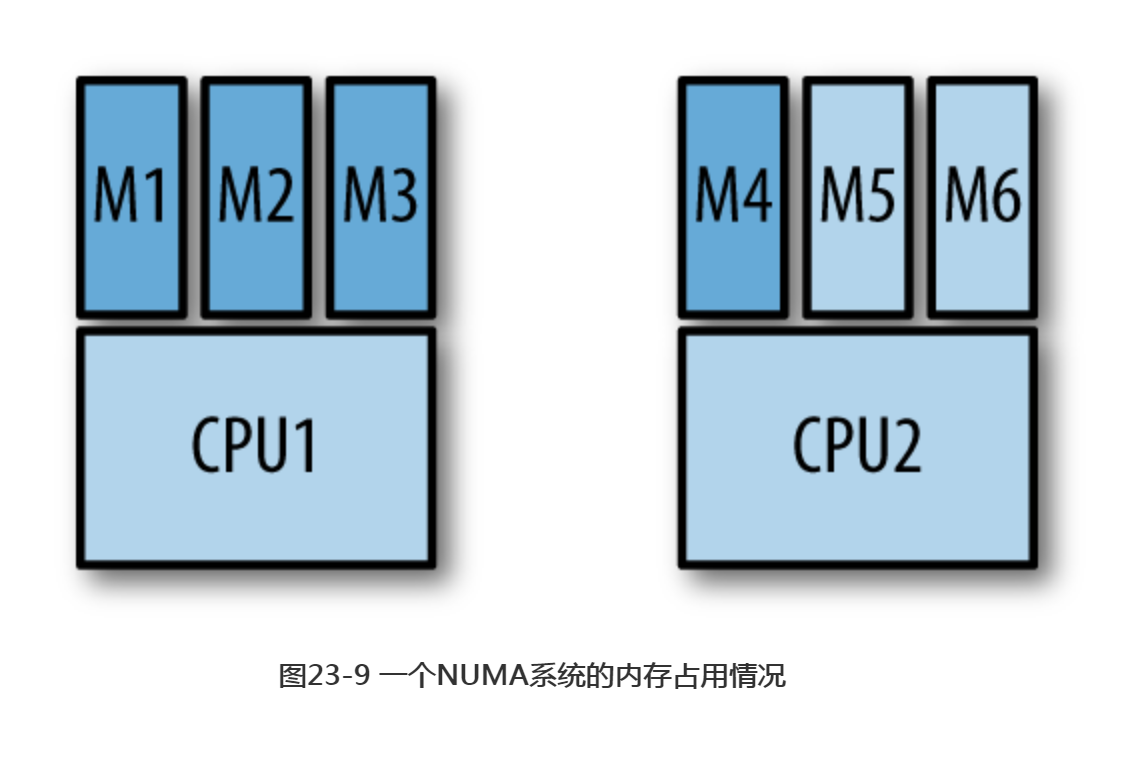
在图23-9的情况下,假设CPU1需要一些内存中没有的数据。此时必须使用其“本地内存”来存放这些还没有被读进内存的数据,但其“本地内存”已经满了。于是“本地内存”中的一些数据就会被移除出去以腾出空间,哪怕CPU2的“本地内存”中还有足够的空间。这一过程使得MongoDB的运行速度要比期望中慢得多,因为只有一小部分内存得到了有效地利用。MongoDB倾向于访问更多的数据,哪怕效率稍低,而非高效地访问一小部分数据。
禁用NUMA是一个能够提升性能的魔法按钮,一定要按下它。就像使用固态磁盘一样,禁用NUMA可提升所有事物的性能。
如果可能的话,应通过BIOS来禁用NUMA。例如,如果在使用grub,可在grub.cfg中添加numa=off选项:
kernel /boot/vmlinuz-2.6.38-8-generic root=/dev/sda ro quiet numa=off
如果系统无法在BIOS中禁用NUMA,则可在启动mongod时使用以下选项:
$ numactl --interleave=all mongod [options]
将这一命令添加到所有使用的初始化脚本中。
此外,禁用zone_reclaim_mode选项。可把该选项认定为“超级NUMA”。该选项被启用后,CPU访问一页内存时,该页内存就会被移动到此CPU的“本地内存”中。于是,如果一个CPU上的threadA和另一 CPU上的threadB同时访问一页内存,则每次访问时,该页内存都会被从一个CPU的“本地内存”复制到另一CPU的“本地内存“中。这会非常、非常得慢。
要禁用zone_reclaim_mode,可运行
$ echo 0 > /proc/sys/vm/zone_reclaim_mode
无需重启mongod, zone_reclaim_mode选项即可生效。
启用NUMA后,主机在MMS上会被显示成黄色,如图23-10所示。可通过“Last Ping”选项卡,查看使其变成黄色的具体警告信息。图23-11显示的警告信息可说明NUMA是否启用。


如果禁用NUMA,那么MMS上的主机会重新显示为蓝色。(主机显示为黄色也可能是由于其他原因。应同时査看其他启动警告信息。)
3.2 更智能地预读取数据
预读(readahead)是一种优化手段,即操作系统从磁盘中读取比实际请求更多的数据。这一优化基于的原理是:计算机所处理的大部分工作都是连续的,即如果载入了一个视频文件的前20MB内容,则接下来很可能需要用到紧随其后的若干MB内容。于是,系统会从磁盘中读取比实际请求更多的内容,并将其存放到内存中,以便随后的调用。
然而,MongoDB并非是典型的工作负载,设置预读也是MongoDB系统中的常见问题。MongoDB倾向于从磁盘中随机读取很多小块的数据,所以默认的系统设置并不能很好地运作。如果预读内容过多,内存中会逐渐充满MongoDB没有请求的内容,迫使MongoDB更多地访问磁盘。
例如,如果希望从磁盘中读取一个扇区(512字节)的内容,则磁盘控制器实际上可能会读取256个扇区,因为它假设我们接下来总会用到这些内容。然而,如果完全随机地访问磁盘数据,则这些预读的扇区都会被浪费掉。如果内存中包含了工作集,则其中的255个扇区会被从内存中移除,从而存放这些不会用到的内容。事实上256个扇区是很小的预读数量,有些系统会默认预读上千扇区的内容。
幸好,有一种很简单的方法,可供查看预读设置是否已带来麻烦:检査MongoDB 驻留集(resident set)的大小,并与系统的总内存容量进行比较。
假设内存容量小于数据大小,MongoDB的驻留集大小应稍小于总内存大小(例如,如果有50 GB的内存,MongoDB应占用了至少46 GB)。如驻留集过小,则说明预读的内容可能太多了。
比较驻留集和总内存大小这一方法所基于的原理是:被预读的数据在内存中,而 MongoDB没有请求这些数据,因此不会被计算在MongoDB的常驻内存大小中。
使用blockdev命令,可查看当前的预读设定:
$ sudo blockdev --report RO RA SSZ BSZ StartSec Size Device rw 256 512 4096 0 80026361856 /dev/sda rw 256 512 4096 2048 80025223168 /dev/sda1 rw 256 512 4096 0 2000398934016 /dev/sdb rw 256 512 1024 2048 98566144 /dev/sdb1 rw 256 512 4096 194560 7999586304 /dev/sdb2 rw 256 512 4096 15818752 19999490048 /dev/sdb3 rw 256 512 4096 54880256 1972300152832 /dev/sdb4
这里显示了每个块设备的配置。RA列表示预读大小,其单位是大小为512字节的扇区数量。因此,该系统中每个设备的预读大小都设置为128 KB (512字节/扇区 x 256个扇区)。
可使用以下命令,并通过- -setra选项来更改这一设定值:
$ sudo blockdev --setra 16 /dev/sdb3
那么,预读大小设为多少为好呢?推荐数值是16到256之间。预读大小也不应设得过小,否则读取一个单独的文档则需多次访问磁盘。如文档较大(大于1MB),则应考虑预读更多的内容。如文档较小,预读的数值则应小一些,例如32。即使文档非常小,也不要将预读大小的值设为16以下,这会导致读取索引信息时效率低下(索引桶(index bucket)的大小为8 KB)。
使用RAID时,RAID控制器和组成RAID的每个分卷上都应对预读进行设置。
需重启MongoDB才能使预读设定生效,这一点看起来有些奇怪。更改磁盘属性设置难道不应该立即对所有正在运行的程序生效吗?但可惜,进程会在启动时复制一份预读大小的设置值,并一直按照该值运作,直到进程停止运行。
3.3 禁用大内存页面
启用大内存页面(hugepage)导致的问题和预读过多内容导致的问题类似。不要启用这一特性,除非:
-
- 所有数据都存放在内存中;
- 不考虑数据大小不断增长最终超过内存容量的情况。
MongoDB需载入数量众多的小块内存,所以启用大页面会导致更多的磁盘IO。
系统以页面为单位在磁盘和内存间转移数据。页面大小通常为若干KB (x86架构中默认为4096字节)。如果一台机器有很多GB的内存,那么页面大小较小时,管理这些页面的开销就会很大,速度就会更慢。而大页面使得页面大小设定值最大可为256 MB (在ia64架构上)。然而使用大页面意味着要将磁盘上一个扇区中几MB的数据存放在内存中。如果数据不能全部存进内存,那么从磁盘中载入大块数据,只会更快地填满内存,而这些内容随后又会被移除出内存。此外,将对数据的修改刷新到磁盘上也会更慢,因为磁盘写入的“脏”数据必须达到几MB,而非几KB。
注意:Windows系统将此特性称为Large Pages而非hugepages。一些版本的Windows默认启用该特性,而另一些版本则不会这样做,因此应检査确定该特性是否已被禁用。
大页面实际上是为了优化数据库系统的性能而开发的,所以有经验的数据库系统管理员,可能会对本节内容感到惊讶。然而,MongoDB对磁盘所进行的顺序访问比一般的关系型数据库要少得多。
3.4 选择一种磁盘调度算法
磁盘控制器从操作系统接收到请求后,会使用一种调度算法来决定处理这些请求的顺序。有时改变这一算法可提高磁盘性能。但对其他硬件和工作负载而言,可能没什么效果。最好的决定方法是进行实地测试。Deadline (截止时间)调度算法和CFQ (completely fair queueing,完全公平队列)调度算法都是不错的选择。
有时noop (“no-op”的缩写,这是最简单的调度算法)调度算法是最好的选择。比如说处于虚拟化环境中使用noop调度算法,该调度算法可基本上以最快的速度把操作传递给下层的磁盘控制器,然后让真正的磁盘控制器来处理所需的重新排序问题。
类似地,在固态磁盘上,noop调度算法通常是最好的选择。固态磁盘并不存在机械磁盘中的磁头位置问题。
最后,如使用RAID控制器进行缓存,则应使用noop调度算法。缓存的表现与固态磁盘类似,可高效地将写入操作分配到不同的磁盘上去。
可在启动配置中使用--elevator选项来更改调度算法。
提示:该选项之所以被称为elevator (电梯),是因为调度算法的功能就像一部电梯,从不同的楼层(进程/时间)接收乘客(磁盘IO请求),再以一种可能的最佳方案,将之送至目的地。
很多时候,所有的调度算法都能很好地运作,可能感觉不到太大的区别。
3.5 不要记录访问时间
系统默认记录文件最后被访问的时间。由于MongoDB访问数据文件十分频繁,如果禁止记录这一时间,则会得到性能上的提升。在Linux系统中,可在/etc/fstab里将atime更改为noatime,以禁止记录访问时间。
/dev/sda7 /data ext4 rw,noatime 1 2
要使该设置更改生效,需先重新挂载设备。
atime在旧的内核中(比如ext3)问题更大些,因为新的内核中使用relatime作为默认值,使得更新不会那么频繁。此外应注意,将此值设为noatime可影响其他程序使用分区,例如mutt或备份工具。
类似地,在Windows系统下应设置disablelastaccess选项来实现相同功能。运行以下命令完成最后访问时间记录的禁止:
C:\> fsutil behavior set disablelastaccess 1
需重启使设置更改生效。该设置可能影响远程存储(Remote Storage)服务。不过由于该服务会自动移动数据到其他磁盘,所以本来也无需使用此服务。
3.6 修改限制
MongoDB可能会受到两个限制的影响:
-
- 进程可建立线程的数量;
- 进程能够打开文件描述符(file descriptor)的数量。
二者通常应被设置为无限制。
客户端与MongoDB服务器建立连接时,服务器就会建立一个线程来处理这个连接上发生的所有活动。因此,如果与数据库建立了3000个连接,数据库就会运行3000个线程(再加上几个用于处理与客户端无关任务的线程)。客户端可与MongoDB建立十几个甚至几千个连接,具体数量取决于应用服务器的配置。
如果客户端可动态地创建更多的子进程以应对增加的流量(大多应用服务器都会这么做),应确保这些子进程数量保持在MongoDB的限制以内。例如,如果有20个应用服务器,其中每一个都被允许创建100个子进程,而每个子进程又可创建10个线程连接到MongoDB,那么最多就可能会有20 x 100 x 10=20 000个连接。MongoDB面对这成千上万的线程可能不会很高兴,另外如果进程中的可用线程数被耗尽,则应拒绝新的连接。
另一个需要修改的限制是,MongoDB能够打开的文件描述符数量。每个连入和连出的连接都要使用一个文件描述符,如果客户端连接的数量真有如上一段描述的那样,则会打开20 000个文件描述符(恰好这也是MongoDB所允许的最大数量)。
特别是mongos,它会与很多分片建立连接。当客户端连接到mongOS并发起请求时,mongos向所有所需的分片建立连接,以完成请求。于是,如果集群中有100个分片,而客户端连接到mongos并尝试查询所有数据,mongos就必须向每个分片建立一个连接,共计100个连接。这会促使连接数的快速增长,可依照之前的例子想象一下。假设一个配置不当的应用服务器向mongos进程建立了 100个连接。也就是说对所有分片建立的连接数是100个连入连接x 100个分片=10 000个!(此处假设每个连接上的查询都没有特定目标,这种设计很差劲,所以这个例子有些极端)。
因此可做些调整:很多人特意使用maxConns选项配置mongos进程,使其只允许特定数量的连入连接。这种方法可确保客户端的正常工作。
文件描述符数量的限制也应该得到增加,因为其默认值(通常是1024)过低。将文件描述符数目的最大值设为无限制,如果觉得不保险的话,可将其设为20 000。每个系统更改这些限制的方法有所不同,但通常来讲,应确保对软限制和硬限制都进行了修改。硬限制是内核级的,只有管理员可进行更改,而软限制则是用户级的。
如果连接数限制为1024, MMS会在主机列表中将主机名称显示为黄色以示警告 (如上述NUMA的例子一样)。如果限制值过低,“Last Ping”选项卡中会出现类似图23-12中所示的信息。

即使不使用分片,应用程序建立的连接数也很少,也应至少将软硬限制均增至 4096。这样,MongoDB就不再会为此发出警告,也给了我们一些喘息空间,有备无患。
4.网络配置
本节将介绍哪些服务器间应建立连接。通常情况下,出于网络安全(和灵敏度)考虑,会希望限制MongoDB服务器的网络连接。注意,多服务器MongoDB的部署应能够处理网络被隔断的情况,但并不推荐将其作为一般情况下的部署方式。
在独立服务器上,客户端须能够与mongod建立连接。
副本集成员必须能够连接到其他各成员。客户端必须能够连接到所有可见的非仲裁器成员。根据网络配置的不同,成员可能会尝试与自身建立连接,所以应允许mongods建立到自身的连接。
分片要稍微复杂一些。它由以下四种组件组成:
-
- mongos服务器;
- 分片;
- 配置服务器;
- 客户端。
连接要求可概括为以下三点:
-
- 客户端必须能够连接到一个mongos服务器;
- mongos服务器必须能够连接到众分片和配置服务器;
- 分片必须能够连接到其他分片和配置服务器。
表23-1中显示了完整的连接需求。
| 表23-1 分片连接 | ||||
| 连接与服务器建立 | 从服务器发出mongos | 分片 | 配置服务器 | 客户端 |
| mongos | 不需要 | 不需要 | 不需要 | 需要 |
| 分片 | 需要 | 需要 | 不需要 | 不推荐 |
| 配置服务器 | 需要 | 需要 | 不需要 | 不推荐 |
| 客户端 | 不需要 | 不需要 | 不需要 | 与MongoDB无关 |
表格中有三种可能的值。
-
- “需要”表示二者间应建立连接,以保证分片正常运行。若由于网络问题导致连接中断的话,MongoDB会尝试进行平稳退化,以尽可能地解决问题,但不应故意做如此配置。
- “不需要”表示二者不会在指定方向进行通信,也就无需建立连接。
- “不推荐”表示二者间不会进行通信,但用户的错误操作则会促使相互通信的完成。 例如,推荐做法是限制客户端只与mongos建立连接,而不与分片建立连接,这 样客户端就不会在无意中直接向分片请求内容。类似地,客户端应无法直接访问 配置服务器,以防意外更改配置数据。
注意,mongos进程和分片会主动与配置服务器进行通信,但配置服务器不会与任何其他节点,甚或是另一个配置服务器建立连接。
分片在进行迁移时必须进行通信,因为可直接连接到其他分片以传输数据。 如前所述,组成分片的副本集成员应能够与其自身建立连接。
5.系统管理
本节我们将介绍一些在部署服务器前应注意的常见问题。
5.1 时钟同步
一般来讲,各系统间的时钟误差不超过一秒是最为安全的。副本集应能够处理几乎所有的时钟偏移(clock skew)。分片则能够处理一部分时钟偏移(如偏移超过几分钟,日志中会出现警告信息),但最好将偏移降至最小。使时钟保持同步,也使得査看日志内容变得更加方便。
为保持时钟同步,在Windows系统中可使用w32tm工具,而在Linux系统中则可使用ntp后台进程。
5.2 OOM Killer
在极偶然的情况下,MongoDB会因分配过多内存而被OOM Killer (Out of Memory killer,内存溢出杀手)盯上。尤其是在建立索引时发生,这也是MongoDB的常驻内存会给系统造成压力的少有情况之一。
如果MongoDB进程突然被终止,而日志中又没有出现错误或退出信息,则应检査/var/log/messages (或内核记录这些内容的其他位置),査看是否存在关于终止mongod进程的信息。
如果内核因为过度使用内存而终止了MongoDB进程,则应在内核日志中看到如下内容:
kernel: Killed process 2771 (mongod)
kernel: init invoked oom-killer: gfp_mask=0x201d2, order=0, oomkilladj=0
如果开启了日志系统(journaling),此时重启mongod进程即可。如没有开启日志系统,则应恢复备份,或重新与副本进行同步。
当系统没有交换空间,并且可用内存开始减少时,OOM killer就会变得尤为敏感,因此为避免麻烦,不妨配置适当的交换空间。MongoDB应不会用到该交换空间,但这可让OOM Killer放松下来。
如果OOM killer终止了一个mongos进程,重启它即可。
5.3 关闭定期任务
检查是否存在计划任务或后台进程,它们可能定期被激活并消耗系统资源,比如软件包管理器的自动更新。这些程序被激活后会消耗大量的内存和CPU资源,然后又消失不见。我们不会希望在生产服务器上见到这些东西。

