Mongo服务器管理之监控MongoDB
在部署前设置某种监控系统很是重要。监控系统应该能够跟踪服务器正在运行的操作,也能够在遇到问题时及时发出警报。以下介绍:
-
- 如何跟踪监测MongoDB的内存使用状况;
- 如何跟踪监测应用的性能指标;
- 如何诊断复制中的问题。
本章以MMS (Mongo Monitoring Service, Mongo监控服务)为例,演示监控时应注意的内容。请于https://mms.10gen.com查找MMS的安装说明。如不想使用 MMS,也可使用其他监控系统。监控系统可在故障发生前检测到潜在问题,并有助于我们对于问题的诊断。
1.监控内存使用状况
访问内存中的数据很快,而访问磁盘中的数据则较慢。不幸的是,二者相比,内存较为昂贵,而MongoDB通常也会优先使用内存。本节将讲述有关MongoDB与内存和磁盘进行交互的监控方式,以及监控中应关注的内容。
1.1 有关电脑内存的介绍
电脑中一般会有容量小且访问速度快的内存,以及容量大但访问速度慢的磁盘。当请求一页存储于磁盘上但尚未存于内存中的数据时,系统就会产生一个缺页中断,而后将此页数据从磁盘复制到内存。此后就可以极快地访问内存中的页面。如程序不再使用此页面内容,而内存又被其他页所占满,旧的页面就会被清除出内存而只存在于磁盘上。
将一页数据从磁盘复制到内存,比从内存中读取一页数据耗时更长。因此,MongoDB从磁盘复制数据的操作越少越好。如果MongoDB能够在内存中进行几乎所有操作,则访问数据的速度就能快很多。所以,MongoDB的内存使用情况,是要跟踪监测的最重要指标之一。
1.2 跟踪监测内存使用状况
MongoDB所使用的内存有几种不同的类型。第一种是常驻内存(residentmemory): MongoDB在物理内存中明确拥有的内存部分。例如,在查询文档时,该页面即被载入内存中,并成为常驻内存的一部分。
MongoDB赋予页面一个地址,此地址并非物理内存中页面的真实地址,而是一个虚拟地址。MongoDB可将此地址传给内核,继而由内核将其翻译成真正的物理地址。这样,即使内核需将此页面从内存中清除出去,MongoDB依然可通过虚拟地址来访问此页面。MongoDB向内核请求内存,内核会在它的页缓存(page cache)中进行查找。但请注意,该页并不在此处。査找失败会产生缺页中断,继而将此页复制至内存,最后返回到MongoDB。这些MongoDB赋予了地址的数据页面,即构成了映射内存(mapped memory),其中包含了MongoDB访问过的所有数据。通常情况下,映射内存的大小约等于整个数据集的大小。
MongoDB为映射内存中的每个页面,都额外维护了一个虚拟地址,以供日记(journaling)使用。这并不意味着内存中有着两份同样的数据,有的只是两个地址而已。所以,MongoDB所使用虚拟内存的总量,约是映射内存的两倍大小,或者说是整个数据集的两倍大小。如关闭了日记机制,则映射内存的大小约等干虚拟内存的大小。
注意:虚拟内存和映射内存均不是‘‘真正的”内存分配:二者与实际占用的内存大小毫无关系,它们只是MongoDB维护的映射罢了。理论上,MongoDB可映射1PB (petabyte, 1PB=1000 TB=1 000 000GB)的内存,但实际只使用了几 GB的物理内存。所以不用担心映射内存或虚拟内存的大小超过物理内存的容量。
图21-1是MMS中内存信息的图像,描述了MongoDB所使用的常驻内存、虚拟内存和映射内存的大小。在一台专门用于运行MongoDB的机器上,假设工作集(working set)的大小不小于内存容量,则常驻内存的大小应稍小于总的内存大小。只有常驻内存的大小才确切地等于其在物理内存中所占用的空间,但这一数据并不能说明MongoDB所使用的内存大小。
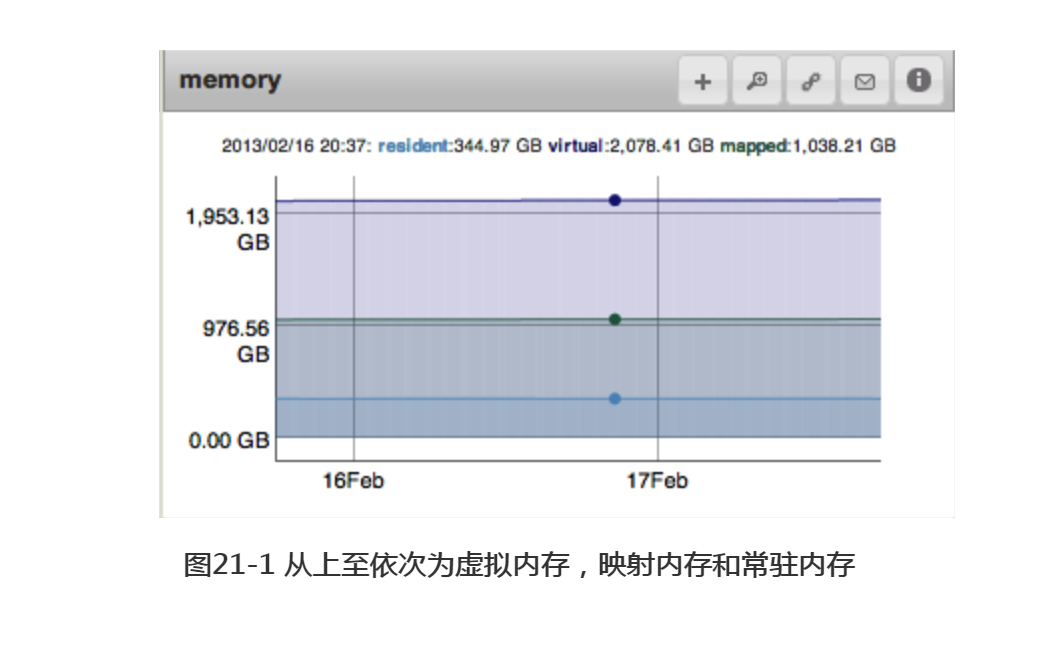
数据如果能全部存放在内存中的话,则常驻内存应与数据差不多大小。当说到数据 “在内存中”时,通常指的是在物理内存中。
1.3 跟踪监测缺页中断
如图21-1所示,内存的使用状况通常比较稳定,但随着数据集的增长,虚拟内存和映射内存也得到了增长。常驻内存会增长到可用物理内存的大小,而后保持不变。
除了以每种内存各占用多少空间为依据,还可通过其他数据得知MongoDB的内存使用方式。其中很实用的一个指标是发生缺页中断的数量,该数量表明了MongoDB所寻找的数据不在物理内存中这一事件的发生频率。图21-2和图21-3为一段时间内发生缺页中断的次数。图21-3中缺页中断的发生次数较少,但这一数据本身并不能说明很多问题。如果图21-2中的磁盘能够处理这么多的缺页中断,而应用程序可以处理这些磁盘操作造成的延迟,那么有这么多缺页中断也没什么问题。另一方面,如果应用程序无法处理从磁盘中读取数据造成的延迟,则只能将所有数据存放到内存中,或者使用固态硬盘(solid state drive, SSD)。

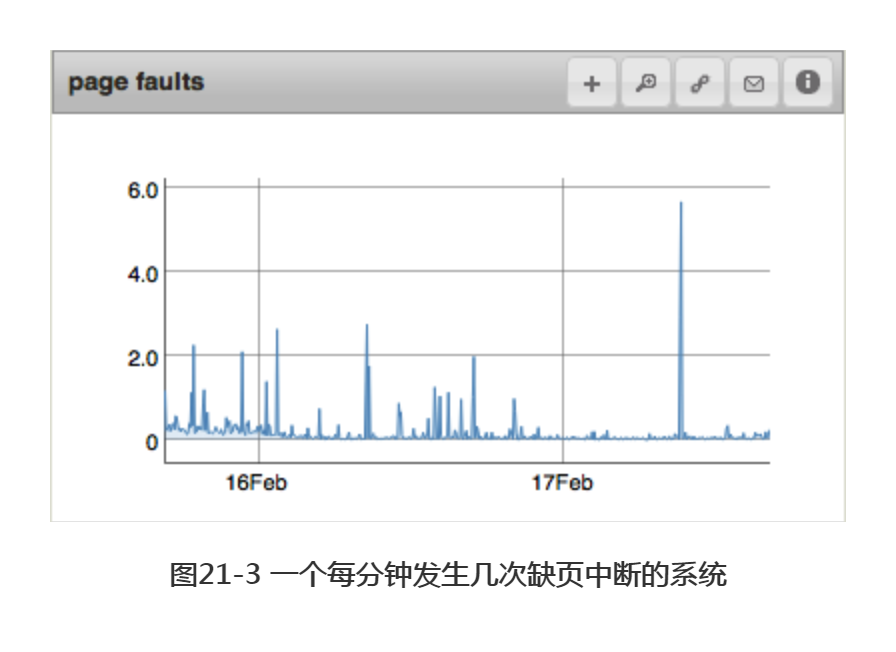
无论应用能否处理这些延迟,缺页中断都会在磁盘超负荷时成为大问题。磁盘能够处理的读取操作数目并非是线性的:一旦磁盘开始超负荷运行,每个操作都必须排队等候更长时间,从而引发连锁反应。磁盘的超负荷运行通常存在一个临界点,超出临界点后磁盘的性能会迅速下降。因此,应避免磁盘的最大负荷运转。
监测一段时间内缺页中断的数量。如应用在某一数量的缺页中断下表现良好,则表明其为系统可处理的缺页中断数量底线。如应用性能在缺页中断上升至某一数值时开始发生恶化,则表明该数值是应发出警告的临界值。
在serverStatus命令输出的recordStats字段中,可看到每个数据库的缺页中断情况:
> db.adminCommand({"serverStatus" : 1})["recordStats"]
{
"accessesNotInMemory": 200632,
"test": {
"accessesNotInMemory": 1,
"pageFaultExceptionsThrown": 0
},
"pageFaultExceptionsThrown": 6633,
"admin": {
"accessesNotInMemory": 1247,
"pageFaultExceptionsThrown": 1
},
"bat": {
"accessesNotInMemory": 199373,
"pageFaultExceptionsThrown": 6632
},
"config": {
"accessesNotInMemory": 0,
"pageFaultExceptionsThrown": 0
},
"local": {
"accessesNotInMemory": 2,
"pageFaultExceptionsThrown": 0
}
},
其中的accessesNotInMemory表示,MongoDB自启动以来必须去磁盘上读取数据的次数。
1.4 减少索引树的脱靶次数
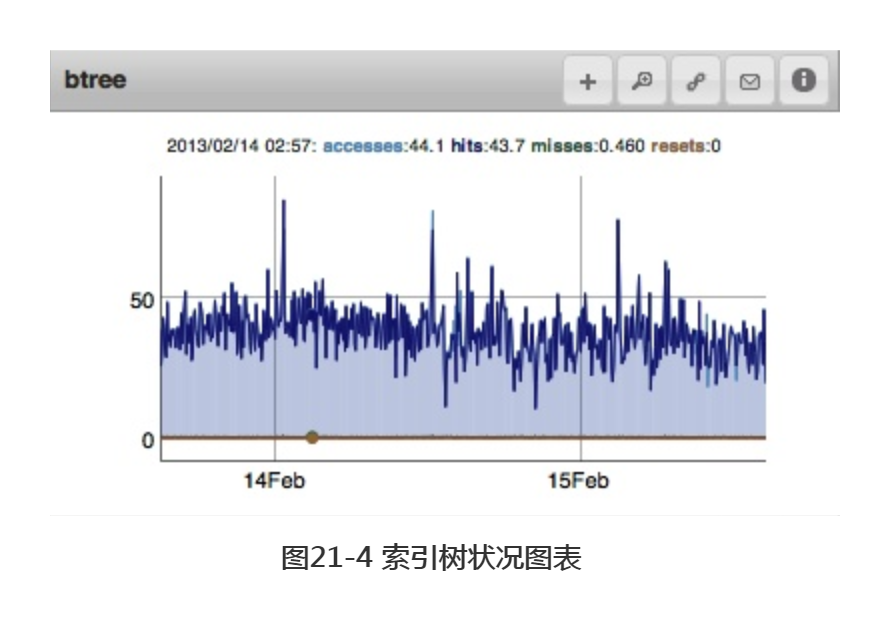
访问不在内存中的索引条目时效率尤其低下,因为这一操作通常会造成两次缺页中断,分别发生在将索引条目和文档加载入内存之际。査询索引造成缺页中断时,我们称其为索引树的脱靶(btree miss)。MongoDB也会监测索引树中靶(btree hits)的次数,即无需到磁盘上访问索引。图21-4中可看到这两个数值。
索引十分常用,通常处于内存中,但如果内存过小而索引又过多,或访问模式不正常(例如进行大量的表扫描),都会造成索引树脱靶次数的增长。通常情况下,脱靶次数应保持在很小的数值,因此,一旦发现该数值过高,则须着手找出问题的源头。
1.5 IO延迟
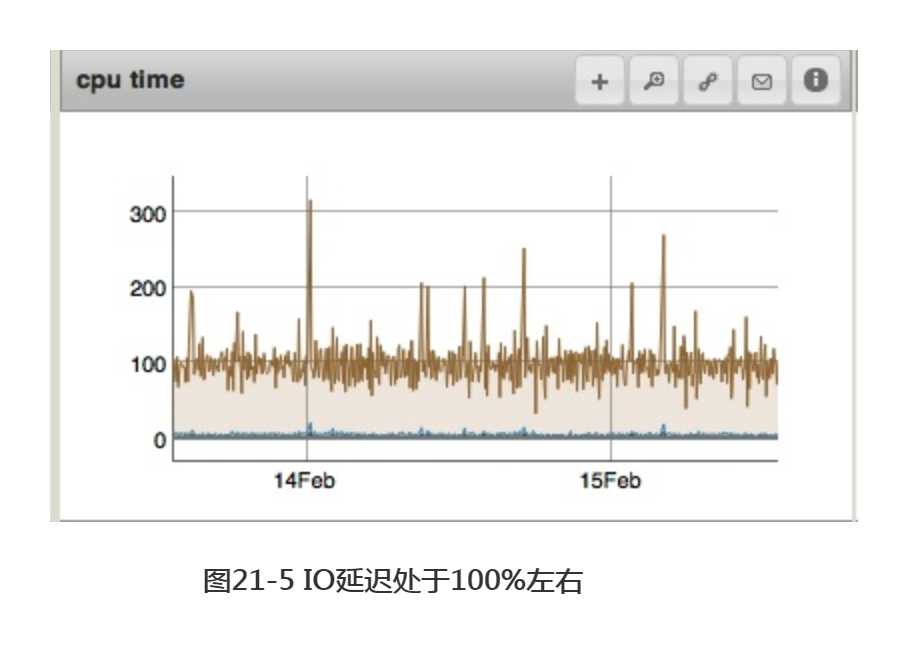
IO延迟指CPU闲置等待磁盘响应的时间。通常情况下,该延迟与缺页中断密切相关。一些IO延迟是正常的,因为MongoDB有时须对磁盘进行访问,且无法完全避免对其他操作的妨碍。重要的是,需保证IO延迟不再持续增长或增至100%左右。如图21-5所示,这表明磁盘正在超负荷运转。
MMS可通过安装插件munin来监测CPU信息。如需查看安装说明,请访问https://mms.10gen.com/help/install.html#hardware-monitoring-with-munin-node。
1.6 跟踪监测后台刷新平均时间
需关注的另一磁盘参数是,MongoDB将脏页(dirty page)写入磁盘所花费的时间,即后台刷新平均时间(background flush average)。该数据相当于一个警钟。一旦所需时间开始延长,就表示磁盘的速度跟不上需要处理的请求。
MongoDB默认会以至少每分钟一次的频率,将所有缓存中的数据刷新到磁盘中。(在有很多脏页的情况下,MongoDB可能会以更高的频率进行刷新,这取决于操作系统。)可在启动mongod时,通过--syncdelay选项后的参数,以秒为单位,来配置这一时间间隔的值。同步的频率越高,每次同步的数据则更小,但效率也会随之降低。
提示:人们常误以为syncdelay选项会影响数据持久性。但实际二者毫无关系。要想确保数据持久性,应使用日志系统(journaling)。Syncdelay只用于调节磁盘性能。
通常情况下,我们希望后台刷新平均时间能够低于一秒。在繁忙的机器上或慢速磁盘上,该时间会有所延长,并且随着磁盘超负荷的运行,所需时间会变得越来越长。在某一时刻,磁盘超出负荷太多,以至于数据刷新用时超过60秒,这意味着MongoDB会不断尝试进行刷新(这又对磁盘造成了更大的负担)。磁盘刷新时间偶尔出现高峰是可以接受的。但不断出现数十秒的长时间写入则是我们不希望看到的。
图21-6为后台刷新平均时间的曲线变化图。该系统的硬盘驱动器压力很大,总是需要大于5秒的时间来写入前一分钟产生的数据。速度有些慢,尤其是经常会出现近20秒时长的高峰期,所以可能有必要将syncdelay的值调低一些,比如说40秒,然后看看每次刷新较少的数据是否会有帮助。
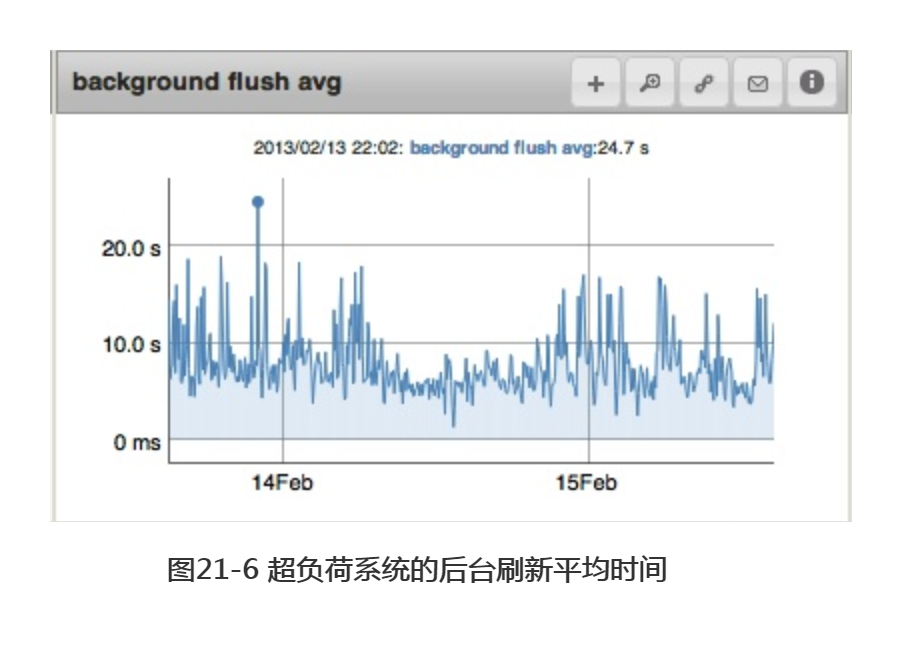
如果后台刷新平均时间长时间超出磁盘所能承受的值(可能只超了几秒钟),就应该开始考虑如何减轻磁盘的负载。
MongoDB只需刷新脏数据(即发生更改的数据),所以后台刷新平均时间通常反映出写入负载的大小,即写入操作和写入数据的数量。因此,如果写入负载很低,后台刷新平均时间可能无法表现出磁盘的压力大小。除后台刷新平均时间外,还应同时监测IO延迟和缺页中断的情况。
2.计算工作集的大小
通常情况下,内存中数据越多,MongoDB的运行速度就越快。因此,应用可遇到如下情况(运行速度从快到慢排列)。
(1) 整个数据集均在内存中。虽然这种情况很不错,但通常代价过大或不可行。此种情况可能需要应用的响应速度足够快才能达成。
(2) 工作集处于内存中。这是最常见的选择。
工作集是应用所使用的数据和索引。这可能是其所有内容,但通常来讲会存在一个能够覆盖90%请求的核心数据集(如用户集合和最近一个月的活动)。如该工作集存在于物理内存中,MongoDB的运行速度通常会很快,因为它只有在遇到少数“不寻常”的请求时才需访问磁盘。
(3) 索引处于内存中。
(4) 索引的工作集处于内存中。通常需要右平衡索引才能达成此种情况。
(5)内存中没有可用的数据子集。可能的话,应避免这种情况。这会使数据库运行缓慢。
我们必须通过了解工作集的内容及大小来判断能否将其存入内存。计算工作集大小的最好方式是跟踪分析一些常用的操作,从而找出应用的读写数据有多少。例如,假设应用每周会创建2GB的新数据,而其中800MB是经常被访问的。用户通常只会访问近一个月的数据,更早的数据则通常不会被用到。这样工作集大小可能是3.2 GB(800MB/周X4周)左右,再根据经验估计一下索引大小,加起来大概是5GB。
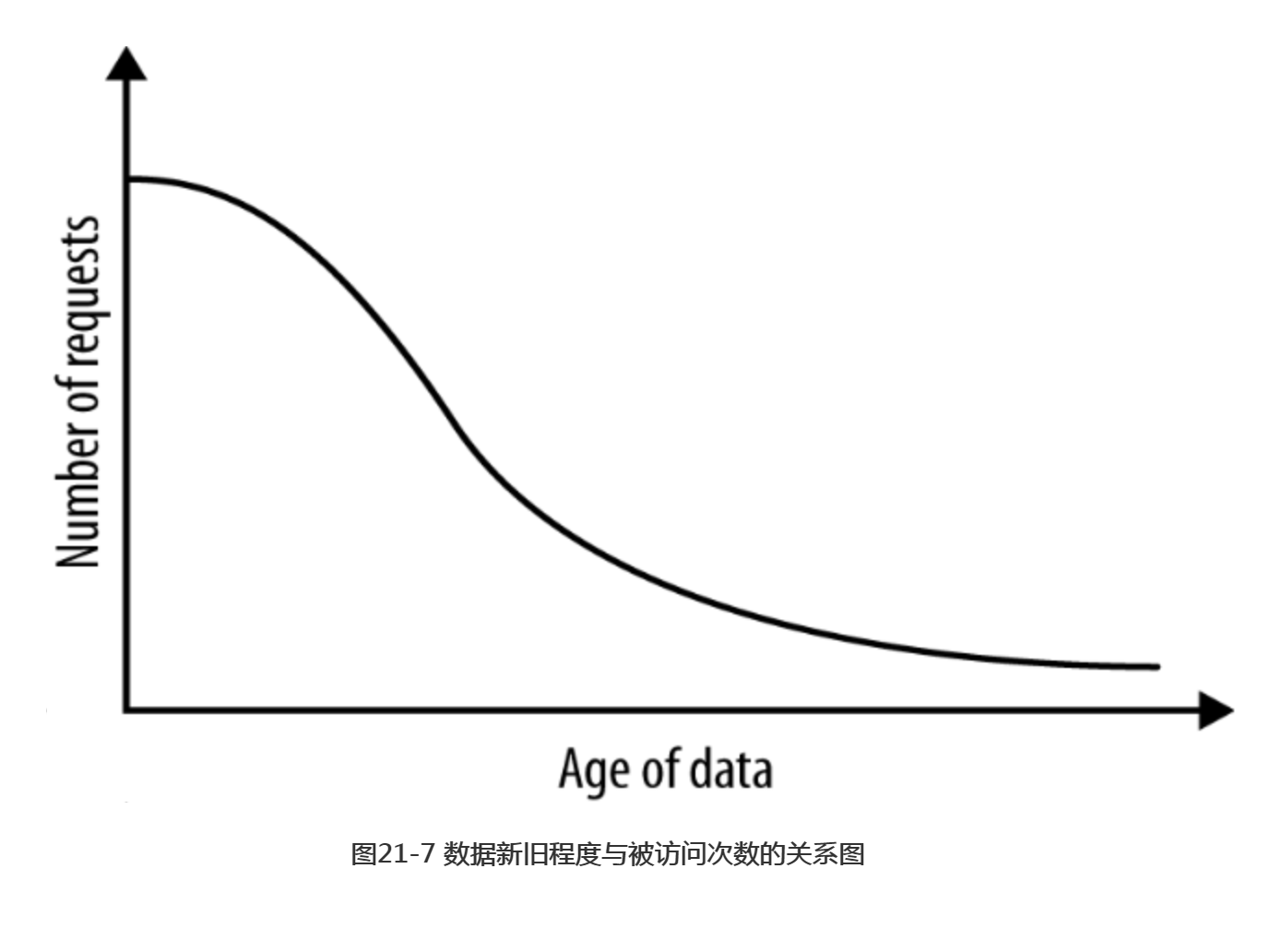
可通过跟踪监测一段时间内被访问的数据来考虑这一问题,如图21-7所示。如选择尽快满足90%的请求,则这一时间段内生成的数据和索引即为工作集,如图21-8所示。可测查这一时间的长短,从而计算出数据集的增长情况。注意,此例使用了时间,即数据的新旧作为参数,但同时可能存在更适用于应用的访问模式(时间是最常用的一种)。

还可通过MongoDB的状态来估计工作集的大小。MongoDB保留有一个记录内存内容的图表,可将“workingSet”: 1参数传入serverStatus来得知这些内容。
> db.adminCommand({"serverStatus" : 1, "workingSet" : 1})
{
...
"workingSet" : {
"note" : "thisIsAnEstimate",
"pagesInMemory" : 18,
"computationTimeMicros" : 3685,
"overSeconds" : 2363
},
...
}
pagesInMemory指MongoDB认为当前内存中的页面数目。实际上,MongoDB并不知道其确切数值,但结果应该很接近。在返回信息中,如果内存中的页面数目与内存大小相等,则该数值没有什么价值;但如果页面数目小于内存大小,则该数值可能与工作集的大小有关。
serverStatus的返回结果默认不包含workingSet字段。
一些工作集的例子
假设工作集大小为40GB。90%的请求能够命中工作集,其他10%则需访问工作集以外的数据。如果有500GB的数据和50GB的内存,则工作集可全部放入内存中。一旦应用访问了需经常访问的数据(即预热过程),则无需在访问工作集时再次访问磁盘。有10GB的空间提供给460GB不常访问的数据。显然,MongoDB几乎总是要到磁盘上访问工作集以外的数据。
另一方面,假设工作集无法放入内存。比如只有35GB的内存。这种情况下工作集通常会占据大部分的内存。工作集中的内容经常被访问,因而更有可能留在内存中,但有时不常访问的数据也会被载入内存,从而将工作集(或其他不常访问的数据)挤出内存。于是,内存和磁盘会频繁进行数据交换,此时无法再预测访问工作集中数据的性能。
3.跟踪监测性能状况
査询的性能通常应重点监测并使其保持稳定。有几种方式可用来监测MongoDB是否能承受当前的请求负荷。
MongoDB占用CPU时,大部分时间花在了处理器的读写上(IO延迟很高,其他指标可忽略)。然而,如果用户或者系统占用的CPU时间接近100% (或者100%乘以CPU的数量),最可能的原因是一个常用的査询缺少合适的索引。另一种可能性是运行了太多的MapRedues或其他的服务器端JavaScript脚本。有必要跟踪监测CPU,从而确保所有査询的表现与预想中的相符,特别是在部署了一个新版本的应用之后。
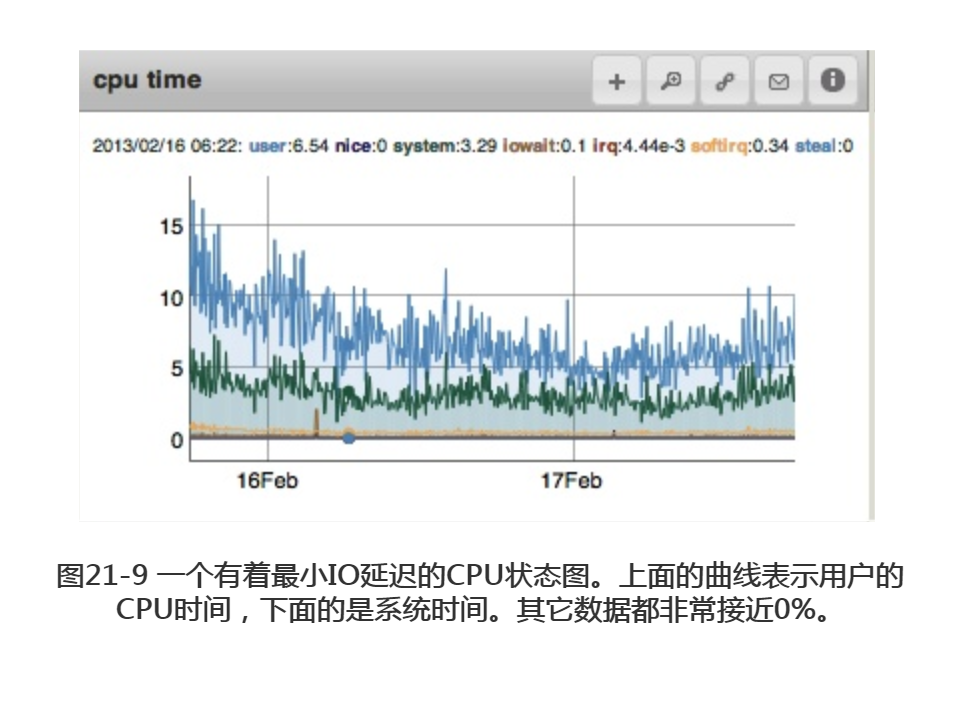
注意,图21-9中显示的是正常的,如果缺页中断的数量较低,IO延迟可能被其他CPU活动所拖累。只有在其他活动增长时,缺少合适的索引才可能是罪魁祸首。
另一个相似的指标是队列长度,即有多少请求正在等待MongoBD的处理。请求在等待锁进行读写操作时,即被认为是处于队列中。图21-10为读写队列随时间变化的图像。不存在队列为最佳(此时图像基本为空白),但无需针对这一指标发出警报。在一个繁忙的系统中,操作需耗时等待以获取所需的锁,这一点很常见。
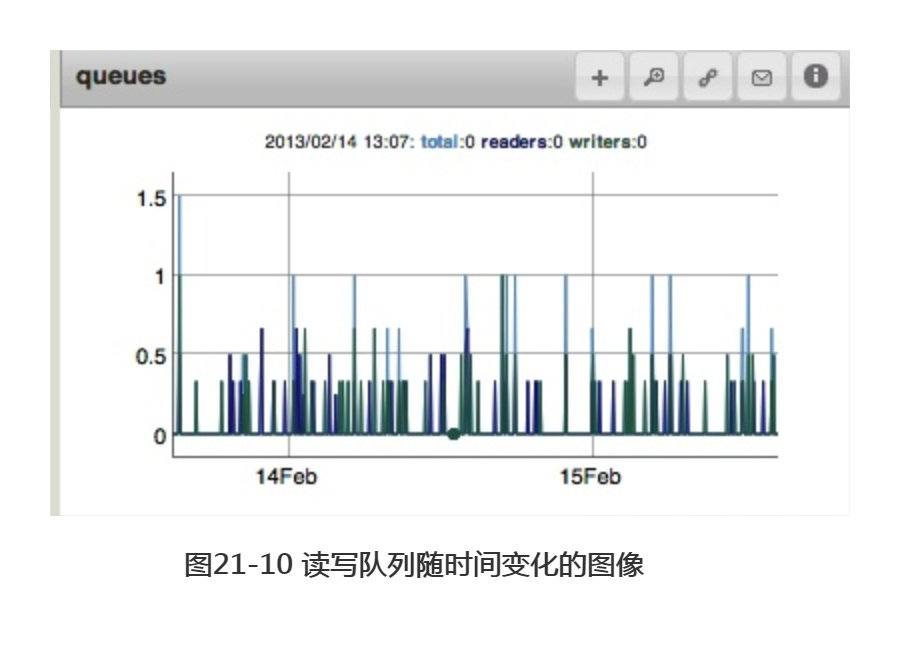
可通过队列中的请求数量,判断是否发生了阻塞。通常队列的长度应该很低。一个很长且始终存在的队列表示mongod无法承受其负载。应尽快减轻该服务器的负荷。
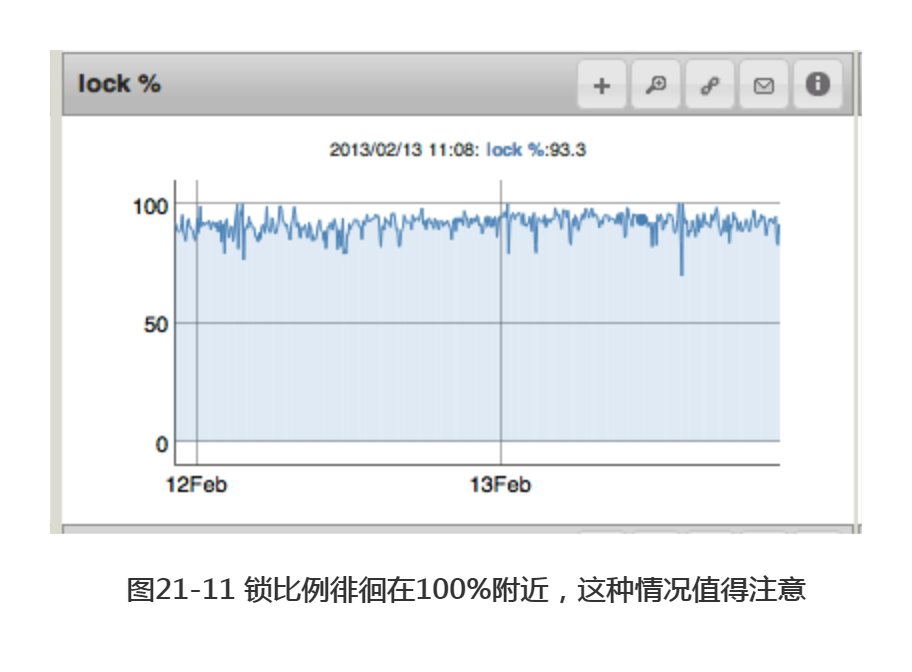
可将队列长度和锁比例(lock percentage)两个指标结合起来,锁比例指MongoDB处于锁定中的时间。一般来讲,相较于发生锁定,磁盘IO更倾向于限制写入。但依然有必要对锁定进行跟踪监测,尤其是磁盘速度快,或连续写入多的系统。重复一遍,锁比例过高的最普遍原因之一就是缺少了合适的索引。随着锁比例的增加,操作取得锁所需的平均等待时间越来越长。因此,过高的锁比例会将所有东西拖慢,导致请求堆积,以及系统中更高的负荷和更高的锁比例。图21-11中显示了极高的锁比例,这种情况应尽快得到处理。
随着流量大小的变化,锁比例常会发生起伏变化。但如果锁比例长时间保持上升趋势,则表明系统所受的压力较大,应做一些调整。因此,应在锁比例长时间保持过高的值后再触发警报(这样当流量突然增加时就不会触发警报了)。
另一方面,我们可能也希望在锁比例突然升高时,比如说高于正常值25%时触发警报。该数值可能表明系统无法承载突然升高的负荷,也许应该提高系统的性能和容量了。
除全局的锁比例外,MongoDB也对每个数据库的锁比例进行跟踪。因此,如果某数据库有很多的连接,可单独查看其锁比例。
跟踪监测空余空间
另一基本但却很重要的监测指标为磁盘的使用情况,即监测磁盘的空余空间。有时用户直到磁盘空间被占满时才想起处理这一问题。通过监测磁盘使用情况,可预测当前磁盘的使用时间,并为磁盘空间不足提前做好准备。
磁盘空间不足时,有以下几个选项。
-
- 如果在使用分片,那就增加一个分片。
- 依次关闭副本集中的每个成员,复制数据到更大的磁盘上进行挂载。重启该成员,然后对下一成员进行同样的操作。
- 把副本集中的成员替换成更大驱动器的成员:移除旧成员,添加新成员。使新成员追赶上副本集中的其余成员。对集合中的每个成员重复此操作。
- 如使用了directoryperdb选项,且数据库增长速度非常快,可将数据库移至其驱动器内。挂载驱动器为数据目录。这样就可不必移动其他数据内容了。
无论采取哪种方法,请提前做好准备,从而使对应用产生的影响降至最低。请先做好备份,依次修改副本集中的每个成员,并将数据从一处复制至另一处。
4.监控副本集
对副本集中的落后(lag)和oplog(operation log)长度进行跟踪监测十分重要。
当备份节点无法与主节点保持一致时,就产生了落后。主节点最后一次操作的时间和备份节点最后一次操作的时间差值,即落后的值。例如,一个备份节点刚刚完成了一次操作,其时间戳为3:26:00 p.m.,主节点刚刚完成了一次操作,其时间戳为3:29:45 p.m.,此时落后的值即为3分45秒。落后的值越接近0越好,且通常为毫秒级别。如果一个备份节点能够与主节点保持同步,副本集落后的值应如图21-12所示,基本保持为0。

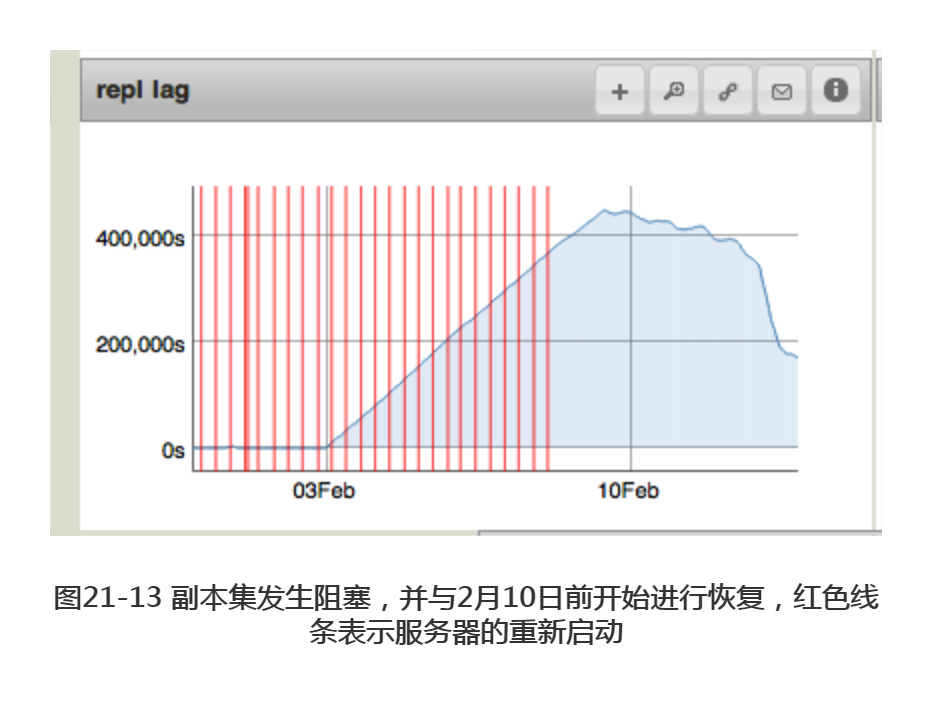
如果备份节点的复制速度赶不上主节点的写入速度,就会开始出现非0的落后值。最极端的情况是副本集发生了阻塞:由于某种原因,副本集无法再接受任何操作。这种情况下,每经过一秒,落后的值就会增加一秒,在图像中呈现一个陡坡的样子,如图21-13所示。这可能是由于网络问题引起的,也可能是由于缺少 _id 索引,副本集要求每个集合都拥有这一索引才能正常工作。
如果集合缺少了 _id 索引,将服务器脱离副本集作为一个独立服务器启动,然后建立_id索引。确保建立的 _id 索引是唯一索引(unique index)。索引建立完成后,除非删除整个集合,否则 _id 索引不能发生删除或更改。
如系统超负荷运行,备份节点可能会逐渐被主节点落下。但图中通常不会显示出特征明显的“每秒增加一秒”的陡坡,因为备份节点还是进行了一些复制的。然而,备份节点到底是因为无法与高峰流量保持一致而被落下的,还是逐渐被主节点落下的,这一点十分重要。
主节点不会为了“帮助”备份节点追赶上来而限制写入,所以在超负荷运行的系统上备份节点追赶不上的情况时有发生(尤其是MongoDB中写入的优先级比读取要髙,这意味着副本集的性能很大程度上取决于主节点)。可在写入时使用“w”参数来强制限制主节点的写入。也可通过将请求路由至其他成员,从而降低备份节点的负载。
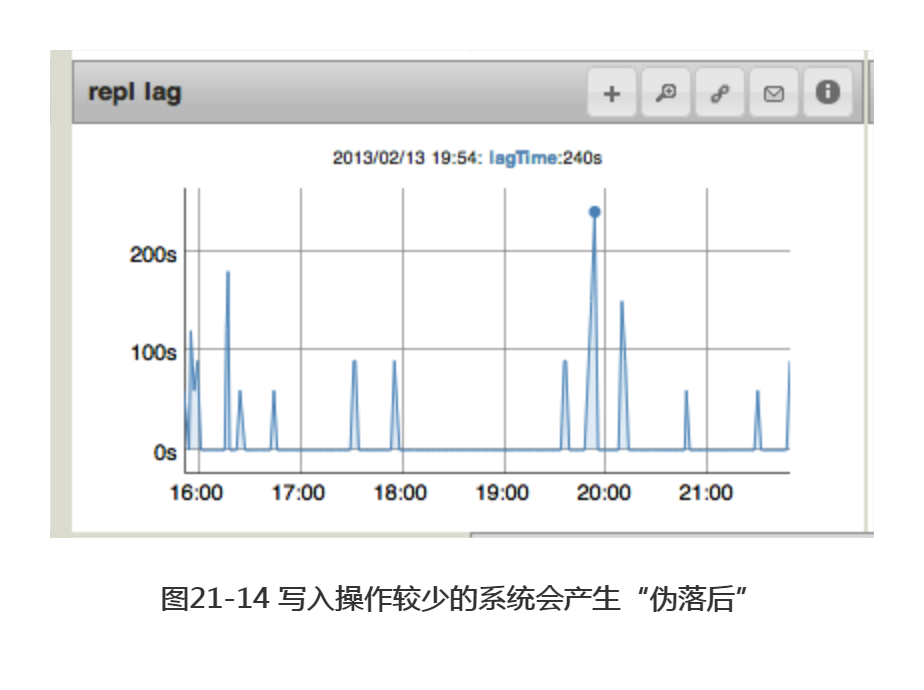
而在一个负载极低的系统上,可在副本集落后值的图像中看到另一种有趣的图案,即突然出现的高峰值,如图21-14所示。这些峰值表示的并不是真正的落后,而是由抽样的变化产生的。mongod每隔几分钟处理一个写入操作。落后的值是主节点和备份节点的时间戳差值,而对备份节点时间戳的测量恰好发生在主节点的写人操作之前,这使得备份节点看起来好像落后了几分钟一样。如果增加写入频率,这些峰值就会消失。
另一需要跟踪监测的重要指标是每个成员的oplog长度。每个可能成为主节点的成员都应拥有一份长度超过一天的oplog。如一个成员可能成为另一个成员的同步源(sync source),则应拥有一份长度足够进行初始化同步(initial sync)的oplog。图21-15为标准的oplog长度图像。该长度极佳,达1111小时,即超过一个月的数据!通常,在保证磁盘空间充足的前提下,oplog应尽可能地长。oplog几乎不占用内存。而且长oplog的缺乏,可能会带来痛苦的回忆。
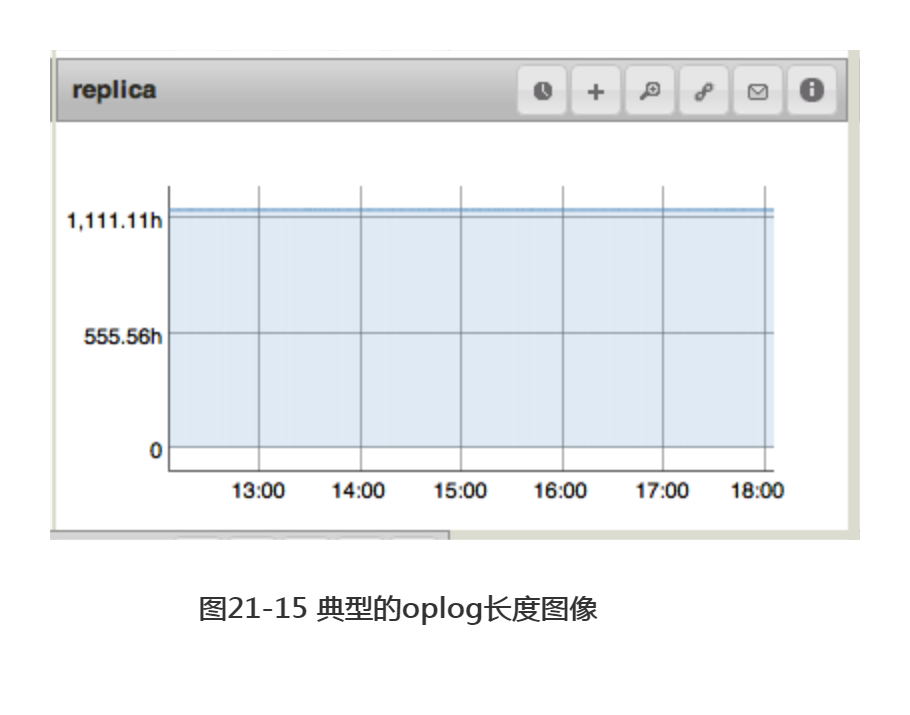
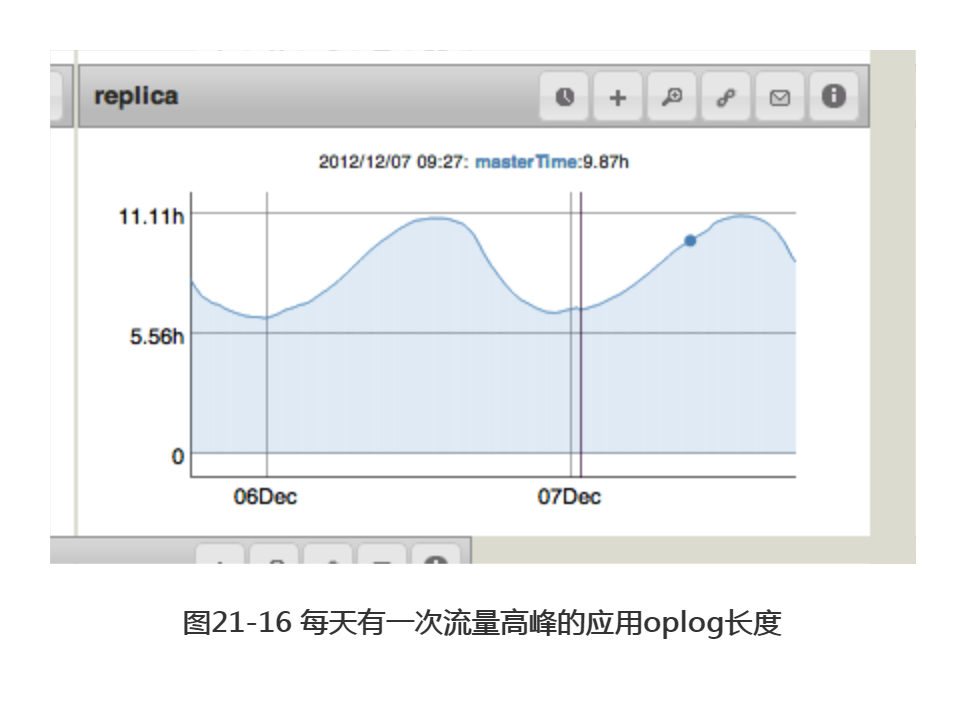
图21-16为较短的oplog和变化的流量引起的稍显不同寻常的变化。运行仍旧正常, 但该机器上的oplog可能太短了(6到11小时的维护时段)。管理员有机会的话应将该oplog的长度加以延长。