
Mongo分片之配置分片
|
导航: Mongo分片: 1.Mongo分片介绍。 2.Mongo分片之配置分片。 3.Mongo分片之选择片键。 4.Mongo分片之分片管理。 |
在上一章中,在一台机器上创建了一个“集群”。本章讲述如何创建一个更实际的集群,以及分片的配置。
-
- 创建配置服务器、分片、mongos进程。
- 增加集群容量。
- 数据的存储和分布。
1.何时分片
决定何时分片是一个值得权衡的问题。通常不必太早分片,因为分片不仅会增加部署的操作复杂度,还要求做出设计决策,而该决策以后很难再改。另外最好也不要在系统运行太久之后再分片,因为在一个过载的系统上不停机进行分片是非常困难的。
通常,分片用来:
-
- 增加可用RAM;
- 增加可用磁盘空间;
- 减轻单台服务器的负载;
- 处理单个mongod无法承受的吞吐量。
因此,良好的监控对于决定应何时分片是十分重要的,必须认真对待其中每一项。由于人们往往过干关注改进其中一个指标,所以应弄明白到底哪一项指标对自己的部署最为重要,并提前做好何时分片以及如何分片的计划。
随着不断增加分片数量,系统性能大致会呈线性增长。但是,如果从一个未分片的系统转换为只有几个分片的系统,性能通常会有所下降。由于迁移数据、维护元数据、路由等开销,少量分片的系统与未分片的系统相比,通常延迟更大,吞吐量甚至可能会更小。因此,至少应该创建3个或以上的分片。
2.启动服务器
创建集群的第一步是启动所有所需进程。如上章所述,需建立mongos和分片。第三个组件——配置服务器也非常重要。配置服务器是普通的mongod服务器,保存着集群的配置信息:集群中有哪些分片、分片的是哪些集合,以及数据块的分布。
2.1 配置服务器
配置服务器相当于集群的大脑,保存着集群和分片的元数据,即各分片包含哪些数据的信息。因此,应该首先建立配置服务器,鉴于它所包含数据的极端重要性,必须启用其日志功能,并确保其数据保存在非易失性驱动器上。每个配置服务器都应位于单独的物理机器上,最好是分布在不同地理位置的机器上。
因mongos需从配置服务器获取配置信息,因此配置服务器应先于任何mongos进程启动。配置服务器是独立的mongod进程,所以可以像启动“普通的”mongod进程一样启动配置服务器:
$ # server-config-1 $ mongod --configsvr --dbpath /var/lib/mongodb -f /var/lib/config/mongod.conf $ $ # server-config-2 $ mongod --configsvr --dbpath /var/lib/mongodb -f /var/lib/config/mongod.conf $ $ # server-config-3 $ mongod --configsvr --dbpath /var/lib/mongodb -f /var/lib/config/mongod.conf
启动配置服务器时,不要使用--「eplSet选项:配置服务器不是副本集成员。 mongos会向所有3台配置服务器发送写请求,执行一个两步提交类型的操作,以确 保3台服务器拥有相同的数据,所以这3台配置服务器都必须是可写的(在副本集 中,只有主节点可以处理客户端的写请求)。
提示:一个常见的疑问是,为什么要用3台配置服务器?因为我们需要考虑不时之需。但是,也不需要过多的配置服务器,因为配置服务器上的确认动作是比较耗时的。另外,如果有服务器宕机了,集群元数据就会变成只读的。 因此,3台就足够了,既可以应对不时之需,又无需承受服务器过多带来的缺点。这个数字未来可能会发生变化。
--configsvr选项指定mongod为新的配置服务器。该选项并非必选项,因为它所做的不过是将mongod的默认监听端口改为27019,并把默认的数据目录改为/data/configdb而已(可使用--port和--dbpath选项修改这两项配置)。
但建议使用--configsvr选项,因为它比较直白地说明了这些配置服务器的用途。当然,如果不用它启动配置服务器也没问题。
配置服务器并不需要太多的空间和资源。配置服务器的1KB空间约等于200 MB真实数据,它保存的只是数据的分布表。由于配置服务器并不需要太多的资源,因此可将其部署在运行着其他程序的机器上,如应用服务器、分片的mongod服务器,或mongos进程的服务器上。
如果所有的配置服务器都不可用,就要对所有分片做数据分析,以便知道每个分片保存的是什么样的数据。这是可行的,但速度较慢,且令人厌烦。比较好的方式是经常对配置服务器做数据备份。应常在执行集群维护操作之前备份配置服务器的数据。
2.2 mongos进程
三个配置服务器均处于运行状态后,启动一个mongos进程供应用程序连接。mongos进程需知道配置服务器的地址,所以必须使用--configdb选项启动mongos:
$ mongos --configdb config-1:27019,config-2:27019,config-3:27019 -f /var/lib/mongos.conf
默认情况下,mongos运行在27017端口。注意,并不需要指定数据目录(mongos自身并不保存数据,它会在启动时从配置服务器加载集群数据)。确保正确设置了logpath,以便将mongos日志保存到安全的地方。
可启动任意数量的mongos进程。通常的设置是每个应用程序服务器使用一个mongos进程(与应用服务器运行在同一台机器上)。
每个mongos进程必须按照列表顺序,使用相同的配置服务器列表。
2.3 将副本集转换为分片
终于可以添加分片了。有两种可能性:已经有了一个副本集,或是从零开始建立集群。下例假设我们已经拥有了一个副本集。如果是从零开始的话,可先初始化一个空的副本集,然后按照本例的步骤进行后续操作。
如已经有一个使用中的副本集,该副本集会成为第一个分片。为了将副本集转换为分片,需告知mongos副本集名称和副本集成员列表。
例如,如果在server-1、server-2、server-3、server-4、server-5 上有一个名为 spock 的副本集,可连接到mongos并运行:
> sh.addShard("spock/server-1:27017,server-2:27017,server-4:27017") { "added" : "spock/server-1:27017,server-2:27017,server-4:27017", "ok" : true }
可在参数中指定副本集的所有成员,但并非一定要这样做。mongos能够自动检测到没有包含在副本集成员表中的成员。如运行sh.status(),可发现MongoDB已经找到了其他的副本集成员:spock/server-1:27017,server-2:27017,server-3:27017,server-4:27017,server-5:27017。
副本集名称spock被用作分片名称。如之后希望移除这个分片或是向这个分片迁移数据,可使用spock来标识这个分片。这比使用特定的服务器名称(如server-1)要好,因为副本集成员和状态是不断改变的。
将副本集作为分片添加到集群后,就可以将应用程序设置从连接到副本集改为连接到mongos。添加分片后,mongos会将副本集内的所有数据库注册为分片的数据库,因此所有查询都会被发送到新的分片上。与客户端库一样,mongos会自动处理应用故障,将错误返回给客户端。
在开发环境中可测试一下让分片的主节点挂掉,以确保应用程序能够正确处理mongos返回的错误。(错误应与直接对话主节点返回的错误相同。)
提示:添加分片后,必须将客户端设置为将所有请求发送到mongos,而不是副本集。如果客户端仍然把请求直接发送给副本集(而不是通过mongos)的话,分片是无法正常工作的。添加分片后,应立即将客户端配置为把请求发送给mongos,同时配置防火墙规则,以确保客户端不能直接将请求发送给分片。
有一个--shardsvr选项,与前面介绍过的--configsvr选项类似,它也没什么实用性(只是将默认端口改为27018),但建议在操作中选择该选项。
也可以创建单mongod服务器的分片(而不是副本集分片),但不建议在生产中使用(上一章中的ShardingTest是这么做的)。直接在addShard()中指定单个mongod的主机名和端口,就可以将其添加为分片了 :
> sh.addShard("some-server:27017")
单一服务器分片默认会被命名为shardOOOO、shardOOO1,依次类推。如打算以后切换为副本集,应先创建一个单成员副本集再添加为分片,而不是直接将单一服务器添加为分片。将单一服务器分片转换为副本集需停机操作。
2.4 增加集群容量
可通过增加分片来增加集群容量。为添加一个新的、空的分片,可先创建一个副本集。确保副本集的名字与其他分片不同。副本集完成初始化并拥有一个主节点后,可在mongos上运行addShard()命令,将副本集作为分片添加到集群中,在参数中指定副本集的名称和主机名作为种子。
如有多个现存的副本集没有作为分片,只要它们没有同名的数据库,就可将它们作为新分片全部添加到集群中。例如,如有一个blog数据库的副本集、一个calendar数据库的副本集,以及一个mail、tel、music数据库的副本集,可将每个副本集作为一个分片添加到集群中,这样就可以得到一个拥有三个分片、五个数据库的集群。但是,如果还有一个数据库名称为tel的副本集,那么mongos会柜绝将这个副本集作为分片添加到集群中。
2.5 数据分片
除非明确指定规则,否则MongoDB不会自动对数据进行拆分。如有必要,必须明确告知数据库和集合。
假设我们希望对music数据库中的artists集合按照name键进行分片。首先,对 music数据库启用分片:
> db.enableSharding("music")
对数据库分片是对集合分片的先决条件。
对数据库启用分片后,就可以使用shardCollection()命令对集合分片了:
> sh.shardCollection("music.artists", {"name" : 1})
现在,集合会按照name键进行分片。如果是对已存在的集合进行分片,那么name键上必须有索引,否则shardCollection()会返回错误。如果出现了错误,就先创建索引(mongos会建议创建的索引作为错误消息的一部分返回),然后重试shardCollection()命令。
如要进行分片的集合还不存在,mongos会自动在片键上创建索引。
shardCoUection()命令会将集合拆分为多个数据块,这是MongoDB迁移数据的基本单元。命令成功执行后,MongoDB会均衡地将集合数据分散到集群的分片上。这个过程不是瞬间完成的,对于比较大的集合,可能会花费几个小时才能完成。
3.MongoDB如何追踪集群数据
每个mongos都必须能够根据给定的片键找到文档的存放位置。理论上来说,MongoDB能够追踪到每个文档的位置,但当集合中包含成百上千万个文档的时候,就会变得难以操作。因此,MongoDB将文档分组为块(chunk),每个块由给定片键特定范围内的文档组成。一个块只存在于一个分片上,所以MongoDB用一个比较小的表就能够维护块跟分片的映射。
例如,如用户集合的片键是{"age" : 1},其中某个块可能是由age值为3~17的文档组成的。如果mongos得到一个{"age":5}的査询请求,它就可以将查询路由到age值为3~17的块所在的分片。
进行写操作时,块内的文档数量和大小可能会发生改变。插入文档可使块包含更多的文档,删除文档则会减少块内文档的数量。如果我们针对儿童和中小学生制作游戏,那么这个age值为3~17的块可能会变得越来越大。几乎所有的用户都会被包含在这个块内,且在同一分片上。这就违背了我们分布式存放数据的初衷。因此,当一个块增长到特定大小时,MongoDB会自动将其拆分为两个较小的块。在本例中,该块可能会被拆分为一个age值为3~11的块和一个age值为12~17的块。注意,这两个小块包含了之前大块的所有文档以及age的全部域值。这些小块变大后,会被继续拆分为更小的块,直到包含age的全部域值。
块与块之间的age值范围不能有交集,如3~15和12~17。如果存在交集的话,那么MongoDB为了査询处于交集中的age值(如14)时,则需分别査找这两个块。只在一个块中进行査找效率会更高,尤其是在块分散在集群中时。
一个文档,属于且只属于一个块。这意味着,不可以使用数组字段作为片键,因为MongoDB会为数组创建多个索引条目。例如,如某个文档的age字段值是[5, 26, 83],该文档就会出现在三个不同的块中。
提示:一个常见的误解是同一个块内的数据保存在磁盘的同一片区域。这是不正确的,块并不影响mongod保存集合数据的方式。
3.1 块范围
可使用块包含的文档范围来描述块。新分片的集合起初只有一个块,所有文档都位于这个块中。此块的范围是负无穷到正无穷,在shell中用$minKey和$maxKey表示。
随着块的增长,MongoDB会自动将其分成两个块,范围分别是负无穷到<some value>和<some value>到正无穷。两个块中的<some value>值相同,范围较小的块包含比<some value>小的所有文档(但不包含<some value>值),范围较大的块包含从<some value>—直到正无穷的所有文档(包含<some value>值)。
用一个例子来更直观地说明:假如我们按照之前提到的"age"字段进行分片。所有"age"值为3~17的文档都包含在一个块中:3 < age <17。该块被拆分后,我们得到了两个较小的块,其中一个范围是3 < age < 12,另一个范围是12 < age < 17。这里的12就叫做拆分点(split point)。
块信息保存在config.chunks集合中。查看集合内容,会发现其中的文档如下(简洁起见,这里忽略了一些字段):
> db.chunks.find(criteria, {"min" : 1, "max" : 1})
{
"_id" : "test.users-age_-100.0",
"min" : {"age" : -100},
"max" : {"age" : 23}
}
{
"_id" : "test.users-age_23.0",
"min" : {"age" : 23},
"max" : {"age" : 100}
}
{
"_id" : "test.users-age_100.0",
"min" : {"age" : 100},
"max" : {"age" : 1000}
}
基于以上config.chunks文档,不同文档在块中的分布情况如下例所示:
- {"id" : 123, "age" : 50}
该文档位于第二个块中,因为第二个块包含age值为23〜100的所有文档。
- {"_id" : 456, "age" : 100}
该文档位于第三个块中,因为较小的边界值是包含在块中的。第二个块包含了 age值小于100的所有文档,但不包含等于100的文档。
- {"_id" : 789, "age" : -101}
该文档不位于上面所示的这些块中,而是位于一个比第一个块范围更小的块中。
可使用复合片键,工作方式与使用复合索引进行排序一样。假如在{__username__ : 1, "age" : 1}上有一个片键,那么可能会存在如下块范围:
{ "_id" : "test.users-username_MinKeyage_MinKey", "min" : { "username" : { "$minKey" : 1 }, "age" : { "$minKey" : 1 } }, "max" : { "username" : "user107487", "age" : 73 } } { "_id" : "test.users-username_\"user107487\"age_73.0", "min" : { "username" : "user107487", "age" : 73 }, "max" : { "username" : "user114978", "age" : 119 } } { "_id" : "test.users-username_\"user114978\"age_119.0", "min" : { "username" : "user114978", "age" : 119 }, "max" : { "username" : "user122468", "age" : 68 } }
因此,对于一个给定的用户名(或者是用户名和年龄),mongos可轻易找到其所对应的文档。但如果只给定年龄,mongos就必须査看所有(或者几乎所有)块。如果希望基于age的査询能够被路由到正确的块上,则需使用“相反”的片键:{"age" :1, "username" : 1}。从这个例子中我们可以得出一个结论:基于片键第二个字段的范围可能会出现在多个块中。
3.2 拆分块
mongos会记录在每个块中插入了多少数据,一旦达到某个阈值,就会检査是否需要对块进行拆分,如图14-1和图14-2所示。如果块确实需要被拆分,mongos就会在配置服务器上更新这个块的元信息。块拆分只需改变块的元数据即可,而无需进行数据移动。进行拆分时,配置服务器会创建新的块文档,同时修改旧的块范围(即"max"值)。拆分完成后,mongos会重置对原始块的追踪器,同时为新的块创建新的追踪器.


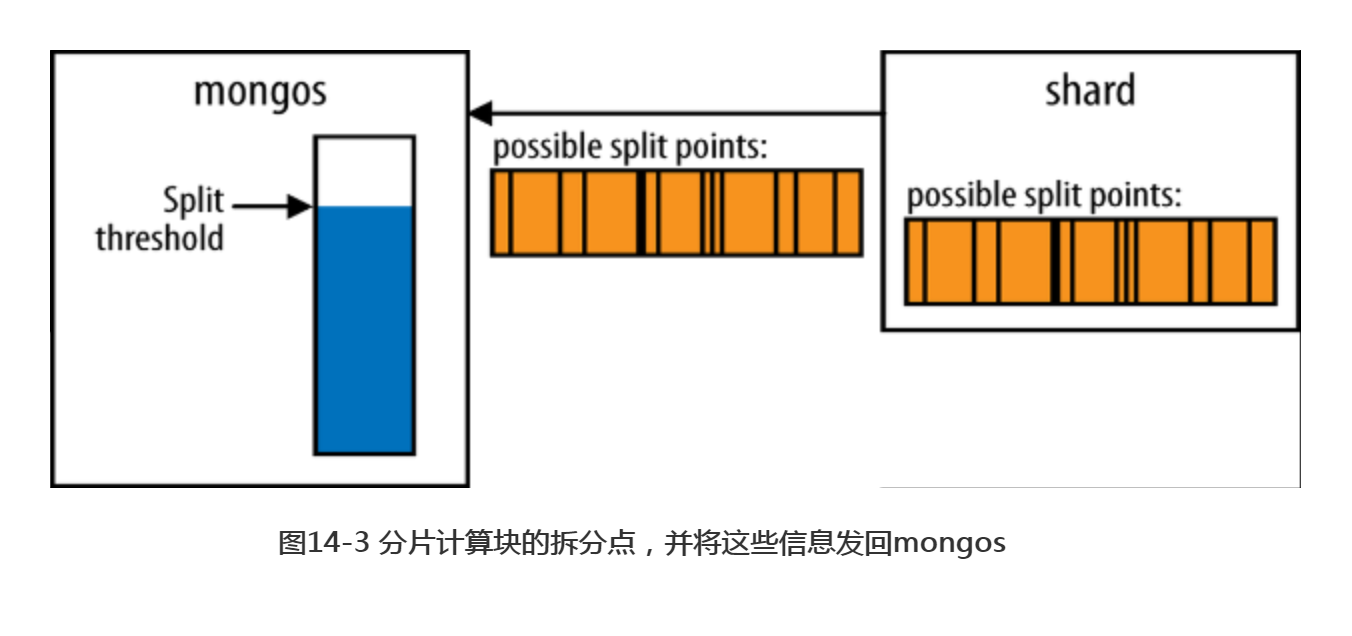
mongos向分片询问某块是否需被拆分时,分片会对块大小进行粗略的计算。如果发现块正在不断变大,它就会计算出合适的拆分点,然后将这些信息发送给mongos,如图14-3所示。
分片有时可能会找不到任何可用的拆分点(即使此块较大),因为合法拆分块方法有限。具有相同片键的文档必须保存在相同的块中,因此块只能在片键的值发生变化的点对块进行拆分。例如,如果片键的值等于age的值,则下列块可在片键发生变化的点被拆分:
{"age" : 13, "username" : "ian"}
{"age" : 13, "username" : "randolph"}
------------ // split point
{"age" : 14, "username" : "randolph"}
{"age" : 14, "username" : "eric"}
{"age" : 14, "username" : "hari"}
{"age" : 14, "username" : "mathias"}
------------ // split point
{"age" : 15, "username" : "greg"}
{"age" : 15, "username" : "andrew"}
mongos无需在每个可用的拆分点对块进行拆分,但拆分时只能从这些拆分点中选择一个。
例如,如果块包含下列文档,则此块不可拆分,除非应用开始插入不同片键的文档:
{"age" : 12, "username" : "kevin"}
{"age" : 12, "username" : "spencer"}
{"age" : 12, "username" : "alberto"}
{"age" : 12, "username" : "tad"}
因此,拥有不同的片键值是非常重要的。其他重要属性会在下一章讲到。
如果在mongos试图进行拆分时有一个配置服务器挂了,那么mongos就无法更新元数据,如图14-4所示。在进行拆分时,所有配置服务器都必须可用且可达。mongos如果不断接收到块的写请求,则会处于尝试拆分与拆分失败的循环中。只要配置服务器不可用于拆分,拆分就无法进行,mongos不断发起的拆分请求就会拖慢mongos和当前分片(每次收到的写请求都会重复图14-1到图14-4演示的过程)。这种mongos不断重复发起拆分请求却无法进行拆分的过程,叫做拆分风暴(split storm)。防止拆分风暴的唯一方法是尽可能保证配置服务器的可用和健康。也可重启mongos,重置写入计数器,这样它就不再处于拆分阈值点了。

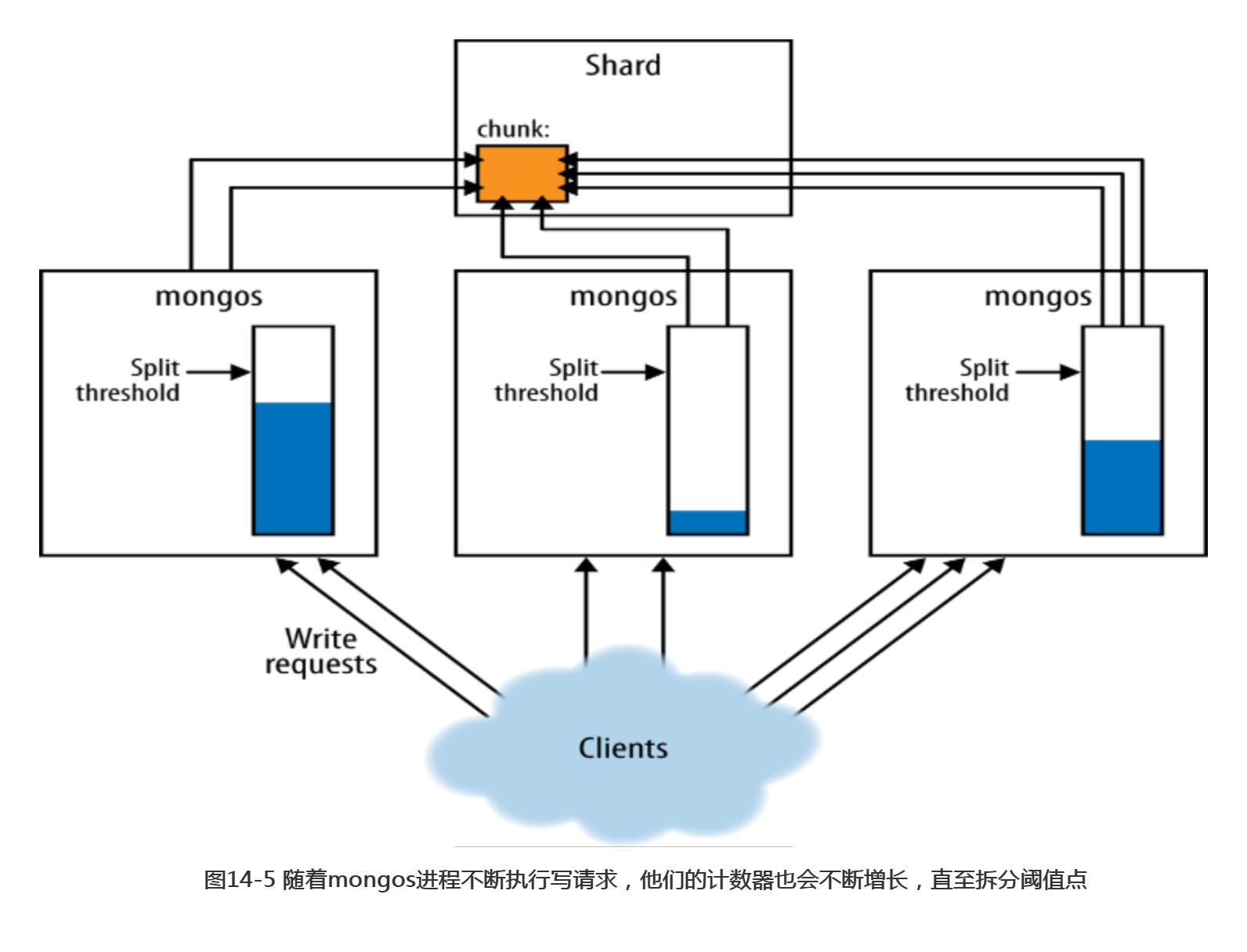
另一个问题是,mongos可能不会意识到它需要拆分一个较大的块。并没有一个全局的计数器用于追踪每个块到底有多大。每个mongos只是计算其收到的写请求是否达到了特定的阈值点(如图14-5所示)。也就是说,如果mongos进程频繁地上线和宕机,那么mongos在再次宕机之前可能永远无法收到足以达到拆分阈值点的写请求,因此块会变得越来越大,如图14-6所示。

防止这种情况发生的第一种方式是减少mongos进程的波动。尽可能保证mongos进程可用,而不是在需要的时候将其开启,不需要的时候又将其关掉。然而,实际部署中可能会发现,维持不需要的mongos持续运行开销过大。这时可选用另一种方式:使块的大小比实际预期稍小些,这样就更容易达到拆分阈值点。
可在启动mongos时指定- -nosplit选项,从而关闭块的拆分。
4.均衡器
均衡器(balancer)负责数据的迁移。它会周期性地检査分片间是否存在不均衡,如果存在,则会开始块的迁移。虽然均衡器通常被看作是单一实体,但毎个mongos有时也会扮演均衡器的角色。
每隔几秒钟,mongos就会尝试变身为均衡器。如果没有其他可用的均衡器,mongos就会对整个集群加锁,以防止配置服务器对集群进行修改,然后做一次均衡。均衡并不会影响mongos的正常路由操作,所以使用mongos的客户端不会受到影响。
查看config.locks集合,可得知哪一个mongos是均衡器:
> db.locks.findOne({"_id" : "balancer"})
{
"_id" : "balancer",
"process" : "router-23:27017:1355763351:1804289383",
"state" : 0,
"ts" : ObjectId("50cf939c051fcdb8139fc72c"),
"when" : ISODate("2012-12-17T21:50:20.023Z"),
"who" : "router-23:27017:1355763351:1804289383:Balancer:846930886",
"why" : "doing balance round"
}
config.locks集合会追踪所有集群范围的锁。_id为balancer的文档就是均衡器。从其中的Who字段可得知当前或曾经作为均衡器的mongos是哪一个:在本例中是 route-23:27017。 state字段表明均衡器是否正在运行:0表示处于非活动状态,2表示正在进行均衡(1表示mongos正在尝试得到锁,但还没有得到,通常不会看到状态1).
mongos成为均衡器后,就会检查每个集合的分块表,从而査看是否有分片达到了均衡阈值(balancing threshold)。不均衡的表现指,一个分片明显比其他分片拥有更多的块(精确的阈值有多种不同情况:集合越大越能承受不均衡状态)。如果检测到不均衡,均衡器就会开始对块进行再分布,以使每个分片拥有数量相当的块。如果没有集合达到均衡阈值,mongos就不再充当均衡器的角色了。
假如有一些集合到达了阈值,均衡器则会开始做块迁移。它会从负载比较大的分片中选择一个块,并询问该分片是否需要在迁移之前对块进行拆分。完成必要的拆分后,就会将块迁移至块数量较少的机器上。
使用集群的应用程序无需知道数据迁移:在数据迁移完成之前,所有的读写请求都会被路由到旧的块上。如果元数据更新完成,那么所有试图访问旧位置数据的mongos进程都会得到一个错误。这些错误应该对客户端不可见:mongos会对这些错误做静默处理,然后在新的分片上重新执行之前的操作。
有时会在mongos的日志中看到“unable to setShardVersion”的信息,这是一种很常见的错误。mongos在收到这种错误时,会查看配置服务器数据的新位置,并更新块分布表,然后重新执行之前的请求。如果成功从新的位置得到了数据,则会将数据返回给客户端。除了日志中会记录一条错误日志外,整个过程好像什么错误都没有发生过一样。
如果由于配置服务器不可用导致mongos无法获取块的新位置,则会向客户端返回错误。所以,应尽可能保证配置服务器处于可用状态。

