
Mongo副本集的组成
|
导航: Mongo副本集: 1.创建Mongo副本集。 2.Mongo副本集的组成。 3.Mongo从应用程序连接副本集。 4.Mongo副本集的管理。 |
本章介绍副本集的各个部分是如何组织在一起的,包括:
-
- 副本集成员如何复制新数据;
- 如何让新成员开始工作;
- 选举机制;
- 可能的服务器和网络故障。
1.同步
复制用于在多台服务器之间备份数据。MongoDB的复制功能是使用操作日志oplog 实现的,操作日志包含了主节点的每一次写操作。oplog是主节点的local数据库中的一个固定集合。备份节点通过査询这个集合就可以知道需要进行复制的操作。
每个备份节点都维护着自己的oplog,记录着每一次从主节点复制数据的操作。这样,每个成员都可以作为同步源提供给其他成员使用,如图10-1所示。备份节点从当前使用的同步源中获取需要执行的操作,然后在自己的数据集上执行这些操作,最后再将这些操作写入自己的oplog。如果遇到某个操作失败的情况(只有当同步源的数据损坏或者数据与主节点不一致时才可能发生),那么备份节点就会停止从当前的同步源复制数据。
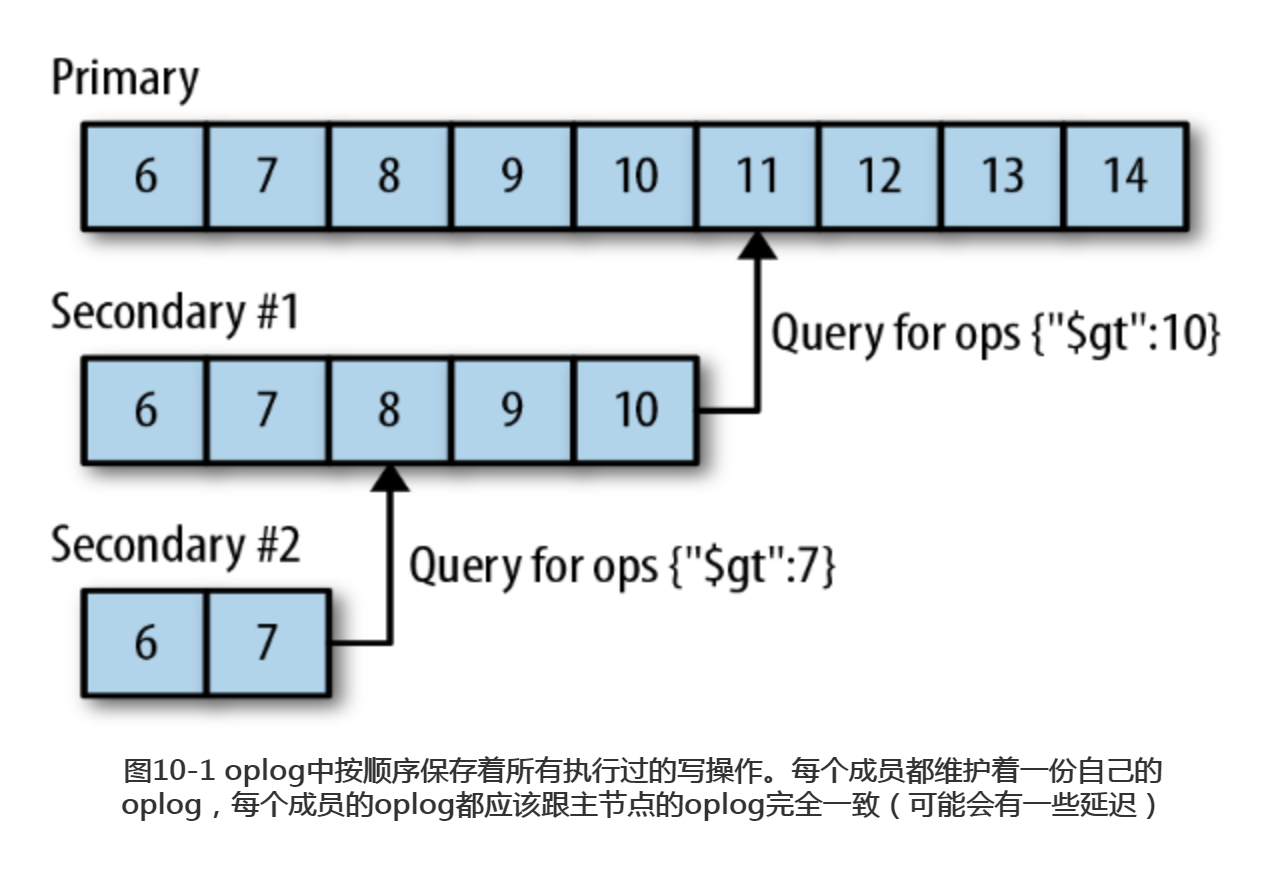
如果某个备份节点由于某些原因挂掉了,当它重新启动之后,就会自动从oplog中最后一个操作开始进行同步。由于复制操作的过程是先复制数据再写入oplog,所以,备份节点可能会在已经同步过的数据上再次执行复制操作。MongoDB在设计之初就考虑到了这种情况:将oplog中的同一个操作执行多次,与只执行一次的效果是一样的。
由于oplog大小是固定的,它只能保存特定数量的操作日志。通常,oplog使用空间的增长速度与系统处理写请求的速率近乎相同:如果主节点上每分钟处理了 1 KB 的写入请求,那么oplog很可能也会在一分钟内写入1KB条操作日志。但是,有一些例外情况:如果单次请求能够影响到多个文档(比如删除多个文档或者是多文档更新),oplog中就会出现多条操作日志。如果单个操作会影响多个文档,那么每个受影响的文档都会对应oplog中的一条日志。因此,如果执行db.coll.remove()删除了 1 000 000个文档,那么oplog中就会有1 000 000条操作日志,每条日志对应一个被删除的文档。如果执行大量的批量操作,oplog很快就会被填满。
1.1 初始化同步
副本集中的成员启动之后,就会检査自身状态,确定是否可以从某个成员那里进行同步。如果不行的话,它会尝试从副本的另一个成员那里进行完整的数据复制。这个过程就是初始化同步(initial syncing),包括几个步骤,可以从mongod的日志中看到。
(1)首先,这个成员会做一些记录前的准备工作:选择一个成员作为同步源,在local.me中为自己创建一个标识符,删除所有已存在的数据库,以一个全新的状态开始进行同步:
Mon Jan 30 11:09:18 [rsSync] replSet initial sync pending Mon Jan 30 11:09:18 [rsSync] replSet syncing to: server-1:27017 Mon Jan 30 11:09:18 [rsSync] build index local.me { _id: 1 } Mon Jan 30 11:09:18 [rsSync] build index done 0 records 0 secs Mon Jan 30 11:09:18 [rsSync] replSet initial sync drop all databases Mon Jan 30 11:09:18 [rsSync] dropAllDatabasesExceptLocal 1
注意,在这个过程中,所有现有的数据都会被删除。应该只在不需要保留现有数据的情况下做初始化同步(或者将数据移到其他地方),因为mongod会首先将现有数据删除。
(2) 然后是克隆(cloning),就是将同步源的所有记录全部复制到本地。这通常是整个过程中最耗时的部分:
Mon Jan 30 11:09:18 [rsSync] replSet initial sync clone all databases Mon Jan 30 11:09:18 [rsSync] replSet initial sync cloning db: db1 Mon Jan 30 11:09:18 [FileAllocator] allocating new datafile /data/db/db1.ns, filling with zeroes...
(3) 然后就进入oplog同步的第一步,克隆过程中的所有操作都会被记录到oplog 中。如果有文档在克隆过程中被移动了,就可能会被遗漏,导致没有被克隆,对于这样的文档,可能需要重新进行克隆:
Mon Jan 30 15:38:36 [rsSync] oplog sync 1 of 3 Mon Jan 30 15:38:36 [rsBackgroundSync] replSet syncing to: server-1:27017 Mon Jan 30 15:38:37 [rsSyncNotifier] replset setting oplog notifier to server-1:27017 Mon Jan 30 15:38:37 [repl writer worker 2] replication update of non-mod failed: { ts: Timestamp 1352215827000|17, h: -5618036261007523082, v: 2, op: "u", ns: "db1.someColl", o2: { _id: ObjectId('50992a2a7852201e750012b7') }, o: { $set: { count.0: 2, count.1: 0 } } } Mon Jan 30 15:38:37 [repl writer worker 2] replication info adding missing object Mon Jan 30 15:38:37 [repl writer worker 2] replication missing object not found on source. presumably deleted later in oplog
上面是一个比较粗略的日志,显示了有文档需要重新克隆的情况。在克隆过程中也可能不会遗漏文档,这取决于流量等级和同步源上的操作类型。
(4) 接下来是oplog同步过程的第二步,用于将第一个oplog同步中的操作记录下来。
Mon Jan 30 15:39:41 [rsSync] oplog sync 2 of 3
这个过程比较简单,也没有太多的输出。只有在没有东西需要克隆时,这个过程才会与第一个不同。
(5) 到目前为止,本地的数据应该与主节点在某个时间点的数据集完全一致了,可以开始创建索引了。如果集合比较大,或者要创建的索引比较多,这个过程会很耗时间:
Mon Jan 30 15:39:43 [rsSync] replSet initial sync building indexes Mon Jan 30 15:39:43 [rsSync] replSet initial sync cloning indexes for : db1 Mon Jan 30 15:39:43 [rsSync] build index db.allObjects { someColl: 1 } Mon Jan 30 15:39:44 [rsSync] build index done. scanned 209844 total records. 1.96 secs
(6) 如果当前节点的数据仍然远远落后于同步源,那么oplog同步过程的最后一步就是将创建索引期间的所有操作全部同步过来,防止该成员成为备份节点。
Tue Nov 6 16:05:59 [rsSync] oplog sync 3 of 3
(7) 现在,当前成员已经完成了初始化同步,切换到普通同步状态,这时当前成员就可以成为备份节点了 :
Mon Jan 30 16:07:52 [rsSync] replSet initial sync done Mon Jan 30 16:07:52 [rsSync] replSet syncing to: server-1:27017 Mon Jan 30 16:07:52 [rsSync] replSet SECONDARY
如果想跟踪初始化同步过程,最好的方式就是查看服务器日志。
从操作者的角度来说,初始化同步是非常简单的:使用空的数据目录启动mongod 即可。但是,更多时候可能需要从备份中恢复(其他章节会详细介绍)而不是进行初始化同步。从备份中恢复的速度比使用mongod复制全部数据的速度快得多。
克隆也可能损坏同步源的工作集(working set)。实际部署之后,可能会有一个频繁使用的数据子集常驻内存(因为操作系统要频繁访问这个子集)。执行初始化同步时,会强制将当前成员的所有数据分页加载到内存中,这会导致需要频繁访问的数据不能常驻内存,所以会导致很多请求变慢,因为原本只要在RAM (内存)中就可以处理的数据要先从磁盘上加载。不过,对于比较小的数据集和性能比较好的服务器,初始化同步仍然是个简单易用的选项。
初始化同步过程中经常遇到的问题是,第(2)步(克隆)或者第(5)步(创建索引) 耗费了太长的时间。这种情况下,新成员就与同步源的oplog “脱节”:新成员远远落后于同步源,导致新成员的数据同步速度赶不上同步源的变化速度,同步源可能会将新成员需要复制的某些数据覆盖掉。
这个问题没有有效的解决办法,除非在不太忙时执行初始化同步,或者是从备份中恢复数据。如果新成员与同步源的oplog脱节,初始化同步就无法正常进行。下一节会更深入地介绍。
1.2 处理陈旧数据
如果备份节点远远落后于同步源当前的操作,那么这个备份节点就是陈旧的 (stale)。陈旧的备份节点无法跟上同步源的节奏,因为同步源上的操作领先太多太多:如果要继续进行同步,备份节点需要跳过一些操作。如果从备份节点曾经停机过,写入量超过了自身处理能力,或者是有太多的读请求,这些情况都可能导致备份节点陈旧。
当一个备份节点陈旧之后,它会査看副本集中的其他成员,如果某个成员的oplog 足够详尽,可以用于处理那些落下的操作,就从这个成员处进行同步。如果任何一个成员的oplog都没有参考价值,那么这个成员上的复制操作就会中止,这个成员需要重新进行完全同步(或者是从最近的备份中恢复)。
为了避免陈旧备份节点的出现,让主节点使用比较大的oplog保存足够多的操作日志是很重要的。大的oplog会占用更多的磁盘空间。通常来说,这是一个比较好的折衷选择,因为磁盘会越来越便宜,而且实际中使用的oplog只有一小部分,因此oplog不占用太多RAM。关于oplog空间占用的更多信息,mongo副本集管理篇章会详细介绍。
2.心跳
每个成员都需要知道其他成员的状态:哪个是主节点?哪个可以作为同步源?哪个挂掉了?为了维护集合的最新视图,每个成员每隔两秒钟就会向其他成员发送一个心跳请求(heartbeat request)。心跳请求的信息量非常小,用于检査每个成员的状态。
心跳最重要的功能之一就是让主节点知道自己是否满足集合“大多数”的条件。如果主节点不再得到“大多数”服务器的支持,它就会退位,变成备份节点。
2.1 成员状态
各个成员会通过心跳将自己的当前状态告诉其他成员。我们已经讨论过两种状态了: 主节点和备份节点。还有其他一些常见状态。
- STARTUP
成员刚启动时处于这个状态。在这个状态下,MongoDB会尝试加载成员的副本集配置。配置加载成功之后,就进入STARTUP2状态。
- STARTUP2
整个初始化同步都处于这个状态,但是如果是在普通成员上,这个状态只会持续几秒钟。在这个状态下,MongoDB会创建几个线程,用于处理复制和选举,然后就会切换到RECOVERING状态。
- RECOVERING
这个状态表明成员运转正常,但是暂时还不能处理读取请求。如果有成员处于这个状态,可能会造成轻微的系统过载,以后可能会经常见到。
启动时,成员需要做一些检查以确保自己处于有效状态,之后才可以处理读取请求。在启动过程中,成为备份节点之前,每个成员都要经历RECOVERING状态。在处理非常耗时的操作时,成员也可能进入RECOVERING状态。,比如压缩或者是响应 replSetMaintenance 命令。
当一个成员与其他成员脱节时,也会进入RECOVERING状态。通常来说,这时这个成员处于无效状态,需要重新同步。但是,成员这时并没有进入错误状态,因为它期望发现一个拥有足够详尽oplog的成员,然后继续同步oplog,最后回到正常状态。
- ARBITER
在正常的操作中,仲裁者应该始终处于ARBITER状态。
系统出现问题时会处于下面这些状态。
- DOWN
如果一个正常运行的成员变得不可达,它就处于DOWN状态。注意,如果有成员被报告为DOWN状态,它有可能仍然处于正常运行状态,不可达的原因可能是网络问题。
- UNKNOWN
如果一个成员无法到达其他任何成员,其他成员就无法知道它处于什么状态,会将其报告为UNKNOWN状态。通常,这表明这个未知状态的成员挂掉了,或者是两个成员之间存在网络访问问题。
- REMOVED
当成员被移出副本集时,它就处于这个状态。如果被移出的成员又被重新添加到副本集中,它就会回到“正常”状态。
- ROLLBACK
如果成员正在进行数据回滚(详见10.4节),它就处于ROLLBACK状态。回滚过 程结束时,服务器会转换为RECOVERING状态,然后成为备份节点。
- FATAL
如果一个成员发生了不可挽回的错误,也不再尝试恢复正常的话,它就处于 FATAL状态。应该査看详细日志来查明为何这个成员处于FATAL状态(使用 "replSet FATAL"关键词在日志上执行grep,就可以找到成员进入FATAL状态的时间点)。这时,通常应该重启服务器,进行重新同步或者是从备份中恢复。
3.选举
当一个成员无法到达主节点时,它就会申请被选举为主节点。希望被选举为主节点的成员,会向它能到达的所有成员发送通知。如果这个成员不符合候选人要求,其他成员可能会知道相关原因:这个成员的数据落后于副本集,或者是已经有一个运行中的主节点(那个力求被选举成为主节点的成员无法到达这个主节点)。在这些情况下,其他成员不会允许进行选举。
假如没有反对的理由,其他成员就会对这个成员进行选举投票。如果这个成员得到副本集中“大多数”赞成票,它就选举成功,会转换到主节点状态。如果达不到“大多数”的要求,那么选举失败,它仍然处于备份节点状态,之后还可以再次申请被选举为主节点。主节点会一直处于主节点状态,除非它由于不再满足“大多数”的要求或者挂了而退位,另外,副本集被重新配置也会导致主节点退位。
假如网络状况良好,“大多数”服务器也都在正常运行,那么选举过程是很快的。如果主节点不可用,2秒钟(之前讲过,心跳的间隔是2秒)之内就会有成员发现这个问题,然后会立即开始选举,整个选举过程只会花费几毫秒。但是,实际情况可能不会这么理想:网络问题,或者是服务器过载导致响应缓慢,都可能触发选举。在这种情况下,心跳会在最多20秒之后超时。如果选举打成平局,每个成员都需要等待30秒才能开始下一次选举。所以,如果有太多错误发生的话,选举可能会花费几分钟的时间。
4.回滚
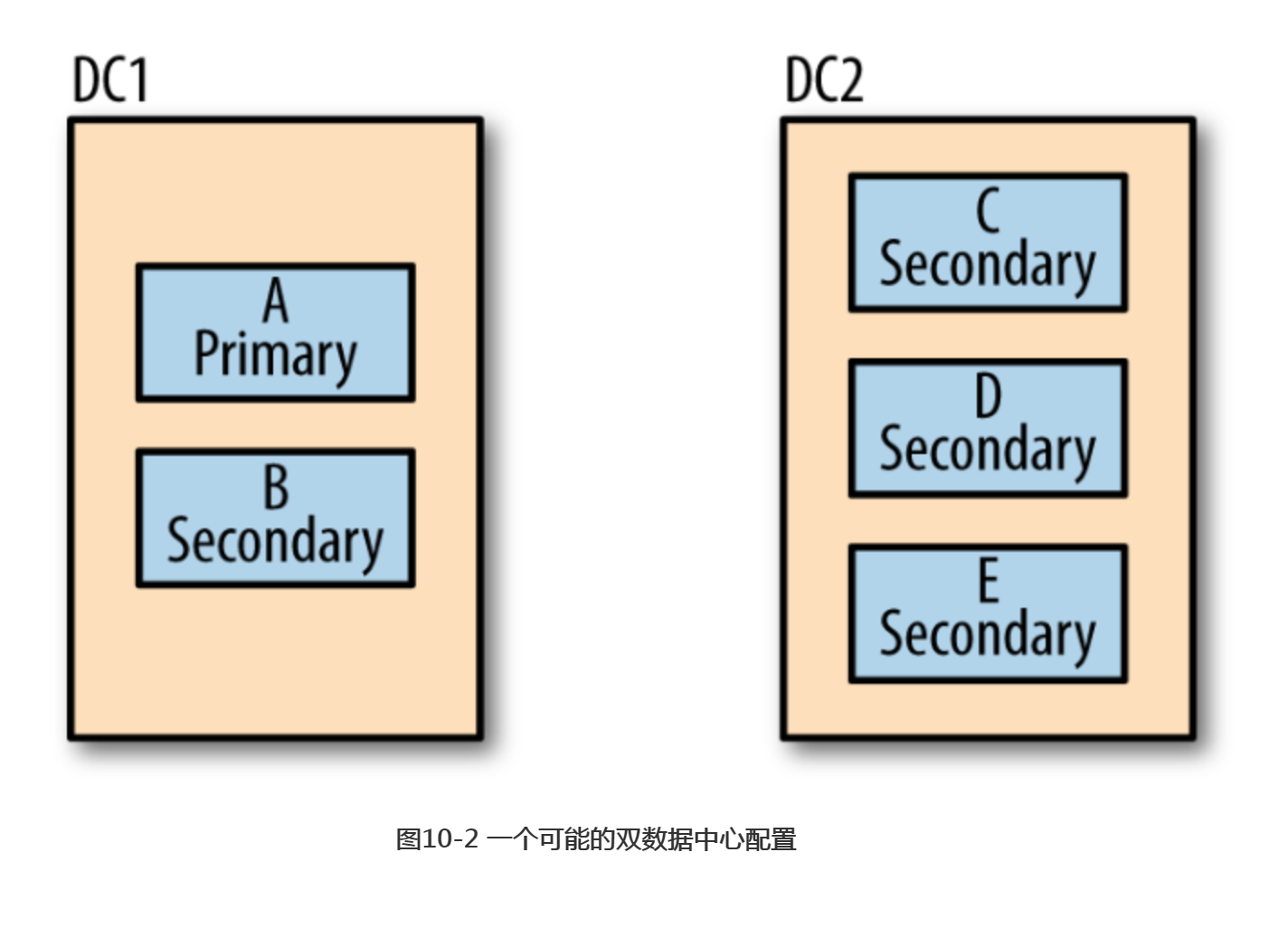
根据上一节讲述的选举过程,如果主节点执行了一个写请求之后挂了,但是备份节点还没来得及复制这次操作,那么新选举出来的主节点就会漏掉这次写操作。假如有两个数据中心,其中一个数据中心拥有一个主节点和一个备份节点,另一个数据中心拥有三个备份节点,如图10-2所示。
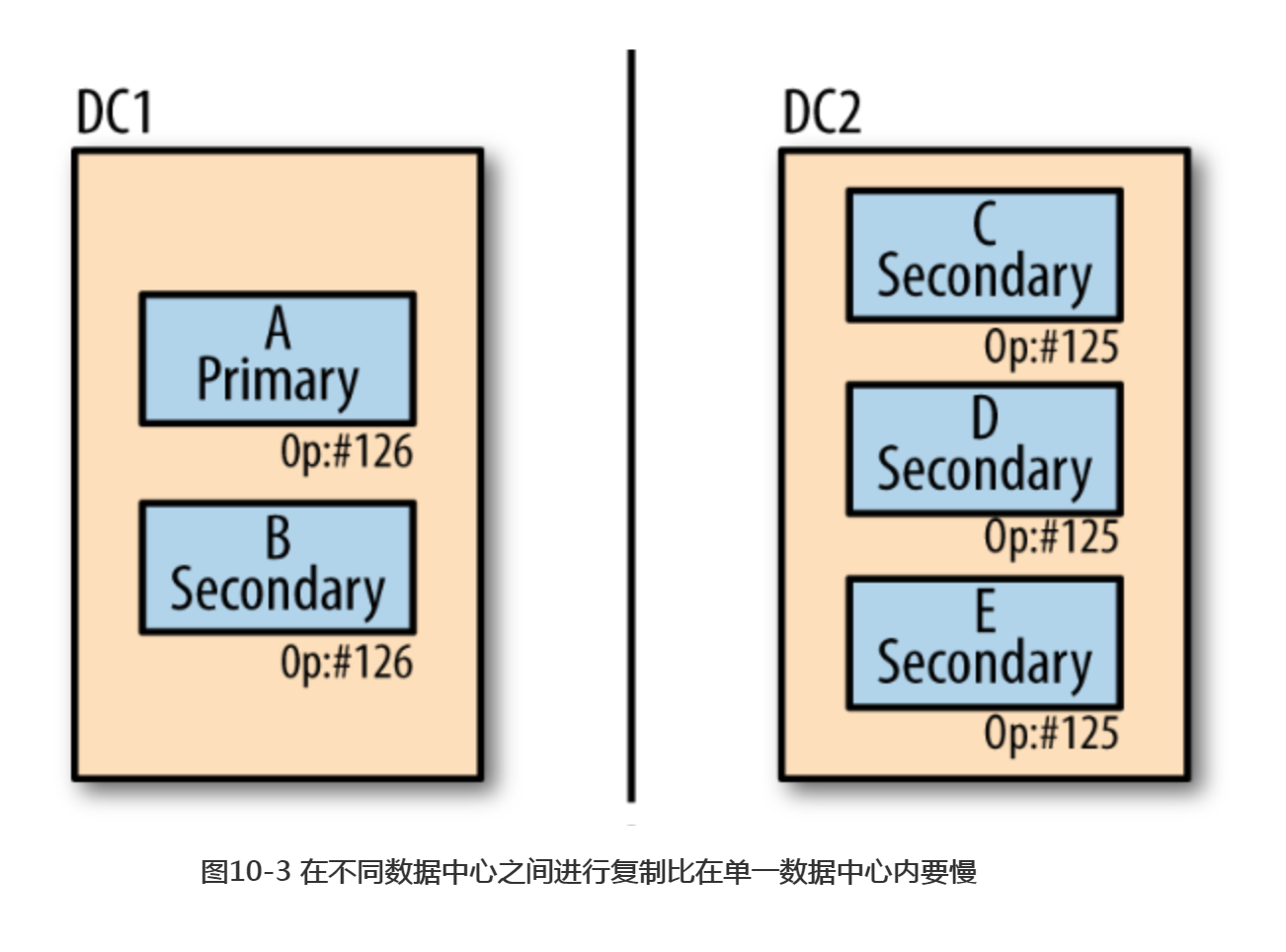
如果这两个数据中心之间出现了网络故障,如图10-3所示。其中左边第一个数据中心最后的操作是126,但是126操作还没有被复制到另边的数据中心。
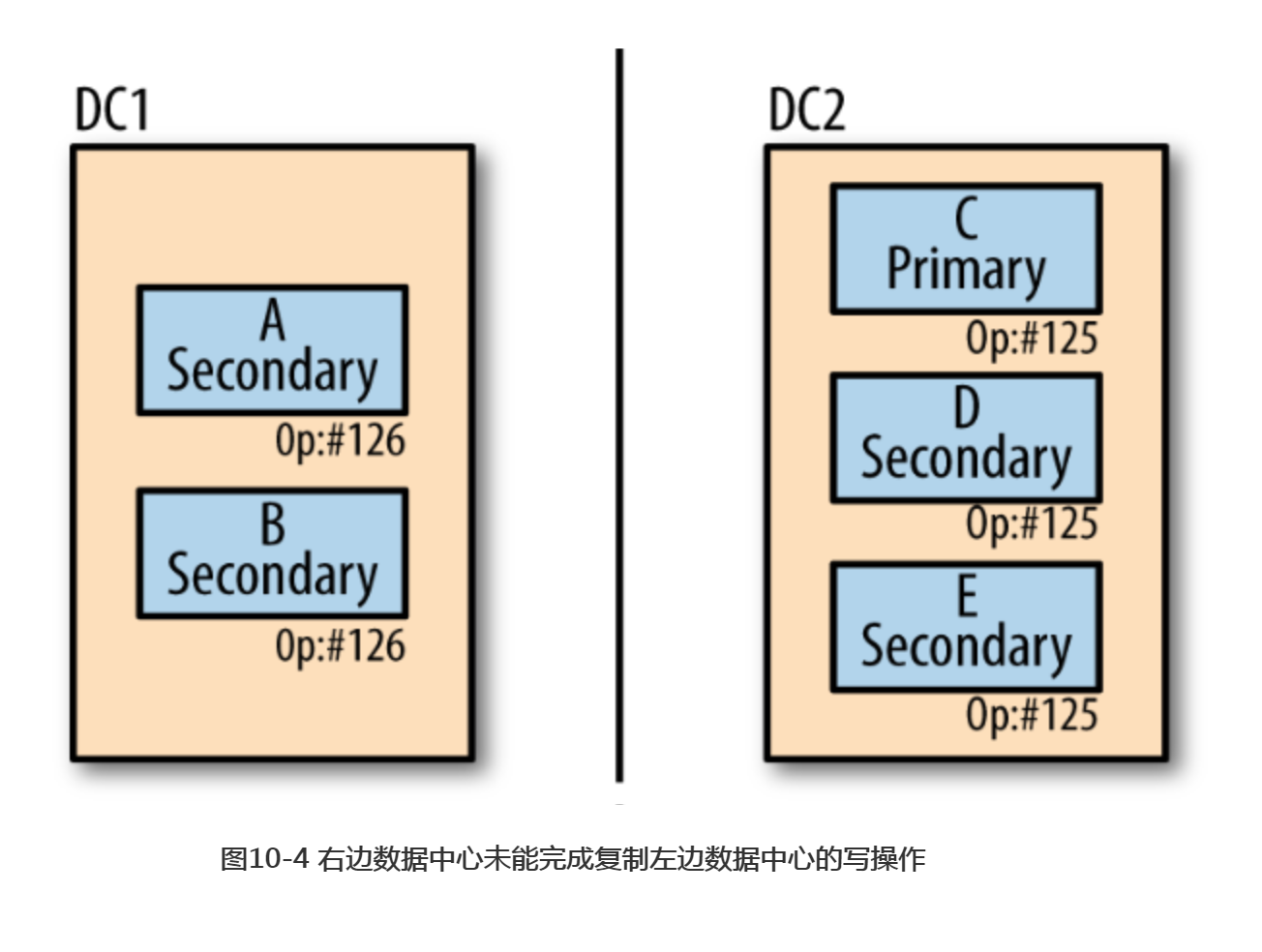
右边的数据中心仍然满足副本集“大多数”的要求(一共5台服务器,3台即可满足要求)。因此,其中一台服务器会被选举成为新的主节点,这个新的主节点会继续处理后续的写入操作,如图10-4所示。
网络恢复之后,左边数据中心的服务器就会从其他服务器开始同步126之后的操作, 但是无法找到这个操作。这种情况发生的时候,A和B会进入回滚(rollback)过程。回滚会将失败之前未复制的操作撤消。拥有126操作的服务器会在右边数据中心服务器的oplog中寻找共同的操作点。之后会定位到125操作,这是两个数据中心相匹配的最后一个操作。图10-5显示了oplog的情况。
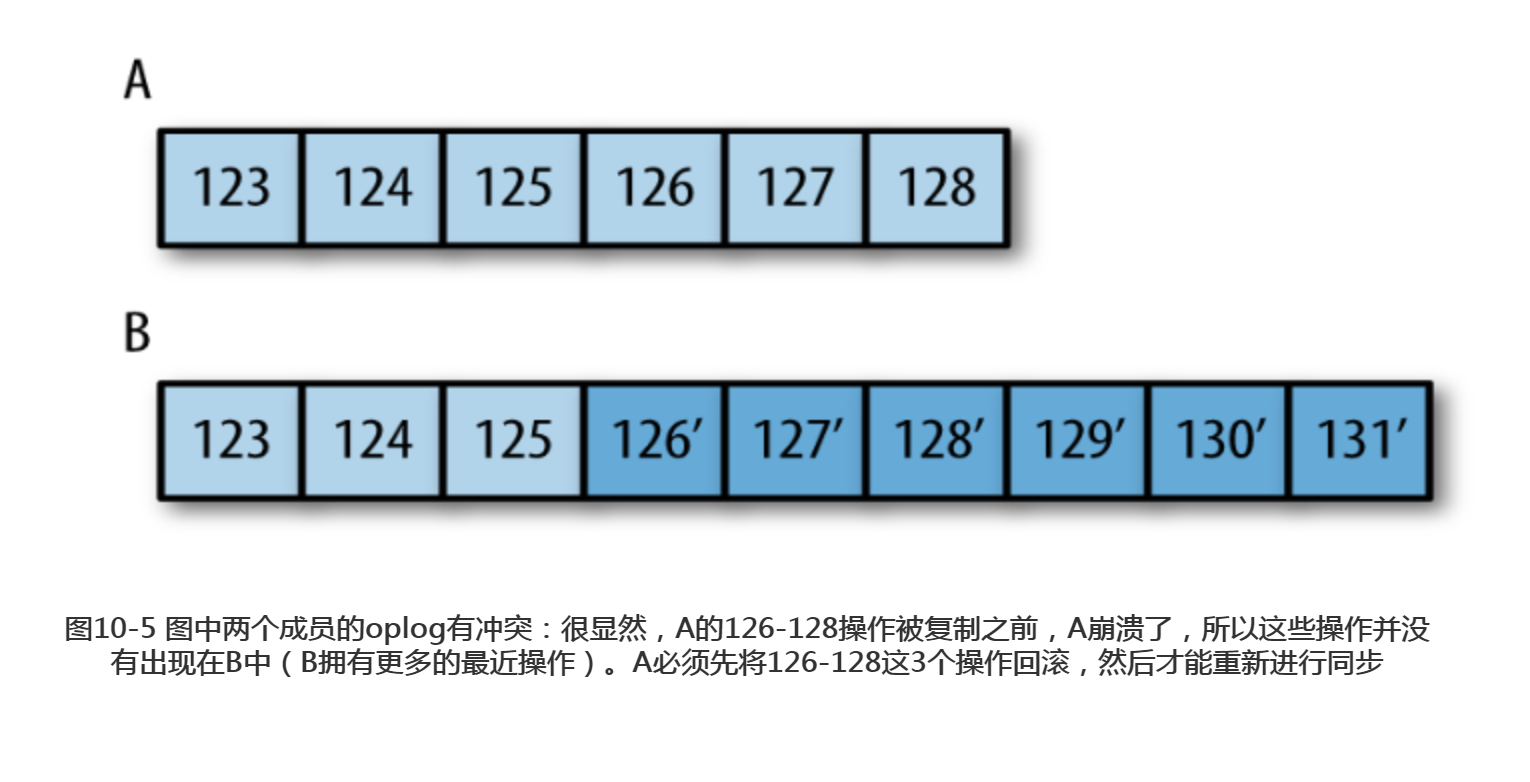
这时,服务器会査看这些没有被复制的操作,将受这些操作影响的文档写入一个.bson文件,保存在数据目录下的rollback目录中。如果126是一个更新操作,服务器会将被126更新的文档写入collectionName.bson文件。然后会从当前主节点中复制这个文档。
下面是一次典型的回滚过程产生的日志:
Fri Oct 7 06:30:35 [rsSync] replSet syncing to: server-1 Fri Oct 7 06:30:35 [rsSync] replSet our last op time written: Oct 7 06:30:05:3 Fri Oct 7 06:30:35 [rsSync] replset source's GTE: Oct 7 06:30:31:1 Fri Oct 7 06:30:35 [rsSync] replSet rollback 0 Fri Oct 7 06:30:35 [rsSync] replSet ROLLBACK Fri Oct 7 06:30:35 [rsSync] replSet rollback 1 Fri Oct 7 06:30:35 [rsSync] replSet rollback 2 FindCommonPoint Fri Oct 7 06:30:35 [rsSync] replSet info rollback our last optime: Oct 7 06:30:05:3 Fri Oct 7 06:30:35 [rsSync] replSet info rollback their last optime: Oct 7 06:30:31:2 Fri Oct 7 06:30:35 [rsSync] replSet info rollback diff in end of log times: -26 seconds Fri Oct 7 06:30:35 [rsSync] replSet rollback found matching events at Oct 7 06:30:03:4118 Fri Oct 7 06:30:35 [rsSync] replSet rollback findcommonpoint scanned : 6 Fri Oct 7 06:30:35 [rsSync] replSet replSet rollback 3 fixup Fri Oct 7 06:30:35 [rsSync] replSet rollback 3.5 Fri Oct 7 06:30:35 [rsSync] replSet rollback 4 n:3 Fri Oct 7 06:30:35 [rsSync] replSet minvalid=Oct 7 06:30:31 4e8ed4c7:2 Fri Oct 7 06:30:35 [rsSync] replSet rollback 4.6 Fri Oct 7 06:30:35 [rsSync] replSet rollback 4.7 Fri Oct 7 06:30:35 [rsSync] replSet rollback 5 d:6 u:0 Fri Oct 7 06:30:35 [rsSync] replSet rollback 6 Fri Oct 7 06:30:35 [rsSync] replSet rollback 7 Fri Oct 7 06:30:35 [rsSync] replSet rollback done Fri Oct 7 06:30:35 [rsSync] replSet RECOVERING Fri Oct 7 06:30:36 [rsSync] replSet syncing to: server-1 Fri Oct 7 06:30:36 [rsSync] replSet SECONDARY
服务器开始从另一个成员进行同步(在本例中是server-1),但是发现无法在同步源中找到自己的最后一次操作。这时,它就会切换到回滚状态("replSet ROLLBACK")进行回滚。
第2步,服务器在两个oplog中找到一个共同的点,是26秒之前的一个操作。然后服务器就会将最近26秒内执行的操作从oplog中撤销。回滚完成之后,服务器就进入RECOVERING状态开始进行正常同步。
如果要将被回滚的操作应用到当前主节点,首先使用mongorestore命令将它们加载到一个临时集合:
$ mongorestore --db stage --collection stuff \
> /data/db/rollback/important.stuff.2012-12-19T18-27-14.0.bson
现在应该在shell中将这些文档与同步后的集合进行比较。例如,如果有人在被回滚的成员上创建了一个“普通”索引,而当前主节点创建了一个唯一索引,那么就需要确保被回滚的数据中没有重复文档,如果有的话要去除重复。
如果希望保留staging集合中当前版本的文档,可以将其载入主集合:
> staging.stuff.find().forEach(function(doc) {
... prod.stuff.insert(doc);
... })
对于只允许插入的集合,可以直接将被回滚的文档插入主集合。但是,如果是在集合上执行更新操作,在合并回滚数据时就要非常小心地对待。
一个经常会被误用的成员配置选项是设置每个成员的投票数量。改变成员的投票数量通常不会得到想要的结果,而且很可能会导致大量的回滚操作(所以上一章的成员属性列表中没有介绍这个选项)。除非做好了定期处理回滚的准备,否则不要改变成员的投票数量。
从应用程序连接至mongo章节会讲述如何阻止回滚。
4.1 如果回滚失败
某些情况下,如果要回滚的内容太多,MongoDB可能承受不了。如果要回滚的数据量大于300 MB,或者要回滚30分钟以上的操作,回滚就会失败。对于回滚失畋的节点,必须要重新同步。
这种情况最常见的原因是备份节点远远落后于主节点,而这时主节点却挂了。如果其中一个备份节点成为主节点,这个主节点与旧的主节点相比,缺少很多操作。为了保证成员不会在回滚中失败,最好的方式是保持备份节点的数据尽可能最新。

