
Nginx负载均衡
|
导航: 这里将Nginx的一些配置进行整合。根据导航比较容易找到对应的文档。资料来自于weixueyuan 5.Nginx 缓存 |
随着业务量的增加,互联网应用产品对业务处理能力和计算强度的要求也相应增大,为了满足业务需求,这些产品广泛应用了提升业务处理能力的负载均衡技术。
负载均衡是 Nginx 最重要的功能应用,Nginx 异步架构的特性,使其可以轻松处理高并发请求。高并发的请求发送到 Nginx 后被 Nginx 按照负载均衡策略分发给被代理服务器来做复杂的计算、处理和响应,当业务量增加的时候可以实现客户端无感知地被代理服务器集群扩容操作。
1.Nginx负载均衡模块简述
Nginx 负载均衡是由代理模块和上游(upstream)模块共同实现的,Nginx 通过代理模块的反向代理功能将用户请求转发到上游服务器组,上游模块通过指定的负载均衡策略及相关的参数配置将用户请求转发到目标服务器上。上游模块可以与 Nginx 的代理指令(proxy_pass)、FastCGI 协议指令(fastcgi_pass)、uWSGI 协议指令(uwsgi_pass)、SCGI 协议指令(scgi_pass)、memcached 指令(memcached_pass)及 gRPC 协议指令(grpc_pass)实现多种协议后端服务器的负载均衡。
1.服务器配置指令
Nginx 上游模块定义了 upstream 指令域,在该指令域内可设置服务器、负载均衡策略等负载均衡配置,配置样例如下,具体指令说明如下面表格中所示。
upstream backend { server backend1.example.com weight=5; # 被代理服务器端口号为80,权重为5 server backend2.example.com:8080; # 被代理服务器端口号为8080,默认权重为1 server unix:/tmp/backend3; server backup1.example.com:8080 backup; # 该被代理服务器为备份状态 server backup2.example.com:8080 backup; # 该被代理服务器为备份状态 } server { location / { proxy_pass http://backend; # 将客户端请求反向代理到上游服务器组backend } }
| 表:服务器指令 | |
| 名称 | 服务器指令 |
| 指令 | server |
| 作用域 | upstream |
| 配置格式 | address[parameters]; |
| 指令说明 | 设定上游服务器组的服务器地址及连接参数 |
关于上表有以下几点需要注意:
-
- 服务器地址可以是指定端口的 IP、域名或 Unix 套接字;
- 如不指定端口,默认端口号为 80。
| 表:服务器指令参数 | ||||
| 参数 | 参数名称 | 参数类型 | 默认值 | 参数说明 |
| weight | 权重 | int | 1 | 设置服务器的权重 |
| max_fails | 最大失败数 | int | 1 |
被代理服务器在 fail timeout 规定时间内的最大请求失败次数,超过设定值后,被代理服务器便被认为不可用。是否失败由 proxy_next_upstream、fastcgi_next_upstream、uwsgi_next_upstream、scgi_next_upstream、memcached_next_upstream 及 grpe_next_upstream 指令定义。0 表示关闭被代理服务器的失败检测功能 |
| fail_timeout | 失败超时 | time | 10s | 被代理服务器被置为不可用的最长时间及被代理服务器被连续失败检测的最长时间 |
| backup | 备份服务器 | -- | -- | 将被代理服务器标为备份状态,当其他非备份被代理服务器不可用时,会把请求转发给备份被代理服务器 |
| down | 无效服务器 | -- | -- | 将被代理服务器标为不可用状态 |
| max_conns | 最大连接数 | int | 0 | 与被代理服务器建立活动连接的最大数量,默认值 0 表示没有限制 |
| resolve | 动态解析 | -- | -- | 在被代理服务器域名对应的 IP 变化时,自动更新被代理服务器的 IP,该参数依赖 resolver 指令设置的域名解析服务器。仅对商业版本有效 |
| service | DNS SRV 记录 | name | -- | DNS SRV 记录设置。仅对商业版本有效 |
| slow_start | 慢恢复时间 | time | 0 | 不可用服务器在设置时间内检测持续有效后便被恢复正常,默认关闭。仅对商业版本有效 |
其中,slow_start 参数不能与 Hash 负载均衡方法一同使用;若上游服务器组中只有一台被代理服务器,则 max_fails、fail_timeout 和 slow_start 参数都会被忽略,并且这个服务器将永远不会被置为无效。
| 表:共享内存区指令 | |
| 名称 | 共享内存区指令 |
| 指令 | zone |
| 作用域 | upstream |
| 配置格式 | name[size]; |
| 指令说明 | 设定共享内存区域的名称及大小,用以在多个工作进程间共享配置及运行时的状态 |
| 表:长连接最大请求数指令 | |
| 名称 | 长连接最大请求数指令 |
| 指令 | keepalive_requests |
| 作用域 | upstream |
| 指令格式 | number; |
| 默认值 | 100; |
| 指令说明 |
设置每个与被代理服务器建立的长连接中传输请求的最大数量,超过这个值后, 该连接将被关闭 |
| 表:长连接缓存数 | |
| 名称 | 长连接缓存数 |
| 指令 | keepalive |
| 作用域 | upstream |
| 指令格式 | connections; |
| 指令说明 |
当 Nginx 与被代理服务器建立长连接时,设定每个工作进程可以缓存的与当前上 游服务器组中被代理服务器保持长连接的数量。当超过设定值时,将根据最近最少 使用算法(LRU)关闭连接 |
注意:该指令不会对活跃的 TCP 连接数有影响。
| 表:长连接缓存超时时间 | |
| 名称 | 长连接缓存超时时间 |
| 指令 | keepalive_timeout |
| 作用域 | upstream |
| 指令格式 | timeout; |
| 默认值 | 60; |
| 指令说明 |
设置长连接缓存中,每个连接的超时时间, 被缓存的连接超过这个时间仍未被激活使用时将被关闭 |
2.负载均衡策略指令
Nginx 支持多种负载均衡策略,如轮询(Round Robin)、一致性哈希(Consistent Hash)、IP 哈希(IP Hash)、最少连接(least_conn)等。Nginx 的默认负载均衡策略为轮询策略,不需要配置指令,轮询策略通过 server 的权重参数可实现手动分配的加权轮询策略。
负载均衡策略配置指令均应编辑在 upstream 指令域的最上方,常见的配置指令如下面表格中所示。
| 表:哈希策略 | |
| 名称 | 哈希策略 |
| 指令 | hash |
| 作用域 | upstream |
| 指令格式 | key[consistent]; |
| 默认值 | -- |
| 指令说明 |
设置用于哈希策略计算哈希值的键值,并对上游服务器组启用哈希的负载均衡策略。 键值可以是文本、变量及其组合,当 consistent 参数被指定时,将启用 Ketama 一致性哈希的负载均衡策略 |
配置样例如下:
upstream backend { hash $request_uri; # 以客户端请求URI为计算哈希值的key ... } upstream backend { hash $request_uri consistent; # 以客户端请求URI为计算哈希值的key,采用一致性哈希算法 ... }
| 表:IP 哈希策略 | |
| 名称 | IP 哈希策略 |
| 指令 | ip_hash |
| 作用域 | upstream |
| 默认值 | -- |
| 指令说明 |
设置启用 IP 哈希负载均衡策略,根据客户端的 IPv4 地址的前三个八位字节或整个 IPv6 地址作为哈希键计算哈希值,该方法确保同一客户端的请求总会被同一被代理服 务器处理。当 IP 哈希值对应的被代理服务器不可用时,请求将被分配给其他服务器 |
配置样例如下:
upstream backend { ip_hash; # 启用IP哈希负载均衡策略 server backend1.example.com; server backend2.example.com; server backend3.example.com down; server backend4.example.com; }
当服务器组中一台服务器被临时删除时,可使用 down 参数标记,那么客户端 IP 哈希值将会保留。
| 表:最少连接策略 | |
| 名称 | 最少连接策略 |
| 指令 | least_conn |
| 作用域 | upstream |
| 默认值 | -- |
| 指令说明 |
在考虑上游服务器组中各服务器权重的前提下,将客户 端请求分配给拥有最少活跃连接被代理服务器的负载均衡策略 |
配置样例如下:
upstream backend { least_conn; # 启用最少连接负载均衡策略 server backend1.example.com; server backend2.example.com; server backend4.example.com; }
| 表:随机负载策略 | |
| 名称 | 随机负载策略 |
| 指令 | random |
| 作用域 | upstream |
| 默认值 | -- |
| 指令说明 |
在考虑上游服务器组中各服务器权重的前提下, 将客户端请求分配给随机选择的被代理服务器 |
配置样例如下:
upstream backend { random; # 每个请求都被随机发送到某个服务器 server backend1.example.com; server backend2.example.com; server backend4.example.com; }
指令值参数 two,该参数表示随机选择两台被代理服务器,然后使用指定的负载策略进行选择,默认方法为 least_conn;可被指定的负载策略为 least_conn、least_time(仅对商业版有效)。
2.Nginx负载均衡策略
负载均衡技术是将大量的客户端请求通过特定的策略分配到集群中的节点,实现快速响应的应用技术。在应对高并发的应用请求时,单节点的应用服务计算能力有限,无法满足客户端的响应需求,通过负载均衡技术,可以将请求分配到集群中的多个节点中,让多个节点分担高并发请求的运算,快速完成客户端的请求响应。
1.轮询
轮询(Round Robin)策略是 Nginx 配置中默认的负载均衡策略,该策略将客户端的请求依次分配给后端的服务器节点,对后端集群中的服务器实现轮流分配。轮询策略绝对均衡,且实现简单,但也会因后端服务器处理能力的不同而影响整个集群的处理性能。
1) 加权轮询
在 Nginx 的轮询策略中,为了避免因集群中服务器性能的差异对整个集群性能造成影响,在轮询策略的基础上增加了权重参数,让使用者可以手动根据集群中各服务器的性能将请求数量按照权重比例分配给不同的被代理服务器。
2) 平滑轮询
在加权轮询策略中,会按照权重的高低分配客户端请求,若按照高权重分配完再进行低权重分配的话,可能会出现的情况是高权重的服务器一直处于繁忙状态,压力相对集中。Nginx 通过平滑轮询算法,使得上游服务器组中的每台服务器在总权重比例分配不变的情况下,均能参与客户端请求的处理,有效避免了在一段时间内集中将请求都分配给高权重服务器的情况发生。
配置样例如下:
http { upstream backend { server a weight=5; server b weight=1; server c weight=1; } server { listen 80; location / { proxy_pass http://backend; } } }
配置样例中 Nginx 平滑轮询策略计算过程如下。
-
- 当前配置中 a,b,c 服务器的配置权重为 {5,1,1};
- 配置样例中 Nginx 平滑轮询计算过程如下表所示。
| 轮询次数 | 当前权重 | 选择后权重 | 选择节点 |
| 0 | {0, 0, 0} | {0, 0, 0} | -- |
| 1 | {5, 1, 1} | {-2, 1, 1} | a |
| 2 | {3, 2, 2} | {-4, 2, 2} | a |
| 3 | {1, 3, 3} | {1, -4, 3} | b |
| 4 | {6, -3, 4} | {-1, -3, 4} | a |
| 5 | {4, -2, 5} | {4, -2, -2} | c |
| 6 | {9, -1, -1} | {2, -1, -1} | a |
| 7 | {7, 0, 0} | {0, 0, 0} | a |
关于上表有以下几点需要说明:
-
- 有效权重(effective_weight),初始值为配置文件中权重的值,会因节点的健康状态而变化;
- 当前权重(current_weight),节点被选择前的权重值,由上一个选择后权重值及各节点与自己的有效权重值相加而得;
- 选择后权重,所有节点中权重最高节点的当前权重值为其初始值与有效总权重相减的值,其他节点的权重值不变;
- 有效总权重为所有节点中非备份、非失败状态的服务器的有效权重之和;
- 根据上述平滑轮询算法,选择节点顺序为 {a,a,b,a,c,a,a}。
2.一致性哈希
Nginx 启用哈希的负载均衡策略,是用 hash 指令来设置的。哈希策略方法可以针对客户端访问的 URL 计算哈希值,对相同的 URL 请求,Nginx 可以因相同的哈希值而将其分配到同一后端服务器。当后端服务器为缓存服务器时,将极大提高命中率,提升访问速度。
一致性哈希的优点是,可以使不同客户端的相似请求发送给同一被代理服务器,当被代理服务器为缓存服务器场景应用时,可以极大提高缓存的命中率。
一致性哈希的缺点是,当上游服务器组中的节点数量发生变化时,将导致所有绑定被代理服务器的哈希值重新计算,影响整个集群的绑定关系,产生大量回源请求。
配置样例如下:
http { upstream backend { hash $request_uri; # 以客户端请求URI为计算哈希值的key server a weight=5; server b weight=1; server c weight=1; } server { listen 80; location / { proxy_pass http://backend; } } }
配置样例中 Nginx 哈希策略计算过程如下。
-
- 首先会根据 $request_uri 计算哈希值;
- 根据哈希值与配置文件中非备份状态服务器的总权重计算出哈希余数;
- 按照轮询策略选出初始被代理服务器,如果哈希余数大于初始被代理服务器的权重,则遍历轮询策略中被代理服务器列表;
- 当遍历轮询策略中被代理服务器列表时,要用哈希余数依次减去轮询策略中的上一个被代理服务器的权重,直到哈希余数小于某个被代理服务器的权重时,该被代理服务器被选出;
- 若循环 20 次仍无法选出,则使用轮询策略进行选择。
针对哈希算法的缺点,Nginx 提供了 consistent 参数启用一致性哈希(Consistent Hash)负载均衡策略。Nginx 采用的是 Ketama 一致性哈希算法,使用一致性哈希策略后,当上游服务器组中的服务器数量变化时,只会影响少部分客户端的请求,不会产生大量回源。
Nginx 一致性哈希计算过程如下。
1) 根据配置文件中非备份状态服务器的总权重乘以 160 计算出总的虚拟节点数量,初始化虚拟节点数组。
2) 遍历轮询策略中的被代理服务器列表,根据每个服务器的权重数乘以160得出该服务器的虚拟节点数量,并根据服务器的 HOST 和 PORT 计算出该服务器的基本哈希(base_hash)。
3) 循环每个服务器虚拟节点总数次数,由基本哈希(base_hash)值与上一个虚拟节点的哈希值(PREV_HASH)依次计算出所有属于该服务器的虚拟节点哈希值,并把虚拟节点哈希值与服务器映射关系保存在虚拟节点哈希值数组中。
4) 对虚拟节点哈希值数组进行排序去重处理,得到新的有效虚拟节点哈希值数组。
配置样例如下:
http { upstream backend { hash $request_uri consistent; # 以客户端请求URI为计算哈希值的key,使用一致性 # 哈希算法 server a weight=1; server b weight=1; server c weight=1; server c weight=1; } server { listen 80; location / { proxy_pass http://backend; } } }
配置样例中 Nginx 一致性哈希策略计算过程如下。
-
- 首先根据 $request_uri 计算哈希值;
- 通过二分法,快速在虚拟节点列表中选出该哈希值所在范围的最大虚拟节点哈希值;
- 通过虚拟节点哈希值与虚拟节点集合总数取余,获得对应的服务器作为备选服务器;
- 遍历轮询策略中被代理服务器列表,判断备选服务器的有效性,选出服务器;
- 若循环 20 次仍无法选出,则使用轮询策略进行选择。
3.IP 哈希
IP 哈希(IP Hash)负载均衡策略根据客户端IP计算出哈希值,然后把请求分配给该数值对应的被代理服务器。在哈希值不变且被代理服务器可用的前提下,同一客户端的请求始终会被分配到同一台被代理服务器上。IP 哈希负载均衡策略常被应用在会话(Session)保持的场景。
HTTP 客户端在与服务端交互时,因为 HTTP 协议是无状态的,所以任何需要上下文逻辑的情景都必须使用会话保持机制,会话保持机制是通过客户端存储由唯一的 Session ID 进行标识的会话信息,每次与服务器交互时都会将会话信息提交给服务端,服务端依照会话信息实现客户端请求上下文的逻辑关联。
会话信息通常存储在被代理服务器的内存中,如果负载均衡将客户端的会话请求分配给其他被代理服务器,则该会话逻辑将因为会话信息失效而中断。所以为确保会话不中断,需要负载均衡将同一客户端的会话请求始终都发送到同一台被代理服务器,通过会话保持实现会话信息的有效传递。
配置样例如下:
http { upstream backend { ip_hash; # 启用IP哈希负载均衡策略 server a weight=5; server b weight=1; server c weight=1; } server { listen 80; location / { proxy_pass http://backend; } } }
配置样例中 Nginx 的 IP 哈希策略计算过程如下。
-
- 在多层代理的场景下,请确保当前 Nginx 可获得真实的客户端源 IP;
- 首先会根据客户端的 IPv4 地址的前三个八位字节或整个 IPv6 地址作为哈希键计算哈希值;
- 根据哈希值与配置文件中非备份状态服务器的总权重计算出哈希余数;
- 按照轮询策略选出初始被代理服务器,如果哈希余数大于初始被代理服务器的权重,则遍历轮询策略中被代理服务器列表,否则初始被代理服务器将被选出;
- 当遍历轮询策略中被代理服务器列表时,要用哈希余数依次减去轮询策略中的上一个被代理服务器的权重,直到哈希余数小于某个被代理服务器的权重时该被代理服务器被选出;
- 若循环 20 次仍无法选出,则使用轮询策略进行选择。
4.最少连接
默认配置下轮询算法是把客户端的请求平均分配给每个被代理服务器,每个被代理服务器的负载大致相同,该场景有个前提就是每个被代理服务器的请求处理能力是相当的。如果集群中某个服务器处理请求的时间比较长,那么该服务器的负载也相对增高。在最少连接(least_conn)负载均衡策略下,会在上游服务器组中各服务器权重的前提下将客户端请求分配给活跃连接最少的被代理服务器,进而有效提高处理性能高的被代理服务器的使用率。
配置样例如下:
upstream backend { least_conn; # 启用最少连接负载均衡策略 server a weight=4; server b weight=2; server c weight=1; } server { listen 80; location / { proxy_pass http://backend; } }
配置样例中 Nginx 最少连接策略计算过程如下。
-
- 遍历轮询策略中被代理服务器列表,比较各个后端的活跃连接数(conns)与其权重(weight)的比值,选取比值最小者分配客户端请求;
- 如果上一次选择了 a 服务器,则当前请求将在 b 和 c 服务器中选择;
- 设 b 的活跃连接数为 100,c 的活跃连接数为 60,则 b 的比值(conns/weight)为 50,c 的比值(conns/weight)为 60,因此当前请求将分配给 b。
5.随机负载算法
在 Nginx 集群环境下,每个 Nginx 均通过自身对上游服务器的了解情况进行负载均衡处理,这种场景下,很容易出现多台 Nginx 同时把请求都分配给同一台被代理服务器的场景,该场景被称为羊群行为(Herd Behavior)。
Nginx 基于两种选择的力量(Power of Two Choices)原理,设计了随机(Random)负载算法。该算法使 Nginx 不再基于片面的情况了解使用固有的负载均衡策略进行被代理服务器的选择,而是随机选择两个,在经过比较后进行最终的选择。随机负载算法提供了一个参数 two,当这个参数被指定时,Nginx 会在考虑权重的前提下,随机选择两台服务器,然后用以下几种方法选择一个服务器。
-
- 最少连接数,配置指令为 least_conn,默认配置;
- 响应头最短平均时间,配置指令为 least_time=header,仅对商业版本有效;
- 完整请求最短平均时间,配置指令为 least_time=last_byte,仅对商业版本有效。
配置样例如下:
upstream backend {
random two least_conn;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
server backend4.example.com;
}
在只有单台 Nginx 服务器时,一般不建议使用随机负载算法。
3.Nginx长连接负载均衡
当客户端通过浏览器访问 HTTP 服务器时,HTTP 请求会通过 TCP 协议与 HTTP 服务器建立一条访问通道,当本次访问数据传输完毕后,该 TCP 连接会立即被断开,由于这个连接存在的时间很短,所以 HTTP 连接也被称为短连接。
在 HTTP/1.1 版本中默认开启 Connection:keep-alive,实现了 HTTP 协议的长连接,可以在一个 TCP 连接中传输多个 HTTP 请求和响应,减少了建立和关闭 TCP 连接的消耗和延迟,提高了传输效率。网络应用中,每个网络请求都会打开一个 TCP 连接,基于上层的软件会根据需要决定这个连接的保持或关闭。例如,FTP 协议的底层也是 TCP,是长连接。
默认配置下,HTTP 协议的负载均衡与上游服务器组中被代理的连接都是 HTTP/1.0 版本的短连接。Nginx 的连接管理机制如下图所示。
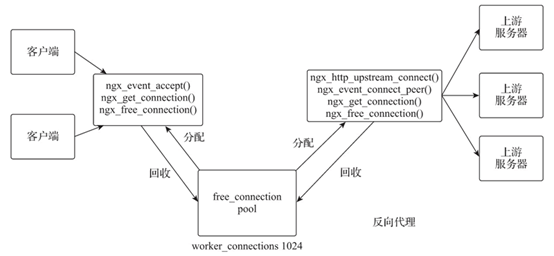
图:Nginx 连接管理机制
相关说明如下。
Nginx 启动初始化时,每个 Nginx 工作进程(Worker Process)会生成一个由配置指令 worker_connections 指定大小的可用连接池(free_connection pool)。工作进程每建立一个连接,都会从可用连接池中分配(ngx_get_connection)到一个连接资源,而关闭连接时再通知(ngx_free_connection)可用连接池回收此连接资源。
客户端向 Nginx 发起 HTTP 连接时,Nginx 的工作进程获得该请求的处理权并接受请求,同时从可用连接池中获得连接资源与客户端建立客户端连接资源。
Nginx 的工作进程从可用连接池获取连接资源,并与通过负载均衡策略选中的被代理服务器建立代理连接。
默认配置下,Nginx 的工作进程与被代理服务器建立的连接都是短连接,所以获取请求响应后就会关闭连接并通知可用连接池回收此代理连接资源。
Nginx 的工作进程将请求响应返回给客户端,若该请求为长连接,则保持连接,否则关闭连接并通知可用连接池回收此客户端连接资源。
Nginx 能建立的最大连接数是 worker_connections×worker_processes。而对于反向代理的连接,最大连接数是 worker_connections×worker_processes/2,但是其会占用与客户端及与被代理服务器建立的两个连接。
在高并发的场景下,Nginx 频繁与被代理服务器建立和关闭连接会消耗大量资源。Nginx 的 upstream_keepalive 模块提供与被代理服务器间建立长连接的管理支持,该模块建立了一个长连接缓存,用于管理和存储与被代理服务器建立的连接。Nginx 长连接管理机制如下图所示。
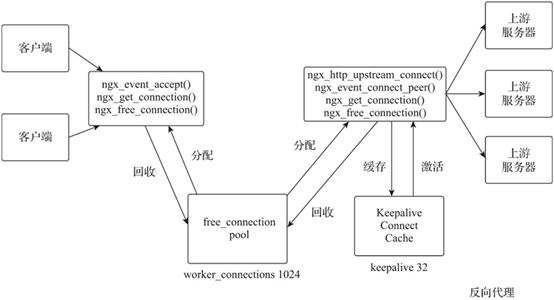
图:Nginx 长连接管理机制
相关说明如下。
当 upstream_keepalive 模块初始化时,将建立按照 upstream 指令域中的 keepalive 指令设置大小的长连接缓存(Keepalive Connect Cache)池。
当 Nginx 的工作进程与被代理服务器新建的连接完成数据传输时,其将该连接缓存在长连接缓存池中。
当工作进程与被代理服务器有新的连接请求时,会先在长连接缓存池中查找符合需求的连接,如果存在则使用该连接,否则创建新连接。
对于超过长连接缓存池数量的连接,将使用最近最少使用(LRU)算法进行关闭或缓存。
长连接缓存池中每个连接最大未被激活的超时时间由 upstream 指令域中 keepalive_timeout 指令设置,超过该指令值时间未被激活的连接将被关闭。
长连接缓存池中每个连接可复用传输的请求数由 upstream 指令域中 keepalive_requests 指令设置,超过该指令值复用请求数的连接将被关闭。
Nginx 与被代理服务器间建立的长连接是通过启用 HTTP/1.1 版本协议实现的。由于 HTTP 代理模块默认会将发往被代理服务器的请求头属性字段 Connection 的值设置为 Close,因此需要通过配置指令清除请求头属性字段 Connection 的内容。
配置样例如下:
upstream http_backend { server 192.168.2.154:8080; server 192.168.2.109:8080; keepalive 32; # 长连接缓存池大小为32 keepalive_requests 2000; # 每条长连接最大复用请求数为2000 } server { location /http/ { proxy_pass http://http_backend; proxy_http_version 1.1; # 启用HTTP/1.1版本与被代理服务器建立连接 proxy_set_header Connection ""; # 清空发送被代理服务器请求头属性字段Connection # 的内容 } }
对于 FastCGI 协议服务器,需要设置 fastcgi_keep_conn 指令启用长连接支持。
upstream fastcgi_backend { server 192.168.2.154:9000; server 192.168.2.109:9000; keepalive 8; # 长连接缓存池大小为8 } server { ... location /fastcgi/ { fastcgi_pass fastcgi_backend; fastcgi_keep_conn on; # 启用长连接支持 ... } }
SCGI 和 uWSGI 协议没有长连接的概念;Memcached 协议(由 ngx_http_memcached_module 模块提供)的长连接配置,只需在 upstream 指令域中设置 keepalive 指令即可。
upstream memcached_backend { server 127.0.0.1:11211; server 10.0.0.2:11211; keepalive 32; # 长连接缓存池大小为32 } server { ... location /memcached/ { set $memcached_key $uri; # 设置$memcached_key为$uri memcached_pass memcached_backend; } }
4.Nginx upstream容错机制详解
Nginx 在 upstream 模块中默认的检测机制是通过用户的真实请求去检查被代理服务器的可用性,这是一种被动的检测机制,通过 upstream 模块中 server 指令的指令值参数 max_fails 及 fail_timeout 实现对被代理服务器的检测和熔断。
配置样例如下:
upstream http_backend { # 10s内出现3次错误,该服务器将被熔断10s server 192.168.2.154:8080 max_fails=3 fail_timeout=10s; server 192.168.2.109:8080 max_fails=3 fail_timeout=10s; server 192.168.2.108:8080 max_fails=3 fail_timeout=10s; server 192.168.2.107:8080 max_fails=3 fail_timeout=10s; } server { proxy_connect_timeout 5s; # 与被代理服务器建立连接的超时时间为5s proxy_read_timeout 10s; # 获取被代理服务器的响应最大超时时间为10s # 当与被代理服务器通信出现指令值指定的情况时,认为被代理出错,并将请求转发给上游服务器组中 # 的下一个可用服务器 proxy_next_upstream http_502 http_504 http_404 error timeout invalid_header; proxy_next_upstream_tries 3; # 转发请求最多3次 proxy_next_upstream_timeout 10s; # 总尝试超时时间为10s location /http/ { proxy_pass http://http_backend; } }
其中的参数和指令说明如下。
-
- 指令值参数 max_fails 是指 10s 内 Nginx 分配给当前服务器的请求失败次数累加值,每 10s 会重置为 0;
- 指令值参数 fail_timeout 既是失败计数的最大时间,又是服务器被置为失败状态的熔断时间,超过这个时间将再次被分配请求;
- 指令 proxy_connect_timeout 或 proxy_read_timeout 为超时状态时,都会触发 proxy_next_upstream 的 timeout 条件;
- proxy_next_upstream 是 Nginx 下提高请求成功率的机制,当被代理服务器返回错误并符合 proxy_next_upstream 指令值设置的条件时,将尝试转发给下一个可用的被代理服务器;
- 指令 proxy_next_upstream_tries 的指令值次数包括第一次转发请求的次数。
Nginx 被动检测机制的优点是不需要增加额外进程进行健康检测,但用该方法检测是不准确的。如当响应超时时,有可能是被代理服务器故障,也可能是业务响应慢引起的。如果是被代理服务器故障,那么 Nginx 仍会在一定时间内将客户端的请求转发给该服务器,用以判断其是否恢复。
Nginx 官方的主动健康检测模块仅集成在商业版本中,对于开源版本,推荐使用 Nginx 扩展版 OpenResty 中的健康检测模块 lua-resty-upstream-healthcheck。该模块的检测参数如下表所示。
| 参数 | 默认值 | 参数说明 |
| shm | -- | 指定用于健康检测的共享内存名称,共享内存名称由 lua_shared_dict 设定 |
| upstream | -- | 指定要做健康检查的 upstream 组名 |
| type | http | 指定检测的协议类型,目前只支持 http |
| http_req | -- | 指定用于健康探测的 raw 格式 http 请求字符串 |
| timeout | 1000 | 检测请求超时时间,单位为 ms |
| interval | 1000 | 健康检测的时间间隔,单位为 ms |
| valid_status | -- | 健康检测请求返回的合法响应码列表,比如 {200, 302} |
| concurrency | 1 | 健康检测请求的并发数,建议大于上游服务器组中的节点数 |
| fall | 5 | 对 UP 状态的设备,连续 fall 次失败,认定为 DOWN |
| rise | 2 | 对 DOWN 状态的设备,连续 rise 次成功,认定为 UP |
| version | 0 | 每次执行健康检测时的版本号,有节点状态改变,版本号加 1 |
模块 lua-resty-upstream-healthcheck 的原理是每到(interval)设定的时间,就会对被代理服务器的 HTTP 端口主动发起 GET 请求(http_req),当请求的响应状态码在确定为合法的列表(valid_status)中出现时,则认为被代理服务器是健康的,如果请求的连续(fall)设定次数返回响应状态码都未在列表(valid_status)中出现,则认为是故障状态。
对处于故障状态的设备,该模块会将其置为 DOWN 状态,直到请求的连续(rise)次返回的状态码都在确定为合法的列表中出现,被代理服务器才会被置为 UP 状态,并获得 Nginx 分配的请求,Nginx 在整个运行过程中不会将请求分配给 DOWN 状态的被代理服务器。
lua-resty-upstream-healthcheck 模块只会使用 Nginx 中的一个工作进程对被代理服务器进行检测,不会对被代理服务器产生大量的重复检测。
配置样例如下:
http { # 关闭socket错误日志 lua_socket_log_errors off; # 上游服务器组样例 upstream foo.com { server 127.0.0.1:12354; server 127.0.0.1:12355; server 127.0.0.1:12356 backup; } # 设置共享内存名称及大小 lua_shared_dict _foo_zone 1m; init_worker_by_lua_block { # 引用resty.upstream.health-check模块 local hc = require "resty.upstream.healthcheck" local ok, err = hc.spawn_checker{ shm = "_foo_zone", # 绑定lua_shared_dict定义的共享内存 upstream = "foo.com", # 绑定upstream指令域 type = "http", http_req = "GET /status HTTP/1.0\r\nHost: foo.com\r\n\r\n", # 用以检测的raw格式http请求 interval = 2000, # 每2s检测一次 timeout = 1000, # 检测请求超时时间为1s fall = 3, # 连续失败3次,被检测节点被置为DOWN状态 rise = 2, # 连续成功2次,被检测节点被置为UP状态 valid_statuses = {200, 302}, # 当健康检测请求返回的响应码为200或302时,被认 # 为检测通过 concurrency = 10, # 健康检测请求的并发数为10 } if not ok then ngx.log(ngx.ERR, "failed to spawn health checker: ", err) return end } server { listen 10080; access_log off; # 关闭access日志输出 error_log off; # 关闭error日志输出 # 健康检测状态页 location = /healthcheck { allow 127.0.0.1; deny all; default_type text/plain; content_by_lua_block { # 引用resty.upstream.healthcheck模块 local hc = require "resty.upstream.healthcheck" ngx.say("Nginx Worker PID: ", ngx.worker.pid()) ngx.print(hc.status_page()) } } } }
以下是对该配置样例的几点说明。
-
- 该配置样例参照 OpenResty 官方样例简单修改;
- 对不同的 upstream 需要通过参数 upstream 进行绑定;
- 建议为每个上游服务器组指定独享的共享内存,并用参数 shm 进行绑定。
5.Nginx动态更新upstream
Nginx 的配置是启动时一次性加载到内存中的,在实际的使用中,对 Nginx 服务器上游服务器组中节点的添加或移除仍需要重启或热加载 Nginx 进程。在 Nginx 的商业版本中,提供了 ngx_http_api_module 模块,可以通过 API 动态添加或移除上游服务器组中的节点。
对于 Nginx 开源版本,通过 Nginx 的扩展版 OpenResty 及 Lua 脚本也可以实现上游服务器组中节点的动态操作,这里只使用 OpenResty 的 lua-upstream-nginx-module 模块简单演示节点的上下线状态动态修改的操作。该模块提供了 set_peer_down 指令,该指令可以对 upstream 的节点实现上下线的控制。
由于该指令只支持 worker 级别的操作,为使得 Nginx 的所有 worker 都生效,此处通过编写 Lua 脚本与 lua-resty-upstream-healthcheck 模块做了简单的集成,利用 lua-resty-upstream-healthcheck 模块的共享内存机制将节点状态同步给其他工作进程,实现对 upstream 的节点状态的控制。
首先在 OpenResty 的 lualib 目录下创建公用函数文件 api_func.lua,lualib/api_func.lua 内容如下:
local _M = { _VERSION = '1.0' }
local cjson = require "cjson"
local upstream = require "ngx.upstream"
local get_servers = upstream.get_servers
local get_primary_peers = upstream.get_primary_peers
local set_peer_down = upstream.set_peer_down
# 分割字符串为table
local function split( str,reps )
local resultStrList = {}
string.gsub(str,"[^"..reps.."]+",function ( w )
table.insert(resultStrList,w)
end)
return resultStrList
end
# 获取server列表
local function get_args_srv( args )
if not args["server"] then
ngx.say("failed to get post args: ", err)
return nil
else
if type(args["server"]) ~= "table" then
server_list=split(args["server"],",")
else
server_list=args["server"]
end
end
return server_list
end
# 获取节点在upstream中的顺序
local function get_peer_id(ups,server_name)
local srvs = get_servers(ups)
for i, srv in ipairs(srvs) do
-- ngx.print(srv["name"])
if srv["name"] == server_name then
target_srv = srv
target_srv["id"] = i-1
break
end
end
return target_srv["id"]
end
# 获取节点共享内存key
local function gen_peer_key(prefix, u, is_backup, id)
if is_backup then
return prefix .. u .. ":b" .. id
end
return prefix .. u .. ":p" .. id
end
# 设置节点状态
local function set_peer_down_globally(ups, is_backup, id, value,zone_define)
local u = ups
local dict = zone_define
local ok, err = set_peer_down(u, is_backup, id, value)
if not ok then
ngx.say(cjson.encode({code = "E002", msg = "failed to set peer down", data = err}))
end
local key = gen_peer_key("d:", u, is_backup, id)
local ok, err = dict:set(key, value)
if not ok then
ngx.say(cjson.encode({code = "E003", msg = "failed to set peer down state", data = err}))
end
end
# 获取指定upstream的节点列表
function _M.list_server(ups)
local srvs, err = get_servers(ups)
ngx.say(cjson.encode(srvs))
end
# 设置节点状态
function _M.set_server(ups,args,status,backup,zone_define)
local server_list = get_args_srv(args)
if server_list == nil then
ngx.say(cjson.encode({code = "E001", msg = "no args",data = server_list}))
return nil
end
for _, s in pairs(server_list) do
local peer_id = get_peer_id(ups,s)
if status then
local key = gen_peer_key("nok:", ups, backup, peer_id)
local ok, err = zone_define:set(key, 1)
set_peer_down_globally(ups, backup, peer_id, true,zone_define)
else
local key = gen_peer_key("ok:", ups, backup, peer_id)
local ok, err = zone_define:set(key, 0)
set_peer_down_globally(ups, backup, peer_id, nil,zone_define)
end
end
ngx.say(cjson.encode({code = "D002", msg = "set peer is success",data = server_list}))
end
return _M
Nginx 配置文件 status.conf 的内容如下:
# 关闭socket错误日志 lua_socket_log_errors off; # 设置共享内存名称及大小 lua_shared_dict _healthcheck_zone 10m; init_worker_by_lua_block { local hc = require "resty.upstream.healthcheck" # 设置需要健康监测的upstream local ups = {"foo.com","sslback"} # 遍历ups,绑定健康监测策略 for k, v in pairs(ups) do local ok, err = hc.spawn_checker{ shm = "_healthcheck_zone", # 绑定lua_shared_dict定义的共享内存 upstream = v, # 绑定upstream指令域 type = "http", http_req = "GET / HTTP/1.0\r\nHost: foo.com\r\n\r\n", # 用以检测的raw格式http请求 interval = 2000, # 每2s检测一次 timeout = 1000, # 检测请求超时时间为1s fall = 3, # 连续失败3次,被检测节点被置为DOWN状态 rise = 2, # 连续成功2次,被检测节点被置为UP状态 # 当健康检测请求返回的响应码为200或302时,被认 # 为检测通过 valid_statuses = {200, 302}, concurrency = 10, # 健康检测请求的并发数为10 } if not ok then ngx.log(ngx.ERR, "failed to spawn health checker: ", err) return end end } upstream foo.com { server 192.168.2.145:8080; server 192.168.2.109:8080; server 127.0.0.1:12356 backup; } upstream sslback { server 192.168.2.145:443; server 192.168.2.159:443; } server { listen 18080; access_log off; error_log off; # 健康检测状态页 location = /healthcheck { access_log off; allow 127.0.0.1; allow 192.168.2.0/24; allow 192.168.101.0/24; deny all; default_type text/plain; content_by_lua_block { local hc = require "resty.upstream.healthcheck" ngx.say("Nginx Worker PID: ", ngx.worker.pid()) ngx.print(hc.status_page()) } } location = /ups_api { default_type application/json; content_by_lua ' # 获取URL参数 local ups = ngx.req.get_uri_args()["ups"] local act = ngx.req.get_uri_args()["act"] if act == nil or ups == nil then ngx.say("usage: /ups_api?ups={name}&act=[down,up,list]") return end # 引用api_func.lua脚本 local api_fun = require "api_func" # 绑定共享内存_healthcheck_zone local zone_define=ngx.shared["_healthcheck_zone"] if act == "list" then # 获取指定upstream的节点列表 api_fun.list_server(ups) else ngx.req.read_body() local args, err = ngx.req.get_post_args() if act == "up" then # 节点状态将设置为UP api_fun.set_server(ups,args,false,false,zone_define) end if act == "down" then # 节点状态将设置为DOWN api_fun.set_server(ups,args,true,false,zone_define) end end '; } }
操作命令如下:
# 查看upstream foo.com的服务器列表 curl "http://127.0.0.1:18080/ups_api?act=list&ups=foo.com" # 将192.168.2.145:8080这个节点设置为DOWN状态 curl -X POST -d "server=192.168.2.145:8080" "http://127.0.0.1:18080/ups_api?act= down&ups=foo.com" # 将192.168.2.145:8080这个节点设置为UP状态 curl -X POST -d "server=192.168.2.145:8080" "http://127.0.0.1:18080/ups_api?act= up&ups=foo.com"
6.Nginx Stream(TCP/UDP)负载均衡
Nginx 的 TCP/UDP 负载均衡是应用 Stream 代理模块(ngx_stream_proxy_module)和 Stream 上游模块(ngx_stream_upstream_module)实现的。Nginx 的 TCP 负载均衡与 LVS 都是四层负载均衡的应用,所不同的是,LVS 是被置于 Linux 内核中的,而 Nginx 是运行于用户层的,基于 Nginx 的 TCP 负载可以实现更灵活的用户访问管理和控制。
1.TCP/UDP 负载均衡
Nginx 的 Stream 上游模块支持与 Nginx HTTP 上游模块一致的轮询(Round Robin)、哈希(Hash)及最少连接数(least_conn)负载均衡策略。Nginx 默认使用轮询负载均衡策略,配置样例如下:
stream { upstream backend { server 192.168.2.145:389 weight=5; server 192.168.2.159:389 weight=1; server 192.168.2.109:389 weight=1; } server { listen 389; proxy_pass backend; } }
哈希负载均衡策略可以通过客户端 IP($remote_addr)实现简单的会话保持,其可将同一 IP 客户端始终转发给同一台后端服务器。
配置样例如下:
stream { upstream backend { hash $remote_addr; server 192.168.2.145:389 weight=5; server 192.168.2.159:389 weight=1; server 192.168.2.109:389 weight=1; } server { listen 389; proxy_pass backend; } }
哈希负载均衡策略通过指令参数 consistent 设定是否开启一致性哈希负载均衡策略。Nginx 的一致性哈希负载均衡策略是采用 Ketama 一致性哈希算法,当后端服务器组中的服务器数量变化时,只会影响少部分客户端的请求。
配置样例如下:
stream { upstream backend { hash $remote_addr consistent; server 192.168.2.145:389 weight=5; server 192.168.2.159:389 weight=1; server 192.168.2.109:389 weight=1; } server { listen 389; proxy_pass backend; } }
最少连接负载均衡策略,可以在后端被代理服务器性能不均时,在考虑上游服务器组中各服务器权重的前提下,将客户端连接分配给活跃连接最少的被代理服务器,从而有效提高处理性能高的被代理服务器的使用率。
配置样例如下:
stream { upstream backend { least_conn; server 192.168.2.145:389 weight=5; server 192.168.2.159:389 weight=1; server 192.168.2.109:389 weight=1; } server { listen 389; proxy_pass backend; } }
2.TCP/UDP 负载均衡的容错机制
Nginx 的 TCP/UDP 负载均衡在连接分配时也支持被动健康检测模式,如果与后端服务器建立连接失败,并在 fail_timeout 参数的时间内连续超过 max_fails 参数设置的次数,Nginx 就会将该服务器置为不可用状态,并且在 fail_timeout 参数的时间内不再给该服务器分配连接。当 fail_timeout 参数的时间结束时将尝试分配连接检测该服务器是否恢复,如果可以建立连接,则判定为恢复。
配置样例如下:
stream { upstream backend { # 10s内出现3次错误,该服务器将被熔断10s server 192.168.2.154:8080 max_fails=3 fail_timeout=10s; server 192.168.2.109:8080 max_fails=3 fail_timeout=10s; server 192.168.2.108:8080 max_fails=3 fail_timeout=10s; server 192.168.2.107:8080 max_fails=3 fail_timeout=10s; } server { proxy_connect_timeout 5s; # 与被代理服务器建立连接的超时时间为5s proxy_timeout 10s; # 获取被代理服务器的响应最大超时时间为10s # 当被代理的服务器返回错误或超时时,将未返回响应的客户端连接请求传递给upstream中的下 # 一个服务器 proxy_next_upstream on; proxy_next_upstream_tries 3; # 转发尝试请求最多3次 proxy_next_upstream_timeout 10s; # 总尝试超时时间为10s proxy_socket_keepalive on; # 开启SO_KEEPALIVE选项进行心跳检测 proxy_pass backend; } }
其中的参数及指令说明如下。
-
- 指令值参数 max_fails 是指 10s 内 Nginx 分配给当前服务器的连接失败次数累加值,每 10s 会重置为 0;
- 指令值参数 fail_timeout 既是失败计数的最大时间,又是服务器被置为失败状态的熔断时间,超过这个时间将再次被分配连接;
- 指令 proxy_connect_timeout 或 proxy_timeout 为超时状态时,都会触发 proxy_next_upstream 机制;
- proxy_next_upstream 是 Nginx 下提高连接成功率的机制,当被代理服务器返回错误或超时时,将尝试转发给下一个可用的被代理服务器;
- 指令 proxy_next_upstream_tries 的指令值次数包括第一次转发请求的次数。
TCP 连接在接收到关闭连接通知前将一直保持连接,当 Nginx 与被代理服务器的两个连续成功的读或写操作的最大间隔时间超过 proxy_timeout 指令配置的时间时,连接将会被关闭。在 TCP 长连接的场景中,应适当调整 proxy_timeout 的设置,同时关注系统内核 SO_KEEPALIVE 选项的配置,可以防止过早地断开连接。

