
Kubernetes在生产环境中的一些讨论
pod是所有一切资源的中心,毫无疑问是Kubernetes中最重要的资源。毕竟, 每个应用都运行在pod中。为了确保知道如何开发能充分利用应用所在环境资源的应用,最后再从应用的角度来仔细看一下pod。
1.了解pod的生命周期
可以将pod比作只运行单个应用的虚拟机。尽管在pod中运行的应用和虚拟机中运行的应用没什么不同,但是还是存在显著的差异。其中一个例子就是pod中运行的应用随时可能会被杀死,因为Kubernetes需要将这个pod调度到另外一个节点,或者是请求缩容。接下来将探讨这方面的内容。
1.1 应用必须预料到会被杀死或者重新调度
在Kubernetes之外,运行在虚拟机中的应用很少会被从一台机器迁移到另外一台。当一个操作者迁移应用的时候,他们可以重新配置应用并且手动检查应用是否在新的位置正常运行。借助于Kubernetes,应用可以更加频繁地进行自动迁移而无须人工介入,也就是说没有人会再对应用进行配置并且确保它们在迁移之后能够正常运行。这就意味着应用开发者必须允许他们的应用可以被相对频繁地迁移。
预料到本地IP和主机名会发生变化
当一个pod被杀死并且在其他地方运行之后(技术上来讲是一个新的pod替换了旧的pod,旧pod没有被迁移),它不仅拥有了一个新的IP地址还有了一个新的名称和主机名。大部分无状态的应用都可以处理这种场景同时不会有不利的影响, 但是有状态服务通常不能。已经了解到有状态应用可以通过一个StatefulSet来运行,StatefulSet会保证在将应用调度到新的节点并启动之后,它可以看到和之前一样的主机名和持久化状态。当然pod的IP还是会发生变化,应用必须能够应对这种变化。因此应用开发者在一个集群应用中不应该依赖成员的IP地址来构建彼此的关系,另外如果使用主机名来构建关系,必须使用StatefulSet。
预料到写入磁盘的数据会消失
还有一件事情需要记住的是,在应用往磁盘写入数据的情况下,当应用在新的pod中启动后这些数据可能会丢失,除非将持久化的存储挂载到应用的数据写入路径。在pod被重新调度的时候,数据丢失是一定的,但是即使在没有调度的情况下,写入磁盘的文件仍然会丢失。甚至是在单个pod的生命周期过程中,pod中的应用写入磁盘的文件也会丢失。通过一个例子来解释一下这个问题。
假设有个应用,它的启动过程是比较耗时的而且需要很多的计算操作。为了能够让这个应用在后续的启动中更快,开发者一般会把启动过程中的一些计算结果缓存到磁盘上(例如启动时扫描所有的用作注解的Java类然后把结果写入到索引文件)。由于在Kubernetes中应用默认运行在容器中,这些文件会被写入到容器的文件系统中。如果这个时候容器重启了,这些文件都会丢失,因为新的容器启动的时候会使用一个全新的可写入层。
不要忘了,单个容器可能因为各种原因被重启,例如进程崩溃了,例如存活探针返回失败了,或者是因为节点内存逐步耗尽,进程被OOMKiller杀死了。当上述情况发生的时候,pod还是一样,但是容器却是全新的了。Kubelet不会一个容器运行多次,而是会重新创建一个容器。
使用存储卷来跨容器持久化数据
当pod的容器重启后,本例中的应用仍然需要执行有大量计算过程的启动程序。这个或许不是你所期望的。为了保证这种情况下数据不丢失,你需要至少使用一个 pod级别的卷。因为卷的存在和销毁与pod生命周期是一致的,所以新的容器将可以重用之前容器写到卷上的数据。
有时候使用存储卷来跨容器存储数据是个好办法,但是也不总是如此。万一由于数据损坏而导致新创建的进程再次崩溃呢?这会导致一个持续性的循环崩溃(Pod会提示CrashLoopBackOff状态)。如果不使用存储卷的话,新的容器会从零开始启动, 并且很可能不会崩溃。使用存储卷来跨容器存储数据是把双刃剑。需要仔细思考是否使用它们。
1.2 重新调度死亡的或者部分死亡的pod
如果一个pod的容器一直处于崩溃状态,Kubelet将会一直不停地重启它们。每次重启的时间间隔将会以指数级增加,直到达到5分钟。在这个5分钟的时间间隔中,pod基本上是死亡了,因为它们的容器进程没有运行。公平来讲,如果是个多容器的Pod,其中的一些容器可能是正常运行的,所以这个pod只是部分死亡了。但是如果pod中仅包含一个容器,那么这个pod是完全死亡的而且己经毫无用处了,因为里面己经没有进程在运行了。
你或许会奇怪,为什么这些pod不会被自动移除或者重新调度,尽管它们是ReplicaSet或者相似控制器的一部分。如果创建了一个期望副本数是3的ReplicaSet,当那些pod中的一个容器开始崩溃,Kubernetes将不会删除或者替换这个pod。结果就是这个ReplicaSet只剩下了两个正确运行的副本,而不是你期望的三个。
你或许期望能够删除这个pod然后重新启动一个可以在其他节点上成功运行的pod。毕竟这个容器可能是因为一个节点相关的问题而导致的崩溃,这个问题在其他的节点上不会出现。很遗憾,并不是这样的。ReplicaSet本身并不关心pod是否处于死亡状态,它只关心pod的数量是否匹配期望的副本数量,在这种情况下,副本数量确实是匹配的。
如果想自己研究一下,这里有一个ReplicaSet的YAML manifest文件,它里面定义的pod会不停地崩溃。如果创建了这个ReplicaSet然后检查一下创建的pod,你会看到如下的代码清单。
#代码清单17.1 ReplicaSet和持续崩溃的pod $ kubectl get po NAME READY STATUS RESTARTS AGE crashing-pods-fltcd 0/1 CrashLoopOff 5 6m crashing-pods-k7l6k 0/1 CrashLoopOff 5 6m crashing-pods-z713v 0/1 CrashLoopOff 5 6m $ kubect1 describe rs crashing-pods Name: crashing-pods Replicas: 3 current/ 3 desired #控制器没有采取任何动作,因为目前的副本数量和期望的相符 Pods Status: 3 Running / 0 Waiting / O Succeeded / O Failed #显示有三个副本在运行中 $ kubectl describe po crashing-pods-fltcd Name: Crashing-pods-fltcd NameSpace: default Node: minikube/192.168.99.102 Start Time: Thu, 02 Mar 2017 14:02:23 +0100 Labels: app=crashing-pods Status: Running #kubectl describe 也显示pod的状态是运行中
在某种程度上,可以理解为什么Kubernetes会这样做。容器将会每5分钟重启一次,在这个过程中Kubernetes期望崩溃的底层原因会被解决。这个机制依据的基本原理就是将pod重新调度到其他节点通常并不会解决崩溃的问题,因为应用运行在容器的内部,所有的节点理论上应该都是相同的。虽然上面的情况并不总是如此,但是大多数情况下都是这样。
1.3 以固定的顺序启动pod
pod中运行的应用和手动运行的应用之间的另外一个不同就是运维人员在手动部署应用的时候知道应用之间的依赖关系,这样他们就可以按照顺序来启动应用。
了解pod是如何启动的
当使用Kubernetes来运行多个pod的应用的时候,Kubernetes没有内置的方法来先运行某些pod然后等这些pod运行成功后再运行其他pod。当然你也可以先发布第一个应用的配置,然后等待pod启动完毕再发布第二个应用的配置。但是你的整个系统通常都是定义在一个单独的YAML或者JSON文件中,这些文件包含了多个pod、服务或者其他对象的定义。
KubernetesAPI服务器确实是按照YAML/JS0N文件中定义的对象的顺序来进行处理的,但是仅仅意味着它们在被写入到etcd的时候是有顺序的。无法确保pod会按照那个顺序启动。
但是可以阻止一个主容器的启动,直到它的预置条件被满足。这个是通过在pod中包含一个叫作init的容器来实现的。
Init容器介绍
除了常规的容器,pod还可以包括init容器。如容器名所示,它们可以用来初始化pod,这通常意味着向容器的存储卷中写入数据,然后将这个存储卷挂载到主容器中。
一个pod可以拥有任意数量的init容器。init容器是顺序执行的,并且仅当最后一个init容器执行完毕才会去启动主容器。换句话说,init容器也可以用来延迟pod的主容器的启动——例如,直到满足某一个条件的时候。init容器可以一直等待直到主容器所依赖的服务启动完成并可以提供服务。当这个服务启动并且可以提供服务之后,init容器就执行结束了,然后主容器就可以启动了。这样主容器就不会发生在所依赖服务准备好之前使用它的情况了。
下面让来看一个pod使用init容器来延迟主容器启动的例子。这里有一个名叫fortune的pod。它是一个能够返回给客户端请求一个人生格言作为响应的web服务。现在假设有一个叫作fortune-client的pod,它的主容器需要依赖fortune服务先启动并且运行之后才能启动。可以给fortune-client的pod添加一个init容器,这个容器主要检查发送给fortune服务的请求是否被响应。如果没有响应,那么这个init容器将一直重试。当这个init容器获得响应之后,它的执行就结束了然后让主容器启动。
将init容器加入pod
init容器可以在pod spec文件中像主容器那样定义,不过是通过字段spec.initContainers来定义的。下面的代码清单展示了init容器定义的部分。
#代码17.2 pod中定义的init容器:fortune-client.yaml apiVersion: v1 kind: Pod metadata: name: fortune-client spec: initContainers: #在定义一个init容器,而不是常规容器 - name: init image: busybox command: - sh - -c - 'while true; do echo "Waiting for fortune service to come up..."; wget http://fortune -q -T 1 -O /dev/null >/dev/null 2>/dev/null && break; sleep 1; done; echo "Service is up! Starting main container."' #init容器运行一个循环并且在fortune服务启动之后循环才退出 containers: - image: busybox name: main command: - sh - -c - 'echo "Main container started. Reading fortune very 10 seconds."; while true; do echo "-------------"; wget -q -O - http://fortune; sleep 10; done'
当部署这个pod的时候,只有pod的init容器会启动起来。这个可以通过命令kubectl get查看pod的状态来展示:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
fortune-client 0/1 init:0/1 0 1m
STATUS列展示了目前没有init容器执行完毕。可以通过kubectl logs命令来查看init容器的日志:
$ kubectl logs fortune-client -c init Waiting for fortune service to come up ...
当运行kubectl logs命令的时候,需要通过选项-c来指定init容器的名称(在这个例子中,pod的init容器的名称就叫作init,如代码清单17.2所示)。
主容器直到部署的fortune服务和fortune-server pod启动之后才会运行。这些配置内容都在文件fortune-sever.yaml中。
处理pod内部依赖的最佳实践
己经了解如何通过init容器来延迟pod主容器的启动,直到预置的条件被满足(例如,为了确保pod所依赖的服务己经准备好),但是更佳的情况是构建一个不需要它所依赖的服务都准备好后才能启动的应用。毕竟,这些服务在后面也有可能下线,但是这个时候应用己经在运行中了。
应用需要自身能够应对它所依赖的服务没有准备好的情况。另外不要忘了Readiness探针。如果一个应用在其中一个依赖缺失的情况下无法工作,那么它需要通过它的Readiness探针来通知这个情况,这样Kubernetes也会知道这个应用没有准备好。需要这样做的原因不仅仅是因为这个就绪探针收到的信号会阻止应用成为一个服务端点,另外还因为Deployment控制器在滚动升级的时候会使用应用的就绪探针,因此可以避免错误版本的出现。
1.4 增加生命周期钩子
己经讨论了如果使用init容器来介入pod的启动过程,另外pod还允许定义两种类型的生命周期钩子:
-
- 启动后(Post-start)钩子
- 停止前(Pre-stop)钩子
这些生命周期的钩子是基于每个容器来指定的,和init容器不同的是,init容器是应用到整个pod。这些钩子,如它们的名字所示,是在容器启动后和停止前执行的。生命周期钩子与存活探针和就绪探针相似的是它们都可以:
-
- 在容器内部执行一个命令
- 向一个URL发送HTTP GET请求
分别来看一下这两个钩子,看看它们是如何在容器的生命周期中起作用的。
使用启动后容器生命周期钩子
启动后钩子是在容器的主进程启动之后立即执行的。可以用它在应用启动时做一些额外的工作。当然,如果你是容器中运行的应用的开发者,可以在应用的代码中加入这些操作。但是,如果在运行一个其他人开发的应用,大部分情况下并不想(或者无法)修改它的源代码。启动后钩子可以让在不改动应用的情况下,运行一些额外的命令。这些命令可能包括向外部监听器发送应用己启动的信号,或者是初始化应用以使得应用能够顺利运行。
这个钩子和主进程是并行执行的。钩子的名称或许有误导性,因为它并不是等到主进程完全启动后(如果这个进程有一个初始化的过程,Kubelet显然不会等待这个过程完成,因为它并不知道什么时候会完成)才执行的。
即使钩子是以异步方式运行的,它确实通过两种方式来影响容器。在钩子执行完毕之前,容器会一直停留在Waiting状态,其原因是ContainerCreating。因此,pod的状态会是Pending而不是Running。如果钩子运行失败或者返回了非零的状态码,主容器会被杀死。
一个包含启动后钩子的pod manifest内容如下面的代码所示。
#代码17.3 一个包含启动后生命周期钩子的pod: post-start-hook.yaml apiVersion: v1 kind: Pod metadata: name: pod-with-poststart-hook spec: containers: - image: luksa/kubia name: kubia lifecycle: #钩子是在容器启动时执行的 postStart: exec: #它在容器内部执行/bin目录下的postStart.sh脚本 command: - sh - -c - "echo 'hook will fail with exit code 15'; sleep 5 ; exit 15"
在这个例子中,命令echo、sleep和exit是在容器创建时和容器的主进程一起执行的。典型情况下,并不会像这样来执行命令,而是通过存储在容器镜像中的shell脚本或者二进制可执行文件来运行。
遗憾的是,如果钩子程序启动的进程将日志输出到标准输出终端,你将无法在任何地方看到它们。这样就会导致调试生命周期钩子程序非常痛苦。如果钩子程序失败了,仅仅会在pod的事件中看到一个FailedPostStartHook的告警信息(可以通过命令kubectl describe pod来查看)。稍等一会儿,你就可以看到更多关于钩子为什么失败的信息,如下面的代码清单所示。
#代码17.4 pod的事件显示了基于命令的钩子程序的退出码 FailedSync Error syncing pod, skipping: failed to "StartContainer" for "kubia" with Poststart handler: command 'sh -c echo 'hook will fail with exit code 15'; sleep 5; exit 15 ' exited with 15: : "PostStartHook Failed"
最后一行的数字15就是命令的退出码。当使用HTTP GET请求作为钩子的时候,失败原因可能类似于如下代码清单。
#HTTPGET apiVersion: v1 kind: Pod metadata: name: pod-with-poststart-hook spec: containers: - image: luksa/kubia name: kubia ports: - containerPort: 8080 protocol: TCP lifecycle: postStart: httpGet: port: 9090 path: postStart #代码17.5 pod的事件显示了基于HTTP GET的钩子程序的失败原因 FailedSync Error syncing pod, skipping: failed to "StartContainer" for "kubia" with PostStart handler: Get http://10.32.0.2:9090/postStart: dial tcp 10.32.0.2:9090: getsockopt: connection refused: "PostStart Hook Failed"
注意:这个启动后钩子是故意地使用错误的端口9090而不是正确的端口8080来演示钩子失败时会发生什么情况的。
基于命令的启动后钩子输出到标准输出终端和错误输出终端的内容在任何地方都不会记录,因此或许想把钩子程序的进程输出记录到容器的文件系统文件中,这样可以通过如下的命令来查看文件的内容:
$ kubectl exec my-pod cat logfile.txt
如果容器因为各种原因重启了(包括由于钩子执行失败导致的),这个文件在你能够查看之前就消失了。这种情况下,可以通过给容器挂载一个emptyDir卷,并且让钩子程序向这个存储卷写入内容来解决。
使用停止前容器生命周期钩子
停止前钩子是在容器被终止之前立即执行的。当一个容器需要终止运行的时候,Kubelet在配置了停止前钩子的时候就会执行这个停止前钩子,并且仅在执行完钩子程序后才会向容器进程发送SIGTERM信号(如果这个进程没有优雅地终止运行,则会被杀死)。
停止前钩子在容器收到SIGTERM信号后没有优雅地关闭的时候,可以利用它来触发容器以优雅的方式关闭。这些钩子也可以在容器终止之前执行任意的操作,并且并不需要在应用内部实现这些操作(当在运行一个第三方应用,并且在无法访问应用或者修改应用源码的情况下很有用)。
在pod的manifest中配置停止前钩子和增加一个启动后钩子方法差不多。上面的例子演示了执行命令的启动后钩子,这里来看看执行一个HTTPGET请求的停止前钩子。下面的代码清单演示了如何在pod中定义一个停止前HTTPGET的钩子。
#代码17.6 停止前钩子的YAML配置片段:pre-stop-hook-httpget.yaml lifecycle: #这是一个执行HTTP GET请求的停止前钩子 prestop: httpGet: port: 8080 #这个请求发送到http://POD_IP:8080/shutdown path: shutdown
这个代码中定义的停止前钩子在Kubelet开始终止容器的时候就立即执行到http://pod_IP:8080 shutdown的HTTPGET请求。除了代码清单中所示的port和path,还可以设置scheme(HTTP或HTTPS)和host,当然也可以设置发送出去的请求的httpHeaders。默认情况下,host的值是pod的IP地址。确保请求不会发送到localhost,因为localhost表示节点,而不是pod。
和启动后钩子不同的是,无论钩子执行是否成功容器都会被终止。无论是HTTP返回的错误状态码或者基于命令的钩子返回的非零退出码都不会阻止容器的终止。如果停止前钩子执行失败了,会在pod的事件中看到一个FailedPreStopHook的告警,但是因为pod不久就会被删除了(毕竟是pod的删除动作触发的停止前钩子的执行),你或许都看不到停止前钩子执行失败了。
在应用没有收到SIGTERM信号时使用停止前钩子
很多开发者在定义停止前钩子的时候会犯错误,他们在钩子中只向应用发送了SIGTERM信号。他们这样做是因为他们没有看到他们的应用接收到Kubelet发送的SIGTERM信号。应用没有接收到信号的原因并不是Kubernetes没有发送信号,而是因为在容器内部信号没有被传递给应用的进程。如果你的容器镜像配置是通过执行一个shell进程,然后在shell进程内部执行应用进程,那么这个信号就被这个shell进程吞没了,这样就不会传递给子进程。
在这种情况下,合理的做法是让shell进程传递这个信号给应用进程,而不是添加一个停止前钩子来发送信号给应用进程。可以通过在作为主进程执行的shell进程内处理信号并把它传递给应用进程的方式来实现。或者如果你无法配置容器镜像执行shell进程,而是通过直接运行应用的二进制文件,可以通过在Dockerfile中使用ENTRYPOINT或者CMD的exec方式来实现,即ENTRYPOINT ["/mybinary"] 而不是ENTRYPOINT /mybinary。
在通过第一种方式运行二进制文件mybinary的容器中,这个进程就是容器的主进程,而在第二种方式中,是先运行一个shell作为主进程,然后mybinary进程作为shell进程的子进程运行。
了解生命周期钩子是针对容器而不是pod
作为对启动后和停止前钩子最后的思考,强调的是这些生命周期的钩子是针对容器而不是pod的。不应该使用停止前钩子来运行那些需要在pod终止的时候执行的操作。原因是停止前钩子只会在容器被终止前调用(大部分可能是因为存活探针失败导致的终止)。这个过程会在pod的生命周期中发生多次,而不仅仅是在pod被关闭的时候。
1.5 了解pod的关闭
己经接触过关于pod终止的话题,所以这里会进一步探讨相关细节来看看pod关闭的时候具体发生了什么。这个对理解如何干净地关闭pod中运行的应用很重要。
从头开始,pod的关闭是通过API服务器删除pod的对象来触发的。当接收到HTTP DELETE请求后,API服务器还没有删除pod对象,而是给pod设置一个deletionTimestamp值。拥有deletionTimestamp的pod就开始停止了。
当Kubelet意识到需要终止pod的时候,它开始终止pod中的每个容器。Kubelet会给每个容器一定的时间来优雅地停止。这个时间叫作终止宽限期(Terniination GracePeriod),每个pod可以单独配置。在终止进程开始之后,计时器就开始计时,接着按照顺序执行以下事件:
1. 执行停止前钩子(如果配置了的话),然后等待它执行完毕
2. 向容器的主进程发送SIGTERM信号
3. 等待容器优雅地关闭或者等待终止宽限期超时
4. 如果容器主进程没有优雅地关闭,使用SIGKILL信号强制终止进程
指定终止宽限期
终止宽限期可以通过pod spec中的spec.terminationGracePeriod Periods字段来设置。默认情况下,值为30,表示容器在被强制终止之前会有30秒的时间来自行优雅地终止。
提示:应该将终止宽限时间设置得足够长,这样容器进程才可以在这个时间段内完成清理工作。
在删除pod的时候,pod spec中指定的终止宽限时间也可以通过如下方式来覆盖:
$ kubectl delete po mypod --grace-period=5
这个命令将会让Kubectl等待5秒钟,让pod自行关闭。当pod所有的容器都停止后,Kubelet会通知API服务器,然后pod资源最终都会被删除。可以强制API服务器立即删除pod资源,而不用等待确认。可以通过设置宽限时间为0,然后增加一个--force选项来实现:
$ kubectl delete po mypod --grace-period=0 --force
在使用这个选项的时候需要注意,尤其是StatefulSet的pod。StatefulSet控制器会非常小心地避免在同一时间运行相同pod的两个实例(两个pod拥有相同的序号、名称,并且挂载到相同的PersistentVolume)。强制删除一个pod会导致控制器不会等待被删的pod里面的容器完成关闭就创建一个替代的pod。换句话说,相同pod的两个实例可能在同一时间运行,这样会导致有状态的集群服务工作异常。只有在确认pod不会再运行,或者无法和集群中的其他成员通信(可以通过托管pod的节点网络连接失败并且无法重连来确认)的情况下再强制删除有状态的pod。
现在己经了解了容器关闭的方式,接下来从应用的角度来看一下应用应该如何处理容器的关闭流程。
在应用中合理地处理容器关闭操作
应用应该通过启动关闭流程来响应SIGTERM信号,并且在流程结束后终止运行。除了处理SIGTERM信号,应用还可以通过停止前钩子来收到关闭通知。在这两种情况下,应用只有固定的时间来干净地终止运行。
但是如果无法预测应用需要多长时间来干净地终止运行怎么办呢?例如,假设你的应用是一个分布式数据存储。在缩容的时候,其中一个pod的实例会被删除然后关闭。在这个关闭的过程中,这个pod需要将它的数据迁移到其他存活的pod上面以确保数据不会丢失。那么这个pod是否应该在接收到终止信号的时候就开始迁移数据(无论是通过SIGTERM信号还是停止前钩子)?
完全不是!这种做法是不推荐的,理由至少有两点:
-
- 一个容器终止运行并不一定代表整个pod被终止了。
- 你无法保证这个关闭流程能够在进程被杀死之前执行完毕。
第二种场景不仅会在应用在超过终止宽限期还没有优雅地关闭时发生,还会在容器关闭过程中运行pod的节点出现故障时发生。即使这个时候节点又重启了,Kubelet不会重启容器的关闭流程(甚至都不会再启动这个容器了)。这样就无法保证pod可以完成它整个关闭的流程。
将重要的关闭流程替换为专注于关闭流程的pod
如何确认一个必须运行完毕的重要的关闭流程真的运行完毕了呢(例如,确认一个pod的数据成功迁移到了另外一个pod) ?
一个解决方案是让应用(在接收到终止信号的时候)创建一个新的Job资源, 这个Job资源会运行一个新的pod,这个pod唯一的工作就是把被删除的pod的数据迁移到仍然存活的pod。但是如果注意到的话,就会了解你无法保证应用每次都能够成功创建这个Job对象。万一当应用要去创建Job的时候节点出现故障呢?
这个问题的合理的解决方案是用一个专门的持续运行中的pod来持续检查是否存在孤立的数据。当这个pod发现孤立的数据的时候,它就可以把它们迁移到仍存活的pod。当然不一定是一个持续运行的pod,也可以使用CronJob资源来周期性地运行这个pod。
你或许以为StatefulSet在这里会有用处,但实际上并不是这样。给StatefulSet缩容会导致PersistentVolumeClaim处于孤立状态,这会导致存储在PersistentVolumeClaim中的数据搁浅。当然,在后续的扩容过程中,PersisitentVolume会被附加到新的pod实例中,但是万一这个扩容操作永远不会发生(或者很久之后才会发生)呢?因此,当在使用StatefulSet的时候或许想运行一个数据迁移的pod。为了避免应用在升级过程中出现数据 迁移,专门用于数据迁移的pod可以在数据迁移之前配置一个等待时间,让有状态的pod有时间启动起来。
2.确保所有的客户端请求都得到了妥善处理
已经了解清楚如何干净地关闭pod了。现在,从pod的客户端角度来看看pod的生命周期(使用pod提供的服务的客户端)。了解这一点很重要,如果你希望pod扩容或者缩容的时候客户端不会遇到问题的话。
毋庸赘言,你希望所有的客户端请求都能够得到妥善的处理。显然不希望pod在启动或者关闭过程中出现断开连接的情况。Kubernetes本身并没有避免这种事情的发生。你的应用需要遵循一些规则来避免遇到连接断开的情况。首先,重点看一下如何在pod启动的时候,确保所有的连接都被妥善处理了。
2.1 在pod启动时避免客户端连接断开
确保pod启动的时候每个连接都被妥善处理很容易,只要理解了服务和服务端点是如何工作的。当一个pod启动的时候,它以服务端点的方式提供给所有的服务,这些服务的标签选择器和pod的标签匹配。pod需要发送信号给Kubernetes通知它自己已经准备好了。pod在准备好之后,它才能变成一个服务端点,否则无法接收任何客户端的连接请求。
如果在pod spec中没有指定就绪探针,那么pod总是被认为是准备好了的。当第一个kube-proxy在它的节点上面更新了iptables规则之后,并且第一个客户端pod开始连接服务的时候,这个默认被认为是准备好了的pod几乎会立即开始接收请求。如果应用这个时候还没有准备好接收连接,那么所有的客户端都会看 到“连接被拒绝”一类的错误信息。
你需要做的是当且仅当你的应用准备好处理进来的请求的时候,才去让就绪探针返回成功。实践第一步是添加一个指向应用根URL的HTTP GET请求的就绪探针。在很多情况下,这样做就足够了,免得还需要在应用中实现一个特殊的readiness endpoint。
2.2 在pod关闭时避免客户端连接断开
现在来看一下在pod生命周期的另一端--当pod被删除,pod的容器被终止的时候会发生什么。己经讨论过pod的容器应该如何在它们收到SIGTERM信号的时候干净地关闭(或者容器的停止前钩子被执行的时候)。但是这就能确保所有的客户端请求都被妥善处理了吗?
当应用接收到终止信号的时候应该如何做呢?它应该继续接收请求么?那些己经被接收但是还没有处理完毕的请求该怎么办呢?那些打开的HTTP长连接(连接上己经没有活跃的请求了)该怎么办呢?在回答这些问题之前,需要详细地看一下当pod删除的时候,集群中的一连串事件是如何发生的。
了解pod删除时发生的一连串事件
Kubernetes组件都是运行在不同机器上面的不同的进程。它们并不是在一个庞大的单一进程中。让集群中的所有组件同步到一致的集群状态需要时间。通过pod删除时集群中发生的一连串事件来探究一下真相。
当API服务器接收到删除pod的请求之后,它首先修改了etcd中的状态并且把删除事件通知给观察者。其中的两个观察者就是Kubelet和端点控制器(Endpoint Controller)。图17.7展示了并行发生的两串事件(用A或B标识)。
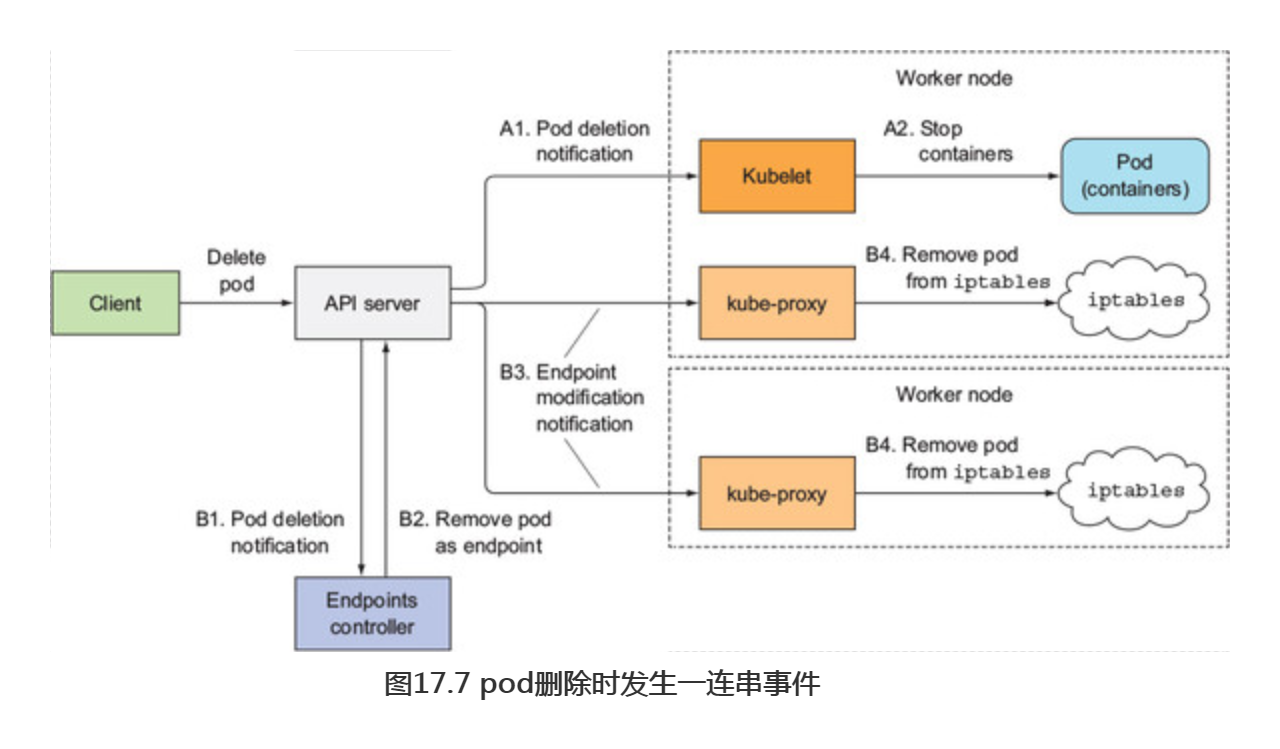
在标识为A的一串事件中,当Kubelet接收到pod应该被终止的通知的时候,它初始化了关闭动作序列(执行停止前钩子,发送SIGTERM信号,等待一段时间,然后在容器没有自我终止时强制杀死容器)。如果应用立即停止接收客户端的请求以作为对SIGTERM信号的响应,那么任何尝试连接到应用的请求都会收到Connection Refused的错误。从pod被删除到发生这个情况的时间相对来说特别短,因为这是API服务器和Kubelet之间的直接通信。
那么,再看看另外一串事件中发生了什么--就是在pod被从iptables规则中移除之前的那些事件(图中标识为B的序列)。当端点控制器(在Kubernetes的控制面板的Controller Manager中运行)接收到pod要被删除的通知时,它从所有pod所在的服务中移除了这个pod的服务端点。它通过向API服务器发送REST请求来修改Endpoint API对象。然后API服务器会通知所有的客户端关注这个Endpoint对象。其中的一些观察者都是运行在工作节点上面的kube-proxy服务。每个kube-proxy服务都会在自己的节点上更新iptables规则,以阻止新的连接被转发到这些处于停止状态的pod上。这里一个重要的细节是,移除iptables规则对已存在的连接没有影响——已经连接到pod的客户端仍然可以通过这些连接向pod发送额外的请求。
上面的两串事件是并行发生的。最有可能的是,关闭pod中应用进程所消耗的时间比完成iptables规则更新所需要的时间稍微短一点。导致iptables规则更新的那一串事件相对比较长(见图17.8),因为这些事件必须先到达Endpoint控制器,然后Endpoint控制器向API服务器发送新的请求,然后API服务器必须修改kube-proxy,最后kube-proxy再修改iptables规则。存在一个很大的可能性是SIGTERM信号会在iptables规则更新到所有的节点之前发送出去。
最终的结果是,在发送终止信号给pod之后,pod仍然可以接收客户端请求。如果应用立即关闭服务端套接字,停止接收请求的话,这会导致客户端收到“连接被拒绝”一类的错误(这个情形和pod启动时应用还无法立即接收请求,并且还没有给pod定义一个就绪探针时发生的一样)。

解决问题
用Google搜索这个问题的解决方案看上去就是给pod添加一个就绪探针来解决问题。假设所需要做的事情就是在pod接收到SIGTERM信号的时候就绪探针开始失败。这会导致pod从服务的端点中被移除。但是这个移除动作只会在就绪探针持续性失败一段时间后才会发生(可以在就绪探针的spec中配置),并且这个移除动作还是需要先到达kube-proxy然后iptables规则才会移除这个pod。
实际上,就绪探针完全不影响这个过程。端点控制器在接收到pod要被删除(当pod spec中的deletionTimestamp字段不再是null)的通知的时候就会从Endpoint中移除pod。从那个时候开始,就绪探针的结果己经无关紧要了。
那么这个问题的合适的解决方案是什么呢?如何保证所有的请求都被处理了呢?
很明显,pod必须在接收到终止信号之后仍然保持接收连接直到所有的kube-proxy完成了iptables规则的更新。当然,不仅仅是kube-proxy,这里还会有Ingress控制器或者负载均衡器直接把请求转发给pod而不经过Service。这也包括使用客户端负载均衡的客户端。为了确保不会有客户端遇到连接断开的情况,需要等到它们通知你它们不会再转发请求给pod的时候。
这是不可能的,因为这些组件分布在不同的机器上面。即使知道每一个组件的位置并且可以等到它们都来通知你可以关闭pod了,万一其中有一个组件未响应呢?这个时候,需要等待这个回复多长时间?记住,在这个时间段内,延阻了关闭的过程。
你可以做的唯一的合理的事情就是等待足够长的时间让所有的kube-proxy可以完成它们的工作。那么多长时间才是足够的呢?在大部分场景下,几秒钟应该就足够了,但是无法保证每次都是足够的。当API服务器或者端点控制器过载的时候,通知到达kube-proxy的时间会更长。你无法完美地解决这个问题,理解这一点很重要,但是即使增加5秒或者10秒延迟也会极大提升用户体验。可以用长一点的延迟时间,但是别太长,因为这会导致容器无法正常关闭,而且会导致pod被删除很长一段时间后还显示在列表里面,这个会给删除pod的用户带来困扰。
小结
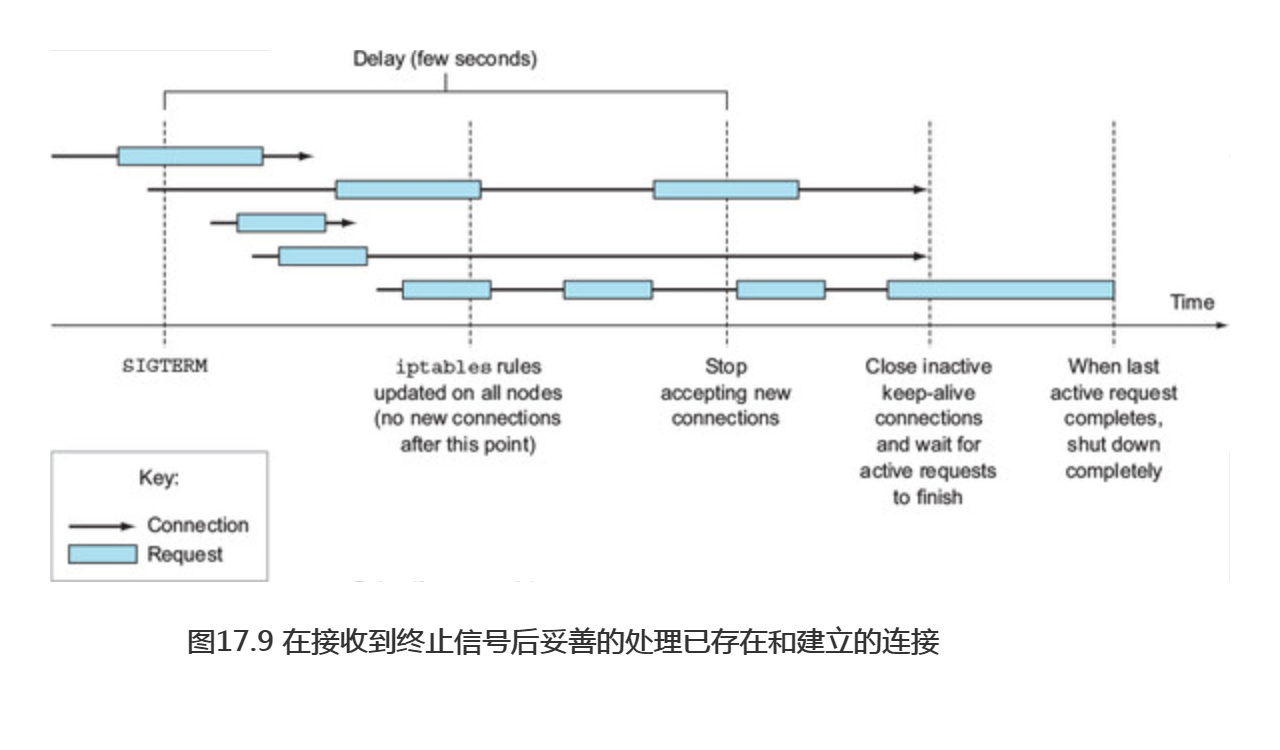
简要概括一下,妥善关闭一个应用包括如下步骤:
-
- 等待几秒钟,然后停止接收新的连接。
- 关闭所有没有请求过来的长连接。
- 等待所有的请求都完成。
- 然后完全关闭应用。
为了理解这个过程中连接和请求都发生了什么,看图17.9。
这个过程不像进程接收到终止信号立即退出那么简单,真的值得这么做吗?这个取决于你。但是至少可以添加一个停止前钩子来等待几秒钟再退出,或许就像下面代码清单中所示的一样。
#代码17.7 用于避免连接断开的停止前钩子 lifecycle: preStop: exec: command: - sh - -c - "sleep 5"
这样就不需要修改代码了。如果应用己经能够确保所有的进来的请求都得到了处理,那么这个停止前钩子带来的等待己经足够了。

