Kubernetes之存储
pod类似逻辑主机,在逻辑主机中运行的进程共享诸如CPU、RAM、网络接口等资源。人们会期望进程也能共享磁盘,但事实并非如此。需要谨记一点,pod中的每个容器都有自己独立的文件系统,因为文件系统来自容器镜像。
每个新容器都是通过在构建镜像时加入的详细配置文件来启动的。将此与pod中容器重新启动的现象结合起来(也许是因为进程崩溃,也许是存活探针向 Kubernetes发送了容器状态异常的信号),你就会意识到新容器并不会识别前一个容器写入文件系统内的任何内容,即使新启动的容器运行在同一个pod中。
在某些场景下,我们可能希望新的容器可以在之前容器结束的位置继续运行, 比如在物理机上重启进程。可能不需要(或者不想要)整个文件系统被持久化,但又希望能保存实际数据的目录。
Kubernetes通过定义存储卷来满足这个需求,它们不像pod这样的顶级资源, 而是被定义为pod的一部分,并和pod共享相同的生命周期。这意味着在pod启动时创建卷,并在删除pod时销毁卷。因此,在容器重新启动期间,卷的内容将保持不变,在重新启动容器之后,新容器可以识别前一个容器写入卷的所有文件。另外, 如果一个pod包含多个容器,那这个卷可以同时被所有的容器使用。
1.介绍卷
Kubernetes的卷是pod的一个组成部分,因此像容器一样在pod的规范中就定义了。它们不是独立的Kubernetes对象,也不能单独创建或删除。pod中的所有容器都可以使用卷,但必须先将它挂载在每个需要访问它的容器中。在每个容器中,都可以在其文件系统的任意位置挂载卷。
1.1 卷的应用示例
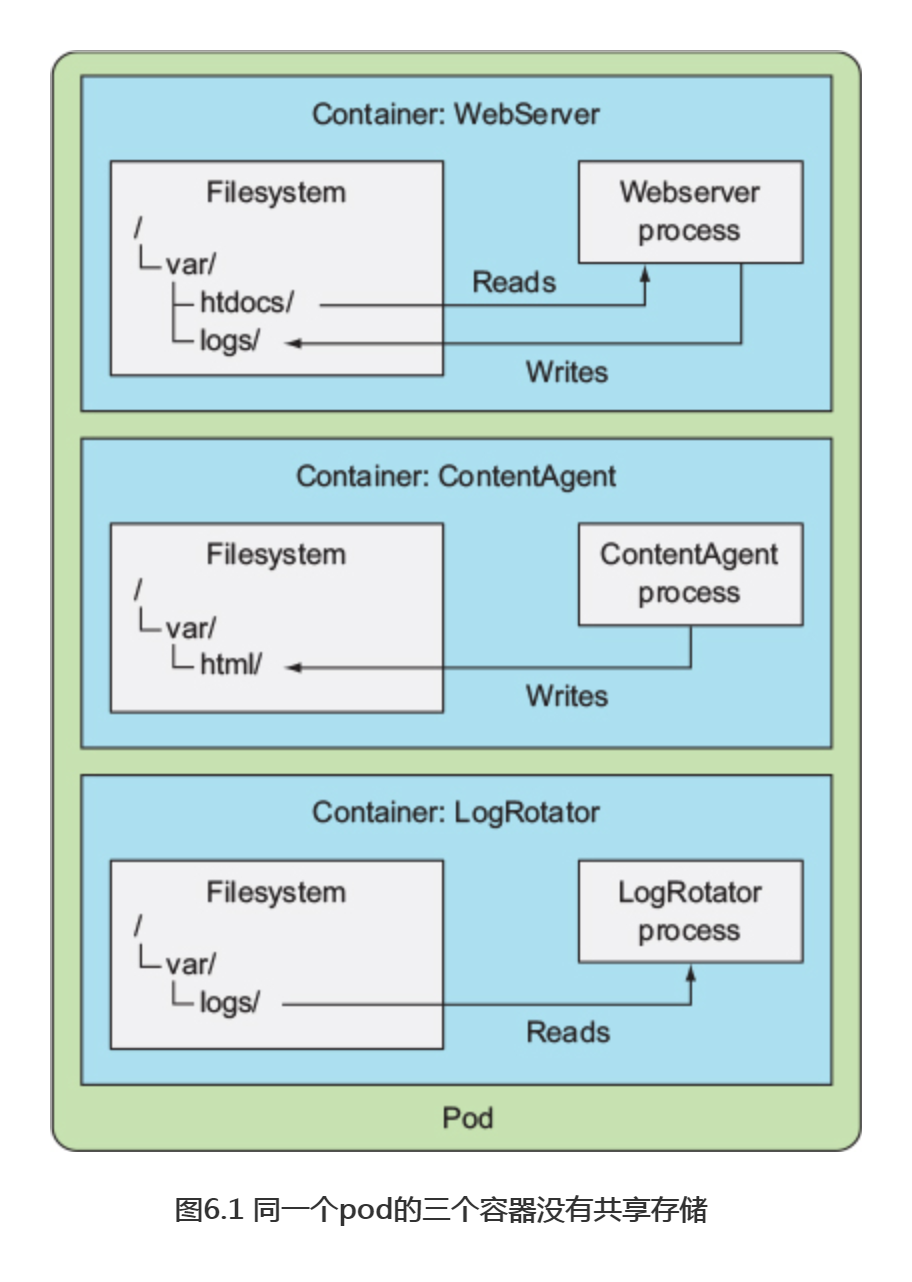
假设有一个带有三个容器的pod(如图6.1所示),一个容器运行了一个web服务器,该web服务器的HTML页面目录位于/var/htdocs,并将站点访问日志存储到/var/logs目录中。第二个容器运行了一个代理来创建HTML文件,并将它们存放在/var/html中,第三个容器处理在/var/logs目录中找到的日志(转换、压缩、分析它们或者做其他处理)。
每个容器都有一个很明确的用途,但是每个容器单独使用就没有多大用处了。在没有共享磁盘存储的情况下,用这三个容器创建一个pod没有任何意义。因为内容生成器(content generator)会在自己的容器中存放生成的HTML文件,而web服务器无法访问这些文件,因为它运行在一个隔离的独立容器内。正好相反,它会托管放置在容器镜像的/var/htdocs目录下的任意内容,或者是放置在容器镜像中/var/htdocs路径下的任意内容。同样,日志转换器(logrotator)也无事可做,因为它的/var/logs目录始终是空的,并没有日志写入。一个有这三个容器而没有挂载卷的pod基本上什么也做不了。
但是,如果将两个卷添加到pod中,并在三个容器的适当路径上挂载它们,如图6.2所示,就己经创建出一个比其各个部分之和更完善的系统。Linux允许在文件树中的任意位置挂载文件系统,当这样做的时候,挂载的文件系统内容在目录中是可以访问的。通过将相同的卷挂载到两个容器中,它们可以对相同的文件进行操作。在这个例子中,只需要在三个容器中挂载两个卷,这样三个容器将可以一起工作,并发挥作用。下面解释一下:
首先,pod有一个名为publicHtml的卷,这个卷被挂载在WebServer容器的/var/htdocs中,因为这是web服务器的服务目录。在ContentAgent容器中也挂载了相同的卷,但在/var/html中,因为代理将文件写入/var/html中。通过这种方式挂载这个卷,web服务器现在将为contentagent生成的内容提供服务。
同样,pod还拥有一个名为logVol的卷,用于存放日志,此卷在Webserver和LogRotator容器中的/var/log中挂载,注意,它没有挂载在ContentAgent 容器中,这个容器不能访问它的文件,即使容器和卷是同一个pod的一部分,在pod的规范中定义卷是不够的。如果我们希望容器能够访问它,还需要在容器的规范中定义一个VolumeMount。

在本例中,两个卷最初都是空的,因此可以使用一种名为emptyDir的卷。 Kubernetes还支持其他类型的卷,这些卷要么是在从外部源初始化卷时填充的,要么是在卷内挂载现有目录。这个填充或装入卷的过程是在pod内的容器启动之前执行的。
卷被绑定到pod的lifecycle(生命周期)中,只有在pod存在时才会存在,但取决于卷的类型,即使在pod和卷消失之后,卷的文件也可能保持原样,并可以挂载到新的卷中。来看看卷有哪些类型。
1.2 介绍可用的卷类型
有多种卷类型可供选择。其中一些是通用的,而另一些则相对于当前常用的存储技术有较大差别。以下是几种可用卷类型的列表:
-
- emptyDir: 用于存储临时数据的简单空目录。
- hostPath: 用于将目录从工作节点的文件系统挂载到pod中。
- gitRepo: 通过检出Git仓库的内容来初始化的卷。
- Nfs: 挂载到pod中的NFS共享卷。
- gcePersistentDisk(Google高效能型存储磁盘卷)、awsElastic BlockStore(AmazonWeb 服务弹性块存储卷)、azureDisk (Microsoft Azure磁盘卷)——用于挂载云服务商提供的特定存储类型。
- cinder、 cephfs、 iscsi、 flocker、 glusterfs、 quobyte、 rbd、 flexVolume、 vsphere-Volume、 photonPersistentDisk、 scaleIO用于挂载其他类型的网络存储。
- configMap、secret、downwardAPI-用于将Kubernetes部分资源和集群信息公开给pod的特殊类型的卷。
- persistentVolumeClaim--种使用预置或者动态配置的持久存储类型(我们将在本章的最后一节对此展开讨论)。
这些卷类型有各种用途。我们将在下面的部分中了解其中一些内容。特殊类型的卷(secret、downwardAPI、configMap)其它篇幅讲解。因为它们不是用于存储数据,而是用于将Kubernetes元数据公开给运行在pod中的应用程序。
单个容器可以同时使用不同类型的多个卷,而且正如我们前面提到的,每个容器都可以装载或不装载卷。
2.通过卷在容器之间共享数据
尽管一个卷即使被单个容器使用也可能很有用,但是我们首先要关注它是如何用于在一个pod的多个容器之间共享数据的。
2.1 使用emptyDir卷
最简单的卷类型是emptyDir卷,所以作为第一个例子让我们看看如何在pod中定义卷。顾名思义,卷从一个空目录开始,运行在pod内的应用程序可以写入它需要的任何文件。因为卷的生存周期与pod的生存周期相关联,所以当删除pod时,卷的内容就会丢失。
一个emptyDir卷对于在同一个pod中运行的容器之间共享文件特别有用。但是它也可以被单个容器用于将数据临时写入磁盘,例如在大型数据集上执行排序操作时,没有那么多内存可供使用。数据也可以写入容器的文件系统本身(还记得容器的顶层读写层吗?),但是这两者之间存在着细微的差别。容器的文件系统甚至可能是不可写的,所以写到挂载的卷可能是唯一的选择。
在pod中使用emptyDir卷
回顾一下前面的例子,其中web服务器、内容代理和日志转换器共享两个卷,但让我们简化一下,现在将构建一个仅有web服务器容器内容代理和单独HTML的卷的pod。
将使用Nginx作为Web服务器和UNIX fortune命令来生成HTML内容,fortune命令每次运行时都会输出一个随机引用,可以创建一个脚本每10秒调用一次执行,并将其输出存储在index.html中,在Docker Hub上可以找到一个现成的Nginx镜像。
创建pod
现在有两个镜像需要运行在pod上,是时候创建pod的manifest了,创建一个名为fortune-pod.yaml的文件,其内容包含在下面的代码清单中。
#代码6.1 一个pod中有两个共用同一个卷的容器:fortune-pod.yaml apiVersion: v1 kind: Pod metadata: name: fortune spec: containers: - image: luksa/fortune #第一个容器名为html-generatro,运行luksa/fortune镜像 name: html-generator volumeMounts: #名为html的卷挂载在容器的/var/htdocs中 - name: html mountPath: /var/htdocs - image: nginx:alpine #第二个容器成为web-server,运行nginx:alpine镜像 name: web-server volumeMounts: #与上面相同的卷挂载在/usr/share/nginx/html上,设为只读 - name: html mountPath: /usr/share/nginx/html readOnly: true ports: - containerPort: 80 protocol: TCP volumes: #一个名为html的单独emptyDir卷,挂载在上面的2个容器上 - name: html emptyDir: {}
pod包含两个容器和一个挂载在两个容器中的共用的卷,但在不同的路径上。当html-generator容器启动时,它每10秒启动一次fortune命令输出到/var/htdocs/index.html文件。因为卷是在/var/htdocs上挂载的,所以index.html文件被写入卷中,而不是容器的顶层。一旦web-server容器启动,它就开始为/usr/share/nginx/html目录中的任意HTML文件提供服务(这是Nginx服务的默认服务文件目录)。因为我们将卷挂载在那个确切的位置,Nginx将为运行fortune循环的容器输出的index.html文件提供服务。最终的效果是,一个客户端向pod上的 80端口发送一个HTTP请求,将接收当前的fortune消息作为响应。
查看pod状态
为了查看fortune消息,需要启用对pod的访问,可以尝试将端口从本地机器转发到pod来实现:
$ kubectl port-forward fortune 8080:80 Forwarding from 127.0.0.1:8080 -> 80 Forwarding from [::1]:8080 -> 80
现在可以通过本地计算机的8080端口来访问Nginx服务器。
$ curl http://localhost:8080
Beware of a tall blond man with one black shoe.
如果等待几秒发送另一个请求,则应该会接收到另一条信息。通过组合两个容 器,就创建了一个简单的应用,通过这个应用可以观察到卷是如何将两个容器组合 在一起,并分别增强它们各自的功能的。
指定用于EMPTYDIR的介质
作为卷来使用的emptyDir,是在承载pod的工作节点的实际磁盘上创建的, 因此其性能取决于节点的磁盘类型。但我们可以通知Kubernetes在tmfs文件系统(存在内存而非硬盘)上创建emptyDir。因此,将emptyDir的medium设置为Memory:
volumes - name: html emptyDir medium: Memory #emptyDir的文件将会存储在内存中
emptyDir卷是最简单的卷类型,但是其他类型的卷都是在它的基础上构建的, 在创建空目录后,它们会用数据填充它。有一种称作gitRepo的卷类型,下面介绍。
2.2 使用GIT仓库作为存储卷
gitRepo卷基本上也是一个emptyDir卷,它通过克隆Git仓库并在pod启动时(但在创建容器之前)检出特定版本来填充数据,如图6.3所示。
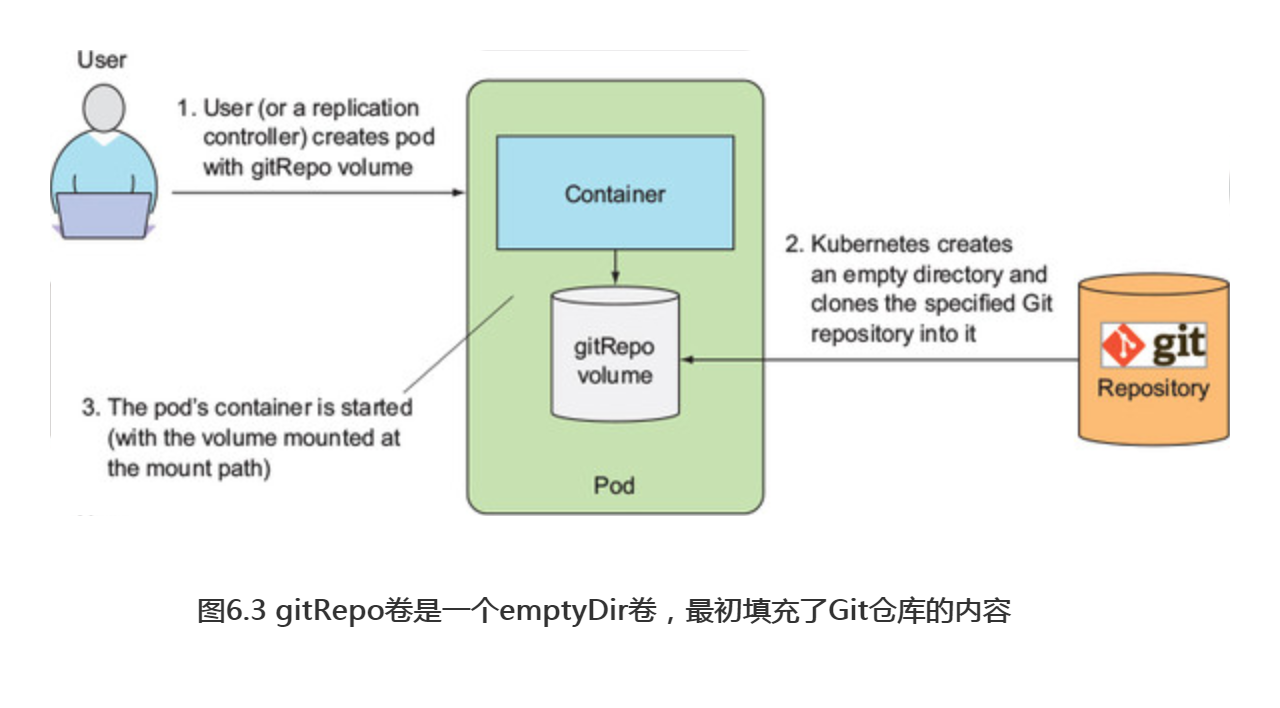
注意:在创建gitRepo卷后,它并不能和对应repo保持同步。当向Git仓库推送新增的提交时,卷中的文件将不会被更新。然而,如果所用的pod是由ReplicationController管理的,删除这个pod将触发新建一个新的pod,而这个新pod的卷中将包含最新的提交。
例如,可以使用Git仓库来存放网站的静态HTML文件,并创建一个包含web服务器容器和gitRepo卷的pod。每当pod创建时,它会拉取网站的最新版本并开始托管网站。唯一的缺点是,每次将更改推送到gitRepo时,都需要删除pod,才能托管新版本的网站。
从一个克隆的Git仓库中运行web服务器pod的服务文件
在创建pod之前,需要有一个包含HTML文件并实际可用的Git仓库,测试链接为:https://github.com/luksa/kubia-website-example.git。现在需要fork这个项目(在github上创建你自己的repo副本),这样就可以在后面对其进行变更修改。
当我们完成了fork操作,就可以继续创建pod了。这次,只需要一个Nginx容器和一个gitRepo卷(确保己将gitRepo卷指向fork来的repo副本),如下面的代码清单所示。
#代码6.2 使用gitRepo卷的pod:gitrepo-volume-pod.yaml apiVersion: v1 kind: Pod metadata: name: gitrepo-volume-pod spec: containers: - image: nginx:alpine name: web-server volumeMounts: - name: html mountPath: /usr/share/nginx/html readOnly: true ports: - containerPort: 80 protocol: TCP volumes: - name: html gitRepo: repository: https://github.com/luksa/kubia-website-example.git #这个卷克隆至一个Git仓库 revision: master #检出主分支 directory: . #将repo克隆到卷的根目录
在创建pod时,首先将卷初始化为一个空目录,然后将制定的Git仓库克隆到其中。如果没有将目录设置为.(句点),存储库将会被克隆到kubia-website-example示例目录中,这不是我们想要的结果。我们预期将repo克隆到卷的根目录中。在设置存储库时,还需要指明让Kubernetes切换到master分支所在的版本来创建存储卷修订变更。
在pod运行时,可以尝试通过端口转发、服务或在pod(或集群中的任意其他pod)中运行curl命令来访问pod。
确认文件未与Git仓库保持同步
现在,将对Github项目中的index.html文件进行更改。
Git仓库的主分支现在包含对HTML文件所做的更改。而这些更改在Nginx web服务器上不可见,因为gitrepo卷与Git仓库未能保持同步。可以通过再次访问pod来确认这一点。
要查看新版本的站点,需要删除pod并重建,每次进行更改时,没必要每次都删除pod,可以运行一个附加进程来使卷与Git仓库保持同步。在这里不详细解释如何实现,相反,建议自己多做练习,这里可以给到一些指引。
介绍sidecar容器
Git同步进程不应该运行在与Nginx站点服务器相同的容器中,而是在第二个容器:它是一种容器,增加了对pod主容器的操作。可以将一个sidecar添加到pod中,这样就可以使用现有的容器镜像,而不是将附加逻辑填入主应用程序的代码中,这会使它过于复杂和不可复用。
为了找到一个保持本地目录与Git仓库同步的现有容器镜像,转到Docker Hub并搜索"git syc”,可以看到很多可以实现的镜像。然后在示例中,从pod的一个新容器使用镜像,挂载pod现有的gitRepo卷到新容器中,并配置Git同步容器来保持文件与Git repo同步。如果正确设置了所有的内容,应该能看到web服务器正在加载的文件与GitHub repo同步。
使用带有专用Git仓库的gitRepo卷
另外还有一个原因,使得必须依赖于Git sync sidecar容器。还没有讨论过是否可以使用对应私有Git repo的gitRepo卷,其实不可行。Kubernetes开发人员的共识是保持gitRepo卷的简单性,而不添加任何通过SSH协议克隆私有存储库的支持,因为这需要向gitRepo卷添加额外的配置选项。
如果想要将私有的Git repo克隆到容器中,则应该使用gitsync sidecar或类似的方法,而不是使用gitRepo卷。
总结gitRepo存储卷
gitRepo容器就像emptyDir卷一样,基本上是一个专用目录,专门用于包含卷的容器并单独使用。当pod被删除时,卷及其内容被删除。然而,其他类型的卷并不创建新目录,而是将现有的外部目录挂载到pod的容器文件系统中。该卷的内容可以保存多个pod实例化,接下来将了解这些类型的卷。
3.访问工作节点文件系统上的文件
大多数pod应该忽略它们的主机节点,因此它们不应该访问节点文件系统上的任何文件。但是某些系统级别的pod(切记,这些通常由DaemonSet管理)确实需要读取节点的文件或使用节点文件系统来访问节点设备。Kubernetes通过hostPath卷实现了这一点。
3.1 介绍hostPath卷
hostPath卷指向节点文件系统上的特定文件或目录(请参见图6.4)。在同一个节点上运行并在其hostPath卷中使用相同路径的pod可以看到相同的文件。

hostPath卷是我们介绍的第一种类型的持久性存储,因为gitRepo和emptyDir卷的内容都会在pod被删除时被删除,而hostPath卷的内容则不会被删除。如果删除了一个pod,并且下一个pod使用了指向主机上相同路径的hostPath卷,则新pod将会发现上一个pod留下的数据,但前提是必须将其调度到与第一个pod相同的节点上。
如果考虑使用hostPath卷作为存储数据库数据的目录,请重新考虑。 因为卷的内容存储在特定节点的文件系统中,所以当数据库pod被重新安排在另一个节点时,会找不到数据。这解释了为什么对常规pod使用hostPath卷不是一个好主意,因为这会使pod对预定规划的节点很敏感。
3.2 检查使用hostPath卷的系统pod
让我们看看如何正确地使用hostPath卷。我们先看一下是否有系统层面的pod己经在使用这种类型的卷,而不是直接创建一个新pod。有几个fluented在kube-system中,再次列出它们:
$ kubectl get pod s --namespace kube-system NAME READY STATUS RESTARTS AGE fluentd-kubia-4ebc2f1e-9a3e 1/1 Running 1 4d fluentd-kubia-4ebc2f1e-e2vz 1/1 Running 1 31d ...
选择一个并查看其使用的卷大小
$ kubectl describe po fluentd-kubia-4ebc2f1e-9a3e --namespace kube-system Name: fluentd-cloud-logging-gke-kubia-default-pool-4ebc2f1e-9a3e Namespace: kube-system ... Volumes: varlog: Type: HostPath (bare host directory volume) Path: /var/log varlibdockercontainers: Type: HostPath (bare host directory volume) Path: /var/lib/docker/containers
pod使用两个hostPath卷来访问节点的/var/log和/var/lib/docker/containers目 录。也许你认为在第一次尝试时就找到一个在使用hostPath卷的pod很幸运,但实际上并不是这样(至少在GKE不是)。检查其他文件,将能看到大多数情况下都使用这种类型的卷来访问节点的日志文件、kubeconfig (Kubernetes配置文件)或CA证书。
如果检查其他pod,则会看到其中没有一个使用hostPath卷来存储自己的数据,都是使用这种卷来访问节点的数据。但是,正如我们在本章后面将看到的,hostPath卷通常用于尝试单节点集群中的持久化存储,譬如Minikube创建的集群。我们将了解即使在多节点集群中也应该使用哪些类型的卷来正确地存储持久化数据。
提示:请记住仅当需要在节点上读取或写入系统文件时才使用hostPath,切勿使用它们来持久化跨pod的数据。
4.用持久化存储
当运行在一个pod中的应用程序需要将数据保存到磁盘上,并且即使该pod重新调度到另一个节点时也要求具有相同的数据可用。这就不能使用到目前为止我们提到的任何卷类型,由于这些数据需要可以从任何集群节点访问,因此必须将其存储在某种类型的网络存储(NAS)中。
要了解允许保存数据的卷,我们将创建一个运行MongoDB(文件类型NoSQL数据库)的pod。除了测试目的,运行没有卷或非持久卷的数据库pod没有任何意义,
所以需要为该pod添加适当类型的卷并将其挂载在MongoDB容器中。
4.1 使用GCE持久磁盘作为pod存储卷
如果是在Google Kubernetes Engine中运行这些示例,那么由于集群节点是运行在Google Compute Engine (GCE)之上,则将使用GCE持久磁盘作为底层存储机制。
在早期版本中,Kubernetes没有自动配置底层存储,必须手动执行此操作。自动配置现在己经可以实现,我们将在本章的后面部分进一步了解。首先,需要手动配置存储,这样可以让你有机会了解背后发生了什么。
创建GCE持久磁盘
首先创建GCE持久磁盘。我们需要在同一区域的Kubernetes集群中创建它, 如果你不记得是在哪个区域创建了集群,可以通过使用gcloud命令来查看:
$ gcloud container clusters list
NAME ZONE MASTER_VERSION MASTER_IP ...
kubia europe-west1-b 1.2.5 104.155.84.137 ...
以上输出说明己经在europe-west1-b区域中创建了集群,因此也需要在同一区域中创建GCE持久磁盘。可以像这样创建磁盘:
$ gcloud compute disks create --size=1GiB --zone=europe-west1-b mongodb WARNING: You have selected a disk size of under [200GB]. This may result in poor I/O performance. For more information, see: https://developers.google.com/compute/docs/disks#pdperformance. Created [https://www.googleapis.com/compute/v1/projects/rapid-pivot- 136513/zones/europe-west1-b/disks/mongodb]. NAME ZONE SIZE_GB TYPE STATUS mongodb europe-west1-b 1 pd-standard READY
这个命令创建了一个1GiB容量并命名为mongodb的GCE持久磁盘。可以忽略有关磁盘大小的告警,因为我们无须关心用于测试的磁盘性能。
创建一个使用GCE持久磁盘卷的pod
现在己经正确设置了物理存储,可以在MongoDB pod的卷中使用它。着手为pod准备YAML,如下面的代码清单所示。
#代码6.4一个使用gce PerSiStent Disk卷的pod:mongodb-pod-gcepd.yaml apiVersion: v1 kind: Pod metadata: name: mongodb spec: volumes: - name: mongodb-data gcePersistentDisk: #类型是GCE持久磁盘 pdName: mongodb #持久磁盘的名称必须与先前创建的实际PD一致 fsType: ext4 containers: - image: mongo name: mongodb volumeMounts: - name: mongodb-data mountPath: /data/db #MongoDB数据存放的路径 ports: - containerPort: 27017 protocol: TCP
提示:如果要使用Minikube,就不能使用GCE持久磁盘,但是可以部署mongodb-pod-hostpath.yaml,这个使用的是hostpath卷而不是GCE持久磁盘。
pod包含一个容器和一个卷,被之前创建的GCE持久磁盘支持(如图6.5所示)。 因为MongoDB就是在/data/db上存储数据的,所以容器中的卷也要挂载在这个路径上。

通过向MongoDB数据库添加文档来将数据写入持久化存储
现在己经创建了pod并且容器也己经启动,我们可以在容器中运行MongoDB shell,从而向数据存储写入一些数据。
如下面的代码清单所示执行shell命令。
$ kubectl exec -it mongodb mongo MongoDB shell version: 3.2.8 connecting to: mongodb://127.0.0.1:27017 Welcome to the MongoDB shell. For interactive help, type "help". For more comprehensive documentation, see http://docs.mongodb.org/ Questions? Try the support group http://groups.google.com/group/mongodb-user ... >
MongoDB允许存储JSON文档,所以我们将存放一个文档,以查看其是否被持久化存储,并且可以在重新创建pod后检索到。使用以下命令插入一个新的JSON文档:
> use mystore switched to db mystore > db.foo.insert({name:'foo'}) WriteResult({ "nInserted" : 1 })
通过find查找
> db.foo.find() { "_id" : ObjectId("57a61eb9de0cfd512374cc75"), "name" : "foo" }
重新创建pod并验证其可以读取由前一个pod保存的数据
现在可以退出mongodbshell(输入exit并按Enter键),然后删除pod并重建:
$ kubectl delete pod mongodb pod "mongodb" deleted $ kubectl create -f mongodb-pod-gcepd.yaml pod "mongodb" created
新的pod使用与前一pod完全相同的GCE Persistent Disk,所以运行在其中的MongoDB容器应该会看到完全相同的数据,即便将pod调度到不同的节点也是一样的。
容器启动后,可以再次运行MongoDB shell来检查是否还可以检索之前存储的文档,如下面的代码清单所示。
#在新pod中检索MongoDB的持久化数据 $ kubectl exec -it mongodb mongo MongoDB shell version: 3.2.8 connecting to: mongodb://127.0.0.1:27017 Welcome to the MongoDB shell. ... > use mystore switched to db mystore > db.foo.find() { "_id" : ObjectId("57a61eb9de0cfd512374cc75"), "name" : "foo" }
符合预期,数据仍然存在,即便删除了pod并重建。这证实了可以使用GCE持久磁盘在多个pod实例中持久化数据。
我们完成了 MongoDB pod的操作,所以继续清理这个pod,目前不删除底层的GCE持久磁盘,我们将在本章后面再次用到。
4.2 通过底层持久化存储使用其他类型的卷
因为你的Kubernetes集群运行在Google Kubernetes引擎上所以需要创建GCE persistent disk。当在其他地方运行Kubernetes集群时,应该根据不同的基础设施使用其他类型的卷。
例如,如果你的Kubernetes集群运行在Amazon的AWS EC2上,就可以使用 awsElasticBlockStore卷给你的pod提供持久化存储。如果集群在Microsoft Azure上运行,则可以使用azureFile或者azureDisk卷。我们无法在这里详细介绍如何去实现,实际上与前面的示例是一样的。首先,需要创建实际的底层存储,然后在卷定义中设置适当的属性。
使用AWS弹性块存储卷
例如,要使用AWS弹性块存储(Aws Elastic Block Store)而不是GCE持久磁盘,只需要更改卷定义。如下面的代码清单所示(请参阅以粗体标注的行)。
#代码6.7使用awsElastic Block Store 卷的pod:mongodb-pod-aws.yaml apiVersion: v1 kind: Pod metadata: name: mongodb-aws spec: volumes: - name: mongodb-data awsElasticBlockStore: #使用awsElasticBlockStore替换了gcePersistentDisk volumeId: my-volume #指定创建EBS卷ID fsType: ext4 containers: - image: mongo name: mongodb volumeMounts: - name: mongodb-data mountPath: /data/db ports: - containerPort: 27017 protocol: TCP
使用NFS卷
如果集群是运行在自有的一组服务器上,那么就有大量其他可移植的选项用于在卷内挂载外部存储。例如,要挂载一个简单的NFS共享,只需指定NFS服务器和共享路径,如下面的代码清单所示。
#代码6.8 使用NFS的pod:mongodb-pod-nfs.yaml apiVersion: v1 kind: Pod metadata: name: mongodb-nfs spec: volumes: - name: mongodb-data nfs: server: 1.2.3.4 #NFS服务的IP path: /some/path #服务器提供的路径 containers: - image: mongo name: mongodb volumeMounts: - name: mongodb-data mountPath: /data/db ports: - containerPort: 27017 protocol: TCP
4.3 使用其他存储技术
其他的支持选项包括用于挂ISCSI磁盘资源的iscsi,用于挂载GlusterFS的glusterfs,适用于RAID块设备的rbd,还有flexVolume、cinder、cephfs、 flocker、fc(光纤通道)等。rbd如果你不会使用到它们,就不需要知道所有的信息。这里提到是为了展示Kubernetes支持广泛的存储技术,并且可以使用喜欢和习惯的任何存储技术。
要了解每个卷类型设置需要哪些属性的详细信息,可以转到KubernetesAPI引用中的KubernetesAPI定义,或者通过kubectl explain查找信息。如果你已经熟悉了一种特定的存储技术,那么使用explain命令可以让轻松地了解如何挂载一个适当类型的卷,并在pod中使用它。
但是开发人员需要知道所有信息吗?开发人员在创建pod时,应该处理与基础设施相关的存储细节,还是应该留给集群管理员处理?
通过pod的卷来隐藏真实的底层基础设施,不就是Kubernetes存在的意义吗? 举个例子,让研发人员来指定NFS服务器的主机名会是一件感觉很糟糕的事情。而这还不是最糟糕的。
将这种涉及基础设施类型的信息塞到一个pod设置中,意味着pod设置与特定的Kubernetes集群有很大耦合度。这就不能在另一个pod中使用相同的设置了。所以使用这样的卷并不是在pod中附加持久化存储的最佳实践。所以有了下面的方案。
5.从底层技术解耦POD
在此之前,所有持久卷类型都要求pod的开发人员了解真是网络基础结构。例如,创建NFS,必须知道NFS所在的服务器。这违背了k8s的理念,这个理念在向应用程序及其开发人员隐藏真是的基础设施,使他们不担心基础设施的具体状态,并应用程序在云服务和数据企业间进行功能迁移。
理想情况是,在kubernetes上开发人员不需要知道底层使用的是什么存储技术,以及物理服务器等。
当开发人员需要持久化存储来进行应用时,可向kubernetes请求,就像创建pod时可以请求CPU、内存和其它资源一样。
5.1 介绍持久卷和持久卷声明
在kubernetes中为了能够正常请求存储资源,同时避免处理基础设施细节,引入了两个新资源,分别是持久卷和持久卷声明。
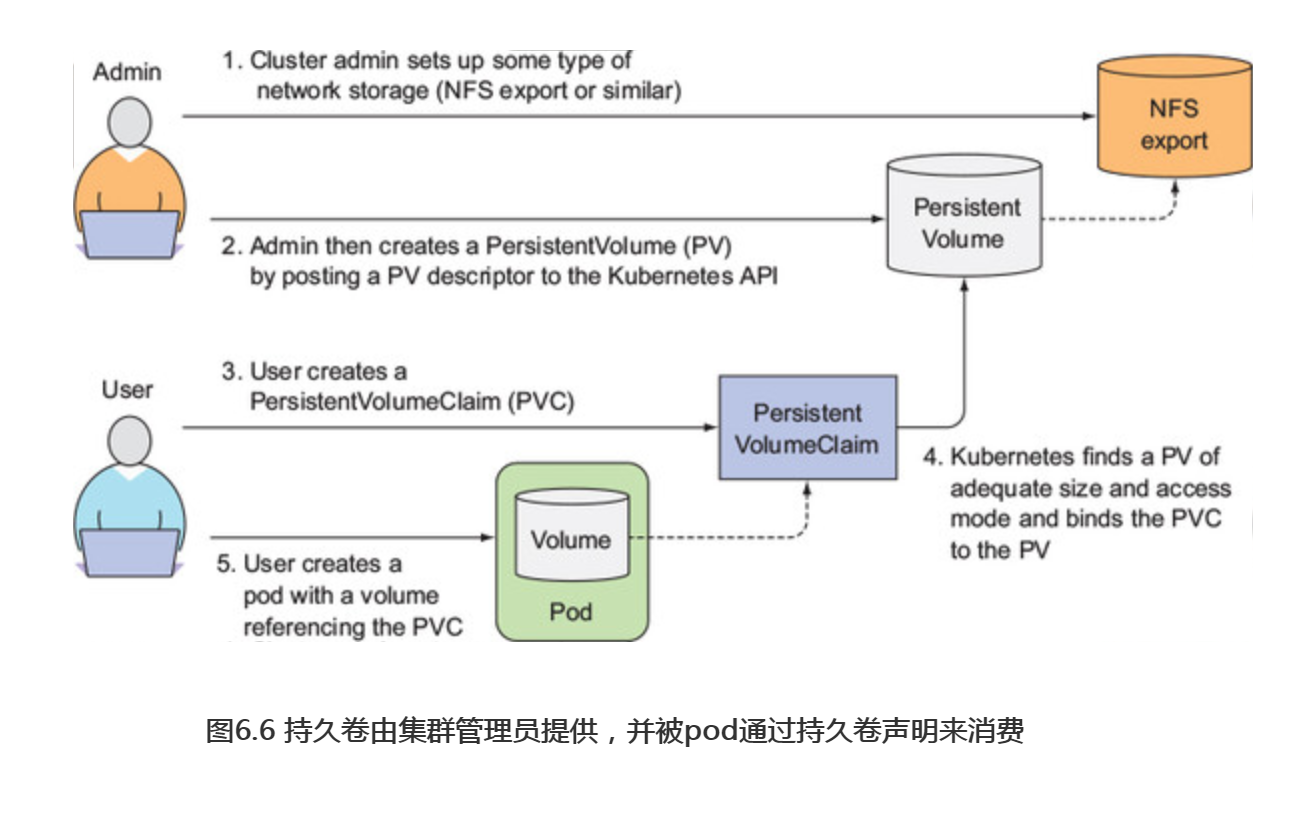
在pod中使用PersistentVolume(持久卷,简称PV)要比使用常规的pod卷复杂一些。
研发人员无需想pod中添加特定技术的卷,而是由集群管理员设置底层存储,然后通过KubernetesAPI服务器创建持久卷并注册。在创建持久卷时,管理员可以指定其大小和所支持的访问模式。
当集群用户需要在pod使用持久化存储时,他们首先创建持久卷声明(PersistentVolumeClaim,简称PVC)清单,指定所需要的最低容量要求和访问模式,然后用户将持久卷声明清单交给KubernetesAPI服务器,Kubernetes将找到可匹配的持久卷并将其绑定到持久卷声明。
持久卷声明可以当做pod中一个卷来使用,其它用户不能使用相同持久卷,除非先通过删除持久卷声明绑定来释放。
5.2 创建持久卷
让我们重新讨论MongoDB示例,但与之前操作不同的是,这次不会直接引用在pod中的GCE持久磁盘。相反,你将首先承担集群管理员的角色,并创建一个支持GCE持久磁盘的持久卷。然后,你将承担应用程序研发人员的角色,首先声明持久卷,然后在pod中使用。
之前,通过使用GCE持久磁盘来设置物理存储,这次不用再这么操作。需要做的就是在Kubernetes中创建持久卷,方法是准备如下所示的代码清单,并将其提交给API服务器。
#代码6.9一个gcePersistentDisk持久卷:mongodb-pv-gcepd.yaml apiVersion: v1 kind: PersistentVolume metadata: name: mongodb-pv spec: capacity: storage: 1Gi #定义PersistemtVolume的大小 accessModes: #可以被单个客户端挂载为读写模式或者被多个客户端挂载为只读模式 - ReadWriteOnce - ReadOnlyMany persistentVolumeReclaimPolicy: Retain #当声明被释放后,PersistentVolume将会被保留(不清理和删除) gcePersistentDisk: #PersistentVolume指定支持之前创建GCE持久磁盘 pdName: mongodb fsType: ext4
在创建持久卷时,管理员需要告诉Kubernetes其对应的容量需求,以及它是否可以由单个节点或多个节点同时读取或写入。管理员还需要告诉Kubernetes如何处理PersistentVolume(当持久卷声明的绑定被删除时)。最后,无疑也很重要的事情是,管理员需要指定持久卷支持的实际存储类型、位置和其他属性。如果仔细观察,当直接在pod卷中引用GCE持久磁盘时,最后一部分配置与前面完全相同(在下面的代码清单中再次显示)。
spec: volumes: - name: mongodb-data gcePersistentDisk: pdName: mongodb fsType: ext4
在使用kubectl create命令创建持久卷之后,应该可以声明它了。看看是否列出了所有的持久卷:
$ kubectl get pv
NAME CAPACITY RECLAIMPOLICY ACCESSMODES STATUS CLAIM
mongodb-pv 1Gi Retain RWO,ROX Available
正如预期的那样,持久卷显示为可用,因为你还没创建持久卷声明。
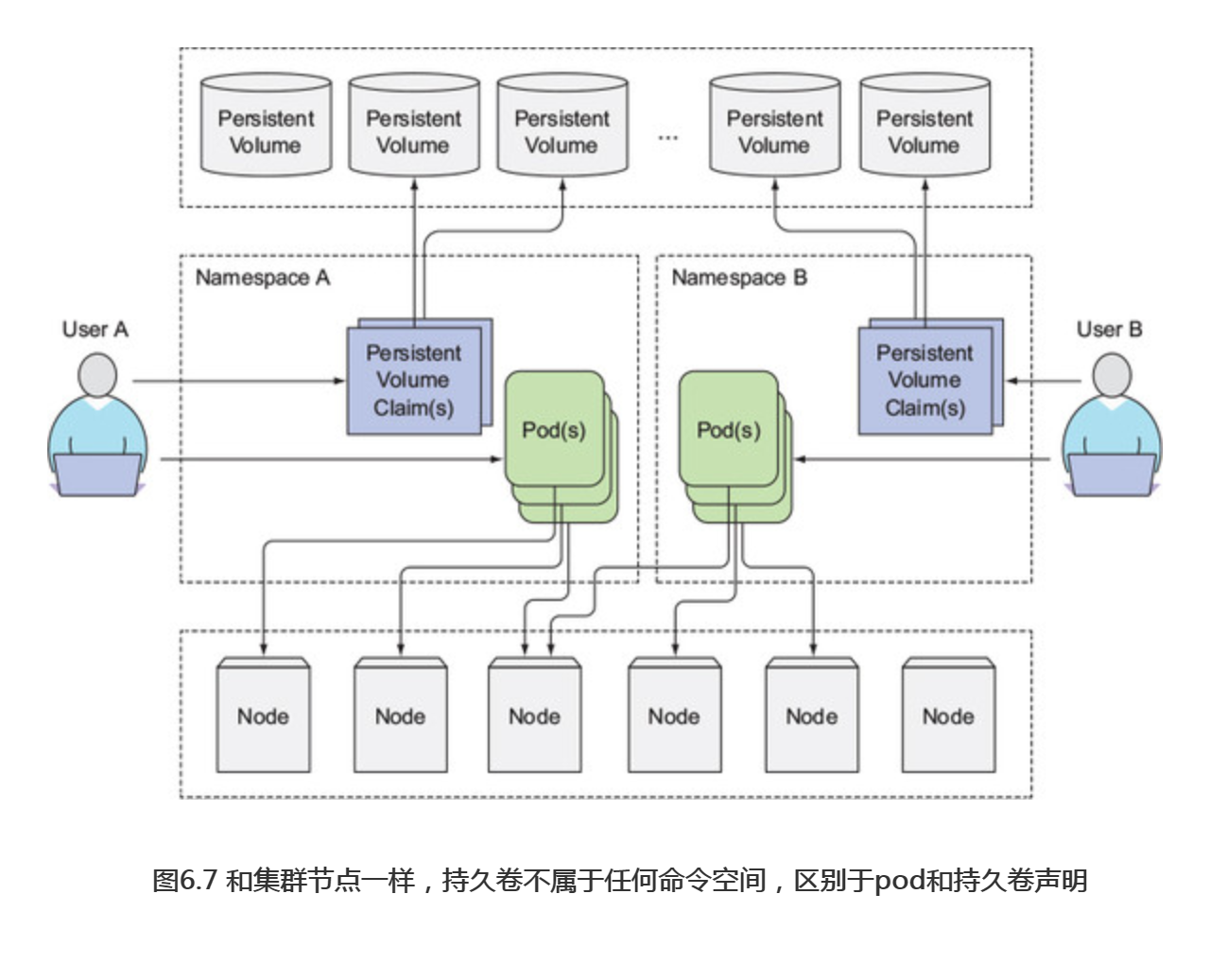
注意:持久卷不属于任何命名空间(见图6.7),它跟节点一样是集群层面的资源。
5.3 通过创建持久卷声明来获取持久卷
假设现在需要部署一个需要持久化存储的pod,将要用到之前创建的持久卷, 但是不能直接在pod内使用,需要先声明一个。
声明一个持久卷和创建一个pod是相对独立的过程,因为即使pod被重新调度 (切记,重新调度意味着先前的pod被删除并且创建了一个新的pod),我们也希望通过相同的持久卷声明来确保可用。
创建持久卷声明
现在开始创建一个声明。先参考下面的代码清单所示的内容来准备一个持久卷声明清单,并通过kubectl create将其发布到KubernetesAPI。
#代码6.11 PersistentColumeClaim:mongodb-pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: mongodb-pvc #声明的名称---稍后将声明当作pod的卷使用是需要用到 spec: resources: requests: storage: 1Gi accessModes: - ReadWriteOnce #予许单个客户端访问(同时支持读取和写入操作) storageClassName: "" #将在关于动态配置的章节了解这个
当创建好声明,Kubernetes就会找到适当的持久卷并将其绑定到声明,持久卷的容量必须足够大以满足声明的需求,并且卷的访问模式必须包含声明中指定的访问模式。在该示例中,声明请求1GiB的存储空间和ReadWriteOnce访问模式。之前创建的持久卷符合刚刚声明中的这两个条件,所以它被绑定到对应的声明中。可以通过检查声明来查看。
列举持久卷声明
列举出所有的持久卷声明来查看PVC的状态:
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
mongodb-pvc Bound mongodb-pv 1Gi RWO,ROX 3s
PVC状态显示己与持久卷的mongodb-pv绑定。请留意访问模式的简写:
-
- RWO-ReadWriteOnce--仅允许单个节点挂载读写。
- ROX-ReadOnlyMany--允许多个节点挂载只读。
- RWX-ReadWriteMany--允许多个节点挂载读写这个卷。
注意:RWO、ROX、RWX涉及可以同时使用卷的工作节点的数量而并非pod的数量。
列举持久卷
通过使用kubectl get命令,我们还可以看到持久卷现在己经Bound,并且不再是Available。
$ kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM AGE
mongodb-pv 1Gi RWO,ROX Bound default/mongodb-pvc 1m
持久卷显示被绑定在default/mongodb-pvc的声明上,这个default部分是声明所在的命名空间(在默认命名空间中创建的声明),我们之前有提到过持久卷是集群范围的,因此不能在特定的命名空间中创建,但是持久卷声明又只能在特定的命名空间创建,所以持久卷和持久卷声明只能被同一命名空间内的pod创建使用。
5.4 在pod中使用持久卷声明
持久卷现在已经可用了,除非先释放掉卷,否则没有人可以申明相同的卷。要在pod中使用持久卷,需要在pod的卷中引用持久卷声明名称,如下面的代码清单所示。
#代码6.12 在使用PVC卷的pod:mongodb-pod-pvc.yaml apiVersion: v1 kind: Pod metadata: name: mongodb spec: containers: - image: mongo name: mongodb volumeMounts: - name: mongodb-data mountPath: /data/db ports: - containerPort: 27017 protocol: TCP volumes: - name: mongodb-data persistentVolumeClaim: claimName: mongodb-pvc #pod卷中通过名称引用持久卷声明
继续创建pod,现在检查这个pod是否确实在使用相同的持久卷和底层GCE PD。通过再次运行MongoDB shell,应该可以看到之前存储的数据,如下面的代码
#代码6.13 在已使用PVC和PV的pod中检索Mongodb持久化数据 $ kubectl exec -it mongodb mongo MongoDB shell version: 3.2.8 connecting to: mongodb://127.0.0.1:27017 Welcome to the MongoDB shell. ... > use mystore switched to db mystore > db.foo.find() { "_id" : ObjectId("57a61eb9de0cfd512374cc75"), "name" : "foo" }
符合预期,可以检索之前存储到MongoDB的文档。
5.5 了解使用持久卷和持久卷声明的好处
通过图6.8,展示了pod可以直接使用,或者通过持久卷和持久卷声明,这两种方式使用GCE持久磁盘。
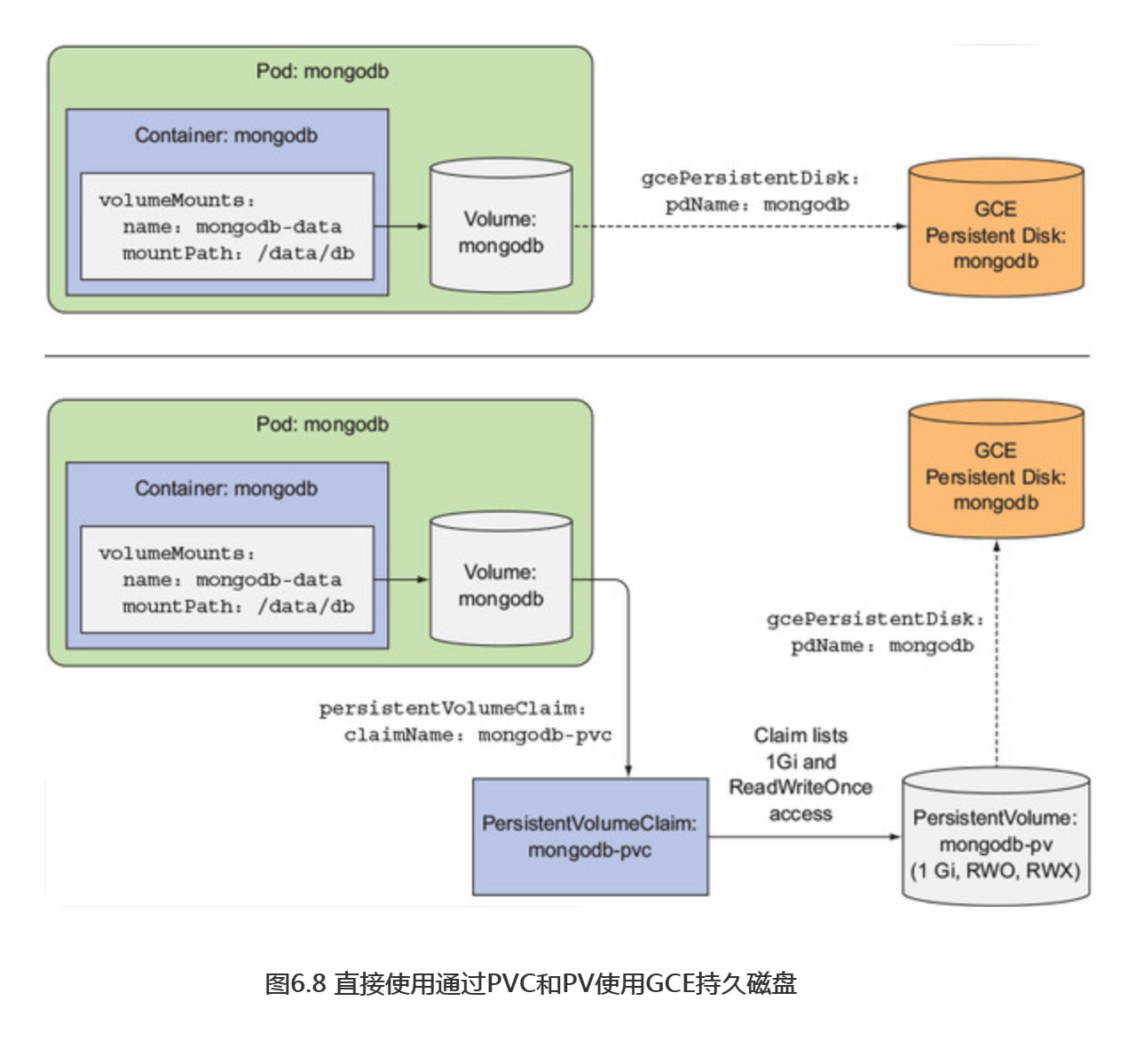
考虑如何使用这种间接方法从基础设施获取存储,对于应用程序开发人员(或者集群用户)来说更加简单。是的,这需要额外的步骤来创建持久卷和持久卷声明,但是研发人员不需要关心底层实际使用的存储技术。
此外,现在可以在许多不同的Kubernetes集群上使用相同的pod和持久卷声明 清单,因为它们不涉及任何特定依赖于基础设施的内容。声明说:“我需要x存储量,并且我需要能够支持一个客户端同时读取和写入。”然后pod通过其中一个卷的名称来引用声明。
5.6 回收持久卷
删除pod和持久卷声明:
$ kubectl delete pod mongodb pod "mongodb" deleted $ kubectl delete pvc mongodb-pvc persistentvolumeclaim "mongodb-pvc" deleted
如果再次创建持久卷声明会怎样?它是否会被绑定到持久卷?在创建声明后, kubectl get pvc命令返回的结果是什么?
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
mongodb-pvc Pending 13s
这个持久卷声明的状态显示为Pending,有趣。之前创建声明的时候,它立即绑定到了持久卷,那么为什么现在不绑定呢?也许列出持久卷可以看得更清楚一些:
$ kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
mongodb-pv 1Gi RWO,ROX Released default/mongodb-pvc 5m
STATUS列显示持久卷的状态是Released,不像之前那样是Available。 原因在于之前己经使用过这个卷,所以它可能包含前一个声明人的数据,如果集群管理员还没来得及清理,那么不应该将这个卷绑定到全新的声明中。除此之外,通过使用相同的持久卷,新的pod可以读取由前一个pod存放的数据,即使声明和pod是在不同的命名空间中创建的(因此有可能属于不同的集群租户)。
回收策略
-
- Retain:PV的默认回收策略,删除pv后,挂载卷的数据会保留。可以通过kubectl get pv看到
- Recycle:删除卷的内容并使卷可用于再次声明。通过这种方式,持久卷可以被不同的持久卷声明和pod反复使用。但是删除pv以后,挂载卷的数据会被删除掉。
- Delete:删除底层存储
手动回收持久卷
通过将persistentVolumeReclaimPolicy设置为Retain从而通知到Kubernetes,我们希望在创建持久卷后将其持久化,让Kubernetes可以在持久卷从持久卷声明中释放后仍然能保留它的卷和数据内容。据我所知,手动回收持久卷并使其恢复可用的唯一方法是删除和重新创建持久卷资源。当这样操作时,你将决定如何处理底层存储中的文件:可以删除这些文件,也可以闲置不用,以便在下一个pod中复用它们。
自动回收持久卷
存在两种其他可行的回收策略:Recycle和Delete。第一种删除卷的内容并使卷可用于再次声明,通过这种方式,持久卷可以被不同的持久卷声明和pod反复使用,如图6.9所示。
而另一边,Delete策略删除底层存储。需要注意当前GCE持久磁盘无法使用Recycle选项。这种类型的持久卷只支持Retain和Delete策略,其他类型的持久磁盘可能支持这些选项,也可能不支持这些选项。因此,在创建自己的持久卷之前,一定要检查卷中所用到的特定底层存储支持什么回收策略。
提示:可以在现有的持久卷上更改持久卷回收策略。比如,如果最初将其设置为Delete,则可以轻松地将其更改为Retain,以防止丢失有价值的数据。

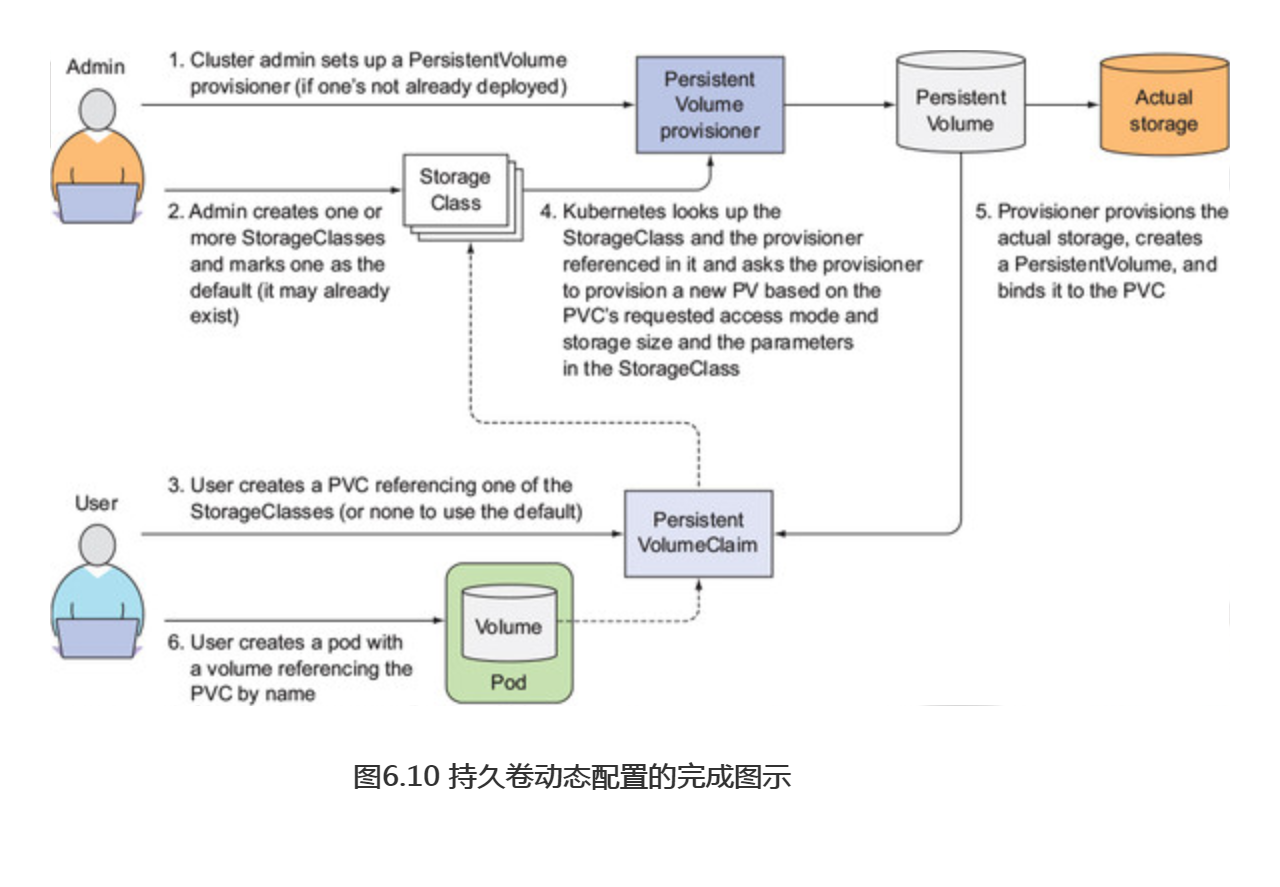
6.持久卷的动态卷配置
使用持久卷和持久卷声明可以轻松获得持久化存储资源,无须研发人员处理下面实际使用的存储技术,但这仍然需要一个集群管理员来支持实际的存储。幸运的是,Kubernetes还可以通过动态配置持久卷来自动执行此任务。
集群管理员可以创建一个持久卷配置,并定义一个或多个StorageClass对象, 从而让用户选择他们想要的持久卷类型而不仅仅只是创建持久卷。用户可以在其持久卷声明中引用StorageClass,而配置程序在配置持久存储时将采用这一点。
注意:与持久卷类似,StorageClass资源并非命名空间。
Kubernetes包括最流行的云服务提供商的置备程序provisioner,所以管理员并不总是需要创建一个置备程序。但是如果Kubernetes部署在本地,则需要配置定制的置备程序。
与管理员预先提供一组持久卷不同的是,它们需要定义一个或两个(或多个)StorageClass,并允许系统在每次通过持久卷声明请求时创建一个新的持久卷。最重要的是,不可能耗尽持久卷(很明显,你可以用完存储空间)。
6.1 通过StorageClass资源定义可用存储类型
在用户创建持久卷声明之前,管理员需要创建一个或多个StorageClass资源, 然后才能创建新的持久卷。来看下面代码清单中的一个例子。
#代码6.14 一个StorageClass定义:storageclass-fast-gcepd.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/gce-pd #用于配置持久卷的卷插件 parameters: type: pd-ssd #传递给parameters的参数 zone: europe-west1-b
注意:如果使用 Minikube,部署文件storageclass-fast-hostpath.yaml。
StorageClass资源指定当久卷声明请求此StorageClass时应使用哪个置备程序来提供持久卷。StorageClass定义中定义的参数将传递给置备程序,并具体到每个供应器插件。StorageClass使用GCE持久磁盘的预配置器,这意味着当Kubernetes在GCE中运行时可供使用。对于其他云提供商,需要使用其他的置备程序。
6.2 请求持久卷声明中的存储类
创建StorageClass资源后,用户可以在其持久卷声明中按名称引用存储类。
创建一个请求特定存储类的PVC定义
可以修改mongodb-pvc以使用动态配置。以下代码清单显示了PVC中更新后的YAML定义。
#代码6.15 一个采用动态配置的PVC:mongodb-pvc-dp.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: mongodb-pvc spec: storageClassName: fast #该PVC请求自定义存储类 resources: requests: storage: 100Mi accessModes: - ReadWriteOnce
除了指定大小和访问模式,持久卷声明现在还会指定要使用的存储类别。在创建声明时,持久卷由fastStorageClass资源中引用的provisioner创建。即使现有手动设置的持久卷与持久卷声明匹配,也可以使用provisioner。
注意:如果在PVC中引用一个不存在的存储类,则PV的配置将失败(在PVC上使用 kubectl describe时,将会看到ProvisioningFailed事件)
检查所创建的PVC和动态配置的PV
接着,创建PVC,然后使用kubectl get进行查看:
$ kubectl get pvc mongodb-pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS
mongodb-pvc Bound pvc-1e6bc048 1Gi RWO fast
VOLUME列显示了与此声明绑定的持久卷(实际名称比上面显示的长)。现在可以尝试列出持久卷,看看是否确实自动创建了一个新的PV:
$ kubectl get pv NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS STORAGECLASS mongodb-pv 1Gi RWO,ROX Retain Released pvc-1e6bc048 1Gi RWO Delete Bound fast
可以看到动态配置的持久卷其容量和访问模式是在pvc中所要求的。它的回收策略是Delete,这意味着当PVC被删除时,持久卷也将被删除。除了PV,置备程序还提供了真实的存储空间,fast StorageClass被配置为使用kubernetes.io/gce-pd从而提供了GCE持久磁盘。可以使用以下命令查看磁盘:
$ gcloud compute disks list NAME ZONE SIZE_GB TYPE STATUS gke-kubia-dyn-pvc-1e6bc048 europe-west1-d 1 pd-ssd READY gke-kubia-default-pool-71df europe-west1-d 100 pd-standard READY gke-kubia-default-pool-79cd europe-west1-d 100 pd-standard READY gke-kubia-default-pool-blc4 europe-west1-d 100 pd-standard READY mongodb europe-west1-d 1 pd-standard READY
第一个持久磁盘的名称表明它是动态配置的,同时它的类型显示为 一个SSD,正如在前面创建的存储类中所指定的那样。
了解存储类的使用
集群管理员可以创建具有不同性能或其他特性的多个存储类,然后研发人员再决定对应每一个声明最适合的存储类。
StorageClasses的好处在于,声明是通过名称引用它们的。因此,只要StorageClass名称在所有这些名称中相同,PVC定义便可跨不同集群移植。要自己查看这个可移植性,可以尝试在Minikube上运行相同的示例,假设你一直在使用GKE。作为集群管理员,你必须创建一个不同的存储类(但名称相同)。storageclass-fast-hostpath.yaml文件中定义的存储类是专用于Minikube的。然后,一旦部署了存储类,作为集群用户,就可以像以前一样部署完全相同的PVC清单和完全相同的pod清单。这展示了 pod和PVC在不同集群间的移植性。
6.3 不指定存储类的动态配置
正如我们在本章中所做的那样,将持久性存储附加到pod上变得越来越简单。本章中的章节反映了存储配置是如何从早期的Kubernetes版本发展到现在的。在最后一节中,我们将看看将持久卷附加到pod的最新和最简单的方法。
列出存储类
当你创建名为fast的自定义存储类时,并未检查集群中是否己定义任何现有存储类。现在为什么不这样试试?以下是GKE中可用的存储类:
$ kubectl get sc NAME TYPE fast kubernetes.io/gce-pd standard (default) kubernetes.io/gce-pd
除了你自己创建的fast存储类,还存在standard存储类并标记为默认存储类。很快就会知道其含义了,列举Minikube中可用的存储类,以便进行比较:
$ kubectl get sc NAME TYPE fast k8s.io/minikube-hostpath standard (default) k8s.io/minikube-hostpath
再来看看,fast存储类是由你创建的,并且此处也存在默认的standard存储类,比较两个列表中的TYPE列,看到GKE正在使用kubernetes.io/gce-pd置备程序,而Minikube正在使用k8s.io/minikube-hostpath。
检查默认存储类
使用kubectl get可查看有关GKE集群中标准存储类的更多信息,如下面的代码清单所示。
#代码6.16 GKE上的标准存储类定义 $ kubectl get sc standard -o yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: annotations: storageclass.beta.kubernetes.io/is-default-class: "true" #此注释将存储类标记为默认 creationTimestamp: 2017-05-16T15:24:11Z labels: addonmanager.kubernetes.io/mode: EnsureExists kubernetes.io/cluster-service: "true" name: standard resourceVersion: "180" selfLink: /apis/storage.k8s.io/v1/storageclassesstandard uid: b6498511-3a4b-11e7-ba2c-42010a840014 parameters: type: pd-standard #置备程序使用类型参数来明确要创建那种类型的GCE PD provisioner: kubernetes.io/gce-pd #GCE持久磁盘配置起被用于配置此类的PV
如果仔细观察清单的顶部,会看到存储类定义会包含一个注释,这会使其成为默认的存储类。如果持久卷声明没有明确指出要使用哪个存储类,则默认存储类会用于动态提供持久卷的内容。
创建一个没有指定存储类别的持久卷声明
可以在不指定storageClassName属性的情况下创建PVC,并且(在Google Kubernetes引擎上)将提供一个pd-standard类型的GCE持久磁盘。试试通过下面的代码清单中的YAML来创建一个声明。
#代码清单 6.17 不指定存储类别的 PVC: mongodb-pvc-dp-nostorageclass.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: mongodb-pvc2 spec: #没有指定StorageClassName属性(与前面的示例不同) resources: requests: storage: 100Mi accessModes: - ReadWriteOnce
此PVC定义仅包含存储大小请求和所需访问模式,并不包含存储级别。在创建PVC时,将使用任何标记为默认的存储类。可以通过如下代码确认:
$ kubectl get pvc mongodb-pvc2 NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS mongodb-pvc2 Bound pvc-95a5ec12 1Gi RWO standard $ kubectl get pv pvc-95a5ec12 NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS STORAGECLASS pvc-95a5ec12 1Gi RWO Delete Bound standard $ gcloud compute disks list NAME ZONE SIZE_GB TYPE STATUS gke-kubia-dyn-pvc-95a5ec12 europe-west1-d 1 pd-standard READY ...
强制将持久卷声明绑定到预配置的其中一个持久卷
这最后会告诉我们为什么要在文章开头代码清单6.11中将storageClassNarne设置为 一个空字符串(当你想让PVC绑定到你手动配置的PV时)。在这里回顾一下这个PVC定义的相关行:
kind: PersistentVolumeClaim spec: storageClassName:"" #将空字符串指定为存储类名可确保PVC绑定到预先配置的PV,而不是动态配置的新的PV
如果尚未将storageClassName属性设置为空字符串,则尽管己存在适当的预配置持久卷,但动态卷置备程序仍将配置新的持久卷。此时,演示一个声明如何绑定到手动预先配置的持久卷,同时不希望置备程序干涉。
提示:如果希望PVC使用预先配置的PV,请将storageClassName显式设置为"“。
了解动态持久卷供应的全貌
总而言之,将持久化存储附加到一个容器的最佳方式是仅创建PVC(如果需要,可以使用明确指定的storgeClassName)和容器(其通过名称引用PVC),其他所有内容都由动态持久卷置备程序处理。
要全面了解获取动态的持久卷所涉及的步骤,请查看图6.10。