
Redis短结构
本章将介绍3种非常有价值的降低Redis内存占用的方法。降低Redis的内存占用有助于减少创建快照和加载快照所需的时间、提升载入AOF文件和重写AOF文件时的效率、缩短从服务器进行同步所需的时间,并且能让Redis存储更多的数据而无需添加额外的硬件。
本章首先会介绍如何使用Redis的短数据结构来更高效地表示数据。接着会介绍如何使用分片技术,将一些体积较大的结构分割为多个体积较小的结构。最后介绍如何将固定长度的数据打包存储到字符串键里面,从而进一步地降低内存占用。
原书作者曾经通过同时使用本章介绍的这几种技术,成功地将分布在3台服务器上的70多GB数据缩小至3GB,并且只使用了 1台服务器进行存储。因为本章介绍的优化技术同样可以应用于本书之前介绍过的某些问题,所以本章在介绍各项优化技术的过程中,会在合适的时候提示如何将这些技术应用到之前介绍过的问题上。
1.短结构
Redis为列表、集合、散列和有序集合提供了一组配置选项,这些选项可以让Redis以更节约空间的方式存储长度较短的结构(后面简称“短结构”)。本节将对相关的配置选项进行介绍讲解如何验证这些配置选项的优化效果,并说明使用短结构带来的一些缺点。
在列表、散列和有序集合的长度较短或者体积较小的时候,Redis可以选择使用一种名为压缩列表(ziplist)的紧凑存储方式来存储这些结构。压缩列表是列表、散列和有序集合这3种不同类型的对象的一种非结构化(unstructured)表示:与Redis在通常情况下使双链表表示列表、使用散列表表示散列、使用散列表加上跳跃表(skiplist)表示有序集合的做法不同,压缩列表会以序列化的方式存储数据,这些序列化数据每次被读取的时候都要进行解码,每次被写入的时候也要进行局部的重新编码,并且可能需要对内存里面的数据进行移动。
1.1 压缩列表显示
为了了解压缩列表比其他数据结构更为节约内存的原因,我们需要对使用压缩列表的几种结构当中,最为简单的列表结构进行观察。在典型的双向链表(doubly linked list)里面,链表包含的每个值都会由一个节点(node )表示,每个节点都会带有指向链表中前一个节点和后一个节点的指针,以及一个指向节点包含的字符串值的指针。每个节点包含的字符串值都会分为3个部分进行存储:第一部分存储的是字符串的长度,第二部分存储的是字符串值中剩余可用的字节数量,而最后一部分存储的则是以空字符结尾的字符串本身。图9-1展示了一个比较长的双向链表的其中一部分,通过这个图可以看到"。ne"、"two"、"ten"这3个字符串是如何存储在双向链表里面的。
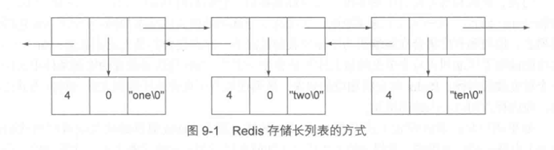
为了让图片保持简洁,图9-1省略了链表的某些细节。图中展示的3个3字符长的字符串,每个都需要空间来存储3个指针、2个整数(一个是字符串的长度,另一个是字符串值的剩余可用空间)、字符串本身以及一个额外的字节。在32位平台上,每存储一个这样的3字节长的字符串,就需要付出21字节的额外开销(overhead),而这还只是保守的估计值,实际的额外开销还会更多一些。
另一方面,压缩列表是由节点组成的序列(sequence),每个节点都由两个长度值和一个字符串组成。第一个长度值记录的是前一个节点的长度,这个长度值将被用于对压缩列表进行从后向前的遍历,第二个长度值记录了当前节点的长度,而位于节点最后的则是被存储的字符串值。尽管压缩列表节点的长度值在实际中还有一些其他的含义,但是对于我们例子中的“one”、“two”、“ten” 这3个3字节长的字符串来说,它们每个的长度都可以用1字节来存储,所以在使用压缩列表存储这3个字符串的时候,每个节点只会有2字节的额外开销。通过避免存储额外的指针和元数据,使用压缩列表可以将存储示例中的3个字符串所需的额外开销从原来的21字节降低至2字节。
下面就让我们来看看,如何使用紧凑的压缩列表编码。
- 使用压缩列表编码
为了确保压缩列表只会在有需要降低内存占用的情况下使用,Redis引入了代码清单9-1展示的配置选项,这些选项决定了列表、散列和有序集合会在什么情况下使用压缩列表表示。
#代码清单9-1 不同结构关于使用压缩列表表示的配置选项 list-max-ziplist-entries 512 list-max-ziplist-value 64 hash-max-ziplist-entries 512 hash-max-ziplist-value 64 zset-max-ziplist-entries 128 zset-max-ziplist-value 64
列表、散列和有序集合的基本配置选项都很相似,它们都由-max-ziplist-entries选项和-max-ziplist-value选项组成,并且这3组选项的语义也基本相同:entries选项说明列表、散列和有序集合在被编码为压缩列表的情况下,允许包含的最大元素数量;而value选项则说明了压缩列表每个节点的最大体积是多少个字节。当这些选项设置的限制条件中的任意一个被突破的时候,Redis就会将相应的列表、散列或是有序集合从压缩列表编码转换为其他结构,而内存占用也会因此而增加。
#代码清单9-2 判断一个结构是否被表示为压缩列表的方法 >>> conn.rpush('test','a','b','c','d') 4 >>> conn.debug_object('test') #debug object命令可以查看特定对象的相关信息 {’encoding': 'ziplist', 'refcount':1, 'lru_seconds_idle': 20, #'encoding'信息表示这个对象的编码为压缩列表,这个压缩列表占用了24字节内存 'lru':274841, 'at':'0xb6c9f120', 'serializedlength':24, 'type':'Value'} >>> conn.rpush('test','e','f','g','h') #再向列表中推入4个元素 8 >>> conn.debug_object('test') {’encoding': 'ziplist', 'refcount':1, 'lru_seconds_idle':0, #对象的编码依然是压缩列表,只是体积增长到了36字节,(前面推入的4个元素,每个元素都需要话费1 'lru':274846, 'at':'0xb6c9f120', 'serializedlength':36, #字节进行存储,并带来2字节的额外开销。) 'type':'Value'} >>> conn.rpush('test',65*'a') 9 >>> conn.debug_object('test') #超出编码予许大小的元素被推入列表里面时,列表从压缩列表编码转为标准的链表 {'encoding': 'linkedlist', 'refcount': 1 , 'lru_seconds_idle':10 , 'lru' : 274851, 'at':'0xb6c9f120 ', 'serializedlength 30, #尽管序列化长度下降,但对于压缩列表拜纳姆以及集合的特殊编码之外来说,这个数值并不代表 'type': 'Value'} #结构的即使内存占用量 >>> conn.rpop('test') 'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa' #当压缩列表被转换为普通的结构之后,即使结构将来重新满足配置选择设置 conn.debug_object('test') #的限制条件,结构也不会重新转换回压缩列表 {'encoding': 'linkedlist', 'refcount':1 , 'lru_seconds_idle':0 , 'lru': 274853, 'at': '0xb6c9f120', 'serializedlength': 17, 'type': 'Value'}
通过使用新介绍的DEBUG OBJECT命令,我们可以很方便地了解一个对象是否被存储成了压缩列表,这对于减少内存占用非常有好处。
跟列表、散列和有序集合不同,集合并没有使用压缩列表表示,而是使用了另外一种具有不同语义和限制的紧凑表示,接下来的一节就会对这种表示进行介绍。
1.2 集合的整数集合编码
跟列表、散列和有序集合一样,体积较小的集合也有自己的紧凑表示:如果整数包含的所有成员都可以被解释为十进制整数,而这些整数又处于平台的有符号整数范围之内,并且集合成员的数量又足够少的话(具体的限制大小稍后就会说明),那么Redis就会以有序整数数组的方式存储集合,这种存储方式又被称为整数集合(insert)。
以有序数组的方式存储集合不仅可以降低内存消耗,还可以提升所有标准集合操作的执行速度。那么一个集合要符合什么条件才能被存储为整数集合呢?代码清单9-3展示了定义整数集合最大元素数量的配置选项。
#代码清单9-3 配合集合在使用整数集合编码时能够包含的最大元素数量 set-max-intset-entries 512 #集合使用整数集合表示的限制条件
只要集合存储的整数数量没有超过配置设定的大小,Redis就会使用整数集合表示以减少数据的体积。代码清单9-4展示了当整数集合包含的元素数量超过配置选项设定的限制时,集合发生的一系列变化。
#代码清单9-4 当整数集合增长至超出限制大小时,它将被表示为散列表 >>> conn.sadd('set-object',*range(500)) #即使向集合添加500个元素,它的编码仍然为整数集合 >>> conn.debug_object('set-object') {'encoding': 'intset', 'refcount':1, 'lru_seconds_idle':0 , 'lru': 283116, 'at': '0xb6d1a1c0', 'serializedlength':1010 , 'type': 'Value'} conn.sadd('set-object', *range(500,1000 )) 5 >>> conn.debug_object('set-object') {'encoding':'hashtable', 'refcount':1 , 'lru_seconds_idle':0 , 'lru':283118, 'at':'0xb6d1a1c0','serializedlength':2874, 'type': 'Value'}
文章开头的简介部分曾经提到过,对一个压缩列表表示的对象的其中一部分进行读取或者更新,可能会需要对整个压缩列表进行解码,甚至还需要对内存里面的数据进行移动,因此读写一个长度较大的压缩列表可能会给性能带来负面的影响。使用整数集合编码的集合结构也有类似的问题,不过整数集合的问题并非来源于编码和解码数据,而在于它在执行插入操作或者删除操作时需要对数据进行移动。在接下来的一节中,我们将对长度较大的压缩列表在执行操作时产生的性能问题进行研究。
1.3 长压缩列表和大整数集合带来的性能问题
当一个结构突破了用户为压缩列表或者整数集合设置的限制条件时,Redis就会自动将它转换为更为典型的底层结构类型。这样做的主要原因在于,随着紧凑结构的体积变得越来越大,操作这些结构的速度也会变得越来越慢。
为了直接观察这个问题是如何发生的,我们首先需要把list-max-ziplist-entries选项的值设置为110000。这个值比实际中应用的值要大很多,但这有助于凸显我们想要发现的问题。在修改配置选项并重新启动Redis之后,我们将对Redis进行性能测试,以此来考察列表在使用长度较大的压缩列表编码时,性能问题是如何出现的。
为了测试列表在使用长度较大的压缩列表作为编码时的性能表现,我们需要用到代码清单9-5展示的测试函数。这个函数首先会创建一个列表,并将指定数量的节点添加到列表里面,然后反复地调用RPOPLPUSH命令,将元素从列表的右端移动到左端,以此来计算列表在使用长度较大的压缩列表作为编码时,执行复杂命令时的性能下界。
正如之前所说,long_ziplist_performance()函数会创建给定长度的列表,然后在流水线里面对列表执行指定数量的RPOPLPUSH命令调用。通过将RPOPLPUSH的调用次数除以执行这些调用花费的时间,程序可以计算出列表在使用给定长度的压缩列表作为编码时,每秒能够执行的操作数量。代码清单9-6展示了在列表长度逐渐增加的情况下,各个long_ziplist_performance()调用的执行结果,这些结果清晰地展示了列表的操作效率是如何随着压缩列表长度的增加而下降的。
#代码清单9-5 对不同的压缩列表进行性能测试的函数 def long_ziplist_performance(conn, key, length, passes, psize): #为了不同的方式进行性能测试,函数需要对所有测试指标进行参数化处理 conn.delete(key) #删除指定的键,确保被测试数据的准确性 conn.rpush(key, *range(length)) #通过从右端推入指定数量的元素来对列表进行初始化 pipeline = conn.pipeline(False) #通过流水线来降低网络通信给测试带来的影响 t = time.time() for p in xrange(passes): #根据passes参数来决定流水线操作的执行次数 for pi in xrange(psize); #每个流水线操作都包含了psize次RPOPLPUSH命令调用 pipeline.rpoplpush (key, key) pipeline.execute() return (passes * psize) / (time.time() - t or .001) #计算每秒执行的RPOPLPUSH调用数量
##代码清单9-6 随着压缩列表编码的列表不断增长,性能出现下降 >>> long_ziplist_performance(conn, 'list', 1, 1000, 100) #当压缩列表编码的列表包含的节点数量不超过1000个时,redis每秒可以执行大约5万次操作 52093.558416505381 >>> long_ziplist_performance(conn,'list' 100, 1000, 100) 51501.15476278667 >>> long_ziplist_performance(conn,'list' 1000, 1000,100) 49732.490843316067 >>> long_ziplist_performance(conn,'list',5000,1000,100) #当压缩列表编码的列表包含的节点数量达到5000个以上时,内存复制带来的消耗就越来越大 43424.056529592635 #导致性能下降 >>> long_ziplist_performance(conn,'list',10000,1000,100) 36727.062573334966 >>> long_ziplist_performance(conn,'list',50000,1000,100) #当压缩节点数量到5万个时,性能明显下降 16695.14068497577 long_ziplist_performance(conn,'list',100000,500,100) #当节点数量达到10万个时,压缩列表的性能根本没法用了 553.10821080054586
初看上去,即使压缩列表的元素数量上升至好几千,测试得出的性能似乎也并不是太坏。但是别忘了这只是执行单个操作时的成绩,而这个操作所做的只不过是取出列表右端的元素然后将它推入列表的左端。尽管压缩列表在执行插入操作时需要移动所有元素的做法导致了性能下降.但压缩列表查找左端和右端的速度并不慢.更别说这个测试还充分地利用了CPU缓存。但是当Redis需要像自动补全例子一样,扫描整个列表以查找某个特定值的时候,又或者需要获取和更新散列的不同域(field) 的时候,Redis就会需要解码很多单独的节点,而CPU缓存的作用也会因此而受到影响:从数据上看,假如我们将long_ziplist_performance()函数中的RPOPLPUSH命令调用改为LINDEX命令调用,并使用LINDEX命令去获取位于列表中间的元素,那么当列表的元素数量超过5000个时,函数的性能将只有之前调用RPOPLPUSH命令时的一半,有兴趣的读者可以自己亲手去验证这一点。
只要将压缩列表的长度限制在500〜2000个元素之内,并将每个元素的体积限制在128字节或以下,那么压缩列表的性能就会处于合理范围之内。笔者的做法是将压缩列表的长度限制在1024个元素之内,并且每个元素的体积不能超过64字节,对于大多数散列应用来说,这种配置可以同时兼顾低内存占用和高性能这两方面优点。
当为示例以外的其他问题开发解决方案的时候,请时刻记住,减少列表、集合、散列和有序集合的体积可以减少内存占用,并且能够帮助读者把Redis应用到解决更多不同的问题上面。
让键名保持简短 :目前为止尚未提到的就是减少键的长度。这里所说的“键”包括所有数据库键、散列的域、集合和有序集合的成员以及所有列表的节点。键的长度越大,Redis需要存储的数据就越多。一般来说,我们应该尽量使用较为简短的信息作为键或者成员,比如使用user:joe就比使用username:joe要好的多;如果user或者username已经不言而喻的,那么直接用joe会更好。尽管这种做法在一般情况下作用并不明显,但是当存储节点的数量达到上百万个的时候,节约的空间可能就有好几个MB甚至好几个GB,这时就能发挥作用了。

