SRAM 测试总结
SoC随着工艺进步设计复杂度增加,embeded sram也越来越多。在40nm SoC产品Sram一般在20Mbits左右,当工艺发展到28nm时Sram就增加到100Mbits。如果考虑AI产品,Sram估计更多。如何更好的测试Sram就成为量产测试的重中之重。
Sram的结构
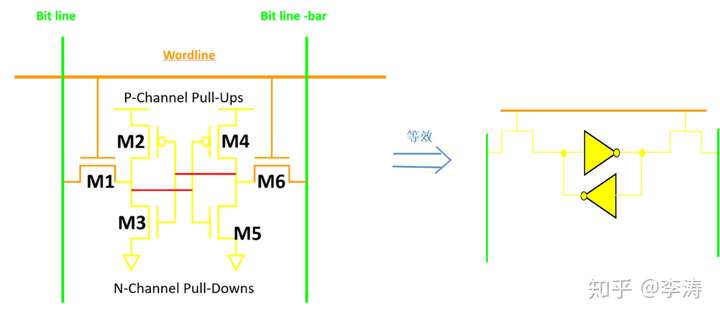
一个6T sram cell的经典结构如图所示:
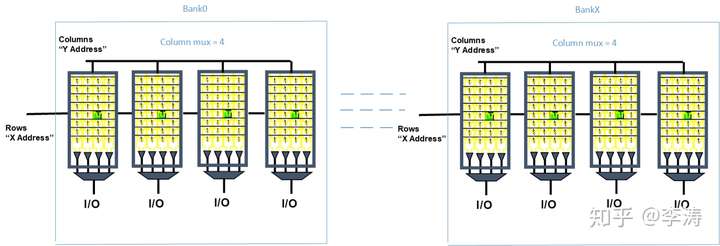
这些Sram cell集合成如下图的多个bank的memory block,每个bank有bank address使能;在一个bank内Row address选择一个完整的wordline,Column address选择某组IO bitlines。
举个例子说明如下:
一个memory block是4096x32 cm16,该memory size = 4096*32= 128k bits, row address is 8bits (4096/16 = 256 wordlines), column address is 4 bits(0~15), Wordline bits = 32*16 = 512 bits.
SRAM的性能
- memory compiler的选择
对于一个memory size大小确定的memory block,Column Mux越大,Row address位宽越小:
- memory读写的访问速度就高 (row译码选择快)
- memory的面积大(cell和cell的横向距离大于纵向距离,column mux增加很增加bits per wordline--横向,减少wordline数--纵向,横向尺寸增加远大于纵向)
- 因为一次选择的row地址对应的cell多,功耗也会增加
- 电流功耗
总电流功耗包括dynamic power和leakage power。不同的sram cell单元(比如HPC,HDC等等)功耗指标不同,体系结构设计需要在面积,速度和功耗之间寻找平衡。
-leakage current是永远存在的
Poweroff模式(cell+periphery off)< Retention模式(cell ON+periphery OFF) < Standby模式(cell+periphery on)
1Mbits memory的standby/Ret leakage电流在0.2mA左右,poweroff leakage电流在0.03mA左右。
-dynamic current:column mux,读写速度,读写辅助电路等都会影响动态电流
如果在常温状态下leakage current比较大,在高温或者大的dynamic current时必须注意thermal runaway的风险,因为温度升高leakage current会增加很快,总功耗的增加会进一步增加温度,形成正反馈。
Sram的fault mode
可以将Sram的故障分类成以下几种,mbist的算法实质就是针对这些不同故障模型设计读写序列捕获可能的defects。

SRAM Read/Write Assist(RAWA)
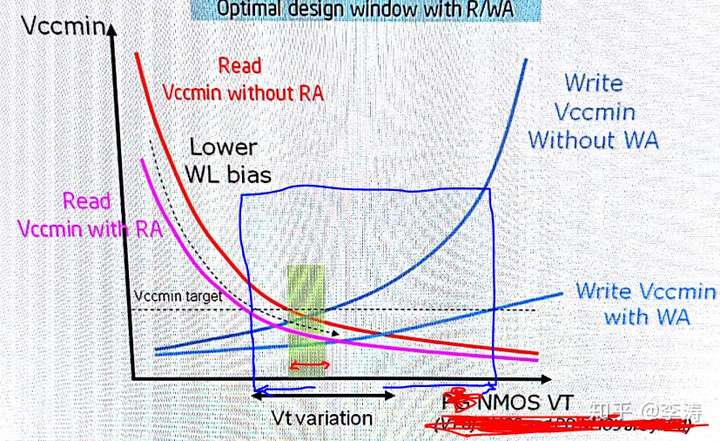
随着Sram的供电电压Vsram越来越低,Sram门单元参数的漂移越来约大,很难找到可以保证read和write都工作的Vsram电压了。
以下图为例,Vccmin的target是设死的,如果没有RAWA则NMOS的Vt必须保证在很小范围内,半导体工艺很难保证参数有这么小的范围;而如果有RAWA,则NMOS的Vt就可以有比较大的范围,减少了对工艺加工的要求。
- Sram的读操作如下面gif所示,有Precharge->Select Wordline->Sense Amplifer strobe
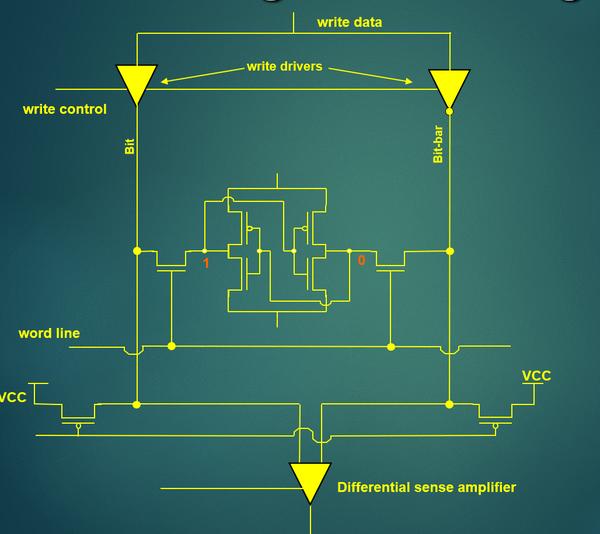
其中select wordline的电压会影响pass gate的电流,wordline电压越高,pass gate的电流越大,cell的内容就越容易丢失。
- read assist 就是减少wordline的select电压,减少pass gate的电流减少对cell的disturb
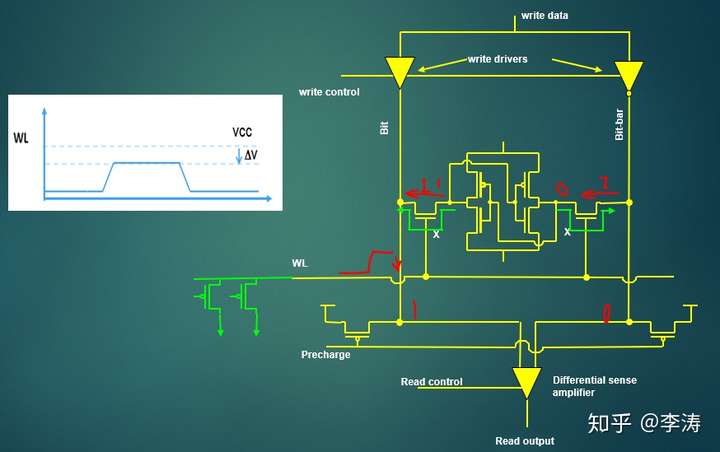
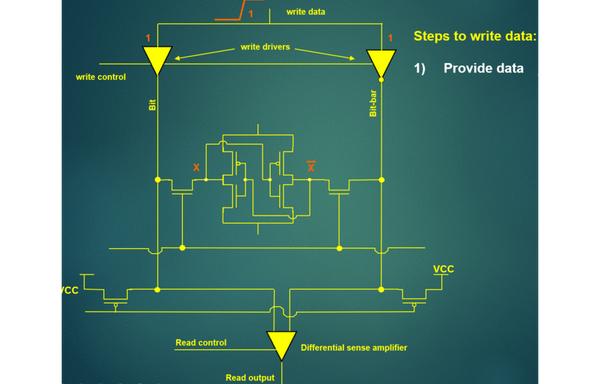
- Sram write和WRA
Sram写入时降低Vsram的电压,可以帮助数据通过M2/M4写入cell中。
SRAM的Quality和Reliability
理论上如果SRAM支持redundancy repair + ECC,在测试的时候做到以下几点:
- 合理的算法覆盖故障模型 (比如PMOVI)
- 使用较低的low Vmin做repair(再低就无法repair)
- 在Vmin+Guardband电压下使用该SRAM,并且ECC on
基本可以保证SRAM没有yield loss和in field reliability的问题。
Cmos的reliability按照类型可以分为空间上和时间上的:
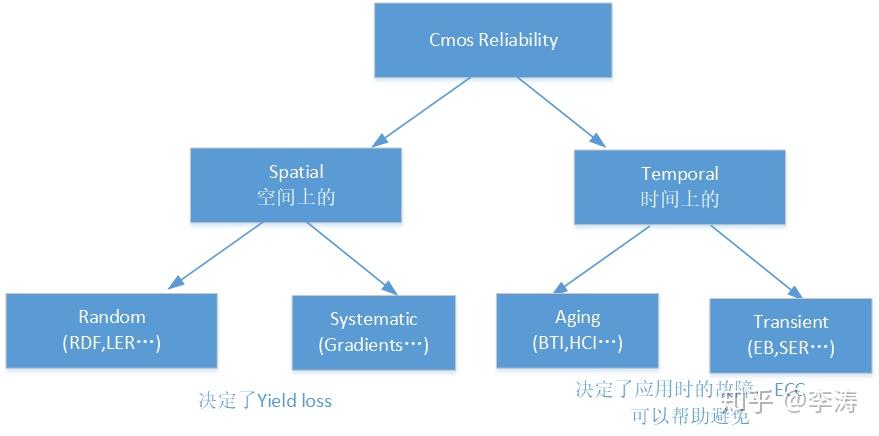
空间上的是process引起的yield loss,只能靠repair提高yield;
时间上的是由aging,Erratic bit,Soft Error rate等因素引起的使用故障,Ecc可以消除很多问题,或者提高使用电压可以帮助;
- Erratic bit导致Pass Vmin 波动很大,如果repeat测试很多遍,可以看到Vmin range在100mV左右。这个会导致Sram repair之后,需要一个比较大的Guardband保证Sram没有Erratic bit 问题;
- Aging会导致Vth随使用时间变大,5年以后一般会增大40mV,因此Vmin也会增加;
因此如果要保证DUT可以使用5年,在T0测试的时候就要用更低的Vscreen,保证足够的aging和EB的guardband。
可见SRAM的reliability是和operation voltage密切相关的,对于mobile应用关心power KPI,一般SRAM会工作在较低电压,SRAM reliability问题就更突出。需要ATE测试可以尽量在更低电压下repair memory,保证T0的pass Vmin比较低,和operation voltage相比有较大的guardband。
SRAM的repair
一般分为Word repair,row repair和column repair。Word repair使用寄存器存储defect cell的地址和数据,scan可以cover这些寄存器;row/column repair需要考虑BIST覆盖问题,在不同温度多次repair时redundancy cells的screen问题。
在量产测试中repair的电压选择也是一个balance的结果,repair voltage应该比target screen电压要低一些(考虑erratic bits的影响),保证把尽量多的weak cells可以替换掉,同时又不能导致太多DUT无法repair
Sram的Stress
为了消除早期失效DUT,SRAM一般需要在量产测试时做高电压的stress。这里有两个考量点:
- voltage和stress time:需要和subcon process确定,电压越高/测试温度高相应stress的时间就可以减少;
- stress pattern的选择:需要考虑如何保证stress pattern有效执行;另外使用什么mbist algorithm也是问题,一般建议使用write1->read1->write0->read0的pattern。优点是保证每个cell都有0<->1的翻转,同时cell在‘0’或者‘1’状态下有同样的stress时间。如果使用其他algorithm,有可能small sram有很长的static stress时间而big sram大多是toggling stress时间。
Sram的其他特性
SRAM的读写时间可以做成self-timing,当读写被时钟上升沿trigger以后,SRAM内有dummy bitline+dummy driver来驱动计时器得到读写的时间。得到读写时间后,用该时间访问实际sram cell保证读写时间ok。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号