
jvm内存模型
本文主要是介绍jvm内存模型
废话不多说,这里直接上图
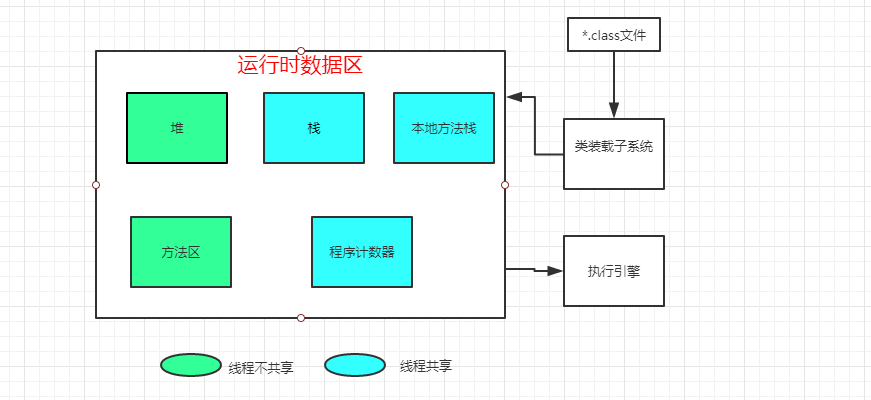
首先上一个粗略草图,大体可以了解清楚
1.jvm大概是有三大部分组成,分别为类装载子系统,运行时数据区和执行引擎组成
2.运行时数据区大概分为5大部分,分别为:堆,栈,本地方法栈,方法区,程序计数器
3.栈,本地方法栈,程序计数器线程是共享的,而堆,方法区是线程不共享的,只有一个
了解以上大体内容,下面就开始讲解每个系统,以及每个子系统分别有什么作用;
类加载子系统:
1.类加载子系统是JVM体系中用于加载类的二进制字节码的重要组成部分,当一个类编译为class文件后,虚拟机便将他加载在方法区中
2.类装载器子系统除了要定位和导入二进制class文件外,还必须负责验证被导入类的正确性,为类变量分配并初始化内存,以及帮助解析符号引用
执行引擎:
执行引擎在我理解就是类被加载成字节码,然后对我们写的代码进行输出的程序
执行引擎在执行java代码的时候都会有解释执行和编译执行两种选择
解释执行:对源语言写成的源语句进行一句一句的翻译,翻译一句就提交给计算机执行一句,并不会形成目标程序。它的优点是翻译本身并不费事。它的缺点是运行速度慢,比如当程序中存在循环条件时,循环体内的语句就会被多次的翻译,从而影响运行速度
编译执行:现需要对源程序进行一个编译,生成一个目标文件,计算机再对这个目标程序进行执行。虽然这的编译的过程比上面提到的翻译的过程要复杂(通常要对代码进行语法分析,还要对代码进行优化,并分配内存,最后形成目标文件),但是一旦形成目标文件,就一劳永逸,不必再进行编译,所以执行速度较快
对于执行引擎来说,在活动线程中,只有位于栈顶的栈帧才是有效的,称为当前栈帧,执行引擎运行的所有字节码指令都是只针对当前栈帧进行操作
运行时数据区:
堆:堆主要存放对象信息,,java中不允许直接访问堆内存的对象,只能通过引用访问。(后续gc还是会讲述)
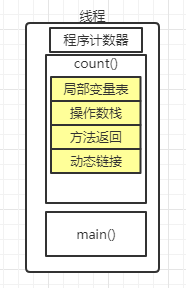
栈:栈中主要存放对象的引用,基本类型变量等。每次函数调用,都为函数开辟一块空间,会成为栈帧(深入理解看下面代码)
栈帧:1.局部变量表2.操作数栈3.方法返回4.动态链接
本地方法栈:本地方法栈主要是执行native的方法,比如线程的start(),实际是执行start0()方法然后找到操作系统里面c写的start0方法 这里就不多叙述了
方法区:方法区又称持久代(永生代) 现在我们将方法区称元空间,方法区主要是保存系统的类信息,比如类的字段,方法,常量池等,如果定义太多类,有可能会出oom的错误(我们经常写的string xxx=""常量信息就是存在于方法区中)

程序计数器:每个线程都有自己的程序计数器,如果当线程执行切换的时,可以在上次执行的基础上继续执行,仅仅从一条线程线性执行的角度而言,代码是一条一条的往下执行的,这个时候就是程序计数器;JVM就是通过读取程序计数器的值来决定下一条需要执行的字节码指令,进而进行选择语句、循环、异常处理等
了解这些常识性东西之后我们来看一段代码

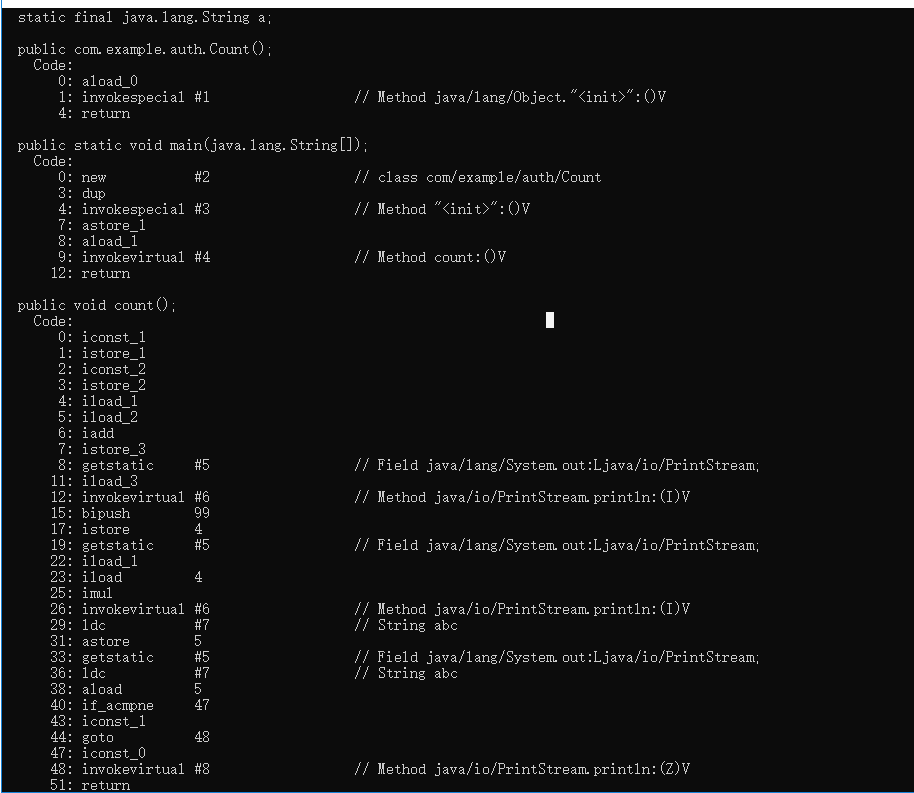
这段代码很简单,那么在运行时是怎么操作的呢?
线程在调用main函数是为main函数开辟的栈空间即栈帧,main调用count方法又开辟一个空间,所以这里有两个栈帧
我们打开cmd 执行下javac Count.java(java文件编译成class文件),再执行javap -c Count进行反编译
百度搜索jvm字节码指令,
或者进官网
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html
会有很好的解释比如iconst_1就是将数字1压进操作数栈,istroe_1将栈顶int型数值存入第二个局部变量,从0开始计数
这里有51行代表程序计数器计数最后就是52
最后动态链接:符号引用和直接引用在运行时进行解析和链接的过程,叫动态链接。
- 一个方法调用另一个方法,或者一个类使用另一个类的成员变量时,
- 需要知道其名字
- 符号引用就相当于名字,
- 这些被调用者的名字就存放在Java字节码文件里(.class 文件)。
-
名字是知道了,但是Java真正运行起来的时候,如何靠这个名字(符号引用)找到相应的类和方法
-
需要解析成相应的直接引用,利用直接引用来准确地找到。
-
posted on 2019-06-23 13:36 鲤🐟 阅读(172) 评论(0) 编辑 收藏 举报

