========================================================================================================================
1. 基类 scrapy.Spider
name: spider的名称
allowed_domains: 允许的域名
start_urls: 初始的urls
custom_settings: 个性化设置,会覆盖全局的设置
crawler: 抓取器,spder将绑定到它上面
settings: 配置示例
logger: 日志示例
method:
from_crawler(crawler, *args, **kwargs): 类方法,用于创建spiders
start_quests(): 生成初始的requests
make_requests_from_url(url): 根据url生成一个request
parse(response): 用来解析网页内容
log()
closed()
========================================================================================================================
2. 子类 CrawlSpider
1) 最常用的spider,用于抓取普通的网页
2) 增加了两个成员
rules: 定义了一些抓取规则--链接怎么跟踪,使用那个parse函数解析此链接
parse_start_url(resposne): 解析初始url的相应
实例:
import scrapy
from scrapy.spiders import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
class MySpiser(CrawlSpider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com']
rules = (
Rule(LinkExtractor(allow=('category\.php',), deny=('subsection\.php')),
Rule(LinkExtractor(allow=('item\.php',)), callback='parse_item)
)
def parse_item(self,resposne):
self.logger.info('Hi')
item = scrapy.Item()
item['id'] = response.xpath()
...
return item
========================================================================================================================
Selector
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
body = '<html><body></body></html>'
Selector(text=body).xpath('//span/text()').extract() => u'good'
resposne = HtmlResponse(url='http://example.com', body=body)
Selector(response=response).xpath('//span/text()').extract()
response.xpath('//title/text()')
response.css('title::text')
response.css('img').xpath('@src').extract_first()
response.css('img').xpath('@src').extract(default='not found')
selector中常用的抽取方法: xpath/css/re/extract
========================================================================================================================
item
========================================================================================================================
item pipeline
1. 数据的清洗
2. 数据的验证(是否符合要求的字段)
3. 去重
4. 存储
示例:
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing Price %s " % item)
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
class DuplicatePipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found : %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用pipeline
item_pipeline = {
'myproject.pipelines.pricepipeline': 300,
}
========================================================================================================================
requests
class scrapy.http.Request(url[,callback,method='GET',headers,body,cookies,meta,encoding='utf-8',priority=0,don't_filter=False,errback]) # 发生错误时调用的函数
示例一:
def parse_page(self, response):
return scrapy.Request('http://www.example',callback=self.parse_page2)
def parse_page2(self, response):
self.logger.info('visited %s', response.url)
示例二:
def parse_page1(self, resposne):
item = MyItem()
item['main_url'] = response.url
request = scrapy.Request('http://www.example.com/some_page.html',callback.parse_page2)
request.meta['item'] = item
return request
def parse_page2(self, response):
item = response.meta['item']
item['other_url'] = response.url
return item
子类: FormRequest
class scrapy.http.FormRequest(url[])
示例:
return [FormRequest(url='http://www.example.com/post/action',formdata={'name':'Jhon Doe','age':'27'},callback=self.after_post]
示例二:
class LoginSpider(scrapy.Spider):
name = 'example.com'
start_urls = ['http://www.example.com/users/login.php']
def parse(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username':'John','password':'secret'},
callback=self,after_login
)
def after_login(self, response):
if 'authentication failed' in response.body:
self.logger.error('Login failed')
return
========================================================================================================================
response
class scrapy.http.Response()
response.xpath('//p')
response.css('p')
子类:HtmlResponse
========================================================================================================================
import logging
logging.warning('This is a warning')
在scrapy中的使用
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['']
def parse(self, response):
self.logger.info('parse function called on %s', response.url)
LOG_FILE
LOG_ENABLED
LOG_ENCODING
LOG_LEVEL
LOG_FORMAT
LOG_DATAFORMAT
LOG_STDOUT
========================================================================================================================
Stats Collections
========================================================================================================================
================================================= 深入理解scrapy框架 =====================================================
========================================================================================================================
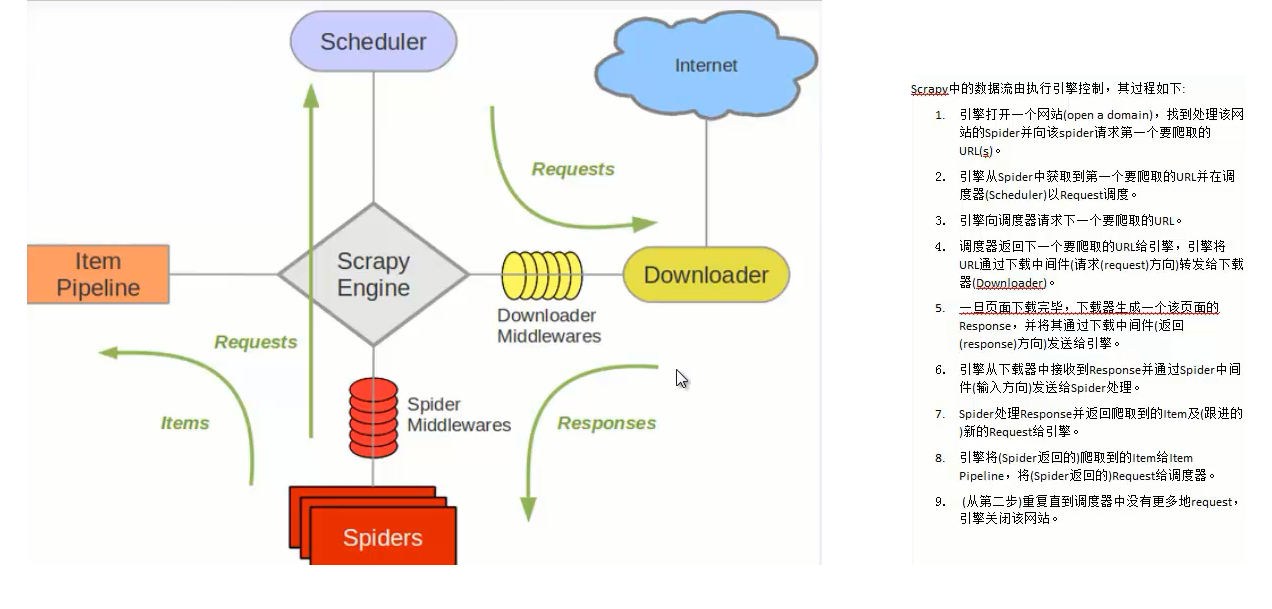
scrapy engine:
负责组件之间数据的流转,当某个动作发生触发事件
scheduler:
接受requests,并把他们入队,以便后续的调度
downloader:
负责抓取页面,并传递给引擎,之后将结果传递给spider
spiders
解析response,产生items和url
item pipeline
负责处理item,清洗-验证-持久化
downloader_middlewares:
位于引擎和下载器之间的一个钩子,处理传送到下载器的requests和传送到引擎的response
1. downloadmiddlerwares (重写)
class scrapy.downloadermiddlerwares.DownloaderMiddleware
process_request(request, spider):
process_response(request, response, spider):
process_exception(request, exception, spider): #出现异常时候的处理
内置的:
class scrapy.downloadermiddlewares.cookies.CookiesMiddleware
2. spidermiddlerwares (重写)
class scrapy.spidermiddlewares.SpiderMiddleware()
process_spider_input(response, spider)
process_spider_output(response, result, spider)
process_spider_exception(response, exception, spider)
process_start_requests(start_requests, spider)
内置的:
DepthMiddleware
HttpErrorMiddleware
================================================= cookies ========================================================
cookies 通过在客户端记录信息确定用户身份
cookies实际上是一段文本信息,客户端请求服务器. 如果服务器要记录用户状态,就使用response向客户端颁发一个cookies。 客户端会把cookies保存起来, 当浏览器在请求该网站时,浏览器把请求的网址连同cookies一起发给服务器,服务器查收cookies,以此来辨认用户的状态,服务器还可以根据需要修改cookies的内容
session 通过在服务器端记录信息确定用户身份
session保存在服务器上
FormRequest
COOKIES_ENABLED # Default: True
if disabled, no cookies will be sent to web services.
示例:
class stackoverflowspider(scrapy.Spider):
name = ''
start_urls = ['',]
def parse_requests(self):
url = ''
cookies = {
'dz_username':'wst_today',
'dz_uid':'2u3873',
'buc_key':'jdofqejj',
'buc_token':'a17384kdjfqi'
}
return [
scrapy.Request(url,cookies=cookies),
]
def parse(self, response):
ele = response.xpath('//table[@class="hello"]/text()')
if ele:
print('success')


