

day08-XML
XML
官方文档:https://www.w3school.com.cn/xml/index.asp
1.为什么需要xml?
- 需求1:两个程序间进行数据通信?
- 需求2:给一台服务器,做一个配置文件,当服务器程序启动时,去读取它应当监听的端口号、还有连接数据库的用户名和密码
- spring中的IOC配置文件beans.xml,mybatis的xxxMapper.xml文件,tomcat的server.xml,web.xml文件
- xml能存储复杂的数据关系
xml技术用于解决什么问题?
-
解决程序间数据传输的问题:
比如qq之间的数据传送,用xml格式来传输数据,具有良好的可读性,可维护性
以前两个程序间的通信用xml作为数据通信的格式,现在一般用json
-
xml可以做配置文件
xml做配置文件可以说是非常的普遍,比如我们的tomcat服务器的server.xml web.xml
-
xml可以充当小型的数据库
我们程序中可能用到的数据,如果放在数据库中读取不合适(因为你要增加维护数据库工作),可以考虑直接用xml文件来做小型数据库,而且直接读取文件显然要比读取数据库快
现在也不太使用xml作数据存储了
2.xml语法
- 快速入门
需求:使用idea创建Students.xml存储多个学生信息
<?xml version="1.0" encoding="UTF-8" ?> <!-- 1.xml:表示该文件的类型为xml 2.version 表示版本 3.encoding="UTF-8" 文件编码为UTF-8 4.students:root元素/根元素,名字自己定义 5.<student> </student>表示一个students的子元素,可以有多个 6.id就是属性,name,age,gender是student元素的子元素 --> <students> <student id="100"> <name>jack</name> <age>10</age> <gender>男</gender> </student> <student id="200"> <name>Mary</name> <age>18</age> <gender>女</gender> </student> </students>
- 一个xml文档分为如下几部分内容
- 文档声明
- 元素
- 属性
- 注释
- CDATA区、特殊字符
2.1文档声明
<?xml version="1.0" encoding="UTF-8" ?>
- xml声明放在xml文档的第一行
- xml声明由以下几个部分组成:
- version:文档符合xml1.0规范,我们学习1.0
- encoding:文档字符编码,比如:utf-8
2.2元素
- 元素语法要求:
- 每个xml文档必须有且只有一个根元素
- 根元素是一个完全包括文档中其他所有元素的元素
- 根元素的起始标记要放在所有其他元素的起始标记之前
- 根元素的结束标记要放在所有其他元素的结束标记之后
- xml元素指xml文件中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写形式
-
包含标签体:
<a>www.baidu.com</a> -
不含标签体:
<a></a>,简写为<a/> -
一个标签中也可以嵌套若干子标签。但所有的标签必须合理地嵌套,绝对不允许交叉嵌套
- 在很多时候,元素,节点,标签是相同的意思
- xml元素命名规则:
- 区分大小写,例如:
<P>和<p>是两个不同的标记 - 不能以数字开头
- 不能包含空格
- 名称中间不能包含冒号
: - 如果标签单词需要间隔,建议使用下划线
- 区分大小写,例如:
2.3属性
属性介绍:
-
属性值用双引号
""或单引号''分隔(如果属性值中有单引号'',就用双引号""分隔,如过属性值中有双引号"",就用单引号''分隔) -
一个元素可以用多个属性,它的基本格式为:
<元素名 属性名="属性值"> -
特定的属性名称在同一个元素标记中只能出现一次
即属性名称在同一个元素中不能重复
-
属性值不能包括&字符
2.4注释
<!--这是一个注释-->- 注释内容中不要出现
-- - 不要把注释放在标记中间。错误写法:
<Name <!--the name-->>TOM</Name> - 注释不能嵌套
- 可以在除标记以外的任何地方放注释
2.5CDATA节
有些内容不想让解析引擎执行,而是当做原始内容(普通文本)处理,可以使用CDATA括起来,CDATA节中的所有字符都会被当做简单文本,而不是xml标记
-
语法:
<![CDATA[这里可以把你输入的字符原样显示,不会解析xml]]> -
可以输入任意字符(除
]]>外) -
不能嵌套
例子
<?xml version="1.0" encoding="UTF-8" ?> <students> <student> <code> <!--如果希望把某些字符串当做普通文本使用,就用CDATA括起来--> <![CDATA[ <script data-compress=strip> function h(obj){ alert("一段js代码"); } </script> ]]> </code> </student> </students>
3.转义字符
对于一些单个字符,若想显示其原始样式,也可以使用转义的形式予以处理
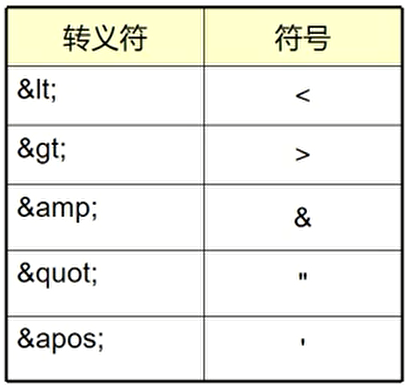
例子
<?xml version="1.0" encoding="UTF-8" ?> <students> <student> <name>jack</name> <age>10</age> <gender>男</gender> <!--转义字符表示一些特殊的字符--> <resume>年龄<>&</resume> </student> </students>
-
小结:
遵循如下规则的xml文档称为格式正规的xml文档:
- xml声明语句
<?xml version="1.0" encoding="UTF-8" ?> - 必须有且仅有一个根元素
- 标记区分大小写
- 属性值用引号
- 标记成对
- 空标记关闭
- 元素正确嵌套
4.DOM4j
4.1xml解析技术原理和介绍
-
xml技术原理
DOM (Document Object Model,文档对象模型)定义了访问和操作文档的标准方法。
- 不管是html文件还是xml文件,都是标记型文档,都可以使用w3c组织制定的dom技术来解析
- document对象表示的是整个文档(可以是html文档,也可以是xml文档)
- DOM 把 XML 文档作为树结构来查看。能够通过 DOM 树来访问所有元素。可以修改或删除它们的内容,并创建新的元素。元素,它们的文本,以及它们的属性,都被认为是节点
-
xml解析技术介绍
早期 JDK 为我们提供了两种xml的解析技术:DOM和Sax
- dom解析技术是W3C组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。Java对dom技术解析也做了实现
- sun公司在JDK5版本对dom解析技术进行升级:SAX(Simple API for XML)解析,它是以类似事件机制通过回调告诉用户当前正在解析的内容。是一行一行地读取xml文件进行解析的,不会创建大量的dom对象。所以它在解析xml的时候,在性能上由于Dom解析
这两种技术已经过时,简单了解即可
- 第三方的XML解析技术
- jdom在dom基础上进行了封装
- dom4j 又对 jdom进行了封装
- pull主要用在Android手机开发,跟sax非常类似,都是事件机制解析xml文件
4.2dom4j介绍
-
dom4j是一个简单、灵活的开放源代码的库(用于解析/处理xml文件)。dom4j是由早期开发JDOM的人分离出来后独立开发的。
-
与JDOM不同的是,dom4j使用接口和抽象基类,虽然dom4j的API相对要复杂一些,但他提供了比JDOM更好的灵活性
-
Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的dom4j
-
使用dom4j开发,需要下载dom4j对象的jar文件
dom4j的jar包下载地址(内有使用案例):dom4j
官方api文档:Overview (dom4j 1.6.1 API)
4.3dom4j获得document对象的方式
开发dom4j要导入dom4j的jar包
DOM4j中,获得document对象的方式有三种:
-
读取XML文件,获得document对象
SAXReader reader = new SAXReader();//创建一个解析器 Document document = reader.read(new File("src/input.xml"));//XML Document -
解析XML形式的文本,得到document对象
String text = "<members></members>";//直接对一个字符串的xml文本进行解析 Document document = DocumentHelper.parseText(text); -
主动创建document对象
Document document = DocumentHelper.createDocument();//创建根节点 Element root = document.addElement("members");
下面只演示方式一的使用:读取XML文件,获得document对象
dom4j应用实例-读取XML文件,获得document对象
-
使用dom4j对students.xml文件进行增删改查
- 重点讲解查询(遍历和指定查询)
- xml增删改使用少,作为拓展,给出案例
-
引入dom4j的依赖的jar包
-
在src文件下创建Dom4j_类以及students.xml文件
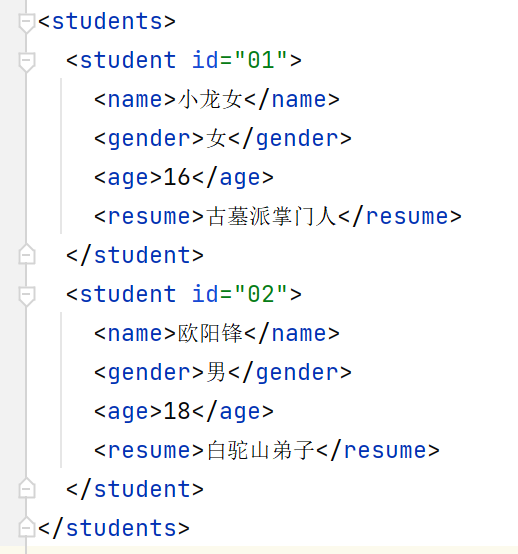
students.xml:
<?xml version="1.0" encoding="UTF-8" ?> <students> <student id="01"> <name>小龙女</name> <gender>女</gender> <age>16</age> <resume>古墓派掌门人</resume> </student> <student id="02"> <name>欧阳锋</name> <gender>男</gender> <age>18</age> <resume>白驼山弟子</resume> </student> </students>
Dom4j_.java:
import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.io.SAXReader; import org.testng.annotations.Test; import java.io.File; public class Dom4j_ { /** * 演示如何加载xml文件 */ @Test public void loadXML() throws DocumentException { //得到一个解析器 SAXReader reader = new SAXReader(); //debug-->看看document对象的属性 Document document = reader.read(new File("src/students.xml")); System.out.println(document); } }
-
如下:在
Document document=reader.read(new File("src/students.xml"));处打上断点:
-
点击debug,点击step over,可以看到document对象,它代表整个文档。
展开document对象,rootElement代表的就是students根元素
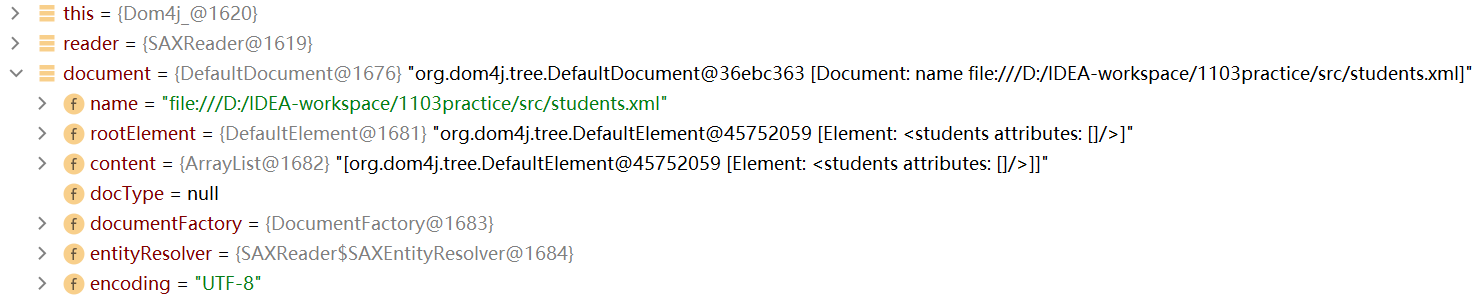
-
rootElement下面有一个content属性,content属性存储着所有的elementData
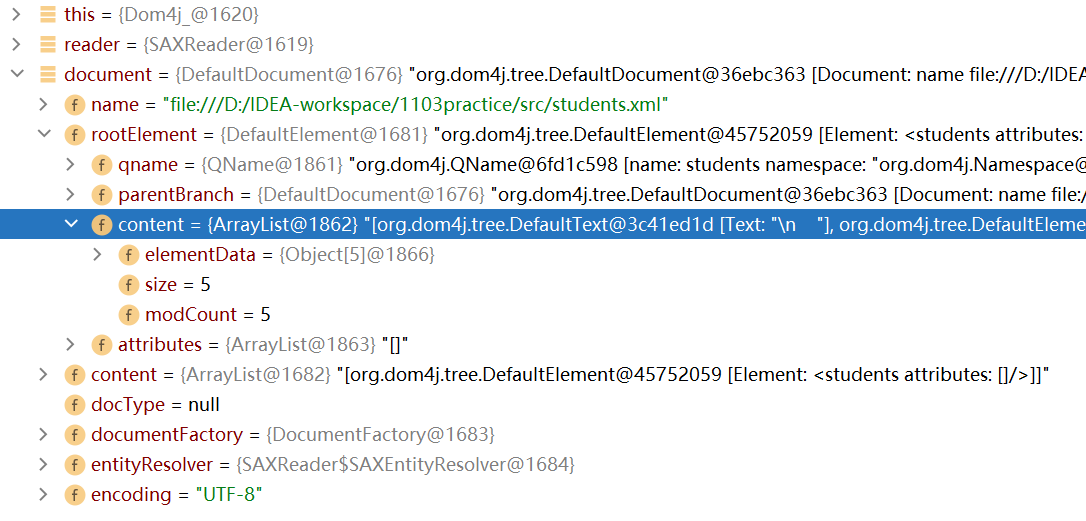
-
点击elementData属性,可以看到该属性有5个对象:
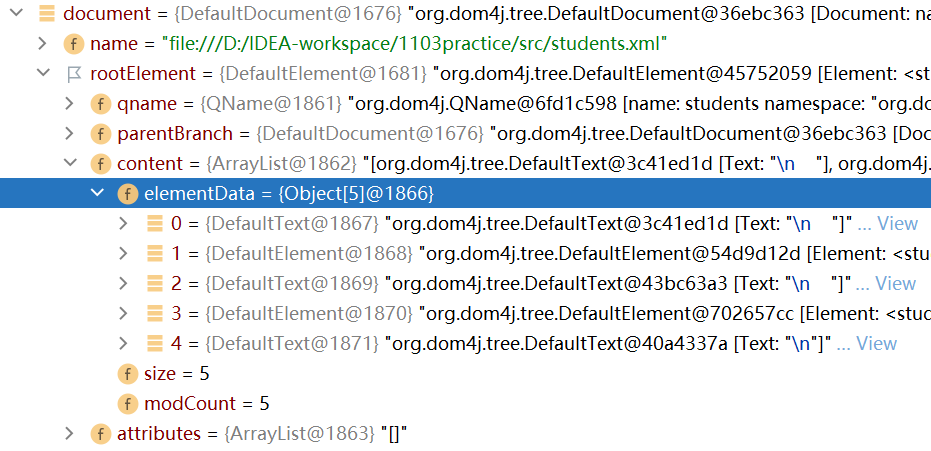
和html-dom解析一样,这五个对象中有三个是换行符号\n,其余的两个才是根元素下面的子元素student
-
点击展开索引为1的元素对象(即student元素),可以看到该元素对象中又包含了9个对象,除了换行符之外,其余的对象就是student元素的子元素,name节点,gender节点,age节点和resume节点

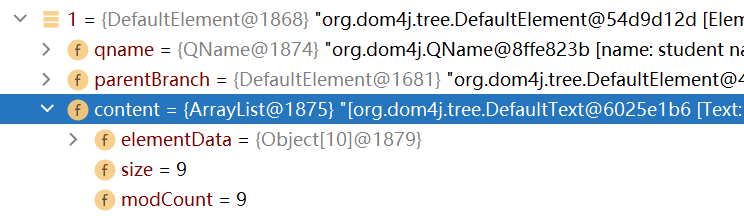
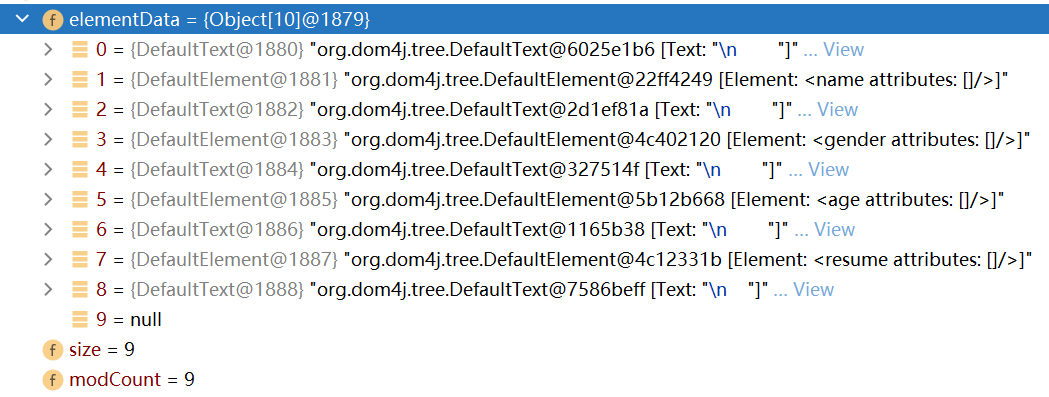
-
点击name节点,展开,即可看到name节点的值

document对象的整体结构为:
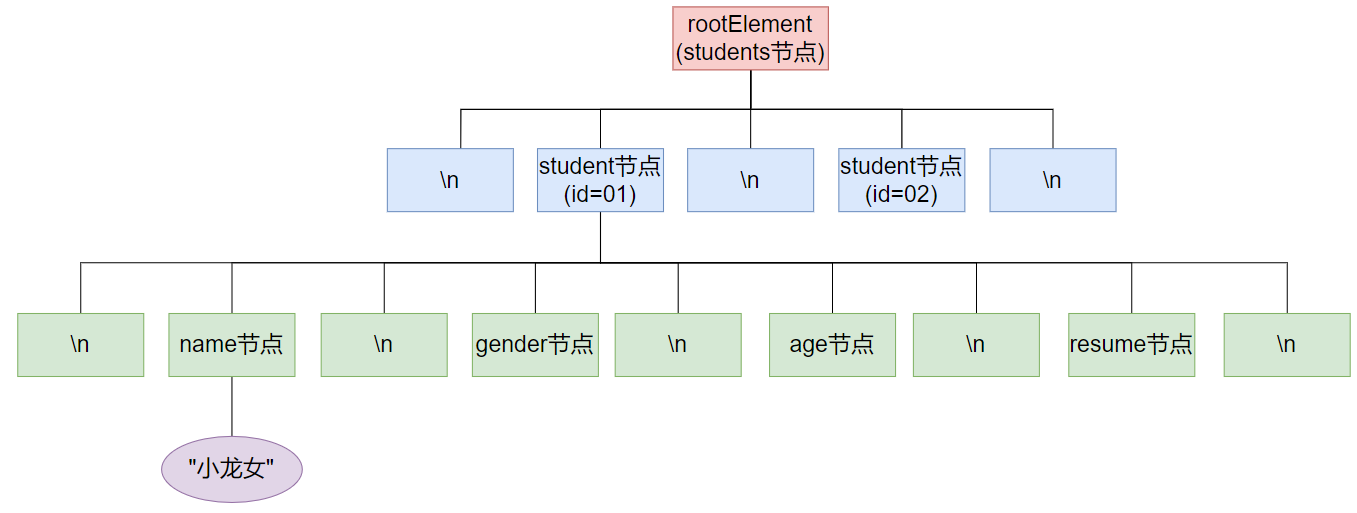
1.方式一遍历
演示案例1:遍历xml指定元素
import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; import org.testng.annotations.Test; import java.io.File; import java.util.List; public class Dom4j_ { /** * 遍历所有的student信息 */ @Test public void listStus() throws DocumentException { //得到一个解析器 SAXReader reader = new SAXReader(); Document document = reader.read(new File("src/students.xml")); //1.得到rootElement Element rootElement = document.getRootElement(); //2.得到rootElement的student节点 List<Element> students = rootElement.elements("student"); System.out.println(students.size());//2 for (Element student : students) {//student就是student节点/元素 //获取student节点的name节点 Element name = student.element("name");//因为name只有一个,这里用element方法 Element age = student.element("age"); Element gender = student.element("gender"); Element resume = student.element("resume"); System.out.println("学生信息=" + name.getText() + " " + age.getText() + " " + gender.getText() + " " + resume.getText()); } } }
2.方式一查询
案例2:读取指定xml元素
import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; import org.testng.annotations.Test; import java.io.File; public class Dom4j_ { /** * 指定读取第一个学生的信息 */ @Test public void readOne() throws DocumentException { //得到一个解析器 SAXReader reader = new SAXReader(); Document document = reader.read(new File("src/students.xml")); //1.得到rootElement Element rootElement = document.getRootElement(); //2.获取第一个学生 Element student = (Element) rootElement.elements("student").get(0); //3.输出该学生的信息 System.out.println("学生信息=" + student.element("name").getText() + " " + student.element("age").getText() + " " + student.element("gender").getText() + " " + student.element("resume").getText()); //4.获取student元素的属性 System.out.println("id="+student.attributeValue("id")); } }
- 如果想要省略层层取元素的步骤,直接在根节点取出指定的元素,可以使用xpath(https://dom4j.github.io/#xpath)
3.方式一增删改(了解即可)
增加元素
/** * 加元素(要求:添加一个学生到xml中)[不要求,使用少,了解即可] */ @Test public void add() throws Exception { //1.得到解析器 SAXReader saxReader = new SAXReader(); //2.指定解析哪个xml文件 Document document = saxReader.read(new File("src/students.xml")); //首先我们来创建一个学生节点对象 Element newStu = DocumentHelper.createElement("student"); Element newStu_name = DocumentHelper.createElement("name"); //如何给元素添加属性 newStu.addAttribute("id", "04"); newStu_name.setText("宋江"); //创建age元素 Element newStu_age = DocumentHelper.createElement("age"); newStu_age.setText("23"); //创建resume元素 Element newStu_intro = DocumentHelper.createElement("resume"); newStu_intro.setText("梁山老大"); //把三个子元素(节点)加到newStu下 newStu.add(newStu_name); newStu.add(newStu_age); newStu.add(newStu_intro); //再把newStu节点加到根元素下面 document.getRootElement().add(newStu); //以上的改变是发生在内存中的,使用输出流将改变写入到对应xml文件中 //直接输出会出现中文乱码: OutputFormat output = OutputFormat.createPrettyPrint(); output.setEncoding("utf-8");//设置输出编码为utf-8 //把我们的xml文件更新 XMLWriter writer = new XMLWriter( new FileOutputStream(new File("src/students.xml")), output); writer.write(document); writer.close(); }
删除元素
/** * 删除元素(要求:删除第三个元素)[不要求,使用少,了解即可] */ @Test public void del() throws Exception { //1.得到解析器 SAXReader saxReader = new SAXReader(); //2.指定解析哪个xml文件 Document document = saxReader.read(new File("src/students.xml")); //找到该元素的第三个学生 Element stu = (Element) document.getRootElement().elements("student").get(2); //在该元素的父节点删除该元素 stu.getParent().remove(stu); //删除某个元素的某个属性 //stu.remove(stu.attribute("id")); //以上的改变是发生在内存中的,使用输出流将改变写入到对应xml文件中 //直接输出会出现中文乱码: OutputFormat output = OutputFormat.createPrettyPrint(); output.setEncoding("utf-8");//设置输出编码为utf-8 //把我们的xml文件更新 XMLWriter writer = new XMLWriter( new FileOutputStream(new File("src/students.xml")), output); writer.write(document); writer.close(); System.out.println("删除成功~"); }
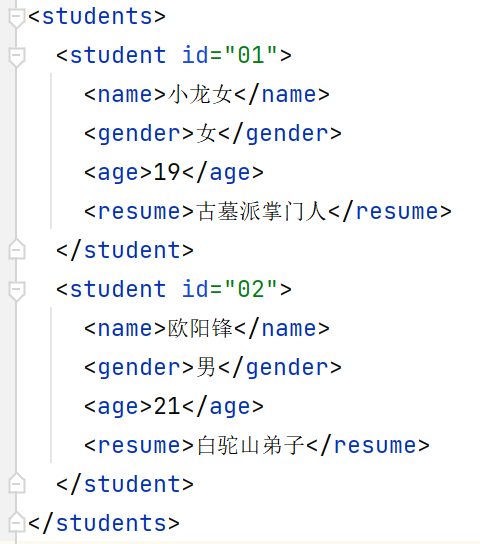
修改元素
/** * 修改元素(要求:把所有学生的年龄加三)[不要求,使用少,了解即可] */ @Test public void update() throws Exception { //1.得到解析器 SAXReader saxReader = new SAXReader(); //2.指定解析哪个xml文件 Document document = saxReader.read(new File("src/students.xml")); //得到所有学生的年龄 List<Element> students = document.getRootElement().elements("student"); //把所有人的年龄都拿出来然后加三 for (Element student : students) { //取出年龄 Element age = student.element("age"); //把年龄取出来转成数值型,加三后再和空串相加转成字符串类型 age.setText((Integer.parseInt(age.getText()) + 3) + ""); } //以上的改变是发生在内存中的,使用输出流将改变写入到对应xml文件中 //直接输出会出现中文乱码: OutputFormat output = OutputFormat.createPrettyPrint(); output.setEncoding("utf-8");//设置输出编码为utf-8 //把我们的xml文件更新 XMLWriter writer = new XMLWriter( new FileOutputStream(new File("src/students.xml")), output); writer.write(document); writer.close(); System.out.println("更改成功~"); }
4.4练习
根据给出的books.xml,创建对应的Book对象(有几个book节点就创建几个对象)
<?xml version="1.0" encoding="utf-8"?> <books> <book id="nds001"> <name>西游记</name> <author>吴承恩</author> <price>34.5</price> </book> <book id="nds002"> <name>三国演义</name> <author>罗贯中</author> <price>50.4</price> </book> <book id="nds003"> <name>红楼梦</name> <author>曹雪芹</author> <price>88.8</price> </book> </books>
思路:
- 遍历所有的book元素,得到每个book元素的信息
- 创建一个Book类,根据book元素信息来创建book对象
import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; import org.testng.annotations.Test; import java.io.File; import java.util.ArrayList; import java.util.List; public class Dom_Homework { @Test public void creatEle() throws DocumentException { //得到解析器 SAXReader saxReader = new SAXReader(); //指定解析哪个xml文件 Document document = saxReader.read(new File("src/Books.xml")); //1. 遍历所有的book元素,得到每个book元素的信息 List<Element> books = document.getRootElement().elements("book"); //2.创建集合存放创建的Book对象 List<Book> listBooks = new ArrayList<>(); //3.遍历节点,取出信息,创建对象并放入集合中 for (Element book : books) { String id = book.attribute("id").getText(); String name = book.element("name").getText(); String author = book.element("author").getText(); String price = book.element("price").getText(); //创建对象并放入集合中 listBooks.add(new Book(id, name, author, price)); } //4.遍历输出 for (Book book : listBooks) { System.out.println(book); } } } //创建一个Book类,根据book元素信息来创建book对象 class Book { private String id; private String name; private String author; private String price; public Book(String id, String name, String author, String price) { this.id = id; this.name = name; this.author = author; this.price = price; } @Override public String toString() { return "Book{" + "id='" + id + '\'' + ", name='" + name + '\'' + ", author='" + author + '\'' + ", price='" + price + '\'' + '}'; } }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!