力扣今日题-729. 我的日程安排表 I
729. 我的日程安排表 I
二分
- 先将所有已经预定的序列进行排序,然后依次遍历区间,看某个区间的
left1,是否大于end
12会和3,5,10进行比较,这是会发现没有比它大的区间,这时就该考虑往它们后面插入了。
- 未找到:那就和最后一个区间的
right1比较,看最后一个区间的right1是否小于插入区间的start,如果可以就返回ture,否则就返回false
12会和最后一个元素的15进行比较,发现15是大于12的,返回false.
而17先和3,7,10进行比较,发现都比它们大,所以考虑往后面放置,然后20和15比较,发现20大于15,返回true。
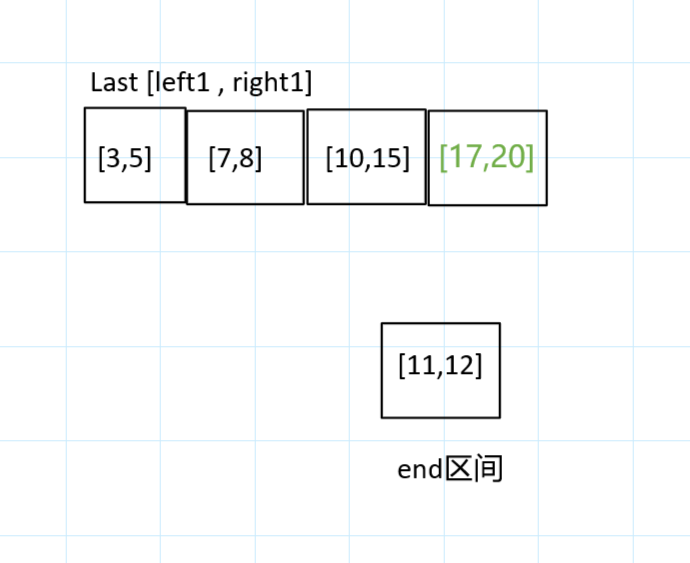
- 判断到第一个就找到了

一判断,就发现
end要小于最小的left1,所以可以插入,就返回true
- 中间插入
中间区间,找到last的上一个区间pre[left2,right2],若right2要大于start,则说明有交集,返回false,否则返回true。

先判断,发现10==10,停下来判断7,一看7<8有交集,返回false。
比如[9,10]这是一个正确的例子,发现 10 =- 10,停下来判断,一看9> 8,返回true。
- 代码:
List<int[]> data;
public MyCalendar() {
data = new ArrayList<>();
}
public boolean book(int start, int end) {
if (data.size() == 0) {
data.add(new int[]{start, end});
return true;
}
data.sort(Comparator.comparingInt(o -> o[0]));
int left = 0, right = data.size() - 1;
//找到第一个start >= end的区间
int ans = -1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (data.get(mid)[0] >= end) {
ans = mid;
right = mid - 1;
} else {
left = mid + 1;
}
}
//没有找到 和最后一个区间比较
if (ans == -1) {
int[] ints = data.get(data.size() - 1);
if (ints[1] > start) {
return false;
}
} else if (ans != 0) {
//不是第一个区间,如果是第一个区间则可以直接插入
int[] pre = data.get(ans - 1);
if (pre[1] > start) {
return false;
}
}
data.add(new int[]{start, end});
return true;
}
直接遍历
class MyCalendar {
// 定义一个booked
List<int[]> booked;
public MyCalendar() {
booked = new ArrayList<int[]>();
}
public boolean book(int start, int end) {
for(int[] arr : booked){
int l = arr[0] ,r = arr[1];
//第二种情况
if(l < end && start < r){
return false;
}
}
booked.add(new int[]{start,end});
return true;
}
}
/**
* Your MyCalendar object will be instantiated and called as such:
* MyCalendar obj = new MyCalendar();
* boolean param_1 = obj.book(start,end);
*/
[s1,e1)和[s2,e2),没有交集满足s1>e2或者s2>e1,反之则说明两者回产生交集。
思路三
转变一下思维,可以把重叠这个概念扩展到广义的相等概念,即一旦重叠就代表两个元素相等,那么这就简单了,set专门用来去重存储。 那么HashSet和TreeSet用哪个呢? 首先HashSet去重是根据对象的哈希值,由于我们要存储的是int[]类型的,我们在写代码的时候是要根据start和end来创建它,那么它们的哈希值基本不同,也就是说就算两个int[]里面的值完全一样,但是哈希值不同,HashSet也会把它们存进去。 由于我们把重叠看作是广义上的相等,那么就需要定义一个比较器要区分它们的是否广义相等,而TreeSet支持自定义比较器,而且根据比较器返回的值进行排序,非常符合我们的需求。
class MyCalendar {
//定义一个TreeSet
TreeSet<int[]> calendars;
public MyCalendar() {
calendars = new TreeSet<>((a, b) -> {
if(a[1] <= b[0])
return -1;
else if(a[0] >= b[1])
return 1;
else
return 0;
});
}
public boolean book(int start, int end) {
int[] e = new int[]{start, end};
return calendars.add(e);
}
}
/**
* Your MyCalendar object will be instantiated and called as such:
* MyCalendar obj = new MyCalendar();
* boolean param_1 = obj.book(start,end);
*/
拓展
TreeSet简介:
有序,不可重复,红黑树,基于Treemap实现,自定义排序等特点。TreeSet 是一个有序的集合,它的作用是提供有序的Set集合。它继承于AbstractSet抽象类,实现了NavigableSet
, Cloneable, java.io.Serializable接口。
TreeSet 继承于AbstractSet,所以它是一个Set集合,具有Set的属性和方法。
TreeSet 实现了NavigableSet接口,意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。
TreeSet 实现了Cloneable接口,意味着它能被克隆。
TreeSet 实现了java.io.Serializable接口,意味着它支持序列化。
TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。
TreeSet为基本操作(add、remove 和 contains)提供受保证的 log(n) 时间开销。
另外,TreeSet是非同步的。 它的iterator 方法返回的迭代器是fail-fast的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号