
《Linux 性能优化实战—倪朋飞 》学习笔记 CPU 篇
平均负载
-
指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,即平均活跃进程数
-
可运行状态:正在使用CPU或者正在等待CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态 (Running 或者 Runnable)的进程
-
不可中断状态:正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态 (Uninterruptible Sleep, 也称为 Disk Sleep )的进程
-
平均负载为多少合理
-
最理想的情况是等于 CPU 个数
-
三种情况分析
-
如果
1分钟、5分钟、15分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。 -
但如果1分钟的值远小于15分钟的值,就说明系统最近1分钟的负载在减少,而过去15分钟内却有很大的负载
-
如果 1分钟的值远大于15分钟的值,就说明最近 1分钟的负载在增加,这种增加可能只是临时的,也有可能还会持续增加下去,所以需要持续观察。一旦 1分钟平均负载接近或超过了CPU的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并想办法优化。
-
-
当平均负载高于 CPU 数量 70% 的时候,就应该分析排查负载高的问题了
平均负载与CPU使用率
-
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的。
-
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高。
-
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
检查系统负载的工具
-
uptime: 当前时间、系统运行时间、正在登陆用户数、过去1分钟、5分钟、15分钟的平均负载
[root@jikeshijian ~]# uptime 14:37:35 up 0 min, 1 user, load average: 0.29, 0.09, 0.03
-
iostat: 查看系统 IO 状态
[root@jikeshijian ~]# iostat Linux 3.10.0-862.14.4.el7.x86_64 (jikeshijian) 12/14/2018 _x86_64_ (2 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.68 0.00 2.21 0.17 0.00 96.94 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 18.67 549.98 36.62 82789 5512
-
mpstat: (Multiprocessor Statistics) 实时监控工具,报告与cpu的一些统计信息这些信息都存在/proc/stat文件中,在多CPU系统里,其不但能查看所有的CPU的平均状况的信息,而且能够有查看特定的cpu信息
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据,共输出 1 组,如果后面是2的话就表示间隔 5 秒输出两组 [root@jikeshijian ~]# mpstat -P ALL 5 1 Linux 3.10.0-862.14.4.el7.x86_64 (jikeshijian) 12/14/2018 _x86_64_ (2 CPU) 13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95 13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 # all 表示 下面两个CPU 和的平均
注意:%iowait选项:centos自带的sysstat版本稍微老一点,11.5.5之后才增加的这个选项
-
pidstat:
# 每隔5秒显示1次CPU的使用统计 [root@jikeshijian ~]# pidstat -u 5 1 Linux 3.10.0-862.14.4.el7.x86_64 (jikeshijian) 12/14/2018 _x86_64_ (2 CPU) 13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command 13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress
注意:pidstat输出中没有%wait的问题,是因为CentOS默认的sysstat稍微有点老,源码或者RPM升级到11.5.5版本以后就可以看到了。而Ubuntu的包一般都比较新,没有这个问题
平均负载总结:
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
-
平均负载高有可能是 CPU 密集型进程导致的;
-
平均负载高并不一定表 CPU 使用率高,还有可能是 I/O 更繁忙了;
-
当发现负载高的时候,你可以使用
mpstat、pidstat等工具,辅助分析负载的来源。
CPU 上下文切换
多个进程竞争 CPU 也会导致负载升高。Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。
而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是 进程上下文切换,线程上下文切换,以及中断上下文切换。
进程上下文切换
-
系统调用(特权模式切换):一个进程用户态与内核态的互相转变
-
上下文切换:从一个进程切换到另一个进程
-
虚拟内存、栈、全局变量等用户空间的资源
-
内核堆栈、寄存器等内核空间的状态
-
-
什么时候会切换上下文?
-
为了保证所有进程可以得到公平调度,CPU 被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。当某个进程的时间片耗尽,就会被系统挂起,切换到其他正在等待 CPU 的进程运行
-
进程在系统资源(比如内存)不足时,要等到资源满足后才可以运行,这个时候进程被挂起,并由系统调度其他进程运行
-
当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度
-
当有优先级更高的进程运行时,为了保证优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
-
硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
-
线程上下文切换
-
线程与进程最大的区别
-
线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
-
当进程只有一个线程时,可以认为进程就等于线程。
-
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源,在上下文切换时,这些资源不需要修改
-
线程有自己的私有数据,比如栈和寄存器等,这些在上下文切换时需要保存
-
-
分为两种情况:
-
前后两个线程属于不通进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换时一样
-
前后两个线程属于同一个进程。此时,因为资源是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的稀有数据、寄存器等不共享的数据。
-
中断上下文切换
-
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。打断其他进程时,需要将进程当前的状态保存下来,中断结束后,进程可以从原来的状态恢复运行。
-
中断上下文切换并不涉及进程的用户态。
-
对同一个 CPU 来说,中断处理比进程拥有更高的优先级
怎么查看系统的上下文切换情况
用于检查系统上下文的工具(vmstat 、 pidstat 和 /proc/interrupts)
-
vmstat: 常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数-
需要特别关注的四列内容
-
cs(context switch) 表示每秒上下文切换的次数 -
in(interrupt)表示每秒中断次数 -
r(Running or Runnable)表示就绪队列的长度,也就是正在运行和等待CPU的进程数 -
b(Blocked)表示处于不可中断睡眠状态的进程数
-
-
# 每隔 5 秒输出 1 组数据 [root@jikeshijian ~]# vmstat 5 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 7756900 10768 130776 0 0 12 1 14 14 0 0 100 0 0
vmstat 只给了系统的总体的上下文切换情况,要想查看每个进程的详细情况就需要使用pidstat
-
pidstat:-
需要重点关注两列内容
-
cswch,表示每秒自愿上下文切换(voluntary context switches)的次数 -
nvcswch,表示每秒非自愿上下文切换(non voluntary context switches)的次数
-
-
自愿上下文切换:进程无法获取所需资源(比如说, I/O、内存等系统资源不足) -
非自愿上下文切换:进程由于时间片已到等原因,被系统强制调度
-
# 每隔 5 秒输出 1 组数据 [root@jikeshijian ~]# pidstat -w 5 Linux 3.10.0-862.14.4.el7.x86_64 (jikeshijian) 12/14/2018 _x86_64_ (2 CPU) 03:47:58 PM UID PID cswch/s nvcswch/s Command 03:48:03 PM 0 3 0.40 0.00 ksoftirqd/0 03:48:03 PM 0 9 2.19 0.00 rcu_sched 03:48:03 PM 0 11 0.40 0.00 watchdog/0 03:48:03 PM 0 12 0.40 0.00 watchdog/1 03:48:03 PM 0 39 0.20 0.00 khugepaged 03:48:03 PM 0 50 0.40 0.00 kworker/1:1 03:48:03 PM 0 96 1.99 0.00 kworker/0:2 03:48:03 PM 0 353 0.20 0.00 irqbalance 03:48:03 PM 0 392 0.20 0.00 crond 03:48:03 PM 0 5468 0.20 0.00 pidstat # 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束) # -w 参数表示输出进程切换指标,而 -u 参数则表示输出 CPU 使用指标 # 默认显示进程 [root@jikeshijian ~]# pidstat -w -u 1 08:06:33 UID PID %usr %system %guest %wait %CPU CPU Command 08:06:34 0 10488 30.00 100.00 0.00 0.00 100.00 0 sysbench 08:06:34 0 26326 0.00 1.00 0.00 0.00 1.00 0 kworker/u4:2 08:06:33 UID PID cswch/s nvcswch/s Command 08:06:34 0 8 11.00 0.00 rcu_sched 08:06:34 0 16 1.00 0.00 ksoftirqd/1 08:06:34 0 471 1.00 0.00 hv_balloon 08:06:34 0 1230 1.00 0.00 iscsid 08:06:34 0 4089 1.00 0.00 kworker/1:5 08:06:34 0 4333 1.00 0.00 kworker/0:3 08:06:34 0 10499 1.00 224.00 pidstat 08:06:34 0 26326 236.00 0.00 kworker/u4:2 08:06:34 1000 26784 223.00 0.00 sshd # pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标 # 每隔 1 秒输出一组数据(需要 Ctrl+C 才结束) # -wt 参数表示输出线程的上下文切换指标 [root@jikeshijian ~]# pidstat -wt 1 08:14:05 UID TGID TID cswch/s nvcswch/s Command ... 08:14:05 0 10551 - 6.00 0.00 sysbench 08:14:05 0 - 10551 6.00 0.00 |__sysbench 08:14:05 0 - 10552 18911.00 103740.00 |__sysbench 08:14:05 0 - 10553 18915.00 100955.00 |__sysbench 08:14:05 0 - 10554 18827.00 103954.00 |__sysbench ...
查看中断类型的方式
从 /proc/interrupts 这个只读文件中读取。/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。
# -d 参数表示高亮显示变化的区域 [root@jikeshijian ~]# watch -d cat /proc/interrupts CPU0 CPU1 ... RES: 2450431 5279697 Rescheduling interrupts ...
观察一段时间可以发现,变化速度最快的是重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)。
所以,这里的中断升高还是因为过多任务的调度问题
每秒上下文切换多少次才算正常?
这个数值其实取决于系统本身的 CPU 性能。在我看来,如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
-
根据上下文切换的类型,再做具体分析
-
自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题
-
非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈
-
中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型
-
CPU 使用率
Linux 作为一个多任务操作系统,将每个 CPU 的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。
节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等。不同的系统可能设置不同数值,你可以通过查询/boot/config内核选项来查看它的配置值。比如在我的系统中,节拍率设置成了 1000,也就是每秒钟触发 1000 次时间中断。
[root@jikeshijian ~]# grep 'CONFIG_HZ=' /boot/config-$(uname -r) CONFIG_HZ=1000
同时,正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
-
查询
/proc/stat-
第一行表示所有CPU的累加
-
其他列表示不同场景下CPU的累加节拍数,单位:
USER_HZ即10ms(1/100秒)
-
# 只保留各个 CPU 的数据 $ cat /proc/stat | grep ^cpu cpu 280580 7407 286084 172900810 83602 0 583 0 0 0 cpu0 144745 4181 176701 86423902 52076 0 301 0 0 0 cpu1 135834 3226 109383 86476907 31525 0 282 0 0 0
与 CPU 使用率相关的重要指标
-
user(通常缩写为
us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。 -
nice(通常缩写为
ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。 -
system(通常缩写为
sys),代表内核态 CPU 时间。 -
idle(通常缩写为
id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。 -
iowait(通常缩写为
wa),代表等待 I/O 的 CPU 时间。 -
irq(通常缩写为
hi),代表处理硬中断的 CPU 时间。 -
softirq(通常缩写为
si),代表处理软中断的 CPU 时间。 -
steal(通常缩写为
st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。 -
guest(通常缩写为
guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。 -
guest_nice(通常缩写为
gnice),代表以低优先级运行虚拟机的时间。
怎么查看CPU使用率
-
ps: 显示了每个进程的资源使用情况 -
top: 显示了系统总体的 CPU 和 内存使用情况,以及各个进程的资源使用情况
[root@jikeshijian ~]# top top - 16:29:38 up 1:52, 1 user, load average: 0.00, 0.01, 0.04 Tasks: 79 total, 1 running, 78 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 3.2 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8009752 total, 7756056 free, 111768 used, 141928 buff/cache KiB Swap: 2097148 total, 2097148 free, 0 used. 7676980 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 127904 6452 4076 S 0.0 0.1 0:01.14 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 6 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kworker/u4:0 7 root rt 0 0 0 0 S 0.0 0.0 0:00.01 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh [root@jikeshijian ~]# top top - 16:29:38 up 1:52, 1 user, load average: 0.00, 0.01, 0.04 Tasks: 79 total, 1 running, 78 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 3.2 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8009752 total, 7756056 free, 111768 used, 141928 buff/cache KiB Swap: 2097148 total, 2097148 free, 0 used. 7676980 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 127904 6452 4076 S 0.0 0.1 0:01.14 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 6 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kworker/u4:0 7 root rt 0 0 0 0 S 0.0 0.0 0:00.01 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh 9 root 20 0 0 0 0 S 0.0 0.0 0:00.19 rcu_sched 10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain 11 root rt 0 0 0 0 S 0.0 0.0 0:00.04 watchdog/0
这个输出结果中,第三行 %Cpu 就是系统的 CPU 使用率,需要注意,top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
继续往下看,空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。
所以,到这里我们可以发现, top 并没有细分进程的用户态 CPU 和内核态 CPU。那要怎么查看每个进程的详细情况呢?你应该刚才用到的 pidstat 吧,它正是一个专门分析每个进程 CPU 使用情况的工具。
-
pidstat:-
需要关注的内容
-
用户态 CPU 使用率 (%usr)
-
内核态 CPU 使用率(%system)
-
运行虚拟机 CPU 使用率(%guest)
-
等待 CPU 使用率(%wait)
-
以及总的 CPU 使用率(%CPU)
-
-
# 每隔 1 秒输出一组数据,共输出 5 组 [root@jikeshijian ~]# pidstat 1 5 Linux 3.10.0-862.14.4.el7.x86_64 (jikeshijian) 12/14/2018 _x86_64_ (2 CPU) 15:56:02 UID PID %usr %system %guest %wait %CPU CPU Command 15:56:03 0 15006 0.00 0.99 0.00 0.00 0.99 1 dockerd ... Average: UID PID %usr %system %guest %wait %CPU CPU Command Average: 0 15006 0.00 0.99 0.00 0.00 0.99 - dockerd
-
实际计算方法
CPU 使用率过高怎么办?
通过 top、ps、pidstat 等工具,你能够轻松找到 CPU 使用率较高(比如 100% )的进程。接下来,你可能又想知道,占用 CPU 的到底是代码里的哪个函数呢?找到它,你才能更高效、更针对性地进行优化。
-
工具选择
-
GDB:(The GNU Project Debugger)GDB 调试程序的过程会中断程序运行,这在线上环境往往是不允许的。所以,GDB 只适合用在性能分析的后期,当你找到了出问题的大致函数后,线下再借助它来进一步调试函数内部的问题。 -
perf: 以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题
-
-
perf top: 实时展示了系统的性能信息,但它的缺点是并不保存数据,无法用于离线或者后续的分析-
需要关注的内容:
-
Samples:采样数 -
event:事件类型 -
Event count:事件总数量 -
Overhead:指该符号的性能事件在所有采用中的比例,用百分比来表示 -
Shared:指该函数或指令所在的动态共享对象,如:内核、进程名、动态链接库名等 -
Object: 动态共享对象的类型-
[.]表示用户空间的可执行程序、或者动态链接库 -
[k]表示内核空间
-
-
Symbol:表示符号名,即函数名,当函数未命名时用16进制地址表示
-
-
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
[root@jikeshijian ~]# perf top Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399 Overhead Shared Object Symbol 7.28% perf [.] 0x00000000001f78a4 4.72% [kernel] [k] vsnprintf 4.32% [kernel] [k] module_get_kallsym 3.65% [kernel] [k] _raw_spin_unlock_irqrestore ...
-
perf record: 提供了保存数据的功能,保存后的数据 -
perf report: 解析perf record保存的采样信息
[root@jikeshijian ~]# perf record # 按 Ctrl+C 终止采样 [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.452 MB perf.data (6093 samples) ] [root@jikeshijian ~]# perf report # 展示类似于 perf top 的报告
-
一般使用的时候会加上
-g参数以开启调用关系的采样
[root@jikeshijian ~]# perf top -g Samples: 36K of event 'cycles:ppp', Event count (approx.): 7290912532 Children Self Shared Object Symbol - 15.23% 1.57% [unknown] [k] 0000000000000000 - 7.58% 0 + 12.19% 0.14% [kernel] [k] entry_SYSCALL_64_after_hwframe - 12.01% 0.28% [kernel] [k] do_syscall_64 - 3.03% do_syscall_64 - 8.65% 0.16% [kernel] [k] do_idle - 1.75% do_idle + 4.22% 0.02% [kernel] [k] call_cpuidle + 4.09% 0.22% [kernel] [k] cpuidle_enter_state + 4.01% 0.02% [kernel]
-
还可以指定进程号
# -g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515 [root@jikeshijian ~]# perf top -g -p 21515
注意:当分析 docker 的进程时候,可以在宿主机执行 perf record ,然后Ctrl+C 将文件用docker cp 拷贝到容器中,容器中安装perf 命令,然后执行 perf report 命令,就可以看到外面看不出来的函数。
CPU 使用率总结
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
-
用户 CPU 和 Nice CPU 高(
us和ni高),说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。 -
系统 CPU 高(
sy高),说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。 -
I/O 等待 CPU 高(
wa高),说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。 -
软中断和硬中断高(
hi和si高),说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
-
pstree:用树状形式显示所有进程之间的关系,查找一个进程的父进程
[root@jikeshijian ~]# pstree | grep stress |-docker-containe-+-php-fpm-+-php-fpm---sh---stress | |-3*[php-fpm---sh---stress---stress]
-
execsnoop: execsnoop 一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。比如,用 execsnoop 监控上述案例,就可以直接得到 stress 进程的父进程 PID 以及它的命令行参数,并可以发现大量的 stress 进程在不停启动:
# 按 Ctrl+C 结束 [root@jikeshijian ~]# execsnoop PCOMM PID PPID RET ARGS sh 30394 30393 0 stress 30396 30394 0 /usr/local/bin/stress -t 1 -d 1 sh 30398 30393 0 stress 30399 30398 0 /usr/local/bin/stress -t 1 -d 1 sh 30402 30400 0 stress 30403 30402 0 /usr/local/bin/stress -t 1 -d 1 sh 30405 30393 0 stress 30407 30405 0 /usr/local/bin/stress -t 1 -d 1 ...
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
-
第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
-
第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。
对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。
系统中出现大量不可中断进程和僵尸进程怎么办?
僵尸进程:僵尸进程是当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程。如果父进程先退出 ,子进程被init接管,子进程退出后init会回收其占用的相关资源
这是多进程应用很容易碰到的问题。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid() 等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送 SIGCHLD 信号,所以,父进程还可以注册 SIGCHLD 信号的处理函数,异步回收资源。
如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,那这时的子进程就会变成僵尸进程。换句话说,父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致“问题少年”的出现。
通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由 init 进程回收后也会消亡。
一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建,所以这种情况一定要避免。
查看进程状态
-
top命令-
R:Running或Runnable的缩写,表示进程在CPU的就绪队列中,正在运行或者正在等待运行 -
D:Disk Sleep的缩写,即不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且过程不允许被其他进程或中断打断。会导致平均负载升高 -
Z:Zombie的缩写,表示僵尸进程,即进程实际上已经结束了,但父进程还没有回收它的资源(如:进程的描述符、PID等) -
S:Interruptible Sleep的缩写,即可中断状态睡眠,表示进程由于等待某个进程而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。 -
I:Idle的缩写,表示空闲状态,用在不可中断睡眠的内核进程上,不会导致平均负载升高 -
T或t:即Stopped或Traced,表示进程处于暂停或者跟踪状态 -
X:Dead的缩写,表示进程已经死亡,所以不会在top或者ps命令中看到它
-
$ top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28961 root 20 0 43816 3148 4040 R 3.2 0.0 0:00.01 top 620 root 20 0 37280 33676 908 D 0.3 0.4 0:00.01 app 1 root 20 0 160072 9416 6752 S 0.0 0.1 0:37.64 systemd 1896 root 20 0 0 0 0 Z 0.0 0.0 0:00.00 devapp 2 root 20 0 0 0 0 S 0.0 0.0 0:00.10 kthreadd 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H 6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq 7 root 20 0 0 0 0 S 0.0 0.0 0:06.37 ksoftirqd/0
小结:
-
不可中断状态和僵尸状态
-
不可中断状态:表示进程正在和硬件交互,为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。
-
僵尸进程: 表示进程已经退出,但它的父进程还没有回收子进程占用的资源。短暂的僵尸状态我们通过不必理会,但进程长时间处于僵尸状态,就应该注意了,可能有应用程序没有正常处理子进程的退出。
-
iowait分析
-
dstat命令
# 间隔 1 秒输出 10 组数据 [root@jikeshijian ~]# dstat 1 10 You did not select any stats, using -cdngy by default. --total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system-- usr sys idl wai stl| read writ| recv send| in out | int csw 0 0 96 4 0|1219k 408k| 0 0 | 0 0 | 42 885 0 0 2 98 0| 34M 0 | 198B 790B| 0 0 | 42 138 0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 42 135 0 0 84 16 0|5633k 0 | 66B 342B| 0 0 | 52 177 0 3 39 58 0| 22M 0 | 66B 342B| 0 0 | 43 144 0 0 0 100 0| 34M 0 | 200B 450B| 0 0 | 46 147 0 0 2 98 0| 34M 0 | 66B 342B| 0 0 | 45 134 0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 39 131 0 0 83 17 0|5633k 0 | 66B 342B| 0 0 | 46 168 0 3 39 59 0| 22M 0 | 66B 342B| 0 0 | 37 134
当 iowait 升高(wai)时,磁盘的读请求(read)都会很大。这说明 iowait 的升高跟磁盘的读请求有关,很可能就是磁盘读导致的。
-
pidstat命令-
kB_rd : 每秒读的 KB 数
-
kB_wr : 每秒写的 KB 数
-
iodelay : 表示 I/O 的延迟(单位是时钟周期)
-
# 观察进程对磁盘的读写 # -d 展示 I/O 统计数据,-p 指定进程号 # 间隔 1 秒输出多组数据 (这里是 20 组) [root@jikeshijian ~]# pidstat -d 1 20 ... 06:48:46 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:47 0 4615 0.00 0.00 0.00 1 kworker/u4:1 06:48:47 0 6080 32768.00 0.00 0.00 170 app 06:48:47 0 6081 32768.00 0.00 0.00 184 app 06:48:47 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:48 0 6080 0.00 0.00 0.00 110 app 06:48:48 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:49 0 6081 0.00 0.00 0.00 191 app 06:48:49 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:51 0 6082 32768.00 0.00 0.00 0 app 06:48:51 0 6083 32768.00 0.00 0.00 0 app 06:48:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:52 0 6082 32768.00 0.00 0.00 184 app 06:48:52 0 6083 32768.00 0.00 0.00 175 app 06:48:52 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:53 0 6083 0.00 0.00 0.00 105 app ... # -d 展示 I/O 统计数据,-p 指定进程号,间隔 1 秒输出 3 组数据 [root@jikeshijian ~]# pidstat -d -p 4344 1 3 06:38:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:38:51 0 4344 0.00 0.00 0.00 0 app 06:38:52 0 4344 0.00 0.00 0.00 0 app 06:38:53 0 4344 0.00 0.00 0.00 0 app
进程如果想要访问磁盘的话,就必须使用系统调用,所以还需要找出 app 进程的系统调用。
-
strace命令:最常用的跟踪进程系统调用的工具。
# -p 参数指定 PID 号 [root@jikeshijian ~]# strace -p 6082 strace: attach: ptrace(PTRACE_SEIZE, 6082): Operation not permitted
如果遇到 Operation not permitted ,可以先查看一下进程的状态是否正常
$ ps aux | grep 6082 root 6082 0.0 0.0 0 0 pts/0 Z+ 13:43 0:00 [app] <defunct>
果然变成了 Z 状态,也就是僵尸进程,是已经退出的进程,所以就没法继续分析它的系统调用了。那么可以接着用perf top 工具来查看分析
如何处理僵尸进程
-
找出父进程,然后在父进程里解决
-
pstree命令
-
# -a 表示输出命令行选项 # p 表 PID # s 表示指定进程的父进程 [root@jikeshijian ~]# pstree -aps 3084 systemd,1 └─dockerd,15006 -H fd:// └─docker-containe,15024 --config /var/run/docker/containerd/containerd.toml └─docker-containe,3991 -namespace moby -workdir... └─app,4009 └─(app,3084)
找出父进程之后,去查看父进程的代码。
如何理解Linux软中断
-
中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。
-
为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行。
为了解决中断处理程序执行过长和中断丢失的问题,Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
-
上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
-
上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行;
-
会打断CPU正在执行的任务,然后立即执行中断处理程序
-
-
下半部用来延迟(异步)处理上半部未完成的工作,通常以内核线程的方式运行。
-
而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行。
-
以内核线程的方式执行,并且每个CPU都对应一个软中断内核线程,名字为
ksoftirqd/CPU编号
-
查看软中断和内核线程
-
/proc/softirqs提供了软中断的运行情况; -
/proc/interrupts提供了硬中断的运行情况。
运行下面的命令,查看 /proc/softirqs 文件的内容,你就可以看到各种类型软中断在不同 CPU 上的累积运行次数:
[root@jikeshijian ~]# cat /proc/softirqs CPU0 CPU1 HI: 0 0 TIMER: 811613 1972736 NET_TX: 49 7 NET_RX: 1136736 1506885 BLOCK: 0 0 IRQ_POLL: 0 0 TASKLET: 304787 3691 SCHED: 689718 1897539 HRTIMER: 0 0 RCU: 1330771 1354737
需要注意以下两点:
-
要注意软中断的类型,即第一列内容,可以看到软中断包含 10 个类别,NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断
-
要注意同一种软中断在不同 CPU 上的分布情况,即同一行的内容,正常情况下,同一种中断在不同 CPU 上的累积次数应该差不多。
不过你可能发现,TASKLET 在不同 CPU 上的分布并不均匀,TASKLET 是最常用的软中断实现机制,每个TASKLET只运行一次就会结束,并且只在调用它的函数所在的CPU上运行,因此会导致调度不均衡,不能在多个CPU上并行而带来性能限制
软中断实际上是以内核线程的方式运行的,每个 CPU 都对应一个软中断内核线程,这个软中断内核线程就叫做 ksoftirqd/CPU 编号。那要怎么查看这些线程的运行状况呢?
其实用 ps 命令就可以做到,比如执行下面的指令:
[root@jikeshijian ~]# ps aux | grep softirq root 7 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/0] root 16 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/1]
注意,这些线程的名字外面都有中括号,这说明 ps 无法获取它们的命令行参数(cmline)。一般来说,ps 的输出中,名字括在中括号里的,一般都是内核线程。
如何处理系统的软中断 CPU 使用率升高
主要使用三个软件 sar、 hping3 和 tcpdump
-
sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
-
hping3 是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。
-
tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题。
打开一个终端,运行一个NGINX出来
# 运行 Nginx 服务并对外开放 80 端口 $ docker run -itd --name=nginx -p 80:80 nginx
接着,还是在第二个终端,我们运行 hping3 命令,来模拟 Nginx 的客户端请求:
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80 # -i u100 表示每隔 100 微秒发送一个网络帧 # 注:如果你在实践过程中现象不明显,可以尝试把 100 调小,比如调成 10 甚至 1 $ hping3 -S -p 80 -i u100 192.168.0.30
现在我们再回到第一个终端,你应该发现了异常。是不是感觉系统响应明显变慢了,即便只是在终端中敲几个回车,都得很久才能得到响应?这个时候应该怎么办呢?
虽然在运行 hping3 命令时,我就已经告诉你,这是一个 SYN FLOOD 攻击,你肯定也会想到从网络方面入手,来分析这个问题。不过,在实际的生产环境中,没人直接告诉你原因。
所以,我希望你把 hping3 模拟 SYN FLOOD 这个操作暂时忘掉,然后重新从观察到的问题开始,分析系统的资源使用情况,逐步找出问题的根源。
那么,该从什么地方入手呢?刚才我们发现,简单的 SHELL 命令都明显变慢了,先看看系统的整体资源使用情况应该是个不错的注意,比如执行下 top 看看是不是出现了 CPU 的瓶颈。我们在第一个终端运行 top 命令,看一下系统整体的资源使用情况。
仔细看 top 的输出,两个 CPU 的使用率虽然分别只有 3.3% 和 4.4%,但都用在了软中断上;而从进程列表上也可以看到,CPU 使用率最高的也是软中断进程 ksoftirqd。看起来,软中断有点可疑了。
# top 运行后按数字 1 切换到显示所有 CPU $ top top - 10:50:58 up 1 days, 22:10, 1 user, load average: 0.00, 0.00, 0.00 Tasks: 122 total, 1 running, 71 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.0 us, 0.0 sy, 0.0 ni, 96.7 id, 0.0 wa, 0.0 hi, 3.3 si, 0.0 st %Cpu1 : 0.0 us, 0.0 sy, 0.0 ni, 95.6 id, 0.0 wa, 0.0 hi, 4.4 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 7 root 20 0 0 0 0 S 0.3 0.0 0:01.64 ksoftirqd/0 16 root 20 0 0 0 0 S 0.3 0.0 0:01.97 ksoftirqd/1 2663 root 20 0 923480 28292 13996 S 0.3 0.3 4:58.66 docker-containe 3699 root 20 0 0 0 0 I 0.3 0.0 0:00.13 kworker/u4:0 3708 root 20 0 44572 4176 3512 R 0.3 0.1 0:00.07 top 1 root 20 0 225384 9136 6724 S 0.0 0.1 0:23.25 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.03 kthreadd ...
/proc/softirqs 是系统运行以来的累积中断次数,中断次数的变化速率才是我们需要关注的
可以动态的查看软中断的变化,看是哪个类型导致的
$ watch -d cat /proc/softirqs CPU0 CPU1 HI: 0 0 TIMER: 1083906 2368646 NET_TX: 53 9 NET_RX: 1550643 1916776 BLOCK: 0 0 IRQ_POLL: 0 0 TASKLET: 333637 3930 SCHED: 963675 2293171 HRTIMER: 0 0 RCU: 1542111 1590625
可以看到 NET_RX 的变化速率变化较快,可以使用 sar 来查看系统的网络收发情况,不仅可以观察网络收发的吞吐量(BPS, 每秒收发的字节数),还可以观察网络收发的 PPS, 即每秒收发的网络帧数。
-
sar命令:
# -n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据 $ sar -n DEV 1 15:03:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 15:03:47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01 15:03:47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00 15:03:47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 15:03:47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05
-
第一列:表示报告的时间。
-
第二列:IFACE 表示网卡。
-
第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
-
第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
-
后面的其他参数基本接近 0,显然跟今天的问题没有直接关系,你可以先忽略掉。
我们具体来看输出的内容,你可以发现:
-
对网卡 eth0 来说,每秒接收的网络帧数比较大,达到了 12607,而发送的网络帧数则比较小,只有 6304;每秒接收的千字节数只有 664 KB,而发送的千字节数更小,只有 358 KB。
-
docker0 和 veth9f6bbcd 的数据跟 eth0 基本一致,只是发送和接收相反,发送的数据较大而接收的数据较小。这是 Linux 内部网桥转发导致的,你暂且不用深究,只要知道这是系统把 eth0 收到的包转发给 Nginx 服务即可。具体工作原理,我会在后面的网络部分详细介绍。
从这些数据,你有没有发现什么异常的地方?
既然怀疑是网络接收中断的问题,我们还是重点来看 eth0 :接收的 PPS 比较大,达到 12607,而接收的 BPS 却很小,只有 664 KB。直观来看网络帧应该都是比较小的,我们稍微计算一下,664*1024/12607 = 54 字节,说明平均每个网络帧只有 54 字节,这显然是很小的网络帧,也就是我们通常所说的小包问题。
那么,有没有办法知道这是一个什么样的网络帧,以及从哪里发过来的呢?
使用 tcpdump 抓取 eth0 上的包就可以了。我们事先已经知道, Nginx 监听在 80 端口,它所提供的 HTTP 服务是基于 TCP 协议的,所以我们可以指定 TCP 协议和 80 端口精确抓包。
接下来,我们在第一个终端中运行 tcpdump 命令,通过 -i eth0 选项指定网卡 eth0,并通过 tcp port 80 选项指定 TCP 协议的 80 端口:
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名 # tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧 $ tcpdump -i eth0 -n tcp port 80 15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0 ...
从 tcpdump 的输出中,你可以发现
-
192.168.0.2.18238 > 192.168.0.30.80 ,表示网络帧从 192.168.0.2 的 18238 端口发送到 192.168.0.30 的 80 端口,也就是从运行 hping3 机器的 18238 端口发送网络帧,目的为 Nginx 所在机器的 80 端口。
-
Flags [S] 则表示这是一个 SYN 包。
再加上前面用 sar 发现的, PPS 超过 12000 的现象,现在我们可以确认,这就是从 192.168.0.2 这个地址发送过来的 SYN FLOOD 攻击。
到这里,我们已经做了全套的性能诊断和分析。从系统的软中断使用率高这个现象出发,通过观察 /proc/softirqs 文件的变化情况,判断出软中断类型是网络接收中断;再通过 sar 和 tcpdump ,确认这是一个 SYN FLOOD 问题。
SYN FLOOD 问题最简单的解决方法,就是从交换机或者硬件防火墙中封掉来源 IP,这样 SYN FLOOD 网络帧就不会发送到服务器中。
如何迅速分析出系统CPU的瓶颈在哪里?
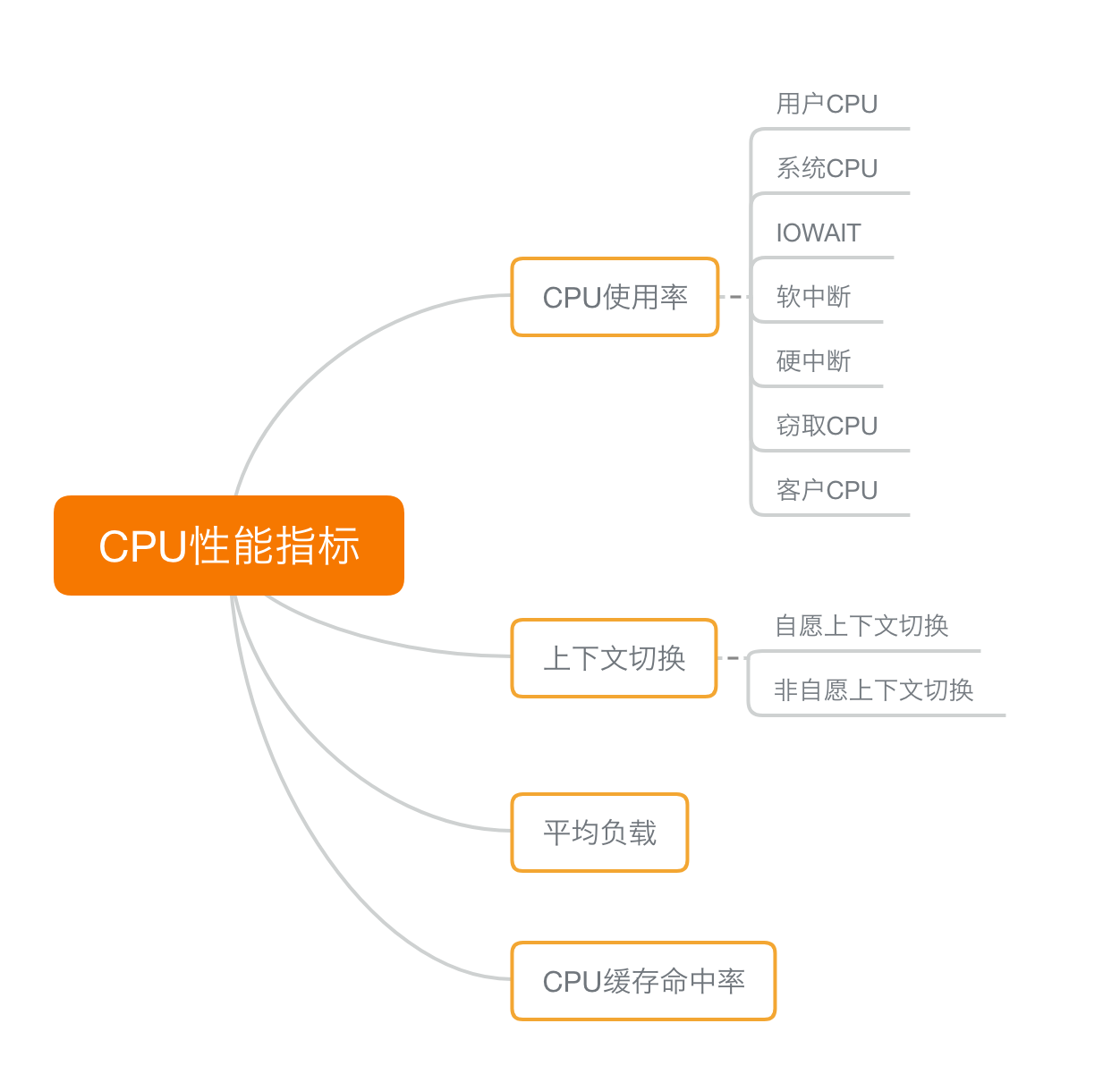
CPU 性能指标
首先,最容易想到的应该是 CPU 使用率,这也是实际环境中最常见的一个性能指标。
CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
-
用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
-
系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
-
等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
-
软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
-
除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
第二个比较容易想到的,应该是平均负载(Load Average),也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
第三个,进程上下文切换,包括:
-
无法获取资源而导致的自愿上下文切换;
-
被系统强制调度导致的非自愿上下文切换。
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
除了上面几种,还有一个指标,CPU 缓存的命中率。由于 CPU 发展的速度远快于内存的发展,CPU 的处理速度就比内存的访问速度快得多。这样,CPU 在访问内存的时候,免不了要等待内存的响应。为了协调这两者巨大的性能差距,CPU 缓存(通常是多级缓存)就出现了。
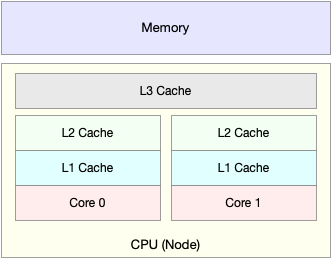
就像上面这张图显示的,CPU 缓存的速度介于 CPU 和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常用在单核中, L3 则用在多核中。
从 L1 到 L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是 CPU 缓存的复用情况,命中率越高,则表示性能越好。
这些指标都很有用,需要我们熟练掌握, 复习查看时,也可以当成 CPU 性能分析的“指标筛选”清单
-
性能工具
-
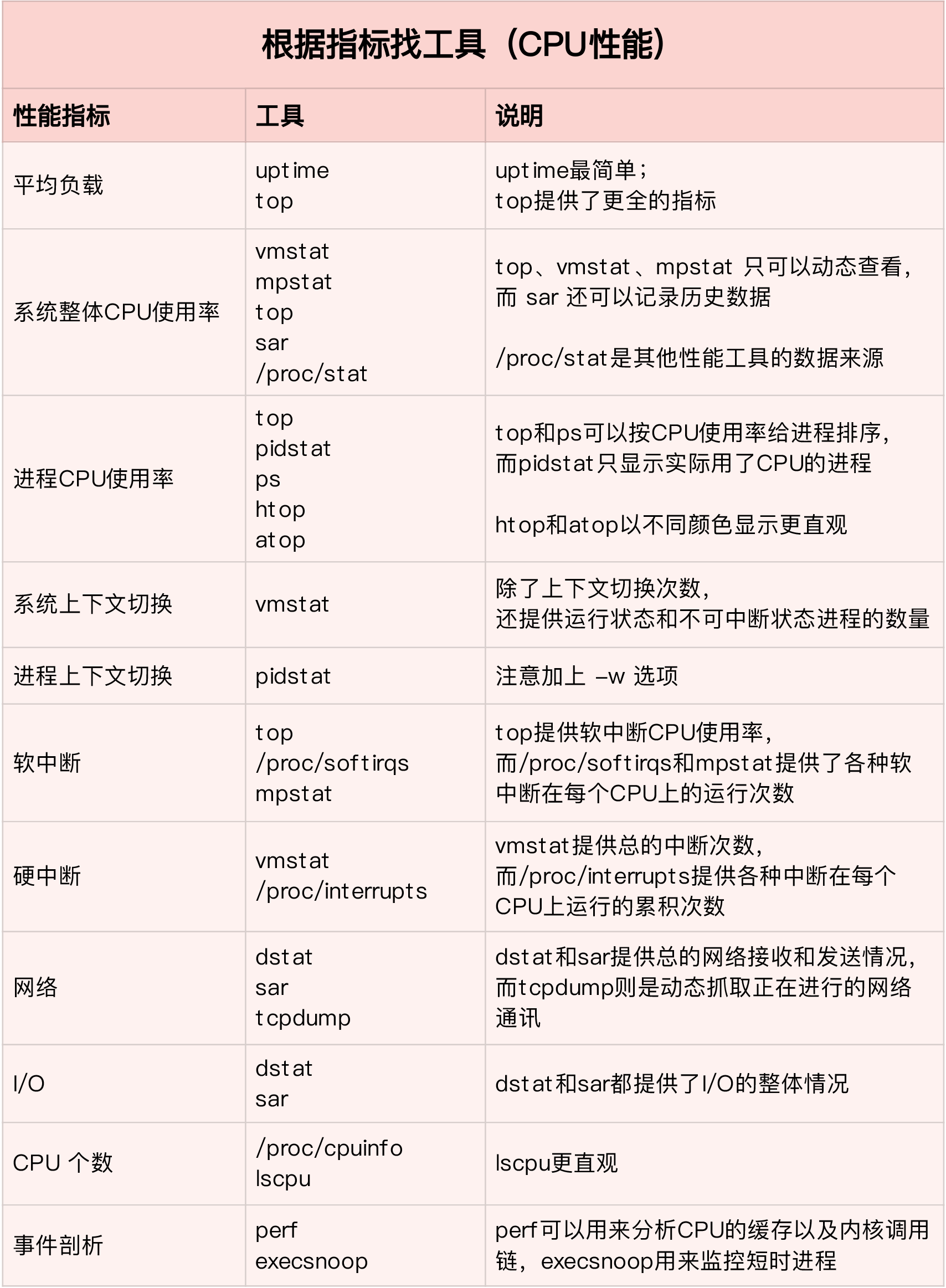
根据指标找工具
-
根据工具查指标
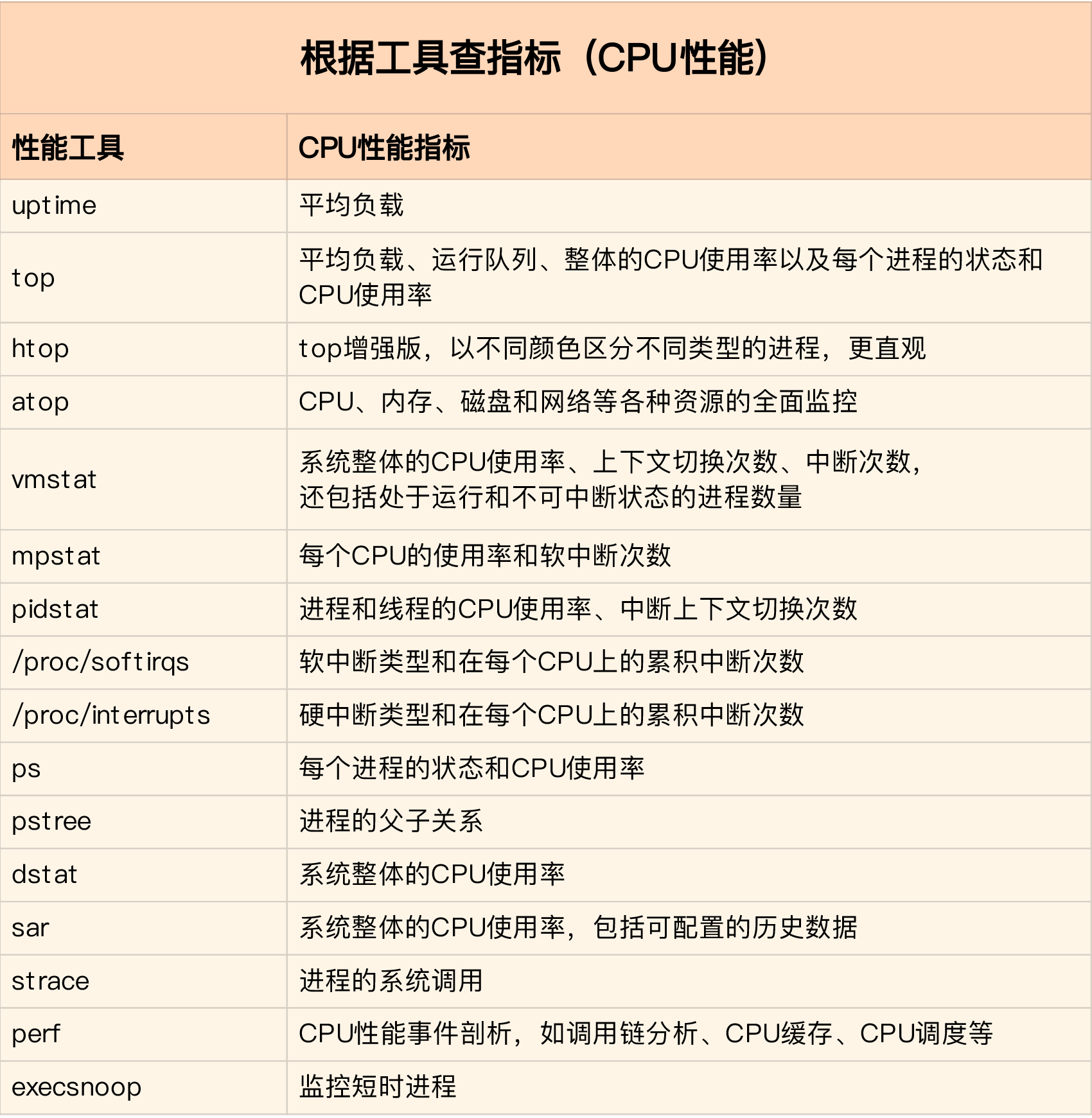
-
-
如何迅速分析 CPU 的性能瓶颈
虽然 CPU 的性能指标比较多,但要知道,既然都是描述系统的 CPU 性能,它们就不会是完全孤立的,很多指标间都有一定的关联。想弄清楚性能指标的关联性,就要通晓每种性能指标的工作原理。这也是为什么我在介绍每个性能指标时,都要穿插讲解相关的系统原理,希望你能记住这一点。
举个例子,用户 CPU 使用率高,我们应该去排查进程的用户态而不是内核态。因为用户 CPU 使用率反映的就是用户态的 CPU 使用情况,而内核态的 CPU 使用情况只会反映到系统 CPU 使用率上。
你看,有这样的基本认识,我们就可以缩小排查的范围,省时省力。
所以,为了缩小排查范围,我通常会先运行几个支持指标较多的工具,如 top、vmstat 和 pidstat 。为什么是这三个工具呢?仔细看看下面这张图,你就清楚了。

这张图里,我列出了 top、vmstat 和 pidstat 分别提供的重要的 CPU 指标,并用虚线表示关联关系,对应出了性能分析下一步的方向。
通过这张图你可以发现,这三个命令,几乎包含了所有重要的 CPU 性能指标,比如:
-
从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
-
从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
-
从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下文切换和非自愿上下文切换情况。
另外,这三个工具输出的很多指标是相互关联的,所以,我也用虚线表示了它们的关联关系,举几个例子你可能会更容易理解。
第一个例子,pidstat 输出的进程用户 CPU 使用率升高,会导致 top 输出的用户 CPU 使用率升高。所以,当发现 top 输出的用户 CPU 使用率有问题时,可以跟 pidstat 的输出做对比,观察是否是某个进程导致的问题。
而找出导致性能问题的进程后,就要用进程分析工具来分析进程的行为,比如使用 strace 分析系统调用情况,以及使用 perf 分析调用链中各级函数的执行情况。
第二个例子,top 输出的平均负载升高,可以跟 vmstat 输出的运行状态和不可中断状态的进程数做对比,观察是哪种进程导致的负载升高。
-
如果是不可中断进程数增多了,那么就需要做 I/O 的分析,也就是用 dstat 或 sar 等工具,进一步分析 I/O 的情况。
-
如果是运行状态进程数增多了,那就需要回到 top 和 pidstat,找出这些处于运行状态的到底是什么进程,然后再用进程分析工具,做进一步分析。
最后一个例子,当发现 top 输出的软中断 CPU 使用率升高时,可以查看 /proc/softirqs 文件中各种类型软中断的变化情况,确定到底是哪种软中断出的问题。比如,发现是网络接收中断导致的问题,那就可以继续用网络分析工具 sar 和 tcpdump 来分析。
CPU性能优化的几个思路
性能优化的效果判断:
三步走理论:
(1)确定性能的量化指标-一般从应用程序纬度和系统资源纬度分析 (2)测试优化前的性能指标 (3)测试性能优化后的性能指标
多个性能问题同时存在,要怎么选择?
找出最重要的、可以最大程度提升性能的问题,比如:
-
第一,如果发现是系统资源达到了瓶颈,比如 CPU 使用率达到了 100%,那么首先优化的一定是系统资源使用问题。完成系统资源瓶颈的优化后,我们才要考虑其他问题。
-
第二,针对不同类型的指标,首先去优化那些由瓶颈导致的,性能指标变化幅度最大的问题。比如产生瓶颈后,用户 CPU 使用率升高了 10%,而系统 CPU 使用率却升高了 50%,这个时候就应该首先优化系统 CPU 的使用。
有多种优化方法时,要如何选择?
综合多方面的因素。
CPU 优化
从应用程序和系统的角度,分别来看看如何才能降低 CPU 使用率,提高 CPU 的并行处理能力。
应用程序优化
首先,从应用程序的角度来说,降低 CPU 使用率的最好方法当然是,排除所有不必要的工作,只保留最核心的逻辑。比如减少循环的层次、减少递归、减少动态内存分配等等。
除此之外,应用程序的性能优化也包括很多种方法,这里列出了最常见的几种,可以记下来。
-
编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得编译器的帮助,来提升性能。比如, gcc 就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
-
算法优化:使用复杂度更低的算法,可以显著加快处理速度。比如,在数据比较大的情况下,可以用 O(nlogn) 的排序算法(如快排、归并排序等),代替 O(n^2) 的排序算法(如冒泡、插入排序等)。
-
异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费 CPU 的问题。
-
多线程代替多进程:前面讲过,相对于进程的上下文切换,线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。
-
善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
系统优化
从系统的角度来说,优化 CPU 的运行,一方面要充分利用 CPU 缓存的本地性,加速缓存访问;另一方面,就是要控制进程的 CPU 使用情况,减少进程间的相互影响。
具体来说,系统层面的 CPU 优化方法也有不少,这里同样列举了最常见的一些方法,方便记忆和使用。
-
CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题。
-
CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU。
-
优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。优先级的数值含义前面我们提到过,忘了的话及时复习一下。在这里,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
-
为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
-
NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会被划分为多个 node,每个 node 都有自己的本地内存空间。NUMA 优化,其实就是让 CPU 尽可能只访问本地内存。
-
中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
千万避免过早优化
性能优化最好是逐步完善,动态进行,不追求一步到位,而要首先保证能满足当前的性能要求。当发现性能不满足要求或者出现性能瓶颈时,再根据性能评估的结果,选择最重要的性能问题进行优化。

