

基础_2022_正则
正则表达式元字符和普通字符:
一、普通字符
大多数的字符仅能够描述它们本身,这些字符称作普通字符,例如所有的字母和数字。
也就是说普通字符只能够匹配字符串中与它们相同的字符。
二、元字符
非打印字符
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |

限定符
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? |
匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 、 "does"、 "doxy" 中的 "do" 。? 等价于 {0,1}。 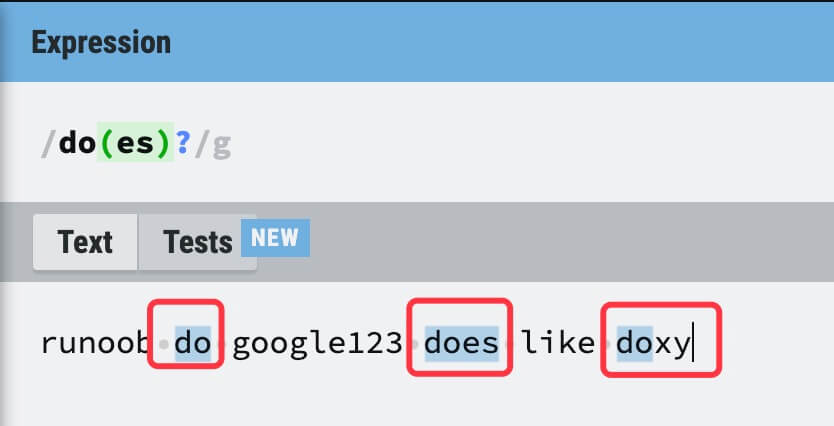 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 "Bob" 中的 o,但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
定位符
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
选择
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
() 表示捕获分组,() 会把每个分组里的匹配的值保存起来, 多个匹配值可以通过数字 n 来查看(n 是一个数字,表示第 n 个捕获组的内容)。
exp1(?=exp2):查找 exp2 前面的 exp1。
exp1(?!exp2):查找后面不是 exp2 的 exp1。
反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
可以使用非捕获元字符 ?:、?= 或 ?! 来重写捕获,忽略对相关匹配的保存。
Is is the cost of of gasoline going up up?
上面的句子很显然有多个重复的单词。如果能设计一种方法定位该句子,而不必查找每个单词的重复出现,那该有多好。下面的正则表达式使用单个子表达式来实现这一点:
实例
查找重复的单词:
三、例子
1、^[0-9]+abc$
-
^ 为匹配输入字符串的开始位置。
-
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
-
abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置
2、^[a-z0-9_-]{3, 15}$
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符 -,并设置用户名的长度,我们就可以使用以下正则表达式来设定。

3、匹配邮箱



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· DeepSeek 开源周回顾「GitHub 热点速览」
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了