
PyTorch进阶训练技巧-模型微调-torchvision
随着深度学习的发展,模型的参数越来越大,许多开源模型都是在较大数据集上进行训练的,比如Imagenet-1k,Imagenet-11k,甚至是ImageNet-21k等。但在实际应用中,我们的数据集可能只有几千张,这时从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。
假设我们想从图像中识别出不同种类的椅⼦,然后将购买链接推荐给用户。一种可能的方法是先找出100种常见的椅子,为每种椅子拍摄1000张不同⻆度的图像,然后在收集到的图像数据集上训练一个分类模型。这个椅子数据集虽然可能比Fashion-MNIST数据集要庞⼤,但样本数仍然不及ImageNet数据集中样本数的十分之⼀。这可能会导致适用于ImageNet数据集的复杂模型在这个椅⼦数据集上过拟合。同时,因为数据量有限,最终训练得到的模型的精度也可能达不到实用的要求。
为了应对上述问题,一个显⽽易⻅的解决办法是收集更多的数据。然而,收集和标注数据会花费大量的时间和资⾦。例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究经费。虽然目前的数据采集成本已降低了不少,但其成本仍然不可忽略。
另外一种解决办法是应用迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上。例如,虽然ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别椅子也可能同样有效。
迁移学习的一大应用场景是模型微调(finetune)。简单来说,就是我们先找到一个同类的别人训练好的模型,把别人现成的训练好了的模型拿过来,换成自己的数据,通过训练调整一下参数。 在PyTorch中提供了许多预训练好的网络模型(VGG,ResNet系列,mobilenet系列......),这些模型都是PyTorch官方在相应的大型数据集训练好的。学习如何进行模型微调,可以方便我们快速使用预训练模型完成自己的任务。
模型微调的流程
-
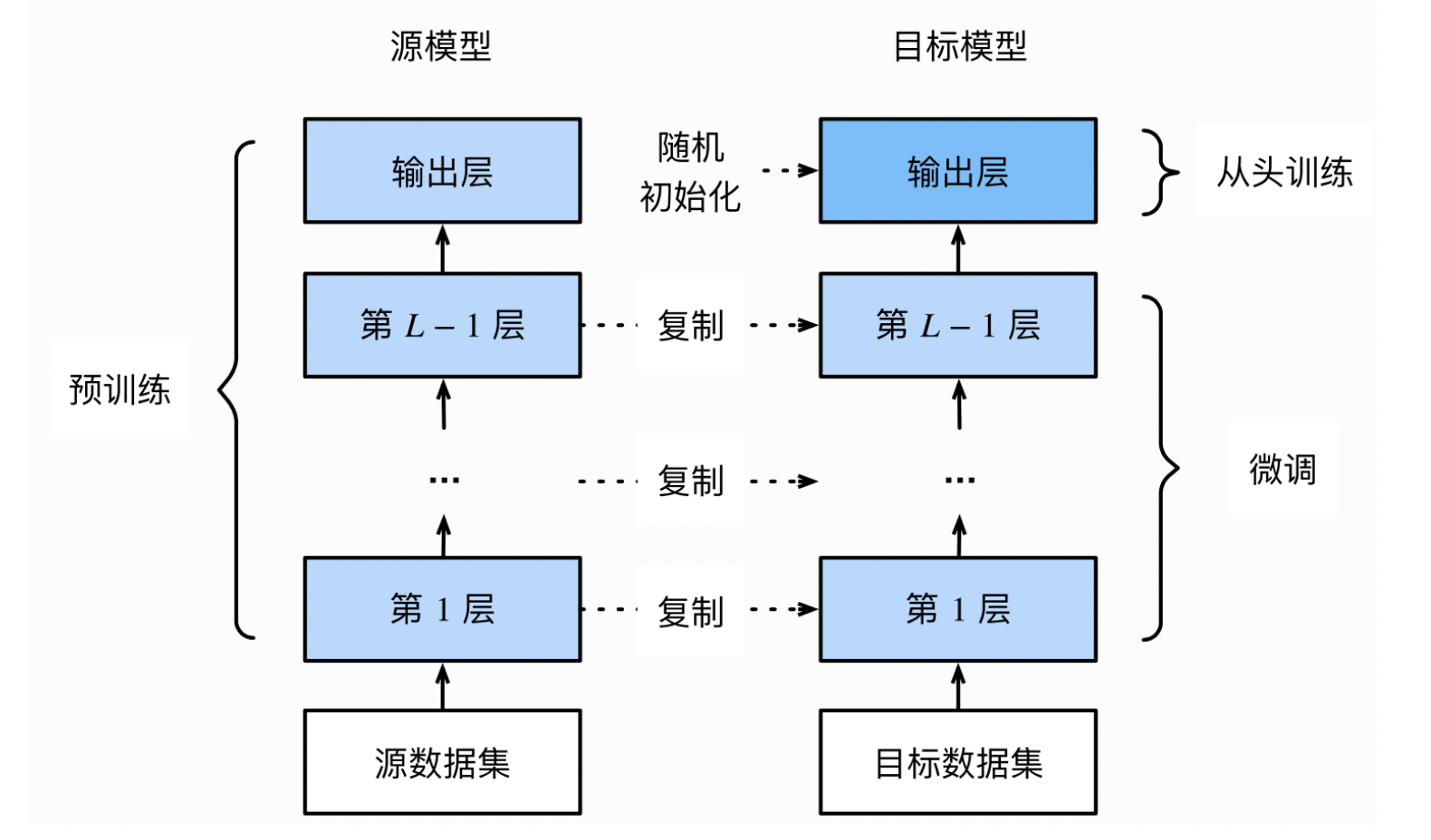
在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
-
创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
-
为目标模型添加一个输出⼤小为⽬标数据集类别个数的输出层,并随机初始化该层的模型参数。
-
在目标数据集上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
 摘录自:https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E5%85%AD%E7%AB%A0/6.3%20%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83-torchvision.html
摘录自:https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E5%85%AD%E7%AB%A0/6.3%20%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83-torchvision.html

