



Spark基本介绍
Hadoop 的缺点
-
批处理模型: Hadoop主要面向批处理,对于实时数据处理的支持相对较弱,无法满足一些对实时性要求较高的应用场景。
-
性能: 在某些情况下,Hadoop的MapReduce模型可能导致较高的磁盘IO开销,影响处理性能。而且,对于迭代算法等工作负载,其性能相对较低。
-
资源占用: Hadoop的MapReduce模型在处理任务时需要频繁读写磁盘,而且对内存的要求不高,这在某些场景下可能导致性能瓶颈。
-
局限性: Hadoop最初设计为处理大规模数据集,对于小规模数据的处理可能显得过于臃肿,不够灵活。
Hadoop每次只能执行一次任务,无法并行调度,每次执行完毕结果还必须要写入磁盘中才能进行下一个任务调度,而下一个任务又要从磁盘读取,而spark是基于内存的,无需经过磁盘迭代过程中。
| MapReduce | Spark |
| 数据存储结构:磁盘HDFS文件系统的split |
数据存储结构:磁盘HDFS文件系统的split对数据进行运算和cache |
| 数据存储结构:磁盘HDFS文件系统的split | DAG: Transformation + Action |
| 计算中间结果落到磁盘,IO及序列化、反序列化代价大 | 计算中间结果在内存中维护 |
| Task以进程的方式维护,需要数秒时间才能启动任务 | Task以进程的方式维护,需要数秒时间才能启动任务 |
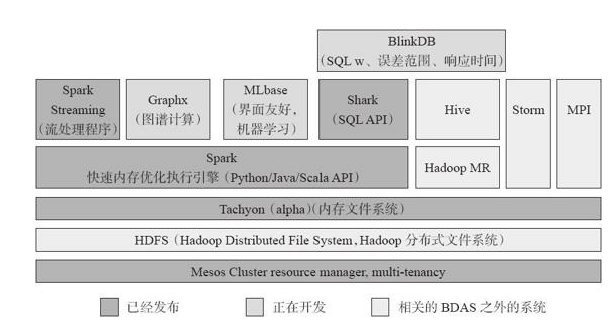
基本概念
-
RDD:RDD 是 Spark 中最基本的数据抽象,代表一个不可变、可分区、元素可并行计算的集合。它是 Spark 提供的分布式数据处理的核心概念,允许用户在执行多个并行操作时显式地将数据缓存在内存中,以加快迭代计算速度。
-
DAG:DAG(Directed Acyclic Graph,有向无环图)是 Spark 中用于表示作业的执行计划的数据结构。Spark 作业的执行过程可以通过构建和执行 DAG 来实现。
-
Executor:Executor是Spark应用程序在集群中运行的工作节点。每个Executor运行在集群中的独立进程中,并负责在给定节点上执行Spark任务。
-
Application:Application通常指的是Spark应用程序,是由开发者编写的用于分布式数据处理的程序。
-
Task:Task(任务)是作业执行的最小单元。任务是由Driver程序创建并分配给Executor节点执行的。Spark应用程序的执行过程被划分为一系列的任务,这些任务并行执行,以完成整个作业。
-
Job:Job(作业)是一组相互依赖的任务(Tasks)的集合,这些任务形成了执行计算的单元。一个Spark应用程序通常被划分为多个作业,每个作业对应着一次由动作(Action)触发的计算过程。作业是Spark中的顶层逻辑单位,用于描述用户想要执行的一系列数据处理操作。
-
Stage:Stage(阶段)是作业(Job)划分的基本执行单元。一个作业可以由一个或多个阶段组成,每个阶段通常对应DAG(有向无环图)中的一个划分,这个划分没有宽依赖关系(即,一个父RDD的分区影响到多个子RDD分区的依赖关系)。
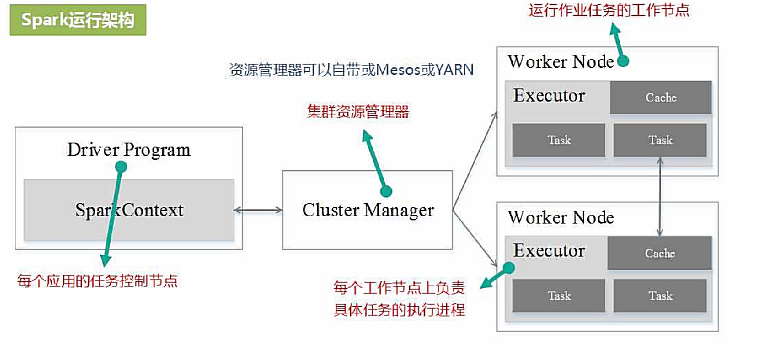
运行架构
-
Driver Program(驱动程序): 驱动程序是Spark应用的主要控制节点,负责整个应用的执行流程。它包含应用的main函数,并通过SparkContext连接到集群管理器。驱动程序负责将应用代码划分成任务,并将这些任务发送到集群中的Executor节点进行执行。
-
SparkContext: SparkContext是Spark应用的入口点,用于与集群通信并控制应用的执行。它负责为应用程序分配资源、调度任务执行、进行容错处理等。在驱动程序中创建SparkContext后,它会与Cluster Manager(集群管理器)通信,获取集群资源并启动Executor节点。
-
Cluster Manager(集群管理器): 集群管理器负责协调集群中的资源分配和任务调度。Spark支持多种集群管理器,包括Standalone、Apache Mesos和Apache Hadoop YARN。集群管理器负责启动Executor进程、监控它们的执行情况,并在需要时重新分配资源。
-
Executor节点: Executor节点是集群中的工作节点,负责执行驱动程序分配的任务。每个Executor节点在启动时都会注册到集群管理器,并根据集群的可用资源启动多个Executor。每个Executor都有自己的内存和处理核心,它们在计算任务期间存储和处理数据。
-
Task(任务): 任务是Spark应用中的最小执行单元,通常对应RDD的一个分区的处理过程。任务由驱动程序划分并发送到Executor节点执行。在Executor节点上,每个任务运行在独立的JVM进程中,执行相应的计算操作。
-
RDD(Resilient Distributed Dataset): RDD是Spark中的基本数据抽象,代表一个可并行处理的不可变数据集。RDD可以分区存储在集群中的多个节点上,支持并行计算和容错。Spark应用通过RDD完成数据的转换和操作,而每个RDD的计算过程由一系列的任务(Task)完成。
-
DAG Scheduler(有向无环图调度器): DAG Scheduler负责将Spark应用中的高级操作(如转换操作)转换成一个有向无环图(DAG)。DAG描述了任务之间的依赖关系,以便优化执行计划和调度任务。
-
Task Scheduler(任务调度器): 任务调度器负责将DAG Scheduler生成的任务调度到Executor节点上执行。它根据任务的依赖关系和资源状况来进行任务的调度和分发。
在 Spark 中,有两种主要的部署执行模式:client 模式和cluster 模式。
Client 模式:在 Client 模式中,Driver 程序运行在提交作业的客户端机器上。Driver 程序负责启动 Spark 应用程序,创建 SparkContext,分配任务给 Executor 执行,并收集任务的执行结果。这种模式下,Driver 程序与集群上的 Executor 之间通过网络进行通信。
Cluster 模式:在 Cluster 模式中,Driver 程序运行在集群的某个节点上,而不是客户端机器上。Driver 程序会在集群中的某个节点上启动,与 Executor 程序一起运行在集群中。这种模式下,Driver 程序与 Executor 之间的通信是通过集群的通信机制(例如:Standalone Cluster Manager、YARN、Mesos)进行的。
Apache Spark程序的运行过程:
-
创建SparkSession: Spark程序开始时,首先需要创建一个
SparkSession对象。SparkSession是Spark 2.x版本中的入口点,负责整个Spark应用程序的配置、资源管理等。 -
读取数据: 使用Spark提供的API或者外部数据源(如HDFS、S3、Kafka等)读取数据,创建一个或多个初始的RDD或DataFrame。数据可以是结构化的,也可以是非结构化的。
-
进行转换操作: 使用Spark的转换算子对初始的RDD或DataFrame进行转换操作,构建计算逻辑的DAG(有向无环图)。这些转换操作包括
map、filter、groupBy、join等。 -
触发行动操作: 当需要将计算结果从Spark应用程序带到驱动程序或输出到外部存储系统时,需要执行行动操作。行动操作会触发Spark作业的执行。
-
作业划分和调度: Spark将DAG划分为阶段(Stages),每个阶段包含一组可以并行执行的任务。作业调度器负责将任务分配到集群的各个节点上。
-
任务执行: 每个节点上的Executor负责执行分配给它的任务。任务会按照DAG的逻辑依赖关系进行计算,处理数据的转换和Shuffle操作。
-
Shuffle阶段: 如果DAG中包含宽依赖操作,那么在任务执行期间会涉及Shuffle操作。这涉及到数据的重新分区和重新组织。
-
结果输出: 执行完所有任务后,Spark会将结果返回给驱动程序或者将结果写回到外部存储系统。
-
关闭SparkSession: 当Spark应用程序执行完成后,需要关闭
SparkSession释放资源。

