



Hive语句概述
创建数据库

location:指定数据库的位置
建表关键字

1.TEMPORARY:临时表,只在当前会话有效。
2.EXTERNAL:外部表,不加该关键字则所建表默认为内部表,主要区别为内部表管理元数据和HDFS数据而外部表只管理元数据,因此删除外部表只会删除元数据而不影响外部数据
3.RowFormat:序列化和反序列化
4.STORED AS:创建分区表
5.CLUSTERED BY...SORTED BY....INTO....BUCKETS:创建分桶表
RowFormat


复杂数据类型
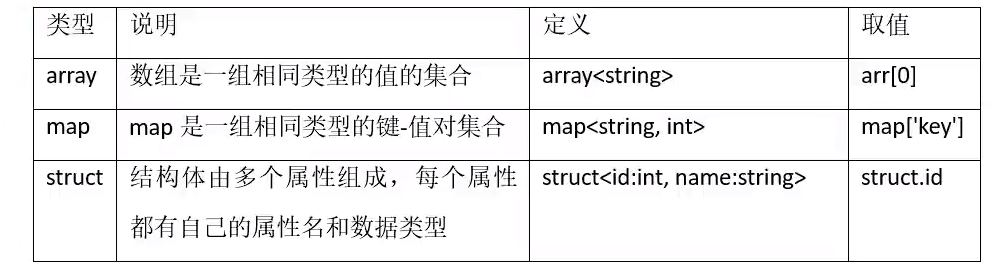
Hive中数据的隐式转换规则
Load将本地文件导入到Hive表中

分区表
所谓分区表就是把一张大表按照需要分散到不同的目录中

分桶表
所谓分桶就是对于一张表的每一行数据计算出一个hash值,把所有hash值相同的表放到一起形成一个文件,这样就把一张表分散为多个文件

创建含有结构体的表,并且读取数据
create table if not exists stu_info(
name string,
age int,
teacher struct<name:string,age:int>
)
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe';
select name,age,teacher.name,teacher.age from stu_info;
hiev插入
insert into/overwrite table 表 () values()
into:插入
overwrite:覆盖
hive导出,导入
export 表 to path
import table 表 from path
导入必须是数据库路径
hive查
与mysql语法一样
炸裂函数UDTF
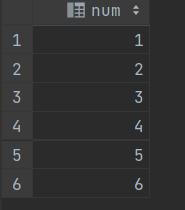
select explode(arry()) as 字段名
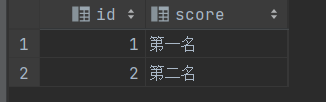
select explode(map()) as (字段名,字段名)
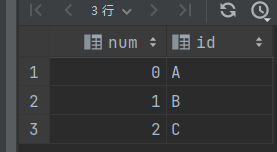
select posexplode(arry()) as (位置,字段名)
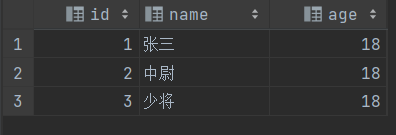
select inline(array(
named_struct(自定义json),
)) as (字段名);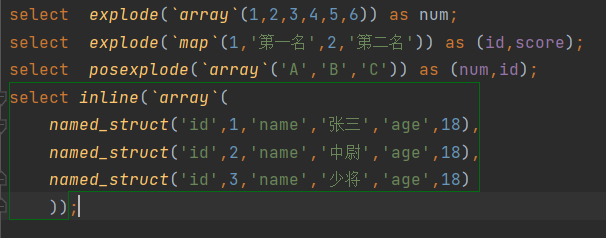
窗口函数
对于某一个字段进行窗口聚合
select id,sum(id) over (order by id range between unbounded preceding and current row ) sumId from stu;
分区表
create table if not exists book(
bookId int,
bookName string,
author string
)
partitioned by (bookCategory string)
row format delimited fields terminated by '|';
一般语法
create 语句
partitioned by (分区字段)
row format delimited fields terminated by '|';
注意分区最好不用中文,会有编码问题
对于分区表的所有操作都要加上分区字段的值,才能确定是哪个分区的
insert into table book partition (bookCategory="history")values (0023,"三国志","陈寿");
load data local inpath "/home/bill/test/book_data"
into table book partition (bookCategory="history");
select * from book where bookCategory="adventure";
这里分区字段相当于一个隐藏的字段,可以自定义分区字段和类型
分区可以当作一个属性进行条件判断
分区相关的操作
--查看表的分区--
show partitions 表;
--注意增加多个分区间用空格,删除用逗号--
--添加分区--
alter table book add partition (分区="分区1") partition (分区="分区2")....;
--删除分区--
alter table book drop partition (分区="分区1"), partition (分区="分区2")....;分桶表
分桶表的实质就是把一张表的数据分散的储存到不同的文件里面,hive会对行数据根据指定的字段计算一个hash值,把所有相同的hash的值放入一个桶
--创建按照movieId分桶的表,总共4个桶,结果对4取余--
create table if not exists movie(
movieId int,
movieName string,
movieDirector string
)
clustered by (movieId) into 4 buckets
row format delimited fields terminated by ' ';行式储存和列式储存
行式储存是更具每一行储存的,即对于每一行数据储存完才会储存下一行
列式储存则是按某一字段储存,即某一字段的值储存完再储存下一字段

