
Hadoop MapReduce编写实现序列化统计各学生的总分
Map类
package org.example.score;
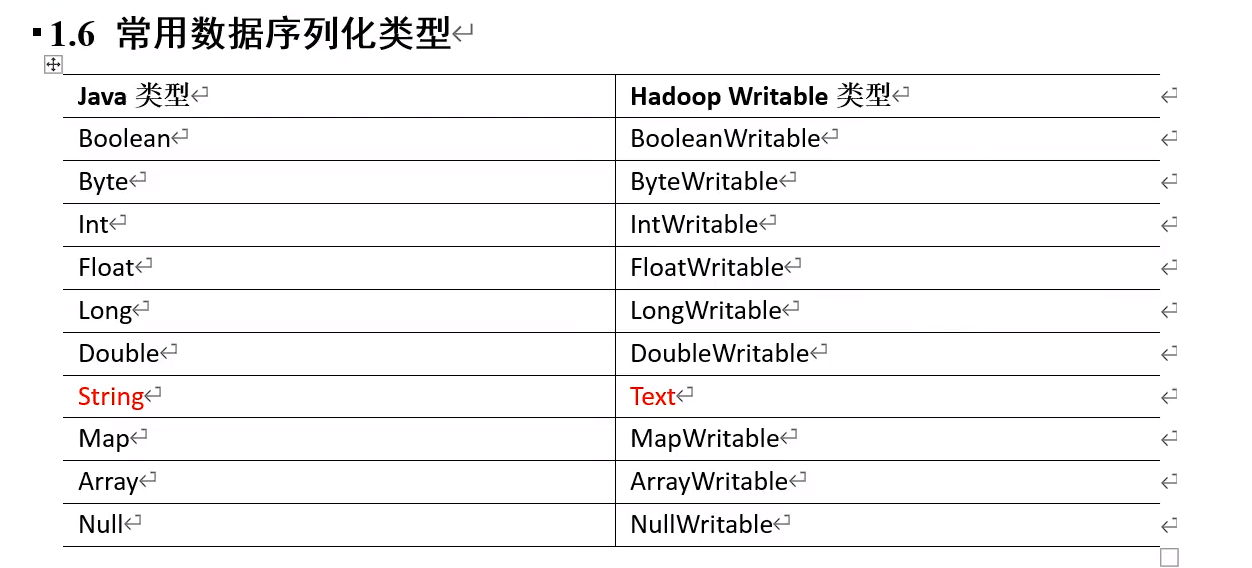
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ScoreMapper extends Mapper<LongWritable, Text, IntWritable,Score> {
private IntWritable outK=new IntWritable();
private Score outV=new Score();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, Score>.Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] s=line.split("\\s+");
outK.set(Integer.parseInt(s[0]));
outV.setStudId(Integer.valueOf(s[0]));
outV.setStuName(s[1]);
outV.setStuCourse(s[2]);
outV.setStuScore(Integer.valueOf(s[3]));
context.write(outK,outV);
}
}Reduce类
package org.example.score;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ScoreReduce extends Reducer<IntWritable,Score,IntWritable,Text> {
private IntWritable outK=new IntWritable();
private Text outV=new Text();
private int sum;
private String Name;
@Override
protected void reduce(IntWritable key, Iterable<Score> values, Reducer<IntWritable, Score, IntWritable, Text>.Context context) throws IOException, InterruptedException {
sum=0;
for(Score i:values){
sum+=i.getStuScore();
Name=i.getStuName();
}
outK.set(key.get());
outV.set("学号: "+String.valueOf(key.get())+" 姓名: "+Name+" 总分: "+String.valueOf(sum));
context.write(null,outV);
}
}Driver类
package org.example.score;
import lombok.SneakyThrows;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class ScoreDriver {
@SneakyThrows
public static void main(String[] args) {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setJarByClass(ScoreDriver.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Score.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("D:\\JavaProject\\Lab\\Hadoop1\\src\\main\\resources\\score"));
FileOutputFormat.setOutputPath(job,new Path("D:\\JavaProject\\Lab\\Hadoop1\\src\\main\\resources\\scoreOutput"));
boolean flag=job.waitForCompletion(true);
System.exit(flag? 0:1);
}
}Score类
package org.example.score;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Score implements Writable {
private Integer studId;
private String stuName;
private String stuCourse;
private Integer stuScore;
//序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(studId);
dataOutput.writeUTF(stuName);
dataOutput.writeUTF(stuCourse);
dataOutput.writeInt(stuScore);
}
//反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.studId=dataInput.readInt();
this.stuName=dataInput.readUTF();
this.stuCourse=dataInput.readUTF();
this.stuScore=dataInput.readInt();
}
}输入
123456 张三 数学 85
123456 张三 语文 92
123456 张三 英语 88
123456 张三 物理 79
123456 张三 化学 81
123456 张三 政治 86
234567 李四 数学 90
234567 李四 语文 87
234567 李四 英语 93
234567 李四 物理 82
234567 李四 化学 84
234567 李四 政治 89
345678 王五 数学 76
345678 王五 语文 80
345678 王五 英语 78
345678 王五 物理 74
345678 王五 化学 77
345678 王五 政治 75
456789 赵六 数学 83
456789 赵六 语文 86
456789 赵六 英语 85
456789 赵六 物理 80
456789 赵六 化学 82
456789 赵六 政治 84
567890 刘七 数学 91
567890 刘七 语文 94
567890 刘七 英语 92
567890 刘七 物理 89
567890 刘七 化学 90
567890 刘七 政治 93
678901 钱八 数学 81
678901 钱八 语文 83
678901 钱八 英语 82
678901 钱八 物理 78
678901 钱八 化学 80
678901 钱八 政治 81
789012 孙九 数学 86
789012 孙九 语文 88
789012 孙九 英语 87
789012 孙九 物理 84
789012 孙九 化学 85
789012 孙九 政治 86
输出
学号: 123456 姓名: 张三 总分: 511
学号: 234567 姓名: 李四 总分: 525
学号: 345678 姓名: 王五 总分: 460
学号: 456789 姓名: 赵六 总分: 500
学号: 567890 姓名: 刘七 总分: 549
学号: 678901 姓名: 钱八 总分: 485
学号: 789012 姓名: 孙九 总分: 516
map阶段默认的key位序列号,即每一行首字母的序号,value默认为每一行字符串
reduce的输入k,v对位map的输出k,v对
driver为启动类
score为序列化
切记序列化和反序列化的顺序要相同
四个类的作用为
首先javabean类序列化传递的参数
map类读入输入的文件,·并且逐行解析字符串,自定义选中一个key,封装为k,v对传入reduce
reduce类读入map传入的k,v对,对于所有相同的k,reduce会读入该k的一个v数组,这里写相同学号的总分计算
driver启动map,reduce阶段,最后得到结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号