



Hadoop3.3.5完全分布式搭建
首先在之前的伪分布基础上克隆两台机器
这样一共三台虚拟机
为这三台虚拟机设置三个不同的静态ip地址和主机名
我的是
billsaifu 192.168.15.130
hadoop1 192.168.15.131
hadoop2 192.168.15.132
静态IP设置
#先进入root
vim /etc/sysconfig/network-scripts/ifcfg-ens33
#修改为如下配置
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static#下面需要自己配置对应的IP地址
IPADDR=192.168.15.130
NETMASK=255.255.255.0
GATEWAY=192.168.15.2
DNS1=192.168.15.2#-----------------------
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=73e49046-f307-4320-9b82-fc9108ff2f23
DEVICE=ens33
ONBOOT=yes
IPV6_PRIVACY=no
PREFIX=24
DEFROUTE=yes
对应下hadoop的各项设置
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://billsaifu:9000</value>
</property>
<property>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>bill</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.5/tmp</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
<dedication> Datanode 有一个同时处理文件的上限,至少要有4096</dedication>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.replication.min</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/data01/hadoop</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/mnt/data01/hdfs_dndata</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>freedom</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.clusterID</name>
<value>hadoopMaster</value>
</property>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>billsaifu:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/mnt/data01/yarn_nmdata</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://billsaifu:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdfs://billsaifu:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>http://billsaifu:19888</value>
</property>
</configuration>
这里我以billsaifu为master主机,hadoop1为资源管理,hadoop2为2nn
并且创建了一个新组为hadoop的超级组,组名为freedom
为freedom创建一个新角色bill,并且把bill加入该组
为给组赋予hadoop文件夹权限
sudo groupadd freedom
sudo useradd -m bill
sudo passwd bill
sudo usermod -aG freedom bill
mkdir -p /home/bill/bin
#改变data01所有组为freedom:bill
sudo chown -R freedom:bill /mnt/data01
sudo chmod -R 755 /mnt/data01

另外还需要配置相应的主机名
vi /etc/hostname #分别设置为billsaifu,hadoop1,hadoop2
#设置主机映射
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.15.130 billsaifu
192.168.15.131 hadoop1
192.168.15.132 hadoop2
以下是一些常用脚本
xsync分发脚本
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in billsaifu hadoop1 hadoop2
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
donemyhadoop启动脚本
if [ $# -lt 1 ]; then
echo "No Args Input..."
exit
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh billsaifu "/usr/local/hadoop-3.3.5/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop1 "/usr/local/hadoop-3.3.5/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh billsaifu "/usr/local/hadoop-3.3.5/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh billsaifu "/usr/local/hadoop-3.3.5/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop1 "/usr/local/hadoop-3.3.5/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh billsaifu "/usr/local/hadoop-3.3.5/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esacjpsall检查脚本
#!/bin/bash
declare -a hosts=("billsaifu" "hadoop1" "hadoop2")
for host in "${hosts[@]}"
do
echo "=============== $host ==============="
ssh -t "$host" /usr/local/java8/jdk1.8.0_371/bin/jps
done现在配置完毕启动一下,注意对应freedom组下面的角色bill,对于这些脚本和hadoop文件需要有对应的权限,不如hadoop无法启动,建议把对应文件的组都修改为freedom:bill
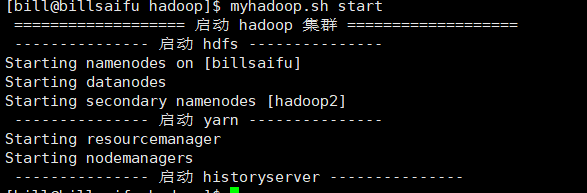


可以看到有三个存活的结点


