

CentOS7+java8+hadoop3.3.5环境搭建
需要的配置文件
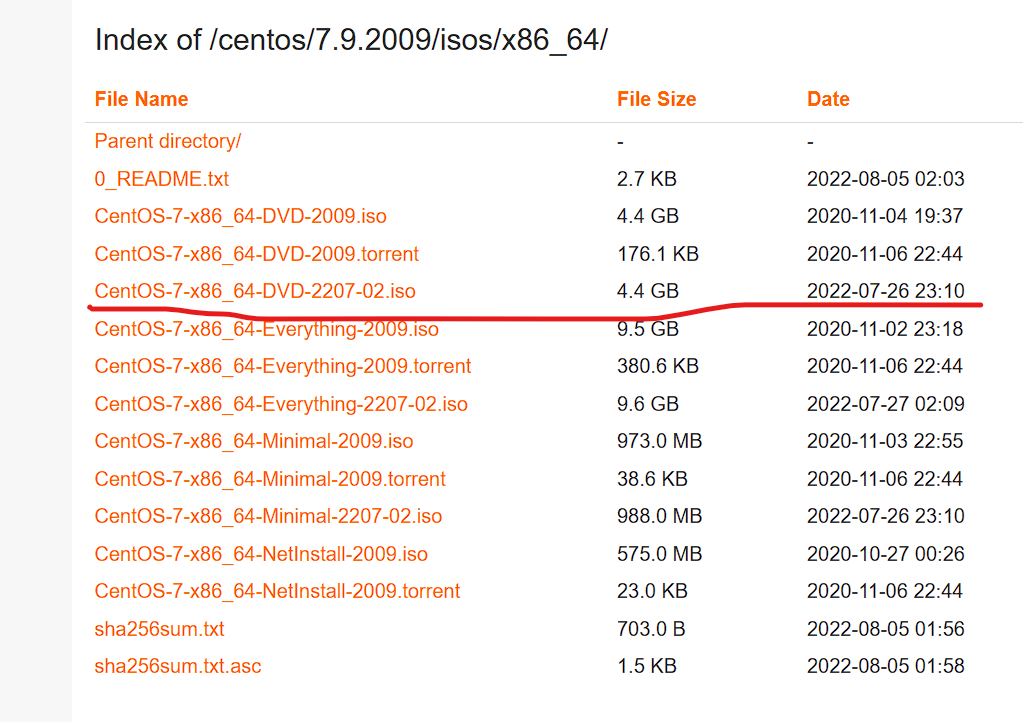
centos7的镜像
centos-7.9.2009-isos-x86_64安装包下载_开源镜像站-阿里云 (aliyun.com)
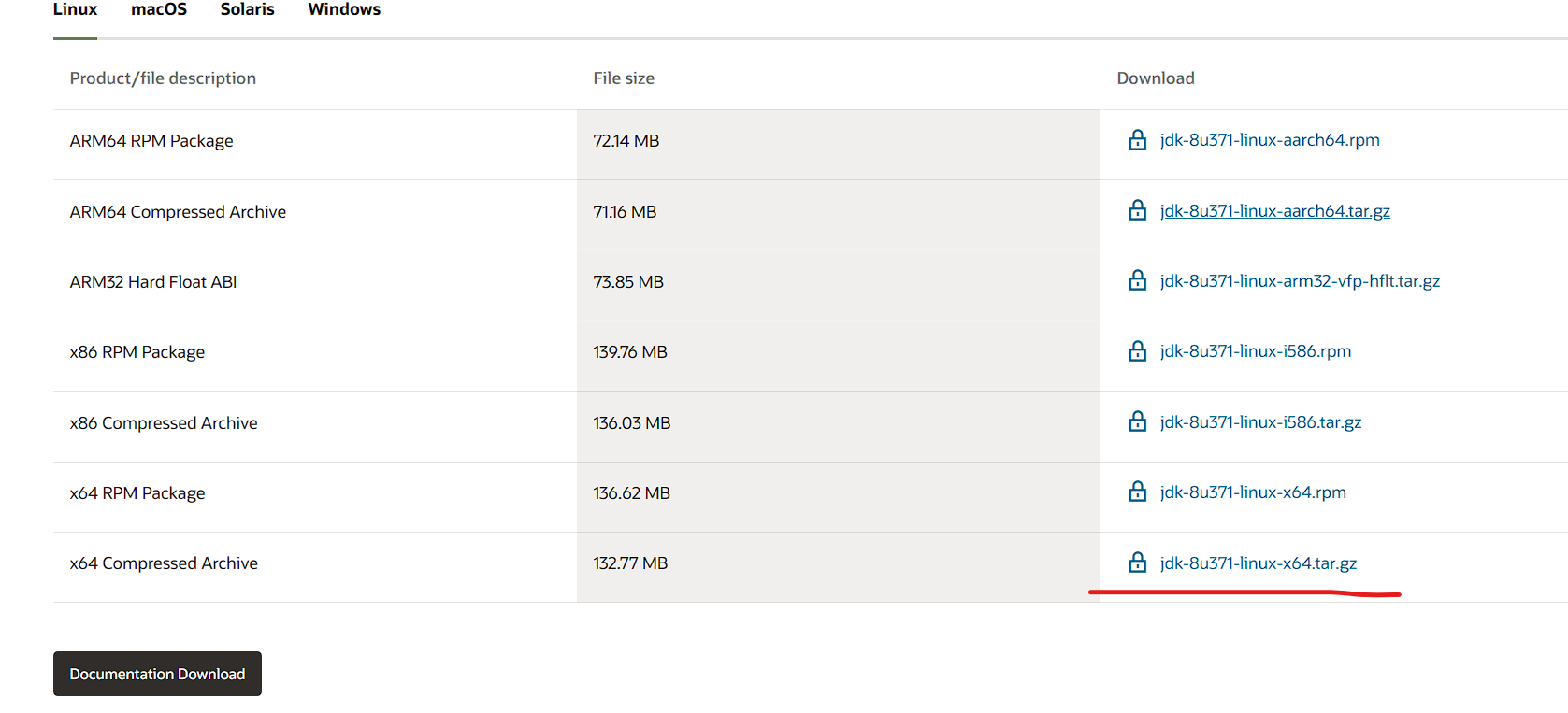
java8
hadoop3.3.5
Index of /dist/hadoop/common/hadoop-3.3.5 (apache.org)

步骤
首先第一步在本地下载好vmware和centos7的镜像

之后的选项根据自己的实际需求选择
创建完之后
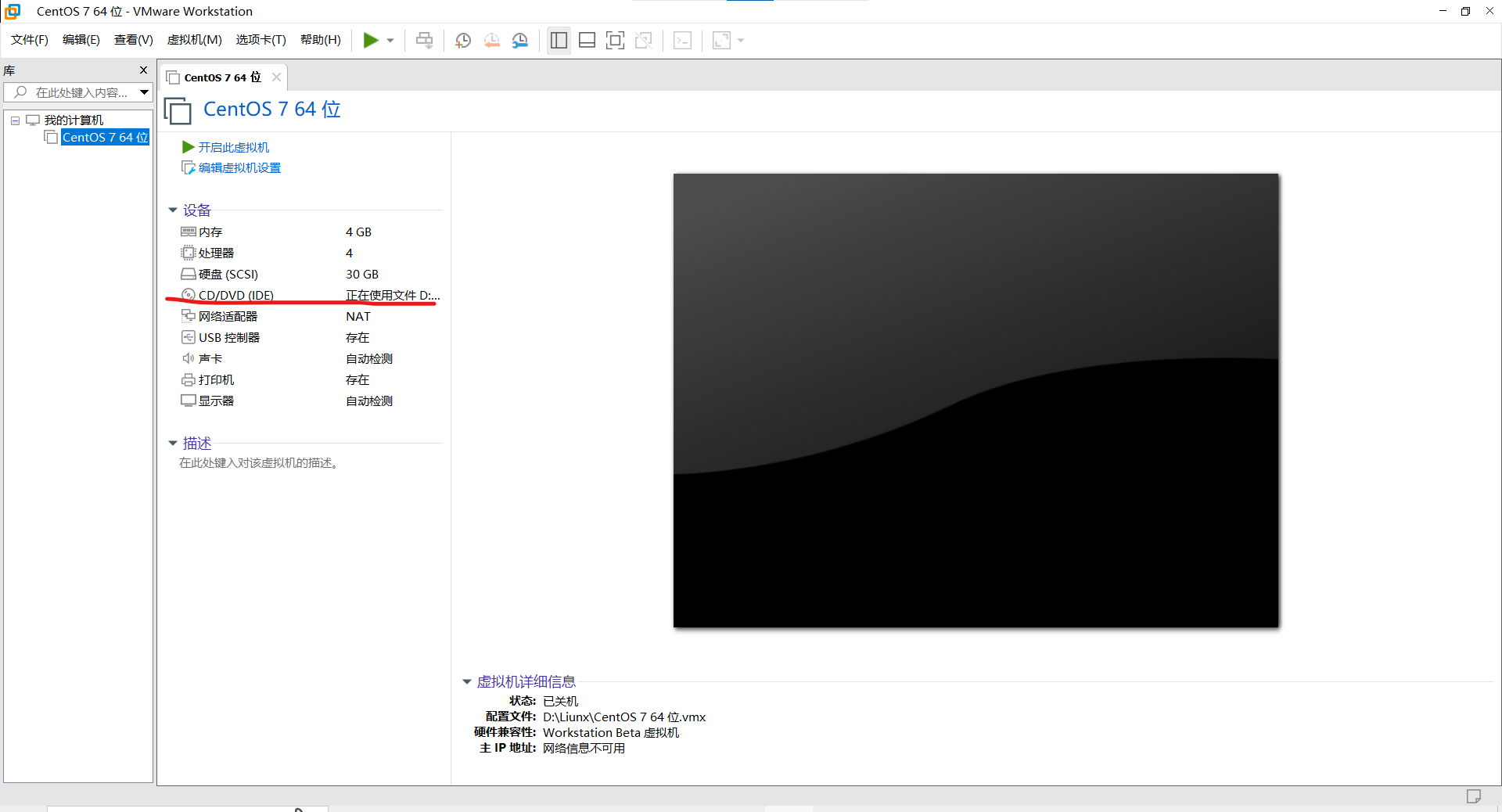

将这个路径换为你自己镜像的路径
然后就可以进入了,完成一些初始的设定之后
开始配置java8环境

下载完后

打开命令窗口,并进入管理员模式
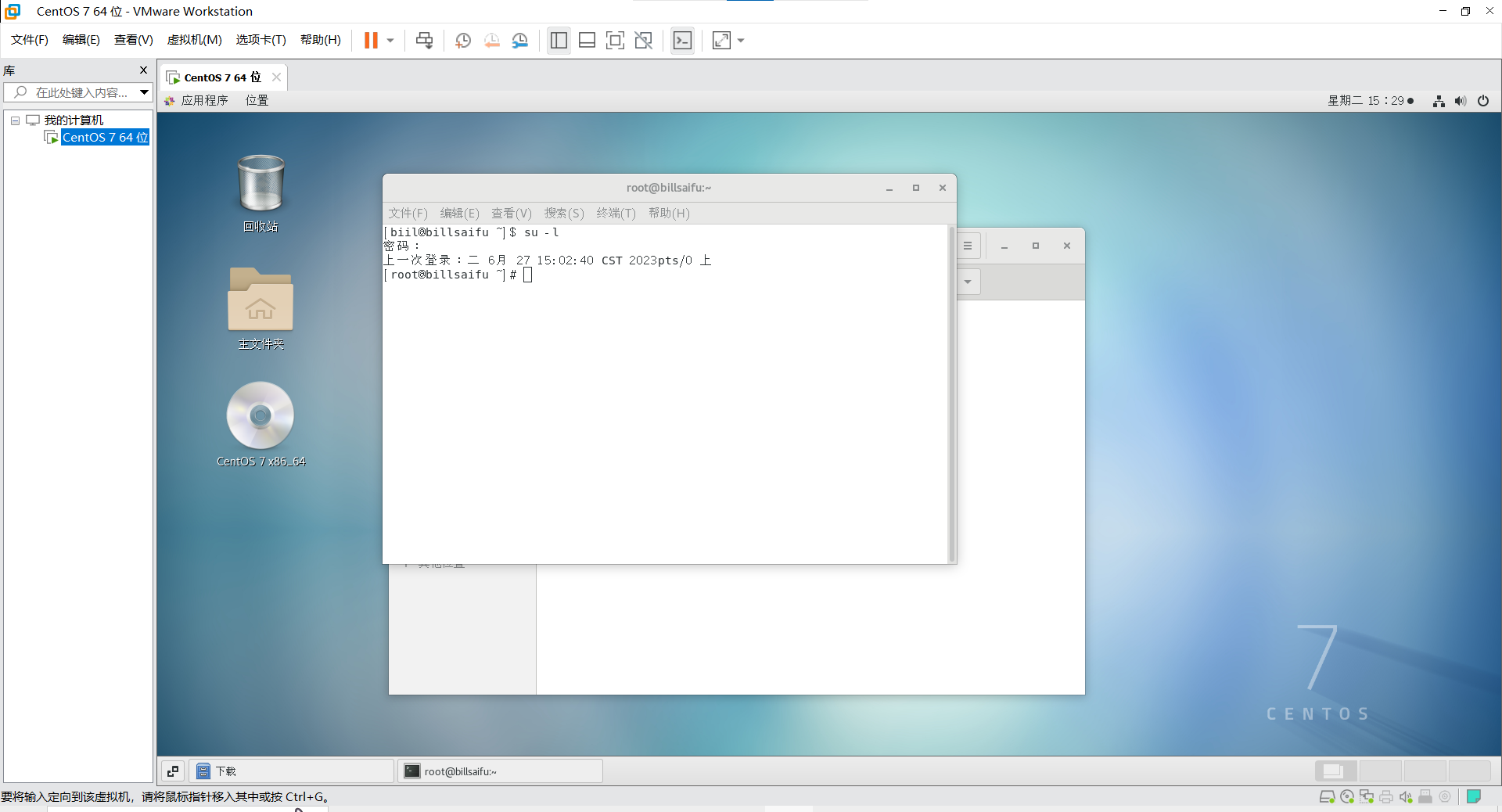
mkdir /usr/local/java8
tar zxvf jdk-8u371-linux-x64.tar.gz -C /usr/local/java8/
cd /usr/local/java8/jdk1.8.0_371/
vi /etc/profile
## JDK8
export JAVA_HOME=/usr/local/java8/jdk1.8.0_371
export JRE_HOME=${JAVA_HOEM}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}source /etc/profile
在执行完vi /ect/profile命令完后,按i键进入编辑模式,在末尾添加上jdk8的环境设置,然后按esc退出,再按shift+:,然后输入wq按回车保存,最后使用source命令刷新配置

出现java版本说明配置成功了
配置hadoop3.3.5伪分布式
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.5/hadoop-arm64-3.3.5.tar.gz
tar zxvf hadoop-3.3.5.tar.gz -C /usr/local/
cd /usr/local/hadoop-3.3.5/
vi /etc/profile
## Hadoop3.3.5
export HADOOP_HOME=/usr/local/hadoop-3.3.5
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source /etc/profile
vi etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/java8/jdk1.8.0_371
export HADOOP_PID_DIR=${HADOOP_HOME}/pids
在hadoop-env.sh末尾添加上面两句话
然后是对hadoop文件的配置
vi etc/hadoop/core-site.xml
#把configuration换位如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.15.130:9000</value>#注意这里是你自己的IP地址不要照抄
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/data01/hadoop</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property><property>
<name>dfs.datanode.data.dir</name>
<value>/mnt/data01/hdfs_dndata</value>
</property>
</configuration>
配置hosts
hostnamectl set-hostname billsaifu #可以任意取主机名称
bash
echo "192.168.15.130 billsaifu" >> /etc/hosts#你自己的主机名和IP地址
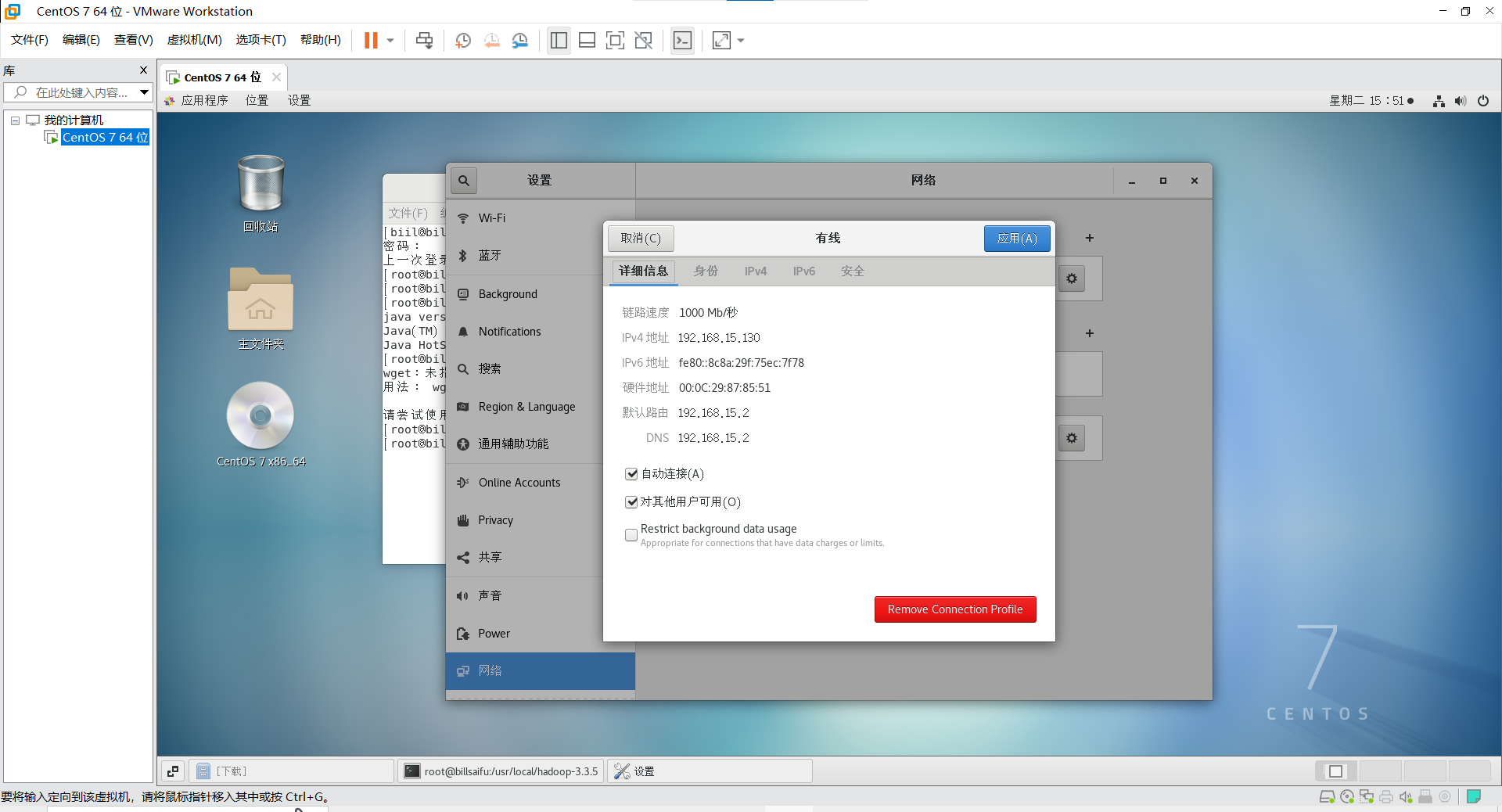
这里可以查看你的IP地址
创建免密
useradd xwp
su - xwp -c "ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa"
su - xwp -c "cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys"
su - xwp -c "chmod 0600 ~/.ssh/authorized_keys"
chown -R xwp:xwp /usr/local/hadoop-3.3.5
mkdir /usr/local/hadoop-3.3.5/pids
chown -R xwp:xwp /usr/local/hadoop-3.3.5/pids
mkdir -p /mnt/data01/hadoop
mkdir -p /mnt/data01/hdfs_dndata
mkdir -p /mnt/data01/yarn_nmdata
chown -R xwp:xwp /mnt/data01/hadoop
chown -R xwp:xwp /mnt/data01/hdfs_dndata
chown -R xwp:xwp /mnt/data01/yarn_nmdata
启动HDFS
su - xwp
cd /usr/local/hadoop-3.3.5
bin/hdfs namenode -format
sbin/start-dfs.sh
创建执行mapreduce任务所需的HDFS目录
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/xwp
执行mapreduce任务
hdfs dfs -mkdir input
hdfs dfs -put etc/hadoop/*.xml input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep input output 'dfs[a-z.]+'
hdfs dfs -get output output
cat output/
启动YARN
vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<!--property>
<name>mapreduce.jobhistory.address</name>
<value>hdfs://192.168.15.130:10020</value>
</property-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>http://192.168.15.130:19888</value>#注意换成自己的IP地址
</property>
</configuration>
vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/mnt/data01/yarn_nmdata</value>
</property>
</configuration>sbin/start-yarn.sh#开启yarn
bin/mapred --daemon start historyserver #开启JobhistoryServer
输入 hadoop version
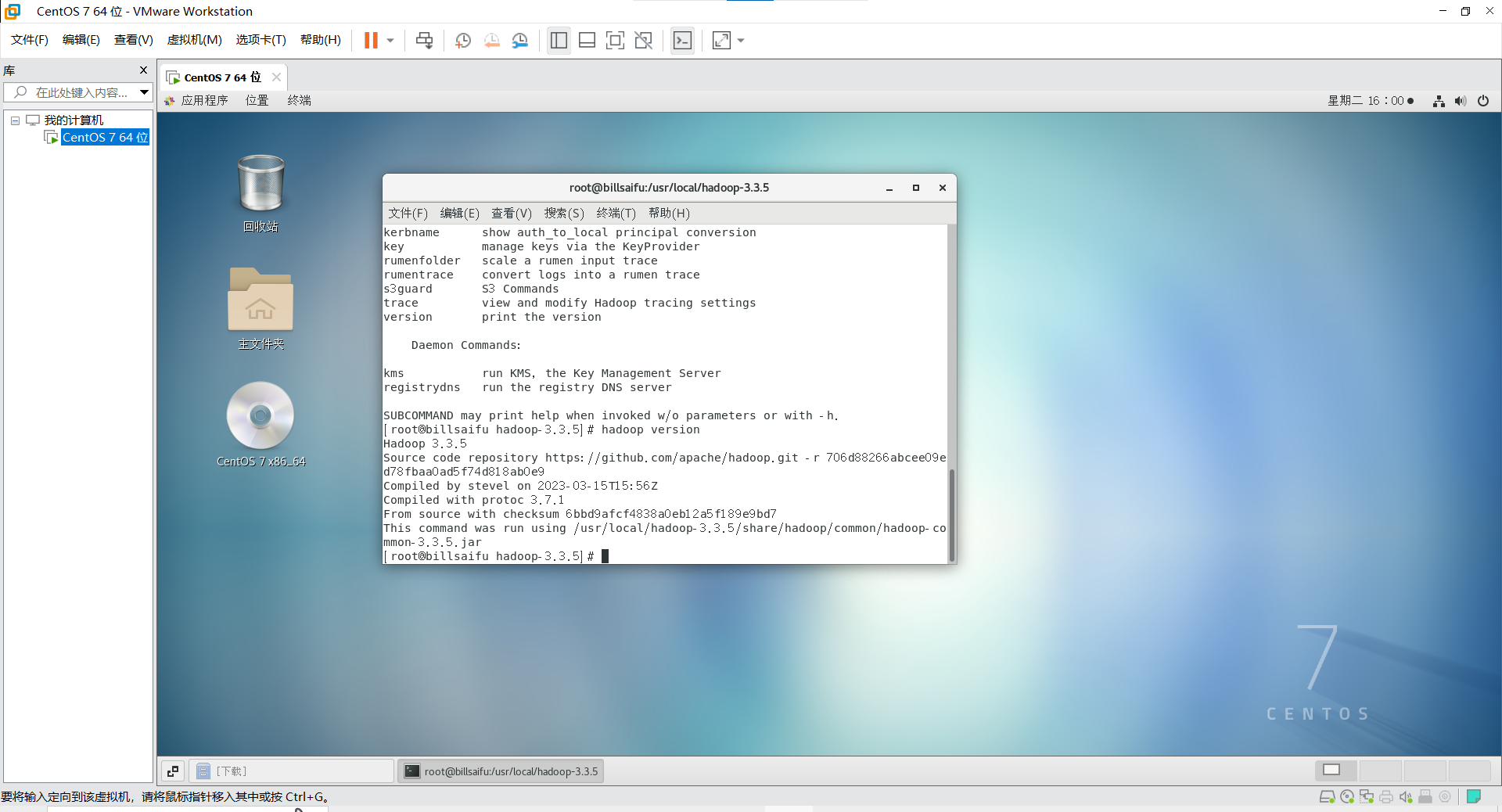
出现对应的版本说明配置成功了
利用jps查看是否启动成功
未启动
[xwp@billsaifu hadoop-3.3.5]$ jps
8129 Jps
成功启动
[xwp@billsaifu hadoop-3.3.5]$ ./sbin/start-dfs.sh
Starting namenodes on [billsaifu]
billsaifu: Warning: Permanently added 'billsaifu,192.168.15.130' (ECDSA) to the list of known hosts.
Starting datanodes
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Starting secondary namenodes [billsaifu]
[xwp@billsaifu hadoop-3.3.5]$ jps
9108 SecondaryNameNode
9259 Jps
8622 NameNode
登录相应的页面

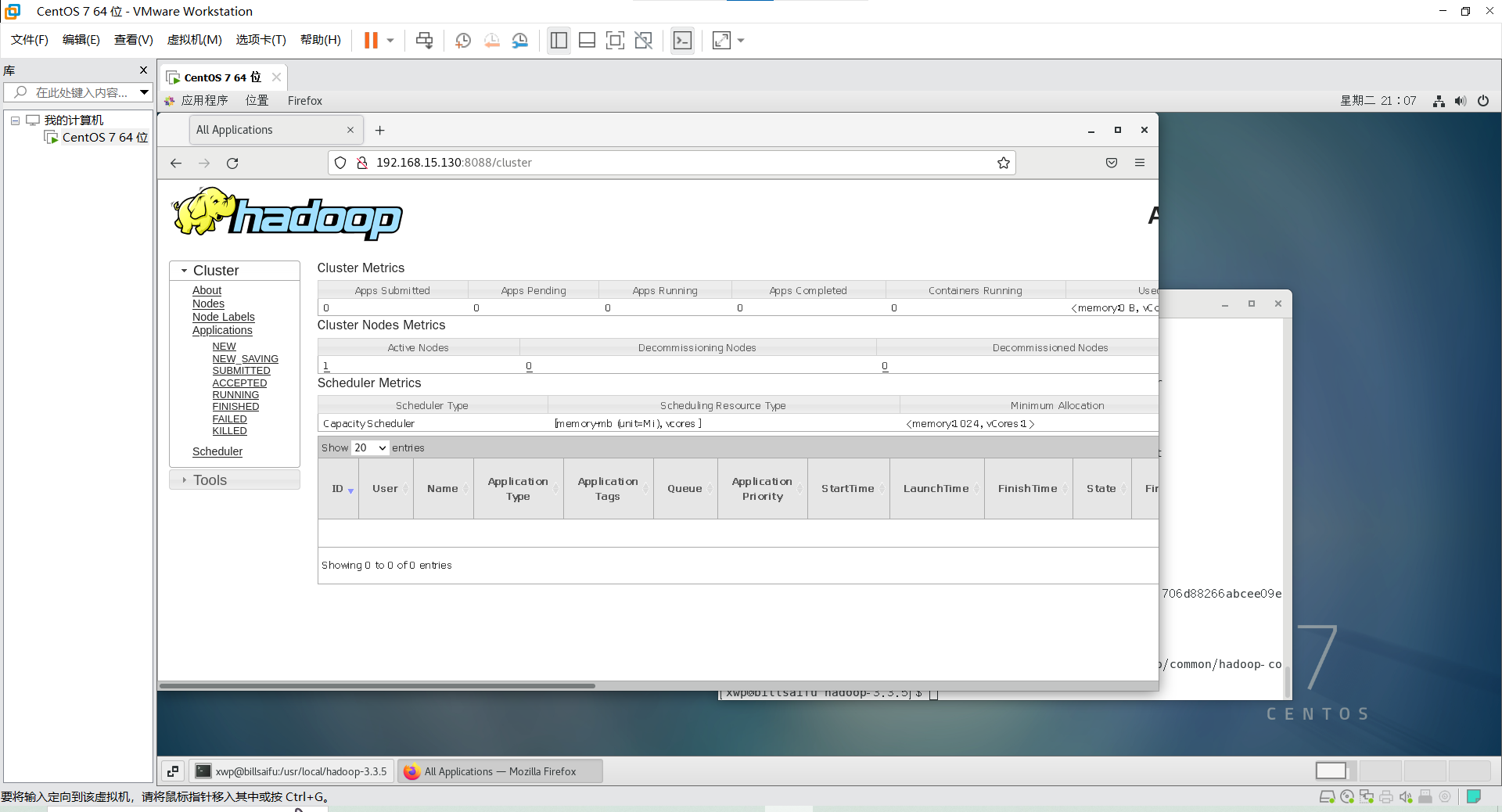
失败是这样的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号