

python爬虫入门
首先下载爬取网页需要和解析html标签需要的包,并且需要对http协议和html标签有一定了解
http协议之前有份博客总结了一些https://www.cnblogs.com/liyiyang/p/17337925.html
pip install requests
pip install beautifulsoup
我们这里以豆瓣电影为例
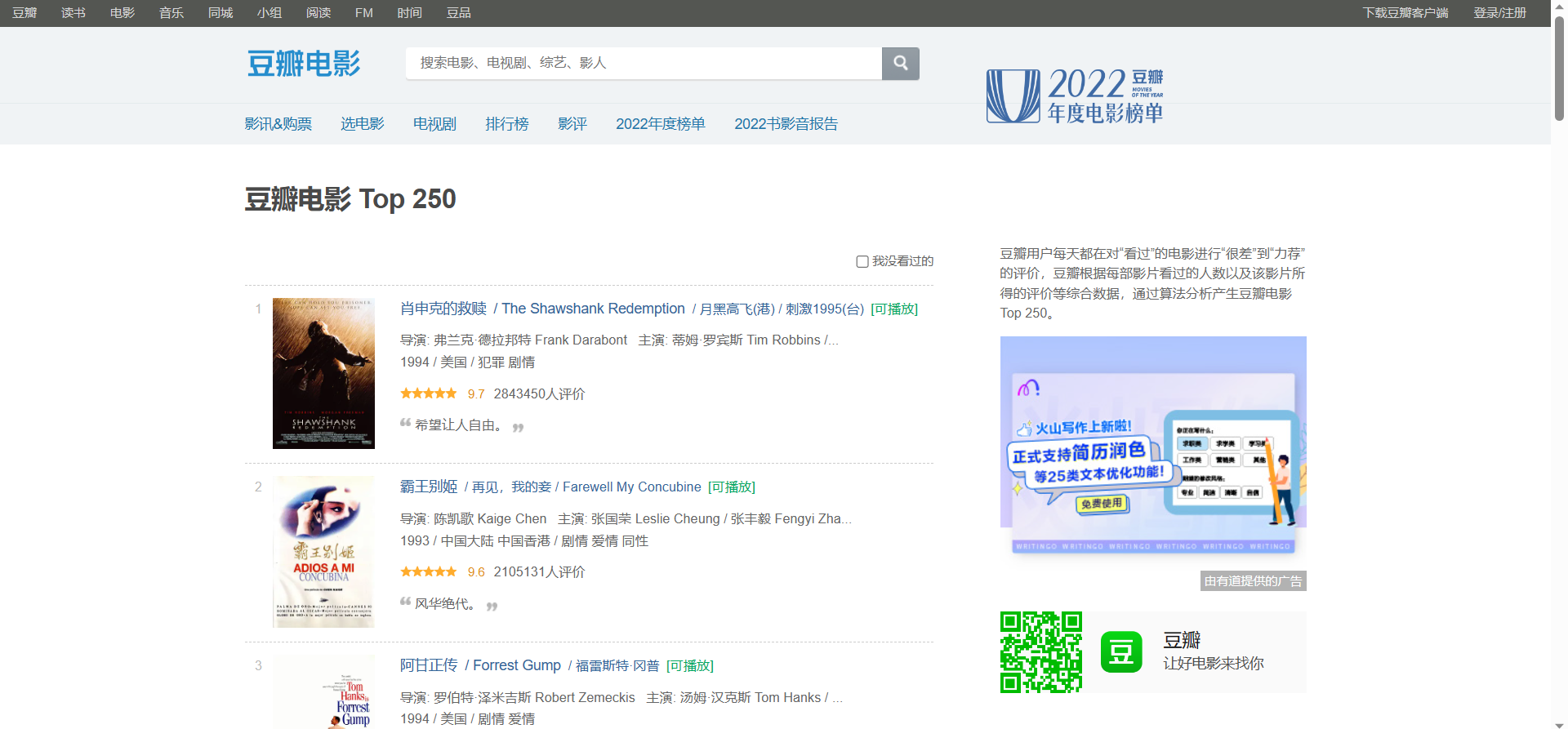
复制其网址https://movie.douban.com/top250
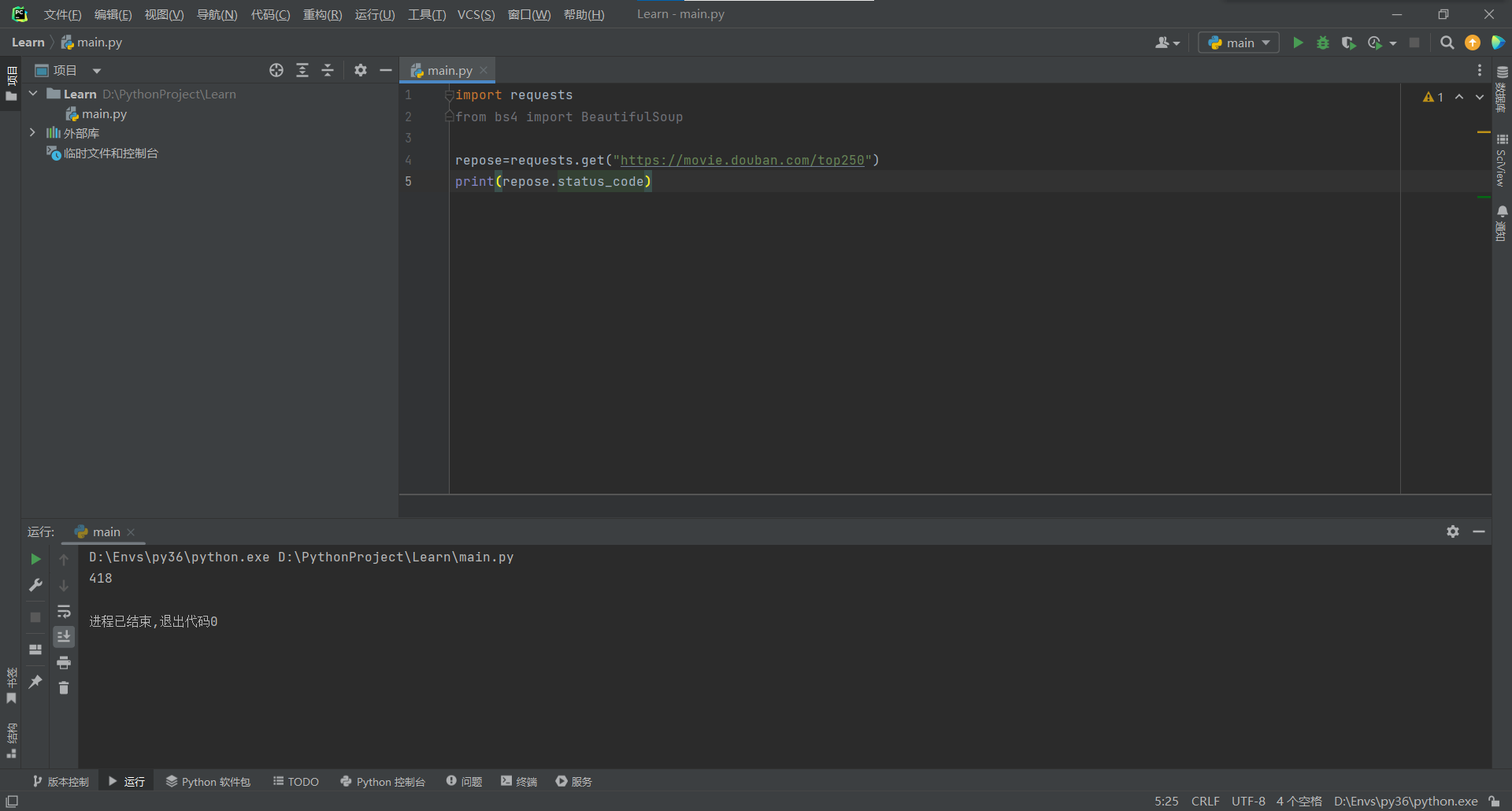
这里状态码为418表示访问失败,原因是豆瓣网站有保护机制防止爬取,但是我们可以伪装为客服端进行访问
打开开发人员管理器
进行页面刷新,并且随便点击一个请求翻到最底下,把蓝色部分复制
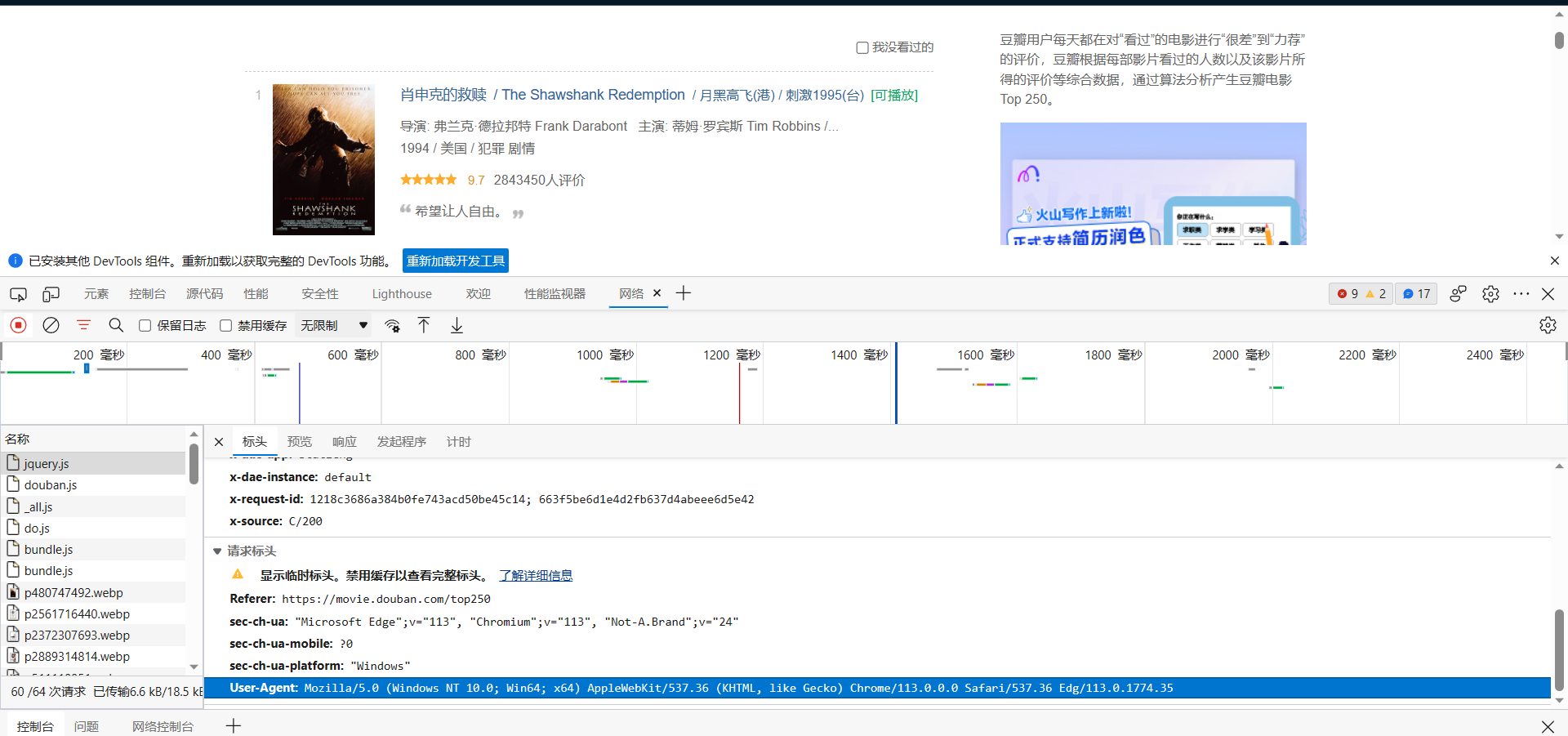
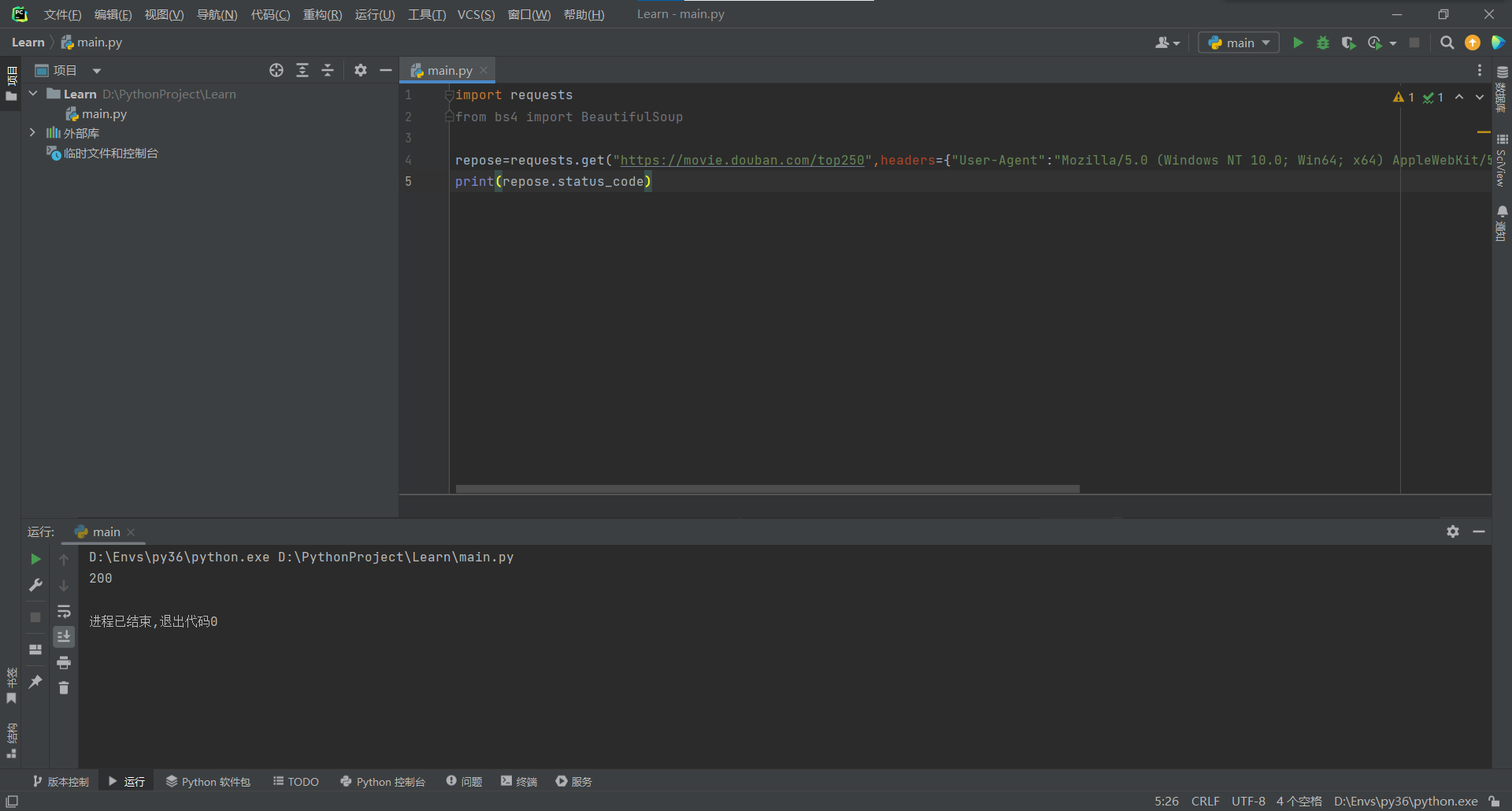
得到运行状态为200表示成功访问
接下来输出该页面的文本
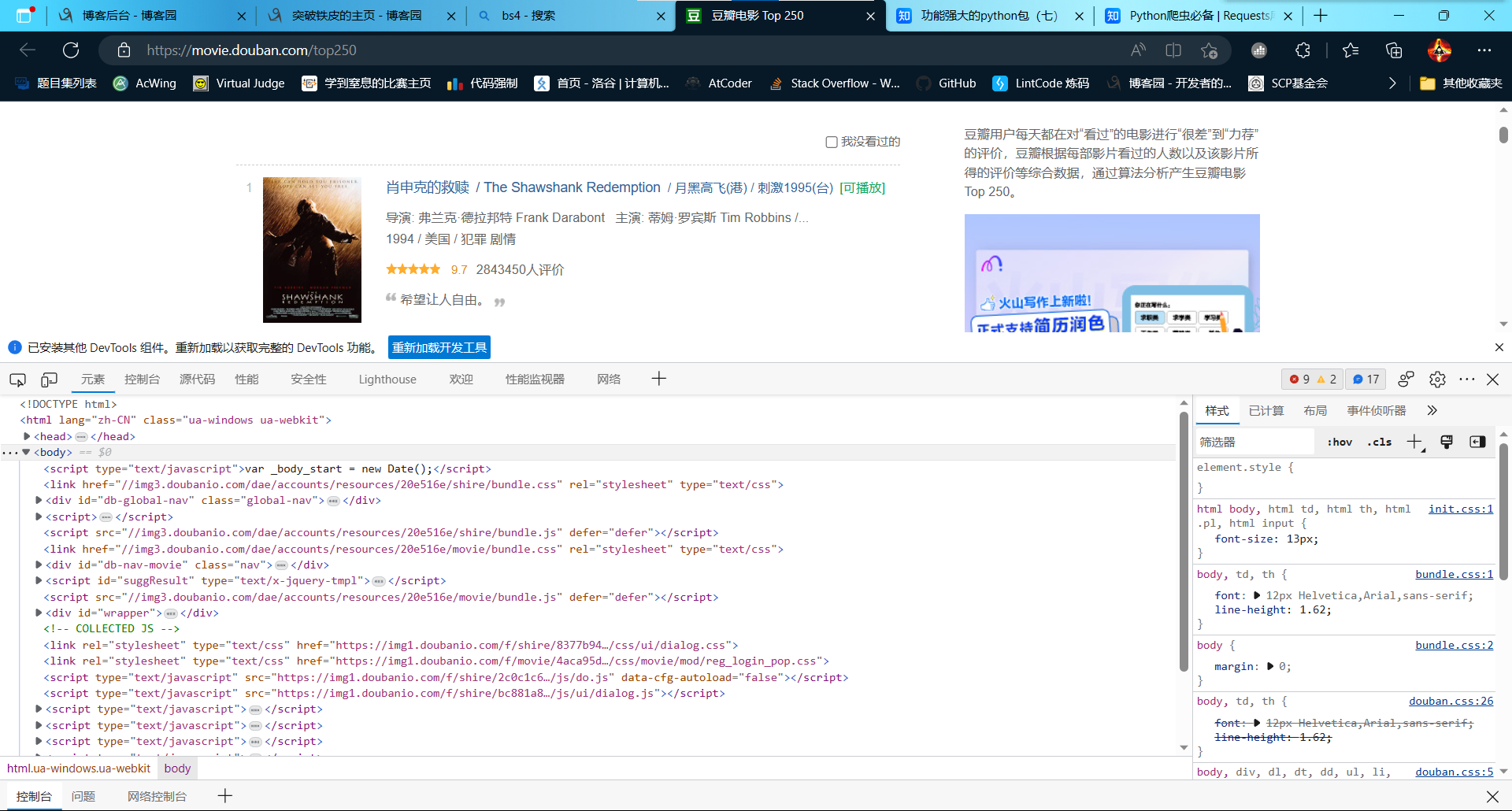
使用beautifulsoup解析页面
例如找寻所有的span标签,并打印出来
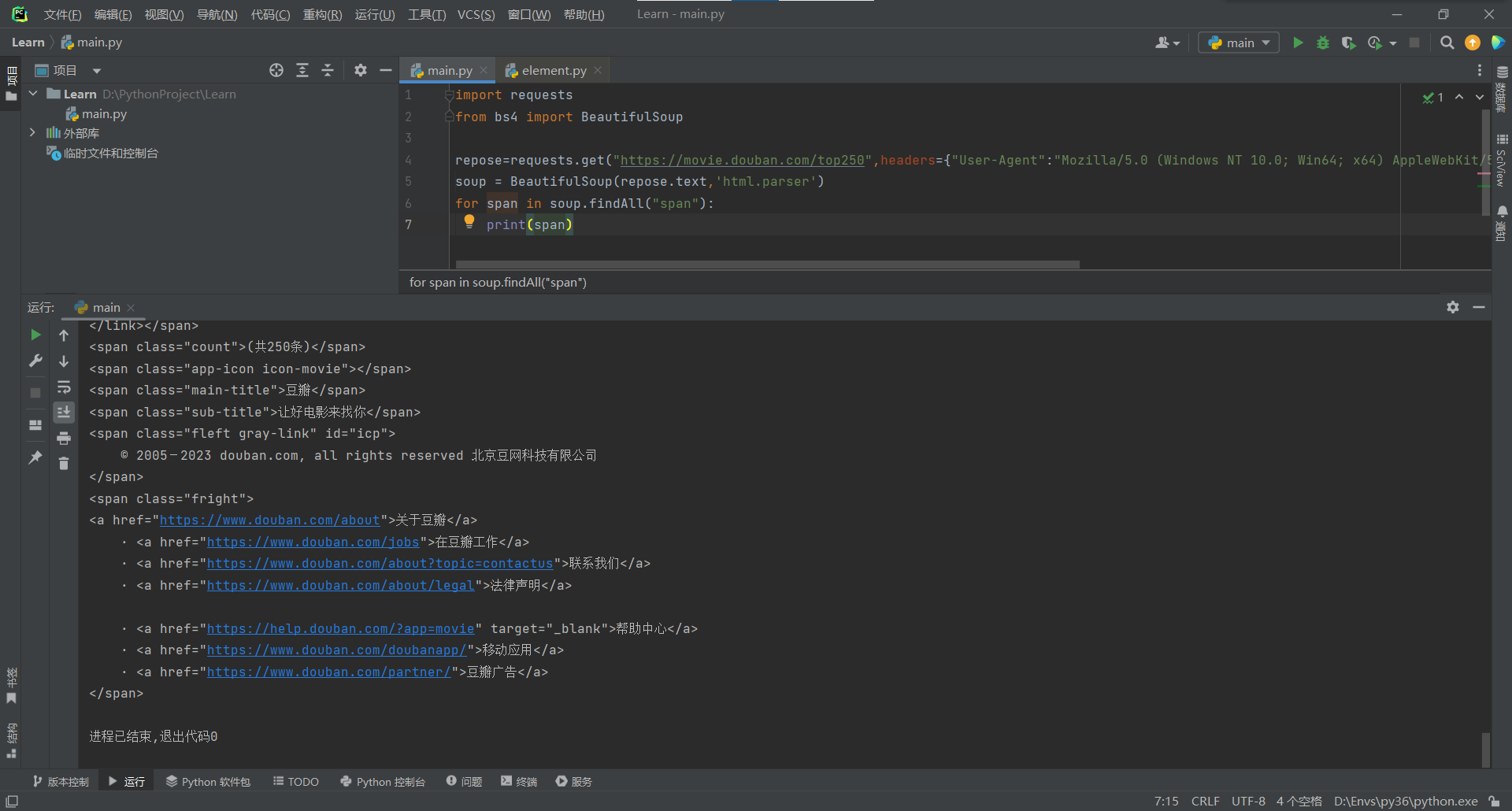
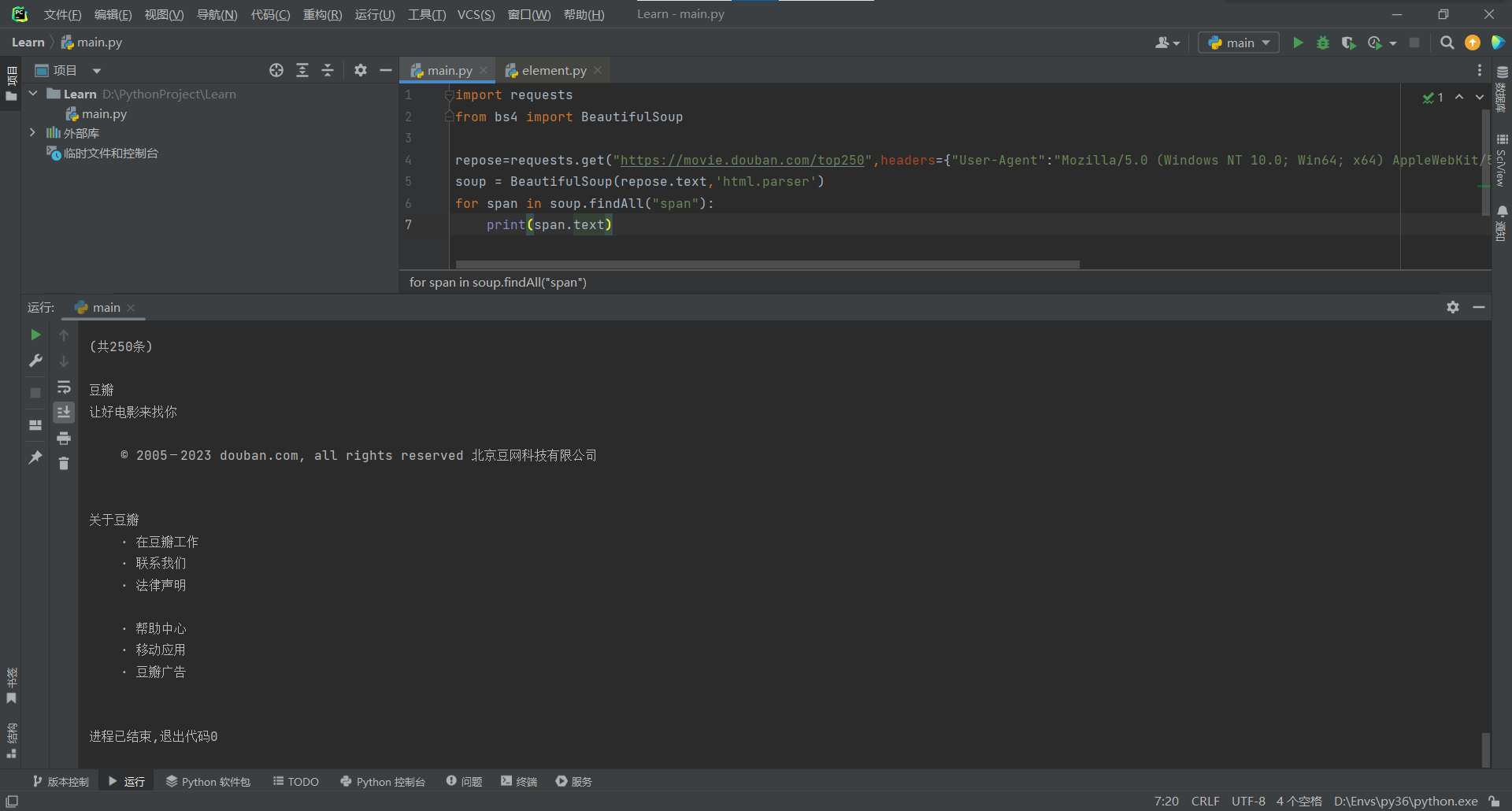
前者会连同标签一起打印,后者则只打印文本
我们注意到,电影名被span包含都属于title类,如果我们想要得到电影名可以这样做
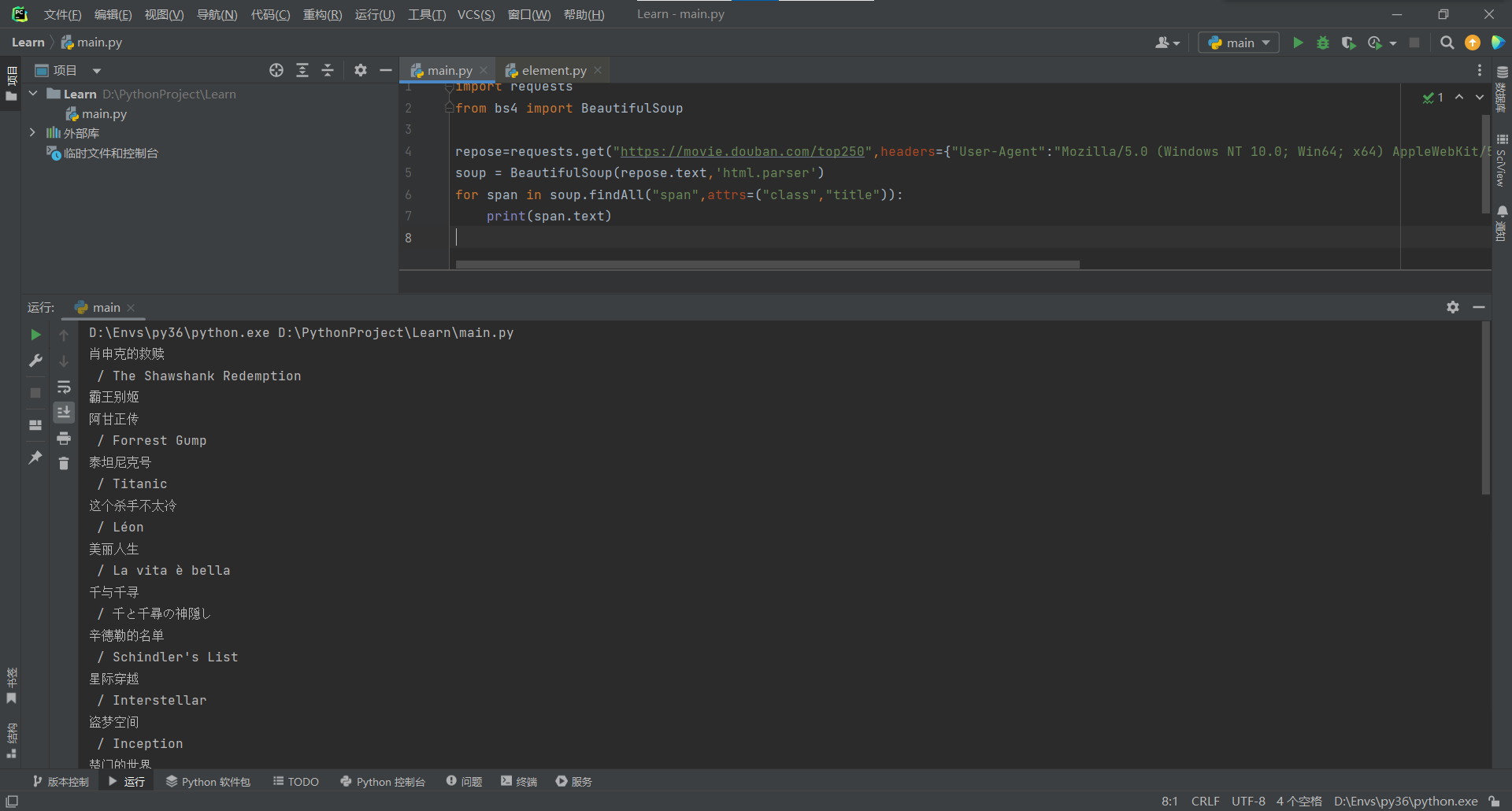
然后通过切片或者正则表达式可以得到我们想要的数据

